
diff options
| author | vanhauser-thc <vh@thc.org> | 2021-07-14 12:16:52 +0200 |
|---|---|---|
| committer | vanhauser-thc <vh@thc.org> | 2021-07-14 12:16:52 +0200 |
| commit | 3a3ef7b6b4efcd8ed12bef80cca51f82e65a985f (patch) | |
| tree | cb0c07f7efe6eaa5aac85de83d736cf8edcb489b | |
| parent | 94999782f1a3742e3e755a66f5d76e84573ae6ef (diff) | |
| download | afl++-3a3ef7b6b4efcd8ed12bef80cca51f82e65a985f.tar.gz | |
update documentation
| -rw-r--r-- | README.md | 55 | ||||
| -rw-r--r-- | docs/Changelog.md | 1 | ||||
| -rw-r--r-- | docs/QuickStartGuide.md | 9 | ||||
| -rw-r--r-- | docs/README.MOpt.md | 54 | ||||
| -rw-r--r-- | docs/historical_notes.md | 143 | ||||
| -rw-r--r-- | docs/notes_for_asan.md | 157 | ||||
| -rw-r--r-- | docs/perf_tips.md | 47 | ||||
| -rw-r--r-- | docs/power_schedules.md | 32 | ||||
| -rw-r--r-- | docs/technical_details.md | 4 | ||||
| -rw-r--r-- | instrumentation/afl-compiler-rt.o.c | 5 |
10 files changed, 79 insertions, 428 deletions
diff --git a/README.md b/README.md index bc5b333c..50f514ab 100644 --- a/README.md +++ b/README.md @@ -387,7 +387,56 @@ afl++ performs "never zero" counting in its bitmap. You can read more about this here: * [instrumentation/README.neverzero.md](instrumentation/README.neverzero.md) -#### c) Modify the target +#### c) Sanitizers + +It is possible to use sanitizers when instrumenting targets for fuzzing, +which allows you to find bugs that would not necessarily result in a crash. + +Note that sanitizers have a huge impact on CPU (= less executions per second) +and RAM usage. Also you should only run one afl-fuz instance per sanitizer type. +This is enough because a user-after-free bug will be picked up, e.g. by +ASAN (address sanitizer) anyway when syncing to other fuzzing instances, +so not all fuzzing instances need to be instrumented with ASAN. + +The wolloing sanitizers have built-in support in afl++: + * ASAN = Address SANitizer, finds memory corruption vulnerabilities like + use-after-free, NULL pointer dereference, buffer overruns, etc. + Enabled with `export AFL_USE_ASAN=1` before compiling. + * MSAN = Memory SANitizer, finds read access to uninitialized memory, eg. + a local variable that is defined and read before it is even set. + Enabled with `export AFL_USE_MSAN=1` before compiling. + * UBSAN = Undefined Behaviour SANitizer, finds instances where - by the + C and C++ standards - undefined behaviour happens, e.g. adding two + signed integers together where the result is larger than a signed integer + can hold. + Enabled with `export AFL_USE_UBSAN=1` before compiling. + * CFISAN = Control Flow Integrity SANitizer, finds instances where the + control flow is found to be illegal. Originally this was rather to + prevent return oriented programming exploit chains from functioning, + in fuzzing this is mostly reduced to detecting type confusion + vulnerabilities - which is however one of the most important and dangerous + C++ memory corruption classes! + Enabled with `export AFL_USE_CFISAN=1` before compiling. + * LSAN = Leak SANitizer, finds memory leaks in a program. This is not really + a security issue, but for developers this can be very valuable. + Note that unlike the other sanitizers above this needs + `__AFL_LEAK_CHECK();` added to all areas of the target source code where you + find a leak check necessary! + Enabled with `export AFL_USE_LSAN=1` before compiling. + +It is possible to further modify the behaviour of the sanitizers at run-time +by setting `ASAN_OPTIONS=...`, `LSAN_OPTIONS` etc. - the availabel parameter +can be looked up in the sanitizer documentation of llvm/clang. +afl-fuzz however requires some specific parameters important for fuzzing to be +set if you want to set your own, and will bail and report what it is missing. + +Note that some sanitizers cannot be used together, e.g. ASAN and MSAN, and +others often cannot work together because of target weirdness, e.g. ASAN and +CFISAN. You might need to experiment which sanitizers you can combine in a +target (which means more instances can be run without a sanitized target, +which is more effective). + +#### d) Modify the target If the target has features that make fuzzing more difficult, e.g. checksums, HMAC, etc. then modify the source