
diff options
| author | richinseattle@gmail.com <richinseattle@gmail.com> | 2021-03-18 01:37:40 -0700 |
|---|---|---|
| committer | richinseattle@gmail.com <richinseattle@gmail.com> | 2021-03-18 01:37:40 -0700 |
| commit | c397becd81229d71b55acf89a31710bead3707aa (patch) | |
| tree | 8306b59e88e22d7090fd786690227dacc99e24e3 | |
| parent | 62508c3b446a893f0afead9a6d0546d53d588a13 (diff) | |
| parent | 94312796f936ba1830b61432a0f958e192dd212f (diff) | |
| download | afl++-c397becd81229d71b55acf89a31710bead3707aa.tar.gz | |
Merge branch 'dev' of https://github.com/AFLplusplus/AFLplusplus into dev
{kind=link}
{kind=link}
431 files changed, 59235 insertions, 21025 deletions
diff --git a/.custom-format.py b/.custom-format.py index 60f6d9c3..346e4b07 100755 --- a/.custom-format.py +++ b/.custom-format.py @@ -29,31 +29,31 @@ CLANG_FORMAT_BIN = os.getenv("CLANG_FORMAT_BIN") if CLANG_FORMAT_BIN is None: o = 0 try: - p = subprocess.Popen(["clang-format-10", "--version"], stdout=subprocess.PIPE) + p = subprocess.Popen(["clang-format-11", "--version"], stdout=subprocess.PIPE) o, _ = p.communicate() o = str(o, "utf-8") o = re.sub(r".*ersion ", "", o) - #o = o[len("clang-format version "):].strip() - o = o[:o.find(".")] + # o = o[len("clang-format version "):].strip() + o = o[: o.find(".")] o = int(o) except: - print ("clang-format-10 is needed. Aborted.") + print("clang-format-11 is needed. Aborted.") exit(1) - #if o < 7: + # if o < 7: # if subprocess.call(['which', 'clang-format-7'], stdout=subprocess.PIPE) == 0: # CLANG_FORMAT_BIN = 'clang-format-7' # elif subprocess.call(['which', 'clang-format-8'], stdout=subprocess.PIPE) == 0: # CLANG_FORMAT_BIN = 'clang-format-8' # elif subprocess.call(['which', 'clang-format-9'], stdout=subprocess.PIPE) == 0: # CLANG_FORMAT_BIN = 'clang-format-9' - # elif subprocess.call(['which', 'clang-format-10'], stdout=subprocess.PIPE) == 0: - # CLANG_FORMAT_BIN = 'clang-format-10' + # elif subprocess.call(['which', 'clang-format-11'], stdout=subprocess.PIPE) == 0: + # CLANG_FORMAT_BIN = 'clang-format-11' # else: # print ("clang-format 7 or above is needed. Aborted.") # exit(1) else: - CLANG_FORMAT_BIN = 'clang-format-10' - + CLANG_FORMAT_BIN = "clang-format-11" + COLUMN_LIMIT = 80 for line in fmt.split("\n"): line = line.split(":") @@ -69,26 +69,47 @@ def custom_format(filename): in_define = False last_line = None out = "" - + for line in src.split("\n"): if line.lstrip().startswith("#"): - if line[line.find("#")+1:].lstrip().startswith("define"): + if line[line.find("#") + 1 :].lstrip().startswith("define"): in_define = True - - if "/*" in line and not line.strip().startswith("/*") and line.endswith("*/") and len(line) < (COLUMN_LIMIT-2): + + if ( + "/*" in line + and not line.strip().startswith("/*") + and line.endswith("*/") + and len(line) < (COLUMN_LIMIT - 2) + ): cmt_start = line.rfind("/*") - line = line[:cmt_start] + " " * (COLUMN_LIMIT-2 - len(line)) + line[cmt_start:] + line = ( + line[:cmt_start] + + " " * (COLUMN_LIMIT - 2 - len(line)) + + line[cmt_start:] + ) define_padding = 0 if last_line is not None and in_define and last_line.endswith("\\"): last_line = last_line[:-1] - define_padding = max(0, len(last_line[last_line.rfind("\n")+1:])) + define_padding = max(0, len(last_line[last_line.rfind("\n") + 1 :])) - if last_line is not None and last_line.strip().endswith("{") and line.strip() != "": + if ( + last_line is not None + and last_line.strip().endswith("{") + and line.strip() != "" + ): line = (" " * define_padding + "\\" if in_define else "") + "\n" + line - elif last_line is not None and last_line.strip().startswith("}") and line.strip() != "": + elif ( + last_line is not None + and last_line.strip().startswith("}") + and line.strip() != "" + ): line = (" " * define_padding + "\\" if in_define else "") + "\n" + line - elif line.strip().startswith("}") and last_line is not None and last_line.strip() != "": + elif ( + line.strip().startswith("}") + and last_line is not None + and last_line.strip() != "" + ): line = (" " * define_padding + "\\" if in_define else "") + "\n" + line if not line.endswith("\\"): @@ -97,14 +118,15 @@ def custom_format(filename): out += line + "\n" last_line = line - return (out) + return out + args = sys.argv[1:] if len(args) == 0: - print ("Usage: ./format.py [-i] <filename>") - print () - print (" The -i option, if specified, let the script to modify in-place") - print (" the source files. By default the results are written to stdout.") + print("Usage: ./format.py [-i] <filename>") + print() + print(" The -i option, if specified, let the script to modify in-place") + print(" the source files. By default the results are written to stdout.") print() exit(1) @@ -120,4 +142,3 @@ for filename in args: f.write(code) else: print(code) - diff --git a/.dockerignore b/.dockerignore new file mode 100644 index 00000000..d05bf1c6 --- /dev/null +++ b/.dockerignore @@ -0,0 +1,65 @@ +.test +.test2 +.sync_tmp +*.o +*.so +*.pyc +*.dSYM +as +ld +in +out +core* +afl-analyze +afl-as +afl-clang +afl-clang\+\+ +afl-clang-fast +afl-clang-fast\+\+ +afl-clang-lto +afl-clang-lto\+\+ +afl-fuzz +afl-g\+\+ +afl-gcc +afl-gcc-fast +afl-g\+\+-fast +afl-gotcpu +afl-ld +afl-ld-lto +afl-qemu-trace +afl-showmap +afl-tmin +afl-analyze.8 +afl-as.8 +afl-clang-fast\+\+.8 +afl-clang-fast.8 +afl-clang-lto.8 +afl-clang-lto\+\+.8 +afl-cmin.8 +afl-cmin.bash.8 +afl-fuzz.8 +afl-gcc.8 +afl-gcc-fast.8 +afl-g\+\+-fast.8 +afl-gotcpu.8 +afl-plot.8 +afl-showmap.8 +afl-system-config.8 +afl-tmin.8 +afl-whatsup.8 +qemu_mode/libcompcov/compcovtest +qemu_mode/qemu-* +unicorn_mode/samples/*/\.test-* +unicorn_mode/samples/*/output +unicorn_mode/unicornafl +test/unittests/unit_maybe_alloc +test/unittests/unit_preallocable +test/unittests/unit_list +test/unittests/unit_rand +test/unittests/unit_hash +examples/afl_network_proxy/afl-network-server +examples/afl_network_proxy/afl-network-client +examples/afl_frida/afl-frida +examples/afl_frida/libtestinstr.so +examples/afl_frida/frida-gum-example.c +examples/afl_frida/frida-gum.h
\ No newline at end of file diff --git a/.github/ISSUE_TEMPLATE/bug_report.md b/.github/ISSUE_TEMPLATE/bug_report.md new file mode 100644 index 00000000..d62da0a8 --- /dev/null +++ b/.github/ISSUE_TEMPLATE/bug_report.md @@ -0,0 +1,31 @@ +--- +name: Bug report +about: Create a report to help us improve +title: '' +labels: '' +assignees: '' + +--- + +**IMPORTANT** +1. You have verified that the issue to be present in the current `dev` branch +2. Please supply the command line options and relevant environment variables, e.g. a copy-paste of the contents of `out/default/fuzzer_setup` + +Thank you for making afl++ better! + +**Describe the bug** +A clear and concise description of what the bug is. + +**To Reproduce** +Steps to reproduce the behavior: +1. ... +2. ... + +**Expected behavior** +A clear and concise description of what you expected to happen. + +**Screen output/Screenshots** +If applicable, add copy-paste of the screen output or screenshot that shows the issue. Please ensure the output is in **English** and not in Chinese, Russian, German, etc. + +**Additional context** +Add any other context about the problem here. diff --git a/.github/ISSUE_TEMPLATE/feature_request.md b/.github/ISSUE_TEMPLATE/feature_request.md new file mode 100644 index 00000000..bbcbbe7d --- /dev/null +++ b/.github/ISSUE_TEMPLATE/feature_request.md @@ -0,0 +1,20 @@ +--- +name: Feature request +about: Suggest an idea for this project +title: '' +labels: '' +assignees: '' + +--- + +**Is your feature request related to a problem? Please describe.** +A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] + +**Describe the solution you'd like** +A clear and concise description of what you want to happen. + +**Describe alternatives you've considered** +A clear and concise description of any alternative solutions or features you've considered. + +**Additional context** +Add any other context or screenshots about the feature request here. diff --git a/.github/workflows/build_aflplusplus_docker.yaml b/.github/workflows/build_aflplusplus_docker.yaml new file mode 100644 index 00000000..be8d795d --- /dev/null +++ b/.github/workflows/build_aflplusplus_docker.yaml @@ -0,0 +1,27 @@ +name: Publish Docker Images +on: + push: + branches: [ stable ] + paths: + - Dockerfile + pull_request: + branches: [ stable ] + paths: + - Dockerfile +jobs: + push_to_registry: + name: Push Docker images to Dockerhub + runs-on: ubuntu-latest + steps: + - uses: actions/checkout@master + - name: Login to Dockerhub + uses: docker/login-action@v1 + with: + username: ${{ secrets.DOCKER_USERNAME }} + password: ${{ secrets.DOCKER_TOKEN }} + - name: Publish aflpp to Registry + uses: docker/build-push-action@v2 + with: + context: . + push: true + tags: aflplusplus/aflplusplus:latest diff --git a/.github/workflows/ci.yml b/.github/workflows/ci.yml new file mode 100644 index 00000000..8412fcbb --- /dev/null +++ b/.github/workflows/ci.yml @@ -0,0 +1,28 @@ +name: CI + +on: + push: + branches: [ stable, dev ] +# pull_request: +# branches: [ stable, dev ] + +jobs: + build: + runs-on: '${{ matrix.os }}' + strategy: + matrix: + os: [ubuntu-20.04, ubuntu-18.04] + steps: + - uses: actions/checkout@v2 + - name: debug + run: apt-cache search plugin-dev | grep gcc- ; echo ; apt-cache search clang-format- | grep clang-format- + - name: install packages + run: sudo apt-get install -y -m -f --install-suggests build-essential git libtool libtool-bin automake bison libglib2.0-0 clang llvm-dev libc++-dev findutils libcmocka-dev python3-dev python3-setuptools + - name: compiler installed + run: gcc -v ; echo ; clang -v + - name: install gcc plugin + run: sudo apt-get install -y -m -f --install-suggests $(readlink /usr/bin/gcc)-plugin-dev + - name: build afl++ + run: make distrib ASAN_BUILD=1 + - name: run tests + run: sudo -E ./afl-system-config ; export AFL_SKIP_CPUFREQ=1 ; make tests diff --git a/.github/workflows/codeql-analysis.yml b/.github/workflows/codeql-analysis.yml new file mode 100644 index 00000000..e6c166f2 --- /dev/null +++ b/.github/workflows/codeql-analysis.yml @@ -0,0 +1,32 @@ +name: "CodeQL" + +on: + push: + branches: [ stable, dev ] +# pull_request: +# branches: [ stable, dev ] + +jobs: + analyze: + name: Analyze + runs-on: ubuntu-latest + + strategy: + fail-fast: false + matrix: + language: [ 'cpp' ] + + steps: + - name: Checkout repository + uses: actions/checkout@v2 + + - name: Initialize CodeQL + uses: github/codeql-action/init@v1 + with: + languages: ${{ matrix.language }} + + - name: Autobuild + uses: github/codeql-action/autobuild@v1 + + - name: Perform CodeQL Analysis + uses: github/codeql-action/analyze@v1 diff --git a/.github/workflows/rust_custom_mutator.yml b/.github/workflows/rust_custom_mutator.yml new file mode 100644 index 00000000..de2b184a --- /dev/null +++ b/.github/workflows/rust_custom_mutator.yml @@ -0,0 +1,30 @@ +name: Rust Custom Mutators + +on: + push: + branches: [ stable, dev ] + pull_request: + branches: [ stable, dev ] + +jobs: + test: + name: Test Rust Custom Mutator Support + runs-on: '${{ matrix.os }}' + defaults: + run: + working-directory: custom_mutators/rust + strategy: + matrix: + os: [ubuntu-20.04] + steps: + - uses: actions/checkout@v2 + - name: Install Rust Toolchain + uses: actions-rs/toolchain@v1 + with: + toolchain: stable + - name: Check Code Compiles + run: cargo check + - name: Run General Tests + run: cargo test + - name: Run Tests for afl_internals feature flag + run: cd custom_mutator && cargo test --features=afl_internals
\ No newline at end of file @@ -1,15 +1,19 @@ .test .test2 .sync_tmp +.vscode *.o *.so +*.swp *.pyc *.dSYM as +a.out ld in out core* +compile_commands.json afl-analyze afl-as afl-clang @@ -38,7 +42,10 @@ afl-clang-lto++.8 afl-cmin.8 afl-cmin.bash.8 afl-fuzz.8 +afl-c++.8 +afl-cc.8 afl-gcc.8 +afl-g++.8 afl-gcc-fast.8 afl-g++-fast.8 afl-gotcpu.8 @@ -47,11 +54,17 @@ afl-showmap.8 afl-system-config.8 afl-tmin.8 afl-whatsup.8 +afl-c++ +afl-cc +afl-lto +afl-lto++ +afl-lto++.8 +afl-lto.8 qemu_mode/libcompcov/compcovtest qemu_mode/qemu-* +qemu_mode/qemuafl unicorn_mode/samples/*/\.test-* unicorn_mode/samples/*/output/ -unicorn_mode/unicornafl test/unittests/unit_maybe_alloc test/unittests/unit_preallocable test/unittests/unit_list @@ -63,3 +76,9 @@ examples/afl_frida/afl-frida examples/afl_frida/libtestinstr.so examples/afl_frida/frida-gum-example.c examples/afl_frida/frida-gum.h +examples/aflpp_driver/libAFLDriver.a +examples/aflpp_driver/libAFLQemuDriver.a +libAFLDriver.a +libAFLQemuDriver.a +test/.afl_performance +gmon.out diff --git a/.gitmodules b/.gitmodules index 80752342..e9f5bb1d 100644 --- a/.gitmodules +++ b/.gitmodules @@ -1,3 +1,9 @@ [submodule "unicorn_mode/unicornafl"] path = unicorn_mode/unicornafl - url = https://github.com/AFLplusplus/unicornafl.git + url = https://github.com/aflplusplus/unicornafl +[submodule "custom_mutators/grammar_mutator"] + path = custom_mutators/grammar_mutator/grammar_mutator + url = https://github.com/AFLplusplus/Grammar-Mutator +[submodule "qemu_mode/qemuafl"] + path = qemu_mode/qemuafl + url = https://github.com/AFLplusplus/qemuafl diff --git a/.travis.yml b/.travis.yml deleted file mode 100644 index dda57bbb..00000000 --- a/.travis.yml +++ /dev/null @@ -1,60 +0,0 @@ -language: c - -sudo: required - -branches: - only: - - master - - dev - -matrix: - include: -# - os: linux # focal errors every run with a timeout while installing packages -# dist: focal -# env: NAME="focal-amd64" MODERN="yes" GCC="9" - - os: linux - dist: bionic - env: NAME="bionic-amd64" MODERN="yes" GCC="7" - - os: linux - dist: xenial - env: NAME="xenial-amd64" MODERN="no" GCC="5" EXTRA="libtool-bin clang-6.0" - - os: linux - dist: trusty - env: NAME="trusty-amd64" MODERN="no" GCC="4.8" -# - os: linux # until travis can fix this! -# dist: xenial -# arch: arm64 -# env: NAME="xenial-arm64" MODERN="no" GCC="5" EXTRA="libtool-bin clang-6.0" AFL_NO_X86="1" CPU_TARGET="aarch64" -# - os: osx -# osx_image: xcode11.2 -# env: NAME="osx" HOMEBREW_NO_ANALYTICS="1" LINK="http://releases.llvm.org/9.0.0/" NAME="clang+llvm-9.0.0-x86_64-darwin-apple" - -jobs: - allow_failures: - - os: osx - - arch: arm64 - -env: - - AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=1 AFL_NO_UI=1 - # - AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=1 AFL_NO_UI=1 AFL_EXIT_WHEN_DONE=1 - # TODO: test AFL_BENCH_UNTIL_CRASH once we have a target that crashes - # - AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=1 AFL_NO_UI=1 AFL_BENCH_JUST_ONE=1 - -before_install: - # export LLVM_DIR=${TRAVIS_BUILD_DIR}/${LLVM_PACKAGE} - - echo Testing on $NAME - - if [ "$TRAVIS_OS_NAME" = "osx" ]; then wget "$LINK""$NAME".tar.xz ; export LLVM_CONFIG=`pwd`/"$NAME" ; tar xJf "$NAME".tar.xz ; fi - - if [ "$MODERN" = "yes" ]; then sudo apt update ; sudo apt upgrade ; sudo apt install -y git libtool libtool-bin automake bison libglib2.0-0 build-essential clang gcc-"$GCC" gcc-"$GCC"-plugin-dev libc++-"$GCC"-dev findutils libcmocka-dev python3-setuptools ; fi - - if [ "$MODERN" = "no" ]; then sudo apt update ; sudo apt install -y git libtool $EXTRA libpixman-1-dev automake bison libglib2.0 build-essential gcc-"$GCC" gcc-"$GCC"-plugin-dev libc++-dev findutils libcmocka-dev python3-setuptools ; fi - -script: - - gcc -v - - clang -v - - sudo -E ./afl-system-config - - sudo sysctl -w kernel.shmmax=10000000000 - - free ; sudo sysctl -a|grep -i shm ; ipcs -m -l ; ipcs -m - - if [ "$TRAVIS_OS_NAME" = "osx" ]; then export LLVM_CONFIG=`pwd`/"$NAME" ; make source-only ASAN_BUILD=1 ; fi - - if [ "$TRAVIS_OS_NAME" = "linux" -a "$TRAVIS_CPU_ARCH" = "amd64" ]; then make distrib ASAN_BUILD=1 ; fi - - if [ "$TRAVIS_CPU_ARCH" = "arm64" ] ; then echo DEBUG ; find / -name llvm-config.h 2>/dev/null; apt-cache search clang | grep clang- ; apt-cache search llvm | grep llvm- ; dpkg -l | egrep 'clang|llvm'; echo DEBUG ; export LLVM_CONFIG=llvm-config-6.0 ; make ASAN_BUILD=1 ; cd qemu_mode && sh ./build_qemu_support.sh ; cd .. ; fi - - make tests -# - travis_terminate 0 @@ -1,7 +1,16 @@ cc_defaults { name: "afl-defaults", + sanitize: { + never: true, + }, + + local_include_dirs: [ + "include", + "instrumentation", + ], cflags: [ + "-flto=full", "-funroll-loops", "-Wno-pointer-sign", "-Wno-pointer-arith", @@ -10,24 +19,35 @@ cc_defaults { "-Wno-unused-function", "-Wno-format", "-Wno-user-defined-warnings", - "-DUSE_TRACE_PC=1", + "-DAFL_LLVM_USE_TRACE_PC=1", "-DBIN_PATH=\"out/host/linux-x86/bin\"", "-DDOC_PATH=\"out/host/linux-x86/shared/doc/afl\"", "-D__USE_GNU", + "-D__aarch64__", + "-DDEBUG_BUILD", + "-U_FORTIFY_SOURCE", + "-ggdb3", + "-g", + "-O0", + "-fno-omit-frame-pointer", ], } cc_binary { name: "afl-fuzz", - static_executable: true, host_supported: true, + compile_multilib: "64", defaults: [ "afl-defaults", ], srcs: [ - "afl-fuzz.c", + "src/afl-fuzz*.c", + "src/afl-common.c", + "src/afl-sharedmem.c", + "src/afl-forkserver.c", + "src/afl-performance.c", ], } @@ -41,7 +61,11 @@ cc_binary { ], srcs: [ - "afl-showmap.c", + "src/afl-showmap.c", + "src/afl-common.c", + "src/afl-sharedmem.c", + "src/afl-forkserver.c", + "src/afl-performance.c", ], } @@ -55,7 +79,11 @@ cc_binary { ], srcs: [ - "afl-tmin.c", + "src/afl-tmin.c", + "src/afl-common.c", + "src/afl-sharedmem.c", + "src/afl-forkserver.c", + "src/afl-performance.c", ], } @@ -69,7 +97,10 @@ cc_binary { ], srcs: [ - "afl-analyze.c", + "src/afl-analyze.c", + "src/afl-common.c", + "src/afl-sharedmem.c", + "src/afl-performance.c", ], } @@ -83,12 +114,13 @@ cc_binary { ], srcs: [ - "afl-gotcpu.c", + "src/afl-gotcpu.c", + "src/afl-common.c", ], } cc_binary_host { - name: "afl-clang-fast", + name: "afl-cc", static_executable: true, defaults: [ @@ -98,44 +130,144 @@ cc_binary_host { cflags: [ "-D__ANDROID__", "-DAFL_PATH=\"out/host/linux-x86/lib64\"", + "-DAFL_CLANG_FLTO=\"-flto=full\"", + "-DUSE_BINDIR=1", + "-DLLVM_BINDIR=\"prebuilts/clang/host/linux-x86/clang-r383902b/bin\"", + "-DLLVM_LIBDIR=\"prebuilts/clang/host/linux-x86/clang-r383902b/lib64\"", + "-DCLANGPP_BIN=\"prebuilts/clang/host/linux-x86/clang-r383902b/bin/clang++\"", + "-DAFL_REAL_LD=\"prebuilts/clang/host/linux-x86/clang-r383902b/bin/ld.lld\"", + "-DLLVM_LTO=1", + "-DLLVM_MAJOR=11", + "-DLLVM_MINOR=2", ], srcs: [ - "llvm_mode/afl-clang-fast.c", + "src/afl-cc.c", + "src/afl-common.c", + ], + + symlinks: [ + "afl-clang-fast", + "afl-clang-fast++", ], } -cc_binary_host { - name: "afl-clang-fast++", - static_executable: true, +cc_library_static { + name: "afl-llvm-rt", + compile_multilib: "64", + vendor_available: true, + host_supported: true, + recovery_available: true, + sdk_version: "9", - defaults: [ - "afl-defaults", + apex_available: [ + "com.android.adbd", + "com.android.appsearch", + "com.android.art", + "com.android.bluetooth.updatable", + "com.android.cellbroadcast", + "com.android.conscrypt", + "com.android.extservices", + "com.android.cronet", + "com.android.neuralnetworks", + "com.android.media", + "com.android.media.swcodec", + "com.android.mediaprovider", + "com.android.permission", + "com.android.runtime", + "com.android.resolv", + "com.android.tethering", + "com.android.wifi", + "com.android.sdkext", + "com.android.os.statsd", + "//any", ], - cflags: [ - "-D__ANDROID__", - "-DAFL_PATH=\"out/host/linux-x86/lib64\"", + defaults: [ + "afl-defaults", ], srcs: [ - "llvm_mode/afl-clang-fast.c", + "instrumentation/afl-compiler-rt.o.c", ], } -cc_library_static { - name: "afl-llvm-rt", - compile_multilib: "both", +cc_library_headers { + name: "libafl_headers", vendor_available: true, host_supported: true, - recovery_available: true, - sdk_version: "9", + + export_include_dirs: [ + "include", + ], +} + +cc_prebuilt_library_static { + name: "libfrida-gum", + compile_multilib: "64", + strip: { + none: true, + }, + + srcs: [ + "utils/afl_frida/android/libfrida-gum.a", + ], + + export_include_dirs: [ + "utils/afl_frida/android", + ], +} + +cc_library_shared { + name: "libtestinstr", + + srcs: [ + "utils/afl_frida/libtestinstr.c", + ], + + cflags: [ + "-O0", + "-fPIC", + ], +} + +cc_binary { + name: "afl-frida", + compile_multilib: "64", defaults: [ "afl-defaults", ], + cflags: [ + "-g", + "-O0", + "-Wno-format", + "-Wno-pointer-sign", + "-fpermissive", + "-fPIC", + ], + + static_libs: [ + "afl-llvm-rt", + "libfrida-gum", + ], + + shared_libs: [ + "libdl", + "liblog", + ], + srcs: [ - "llvm_mode/afl-llvm-rt.o.c", + "utils/afl_frida/afl-frida.c", + ], + + local_include_dirs: [ + "utils/afl_frida", + "utils/afl_frida/android", ], } + +subdirs = [ + "custom_mutators", +] diff --git a/Android.mk b/Android.mk deleted file mode 120000 index 33ceb8f0..00000000 --- a/Android.mk +++ /dev/null @@ -1 +0,0 @@ -Makefile
\ No newline at end of file diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md index ccacef5f..c36ed9d8 100644 --- a/CONTRIBUTING.md +++ b/CONTRIBUTING.md @@ -16,9 +16,9 @@ project, or added a file in a directory we already format, otherwise run: ``` Regarding the coding style, please follow the AFL style. -No camel case at all and use the AFL's macros wherever possible +No camel case at all and use AFL's macros wherever possible (e.g. WARNF, FATAL, MAP_SIZE, ...). Remember that AFLplusplus has to build and run on many platforms, so generalize your Makefiles/GNUmakefile (or your patches to our pre-existing -Makefiles) to be as much generic as possible. +Makefiles) to be as generic as possible. @@ -2,59 +2,69 @@ # This Dockerfile for AFLplusplus uses Ubuntu 20.04 focal and # installs LLVM 11 from llvm.org for afl-clang-lto support :-) # It also installs gcc/g++ 10 from the Ubuntu development platform -# has focal has gcc-10 but not g++-10 ... +# since focal has gcc-10 but not g++-10 ... # FROM ubuntu:20.04 AS aflplusplus -MAINTAINER afl++ team <afl@aflplus.plus> +LABEL "maintainer"="afl++ team <afl@aflplus.plus>" LABEL "about"="AFLplusplus docker image" ARG DEBIAN_FRONTEND=noninteractive -RUN apt-get update && apt-get upgrade -y && \ +env NO_ARCH_OPT 1 + +RUN apt-get update && \ apt-get -y install --no-install-suggests --no-install-recommends \ automake \ + ninja-build \ bison flex \ build-essential \ git \ python3 python3-dev python3-setuptools python-is-python3 \ libtool libtool-bin \ libglib2.0-dev \ - wget vim jupp nano bash-completion \ + wget vim jupp nano bash-completion less \ apt-utils apt-transport-https ca-certificates gnupg dialog \ - libpixman-1-dev + libpixman-1-dev \ + gnuplot-nox \ + && rm -rf /var/lib/apt/lists/* -RUN echo deb http://apt.llvm.org/focal/ llvm-toolchain-focal main >> /etc/apt/sources.list && \ - wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | apt-key add - - -RUN echo deb http://ppa.launchpad.net/ubuntu-toolchain-r/test/ubuntu focal main >> /etc/apt/sources.list && \ - apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 1E9377A2BA9EF27F - -RUN apt-get update && apt-get upgrade -y +RUN echo "deb http://apt.llvm.org/focal/ llvm-toolchain-focal-12 main" >> /etc/apt/sources.list && \ + wget -qO - https://apt.llvm.org/llvm-snapshot.gpg.key | apt-key add - -RUN apt-get install -y gcc-10 g++-10 gcc-10-plugin-dev gcc-10-multilib \ - libc++-10-dev gdb lcov +RUN echo "deb http://ppa.launchpad.net/ubuntu-toolchain-r/test/ubuntu focal main" >> /etc/apt/sources.list && \ + apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 1E9377A2BA9EF27F -RUN apt-get install -y clang-11 clang-tools-11 libc++1-11 libc++-11-dev \ - libc++abi1-11 libc++abi-11-dev libclang1-11 libclang-11-dev \ - libclang-common-11-dev libclang-cpp11 libclang-cpp11-dev liblld-11 \ - liblld-11-dev liblldb-11 liblldb-11-dev libllvm11 libomp-11-dev \ - libomp5-11 lld-11 lldb-11 llvm-11 llvm-11-dev llvm-11-runtime llvm-11-tools +RUN apt-get update && apt-get full-upgrade -y && \ + apt-get -y install --no-install-suggests --no-install-recommends \ + gcc-10 g++-10 gcc-10-plugin-dev gcc-10-multilib gdb lcov \ + clang-12 clang-tools-12 libc++1-12 libc++-12-dev \ + libc++abi1-12 libc++abi-12-dev libclang1-12 libclang-12-dev \ + libclang-common-12-dev libclang-cpp12 libclang-cpp12-dev liblld-12 \ + liblld-12-dev liblldb-12 liblldb-12-dev libllvm12 libomp-12-dev \ + libomp5-12 lld-12 lldb-12 llvm-12 llvm-12-dev llvm-12-runtime llvm-12-tools \ + && rm -rf /var/lib/apt/lists/* RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-10 0 RUN update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-10 0 -RUN rm -rf /var/cache/apt/archives/* - -ENV LLVM_CONFIG=llvm-config-11 +ENV LLVM_CONFIG=llvm-config-12 ENV AFL_SKIP_CPUFREQ=1 +ENV AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=1 + +RUN git clone --depth=1 https://github.com/vanhauser-thc/afl-cov /afl-cov +RUN cd /afl-cov && make install && cd .. -RUN git clone https://github.com/AFLplusplus/AFLplusplus /AFLplusplus -RUN cd /AFLplusplus && export REAL_CXX=g++-10 && export CC=gcc-10 && \ - export CXX=g++-10 && make distrib && make install && make clean +COPY . /AFLplusplus +WORKDIR /AFLplusplus -RUN git clone https://github.com/vanhauser-thc/afl-cov /afl-cov -RUN cd /afl-cov && make install +RUN export CC=gcc-10 && export CXX=g++-10 && make clean && \ + make distrib && make install && make clean RUN echo 'alias joe="jupp --wordwrap"' >> ~/.bashrc +RUN echo 'export PS1="[afl++]$PS1"' >> ~/.bashrc +ENV IS_DOCKER="1" +# Disabled until we have the container ready +#COPY --from=aflplusplus/afl-dyninst /usr/local/lib/libdyninstAPI_RT.so /usr/local/lib/libdyninstAPI_RT.so +#COPY --from=aflplusplus/afl-dyninst /afl-dyninst/libAflDyninst.so /usr/local/lib/libAflDyninst.so diff --git a/GNUmakefile b/GNUmakefile index 7ed892ab..f885f998 100644 --- a/GNUmakefile +++ b/GNUmakefile @@ -24,18 +24,39 @@ BIN_PATH = $(PREFIX)/bin HELPER_PATH = $(PREFIX)/lib/afl DOC_PATH = $(PREFIX)/share/doc/afl MISC_PATH = $(PREFIX)/share/afl -MAN_PATH = $(PREFIX)/man/man8 +MAN_PATH = $(PREFIX)/share/man/man8 PROGNAME = afl VERSION = $(shell grep '^$(HASH)define VERSION ' ../config.h | cut -d '"' -f2) # PROGS intentionally omit afl-as, which gets installed elsewhere. -PROGS = afl-gcc afl-fuzz afl-showmap afl-tmin afl-gotcpu afl-analyze +PROGS = afl-fuzz afl-showmap afl-tmin afl-gotcpu afl-analyze SH_PROGS = afl-plot afl-cmin afl-cmin.bash afl-whatsup afl-system-config MANPAGES=$(foreach p, $(PROGS) $(SH_PROGS), $(p).8) afl-as.8 ASAN_OPTIONS=detect_leaks=0 +ifdef NO_SPLICING + override CFLAGS += -DNO_SPLICING +endif + +ifdef ASAN_BUILD + $(info Compiling ASAN version of binaries) + override CFLAGS += $(ASAN_CFLAGS) + LDFLAGS += $(ASAN_LDFLAGS) +endif +ifdef UBSAN_BUILD + $(info Compiling UBSAN version of binaries) + override CFLAGS += -fsanitize=undefined -fno-omit-frame-pointer + override LDFLAGS += -fsanitize=undefined +endif +ifdef MSAN_BUILD + $(info Compiling MSAN version of binaries) + CC := clang + override CFLAGS += -fsanitize=memory -fno-omit-frame-pointer + override LDFLAGS += -fsanitize=memory +endif + ifeq "$(findstring android, $(shell $(CC) --version 2>/dev/null))" "" ifeq "$(shell echo 'int main() {return 0; }' | $(CC) $(CFLAGS) -Werror -x c - -flto=full -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" CFLAGS_FLTO ?= -flto=full @@ -54,28 +75,34 @@ ifeq "$(shell echo 'int main() {return 0; }' | $(CC) -fno-move-loop-invariants - SPECIAL_PERFORMANCE += -fno-move-loop-invariants -fdisable-tree-cunrolli endif +#ifeq "$(shell echo 'int main() {return 0; }' | $(CC) $(CFLAGS) -Werror -x c - -march=native -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" +# ifndef SOURCE_DATE_EPOCH +# HAVE_MARCHNATIVE = 1 +# CFLAGS_OPT += -march=native +# endif +#endif + ifneq "$(shell uname)" "Darwin" - ifeq "$(shell echo 'int main() {return 0; }' | $(CC) $(CFLAGS) -Werror -x c - -march=native -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" - ifndef SOURCE_DATE_EPOCH - #CFLAGS_OPT += -march=native - SPECIAL_PERFORMANCE += -march=native - endif - endif + #ifeq "$(HAVE_MARCHNATIVE)" "1" + # SPECIAL_PERFORMANCE += -march=native + #endif # OS X does not like _FORTIFY_SOURCE=2 - CFLAGS_OPT += -D_FORTIFY_SOURCE=2 + ifndef DEBUG + CFLAGS_OPT += -D_FORTIFY_SOURCE=2 + endif endif ifeq "$(shell uname)" "SunOS" - CFLAGS_OPT += -Wno-format-truncation - LDFLAGS=-lkstat -lrt + CFLAGS_OPT += -Wno-format-truncation + LDFLAGS = -lkstat -lrt endif ifdef STATIC $(info Compiling static version of binaries, disabling python though) # Disable python for static compilation to simplify things - PYTHON_OK=0 + PYTHON_OK = 0 PYFLAGS= - PYTHON_INCLUDE=/ + PYTHON_INCLUDE = / CFLAGS_OPT += -static LDFLAGS += -lm -lpthread -lz -lutil @@ -87,6 +114,12 @@ ifdef PROFILING LDFLAGS += -pg endif +ifdef INTROSPECTION + $(info Compiling with introspection documentation) + CFLAGS_OPT += -DINTROSPECTION=1 +endif + + ifneq "$(shell uname -m)" "x86_64" ifneq "$(patsubst i%86,i386,$(shell uname -m))" "i386" ifneq "$(shell uname -m)" "amd64" @@ -97,8 +130,14 @@ ifneq "$(shell uname -m)" "x86_64" endif endif -CFLAGS ?= -O3 -funroll-loops $(CFLAGS_OPT) -override CFLAGS += -Wall -g -Wno-pointer-sign -Wmissing-declarations -Wno-unused-result \ +ifdef DEBUG + $(info Compiling DEBUG version of binaries) + CFLAGS += -ggdb3 -O0 -Wall -Wextra -Werror +else + CFLAGS ?= -O3 -funroll-loops $(CFLAGS_OPT) +endif + +override CFLAGS += -g -Wno-pointer-sign -Wno-variadic-macros -Wall -Wextra -Wpointer-arith \ -I include/ -DAFL_PATH=\"$(HELPER_PATH)\" \ -DBIN_PATH=\"$(BIN_PATH)\" -DDOC_PATH=\"$(DOC_PATH)\" @@ -198,7 +237,10 @@ else endif ifneq "$(filter Linux GNU%,$(shell uname))" "" - LDFLAGS += -ldl -lrt + ifndef DEBUG + override CFLAGS += -D_FORTIFY_SOURCE=2 + endif + LDFLAGS += -ldl -lrt -lm endif ifneq "$(findstring FreeBSD, $(shell uname))" "" @@ -211,10 +253,9 @@ ifneq "$(findstring NetBSD, $(shell uname))" "" LDFLAGS += -lpthread endif -ifeq "$(findstring clang, $(shell $(CC) --version 2>/dev/null))" "" - TEST_CC = afl-gcc -else - TEST_CC = afl-clang +ifneq "$(findstring OpenBSD, $(shell uname))" "" + override CFLAGS += -pthread + LDFLAGS += -lpthread endif COMM_HDR = include/alloc-inl.h include/config.h include/debug.h include/types.h @@ -241,16 +282,10 @@ ifeq "$(shell command -v svn >/dev/null && svn proplist . 2>/dev/null && echo 1 endif ifeq "$(shell echo 'int main() { return 0;}' | $(CC) $(CFLAGS) -fsanitize=address -x c - -o .test2 2>/dev/null && echo 1 || echo 0 ; rm -f .test2 )" "1" - ASAN_CFLAGS=-fsanitize=address -fstack-protector-all -fno-omit-frame-pointer + ASAN_CFLAGS=-fsanitize=address -fstack-protector-all -fno-omit-frame-pointer -DASAN_BUILD ASAN_LDFLAGS=-fsanitize=address -fstack-protector-all -fno-omit-frame-pointer endif -ifdef ASAN_BUILD - $(info Compiling ASAN version of binaries) - override CFLAGS+=$(ASAN_CFLAGS) - LDFLAGS+=$(ASAN_LDFLAGS) -endif - ifeq "$(shell echo '$(HASH)include <sys/ipc.h>@$(HASH)include <sys/shm.h>@int main() { int _id = shmget(IPC_PRIVATE, 65536, IPC_CREAT | IPC_EXCL | 0600); shmctl(_id, IPC_RMID, 0); return 0;}' | tr @ '\n' | $(CC) $(CFLAGS) -x c - -o .test2 2>/dev/null && echo 1 || echo 0 ; rm -f .test2 )" "1" SHMAT_OK=1 else @@ -265,28 +300,47 @@ ifdef TEST_MMAP LDFLAGS += -Wno-deprecated-declarations endif -all: test_x86 test_shm test_python ready $(PROGS) afl-as test_build all_done +.PHONY: all +all: test_x86 test_shm test_python ready $(PROGS) afl-as llvm gcc_plugin test_build all_done + +.PHONY: llvm +llvm: + -$(MAKE) -j -f GNUmakefile.llvm + @test -e afl-cc || { echo "[-] Compiling afl-cc failed. You seem not to have a working compiler." ; exit 1; } +.PHONY: gcc_plugin +gcc_plugin: + -$(MAKE) -f GNUmakefile.gcc_plugin + +.PHONY: man man: $(MANPAGES) +.PHONY: test +test: tests + +.PHONY: tests tests: source-only - @cd test ; ./test.sh + @cd test ; ./test-all.sh @rm -f test/errors +.PHONY: performance-tests performance-tests: performance-test +.PHONY: test-performance test-performance: performance-test +.PHONY: performance-test performance-test: source-only @cd test ; ./test-performance.sh # hint: make targets are also listed in the top level README.md +.PHONY: help help: @echo "HELP --- the following make targets exist:" @echo "==========================================" @echo "all: just the main afl++ binaries" @echo "binary-only: everything for binary-only fuzzing: qemu_mode, unicorn_mode, libdislocator, libtokencap" - @echo "source-only: everything for source code fuzzing: llvm_mode, gcc_plugin, libdislocator, libtokencap" + @echo "source-only: everything for source code fuzzing: gcc_plugin, libdislocator, libtokencap" @echo "distrib: everything (for both binary-only and source code fuzzing)" @echo "man: creates simple man pages from the help option of the programs" @echo "install: installs everything you have compiled with the build option above" @@ -304,13 +358,18 @@ help: @echo "==========================================" @echo STATIC - compile AFL++ static @echo ASAN_BUILD - compiles with memory sanitizer for debug purposes + @echo DEBUG - no optimization, -ggdb3, all warnings and -Werror @echo PROFILING - compile afl-fuzz with profiling information + @echo INTROSPECTION - compile afl-fuzz with mutation introspection + @echo NO_PYTHON - disable python support + @echo NO_SPLICING - disables splicing mutation in afl-fuzz, not recommended for normal fuzzing @echo AFL_NO_X86 - if compiling on non-intel/amd platforms + @echo "LLVM_CONFIG - if your distro doesn't use the standard name for llvm-config (e.g. Debian)" @echo "==========================================" @echo e.g.: make ASAN_BUILD=1 +.PHONY: test_x86 ifndef AFL_NO_X86 - test_x86: @echo "[*] Checking for the default compiler cc..." @type $(CC) >/dev/null || ( echo; echo "Oops, looks like there is no compiler '"$(CC)"' in your path."; echo; echo "Don't panic! You can restart with '"$(_)" CC=<yourCcompiler>'."; echo; exit 1 ) @@ -319,56 +378,41 @@ test_x86: @echo "[*] Checking for the ability to compile x86 code..." @echo 'main() { __asm__("xorb %al, %al"); }' | $(CC) $(CFLAGS) -w -x c - -o .test1 || ( echo; echo "Oops, looks like your compiler can't generate x86 code."; echo; echo "Don't panic! You can use the LLVM or QEMU mode, but see docs/INSTALL first."; echo "(To ignore this error, set AFL_NO_X86=1 and try again.)"; echo; exit 1 ) @rm -f .test1 - else - test_x86: @echo "[!] Note: skipping x86 compilation checks (AFL_NO_X86 set)." - endif - +.PHONY: test_shm ifeq "$(SHMAT_OK)" "1" - test_shm: @echo "[+] shmat seems to be working." @rm -f .test2 - else - test_shm: @echo "[-] shmat seems not to be working, switching to mmap implementation" - endif - +.PHONY: test_python ifeq "$(PYTHON_OK)" "1" - test_python: @rm -f .test 2> /dev/null @echo "[+] $(PYTHON_VERSION) support seems to be working." - else - test_python: @echo "[-] You seem to need to install the package python3-dev, python2-dev or python-dev (and perhaps python[23]-apt), but it is optional so we continue" - endif - +.PHONY: ready ready: @echo "[+] Everything seems to be working, ready to compile." -afl-gcc: src/afl-gcc.c $(COMM_HDR) | test_x86 - $(CC) $(CFLAGS) src/$@.c -o $@ $(LDFLAGS) - set -e; for i in afl-g++ afl-clang afl-clang++; do ln -sf afl-gcc $$i; done - afl-as: src/afl-as.c include/afl-as.h $(COMM_HDR) | test_x86 $(CC) $(CFLAGS) src/$@.c -o $@ $(LDFLAGS) - ln -sf afl-as as + @ln -sf afl-as as src/afl-performance.o : $(COMM_HDR) src/afl-performance.c include/hash.h - $(CC) -Iinclude $(SPECIAL_PERFORMANCE) -O3 -fno-unroll-loops -c src/afl-performance.c -o src/afl-performance.o + $(CC) $(CFLAGS) -Iinclude $(SPECIAL_PERFORMANCE) -O3 -fno-unroll-loops -c src/afl-performance.c -o src/afl-performance.o src/afl-common.o : $(COMM_HDR) src/afl-common.c include/common.h $(CC) $(CFLAGS) $(CFLAGS_FLTO) -c src/afl-common.c -o src/afl-common.o @@ -380,10 +424,10 @@ src/afl-sharedmem.o : $(COMM_HDR) src/afl-sharedmem.c include/sharedmem.h $(CC) $(CFLAGS) $(CFLAGS_FLTO) -c src/afl-sharedmem.c -o src/afl-sharedmem.o afl-fuzz: $(COMM_HDR) include/afl-fuzz.h $(AFL_FUZZ_FILES) src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o src/afl-performance.o | test_x86 - $(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) $(AFL_FUZZ_FILES) src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o src/afl-performance.o -o $@ $(PYFLAGS) $(LDFLAGS) + $(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) $(AFL_FUZZ_FILES) src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o src/afl-performance.o -o $@ $(PYFLAGS) $(LDFLAGS) -lm -afl-showmap: src/afl-showmap.c src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o $(COMM_HDR) | test_x86 - $(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) src/$@.c src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o -o $@ $(LDFLAGS) +afl-showmap: src/afl-showmap.c src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o src/afl-performance.o $(COMM_HDR) | test_x86 + $(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) src/$@.c src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o src/afl-performance.o -o $@ $(LDFLAGS) afl-tmin: src/afl-tmin.c src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o src/afl-performance.o $(COMM_HDR) | test_x86 $(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) src/$@.c src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.o src/afl-performance.o -o $@ $(LDFLAGS) @@ -394,9 +438,11 @@ afl-analyze: src/afl-analyze.c src/afl-common.o src/afl-sharedmem.o src/afl-perf afl-gotcpu: src/afl-gotcpu.c src/afl-common.o $(COMM_HDR) | test_x86 $(CC) $(CFLAGS) $(COMPILE_STATIC) $(CFLAGS_FLTO) src/$@.c src/afl-common.o -o $@ $(LDFLAGS) +.PHONY: document +document: afl-fuzz-document # document all mutations and only do one run (use with only one input file!) -document: $(COMM_HDR) include/afl-fuzz.h $(AFL_FUZZ_FILES) src/afl-common.o src/afl-sharedmem.o src/afl-performance.o | test_x86 +afl-fuzz-document: $(COMM_HDR) include/afl-fuzz.h $(AFL_FUZZ_FILES) src/afl-common.o src/afl-sharedmem.o src/afl-performance.o | test_x86 $(CC) -D_DEBUG=\"1\" -D_AFL_DOCUMENT_MUTATIONS $(CFLAGS) $(CFLAGS_FLTO) $(AFL_FUZZ_FILES) src/afl-common.o src/afl-sharedmem.o src/afl-forkserver.c src/afl-performance.o -o afl-fuzz-document $(PYFLAGS) $(LDFLAGS) test/unittests/unit_maybe_alloc.o : $(COMM_HDR) include/alloc-inl.h test/unittests/unit_maybe_alloc.c $(AFL_FUZZ_FILES) @@ -434,126 +480,138 @@ unit_preallocable: test/unittests/unit_preallocable.o @$(CC) $(CFLAGS) $(ASAN_CFLAGS) -Wl,--wrap=exit -Wl,--wrap=printf test/unittests/unit_preallocable.o -o test/unittests/unit_preallocable $(LDFLAGS) $(ASAN_LDFLAGS) -lcmocka ./test/unittests/unit_preallocable +.PHONY: unit_clean unit_clean: @rm -f ./test/unittests/unit_preallocable ./test/unittests/unit_list ./test/unittests/unit_maybe_alloc test/unittests/*.o +.PHONY: unit ifneq "$(shell uname)" "Darwin" - -unit: unit_maybe_alloc unit_preallocable unit_list unit_clean unit_rand unit_hash - +unit: unit_maybe_alloc unit_preallocable unit_list unit_clean unit_rand unit_hash else - unit: @echo [-] unit tests are skipped on Darwin \(lacks GNU linker feature --wrap\) - endif +.PHONY: code-format code-format: ./.custom-format.py -i src/*.c ./.custom-format.py -i include/*.h - ./.custom-format.py -i libdislocator/*.c - ./.custom-format.py -i libtokencap/*.c - ./.custom-format.py -i llvm_mode/*.c - ./.custom-format.py -i llvm_mode/*.h - ./.custom-format.py -i llvm_mode/*.cc - ./.custom-format.py -i gcc_plugin/*.c - @#./.custom-format.py -i gcc_plugin/*.h - ./.custom-format.py -i gcc_plugin/*.cc - ./.custom-format.py -i custom_mutators/*/*.c - @#./.custom-format.py -i custom_mutators/*/*.h # destroys input.h :-( - ./.custom-format.py -i examples/*/*.c - ./.custom-format.py -i examples/*/*.h + ./.custom-format.py -i instrumentation/*.h + ./.custom-format.py -i instrumentation/*.cc + ./.custom-format.py -i instrumentation/*.c + @#./.custom-format.py -i custom_mutators/*/*.c* # destroys libfuzzer :-( + @#./.custom-format.py -i custom_mutators/*/*.h # destroys honggfuzz :-( + ./.custom-format.py -i utils/*/*.c* + ./.custom-format.py -i utils/*/*.h ./.custom-format.py -i test/*.c - ./.custom-format.py -i qemu_mode/patches/*.h ./.custom-format.py -i qemu_mode/libcompcov/*.c ./.custom-format.py -i qemu_mode/libcompcov/*.cc ./.custom-format.py -i qemu_mode/libcompcov/*.h - ./.custom-format.py -i qbdi_mode/*.c - ./.custom-format.py -i qbdi_mode/*.cpp + ./.custom-format.py -i qemu_mode/libqasan/*.c + ./.custom-format.py -i qemu_mode/libqasan/*.h ./.custom-format.py -i *.h ./.custom-format.py -i *.c +.PHONY: test_build ifndef AFL_NO_X86 - -test_build: afl-gcc afl-as afl-showmap - @echo "[*] Testing the CC wrapper and instrumentation output..." - @unset AFL_USE_ASAN AFL_USE_MSAN AFL_CC; AFL_DEBUG=1 AFL_INST_RATIO=100 AFL_PATH=. ./$(TEST_CC) $(CFLAGS) test-instr.c -o test-instr $(LDFLAGS) 2>&1 | grep 'afl-as' >/dev/null || (echo "Oops, afl-as did not get called from "$(TEST_CC)". This is normally achieved by "$(CC)" honoring the -B option."; exit 1 ) +test_build: afl-cc afl-gcc afl-as afl-showmap + @echo "[*] Testing the CC wrapper afl-cc and its instrumentation output..." + @unset AFL_MAP_SIZE AFL_USE_UBSAN AFL_USE_CFISAN AFL_USE_ASAN AFL_USE_MSAN; ASAN_OPTIONS=detect_leaks=0 AFL_INST_RATIO=100 AFL_PATH=. ./afl-cc test-instr.c -o test-instr 2>&1 || (echo "Oops, afl-cc failed"; exit 1 ) ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr0 ./test-instr < /dev/null echo 1 | ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr1 ./test-instr @rm -f test-instr - @cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation does not seem to be behaving correctly!"; echo; echo "Please post to https://github.com/AFLplusplus/AFLplusplus/issues to troubleshoot the issue."; echo; exit 1; fi - @echo "[+] All right, the instrumentation seems to be working!" - + @cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation of afl-cc does not seem to be behaving correctly!"; echo; echo "Please post to https://github.com/AFLplusplus/AFLplusplus/issues to troubleshoot the issue."; echo; exit 1; fi + @echo + @echo "[+] All right, the instrumentation of afl-cc seems to be working!" +# @echo "[*] Testing the CC wrapper afl-gcc and its instrumentation output..." +# @unset AFL_MAP_SIZE AFL_USE_UBSAN AFL_USE_CFISAN AFL_USE_ASAN AFL_USE_MSAN; AFL_CC=$(CC) ASAN_OPTIONS=detect_leaks=0 AFL_INST_RATIO=100 AFL_PATH=. ./afl-gcc test-instr.c -o test-instr 2>&1 || (echo "Oops, afl-gcc failed"; exit 1 ) +# ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr0 ./test-instr < /dev/null +# echo 1 | ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr1 ./test-instr +# @rm -f test-instr +# @cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation of afl-gcc does not seem to be behaving correctly!"; \ +# gcc -v 2>&1 | grep -q -- --with-as= && ( echo; echo "Gcc is configured not to use an external assembler with the -B option."; echo "See docs/INSTALL.md section 5 how to build a -B enabled gcc." ) || \ +# ( echo; echo "Please post to https://github.com/AFLplusplus/AFLplusplus/issues to troubleshoot the issue." ); echo; exit 0; fi +# @echo +# @echo "[+] All right, the instrumentation of afl-gcc seems to be working!" else - -test_build: afl-gcc afl-as afl-showmap +test_build: afl-cc afl-as afl-showmap @echo "[!] Note: skipping build tests (you may need to use LLVM or QEMU mode)." - endif - +.PHONY: all_done all_done: test_build - @if [ ! "`type clang 2>/dev/null`" = "" ]; then echo "[+] LLVM users: see llvm_mode/README.md for a faster alternative to afl-gcc."; fi + @test -e afl-cc && echo "[+] Main compiler 'afl-cc' successfully built!" || { echo "[-] Main compiler 'afl-cc' failed to build, set up a working build environment first!" ; exit 1 ; } + @test -e cmplog-instructions-pass.so && echo "[+] LLVM mode for 'afl-cc' successfully built!" || echo "[-] LLVM mode for 'afl-cc' failed to build, likely you either don't have llvm installed, or you need to set LLVM_CONFIG, to point to e.g. llvm-config-11. See instrumentation/README.llvm.md how to do this. Highly recommended!" + @test -e SanitizerCoverageLTO.so && echo "[+] LLVM LTO mode for 'afl-cc' successfully built!" || echo "[-] LLVM LTO mode for 'afl-cc' failed to build, this would need LLVM 11+, see instrumentation/README.lto.md how to build it" + @test -e afl-gcc-pass.so && echo "[+] gcc_plugin for 'afl-cc' successfully built!" || echo "[-] gcc_plugin for 'afl-cc' failed to build, unless you really need it that is fine - or read instrumentation/README.gcc_plugin.md how to build it" @echo "[+] All done! Be sure to review the README.md - it's pretty short and useful." @if [ "`uname`" = "Darwin" ]; then printf "\nWARNING: Fuzzing on MacOS X is slow because of the unusually high overhead of\nfork() on this OS. Consider using Linux or *BSD. You can also use VirtualBox\n(virtualbox.org) to put AFL inside a Linux or *BSD VM.\n\n"; fi @! tty <&1 >/dev/null || printf "\033[0;30mNOTE: If you can read this, your terminal probably uses white background.\nThis will make the UI hard to read. See docs/status_screen.md for advice.\033[0m\n" 2>/dev/null .NOTPARALLEL: clean all +.PHONY: clean clean: - rm -f $(PROGS) libradamsa.so afl-fuzz-document afl-as as afl-g++ afl-clang afl-clang++ *.o src/*.o *~ a.out core core.[1-9][0-9]* *.stackdump .test .test1 .test2 test-instr .test-instr0 .test-instr1 afl-qemu-trace afl-gcc-fast afl-gcc-pass.so afl-gcc-rt.o afl-g++-fast ld *.so *.8 test/unittests/*.o test/unittests/unit_maybe_alloc test/unittests/preallocable .afl-* - rm -rf out_dir qemu_mode/qemu-3.1.1 *.dSYM */*.dSYM - -$(MAKE) -C llvm_mode clean - -$(MAKE) -C gcc_plugin clean - $(MAKE) -C libdislocator clean - $(MAKE) -C libtokencap clean - $(MAKE) -C examples/afl_network_proxy clean - $(MAKE) -C examples/socket_fuzzing clean - $(MAKE) -C examples/argv_fuzzing clean + rm -f $(PROGS) libradamsa.so afl-fuzz-document afl-as as afl-g++ afl-clang afl-clang++ *.o src/*.o *~ a.out core core.[1-9][0-9]* *.stackdump .test .test1 .test2 test-instr .test-instr0 .test-instr1 afl-qemu-trace afl-gcc-fast afl-gcc-pass.so afl-g++-fast ld *.so *.8 test/unittests/*.o test/unittests/unit_maybe_alloc test/unittests/preallocable .afl-* afl-gcc afl-g++ afl-clang afl-clang++ test/unittests/unit_hash test/unittests/unit_rand + -$(MAKE) -f GNUmakefile.llvm clean + -$(MAKE) -f GNUmakefile.gcc_plugin clean + $(MAKE) -C utils/libdislocator clean + $(MAKE) -C utils/libtokencap clean + $(MAKE) -C utils/afl_network_proxy clean + $(MAKE) -C utils/socket_fuzzing clean + $(MAKE) -C utils/argv_fuzzing clean $(MAKE) -C qemu_mode/unsigaction clean $(MAKE) -C qemu_mode/libcompcov clean - rm -rf qemu_mode/qemu-3.1.1 + $(MAKE) -C qemu_mode/libqasan clean ifeq "$(IN_REPO)" "1" - test -d unicorn_mode/unicornafl && $(MAKE) -C unicorn_mode/unicornafl clean || true + test -e qemu_mode/qemuafl/Makefile && $(MAKE) -C qemu_mode/qemuafl clean || true + test -e unicorn_mode/unicornafl/Makefile && $(MAKE) -C unicorn_mode/unicornafl clean || true else - rm -rf qemu_mode/qemu-3.1.1.tar.xz + rm -rf qemu_mode/qemuafl rm -rf unicorn_mode/unicornafl endif +.PHONY: deepclean deepclean: clean - rm -rf qemu_mode/qemu-3.1.1.tar.xz rm -rf unicorn_mode/unicornafl - git reset --hard >/dev/null 2>&1 || true + rm -rf qemu_mode/qemuafl +ifeq "$(IN_REPO)" "1" +# NEVER EVER ACTIVATE THAT!!!!! git reset --hard >/dev/null 2>&1 || true + git checkout unicorn_mode/unicornafl + git checkout qemu_mode/qemuafl +endif +.PHONY: distrib distrib: all - -$(MAKE) -C llvm_mode - -$(MAKE) -C gcc_plugin - $(MAKE) -C libdislocator - $(MAKE) -C libtokencap - $(MAKE) -C examples/afl_network_proxy - $(MAKE) -C examples/socket_fuzzing - $(MAKE) -C examples/argv_fuzzing + -$(MAKE) -j -f GNUmakefile.llvm + -$(MAKE) -f GNUmakefile.gcc_plugin + $(MAKE) -C utils/libdislocator + $(MAKE) -C utils/libtokencap + -$(MAKE) -C utils/aflpp_driver + $(MAKE) -C utils/afl_network_proxy + $(MAKE) -C utils/socket_fuzzing + $(MAKE) -C utils/argv_fuzzing -cd qemu_mode && sh ./build_qemu_support.sh - cd unicorn_mode && unset CFLAGS && sh ./build_unicorn_support.sh - -binary-only: all - $(MAKE) -C libdislocator - $(MAKE) -C libtokencap - $(MAKE) -C examples/afl_network_proxy - $(MAKE) -C examples/socket_fuzzing - $(MAKE) -C examples/argv_fuzzing + -cd unicorn_mode && unset CFLAGS && sh ./build_unicorn_support.sh + +.PHONY: binary-only +binary-only: test_shm test_python ready $(PROGS) + $(MAKE) -C utils/libdislocator + $(MAKE) -C utils/libtokencap + $(MAKE) -C utils/afl_network_proxy + $(MAKE) -C utils/socket_fuzzing + $(MAKE) -C utils/argv_fuzzing -cd qemu_mode && sh ./build_qemu_support.sh - cd unicorn_mode && unset CFLAGS && sh ./build_unicorn_support.sh + -cd unicorn_mode && unset CFLAGS && sh ./build_unicorn_support.sh +.PHONY: source-only source-only: all - -$(MAKE) -C llvm_mode - -$(MAKE) -C gcc_plugin - $(MAKE) -C libdislocator - $(MAKE) -C libtokencap - #$(MAKE) -C examples/afl_network_proxy - #$(MAKE) -C examples/socket_fuzzing - #$(MAKE) -C examples/argv_fuzzing + -$(MAKE) -j -f GNUmakefile.llvm + -$(MAKE) -f GNUmakefile.gcc_plugin + $(MAKE) -C utils/libdislocator + $(MAKE) -C utils/libtokencap + -$(MAKE) -C utils/aflpp_driver %.8: % @echo .TH $* 8 $(BUILD_DATE) "afl++" > $@ @@ -574,28 +632,32 @@ source-only: all @echo .SH LICENSE >> $@ @echo Apache License Version 2.0, January 2004 >> $@ +.PHONY: install install: all $(MANPAGES) - install -d -m 755 $${DESTDIR}$(BIN_PATH) $${DESTDIR}$(HELPER_PATH) $${DESTDIR}$(DOC_PATH) $${DESTDIR}$(MISC_PATH) - rm -f $${DESTDIR}$(BIN_PATH)/afl-plot.sh + @install -d -m 755 $${DESTDIR}$(BIN_PATH) $${DESTDIR}$(HELPER_PATH) $${DESTDIR}$(DOC_PATH) $${DESTDIR}$(MISC_PATH) + @rm -f $${DESTDIR}$(BIN_PATH)/afl-plot.sh + @rm -f $${DESTDIR}$(BIN_PATH)/afl-as + @rm -f $${DESTDIR}$(HELPER_PATH)/afl-llvm-rt.o $${DESTDIR}$(HELPER_PATH)/afl-llvm-rt-32.o $${DESTDIR}$(HELPER_PATH)/afl-llvm-rt-64.o $${DESTDIR}$(HELPER_PATH)/afl-gcc-rt.o install -m 755 $(PROGS) $(SH_PROGS) $${DESTDIR}$(BIN_PATH) - rm -f $${DESTDIR}$(BIN_PATH)/afl-as - if [ -f afl-qemu-trace ]; then install -m 755 afl-qemu-trace $${DESTDIR}$(BIN_PATH); fi - if [ -f afl-gcc-fast ]; then set e; install -m 755 afl-gcc-fast $${DESTDIR}$(BIN_PATH); ln -sf afl-gcc-fast $${DESTDIR}$(BIN_PATH)/afl-g++-fast; install -m 755 afl-gcc-pass.so afl-gcc-rt.o $${DESTDIR}$(HELPER_PATH); fi - if [ -f afl-clang-fast ]; then $(MAKE) -C llvm_mode install; fi - if [ -f libdislocator.so ]; then set -e; install -m 755 libdislocator.so $${DESTDIR}$(HELPER_PATH); fi - if [ -f libtokencap.so ]; then set -e; install -m 755 libtokencap.so $${DESTDIR}$(HELPER_PATH); fi - if [ -f libcompcov.so ]; then set -e; install -m 755 libcompcov.so $${DESTDIR}$(HELPER_PATH); fi - if [ -f afl-fuzz-document ]; then set -e; install -m 755 afl-fuzz-document $${DESTDIR}$(BIN_PATH); fi - if [ -f socketfuzz32.so -o -f socketfuzz64.so ]; then $(MAKE) -C examples/socket_fuzzing install; fi - if [ -f argvfuzz32.so -o -f argvfuzz64.so ]; then $(MAKE) -C examples/argv_fuzzing install; fi - if [ -f examples/afl_network_proxy/afl-network-server ]; then $(MAKE) -C examples/afl_network_proxy install; fi - - set -e; ln -sf afl-gcc $${DESTDIR}$(BIN_PATH)/afl-g++ - set -e; if [ -f afl-clang-fast ] ; then ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang ; ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang++ ; else ln -sf afl-gcc $${DESTDIR}$(BIN_PATH)/afl-clang ; ln -sf afl-gcc $${DESTDIR}$(BIN_PATH)/afl-clang++; fi - - mkdir -m 0755 -p ${DESTDIR}$(MAN_PATH) + @if [ -f afl-qemu-trace ]; then install -m 755 afl-qemu-trace $${DESTDIR}$(BIN_PATH); fi + @if [ -f libdislocator.so ]; then set -e; install -m 755 libdislocator.so $${DESTDIR}$(HELPER_PATH); fi + @if [ -f libtokencap.so ]; then set -e; install -m 755 libtokencap.so $${DESTDIR}$(HELPER_PATH); fi + @if [ -f libcompcov.so ]; then set -e; install -m 755 libcompcov.so $${DESTDIR}$(HELPER_PATH); fi + @if [ -f libqasan.so ]; then set -e; install -m 755 libqasan.so $${DESTDIR}$(HELPER_PATH); fi + @if [ -f afl-fuzz-document ]; then set -e; install -m 755 afl-fuzz-document $${DESTDIR}$(BIN_PATH); fi + @if [ -f socketfuzz32.so -o -f socketfuzz64.so ]; then $(MAKE) -C utils/socket_fuzzing install; fi + @if [ -f argvfuzz32.so -o -f argvfuzz64.so ]; then $(MAKE) -C utils/argv_fuzzing install; fi + @if [ -f utils/afl_network_proxy/afl-network-server ]; then $(MAKE) -C utils/afl_network_proxy install; fi + @if [ -f utils/aflpp_driver/libAFLDriver.a ]; then set -e; install -m 644 utils/aflpp_driver/libAFLDriver.a $${DESTDIR}$(HELPER_PATH); fi + @if [ -f utils/aflpp_driver/libAFLQemuDriver.a ]; then set -e; install -m 644 utils/aflpp_driver/libAFLQemuDriver.a $${DESTDIR}$(HELPER_PATH); fi + -$(MAKE) -f GNUmakefile.llvm install + -$(MAKE) -f GNUmakefile.gcc_plugin install + ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-gcc + ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-g++ + ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-clang + ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-clang++ + @mkdir -m 0755 -p ${DESTDIR}$(MAN_PATH) install -m0644 *.8 ${DESTDIR}$(MAN_PATH) - install -m 755 afl-as $${DESTDIR}$(HELPER_PATH) ln -sf afl-as $${DESTDIR}$(HELPER_PATH)/as install -m 644 docs/*.md $${DESTDIR}$(DOC_PATH) diff --git a/gcc_plugin/GNUmakefile b/GNUmakefile.gcc_plugin index 4a4f0dcd..aa93c688 100644 --- a/gcc_plugin/GNUmakefile +++ b/GNUmakefile.gcc_plugin @@ -19,24 +19,24 @@ # # http://www.apache.org/licenses/LICENSE-2.0 # - +#TEST_MMAP=1 PREFIX ?= /usr/local HELPER_PATH ?= $(PREFIX)/lib/afl BIN_PATH ?= $(PREFIX)/bin DOC_PATH ?= $(PREFIX)/share/doc/afl -MAN_PATH ?= $(PREFIX)/man/man8 +MAN_PATH ?= $(PREFIX)/share/man/man8 -VERSION = $(shell grep '^$(HASH)define VERSION ' ../config.h | cut -d '"' -f2) +VERSION = $(shell grep '^$(HASH)define VERSION ' ./config.h | cut -d '"' -f2) CFLAGS ?= -O3 -g -funroll-loops -D_FORTIFY_SOURCE=2 -CFLAGS_SAFE := -Wall -I../include -Wno-pointer-sign \ +CFLAGS_SAFE := -Wall -Iinclude -Wno-pointer-sign \ -DAFL_PATH=\"$(HELPER_PATH)\" -DBIN_PATH=\"$(BIN_PATH)\" \ -DGCC_VERSION=\"$(GCCVER)\" -DGCC_BINDIR=\"$(GCCBINDIR)\" \ -Wno-unused-function override CFLAGS += $(CFLAGS_SAFE) CXXFLAGS ?= -O3 -g -funroll-loops -D_FORTIFY_SOURCE=2 -CXXEFLAGS := $(CXXFLAGS) -Wall +CXXEFLAGS := $(CXXFLAGS) -Wall -std=c++11 CC ?= gcc CXX ?= g++ @@ -51,7 +51,13 @@ ifeq "clang++" "$(CXX)" CXX = g++ endif -PLUGIN_FLAGS = -fPIC -fno-rtti -I"$(shell $(CC) -print-file-name=plugin)/include" +ifeq "$(findstring Foundation,$(shell $(CC) --version))" "" + CC = gcc + CXX = g++ +endif + +PLUGIN_BASE = "$(shell $(CC) -print-file-name=plugin)" +PLUGIN_FLAGS = -fPIC -fno-rtti -I$(PLUGIN_BASE)/include -I$(PLUGIN_BASE) HASH=\# GCCVER = $(shell $(CC) --version 2>/dev/null | awk 'NR == 1 {print $$NF}') @@ -61,110 +67,119 @@ ifeq "$(shell echo '$(HASH)include <sys/ipc.h>@$(HASH)include <sys/shm.h>@int ma SHMAT_OK=1 else SHMAT_OK=0 - override CFLAGS += -DUSEMMAP=1 + override CFLAGS_SAFE += -DUSEMMAP=1 endif ifeq "$(TEST_MMAP)" "1" SHMAT_OK=0 - override CFLAGS += -DUSEMMAP=1 + override CFLAGS_SAFE += -DUSEMMAP=1 endif ifneq "$(shell uname -s)" "Haiku" +ifneq "$(shell uname -s)" "OpenBSD" LDFLAGS += -lrt +endif else CFLAGS_SAFE += -DUSEMMAP=1 endif +ifeq "$(shell uname -s)" "OpenBSD" + CC = egcc + CXX = eg++ + PLUGIN_FLAGS += -I/usr/local/include +endif + +ifeq "$(shell uname -s)" "DragonFly" + PLUGIN_FLAGS += -I/usr/local/include +endif + ifeq "$(shell uname -s)" "SunOS" PLUGIN_FLAGS += -I/usr/include/gmp endif -PROGS = ../afl-gcc-fast ../afl-gcc-pass.so ../afl-gcc-rt.o +PROGS = ./afl-gcc-pass.so +.PHONY: all +all: test_shm test_deps $(PROGS) test_build all_done -all: test_shm test_deps $(PROGS) afl-gcc-fast.8 test_build all_done - +.PHONY: test_shm ifeq "$(SHMAT_OK)" "1" - test_shm: @echo "[+] shmat seems to be working." @rm -f .test2 - else - test_shm: @echo "[-] shmat seems not to be working, switching to mmap implementation" - endif - +.PHONY: test_deps test_deps: @echo "[*] Checking for working '$(CC)'..." - @type $(CC) >/dev/null 2>&1 || ( echo "[-] Oops, can't find '$(CC)'. Make sure that it's in your \$$PATH (or set \$$CC and \$$CXX)."; exit 1 ) + @command -v $(CC) >/dev/null 2>&1 || ( echo "[-] Oops, can't find '$(CC)'. Make sure that it's in your \$$PATH (or set \$$CC and \$$CXX)."; exit 1 ) # @echo "[*] Checking for gcc for plugin support..." # @$(CC) -v 2>&1 | grep -q -- --enable-plugin || ( echo "[-] Oops, this gcc has not been configured with plugin support."; exit 1 ) @echo "[*] Checking for gcc plugin development header files..." @test -d `$(CC) -print-file-name=plugin`/include || ( echo "[-] Oops, can't find gcc header files. Be sure to install 'gcc-X-plugin-dev'."; exit 1 ) - @echo "[*] Checking for '../afl-showmap'..." - @test -f ../afl-showmap || ( echo "[-] Oops, can't find '../afl-showmap'. Be sure to compile AFL first."; exit 1 ) + @echo "[*] Checking for './afl-showmap'..." + @test -f ./afl-showmap || ( echo "[-] Oops, can't find './afl-showmap'. Be sure to compile AFL first."; exit 1 ) @echo "[+] All set and ready to build." -afl-common.o: ../src/afl-common.c - $(CC) $(CFLAGS) -c $< -o $@ $(LDFLAGS) - -../afl-gcc-fast: afl-gcc-fast.c afl-common.o | test_deps - $(CC) -DAFL_GCC_CC=\"$(CC)\" -DAFL_GCC_CXX=\"$(CXX)\" $(CFLAGS) $< afl-common.o -o $@ $(LDFLAGS) - ln -sf afl-gcc-fast ../afl-g++-fast +afl-common.o: ./src/afl-common.c + $(CC) $(CFLAGS) $(CPPFLAGS) -c $< -o $@ $(LDFLAGS) -../afl-gcc-pass.so: afl-gcc-pass.so.cc | test_deps +./afl-gcc-pass.so: instrumentation/afl-gcc-pass.so.cc | test_deps $(CXX) $(CXXEFLAGS) $(PLUGIN_FLAGS) -shared $< -o $@ + ln -sf afl-cc afl-gcc-fast + ln -sf afl-cc afl-g++-fast + ln -sf afl-cc.8 afl-gcc-fast.8 + ln -sf afl-cc.8 afl-g++-fast.8 -../afl-gcc-rt.o: afl-gcc-rt.o.c | test_deps - $(CC) $(CFLAGS_SAFE) -fPIC -c $< -o $@ - +.PHONY: test_build test_build: $(PROGS) @echo "[*] Testing the CC wrapper and instrumentation output..." - unset AFL_USE_ASAN AFL_USE_MSAN; AFL_QUIET=1 AFL_INST_RATIO=100 AFL_PATH=. AFL_CC=$(CC) ../afl-gcc-fast $(CFLAGS) ../test-instr.c -o test-instr $(LDFLAGS) -# unset AFL_USE_ASAN AFL_USE_MSAN; AFL_INST_RATIO=100 AFL_PATH=. AFL_CC=$(CC) ../afl-gcc-fast $(CFLAGS) ../test-instr.c -o test-instr $(LDFLAGS) - ASAN_OPTIONS=detect_leaks=0 ../afl-showmap -m none -q -o .test-instr0 ./test-instr </dev/null - echo 1 | ASAN_OPTIONS=detect_leaks=0 ../afl-showmap -m none -q -o .test-instr1 ./test-instr + unset AFL_USE_ASAN AFL_USE_MSAN; ASAN_OPTIONS=detect_leaks=0 AFL_QUIET=1 AFL_INST_RATIO=100 AFL_PATH=. AFL_CC=$(CC) ./afl-gcc-fast $(CFLAGS) $(CPPFLAGS) ./test-instr.c -o test-instr $(LDFLAGS) + ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr0 ./test-instr </dev/null + echo 1 | ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr1 ./test-instr @rm -f test-instr @cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation does not seem to be behaving correctly!"; echo; echo "Please post to https://github.com/AFLplusplus/AFLplusplus/issues to troubleshoot the issue."; echo; exit 1; fi @echo "[+] All right, the instrumentation seems to be working!" +.PHONY: all_done all_done: test_build - @echo "[+] All done! You can now use '../afl-gcc-fast' to compile programs." + @echo "[+] All done! You can now use './afl-gcc-fast' to compile programs." .NOTPARALLEL: clean -vpath % .. %.8: % - @echo .TH $* 8 `date "+%Y-%m-%d"` "afl++" > ../$@ - @echo .SH NAME >> ../$@ - @echo .B $* >> ../$@ - @echo >> ../$@ - @echo .SH SYNOPSIS >> ../$@ - @../$* -h 2>&1 | head -n 3 | tail -n 1 | sed 's/^\.\///' >> ../$@ - @echo >> ../$@ - @echo .SH OPTIONS >> ../$@ - @echo .nf >> ../$@ - @../$* -h 2>&1 | tail -n +4 >> ../$@ - @echo >> ../$@ - @echo .SH AUTHOR >> ../$@ - @echo "afl++ was written by Michal \"lcamtuf\" Zalewski and is maintained by Marc \"van Hauser\" Heuse <mh@mh-sec.de>, Heiko \"hexcoder-\" Eissfeldt <heiko.eissfeldt@hexco.de>, Andrea Fioraldi <andreafioraldi@gmail.com> and Dominik Maier <domenukk@gmail.com>" >> ../$@ - @echo The homepage of afl++ is: https://github.com/AFLplusplus/AFLplusplus >> ../$@ - @echo >> ../$@ - @echo .SH LICENSE >> ../$@ - @echo Apache License Version 2.0, January 2004 >> ../$@ - ln -sf afl-gcc-fast.8 ../afl-g++-fast.8 - + @echo .TH $* 8 `date "+%Y-%m-%d"` "afl++" > ./$@ + @echo .SH NAME >> ./$@ + @echo .B $* >> ./$@ + @echo >> ./$@ + @echo .SH SYNOPSIS >> ./$@ + @./$* -h 2>&1 | head -n 3 | tail -n 1 | sed 's/^\.\///' >> ./$@ + @echo >> ./$@ + @echo .SH OPTIONS >> ./$@ + @echo .nf >> ./$@ + @./$* -h 2>&1 | tail -n +4 >> ./$@ + @echo >> ./$@ + @echo .SH AUTHOR >> ./$@ + @echo "afl++ was written by Michal \"lcamtuf\" Zalewski and is maintained by Marc \"van Hauser\" Heuse <mh@mh-sec.de>, Heiko \"hexcoder-\" Eissfeldt <heiko.eissfeldt@hexco.de>, Andrea Fioraldi <andreafioraldi@gmail.com> and Dominik Maier <domenukk@gmail.com>" >> ./$@ + @echo The homepage of afl++ is: https://github.com/AFLplusplus/AFLplusplus >> ./$@ + @echo >> ./$@ + @echo .SH LICENSE >> ./$@ + @echo Apache License Version 2.0, January 2004 >> ./$@ + ln -sf afl-cc.8 ./afl-g++-fast.8 + +.PHONY: install install: all - install -m 755 ../afl-gcc-fast $${DESTDIR}$(BIN_PATH) - install -m 755 ../afl-gcc-pass.so ../afl-gcc-rt.o $${DESTDIR}$(HELPER_PATH) - install -m 644 -T README.md $${DESTDIR}$(DOC_PATH)/README.gcc_plugin.md - install -m 644 -T README.instrument_file.md $${DESTDIR}$(DOC_PATH)/README.gcc_plugin.instrument_file.md + ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-gcc-fast + ln -sf afl-c++ $${DESTDIR}$(BIN_PATH)/afl-g++-fast + ln -sf afl-compiler-rt.o $${DESTDIR}$(HELPER_PATH)/afl-gcc-rt.o + install -m 755 ./afl-gcc-pass.so $${DESTDIR}$(HELPER_PATH) + install -m 644 -T instrumentation/README.gcc_plugin.md $${DESTDIR}$(DOC_PATH)/README.gcc_plugin.md +.PHONY: clean clean: rm -f *.o *.so *~ a.out core core.[1-9][0-9]* test-instr .test-instr0 .test-instr1 .test2 - rm -f $(PROGS) afl-common.o ../afl-g++-fast ../afl-g*-fast.8 + rm -f $(PROGS) afl-common.o ./afl-g++-fast ./afl-g*-fast.8 instrumentation/*.o diff --git a/GNUmakefile.llvm b/GNUmakefile.llvm new file mode 100644 index 00000000..cc332f6c --- /dev/null +++ b/GNUmakefile.llvm @@ -0,0 +1,522 @@ +# american fuzzy lop++ - LLVM instrumentation +# ----------------------------------------- +# +# Written by Laszlo Szekeres <lszekeres@google.com> and +# Michal Zalewski +# +# LLVM integration design comes from Laszlo Szekeres. +# +# Copyright 2015, 2016 Google Inc. All rights reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at: +# +# http://www.apache.org/licenses/LICENSE-2.0 +# + +# For Heiko: +#TEST_MMAP=1 +HASH=\# + +PREFIX ?= /usr/local +HELPER_PATH ?= $(PREFIX)/lib/afl +BIN_PATH ?= $(PREFIX)/bin +DOC_PATH ?= $(PREFIX)/share/doc/afl +MISC_PATH ?= $(PREFIX)/share/afl +MAN_PATH ?= $(PREFIX)/share/man/man8 + +BUILD_DATE ?= $(shell date -u -d "@$(SOURCE_DATE_EPOCH)" "+%Y-%m-%d" 2>/dev/null || date -u -r "$(SOURCE_DATE_EPOCH)" "+%Y-%m-%d" 2>/dev/null || date -u "+%Y-%m-%d") + +VERSION = $(shell grep '^$(HASH)define VERSION ' ./config.h | cut -d '"' -f2) + +ifeq "$(shell uname)" "OpenBSD" + LLVM_CONFIG ?= $(BIN_PATH)/llvm-config + HAS_OPT = $(shell test -x $(BIN_PATH)/opt && echo 0 || echo 1) + ifeq "$(HAS_OPT)" "1" + $(warning llvm_mode needs a complete llvm installation (versions 3.4 up to 12) -> e.g. "pkg_add llvm-7.0.1p9") + endif +else + LLVM_CONFIG ?= llvm-config +endif + +LLVMVER = $(shell $(LLVM_CONFIG) --version 2>/dev/null | sed 's/git//' | sed 's/svn//' ) +LLVM_MAJOR = $(shell $(LLVM_CONFIG) --version 2>/dev/null | sed 's/\..*//' ) +LLVM_MINOR = $(shell $(LLVM_CONFIG) --version 2>/dev/null | sed 's/.*\.//' | sed 's/git//' | sed 's/svn//' | sed 's/ .*//' ) +LLVM_UNSUPPORTED = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^3\.[0-3]|^[0-2]\.' && echo 1 || echo 0 ) +LLVM_TOO_NEW = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[3-9]' && echo 1 || echo 0 ) +LLVM_NEW_API = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[0-9]' && echo 1 || echo 0 ) +LLVM_10_OK = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[1-9]|^10\.[1-9]|^10\.0.[1-9]' && echo 1 || echo 0 ) +LLVM_HAVE_LTO = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[1-9]' && echo 1 || echo 0 ) +LLVM_BINDIR = $(shell $(LLVM_CONFIG) --bindir 2>/dev/null) +LLVM_LIBDIR = $(shell $(LLVM_CONFIG) --libdir 2>/dev/null) +LLVM_STDCXX = gnu++11 +LLVM_APPLE_XCODE = $(shell clang -v 2>&1 | grep -q Apple && echo 1 || echo 0) +LLVM_LTO = 0 + +ifeq "$(LLVMVER)" "" + $(warning [!] llvm_mode needs llvm-config, which was not found) +endif + +ifeq "$(LLVM_UNSUPPORTED)" "1" + $(error llvm_mode only supports llvm from version 3.4 onwards) +endif + +ifeq "$(LLVM_TOO_NEW)" "1" + $(warning you are using an in-development llvm version - this might break llvm_mode!) +endif + +LLVM_TOO_OLD=1 + +ifeq "$(LLVM_MAJOR)" "9" + $(info [+] llvm_mode detected llvm 9, enabling neverZero implementation) + LLVM_TOO_OLD=0 +endif + +ifeq "$(LLVM_NEW_API)" "1" + $(info [+] llvm_mode detected llvm 10+, enabling neverZero implementation and c++14) + LLVM_STDCXX = c++14 + LLVM_TOO_OLD=0 +endif + +ifeq "$(LLVM_TOO_OLD)" "1" + $(info [!] llvm_mode detected an old version of llvm, upgrade to at least 9 or preferable 11!) + $(shell sleep 1) +endif + +ifeq "$(LLVM_HAVE_LTO)" "1" + $(info [+] llvm_mode detected llvm 11+, enabling afl-lto LTO implementation) + LLVM_LTO = 1 + #TEST_MMAP = 1 +endif + +ifeq "$(LLVM_LTO)" "0" + $(info [+] llvm_mode detected llvm < 11, afl-lto LTO will not be build.) +endif + +ifeq "$(LLVM_APPLE_XCODE)" "1" + $(warning llvm_mode will not compile with Xcode clang...) +endif + +# We were using llvm-config --bindir to get the location of clang, but +# this seems to be busted on some distros, so using the one in $PATH is +# probably better. + +CC = $(LLVM_BINDIR)/clang +CXX = $(LLVM_BINDIR)/clang++ + +# llvm-config --bindir may not providing a valid path, so ... +ifeq "$(shell test -e $(CC) || echo 1 )" "1" + # however we must ensure that this is not a "CC=gcc make" + ifeq "$(shell command -v $(CC) 2> /dev/null)" "" + # we do not have a valid CC variable so we try alternatives + ifeq "$(shell test -e '$(BIN_DIR)/clang' && echo 1)" "1" + # we found one in the local install directory, lets use these + CC = $(BIN_DIR)/clang + else + # hope for the best + $(warning we have trouble finding clang - llvm-config is not helping us) + CC = clang + endif + endif +endif +# llvm-config --bindir may not providing a valid path, so ... +ifeq "$(shell test -e $(CXX) || echo 1 )" "1" + # however we must ensure that this is not a "CXX=g++ make" + ifeq "$(shell command -v $(CXX) 2> /dev/null)" "" + # we do not have a valid CXX variable so we try alternatives + ifeq "$(shell test -e '$(BIN_DIR)/clang++' && echo 1)" "1" + # we found one in the local install directory, lets use these + CXX = $(BIN_DIR)/clang++ + else + # hope for the best + $(warning we have trouble finding clang++ - llvm-config is not helping us) + CXX = clang++ + endif + endif +endif + +# sanity check. +# Are versions of clang --version and llvm-config --version equal? +CLANGVER = $(shell $(CC) --version | sed -E -ne '/^.*version\ (1?[0-9]\.[0-9]\.[0-9]).*/s//\1/p') + +# I disable this because it does not make sense with what we did before (marc) +# We did exactly set these 26 lines above with these values, and it would break +# "CC=gcc make" etc. usages +ifeq "$(findstring clang, $(shell $(CC) --version 2>/dev/null))" "" + CC_SAVE := $(LLVM_BINDIR)/clang +else + CC_SAVE := $(CC) +endif +ifeq "$(findstring clang, $(shell $(CXX) --version 2>/dev/null))" "" + CXX_SAVE := $(LLVM_BINDIR)/clang++ +else + CXX_SAVE := $(CXX) +endif + +CLANG_BIN := $(CC_SAVE) +CLANGPP_BIN := $(CXX_SAVE) + +ifeq "$(CC_SAVE)" "$(LLVM_BINDIR)/clang" + USE_BINDIR = 1 +else + ifeq "$(CXX_SAVE)" "$(LLVM_BINDIR)/clang++" + USE_BINDIR = 1 + else + USE_BINDIR = 0 + endif +endif + +# On old platform we cannot compile with clang because std++ libraries are too +# old. For these we need to use gcc/g++, so if we find REAL_CC and REAL_CXX +# variable we override the compiler variables here +ifneq "$(REAL_CC)" "" + CC = $(REAL_CC) +endif +ifneq "$(REAL_CXX)" "" + CXX = $(REAL_CXX) +endif + +# +# Now it can happen that CC points to clang - but there is no clang on the +# system. Then we fall back to cc +# +ifeq "$(shell command -v $(CC) 2>/dev/null)" "" + CC = cc +endif +ifeq "$(shell command -v $(CXX) 2>/dev/null)" "" + CXX = c++ +endif + + +# After we set CC/CXX we can start makefile magic tests + +#ifeq "$(shell echo 'int main() {return 0; }' | $(CC) -x c - -march=native -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" +# CFLAGS_OPT = -march=native +#endif + +ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -flto=full -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" + AFL_CLANG_FLTO ?= -flto=full +else + ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -flto=thin -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" + AFL_CLANG_FLTO ?= -flto=thin + else + ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -flto -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" + AFL_CLANG_FLTO ?= -flto + endif + endif +endif + +ifeq "$(LLVM_LTO)" "1" + ifneq "$(AFL_CLANG_FLTO)" "" + ifeq "$(AFL_REAL_LD)" "" + ifneq "$(shell readlink $(LLVM_BINDIR)/ld.lld 2>&1)" "" + AFL_REAL_LD = $(LLVM_BINDIR)/ld.lld + else + $(warning ld.lld not found, cannot enable LTO mode) + LLVM_LTO = 0 + endif + endif + else + $(warning clang option -flto is not working - maybe LLVMgold.so not found - cannot enable LTO mode) + LLVM_LTO = 0 + endif +endif + +AFL_CLANG_FUSELD= +ifeq "$(LLVM_LTO)" "1" + ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -fuse-ld=`command -v ld` -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" + AFL_CLANG_FUSELD=1 + ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -fuse-ld=ld.lld --ld-path=$(LLVM_BINDIR)/ld.lld -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" + AFL_CLANG_LDPATH=1 + endif + else + $(warning -fuse-ld is not working, cannot enable LTO mode) + LLVM_LTO = 0 + endif +endif + +ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -fdebug-prefix-map=$(CURDIR)=llvm_mode -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" + AFL_CLANG_DEBUG_PREFIX = -fdebug-prefix-map="$(CURDIR)=llvm_mode" +else + AFL_CLANG_DEBUG_PREFIX = +endif + +CFLAGS ?= -O3 -funroll-loops -fPIC -D_FORTIFY_SOURCE=2 +CFLAGS_SAFE := -Wall -g -Wno-cast-qual -Wno-variadic-macros -Wno-pointer-sign -I ./include/ -I ./instrumentation/ \ + -DAFL_PATH=\"$(HELPER_PATH)\" -DBIN_PATH=\"$(BIN_PATH)\" \ + -DLLVM_BINDIR=\"$(LLVM_BINDIR)\" -DVERSION=\"$(VERSION)\" \ + -DLLVM_LIBDIR=\"$(LLVM_LIBDIR)\" -DLLVM_VERSION=\"$(LLVMVER)\" \ + -Wno-deprecated -DAFL_CLANG_FLTO=\"$(AFL_CLANG_FLTO)\" \ + -DAFL_REAL_LD=\"$(AFL_REAL_LD)\" \ + -DAFL_CLANG_LDPATH=\"$(AFL_CLANG_LDPATH)\" \ + -DAFL_CLANG_FUSELD=\"$(AFL_CLANG_FUSELD)\" \ + -DCLANG_BIN=\"$(CLANG_BIN)\" -DCLANGPP_BIN=\"$(CLANGPP_BIN)\" -DUSE_BINDIR=$(USE_BINDIR) -Wno-unused-function \ + $(AFL_CLANG_DEBUG_PREFIX) +override CFLAGS += $(CFLAGS_SAFE) + +ifdef AFL_TRACE_PC + $(info Compile option AFL_TRACE_PC is deprecated, just set AFL_LLVM_INSTRUMENT=PCGUARD to activate when compiling targets ) +endif + +CXXFLAGS ?= -O3 -funroll-loops -fPIC -D_FORTIFY_SOURCE=2 +override CXXFLAGS += -Wall -g -I ./include/ \ + -DVERSION=\"$(VERSION)\" -Wno-variadic-macros \ + -DLLVM_MINOR=$(LLVM_MINOR) -DLLVM_MAJOR=$(LLVM_MAJOR) + +ifneq "$(shell $(LLVM_CONFIG) --includedir) 2> /dev/null" "" + CLANG_CFL = -I$(shell $(LLVM_CONFIG) --includedir) +endif +ifneq "$(LLVM_CONFIG)" "" + CLANG_CFL += -I$(shell dirname $(LLVM_CONFIG))/../include +endif +CLANG_CPPFL = `$(LLVM_CONFIG) --cxxflags` -fno-rtti -fPIC $(CXXFLAGS) -Wno-deprecated-declarations +CLANG_LFL = `$(LLVM_CONFIG) --ldflags` $(LDFLAGS) + + +# User teor2345 reports that this is required to make things work on MacOS X. +ifeq "$(shell uname)" "Darwin" + CLANG_LFL += -Wl,-flat_namespace -Wl,-undefined,suppress +else + CLANG_CPPFL += -Wl,-znodelete +endif + +ifeq "$(shell uname)" "OpenBSD" + CLANG_LFL += `$(LLVM_CONFIG) --libdir`/libLLVM.so + CLANG_CPPFL += -mno-retpoline + CFLAGS += -mno-retpoline + # Needed for unwind symbols + LDFLAGS += -lc++abi -lpthread +endif + +ifeq "$(shell echo '$(HASH)include <sys/ipc.h>@$(HASH)include <sys/shm.h>@int main() { int _id = shmget(IPC_PRIVATE, 65536, IPC_CREAT | IPC_EXCL | 0600); shmctl(_id, IPC_RMID, 0); return 0;}' | tr @ '\n' | $(CC) -x c - -o .test2 2>/dev/null && echo 1 || echo 0 ; rm -f .test2 )" "1" + SHMAT_OK=1 +else + SHMAT_OK=0 + CFLAGS_SAFE += -DUSEMMAP=1 + LDFLAGS += -Wno-deprecated-declarations +endif + +ifeq "$(TEST_MMAP)" "1" + SHMAT_OK=0 + CFLAGS_SAFE += -DUSEMMAP=1 + LDFLAGS += -Wno-deprecated-declarations +endif + +PROGS_ALWAYS = ./afl-cc ./afl-compiler-rt.o ./afl-compiler-rt-32.o ./afl-compiler-rt-64.o +PROGS = $(PROGS_ALWAYS) ./afl-llvm-pass.so ./SanitizerCoveragePCGUARD.so ./split-compares-pass.so ./split-switches-pass.so ./cmplog-routines-pass.so ./cmplog-instructions-pass.so ./afl-llvm-dict2file.so ./compare-transform-pass.so ./libLLVMInsTrim.so ./afl-ld-lto ./afl-llvm-lto-instrumentlist.so ./afl-llvm-lto-instrumentation.so ./SanitizerCoverageLTO.so + +# If prerequisites are not given, warn, do not build anything, and exit with code 0 +ifeq "$(LLVMVER)" "" + NO_BUILD = 1 +endif + +ifneq "$(LLVM_UNSUPPORTED)$(LLVM_APPLE_XCODE)" "00" + NO_BUILD = 1 +endif + +ifeq "$(NO_BUILD)" "1" + TARGETS = test_shm $(PROGS_ALWAYS) afl-cc.8 +else + TARGETS = test_shm test_deps $(PROGS) afl-cc.8 test_build all_done +endif + +LLVM_MIN_4_0_1 = $(shell awk 'function tonum(ver, a) {split(ver,a,"."); return a[1]*1000000+a[2]*1000+a[3]} BEGIN { exit tonum(ARGV[1]) >= tonum(ARGV[2]) }' $(LLVMVER) 4.0.1; echo $$?) + +.PHONY: all +all: $(TARGETS) + +.PHONY: test_shm +ifeq "$(SHMAT_OK)" "1" +test_shm: + @echo "[+] shmat seems to be working." + @rm -f .test2 +else +test_shm: + @echo "[-] shmat seems not to be working, switching to mmap implementation" +endif + +.PHONY: no_build +no_build: + @printf "%b\\n" "\\033[0;31mPrerequisites are not met, skipping build llvm_mode\\033[0m" + +.PHONY: test_deps +test_deps: + @echo "[*] Checking for working 'llvm-config'..." + ifneq "$(LLVM_APPLE_XCODE)" "1" + @type $(LLVM_CONFIG) >/dev/null 2>&1 || ( echo "[-] Oops, can't find 'llvm-config'. Install clang or set \$$LLVM_CONFIG or \$$PATH beforehand."; echo " (Sometimes, the binary will be named llvm-config-3.5 or something like that.)"; exit 1 ) + endif + @echo "[*] Checking for working '$(CC)'..." + @type $(CC) >/dev/null 2>&1 || ( echo "[-] Oops, can't find '$(CC)'. Make sure that it's in your \$$PATH (or set \$$CC and \$$CXX)."; exit 1 ) + @echo "[*] Checking for matching versions of '$(CC)' and '$(LLVM_CONFIG)'" +ifneq "$(CLANGVER)" "$(LLVMVER)" + @echo "[!] WARNING: we have llvm-config version $(LLVMVER) and a clang version $(CLANGVER)" +else + @echo "[*] We have llvm-config version $(LLVMVER) with a clang version $(CLANGVER), good." +endif + @echo "[*] Checking for './afl-showmap'..." + @test -f ./afl-showmap || ( echo "[-] Oops, can't find './afl-showmap'. Be sure to compile AFL first."; exit 1 ) + @echo "[+] All set and ready to build." + +instrumentation/afl-common.o: ./src/afl-common.c + $(CC) $(CFLAGS) $(CPPFLAGS) -c $< -o $@ $(LDFLAGS) + +./afl-cc: src/afl-cc.c instrumentation/afl-common.o + $(CC) $(CLANG_CFL) $(CFLAGS) $(CPPFLAGS) $< instrumentation/afl-common.o -o $@ -DLLVM_MINOR=$(LLVM_MINOR) -DLLVM_MAJOR=$(LLVM_MAJOR) $(LDFLAGS) -DCFLAGS_OPT=\"$(CFLAGS_OPT)\" -lm + @ln -sf afl-cc ./afl-c++ + @ln -sf afl-cc ./afl-gcc + @ln -sf afl-cc ./afl-g++ + @ln -sf afl-cc ./afl-clang + @ln -sf afl-cc ./afl-clang++ + @ln -sf afl-cc ./afl-clang-fast + @ln -sf afl-cc ./afl-clang-fast++ +ifneq "$(AFL_CLANG_FLTO)" "" +ifeq "$(LLVM_LTO)" "1" + @ln -sf afl-cc ./afl-clang-lto + @ln -sf afl-cc ./afl-clang-lto++ + @ln -sf afl-cc ./afl-lto + @ln -sf afl-cc ./afl-lto++ +endif +endif + +instrumentation/afl-llvm-common.o: instrumentation/afl-llvm-common.cc instrumentation/afl-llvm-common.h + $(CXX) $(CFLAGS) $(CPPFLAGS) `$(LLVM_CONFIG) --cxxflags` -fno-rtti -fPIC -std=$(LLVM_STDCXX) -c $< -o $@ + +./libLLVMInsTrim.so: instrumentation/LLVMInsTrim.so.cc instrumentation/MarkNodes.cc instrumentation/afl-llvm-common.o | test_deps + -$(CXX) $(CLANG_CPPFL) -DLLVMInsTrim_EXPORTS -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< instrumentation/MarkNodes.cc -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o + +./afl-llvm-pass.so: instrumentation/afl-llvm-pass.so.cc instrumentation/afl-llvm-common.o | test_deps +ifeq "$(LLVM_MIN_4_0_1)" "0" + $(info [!] N-gram branch coverage instrumentation is not available for llvm version $(LLVMVER)) +endif + $(CXX) $(CLANG_CPPFL) -DLLVMInsTrim_EXPORTS -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o + +./SanitizerCoveragePCGUARD.so: instrumentation/SanitizerCoveragePCGUARD.so.cc instrumentation/afl-llvm-common.o | test_deps +ifeq "$(LLVM_10_OK)" "1" + -$(CXX) $(CLANG_CPPFL) -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o +endif + +./afl-llvm-lto-instrumentlist.so: instrumentation/afl-llvm-lto-instrumentlist.so.cc instrumentation/afl-llvm-common.o +ifeq "$(LLVM_LTO)" "1" + $(CXX) $(CLANG_CPPFL) -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o +endif + +./afl-ld-lto: src/afl-ld-lto.c +ifeq "$(LLVM_LTO)" "1" + $(CC) $(CFLAGS) $(CPPFLAGS) $< -o $@ +endif + +./SanitizerCoverageLTO.so: instrumentation/SanitizerCoverageLTO.so.cc +ifeq "$(LLVM_LTO)" "1" + $(CXX) $(CLANG_CPPFL) -Wno-writable-strings -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o +endif + +./afl-llvm-lto-instrumentation.so: instrumentation/afl-llvm-lto-instrumentation.so.cc instrumentation/afl-llvm-common.o +ifeq "$(LLVM_LTO)" "1" + $(CXX) $(CLANG_CPPFL) -Wno-writable-strings -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o + $(CLANG_BIN) $(CFLAGS_SAFE) $(CPPFLAGS) -Wno-unused-result -O0 $(AFL_CLANG_FLTO) -fPIC -c instrumentation/afl-llvm-rt-lto.o.c -o ./afl-llvm-rt-lto.o + @$(CLANG_BIN) $(CFLAGS_SAFE) $(CPPFLAGS) -Wno-unused-result -O0 $(AFL_CLANG_FLTO) -m64 -fPIC -c instrumentation/afl-llvm-rt-lto.o.c -o ./afl-llvm-rt-lto-64.o 2>/dev/null; if [ "$$?" = "0" ]; then : ; fi + @$(CLANG_BIN) $(CFLAGS_SAFE) $(CPPFLAGS) -Wno-unused-result -O0 $(AFL_CLANG_FLTO) -m32 -fPIC -c instrumentation/afl-llvm-rt-lto.o.c -o ./afl-llvm-rt-lto-32.o 2>/dev/null; if [ "$$?" = "0" ]; then : ; fi +endif + +# laf +./split-switches-pass.so: instrumentation/split-switches-pass.so.cc instrumentation/afl-llvm-common.o | test_deps + $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o +./compare-transform-pass.so: instrumentation/compare-transform-pass.so.cc instrumentation/afl-llvm-common.o | test_deps + $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o +./split-compares-pass.so: instrumentation/split-compares-pass.so.cc instrumentation/afl-llvm-common.o | test_deps + $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o +# /laf + +./cmplog-routines-pass.so: instrumentation/cmplog-routines-pass.cc instrumentation/afl-llvm-common.o | test_deps + $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o + +./cmplog-instructions-pass.so: instrumentation/cmplog-instructions-pass.cc instrumentation/afl-llvm-common.o | test_deps + $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o + +afl-llvm-dict2file.so: instrumentation/afl-llvm-dict2file.so.cc instrumentation/afl-llvm-common.o | test_deps + $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) instrumentation/afl-llvm-common.o + +.PHONY: document +document: + $(CLANG_BIN) -D_AFL_DOCUMENT_MUTATIONS $(CFLAGS_SAFE) $(CPPFLAGS) $(CLANG_CFL) -O3 -Wno-unused-result -fPIC -c instrumentation/afl-compiler-rt.o.c -o ./afl-compiler-rt.o + @$(CLANG_BIN) -D_AFL_DOCUMENT_MUTATIONS $(CFLAGS_SAFE) $(CPPFLAGS) $(CLANG_CFL) -O3 -Wno-unused-result -m32 -fPIC -c instrumentation/afl-compiler-rt.o.c -o ./afl-compiler-rt-32.o 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; else echo "failed (that's fine)"; fi + @$(CLANG_BIN) -D_AFL_DOCUMENT_MUTATIONS $(CFLAGS_SAFE) $(CPPFLAGS) $(CLANG_CFL) -O3 -Wno-unused-result -m64 -fPIC -c instrumentation/afl-compiler-rt.o.c -o ./afl-compiler-rt-64.o 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; else echo "failed (that's fine)"; fi + +./afl-compiler-rt.o: instrumentation/afl-compiler-rt.o.c + $(CC) $(CLANG_CFL) $(CFLAGS_SAFE) $(CPPFLAGS) -O3 -Wno-unused-result -fPIC -c $< -o $@ + +./afl-compiler-rt-32.o: instrumentation/afl-compiler-rt.o.c + @printf "[*] Building 32-bit variant of the runtime (-m32)... " + @$(CC) $(CLANG_CFL) $(CFLAGS_SAFE) $(CPPFLAGS) -O3 -Wno-unused-result -m32 -fPIC -c $< -o $@ 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; ln -sf afl-compiler-rt-32.o afl-llvm-rt-32.o; else echo "failed (that's fine)"; fi + +./afl-compiler-rt-64.o: instrumentation/afl-compiler-rt.o.c + @printf "[*] Building 64-bit variant of the runtime (-m64)... " + @$(CC) $(CLANG_CFL) $(CFLAGS_SAFE) $(CPPFLAGS) -O3 -Wno-unused-result -m64 -fPIC -c $< -o $@ 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; ln -sf afl-compiler-rt-64.o afl-llvm-rt-64.o; else echo "failed (that's fine)"; fi + +.PHONY: test_build +test_build: $(PROGS) + @echo "[*] Testing the CC wrapper and instrumentation output..." + unset AFL_USE_ASAN AFL_USE_MSAN AFL_INST_RATIO; ASAN_OPTIONS=detect_leaks=0 AFL_QUIET=1 AFL_PATH=. AFL_LLVM_LAF_ALL=1 ./afl-cc $(CFLAGS) $(CPPFLAGS) ./test-instr.c -o test-instr $(LDFLAGS) + ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr0 ./test-instr < /dev/null + echo 1 | ASAN_OPTIONS=detect_leaks=0 ./afl-showmap -m none -q -o .test-instr1 ./test-instr + @rm -f test-instr + @cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation does not seem to be behaving correctly!"; echo; echo "Please post to https://github.com/AFLplusplus/AFLplusplus/issues to troubleshoot the issue."; echo; exit 1; fi + @echo "[+] All right, the instrumentation seems to be working!" + +.PHONY: all_done +all_done: test_build + @echo "[+] All done! You can now use './afl-cc' to compile programs." + +.NOTPARALLEL: clean + +.PHONY: install +install: all + @install -d -m 755 $${DESTDIR}$(BIN_PATH) $${DESTDIR}$(HELPER_PATH) $${DESTDIR}$(DOC_PATH) $${DESTDIR}$(MISC_PATH) + @if [ -f ./afl-cc ]; then set -e; install -m 755 ./afl-cc $${DESTDIR}$(BIN_PATH); ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-c++; fi + @rm -f $${DESTDIR}$(HELPER_PATH)/afl-llvm-rt*.o $${DESTDIR}$(HELPER_PATH)/afl-gcc-rt*.o + @if [ -f ./afl-compiler-rt.o ]; then set -e; install -m 755 ./afl-compiler-rt.o $${DESTDIR}$(HELPER_PATH); ln -sf afl-compiler-rt.o $${DESTDIR}$(HELPER_PATH)/afl-llvm-rt.o ;fi + @if [ -f ./afl-lto ]; then set -e; ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-lto; ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-lto++; ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-clang-lto; ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-clang-lto++; install -m 755 ./afl-llvm-lto-instrumentation.so ./afl-llvm-rt-lto*.o ./afl-llvm-lto-instrumentlist.so $${DESTDIR}$(HELPER_PATH); fi + @if [ -f ./afl-ld-lto ]; then set -e; install -m 755 ./afl-ld-lto $${DESTDIR}$(BIN_PATH); fi + @if [ -f ./afl-compiler-rt-32.o ]; then set -e; install -m 755 ./afl-compiler-rt-32.o $${DESTDIR}$(HELPER_PATH); ln -sf afl-compiler-rt-32.o $${DESTDIR}$(HELPER_PATH)/afl-llvm-rt-32.o ;fi + @if [ -f ./afl-compiler-rt-64.o ]; then set -e; install -m 755 ./afl-compiler-rt-64.o $${DESTDIR}$(HELPER_PATH); ln -sf afl-compiler-rt-64.o $${DESTDIR}$(HELPER_PATH)/afl-llvm-rt-64.o ; fi + @if [ -f ./compare-transform-pass.so ]; then set -e; install -m 755 ./*.so $${DESTDIR}$(HELPER_PATH); fi + @if [ -f ./compare-transform-pass.so ]; then set -e; ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-clang-fast ; ln -sf ./afl-c++ $${DESTDIR}$(BIN_PATH)/afl-clang-fast++ ; ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-clang ; ln -sf ./afl-c++ $${DESTDIR}$(BIN_PATH)/afl-clang++ ; fi + @if [ -f ./SanitizerCoverageLTO.so ]; then set -e; ln -sf afl-cc $${DESTDIR}$(BIN_PATH)/afl-clang-lto ; ln -sf ./afl-c++ $${DESTDIR}$(BIN_PATH)/afl-clang-lto++ ; fi + set -e; install -m 644 ./dynamic_list.txt $${DESTDIR}$(HELPER_PATH) + install -m 644 instrumentation/README.*.md $${DESTDIR}$(DOC_PATH)/ + +%.8: % + @echo .TH $* 8 $(BUILD_DATE) "afl++" > ./$@ + @echo .SH NAME >> ./$@ + @printf "%s" ".B $* \- " >> ./$@ + @./$* -h 2>&1 | head -n 1 | sed -e "s/$$(printf '\e')[^m]*m//g" >> ./$@ + @echo .B $* >> ./$@ + @echo >> ./$@ + @echo .SH SYNOPSIS >> ./$@ + @./$* -h 2>&1 | head -n 3 | tail -n 1 | sed 's/^\.\///' >> ./$@ + @echo >> ./$@ + @echo .SH OPTIONS >> ./$@ + @echo .nf >> ./$@ + @./$* -h 2>&1 | tail -n +4 >> ./$@ + @echo >> ./$@ + @echo .SH AUTHOR >> ./$@ + @echo "afl++ was written by Michal \"lcamtuf\" Zalewski and is maintained by Marc \"van Hauser\" Heuse <mh@mh-sec.de>, Heiko \"hexcoder-\" Eissfeldt <heiko.eissfeldt@hexco.de>, Andrea Fioraldi <andreafioraldi@gmail.com> and Dominik Maier <domenukk@gmail.com>" >> ./$@ + @echo The homepage of afl++ is: https://github.com/AFLplusplus/AFLplusplus >> ./$@ + @echo >> ./$@ + @echo .SH LICENSE >> ./$@ + @echo Apache License Version 2.0, January 2004 >> ./$@ + @ln -sf afl-cc.8 ./afl-c++.8 +ifneq "$(AFL_CLANG_FLTO)" "" +ifeq "$(LLVM_LTO)" "1" + @ln -sf afl-cc.8 ./afl-clang-lto.8 + @ln -sf afl-cc.8 ./afl-clang-lto++.8 + @ln -sf afl-cc.8 ./afl-lto.8 + @ln -sf afl-cc.8 ./afl-lto++.8 +endif +endif + +.PHONY: clean +clean: + rm -f *.o *.so *~ a.out core core.[1-9][0-9]* .test2 test-instr .test-instr0 .test-instr1 *.dwo + rm -f $(PROGS) afl-common.o ./afl-c++ ./afl-lto ./afl-lto++ ./afl-clang-lto* ./afl-clang-fast* ./afl-clang*.8 ./ld ./afl-ld ./afl-llvm-rt*.o instrumentation/*.o @@ -2,11 +2,9 @@ <img align="right" src="https://raw.githubusercontent.com/andreafioraldi/AFLplusplus-website/master/static/logo_256x256.png" alt="AFL++ Logo"> -  + Release Version: [3.11c](https://github.com/AFLplusplus/AFLplusplus/releases) - Release Version: [2.66c](https://github.com/AFLplusplus/AFLplusplus/releases) - - Github Version: 2.66d + Github Version: 3.12a Repository: [https://github.com/AFLplusplus/AFLplusplus](https://github.com/AFLplusplus/AFLplusplus) @@ -17,11 +15,57 @@ * Andrea Fioraldi <andreafioraldi@gmail.com> and * Dominik Maier <mail@dmnk.co>. - Originally developed by Michal "lcamtuf" Zalewski. + Originally developed by Michał "lcamtuf" Zalewski. - afl++ is a superiour fork to Google's afl - more speed, more and better + afl++ is a superior fork to Google's afl - more speed, more and better mutations, more and better instrumentation, custom module support, etc. + If you want to use afl++ for your academic work, check the [papers page](https://aflplus.plus/papers/) + on the website. To cite our work, look at the [Cite](#cite) section. + For comparisons use the fuzzbench `aflplusplus` setup, or use `afl-clang-fast` + with `AFL_LLVM_CMPLOG=1`. + +## Major changes in afl++ 3.00 + 3.10 + +With afl++ 3.10 we introduced the following changes from previous behaviours: + * The '+' feature of the '-t' option now means to auto-calculate the timeout + with the value given being the maximum timeout. The original meaning of + "skipping timeouts instead of abort" is now inherent to the -t option. + +With afl++ 3.00 we introduced changes that break some previous afl and afl++ +behaviours and defaults: + + * There are no llvm_mode and gcc_plugin subdirectories anymore and there is + only one compiler: afl-cc. All previous compilers now symlink to this one. + All instrumentation source code is now in the `instrumentation/` folder. + * The gcc_plugin was replaced with a new version submitted by AdaCore that + supports more features. Thank you! + * qemu_mode got upgraded to QEMU 5.1, but to be able to build this a current + ninja build tool version and python3 setuptools are required. + qemu_mode also got new options like snapshotting, instrumenting specific + shared libraries, etc. Additionally QEMU 5.1 supports more CPU targets so + this is really worth it. + * When instrumenting targets, afl-cc will not supersede optimizations anymore + if any were given. This allows to fuzz targets as same as they are built + for debug or release. + * afl-fuzz: + * if neither -M or -S is specified, `-S default` is assumed, so more + fuzzers can easily be added later + * `-i` input directory option now descends into subdirectories. It also + does not fatal on crashes and too large files, instead it skips them + and uses them for splicing mutations + * -m none is now default, set memory limits (in MB) with e.g. -m 250 + * deterministic fuzzing is now disabled by default (unless using -M) and + can be enabled with -D + * a caching of testcases can now be performed and can be modified by + editing config.h for TESTCASE_CACHE or by specifying the env variable + `AFL_TESTCACHE_SIZE` (in MB). Good values are between 50-500 (default: 50). + * -M mains do not perform trimming + * examples/ got renamed to utils/ + * libtokencap/ libdislocator/ and qdbi_mode/ were moved to utils/ + * afl-cmin/afl-cmin.bash now search first in PATH and last in AFL_PATH + + ## Contents 1. [Features](#important-features-of-afl) @@ -29,56 +73,53 @@ 3. [How to fuzz a target](#how-to-fuzz-with-afl) 4. [Fuzzing binary-only targets](#fuzzing-binary-only-targets) 5. [Good examples and writeups of afl++ usages](#good-examples-and-writeups) - 6. [Branches](#branches) - 7. [Want to help?](#help-wanted) - 8. [Detailed help and description of afl++](#challenges-of-guided-fuzzing) + 6. [CI Fuzzing](#ci-fuzzing) + 7. [Branches](#branches) + 8. [Want to help?](#help-wanted) + 9. [Detailed help and description of afl++](#challenges-of-guided-fuzzing) ## Important features of afl++ - afl++ supports llvm up to version 12, very fast binary fuzzing with QEMU 3.1 + afl++ supports llvm up to version 12, very fast binary fuzzing with QEMU 5.1 with laf-intel and redqueen, unicorn mode, gcc plugin, full *BSD, Solaris and Android support and much, much, much more. - | Feature/Instrumentation | afl-gcc | llvm_mode | gcc_plugin | qemu_mode | unicorn_mode | - | ----------------------- |:-------:|:---------:|:----------:|:----------------:|:------------:| - | NeverZero | x | x(1) | (2) | x | x | - | Persistent mode | | x | x | x86[_64]/arm[64] | x | - | LAF-Intel / CompCov | | x | | x86[_64]/arm[64] | x86[_64]/arm | - | CmpLog | | x | | x86[_64]/arm[64] | | - | Instrument file list | | x | x | (x)(3) | | - | Non-colliding coverage | | x(4) | | (x)(5) | | - | InsTrim | | x | | | | - | Ngram prev_loc coverage | | x(6) | | | | - | Context coverage | | x | | | | - | Auto dictionary | | x(7) | | | | - | Snapshot LKM support | | x | | (x)(5) | | + | Feature/Instrumentation | afl-gcc | llvm | gcc_plugin | qemu_mode | unicorn_mode | + | -------------------------|:-------:|:---------:|:----------:|:----------------:|:------------:| + | NeverZero | x86[_64]| x(1) | x | x | x | + | Persistent Mode | | x | x | x86[_64]/arm[64] | x | + | LAF-Intel / CompCov | | x | | x86[_64]/arm[64] | x86[_64]/arm | + | CmpLog | | x | | x86[_64]/arm[64] | | + | Selective Instrumentation| | x | x | x | | + | Non-Colliding Coverage | | x(4) | | (x)(5) | | + | Ngram prev_loc Coverage | | x(6) | | | | + | Context Coverage | | x(6) | | | | + | Auto Dictionary | | x(7) | | | | + | Snapshot LKM Support | | x(8) | x(8) | (x)(5) | | 1. default for LLVM >= 9.0, env var for older version due an efficiency bug in llvm <= 8 2. GCC creates non-performant code, hence it is disabled in gcc_plugin - 3. partially via AFL_CODE_START/AFL_CODE_END + 3. (currently unassigned) 4. with pcguard mode and LTO mode for LLVM >= 11 5. upcoming, development in the branch 6. not compatible with LTO instrumentation and needs at least LLVM >= 4.1 - 7. only in LTO mode with LLVM >= 11 + 7. automatic in LTO mode with LLVM >= 11, an extra pass for all LLVM version that writes to a file to use with afl-fuzz' `-x` + 8. the snapshot LKM is currently unmaintained due to too many kernel changes coming too fast :-( Among others, the following features and patches have been integrated: - * NeverZero patch for afl-gcc, llvm_mode, qemu_mode and unicorn_mode which prevents a wrapping map value to zero, increases coverage - * Persistent mode and deferred forkserver for qemu_mode + * NeverZero patch for afl-gcc, instrumentation, qemu_mode and unicorn_mode which prevents a wrapping map value to zero, increases coverage + * Persistent mode, deferred forkserver and in-memory fuzzing for qemu_mode * Unicorn mode which allows fuzzing of binaries from completely different platforms (integration provided by domenukk) * The new CmpLog instrumentation for LLVM and QEMU inspired by [Redqueen](https://www.syssec.ruhr-uni-bochum.de/media/emma/veroeffentlichungen/2018/12/17/NDSS19-Redqueen.pdf) * Win32 PE binary-only fuzzing with QEMU and Wine * AFLfast's power schedules by Marcel Böhme: [https://github.com/mboehme/aflfast](https://github.com/mboehme/aflfast) * The MOpt mutator: [https://github.com/puppet-meteor/MOpt-AFL](https://github.com/puppet-meteor/MOpt-AFL) * LLVM mode Ngram coverage by Adrian Herrera [https://github.com/adrianherrera/afl-ngram-pass](https://github.com/adrianherrera/afl-ngram-pass) - * InsTrim, an effective CFG llvm_mode instrumentation implementation for large targets: [https://github.com/csienslab/instrim](https://github.com/csienslab/instrim) - * C. Holler's afl-fuzz Python mutator module and llvm_mode instrument file support: [https://github.com/choller/afl](https://github.com/choller/afl) - * Custom mutator by a library (instead of Python) by kyakdan - * LAF-Intel/CompCov support for llvm_mode, qemu_mode and unicorn_mode (with enhanced capabilities) - * Radamsa and hongfuzz mutators (as custom mutators). - * QBDI mode to fuzz android native libraries via QBDI framework - - A more thorough list is available in the [PATCHES](docs/PATCHES.md) file. + * LAF-Intel/CompCov support for instrumentation, qemu_mode and unicorn_mode (with enhanced capabilities) + * Radamsa and honggfuzz mutators (as custom mutators). + * QBDI mode to fuzz android native libraries via Quarkslab's [QBDI](https://github.com/QBDI/QBDI) framework + * Frida and ptrace mode to fuzz binary-only libraries, etc. So all in all this is the best-of afl that is out there :-) @@ -89,14 +130,14 @@ send a mail to <afl-users+subscribe@googlegroups.com>. See [docs/QuickStartGuide.md](docs/QuickStartGuide.md) if you don't have time to - read this file. + read this file - however this is not recommended! ## Branches The following branches exist: * [stable/trunk](https://github.com/AFLplusplus/AFLplusplus/) : stable state of afl++ - it is synced from dev from time to - time when we are satisfied with it's stability + time when we are satisfied with its stability * [dev](https://github.com/AFLplusplus/AFLplusplus/tree/dev) : development state of afl++ - bleeding edge and you might catch a checkout which does not compile or has a bug. *We only accept PRs in dev!!* * (any other) : experimental branches to work on specific features or testing @@ -106,13 +147,11 @@ ## Help wanted -We are happy to be part of [Google Summer of Code 2020](https://summerofcode.withgoogle.com/organizations/5100744400699392/)! :-) - We have several ideas we would like to see in AFL++ to make it even better. However, we already work on so many things that we do not have the time for all the big ideas. -This can be your way to support and contribute to AFL++ - extend it to +This can be your way to support and contribute to AFL++ - extend it to do something cool. We have an idea list in [docs/ideas.md](docs/ideas.md). @@ -129,23 +168,23 @@ hence afl-clang-lto is available!) or just pull directly from the docker hub: docker pull aflplusplus/aflplusplus docker run -ti -v /location/of/your/target:/src aflplusplus/aflplusplus ``` -This image is automatically generated when a push to master happens. +This image is automatically generated when a push to the stable repo happens. You will find your target source code in /src in the container. If you want to build afl++ yourself you have many options. -The easiest is to build and install everything: +The easiest choice is to build and install everything: ```shell -sudo apt install build-essential libtool-bin python3-dev automake flex bison libglib2.0-dev libpixman-1-dev clang python3-setuptools llvm +sudo apt install build-essential python3-dev automake flex bison libglib2.0-dev libpixman-1-dev python3-setuptools clang lld llvm llvm-dev libstdc++-dev make distrib sudo make install ``` It is recommended to install the newest available gcc, clang and llvm-dev possible in your distribution! -Note that "make distrib" also builds llvm_mode, qemu_mode, unicorn_mode and +Note that "make distrib" also builds instrumentation, qemu_mode, unicorn_mode and more. If you just want plain afl++ then do "make all", however compiling and -using at least llvm_mode is highly recommended for much better results - +using at least instrumentation is highly recommended for much better results - hence in this case ```shell @@ -157,7 +196,7 @@ These build targets exist: * all: just the main afl++ binaries * binary-only: everything for binary-only fuzzing: qemu_mode, unicorn_mode, libdislocator, libtokencap -* source-only: everything for source code fuzzing: llvm_mode, libdislocator, libtokencap +* source-only: everything for source code fuzzing: instrumentation, libdislocator, libtokencap * distrib: everything (for both binary-only and source code fuzzing) * man: creates simple man pages from the help option of the programs * install: installs everything you have compiled with the build options above @@ -172,19 +211,22 @@ These build targets exist: afl++ binaries by passing the STATIC=1 argument to make: ```shell -make all STATIC=1 +make STATIC=1 ``` These build options exist: * STATIC - compile AFL++ static * ASAN_BUILD - compiles with memory sanitizer for debug purposes +* DEBUG - no optimization, -ggdb3, all warnings and -Werror * PROFILING - compile with profiling information (gprof) +* INTROSPECTION - compile afl-fuzz with mutation introspection * NO_PYTHON - disable python support +* NO_SPLICING - disables splicing mutation in afl-fuzz, not recommended for normal fuzzing * AFL_NO_X86 - if compiling on non-intel/amd platforms * LLVM_CONFIG - if your distro doesn't use the standard name for llvm-config (e.g. Debian) -e.g.: make ASAN_BUILD=1 +e.g.: `make ASAN_BUILD=1` ## Good examples and writeups @@ -195,6 +237,8 @@ Here are some good writeups to show how to effectively use AFL++: * [https://securitylab.github.com/research/fuzzing-challenges-solutions-1](https://securitylab.github.com/research/fuzzing-challenges-solutions-1) * [https://securitylab.github.com/research/fuzzing-software-2](https://securitylab.github.com/research/fuzzing-software-2) * [https://securitylab.github.com/research/fuzzing-sockets-FTP](https://securitylab.github.com/research/fuzzing-sockets-FTP) + * [https://securitylab.github.com/research/fuzzing-sockets-FreeRDP](https://securitylab.github.com/research/fuzzing-sockets-FreeRDP) + * [https://securitylab.github.com/research/fuzzing-apache-1](https://securitylab.github.com/research/fuzzing-apache-1) If you are interested in fuzzing structured data (where you define what the structure is), these links have you covered: @@ -209,20 +253,21 @@ If you find other good ones, please send them to us :-) The following describes how to fuzz with a target if source code is available. If you have a binary-only target please skip to [#Instrumenting binary-only apps](#Instrumenting binary-only apps) -Fuzzing source code is a two step process. +Fuzzing source code is a three-step process. -1. compile the target with a special compiler that prepares the target to be +1. Compile the target with a special compiler that prepares the target to be fuzzed efficiently. This step is called "instrumenting a target". 2. Prepare the fuzzing by selecting and optimizing the input corpus for the target. -3. perform the fuzzing of the target by randomly mutating input and assessing - if a generated input was processed in a new path in the target binary +3. Perform the fuzzing of the target by randomly mutating input and assessing + if a generated input was processed in a new path in the target binary. ### 1. Instrumenting that target #### a) Selecting the best afl++ compiler for instrumenting the target -afl++ comes with different compilers and instrumentation options. +afl++ comes with a central compiler `afl-cc` that incorporates various different +kinds of compiler targets and and instrumentation options. The following evaluation flow will help you to select the best possible. It is highly recommended to have the newest llvm version possible installed, @@ -230,85 +275,107 @@ anything below 9 is not recommended. ``` +--------------------------------+ -| clang/clang++ 11+ is available | --> use afl-clang-lto and afl-clang-lto++ -+--------------------------------+ see [llvm/README.lto.md](llvm/README.lto.md) +| clang/clang++ 11+ is available | --> use LTO mode (afl-clang-lto/afl-clang-lto++) ++--------------------------------+ see [instrumentation/README.lto.md](instrumentation/README.lto.md) | - | if not, or if the target fails with afl-clang-lto/++ + | if not, or if the target fails with LTO afl-clang-lto/++ | v +---------------------------------+ -| clang/clang++ 3.3+ is available | --> use afl-clang-fast and afl-clang-fast++ -+---------------------------------+ see [llvm/README.md](llvm/README.md) +| clang/clang++ 3.3+ is available | --> use LLVM mode (afl-clang-fast/afl-clang-fast++) ++---------------------------------+ see [instrumentation/README.llvm.md](instrumentation/README.llvm.md) | - | if not, or if the target fails with afl-clang-fast/++ + | if not, or if the target fails with LLVM afl-clang-fast/++ | v +--------------------------------+ - | if you want to instrument only | -> use afl-gcc-fast and afl-gcc-fast++ - | parts of the target | see [gcc_plugin/README.md](gcc_plugin/README.md) and - +--------------------------------+ [gcc_plugin/README.instrument_file.md](gcc_plugin/README.instrument_file.md) + | gcc 5+ is available | -> use GCC_PLUGIN mode (afl-gcc-fast/afl-g++-fast) + +--------------------------------+ see [instrumentation/README.gcc_plugin.md](instrumentation/README.gcc_plugin.md) and + [instrumentation/README.instrument_list.md](instrumentation/README.instrument_list.md) | | if not, or if you do not have a gcc with plugin support | v - use afl-gcc and afl-g++ + use GCC mode (afl-gcc/afl-g++) (or afl-clang/afl-clang++ for clang) ``` Clickable README links for the chosen compiler: - * [afl-clang-lto](llvm/README.lto.md) - * [afl-clang-fast](llvm/README.md) - * [afl-gcc-fast](gcc_plugin/README.md) - * afl-gcc has no README as it has no features + * [LTO mode - afl-clang-lto](instrumentation/README.lto.md) + * [LLVM mode - afl-clang-fast](instrumentation/README.llvm.md) + * [GCC_PLUGIN mode - afl-gcc-fast](instrumentation/README.gcc_plugin.md) + * GCC/CLANG modes (afl-gcc/afl-clang) have no README as they have no own features + +You can select the mode for the afl-cc compiler by: + 1. use a symlink to afl-cc: afl-gcc, afl-g++, afl-clang, afl-clang++, + afl-clang-fast, afl-clang-fast++, afl-clang-lto, afl-clang-lto++, + afl-gcc-fast, afl-g++-fast (recommended!) + 2. using the environment variable AFL_CC_COMPILER with MODE + 3. passing --afl-MODE command line options to the compiler via CFLAGS/CXXFLAGS/CPPFLAGS + +MODE can be one of: LTO (afl-clang-lto*), LLVM (afl-clang-fast*), GCC_PLUGIN +(afl-g*-fast) or GCC (afl-gcc/afl-g++) or CLANG(afl-clang/afl-clang++). + +Because no afl specific command-line options are accepted (beside the +--afl-MODE command), the compile-time tools make fairly broad use of environment +variables, which can be listed with `afl-cc -hh` or by reading [docs/env_variables.md](docs/env_variables.md). #### b) Selecting instrumentation options -The following options are available when you instrument with afl-clang-fast or -afl-clang-lto: +The following options are available when you instrument with LTO mode (afl-clang-fast/afl-clang-lto): - * Splitting integer, string, float and switch compares so afl++ can easier + * Splitting integer, string, float and switch comparisons so afl++ can easier solve these. This is an important option if you do not have a very good - good and large input corpus. This technique is called laf-intel or COMPCOV. + and large input corpus. This technique is called laf-intel or COMPCOV. To use this set the following environment variable before compiling the target: `export AFL_LLVM_LAF_ALL=1` - You can read more about this in [llvm/README.laf-intel.md](llvm/README.laf-intel.md) - * A different technique (and usually a bit better than laf-intel) is to + You can read more about this in [instrumentation/README.laf-intel.md](instrumentation/README.laf-intel.md) + * A different technique (and usually a better one than laf-intel) is to instrument the target so that any compare values in the target are sent to - afl++ which then tries to put this value into the fuzzing data at different + afl++ which then tries to put these values into the fuzzing data at different locations. This technique is very fast and good - if the target does not transform input data before comparison. Therefore this technique is called `input to state` or `redqueen`. If you want to use this technique, then you have to compile the target - twice, once specifically with/for this mode. - You can read more about this in [llvm_mode/README.cmplog.md](llvm_mode/README.cmplog.md) + twice, once specifically with/for this mode, and pass this binary to afl-fuzz + via the `-c` parameter. + Note that you can compile also just a cmplog binary and use that for both + however there will be a performance penality. + You can read more about this in [instrumentation/README.cmplog.md](instrumentation/README.cmplog.md) -If you use afl-clang-fast, afl-clang-lto or afl-gcc-fast you have the option to -selectivly only instrument parts of the target that you are interested in: +If you use LTO, LLVM or GCC_PLUGIN mode (afl-clang-fast/afl-clang-lto/afl-gcc-fast) +you have the option to selectively only instrument parts of the target that you +are interested in: * To instrument only those parts of the target that you are interested in create a file with all the filenames of the source code that should be instrumented. - For afl-clang-lto and afl-gcc-fast - or afl-clang-fast if either the clang - version is < 7 or the CLASSIC instrumentation is used - just put one - filename per line, no directory information necessary, and set - `export AFL_LLVM_INSTRUMENT_FILE=yourfile.txt` - see [llvm_mode/README.instrument_file.md](llvm_mode/README.instrument_file.md) - For afl-clang-fast > 6.0 or if PCGUARD instrumentation is used then use the - llvm sancov allow-list feature: [http://clang.llvm.org/docs/SanitizerCoverage.html](http://clang.llvm.org/docs/SanitizerCoverage.html) + For afl-clang-lto and afl-gcc-fast - or afl-clang-fast if a mode other than + DEFAULT/PCGUARD is used or you have llvm > 10.0.0 - just put one + filename or function per line (no directory information necessary for + filenames9, and either set `export AFL_LLVM_ALLOWLIST=allowlist.txt` **or** + `export AFL_LLVM_DENYLIST=denylist.txt` - depending on if you want per + default to instrument unless noted (DENYLIST) or not perform instrumentation + unless requested (ALLOWLIST). + **NOTE:** During optimization functions might be inlined and then would not match! + See [instrumentation/README.instrument_list.md](instrumentation/README.instrument_list.md) There are many more options and modes available however these are most of the time less effective. See: - * [llvm_mode/README.ctx.md](llvm_mode/README.ctx.md) - * [llvm_mode/README.ngram.md](llvm_mode/README.ngram.md) - * [llvm_mode/README.instrim.md](llvm_mode/README.instrim.md) - * [llvm_mode/README.neverzero.md](llvm_mode/README.neverzero.md) + * [instrumentation/README.ctx.md](instrumentation/README.ctx.md) + * [instrumentation/README.ngram.md](instrumentation/README.ngram.md) + * [instrumentation/README.instrim.md](instrumentation/README.instrim.md) + +afl++ performs "never zero" counting in its bitmap. You can read more about this +here: + * [instrumentation/README.neverzero.md](instrumentation/README.neverzero.md) #### c) Modify the target -If the target has features that makes fuzzing more difficult, e.g. -checksums, HMAC etc. then modify the source code so that this is +If the target has features that make fuzzing more difficult, e.g. +checksums, HMAC, etc. then modify the source code so that this is removed. -This can even be done for productional source code be eliminating +This can even be done for operational source code by eliminating these checks within this specific defines: ``` @@ -319,45 +386,63 @@ these checks within this specific defines: #endif ``` +All afl++ compilers will set this preprocessor definition automatically. + #### d) Instrument the target In this step the target source code is compiled so that it can be fuzzed. Basically you have to tell the target build system that the selected afl++ compiler is used. Also - if possible - you should always configure the -build system that the target is compiled statically and not dynamically. +build system such that the target is compiled statically and not dynamically. How to do this is described below. Then build the target. (Usually with `make`) +**NOTES** + +1. sometimes configure and build systems are fickle and do not like + stderr output (and think this means a test failure) - which is something + afl++ likes to do to show statistics. It is recommended to disable them via + `export AFL_QUIET=1`. + +2. sometimes configure and build systems error on warnings - these should be + disabled (e.g. `--disable-werror` for some configure scripts). + +3. in case the configure/build system complains about afl++'s compiler and + aborts then set `export AFL_NOOPT=1` which will then just behave like the + real compiler. This option has to be unset again before building the target! + ##### configure For `configure` build systems this is usually done by: `CC=afl-clang-fast CXX=afl-clang-fast++ ./configure --disable-shared` -Note that if you using the (better) afl-clang-lto compiler you also have to -AR to llvm-ar[-VERSION] and RANLIB to llvm-ranlib[-VERSION] - as it is -described in [llvm/README.lto.md](llvm/README.lto.md) +Note that if you are using the (better) afl-clang-lto compiler you also have to +set AR to llvm-ar[-VERSION] and RANLIB to llvm-ranlib[-VERSION] - as is +described in [instrumentation/README.lto.md](instrumentation/README.lto.md). ##### cmake -For `configure` build systems this is usually done by: -`mkdir build; cd build; CC=afl-clang-fast CXX=afl-clang-fast++ cmake ..` +For `cmake` build systems this is usually done by: +`mkdir build; cmake -DCMAKE_C_COMPILERC=afl-cc -DCMAKE_CXX_COMPILER=afl-c++ ..` -Some cmake scripts require something like `-DCMAKE_CC=... -DCMAKE_CXX=...` -or `-DCMAKE_C_COMPILER=... DCMAKE_CPP_COMPILER=...