
diff options
| author | van Hauser <vh@thc.org> | 2019-05-29 14:10:37 +0200 |
|---|---|---|
| committer | van Hauser <vh@thc.org> | 2019-05-29 14:10:37 +0200 |
| commit | dacb2821b3a267b336b4465a24e1de22033ea279 (patch) | |
| tree | f1ac208668829667845271f1ce923c582c24fdd6 | |
| parent | dfa0c9cfd1ec4bea84ea399e25889b5fc93c648b (diff) | |
| download | afl++-dacb2821b3a267b336b4465a24e1de22033ea279.tar.gz | |
added AFLfast power schedules from Marcel Boehme and updated the documenation
| -rw-r--r-- | afl-fuzz.c | 214 | ||||
| -rw-r--r-- | config.h | 4 | ||||
| -rw-r--r-- | docs/ChangeLog | 3 | ||||
| -rw-r--r-- | docs/README | 6 | ||||
| -rw-r--r-- | docs/parallel_fuzzing.txt | 7 | ||||
| -rw-r--r-- | docs/power_schedules.txt | 33 |
6 files changed, 231 insertions, 36 deletions
diff --git a/afl-fuzz.c b/afl-fuzz.c index 6bd6f79d..ca3c8dee 100644 --- a/afl-fuzz.c +++ b/afl-fuzz.c @@ -100,6 +100,17 @@ EXP_ST u64 mem_limit = MEM_LIMIT; /* Memory cap for child (MB) */ static u32 stats_update_freq = 1; /* Stats update frequency (execs) */ +enum { + /* 00 */ EXPLORE, /* AFL default, Exploration-based constant schedule */ + /* 01 */ FAST, /* Exponential schedule */ + /* 02 */ COE, /* Cut-Off Exponential schedule */ + /* 03 */ LIN, /* Linear schedule */ + /* 04 */ QUAD, /* Quadratic schedule */ + /* 05 */ EXPLOIT /* AFL's exploitation-based const. */ +}; + +static u8 schedule = EXPLORE; /* Power schedule (default: EXPLORE)*/ + EXP_ST u8 skip_deterministic, /* Skip deterministic stages? */ force_deterministic, /* Force deterministic stages? */ use_splicing, /* Recombine input files? */ @@ -232,7 +243,6 @@ struct queue_entry { u8 cal_failed, /* Calibration failed? */ trim_done, /* Trimmed? */ - was_fuzzed, /* Had any fuzzing done yet? */ passed_det, /* Deterministic stages passed? */ has_new_cov, /* Triggers new coverage? */ var_behavior, /* Variable behavior? */ @@ -240,10 +250,12 @@ struct queue_entry { fs_redundant; /* Marked as redundant in the fs? */ u32 bitmap_size, /* Number of bits set in bitmap */ + fuzz_level, /* Number of fuzzing iterations */ exec_cksum; /* Checksum of the execution trace */ u64 exec_us, /* Execution time (us) */ handicap, /* Number of queue cycles behind */ + n_fuzz, /* Number of fuzz, does not overflow */ depth; /* Path depth */ u8* trace_mini; /* Trace bytes, if kept */ @@ -783,6 +795,7 @@ static void add_to_queue(u8* fname, u32 len, u8 passed_det) { q->len = len; q->depth = cur_depth + 1; q->passed_det = passed_det; + q->n_fuzz = 1; if (q->depth > max_depth) max_depth = q->depth; @@ -1225,6 +1238,18 @@ static void minimize_bits(u8* dst, u8* src) { } +/* Find first power of two greater or equal to val (assuming val under + 2^63). */ + +static u64 next_p2(u64 val) { + + u64 ret = 1; + while (val > ret) ret <<= 1; + return ret; + +} + + /* When we bump into a new path, we call this to see if the path appears more "favorable" than any of the existing ones. The purpose of the "favorables" is to have a minimal set of paths that trigger all the bits @@ -1239,6 +1264,7 @@ static void update_bitmap_score(struct queue_entry* q) { u32 i; u64 fav_factor = q->exec_us * q->len; + u64 fuzz_p2 = next_p2 (q->n_fuzz); /* For every byte set in trace_bits[], see if there is a previous winner, and how it compares to us. */ @@ -1249,7 +1275,15 @@ static void update_bitmap_score(struct queue_entry* q) { if (top_rated[i]) { - /* Faster-executing