code so that this is @@ -405,7 +454,7 @@ these checks within this specific defines: All afl++ compilers will set this preprocessor definition automatically. -#### d) Instrument the target +#### e) Instrument the target In this step the target source code is compiled so that it can be fuzzed. @@ -462,7 +511,7 @@ non-standard way to set this, otherwise set up the build normally and edit the generated build environment afterwards manually to point it to the right compiler (and/or ranlib and ar). -#### d) Better instrumentation +#### f) Better instrumentation If you just fuzz a target program as-is you are wasting a great opportunity for much more fuzzing speed. diff --git a/docs/Changelog.md b/docs/Changelog.md index aebd3fa9..705daa40 100644 --- a/docs/Changelog.md +++ b/docs/Changelog.md @@ -38,6 +38,7 @@ sending a mail to <afl-users+subscribe@googlegroups.com>. - ensure afl-compiler-rt is built for gcc_module - added `AFL_NO_FORKSRV` env variable support to afl-cmin, afl-tmin, and afl-showmap, by @jhertz + - removed outdated documents, improved existing documentation ### Version ++3.13c (release) - Note: plot_data switched to relative time from unix time in 3.10 diff --git a/docs/QuickStartGuide.md b/docs/QuickStartGuide.md index d1966170..2d056ecf 100644 --- a/docs/QuickStartGuide.md +++ b/docs/QuickStartGuide.md @@ -18,14 +18,12 @@ how to hit the ground running: custom SIGSEGV or SIGABRT handlers and background processes. For tips on detecting non-crashing flaws, see section 11 in [README.md](README.md) . -3) Compile the program / library to be fuzzed using afl-gcc. A common way to +3) Compile the program / library to be fuzzed using afl-cc. A common way to do this would be: - CC=/path/to/afl-gcc CXX=/path/to/afl-g++ ./configure --disable-shared + CC=/path/to/afl-cc CXX=/path/to/afl-c++ ./configure --disable-shared make clean all - If program build fails, ping <afl-users@googlegroups.com>. - 4) Get a small but valid input file that makes sense to the program. When fuzzing verbose syntax (SQL, HTTP, etc), create a dictionary as described in dictionaries/README.md, too. @@ -41,9 +39,6 @@ how to hit the ground running: 6) Investigate anything shown in red in the fuzzer UI by promptly consulting [status_screen.md](status_screen.md). -7) compile and use llvm_mode (afl-clang-fast/afl-clang-fast++) as it is way - faster and has a few cool features - 8) There is a basic docker build with 'docker build -t aflplusplus .' That's it. Sit back, relax, and - time permitting - try to skim through the diff --git a/docs/README.MOpt.md b/docs/README.MOpt.md deleted file mode 100644 index 3de6d670..00000000 --- a/docs/README.MOpt.md +++ /dev/null @@ -1,54 +0,0 @@ -# MOpt(imized) AFL by <puppet@zju.edu.cn> - -### 1. Description -MOpt-AFL is a AFL-based fuzzer that utilizes a customized Particle Swarm -Optimization (PSO) algorithm to find the optimal selection probability -distribution of operators with respect to fuzzing effectiveness. -More details can be found in the technical report. - -### 2. Cite Information -Chenyang Lyu, Shouling Ji, Chao Zhang, Yuwei Li, Wei-Han Lee, Yu Song and -Raheem Beyah, MOPT: Optimized Mutation Scheduling for Fuzzers, -USENIX Security 2019. - -### 3. Seed Sets -We open source all the seed sets used in the paper -"MOPT: Optimized Mutation Scheduling for Fuzzers". - -### 4. Experiment Results -The experiment results can be found in -https://drive.google.com/drive/folders/184GOzkZGls1H2NuLuUfSp9gfqp1E2-lL?usp=sharing. -We only open source the crash files since the space is limited. - -### 5. Technical Report -MOpt_TechReport.pdf is the technical report of the paper -"MOPT: Optimized Mutation Scheduling for Fuzzers", which contains more deatails. - -### 6. Parameter Introduction -Most important, you must add the parameter `-L` (e.g., `-L 0`) to launch the -MOpt scheme. - -Option '-L' controls the time to move on to the pacemaker fuzzing mode. -'-L t': when MOpt-AFL finishes the mutation of one input, if it has not -discovered any new unique crash or path for more than t minutes, MOpt-AFL will -enter the pacemaker fuzzing mode. - -Setting 0 will enter the pacemaker fuzzing mode at first, which is -recommended in a short time-scale evaluation. - -Setting -1 