` instead. +Note that if you are using the (better) afl-clang-lto compiler you also have to +set AR to llvm-ar[-VERSION] and RANLIB to llvm-ranlib[-VERSION] - as is +described in [instrumentation/README.lto.md](instrumentation/README.lto.md). -Note that if you using the (better) afl-clang-lto compiler you also have to -AR to llvm-ar[-VERSION] and RANLIB to llvm-ranlib[-VERSION] - as it is -described in [llvm/README.lto.md](llvm/README.lto.md) +##### meson + +For meson you have to set the afl++ compiler with the very first command! +`CC=afl-cc CXX=afl-c++ meson` ##### other build systems or if configure/cmake didn't work Sometimes cmake and configure do not pick up the afl++ compiler, or the ranlib/ar that is needed - because this was just not foreseen by the developer of the target. Or they have non-standard options. Figure out if there is a -non-standard way to set this, otherwise set the build normally and edit the -generated build environment afterwards by hand to point to the right compiler +non-standard way to set this, otherwise set up the build normally and edit the +generated build environment afterwards manually to point it to the right compiler (and/or ranlib and ar). #### d) Better instrumentation @@ -365,51 +450,52 @@ generated build environment afterwards by hand to point to the right compiler If you just fuzz a target program as-is you are wasting a great opportunity for much more fuzzing speed. -This requires the usage of afl-clang-lto or afl-clang-fast +This requires the usage of afl-clang-lto or afl-clang-fast. This is the so-called `persistent mode`, which is much, much faster but requires that you code a source file that is specifically calling the target functions that you want to fuzz, plus a few specific afl++ functions around -it. See [llvm_mode/README.persistent_mode.md](llvm_mode/README.persistent_mode.md) for details. +it. See [instrumentation/README.persistent_mode.md](instrumentation/README.persistent_mode.md) for details. Basically if you do not fuzz a target in persistent mode then you are just doing it for a hobby and not professionally :-) -### 2. Preparing the fuzzing +### 2. Preparing the fuzzing campaign As you fuzz the target with mutated input, having as diverse inputs for the target as possible improves the efficiency a lot. #### a) Collect inputs -Try to gather valid inputs for the target from wherever you can. E.g. if it + +Try to gather valid inputs for the target from wherever you can. E.g. if it is the PNG picture format try to find as many png files as possible, e.g. from reported bugs, test suites, random downloads from the internet, unit test case data - from all kind of PNG software. -If the input is not known files, you can also modify a target program to write -away normal data it receives and processes to a file and use these. +If the input format is not known, you can also modify a target program to write +normal data it receives and processes to a file and use these. #### b) Making the input corpus unique Use the afl++ tool `afl-cmin` to remove inputs from the corpus that do not -use a different paths in the target. -Put all files from step a) into one directory, e.g. INPUTS. +produce a new path in the target. -Put all the files from step a) +Put all files from step a) into one directory, e.g. INPUTS. If the target program is to be called by fuzzing as `bin/target -d INPUTFILE` the run afl-cmin like this: `afl-cmin -i INPUTS -o INPUTS_UNIQUE -- bin/target -d @@` -Note that the INPUTFILE that the target program would read has to be set as `@@`. +Note that the INPUTFILE argument that the target program would read from has to be set as `@@`. -If the target reads from stdin instead, just omit the `@@` as this is the +If the target reads from stdin instead, just omit the `@@` as this is the default. -#### b) Minimizing all corpus files +#### c) Minimizing all corpus files -The shorter the input files are so that they still traverse the same path -within the target, the better the fuzzing will be. This is done with `afl-tmin` -however it is a long processes as this has to be done for every file: +The shorter the input files that still traverse the same path +within the target, the better the fuzzing will be. This minimization +is done with `afl-tmin` however it is a long process as this has to +be done for every file: ``` mkdir input @@ -419,121 +505,132 @@ for i in *; do done ``` -This can also be parallelized, e.g. with `parallel` +This step can also be parallelized, e.g. with `parallel` -#### c) done! +#### Done! -The INPUTS_UNIQUE/ directory from step a) - or even better if you minimized the -corpus in step b) then the files in input/ is then the input corpus directory +The INPUTS_UNIQUE/ directory from step b) - or even better the directory input/ +if you minimized the corpus in step c) - is the resulting input corpus directory to be used in fuzzing! :-) -### Fuzzing the target +### 3. Fuzzing the target In this final step we fuzz the target. -There are not that many useful options to run the target - unless you want to -use many CPU cores/threads for the fuzzing, which will make the fuzzing much +There are not that many important options to run the target - unless you want +to use many CPU cores/threads for the fuzzing, which will make the fuzzing much more useful. If you just use one CPU for fuzzing, then you are fuzzing just for fun and not seriously :-) -Pro tip: load the [afl++ snapshot module](https://github.com/AFLplusplus/AFL-Snapshot-LKM) before start afl-fuzz as this improves -performance by a x2 speed increase! - -#### a) running afl-fuzz +#### a) Running afl-fuzz -Before to do even a test run of afl-fuzz execute `sudo afl-system-config` (on -the host if you execute afl-fuzz in a docker container). This reconfigured the +Before you do even a test run of afl-fuzz execute `sudo afl-system-config` (on +the host if you execute afl-fuzz in a docker container). This reconfigures the system for optimal speed - which afl-fuzz checks and bails otherwise. -Set `export AFL_SKIP_CPUFREQ=1` for afl-fuzz to skip this if you cannot run -afl-system-config with root privileges on the host for whatever reason. +Set `export AFL_SKIP_CPUFREQ=1` for afl-fuzz to skip this check if you cannot +run afl-system-config with root privileges on the host for whatever reason. If you have an input corpus from step 2 then specify this directory with the `-i` option. Otherwise create a new directory and create a file with any content -in there. +as test data in there. -If you do not want anything special, the defaults are already the usual best, -hence all you need (from the example in 2a): +If you do not want anything special, the defaults are already usually best, +hence all you need is to specify the seed input directory with the result of +step [2a. Collect inputs](#a-collect-inputs): `afl-fuzz -i input -o output -- bin/target -d @@` Note that the directory specified with -o will be created if it does not exist. -If you need to stop and re-start the fuzzing, use the same command line option -and switch the input directory with a dash (`-`): +If you need to stop and re-start the fuzzing, use the same command line options +(or even change them by selecting a different power schedule or another +mutation mode!) and switch the input directory with a dash (`-`): `afl-fuzz -i - -o output -- bin/target -d @@` -Note that afl-fuzz enforces memory limits to prevent the system to run out -of memory. By default this is 50MB for a process. If this is too little for -the target (which can can usually see that afl-fuzz bails with the message -that it could not connect to the forkserver), then you can increase this -with the `-m` option, the value is in MB. To disable any memory limits -(beware!) set `-m 0` - which is usually required for ASAN compiled targets. +Memory limits are not enforced by afl-fuzz by default and the system may run +out of memory. You can decrease the memory with the `-m` option, the value is +in MB. If this is too small for the target, you can usually see this by +afl-fuzz bailing with the message that it could not connect to the forkserver. -Adding a dictionary helpful. See the [dictionaries/](dictionaries/) if +Adding a dictionary is helpful. See the directory [dictionaries/](dictionaries/) if something is already included for your data format, and tell afl-fuzz to load -that dictionary by adding `-x dicationaries/FORMAT.dict`. With afl-clang-lto +that dictionary by adding `-x dictionaries/FORMAT.dict`. With afl-clang-lto you have an autodictionary generation for which you need to do nothing except to use afl-clang-lto as the compiler. You also have the option to generate -a dictionary yourself, see [libtokencap/README.md](libtokencap/README.md) +a dictionary yourself, see [utils/libtokencap/README.md](utils/libtokencap/README.md). afl-fuzz has a variety of options that help to workaround target quirks like specific locations for the input file (`-f`), not performing deterministic fuzzing (`-d`) and many more. Check out `afl-fuzz -h`. -afl-fuzz never stops fuzzing. To terminate afl++ simply press Control-C. +By default afl-fuzz never stops fuzzing. To terminate afl++ simply press Control-C +or send a signal SIGINT. You can limit the number of executions or approximate runtime +in seconds with options also. When you start afl-fuzz you will see a user interface that shows what the status is:  -All labels are explained in [docs/status_screen.md](docs/status_screen.md) +All labels are explained in [docs/status_screen.md](docs/status_screen.md). -#### b) Using multiple cores/threads +#### b) Using multiple cores If you want to seriously fuzz then use as many cores/threads as possible to fuzz your target. -On the same machine - due to the nature how afl++ works - there is a maximum -number of CPU cores/threads that are useful, more and the overall performance -degrades instead. This value depends on the target and the limit is between 48 -and 96 cores/threads per machine. +On the same machine - due to the design of how afl++ works - there is a maximum +number of CPU cores/threads that are useful, use more and the overall performance +degrades instead. This value depends on the target, and the limit is between 32 +and 64 cores per machine. + +If you have the RAM, it is highly recommended run the instances with a caching +of the testcases. Depending on the average testcase size (and those found +during fuzzing) and their number, a value between 50-500MB is recommended. +You can set the cache size (in MB) by setting the environment variable `AFL_TESTCACHE_SIZE`. There should be one main fuzzer (`-M main` option) and as many secondary -fuzzers (eg `-S variant1`) as you cores that you use. +fuzzers (eg `-S variant1`) as you have cores that you use. Every -M/-S entry needs a unique name (that can be whatever), however the same --o output directory location has to be used for all. +-o output directory location has to be used for all instances. -For every secondary there should be a variation, e.g.: +For every secondary fuzzer there should be a variation, e.g.: * one should fuzz the target that was compiled differently: with sanitizers activated (`export AFL_USE_ASAN=1 ; export AFL_USE_UBSAN=1 ; export AFL_USE_CFISAN=1 ; ` * one should fuzz the target with CMPLOG/redqueen (see above) - * At 1-2 should fuzz a target compiled with laf-intel/COMPCOV (see above). + * one to three fuzzers should fuzz a target compiled with laf-intel/COMPCOV + (see above). Important note: If you run more than one laf-intel/COMPCOV + fuzzer and you want them to share their intermediate results, the main + fuzzer (`-M`) must be one of the them! -All other secondaries should be: - * 1/2 with MOpt option enabled: `-L 0` +All other secondaries should be used like this: + * A third to a half with the MOpt mutator enabled: `-L 0` * run with a different power schedule, available are: - `explore (default), fast, coe, lin, quad, exploit, mmopt, rare, seek` + `fast (default), explore, coe, lin, quad, exploit, mmopt, rare, seek` which you can set with e.g. `-p seek` +Also it is recommended to set `export AFL_IMPORT_FIRST=1` to load testcases +from other fuzzers in the campaign first. + You can also use different fuzzers. If you are using afl spinoffs or afl conforming fuzzers, then just use the same -o directory and give it a unique `-S` name. -Examples are e.g.: - * [Angora](https://github.com/AngoraFuzzer/Angora) +Examples are: + * [Eclipser](https://github.com/SoftSec-KAIST/Eclipser/) * [Untracer](https://github.com/FoRTE-Research/UnTracer-AFL) * [AFLsmart](https://github.com/aflsmart/aflsmart) * [FairFuzz](https://github.com/carolemieux/afl-rb) * [Neuzz](https://github.com/Dongdongshe/neuzz) + * [Angora](https://github.com/AngoraFuzzer/Angora) A long list can be found at [https://github.com/Microsvuln/Awesome-AFL](https://github.com/Microsvuln/Awesome-AFL) -However you can also sync afl++ with honggfuzz, libfuzzer, entropic, etc. -Just show the main fuzzer (-M) with the `-F` option where the queue -directory of these other fuzzers are, e.g. `-F /src/target/honggfuzz` +However you can also sync afl++ with honggfuzz, libfuzzer with -entropic, etc. +Just show the main fuzzer (-M) with the `-F` option where the queue/work +directory of a different fuzzer is, e.g. `-F /src/target/honggfuzz`. #### c) The status of the fuzz campaign -afl++ comes with the `afl-whatsup` script to show the status of fuzzing +afl++ comes with the `afl-whatsup` script to show the status of the fuzzing campaign. Just supply the directory that afl-fuzz is given with the -o option and @@ -545,11 +642,25 @@ To have only the summary use the `-s` switch e.g.: `afl-whatsup -s output/` #### d) Checking the coverage of the fuzzing The `paths found` value is a bad indicator how good the coverage is. -It is better to check out the exact lines of code that have been reached - + +A better indicator - if you use default llvm instrumentation with at least +version 9 - is to use `afl-showmap` with the collect coverage option `-C` on +the output directory: +``` +$ afl-showmap -C -i out -o /dev/null -- ./target -params @@ +... +[*] Using SHARED MEMORY FUZZING feature. +[*] Target map size: 9960 +[+] Processed 7849 input files. +[+] Captured 4331 tuples (highest value 255, total values 67130596) in '/dev/nul +l'. +[+] A coverage of 4331 edges were achieved out of 9960 existing (43.48%) with 7849 input files. +``` +It is even better to check out the exact lines of code that have been reached - and which have not been found so far. An "easy" helper script for this is [https://github.com/vanhauser-thc/afl-cov](https://github.com/vanhauser-thc/afl-cov), -just follow the README of that seperate project. +just follow the README of that separate project. If you see that an important area or a feature has not been covered so far then try to find an input that is able to reach that and start a new secondary in @@ -558,6 +669,11 @@ then terminate it. The main node will pick it up and make it available to the other secondary nodes over time. Set `export AFL_NO_AFFINITY=1` if you have no free core. +Note that you in nearly all cases can never reach full coverage. A lot of +functionality is usually behind options that were not activated or fuzz e.g. +if you fuzz a library to convert image formats and your target is the png to +tiff API then you will not touch any of the other library APIs and features. + #### e) How long to fuzz a target? This is a difficult question. @@ -566,13 +682,16 @@ then you can expect that your fuzzing won't be fruitful anymore. However often this just means that you should switch out secondaries for others, e.g. custom mutator modules, sync to very different fuzzers, etc. -#### f) improve the speed! +Keep the queue/ directory (for future fuzzings of the same or similar targets) +and use them to seed other good fuzzers like libfuzzer with the -entropic +switch or honggfuzz. + +#### f) Improve the speed! - * Use [persistent mode](llvm_mode/README.persistent_mode.md) (x2-x20 speed increase) - * Use the [afl++ snapshot module](https://github.com/AFLplusplus/AFL-Snapshot-LKM) (x2 speed increase) + * Use [persistent mode](instrumentation/README.persistent_mode.md) (x2-x20 speed increase) * If you do not use shmem persistent mode, use `AFL_TMPDIR` to point the input file on a tempfs location, see [docs/env_variables.md](docs/env_variables.md) - * Improve kernel performance: modify `/etc/default/grub`, set `GRUB_CMDLINE_LINUX_DEFAULT="ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off"`; then `update-grub` and `reboot` (warning: makes the system more insecure) - * Running on an `ext2` filesystem with `noatime` mount option will be a bit faster than on any other journaling filesystem + * Linux: Improve kernel performance: modify `/etc/default/grub`, set `GRUB_CMDLINE_LINUX_DEFAULT="ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off"`; then `update-grub` and `reboot` (warning: makes the system more insecure) + * Linux: Running on an `ext2` filesystem with `noatime` mount option will be a bit faster than on any other journaling filesystem * Use your cores! [3.b) Using multiple cores/threads](#b-using-multiple-coresthreads) ### The End @@ -587,8 +706,11 @@ If you want to know more, the rest of this README and the tons of texts in Note that there are also a lot of tools out there that help fuzzing with afl++ (some might be deprecated or unsupported): +Speeding up fuzzing: + * [libfiowrapper](https://github.com/marekzmyslowski/libfiowrapper) - if the function you want to fuzz requires loading a file, this allows using the shared memory testcase feature :-) - recommended. + Minimization of test cases: - * [afl-pytmin](https://github.com/ilsani/afl-pytmin) - a wrapper for afl-tmin that tries to speed up the process of the minimization of test case by using many CPU cores. + * [afl-pytmin](https://github.com/ilsani/afl-pytmin) - a wrapper for afl-tmin that tries to speed up the process of minimization of a single test case by using many CPU cores. * [afl-ddmin-mod](https://github.com/MarkusTeufelberger/afl-ddmin-mod) - a variation of afl-tmin based on the ddmin algorithm. * [halfempty](https://github.com/googleprojectzero/halfempty) - is a fast utility for minimizing test cases by Tavis Ormandy based on parallelization. @@ -600,14 +722,15 @@ Distributed execution: * [afl-in-the-cloud](https://github.com/abhisek/afl-in-the-cloud) - another script for running AFL in AWS. Deployment, management, monitoring, reporting + * [afl-utils](https://gitlab.com/rc0r/afl-utils) - a set of utilities for automatic processing/analysis of crashes and reducing the number of test cases. * [afl-other-arch](https://github.com/shellphish/afl-other-arch) - is a set of patches and scripts for easily adding support for various non-x86 architectures for AFL. * [afl-trivia](https://github.com/bnagy/afl-trivia) - a few small scripts to simplify the management of AFL. * [afl-monitor](https://github.com/reflare/afl-monitor) - a script for monitoring AFL. * [afl-manager](https://github.com/zx1340/afl-manager) - a web server on Python for managing multi-afl. * [afl-remote](https://github.com/block8437/afl-remote) - a web server for the remote management of AFL instances. + * [afl-extras](https://github.com/fekir/afl-extras) - shell scripts to parallelize afl-tmin, startup, and data collection. Crash processing - * [afl-utils](https://gitlab.com/rc0r/afl-utils) - a set of utilities for automatic processing/analysis of crashes and reducing the number of test cases. * [afl-crash-analyzer](https://github.com/floyd-fuh/afl-crash-analyzer) - another crash analyzer for AFL. * [fuzzer-utils](https://github.com/ThePatrickStar/fuzzer-utils) - a set of scripts for the analysis of results. * [atriage](https://github.com/Ayrx/atriage) - a simple triage tool. @@ -615,14 +738,60 @@ Crash processing * [AFLize](https://github.com/d33tah/aflize) - a tool that automatically generates builds of debian packages suitable for AFL. * [afl-fid](https://github.com/FoRTE-Research/afl-fid) - a set of tools for working with input data. +## CI Fuzzing + +Some notes on CI Fuzzing - this fuzzing is different to normal fuzzing +campaigns as these are much shorter runnings. + +1. Always: + * LTO has a much longer compile time which is diametrical to short fuzzing - + hence use afl-clang-fast instead. + * If you compile with CMPLOG then you can save fuzzing time and reuse that + compiled target for both the -c option and the main fuzz target. + This will impact the speed by ~15% though. + * `AFL_FAST_CAL` - Enable fast calibration, this halfs the time the saturated + corpus needs to be loaded. + * `AFL_CMPLOG_ONLY_NEW` - only perform cmplog on new found paths, not the + initial corpus as this very likely has been done for them already. + * Keep the generated corpus, use afl-cmin and reuse it everytime! + +2. Additionally randomize the afl++ compilation options, e.g. + * 40% for `AFL_LLVM_CMPLOG` + * 10% for `AFL_LLVM_LAF_ALL` + +3. Also randomize the afl-fuzz runtime options, e.g. + * 60% for `AFL_DISABLE_TRIM` + * 50% use a dictionary generated by `AFL_LLVM_DICT2FILE` + * 50% use MOpt (`-L 0`) + * 40% for `AFL_EXPAND_HAVOC_NOW` + * 30% for old queue processing (`-Z`) + * for CMPLOG targets, 60% for `-l 2`, 40% for `-l 3` + +4. Do *not* run any `-M` modes, just running `-S` modes is better for CI fuzzing. + `-M` enables deterministic fuzzing, old queue handling etc. which is good for + a fuzzing campaign but not good for short CI runs. + +How this can look like can e.g. be seen at afl++'s setup in Google's [oss-fuzz](https://github.com/google/oss-fuzz/blob/4bb61df7905c6005000f5766e966e6fe30ab4559/infra/base-images/base-builder/compile_afl#L69). + ## Fuzzing binary-only targets When source code is *NOT* available, afl++ offers various support for fast, on-the-fly instrumentation of black-box binaries. +If you do not have to use Unicorn the following setup is recommended: + * run 1 afl-fuzz -Q instance with CMPLOG (`-c 0` + `AFL_COMPCOV_LEVEL=2`) + * run 1 afl-fuzz -Q instance with QASAN (`AFL_USE_QASAN=1`) + * run 1 afl-fuzz -Q instance with LAF (``AFL_PRELOAD=libcmpcov.so` + `AFL_COMPCOV_LEVEL=2`) + +Then run as many instances as you have cores left with either -Q mode or - better - +use a binary rewriter like afl-dyninst, retrowrite, zipr, fibre, etc. + +For Qemu mode, check out the persistent mode and snapshot features, they give +a huge speed improvement! + ### QEMU -For linux programs and it's libraries this is accomplished with a version of +For linux programs and its libraries this is accomplished with a version of QEMU running in the lesser-known "user space emulation" mode. QEMU is a project separate from AFL, but you can conveniently build the feature by doing: @@ -630,7 +799,8 @@ feature by doing: cd qemu_mode ./build_qemu_support.sh ``` -For additional instructions and caveats, see [qemu_mode/README.md](qemu_mode/README.md). +For additional instructions and caveats, see [qemu_mode/README.md](qemu_mode/README.md) - +check out the snapshot feature! :-) If possible you should use the persistent mode, see [qemu_mode/README.persistent.md](qemu_mode/README.persistent.md). The mode is approximately 2-5x slower than compile-time instrumentation, and is less conducive to parallelization. @@ -638,14 +808,16 @@ less conducive to parallelization. If [afl-dyninst](https://github.com/vanhauser-thc/afl-dyninst) works for your binary, then you can use afl-fuzz normally and it will have twice the speed compared to qemu_mode (but slower than persistent mode). +Note that several other binary rewriters exist, all with their advantages and +caveats. ### Unicorn For non-Linux binaries you can use afl++'s unicorn mode which can emulate -anything you want - for the price of speed and the user writing scripts. +anything you want - for the price of speed and user written scripts. See [unicorn_mode](unicorn_mode/README.md). -It can be easily build by: +It can be easily built by: ```shell cd unicorn_mode ./build_unicorn_support.sh @@ -654,16 +826,16 @@ cd unicorn_mode ### Shared libraries If the goal is to fuzz a dynamic library then there are two options available. -For both you need to write a small hardness that loads and calls the library. -Faster is the frida solution: [examples/afl_frida/README.md](examples/afl_frida/README.md) +For both you need to write a small harness that loads and calls the library. +Faster is the frida solution: [utils/afl_frida/README.md](utils/afl_frida/README.md) Another, less precise and slower option is using ptrace with debugger interrupt -instrumentation: [examples/afl_untracer/README.md](examples/afl_untracer/README.md) +instrumentation: [utils/afl_untracer/README.md](utils/afl_untracer/README.md). ### More A more comprehensive description of these and other options can be found in -[docs/binaryonly_fuzzing.md](docs/binaryonly_fuzzing.md) +[docs/binaryonly_fuzzing.md](docs/binaryonly_fuzzing.md). ## Challenges of guided fuzzing @@ -909,6 +1081,14 @@ tasks, fuzzing may put a strain on your hardware and on the OS. In particular: $ iostat -d 3 -x -k [...optional disk ID...] ``` + Using the `AFL_TMPDIR` environment variable and a RAM-disk you can have the + heavy writing done in RAM to prevent the aforementioned wear and tear. For + example the following line will run a Docker container with all this preset: + + ```shell + # docker run -ti --mount type=tmpfs,destination=/ramdisk -e AFL_TMPDIR=/ramdisk aflplusplus/aflplusplus + ``` + ## Known limitations & areas for improvement Here are some of the most important caveats for AFL: @@ -924,7 +1104,7 @@ Here are some of the most important caveats for AFL: wholly wrap the actual data format to be tested. To work around this, you can comment out the relevant checks (see - examples/libpng_no_checksum/ for inspiration); if this is not possible, + utils/libpng_no_checksum/ for inspiration); if this is not possible, you can also write a postprocessor, one of the hooks of custom mutators. See [docs/custom_mutators.md](docs/custom_mutators.md) on how to use `AFL_CUSTOM_MUTATOR_LIBRARY` @@ -996,11 +1176,37 @@ without feedback, bug reports, or patches from: Andrea Biondo Vincent Le Garrec Khaled Yakdan Kuang-che Wu Josephine Calliotte Konrad Welc + Thomas Rooijakkers David Carlier + Ruben ten Hove Joey Jiao ``` Thank you! (For people sending pull requests - please add yourself to this list :-) +## Cite + +If you use AFLpluplus to compare to your work, please use either `afl-clang-lto` +or `afl-clang-fast` with `AFL_LLVM_CMPLOG=1` for building targets and +`afl-fuzz` with the command line option `-l 2` for fuzzing. +The most effective setup is the `aflplusplus` default configuration on Google's [fuzzbench](https://github.com/google/fuzzbench/tree/master/fuzzers/aflplusplus). + +If you use AFLplusplus in scientific work, consider citing [our paper](https://www.usenix.org/conference/woot20/presentation/fioraldi) presented at WOOT'20: + ++ Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. “AFL++: Combining incremental steps of fuzzing research”. In 14th USENIX Workshop on Offensive Technologies (WOOT 20). USENIX Association, Aug. 2020. + +Bibtex: + +```bibtex +@inproceedings {AFLplusplus-Woot20, + author = {Andrea Fioraldi and Dominik Maier and Heiko Ei{\ss}feldt and Marc Heuse}, + title = {{AFL++}: Combining Incremental Steps of Fuzzing Research}, + booktitle = {14th {USENIX} Workshop on Offensive Technologies ({WOOT} 20)}, + year = {2020}, + publisher = {{USENIX} Association}, + month = aug, +} +``` + ## Contact Questions? Concerns? Bug reports? The contributors can be reached via @@ -1009,3 +1215,4 @@ Questions? Concerns? Bug reports? The contributors can be reached via There is also a mailing list for the afl/afl++ project; to join, send a mail to <afl-users+subscribe@googlegroups.com>. Or, if you prefer to browse archives first, try: [https://groups.google.com/group/afl-users](https://groups.google.com/group/afl-users) + @@ -1,31 +1,23 @@ # TODO list for AFL++ -## Roadmap 2.67+ +## Roadmap 3.00+ - - expand on AFL_LLVM_INSTRUMENT_FILE to also support sancov allowlist format - - AFL_MAP_SIZE for qemu_mode and unicorn_mode - CPU affinity for many cores? There seems to be an issue > 96 cores + - afl-plot to support multiple plot_data + - afl_custom_fuzz_splice_optin() + - afl_custom_splice() + - intel-pt tracer + - better autodetection of shifting runtime timeout values + - cmplog: use colorization input for havoc? + - cmplog: too much tainted bytes, directly add to dict and skip? + ## Further down the road afl-fuzz: - setting min_len/max_len/start_offset/end_offset limits for mutation output -llvm_mode: - - LTO - imitate sancov - -gcc_plugin: - - (wait for submission then decide) - - laf-intel - - better instrumentation (seems to be better with gcc-9+) - -better documentation: - - flow graph - - short intro - - faq (how to increase stability, speed, many parallel ...) - qemu_mode: - - update to 5.x (if the performance bug if gone) - non colliding instrumentation - rename qemu specific envs to AFL_QEMU (AFL_ENTRYPOINT, AFL_CODE_START/END, AFL_COMPCOV_LEVEL?) @@ -33,3 +25,13 @@ qemu_mode: persistent mode - add/implement AFL_QEMU_INST_LIBLIST and AFL_QEMU_NOINST_PROGRAM - add/implement AFL_QEMU_INST_REGIONS as a list of _START/_END addresses + + +## Ideas + + - LTO/sancov: write current edge to prev_loc and use that information when + using cmplog or __sanitizer_cov_trace_cmp*. maybe we can deduct by follow + up edge numbers that both following cmp paths have been found and then + disable working on this edge id -> cmplog_intelligence branch + - use cmplog colorization taint result for havoc locations? + @@ -113,13 +113,16 @@ function usage() { " -C - keep crashing inputs, reject everything else\n" \ " -e - solve for edge coverage only, ignore hit counts\n" \ "\n" \ -"For additional tips, please consult docs/README.md\n" \ +"For additional tips, please consult README.md\n" \ "\n" \ "Environment variables used:\n" \ +"AFL_ALLOW_TMP: allow unsafe use of input/output directories under {/var}/tmp\n" \ +"AFL_CRASH_EXITCODE: optional child exit code to be interpreted as crash\n" \ +"AFL_FORKSRV_INIT_TMOUT: time the fuzzer waits for the target to come up, initially\n" \ "AFL_KEEP_TRACES: leave the temporary <out_dir>/.traces directory\n" \ -"AFL_PATH: path for the afl-showmap binary\n" \ -"AFL_SKIP_BIN_CHECK: skip check for target binary\n" \ -"AFL_ALLOW_TMP: allow unsafe use of input/output directories under {/var}/tmp\n" +"AFL_KILL_SIGNAL: Signal ID delivered to child processes on timeout, etc. (default: SIGKILL)\n" +"AFL_PATH: path for the afl-showmap binary if not found anywhere else\n" \ +"AFL_SKIP_BIN_CHECK: skip check for target binary\n" exit 1 } @@ -132,6 +135,8 @@ BEGIN { # defaults extra_par = "" + AFL_CMIN_CRASHES_ONLY = "" + # process options Opterr = 1 # default is to diagnose Optind = 1 # skip ARGV[0] @@ -168,7 +173,7 @@ BEGIN { continue } else if (_go_c == "C") { - ENVIRON["AFL_CMIN_CRASHES_ONLY"] = 1 + AFL_CMIN_CRASHES_ONLY = "AFL_CMIN_CRASHES_ONLY=1 " continue } else if (_go_c == "e") { @@ -178,14 +183,12 @@ BEGIN { if (_go_c == "Q") { if (qemu_mode) { print "Option "_go_c" is only allowed once" > "/dev/stderr"} extra_par = extra_par " -Q" - if ( !mem_limit_given ) mem_limit = "250" qemu_mode = 1 continue } else if (_go_c == "U") { if (unicorn_mode) { print "Option "_go_c" is only allowed once" > "/dev/stderr"} extra_par = extra_par " -U" - if ( !mem_limit_given ) mem_limit = "250" unicorn_mode = 1 continue } else @@ -195,7 +198,7 @@ BEGIN { usage() } # while options - if (!mem_limit) mem_limit = 200 + if (!mem_limit) mem_limit = "none" if (!timeout) timeout = "none" # get program args @@ -284,6 +287,10 @@ BEGIN { exit 1 } + if (0 == system( "test -d "in_dir"/default" )) { + in_dir = in_dir "/default" + } + if (0 == system( "test -d "in_dir"/queue" )) { in_dir = in_dir "/queue" } @@ -309,14 +316,18 @@ BEGIN { close( stdin_file ) } - if (!ENVIRON["AFL_PATH"]) { - if (0 == system("test -f afl-cmin")) { + # First we look in PATH + if (0 == system("command -v afl-showmap >/dev/null 2>&1")) { + "command -v afl-showmap 2>/dev/null" | getline showmap + } else { + # then we look in the current directory + if (0 == system("test -x ./afl-showmap")) { showmap = "./afl-showmap" } else { - "command -v afl-showmap 2>/dev/null" | getline showmap + if (ENVIRON["AFL_PATH"]) { + showmap = ENVIRON["AFL_PATH"] "/afl-showmap" + } } - } else { - showmap = ENVIRON["AFL_PATH"] "/afl-showmap" } if (!showmap || 0 != system("test -x "showmap )) { @@ -335,8 +346,10 @@ BEGIN { } else { stat_format = "-f '%z %N'" # *BSD, MacOS } - cmdline = "cd "in_dir" && find . \\( ! -name . -a -type d -prune \\) -o -type f -exec stat "stat_format" \\{\\} \\; | sort -k1n -k2r" - cmdline = "ls "in_dir" | (cd "in_dir" && xargs stat "stat_format") | sort -k1n -k2r" + cmdline = "(cd "in_dir" && find . \\( ! -name . -a -type d -prune \\) -o -type f -exec stat "stat_format" \\{\\} + | sort -k1n -k2r)" + #cmdline = "ls "in_dir" | (cd "in_dir" && xargs stat "stat_format" 2>/dev/null) | sort -k1n -k2r" + #cmdline = "(cd "in_dir" && stat "stat_format" *) | sort -k1n -k2r" + #cmdline = "(cd "in_dir" && ls | xargs stat "stat_format" ) | sort -k1n -k2r" while (cmdline | getline) { sub(/^[0-9]+ (\.\/)?/,"",$0) infilesSmallToBig[i++] = $0 @@ -347,44 +360,46 @@ BEGIN { # Make sure that we're not dealing with a directory. - if (0 == system("test -d "in_dir"/"first_file)) { - print "[-] Error: The input directory contains subdirectories - please fix." > "/dev/stderr" + if (0 == system("test -d ""\""in_dir"/"first_file"\"")) { + print "[-] Error: The input directory is empty or contains subdirectories - please fix." > "/dev/stderr" exit 1 } - if (0 == system("ln "in_dir"/"first_file" "trace_dir"/.link_test")) { + if (0 == system("ln \""in_dir"/"first_file"\" "trace_dir"/.link_test")) { cp_tool = "ln" } else { cp_tool = "cp" } - # Make sure that we can actually get anything out of afl-showmap before we - # waste too much time. + if (!ENVIRON["AFL_SKIP_BIN_CHECK"]) { + # Make sure that we can actually get anything out of afl-showmap before we + # waste too much time. - print "[*] Testing the target binary..." + print "[*] Testing the target binary..." - if (!stdin_file) { - system( "AFL_CMIN_ALLOW_ANY=1 \""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"/.run_test\" -Z "extra_par" -- \""target_bin"\" "prog_args_string" <\""in_dir"/"first_file"\"") - } else { - system("cp "in_dir"/"first_file" "stdin_file) - system( "AFL_CMIN_ALLOW_ANY=1 \""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"/.run_test\" -Z "extra_par" -A \""stdin_file"\" -- \""target_bin"\" "prog_args_string" </dev/null") - } + if (!stdin_file) { + system( "AFL_CMIN_ALLOW_ANY=1 "AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"/.run_test\" -Z "extra_par" -- \""target_bin"\" "prog_args_string" <\""in_dir"/"first_file"\"") + } else { + system("cp \""in_dir"/"first_file"\" "stdin_file) + system( "AFL_CMIN_ALLOW_ANY=1 "AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"/.run_test\" -Z "extra_par" -A \""stdin_file"\" -- \""target_bin"\" "prog_args_string" </dev/null") + } - first_count = 0 + first_count = 0 - runtest = trace_dir"/.run_test" - while ((getline < runtest) > 0) { - ++first_count - } + runtest = trace_dir"/.run_test" + while ((getline < runtest) > 0) { + ++first_count + } - if (first_count) { - print "[+] OK, "first_count" tuples recorded." - } else { - print "[-] Error: no instrumentation output detected (perhaps crash or timeout)." > "/dev/stderr" - if (!ENVIRON["AFL_KEEP_TRACES"]) { - system("rm -rf "trace_dir" 2>/dev/null") + if (first_count) { + print "[+] OK, "first_count" tuples recorded." + } else { + print "[-] Error: no instrumentation output detected (perhaps crash or timeout)." > "/dev/stderr" + if (!ENVIRON["AFL_KEEP_TRACES"]) { + system("rm -rf "trace_dir" 2>/dev/null") + } + exit 1 } - exit 1 } # Let's roll! @@ -398,14 +413,16 @@ BEGIN { cur = 0; if (!stdin_file) { print " Processing "in_count" files (forkserver mode)..." - retval = system( "AFL_CMIN_ALLOW_ANY=1 \""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -- \""target_bin"\" "prog_args_string) +# print AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -- \""target_bin"\" "prog_args_string + retval = system( AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -- \""target_bin"\" "prog_args_string) } else { print " Processing "in_count" files (forkserver mode)..." - retval = system( "AFL_CMIN_ALLOW_ANY=1 \""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -- \""target_bin"\" "prog_args_string" </dev/null") +# print AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -A \""stdin_file"\" -- \""target_bin"\" "prog_args_string" </dev/null" + retval = system( AFL_CMIN_CRASHES_ONLY"\""showmap"\" -m "mem_limit" -t "timeout" -o \""trace_dir"\" -Z "extra_par" -i \""in_dir"\" -A \""stdin_file"\" -- \""target_bin"\" "prog_args_string" </dev/null") } - if (retval) { - print "[!]Exit code != 0 received from afl-showmap, terminating..." + if (retval && !AFL_CMIN_CRASHES_ONLY) { + print "[!] Exit code "retval" != 0 received from afl-showmap, terminating..." if (!ENVIRON["AFL_KEEP_TRACES"]) { system("rm -rf "trace_dir" 2>/dev/null") @@ -485,7 +502,7 @@ BEGIN { # copy file unless already done if (! (fn in file_already_copied)) { - system(cp_tool" "in_dir"/"fn" "out_dir"/"fn) + system(cp_tool" \""in_dir"/"fn"\" \""out_dir"/"fn"\"") file_already_copied[fn] = "" ++out_count #printf "tuple nr %d (%d cnt=%d) -> %s\n",tcnt,key,key_count[key],fn > trace_dir"/.log" diff --git a/afl-cmin.bash b/afl-cmin.bash index 3e29aa5c..5b2c3894 100755 --- a/afl-cmin.bash +++ b/afl-cmin.bash @@ -45,7 +45,7 @@ echo # Process command-line options... -MEM_LIMIT=200 +MEM_LIMIT=none TIMEOUT=none unset IN_DIR OUT_DIR STDIN_FILE EXTRA_PAR MEM_LIMIT_GIVEN \ @@ -85,12 +85,10 @@ while getopts "+i:o:f:m:t:eQUCh" opt; do ;; "Q") EXTRA_PAR="$EXTRA_PAR -Q" - test "$MEM_LIMIT_GIVEN" = "" && MEM_LIMIT=250 QEMU_MODE=1 ;; "U") EXTRA_PAR="$EXTRA_PAR -U" - test "$MEM_LIMIT_GIVEN" = "" && MEM_LIMIT=250 UNICORN_MODE=1 ;; "?") @@ -128,11 +126,11 @@ Minimization settings: -C - keep crashing inputs, reject everything else -e - solve for edge coverage only, ignore hit counts -For additional tips, please consult docs/README.md. +For additional tips, please consult README.md. Environment variables used: AFL_KEEP_TRACES: leave the temporary <out_dir>\.traces directory -AFL_PATH: path for the afl-showmap binary +AFL_PATH: last resort location to find the afl-showmap binary AFL_SKIP_BIN_CHECK: skip check for target binary _EOF_ exit 1 @@ -225,6 +223,7 @@ if [ ! -d "$IN_DIR" ]; then exit 1 fi +test -d "$IN_DIR/default" && IN_DIR="$IN_DIR/default" test -d "$IN_DIR/queue" && IN_DIR="$IN_DIR/queue" find "$OUT_DIR" -name 'id[:_]*' -maxdepth 1 -exec rm -- {} \; 2>/dev/null @@ -244,10 +243,21 @@ if [ ! "$STDIN_FILE" = "" ]; then touch "$STDIN_FILE" || exit 1 fi -if [ "$AFL_PATH" = "" ]; then - SHOWMAP="${0%/afl-cmin.bash}/afl-showmap" +SHOWMAP=`command -v afl-showmap 2>/dev/null` + +if [ -z "$SHOWMAP" ]; then + TMP="${0%/afl-cmin.bash}/afl-showmap" + if [ -x "$TMP" ]; then + SHOWMAP=$TMP + fi +fi + +if [ -z "$SHOWMAP" -a -x "./afl-showmap" ]; then + SHOWMAP="./afl-showmap" else - SHOWMAP="$AFL_PATH/afl-showmap" + if [ -n "$AFL_PATH" ]; then + SHOWMAP="$AFL_PATH/afl-showmap" + fi fi if [ ! -x "$SHOWMAP" ]; then @@ -99,7 +99,7 @@ if [ ! -d "$outputdir" ]; then fi -rm -f "$outputdir/high_freq.png" "$outputdir/low_freq.png" "$outputdir/exec_speed.png" +rm -f "$outputdir/high_freq.png" "$outputdir/low_freq.png" "$outputdir/exec_speed.png" "$outputdir/edges.png" mv -f "$outputdir/index.html" "$outputdir/index.html.orig" 2>/dev/null echo "[*] Generating plots..." @@ -152,6 +152,12 @@ set ytics auto plot '$inputdir/plot_data' using 1:11 with filledcurve x1 title '' linecolor rgb '#0090ff' fillstyle transparent solid 0.2 noborder, \\ '$inputdir/plot_data' using 1:11 with lines title ' execs/sec' linecolor rgb '#0090ff' linewidth 3 smooth bezier; +set terminal png truecolor enhanced size 1000,300 butt +set output '$outputdir/edges.png' + +set ytics auto +plot '$inputdir/plot_data' using 1:13 with lines title ' edges' linecolor rgb '#0090ff' linewidth 3 + _EOF_ ) | gnuplot @@ -172,6 +178,7 @@ cat >"$outputdir/index.html" <<_EOF_ <tr><td><b>Generated on:</b></td><td>`date`</td></tr> </table> <p> +<img src="edges.png" width=1000 height=300> <img src="high_freq.png" width=1000 height=300><p> <img src="low_freq.png" width=1000 height=200><p> <img src="exec_speed.png" width=1000 height=200> @@ -183,7 +190,7 @@ _EOF_ # sensitive, this seems like a reasonable trade-off. chmod 755 "$outputdir" -chmod 644 "$outputdir/high_freq.png" "$outputdir/low_freq.png" "$outputdir/exec_speed.png" "$outputdir/index.html" +chmod 644 "$outputdir/high_freq.png" "$outputdir/low_freq.png" "$outputdir/exec_speed.png" "$outputdir/edges.png" "$outputdir/index.html" echo "[+] All done - enjoy your charts!" diff --git a/afl-system-config b/afl-system-config index 34db61aa..ae37a062 100755 --- a/afl-system-config +++ b/afl-system-config @@ -34,11 +34,12 @@ if [ "$PLATFORM" = "Linux" ] ; then test -e /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor && echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor test -e /sys/devices/system/cpu/intel_pstate/no_turbo && echo 0 > /sys/devices/system/cpu/intel_pstate/no_turbo test -e /sys/devices/system/cpu/cpufreq/boost && echo 1 > /sys/devices/system/cpu/cpufreq/boost + test -e /sys/devices/system/cpu/intel_pstate/max_perf_pct && echo 100 > /sys/devices/system/cpu/intel_pstate/max_perf_pct } > /dev/null echo Settings applied. dmesg | egrep -q 'nospectre_v2|spectre_v2=off' || { echo It is recommended to boot the kernel with lots of security off - if you are running a machine that is in a secured network - so set this: - echo ' /etc/default/grub:GRUB_CMDLINE_LINUX_DEFAULT="ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off"' + echo ' /etc/default/grub:GRUB_CMDLINE_LINUX_DEFAULT="ibpb=off ibrs=off kpti=0 l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off srbds=off noexec=off noexec32=off tsx=on tsx_async_abort=off arm64.nopauth audit=0 hardened_usercopy=off ssbd=force-off"' } DONE=1 fi @@ -48,6 +49,12 @@ if [ "$PLATFORM" = "FreeBSD" ] ; then sysctl kern.elf64.aslr.enable=0 } > /dev/null echo Settings applied. + cat <<EOF +In order to suppress core file generation during fuzzing it is recommended to set +me:\\ + :coredumpsize=0: +in the ~/.login_conf file for the user used for fuzzing. +EOF echo It is recommended to boot the kernel with lots of security off - if you are running a machine that is in a secured network - so set this: echo ' sysctl hw.ibrs_disable=1' echo 'Setting kern.pmap.pg_ps_enabled=0 into /boot/loader.conf might be helpful too.' @@ -58,6 +65,17 @@ if [ "$PLATFORM" = "OpenBSD" ] ; then echo 'System security features cannot be disabled on OpenBSD.' DONE=1 fi +if [ "$PLATFORM" = "DragonFly" ] ; then + #/sbin/sysctl kern.corefile=/dev/null + #echo Settings applied. + cat <<EOF +In order to suppress core file generation during fuzzing it is recommended to set +me:\\ + :coredumpsize=0: +in the ~/.login_conf file for the user used for fuzzing. +EOF + DONE=1 +fi if [ "$PLATFORM" = "NetBSD" ] ; then { #echo It is recommended to enable unprivileged users to set cpu affinity @@ -79,5 +97,14 @@ if [ "$PLATFORM" = "Darwin" ] ; then fi DONE=1 fi +if [ "$PLATFORM" = "Haiku" ] ; then + SETTINGS=~/config/settings/system/debug_server/settings + [ -r ${SETTINGS} ] && grep -qE "default_action\s+kill" ${SETTINGS} && { echo "Nothing to do"; } || { \ + echo We change the debug_server default_action from user to silently kill; \ + [ ! -r ${SETTINGS} ] && echo "default_action kill" >${SETTINGS} || { mv ${SETTINGS} s.tmp; sed -e "s/default_action\s\s*user/default_action kill/" s.tmp > ${SETTINGS}; rm s.tmp; }; \ + echo Settings applied.; \ + } + DONE=1 +fi test -z "$DONE" && echo Error: Unknown platform: $PLATFORM -test -z "$AFL_TMPDIR" && echo Also use AFL_TMPDIR and point it to a tmpfs for the input file caching +exit 0 diff --git a/afl-whatsup b/afl-whatsup index abcddbf1..e92b24bd 100755 --- a/afl-whatsup +++ b/afl-whatsup @@ -99,7 +99,7 @@ fi fmt_duration() { DUR_STRING= - if [ $1 -eq 0 ]; then + if [ $1 -le 0 ]; then return 1 fi @@ -109,7 +109,11 @@ fmt_duration() local minutes=$(((duration / 60) % 60)) local seconds=$((duration % 60)) - if [ $days -gt 0 ]; then + if [ $duration -le 0 ]; then + DUR_STRING="0 seconds" + elif [ $duration -eq 1 ]; then + DUR_STRING="1 second" + elif [ $days -gt 0 ]; then DUR_STRING="$days days, $hours hours" elif [ $hours -gt 0 ]; then DUR_STRING="$hours hours, $minutes minutes" diff --git a/afl-wine-trace b/afl-wine-trace index 8853a757..63ff896b 100755 --- a/afl-wine-trace +++ b/afl-wine-trace @@ -28,9 +28,9 @@ if not os.getenv("AFL_INST_LIBS"): os.environ["AFL_CODE_END"] = "0x%x" % (pe.OPTIONAL_HEADER.ImageBase + pe.OPTIONAL_HEADER.BaseOfCode + pe.OPTIONAL_HEADER.SizeOfCode) if pe.FILE_HEADER.Machine == pefile.MACHINE_TYPE["IMAGE_FILE_MACHINE_AMD64"] or pe.FILE_HEADER.Machine == pefile.MACHINE_TYPE["IMAGE_FILE_MACHINE_IA64"]: - os.environ["LD_PRELOAD"] = os.path.join(my_dir, "qemu_mode/unsigaction/unsigaction64.so") + os.environ["QEMU_SET_ENV"] = "LD_PRELOAD=" + os.path.join(my_dir, "qemu_mode/unsigaction/unsigaction64.so") + ",WINEARCH=win64" else: - os.environ["LD_PRELOAD"] = os.path.join(my_dir, "qemu_mode/unsigaction/unsigaction32.so") + os.environ["QEMU_SET_ENV"] = "LD_PRELOAD=" + os.path.join(my_dir, "qemu_mode/unsigaction/unsigaction32.so") + ",WINEARCH=win32" if os.getenv("WINECOV_QEMU_PATH"): qemu_path = os.getenv("WINECOV_QEMU_PATH") diff --git a/custom_mutators/Android.bp b/custom_mutators/Android.bp new file mode 100644 index 00000000..89abc3e9 --- /dev/null +++ b/custom_mutators/Android.bp @@ -0,0 +1,115 @@ +cc_library_shared { + name: "libfuzzer-mutator", + vendor_available: true, + host_supported: true, + + cflags: [ + "-g", + "-O0", + "-funroll-loops", + "-fPIC", + "-fpermissive", + "-std=c++11", + ], + + srcs: [ + "libfuzzer/FuzzerCrossOver.cpp", + "libfuzzer/FuzzerDataFlowTrace.cpp", + "libfuzzer/FuzzerDriver.cpp", + "libfuzzer/FuzzerExtFunctionsDlsym.cpp", + "libfuzzer/FuzzerExtFunctionsWeak.cpp", + "libfuzzer/FuzzerExtFunctionsWindows.cpp", + "libfuzzer/FuzzerExtraCounters.cpp", + "libfuzzer/FuzzerFork.cpp", + "libfuzzer/FuzzerIO.cpp", + "libfuzzer/FuzzerIOPosix.cpp", + "libfuzzer/FuzzerIOWindows.cpp", + "libfuzzer/FuzzerLoop.cpp", + "libfuzzer/FuzzerMerge.cpp", + "libfuzzer/FuzzerMutate.cpp", + "libfuzzer/FuzzerSHA1.cpp", + "libfuzzer/FuzzerTracePC.cpp", + "libfuzzer/FuzzerUtil.cpp", + "libfuzzer/FuzzerUtilDarwin.cpp", + "libfuzzer/FuzzerUtilFuchsia.cpp", + "libfuzzer/FuzzerUtilLinux.cpp", + "libfuzzer/FuzzerUtilPosix.cpp", + "libfuzzer/FuzzerUtilWindows.cpp", + "libfuzzer/libfuzzer.cpp", + ], + + header_libs: [ + "libafl_headers", + ], +} + +/*cc_library_shared { + name: "honggfuzz-mutator", + vendor_available: true, + host_supported: true, + + cflags: [ + "-g", + "-O0", + "-funroll-loops", + "-fPIC", + "-Wl,-Bsymbolic", + ], + + srcs: [ + "honggfuzz/honggfuzz.c", + "honggfuzz/mangle.c", +// "../src/afl-perfomance.c", + ], + + header_libs: [ + "libafl_headers", + ], +}*/ + +cc_library_shared { + name: "radamsa-mutator", + vendor_available: true, + host_supported: true, + + cflags: [ + "-g", + "-O0", + "-funroll-loops", + "-fPIC", + ], + + srcs: [ + "radamsa/libradamsa.c", + "radamsa/radamsa-mutator.c", + ], + + header_libs: [ + "libafl_headers", + ], +} + +cc_library_shared { + name: "symcc-mutator", + vendor_available: true, + host_supported: true, + + cflags: [ + "-g", + "-O0", + "-funroll-loops", + "-fPIC", + ], + + srcs: [ + "symcc/symcc.c", + ], + + header_libs: [ + "libafl_headers", + ], +} + +subdirs = [ + "libprotobuf-mutator-example", +] diff --git a/custom_mutators/README.md b/custom_mutators/README.md index a3b164be..b0444c85 100644 --- a/custom_mutators/README.md +++ b/custom_mutators/README.md @@ -1,4 +1,21 @@ -# production ready custom mutators +# Custom Mutators + +Custom mutators enhance and alter the mutation strategies of afl++. +For further information and documentation on how to write your own, read [the docs](../docs/custom_mutators.md). + +## The afl++ Grammar Mutator + +If you use git to clone afl++, then the following will incorporate our +excellent grammar custom mutator: +```sh +git submodule update --init +``` + +Read the README in the [Grammar-Mutator] repository on how to use it. + +[Grammar-Mutator]: https://github.com/AFLplusplus/Grammar-Mutator + +## Production-Ready Custom Mutators This directory holds ready to use custom mutators. Just type "make" in the individual subdirectories. @@ -11,15 +28,15 @@ and add `AFL_CUSTOM_MUTATOR_ONLY=1` if you only want to use the custom mutator. Multiple custom mutators can be used by separating their paths with `:` in the environment variable. -# Other custom mutators +## 3rd Party Custom Mutators -## Superion port +### Superion Mutators Adrian Tiron ported the Superion grammar fuzzer to afl++, it is WIP and requires cmake (among other things): [https://github.com/adrian-rt/superion-mutator](https://github.com/adrian-rt/superion-mutator) -## Protobuf +### libprotobuf Mutators There are two WIP protobuf projects, that require work to be working though: diff --git a/custom_mutators/grammar_mutator/GRAMMAR_VERSION b/custom_mutators/grammar_mutator/GRAMMAR_VERSION new file mode 100644 index 00000000..a3fe6bb1 --- /dev/null +++ b/custom_mutators/grammar_mutator/GRAMMAR_VERSION @@ -0,0 +1 @@ +b3c4fcf diff --git a/custom_mutators/grammar_mutator/README.md b/custom_mutators/grammar_mutator/README.md new file mode 100644 index 00000000..a015744c --- /dev/null +++ b/custom_mutators/grammar_mutator/README.md @@ -0,0 +1,6 @@ +# Grammar-Mutator + +This is just a stub directory that will clone the real grammar mutator +directory. + +Execute `./build_grammar_mutator.sh` to set everything up. diff --git a/custom_mutators/grammar_mutator/build_grammar_mutator.sh b/custom_mutators/grammar_mutator/build_grammar_mutator.sh new file mode 100755 index 00000000..ef145dfe --- /dev/null +++ b/custom_mutators/grammar_mutator/build_grammar_mutator.sh @@ -0,0 +1,140 @@ +#!/bin/sh +# +# american fuzzy lop++ - unicorn mode build script +# ------------------------------------------------ +# +# Originally written by Nathan Voss <njvoss99@gmail.com> +# +# Adapted from code by Andrew Griffiths <agriffiths@google.com> and +# Michal Zalewski +# +# Adapted for AFLplusplus by Dominik Maier <mail@dmnk.co> +# +# CompareCoverage and NeverZero counters by Andrea Fioraldi +# <andreafioraldi@gmail.com> +# +# Copyright 2017 Battelle Memorial Institute. All rights reserved. +# Copyright 2019-2020 AFLplusplus Project. All rights reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at: +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# This script downloads, patches, and builds a version of Unicorn with +# minor tweaks to allow Unicorn-emulated binaries to be run under +# afl-fuzz. +# +# The modifications reside in patches/*. The standalone Unicorn library +# will be written to /usr/lib/libunicornafl.so, and the Python bindings +# will be installed system-wide. +# +# You must make sure that Unicorn Engine is not already installed before +# running this script. If it is, please uninstall it first. + +GRAMMAR_VERSION="$(cat ./GRAMMAR_VERSION)" +GRAMMAR_REPO="https://github.com/AFLplusplus/grammar-mutator" + +echo "=================================================" +echo "Grammar Mutator build script" +echo "=================================================" +echo + +echo "[*] Performing basic sanity checks..." + +PLT=`uname -s` + +if [ ! -f "../../config.h" ]; then + + echo "[-] Error: key files not found - wrong working directory?" + exit 1 + +fi + +PYTHONBIN=`command -v python3 || command -v python || command -v python2 || echo python3` +MAKECMD=make +TARCMD=tar + +if [ "$PLT" = "Darwin" ]; then + CORES=`sysctl -n hw.ncpu` + TARCMD=tar +fi + +if [ "$PLT" = "FreeBSD" ]; then + MAKECMD=gmake + CORES=`sysctl -n hw.ncpu` + TARCMD=gtar +fi + +if [ "$PLT" = "NetBSD" ] || [ "$PLT" = "OpenBSD" ]; then + MAKECMD=gmake + CORES=`sysctl -n hw.ncpu` + TARCMD=gtar +fi + +PREREQ_NOTFOUND= +for i in git $MAKECMD $TARCMD; do + + T=`command -v "$i" 2>/dev/null` + + if [ "$T" = "" ]; then + + echo "[-] Error: '$i' not found. Run 'sudo apt-get install $i' or similar." + PREREQ_NOTFOUND=1 + + fi + +done + +if echo "$CC" | grep -qF /afl-; then + + echo "[-] Error: do not use afl-gcc or afl-clang to compile this tool." + PREREQ_NOTFOUND=1 + +fi + +if [ "$PREREQ_NOTFOUND" = "1" ]; then + exit 1 +fi + +echo "[+] All checks passed!" + +echo "[*] Making sure grammar mutator is checked out" + +git status 1>/dev/null 2>/dev/null +if [ $? -eq 0 ]; then + echo "[*] initializing grammar mutator submodule" + git submodule init || exit 1 + git submodule update ./grammar-mutator 2>/dev/null # ignore errors +else + echo "[*] cloning grammar mutator" + test -d grammar-mutator || { + CNT=1 + while [ '!' -d grammar-mutator -a "$CNT" -lt 4 ]; do + echo "Trying to clone grammar-mutator (attempt $CNT/3)" + git clone "$GRAMMAR_REPO" + CNT=`expr "$CNT" + 1` + done + } +fi + +test -d grammar-mutator || { echo "[-] not checked out, please install git or check your internet connection." ; exit 1 ; } +echo "[+] Got grammar mutator." + +cd "grammar-mutator" || exit 1 +echo "[*] Checking out $GRAMMAR_VERSION" +sh -c 'git stash && git stash drop' 1>/dev/null 2>/dev/null +git checkout "$GRAMMAR_VERSION" || exit 1 +echo "[*] Downloading antlr..." +wget -c https://www.antlr.org/download/antlr-4.8-complete.jar +cd .. + +echo +echo +echo "[+] All successfully prepared!" +echo "[!] To build for your grammar just do:" +echo " cd grammar-mutator" +echo " make GRAMMAR_FILE=/path/to/your/grammar" +echo "[+] You will find a JSON and RUBY grammar in grammar-mutator/grammars to play with." +echo diff --git a/custom_mutators/grammar_mutator/grammar_mutator b/custom_mutators/grammar_mutator/grammar_mutator new file mode 160000 +Subproject b3c4fcfa6ae28918bc410f7747135eafd4fb726 diff --git a/custom_mutators/grammar_mutator/update_grammar_ref.sh b/custom_mutators/grammar_mutator/update_grammar_ref.sh new file mode 100755 index 00000000..89067b13 --- /dev/null +++ b/custom_mutators/grammar_mutator/update_grammar_ref.sh @@ -0,0 +1,50 @@ +#!/bin/sh + +################################################## +# AFL++ tool to update a git ref. +# Usage: ./<script>.sh <new commit hash> +# If no commit hash was provided, it'll take HEAD. +################################################## + +TOOL="grammar mutator" +VERSION_FILE='./GRAMMAR_VERSION' +REPO_FOLDER='./grammar_mutator' +THIS_SCRIPT=`basename $0` +BRANCH="stable" + +NEW_VERSION="$1" + +if [ "$NEW_VERSION" = "-h" ]; then + echo "Internal script to update bound $TOOL version." + echo + echo "Usage: $THIS_SCRIPT <new commit hash>" + echo "If no commit hash is provided, will use HEAD." + echo "-h to show this help screen." + exit 1 +fi + +git submodule init && git submodule update ./grammar_mutator || exit 1 +cd "$REPO_FOLDER" || exit 1 +git fetch origin $BRANCH 1>/dev/null || exit 1 +git stash 1>/dev/null 2>/dev/null +git stash drop 1>/dev/null 2>/dev/null +git checkout $BRANCH + +if [ -z "$NEW_VERSION" ]; then + # No version provided, take HEAD. + NEW_VERSION=$(git rev-parse --short HEAD) +fi + +if [ -z "$NEW_VERSION" ]; then + echo "Error getting version." + exit 1 +fi + +git checkout "$NEW_VERSION" || exit 1 + +cd .. + +rm "$VERSION_FILE" +echo "$NEW_VERSION" > "$VERSION_FILE" + +echo "Done. New $TOOL version is $NEW_VERSION." diff --git a/custom_mutators/honggfuzz/Makefile b/custom_mutators/honggfuzz/Makefile index 2f46d0e7..5c2fcddb 100644 --- a/custom_mutators/honggfuzz/Makefile +++ b/custom_mutators/honggfuzz/Makefile @@ -1,12 +1,14 @@ CFLAGS = -O3 -funroll-loops -fPIC -Wl,-Bsymbolic -all: honggfuzz.so +all: honggfuzz-mutator.so -honggfuzz.so: honggfuzz.c input.h mangle.c ../../src/afl-performance.c - $(CC) $(CFLAGS) -I../../include -I. -shared -o honggfuzz.so honggfuzz.c mangle.c ../../src/afl-performance.c +honggfuzz-mutator.so: honggfuzz.c input.h mangle.c ../../src/afl-performance.c + $(CC) $(CFLAGS) -I../../include -I. -shared -o honggfuzz-mutator.so honggfuzz.c mangle.c ../../src/afl-performance.c update: + @# seriously? --unlink is a dud option? sigh ... + rm -f mangle.c mangle.h honggfuzz.h wget --unlink https://github.com/google/honggfuzz/raw/master/mangle.c wget --unlink https://github.com/google/honggfuzz/raw/master/mangle.h wget --unlink https://github.com/google/honggfuzz/raw/master/honggfuzz.h diff --git a/custom_mutators/honggfuzz/README.md b/custom_mutators/honggfuzz/README.md index 8824976f..e1cab281 100644 --- a/custom_mutators/honggfuzz/README.md +++ b/custom_mutators/honggfuzz/README.md @@ -1,12 +1,12 @@ # custum mutator: honggfuzz mangle -this is the very good honggfuzz mutator in mangle.c as a custom mutator +this is the honggfuzz mutator in mangle.c as a custom mutator module for afl++. It is the original mangle.c, mangle.h and honggfuzz.h with a lot of mocking around it :-) just type `make` to build -```AFL_CUSTOM_MUTATOR_LIBRARY=custom_mutators/honggfuzz/honggfuzz.so afl-fuzz ...``` +```AFL_CUSTOM_MUTATOR_LIBRARY=custom_mutators/honggfuzz/honggfuzz-mutator.so afl-fuzz ...``` > Original repository: https://github.com/google/honggfuzz > Source commit: d0fbcb0373c32436b8fb922e6937da93b17291f5 diff --git a/custom_mutators/honggfuzz/common.h b/custom_mutators/honggfuzz/common.h deleted file mode 100644 index e69de29b..00000000 --- a/custom_mutators/honggfuzz/common.h +++ /dev/null diff --git a/custom_mutators/honggfuzz/honggfuzz.c b/custom_mutators/honggfuzz/honggfuzz.c index bde922c6..b4f07258 100644 --- a/custom_mutators/honggfuzz/honggfuzz.c +++ b/custom_mutators/honggfuzz/honggfuzz.c @@ -37,6 +37,7 @@ my_mutator_t *afl_custom_init(afl_state_t *afl, unsigned int seed) { if ((data->mutator_buf = malloc(MAX_FILE)) == NULL) { + free(data); perror("mutator_buf alloc"); return NULL; diff --git a/custom_mutators/honggfuzz/honggfuzz.h b/custom_mutators/honggfuzz/honggfuzz.h index 4e045272..c80cdd87 100644 --- a/custom_mutators/honggfuzz/honggfuzz.h +++ b/custom_mutators/honggfuzz/honggfuzz.h @@ -38,18 +38,17 @@ #include "libhfcommon/util.h" -#define PROG_NAME "honggfuzz" -#define PROG_VERSION "2.2" +#define PROG_NAME "honggfuzz" +#define PROG_VERSION "2.4" -/* Name of the template which will be replaced with the proper name of the file - */ +/* Name of the template which will be replaced with the proper name of the file */ #define _HF_FILE_PLACEHOLDER "___FILE___" /* Default name of the report created with some architectures */ #define _HF_REPORT_FILE "HONGGFUZZ.REPORT.TXT" /* Default stack-size of created threads. */ -#define _HF_PTHREAD_STACKSIZE (1024ULL * 1024ULL * 2ULL) /* 2MB */ +#define _HF_PTHREAD_STACKSIZE (1024ULL * 1024ULL * 2ULL) /* 2MB */ /* Name of envvar which indicates sequential number of fuzzer */ #define _HF_THREAD_NO_ENV "HFUZZ_THREAD_NO" @@ -63,12 +62,11 @@ /* Number of crash verifier iterations before tag crash as stable */ #define _HF_VERIFIER_ITER 5 -/* Size (in bytes) for report data to be stored in stack before written to file - */ +/* Size (in bytes) for report data to be stored in stack before written to file */ #define _HF_REPORT_SIZE 32768 /* Perf bitmap size */ -#define _HF_PERF_BITMAP_SIZE_16M (1024U * 1024U * 16U) +#define _HF_PERF_BITMAP_SIZE_16M (1024U * 1024U * 16U) #define _HF_PERF_BITMAP_BITSZ_MASK 0x7FFFFFFULL /* Maximum number of PC guards (=trace-pc-guard) we support */ #define _HF_PC_GUARD_MAX (1024ULL * 1024ULL * 64ULL) @@ -89,7 +87,7 @@ #define _HF_INPUT_FD 1021 /* FD used to pass coverage feedback from the fuzzed process */ #define _HF_COV_BITMAP_FD 1022 -#define _HF_BITMAP_FD _HF_COV_BITMAP_FD /* Old name for _HF_COV_BITMAP_FD */ +#define _HF_BITMAP_FD _HF_COV_BITMAP_FD /* Old name for _HF_COV_BITMAP_FD */ /* FD used to pass data to a persistent process */ #define _HF_PERSISTENT_FD 1023 @@ -105,356 +103,284 @@ static const uint8_t HFReadyTag = 'R'; /* Maximum number of active fuzzing threads */ #define _HF_THREAD_MAX 1024U -/* Persistent-binary signature - if found within file, it means it's a - * persistent mode binary */ +/* Persistent-binary signature - if found within file, it means it's a persistent mode binary */ #define _HF_PERSISTENT_SIG "\x01_LIBHFUZZ_PERSISTENT_BINARY_SIGNATURE_\x02\xFF" -/* HF NetDriver signature - if found within file, it means it's a - * NetDriver-based binary */ +/* HF NetDriver signature - if found within file, it means it's a NetDriver-based binary */ #define _HF_NETDRIVER_SIG "\x01_LIBHFUZZ_NETDRIVER_BINARY_SIGNATURE_\x02\xFF" -/* printf() nonmonetary separator. According to MacOSX's man it's supported - * there as well */ +/* printf() nonmonetary separator. According to MacOSX's man it's supported there as well */ #define _HF_NONMON_SEP "'" typedef enum { - - _HF_DYNFILE_NONE = 0x0, - _HF_DYNFILE_INSTR_COUNT = 0x1, - _HF_DYNFILE_BRANCH_COUNT = 0x2, - _HF_DYNFILE_BTS_EDGE = 0x10, - _HF_DYNFILE_IPT_BLOCK = 0x20, - _HF_DYNFILE_SOFT = 0x40, - + _HF_DYNFILE_NONE = 0x0, + _HF_DYNFILE_INSTR_COUNT = 0x1, + _HF_DYNFILE_BRANCH_COUNT = 0x2, + _HF_DYNFILE_BTS_EDGE = 0x10, + _HF_DYNFILE_IPT_BLOCK = 0x20, + _HF_DYNFILE_SOFT = 0x40, } dynFileMethod_t; typedef struct { - - uint64_t cpuInstrCnt; - uint64_t cpuBranchCnt; - uint64_t bbCnt; - uint64_t newBBCnt; - uint64_t softCntPc; - uint64_t softCntEdge; - uint64_t softCntCmp; - + uint64_t cpuInstrCnt; + uint64_t cpuBranchCnt; + uint64_t bbCnt; + uint64_t newBBCnt; + uint64_t softCntPc; + uint64_t softCntEdge; + uint64_t softCntCmp; } hwcnt_t; typedef enum { - - _HF_STATE_UNSET = 0, - _HF_STATE_STATIC, - _HF_STATE_DYNAMIC_DRY_RUN, - _HF_STATE_DYNAMIC_MAIN, - _HF_STATE_DYNAMIC_MINIMIZE, - + _HF_STATE_UNSET = 0, + _HF_STATE_STATIC, + _HF_STATE_DYNAMIC_DRY_RUN, + _HF_STATE_DYNAMIC_MAIN, + _HF_STATE_DYNAMIC_MINIMIZE, } fuzzState_t; typedef enum { - - HF_MAYBE = -1, - HF_NO = 0, - HF_YES = 1, - + HF_MAYBE = -1, + HF_NO = 0, + HF_YES = 1, } tristate_t; struct _dynfile_t { - - size_t size; - uint64_t cov[4]; - size_t idx; - int fd; - uint64_t timeExecUSecs; - char path[PATH_MAX]; - struct _dynfile_t *src; - uint32_t refs; - uint8_t * data; - TAILQ_ENTRY(_dynfile_t) pointers; - + size_t size; + uint64_t cov[4]; + size_t idx; + int fd; + uint64_t timeExecUSecs; + char path[PATH_MAX]; + struct _dynfile_t* src; + uint32_t refs; + uint8_t* data; + TAILQ_ENTRY(_dynfile_t) pointers; }; typedef struct _dynfile_t dynfile_t; struct strings_t { - - size_t len; - TAILQ_ENTRY(strings_t) pointers; - char s[]; - + size_t len; + TAILQ_ENTRY(strings_t) pointers; + char s[]; }; typedef struct { - - uint8_t pcGuardMap[_HF_PC_GUARD_MAX]; - uint8_t bbMapPc[_HF_PERF_BITMAP_SIZE_16M]; - uint32_t bbMapCmp[_HF_PERF_BITMAP_SIZE_16M]; - uint64_t pidNewPC[_HF_THREAD_MAX]; - uint64_t pidNewEdge[_HF_THREAD_MAX]; - uint64_t pidNewCmp[_HF_THREAD_MAX]; - uint64_t guardNb; - uint64_t pidTotalPC[_HF_THREAD_MAX]; - uint64_t pidTotalEdge[_HF_THREAD_MAX]; - uint64_t pidTotalCmp[_HF_THREAD_MAX]; - + uint8_t pcGuardMap[_HF_PC_GUARD_MAX]; + uint8_t bbMapPc[_HF_PERF_BITMAP_SIZE_16M]; + uint32_t bbMapCmp[_HF_PERF_BITMAP_SIZE_16M]; + uint64_t pidNewPC[_HF_THREAD_MAX]; + uint64_t pidNewEdge[_HF_THREAD_MAX]; + uint64_t pidNewCmp[_HF_THREAD_MAX]; + uint64_t guardNb; + uint64_t pidTotalPC[_HF_THREAD_MAX]; + uint64_t pidTotalEdge[_HF_THREAD_MAX]; + uint64_t pidTotalCmp[_HF_THREAD_MAX]; } feedback_t; typedef struct { - - uint32_t cnt; - struct { - - uint8_t val[32]; - uint32_t len; - - } valArr[1024 * 16]; - + uint32_t cnt; + struct { + uint8_t val[32]; + uint32_t len; + } valArr[1024 * 16]; } cmpfeedback_t; typedef struct { - - struct { - - size_t threadsMax; - size_t threadsFinished; - uint32_t threadsActiveCnt; - pthread_t mainThread; - pid_t mainPid; - pthread_t threads[_HF_THREAD_MAX]; - - } threads; - - struct { - - const char *inputDir; - const char *outputDir; - DIR * inputDirPtr; - size_t fileCnt; - size_t testedFileCnt; - const char *fileExtn; - size_t maxFileSz; - size_t newUnitsAdded; - char workDir[PATH_MAX]; - const char *crashDir; - const char *covDirNew; - bool saveUnique; - size_t dynfileqMaxSz; - size_t dynfileqCnt; - dynfile_t * dynfileqCurrent; - dynfile_t * dynfileq2Current; - TAILQ_HEAD(dyns_t, _dynfile_t) dynfileq; - bool exportFeedback; - - } io; - - struct { - - int argc; - const char *const *cmdline; - bool nullifyStdio; - bool fuzzStdin; - const char * externalCommand; - const char * postExternalCommand; - const char * feedbackMutateCommand; - bool netDriver; - bool persistent; - uint64_t asLimit; - uint64_t rssLimit; - uint64_t dataLimit; - uint64_t coreLimit; - uint64_t stackLimit; - bool clearEnv; - char * env_ptrs[128]; - char env_vals[128][4096]; - sigset_t waitSigSet; - - } exe; - - struct { - - time_t timeStart; - time_t runEndTime; - time_t tmOut; - time_t lastCovUpdate; - int64_t timeOfLongestUnitUSecs; - bool tmoutVTALRM; - - } timing; - - struct { - struct { - - uint8_t val[256]; - size_t len; - - } dictionary[1024]; - - size_t dictionaryCnt; - const char *dictionaryFile; - size_t mutationsMax; - unsigned mutationsPerRun; - size_t maxInputSz; - - } mutate; - - struct { - - bool useScreen; - char cmdline_txt[65]; - int64_t lastDisplayUSecs; - - } display; - - struct { - - bool useVerifier; - bool exitUponCrash; - const char *reportFile; - size_t dynFileIterExpire; - bool only_printable; - bool minimize; - bool switchingToFDM; - - } cfg; - - struct { - - bool enable; - bool del_report; - - } sanitizer; - - struct { - - fuzzState_t state; - feedback_t * covFeedbackMap; - int covFeedbackFd; - cmpfeedback_t * cmpFeedbackMap; - int cmpFeedbackFd; - bool cmpFeedback; - const char * blacklistFile; - uint64_t * blacklist; - size_t blacklistCnt; - bool skipFeedbackOnTimeout; - uint64_t maxCov[4]; - dynFileMethod_t dynFileMethod; - hwcnt_t hwCnts; - - } feedback; - - struct { - - size_t mutationsCnt; - size_t crashesCnt; - size_t uniqueCrashesCnt; - size_t verifiedCrashesCnt; - size_t blCrashesCnt; - size_t timeoutedCnt; - - } cnts; - - struct { - - bool enabled; - int serverSocket; - int clientSocket; - - } socketFuzzer; - - struct { - - pthread_rwlock_t dynfileq; - pthread_mutex_t feedback; - pthread_mutex_t report; - pthread_mutex_t state; - pthread_mutex_t input; - pthread_mutex_t timing; - - } mutex; - - /* For the Linux code */ - struct { - - int exeFd; - uint64_t dynamicCutOffAddr; - bool disableRandomization; - void * ignoreAddr; - const char *symsBlFile; - char ** symsBl; - size_t symsBlCnt; - const char *symsWlFile; - char ** symsWl; - size_t symsWlCnt; - uintptr_t cloneFlags; - tristate_t useNetNs; - bool kernelOnly; - bool useClone; - - } arch_linux; - - /* For the NetBSD code */ - struct { - - void * ignoreAddr; - const char *symsBlFile; - char ** symsBl; - size_t symsBlCnt; - const char *symsWlFile; - char ** symsWl; - size_t symsWlCnt; - - } arch_netbsd; - + size_t threadsMax; + size_t threadsFinished; + uint32_t threadsActiveCnt; + pthread_t mainThread; + pid_t mainPid; + pthread_t threads[_HF_THREAD_MAX]; + } threads; + struct { + const char* inputDir; + const char* outputDir; + DIR* inputDirPtr; + size_t fileCnt; + size_t testedFileCnt; + const char* fileExtn; + size_t maxFileSz; + size_t newUnitsAdded; + char workDir[PATH_MAX]; + const char* crashDir; + const char* covDirNew; + bool saveUnique; + bool saveSmaller; + size_t dynfileqMaxSz; + size_t dynfileqCnt; + dynfile_t* dynfileqCurrent; + dynfile_t* dynfileq2Current; + TAILQ_HEAD(dyns_t, _dynfile_t) dynfileq; + bool exportFeedback; + } io; + struct { + int argc; + const char* const* cmdline; + bool nullifyStdio; + bool fuzzStdin; + const char* externalCommand; + const char* postExternalCommand; + const char* feedbackMutateCommand; + bool netDriver; + bool persistent; + uint64_t asLimit; + uint64_t rssLimit; + uint64_t dataLimit; + uint64_t coreLimit; + uint64_t stackLimit; + bool clearEnv; + char* env_ptrs[128]; + char env_vals[128][4096]; + sigset_t waitSigSet; + } exe; + struct { + time_t timeStart; + time_t runEndTime; + time_t tmOut; + time_t lastCovUpdate; + int64_t timeOfLongestUnitUSecs; + bool tmoutVTALRM; + } timing; + struct { + struct { + uint8_t val[256]; + size_t len; + } dictionary[1024]; + size_t dictionaryCnt; + const char* dictionaryFile; + size_t mutationsMax; + unsigned mutationsPerRun; + size_t maxInputSz; + } mutate; + struct { + bool useScreen; + char cmdline_txt[65]; + int64_t lastDisplayUSecs; + } display; + struct { + bool useVerifier; + bool exitUponCrash; + const char* reportFile; + size_t dynFileIterExpire; + bool only_printable; + bool minimize; + bool switchingToFDM; + } cfg; + struct { + bool enable; + bool del_report; + } sanitizer; + struct { + fuzzState_t state; + feedback_t* covFeedbackMap; + int covFeedbackFd; + cmpfeedback_t* cmpFeedbackMap; + int cmpFeedbackFd; + bool cmpFeedback; + const char* blocklistFile; + uint64_t* blocklist; + size_t blocklistCnt; + bool skipFeedbackOnTimeout; + uint64_t maxCov[4]; + dynFileMethod_t dynFileMethod; + hwcnt_t hwCnts; + } feedback; + struct { + size_t mutationsCnt; + size_t crashesCnt; + size_t uniqueCrashesCnt; + size_t verifiedCrashesCnt; + size_t blCrashesCnt; + size_t timeoutedCnt; + } cnts; + struct { + bool enabled; + int serverSocket; + int clientSocket; + } socketFuzzer; + struct { + pthread_rwlock_t dynfileq; + pthread_mutex_t feedback; + pthread_mutex_t report; + pthread_mutex_t state; + pthread_mutex_t input; + pthread_mutex_t timing; + } mutex; + + /* For the Linux code */ + struct { + int exeFd; + uint64_t dynamicCutOffAddr; + bool disableRandomization; + void* ignoreAddr; + const char* symsBlFile; + char** symsBl; + size_t symsBlCnt; + const char* symsWlFile; + char** symsWl; + size_t symsWlCnt; + uintptr_t cloneFlags; + tristate_t useNetNs; + bool kernelOnly; + bool useClone; + } arch_linux; + /* For the NetBSD code */ + struct { + void* ignoreAddr; + const char* symsBlFile; + char** symsBl; + size_t symsBlCnt; + const char* symsWlFile; + char** symsWl; + size_t symsWlCnt; + } arch_netbsd; } honggfuzz_t; typedef enum { - - _HF_RS_UNKNOWN = 0, - _HF_RS_WAITING_FOR_INITIAL_READY = 1, - _HF_RS_WAITING_FOR_READY = 2, - _HF_RS_SEND_DATA = 3, - + _HF_RS_UNKNOWN = 0, + _HF_RS_WAITING_FOR_INITIAL_READY = 1, + _HF_RS_WAITING_FOR_READY = 2, + _HF_RS_SEND_DATA = 3, } runState_t; typedef struct { - - honggfuzz_t *global; - pid_t pid; - int64_t timeStartedUSecs; - char crashFileName[PATH_MAX]; - uint64_t pc; - uint64_t backtrace; - uint64_t access; - int exception; - char report[_HF_REPORT_SIZE]; - bool mainWorker; - unsigned mutationsPerRun; - dynfile_t * dynfile; - bool staticFileTryMore; - uint32_t fuzzNo; - int persistentSock; - runState_t runState; - bool tmOutSignaled; - char * args[_HF_ARGS_MAX + 1]; - int perThreadCovFeedbackFd; - unsigned triesLeft; - dynfile_t * current; + honggfuzz_t* global; + pid_t pid; + int64_t timeStartedUSecs; + char crashFileName[PATH_MAX]; + uint64_t pc; + uint64_t backtrace; + uint64_t access; + int exception; + char report[_HF_REPORT_SIZE]; + bool mainWorker; + unsigned mutationsPerRun; + dynfile_t* dynfile; + bool staticFileTryMore; + uint32_t fuzzNo; + int persistentSock; + runState_t runState; + bool tmOutSignaled; + char* args[_HF_ARGS_MAX + 1]; + int perThreadCovFeedbackFd; + unsigned triesLeft; + dynfile_t* current; #if !defined(_HF_ARCH_DARWIN) - timer_t timerId; -#endif // !defined(_HF_ARCH_DARWIN) - hwcnt_t hwCnts; - - struct { - - /* For Linux code */ - uint8_t *perfMmapBuf; - uint8_t *perfMmapAux; - int cpuInstrFd; - int cpuBranchFd; - int cpuIptBtsFd; - - } arch_linux; + timer_t timerId; +#endif // !defined(_HF_ARCH_DARWIN) + hwcnt_t hwCnts; + struct { + /* For Linux code */ + uint8_t* perfMmapBuf; + uint8_t* perfMmapAux; + int cpuInstrFd; + int cpuBranchFd; + int cpuIptBtsFd; + } arch_linux; } run_t; #endif - diff --git a/custom_mutators/honggfuzz/input.h b/custom_mutators/honggfuzz/input.h index 7b0c55ae..09712f54 100644 --- a/custom_mutators/honggfuzz/input.h +++ b/custom_mutators/honggfuzz/input.h @@ -77,11 +77,11 @@ static inline uint64_t util_rndGet(uint64_t min, uint64_t max) { } static inline uint64_t util_rnd64() { return rand_below(afl_struct, 1 << 30); } -static inline size_t input_getRandomInputAsBuf(run_t *run, const uint8_t **buf) { - *buf = queue_input; +static inline const uint8_t* input_getRandomInputAsBuf(run_t* run, size_t* len) { + *len = queue_input_size; run->dynfile->data = queue_input; run->dynfile->size = queue_input_size; - return queue_input_size; + return queue_input; } static inline void input_setSize(run_t* run, size_t sz) { run->dynfile->size = sz; diff --git a/custom_mutators/honggfuzz/libhfcommon b/custom_mutators/honggfuzz/libhfcommon deleted file mode 120000 index 945c9b46..00000000 --- a/custom_mutators/honggfuzz/libhfcommon +++ /dev/null @@ -1 +0,0 @@ -.
\ No newline at end of file diff --git a/custom_mutators/honggfuzz/libhfcommon/common.h b/custom_mutators/honggfuzz/libhfcommon/common.h new file mode 100644 index 00000000..c8cf1329 --- /dev/null +++ b/custom_mutators/honggfuzz/libhfcommon/common.h @@ -0,0 +1,3 @@ +#ifndef LOG_E + #define LOG_E LOG_F +#endif diff --git a/custom_mutators/honggfuzz/log.h b/custom_mutators/honggfuzz/libhfcommon/log.h index 51e19654..51e19654 120000 --- a/custom_mutators/honggfuzz/log.h +++ b/custom_mutators/honggfuzz/libhfcommon/log.h diff --git a/custom_mutators/honggfuzz/util.h b/custom_mutators/honggfuzz/libhfcommon/util.h index 51e19654..51e19654 120000 --- a/custom_mutators/honggfuzz/util.h +++ b/custom_mutators/honggfuzz/libhfcommon/util.h diff --git a/custom_mutators/honggfuzz/mangle.c b/custom_mutators/honggfuzz/mangle.c index 05e0dcfa..637d428d 100644 --- a/custom_mutators/honggfuzz/mangle.c +++ b/custom_mutators/honggfuzz/mangle.c @@ -39,254 +39,208 @@ #include "libhfcommon/log.h" #include "libhfcommon/util.h" -static inline size_t mangle_LenLeft(run_t *run, size_t off) { - - if (off >= run->dynfile->size) { - - LOG_F("Offset is too large: off:%zu >= len:%zu", off, run->dynfile->size); - - } - - return (run->dynfile->size - off - 1); - +static inline size_t mangle_LenLeft(run_t* run, size_t off) { + if (off >= run->dynfile->size) { + LOG_F("Offset is too large: off:%zu >= len:%zu", off, run->dynfile->size); + } + return (run->dynfile->size - off - 1); } -/* Get a random value between <1:max> with x^2 distribution */ +/* + * Get a random value <1:max>, but prefer smaller ones + * Based on an idea by https://twitter.com/gamozolabs + */ static inline size_t mangle_getLen(size_t max) { + if (max > _HF_INPUT_MAX_SIZE) { + LOG_F("max (%zu) > _HF_INPUT_MAX_SIZE (%zu)", max, (size_t)_HF_INPUT_MAX_SIZE); + } + if (max == 0) { + LOG_F("max == 0"); + } + if (max == 1) { + return 1; + } - if (max > _HF_INPUT_MAX_SIZE) { - - LOG_F("max (%zu) > _HF_INPUT_MAX_SIZE (%zu)", max, - (size_t)_HF_INPUT_MAX_SIZE); - - } - - if (max == 0) { LOG_F("max == 0"); } - if (max == 1) { return 1; } - - const uint64_t max2 = (uint64_t)max * max; - const uint64_t max3 = (uint64_t)max * max * max; - const uint64_t rnd = util_rndGet(1, max2 - 1); - - uint64_t ret = rnd * rnd; - ret /= max3; - ret += 1; - - if (ret < 1) { - - LOG_F("ret (%" PRIu64 ") < 1, max:%zu, rnd:%" PRIu64, ret, max, rnd); - - } - - if (ret > max) { - - LOG_F("ret (%" PRIu64 ") > max (%zu), rnd:%" PRIu64, ret, max, rnd); - - } - - return (size_t)ret; + /* Give 50% chance the the uniform distribution */ + if (util_rnd64() & 1) { + return (size_t)util_rndGet(1, max); + } + /* effectively exprand() */ + return (size_t)util_rndGet(1, util_rndGet(1, max)); } /* Prefer smaller values here, so use mangle_getLen() */ -static inline size_t mangle_getOffSet(run_t *run) { - - return mangle_getLen(run->dynfile->size) - 1; - +static inline size_t mangle_getOffSet(run_t* run) { + return mangle_getLen(run->dynfile->size) - 1; } /* Offset which can be equal to the file size */ -static inline size_t mangle_getOffSetPlus1(run_t *run) { - - size_t reqlen = HF_MIN(run->dynfile->size + 1, _HF_INPUT_MAX_SIZE); - return mangle_getLen(reqlen) - 1; - +static inline size_t mangle_getOffSetPlus1(run_t* run) { + size_t reqlen = HF_MIN(run->dynfile->size + 1, _HF_INPUT_MAX_SIZE); + return mangle_getLen(reqlen) - 1; } -static inline void mangle_Move(run_t *run, size_t off_from, size_t off_to, - size_t len) { - - if (off_from >= run->dynfile->size) { return; } - if (off_to >= run->dynfile->size) { return; } - if (off_from == off_to) { return; } - - size_t len_from = run->dynfile->size - off_from; - len = HF_MIN(len, len_from); +static inline void mangle_Move(run_t* run, size_t off_from, size_t off_to, size_t len) { + if (off_from >= run->dynfile->size) { + return; + } + if (off_to >= run->dynfile->size) { + return; + } + if (off_from == off_to) { + return; + } - size_t len_to = run->dynfile->size - off_to; - len = HF_MIN(len, len_to); + size_t len_from = run->dynfile->size - off_from; + len = HF_MIN(len, len_from); - memmove(&run->dynfile->data[off_to], &run->dynfile->data[off_from], len); + size_t len_to = run->dynfile->size - off_to; + len = HF_MIN(len, len_to); + memmove(&run->dynfile->data[off_to], &run->dynfile->data[off_from], len); } -static inline void mangle_Overwrite(run_t *run, size_t off, const uint8_t *src, - size_t len, bool printable) { - - if (len == 0) { return; } - size_t maxToCopy = run->dynfile->size - off; - if (len > maxToCopy) { len = maxToCopy; } - - memmove(&run->dynfile->data[off], src, len); - if (printable) { util_turnToPrintable(&run->dynfile->data[off], len); } +static inline void mangle_Overwrite( + run_t* run, size_t off, const uint8_t* src, size_t len, bool printable) { + if (len == 0) { + return; + } + size_t maxToCopy = run->dynfile->size - off; + if (len > maxToCopy) { + len = maxToCopy; + } + memmove(&run->dynfile->data[off], src, len); + if (printable) { + util_turnToPrintable(&run->dynfile->data[off], len); + } } -static inline size_t mangle_Inflate(run_t *run, size_t off, size_t len, - bool printable) { - - if (run->dynfile->size >= run->global->mutate.maxInputSz) { return 0; } - if (len > (run->global->mutate.maxInputSz - run->dynfile->size)) { - - len = run->global->mutate.maxInputSz - run->dynfile->size; - - } - - input_setSize(run, run->dynfile->size + len); - mangle_Move(run, off, off + len, run->dynfile->size); - if (printable) { memset(&run->dynfile->data[off], ' ', len); } +static inline size_t mangle_Inflate(run_t* run, size_t off, size_t len, bool printable) { + if (run->dynfile->size >= run->global->mutate.maxInputSz) { + return 0; + } + if (len > (run->global->mutate.maxInputSz - run->dynfile->size)) { + len = run->global->mutate.maxInputSz - run->dynfile->size; + } - return len; + input_setSize(run, run->dynfile->size + len); + mangle_Move(run, off, off + len, run->dynfile->size); + if (printable) { + memset(&run->dynfile->data[off], ' ', len); + } + return len; } -static inline void mangle_Insert(run_t *run, size_t off, const uint8_t *val, - size_t len, bool printable) { - - len = mangle_Inflate(run, off, len, printable); - mangle_Overwrite(run, off, val, len, printable); - +static inline void mangle_Insert( + run_t* run, size_t off, const uint8_t* val, size_t len, bool printable) { + len = mangle_Inflate(run, off, len, printable); + mangle_Overwrite(run, off, val, len, printable); } -static inline void mangle_UseValue(run_t *run, const uint8_t *val, size_t len, - bool printable) { - - if (util_rnd64() % 2) { - - mangle_Insert(run, mangle_getOffSetPlus1(run), val, len, printable); - - } else { - - mangle_Overwrite(run, mangle_getOffSet(run), val, len, printable); - - } - +static inline void mangle_UseValue(run_t* run, const uint8_t* val, size_t len, bool printable) { + if (util_rnd64() & 1) { + mangle_Overwrite(run, mangle_getOffSet(run), val, len, printable); + } else { + mangle_Insert(run, mangle_getOffSetPlus1(run), val, len, printable); + } } -static void mangle_MemSwap(run_t *run, bool printable HF_ATTR_UNUSED) { - - size_t off1 = mangle_getOffSet(run); - size_t maxlen1 = run->dynfile->size - off1; - - size_t off2 = mangle_getOffSet(run); - size_t maxlen2 = run->dynfile->size - off2; - - size_t len = mangle_getLen(HF_MIN(maxlen1, maxlen2)); - uint8_t *tmpbuf = (uint8_t *)util_Malloc(len); - defer { - - free(tmpbuf); - - }; - - memcpy(tmpbuf, &run->dynfile->data[off1], len); - memmove(&run->dynfile->data[off1], &run->dynfile->data[off2], len); - memcpy(&run->dynfile->data[off2], tmpbuf, len); - +static inline void mangle_UseValueAt( + run_t* run, size_t off, const uint8_t* val, size_t len, bool printable) { + if (util_rnd64() & 1) { + mangle_Overwrite(run, off, val, len, printable); + } else { + mangle_Insert(run, off, val, len, printable); + } } -static void mangle_MemCopy(run_t *run, bool printable HF_ATTR_UNUSED) { - - size_t off = mangle_getOffSet(run); - size_t len = mangle_getLen(run->dynfile->size - off); - - /* Use a temp buf, as Insert/Inflate can change source bytes */ - uint8_t *tmpbuf = (uint8_t *)util_Malloc(len); - defer { +static void mangle_MemSwap(run_t* run, bool printable HF_ATTR_UNUSED) { + /* No big deal if those two are overlapping */ + size_t off1 = mangle_getOffSet(run); + size_t maxlen1 = run->dynfile->size - off1; + size_t off2 = mangle_getOffSet(run); + size_t maxlen2 = run->dynfile->size - off2; + size_t len = mangle_getLen(HF_MIN(maxlen1, maxlen2)); - free(tmpbuf); - - }; - - memcpy(tmpbuf, &run->dynfile->data[off], len); - - mangle_UseValue(run, tmpbuf, len, printable); + if (off1 == off2) { + return; + } + for (size_t i = 0; i < (len / 2); i++) { + /* + * First - from the head, next from the tail. Don't worry about layout of the overlapping + * part - there's no good solution to that, and it can be left somewhat scrambled, + * while still preserving the entropy + */ + const uint8_t tmp1 = run->dynfile->data[off2 + i]; + run->dynfile->data[off2 + i] = run->dynfile->data[off1 + i]; + run->dynfile->data[off1 + i] = tmp1; + const uint8_t tmp2 = run->dynfile->data[off2 + (len - 1) - i]; + run->dynfile->data[off2 + (len - 1) - i] = run->dynfile->data[off1 + (len - 1) - i]; + run->dynfile->data[off1 + (len - 1) - i] = tmp2; + } } -static void mangle_Bytes(run_t *run, bool printable) { - - uint16_t buf; - if (printable) { - - util_rndBufPrintable((uint8_t *)&buf, sizeof(buf)); - - } else { - - buf = util_rnd64(); +static void mangle_MemCopy(run_t* run, bool printable HF_ATTR_UNUSED) { + size_t off = mangle_getOffSet(run); + size_t len = mangle_getLen(run->dynfile->size - off); - } - - /* Overwrite with random 1-2-byte values */ - size_t toCopy = util_rndGet(1, 2); - mangle_UseValue(run, (const uint8_t *)&buf, toCopy, printable); + /* Use a temp buf, as Insert/Inflate can change source bytes */ + uint8_t* tmpbuf = (uint8_t*)util_Malloc(len); + defer { + free(tmpbuf); + }; + memmove(tmpbuf, &run->dynfile->data[off], len); + mangle_UseValue(run, tmpbuf, len, printable); } -static void mangle_ByteRepeatOverwrite(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - size_t destOff = off + 1; - size_t maxSz = run->dynfile->size - destOff; - - /* No space to repeat */ - if (!maxSz) { - - mangle_Bytes(run, printable); - return; - - } - - size_t len = mangle_getLen(maxSz); - memset(&run->dynfile->data[destOff], run->dynfile->data[off], len); +static void mangle_Bytes(run_t* run, bool printable) { + uint16_t buf; + if (printable) { + util_rndBufPrintable((uint8_t*)&buf, sizeof(buf)); + } else { + buf = util_rnd64(); + } + /* Overwrite with random 1-2-byte values */ + size_t toCopy = util_rndGet(1, 2); + mangle_UseValue(run, (const uint8_t*)&buf, toCopy, printable); } -static void mangle_ByteRepeatInsert(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - size_t destOff = off + 1; - size_t maxSz = run->dynfile->size - destOff; +static void mangle_ByteRepeat(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + size_t destOff = off + 1; + size_t maxSz = run->dynfile->size - destOff; - /* No space to repeat */ - if (!maxSz) { - - mangle_Bytes(run, printable); - return; - - } - - size_t len = mangle_getLen(maxSz); - len = mangle_Inflate(run, destOff, len, printable); - memset(&run->dynfile->data[destOff], run->dynfile->data[off], len); + /* No space to repeat */ + if (!maxSz) { + mangle_Bytes(run, printable); + return; + } + size_t len = mangle_getLen(maxSz); + if (util_rnd64() & 0x1) { + len = mangle_Inflate(run, destOff, len, printable); + } + memset(&run->dynfile->data[destOff], run->dynfile->data[off], len); } -static void mangle_Bit(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - run->dynfile->data[off] ^= (uint8_t)(1U << util_rndGet(0, 7)); - if (printable) { util_turnToPrintable(&(run->dynfile->data[off]), 1); } - +static void mangle_Bit(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + run->dynfile->data[off] ^= (uint8_t)(1U << util_rndGet(0, 7)); + if (printable) { + util_turnToPrintable(&(run->dynfile->data[off]), 1); + } } static const struct { - - const uint8_t val[8]; - const size_t size; - + const uint8_t val[8]; + const size_t size; } mangleMagicVals[] = { - /* 1B - No endianness */ {"\x00\x00\x00\x00\x00\x00\x00\x00", 1}, {"\x01\x00\x00\x00\x00\x00\x00\x00", 1}, @@ -518,522 +472,436 @@ static const struct { {"\x00\x00\x00\x00\x00\x00\x00\x80", 8}, {"\x01\x00\x00\x00\x00\x00\x00\x80", 8}, {"\xFE\xFF\xFF\xFF\xFF\xFF\xFF\xFF", 8}, - }; -static void mangle_Magic(run_t *run, bool printable) { - - uint64_t choice = util_rndGet(0, ARRAYSIZE(mangleMagicVals) - 1); - mangle_UseValue(run, mangleMagicVals[choice].val, - mangleMagicVals[choice].size, printable); - -} - -static void mangle_StaticDict(run_t *run, bool printable) { - - if (run->global->mutate.dictionaryCnt == 0) { - - mangle_Bytes(run, printable); - return; - - } - - uint64_t choice = util_rndGet(0, run->global->mutate.dictionaryCnt - 1); - mangle_UseValue(run, run->global->mutate.dictionary[choice].val, - run->global->mutate.dictionary[choice].len, printable); - +static void mangle_Magic(run_t* run, bool printable) { + uint64_t choice = util_rndGet(0, ARRAYSIZE(mangleMagicVals) - 1); + mangle_UseValue(run, mangleMagicVals[choice].val, mangleMagicVals[choice].size, printable); } -static inline const uint8_t *mangle_FeedbackDict(run_t *run, size_t *len) { - - if (!run->global->feedback.cmpFeedback) { return NULL; } - cmpfeedback_t *cmpf = run->global->feedback.cmpFeedbackMap; - uint32_t cnt = ATOMIC_GET(cmpf->cnt); - if (cnt == 0) { return NULL; } - if (cnt > ARRAYSIZE(cmpf->valArr)) { cnt = ARRAYSIZE(cmpf->valArr); } - uint32_t choice = util_rndGet(0, cnt - 1); - *len = (size_t)ATOMIC_GET(cmpf->valArr[choice].len); - if (*len == 0) { return NULL; } - return cmpf->valArr[choice].val; - +static void mangle_StaticDict(run_t* run, bool printable) { + if (run->global->mutate.dictionaryCnt == 0) { + mangle_Bytes(run, printable); + return; + } + uint64_t choice = util_rndGet(0, run->global->mutate.dictionaryCnt - 1); + mangle_UseValue(run, run->global->mutate.dictionary[choice].val, + run->global->mutate.dictionary[choice].len, printable); } -static void mangle_ConstFeedbackDict(run_t *run, bool printable) { - - size_t len; - const uint8_t *val = mangle_FeedbackDict(run, &len); - if (val == NULL) { - - mangle_Bytes(run, printable); - return; - - } - - mangle_UseValue(run, val, len, printable); - +static inline const uint8_t* mangle_FeedbackDict(run_t* run, size_t* len) { + if (!run->global->feedback.cmpFeedback) { + return NULL; + } + cmpfeedback_t* cmpf = run->global->feedback.cmpFeedbackMap; + uint32_t cnt = ATOMIC_GET(cmpf->cnt); + if (cnt == 0) { + return NULL; + } + if (cnt > ARRAYSIZE(cmpf->valArr)) { + cnt = ARRAYSIZE(cmpf->valArr); + } + uint32_t choice = util_rndGet(0, cnt - 1); + *len = (size_t)ATOMIC_GET(cmpf->valArr[choice].len); + if (*len == 0) { + return NULL; + } + return cmpf->valArr[choice].val; } -static void mangle_MemSet(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - size_t len = mangle_getLen(run->dynfile->size - off); - int val = - printable ? (int)util_rndPrintable() : (int)util_rndGet(0, UINT8_MAX); - - memset(&run->dynfile->data[off], val, len); - +static void mangle_ConstFeedbackDict(run_t* run, bool printable) { + size_t len; + const uint8_t* val = mangle_FeedbackDict(run, &len); + if (val == NULL) { + mangle_Bytes(run, printable); + return; + } + mangle_UseValue(run, val, len, printable); } -static void mangle_RandomOverwrite(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - size_t len = mangle_getLen(run->dynfile->size - off); - if (printable) { +static void mangle_MemSet(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + size_t len = mangle_getLen(run->dynfile->size - off); + int val = printable ? (int)util_rndPrintable() : (int)util_rndGet(0, UINT8_MAX); - util_rndBufPrintable(&run->dynfile->data[off], len); - - } else { - - util_rndBuf(&run->dynfile->data[off], len); - - } + if (util_rnd64() & 1) { + len = mangle_Inflate(run, off, len, printable); + } + memset(&run->dynfile->data[off], val, len); } -static void mangle_RandomInsert(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - size_t len = mangle_getLen(run->dynfile->size - off); - - len = mangle_Inflate(run, off, len, printable); - - if (printable) { - - util_rndBufPrintable(&run->dynfile->data[off], len); +static void mangle_MemClr(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + size_t len = mangle_getLen(run->dynfile->size - off); + int val = printable ? ' ' : 0; - } else { - - util_rndBuf(&run->dynfile->data[off], len); - - } + if (util_rnd64() & 1) { + len = mangle_Inflate(run, off, len, printable); + } + memset(&run->dynfile->data[off], val, len); } -static inline void mangle_AddSubWithRange(run_t *run, size_t off, size_t varLen, - uint64_t range, bool printable) { - - int64_t delta = (int64_t)util_rndGet(0, range * 2) - (int64_t)range; - - switch (varLen) { - - case 1: { - - run->dynfile->data[off] += delta; - break; +static void mangle_RandomBuf(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + size_t len = mangle_getLen(run->dynfile->size - off); + if (util_rnd64() & 1) { + len = mangle_Inflate(run, off, len, printable); } - case 2: { - - int16_t val; - memcpy(&val, &run->dynfile->data[off], sizeof(val)); - if (util_rnd64() & 0x1) { - - val += delta; - - } else { - - /* Foreign endianess */ - val = __builtin_bswap16(val); - val += delta; - val = __builtin_bswap16(val); - - } - - mangle_Overwrite(run, off, (uint8_t *)&val, varLen, printable); - break; - + if (printable) { + util_rndBufPrintable(&run->dynfile->data[off], len); + } else { + util_rndBuf(&run->dynfile->data[off], len); } +} - case 4: { - - int32_t val; - memcpy(&val, &run->dynfile->data[off], sizeof(val)); - if (util_rnd64() & 0x1) { - - val += delta; - - } else { - - /* Foreign endianess */ - val = __builtin_bswap32(val); - val += delta; - val = __builtin_bswap32(val); - - } - - mangle_Overwrite(run, off, (uint8_t *)&val, varLen, printable); - break; - +static inline void mangle_AddSubWithRange( + run_t* run, size_t off, size_t varLen, uint64_t range, bool printable) { + int64_t delta = (int64_t)util_rndGet(0, range * 2) - (int64_t)range; + + switch (varLen) { + case 1: { + run->dynfile->data[off] += delta; + break; + } + case 2: { + int16_t val; + memcpy(&val, &run->dynfile->data[off], sizeof(val)); + if (util_rnd64() & 0x1) { + val += delta; + } else { + /* Foreign endianess */ + val = __builtin_bswap16(val); + val += delta; + val = __builtin_bswap16(val); + } + mangle_Overwrite(run, off, (uint8_t*)&val, varLen, printable); + break; + } + case 4: { + int32_t val; + memcpy(&val, &run->dynfile->data[off], sizeof(val)); + if (util_rnd64() & 0x1) { + val += delta; + } else { + /* Foreign endianess */ + val = __builtin_bswap32(val); + val += delta; + val = __builtin_bswap32(val); + } + mangle_Overwrite(run, off, (uint8_t*)&val, varLen, printable); + break; + } + case 8: { + int64_t val; + memcpy(&val, &run->dynfile->data[off], sizeof(val)); + if (util_rnd64() & 0x1) { + val += delta; + } else { + /* Foreign endianess */ + val = __builtin_bswap64(val); + val += delta; + val = __builtin_bswap64(val); + } + mangle_Overwrite(run, off, (uint8_t*)&val, varLen, printable); + break; + } + default: { + LOG_F("Unknown variable length size: %zu", varLen); + } } +} - case 8: { - - int64_t val; - memcpy(&val, &run->dynfile->data[off], sizeof(val)); - if (util_rnd64() & 0x1) { - - val += delta; - - } else { - - /* Foreign endianess */ - val = __builtin_bswap64(val); - val += delta; - val = __builtin_bswap64(val); - - } - - mangle_Overwrite(run, off, (uint8_t *)&val, varLen, printable); - break; +static void mangle_AddSub(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + /* 1,2,4,8 */ + size_t varLen = 1U << util_rndGet(0, 3); + if ((run->dynfile->size - off) < varLen) { + varLen = 1; } - default: { - - LOG_F("Unknown variable length size: %zu", varLen); - + uint64_t range; + switch (varLen) { + case 1: + range = 16; + break; + case 2: + range = 4096; + break; + case 4: + range = 1048576; + break; + case 8: + range = 268435456; + break; + default: + LOG_F("Invalid operand size: %zu", varLen); } - } - -} - -static void mangle_AddSub(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - - /* 1,2,4,8 */ - size_t varLen = 1U << util_rndGet(0, 3); - if ((run->dynfile->size - off) < varLen) { varLen = 1; } - - uint64_t range; - switch (varLen) { - - case 1: - range = 16; - break; - case 2: - range = 4096; - break; - case 4: - range = 1048576; - break; - case 8: - range = 268435456; - break; - default: - LOG_F("Invalid operand size: %zu", varLen); - - } - - mangle_AddSubWithRange(run, off, varLen, range, printable); - -} - -static void mangle_IncByte(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - if (printable) { - - run->dynfile->data[off] = (run->dynfile->data[off] - 32 + 1) % 95 + 32; - - } else { - - run->dynfile->data[off] += (uint8_t)1UL; - - } - + mangle_AddSubWithRange(run, off, varLen, range, printable); } -static void mangle_DecByte(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - if (printable) { - - run->dynfile->data[off] = (run->dynfile->data[off] - 32 + 94) % 95 + 32; - - } else { - - run->dynfile->data[off] -= (uint8_t)1UL; - - } - -} - -static void mangle_NegByte(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - if (printable) { - - run->dynfile->data[off] = 94 - (run->dynfile->data[off] - 32) + 32; - - } else { - - run->dynfile->data[off] = ~(run->dynfile->data[off]); - - } - +static void mangle_IncByte(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + if (printable) { + run->dynfile->data[off] = (run->dynfile->data[off] - 32 + 1) % 95 + 32; + } else { + run->dynfile->data[off] += (uint8_t)1UL; + } } -static void mangle_Expand(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - size_t len; - if (util_rnd64() % 16) { - - len = mangle_getLen(HF_MIN(16, run->global->mutate.maxInputSz - off)); - - } else { - - len = mangle_getLen(run->global->mutate.maxInputSz - off); - - } - - mangle_Inflate(run, off, len, printable); - +static void mangle_DecByte(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + if (printable) { + run->dynfile->data[off] = (run->dynfile->data[off] - 32 + 94) % 95 + 32; + } else { + run->dynfile->data[off] -= (uint8_t)1UL; + } } -static void mangle_Shrink(run_t *run, bool printable HF_ATTR_UNUSED) { - - if (run->dynfile->size <= 2U) { return; } - - size_t off_start = mangle_getOffSet(run); - size_t len = mangle_LenLeft(run, off_start); - if (len == 0) { return; } - if (util_rnd64() % 16) { - - len = mangle_getLen(HF_MIN(16, len)); - - } else { - - len = mangle_getLen(len); - - } - - size_t off_end = off_start + len; - size_t len_to_move = run->dynfile->size - off_end; - - mangle_Move(run, off_end, off_start, len_to_move); - input_setSize(run, run->dynfile->size - len); - +static void mangle_NegByte(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + if (printable) { + run->dynfile->data[off] = 94 - (run->dynfile->data[off] - 32) + 32; + } else { + run->dynfile->data[off] = ~(run->dynfile->data[off]); + } } -static void mangle_ASCIINum(run_t *run, bool printable) { - - size_t len = util_rndGet(2, 8); - - char buf[20]; - snprintf(buf, sizeof(buf), "%-19" PRId64, (int64_t)util_rnd64()); - - mangle_UseValue(run, (const uint8_t *)buf, len, printable); +static void mangle_Expand(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); + size_t len; + if (util_rnd64() % 16) { + len = mangle_getLen(HF_MIN(16, run->global->mutate.maxInputSz - off)); + } else { + len = mangle_getLen(run->global->mutate.maxInputSz - off); + } + mangle_Inflate(run, off, len, printable); } -static void mangle_ASCIINumChange(run_t *run, bool printable) { - - size_t off = mangle_getOffSet(run); - - /* Find a digit */ - for (; off < run->dynfile->size; off++) { - - if (isdigit(run->dynfile->data[off])) { break; } - - } - - if (off == run->dynfile->size) { - - mangle_Bytes(run, printable); - return; - - } - - size_t len = HF_MIN(20, run->dynfile->size - off); - char numbuf[21] = {}; - strncpy(numbuf, (const char *)&run->dynfile->data[off], len); - uint64_t val = (uint64_t)strtoull(numbuf, NULL, 10); - - switch (util_rndGet(0, 5)) { - - case 0: - val += util_rndGet(1, 256); - break; - case 1: - val -= util_rndGet(1, 256); - break; - case 2: - val *= util_rndGet(1, 256); - break; - case 3: - val /= util_rndGet(1, 256); - break; - case 4: - val = ~(val); - break; - case 5: - val = util_rnd64(); - break; - default: - LOG_F("Invalid choice"); - - }; +static void mangle_Shrink(run_t* run, bool printable HF_ATTR_UNUSED) { + if (run->dynfile->size <= 2U) { + return; + } - len = HF_MIN((size_t)snprintf(numbuf, sizeof(numbuf), "%" PRIu64, val), len); - mangle_Overwrite(run, off, (const uint8_t *)numbuf, len, printable); + size_t off_start = mangle_getOffSet(run); + size_t len = mangle_LenLeft(run, off_start); + if (len == 0) { + return; + } + if (util_rnd64() % 16) { + len = mangle_getLen(HF_MIN(16, len)); + } else { + len = mangle_getLen(len); + } + size_t off_end = off_start + len; + size_t len_to_move = run->dynfile->size - off_end; + mangle_Move(run, off_end, off_start, len_to_move); + input_setSize(run, run->dynfile->size - len); } +static void mangle_ASCIINum(run_t* run, bool printable) { + size_t len = util_rndGet(2, 8); -static void mangle_Splice(run_t *run, bool printable) { - - const uint8_t *buf; - size_t sz = input_getRandomInputAsBuf(run, &buf); - if (!sz) { - - mangle_Bytes(run, printable); - return; - - } - - size_t remoteOff = mangle_getLen(sz) - 1; - size_t len = mangle_getLen(sz - remoteOff); - mangle_UseValue(run, &buf[remoteOff], len, printable); + char buf[20]; + snprintf(buf, sizeof(buf), "%-19" PRId64, (int64_t)util_rnd64()); + mangle_UseValue(run, (const uint8_t*)buf, len, printable); } -static void mangle_Resize(run_t *run, bool printable) { - - ssize_t oldsz = run->dynfile->size; - ssize_t newsz = 0; - - uint64_t choice = util_rndGet(0, 32); - switch (choice) { +static void mangle_ASCIINumChange(run_t* run, bool printable) { + size_t off = mangle_getOffSet(run); - case 0: /* Set new size arbitrarily */ - newsz = (ssize_t)util_rndGet(1, run->global->mutate.maxInputSz); - break; - case 1 ... 4: /* Increase size by a small value */ - newsz = oldsz + (ssize_t)util_rndGet(0, 8); - break; - case 5: /* Increase size by a larger value */ - newsz = oldsz + (ssize_t)util_rndGet(9, 128); - break; - case 6 ... 9: /* Decrease size by a small value */ - newsz = oldsz - (ssize_t)util_rndGet(0, 8); - break; - case 10: /* Decrease size by a larger value */ - newsz = oldsz - (ssize_t)util_rndGet(9, 128); - break; - case 11 ... 32: /* Do nothing */ - newsz = oldsz; - break; - default: - LOG_F("Illegal value from util_rndGet: %" PRIu64, choice); - break; - - } - - if (newsz < 1) { newsz = 1; } - if (newsz > (ssize_t)run->global->mutate.maxInputSz) { - - newsz = run->global->mutate.maxInputSz; + /* Find a digit */ + for (; off < run->dynfile->size; off++) { + if (isdigit(run->dynfile->data[off])) { + break; + } + } + size_t left = run->dynfile->size - off; + if (left == 0) { + return; + } - } + size_t len = 0; + uint64_t val = 0; + /* 20 is maximum lenght of a string representing a 64-bit unsigned value */ + for (len = 0; (len < 20) && (len < left); len++) { + char c = run->dynfile->data[off + len]; + if (!isdigit(c)) { + break; + } + val *= 10; + val += (c - '0'); + } - input_setSize(run, (size_t)newsz); - if (newsz > oldsz) { + switch (util_rndGet(0, 7)) { + case 0: + val++; + break; + case 1: + val--; + break; + case 2: + val *= 2; + break; + case 3: + val /= 2; + break; + case 4: + val = util_rnd64(); + break; + case 5: + val += util_rndGet(1, 256); + break; + case 6: + val -= util_rndGet(1, 256); + break; + case 7: + val = ~(val); + break; + default: + LOG_F("Invalid choice"); + }; + + char buf[20]; + snprintf(buf, sizeof(buf), "%-19" PRIu64, val); + + mangle_UseValueAt(run, off, (const uint8_t*)buf, len, printable); +} + +static void mangle_Splice(run_t* run, bool printable) { + if (run->global->feedback.dynFileMethod == _HF_DYNFILE_NONE) { + mangle_Bytes(run, printable); + return; + } - if (printable) { memset(&run->dynfile->data[oldsz], ' ', newsz - oldsz); } + size_t sz = 0; + const uint8_t* buf = input_getRandomInputAsBuf(run, &sz); + if (!buf) { + LOG_E("input_getRandomInputAsBuf() returned no input"); + mangle_Bytes(run, printable); + return; + } + if (!sz) { + mangle_Bytes(run, printable); + return; + } - } + size_t remoteOff = mangle_getLen(sz) - 1; + size_t len = mangle_getLen(sz - remoteOff); + mangle_UseValue(run, &buf[remoteOff], len, printable); +} + +static void mangle_Resize(run_t* run, bool printable) { + ssize_t oldsz = run->dynfile->size; + ssize_t newsz = 0; + + uint64_t choice = util_rndGet(0, 32); + switch (choice) { + case 0: /* Set new size arbitrarily */ + newsz = (ssize_t)util_rndGet(1, run->global->mutate.maxInputSz); + break; + case 1 ... 4: /* Increase size by a small value */ + newsz = oldsz + (ssize_t)util_rndGet(0, 8); + break; + case 5: /* Increase size by a larger value */ + newsz = oldsz + (ssize_t)util_rndGet(9, 128); + break; + case 6 ... 9: /* Decrease size by a small value */ + newsz = oldsz - (ssize_t)util_rndGet(0, 8); + break; + case 10: /* Decrease size by a larger value */ + newsz = oldsz - (ssize_t)util_rndGet(9, 128); + break; + case 11 ... 32: /* Do nothing */ + newsz = oldsz; + break; + default: + LOG_F("Illegal value from util_rndGet: %" PRIu64, choice); + break; + } + if (newsz < 1) { + newsz = 1; + } + if (newsz > (ssize_t)run->global->mutate.maxInputSz) { + newsz = run->global->mutate.maxInputSz; + } + input_setSize(run, (size_t)newsz); + if (newsz > oldsz) { + if (printable) { + memset(&run->dynfile->data[oldsz], ' ', newsz - oldsz); + } + } } -void mangle_mangleContent(run_t *run, int speed_factor) { - - static void (*const mangleFuncs[])(run_t * run, bool printable) = { - - /* Every *Insert or Expand expands file, so add more Shrink's */ - mangle_Shrink, - mangle_Shrink, - mangle_Shrink, - mangle_Shrink, - mangle_Expand, - mangle_Bit, - mangle_IncByte, - mangle_DecByte, - mangle_NegByte, - mangle_AddSub, - mangle_MemSet, - mangle_MemSwap, - mangle_MemCopy, - mangle_Bytes, - mangle_ASCIINum, - mangle_ASCIINumChange, - mangle_ByteRepeatOverwrite, - mangle_ByteRepeatInsert, - mangle_Magic, - mangle_StaticDict, - mangle_ConstFeedbackDict, - mangle_RandomOverwrite, - mangle_RandomInsert, - mangle_Splice, - - }; - - if (run->mutationsPerRun == 0U) { return; } - if (run->dynfile->size == 0U) { - - mangle_Resize(run, /* printable= */ run->global->cfg.only_printable); - - } - - uint64_t changesCnt = run->global->mutate.mutationsPerRun; - - if (speed_factor < 5) { - - changesCnt = util_rndGet(1, run->global->mutate.mutationsPerRun); - - } else if (speed_factor < 10) { - - changesCnt = run->global->mutate.mutationsPerRun; - - } else { - - changesCnt = HF_MIN(speed_factor, 12); - changesCnt = HF_MAX(changesCnt, run->global->mutate.mutationsPerRun); - - } - - /* If last coverage acquisition was more than 5 secs ago, use splicing more - * frequently */ - if ((time(NULL) - ATOMIC_GET(run->global->timing.lastCovUpdate)) > 5) { - - if (util_rnd64() % 2) { - - mangle_Splice(run, run->global->cfg.only_printable); - +void mangle_mangleContent(run_t* run, int speed_factor) { + static void (*const mangleFuncs[])(run_t * run, bool printable) = { + mangle_Shrink, + mangle_Expand, + mangle_Bit, + mangle_IncByte, + mangle_DecByte, + mangle_NegByte, + mangle_AddSub, + mangle_MemSet, + mangle_MemClr, + mangle_MemSwap, + mangle_MemCopy, + mangle_Bytes, + mangle_ASCIINum, + mangle_ASCIINumChange, + mangle_ByteRepeat, + mangle_Magic, + mangle_StaticDict, + mangle_ConstFeedbackDict, + mangle_RandomBuf, + mangle_Splice, + }; + + if (run->mutationsPerRun == 0U) { + return; + } + if (run->dynfile->size == 0U) { + mangle_Resize(run, /* printable= */ run->global->cfg.only_printable); } - } - - for (uint64_t x = 0; x < changesCnt; x++) { + uint64_t changesCnt = run->global->mutate.mutationsPerRun; - uint64_t choice = util_rndGet(0, ARRAYSIZE(mangleFuncs) - 1); - mangleFuncs[choice](run, /* printable= */ run->global->cfg.only_printable); + if (speed_factor < 5) { + changesCnt = util_rndGet(1, run->global->mutate.mutationsPerRun); + } else if (speed_factor < 10) { + changesCnt = run->global->mutate.mutationsPerRun; + } else { + changesCnt = HF_MIN(speed_factor, 10); + changesCnt = HF_MAX(changesCnt, (run->global->mutate.mutationsPerRun * 5)); + } - } + /* If last coverage acquisition was more than 5 secs ago, use splicing more frequently */ + if ((time(NULL) - ATOMIC_GET(run->global->timing.lastCovUpdate)) > 5) { + if (util_rnd64() & 0x1) { + mangle_Splice(run, run->global->cfg.only_printable); + } + } - wmb(); + for (uint64_t x = 0; x < changesCnt; x++) { + if (run->global->feedback.cmpFeedback && (util_rnd64() & 0x1)) { + /* + * mangle_ConstFeedbackDict() is quite powerful if the dynamic feedback dictionary + * exists. If so, give it 50% chance of being used among all mangling functions. + */ + mangle_ConstFeedbackDict(run, /* printable= */ run->global->cfg.only_printable); + } else { + uint64_t choice = util_rndGet(0, ARRAYSIZE(mangleFuncs) - 1); + mangleFuncs[choice](run, /* printable= */ run->global->cfg.only_printable); + } + } + wmb(); } - diff --git a/custom_mutators/honggfuzz/mangle.h b/custom_mutators/honggfuzz/mangle.h index 1b6a4943..f8f3988c 100644 --- a/custom_mutators/honggfuzz/mangle.h +++ b/custom_mutators/honggfuzz/mangle.h @@ -26,7 +26,6 @@ #include "honggfuzz.h" -extern void mangle_mangleContent(run_t *run, int speed_factor); +extern void mangle_mangleContent(run_t* run, int speed_factor); #endif - diff --git a/custom_mutators/libfuzzer/FuzzerBuiltins.h b/custom_mutators/libfuzzer/FuzzerBuiltins.h new file mode 100644 index 00000000..7330c9d3 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerBuiltins.h @@ -0,0 +1,35 @@ +//===- FuzzerBuiltins.h - Internal header for builtins ----------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Wrapper functions and macros around builtin functions. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_BUILTINS_H +#define LLVM_FUZZER_BUILTINS_H + +#include "FuzzerPlatform.h" + +#if !LIBFUZZER_MSVC +#include <cstdint> + +#define GET_CALLER_PC() __builtin_return_address(0) + +namespace fuzzer { + +inline uint8_t Bswap(uint8_t x) { return x; } +inline uint16_t Bswap(uint16_t x) { return __builtin_bswap16(x); } +inline uint32_t Bswap(uint32_t x) { return __builtin_bswap32(x); } +inline uint64_t Bswap(uint64_t x) { return __builtin_bswap64(x); } + +inline uint32_t Clzll(unsigned long long X) { return __builtin_clzll(X); } +inline uint32_t Clz(unsigned long long X) { return __builtin_clz(X); } +inline int Popcountll(unsigned long long X) { return __builtin_popcountll(X); } + +} // namespace fuzzer + +#endif // !LIBFUZZER_MSVC +#endif // LLVM_FUZZER_BUILTINS_H diff --git a/custom_mutators/libfuzzer/FuzzerBuiltinsMsvc.h b/custom_mutators/libfuzzer/FuzzerBuiltinsMsvc.h new file mode 100644 index 00000000..6754577c --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerBuiltinsMsvc.h @@ -0,0 +1,72 @@ +//===- FuzzerBuiltinsMSVC.h - Internal header for builtins ------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Wrapper functions and macros that use intrinsics instead of builtin functions +// which cannot be compiled by MSVC. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_BUILTINS_MSVC_H +#define LLVM_FUZZER_BUILTINS_MSVC_H + +#include "FuzzerPlatform.h" + +#if LIBFUZZER_MSVC +#include <intrin.h> +#include <cstdint> +#include <cstdlib> + +// __builtin_return_address() cannot be compiled with MSVC. Use the equivalent +// from <intrin.h> +#define GET_CALLER_PC() _ReturnAddress() + +namespace fuzzer { + +inline uint8_t Bswap(uint8_t x) { return x; } +// Use alternatives to __builtin functions from <stdlib.h> and <intrin.h> on +// Windows since the builtins are not supported by MSVC. +inline uint16_t Bswap(uint16_t x) { return _byteswap_ushort(x); } +inline uint32_t Bswap(uint32_t x) { return _byteswap_ulong(x); } +inline uint64_t Bswap(uint64_t x) { return _byteswap_uint64(x); } + +// The functions below were mostly copied from +// compiler-rt/lib/builtins/int_lib.h which defines the __builtin functions used +// outside of Windows. +inline uint32_t Clzll(uint64_t X) { + unsigned long LeadZeroIdx = 0; + +#if !defined(_M_ARM) && !defined(_M_X64) + // Scan the high 32 bits. + if (_BitScanReverse(&LeadZeroIdx, static_cast<unsigned long>(X >> 32))) + return static_cast<int>(63 - (LeadZeroIdx + 32)); // Create a bit offset from the MSB. + // Scan the low 32 bits. + if (_BitScanReverse(&LeadZeroIdx, static_cast<unsigned long>(X))) + return static_cast<int>(63 - LeadZeroIdx); + +#else + if (_BitScanReverse64(&LeadZeroIdx, X)) return 63 - LeadZeroIdx; +#endif + return 64; +} + +inline uint32_t Clz(uint32_t X) { + unsigned long LeadZeroIdx = 0; + if (_BitScanReverse(&LeadZeroIdx, X)) return 31 - LeadZeroIdx; + return 32; +} + +inline int Popcountll(unsigned long long X) { +#if !defined(_M_ARM) && !defined(_M_X64) + return __popcnt(X) + __popcnt(X >> 32); +#else + return __popcnt64(X); +#endif +} + +} // namespace fuzzer + +#endif // LIBFUZER_MSVC +#endif // LLVM_FUZZER_BUILTINS_MSVC_H diff --git a/custom_mutators/libfuzzer/FuzzerCommand.h b/custom_mutators/libfuzzer/FuzzerCommand.h new file mode 100644 index 00000000..87308864 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerCommand.h @@ -0,0 +1,178 @@ +//===- FuzzerCommand.h - Interface representing a process -------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// FuzzerCommand represents a command to run in a subprocess. It allows callers +// to manage command line arguments and output and error streams. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_COMMAND_H +#define LLVM_FUZZER_COMMAND_H + +#include "FuzzerDefs.h" +#include "FuzzerIO.h" + +#include <algorithm> +#include <sstream> +#include <string> +#include <vector> + +namespace fuzzer { + +class Command final { +public: + // This command line flag is used to indicate that the remaining command line + // is immutable, meaning this flag effectively marks the end of the mutable + // argument list. + static inline const char *ignoreRemainingArgs() { + return "-ignore_remaining_args=1"; + } + + Command() : CombinedOutAndErr(false) {} + + explicit Command(const Vector<std::string> &ArgsToAdd) + : Args(ArgsToAdd), CombinedOutAndErr(false) {} + + explicit Command(const Command &Other) + : Args(Other.Args), CombinedOutAndErr(Other.CombinedOutAndErr), + OutputFile(Other.OutputFile) {} + + Command &operator=(const Command &Other) { + Args = Other.Args; + CombinedOutAndErr = Other.CombinedOutAndErr; + OutputFile = Other.OutputFile; + return *this; + } + + ~Command() {} + + // Returns true if the given Arg is present in Args. Only checks up to + // "-ignore_remaining_args=1". + bool hasArgument(const std::string &Arg) const { + auto i = endMutableArgs(); + return std::find(Args.begin(), i, Arg) != i; + } + + // Gets all of the current command line arguments, **including** those after + // "-ignore-remaining-args=1". + const Vector<std::string> &getArguments() const { return Args; } + + // Adds the given argument before "-ignore_remaining_args=1", or at the end + // if that flag isn't present. + void addArgument(const std::string &Arg) { + Args.insert(endMutableArgs(), Arg); + } + + // Adds all given arguments before "-ignore_remaining_args=1", or at the end + // if that flag isn't present. + void addArguments(const Vector<std::string> &ArgsToAdd) { + Args.insert(endMutableArgs(), ArgsToAdd.begin(), ArgsToAdd.end()); + } + + // Removes the given argument from the command argument list. Ignores any + // occurrences after "-ignore_remaining_args=1", if present. + void removeArgument(const std::string &Arg) { + auto i = endMutableArgs(); + Args.erase(std::remove(Args.begin(), i, Arg), i); + } + + // Like hasArgument, but checks for "-[Flag]=...". + bool hasFlag(const std::string &Flag) const { + std::string Arg("-" + Flag + "="); + auto IsMatch = [&](const std::string &Other) { + return Arg.compare(0, std::string::npos, Other, 0, Arg.length()) == 0; + }; + return std::any_of(Args.begin(), endMutableArgs(), IsMatch); + } + + // Returns the value of the first instance of a given flag, or an empty string + // if the flag isn't present. Ignores any occurrences after + // "-ignore_remaining_args=1", if present. + std::string getFlagValue(const std::string &Flag) const { + std::string Arg("-" + Flag + "="); + auto IsMatch = [&](const std::string &Other) { + return Arg.compare(0, std::string::npos, Other, 0, Arg.length()) == 0; + }; + auto i = endMutableArgs(); + auto j = std::find_if(Args.begin(), i, IsMatch); + std::string result; + if (j != i) { + result = j->substr(Arg.length()); + } + return result; + } + + // Like AddArgument, but adds "-[Flag]=[Value]". + void addFlag(const std::string &Flag, const std::string &Value) { + addArgument("-" + Flag + "=" + Value); + } + + // Like RemoveArgument, but removes "-[Flag]=...". + void removeFlag(const std::string &Flag) { + std::string Arg("-" + Flag + "="); + auto IsMatch = [&](const std::string &Other) { + return Arg.compare(0, std::string::npos, Other, 0, Arg.length()) == 0; + }; + auto i = endMutableArgs(); + Args.erase(std::remove_if(Args.begin(), i, IsMatch), i); + } + + // Returns whether the command's stdout is being written to an output file. + bool hasOutputFile() const { return !OutputFile.empty(); } + + // Returns the currently set output file. + const std::string &getOutputFile() const { return OutputFile; } + + // Configures the command to redirect its output to the name file. + void setOutputFile(const std::string &FileName) { OutputFile = FileName; } + + // Returns whether the command's stderr is redirected to stdout. + bool isOutAndErrCombined() const { return CombinedOutAndErr; } + + // Sets whether to redirect the command's stderr to its stdout. + void combineOutAndErr(bool combine = true) { CombinedOutAndErr = combine; } + + // Returns a string representation of the command. On many systems this will + // be the equivalent command line. + std::string toString() const { + std::stringstream SS; + for (auto arg : getArguments()) + SS << arg << " "; + if (hasOutputFile()) + SS << ">" << getOutputFile() << " "; + if (isOutAndErrCombined()) + SS << "2>&1 "; + std::string result = SS.str(); + if (!result.empty()) + result = result.substr(0, result.length() - 1); + return result; + } + +private: + Command(Command &&Other) = delete; + Command &operator=(Command &&Other) = delete; + + Vector<std::string>::iterator endMutableArgs() { + return std::find(Args.begin(), Args.end(), ignoreRemainingArgs()); + } + + Vector<std::string>::const_iterator endMutableArgs() const { + return std::find(Args.begin(), Args.end(), ignoreRemainingArgs()); + } + + // The command arguments. Args[0] is the command name. + Vector<std::string> Args; + + // True indicates stderr is redirected to stdout. + bool CombinedOutAndErr; + + // If not empty, stdout is redirected to the named file. + std::string OutputFile; +}; + +} // namespace fuzzer + +#endif // LLVM_FUZZER_COMMAND_H diff --git a/custom_mutators/libfuzzer/FuzzerCorpus.h b/custom_mutators/libfuzzer/FuzzerCorpus.h new file mode 100644 index 00000000..daea4f52 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerCorpus.h @@ -0,0 +1,581 @@ +//===- FuzzerCorpus.h - Internal header for the Fuzzer ----------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// fuzzer::InputCorpus +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_CORPUS +#define LLVM_FUZZER_CORPUS + +#include "FuzzerDataFlowTrace.h" +#include "FuzzerDefs.h" +#include "FuzzerIO.h" +#include "FuzzerRandom.h" +#include "FuzzerSHA1.h" +#include "FuzzerTracePC.h" +#include <algorithm> +#include <chrono> +#include <numeric> +#include <random> +#include <unordered_set> + +namespace fuzzer { + +struct InputInfo { + Unit U; // The actual input data. + std::chrono::microseconds TimeOfUnit; + uint8_t Sha1[kSHA1NumBytes]; // Checksum. + // Number of features that this input has and no smaller input has. + size_t NumFeatures = 0; + size_t Tmp = 0; // Used by ValidateFeatureSet. + // Stats. + size_t NumExecutedMutations = 0; + size_t NumSuccessfullMutations = 0; + bool NeverReduce = false; + bool MayDeleteFile = false; + bool Reduced = false; + bool HasFocusFunction = false; + Vector<uint32_t> UniqFeatureSet; + Vector<uint8_t> DataFlowTraceForFocusFunction; + // Power schedule. + bool NeedsEnergyUpdate = false; + double Energy = 0.0; + size_t SumIncidence = 0; + Vector<std::pair<uint32_t, uint16_t>> FeatureFreqs; + + // Delete feature Idx and its frequency from FeatureFreqs. + bool DeleteFeatureFreq(uint32_t Idx) { + if (FeatureFreqs.empty()) + return false; + + // Binary search over local feature frequencies sorted by index. + auto Lower = std::lower_bound(FeatureFreqs.begin(), FeatureFreqs.end(), + std::pair<uint32_t, uint16_t>(Idx, 0)); + + if (Lower != FeatureFreqs.end() && Lower->first == Idx) { + FeatureFreqs.erase(Lower); + return true; + } + return false; + } + + // Assign more energy to a high-entropy seed, i.e., that reveals more + // information about the globally rare features in the neighborhood of the + // seed. Since we do not know the entropy of a seed that has never been + // executed we assign fresh seeds maximum entropy and let II->Energy approach + // the true entropy from above. If ScalePerExecTime is true, the computed + // entropy is scaled based on how fast this input executes compared to the + // average execution time of inputs. The faster an input executes, the more + // energy gets assigned to the input. + void UpdateEnergy(size_t GlobalNumberOfFeatures, bool ScalePerExecTime, + std::chrono::microseconds AverageUnitExecutionTime) { + Energy = 0.0; + SumIncidence = 0; + + // Apply add-one smoothing to locally discovered features. + for (auto F : FeatureFreqs) { + size_t LocalIncidence = F.second + 1; + Energy -= LocalIncidence * logl(LocalIncidence); + SumIncidence += LocalIncidence; + } + + // Apply add-one smoothing to locally undiscovered features. + // PreciseEnergy -= 0; // since logl(1.0) == 0) + SumIncidence += (GlobalNumberOfFeatures - FeatureFreqs.size()); + + // Add a single locally abundant feature apply add-one smoothing. + size_t AbdIncidence = NumExecutedMutations + 1; + Energy -= AbdIncidence * logl(AbdIncidence); + SumIncidence += AbdIncidence; + + // Normalize. + if (SumIncidence != 0) + Energy = (Energy / SumIncidence) + logl(SumIncidence); + + if (ScalePerExecTime) { + // Scaling to favor inputs with lower execution time. + uint32_t PerfScore = 100; + if (TimeOfUnit.count() > AverageUnitExecutionTime.count() * 10) + PerfScore = 10; + else if (TimeOfUnit.count() > AverageUnitExecutionTime.count() * 4) + PerfScore = 25; + else if (TimeOfUnit.count() > AverageUnitExecutionTime.count() * 2) + PerfScore = 50; + else if (TimeOfUnit.count() * 3 > AverageUnitExecutionTime.count() * 4) + PerfScore = 75; + else if (TimeOfUnit.count() * 4 < AverageUnitExecutionTime.count()) + PerfScore = 300; + else if (TimeOfUnit.count() * 3 < AverageUnitExecutionTime.count()) + PerfScore = 200; + else if (TimeOfUnit.count() * 2 < AverageUnitExecutionTime.count()) + PerfScore = 150; + + Energy *= PerfScore; + } + } + + // Increment the frequency of the feature Idx. + void UpdateFeatureFrequency(uint32_t Idx) { + NeedsEnergyUpdate = true; + + // The local feature frequencies is an ordered vector of pairs. + // If there are no local feature frequencies, push_back preserves order. + // Set the feature frequency for feature Idx32 to 1. + if (FeatureFreqs.empty()) { + FeatureFreqs.push_back(std::pair<uint32_t, uint16_t>(Idx, 1)); + return; + } + + // Binary search over local feature frequencies sorted by index. + auto Lower = std::lower_bound(FeatureFreqs.begin(), FeatureFreqs.end(), + std::pair<uint32_t, uint16_t>(Idx, 0)); + + // If feature Idx32 already exists, increment its frequency. + // Otherwise, insert a new pair right after the next lower index. + if (Lower != FeatureFreqs.end() && Lower->first == Idx) { + Lower->second++; + } else { + FeatureFreqs.insert(Lower, std::pair<uint32_t, uint16_t>(Idx, 1)); + } + } +}; + +struct EntropicOptions { + bool Enabled; + size_t NumberOfRarestFeatures; + size_t FeatureFrequencyThreshold; + bool ScalePerExecTime; +}; + +class InputCorpus { + static const uint32_t kFeatureSetSize = 1 << 21; + static const uint8_t kMaxMutationFactor = 20; + static const size_t kSparseEnergyUpdates = 100; + + size_t NumExecutedMutations = 0; + + EntropicOptions Entropic; + +public: + InputCorpus(const std::string &OutputCorpus, EntropicOptions Entropic) + : Entropic(Entropic), OutputCorpus(OutputCorpus) { + memset(InputSizesPerFeature, 0, sizeof(InputSizesPerFeature)); + memset(SmallestElementPerFeature, 0, sizeof(SmallestElementPerFeature)); + } + ~InputCorpus() { + for (auto II : Inputs) + delete II; + } + size_t size() const { return Inputs.size(); } + size_t SizeInBytes() const { + size_t Res = 0; + for (auto II : Inputs) + Res += II->U.size(); + return Res; + } + size_t NumActiveUnits() const { + size_t Res = 0; + for (auto II : Inputs) + Res += !II->U.empty(); + return Res; + } + size_t MaxInputSize() const { + size_t Res = 0; + for (auto II : Inputs) + Res = std::max(Res, II->U.size()); + return Res; + } + void IncrementNumExecutedMutations() { NumExecutedMutations++; } + + size_t NumInputsThatTouchFocusFunction() { + return std::count_if(Inputs.begin(), Inputs.end(), [](const InputInfo *II) { + return II->HasFocusFunction; + }); + } + + size_t NumInputsWithDataFlowTrace() { + return std::count_if(Inputs.begin(), Inputs.end(), [](const InputInfo *II) { + return !II->DataFlowTraceForFocusFunction.empty(); + }); + } + + bool empty() const { return Inputs.empty(); } + const Unit &operator[] (size_t Idx) const { return Inputs[Idx]->U; } + InputInfo *AddToCorpus(const Unit &U, size_t NumFeatures, bool MayDeleteFile, + bool HasFocusFunction, bool NeverReduce, + std::chrono::microseconds TimeOfUnit, + const Vector<uint32_t> &FeatureSet, + const DataFlowTrace &DFT, const InputInfo *BaseII) { + assert(!U.empty()); + if (FeatureDebug) + Printf("ADD_TO_CORPUS %zd NF %zd\n", Inputs.size(), NumFeatures); + Inputs.push_back(new InputInfo()); + InputInfo &II = *Inputs.back(); + II.U = U; + II.NumFeatures = NumFeatures; + II.NeverReduce = NeverReduce; + II.TimeOfUnit = TimeOfUnit; + II.MayDeleteFile = MayDeleteFile; + II.UniqFeatureSet = FeatureSet; + II.HasFocusFunction = HasFocusFunction; + // Assign maximal energy to the new seed. + II.Energy = RareFeatures.empty() ? 