or smaller test cases are favored. */ + u64 top_rated_fuzz_p2 = next_p2 (top_rated[i]->n_fuzz); + u64 top_rated_fav_factor = top_rated[i]->exec_us * top_rated[i]->len; + + if (fuzz_p2 > top_rated_fuzz_p2) { + continue; + } else if (fuzz_p2 == top_rated_fuzz_p2) { + if (fav_factor > top_rated_fav_factor) + continue; + } if (fav_factor > top_rated[i]->exec_us * top_rated[i]->len) continue; @@ -1325,7 +1359,7 @@ static void cull_queue(void) { top_rated[i]->favored = 1; queued_favored++; - if (!top_rated[i]->was_fuzzed) pending_favored++; + if (top_rated[i]->fuzz_level == 0) pending_favored++; } @@ -3123,6 +3157,18 @@ static u8 save_if_interesting(char** argv, void* mem, u32 len, u8 fault) { s32 fd; u8 keeping = 0, res; + /* Update path frequency. */ + u32 cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST); + + struct queue_entry* q = queue; + while (q) { + if (q->exec_cksum == cksum) + q->n_fuzz = q->n_fuzz + 1; + + q = q->next; + + } + if (fault == crash_mode) { /* Keep only if there are new bits in the map, add to queue for @@ -3151,7 +3197,7 @@ static u8 save_if_interesting(char** argv, void* mem, u32 len, u8 fault) { queued_with_cov++; } - queue_top->exec_cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST); + queue_top->exec_cksum = cksum; /* Try to calibrate inline; this also calls update_bitmap_score() when successful. */ @@ -4101,8 +4147,8 @@ static void show_stats(void) { together, but then cram them into a fixed-width field - so we need to put them in a temporary buffer first. */ - sprintf(tmp, "%s%s (%0.02f%%)", DI(current_entry), - queue_cur->favored ? "" : "*", + sprintf(tmp, "%s%s%d (%0.02f%%)", DI(current_entry), + queue_cur->favored ? "." : "*", queue_cur->fuzz_level, ((double)current_entry * 100) / queued_paths); SAYF(bV bSTOP " now processing : " cRST "%-17s " bSTG bV bSTOP, tmp); @@ -4452,18 +4498,6 @@ static void show_init_stats(void) { } -/* Find first power of two greater or equal to val (assuming val under - 2^31). */ - -static u32 next_p2(u32 val) { - - u32 ret = 1; - while (val > ret) ret <<= 1; - return ret; - -} - - /* Trim all new test cases to save cycles when doing deterministic checks. The trimmer uses power-of-two increments somewhere between 1/16 and 1/1024 of file size, to keep the stage short and sweet. */ @@ -4746,6 +4780,67 @@ static u32 calculate_score(struct queue_entry* q) { } + u64 fuzz = q->n_fuzz; + u64 fuzz_total; + + u32 n_paths, fuzz_mu; + u32 factor = 1; + + switch (schedule) { + + case EXPLORE: + break; + + case EXPLOIT: + factor = MAX_FACTOR; + break; + + case COE: + fuzz_total = 0; + n_paths = 0; + + struct queue_entry *queue_it = queue; + while (queue_it) { + fuzz_total += queue_it->n_fuzz; + n_paths ++; + queue_it = queue_it->next; + } + + fuzz_mu = fuzz_total / n_paths; + if (fuzz <= fuzz_mu) { + if (q->fuzz_level < 16) + factor = ((u32) (1 << q->fuzz_level)); + else + factor = MAX_FACTOR; + } else { + factor = 0; + } + break; + + case FAST: + if (q->fuzz_level < 16) { + factor = ((u32) (1 << q->fuzz_level)) / (fuzz == 0 ? 1 : fuzz); + } else + factor = MAX_FACTOR / (fuzz == 0 ? 1 : next_p2 (fuzz)); + break; + + case LIN: + factor = q->fuzz_level / (fuzz == 0 ? 1 : fuzz); + break; + + case QUAD: + factor = q->fuzz_level * q->fuzz_level / (fuzz == 0 ? 