
diff options
Diffstat (limited to 'docs')
| -rw-r--r-- | docs/Changelog.md | 11 | ||||
| -rw-r--r-- | docs/README.radamsa.md | 9 | ||||
| -rw-r--r-- | docs/ideas.md | 36 | ||||
| -rw-r--r-- | docs/power_schedules.md | 1 |
4 files changed, 20 insertions, 37 deletions
diff --git a/docs/Changelog.md b/docs/Changelog.md index efc18ab5..1ecea274 100644 --- a/docs/Changelog.md +++ b/docs/Changelog.md @@ -14,6 +14,7 @@ sending a mail to <afl-users+subscribe@googlegroups.com>. - -S secondary nodes now only sync from the main node to increase performance, the -M main node still syncs from everyone. Added checks that ensure exactly one main node is present and warn otherwise + - Add -D after -S to force a secondary to perform deterministic fuzzing - If no main node is present at a sync one secondary node automatically becomes a temporary main node until a real main nodes shows up - Fixed a mayor performance issue we inherited from AFLfast @@ -23,11 +24,15 @@ sending a mail to <afl-users+subscribe@googlegroups.com>. - Ensure that the targets are killed on exit - fix/update to MOpt (thanks to arnow117) - added MOpt dictionary support from repo + - added experimental SEEK power schedule. It is EXPLORE with ignoring + the runtime and less focus on the length of the test case - llvm_mode: - the default instrumentation is now PCGUARD if the llvm version is >= 7, as it is faster and provides better coverage. The original afl instrumentation can be set via AFL_LLVM_INSTRUMENT=AFL. This is automatically done when the WHITELIST feature is used. + - PCGUARD mode is now even better because we made it collision free - plus + it has a fixed map size, so it is also faster! :) - some targets want a ld variant for LD that is not gcc/clang but ld, added afl-ld-lto to solve this - lowered minimum required llvm version to 3.4 (except LLVMInsTrim, which @@ -44,9 +49,15 @@ sending a mail to <afl-users+subscribe@googlegroups.com>. - Unicornafl - Added powerPC support from unicorn/next - rust bindings! + - CMPLOG/Redqueen now also works for MMAP sharedmem + - ensure shmem is released on errors + - we moved radamsa to be a custom mutator in ./custom_mutators/. It is not + compiled by default anymore. + - allow running in /tmp (only unsafe with umask 0) - persistent mode shared memory testcase handover (instead of via files/stdin) - 10-100% performance increase - General support for 64 bit PowerPC, RiscV, Sparc etc. + - fix afl-cmin.bash - slightly better performance compilation options for afl++ and targets - fixed afl-gcc/afl-as that could break on fast systems reusing pids in the same second diff --git a/docs/README.radamsa.md b/docs/README.radamsa.md deleted file mode 100644 index b01a4c83..00000000 --- a/docs/README.radamsa.md +++ /dev/null @@ -1,9 +0,0 @@ -# libradamsa - -Pretranslated radamsa library. This code belongs to the radamsa author. - -> Original repository: https://gitlab.com/akihe/radamsa - -> Source commit: 7b2cc2d0 - -> The code here is adapted for AFL++ with minor changes respect the original version diff --git a/docs/ideas.md b/docs/ideas.md index 686c262d..65e2e8e6 100644 --- a/docs/ideas.md +++ b/docs/ideas.md @@ -6,7 +6,7 @@ for future AFL++ versions. For GSOC2020 interested students please see [https://github.com/AFLplusplus/AFLplusplus/issues/208](https://github.com/AFLplusplus/AFLplusplus/issues/208) -## Flexible Grammar Mutator +## Flexible Grammar Mutator (currently in development) Currently, AFL++'s mutation does not have deeper knowledge about the fuzzed binary, apart from feedback, even though the developer may have insights @@ -25,41 +25,21 @@ various results. Mentor: andreafioraldi -## Expand on the MOpt mutator - -Work on the MOpt mutator that is already in AFL++. - -This is an excellent mutations scheduler based on Particle Swarm -Optimization but the current implementation schedule only the mutations -that were present on AFL. - -AFL++ added a lot of optional mutators like the Input-2-State one based -on Redqueen, the Radamsa mutator, the Custom mutator (the user can define -its own mutator) and the work is to generalize MOpt for all the current -and future mutators. - -Mentor: vanhauser-thc or andreafioraldi - ## perf-fuzz Linux Kernel Module -Either Port the patch to the upcoming Ubuntu LTS 20.04 default kernel -and provide a qemu-kvm image or find a different userspace snapshot -solution that has a good performance and is reliable, e.g. with docker. -[perf-fuzz](https://gts3.org/assets/papers/2017/xu:os-fuzz.pdf) -The perf-fuzz kernel can be found at [https://github.com/sslab-gatech/perf-fuzz](https://github.com/sslab-gatech/perf-fuzz) -There also is/was a FreeBSD project at [https://github.com/veracode-research/freebsd-perf-fuzz](https://github.com/veracode-research/freebsd-perf-fuzz) - -This enables snapshot fuzzing on Linux with an incredible performance! +Expand on [snapshot LKM](https://github.com/AFLplusplus/AFL-Snapshot-LKM) +To make it thread safe, can snapshot several processes at once and increase +overall performance. Mentor: any -Idea/Issue tracker: [https://github.com/AFLplusplus/AFLplusplus/issues/248](https://github.com/AFLplusplus/AFLplusplus/issues/248) -## QEMU 4-based Instrumentation +## QEMU 5-based Instrumentation First tests to use QEMU 4 for binary-only AFL++ showed that caching behavior changed, which vastly decreases fuzzing speeds. -This is the cause why, right now, we cannot switch to QEMU 4.2. +In this task test if QEMU 5 performs better and port the afl++ QEMU 3.1 +patches to QEMU 5. Understanding the current instrumentation and fixing the current caching issues will be needed. @@ -86,7 +66,7 @@ Either improve a single mutator thorugh learning of many different bugs Mentor: domenukk -## Reengineer `afl-fuzz` as Thread Safe, Embeddable Library +## Reengineer `afl-fuzz` as Thread Safe, Embeddable Library (currently in development) Right now, afl-fuzz is single threaded, cannot safely be embedded in tools, and not multi-threaded. It makes use of a large number of globals, must always diff --git a/docs/power_schedules.md b/docs/power_schedules.md index 067a1d91..06fefa12 100644 --- a/docs/power_schedules.md +++ b/docs/power_schedules.md @@ -21,6 +21,7 @@ We find that AFL's exploitation-based constant schedule assigns **too much energ | `-p exploit` (AFL) | 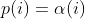 | | `-p mmopt` | Experimental: `explore` with no weighting to runtime and increased weighting on the last 5 queue entries | | `-p rare` | Experimental: `rare` puts focus on queue entries that hit rare edges | +| `-p seek` | Experimental: `seek` is EXPLORE but ignoring the runtime of the queue input and less focus on the size | where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path. More details can be found in the paper that was accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). |