1.0 : log(RareFeatures.size()); + II.SumIncidence = RareFeatures.size(); + II.NeedsEnergyUpdate = false; + std::sort(II.UniqFeatureSet.begin(), II.UniqFeatureSet.end()); + ComputeSHA1(U.data(), U.size(), II.Sha1); + auto Sha1Str = Sha1ToString(II.Sha1); + Hashes.insert(Sha1Str); + if (HasFocusFunction) + if (auto V = DFT.Get(Sha1Str)) + II.DataFlowTraceForFocusFunction = *V; + // This is a gross heuristic. + // Ideally, when we add an element to a corpus we need to know its DFT. + // But if we don't, we'll use the DFT of its base input. + if (II.DataFlowTraceForFocusFunction.empty() && BaseII) + II.DataFlowTraceForFocusFunction = BaseII->DataFlowTraceForFocusFunction; + DistributionNeedsUpdate = true; + PrintCorpus(); + // ValidateFeatureSet(); + return &II; + } + + // Debug-only + void PrintUnit(const Unit &U) { + if (!FeatureDebug) return; + for (uint8_t C : U) { + if (C != 'F' && C != 'U' && C != 'Z') + C = '.'; + Printf("%c", C); + } + } + + // Debug-only + void PrintFeatureSet(const Vector<uint32_t> &FeatureSet) { + if (!FeatureDebug) return; + Printf("{"); + for (uint32_t Feature: FeatureSet) + Printf("%u,", Feature); + Printf("}"); + } + + // Debug-only + void PrintCorpus() { + if (!FeatureDebug) return; + Printf("======= CORPUS:\n"); + int i = 0; + for (auto II : Inputs) { + if (std::find(II->U.begin(), II->U.end(), 'F') != II->U.end()) { + Printf("[%2d] ", i); + Printf("%s sz=%zd ", Sha1ToString(II->Sha1).c_str(), II->U.size()); + PrintUnit(II->U); + Printf(" "); + PrintFeatureSet(II->UniqFeatureSet); + Printf("\n"); + } + i++; + } + } + + void Replace(InputInfo *II, const Unit &U) { + assert(II->U.size() > U.size()); + Hashes.erase(Sha1ToString(II->Sha1)); + DeleteFile(*II); + ComputeSHA1(U.data(), U.size(), II->Sha1); + Hashes.insert(Sha1ToString(II->Sha1)); + II->U = U; + II->Reduced = true; + DistributionNeedsUpdate = true; + } + + bool HasUnit(const Unit &U) { return Hashes.count(Hash(U)); } + bool HasUnit(const std::string &H) { return Hashes.count(H); } + InputInfo &ChooseUnitToMutate(Random &Rand) { + InputInfo &II = *Inputs[ChooseUnitIdxToMutate(Rand)]; + assert(!II.U.empty()); + return II; + } + + InputInfo &ChooseUnitToCrossOverWith(Random &Rand, bool UniformDist) { + if (!UniformDist) { + return ChooseUnitToMutate(Rand); + } + InputInfo &II = *Inputs[Rand(Inputs.size())]; + assert(!II.U.empty()); + return II; + } + + // Returns an index of random unit from the corpus to mutate. + size_t ChooseUnitIdxToMutate(Random &Rand) { + UpdateCorpusDistribution(Rand); + size_t Idx = static_cast<size_t>(CorpusDistribution(Rand)); + assert(Idx < Inputs.size()); + return Idx; + } + + void PrintStats() { + for (size_t i = 0; i < Inputs.size(); i++) { + const auto &II = *Inputs[i]; + Printf(" [% 3zd %s] sz: % 5zd runs: % 5zd succ: % 5zd focus: %d\n", i, + Sha1ToString(II.Sha1).c_str(), II.U.size(), + II.NumExecutedMutations, II.NumSuccessfullMutations, II.HasFocusFunction); + } + } + + void PrintFeatureSet() { + for (size_t i = 0; i < kFeatureSetSize; i++) { + if(size_t Sz = GetFeature(i)) + Printf("[%zd: id %zd sz%zd] ", i, SmallestElementPerFeature[i], Sz); + } + Printf("\n\t"); + for (size_t i = 0; i < Inputs.size(); i++) + if (size_t N = Inputs[i]->NumFeatures) + Printf(" %zd=>%zd ", i, N); + Printf("\n"); + } + + void DeleteFile(const InputInfo &II) { + if (!OutputCorpus.empty() && II.MayDeleteFile) + RemoveFile(DirPlusFile(OutputCorpus, Sha1ToString(II.Sha1))); + } + + void DeleteInput(size_t Idx) { + InputInfo &II = *Inputs[Idx]; + DeleteFile(II); + Unit().swap(II.U); + II.Energy = 0.0; + II.NeedsEnergyUpdate = false; + DistributionNeedsUpdate = true; + if (FeatureDebug) + Printf("EVICTED %zd\n", Idx); + } + + void AddRareFeature(uint32_t Idx) { + // Maintain *at least* TopXRarestFeatures many rare features + // and all features with a frequency below ConsideredRare. + // Remove all other features. + while (RareFeatures.size() > Entropic.NumberOfRarestFeatures && + FreqOfMostAbundantRareFeature > Entropic.FeatureFrequencyThreshold) { + + // Find most and second most abbundant feature. + uint32_t MostAbundantRareFeatureIndices[2] = {RareFeatures[0], + RareFeatures[0]}; + size_t Delete = 0; + for (size_t i = 0; i < RareFeatures.size(); i++) { + uint32_t Idx2 = RareFeatures[i]; + if (GlobalFeatureFreqs[Idx2] >= + GlobalFeatureFreqs[MostAbundantRareFeatureIndices[0]]) { + MostAbundantRareFeatureIndices[1] = MostAbundantRareFeatureIndices[0]; + MostAbundantRareFeatureIndices[0] = Idx2; + Delete = i; + } + } + + // Remove most abundant rare feature. + RareFeatures[Delete] = RareFeatures.back(); + RareFeatures.pop_back(); + + for (auto II : Inputs) { + if (II->DeleteFeatureFreq(MostAbundantRareFeatureIndices[0])) + II->NeedsEnergyUpdate = true; + } + + // Set 2nd most abundant as the new most abundant feature count. + FreqOfMostAbundantRareFeature = + GlobalFeatureFreqs[MostAbundantRareFeatureIndices[1]]; + } + + // Add rare feature, handle collisions, and update energy. + RareFeatures.push_back(Idx); + GlobalFeatureFreqs[Idx] = 0; + for (auto II : Inputs) { + II->DeleteFeatureFreq(Idx); + + // Apply add-one smoothing to this locally undiscovered feature. + // Zero energy seeds will never be fuzzed and remain zero energy. + if (II->Energy > 0.0) { + II->SumIncidence += 1; + II->Energy += logl(II->SumIncidence) / II->SumIncidence; + } + } + + DistributionNeedsUpdate = true; + } + + bool AddFeature(size_t Idx, uint32_t NewSize, bool Shrink) { + assert(NewSize); + Idx = Idx % kFeatureSetSize; + uint32_t OldSize = GetFeature(Idx); + if (OldSize == 0 || (Shrink && OldSize > NewSize)) { + if (OldSize > 0) { + size_t OldIdx = SmallestElementPerFeature[Idx]; + InputInfo &II = *Inputs[OldIdx]; + assert(II.NumFeatures > 0); + II.NumFeatures--; + if (II.NumFeatures == 0) + DeleteInput(OldIdx); + } else { + NumAddedFeatures++; + if (Entropic.Enabled) + AddRareFeature((uint32_t)Idx); + } + NumUpdatedFeatures++; + if (FeatureDebug) + Printf("ADD FEATURE %zd sz %d\n", Idx, NewSize); + SmallestElementPerFeature[Idx] = Inputs.size(); + InputSizesPerFeature[Idx] = NewSize; + return true; + } + return false; + } + + // Increment frequency of feature Idx globally and locally. + void UpdateFeatureFrequency(InputInfo *II, size_t Idx) { + uint32_t Idx32 = Idx % kFeatureSetSize; + + // Saturated increment. + if (GlobalFeatureFreqs[Idx32] == 0xFFFF) + return; + uint16_t Freq = GlobalFeatureFreqs[Idx32]++; + + // Skip if abundant. + if (Freq > FreqOfMostAbundantRareFeature || + std::find(RareFeatures.begin(), RareFeatures.end(), Idx32) == + RareFeatures.end()) + return; + + // Update global frequencies. + if (Freq == FreqOfMostAbundantRareFeature) + FreqOfMostAbundantRareFeature++; + + // Update local frequencies. + if (II) + II->UpdateFeatureFrequency(Idx32); + } + + size_t NumFeatures() const { return NumAddedFeatures; } + size_t NumFeatureUpdates() const { return NumUpdatedFeatures; } + +private: + + static const bool FeatureDebug = false; + + size_t GetFeature(size_t Idx) const { return InputSizesPerFeature[Idx]; } + + void ValidateFeatureSet() { + if (FeatureDebug) + PrintFeatureSet(); + for (size_t Idx = 0; Idx < kFeatureSetSize; Idx++) + if (GetFeature(Idx)) + Inputs[SmallestElementPerFeature[Idx]]->Tmp++; + for (auto II: Inputs) { + if (II->Tmp != II->NumFeatures) + Printf("ZZZ %zd %zd\n", II->Tmp, II->NumFeatures); + assert(II->Tmp == II->NumFeatures); + II->Tmp = 0; + } + } + + // Updates the probability distribution for the units in the corpus. + // Must be called whenever the corpus or unit weights are changed. + // + // Hypothesis: inputs that maximize information about globally rare features + // are interesting. + void UpdateCorpusDistribution(Random &Rand) { + // Skip update if no seeds or rare features were added/deleted. + // Sparse updates for local change of feature frequencies, + // i.e., randomly do not skip. + if (!DistributionNeedsUpdate && + (!Entropic.Enabled || Rand(kSparseEnergyUpdates))) + return; + + DistributionNeedsUpdate = false; + + size_t N = Inputs.size(); + assert(N); + Intervals.resize(N + 1); + Weights.resize(N); + std::iota(Intervals.begin(), Intervals.end(), 0); + + std::chrono::microseconds AverageUnitExecutionTime(0); + for (auto II : Inputs) { + AverageUnitExecutionTime += II->TimeOfUnit; + } + AverageUnitExecutionTime /= N; + + bool VanillaSchedule = true; + if (Entropic.Enabled) { + for (auto II : Inputs) { + if (II->NeedsEnergyUpdate && II->Energy != 0.0) { + II->NeedsEnergyUpdate = false; + II->UpdateEnergy(RareFeatures.size(), Entropic.ScalePerExecTime, + AverageUnitExecutionTime); + } + } + + for (size_t i = 0; i < N; i++) { + + if (Inputs[i]->NumFeatures == 0) { + // If the seed doesn't represent any features, assign zero energy. + Weights[i] = 0.; + } else if (Inputs[i]->NumExecutedMutations / kMaxMutationFactor > + NumExecutedMutations / Inputs.size()) { + // If the seed was fuzzed a lot more than average, assign zero energy. + Weights[i] = 0.; + } else { + // Otherwise, simply assign the computed energy. + Weights[i] = Inputs[i]->Energy; + } + + // If energy for all seeds is zero, fall back to vanilla schedule. + if (Weights[i] > 0.0) + VanillaSchedule = false; + } + } + + if (VanillaSchedule) { + for (size_t i = 0; i < N; i++) + Weights[i] = Inputs[i]->NumFeatures + ? (i + 1) * (Inputs[i]->HasFocusFunction ? 1000 : 1) + : 0.; + } + + if (FeatureDebug) { + for (size_t i = 0; i < N; i++) + Printf("%zd ", Inputs[i]->NumFeatures); + Printf("SCORE\n"); + for (size_t i = 0; i < N; i++) + Printf("%f ", Weights[i]); + Printf("Weights\n"); + } + CorpusDistribution = std::piecewise_constant_distribution<double>( + Intervals.begin(), Intervals.end(), Weights.begin()); + } + std::piecewise_constant_distribution<double> CorpusDistribution; + + Vector<double> Intervals; + Vector<double> Weights; + + std::unordered_set<std::string> Hashes; + Vector<InputInfo*> Inputs; + + size_t NumAddedFeatures = 0; + size_t NumUpdatedFeatures = 0; + uint32_t InputSizesPerFeature[kFeatureSetSize]; + uint32_t SmallestElementPerFeature[kFeatureSetSize]; + + bool DistributionNeedsUpdate = true; + uint16_t FreqOfMostAbundantRareFeature = 0; + uint16_t GlobalFeatureFreqs[kFeatureSetSize] = {}; + Vector<uint32_t> RareFeatures; + + std::string OutputCorpus; +}; + +} // namespace fuzzer + +#endif // LLVM_FUZZER_CORPUS diff --git a/custom_mutators/libfuzzer/FuzzerCrossOver.cpp b/custom_mutators/libfuzzer/FuzzerCrossOver.cpp new file mode 100644 index 00000000..3b3fd94a --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerCrossOver.cpp @@ -0,0 +1,60 @@ +//===- FuzzerCrossOver.cpp - Cross over two test inputs -------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Cross over test inputs. +//===----------------------------------------------------------------------===// + +#include "FuzzerDefs.h" +#include "FuzzerMutate.h" +#include "FuzzerRandom.h" +#include <cstring> + +namespace fuzzer { + +// Cross Data1 and Data2, store the result (up to MaxOutSize bytes) in Out. +size_t MutationDispatcher::CrossOver(const uint8_t *Data1, size_t Size1, + const uint8_t *Data2, size_t Size2, + uint8_t *Out, size_t MaxOutSize) { + + assert(Size1 || Size2); + MaxOutSize = Rand(MaxOutSize) + 1; + size_t OutPos = 0; + size_t Pos1 = 0; + size_t Pos2 = 0; + size_t * InPos = &Pos1; + size_t InSize = Size1; + const uint8_t *Data = Data1; + bool CurrentlyUsingFirstData = true; + while (OutPos < MaxOutSize && (Pos1 < Size1 || Pos2 < Size2)) { + + // Merge a part of Data into Out. + size_t OutSizeLeft = MaxOutSize - OutPos; + if (*InPos < InSize) { + + size_t InSizeLeft = InSize - *InPos; + size_t MaxExtraSize = std::min(OutSizeLeft, InSizeLeft); + size_t ExtraSize = Rand(MaxExtraSize) + 1; + memcpy(Out + OutPos, Data + *InPos, ExtraSize); + OutPos += ExtraSize; + (*InPos) += ExtraSize; + + } + + // Use the other input data on the next iteration. + InPos = CurrentlyUsingFirstData ? &Pos2 : &Pos1; + InSize = CurrentlyUsingFirstData ? Size2 : Size1; + Data = CurrentlyUsingFirstData ? Data2 : Data1; + CurrentlyUsingFirstData = !CurrentlyUsingFirstData; + + } + + return OutPos; + +} + +} // namespace fuzzer + diff --git a/custom_mutators/libfuzzer/FuzzerDataFlowTrace.cpp b/custom_mutators/libfuzzer/FuzzerDataFlowTrace.cpp new file mode 100644 index 00000000..489665f7 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerDataFlowTrace.cpp @@ -0,0 +1,344 @@ +//===- FuzzerDataFlowTrace.cpp - DataFlowTrace ---*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// fuzzer::DataFlowTrace +//===----------------------------------------------------------------------===// + +#include "FuzzerDataFlowTrace.h" + +#include "FuzzerCommand.h" +#include "FuzzerIO.h" +#include "FuzzerRandom.h" +#include "FuzzerSHA1.h" +#include "FuzzerUtil.h" + +#include <cstdlib> +#include <fstream> +#include <numeric> +#include <queue> +#include <sstream> +#include <string> +#include <unordered_map> +#include <unordered_set> +#include <vector> + +namespace fuzzer { + +static const char *kFunctionsTxt = "functions.txt"; + +bool BlockCoverage::AppendCoverage(const std::string &S) { + + std::stringstream SS(S); + return AppendCoverage(SS); + +} + +// Coverage lines have this form: +// CN X Y Z T +// where N is the number of the function, T is the total number of instrumented +// BBs, and X,Y,Z, if present, are the indecies of covered BB. +// BB #0, which is the entry block, is not explicitly listed. +bool BlockCoverage::AppendCoverage(std::istream &IN) { + + std::string L; + while (std::getline(IN, L, '\n')) { + + if (L.empty()) continue; + std::stringstream SS(L.c_str() + 1); + size_t FunctionId = 0; + SS >> FunctionId; + if (L[0] == 'F') { + + FunctionsWithDFT.insert(FunctionId); + continue; + + } + + if (L[0] != 'C') continue; + Vector<uint32_t> CoveredBlocks; + while (true) { + + uint32_t BB = 0; + SS >> BB; + if (!SS) break; + CoveredBlocks.push_back(BB); + + } + + if (CoveredBlocks.empty()) return false; + uint32_t NumBlocks = CoveredBlocks.back(); + CoveredBlocks.pop_back(); + for (auto BB : CoveredBlocks) + if (BB >= NumBlocks) return false; + auto It = Functions.find(FunctionId); + auto &Counters = + It == Functions.end() + ? Functions.insert({FunctionId, Vector<uint32_t>(NumBlocks)}) + .first->second + : It->second; + + if (Counters.size() != NumBlocks) return false; // wrong number of blocks. + + Counters[0]++; + for (auto BB : CoveredBlocks) + Counters[BB]++; + + } + + return true; + +} + +// Assign weights to each function. +// General principles: +// * any uncovered function gets weight 0. +// * a function with lots of uncovered blocks gets bigger weight. +// * a function with a less frequently executed code gets bigger weight. +Vector<double> BlockCoverage::FunctionWeights(size_t NumFunctions) const { + + Vector<double> Res(NumFunctions); + for (auto It : Functions) { + + auto FunctionID = It.first; + auto Counters = It.second; + assert(FunctionID < NumFunctions); + auto &Weight = Res[FunctionID]; + // Give higher weight if the function has a DFT. + Weight = FunctionsWithDFT.count(FunctionID) ? 1000. : 1; + // Give higher weight to functions with less frequently seen basic blocks. + Weight /= SmallestNonZeroCounter(Counters); + // Give higher weight to functions with the most uncovered basic blocks. + Weight *= NumberOfUncoveredBlocks(Counters) + 1; + + } + + return Res; + +} + +void DataFlowTrace::ReadCoverage(const std::string &DirPath) { + + Vector<SizedFile> Files; + GetSizedFilesFromDir(DirPath, &Files); + for (auto &SF : Files) { + + auto Name = Basename(SF.File); + if (Name == kFunctionsTxt) continue; + if (!CorporaHashes.count(Name)) continue; + std::ifstream IF(SF.File); + Coverage.AppendCoverage(IF); + + } + +} + +static void DFTStringAppendToVector(Vector<uint8_t> * DFT, + const std::string &DFTString) { + + assert(DFT->size() == DFTString.size()); + for (size_t I = 0, Len = DFT->size(); I < Len; I++) + (*DFT)[I] = DFTString[I] == '1'; + +} + +// converts a string of '0' and '1' into a Vector<uint8_t> +static Vector<uint8_t> DFTStringToVector(const std::string &DFTString) { + + Vector<uint8_t> DFT(DFTString.size()); + DFTStringAppendToVector(&DFT, DFTString); + return DFT; + +} + +static bool ParseError(const char *Err, const std::string &Line) { + + Printf("DataFlowTrace: parse error: %s: Line: %s\n", Err, Line.c_str()); + return false; + +} + +// TODO(metzman): replace std::string with std::string_view for +// better performance. Need to figure our how to use string_view on Windows. +static bool ParseDFTLine(const std::string &Line, size_t *FunctionNum, + std::string *DFTString) { + + if (!Line.empty() && Line[0] != 'F') return false; // Ignore coverage. + size_t SpacePos = Line.find(' '); + if (SpacePos == std::string::npos) + return ParseError("no space in the trace line", Line); + if (Line.empty() || Line[0] != 'F') + return ParseError("the trace line doesn't start with 'F'", Line); + *FunctionNum = std::atol(Line.c_str() + 1); + const char *Beg = Line.c_str() + SpacePos + 1; + const char *End = Line.c_str() + Line.size(); + assert(Beg < End); + size_t Len = End - Beg; + for (size_t I = 0; I < Len; I++) { + + if (Beg[I] != '0' && Beg[I] != '1') + return ParseError("the trace should contain only 0 or 1", Line); + + } + + *DFTString = Beg; + return true; + +} + +bool DataFlowTrace::Init(const std::string &DirPath, std::string *FocusFunction, + Vector<SizedFile> &CorporaFiles, Random &Rand) { + + if (DirPath.empty()) return false; + Printf("INFO: DataFlowTrace: reading from '%s'\n", DirPath.c_str()); + Vector<SizedFile> Files; + GetSizedFilesFromDir(DirPath, &Files); + std::string L; + size_t FocusFuncIdx = SIZE_MAX; + Vector<std::string> FunctionNames; + + // Collect the hashes of the corpus files. + for (auto &SF : CorporaFiles) + CorporaHashes.insert(Hash(FileToVector(SF.File))); + + // Read functions.txt + std::ifstream IF(DirPlusFile(DirPath, kFunctionsTxt)); + size_t NumFunctions = 0; + while (std::getline(IF, L, '\n')) { + + FunctionNames.push_back(L); + NumFunctions++; + if (*FocusFunction == L) FocusFuncIdx = NumFunctions - 1; + + } + + if (!NumFunctions) return false; + + if (*FocusFunction == "auto") { + + // AUTOFOCUS works like this: + // * reads the coverage data from the DFT files. + // * assigns weights to functions based on coverage. + // * chooses a random function according to the weights. + ReadCoverage(DirPath); + auto Weights = Coverage.FunctionWeights(NumFunctions); + Vector<double> Intervals(NumFunctions + 1); + std::iota(Intervals.begin(), Intervals.end(), 0); + auto Distribution = std::piecewise_constant_distribution<double>( + Intervals.begin(), Intervals.end(), Weights.begin()); + FocusFuncIdx = static_cast<size_t>(Distribution(Rand)); + *FocusFunction = FunctionNames[FocusFuncIdx]; + assert(FocusFuncIdx < NumFunctions); + Printf("INFO: AUTOFOCUS: %zd %s\n", FocusFuncIdx, + FunctionNames[FocusFuncIdx].c_str()); + for (size_t i = 0; i < NumFunctions; i++) { + + if (!Weights[i]) continue; + Printf(" [%zd] W %g\tBB-tot %u\tBB-cov %u\tEntryFreq %u:\t%s\n", i, + Weights[i], Coverage.GetNumberOfBlocks(i), + Coverage.GetNumberOfCoveredBlocks(i), Coverage.GetCounter(i, 0), + FunctionNames[i].c_str()); + + } + + } + + if (FocusFuncIdx == SIZE_MAX || Files.size() <= 1) + return false; + + // Read traces. + size_t NumTraceFiles = 0; + size_t NumTracesWithFocusFunction = 0; + for (auto &SF : Files) { + + auto Name = Basename(SF.File); + if (Name == kFunctionsTxt) continue; + if (!CorporaHashes.count(Name)) continue; // not in the corpus. + NumTraceFiles++; + // Printf("=== %s\n", Name.c_str()); + std::ifstream IF2(SF.File); + while (std::getline(IF2, L, '\n')) { + + size_t FunctionNum = 0; + std::string DFTString; + if (ParseDFTLine(L, &FunctionNum, &DFTString) && + FunctionNum == FocusFuncIdx) { + + NumTracesWithFocusFunction++; + + if (FunctionNum >= NumFunctions) + return ParseError("N is greater than the number of functions", L); + Traces[Name] = DFTStringToVector(DFTString); + // Print just a few small traces. + if (NumTracesWithFocusFunction <= 3 && DFTString.size() <= 16) + Printf("%s => |%s|\n", Name.c_str(), std::string(DFTString).c_str()); + break; // No need to parse the following lines. + + } + + } + + } + + Printf( + "INFO: DataFlowTrace: %zd trace files, %zd functions, " + "%zd traces with focus function\n", + NumTraceFiles, NumFunctions, NumTracesWithFocusFunction); + return NumTraceFiles > 0; + +} + +int CollectDataFlow(const std::string &DFTBinary, const std::string &DirPath, + const Vector<SizedFile> &CorporaFiles) { + + Printf("INFO: collecting data flow: bin: %s dir: %s files: %zd\n", + DFTBinary.c_str(), DirPath.c_str(), CorporaFiles.size()); + if (CorporaFiles.empty()) { + + Printf("ERROR: can't collect data flow without corpus provided."); + return 1; + + } + + static char DFSanEnv[] = "DFSAN_OPTIONS=warn_unimplemented=0"; + putenv(DFSanEnv); + MkDir(DirPath); + for (auto &F : CorporaFiles) { + + // For every input F we need to collect the data flow and the coverage. + // Data flow collection may fail if we request too many DFSan tags at once. + // So, we start from requesting all tags in range [0,Size) and if that fails + // we then request tags in [0,Size/2) and [Size/2, Size), and so on. + // Function number => DFT. + auto OutPath = DirPlusFile(DirPath, Hash(FileToVector(F.File))); +// std::unordered_map<size_t, Vector<uint8_t>> DFTMap; +// std::unordered_set<std::string> Cov; + Command Cmd; + Cmd.addArgument(DFTBinary); + Cmd.addArgument(F.File); + Cmd.addArgument(OutPath); + Printf("CMD: %s\n", Cmd.toString().c_str()); + ExecuteCommand(Cmd); + + } + + // Write functions.txt if it's currently empty or doesn't exist. + auto FunctionsTxtPath = DirPlusFile(DirPath, kFunctionsTxt); + if (FileToString(FunctionsTxtPath).empty()) { + + Command Cmd; + Cmd.addArgument(DFTBinary); + Cmd.setOutputFile(FunctionsTxtPath); + ExecuteCommand(Cmd); + + } + + return 0; + +} + +} // namespace fuzzer + diff --git a/custom_mutators/libfuzzer/FuzzerDataFlowTrace.h b/custom_mutators/libfuzzer/FuzzerDataFlowTrace.h new file mode 100644 index 00000000..d6e3de30 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerDataFlowTrace.h @@ -0,0 +1,135 @@ +//===- FuzzerDataFlowTrace.h - Internal header for the Fuzzer ---*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// fuzzer::DataFlowTrace; reads and handles a data-flow trace. +// +// A data flow trace is generated by e.g. dataflow/DataFlow.cpp +// and is stored on disk in a separate directory. +// +// The trace dir contains a file 'functions.txt' which lists function names, +// oner per line, e.g. +// ==> functions.txt <== +// Func2 +// LLVMFuzzerTestOneInput +// Func1 +// +// All other files in the dir are the traces, see dataflow/DataFlow.cpp. +// The name of the file is sha1 of the input used to generate the trace. +// +// Current status: +// the data is parsed and the summary is printed, but the data is not yet +// used in any other way. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_DATA_FLOW_TRACE +#define LLVM_FUZZER_DATA_FLOW_TRACE + +#include "FuzzerDefs.h" +#include "FuzzerIO.h" + +#include <unordered_map> +#include <unordered_set> +#include <vector> +#include <string> + +namespace fuzzer { + +int CollectDataFlow(const std::string &DFTBinary, const std::string &DirPath, + const Vector<SizedFile> &CorporaFiles); + +class BlockCoverage { + public: + bool AppendCoverage(std::istream &IN); + bool AppendCoverage(const std::string &S); + + size_t NumCoveredFunctions() const { return Functions.size(); } + + uint32_t GetCounter(size_t FunctionId, size_t BasicBlockId) { + auto It = Functions.find(FunctionId); + if (It == Functions.end()) return 0; + const auto &Counters = It->second; + if (BasicBlockId < Counters.size()) + return Counters[BasicBlockId]; + return 0; + } + + uint32_t GetNumberOfBlocks(size_t FunctionId) { + auto It = Functions.find(FunctionId); + if (It == Functions.end()) return 0; + const auto &Counters = It->second; + return Counters.size(); + } + + uint32_t GetNumberOfCoveredBlocks(size_t FunctionId) { + auto It = Functions.find(FunctionId); + if (It == Functions.end()) return 0; + const auto &Counters = It->second; + uint32_t Result = 0; + for (auto Cnt: Counters) + if (Cnt) + Result++; + return Result; + } + + Vector<double> FunctionWeights(size_t NumFunctions) const; + void clear() { Functions.clear(); } + + private: + + typedef Vector<uint32_t> CoverageVector; + + uint32_t NumberOfCoveredBlocks(const CoverageVector &Counters) const { + uint32_t Res = 0; + for (auto Cnt : Counters) + if (Cnt) + Res++; + return Res; + } + + uint32_t NumberOfUncoveredBlocks(const CoverageVector &Counters) const { + return Counters.size() - NumberOfCoveredBlocks(Counters); + } + + uint32_t SmallestNonZeroCounter(const CoverageVector &Counters) const { + assert(!Counters.empty()); + uint32_t Res = Counters[0]; + for (auto Cnt : Counters) + if (Cnt) + Res = Min(Res, Cnt); + assert(Res); + return Res; + } + + // Function ID => vector of counters. + // Each counter represents how many input files trigger the given basic block. + std::unordered_map<size_t, CoverageVector> Functions; + // Functions that have DFT entry. + std::unordered_set<size_t> FunctionsWithDFT; +}; + +class DataFlowTrace { + public: + void ReadCoverage(const std::string &DirPath); + bool Init(const std::string &DirPath, std::string *FocusFunction, + Vector<SizedFile> &CorporaFiles, Random &Rand); + void Clear() { Traces.clear(); } + const Vector<uint8_t> *Get(const std::string &InputSha1) const { + auto It = Traces.find(InputSha1); + if (It != Traces.end()) + return &It->second; + return nullptr; + } + + private: + // Input's sha1 => DFT for the FocusFunction. + std::unordered_map<std::string, Vector<uint8_t> > Traces; + BlockCoverage Coverage; + std::unordered_set<std::string> CorporaHashes; +}; +} // namespace fuzzer + +#endif // LLVM_FUZZER_DATA_FLOW_TRACE diff --git a/custom_mutators/libfuzzer/FuzzerDefs.h b/custom_mutators/libfuzzer/FuzzerDefs.h new file mode 100644 index 00000000..3952ac51 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerDefs.h @@ -0,0 +1,75 @@ +//===- FuzzerDefs.h - Internal header for the Fuzzer ------------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Basic definitions. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_DEFS_H +#define LLVM_FUZZER_DEFS_H + +#include <cassert> +#include <cstddef> +#include <cstdint> +#include <cstring> +#include <memory> +#include <set> +#include <string> +#include <vector> + + +namespace fuzzer { + +template <class T> T Min(T a, T b) { return a < b ? a : b; } +template <class T> T Max(T a, T b) { return a > b ? a : b; } + +class Random; +class Dictionary; +class DictionaryEntry; +class MutationDispatcher; +struct FuzzingOptions; +class InputCorpus; +struct InputInfo; +struct ExternalFunctions; + +// Global interface to functions that may or may not be available. +extern ExternalFunctions *EF; + +// We are using a custom allocator to give a different symbol name to STL +// containers in order to avoid ODR violations. +template<typename T> + class fuzzer_allocator: public std::allocator<T> { + public: + fuzzer_allocator() = default; + + template<class U> + explicit fuzzer_allocator(const fuzzer_allocator<U>&) {} + + template<class Other> + struct rebind { typedef fuzzer_allocator<Other> other; }; + }; + +template<typename T> +using Vector = std::vector<T, fuzzer_allocator<T>>; + +template<typename T> +using Set = std::set<T, std::less<T>, fuzzer_allocator<T>>; + +typedef Vector<uint8_t> Unit; +typedef Vector<Unit> UnitVector; +typedef int (*UserCallback)(const uint8_t *Data, size_t Size); + +int FuzzerDriver(int *argc, char ***argv, UserCallback Callback); + +uint8_t *ExtraCountersBegin(); +uint8_t *ExtraCountersEnd(); +void ClearExtraCounters(); + +extern bool RunningUserCallback; + +} // namespace fuzzer + +#endif // LLVM_FUZZER_DEFS_H diff --git a/custom_mutators/libfuzzer/FuzzerDictionary.h b/custom_mutators/libfuzzer/FuzzerDictionary.h new file mode 100644 index 00000000..ddd2d2f1 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerDictionary.h @@ -0,0 +1,118 @@ +//===- FuzzerDictionary.h - Internal header for the Fuzzer ------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// fuzzer::Dictionary +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_DICTIONARY_H +#define LLVM_FUZZER_DICTIONARY_H + +#include "FuzzerDefs.h" +#include "FuzzerIO.h" +#include "FuzzerUtil.h" +#include <algorithm> +#include <limits> + +namespace fuzzer { +// A simple POD sized array of bytes. +template <size_t kMaxSizeT> class FixedWord { +public: + static const size_t kMaxSize = kMaxSizeT; + FixedWord() {} + FixedWord(const uint8_t *B, uint8_t S) { Set(B, S); } + + void Set(const uint8_t *B, uint8_t S) { + assert(S <= kMaxSize); + memcpy(Data, B, S); + Size = S; + } + + bool operator==(const FixedWord<kMaxSize> &w) const { + return Size == w.Size && 0 == memcmp(Data, w.Data, Size); + } + + static size_t GetMaxSize() { return kMaxSize; } + const uint8_t *data() const { return Data; } + uint8_t size() const { return Size; } + +private: + uint8_t Size = 0; + uint8_t Data[kMaxSize]; +}; + +typedef FixedWord<64> Word; + +class DictionaryEntry { + public: + DictionaryEntry() {} + explicit DictionaryEntry(Word W) : W(W) {} + DictionaryEntry(Word W, size_t PositionHint) : W(W), PositionHint(PositionHint) {} + const Word &GetW() const { return W; } + + bool HasPositionHint() const { return PositionHint != std::numeric_limits<size_t>::max(); } + size_t GetPositionHint() const { + assert(HasPositionHint()); + return PositionHint; + } + void IncUseCount() { UseCount++; } + void IncSuccessCount() { SuccessCount++; } + size_t GetUseCount() const { return UseCount; } + size_t GetSuccessCount() const {return SuccessCount; } + + void Print(const char *PrintAfter = "\n") { + PrintASCII(W.data(), W.size()); + if (HasPositionHint()) + Printf("@%zd", GetPositionHint()); + Printf("%s", PrintAfter); + } + +private: + Word W; + size_t PositionHint = std::numeric_limits<size_t>::max(); + size_t UseCount = 0; + size_t SuccessCount = 0; +}; + +class Dictionary { + public: + static const size_t kMaxDictSize = 1 << 14; + + bool ContainsWord(const Word &W) const { + return std::any_of(begin(), end(), [&](const DictionaryEntry &DE) { + return DE.GetW() == W; + }); + } + const DictionaryEntry *begin() const { return &DE[0]; } + const DictionaryEntry *end() const { return begin() + Size; } + DictionaryEntry & operator[] (size_t Idx) { + assert(Idx < Size); + return DE[Idx]; + } + void push_back(const DictionaryEntry &DE) { + if (Size < kMaxDictSize) + this->DE[Size++] = DE; + } + void clear() { Size = 0; } + bool empty() const { return Size == 0; } + size_t size() const { return Size; } + +private: + DictionaryEntry DE[kMaxDictSize]; + size_t Size = 0; +}; + +// Parses one dictionary entry. +// If successful, write the enty to Unit and returns true, +// otherwise returns false. +bool ParseOneDictionaryEntry(const std::string &Str, Unit *U); +// Parses the dictionary file, fills Units, returns true iff all lines +// were parsed successfully. +bool ParseDictionaryFile(const std::string &Text, Vector<Unit> *Units); + +} // namespace fuzzer + +#endif // LLVM_FUZZER_DICTIONARY_H diff --git a/custom_mutators/libfuzzer/FuzzerDriver.cpp b/custom_mutators/libfuzzer/FuzzerDriver.cpp new file mode 100644 index 00000000..c79278bd --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerDriver.cpp @@ -0,0 +1,1111 @@ +//===- FuzzerDriver.cpp - FuzzerDriver function and flags -----------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// FuzzerDriver and flag parsing. +//===----------------------------------------------------------------------===// + +#include "FuzzerCommand.h" +#include "FuzzerCorpus.h" +#include "FuzzerFork.h" +#include "FuzzerIO.h" +#include "FuzzerInterface.h" +#include "FuzzerInternal.h" +#include "FuzzerMerge.h" +#include "FuzzerMutate.h" +#include "FuzzerPlatform.h" +#include "FuzzerRandom.h" +#include "FuzzerTracePC.h" +#include <algorithm> +#include <atomic> +#include <chrono> +#include <cstdlib> +#include <cstring> +#include <mutex> +#include <string> +#include <thread> +#include <fstream> + +// This function should be present in the libFuzzer so that the client +// binary can test for its existence. +#if LIBFUZZER_MSVC +extern "C" void __libfuzzer_is_present() { + +} + + #if defined(_M_IX86) || defined(__i386__) + #pragma comment(linker, "/include:___libfuzzer_is_present") + #else + #pragma comment(linker, "/include:__libfuzzer_is_present") + #endif +#else +extern "C" __attribute__((used)) void __libfuzzer_is_present() { + +} + +#endif // LIBFUZZER_MSVC + +namespace fuzzer { + +// Program arguments. +struct FlagDescription { + + const char * Name; + const char * Description; + int Default; + int * IntFlag; + const char ** StrFlag; + unsigned int *UIntFlag; + +}; + +struct { +\ +#define FUZZER_DEPRECATED_FLAG(Name) +#define FUZZER_FLAG_INT(Name, Default, Description) int Name; +#define FUZZER_FLAG_UNSIGNED(Name, Default, Description) unsigned int Name; +#define FUZZER_FLAG_STRING(Name, Description) const char *Name; +#include "FuzzerFlags.def" +#undef FUZZER_DEPRECATED_FLAG +#undef FUZZER_FLAG_INT +#undef FUZZER_FLAG_UNSIGNED +#undef FUZZER_FLAG_STRING + +} Flags; + +static const FlagDescription FlagDescriptions[]{ +\ +#define FUZZER_DEPRECATED_FLAG(Name) \ + {#Name, "Deprecated; don't use", 0, nullptr, nullptr, nullptr}, +#define FUZZER_FLAG_INT(Name, Default, Description) \ + {#Name, Description, Default, &Flags.Name, nullptr, nullptr}, +#define FUZZER_FLAG_UNSIGNED(Name, Default, Description) \ + {#Name, Description, static_cast<int>(Default), \ + nullptr, nullptr, &Flags.Name}, +#define FUZZER_FLAG_STRING(Name, Description) \ + {#Name, Description, 0, nullptr, &Flags.Name, nullptr}, +#include "FuzzerFlags.def" +#undef FUZZER_DEPRECATED_FLAG +#undef FUZZER_FLAG_INT +#undef FUZZER_FLAG_UNSIGNED +#undef FUZZER_FLAG_STRING + +}; + +static const size_t kNumFlags = + sizeof(FlagDescriptions) / sizeof(FlagDescriptions[0]); + +static Vector<std::string> *Inputs; +static std::string * ProgName; + +static void PrintHelp() { + + Printf("Usage:\n"); + auto Prog = ProgName->c_str(); + Printf("\nTo run fuzzing pass 0 or more directories.\n"); + Printf("%s [-flag1=val1 [-flag2=val2 ...] ] [dir1 [dir2 ...] ]\n", Prog); + + Printf("\nTo run individual tests without fuzzing pass 1 or more files:\n"); + Printf("%s [-flag1=val1 [-flag2=val2 ...] ] file1 [file2 ...]\n", Prog); + + Printf("\nFlags: (strictly in form -flag=value)\n"); + size_t MaxFlagLen = 0; + for (size_t F = 0; F < kNumFlags; F++) + MaxFlagLen = std::max(strlen(FlagDescriptions[F].Name), MaxFlagLen); + + for (size_t F = 0; F < kNumFlags; F++) { + + const auto &D = FlagDescriptions[F]; + if (strstr(D.Description, "internal flag") == D.Description) continue; + Printf(" %s", D.Name); + for (size_t i = 0, n = MaxFlagLen - strlen(D.Name); i < n; i++) + Printf(" "); + Printf("\t"); + Printf("%d\t%s\n", D.Default, D.Description); + + } + + Printf( + "\nFlags starting with '--' will be ignored and " + "will be passed verbatim to subprocesses.\n"); + +} + +static const char *FlagValue(const char *Param, const char *Name) { + + size_t Len = strlen(Name); + if (Param[0] == '-' && strstr(Param + 1, Name) == Param + 1 && + Param[Len + 1] == '=') + return &Param[Len + 2]; + return nullptr; + +} + +// Avoid calling stol as it triggers a bug in clang/glibc build. +static long MyStol(const char *Str) { + + long Res = 0; + long Sign = 1; + if (*Str == '-') { + + Str++; + Sign = -1; + + } + + for (size_t i = 0; Str[i]; i++) { + + char Ch = Str[i]; + if (Ch < '0' || Ch > '9') return Res; + Res = Res * 10 + (Ch - '0'); + + } + + return Res * Sign; + +} + +static bool ParseOneFlag(const char *Param) { + + if (Param[0] != '-') return false; + if (Param[1] == '-') { + + static bool PrintedWarning = false; + if (!PrintedWarning) { + + PrintedWarning = true; + Printf("INFO: libFuzzer ignores flags that start with '--'\n"); + + } + + for (size_t F = 0; F < kNumFlags; F++) + if (FlagValue(Param + 1, FlagDescriptions[F].Name)) + Printf("WARNING: did you mean '%s' (single dash)?\n", Param + 1); + return true; + + } + + for (size_t F = 0; F < kNumFlags; F++) { + + const char *Name = FlagDescriptions[F].Name; + const char *Str = FlagValue(Param, Name); + if (Str) { + + if (FlagDescriptions[F].IntFlag) { + + int Val = MyStol(Str); + *FlagDescriptions[F].IntFlag = Val; + if (Flags.verbosity >= 2) Printf("Flag: %s %d\n", Name, Val); + return true; + + } else if (FlagDescriptions[F].UIntFlag) { + + unsigned int Val = std::stoul(Str); + *FlagDescriptions[F].UIntFlag = Val; + if (Flags.verbosity >= 2) Printf("Flag: %s %u\n", Name, Val); + return true; + + } else if (FlagDescriptions[F].StrFlag) { + + *FlagDescriptions[F].StrFlag = Str; + if (Flags.verbosity >= 2) Printf("Flag: %s %s\n", Name, Str); + return true; + + } else { // Deprecated flag. + + Printf("Flag: %s: deprecated, don't use\n", Name); + return true; + + } + + } + + } + + Printf( + "\n\nWARNING: unrecognized flag '%s'; " + "use -help=1 to list all flags\n\n", + Param); + return true; + +} + +// We don't use any library to minimize dependencies. +static void ParseFlags(const Vector<std::string> &Args, + const ExternalFunctions * EF) { + + for (size_t F = 0; F < kNumFlags; F++) { + + if (FlagDescriptions[F].IntFlag) + *FlagDescriptions[F].IntFlag = FlagDescriptions[F].Default; + if (FlagDescriptions[F].UIntFlag) + *FlagDescriptions[F].UIntFlag = + static_cast<unsigned int>(FlagDescriptions[F].Default); + if (FlagDescriptions[F].StrFlag) *FlagDescriptions[F].StrFlag = nullptr; + + } + + // Disable len_control by default, if LLVMFuzzerCustomMutator is used. + if (EF->LLVMFuzzerCustomMutator) { + + Flags.len_control = 0; + Printf( + "INFO: found LLVMFuzzerCustomMutator (%p). " + "Disabling -len_control by default.\n", + EF->LLVMFuzzerCustomMutator); + + } + + Inputs = new Vector<std::string>; + for (size_t A = 1; A < Args.size(); A++) { + + if (ParseOneFlag(Args[A].c_str())) { + + if (Flags.ignore_remaining_args) break; + continue; + + } + + Inputs->push_back(Args[A]); + + } + +} + +static std::mutex Mu; + +static void PulseThread() { + + while (true) { + + SleepSeconds(600); + std::lock_guard<std::mutex> Lock(Mu); + Printf("pulse...\n"); + + } + +} + +static void WorkerThread(const Command &BaseCmd, std::atomic<unsigned> *Counter, + unsigned NumJobs, std::atomic<bool> *HasErrors) { + + while (true) { + + unsigned C = (*Counter)++; + if (C >= NumJobs) break; + std::string Log = "fuzz-" + std::to_string(C) + ".log"; + Command Cmd(BaseCmd); + Cmd.setOutputFile(Log); + Cmd.combineOutAndErr(); + if (Flags.verbosity) { + + std::string CommandLine = Cmd.toString(); + Printf("%s\n", CommandLine.c_str()); + + } + + int ExitCode = ExecuteCommand(Cmd); + if (ExitCode != 0) *HasErrors = true; + std::lock_guard<std::mutex> Lock(Mu); + Printf("================== Job %u exited with exit code %d ============\n", + C, ExitCode); + fuzzer::CopyFileToErr(Log); + + } + +} + +static void ValidateDirectoryExists(const std::string &Path, + bool CreateDirectory) { + + if (Path.empty()) { + + Printf("ERROR: Provided directory path is an empty string\n"); + exit(1); + + } + + if (IsDirectory(Path)) return; + + if (CreateDirectory) { + + if (!MkDirRecursive(Path)) { + + Printf("ERROR: Failed to create directory \"%s\"\n", Path.c_str()); + exit(1); + + } + + return; + + } + + Printf("ERROR: The required directory \"%s\" does not exist\n", Path.c_str()); + exit(1); + +} + +std::string CloneArgsWithoutX(const Vector<std::string> &Args, const char *X1, + const char *X2) { + + std::string Cmd; + for (auto &S : Args) { + + if (FlagValue(S.c_str(), X1) || FlagValue(S.c_str(), X2)) continue; + Cmd += S + " "; + + } + + return Cmd; + +} + +static int RunInMultipleProcesses(const Vector<std::string> &Args, + unsigned NumWorkers, unsigned NumJobs) { + + std::atomic<unsigned> Counter(0); + std::atomic<bool> HasErrors(false); + Command Cmd(Args); + Cmd.removeFlag("jobs"); + Cmd.removeFlag("workers"); + Vector<std::thread> V; + std::thread Pulse(PulseThread); + Pulse.detach(); + for (unsigned i = 0; i < NumWorkers; i++) + V.push_back(std::thread(WorkerThread, std::ref(Cmd), &Counter, NumJobs, + &HasErrors)); + for (auto &T : V) + T.join(); + return HasErrors ? 1 : 0; + +} + +static void RssThread(Fuzzer *F, size_t RssLimitMb) { + + while (true) { + + SleepSeconds(1); + size_t Peak = GetPeakRSSMb(); + if (Peak > RssLimitMb) F->RssLimitCallback(); + + } + +} + +static void StartRssThread(Fuzzer *F, size_t RssLimitMb) { + + if (!RssLimitMb) return; + std::thread T(RssThread, F, RssLimitMb); + T.detach(); + +} + +int RunOneTest(Fuzzer *F, const char *InputFilePath, size_t MaxLen) { + + Unit U = FileToVector(InputFilePath); + if (MaxLen && MaxLen < U.size()) U.resize(MaxLen); + F->ExecuteCallback(U.data(), U.size()); + F->TryDetectingAMemoryLeak(U.data(), U.size(), true); + return 0; + +} + +static bool AllInputsAreFiles() { + + if (Inputs->empty()) return false; + for (auto &Path : *Inputs) + if (!IsFile(Path)) return false; + return true; + +} + +static std::string GetDedupTokenFromCmdOutput(const std::string &S) { + + auto Beg = S.find("DEDUP_TOKEN:"); + if (Beg == std::string::npos) return ""; + auto End = S.find('\n', Beg); + if (End == std::string::npos) return ""; + return S.substr(Beg, End - Beg); + +} + +int CleanseCrashInput(const Vector<std::string> &Args, + const FuzzingOptions & Options) { + + if (Inputs->size() != 1 || !Flags.exact_artifact_path) { + + Printf( + "ERROR: -cleanse_crash should be given one input file and" + " -exact_artifact_path\n"); + exit(1); + + } + + std::string InputFilePath = Inputs->at(0); + std::string OutputFilePath = Flags.exact_artifact_path; + Command Cmd(Args); + Cmd.removeFlag("cleanse_crash"); + + assert(Cmd.hasArgument(InputFilePath)); + Cmd.removeArgument(InputFilePath); + + auto TmpFilePath = TempPath("CleanseCrashInput", ".repro"); + Cmd.addArgument(TmpFilePath); + Cmd.setOutputFile(getDevNull()); + Cmd.combineOutAndErr(); + + std::string CurrentFilePath = InputFilePath; + auto U = FileToVector(CurrentFilePath); + size_t Size = U.size(); + + const Vector<uint8_t> ReplacementBytes = {' ', 0xff}; + for (int NumAttempts = 0; NumAttempts < 5; NumAttempts++) { + + bool Changed = false; + for (size_t Idx = 0; Idx < Size; Idx++) { + + Printf("CLEANSE[%d]: Trying to replace byte %zd of %zd\n", NumAttempts, + Idx, Size); + uint8_t OriginalByte = U[Idx]; + if (ReplacementBytes.end() != std::find(ReplacementBytes.begin(), + ReplacementBytes.end(), + OriginalByte)) + continue; + for (auto NewByte : ReplacementBytes) { + + U[Idx] = NewByte; + WriteToFile(U, TmpFilePath); + auto ExitCode = ExecuteCommand(Cmd); + RemoveFile(TmpFilePath); + if (!ExitCode) { + + U[Idx] = OriginalByte; + + } else { + + Changed = true; + Printf("CLEANSE: Replaced byte %zd with 0x%x\n", Idx, NewByte); + WriteToFile(U, OutputFilePath); + break; + + } + + } + + } + + if (!Changed) break; + + } + + return 0; + +} + +int MinimizeCrashInput(const Vector<std::string> &Args, + const FuzzingOptions & Options) { + + if (Inputs->size() != 1) { + + Printf("ERROR: -minimize_crash should be given one input file\n"); + exit(1); + + } + + std::string InputFilePath = Inputs->at(0); + Command BaseCmd(Args); + BaseCmd.removeFlag("minimize_crash"); + BaseCmd.removeFlag("exact_artifact_path"); + assert(BaseCmd.hasArgument(InputFilePath)); + BaseCmd.removeArgument(InputFilePath); + if (Flags.runs <= 0 && Flags.max_total_time == 0) { + + Printf( + "INFO: you need to specify -runs=N or " + "-max_total_time=N with -minimize_crash=1\n" + "INFO: defaulting to -max_total_time=600\n"); + BaseCmd.addFlag("max_total_time", "600"); + + } + + BaseCmd.combineOutAndErr(); + + std::string CurrentFilePath = InputFilePath; + while (true) { + + Unit U = FileToVector(CurrentFilePath); + Printf("CRASH_MIN: minimizing crash input: '%s' (%zd bytes)\n", + CurrentFilePath.c_str(), U.size()); + + Command Cmd(BaseCmd); + Cmd.addArgument(CurrentFilePath); + + Printf("CRASH_MIN: executing: %s\n", Cmd.toString().c_str()); + std::string CmdOutput; + bool Success = ExecuteCommand(Cmd, &CmdOutput); + if (Success) { + + Printf("ERROR: the input %s did not crash\n", CurrentFilePath.c_str()); + exit(1); + + } + + Printf( + "CRASH_MIN: '%s' (%zd bytes) caused a crash. Will try to minimize " + "it further\n", + CurrentFilePath.c_str(), U.size()); + auto DedupToken1 = GetDedupTokenFromCmdOutput(CmdOutput); + if (!DedupToken1.empty()) + Printf("CRASH_MIN: DedupToken1: %s\n", DedupToken1.c_str()); + + std::string ArtifactPath = + Flags.exact_artifact_path + ? Flags.exact_artifact_path + : Options.ArtifactPrefix + "minimized-from-" + Hash(U); + Cmd.addFlag("minimize_crash_internal_step", "1"); + Cmd.addFlag("exact_artifact_path", ArtifactPath); + Printf("CRASH_MIN: executing: %s\n", Cmd.toString().c_str()); + CmdOutput.clear(); + Success = ExecuteCommand(Cmd, &CmdOutput); + Printf("%s", CmdOutput.c_str()); + if (Success) { + + if (Flags.exact_artifact_path) { + + CurrentFilePath = Flags.exact_artifact_path; + WriteToFile(U, CurrentFilePath); + + } + + Printf("CRASH_MIN: failed to minimize beyond %s (%d bytes), exiting\n", + CurrentFilePath.c_str(), U.size()); + break; + + } + + auto DedupToken2 = GetDedupTokenFromCmdOutput(CmdOutput); + if (!DedupToken2.empty()) + Printf("CRASH_MIN: DedupToken2: %s\n", DedupToken2.c_str()); + + if (DedupToken1 != DedupToken2) { + + if (Flags.exact_artifact_path) { + + CurrentFilePath = Flags.exact_artifact_path; + WriteToFile(U, CurrentFilePath); + + } + + Printf( + "CRASH_MIN: mismatch in dedup tokens" + " (looks like a different bug). Won't minimize further\n"); + break; + + } + + CurrentFilePath = ArtifactPath; + Printf("*********************************\n"); + + } + + return 0; + +} + +int MinimizeCrashInputInternalStep(Fuzzer *F, InputCorpus *Corpus) { + + assert(Inputs->size() == 1); + std::string InputFilePath = Inputs->at(0); + Unit U = FileToVector(InputFilePath); + Printf("INFO: Starting MinimizeCrashInputInternalStep: %zd\n", U.size()); + if (U.size() < 2) { + + Printf("INFO: The input is small enough, exiting\n"); + exit(0); + + } + + F->SetMaxInputLen(U.size()); + F->SetMaxMutationLen(U.size() - 1); + F->MinimizeCrashLoop(U); + Printf("INFO: Done MinimizeCrashInputInternalStep, no crashes found\n"); + exit(0); + return 0; + +} + +void Merge(Fuzzer *F, FuzzingOptions &Options, const Vector<std::string> &Args, + const Vector<std::string> &Corpora, const char *CFPathOrNull) { + + if (Corpora.size() < 2) { + + Printf("INFO: Merge requires two or more corpus dirs\n"); + exit(0); + + } + + Vector<SizedFile> OldCorpus, NewCorpus; + GetSizedFilesFromDir(Corpora[0], &OldCorpus); + for (size_t i = 1; i < Corpora.size(); i++) + GetSizedFilesFromDir(Corpora[i], &NewCorpus); + std::sort(OldCorpus.begin(), OldCorpus.end()); + std::sort(NewCorpus.begin(), NewCorpus.end()); + + std::string CFPath = CFPathOrNull ? CFPathOrNull : TempPath("Merge", ".txt"); + Vector<std::string> NewFiles; + Set<uint32_t> NewFeatures, NewCov; + CrashResistantMerge(Args, OldCorpus, NewCorpus, &NewFiles, {}, &NewFeatures, + {}, &NewCov, CFPath, true); + for (auto &Path : NewFiles) + F->WriteToOutputCorpus(FileToVector(Path, Options.MaxLen)); + // We are done, delete the control file if it was a temporary one. + if (!Flags.merge_control_file) RemoveFile(CFPath); + + exit(0); + +} + +int AnalyzeDictionary(Fuzzer *F, const Vector<Unit> &Dict, UnitVector &Corpus) { + + Printf("Started dictionary minimization (up to %d tests)\n", + Dict.size() * Corpus.size() * 2); + + // Scores and usage count for each dictionary unit. + Vector<int> Scores(Dict.size()); + Vector<int> Usages(Dict.size()); + + Vector<size_t> InitialFeatures; + Vector<size_t> ModifiedFeatures; + for (auto &C : Corpus) { + + // Get coverage for the testcase without modifications. + F->ExecuteCallback(C.data(), C.size()); + InitialFeatures.clear(); + TPC.CollectFeatures( + [&](size_t Feature) { InitialFeatures.push_back(Feature); }); + + for (size_t i = 0; i < Dict.size(); ++i) { + + Vector<uint8_t> Data = C; + auto StartPos = + std::search(Data.begin(), Data.end(), Dict[i].begin(), Dict[i].end()); + // Skip dictionary unit, if the testcase does not contain it. + if (StartPos == Data.end()) continue; + + ++Usages[i]; + while (StartPos != Data.end()) { + + // Replace all occurrences of dictionary unit in the testcase. + auto EndPos = StartPos + Dict[i].size(); + for (auto It = StartPos; It != EndPos; ++It) + *It ^= 0xFF; + + StartPos = + std::search(EndPos, Data.end(), Dict[i].begin(), Dict[i].end()); + + } + + // Get coverage for testcase with masked occurrences of dictionary unit. + F->ExecuteCallback(Data.data(), Data.size()); + ModifiedFeatures.clear(); + TPC.CollectFeatures( + [&](size_t Feature) { ModifiedFeatures.push_back(Feature); }); + + if (InitialFeatures == ModifiedFeatures) + --Scores[i]; + else + Scores[i] += 2; + + } + + } + + Printf("###### Useless dictionary elements. ######\n"); + for (size_t i = 0; i < Dict.size(); ++i) { + + // Dictionary units with positive score are treated as useful ones. + if (Scores[i] > 0) continue; + + Printf("\""); + PrintASCII(Dict[i].data(), Dict[i].size(), "\""); + Printf(" # Score: %d, Used: %d\n", Scores[i], Usages[i]); + + } + + Printf("###### End of useless dictionary elements. ######\n"); + return 0; + +} + +Vector<std::string> ParseSeedInuts(const char *seed_inputs) { + + // Parse -seed_inputs=file1,file2,... or -seed_inputs=@seed_inputs_file + Vector<std::string> Files; + if (!seed_inputs) return Files; + std::string SeedInputs; + if (Flags.seed_inputs[0] == '@') + SeedInputs = FileToString(Flags.seed_inputs + 1); // File contains list. + else + SeedInputs = Flags.seed_inputs; // seed_inputs contains the list. + if (SeedInputs.empty()) { + + Printf("seed_inputs is empty or @file does not exist.\n"); + exit(1); + + } + + // Parse SeedInputs. + size_t comma_pos = 0; + while ((comma_pos = SeedInputs.find_last_of(',')) != std::string::npos) { + + Files.push_back(SeedInputs.substr(comma_pos + 1)); + SeedInputs = SeedInputs.substr(0, comma_pos); + + } + + Files.push_back(SeedInputs); + return Files; + +} + +static Vector<SizedFile> ReadCorpora( + const Vector<std::string> &CorpusDirs, + const Vector<std::string> &ExtraSeedFiles) { + + Vector<SizedFile> SizedFiles; + size_t LastNumFiles = 0; + for (auto &Dir : CorpusDirs) { + + GetSizedFilesFromDir(Dir, &SizedFiles); + Printf("INFO: % 8zd files found in %s\n", SizedFiles.size() - LastNumFiles, + Dir.c_str()); + LastNumFiles = SizedFiles.size(); + + } + + for (auto &File : ExtraSeedFiles) + if (auto Size = FileSize(File)) SizedFiles.push_back({File, Size}); + return SizedFiles; + +} + +int FuzzerDriver(int *argc, char ***argv, UserCallback Callback) { + + using namespace fuzzer; + assert(argc && argv && "Argument pointers cannot be nullptr"); + std::string Argv0((*argv)[0]); + EF = new ExternalFunctions(); + if (EF->LLVMFuzzerInitialize) EF->LLVMFuzzerInitialize(argc, argv); + if (EF->__msan_scoped_disable_interceptor_checks) + EF->__msan_scoped_disable_interceptor_checks(); + const Vector<std::string> Args(*argv, *argv + *argc); + assert(!Args.empty()); + ProgName = new std::string(Args[0]); + if (Argv0 != *ProgName) { + + Printf("ERROR: argv[0] has been modified in LLVMFuzzerInitialize\n"); + exit(1); + + } + + ParseFlags(Args, EF); + if (Flags.help) { + + PrintHelp(); + return 0; + + } + + if (Flags.close_fd_mask & 2) DupAndCloseStderr(); + if (Flags.close_fd_mask & 1) CloseStdout(); + + if (Flags.jobs > 0 && Flags.workers == 0) { + + Flags.workers = std::min(NumberOfCpuCores() / 2, Flags.jobs); + if (Flags.workers > 1) Printf("Running %u workers\n", Flags.workers); + + } + + if (Flags.workers > 0 && Flags.jobs > 0) + return RunInMultipleProcesses(Args, Flags.workers, Flags.jobs); + + FuzzingOptions Options; + Options.Verbosity = Flags.verbosity; + Options.MaxLen = Flags.max_len; + Options.LenControl = Flags.len_control; + Options.KeepSeed = Flags.keep_seed; + Options.UnitTimeoutSec = Flags.timeout; + Options.ErrorExitCode = Flags.error_exitcode; + Options.TimeoutExitCode = Flags.timeout_exitcode; + Options.IgnoreTimeouts = Flags.ignore_timeouts; + Options.IgnoreOOMs = Flags.ignore_ooms; + Options.IgnoreCrashes = Flags.ignore_crashes; + Options.MaxTotalTimeSec = Flags.max_total_time; + Options.DoCrossOver = Flags.cross_over; + Options.CrossOverUniformDist = Flags.cross_over_uniform_dist; + Options.MutateDepth = Flags.mutate_depth; + Options.ReduceDepth = Flags.reduce_depth; + Options.UseCounters = Flags.use_counters; + Options.UseMemmem = Flags.use_memmem; + Options.UseCmp = Flags.use_cmp; + Options.UseValueProfile = Flags.use_value_profile; + Options.Shrink = Flags.shrink; + Options.ReduceInputs = Flags.reduce_inputs; + Options.ShuffleAtStartUp = Flags.shuffle; + Options.PreferSmall = Flags.prefer_small; + Options.ReloadIntervalSec = Flags.reload; + Options.OnlyASCII = Flags.only_ascii; + Options.DetectLeaks = Flags.detect_leaks; + Options.PurgeAllocatorIntervalSec = Flags.purge_allocator_interval; + Options.TraceMalloc = Flags.trace_malloc; + Options.RssLimitMb = Flags.rss_limit_mb; + Options.MallocLimitMb = Flags.malloc_limit_mb; + if (!Options.MallocLimitMb) Options.MallocLimitMb = Options.RssLimitMb; + if (Flags.runs >= 0) Options.MaxNumberOfRuns = Flags.runs; + if (!Inputs->empty() && !Flags.minimize_crash_internal_step) { + + // Ensure output corpus assumed to be the first arbitrary argument input + // is not a path to an existing file. + std::string OutputCorpusDir = (*Inputs)[0]; + if (!IsFile(OutputCorpusDir)) { + + Options.OutputCorpus = OutputCorpusDir; + ValidateDirectoryExists(Options.OutputCorpus, Flags.create_missing_dirs); + + } + + } + + Options.ReportSlowUnits = Flags.report_slow_units; + if (Flags.artifact_prefix) { + + Options.ArtifactPrefix = Flags.artifact_prefix; + + // Since the prefix could be a full path to a file name prefix, assume + // that if the path ends with the platform's separator that a directory + // is desired + std::string ArtifactPathDir = Options.ArtifactPrefix; + if (!IsSeparator(ArtifactPathDir[ArtifactPathDir.length() - 1])) { + + ArtifactPathDir = DirName(ArtifactPathDir); + + } + + ValidateDirectoryExists(ArtifactPathDir, Flags.create_missing_dirs); + + } + + if (Flags.exact_artifact_path) { + + Options.ExactArtifactPath = Flags.exact_artifact_path; + ValidateDirectoryExists(DirName(Options.ExactArtifactPath), + Flags.create_missing_dirs); + + } + + Vector<Unit> Dictionary; + if (Flags.dict) + if (!ParseDictionaryFile(FileToString(Flags.dict), &Dictionary)) return 1; + if (Flags.verbosity > 0 && !Dictionary.empty()) + Printf("Dictionary: %zd entries\n", Dictionary.size()); + bool RunIndividualFiles = AllInputsAreFiles(); + Options.SaveArtifacts = + !RunIndividualFiles || Flags.minimize_crash_internal_step; + Options.PrintNewCovPcs = Flags.print_pcs; + Options.PrintNewCovFuncs = Flags.print_funcs; + Options.PrintFinalStats = Flags.print_final_stats; + Options.PrintCorpusStats = Flags.print_corpus_stats; + Options.PrintCoverage = Flags.print_coverage; + if (Flags.exit_on_src_pos) Options.ExitOnSrcPos = Flags.exit_on_src_pos; + if (Flags.exit_on_item) Options.ExitOnItem = Flags.exit_on_item; + if (Flags.focus_function) Options.FocusFunction = Flags.focus_function; + if (Flags.data_flow_trace) Options.DataFlowTrace = Flags.data_flow_trace; + if (Flags.features_dir) { + + Options.FeaturesDir = Flags.features_dir; + ValidateDirectoryExists(Options.FeaturesDir, Flags.create_missing_dirs); + + } + + if (Flags.mutation_graph_file) + Options.MutationGraphFile = Flags.mutation_graph_file; + if (Flags.collect_data_flow) + Options.CollectDataFlow = Flags.collect_data_flow; + if (Flags.stop_file) Options.StopFile = Flags.stop_file; + Options.Entropic = Flags.entropic; + Options.EntropicFeatureFrequencyThreshold = + (size_t)Flags.entropic_feature_frequency_threshold; + Options.EntropicNumberOfRarestFeatures = + (size_t)Flags.entropic_number_of_rarest_features; + Options.EntropicScalePerExecTime = Flags.entropic_scale_per_exec_time; + if (!Options.FocusFunction.empty()) + Options.Entropic = false; // FocusFunction overrides entropic scheduling. + if (Options.Entropic) + Printf("INFO: Running with entropic power schedule (0x%X, %d).\n", + Options.EntropicFeatureFrequencyThreshold, + Options.EntropicNumberOfRarestFeatures); + struct EntropicOptions Entropic; + Entropic.Enabled = Options.Entropic; + Entropic.FeatureFrequencyThreshold = + Options.EntropicFeatureFrequencyThreshold; + Entropic.NumberOfRarestFeatures = Options.EntropicNumberOfRarestFeatures; + Entropic.ScalePerExecTime = Options.EntropicScalePerExecTime; + + unsigned Seed = Flags.seed; + // Initialize Seed. + if (Seed == 0) + Seed = + std::chrono::system_clock::now().time_since_epoch().count() + GetPid(); + if (Flags.verbosity) Printf("INFO: Seed: %u\n", Seed); + + if (Flags.collect_data_flow && !Flags.fork && !Flags.merge) { + + if (RunIndividualFiles) + return CollectDataFlow(Flags.collect_data_flow, Flags.data_flow_trace, + ReadCorpora({}, *Inputs)); + else + return CollectDataFlow(Flags.collect_data_flow, Flags.data_flow_trace, + ReadCorpora(*Inputs, {})); + + } + + Random Rand(Seed); + auto * MD = new MutationDispatcher(Rand, Options); + auto * Corpus = new InputCorpus(Options.OutputCorpus, Entropic); + auto * F = new Fuzzer(Callback, *Corpus, *MD, Options); + + for (auto &U : Dictionary) + if (U.size() <= Word::GetMaxSize()) + MD->AddWordToManualDictionary(Word(U.data(), U.size())); + + // Threads are only supported by Chrome. Don't use them with emscripten + // for now. +#if !LIBFUZZER_EMSCRIPTEN + StartRssThread(F, Flags.rss_limit_mb); +#endif // LIBFUZZER_EMSCRIPTEN + + Options.HandleAbrt = Flags.handle_abrt; + Options.HandleAlrm = !Flags.minimize_crash; + Options.HandleBus = Flags.handle_bus; + Options.HandleFpe = Flags.handle_fpe; + Options.HandleIll = Flags.handle_ill; + Options.HandleInt = Flags.handle_int; + Options.HandleSegv = Flags.handle_segv; + Options.HandleTerm = Flags.handle_term; + Options.HandleXfsz = Flags.handle_xfsz; + Options.HandleUsr1 = Flags.handle_usr1; + Options.HandleUsr2 = Flags.handle_usr2; + SetSignalHandler(Options); + + std::atexit(Fuzzer::StaticExitCallback); + + if (Flags.minimize_crash) return MinimizeCrashInput(Args, Options); + + if (Flags.minimize_crash_internal_step) + return MinimizeCrashInputInternalStep(F, Corpus); + + if (Flags.cleanse_crash) return CleanseCrashInput(Args, Options); + + if (RunIndividualFiles) { + + Options.SaveArtifacts = false; + int Runs = std::max(1, Flags.runs); + Printf("%s: Running %zd inputs %d time(s) each.\n", ProgName->c_str(), + Inputs->size(), Runs); + for (auto &Path : *Inputs) { + + auto StartTime = system_clock::now(); + Printf("Running: %s\n", Path.c_str()); + for (int Iter = 0; Iter < Runs; Iter++) + RunOneTest(F, Path.c_str(), Options.MaxLen); + auto StopTime = system_clock::now(); + auto MS = duration_cast<milliseconds>(StopTime - StartTime).count(); + Printf("Executed %s in %zd ms\n", Path.c_str(), (long)MS); + + } + + Printf( + "***\n" + "*** NOTE: fuzzing was not performed, you have only\n" + "*** executed the target code on a fixed set of inputs.\n" + "***\n"); + F->PrintFinalStats(); + exit(0); + + } + + if (Flags.fork) + FuzzWithFork(F->GetMD().GetRand(), Options, Args, *Inputs, Flags.fork); + + if (Flags.merge) Merge(F, Options, Args, *Inputs, Flags.merge_control_file); + + if (Flags.merge_inner) { + + const size_t kDefaultMaxMergeLen = 1 << 20; + if (Options.MaxLen == 0) F->SetMaxInputLen(kDefaultMaxMergeLen); + assert(Flags.merge_control_file); + F->CrashResistantMergeInternalStep(Flags.merge_control_file); + exit(0); + + } + + if (Flags.analyze_dict) { + + size_t MaxLen = INT_MAX; // Large max length. + UnitVector InitialCorpus; + for (auto &Inp : *Inputs) { + + Printf("Loading corpus dir: %s\n", Inp.c_str()); + ReadDirToVectorOfUnits(Inp.c_str(), &InitialCorpus, nullptr, MaxLen, + /*ExitOnError=*/false); + + } + + if (Dictionary.empty() || Inputs->empty()) { + + Printf("ERROR: can't analyze dict without dict and corpus provided\n"); + return 1; + + } + + if (AnalyzeDictionary(F, Dictionary, InitialCorpus)) { + + Printf("Dictionary analysis failed\n"); + exit(1); + + } + + Printf("Dictionary analysis succeeded\n"); + exit(0); + + } + + auto CorporaFiles = ReadCorpora(*Inputs, ParseSeedInuts(Flags.seed_inputs)); + F->Loop(CorporaFiles); + + if (Flags.verbosity) + Printf("Done %zd runs in %zd second(s)\n", F->getTotalNumberOfRuns(), + F->secondsSinceProcessStartUp()); + F->PrintFinalStats(); + + exit(0); // Don't let F destroy itself. + +} + +extern "C" ATTRIBUTE_INTERFACE int LLVMFuzzerRunDriver( + int *argc, char ***argv, int (*UserCb)(const uint8_t *Data, size_t Size)) { + + return FuzzerDriver(argc, argv, UserCb); + +} + +#include "libfuzzer.inc" + +// Storage for global ExternalFunctions object. +ExternalFunctions *EF = nullptr; + +} // namespace fuzzer + diff --git a/custom_mutators/libfuzzer/FuzzerExtFunctions.def b/custom_mutators/libfuzzer/FuzzerExtFunctions.def new file mode 100644 index 00000000..51edf844 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerExtFunctions.def @@ -0,0 +1,50 @@ +//===- FuzzerExtFunctions.def - External functions --------------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// This defines the external function pointers that +// ``fuzzer::ExternalFunctions`` should contain and try to initialize. The +// EXT_FUNC macro must be defined at the point of inclusion. The signature of +// the macro is: +// +// EXT_FUNC(<name>, <return_type>, <function_signature>, <warn_if_missing>) +//===----------------------------------------------------------------------===// + +// Optional user functions +EXT_FUNC(LLVMFuzzerInitialize, int, (int *argc, char ***argv), false); +EXT_FUNC(LLVMFuzzerCustomMutator, size_t, + (uint8_t *Data, size_t Size, size_t MaxSize, unsigned int Seed), + false); +EXT_FUNC(LLVMFuzzerCustomCrossOver, size_t, + (const uint8_t *Data1, size_t Size1, + const uint8_t *Data2, size_t Size2, + uint8_t *Out, size_t MaxOutSize, unsigned int Seed), + false); + +// Sanitizer functions +EXT_FUNC(__lsan_enable, void, (), false); +EXT_FUNC(__lsan_disable, void, (), false); +EXT_FUNC(__lsan_do_recoverable_leak_check, int, (), false); +EXT_FUNC(__sanitizer_acquire_crash_state, int, (), true); +EXT_FUNC(__sanitizer_install_malloc_and_free_hooks, int, + (void (*malloc_hook)(const volatile void *, size_t), + void (*free_hook)(const volatile void *)), + false); +EXT_FUNC(__sanitizer_log_write, void, (const char *buf, size_t len), false); +EXT_FUNC(__sanitizer_purge_allocator, void, (), false); +EXT_FUNC(__sanitizer_print_memory_profile, void, (size_t, size_t), false); +EXT_FUNC(__sanitizer_print_stack_trace, void, (), true); +EXT_FUNC(__sanitizer_symbolize_pc, void, + (void *, const char *fmt, char *out_buf, size_t out_buf_size), false); +EXT_FUNC(__sanitizer_get_module_and_offset_for_pc, int, + (void *pc, char *module_path, + size_t module_path_len,void **pc_offset), false); +EXT_FUNC(__sanitizer_set_death_callback, void, (void (*)(void)), true); +EXT_FUNC(__sanitizer_set_report_fd, void, (void*), false); +EXT_FUNC(__msan_scoped_disable_interceptor_checks, void, (), false); +EXT_FUNC(__msan_scoped_enable_interceptor_checks, void, (), false); +EXT_FUNC(__msan_unpoison, void, (const volatile void *, size_t size), false); +EXT_FUNC(__msan_unpoison_param, void, (size_t n), false); diff --git a/custom_mutators/libfuzzer/FuzzerExtFunctions.h b/custom_mutators/libfuzzer/FuzzerExtFunctions.h new file mode 100644 index 00000000..c88aac4e --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerExtFunctions.h @@ -0,0 +1,34 @@ +//===- FuzzerExtFunctions.h - Interface to external functions ---*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Defines an interface to (possibly optional) functions. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_EXT_FUNCTIONS_H +#define LLVM_FUZZER_EXT_FUNCTIONS_H + +#include <stddef.h> +#include <stdint.h> + +namespace fuzzer { + +struct ExternalFunctions { + // Initialize function pointers. Functions that are not available will be set + // to nullptr. Do not call this constructor before ``main()`` has been + // entered. + ExternalFunctions(); + +#define EXT_FUNC(NAME, RETURN_TYPE, FUNC_SIG, WARN) \ + RETURN_TYPE(*NAME) FUNC_SIG = nullptr + +#include "FuzzerExtFunctions.def" + +#undef EXT_FUNC +}; +} // namespace fuzzer + +#endif diff --git a/custom_mutators/libfuzzer/FuzzerExtFunctionsDlsym.cpp b/custom_mutators/libfuzzer/FuzzerExtFunctionsDlsym.cpp new file mode 100644 index 00000000..8009b237 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerExtFunctionsDlsym.cpp @@ -0,0 +1,60 @@ +//===- FuzzerExtFunctionsDlsym.cpp - Interface to external functions ------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Implementation for operating systems that support dlsym(). We only use it on +// Apple platforms for now. We don't use this approach on Linux because it +// requires that clients of LibFuzzer pass ``--export-dynamic`` to the linker. +// That is a complication we don't wish to expose to clients right now. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" +#if LIBFUZZER_APPLE + + #include "FuzzerExtFunctions.h" + #include "FuzzerIO.h" + #include <dlfcn.h> + +using namespace fuzzer; + +template <typename T> +static T GetFnPtr(const char *FnName, bool WarnIfMissing) { + + dlerror(); // Clear any previous errors. + void *Fn = dlsym(RTLD_DEFAULT, FnName); + if (Fn == nullptr) { + + if (WarnIfMissing) { + + const char *ErrorMsg = dlerror(); + Printf("WARNING: Failed to find function \"%s\".", FnName); + if (ErrorMsg) Printf(" Reason %s.", ErrorMsg); + Printf("\n"); + + } + + } + + return reinterpret_cast<T>(Fn); + +} + +namespace fuzzer { + +ExternalFunctions::ExternalFunctions() { +\ + #define EXT_FUNC(NAME, RETURN_TYPE, FUNC_SIG, WARN) \ + this->NAME = GetFnPtr<decltype(ExternalFunctions::NAME)>(#NAME, WARN) + + #include "FuzzerExtFunctions.def" + + #undef EXT_FUNC + +} + +} // namespace fuzzer + +#endif // LIBFUZZER_APPLE + diff --git a/custom_mutators/libfuzzer/FuzzerExtFunctionsWeak.cpp b/custom_mutators/libfuzzer/FuzzerExtFunctionsWeak.cpp new file mode 100644 index 00000000..c7a1d05e --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerExtFunctionsWeak.cpp @@ -0,0 +1,63 @@ +//===- FuzzerExtFunctionsWeak.cpp - Interface to external functions -------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Implementation for Linux. This relies on the linker's support for weak +// symbols. We don't use this approach on Apple platforms because it requires +// clients of LibFuzzer to pass ``-U _<symbol_name>`` to the linker to allow +// weak symbols to be undefined. That is a complication we don't want to expose +// to clients right now. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" +#if LIBFUZZER_LINUX || LIBFUZZER_NETBSD || LIBFUZZER_FUCHSIA || \ + LIBFUZZER_FREEBSD || LIBFUZZER_OPENBSD || LIBFUZZER_EMSCRIPTEN + + #include "FuzzerExtFunctions.h" + #include "FuzzerIO.h" + +extern "C" { + + // Declare these symbols as weak to allow them to be optionally defined. + #define EXT_FUNC(NAME, RETURN_TYPE, FUNC_SIG, WARN) \ + __attribute__((weak, visibility("default"))) RETURN_TYPE NAME FUNC_SIG + + #include "FuzzerExtFunctions.def" + + #undef EXT_FUNC + +} + +using namespace fuzzer; + +static void CheckFnPtr(void *FnPtr, const char *FnName, bool WarnIfMissing) { + + if (FnPtr == nullptr && WarnIfMissing) { + + Printf("WARNING: Failed to find function \"%s\".\n", FnName); + + } + +} + +namespace fuzzer { + +ExternalFunctions::ExternalFunctions() { +\ + #define EXT_FUNC(NAME, RETURN_TYPE, FUNC_SIG, WARN) \ + this->NAME = ::NAME; \ + CheckFnPtr(reinterpret_cast<void *>(reinterpret_cast<uintptr_t>(::NAME)), \ + #NAME, WARN); + + #include "FuzzerExtFunctions.def" + + #undef EXT_FUNC + +} + +} // namespace fuzzer + +#endif + diff --git a/custom_mutators/libfuzzer/FuzzerExtFunctionsWindows.cpp b/custom_mutators/libfuzzer/FuzzerExtFunctionsWindows.cpp new file mode 100644 index 00000000..a727220a --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerExtFunctionsWindows.cpp @@ -0,0 +1,95 @@ +//=== FuzzerExtWindows.cpp - Interface to external functions --------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Implementation of FuzzerExtFunctions for Windows. Uses alternatename when +// compiled with MSVC. Uses weak aliases when compiled with clang. Unfortunately +// the method each compiler supports is not supported by the other. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" +#if LIBFUZZER_WINDOWS + + #include "FuzzerExtFunctions.h" + #include "FuzzerIO.h" + +using namespace fuzzer; + + // Intermediate macro to ensure the parameter is expanded before stringified. + #define STRINGIFY_(A) #A + #define STRINGIFY(A) STRINGIFY_(A) + + #if LIBFUZZER_MSVC + // Copied from compiler-rt/lib/sanitizer_common/sanitizer_win_defs.h + #if defined(_M_IX86) || defined(__i386__) + #define WIN_SYM_PREFIX "_" + #else + #define WIN_SYM_PREFIX + #endif + + // Declare external functions as having alternativenames, so that we can + // determine if they are not defined. + #define EXTERNAL_FUNC(Name, Default) \ + __pragma( \ + comment(linker, "/alternatename:" WIN_SYM_PREFIX STRINGIFY( \ + Name) "=" WIN_SYM_PREFIX STRINGIFY(Default))) + #else + // Declare external functions as weak to allow them to default to a + // specified function if not defined explicitly. We must use weak symbols + // because clang's support for alternatename is not 100%, see + // https://bugs.llvm.org/show_bug.cgi?id=40218 for more details. + #define EXTERNAL_FUNC(Name, Default) \ + __attribute__((weak, alias(STRINGIFY(Default)))) + #endif // LIBFUZZER_MSVC + +extern "C" { +\ + #define EXT_FUNC(NAME, RETURN_TYPE, FUNC_SIG, WARN) \ + RETURN_TYPE NAME##Def FUNC_SIG { \ + \ + Printf("ERROR: Function \"%s\" not defined.\n", #NAME); \ + exit(1); \ + \ + } \ + EXTERNAL_FUNC(NAME, NAME##Def) RETURN_TYPE NAME FUNC_SIG + + #include "FuzzerExtFunctions.def" + + #undef EXT_FUNC + +} + +template <typename T> +static T *GetFnPtr(T *Fun, T *FunDef, const char *FnName, bool WarnIfMissing) { + + if (Fun == FunDef) { + + if (WarnIfMissing) + Printf("WARNING: Failed to find function \"%s\".\n", FnName); + return nullptr; + + } + + return Fun; + +} + +namespace fuzzer { + +ExternalFunctions::ExternalFunctions() { +\ + #define EXT_FUNC(NAME, RETURN_TYPE, FUNC_SIG, WARN) \ + this->NAME = GetFnPtr<decltype(::NAME)>(::NAME, ::NAME##Def, #NAME, WARN); + + #include "FuzzerExtFunctions.def" + + #undef EXT_FUNC + +} + +} // namespace fuzzer + +#endif // LIBFUZZER_WINDOWS + diff --git a/custom_mutators/libfuzzer/FuzzerExtraCounters.cpp b/custom_mutators/libfuzzer/FuzzerExtraCounters.cpp new file mode 100644 index 00000000..3ff9b0d5 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerExtraCounters.cpp @@ -0,0 +1,71 @@ +//===- FuzzerExtraCounters.cpp - Extra coverage counters ------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Extra coverage counters defined by user code. +//===----------------------------------------------------------------------===// + +#include "FuzzerPlatform.h" +#include <cstdint> + +#if LIBFUZZER_LINUX || LIBFUZZER_NETBSD || LIBFUZZER_FREEBSD || \ + LIBFUZZER_OPENBSD || LIBFUZZER_FUCHSIA || LIBFUZZER_EMSCRIPTEN +__attribute__((weak)) extern uint8_t __start___libfuzzer_extra_counters; +__attribute__((weak)) extern uint8_t __stop___libfuzzer_extra_counters; + +namespace fuzzer { + +uint8_t *ExtraCountersBegin() { + + return &__start___libfuzzer_extra_counters; + +} + +uint8_t *ExtraCountersEnd() { + + return &__stop___libfuzzer_extra_counters; + +} + +ATTRIBUTE_NO_SANITIZE_ALL +void ClearExtraCounters() { // hand-written memset, don't asan-ify. + uintptr_t *Beg = reinterpret_cast<uintptr_t *>(ExtraCountersBegin()); + uintptr_t *End = reinterpret_cast<uintptr_t *>(ExtraCountersEnd()); + for (; Beg < End; Beg++) { + + *Beg = 0; + __asm__ __volatile__("" : : : "memory"); + + } + +} + +} // namespace fuzzer + +#else +// TODO: implement for other platforms. +namespace fuzzer { + +uint8_t *ExtraCountersBegin() { + + return nullptr; + +} + +uint8_t *ExtraCountersEnd() { + + return nullptr; + +} + +void ClearExtraCounters() { + +} + +} // namespace fuzzer + +#endif + diff --git a/custom_mutators/libfuzzer/FuzzerFlags.def b/custom_mutators/libfuzzer/FuzzerFlags.def new file mode 100644 index 00000000..4d4841b1 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerFlags.def @@ -0,0 +1,198 @@ +//===- FuzzerFlags.def - Run-time flags -------------------------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Flags. FUZZER_FLAG_INT/FUZZER_FLAG_STRING macros should be defined at the +// point of inclusion. We are not using any flag parsing library for better +// portability and independence. +//===----------------------------------------------------------------------===// +FUZZER_FLAG_INT(verbosity, 1, "Verbosity level.") +FUZZER_FLAG_UNSIGNED(seed, 0, "Random seed. If 0, seed is generated.") +FUZZER_FLAG_INT(runs, -1, + "Number of individual test runs (-1 for infinite runs).") +FUZZER_FLAG_INT(max_len, 0, "Maximum length of the test input. " + "If 0, libFuzzer tries to guess a good value based on the corpus " + "and reports it. ") +FUZZER_FLAG_INT(len_control, 100, "Try generating small inputs first, " + "then try larger inputs over time. Specifies the rate at which the length " + "limit is increased (smaller == faster). If 0, immediately try inputs with " + "size up to max_len. Default value is 0, if LLVMFuzzerCustomMutator is used.") +FUZZER_FLAG_STRING(seed_inputs, "A comma-separated list of input files " + "to use as an additional seed corpus. Alternatively, an \"@\" followed by " + "the name of a file containing the comma-separated list.") +FUZZER_FLAG_INT(keep_seed, 0, "If 1, keep seed inputs in the corpus even if " + "they do not produce new coverage. When used with |reduce_inputs==1|, the " + "seed inputs will never be reduced. This option can be useful when seeds are" + "not properly formed for the fuzz target but still have useful snippets.") +FUZZER_FLAG_INT(cross_over, 1, "If 1, cross over inputs.") +FUZZER_FLAG_INT(cross_over_uniform_dist, 0, "Experimental. If 1, use a " + "uniform probability distribution when choosing inputs to cross over with. " + "Some of the inputs in the corpus may never get chosen for mutation " + "depending on the input mutation scheduling policy. With this flag, all " + "inputs, regardless of the input mutation scheduling policy, can be chosen " + "as an input to cross over with. This can be particularly useful with " + "|keep_seed==1|; all the initial seed inputs, even though they do not " + "increase coverage because they are not properly formed, will still be " + "chosen as an input to cross over with.") + +FUZZER_FLAG_INT(mutate_depth, 5, + "Apply this number of consecutive mutations to each input.") +FUZZER_FLAG_INT(reduce_depth, 0, "Experimental/internal. " + "Reduce depth if mutations lose unique features") +FUZZER_FLAG_INT(shuffle, 1, "Shuffle inputs at startup") +FUZZER_FLAG_INT(prefer_small, 1, + "If 1, always prefer smaller inputs during the corpus shuffle.") +FUZZER_FLAG_INT( + timeout, 1200, + "Timeout in seconds (if positive). " + "If one unit runs more than this number of seconds the process will abort.") +FUZZER_FLAG_INT(error_exitcode, 77, "When libFuzzer itself reports a bug " + "this exit code will be used.") +FUZZER_FLAG_INT(timeout_exitcode, 70, "When libFuzzer reports a timeout " + "this exit code will be used.") +FUZZER_FLAG_INT(max_total_time, 0, "If positive, indicates the maximal total " + "time in seconds to run the fuzzer.") +FUZZER_FLAG_INT(help, 0, "Print help.") +FUZZER_FLAG_INT(fork, 0, "Experimental mode where fuzzing happens " + "in a subprocess") +FUZZER_FLAG_INT(ignore_timeouts, 1, "Ignore timeouts in fork mode") +FUZZER_FLAG_INT(ignore_ooms, 1, "Ignore OOMs in fork mode") +FUZZER_FLAG_INT(ignore_crashes, 0, "Ignore crashes in fork mode") +FUZZER_FLAG_INT(merge, 0, "If 1, the 2-nd, 3-rd, etc corpora will be " + "merged into the 1-st corpus. Only interesting units will be taken. " + "This flag can be used to minimize a corpus.") +FUZZER_FLAG_STRING(stop_file, "Stop fuzzing ASAP if this file exists") +FUZZER_FLAG_STRING(merge_inner, "internal flag") +FUZZER_FLAG_STRING(merge_control_file, + "Specify a control file used for the merge process. " + "If a merge process gets killed it tries to leave this file " + "in a state suitable for resuming the merge. " + "By default a temporary file will be used." + "The same file can be used for multistep merge process.") +FUZZER_FLAG_INT(minimize_crash, 0, "If 1, minimizes the provided" + " crash input. Use with -runs=N or -max_total_time=N to limit " + "the number attempts." + " Use with -exact_artifact_path to specify the output." + " Combine with ASAN_OPTIONS=dedup_token_length=3 (or similar) to ensure that" + " the minimized input triggers the same crash." + ) +FUZZER_FLAG_INT(cleanse_crash, 0, "If 1, tries to cleanse the provided" + " crash input to make it contain fewer original bytes." + " Use with -exact_artifact_path to specify the output." + ) +FUZZER_FLAG_INT(minimize_crash_internal_step, 0, "internal flag") +FUZZER_FLAG_STRING(features_dir, "internal flag. Used to dump feature sets on disk." + "Every time a new input is added to the corpus, a corresponding file in the features_dir" + " is created containing the unique features of that input." + " Features are stored in binary format.") +FUZZER_FLAG_STRING(mutation_graph_file, "Saves a graph (in DOT format) to" + " mutation_graph_file. The graph contains a vertex for each input that has" + " unique coverage; directed edges are provided between parents and children" + " where the child has unique coverage, and are recorded with the type of" + " mutation that caused the child.") +FUZZER_FLAG_INT(use_counters, 1, "Use coverage counters") +FUZZER_FLAG_INT(use_memmem, 1, + "Use hints from intercepting memmem, strstr, etc") +FUZZER_FLAG_INT(use_value_profile, 0, + "Experimental. Use value profile to guide fuzzing.") +FUZZER_FLAG_INT(use_cmp, 1, "Use CMP traces to guide mutations") +FUZZER_FLAG_INT(shrink, 0, "Experimental. Try to shrink corpus inputs.") +FUZZER_FLAG_INT(reduce_inputs, 1, + "Try to reduce the size of inputs while preserving their full feature sets") +FUZZER_FLAG_UNSIGNED(jobs, 0, "Number of jobs to run. If jobs >= 1 we spawn" + " this number of jobs in separate worker processes" + " with stdout/stderr redirected to fuzz-JOB.log.") +FUZZER_FLAG_UNSIGNED(workers, 0, + "Number of simultaneous worker processes to run the jobs." + " If zero, \"min(jobs,NumberOfCpuCores()/2)\" is used.") +FUZZER_FLAG_INT(reload, 1, + "Reload the main corpus every <N> seconds to get new units" + " discovered by other processes. If 0, disabled") +FUZZER_FLAG_INT(report_slow_units, 10, + "Report slowest units if they run for more than this number of seconds.") +FUZZER_FLAG_INT(only_ascii, 0, + "If 1, generate only ASCII (isprint+isspace) inputs.") +FUZZER_FLAG_STRING(dict, "Experimental. Use the dictionary file.") +FUZZER_FLAG_STRING(artifact_prefix, "Write fuzzing artifacts (crash, " + "timeout, or slow inputs) as " + "$(artifact_prefix)file") +FUZZER_FLAG_STRING(exact_artifact_path, + "Write the single artifact on failure (crash, timeout) " + "as $(exact_artifact_path). This overrides -artifact_prefix " + "and will not use checksum in the file name. Do not " + "use the same path for several parallel processes.") +FUZZER_FLAG_INT(print_pcs, 0, "If 1, print out newly covered PCs.") +FUZZER_FLAG_INT(print_funcs, 2, "If >=1, print out at most this number of " + "newly covered functions.") +FUZZER_FLAG_INT(print_final_stats, 0, "If 1, print statistics at exit.") +FUZZER_FLAG_INT(print_corpus_stats, 0, + "If 1, print statistics on corpus elements at exit.") +FUZZER_FLAG_INT(print_coverage, 0, "If 1, print coverage information as text" + " at exit.") +FUZZER_FLAG_INT(dump_coverage, 0, "Deprecated.") +FUZZER_FLAG_INT(handle_segv, 1, "If 1, try to intercept SIGSEGV.") +FUZZER_FLAG_INT(handle_bus, 1, "If 1, try to intercept SIGBUS.") +FUZZER_FLAG_INT(handle_abrt, 1, "If 1, try to intercept SIGABRT.") +FUZZER_FLAG_INT(handle_ill, 1, "If 1, try to intercept SIGILL.") +FUZZER_FLAG_INT(handle_fpe, 1, "If 1, try to intercept SIGFPE.") +FUZZER_FLAG_INT(handle_int, 1, "If 1, try to intercept SIGINT.") +FUZZER_FLAG_INT(handle_term, 1, "If 1, try to intercept SIGTERM.") +FUZZER_FLAG_INT(handle_xfsz, 1, "If 1, try to intercept SIGXFSZ.") +FUZZER_FLAG_INT(handle_usr1, 1, "If 1, try to intercept SIGUSR1.") +FUZZER_FLAG_INT(handle_usr2, 1, "If 1, try to intercept SIGUSR2.") +FUZZER_FLAG_INT(close_fd_mask, 0, "If 1, close stdout at startup; " + "if 2, close stderr; if 3, close both. " + "Be careful, this will also close e.g. stderr of asan.") +FUZZER_FLAG_INT(detect_leaks, 1, "If 1, and if LeakSanitizer is enabled " + "try to detect memory leaks during fuzzing (i.e. not only at shut down).") +FUZZER_FLAG_INT(purge_allocator_interval, 1, "Purge allocator caches and " + "quarantines every <N> seconds. When rss_limit_mb is specified (>0), " + "purging starts when RSS exceeds 50% of rss_limit_mb. Pass " + "purge_allocator_interval=-1 to disable this functionality.") +FUZZER_FLAG_INT(trace_malloc, 0, "If >= 1 will print all mallocs/frees. " + "If >= 2 will also print stack traces.") +FUZZER_FLAG_INT(rss_limit_mb, 2048, "If non-zero, the fuzzer will exit upon" + "reaching this limit of RSS memory usage.") +FUZZER_FLAG_INT(malloc_limit_mb, 0, "If non-zero, the fuzzer will exit " + "if the target tries to allocate this number of Mb with one malloc call. " + "If zero (default) same limit as rss_limit_mb is applied.") +FUZZER_FLAG_STRING(exit_on_src_pos, "Exit if a newly found PC originates" + " from the given source location. Example: -exit_on_src_pos=foo.cc:123. " + "Used primarily for testing libFuzzer itself.") +FUZZER_FLAG_STRING(exit_on_item, "Exit if an item with a given sha1 sum" + " was added to the corpus. " + "Used primarily for testing libFuzzer itself.") +FUZZER_FLAG_INT(ignore_remaining_args, 0, "If 1, ignore all arguments passed " + "after this one. Useful for fuzzers that need to do their own " + "argument parsing.") +FUZZER_FLAG_STRING(focus_function, "Experimental. " + "Fuzzing will focus on inputs that trigger calls to this function. " + "If -focus_function=auto and -data_flow_trace is used, libFuzzer " + "will choose the focus functions automatically. Disables -entropic when " + "specified.") +FUZZER_FLAG_INT(entropic, 1, "Enables entropic power schedule.") +FUZZER_FLAG_INT(entropic_feature_frequency_threshold, 0xFF, "Experimental. If " + "entropic is enabled, all features which are observed less often than " + "the specified value are considered as rare.") +FUZZER_FLAG_INT(entropic_number_of_rarest_features, 100, "Experimental. If " + "entropic is enabled, we keep track of the frequencies only for the " + "Top-X least abundant features (union features that are considered as " + "rare).") +FUZZER_FLAG_INT(entropic_scale_per_exec_time, 0, "Experimental. If 1, " + "the Entropic power schedule gets scaled based on the input execution " + "time. Inputs with lower execution time get scheduled more (up to 30x). " + "Note that, if 1, fuzzer stops from being deterministic even if a " + "non-zero random seed is given.") + +FUZZER_FLAG_INT(analyze_dict, 0, "Experimental") +FUZZER_DEPRECATED_FLAG(use_clang_coverage) +FUZZER_FLAG_STRING(data_flow_trace, "Experimental: use the data flow trace") +FUZZER_FLAG_STRING(collect_data_flow, + "Experimental: collect the data flow trace") + +FUZZER_FLAG_INT(create_missing_dirs, 0, "Automatically attempt to create " + "directories for arguments that would normally expect them to already " + "exist (i.e. artifact_prefix, exact_artifact_path, features_dir, corpus)") diff --git a/custom_mutators/libfuzzer/FuzzerFork.cpp b/custom_mutators/libfuzzer/FuzzerFork.cpp new file mode 100644 index 00000000..d6ffed74 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerFork.cpp @@ -0,0 +1,501 @@ +//===- FuzzerFork.cpp - run fuzzing in separate subprocesses --------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Spawn and orchestrate separate fuzzing processes. +//===----------------------------------------------------------------------===// + +#include "FuzzerCommand.h" +#include "FuzzerFork.h" +#include "FuzzerIO.h" +#include "FuzzerInternal.h" +#include "FuzzerMerge.h" +#include "FuzzerSHA1.h" +#include "FuzzerTracePC.h" +#include "FuzzerUtil.h" + +#include <atomic> +#include <chrono> +#include <condition_variable> +#include <fstream> +#include <memory> +#include <mutex> +#include <queue> +#include <sstream> +#include <thread> + +namespace fuzzer { + +struct Stats { + + size_t number_of_executed_units = 0; + size_t peak_rss_mb = 0; + size_t average_exec_per_sec = 0; + +}; + +static Stats ParseFinalStatsFromLog(const std::string &LogPath) { + + std::ifstream In(LogPath); + std::string Line; + Stats Res; + struct { + + const char *Name; + size_t * Var; + + } NameVarPairs[] = { + + {"stat::number_of_executed_units:", &Res.number_of_executed_units}, + {"stat::peak_rss_mb:", &Res.peak_rss_mb}, + {"stat::average_exec_per_sec:", &Res.average_exec_per_sec}, + {nullptr, nullptr}, + + }; + + while (std::getline(In, Line, '\n')) { + + if (Line.find("stat::") != 0) continue; + std::istringstream ISS(Line); + std::string Name; + size_t Val; + ISS >> Name >> Val; + for (size_t i = 0; NameVarPairs[i].Name; i++) + if (Name == NameVarPairs[i].Name) *NameVarPairs[i].Var = Val; + + } + + return Res; + +} + +struct FuzzJob { + + // Inputs. + Command Cmd; + std::string CorpusDir; + std::string FeaturesDir; + std::string LogPath; + std::string SeedListPath; + std::string CFPath; + size_t JobId; + + int DftTimeInSeconds = 0; + + // Fuzzing Outputs. + int ExitCode; + + ~FuzzJob() { + + RemoveFile(CFPath); + RemoveFile(LogPath); + RemoveFile(SeedListPath); + RmDirRecursive(CorpusDir); + RmDirRecursive(FeaturesDir); + + } + +}; + +struct GlobalEnv { + + Vector<std::string> Args; + Vector<std::string> CorpusDirs; + std::string MainCorpusDir; + std::string TempDir; + std::string DFTDir; + std::string DataFlowBinary; + Set<uint32_t> Features, Cov; + Set<std::string> FilesWithDFT; + Vector<std::string> Files; + Random * Rand; + std::chrono::system_clock::time_point ProcessStartTime; + int Verbosity = 0; + + size_t NumTimeouts = 0; + size_t NumOOMs = 0; + size_t NumCrashes = 0; + + size_t NumRuns = 0; + + std::string StopFile() { + + return DirPlusFile(TempDir, "STOP"); + + } + + size_t secondsSinceProcessStartUp() const { + + return std::chrono::duration_cast<std::chrono::seconds>( + std::chrono::system_clock::now() - ProcessStartTime) + .count(); + + } + + FuzzJob *CreateNewJob(size_t JobId) { + + Command Cmd(Args); + Cmd.removeFlag("fork"); + Cmd.removeFlag("runs"); + Cmd.removeFlag("collect_data_flow"); + for (auto &C : CorpusDirs) // Remove all corpora from the args. + Cmd.removeArgument(C); + Cmd.addFlag("reload", "0"); // working in an isolated dir, no reload. + Cmd.addFlag("print_final_stats", "1"); + Cmd.addFlag("print_funcs", "0"); // no need to spend time symbolizing. + Cmd.addFlag("max_total_time", std::to_string(std::min((size_t)300, JobId))); + Cmd.addFlag("stop_file", StopFile()); + if (!DataFlowBinary.empty()) { + + Cmd.addFlag("data_flow_trace", DFTDir); + if (!Cmd.hasFlag("focus_function")) Cmd.addFlag("focus_function", "auto"); + + } + + auto Job = new FuzzJob; + std::string Seeds; + if (size_t CorpusSubsetSize = + std::min(Files.size(), (size_t)sqrt(Files.size() + 2))) { + + auto Time1 = std::chrono::system_clock::now(); + for (size_t i = 0; i < CorpusSubsetSize; i++) { + + auto &SF = Files[Rand->SkewTowardsLast(Files.size())]; + Seeds += (Seeds.empty() ? "" : ",") + SF; + CollectDFT(SF); + + } + + auto Time2 = std::chrono::system_clock::now(); + Job->DftTimeInSeconds = duration_cast<seconds>(Time2 - Time1).count(); + + } + + if (!Seeds.empty()) { + + Job->SeedListPath = + DirPlusFile(TempDir, std::to_string(JobId) + ".seeds"); + WriteToFile(Seeds, Job->SeedListPath); + Cmd.addFlag("seed_inputs", "@" + Job->SeedListPath); + + } + + Job->LogPath = DirPlusFile(TempDir, std::to_string(JobId) + ".log"); + Job->CorpusDir = DirPlusFile(TempDir, "C" + std::to_string(JobId)); + Job->FeaturesDir = DirPlusFile(TempDir, "F" + std::to_string(JobId)); + Job->CFPath = DirPlusFile(TempDir, std::to_string(JobId) + ".merge"); + Job->JobId = JobId; + + Cmd.addArgument(Job->CorpusDir); + Cmd.addFlag("features_dir", Job->FeaturesDir); + + for (auto &D : {Job->CorpusDir, Job->FeaturesDir}) { + + RmDirRecursive(D); + MkDir(D); + + } + + Cmd.setOutputFile(Job->LogPath); + Cmd.combineOutAndErr(); + + Job->Cmd = Cmd; + + if (Verbosity >= 2) + Printf("Job %zd/%p Created: %s\n", JobId, Job, + Job->Cmd.toString().c_str()); + // Start from very short runs and gradually increase them. + return Job; + + } + + void RunOneMergeJob(FuzzJob *Job) { + + auto Stats = ParseFinalStatsFromLog(Job->LogPath); + NumRuns += Stats.number_of_executed_units; + + Vector<SizedFile> TempFiles, MergeCandidates; + // Read all newly created inputs and their feature sets. + // Choose only those inputs that have new features. + GetSizedFilesFromDir(Job->CorpusDir, &TempFiles); + std::sort(TempFiles.begin(), TempFiles.end()); + for (auto &F : TempFiles) { + + auto FeatureFile = F.File; + FeatureFile.replace(0, Job->CorpusDir.size(), Job->FeaturesDir); + auto FeatureBytes = FileToVector(FeatureFile, 0, false); + assert((FeatureBytes.size() % sizeof(uint32_t)) == 0); + Vector<uint32_t> NewFeatures(FeatureBytes.size() / sizeof(uint32_t)); + memcpy(NewFeatures.data(), FeatureBytes.data(), FeatureBytes.size()); + for (auto Ft : NewFeatures) { + + if (!Features.count(Ft)) { + + MergeCandidates.push_back(F); + break; + + } + + } + + } + + // if (!FilesToAdd.empty() || Job->ExitCode != 0) + Printf( + "#%zd: cov: %zd ft: %zd corp: %zd exec/s %zd " + "oom/timeout/crash: %zd/%zd/%zd time: %zds job: %zd dft_time: %d\n", + NumRuns, Cov.size(), Features.size(), Files.size(), + Stats.average_exec_per_sec, NumOOMs, NumTimeouts, NumCrashes, + secondsSinceProcessStartUp(), Job->JobId, Job->DftTimeInSeconds); + + if (MergeCandidates.empty()) return; + + Vector<std::string> FilesToAdd; + Set<uint32_t> NewFeatures, NewCov; + CrashResistantMerge(Args, {}, MergeCandidates, &FilesToAdd, Features, + &NewFeatures, Cov, &NewCov, Job->CFPath, false); + for (auto &Path : FilesToAdd) { + + auto U = FileToVector(Path); + auto NewPath = DirPlusFile(MainCorpusDir, Hash(U)); + WriteToFile(U, NewPath); + Files.push_back(NewPath); + + } + + Features.insert(NewFeatures.begin(), NewFeatures.end()); + Cov.insert(NewCov.begin(), NewCov.end()); + for (auto Idx : NewCov) + if (auto *TE = TPC.PCTableEntryByIdx(Idx)) + if (TPC.PcIsFuncEntry(TE)) + PrintPC(" NEW_FUNC: %p %F %L\n", "", + TPC.GetNextInstructionPc(TE->PC)); + + } + + void CollectDFT(const std::string &InputPath) { + + if (DataFlowBinary.empty()) return; + if (!FilesWithDFT.insert(InputPath).second) return; + Command Cmd(Args); + Cmd.removeFlag("fork"); + Cmd.removeFlag("runs"); + Cmd.addFlag("data_flow_trace", DFTDir); + Cmd.addArgument(InputPath); + for (auto &C : CorpusDirs) // Remove all corpora from the args. + Cmd.removeArgument(C); + Cmd.setOutputFile(DirPlusFile(TempDir, "dft.log")); + Cmd.combineOutAndErr(); + // Printf("CollectDFT: %s\n", Cmd.toString().c_str()); + ExecuteCommand(Cmd); + + } + +}; + +struct JobQueue { + + std::queue<FuzzJob *> Qu; + std::mutex Mu; + std::condition_variable Cv; + + void Push(FuzzJob *Job) { + + { + + std::lock_guard<std::mutex> Lock(Mu); + Qu.push(Job); + + } + + Cv.notify_one(); + + } + + FuzzJob *Pop() { + + std::unique_lock<std::mutex> Lk(Mu); + // std::lock_guard<std::mutex> Lock(Mu); + Cv.wait(Lk, [&] { return !Qu.empty(); }); + assert(!Qu.empty()); + auto Job = Qu.front(); + Qu.pop(); + return Job; + + } + +}; + +void WorkerThread(JobQueue *FuzzQ, JobQueue *MergeQ) { + + while (auto Job = FuzzQ->Pop()) { + + // Printf("WorkerThread: job %p\n", Job); + Job->ExitCode = ExecuteCommand(Job->Cmd); + MergeQ->Push(Job); + + } + +} + +// This is just a skeleton of an experimental -fork=1 feature. +void FuzzWithFork(Random &Rand, const FuzzingOptions &Options, + const Vector<std::string> &Args, + const Vector<std::string> &CorpusDirs, int NumJobs) { + + Printf("INFO: -fork=%d: fuzzing in separate process(s)\n", NumJobs); + + GlobalEnv Env; + Env.Args = Args; + Env.CorpusDirs = CorpusDirs; + Env.Rand = &Rand; + Env.Verbosity = Options.Verbosity; + Env.ProcessStartTime = std::chrono::system_clock::now(); + Env.DataFlowBinary = Options.CollectDataFlow; + + Vector<SizedFile> SeedFiles; + for (auto &Dir : CorpusDirs) + GetSizedFilesFromDir(Dir, &SeedFiles); + std::sort(SeedFiles.begin(), SeedFiles.end()); + Env.TempDir = TempPath("FuzzWithFork", ".dir"); + Env.DFTDir = DirPlusFile(Env.TempDir, "DFT"); + RmDirRecursive(Env.TempDir); // in case there is a leftover from old runs. + MkDir(Env.TempDir); + MkDir(Env.DFTDir); + + if (CorpusDirs.empty()) + MkDir(Env.MainCorpusDir = DirPlusFile(Env.TempDir, "C")); + else + Env.MainCorpusDir = CorpusDirs[0]; + + if (Options.KeepSeed) { + + for (auto &File : SeedFiles) + Env.Files.push_back(File.File); + + } else { + + auto CFPath = DirPlusFile(Env.TempDir, "merge.txt"); + CrashResistantMerge(Env.Args, {}, SeedFiles, &Env.Files, {}, &Env.Features, + {}, &Env.Cov, CFPath, false); + RemoveFile(CFPath); + + } + + Printf("INFO: -fork=%d: %zd seed inputs, starting to fuzz in %s\n", NumJobs, + Env.Files.size(), Env.TempDir.c_str()); + + int ExitCode = 0; + + JobQueue FuzzQ, MergeQ; + + auto StopJobs = [&]() { + + for (int i = 0; i < NumJobs; i++) + FuzzQ.Push(nullptr); + MergeQ.Push(nullptr); + WriteToFile(Unit({1}), Env.StopFile()); + + }; + + size_t JobId = 1; + Vector<std::thread> Threads; + for (int t = 0; t < NumJobs; t++) { + + Threads.push_back(std::thread(WorkerThread, &FuzzQ, &MergeQ)); + FuzzQ.Push(Env.CreateNewJob(JobId++)); + + } + + while (true) { + + std::unique_ptr<FuzzJob> Job(MergeQ.Pop()); + if (!Job) break; + ExitCode = Job->ExitCode; + if (ExitCode == Options.InterruptExitCode) { + + Printf("==%lu== libFuzzer: a child was interrupted; exiting\n", GetPid()); + StopJobs(); + break; + + } + + Fuzzer::MaybeExitGracefully(); + + Env.RunOneMergeJob(Job.get()); + + // Continue if our crash is one of the ignorred ones. + if (Options.IgnoreTimeouts && ExitCode == Options.TimeoutExitCode) + Env.NumTimeouts++; + else if (Options.IgnoreOOMs && ExitCode == Options.OOMExitCode) + Env.NumOOMs++; + else if (ExitCode != 0) { + + Env.NumCrashes++; + if (Options.IgnoreCrashes) { + + std::ifstream In(Job->LogPath); + std::string Line; + while (std::getline(In, Line, '\n')) + if (Line.find("ERROR:") != Line.npos || + Line.find("runtime error:") != Line.npos) + Printf("%s\n", Line.c_str()); + + } else { + + // And exit if we don't ignore this crash. + Printf("INFO: log from the inner process:\n%s", + FileToString(Job->LogPath).c_str()); + StopJobs(); + break; + + } + + } + + // Stop if we are over the time budget. + // This is not precise, since other threads are still running + // and we will wait while joining them. + // We also don't stop instantly: other jobs need to finish. + if (Options.MaxTotalTimeSec > 0 && + Env.secondsSinceProcessStartUp() >= (size_t)Options.MaxTotalTimeSec) { + + Printf("INFO: fuzzed for %zd seconds, wrapping up soon\n", + Env.secondsSinceProcessStartUp()); + StopJobs(); + break; + + } + + if (Env.NumRuns >= Options.MaxNumberOfRuns) { + + Printf("INFO: fuzzed for %zd iterations, wrapping up soon\n", + Env.NumRuns); + StopJobs(); + break; + + } + + FuzzQ.Push(Env.CreateNewJob(JobId++)); + + } + + for (auto &T : Threads) + T.join(); + + // The workers have terminated. Don't try to remove the directory before they + // terminate to avoid a race condition preventing cleanup on Windows. + RmDirRecursive(Env.TempDir); + + // Use the exit code from the last child process. + Printf("INFO: exiting: %d time: %zds\n", ExitCode, + Env.secondsSinceProcessStartUp()); + exit(ExitCode); + +} + +} // namespace fuzzer + diff --git a/custom_mutators/libfuzzer/FuzzerFork.h b/custom_mutators/libfuzzer/FuzzerFork.h new file mode 100644 index 00000000..b29a43e1 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerFork.h @@ -0,0 +1,24 @@ +//===- FuzzerFork.h - run fuzzing in sub-processes --------------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_FORK_H +#define LLVM_FUZZER_FORK_H + +#include "FuzzerDefs.h" +#include "FuzzerOptions.h" +#include "FuzzerRandom.h" + +#include <string> + +namespace fuzzer { +void FuzzWithFork(Random &Rand, const FuzzingOptions &Options, + const Vector<std::string> &Args, + const Vector<std::string> &CorpusDirs, int NumJobs); +} // namespace fuzzer + +#endif // LLVM_FUZZER_FORK_H diff --git a/custom_mutators/libfuzzer/FuzzerIO.cpp b/custom_mutators/libfuzzer/FuzzerIO.cpp new file mode 100644 index 00000000..d8d52b63 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerIO.cpp @@ -0,0 +1,255 @@ +//===- FuzzerIO.cpp - IO utils. -------------------------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// IO functions. +//===----------------------------------------------------------------------===// + +#include "FuzzerDefs.h" +#include "FuzzerExtFunctions.h" +#include "FuzzerIO.h" +#include "FuzzerUtil.h" +#include <algorithm> +#include <cstdarg> +#include <fstream> +#include <iterator> +#include <sys/stat.h> +#include <sys/types.h> + +namespace fuzzer { + +static FILE *OutputFile = stderr; + +long GetEpoch(const std::string &Path) { + + struct stat St; + if (stat(Path.c_str(), &St)) return 0; // Can't stat, be conservative. + return St.st_mtime; + +} + +Unit FileToVector(const std::string &Path, size_t MaxSize, bool ExitOnError) { + + std::ifstream T(Path, std::ios::binary); + if (ExitOnError && !T) { + + Printf("No such directory: %s; exiting\n", Path.c_str()); + exit(1); + + } + + T.seekg(0, T.end); + auto EndPos = T.tellg(); + if (EndPos < 0) return {}; + size_t FileLen = EndPos; + if (MaxSize) FileLen = std::min(FileLen, MaxSize); + + T.seekg(0, T.beg); + Unit Res(FileLen); + T.read(reinterpret_cast<char *>(Res.data()), FileLen); + return Res; + +} + +std::string FileToString(const std::string &Path) { + + std::ifstream T(Path, std::ios::binary); + return std::string((std::istreambuf_iterator<char>(T)), + std::istreambuf_iterator<char>()); + +} + +void CopyFileToErr(const std::string &Path) { + + Printf("%s", FileToString(Path).c_str()); + +} + +void WriteToFile(const Unit &U, const std::string &Path) { + + WriteToFile(U.data(), U.size(), Path); + +} + +void WriteToFile(const std::string &Data, const std::string &Path) { + + WriteToFile(reinterpret_cast<const uint8_t *>(Data.c_str()), Data.size(), + Path); + +} + +void WriteToFile(const uint8_t *Data, size_t Size, const std::string &Path) { + + return; + + // Use raw C interface because this function may be called from a sig handler. + FILE *Out = fopen(Path.c_str(), "wb"); + if (!Out) return; + fwrite(Data, sizeof(Data[0]), Size, Out); + fclose(Out); + +} + +void AppendToFile(const std::string &Data, const std::string &Path) { + + return; + + AppendToFile(reinterpret_cast<const uint8_t *>(Data.data()), Data.size(), + Path); + +} + +void AppendToFile(const uint8_t *Data, size_t Size, const std::string &Path) { + + return; + + FILE *Out = fopen(Path.c_str(), "a"); + if (!Out) return; + fwrite(Data, sizeof(Data[0]), Size, Out); + fclose(Out); + +} + +void ReadDirToVectorOfUnits(const char *Path, Vector<Unit> *V, long *Epoch, + size_t MaxSize, bool ExitOnError) { + + long E = Epoch ? *Epoch : 0; + Vector<std::string> Files; + ListFilesInDirRecursive(Path, Epoch, &Files, /*TopDir*/ true); + size_t NumLoaded = 0; + for (size_t i = 0; i < Files.size(); i++) { + + auto &X = Files[i]; + if (Epoch && GetEpoch(X) < E) continue; + NumLoaded++; + if ((NumLoaded & (NumLoaded - 1)) == 0 && NumLoaded >= 1024) + Printf("Loaded %zd/%zd files from %s\n", NumLoaded, Files.size(), Path); + auto S = FileToVector(X, MaxSize, ExitOnError); + if (!S.empty()) V->push_back(S); + + } + +} + +void GetSizedFilesFromDir(const std::string &Dir, Vector<SizedFile> *V) { + + Vector<std::string> Files; + ListFilesInDirRecursive(Dir, 0, &Files, /*TopDir*/ true); + for (auto &File : Files) + if (size_t Size = FileSize(File)) V->push_back({File, Size}); + +} + +std::string DirPlusFile(const std::string &DirPath, + const std::string &FileName) { + + return DirPath + GetSeparator() + FileName; + +} + +void DupAndCloseStderr() { + + int OutputFd = DuplicateFile(2); + if (OutputFd >= 0) { + + FILE *NewOutputFile = OpenFile(OutputFd, "w"); + if (NewOutputFile) { + + OutputFile = NewOutputFile; + if (EF->__sanitizer_set_report_fd) + EF->__sanitizer_set_report_fd( + reinterpret_cast<void *>(GetHandleFromFd(OutputFd))); + DiscardOutput(2); + + } + + } + +} + +void CloseStdout() { + + DiscardOutput(1); + +} + +void Printf(const char *Fmt, ...) { + + va_list ap; + va_start(ap, Fmt); + vfprintf(OutputFile, Fmt, ap); + va_end(ap); + fflush(OutputFile); + +} + +void VPrintf(bool Verbose, const char *Fmt, ...) { + + return; + if (!Verbose) return; + va_list ap; + va_start(ap, Fmt); + vfprintf(OutputFile, Fmt, ap); + va_end(ap); + fflush(OutputFile); + +} + +static bool MkDirRecursiveInner(const std::string &Leaf) { + + // Prevent chance of potential infinite recursion + if (Leaf == ".") return true; + + const std::string &Dir = DirName(Leaf); + + if (IsDirectory(Dir)) { + + MkDir(Leaf); + return IsDirectory(Leaf); + + } + + bool ret = MkDirRecursiveInner(Dir); + if (!ret) { + + // Give up early if a previous MkDir failed + return ret; + + } + + MkDir(Leaf); + return IsDirectory(Leaf); + +} + +bool MkDirRecursive(const std::string &Dir) { + + if (Dir.empty()) return false; + + if (IsDirectory(Dir)) return true; + + return MkDirRecursiveInner(Dir); + +} + +void RmDirRecursive(const std::string &Dir) { + + IterateDirRecursive( + Dir, [](const std::string &Path) {}, + [](const std::string &Path) { RmDir(Path); }, + [](const std::string &Path) { RemoveFile(Path); }); + +} + +std::string TempPath(const char *Prefix, const char *Extension) { + + return DirPlusFile(TmpDir(), std::string("libFuzzerTemp.") + Prefix + + std::to_string(GetPid()) + Extension); + +} + +} // namespace fuzzer + diff --git a/custom_mutators/libfuzzer/FuzzerIO.h b/custom_mutators/libfuzzer/FuzzerIO.h new file mode 100644 index 00000000..abd25110 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerIO.h @@ -0,0 +1,112 @@ +//===- FuzzerIO.h - Internal header for IO utils ----------------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// IO interface. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_IO_H +#define LLVM_FUZZER_IO_H + +#include "FuzzerDefs.h" + +namespace fuzzer { + +long GetEpoch(const std::string &Path); + +Unit FileToVector(const std::string &Path, size_t MaxSize = 0, + bool ExitOnError = true); + +std::string FileToString(const std::string &Path); + +void CopyFileToErr(const std::string &Path); + +void WriteToFile(const uint8_t *Data, size_t Size, const std::string &Path); +// Write Data.c_str() to the file without terminating null character. +void WriteToFile(const std::string &Data, const std::string &Path); +void WriteToFile(const Unit &U, const std::string &Path); + +void AppendToFile(const uint8_t *Data, size_t Size, const std::string &Path); +void AppendToFile(const std::string &Data, const std::string &Path); + +void ReadDirToVectorOfUnits(const char *Path, Vector<Unit> *V, + long *Epoch, size_t MaxSize, bool ExitOnError); + +// Returns "Dir/FileName" or equivalent for the current OS. +std::string DirPlusFile(const std::string &DirPath, + const std::string &FileName); + +// Returns the name of the dir, similar to the 'dirname' utility. +std::string DirName(const std::string &FileName); + +// Returns path to a TmpDir. +std::string TmpDir(); + +std::string TempPath(const char *Prefix, const char *Extension); + +bool IsInterestingCoverageFile(const std::string &FileName); + +void DupAndCloseStderr(); + +void CloseStdout(); + +void Printf(const char *Fmt, ...); +void VPrintf(bool Verbose, const char *Fmt, ...); + +// Print using raw syscalls, useful when printing at early init stages. +void RawPrint(const char *Str); + +// Platform specific functions: +bool IsFile(const std::string &Path); +bool IsDirectory(const std::string &Path); +size_t FileSize(const std::string &Path); + +void ListFilesInDirRecursive(const std::string &Dir, long *Epoch, + Vector<std::string> *V, bool TopDir); + +bool MkDirRecursive(const std::string &Dir); +void RmDirRecursive(const std::string &Dir); + +// Iterate files and dirs inside Dir, recursively. +// Call DirPreCallback/DirPostCallback on dirs before/after +// calling FileCallback on files. +void IterateDirRecursive(const std::string &Dir, + void (*DirPreCallback)(const std::string &Dir), + void (*DirPostCallback)(const std::string &Dir), + void (*FileCallback)(const std::string &Dir)); + +struct SizedFile { + std::string File; + size_t Size; + bool operator<(const SizedFile &B) const { return Size < B.Size; } +}; + +void GetSizedFilesFromDir(const std::string &Dir, Vector<SizedFile> *V); + +char GetSeparator(); +bool IsSeparator(char C); +// Similar to the basename utility: returns the file name w/o the dir prefix. +std::string Basename(const std::string &Path); + +FILE* OpenFile(int Fd, const char *Mode); + +int CloseFile(int Fd); + +int DuplicateFile(int Fd); + +void RemoveFile(const std::string &Path); +void RenameFile(const std::string &OldPath, const std::string &NewPath); + +intptr_t GetHandleFromFd(int fd); + +void MkDir(const std::string &Path); +void RmDir(const std::string &Path); + +const std::string &getDevNull(); + +} // namespace fuzzer + +#endif // LLVM_FUZZER_IO_H diff --git a/custom_mutators/libfuzzer/FuzzerIOPosix.cpp b/custom_mutators/libfuzzer/FuzzerIOPosix.cpp new file mode 100644 index 00000000..36ec5a9c --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerIOPosix.cpp @@ -0,0 +1,223 @@ +//===- FuzzerIOPosix.cpp - IO utils for Posix. ----------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// IO functions implementation using Posix API. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" +#if LIBFUZZER_POSIX || LIBFUZZER_FUCHSIA + + #include "FuzzerExtFunctions.h" + #include "FuzzerIO.h" + #include <cstdarg> + #include <cstdio> + #include <dirent.h> + #include <fstream> + #include <iterator> + #include <libgen.h> + #include <sys/stat.h> + #include <sys/types.h> + #include <unistd.h> + +namespace fuzzer { + +bool IsFile(const std::string &Path) { + + struct stat St; + if (stat(Path.c_str(), &St)) return false; + return S_ISREG(St.st_mode); + +} + +bool IsDirectory(const std::string &Path) { + + struct stat St; + if (stat(Path.c_str(), &St)) return false; + return S_ISDIR(St.st_mode); + +} + +size_t FileSize(const std::string &Path) { + + struct stat St; + if (stat(Path.c_str(), &St)) return 0; + return St.st_size; + +} + +std::string Basename(const std::string &Path) { + + size_t Pos = Path.rfind(GetSeparator()); + if (Pos == std::string::npos) return Path; + assert(Pos < Path.size()); + return Path.substr(Pos + 1); + +} + +void ListFilesInDirRecursive(const std::string &Dir, long *Epoch, + Vector<std::string> *V, bool TopDir) { + + auto E = GetEpoch(Dir); + if (Epoch) + if (E && *Epoch >= E) return; + + DIR *D = opendir(Dir.c_str()); + if (!D) { + + Printf("%s: %s; exiting\n", strerror(errno), Dir.c_str()); + exit(1); + + } + + while (auto E = readdir(D)) { + + std::string Path = DirPlusFile(Dir, E->d_name); + if (E->d_type == DT_REG || E->d_type == DT_LNK || + (E->d_type == DT_UNKNOWN && IsFile(Path))) + V->push_back(Path); + else if ((E->d_type == DT_DIR || + (E->d_type == DT_UNKNOWN && IsDirectory(Path))) && + *E->d_name != '.') + ListFilesInDirRecursive(Path, Epoch, V, false); + + } + + closedir(D); + if (Epoch && TopDir) *Epoch = E; + +} + +void IterateDirRecursive(const std::string &Dir, + void (*DirPreCallback)(const std::string &Dir), + void (*DirPostCallback)(const std::string &Dir), + void (*FileCallback)(const std::string &Dir)) { + + DirPreCallback(Dir); + DIR *D = opendir(Dir.c_str()); + if (!D) return; + while (auto E = readdir(D)) { + + std::string Path = DirPlusFile(Dir, E->d_name); + if (E->d_type == DT_REG || E->d_type == DT_LNK || + (E->d_type == DT_UNKNOWN && IsFile(Path))) + FileCallback(Path); + else if ((E->d_type == DT_DIR || + (E->d_type == DT_UNKNOWN && IsDirectory(Path))) && + *E->d_name != '.') + IterateDirRecursive(Path, DirPreCallback, DirPostCallback, FileCallback); + + } + + closedir(D); + DirPostCallback(Dir); + +} + +char GetSeparator() { + + return '/'; + +} + +bool IsSeparator(char C) { + + return C == '/'; + +} + +FILE *OpenFile(int Fd, const char *Mode) { + + return fdopen(Fd, Mode); + +} + +int CloseFile(int fd) { + + return close(fd); + +} + +int DuplicateFile(int Fd) { + + return dup(Fd); + +} + +void RemoveFile(const std::string &Path) { + + unlink(Path.c_str()); + +} + +void RenameFile(const std::string &OldPath, const std::string &NewPath) { + + rename(OldPath.c_str(), NewPath.c_str()); + +} + +intptr_t GetHandleFromFd(int fd) { + + return static_cast<intptr_t>(fd); + +} + +std::string DirName(const std::string &FileName) { + + char *Tmp = new char[FileName.size() + 1]; + memcpy(Tmp, FileName.c_str(), FileName.size() + 1); + std::string Res = dirname(Tmp); + delete[] Tmp; + return Res; + +} + +std::string TmpDir() { + + if (auto Env = getenv("TMPDIR")) return Env; + return "/tmp"; + +} + +bool IsInterestingCoverageFile(const std::string &FileName) { + + if (FileName.find("compiler-rt/lib/") != std::string::npos) + return false; // sanitizer internal. + if (FileName.find("/usr/lib/") != std::string::npos) return false; + if (FileName.find("/usr/include/") != std::string::npos) return false; + if (FileName == "<null>") return false; + return true; + +} + +void RawPrint(const char *Str) { + + write(2, Str, strlen(Str)); + +} + +void MkDir(const std::string &Path) { + + mkdir(Path.c_str(), 0700); + +} + +void RmDir(const std::string &Path) { + + rmdir(Path.c_str()); + +} + +const std::string &getDevNull() { + + static const std::string devNull = "/dev/null"; + return devNull; + +} + +} // namespace fuzzer + +#endif // LIBFUZZER_POSIX + diff --git a/custom_mutators/libfuzzer/FuzzerIOWindows.cpp b/custom_mutators/libfuzzer/FuzzerIOWindows.cpp new file mode 100644 index 00000000..9352984a --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerIOWindows.cpp @@ -0,0 +1,513 @@ +//===- FuzzerIOWindows.cpp - IO utils for Windows. ------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// IO functions implementation for Windows. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" +#if LIBFUZZER_WINDOWS + + #include "FuzzerExtFunctions.h" + #include "FuzzerIO.h" + #include <cstdarg> + #include <cstdio> + #include <fstream> + #include <io.h> + #include <iterator> + #include <sys/stat.h> + #include <sys/types.h> + #include <windows.h> + +namespace fuzzer { + +static bool IsFile(const std::string &Path, const DWORD &FileAttributes) { + + if (FileAttributes & FILE_ATTRIBUTE_NORMAL) return true; + + if (FileAttributes & FILE_ATTRIBUTE_DIRECTORY) return false; + + HANDLE FileHandle(CreateFileA(Path.c_str(), 0, FILE_SHARE_READ, NULL, + OPEN_EXISTING, FILE_FLAG_BACKUP_SEMANTICS, 0)); + + if (FileHandle == INVALID_HANDLE_VALUE) { + + Printf("CreateFileA() failed for \"%s\" (Error code: %lu).\n", Path.c_str(), + GetLastError()); + return false; + + } + + DWORD FileType = GetFileType(FileHandle); + + if (FileType == FILE_TYPE_UNKNOWN) { + + Printf("GetFileType() failed for \"%s\" (Error code: %lu).\n", Path.c_str(), + GetLastError()); + CloseHandle(FileHandle); + return false; + + } + + if (FileType != FILE_TYPE_DISK) { + + CloseHandle(FileHandle); + return false; + + } + + CloseHandle(FileHandle); + return true; + +} + +bool IsFile(const std::string &Path) { + + DWORD Att = GetFileAttributesA(Path.c_str()); + + if (Att == INVALID_FILE_ATTRIBUTES) { + + Printf("GetFileAttributesA() failed for \"%s\" (Error code: %lu).\n", + Path.c_str(), GetLastError()); + return false; + + } + + return IsFile(Path, Att); + +} + +static bool IsDir(DWORD FileAttrs) { + + if (FileAttrs == INVALID_FILE_ATTRIBUTES) return false; + return FileAttrs & FILE_ATTRIBUTE_DIRECTORY; + +} + +bool IsDirectory(const std::string &Path) { + + DWORD Att = GetFileAttributesA(Path.c_str()); + + if (Att == INVALID_FILE_ATTRIBUTES) { + + Printf("GetFileAttributesA() failed for \"%s\" (Error code: %lu).\n", + Path.c_str(), GetLastError()); + return false; + + } + + return IsDir(Att); + +} + +std::string Basename(const std::string &Path) { + + size_t Pos = Path.find_last_of("/\\"); + if (Pos == std::string::npos) return Path; + assert(Pos < Path.size()); + return Path.substr(Pos + 1); + +} + +size_t FileSize(const std::string &Path) { + + WIN32_FILE_ATTRIBUTE_DATA attr; + if (!GetFileAttributesExA(Path.c_str(), GetFileExInfoStandard, &attr)) { + + DWORD LastError = GetLastError(); + if (LastError != ERROR_FILE_NOT_FOUND) + Printf("GetFileAttributesExA() failed for \"%s\" (Error code: %lu).\n", + Path.c_str(), LastError); + return 0; + + } + + ULARGE_INTEGER size; + size.HighPart = attr.nFileSizeHigh; + size.LowPart = attr.nFileSizeLow; + return size.QuadPart; + +} + +void ListFilesInDirRecursive(const std::string &Dir, long *Epoch, + Vector<std::string> *V, bool TopDir) { + + auto E = GetEpoch(Dir); + if (Epoch) + if (E && *Epoch >= E) return; + + std::string Path(Dir); + assert(!Path.empty()); + if (Path.back() != '\\') Path.push_back('\\'); + Path.push_back('*'); + + // Get the first directory entry. + WIN32_FIND_DATAA FindInfo; + HANDLE FindHandle(FindFirstFileA(Path.c_str(), &FindInfo)); + if (FindHandle == INVALID_HANDLE_VALUE) { + + if (GetLastError() == ERROR_FILE_NOT_FOUND) return; + Printf("No such file or directory: %s; exiting\n", Dir.c_str()); + exit(1); + + } + + do { + + std::string FileName = DirPlusFile(Dir, FindInfo.cFileName); + + if (FindInfo.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY) { + + size_t FilenameLen = strlen(FindInfo.cFileName); + if ((FilenameLen == 1 && FindInfo.cFileName[0] == '.') || + (FilenameLen == 2 && FindInfo.cFileName[0] == '.' && + FindInfo.cFileName[1] == '.')) + continue; + + ListFilesInDirRecursive(FileName, Epoch, V, false); + + } else if (IsFile(FileName, FindInfo.dwFileAttributes)) + + V->push_back(FileName); + + } while (FindNextFileA(FindHandle, &FindInfo)); + + DWORD LastError = GetLastError(); + if (LastError != ERROR_NO_MORE_FILES) + Printf("FindNextFileA failed (Error code: %lu).\n", LastError); + + FindClose(FindHandle); + + if (Epoch && TopDir) *Epoch = E; + +} + +void IterateDirRecursive(const std::string &Dir, + void (*DirPreCallback)(const std::string &Dir), + void (*DirPostCallback)(const std::string &Dir), + void (*FileCallback)(const std::string &Dir)) { + + // TODO(metzman): Implement ListFilesInDirRecursive via this function. + DirPreCallback(Dir); + + DWORD DirAttrs = GetFileAttributesA(Dir.c_str()); + if (!IsDir(DirAttrs)) return; + + std::string TargetDir(Dir); + assert(!TargetDir.empty()); + if (TargetDir.back() != '\\') TargetDir.push_back('\\'); + TargetDir.push_back('*'); + + WIN32_FIND_DATAA FindInfo; + // Find the directory's first file. + HANDLE FindHandle = FindFirstFileA(TargetDir.c_str(), &FindInfo); + if (FindHandle == INVALID_HANDLE_VALUE) { + + DWORD LastError = GetLastError(); + if (LastError != ERROR_FILE_NOT_FOUND) { + + // If the directory isn't empty, then something abnormal is going on. + Printf("FindFirstFileA failed for %s (Error code: %lu).\n", Dir.c_str(), + LastError); + + } + + return; + + } + + do { + + std::string Path = DirPlusFile(Dir, FindInfo.cFileName); + DWORD PathAttrs = FindInfo.dwFileAttributes; + if (IsDir(PathAttrs)) { + + // Is Path the current directory (".") or the parent ("..")? + if (strcmp(FindInfo.cFileName, ".") == 0 || + strcmp(FindInfo.cFileName, "..") == 0) + continue; + IterateDirRecursive(Path, DirPreCallback, DirPostCallback, FileCallback); + + } else if (PathAttrs != INVALID_FILE_ATTRIBUTES) { + + FileCallback(Path); + + } + + } while (FindNextFileA(FindHandle, &FindInfo)); + + DWORD LastError = GetLastError(); + if (LastError != ERROR_NO_MORE_FILES) + Printf("FindNextFileA failed for %s (Error code: %lu).\n", Dir.c_str(), + LastError); + + FindClose(FindHandle); + DirPostCallback(Dir); + +} + +char GetSeparator() { + + return '\\'; + +} + +FILE *OpenFile(int Fd, const char *Mode) { + + return _fdopen(Fd, Mode); + +} + +int CloseFile(int Fd) { + + return _close(Fd); + +} + +int DuplicateFile(int Fd) { + + return _dup(Fd); + +} + +void RemoveFile(const std::string &Path) { + + _unlink(Path.c_str()); + +} + +void RenameFile(const std::string &OldPath, const std::string &NewPath) { + + rename(OldPath.c_str(), NewPath.c_str()); + +} + +intptr_t GetHandleFromFd(int fd) { + + return _get_osfhandle(fd); + +} + +bool IsSeparator(char C) { + + return C == '\\' || C == '/'; + +} + +// Parse disk designators, like "C:\". If Relative == true, also accepts: "C:". +// Returns number of characters considered if successful. +static size_t ParseDrive(const std::string &FileName, const size_t Offset, + bool Relative = true) { + + if (Offset + 1 >= FileName.size() || FileName[Offset + 1] != ':') return 0; + if (Offset + 2 >= FileName.size() || !IsSeparator(FileName[Offset + 2])) { + + if (!Relative) // Accept relative path? + return 0; + else + return 2; + + } + + return 3; + +} + +// Parse a file name, like: SomeFile.txt +// Returns number of characters considered if successful. +static size_t ParseFileName(const std::string &FileName, const size_t Offset) { + + size_t Pos = Offset; + const size_t End = FileName.size(); + for (; Pos < End && !IsSeparator(FileName[Pos]); ++Pos) + ; + return Pos - Offset; + +} + +// Parse a directory ending in separator, like: `SomeDir\` +// Returns number of characters considered if successful. +static size_t ParseDir(const std::string &FileName, const size_t Offset) { + + size_t Pos = Offset; + const size_t End = FileName.size(); + if (Pos >= End || IsSeparator(FileName[Pos])) return 0; + for (; Pos < End && !IsSeparator(FileName[Pos]); ++Pos) + ; + if (Pos >= End) return 0; + ++Pos; // Include separator. + return Pos - Offset; + +} + +// Parse a servername and share, like: `SomeServer\SomeShare\` +// Returns number of characters considered if successful. +static size_t ParseServerAndShare(const std::string &FileName, + const size_t Offset) { + + size_t Pos = Offset, Res; + if (!(Res = ParseDir(FileName, Pos))) return 0; + Pos += Res; + if (!(Res = ParseDir(FileName, Pos))) return 0; + Pos += Res; + return Pos - Offset; + +} + +// Parse the given Ref string from the position Offset, to exactly match the +// given string Patt. Returns number of characters considered if successful. +static size_t ParseCustomString(const std::string &Ref, size_t Offset, + const char *Patt) { + + size_t Len = strlen(Patt); + if (Offset + Len > Ref.size()) return 0; + return Ref.compare(Offset, Len, Patt) == 0 ? Len : 0; + +} + +// Parse a location, like: +// \\?\UNC\Server\Share\ \\?\C:\ \\Server\Share\ \ C:\ C: +// Returns number of characters considered if successful. +static size_t ParseLocation(const std::string &FileName) { + + size_t Pos = 0, Res; + + if ((Res = ParseCustomString(FileName, Pos, R"(\\?