1 : fuzz); + break; + + default: + PFATAL ("Unkown Power Schedule"); + } + if (factor > MAX_FACTOR) + factor = MAX_FACTOR; + + perf_score *= factor / POWER_BETA; + + /* Make sure that we don't go over limit. */ if (perf_score > HAVOC_MAX_MULT * 100) perf_score = HAVOC_MAX_MULT * 100; @@ -4972,7 +5067,7 @@ static u8 fuzz_one(char** argv) { possibly skip to them at the expense of already-fuzzed or non-favored cases. */ - if ((queue_cur->was_fuzzed || !queue_cur->favored) && + if ((queue_cur->fuzz_level > 0 || !queue_cur->favored) && UR(100) < SKIP_TO_NEW_PROB) return 1; } else if (!dumb_mode && !queue_cur->favored && queued_paths > 10) { @@ -4981,7 +5076,7 @@ static u8 fuzz_one(char** argv) { The odds of skipping stuff are higher for already-fuzzed inputs and lower for never-fuzzed entries. */ - if (queue_cycle > 1 && !queue_cur->was_fuzzed) { + if (queue_cycle > 1 && queue_cur->fuzz_level == 0) { if (UR(100) < SKIP_NFAV_NEW_PROB) return 1; @@ -5081,11 +5176,20 @@ static u8 fuzz_one(char** argv) { orig_perf = perf_score = calculate_score(queue_cur); - /* Skip right away if -d is given, if we have done deterministic fuzzing on - this entry ourselves (was_fuzzed), or if it has gone through deterministic - testing in earlier, resumed runs (passed_det). */ + if (perf_score == 0) goto abandon_entry; + + /* Skip right away if -d is given, if it has not been chosen sufficiently + often to warrant the expensive deterministic stage (fuzz_level), or + if it has gone through deterministic testing in earlier, resumed runs + (passed_det). */ - if (skip_deterministic || queue_cur->was_fuzzed || queue_cur->passed_det) + if (skip_deterministic + || ((!queue_cur->passed_det) + && perf_score < ( + queue_cur->depth * 30 <= HAVOC_MAX_MULT * 100 + ? queue_cur->depth * 30 + : HAVOC_MAX_MULT * 100)) + || queue_cur->passed_det) goto havoc_stage; /* Skip deterministic fuzzing if exec path checksum puts this out of scope @@ -6610,12 +6714,13 @@ abandon_entry: /* Update pending_not_fuzzed count if we made it through the calibration cycle and have not seen this entry before. */ - if (!stop_soon && !queue_cur->cal_failed && !queue_cur->was_fuzzed) { - queue_cur->was_fuzzed = 1; + if (!stop_soon && !queue_cur->cal_failed && queue_cur->fuzz_level == 0) { pending_not_fuzzed--; if (queue_cur->favored) pending_favored--; } + queue_cur->fuzz_level++; + munmap(orig_in, queue_cur->len); if (in_buf != orig_in) ck_free(in_buf); @@ -7052,26 +7157,24 @@ static void usage(u8* argv0) { SAYF("\n%s [ options ] -- /path/to/fuzzed_app [ ... ]\n\n" - "Required parameters:\n\n" - + "Required parameters:\n" " -i dir - input directory with test cases\n" " -o dir - output directory for fuzzer findings\n\n" - "Execution control settings:\n\n" - + "Execution control settings:\n" + " -p schedule - power schedules recompute a seed's performance score.\n" + " <explore (default), fast, coe, lin, quad, or exploit>\n" " -f file - location read by the fuzzed program (stdin)\n" " -t msec - timeout for each run (auto-scaled, 50-%u ms)\n" " -m megs - memory limit for child process (%u MB)\n" " -Q - use binary-only instrumentation (QEMU mode)\n\n" - "Fuzzing behavior settings:\n\n" - + "Fuzzing behavior settings:\n" " -d - quick & dirty mode (skips deterministic steps)\n" " -n - fuzz without instrumentation (dumb mode)\n" " -x dir - optional fuzzer dictionary (see README)\n\n" - "Other stuff:\n\n" - + "Other stuff:\n" " -T text - text banner to show on the screen\n" " -M / -S id - distributed mode (see parallel_fuzzing.txt)\n" " -C - crash exploration mode (the peruvian rabbit thing)\n" @@ -7714,6 +7817,14 @@ static void save_cmdline(u32 argc, char** argv) { } +int stricmp(char const *a, char const *b) { + int d; + for (;; a++, b++) { + d = tolower(*a) - tolower(*b); + if (d != 0 || !