will enable both pacemaker mode and normal aflmutation fuzzing in -parallel. - -Other important parameters can be found in afl-fuzz.c, for instance, - -'swarm_num': the number of the PSO swarms used in the fuzzing process. -'period_pilot': how many times MOpt-AFL will execute the target program - in the pilot fuzzing module, then it will enter the core fuzzing module. -'period_core': how many times MOpt-AFL will execute the target program in the - core fuzzing module, then it will enter the PSO updating module. -'limit_time_bound': control how many interesting test cases need to be found - before MOpt-AFL quits the pacemaker fuzzing mode and reuses the deterministic stage. - 0 < 'limit_time_bound' < 1, MOpt-AFL-tmp. - 'limit_time_bound' >= 1, MOpt-AFL-ever. - -Have fun with MOpt in AFL! diff --git a/docs/historical_notes.md b/docs/historical_notes.md deleted file mode 100644 index b5d3d157..00000000 --- a/docs/historical_notes.md +++ /dev/null @@ -1,143 +0,0 @@ -# Historical notes - - This doc talks about the rationale of some of the high-level design decisions - for American Fuzzy Lop. It's adopted from a discussion with Rob Graham. - See README.md for the general instruction manual, and technical_details.md for - additional implementation-level insights. - -## 1) Influences - -In short, `afl-fuzz` is inspired chiefly by the work done by Tavis Ormandy back -in 2007. Tavis did some very persuasive experiments using `gcov` block coverage -to select optimal test cases out of a large corpus of data, and then using -them as a starting point for traditional fuzzing workflows. - -(By "persuasive", I mean: netting a significant number of interesting -vulnerabilities.) - -In parallel to this, both Tavis and I were interested in evolutionary fuzzing. -Tavis had his experiments, and I was working on a tool called bunny-the-fuzzer, -released somewhere in 2007. - -Bunny used a generational algorithm not much different from `afl-fuzz`, but -also tried to reason about the relationship between various input bits and -the internal state of the program, with hopes of deriving some additional value -from that. The reasoning / correlation part was probably in part inspired by -other projects done around the same time by Will Drewry and Chris Evans. - -The state correlation approach sounded very sexy on paper, but ultimately, made -the fuzzer complicated, brittle, and cumbersome to use; every other target -program would require a tweak or two. Because Bunny didn't fare a whole lot -better than less sophisticated brute-force tools, I eventually decided to write -it off. You can still find its original documentation at: - - https://code.google.com/p/bunny-the-fuzzer/wiki/BunnyDoc - -There has been a fair amount of independent work, too. Most notably, a few -weeks earlier that year, Jared DeMott had a Defcon presentation about a -coverage-driven fuzzer that relied on coverage as a fitness function. - -Jared's approach was by no means identical to what afl-fuzz does, but it was in -the same ballpark. His fuzzer tried to explicitly solve for the maximum coverage -with a single input file; in comparison, afl simply selects for cases that do -something new (which yields better results - see [technical_details.md](technical_details.md)). - -A few years later, Gabriel Campana released fuzzgrind, a tool that relied purely -on Valgrind and a constraint solver to maximize coverage without any brute-force -bits; and Microsoft Research folks talked extensively about their still -non-public, solver-based SAGE framework. - -In the past six years or so, I've also seen a fair number of academic papers -that dealt with smart fuzzing (focusing chiefly on symbolic execution) and a -couple papers that discussed proof-of-concept applications of genetic -algorithms with the same goals in mind. I'm unconvinced how practical most of -these experiments were; I suspect that many of them suffer from the -bunny-the-fuzzer's curse of being cool on paper and in carefully designed -experiments, but failing the ultimate test of being able to find new, -worthwhile security bugs in otherwise well-fuzzed, real-world software. - -In some ways, the baseline that the "cool" solutions have to compete against is -a lot more