\)"))) { + + Pos += Res; + if ((Res = ParseCustomString(FileName, Pos, R"(UNC\)"))) { + + Pos += Res; + if ((Res = ParseServerAndShare(FileName, Pos))) return Pos + Res; + return 0; + + } + + if ((Res = ParseDrive(FileName, Pos, false))) return Pos + Res; + return 0; + + } + + if (Pos < FileName.size() && IsSeparator(FileName[Pos])) { + + ++Pos; + if (Pos < FileName.size() && IsSeparator(FileName[Pos])) { + + ++Pos; + if ((Res = ParseServerAndShare(FileName, Pos))) return Pos + Res; + return 0; + + } + + return Pos; + + } + + if ((Res = ParseDrive(FileName, Pos))) return Pos + Res; + + return Pos; + +} + +std::string DirName(const std::string &FileName) { + + size_t LocationLen = ParseLocation(FileName); + size_t DirLen = 0, Res; + while ((Res = ParseDir(FileName, LocationLen + DirLen))) + DirLen += Res; + size_t FileLen = ParseFileName(FileName, LocationLen + DirLen); + + if (LocationLen + DirLen + FileLen != FileName.size()) { + + Printf("DirName() failed for \"%s\", invalid path.\n", FileName.c_str()); + exit(1); + + } + + if (DirLen) { + + --DirLen; // Remove trailing separator. + if (!FileLen) { // Path ended in separator. + assert(DirLen); + // Remove file name from Dir. + while (DirLen && !IsSeparator(FileName[LocationLen + DirLen - 1])) + --DirLen; + if (DirLen) // Remove trailing separator. + --DirLen; + + } + + } + + if (!LocationLen) { // Relative path. + if (!DirLen) return "."; + return std::string(".\\").append(FileName, 0, DirLen); + + } + + return FileName.substr(0, LocationLen + DirLen); + +} + +std::string TmpDir() { + + std::string Tmp; + Tmp.resize(MAX_PATH + 1); + DWORD Size = GetTempPathA(Tmp.size(), &Tmp[0]); + if (Size == 0) { + + Printf("Couldn't get Tmp path.\n"); + exit(1); + + } + + Tmp.resize(Size); + return Tmp; + +} + +bool IsInterestingCoverageFile(const std::string &FileName) { + + if (FileName.find("Program Files") != std::string::npos) return false; + if (FileName.find("compiler-rt\\lib\\") != std::string::npos) + return false; // sanitizer internal. + if (FileName == "<null>") return false; + return true; + +} + +void RawPrint(const char *Str) { + + _write(2, Str, strlen(Str)); + +} + +void MkDir(const std::string &Path) { + + if (CreateDirectoryA(Path.c_str(), nullptr)) return; + Printf("CreateDirectoryA failed for %s (Error code: %lu).\n", Path.c_str(), + GetLastError()); + +} + +void RmDir(const std::string &Path) { + + if (RemoveDirectoryA(Path.c_str())) return; + Printf("RemoveDirectoryA failed for %s (Error code: %lu).\n", Path.c_str(), + GetLastError()); + +} + +const std::string &getDevNull() { + + static const std::string devNull = "NUL"; + return devNull; + +} + +} // namespace fuzzer + +#endif // LIBFUZZER_WINDOWS + diff --git a/custom_mutators/libfuzzer/FuzzerInterceptors.cpp b/custom_mutators/libfuzzer/FuzzerInterceptors.cpp new file mode 100644 index 00000000..442ab79a --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerInterceptors.cpp @@ -0,0 +1,290 @@ +//===-- FuzzerInterceptors.cpp --------------------------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Intercept certain libc functions to aid fuzzing. +// Linked only when other RTs that define their own interceptors are not linked. +//===----------------------------------------------------------------------===// + +#include "FuzzerPlatform.h" + +#if LIBFUZZER_LINUX + + #define GET_CALLER_PC() __builtin_return_address(0) + + #define PTR_TO_REAL(x) real_##x + #define REAL(x) __interception::PTR_TO_REAL(x) + #define FUNC_TYPE(x) x##_type + #define DEFINE_REAL(ret_type, func, ...) \ + typedef ret_type (*FUNC_TYPE(func))(__VA_ARGS__); \ + namespace __interception { \ + \ + FUNC_TYPE(func) PTR_TO_REAL(func); \ + \ + } + + #include <cassert> + #include <cstdint> + #include <dlfcn.h> // for dlsym() + +static void *getFuncAddr(const char *name, uintptr_t wrapper_addr) { + + void *addr = dlsym(RTLD_NEXT, name); + if (!addr) { + + // If the lookup using RTLD_NEXT failed, the sanitizer runtime library is + // later in the library search order than the DSO that we are trying to + // intercept, which means that we cannot intercept this function. We still + // want the address of the real definition, though, so look it up using + // RTLD_DEFAULT. + addr = dlsym(RTLD_DEFAULT, name); + + // In case `name' is not loaded, dlsym ends up finding the actual wrapper. + // We don't want to intercept the wrapper and have it point to itself. + if (reinterpret_cast<uintptr_t>(addr) == wrapper_addr) addr = nullptr; + + } + + return addr; + +} + +static int FuzzerInited = 0; +static bool FuzzerInitIsRunning; + +static void fuzzerInit(); + +static void ensureFuzzerInited() { + + assert(!FuzzerInitIsRunning); + if (!FuzzerInited) { fuzzerInit(); } + +} + +static int internal_strcmp_strncmp(const char *s1, const char *s2, bool strncmp, + size_t n) { + + size_t i = 0; + while (true) { + + if (strncmp) { + + if (i == n) break; + i++; + + } + + unsigned c1 = *s1; + unsigned c2 = *s2; + if (c1 != c2) return (c1 < c2) ? -1 : 1; + if (c1 == 0) break; + s1++; + s2++; + + } + + return 0; + +} + +static int internal_strncmp(const char *s1, const char *s2, size_t n) { + + return internal_strcmp_strncmp(s1, s2, true, n); + +} + +static int internal_strcmp(const char *s1, const char *s2) { + + return internal_strcmp_strncmp(s1, s2, false, 0); + +} + +static int internal_memcmp(const void *s1, const void *s2, size_t n) { + + const uint8_t *t1 = static_cast<const uint8_t *>(s1); + const uint8_t *t2 = static_cast<const uint8_t *>(s2); + for (size_t i = 0; i < n; ++i, ++t1, ++t2) + if (*t1 != *t2) return *t1 < *t2 ? -1 : 1; + return 0; + +} + +static size_t internal_strlen(const char *s) { + + size_t i = 0; + while (s[i]) + i++; + return i; + +} + +static char *internal_strstr(const char *haystack, const char *needle) { + + // This is O(N^2), but we are not using it in hot places. + size_t len1 = internal_strlen(haystack); + size_t len2 = internal_strlen(needle); + if (len1 < len2) return nullptr; + for (size_t pos = 0; pos <= len1 - len2; pos++) { + + if (internal_memcmp(haystack + pos, needle, len2) == 0) + return const_cast<char *>(haystack) + pos; + + } + + return nullptr; + +} + +extern "C" { + +// Weak hooks forward-declared to avoid dependency on +// <sanitizer/common_interface_defs.h>. +void __sanitizer_weak_hook_memcmp(void *called_pc, const void *s1, + const void *s2, size_t n, int result); +void __sanitizer_weak_hook_strncmp(void *called_pc, const char *s1, + const char *s2, size_t n, int result); +void __sanitizer_weak_hook_strncasecmp(void *called_pc, const char *s1, + const char *s2, size_t n, int result); +void __sanitizer_weak_hook_strcmp(void *called_pc, const char *s1, + const char *s2, int result); +void __sanitizer_weak_hook_strcasecmp(void *called_pc, const char *s1, + const char *s2, int result); +void __sanitizer_weak_hook_strstr(void *called_pc, const char *s1, + const char *s2, char *result); +void __sanitizer_weak_hook_strcasestr(void *called_pc, const char *s1, + const char *s2, char *result); +void __sanitizer_weak_hook_memmem(void *called_pc, const void *s1, size_t len1, + const void *s2, size_t len2, void *result); + +DEFINE_REAL(int, bcmp, const void *, const void *, size_t) +DEFINE_REAL(int, memcmp, const void *, const void *, size_t) +DEFINE_REAL(int, strncmp, const char *, const char *, size_t) +DEFINE_REAL(int, strcmp, const char *, const char *) +DEFINE_REAL(int, strncasecmp, const char *, const char *, size_t) +DEFINE_REAL(int, strcasecmp, const char *, const char *) +DEFINE_REAL(char *, strstr, const char *, const char *) +DEFINE_REAL(char *, strcasestr, const char *, const char *) +DEFINE_REAL(void *, memmem, const void *, size_t, const void *, size_t) + +ATTRIBUTE_INTERFACE int bcmp(const char *s1, const char *s2, size_t n) { + + if (!FuzzerInited) return internal_memcmp(s1, s2, n); + int result = REAL(bcmp)(s1, s2, n); + __sanitizer_weak_hook_memcmp(GET_CALLER_PC(), s1, s2, n, result); + return result; + +} + +ATTRIBUTE_INTERFACE int memcmp(const void *s1, const void *s2, size_t n) { + + if (!FuzzerInited) return internal_memcmp(s1, s2, n); + int result = REAL(memcmp)(s1, s2, n); + __sanitizer_weak_hook_memcmp(GET_CALLER_PC(), s1, s2, n, result); + return result; + +} + +ATTRIBUTE_INTERFACE int strncmp(const char *s1, const char *s2, size_t n) { + + if (!FuzzerInited) return internal_strncmp(s1, s2, n); + int result = REAL(strncmp)(s1, s2, n); + __sanitizer_weak_hook_strncmp(GET_CALLER_PC(), s1, s2, n, result); + return result; + +} + +ATTRIBUTE_INTERFACE int strcmp(const char *s1, const char *s2) { + + if (!FuzzerInited) return internal_strcmp(s1, s2); + int result = REAL(strcmp)(s1, s2); + __sanitizer_weak_hook_strcmp(GET_CALLER_PC(), s1, s2, result); + return result; + +} + +ATTRIBUTE_INTERFACE int strncasecmp(const char *s1, const char *s2, size_t n) { + + ensureFuzzerInited(); + int result = REAL(strncasecmp)(s1, s2, n); + __sanitizer_weak_hook_strncasecmp(GET_CALLER_PC(), s1, s2, n, result); + return result; + +} + +ATTRIBUTE_INTERFACE int strcasecmp(const char *s1, const char *s2) { + + ensureFuzzerInited(); + int result = REAL(strcasecmp)(s1, s2); + __sanitizer_weak_hook_strcasecmp(GET_CALLER_PC(), s1, s2, result); + return result; + +} + +ATTRIBUTE_INTERFACE char *strstr(const char *s1, const char *s2) { + + if (!FuzzerInited) return internal_strstr(s1, s2); + char *result = REAL(strstr)(s1, s2); + __sanitizer_weak_hook_strstr(GET_CALLER_PC(), s1, s2, result); + return result; + +} + +ATTRIBUTE_INTERFACE char *strcasestr(const char *s1, const char *s2) { + + ensureFuzzerInited(); + char *result = REAL(strcasestr)(s1, s2); + __sanitizer_weak_hook_strcasestr(GET_CALLER_PC(), s1, s2, result); + return result; + +} + +ATTRIBUTE_INTERFACE +void *memmem(const void *s1, size_t len1, const void *s2, size_t len2) { + + ensureFuzzerInited(); + void *result = REAL(memmem)(s1, len1, s2, len2); + __sanitizer_weak_hook_memmem(GET_CALLER_PC(), s1, len1, s2, len2, result); + return result; + +} + +__attribute__((section(".preinit_array"), + used)) static void (*__local_fuzzer_preinit)(void) = fuzzerInit; + +} // extern "C" + +static void fuzzerInit() { + + assert(!FuzzerInitIsRunning); + if (FuzzerInited) return; + FuzzerInitIsRunning = true; + + REAL(bcmp) = reinterpret_cast<memcmp_type>( + getFuncAddr("bcmp", reinterpret_cast<uintptr_t>(&bcmp))); + REAL(memcmp) = reinterpret_cast<memcmp_type>( + getFuncAddr("memcmp", reinterpret_cast<uintptr_t>(&memcmp))); + REAL(strncmp) = reinterpret_cast<strncmp_type>( + getFuncAddr("strncmp", reinterpret_cast<uintptr_t>(&strncmp))); + REAL(strcmp) = reinterpret_cast<strcmp_type>( + getFuncAddr("strcmp", reinterpret_cast<uintptr_t>(&strcmp))); + REAL(strncasecmp) = reinterpret_cast<strncasecmp_type>( + getFuncAddr("strncasecmp", reinterpret_cast<uintptr_t>(&strncasecmp))); + REAL(strcasecmp) = reinterpret_cast<strcasecmp_type>( + getFuncAddr("strcasecmp", reinterpret_cast<uintptr_t>(&strcasecmp))); + REAL(strstr) = reinterpret_cast<strstr_type>( + getFuncAddr("strstr", reinterpret_cast<uintptr_t>(&strstr))); + REAL(strcasestr) = reinterpret_cast<strcasestr_type>( + getFuncAddr("strcasestr", reinterpret_cast<uintptr_t>(&strcasestr))); + REAL(memmem) = reinterpret_cast<memmem_type>( + getFuncAddr("memmem", reinterpret_cast<uintptr_t>(&memmem))); + + FuzzerInitIsRunning = false; + FuzzerInited = 1; + +} + +#endif + diff --git a/custom_mutators/libfuzzer/FuzzerInterface.h b/custom_mutators/libfuzzer/FuzzerInterface.h new file mode 100644 index 00000000..4f62822e --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerInterface.h @@ -0,0 +1,79 @@ +//===- FuzzerInterface.h - Interface header for the Fuzzer ------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Define the interface between libFuzzer and the library being tested. +//===----------------------------------------------------------------------===// + +// NOTE: the libFuzzer interface is thin and in the majority of cases +// you should not include this file into your target. In 95% of cases +// all you need is to define the following function in your file: +// extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size); + +// WARNING: keep the interface in C. + +#ifndef LLVM_FUZZER_INTERFACE_H +#define LLVM_FUZZER_INTERFACE_H + +#include <stddef.h> +#include <stdint.h> + +#ifdef __cplusplus +extern "C" { +#endif // __cplusplus + +// Define FUZZER_INTERFACE_VISIBILITY to set default visibility in a way that +// doesn't break MSVC. +#if defined(_WIN32) +#define FUZZER_INTERFACE_VISIBILITY __declspec(dllexport) +#else +#define FUZZER_INTERFACE_VISIBILITY __attribute__((visibility("default"))) +#endif + +// Mandatory user-provided target function. +// Executes the code under test with [Data, Data+Size) as the input. +// libFuzzer will invoke this function *many* times with different inputs. +// Must return 0. +FUZZER_INTERFACE_VISIBILITY int +LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size); + +// Optional user-provided initialization function. +// If provided, this function will be called by libFuzzer once at startup. +// It may read and modify argc/argv. +// Must return 0. +FUZZER_INTERFACE_VISIBILITY int LLVMFuzzerInitialize(int *argc, char ***argv); + +// Optional user-provided custom mutator. +// Mutates raw data in [Data, Data+Size) inplace. +// Returns the new size, which is not greater than MaxSize. +// Given the same Seed produces the same mutation. +FUZZER_INTERFACE_VISIBILITY size_t +LLVMFuzzerCustomMutator(uint8_t *Data, size_t Size, size_t MaxSize, + unsigned int Seed); + +// Optional user-provided custom cross-over function. +// Combines pieces of Data1 & Data2 together into Out. +// Returns the new size, which is not greater than MaxOutSize. +// Should produce the same mutation given the same Seed. +FUZZER_INTERFACE_VISIBILITY size_t +LLVMFuzzerCustomCrossOver(const uint8_t *Data1, size_t Size1, + const uint8_t *Data2, size_t Size2, uint8_t *Out, + size_t MaxOutSize, unsigned int Seed); + +// Experimental, may go away in future. +// libFuzzer-provided function to be used inside LLVMFuzzerCustomMutator. +// Mutates raw data in [Data, Data+Size) inplace. +// Returns the new size, which is not greater than MaxSize. +FUZZER_INTERFACE_VISIBILITY size_t +LLVMFuzzerMutate(uint8_t *Data, size_t Size, size_t MaxSize); + +#undef FUZZER_INTERFACE_VISIBILITY + +#ifdef __cplusplus +} // extern "C" +#endif // __cplusplus + +#endif // LLVM_FUZZER_INTERFACE_H diff --git a/custom_mutators/libfuzzer/FuzzerInternal.h b/custom_mutators/libfuzzer/FuzzerInternal.h new file mode 100644 index 00000000..2b172d91 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerInternal.h @@ -0,0 +1,173 @@ +//===- FuzzerInternal.h - Internal header for the Fuzzer --------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Define the main class fuzzer::Fuzzer and most functions. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_INTERNAL_H +#define LLVM_FUZZER_INTERNAL_H + +#include "FuzzerDataFlowTrace.h" +#include "FuzzerDefs.h" +#include "FuzzerExtFunctions.h" +#include "FuzzerInterface.h" +#include "FuzzerOptions.h" +#include "FuzzerSHA1.h" +#include "FuzzerValueBitMap.h" +#include <algorithm> +#include <atomic> +#include <chrono> +#include <climits> +#include <cstdlib> +#include <string.h> + +namespace fuzzer { + +using namespace std::chrono; + +class Fuzzer { +public: + + Fuzzer(UserCallback CB, InputCorpus &Corpus, MutationDispatcher &MD, + FuzzingOptions Options); + ~Fuzzer(); + void Loop(Vector<SizedFile> &CorporaFiles); + void ReadAndExecuteSeedCorpora(Vector<SizedFile> &CorporaFiles); + void MinimizeCrashLoop(const Unit &U); + void RereadOutputCorpus(size_t MaxSize); + + size_t secondsSinceProcessStartUp() { + return duration_cast<seconds>(system_clock::now() - ProcessStartTime) + .count(); + } + + bool TimedOut() { + return Options.MaxTotalTimeSec > 0 && + secondsSinceProcessStartUp() > + static_cast<size_t>(Options.MaxTotalTimeSec); + } + + size_t execPerSec() { + size_t Seconds = secondsSinceProcessStartUp(); + return Seconds ? TotalNumberOfRuns / Seconds : 0; + } + + size_t getTotalNumberOfRuns() { return TotalNumberOfRuns; } + + static void StaticAlarmCallback(); + static void StaticCrashSignalCallback(); + static void StaticExitCallback(); + static void StaticInterruptCallback(); + static void StaticFileSizeExceedCallback(); + static void StaticGracefulExitCallback(); + + void ExecuteCallback(const uint8_t *Data, size_t Size); + bool RunOne(const uint8_t *Data, size_t Size, bool MayDeleteFile = false, + InputInfo *II = nullptr, bool ForceAddToCorpus = false, + bool *FoundUniqFeatures = nullptr); + + // Merge Corpora[1:] into Corpora[0]. + void Merge(const Vector<std::string> &Corpora); + void CrashResistantMergeInternalStep(const std::string &ControlFilePath); + MutationDispatcher &GetMD() { return MD; } + void PrintFinalStats(); + void SetMaxInputLen(size_t MaxInputLen); + void SetMaxMutationLen(size_t MaxMutationLen); + void RssLimitCallback(); + + bool InFuzzingThread() const { return IsMyThread; } + size_t GetCurrentUnitInFuzzingThead(const uint8_t **Data) const; + void TryDetectingAMemoryLeak(const uint8_t *Data, size_t Size, + bool DuringInitialCorpusExecution); + + void HandleMalloc(size_t Size); + static void MaybeExitGracefully(); + std::string WriteToOutputCorpus(const Unit &U); + +private: + void AlarmCallback(); + void CrashCallback(); + void ExitCallback(); + void CrashOnOverwrittenData(); + void InterruptCallback(); + void MutateAndTestOne(); + void PurgeAllocator(); + void ReportNewCoverage(InputInfo *II, const Unit &U); + void PrintPulseAndReportSlowInput(const uint8_t *Data, size_t Size); + void WriteUnitToFileWithPrefix(const Unit &U, const char *Prefix); + void PrintStats(const char *Where, const char *End = "\n", size_t Units = 0, + size_t Features = 0); + void PrintStatusForNewUnit(const Unit &U, const char *Text); + void CheckExitOnSrcPosOrItem(); + + static void StaticDeathCallback(); + void DumpCurrentUnit(const char *Prefix); + void DeathCallback(); + + void AllocateCurrentUnitData(); + uint8_t *CurrentUnitData = nullptr; + std::atomic<size_t> CurrentUnitSize; + uint8_t BaseSha1[kSHA1NumBytes]; // Checksum of the base unit. + + bool GracefulExitRequested = false; + + size_t TotalNumberOfRuns = 0; + size_t NumberOfNewUnitsAdded = 0; + + size_t LastCorpusUpdateRun = 0; + + bool HasMoreMallocsThanFrees = false; + size_t NumberOfLeakDetectionAttempts = 0; + + system_clock::time_point LastAllocatorPurgeAttemptTime = system_clock::now(); + + UserCallback CB; + InputCorpus &Corpus; + MutationDispatcher &MD; + FuzzingOptions Options; + DataFlowTrace DFT; + + system_clock::time_point ProcessStartTime = system_clock::now(); + system_clock::time_point UnitStartTime, UnitStopTime; + long TimeOfLongestUnitInSeconds = 0; + long EpochOfLastReadOfOutputCorpus = 0; + + size_t MaxInputLen = 0; + size_t MaxMutationLen = 0; + size_t TmpMaxMutationLen = 0; + + Vector<uint32_t> UniqFeatureSetTmp; + + // Need to know our own thread. + static thread_local bool IsMyThread; +}; + +struct ScopedEnableMsanInterceptorChecks { + ScopedEnableMsanInterceptorChecks() { + if (EF->__msan_scoped_enable_interceptor_checks) + EF->__msan_scoped_enable_interceptor_checks(); + } + ~ScopedEnableMsanInterceptorChecks() { + if (EF->__msan_scoped_disable_interceptor_checks) + EF->__msan_scoped_disable_interceptor_checks(); + } +}; + +struct ScopedDisableMsanInterceptorChecks { + ScopedDisableMsanInterceptorChecks() { + if (EF->__msan_scoped_disable_interceptor_checks) + EF->__msan_scoped_disable_interceptor_checks(); + } + ~ScopedDisableMsanInterceptorChecks() { + if (EF->__msan_scoped_enable_interceptor_checks) + EF->__msan_scoped_enable_interceptor_checks(); + } +}; + +} // namespace fuzzer + +#endif // LLVM_FUZZER_INTERNAL_H diff --git a/custom_mutators/libfuzzer/FuzzerLoop.cpp b/custom_mutators/libfuzzer/FuzzerLoop.cpp new file mode 100644 index 00000000..08fda520 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerLoop.cpp @@ -0,0 +1,1098 @@ +//===- FuzzerLoop.cpp - Fuzzer's main loop --------------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Fuzzer's main loop. +//===----------------------------------------------------------------------===// + +#include "FuzzerCorpus.h" +#include "FuzzerIO.h" +#include "FuzzerInternal.h" +#include "FuzzerMutate.h" +#include "FuzzerPlatform.h" +#include "FuzzerRandom.h" +#include "FuzzerTracePC.h" +#include <algorithm> +#include <cstring> +#include <memory> +#include <mutex> +#include <set> + +#if defined(__has_include) + #if __has_include(<sanitizer / lsan_interface.h>) + #include <sanitizer/lsan_interface.h> + #endif +#endif + +#define NO_SANITIZE_MEMORY +#if defined(__has_feature) + #if __has_feature(memory_sanitizer) + #undef NO_SANITIZE_MEMORY + #define NO_SANITIZE_MEMORY __attribute__((no_sanitize_memory)) + #endif +#endif + +namespace fuzzer { + +static const size_t kMaxUnitSizeToPrint = 256; + +thread_local bool Fuzzer::IsMyThread; + +bool RunningUserCallback = false; + +// Only one Fuzzer per process. +static Fuzzer *F; + +// Leak detection is expensive, so we first check if there were more mallocs +// than frees (using the sanitizer malloc hooks) and only then try to call lsan. +struct MallocFreeTracer { + + void Start(int TraceLevel) { + + this->TraceLevel = TraceLevel; + if (TraceLevel) Printf("MallocFreeTracer: START\n"); + Mallocs = 0; + Frees = 0; + + } + + // Returns true if there were more mallocs than frees. + bool Stop() { + + if (TraceLevel) + Printf("MallocFreeTracer: STOP %zd %zd (%s)\n", Mallocs.load(), + Frees.load(), Mallocs == Frees ? "same" : "DIFFERENT"); + bool Result = Mallocs > Frees; + Mallocs = 0; + Frees = 0; + TraceLevel = 0; + return Result; + + } + + std::atomic<size_t> Mallocs; + std::atomic<size_t> Frees; + int TraceLevel = 0; + + std::recursive_mutex TraceMutex; + bool TraceDisabled = false; + +}; + +static MallocFreeTracer AllocTracer; + +// Locks printing and avoids nested hooks triggered from mallocs/frees in +// sanitizer. +class TraceLock { + + public: + TraceLock() : Lock(AllocTracer.TraceMutex) { + + AllocTracer.TraceDisabled = !AllocTracer.TraceDisabled; + + } + + ~TraceLock() { + + AllocTracer.TraceDisabled = !AllocTracer.TraceDisabled; + + } + + bool IsDisabled() const { + + // This is already inverted value. + return !AllocTracer.TraceDisabled; + + } + + private: + std::lock_guard<std::recursive_mutex> Lock; + +}; + +ATTRIBUTE_NO_SANITIZE_MEMORY +void MallocHook(const volatile void *ptr, size_t size) { + + size_t N = AllocTracer.Mallocs++; + F->HandleMalloc(size); + if (int TraceLevel = AllocTracer.TraceLevel) { + + TraceLock Lock; + if (Lock.IsDisabled()) return; + Printf("MALLOC[%zd] %p %zd\n", N, ptr, size); + if (TraceLevel >= 2 && EF) PrintStackTrace(); + + } + +} + +ATTRIBUTE_NO_SANITIZE_MEMORY +void FreeHook(const volatile void *ptr) { + + size_t N = AllocTracer.Frees++; + if (int TraceLevel = AllocTracer.TraceLevel) { + + TraceLock Lock; + if (Lock.IsDisabled()) return; + Printf("FREE[%zd] %p\n", N, ptr); + if (TraceLevel >= 2 && EF) PrintStackTrace(); + + } + +} + +// Crash on a single malloc that exceeds the rss limit. +void Fuzzer::HandleMalloc(size_t Size) { + + if (!Options.MallocLimitMb || (Size >> 20) < (size_t)Options.MallocLimitMb) + return; + Printf("==%d== ERROR: libFuzzer: out-of-memory (malloc(%zd))\n", GetPid(), + Size); + Printf(" To change the out-of-memory limit use -rss_limit_mb=<N>\n\n"); + PrintStackTrace(); + DumpCurrentUnit("oom-"); + Printf("SUMMARY: libFuzzer: out-of-memory\n"); + PrintFinalStats(); + _Exit(Options.OOMExitCode); // Stop right now. + +} + +Fuzzer::Fuzzer(UserCallback CB, InputCorpus &Corpus, MutationDispatcher &MD, + FuzzingOptions Options) + : CB(CB), Corpus(Corpus), MD(MD), Options(Options) { + + if (EF->__sanitizer_set_death_callback) + EF->__sanitizer_set_death_callback(StaticDeathCallback); + assert(!F); + F = this; + TPC.ResetMaps(); + IsMyThread = true; + if (Options.DetectLeaks && EF->__sanitizer_install_malloc_and_free_hooks) + EF->__sanitizer_install_malloc_and_free_hooks(MallocHook, FreeHook); + TPC.SetUseCounters(Options.UseCounters); + TPC.SetUseValueProfileMask(Options.UseValueProfile); + + if (Options.Verbosity) TPC.PrintModuleInfo(); + if (!Options.OutputCorpus.empty() && Options.ReloadIntervalSec) + EpochOfLastReadOfOutputCorpus = GetEpoch(Options.OutputCorpus); + MaxInputLen = MaxMutationLen = Options.MaxLen; + TmpMaxMutationLen = 0; // Will be set once we load the corpus. + AllocateCurrentUnitData(); + CurrentUnitSize = 0; + memset(BaseSha1, 0, sizeof(BaseSha1)); + +} + +Fuzzer::~Fuzzer() { + +} + +void Fuzzer::AllocateCurrentUnitData() { + + if (CurrentUnitData || MaxInputLen == 0) return; + CurrentUnitData = new uint8_t[MaxInputLen]; + +} + +void Fuzzer::StaticDeathCallback() { + + assert(F); + F->DeathCallback(); + +} + +void Fuzzer::DumpCurrentUnit(const char *Prefix) { + + return; + + if (!CurrentUnitData) return; // Happens when running individual inputs. + ScopedDisableMsanInterceptorChecks S; + MD.PrintMutationSequence(); + Printf("; base unit: %s\n", Sha1ToString(BaseSha1).c_str()); + size_t UnitSize = CurrentUnitSize; + if (UnitSize <= kMaxUnitSizeToPrint) { + + PrintHexArray(CurrentUnitData, UnitSize, "\n"); + PrintASCII(CurrentUnitData, UnitSize, "\n"); + + } + + WriteUnitToFileWithPrefix({CurrentUnitData, CurrentUnitData + UnitSize}, + Prefix); + +} + +NO_SANITIZE_MEMORY +void Fuzzer::DeathCallback() { + + DumpCurrentUnit("crash-"); + PrintFinalStats(); + +} + +void Fuzzer::StaticAlarmCallback() { + + assert(F); + F->AlarmCallback(); + +} + +void Fuzzer::StaticCrashSignalCallback() { + + assert(F); + F->CrashCallback(); + +} + +void Fuzzer::StaticExitCallback() { + + assert(F); + F->ExitCallback(); + +} + +void Fuzzer::StaticInterruptCallback() { + + assert(F); + F->InterruptCallback(); + +} + +void Fuzzer::StaticGracefulExitCallback() { + + assert(F); + F->GracefulExitRequested = true; + Printf("INFO: signal received, trying to exit gracefully\n"); + +} + +void Fuzzer::StaticFileSizeExceedCallback() { + + Printf("==%lu== ERROR: libFuzzer: file size exceeded\n", GetPid()); + exit(1); + +} + +void Fuzzer::CrashCallback() { + + if (EF->__sanitizer_acquire_crash_state && + !EF->__sanitizer_acquire_crash_state()) + return; + Printf("==%lu== ERROR: libFuzzer: deadly signal\n", GetPid()); + PrintStackTrace(); + Printf( + "NOTE: libFuzzer has rudimentary signal handlers.\n" + " Combine libFuzzer with AddressSanitizer or similar for better " + "crash reports.\n"); + Printf("SUMMARY: libFuzzer: deadly signal\n"); + DumpCurrentUnit("crash-"); + PrintFinalStats(); + _Exit(Options.ErrorExitCode); // Stop right now. + +} + +void Fuzzer::ExitCallback() { + + if (!RunningUserCallback) + return; // This exit did not come from the user callback + if (EF->__sanitizer_acquire_crash_state && + !EF->__sanitizer_acquire_crash_state()) + return; + Printf("==%lu== ERROR: libFuzzer: fuzz target exited\n", GetPid()); + PrintStackTrace(); + Printf("SUMMARY: libFuzzer: fuzz target exited\n"); + DumpCurrentUnit("crash-"); + PrintFinalStats(); + _Exit(Options.ErrorExitCode); + +} + +void Fuzzer::MaybeExitGracefully() { + + if (!F->GracefulExitRequested) return; + Printf("==%lu== INFO: libFuzzer: exiting as requested\n", GetPid()); + RmDirRecursive(TempPath("FuzzWithFork", ".dir")); + F->PrintFinalStats(); + _Exit(0); + +} + +void Fuzzer::InterruptCallback() { + + Printf("==%lu== libFuzzer: run interrupted; exiting\n", GetPid()); + PrintFinalStats(); + ScopedDisableMsanInterceptorChecks S; // RmDirRecursive may call opendir(). + RmDirRecursive(TempPath("FuzzWithFork", ".dir")); + // Stop right now, don't perform any at-exit actions. + _Exit(Options.InterruptExitCode); + +} + +NO_SANITIZE_MEMORY +void Fuzzer::AlarmCallback() { + + assert(Options.UnitTimeoutSec > 0); + // In Windows and Fuchsia, Alarm callback is executed by a different thread. + // NetBSD's current behavior needs this change too. +#if !LIBFUZZER_WINDOWS && !LIBFUZZER_NETBSD && !LIBFUZZER_FUCHSIA + if (!InFuzzingThread()) return; +#endif + if (!RunningUserCallback) return; // We have not started running units yet. + size_t Seconds = + duration_cast<seconds>(system_clock::now() - UnitStartTime).count(); + if (Seconds == 0) return; + if (Options.Verbosity >= 2) Printf("AlarmCallback %zd\n", Seconds); + if (Seconds >= (size_t)Options.UnitTimeoutSec) { + + if (EF->__sanitizer_acquire_crash_state && + !EF->__sanitizer_acquire_crash_state()) + return; + Printf("ALARM: working on the last Unit for %zd seconds\n", Seconds); + Printf(" and the timeout value is %d (use -timeout=N to change)\n", + Options.UnitTimeoutSec); + DumpCurrentUnit("timeout-"); + Printf("==%lu== ERROR: libFuzzer: timeout after %d seconds\n", GetPid(), + Seconds); + PrintStackTrace(); + Printf("SUMMARY: libFuzzer: timeout\n"); + PrintFinalStats(); + _Exit(Options.TimeoutExitCode); // Stop right now. + + } + +} + +void Fuzzer::RssLimitCallback() { + + if (EF->__sanitizer_acquire_crash_state && + !EF->__sanitizer_acquire_crash_state()) + return; + Printf( + "==%lu== ERROR: libFuzzer: out-of-memory (used: %zdMb; limit: %zdMb)\n", + GetPid(), GetPeakRSSMb(), Options.RssLimitMb); + Printf(" To change the out-of-memory limit use -rss_limit_mb=<N>\n\n"); + PrintMemoryProfile(); + DumpCurrentUnit("oom-"); + Printf("SUMMARY: libFuzzer: out-of-memory\n"); + PrintFinalStats(); + _Exit(Options.OOMExitCode); // Stop right now. + +} + +void Fuzzer::PrintStats(const char *Where, const char *End, size_t Units, + size_t Features) { + + size_t ExecPerSec = execPerSec(); + if (!Options.Verbosity) return; + Printf("#%zd\t%s", TotalNumberOfRuns, Where); + if (size_t N = TPC.GetTotalPCCoverage()) Printf(" cov: %zd", N); + if (size_t N = Features ? Features : Corpus.NumFeatures()) + Printf(" ft: %zd", N); + if (!Corpus.empty()) { + + Printf(" corp: %zd", Corpus.NumActiveUnits()); + if (size_t N = Corpus.SizeInBytes()) { + + if (N < (1 << 14)) + Printf("/%zdb", N); + else if (N < (1 << 24)) + Printf("/%zdKb", N >> 10); + else + Printf("/%zdMb", N >> 20); + + } + + if (size_t FF = Corpus.NumInputsThatTouchFocusFunction()) + Printf(" focus: %zd", FF); + + } + + if (TmpMaxMutationLen) Printf(" lim: %zd", TmpMaxMutationLen); + if (Units) Printf(" units: %zd", Units); + + Printf(" exec/s: %zd", ExecPerSec); + Printf(" rss: %zdMb", GetPeakRSSMb()); + Printf("%s", End); + +} + +void Fuzzer::PrintFinalStats() { + + if (Options.PrintCoverage) TPC.PrintCoverage(); + if (Options.PrintCorpusStats) Corpus.PrintStats(); + if (!Options.PrintFinalStats) return; + size_t ExecPerSec = execPerSec(); + Printf("stat::number_of_executed_units: %zd\n", TotalNumberOfRuns); + Printf("stat::average_exec_per_sec: %zd\n", ExecPerSec); + Printf("stat::new_units_added: %zd\n", NumberOfNewUnitsAdded); + Printf("stat::slowest_unit_time_sec: %zd\n", TimeOfLongestUnitInSeconds); + Printf("stat::peak_rss_mb: %zd\n", GetPeakRSSMb()); + +} + +void Fuzzer::SetMaxInputLen(size_t MaxInputLen) { + + assert(this->MaxInputLen == + 0); // Can only reset MaxInputLen from 0 to non-0. + assert(MaxInputLen); + this->MaxInputLen = MaxInputLen; + this->MaxMutationLen = MaxInputLen; + AllocateCurrentUnitData(); + Printf( + "INFO: -max_len is not provided; " + "libFuzzer will not generate inputs larger than %zd bytes\n", + MaxInputLen); + +} + +void Fuzzer::SetMaxMutationLen(size_t MaxMutationLen) { + + assert(MaxMutationLen && MaxMutationLen <= MaxInputLen); + this->MaxMutationLen = MaxMutationLen; + +} + +void Fuzzer::CheckExitOnSrcPosOrItem() { + + if (!Options.ExitOnSrcPos.empty()) { + + static auto *PCsSet = new Set<uintptr_t>; + auto HandlePC = [&](const TracePC::PCTableEntry *TE) { + + if (!PCsSet->insert(TE->PC).second) return; + std::string Descr = DescribePC("%F %L", TE->PC + 1); + if (Descr.find(Options.ExitOnSrcPos) != std::string::npos) { + + Printf("INFO: found line matching '%s', exiting.\n", + Options.ExitOnSrcPos.c_str()); + _Exit(0); + + } + + }; + + TPC.ForEachObservedPC(HandlePC); + + } + + if (!Options.ExitOnItem.empty()) { + + if (Corpus.HasUnit(Options.ExitOnItem)) { + + Printf("INFO: found item with checksum '%s', exiting.\n", + Options.ExitOnItem.c_str()); + _Exit(0); + + } + + } + +} + +void Fuzzer::RereadOutputCorpus(size_t MaxSize) { + + if (Options.OutputCorpus.empty() || !Options.ReloadIntervalSec) return; + Vector<Unit> AdditionalCorpus; + ReadDirToVectorOfUnits(Options.OutputCorpus.c_str(), &AdditionalCorpus, + &EpochOfLastReadOfOutputCorpus, MaxSize, + /*ExitOnError*/ false); + if (Options.Verbosity >= 2) + Printf("Reload: read %zd new units.\n", AdditionalCorpus.size()); + bool Reloaded = false; + for (auto &U : AdditionalCorpus) { + + if (U.size() > MaxSize) U.resize(MaxSize); + if (!Corpus.HasUnit(U)) { + + if (RunOne(U.data(), U.size())) { + + CheckExitOnSrcPosOrItem(); + Reloaded = true; + + } + + } + + } + + if (Reloaded) PrintStats("RELOAD"); + +} + +void Fuzzer::PrintPulseAndReportSlowInput(const uint8_t *Data, size_t Size) { + + auto TimeOfUnit = + duration_cast<seconds>(UnitStopTime - UnitStartTime).count(); + if (!(TotalNumberOfRuns & (TotalNumberOfRuns - 1)) && + secondsSinceProcessStartUp() >= 2) + PrintStats("pulse "); + if (TimeOfUnit > TimeOfLongestUnitInSeconds * 1.1 && + TimeOfUnit >= Options.ReportSlowUnits) { + + TimeOfLongestUnitInSeconds = TimeOfUnit; + Printf("Slowest unit: %zd s:\n", TimeOfLongestUnitInSeconds); + WriteUnitToFileWithPrefix({Data, Data + Size}, "slow-unit-"); + + } + +} + +static void WriteFeatureSetToFile(const std::string & FeaturesDir, + const std::string & FileName, + const Vector<uint32_t> &FeatureSet) { + + if (FeaturesDir.empty() || FeatureSet.empty()) return; + WriteToFile(reinterpret_cast<const uint8_t *>(FeatureSet.data()), + FeatureSet.size() * sizeof(FeatureSet[0]), + DirPlusFile(FeaturesDir, FileName)); + +} + +static void RenameFeatureSetFile(const std::string &FeaturesDir, + const std::string &OldFile, + const std::string &NewFile) { + + if (FeaturesDir.empty()) return; + RenameFile(DirPlusFile(FeaturesDir, OldFile), + DirPlusFile(FeaturesDir, NewFile)); + +} + +static void WriteEdgeToMutationGraphFile(const std::string &MutationGraphFile, + const InputInfo * II, + const InputInfo * BaseII, + const std::string &MS) { + + if (MutationGraphFile.empty()) return; + + std::string Sha1 = Sha1ToString(II->Sha1); + + std::string OutputString; + + // Add a new vertex. + OutputString.append("\""); + OutputString.append(Sha1); + OutputString.append("\"\n"); + + // Add a new edge if there is base input. + if (BaseII) { + + std::string BaseSha1 = Sha1ToString(BaseII->Sha1); + OutputString.append("\""); + OutputString.append(BaseSha1); + OutputString.append("\" -> \""); + OutputString.append(Sha1); + OutputString.append("\" [label=\""); + OutputString.append(MS); + OutputString.append("\"];\n"); + + } + + AppendToFile(OutputString, MutationGraphFile); + +} + +bool Fuzzer::RunOne(const uint8_t *Data, size_t Size, bool MayDeleteFile, + InputInfo *II, bool ForceAddToCorpus, + bool *FoundUniqFeatures) { + + if (!Size) return false; + + ExecuteCallback(Data, Size); + auto TimeOfUnit = duration_cast<microseconds>(UnitStopTime - UnitStartTime); + + UniqFeatureSetTmp.clear(); + size_t FoundUniqFeaturesOfII = 0; + size_t NumUpdatesBefore = Corpus.NumFeatureUpdates(); + TPC.CollectFeatures([&](size_t Feature) { + + if (Corpus.AddFeature(Feature, Size, Options.Shrink)) + UniqFeatureSetTmp.push_back(Feature); + if (Options.Entropic) Corpus.UpdateFeatureFrequency(II, Feature); + if (Options.ReduceInputs && II && !II->NeverReduce) + if (std::binary_search(II->UniqFeatureSet.begin(), + II->UniqFeatureSet.end(), Feature)) + FoundUniqFeaturesOfII++; + + }); + + if (FoundUniqFeatures) *FoundUniqFeatures = FoundUniqFeaturesOfII; + PrintPulseAndReportSlowInput(Data, Size); + size_t NumNewFeatures = Corpus.NumFeatureUpdates() - NumUpdatesBefore; + if (NumNewFeatures || ForceAddToCorpus) { + + TPC.UpdateObservedPCs(); + auto NewII = + Corpus.AddToCorpus({Data, Data + Size}, NumNewFeatures, MayDeleteFile, + TPC.ObservedFocusFunction(), ForceAddToCorpus, + TimeOfUnit, UniqFeatureSetTmp, DFT, II); + WriteFeatureSetToFile(Options.FeaturesDir, Sha1ToString(NewII->Sha1), + NewII->UniqFeatureSet); + WriteEdgeToMutationGraphFile(Options.MutationGraphFile, NewII, II, + MD.MutationSequence()); + return true; + + } + + if (II && FoundUniqFeaturesOfII && + II->DataFlowTraceForFocusFunction.empty() && + FoundUniqFeaturesOfII == II->UniqFeatureSet.size() && + II->U.size() > Size) { + + auto OldFeaturesFile = Sha1ToString(II->Sha1); + Corpus.Replace(II, {Data, Data + Size}); + RenameFeatureSetFile(Options.FeaturesDir, OldFeaturesFile, + Sha1ToString(II->Sha1)); + return true; + + } + + return false; + +} + +size_t Fuzzer::GetCurrentUnitInFuzzingThead(const uint8_t **Data) const { + + assert(InFuzzingThread()); + *Data = CurrentUnitData; + return CurrentUnitSize; + +} + +void Fuzzer::CrashOnOverwrittenData() { + + Printf("==%d== ERROR: libFuzzer: fuzz target overwrites its const input\n", + GetPid()); + PrintStackTrace(); + Printf("SUMMARY: libFuzzer: overwrites-const-input\n"); + DumpCurrentUnit("crash-"); + PrintFinalStats(); + _Exit(Options.ErrorExitCode); // Stop right now. + +} + +// Compare two arrays, but not all bytes if the arrays are large. +static bool LooseMemeq(const uint8_t *A, const uint8_t *B, size_t Size) { + + const size_t Limit = 64; + if (Size <= 64) return !memcmp(A, B, Size); + // Compare first and last Limit/2 bytes. + return !memcmp(A, B, Limit / 2) && + !memcmp(A + Size - Limit / 2, B + Size - Limit / 2, Limit / 2); + +} + +void Fuzzer::ExecuteCallback(const uint8_t *Data, size_t Size) { + + TPC.RecordInitialStack(); + TotalNumberOfRuns++; + assert(InFuzzingThread()); + // We copy the contents of Unit into a separate heap buffer + // so that we reliably find buffer overflows in it. + uint8_t *DataCopy = new uint8_t[Size]; + memcpy(DataCopy, Data, Size); + if (EF->__msan_unpoison) EF->__msan_unpoison(DataCopy, Size); + if (EF->__msan_unpoison_param) EF->__msan_unpoison_param(2); + if (CurrentUnitData && CurrentUnitData != Data) + memcpy(CurrentUnitData, Data, Size); + CurrentUnitSize = Size; + { + + ScopedEnableMsanInterceptorChecks S; + AllocTracer.Start(Options.TraceMalloc); + UnitStartTime = system_clock::now(); + TPC.ResetMaps(); + RunningUserCallback = true; + int Res = CB(DataCopy, Size); + RunningUserCallback = false; + UnitStopTime = system_clock::now(); + (void)Res; + assert(Res == 0); + HasMoreMallocsThanFrees = AllocTracer.Stop(); + + } + + if (!LooseMemeq(DataCopy, Data, Size)) CrashOnOverwrittenData(); + CurrentUnitSize = 0; + delete[] DataCopy; + +} + +std::string Fuzzer::WriteToOutputCorpus(const Unit &U) { + + if (Options.OnlyASCII) assert(IsASCII(U)); + if (Options.OutputCorpus.empty()) return ""; + std::string Path = DirPlusFile(Options.OutputCorpus, Hash(U)); + WriteToFile(U, Path); + if (Options.Verbosity >= 2) + Printf("Written %zd bytes to %s\n", U.size(), Path.c_str()); + return Path; + +} + +void Fuzzer::WriteUnitToFileWithPrefix(const Unit &U, const char *Prefix) { + + return; + if (!Options.SaveArtifacts) return; + std::string Path = Options.ArtifactPrefix + Prefix + Hash(U); + if (!Options.ExactArtifactPath.empty()) + Path = Options.ExactArtifactPath; // Overrides ArtifactPrefix. + WriteToFile(U, Path); + Printf("artifact_prefix='%s'; Test unit written to %s\n", + Options.ArtifactPrefix.c_str(), Path.c_str()); + if (U.size() <= kMaxUnitSizeToPrint) + Printf("Base64: %s\n", Base64(U).c_str()); + +} + +void Fuzzer::PrintStatusForNewUnit(const Unit &U, const char *Text) { + + if (!Options.PrintNEW) return; + PrintStats(Text, ""); + if (Options.Verbosity) { + + Printf(" L: %zd/%zd ", U.size(), Corpus.MaxInputSize()); + MD.PrintMutationSequence(Options.Verbosity >= 2); + Printf("\n"); + + } + +} + +void Fuzzer::ReportNewCoverage(InputInfo *II, const Unit &U) { + + II->NumSuccessfullMutations++; + MD.RecordSuccessfulMutationSequence(); + PrintStatusForNewUnit(U, II->Reduced ? "REDUCE" : "NEW "); + WriteToOutputCorpus(U); + NumberOfNewUnitsAdded++; + CheckExitOnSrcPosOrItem(); // Check only after the unit is saved to corpus. + LastCorpusUpdateRun = TotalNumberOfRuns; + +} + +// Tries detecting a memory leak on the particular input that we have just +// executed before calling this function. +void Fuzzer::TryDetectingAMemoryLeak(const uint8_t *Data, size_t Size, + bool DuringInitialCorpusExecution) { + + if (!HasMoreMallocsThanFrees) return; // mallocs==frees, a leak is unlikely. + if (!Options.DetectLeaks) return; + if (!DuringInitialCorpusExecution && + TotalNumberOfRuns >= Options.MaxNumberOfRuns) + return; + if (!&(EF->__lsan_enable) || !&(EF->__lsan_disable) || + !(EF->__lsan_do_recoverable_leak_check)) + return; // No lsan. + // Run the target once again, but with lsan disabled so that if there is + // a real leak we do not report it twice. + EF->__lsan_disable(); + ExecuteCallback(Data, Size); + EF->__lsan_enable(); + if (!HasMoreMallocsThanFrees) return; // a leak is unlikely. + if (NumberOfLeakDetectionAttempts++ > 1000) { + + Options.DetectLeaks = false; + Printf( + "INFO: libFuzzer disabled leak detection after every mutation.\n" + " Most likely the target function accumulates allocated\n" + " memory in a global state w/o actually leaking it.\n" + " You may try running this binary with -trace_malloc=[12]" + " to get a trace of mallocs and frees.\n" + " If LeakSanitizer is enabled in this process it will still\n" + " run on the process shutdown.\n"); + return; + + } + + // Now perform the actual lsan pass. This is expensive and we must ensure + // we don't call it too often. + if (EF->__lsan_do_recoverable_leak_check()) { // Leak is found, report it. + if (DuringInitialCorpusExecution) + Printf("\nINFO: a leak has been found in the initial corpus.\n\n"); + Printf("INFO: to ignore leaks on libFuzzer side use -detect_leaks=0.\n\n"); + CurrentUnitSize = Size; + DumpCurrentUnit("leak-"); + PrintFinalStats(); + _Exit(Options.ErrorExitCode); // not exit() to disable lsan further on. + + } + +} + +void Fuzzer::MutateAndTestOne() { + + MD.StartMutationSequence(); + + auto &II = Corpus.ChooseUnitToMutate(MD.GetRand()); + if (Options.DoCrossOver) { + + auto &CrossOverII = Corpus.ChooseUnitToCrossOverWith( + MD.GetRand(), Options.CrossOverUniformDist); + MD.SetCrossOverWith(&CrossOverII.U); + + } + + const auto &U = II.U; + memcpy(BaseSha1, II.Sha1, sizeof(BaseSha1)); + assert(CurrentUnitData); + size_t Size = U.size(); + assert(Size <= MaxInputLen && "Oversized Unit"); + memcpy(CurrentUnitData, U.data(), Size); + + assert(MaxMutationLen > 0); + + size_t CurrentMaxMutationLen = + Min(MaxMutationLen, Max(U.size(), TmpMaxMutationLen)); + assert(CurrentMaxMutationLen > 0); + + for (int i = 0; i < Options.MutateDepth; i++) { + + if (TotalNumberOfRuns >= Options.MaxNumberOfRuns) break; + MaybeExitGracefully(); + size_t NewSize = 0; + if (II.HasFocusFunction && !II.DataFlowTraceForFocusFunction.empty() && + Size <= CurrentMaxMutationLen) + NewSize = MD.MutateWithMask(CurrentUnitData, Size, Size, + II.DataFlowTraceForFocusFunction); + + // If MutateWithMask either failed or wasn't called, call default Mutate. + if (!NewSize) + NewSize = MD.Mutate(CurrentUnitData, Size, CurrentMaxMutationLen); + assert(NewSize > 0 && "Mutator returned empty unit"); + assert(NewSize <= CurrentMaxMutationLen && "Mutator return oversized unit"); + Size = NewSize; + II.NumExecutedMutations++; + Corpus.IncrementNumExecutedMutations(); + + bool FoundUniqFeatures = false; + bool NewCov = RunOne(CurrentUnitData, Size, /*MayDeleteFile=*/true, &II, + /*ForceAddToCorpus*/ false, &FoundUniqFeatures); + TryDetectingAMemoryLeak(CurrentUnitData, Size, + /*DuringInitialCorpusExecution*/ false); + if (NewCov) { + + ReportNewCoverage(&II, {CurrentUnitData, CurrentUnitData + Size}); + break; // We will mutate this input more in the next rounds. + + } + + if (Options.ReduceDepth && !FoundUniqFeatures) break; + + } + + II.NeedsEnergyUpdate = true; + +} + +void Fuzzer::PurgeAllocator() { + + if (Options.PurgeAllocatorIntervalSec < 0 || !EF->__sanitizer_purge_allocator) + return; + if (duration_cast<seconds>(system_clock::now() - + LastAllocatorPurgeAttemptTime) + .count() < Options.PurgeAllocatorIntervalSec) + return; + + if (Options.RssLimitMb <= 0 || + GetPeakRSSMb() > static_cast<size_t>(Options.RssLimitMb) / 2) + EF->__sanitizer_purge_allocator(); + + LastAllocatorPurgeAttemptTime = system_clock::now(); + +} + +void Fuzzer::ReadAndExecuteSeedCorpora(Vector<SizedFile> &CorporaFiles) { + + const size_t kMaxSaneLen = 1 << 20; + const size_t kMinDefaultLen = 4096; + size_t MaxSize = 0; + size_t MinSize = -1; + size_t TotalSize = 0; + for (auto &File : CorporaFiles) { + + MaxSize = Max(File.Size, MaxSize); + MinSize = Min(File.Size, MinSize); + TotalSize += File.Size; + + } + + if (Options.MaxLen == 0) + SetMaxInputLen(std::min(std::max(kMinDefaultLen, MaxSize), kMaxSaneLen)); + assert(MaxInputLen > 0); + + // Test the callback with empty input and never try it again. + uint8_t dummy = 0; + ExecuteCallback(&dummy, 0); + + if (CorporaFiles.empty()) { + + Printf("INFO: A corpus is not provided, starting from an empty corpus\n"); + Unit U({'\n'}); // Valid ASCII input. + RunOne(U.data(), U.size()); + + } else { + + Printf( + "INFO: seed corpus: files: %zd min: %zdb max: %zdb total: %zdb" + " rss: %zdMb\n", + CorporaFiles.size(), MinSize, MaxSize, TotalSize, GetPeakRSSMb()); + if (Options.ShuffleAtStartUp) + std::shuffle(CorporaFiles.begin(), CorporaFiles.end(), MD.GetRand()); + + if (Options.PreferSmall) { + + std::stable_sort(CorporaFiles.begin(), CorporaFiles.end()); + assert(CorporaFiles.front().Size <= CorporaFiles.back().Size); + + } + + // Load and execute inputs one by one. + for (auto &SF : CorporaFiles) { + + auto U = FileToVector(SF.File, MaxInputLen, /*ExitOnError=*/false); + assert(U.size() <= MaxInputLen); + RunOne(U.data(), U.size(), /*MayDeleteFile*/ false, /*II*/ nullptr, + /*ForceAddToCorpus*/ Options.KeepSeed, + /*FoundUniqFeatures*/ nullptr); + CheckExitOnSrcPosOrItem(); + TryDetectingAMemoryLeak(U.data(), U.size(), + /*DuringInitialCorpusExecution*/ true); + + } + + } + + PrintStats("INITED"); + if (!Options.FocusFunction.empty()) { + + Printf("INFO: %zd/%zd inputs touch the focus function\n", + Corpus.NumInputsThatTouchFocusFunction(), Corpus.size()); + if (!Options.DataFlowTrace.empty()) + Printf("INFO: %zd/%zd inputs have the Data Flow Trace\n", + Corpus.NumInputsWithDataFlowTrace(), + Corpus.NumInputsThatTouchFocusFunction()); + + } + + if (Corpus.empty() && Options.MaxNumberOfRuns) { + + Printf( + "ERROR: no interesting inputs were found. " + "Is the code instrumented for coverage? Exiting.\n"); + exit(1); + + } + +} + +void Fuzzer::Loop(Vector<SizedFile> &CorporaFiles) { + + auto FocusFunctionOrAuto = Options.FocusFunction; + DFT.Init(Options.DataFlowTrace, &FocusFunctionOrAuto, CorporaFiles, + MD.GetRand()); + TPC.SetFocusFunction(FocusFunctionOrAuto); + ReadAndExecuteSeedCorpora(CorporaFiles); + DFT.Clear(); // No need for DFT any more. + TPC.SetPrintNewPCs(Options.PrintNewCovPcs); + TPC.SetPrintNewFuncs(Options.PrintNewCovFuncs); + system_clock::time_point LastCorpusReload = system_clock::now(); + + TmpMaxMutationLen = + Min(MaxMutationLen, Max(size_t(4), Corpus.MaxInputSize())); + + while (true) { + + auto Now = system_clock::now(); + if (!Options.StopFile.empty() && + !FileToVector(Options.StopFile, 1, false).empty()) + break; + if (duration_cast<seconds>(Now - LastCorpusReload).count() >= + Options.ReloadIntervalSec) { + + RereadOutputCorpus(MaxInputLen); + LastCorpusReload = system_clock::now(); + + } + + if (TotalNumberOfRuns >= Options.MaxNumberOfRuns) break; + if (TimedOut()) break; + + // Update TmpMaxMutationLen + if (Options.LenControl) { + + if (TmpMaxMutationLen < MaxMutationLen && + TotalNumberOfRuns - LastCorpusUpdateRun > + Options.LenControl * Log(TmpMaxMutationLen)) { + + TmpMaxMutationLen = + Min(MaxMutationLen, TmpMaxMutationLen + Log(TmpMaxMutationLen)); + LastCorpusUpdateRun = TotalNumberOfRuns; + + } + + } else { + + TmpMaxMutationLen = MaxMutationLen; + + } + + // Perform several mutations and runs. + MutateAndTestOne(); + + PurgeAllocator(); + + } + + PrintStats("DONE ", "\n"); + MD.PrintRecommendedDictionary(); + +} + +void Fuzzer::MinimizeCrashLoop(const Unit &U) { + + if (U.size() <= 1) return; + while (!TimedOut() && TotalNumberOfRuns < Options.MaxNumberOfRuns) { + + MD.StartMutationSequence(); + memcpy(CurrentUnitData, U.data(), U.size()); + for (int i = 0; i < Options.MutateDepth; i++) { + + size_t NewSize = MD.Mutate(CurrentUnitData, U.size(), MaxMutationLen); + assert(NewSize > 0 && NewSize <= MaxMutationLen); + ExecuteCallback(CurrentUnitData, NewSize); + PrintPulseAndReportSlowInput(CurrentUnitData, NewSize); + TryDetectingAMemoryLeak(CurrentUnitData, NewSize, + /*DuringInitialCorpusExecution*/ false); + + } + + } + +} + +} // namespace fuzzer + +#ifdef INTROSPECTION + extern const char *introspection_ptr; +#endif + +extern "C" { + +ATTRIBUTE_INTERFACE size_t LLVMFuzzerMutate(uint8_t *Data, size_t Size, + size_t MaxSize) { + + assert(fuzzer::F); + size_t r = fuzzer::F->GetMD().DefaultMutate(Data, Size, MaxSize); +#ifdef INTROSPECTION + introspection_ptr = fuzzer::F->GetMD().WriteMutationSequence(); +#endif + return r; + +} + +} // extern "C" + diff --git a/custom_mutators/libfuzzer/FuzzerMain.cpp b/custom_mutators/libfuzzer/FuzzerMain.cpp new file mode 100644 index 00000000..b02c88e9 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerMain.cpp @@ -0,0 +1,26 @@ +//===- FuzzerMain.cpp - main() function and flags -------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// main() and flags. +//===----------------------------------------------------------------------===// + +#include "FuzzerDefs.h" +#include "FuzzerPlatform.h" + +extern "C" { + +// This function should be defined by the user. +int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size); + +} // extern "C" + +ATTRIBUTE_INTERFACE int main(int argc, char **argv) { + + return fuzzer::FuzzerDriver(&argc, &argv, LLVMFuzzerTestOneInput); + +} + diff --git a/custom_mutators/libfuzzer/FuzzerMerge.cpp b/custom_mutators/libfuzzer/FuzzerMerge.cpp new file mode 100644 index 00000000..b341f5b3 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerMerge.cpp @@ -0,0 +1,485 @@ +//===- FuzzerMerge.cpp - merging corpora ----------------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Merging corpora. +//===----------------------------------------------------------------------===// + +#include "FuzzerCommand.h" +#include "FuzzerMerge.h" +#include "FuzzerIO.h" +#include "FuzzerInternal.h" +#include "FuzzerTracePC.h" +#include "FuzzerUtil.h" + +#include <fstream> +#include <iterator> +#include <set> +#include <sstream> +#include <unordered_set> + +namespace fuzzer { + +bool Merger::Parse(const std::string &Str, bool ParseCoverage) { + + std::istringstream SS(Str); + return Parse(SS, ParseCoverage); + +} + +void Merger::ParseOrExit(std::istream &IS, bool ParseCoverage) { + + if (!Parse(IS, ParseCoverage)) { + + Printf("MERGE: failed to parse the control file (unexpected error)\n"); + exit(1); + + } + +} + +// The control file example: +// +// 3 # The number of inputs +// 1 # The number of inputs in the first corpus, <= the previous number +// file0 +// file1 +// file2 # One file name per line. +// STARTED 0 123 # FileID, file size +// FT 0 1 4 6 8 # FileID COV1 COV2 ... +// COV 0 7 8 9 # FileID COV1 COV1 +// STARTED 1 456 # If FT is missing, the input crashed while processing. +// STARTED 2 567 +// FT 2 8 9 +// COV 2 11 12 +bool Merger::Parse(std::istream &IS, bool ParseCoverage) { + + LastFailure.clear(); + std::string Line; + + // Parse NumFiles. + if (!std::getline(IS, Line, '\n')) return false; + std::istringstream L1(Line); + size_t NumFiles = 0; + L1 >> NumFiles; + if (NumFiles == 0 || NumFiles > 10000000) return false; + + // Parse NumFilesInFirstCorpus. + if (!std::getline(IS, Line, '\n')) return false; + std::istringstream L2(Line); + NumFilesInFirstCorpus = NumFiles + 1; + L2 >> NumFilesInFirstCorpus; + if (NumFilesInFirstCorpus > NumFiles) return false; + + // Parse file names. + Files.resize(NumFiles); + for (size_t i = 0; i < NumFiles; i++) + if (!std::getline(IS, Files[i].Name, '\n')) return false; + + // Parse STARTED, FT, and COV lines. + size_t ExpectedStartMarker = 0; + const size_t kInvalidStartMarker = -1; + size_t LastSeenStartMarker = kInvalidStartMarker; + Vector<uint32_t> TmpFeatures; + Set<uint32_t> PCs; + while (std::getline(IS, Line, '\n')) { + + std::istringstream ISS1(Line); + std::string Marker; + size_t N; + ISS1 >> Marker; + ISS1 >> N; + if (Marker == "STARTED") { + + // STARTED FILE_ID FILE_SIZE + if (ExpectedStartMarker != N) return false; + ISS1 >> Files[ExpectedStartMarker].Size; + LastSeenStartMarker = ExpectedStartMarker; + assert(ExpectedStartMarker < Files.size()); + ExpectedStartMarker++; + + } else if (Marker == "FT") { + + // FT FILE_ID COV1 COV2 COV3 ... + size_t CurrentFileIdx = N; + if (CurrentFileIdx != LastSeenStartMarker) return false; + LastSeenStartMarker = kInvalidStartMarker; + if (ParseCoverage) { + + TmpFeatures.clear(); // use a vector from outer scope to avoid resizes. + while (ISS1 >> N) + TmpFeatures.push_back(N); + std::sort(TmpFeatures.begin(), TmpFeatures.end()); + Files[CurrentFileIdx].Features = TmpFeatures; + + } + + } else if (Marker == "COV") { + + size_t CurrentFileIdx = N; + if (ParseCoverage) + while (ISS1 >> N) + if (PCs.insert(N).second) Files[CurrentFileIdx].Cov.push_back(N); + + } else { + + return false; + + } + + } + + if (LastSeenStartMarker != kInvalidStartMarker) + LastFailure = Files[LastSeenStartMarker].Name; + + FirstNotProcessedFile = ExpectedStartMarker; + return true; + +} + +size_t Merger::ApproximateMemoryConsumption() const { + + size_t Res = 0; + for (const auto &F : Files) + Res += sizeof(F) + F.Features.size() * sizeof(F.Features[0]); + return Res; + +} + +// Decides which files need to be merged (add those to NewFiles). +// Returns the number of new features added. +size_t Merger::Merge(const Set<uint32_t> &InitialFeatures, + Set<uint32_t> * NewFeatures, + const Set<uint32_t> &InitialCov, Set<uint32_t> *NewCov, + Vector<std::string> *NewFiles) { + + NewFiles->clear(); + assert(NumFilesInFirstCorpus <= Files.size()); + Set<uint32_t> AllFeatures = InitialFeatures; + + // What features are in the initial corpus? + for (size_t i = 0; i < NumFilesInFirstCorpus; i++) { + + auto &Cur = Files[i].Features; + AllFeatures.insert(Cur.begin(), Cur.end()); + + } + + // Remove all features that we already know from all other inputs. + for (size_t i = NumFilesInFirstCorpus; i < Files.size(); i++) { + + auto & Cur = Files[i].Features; + Vector<uint32_t> Tmp; + std::set_difference(Cur.begin(), Cur.end(), AllFeatures.begin(), + AllFeatures.end(), std::inserter(Tmp, Tmp.begin())); + Cur.swap(Tmp); + + } + + // Sort. Give preference to + // * smaller files + // * files with more features. + std::sort(Files.begin() + NumFilesInFirstCorpus, Files.end(), + [&](const MergeFileInfo &a, const MergeFileInfo &b) -> bool { + + if (a.Size != b.Size) return a.Size < b.Size; + return a.Features.size() > b.Features.size(); + + }); + + // One greedy pass: add the file's features to AllFeatures. + // If new features were added, add this file to NewFiles. + for (size_t i = NumFilesInFirstCorpus; i < Files.size(); i++) { + + auto &Cur = Files[i].Features; + // Printf("%s -> sz %zd ft %zd\n", Files[i].Name.c_str(), + // Files[i].Size, Cur.size()); + bool FoundNewFeatures = false; + for (auto Fe : Cur) { + + if (AllFeatures.insert(Fe).second) { + + FoundNewFeatures = true; + NewFeatures->insert(Fe); + + } + + } + + if (FoundNewFeatures) NewFiles->push_back(Files[i].Name); + for (auto Cov : Files[i].Cov) + if (InitialCov.find(Cov) == InitialCov.end()) NewCov->insert(Cov); + + } + + return NewFeatures->size(); + +} + +Set<uint32_t> Merger::AllFeatures() const { + + Set<uint32_t> S; + for (auto &File : Files) + S.insert(File.Features.begin(), File.Features.end()); + return S; + +} + +// Inner process. May crash if the target crashes. +void Fuzzer::CrashResistantMergeInternalStep(const std::string &CFPath) { + + Printf("MERGE-INNER: using the control file '%s'\n", CFPath.c_str()); + Merger M; + std::ifstream IF(CFPath); + M.ParseOrExit(IF, false); + IF.close(); + if (!M.LastFailure.empty()) + Printf("MERGE-INNER: '%s' caused a failure at the previous merge step\n", + M.LastFailure.c_str()); + + Printf( + "MERGE-INNER: %zd total files;" + " %zd processed earlier; will process %zd files now\n", + M.Files.size(), M.FirstNotProcessedFile, + M.Files.size() - M.FirstNotProcessedFile); + + std::ofstream OF(CFPath, std::ofstream::out | std::ofstream::app); + Set<size_t> AllFeatures; + auto PrintStatsWrapper = [this, &AllFeatures](const char *Where) { + + this->PrintStats(Where, "\n", 0, AllFeatures.size()); + + }; + + Set<const TracePC::PCTableEntry *> AllPCs; + for (size_t i = M.FirstNotProcessedFile; i < M.Files.size(); i++) { + + Fuzzer::MaybeExitGracefully(); + auto U = FileToVector(M.Files[i].Name); + if (U.size() > MaxInputLen) { + + U.resize(MaxInputLen); + U.shrink_to_fit(); + + } + + // Write the pre-run marker. + OF << "STARTED " << i << " " << U.size() << "\n"; + OF.flush(); // Flush is important since Command::Execute may crash. + // Run. + TPC.ResetMaps(); + ExecuteCallback(U.data(), U.size()); + // Collect coverage. We are iterating over the files in this order: + // * First, files in the initial corpus ordered by size, smallest first. + // * Then, all other files, smallest first. + // So it makes no sense to record all features for all files, instead we + // only record features that were not seen before. + Set<size_t> UniqFeatures; + TPC.CollectFeatures([&](size_t Feature) { + + if (AllFeatures.insert(Feature).second) UniqFeatures.insert(Feature); + + }); + + TPC.UpdateObservedPCs(); + // Show stats. + if (!(TotalNumberOfRuns & (TotalNumberOfRuns - 1))) + PrintStatsWrapper("pulse "); + if (TotalNumberOfRuns == M.NumFilesInFirstCorpus) + PrintStatsWrapper("LOADED"); + // Write the post-run marker and the coverage. + OF << "FT " << i; + for (size_t F : UniqFeatures) + OF << " " << F; + OF << "\n"; + OF << "COV " << i; + TPC.ForEachObservedPC([&](const TracePC::PCTableEntry *TE) { + + if (AllPCs.insert(TE).second) OF << " " << TPC.PCTableEntryIdx(TE); + + }); + + OF << "\n"; + OF.flush(); + + } + + PrintStatsWrapper("DONE "); + +} + +static size_t WriteNewControlFile(const std::string & CFPath, + const Vector<SizedFile> & OldCorpus, + const Vector<SizedFile> & NewCorpus, + const Vector<MergeFileInfo> &KnownFiles) { + + std::unordered_set<std::string> FilesToSkip; + for (auto &SF : KnownFiles) + FilesToSkip.insert(SF.Name); + + Vector<std::string> FilesToUse; + auto MaybeUseFile = [=, &FilesToUse](std::string Name) { + + if (FilesToSkip.find(Name) == FilesToSkip.end()) FilesToUse.push_back(Name); + + }; + + for (auto &SF : OldCorpus) + MaybeUseFile(SF.File); + auto FilesToUseFromOldCorpus = FilesToUse.size(); + for (auto &SF : NewCorpus) + MaybeUseFile(SF.File); + + RemoveFile(CFPath); + std::ofstream ControlFile(CFPath); + ControlFile << FilesToUse.size() << "\n"; + ControlFile << FilesToUseFromOldCorpus << "\n"; + for (auto &FN : FilesToUse) + ControlFile << FN << "\n"; + + if (!ControlFile) { + + Printf("MERGE-OUTER: failed to write to the control file: %s\n", + CFPath.c_str()); + exit(1); + + } + + return FilesToUse.size(); + +} + +// Outer process. Does not call the target code and thus should not fail. +void CrashResistantMerge(const Vector<std::string> &Args, + const Vector<SizedFile> & OldCorpus, + const Vector<SizedFile> & NewCorpus, + Vector<std::string> * NewFiles, + const Set<uint32_t> & InitialFeatures, + Set<uint32_t> * NewFeatures, + const Set<uint32_t> &InitialCov, Set<uint32_t> *NewCov, + const std::string &CFPath, bool V /*Verbose*/) { + + if (NewCorpus.empty() && OldCorpus.empty()) return; // Nothing to merge. + size_t NumAttempts = 0; + Vector<MergeFileInfo> KnownFiles; + if (FileSize(CFPath)) { + + VPrintf(V, "MERGE-OUTER: non-empty control file provided: '%s'\n", + CFPath.c_str()); + Merger M; + std::ifstream IF(CFPath); + if (M.Parse(IF, /*ParseCoverage=*/true)) { + + VPrintf(V, + "MERGE-OUTER: control file ok, %zd files total," + " first not processed file %zd\n", + M.Files.size(), M.FirstNotProcessedFile); + if (!M.LastFailure.empty()) + VPrintf(V, + "MERGE-OUTER: '%s' will be skipped as unlucky " + "(merge has stumbled on it the last time)\n", + M.LastFailure.c_str()); + if (M.FirstNotProcessedFile >= M.Files.size()) { + + // Merge has already been completed with the given merge control file. + if (M.Files.size() == OldCorpus.size() + NewCorpus.size()) { + + VPrintf( + V, + "MERGE-OUTER: nothing to do, merge has been completed before\n"); + exit(0); + + } + + // Number of input files likely changed, start merge from scratch, but + // reuse coverage information from the given merge control file. + VPrintf( + V, + "MERGE-OUTER: starting merge from scratch, but reusing coverage " + "information from the given control file\n"); + KnownFiles = M.Files; + + } else { + + // There is a merge in progress, continue. + NumAttempts = M.Files.size() - M.FirstNotProcessedFile; + + } + + } else { + + VPrintf(V, "MERGE-OUTER: bad control file, will overwrite it\n"); + + } + + } + + if (!NumAttempts) { + + // The supplied control file is empty or bad, create a fresh one. + VPrintf(V, + "MERGE-OUTER: " + "%zd files, %zd in the initial corpus, %zd processed earlier\n", + OldCorpus.size() + NewCorpus.size(), OldCorpus.size(), + KnownFiles.size()); + NumAttempts = WriteNewControlFile(CFPath, OldCorpus, NewCorpus, KnownFiles); + + } + + // Execute the inner process until it passes. + // Every inner process should execute at least one input. + Command BaseCmd(Args); + BaseCmd.removeFlag("merge"); + BaseCmd.removeFlag("fork"); + BaseCmd.removeFlag("collect_data_flow"); + for (size_t Attempt = 1; Attempt <= NumAttempts; Attempt++) { + + Fuzzer::MaybeExitGracefully(); + VPrintf(V, "MERGE-OUTER: attempt %zd\n", Attempt); + Command Cmd(BaseCmd); + Cmd.addFlag("merge_control_file", CFPath); + Cmd.addFlag("merge_inner", "1"); + if (!V) { + + Cmd.setOutputFile(getDevNull()); + Cmd.combineOutAndErr(); + + } + + auto ExitCode = ExecuteCommand(Cmd); + if (!ExitCode) { + + VPrintf(V, "MERGE-OUTER: succesfull in %zd attempt(s)\n", Attempt); + break; + + } + + } + + // Read the control file and do the merge. + Merger M; + std::ifstream IF(CFPath); + IF.seekg(0, IF.end); + VPrintf(V, "MERGE-OUTER: the control file has %zd bytes\n", + (size_t)IF.tellg()); + IF.seekg(0, IF.beg); + M.ParseOrExit(IF, true); + IF.close(); + VPrintf(V, + "MERGE-OUTER: consumed %zdMb (%zdMb rss) to parse the control file\n", + M.ApproximateMemoryConsumption() >> 20, GetPeakRSSMb()); + + M.Files.insert(M.Files.end(), KnownFiles.begin(), KnownFiles.end()); + M.Merge(InitialFeatures, NewFeatures, InitialCov, NewCov, NewFiles); + VPrintf(V, + "MERGE-OUTER: %zd new files with %zd new features added; " + "%zd new coverage edges\n", + NewFiles->size(), NewFeatures->size(), NewCov->size()); + +} + +} // namespace fuzzer + diff --git a/custom_mutators/libfuzzer/FuzzerMerge.h b/custom_mutators/libfuzzer/FuzzerMerge.h new file mode 100644 index 00000000..e0c6bc53 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerMerge.h @@ -0,0 +1,87 @@ +//===- FuzzerMerge.h - merging corpa ----------------------------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Merging Corpora. +// +// The task: +// Take the existing corpus (possibly empty) and merge new inputs into +// it so that only inputs with new coverage ('features') are added. +// The process should tolerate the crashes, OOMs, leaks, etc. +// +// Algorithm: +// The outer process collects the set of files and writes their names +// into a temporary "control" file, then repeatedly launches the inner +// process until all inputs are processed. +// The outer process does not actually execute the target code. +// +// The inner process reads the control file and sees a) list of all the inputs +// and b) the last processed input. Then it starts processing the inputs one +// by one. Before processing every input it writes one line to control file: +// STARTED INPUT_ID INPUT_SIZE +// After processing an input it writes the following lines: +// FT INPUT_ID Feature1 Feature2 Feature3 ... +// COV INPUT_ID Coverage1 Coverage2 Coverage3 ... +// If a crash happens while processing an input the last line in the control +// file will be "STARTED INPUT_ID" and so the next process will know +// where to resume. +// +// Once all inputs are processed by the inner process(es) the outer process +// reads the control files and does the merge based entirely on the contents +// of control file. +// It uses a single pass greedy algorithm choosing first the smallest inputs +// within the same size the inputs that have more new features. +// +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_MERGE_H +#define LLVM_FUZZER_MERGE_H + +#include "FuzzerDefs.h" + +#include <istream> +#include <ostream> +#include <set> +#include <vector> + +namespace fuzzer { + +struct MergeFileInfo { + std::string Name; + size_t Size = 0; + Vector<uint32_t> Features, Cov; +}; + +struct Merger { + Vector<MergeFileInfo> Files; + size_t NumFilesInFirstCorpus = 0; + size_t FirstNotProcessedFile = 0; + std::string LastFailure; + + bool Parse(std::istream &IS, bool ParseCoverage); + bool Parse(const std::string &Str, bool ParseCoverage); + void ParseOrExit(std::istream &IS, bool ParseCoverage); + size_t Merge(const Set<uint32_t> &InitialFeatures, Set<uint32_t> *NewFeatures, + const Set<uint32_t> &InitialCov, Set<uint32_t> *NewCov, + Vector<std::string> *NewFiles); + size_t ApproximateMemoryConsumption() const; + Set<uint32_t> AllFeatures() const; +}; + +void CrashResistantMerge(const Vector<std::string> &Args, + const Vector<SizedFile> &OldCorpus, + const Vector<SizedFile> &NewCorpus, + Vector<std::string> *NewFiles, + const Set<uint32_t> &InitialFeatures, + Set<uint32_t> *NewFeatures, + const Set<uint32_t> &InitialCov, + Set<uint32_t> *NewCov, + const std::string &CFPath, + bool Verbose); + +} // namespace fuzzer + +#endif // LLVM_FUZZER_MERGE_H diff --git a/custom_mutators/libfuzzer/FuzzerMutate.cpp b/custom_mutators/libfuzzer/FuzzerMutate.cpp new file mode 100644 index 00000000..edfe0455 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerMutate.cpp @@ -0,0 +1,747 @@ +//===- FuzzerMutate.cpp - Mutate a test input -----------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Mutate a test input. +//===----------------------------------------------------------------------===// + +#include "FuzzerDefs.h" +#include "FuzzerExtFunctions.h" +#include "FuzzerIO.h" +#include "FuzzerMutate.h" +#include "FuzzerOptions.h" +#include "FuzzerTracePC.h" +#include <random> +#include <chrono> + +namespace fuzzer { + +const size_t Dictionary::kMaxDictSize; +static const size_t kMaxMutationsToPrint = 10; + +static void PrintASCII(const Word &W, const char *PrintAfter) { + + PrintASCII(W.data(), W.size(), PrintAfter); + +} + +MutationDispatcher::MutationDispatcher(Random & Rand, + const FuzzingOptions &Options) + : Rand(Rand), Options(Options) { + + DefaultMutators.insert( + DefaultMutators.begin(), + { + + {&MutationDispatcher::Mutate_EraseBytes, "EraseBytes"}, + {&MutationDispatcher::Mutate_InsertByte, "InsertByte"}, + {&MutationDispatcher::Mutate_InsertRepeatedBytes, + "InsertRepeatedBytes"}, + {&MutationDispatcher::Mutate_ChangeByte, "ChangeByte"}, + {&MutationDispatcher::Mutate_ChangeBit, "ChangeBit"}, + {&MutationDispatcher::Mutate_ShuffleBytes, "ShuffleBytes"}, + {&MutationDispatcher::Mutate_ChangeASCIIInteger, "ChangeASCIIInt"}, + {&MutationDispatcher::Mutate_ChangeBinaryInteger, "ChangeBinInt"}, + {&MutationDispatcher::Mutate_CopyPart, "CopyPart"}, + {&MutationDispatcher::Mutate_CrossOver, "CrossOver"}, + {&MutationDispatcher::Mutate_AddWordFromManualDictionary, + "ManualDict"}, + {&MutationDispatcher::Mutate_AddWordFromPersistentAutoDictionary, + "PersAutoDict"}, + + }); + + if (Options.UseCmp) + DefaultMutators.push_back( + {&MutationDispatcher::Mutate_AddWordFromTORC, "CMP"}); + + if (EF->LLVMFuzzerCustomMutator) + Mutators.push_back({&MutationDispatcher::Mutate_Custom, "Custom"}); + else + Mutators = DefaultMutators; + + if (EF->LLVMFuzzerCustomCrossOver) + Mutators.push_back( + {&MutationDispatcher::Mutate_CustomCrossOver, "CustomCrossOver"}); + +} + +static char RandCh(Random &Rand) { + + if (Rand.RandBool()) return Rand(256); + const char Special[] = "!*'();:@&=+$,/?%#[]012Az-`~.\xff\x00"; + return Special[Rand(sizeof(Special) - 1)]; + +} + +size_t MutationDispatcher::Mutate_Custom(uint8_t *Data, size_t Size, + size_t MaxSize) { + + return EF->LLVMFuzzerCustomMutator(Data, Size, MaxSize, Rand.Rand()); + +} + +size_t MutationDispatcher::Mutate_CustomCrossOver(uint8_t *Data, size_t Size, + size_t MaxSize) { + + if (Size == 0) return 0; + if (!CrossOverWith) return 0; + const Unit &Other = *CrossOverWith; + if (Other.empty()) return 0; + CustomCrossOverInPlaceHere.resize(MaxSize); + auto & U = CustomCrossOverInPlaceHere; + size_t NewSize = EF->LLVMFuzzerCustomCrossOver( + Data, Size, Other.data(), Other.size(), U.data(), U.size(), Rand.Rand()); + if (!NewSize) return 0; + assert(NewSize <= MaxSize && "CustomCrossOver returned overisized unit"); + memcpy(Data, U.data(), NewSize); + return NewSize; + +} + + +size_t MutationDispatcher::Mutate_ShuffleBytes(uint8_t *Data, size_t Size, + size_t MaxSize) { + if (Size > MaxSize || Size == 0) return 0; + size_t ShuffleAmount = + Rand(std::min(Size, (size_t)8)) + 1; // [1,8] and <= Size. + size_t ShuffleStart = Rand(Size - ShuffleAmount); + assert(ShuffleStart + ShuffleAmount <= Size); + unsigned num = std::chrono::system_clock::now().time_since_epoch().count(); + std::shuffle(Data + ShuffleStart, Data + ShuffleStart + ShuffleAmount, std::default_random_engine(num)); + //std::shuffle(Data + ShuffleStart, Data + ShuffleStart + ShuffleAmount, Rand); + return Size; + +} + +size_t MutationDispatcher::Mutate_EraseBytes(uint8_t *Data, size_t Size, + size_t MaxSize) { + + if (Size <= 1) return 0; + size_t N = Rand(Size / 2) + 1; + assert(N < Size); + size_t Idx = Rand(Size - N + 1); + // Erase Data[Idx:Idx+N]. + memmove(Data + Idx, Data + Idx + N, Size - Idx - N); + // Printf("Erase: %zd %zd => %zd; Idx %zd\n", N, Size, Size - N, Idx); + return Size - N; + +} + +size_t MutationDispatcher::Mutate_InsertByte(uint8_t *Data, size_t Size, + size_t MaxSize) { + + if (Size >= MaxSize) return 0; + size_t Idx = Rand(Size + 1); + // Insert new value at Data[Idx]. + memmove(Data + Idx + 1, Data + Idx, Size - Idx); + Data[Idx] = RandCh(Rand); + return Size + 1; + +} + +size_t MutationDispatcher::Mutate_InsertRepeatedBytes(uint8_t *Data, + size_t Size, + size_t MaxSize) { + + const size_t kMinBytesToInsert = 3; + if (Size + kMinBytesToInsert >= MaxSize) return 0; + size_t MaxBytesToInsert = std::min(MaxSize - Size, (size_t)128); + size_t N = Rand(MaxBytesToInsert - kMinBytesToInsert + 1) + kMinBytesToInsert; + assert(Size + N <= MaxSize && N); + size_t Idx = Rand(Size + 1); + // Insert new values at Data[Idx]. + memmove(Data + Idx + N, Data + Idx, Size - Idx); + // Give preference to 0x00 and 0xff. + uint8_t Byte = Rand.RandBool() ? Rand(256) : (Rand.RandBool() ? 0 : 255); + for (size_t i = 0; i < N; i++) + Data[Idx + i] = Byte; + return Size + N; + +} + +size_t MutationDispatcher::Mutate_ChangeByte(uint8_t *Data, size_t Size, + size_t MaxSize) { + + if (Size > MaxSize) return 0; + size_t Idx = Rand(Size); + Data[Idx] = RandCh(Rand); + return Size; + +} + +size_t MutationDispatcher::Mutate_ChangeBit(uint8_t *Data, size_t Size, + size_t MaxSize) { + + if (Size > MaxSize) return 0; + size_t Idx = Rand(Size); + Data[Idx] ^= 1 << Rand(8); + return Size; + +} + +size_t MutationDispatcher::Mutate_AddWordFromManualDictionary(uint8_t *Data, + size_t Size, + size_t MaxSize) { + + return AddWordFromDictionary(ManualDictionary, Data, Size, MaxSize); + +} + +size_t MutationDispatcher::ApplyDictionaryEntry(uint8_t *Data, size_t Size, + size_t MaxSize, + DictionaryEntry &DE) { + + const Word &W = DE.GetW(); + bool UsePositionHint = DE.HasPositionHint() && + DE.GetPositionHint() + W.size() < Size && + Rand.RandBool(); + if (Rand.RandBool()) { // Insert W. + if (Size + W.size() > MaxSize) return 0; + size_t Idx = UsePositionHint ? DE.GetPositionHint() : Rand(Size + 1); + memmove(Data + Idx + W.size(), Data + Idx, Size - Idx); + memcpy(Data + Idx, W.data(), W.size()); + Size += W.size(); + + } else { // Overwrite some bytes with W. + + if (W.size() > Size) return 0; + size_t Idx = UsePositionHint ? DE.GetPositionHint() : Rand(Size - W.size()); + memcpy(Data + Idx, W.data(), W.size()); + + } + + return Size; + +} + +// Somewhere in the past we have observed a comparison instructions +// with arguments Arg1 Arg2. This function tries to guess a dictionary +// entry that will satisfy that comparison. +// It first tries to find one of the arguments (possibly swapped) in the +// input and if it succeeds it creates a DE with a position hint. +// Otherwise it creates a DE with one of the arguments w/o a position hint. +DictionaryEntry MutationDispatcher::MakeDictionaryEntryFromCMP( + const void *Arg1, const void *Arg2, const void *Arg1Mutation, + const void *Arg2Mutation, size_t ArgSize, const uint8_t *Data, + size_t Size) { + + bool HandleFirst = Rand.RandBool(); + const void * ExistingBytes, *DesiredBytes; + Word W; + const uint8_t *End = Data + Size; + for (int Arg = 0; Arg < 2; Arg++) { + + ExistingBytes = HandleFirst ? Arg1 : Arg2; + DesiredBytes = HandleFirst ? Arg2Mutation : Arg1Mutation; + HandleFirst = !HandleFirst; + W.Set(reinterpret_cast<const uint8_t *>(DesiredBytes), ArgSize); + const size_t kMaxNumPositions = 8; + size_t Positions[kMaxNumPositions]; + size_t NumPositions = 0; + for (const uint8_t *Cur = Data; + Cur < End && NumPositions < kMaxNumPositions; Cur++) { + + Cur = + (const uint8_t *)SearchMemory(Cur, End - Cur, ExistingBytes, ArgSize); + if (!Cur) break; + Positions[NumPositions++] = Cur - Data; + + } + + if (!NumPositions) continue; + return DictionaryEntry(W, Positions[Rand(NumPositions)]); + + } + + DictionaryEntry DE(W); + return DE; + +} + +template <class T> +DictionaryEntry MutationDispatcher::MakeDictionaryEntryFromCMP( + T Arg1, T Arg2, const uint8_t *Data, size_t Size) { + + if (Rand.RandBool()) Arg1 = Bswap(Arg1); + if (Rand.RandBool()) Arg2 = Bswap(Arg2); + T Arg1Mutation = Arg1 + Rand(-1, 1); + T Arg2Mutation = Arg2 + Rand(-1, 1); + return MakeDictionaryEntryFromCMP(&Arg1, &Arg2, &Arg1Mutation, &Arg2Mutation, + sizeof(Arg1), Data, Size); + +} + +DictionaryEntry MutationDispatcher::MakeDictionaryEntryFromCMP( + const Word &Arg1, const Word &Arg2, const uint8_t *Data, size_t Size) { + + return MakeDictionaryEntryFromCMP(Arg1.data(), Arg2.data(), Arg1.data(), + Arg2.data(), Arg1.size(), Data, Size); + +} + +size_t MutationDispatcher::Mutate_AddWordFromTORC(uint8_t *Data, size_t Size, + size_t MaxSize) { + + Word W; + DictionaryEntry DE; + switch (Rand(4)) { + + case 0: { + + auto X = TPC.TORC8.Get(Rand.Rand()); + DE = MakeDictionaryEntryFromCMP(X.A, X.B, Data, Size); + + } break; + + case 1: { + + auto X = TPC.TORC4.Get(Rand.Rand()); + if ((X.A >> 16) == 0 && (X.B >> 16) == 0 && Rand.RandBool()) + DE = MakeDictionaryEntryFromCMP((uint16_t)X.A, (uint16_t)X.B, Data, + Size); + else + DE = MakeDictionaryEntryFromCMP(X.A, X.B, Data, Size); + + } break; + + case 2: { + + auto X = TPC.TORCW.Get(Rand.Rand()); + DE = MakeDictionaryEntryFromCMP(X.A, X.B, Data, Size); + + } break; + + case 3: + if (Options.UseMemmem) { + + auto X = TPC.MMT.Get(Rand.Rand()); + DE = DictionaryEntry(X); + + } + + break; + default: + assert(0); + + } + + if (!DE.GetW().size()) return 0; + Size = ApplyDictionaryEntry(Data, Size, MaxSize, DE); + if (!Size) return 0; + DictionaryEntry &DERef = + CmpDictionaryEntriesDeque[CmpDictionaryEntriesDequeIdx++ % + kCmpDictionaryEntriesDequeSize]; + DERef = DE; + CurrentDictionaryEntrySequence.push_back(&DERef); + return Size; + +} + +size_t MutationDispatcher::Mutate_AddWordFromPersistentAutoDictionary( + uint8_t *Data, size_t Size, size_t MaxSize) { + + return AddWordFromDictionary(PersistentAutoDictionary, Data, Size, MaxSize); + +} + +size_t MutationDispatcher::AddWordFromDictionary(Dictionary &D, uint8_t *Data, + size_t Size, size_t MaxSize) { + + if (Size > MaxSize) return 0; + if (D.empty()) return 0; + DictionaryEntry &DE = D[Rand(D.size())]; + Size = ApplyDictionaryEntry(Data, Size, MaxSize, DE); + if (!Size) return 0; + DE.IncUseCount(); + CurrentDictionaryEntrySequence.push_back(&DE); + return Size; + +} + +// Overwrites part of To[0,ToSize) with a part of From[0,FromSize). +// Returns ToSize. +size_t MutationDispatcher::CopyPartOf(const uint8_t *From, size_t FromSize, + uint8_t *To, size_t ToSize) { + + // Copy From[FromBeg, FromBeg + CopySize) into To[ToBeg, ToBeg + CopySize). + size_t ToBeg = Rand(ToSize); + size_t CopySize = Rand(ToSize - ToBeg) + 1; + assert(ToBeg + CopySize <= ToSize); + CopySize = std::min(CopySize, FromSize); + size_t FromBeg = Rand(FromSize - CopySize + 1); + assert(FromBeg + CopySize <= FromSize); + memmove(To + ToBeg, From + FromBeg, CopySize); + return ToSize; + +} + +// Inserts part of From[0,ToSize) into To. +// Returns new size of To on success or 0 on failure. +size_t MutationDispatcher::InsertPartOf(const uint8_t *From, size_t FromSize, + uint8_t *To, size_t ToSize, + size_t MaxToSize) { + + if (ToSize >= MaxToSize) return 0; + size_t AvailableSpace = MaxToSize - ToSize; + size_t MaxCopySize = std::min(AvailableSpace, FromSize); + size_t CopySize = Rand(MaxCopySize) + 1; + size_t FromBeg = Rand(FromSize - CopySize + 1); + assert(FromBeg + CopySize <= FromSize); + size_t ToInsertPos = Rand(ToSize + 1); + assert(ToInsertPos + CopySize <= MaxToSize); + size_t TailSize = ToSize - ToInsertPos; + if (To == From) { + + MutateInPlaceHere.resize(MaxToSize); + memcpy(MutateInPlaceHere.data(), From + FromBeg, CopySize); + memmove(To + ToInsertPos + CopySize, To + ToInsertPos, TailSize); + memmove(To + ToInsertPos, MutateInPlaceHere.data(), CopySize); + + } else { + + memmove(To + ToInsertPos + CopySize, To + ToInsertPos, TailSize); + memmove(To + ToInsertPos, From + FromBeg, CopySize); + + } + + return ToSize + CopySize; + +} + +size_t MutationDispatcher::Mutate_CopyPart(uint8_t *Data, size_t Size, + size_t MaxSize) { + + if (Size > MaxSize || Size == 0) return 0; + // If Size == MaxSize, `InsertPartOf(...)` will + // fail so there's no point using it in this case. + if (Size == MaxSize || Rand.RandBool()) + return CopyPartOf(Data, Size, Data, Size); + else + return InsertPartOf(Data, Size, Data, Size, MaxSize); + +} + +size_t MutationDispatcher::Mutate_ChangeASCIIInteger(uint8_t *Data, size_t Size, + size_t MaxSize) { + + if (Size > MaxSize) return 0; + size_t B = Rand(Size); + while (B < Size && !isdigit(Data[B])) + B++; + if (B == Size) return 0; + size_t E = B; + while (E < Size && isdigit(Data[E])) + E++; + assert(B < E); + // now we have digits in [B, E). + // strtol and friends don't accept non-zero-teminated data, parse it manually. + uint64_t Val = Data[B] - '0'; + for (size_t i = B + 1; i < E; i++) + Val = Val * 10 + Data[i] - '0'; + + // Mutate the integer value. + switch (Rand(5)) { + + case 0: + Val++; + break; + case 1: + Val--; + break; + case 2: + Val /= 2; + break; + case 3: + Val *= 2; + break; + case 4: + Val = Rand(Val * Val); + break; + default: + assert(0); + + } + + // Just replace the bytes with the new ones, don't bother moving bytes. + for (size_t i = B; i < E; i++) { + + size_t Idx = E + B - i - 1; + assert(Idx >= B && Idx < E); + Data[Idx] = (Val % 10) + '0'; + Val /= 10; + + } + + return Size; + +} + +template <class T> +size_t ChangeBinaryInteger(uint8_t *Data, size_t Size, Random &Rand) { + + if (Size < sizeof(T)) return 0; + size_t Off = Rand(Size - sizeof(T) + 1); + assert(Off + sizeof(T) <= Size); + T Val; + if (Off < 64 && !Rand(4)) { + + Val = Size; + if (Rand.RandBool()) Val = Bswap(Val); + + } else { + + memcpy(&Val, Data + Off, sizeof(Val)); + T Add = Rand(21); + Add -= 10; + if (Rand.RandBool()) + Val = Bswap(T(Bswap(Val) + Add)); // Add assuming different endiannes. + else + Val = Val + Add; // Add assuming current endiannes. + if (Add == 0 || Rand.RandBool()) // Maybe negate. + Val = -Val; + + } + + memcpy(Data + Off, &Val, sizeof(Val)); + return Size; + +} + +size_t MutationDispatcher::Mutate_ChangeBinaryInteger(uint8_t *Data, + size_t Size, + size_t MaxSize) { + + if (Size > MaxSize) return 0; + switch (Rand(4)) { + + case 3: + return ChangeBinaryInteger<uint64_t>(Data, Size, Rand); + case 2: + return ChangeBinaryInteger<uint32_t>(Data, Size, Rand); + case 1: + return ChangeBinaryInteger<uint16_t>(Data, Size, Rand); + case 0: + return ChangeBinaryInteger<uint8_t>(Data, Size, Rand); + default: + assert(0); + + } + + return 0; + +} + +size_t MutationDispatcher::Mutate_CrossOver(uint8_t *Data, size_t Size, + size_t MaxSize) { + + if (Size > MaxSize) return 0; + if (Size == 0) return 0; + if (!CrossOverWith) return 0; + const Unit &O = *CrossOverWith; + if (O.empty()) return 0; + size_t NewSize = 0; + switch (Rand(3)) { + + case 0: + MutateInPlaceHere.resize(MaxSize); + NewSize = CrossOver(Data, Size, O.data(), O.size(), + MutateInPlaceHere.data(), MaxSize); + memcpy(Data, MutateInPlaceHere.data(), NewSize); + break; + case 1: + NewSize = InsertPartOf(O.data(), O.size(), Data, Size, MaxSize); + if (!NewSize) NewSize = CopyPartOf(O.data(), O.size(), Data, Size); + break; + case 2: + NewSize = CopyPartOf(O.data(), O.size(), Data, Size); + break; + default: + assert(0); + + } + + assert(NewSize > 0 && "CrossOver returned empty unit"); + assert(NewSize <= MaxSize && "CrossOver returned overisized unit"); + return NewSize; + +} + +void MutationDispatcher::StartMutationSequence() { + + CurrentMutatorSequence.clear(); + CurrentDictionaryEntrySequence.clear(); + +} + +// Copy successful dictionary entries to PersistentAutoDictionary. +void MutationDispatcher::RecordSuccessfulMutationSequence() { + + for (auto DE : CurrentDictionaryEntrySequence) { + + // PersistentAutoDictionary.AddWithSuccessCountOne(DE); + DE->IncSuccessCount(); + assert(DE->GetW().size()); + // Linear search is fine here as this happens seldom. + if (!PersistentAutoDictionary.ContainsWord(DE->GetW())) + PersistentAutoDictionary.push_back({DE->GetW(), 1}); + + } + +} + +void MutationDispatcher::PrintRecommendedDictionary() { + + Vector<DictionaryEntry> V; + for (auto &DE : PersistentAutoDictionary) + if (!ManualDictionary.ContainsWord(DE.GetW())) V.push_back(DE); + if (V.empty()) return; + Printf("###### Recommended dictionary. ######\n"); + for (auto &DE : V) { + + assert(DE.GetW().size()); + Printf("\""); + PrintASCII(DE.GetW(), "\""); + Printf(" # Uses: %zd\n", DE.GetUseCount()); + + } + + Printf("###### End of recommended dictionary. ######\n"); + +} + +const char *MutationDispatcher::WriteMutationSequence() { + + static std::string buf; + buf = ""; + + for (size_t i = 0; i < CurrentMutatorSequence.size(); i++) { + + buf = buf + " " + CurrentMutatorSequence[i].Name; + + } + + return buf.c_str(); + +} + +void MutationDispatcher::PrintMutationSequence(bool Verbose) { + + return; + Printf("MS: %zd ", CurrentMutatorSequence.size()); + size_t EntriesToPrint = + Verbose ? CurrentMutatorSequence.size() + : std::min(kMaxMutationsToPrint, CurrentMutatorSequence.size()); + for (size_t i = 0; i < EntriesToPrint; i++) + Printf("%s-", CurrentMutatorSequence[i].Name); + if (!CurrentDictionaryEntrySequence.empty()) { + + Printf(" DE: "); + EntriesToPrint = Verbose ? CurrentDictionaryEntrySequence.size() + : std::min(kMaxMutationsToPrint, + CurrentDictionaryEntrySequence.size()); + for (size_t i = 0; i < EntriesToPrint; i++) { + + Printf("\""); + PrintASCII(CurrentDictionaryEntrySequence[i]->GetW(), "\"-"); + + } + + } + +} + +std::string MutationDispatcher::MutationSequence() { + + std::string MS; + for (auto M : CurrentMutatorSequence) { + + MS += M.Name; + MS += "-"; + + } + + return MS; + +} + +size_t MutationDispatcher::Mutate(uint8_t *Data, size_t Size, size_t MaxSize) { + + return MutateImpl(Data, Size, MaxSize, Mutators); + +} + +size_t MutationDispatcher::DefaultMutate(uint8_t *Data, size_t Size, + size_t MaxSize) { + + return MutateImpl(Data, Size, MaxSize, DefaultMutators); + +} + +// Mutates Data in place, returns new size. +size_t MutationDispatcher::MutateImpl(uint8_t *Data, size_t Size, + size_t MaxSize, + Vector<Mutator> &Mutators) { + + assert(MaxSize > 0); + // Some mutations may fail (e.g. can't insert more bytes if Size == MaxSize), + // in which case they will return 0. + // Try several times before returning un-mutated data. + for (int Iter = 0; Iter < 100; Iter++) { + + auto M = Mutators[Rand(Mutators.size())]; + size_t NewSize = (this->*(M.Fn))(Data, Size, MaxSize); + if (NewSize && NewSize <= MaxSize) { + + if (Options.OnlyASCII) ToASCII(Data, NewSize); + CurrentMutatorSequence.push_back(M); + return NewSize; + + } + + } + + *Data = ' '; + return 1; // Fallback, should not happen frequently. + +} + +// Mask represents the set of Data bytes that are worth mutating. +size_t MutationDispatcher::MutateWithMask(uint8_t *Data, size_t Size, + size_t MaxSize, + const Vector<uint8_t> &Mask) { + + size_t MaskedSize = std::min(Size, Mask.size()); + // * Copy the worthy bytes into a temporary array T + // * Mutate T + // * Copy T back. + // This is totally unoptimized. + auto &T = MutateWithMaskTemp; + if (T.size() < Size) T.resize(Size); + size_t OneBits = 0; + for (size_t I = 0; I < MaskedSize; I++) + if (Mask[I]) T[OneBits++] = Data[I]; + + if (!OneBits) return 0; + assert(!T.empty()); + size_t NewSize = Mutate(T.data(), OneBits, OneBits); + assert(NewSize <= OneBits); + (void)NewSize; + // Even if NewSize < OneBits we still use all OneBits bytes. + for (size_t I = 0, J = 0; I < MaskedSize; I++) + if (Mask[I]) Data[I] = T[J++]; + return Size; + +} + +void MutationDispatcher::AddWordToManualDictionary(const Word &W) { + + ManualDictionary.push_back({W, std::numeric_limits<size_t>::max()}); + +} + +} // namespace fuzzer + diff --git a/custom_mutators/libfuzzer/FuzzerMutate.h b/custom_mutators/libfuzzer/FuzzerMutate.h new file mode 100644 index 00000000..6252f265 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerMutate.h @@ -0,0 +1,160 @@ +//===- FuzzerMutate.h - Internal header for the Fuzzer ----------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// fuzzer::MutationDispatcher +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_MUTATE_H +#define LLVM_FUZZER_MUTATE_H + +#include "FuzzerDefs.h" +#include "FuzzerDictionary.h" +#include "FuzzerOptions.h" +#include "FuzzerRandom.h" + +namespace fuzzer { + +class MutationDispatcher { +public: + MutationDispatcher(Random &Rand, const FuzzingOptions &Options); + ~MutationDispatcher() {} + /// Indicate that we are about to start a new sequence of mutations. + void StartMutationSequence(); + /// Print the current sequence of mutations. Only prints the full sequence + /// when Verbose is true. + const char *WriteMutationSequence(); + void PrintMutationSequence(bool Verbose = true); + /// Return the current sequence of mutations. + std::string MutationSequence(); + /// Indicate that the current sequence of mutations was successful. + void RecordSuccessfulMutationSequence(); + /// Mutates data by invoking user-provided mutator. + size_t Mutate_Custom(uint8_t *Data, size_t Size, size_t MaxSize); + /// Mutates data by invoking user-provided crossover. + size_t Mutate_CustomCrossOver(uint8_t *Data, size_t Size, size_t MaxSize); + /// Mutates data by shuffling bytes. + size_t Mutate_ShuffleBytes(uint8_t *Data, size_t Size, size_t MaxSize); + /// Mutates data by erasing bytes. + size_t Mutate_EraseBytes(uint8_t *Data, size_t Size, size_t MaxSize); + /// Mutates data by inserting a byte. + size_t Mutate_InsertByte(uint8_t *Data, size_t Size, size_t MaxSize); + /// Mutates data by inserting several repeated bytes. + size_t Mutate_InsertRepeatedBytes(uint8_t *Data, size_t Size, size_t MaxSize); + /// Mutates data by chanding one byte. + size_t Mutate_ChangeByte(uint8_t *Data, size_t Size, size_t MaxSize); + /// Mutates data by chanding one bit. + size_t Mutate_ChangeBit(uint8_t *Data, size_t Size, size_t MaxSize); + /// Mutates data by copying/inserting a part of data into a different place. + size_t Mutate_CopyPart(uint8_t *Data, size_t Size, size_t MaxSize); + + /// Mutates data by adding a word from the manual dictionary. + size_t Mutate_AddWordFromManualDictionary(uint8_t *Data, size_t Size, + size_t MaxSize); + + /// Mutates data by adding a word from the TORC. + size_t Mutate_AddWordFromTORC(uint8_t *Data, size_t Size, size_t MaxSize); + + /// Mutates data by adding a word from the persistent automatic dictionary. + size_t Mutate_AddWordFromPersistentAutoDictionary(uint8_t *Data, size_t Size, + size_t MaxSize); + + /// Tries to find an ASCII integer in Data, changes it to another ASCII int. + size_t Mutate_ChangeASCIIInteger(uint8_t *Data, size_t Size, size_t MaxSize); + /// Change a 1-, 2-, 4-, or 8-byte integer in interesting ways. + size_t Mutate_ChangeBinaryInteger(uint8_t *Data, size_t Size, size_t MaxSize); + + /// CrossOver Data with CrossOverWith. + size_t Mutate_CrossOver(uint8_t *Data, size_t Size, size_t MaxSize); + + /// Applies one of the configured mutations. + /// Returns the new size of data which could be up to MaxSize. + size_t Mutate(uint8_t *Data, size_t Size, size_t MaxSize); + + /// Applies one of the configured mutations to the bytes of Data + /// that have '1' in Mask. + /// Mask.size() should be >= Size. + size_t MutateWithMask(uint8_t *Data, size_t Size, size_t MaxSize, + const Vector<uint8_t> &Mask); + + /// Applies one of the default mutations. Provided as a service + /// to mutation authors. + size_t DefaultMutate(uint8_t *Data, size_t Size, size_t MaxSize); + + /// Creates a cross-over of two pieces of Data, returns its size. + size_t CrossOver(const uint8_t *Data1, size_t Size1, const uint8_t *Data2, + size_t Size2, uint8_t *Out, size_t MaxOutSize); + + void AddWordToManualDictionary(const Word &W); + + void PrintRecommendedDictionary(); + + void SetCrossOverWith(const Unit *U) { CrossOverWith = U; } + + Random &GetRand() { return Rand; } + + private: + struct Mutator { + size_t (MutationDispatcher::*Fn)(uint8_t *Data, size_t Size, size_t Max); + const char *Name; + }; + + size_t AddWordFromDictionary(Dictionary &D, uint8_t *Data, size_t Size, + size_t MaxSize); + size_t MutateImpl(uint8_t *Data, size_t Size, size_t MaxSize, + Vector<Mutator> &Mutators); + + size_t InsertPartOf(const uint8_t *From, size_t FromSize, uint8_t *To, + size_t ToSize, size_t MaxToSize); + size_t CopyPartOf(const uint8_t *From, size_t FromSize, uint8_t *To, + size_t ToSize); + size_t ApplyDictionaryEntry(uint8_t *Data, size_t Size, size_t MaxSize, + DictionaryEntry &DE); + + template <class T> + DictionaryEntry MakeDictionaryEntryFromCMP(T Arg1, T Arg2, + const uint8_t *Data, size_t Size); + DictionaryEntry MakeDictionaryEntryFromCMP(const Word &Arg1, const Word &Arg2, + const uint8_t *Data, size_t Size); + DictionaryEntry MakeDictionaryEntryFromCMP(const void *Arg1, const void *Arg2, + const void *Arg1Mutation, + const void *Arg2Mutation, + size_t ArgSize, + const uint8_t *Data, size_t Size); + + Random &Rand; + const FuzzingOptions Options; + + // Dictionary provided by the user via -dict=DICT_FILE. + Dictionary ManualDictionary; + // Temporary dictionary modified by the fuzzer itself, + // recreated periodically. + Dictionary TempAutoDictionary; + // Persistent dictionary modified by the fuzzer, consists of + // entries that led to successful discoveries in the past mutations. + Dictionary PersistentAutoDictionary; + + Vector<DictionaryEntry *> CurrentDictionaryEntrySequence; + + static const size_t kCmpDictionaryEntriesDequeSize = 16; + DictionaryEntry CmpDictionaryEntriesDeque[kCmpDictionaryEntriesDequeSize]; + size_t CmpDictionaryEntriesDequeIdx = 0; + + const Unit *CrossOverWith = nullptr; + Vector<uint8_t> MutateInPlaceHere; + Vector<uint8_t> MutateWithMaskTemp; + // CustomCrossOver needs its own buffer as a custom implementation may call + // LLVMFuzzerMutate, which in turn may resize MutateInPlaceHere. + Vector<uint8_t> CustomCrossOverInPlaceHere; + + Vector<Mutator> Mutators; + Vector<Mutator> DefaultMutators; + Vector<Mutator> CurrentMutatorSequence; +}; + +} // namespace fuzzer + +#endif // LLVM_FUZZER_MUTATE_H diff --git a/custom_mutators/libfuzzer/FuzzerOptions.h b/custom_mutators/libfuzzer/FuzzerOptions.h new file mode 100644 index 00000000..20b810b2 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerOptions.h @@ -0,0 +1,90 @@ +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// fuzzer::FuzzingOptions +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_OPTIONS_H +#define LLVM_FUZZER_OPTIONS_H + +#include "FuzzerDefs.h" + +namespace fuzzer { + +struct FuzzingOptions { + int Verbosity = 1; + size_t MaxLen = 0; + size_t LenControl = 1000; + bool KeepSeed = false; + int UnitTimeoutSec = 300; + int TimeoutExitCode = 70; + int OOMExitCode = 71; + int InterruptExitCode = 72; + int ErrorExitCode = 77; + bool IgnoreTimeouts = true; + bool IgnoreOOMs = true; + bool IgnoreCrashes = false; + int MaxTotalTimeSec = 0; + int RssLimitMb = 0; + int MallocLimitMb = 0; + bool DoCrossOver = true; + bool CrossOverUniformDist = false; + int MutateDepth = 5; + bool ReduceDepth = false; + bool UseCounters = false; + bool UseMemmem = true; + bool UseCmp = false; + int UseValueProfile = false; + bool Shrink = false; + bool ReduceInputs = false; + int ReloadIntervalSec = 1; + bool ShuffleAtStartUp = true; + bool PreferSmall = true; + size_t MaxNumberOfRuns = -1L; + int ReportSlowUnits = 10; + bool OnlyASCII = false; + bool Entropic = true; + size_t EntropicFeatureFrequencyThreshold = 0xFF; + size_t EntropicNumberOfRarestFeatures = 100; + bool EntropicScalePerExecTime = false; + std::string OutputCorpus; + std::string ArtifactPrefix = "./"; + std::string ExactArtifactPath; + std::string ExitOnSrcPos; + std::string ExitOnItem; + std::string FocusFunction; + std::string DataFlowTrace; + std::string CollectDataFlow; + std::string FeaturesDir; + std::string MutationGraphFile; + std::string StopFile; + bool SaveArtifacts = true; + bool PrintNEW = true; // Print a status line when new units are found; + bool PrintNewCovPcs = false; + int PrintNewCovFuncs = 0; + bool PrintFinalStats = false; + bool PrintCorpusStats = false; + bool PrintCoverage = false; + bool DumpCoverage = false; + bool DetectLeaks = true; + int PurgeAllocatorIntervalSec = 1; + int TraceMalloc = 0; + bool HandleAbrt = false; + bool HandleAlrm = false; + bool HandleBus = false; + bool HandleFpe = false; + bool HandleIll = false; + bool HandleInt = false; + bool HandleSegv = false; + bool HandleTerm = false; + bool HandleXfsz = false; + bool HandleUsr1 = false; + bool HandleUsr2 = false; +}; + +} // namespace fuzzer + +#endif // LLVM_FUZZER_OPTIONS_H diff --git a/custom_mutators/libfuzzer/FuzzerPlatform.h b/custom_mutators/libfuzzer/FuzzerPlatform.h new file mode 100644 index 00000000..8befdb88 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerPlatform.h @@ -0,0 +1,163 @@ +//===-- FuzzerPlatform.h --------------------------------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Common platform macros. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_PLATFORM_H +#define LLVM_FUZZER_PLATFORM_H + +// Platform detection. +#ifdef __linux__ +#define LIBFUZZER_APPLE 0 +#define LIBFUZZER_FUCHSIA 0 +#define LIBFUZZER_LINUX 1 +#define LIBFUZZER_NETBSD 0 +#define LIBFUZZER_FREEBSD 0 +#define LIBFUZZER_OPENBSD 0 +#define LIBFUZZER_WINDOWS 0 +#define LIBFUZZER_EMSCRIPTEN 0 +#elif __APPLE__ +#define LIBFUZZER_APPLE 1 +#define LIBFUZZER_FUCHSIA 0 +#define LIBFUZZER_LINUX 0 +#define LIBFUZZER_NETBSD 0 +#define LIBFUZZER_FREEBSD 0 +#define LIBFUZZER_OPENBSD 0 +#define LIBFUZZER_WINDOWS 0 +#define LIBFUZZER_EMSCRIPTEN 0 +#elif __NetBSD__ +#define LIBFUZZER_APPLE 0 +#define LIBFUZZER_FUCHSIA 0 +#define LIBFUZZER_LINUX 0 +#define LIBFUZZER_NETBSD 1 +#define LIBFUZZER_FREEBSD 0 +#define LIBFUZZER_OPENBSD 0 +#define LIBFUZZER_WINDOWS 0 +#define LIBFUZZER_EMSCRIPTEN 0 +#elif __FreeBSD__ +#define LIBFUZZER_APPLE 0 +#define LIBFUZZER_FUCHSIA 0 +#define LIBFUZZER_LINUX 0 +#define LIBFUZZER_NETBSD 0 +#define LIBFUZZER_FREEBSD 1 +#define LIBFUZZER_OPENBSD 0 +#define LIBFUZZER_WINDOWS 0 +#define LIBFUZZER_EMSCRIPTEN 0 +#elif __OpenBSD__ +#define LIBFUZZER_APPLE 0 +#define LIBFUZZER_FUCHSIA 0 +#define LIBFUZZER_LINUX 0 +#define LIBFUZZER_NETBSD 0 +#define LIBFUZZER_FREEBSD 0 +#define LIBFUZZER_OPENBSD 1 +#define LIBFUZZER_WINDOWS 0 +#define LIBFUZZER_EMSCRIPTEN 0 +#elif _WIN32 +#define LIBFUZZER_APPLE 0 +#define LIBFUZZER_FUCHSIA 0 +#define LIBFUZZER_LINUX 0 +#define LIBFUZZER_NETBSD 0 +#define LIBFUZZER_FREEBSD 0 +#define LIBFUZZER_OPENBSD 0 +#define LIBFUZZER_WINDOWS 1 +#define LIBFUZZER_EMSCRIPTEN 0 +#elif __Fuchsia__ +#define LIBFUZZER_APPLE 0 +#define LIBFUZZER_FUCHSIA 1 +#define LIBFUZZER_LINUX 0 +#define LIBFUZZER_NETBSD 0 +#define LIBFUZZER_FREEBSD 0 +#define LIBFUZZER_OPENBSD 0 +#define LIBFUZZER_WINDOWS 0 +#define LIBFUZZER_EMSCRIPTEN 0 +#elif __EMSCRIPTEN__ +#define LIBFUZZER_APPLE 0 +#define LIBFUZZER_FUCHSIA 0 +#define LIBFUZZER_LINUX 0 +#define LIBFUZZER_NETBSD 0 +#define LIBFUZZER_FREEBSD 0 +#define LIBFUZZER_OPENBSD 0 +#define LIBFUZZER_WINDOWS 0 +#define LIBFUZZER_EMSCRIPTEN 1 +#else +#error "Support for your platform has not been implemented" +#endif + +#if defined(_MSC_VER) && !defined(__clang__) +// MSVC compiler is being used. +#define LIBFUZZER_MSVC 1 +#else +#define LIBFUZZER_MSVC 0 +#endif + +#ifndef __has_attribute +#define __has_attribute(x) 0 +#endif + +#define LIBFUZZER_POSIX \ + (LIBFUZZER_APPLE || LIBFUZZER_LINUX || LIBFUZZER_NETBSD || \ + LIBFUZZER_FREEBSD || LIBFUZZER_OPENBSD || LIBFUZZER_EMSCRIPTEN) + +#ifdef __x86_64 +#if __has_attribute(target) +#define ATTRIBUTE_TARGET_POPCNT __attribute__((target("popcnt"))) +#else +#define ATTRIBUTE_TARGET_POPCNT +#endif +#else +#define ATTRIBUTE_TARGET_POPCNT +#endif + +#ifdef __clang__ // avoid gcc warning. +#if __has_attribute(no_sanitize) +#define ATTRIBUTE_NO_SANITIZE_MEMORY __attribute__((no_sanitize("memory"))) +#else +#define ATTRIBUTE_NO_SANITIZE_MEMORY +#endif +#define ALWAYS_INLINE __attribute__((always_inline)) +#else +#define ATTRIBUTE_NO_SANITIZE_MEMORY +#define ALWAYS_INLINE +#endif // __clang__ + +#if LIBFUZZER_WINDOWS +#define ATTRIBUTE_NO_SANITIZE_ADDRESS +#else +#define ATTRIBUTE_NO_SANITIZE_ADDRESS __attribute__((no_sanitize_address)) +#endif + +#if LIBFUZZER_WINDOWS +#define ATTRIBUTE_ALIGNED(X) __declspec(align(X)) +#define ATTRIBUTE_INTERFACE __declspec(dllexport) +// This is used for __sancov_lowest_stack which is needed for +// -fsanitize-coverage=stack-depth. That feature is not yet available on +// Windows, so make the symbol static to avoid linking errors. +#define ATTRIBUTES_INTERFACE_TLS_INITIAL_EXEC static +#define ATTRIBUTE_NOINLINE __declspec(noinline) +#else +#define ATTRIBUTE_ALIGNED(X) __attribute__((aligned(X))) +#define ATTRIBUTE_INTERFACE __attribute__((visibility("default"))) +#define ATTRIBUTES_INTERFACE_TLS_INITIAL_EXEC \ + ATTRIBUTE_INTERFACE __attribute__((tls_model("initial-exec"))) thread_local + +#define ATTRIBUTE_NOINLINE __attribute__((noinline)) +#endif + +#if defined(__has_feature) +#if __has_feature(address_sanitizer) +#define ATTRIBUTE_NO_SANITIZE_ALL ATTRIBUTE_NO_SANITIZE_ADDRESS +#elif __has_feature(memory_sanitizer) +#define ATTRIBUTE_NO_SANITIZE_ALL ATTRIBUTE_NO_SANITIZE_MEMORY +#else +#define ATTRIBUTE_NO_SANITIZE_ALL +#endif +#else +#define ATTRIBUTE_NO_SANITIZE_ALL +#endif + +#endif // LLVM_FUZZER_PLATFORM_H diff --git a/custom_mutators/libfuzzer/FuzzerRandom.h b/custom_mutators/libfuzzer/FuzzerRandom.h new file mode 100644 index 00000000..7b1e1b1d --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerRandom.h @@ -0,0 +1,38 @@ +//===- FuzzerRandom.h - Internal header for the Fuzzer ----------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// fuzzer::Random +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_RANDOM_H +#define LLVM_FUZZER_RANDOM_H + +#include <random> + +namespace fuzzer { +class Random : public std::minstd_rand { + public: + explicit Random(unsigned int seed) : std::minstd_rand(seed) {} + result_type operator()() { return this->std::minstd_rand::operator()(); } + size_t Rand() { return this->operator()(); } + size_t RandBool() { return Rand() % 2; } + size_t SkewTowardsLast(size_t n) { + size_t T = this->operator()(n * n); + size_t Res = sqrt(T); + return Res; + } + size_t operator()(size_t n) { return n ? Rand() % n : 0; } + intptr_t operator()(intptr_t From, intptr_t To) { + assert(From < To); + intptr_t RangeSize = To - From + 1; + return operator()(RangeSize) + From; + } +}; + +} // namespace fuzzer + +#endif // LLVM_FUZZER_RANDOM_H diff --git a/custom_mutators/libfuzzer/FuzzerSHA1.cpp b/custom_mutators/libfuzzer/FuzzerSHA1.cpp new file mode 100644 index 00000000..0a58b661 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerSHA1.cpp @@ -0,0 +1,269 @@ +//===- FuzzerSHA1.h - Private copy of the SHA1 implementation ---*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// This code is taken from public domain +// (http://oauth.googlecode.com/svn/code/c/liboauth/src/sha1.c) +// and modified by adding anonymous namespace, adding an interface +// function fuzzer::ComputeSHA1() and removing unnecessary code. +// +// lib/Fuzzer can not use SHA1 implementation from openssl because +// openssl may not be available and because we may be fuzzing openssl itself. +// For the same reason we do not want to depend on SHA1 from LLVM tree. +//===----------------------------------------------------------------------===// + +#include "FuzzerSHA1.h" +#include "FuzzerDefs.h" +#include "FuzzerPlatform.h" + +/* This code is public-domain - it is based on libcrypt + * placed in the public domain by Wei Dai and other contributors. + */ + +#include <iomanip> +#include <sstream> +#include <stdint.h> +#include <string.h> + +namespace { // Added for LibFuzzer + +#ifdef __BIG_ENDIAN__ + #define SHA_BIG_ENDIAN +// Windows is always little endian and MSVC doesn't have <endian.h> +#elif defined __LITTLE_ENDIAN__ || LIBFUZZER_WINDOWS +/* override */ +#elif defined __BYTE_ORDER + #if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__ + #define SHA_BIG_ENDIAN + #endif +#else // ! defined __LITTLE_ENDIAN__ + #include <endian.h> // machine/endian.h + #if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__ + #define SHA_BIG_ENDIAN + #endif +#endif + +/* header */ + +#define HASH_LENGTH 20 +#define BLOCK_LENGTH 64 + +typedef struct sha1nfo { + + uint32_t buffer[BLOCK_LENGTH / 4]; + uint32_t state[HASH_LENGTH / 4]; + uint32_t byteCount; + uint8_t bufferOffset; + uint8_t keyBuffer[BLOCK_LENGTH]; + uint8_t innerHash[HASH_LENGTH]; + +} sha1nfo; + +/* public API - prototypes - TODO: doxygen*/ + +/** + */ +void sha1_init(sha1nfo *s); +/** + */ +void sha1_writebyte(sha1nfo *s, uint8_t data); +/** + */ +void sha1_write(sha1nfo *s, const char *data, size_t len); +/** + */ +uint8_t *sha1_result(sha1nfo *s); + +/* code */ +#define SHA1_K0 0x5a827999 +#define SHA1_K20 0x6ed9eba1 +#define SHA1_K40 0x8f1bbcdc +#define SHA1_K60 0xca62c1d6 + +void sha1_init(sha1nfo *s) { + + s->state[0] = 0x67452301; + s->state[1] = 0xefcdab89; + s->state[2] = 0x98badcfe; + s->state[3] = 0x10325476; + s->state[4] = 0xc3d2e1f0; + s->byteCount = 0; + s->bufferOffset = 0; + +} + +uint32_t sha1_rol32(uint32_t number, uint8_t bits) { + + return ((number << bits) | (number >> (32 - bits))); + +} + +void sha1_hashBlock(sha1nfo *s) { + + uint8_t i; + uint32_t a, b, c, d, e, t; + + a = s->state[0]; + b = s->state[1]; + c = s->state[2]; + d = s->state[3]; + e = s->state[4]; + for (i = 0; i < 80; i++) { + + if (i >= 16) { + + t = s->buffer[(i + 13) & 15] ^ s->buffer[(i + 8) & 15] ^ + s->buffer[(i + 2) & 15] ^ s->buffer[i & 15]; + s->buffer[i & 15] = sha1_rol32(t, 1); + + } + + if (i < 20) { + + t = (d ^ (b & (c ^ d))) + SHA1_K0; + + } else if (i < 40) { + + t = (b ^ c ^ d) + SHA1_K20; + + } else if (i < 60) { + + t = ((b & c) | (d & (b | c))) + SHA1_K40; + + } else { + + t = (b ^ c ^ d) + SHA1_K60; + + } + + t += sha1_rol32(a, 5) + e + s->buffer[i & 15]; + e = d; + d = c; + c = sha1_rol32(b, 30); + b = a; + a = t; + + } + + s->state[0] += a; + s->state[1] += b; + s->state[2] += c; + s->state[3] += d; + s->state[4] += e; + +} + +void sha1_addUncounted(sha1nfo *s, uint8_t data) { + + uint8_t *const b = (uint8_t *)s->buffer; +#ifdef SHA_BIG_ENDIAN + b[s->bufferOffset] = data; +#else + b[s->bufferOffset ^ 3] = data; +#endif + s->bufferOffset++; + if (s->bufferOffset == BLOCK_LENGTH) { + + sha1_hashBlock(s); + s->bufferOffset = 0; + + } + +} + +void sha1_writebyte(sha1nfo *s, uint8_t data) { + + ++s->byteCount; + sha1_addUncounted(s, data); + +} + +void sha1_write(sha1nfo *s, const char *data, size_t len) { + + for (; len--;) + sha1_writebyte(s, (uint8_t)*data++); + +} + +void sha1_pad(sha1nfo *s) { + + // Implement SHA-1 padding (fips180-2 §5.1.1) + + // Pad with 0x80 followed by 0x00 until the end of the block + sha1_addUncounted(s, 0x80); + while (s->bufferOffset != 56) + sha1_addUncounted(s, 0x00); + + // Append length in the last 8 bytes + sha1_addUncounted(s, 0); // We're only using 32 bit lengths + sha1_addUncounted(s, 0); // But SHA-1 supports 64 bit lengths + sha1_addUncounted(s, 0); // So zero pad the top bits + sha1_addUncounted(s, s->byteCount >> 29); // Shifting to multiply by 8 + sha1_addUncounted( + s, s->byteCount >> 21); // as SHA-1 supports bitstreams as well as + sha1_addUncounted(s, s->byteCount >> 13); // byte. + sha1_addUncounted(s, s->byteCount >> 5); + sha1_addUncounted(s, s->byteCount << 3); + +} + +uint8_t *sha1_result(sha1nfo *s) { + + // Pad to complete the last block + sha1_pad(s); + +#ifndef SHA_BIG_ENDIAN + // Swap byte order back + int i; + for (i = 0; i < 5; i++) { + + s->state[i] = (((s->state[i]) << 24) & 0xff000000) | + (((s->state[i]) << 8) & 0x00ff0000) | + (((s->state[i]) >> 8) & 0x0000ff00) | + (((s->state[i]) >> 24) & 0x000000ff); + + } + +#endif + + // Return pointer to hash (20 characters) + return (uint8_t *)s->state; + +} + +} // namespace + +namespace fuzzer { + +// The rest is added for LibFuzzer +void ComputeSHA1(const uint8_t *Data, size_t Len, uint8_t *Out) { + + sha1nfo s; + sha1_init(&s); + sha1_write(&s, (const char *)Data, Len); + memcpy(Out, sha1_result(&s), HASH_LENGTH); + +} + +std::string Sha1ToString(const uint8_t Sha1[kSHA1NumBytes]) { + + std::stringstream SS; + for (int i = 0; i < kSHA1NumBytes; i++) + SS << std::hex << std::setfill('0') << std::setw(2) << (unsigned)Sha1[i]; + return SS.str(); + +} + +std::string Hash(const Unit &U) { + + uint8_t Hash[kSHA1NumBytes]; + ComputeSHA1(U.data(), U.size(), Hash); + return Sha1ToString(Hash); + +} + +} // namespace fuzzer + diff --git a/custom_mutators/libfuzzer/FuzzerSHA1.h b/custom_mutators/libfuzzer/FuzzerSHA1.h new file mode 100644 index 00000000..05cbacda --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerSHA1.h @@ -0,0 +1,32 @@ +//===- FuzzerSHA1.h - Internal header for the SHA1 utils --------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// SHA1 utils. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_SHA1_H +#define LLVM_FUZZER_SHA1_H + +#include "FuzzerDefs.h" +#include <cstddef> +#include <stdint.h> + +namespace fuzzer { + +// Private copy of SHA1 implementation. +static const int kSHA1NumBytes = 20; + +// Computes SHA1 hash of 'Len' bytes in 'Data', writes kSHA1NumBytes to 'Out'. +void ComputeSHA1(const uint8_t *Data, size_t Len, uint8_t *Out); + +std::string Sha1ToString(const uint8_t Sha1[kSHA1NumBytes]); + +std::string Hash(const Unit &U); + +} // namespace fuzzer + +#endif // LLVM_FUZZER_SHA1_H diff --git a/custom_mutators/libfuzzer/FuzzerTracePC.cpp b/custom_mutators/libfuzzer/FuzzerTracePC.cpp new file mode 100644 index 00000000..1177325e --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerTracePC.cpp @@ -0,0 +1,819 @@ +//===- FuzzerTracePC.cpp - PC tracing--------------------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Trace PCs. +// This module implements __sanitizer_cov_trace_pc_guard[_init], +// the callback required for -fsanitize-coverage=trace-pc-guard instrumentation. +// +//===----------------------------------------------------------------------===// + +#include "FuzzerTracePC.h" +#include "FuzzerBuiltins.h" +#include "FuzzerBuiltinsMsvc.h" +#include "FuzzerCorpus.h" +#include "FuzzerDefs.h" +#include "FuzzerDictionary.h" +#include "FuzzerExtFunctions.h" +#include "FuzzerIO.h" +#include "FuzzerPlatform.h" +#include "FuzzerUtil.h" +#include "FuzzerValueBitMap.h" +#include <set> + +// Used by -fsanitize-coverage=stack-depth to track stack depth +ATTRIBUTES_INTERFACE_TLS_INITIAL_EXEC uintptr_t __sancov_lowest_stack; + +namespace fuzzer { + +TracePC TPC; + +size_t TracePC::GetTotalPCCoverage() { + + return ObservedPCs.size(); + +} + +void TracePC::HandleInline8bitCountersInit(uint8_t *Start, uint8_t *Stop) { + + if (Start == Stop) return; + if (NumModules && Modules[NumModules - 1].Start() == Start) return; + assert(NumModules < sizeof(Modules) / sizeof(Modules[0])); + auto & M = Modules[NumModules++]; + uint8_t *AlignedStart = RoundUpByPage(Start); + uint8_t *AlignedStop = RoundDownByPage(Stop); + size_t NumFullPages = AlignedStop > AlignedStart + ? (AlignedStop - AlignedStart) / PageSize() + : 0; + bool NeedFirst = Start < AlignedStart || !NumFullPages; + bool NeedLast = Stop > AlignedStop && AlignedStop >= AlignedStart; + M.NumRegions = NumFullPages + NeedFirst + NeedLast; + ; + assert(M.NumRegions > 0); + M.Regions = new Module::Region[M.NumRegions]; + assert(M.Regions); + size_t R = 0; + if (NeedFirst) + M.Regions[R++] = {Start, std::min(Stop, AlignedStart), true, false}; + for (uint8_t *P = AlignedStart; P < AlignedStop; P += PageSize()) + M.Regions[R++] = {P, P + PageSize(), true, true}; + if (NeedLast) M.Regions[R++] = {AlignedStop, Stop, true, false}; + assert(R == M.NumRegions); + assert(M.Size() == (size_t)(Stop - Start)); + assert(M.Stop() == Stop); + assert(M.Start() == Start); + NumInline8bitCounters += M.Size(); + +} + +void TracePC::HandlePCsInit(const uintptr_t *Start, const uintptr_t *Stop) { + + const PCTableEntry *B = reinterpret_cast<const PCTableEntry *>(Start); + const PCTableEntry *E = reinterpret_cast<const PCTableEntry *>(Stop); + if (NumPCTables && ModulePCTable[NumPCTables - 1].Start == B) return; + assert(NumPCTables < sizeof(ModulePCTable) / sizeof(ModulePCTable[0])); + ModulePCTable[NumPCTables++] = {B, E}; + NumPCsInPCTables += E - B; + +} + +void TracePC::PrintModuleInfo() { + + if (NumModules) { + + Printf("INFO: Loaded %zd modules (%zd inline 8-bit counters): ", + NumModules, NumInline8bitCounters); + for (size_t i = 0; i < NumModules; i++) + Printf("%zd [%p, %p), ", Modules[i].Size(), Modules[i].Start(), + Modules[i].Stop()); + Printf("\n"); + + } + + if (NumPCTables) { + + Printf("INFO: Loaded %zd PC tables (%zd PCs): ", NumPCTables, + NumPCsInPCTables); + for (size_t i = 0; i < NumPCTables; i++) { + + Printf("%zd [%p,%p), ", ModulePCTable[i].Stop - ModulePCTable[i].Start, + ModulePCTable[i].Start, ModulePCTable[i].Stop); + + } + + Printf("\n"); + + if (NumInline8bitCounters && NumInline8bitCounters != NumPCsInPCTables) { + + Printf( + "ERROR: The size of coverage PC tables does not match the\n" + "number of instrumented PCs. This might be a compiler bug,\n" + "please contact the libFuzzer developers.\n" + "Also check https://bugs.llvm.org/show_bug.cgi?id=34636\n" + "for possible workarounds (tl;dr: don't use the old GNU ld)\n"); + _Exit(1); + + } + + } + + if (size_t NumExtraCounters = ExtraCountersEnd() - ExtraCountersBegin()) + Printf("INFO: %zd Extra Counters\n", NumExtraCounters); + +} + +ATTRIBUTE_NO_SANITIZE_ALL +void TracePC::HandleCallerCallee(uintptr_t Caller, uintptr_t Callee) { + + const uintptr_t kBits = 12; + const uintptr_t kMask = (1 << kBits) - 1; + uintptr_t Idx = (Caller & kMask) | ((Callee & kMask) << kBits); + ValueProfileMap.AddValueModPrime(Idx); + +} + +/// \return the address of the previous instruction. +/// Note: the logic is copied from `sanitizer_common/sanitizer_stacktrace.h` +inline ALWAYS_INLINE uintptr_t GetPreviousInstructionPc(uintptr_t PC) { + +#if defined(__arm__) + // T32 (Thumb) branch instructions might be 16 or 32 bit long, + // so we return (pc-2) in that case in order to be safe. + // For A32 mode we return (pc-4) because all instructions are 32 bit long. + return (PC - 3) & (~1); +#elif defined(__powerpc__) || defined(__powerpc64__) || defined(__aarch64__) + // PCs are always 4 byte aligned. + return PC - 4; +#elif defined(__sparc__) || defined(__mips__) + return PC - 8; +#else + return PC - 1; +#endif + +} + +/// \return the address of the next instruction. +/// Note: the logic is copied from `sanitizer_common/sanitizer_stacktrace.cpp` +ALWAYS_INLINE uintptr_t TracePC::GetNextInstructionPc(uintptr_t PC) { + +#if defined(__mips__) + return PC + 8; +#elif defined(__powerpc__) || defined(__sparc__) || defined(__arm__) || \ + defined(__aarch64__) + return PC + 4; +#else + return PC + 1; +#endif + +} + +void TracePC::UpdateObservedPCs() { + + Vector<uintptr_t> CoveredFuncs; + auto ObservePC = [&](const PCTableEntry *TE) { + + if (ObservedPCs.insert(TE).second && DoPrintNewPCs) { + + PrintPC("\tNEW_PC: %p %F %L", "\tNEW_PC: %p", + GetNextInstructionPc(TE->PC)); + Printf("\n"); + + } + + }; + + auto Observe = [&](const PCTableEntry *TE) { + + if (PcIsFuncEntry(TE)) + if (++ObservedFuncs[TE->PC] == 1 && NumPrintNewFuncs) + CoveredFuncs.push_back(TE->PC); + ObservePC(TE); + + }; + + if (NumPCsInPCTables) { + + if (NumInline8bitCounters == NumPCsInPCTables) { + + for (size_t i = 0; i < NumModules; i++) { + + auto &M = Modules[i]; + assert(M.Size() == + (size_t)(ModulePCTable[i].Stop - ModulePCTable[i].Start)); + for (size_t r = 0; r < M.NumRegions; r++) { + + auto &R = M.Regions[r]; + if (!R.Enabled) continue; + for (uint8_t *P = R.Start; P < R.Stop; P++) + if (*P) Observe(&ModulePCTable[i].Start[M.Idx(P)]); + + } + + } + + } + + } + + for (size_t i = 0, N = Min(CoveredFuncs.size(), NumPrintNewFuncs); i < N; + i++) { + + Printf("\tNEW_FUNC[%zd/%zd]: ", i + 1, CoveredFuncs.size()); + PrintPC("%p %F %L", "%p", GetNextInstructionPc(CoveredFuncs[i])); + Printf("\n"); + + } + +} + +uintptr_t TracePC::PCTableEntryIdx(const PCTableEntry *TE) { + + size_t TotalTEs = 0; + for (size_t i = 0; i < NumPCTables; i++) { + + auto &M = ModulePCTable[i]; + if (TE >= M.Start && TE < M.Stop) return TotalTEs + TE - M.Start; + TotalTEs += M.Stop - M.Start; + + } + + assert(0); + return 0; + +} + +const TracePC::PCTableEntry *TracePC::PCTableEntryByIdx(uintptr_t Idx) { + + for (size_t i = 0; i < NumPCTables; i++) { + + auto & M = ModulePCTable[i]; + size_t Size = M.Stop - M.Start; + if (Idx < Size) return &M.Start[Idx]; + Idx -= Size; + + } + + return nullptr; + +} + +static std::string GetModuleName(uintptr_t PC) { + + char ModulePathRaw[4096] = ""; // What's PATH_MAX in portable C++? + void *OffsetRaw = nullptr; + if (!EF->__sanitizer_get_module_and_offset_for_pc( + reinterpret_cast<void *>(PC), ModulePathRaw, sizeof(ModulePathRaw), + &OffsetRaw)) + return ""; + return ModulePathRaw; + +} + +template <class CallBack> +void TracePC::IterateCoveredFunctions(CallBack CB) { + + for (size_t i = 0; i < NumPCTables; i++) { + + auto &M = ModulePCTable[i]; + assert(M.Start < M.Stop); + auto ModuleName = GetModuleName(M.Start->PC); + for (auto NextFE = M.Start; NextFE < M.Stop;) { + + auto FE = NextFE; + assert(PcIsFuncEntry(FE) && "Not a function entry point"); + do { + + NextFE++; + + } while (NextFE < M.Stop && !(PcIsFuncEntry(NextFE))); + + CB(FE, NextFE, ObservedFuncs[FE->PC]); + + } + + } + +} + +void TracePC::SetFocusFunction(const std::string &FuncName) { + + // This function should be called once. + assert(!FocusFunctionCounterPtr); + // "auto" is not a valid function name. If this function is called with "auto" + // that means the auto focus functionality failed. + if (FuncName.empty() || FuncName == "auto") return; + for (size_t M = 0; M < NumModules; M++) { + + auto & PCTE = ModulePCTable[M]; + size_t N = PCTE.Stop - PCTE.Start; + for (size_t I = 0; I < N; I++) { + + if (!(PcIsFuncEntry(&PCTE.Start[I]))) continue; // not a function entry. + auto Name = DescribePC("%F", GetNextInstructionPc(PCTE.Start[I].PC)); + if (Name[0] == 'i' && Name[1] == 'n' && Name[2] == ' ') + Name = Name.substr(3, std::string::npos); + if (FuncName != Name) continue; + Printf("INFO: Focus function is set to '%s'\n", Name.c_str()); + FocusFunctionCounterPtr = Modules[M].Start() + I; + return; + + } + + } + + Printf( + "ERROR: Failed to set focus function. Make sure the function name is " + "valid (%s) and symbolization is enabled.