
diff options
| -rw-r--r-- | afl-fuzz.c | 1 | ||||
| -rw-r--r-- | docs/README | 72 | ||||
| -rw-r--r-- | docs/power_schedules.txt | 27 |
3 files changed, 73 insertions, 27 deletions
diff --git a/afl-fuzz.c b/afl-fuzz.c index cda2434a..4235bec5 100644 --- a/afl-fuzz.c +++ b/afl-fuzz.c @@ -7611,6 +7611,7 @@ static void usage(u8* argv0) { "Execution control settings:\n" " -p schedule - power schedules recompute a seed's performance score.\n" " <explore (default), fast, coe, lin, quad, or exploit>\n" + " see docs/power_schedules.txt\n" " -f file - location read by the fuzzed program (stdin)\n" " -t msec - timeout for each run (auto-scaled, 50-%u ms)\n" " -m megs - memory limit for child process (%u MB)\n" diff --git a/docs/README b/docs/README index cc42d767..1d0dfb34 100644 --- a/docs/README +++ b/docs/README @@ -38,6 +38,7 @@ american fuzzy lop plus plus ** See QuickStartGuide.txt if you don't have time to read this file. ** + 1) Challenges of guided fuzzing ------------------------------- @@ -65,6 +66,7 @@ All these methods are extremely promising in experimental settings, but tend to suffer from reliability and performance problems in practical uses - and currently do not offer a viable alternative to "dumb" fuzzing techniques. + 2) The afl-fuzz approach ------------------------ @@ -104,6 +106,7 @@ closed-source tools. The fuzzer is thoroughly tested to deliver out-of-the-box performance far superior to blind fuzzing or coverage-only tools. + 3) Instrumenting programs for use with AFL ------------------------------------------ @@ -148,6 +151,7 @@ libdislocator/README.dislocator) can help uncover heap corruption issues, too. PS. ASAN users are advised to review notes_for_asan.txt file for important caveats. + 4) Instrumenting binary-only apps --------------------------------- @@ -166,7 +170,43 @@ For additional instructions and caveats, see qemu_mode/README.qemu. The mode is approximately 2-5x slower than compile-time instrumentation, is less conductive to parallelization, and may have some other quirks. -5) Choosing initial test cases +If [afl-dyninst](https://github.com/vanhauser-thc/afl-dyninst) works for +your binary, then you can use afl-fuzz normally and it will have twice +the speed compared to qemu_mode. + + +5) Power schedules +------------------ + +The power schedules were copied from Marcel Böhme's excellent AFLfast +implementation and expands on the ability to discover new paths and +therefore the coverage. + +| AFL flag | Power Schedule | +| ------------- | -------------------------- | +| `-p explore` (default)| 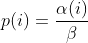 | +| `-p fast` | 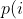=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | +| `-p coe` | 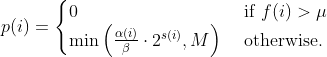 | +| `-p quad` | 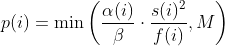 | +| `-p lin` | 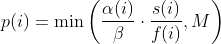 | +| `-p exploit` (AFL) | 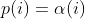 | +where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path. + +In parallel mode (-M/-S, several instances with shared queue), we suggest to +run the master using the exploit schedule (-p exploit) and the slaves with a +combination of cut-off-exponential (-p coe), exponential (-p fast; default), +and explore (-p explore) schedules. + +In single mode, using -p fast is usually more beneficial than the default +explore mode. +(We don't want to change the default behaviour of afl, so "fast" has not been +made the default mode) + +More details can be found in the paper: +[23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). + + +6) Choosing initial test cases ------------------------------ To operate correctly, the fuzzer requires one or more starting file that @@ -187,7 +227,8 @@ PS. If a large corpus of data is available for screening, you may want to use the afl-cmin utility to identify a subset of functionally distinct files that exercise different code paths in the target binary. -6) Fuzzing binaries + +7) Fuzzing binaries ------------------- The fuzzing process itself is carried out by the afl-fuzz utility. This program @@ -221,7 +262,8 @@ steps, which can take several days, but tend to produce neat test cases. If you want quick & dirty results right away - akin to zzuf and other traditional fuzzers - add the -d option to the command line. -7) Interpreting output + +8) Interpreting output ---------------------- See the status_screen.txt file for information on how to interpret the @@ -278,7 +320,8 @@ If you have gnuplot installed, you can also generate some pretty graphs for any active fuzzing task using afl-plot. For an example of how this looks like, see http://lcamtuf.coredump.cx/afl/plot/. -8) Parallelized fuzzing + +9) Parallelized fuzzing ----------------------- Every instance of afl-fuzz takes up roughly one core. This means that on @@ -290,7 +333,8 @@ The parallel fuzzing mode also offers a simple way for interfacing AFL to other fuzzers, to symbolic or concolic execution engines, and so forth; again, see the last section of parallel_fuzzing.txt for tips. -9) Fuzzer dictionaries + +10) Fuzzer dictionaries ---------------------- By default, afl-fuzz mutation engine is optimized for compact data formats - @@ -326,7 +370,8 @@ If a dictionary is really hard to come by, another option is to let AFL run for a while, and then use the token capture library that comes as a companion utility with AFL. For that, see libtokencap/README.tokencap. -10) Crash triage + +11) Crash triage ---------------- The coverage-based grouping of crashes usually produces a small data set that @@ -372,7 +417,8 @@ be critical, and which are not; while not bulletproof, it can often offer quick insights into complex file formats. More info about its operation can be found near the end of technical_details.txt. -11) Going beyond crashes + +12) Going beyond crashes ------------------------ Fuzzing is a wonderful and underutilized technique for discovering non-crashing @@ -396,7 +442,8 @@ if you are the maintainer of a particular package, you can make this code conditional with #ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION (a flag also shared with libfuzzer) or #ifdef __AFL_COMPILER (this one is just for AFL). -12) Common-sense risks + +13) Common-sense risks ---------------------- Please keep in mind that, similarly to many other computationally-intensive @@ -424,7 +471,8 @@ tasks, fuzzing may put strain on your hardware and on the OS. In particular: $ iostat -d 3 -x -k [...optional disk ID...] -13) Known limitations & areas for improvement + +14) Known limitations & areas for improvement --------------------------------------------- Here are some of the most important caveats for AFL: @@ -465,7 +513,8 @@ Here are some of the most important caveats for AFL: Beyond this, see INSTALL for platform-specific tips. -14) Special thanks + +15) Special thanks ------------------ Many of the improvements to afl-fuzz wouldn't be possible without feedback, @@ -513,7 +562,8 @@ bug reports, or patches from: Thank you! -15) Contact + +16) Contact ----------- Questions? Concerns? Bug reports? The contributors can be reached via diff --git a/docs/power_schedules.txt b/docs/power_schedules.txt index cb4ca6e7..f5f66bd6 100644 --- a/docs/power_schedules.txt +++ b/docs/power_schedules.txt @@ -1,33 +1,28 @@ -This document was copied and modified from AFLfast at github.com/mboehme/aflfast +afl++'s power schedules based on AFLfast +<a href="https://comp.nus.edu.sg/~mboehme/paper/CCS16.pdf"><img src="https://comp.nus.edu.sg/~mboehme/paper/CCS16.png" align="right" width="250"></a> +Power schedules implemented by Marcel Böhme \<marcel.boehme@acm.org\>. +AFLFast is an extension of AFL which was written by Michal Zalewski \<lcamtuf@google.com\>. -Essentially, we observed that most generated inputs exercise the same few -"high-frequency" paths and developed strategies to gravitate towards -low-frequency paths, to stress significantly more program behavior in the -same amount of time. We devised several **search strategies** that decide -in which order the seeds should be fuzzed and **power schedules** that -smartly regulate the number of inputs generated from a seed (i.e., the -time spent fuzzing a seed). We call the number of inputs generated from a -seed, the seed's **energy**. +AFLfast has helped in the success of Team Codejitsu at the finals of the DARPA Cyber Grand Challenge where their bot Galactica took **2nd place** in terms of #POVs proven (see red bar at https://www.cybergrandchallenge.com/event#results). AFLFast exposed several previously unreported CVEs that could not be exposed by AFL in 24 hours and otherwise exposed vulnerabilities significantly faster than AFL while generating orders of magnitude more unique crashes. -Old AFL used -p exploit which had a too high cost, current AFL uses -p explore. +Essentially, we observed that most generated inputs exercise the same few "high-frequency" paths and developed strategies to gravitate towards low-frequency paths, to stress significantly more program behavior in the same amount of time. We devised several **search strategies** that decide in which order the seeds should be fuzzed and **power schedules** that smartly regulate the number of inputs generated from a seed (i.e., the time spent fuzzing a seed). We call the number of inputs generated from a seed, the seed's **energy**. -AFLfast implemented 4 new power schedules which are highly recommended to run -in parallel. +We find that AFL's exploitation-based constant schedule assigns **too much energy to seeds exercising high-frequency paths** (e.g., paths that reject invalid inputs) and not enough energy to seeds exercising low-frequency paths (e.g., paths that stress interesting behaviors). Technically, we modified the computation of a seed's performance score (`calculate_score`), which seed is marked as favourite (`update_bitmap_score`), and which seed is chosen next from the circular queue (`main`). We implemented the following schedules (in the order of their effectiveness, best first): | AFL flag | Power Schedule | | ------------- | -------------------------- | -| `-p fast` (default)| 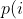=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | +| `-p explore` (default)| 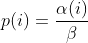 | +| `-p fast` | 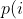=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | | `-p coe` | 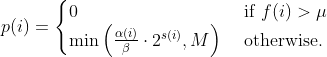 | -| `-p explore` | 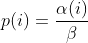 | | `-p quad` | 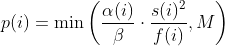 | | `-p lin` | 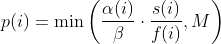 | | `-p exploit` (AFL) | 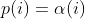 | where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path. -More details can be found in our paper that was recently accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). +More details can be found in the paper that was accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). -PS: In parallel mode (several instances with shared queue), we suggest to run the master using the exploit schedule (-p exploit) and the slaves with a combination of cut-off-exponential (-p coe), exponential (-p fast; default), and explore (-p explore) schedules. In single mode, the default settings will do. **EDIT:** In parallel mode, AFLFast seems to perform poorly because the path probability estimates are incorrect for the imported seeds. Pull requests to fix this issue by syncing the estimates across instances are appreciated :) +PS: In parallel mode (several instances with shared queue), we suggest to run the master using the exploit schedule (-p exploit) and the slaves with a combination of cut-off-exponential (-p coe), exponential (-p fast; default), and explore (-p explore) schedules. In single mode, the default settings will do. **EDIT:** In parallel mode, AFLFast seems to perform poorly because the path probability estimates are incorrect for the imported seeds. Pull requests to fix this issue by syncing the estimates accross instances are appreciated :) Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved. Released under terms and conditions of Apache License, Version 2.0. |