
diff options
| author | van Hauser <vh@thc.org> | 2019-05-29 14:10:37 +0200 |
|---|---|---|
| committer | van Hauser <vh@thc.org> | 2019-05-29 14:10:37 +0200 |
| commit | dacb2821b3a267b336b4465a24e1de22033ea279 (patch) | |
| tree | f1ac208668829667845271f1ce923c582c24fdd6 /docs/power_schedules.txt | |
| parent | dfa0c9cfd1ec4bea84ea399e25889b5fc93c648b (diff) | |
| download | afl++-dacb2821b3a267b336b4465a24e1de22033ea279.tar.gz | |
added AFLfast power schedules from Marcel Boehme and updated the documenation
Diffstat (limited to 'docs/power_schedules.txt')
| -rw-r--r-- | docs/power_schedules.txt | 33 |
1 files changed, 33 insertions, 0 deletions
diff --git a/docs/power_schedules.txt b/docs/power_schedules.txt new file mode 100644 index 00000000..578ff020 --- /dev/null +++ b/docs/power_schedules.txt @@ -0,0 +1,33 @@ +This document was copied and modified from AFLfast at github.com/mboehme/aflfast + + +Essentially, we observed that most generated inputs exercise the same few +"high-frequency" paths and developed strategies to gravitate towards +low-frequency paths, to stress significantly more program behavior in the +same amount of time. We devised several **search strategies** that decide +in which order the seeds should be fuzzed and **power schedules** that +smartly regulate the number of inputs generated from a seed (i.e., the +time spent fuzzing a seed). We call the number of inputs generated from a +seed, the seed's **energy**. + +Old AFL used -p exploit which had a too high cost, current AFL uses -p explore. + +AFLfast implemented 4 new power schedules which are highly recommended to run +in parallel. + +| AFL flag | Power Schedule | +| ------------- | -------------------------- | +| `-p fast` (default)| 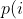=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | +| `-p coe` | 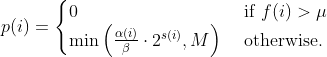 | +| `-p explore` | 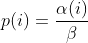 | +| `-p quad` | 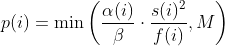 | +| `-p lin` | 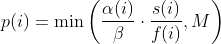 | +| `-p exploit` (AFL) | 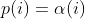 | +where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path. + +More details can be found in our paper that was recently accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). + +PS: In parallel mode (several instances with shared queue), we suggest to run the master using the exploit schedule (-p exploit) and the slaves with a combination of cut-off-exponential (-p coe), exponential (-p fast; default), and explore (-p explore) schedules. In single mode, the default settings will do. **EDIT:** In parallel mode, AFLFast seems to perform poorly because the path probability estimates are incorrect for the imported seeds. Pull requests to fix this issue by syncing the estimates accross instances are appreciated :) + +Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved. +Released under terms and conditions of Apache License, Version 2.0. |