\n", + FuncName.c_str()); + exit(1); + +} + +bool TracePC::ObservedFocusFunction() { + + return FocusFunctionCounterPtr && *FocusFunctionCounterPtr; + +} + +void TracePC::PrintCoverage() { + + if (!EF->__sanitizer_symbolize_pc || + !EF->__sanitizer_get_module_and_offset_for_pc) { + + Printf( + "INFO: __sanitizer_symbolize_pc or " + "__sanitizer_get_module_and_offset_for_pc is not available," + " not printing coverage\n"); + return; + + } + + Printf("COVERAGE:\n"); + auto CoveredFunctionCallback = [&](const PCTableEntry *First, + const PCTableEntry *Last, + uintptr_t Counter) { + + assert(First < Last); + auto VisualizePC = GetNextInstructionPc(First->PC); + std::string FileStr = DescribePC("%s", VisualizePC); + if (!IsInterestingCoverageFile(FileStr)) return; + std::string FunctionStr = DescribePC("%F", VisualizePC); + if (FunctionStr.find("in ") == 0) FunctionStr = FunctionStr.substr(3); + std::string LineStr = DescribePC("%l", VisualizePC); + size_t NumEdges = Last - First; + Vector<uintptr_t> UncoveredPCs; + for (auto TE = First; TE < Last; TE++) + if (!ObservedPCs.count(TE)) UncoveredPCs.push_back(TE->PC); + Printf("%sCOVERED_FUNC: hits: %zd", Counter ? "" : "UN", Counter); + Printf(" edges: %zd/%zd", NumEdges - UncoveredPCs.size(), NumEdges); + Printf(" %s %s:%s\n", FunctionStr.c_str(), FileStr.c_str(), + LineStr.c_str()); + if (Counter) + for (auto PC : UncoveredPCs) + Printf(" UNCOVERED_PC: %s\n", + DescribePC("%s:%l", GetNextInstructionPc(PC)).c_str()); + + }; + + IterateCoveredFunctions(CoveredFunctionCallback); + +} + +// Value profile. +// We keep track of various values that affect control flow. +// These values are inserted into a bit-set-based hash map. +// Every new bit in the map is treated as a new coverage. +// +// For memcmp/strcmp/etc the interesting value is the length of the common +// prefix of the parameters. +// For cmp instructions the interesting value is a XOR of the parameters. +// The interesting value is mixed up with the PC and is then added to the map. + +ATTRIBUTE_NO_SANITIZE_ALL +void TracePC::AddValueForMemcmp(void *caller_pc, const void *s1, const void *s2, + size_t n, bool StopAtZero) { + + if (!n) return; + size_t Len = std::min(n, Word::GetMaxSize()); + const uint8_t *A1 = reinterpret_cast<const uint8_t *>(s1); + const uint8_t *A2 = reinterpret_cast<const uint8_t *>(s2); + uint8_t B1[Word::kMaxSize]; + uint8_t B2[Word::kMaxSize]; + // Copy the data into locals in this non-msan-instrumented function + // to avoid msan complaining further. + size_t Hash = 0; // Compute some simple hash of both strings. + for (size_t i = 0; i < Len; i++) { + + B1[i] = A1[i]; + B2[i] = A2[i]; + size_t T = B1[i]; + Hash ^= (T << 8) | B2[i]; + + } + + size_t I = 0; + uint8_t HammingDistance = 0; + for (; I < Len; I++) { + + if (B1[I] != B2[I] || (StopAtZero && B1[I] == 0)) { + + HammingDistance = Popcountll(B1[I] ^ B2[I]); + break; + + } + + } + + size_t PC = reinterpret_cast<size_t>(caller_pc); + size_t Idx = (PC & 4095) | (I << 12); + Idx += HammingDistance; + ValueProfileMap.AddValue(Idx); + TORCW.Insert(Idx ^ Hash, Word(B1, Len), Word(B2, Len)); + +} + +template <class T> +ATTRIBUTE_TARGET_POPCNT ALWAYS_INLINE ATTRIBUTE_NO_SANITIZE_ALL void +TracePC::HandleCmp(uintptr_t PC, T Arg1, T Arg2) { + + uint64_t ArgXor = Arg1 ^ Arg2; + if (sizeof(T) == 4) + TORC4.Insert(ArgXor, Arg1, Arg2); + else if (sizeof(T) == 8) + TORC8.Insert(ArgXor, Arg1, Arg2); + uint64_t HammingDistance = Popcountll(ArgXor); // [0,64] + uint64_t AbsoluteDistance = (Arg1 == Arg2 ? 0 : Clzll(Arg1 - Arg2) + 1); + ValueProfileMap.AddValue(PC * 128 + HammingDistance); + ValueProfileMap.AddValue(PC * 128 + 64 + AbsoluteDistance); + +} + +static size_t InternalStrnlen(const char *S, size_t MaxLen) { + + size_t Len = 0; + for (; Len < MaxLen && S[Len]; Len++) {} + return Len; + +} + +// Finds min of (strlen(S1), strlen(S2)). +// Needed bacause one of these strings may actually be non-zero terminated. +static size_t InternalStrnlen2(const char *S1, const char *S2) { + + size_t Len = 0; + for (; S1[Len] && S2[Len]; Len++) {} + return Len; + +} + +void TracePC::ClearInlineCounters() { + + IterateCounterRegions([](const Module::Region &R) { + + if (R.Enabled) memset(R.Start, 0, R.Stop - R.Start); + + }); + +} + +ATTRIBUTE_NO_SANITIZE_ALL +void TracePC::RecordInitialStack() { + + int stack; + __sancov_lowest_stack = InitialStack = reinterpret_cast<uintptr_t>(&stack); + +} + +uintptr_t TracePC::GetMaxStackOffset() const { + + return InitialStack - __sancov_lowest_stack; // Stack grows down + +} + +void WarnAboutDeprecatedInstrumentation(const char *flag) { + + // Use RawPrint because Printf cannot be used on Windows before OutputFile is + // initialized. + RawPrint(flag); + RawPrint( + " is no longer supported by libFuzzer.\n" + "Please either migrate to a compiler that supports -fsanitize=fuzzer\n" + "or use an older version of libFuzzer\n"); + exit(1); + +} + +} // namespace fuzzer + +extern "C" { + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +void __sanitizer_cov_trace_pc_guard(uint32_t *Guard) { + + fuzzer::WarnAboutDeprecatedInstrumentation( + "-fsanitize-coverage=trace-pc-guard"); + +} + +// Best-effort support for -fsanitize-coverage=trace-pc, which is available +// in both Clang and GCC. +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +void __sanitizer_cov_trace_pc() { + + fuzzer::WarnAboutDeprecatedInstrumentation("-fsanitize-coverage=trace-pc"); + +} + +ATTRIBUTE_INTERFACE +void __sanitizer_cov_trace_pc_guard_init(uint32_t *Start, uint32_t *Stop) { + + fuzzer::WarnAboutDeprecatedInstrumentation( + "-fsanitize-coverage=trace-pc-guard"); + +} + +ATTRIBUTE_INTERFACE +void __sanitizer_cov_8bit_counters_init(uint8_t *Start, uint8_t *Stop) { + + fuzzer::TPC.HandleInline8bitCountersInit(Start, Stop); + +} + +ATTRIBUTE_INTERFACE +void __sanitizer_cov_pcs_init(const uintptr_t *pcs_beg, + const uintptr_t *pcs_end) { + + fuzzer::TPC.HandlePCsInit(pcs_beg, pcs_end); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +void __sanitizer_cov_trace_pc_indir(uintptr_t Callee) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCallerCallee(PC, Callee); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_cmp8(uint64_t Arg1, uint64_t Arg2) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Arg1, Arg2); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +// Now the __sanitizer_cov_trace_const_cmp[1248] callbacks just mimic +// the behaviour of __sanitizer_cov_trace_cmp[1248] ones. This, however, +// should be changed later to make full use of instrumentation. +void __sanitizer_cov_trace_const_cmp8(uint64_t Arg1, uint64_t Arg2) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Arg1, Arg2); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_cmp4(uint32_t Arg1, uint32_t Arg2) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Arg1, Arg2); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_const_cmp4(uint32_t Arg1, uint32_t Arg2) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Arg1, Arg2); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_cmp2(uint16_t Arg1, uint16_t Arg2) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Arg1, Arg2); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_const_cmp2(uint16_t Arg1, uint16_t Arg2) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Arg1, Arg2); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_cmp1(uint8_t Arg1, uint8_t Arg2) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Arg1, Arg2); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_const_cmp1(uint8_t Arg1, uint8_t Arg2) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Arg1, Arg2); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_switch(uint64_t Val, uint64_t *Cases) { + + uint64_t N = Cases[0]; + uint64_t ValSizeInBits = Cases[1]; + uint64_t *Vals = Cases + 2; + // Skip the most common and the most boring case: all switch values are small. + // We may want to skip this at compile-time, but it will make the + // instrumentation less general. + if (Vals[N - 1] < 256) return; + // Also skip small inputs values, they won't give good signal. + if (Val < 256) return; + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + size_t i; + uint64_t Smaller = 0; + uint64_t Larger = ~(uint64_t)0; + // Find two switch values such that Smaller < Val < Larger. + // Use 0 and 0xfff..f as the defaults. + for (i = 0; i < N; i++) { + + if (Val < Vals[i]) { + + Larger = Vals[i]; + break; + + } + + if (Val > Vals[i]) Smaller = Vals[i]; + + } + + // Apply HandleCmp to {Val,Smaller} and {Val, Larger}, + // use i as the PC modifier for HandleCmp. + if (ValSizeInBits == 16) { + + fuzzer::TPC.HandleCmp(PC + 2 * i, static_cast<uint16_t>(Val), + (uint16_t)(Smaller)); + fuzzer::TPC.HandleCmp(PC + 2 * i + 1, static_cast<uint16_t>(Val), + (uint16_t)(Larger)); + + } else if (ValSizeInBits == 32) { + + fuzzer::TPC.HandleCmp(PC + 2 * i, static_cast<uint32_t>(Val), + (uint32_t)(Smaller)); + fuzzer::TPC.HandleCmp(PC + 2 * i + 1, static_cast<uint32_t>(Val), + (uint32_t)(Larger)); + + } else { + + fuzzer::TPC.HandleCmp(PC + 2 * i, Val, Smaller); + fuzzer::TPC.HandleCmp(PC + 2 * i + 1, Val, Larger); + + } + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_div4(uint32_t Val) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Val, (uint32_t)0); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_div8(uint64_t Val) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Val, (uint64_t)0); + +} + +ATTRIBUTE_INTERFACE +ATTRIBUTE_NO_SANITIZE_ALL +ATTRIBUTE_TARGET_POPCNT +void __sanitizer_cov_trace_gep(uintptr_t Idx) { + + uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC()); + fuzzer::TPC.HandleCmp(PC, Idx, (uintptr_t)0); + +} + +ATTRIBUTE_INTERFACE ATTRIBUTE_NO_SANITIZE_MEMORY void +__sanitizer_weak_hook_memcmp(void *caller_pc, const void *s1, const void *s2, + size_t n, int result) { + + if (!fuzzer::RunningUserCallback) return; + if (result == 0) return; // No reason to mutate. + if (n <= 1) return; // Not interesting. + fuzzer::TPC.AddValueForMemcmp(caller_pc, s1, s2, n, /*StopAtZero*/ false); + +} + +ATTRIBUTE_INTERFACE ATTRIBUTE_NO_SANITIZE_MEMORY void +__sanitizer_weak_hook_strncmp(void *caller_pc, const char *s1, const char *s2, + size_t n, int result) { + + if (!fuzzer::RunningUserCallback) return; + if (result == 0) return; // No reason to mutate. + size_t Len1 = fuzzer::InternalStrnlen(s1, n); + size_t Len2 = fuzzer::InternalStrnlen(s2, n); + n = std::min(n, Len1); + n = std::min(n, Len2); + if (n <= 1) return; // Not interesting. + fuzzer::TPC.AddValueForMemcmp(caller_pc, s1, s2, n, /*StopAtZero*/ true); + +} + +ATTRIBUTE_INTERFACE ATTRIBUTE_NO_SANITIZE_MEMORY void +__sanitizer_weak_hook_strcmp(void *caller_pc, const char *s1, const char *s2, + int result) { + + if (!fuzzer::RunningUserCallback) return; + if (result == 0) return; // No reason to mutate. + size_t N = fuzzer::InternalStrnlen2(s1, s2); + if (N <= 1) return; // Not interesting. + fuzzer::TPC.AddValueForMemcmp(caller_pc, s1, s2, N, /*StopAtZero*/ true); + +} + +ATTRIBUTE_INTERFACE ATTRIBUTE_NO_SANITIZE_MEMORY void +__sanitizer_weak_hook_strncasecmp(void *called_pc, const char *s1, + const char *s2, size_t n, int result) { + + if (!fuzzer::RunningUserCallback) return; + return __sanitizer_weak_hook_strncmp(called_pc, s1, s2, n, result); + +} + +ATTRIBUTE_INTERFACE ATTRIBUTE_NO_SANITIZE_MEMORY void +__sanitizer_weak_hook_strcasecmp(void *called_pc, const char *s1, + const char *s2, int result) { + + if (!fuzzer::RunningUserCallback) return; + return __sanitizer_weak_hook_strcmp(called_pc, s1, s2, result); + +} + +ATTRIBUTE_INTERFACE ATTRIBUTE_NO_SANITIZE_MEMORY void +__sanitizer_weak_hook_strstr(void *called_pc, const char *s1, const char *s2, + char *result) { + + if (!fuzzer::RunningUserCallback) return; + fuzzer::TPC.MMT.Add(reinterpret_cast<const uint8_t *>(s2), strlen(s2)); + +} + +ATTRIBUTE_INTERFACE ATTRIBUTE_NO_SANITIZE_MEMORY void +__sanitizer_weak_hook_strcasestr(void *called_pc, const char *s1, + const char *s2, char *result) { + + if (!fuzzer::RunningUserCallback) return; + fuzzer::TPC.MMT.Add(reinterpret_cast<const uint8_t *>(s2), strlen(s2)); + +} + +ATTRIBUTE_INTERFACE ATTRIBUTE_NO_SANITIZE_MEMORY void +__sanitizer_weak_hook_memmem(void *called_pc, const void *s1, size_t len1, + const void *s2, size_t len2, void *result) { + + if (!fuzzer::RunningUserCallback) return; + fuzzer::TPC.MMT.Add(reinterpret_cast<const uint8_t *>(s2), len2); + +} + +} // extern "C" + diff --git a/custom_mutators/libfuzzer/FuzzerTracePC.h b/custom_mutators/libfuzzer/FuzzerTracePC.h new file mode 100644 index 00000000..a58fdf8d --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerTracePC.h @@ -0,0 +1,291 @@ +//===- FuzzerTracePC.h - Internal header for the Fuzzer ---------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// fuzzer::TracePC +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_TRACE_PC +#define LLVM_FUZZER_TRACE_PC + +#include "FuzzerDefs.h" +#include "FuzzerDictionary.h" +#include "FuzzerValueBitMap.h" + +#include <set> +#include <unordered_map> + +namespace fuzzer { + +// TableOfRecentCompares (TORC) remembers the most recently performed +// comparisons of type T. +// We record the arguments of CMP instructions in this table unconditionally +// because it seems cheaper this way than to compute some expensive +// conditions inside __sanitizer_cov_trace_cmp*. +// After the unit has been executed we may decide to use the contents of +// this table to populate a Dictionary. +template<class T, size_t kSizeT> +struct TableOfRecentCompares { + static const size_t kSize = kSizeT; + struct Pair { + T A, B; + }; + ATTRIBUTE_NO_SANITIZE_ALL + void Insert(size_t Idx, const T &Arg1, const T &Arg2) { + Idx = Idx % kSize; + Table[Idx].A = Arg1; + Table[Idx].B = Arg2; + } + + Pair Get(size_t I) { return Table[I % kSize]; } + + Pair Table[kSize]; +}; + +template <size_t kSizeT> +struct MemMemTable { + static const size_t kSize = kSizeT; + Word MemMemWords[kSize]; + Word EmptyWord; + + void Add(const uint8_t *Data, size_t Size) { + if (Size <= 2) return; + Size = std::min(Size, Word::GetMaxSize()); + size_t Idx = SimpleFastHash(Data, Size) % kSize; + MemMemWords[Idx].Set(Data, Size); + } + const Word &Get(size_t Idx) { + for (size_t i = 0; i < kSize; i++) { + const Word &W = MemMemWords[(Idx + i) % kSize]; + if (W.size()) return W; + } + EmptyWord.Set(nullptr, 0); + return EmptyWord; + } +}; + +class TracePC { + public: + void HandleInline8bitCountersInit(uint8_t *Start, uint8_t *Stop); + void HandlePCsInit(const uintptr_t *Start, const uintptr_t *Stop); + void HandleCallerCallee(uintptr_t Caller, uintptr_t Callee); + template <class T> void HandleCmp(uintptr_t PC, T Arg1, T Arg2); + size_t GetTotalPCCoverage(); + void SetUseCounters(bool UC) { UseCounters = UC; } + void SetUseValueProfileMask(uint32_t VPMask) { UseValueProfileMask = VPMask; } + void SetPrintNewPCs(bool P) { DoPrintNewPCs = P; } + void SetPrintNewFuncs(size_t P) { NumPrintNewFuncs = P; } + void UpdateObservedPCs(); + template <class Callback> void CollectFeatures(Callback CB) const; + + void ResetMaps() { + ValueProfileMap.Reset(); + ClearExtraCounters(); + ClearInlineCounters(); + } + + void ClearInlineCounters(); + + void UpdateFeatureSet(size_t CurrentElementIdx, size_t CurrentElementSize); + void PrintFeatureSet(); + + void PrintModuleInfo(); + + void PrintCoverage(); + + template<class CallBack> + void IterateCoveredFunctions(CallBack CB); + + void AddValueForMemcmp(void *caller_pc, const void *s1, const void *s2, + size_t n, bool StopAtZero); + + TableOfRecentCompares<uint32_t, 32> TORC4; + TableOfRecentCompares<uint64_t, 32> TORC8; + TableOfRecentCompares<Word, 32> TORCW; + MemMemTable<1024> MMT; + + void RecordInitialStack(); + uintptr_t GetMaxStackOffset() const; + + template<class CallBack> + void ForEachObservedPC(CallBack CB) { + for (auto PC : ObservedPCs) + CB(PC); + } + + void SetFocusFunction(const std::string &FuncName); + bool ObservedFocusFunction(); + + struct PCTableEntry { + uintptr_t PC, PCFlags; + }; + + uintptr_t PCTableEntryIdx(const PCTableEntry *TE); + const PCTableEntry *PCTableEntryByIdx(uintptr_t Idx); + static uintptr_t GetNextInstructionPc(uintptr_t PC); + bool PcIsFuncEntry(const PCTableEntry *TE) { return TE->PCFlags & 1; } + +private: + bool UseCounters = false; + uint32_t UseValueProfileMask = false; + bool DoPrintNewPCs = false; + size_t NumPrintNewFuncs = 0; + + // Module represents the array of 8-bit counters split into regions + // such that every region, except maybe the first and the last one, is one + // full page. + struct Module { + struct Region { + uint8_t *Start, *Stop; + bool Enabled; + bool OneFullPage; + }; + Region *Regions; + size_t NumRegions; + uint8_t *Start() const { return Regions[0].Start; } + uint8_t *Stop() const { return Regions[NumRegions - 1].Stop; } + size_t Size() const { return Stop() - Start(); } + size_t Idx(uint8_t *P) const { + assert(P >= Start() && P < Stop()); + return P - Start(); + } + }; + + Module Modules[4096]; + size_t NumModules; // linker-initialized. + size_t NumInline8bitCounters; + + template <class Callback> + void IterateCounterRegions(Callback CB) { + for (size_t m = 0; m < NumModules; m++) + for (size_t r = 0; r < Modules[m].NumRegions; r++) + CB(Modules[m].Regions[r]); + } + + struct { const PCTableEntry *Start, *Stop; } ModulePCTable[4096]; + size_t NumPCTables; + size_t NumPCsInPCTables; + + Set<const PCTableEntry*> ObservedPCs; + std::unordered_map<uintptr_t, uintptr_t> ObservedFuncs; // PC => Counter. + + uint8_t *FocusFunctionCounterPtr = nullptr; + + ValueBitMap ValueProfileMap; + uintptr_t InitialStack; +}; + +template <class Callback> +// void Callback(size_t FirstFeature, size_t Idx, uint8_t Value); +ATTRIBUTE_NO_SANITIZE_ALL +size_t ForEachNonZeroByte(const uint8_t *Begin, const uint8_t *End, + size_t FirstFeature, Callback Handle8bitCounter) { + typedef uintptr_t LargeType; + const size_t Step = sizeof(LargeType) / sizeof(uint8_t); + const size_t StepMask = Step - 1; + auto P = Begin; + // Iterate by 1 byte until either the alignment boundary or the end. + for (; reinterpret_cast<uintptr_t>(P) & StepMask && P < End; P++) + if (uint8_t V = *P) + Handle8bitCounter(FirstFeature, P - Begin, V); + + // Iterate by Step bytes at a time. + for (; P < End; P += Step) + if (LargeType Bundle = *reinterpret_cast<const LargeType *>(P)) { + Bundle = HostToLE(Bundle); + for (size_t I = 0; I < Step; I++, Bundle >>= 8) + if (uint8_t V = Bundle & 0xff) + Handle8bitCounter(FirstFeature, P - Begin + I, V); + } + + // Iterate by 1 byte until the end. + for (; P < End; P++) + if (uint8_t V = *P) + Handle8bitCounter(FirstFeature, P - Begin, V); + return End - Begin; +} + +// Given a non-zero Counter returns a number in the range [0,7]. +template<class T> +unsigned CounterToFeature(T Counter) { + // Returns a feature number by placing Counters into buckets as illustrated + // below. + // + // Counter bucket: [1] [2] [3] [4-7] [8-15] [16-31] [32-127] [128+] + // Feature number: 0 1 2 3 4 5 6 7 + // + // This is a heuristic taken from AFL (see + // http://lcamtuf.coredump.cx/afl/technical_details.txt). + // + // This implementation may change in the future so clients should + // not rely on it. + assert(Counter); + unsigned Bit = 0; + /**/ if (Counter >= 128) Bit = 7; + else if (Counter >= 32) Bit = 6; + else if (Counter >= 16) Bit = 5; + else if (Counter >= 8) Bit = 4; + else if (Counter >= 4) Bit = 3; + else if (Counter >= 3) Bit = 2; + else if (Counter >= 2) Bit = 1; + return Bit; +} + +template <class Callback> // void Callback(size_t Feature) +ATTRIBUTE_NO_SANITIZE_ADDRESS +ATTRIBUTE_NOINLINE +void TracePC::CollectFeatures(Callback HandleFeature) const { + auto Handle8bitCounter = [&](size_t FirstFeature, + size_t Idx, uint8_t Counter) { + if (UseCounters) + HandleFeature(FirstFeature + Idx * 8 + CounterToFeature(Counter)); + else + HandleFeature(FirstFeature + Idx); + }; + + size_t FirstFeature = 0; + + for (size_t i = 0; i < NumModules; i++) { + for (size_t r = 0; r < Modules[i].NumRegions; r++) { + if (!Modules[i].Regions[r].Enabled) continue; + FirstFeature += 8 * ForEachNonZeroByte(Modules[i].Regions[r].Start, + Modules[i].Regions[r].Stop, + FirstFeature, Handle8bitCounter); + } + } + + FirstFeature += + 8 * ForEachNonZeroByte(ExtraCountersBegin(), ExtraCountersEnd(), + FirstFeature, Handle8bitCounter); + + if (UseValueProfileMask) { + ValueProfileMap.ForEach([&](size_t Idx) { + HandleFeature(FirstFeature + Idx); + }); + FirstFeature += ValueProfileMap.SizeInBits(); + } + + // Step function, grows similar to 8 * Log_2(A). + auto StackDepthStepFunction = [](uint32_t A) -> uint32_t { + if (!A) return A; + uint32_t Log2 = Log(A); + if (Log2 < 3) return A; + Log2 -= 3; + return (Log2 + 1) * 8 + ((A >> Log2) & 7); + }; + assert(StackDepthStepFunction(1024) == 64); + assert(StackDepthStepFunction(1024 * 4) == 80); + assert(StackDepthStepFunction(1024 * 1024) == 144); + + if (auto MaxStackOffset = GetMaxStackOffset()) + HandleFeature(FirstFeature + StackDepthStepFunction(MaxStackOffset / 8)); +} + +extern TracePC TPC; + +} // namespace fuzzer + +#endif // LLVM_FUZZER_TRACE_PC diff --git a/custom_mutators/libfuzzer/FuzzerUtil.cpp b/custom_mutators/libfuzzer/FuzzerUtil.cpp new file mode 100644 index 00000000..7c395f7d --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerUtil.cpp @@ -0,0 +1,314 @@ +//===- FuzzerUtil.cpp - Misc utils ----------------------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Misc utils. +//===----------------------------------------------------------------------===// + +#include "FuzzerUtil.h" +#include "FuzzerIO.h" +#include "FuzzerInternal.h" +#include <cassert> +#include <chrono> +#include <cstring> +#include <errno.h> +#include <mutex> +#include <signal.h> +#include <sstream> +#include <stdio.h> +#include <sys/types.h> +#include <thread> + +namespace fuzzer { + +void PrintHexArray(const uint8_t *Data, size_t Size, const char *PrintAfter) { + + for (size_t i = 0; i < Size; i++) + Printf("0x%x,", (unsigned)Data[i]); + Printf("%s", PrintAfter); + +} + +void Print(const Unit &v, const char *PrintAfter) { + + PrintHexArray(v.data(), v.size(), PrintAfter); + +} + +void PrintASCIIByte(uint8_t Byte) { + + if (Byte == '\\') + Printf("\\\\"); + else if (Byte == '"') + Printf("\\\""); + else if (Byte >= 32 && Byte < 127) + Printf("%c", Byte); + else + Printf("\\x%02x", Byte); + +} + +void PrintASCII(const uint8_t *Data, size_t Size, const char *PrintAfter) { + + for (size_t i = 0; i < Size; i++) + PrintASCIIByte(Data[i]); + Printf("%s", PrintAfter); + +} + +void PrintASCII(const Unit &U, const char *PrintAfter) { + + PrintASCII(U.data(), U.size(), PrintAfter); + +} + +bool ToASCII(uint8_t *Data, size_t Size) { + + bool Changed = false; + for (size_t i = 0; i < Size; i++) { + + uint8_t &X = Data[i]; + auto NewX = X; + NewX &= 127; + if (!isspace(NewX) && !isprint(NewX)) NewX = ' '; + Changed |= NewX != X; + X = NewX; + + } + + return Changed; + +} + +bool IsASCII(const Unit &U) { + + return IsASCII(U.data(), U.size()); + +} + +bool IsASCII(const uint8_t *Data, size_t Size) { + + for (size_t i = 0; i < Size; i++) + if (!(isprint(Data[i]) || isspace(Data[i]))) return false; + return true; + +} + +bool ParseOneDictionaryEntry(const std::string &Str, Unit *U) { + + U->clear(); + if (Str.empty()) return false; + size_t L = 0, R = Str.size() - 1; // We are parsing the range [L,R]. + // Skip spaces from both sides. + while (L < R && isspace(Str[L])) + L++; + while (R > L && isspace(Str[R])) + R--; + if (R - L < 2) return false; + // Check the closing " + if (Str[R] != '"') return false; + R--; + // Find the opening " + while (L < R && Str[L] != '"') + L++; + if (L >= R) return false; + assert(Str[L] == '\"'); + L++; + assert(L <= R); + for (size_t Pos = L; Pos <= R; Pos++) { + + uint8_t V = (uint8_t)Str[Pos]; + if (!isprint(V) && !isspace(V)) return false; + if (V == '\\') { + + // Handle '\\' + if (Pos + 1 <= R && (Str[Pos + 1] == '\\' || Str[Pos + 1] == '"')) { + + U->push_back(Str[Pos + 1]); + Pos++; + continue; + + } + + // Handle '\xAB' + if (Pos + 3 <= R && Str[Pos + 1] == 'x' && isxdigit(Str[Pos + 2]) && + isxdigit(Str[Pos + 3])) { + + char Hex[] = "0xAA"; + Hex[2] = Str[Pos + 2]; + Hex[3] = Str[Pos + 3]; + U->push_back(strtol(Hex, nullptr, 16)); + Pos += 3; + continue; + + } + + return false; // Invalid escape. + + } else { + + // Any other character. + U->push_back(V); + + } + + } + + return true; + +} + +bool ParseDictionaryFile(const std::string &Text, Vector<Unit> *Units) { + + if (Text.empty()) { + + Printf("ParseDictionaryFile: file does not exist or is empty\n"); + return false; + + } + + std::istringstream ISS(Text); + Units->clear(); + Unit U; + int LineNo = 0; + std::string S; + while (std::getline(ISS, S, '\n')) { + + LineNo++; + size_t Pos = 0; + while (Pos < S.size() && isspace(S[Pos])) + Pos++; // Skip spaces. + if (Pos == S.size()) continue; // Empty line. + if (S[Pos] == '#') continue; // Comment line. + if (ParseOneDictionaryEntry(S, &U)) { + + Units->push_back(U); + + } else { + + Printf("ParseDictionaryFile: error in line %d\n\t\t%s\n", LineNo, + S.c_str()); + return false; + + } + + } + + return true; + +} + +// Code duplicated (and tested) in llvm/include/llvm/Support/Base64.h +std::string Base64(const Unit &U) { + + static const char Table[] = + "ABCDEFGHIJKLMNOPQRSTUVWXYZ" + "abcdefghijklmnopqrstuvwxyz" + "0123456789+/"; + std::string Buffer; + Buffer.resize(((U.size() + 2) / 3) * 4); + + size_t i = 0, j = 0; + for (size_t n = U.size() / 3 * 3; i < n; i += 3, j += 4) { + + uint32_t x = ((unsigned char)U[i] << 16) | ((unsigned char)U[i + 1] << 8) | + (unsigned char)U[i + 2]; + Buffer[j + 0] = Table[(x >> 18) & 63]; + Buffer[j + 1] = Table[(x >> 12) & 63]; + Buffer[j + 2] = Table[(x >> 6) & 63]; + Buffer[j + 3] = Table[x & 63]; + + } + + if (i + 1 == U.size()) { + + uint32_t x = ((unsigned char)U[i] << 16); + Buffer[j + 0] = Table[(x >> 18) & 63]; + Buffer[j + 1] = Table[(x >> 12) & 63]; + Buffer[j + 2] = '='; + Buffer[j + 3] = '='; + + } else if (i + 2 == U.size()) { + + uint32_t x = ((unsigned char)U[i] << 16) | ((unsigned char)U[i + 1] << 8); + Buffer[j + 0] = Table[(x >> 18) & 63]; + Buffer[j + 1] = Table[(x >> 12) & 63]; + Buffer[j + 2] = Table[(x >> 6) & 63]; + Buffer[j + 3] = '='; + + } + + return Buffer; + +} + +static std::mutex SymbolizeMutex; + +std::string DescribePC(const char *SymbolizedFMT, uintptr_t PC) { + + std::unique_lock<std::mutex> l(SymbolizeMutex, std::try_to_lock); + if (!EF->__sanitizer_symbolize_pc || !l.owns_lock()) + return "<can not symbolize>"; + char PcDescr[1024] = {}; + EF->__sanitizer_symbolize_pc(reinterpret_cast<void *>(PC), SymbolizedFMT, + PcDescr, sizeof(PcDescr)); + PcDescr[sizeof(PcDescr) - 1] = 0; // Just in case. + return PcDescr; + +} + +void PrintPC(const char *SymbolizedFMT, const char *FallbackFMT, uintptr_t PC) { + + if (EF->__sanitizer_symbolize_pc) + Printf("%s", DescribePC(SymbolizedFMT, PC).c_str()); + else + Printf(FallbackFMT, PC); + +} + +void PrintStackTrace() { + + std::unique_lock<std::mutex> l(SymbolizeMutex, std::try_to_lock); + if (EF->__sanitizer_print_stack_trace && l.owns_lock()) + EF->__sanitizer_print_stack_trace(); + +} + +void PrintMemoryProfile() { + + std::unique_lock<std::mutex> l(SymbolizeMutex, std::try_to_lock); + if (EF->__sanitizer_print_memory_profile && l.owns_lock()) + EF->__sanitizer_print_memory_profile(95, 8); + +} + +unsigned NumberOfCpuCores() { + + unsigned N = std::thread::hardware_concurrency(); + if (!N) { + + Printf( + "WARNING: std::thread::hardware_concurrency not well defined for " + "your platform. Assuming CPU count of 1.\n"); + N = 1; + + } + + return N; + +} + +size_t SimpleFastHash(const uint8_t *Data, size_t Size) { + + size_t Res = 0; + for (size_t i = 0; i < Size; i++) + Res = Res * 11 + Data[i]; + return Res; + +} + +} // namespace fuzzer + diff --git a/custom_mutators/libfuzzer/FuzzerUtil.h b/custom_mutators/libfuzzer/FuzzerUtil.h new file mode 100644 index 00000000..e90be085 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerUtil.h @@ -0,0 +1,117 @@ +//===- FuzzerUtil.h - Internal header for the Fuzzer Utils ------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Util functions. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_UTIL_H +#define LLVM_FUZZER_UTIL_H + +#include "FuzzerBuiltins.h" +#include "FuzzerBuiltinsMsvc.h" +#include "FuzzerCommand.h" +#include "FuzzerDefs.h" + +namespace fuzzer { + +void PrintHexArray(const Unit &U, const char *PrintAfter = ""); + +void PrintHexArray(const uint8_t *Data, size_t Size, + const char *PrintAfter = ""); + +void PrintASCII(const uint8_t *Data, size_t Size, const char *PrintAfter = ""); + +void PrintASCII(const Unit &U, const char *PrintAfter = ""); + +// Changes U to contain only ASCII (isprint+isspace) characters. +// Returns true iff U has been changed. +bool ToASCII(uint8_t *Data, size_t Size); + +bool IsASCII(const Unit &U); + +bool IsASCII(const uint8_t *Data, size_t Size); + +std::string Base64(const Unit &U); + +void PrintPC(const char *SymbolizedFMT, const char *FallbackFMT, uintptr_t PC); + +std::string DescribePC(const char *SymbolizedFMT, uintptr_t PC); + +void PrintStackTrace(); + +void PrintMemoryProfile(); + +unsigned NumberOfCpuCores(); + +// Platform specific functions. +void SetSignalHandler(const FuzzingOptions& Options); + +void SleepSeconds(int Seconds); + +unsigned long GetPid(); + +size_t GetPeakRSSMb(); + +int ExecuteCommand(const Command &Cmd); +bool ExecuteCommand(const Command &Cmd, std::string *CmdOutput); + +// Fuchsia does not have popen/pclose. +FILE *OpenProcessPipe(const char *Command, const char *Mode); +int CloseProcessPipe(FILE *F); + +const void *SearchMemory(const void *haystack, size_t haystacklen, + const void *needle, size_t needlelen); + +std::string CloneArgsWithoutX(const Vector<std::string> &Args, + const char *X1, const char *X2); + +inline std::string CloneArgsWithoutX(const Vector<std::string> &Args, + const char *X) { + return CloneArgsWithoutX(Args, X, X); +} + +inline std::pair<std::string, std::string> SplitBefore(std::string X, + std::string S) { + auto Pos = S.find(X); + if (Pos == std::string::npos) + return std::make_pair(S, ""); + return std::make_pair(S.substr(0, Pos), S.substr(Pos)); +} + +void DiscardOutput(int Fd); + +std::string DisassembleCmd(const std::string &FileName); + +std::string SearchRegexCmd(const std::string &Regex); + +size_t SimpleFastHash(const uint8_t *Data, size_t Size); + +inline uint32_t Log(uint32_t X) { return 32 - Clz(X) - 1; } + +inline size_t PageSize() { return 4096; } +inline uint8_t *RoundUpByPage(uint8_t *P) { + uintptr_t X = reinterpret_cast<uintptr_t>(P); + size_t Mask = PageSize() - 1; + X = (X + Mask) & ~Mask; + return reinterpret_cast<uint8_t *>(X); +} +inline uint8_t *RoundDownByPage(uint8_t *P) { + uintptr_t X = reinterpret_cast<uintptr_t>(P); + size_t Mask = PageSize() - 1; + X = X & ~Mask; + return reinterpret_cast<uint8_t *>(X); +} + +#if __BYTE_ORDER == __LITTLE_ENDIAN +template <typename T> T HostToLE(T X) { return X; } +#else +template <typename T> T HostToLE(T X) { return Bswap(X); } +#endif + +} // namespace fuzzer + +#endif // LLVM_FUZZER_UTIL_H diff --git a/custom_mutators/libfuzzer/FuzzerUtilDarwin.cpp b/custom_mutators/libfuzzer/FuzzerUtilDarwin.cpp new file mode 100644 index 00000000..420d8c23 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerUtilDarwin.cpp @@ -0,0 +1,205 @@ +//===- FuzzerUtilDarwin.cpp - Misc utils ----------------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Misc utils for Darwin. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" +#if LIBFUZZER_APPLE + #include "FuzzerCommand.h" + #include "FuzzerIO.h" + #include <mutex> + #include <signal.h> + #include <spawn.h> + #include <stdlib.h> + #include <string.h> + #include <sys/wait.h> + #include <unistd.h> + +// There is no header for this on macOS so declare here +extern "C" char **environ; + +namespace fuzzer { + +static std::mutex SignalMutex; +// Global variables used to keep track of how signal handling should be +// restored. They should **not** be accessed without holding `SignalMutex`. +static int ActiveThreadCount = 0; +static struct sigaction OldSigIntAction; +static struct sigaction OldSigQuitAction; +static sigset_t OldBlockedSignalsSet; + +// This is a reimplementation of Libc's `system()`. On Darwin the Libc +// implementation contains a mutex which prevents it from being used +// concurrently. This implementation **can** be used concurrently. It sets the +// signal handlers when the first thread enters and restores them when the last +// thread finishes execution of the function and ensures this is not racey by +// using a mutex. +int ExecuteCommand(const Command &Cmd) { + + std::string CmdLine = Cmd.toString(); + posix_spawnattr_t SpawnAttributes; + if (posix_spawnattr_init(&SpawnAttributes)) return -1; + // Block and ignore signals of the current process when the first thread + // enters. + { + + std::lock_guard<std::mutex> Lock(SignalMutex); + if (ActiveThreadCount == 0) { + + static struct sigaction IgnoreSignalAction; + sigset_t BlockedSignalsSet; + memset(&IgnoreSignalAction, 0, sizeof(IgnoreSignalAction)); + IgnoreSignalAction.sa_handler = SIG_IGN; + + if (sigaction(SIGINT, &IgnoreSignalAction, &OldSigIntAction) == -1) { + + Printf("Failed to ignore SIGINT\n"); + (void)posix_spawnattr_destroy(&SpawnAttributes); + return -1; + + } + + if (sigaction(SIGQUIT, &IgnoreSignalAction, &OldSigQuitAction) == -1) { + + Printf("Failed to ignore SIGQUIT\n"); + // Try our best to restore the signal handlers. + (void)sigaction(SIGINT, &OldSigIntAction, NULL); + (void)posix_spawnattr_destroy(&SpawnAttributes); + return -1; + + } + + (void)sigemptyset(&BlockedSignalsSet); + (void)sigaddset(&BlockedSignalsSet, SIGCHLD); + if (sigprocmask(SIG_BLOCK, &BlockedSignalsSet, &OldBlockedSignalsSet) == + -1) { + + Printf("Failed to block SIGCHLD\n"); + // Try our best to restore the signal handlers. + (void)sigaction(SIGQUIT, &OldSigQuitAction, NULL); + (void)sigaction(SIGINT, &OldSigIntAction, NULL); + (void)posix_spawnattr_destroy(&SpawnAttributes); + return -1; + + } + + } + + ++ActiveThreadCount; + + } + + // NOTE: Do not introduce any new `return` statements past this + // point. It is important that `ActiveThreadCount` always be decremented + // when leaving this function. + + // Make sure the child process uses the default handlers for the + // following signals rather than inheriting what the parent has. + sigset_t DefaultSigSet; + (void)sigemptyset(&DefaultSigSet); + (void)sigaddset(&DefaultSigSet, SIGQUIT); + (void)sigaddset(&DefaultSigSet, SIGINT); + (void)posix_spawnattr_setsigdefault(&SpawnAttributes, &DefaultSigSet); + // Make sure the child process doesn't block SIGCHLD + (void)posix_spawnattr_setsigmask(&SpawnAttributes, &OldBlockedSignalsSet); + short SpawnFlags = POSIX_SPAWN_SETSIGDEF | POSIX_SPAWN_SETSIGMASK; + (void)posix_spawnattr_setflags(&SpawnAttributes, SpawnFlags); + + pid_t Pid; + char ** Environ = environ; // Read from global + const char *CommandCStr = CmdLine.c_str(); + char *const Argv[] = {strdup("sh"), strdup("-c"), strdup(CommandCStr), NULL}; + int ErrorCode = 0, ProcessStatus = 0; + // FIXME: We probably shouldn't hardcode the shell path. + ErrorCode = + posix_spawn(&Pid, "/bin/sh", NULL, &SpawnAttributes, Argv, Environ); + (void)posix_spawnattr_destroy(&SpawnAttributes); + if (!ErrorCode) { + + pid_t SavedPid = Pid; + do { + + // Repeat until call completes uninterrupted. + Pid = waitpid(SavedPid, &ProcessStatus, /*options=*/0); + + } while (Pid == -1 && errno == EINTR); + + if (Pid == -1) { + + // Fail for some other reason. + ProcessStatus = -1; + + } + + } else if (ErrorCode == ENOMEM || ErrorCode == EAGAIN) { + + // Fork failure. + ProcessStatus = -1; + + } else { + + // Shell execution failure. + ProcessStatus = W_EXITCODE(127, 0); + + } + + for (unsigned i = 0, n = sizeof(Argv) / sizeof(Argv[0]); i < n; ++i) + free(Argv[i]); + + // Restore the signal handlers of the current process when the last thread + // using this function finishes. + { + + std::lock_guard<std::mutex> Lock(SignalMutex); + --ActiveThreadCount; + if (ActiveThreadCount == 0) { + + bool FailedRestore = false; + if (sigaction(SIGINT, &OldSigIntAction, NULL) == -1) { + + Printf("Failed to restore SIGINT handling\n"); + FailedRestore = true; + + } + + if (sigaction(SIGQUIT, &OldSigQuitAction, NULL) == -1) { + + Printf("Failed to restore SIGQUIT handling\n"); + FailedRestore = true; + + } + + if (sigprocmask(SIG_BLOCK, &OldBlockedSignalsSet, NULL) == -1) { + + Printf("Failed to unblock SIGCHLD\n"); + FailedRestore = true; + + } + + if (FailedRestore) ProcessStatus = -1; + + } + + } + + return ProcessStatus; + +} + +void DiscardOutput(int Fd) { + + FILE *Temp = fopen("/dev/null", "w"); + if (!Temp) return; + dup2(fileno(Temp), Fd); + fclose(Temp); + +} + +} // namespace fuzzer + +#endif // LIBFUZZER_APPLE + diff --git a/custom_mutators/libfuzzer/FuzzerUtilFuchsia.cpp b/custom_mutators/libfuzzer/FuzzerUtilFuchsia.cpp new file mode 100644 index 00000000..45ecbca8 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerUtilFuchsia.cpp @@ -0,0 +1,658 @@ +//===- FuzzerUtilFuchsia.cpp - Misc utils for Fuchsia. --------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Misc utils implementation using Fuchsia/Zircon APIs. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" + +#if LIBFUZZER_FUCHSIA + + #include "FuzzerInternal.h" + #include "FuzzerUtil.h" + #include <cassert> + #include <cerrno> + #include <cinttypes> + #include <cstdint> + #include <fcntl.h> + #include <lib/fdio/fdio.h> + #include <lib/fdio/spawn.h> + #include <string> + #include <sys/select.h> + #include <thread> + #include <unistd.h> + #include <zircon/errors.h> + #include <zircon/process.h> + #include <zircon/sanitizer.h> + #include <zircon/status.h> + #include <zircon/syscalls.h> + #include <zircon/syscalls/debug.h> + #include <zircon/syscalls/exception.h> + #include <zircon/syscalls/object.h> + #include <zircon/types.h> + + #include <vector> + +namespace fuzzer { + +// Given that Fuchsia doesn't have the POSIX signals that libFuzzer was written +// around, the general approach is to spin up dedicated threads to watch for +// each requested condition (alarm, interrupt, crash). Of these, the crash +// handler is the most involved, as it requires resuming the crashed thread in +// order to invoke the sanitizers to get the needed state. + +// Forward declaration of assembly trampoline needed to resume crashed threads. +// This appears to have external linkage to C++, which is why it's not in the +// anonymous namespace. The assembly definition inside MakeTrampoline() +// actually defines the symbol with internal linkage only. +void CrashTrampolineAsm() __asm__("CrashTrampolineAsm"); + +namespace { + +// Helper function to handle Zircon syscall failures. +void ExitOnErr(zx_status_t Status, const char *Syscall) { + + if (Status != ZX_OK) { + + Printf("libFuzzer: %s failed: %s\n", Syscall, + _zx_status_get_string(Status)); + exit(1); + + } + +} + +void AlarmHandler(int Seconds) { + + while (true) { + + SleepSeconds(Seconds); + Fuzzer::StaticAlarmCallback(); + + } + +} + +void InterruptHandler() { + + fd_set readfds; + // Ctrl-C sends ETX in Zircon. + do { + + FD_ZERO(&readfds); + FD_SET(STDIN_FILENO, &readfds); + select(STDIN_FILENO + 1, &readfds, nullptr, nullptr, nullptr); + + } while (!FD_ISSET(STDIN_FILENO, &readfds) || getchar() != 0x03); + + Fuzzer::StaticInterruptCallback(); + +} + + // CFAOffset is used to reference the stack pointer before entering the + // trampoline (Stack Pointer + CFAOffset = prev Stack Pointer). Before jumping + // to the trampoline we copy all the registers onto the stack. We need to make + // sure that the new stack has enough space to store all the registers. + // + // The trampoline holds CFI information regarding the registers stored in the + // stack, which is then used by the unwinder to restore them. + #if defined(__x86_64__) +// In x86_64 the crashing function might also be using the red zone (128 bytes +// on top of their rsp). +constexpr size_t CFAOffset = 128 + sizeof(zx_thread_state_general_regs_t); + #elif defined(__aarch64__) +// In aarch64 we need to always have the stack pointer aligned to 16 bytes, so +// we make sure that we are keeping that same alignment. +constexpr size_t CFAOffset = + (sizeof(zx_thread_state_general_regs_t) + 15) & -(uintptr_t)16; + #endif + + // For the crash handler, we need to call Fuzzer::StaticCrashSignalCallback + // without POSIX signal handlers. To achieve this, we use an assembly + // function to add the necessary CFI unwinding information and a C function to + // bridge from that back into C++. + + // FIXME: This works as a short-term solution, but this code really shouldn't + // be architecture dependent. A better long term solution is to implement + // remote unwinding and expose the necessary APIs through sanitizer_common + // and/or ASAN to allow the exception handling thread to gather the crash + // state directly. + // + // Alternatively, Fuchsia may in future actually implement basic signal + // handling for the machine trap signals. + #if defined(__x86_64__) + #define FOREACH_REGISTER(OP_REG, OP_NUM) \ + OP_REG(rax) \ + OP_REG(rbx) \ + OP_REG(rcx) \ + OP_REG(rdx) \ + OP_REG(rsi) \ + OP_REG(rdi) \ + OP_REG(rbp) \ + OP_REG(rsp) \ + OP_REG(r8) \ + OP_REG(r9) \ + OP_REG(r10) \ + OP_REG(r11) \ + OP_REG(r12) \ + OP_REG(r13) \ + OP_REG(r14) \ + OP_REG(r15) \ + OP_REG(rip) + + #elif defined(__aarch64__) + #define FOREACH_REGISTER(OP_REG, OP_NUM) \ + OP_NUM(0) \ + OP_NUM(1) \ + OP_NUM(2) \ + OP_NUM(3) \ + OP_NUM(4) \ + OP_NUM(5) \ + OP_NUM(6) \ + OP_NUM(7) \ + OP_NUM(8) \ + OP_NUM(9) \ + OP_NUM(10) \ + OP_NUM(11) \ + OP_NUM(12) \ + OP_NUM(13) \ + OP_NUM(14) \ + OP_NUM(15) \ + OP_NUM(16) \ + OP_NUM(17) \ + OP_NUM(18) \ + OP_NUM(19) \ + OP_NUM(20) \ + OP_NUM(21) \ + OP_NUM(22) \ + OP_NUM(23) \ + OP_NUM(24) \ + OP_NUM(25) \ + OP_NUM(26) \ + OP_NUM(27) \ + OP_NUM(28) \ + OP_NUM(29) \ + OP_REG(sp) + + #else + #error "Unsupported architecture for fuzzing on Fuchsia" + #endif + + // Produces a CFI directive for the named or numbered register. + // The value used refers to an assembler immediate operand with the same name + // as the register (see ASM_OPERAND_REG). + #define CFI_OFFSET_REG(reg) ".cfi_offset " #reg ", %c[" #reg "]\n" + #define CFI_OFFSET_NUM(num) CFI_OFFSET_REG(x##num) + + // Produces an assembler immediate operand for the named or numbered register. + // This operand contains the offset of the register relative to the CFA. + #define ASM_OPERAND_REG(reg) \ + [reg] "i"(offsetof(zx_thread_state_general_regs_t, reg) - CFAOffset), + #define ASM_OPERAND_NUM(num) \ + [x##num] "i"(offsetof(zx_thread_state_general_regs_t, r[num]) - CFAOffset), + +// Trampoline to bridge from the assembly below to the static C++ crash +// callback. +__attribute__((noreturn)) static void StaticCrashHandler() { + + Fuzzer::StaticCrashSignalCallback(); + for (;;) { + + _Exit(1); + + } + +} + +// Creates the trampoline with the necessary CFI information to unwind through +// to the crashing call stack: +// * Defining the CFA so that it points to the stack pointer at the point +// of crash. +// * Storing all registers at the point of crash in the stack and refer to them +// via CFI information (relative to the CFA). +// * Setting the return column so the unwinder knows how to continue unwinding. +// * (x86_64) making sure rsp is aligned before calling StaticCrashHandler. +// * Calling StaticCrashHandler that will trigger the unwinder. +// +// The __attribute__((used)) is necessary because the function +// is never called; it's just a container around the assembly to allow it to +// use operands for compile-time computed constants. +__attribute__((used)) void MakeTrampoline() { + + __asm__(".cfi_endproc\n" + ".pushsection .text.CrashTrampolineAsm\n" + ".type CrashTrampolineAsm,STT_FUNC\n" +"CrashTrampolineAsm:\n" + ".cfi_startproc simple\n" + ".cfi_signal_frame\n" + #if defined(__x86_64__) + ".cfi_return_column rip\n" + ".cfi_def_cfa rsp, %c[CFAOffset]\n" + FOREACH_REGISTER(CFI_OFFSET_REG, CFI_OFFSET_NUM) + "mov %%rsp, %%rbp\n" + ".cfi_def_cfa_register rbp\n" + "andq $-16, %%rsp\n" + "call %c[StaticCrashHandler]\n" + "ud2\n" + #elif defined(__aarch64__) + ".cfi_return_column 33\n" + ".cfi_def_cfa sp, %c[CFAOffset]\n" + FOREACH_REGISTER(CFI_OFFSET_REG, CFI_OFFSET_NUM) + ".cfi_offset 33, %c[pc]\n" + ".cfi_offset 30, %c[lr]\n" + "bl %c[StaticCrashHandler]\n" + "brk 1\n" + #else + #error "Unsupported architecture for fuzzing on Fuchsia" + #endif + ".cfi_endproc\n" + ".size CrashTrampolineAsm, . - CrashTrampolineAsm\n" + ".popsection\n" + ".cfi_startproc\n" + : // No outputs + : FOREACH_REGISTER(ASM_OPERAND_REG, ASM_OPERAND_NUM) + #if defined(__aarch64__) + ASM_OPERAND_REG(pc) + ASM_OPERAND_REG(lr) + #endif + [StaticCrashHandler] "i" (StaticCrashHandler), + [CFAOffset] "i" (CFAOffset)); + +} + +void CrashHandler(zx_handle_t *Event) { + + // This structure is used to ensure we close handles to objects we create in + // this handler. + struct ScopedHandle { + + ~ScopedHandle() { + + _zx_handle_close(Handle); + + } + + zx_handle_t Handle = ZX_HANDLE_INVALID; + + }; + + // Create the exception channel. We need to claim to be a "debugger" so the + // kernel will allow us to modify and resume dying threads (see below). Once + // the channel is set, we can signal the main thread to continue and wait + // for the exception to arrive. + ScopedHandle Channel; + zx_handle_t Self = _zx_process_self(); + ExitOnErr(_zx_task_create_exception_channel( + Self, ZX_EXCEPTION_CHANNEL_DEBUGGER, &Channel.Handle), + "_zx_task_create_exception_channel"); + + ExitOnErr(_zx_object_signal(*Event, 0, ZX_USER_SIGNAL_0), + "_zx_object_signal"); + + // This thread lives as long as the process in order to keep handling + // crashes. In practice, the first crashed thread to reach the end of the + // StaticCrashHandler will end the process. + while (true) { + + ExitOnErr(_zx_object_wait_one(Channel.Handle, ZX_CHANNEL_READABLE, + ZX_TIME_INFINITE, nullptr), + "_zx_object_wait_one"); + + zx_exception_info_t ExceptionInfo; + ScopedHandle Exception; + ExitOnErr( + _zx_channel_read(Channel.Handle, 0, &ExceptionInfo, &Exception.Handle, + sizeof(ExceptionInfo), 1, nullptr, nullptr), + "_zx_channel_read"); + + // Ignore informational synthetic exceptions. + if (ZX_EXCP_THREAD_STARTING == ExceptionInfo.type || + ZX_EXCP_THREAD_EXITING == ExceptionInfo.type || + ZX_EXCP_PROCESS_STARTING == ExceptionInfo.type) { + + continue; + + } + + // At this point, we want to get the state of the crashing thread, but + // libFuzzer and the sanitizers assume this will happen from that same + // thread via a POSIX signal handler. "Resurrecting" the thread in the + // middle of the appropriate callback is as simple as forcibly setting the + // instruction pointer/program counter, provided we NEVER EVER return from + // that function (since otherwise our stack will not be valid). + ScopedHandle Thread; + ExitOnErr(_zx_exception_get_thread(Exception.Handle, &Thread.Handle), + "_zx_exception_get_thread"); + + zx_thread_state_general_regs_t GeneralRegisters; + ExitOnErr( + _zx_thread_read_state(Thread.Handle, ZX_THREAD_STATE_GENERAL_REGS, + &GeneralRegisters, sizeof(GeneralRegisters)), + "_zx_thread_read_state"); + + // To unwind properly, we need to push the crashing thread's register state + // onto the stack and jump into a trampoline with CFI instructions on how + // to restore it. + #if defined(__x86_64__) + uintptr_t StackPtr = GeneralRegisters.rsp - CFAOffset; + __unsanitized_memcpy(reinterpret_cast<void *>(StackPtr), &GeneralRegisters, + sizeof(GeneralRegisters)); + GeneralRegisters.rsp = StackPtr; + GeneralRegisters.rip = reinterpret_cast<zx_vaddr_t>(CrashTrampolineAsm); + + #elif defined(__aarch64__) + uintptr_t StackPtr = GeneralRegisters.sp - CFAOffset; + __unsanitized_memcpy(reinterpret_cast<void *>(StackPtr), &GeneralRegisters, + sizeof(GeneralRegisters)); + GeneralRegisters.sp = StackPtr; + GeneralRegisters.pc = reinterpret_cast<zx_vaddr_t>(CrashTrampolineAsm); + + #else + #error "Unsupported architecture for fuzzing on Fuchsia" + #endif + + // Now force the crashing thread's state. + ExitOnErr( + _zx_thread_write_state(Thread.Handle, ZX_THREAD_STATE_GENERAL_REGS, + &GeneralRegisters, sizeof(GeneralRegisters)), + "_zx_thread_write_state"); + + // Set the exception to HANDLED so it resumes the thread on close. + uint32_t ExceptionState = ZX_EXCEPTION_STATE_HANDLED; + ExitOnErr(_zx_object_set_property(Exception.Handle, ZX_PROP_EXCEPTION_STATE, + &ExceptionState, sizeof(ExceptionState)), + "zx_object_set_property"); + + } + +} + +} // namespace + +// Platform specific functions. +void SetSignalHandler(const FuzzingOptions &Options) { + + // Make sure information from libFuzzer and the sanitizers are easy to + // reassemble. `__sanitizer_log_write` has the added benefit of ensuring the + // DSO map is always available for the symbolizer. + // A uint64_t fits in 20 chars, so 64 is plenty. + char Buf[64]; + memset(Buf, 0, sizeof(Buf)); + snprintf(Buf, sizeof(Buf), "==%lu== INFO: libFuzzer starting.\n", GetPid()); + if (EF->__sanitizer_log_write) __sanitizer_log_write(Buf, sizeof(Buf)); + Printf("%s", Buf); + + // Set up alarm handler if needed. + if (Options.HandleAlrm && Options.UnitTimeoutSec > 0) { + + std::thread T(AlarmHandler, Options.UnitTimeoutSec / 2 + 1); + T.detach(); + + } + + // Set up interrupt handler if needed. + if (Options.HandleInt || Options.HandleTerm) { + + std::thread T(InterruptHandler); + T.detach(); + + } + + // Early exit if no crash handler needed. + if (!Options.HandleSegv && !Options.HandleBus && !Options.HandleIll && + !Options.HandleFpe && !Options.HandleAbrt) + return; + + // Set up the crash handler and wait until it is ready before proceeding. + zx_handle_t Event; + ExitOnErr(_zx_event_create(0, &Event), "_zx_event_create"); + + std::thread T(CrashHandler, &Event); + zx_status_t Status = + _zx_object_wait_one(Event, ZX_USER_SIGNAL_0, ZX_TIME_INFINITE, nullptr); + _zx_handle_close(Event); + ExitOnErr(Status, "_zx_object_wait_one"); + + T.detach(); + +} + +void SleepSeconds(int Seconds) { + + _zx_nanosleep(_zx_deadline_after(ZX_SEC(Seconds))); + +} + +unsigned long GetPid() { + + zx_status_t rc; + zx_info_handle_basic_t Info; + if ((rc = _zx_object_get_info(_zx_process_self(), ZX_INFO_HANDLE_BASIC, &Info, + sizeof(Info), NULL, NULL)) != ZX_OK) { + + Printf("libFuzzer: unable to get info about self: %s\n", + _zx_status_get_string(rc)); + exit(1); + + } + + return Info.koid; + +} + +size_t GetPeakRSSMb() { + + zx_status_t rc; + zx_info_task_stats_t Info; + if ((rc = _zx_object_get_info(_zx_process_self(), ZX_INFO_TASK_STATS, &Info, + sizeof(Info), NULL, NULL)) != ZX_OK) { + + Printf("libFuzzer: unable to get info about self: %s\n", + _zx_status_get_string(rc)); + exit(1); + + } + + return (Info.mem_private_bytes + Info.mem_shared_bytes) >> 20; + +} + +template <typename Fn> +class RunOnDestruction { + + public: + explicit RunOnDestruction(Fn fn) : fn_(fn) { + + } + + ~RunOnDestruction() { + + fn_(); + + } + + private: + Fn fn_; + +}; + +template <typename Fn> +RunOnDestruction<Fn> at_scope_exit(Fn fn) { + + return RunOnDestruction<Fn>(fn); + +} + +static fdio_spawn_action_t clone_fd_action(int localFd, int targetFd) { + + return { + + .action = FDIO_SPAWN_ACTION_CLONE_FD, + .fd = + { + + .local_fd = localFd, + .target_fd = targetFd, + + }, + + }; + +} + +int ExecuteCommand(const Command &Cmd) { + + zx_status_t rc; + + // Convert arguments to C array + auto Args = Cmd.getArguments(); + size_t Argc = Args.size(); + assert(Argc != 0); + std::unique_ptr<const char *[]> Argv(new const char *[Argc + 1]); + for (size_t i = 0; i < Argc; ++i) + Argv[i] = Args[i].c_str(); + Argv[Argc] = nullptr; + + // Determine output. On Fuchsia, the fuzzer is typically run as a component + // that lacks a mutable working directory. Fortunately, when this is the case + // a mutable output directory must be specified using "-artifact_prefix=...", + // so write the log file(s) there. + // However, we don't want to apply this logic for absolute paths. + int FdOut = STDOUT_FILENO; + bool discardStdout = false; + bool discardStderr = false; + + if (Cmd.hasOutputFile()) { + + std::string Path = Cmd.getOutputFile(); + if (Path == getDevNull()) { + + // On Fuchsia, there's no "/dev/null" like-file, so we + // just don't copy the FDs into the spawned process. + discardStdout = true; + + } else { + + bool IsAbsolutePath = Path.length() > 1 && Path[0] == '/'; + if (!IsAbsolutePath && Cmd.hasFlag("artifact_prefix")) + Path = Cmd.getFlagValue("artifact_prefix") + "/" + Path; + + FdOut = open(Path.c_str(), O_WRONLY | O_CREAT | O_TRUNC, 0); + if (FdOut == -1) { + + Printf("libFuzzer: failed to open %s: %s\n", Path.c_str(), + strerror(errno)); + return ZX_ERR_IO; + + } + + } + + } + + auto CloseFdOut = at_scope_exit([FdOut]() { + + if (FdOut != STDOUT_FILENO) close(FdOut); + + }); + + // Determine stderr + int FdErr = STDERR_FILENO; + if (Cmd.isOutAndErrCombined()) { + + FdErr = FdOut; + if (discardStdout) discardStderr = true; + + } + + // Clone the file descriptors into the new process + std::vector<fdio_spawn_action_t> SpawnActions; + SpawnActions.push_back(clone_fd_action(STDIN_FILENO, STDIN_FILENO)); + + if (!discardStdout) + SpawnActions.push_back(clone_fd_action(FdOut, STDOUT_FILENO)); + if (!discardStderr) + SpawnActions.push_back(clone_fd_action(FdErr, STDERR_FILENO)); + + // Start the process. + char ErrorMsg[FDIO_SPAWN_ERR_MSG_MAX_LENGTH]; + zx_handle_t ProcessHandle = ZX_HANDLE_INVALID; + rc = fdio_spawn_etc(ZX_HANDLE_INVALID, + FDIO_SPAWN_CLONE_ALL & (~FDIO_SPAWN_CLONE_STDIO), Argv[0], + Argv.get(), nullptr, SpawnActions.size(), + SpawnActions.data(), &ProcessHandle, ErrorMsg); + + if (rc != ZX_OK) { + + Printf("libFuzzer: failed to launch '%s': %s, %s\n", Argv[0], ErrorMsg, + _zx_status_get_string(rc)); + return rc; + + } + + auto CloseHandle = at_scope_exit([&]() { _zx_handle_close(ProcessHandle); }); + + // Now join the process and return the exit status. + if ((rc = _zx_object_wait_one(ProcessHandle, ZX_PROCESS_TERMINATED, + ZX_TIME_INFINITE, nullptr)) != ZX_OK) { + + Printf("libFuzzer: failed to join '%s': %s\n", Argv[0], + _zx_status_get_string(rc)); + return rc; + + } + + zx_info_process_t Info; + if ((rc = _zx_object_get_info(ProcessHandle, ZX_INFO_PROCESS, &Info, + sizeof(Info), nullptr, nullptr)) != ZX_OK) { + + Printf("libFuzzer: unable to get return code from '%s': %s\n", Argv[0], + _zx_status_get_string(rc)); + return rc; + + } + + return Info.return_code; + +} + +bool ExecuteCommand(const Command &BaseCmd, std::string *CmdOutput) { + + auto LogFilePath = TempPath("SimPopenOut", ".txt"); + Command Cmd(BaseCmd); + Cmd.setOutputFile(LogFilePath); + int Ret = ExecuteCommand(Cmd); + *CmdOutput = FileToString(LogFilePath); + RemoveFile(LogFilePath); + return Ret == 0; + +} + +const void *SearchMemory(const void *Data, size_t DataLen, const void *Patt, + size_t PattLen) { + + return memmem(Data, DataLen, Patt, PattLen); + +} + +// In fuchsia, accessing /dev/null is not supported. There's nothing +// similar to a file that discards everything that is written to it. +// The way of doing something similar in fuchsia is by using +// fdio_null_create and binding that to a file descriptor. +void DiscardOutput(int Fd) { + + fdio_t *fdio_null = fdio_null_create(); + if (fdio_null == nullptr) return; + int nullfd = fdio_bind_to_fd(fdio_null, -1, 0); + if (nullfd < 0) return; + dup2(nullfd, Fd); + +} + +} // namespace fuzzer + +#endif // LIBFUZZER_FUCHSIA + diff --git a/custom_mutators/libfuzzer/FuzzerUtilLinux.cpp b/custom_mutators/libfuzzer/FuzzerUtilLinux.cpp new file mode 100644 index 00000000..f2531bee --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerUtilLinux.cpp @@ -0,0 +1,43 @@ +//===- FuzzerUtilLinux.cpp - Misc utils for Linux. ------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Misc utils for Linux. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" +#if LIBFUZZER_LINUX || LIBFUZZER_NETBSD || LIBFUZZER_FREEBSD || \ + LIBFUZZER_OPENBSD || LIBFUZZER_EMSCRIPTEN + #include "FuzzerCommand.h" + + #include <stdlib.h> + #include <sys/types.h> + #include <sys/wait.h> + #include <unistd.h> + +namespace fuzzer { + +int ExecuteCommand(const Command &Cmd) { + + std::string CmdLine = Cmd.toString(); + int exit_code = system(CmdLine.c_str()); + if (WIFEXITED(exit_code)) return WEXITSTATUS(exit_code); + return exit_code; + +} + +void DiscardOutput(int Fd) { + + FILE *Temp = fopen("/dev/null", "w"); + if (!Temp) return; + dup2(fileno(Temp), Fd); + fclose(Temp); + +} + +} // namespace fuzzer + +#endif + diff --git a/custom_mutators/libfuzzer/FuzzerUtilPosix.cpp b/custom_mutators/libfuzzer/FuzzerUtilPosix.cpp new file mode 100644 index 00000000..372bfa5e --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerUtilPosix.cpp @@ -0,0 +1,239 @@ +//===- FuzzerUtilPosix.cpp - Misc utils for Posix. ------------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Misc utils implementation using Posix API. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" +#if LIBFUZZER_POSIX + #include "FuzzerIO.h" + #include "FuzzerInternal.h" + #include "FuzzerTracePC.h" + #include <cassert> + #include <chrono> + #include <cstring> + #include <errno.h> + #include <iomanip> + #include <signal.h> + #include <stdio.h> + #include <sys/mman.h> + #include <sys/resource.h> + #include <sys/syscall.h> + #include <sys/time.h> + #include <sys/types.h> + #include <thread> + #include <unistd.h> + +namespace fuzzer { + +static void AlarmHandler(int, siginfo_t *, void *) { + + Fuzzer::StaticAlarmCallback(); + +} + +static void (*upstream_segv_handler)(int, siginfo_t *, void *); + +static void SegvHandler(int sig, siginfo_t *si, void *ucontext) { + + assert(si->si_signo == SIGSEGV); + if (upstream_segv_handler) return upstream_segv_handler(sig, si, ucontext); + Fuzzer::StaticCrashSignalCallback(); + +} + +static void CrashHandler(int, siginfo_t *, void *) { + + Fuzzer::StaticCrashSignalCallback(); + +} + +static void InterruptHandler(int, siginfo_t *, void *) { + + Fuzzer::StaticInterruptCallback(); + +} + +static void GracefulExitHandler(int, siginfo_t *, void *) { + + Fuzzer::StaticGracefulExitCallback(); + +} + +static void FileSizeExceedHandler(int, siginfo_t *, void *) { + + Fuzzer::StaticFileSizeExceedCallback(); + +} + +static void SetSigaction(int signum, + void (*callback)(int, siginfo_t *, void *)) { + + struct sigaction sigact = {}; + if (sigaction(signum, nullptr, &sigact)) { + + Printf("libFuzzer: sigaction failed with %d\n", errno); + exit(1); + + } + + if (sigact.sa_flags & SA_SIGINFO) { + + if (sigact.sa_sigaction) { + + if (signum != SIGSEGV) return; + upstream_segv_handler = sigact.sa_sigaction; + + } + + } else { + + if (sigact.sa_handler != SIG_DFL && sigact.sa_handler != SIG_IGN && + sigact.sa_handler != SIG_ERR) + return; + + } + + sigact = {}; + sigact.sa_flags = SA_SIGINFO; + sigact.sa_sigaction = callback; + if (sigaction(signum, &sigact, 0)) { + + Printf("libFuzzer: sigaction failed with %d\n", errno); + exit(1); + + } + +} + +// Return true on success, false otherwise. +bool ExecuteCommand(const Command &Cmd, std::string *CmdOutput) { + + FILE *Pipe = popen(Cmd.toString().c_str(), "r"); + if (!Pipe) return false; + + if (CmdOutput) { + + char TmpBuffer[128]; + while (fgets(TmpBuffer, sizeof(TmpBuffer), Pipe)) + CmdOutput->append(TmpBuffer); + + } + + return pclose(Pipe) == 0; + +} + +void SetTimer(int Seconds) { + + struct itimerval T { + + {Seconds, 0}, { + + Seconds, 0 + + } + + }; + + if (setitimer(ITIMER_REAL, &T, nullptr)) { + + Printf("libFuzzer: setitimer failed with %d\n", errno); + exit(1); + + } + + SetSigaction(SIGALRM, AlarmHandler); + +} + +void SetSignalHandler(const FuzzingOptions &Options) { + + // setitimer is not implemented in emscripten. + if (Options.HandleAlrm && Options.UnitTimeoutSec > 0 && !LIBFUZZER_EMSCRIPTEN) + SetTimer(Options.UnitTimeoutSec / 2 + 1); + if (Options.HandleInt) SetSigaction(SIGINT, InterruptHandler); + if (Options.HandleTerm) SetSigaction(SIGTERM, InterruptHandler); + if (Options.HandleSegv) SetSigaction(SIGSEGV, SegvHandler); + if (Options.HandleBus) SetSigaction(SIGBUS, CrashHandler); + if (Options.HandleAbrt) SetSigaction(SIGABRT, CrashHandler); + if (Options.HandleIll) SetSigaction(SIGILL, CrashHandler); + if (Options.HandleFpe) SetSigaction(SIGFPE, CrashHandler); + if (Options.HandleXfsz) SetSigaction(SIGXFSZ, FileSizeExceedHandler); + if (Options.HandleUsr1) SetSigaction(SIGUSR1, GracefulExitHandler); + if (Options.HandleUsr2) SetSigaction(SIGUSR2, GracefulExitHandler); + +} + +void SleepSeconds(int Seconds) { + + sleep(Seconds); // Use C API to avoid coverage from instrumented libc++. + +} + +unsigned long GetPid() { + + return (unsigned long)getpid(); + +} + +size_t GetPeakRSSMb() { + + struct rusage usage; + if (getrusage(RUSAGE_SELF, &usage)) return 0; + if (LIBFUZZER_LINUX || LIBFUZZER_FREEBSD || LIBFUZZER_NETBSD || + LIBFUZZER_OPENBSD || LIBFUZZER_EMSCRIPTEN) { + + // ru_maxrss is in KiB + return usage.ru_maxrss >> 10; + + } else if (LIBFUZZER_APPLE) { + + // ru_maxrss is in bytes + return usage.ru_maxrss >> 20; + + } + + assert(0 && "GetPeakRSSMb() is not implemented for your platform"); + return 0; + +} + +FILE *OpenProcessPipe(const char *Command, const char *Mode) { + + return popen(Command, Mode); + +} + +int CloseProcessPipe(FILE *F) { + + return pclose(F); + +} + +const void *SearchMemory(const void *Data, size_t DataLen, const void *Patt, + size_t PattLen) { + + return memmem(Data, DataLen, Patt, PattLen); + +} + +std::string DisassembleCmd(const std::string &FileName) { + + return "objdump -d " + FileName; + +} + +std::string SearchRegexCmd(const std::string &Regex) { + + return "grep '" + Regex + "'"; + +} + +} // namespace fuzzer + +#endif // LIBFUZZER_POSIX + diff --git a/custom_mutators/libfuzzer/FuzzerUtilWindows.cpp b/custom_mutators/libfuzzer/FuzzerUtilWindows.cpp new file mode 100644 index 00000000..dca5630f --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerUtilWindows.cpp @@ -0,0 +1,279 @@ +//===- FuzzerUtilWindows.cpp - Misc utils for Windows. --------------------===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// Misc utils implementation for Windows. +//===----------------------------------------------------------------------===// +#include "FuzzerPlatform.h" +#if LIBFUZZER_WINDOWS + #include "FuzzerCommand.h" + #include "FuzzerIO.h" + #include "FuzzerInternal.h" + #include <cassert> + #include <chrono> + #include <cstring> + #include <errno.h> + #include <io.h> + #include <iomanip> + #include <signal.h> + #include <stdio.h> + #include <sys/types.h> + #include <windows.h> + + // This must be included after windows.h. + #include <psapi.h> + +namespace fuzzer { + +static const FuzzingOptions *HandlerOpt = nullptr; + +static LONG CALLBACK ExceptionHandler(PEXCEPTION_POINTERS ExceptionInfo) { + + switch (ExceptionInfo->ExceptionRecord->ExceptionCode) { + + case EXCEPTION_ACCESS_VIOLATION: + case EXCEPTION_ARRAY_BOUNDS_EXCEEDED: + case EXCEPTION_STACK_OVERFLOW: + if (HandlerOpt->HandleSegv) Fuzzer::StaticCrashSignalCallback(); + break; + case EXCEPTION_DATATYPE_MISALIGNMENT: + case EXCEPTION_IN_PAGE_ERROR: + if (HandlerOpt->HandleBus) Fuzzer::StaticCrashSignalCallback(); + break; + case EXCEPTION_ILLEGAL_INSTRUCTION: + case EXCEPTION_PRIV_INSTRUCTION: + if (HandlerOpt->HandleIll) Fuzzer::StaticCrashSignalCallback(); + break; + case EXCEPTION_FLT_DENORMAL_OPERAND: + case EXCEPTION_FLT_DIVIDE_BY_ZERO: + case EXCEPTION_FLT_INEXACT_RESULT: + case EXCEPTION_FLT_INVALID_OPERATION: + case EXCEPTION_FLT_OVERFLOW: + case EXCEPTION_FLT_STACK_CHECK: + case EXCEPTION_FLT_UNDERFLOW: + case EXCEPTION_INT_DIVIDE_BY_ZERO: + case EXCEPTION_INT_OVERFLOW: + if (HandlerOpt->HandleFpe) Fuzzer::StaticCrashSignalCallback(); + break; + // TODO: handle (Options.HandleXfsz) + + } + + return EXCEPTION_CONTINUE_SEARCH; + +} + +BOOL WINAPI CtrlHandler(DWORD dwCtrlType) { + + switch (dwCtrlType) { + + case CTRL_C_EVENT: + if (HandlerOpt->HandleInt) Fuzzer::StaticInterruptCallback(); + return TRUE; + case CTRL_BREAK_EVENT: + if (HandlerOpt->HandleTerm) Fuzzer::StaticInterruptCallback(); + return TRUE; + + } + + return FALSE; + +} + +void CALLBACK AlarmHandler(PVOID, BOOLEAN) { + + Fuzzer::StaticAlarmCallback(); + +} + +class TimerQ { + + HANDLE TimerQueue; + + public: + TimerQ() : TimerQueue(NULL) { + + } + + ~TimerQ() { + + if (TimerQueue) DeleteTimerQueueEx(TimerQueue, NULL); + + } + + void SetTimer(int Seconds) { + + if (!TimerQueue) { + + TimerQueue = CreateTimerQueue(); + if (!TimerQueue) { + + Printf("libFuzzer: CreateTimerQueue failed.\n"); + exit(1); + + } + + } + + HANDLE Timer; + if (!CreateTimerQueueTimer(&Timer, TimerQueue, AlarmHandler, NULL, + Seconds * 1000, Seconds * 1000, 0)) { + + Printf("libFuzzer: CreateTimerQueueTimer failed.\n"); + exit(1); + + } + + } + +}; + +static TimerQ Timer; + +static void CrashHandler(int) { + + Fuzzer::StaticCrashSignalCallback(); + +} + +void SetSignalHandler(const FuzzingOptions &Options) { + + HandlerOpt = &Options; + + if (Options.HandleAlrm && Options.UnitTimeoutSec > 0) + Timer.SetTimer(Options.UnitTimeoutSec / 2 + 1); + + if (Options.HandleInt || Options.HandleTerm) + if (!SetConsoleCtrlHandler(CtrlHandler, TRUE)) { + + DWORD LastError = GetLastError(); + Printf("libFuzzer: SetConsoleCtrlHandler failed (Error code: %lu).\n", + LastError); + exit(1); + + } + + if (Options.HandleSegv || Options.HandleBus || Options.HandleIll || + Options.HandleFpe) + SetUnhandledExceptionFilter(ExceptionHandler); + + if (Options.HandleAbrt) + if (SIG_ERR == signal(SIGABRT, CrashHandler)) { + + Printf("libFuzzer: signal failed with %d\n", errno); + exit(1); + + } + +} + +void SleepSeconds(int Seconds) { + + Sleep(Seconds * 1000); + +} + +unsigned long GetPid() { + + return GetCurrentProcessId(); + +} + +size_t GetPeakRSSMb() { + + PROCESS_MEMORY_COUNTERS info; + if (!GetProcessMemoryInfo(GetCurrentProcess(), &info, sizeof(info))) return 0; + return info.PeakWorkingSetSize >> 20; + +} + +FILE *OpenProcessPipe(const char *Command, const char *Mode) { + + return _popen(Command, Mode); + +} + +int CloseProcessPipe(FILE *F) { + + return _pclose(F); + +} + +int ExecuteCommand(const Command &Cmd) { + + std::string CmdLine = Cmd.toString(); + return system(CmdLine.c_str()); + +} + +bool ExecuteCommand(const Command &Cmd, std::string *CmdOutput) { + + FILE *Pipe = _popen(Cmd.toString().c_str(), "r"); + if (!Pipe) return false; + + if (CmdOutput) { + + char TmpBuffer[128]; + while (fgets(TmpBuffer, sizeof(TmpBuffer), Pipe)) + CmdOutput->append(TmpBuffer); + + } + + return _pclose(Pipe) == 0; + +} + +const void *SearchMemory(const void *Data, size_t DataLen, const void *Patt, + size_t PattLen) { + + // TODO: make this implementation more efficient. + const char *Cdata = (const char *)Data; + const char *Cpatt = (const char *)Patt; + + if (!Data || !Patt || DataLen == 0 || PattLen == 0 || DataLen < PattLen) + return NULL; + + if (PattLen == 1) return memchr(Data, *Cpatt, DataLen); + + const char *End = Cdata + DataLen - PattLen + 1; + + for (const char *It = Cdata; It < End; ++It) + if (It[0] == Cpatt[0] && memcmp(It, Cpatt, PattLen) == 0) return It; + + return NULL; + +} + +std::string DisassembleCmd(const std::string &FileName) { + + Vector<std::string> command_vector; + command_vector.push_back("dumpbin /summary > nul"); + if (ExecuteCommand(Command(command_vector)) == 0) + return "dumpbin /disasm " + FileName; + Printf("libFuzzer: couldn't find tool to disassemble (dumpbin)\n"); + exit(1); + +} + +std::string SearchRegexCmd(const std::string &Regex) { + + return "findstr /r \"" + Regex + "\""; + +} + +void DiscardOutput(int Fd) { + + FILE *Temp = fopen("nul", "w"); + if (!Temp) return; + _dup2(_fileno(Temp), Fd); + fclose(Temp); + +} + +} // namespace fuzzer + +#endif // LIBFUZZER_WINDOWS + diff --git a/custom_mutators/libfuzzer/FuzzerValueBitMap.h b/custom_mutators/libfuzzer/FuzzerValueBitMap.h new file mode 100644 index 00000000..ddbfe200 --- /dev/null +++ b/custom_mutators/libfuzzer/FuzzerValueBitMap.h @@ -0,0 +1,73 @@ +//===- FuzzerValueBitMap.h - INTERNAL - Bit map -----------------*- C++ -* ===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// ValueBitMap. +//===----------------------------------------------------------------------===// + +#ifndef LLVM_FUZZER_VALUE_BIT_MAP_H +#define LLVM_FUZZER_VALUE_BIT_MAP_H + +#include "FuzzerPlatform.h" +#include <cstdint> + +namespace fuzzer { + +// A bit map containing kMapSizeInWords bits. +struct ValueBitMap { + static const size_t kMapSizeInBits = 1 << 16; + static const size_t kMapPrimeMod = 65371; // Largest Prime < kMapSizeInBits; + static const size_t kBitsInWord = (sizeof(uintptr_t) * 8); + static const size_t kMapSizeInWords = kMapSizeInBits / kBitsInWord; + public: + + // Clears all bits. + void Reset() { memset(Map, 0, sizeof(Map)); } + + // Computes a hash function of Value and sets the corresponding bit. + // Returns true if the bit was changed from 0 to 1. + ATTRIBUTE_NO_SANITIZE_ALL + inline bool AddValue(uintptr_t Value) { + uintptr_t Idx = Value % kMapSizeInBits; + uintptr_t WordIdx = Idx / kBitsInWord; + uintptr_t BitIdx = Idx % kBitsInWord; + uintptr_t Old = Map[WordIdx]; + uintptr_t New = Old | (1ULL << BitIdx); + Map[WordIdx] = New; + return New != Old; + } + + ATTRIBUTE_NO_SANITIZE_ALL + inline bool AddValueModPrime(uintptr_t Value) { + return AddValue(Value % kMapPrimeMod); + } + + inline bool Get(uintptr_t Idx) { + assert(Idx < kMapSizeInBits); + uintptr_t WordIdx = Idx / kBitsInWord; + uintptr_t BitIdx = Idx % kBitsInWord; + return Map[WordIdx] & (1ULL << BitIdx); + } + + size_t SizeInBits() const { return kMapSizeInBits; } + + template <class Callback> + ATTRIBUTE_NO_SANITIZE_ALL + void ForEach(Callback CB) const { + for (size_t i = 0; i < kMapSizeInWords; i++) + if (uintptr_t M = Map[i]) + for (size_t j = 0; j < sizeof(M) * 8; j++) + if (M & ((uintptr_t)1 << j)) + CB(i * sizeof(M) * 8 + j); + } + + private: + ATTRIBUTE_ALIGNED(512) uintptr_t Map[kMapSizeInWords]; +}; + +} // namespace fuzzer + +#endif // LLVM_FUZZER_VALUE_BIT_MAP_H diff --git a/custom_mutators/libfuzzer/Makefile b/custom_mutators/libfuzzer/Makefile new file mode 100644 index 00000000..51263b89 --- /dev/null +++ b/custom_mutators/libfuzzer/Makefile @@ -0,0 +1,86 @@ + +CFLAGS = -g -O3 -funroll-loops -fPIC -fpermissive -std=c++11 +#CFLAGS = -g -O0 -fPIC -fpermissive -std=c++11 +CXX ?= clang++ + +ifdef INTROSPECTION + $(info Compiling with introspection documentation) + CFLAGS += -DINTROSPECTION=1 +endif + +all: libfuzzer-mutator.so + +FuzzerCrossOver.o: FuzzerCrossOver.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerDataFlowTrace.o: FuzzerDataFlowTrace.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerDriver.o: FuzzerDriver.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerExtFunctionsDlsym.o: FuzzerExtFunctionsDlsym.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerExtFunctionsWeak.o: FuzzerExtFunctionsWeak.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerExtFunctionsWindows.o: FuzzerExtFunctionsWindows.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerExtraCounters.o: FuzzerExtraCounters.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerFork.o: FuzzerFork.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerIO.o: FuzzerIO.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerIOPosix.o: FuzzerIOPosix.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerIOWindows.o: FuzzerIOWindows.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerLoop.o: FuzzerLoop.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerMerge.o: FuzzerMerge.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerMutate.o: FuzzerMutate.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerSHA1.o: FuzzerSHA1.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerTracePC.o: FuzzerTracePC.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerUtil.o: FuzzerUtil.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerUtilDarwin.o: FuzzerUtilDarwin.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerUtilFuchsia.o: FuzzerUtilFuchsia.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerUtilLinux.o: FuzzerUtilLinux.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerUtilPosix.o: FuzzerUtilPosix.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +FuzzerUtilWindows.o: FuzzerUtilWindows.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +libfuzzer.o: libfuzzer.cpp + $(CXX) $(CFLAGS) -I../../include -I. -c $^ + +libfuzzer-mutator.so: FuzzerCrossOver.o FuzzerDataFlowTrace.o FuzzerDriver.o FuzzerExtFunctionsDlsym.o FuzzerExtFunctionsWeak.o FuzzerExtFunctionsWindows.o FuzzerExtraCounters.o FuzzerFork.o FuzzerIO.o FuzzerIOPosix.o FuzzerIOWindows.o FuzzerLoop.o FuzzerMerge.o FuzzerMutate.o FuzzerSHA1.o FuzzerTracePC.o FuzzerUtil.o FuzzerUtilDarwin.o FuzzerUtilFuchsia.o FuzzerUtilLinux.o FuzzerUtilPosix.o FuzzerUtilWindows.o libfuzzer.o + $(CXX) $(CFLAGS) -I../../include -I. -shared -o libfuzzer-mutator.so *.o + +clean: + rm -f *.o *~ *.so core diff --git a/custom_mutators/libfuzzer/README.md b/custom_mutators/libfuzzer/README.md new file mode 100644 index 00000000..fb3025f2 --- /dev/null +++ b/custom_mutators/libfuzzer/README.md @@ -0,0 +1,24 @@ +# custum mutator: libfuzzer LLVMFuzzerMutate() + +This uses the libfuzzer LLVMFuzzerMutate() function in llvm 12. + +just type `make` to build + +```AFL_CUSTOM_MUTATOR_LIBRARY=custom_mutators/libfuzzer/libfuzzer-mutator.so afl-fuzz ...``` + +Note that this is currently a simple implementation and it is missing two features: + * Splicing ("Crossover") + * Dictionary support + +To update the source, all that is needed is that FuzzerDriver.cpp has to receive +``` +#include "libfuzzer.inc" +``` +before the closing namespace bracket. + +It is also libfuzzer.inc where the configuration of the libfuzzer mutations +are done. + +> Original repository: https://github.com/llvm/llvm-project +> Path: compiler-rt/lib/fuzzer/*.{h|cpp} +> Source commit: df3e903655e2499968fc7af64fb5fa52b2ee79bb diff --git a/custom_mutators/libfuzzer/libfuzzer.cpp b/custom_mutators/libfuzzer/libfuzzer.cpp new file mode 100644 index 00000000..dc1fbeb2 --- /dev/null +++ b/custom_mutators/libfuzzer/libfuzzer.cpp @@ -0,0 +1,160 @@ +#include <stdio.h> +#include <stdint.h> +#include <stdlib.h> +#include <string.h> +//#include "config.h" +//#include "debug.h" +#include "afl-fuzz.h" + +#ifdef INTROSPECTION + const char *introspection_ptr; +#endif + +afl_state_t *afl_struct; + +extern "C" size_t LLVMFuzzerMutate(uint8_t *Data, size_t Size, size_t MaxSize); +extern "C" int LLVMFuzzerRunDriver(int *argc, char ***argv, + int (*UserCb)(const uint8_t *Data, + size_t Size)); +extern "C" void LLVMFuzzerMyInit(int (*UserCb)(const uint8_t *Data, + size_t Size), + unsigned int Seed); + +typedef struct my_mutator { + + afl_state_t *afl; + u8 * mutator_buf; + unsigned int seed; + unsigned int extras_cnt, a_extras_cnt; + +} my_mutator_t; + +extern "C" int dummy(const uint8_t *Data, size_t Size) { + + (void)(Data); + (void)(Size); + fprintf(stderr, "dummy() called\n"); + return 0; + +} + +extern "C" my_mutator_t *afl_custom_init(afl_state_t *afl, unsigned int seed) { + + my_mutator_t *data = (my_mutator_t *)calloc(1, sizeof(my_mutator_t)); + if (!data) { + + perror("afl_custom_init alloc"); + return NULL; + + } + + if ((data->mutator_buf = (u8 *)malloc(MAX_FILE)) == NULL) { + + free(data); + perror("mutator_buf alloc"); + return NULL; + + } + + data->afl = afl; + data->seed = seed; + afl_struct = afl; + + /* + char **argv; + argv = (char**)malloc(sizeof(size_t) * 2); + argv[0] = (char*)"foo"; + argv[1] = NULL; + int eins = 1; + LLVMFuzzerRunDriver(&eins, &argv, dummy); + */ + + LLVMFuzzerMyInit(dummy, seed); + + return data; + +} + +/* When a new queue entry is added we check if there are new dictionary + entries to add to honggfuzz structure */ +#if 0 +extern "C" void afl_custom_queue_new_entry(my_mutator_t * data, + const uint8_t *filename_new_queue, + const uint8_t *filename_orig_queue) { + + while (data->extras_cnt < afl_struct->extras_cnt) { + + /* + memcpy(run.global->mutate.dictionary[run.global->mutate.dictionaryCnt].val, + afl_struct->extras[data->extras_cnt].data, + afl_struct->extras[data->extras_cnt].len); + run.global->mutate.dictionary[run.global->mutate.dictionaryCnt].len = + afl_struct->extras[data->extras_cnt].len; + run.global->mutate.dictionaryCnt++; + */ + data->extras_cnt++; + + } + + while (data->a_extras_cnt < afl_struct->a_extras_cnt) { + + /* + memcpy(run.global->mutate.dictionary[run.global->mutate.dictionaryCnt].val, + afl_struct->a_extras[data->a_extras_cnt].data, + afl_struct->a_extras[data->a_extras_cnt].len); + run.global->mutate.dictionary[run.global->mutate.dictionaryCnt].len = + afl_struct->a_extras[data->a_extras_cnt].len; + run.global->mutate.dictionaryCnt++; + data->a_extras_cnt++; + */ + + } + +} + +#endif +/* we could set only_printable if is_ascii is set ... let's see +uint8_t afl_custom_queue_get(void *data, const uint8_t *filename) { + + //run.global->cfg.only_printable = ... + +} + +*/ + +/* here we run the honggfuzz mutator, which is really good */ + +extern "C" size_t afl_custom_fuzz(my_mutator_t *data, uint8_t *buf, + size_t buf_size, u8 **out_buf, + uint8_t *add_buf, size_t add_buf_size, + size_t max_size) { + + memcpy(data->mutator_buf, buf, buf_size); + size_t ret = LLVMFuzzerMutate(data->mutator_buf, buf_size, max_size); + + /* return size of mutated data */ + *out_buf = data->mutator_buf; + return ret; + +} + +#ifdef INTROSPECTION +extern "C" const char* afl_custom_introspection(my_mutator_t *data) { + + return introspection_ptr; + +} +#endif + +/** + * Deinitialize everything + * + * @param data The data ptr from afl_custom_init + */ +extern "C" void afl_custom_deinit(my_mutator_t *data) { + + free(data->mutator_buf); + free(data); + +} + diff --git a/custom_mutators/libfuzzer/libfuzzer.inc b/custom_mutators/libfuzzer/libfuzzer.inc new file mode 100644 index 00000000..01f21dbe --- /dev/null +++ b/custom_mutators/libfuzzer/libfuzzer.inc @@ -0,0 +1,36 @@ + + +extern "C" ATTRIBUTE_INTERFACE void +LLVMFuzzerMyInit(int (*Callback)(const uint8_t *Data, size_t Size), unsigned int Seed) { + Random Rand(Seed); + FuzzingOptions Options; + Options.Verbosity = 3; + Options.MaxLen = 1024000; + Options.LenControl = true; + Options.DoCrossOver = false; + Options.MutateDepth = 6; + Options.UseCounters = false; + Options.UseMemmem = false; + Options.UseCmp = false; + Options.UseValueProfile = false; + Options.Shrink = false; + Options.ReduceInputs = false; + Options.PreferSmall = false; + Options.ReloadIntervalSec = 0; + Options.OnlyASCII = false; + Options.DetectLeaks = false; + Options.PurgeAllocatorIntervalSec = 0; + Options.TraceMalloc = false; + Options.RssLimitMb = 100; + Options.MallocLimitMb = 100; + Options.MaxNumberOfRuns = 0; + Options.ReportSlowUnits = false; + Options.Entropic = false; + + struct EntropicOptions Entropic; + Entropic.Enabled = Options.Entropic; + EF = new ExternalFunctions(); + auto *MD = new MutationDispatcher(Rand, Options); + auto *Corpus = new InputCorpus(Options.OutputCorpus, Entropic); + auto *F = new Fuzzer(Callback, *Corpus, *MD, Options); +} diff --git a/custom_mutators/libprotobuf-mutator-example/Android.bp b/custom_mutators/libprotobuf-mutator-example/Android.bp new file mode 100644 index 00000000..01f1c23e --- /dev/null +++ b/custom_mutators/libprotobuf-mutator-example/Android.bp @@ -0,0 +1,32 @@ +cc_library_shared { + name: "libprotobuf-mutator-example-afl", + vendor_available: true, + host_supported: true, + + cflags: [ + "-g", + "-O0", + "-fPIC", + "-Wall", + ], + + srcs: [ + "lpm_aflpp_custom_mutator_input.cc", + "test.proto", + ], + + shared_libs: [ + "libprotobuf-cpp-full", + "libprotobuf-mutator", + ], +} + +cc_binary { + name: "libprotobuf-mutator-vuln", + vendor_available: true, + host_supported: true, + + srcs: [ + "vuln.c", + ], +} diff --git a/custom_mutators/libprotobuf-mutator-example/README.md b/custom_mutators/libprotobuf-mutator-example/README.md new file mode 100644 index 00000000..5a844c00 --- /dev/null +++ b/custom_mutators/libprotobuf-mutator-example/README.md @@ -0,0 +1 @@ +Ported from [https://github.com/bruce30262/libprotobuf-mutator_fuzzing_learning/tree/master/5_libprotobuf_aflpp_custom_mutator_input](https://github.com/bruce30262/libprotobuf-mutator_fuzzing_learning/tree/master/5_libprotobuf_aflpp_custom_mutator_input) diff --git a/custom_mutators/libprotobuf-mutator-example/lpm_aflpp_custom_mutator_input.cc b/custom_mutators/libprotobuf-mutator-example/lpm_aflpp_custom_mutator_input.cc new file mode 100644 index 00000000..e0273849 --- /dev/null +++ b/custom_mutators/libprotobuf-mutator-example/lpm_aflpp_custom_mutator_input.cc @@ -0,0 +1,118 @@ +#include "lpm_aflpp_custom_mutator_input.h" +#include <iostream> +#include <sstream> +#include <fstream> + +using std::cin; +using std::cout; +using std::endl; + +std::string ProtoToData(const TEST &test_proto) { + std::stringstream all; + const auto &aa = test_proto.a(); + const auto &bb = test_proto.b(); + all.write((const char*)&aa, sizeof(aa)); + if(bb.size() != 0) { + all.write(bb.c_str(), bb.size()); + } + + std::string res = all.str(); + if (bb.size() != 0 && res.size() != 0) { + // set PROTO_FUZZER_DUMP_PATH env to dump the serialized protobuf + if (const char *dump_path = getenv("PROTO_FUZZER_DUMP_PATH")) { + std::ofstream of(dump_path); + of.write(res.data(), res.size()); + } + } + return res; +} + +/** + * Initialize this custom mutator + * + * @param[in] afl a pointer to the internal state object. Can be ignored for + * now. + * @param[in] seed A seed for this mutator - the same seed should always mutate + * in the same way. + * @return Pointer to the data object this custom mutator instance should use. + * There may be multiple instances of this mutator in one afl-fuzz run! + * Return NULL on error. + */ +extern "C" MyMutator *afl_custom_init(void *afl, unsigned int seed) { + MyMutator *mutator = new MyMutator(); + + mutator->RegisterPostProcessor( + TEST::descriptor(), + [](google::protobuf::Message* message, unsigned int seed) { + // libprotobuf-mutator's built-in mutator is kind of....crappy :P + // Even a dumb fuzz like `TEST.a = rand();` is better in this case... Q_Q + // We register a post processor to apply our dumb fuzz + + TEST *t = static_cast<TEST *>(message); + t->set_a(rand()); + }); + + srand(seed); + return mutator; +} + +/** + * Perform custom mutations on a given input + * + * @param[in] data pointer returned in afl_custom_init for this fuzz case + * @param[in] buf Pointer to input data to be mutated + * @param[in] buf_size Size of input data + * @param[out] out_buf the buffer we will work on. we can reuse *buf. NULL on + * error. + * @param[in] add_buf Buffer containing the additional test case + * @param[in] add_buf_size Size of the additional test case + * @param[in] max_size Maximum size of the mutated output. The mutation must not + * produce data larger than max_size. + * @return Size of the mutated output. + */ +extern "C" size_t afl_custom_fuzz(MyMutator *mutator, // return value from afl_custom_init + uint8_t *buf, size_t buf_size, // input data to be mutated + uint8_t **out_buf, // output buffer + uint8_t *add_buf, size_t add_buf_size, // add_buf can be NULL + size_t max_size) { + // This function can be named either "afl_custom_fuzz" or "afl_custom_mutator" + // A simple test shows that "buf" will be the content of the current test case + // "add_buf" will be the next test case ( from AFL++'s input queue ) + + TEST input; + // parse input data to TEST + // Notice that input data should be a serialized protobuf data + // Check ./in/ii and test_protobuf_serializer for more detail + bool parse_ok = input.ParseFromArray(buf, buf_size); + if(!parse_ok) { + // Invalid serialize protobuf data. Don't mutate. + // Return a dummy buffer. Also mutated_size = 0 + static uint8_t *dummy = new uint8_t[10]; // dummy buffer with no data + *out_buf = dummy; + return 0; + } + // mutate the protobuf + mutator->Mutate(&input, max_size); + + // Convert protobuf to raw data + const TEST *p = &input; + std::string s = ProtoToData(*p); + // Copy to a new buffer ( mutated_out ) + size_t mutated_size = s.size() <= max_size ? s.size() : max_size; // check if raw data's size is larger than max_size + uint8_t *mutated_out = new uint8_t[mutated_size+1]; + memcpy(mutated_out, s.c_str(), mutated_size); // copy the mutated data + // Assign the mutated data and return mutated_size + *out_buf = mutated_out; + return mutated_size; +} + +/** + * Deinitialize everything + * + * @param data The data ptr from afl_custom_init + */ +extern "C" void afl_custom_deinit(void *data) { + // Honestly I don't know what to do with this... + return; +} + diff --git a/custom_mutators/libprotobuf-mutator-example/lpm_aflpp_custom_mutator_input.h b/custom_mutators/libprotobuf-mutator-example/lpm_aflpp_custom_mutator_input.h new file mode 100644 index 00000000..ebd3ca65 --- /dev/null +++ b/custom_mutators/libprotobuf-mutator-example/lpm_aflpp_custom_mutator_input.h @@ -0,0 +1,5 @@ +#include <src/mutator.h> +#include "test.pb.h" + +class MyMutator : public protobuf_mutator::Mutator { +}; diff --git a/custom_mutators/libprotobuf-mutator-example/test.proto b/custom_mutators/libprotobuf-mutator-example/test.proto new file mode 100644 index 00000000..e2256c6e --- /dev/null +++ b/custom_mutators/libprotobuf-mutator-example/test.proto @@ -0,0 +1,7 @@ +syntax = "proto2"; + +message TEST { + required uint32 a = 1; + required string b = 2; +} + diff --git a/custom_mutators/libprotobuf-mutator-example/vuln.c b/custom_mutators/libprotobuf-mutator-example/vuln.c new file mode 100644 index 00000000..8ffb7080 --- /dev/null +++ b/custom_mutators/libprotobuf-mutator-example/vuln.c @@ -0,0 +1,17 @@ +#include <stdio.h> +#include <string.h> +#include <math.h> +#include <stdlib.h> +#include <unistd.h> + +int main(int argc, char *argv[]) +{ + char str[100]={}; + read(0, str, 100); + int *ptr = NULL; + if( str[0] == '\x02' || str[0] == '\xe8') { + *ptr = 123; + } + return 0; +} + diff --git a/custom_mutators/radamsa/GNUmakefile b/custom_mutators/radamsa/GNUmakefile index 60e43b17..3798b110 100644 --- a/custom_mutators/radamsa/GNUmakefile +++ b/custom_mutators/radamsa/GNUmakefile @@ -15,14 +15,14 @@ libradamsa.a: libradamsa.c radamsa.h @echo " ***************************************************************" @echo " * Compiling libradamsa, wait some minutes (~3 on modern CPUs) *" @echo " ***************************************************************" - $(CC) -fPIC $(CFLAGS) -I $(CUR_DIR) -o libradamsa.a -c libradamsa.c + $(CC) -fPIC $(CFLAGS) $(CPPFLAGS) -I $(CUR_DIR) -o libradamsa.a -c libradamsa.c radamsa-mutator.so: radamsa-mutator.c libradamsa.a - $(CC) $(CFLAGS) -g -I. -I../../include -shared -fPIC -c radamsa-mutator.c - $(CC) $(CFLAGS) -shared -fPIC -o radamsa-mutator.so radamsa-mutator.o libradamsa.a + $(CC) $(CFLAGS) $(CPPFLAGS) -g -I. -I../../include -shared -fPIC -c radamsa-mutator.c + $(CC) $(CFLAGS) $(CPPFLAGS) -shared -fPIC -o radamsa-mutator.so radamsa-mutator.o libradamsa.a test: libradamsa.a libradamsa-test.c - $(CC) $(CFLAGS) -I $(CUR_DIR) -o libradamsa-test libradamsa-test.c libradamsa.a + $(CC) $(CFLAGS) $(CPPFLAGS) -I $(CUR_DIR) -o libradamsa-test libradamsa-test.c libradamsa.a ./libradamsa-test libradamsa-test.c | grep "library test passed" rm /tmp/libradamsa-*.fuzz diff --git a/custom_mutators/radamsa/custom_mutator_helpers.h b/custom_mutators/radamsa/custom_mutator_helpers.h index 0848321f..e23c0b6a 100644 --- a/custom_mutators/radamsa/custom_mutator_helpers.h +++ b/custom_mutators/radamsa/custom_mutator_helpers.h @@ -324,7 +324,7 @@ static inline void *maybe_grow(void **buf, size_t *size, size_t size_needed) { } /* Swaps buf1 ptr and buf2 ptr, as well as their sizes */ -static inline void swap_bufs(void **buf1, size_t *size1, void **buf2, +static inline void afl_swap_bufs(void **buf1, size_t *size1, void **buf2, size_t *size2) { void * scratch_buf = *buf1; diff --git a/custom_mutators/radamsa/radamsa-mutator.c b/custom_mutators/radamsa/radamsa-mutator.c index 82d28001..624ace3d 100644 --- a/custom_mutators/radamsa/radamsa-mutator.c +++ b/custom_mutators/radamsa/radamsa-mutator.c @@ -33,6 +33,7 @@ my_mutator_t *afl_custom_init(afl_t *afl, unsigned int seed) { if ((data->mutator_buf = malloc(MAX_FILE)) == NULL) { + free(data); perror("mutator_buf alloc"); return NULL; diff --git a/custom_mutators/rust/.gitignore b/custom_mutators/rust/.gitignore new file mode 100644 index 00000000..088ba6ba --- /dev/null +++ b/custom_mutators/rust/.gitignore @@ -0,0 +1,10 @@ +# Generated by Cargo +# will have compiled files and executables +/target/ + +# Remove Cargo.lock from gitignore if creating an executable, leave it for libraries +# More information here https://doc.rust-lang.org/cargo/guide/cargo-toml-vs-cargo-lock.html +Cargo.lock + +# These are backup files generated by rustfmt +**/*.rs.bk diff --git a/custom_mutators/rust/Cargo.toml b/custom_mutators/rust/Cargo.toml new file mode 100644 index 00000000..e36d24b5 --- /dev/null +++ b/custom_mutators/rust/Cargo.toml @@ -0,0 +1,8 @@ +[workspace] +members = [ + "custom_mutator-sys", + "custom_mutator", + "example", + # Lain needs a nightly toolchain + # "example_lain", +]
\ No newline at end of file diff --git a/custom_mutators/rust/README.md b/custom_mutators/rust/README.md new file mode 100644 index 00000000..e2cc38b4 --- /dev/null +++ b/custom_mutators/rust/README.md @@ -0,0 +1,11 @@ +# Rust Custom Mutators + +Bindings to create custom mutators in Rust. + +These bindings are documented with rustdoc. To view the documentation run +```cargo doc -p custom_mutator --open```. + +A minimal example can be found in `example`. Build it using `cargo build --example example_mutator`. + +An example using [lain](https://github.com/microsoft/lain) for structured fuzzing can be found in `example_lain`. +Since lain requires a nightly rust toolchain, you need to set one up before you can play with it. diff --git a/custom_mutators/rust/custom_mutator-sys/Cargo.toml b/custom_mutators/rust/custom_mutator-sys/Cargo.toml new file mode 100644 index 00000000..104f7df0 --- /dev/null +++ b/custom_mutators/rust/custom_mutator-sys/Cargo.toml @@ -0,0 +1,12 @@ +[package] +name = "custom_mutator-sys" +version = "0.1.0" +authors = ["Julius Hohnerlein <julihoh@users.noreply.github.com>"] +edition = "2018" + +# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html + +[dependencies] + +[build-dependencies] +bindgen = "0.56" diff --git a/custom_mutators/rust/custom_mutator-sys/build.rs b/custom_mutators/rust/custom_mutator-sys/build.rs new file mode 100644 index 00000000..3c88a90d --- /dev/null +++ b/custom_mutators/rust/custom_mutator-sys/build.rs @@ -0,0 +1,42 @@ +extern crate bindgen; + +use std::env; +use std::path::PathBuf; + +// this code is largely taken straight from the handbook: https://github.com/fitzgen/bindgen-tutorial-bzip2-sys +fn main() { + // Tell cargo to invalidate the built crate whenever the wrapper changes + println!("cargo:rerun-if-changed=wrapper.h"); + + // The bindgen::Builder is the main entry point + // to bindgen, and lets you build up options for + // the resulting bindings. + let bindings = bindgen::Builder::default() + // The input header we would like to generate + // bindings for. + .header("wrapper.h") + .whitelist_type("afl_state_t") + .blacklist_type(r"u\d+") + .opaque_type(r"_.*") + .opaque_type("FILE") + .opaque_type("in_addr(_t)?") + .opaque_type("in_port(_t)?") + .opaque_type("sa_family(_t)?") + .opaque_type("sockaddr_in(_t)?") + .opaque_type("time_t") + .rustfmt_bindings(true) + .size_t_is_usize(true) + // Tell cargo to invalidate the built crate whenever any of the + // included header files changed. + .parse_callbacks(Box::new(bindgen::CargoCallbacks)) + // Finish the builder and generate the bindings. + .generate() + // Unwrap the Result and panic on failure. + .expect("Unable to generate bindings"); + + // Write the bindings to the $OUT_DIR/bindings.rs file. + let out_path = PathBuf::from(env::var("OUT_DIR").unwrap()); + bindings + .write_to_file(out_path.join("bindings.rs")) + .expect("Couldn't write bindings!"); +} diff --git a/custom_mutators/rust/custom_mutator-sys/src/lib.rs b/custom_mutators/rust/custom_mutator-sys/src/lib.rs new file mode 100644 index 00000000..a38a13a8 --- /dev/null +++ b/custom_mutators/rust/custom_mutator-sys/src/lib.rs @@ -0,0 +1,5 @@ +#![allow(non_upper_case_globals)] +#![allow(non_camel_case_types)] +#![allow(non_snake_case)] + +include!(concat!(env!("OUT_DIR"), "/bindings.rs")); diff --git a/custom_mutators/rust/custom_mutator-sys/wrapper.h b/custom_mutators/rust/custom_mutator-sys/wrapper.h new file mode 100644 index 00000000..81cdb90f --- /dev/null +++ b/custom_mutators/rust/custom_mutator-sys/wrapper.h @@ -0,0 +1,4 @@ +#include "../../../include/afl-fuzz.h" +#include "../../../include/common.h" +#include "../../../include/config.h" +#include "../../../include/debug.h" diff --git a/custom_mutators/rust/custom_mutator/Cargo.toml b/custom_mutators/rust/custom_mutator/Cargo.toml new file mode 100644 index 00000000..2d3cdbfa --- /dev/null +++ b/custom_mutators/rust/custom_mutator/Cargo.toml @@ -0,0 +1,13 @@ +[package] +name = "custom_mutator" +version = "0.1.0" +authors = ["Julius Hohnerlein <julihoh@users.noreply.github.com>"] +edition = "2018" + +# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html + +[features] +afl_internals = ["custom_mutator-sys"] + +[dependencies] +custom_mutator-sys = { path = "../custom_mutator-sys", optional=true } diff --git a/custom_mutators/rust/custom_mutator/src/lib.rs b/custom_mutators/rust/custom_mutator/src/lib.rs new file mode 100644 index 00000000..9444e4d1 --- /dev/null +++ b/custom_mutators/rust/custom_mutator/src/lib.rs @@ -0,0 +1,740 @@ +#![cfg(unix)] +//! Somewhat safe and somewhat ergonomic bindings for creating [AFL++](https://github.com/AFLplusplus/AFLplusplus) [custom mutators](https://github.com/AFLplusplus/AFLplusplus/blob/stable/docs/custom_mutators.md) in Rust. +//! +//! # Usage +//! AFL++ custom mutators are expected to be dynamic libraries which expose a set of symbols. +//! Check out [`CustomMutator`] to see which functions of the API are supported. +//! Then use [`export_mutator`] to export the correct symbols for your mutator. +//! In order to use the mutator, your crate needs to be a library crate and have a `crate-type` of `cdylib`. +//! Putting +//! ```yaml +//! [lib] +//! crate-type = ["cdylib"] +//! ``` +//! into your `Cargo.toml` should do the trick. +//! The final executable can be found in `target/(debug|release)/your_crate_name.so`. +//! # Example +//! See [`export_mutator`] for an example. +//! +//! # On `panic`s +//! This binding is panic-safe in that it will prevent panics from unwinding into AFL++. Any panic will `abort` at the boundary between the custom mutator and AFL++. +//! +//! # Access to AFL++ internals +//! This crate has an optional feature "afl_internals", which gives access to AFL++'s internal state. +//! The state is passed to [`CustomMutator::init`], when the feature is activated. +//! +//! _This is completely unsafe and uses automatically generated types extracted from the AFL++ source._ +use std::{fmt::Debug, path::Path}; + +#[cfg(feature = "afl_internals")] +#[doc(hidden)] +pub use custom_mutator_sys::afl_state; + +#[allow(unused_variables)] +#[doc(hidden)] +pub trait RawCustomMutator { + #[cfg(feature = "afl_internals")] + fn init(afl: &'static afl_state, seed: u32) -> Self + where + Self: Sized; + #[cfg(not(feature = "afl_internals"))] + fn init(seed: u32) -> Self + where + Self: Sized; + + fn fuzz<'b, 's: 'b>( + &'s mut self, + buffer: &'b mut [u8], + add_buff: Option<&[u8]>, + max_size: usize, + ) -> Option<&'b [u8]>; + + fn fuzz_count(&mut self, buffer: &[u8]) -> u32 { + 1 + } + + fn queue_new_entry(&mut self, filename_new_queue: &Path, _filename_orig_queue: Option<&Path>) {} + + fn queue_get(&mut self, filename: &Path) -> bool { + true + } + + fn describe(&mut self, max_description: usize) -> Option<&str> { + Some(default_mutator_describe::<Self>(max_description)) + } + + fn introspection(&mut self) -> Option<&str> { + None + } + + /*fn post_process(&self, buffer: &[u8], unsigned char **out_buf)-> usize; + int afl_custom_init_trim(&self, buffer: &[u8]); + size_t afl_custom_trim(&self, unsigned char **out_buf); + int afl_custom_post_trim(&self, unsigned char success); + size_t afl_custom_havoc_mutation(&self, buffer: &[u8], unsigned char **out_buf, size_t max_size); + unsigned char afl_custom_havoc_mutation_probability(&self);*/ +} + +/// Wrappers for the custom mutator which provide the bridging between the C API and CustomMutator. +/// These wrappers are not intended to be used directly, rather export_mutator will use them to publish the custom mutator C API. +#[doc(hidden)] +pub mod wrappers { + #[cfg(feature = "afl_internals")] + use custom_mutator_sys::afl_state; + + use std::{ + any::Any, + convert::TryInto, + ffi::{c_void, CStr, OsStr}, + mem::ManuallyDrop, + os::{raw::c_char, unix::ffi::OsStrExt}, + panic::catch_unwind, + path::Path, + process::abort, + ptr::null, + slice, + }; + + use crate::RawCustomMutator; + + /// A structure to be used as the data pointer for our custom mutator. This was used as additional storage and is kept for now in case its needed later. + /// Also has some convenience functions for FFI conversions (from and to ptr) and tries to make misuse hard (see [`FFIContext::from`]). + struct FFIContext<M: RawCustomMutator> { + mutator: M, + /// buffer for storing the description returned by [`RawCustomMutator::describe`] as a CString + description_buffer: Vec<u8>, + /// buffer for storing the introspection returned by [`RawCustomMutator::introspect`] as a CString + introspection_buffer: Vec<u8>, + } + + impl<M: RawCustomMutator> FFIContext<M> { + fn from(ptr: *mut c_void) -> ManuallyDrop<Box<Self>> { + assert!(!ptr.is_null()); + ManuallyDrop::new(unsafe { Box::from_raw(ptr as *mut Self) }) + } + + fn into_ptr(self: Box<Self>) -> *const c_void { + Box::into_raw(self) as *const c_void + } + + #[cfg(feature = "afl_internals")] + fn new(afl: &'static afl_state, seed: u32) -> Box<Self> { + Box::new(Self { + mutator: M::init(afl, seed), + description_buffer: Vec::new(), + introspection_buffer: Vec::new(), + }) + } + #[cfg(not(feature = "afl_internals"))] + fn new(seed: u32) -> Box<Self> { + Box::new(Self { + mutator: M::init(seed), + description_buffer: Vec::new(), + introspection_buffer: Vec::new(), + }) + } + } + + /// panic handler called for every panic + fn panic_handler(method: &str, panic_info: Box<dyn Any + Send + 'static>) -> ! { + use std::ops::Deref; + let cause = panic_info + .downcast_ref::<String>() + .map(String::deref) + .unwrap_or_else(|| { + panic_info + .downcast_ref::<&str>() + .copied() + .unwrap_or("<cause unknown>") + }); + eprintln!("A panic occurred at {}: {}", method, cause); + abort() + } + + /// Internal function used in the macro + #[cfg(not(feature = "afl_internals"))] + pub fn afl_custom_init_<M: RawCustomMutator>(seed: u32) -> *const c_void { + match catch_unwind(|| FFIContext::<M>::new(seed).into_ptr()) { + Ok(ret) => ret, + Err(err) => panic_handler("afl_custom_init", err), + } + } + + /// Internal function used in the macro + #[cfg(feature = "afl_internals")] + pub fn afl_custom_init_<M: RawCustomMutator>( + afl: Option<&'static afl_state>, + seed: u32, + ) -> *const c_void { + match catch_unwind(|| { + let afl = afl.expect("mutator func called with NULL afl"); + FFIContext::<M>::new(afl, seed).into_ptr() + }) { + Ok(ret) => ret, + Err(err) => panic_handler("afl_custom_init", err), + } + } + + /// Internal function used in the macro + pub unsafe fn afl_custom_fuzz_<M: RawCustomMutator>( + data: *mut c_void, + buf: *mut u8, + buf_size: usize, + out_buf: *mut *const u8, + add_buf: *mut u8, + add_buf_size: usize, + max_size: usize, + ) -> usize { + match catch_unwind(|| { + let mut context = FFIContext::<M>::from(data); + if buf.is_null() { + panic!("null buf passed to afl_custom_fuzz") + } + if out_buf.is_null() { + panic!("null out_buf passed to afl_custom_fuzz") + } + let buff_slice = slice::from_raw_parts_mut(buf, buf_size); + let add_buff_slice = if add_buf.is_null() { + None + } else { + Some(slice::from_raw_parts(add_buf, add_buf_size)) + }; + match context + .mutator + .fuzz(buff_slice, add_buff_slice, max_size.try_into().unwrap()) + { + Some(buffer) => { + *out_buf = buffer.as_ptr(); + buffer.len().try_into().unwrap() + } + None => { + // return the input buffer with 0-length to let AFL skip this mutation attempt + *out_buf = buf; + 0 + } + } + }) { + Ok(ret) => ret, + Err(err) => panic_handler("afl_custom_fuzz", err), + } + } + + /// Internal function used in the macro + pub unsafe fn afl_custom_fuzz_count_<M: RawCustomMutator>( + data: *mut c_void, + buf: *const u8, + buf_size: usize, + ) -> u32 { + match catch_unwind(|| { + let mut context = FFIContext::<M>::from(data); + if buf.is_null() { + panic!("null buf passed to afl_custom_fuzz") + } + let buf_slice = slice::from_raw_parts(buf, buf_size); + // see https://doc.rust-lang.org/nomicon/borrow-splitting.html + let ctx = &mut **context; + let mutator = &mut ctx.mutator; + mutator.fuzz_count(buf_slice) + }) { + Ok(ret) => ret, + Err(err) => panic_handler("afl_custom_fuzz_count", err), + } + } + + /// Internal function used in the macro + pub fn afl_custom_queue_new_entry_<M: RawCustomMutator>( + data: *mut c_void, + filename_new_queue: *const c_char, + filename_orig_queue: *const c_char, + ) { + match catch_unwind(|| { + let mut context = FFIContext::<M>::from(data); + if filename_new_queue.is_null() { + panic!("received null filename_new_queue in afl_custom_queue_new_entry"); + } + let filename_new_queue = Path::new(OsStr::from_bytes( + unsafe { CStr::from_ptr(filename_new_queue) }.to_bytes(), + )); + let filename_orig_queue = if !filename_orig_queue.is_null() { + Some(Path::new(OsStr::from_bytes( + unsafe { CStr::from_ptr(filename_orig_queue) }.to_bytes(), + ))) + } else { + None + }; + context + .mutator + .queue_new_entry(filename_new_queue, filename_orig_queue); + }) { + Ok(ret) => ret, + Err(err) => panic_handler("afl_custom_queue_new_entry", err), + } + } + + /// Internal function used in the macro + pub unsafe fn afl_custom_deinit_<M: RawCustomMutator>(data: *mut c_void) { + match catch_unwind(|| { + // drop the context + ManuallyDrop::into_inner(FFIContext::<M>::from(data)); + }) { + Ok(ret) => ret, + Err(err) => panic_handler("afl_custom_deinit", err), + } + } + + /// Internal function used in the macro + pub fn afl_custom_introspection_<M: RawCustomMutator>(data: *mut c_void) -> *const c_char { + match catch_unwind(|| { + let context = &mut *FFIContext::<M>::from(data); + if let Some(res) = context.mutator.introspection() { + let buf = &mut context.introspection_buffer; + buf.clear(); + buf.extend_from_slice(res.as_bytes()); + buf.push(0); + // unwrapping here, as the error case should be extremely rare + CStr::from_bytes_with_nul(&buf).unwrap().as_ptr() + } else { + null() + } + }) { + Ok(ret) => ret, + Err(err) => panic_handler("afl_custom_introspection", err), + } + } + + /// Internal function used in the macro + pub fn afl_custom_describe_<M: RawCustomMutator>( + data: *mut c_void, + max_description_len: usize, + ) -> *const c_char { + match catch_unwind(|| { + let context = &mut *FFIContext::<M>::from(data); + if let Some(res) = context.mutator.describe(max_description_len) { + let buf = &mut context.description_buffer; + buf.clear(); + buf.extend_from_slice(res.as_bytes()); + buf.push(0); + // unwrapping here, as the error case should be extremely rare + CStr::from_bytes_with_nul(&buf).unwrap().as_ptr() + } else { + null() + } + }) { + Ok(ret) => ret, + Err(err) => panic_handler("afl_custom_describe", err), + } + } + + /// Internal function used in the macro + pub fn afl_custom_queue_get_<M: RawCustomMutator>( + data: *mut c_void, + filename: *const c_char, + ) -> u8 { + match catch_unwind(|| { + let mut context = FFIContext::<M>::from(data); + assert!(!filename.is_null()); + + context.mutator.queue_get(Path::new(OsStr::from_bytes( + unsafe { CStr::from_ptr(filename) }.to_bytes(), + ))) as u8 + }) { + Ok(ret) => ret, + Err(err) => panic_handler("afl_custom_queue_get", err), + } + } +} + +/// exports the given Mutator as a custom mutator as the C interface that AFL++ expects. +/// It is not possible to call this macro multiple times, because it would define the custom mutator symbols multiple times. +/// # Example +/// ``` +/// # #[macro_use] extern crate custom_mutator; +/// # #[cfg(feature = "afl_internals")] +/// # use custom_mutator::afl_state; +/// # use custom_mutator::CustomMutator; +/// struct MyMutator; +/// impl CustomMutator for MyMutator { +/// /// ... +/// # type Error = (); +/// # #[cfg(feature = "afl_internals")] +/// # fn init(_afl_state: &afl_state, _seed: u32) -> Result<Self,()> {unimplemented!()} +/// # #[cfg(not(feature = "afl_internals"))] +/// # fn init(_seed: u32) -> Result<Self, Self::Error> {unimplemented!()} +/// # fn fuzz<'b,'s:'b>(&'s mut self, _buffer: &'b mut [u8], _add_buff: Option<&[u8]>, _max_size: usize) -> Result<Option<&'b [u8]>, Self::Error> {unimplemented!()} +/// } +/// export_mutator!(MyMutator); +/// ``` +#[macro_export] +macro_rules! export_mutator { + ($mutator_type:ty) => { + #[cfg(feature = "afl_internals")] + #[no_mangle] + pub extern "C" fn afl_custom_init( + afl: ::std::option::Option<&'static $crate::afl_state>, + seed: ::std::os::raw::c_uint, + ) -> *const ::std::os::raw::c_void { + $crate::wrappers::afl_custom_init_::<$mutator_type>(afl, seed as u32) + } + + #[cfg(not(feature = "afl_internals"))] + #[no_mangle] + pub extern "C" fn afl_custom_init( + _afl: *const ::std::os::raw::c_void, + seed: ::std::os::raw::c_uint, + ) -> *const ::std::os::raw::c_void { + $crate::wrappers::afl_custom_init_::<$mutator_type>(seed as u32) + } + + #[no_mangle] + pub extern "C" fn afl_custom_fuzz_count( + data: *mut ::std::os::raw::c_void, + buf: *const u8, + buf_size: usize, + ) -> u32 { + unsafe { + $crate::wrappers::afl_custom_fuzz_count_::<$mutator_type>(data, buf, buf_size) + } + } + + #[no_mangle] + pub extern "C" fn afl_custom_fuzz( + data: *mut ::std::os::raw::c_void, + buf: *mut u8, + buf_size: usize, + out_buf: *mut *const u8, + add_buf: *mut u8, + add_buf_size: usize, + max_size: usize, + ) -> usize { + unsafe { + $crate::wrappers::afl_custom_fuzz_::<$mutator_type>( + data, + buf, + buf_size, + out_buf, + add_buf, + add_buf_size, + max_size, + ) + } + } + + #[no_mangle] + pub extern "C" fn afl_custom_queue_new_entry( + data: *mut ::std::os::raw::c_void, + filename_new_queue: *const ::std::os::raw::c_char, + filename_orig_queue: *const ::std::os::raw::c_char, + ) { + $crate::wrappers::afl_custom_queue_new_entry_::<$mutator_type>( + data, + filename_new_queue, + filename_orig_queue, + ) + } + + #[no_mangle] + pub extern "C" fn afl_custom_queue_get( + data: *mut ::std::os::raw::c_void, + filename: *const ::std::os::raw::c_char, + ) -> u8 { + $crate::wrappers::afl_custom_queue_get_::<$mutator_type>(data, filename) + } + + #[no_mangle] + pub extern "C" fn afl_custom_introspection( + data: *mut ::std::os::raw::c_void, + ) -> *const ::std::os::raw::c_char { + $crate::wrappers::afl_custom_introspection_::<$mutator_type>(data) + } + + #[no_mangle] + pub extern "C" fn afl_custom_describe( + data: *mut ::std::os::raw::c_void, + max_description_len: usize, + ) -> *const ::std::os::raw::c_char { + $crate::wrappers::afl_custom_describe_::<$mutator_type>(data, max_description_len) + } + + #[no_mangle] + pub extern "C" fn afl_custom_deinit(data: *mut ::std::os::raw::c_void) { + unsafe { $crate::wrappers::afl_custom_deinit_::<$mutator_type>(data) } + } + }; +} + +#[cfg(test)] +/// this sanity test is supposed to just find out whether an empty mutator being exported by the macro compiles +mod sanity_test { + #[cfg(feature = "afl_internals")] + use super::afl_state; + + use super::{export_mutator, RawCustomMutator}; + + struct ExampleMutator; + + impl RawCustomMutator for ExampleMutator { + #[cfg(feature = "afl_internals")] + fn init(_afl: &afl_state, _seed: u32) -> Self { + unimplemented!() + } + + #[cfg(not(feature = "afl_internals"))] + fn init(_seed: u32) -> Self { + unimplemented!() + } + + fn fuzz<'b, 's: 'b>( + &'s mut self, + _buffer: &'b mut [u8], + _add_buff: Option<&[u8]>, + _max_size: usize, + ) -> Option<&'b [u8]> { + unimplemented!() + } + } + + export_mutator!(ExampleMutator); +} + +#[allow(unused_variables)] +/// A custom mutator. +/// [`CustomMutator::handle_error`] will be called in case any method returns an [`Result::Err`]. +pub trait CustomMutator { + /// The error type. All methods must return the same error type. + type Error: Debug; + + /// The method which handles errors. + /// By default, this method will log the error to stderr if the environment variable "`AFL_CUSTOM_MUTATOR_DEBUG`" is set and non-empty. + /// After logging the error, execution will continue on a best-effort basis. + /// + /// This default behaviour can be customized by implementing this method. + fn handle_error(err: Self::Error) { + if std::env::var("AFL_CUSTOM_MUTATOR_DEBUG") + .map(|v| !v.is_empty()) + .unwrap_or(false) + { + eprintln!("Error in custom mutator: {:?}", err) + } + } + + #[cfg(feature = "afl_internals")] + fn init(afl: &'static afl_state, seed: u32) -> Result<Self, Self::Error> + where + Self: Sized; + + #[cfg(not(feature = "afl_internals"))] + fn init(seed: u32) -> Result<Self, Self::Error> + where + Self: Sized; + + fn fuzz_count(&mut self, buffer: &[u8]) -> Result<u32, Self::Error> { + Ok(1) + } + + fn fuzz<'b, 's: 'b>( + &'s mut self, + buffer: &'b mut [u8], + add_buff: Option<&[u8]>, + max_size: usize, + ) -> Result<Option<&'b [u8]>, Self::Error>; + + fn queue_new_entry( + &mut self, + filename_new_queue: &Path, + filename_orig_queue: Option<&Path>, + ) -> Result<(), Self::Error> { + Ok(()) + } + + fn queue_get(&mut self, filename: &Path) -> Result<bool, Self::Error> { + Ok(true) + } + + fn describe(&mut self, max_description: usize) -> Result<Option<&str>, Self::Error> { + Ok(Some(default_mutator_describe::<Self>(max_description))) + } + + fn introspection(&mut self) -> Result<Option<&str>, Self::Error> { + Ok(None) + } +} + +impl<M> RawCustomMutator for M +where + M: CustomMutator, + M::Error: Debug, +{ + #[cfg(feature = "afl_internals")] + fn init(afl: &'static afl_state, seed: u32) -> Self + where + Self: Sized, + { + match Self::init(afl, seed) { + Ok(r) => r, + Err(e) => { + Self::handle_error(e); + panic!("Error in afl_custom_init") + } + } + } + + #[cfg(not(feature = "afl_internals"))] + fn init(seed: u32) -> Self + where + Self: Sized, + { + match Self::init(seed) { + Ok(r) => r, + Err(e) => { + Self::handle_error(e); + panic!("Error in afl_custom_init") + } + } + } + + fn fuzz_count(&mut self, buffer: &[u8]) -> u32 { + match self.fuzz_count(buffer) { + Ok(r) => r, + Err(e) => { + Self::handle_error(e); + 0 + } + } + } + + fn fuzz<'b, 's: 'b>( + &'s mut self, + buffer: &'b mut [u8], + add_buff: Option<&[u8]>, + max_size: usize, + ) -> Option<&'b [u8]> { + match self.fuzz(buffer, add_buff, max_size) { + Ok(r) => r, + Err(e) => { + Self::handle_error(e); + None + } + } + } + + fn queue_new_entry(&mut self, filename_new_queue: &Path, filename_orig_queue: Option<&Path>) { + match self.queue_new_entry(filename_new_queue, filename_orig_queue) { + Ok(r) => r, + Err(e) => { + Self::handle_error(e); + } + } + } + + fn queue_get(&mut self, filename: &Path) -> bool { + match self.queue_get(filename) { + Ok(r) => r, + Err(e) => { + Self::handle_error(e); + false + } + } + } + + fn describe(&mut self, max_description: usize) -> Option<&str> { + match self.describe(max_description) { + Ok(r) => r, + Err(e) => { + Self::handle_error(e); + None + } + } + } + + fn introspection(&mut self) -> Option<&str> { + match self.introspection() { + Ok(r) => r, + Err(e) => { + Self::handle_error(e); + None + } + } + } +} + +/// the default value to return from [`CustomMutator::describe`]. +fn default_mutator_describe<T: ?Sized>(max_len: usize) -> &'static str { + truncate_str_unicode_safe(std::any::type_name::<T>(), max_len) +} + +#[cfg(all(test, not(feature = "afl_internals")))] +mod default_mutator_describe { + struct MyMutator; + use super::CustomMutator; + impl CustomMutator for MyMutator { + type Error = (); + + fn init(_: u32) -> Result<Self, Self::Error> { + Ok(Self) + } + + fn fuzz<'b, 's: 'b>( + &'s mut self, + _: &'b mut [u8], + _: Option<&[u8]>, + _: usize, + ) -> Result<Option<&'b [u8]>, Self::Error> { + unimplemented!() + } + } + + #[test] + fn test_default_describe() { + assert_eq!( + MyMutator::init(0).unwrap().describe(64).unwrap().unwrap(), + "custom_mutator::default_mutator_describe::MyMutator" + ); + } +} + +/// little helper function to truncate a `str` to a maximum of bytes while retaining unicode safety +fn truncate_str_unicode_safe(s: &str, max_len: usize) -> &str { + if s.len() <= max_len { + s + } else { + if let Some((last_index, _)) = s + .char_indices() + .take_while(|(index, _)| *index <= max_len) + .last() + { + &s[..last_index] + } else { + "" + } + } +} + +#[cfg(test)] +mod truncate_test { + use super::truncate_str_unicode_safe; + + #[test] + fn test_truncate() { + for (max_len, input, expected_output) in &[ + (0usize, "a", ""), + (1, "a", "a"), + (1, "ä", ""), + (2, "ä", "ä"), + (3, "äa", "äa"), + (4, "äa", "äa"), + (1, "👎", ""), + (2, "👎", ""), + (3, "👎", ""), + (4, "👎", "👎"), + (1, "abc", "a"), + (2, "abc", "ab"), + ] { + let actual_output = truncate_str_unicode_safe(input, *max_len); + assert_eq!( + &actual_output, expected_output, + "{:#?} truncated to {} bytes should be {:#?}, but is {:#?}", + input, max_len, expected_output, actual_output + ); + } + } +} diff --git a/custom_mutators/rust/example/Cargo.toml b/custom_mutators/rust/example/Cargo.toml new file mode 100644 index 00000000..070d23b1 --- /dev/null +++ b/custom_mutators/rust/example/Cargo.toml @@ -0,0 +1,15 @@ +[package] +name = "example_mutator" +version = "0.1.0" +authors = ["Julius Hohnerlein <julihoh@users.noreply.github.com>"] +edition = "2018" + +# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html + +[dependencies] +custom_mutator = { path = "../custom_mutator" } + +[[example]] +name = "example_mutator" +path = "./src/example_mutator.rs" +crate-type = ["cdylib"]
\ No newline at end of file diff --git a/custom_mutators/rust/example/src/example_mutator.rs b/custom_mutators/rust/example/src/example_mutator.rs new file mode 100644 index 00000000..c4711dd1 --- /dev/null +++ b/custom_mutators/rust/example/src/example_mutator.rs @@ -0,0 +1,50 @@ +#![cfg(unix)] +#![allow(unused_variables)] + +use custom_mutator::{export_mutator, CustomMutator}; + +struct ExampleMutator; + +impl CustomMutator for ExampleMutator { + type Error = (); + + fn init(seed: u32) -> Result<Self, Self::Error> { + Ok(Self) + } + + fn fuzz<'b, 's: 'b>( + &'s mut self, + buffer: &'b mut [u8], + add_buff: Option<&[u8]>, + max_size: usize, + ) -> Result<Option<&'b [u8]>, Self::Error> { + buffer.reverse(); + Ok(Some(buffer)) + } +} + +struct OwnBufferExampleMutator { + own_buffer: Vec<u8>, +} + +impl CustomMutator for OwnBufferExampleMutator { + type Error = (); + + fn init(seed: u32) -> Result<Self, Self::Error> { + Ok(Self { + own_buffer: Vec::new(), + }) + } + + fn fuzz<'b, 's: 'b>( + &'s mut self, + buffer: &'b mut [u8], + add_buff: Option<&[u8]>, + max_size: usize, + ) -> Result<Option<&'b [u8]>, ()> { + self.own_buffer.reverse(); + Ok(Some(self.own_buffer.as_slice())) + } +} + +export_mutator!(ExampleMutator); diff --git a/custom_mutators/rust/example_lain/Cargo.toml b/custom_mutators/rust/example_lain/Cargo.toml new file mode 100644 index 00000000..29d606a4 --- /dev/null +++ b/custom_mutators/rust/example_lain/Cargo.toml @@ -0,0 +1,16 @@ +[package] +name = "example_lain" +version = "0.1.0" +authors = ["Julius Hohnerlein <julihoh@users.noreply.github.com>"] +edition = "2018" + +# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html + +[dependencies] +custom_mutator = { path = "../custom_mutator" } +lain="0.5" + +[[example]] +name = "example_lain" +path = "./src/lain_mutator.rs" +crate-type = ["cdylib"]
\ No newline at end of file diff --git a/custom_mutators/rust/example_lain/rust-toolchain b/custom_mutators/rust/example_lain/rust-toolchain new file mode 100644 index 00000000..07ade694 --- /dev/null +++ b/custom_mutators/rust/example_lain/rust-toolchain @@ -0,0 +1 @@ +nightly