*a) + return d; + } +} #ifndef AFL_LIB @@ -7732,17 +7843,38 @@ int main(int argc, char** argv) { struct timeval tv; struct timezone tz; - SAYF(cCYA "afl-fuzz" VERSION cRST " by <lcamtuf@google.com>\n"); + SAYF(cCYA "afl-fuzz" VERSION cRST " by <lcamtuf@google.com>, schedules by <marcel.boehme@acm.org>\n"); doc_path = access(DOC_PATH, F_OK) ? "docs" : DOC_PATH; gettimeofday(&tv, &tz); srandom(tv.tv_sec ^ tv.tv_usec ^ getpid()); - while ((opt = getopt(argc, argv, "+i:o:f:m:t:T:dnCB:S:M:x:Qe:")) > 0) + while ((opt = getopt(argc, argv, "+i:o:f:m:t:T:dnCB:S:M:x:Qe:p:")) > 0) switch (opt) { + case 'p': /* Power schedule */ + + if (!stricmp(optarg, "fast")) { + schedule = FAST; + } else if (!stricmp(optarg, "coe")) { + schedule = COE; + } else if (!stricmp(optarg, "exploit")) { + schedule = EXPLOIT; + } else if (!stricmp(optarg, "lin")) { + schedule = LIN; + } else if (!stricmp(optarg, "quad")) { + schedule = QUAD; + } else if (!stricmp(optarg, "explore")) { + schedule = EXPLORE; + } else { + FATAL("Unknown -p power schedule"); + } + + break; + + case 'e': if (file_extension) FATAL("Multiple -e options not supported"); @@ -7946,6 +8078,16 @@ int main(int argc, char** argv) { } + switch (schedule) { + case FAST: OKF ("Using exponential power schedule (FAST)"); break; + case COE: OKF ("Using cut-off exponential power schedule (COE)"); break; + case EXPLOIT: OKF ("Using exploitation-based constant power schedule (EXPLOIT)"); break; + case LIN: OKF ("Using linear power schedule (LIN)"); break; + case QUAD: OKF ("Using quadratic power schedule (QUAD)"); break; + case EXPLORE: OKF ("Using exploration-based constant power schedule (EXPLORE)"); break; + default : FATAL ("Unkown power schedule"); break; + } + if (getenv("AFL_NO_FORKSRV")) no_forkserver = 1; if (getenv("AFL_NO_CPU_RED")) no_cpu_meter_red = 1; if (getenv("AFL_NO_ARITH")) no_arith = 1; diff --git a/config.h b/config.h index 61ba393e..2ae510ea 100644 --- a/config.h +++ b/config.h @@ -88,6 +88,10 @@ #define HAVOC_MIN 16 +/* Power Schedule Divisor */ +#define POWER_BETA 1 +#define MAX_FACTOR (POWER_BETA * 32) + /* Maximum stacking for havoc-stage tweaks. The actual value is calculated like this: diff --git a/docs/ChangeLog b/docs/ChangeLog index e0db8b71..558bb427 100644 --- a/docs/ChangeLog +++ b/docs/ChangeLog @@ -23,6 +23,9 @@ Version ++2.52c (2019-05-28): afl-fuzz: -e EXTENSION commandline option llvm_mode: LAF-intel performance (needs activation, see llvm/README.laf-intel) a few new environment variables for afl-fuzz, llvm and qemu, see docs/env_variables.txt + - Added the power schedules of AFLfast by Marcel Boehme, but set the default + to the AFL schedule, not to the FAST schedule. So nothing changes unless + you use the new -p option :-) - see docs/power_schedules.txt - added afl-system-config script to set all system performance options for fuzzing diff --git a/docs/README b/docs/README index 3f8ae63e..2351f3ae 100644 --- a/docs/README +++ b/docs/README @@ -13,6 +13,12 @@ american fuzzy lop plus plus based on community patches from https://github.com/vanhauser-thc/afl-patches To see the list of which patches