impressive than it may seem, making it difficult for competitors to -stand out. For a singular example, check out the work by Gynvael and Mateusz -Jurczyk, applying "dumb" fuzzing to ffmpeg, a prominent and security-critical -component of modern browsers and media players: - - http://googleonlinesecurity.blogspot.com/2014/01/ffmpeg-and-thousand-fixes.html - -Effortlessly getting comparable results with state-of-the-art symbolic execution -in equally complex software still seems fairly unlikely, and hasn't been -demonstrated in practice so far. - -But I digress; ultimately, attribution is hard, and glorying the fundamental -concepts behind AFL is probably a waste of time. The devil is very much in the -often-overlooked details, which brings us to... - -## 2. Design goals for afl-fuzz - -In short, I believe that the current implementation of afl-fuzz takes care of -several itches that seemed impossible to scratch with other tools: - -1) Speed. It's genuinely hard to compete with brute force when your "smart" - approach is resource-intensive. If your instrumentation makes it 10x more - likely to find a bug, but runs 100x slower, your users are getting a bad - deal. - - To avoid starting with a handicap, `afl-fuzz` is meant to let you fuzz most of - the intended targets at roughly their native speed - so even if it doesn't - add value, you do not lose much. - - On top of this, the tool leverages instrumentation to actually reduce the - amount of work in a couple of ways: for example, by carefully trimming the - corpus or skipping non-functional but non-trimmable regions in the input - files. - -2) Rock-solid reliability. It's hard to compete with brute force if your - approach is brittle and fails unexpectedly. Automated testing is attractive - because it's simple to use and scalable; anything that goes against these - principles is an unwelcome trade-off and means that your tool will be used - less often and with less consistent results. - - Most of the approaches based on symbolic execution, taint tracking, or - complex syntax-aware instrumentation are currently fairly unreliable with - real-world targets. Perhaps more importantly, their failure modes can render - them strictly worse than "dumb" tools, and such degradation can be difficult - for less experienced users to notice and correct. - - In contrast, `afl-fuzz` is designed to be rock solid, chiefly by keeping it - simple. In fact, at its core, it's designed to be just a very good - traditional fuzzer with a wide range of interesting, well-researched - strategies to go by. The fancy parts just help it focus the effort in - places where it matters the most. - -3) Simplicity. The author of a testing framework is probably the only person - who truly understands the impact of all the settings offered by the tool - - and who can dial them in just right. Yet, even the most rudimentary fuzzer - frameworks often come with countless knobs and fuzzing ratios that need to - be guessed by the operator ahead of the time. This can do more harm than - good. - - AFL is designed to avoid this as much as possible. The three knobs you - can play with are the output file, the memory limit, and the ability to - override the default, auto-calibrated timeout. The rest is just supposed to - work. When it doesn't, user-friendly error messages outline the probable - causes and workarounds, and get you back on track right away. - -4) Chainability. Most general-purpose fuzzers can't be easily employed - against resource-hungry or interaction-heavy tools, necessitating the - creation of custom in-process fuzzers or the investment of massive CPU - power (most of which is wasted on tasks not directly related to the code - we actually want to test). - - AFL tries to scratch this itch by allowing users to use more lightweight - targets (e.g., standalone image parsing libraries) to create small - corpora of interesting test cases that can be fed into a manual testing - process or a UI harness later on. - -As mentioned in [technical_details.md](technical_details.md), AFL does all this not by systematically -applying a single overarching CS concept, but by experimenting with a variety -of small, complementary methods that were shown to reliably yields