\ No newline at end of file diff --git a/custom_mutators/rust/example_lain/src/lain_mutator.rs b/custom_mutators/rust/example_lain/src/lain_mutator.rs new file mode 100644 index 00000000..7099aeae --- /dev/null +++ b/custom_mutators/rust/example_lain/src/lain_mutator.rs @@ -0,0 +1,61 @@ +#![cfg(unix)] + +use custom_mutator::{export_mutator, CustomMutator}; +use lain::{ + mutator::Mutator, + prelude::*, + rand::{rngs::StdRng, SeedableRng}, +}; + +#[derive(Debug, Mutatable, NewFuzzed, BinarySerialize)] +struct MyStruct { + field_1: u8, + + #[lain(bits = 3)] + field_2: u8, + + #[lain(bits = 5)] + field_3: u8, + + #[lain(min = 5, max = 10000)] + field_4: u32, + + #[lain(ignore)] + ignored_field: u64, +} + +struct LainMutator { + mutator: Mutator<StdRng>, + buffer: Vec<u8>, +} + +impl CustomMutator for LainMutator { + type Error = (); + + fn init(seed: u32) -> Result<Self, ()> { + Ok(Self { + mutator: Mutator::new(StdRng::seed_from_u64(seed as u64)), + buffer: Vec::new(), + }) + } + + fn fuzz<'b, 's: 'b>( + &'s mut self, + _buffer: &'b mut [u8], + _add_buff: Option<&[u8]>, + max_size: usize, + ) -> Result<Option<&'b [u8]>, ()> { + // we just sample an instance of MyStruct, ignoring the current input + let instance = MyStruct::new_fuzzed(&mut self.mutator, None); + let size = instance.serialized_size(); + if size > max_size { + return Err(()); + } + self.buffer.clear(); + self.buffer.reserve(size); + instance.binary_serialize::<_, BigEndian>(&mut self.buffer); + Ok(Some(self.buffer.as_slice())) + } +} + +export_mutator!(LainMutator); diff --git a/custom_mutators/symcc/Makefile b/custom_mutators/symcc/Makefile new file mode 100644 index 00000000..7e2f7b4d --- /dev/null +++ b/custom_mutators/symcc/Makefile @@ -0,0 +1,14 @@ + +ifdef DEBUG + CFLAGS += -DDEBUG +endif + +all: symcc-mutator.so + +CFLAGS += -O3 -funroll-loops + +symcc-mutator.so: symcc.c + $(CC) $(CFLAGS) $(CPPFLAGS) -g -I../../include -shared -fPIC -o symcc-mutator.so symcc.c + +clean: + rm -f symcc-mutator.so *.o *~ core diff --git a/custom_mutators/symcc/README.md b/custom_mutators/symcc/README.md new file mode 100644 index 00000000..337362ae --- /dev/null +++ b/custom_mutators/symcc/README.md @@ -0,0 +1,15 @@ +# custum mutator: symcc + +This uses the excellent symcc to find new paths into the target. + +To use this custom mutator follow the steps in the symcc repository +[https://github.com/eurecom-s3/symcc/](https://github.com/eurecom-s3/symcc/) +on how to build symcc and how to instrument a target binary (the same target +that you are fuzzing). + +The target program compiled with symcc has to be pointed to with the +`SYMCC_TARGET` environment variable. + +just type `make` to build this custom mutator. + +```SYMCC_TARGET=/prg/to/symcc/compiled/target AFL_CUSTOM_MUTATOR_LIBRARY=custom_mutators/symcc/symcc-mutator.so afl-fuzz ...``` diff --git a/custom_mutators/symcc/symcc.c b/custom_mutators/symcc/symcc.c new file mode 100644 index 00000000..a609dafb --- /dev/null +++ b/custom_mutators/symcc/symcc.c @@ -0,0 +1,332 @@ +#define _GNU_SOURCE +#include <stdio.h> +#include <stdint.h> +#include <stdlib.h> +#include <string.h> +#include <unistd.h> +#include <fcntl.h> +#include "config.h" +#include "debug.h" +#include "afl-fuzz.h" +#include "common.h" + +afl_state_t *afl_struct; + +#ifdef DEBUG + #define DBG(x...) fprintf(stderr, x) +#else + #define DBG(x...) \ + {} +#endif + +typedef struct my_mutator { + + afl_state_t *afl; + u8 * mutator_buf; + u8 * out_dir; + u8 * tmp_dir; + u8 * target; + uint32_t seed; + +} my_mutator_t; + +my_mutator_t *afl_custom_init(afl_state_t *afl, unsigned int seed) { + + if (getenv("AFL_CUSTOM_MUTATOR_ONLY")) + FATAL("the symcc module cannot be used with AFL_CUSTOM_MUTATOR_ONLY."); + + my_mutator_t *data = calloc(1, sizeof(my_mutator_t)); + if (!data) { + + perror("afl_custom_init alloc"); + return NULL; + + } + + if ((data->mutator_buf = malloc(MAX_FILE)) == NULL) { + + free(data); + perror("mutator_buf alloc"); + return NULL; + + } + + if (!(data->target = getenv("SYMCC_TARGET"))) + FATAL( + "SYMCC_TARGET not defined, this should point to the full path of the " + "symcc compiled binary."); + + if (!(data->out_dir = getenv("SYMCC_OUTPUT_DIR"))) { + + data->out_dir = alloc_printf("%s/symcc", afl->out_dir); + + } + + data->tmp_dir = alloc_printf("%s/tmp", data->out_dir); + setenv("SYMCC_OUTPUT_DIR", data->tmp_dir, 1); + int pid = fork(); + + if (pid == -1) return NULL; + + if (pid) pid = waitpid(pid, NULL, 0); + + if (pid == 0) { + + char *args[4]; + args[0] = "/bin/rm"; + args[1] = "-rf"; + args[2] = data->out_dir; + args[3] = NULL; + execvp(args[0], args); + DBG("exec:FAIL\n"); + exit(-1); + + } + + data->afl = afl; + data->seed = seed; + afl_struct = afl; + + if (mkdir(data->out_dir, 0755)) + PFATAL("Could not create directory %s", data->out_dir); + + if (mkdir(data->tmp_dir, 0755)) + PFATAL("Could not create directory %s", data->tmp_dir); + + DBG("out_dir=%s, target=%s\n", data->out_dir, data->target); + + return data; + +} + +/* When a new queue entry is added we run this input with the symcc + instrumented binary */ +void afl_custom_queue_new_entry(my_mutator_t * data, + const uint8_t *filename_new_queue, + const uint8_t *filename_orig_queue) { + + int pipefd[2]; + struct stat st; + ACTF("Queueing to symcc: %s", filename_new_queue); + u8 *fn = alloc_printf("%s", filename_new_queue); + if (!(stat(fn, &st) == 0 && S_ISREG(st.st_mode) && st.st_size)) { + + ck_free(fn); + PFATAL("Couldn't find enqueued file: %s", fn); + + } + + if (afl_struct->fsrv.use_stdin) { + + if (pipe(pipefd) == -1) { + + ck_free(fn); + PFATAL("Couldn't create a pipe for interacting with symcc child process"); + + } + + } + + int pid = fork(); + + if (pid == -1) return; + + if (pid) { + + if (afl_struct->fsrv.use_stdin) { + + close(pipefd[0]); + int fd = open(fn, O_RDONLY); + + if (fd >= 0) { + + ssize_t r = read(fd, data->mutator_buf, MAX_FILE); + DBG("fn=%s, fd=%d, size=%ld\n", fn, fd, r); + ck_free(fn); + close(fd); + if (r <= 0) { + + close(pipefd[1]); + return; + + } + + if (r > fcntl(pipefd[1], F_GETPIPE_SZ)) + fcntl(pipefd[1], F_SETPIPE_SZ, MAX_FILE); + ck_write(pipefd[1], data->mutator_buf, r, filename_new_queue); + + } else { + + ck_free(fn); + close(pipefd[1]); + PFATAL( + "Something happened to the enqueued file before sending its " + "contents to symcc binary"); + + } + + close(pipefd[1]); + + } + + pid = waitpid(pid, NULL, 0); + + // At this point we need to transfer files to output dir, since their names + // collide and symcc will just overwrite them + + struct dirent **nl; + int32_t items = scandir(data->tmp_dir, &nl, NULL, NULL); + u8 * origin_name = basename(filename_new_queue); + int32_t i; + if (items > 0) { + + for (i = 0; i < (u32)items; ++i) { + + struct stat st; + u8 *source_name = alloc_printf("%s/%s", data->tmp_dir, nl[i]->d_name); + DBG("test=%s\n", fn); + if (stat(source_name, &st) == 0 && S_ISREG(st.st_mode) && st.st_size) { + + u8 *destination_name = + alloc_printf("%s/%s.%s", data->out_dir, origin_name, nl[i]->d_name); + rename(source_name, destination_name); + ck_free(destination_name); + DBG("found=%s\n", source_name); + + } + + ck_free(source_name); + free(nl[i]); + + } + + free(nl); + + } + + } + + if (pid == 0) { + + if (afl_struct->fsrv.use_stdin) { + + unsetenv("SYMCC_INPUT_FILE"); + close(pipefd[1]); + dup2(pipefd[0], 0); + + } else { + + setenv("SYMCC_INPUT_FILE", afl_struct->fsrv.out_file, 1); + + } + + DBG("exec=%s\n", data->target); + close(1); + close(2); + dup2(afl_struct->fsrv.dev_null_fd, 1); + dup2(afl_struct->fsrv.dev_null_fd, 2); + + execvp(data->target, afl_struct->argv); + DBG("exec=FAIL\n"); + exit(-1); + + } + +} + +uint32_t afl_custom_fuzz_count(my_mutator_t *data, const u8 *buf, + size_t buf_size) { + + uint32_t count = 0, i; + struct dirent **nl; + int32_t items = scandir(data->out_dir, &nl, NULL, NULL); + + if (items > 0) { + + for (i = 0; i < (u32)items; ++i) { + + struct stat st; + u8 * fn = alloc_printf("%s/%s", data->out_dir, nl[i]->d_name); + DBG("test=%s\n", fn); + if (stat(fn, &st) == 0 && S_ISREG(st.st_mode) && st.st_size) { + + DBG("found=%s\n", fn); + count++; + + } + + ck_free(fn); + free(nl[i]); + + } + + free(nl); + + } + + DBG("dir=%s, count=%u\n", data->out_dir, count); + return count; + +} + +/* here we actually just read the files generated from symcc */ +size_t afl_custom_fuzz(my_mutator_t *data, uint8_t *buf, size_t buf_size, + u8 **out_buf, uint8_t *add_buf, size_t add_buf_size, + size_t max_size) { + + struct dirent **nl; + int32_t i, done = 0, items = scandir(data->out_dir, &nl, NULL, NULL); + ssize_t size = 0; + + if (items <= 0) return 0; + + for (i = 0; i < (u32)items; ++i) { + + struct stat st; + u8 * fn = alloc_printf("%s/%s", data->out_dir, nl[i]->d_name); + + if (done == 0) { + + if (stat(fn, &st) == 0 && S_ISREG(st.st_mode) && st.st_size) { + + int fd = open(fn, O_RDONLY); + + if (fd >= 0) { + + size = read(fd, data->mutator_buf, max_size); + *out_buf = data->mutator_buf; + + close(fd); + done = 1; + + } + + } + + unlink(fn); + + } + + ck_free(fn); + free(nl[i]); + + } + + free(nl); + DBG("FUZZ size=%lu\n", size); + return (uint32_t)size; + +} + +/** + * Deinitialize everything + * + * @param data The data ptr from afl_custom_init + */ +void afl_custom_deinit(my_mutator_t *data) { + + free(data->mutator_buf); + free(data); + +} + diff --git a/custom_mutators/symcc/test_examples/file_test.c b/custom_mutators/symcc/test_examples/file_test.c new file mode 100644 index 00000000..f2b92986 --- /dev/null +++ b/custom_mutators/symcc/test_examples/file_test.c @@ -0,0 +1,36 @@ +#include <stdio.h> +#include <stdint.h> +#include <stdlib.h> +#include <unistd.h> +#include <fcntl.h> + +int main(int argc, char **argv) { + + if (argc < 2) { + + printf("Need a file argument\n"); + return 1; + + } + + int fd = open(argv[1], O_RDONLY); + if (fd < 0) { + + printf("Couldn't open file\n"); + return 1; + + } + + uint32_t value = 0; + + read(fd, &value, sizeof(value)); + close(fd); + + value = value ^ 0xffffffff; + if (value == 0x11223344) printf("Value one\n"); + if (value == 0x44332211) printf("Value two\n"); + if (value != 0x0) printf("Not zero\n"); + return 0; + +} + diff --git a/custom_mutators/symcc/test_examples/stdin_test.c b/custom_mutators/symcc/test_examples/stdin_test.c new file mode 100644 index 00000000..3acfc523 --- /dev/null +++ b/custom_mutators/symcc/test_examples/stdin_test.c @@ -0,0 +1,28 @@ +#include <stdio.h> +#include <stdint.h> +#include <stdlib.h> +#include <unistd.h> + +int main(int argc, char **argv) { + + char input_buffer[16]; + uint32_t comparisonValue; + size_t bytesRead; + bytesRead = read(STDIN_FILENO, input_buffer, sizeof(input_buffer)); + if (bytesRead < 0) exit(-1); + comparisonValue = *(uint32_t *)input_buffer; + comparisonValue = comparisonValue ^ 0xff112233; + if (comparisonValue == 0x66554493) { + + printf("First value\n"); + + } else { + + if (comparisonValue == 0x84444415) printf("Second value\n"); + + } + + return 0; + +} + diff --git a/dictionaries/README.md b/dictionaries/README.md index 616a83cc..7c587abb 100644 --- a/dictionaries/README.md +++ b/dictionaries/README.md @@ -1,6 +1,6 @@ # AFL dictionaries -(See [../docs/README.md](../docs/README.md) for the general instruction manual.) +(See [../README.md](../README.md) for the general instruction manual.) This subdirectory contains a set of dictionaries that can be used in conjunction with the -x option to allow the fuzzer to effortlessly explore the diff --git a/docs/Changelog.md b/docs/Changelog.md index 1e7a1c1d..8dc218af 100644 --- a/docs/Changelog.md +++ b/docs/Changelog.md @@ -8,25 +8,250 @@ Want to stay in the loop on major new features? Join our mailing list by sending a mail to <afl-users+subscribe@googlegroups.com>. +### Version ++3.12a (dev) + - afl-cc: + - fix cmplog rtn (rare crash and not being able to gather ptr data) + - link runtime not to shared libs + - ensure shared libraries are properly built and instrumented + - qemu_mode (thanks @realmadsci): + - move AFL_PRELOAD and AFL_USE_QASAN logic inside afl-qemu-trace + - add AFL_QEMU_CUSTOM_BIN + +### Version ++3.11c (release) + - afl-fuzz: + - better auto detection of map size + - fix sanitizer settings (bug since 3.10c) + - fix an off-by-one overwrite in cmplog + - add non-unicode variants from unicode-looking dictionary entries + - Rust custom mutator API improvements + - Imported crash stats painted yellow on resume (only new ones are red) + - afl-cc: + - added AFL_NOOPT that will just pass everything to the normal + gcc/clang compiler without any changes - to pass weird configure + scripts + - fixed a crash that can occur with ASAN + CMPLOG together plus + better support for unicode (thanks to @stbergmann for reporting!) + - fixed a crash in LAF transform for empty strings + - handle erroneous setups in which multiple afl-compiler-rt are + compiled into the target. This now also supports dlopen() + instrumented libs loaded before the forkserver and even after the + forkserver is started (then with collisions though) + - the compiler rt was added also in object building (-c) which + should have been fixed years ago but somewhere got lost :( + - Renamed CTX to CALLER, added correct/real CTX implementation to + CLASSIC + - qemu_mode: + - added AFL_QEMU_EXCLUDE_RANGES env by @realmadsci, thanks! + - if no new/updated checkout is wanted, build with: + NO_CHECKOUT=1 ./build_qemu_support.sh + - we no longer perform a "git drop" + - afl-cmin: support filenames with spaces + +### Version ++3.10c (release) + - Mac OS ARM64 support + - Android support fixed and updated by Joey Jiaojg - thanks! + - New selective instrumentation option with __AFL_COVERAGE_* commands + to be placed in the source code. + Check out instrumentation/README.instrument_list.md + - afl-fuzz + - Making AFL_MAP_SIZE (mostly) obsolete - afl-fuzz now learns on + start the target map size + - upgraded cmplog/redqueen: solving for floating point, solving + transformations (e.g. toupper, tolower, to/from hex, xor, + arithmetics, etc.). This is costly hence new command line option + `-l` that sets the intensity (values 1 to 3). Recommended is 2. + - added `AFL_CMPLOG_ONLY_NEW` to not use cmplog on initial seeds + from `-i` or resumes (these have most likely already been done) + - fix crash for very, very fast targets+systems (thanks to mhlakhani + for reporting) + - on restarts (`-i`)/autoresume (AFL_AUTORESUME) the stats are now + reloaded and used, thanks to Vimal Joseph for this patch! + - changed the meaning of '+' of the '-t' option, it now means to + auto-calculate the timeout with the value given being the max + timeout. The original meaning of skipping timeouts instead of + abort is now inherent to the -t option. + - if deterministic mode is active (`-D`, or `-M` without `-d`) then + we sync after every queue entry as this can take very long time + otherwise + - added minimum SYNC_TIME to include/config.h (30 minutes default) + - better detection if a target needs a large shared map + - fix for `-Z` + - fixed a few crashes + - switched to an even faster RNG + - added hghwng's patch for faster trace map analysis + - printing suggestions for mistyped `AFL_` env variables + - added Rust bindings for custom mutators (thanks @julihoh) + - afl-cc + - allow instrumenting LLVMFuzzerTestOneInput + - fixed endless loop for allow/blocklist lines starting with a + comment (thanks to Zherya for reporting) + - cmplog/redqueen now also tracks floating point, _ExtInt() + 128bit + - cmplog/redqueen can now process basic libc++ and libstdc++ + std::string comparisons (no position or length type variants) + - added support for __afl_coverage_interesting() for LTO and our + own PCGUARD (llvm 10.0.1+), read more about this function and + selective coverage in instrumentation/README.instrument_list.md + - added AFL_LLVM_INSTRUMENT option NATIVE for native clang pc-guard + support (less performant than our own), GCC for old afl-gcc and + CLANG for old afl-clang + - fixed a potential crash in the LAF feature + - workaround for llvm bitcast lto bug + - workaround for llvm 13 + - qemuafl + - QASan (address sanitizer for Qemu) ported to qemuafl! + See qemu_mode/libqasan/README.md + - solved some persistent mode bugs (thanks Dil4rd) + - solved an issue when dumping the memory maps (thanks wizche) + - Android support for QASan + - unicornafl + - Substantial speed gains in python bindings for certain use cases + - Improved rust bindings + - Added a new example harness to compare python, c and rust bindings + - afl-cmin and afl-showmap now support the -f option + - afl_plot now also generates a graph on the discovered edges + - changed default: no memory limit for afl-cmin and afl-cmin.bash + - warn on any _AFL and __AFL env vars. + - set AFL_IGNORE_UNKNOWN_ENVS to not warn on unknown AFL_... env vars + - added dummy Makefile to instrumentation/ + - Updated utils/afl_frida to be 5% faster, 7% on x86_x64 + - Added `AFL_KILL_SIGNAL` env variable (thanks @v-p-b) + - @Edznux added a nice documentation on how to use rpc.statsd with + afl++ in docs/rpc_statsd.md, thanks! + +### Version ++3.00c (release) + - llvm_mode/ and gcc_plugin/ moved to instrumentation/ + - examples/ renamed to utils/ + - moved libdislocator, libtokencap and qdbi_mode to utils/ + - all compilers combined to afl-cc which emulates the previous ones + - afl-llvm/gcc-rt.o merged into afl-compiler-rt.o + - afl-fuzz + - not specifying -M or -S will now auto-set "-S default" + - deterministic fuzzing is now disabled by default and can be enabled with + -D. It is still enabled by default for -M. + - a new seed selection was implemented that uses weighted randoms based on + a schedule performance score, which is much better that the previous + walk the whole queue approach. Select the old mode with -Z (auto enabled + with -M) + - Marcel Boehme submitted a patch that improves all AFFast schedules :) + - the default schedule is now FAST + - memory limits are now disabled by default, set them with -m if required + - rpc.statsd support, for stats and charts, by Edznux, thanks a lot! + - reading testcases from -i now descends into subdirectories + - allow the -x command line option up to 4 times + - loaded extras now have a duplication protection + - If test cases are too large we do a partial read on the maximum + supported size + - longer seeds with the same trace information will now be ignored + for fuzzing but still be used for splicing + - crashing seeds are now not prohibiting a run anymore but are + skipped - they are used for splicing, though + - update MOpt for expanded havoc modes + - setting the env var AFL_NO_AUTODICT will not load an LTO autodictionary + - added NO_SPLICING compile option and makefile define + - added INTROSPECTION make target that writes all mutations to + out/NAME/introspection.txt + - print special compile time options used in help output + - when using -c cmplog, one of the childs was not killed, fixed + - somewhere we broke -n dumb fuzzing, fixed + - added afl_custom_describe to the custom mutator API to allow for easy + mutation reproduction on crashing inputs + - new env. var. AFL_NO_COLOR (or AFL_NO_COLOUR) to suppress colored + console output (when configured with USE_COLOR and not ALWAYS_COLORED) + - instrumentation + - We received an enhanced gcc_plugin module from AdaCore, thank you + very much!! + - not overriding -Ox or -fno-unroll-loops anymore + - we now have our own trace-pc-guard implementation. It is the same as + -fsanitize-coverage=trace-pc-guard from llvm 12, but: it is a) inline + and b) works from llvm 10.0.1 + onwards :) + - new llvm pass: dict2file via AFL_LLVM_DICT2FILE, create afl-fuzz + -x dictionary of string comparisons found during compilation + - LTO autodict now also collects interesting cmp comparisons, + std::string compare + find + ==, bcmp + - fix crash in dict2file for integers > 64 bit + - custom mutators + - added a new custom mutator: symcc -> https://github.com/eurecom-s3/symcc/ + - added a new custom mutator: libfuzzer that integrates libfuzzer mutations + - Our afl++ Grammar-Mutator is now better integrated into custom_mutators/ + - added INTROSPECTION support for custom modules + - python fuzz function was not optional, fixed + - some python mutator speed improvements + - afl-cmin/afl-cmin.bash now search first in PATH and last in AFL_PATH + - unicornafl synced with upstream version 1.02 (fixes, better rust bindings) + - renamed AFL_DEBUG_CHILD_OUTPUT to AFL_DEBUG_CHILD + - added AFL_CRASH_EXITCODE env variable to treat a child exitcode as crash + + +### Version ++2.68c (release) + - added the GSoC excellent afl++ grammar mutator by Shengtuo to our + custom_mutators/ (see custom_mutators/README.md) - or get it here: + https://github.com/AFLplusplus/Grammar-Mutator + - a few QOL changes for Apple and its outdated gmake + - afl-fuzz: + - fix for auto dictionary entries found during fuzzing to not throw out + a -x dictionary + - added total execs done to plot file + - AFL_MAX_DET_EXTRAS env variable added to control the amount of + deterministic dict entries without recompiling. + - AFL_FORKSRV_INIT_TMOUT env variable added to control the time to wait + for the forkserver to come up without the need to increase the overall + timeout. + - bugfix for cmplog that results in a heap overflow based on target data + (thanks to the magma team for reporting!) + - write fuzzing setup into out/fuzzer_setup (environment variables and + command line) + - custom mutators: + - added afl_custom_fuzz_count/fuzz_count function to allow specifying + the number of fuzz attempts for custom_fuzz + - llvm_mode: + - ported SanCov to LTO, and made it the default for LTO. better + instrumentation locations + - Further llvm 12 support (fast moving target like afl++ :-) ) + - deprecated LLVM SKIPSINGLEBLOCK env environment + -### Version ++2.66d (devel) +### Version ++2.67c (release) - Support for improved afl++ snapshot module: https://github.com/AFLplusplus/AFL-Snapshot-LKM + - Due to the instrumentation needing more memory, the initial memory sizes + for -m have been increased - afl-fuzz: - added -F option to allow -M main fuzzers to sync to foreign fuzzers, e.g. honggfuzz or libfuzzer + - added -b option to bind to a specific CPU - eliminated CPU affinity race condition for -S/-M runs - expanded havoc mode added, on no cycle finds add extra splicing and MOpt into the mix + - fixed a bug in redqueen for strings and made deterministic with -s + - Compiletime autodictionary fixes - llvm_mode: - - now supports llvm 12! + - now supports llvm 12 + - support for AFL_LLVM_ALLOWLIST/AFL_LLVM_DENYLIST (previous + AFL_LLVM_WHITELIST and AFL_LLVM_INSTRUMENT_FILE are deprecated and + are matched to AFL_LLVM_ALLOWLIST). The format is compatible to llvm + sancov, and also supports function matching :) + - added neverzero counting to trace-pc/pcgard - fixes for laf-intel float splitting (thanks to mark-griffin for reporting) - - LTO: autodictionary mode is a default + - fixes for llvm 4.0 + - skipping ctors and ifuncs for instrumentation + - LTO: switch default to the dynamic memory map, set AFL_LLVM_MAP_ADDR + for a fixed map address (eg. 0x10000) + - LTO: improved stability for persistent mode, no other instrumentation + has that advantage + - LTO: fixed autodict for long strings + - LTO: laf-intel and redqueen/cmplog are now applied at link time + to prevent llvm optimizing away the splits + - LTO: autodictionary mode is a fixed default now - LTO: instrim instrumentation disabled, only classic support used as it is always better + - LTO: env var AFL_LLVM_DOCUMENT_IDS=file will document which edge ID + was given to which function during compilation + - LTO: single block functions were not implemented by default, fixed + - LTO: AFL_LLVM_SKIP_NEVERZERO behaviour was inversed, fixed - setting AFL_LLVM_LAF_SPLIT_FLOATS now activates AFL_LLVM_LAF_SPLIT_COMPARES + - support for -E and -shared compilation runs - added honggfuzz mangle as a custom mutator in custom_mutators/honggfuzz - added afl-frida gum solution to examples/afl_frida (mostly imported from https://github.com/meme/hotwax/) @@ -373,7 +598,7 @@ sending a mail to <afl-users+subscribe@googlegroups.com>. - big code refactoring: * all includes are now in include/ * all afl sources are now in src/ - see src/README.md - * afl-fuzz was splitted up in various individual files for including + * afl-fuzz was split up in various individual files for including functionality in other programs (e.g. forkserver, memory map, etc.) for better readability. * new code indention everywhere diff --git a/docs/FAQ.md b/docs/FAQ.md index e09385a8..714d50eb 100644 --- a/docs/FAQ.md +++ b/docs/FAQ.md @@ -2,31 +2,94 @@ ## Contents - 1. [How to improve the fuzzing speed?](#how-to-improve-the-fuzzing-speed) - 2. [What is an edge?](#what-is-an-edge) - 3. [Why is my stability below 100%?](#why-is-my-stability-below-100) - 4. [How can I improve the stability value](#how-can-i-improve-the-stability-value) + * [What is the difference between afl and afl++?](#what-is-the-difference-between-afl-and-afl) + * [How to improve the fuzzing speed?](#how-to-improve-the-fuzzing-speed) + * [How do I fuzz a network service?](#how-do-i-fuzz-a-network-service) + * [How do I fuzz a GUI program?](#how-do-i-fuzz-a-gui-program) + * [What is an edge?](#what-is-an-edge) + * [Why is my stability below 100%?](#why-is-my-stability-below-100) + * [How can I improve the stability value?](#how-can-i-improve-the-stability-value) If you find an interesting or important question missing, submit it via [https://github.com/AFLplusplus/AFLplusplus/issues](https://github.com/AFLplusplus/AFLplusplus/issues) -## How to improve the fuzzing speed +## What is the difference between afl and afl++? - 1. use [llvm_mode](docs/llvm_mode/README.md): afl-clang-lto (llvm >= 11) or afl-clang-fast (llvm >= 9 recommended) +American Fuzzy Lop (AFL) was developed by Michał "lcamtuf" Zalewski starting in +2013/2014, and when he left Google end of 2017 he stopped developing it. + +At the end of 2019 the Google fuzzing team took over maintenance of AFL, however +it is only accepting PRs from the community and is not developing enhancements +anymore. + +In the second quarter of 2019, 1 1/2 year later when no further development of +AFL had happened and it became clear there would none be coming, afl++ +was born, where initially community patches were collected and applied +for bug fixes and enhancements. Then from various AFL spin-offs - mostly academic +research - features were integrated. This already resulted in a much advanced +AFL. + +Until the end of 2019 the afl++ team had grown to four active developers which +then implemented their own research and features, making it now by far the most +flexible and feature rich guided fuzzer available as open source. +And in independent fuzzing benchmarks it is one of the best fuzzers available, +e.g. [Fuzzbench Report](https://www.fuzzbench.com/reports/2020-08-03/index.html) + +## How to improve the fuzzing speed? + + 1. Use [llvm_mode](docs/llvm_mode/README.md): afl-clang-lto (llvm >= 11) or afl-clang-fast (llvm >= 9 recommended) 2. Use [persistent mode](llvm_mode/README.persistent_mode.md) (x2-x20 speed increase) 3. Use the [afl++ snapshot module](https://github.com/AFLplusplus/AFL-Snapshot-LKM) (x2 speed increase) - 4. If you do not use shmem persistent mode, use `AFL_TMPDIR` to point the input file on a tempfs location, see [docs/env_variables.md](docs/env_variables.md) - 5. Improve kernel performance: modify `/etc/default/grub`, set `GRUB_CMDLINE_LINUX_DEFAULT="ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off"`; then `update-grub` and `reboot` (warning: makes the system more insecure) + 4. If you do not use shmem persistent mode, use `AFL_TMPDIR` to put the input file directory on a tempfs location, see [docs/env_variables.md](docs/env_variables.md) + 5. Improve Linux kernel performance: modify `/etc/default/grub`, set `GRUB_CMDLINE_LINUX_DEFAULT="ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off"`; then `update-grub` and `reboot` (warning: makes the system less secure) 6. Running on an `ext2` filesystem with `noatime` mount option will be a bit faster than on any other journaling filesystem 7. Use your cores! [README.md:3.b) Using multiple cores/threads](../README.md#b-using-multiple-coresthreads) -## What is an "edge" +## How do I fuzz a network service? + +The short answer is - you cannot, at least not "out of the box". + +Using a network channel is inadequate for several reasons: +- it has a slow-down of x10-20 on the fuzzing speed +- it does not scale to fuzzing multiple instances easily, +- instead of one initial data packet often a back-and-forth interplay of packets is needed for stateful protocols (which is totally unsupported by most coverage aware fuzzers). + +The established method to fuzz network services is to modify the source code +to read from a file or stdin (fd 0) (or even faster via shared memory, combine +this with persistent mode [llvm_mode/README.persistent_mode.md](llvm_mode/README.persistent_mode.md) +and you have a performance gain of x10 instead of a performance loss of over +x10 - that is a x100 difference!). + +If modifying the source is not an option (e.g. because you only have a binary +and perform binary fuzzing) you can also use a shared library with AFL_PRELOAD +to emulate the network. This is also much faster than the real network would be. +See [utils/socket_fuzzing/](../utils/socket_fuzzing/). + +There is an outdated afl++ branch that implements networking if you are +desperate though: [https://github.com/AFLplusplus/AFLplusplus/tree/networking](https://github.com/AFLplusplus/AFLplusplus/tree/networking) - +however a better option is AFLnet ([https://github.com/aflnet/aflnet](https://github.com/aflnet/aflnet)) +which allows you to define network state with different type of data packets. + +## How do I fuzz a GUI program? + +If the GUI program can read the fuzz data from a file (via the command line, +a fixed location or via an environment variable) without needing any user +interaction then it would be suitable for fuzzing. + +Otherwise it is not possible without modifying the source code - which is a +very good idea anyway as the GUI functionality is a huge CPU/time overhead +for the fuzzing. + +So create a new `main()` that just reads the test case and calls the +functionality for processing the input that the GUI program is using. + +## What is an "edge"? A program contains `functions`, `functions` contain the compiled machine code. The compiled machine code in a `function` can be in a single or many `basic blocks`. A `basic block` is the largest possible number of subsequent machine code -instructions that runs independent, meaning it does not split up to different -locations nor is it jumped into it from a different location: +instructions that has exactly one entrypoint (which can be be entered by multiple other basic blocks) +and runs linearly without branching or jumping to other addresses (except at the end). ``` function() { A: @@ -36,7 +99,7 @@ function() { if (x) goto C; else goto D; C: some code - goto D + goto E D: some code goto B @@ -46,7 +109,7 @@ function() { ``` Every code block between two jump locations is a `basic block`. -An `edge` is then the unique relationship between two `basic blocks` (from the +An `edge` is then the unique relationship between two directly connected `basic blocks` (from the code example above): ``` Block A @@ -61,31 +124,48 @@ code example above): Block E ``` Every line between two blocks is an `edge`. +Note that a few basic block loop to itself, this too would be an edge. -## Why is my stability below 100 +## Why is my stability below 100%? Stability is measured by how many percent of the edges in the target are "stable". Sending the same input again and again should take the exact same path through the target every time. If that is the case, the stability is 100%. -If however randomness happens, e.g. a thread reading from shared memory, +If however randomness happens, e.g. a thread reading other external data, reaction to timing, etc. then in some of the re-executions with the same data -will result in the edge information being different accross runs. +the edge coverage result will be different accross runs. Those edges that change are then flagged "unstable". The more "unstable" edges, the more difficult for afl++ to identify valid new paths. A value above 90% is usually fine and a value above 80% is also still ok, and -even above 20% can still result in successful finds of bugs. -However, it is recommended that below 90% or 80% you should take measures to -improve the stability. +even a value above 20% can still result in successful finds of bugs. +However, it is recommended that for values below 90% or 80% you should take +countermeasures to improve stability. + +## How can I improve the stability value? -## How can I improve the stability value +For fuzzing a 100% stable target that covers all edges is the best case. +A 90% stable target that covers all edges is however better than a 100% stable +target that ignores 10% of the edges. -Four steps are required to do this and requires quite some knowledge of -coding and/or disassembly and it is only effectively possible with -afl-clang-fast PCGUARD and afl-clang-lto LTO instrumentation! +With instability you basically have a partial coverage loss on an edge, with +ignored functions you have a full loss on that edges. + +There are functions that are unstable, but also provide value to coverage, eg +init functions that use fuzz data as input for example. +If however a function that has nothing to do with the input data is the +source of instability, e.g. checking jitter, or is a hash map function etc. +then it should not be instrumented. + +To be able to exclude these functions (based on AFL++'s measured stability) +the following process will allow to identify functions with variable edges. + +Four steps are required to do this and it also requires quite some knowledge +of coding and/or disassembly and is effectively possible only with +afl-clang-fast PCGUARD and afl-clang-lto LTO instrumentation. 1. First step: Identify which edge ID numbers are unstable @@ -93,32 +173,48 @@ afl-clang-fast PCGUARD and afl-clang-lto LTO instrumentation! The out/fuzzer_stats file will then show the edge IDs that were identified as unstable. - 2. Second step: Find the responsible function. + 2. Second step: Find the responsible function(s). - a) For LTO instrumented binaries just disassemble or decompile the target - and look which edge is writing to that edge ID. Ghidra is a good tool - for this: [https://ghidra-sre.org/](https://ghidra-sre.org/) + a) For LTO instrumented binaries this can be documented during compile + time, just set `export AFL_LLVM_DOCUMENT_IDS=/path/to/a/file`. + This file will have one assigned edge ID and the corresponding + function per line. - b) For PCGUARD instrumented binaries it is more difficult. Here you can - either modify the __sanitizer_cov_trace_pc_guard function in + b) For PCGUARD instrumented binaries it is much more difficult. Here you + can either modify the __sanitizer_cov_trace_pc_guard function in llvm_mode/afl-llvm-rt.o.c to write a backtrace to a file if the ID in - __afl_area_ptr[*guard] is one of the unstable edge IDs. Then recompile - and reinstall llvm_mode and rebuild your target. Run the recompiled - target with afl-fuzz for a while and then check the file that you - wrote with the backtrace information. + __afl_area_ptr[*guard] is one of the unstable edge IDs. + (Example code is already there). + Then recompile and reinstall llvm_mode and rebuild your target. + Run the recompiled target with afl-fuzz for a while and then check the + file that you wrote with the backtrace information. Alternatively you can use `gdb` to hook __sanitizer_cov_trace_pc_guard_init on start, check to which memory address the edge ID value is written and set a write breakpoint to that address (`watch 0x.....`). - 3. Third step: create a text file with the filenames + c) in all other instrumentation types this is not possible. So just + recompile with the two mentioned above. This is just for + identifying the functions that have unstable edges. + + 3. Third step: create a text file with the filenames/functions Identify which source code files contain the functions that you need to - remove from instrumentation. + remove from instrumentation, or just specify the functions you want to + skip for instrumentation. Note that optimization might inline functions! + + Simply follow this document on how to do this: [llvm_mode/README.instrument_list.md](llvm_mode/README.instrument_list.md) + If PCGUARD is used, then you need to follow this guide (needs llvm 12+!): + [http://clang.llvm.org/docs/SanitizerCoverage.html#partially-disabling-instrumentation](http://clang.llvm.org/docs/SanitizerCoverage.html#partially-disabling-instrumentation) - Simply follow this document on how to do this: [llvm_mode/README.instrument_file.md](llvm_mode/README.instrument_file.md) - If PCGUARD is used, then you need to follow this guide: [http://clang.llvm.org/docs/SanitizerCoverage.html#partially-disabling-instrumentation](http://clang.llvm.org/docs/SanitizerCoverage.html#partially-disabling-instrumentation) + Only exclude those functions from instrumentation that provide no value + for coverage - that is if it does not process any fuzz data directly + or indirectly (e.g. hash maps, thread management etc.). + If however a function directly or indirectly handles fuzz data then you + should not put the function in a deny instrumentation list and rather + live with the instability it comes with. 4. Fourth step: recompile the target Recompile, fuzz it, be happy :) + This link explains this process for [Fuzzbench](https://github.com/google/fuzzbench/issues/677) diff --git a/docs/INSTALL.md b/docs/INSTALL.md index 766f24d7..e3c06c9d 100644 --- a/docs/INSTALL.md +++ b/docs/INSTALL.md @@ -4,7 +4,7 @@ issues for a variety of platforms. See README.md for the general instruction manual. -## 1) Linux on x86 +## 1. Linux on x86 --------------- This platform is expected to work well. Compile the program with: @@ -24,15 +24,17 @@ There are no special dependencies to speak of; you will need GNU make and a working compiler (gcc or clang). Some of the optional scripts bundled with the program may depend on bash, gdb, and similar basic tools. -If you are using clang, please review llvm_mode/README.md; the LLVM +If you are using clang, please review README.llvm.md; the LLVM integration mode can offer substantial performance gains compared to the traditional approach. +Likewise, if you are using GCC, please review instrumentation/README.gcc_plugin.md. + You may have to change several settings to get optimal results (most notably, disable crash reporting utilities and switch to a different CPU governor), but afl-fuzz will guide you through that if necessary. -## OpenBSD, FreeBSD, NetBSD on x86 +## 2. OpenBSD, FreeBSD, NetBSD on x86 Similarly to Linux, these platforms are expected to work well and are regularly tested. Compile everything with GNU make: @@ -52,10 +54,10 @@ sudo gmake install Keep in mind that if you are using csh as your shell, the syntax of some of the shell commands given in the README.md and other docs will be different. -The `llvm_mode` requires a dynamically linked, fully-operational installation of +The `llvm` requires a dynamically linked, fully-operational installation of clang. At least on FreeBSD, the clang binaries are static and do not include some of the essential tools, so if you want to make it work, you may need to -follow the instructions in llvm_mode/README.md. +follow the instructions in README.llvm.md. Beyond that, everything should work as advertised. @@ -97,27 +99,24 @@ and definitely don't look POSIX-compliant. This means two things: User emulation mode of QEMU does not appear to be supported on MacOS X, so black-box instrumentation mode (`-Q`) will not work. -The llvm_mode requires a fully-operational installation of clang. The one that +The llvm instrumentation requires a fully-operational installation of clang. The one that comes with Xcode is missing some of the essential headers and helper tools. -See llvm_mode/README.md for advice on how to build the compiler from scratch. +See README.llvm.md for advice on how to build the compiler from scratch. ## 4. Linux or *BSD on non-x86 systems Standard build will fail on non-x86 systems, but you should be able to leverage two other options: - - The LLVM mode (see llvm_mode/README.md), which does not rely on + - The LLVM mode (see README.llvm.md), which does not rely on x86-specific assembly shims. It's fast and robust, but requires a complete installation of clang. - The QEMU mode (see qemu_mode/README.md), which can be also used for fuzzing cross-platform binaries. It's slower and more fragile, but can be used even when you don't have the source for the tested app. -If you're not sure what you need, you need the LLVM mode. To get it, try: - -```bash -AFL_NO_X86=1 gmake && gmake -C llvm_mode -``` +If you're not sure what you need, you need the LLVM mode, which is built by +default. ...and compile your target program with afl-clang-fast or afl-clang-fast++ instead of the traditional afl-gcc or afl-clang wrappers. @@ -160,7 +159,8 @@ instrumentation mode (`-Q`) will not work. ## 6. Everything else You're on your own. On POSIX-compliant systems, you may be able to compile and -run the fuzzer; and the LLVM mode may offer a way to instrument non-x86 code. +run the fuzzer; and the LLVM and GCC plugin modes may offer a way to instrument +non-x86 code. The fuzzer will run on Windows in WSL only. It will not work under Cygwin on in the normal Windows world. It could be ported to the latter platform fairly easily, but it's a pretty bad diff --git a/docs/README.md b/docs/README.md deleted file mode 120000 index 32d46ee8..00000000 --- a/docs/README.md +++ /dev/null @@ -1 +0,0 @@ -../README.md
\ No newline at end of file diff --git a/docs/binaryonly_fuzzing.md b/docs/binaryonly_fuzzing.md index 111147e2..787d970d 100644 --- a/docs/binaryonly_fuzzing.md +++ b/docs/binaryonly_fuzzing.md @@ -6,18 +6,18 @@ However, if there is only the binary program and no source code available, then standard `afl-fuzz -n` (non-instrumented mode) is not effective. - The following is a description of how these binaries can be fuzzed with afl++ + The following is a description of how these binaries can be fuzzed with afl++. ## TL;DR: qemu_mode in persistent mode is the fastest - if the stability is high enough. Otherwise try retrowrite, afl-dyninst and if these - fail too then standard qemu_mode with AFL_ENTRYPOINT to where you need it. + fail too then try standard qemu_mode with AFL_ENTRYPOINT to where you need it. - If your a target is library use examples/afl_frida/. + If your target is a library use utils/afl_frida/. - If your target is non-linux then use unicorn_mode/ + If your target is non-linux then use unicorn_mode/. ## QEMU @@ -29,10 +29,10 @@ The speed decrease is at about 50%. However various options exist to increase the speed: - - using AFL_ENTRYPOINT to move the forkserver to a later basic block in + - using AFL_ENTRYPOINT to move the forkserver entry to a later basic block in the binary (+5-10% speed) - using persistent mode [qemu_mode/README.persistent.md](../qemu_mode/README.persistent.md) - this will result in 150-300% overall speed - so 3-8x the original + this will result in 150-300% overall speed increase - so 3-8x the original qemu_mode speed! - using AFL_CODE_START/AFL_CODE_END to only instrument specific parts @@ -65,14 +65,14 @@ ## AFL FRIDA If you want to fuzz a binary-only shared library then you can fuzz it with - frida-gum via examples/afl_frida/, you will have to write a harness to + frida-gum via utils/afl_frida/, you will have to write a harness to call the target function in the library, use afl-frida.c as a template. ## AFL UNTRACER If you want to fuzz a binary-only shared library then you can fuzz it with - examples/afl_untracer/, use afl-untracer.c as a template. + utils/afl_untracer/, use afl-untracer.c as a template. It is slower than AFL FRIDA (see above). @@ -104,7 +104,7 @@ ## RETROWRITE - If you have an x86/x86_64 binary that still has it's symbols, is compiled + If you have an x86/x86_64 binary that still has its symbols, is compiled with position independant code (PIC/PIE) and does not use most of the C++ features then the retrowrite solution might be for you. It decompiles to ASM files which can then be instrumented with afl-gcc. @@ -148,7 +148,7 @@ ## CORESIGHT Coresight is ARM's answer to Intel's PT. - There is no implementation so far which handle coresight and getting + There is no implementation so far which handles coresight and getting it working on an ARM Linux is very difficult due to custom kernel building on embedded systems is difficult. And finding one that has coresight in the ARM chip is difficult too. @@ -174,7 +174,7 @@ Pintool and Dynamorio are dynamic instrumentation engines, and they can be used for getting basic block information at runtime. - Pintool is only available for Intel x32/x64 on Linux, Mac OS and Windows + Pintool is only available for Intel x32/x64 on Linux, Mac OS and Windows, whereas Dynamorio is additionally available for ARM and AARCH64. Dynamorio is also 10x faster than Pintool. @@ -182,7 +182,7 @@ Dynamorio has a speed decrease of 98-99% Pintool has a speed decrease of 99.5% - Hence Dynamorio is the option to go for if everything fails, and Pintool + Hence Dynamorio is the option to go for if everything else fails, and Pintool only if Dynamorio fails too. Dynamorio solutions: @@ -205,6 +205,7 @@ * QSYM: [https://github.com/sslab-gatech/qsym](https://github.com/sslab-gatech/qsym) * Manticore: [https://github.com/trailofbits/manticore](https://github.com/trailofbits/manticore) * S2E: [https://github.com/S2E](https://github.com/S2E) + * Tinyinst [https://github.com/googleprojectzero/TinyInst](https://github.com/googleprojectzero/TinyInst) (Mac/Windows only) * ... please send me any missing that are good diff --git a/docs/custom_mutators.md b/docs/custom_mutators.md index a22c809b..61d711e4 100644 --- a/docs/custom_mutators.md +++ b/docs/custom_mutators.md @@ -4,6 +4,11 @@ This file describes how you can implement custom mutations to be used in AFL. For now, we support C/C++ library and Python module, collectivelly named as the custom mutator. +There is also experimental support for Rust in `custom_mutators/rust`. +Please refer to that directory for documentation. +Run ```cargo doc -p custom_mutator --open``` in that directory to view the +documentation in your web browser. + Implemented by - C/C++ library (`*.so`): Khaled Yakdan from Code Intelligence (<yakdan@code-intelligence.de>) - Python module: Christian Holler from Mozilla (<choller@mozilla.com>) @@ -31,16 +36,19 @@ performed with the custom mutator. C/C++: ```c -void *afl_custom_init(afl_t *afl, unsigned int seed); -size_t afl_custom_fuzz(void *data, uint8_t *buf, size_t buf_size, u8 **out_buf, uint8_t *add_buf, size_t add_buf_size, size_t max_size); -size_t afl_custom_post_process(void *data, uint8_t *buf, size_t buf_size, uint8_t **out_buf); -int32_t afl_custom_init_trim(void *data, uint8_t *buf, size_t buf_size); -size_t afl_custom_trim(void *data, uint8_t **out_buf); -int32_t afl_custom_post_trim(void *data, int success); -size_t afl_custom_havoc_mutation(void *data, u8 *buf, size_t buf_size, u8 **out_buf, size_t max_size); -uint8_t afl_custom_havoc_mutation_probability(void *data); -uint8_t afl_custom_queue_get(void *data, const uint8_t *filename); -void afl_custom_queue_new_entry(void *data, const uint8_t *filename_new_queue, const uint8_t *filename_orig_queue); +void *afl_custom_init(afl_state_t *afl, unsigned int seed); +unsigned int afl_custom_fuzz_count(void *data, const unsigned char *buf, size_t buf_size); +size_t afl_custom_fuzz(void *data, unsigned char *buf, size_t buf_size, unsigned char **out_buf, unsigned char *add_buf, size_t add_buf_size, size_t max_size); +const char *afl_custom_describe(void *data, size_t max_description_len); +size_t afl_custom_post_process(void *data, unsigned char *buf, size_t buf_size, unsigned char **out_buf); +int afl_custom_init_trim(void *data, unsigned char *buf, size_t buf_size); +size_t afl_custom_trim(void *data, unsigned char **out_buf); +int afl_custom_post_trim(void *data, unsigned char success); +size_t afl_custom_havoc_mutation(void *data, unsigned char *buf, size_t buf_size, unsigned char **out_buf, size_t max_size); +unsigned char afl_custom_havoc_mutation_probability(void *data); +unsigned char afl_custom_queue_get(void *data, const unsigned char *filename); +void afl_custom_queue_new_entry(void *data, const unsigned char *filename_new_queue, const unsigned int *filename_orig_queue); +const char* afl_custom_introspection(my_mutator_t *data); void afl_custom_deinit(void *data); ``` @@ -49,9 +57,15 @@ Python: def init(seed): pass +def fuzz_count(buf, add_buf, max_size): + return cnt + def fuzz(buf, add_buf, max_size): return mutated_out +def describe(max_description_length): + return "description_of_current_mutation" + def post_process(buf): return out_buf @@ -77,6 +91,9 @@ def queue_new_entry(filename_new_queue, filename_orig_queue): pass ``` +def introspection(): + return string + ### Custom Mutation - `init`: @@ -88,18 +105,33 @@ def queue_new_entry(filename_new_queue, filename_orig_queue): This method determines whether the custom fuzzer should fuzz the current queue entry or not +- `fuzz_count` (optional): + + When a queue entry is selected to be fuzzed, afl-fuzz selects the number + of fuzzing attempts with this input based on a few factors. + If however the custom mutator wants to set this number instead on how often + it is called for a specific queue entry, use this function. + This function is most useful if `AFL_CUSTOM_MUTATOR_ONLY` is **not** used. + - `fuzz` (optional): This method performs custom mutations on a given input. It also accepts an additional test case. Note that this function is optional - but it makes sense to use it. You would only skip this if `post_process` is used to fix checksums etc. - so you are using it e.g. as a post processing library. + so if you are using it e.g. as a post processing library. + +- `describe` (optional): + + When this function is called, it shall describe the current testcase, + generated by the last mutation. This will be called, for example, + to name the written testcase file after a crash occurred. + Using it can help to reproduce crashing mutations. - `havoc_mutation` and `havoc_mutation_probability` (optional): `havoc_mutation` performs a single custom mutation on a given input. This - mutation is stacked with the other mutations in havoc. The other method, + mutation is stacked with other mutations in havoc. The other method, `havoc_mutation_probability`, returns the probability that `havoc_mutation` is called in havoc. By default, it is 6%. @@ -114,10 +146,19 @@ def queue_new_entry(filename_new_queue, filename_orig_queue): `post_process` function. This function is then transforming the data into the format expected by the API before executing the target. + This can return any python object that implements the buffer protocol and + supports PyBUF_SIMPLE. These include bytes, bytearray, etc. + - `queue_new_entry` (optional): This methods is called after adding a new test case to the queue. +- `introspection` (optional): + + This method is called after a new queue entry, crash or timeout is + discovered if compiled with INTROSPECTION. The custom mutator can then + return a string (const char *) that reports the exact mutations used. + - `deinit`: The last method to be called, deinitializing the state. @@ -146,7 +187,7 @@ trimmed input. Here's a quick API description: on this input (e.g. if your input has n elements and you want to remove them one by one, return n, if you do a binary search, return log(n), and so on). - If your trimming algorithm doesn't allow you to determine the amount of + If your trimming algorithm doesn't allow to determine the amount of (remaining) steps easily (esp. while running), then you can alternatively return 1 here and always return 0 in `post_trim` until you are finished and no steps remain. In that case, returning 1 in `post_trim` will end the @@ -188,19 +229,20 @@ Optionally, the following environment variables are supported: - `AFL_PYTHON_ONLY` - Deprecated and removed, use `AFL_CUSTOM_MUTATOR_ONLY` instead - trimming can cause the same test breakage like havoc and splice. + Deprecated and removed, use `AFL_CUSTOM_MUTATOR_ONLY` instead. - `AFL_DEBUG` - When combined with `AFL_NO_UI`, this causes the C trimming code to emit additional messages about the performance and actions of your custom trimmer. Use this to see if it works :) + When combined with `AFL_NO_UI`, this causes the C trimming code to emit + additional messages about the performance and actions of your custom + trimmer. Use this to see if it works :) ## 3) Usage ### Prerequisite -For Python mutator, the python 3 or 2 development package is required. On -Debian/Ubuntu/Kali this can be done: +For Python mutators, the python 3 or 2 development package is required. On +Debian/Ubuntu/Kali it can be installed like this: ```bash sudo apt install python3-dev @@ -218,13 +260,13 @@ In case your setup is different, set the necessary variables like this: ### Custom Mutator Preparation -For C/C++ mutator, the source code must be compiled as a shared object: +For C/C++ mutators, the source code must be compiled as a shared object: ```bash gcc -shared -Wall -O3 example.c -o example.so ``` Note that if you specify multiple custom mutators, the corresponding functions will be called in the order in which they are specified. e.g first `post_process` function of -`example_first.so` will be called and then that of `example_second.so` +`example_first.so` will be called and then that of `example_second.so`. ### Run @@ -243,8 +285,8 @@ afl-fuzz /path/to/program ## 4) Example -Please see [example.c](../examples/custom_mutators/example.c) and -[example.py](../examples/custom_mutators/example.py) +Please see [example.c](../utils/custom_mutators/example.c) and +[example.py](../utils/custom_mutators/example.py) ## 5) Other Resources diff --git a/docs/docs.md b/docs/docs.md new file mode 100644 index 00000000..ed6ec85e --- /dev/null +++ b/docs/docs.md @@ -0,0 +1,122 @@ +# Restructure afl++'s documentation + +## About us + +We are dedicated to everything around fuzzing, our main and most well known +contribution is the fuzzer `afl++` which is part of all major Unix +distributions (e.g. Debian, Arch, FreeBSD, etc.) and is deployed on Google's +oss-fuzz and clusterfuzz. It is rated the top fuzzer on Google's fuzzbench. + +We are four individuals from Europe supported by a large community. + +All our tools are open source. + +## About the afl++ fuzzer project + +afl++ inherited it's documentation from the original Google afl project. +Since then it has been massively improved - feature and performance wise - +and although the documenation has likewise been continued it has grown out +of proportion. +The documentation is done by non-natives to the English language, plus +none of us has a writer background. + +We see questions on afl++ usage on mailing lists (e.g. afl-users), discord +channels, web forums and as issues in our repository. + +This only increases as afl++ has been on the top of Google's fuzzbench +statistics (which measures the performance of fuzzers) and is now being +integrated in Google's oss-fuzz and clusterfuzz - and is in many Unix +packaging repositories, e.g. Debian, FreeBSD, etc. + +afl++ now has 44 (!) documentation files with 13k total lines of content. +This is way too much. + +Hence afl++ needs a complete overhaul of it's documentation, both on a +organisation/structural level as well as the content. + +Overall the following actions have to be performed: + * Create a better structure of documentation so it is easier to find the + information that is being looked for, combining and/or splitting up the + existing documents as needed. + * Rewrite some documentation to remove duplication. Several information is + present several times in the documentation. These should be removed to + where needed so that we have as little bloat as possible. + * The documents have been written and modified by a lot of different people, + most of them non-native English speaker. Hence an overall review where + parts should be rewritten has to be performed and then the rewrite done. + * Create a cheat-sheet for a very short best-setup build and run of afl++ + * Pictures explain more than 1000 words. We need at least 4 images that + explain the workflow with afl++: + - the build workflow + - the fuzzing workflow + - the fuzzing campaign management workflow + - the overall workflow that is an overview of the above + - maybe more? where the technical writes seems it necessary for + understanding. + +Requirements: + * Documentation has to be in Markdown format + * Images have to be either in SVG or PNG format. + * All documentation should be (moved) in(to) docs/ + +The project does not require writing new documentation or tutorials beside the +cheat sheet. The technical information for the cheat sheet will be provided by +us. + +## Metrics + +afl++ is a the highest performant fuzzer publicly available - but is also the +most feature rich and complex. With the publicity of afl++' success and +deployment in Google projects internally and externally and availability as +a package on most Linux distributions we see more and more issues being +created and help requests on our Discord channel that would not be +necessary if people would have read through all our documentation - which +is unrealistic. + +We expect the the new documenation after this project to be cleaner, easier +accessible and lighter to digest by our users, resulting in much less +help requests. On the other hand the amount of users using afl++ should +increase as well as it will be more accessible which would also increase +questions again - but overall resulting in a reduction of help requests. + +In numbers: we currently have per week on average 5 issues on Github, +10 questions on discord and 1 on mailing lists that would not be necessary +with perfect documentation and perfect people. + +We would consider this project a success if afterwards we only have +2 issues on Github and 3 questions on discord anymore that would be answered +by reading the documentation. The mailing list is usually used by the most +novice users and we don't expect any less questions there. + +## Project Budget + +We have zero experience with technical writers, so this is very hard for us +to calculate. We expect it to be a lot of work though because of the amount +of documentation we have that needs to be restructured and partially rewritten +(44 documents with 13k total lines of content). + +We assume the daily rate of a very good and experienced technical writer in +times of a pandemic to be ~500$ (according to web research), and calculate +the overall amout of work to be around 20 days for everything incl. the +graphics (but again - this is basically just guessing). + +Technical Writer 10000$ +Volunteer stipends 0$ (waved) +T-Shirts for the top 10 contributors and helpers to this documentation project: + 10 afl++ logo t-shirts 20$ each 200$ + 10 shipping cost of t-shirts 10$ each 100$ + +Total: 10.300$ +(in the submission form 10.280$ was entered) + +## Additional Information + +We have participated in Google Summer of Code in 2020 and hope to be selected +again in 2021. + +We have no experience with a technical writer, but we will support that person +with video calls, chats, emails and messaging, provide all necessary information +and write technical contents that is required for the success of this project. +It is clear to us that a technical writer knows how to write, but cannot know +the technical details in a complex tooling like in afl++. This guidance, input, +etc. has to come from us. diff --git a/docs/env_variables.md b/docs/env_variables.md index 87344331..c6ad0aa4 100644 --- a/docs/env_variables.md +++ b/docs/env_variables.md @@ -2,49 +2,78 @@ This document discusses the environment variables used by American Fuzzy Lop++ to expose various exotic functions that may be (rarely) useful for power - users or for some types of custom fuzzing setups. See README.md for the general + users or for some types of custom fuzzing setups. See [README.md](README.md) for the general instruction manual. -## 1) Settings for afl-gcc, afl-clang, and afl-as - and gcc_plugin afl-gcc-fast - -Because they can't directly accept command-line options, the compile-time -tools make fairly broad use of environmental variables: - - - Most afl tools do not print any ouput if stout/stderr are redirected. - If you want to have the output into a file then set the AFL_DEBUG + Note that most tools will warn on any unknown AFL environment variables. + This is for warning on typos that can happen. If you want to disable this + check then set the `AFL_IGNORE_UNKNOWN_ENVS` environment variable. + +## 1) Settings for all compilers + +Starting with afl++ 3.0 there is only one compiler: afl-cc +To select the different instrumentation modes this can be done by + 1. passing the --afl-MODE command line option to the compiler + 2. or using a symlink to afl-cc: afl-gcc, afl-g++, afl-clang, afl-clang++, + afl-clang-fast, afl-clang-fast++, afl-clang-lto, afl-clang-lto++, + afl-gcc-fast, afl-g++-fast + 3. or using the environment variable `AFL_CC_COMPILER` with `MODE` + +`MODE` can be one of `LTO` (afl-clang-lto*), `LLVM` (afl-clang-fast*), `GCC_PLUGIN` +(afl-g*-fast) or `GCC` (afl-gcc/afl-g++). + +Because (with the exception of the --afl-MODE command line option) the +compile-time tools do not accept afl specific command-line options, they +make fairly broad use of environmental variables instead: + + - Some build/configure scripts break with afl++ compilers. To be able to + pass them, do: +``` + export CC=afl-cc + export CXX=afl-c++ + export AFL_NOOPT=1 + ./configure --disable-shared --disabler-werror + unset AFL_NOOPT + make +``` + + - Most afl tools do not print any output if stdout/stderr are redirected. + If you want to get the output into a file then set the `AFL_DEBUG` environment variable. This is sadly necessary for various build processes which fail otherwise. - - Setting AFL_HARDEN automatically adds code hardening options when invoking - the downstream compiler. This currently includes -D_FORTIFY_SOURCE=2 and - -fstack-protector-all. The setting is useful for catching non-crashing + - Setting `AFL_HARDEN` automatically adds code hardening options when invoking + the downstream compiler. This currently includes `-D_FORTIFY_SOURCE=2` and + `-fstack-protector-all`. The setting is useful for catching non-crashing memory bugs at the expense of a very slight (sub-5%) performance loss. - - By default, the wrapper appends -O3 to optimize builds. Very rarely, this - will cause problems in programs built with -Werror, simply because -O3 + - By default, the wrapper appends `-O3` to optimize builds. Very rarely, this + will cause problems in programs built with -Werror, simply because `-O3` enables more thorough code analysis and can spew out additional warnings. - To disable optimizations, set AFL_DONT_OPTIMIZE. + To disable optimizations, set `AFL_DONT_OPTIMIZE`. + However if `-O...` and/or `-fno-unroll-loops` are set, these are not + overridden. - - Setting AFL_USE_ASAN automatically enables ASAN, provided that your + - Setting `AFL_USE_ASAN` automatically enables ASAN, provided that your compiler supports that. Note that fuzzing with ASAN is mildly challenging - see [notes_for_asan.md](notes_for_asan.md). - (You can also enable MSAN via AFL_USE_MSAN; ASAN and MSAN come with the + (You can also enable MSAN via `AFL_USE_MSAN`; ASAN and MSAN come with the same gotchas; the modes are mutually exclusive. UBSAN can be enabled - similarly by setting the environment variable AFL_USE_UBSAN=1. Finally + similarly by setting the environment variable `AFL_USE_UBSAN=1`. Finally there is the Control Flow Integrity sanitizer that can be activated by - AFL_USE_CFISAN=1) + `AFL_USE_CFISAN=1`) - - Setting AFL_CC, AFL_CXX, and AFL_AS lets you use alternate downstream + - Setting `AFL_CC`, `AFL_CXX`, and `AFL_AS` lets you use alternate downstream compilation tools, rather than the default 'clang', 'gcc', or 'as' binaries - in your $PATH. + in your `$PATH`. - - AFL_PATH can be used to point afl-gcc to an alternate location of afl-as. - One possible use of this is examples/clang_asm_normalize/, which lets + - `AFL_PATH` can be used to point afl-gcc to an alternate location of afl-as. + One possible use of this is utils/clang_asm_normalize/, which lets you instrument hand-written assembly when compiling clang code by plugging a normalizer into the chain. (There is no equivalent feature for GCC.) - - Setting AFL_INST_RATIO to a percentage between 0 and 100% controls the + - Setting `AFL_INST_RATIO` to a percentage between 0 and 100 controls the probability of instrumenting every branch. This is (very rarely) useful when dealing with exceptionally complex programs that saturate the output bitmap. Examples include v8, ffmpeg, and perl. @@ -52,467 +81,554 @@ tools make fairly broad use of environmental variables: (If this ever happens, afl-fuzz will warn you ahead of the time by displaying the "bitmap density" field in fiery red.) - Setting AFL_INST_RATIO to 0 is a valid choice. This will instrument only + Setting `AFL_INST_RATIO` to 0 is a valid choice. This will instrument only the transitions between function entry points, but not individual branches. - - AFL_NO_BUILTIN causes the compiler to generate code suitable for use with + Note that this is an outdated variable. A few instances (e.g. afl-gcc) + still support these, but state-of-the-art (e.g. LLVM LTO and LLVM PCGUARD) + do not need this. + + - `AFL_NO_BUILTIN` causes the compiler to generate code suitable for use with libtokencap.so (but perhaps running a bit slower than without the flag). - - TMPDIR is used by afl-as for temporary files; if this variable is not set, + - `TMPDIR` is used by afl-as for temporary files; if this variable is not set, the tool defaults to /tmp. - - Setting AFL_KEEP_ASSEMBLY prevents afl-as from deleting instrumented - assembly files. Useful for troubleshooting problems or understanding how - the tool works. To get them in a predictable place, try something like: - - mkdir assembly_here - TMPDIR=$PWD/assembly_here AFL_KEEP_ASSEMBLY=1 make clean all - - If you are a weird person that wants to compile and instrument asm - text files then use the AFL_AS_FORCE_INSTRUMENT variable: - AFL_AS_FORCE_INSTRUMENT=1 afl-gcc foo.s -o foo + text files then use the `AFL_AS_FORCE_INSTRUMENT` variable: + `AFL_AS_FORCE_INSTRUMENT=1 afl-gcc foo.s -o foo` - - Setting AFL_QUIET will prevent afl-cc and afl-as banners from being + - Setting `AFL_QUIET` will prevent afl-cc and afl-as banners from being displayed during compilation, in case you find them distracting. - - Setting AFL_CAL_FAST will speed up the initial calibration, if the - application is very slow + - Setting `AFL_CAL_FAST` will speed up the initial calibration, if the + application is very slow. -## 2) Settings for afl-clang-fast / afl-clang-fast++ / afl-gcc-fast / afl-g++-fast +## 2) Settings for LLVM and LTO: afl-clang-fast / afl-clang-fast++ / afl-clang-lto / afl-clang-lto++ -The native instrumentation helpers (llvm_mode and gcc_plugin) accept a subset -of the settings discussed in section #1, with the exception of: +The native instrumentation helpers (instrumentation and gcc_plugin) accept a subset +of the settings discussed in section 1, with the exception of: - - Setting AFL_LLVM_SKIPSINGLEBLOCK=1 will skip instrumenting - functions with a single basic block. This is useful for most C and - some C++ targets. This works for all instrumentation modes. + - LLVM modes support `AFL_LLVM_DICT2FILE=/absolute/path/file.txt` which will + write all constant string comparisons to this file to be used later with + afl-fuzz' `-x` option. - - AFL_AS, since this toolchain does not directly invoke GNU as. + - `AFL_AS`, since this toolchain does not directly invoke GNU as. - - TMPDIR and AFL_KEEP_ASSEMBLY, since no temporary assembly files are + - `TMPDIR` and `AFL_KEEP_ASSEMBLY`, since no temporary assembly files are created. - - AFL_INST_RATIO, as we switched for instrim instrumentation which - is more effective but makes not much sense together with this option. + - `AFL_INST_RATIO`, as we by default use collision free instrumentation. + Not all passes support this option though as it is an outdated feature. -Then there are a few specific features that are only available in llvm_mode: +Then there are a few specific features that are only available in instrumentation mode: ### Select the instrumentation mode - - AFL_LLVM_INSTRUMENT - this configures the instrumentation mode. + - `AFL_LLVM_INSTRUMENT` - this configures the instrumentation mode. Available options: + PCGUARD - our own pcgard based instrumentation (default) + NATIVE - clang's original pcguard based instrumentation CLASSIC - classic AFL (map[cur_loc ^ prev_loc >> 1]++) (default) CFG - InsTrim instrumentation (see below) LTO - LTO instrumentation (see below) CTX - context sensitive instrumentation (see below) NGRAM-x - deeper previous location coverage (from NGRAM-2 up to NGRAM-16) + GCC - outdated gcc instrumentation + CLANG - outdated clang instrumentation In CLASSIC (default) and CFG/INSTRIM you can also specify CTX and/or NGRAM, seperate the options with a comma "," then, e.g.: - AFL_LLVM_INSTRUMENT=CFG,CTX,NGRAM-4 + `AFL_LLVM_INSTRUMENT=CFG,CTX,NGRAM-4` Not that this is a good idea to use both CTX and NGRAM :) ### LTO - This is a different kind way of instrumentation: first it compiles all + This is a different kind way of instrumentation: first it compiles all code in LTO (link time optimization) and then performs an edge inserting instrumentation which is 100% collision free (collisions are a big issue in afl and afl-like instrumentations). This is performed by using afl-clang-lto/afl-clang-lto++ instead of afl-clang-fast, but is only built if LLVM 11 or newer is used. - - AFL_LLVM_INSTRUMENT=CFG will use Control Flow Graph instrumentation. - (recommended) - - - AFL_LLVM_LTO_AUTODICTIONARY will generate a dictionary in the target - binary based on string compare and memory compare functions. - afl-fuzz will automatically get these transmitted when starting to - fuzz. + - `AFL_LLVM_INSTRUMENT=CFG` will use Control Flow Graph instrumentation. + (not recommended for afl-clang-fast, default for afl-clang-lto as there + it is a different and better kind of instrumentation.) - None of the following options are necessary to be used and are rather for + None of the following options are necessary to be used and are rather for manual use (which only ever the author of this LTO implementation will use). - These are used if several seperated instrumentation are performed which + These are used if several separated instrumentations are performed which are then later combined. - - AFL_LLVM_MAP_ADDR sets the fixed map address to a different address than - the default 0x10000. A value of 0 or empty sets the map address to be + - `AFL_LLVM_DOCUMENT_IDS=file` will document to a file which edge ID was given + to which function. This helps to identify functions with variable bytes + or which functions were touched by an input. + - `AFL_LLVM_MAP_ADDR` sets the fixed map address to a different address than + the default `0x10000`. A value of 0 or empty sets the map address to be dynamic (the original afl way, which is slower) - - AFL_LLVM_MAP_DYNAMIC sets the shared memory address to be dynamic - - AFL_LLVM_LTO_STARTID sets the starting location ID for the instrumentation. + - `AFL_LLVM_MAP_DYNAMIC` sets the shared memory address to be dynamic + - `AFL_LLVM_LTO_STARTID` sets the starting location ID for the instrumentation. This defaults to 1 - - AFL_LLVM_LTO_DONTWRITEID prevents that the highest location ID written + - `AFL_LLVM_LTO_DONTWRITEID` prevents that the highest location ID written into the instrumentation is set in a global variable - See llvm_mode/README.LTO.md for more information. + See [instrumentation/README.lto.md](../instrumentation/README.lto.md) for more information. ### INSTRIM - This feature increases the speed by ~15% without any disadvantages to the + This feature increases the speed by ~15% without any disadvantages to the classic instrumentation. - Note that there is also an LTO version (if you have llvm 11 or higher) - + Note that there is also an LTO version (if you have llvm 11 or higher) - that is the best instrumentation we have. Use `afl-clang-lto` to activate. The InsTrim LTO version additionally has all the options and features of LTO (see above). - - Setting AFL_LLVM_INSTRIM or AFL_LLVM_INSTRUMENT=CFG to activates this mode + - Setting `AFL_LLVM_INSTRIM` or `AFL_LLVM_INSTRUMENT=CFG` activates this mode - - Setting AFL_LLVM_INSTRIM_LOOPHEAD=1 expands on INSTRIM to optimize loops. + - Setting `AFL_LLVM_INSTRIM_LOOPHEAD=1` expands on INSTRIM to optimize loops. afl-fuzz will only be able to see the path the loop took, but not how many times it was called (unless it is a complex loop). - See llvm_mode/README.instrim.md + See [instrumentation/README.instrim.md](../instrumentation/README.instrim.md) ### NGRAM - - Setting AFL_LLVM_NGRAM_SIZE or AFL_LLVM_INSTRUMENT=NGRAM-{value} + - Setting `AFL_LLVM_NGRAM_SIZE` or `AFL_LLVM_INSTRUMENT=NGRAM-{value}` activates ngram prev_loc coverage, good values are 2, 4 or 8 (any value between 2 and 16 is valid). - It is highly recommended to increase the MAP_SIZE_POW2 definition in + It is highly recommended to increase the `MAP_SIZE_POW2` definition in config.h to at least 18 and maybe up to 20 for this as otherwise too many map collisions occur. - See llvm_mode/README.ctx.md + See [instrumentation/README.ngram.md](../instrumentation/README.ngram.md) ### CTX - - Setting AFL_LLVM_CTX or AFL_LLVM_INSTRUMENT=CTX + - Setting `AFL_LLVM_CTX` or `AFL_LLVM_INSTRUMENT=CTX` activates context sensitive branch coverage - meaning that each edge is additionally combined with its caller. - It is highly recommended to increase the MAP_SIZE_POW2 definition in + It is highly recommended to increase the `MAP_SIZE_POW2` definition in config.h to at least 18 and maybe up to 20 for this as otherwise too many map collisions occur. - See llvm_mode/README.ngram.md + See [instrumentation/README.ctx.md](../instrumentation/README.ctx.md) ### LAF-INTEL - This great feature will split compares to series of single byte comparisons + This great feature will split compares into series of single byte comparisons to allow afl-fuzz to find otherwise rather impossible paths. It is not restricted to Intel CPUs ;-) - - Setting AFL_LLVM_LAF_TRANSFORM_COMPARES will split string compare functions + - Setting `AFL_LLVM_LAF_TRANSFORM_COMPARES` will split string compare functions - - Setting AFL_LLVM_LAF_SPLIT_SWITCHES will split switch()es + - Setting `AFL_LLVM_LAF_SPLIT_SWITCHES` will split all `switch` constructs - - Setting AFL_LLVM_LAF_SPLIT_COMPARES will split all floating point and + - Setting `AFL_LLVM_LAF_SPLIT_COMPARES` will split all floating point and 64, 32 and 16 bit integer CMP instructions - - Setting AFL_LLVM_LAF_SPLIT_FLOATS will split floating points, needs + - Setting `AFL_LLVM_LAF_SPLIT_FLOATS` will split floating points, needs AFL_LLVM_LAF_SPLIT_COMPARES to be set - - Setting AFL_LLVM_LAF_ALL sets all of the above + - Setting `AFL_LLVM_LAF_ALL` sets all of the above - See llvm_mode/README.laf-intel.md for more information. + See [instrumentation/README.laf-intel.md](../instrumentation/README.laf-intel.md) for more information. -### INSTRUMENT_FILE +### INSTRUMENT LIST (selectively instrument files and functions) - This feature allows selectively instrumentation of the source + This feature allows selective instrumentation of the source - - Setting AFL_LLVM_INSTRUMENT_FILE with a filename will only instrument those - files that match the names listed in this file. + - Setting `AFL_LLVM_ALLOWLIST` or `AFL_LLVM_DENYLIST` with a filenames and/or + function will only instrument (or skip) those files that match the names + listed in the specified file. - See llvm_mode/README.instrument_file.md for more information. + See [instrumentation/README.instrument_list.md](../instrumentation/README.instrument_list.md) for more information. ### NOT_ZERO - - Setting AFL_LLVM_NOT_ZERO=1 during compilation will use counters + - Setting `AFL_LLVM_NOT_ZERO=1` during compilation will use counters that skip zero on overflow. This is the default for llvm >= 9, however for llvm versions below that this will increase an unnecessary slowdown due a performance issue that is only fixed in llvm 9+. This feature increases path discovery by a little bit. - - Setting AFL_LLVM_SKIP_NEVERZERO=1 will not implement the skip zero + - Setting `AFL_LLVM_SKIP_NEVERZERO=1` will not implement the skip zero test. If the target performs only few loops then this will give a small performance boost. - See llvm_mode/README.neverzero.md + See [instrumentation/README.neverzero.md](../instrumentation/README.neverzero.md) ### CMPLOG - - Setting AFL_LLVM_CMPLOG=1 during compilation will tell afl-clang-fast to - produce a CmpLog binary. See llvm_mode/README.cmplog.md + - Setting `AFL_LLVM_CMPLOG=1` during compilation will tell afl-clang-fast to + produce a CmpLog binary. - See llvm_mode/README.neverzero.md + See [instrumentation/README.cmplog.md](../instrumentation/README.cmplog.md) -Then there are a few specific features that are only available in the gcc_plugin: +## 3) Settings for GCC / GCC_PLUGIN modes -### INSTRUMENT_FILE +Then there are a few specific features that are only available in GCC and +GCC_PLUGIN mode. - This feature allows selective instrumentation of the source - - - Setting AFL_GCC_INSTRUMENT_FILE with a filename will only instrument those - files that match the names listed in this file (one filename per line). - - See gcc_plugin/README.instrument_file.md for more information. + - Setting `AFL_KEEP_ASSEMBLY` prevents afl-as from deleting instrumented + assembly files. Useful for troubleshooting problems or understanding how + the tool works. (GCC mode only) + To get them in a predictable place, try something like: +``` + mkdir assembly_here + TMPDIR=$PWD/assembly_here AFL_KEEP_ASSEMBLY=1 make clean all +``` + - Setting `AFL_GCC_INSTRUMENT_FILE` with a filename will only instrument those + files that match the names listed in this file (one filename per line). + See [instrumentation/README.instrument_list.md](../instrumentation/README.instrument_list.md) for more information. + (GCC_PLUGIN mode only) -## 3) Settings for afl-fuzz +## 4) Settings for afl-fuzz The main fuzzer binary accepts several options that disable a couple of sanity checks or alter some of the more exotic semantics of the tool: - - Setting AFL_SKIP_CPUFREQ skips the check for CPU scaling policy. This is + - Setting `AFL_SKIP_CPUFREQ` skips the check for CPU scaling policy. This is useful if you can't change the defaults (e.g., no root access to the system) and are OK with some performance loss. - - Setting AFL_NO_FORKSRV disables the forkserver optimization, reverting to - fork + execve() call for every tested input. This is useful mostly when - working with unruly libraries that create threads or do other crazy - things when initializing (before the instrumentation has a chance to run). - - Note that this setting inhibits some of the user-friendly diagnostics - normally done when starting up the forkserver and causes a pretty - significant performance drop. - - - AFL_EXIT_WHEN_DONE causes afl-fuzz to terminate when all existing paths + - `AFL_EXIT_WHEN_DONE` causes afl-fuzz to terminate when all existing paths have been fuzzed and there were no new finds for a while. This would be normally indicated by the cycle counter in the UI turning green. May be convenient for some types of automated jobs. - - AFL_MAP_SIZE sets the size of the shared map that afl-fuzz, afl-showmap, + - `AFL_MAP_SIZE` sets the size of the shared map that afl-fuzz, afl-showmap, afl-tmin and afl-analyze create to gather instrumentation data from the target. This must be equal or larger than the size the target was compiled with. - - Setting AFL_NO_AFFINITY disables attempts to bind to a specific CPU core + - `AFL_CMPLOG_ONLY_NEW` will only perform the expensive cmplog feature for + newly found testcases and not for testcases that are loaded on startup + (`-i in`). This is an important feature to set when resuming a fuzzing + session. + + - `AFL_TESTCACHE_SIZE` allows you to override the size of `#define TESTCASE_CACHE` + in config.h. Recommended values are 50-250MB - or more if your fuzzing + finds a huge amount of paths for large inputs. + + - Setting `AFL_DISABLE_TRIM` tells afl-fuzz not to trim test cases. This is + usually a bad idea! + + - Setting `AFL_NO_AFFINITY` disables attempts to bind to a specific CPU core on Linux systems. This slows things down, but lets you run more instances of afl-fuzz than would be prudent (if you really want to). - - AFL_SKIP_CRASHES causes AFL to tolerate crashing files in the input + - Setting `AFL_NO_AUTODICT` will not load an LTO generated auto dictionary + that is compiled into the target. + + - `AFL_SKIP_CRASHES` causes AFL++ to tolerate crashing files in the input queue. This can help with rare situations where a program crashes only intermittently, but it's not really recommended under normal operating conditions. - - Setting AFL_HANG_TMOUT allows you to specify a different timeout for + - Setting `AFL_HANG_TMOUT` allows you to specify a different timeout for deciding if a particular test case is a "hang". The default is 1 second - or the value of the -t parameter, whichever is larger. Dialing the value + or the value of the `-t` parameter, whichever is larger. Dialing the value down can be useful if you are very concerned about slow inputs, or if you - don't want AFL to spend too much time classifying that stuff and just + don't want AFL++ to spend too much time classifying that stuff and just rapidly put all timeouts in that bin. - - AFL_NO_ARITH causes AFL to skip most of the deterministic arithmetics. + - Setting `AFL_FORKSRV_INIT_TMOUT` allows you to specify a different timeout + to wait for the forkserver to spin up. The default is the `-t` value times + `FORK_WAIT_MULT` from `config.h` (usually 10), so for a `-t 100`, the + default would wait for `1000` milliseconds. Setting a different time here is useful + if the target has a very slow startup time, for example when doing + full-system fuzzing or emulation, but you don't want the actual runs + to wait too long for timeouts. + + - `AFL_NO_ARITH` causes AFL++ to skip most of the deterministic arithmetics. This can be useful to speed up the fuzzing of text-based file formats. - - AFL_NO_SNAPSHOT will advice afl-fuzz not to use the snapshot feature + - `AFL_NO_SNAPSHOT` will advice afl-fuzz not to use the snapshot feature if the snapshot lkm is loaded - - AFL_SHUFFLE_QUEUE randomly reorders the input queue on startup. Requested + - `AFL_SHUFFLE_QUEUE` randomly reorders the input queue on startup. Requested by some users for unorthodox parallelized fuzzing setups, but not advisable otherwise. - - AFL_TMPDIR is used to write the .cur_input file to if exists, and in + - `AFL_TMPDIR` is used to write the `.cur_input` file to if exists, and in the normal output directory otherwise. You would use this to point to a ramdisk/tmpfs. This increases the speed by a small value but also reduces the stress on SSDs. - When developing custom instrumentation on top of afl-fuzz, you can use - AFL_SKIP_BIN_CHECK to inhibit the checks for non-instrumented binaries - and shell scripts; and AFL_DUMB_FORKSRV in conjunction with the -n + `AFL_SKIP_BIN_CHECK` to inhibit the checks for non-instrumented binaries + and shell scripts; and `AFL_DUMB_FORKSRV` in conjunction with the `-n` setting to instruct afl-fuzz to still follow the fork server protocol without expecting any instrumentation data in return. - - When running in the -M or -S mode, setting AFL_IMPORT_FIRST causes the + - When running in the `-M` or `-S` mode, setting `AFL_IMPORT_FIRST` causes the fuzzer to import test cases from other instances before doing anything else. This makes the "own finds" counter in the UI more accurate. Beyond counter aesthetics, not much else should change. - - Note that AFL_POST_LIBRARY is deprecated, use AFL_CUSTOM_MUTATOR_LIBRARY + - Note that `AFL_POST_LIBRARY` is deprecated, use `AFL_CUSTOM_MUTATOR_LIBRARY` instead (see below). - - Setting AFL_CUSTOM_MUTATOR_LIBRARY to a shared library with + - `AFL_KILL_SIGNAL`: Set the signal ID to be delivered to child processes on timeout. + Unless you implement your own targets or instrumentation, you likely don't have to set it. + By default, on timeout and on exit, `SIGKILL` (`AFL_KILL_SIGNAL=9`) will be delivered to the child. + + - Setting `AFL_CUSTOM_MUTATOR_LIBRARY` to a shared library with afl_custom_fuzz() creates additional mutations through this library. If afl-fuzz is compiled with Python (which is autodetected during builing - afl-fuzz), setting AFL_PYTHON_MODULE to a Python module can also provide + afl-fuzz), setting `AFL_PYTHON_MODULE` to a Python module can also provide additional mutations. - If AFL_CUSTOM_MUTATOR_ONLY is also set, all mutations will solely be + If `AFL_CUSTOM_MUTATOR_ONLY` is also set, all mutations will solely be performed with the custom mutator. This feature allows to configure custom mutators which can be very helpful, e.g. fuzzing XML or other highly flexible structured input. Please see [custom_mutators.md](custom_mutators.md). - - AFL_FAST_CAL keeps the calibration stage about 2.5x faster (albeit less + - `AFL_FAST_CAL` keeps the calibration stage about 2.5x faster (albeit less precise), which can help when starting a session against a slow target. - The CPU widget shown at the bottom of the screen is fairly simplistic and may complain of high load prematurely, especially on systems with low core - counts. To avoid the alarming red color, you can set AFL_NO_CPU_RED. + counts. To avoid the alarming red color, you can set `AFL_NO_CPU_RED`. + + - In QEMU mode (-Q), `AFL_PATH` will be searched for afl-qemu-trace. - - In QEMU mode (-Q), AFL_PATH will be searched for afl-qemu-trace. + - In QEMU mode (-Q), setting `AFL_QEMU_CUSTOM_BIN` cause afl-fuzz to skip + prepending `afl-qemu-trace` to your command line. Use this if you wish to use a + custom afl-qemu-trace or if you need to modify the afl-qemu-trace arguments. - - Setting AFL_PRELOAD causes AFL to set LD_PRELOAD for the target binary + - Setting `AFL_CYCLE_SCHEDULES` will switch to a different schedule everytime + a cycle is finished. + + - Setting `AFL_EXPAND_HAVOC_NOW` will start in the extended havoc mode that + includes costly mutations. afl-fuzz automatically enables this mode when + deemed useful otherwise. + + - Setting `AFL_PRELOAD` causes AFL++ to set `LD_PRELOAD` for the target binary without disrupting the afl-fuzz process itself. This is useful, among other things, for bootstrapping libdislocator.so. - - Setting AFL_NO_UI inhibits the UI altogether, and just periodically prints + - Setting `AFL_NO_UI` inhibits the UI altogether, and just periodically prints some basic stats. This behavior is also automatically triggered when the output from afl-fuzz is redirected to a file or to a pipe. - - Setting AFL_FORCE_UI will force painting the UI on the screen even if + - Setting `AFL_NO_COLOR` or `AFL_NO_COLOUR` will omit control sequences for + coloring console output when configured with USE_COLOR and not ALWAYS_COLORED. + + - Setting `AFL_FORCE_UI` will force painting the UI on the screen even if no valid terminal was detected (for virtual consoles) - - If you are Jakub, you may need AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES. + - If you are Jakub, you may need `AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES`. Others need not apply. - - Benchmarking only: AFL_BENCH_JUST_ONE causes the fuzzer to exit after - processing the first queue entry; and AFL_BENCH_UNTIL_CRASH causes it to + - Benchmarking only: `AFL_BENCH_JUST_ONE` causes the fuzzer to exit after + processing the first queue entry; and `AFL_BENCH_UNTIL_CRASH` causes it to exit soon after the first crash is found. - - Setting AFL_DEBUG_CHILD_OUTPUT will not suppress the child output. + - Setting `AFL_DEBUG_CHILD` will not suppress the child output. + This lets you see all output of the child, making setup issues obvious. + For example, in an unicornafl harness, you might see python stacktraces. + You may also see other logs that way, indicating why the forkserver won't start. Not pretty but good for debugging purposes. + Note that `AFL_DEBUG_CHILD_OUTPUT` is deprecated. - - Setting AFL_NO_CPU_RED will not display very high cpu usages in red color. + - Setting `AFL_NO_CPU_RED` will not display very high cpu usages in red color. - - Setting AFL_AUTORESUME will resume a fuzz run (same as providing `-i -`) + - Setting `AFL_AUTORESUME` will resume a fuzz run (same as providing `-i -`) for an existing out folder, even if a different `-i` was provided. Without this setting, afl-fuzz will refuse execution for a long-fuzzed out dir. - - Outdated environment variables that are that not supported anymore: - AFL_DEFER_FORKSRV - AFL_PERSISTENT + - Setting `AFL_MAX_DET_EXRAS` will change the threshold at what number of elements + in the `-x` dictionary and LTO autodict (combined) the probabilistic mode will + kick off. In probabilistic mode not all dictionary entires will be used all + of the times for fuzzing mutations to not slow down fuzzing. + The default count is `200` elements. So for the 200 + 1st element, there is a + 1 in 201 chance, that one of the dictionary entries will not be used directly. -## 4) Settings for afl-qemu-trace + - Setting `AFL_NO_FORKSRV` disables the forkserver optimization, reverting to + fork + execve() call for every tested input. This is useful mostly when + working with unruly libraries that create threads or do other crazy + things when initializing (before the instrumentation has a chance to run). + + Note that this setting inhibits some of the user-friendly diagnostics + normally done when starting up the forkserver and causes a pretty + significant performance drop. + + - Setting `AFL_STATSD` enables StatsD metrics collection. + By default AFL++ will send these metrics over UDP to 127.0.0.1:8125. + The host and port are configurable with `AFL_STATSD_HOST` and `AFL_STATSD_PORT` respectively. + To enable tags (banner and afl_version) you should provide `AFL_STATSD_TAGS_FLAVOR` that matches + your StatsD server (see `AFL_STATSD_TAGS_FLAVOR`) + + - Setting `AFL_STATSD_TAGS_FLAVOR` to one of `dogstatsd`, `librato`, `signalfx` or `influxdb` + allows you to add tags to your fuzzing instances. This is especially useful when running + multiple instances (`-M/-S` for example). Applied tags are `banner` and `afl_version`. + `banner` corresponds to the name of the fuzzer provided through `-M/-S`. + `afl_version` corresponds to the currently running afl version (e.g `++3.0c`). + Default (empty/non present) will add no tags to the metrics. + See [rpc_statsd.md](rpc_statsd.md) for more information. + + - Setting `AFL_CRASH_EXITCODE` sets the exit code afl treats as crash. + For example, if `AFL_CRASH_EXITCODE='-1'` is set, each input resulting + in an `-1` return code (i.e. `exit(-1)` got called), will be treated + as if a crash had ocurred. + This may be beneficial if you look for higher-level faulty conditions in which your + target still exits gracefully. + + - Outdated environment variables that are not supported anymore: + `AFL_DEFER_FORKSRV` + `AFL_PERSISTENT` + +## 5) Settings for afl-qemu-trace The QEMU wrapper used to instrument binary-only code supports several settings: - - It is possible to set AFL_INST_RATIO to skip the instrumentation on some + - It is possible to set `AFL_INST_RATIO` to skip the instrumentation on some of the basic blocks, which can be useful when dealing with very complex binaries. - - Setting AFL_INST_LIBS causes the translator to also instrument the code + - Setting `AFL_INST_LIBS` causes the translator to also instrument the code inside any dynamically linked libraries (notably including glibc). - - Setting AFL_COMPCOV_LEVEL enables the CompareCoverage tracing of all cmp + - Setting `AFL_COMPCOV_LEVEL` enables the CompareCoverage tracing of all cmp and sub in x86 and x86_64 and memory comparions functions (e.g. strcmp, - memcmp, ...) when libcompcov is preloaded using AFL_PRELOAD. + memcmp, ...) when libcompcov is preloaded using `AFL_PRELOAD`. More info at qemu_mode/libcompcov/README.md. - There are two levels at the moment, AFL_COMPCOV_LEVEL=1 that instruments + There are two levels at the moment, `AFL_COMPCOV_LEVEL=1` that instruments only comparisons with immediate values / read-only memory and - AFL_COMPCOV_LEVEL=2 that instruments all the comparions. Level 2 is more + `AFL_COMPCOV_LEVEL=2` that instruments all the comparions. Level 2 is more accurate but may need a larger shared memory. - - Setting AFL_QEMU_COMPCOV enables the CompareCoverage tracing of all + - Setting `AFL_QEMU_COMPCOV` enables the CompareCoverage tracing of all cmp and sub in x86 and x86_64. - This is an alias of AFL_COMPCOV_LEVEL=1 when AFL_COMPCOV_LEVEL is + This is an alias of `AFL_COMPCOV_LEVEL=1` when `AFL_COMPCOV_LEVEL` is not specified. - The underlying QEMU binary will recognize any standard "user space - emulation" variables (e.g., QEMU_STACK_SIZE), but there should be no + emulation" variables (e.g., `QEMU_STACK_SIZE`), but there should be no reason to touch them. - - AFL_DEBUG will print the found entrypoint for the binary to stderr. + - `AFL_DEBUG` will print the found entrypoint for the binary to stderr. Use this if you are unsure if the entrypoint might be wrong - but - use it directly, e.g. afl-qemu-trace ./program + use it directly, e.g. `afl-qemu-trace ./program` - - AFL_ENTRYPOINT allows you to specify a specific entrypoint into the + - `AFL_ENTRYPOINT` allows you to specify a specific entrypoint into the binary (this can be very good for the performance!). - The entrypoint is specified as hex address, e.g. 0x4004110 + The entrypoint is specified as hex address, e.g. `0x4004110` Note that the address must be the address of a basic block. - When the target is i386/x86_64 you can specify the address of the function that has to be the body of the persistent loop using - AFL_QEMU_PERSISTENT_ADDR=`start addr`. + `AFL_QEMU_PERSISTENT_ADDR=start addr`. - Another modality to execute the persistent loop is to specify also the - AFL_QEMU_PERSISTENT_RET=`end addr` env variable. + `AFL_QEMU_PERSISTENT_RET=end addr` env variable. With this variable assigned, instead of patching the return address, the specified instruction is transformed to a jump towards `start addr`. - - AFL_QEMU_PERSISTENT_GPR=1 QEMU will save the original value of general + - `AFL_QEMU_PERSISTENT_GPR=1` QEMU will save the original value of general purpose registers and restore them in each persistent cycle. - - With AFL_QEMU_PERSISTENT_RETADDR_OFFSET you can specify the offset from the + - With `AFL_QEMU_PERSISTENT_RETADDR_OFFSET` you can specify the offset from the stack pointer in which QEMU can find the return address when `start addr` is - hitted. + hit. + + - With `AFL_USE_QASAN` you can enable QEMU AddressSanitizer for dynamically + linked binaries. -## 5) Settings for afl-cmin + - With `AFL_QEMU_FORCE_DFL` you force QEMU to ignore the registered signal + handlers of the target. + +## 6) Settings for afl-cmin The corpus minimization script offers very little customization: - - Setting AFL_PATH offers a way to specify the location of afl-showmap - and afl-qemu-trace (the latter only in -Q mode). + - Setting `AFL_PATH` offers a way to specify the location of afl-showmap + and afl-qemu-trace (the latter only in `-Q` mode). - - AFL_KEEP_TRACES makes the tool keep traces and other metadata used for + - `AFL_KEEP_TRACES` makes the tool keep traces and other metadata used for minimization and normally deleted at exit. The files can be found in the - <out_dir>/.traces/*. + `<out_dir>/.traces/` directory. - - AFL_ALLOW_TMP permits this and some other scripts to run in /tmp. This is + - `AFL_ALLOW_TMP` permits this and some other scripts to run in /tmp. This is a modest security risk on multi-user systems with rogue users, but should be safe on dedicated fuzzing boxes. -# #6) Settings for afl-tmin +## 7) Settings for afl-tmin -Virtually nothing to play with. Well, in QEMU mode (-Q), AFL_PATH will be -searched for afl-qemu-trace. In addition to this, TMPDIR may be used if a +Virtually nothing to play with. Well, in QEMU mode (`-Q`), `AFL_PATH` will be +searched for afl-qemu-trace. In addition to this, `TMPDIR` may be used if a temporary file can't be created in the current working directory. -You can specify AFL_TMIN_EXACT if you want afl-tmin to require execution paths +You can specify `AFL_TMIN_EXACT` if you want afl-tmin to require execution paths to match when minimizing crashes. This will make minimization less useful, but may prevent the tool from "jumping" from one crashing condition to another in -very buggy software. You probably want to combine it with the -e flag. +very buggy software. You probably want to combine it with the `-e` flag. -## 7) Settings for afl-analyze +## 8) Settings for afl-analyze -You can set AFL_ANALYZE_HEX to get file offsets printed as hexadecimal instead +You can set `AFL_ANALYZE_HEX` to get file offsets printed as hexadecimal instead of decimal. -## 8) Settings for libdislocator +## 9) Settings for libdislocator The library honors these environmental variables: - - AFL_LD_LIMIT_MB caps the size of the maximum heap usage permitted by the + - `AFL_LD_LIMIT_MB` caps the size of the maximum heap usage permitted by the library, in megabytes. The default value is 1 GB. Once this is exceeded, allocations will return NULL. - - AFL_LD_HARD_FAIL alters the behavior by calling abort() on excessive - allocations, thus causing what AFL would perceive as a crash. Useful for + - `AFL_LD_HARD_FAIL` alters the behavior by calling `abort()` on excessive + allocations, thus causing what AFL++ would perceive as a crash. Useful for programs that are supposed to maintain a specific memory footprint. - - AFL_LD_VERBOSE causes the library to output some diagnostic messages + - `AFL_LD_VERBOSE` causes the library to output some diagnostic messages that may be useful for pinpointing the cause of any observed issues. - - AFL_LD_NO_CALLOC_OVER inhibits abort() on calloc() overflows. Most + - `AFL_LD_NO_CALLOC_OVER` inhibits `abort()` on `calloc()` overflows. Most of the common allocators check for that internally and return NULL, so it's a security risk only in more exotic setups. - - AFL_ALIGNED_ALLOC=1 will force the alignment of the allocation size to - max_align_t to be compliant with the C standard. + - `AFL_ALIGNED_ALLOC=1` will force the alignment of the allocation size to + `max_align_t` to be compliant with the C standard. -## 9) Settings for libtokencap +## 10) Settings for libtokencap -This library accepts AFL_TOKEN_FILE to indicate the location to which the +This library accepts `AFL_TOKEN_FILE` to indicate the location to which the discovered tokens should be written. -## 10) Third-party variables set by afl-fuzz & other tools +## 11) Third-party variables set by afl-fuzz & other tools Several variables are not directly interpreted by afl-fuzz, but are set to optimal values if not already present in the environment: - - By default, LD_BIND_NOW is set to speed up fuzzing by forcing the + - By default, `LD_BIND_NOW` is set to speed up fuzzing by forcing the linker to do all the work before the fork server kicks in. You can - override this by setting LD_BIND_LAZY beforehand, but it is almost + override this by setting `LD_BIND_LAZY` beforehand, but it is almost certainly pointless. - - By default, ASAN_OPTIONS are set to: - + - By default, `ASAN_OPTIONS` are set to: +``` abort_on_error=1 detect_leaks=0 malloc_context_size=0 symbolize=0 allocator_may_return_null=1 - - If you want to set your own options, be sure to include abort_on_error=1 - +``` + If you want to set your own options, be sure to include `abort_on_error=1` - otherwise, the fuzzer will not be able to detect crashes in the tested - app. Similarly, include symbolize=0, since without it, AFL may have + app. Similarly, include `symbolize=0`, since without it, AFL++ may have difficulty telling crashes and hangs apart. - - In the same vein, by default, MSAN_OPTIONS are set to: - + - In the same vein, by default, `MSAN_OPTIONS` are set to: +``` exit_code=86 (required for legacy reasons) abort_on_error=1 symbolize=0 msan_track_origins=0 allocator_may_return_null=1 - - Be sure to include the first one when customizing anything, since some - MSAN versions don't call abort() on error, and we need a way to detect +``` + Be sure to include the first one when customizing anything, since some + MSAN versions don't call `abort()` on error, and we need a way to detect faults. diff --git a/docs/ideas.md b/docs/ideas.md index 65e2e8e6..0130cf61 100644 --- a/docs/ideas.md +++ b/docs/ideas.md @@ -3,48 +3,56 @@ In the following, we describe a variety of ideas that could be implemented for future AFL++ versions. -For GSOC2020 interested students please see -[https://github.com/AFLplusplus/AFLplusplus/issues/208](https://github.com/AFLplusplus/AFLplusplus/issues/208) +# GSoC 2021 -## Flexible Grammar Mutator (currently in development) +All GSoC 2021 projects will be in the Rust development language! -Currently, AFL++'s mutation does not have deeper knowledge about the fuzzed -binary, apart from feedback, even though the developer may have insights -about the target. +## UI for libaflrs -A developer may choose to provide dictionaries and implement own mutations -in python or C, but an easy mutator that behaves according to a given grammar, -does not exist. +Write a user interface to libaflrs, the upcoming backend of afl++. +This might look like the afl-fuzz UI, but you can improve on it - and should! -State-of-the-art research on grammar fuzzing has some problems in their -implementations like code quality, scalability, or ease of use and other -common issues of the academic code. +## Schedulers for libaflrs -We aim to develop a pluggable grammar mutator for afl++ that combines -various results. +Schedulers is a mechanism that selects items from the fuzzing corpus based +on strategy and randomness. One scheduler might focus on long paths, +another on rarity of edges disocvered, still another on a combination on +things. Some of the schedulers in afl++ have to be ported, but you are free +to come up with your own if you want to - and see how it performs. -Mentor: andreafioraldi +## Forkserver support for libaflrs -## perf-fuzz Linux Kernel Module +The current libaflrs implementation fuzzes in-memory, however obviously we +want to support afl instrumented binaries as well. +Hence a forkserver support needs to be implemented - forking off the target +and talking to the target via a socketpair and the communication protocol +within. -Expand on [snapshot LKM](https://github.com/AFLplusplus/AFL-Snapshot-LKM) -To make it thread safe, can snapshot several processes at once and increase -overall performance. +## More Observers for libaflrs -Mentor: any +An observer is measuring functionality that looks at the target being fuzzed +and documents something about it. In traditional fuzzing this is the coverage +in the target, however we want to add various more observers, e.g. stack depth, +heap usage, etc. - this is a topic for an experienced Rust developer. -## QEMU 5-based Instrumentation +# Generic ideas and wishlist - NOT PART OF GSoC 2021 ! -First tests to use QEMU 4 for binary-only AFL++ showed that caching behavior -changed, which vastly decreases fuzzing speeds. +The below list is not part of GSoC 2021. -In this task test if QEMU 5 performs better and port the afl++ QEMU 3.1 -patches to QEMU 5. +## Analysis software -Understanding the current instrumentation and fixing the current caching -issues will be needed. +Currently analysis is done by using afl-plot, which is rather outdated. +A GTK or browser tool to create run-time analysis based on fuzzer_stats, +queue/id* information and plot_data that allows for zooming in and out, +changing min/max display values etc. and doing that for a single run, +different runs and campaigns vs campaigns. +Interesting values are execs, and execs/s, edges discovered (total, when +each edge was discovered and which other fuzzer share finding that edge), +test cases executed. +It should be clickable which value is X and Y axis, zoom factor, log scaling +on-off, etc. -Mentor: andreafioraldi +Mentor: vanhauser-thc ## WASM Instrumentation @@ -66,33 +74,6 @@ Either improve a single mutator thorugh learning of many different bugs Mentor: domenukk -## Reengineer `afl-fuzz` as Thread Safe, Embeddable Library (currently in development) - -Right now, afl-fuzz is single threaded, cannot safely be embedded in tools, -and not multi-threaded. It makes use of a large number of globals, must always -be the parent process and exec child processes. -Instead, afl-fuzz could be refactored to contain no global state and globals. -This allows for different use cases that could be implemented during this -project. -Note that in the mean time a lot has happened here already, but e.g. making -it all work and implement multithreading in afl-fuzz ... there is still quite -some work to do. - -Mentor: hexcoder- or vanhauser-thc - -## Collision-free Binary-Only Maps - -AFL++ supports collison-free maps using an LTO (link-time-optimization) pass. -This should be possible to implement for QEMU and Unicorn instrumentations. -As the forkserver parent caches just in time translated translation blocks, -adding a simple counter between jumps should be doable. - -Note: this is already in development for qemu by Andrea, so for people who -want to contribute it might make more sense to port his solution to unicorn. - -Mentor: andreafioraldi or domenukk -Issue/idea tracker: [https://github.com/AFLplusplus/AFLplusplus/issues/237](https://github.com/AFLplusplus/AFLplusplus/issues/237) - ## Your idea! Finally, we are open to proposals! diff --git a/docs/life_pro_tips.md b/docs/life_pro_tips.md index a5bd7286..50ad75d4 100644 --- a/docs/life_pro_tips.md +++ b/docs/life_pro_tips.md @@ -13,7 +13,7 @@ See [parallel_fuzzing.md](parallel_fuzzing.md) for step-by-step tips. ## Improve the odds of spotting memory corruption bugs with libdislocator.so! -It's easy. Consult [libdislocator/README.md](../libdislocator/README.md) for usage tips. +It's easy. Consult [utils/libdislocator/README.md](../utils/libdislocator/README.md) for usage tips. ## Want to understand how your target parses a particular input file? @@ -30,10 +30,10 @@ Check out the `fuzzer_stats` file in the AFL output dir or try `afl-whatsup`. It could be important - consult docs/status_screen.md right away! ## Know your target? Convert it to persistent mode for a huge performance gain! -Consult section #5 in llvm_mode/README.md for tips. +Consult section #5 in README.llvm.md for tips. ## Using clang? -Check out llvm_mode/ for a faster alternative to afl-gcc! +Check out instrumentation/ for a faster alternative to afl-gcc! ## Did you know that AFL can fuzz closed-source or cross-platform binaries? Check out qemu_mode/README.md and unicorn_mode/README.md for more. @@ -78,13 +78,10 @@ Be sure to check out docs/sister_projects.md before writing your own. ## Need to fuzz the command-line arguments of a particular program? -You can find a simple solution in examples/argv_fuzzing. +You can find a simple solution in utils/argv_fuzzing. ## Attacking a format that uses checksums? Remove the checksum-checking code or use a postprocessor! -See examples/custom_mutators/ for more. +See utils/custom_mutators/ for more. -## Dealing with a very slow target or hoping for instant results? - -Specify `-d` when calling afl-fuzz! diff --git a/docs/notes_for_asan.md b/docs/notes_for_asan.md index 2e18c15f..2b3bc028 100644 --- a/docs/notes_for_asan.md +++ b/docs/notes_for_asan.md @@ -20,7 +20,7 @@ Because of this, fuzzing with ASAN is recommended only in four scenarios: - Precisely gauge memory needs using http://jwilk.net/software/recidivm . - Limit the memory available to process using cgroups on Linux (see - examples/asan_cgroups). + utils/asan_cgroups). To compile with ASAN, set AFL_USE_ASAN=1 before calling 'make clean all'. The afl-gcc / afl-clang wrappers will pick that up and add the appropriate flags. @@ -35,7 +35,7 @@ no sanitizers compiled in. There is also the option of generating a corpus using a non-ASAN binary, and then feeding it to an ASAN-instrumented one to check for bugs. This is faster, and can give you somewhat comparable results. You can also try using -libdislocator (see libdislocator/README.dislocator.md in the parent directory) as a +libdislocator (see [utils/libdislocator/README.dislocator.md](../utils/libdislocator/README.dislocator.md) in the parent directory) as a lightweight and hassle-free (but less thorough) alternative. ## 2) Long version @@ -74,7 +74,7 @@ There are also cgroups, but they are Linux-specific, not universally available even on Linux systems, and they require root permissions to set up; I'm a bit hesitant to make afl-fuzz require root permissions just for that. That said, if you are on Linux and want to use cgroups, check out the contributed script -that ships in examples/asan_cgroups/. +that ships in utils/asan_cgroups/. In settings where cgroups aren't available, we have no nice, portable way to avoid counting the ASAN allocation toward the limit. On 32-bit systems, or for diff --git a/docs/parallel_fuzzing.md b/docs/parallel_fuzzing.md index 2ab1466c..8f2afe1b 100644 --- a/docs/parallel_fuzzing.md +++ b/docs/parallel_fuzzing.md @@ -10,8 +10,8 @@ n-core system, you can almost always run around n concurrent fuzzing jobs with virtually no performance hit (you can use the afl-gotcpu tool to make sure). In fact, if you rely on just a single job on a multi-core system, you will -be underutilizing the hardware. So, parallelization is usually the right -way to go. +be underutilizing the hardware. So, parallelization is always the right way to +go. When targeting multiple unrelated binaries or using the tool in "non-instrumented" (-n) mode, it is perfectly fine to just start up several @@ -65,22 +65,7 @@ still perform deterministic checks; while the secondary instances will proceed straight to random tweaks. Note that you must always have one -M main instance! - -Note that running multiple -M instances is wasteful, although there is an -experimental support for parallelizing the deterministic checks. To leverage -that, you need to create -M instances like so: - -``` -./afl-fuzz -i testcase_dir -o sync_dir -M mainA:1/3 [...] -./afl-fuzz -i testcase_dir -o sync_dir -M mainB:2/3 [...] -./afl-fuzz -i testcase_dir -o sync_dir -M mainC:3/3 [...] -``` - -...where the first value after ':' is the sequential ID of a particular main -instance (starting at 1), and the second value is the total number of fuzzers to -distribute the deterministic fuzzing across. Note that if you boot up fewer -fuzzers than indicated by the second number passed to -M, you may end up with -poor coverage. +Running multiple -M instances is wasteful! You can also monitor the progress of your jobs from the command line with the provided afl-whatsup tool. When the instances are no longer finding new paths, @@ -99,61 +84,88 @@ example may be: This is not a concern if you use @@ without -f and let afl-fuzz come up with the file name. -## 3) Syncing with non-afl fuzzers or independant instances +## 3) Multiple -M mains + + +There is support for parallelizing the deterministic checks. +This is only needed where + + 1. many new paths are found fast over a long time and it looks unlikely that + main node will ever catch up, and + 2. deterministic fuzzing is actively helping path discovery (you can see this + in the main node for the first for lines in the "fuzzing strategy yields" + section. If the ration `found/attemps` is high, then it is effective. It + most commonly isn't.) + +Only if both are true it is beneficial to have more than one main. +You can leverage this by creating -M instances like so: + +``` +./afl-fuzz -i testcase_dir -o sync_dir -M mainA:1/3 [...] +./afl-fuzz -i testcase_dir -o sync_dir -M mainB:2/3 [...] +./afl-fuzz -i testcase_dir -o sync_dir -M mainC:3/3 [...] +``` + +... where the first value after ':' is the sequential ID of a particular main +instance (starting at 1), and the second value is the total number of fuzzers to +distribute the deterministic fuzzing across. Note that if you boot up fewer +fuzzers than indicated by the second number passed to -M, you may end up with +poor coverage. + +## 4) Syncing with non-afl fuzzers or independant instances A -M main node can be told with the `-F other_fuzzer_queue_directory` option to sync results from other fuzzers, e.g. libfuzzer or honggfuzz. Only the specified directory will by synced into afl, not subdirectories. -The specified directories do not need to exist yet at the start of afl. +The specified directory does not need to exist yet at the start of afl. -## 4) Multi-system parallelization +The `-F` option can be passed to the main node several times. + +## 5) Multi-system parallelization The basic operating principle for multi-system parallelization is similar to the mechanism explained in section 2. The key difference is that you need to write a simple script that performs two actions: - Uses SSH with authorized_keys to connect to every machine and retrieve - a tar archive of the /path/to/sync_dir/<fuzzer_id>/queue/ directories for - every <fuzzer_id> local to the machine. It's best to use a naming scheme - that includes host name in the fuzzer ID, so that you can do something - like: + a tar archive of the /path/to/sync_dir/<main_node(s)> directory local to + the machine. + It is best to use a naming scheme that includes host name and it's being + a main node (e.g. main1, main2) in the fuzzer ID, so that you can do + something like: ```sh - for s in {1..10}; do - ssh user@host${s} "tar -czf - sync/host${s}_fuzzid*/[qf]*" >host${s}.tgz + for host in `cat HOSTLIST`; do + ssh user@$host "tar -czf - sync/$host_main*/" > $host.tgz done ``` - Distributes and unpacks these files on all the remaining machines, e.g.: ```sh - for s in {1..10}; do - for d in {1..10}; do - test "$s" = "$d" && continue - ssh user@host${d} 'tar -kxzf -' <host${s}.tgz + for srchost in `cat HOSTLIST`; do + for dsthost in `cat HOSTLIST`; do + test "$srchost" = "$dsthost" && continue + ssh user@$srchost 'tar -kxzf -' < $dsthost.tgz done done ``` -There is an example of such a script in examples/distributed_fuzzing/; -you can also find a more featured, experimental tool developed by -Martijn Bogaard at: - - https://github.com/MartijnB/disfuzz-afl - -Another client-server implementation from Richo Healey is: +There is an example of such a script in utils/distributed_fuzzing/. - https://github.com/richo/roving +There are other (older) more featured, experimental tools: + * https://github.com/richo/roving + * https://github.com/MartijnB/disfuzz-afl -Note that these third-party tools are unsafe to run on systems exposed to the -Internet or to untrusted users. +However these do not support syncing just main nodes (yet). When developing custom test case sync code, there are several optimizations to keep in mind: - The synchronization does not have to happen very often; running the - task every 30 minutes or so may be perfectly fine. + task every 60 minutes or even less often at later fuzzing stages is + fine - There is no need to synchronize crashes/ or hangs/; you only need to copy over queue/* (and ideally, also fuzzer_stats). @@ -179,19 +191,24 @@ to keep in mind: - You do not want a "main" instance of afl-fuzz on every system; you should run them all with -S, and just designate a single process somewhere within the fleet to run with -M. + + - Syncing is only necessary for the main nodes on a system. It is possible + to run main-less with only secondaries. However then you need to find out + which secondary took over the temporary role to be the main node. Look for + the `is_main_node` file in the fuzzer directories, eg. `sync-dir/hostname-*/is_main_node` It is *not* advisable to skip the synchronization script and run the fuzzers directly on a network filesystem; unexpected latency and unkillable processes in I/O wait state can mess things up. -## 5) Remote monitoring and data collection +## 6) Remote monitoring and data collection You can use screen, nohup, tmux, or something equivalent to run remote instances of afl-fuzz. If you redirect the program's output to a file, it will automatically switch from a fancy UI to more limited status reports. There is -also basic machine-readable information always written to the fuzzer_stats file -in the output directory. Locally, that information can be interpreted with -afl-whatsup. +also basic machine-readable information which is always written to the +fuzzer_stats file in the output directory. Locally, that information can be +interpreted with afl-whatsup. In principle, you can use the status screen of the main (-M) instance to monitor the overall fuzzing progress and decide when to stop. In this @@ -208,7 +225,7 @@ Keep in mind that crashing inputs are *not* automatically propagated to the main instance, so you may still want to monitor for crashes fleet-wide from within your synchronization or health checking scripts (see afl-whatsup). -## 6) Asymmetric setups +## 7) Asymmetric setups It is perhaps worth noting that all of the following is permitted: @@ -224,7 +241,7 @@ It is perhaps worth noting that all of the following is permitted: the discovered test cases can have synergistic effects and improve the overall coverage. - (In this case, running one -M instance per each binary is a good plan.) + (In this case, running one -M instance per target is necessary.) - Having some of the fuzzers invoke the binary in different ways. For example, 'djpeg' supports several DCT modes, configurable with diff --git a/docs/perf_tips.md b/docs/perf_tips.md index 7a690b77..fbcb4d8d 100644 --- a/docs/perf_tips.md +++ b/docs/perf_tips.md @@ -51,7 +51,7 @@ a file. ## 3. Use LLVM instrumentation When fuzzing slow targets, you can gain 20-100% performance improvement by -using the LLVM-based instrumentation mode described in [the llvm_mode README](../llvm_mode/README.md). +using the LLVM-based instrumentation mode described in [the instrumentation README](../instrumentation/README.llvm.md). Note that this mode requires the use of clang and will not work with GCC. The LLVM mode also offers a "persistent", in-process fuzzing mode that can @@ -62,12 +62,12 @@ modes require you to edit the source code of the fuzzed program, but the changes often amount to just strategically placing a single line or two. If there are important data comparisons performed (e.g. `strcmp(ptr, MAGIC_HDR)`) -then using laf-intel (see llvm_mode/README.laf-intel.md) will help `afl-fuzz` a lot +then using laf-intel (see instrumentation/README.laf-intel.md) will help `afl-fuzz` a lot to get to the important parts in the code. If you are only interested in specific parts of the code being fuzzed, you can instrument_files the files that are actually relevant. This improves the speed and -accuracy of afl. See llvm_mode/README.instrument_file.md +accuracy of afl. See instrumentation/README.instrument_list.md Also use the InsTrim mode on larger binaries, this improves performance and coverage a lot. @@ -110,7 +110,7 @@ e.g.: https://launchpad.net/libeatmydata In programs that are slow due to unavoidable initialization overhead, you may -want to try the LLVM deferred forkserver mode (see llvm_mode/README.md), +want to try the LLVM deferred forkserver mode (see README.llvm.md), which can give you speed gains up to 10x, as mentioned above. Last but not least, if you are using ASAN and the performance is unacceptable, diff --git a/docs/power_schedules.md b/docs/power_schedules.md index 06fefa12..493f9609 100644 --- a/docs/power_schedules.md +++ b/docs/power_schedules.md @@ -13,8 +13,8 @@ We find that AFL's exploitation-based constant schedule assigns **too much energ | AFL flag | Power Schedule | | ------------- | -------------------------- | -| `-p explore` (default)| 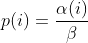 | -| `-p fast` | 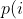=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | +| `-p explore` | 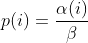 | +| `-p fast` (default)| 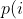=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | | `-p coe` | 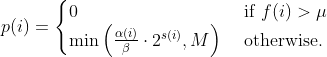 | | `-p quad` | 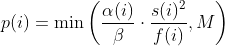 | | `-p lin` | 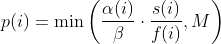 | diff --git a/docs/rpc_statsd.md b/docs/rpc_statsd.md new file mode 100644 index 00000000..fb97aa09 --- /dev/null +++ b/docs/rpc_statsd.md @@ -0,0 +1,143 @@ +# Remote monitoring with StatsD + +StatsD allows you to receive and aggregate metrics from a wide range of applications and retransmit them to the backend of your choice. +This enables you to create nice and readable dashboards containing all the information you need on your fuzzer instances. +No need to write your own statistics parsing system, deploy and maintain it to all your instances, sync with your graph rendering system... + +The available metrics are : +- cycle_done +- cycles_wo_finds +- execs_done +- execs_per_sec +- paths_total +- paths_favored +- paths_found +- paths_imported +- max_depth +- cur_path +- pending_favs +- pending_total +- variable_paths +- unique_crashes +- unique_hangs +- total_crashes +- slowest_exec_ms +- edges_found +- var_byte_count +- havoc_expansion + +Compared to the default integrated UI, these metrics give you the opportunity to visualize trends and fuzzing state over time. +By doing so, you might be able to see when the fuzzing process has reached a state of no progress, visualize what are the "best strategies" +(according to your own criteria) for your targets, etc. And doing so without requiring to log into each instance manually. + +An example visualisation may look like the following: + + +*Notes: The exact same dashboard can be imported with [this JSON template](statsd/grafana-afl++.json).* + +## How to use + +To enable the StatsD reporting on your fuzzer instances, you need to set the environment variable `AFL_STATSD=1`. + +Setting `AFL_STATSD_TAGS_FLAVOR` to the provider of your choice will assign tags / labels to each metric based on their format. +The possible values are `dogstatsd`, `librato`, `signalfx` or `influxdb`. +For more information on these env vars, check out `docs/env_variables.md`. + +The simplest way of using this feature is to use any metric provider and change the host/port of your StatsD daemon, +with `AFL_STATSD_HOST` and `AFL_STATSD_PORT`, if required (defaults are `localhost` and port `8125`). +To get started, here are some instructions with free and open source tools. +The following setup is based on Prometheus, statsd_exporter and Grafana. +Grafana here is not mandatory, but gives you some nice graphs and features. + +Depending on your setup and infrastructure, you may want to run these applications not on your fuzzer instances. +Only one instance of these 3 application is required for all your fuzzers. + +To simplify everything, we will use Docker and docker-compose. +Make sure you have them both installed. On most common Linux distributions, it's as simple as: + +```sh +curl -fsSL https://get.docker.com -o get-docker.sh +sh get-docker.sh +``` + +Once that's done, we can create the infrastructure. +Create and move into the directory of your choice. This will store all the configurations files required. + +First, create a `docker-compose.yml` containing the following: +```yml +version: '3' + +networks: + statsd-net: + driver: bridge + +services: + prometheus: + image: prom/prometheus + container_name: prometheus + volumes: + - ./prometheus.yml:/prometheus.yml + command: + - '--config.file=/prometheus.yml' + restart: unless-stopped + ports: + - "9090:9090" + networks: + - statsd-net + + statsd_exporter: + image: prom/statsd-exporter + container_name: statsd_exporter + volumes: + - ./statsd_mapping.yml:/statsd_mapping.yml + command: + - "--statsd.mapping-config=/statsd_mapping.yml" + ports: + - "9102:9102/tcp" + - "8125:9125/udp" + networks: + - statsd-net + + grafana: + image: grafana/grafana + container_name: grafana + restart: unless-stopped + ports: + - "3000:3000" + networks: + - statsd-net +``` + +Then `prometheus.yml` +```yml +global: + scrape_interval: 15s + evaluation_interval: 15s + +scrape_configs: + - job_name: 'fuzzing_metrics' + static_configs: + - targets: ['statsd_exporter:9102'] +``` + +And finally `statsd_mapping.yml` +```yml +mappings: +- match: "fuzzing.*" + name: "fuzzing" + labels: + type: "$1" +``` + +Run `docker-compose up -d`. + +Everything should now be setup, you are now able to run your fuzzers with + +``` +AFL_STATSD_TAGS_FLAVOR=dogstatsd AFL_STATSD=1 afl-fuzz -M test-fuzzer-1 -i i -o o ./bin/my-application @@ +AFL_STATSD_TAGS_FLAVOR=dogstatsd AFL_STATSD=1 afl-fuzz -S test-fuzzer-2 -i i -o o ./bin/my-application @@ +... +``` + +This setup may be modified before use in a production environment. Depending on your needs: adding passwords, creating volumes for storage, +tweaking the metrics gathering to get host metrics (CPU, RAM ...). diff --git a/docs/sister_projects.md b/docs/sister_projects.md index a501ecbd..5cb3a102 100644 --- a/docs/sister_projects.md +++ b/docs/sister_projects.md @@ -52,7 +52,7 @@ options. Provides an evolutionary instrumentation-guided fuzzing harness that allows some programs to be fuzzed without the fork / execve overhead. (Similar functionality is now available as the "persistent" feature described in -[the llvm_mode readme](../llvm_mode/README.md)) +[the llvm_mode readme](../instrumentation/README.llvm.md)) http://llvm.org/docs/LibFuzzer.html @@ -119,10 +119,18 @@ Simplifies the triage of discovered crashes, start parallel instances, etc. https://github.com/rc0r/afl-utils +### AFL crash analyzer (floyd) + Another crash triage tool: https://github.com/floyd-fuh/afl-crash-analyzer +### afl-extras (fekir) + +Collect data, parallel afl-tmin, startup scripts. + +https://github.com/fekir/afl-extras + ### afl-fuzzing-scripts (Tobias Ospelt) Simplifies starting up multiple parallel AFL jobs. @@ -245,7 +253,7 @@ https://code.google.com/p/address-sanitizer/wiki/AsanCoverage#Coverage_counters ### AFL JS (Han Choongwoo) One-off optimizations to speed up the fuzzing of JavaScriptCore (now likely -superseded by LLVM deferred forkserver init - see llvm_mode/README.md). +superseded by LLVM deferred forkserver init - see README.llvm.md). https://github.com/tunz/afl-fuzz-js diff --git a/docs/statsd/grafana-afl++.json b/docs/statsd/grafana-afl++.json new file mode 100644 index 00000000..96e824de --- /dev/null +++ b/docs/statsd/grafana-afl++.json @@ -0,0 +1,1816 @@ +{ + "annotations": { + "list": [ + { + "builtIn": 1, + "datasource": "-- Grafana --", + "enable": true, + "hide": true, + "iconColor": "rgba(0, 211, 255, 1)", + "name": "Annotations & Alerts", + "type": "dashboard" + } + ] + }, + "editable": true, + "gnetId": null, + "graphTooltip": 0, + "id": 1, + "links": [], + "panels": [ + { + "datasource": null, + "gridPos": { + "h": 1, + "w": 24, + "x": 0, + "y": 0 + }, + "id": 16, + "title": "Row title", + "type": "row" + }, + { + "alert": { + "alertRuleTags": {}, + "conditions": [ + { + "evaluator": { + "params": [ + 500 + ], + "type": "lt" + }, + "operator": { + "type": "and" + }, + "query": { + "params": [ + "A", + "5m", + "now" + ] + }, + "reducer": { + "params": [], + "type": "avg" + }, + "type": "query" + } + ], + "executionErrorState": "alerting", + "for": "5m", + "frequency": "1m", + "handler": 1, + "name": "Slow exec per sec", + "noDataState": "no_data", + "notifications": [] + }, + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 6, + "w": 10, + "x": 0, + "y": 1 + }, + "hiddenSeries": false, + "id": 12, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"execs_per_sec\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [ + { + "colorMode": "critical", + "fill": true, + "line": true, + "op": "lt", + "value": 500 + } + ], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Exec/s", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 6, + "w": 10, + "x": 10, + "y": 1 + }, + "hiddenSeries": false, + "id": 8, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"total_crashes\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [], + "timeShift": null, + "title": "Total Crashes", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 4, + "x": 20, + "y": 1 + }, + "hiddenSeries": false, + "id": 19, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"var_byte_count\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Var Byte Count", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 6, + "w": 10, + "x": 0, + "y": 7 + }, + "hiddenSeries": false, + "id": 10, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"unique_crashes\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [], + "timeShift": null, + "title": "Unique Crashes", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 6, + "w": 10, + "x": 10, + "y": 7 + }, + "hiddenSeries": false, + "id": 14, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"unique_hangs\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Unique Hangs", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 0, + "y": 13 + }, + "hiddenSeries": false, + "id": 23, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"slowest_exec_ms\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Slowest Exec Ms", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 5, + "y": 13 + }, + "hiddenSeries": false, + "id": 4, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"cycle_done\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [], + "timeShift": null, + "title": "Cycles dones", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 10, + "y": 13 + }, + "hiddenSeries": false, + "id": 13, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"execs_done\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Total Execs", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 15, + "y": 13 + }, + "hiddenSeries": false, + "id": 2, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"cur_path\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [], + "timeShift": null, + "title": "Curent path", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 0, + "y": 18 + }, + "hiddenSeries": false, + "id": 6, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"cycles_wo_finds\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [], + "timeShift": null, + "title": "Cycles done without find", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 5, + "y": 18 + }, + "hiddenSeries": false, + "id": 25, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"paths_favored\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Path Favored", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 10, + "y": 18 + }, + "hiddenSeries": false, + "id": 22, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"havoc_expansion\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Havoc Expansion", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 15, + "y": 18 + }, + "hiddenSeries": false, + "id": 17, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"edges_found\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Edges Found", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 0, + "y": 23 + }, + "hiddenSeries": false, + "id": 24, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"paths_imported\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Path Imported", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 5, + "y": 23 + }, + "hiddenSeries": false, + "id": 21, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"pending_total\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Pending Total", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 10, + "y": 23 + }, + "hiddenSeries": false, + "id": 20, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"pending_favs\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Pending favs", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + }, + { + "aliasColors": {}, + "bars": false, + "dashLength": 10, + "dashes": false, + "datasource": null, + "fieldConfig": { + "defaults": { + "custom": {} + }, + "overrides": [] + }, + "fill": 1, + "fillGradient": 0, + "gridPos": { + "h": 5, + "w": 5, + "x": 15, + "y": 23 + }, + "hiddenSeries": false, + "id": 18, + "legend": { + "avg": false, + "current": false, + "max": false, + "min": false, + "show": false, + "total": false, + "values": false + }, + "lines": true, + "linewidth": 1, + "nullPointMode": "null", + "options": { + "alertThreshold": true + }, + "percentage": false, + "pluginVersion": "7.3.7", + "pointradius": 2, + "points": false, + "renderer": "flot", + "seriesOverrides": [], + "spaceLength": 10, + "stack": false, + "steppedLine": false, + "targets": [ + { + "expr": "fuzzing{type=\"max_depth\"}", + "interval": "", + "legendFormat": "", + "refId": "A" + } + ], + "thresholds": [], + "timeFrom": null, + "timeRegions": [ + { + "colorMode": "background6", + "fill": true, + "fillColor": "rgba(234, 112, 112, 0.12)", + "line": false, + "lineColor": "rgba(237, 46, 24, 0.60)", + "op": "time" + } + ], + "timeShift": null, + "title": "Max Depth", + "tooltip": { + "shared": true, + "sort": 0, + "value_type": "individual" + }, + "type": "graph", + "xaxis": { + "buckets": null, + "mode": "time", + "name": null, + "show": true, + "values": [] + }, + "yaxes": [ + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": "0", + "show": true + }, + { + "format": "short", + "label": null, + "logBase": 1, + "max": null, + "min": null, + "show": true + } + ], + "yaxis": { + "align": false, + "alignLevel": null + } + } + ], + "refresh": false, + "schemaVersion": 26, + "style": "dark", + "tags": [], + "templating": { + "list": [] + }, + "time": { + "from": "now-30m", + "to": "now" + }, + "timepicker": {}, + "timezone": "", + "title": "Fuzzing", + "uid": "sRI6PCfGz", + "version": 2 +}
