
diff options
| author | van Hauser <vh@thc.org> | 2019-06-23 11:19:51 +0200 |
|---|---|---|
| committer | van Hauser <vh@thc.org> | 2019-06-23 11:19:51 +0200 |
| commit | 2db576f52b9b849cca1ebffafa310ee27b150cd8 (patch) | |
| tree | 745f4a8f527fd94dc48c42ebcce7b13de7fcef50 /docs/README | |
| parent | 421edce6236ffec860fe554d6b41266d8f3ff77d (diff) | |
| download | afl++-2db576f52b9b849cca1ebffafa310ee27b150cd8.tar.gz | |
better power schedule documentation
Diffstat (limited to 'docs/README')
| -rw-r--r-- | docs/README | 72 |
1 files changed, 61 insertions, 11 deletions
diff --git a/docs/README b/docs/README index cc42d767..1d0dfb34 100644 --- a/docs/README +++ b/docs/README @@ -38,6 +38,7 @@ american fuzzy lop plus plus ** See QuickStartGuide.txt if you don't have time to read this file. ** + 1) Challenges of guided fuzzing ------------------------------- @@ -65,6 +66,7 @@ All these methods are extremely promising in experimental settings, but tend to suffer from reliability and performance problems in practical uses - and currently do not offer a viable alternative to "dumb" fuzzing techniques. + 2) The afl-fuzz approach ------------------------ @@ -104,6 +106,7 @@ closed-source tools. The fuzzer is thoroughly tested to deliver out-of-the-box performance far superior to blind fuzzing or coverage-only tools. + 3) Instrumenting programs for use with AFL ------------------------------------------ @@ -148,6 +151,7 @@ libdislocator/README.dislocator) can help uncover heap corruption issues, too. PS. ASAN users are advised to review notes_for_asan.txt file for important caveats. + 4) Instrumenting binary-only apps --------------------------------- @@ -166,7 +170,43 @@ For additional instructions and caveats, see qemu_mode/README.qemu. The mode is approximately 2-5x slower than compile-time instrumentation, is less conductive to parallelization, and may have some other quirks. -5) Choosing initial test cases +If [afl-dyninst](https://github.com/vanhauser-thc/afl-dyninst) works for +your binary, then you can use afl-fuzz normally and it will have twice +the speed compared to qemu_mode. + + +5) Power schedules +------------------ + +The power schedules were copied from Marcel Böhme's excellent AFLfast +implementation and expands on the ability to discover new paths and +therefore the coverage. + +| AFL flag | Power Schedule | +| ------------- | -------------------------- | +| `-p explore` (default)| 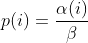 | +| `-p fast` | 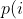=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | +| `-p coe` | 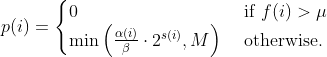 | +| `-p quad` | 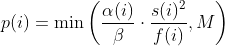 | +| `-p lin` | 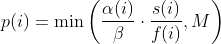 | +| `-p exploit` (AFL) | 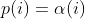 | +where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path. + +In parallel mode (-M/-S, several instances with shared queue), we suggest to +run the master using the exploit schedule (-p exploit) and the slaves with a +combination of cut-off-exponential (-p coe), exponential (-p fast; default), +and explore (-p explore) schedules. + +In single mode, using -p fast is usually more beneficial than the default +explore mode. +(We don't want to change the default behaviour of afl, so "fast" has not been +made the default mode) + +More details can be found in the paper: +[23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). + + +6) Choosing initial test cases ------------------------------ To operate correctly, the fuzzer requires one or more starting file that @@ -187,7 +227,8 @@ PS. If a large corpus of data is available for screening, you may want to use the afl-cmin utility to identify a subset of functionally distinct files that exercise different code paths in the target binary. -6) Fuzzing binaries + +7) Fuzzing binaries ------------------- The fuzzing process itself is carried out by the afl-fuzz utility. This program @@ -221,7 +262,8 @@ steps, which can take several days, but tend to produce neat test cases. If you want quick & dirty results right away - akin to zzuf and other traditional fuzzers - add the -d option to the command line. -7) Interpreting output + +8) Interpreting output ---------------------- See the status_screen.txt file for information on how to interpret the @@ -278,7 +320,8 @@ If you have gnuplot installed, you can also generate some pretty graphs for any active fuzzing task using afl-plot. For an example of how this looks like, see http://lcamtuf.coredump.cx/afl/plot/. -8) Parallelized fuzzing + +9) Parallelized fuzzing ----------------------- Every instance of afl-fuzz takes up roughly one core. This means that on @@ -290,7 +333,8 @@ The parallel fuzzing mode also offers a simple way for interfacing AFL to other fuzzers, to symbolic or concolic execution engines, and so forth; again, see the last section of parallel_fuzzing.txt for tips. -9) Fuzzer dictionaries + +10) Fuzzer dictionaries ---------------------- By default, afl-fuzz mutation engine is optimized for compact data formats - @@ -326,7 +370,8 @@ If a dictionary is really hard to come by, another option is to let AFL run for a while, and then use the token capture library that comes as a companion utility with AFL. For that, see libtokencap/README.tokencap. -10) Crash triage + +11) Crash triage ---------------- The coverage-based grouping of crashes usually produces a small data set that @@ -372,7 +417,8 @@ be critical, and which are not; while not bulletproof, it can often offer quick insights into complex file formats. More info about its operation can be found near the end of technical_details.txt. -11) Going beyond crashes + +12) Going beyond crashes ------------------------ Fuzzing is a wonderful and underutilized technique for discovering non-crashing @@ -396,7 +442,8 @@ if you are the maintainer of a particular package, you can make this code conditional with #ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION (a flag also shared with libfuzzer) or #ifdef __AFL_COMPILER (this one is just for AFL). -12) Common-sense risks + +13) Common-sense risks ---------------------- Please keep in mind that, similarly to many other computationally-intensive @@ -424,7 +471,8 @@ tasks, fuzzing may put strain on your hardware and on the OS. In particular: $ iostat -d 3 -x -k [...optional disk ID...] -13) Known limitations & areas for improvement + +14) Known limitations & areas for improvement --------------------------------------------- Here are some of the most important caveats for AFL: @@ -465,7 +513,8 @@ Here are some of the most important caveats for AFL: Beyond this, see INSTALL for platform-specific tips. -14) Special thanks + +15) Special thanks ------------------ Many of the improvements to afl-fuzz wouldn't be possible without feedback, @@ -513,7 +562,8 @@ bug reports, or patches from: Thank you! -15) Contact + +16) Contact ----------- Questions? Concerns? Bug reports? The contributors can be reached via |