results -better than chance. The use of instrumentation is a part of that toolkit, but is -far from being the most important one. - -Ultimately, what matters is that `afl-fuzz` is designed to find cool bugs - and -has a pretty robust track record of doing just that. diff --git a/docs/notes_for_asan.md b/docs/notes_for_asan.md deleted file mode 100644 index f55aeaf2..00000000 --- a/docs/notes_for_asan.md +++ /dev/null @@ -1,157 +0,0 @@ -# Notes for using ASAN with afl-fuzz - - This file discusses some of the caveats for fuzzing under ASAN, and suggests - a handful of alternatives. See README.md for the general instruction manual. - -## 1) Short version - -ASAN on 64-bit systems requests a lot of memory in a way that can't be easily -distinguished from a misbehaving program bent on crashing your system. - -Because of this, fuzzing with ASAN is recommended only in four scenarios: - - - On 32-bit systems, where we can always enforce a reasonable memory limit - (-m 800 or so is a good starting point), - - - On 64-bit systems only if you can do one of the following: - - - Compile the binary in 32-bit mode (gcc -m32), - - - Precisely gauge memory needs using http://jwilk.net/software/recidivm . - - - Limit the memory available to process using cgroups on Linux (see - utils/asan_cgroups). - -To compile with ASAN, set AFL_USE_ASAN=1 before calling 'make clean all'. The -afl-gcc / afl-clang wrappers will pick that up and add the appropriate flags. -Note that ASAN is incompatible with -static, so be mindful of that. - -(You can also use AFL_USE_MSAN=1 to enable MSAN instead.) - -When compiling with AFL_USE_LSAN, the leak sanitizer will normally run -when the program exits. In order to utilize this check at different times, -such as at the end of a loop, you may use the macro __AFL_LEAK_CHECK();. -This macro will report a crash in afl-fuzz if any memory is left leaking -at this stage. You can also use LSAN_OPTIONS and a supressions file -for more fine-tuned checking, however make sure you keep exitcode=23. - -NOTE: if you run several secondary instances, only one should run the target -compiled with ASAN (and UBSAN, CFISAN), the others should run the target with -no sanitizers compiled in. - -There is also the option of generating a corpus using a non-ASAN binary, and -then feeding it to an ASAN-instrumented one to check for bugs. This is faster, -and can give you somewhat comparable results. You can also try using -libdislocator (see [utils/libdislocator/README.dislocator.md](../utils/libdislocator/README.dislocator.md) in the parent directory) as a -lightweight and hassle-free (but less thorough) alternative. - -## 2) Long version - -ASAN allocates a huge region of virtual address space for bookkeeping purposes. -Most of this is never actually accessed, so the OS never has to allocate any -real pages of memory for the process, and the VM grabbed by ASAN is essentially -"free" - but the mapping counts against the standard OS-enforced limit -(RLIMIT_AS, aka ulimit -v). - -On our end, afl-fuzz tries to protect you from processes that go off-rails -and start consuming all the available memory in a vain attempt to parse a -malformed input file. This happens surprisingly often, so enforcing such a limit -is important for almost any fuzzer: the alternative is for the kernel OOM -handler to step in and start killing random processes to free up resources. -Needless to say, that's not a very nice prospect to live with. - -Unfortunately, un*x systems offer no portable way to limit the amount of -pages actually given to a process in a way that distinguishes between that -and the harmless "land grab" done by ASAN. In principle, there are three standard -ways to limit the size of the heap: - - - The RLIMIT_AS mechanism (ulimit -v) caps the size of the virtual space - - but as noted, this pays no attention to the number of pages actually - in use by the process, and doesn't help us here. - - - The RLIMIT_DATA mechanism (ulimit -d) seems like a good fit, but it applies - only to the traditional sbrk() / brk() methods of requesting heap space; - modern allocators, including the one in glibc, routinely rely on mmap() - instead, and circumvent this limit completely. - - - Finally, the RLIMIT_RSS limit (ulimit -m) sounds like what we need, but - doesn't work on Linux - mostly because nobody felt like implementing it. - -There are also cgroups, but they are Linux-specific, not universally available -even on Linux systems, and they require root permissions to set up; I'm a bit -hesitant to make afl-fuzz require root permissions just for that. That said, -if you are on Linux and want to use cgroups, check out the contributed script -that ships in utils/asan_cgroups/. - -In settings where cgroups aren't available, we have no nice, portable way to -avoid counting the ASAN allocation toward the limit. On 32-bit systems, or for -binaries compiled in 32-bit mode (-m32), this is not a big deal: ASAN needs -around 600-800 MB or so, depending on the compiler - so all you need to do is -to specify -m that is a bit higher than that. - -On 64-bit systems, the situation is more murky, because the ASAN allocation -is completely outlandish - around 17.5 TB in older versions, and closer to -20 TB with newest ones. The actual amount of memory on your system is -(probably!) just a tiny fraction of that - so unless you dial the limit -with surgical precision, you will get no protection from OOM bugs. - -On my system, the amount of memory grabbed by ASAN with a slightly older -version of gcc is around 17,825,850 MB; for newest clang, it's 20,971,600. -But there is no guarantee that these numbers are stable, and if you get them -wrong by "just" a couple gigs or so, you will be at risk. - -To get the precise number, you can use the recidivm tool developed by Jakub -Wilk (http://jwilk.net/software/recidivm). In absence of this, ASAN is *not* -recommended when fuzzing 64-bit binaries, unless you are confident that they -are robust and enforce reasonable memory limits (in which case, you can -specify '-m none' when calling afl-fuzz). - -Using recidivm or running with no limits aside, there are two other decent -alternatives: build a corpus of test cases using a non-ASAN binary, and then -examine them with ASAN, Valgrind, or other heavy-duty tools in a more -controlled setting; or compile the target program with -m32 (32-bit mode) -if your system supports that. - -## 3) Interactions with the QEMU mode - -ASAN, MSAN, and other sanitizers appear to be incompatible with QEMU user -emulation, so please do not try to use them with the -Q option; QEMU doesn't -seem to appreciate the shadow VM trick used by these tools, and will likely -just allocate all your physical memory, then crash. - -You can, however, use QASan to run binaries that are not instrumented with ASan -under QEMU with the AFL++ instrumentation. - -https://github.com/andreafioraldi/qasan - -## 4) ASAN and OOM crashes - -By default, ASAN treats memory allocation failures as fatal errors, immediately -causing the program to crash. Since this is a departure from normal POSIX -semantics (and creates the appearance of security issues in otherwise -properly-behaving programs), we try to disable this by specifying -allocator_may_return_null=1 in ASAN_OPTIONS. - -Unfortunately, it's been reported that this setting still causes ASAN to -trigger phantom crashes in situations where the standard allocator would -simply return NULL. If this is interfering with your fuzzing jobs, you may -want to cc: yourself on this bug: - - https://bugs.llvm.org/show_bug.cgi?id=22026 - -## 5) What about UBSAN? - -New versions of UndefinedBehaviorSanitizer offers the --fsanitize=undefined-trap-on-error compiler flag that tells UBSan to insert an -istruction that will cause SIGILL (ud2 on x86) when an undefined behaviour -is detected. This is the option that you want to use when combining AFL++ -and UBSan. - -AFL_USE_UBSAN=1 env var will add this compiler flag to afl-clang-fast, -afl-gcc-fast and afl-gcc for you. - -Old versions of UBSAN don't offer a consistent way -to abort() on fault conditions or to terminate with a distinctive exit code -but there are some versions of the library can be binary-patched to address this -issue. You can also preload a shared library that substitute all the UBSan -routines used to report errors with abort(). diff --git a/docs/perf_tips.md b/docs/perf_tips.md index c5968206..7c14cbbc 100644 --- a/docs/perf_tips.md +++ b/docs/perf_tips.md @@ -48,13 +48,9 @@ be then manually fed to a more resource-hungry program later on. Also note that reading the fuzzing input via stdin is faster than reading from a file. -## 3. Use LLVM instrumentation +## 3. Use LLVM persistent instrumentation -When fuzzing slow targets, you can gain 20-100% performance improvement by -using the LLVM-based instrumentation mode described in [the instrumentation README](../instrumentation/README.llvm.md). -Note that this mode requires the use of clang and will not work with GCC. - -The LLVM mode also offers a "persistent", in-process fuzzing mode that can +The LLVM mode offers a "persistent", in-process fuzzing mode that can work well for certain types of self-contained libraries, and for fast targets, can offer performance gains up to 5-10x; and a "deferred fork server" mode that can offer huge benefits for programs with high startup overhead. Both @@ -138,8 +134,7 @@ misses, or similar factors, but they are less likely to be a concern.) ## 7. Keep memory use and timeouts in check -If you have increased the `-m` or `-t` limits more than truly necessary, consider -dialing them back down. +Consider setting low values for -m and -t. For programs that are nominally very fast, but get sluggish for some inputs, you can also try setting `-t` values that are more punishing than what `afl-fuzz` @@ -164,6 +159,20 @@ There are several OS-level factors that may affect fuzzing speed: - Network filesystems, either used for fuzzer input / output, or accessed by the fuzzed binary to read configuration files (pay special attention to the home directory - many programs search it for dot-files). + - Disable all the spectre, meltdown etc. security countermeasures in the + kernel if your machine is properly separated: + +``` +ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off +no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable +nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off +spectre_v2=off stf_barrier=off +``` + In most Linux distributions you can put this into a `/etc/default/grub` + variable. + +The following list of changes are made when executing `afl-system-config`: + - On-demand CPU scaling. The Linux `ondemand` governor performs its analysis on a particular schedule and is known to underestimate the needs of short-lived processes spawned by `afl-fuzz` (or any other fuzzer). On Linux, @@ -196,26 +205,4 @@ There are several OS-level factors that may affect fuzzing speed: Setting a different scheduling policy for the fuzzer process - say `SCHED_RR` - can usually speed things up, too, but needs to be done with care. - - Use the `afl-system-config` script to set all proc/sys settings above in one go. - - Disable all the spectre, meltdown etc. security countermeasures in the - kernel if your machine is properly separated: - -``` -ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off -no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable -nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off -spectre_v2=off stf_barrier=off -``` - In most Linux distributions you can put this into a `/etc/default/grub` - variable. - -## 9. If all other options fail, use `-d` - -For programs that are genuinely slow, in cases where you really can't escape -using huge input files, or when you simply want to get quick and dirty results -early on, you can always resort to the `-d` mode. -The mode causes `afl-fuzz` to skip all the deterministic fuzzing steps, which -makes output a lot less neat and can ultimately make the testing a bit less -in-depth, but it will give you an experience more familiar from other fuzzing -tools. diff --git a/docs/power_schedules.md b/docs/power_schedules.md deleted file mode 100644 index 493f9609..00000000 --- a/docs/power_schedules.md +++ /dev/null @@ -1,32 +0,0 @@ -# afl++'s power schedules based on AFLfast - -<a href="https://mboehme.github.io/paper/CCS16.pdf"><img src="https://mboehme.github.io/paper/CCS16.png" align="right" width="250"></a> -Power schedules implemented by Marcel Böhme \<marcel.boehme@acm.org\>. -AFLFast is an extension of AFL which is written and maintained by -Michal Zalewski \<lcamtuf@google.com\>. - -AFLfast has helped in the success of Team Codejitsu at the finals of the DARPA