\ No newline at end of file diff --git a/docs/status_screen.md b/docs/status_screen.md index b89468ce..0329d960 100644 --- a/docs/status_screen.md +++ b/docs/status_screen.md @@ -29,13 +29,18 @@ With that out of the way, let's talk about what's actually on the screen... ### The status bar +``` +american fuzzy lop ++3.01a (default) [fast] {0} +``` + The top line shows you which mode afl-fuzz is running in (normal: "american fuzy lop", crash exploration mode: "peruvian rabbit mode") and the version of afl++. Next to the version is the banner, which, if not set with -T by hand, will either show the binary name being fuzzed, or the -M/-S main/secondary name for parallel fuzzing. -Finally, the last item is the power schedule mode being run (default: explore). +Second to last is the power schedule mode being run (default: fast). +Finally, the last item is the CPU id. ### Process timing @@ -86,10 +91,7 @@ Every fuzzing session should be allowed to complete at least one cycle; and ideally, should run much longer than that. As noted earlier, the first pass can take a day or longer, so sit back and -relax. If you want to get broader but more shallow coverage right away, try -the `-d` option - it gives you a more familiar experience by skipping the -deterministic fuzzing steps. It is, however, inferior to the standard mode in -a couple of subtle ways. +relax. To help make the call on when to hit `Ctrl-C`, the cycle counter is color-coded. It is shown in magenta during the first pass, progresses to yellow if new finds @@ -118,9 +120,6 @@ inputs it decided to ditch because they were persistently timing out. The "*" suffix sometimes shown in the first line means that the currently processed path is not "favored" (a property discussed later on). -If you feel that the fuzzer is progressing too slowly, see the note about the -`-d` option in this doc. - ### Map coverage ``` @@ -324,7 +323,7 @@ there are several things to look at: - Multiple threads executing at once in semi-random order. This is harmless when the 'stability' metric stays over 90% or so, but can become an issue if not. Here's what to try: - * Use afl-clang-fast from [llvm_mode](../llvm_mode/) - it uses a thread-local tracking + * Use afl-clang-fast from [instrumentation](../instrumentation/) - it uses a thread-local tracking model that is less prone to concurrency issues, * See if the target can be compiled or run without threads. Common `./configure` options include `--without-threads`, `--disable-pthreads`, or @@ -412,3 +411,27 @@ Most of these map directly to the UI elements discussed earlier on. On top of that, you can also find an entry called `plot_data`, containing a plottable history for most of these fields. If you have gnuplot installed, you can turn this into a nice progress report with the included `afl-plot` tool. + + +### Addendum: Automatically send metrics with StatsD + +In a CI environment or when running multiple fuzzers, it can be tedious to +log into each of them or deploy scripts to read the fuzzer statistics. +Using `AFL_STATSD` (and the other related environment variables `AFL_STATSD_HOST`, +`AFL_STATSD_PORT`, `AFL_STATSD_TAGS_FLAVOR`) you can automatically send metrics +to your favorite StatsD server. Depending on your StatsD server you will be able +to monitor, trigger alerts or perform actions based on these metrics (e.g: alert on +slow exec/s for a new build, threshold of crashes, time since last crash > X, etc). + +The selected metrics are a subset of all the metrics found in the status and in +the plot file. The list is the following: `cycle_done`, `cycles_wo_finds`, +`execs_done`,`execs_per_sec`, `paths_total`, `paths_favored`, `paths_found`, +`paths_imported`, `max_depth`, `cur_path`, `pending_favs`, `pending_total`, +`variable_paths`, `unique_crashes`, `unique_hangs`, `total_crashes`, +`slowest_exec_ms`, `edges_found`, `var_byte_count`, `havoc_expansion`. +Their definitions can be found in the addendum above. + +When using multiple fuzzer instances with StatsD it is *strongly* recommended to setup +the flavor (AFL_STATSD_TAGS_FLAVOR) to match your StatsD server. This will allow you +to see individual fuzzer performance, detect bad ones, see the progress of each +strategy... diff --git a/docs/visualization/statsd-grafana.png b/docs/visualization/statsd-grafana.png Binary files differnew file mode 100644 index 00000000..1bdc1722 --- /dev/null +++ b/docs/visualization/statsd-grafana.png diff --git a/dynamic_list.txt b/dynamic_list.txt new file mode 100644 index 00000000..4b92d154 --- /dev/null +++ b/dynamic_list.txt @@ -0,0 +1,26 @@ +{ + "__afl_area_ptr"; + "__afl_manual_init"; + "__afl_persistent_loop"; + "__afl_auto_init"; + "__afl_area_initial"; + "__afl_prev_loc"; + "__afl_prev_caller"; + "__afl_prev_ctx"; + "__afl_final_loc"; + "__afl_map_addr"; + "__afl_dictionary"; + "__afl_dictionary_len"; + "__afl_selective_coverage"; + "__afl_selective_coverage_start_off"; + "__afl_selective_coverage_temp"; + "__afl_coverage_discard"; + "__afl_coverage_skip"; + "__afl_coverage_on"; + "__afl_coverage_off"; + "__afl_coverage_interesting"; + "__afl_fuzz_len"; + "__afl_fuzz_ptr"; + "__sanitizer_cov_trace_pc_guard"; + "__sanitizer_cov_trace_pc_guard_init"; +}; diff --git a/examples/afl_frida/afl-frida.c b/examples/afl_frida/afl-frida.c deleted file mode 100644 index 2ad5a72a..00000000 --- a/examples/afl_frida/afl-frida.c +++ /dev/null @@ -1,541 +0,0 @@ -/* - american fuzzy lop++ - afl-frida skeleton example - ------------------------------------------------- - - Copyright 2020 AFLplusplus Project. All rights reserved. - - Written mostly by meme -> https://github.com/meme/hotwax - - Modificationy by Marc Heuse <mh@mh-sec.de> - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - HOW-TO - ====== - - You only need to change the following: - - 1. set the defines and function call parameters. - 2. dl load the library you want to fuzz, lookup the functions you need - and setup the calls to these. - 3. in the while loop you call the functions in the necessary order - - incl the cleanup. the cleanup is important! - - Just look these steps up in the code, look for "// STEP x:" - -*/ - -#include <stdio.h> -#include <stdint.h> -#include <unistd.h> -#include <stdint.h> -#include <stddef.h> -#include <sys/shm.h> -#include <dlfcn.h> - -#ifndef __APPLE__ - #include <sys/wait.h> - #include <sys/personality.h> -#endif - -int debug = 0; - -// STEP 1: - -// The presets are for the example libtestinstr.so: - -/* What is the name of the library to fuzz */ -#define TARGET_LIBRARY "libtestinstr.so" - -/* What is the name of the function to fuzz */ -#define TARGET_FUNCTION "testinstr" - -/* here you need to specify the parameter for the target function */ -static void *(*o_function)(uint8_t *, int); - -// END STEP 1 - -#include "frida-gum.h" - -G_BEGIN_DECLS - -#define GUM_TYPE_FAKE_EVENT_SINK (gum_fake_event_sink_get_type()) -G_DECLARE_FINAL_TYPE(GumFakeEventSink, gum_fake_event_sink, GUM, - FAKE_EVENT_SINK, GObject) - -struct _GumFakeEventSink { - - GObject parent; - GumEventType mask; - -}; - -GumEventSink *gum_fake_event_sink_new(void); -void gum_fake_event_sink_reset(GumFakeEventSink *self); - -G_END_DECLS - -static void gum_fake_event_sink_iface_init(gpointer g_iface, - gpointer iface_data); -static void gum_fake_event_sink_finalize(GObject *obj); -static GumEventType gum_fake_event_sink_query_mask(GumEventSink *sink); -static void gum_fake_event_sink_process(GumEventSink *sink, const GumEvent *ev); -void instr_basic_block(GumStalkerIterator *iterator, GumStalkerOutput *output, - gpointer user_data); -void afl_setup(void); -void afl_start_forkserver(void); -int __afl_persistent_loop(unsigned int max_cnt); - -static void gum_fake_event_sink_class_init(GumFakeEventSinkClass *klass) { - - GObjectClass *object_class = G_OBJECT_CLASS(klass); - object_class->finalize = gum_fake_event_sink_finalize; - -} - -static void gum_fake_event_sink_iface_init(gpointer g_iface, - gpointer iface_data) { - - GumEventSinkInterface *iface = (GumEventSinkInterface *)g_iface; - iface->query_mask = gum_fake_event_sink_query_mask; - iface->process = gum_fake_event_sink_process; - -} - -G_DEFINE_TYPE_EXTENDED(GumFakeEventSink, gum_fake_event_sink, G_TYPE_OBJECT, 0, - G_IMPLEMENT_INTERFACE(GUM_TYPE_EVENT_SINK, - gum_fake_event_sink_iface_init)) - -#include "../../config.h" - -// Shared memory fuzzing. -int __afl_sharedmem_fuzzing = 1; -extern unsigned int * __afl_fuzz_len; -extern unsigned char *__afl_fuzz_ptr; - -// Notify AFL about persistent mode. -static volatile char AFL_PERSISTENT[] = "##SIG_AFL_PERSISTENT##"; -int __afl_persistent_loop(unsigned int); - -// Notify AFL about deferred forkserver. -static volatile char AFL_DEFER_FORKSVR[] = "##SIG_AFL_DEFER_FORKSRV##"; -void __afl_manual_init(); - -// Because we do our own logging. -extern uint8_t * __afl_area_ptr; -static __thread guint64 previous_pc; - -// Frida stuff below. -typedef struct { - - GumAddress base_address; - guint64 code_start, code_end; - -} range_t; - -inline static void afl_maybe_log(guint64 current_pc) { - - // fprintf(stderr, "PC: %p ^ %p\n", current_pc, previous_pc); - - current_pc = (current_pc >> 4) ^ (current_pc << 8); - current_pc &= MAP_SIZE - 1; - - __afl_area_ptr[current_pc ^ previous_pc]++; - previous_pc = current_pc >> 1; - -} - -static void on_basic_block(GumCpuContext *context, gpointer user_data) { - - afl_maybe_log((guint64)user_data); - -} - -void instr_basic_block(GumStalkerIterator *iterator, GumStalkerOutput *output, - gpointer user_data) { - - range_t *range = (range_t *)user_data; - - const cs_insn *instr; - gboolean begin = TRUE; - while (gum_stalker_iterator_next(iterator, &instr)) { - - if (begin) { - - if (instr->address >= range->code_start && - instr->address <= range->code_end) { - - gum_stalker_iterator_put_callout(iterator, on_basic_block, - (gpointer)instr->address, NULL); - begin = FALSE; - - } - - } - - gum_stalker_iterator_keep(iterator); - - } - -} - -static void gum_fake_event_sink_init(GumFakeEventSink *self) { - -} - -static void gum_fake_event_sink_finalize(GObject *obj) { - - G_OBJECT_CLASS(gum_fake_event_sink_parent_class)->finalize(obj); - -} - -GumEventSink *gum_fake_event_sink_new(void) { - - GumFakeEventSink *sink; - sink = (GumFakeEventSink *)g_object_new(GUM_TYPE_FAKE_EVENT_SINK, NULL); - return GUM_EVENT_SINK(sink); - -} - -void gum_fake_event_sink_reset(GumFakeEventSink *self) { - -} - -static GumEventType gum_fake_event_sink_query_mask(GumEventSink *sink) { - - return 0; - -} - -typedef struct library_list { - - uint8_t *name; - uint64_t addr_start, addr_end; - -} library_list_t; - -#define MAX_LIB_COUNT 256 -static library_list_t liblist[MAX_LIB_COUNT]; -static u32 liblist_cnt; - -void read_library_information() { - -#if defined(__linux__) - FILE *f; - u8 buf[1024], *b, *m, *e, *n; - - if ((f = fopen("/proc/self/maps", "r")) == NULL) { - - fprintf(stderr, "Error: cannot open /proc/self/maps\n"); - exit(-1); - - } - - if (debug) fprintf(stderr, "Library list:\n"); - while (fgets(buf, sizeof(buf), f)) { - - if (strstr(buf, " r-x")) { - - if (liblist_cnt >= MAX_LIB_COUNT) { - - fprintf( - stderr, - "Warning: too many libraries to old, maximum count of %d reached\n", - liblist_cnt); - return; - - } - - b = buf; - m = index(buf, '-'); - e = index(buf, ' '); - if ((n = rindex(buf, '/')) == NULL) n = rindex(buf, ' '); - if (n && - ((*n >= '0' && *n <= '9') || *n == '[' || *n == '{' || *n == '(')) - n = NULL; - else - n++; - if (b && m && e && n && *n) { - - *m++ = 0; - *e = 0; - if (n[strlen(n) - 1] == '\n') n[strlen(n) - 1] = 0; - - if (rindex(n, '/') != NULL) { - - n = rindex(n, '/'); - n++; - - } - - liblist[liblist_cnt].name = strdup(n); - liblist[liblist_cnt].addr_start = strtoull(b, NULL, 16); - liblist[liblist_cnt].addr_end = strtoull(m, NULL, 16); - if (debug) - fprintf( - stderr, "%s:%llx (%llx-%llx)\n", liblist[liblist_cnt].name, - liblist[liblist_cnt].addr_end - liblist[liblist_cnt].addr_start, - liblist[liblist_cnt].addr_start, - liblist[liblist_cnt].addr_end - 1); - liblist_cnt++; - - } - - } - - } - - if (debug) fprintf(stderr, "\n"); - -#elif defined(__FreeBSD__) - int mib[] = {CTL_KERN, KERN_PROC, KERN_PROC_VMMAP, getpid()}; - char * buf, *start, *end; - size_t miblen = sizeof(mib) / sizeof(mib[0]); - size_t len; - - if (debug) fprintf(stderr, "Library list:\n"); - if (sysctl(mib, miblen, NULL, &len, NULL, 0) == -1) { return; } - - len = len * 4 / 3; - - buf = mmap(NULL, len, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANON, -1, 0); - if (buf == MAP_FAILED) { return; } - if (sysctl(mib, miblen, buf, &len, NULL, 0) == -1) { - - munmap(buf, len); - return; - - } - - start = buf; - end = buf + len; - - while (start < end) { - - struct kinfo_vmentry *region = (struct kinfo_vmentry *)start; - size_t size = region->kve_structsize; - - if (size == 0) { break; } - - if ((region->kve_protection & KVME_PROT_READ) && - !(region->kve_protection & KVME_PROT_EXEC)) { - - liblist[liblist_cnt].name = - region->kve_path[0] != '\0' ? strdup(region->kve_path) : 0; - liblist[liblist_cnt].addr_start = region->kve_start; - liblist[liblist_cnt].addr_end = region->kve_end; - - if (debug) { - - fprintf(stderr, "%s:%x (%lx-%lx)\n", liblist[liblist_cnt].name, - liblist[liblist_cnt].addr_end - liblist[liblist_cnt].addr_start, - liblist[liblist_cnt].addr_start, - liblist[liblist_cnt].addr_end - 1); - - } - - liblist_cnt++; - - } - - start += size; - - } - -#endif - -} - -library_list_t *find_library(char *name) { - - char *filename = rindex(name, '/'); - - if (filename) - filename++; - else - filename = name; - -#if defined(__linux__) - u32 i; - for (i = 0; i < liblist_cnt; i++) - if (strcmp(liblist[i].name, filename) == 0) return &liblist[i]; -#elif defined(__APPLE__) && defined(__LP64__) - kern_return_t err; - static library_list_t lib; - - // get the list of all loaded modules from dyld - // the task_info mach API will get the address of the dyld all_image_info - // struct for the given task from which we can get the names and load - // addresses of all modules - task_dyld_info_data_t task_dyld_info; - mach_msg_type_number_t count = TASK_DYLD_INFO_COUNT; - err = task_info(mach_task_self(), TASK_DYLD_INFO, - (task_info_t)&task_dyld_info, &count); - - const struct dyld_all_image_infos *all_image_infos = - (const struct dyld_all_image_infos *)task_dyld_info.all_image_info_addr; - const struct dyld_image_info *image_infos = all_image_infos->infoArray; - - for (size_t i = 0; i < all_image_infos->infoArrayCount; i++) { - - const char * image_name = image_infos[i].imageFilePath; - mach_vm_address_t image_load_address = - (mach_vm_address_t)image_infos[i].imageLoadAddress; - if (strstr(image_name, name)) { - - lib.name = name; - lib.addr_start = (u64)image_load_address; - lib.addr_end = 0; - return &lib; - - } - - } - -#endif - - return NULL; - -} - -static void gum_fake_event_sink_process(GumEventSink * sink, - const GumEvent *ev) { - -} - -/* Because this CAN be called more than once, it will return the LAST range */ -static int enumerate_ranges(const GumRangeDetails *details, - gpointer user_data) { - - GumMemoryRange *code_range = (GumMemoryRange *)user_data; - memcpy(code_range, details->range, sizeof(*code_range)); - return 0; - -} - -int main() { - -#ifndef __APPLE__ - (void)personality(ADDR_NO_RANDOMIZE); // disable ASLR -#endif - - // STEP 2: load the library you want to fuzz and lookup the functions, - // inclusive of the cleanup functions. - // If there is just one function, then there is nothing to change - // or add here. - - void *dl = dlopen(TARGET_LIBRARY, RTLD_LAZY); - if (!dl) { - - fprintf(stderr, "Could not load %s\n", TARGET_LIBRARY); - exit(-1); - - } - - if (!(o_function = dlsym(dl, TARGET_FUNCTION))) { - - fprintf(stderr, "Could not find function %s\n", TARGET_FUNCTION); - exit(-1); - - } - - // END STEP 2 - - read_library_information(); - library_list_t *lib = find_library(TARGET_LIBRARY); - - if (lib == NULL) { - - fprintf(stderr, "Could not find target library\n"); - exit(-1); - - } - - gum_init_embedded(); - if (!gum_stalker_is_supported()) { - - gum_deinit_embedded(); - return 1; - - } - - GumStalker *stalker = gum_stalker_new(); - - /* - This does not work here as we load a shared library. pretty sure this - would also be easily solvable with frida gum, but I already have all the - code I need from afl-untracer - - GumAddress base_address = gum_module_find_base_address(TARGET_LIBRARY); - GumMemoryRange code_range; - gum_module_enumerate_ranges(TARGET_LIBRARY, GUM_PAGE_RX, enumerate_ranges, - &code_range); - guint64 code_start = code_range.base_address - base_address; - guint64 code_end = (code_range.base_address + code_range.size) - base_address; - range_t instr_range = {base_address, code_start, code_end}; - */ - range_t instr_range = {0, lib->addr_start, lib->addr_end}; - - GumStalkerTransformer *transformer = - gum_stalker_transformer_make_from_callback(instr_basic_block, - &instr_range, NULL); - - GumEventSink *event_sink = gum_fake_event_sink_new(); - - // to ensure that the signatures are not optimized out - memcpy(__afl_area_ptr, (void *)AFL_PERSISTENT, sizeof(AFL_PERSISTENT) + 1); - memcpy(__afl_area_ptr + 32, (void *)AFL_DEFER_FORKSVR, - sizeof(AFL_DEFER_FORKSVR) + 1); - __afl_manual_init(); - - // - // any expensive target library initialization that has to be done just once - // - put that here - // - - gum_stalker_follow_me(stalker, transformer, event_sink); - - while (__afl_persistent_loop(UINT32_MAX) != 0) { - - previous_pc = 0; // Required! - -#ifdef _DEBUG - fprintf(stderr, "CLIENT crc: %016llx len: %u\n", hash64(__afl_fuzz_ptr, *__a - fprintf(stderr, "RECV:"); - for (int i = 0; i < *__afl_fuzz_len; i++) - fprintf(stderr, "%02x", __afl_fuzz_ptr[i]); - fprintf(stderr,"\n"); -#endif - - // STEP 3: ensure the minimum length is present and setup the target - // function to fuzz. - - if (*__afl_fuzz_len > 0) { - - __afl_fuzz_ptr[*__afl_fuzz_len] = 0; // if you need to null terminate - (*o_function)(__afl_fuzz_ptr, *__afl_fuzz_len); - - } - - // END STEP 3 - - } - - gum_stalker_unfollow_me(stalker); - - while (gum_stalker_garbage_collect(stalker)) - g_usleep(10000); - - g_object_unref(stalker); - g_object_unref(transformer); - g_object_unref(event_sink); - gum_deinit_embedded(); - - return 0; - -} - diff --git a/examples/afl_untracer/patches.txt b/examples/afl_untracer/patches.txt deleted file mode 100644 index b3063e3a..00000000 --- a/examples/afl_untracer/patches.txt +++ /dev/null @@ -1,23 +0,0 @@ -libtestinstr.so:0x2000L
-0x1050L
-0x1063L
-0x106fL
-0x1078L
-0x1080L
-0x10a4L
-0x10b0L
-0x10b8L
-0x10c0L
-0x10c9L
-0x10d7L
-0x10e3L
-0x10f8L
-0x1100L
-0x1105L
-0x111aL
-0x1135L
-0x1143L
-0x114eL
-0x115cL
-0x116aL
-0x116bL
diff --git a/examples/aflpp_driver/GNUmakefile b/examples/aflpp_driver/GNUmakefile deleted file mode 100644 index a993c8a9..00000000 --- a/examples/aflpp_driver/GNUmakefile +++ /dev/null @@ -1,44 +0,0 @@ -ifeq "" "$(LLVM_CONFIG)" - LLVM_CONFIG=llvm-config -endif - -LLVM_BINDIR = $(shell $(LLVM_CONFIG) --bindir 2>/dev/null) -ifneq "" "$(LLVM_BINDIR)" - LLVM_BINDIR := $(LLVM_BINDIR)/ -endif - -FLAGS=-O3 -funroll-loops -g - -all: libAFLDriver.a libAFLQemuDriver.a aflpp_qemu_driver_hook.so - -aflpp_driver.o: aflpp_driver.cpp - $(LLVM_BINDIR)clang++ $(FLAGS) -stdlib=libc++ -std=c++11 -c aflpp_driver.cpp - -libAFLDriver.a: aflpp_driver.o - ar ru libAFLDriver.a aflpp_driver.o - -debug: - $(LLVM_BINDIR)clang++ -Wno-deprecated -I../../include $(FLAGS) -D_DEBUG=\"1\" -c -o afl-performance.o ../../src/afl-performance.c - $(LLVM_BINDIR)clang++ -I../../include -D_DEBUG=\"1\" -g -stdlib=libc++ -funroll-loops -std=c++11 -c aflpp_driver.cpp - #$(LLVM_BINDIR)clang++ -S -emit-llvm -Wno-deprecated -I../../include $(FLAGS) -D_DEBUG=\"1\" -c -o afl-performance.ll ../../src/afl-performance.c - #$(LLVM_BINDIR)clang++ -S -emit-llvm -I../../include -D_DEBUG=\"1\" -g -stdlib=libc++ -funroll-loops -std=c++11 -c aflpp_driver.cpp - ar ru libAFLDriver.a afl-performance.o aflpp_driver.o - -aflpp_qemu_driver.o: aflpp_qemu_driver.c - $(LLVM_BINDIR)clang $(FLAGS) -O0 -funroll-loops -c aflpp_qemu_driver.c - -libAFLQemuDriver.a: aflpp_qemu_driver.o - ar ru libAFLQemuDriver.a aflpp_qemu_driver.o - -aflpp_qemu_driver_hook.so: aflpp_qemu_driver_hook.o - $(LLVM_BINDIR)clang -shared aflpp_qemu_driver_hook.o -o aflpp_qemu_driver_hook.so - -aflpp_qemu_driver_hook.o: aflpp_qemu_driver_hook.c - $(LLVM_BINDIR)clang -fPIC $(FLAGS) -funroll-loops -c aflpp_qemu_driver_hook.c - -test: debug - #clang++ -S -emit-llvm -D_DEBUG=\"1\" -I../../include -Wl,--allow-multiple-definition -stdlib=libc++ -funroll-loops -std=c++11 -o aflpp_driver_test.ll aflpp_driver_test.cpp - afl-clang-fast++ -D_DEBUG=\"1\" -I../../include -Wl,--allow-multiple-definition -stdlib=libc++ -funroll-loops -std=c++11 -o aflpp_driver_test aflpp_driver_test.cpp libAFLDriver.a - -clean: - rm -f *.o libAFLDriver*.a libAFLQemuDriver.a aflpp_qemu_driver_hook.so *~ core aflpp_driver_test diff --git a/examples/aflpp_driver/aflpp_driver.cpp b/examples/aflpp_driver/aflpp_driver.cpp deleted file mode 100644 index d6163bdf..00000000 --- a/examples/aflpp_driver/aflpp_driver.cpp +++ /dev/null @@ -1,292 +0,0 @@ -//===- afl_driver.cpp - a glue between AFL and libFuzzer --------*- C++ -* ===// -// -// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. -// See https://llvm.org/LICENSE.txt for license information. -// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception -//===----------------------------------------------------------------------===// - -/* This file allows to fuzz libFuzzer-style target functions - (LLVMFuzzerTestOneInput) with AFL using AFL's persistent (in-process) mode. - -Usage: -################################################################################ -cat << EOF > test_fuzzer.cc -#include <stddef.h> -#include <stdint.h> -extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) { - if (size > 0 && data[0] == 'H') - if (size > 1 && data[1] == 'I') - if (size > 2 && data[2] == '!') - __builtin_trap(); - return 0; -} -EOF -# Build your target with -fsanitize-coverage=trace-pc-guard using fresh clang. -clang -g -fsanitize-coverage=trace-pc-guard test_fuzzer.cc -c -# Build afl-llvm-rt.o.c from the AFL distribution. -clang -c -w $AFL_HOME/llvm_mode/afl-llvm-rt.o.c -# Build this file, link it with afl-llvm-rt.o.o and the target code. -clang++ afl_driver.cpp test_fuzzer.o afl-llvm-rt.o.o -# Run AFL: -rm -rf IN OUT; mkdir IN OUT; echo z > IN/z; -$AFL_HOME/afl-fuzz -i IN -o OUT ./a.out -################################################################################ -AFL_DRIVER_STDERR_DUPLICATE_FILENAME: Setting this *appends* stderr to the file -specified. If the file does not exist, it is created. This is useful for getting -stack traces (when using ASAN for example) or original error messages on hard -to reproduce bugs. Note that any content written to stderr will be written to -this file instead of stderr's usual location. - -AFL_DRIVER_CLOSE_FD_MASK: Similar to libFuzzer's -close_fd_mask behavior option. -If 1, close stdout at startup. If 2 close stderr; if 3 close both. - -*/ -#include <assert.h> -#include <errno.h> -#include <stdarg.h> -#include <stdint.h> -#include <stdio.h> -#include <stdlib.h> -#include <string.h> -#include <unistd.h> - -#include <fstream> -#include <iostream> -#include <vector> - -#ifdef _DEBUG -#include "hash.h" -#endif - -// Platform detection. Copied from FuzzerInternal.h -#ifdef __linux__ -#define LIBFUZZER_LINUX 1 -#define LIBFUZZER_APPLE 0 -#define LIBFUZZER_NETBSD 0 -#define LIBFUZZER_FREEBSD 0 -#define LIBFUZZER_OPENBSD 0 -#elif __APPLE__ -#define LIBFUZZER_LINUX 0 -#define LIBFUZZER_APPLE 1 -#define LIBFUZZER_NETBSD 0 -#define LIBFUZZER_FREEBSD 0 -#define LIBFUZZER_OPENBSD 0 -#elif __NetBSD__ -#define LIBFUZZER_LINUX 0 -#define LIBFUZZER_APPLE 0 -#define LIBFUZZER_NETBSD 1 -#define LIBFUZZER_FREEBSD 0 -#define LIBFUZZER_OPENBSD 0 -#elif __FreeBSD__ -#define LIBFUZZER_LINUX 0 -#define LIBFUZZER_APPLE 0 -#define LIBFUZZER_NETBSD 0 -#define LIBFUZZER_FREEBSD 1 -#define LIBFUZZER_OPENBSD 0 -#elif __OpenBSD__ -#define LIBFUZZER_LINUX 0 -#define LIBFUZZER_APPLE 0 -#define LIBFUZZER_NETBSD 0 -#define LIBFUZZER_FREEBSD 0 -#define LIBFUZZER_OPENBSD 1 -#else -#error "Support for your platform has not been implemented" -#endif - -int __afl_sharedmem_fuzzing = 1; -extern unsigned int *__afl_fuzz_len; -extern unsigned char *__afl_fuzz_ptr; - -// libFuzzer interface is thin, so we don't include any libFuzzer headers. -extern "C" { -int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size); -__attribute__((weak)) int LLVMFuzzerInitialize(int *argc, char ***argv); -} - -// Notify AFL about persistent mode. -static volatile char AFL_PERSISTENT[] = "##SIG_AFL_PERSISTENT##"; -extern "C" int __afl_persistent_loop(unsigned int); -static volatile char suppress_warning2 = AFL_PERSISTENT[0]; - -// Notify AFL about deferred forkserver. -static volatile char AFL_DEFER_FORKSVR[] = "##SIG_AFL_DEFER_FORKSRV##"; -extern "C" void __afl_manual_init(); -static volatile char suppress_warning1 = AFL_DEFER_FORKSVR[0]; - -// Input buffer. -static const size_t kMaxAflInputSize = 1 << 20; -static uint8_t AflInputBuf[kMaxAflInputSize]; - -// Use this optionally defined function to output sanitizer messages even if -// user asks to close stderr. -__attribute__((weak)) extern "C" void __sanitizer_set_report_fd(void *); - -// Keep track of where stderr content is being written to, so that -// dup_and_close_stderr can use the correct one. -static FILE *output_file = stderr; - -// Experimental feature to use afl_driver without AFL's deferred mode. -// Needs to run before __afl_auto_init. -__attribute__((constructor(0))) static void __decide_deferred_forkserver(void) { - if (getenv("AFL_DRIVER_DONT_DEFER")) { - if (unsetenv("__AFL_DEFER_FORKSRV")) { - perror("Failed to unset __AFL_DEFER_FORKSRV"); - abort(); - } - } -} - -// If the user asks us to duplicate stderr, then do it. -static void maybe_duplicate_stderr() { - char *stderr_duplicate_filename = - getenv("AFL_DRIVER_STDERR_DUPLICATE_FILENAME"); - - if (!stderr_duplicate_filename) - return; - - FILE *stderr_duplicate_stream = - freopen(stderr_duplicate_filename, "a+", stderr); - - if (!stderr_duplicate_stream) { - fprintf( - stderr, - "Failed to duplicate stderr to AFL_DRIVER_STDERR_DUPLICATE_FILENAME"); - abort(); - } - output_file = stderr_duplicate_stream; -} - -// Most of these I/O functions were inspired by/copied from libFuzzer's code. -static void discard_output(int fd) { - FILE *temp = fopen("/dev/null", "w"); - if (!temp) - abort(); - dup2(fileno(temp), fd); - fclose(temp); -} - -static void close_stdout() { discard_output(STDOUT_FILENO); } - -// Prevent the targeted code from writing to "stderr" but allow sanitizers and -// this driver to do so. -static void dup_and_close_stderr() { - int output_fileno = fileno(output_file); - int output_fd = dup(output_fileno); - if (output_fd <= 0) - abort(); - FILE *new_output_file = fdopen(output_fd, "w"); - if (!new_output_file) - abort(); - if (!__sanitizer_set_report_fd) - return; - __sanitizer_set_report_fd(reinterpret_cast<void *>(output_fd)); - discard_output(output_fileno); -} - -static void Printf(const char *Fmt, ...) { - va_list ap; - va_start(ap, Fmt); - vfprintf(output_file, Fmt, ap); - va_end(ap); - fflush(output_file); -} - -// Close stdout and/or stderr if user asks for it. -static void maybe_close_fd_mask() { - char *fd_mask_str = getenv("AFL_DRIVER_CLOSE_FD_MASK"); - if (!fd_mask_str) - return; - int fd_mask = atoi(fd_mask_str); - if (fd_mask & 2) - dup_and_close_stderr(); - if (fd_mask & 1) - close_stdout(); -} - -// Define LLVMFuzzerMutate to avoid link failures for targets that use it -// with libFuzzer's LLVMFuzzerCustomMutator. -extern "C" size_t LLVMFuzzerMutate(uint8_t *Data, size_t Size, size_t MaxSize) { - assert(false && "LLVMFuzzerMutate should not be called from afl_driver"); - return 0; -} - -// Execute any files provided as parameters. -static int ExecuteFilesOnyByOne(int argc, char **argv) { - for (int i = 1; i < argc; i++) { - std::ifstream in(argv[i], std::ios::binary); - in.seekg(0, in.end); - size_t length = in.tellg(); - in.seekg (0, in.beg); - std::cout << "Reading " << length << " bytes from " << argv[i] << std::endl; - // Allocate exactly length bytes so that we reliably catch buffer overflows. - std::vector<char> bytes(length); - in.read(bytes.data(), bytes.size()); - assert(in); - LLVMFuzzerTestOneInput(reinterpret_cast<const uint8_t *>(bytes.data()), - bytes.size()); - std::cout << "Execution successful" << std::endl; - } - return 0; -} - -int main(int argc, char **argv) { - Printf( - "======================= INFO =========================\n" - "This binary is built for AFL-fuzz.\n" - "To run the target function on individual input(s) execute this:\n" - " %s < INPUT_FILE\n" - "or\n" - " %s INPUT_FILE1 [INPUT_FILE2 ... ]\n" - "To fuzz with afl-fuzz execute this:\n" - " afl-fuzz [afl-flags] %s [-N]\n" - "afl-fuzz will run N iterations before " - "re-spawning the process (default: 1000)\n" - "======================================================\n", - argv[0], argv[0], argv[0]); - - maybe_duplicate_stderr(); - maybe_close_fd_mask(); - if (LLVMFuzzerInitialize) - LLVMFuzzerInitialize(&argc, &argv); - // Do any other expensive one-time initialization here. - - uint8_t dummy_input[1] = {0}; - int N = 100000; - if (argc == 2 && argv[1][0] == '-') - N = atoi(argv[1] + 1); - else if(argc == 2 && (N = atoi(argv[1])) > 0) - Printf("WARNING: using the deprecated call style `%s %d`\n", argv[0], N); - else if (argc > 1) { -// if (!getenv("AFL_DRIVER_DONT_DEFER")) { - __afl_sharedmem_fuzzing = 0; - __afl_manual_init(); -// } - return ExecuteFilesOnyByOne(argc, argv); - exit(0); - } - - assert(N > 0); - -// if (!getenv("AFL_DRIVER_DONT_DEFER")) - __afl_manual_init(); - - // Call LLVMFuzzerTestOneInput here so that coverage caused by initialization - // on the first execution of LLVMFuzzerTestOneInput is ignored. - LLVMFuzzerTestOneInput(dummy_input, 1); - - int num_runs = 0; - while (__afl_persistent_loop(N)) { -#ifdef _DEBUG - fprintf(stderr, "CLIENT crc: %016llx len: %u\n", hash64(__afl_fuzz_ptr, *__afl_fuzz_len, 0xa5b35705), *__afl_fuzz_len); - fprintf(stderr, "RECV:"); - for (int i = 0; i < *__afl_fuzz_len; i++) - fprintf(stderr, "%02x", __afl_fuzz_ptr[i]); - fprintf(stderr,"\n"); -#endif - if (*__afl_fuzz_len) { - num_runs++; - LLVMFuzzerTestOneInput(__afl_fuzz_ptr, *__afl_fuzz_len); - } - } - Printf("%s: successfully executed %d input(s)\n", argv[0], num_runs); -} diff --git a/examples/aflpp_driver/aflpp_driver_test.cpp b/examples/aflpp_driver/aflpp_driver_test.cpp deleted file mode 100644 index 13dc09b9..00000000 --- a/examples/aflpp_driver/aflpp_driver_test.cpp +++ /dev/null @@ -1,22 +0,0 @@ -#include <stdio.h> -#include <stdlib.h> -#include <stdint.h> -#include "hash.h" - -extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) { - - fprintf(stderr, "FUNC crc: %016llx len: %lu\n", hash64((u8*)Data, (unsigned int) Size, (unsigned long long int) 0xa5b35705), Size); - - if (Size < 5) - return 0; - - if (Data[0] == 'F') - if (Data[1] == 'A') - if (Data[2] == '$') - if (Data[3] == '$') - if (Data[4] == '$') - abort(); - - return 0; - -} diff --git a/examples/defork/forking_target b/examples/defork/forking_target Binary files differdeleted file mode 100755 index 0f7a04fc..00000000 --- a/examples/defork/forking_target +++ /dev/null diff --git a/examples/persistent_demo/Makefile b/examples/persistent_demo/Makefile deleted file mode 100644 index 6fa1c30e..00000000 --- a/examples/persistent_demo/Makefile +++ /dev/null @@ -1,10 +0,0 @@ -all: - afl-clang-fast -o persistent_demo persistent_demo.c - afl-clang-fast -o persistent_demo_new persistent_demo_new.c - AFL_DONT_OPTIMIZE=1 afl-clang-fast -o test-instr test-instr.c - -document: - AFL_DONT_OPTIMIZE=1 afl-clang-fast -D_AFL_DOCUMENT_MUTATIONS -o test-instr test-instr.c - -clean: - rm -f persistent_demo persistent_demo_new test-instr diff --git a/examples/qemu_persistent_hook/read_into_rdi.c b/examples/qemu_persistent_hook/read_into_rdi.c deleted file mode 100644 index bd6d3f45..00000000 --- a/examples/qemu_persistent_hook/read_into_rdi.c +++ /dev/null @@ -1,61 +0,0 @@ -#include <stdint.h> -#include <stdio.h> -#include <unistd.h> -#include <string.h> - -#define g2h(x) ((void *)((unsigned long)(x) + guest_base)) -#define h2g(x) ((uint64_t)(x)-guest_base) - -enum { - - R_EAX = 0, - R_ECX = 1, - R_EDX = 2, - R_EBX = 3, - R_ESP = 4, - R_EBP = 5, - R_ESI = 6, - R_EDI = 7, - R_R8 = 8, - R_R9 = 9, - R_R10 = 10, - R_R11 = 11, - R_R12 = 12, - R_R13 = 13, - R_R14 = 14, - R_R15 = 15, - - R_AL = 0, - R_CL = 1, - R_DL = 2, - R_BL = 3, - R_AH = 4, - R_CH = 5, - R_DH = 6, - R_BH = 7, - -}; - -void afl_persistent_hook(uint64_t *regs, uint64_t guest_base, - uint8_t *input_buf, uint32_t input_len) { - - // In this example the register RDI is pointing to the memory location - // of the target buffer, and the length of the input is in RSI. - // This can be seen with a debugger, e.g. gdb (and "disass main") - - printf("placing input into %p\n", regs[R_EDI]); - - if (input_len > 1024) input_len = 1024; - memcpy(g2h(regs[R_EDI]), input_buf, input_len); - regs[R_ESI] = input_len; - -} - -int afl_persistent_hook_init(void) { - - // 1 for shared memory input (faster), 0 for normal input (you have to use - // read(), input_buf will be NULL) - return 1; - -} - diff --git a/gcc_plugin/Makefile b/gcc_plugin/Makefile deleted file mode 100644 index f720112f..00000000 --- a/gcc_plugin/Makefile +++ /dev/null @@ -1,159 +0,0 @@ -# -# american fuzzy lop++ - GCC plugin instrumentation -# ----------------------------------------------- -# -# Written by Austin Seipp <aseipp@pobox.com> and -# Laszlo Szekeres <lszekeres@google.com> and -# Michal Zalewski and -# Heiko Eißfeldt <heiko@hexco.de> -# -# GCC integration design is based on the LLVM design, which comes -# from Laszlo Szekeres. -# -# Copyright 2015 Google Inc. All rights reserved. -# Copyright 2019-2020 AFLplusplus Project. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at: -# -# http://www.apache.org/licenses/LICENSE-2.0 -# - -PREFIX ?= /usr/local -HELPER_PATH ?= $(PREFIX)/lib/afl -BIN_PATH ?= $(PREFIX)/bin -DOC_PATH ?= $(PREFIX)/share/doc/afl -MAN_PATH ?= $(PREFIX)/man/man8 - -VERSION = $(shell grep '^$(HASH)define VERSION ' ../config.h | cut -d '"' -f2) -VERSION:sh= grep '^$(HASH)define VERSION ' ../config.h | cut -d '"' -f2 - -CFLAGS ?= -O3 -g -funroll-loops -D_FORTIFY_SOURCE=2 -CFLAGS = -Wall -I../include -Wno-pointer-sign \ - -DAFL_PATH=\"$(HELPER_PATH)\" -DBIN_PATH=\"$(BIN_PATH)\" \ - -DGCC_VERSION=\"$(GCCVER)\" -DGCC_BINDIR=\"$(GCCBINDIR)\" \ - -Wno-unused-function - -CXXFLAGS = -O3 -g -funroll-loops -D_FORTIFY_SOURCE=2 -CXXEFLAGS = $(CXXFLAGS) -Wall - -CC = gcc -CXX = g++ - -MYCC=$(CC:clang=gcc) -MYCXX=$(CXX:clang++=g++) - -PLUGIN_PATH = $(shell $(MYCC) -print-file-name=plugin) -PLUGIN_PATH:sh= $(MYCC) -print-file-name=plugin -PLUGIN_FLAGS = -fPIC -fno-rtti -I"$(PLUGIN_PATH)/include" -HASH=\# - -GCCVER = $(shell $(MYCC) --version 2>/dev/null | awk 'NR == 1 {print $$NF}') -GCCVER:sh= gcc --version 2>/dev/null | awk 'NR == 1 {print $$NF}' -GCCBINDIR = $(shell dirname `command -v $(MYCC)` 2>/dev/null ) -GCCBINDIR:sh= dirname `command -v $(MYCC)` 2>/dev/null - -_SHMAT_OK= $(shell echo '$(HASH)include <sys/ipc.h>@$(HASH)include <sys/shm.h>@int main() { int _id = shmget(IPC_PRIVATE, 65536, IPC_CREAT | IPC_EXCL | 0600); shmctl(_id, IPC_RMID, 0); return 0;}' | tr @ '\n' | $(MYCC) -x c - -o .test2 2>/dev/null && echo 1 || echo 0 ; rm -f .test2 ) -_SHMAT_OK:sh= echo '$(HASH)include <sys/ipc.h>@$(HASH)include <sys/shm.h>@int main() { int _id = shmget(IPC_PRIVATE, 65536, IPC_CREAT | IPC_EXCL | 0600); shmctl(_id, IPC_RMID, 0); return 0;}' | tr @ '\n' | $(MYCC) -x c - -o .test2 2>/dev/null && echo 1 || echo 0 ; rm -f .test2 - -IGNORE_MMAP=$(TEST_MMAP:1=0) -__SHMAT_OK=$(_SHMAT_OK)$(IGNORE_MMAP) -___SHMAT_OK=$(__SHMAT_OK:10=0) -SHMAT_OK=$(___SHMAT_OK:1=1) -_CFLAGS_ADD=$(SHMAT_OK:1=) -CFLAGS_ADD=$(_CFLAGS_ADD:0=-DUSEMMAP=1) - -_LDFLAGS_ADD=$(SHMAT_OK:1=) -LDFLAGS_ADD=$(_LDFLAGS_ADD:0=-lrt) - -CFLAGS += $(CFLAGS_ADD) -LDFLAGS += $(LDFLAGS_ADD) - -PROGS = ../afl-gcc-pass.so ../afl-gcc-fast ../afl-gcc-rt.o - -all: test_shm test_deps $(PROGS) ../afl-gcc-fast.8 test_build all_done - -debug: - @echo _SHMAT_OK = $(_SHMAT_OK) - @echo IGNORE_MMAP = $(IGNORE_MMAP) - @echo __SHMAT_OK = $(__SHMAT_OK) - @echo ___SHMAT_OK = $(___SHMAT_OK) - @echo SHMAT_OK = $(SHMAT_OK) - -test_shm: - @if [ "$(SHMAT_OK)" == "1" ]; then \ - echo "[+] shmat seems to be working."; \ - rm -f .test2; \ - else \ - echo "[-] shmat seems not to be working, switching to mmap implementation"; \ - fi - -test_deps: - @echo "[*] Checking for working '$(MYCC)'..." - @type $(MYCC) >/dev/null 2>&1 || ( echo "[-] Oops, can't find '$(MYCC)'. Make sure that it's in your \$$PATH (or set \$$CC and \$$CXX)."; exit 1 ) -# @echo "[*] Checking for gcc for plugin support..." -# @$(MYCC) -v 2>&1 | grep -q -- --enable-plugin || ( echo "[-] Oops, this gcc has not been configured with plugin support."; exit 1 ) - @echo "[*] Checking for gcc plugin development header files..." - @test -d `$(MYCC) -print-file-name=plugin`/include || ( echo "[-] Oops, can't find gcc header files. Be sure to install 'gcc-X-plugin-dev'."; exit 1 ) - @echo "[*] Checking for '../afl-showmap'..." - @test -f ../afl-showmap || ( echo "[-] Oops, can't find '../afl-showmap'. Be sure to compile AFL first."; exit 1 ) - @echo "[+] All set and ready to build." - -afl-common.o: ../src/afl-common.c - $(MYCC) $(CFLAGS) -c $< -o $@ $(LDFLAGS) - -../afl-gcc-fast: afl-gcc-fast.c afl-common.o - $(MYCC) -DAFL_GCC_CC=\"$(MYCC)\" -DAFL_GCC_CXX=\"$(MYCXX)\" $(CFLAGS) afl-gcc-fast.c afl-common.o -o $@ $(LDFLAGS) - ln -sf afl-gcc-fast ../afl-g++-fast - -../afl-gcc-pass.so: afl-gcc-pass.so.cc - $(MYCXX) $(CXXEFLAGS) $(PLUGIN_FLAGS) -shared afl-gcc-pass.so.cc -o $@ - -../afl-gcc-rt.o: afl-gcc-rt.o.c - $(MYCC) $(CFLAGS) -fPIC -c afl-gcc-rt.o.c -o $@ - -test_build: $(PROGS) - @echo "[*] Testing the CC wrapper and instrumentation output..." - @unset AFL_USE_ASAN AFL_USE_MSAN; AFL_QUIET=1 AFL_INST_RATIO=100 AFL_PATH=. AFL_CC=$(CC) ../afl-gcc-fast $(CFLAGS) ../test-instr.c -o test-instr $(LDFLAGS) -# unset AFL_USE_ASAN AFL_USE_MSAN; AFL_INST_RATIO=100 AFL_PATH=. AFL_CC=$(CC) ../afl-gcc-fast $(CFLAGS) ../test-instr.c -o test-instr $(LDFLAGS) - @ASAN_OPTIONS=detect_leaks=0 ../afl-showmap -m none -q -o .test-instr0 ./test-instr </dev/null - @ASAN_OPTIONS=detect_leaks=0 echo 1 | ../afl-showmap -m none -q -o .test-instr1 ./test-instr - @rm -f test-instr - @trap 'rm .test-instr0 .test-instr1' 0;if cmp -s .test-instr0 .test-instr1; then echo; echo "Oops, the instrumentation does not seem to be behaving correctly!"; echo; echo "Please post to https://github.com/AFLplusplus/AFLplusplus/issues to troubleshoot the issue."; echo; exit 1; fi - @echo "[+] All right, the instrumentation seems to be working!" - -all_done: test_build - @echo "[+] All done! You can now use '../afl-gcc-fast' to compile programs." - -.NOTPARALLEL: clean - -../afl-gcc-fast.8: ../afl-gcc-fast - @echo .TH $* 8 `date "+%Y-%m-%d"` "afl++" > ../$@ - @echo .SH NAME >> ../$@ - @echo .B $* >> ../$@ - @echo >> ../$@ - @echo .SH SYNOPSIS >> ../$@ - @../$* -h 2>&1 | head -n 3 | tail -n 1 | sed 's/^\.\///' >> ../$@ - @echo >> ../$@ - @echo .SH OPTIONS >> ../$@ - @echo .nf >> ../$@ - @../$* -h 2>&1 | tail -n +4 >> ../$@ - @echo >> ../$@ - @echo .SH AUTHOR >> ../$@ - @echo "afl++ was written by Michal \"lcamtuf\" Zalewski and is maintained by Marc \"van Hauser\" Heuse <mh@mh-sec.de>, Heiko \"hexcoder-\" Eissfeldt <heiko.eissfeldt@hexco.de>, Andrea Fioraldi <andreafioraldi@gmail.com> and Dominik Maier <domenukk@gmail.com>" >> ../$@ - @echo The homepage of afl++ is: https://github.com/AFLplusplus/AFLplusplus >> ../$@ - @echo >> ../$@ - @echo .SH LICENSE >> ../$@ - @echo Apache License Version 2.0, January 2004 >> ../$@ - ln -sf afl-gcc-fast.8 ../afl-g++-fast.8 - -install: all - install -m 755 ../afl-gcc-fast $${DESTDIR}$(BIN_PATH) - install -m 755 ../afl-gcc-pass.so ../afl-gcc-rt.o $${DESTDIR}$(HELPER_PATH) - install -m 644 -T README.md $${DESTDIR}$(DOC_PATH)/README.gcc_plugin.md - install -m 644 -T README.instrument_file.md $${DESTDIR}$(DOC_PATH)/README.gcc_plugin.instrument_file.md - -clean: - rm -f *.o *.so *~ a.out core core.[1-9][0-9]* test-instr .test-instr0 .test-instr1 .test2 - rm -f $(PROGS) afl-common.o ../afl-g++-fast ../afl-g*-fast.8 diff --git a/gcc_plugin/README.instrument_file.md b/gcc_plugin/README.instrument_file.md deleted file mode 100644 index d0eaf6ff..00000000 --- a/gcc_plugin/README.instrument_file.md +++ /dev/null @@ -1,73 +0,0 @@ -======================================== -Using afl++ with partial instrumentation -======================================== - - This file describes how you can selectively instrument only the source files - that are interesting to you using the gcc instrumentation provided by - afl++. - - Plugin by hexcoder-. - - -## 1) Description and purpose - -When building and testing complex programs where only a part of the program is -the fuzzing target, it often helps to only instrument the necessary parts of -the program, leaving the rest uninstrumented. This helps to focus the fuzzer -on the important parts of the program, avoiding undesired noise and -disturbance by uninteresting code being exercised. - -For this purpose, I have added a "partial instrumentation" support to the gcc -plugin of AFLFuzz that allows you to specify on a source file level which files -should be compiled with or without instrumentation. - - -## 2) Building the gcc plugin - -The new code is part of the existing afl++ gcc plugin in the gcc_plugin/ -subdirectory. There is nothing specifically to do :) - - -## 3) How to use the partial instrumentation mode - -In order to build with partial instrumentation, you need to build with -afl-gcc-fast and afl-g++-fast respectively. The only required change is -that you need to set the environment variable AFL_GCC_INSTRUMENT_FILE when calling -the compiler. - -The environment variable must point to a file containing all the filenames -that should be instrumented. For matching, the filename that is being compiled -must end in the filename entry contained in this instrument list (to avoid breaking -the matching when absolute paths are used during compilation). - -For example if your source tree looks like this: - -``` -project/ -project/feature_a/a1.cpp -project/feature_a/a2.cpp -project/feature_b/b1.cpp -project/feature_b/b2.cpp -``` - -and you only want to test feature_a, then create a instrument list file containing: - -``` -feature_a/a1.cpp -feature_a/a2.cpp -``` - -However if the instrument list file contains only this, it works as well: - -``` -a1.cpp -a2.cpp -``` - -but it might lead to files being unwantedly instrumented if the same filename -exists somewhere else in the project directories. - -The created instrument list file is then set to AFL_GCC_INSTRUMENT_FILE when you compile -your program. For each file that didn't match the instrument list, the compiler will -issue a warning at the end stating that no blocks were instrumented. If you -didn't intend to instrument that file, then you can safely ignore that warning. diff --git a/gcc_plugin/afl-gcc-fast.c b/gcc_plugin/afl-gcc-fast.c deleted file mode 100644 index b1bacfbd..00000000 --- a/gcc_plugin/afl-gcc-fast.c +++ /dev/null @@ -1,406 +0,0 @@ -/* - american fuzzy lop++ - GCC wrapper for GCC plugin - ------------------------------------------------ - - Written by Austin Seipp <aseipp@pobox.com> and - Laszlo Szekeres <lszekeres@google.com> and - Michal Zalewski - - GCC integration design is based on the LLVM design, which comes - from Laszlo Szekeres. - - Copyright 2015 Google Inc. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This program is a drop-in replacement for gcc, similar in most - respects to ../afl-gcc, but with compiler instrumentation through a - plugin. It tries to figure out compilation mode, adds a bunch of - flags, and then calls the real compiler. - - */ - -#define AFL_MAIN - -#include "config.h" -#include "types.h" -#include "debug.h" -#include "common.h" -#include "alloc-inl.h" - -#include <stdio.h> -#include <unistd.h> -#include <stdlib.h> -#include <string.h> - -static u8 * obj_path; /* Path to runtime libraries */ -static u8 **cc_params; /* Parameters passed to the real CC */ -static u32 cc_par_cnt = 1; /* Param count, including argv0 */ -u8 use_stdin = 0; /* dummy */ - -/* Try to find the runtime libraries. If that fails, abort. */ - -static void find_obj(u8 *argv0) { - - u8 *afl_path = getenv("AFL_PATH"); - u8 *slash, *tmp; - - if (afl_path) { - - tmp = alloc_printf("%s/afl-gcc-rt.o", afl_path); - - if (!access(tmp, R_OK)) { - - obj_path = afl_path; - ck_free(tmp); - return; - - } - - ck_free(tmp); - - } - - slash = strrchr(argv0, '/'); - - if (slash) { - - u8 *dir; - - *slash = 0; - dir = ck_strdup(argv0); - *slash = '/'; - - tmp = alloc_printf("%s/afl-gcc-rt.o", dir); - - if (!access(tmp, R_OK)) { - - obj_path = dir; - ck_free(tmp); - return; - - } - - ck_free(tmp); - ck_free(dir); - - } - - if (!access(AFL_PATH "/afl-gcc-rt.o", R_OK)) { - - obj_path = AFL_PATH; - return; - - } - - FATAL( - "Unable to find 'afl-gcc-rt.o' or 'afl-gcc-pass.so'. Please set " - "AFL_PATH"); - -} - -/* Copy argv to cc_params, making the necessary edits. */ - -static void edit_params(u32 argc, char **argv) { - - u8 fortify_set = 0, asan_set = 0, x_set = 0, maybe_linking = 1; - u8 *name; - - cc_params = ck_alloc((argc + 128) * sizeof(u8 *)); - - name = strrchr(argv[0], '/'); - if (!name) - name = argv[0]; - else - ++name; - - if (!strcmp(name, "afl-g++-fast")) { - - u8 *alt_cxx = getenv("AFL_CXX"); - cc_params[0] = alt_cxx && *alt_cxx ? alt_cxx : (u8 *)AFL_GCC_CXX; - - } else if (!strcmp(name, "afl-gcc-fast")) { - - u8 *alt_cc = getenv("AFL_CC"); - cc_params[0] = alt_cc && *alt_cc ? alt_cc : (u8 *)AFL_GCC_CC; - - } else { - - fprintf(stderr, "Name of the binary: %s\n", argv[0]); - FATAL( - "Name of the binary is not a known name, expected afl-(gcc|g++)-fast"); - - } - - char *fplugin_arg = alloc_printf("-fplugin=%s/afl-gcc-pass.so", obj_path); - cc_params[cc_par_cnt++] = fplugin_arg; - - /* Detect stray -v calls from ./configure scripts. */ - - if (argc == 1 && !strcmp(argv[1], "-v")) maybe_linking = 0; - - while (--argc) { - - u8 *cur = *(++argv); - -#if defined(__x86_64__) - if (!strcmp(cur, "-m32")) FATAL("-m32 is not supported"); -#endif - - if (!strcmp(cur, "-x")) x_set = 1; - - if (!strcmp(cur, "-c") || !strcmp(cur, "-S") || !strcmp(cur, "-E") || - !strcmp(cur, "-v")) - maybe_linking = 0; - - if (!strcmp(cur, "-fsanitize=address") || !strcmp(cur, "-fsanitize=memory")) - asan_set = 1; - - if (strstr(cur, "FORTIFY_SOURCE")) fortify_set = 1; - - if (!strcmp(cur, "-shared")) maybe_linking = 0; - - cc_params[cc_par_cnt++] = cur; - - } - - if (getenv("AFL_HARDEN")) { - - cc_params[cc_par_cnt++] = "-fstack-protector-all"; - - if (!fortify_set) cc_params[cc_par_cnt++] = "-D_FORTIFY_SOURCE=2"; - - } - - if (!asan_set) { - - if (getenv("AFL_USE_ASAN")) { - - if (getenv("AFL_USE_MSAN")) FATAL("ASAN and MSAN are mutually exclusive"); - - if (getenv("AFL_HARDEN")) - FATAL("ASAN and AFL_HARDEN are mutually exclusive"); - - cc_params[cc_par_cnt++] = "-U_FORTIFY_SOURCE"; - cc_params[cc_par_cnt++] = "-fsanitize=address"; - - } else if (getenv("AFL_USE_MSAN")) { - - if (getenv("AFL_USE_ASAN")) FATAL("ASAN and MSAN are mutually exclusive"); - - if (getenv("AFL_HARDEN")) - FATAL("MSAN and AFL_HARDEN are mutually exclusive"); - - cc_params[cc_par_cnt++] = "-U_FORTIFY_SOURCE"; - cc_params[cc_par_cnt++] = "-fsanitize=memory"; - - } - - } - - if (getenv("AFL_USE_UBSAN")) { - - cc_params[cc_par_cnt++] = "-fsanitize=undefined"; - cc_params[cc_par_cnt++] = "-fsanitize-undefined-trap-on-error"; - cc_params[cc_par_cnt++] = "-fno-sanitize-recover=all"; - - } - - if (!getenv("AFL_DONT_OPTIMIZE")) { - - cc_params[cc_par_cnt++] = "-g"; - cc_params[cc_par_cnt++] = "-O3"; - cc_params[cc_par_cnt++] = "-funroll-loops"; - - } - - if (getenv("AFL_NO_BUILTIN")) { - - cc_params[cc_par_cnt++] = "-fno-builtin-strcmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strncmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strcasecmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strncasecmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-memcmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-bcmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strstr"; - cc_params[cc_par_cnt++] = "-fno-builtin-strcasestr"; - - } - -#if defined(USEMMAP) && !defined(__HAIKU__) - cc_params[cc_par_cnt++] = "-lrt"; -#endif - - cc_params[cc_par_cnt++] = "-D__AFL_HAVE_MANUAL_CONTROL=1"; - cc_params[cc_par_cnt++] = "-D__AFL_COMPILER=1"; - cc_params[cc_par_cnt++] = "-DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1"; - - /* When the user tries to use persistent or deferred forkserver modes by - appending a single line to the program, we want to reliably inject a - signature into the binary (to be picked up by afl-fuzz) and we want - to call a function from the runtime .o file. This is unnecessarily - painful for three reasons: - - 1) We need to convince the compiler not to optimize out the signature. - This is done with __attribute__((used)). - - 2) We need to convince the linker, when called with -Wl,--gc-sections, - not to do the same. This is done by forcing an assignment to a - 'volatile' pointer. - - 3) We need to declare __afl_persistent_loop() in the global namespace, - but doing this within a method in a class is hard - :: and extern "C" - are forbidden and __attribute__((alias(...))) doesn't work. Hence the - __asm__ aliasing trick. - - */ - - cc_params[cc_par_cnt++] = - "-D__AFL_LOOP(_A)=" - "({ static volatile char *_B __attribute__((used)); " - " _B = (char*)\"" PERSIST_SIG - "\"; " -#ifdef __APPLE__ - "int _L(unsigned int) __asm__(\"___afl_persistent_loop\"); " -#else - "int _L(unsigned int) __asm__(\"__afl_persistent_loop\"); " -#endif /* ^__APPLE__ */ - "_L(_A); })"; - - cc_params[cc_par_cnt++] = - "-D__AFL_INIT()=" - "do { static volatile char *_A __attribute__((used)); " - " _A = (char*)\"" DEFER_SIG - "\"; " -#ifdef __APPLE__ - "void _I(void) __asm__(\"___afl_manual_init\"); " -#else - "void _I(void) __asm__(\"__afl_manual_init\"); " -#endif /* ^__APPLE__ */ - "_I(); } while (0)"; - - if (maybe_linking) { - - if (x_set) { - - cc_params[cc_par_cnt++] = "-x"; - cc_params[cc_par_cnt++] = "none"; - - } - - cc_params[cc_par_cnt++] = alloc_printf("%s/afl-gcc-rt.o", obj_path); - - } - - cc_params[cc_par_cnt] = NULL; - -} - -/* Main entry point */ - -int main(int argc, char **argv, char **envp) { - - if (argc < 2 || strcmp(argv[1], "-h") == 0) { - - printf(cCYA - "afl-gcc-fast" VERSION cRST - " initially by <aseipp@pobox.com>, maintainer: hexcoder-\n" - "\n" - "afl-gcc-fast [options]\n" - "\n" - "This is a helper application for afl-fuzz. It serves as a drop-in " - "replacement\n" - "for gcc, letting you recompile third-party code with the required " - "runtime\n" - "instrumentation. A common use pattern would be one of the " - "following:\n\n" - - " CC=%s/afl-gcc-fast ./configure\n" - " CXX=%s/afl-g++-fast ./configure\n\n" - - "In contrast to the traditional afl-gcc tool, this version is " - "implemented as\n" - "a GCC plugin and tends to offer improved performance with slow " - "programs\n" - "(similarly to the LLVM plugin used by afl-clang-fast).\n\n" - - "Environment variables used:\n" - "AFL_CC: path to the C compiler to use\n" - "AFL_CXX: path to the C++ compiler to use\n" - "AFL_PATH: path to instrumenting pass and runtime (afl-gcc-rt.*o)\n" - "AFL_DONT_OPTIMIZE: disable optimization instead of -O3\n" - "AFL_NO_BUILTIN: compile for use with libtokencap.so\n" - "AFL_INST_RATIO: percentage of branches to instrument\n" - "AFL_QUIET: suppress verbose output\n" - "AFL_DEBUG: enable developer debugging output\n" - "AFL_HARDEN: adds code hardening to catch memory bugs\n" - "AFL_USE_ASAN: activate address sanitizer\n" - "AFL_USE_MSAN: activate memory sanitizer\n" - "AFL_USE_UBSAN: activate undefined behaviour sanitizer\n" - "AFL_GCC_INSTRUMENT_FILE: enable selective instrumentation by " - "filename\n" - - "\nafl-gcc-fast was built for gcc %s with the gcc binary path of " - "\"%s\".\n\n", - BIN_PATH, BIN_PATH, GCC_VERSION, GCC_BINDIR); - - exit(1); - - } else if ((isatty(2) && !getenv("AFL_QUIET")) || - - getenv("AFL_DEBUG") != NULL) { - - SAYF(cCYA "afl-gcc-fast" VERSION cRST - " initially by <aseipp@pobox.com>, maintainer: hexcoder-\n"); - - if (getenv("AFL_GCC_INSTRUMENT_FILE") == NULL && - getenv("AFL_GCC_WHITELIST") == NULL) { - - SAYF( - cYEL - "Warning:" cRST - " using afl-gcc-fast without using AFL_GCC_INSTRUMENT_FILE currently " - "produces worse results than afl-gcc. Even better, use " - "llvm_mode for now.\n"); - - } - - } else - - be_quiet = 1; - - u8 *ptr; - if (!be_quiet && - ((ptr = getenv("AFL_MAP_SIZE")) || (ptr = getenv("AFL_MAPSIZE")))) { - - u32 map_size = atoi(ptr); - if (map_size != MAP_SIZE) - WARNF("AFL_MAP_SIZE is not supported by afl-gcc-fast"); - - } - - check_environment_vars(envp); - - find_obj(argv[0]); - - edit_params(argc, argv); - /*if (isatty(2) && !getenv("AFL_QUIET")) { - - printf("Calling \"%s\" with:\n", cc_params[0]); - for(int i=1; i<cc_par_cnt; i++) printf("%s\n", cc_params[i]); - - } - - */ - execvp(cc_params[0], (char **)cc_params); - - FATAL("Oops, failed to execute '%s' - check your PATH", cc_params[0]); - - return 0; - -} - diff --git a/gcc_plugin/afl-gcc-pass.so.cc b/gcc_plugin/afl-gcc-pass.so.cc deleted file mode 100644 index c5614aca..00000000 --- a/gcc_plugin/afl-gcc-pass.so.cc +++ /dev/null @@ -1,601 +0,0 @@ -// -// There are some TODOs in this file: -// - fix instrumentation via external call -// - fix inline instrumentation -// - implement instrument list feature -// - dont instrument blocks that are uninteresting -// - implement neverZero -// - -/* - american fuzzy lop++ - GCC instrumentation pass - --------------------------------------------- - - Written by Austin Seipp <aseipp@pobox.com> with bits from - Emese Revfy <re.emese@gmail.com> - - Fixed by Heiko Eißfeldt 2019-2020 for AFL++ - - GCC integration design is based on the LLVM design, which comes - from Laszlo Szekeres. Some of the boilerplate code below for - afl_pass to adapt to different GCC versions was taken from Emese - Revfy's Size Overflow plugin for GCC, licensed under the GPLv2/v3. - - (NOTE: this plugin code is under GPLv3, in order to comply with the - GCC runtime library exception, which states that you may distribute - "Target Code" from the compiler under a license of your choice, as - long as the "Compilation Process" is "Eligible", and contains no - GPL-incompatible software in GCC "during the process of - transforming high level code to target code". In this case, the - plugin will be used to generate "Target Code" during the - "Compilation Process", and thus it must be GPLv3 to be "eligible".) - - Copyright (C) 2015 Austin Seipp - - This program is free software: you can redistribute it and/or modify - it under the terms of the GNU General Public License as published by - the Free Software Foundation, either version 3 of the License, or - (at your option) any later version. - - This program is distributed in the hope that it will be useful, - but WITHOUT ANY WARRANTY; without even the implied warranty of - MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the - GNU General Public License for more details. - - You should have received a copy of the GNU General Public License - along with this program. If not, see <http://www.gnu.org/licenses/>. - - */ - -#define BUILD_INLINE_INST - -#include "../include/config.h" -#include "../include/debug.h" - -/* clear helper macros AFL types pull in, which intervene with gcc-plugin - * headers from GCC-8 */ -#ifdef likely - #undef likely -#endif -#ifdef unlikely - #undef unlikely -#endif - -#include <stdio.h> -#include <stdlib.h> -#include <unistd.h> - -#include <list> -#include <string> -#include <fstream> - -#include <gcc-plugin.h> -#include <plugin-version.h> -#include <diagnostic.h> -#include <tree.h> -#include <tree-ssa.h> -#include <tree-pass.h> -#include <tree-ssa-alias.h> -#include <basic-block.h> -#include <gimple-expr.h> -#include <gimple.h> -#include <gimple-iterator.h> -#include <gimple-ssa.h> -#include <version.h> -#include <toplev.h> -#include <intl.h> -#include <context.h> -#include <stringpool.h> -#include <cgraph.h> -#include <cfgloop.h> - -/* -------------------------------------------------------------------------- */ -/* -- AFL instrumentation pass ---------------------------------------------- */ - -static int be_quiet = 0; -static unsigned int inst_ratio = 100; -static bool inst_ext = true; -static std::list<std::string> myInstrumentList; - -static unsigned int ext_call_instrument(function *fun) { - - /* Instrument all the things! */ - basic_block bb; - unsigned finst_blocks = 0; - unsigned fcnt_blocks = 0; - - tree fntype = build_function_type_list(void_type_node, /* return */ - uint32_type_node, /* args */ - NULL_TREE); /* done */ - tree fndecl = build_fn_decl("__afl_trace", fntype); - TREE_STATIC(fndecl) = 1; /* Defined elsewhere */ - TREE_PUBLIC(fndecl) = 1; /* Public */ - DECL_EXTERNAL(fndecl) = 1; /* External linkage */ - DECL_ARTIFICIAL(fndecl) = 1; /* Injected by compiler */ - - FOR_EACH_BB_FN(bb, fun) { - - gimple_seq fcall; - gimple_seq seq = NULL; - gimple_stmt_iterator bentry; - ++fcnt_blocks; - - // only instrument if this basic block is the destination of a previous - // basic block that has multiple successors - // this gets rid of ~5-10% of instrumentations that are unnecessary - // result: a little more speed and less map pollution - - int more_than_one = -1; - edge ep; - edge_iterator eip; - - FOR_EACH_EDGE(ep, eip, bb->preds) { - - int count = 0; - if (more_than_one == -1) more_than_one = 0; - - basic_block Pred = ep->src; - edge es; - edge_iterator eis; - FOR_EACH_EDGE(es, eis, Pred->succs) { - - basic_block Succ = es->dest; - if (Succ != NULL) count++; - - } - - if (count > 1) more_than_one = 1; - - } - - if (more_than_one != 1) continue; - - /* Bail on this block if we trip the specified ratio */ - if (R(100) >= inst_ratio) continue; - - /* Make up cur_loc */ - unsigned int rand_loc = R(MAP_SIZE); - tree cur_loc = build_int_cst(uint32_type_node, rand_loc); - - /* Update bitmap via external call */ - /* to quote: - * /+ Trace a basic block with some ID +/ - * void __afl_trace(u32 x); - */ - - fcall = gimple_build_call( - fndecl, 1, - cur_loc); /* generate the function _call_ to above built reference, with - *1* parameter -> the random const for the location */ - gimple_seq_add_stmt(&seq, fcall); /* and insert into a sequence */ - - /* Done - grab the entry to the block and insert sequence */ - bentry = gsi_after_labels(bb); - gsi_insert_seq_before(&bentry, seq, GSI_SAME_STMT); - - ++finst_blocks; - - } - - /* Say something nice. */ - if (!be_quiet) { - - if (!finst_blocks) - WARNF(G_("No instrumentation targets found in " cBRI "%s" cRST), - function_name(fun)); - else if (finst_blocks < fcnt_blocks) - OKF(G_("Instrumented %2u /%2u locations in " cBRI "%s" cRST), - finst_blocks, fcnt_blocks, function_name(fun)); - else - OKF(G_("Instrumented %2u locations in " cBRI "%s" cRST), finst_blocks, - function_name(fun)); - - } - - return 0; - -} - -static unsigned int inline_instrument(function *fun) { - - /* Instrument all the things! */ - basic_block bb; - unsigned finst_blocks = 0; - unsigned fcnt_blocks = 0; - tree one = build_int_cst(unsigned_char_type_node, 1); - // tree zero = build_int_cst(unsigned_char_type_node, 0); - - /* Set up global type declarations */ - tree map_type = build_pointer_type(unsigned_char_type_node); - tree map_ptr_g = - build_decl(UNKNOWN_LOCATION, VAR_DECL, - get_identifier_with_length("__afl_area_ptr", 14), map_type); - TREE_USED(map_ptr_g) = 1; - TREE_STATIC(map_ptr_g) = 1; /* Defined elsewhere */ - DECL_EXTERNAL(map_ptr_g) = 1; /* External linkage */ - DECL_PRESERVE_P(map_ptr_g) = 1; - DECL_ARTIFICIAL(map_ptr_g) = 1; /* Injected by compiler */ - rest_of_decl_compilation(map_ptr_g, 1, 0); - - tree prev_loc_g = build_decl(UNKNOWN_LOCATION, VAR_DECL, - get_identifier_with_length("__afl_prev_loc", 14), - uint32_type_node); - TREE_USED(prev_loc_g) = 1; - TREE_STATIC(prev_loc_g) = 1; /* Defined elsewhere */ - DECL_EXTERNAL(prev_loc_g) = 1; /* External linkage */ - DECL_PRESERVE_P(prev_loc_g) = 1; - DECL_ARTIFICIAL(prev_loc_g) = 1; /* Injected by compiler */ - set_decl_tls_model(prev_loc_g, TLS_MODEL_REAL); /* TLS attribute */ - rest_of_decl_compilation(prev_loc_g, 1, 0); - - FOR_EACH_BB_FN(bb, fun) { - - gimple_seq seq = NULL; - gimple_stmt_iterator bentry; - ++fcnt_blocks; - - // only instrument if this basic block is the destination of a previous - // basic block that has multiple successors - // this gets rid of ~5-10% of instrumentations that are unnecessary - // result: a little more speed and less map pollution - - int more_than_one = -1; - edge ep; - edge_iterator eip; - FOR_EACH_EDGE(ep, eip, bb->preds) { - - int count = 0; - if (more_than_one == -1) more_than_one = 0; - - basic_block Pred = ep->src; - edge es; - edge_iterator eis; - FOR_EACH_EDGE(es, eis, Pred->succs) { - - basic_block Succ = es->dest; - if (Succ != NULL) count++; - - } - - if (count > 1) more_than_one = 1; - - } - - if (more_than_one != 1) continue; - - /* Bail on this block if we trip the specified ratio */ - if (R(100) >= inst_ratio) continue; - - /* Make up cur_loc */ - - unsigned int rand_loc = R(MAP_SIZE); - tree cur_loc = build_int_cst(uint32_type_node, rand_loc); - - /* Load prev_loc, xor with cur_loc */ - // gimple_assign <var_decl, prev_loc.0_1, prev_loc, NULL, NULL> - tree prev_loc = create_tmp_var_raw(uint32_type_node, "prev_loc"); - gassign *g = gimple_build_assign(prev_loc, VAR_DECL, prev_loc_g); - gimple_seq_add_stmt(&seq, g); // load prev_loc - update_stmt(g); - - // gimple_assign <bit_xor_expr, _2, prev_loc.0_1, 47231, NULL> - tree area_off = create_tmp_var_raw(uint32_type_node, "area_off"); - g = gimple_build_assign(area_off, BIT_XOR_EXPR, prev_loc, cur_loc); - gimple_seq_add_stmt(&seq, g); // area_off = prev_loc ^ cur_loc - update_stmt(g); - - /* Update bitmap */ - - // gimple_assign <addr_expr, p_6, &map[_2], NULL, NULL> - tree map_ptr = create_tmp_var(map_type, "map_ptr"); - tree map_ptr2 = create_tmp_var(map_type, "map_ptr2"); - - g = gimple_build_assign(map_ptr, map_ptr_g); - gimple_seq_add_stmt(&seq, g); // map_ptr = __afl_area_ptr - update_stmt(g); - -#if 1 - #if 0 - tree addr = build2(ADDR_EXPR, map_type, map_ptr, area_off); - g = gimple_build_assign(map_ptr2, MODIFY_EXPR, addr); - gimple_seq_add_stmt(&seq, g); // map_ptr2 = map_ptr + area_off - update_stmt(g); - #else - g = gimple_build_assign(map_ptr2, PLUS_EXPR, map_ptr, area_off); - gimple_seq_add_stmt(&seq, g); // map_ptr2 = map_ptr + area_off - update_stmt(g); - #endif - - // gimple_assign <mem_ref, _3, *p_6, NULL, NULL> - tree tmp1 = create_tmp_var_raw(unsigned_char_type_node, "tmp1"); - g = gimple_build_assign(tmp1, MEM_REF, map_ptr2); - gimple_seq_add_stmt(&seq, g); // tmp1 = *map_ptr2 - update_stmt(g); -#else - tree atIndex = build2(PLUS_EXPR, uint32_type_node, map_ptr, area_off); - tree array_address = build1(ADDR_EXPR, map_type, atIndex); - tree array_access = build1(INDIRECT_REF, map_type, array_address); - tree tmp1 = create_tmp_var(unsigned_char_type_node, "tmp1"); - g = gimple_build_assign(tmp1, array_access); - gimple_seq_add_stmt(&seq, g); // tmp1 = *(map_ptr + area_off) - update_stmt(g); -#endif - // gimple_assign <plus_expr, _4, _3, 1, NULL> - tree tmp2 = create_tmp_var_raw(unsigned_char_type_node, "tmp2"); - g = gimple_build_assign(tmp2, PLUS_EXPR, tmp1, one); - gimple_seq_add_stmt(&seq, g); // tmp2 = tmp1 + 1 - update_stmt(g); - - // TODO: neverZero: here we have to check if tmp3 == 0 - // and add 1 if so - - // gimple_assign <ssa_name, *p_6, _4, NULL, NULL> - // tree map_ptr3 = create_tmp_var_raw(map_type, "map_ptr3"); - g = gimple_build_assign(map_ptr2, INDIRECT_REF, tmp2); - gimple_seq_add_stmt(&seq, g); // *map_ptr2 = tmp2 - update_stmt(g); - - /* Set prev_loc to cur_loc >> 1 */ - - // gimple_assign <integer_cst, prev_loc, 23615, NULL, NULL> - tree shifted_loc = build_int_cst(TREE_TYPE(prev_loc_g), rand_loc >> 1); - tree prev_loc2 = create_tmp_var_raw(uint32_type_node, "prev_loc2"); - g = gimple_build_assign(prev_loc2, shifted_loc); - gimple_seq_add_stmt(&seq, g); // __afl_prev_loc = cur_loc >> 1 - update_stmt(g); - g = gimple_build_assign(prev_loc_g, prev_loc2); - gimple_seq_add_stmt(&seq, g); // __afl_prev_loc = cur_loc >> 1 - update_stmt(g); - - /* Done - grab the entry to the block and insert sequence */ - - bentry = gsi_after_labels(bb); - gsi_insert_seq_before(&bentry, seq, GSI_NEW_STMT); - - ++finst_blocks; - - } - - /* Say something nice. */ - if (!be_quiet) { - - if (!finst_blocks) - WARNF(G_("No instrumentation targets found in " cBRI "%s" cRST), - function_name(fun)); - else if (finst_blocks < fcnt_blocks) - OKF(G_("Instrumented %2u /%2u locations in " cBRI "%s" cRST), - finst_blocks, fcnt_blocks, function_name(fun)); - else - OKF(G_("Instrumented %2u locations in " cBRI "%s" cRST), finst_blocks, - function_name(fun)); - - } - - return 0; - -} - -/* -------------------------------------------------------------------------- */ -/* -- Boilerplate and initialization ---------------------------------------- */ - -static const struct pass_data afl_pass_data = { - - .type = GIMPLE_PASS, - .name = "afl-inst", - .optinfo_flags = OPTGROUP_NONE, - - .tv_id = TV_NONE, - .properties_required = 0, - .properties_provided = 0, - .properties_destroyed = 0, - .todo_flags_start = 0, - // NOTE(aseipp): it's very, very important to include - // at least 'TODO_update_ssa' here so that GCC will - // properly update the resulting SSA form, e.g., to - // include new PHI nodes for newly added symbols or - // names. Do not remove this. Do not taunt Happy Fun - // Ball. - .todo_flags_finish = TODO_update_ssa | TODO_verify_il | TODO_cleanup_cfg, - -}; - -namespace { - -class afl_pass : public gimple_opt_pass { - - private: - bool do_ext_call; - - public: - afl_pass(bool ext_call, gcc::context *g) - : gimple_opt_pass(afl_pass_data, g), do_ext_call(ext_call) { - - } - - unsigned int execute(function *fun) override { - - if (!myInstrumentList.empty()) { - - bool instrumentBlock = false; - std::string instFilename; - unsigned int instLine = 0; - - /* EXPR_FILENAME - This macro returns the name of the file in which the entity was declared, - as a char*. For an entity declared implicitly by the compiler (like - __builtin_ memcpy), this will be the string "<internal>". - */ - const char *fname = DECL_SOURCE_FILE(fun->decl); - - if (0 != strncmp("<internal>", fname, 10) && - 0 != strncmp("<built-in>", fname, 10)) { - - instFilename = fname; - instLine = DECL_SOURCE_LINE(fun->decl); - - /* Continue only if we know where we actually are */ - if (!instFilename.empty()) { - - for (std::list<std::string>::iterator it = myInstrumentList.begin(); - it != myInstrumentList.end(); ++it) { - - /* We don't check for filename equality here because - * filenames might actually be full paths. Instead we - * check that the actual filename ends in the filename - * specified in the list. */ - if (instFilename.length() >= it->length()) { - - if (instFilename.compare(instFilename.length() - it->length(), - it->length(), *it) == 0) { - - instrumentBlock = true; - break; - - } - - } - - } - - } - - } - - /* Either we couldn't figure out our location or the location is - * not in the instrument list, so we skip instrumentation. */ - if (!instrumentBlock) { - - if (!be_quiet) { - - if (!instFilename.empty()) - SAYF(cYEL "[!] " cBRI - "Not in instrument list, skipping %s line %u...\n", - instFilename.c_str(), instLine); - else - SAYF(cYEL "[!] " cBRI "No filename information found, skipping it"); - - } - - return 0; - - } - - } - - return do_ext_call ? ext_call_instrument(fun) : inline_instrument(fun); - - } - -}; /* class afl_pass */ - -} // namespace - -static struct opt_pass *make_afl_pass(bool ext_call, gcc::context *ctxt) { - - return new afl_pass(ext_call, ctxt); - -} - -/* -------------------------------------------------------------------------- */ -/* -- Initialization -------------------------------------------------------- */ - -int plugin_is_GPL_compatible = 1; - -static struct plugin_info afl_plugin_info = { - - .version = "20200519", - .help = "AFL++ gcc plugin\n", - -}; - -int plugin_init(struct plugin_name_args * plugin_info, - struct plugin_gcc_version *version) { - - struct register_pass_info afl_pass_info; - struct timeval tv; - struct timezone tz; - u32 rand_seed; - - /* Setup random() so we get Actually Random(TM) outputs from R() */ - gettimeofday(&tv, &tz); - rand_seed = tv.tv_sec ^ tv.tv_usec ^ getpid(); - SR(rand_seed); - - /* Pass information */ - afl_pass_info.pass = make_afl_pass(inst_ext, g); - afl_pass_info.reference_pass_name = "ssa"; - afl_pass_info.ref_pass_instance_number = 1; - afl_pass_info.pos_op = PASS_POS_INSERT_AFTER; - - if (!plugin_default_version_check(version, &gcc_version)) { - - FATAL(G_("Incompatible gcc/plugin versions! Expected GCC %d.%d"), - GCCPLUGIN_VERSION_MAJOR, GCCPLUGIN_VERSION_MINOR); - - } - - /* Show a banner */ - if ((isatty(2) && !getenv("AFL_QUIET")) || getenv("AFL_DEBUG") != NULL) { - - SAYF(G_(cCYA "afl-gcc-pass" VERSION cRST - " initially by <aseipp@pobox.com>, maintainer: hexcoder-\n")); - - } else - - be_quiet = 1; - - /* Decide instrumentation ratio */ - char *inst_ratio_str = getenv("AFL_INST_RATIO"); - - if (inst_ratio_str) { - - if (sscanf(inst_ratio_str, "%u", &inst_ratio) != 1 || !inst_ratio || - inst_ratio > 100) - FATAL(G_("Bad value of AFL_INST_RATIO (must be between 1 and 100)")); - else { - - if (!be_quiet) - ACTF(G_("%s instrumentation at ratio of %u%% in %s mode."), - inst_ext ? G_("Call-based") : G_("Inline"), inst_ratio, - getenv("AFL_HARDEN") ? G_("hardened") : G_("non-hardened")); - - } - - } - - char *instInstrumentListFilename = getenv("AFL_GCC_INSTRUMENT_FILE"); - if (!instInstrumentListFilename) - instInstrumentListFilename = getenv("AFL_GCC_WHITELIST"); - if (instInstrumentListFilename) { - - std::string line; - std::ifstream fileStream; - fileStream.open(instInstrumentListFilename); - if (!fileStream) PFATAL("Unable to open AFL_GCC_INSTRUMENT_FILE"); - getline(fileStream, line); - while (fileStream) { - - myInstrumentList.push_back(line); - getline(fileStream, line); - - } - - } else if (!be_quiet && (getenv("AFL_LLVM_WHITELIST") || - - getenv("AFL_LLVM_INSTRUMENT_FILE"))) { - - SAYF(cYEL "[-] " cRST - "AFL_LLVM_INSTRUMENT_FILE environment variable detected - did " - "you mean AFL_GCC_INSTRUMENT_FILE?\n"); - - } - - /* Go go gadget */ - register_callback(plugin_info->base_name, PLUGIN_INFO, NULL, - &afl_plugin_info); - register_callback(plugin_info->base_name, PLUGIN_PASS_MANAGER_SETUP, NULL, - &afl_pass_info); - return 0; - -} - diff --git a/gcc_plugin/afl-gcc-rt.o.c b/gcc_plugin/afl-gcc-rt.o.c deleted file mode 100644 index 49a03cae..00000000 --- a/gcc_plugin/afl-gcc-rt.o.c +++ /dev/null @@ -1,315 +0,0 @@ -/* - american fuzzy lop++ - GCC plugin instrumentation bootstrap - --------------------------------------------------------- - - Written by Austin Seipp <aseipp@pobox.com> and - Laszlo Szekeres <lszekeres@google.com> and - Michal Zalewski - - GCC integration design is based on the LLVM design, which comes - from Laszlo Szekeres. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This code is the rewrite of afl-as.h's main_payload. - -*/ - -#ifdef __ANDROID__ - #include "android-ashmem.h" -#endif -#include "../config.h" -#include "../types.h" - -#ifdef USEMMAP - #include <stdio.h> -#endif -#include <stdlib.h> -#include <signal.h> -#include <unistd.h> -#include <string.h> -#include <assert.h> - -#include <sys/mman.h> -#ifndef USEMMAP - #include <sys/shm.h> -#endif -#include <sys/wait.h> -#include <sys/types.h> - -#include <sys/mman.h> -#include <fcntl.h> - -/* Globals needed by the injected instrumentation. The __afl_area_initial region - is used for instrumentation output before __afl_map_shm() has a chance to - run. It will end up as .comm, so it shouldn't be too wasteful. */ - -u8 __afl_area_initial[MAP_SIZE]; -u8 *__afl_area_ptr = __afl_area_initial; - -#ifdef __ANDROID__ -u32 __afl_prev_loc; -u32 __afl_final_loc; -#else -__thread u32 __afl_prev_loc; -__thread u32 __afl_final_loc; -#endif - -/* Trace a basic block with some ID */ -void __afl_trace(const u32 x) { - -#if 1 /* enable for neverZero feature. */ - __afl_area_ptr[__afl_prev_loc ^ x] += - 1 + ((u8)(1 + __afl_area_ptr[__afl_prev_loc ^ x]) == 0); -#else - ++__afl_area_ptr[__afl_prev_loc ^ x]; -#endif - - __afl_prev_loc = (x >> 1); - return; - -} - -/* Running in persistent mode? */ - -static u8 is_persistent; - -/* SHM setup. */ - -static void __afl_map_shm(void) { - - u8 *id_str = getenv(SHM_ENV_VAR); - - /* If we're running under AFL, attach to the appropriate region, replacing the - early-stage __afl_area_initial region that is needed to allow some really - hacky .init code to work correctly in projects such as OpenSSL. */ - - if (id_str) { - -#ifdef USEMMAP - const char * shm_file_path = id_str; - int shm_fd = -1; - unsigned char *shm_base = NULL; - - /* create the shared memory segment as if it was a file */ - shm_fd = shm_open(shm_file_path, O_RDWR, 0600); - if (shm_fd == -1) { - - fprintf(stderr, "shm_open() failed\n"); - exit(1); - - } - - /* map the shared memory segment to the address space of the process */ - shm_base = mmap(0, MAP_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, shm_fd, 0); - if (shm_base == MAP_FAILED) { - - close(shm_fd); - shm_fd = -1; - - fprintf(stderr, "mmap() failed\n"); - exit(2); - - } - - __afl_area_ptr = shm_base; -#else - u32 shm_id = atoi(id_str); - - __afl_area_ptr = shmat(shm_id, NULL, 0); -#endif - - /* Whooooops. */ - - if (__afl_area_ptr == (void *)-1) exit(1); - - /* Write something into the bitmap so that even with low AFL_INST_RATIO, - our parent doesn't give up on us. */ - - __afl_area_ptr[0] = 1; - - } - -} - -/* Fork server logic. */ - -static void __afl_start_forkserver(void) { - - u8 tmp[4] = {0, 0, 0, 0}; - u32 map_size = MAP_SIZE; - s32 child_pid; - - u8 child_stopped = 0; - - void (*old_sigchld_handler)(int) = signal(SIGCHLD, SIG_DFL); - - /* Phone home and tell the parent that we're OK. If parent isn't there, - assume we're not running in forkserver mode and just execute program. */ - - if (MAP_SIZE <= 0x800000) { - - map_size = (FS_OPT_ENABLED | FS_OPT_MAPSIZE | FS_OPT_SET_MAPSIZE(MAP_SIZE)); - memcpy(tmp, &map_size, 4); - - } - - if (write(FORKSRV_FD + 1, tmp, 4) != 4) return; - - while (1) { - - u32 was_killed; - int status; - - /* Wait for parent by reading from the pipe. Abort if read fails. */ - - if (read(FORKSRV_FD, &was_killed, 4) != 4) exit(1); - - /* If we stopped the child in persistent mode, but there was a race - condition and afl-fuzz already issued SIGKILL, write off the old - process. */ - - if (child_stopped && was_killed) { - - child_stopped = 0; - if (waitpid(child_pid, &status, 0) < 0) exit(1); - - } - - if (!child_stopped) { - - /* Once woken up, create a clone of our process. */ - - child_pid = fork(); - if (child_pid < 0) exit(1); - - /* In child process: close fds, resume execution. */ - - if (!child_pid) { - - signal(SIGCHLD, old_sigchld_handler); - - close(FORKSRV_FD); - close(FORKSRV_FD + 1); - return; - - } - - } else { - - /* Special handling for persistent mode: if the child is alive but - currently stopped, simply restart it with SIGCONT. */ - - kill(child_pid, SIGCONT); - child_stopped = 0; - - } - - /* In parent process: write PID to pipe, then wait for child. */ - - if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) exit(1); - - if (waitpid(child_pid, &status, is_persistent ? WUNTRACED : 0) < 0) exit(1); - - /* In persistent mode, the child stops itself with SIGSTOP to indicate - a successful run. In this case, we want to wake it up without forking - again. */ - - if (WIFSTOPPED(status)) child_stopped = 1; - - /* Relay wait status to pipe, then loop back. */ - - if (write(FORKSRV_FD + 1, &status, 4) != 4) exit(1); - - } - -} - -/* A simplified persistent mode handler, used as explained in README.md. */ - -int __afl_persistent_loop(unsigned int max_cnt) { - - static u8 first_pass = 1; - static u32 cycle_cnt; - - if (first_pass) { - - /* Make sure that every iteration of __AFL_LOOP() starts with a clean slate. - On subsequent calls, the parent will take care of that, but on the first - iteration, it's our job to erase any trace of whatever happened - before the loop. */ - - if (is_persistent) { - - memset(__afl_area_ptr, 0, MAP_SIZE); - __afl_area_ptr[0] = 1; - __afl_prev_loc = 0; - - } - - cycle_cnt = max_cnt; - first_pass = 0; - return 1; - - } - - if (is_persistent) { - - if (--cycle_cnt) { - - raise(SIGSTOP); - - __afl_area_ptr[0] = 1; - __afl_prev_loc = 0; - - return 1; - - } else { - - /* When exiting __AFL_LOOP(), make sure that the subsequent code that - follows the loop is not traced. We do that by pivoting back to the - dummy output region. */ - - __afl_area_ptr = __afl_area_initial; - - } - - } - - return 0; - -} - -/* This one can be called from user code when deferred forkserver mode - is enabled. */ - -void __afl_manual_init(void) { - - static u8 init_done; - - if (!init_done) { - - __afl_map_shm(); - __afl_start_forkserver(); - init_done = 1; - - } - -} - -/* Proper initialization routine. */ - -__attribute__((constructor(101))) void __afl_auto_init(void) { - - is_persistent = !!getenv(PERSIST_ENV_VAR); - - if (getenv(DEFER_ENV_VAR)) return; - - __afl_manual_init(); - -} - diff --git a/include/afl-fuzz.h b/include/afl-fuzz.h index 1c1be711..5003b563 100644 --- a/include/afl-fuzz.h +++ b/include/afl-fuzz.h @@ -37,10 +37,6 @@ #define _FILE_OFFSET_BITS 64 #endif -#ifdef __ANDROID__ - #include "android-ashmem.h" -#endif - #include "config.h" #include "types.h" #include "debug.h" @@ -65,6 +61,9 @@ #include <dlfcn.h> #include <sched.h> +#include <netdb.h> +#include <netinet/in.h> + #include <sys/wait.h> #include <sys/time.h> #ifndef USEMMAP @@ -76,12 +75,18 @@ #include <sys/mman.h> #include <sys/ioctl.h> #include <sys/file.h> +#include <sys/types.h> #if defined(__APPLE__) || defined(__FreeBSD__) || defined(__OpenBSD__) || \ defined(__NetBSD__) || defined(__DragonFly__) #include <sys/sysctl.h> #endif /* __APPLE__ || __FreeBSD__ || __OpenBSD__ */ +#if defined(__HAIKU__) + #include <kernel/OS.h> + #include <kernel/scheduler.h> +#endif + /* For systems that have sched_setaffinity; right now just Linux, but one can hope... */ @@ -104,6 +109,7 @@ #include <kstat.h> #include <sys/sysinfo.h> #include <sys/pset.h> + #include <strings.h> #endif #endif /* __linux__ */ @@ -121,41 +127,72 @@ #define STAGE_BUF_SIZE (64) /* usable size for stage name buf in afl_state */ +// Little helper to access the ptr to afl->##name_buf - for use in afl_realloc. +#define AFL_BUF_PARAM(name) ((void **)&afl->name##_buf) + +#ifdef WORD_SIZE_64 + #define AFL_RAND_RETURN u64 +#else + #define AFL_RAND_RETURN u32 +#endif + extern s8 interesting_8[INTERESTING_8_LEN]; extern s16 interesting_16[INTERESTING_8_LEN + INTERESTING_16_LEN]; extern s32 interesting_32[INTERESTING_8_LEN + INTERESTING_16_LEN + INTERESTING_32_LEN]; +struct tainted { + + u32 pos; + u32 len; + struct tainted *next; + struct tainted *prev; + +}; + struct queue_entry { u8 *fname; /* File name for the test case */ u32 len; /* Input length */ + u32 id; /* entry number in queue_buf */ - u8 cal_failed, /* Calibration failed? */ - trim_done, /* Trimmed? */ + u8 colorized, /* Do not run redqueen stage again */ + cal_failed; /* Calibration failed? */ + bool trim_done, /* Trimmed? */ was_fuzzed, /* historical, but needed for MOpt */ passed_det, /* Deterministic stages passed? */ has_new_cov, /* Triggers new coverage? */ var_behavior, /* Variable behavior? */ favored, /* Currently favored? */ fs_redundant, /* Marked as redundant in the fs? */ - fully_colorized, /* Do not run redqueen stage again */ - is_ascii; /* Is the input just ascii text? */ + is_ascii, /* Is the input just ascii text? */ + disabled; /* Is disabled from fuzz selection */ u32 bitmap_size, /* Number of bits set in bitmap */ - fuzz_level; /* Number of fuzzing iterations */ + fuzz_level, /* Number of fuzzing iterations */ + n_fuzz_entry; /* offset in n_fuzz */ u64 exec_us, /* Execution time (us) */ handicap, /* Number of queue cycles behind */ - n_fuzz, /* Number of fuzz, does not overflow*/ depth, /* Path depth */ exec_cksum; /* Checksum of the execution trace */ u8 *trace_mini; /* Trace bytes, if kept */ u32 tc_ref; /* Trace bytes ref count */ - struct queue_entry *next, /* Next element, if any */ - *next_100; /* 100 elements ahead */ +#ifdef INTROSPECTION + u32 bitsmap_size; +#endif + + double perf_score, /* performance score */ + weight; + + u8 *testcase_buf; /* The testcase buffer, if loaded. */ + + u8 * cmplog_colorinput; /* the result buf of colorization */ + struct tainted *taint; /* Taint information from CmpLog */ + + struct queue_entry *mother; /* queue entry this based on */ }; @@ -167,6 +204,14 @@ struct extra_data { }; +struct auto_extra_data { + + u8 data[MAX_AUTO_EXTRA]; /* Dictionary token data */ + u32 len; /* Dictionary token length */ + u32 hit_cnt; /* Use count in the corpus */ + +}; + /* Fuzzing stages */ enum { @@ -207,7 +252,7 @@ enum { }; -#define operator_num 18 +#define operator_num 19 #define swarm_num 5 #define period_core 500000 @@ -223,18 +268,19 @@ enum { #define STAGE_OverWrite75 15 #define STAGE_OverWriteExtra 16 #define STAGE_InsertExtra 17 +#define STAGE_Splice 18 #define period_pilot 50000 enum { /* 00 */ EXPLORE, /* AFL default, Exploration-based constant schedule */ - /* 01 */ EXPLOIT, /* AFL's exploitation-based const. */ - /* 02 */ FAST, /* Exponential schedule */ - /* 03 */ COE, /* Cut-Off Exponential schedule */ - /* 04 */ LIN, /* Linear schedule */ - /* 05 */ QUAD, /* Quadratic schedule */ - /* 06 */ RARE, /* Rare edges */ - /* 07 */ MMOPT, /* Modified MOPT schedule */ + /* 01 */ MMOPT, /* Modified MOPT schedule */ + /* 02 */ EXPLOIT, /* AFL's exploitation-based const. */ + /* 03 */ FAST, /* Exponential schedule */ + /* 04 */ COE, /* Cut-Off Exponential schedule */ + /* 05 */ LIN, /* Linear schedule */ + /* 06 */ QUAD, /* Quadratic schedule */ + /* 07 */ RARE, /* Rare edges */ /* 08 */ SEEK, /* EXPLORE that ignores timings */ POWER_SCHEDULES_NUM @@ -272,16 +318,21 @@ enum { enum { /* 00 */ PY_FUNC_INIT, - /* 01 */ PY_FUNC_FUZZ, - /* 02 */ PY_FUNC_POST_PROCESS, - /* 03 */ PY_FUNC_INIT_TRIM, - /* 04 */ PY_FUNC_POST_TRIM, - /* 05 */ PY_FUNC_TRIM, - /* 06 */ PY_FUNC_HAVOC_MUTATION, - /* 07 */ PY_FUNC_HAVOC_MUTATION_PROBABILITY, - /* 08 */ PY_FUNC_QUEUE_GET, - /* 09 */ PY_FUNC_QUEUE_NEW_ENTRY, - /* 10 */ PY_FUNC_DEINIT, + /* 01 */ PY_FUNC_DEINIT, + /* FROM HERE ON BELOW ALL ARE OPTIONAL */ + /* 02 */ PY_OPTIONAL = 2, + /* 02 */ PY_FUNC_FUZZ = 2, + /* 03 */ PY_FUNC_FUZZ_COUNT, + /* 04 */ PY_FUNC_POST_PROCESS, + /* 05 */ PY_FUNC_INIT_TRIM, + /* 06 */ PY_FUNC_POST_TRIM, + /* 07 */ PY_FUNC_TRIM, + /* 08 */ PY_FUNC_HAVOC_MUTATION, + /* 09 */ PY_FUNC_HAVOC_MUTATION_PROBABILITY, + /* 10 */ PY_FUNC_QUEUE_GET, + /* 11 */ PY_FUNC_QUEUE_NEW_ENTRY, + /* 12 */ PY_FUNC_INTROSPECTION, + /* 13 */ PY_FUNC_DESCRIBE, PY_FUNC_COUNT }; @@ -296,8 +347,7 @@ typedef struct py_mutator { u8 * fuzz_buf; size_t fuzz_size; - u8 * post_process_buf; - size_t post_process_size; + Py_buffer post_process_buf; u8 * trim_buf; size_t trim_size; @@ -333,11 +383,14 @@ typedef struct afl_env_vars { u8 afl_skip_cpufreq, afl_exit_when_done, afl_no_affinity, afl_skip_bin_check, afl_dumb_forksrv, afl_import_first, afl_custom_mutator_only, afl_no_ui, afl_force_ui, afl_i_dont_care_about_missing_crashes, afl_bench_just_one, - afl_bench_until_crash, afl_debug_child_output, afl_autoresume, - afl_cal_fast, afl_cycle_schedules, afl_expand_havoc; + afl_bench_until_crash, afl_debug_child, afl_autoresume, afl_cal_fast, + afl_cycle_schedules, afl_expand_havoc, afl_statsd, afl_cmplog_only_new; u8 *afl_tmpdir, *afl_custom_mutator_library, *afl_python_module, *afl_path, - *afl_hang_tmout, *afl_skip_crashes, *afl_preload; + *afl_hang_tmout, *afl_forksrv_init_tmout, *afl_skip_crashes, *afl_preload, + *afl_max_det_extras, *afl_statsd_host, *afl_statsd_port, + *afl_crash_exitcode, *afl_statsd_tags_flavor, *afl_testcache_size, + *afl_testcache_entries, *afl_kill_signal; } afl_env_vars_t; @@ -351,7 +404,7 @@ struct afl_pass_stat { struct foreign_sync { u8 * dir; - time_t ctime; + time_t mtime; }; @@ -372,7 +425,8 @@ typedef struct afl_state { really makes no sense to haul them around as function parameters. */ u64 orig_hit_cnt_puppet, last_limit_time_start, tmp_pilot_time, total_pacemaker_time, total_puppet_find, temp_puppet_find, most_time_key, - most_time, most_execs_key, most_execs, old_hit_count, force_ui_update; + most_time, most_execs_key, most_execs, old_hit_count, force_ui_update, + prev_run_time; MOpt_globals_t mopt_globals_core, mopt_globals_pilot; @@ -424,6 +478,7 @@ typedef struct afl_state { u8 cal_cycles, /* Calibration cycles defaults */ cal_cycles_long, /* Calibration cycles defaults */ + havoc_stack_pow2, /* HAVOC_STACK_POW2 */ no_unlink, /* do not unlink cur_input */ debug, /* Debug mode */ custom_only, /* Custom mutator only mode */ @@ -464,14 +519,22 @@ typedef struct afl_state { disable_trim, /* Never trim in fuzz_one */ shmem_testcase_mode, /* If sharedmem testcases are used */ expand_havoc, /* perform expensive havoc after no find */ - cycle_schedules; /* cycle power schedules ? */ + cycle_schedules, /* cycle power schedules? */ + old_seed_selection; /* use vanilla afl seed selection */ u8 *virgin_bits, /* Regions yet untouched by fuzzing */ *virgin_tmout, /* Bits we haven't seen in tmouts */ *virgin_crash; /* Bits we haven't seen in crashes */ + double *alias_probability; /* alias weighted probabilities */ + u32 * alias_table; /* alias weighted random lookup table */ + u32 active_paths; /* enabled entries in the queue */ + u8 *var_bytes; /* Bytes that appear to be variable */ +#define N_FUZZ_SIZE (1 << 21) + u32 *n_fuzz; + volatile u8 stop_soon, /* Ctrl-C pressed? */ clear_screen; /* Window resized? */ @@ -490,7 +553,8 @@ typedef struct afl_state { useless_at_start, /* Number of useless starting paths */ var_byte_count, /* Bitmap bytes with var behavior */ current_entry, /* Current queue entry ID */ - havoc_div; /* Cycle count divisor for havoc */ + havoc_div, /* Cycle count divisor for havoc */ + max_det_extras; /* deterministic extra count (dicts)*/ u64 total_crashes, /* Total number of crashes */ unique_crashes, /* Crashes with unique signatures */ @@ -506,6 +570,7 @@ typedef struct afl_state { blocks_eff_total, /* Blocks subject to effector maps */ blocks_eff_select, /* Blocks selected as fuzzable */ start_time, /* Unix start time (ms) */ + last_sync_time, /* Time of last sync */ last_path_time, /* Time for most recent path (ms) */ last_crash_time, /* Time for most recent crash (ms) */ last_hang_time; /* Time for most recent hang (ms) */ @@ -519,7 +584,7 @@ typedef struct afl_state { u8 stage_name_buf[STAGE_BUF_SIZE]; /* reused stagename buf with len 64 */ - s32 stage_cur, stage_max; /* Stage progression */ + u32 stage_cur, stage_max; /* Stage progression */ s32 splicing_with; /* Splicing with which test case? */ u32 main_node_id, main_node_max; /* Main instance job splitting */ @@ -536,8 +601,9 @@ typedef struct afl_state { u32 rand_cnt; /* Random number counter */ - u64 rand_seed[4]; - s64 init_seed; + /* unsigned long rand_seed[3]; would also work */ + AFL_RAND_RETURN rand_seed[3]; + s64 init_seed; u64 total_cal_us, /* Total calibration time (us) */ total_cal_cycles; /* Total calibration cycles */ @@ -545,7 +611,8 @@ typedef struct afl_state { u64 total_bitmap_size, /* Total bit count for all bitmaps */ total_bitmap_entries; /* Number of bitmaps counted */ - s32 cpu_core_count; /* CPU core count */ + s32 cpu_core_count, /* CPU core count */ + cpu_to_bind; /* bind to specific CPU */ #ifdef HAVE_AFFINITY s32 cpu_aff; /* Selected CPU core */ @@ -553,20 +620,19 @@ typedef struct afl_state { struct queue_entry *queue, /* Fuzzing queue (linked list) */ *queue_cur, /* Current offset within the queue */ - *queue_top, /* Top of the list */ - *q_prev100; /* Previous 100 marker */ + *queue_top; /* Top of the list */ // growing buf struct queue_entry **queue_buf; - size_t queue_size; struct queue_entry **top_rated; /* Top entries for bitmap bytes */ struct extra_data *extras; /* Extra tokens to fuzz with */ u32 extras_cnt; /* Total number of tokens read */ - struct extra_data *a_extras; /* Automatically selected extras */ - u32 a_extras_cnt; /* Total number of tokens available */ + struct auto_extra_data + a_extras[MAX_AUTO_EXTRAS]; /* Automatically selected extras */ + u32 a_extras_cnt; /* Total number of tokens available */ /* afl_postprocess API - Now supported via custom mutators */ @@ -581,6 +647,10 @@ typedef struct afl_state { /* cmplog forkserver ids */ s32 cmplog_fsrv_ctl_fd, cmplog_fsrv_st_fd; u32 cmplog_prev_timed_out; + u32 cmplog_max_filesize; + u32 cmplog_lvl; + u32 colorize_success; + u8 cmplog_enable_arith, cmplog_enable_transform; struct afl_pass_stat *pass_stats; struct cmp_map * orig_cmp_map; @@ -590,10 +660,10 @@ typedef struct afl_state { unsigned long long int last_avg_exec_update; u32 last_avg_execs; - float last_avg_execs_saved; + double last_avg_execs_saved; /* foreign sync */ -#define FOREIGN_SYNCS_MAX 32 +#define FOREIGN_SYNCS_MAX 32U u8 foreign_sync_cnt; struct foreign_sync foreign_syncs[FOREIGN_SYNCS_MAX]; @@ -602,16 +672,24 @@ typedef struct afl_state { u32 document_counter; #endif - void *maybe_add_auto; - /* statistics file */ double last_bitmap_cvg, last_stability, last_eps; /* plot file saves from last run */ u32 plot_prev_qp, plot_prev_pf, plot_prev_pnf, plot_prev_ce, plot_prev_md; - u64 plot_prev_qc, plot_prev_uc, plot_prev_uh; + u64 plot_prev_qc, plot_prev_uc, plot_prev_uh, plot_prev_ed; u64 stats_last_stats_ms, stats_last_plot_ms, stats_last_ms, stats_last_execs; + + /* StatsD */ + u64 statsd_last_send_ms; + struct sockaddr_in statsd_server; + int statsd_sock; + char * statsd_tags_flavor; + char * statsd_tags_format; + char * statsd_metric_format; + int statsd_metric_format_type; + double stats_avg_exec; u8 *clean_trace; @@ -620,24 +698,23 @@ typedef struct afl_state { /*needed for afl_fuzz_one */ // TODO: see which we can reuse - u8 * out_buf; - size_t out_size; + u8 *out_buf; + + u8 *out_scratch_buf; - u8 * out_scratch_buf; - size_t out_scratch_size; + u8 *eff_buf; - u8 * eff_buf; - size_t eff_size; + u8 *in_buf; - u8 * in_buf; - size_t in_size; + u8 *in_scratch_buf; - u8 * in_scratch_buf; - size_t in_scratch_size; + u8 *ex_buf; - u8 * ex_buf; - size_t ex_size; - u32 custom_mutators_count; + u8 *testcase_buf, *splicecase_buf; + + u32 custom_mutators_count; + + struct custom_mutator *current_custom_fuzz; list_t custom_mutator_list; @@ -645,14 +722,49 @@ typedef struct afl_state { * they do not call another function */ u8 *map_tmp_buf; + /* queue entries ready for splicing count (len > 4) */ + u32 ready_for_splicing_count; + + /* This is the user specified maximum size to use for the testcase cache */ + u64 q_testcase_max_cache_size; + + /* This is the user specified maximum entries in the testcase cache */ + u32 q_testcase_max_cache_entries; + + /* How much of the testcase cache is used so far */ + u64 q_testcase_cache_size; + + /* highest cache count so far */ + u32 q_testcase_max_cache_count; + + /* How many queue entries currently have cached testcases */ + u32 q_testcase_cache_count; + + /* the smallest id currently known free entry */ + u32 q_testcase_smallest_free; + + /* How often did we evict from the cache (for statistics only) */ + u32 q_testcase_evictions; + + /* Refs to each queue entry with cached testcase (for eviction, if cache_count + * is too large) */ + struct queue_entry **q_testcase_cache; + +#ifdef INTROSPECTION + char mutation[8072]; + char m_tmp[4096]; + FILE *introspection_file; + u32 bitsmap_size; +#endif + } afl_state_t; struct custom_mutator { const char *name; + char * name_short; void * dh; u8 * post_process_buf; - size_t post_process_size; u8 stacked_custom_prob, stacked_custom; void *data; /* custom mutator data ptr */ @@ -669,11 +781,38 @@ struct custom_mutator { void *(*afl_custom_init)(afl_state_t *afl, unsigned int seed); /** + * When afl-fuzz was compiled with INTROSPECTION=1 then custom mutators can + * also give introspection information back with this function. + * + * @param data pointer returned in afl_custom_init by this custom mutator + * @return pointer to a text string (const char*) + */ + const char *(*afl_custom_introspection)(void *data); + + /** + * This method is called just before fuzzing a queue entry with the custom + * mutator, and receives the initial buffer. It should return the number of + * fuzzes to perform. + * + * A value of 0 means no fuzzing of this queue entry. + * + * The function is now allowed to change the data. + * + * (Optional) + * + * @param data pointer returned in afl_custom_init by this custom mutator + * @param buf Buffer containing the test case + * @param buf_size Size of the test case + * @return The amount of fuzzes to perform on this queue entry, 0 = skip + */ + u32 (*afl_custom_fuzz_count)(void *data, const u8 *buf, size_t buf_size); + + /** * Perform custom mutations on a given input * * (Optional for now. Required in the future) * - * @param data pointer returned in afl_custom_init for this fuzz case + * @param data pointer returned in afl_custom_init by this custom mutator * @param[in] buf Pointer to the input data to be mutated and the mutated * output * @param[in] buf_size Size of the input/output data @@ -689,13 +828,28 @@ struct custom_mutator { u8 *add_buf, size_t add_buf_size, size_t max_size); /** + * Describe the current testcase, generated by the last mutation. + * This will be called, for example, to give the written testcase a name + * after a crash ocurred. It can help to reproduce crashing mutations. + * + * (Optional) + * + * @param data pointer returned by afl_customm_init for this custom mutator + * @paramp[in] max_description_len maximum size avaliable for the description. + * A longer return string is legal, but will be truncated. + * @return A valid ptr to a 0-terminated string. + * An empty or NULL return will result in a default description + */ + const char *(*afl_custom_describe)(void *data, size_t max_description_len); + + /** * A post-processing function to use right before AFL writes the test case to * disk in order to execute the target. * * (Optional) If this functionality is not needed, simply don't define this * function. * - * @param[in] data pointer returned in afl_custom_init for this fuzz case + * @param[in] data pointer returned in afl_custom_init by this custom mutator * @param[in] buf Buffer containing the test case to be executed * @param[in] buf_size Size of the test case * @param[out] out_buf Pointer to the buffer storing the test case after @@ -722,7 +876,7 @@ struct custom_mutator { * * (Optional) * - * @param data pointer returned in afl_custom_init for this fuzz case + * @param data pointer returned in afl_custom_init by this custom mutator * @param buf Buffer containing the test case * @param buf_size Size of the test case * @return The amount of possible iteration steps to trim the input. @@ -741,7 +895,7 @@ struct custom_mutator { * * (Optional) * - * @param data pointer returned in afl_custom_init for this fuzz case + * @param data pointer returned in afl_custom_init by this custom mutator * @param[out] out_buf Pointer to the buffer containing the trimmed test case. * The library can reuse a buffer for each call * and will have to free the buf (for example in deinit) @@ -756,7 +910,7 @@ struct custom_mutator { * * (Optional) * - * @param data pointer returned in afl_custom_init for this fuzz case + * @param data pointer returned in afl_custom_init by this custom mutator * @param success Indicates if the last trim operation was successful. * @return The next trim iteration index (from 0 to the maximum amount of * steps returned in init_trim). Negative on error. @@ -769,7 +923,7 @@ struct custom_mutator { * * (Optional) * - * @param[in] data pointer returned in afl_custom_init for this fuzz case + * @param[in] data pointer returned in afl_custom_init by this custom mutator * @param[in] buf Pointer to the input data to be mutated and the mutated * output * @param[in] buf_size Size of input data @@ -788,7 +942,7 @@ struct custom_mutator { * * (Optional) * - * @param data pointer returned in afl_custom_init for this fuzz case + * @param data pointer returned in afl_custom_init by this custom mutator * @return The probability (0-100). */ u8 (*afl_custom_havoc_mutation_probability)(void *data); @@ -798,7 +952,7 @@ struct custom_mutator { * * (Optional) * - * @param data pointer returned in afl_custom_init for this fuzz case + * @param data pointer returned in afl_custom_init by this custom mutator * @param filename File name of the test case in the queue entry * @return Return True(1) if the fuzzer will fuzz the queue entry, and * False(0) otherwise. @@ -811,7 +965,7 @@ struct custom_mutator { * * (Optional) * - * @param data pointer returned in afl_custom_init for this fuzz case + * @param data pointer returned in afl_custom_init by this custom mutator * @param filename_new_queue File name of the new queue entry * @param filename_orig_queue File name of the original queue entry. This * argument can be NULL while initializing the fuzzer @@ -821,7 +975,7 @@ struct custom_mutator { /** * Deinitialize the custom mutator. * - * @param data pointer returned in afl_custom_init for this fuzz case + * @param data pointer returned in afl_custom_init by this custom mutator */ void (*afl_custom_deinit)(void *data); @@ -856,15 +1010,17 @@ u8 trim_case_custom(afl_state_t *, struct queue_entry *q, u8 *in_buf, struct custom_mutator *load_custom_mutator_py(afl_state_t *, char *); void finalize_py_module(void *); -size_t post_process_py(void *, u8 *, size_t, u8 **); -s32 init_trim_py(void *, u8 *, size_t); -s32 post_trim_py(void *, u8); -size_t trim_py(void *, u8 **); -size_t havoc_mutation_py(void *, u8 *, size_t, u8 **, size_t); -u8 havoc_mutation_probability_py(void *); -u8 queue_get_py(void *, const u8 *); -void queue_new_entry_py(void *, const u8 *, const u8 *); -void deinit_py(void *); +u32 fuzz_count_py(void *, const u8 *, size_t); +size_t post_process_py(void *, u8 *, size_t, u8 **); +s32 init_trim_py(void *, u8 *, size_t); +s32 post_trim_py(void *, u8); +size_t trim_py(void *, u8 **); +size_t havoc_mutation_py(void *, u8 *, size_t, u8 **, size_t); +u8 havoc_mutation_probability_py(void *); +u8 queue_get_py(void *, const u8 *); +const char *introspection_py(void *); +void queue_new_entry_py(void *, const u8 *, const u8 *); +void deinit_py(void *); #endif @@ -885,37 +1041,50 @@ void write_bitmap(afl_state_t *); u32 count_bits(afl_state_t *, u8 *); u32 count_bytes(afl_state_t *, u8 *); u32 count_non_255_bytes(afl_state_t *, u8 *); -#ifdef WORD_SIZE_64 -void simplify_trace(afl_state_t *, u64 *); +void simplify_trace(afl_state_t *, u8 *); void classify_counts(afl_forkserver_t *); +#ifdef WORD_SIZE_64 +void discover_word(u8 *ret, u64 *current, u64 *virgin); #else -void simplify_trace(afl_state_t *, u32 *); -void classify_counts(afl_forkserver_t *); +void discover_word(u8 *ret, u32 *current, u32 *virgin); #endif void init_count_class16(void); void minimize_bits(afl_state_t *, u8 *, u8 *); #ifndef SIMPLE_FILES -u8 *describe_op(afl_state_t *, u8); +u8 *describe_op(afl_state_t *, u8, size_t); #endif u8 save_if_interesting(afl_state_t *, void *, u32, u8); u8 has_new_bits(afl_state_t *, u8 *); +u8 has_new_bits_unclassified(afl_state_t *, u8 *); /* Extras */ void load_extras_file(afl_state_t *, u8 *, u32 *, u32 *, u32); void load_extras(afl_state_t *, u8 *); -void maybe_add_auto(void *, u8 *, u32); +void dedup_extras(afl_state_t *); +void deunicode_extras(afl_state_t *); +void add_extra(afl_state_t *afl, u8 *mem, u32 len); +void maybe_add_auto(afl_state_t *, u8 *, u32); void save_auto(afl_state_t *); void load_auto(afl_state_t *); void destroy_extras(afl_state_t *); /* Stats */ -void write_stats_file(afl_state_t *, double, double, double); -void maybe_update_plot_file(afl_state_t *, double, double); +void load_stats_file(afl_state_t *); +void write_setup_file(afl_state_t *, u32, char **); +void write_stats_file(afl_state_t *, u32, double, double, double); +void maybe_update_plot_file(afl_state_t *, u32, double, double); void show_stats(afl_state_t *); void show_init_stats(afl_state_t *); +/* StatsD */ + +void statsd_setup_format(afl_state_t *afl); +int statsd_socket_init(afl_state_t *afl); +int statsd_send_metric(afl_state_t *afl); +int statsd_format_metric(afl_state_t *afl, char *buff, size_t bufflen); + /* Run */ fsrv_run_result_t fuzz_run_target(afl_state_t *, afl_forkserver_t *fsrv, u32); @@ -939,7 +1108,7 @@ u8 fuzz_one(afl_state_t *); void bind_to_free_cpu(afl_state_t *); #endif void setup_post(afl_state_t *); -void read_testcases(afl_state_t *); +void read_testcases(afl_state_t *, u8 *); void perform_dry_run(afl_state_t *); void pivot_inputs(afl_state_t *); u32 find_start_position(afl_state_t *); @@ -947,6 +1116,8 @@ void find_timeout(afl_state_t *); double get_runnable_processes(void); void nuke_resume_dir(afl_state_t *); int check_main_node_exists(afl_state_t *); +u32 select_next_queue_entry(afl_state_t *afl); +void create_alias_table(afl_state_t *afl); void setup_dirs_fds(afl_state_t *); void setup_cmdline_file(afl_state_t *, char **); void setup_stdio_file(afl_state_t *); @@ -954,7 +1125,7 @@ void check_crash_handling(void); void check_cpu_governor(afl_state_t *); void get_core_count(afl_state_t *); void fix_up_sync(afl_state_t *); -void check_asan_opts(void); +void check_asan_opts(afl_state_t *); void check_binary(afl_state_t *, u8 *); void fix_up_banner(afl_state_t *, u8 *); void check_if_tty(afl_state_t *); @@ -967,11 +1138,13 @@ void read_foreign_testcases(afl_state_t *, int); u8 common_fuzz_cmplog_stuff(afl_state_t *afl, u8 *out_buf, u32 len); /* RedQueen */ -u8 input_to_state_stage(afl_state_t *afl, u8 *orig_buf, u8 *buf, u32 len, - u64 exec_cksum); +u8 input_to_state_stage(afl_state_t *afl, u8 *orig_buf, u8 *buf, u32 len); + +/* our RNG wrapper */ +AFL_RAND_RETURN rand_next(afl_state_t *afl); -/* xoshiro256** */ -uint64_t rand_next(afl_state_t *afl); +/* probability between 0.0 and 1.0 */ +double rand_next_percent(afl_state_t *afl); /**** Inline routines ****/ @@ -980,6 +1153,8 @@ uint64_t rand_next(afl_state_t *afl); static inline u32 rand_below(afl_state_t *afl, u32 