
diff options
| author | van Hauser <vh@thc.org> | 2020-03-17 21:42:36 +0100 |
|---|---|---|
| committer | van Hauser <vh@thc.org> | 2020-03-17 21:42:36 +0100 |
| commit | 3aa72429256d0d24d435abd1f641bfce0d4da557 (patch) | |
| tree | de9057b0fa0da27ae8985198e66629ffc7bbec41 | |
| parent | 4009f3a987f652639bacc91a7d8320307165ec72 (diff) | |
| download | afl++-3aa72429256d0d24d435abd1f641bfce0d4da557.tar.gz | |
added mmopt power schedule
| -rw-r--r-- | README.md | 12 | ||||
| -rw-r--r-- | docs/Changelog.md | 8 | ||||
| -rw-r--r-- | docs/power_schedules.md | 1 | ||||
| -rw-r--r-- | include/afl-fuzz.h | 1 | ||||
| -rw-r--r-- | src/afl-fuzz-globals.c | 4 | ||||
| -rw-r--r-- | src/afl-fuzz-queue.c | 49 | ||||
| -rw-r--r-- | src/afl-fuzz.c | 9 |
7 files changed, 52 insertions, 32 deletions
@@ -353,14 +353,16 @@ The available schedules are: - quad - lin - exploit + - mmopt In parallel mode (-M/-S, several instances with shared queue), we suggest to -run the master using the exploit schedule (-p exploit) and the slaves with a -combination of cut-off-exponential (-p coe), exponential (-p fast; default), -and explore (-p explore) schedules. +run the master using the explore or fast schedule (-p explore) and the slaves +with a combination of cut-off-exponential (-p coe), exponential (-p fast), +explore (-p explore) and mmopt (-p mmopt) schedules. If a schedule does +not perform well for a target, restart the slave with a different schedule. -In single mode, using -p fast is usually more beneficial than the default -explore mode. +In single mode, using -p fast is usually slightly more beneficial than the +default explore mode. (We don't want to change the default behaviour of afl, so "fast" has not been made the default mode). diff --git a/docs/Changelog.md b/docs/Changelog.md index 177054e2..e1f3cd7e 100644 --- a/docs/Changelog.md +++ b/docs/Changelog.md @@ -20,17 +20,21 @@ sending a mail to <afl-users+subscribe@googlegroups.com>. - python mutator modules and custom mutator modules now use the same interface and hence the API changed - AFL_AUTORESUME will resume execution without the need to specify `-i -` + - added experimental power schedule -p mmopt that ignores the runtime of + queue entries and gives higher weighting to the last 5 queue entries + it is currently experimental and subject to change but preliminary + results are good - LTO collision free instrumented added in llvm_mode with afl-clang-lto - note that this mode is amazing, but quite some targets won't compile - llvm_mode InsTrim mode: - removed workaround for bug where paths were not instrumented and imported fix by author - made skipping 1 block functions an option and is disable by default, - set AFL_LLVM_INSTRIM_SKIPSINGLEBLOCK=1 to renable this + set AFL_LLVM_INSTRIM_SKIPSINGLEBLOCK=1 to re-enable this - qemu_mode: - qemu_mode now uses solely the internal capstone version to fix builds on modern Linux distributions - - QEMU now logs routines arguments for CmpLog when the target is x86 + - QEMU now logs routine arguments for CmpLog when the target is x86 - afl-tmin: - now supports hang mode `-H` to minimize hangs - fixed potential afl-tmin missbehavior for targets with multiple hangs diff --git a/docs/power_schedules.md b/docs/power_schedules.md index 4026aedf..cdada0f6 100644 --- a/docs/power_schedules.md +++ b/docs/power_schedules.md @@ -19,6 +19,7 @@ We find that AFL's exploitation-based constant schedule assigns **too much energ | `-p quad` | 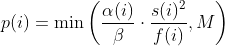 | | `-p lin` | 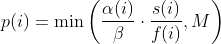 | | `-p exploit` (AFL) | 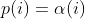 | +| `-p mmopt` | Experimental: `explore` with no weighting to runtime and increased weighting on the last 5 queue entries | where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path. More details can be found in the paper that was accepted at the [23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). diff --git a/include/afl-fuzz.h b/include/afl-fuzz.h index 04a4e5cc..620f5062 100644 --- a/include/afl-fuzz.h +++ b/include/afl-fuzz.h @@ -230,6 +230,7 @@ enum { /* 03 */ LIN, /* Linear schedule */ /* 04 */ QUAD, /* Quadratic schedule */ /* 05 */ EXPLOIT, /* AFL's exploitation-based const. */ + /* 06 */ MMOPT, /* Modified MOPT schedule */ POWER_SCHEDULES_NUM diff --git a/src/afl-fuzz-globals.c b/src/afl-fuzz-globals.c index f9f56e09..efffa749 100644 --- a/src/afl-fuzz-globals.c +++ b/src/afl-fuzz-globals.c @@ -30,8 +30,8 @@ s8 interesting_8[] = {INTERESTING_8}; s16 interesting_16[] = {INTERESTING_8, INTERESTING_16}; s32 interesting_32[] = {INTERESTING_8, INTERESTING_16, INTERESTING_32}; -char *power_names[POWER_SCHEDULES_NUM] = {"explore", "fast", "coe", - "lin", "quad", "exploit"}; +char *power_names[POWER_SCHEDULES_NUM] = {"explore", "fast", "coe", "lin", + "quad", "exploit", "mmopt"}; u8 *doc_path = NULL; /* gath to documentation dir */ diff --git a/src/afl-fuzz-queue.c b/src/afl-fuzz-queue.c index 37d18a2d..cfeab798 100644 --- a/src/afl-fuzz-queue.c +++ b/src/afl-fuzz-queue.c @@ -328,20 +328,24 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { // Longer execution time means longer work on the input, the deeper in // coverage, the better the fuzzing, right? -mh - if (q->exec_us * 0.1 > avg_exec_us) - perf_score = 10; - else if (q->exec_us * 0.25 > avg_exec_us) - perf_score = 25; - else if (q->exec_us * 0.5 > avg_exec_us) - perf_score = 50; - else if (q->exec_us * 0.75 > avg_exec_us) - perf_score = 75; - else if (q->exec_us * 4 < avg_exec_us) - perf_score = 300; - else if (q->exec_us * 3 < avg_exec_us) - perf_score = 200; - else if (q->exec_us * 2 < avg_exec_us) - perf_score = 150; + if (afl->schedule != MMOPT) { + + if (q->exec_us * 0.1 > avg_exec_us) + perf_score = 10; + else if (q->exec_us * 0.25 > avg_exec_us) + perf_score = 25; + else if (q->exec_us * 0.5 > avg_exec_us) + perf_score = 50; + else if (q->exec_us * 0.75 > avg_exec_us) + perf_score = 75; + else if (q->exec_us * 4 < avg_exec_us) + perf_score = 300; + else if (q->exec_us * 3 < avg_exec_us) + perf_score = 200; + else if (q->exec_us * 2 < avg_exec_us) + perf_score = 150; + + } /* Adjust score based on bitmap size. The working theory is that better coverage translates to better targets. Multiplier from 0.25x to 3x. */ @@ -431,12 +435,9 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { break; case FAST: - if (q->fuzz_level < 16) { - + if (q->fuzz_level < 16) factor = ((u32)(1 << q->fuzz_level)) / (fuzz == 0 ? 1 : fuzz); - - } else - + else factor = MAX_FACTOR / (fuzz == 0 ? 1 : next_p2(fuzz)); break; @@ -446,6 +447,12 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { factor = q->fuzz_level * q->fuzz_level / (fuzz == 0 ? 1 : fuzz); break; + case MMOPT: + + if (afl->max_depth - q->depth < 5) perf_score *= 1.5; + + break; + default: PFATAL("Unknown Power Schedule"); } @@ -458,8 +465,8 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { if (afl->limit_time_sig != 0 && afl->max_depth - q->depth < 3) perf_score *= 2; else if (perf_score < 1) - perf_score = - 1; // Add a lower bound to AFLFast's energy assignment strategies + // Add a lower bound to AFLFast's energy assignment strategies + perf_score = 1; /* Make sure that we don't go over limit. */ diff --git a/src/afl-fuzz.c b/src/afl-fuzz.c index 5e2b89ad..fcad0958 100644 --- a/src/afl-fuzz.c +++ b/src/afl-fuzz.c @@ -96,8 +96,8 @@ static void usage(afl_state_t *afl, u8 *argv0, int more_help) { "Execution control settings:\n" " -p schedule - power schedules recompute a seed's performance " "score.\n" - " <explore (default), fast, coe, lin, quad, or " - "exploit>\n" + " <explore (default), fast, coe, lin, quad, exploit, " + "mmopt>\n" " see docs/power_schedules.md\n" " -f file - location read by the fuzzed program (stdin)\n" " -t msec - timeout for each run (auto-scaled, 50-%d ms)\n" @@ -300,6 +300,10 @@ int main(int argc, char **argv_orig, char **envp) { afl->schedule = QUAD; + } else if (!stricmp(optarg, "mopt") || !stricmp(optarg, "mmopt")) { + + afl->schedule = MMOPT; + } else if (!stricmp(optarg, "explore") || !stricmp(optarg, "default") || !stricmp(optarg, "normal") || !stricmp(optarg, "afl")) { @@ -755,6 +759,7 @@ int main(int argc, char **argv_orig, char **envp) { break; case LIN: OKF("Using linear power schedule (LIN)"); break; case QUAD: OKF("Using quadratic power schedule (QUAD)"); break; + case MMOPT: OKF("Using modified MOpt power schedule (MMOPT)"); break; case EXPLORE: OKF("Using exploration-based constant power schedule (EXPLORE)"); break; |