Cyber Grand Challenge where their bot Galactica took **2nd place** in terms of #POVs proven (see red bar at https://www.cybergrandchallenge.com/event#results). AFLFast exposed several previously unreported CVEs that could not be exposed by AFL in 24 hours and otherwise exposed vulnerabilities significantly faster than AFL while generating orders of magnitude more unique crashes. - -Essentially, we observed that most generated inputs exercise the same few "high-frequency" paths and developed strategies to gravitate towards low-frequency paths, to stress significantly more program behavior in the same amount of time. We devised several **search strategies** that decide in which order the seeds should be fuzzed and **power schedules** that smartly regulate the number of inputs generated from a seed (i.e., the time spent fuzzing a seed). We call the number of inputs generated from a seed, the seed's **energy**. - -We find that AFL's exploitation-based constant schedule assigns **too much energy to seeds exercising high-frequency paths** (e.g., paths that reject invalid inputs) and not enough energy to seeds exercising low-frequency paths (e.g., paths that stress interesting behaviors). Technically, we modified the computation of a seed's performance score (`calculate_score`), which seed is marked as favourite (`update_bitmap_score`), and which seed is chosen next from the circular queue (`main`). We implemented the following schedules (in the order of their effectiveness, best first): - -| AFL flag | Power Schedule | -| ------------- | -------------------------- | -| `-p explore` | 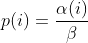 | -| `-p fast` (default)| 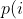=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | -| `-p coe` | 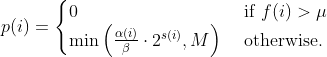 | -| `-p quad` | 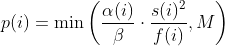 | -| `-p lin` | 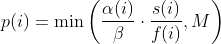 | -| `-p exploit` (AFL) | 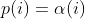 | -| `-p mmopt` | Experimental: `explore` with no weighting to runtime and increased weighting on the last 5 queue entries | -| `-p rare` | Experimental: `rare` puts focus on queue entries that hit rare edges | -| `-p seek` | Experimental: `seek` is EXPLORE but ignoring the runtime of the queue input and less focus on the size | -where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path. - -More details can be found in the paper that was accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). - -PS: In parallel mode (several instances with shared queue), we suggest to run the main node using the exploit schedule (-p exploit) and the secondary nodes with a combination of cut-off-exponential (-p coe), exponential (-p fast; default), and explore (-p explore) schedules. In single mode, the default settings will do. **EDIT:** In parallel mode, AFLFast seems to perform poorly because the path probability estimates are incorrect for the imported seeds. Pull requests to fix this issue by syncing the estimates across instances are appreciated :) - -Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved. -Released under terms and conditions of Apache License, Version 2.0. diff --git a/docs/technical_details.md b/docs/technical_details.md index a0453c91..6a4660a2 100644 --- a/docs/technical_details.md +++ b/docs/technical_details.md @@ -1,5 +1,9 @@ # Technical "whitepaper" for afl-fuzz + +NOTE: this document is rather outdated! + + This document provides a quick overview of the guts of American Fuzzy Lop. See README.md for the general instruction manual; and for a discussion of motivations and design goals behind AFL, see historical_notes.md. diff --git a/instrumentation/afl-compiler-rt.o.c b/instrumentation/afl-compiler-rt.o.c index 3f518b55..b01ea987 100644 --- a/instrumentation/afl-compiler-rt.o.c +++ b/instrumentation/afl-compiler-rt.o.c @@ -299,8 +299,9 @@ static void __afl_map_shm(void) { if (!getenv("AFL_QUIET")) fprintf(stderr, - "Warning: AFL++ tools will need to set AFL_MAP_SIZE to %u " - "to be able to run this instrumented program!\n", + "Warning: AFL++ tools might need to set AFL_MAP_SIZE to %u " + "to be able to run this instrumented program if this " + "crashes!\n", __afl_final_loc); } |