have been applied, see the PATCHES file. + Additionally AFLfast's power schedules by Marcel Boehme from + github.com/mboehme/aflfast have been incorporated. + + So all in all this is the best-of AFL that is currently out there :-) + + Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved. Released under terms and conditions of Apache License, Version 2.0. diff --git a/docs/parallel_fuzzing.txt b/docs/parallel_fuzzing.txt index 58f8d2f4..1e65c01f 100644 --- a/docs/parallel_fuzzing.txt +++ b/docs/parallel_fuzzing.txt @@ -26,6 +26,13 @@ that input to guide their work. To help with this problem, afl-fuzz offers a simple way to synchronize test cases on the fly. +Note that afl++ has AFLfast's power schedules implemented. +It is therefore a good idea to use different power schedules if you run +several instances in parallel. See docs/power_schedules.txt + +Alternatively running other AFL spinoffs in parallel can be of value, +e.g. Angora (https://github.com/AngoraFuzzer/Angora/) + 2) Single-system parallelization -------------------------------- diff --git a/docs/power_schedules.txt b/docs/power_schedules.txt new file mode 100644 index 00000000..578ff020 --- /dev/null +++ b/docs/power_schedules.txt @@ -0,0 +1,33 @@ +This document was copied and modified from AFLfast at github.com/mboehme/aflfast + + +Essentially, we observed that most generated inputs exercise the same few +"high-frequency" paths and developed strategies to gravitate towards +low-frequency paths, to stress significantly more program behavior in the +same amount of time. We devised several **search strategies** that decide +in which order the seeds should be fuzzed and **power schedules** that +smartly regulate the number of inputs generated from a seed (i.e., the +time spent fuzzing a seed). We call the number of inputs generated from a +seed, the seed's **energy**. + +Old AFL used -p exploit which had a too high cost, current AFL uses -p explore. + +AFLfast implemented 4 new power schedules which are highly recommended to run +in parallel. + +| AFL flag | Power Schedule | +| ------------- | -------------------------- | +| `-p fast` (default)| 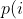=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | +| `-p coe` | 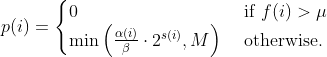 | +| `-p explore` | 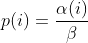 | +| `-p quad` | 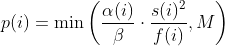 | +| `-p lin` | 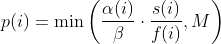 | +| `-p exploit` (AFL) | 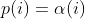 | +where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path. + +More details can be found in our paper that was recently accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). + +PS: In parallel mode (several instances with shared queue), we suggest to run the master using the exploit schedule (-p exploit) and the slaves with a combination of cut-off-exponential (-p coe), exponential (-p fast; default), and explore (-p explore) schedules. In single mode, the default settings will do. **EDIT:** In parallel mode, AFLFast seems to perform poorly because the path probability estimates are incorrect for the imported seeds. Pull requests to fix this issue by syncing the estimates accross instances are appreciated :) + +Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved. +Released under terms and conditions of Apache License, Version 2.0. |