limit) { + if (limit <= 1) return 0; + /* The boundary not being necessarily a power of 2, we need to ensure the result uniformity. */ if (unlikely(!afl->rand_cnt--) && likely(!afl->fixed_seed)) { @@ -991,7 +1166,44 @@ static inline u32 rand_below(afl_state_t *afl, u32 limit) { } - return rand_next(afl) % limit; + /* Modulo is biased - we don't want our fuzzing to be biased so let's do it + right. See: + https://stackoverflow.com/questions/10984974/why-do-people-say-there-is-modulo-bias-when-using-a-random-number-generator + */ + u64 unbiased_rnd; + do { + + unbiased_rnd = rand_next(afl); + + } while (unlikely(unbiased_rnd >= (UINT64_MAX - (UINT64_MAX % limit)))); + + return unbiased_rnd % limit; + +} + +/* we prefer lower range values here */ +/* this is only called with normal havoc, not MOpt, to have an equalizer for + expand havoc mode */ +static inline u32 rand_below_datalen(afl_state_t *afl, u32 limit) { + + if (limit <= 1) return 0; + + switch (rand_below(afl, 3)) { + + case 2: + return (rand_below(afl, limit) % (1 + rand_below(afl, limit - 1))) % + (1 + rand_below(afl, limit - 1)); + break; + case 1: + return rand_below(afl, limit) % (1 + rand_below(afl, limit - 1)); + break; + case 0: + return rand_below(afl, limit); + break; + + } + + return 1; // cannot be reached } @@ -1021,5 +1233,25 @@ static inline u64 next_p2(u64 val) { } +/* Returns the testcase buf from the file behind this queue entry. + Increases the refcount. */ +u8 *queue_testcase_get(afl_state_t *afl, struct queue_entry *q); + +/* If trimming changes the testcase size we have to reload it */ +void queue_testcase_retake(afl_state_t *afl, struct queue_entry *q, + u32 old_len); + +/* If trimming changes the testcase size we have to replace it */ +void queue_testcase_retake_mem(afl_state_t *afl, struct queue_entry *q, u8 *in, + u32 len, u32 old_len); + +/* Add a new queue entry directly to the cache */ + +void queue_testcase_store_mem(afl_state_t *afl, struct queue_entry *q, u8 *mem); + +#if TESTCASE_CACHE == 1 + #error define of TESTCASE_CACHE must be zero or larger than 1 +#endif + #endif diff --git a/include/afl-prealloc.h b/include/afl-prealloc.h index edf69a67..fa6c9b70 100644 --- a/include/afl-prealloc.h +++ b/include/afl-prealloc.h @@ -60,7 +60,7 @@ typedef enum prealloc_status { \ if ((prealloc_counter) >= (prealloc_size)) { \ \ - el_ptr = (void *)malloc(sizeof(*el_ptr)); \ + el_ptr = (element_t *)malloc(sizeof(*el_ptr)); \ if (!el_ptr) { FATAL("error in list.h -> out of memory for element!"); } \ el_ptr->pre_status = PRE_STATUS_MALLOC; \ \ diff --git a/include/alloc-inl.h b/include/alloc-inl.h index 832b2de4..c914da5f 100644 --- a/include/alloc-inl.h +++ b/include/alloc-inl.h @@ -30,12 +30,13 @@ #include <stdio.h> #include <stdlib.h> #include <string.h> +#include <stddef.h> #include "config.h" #include "types.h" #include "debug.h" -/* Initial size used for ck_maybe_grow */ +/* Initial size used for afl_realloc */ #define INITIAL_GROWTH_SIZE (64) // Be careful! _WANT_ORIGINAL_AFL_ALLOC is not compatible with custom mutators @@ -76,10 +77,6 @@ \ } while (0) - /* Allocator increments for ck_realloc_block(). */ - - #define ALLOC_BLK_INC 256 - /* Allocate a buffer, explicitly not zeroing it. Returns NULL for zero-sized requests. */ @@ -97,7 +94,8 @@ static inline void *DFL_ck_alloc_nozero(u32 size) { } -/* Allocate a buffer, returning zeroed memory. */ +/* Allocate a buffer, returning zeroed memory. + Returns null for 0 size */ static inline void *DFL_ck_alloc(u32 size) { @@ -149,15 +147,6 @@ static inline void *DFL_ck_realloc(void *orig, u32 size) { } -/* Re-allocate a buffer with ALLOC_BLK_INC increments (used to speed up - repeated small reallocs without complicating the user code). */ - -static inline void *DFL_ck_realloc_block(void *orig, u32 size) { - - return DFL_ck_realloc(orig, size); - -} - /* Create a buffer with a copy of a string. Returns NULL for NULL inputs. */ static inline u8 *DFL_ck_strdup(u8 *str) { @@ -177,53 +166,13 @@ static inline u8 *DFL_ck_strdup(u8 *str) { } -/* Create a buffer with a copy of a memory block. Returns NULL for zero-sized - or NULL inputs. */ - -static inline void *DFL_ck_memdup(void *mem, u32 size) { - - void *ret; - - if (!mem || !size) { return NULL; } - - ALLOC_CHECK_SIZE(size); - ret = malloc(size); - ALLOC_CHECK_RESULT(ret, size); - - return memcpy(ret, mem, size); - -} - -/* Create a buffer with a block of text, appending a NUL terminator at the end. - Returns NULL for zero-sized or NULL inputs. */ - -static inline u8 *DFL_ck_memdup_str(u8 *mem, u32 size) { - - u8 *ret; - - if (!mem || !size) { return NULL; } - - ALLOC_CHECK_SIZE(size); - ret = (u8 *)malloc(size + 1); - ALLOC_CHECK_RESULT(ret, size); - - memcpy(ret, mem, size); - ret[size] = 0; - - return ret; - -} - /* In non-debug mode, we just do straightforward aliasing of the above functions to user-visible names such as ck_alloc(). */ #define ck_alloc DFL_ck_alloc #define ck_alloc_nozero DFL_ck_alloc_nozero #define ck_realloc DFL_ck_realloc - #define ck_realloc_block DFL_ck_realloc_block #define ck_strdup DFL_ck_strdup - #define ck_memdup DFL_ck_memdup - #define ck_memdup_str DFL_ck_memdup_str #define ck_free DFL_ck_free #define alloc_report() @@ -278,10 +227,6 @@ static inline u8 *DFL_ck_memdup_str(u8 *mem, u32 size) { #define ALLOC_OFF_HEAD 8 #define ALLOC_OFF_TOTAL (ALLOC_OFF_HEAD + 1) - /* Allocator increments for ck_realloc_block(). */ - - #define ALLOC_BLK_INC 256 - /* Sanity-checking macros for pointers. */ #define CHECK_PTR(_p) \ @@ -326,7 +271,7 @@ static inline void *DFL_ck_alloc_nozero(u32 size) { ret = malloc(size + ALLOC_OFF_TOTAL); ALLOC_CHECK_RESULT(ret, size); - ret += ALLOC_OFF_HEAD; + ret = (char *)ret + ALLOC_OFF_HEAD; ALLOC_C1(ret) = ALLOC_MAGIC_C1; ALLOC_S(ret) = size; @@ -366,7 +311,7 @@ static inline void DFL_ck_free(void *mem) { ALLOC_C1(mem) = ALLOC_MAGIC_F; - free(mem - ALLOC_OFF_HEAD); + free((char *)mem - ALLOC_OFF_HEAD); } @@ -395,7 +340,7 @@ static inline void *DFL_ck_realloc(void *orig, u32 size) { #endif /* !DEBUG_BUILD */ old_size = ALLOC_S(orig); - orig -= ALLOC_OFF_HEAD; + orig = (char *)orig - ALLOC_OFF_HEAD; ALLOC_CHECK_SIZE(old_size); @@ -418,10 +363,11 @@ static inline void *DFL_ck_realloc(void *orig, u32 size) { if (orig) { - memcpy(ret + ALLOC_OFF_HEAD, orig + ALLOC_OFF_HEAD, MIN(size, old_size)); - memset(orig + ALLOC_OFF_HEAD, 0xFF, old_size); + memcpy((char *)ret + ALLOC_OFF_HEAD, (char *)orig + ALLOC_OFF_HEAD, + MIN(size, old_size)); + memset((char *)orig + ALLOC_OFF_HEAD, 0xFF, old_size); - ALLOC_C1(orig + ALLOC_OFF_HEAD) = ALLOC_MAGIC_F; + ALLOC_C1((char *)orig + ALLOC_OFF_HEAD) = ALLOC_MAGIC_F; free(orig); @@ -429,41 +375,18 @@ static inline void *DFL_ck_realloc(void *orig, u32 size) { #endif /* ^!DEBUG_BUILD */ - ret += ALLOC_OFF_HEAD; + ret = (char *)ret + ALLOC_OFF_HEAD; ALLOC_C1(ret) = ALLOC_MAGIC_C1; ALLOC_S(ret) = size; ALLOC_C2(ret) = ALLOC_MAGIC_C2; - if (size > old_size) memset(ret + old_size, 0, size - old_size); + if (size > old_size) memset((char *)ret + old_size, 0, size - old_size); return ret; } -/* Re-allocate a buffer with ALLOC_BLK_INC increments (used to speed up - repeated small reallocs without complicating the user code). */ - -static inline void *DFL_ck_realloc_block(void *orig, u32 size) { - - #ifndef DEBUG_BUILD - - if (orig) { - - CHECK_PTR(orig); - - if (ALLOC_S(orig) >= size) return orig; - - size += ALLOC_BLK_INC; - - } - - #endif /* !DEBUG_BUILD */ - - return DFL_ck_realloc(orig, size); - -} - /* Create a buffer with a copy of a string. Returns NULL for NULL inputs. */ static inline u8 *DFL_ck_strdup(u8 *str) { @@ -479,7 +402,7 @@ static inline u8 *DFL_ck_strdup(u8 *str) { ret = malloc(size + ALLOC_OFF_TOTAL); ALLOC_CHECK_RESULT(ret, size); - ret += ALLOC_OFF_HEAD; + ret = (char *)ret + ALLOC_OFF_HEAD; ALLOC_C1(ret) = ALLOC_MAGIC_C1; ALLOC_S(ret) = size; @@ -489,55 +412,6 @@ static inline u8 *DFL_ck_strdup(u8 *str) { } -/* Create a buffer with a copy of a memory block. Returns NULL for zero-sized - or NULL inputs. */ - -static inline void *DFL_ck_memdup(void *mem, u32 size) { - - void *ret; - - if (!mem || !size) return NULL; - - ALLOC_CHECK_SIZE(size); - ret = malloc(size + ALLOC_OFF_TOTAL); - ALLOC_CHECK_RESULT(ret, size); - - ret += ALLOC_OFF_HEAD; - - ALLOC_C1(ret) = ALLOC_MAGIC_C1; - ALLOC_S(ret) = size; - ALLOC_C2(ret) = ALLOC_MAGIC_C2; - - return memcpy(ret, mem, size); - -} - -/* Create a buffer with a block of text, appending a NUL terminator at the end. - Returns NULL for zero-sized or NULL inputs. */ - -static inline u8 *DFL_ck_memdup_str(u8 *mem, u32 size) { - - u8 *ret; - - if (!mem || !size) return NULL; - - ALLOC_CHECK_SIZE(size); - ret = malloc(size + ALLOC_OFF_TOTAL + 1); - ALLOC_CHECK_RESULT(ret, size); - - ret += ALLOC_OFF_HEAD; - - ALLOC_C1(ret) = ALLOC_MAGIC_C1; - ALLOC_S(ret) = size; - ALLOC_C2(ret) = ALLOC_MAGIC_C2; - - memcpy(ret, mem, size); - ret[size] = 0; - - return ret; - -} - #ifndef DEBUG_BUILD /* In non-debug mode, we just do straightforward aliasing of the above @@ -546,10 +420,7 @@ static inline u8 *DFL_ck_memdup_str(u8 *mem, u32 size) { #define ck_alloc DFL_ck_alloc #define ck_alloc_nozero DFL_ck_alloc_nozero #define ck_realloc DFL_ck_realloc - #define ck_realloc_block DFL_ck_realloc_block #define ck_strdup DFL_ck_strdup - #define ck_memdup DFL_ck_memdup - #define ck_memdup_str DFL_ck_memdup_str #define ck_free DFL_ck_free #define alloc_report() @@ -618,8 +489,8 @@ static inline void TRK_alloc_buf(void *ptr, const char *file, const char *func, /* No space available - allocate more. */ - TRK[bucket] = DFL_ck_realloc_block( - TRK[bucket], (TRK_cnt[bucket] + 1) * sizeof(struct TRK_obj)); + TRK[bucket] = DFL_ck_realloc(TRK[bucket], + (TRK_cnt[bucket] + 1) * sizeof(struct TRK_obj)); TRK[bucket][i].ptr = ptr; TRK[bucket][i].file = (char *)file; @@ -694,16 +565,6 @@ static inline void *TRK_ck_realloc(void *orig, u32 size, const char *file, } -static inline void *TRK_ck_realloc_block(void *orig, u32 size, const char *file, - const char *func, u32 line) { - - void *ret = DFL_ck_realloc_block(orig, size); - TRK_free_buf(orig, file, func, line); - TRK_alloc_buf(ret, file, func, line); - return ret; - -} - static inline void *TRK_ck_strdup(u8 *str, const char *file, const char *func, u32 line) { @@ -713,24 +574,6 @@ static inline void *TRK_ck_strdup(u8 *str, const char *file, const char *func, } -static inline void *TRK_ck_memdup(void *mem, u32 size, const char *file, - const char *func, u32 line) { - - void *ret = DFL_ck_memdup(mem, size); - TRK_alloc_buf(ret, file, func, line); - return ret; - -} - -static inline void *TRK_ck_memdup_str(void *mem, u32 size, const char *file, - const char *func, u32 line) { - - void *ret = DFL_ck_memdup_str(mem, size); - TRK_alloc_buf(ret, file, func, line); - return ret; - -} - static inline void TRK_ck_free(void *ptr, const char *file, const char *func, u32 line) { @@ -749,17 +592,8 @@ static inline void TRK_ck_free(void *ptr, const char *file, const char *func, #define ck_realloc(_p1, _p2) \ TRK_ck_realloc(_p1, _p2, __FILE__, __FUNCTION__, __LINE__) - #define ck_realloc_block(_p1, _p2) \ - TRK_ck_realloc_block(_p1, _p2, __FILE__, __FUNCTION__, __LINE__) - #define ck_strdup(_p1) TRK_ck_strdup(_p1, __FILE__, __FUNCTION__, __LINE__) - #define ck_memdup(_p1, _p2) \ - TRK_ck_memdup(_p1, _p2, __FILE__, __FUNCTION__, __LINE__) - - #define ck_memdup_str(_p1, _p2) \ - TRK_ck_memdup_str(_p1, _p2, __FILE__, __FUNCTION__, __LINE__) - #define ck_free(_p1) TRK_ck_free(_p1, __FILE__, __FUNCTION__, __LINE__) #endif /* ^!DEBUG_BUILD */ @@ -771,11 +605,14 @@ static inline void TRK_ck_free(void *ptr, const char *file, const char *func, */ static inline size_t next_pow2(size_t in) { - if (in == 0 || in > (size_t)-1) { - - return 0; /* avoid undefined behaviour under-/overflow */ + // Commented this out as this behavior doesn't change, according to unittests + // if (in == 0 || in > (size_t)-1) { - } + // + // return 0; /* avoid undefined behaviour under-/overflow + // */ + // + // } size_t out = in - 1; out |= out >> 1; @@ -787,6 +624,35 @@ static inline size_t next_pow2(size_t in) { } +/* AFL alloc buffer, the struct is here so we don't need to do fancy ptr + * arithmetics */ +struct afl_alloc_buf { + + /* The complete allocated size, including the header of len + * AFL_ALLOC_SIZE_OFFSET */ + size_t complete_size; + /* ptr to the first element of the actual buffer */ + u8 buf[0]; + +}; + +#define AFL_ALLOC_SIZE_OFFSET (offsetof(struct afl_alloc_buf, buf)) + +/* Returns the container element to this ptr */ +static inline struct afl_alloc_buf *afl_alloc_bufptr(void *buf) { + + return (struct afl_alloc_buf *)((u8 *)buf - AFL_ALLOC_SIZE_OFFSET); + +} + +/* Gets the maximum size of the buf contents (ptr->complete_size - + * AFL_ALLOC_SIZE_OFFSET) */ +static inline size_t afl_alloc_bufsize(void *buf) { + + return afl_alloc_bufptr(buf)->complete_size - AFL_ALLOC_SIZE_OFFSET; + +} + /* This function makes sure *size is > size_needed after call. It will realloc *buf otherwise. *size will grow exponentially as per: @@ -794,71 +660,116 @@ static inline size_t next_pow2(size_t in) { Will return NULL and free *buf if size_needed is <1 or realloc failed. @return For convenience, this function returns *buf. */ -static inline void *maybe_grow(void **buf, size_t *size, size_t size_needed) { +static inline void *afl_realloc(void **buf, size_t size_needed) { + + struct afl_alloc_buf *new_buf = NULL; + + size_t current_size = 0; + size_t next_size = 0; + + if (likely(*buf)) { + + /* the size is always stored at buf - 1*size_t */ + new_buf = (struct afl_alloc_buf *)afl_alloc_bufptr(*buf); + current_size = new_buf->complete_size; + + } + + size_needed += AFL_ALLOC_SIZE_OFFSET; /* No need to realloc */ - if (likely(size_needed && *size >= size_needed)) { return *buf; } + if (likely(current_size >= size_needed)) { return *buf; } /* No initial size was set */ - if (size_needed < INITIAL_GROWTH_SIZE) { size_needed = INITIAL_GROWTH_SIZE; } + if (size_needed < INITIAL_GROWTH_SIZE) { + + next_size = INITIAL_GROWTH_SIZE; - /* grow exponentially */ - size_t next_size = next_pow2(size_needed); + } else { - /* handle overflow and zero size_needed */ - if (!next_size) { next_size = size_needed; } + /* grow exponentially */ + next_size = next_pow2(size_needed); + + /* handle overflow: fall back to the original size_needed */ + if (unlikely(!next_size)) { next_size = size_needed; } + + } /* alloc */ - *buf = realloc(*buf, next_size); - *size = *buf ? next_size : 0; + struct afl_alloc_buf *newer_buf = + (struct afl_alloc_buf *)realloc(new_buf, next_size); + if (unlikely(!newer_buf)) { + + free(new_buf); // avoid a leak + *buf = NULL; + return NULL; + + } else { + + new_buf = newer_buf; + } + + new_buf->complete_size = next_size; + *buf = (void *)(new_buf->buf); return *buf; } -/* This function makes sure *size is > size_needed after call. - It will realloc *buf otherwise. - *size will grow exponentially as per: - https://blog.mozilla.org/nnethercote/2014/11/04/please-grow-your-buffers-exponentially/ - Will FATAL if size_needed is <1. - @return For convenience, this function returns *buf. - */ -static inline void *ck_maybe_grow(void **buf, size_t *size, - size_t size_needed) { +/* afl_realloc_exact uses afl alloc buffers but sets it to a specific size */ - /* Oops. found a bug? */ - if (unlikely(size_needed < 1)) { FATAL("cannot grow to non-positive size"); } +static inline void *afl_realloc_exact(void **buf, size_t size_needed) { - /* No need to realloc */ - if (likely(*size >= size_needed)) { return *buf; } + struct afl_alloc_buf *new_buf = NULL; - /* No initial size was set */ - if (size_needed < INITIAL_GROWTH_SIZE) { size_needed = INITIAL_GROWTH_SIZE; } + size_t current_size = 0; - /* grow exponentially */ - size_t next_size = next_pow2(size_needed); + if (likely(*buf)) { - /* handle overflow */ - if (!next_size) { next_size = size_needed; } + /* the size is always stored at buf - 1*size_t */ + new_buf = (struct afl_alloc_buf *)afl_alloc_bufptr(*buf); + current_size = new_buf->complete_size; + + } + + size_needed += AFL_ALLOC_SIZE_OFFSET; + + /* No need to realloc */ + if (unlikely(current_size == size_needed)) { return *buf; } /* alloc */ - *buf = ck_realloc(*buf, next_size); - *size = next_size; + struct afl_alloc_buf *newer_buf = + (struct afl_alloc_buf *)realloc(new_buf, size_needed); + if (unlikely(!newer_buf)) { + free(new_buf); // avoid a leak + *buf = NULL; + return NULL; + + } else { + + new_buf = newer_buf; + + } + + new_buf->complete_size = size_needed; + *buf = (void *)(new_buf->buf); return *buf; } +static inline void afl_free(void *buf) { + + if (buf) { free(afl_alloc_bufptr(buf)); } + +} + /* Swaps buf1 ptr and buf2 ptr, as well as their sizes */ -static inline void swap_bufs(void **buf1, size_t *size1, void **buf2, - size_t *size2) { +static inline void afl_swap_bufs(void **buf1, void **buf2) { - void * scratch_buf = *buf1; - size_t scratch_size = *size1; + void *scratch_buf = *buf1; *buf1 = *buf2; - *size1 = *size2; *buf2 = scratch_buf; - *size2 = scratch_size; } diff --git a/include/android-ashmem.h b/include/android-ashmem.h index 41d4d2da..91699b27 100644 --- a/include/android-ashmem.h +++ b/include/android-ashmem.h @@ -1,62 +1,34 @@ -/* - american fuzzy lop++ - android shared memory compatibility layer - ---------------------------------------------------------------- - - Originally written by Michal Zalewski - - Now maintained by Marc Heuse <mh@mh-sec.de>, - Heiko Eißfeldt <heiko.eissfeldt@hexco.de>, - Andrea Fioraldi <andreafioraldi@gmail.com>, - Dominik Maier <mail@dmnk.co> - - Copyright 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This header re-defines the shared memory routines used by AFL++ - using the Andoid API. - - */ - -#ifndef _ANDROID_ASHMEM_H -#define _ANDROID_ASHMEM_H - #ifdef __ANDROID__ - - #include <fcntl.h> - #include <linux/shm.h> - #include <linux/ashmem.h> - #include <sys/ioctl.h> - #include <sys/mman.h> - - #if __ANDROID_API__ >= 26 - #define shmat bionic_shmat - #define shmctl bionic_shmctl - #define shmdt bionic_shmdt - #define shmget bionic_shmget - #endif - - #include <sys/shm.h> - #undef shmat - #undef shmctl - #undef shmdt - #undef shmget - #include <stdio.h> - - #define ASHMEM_DEVICE "/dev/ashmem" - -static inline int shmctl(int __shmid, int __cmd, struct shmid_ds *__buf) { + #ifndef _ANDROID_ASHMEM_H + #define _ANDROID_ASHMEM_H + + #include <fcntl.h> + #include <linux/ashmem.h> + #include <sys/ioctl.h> + #include <sys/mman.h> + + #if __ANDROID_API__ >= 26 + #define shmat bionic_shmat + #define shmctl bionic_shmctl + #define shmdt bionic_shmdt + #define shmget bionic_shmget + #endif + #include <sys/shm.h> + #undef shmat + #undef shmctl + #undef shmdt + #undef shmget + #include <stdio.h> + + #define ASHMEM_DEVICE "/dev/ashmem" + +int shmctl(int __shmid, int __cmd, struct shmid_ds *__buf) { int ret = 0; if (__cmd == IPC_RMID) { int length = ioctl(__shmid, ASHMEM_GET_SIZE, NULL); - struct ashmem_pin pin = {0, (unsigned int)length}; + struct ashmem_pin pin = {0, length}; ret = ioctl(__shmid, ASHMEM_UNPIN, &pin); close(__shmid); @@ -66,7 +38,7 @@ static inline int shmctl(int __shmid, int __cmd, struct shmid_ds *__buf) { } -static inline int shmget(key_t __key, size_t __size, int __shmflg) { +int shmget(key_t __key, size_t __size, int __shmflg) { (void)__shmflg; int fd, ret; @@ -90,7 +62,7 @@ error: } -static inline void *shmat(int __shmid, const void *__shmaddr, int __shmflg) { +void *shmat(int __shmid, const void *__shmaddr, int __shmflg) { (void)__shmflg; int size; @@ -106,7 +78,6 @@ static inline void *shmat(int __shmid, const void *__shmaddr, int __shmflg) { } -#endif /* __ANDROID__ */ - -#endif + #endif /* !_ANDROID_ASHMEM_H */ +#endif /* !__ANDROID__ */ diff --git a/include/cmplog.h b/include/cmplog.h index 74e6a3bb..878ed60c 100644 --- a/include/cmplog.h +++ b/include/cmplog.h @@ -29,26 +29,26 @@ #define _AFL_CMPLOG_H #include "config.h" -#include "forkserver.h" + +#define CMPLOG_LVL_MAX 3 #define CMP_MAP_W 65536 -#define CMP_MAP_H 256 +#define CMP_MAP_H 32 #define CMP_MAP_RTN_H (CMP_MAP_H / 4) #define SHAPE_BYTES(x) (x + 1) -#define CMP_TYPE_INS 0 -#define CMP_TYPE_RTN 1 +#define CMP_TYPE_INS 1 +#define CMP_TYPE_RTN 2 struct cmp_header { - unsigned hits : 20; - - unsigned cnt : 20; - unsigned id : 16; - - unsigned shape : 5; // from 0 to 31 - unsigned type : 1; + unsigned hits : 24; + unsigned id : 24; + unsigned shape : 5; + unsigned type : 2; + unsigned attribute : 4; + unsigned reserved : 5; } __attribute__((packed)); @@ -56,6 +56,8 @@ struct cmp_operands { u64 v0; u64 v1; + u64 v0_128; + u64 v1_128; }; @@ -77,7 +79,8 @@ struct cmp_map { /* Execs the child */ -void cmplog_exec_child(afl_forkserver_t *fsrv, char **argv); +struct afl_forkserver; +void cmplog_exec_child(struct afl_forkserver *fsrv, char **argv); #endif diff --git a/include/common.h b/include/common.h index 87a7425b..b7adbaec 100644 --- a/include/common.h +++ b/include/common.h @@ -31,14 +31,15 @@ #include <string.h> #include <unistd.h> #include <sys/time.h> +#include <stdbool.h> #include "types.h" -#include "stdbool.h" /* STRINGIFY_VAL_SIZE_MAX will fit all stringify_ strings. */ #define STRINGIFY_VAL_SIZE_MAX (16) -void detect_file_args(char **argv, u8 *prog_in, u8 *use_stdin); +void detect_file_args(char **argv, u8 *prog_in, bool *use_stdin); +void print_suggested_envs(char *mispelled_env); void check_environment_vars(char **env); char **argv_cpy_dup(int argc, char **argv); @@ -56,6 +57,11 @@ extern u8 *doc_path; /* path to documentation dir */ u8 *find_binary(u8 *fname); +/* Parses the kill signal environment variable, FATALs on error. + If the env is not set, sets the env to default_signal for the signal handlers + and returns the default_signal. */ +int parse_afl_kill_signal_env(u8 *afl_kill_signal_env, int default_signal); + /* Read a bitmap from file fname to memory This is for the -B option again. */ @@ -110,5 +116,11 @@ u8 *u_stringify_time_diff(u8 *buf, u64 cur_ms, u64 event_ms); /* Reads the map size from ENV */ u32 get_map_size(void); +/* create a stream file */ +FILE *create_ffile(u8 *fn); + +/* create a file */ +s32 create_file(u8 *fn); + #endif diff --git a/include/config.h b/include/config.h index 344a368f..29225f6b 100644 --- a/include/config.h +++ b/include/config.h @@ -10,7 +10,7 @@ Dominik Maier <mail@dmnk.co> Copyright 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. + Copyright 2019-2021 AFLplusplus Project. All rights reserved. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. @@ -23,12 +23,10 @@ #ifndef _HAVE_CONFIG_H #define _HAVE_CONFIG_H -#include "types.h" - /* Version string: */ -// c = release, d = volatile github dev, e = experimental branch -#define VERSION "++2.66d" +// c = release, a = volatile github dev, e = experimental branch +#define VERSION "++3.12a" /****************************************************** * * @@ -36,15 +34,76 @@ * * ******************************************************/ +/* Default shared memory map size. Most targets just need a coverage map + between 20-250kb. Plus there is an auto-detection feature in afl-fuzz. + However if a target has problematic constructors and init arrays then + this can fail. Hence afl-fuzz deploys a larger default map. The largest + map seen so far is the xlsx fuzzer for libreoffice which is 5MB. + At runtime this value can be overriden via AFL_MAP_SIZE. + Default: 8MB (defined in bytes) */ +#define DEFAULT_SHMEM_SIZE (8 * 1024 * 1024) + +/* CMPLOG/REDQUEEN TUNING + * + * Here you can modify tuning and solving options for CMPLOG. + * Note that these are run-time options for afl-fuzz, no target + * recompilation required. + * + */ + +/* if TRANSFORM is enabled with '-l T', this additionally enables base64 + encoding/decoding */ +// #define CMPLOG_SOLVE_TRANSFORM_BASE64 + +/* If a redqueen pass finds more than one solution, try to combine them? */ +#define CMPLOG_COMBINE + +/* Minimum % of the corpus to perform cmplog on. Default: 10% */ +#define CMPLOG_CORPUS_PERCENT 5U + +/* Number of potential positions from which we decide if cmplog becomes + useless, default 8096 */ +#define CMPLOG_POSITIONS_MAX (12 * 1024) + +/* Maximum allowed fails per CMP value. Default: 128 */ +#define CMPLOG_FAIL_MAX 96 + +/* Now non-cmplog configuration options */ + +/* console output colors: There are three ways to configure its behavior + * 1. default: colored outputs fixed on: defined USE_COLOR && defined + * ALWAYS_COLORED The env var. AFL_NO_COLOR will have no effect + * 2. defined USE_COLOR && !defined ALWAYS_COLORED + * -> depending on env var AFL_NO_COLOR=1 colors can be switched off + * at run-time. Default is to use colors. + * 3. colored outputs fixed off: !defined USE_COLOR + * The env var. AFL_NO_COLOR will have no effect + */ + /* Comment out to disable terminal colors (note that this makes afl-analyze a lot less nice): */ #define USE_COLOR +#ifdef USE_COLOR + /* Comment in to always enable terminal colors */ + /* Comment out to enable runtime controlled terminal colors via AFL_NO_COLOR + */ + #define ALWAYS_COLORED 1 +#endif + +/* StatsD config + Config can be adjusted via AFL_STATSD_HOST and AFL_STATSD_PORT environment + variable. +*/ +#define STATSD_UPDATE_SEC 1 +#define STATSD_DEFAULT_PORT 8125 +#define STATSD_DEFAULT_HOST "127.0.0.1" + /* If you want to have the original afl internal memory corruption checks. Disabled by default for speed. it is better to use "make ASAN_BUILD=1". */ -//#define _WANT_ORIGINAL_AFL_ALLOC +// #define _WANT_ORIGINAL_AFL_ALLOC /* Comment out to disable fancy ANSI boxes and use poor man's 7-bit UI: */ @@ -55,69 +114,61 @@ /* Default timeout for fuzzed code (milliseconds). This is the upper bound, also used for detecting hangs; the actual value is auto-scaled: */ -#define EXEC_TIMEOUT 1000 +#define EXEC_TIMEOUT 1000U /* Timeout rounding factor when auto-scaling (milliseconds): */ -#define EXEC_TM_ROUND 20 +#define EXEC_TM_ROUND 20U /* 64bit arch MACRO */ #if (defined(__x86_64__) || defined(__arm64__) || defined(__aarch64__)) #define WORD_SIZE_64 1 #endif -/* Default memory limit for child process (MB): */ - -#ifndef __NetBSD__ - #ifndef WORD_SIZE_64 - #define MEM_LIMIT 25 - #else - #define MEM_LIMIT 50 - #endif /* ^!WORD_SIZE_64 */ -#else /* NetBSD's kernel needs more space for stack, see discussion for issue \ - #165 */ - #define MEM_LIMIT 200 -#endif -/* Default memory limit when running in QEMU mode (MB): */ +/* Default memory limit for child process (MB) 0 = disabled : */ + +#define MEM_LIMIT 0U -#define MEM_LIMIT_QEMU 200 +/* Default memory limit when running in QEMU mode (MB) 0 = disabled : */ -/* Default memory limit when running in Unicorn mode (MB): */ +#define MEM_LIMIT_QEMU 0U -#define MEM_LIMIT_UNICORN 200 +/* Default memory limit when running in Unicorn mode (MB) 0 = disabled : */ + +#define MEM_LIMIT_UNICORN 0U /* Number of calibration cycles per every new test case (and for test cases that show variable behavior): */ -#define CAL_CYCLES 8 -#define CAL_CYCLES_LONG 40 +#define CAL_CYCLES 8U +#define CAL_CYCLES_LONG 40U /* Number of subsequent timeouts before abandoning an input file: */ -#define TMOUT_LIMIT 250 +#define TMOUT_LIMIT 250U /* Maximum number of unique hangs or crashes to record: */ -#define KEEP_UNIQUE_HANG 500 -#define KEEP_UNIQUE_CRASH 5000 +#define KEEP_UNIQUE_HANG 500U +#define KEEP_UNIQUE_CRASH 5000U /* Baseline number of random tweaks during a single 'havoc' stage: */ -#define HAVOC_CYCLES 256 -#define HAVOC_CYCLES_INIT 1024 +#define HAVOC_CYCLES 256U +#define HAVOC_CYCLES_INIT 1024U /* Maximum multiplier for the above (should be a power of two, beware of 32-bit int overflows): */ -#define HAVOC_MAX_MULT 16 -#define HAVOC_MAX_MULT_MOPT 32 +#define HAVOC_MAX_MULT 64U +#define HAVOC_MAX_MULT_MOPT 64U /* Absolute minimum number of havoc cycles (after all adjustments): */ -#define HAVOC_MIN 16 +#define HAVOC_MIN 12U /* Power Schedule Divisor */ -#define POWER_BETA 1 +#define POWER_BETA 1U #define MAX_FACTOR (POWER_BETA * 32) /* Maximum stacking for havoc-stage tweaks. The actual value is calculated @@ -126,22 +177,22 @@ n = random between 1 and HAVOC_STACK_POW2 stacking = 2^n - In other words, the default (n = 7) produces 2, 4, 8, 16, 32, 64, or - 128 stacked tweaks: */ + In other words, the default (n = 4) produces 2, 4, 8, 16 + stacked tweaks: */ -#define HAVOC_STACK_POW2 7 +#define HAVOC_STACK_POW2 4U /* Caps on block sizes for cloning and deletion operations. Each of these ranges has a 33% probability of getting picked, except for the first two cycles where smaller blocks are favored: */ -#define HAVOC_BLK_SMALL 32 -#define HAVOC_BLK_MEDIUM 128 -#define HAVOC_BLK_LARGE 1500 +#define HAVOC_BLK_SMALL 32U +#define HAVOC_BLK_MEDIUM 128U +#define HAVOC_BLK_LARGE 1500U /* Extra-large blocks, selected very rarely (<5% of the time): */ -#define HAVOC_BLK_XL 32768 +#define HAVOC_BLK_XL 32768U /* Probabilities of skipping non-favored entries in the queue, expressed as percentages: */ @@ -169,9 +220,11 @@ #define TRIM_START_STEPS 16 #define TRIM_END_STEPS 1024 -/* Maximum size of input file, in bytes (keep under 100MB): */ +/* Maximum size of input file, in bytes (keep under 100MB, default 1MB): + (note that if this value is changed, several areas in afl-cc.c, afl-fuzz.c + and afl-fuzz-state.c have to be changed as well! */ -#define MAX_FILE (1 * 1024 * 1024) +#define MAX_FILE (1 * 1024 * 1024U) /* The same, for the test case minimizer: */ @@ -195,7 +248,7 @@ steps; past this point, the "extras/user" step will be still carried out, but with proportionally lower odds: */ -#define MAX_DET_EXTRAS 200 +#define MAX_DET_EXTRAS 256 /* Maximum number of auto-extracted dictionary tokens to actually use in fuzzing (first value), and to keep in memory as candidates. The latter should be much @@ -236,6 +289,11 @@ #define SYNC_INTERVAL 8 +/* Sync time (minimum time between syncing in ms, time is halfed for -M main + nodes) - default is 30 minutes: */ + +#define SYNC_TIME (30 * 60 * 1000) + /* Output directory reuse grace period (minutes): */ #define OUTPUT_GRACE 25 @@ -295,6 +353,13 @@ #define RESEED_RNG 100000 +/* The default maximum testcase cache size in MB, 0 = disable. + A value between 50 and 250 is a good default value. Note that the + number of entries will be auto assigned if not specified via the + AFL_TESTCACHE_ENTRIES env variable */ + +#define TESTCASE_CACHE_SIZE 50 + /* Maximum line length passed from GCC to 'as' and used for parsing configuration files: */ @@ -356,7 +421,7 @@ after changing this - otherwise, SEGVs may ensue. */ #define MAP_SIZE_POW2 16 -#define MAP_SIZE (1 << MAP_SIZE_POW2) +#define MAP_SIZE (1U << MAP_SIZE_POW2) /* Maximum allocator request size (keep well under INT_MAX): */ diff --git a/include/coverage-32.h b/include/coverage-32.h new file mode 100644 index 00000000..ca36c29f --- /dev/null +++ b/include/coverage-32.h @@ -0,0 +1,112 @@ +#include "config.h" +#include "types.h" + +u32 skim(const u32 *virgin, const u32 *current, const u32 *current_end); +u32 classify_word(u32 word); + +inline u32 classify_word(u32 word) { + + u16 mem16[2]; + memcpy(mem16, &word, sizeof(mem16)); + + mem16[0] = count_class_lookup16[mem16[0]]; + mem16[1] = count_class_lookup16[mem16[1]]; + + memcpy(&word, mem16, sizeof(mem16)); + return word; + +} + +void simplify_trace(afl_state_t *afl, u8 *bytes) { + + u32 *mem = (u32 *)bytes; + u32 i = (afl->fsrv.map_size >> 2); + + while (i--) { + + /* Optimize for sparse bitmaps. */ + + if (unlikely(*mem)) { + + u8 *mem8 = (u8 *)mem; + + mem8[0] = simplify_lookup[mem8[0]]; + mem8[1] = simplify_lookup[mem8[1]]; + mem8[2] = simplify_lookup[mem8[2]]; + mem8[3] = simplify_lookup[mem8[3]]; + + } else + + *mem = 0x01010101; + + mem++; + + } + +} + +inline void classify_counts(afl_forkserver_t *fsrv) { + + u32 *mem = (u32 *)fsrv->trace_bits; + u32 i = (fsrv->map_size >> 2); + + while (i--) { + + /* Optimize for sparse bitmaps. */ + + if (unlikely(*mem)) { *mem = classify_word(*mem); } + + mem++; + + } + +} + +/* Updates the virgin bits, then reflects whether a new count or a new tuple is + * seen in ret. */ +inline void discover_word(u8 *ret, u32 *current, u32 *virgin) { + + /* Optimize for (*current & *virgin) == 0 - i.e., no bits in current bitmap + that have not been already cleared from the virgin map - since this will + almost always be the case. */ + + if (*current & *virgin) { + + if (likely(*ret < 2)) { + + u8 *cur = (u8 *)current; + u8 *vir = (u8 *)virgin; + + /* Looks like we have not found any new bytes yet; see if any non-zero + bytes in current[] are pristine in virgin[]. */ + + if ((cur[0] && vir[0] == 0xff) || (cur[1] && vir[1] == 0xff) || + (cur[2] && vir[2] == 0xff) || (cur[3] && vir[3] == 0xff)) + *ret = 2; + else + *ret = 1; + + } + + *virgin &= ~*current; + + } + +} + +#define PACK_SIZE 16 +inline u32 skim(const u32 *virgin, const u32 *current, const u32 *current_end) { + + for (; current < current_end; virgin += 4, current += 4) { + + if (current[0] && classify_word(current[0]) & virgin[0]) return 1; + if (current[1] && classify_word(current[1]) & virgin[1]) return 1; + if (current[2] && classify_word(current[2]) & virgin[2]) return 1; + if (current[3] && classify_word(current[3]) & virgin[3]) return 1; + + } + + return 0; + +} + diff --git a/include/coverage-64.h b/include/coverage-64.h new file mode 100644 index 00000000..54fe9d33 --- /dev/null +++ b/include/coverage-64.h @@ -0,0 +1,189 @@ +#include "config.h" +#include "types.h" + +#if (defined(__AVX512F__) && defined(__AVX512DQ__)) || defined(__AVX2__) + #include <immintrin.h> +#endif + +u32 skim(const u64 *virgin, const u64 *current, const u64 *current_end); +u64 classify_word(u64 word); + +inline u64 classify_word(u64 word) { + + u16 mem16[4]; + memcpy(mem16, &word, sizeof(mem16)); + + mem16[0] = count_class_lookup16[mem16[0]]; + mem16[1] = count_class_lookup16[mem16[1]]; + mem16[2] = count_class_lookup16[mem16[2]]; + mem16[3] = count_class_lookup16[mem16[3]]; + + memcpy(&word, mem16, sizeof(mem16)); + return word; + +} + +void simplify_trace(afl_state_t *afl, u8 *bytes) { + + u64 *mem = (u64 *)bytes; + u32 i = (afl->fsrv.map_size >> 3); + + while (i--) { + + /* Optimize for sparse bitmaps. */ + + if (unlikely(*mem)) { + + u8 *mem8 = (u8 *)mem; + + mem8[0] = simplify_lookup[mem8[0]]; + mem8[1] = simplify_lookup[mem8[1]]; + mem8[2] = simplify_lookup[mem8[2]]; + mem8[3] = simplify_lookup[mem8[3]]; + mem8[4] = simplify_lookup[mem8[4]]; + mem8[5] = simplify_lookup[mem8[5]]; + mem8[6] = simplify_lookup[mem8[6]]; + mem8[7] = simplify_lookup[mem8[7]]; + + } else + + *mem = 0x0101010101010101ULL; + + mem++; + + } + +} + +inline void classify_counts(afl_forkserver_t *fsrv) { + + u64 *mem = (u64 *)fsrv->trace_bits; + u32 i = (fsrv->map_size >> 3); + + while (i--) { + + /* Optimize for sparse bitmaps. */ + + if (unlikely(*mem)) { *mem = classify_word(*mem); } + + mem++; + + } + +} + +/* Updates the virgin bits, then reflects whether a new count or a new tuple is + * seen in ret. */ +inline void discover_word(u8 *ret, u64 *current, u64 *virgin) { + + /* Optimize for (*current & *virgin) == 0 - i.e., no bits in current bitmap + that have not been already cleared from the virgin map - since this will + almost always be the case. */ + + if (*current & *virgin) { + + if (likely(*ret < 2)) { + + u8 *cur = (u8 *)current; + u8 *vir = (u8 *)virgin; + + /* Looks like we have not found any new bytes yet; see if any non-zero + bytes in current[] are pristine in virgin[]. */ + + if ((cur[0] && vir[0] == 0xff) || (cur[1] && vir[1] == 0xff) || + (cur[2] && vir[2] == 0xff) || (cur[3] && vir[3] == 0xff) || + (cur[4] && vir[4] == 0xff) || (cur[5] && vir[5] == 0xff) || + (cur[6] && vir[6] == 0xff) || (cur[7] && vir[7] == 0xff)) + *ret = 2; + else + *ret = 1; + + } + + *virgin &= ~*current; + + } + +} + +#if defined(__AVX512F__) && defined(__AVX512DQ__) + #define PACK_SIZE 64 +inline u32 skim(const u64 *virgin, const u64 *current, const u64 *current_end) { + + for (; current != current_end; virgin += 8, current += 8) { + + __m512i value = *(__m512i *)current; + __mmask8 mask = _mm512_testn_epi64_mask(value, value); + + /* All bytes are zero. */ + if (mask == 0xff) continue; + + /* Look for nonzero bytes and check for new bits. */ + #define UNROLL(x) \ + if (!(mask & (1 << x)) && classify_word(current[x]) & virgin[x]) return 1 + UNROLL(0); + UNROLL(1); + UNROLL(2); + UNROLL(3); + UNROLL(4); + UNROLL(5); + UNROLL(6); + UNROLL(7); + #undef UNROLL + + } + + return 0; + +} + +#endif + +#if !defined(PACK_SIZE) && defined(__AVX2__) + #define PACK_SIZE 32 +inline u32 skim(const u64 *virgin, const u64 *current, const u64 *current_end) { + + __m256i zeroes = _mm256_setzero_si256(); + + for (; current < current_end; virgin += 4, current += 4) { + + __m256i value = *(__m256i *)current; + __m256i cmp = _mm256_cmpeq_epi64(value, zeroes); + u32 mask = _mm256_movemask_epi8(cmp); + + /* All bytes are zero. */ + if (mask == (u32)-1) continue; + + /* Look for nonzero bytes and check for new bits. */ + if (!(mask & 0xff) && classify_word(current[0]) & virgin[0]) return 1; + if (!(mask & 0xff00) && classify_word(current[1]) & virgin[1]) return 1; + if (!(mask & 0xff0000) && classify_word(current[2]) & virgin[2]) return 1; + if (!(mask & 0xff000000) && classify_word(current[3]) & virgin[3]) return 1; + + } + + return 0; + +} + +#endif + +#if !defined(PACK_SIZE) + #define PACK_SIZE 32 +inline u32 skim(const u64 *virgin, const u64 *current, const u64 *current_end) { + + for (; current < current_end; virgin += 4, current += 4) { + + if (current[0] && classify_word(current[0]) & virgin[0]) return 1; + if (current[1] && classify_word(current[1]) & virgin[1]) return 1; + if (current[2] && classify_word(current[2]) & virgin[2]) return 1; + if (current[3] && classify_word(current[3]) & virgin[3]) return 1; + + } + + return 0; + +} + +#endif + diff --git a/include/debug.h b/include/debug.h index d1bd971b..fc1f39cb 100644 --- a/include/debug.h +++ b/include/debug.h @@ -28,11 +28,6 @@ #include "types.h" #include "config.h" -/* __FUNCTION__ is non-iso */ -#ifdef __func__ - #define __FUNCTION__ __func__ -#endif - /******************* * Terminal colors * *******************/ @@ -173,12 +168,84 @@ * Debug & error macros * ************************/ -/* Just print stuff to the appropriate stream. */ +#if defined USE_COLOR && !defined ALWAYS_COLORED + #include <unistd.h> + #pragma GCC diagnostic ignored "-Wformat-security" +static inline const char *colorfilter(const char *x) { + + static int once = 1; + static int disabled = 0; + + if (once) { + + /* when there is no tty -> we always want filtering + * when AFL_NO_UI is set filtering depends on AFL_NO_COLOR + * otherwise we want always colors + */ + disabled = + isatty(2) && (!getenv("AFL_NO_UI") || + (!getenv("AFL_NO_COLOR") && !getenv("AFL_NO_COLOUR"))); + once = 0; + + } + + if (likely(disabled)) return x; + + static char monochromestring[4096]; + char * d = monochromestring; + int in_seq = 0; + + while (*x) { + + if (in_seq && *x == 'm') { + + in_seq = 0; + + } else { + + if (!in_seq && *x == '\x1b') { in_seq = 1; } + if (!in_seq) { *d++ = *x; } + } + + ++x; + + } + + *d = '\0'; + return monochromestring; + +} + +#else + #define colorfilter(x) x /* no filtering necessary */ +#endif + +/* macro magic to transform the first parameter to SAYF + * through colorfilter which strips coloring */ +#define GET_MACRO(_1, _2, _3, _4, _5, _6, _7, _8, _9, _10, _11, _12, _13, _14, \ + _15, _16, _17, _18, _19, _20, _21, _22, _23, _24, _25, _26, \ + _27, _28, _29, _30, _31, _32, _33, _34, _35, _36, _37, _38, \ + _39, _40, NAME, ...) \ + NAME + +#define SAYF(...) \ + GET_MACRO(__VA_ARGS__, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, \ + SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, \ + SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, \ + SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, \ + SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, SAYF_N, \ + SAYF_N, SAYF_1) \ + (__VA_ARGS__) + +#define SAYF_1(x) MY_SAYF(colorfilter(x)) +#define SAYF_N(x, ...) MY_SAYF(colorfilter(x), __VA_ARGS__) + +/* Just print stuff to the appropriate stream. */ #ifdef MESSAGES_TO_STDOUT - #define SAYF(x...) printf(x) + #define MY_SAYF(x...) printf(x) #else - #define SAYF(x...) fprintf(stderr, x) + #define MY_SAYF(x...) fprintf(stderr, x) #endif /* ^MESSAGES_TO_STDOUT */ /* Show a prefixed warning. */ @@ -223,43 +290,43 @@ /* Die with a verbose non-OS fatal error message. */ -#define FATAL(x...) \ - do { \ - \ - SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD \ - "\n[-] PROGRAM ABORT : " cRST x); \ - SAYF(cLRD "\n Location : " cRST "%s(), %s:%u\n\n", __FUNCTION__, \ - __FILE__, __LINE__); \ - exit(1); \ - \ +#define FATAL(x...) \ + do { \ + \ + SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD \ + "\n[-] PROGRAM ABORT : " cRST x); \ + SAYF(cLRD "\n Location : " cRST "%s(), %s:%u\n\n", __func__, \ + __FILE__, (u32)__LINE__); \ + exit(1); \ + \ } while (0) /* Die by calling abort() to provide a core dump. */ -#define ABORT(x...) \ - do { \ - \ - SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD \ - "\n[-] PROGRAM ABORT : " cRST x); \ - SAYF(cLRD "\n Stop location : " cRST "%s(), %s:%u\n\n", __FUNCTION__, \ - __FILE__, __LINE__); \ - abort(); \ - \ +#define ABORT(x...) \ + do { \ + \ + SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD \ + "\n[-] PROGRAM ABORT : " cRST x); \ + SAYF(cLRD "\n Stop location : " cRST "%s(), %s:%u\n\n", __func__, \ + __FILE__, (u32)__LINE__); \ + abort(); \ + \ } while (0) /* Die while also including the output of perror(). */ -#define PFATAL(x...) \ - do { \ - \ - fflush(stdout); \ - SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD \ - "\n[-] SYSTEM ERROR : " cRST x); \ - SAYF(cLRD "\n Stop location : " cRST "%s(), %s:%u\n", __FUNCTION__, \ - __FILE__, __LINE__); \ - SAYF(cLRD " OS message : " cRST "%s\n", strerror(errno)); \ - exit(1); \ - \ +#define PFATAL(x...) \ + do { \ + \ + fflush(stdout); \ + SAYF(bSTOP RESET_G1 CURSOR_SHOW cRST cLRD \ + "\n[-] SYSTEM ERROR : " cRST x); \ + SAYF(cLRD "\n Stop location : " cRST "%s(), %s:%u\n", __func__, \ + __FILE__, (u32)__LINE__); \ + SAYF(cLRD " OS message : " cRST "%s\n", strerror(errno)); \ + exit(1); \ + \ } while (0) /* Die with FATAL() or PFATAL() depending on the value of res (used to @@ -275,22 +342,34 @@ \ } while (0) +/* Show a prefixed debug output. */ + +#define DEBUGF(x...) \ + do { \ + \ + fprintf(stderr, cMGN "[D] " cBRI "DEBUG: " cRST x); \ + fprintf(stderr, cRST ""); \ + \ + } while (0) + /* Error-checking versions of read() and write() that call RPFATAL() as appropriate. */ -#define ck_write(fd, buf, len, fn) \ - do { \ - \ - u32 _len = (len); \ - s32 _res = write(fd, buf, _len); \ - if (_res != _len) RPFATAL(_res, "Short write to %s", fn); \ - \ +#define ck_write(fd, buf, len, fn) \ + do { \ + \ + int _fd = (fd); \ + \ + s32 _len = (s32)(len); \ + s32 _res = write(_fd, (buf), _len); \ + if (_res != _len) RPFATAL(_res, "Short write to %s, fd %d", fn, _fd); \ + \ } while (0) #define ck_read(fd, buf, len, fn) \ do { \ \ - u32 _len = (len); \ + s32 _len = (s32)(len); \ s32 _res = read(fd, buf, _len); \ if (_res != _len) RPFATAL(_res, "Short read from %s", fn); \ \ diff --git a/include/envs.h b/include/envs.h index c1c7d387..cfd73b68 100644 --- a/include/envs.h +++ b/include/envs.h @@ -6,6 +6,7 @@ static char *afl_environment_deprecated[] = { "AFL_LLVM_WHITELIST", "AFL_GCC_WHITELIST", + "AFL_DEBUG_CHILD_OUTPUT", "AFL_DEFER_FORKSRV", "AFL_POST_LIBRARY", "AFL_PERSISTENT", @@ -27,32 +28,45 @@ static char *afl_environment_variables[] = { "AFL_CC", "AFL_CMIN_ALLOW_ANY", "AFL_CMIN_CRASHES_ONLY", + "AFL_CMPLOG_ONLY_NEW", "AFL_CODE_END", "AFL_CODE_START", "AFL_COMPCOV_BINNAME", "AFL_COMPCOV_LEVEL", + "AFL_CRASH_EXITCODE", "AFL_CUSTOM_MUTATOR_LIBRARY", "AFL_CUSTOM_MUTATOR_ONLY", "AFL_CXX", "AFL_CYCLE_SCHEDULES", "AFL_DEBUG", - "AFL_DEBUG_CHILD_OUTPUT", + "AFL_DEBUG_CHILD", "AFL_DEBUG_GDB", "AFL_DISABLE_TRIM", "AFL_DONT_OPTIMIZE", + "AFL_DRIVER_STDERR_DUPLICATE_FILENAME", "AFL_DUMB_FORKSRV", "AFL_ENTRYPOINT", "AFL_EXIT_WHEN_DONE", "AFL_FAST_CAL", "AFL_FORCE_UI", + "AFL_FUZZER_ARGS", // oss-fuzz + "AFL_GDB", + "AFL_GCC_ALLOWLIST", + "AFL_GCC_DENYLIST", + "AFL_GCC_BLOCKLIST", "AFL_GCC_INSTRUMENT_FILE", + "AFL_GCC_OUT_OF_LINE", + "AFL_GCC_SKIP_NEVERZERO", "AFL_GCJ", "AFL_HANG_TMOUT", + "AFL_FORKSRV_INIT_TMOUT", "AFL_HARDEN", "AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES", + "AFL_IGNORE_UNKNOWN_ENVS", "AFL_IMPORT_FIRST", "AFL_INST_LIBS", "AFL_INST_RATIO", + "AFL_KILL_SIGNAL", "AFL_KEEP_TRACES", "AFL_KEEP_ASSEMBLY", "AFL_LD_HARD_FAIL", @@ -62,11 +76,18 @@ static char *afl_environment_variables[] = { "AFL_REAL_LD", "AFL_LD_PRELOAD", "AFL_LD_VERBOSE", + "AFL_LLVM_ALLOWLIST", + "AFL_LLVM_DENYLIST", + "AFL_LLVM_BLOCKLIST", "AFL_LLVM_CMPLOG", "AFL_LLVM_INSTRIM", + "AFL_LLVM_CALLER", "AFL_LLVM_CTX", - "AFL_LLVM_INSTRUMENT", + "AFL_LLVM_CTX_K", + "AFL_LLVM_DICT2FILE", + "AFL_LLVM_DOCUMENT_IDS", "AFL_LLVM_INSTRIM_LOOPHEAD", + "AFL_LLVM_INSTRUMENT", "AFL_LLVM_LTO_AUTODICTIONARY", "AFL_LLVM_AUTODICTIONARY", "AFL_LLVM_SKIPSINGLEBLOCK", @@ -88,30 +109,46 @@ static char *afl_environment_variables[] = { "AFL_LLVM_LTO_STARTID", "AFL_LLVM_LTO_DONTWRITEID", "AFL_NO_ARITH", + "AFL_NO_AUTODICT", "AFL_NO_BUILTIN", +#if defined USE_COLOR && !defined ALWAYS_COLORED + "AFL_NO_COLOR", + "AFL_NO_COLOUR", +#endif "AFL_NO_CPU_RED", "AFL_NO_FORKSRV", "AFL_NO_UI", "AFL_NO_PYTHON", "AFL_UNTRACER_FILE", "AFL_LLVM_USE_TRACE_PC", - "AFL_NO_X86", // not really an env but we dont want to warn on it "AFL_MAP_SIZE", "AFL_MAPSIZE", + "AFL_MAX_DET_EXTRAS", + "AFL_NO_X86", // not really an env but we dont want to warn on it + "AFL_NOOPT", + "AFL_PASSTHROUGH", "AFL_PATH", "AFL_PERFORMANCE_FILE", "AFL_PRELOAD", "AFL_PYTHON_MODULE", + "AFL_QEMU_CUSTOM_BIN", "AFL_QEMU_COMPCOV", "AFL_QEMU_COMPCOV_DEBUG", "AFL_QEMU_DEBUG_MAPS", "AFL_QEMU_DISABLE_CACHE", + "AFL_QEMU_DRIVER_NO_HOOK", + "AFL_QEMU_FORCE_DFL", "AFL_QEMU_PERSISTENT_ADDR", "AFL_QEMU_PERSISTENT_CNT", "AFL_QEMU_PERSISTENT_GPR", "AFL_QEMU_PERSISTENT_HOOK", + "AFL_QEMU_PERSISTENT_MEM", "AFL_QEMU_PERSISTENT_RET", "AFL_QEMU_PERSISTENT_RETADDR_OFFSET", + "AFL_QEMU_PERSISTENT_EXITS", + "AFL_QEMU_INST_RANGES", + "AFL_QEMU_EXCLUDE_RANGES", + "AFL_QEMU_SNAPSHOT", "AFL_QUIET", "AFL_RANDOM_ALLOC_CANARY", "AFL_REAL_PATH", @@ -119,6 +156,12 @@ static char *afl_environment_variables[] = { "AFL_SKIP_BIN_CHECK", "AFL_SKIP_CPUFREQ", "AFL_SKIP_CRASHES", + "AFL_STATSD", + "AFL_STATSD_HOST", + "AFL_STATSD_PORT", + "AFL_STATSD_TAGS_FLAVOR", + "AFL_TESTCACHE_SIZE", + "AFL_TESTCACHE_ENTRIES", "AFL_TMIN_EXACT", "AFL_TMPDIR", "AFL_TOKEN_FILE", @@ -131,6 +174,7 @@ static char *afl_environment_variables[] = { "AFL_WINE_PATH", "AFL_NO_SNAPSHOT", "AFL_EXPAND_HAVOC_NOW", + "AFL_USE_QASAN", NULL }; diff --git a/include/forkserver.h b/include/forkserver.h index 717493db..ac027f81 100644 --- a/include/forkserver.h +++ b/include/forkserver.h @@ -37,9 +37,7 @@ typedef struct afl_forkserver { /* a program that includes afl-forkserver needs to define these */ - u8 uses_asan; /* Target uses ASAN? */ u8 *trace_bits; /* SHM with instrumentation bitmap */ - u8 use_stdin; /* use stdin for sending data */ s32 fsrv_pid, /* PID of the fork server */ child_pid, /* PID of the fuzzed program */ @@ -53,9 +51,8 @@ typedef struct afl_forkserver { fsrv_ctl_fd, /* Fork server control pipe (write) */ fsrv_st_fd; /* Fork server status pipe (read) */ - u8 no_unlink; /* do not unlink cur_input */ - u32 exec_tmout; /* Configurable exec timeout (ms) */ + u32 init_tmout; /* Configurable init timeout (ms) */ u32 map_size; /* map size used by the target */ u32 snapshot; /* is snapshot feature used */ u64 mem_limit; /* Memory cap for child (MB) */ @@ -67,18 +64,29 @@ typedef struct afl_forkserver { FILE *plot_file; /* Gnuplot output file */ - /* Note: lat_run_timed_out is u32 to send it to the child as 4 byte array */ + /* Note: last_run_timed_out is u32 to send it to the child as 4 byte array */ u32 last_run_timed_out; /* Traced process timed out? */ u8 last_kill_signal; /* Signal that killed the child */ - u8 use_shmem_fuzz; /* use shared mem for test cases */ + bool use_shmem_fuzz; /* use shared mem for test cases */ + + bool support_shmem_fuzz; /* set by afl-fuzz */ + + bool use_fauxsrv; /* Fauxsrv for non-forking targets? */ + + bool qemu_mode; /* if running in qemu mode or not */ - u8 support_shmem_fuzz; /* set by afl-fuzz */ + bool use_stdin; /* use stdin for sending data */ - u8 use_fauxsrv; /* Fauxsrv for non-forking targets? */ + bool no_unlink; /* do not unlink cur_input */ - u8 qemu_mode; /* if running in qemu mode or not */ + bool uses_asan; /* Target uses ASAN? */ + + bool debug; /* debug mode? */ + + bool uses_crash_exitcode; /* Custom crash exitcode specified? */ + u8 crash_exitcode; /* The crash exitcode specified */ u32 *shmem_fuzz_len; /* length of the fuzzing test case */ @@ -89,9 +97,11 @@ typedef struct afl_forkserver { /* Function to kick off the forkserver child */ void (*init_child_func)(struct afl_forkserver *fsrv, char **argv); - u8 *function_opt; /* for autodictionary: afl ptr */ + u8 *afl_ptr; /* for autodictionary: afl ptr */ + + void (*add_extra_func)(void *afl_ptr, u8 *mem, u32 len); - void (*function_ptr)(void *afl_tmp, u8 *mem, u32 len); + u8 kill_signal; } afl_forkserver_t; @@ -110,11 +120,14 @@ void afl_fsrv_init(afl_forkserver_t *fsrv); void afl_fsrv_init_dup(afl_forkserver_t *fsrv_to, afl_forkserver_t *from); void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, volatile u8 *stop_soon_p, u8 debug_child_output); +u32 afl_fsrv_get_mapsize(afl_forkserver_t *fsrv, char **argv, + volatile u8 *stop_soon_p, u8 debug_child_output); void afl_fsrv_write_to_testcase(afl_forkserver_t *fsrv, u8 *buf, size_t len); fsrv_run_result_t afl_fsrv_run_target(afl_forkserver_t *fsrv, u32 timeout, volatile u8 *stop_soon_p); void afl_fsrv_killall(void); void afl_fsrv_deinit(afl_forkserver_t *fsrv); +void afl_fsrv_kill(afl_forkserver_t *fsrv); #ifdef __APPLE__ #define MSG_FORK_ON_APPLE \ diff --git a/include/list.h b/include/list.h index 88cbe062..7ec81cbe 100644 --- a/include/list.h +++ b/include/list.h @@ -81,6 +81,7 @@ static inline void list_append(list_t *list, void *el) { } element_t *el_box = NULL; + PRE_ALLOC(el_box, list->element_prealloc_buf, LIST_PREALLOC_SIZE, list->element_prealloc_count); if (!el_box) { FATAL("failed to allocate list element"); } diff --git a/include/sharedmem.h b/include/sharedmem.h index b15d0535..fdc947f9 100644 --- a/include/sharedmem.h +++ b/include/sharedmem.h @@ -51,6 +51,7 @@ typedef struct sharedmem { size_t map_size; /* actual allocated size */ int cmplog_mode; + int shmemfuzz_mode; struct cmp_map *cmp_map; } sharedmem_t; diff --git a/include/snapshot-inl.h b/include/snapshot-inl.h index a75d69c0..a18187ef 100644 --- a/include/snapshot-inl.h +++ b/include/snapshot-inl.h @@ -66,7 +66,7 @@ struct afl_snapshot_vmrange_args { static int afl_snapshot_dev_fd; -static int afl_snapshot_init() { +static int afl_snapshot_init(void) { afl_snapshot_dev_fd = open(AFL_SNAPSHOT_FILE_NAME, 0); return afl_snapshot_dev_fd; diff --git a/include/types.h b/include/types.h index 39f599a0..7b94fb83 100644 --- a/include/types.h +++ b/include/types.h @@ -25,10 +25,15 @@ #include <stdint.h> #include <stdlib.h> +#include "config.h" typedef uint8_t u8; typedef uint16_t u16; typedef uint32_t u32; +#ifdef WORD_SIZE_64 +typedef unsigned __int128 uint128_t; +typedef uint128_t u128; +#endif /* Extended forkserver option values */ @@ -50,7 +55,7 @@ typedef uint32_t u32; #define FS_OPT_SHDMEM_FUZZ 0x01000000 #define FS_OPT_OLD_AFLPP_WORKAROUND 0x0f000000 // FS_OPT_MAX_MAPSIZE is 8388608 = 0x800000 = 2^23 = 1 << 22 -#define FS_OPT_MAX_MAPSIZE ((0x00fffffe >> 1) + 1) +#define FS_OPT_MAX_MAPSIZE ((0x00fffffeU >> 1) + 1) #define FS_OPT_GET_MAPSIZE(x) (((x & 0x00fffffe) >> 1) + 1) #define FS_OPT_SET_MAPSIZE(x) \ (x <= 1 || x > FS_OPT_MAX_MAPSIZE ? 0 : ((x - 1) << 1)) @@ -61,6 +66,10 @@ typedef int8_t s8; typedef int16_t s16; typedef int32_t s32; typedef int64_t s64; +#ifdef WORD_SIZE_64 +typedef __int128 int128_t; +typedef int128_t s128; +#endif #ifndef MIN #define MIN(a, b) \ @@ -114,6 +123,33 @@ typedef int64_t s64; \ }) +// It is impossible to define 128 bit constants, so ... +#ifdef WORD_SIZE_64 + #define SWAPN(_x, _l) \ + ({ \ + \ + u128 _res = (_x), _ret; \ + char *d = (char *)&_ret, *s = (char *)&_res; \ + int i; \ + for (i = 0; i < 16; i++) \ + d[15 - i] = s[i]; \ + u32 sr = 128U - ((_l) << 3U); \ + (_ret >>= sr); \ + (u128) _ret; \ + \ + }) +#endif + +#define SWAPNN(_x, _y, _l) \ + ({ \ + \ + char *d = (char *)(_x), *s = (char *)(_y); \ + u32 i, l = (_l)-1; \ + for (i = 0; i <= l; i++) \ + d[l - i] = s[i]; \ + \ + }) + #ifdef AFL_LLVM_PASS #if defined(__linux__) || !defined(__ANDROID__) #define AFL_SR(s) (srandom(s)) diff --git a/include/xxh3.h b/include/xxh3.h deleted file mode 100644 index 2354bde9..00000000 --- a/include/xxh3.h +++ /dev/null @@ -1,3187 +0,0 @@ -/* - * xxHash - Extremely Fast Hash algorithm - * Development source file for `xxh3` - * Copyright (C) 2019-2020 Yann Collet - * - * BSD 2-Clause License (https://www.opensource.org/licenses/bsd-license.php) - * - * Redistribution and use in source and binary forms, with or without - * modification, are permitted provided that the following conditions are - * met: - * - * * Redistributions of source code must retain the above copyright - * notice, this list of conditions and the following disclaimer. - * * Redistributions in binary form must reproduce the above - * copyright notice, this list of conditions and the following disclaimer - * in the documentation and/or other materials provided with the - * distribution. - * - * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS - * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT - * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR - * A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT - * OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, - * SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT - * LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, - * DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY - * THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT - * (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE - * OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - * - * You can contact the author at: - * - xxHash homepage: https://www.xxhash.com - * - xxHash source repository: https://github.com/Cyan4973/xxHash - */ - -/* - * Note: This file is separated for development purposes. - * It will be integrated into `xxhash.h` when development stage is completed. - * - * Credit: most of the work on vectorial and asm variants comes from - * @easyaspi314 - */ - -#ifndef XXH3_H_1397135465 -#define XXH3_H_1397135465 - -/* === Dependencies === */ -#ifndef XXHASH_H_5627135585666179 - /* special: when including `xxh3.h` directly, turn on XXH_INLINE_ALL */ - #undef XXH_INLINE_ALL /* avoid redefinition */ - #define XXH_INLINE_ALL -#endif -#include "xxhash.h" - -/* === Compiler specifics === */ - -#if defined(__STDC_VERSION__) && __STDC_VERSION__ >= 199901L /* >= C99 */ - #define XXH_RESTRICT restrict -#else - /* Note: it might be useful to define __restrict or __restrict__ for some C++ - * compilers */ - #define XXH_RESTRICT /* disable */ -#endif - -#if (defined(__GNUC__) && (__GNUC__ >= 3)) || \ - (defined(__INTEL_COMPILER) && (__INTEL_COMPILER >= 800)) || \ - defined(__clang__) - #define XXH_likely(x) __builtin_expect(x, 1) - #define XXH_unlikely(x) __builtin_expect(x, 0) -#else - #define XXH_likely(x) (x) - #define XXH_unlikely(x) (x) -#endif - -#if defined(__GNUC__) - #if defined(__AVX2__) - #include <immintrin.h> - #elif defined(__SSE2__) - #include <emmintrin.h> - #elif defined(__ARM_NEON__) || defined(__ARM_NEON) - #define inline __inline__ /* clang bug */ - #include <arm_neon.h> - #undef inline - #endif -#elif defined(_MSC_VER) - #include <intrin.h> -#endif - -/* - * One goal of XXH3 is to make it fast on both 32-bit and 64-bit, while - * remaining a true 64-bit/128-bit hash function. - * - * This is done by prioritizing a subset of 64-bit operations that can be - * emulated without too many steps on the average 32-bit machine. - * - * For example, these two lines seem similar, and run equally fast on 64-bit: - * - * xxh_u64 x; - * x ^= (x >> 47); // good - * x ^= (x >> 13); // bad - * - * However, to a 32-bit machine, there is a major difference. - * - * x ^= (x >> 47) looks like this: - * - * x.lo ^= (x.hi >> (47 - 32)); - * - * while x ^= (x >> 13) looks like this: - * - * // note: funnel shifts are not usually cheap. - * x.lo ^= (x.lo >> 13) | (x.hi << (32 - 13)); - * x.hi ^= (x.hi >> 13); - * - * The first one is significantly faster than the second, simply because the - * shift is larger than 32. This means: - * - All the bits we need are in the upper 32 bits, so we can ignore the lower - * 32 bits in the shift. - * - The shift result will always fit in the lower 32 bits, and therefore, - * we can ignore the upper 32 bits in the xor. - * - * Thanks to this optimization, XXH3 only requires these features to be - * efficient: - * - * - Usable unaligned access - * - A 32-bit or 64-bit ALU - * - If 32-bit, a decent ADC instruction - * - A 32 or 64-bit multiply with a 64-bit result - * - For the 128-bit variant, a decent byteswap helps short inputs. - * - * The first two are already required by XXH32, and almost all 32-bit and 64-bit - * platforms which can run XXH32 can run XXH3 efficiently. - * - * Thumb-1, the classic 16-bit only subset of ARM's instruction set, is one - * notable exception. - * - * First of all, Thumb-1 lacks support for the UMULL instruction which - * performs the important long multiply. This means numerous __aeabi_lmul - * calls. - * - * Second of all, the 8 functional registers are just not enough. - * Setup for __aeabi_lmul, byteshift loads, pointers, and all arithmetic need - * Lo registers, and this shuffling results in thousands more MOVs than A32. - * - * A32 and T32 don't have this limitation. They can access all 14 registers, - * do a 32->64 multiply with UMULL, and the flexible operand allowing free - * shifts is helpful, too. - * - * Therefore, we do a quick sanity check. - * - * If compiling Thumb-1 for a target which supports ARM instructions, we will - * emit a warning, as it is not a "sane" platform to compile for. - * - * Usually, if this happens, it is because of an accident and you probably need - * to specify -march, as you likely meant to compile for a newer architecture. - */ -#if defined(__thumb__) && !defined(__thumb2__) && defined(__ARM_ARCH_ISA_ARM) - #warning "XXH3 is highly inefficient without ARM or Thumb-2." -#endif - -/* ========================================== - * Vectorization detection - * ========================================== */ -#define XXH_SCALAR 0 /* Portable scalar version */ -#define XXH_SSE2 1 /* SSE2 for Pentium 4 and all x86_64 */ -#define XXH_AVX2 2 /* AVX2 for Haswell and Bulldozer */ -#define XXH_AVX512 3 /* AVX512 for Skylake and Icelake */ -#define XXH_NEON 4 /* NEON for most ARMv7-A and all AArch64 */ -#define XXH_VSX 5 /* VSX and ZVector for POWER8/z13 */ - -#ifndef XXH_VECTOR /* can be defined on command line */ - #if defined(__AVX512F__) - #define XXH_VECTOR XXH_AVX512 - #elif defined(__AVX2__) - #define XXH_VECTOR XXH_AVX2 - #elif defined(__SSE2__) || defined(_M_AMD64) || defined(_M_X64) || \ - (defined(_M_IX86_FP) && (_M_IX86_FP == 2)) - #define XXH_VECTOR XXH_SSE2 - #elif defined(__GNUC__) /* msvc support maybe later */ \ - && (defined(__ARM_NEON__) || defined(__ARM_NEON)) && \ - (defined(__LITTLE_ENDIAN__) /* We only support little endian NEON */ \ - || \ - (defined(__BYTE_ORDER__) && __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__)) - #define XXH_VECTOR XXH_NEON - #elif (defined(__PPC64__) && defined(__POWER8_VECTOR__)) || \ - (defined(__s390x__) && defined(__VEC__)) && \ - defined(__GNUC__) /* TODO: IBM XL */ - #define XXH_VECTOR XXH_VSX - #else - #define XXH_VECTOR XXH_SCALAR - #endif -#endif - -/* - * Controls the alignment of the accumulator, - * for compatibility with aligned vector loads, which are usually faster. - */ -#ifndef XXH_ACC_ALIGN - #if defined(XXH_X86DISPATCH) - #define XXH_ACC_ALIGN 64 /* for compatibility with avx512 */ - #elif XXH_VECTOR == XXH_SCALAR /* scalar */ - #define XXH_ACC_ALIGN 8 - #elif XXH_VECTOR == XXH_SSE2 /* sse2 */ - #define XXH_ACC_ALIGN 16 - #elif XXH_VECTOR == XXH_AVX2 /* avx2 */ - #define XXH_ACC_ALIGN 32 - #elif XXH_VECTOR == XXH_NEON /* neon */ - #define XXH_ACC_ALIGN 16 - #elif XXH_VECTOR == XXH_VSX /* vsx */ - #define XXH_ACC_ALIGN 16 - #elif XXH_VECTOR == XXH_AVX512 /* avx512 */ - #define XXH_ACC_ALIGN 64 - #endif -#endif - -#if defined(XXH_X86DISPATCH) || XXH_VECTOR == XXH_SSE2 || \ - XXH_VECTOR == XXH_AVX2 || XXH_VECTOR == XXH_AVX512 - #define XXH_SEC_ALIGN XXH_ACC_ALIGN -#else - #define XXH_SEC_ALIGN 8 -#endif - -/* - * UGLY HACK: - * GCC usually generates the best code with -O3 for xxHash. - * - * However, when targeting AVX2, it is overzealous in its unrolling resulting - * in code roughly 3/4 the speed of Clang. - * - * There are other issues, such as GCC splitting _mm256_loadu_si256 into - * _mm_loadu_si128 + _mm256_inserti128_si256. This is an optimization which - * only applies to Sandy and Ivy Bridge... which don't even support AVX2. - * - * That is why when compiling the AVX2 version, it is recommended to use either - * -O2 -mavx2 -march=haswell - * or - * -O2 -mavx2 -mno-avx256-split-unaligned-load - * for decent performance, or to use Clang instead. - * - * Fortunately, we can control the first one with a pragma that forces GCC into - * -O2, but the other one we can't control without "failed to inline always - * inline function due to target mismatch" warnings. - */ -#if XXH_VECTOR == XXH_AVX2 /* AVX2 */ \ - && defined(__GNUC__) && !defined(__clang__) /* GCC, not Clang */ \ - && defined(__OPTIMIZE__) && \ - !defined(__OPTIMIZE_SIZE__) /* respect -O0 and -Os */ - #pragma GCC push_options - #pragma GCC optimize("-O2") -#endif - -#if XXH_VECTOR == XXH_NEON - /* - * NEON's setup for vmlal_u32 is a little more complicated than it is on - * SSE2, AVX2, and VSX. - * - * While PMULUDQ and VMULEUW both perform a mask, VMLAL.U32 performs an - * upcast. - * - * To do the same operation, the 128-bit 'Q' register needs to be split into - * two 64-bit 'D' registers, performing this operation:: - * - * [ a | b ] - * | '---------. .--------' | - * | x | - * | .---------' '--------. | - * [ a & 0xFFFFFFFF | b & 0xFFFFFFFF ],[ a >> 32 | b >> 32 ] - * - * Due to significant changes in aarch64, the fastest method for aarch64 is - * completely different than the fastest method for ARMv7-A. - * - * ARMv7-A treats D registers as unions overlaying Q registers, so modifying - * D11 will modify the high half of Q5. This is similar to how modifying AH - * will only affect bits 8-15 of AX on x86. - * - * VZIP takes two registers, and puts even lanes in one register and odd lanes - * in the other. - * - * On ARMv7-A, this strangely modifies both parameters in place instead of - * taking the usual 3-operand form. - * - * Therefore, if we want to do this, we can simply use a D-form VZIP.32 on the - * lower and upper halves of the Q register to end up with the high and low - * halves where we want - all in one instruction. - * - * vzip.32 d10, d11 @ d10 = { d10[0], d11[0] }; d11 = { d10[1], - * d11[1] } - * - * Unfortunately we need inline assembly for this: Instructions modifying two - * registers at once is not possible in GCC or Clang's IR, and they have to - * create a copy. - * - * aarch64 requires a different approach. - * - * In order to make it easier to write a decent compiler for aarch64, many - * quirks were removed, such as conditional execution. - * - * NEON was also affected by this. - * - * aarch64 cannot access the high bits of a Q-form register, and writes to a - * D-form register zero the high bits, similar to how writes to W-form scalar - * registers (or DWORD registers on x86_64) work. - * - * The formerly free vget_high intrinsics now require a vext (with a few - * exceptions) - * - * Additionally, VZIP was replaced by ZIP1 and ZIP2, which are the equivalent - * of PUNPCKL* and PUNPCKH* in SSE, respectively, in order to only modify one - * operand. - * - * The equivalent of the VZIP.32 on the lower and upper halves would be this - * mess: - * - * ext v2.4s, v0.4s, v0.4s, #2 // v2 = { v0[2], v0[3], v0[0], v0[1] } - * zip1 v1.2s, v0.2s, v2.2s // v1 = { v0[0], v2[0] } - * zip2 v0.2s, v0.2s, v1.2s // v0 = { v0[1], v2[1] } - * - * Instead, we use a literal downcast, vmovn_u64 (XTN), and vshrn_n_u64 - * (SHRN): - * - * shrn v1.2s, v0.2d, #32 // v1 = (uint32x2_t)(v0 >> 32); - * xtn v0.2s, v0.2d // v0 = (uint32x2_t)(v0 & 0xFFFFFFFF); - * - * This is available on ARMv7-A, but is less efficient than a single VZIP.32. - */ - - /* - * Function-like macro: - * void XXH_SPLIT_IN_PLACE(uint64x2_t &in, uint32x2_t &outLo, uint32x2_t - * &outHi) - * { - - * outLo = (uint32x2_t)(in & 0xFFFFFFFF); - * outHi = (uint32x2_t)(in >> 32); - * in = UNDEFINED; - * } - */ - #if !defined(XXH_NO_VZIP_HACK) /* define to disable */ \ - && defined(__GNUC__) && !defined(__aarch64__) && !defined(__arm64__) - #define XXH_SPLIT_IN_PLACE(in, outLo, outHi) \ - do { \ - \ - /* Undocumented GCC/Clang operand modifier: %e0 = lower D half, %f0 = \ - * upper D half */ \ - /* https://github.com/gcc-mirror/gcc/blob/38cf91e5/gcc/config/arm/arm.c#L22486 \ - */ \ - /* https://github.com/llvm-mirror/llvm/blob/2c4ca683/lib/Target/ARM/ARMAsmPrinter.cpp#L399 \ - */ \ - __asm__("vzip.32 %e0, %f0" : "+w"(in)); \ - (outLo) = vget_low_u32(vreinterpretq_u32_u64(in)); \ - (outHi) = vget_high_u32(vreinterpretq_u32_u64(in)); \ - \ - } while (0) - - #else - #define XXH_SPLIT_IN_PLACE(in, outLo, outHi) \ - do { \ - \ - (outLo) = vmovn_u64(in); \ - (outHi) = vshrn_n_u64((in), 32); \ - \ - } while (0) - - #endif -#endif /* XXH_VECTOR == XXH_NEON */ - -/* - * VSX and Z Vector helpers. - * - * This is very messy, and any pull requests to clean this up are welcome. - * - * There are a lot of problems with supporting VSX and s390x, due to - * inconsistent intrinsics, spotty coverage, and multiple endiannesses. - */ -#if XXH_VECTOR == XXH_VSX - #if defined(__s390x__) - #include <s390intrin.h> - #else - #include <altivec.h> - #endif - - #undef vector /* Undo the pollution */ - -typedef __vector unsigned long long xxh_u64x2; -typedef __vector unsigned char xxh_u8x16; -typedef __vector unsigned xxh_u32x4; - - #ifndef XXH_VSX_BE - #if defined(__BIG_ENDIAN__) || \ - (defined(__BYTE_ORDER__) && __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__) - #define XXH_VSX_BE 1 - #elif defined(__VEC_ELEMENT_REG_ORDER__) && \ - __VEC_ELEMENT_REG_ORDER__ == __ORDER_BIG_ENDIAN__ - #warning "-maltivec=be is not recommended. Please use native endianness." - #define XXH_VSX_BE 1 - #else - #define XXH_VSX_BE 0 - #endif - #endif /* !defined(XXH_VSX_BE) */ - - #if XXH_VSX_BE - /* A wrapper for POWER9's vec_revb. */ - #if defined(__POWER9_VECTOR__) || (defined(__clang__) && defined(__s390x__)) - #define XXH_vec_revb vec_revb - #else -XXH_FORCE_INLINE xxh_u64x2 XXH_vec_revb(xxh_u64x2 val) { - - xxh_u8x16 const vByteSwap = {0x07, 0x06, 0x05, 0x04, 0x03, 0x02, 0x01, 0x00, - 0x0F, 0x0E, 0x0D, 0x0C, 0x0B, 0x0A, 0x09, 0x08}; - return vec_perm(val, val, vByteSwap); - -} - - #endif - #endif /* XXH_VSX_BE */ - -/* - * Performs an unaligned load and byte swaps it on big endian. - */ -XXH_FORCE_INLINE xxh_u64x2 XXH_vec_loadu(const void *ptr) { - - xxh_u64x2 ret; - memcpy(&ret, ptr, sizeof(xxh_u64x2)); - #if XXH_VSX_BE - ret = XXH_vec_revb(ret); - #endif - return ret; - -} - - /* - * vec_mulo and vec_mule are very problematic intrinsics on PowerPC - * - * These intrinsics weren't added until GCC 8, despite existing for a while, - * and they are endian dependent. Also, their meaning swap depending on - * version. - * */ - #if defined(__s390x__) - /* s390x is always big endian, no issue on this platform */ - #define XXH_vec_mulo vec_mulo - #define XXH_vec_mule vec_mule - #elif defined(__clang__) && XXH_HAS_BUILTIN(__builtin_altivec_vmuleuw) - /* Clang has a better way to control this, we can just use the builtin which - * doesn't swap. */ - #define XXH_vec_mulo __builtin_altivec_vmulouw - #define XXH_vec_mule __builtin_altivec_vmuleuw - #else -/* gcc needs inline assembly */ -/* Adapted from - * https://github.com/google/highwayhash/blob/master/highwayhash/hh_vsx.h. */ -XXH_FORCE_INLINE xxh_u64x2 XXH_vec_mulo(xxh_u32x4 a, xxh_u32x4 b) { - - xxh_u64x2 result; - __asm__("vmulouw %0, %1, %2" : "=v"(result) : "v"(a), "v"(b)); - return result; - -} - -XXH_FORCE_INLINE xxh_u64x2 XXH_vec_mule(xxh_u32x4 a, xxh_u32x4 b) { - - xxh_u64x2 result; - __asm__("vmuleuw %0, %1, %2" : "=v"(result) : "v"(a), "v"(b)); - return result; - -} - - #endif /* XXH_vec_mulo, XXH_vec_mule */ -#endif /* XXH_VECTOR == XXH_VSX */ - -/* prefetch - * can be disabled, by declaring XXH_NO_PREFETCH build macro */ -#if defined(XXH_NO_PREFETCH) - #define XXH_PREFETCH(ptr) (void)(ptr) /* disabled */ -#else - #if defined(_MSC_VER) && \ - (defined(_M_X64) || \ - defined(_M_I86)) /* _mm_prefetch() is not defined outside of x86/x64 */ - #include <mmintrin.h> /* https://msdn.microsoft.com/fr-fr/library/84szxsww(v=vs.90).aspx */ - #define XXH_PREFETCH(ptr) _mm_prefetch((const char *)(ptr), _MM_HINT_T0) - #elif defined(__GNUC__) && \ - ((__GNUC__ >= 4) || ((__GNUC__ == 3) && (__GNUC_MINOR__ >= 1))) - #define XXH_PREFETCH(ptr) \ - __builtin_prefetch((ptr), 0 /* rw==read */, 3 /* locality */) - #else - #define XXH_PREFETCH(ptr) (void)(ptr) /* disabled */ - #endif -#endif /* XXH_NO_PREFETCH */ - -/* ========================================== - * XXH3 default settings - * ========================================== */ - -#define XXH_SECRET_DEFAULT_SIZE 192 /* minimum XXH3_SECRET_SIZE_MIN */ - -#if (XXH_SECRET_DEFAULT_SIZE < XXH3_SECRET_SIZE_MIN) - #error "default keyset is not large enough" -#endif - -/* Pseudorandom secret taken directly from FARSH */ -XXH_ALIGN(64) -static const xxh_u8 XXH3_kSecret[XXH_SECRET_DEFAULT_SIZE] = { - - 0xb8, 0xfe, 0x6c, 0x39, 0x23, 0xa4, 0x4b, 0xbe, 0x7c, 0x01, 0x81, 0x2c, - 0xf7, 0x21, 0xad, 0x1c, 0xde, 0xd4, 0x6d, 0xe9, 0x83, 0x90, 0x97, 0xdb, - 0x72, 0x40, 0xa4, 0xa4, 0xb7, 0xb3, 0x67, 0x1f, 0xcb, 0x79, 0xe6, 0x4e, - 0xcc, 0xc0, 0xe5, 0x78, 0x82, 0x5a, 0xd0, 0x7d, 0xcc, 0xff, 0x72, 0x21, - 0xb8, 0x08, 0x46, 0x74, 0xf7, 0x43, 0x24, 0x8e, 0xe0, 0x35, 0x90, 0xe6, - 0x81, 0x3a, 0x26, 0x4c, 0x3c, 0x28, 0x52, 0xbb, 0x91, 0xc3, 0x00, 0xcb, - 0x88, 0xd0, 0x65, 0x8b, 0x1b, 0x53, 0x2e, 0xa3, 0x71, 0x64, 0x48, 0x97, - 0xa2, 0x0d, 0xf9, 0x4e, 0x38, 0x19, 0xef, 0x46, 0xa9, 0xde, 0xac, 0xd8, - 0xa8, 0xfa, 0x76, 0x3f, 0xe3, 0x9c, 0x34, 0x3f, 0xf9, 0xdc, 0xbb, 0xc7, - 0xc7, 0x0b, 0x4f, 0x1d, 0x8a, 0x51, 0xe0, 0x4b, 0xcd, 0xb4, 0x59, 0x31, - 0xc8, 0x9f, 0x7e, 0xc9, 0xd9, 0x78, 0x73, 0x64, - - 0xea, 0xc5, 0xac, 0x83, 0x34, 0xd3, 0xeb, 0xc3, 0xc5, 0x81, 0xa0, 0xff, - 0xfa, 0x13, 0x63, 0xeb, 0x17, 0x0d, 0xdd, 0x51, 0xb7, 0xf0, 0xda, 0x49, - 0xd3, 0x16, 0x55, 0x26, 0x29, 0xd4, 0x68, 0x9e, 0x2b, 0x16, 0xbe, 0x58, - 0x7d, 0x47, 0xa1, 0xfc, 0x8f, 0xf8, 0xb8, 0xd1, 0x7a, 0xd0, 0x31, 0xce, - 0x45, 0xcb, 0x3a, 0x8f, 0x95, 0x16, 0x04, 0x28, 0xaf, 0xd7, 0xfb, 0xca, - 0xbb, 0x4b, 0x40, 0x7e, - -}; - -#ifdef XXH_OLD_NAMES - #define kSecret XXH3_kSecret -#endif - -/* - * Calculates a 32-bit to 64-bit long multiply. - * - * Wraps __emulu on MSVC x86 because it tends to call __allmul when it doesn't - * need to (but it shouldn't need to anyways, it is about 7 instructions to do - * a 64x64 multiply...). Since we know that this will _always_ emit MULL, we - * use that instead of the normal method. - * - * If you are compiling for platforms like Thumb-1 and don't have a better - * option, you may also want to write your own long multiply routine here. - * - * XXH_FORCE_INLINE xxh_u64 XXH_mult32to64(xxh_u64 x, xxh_u64 y) - * { - - * return (x & 0xFFFFFFFF) * (y & 0xFFFFFFFF); - * } - */ -#if defined(_MSC_VER) && defined(_M_IX86) - #include <intrin.h> - #define XXH_mult32to64(x, y) __emulu((unsigned)(x), (unsigned)(y)) -#else - /* - * Downcast + upcast is usually better than masking on older compilers like - * GCC 4.2 (especially 32-bit ones), all without affecting newer compilers. - * - * The other method, (x & 0xFFFFFFFF) * (y & 0xFFFFFFFF), will AND both - * operands and perform a full 64x64 multiply -- entirely redundant on 32-bit. - */ - #define XXH_mult32to64(x, y) ((xxh_u64)(xxh_u32)(x) * (xxh_u64)(xxh_u32)(y)) -#endif - -/* - * Calculates a 64->128-bit long multiply. - * - * Uses __uint128_t and _umul128 if available, otherwise uses a scalar version. - */ -static XXH128_hash_t XXH_mult64to128(xxh_u64 lhs, xxh_u64 rhs) { - - /* - * GCC/Clang __uint128_t method. - * - * On most 64-bit targets, GCC and Clang define a __uint128_t type. - * This is usually the best way as it usually uses a native long 64-bit - * multiply, such as MULQ on x86_64 or MUL + UMULH on aarch64. - * - * Usually. - * - * Despite being a 32-bit platform, Clang (and emscripten) define this type - * despite not having the arithmetic for it. This results in a laggy - * compiler builtin call which calculates a full 128-bit multiply. - * In that case it is best to use the portable one. - * https://github.com/Cyan4973/xxHash/issues/211#issuecomment-515575677 - */ -#if defined(__GNUC__) && !defined(__wasm__) && defined(__SIZEOF_INT128__) || \ - (defined(_INTEGRAL_MAX_BITS) && _INTEGRAL_MAX_BITS >= 128) - - __uint128_t const product = (__uint128_t)lhs * (__uint128_t)rhs; - XXH128_hash_t r128; - r128.low64 = (xxh_u64)(product); - r128.high64 = (xxh_u64)(product >> 64); - return r128; - - /* - * MSVC for x64's _umul128 method. - * - * xxh_u64 _umul128(xxh_u64 Multiplier, xxh_u64 Multiplicand, xxh_u64 - * *HighProduct); - * - * This compiles to single operand MUL on x64. - */ -#elif defined(_M_X64) || defined(_M_IA64) - - #ifndef _MSC_VER - #pragma intrinsic(_umul128) - #endif - xxh_u64 product_high; - xxh_u64 const product_low = _umul128(lhs, rhs, &product_high); - XXH128_hash_t r128; - r128.low64 = product_low; - r128.high64 = product_high; - return r128; - -#else - /* - * Portable scalar method. Optimized for 32-bit and 64-bit ALUs. - * - * This is a fast and simple grade school multiply, which is shown below - * with base 10 arithmetic instead of base 0x100000000. - * - * 9 3 // D2 lhs = 93 - * x 7 5 // D2 rhs = 75 - * ---------- - * 1 5 // D2 lo_lo = (93 % 10) * (75 % 10) = 15 - * 4 5 | // D2 hi_lo = (93 / 10) * (75 % 10) = 45 - * 2 1 | // D2 lo_hi = (93 % 10) * (75 / 10) = 21 - * + 6 3 | | // D2 hi_hi = (93 / 10) * (75 / 10) = 63 - * --------- - * 2 7 | // D2 cross = (15 / 10) + (45 % 10) + 21 = 27 - * + 6 7 | | // D2 upper = (27 / 10) + (45 / 10) + 63 = 67 - * --------- - * 6 9 7 5 // D4 res = (27 * 10) + (15 % 10) + (67 * 100) = 6975 - * - * The reasons for adding the products like this are: - * 1. It avoids manual carry tracking. Just like how - * (9 * 9) + 9 + 9 = 99, the same applies with this for UINT64_MAX. - * This avoids a lot of complexity. - * - * 2. It hints for, and on Clang, compiles to, the powerful UMAAL - * instruction available in ARM's Digital Signal Processing extension - * in 32-bit ARMv6 and later, which is shown below: - * - * void UMAAL(xxh_u32 *RdLo, xxh_u32 *RdHi, xxh_u32 Rn, xxh_u32 Rm) - * { - - * xxh_u64 product = (xxh_u64)*RdLo * (xxh_u64)*RdHi + Rn + Rm; - * *RdLo = (xxh_u32)(product & 0xFFFFFFFF); - * *RdHi = (xxh_u32)(product >> 32); - * } - * - * This instruction was designed for efficient long multiplication, and - * allows this to be calculated in only 4 instructions at speeds - * comparable to some 64-bit ALUs. - * - * 3. It isn't terrible on other platforms. Usually this will be a couple - * of 32-bit ADD/ADCs. - */ - - /* First calculate all of the cross products. */ - xxh_u64 const lo_lo = XXH_mult32to64(lhs & 0xFFFFFFFF, rhs & 0xFFFFFFFF); - xxh_u64 const hi_lo = XXH_mult32to64(lhs >> 32, rhs & 0xFFFFFFFF); - xxh_u64 const lo_hi = XXH_mult32to64(lhs & 0xFFFFFFFF, rhs >> 32); - xxh_u64 const hi_hi = XXH_mult32to64(lhs >> 32, rhs >> 32); - - /* Now add the products together. These will never overflow. */ - xxh_u64 const cross = (lo_lo >> 32) + (hi_lo & 0xFFFFFFFF) + lo_hi; - xxh_u64 const upper = (hi_lo >> 32) + (cross >> 32) + hi_hi; - xxh_u64 const lower = (cross << 32) | (lo_lo & 0xFFFFFFFF); - - XXH128_hash_t r128; - r128.low64 = lower; - r128.high64 = upper; - return r128; -#endif - -} - -/* - * Does a 64-bit to 128-bit multiply, then XOR folds it. - * - * The reason for the separate function is to prevent passing too many structs - * around by value. This will hopefully inline the multiply, but we don't force - * it. - */ -static xxh_u64 XXH3_mul128_fold64(xxh_u64 lhs, xxh_u64 rhs) { - - XXH128_hash_t product = XXH_mult64to128(lhs, rhs); - return product.low64 ^ product.high64; - -} - -/* Seems to produce slightly better code on GCC for some reason. */ -XXH_FORCE_INLINE xxh_u64 XXH_xorshift64(xxh_u64 v64, int shift) { - - XXH_ASSERT(0 <= shift && shift < 64); - return v64 ^ (v64 >> shift); - -} - -/* - * We don't need to (or want to) mix as much as XXH64. - * - * Short hashes are more evenly distributed, so it isn't necessary. - */ -static XXH64_hash_t XXH3_avalanche(xxh_u64 h64) { - - h64 = XXH_xorshift64(h64, 37); - h64 *= 0x165667919E3779F9ULL; - h64 = XXH_xorshift64(h64, 32); - return h64; - -} - -/* ========================================== - * Short keys - * ========================================== - * One of the shortcomings of XXH32 and XXH64 was that their performance was - * sub-optimal on short lengths. It used an iterative algorithm which strongly - * favored lengths that were a multiple of 4 or 8. - * - * Instead of iterating over individual inputs, we use a set of single shot - * functions which piece together a range of lengths and operate in constant - * time. - * - * Additionally, the number of multiplies has been significantly reduced. This - * reduces latency, especially when emulating 64-bit multiplies on 32-bit. - * - * Depending on the platform, this may or may not be faster than XXH32, but it - * is almost guaranteed to be faster than XXH64. - */ - -/* - * At very short lengths, there isn't enough input to fully hide secrets, or use - * the entire secret. - * - * There is also only a limited amount of mixing we can do before significantly - * impacting performance. - * - * Therefore, we use different sections of the secret and always mix two secret - * samples with an XOR. This should have no effect on performance on the - * seedless or withSeed variants because everything _should_ be constant folded - * by modern compilers. - * - * The XOR mixing hides individual parts of the secret and increases entropy. - * - * This adds an extra layer of strength for custom secrets. - */ -XXH_FORCE_INLINE XXH64_hash_t XXH3_len_1to3_64b(const xxh_u8 *input, size_t len, - const xxh_u8 *secret, - XXH64_hash_t seed) { - - XXH_ASSERT(input != NULL); - XXH_ASSERT(1 <= len && len <= 3); - XXH_ASSERT(secret != NULL); - /* - * len = 1: combined = { input[0], 0x01, input[0], input[0] } - * len = 2: combined = { input[1], 0x02, input[0], input[1] } - * len = 3: combined = { input[2], 0x03, input[0], input[1] } - */ - { - - xxh_u8 const c1 = input[0]; - xxh_u8 const c2 = input[len >> 1]; - xxh_u8 const c3 = input[len - 1]; - xxh_u32 const combined = ((xxh_u32)c1 << 16) | ((xxh_u32)c2 << 24) | - ((xxh_u32)c3 << 0) | ((xxh_u32)len << 8); - xxh_u64 const bitflip = - (XXH_readLE32(secret) ^ XXH_readLE32(secret + 4)) + seed; - xxh_u64 const keyed = (xxh_u64)combined ^ bitflip; - xxh_u64 const mixed = keyed * XXH_PRIME64_1; - return XXH3_avalanche(mixed); - - } - -} - -XXH_FORCE_INLINE XXH64_hash_t XXH3_len_4to8_64b(const xxh_u8 *input, size_t len, - const xxh_u8 *secret, - XXH64_hash_t seed) { - - XXH_ASSERT(input != NULL); - XXH_ASSERT(secret != NULL); - XXH_ASSERT(4 <= len && len < 8); - seed ^= (xxh_u64)XXH_swap32((xxh_u32)seed) << 32; - { - - xxh_u32 const input1 = XXH_readLE32(input); - xxh_u32 const input2 = XXH_readLE32(input + len - 4); - xxh_u64 const bitflip = - (XXH_readLE64(secret + 8) ^ XXH_readLE64(secret + 16)) - seed; - xxh_u64 const input64 = input2 + (((xxh_u64)input1) << 32); - xxh_u64 x = input64 ^ bitflip; - /* this mix is inspired by Pelle Evensen's rrmxmx */ - x ^= XXH_rotl64(x, 49) ^ XXH_rotl64(x, 24); - x *= 0x9FB21C651E98DF25ULL; - x ^= (x >> 35) + len; - x *= 0x9FB21C651E98DF25ULL; - return XXH_xorshift64(x, 28); - - } - -} - -XXH_FORCE_INLINE XXH64_hash_t XXH3_len_9to16_64b(const xxh_u8 *input, - size_t len, - const xxh_u8 *secret, - XXH64_hash_t seed) { - - XXH_ASSERT(input != NULL); - XXH_ASSERT(secret != NULL); - XXH_ASSERT(8 <= len && len <= 16); - { - - xxh_u64 const bitflip1 = - (XXH_readLE64(secret + 24) ^ XXH_readLE64(secret + 32)) + seed; - xxh_u64 const bitflip2 = - (XXH_readLE64(secret + 40) ^ XXH_readLE64(secret + 48)) - seed; - xxh_u64 const input_lo = XXH_readLE64(input) ^ bitflip1; - xxh_u64 const input_hi = XXH_readLE64(input + len - 8) ^ bitflip2; - xxh_u64 const acc = len + XXH_swap64(input_lo) + input_hi + - XXH3_mul128_fold64(input_lo, input_hi); - return XXH3_avalanche(acc); - - } - -} - -XXH_FORCE_INLINE XXH64_hash_t XXH3_len_0to16_64b(const xxh_u8 *input, - size_t len, - const xxh_u8 *secret, - XXH64_hash_t seed) { - - XXH_ASSERT(len <= 16); - { - - if (XXH_likely(len > 8)) - return XXH3_len_9to16_64b(input, len, secret, seed); - if (XXH_likely(len >= 4)) - return XXH3_len_4to8_64b(input, len, secret, seed); - if (len) return XXH3_len_1to3_64b(input, len, secret, seed); - return XXH3_avalanche((XXH_PRIME64_1 + seed) ^ (XXH_readLE64(secret + 56) ^ - XXH_readLE64(secret + 64))); - - } - -} - -/* - * DISCLAIMER: There are known *seed-dependent* multicollisions here due to - * multiplication by zero, affecting hashes of lengths 17 to 240. - * - * However, they are very unlikely. - * - * Keep this in mind when using the unseeded XXH3_64bits() variant: As with all - * unseeded non-cryptographic hashes, it does not attempt to defend itself - * against specially crafted inputs, only random inputs. - * - * Compared to classic UMAC where a 1 in 2^31 chance of 4 consecutive bytes - * cancelling out the secret is taken an arbitrary number of times (addressed - * in XXH3_accumulate_512), this collision is very unlikely with random inputs - * and/or proper seeding: - * - * This only has a 1 in 2^63 chance of 8 consecutive bytes cancelling out, in a - * function that is only called up to 16 times per hash with up to 240 bytes of - * input. - * - * This is not too bad for a non-cryptographic hash function, especially with - * only 64 bit outputs. - * - * The 128-bit variant (which trades some speed for strength) is NOT affected - * by this, although it is always a good idea to use a proper seed if you care - * about strength. - */ -XXH_FORCE_INLINE xxh_u64 XXH3_mix16B(const xxh_u8 *XXH_RESTRICT input, - const xxh_u8 *XXH_RESTRICT secret, - xxh_u64 seed64) { - -#if defined(__GNUC__) && !defined(__clang__) /* GCC, not Clang */ \ - && defined(__i386__) && defined(__SSE2__) /* x86 + SSE2 */ \ - && \ - !defined(XXH_ENABLE_AUTOVECTORIZE) /* Define to disable like XXH32 hack */ - /* - * UGLY HACK: - * GCC for x86 tends to autovectorize the 128-bit multiply, resulting in - * slower code. - * - * By forcing seed64 into a register, we disrupt the cost model and - * cause it to scalarize. See `XXH32_round()` - * - * FIXME: Clang's output is still _much_ faster -- On an AMD Ryzen 3600, - * XXH3_64bits @ len=240 runs at 4.6 GB/s with Clang 9, but 3.3 GB/s on - * GCC 9.2, despite both emitting scalar code. - * - * GCC generates much better scalar code than Clang for the rest of XXH3, - * which is why finding a more optimal codepath is an interest. - */ - __asm__("" : "+r"(seed64)); -#endif - { - - xxh_u64 const input_lo = XXH_readLE64(input); - xxh_u64 const input_hi = XXH_readLE64(input + 8); - return XXH3_mul128_fold64(input_lo ^ (XXH_readLE64(secret) + seed64), - input_hi ^ (XXH_readLE64(secret + 8) - seed64)); - - } - -} - -/* For mid range keys, XXH3 uses a Mum-hash variant. */ -XXH_FORCE_INLINE XXH64_hash_t XXH3_len_17to128_64b( - const xxh_u8 *XXH_RESTRICT input, size_t len, - const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, XXH64_hash_t seed) { - - XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); - (void)secretSize; - XXH_ASSERT(16 < len && len <= 128); - - { - - xxh_u64 acc = len * XXH_PRIME64_1; - if (len > 32) { - - if (len > 64) { - - if (len > 96) { - - acc += XXH3_mix16B(input + 48, secret + 96, seed); - acc += XXH3_mix16B(input + len - 64, secret + 112, seed); - - } - - acc += XXH3_mix16B(input + 32, secret + 64, seed); - acc += XXH3_mix16B(input + len - 48, secret + 80, seed); - - } - - acc += XXH3_mix16B(input + 16, secret + 32, seed); - acc += XXH3_mix16B(input + len - 32, secret + 48, seed); - - } - - acc += XXH3_mix16B(input + 0, secret + 0, seed); - acc += XXH3_mix16B(input + len - 16, secret + 16, seed); - - return XXH3_avalanche(acc); - - } - -} - -#define XXH3_MIDSIZE_MAX 240 - -XXH_NO_INLINE XXH64_hash_t XXH3_len_129to240_64b( - const xxh_u8 *XXH_RESTRICT input, size_t len, - const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, XXH64_hash_t seed) { - - XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); - (void)secretSize; - XXH_ASSERT(128 < len && len <= XXH3_MIDSIZE_MAX); - -#define XXH3_MIDSIZE_STARTOFFSET 3 -#define XXH3_MIDSIZE_LASTOFFSET 17 - - { - - xxh_u64 acc = len * XXH_PRIME64_1; - int const nbRounds = (int)len / 16; - int i; - for (i = 0; i < 8; i++) { - - acc += XXH3_mix16B(input + (16 * i), secret + (16 * i), seed); - - } - - acc = XXH3_avalanche(acc); - XXH_ASSERT(nbRounds >= 8); -#if defined(__clang__) /* Clang */ \ - && (defined(__ARM_NEON) || defined(__ARM_NEON__)) /* NEON */ \ - && !defined(XXH_ENABLE_AUTOVECTORIZE) /* Define to disable */ - /* - * UGLY HACK: - * Clang for ARMv7-A tries to vectorize this loop, similar to GCC x86. - * In everywhere else, it uses scalar code. - * - * For 64->128-bit multiplies, even if the NEON was 100% optimal, it - * would still be slower than UMAAL (see XXH_mult64to128). - * - * Unfortunately, Clang doesn't handle the long multiplies properly and - * converts them to the nonexistent "vmulq_u64" intrinsic, which is then - * scalarized into an ugly mess of VMOV.32 instructions. - * - * This mess is difficult to avoid without turning autovectorization - * off completely, but they are usually relatively minor and/or not - * worth it to fix. - * - * This loop is the easiest to fix, as unlike XXH32, this pragma - * _actually works_ because it is a loop vectorization instead of an - * SLP vectorization. - */ - #pragma clang loop vectorize(disable) -#endif - for (i = 8; i < nbRounds; i++) { - - acc += - XXH3_mix16B(input + (16 * i), - secret + (16 * (i - 8)) + XXH3_MIDSIZE_STARTOFFSET, seed); - - } - - /* last bytes */ - acc += XXH3_mix16B(input + len - 16, - secret + XXH3_SECRET_SIZE_MIN - XXH3_MIDSIZE_LASTOFFSET, - seed); - return XXH3_avalanche(acc); - - } - -} - -/* ======= Long Keys ======= */ - -#define XXH_STRIPE_LEN 64 -#define XXH_SECRET_CONSUME_RATE \ - 8 /* nb of secret bytes consumed at each accumulation */ -#define XXH_ACC_NB (XXH_STRIPE_LEN / sizeof(xxh_u64)) - -#ifdef XXH_OLD_NAMES - #define STRIPE_LEN XXH_STRIPE_LEN - #define ACC_NB XXH_ACC_NB -#endif - -typedef enum { XXH3_acc_64bits, XXH3_acc_128bits } XXH3_accWidth_e; - -XXH_FORCE_INLINE void XXH_writeLE64(void *dst, xxh_u64 v64) { - - if (!XXH_CPU_LITTLE_ENDIAN) v64 = XXH_swap64(v64); - memcpy(dst, &v64, sizeof(v64)); - -} - -/* Several intrinsic functions below are supposed to accept __int64 as argument, - * as documented in - * https://software.intel.com/sites/landingpage/IntrinsicsGuide/ . However, - * several environments do not define __int64 type, requiring a workaround. - */ -#if !defined(__VMS) && \ - (defined(__cplusplus) || \ - (defined(__STDC_VERSION__) && (__STDC_VERSION__ >= 199901L) /* C99 */)) -typedef int64_t xxh_i64; -#else -/* the following type must have a width of 64-bit */ -typedef long long xxh_i64; -#endif - -/* - * XXH3_accumulate_512 is the tightest loop for long inputs, and it is the most - * optimized. - * - * It is a hardened version of UMAC, based off of FARSH's implementation. - * - * This was chosen because it adapts quite well to 32-bit, 64-bit, and SIMD - * implementations, and it is ridiculously fast. - * - * We harden it by mixing the original input to the accumulators as well as the - * product. - * - * This means that in the (relatively likely) case of a multiply by zero, the - * original input is preserved. - * - * On 128-bit inputs, we swap 64-bit pairs when we add the input to improve - * cross-pollination, as otherwise the upper and lower halves would be - * essentially independent. - * - * This doesn't matter on 64-bit hashes since they all get merged together in - * the end, so we skip the extra step. - * - * Both XXH3_64bits and XXH3_128bits use this subroutine. - */ - -#if (XXH_VECTOR == XXH_AVX512) || defined(XXH_X86DISPATCH) - - #ifndef XXH_TARGET_AVX512 - #define XXH_TARGET_AVX512 /* disable attribute target */ - #endif - -XXH_FORCE_INLINE XXH_TARGET_AVX512 void XXH3_accumulate_512_avx512( - void *XXH_RESTRICT acc, const void *XXH_RESTRICT input, - const void *XXH_RESTRICT secret, XXH3_accWidth_e accWidth) { - - XXH_ALIGN(64) __m512i *const xacc = (__m512i *)acc; - XXH_ASSERT((((size_t)acc) & 63) == 0); - XXH_STATIC_ASSERT(XXH_STRIPE_LEN == sizeof(__m512i)); - - { - - /* data_vec = input[0]; */ - __m512i const data_vec = _mm512_loadu_si512(input); - /* key_vec = secret[0]; */ - __m512i const key_vec = _mm512_loadu_si512(secret); - /* data_key = data_vec ^ key_vec; */ - __m512i const data_key = _mm512_xor_si512(data_vec, key_vec); - /* data_key_lo = data_key >> 32; */ - __m512i const data_key_lo = - _mm512_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); - /* product = (data_key & 0xffffffff) * (data_key_lo & 0xffffffff); */ - __m512i const product = _mm512_mul_epu32(data_key, data_key_lo); - if (accWidth == XXH3_acc_128bits) { - - /* xacc[0] += swap(data_vec); */ - __m512i const data_swap = - _mm512_shuffle_epi32(data_vec, _MM_SHUFFLE(1, 0, 3, 2)); - __m512i const sum = _mm512_add_epi64(*xacc, data_swap); - /* xacc[0] += product; */ - *xacc = _mm512_add_epi64(product, sum); - - } else { /* XXH3_acc_64bits */ - - /* xacc[0] += data_vec; */ - __m512i const sum = _mm512_add_epi64(*xacc, data_vec); - /* xacc[0] += product; */ - *xacc = _mm512_add_epi64(product, sum); - - } - - } - -} - -/* - * XXH3_scrambleAcc: Scrambles the accumulators to improve mixing. - * - * Multiplication isn't perfect, as explained by Google in HighwayHash: - * - * // Multiplication mixes/scrambles bytes 0-7 of the 64-bit result to - * // varying degrees. In descending order of goodness, bytes - * // 3 4 2 5 1 6 0 7 have quality 228 224 164 160 100 96 36 32. - * // As expected, the upper and lower bytes are much worse. - * - * Source: - * https://github.com/google/highwayhash/blob/0aaf66b/highwayhash/hh_avx2.h#L291 - * - * Since our algorithm uses a pseudorandom secret to add some variance into the - * mix, we don't need to (or want to) mix as often or as much as HighwayHash - * does. - * - * This isn't as tight as XXH3_accumulate, but still written in SIMD to avoid - * extraction. - * - * Both XXH3_64bits and XXH3_128bits use this subroutine. - */ - -XXH_FORCE_INLINE XXH_TARGET_AVX512 void XXH3_scrambleAcc_avx512( - void *XXH_RESTRICT acc, const void *XXH_RESTRICT secret) { - - XXH_ASSERT((((size_t)acc) & 63) == 0); - XXH_STATIC_ASSERT(XXH_STRIPE_LEN == sizeof(__m512i)); - { - - XXH_ALIGN(64) __m512i *const xacc = (__m512i *)acc; - const __m512i prime32 = _mm512_set1_epi32((int)XXH_PRIME32_1); - - /* xacc[0] ^= (xacc[0] >> 47) */ - __m512i const acc_vec = *xacc; - __m512i const shifted = _mm512_srli_epi64(acc_vec, 47); - __m512i const data_vec = _mm512_xor_si512(acc_vec, shifted); - /* xacc[0] ^= secret; */ - __m512i const key_vec = _mm512_loadu_si512(secret); - __m512i const data_key = _mm512_xor_si512(data_vec, key_vec); - - /* xacc[0] *= XXH_PRIME32_1; */ - __m512i const data_key_hi = - _mm512_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); - __m512i const prod_lo = _mm512_mul_epu32(data_key, prime32); - __m512i const prod_hi = _mm512_mul_epu32(data_key_hi, prime32); - *xacc = _mm512_add_epi64(prod_lo, _mm512_slli_epi64(prod_hi, 32)); - - } - -} - -XXH_FORCE_INLINE XXH_TARGET_AVX512 void XXH3_initCustomSecret_avx512( - void *XXH_RESTRICT customSecret, xxh_u64 seed64) { - - XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE & 63) == 0); - XXH_STATIC_ASSERT(XXH_SEC_ALIGN == 64); - XXH_ASSERT(((size_t)customSecret & 63) == 0); - (void)(&XXH_writeLE64); - { - - int const nbRounds = XXH_SECRET_DEFAULT_SIZE / sizeof(__m512i); - __m512i const seed = _mm512_mask_set1_epi64( - _mm512_set1_epi64((xxh_i64)seed64), 0xAA, -(xxh_i64)seed64); - - XXH_ALIGN(64) const __m512i *const src = (const __m512i *)XXH3_kSecret; - XXH_ALIGN(64) __m512i *const dest = (__m512i *)customSecret; - int i; - for (i = 0; i < nbRounds; ++i) { - - // GCC has a bug, _mm512_stream_load_si512 accepts 'void*', not 'void - // const*', this will warn "discards ‘const’ qualifier". - union { - - XXH_ALIGN(64) const __m512i *const cp; - XXH_ALIGN(64) void *const p; - - } const remote_const_void = {.cp = src + i}; - - dest[i] = - _mm512_add_epi64(_mm512_stream_load_si512(remote_const_void.p), seed); - - } - - } - -} - -#endif - -#if (XXH_VECTOR == XXH_AVX2) || defined(XXH_X86DISPATCH) - - #ifndef XXH_TARGET_AVX2 - #define XXH_TARGET_AVX2 /* disable attribute target */ - #endif - -XXH_FORCE_INLINE XXH_TARGET_AVX2 void XXH3_accumulate_512_avx2( - void *XXH_RESTRICT acc, const void *XXH_RESTRICT input, - const void *XXH_RESTRICT secret, XXH3_accWidth_e accWidth) { - - XXH_ASSERT((((size_t)acc) & 31) == 0); - { - - XXH_ALIGN(32) __m256i *const xacc = (__m256i *)acc; - /* Unaligned. This is mainly for pointer arithmetic, and because - * _mm256_loadu_si256 requires a const __m256i * pointer for some reason. - */ - const __m256i *const xinput = (const __m256i *)input; - /* Unaligned. This is mainly for pointer arithmetic, and because - * _mm256_loadu_si256 requires a const __m256i * pointer for some reason. */ - const __m256i *const xsecret = (const __m256i *)secret; - - size_t i; - for (i = 0; i < XXH_STRIPE_LEN / sizeof(__m256i); i++) { - - /* data_vec = xinput[i]; */ - __m256i const data_vec = _mm256_loadu_si256(xinput + i); - /* key_vec = xsecret[i]; */ - __m256i const key_vec = _mm256_loadu_si256(xsecret + i); - /* data_key = data_vec ^ key_vec; */ - __m256i const data_key = _mm256_xor_si256(data_vec, key_vec); - /* data_key_lo = data_key >> 32; */ - __m256i const data_key_lo = - _mm256_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); - /* product = (data_key & 0xffffffff) * (data_key_lo & 0xffffffff); */ - __m256i const product = _mm256_mul_epu32(data_key, data_key_lo); - if (accWidth == XXH3_acc_128bits) { - - /* xacc[i] += swap(data_vec); */ - __m256i const data_swap = - _mm256_shuffle_epi32(data_vec, _MM_SHUFFLE(1, 0, 3, 2)); - __m256i const sum = _mm256_add_epi64(xacc[i], data_swap); - /* xacc[i] += product; */ - xacc[i] = _mm256_add_epi64(product, sum); - - } else { /* XXH3_acc_64bits */ - - /* xacc[i] += data_vec; */ - __m256i const sum = _mm256_add_epi64(xacc[i], data_vec); - /* xacc[i] += product; */ - xacc[i] = _mm256_add_epi64(product, sum); - - } - - } - - } - -} - -XXH_FORCE_INLINE XXH_TARGET_AVX2 void XXH3_scrambleAcc_avx2( - void *XXH_RESTRICT acc, const void *XXH_RESTRICT secret) { - - XXH_ASSERT((((size_t)acc) & 31) == 0); - { - - XXH_ALIGN(32) __m256i *const xacc = (__m256i *)acc; - /* Unaligned. This is mainly for pointer arithmetic, and because - * _mm256_loadu_si256 requires a const __m256i * pointer for some reason. */ - const __m256i *const xsecret = (const __m256i *)secret; - const __m256i prime32 = _mm256_set1_epi32((int)XXH_PRIME32_1); - - size_t i; - for (i = 0; i < XXH_STRIPE_LEN / sizeof(__m256i); i++) { - - /* xacc[i] ^= (xacc[i] >> 47) */ - __m256i const acc_vec = xacc[i]; - __m256i const shifted = _mm256_srli_epi64(acc_vec, 47); - __m256i const data_vec = _mm256_xor_si256(acc_vec, shifted); - /* xacc[i] ^= xsecret; */ - __m256i const key_vec = _mm256_loadu_si256(xsecret + i); - __m256i const data_key = _mm256_xor_si256(data_vec, key_vec); - - /* xacc[i] *= XXH_PRIME32_1; */ - __m256i const data_key_hi = - _mm256_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); - __m256i const prod_lo = _mm256_mul_epu32(data_key, prime32); - __m256i const prod_hi = _mm256_mul_epu32(data_key_hi, prime32); - xacc[i] = _mm256_add_epi64(prod_lo, _mm256_slli_epi64(prod_hi, 32)); - - } - - } - -} - -XXH_FORCE_INLINE XXH_TARGET_AVX2 void XXH3_initCustomSecret_avx2( - void *XXH_RESTRICT customSecret, xxh_u64 seed64) { - - XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE & 31) == 0); - XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE / sizeof(__m256i)) == 6); - XXH_STATIC_ASSERT(XXH_SEC_ALIGN <= 64); - (void)(&XXH_writeLE64); - XXH_PREFETCH(customSecret); - { - - __m256i const seed = _mm256_set_epi64x(-(xxh_i64)seed64, (xxh_i64)seed64, - -(xxh_i64)seed64, (xxh_i64)seed64); - - XXH_ALIGN(64) const __m256i *const src = (const __m256i *)XXH3_kSecret; - XXH_ALIGN(64) __m256i * dest = (__m256i *)customSecret; - - #if defined(__GNUC__) || defined(__clang__) - /* - * On GCC & Clang, marking 'dest' as modified will cause the compiler: - * - do not extract the secret from sse registers in the internal loop - * - use less common registers, and avoid pushing these reg into stack - * The asm hack causes Clang to assume that XXH3_kSecretPtr aliases with - * customSecret, and on aarch64, this prevented LDP from merging two - * loads together for free. Putting the loads together before the stores - * properly generates LDP. - */ - __asm__("" : "+r"(dest)); - #endif - - /* GCC -O2 need unroll loop manually */ - dest[0] = _mm256_add_epi64(_mm256_stream_load_si256(src + 0), seed); - dest[1] = _mm256_add_epi64(_mm256_stream_load_si256(src + 1), seed); - dest[2] = _mm256_add_epi64(_mm256_stream_load_si256(src + 2), seed); - dest[3] = _mm256_add_epi64(_mm256_stream_load_si256(src + 3), seed); - dest[4] = _mm256_add_epi64(_mm256_stream_load_si256(src + 4), seed); - dest[5] = _mm256_add_epi64(_mm256_stream_load_si256(src + 5), seed); - - } - -} - -#endif - -#if (XXH_VECTOR == XXH_SSE2) || defined(XXH_X86DISPATCH) - - #ifndef XXH_TARGET_SSE2 - #define XXH_TARGET_SSE2 /* disable attribute target */ - #endif - -XXH_FORCE_INLINE XXH_TARGET_SSE2 void XXH3_accumulate_512_sse2( - void *XXH_RESTRICT acc, const void *XXH_RESTRICT input, - const void *XXH_RESTRICT secret, XXH3_accWidth_e accWidth) { - - /* SSE2 is just a half-scale version of the AVX2 version. */ - XXH_ASSERT((((size_t)acc) & 15) == 0); - { - - XXH_ALIGN(16) __m128i *const xacc = (__m128i *)acc; - /* Unaligned. This is mainly for pointer arithmetic, and because - * _mm_loadu_si128 requires a const __m128i * pointer for some reason. */ - const __m128i *const xinput = (const __m128i *)input; - /* Unaligned. This is mainly for pointer arithmetic, and because - * _mm_loadu_si128 requires a const __m128i * pointer for some reason. */ - const __m128i *const xsecret = (const __m128i *)secret; - - size_t i; - for (i = 0; i < XXH_STRIPE_LEN / sizeof(__m128i); i++) { - - /* data_vec = xinput[i]; */ - __m128i const data_vec = _mm_loadu_si128(xinput + i); - /* key_vec = xsecret[i]; */ - __m128i const key_vec = _mm_loadu_si128(xsecret + i); - /* data_key = data_vec ^ key_vec; */ - __m128i const data_key = _mm_xor_si128(data_vec, key_vec); - /* data_key_lo = data_key >> 32; */ - __m128i const data_key_lo = - _mm_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); - /* product = (data_key & 0xffffffff) * (data_key_lo & 0xffffffff); */ - __m128i const product = _mm_mul_epu32(data_key, data_key_lo); - if (accWidth == XXH3_acc_128bits) { - - /* xacc[i] += swap(data_vec); */ - __m128i const data_swap = - _mm_shuffle_epi32(data_vec, _MM_SHUFFLE(1, 0, 3, 2)); - __m128i const sum = _mm_add_epi64(xacc[i], data_swap); - /* xacc[i] += product; */ - xacc[i] = _mm_add_epi64(product, sum); - - } else { /* XXH3_acc_64bits */ - - /* xacc[i] += data_vec; */ - __m128i const sum = _mm_add_epi64(xacc[i], data_vec); - /* xacc[i] += product; */ - xacc[i] = _mm_add_epi64(product, sum); - - } - - } - - } - -} - -XXH_FORCE_INLINE XXH_TARGET_SSE2 void XXH3_scrambleAcc_sse2( - void *XXH_RESTRICT acc, const void *XXH_RESTRICT secret) { - - XXH_ASSERT((((size_t)acc) & 15) == 0); - { - - XXH_ALIGN(16) __m128i *const xacc = (__m128i *)acc; - /* Unaligned. This is mainly for pointer arithmetic, and because - * _mm_loadu_si128 requires a const __m128i * pointer for some reason. */ - const __m128i *const xsecret = (const __m128i *)secret; - const __m128i prime32 = _mm_set1_epi32((int)XXH_PRIME32_1); - - size_t i; - for (i = 0; i < XXH_STRIPE_LEN / sizeof(__m128i); i++) { - - /* xacc[i] ^= (xacc[i] >> 47) */ - __m128i const acc_vec = xacc[i]; - __m128i const shifted = _mm_srli_epi64(acc_vec, 47); - __m128i const data_vec = _mm_xor_si128(acc_vec, shifted); - /* xacc[i] ^= xsecret[i]; */ - __m128i const key_vec = _mm_loadu_si128(xsecret + i); - __m128i const data_key = _mm_xor_si128(data_vec, key_vec); - - /* xacc[i] *= XXH_PRIME32_1; */ - __m128i const data_key_hi = - _mm_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); - __m128i const prod_lo = _mm_mul_epu32(data_key, prime32); - __m128i const prod_hi = _mm_mul_epu32(data_key_hi, prime32); - xacc[i] = _mm_add_epi64(prod_lo, _mm_slli_epi64(prod_hi, 32)); - - } - - } - -} - -XXH_FORCE_INLINE XXH_TARGET_SSE2 void XXH3_initCustomSecret_sse2( - void *XXH_RESTRICT customSecret, xxh_u64 seed64) { - - XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE & 15) == 0); - (void)(&XXH_writeLE64); - { - - int const nbRounds = XXH_SECRET_DEFAULT_SIZE / sizeof(__m128i); - - #if defined(_MSC_VER) && defined(_M_IX86) && _MSC_VER < 1900 - // MSVC 32bit mode does not support _mm_set_epi64x before 2015 - XXH_ALIGN(16) - const xxh_i64 seed64x2[2] = {(xxh_i64)seed64, -(xxh_i64)seed64}; - __m128i const seed = _mm_load_si128((__m128i const *)seed64x2); - #else - __m128i const seed = _mm_set_epi64x(-(xxh_i64)seed64, (xxh_i64)seed64); - #endif - int i; - - XXH_ALIGN(64) const float *const src = (float const *)XXH3_kSecret; - XXH_ALIGN(XXH_SEC_ALIGN) __m128i *dest = (__m128i *)customSecret; - #if defined(__GNUC__) || defined(__clang__) - /* - * On GCC & Clang, marking 'dest' as modified will cause the compiler: - * - do not extract the secret from sse registers in the internal loop - * - use less common registers, and avoid pushing these reg into stack - */ - __asm__("" : "+r"(dest)); - #endif - - for (i = 0; i < nbRounds; ++i) { - - dest[i] = _mm_add_epi64(_mm_castps_si128(_mm_load_ps(src + i * 4)), seed); - - } - - } - -} - -#endif - -#if (XXH_VECTOR == XXH_NEON) - -XXH_FORCE_INLINE void XXH3_accumulate_512_neon(void *XXH_RESTRICT acc, - const void *XXH_RESTRICT input, - const void *XXH_RESTRICT secret, - XXH3_accWidth_e accWidth) { - - XXH_ASSERT((((size_t)acc) & 15) == 0); - { - - XXH_ALIGN(16) uint64x2_t *const xacc = (uint64x2_t *)acc; - /* We don't use a uint32x4_t pointer because it causes bus errors on ARMv7. - */ - uint8_t const *const xinput = (const uint8_t *)input; - uint8_t const *const xsecret = (const uint8_t *)secret; - - size_t i; - for (i = 0; i < XXH_STRIPE_LEN / sizeof(uint64x2_t); i++) { - - /* data_vec = xinput[i]; */ - uint8x16_t data_vec = vld1q_u8(xinput + (i * 16)); - /* key_vec = xsecret[i]; */ - uint8x16_t key_vec = vld1q_u8(xsecret + (i * 16)); - uint64x2_t data_key; - uint32x2_t data_key_lo, data_key_hi; - if (accWidth == XXH3_acc_64bits) { - - /* xacc[i] += data_vec; */ - xacc[i] = vaddq_u64(xacc[i], vreinterpretq_u64_u8(data_vec)); - - } else { /* XXH3_acc_128bits */ - - /* xacc[i] += swap(data_vec); */ - uint64x2_t const data64 = vreinterpretq_u64_u8(data_vec); - uint64x2_t const swapped = vextq_u64(data64, data64, 1); - xacc[i] = vaddq_u64(xacc[i], swapped); - - } - - /* data_key = data_vec ^ key_vec; */ - data_key = vreinterpretq_u64_u8(veorq_u8(data_vec, key_vec)); - /* data_key_lo = (uint32x2_t) (data_key & 0xFFFFFFFF); - * data_key_hi = (uint32x2_t) (data_key >> 32); - * data_key = UNDEFINED; */ - XXH_SPLIT_IN_PLACE(data_key, data_key_lo, data_key_hi); - /* xacc[i] += (uint64x2_t) data_key_lo * (uint64x2_t) data_key_hi; */ - xacc[i] = vmlal_u32(xacc[i], data_key_lo, data_key_hi); - - } - - } - -} - -XXH_FORCE_INLINE void XXH3_scrambleAcc_neon(void *XXH_RESTRICT acc, - const void *XXH_RESTRICT secret) { - - XXH_ASSERT((((size_t)acc) & 15) == 0); - - { - - uint64x2_t * xacc = (uint64x2_t *)acc; - uint8_t const *xsecret = (uint8_t const *)secret; - uint32x2_t prime = vdup_n_u32(XXH_PRIME32_1); - - size_t i; - for (i = 0; i < XXH_STRIPE_LEN / sizeof(uint64x2_t); i++) { - - /* xacc[i] ^= (xacc[i] >> 47); */ - uint64x2_t acc_vec = xacc[i]; - uint64x2_t shifted = vshrq_n_u64(acc_vec, 47); - uint64x2_t data_vec = veorq_u64(acc_vec, shifted); - - /* xacc[i] ^= xsecret[i]; */ - uint8x16_t key_vec = vld1q_u8(xsecret + (i * 16)); - uint64x2_t data_key = veorq_u64(data_vec, vreinterpretq_u64_u8(key_vec)); - - /* xacc[i] *= XXH_PRIME32_1 */ - uint32x2_t data_key_lo, data_key_hi; - /* data_key_lo = (uint32x2_t) (xacc[i] & 0xFFFFFFFF); - * data_key_hi = (uint32x2_t) (xacc[i] >> 32); - * xacc[i] = UNDEFINED; */ - XXH_SPLIT_IN_PLACE(data_key, data_key_lo, data_key_hi); - { /* - * prod_hi = (data_key >> 32) * XXH_PRIME32_1; - * - * Avoid vmul_u32 + vshll_n_u32 since Clang 6 and 7 will - * incorrectly "optimize" this: - * tmp = vmul_u32(vmovn_u64(a), vmovn_u64(b)); - * shifted = vshll_n_u32(tmp, 32); - * to this: - * tmp = "vmulq_u64"(a, b); // no such thing! - * shifted = vshlq_n_u64(tmp, 32); - * - * However, unlike SSE, Clang lacks a 64-bit multiply routine - * for NEON, and it scalarizes two 64-bit multiplies instead. - * - * vmull_u32 has the same timing as vmul_u32, and it avoids - * this bug completely. - * See https://bugs.llvm.org/show_bug.cgi?id=39967 - */ - uint64x2_t prod_hi = vmull_u32(data_key_hi, prime); - /* xacc[i] = prod_hi << 32; */ - xacc[i] = vshlq_n_u64(prod_hi, 32); - /* xacc[i] += (prod_hi & 0xFFFFFFFF) * XXH_PRIME32_1; */ - xacc[i] = vmlal_u32(xacc[i], data_key_lo, prime); - - } - - } - - } - -} - -#endif - -#if (XXH_VECTOR == XXH_VSX) - -XXH_FORCE_INLINE void XXH3_accumulate_512_vsx(void *XXH_RESTRICT acc, - const void *XXH_RESTRICT input, - const void *XXH_RESTRICT secret, - XXH3_accWidth_e accWidth) { - - xxh_u64x2 *const xacc = (xxh_u64x2 *)acc; /* presumed aligned */ - xxh_u64x2 const *const xinput = - (xxh_u64x2 const *)input; /* no alignment restriction */ - xxh_u64x2 const *const xsecret = - (xxh_u64x2 const *)secret; /* no alignment restriction */ - xxh_u64x2 const v32 = {32, 32}; - size_t i; - for (i = 0; i < XXH_STRIPE_LEN / sizeof(xxh_u64x2); i++) { - - /* data_vec = xinput[i]; */ - xxh_u64x2 const data_vec = XXH_vec_loadu(xinput + i); - /* key_vec = xsecret[i]; */ - xxh_u64x2 const key_vec = XXH_vec_loadu(xsecret + i); - xxh_u64x2 const data_key = data_vec ^ key_vec; - /* shuffled = (data_key << 32) | (data_key >> 32); */ - xxh_u32x4 const shuffled = (xxh_u32x4)vec_rl(data_key, v32); - /* product = ((xxh_u64x2)data_key & 0xFFFFFFFF) * ((xxh_u64x2)shuffled & - * 0xFFFFFFFF); */ - xxh_u64x2 const product = XXH_vec_mulo((xxh_u32x4)data_key, shuffled); - xacc[i] += product; - - if (accWidth == XXH3_acc_64bits) { - - xacc[i] += data_vec; - - } else { /* XXH3_acc_128bits */ - - /* swap high and low halves */ - #ifdef __s390x__ - xxh_u64x2 const data_swapped = vec_permi(data_vec, data_vec, 2); - #else - xxh_u64x2 const data_swapped = vec_xxpermdi(data_vec, data_vec, 2); - #endif - xacc[i] += data_swapped; - - } - - } - -} - -XXH_FORCE_INLINE void XXH3_scrambleAcc_vsx(void *XXH_RESTRICT acc, - const void *XXH_RESTRICT secret) { - - XXH_ASSERT((((size_t)acc) & 15) == 0); - - { - - xxh_u64x2 *const xacc = (xxh_u64x2 *)acc; - const xxh_u64x2 *const xsecret = (const xxh_u64x2 *)secret; - /* constants */ - xxh_u64x2 const v32 = {32, 32}; - xxh_u64x2 const v47 = {47, 47}; - xxh_u32x4 const prime = {XXH_PRIME32_1, XXH_PRIME32_1, XXH_PRIME32_1, - XXH_PRIME32_1}; - size_t i; - for (i = 0; i < XXH_STRIPE_LEN / sizeof(xxh_u64x2); i++) { - - /* xacc[i] ^= (xacc[i] >> 47); */ - xxh_u64x2 const acc_vec = xacc[i]; - xxh_u64x2 const data_vec = acc_vec ^ (acc_vec >> v47); - - /* xacc[i] ^= xsecret[i]; */ - xxh_u64x2 const key_vec = XXH_vec_loadu(xsecret + i); - xxh_u64x2 const data_key = data_vec ^ key_vec; - - /* xacc[i] *= XXH_PRIME32_1 */ - /* prod_lo = ((xxh_u64x2)data_key & 0xFFFFFFFF) * ((xxh_u64x2)prime & - * 0xFFFFFFFF); */ - xxh_u64x2 const prod_even = XXH_vec_mule((xxh_u32x4)data_key, prime); - /* prod_hi = ((xxh_u64x2)data_key >> 32) * ((xxh_u64x2)prime >> 32); */ - xxh_u64x2 const prod_odd = XXH_vec_mulo((xxh_u32x4)data_key, prime); - xacc[i] = prod_odd + (prod_even << v32); - - } - - } - -} - -#endif - -/* scalar variants - universal */ - -XXH_FORCE_INLINE void XXH3_accumulate_512_scalar( - void *XXH_RESTRICT acc, const void *XXH_RESTRICT input, - const void *XXH_RESTRICT secret, XXH3_accWidth_e accWidth) { - - XXH_ALIGN(XXH_ACC_ALIGN) - xxh_u64 *const xacc = (xxh_u64 *)acc; /* presumed aligned */ - const xxh_u8 *const xinput = - (const xxh_u8 *)input; /* no alignment restriction */ - const xxh_u8 *const xsecret = - (const xxh_u8 *)secret; /* no alignment restriction */ - size_t i; - XXH_ASSERT(((size_t)acc & (XXH_ACC_ALIGN - 1)) == 0); - for (i = 0; i < XXH_ACC_NB; i++) { - - xxh_u64 const data_val = XXH_readLE64(xinput + 8 * i); - xxh_u64 const data_key = data_val ^ XXH_readLE64(xsecret + i * 8); - - if (accWidth == XXH3_acc_64bits) { - - xacc[i] += data_val; - - } else { - - xacc[i ^ 1] += data_val; /* swap adjacent lanes */ - - } - - xacc[i] += XXH_mult32to64(data_key & 0xFFFFFFFF, data_key >> 32); - - } - -} - -XXH_FORCE_INLINE void XXH3_scrambleAcc_scalar(void *XXH_RESTRICT acc, - const void *XXH_RESTRICT secret) { - - XXH_ALIGN(XXH_ACC_ALIGN) - xxh_u64 *const xacc = (xxh_u64 *)acc; /* presumed aligned */ - const xxh_u8 *const xsecret = - (const xxh_u8 *)secret; /* no alignment restriction */ - size_t i; - XXH_ASSERT((((size_t)acc) & (XXH_ACC_ALIGN - 1)) == 0); - for (i = 0; i < XXH_ACC_NB; i++) { - - xxh_u64 const key64 = XXH_readLE64(xsecret + 8 * i); - xxh_u64 acc64 = xacc[i]; - acc64 = XXH_xorshift64(acc64, 47); - acc64 ^= key64; - acc64 *= XXH_PRIME32_1; - xacc[i] = acc64; - - } - -} - -XXH_FORCE_INLINE void XXH3_initCustomSecret_scalar( - void *XXH_RESTRICT customSecret, xxh_u64 seed64) { - - /* - * We need a separate pointer for the hack below, - * which requires a non-const pointer. - * Any decent compiler will optimize this out otherwise. - */ - const xxh_u8 *kSecretPtr = XXH3_kSecret; - XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE & 15) == 0); - -#if defined(__clang__) && defined(__aarch64__) - /* - * UGLY HACK: - * Clang generates a bunch of MOV/MOVK pairs for aarch64, and they are - * placed sequentially, in order, at the top of the unrolled loop. - * - * While MOVK is great for generating constants (2 cycles for a 64-bit - * constant compared to 4 cycles for LDR), long MOVK chains stall the - * integer pipelines: - * I L S - * MOVK - * MOVK - * MOVK - * MOVK - * ADD - * SUB STR - * STR - * By forcing loads from memory (as the asm line causes Clang to assume - * that XXH3_kSecretPtr has been changed), the pipelines are used more - * efficiently: - * I L S - * LDR - * ADD LDR - * SUB STR - * STR - * XXH3_64bits_withSeed, len == 256, Snapdragon 835 - * without hack: 2654.4 MB/s - * with hack: 3202.9 MB/s - */ - __asm__("" : "+r"(kSecretPtr)); -#endif - /* - * Note: in debug mode, this overrides the asm optimization - * and Clang will emit MOVK chains again. - */ - XXH_ASSERT(kSecretPtr == XXH3_kSecret); - - { - - int const nbRounds = XXH_SECRET_DEFAULT_SIZE / 16; - int i; - for (i = 0; i < nbRounds; i++) { - - /* - * The asm hack causes Clang to assume that kSecretPtr aliases with - * customSecret, and on aarch64, this prevented LDP from merging two - * loads together for free. Putting the loads together before the stores - * properly generates LDP. - */ - xxh_u64 lo = XXH_readLE64(kSecretPtr + 16 * i) + seed64; - xxh_u64 hi = XXH_readLE64(kSecretPtr + 16 * i + 8) - seed64; - XXH_writeLE64((xxh_u8 *)customSecret + 16 * i, lo); - XXH_writeLE64((xxh_u8 *)customSecret + 16 * i + 8, hi); - - } - - } - -} - -typedef void (*XXH3_f_accumulate_512)(void *XXH_RESTRICT, const void *, - const void *, XXH3_accWidth_e); -typedef void (*XXH3_f_scrambleAcc)(void *XXH_RESTRICT, const void *); -typedef void (*XXH3_f_initCustomSecret)(void *XXH_RESTRICT, xxh_u64); - -#if (XXH_VECTOR == XXH_AVX512) - - #define XXH3_accumulate_512 XXH3_accumulate_512_avx512 - #define XXH3_scrambleAcc XXH3_scrambleAcc_avx512 - #define XXH3_initCustomSecret XXH3_initCustomSecret_avx512 - -#elif (XXH_VECTOR == XXH_AVX2) - - #define XXH3_accumulate_512 XXH3_accumulate_512_avx2 - #define XXH3_scrambleAcc XXH3_scrambleAcc_avx2 - #define XXH3_initCustomSecret XXH3_initCustomSecret_avx2 - -#elif (XXH_VECTOR == XXH_SSE2) - - #define XXH3_accumulate_512 XXH3_accumulate_512_sse2 - #define XXH3_scrambleAcc XXH3_scrambleAcc_sse2 - #define XXH3_initCustomSecret XXH3_initCustomSecret_sse2 - -#elif (XXH_VECTOR == XXH_NEON) - - #define XXH3_accumulate_512 XXH3_accumulate_512_neon - #define XXH3_scrambleAcc XXH3_scrambleAcc_neon - #define XXH3_initCustomSecret XXH3_initCustomSecret_scalar - -#elif (XXH_VECTOR == XXH_VSX) - - #define XXH3_accumulate_512 XXH3_accumulate_512_vsx - #define XXH3_scrambleAcc XXH3_scrambleAcc_vsx - #define XXH3_initCustomSecret XXH3_initCustomSecret_scalar - -#else /* scalar */ - - #define XXH3_accumulate_512 XXH3_accumulate_512_scalar - #define XXH3_scrambleAcc XXH3_scrambleAcc_scalar - #define XXH3_initCustomSecret XXH3_initCustomSecret_scalar - -#endif - -#ifndef XXH_PREFETCH_DIST - #ifdef __clang__ - #define XXH_PREFETCH_DIST 320 - #else - #if (XXH_VECTOR == XXH_AVX512) - #define XXH_PREFETCH_DIST 512 - #else - #define XXH_PREFETCH_DIST 384 - #endif - #endif /* __clang__ */ -#endif /* XXH_PREFETCH_DIST */ - -/* - * XXH3_accumulate() - * Loops over XXH3_accumulate_512(). - * Assumption: nbStripes will not overflow the secret size - */ -XXH_FORCE_INLINE void XXH3_accumulate(xxh_u64 *XXH_RESTRICT acc, - const xxh_u8 *XXH_RESTRICT input, - const xxh_u8 *XXH_RESTRICT secret, - size_t nbStripes, - XXH3_accWidth_e accWidth, - XXH3_f_accumulate_512 f_acc512) { - - size_t n; - for (n = 0; n < nbStripes; n++) { - - const xxh_u8 *const in = input + n * XXH_STRIPE_LEN; - XXH_PREFETCH(in + XXH_PREFETCH_DIST); - f_acc512(acc, in, secret + n * XXH_SECRET_CONSUME_RATE, accWidth); - - } - -} - -XXH_FORCE_INLINE void XXH3_hashLong_internal_loop( - xxh_u64 *XXH_RESTRICT acc, const xxh_u8 *XXH_RESTRICT input, size_t len, - const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, - XXH3_accWidth_e accWidth, XXH3_f_accumulate_512 f_acc512, - XXH3_f_scrambleAcc f_scramble) { - - size_t const nb_rounds = - (secretSize - XXH_STRIPE_LEN) / XXH_SECRET_CONSUME_RATE; - size_t const block_len = XXH_STRIPE_LEN * nb_rounds; - size_t const nb_blocks = len / block_len; - - size_t n; - - XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); - - for (n = 0; n < nb_blocks; n++) { - - XXH3_accumulate(acc, input + n * block_len, secret, nb_rounds, accWidth, - f_acc512); - f_scramble(acc, secret + secretSize - XXH_STRIPE_LEN); - - } - - /* last partial block */ - XXH_ASSERT(len > XXH_STRIPE_LEN); - { - - size_t const nbStripes = (len - (block_len * nb_blocks)) / XXH_STRIPE_LEN; - XXH_ASSERT(nbStripes <= (secretSize / XXH_SECRET_CONSUME_RATE)); - XXH3_accumulate(acc, input + nb_blocks * block_len, secret, nbStripes, - accWidth, f_acc512); - - /* last stripe */ - if (len & (XXH_STRIPE_LEN - 1)) { - - const xxh_u8 *const p = input + len - XXH_STRIPE_LEN; - /* Do not align on 8, so that the secret is different from the scrambler - */ -#define XXH_SECRET_LASTACC_START 7 - f_acc512(acc, p, - secret + secretSize - XXH_STRIPE_LEN - XXH_SECRET_LASTACC_START, - accWidth); - - } - - } - -} - -XXH_FORCE_INLINE xxh_u64 XXH3_mix2Accs(const xxh_u64 *XXH_RESTRICT acc, - const xxh_u8 *XXH_RESTRICT secret) { - - return XXH3_mul128_fold64(acc[0] ^ XXH_readLE64(secret), - acc[1] ^ XXH_readLE64(secret + 8)); - -} - -static XXH64_hash_t XXH3_mergeAccs(const xxh_u64 *XXH_RESTRICT acc, - const xxh_u8 *XXH_RESTRICT secret, - xxh_u64 start) { - - xxh_u64 result64 = start; - size_t i = 0; - - for (i = 0; i < 4; i++) { - - result64 += XXH3_mix2Accs(acc + 2 * i, secret + 16 * i); -#if defined(__clang__) /* Clang */ \ - && (defined(__arm__) || defined(__thumb__)) /* ARMv7 */ \ - && (defined(__ARM_NEON) || defined(__ARM_NEON__)) /* NEON */ \ - && !defined(XXH_ENABLE_AUTOVECTORIZE) /* Define to disable */ - /* - * UGLY HACK: - * Prevent autovectorization on Clang ARMv7-a. Exact same problem as - * the one in XXH3_len_129to240_64b. Speeds up shorter keys > 240b. - * XXH3_64bits, len == 256, Snapdragon 835: - * without hack: 2063.7 MB/s - * with hack: 2560.7 MB/s - */ - __asm__("" : "+r"(result64)); -#endif - - } - - return XXH3_avalanche(result64); - -} - -#define XXH3_INIT_ACC \ - { \ - \ - XXH_PRIME32_3, XXH_PRIME64_1, XXH_PRIME64_2, XXH_PRIME64_3, XXH_PRIME64_4, \ - XXH_PRIME32_2, XXH_PRIME64_5, XXH_PRIME32_1 \ - \ - } - -XXH_FORCE_INLINE XXH64_hash_t XXH3_hashLong_64b_internal( - const xxh_u8 *XXH_RESTRICT input, size_t len, - const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, - XXH3_f_accumulate_512 f_acc512, XXH3_f_scrambleAcc f_scramble) { - - XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64 acc[XXH_ACC_NB] = XXH3_INIT_ACC; - - XXH3_hashLong_internal_loop(acc, input, len, secret, secretSize, - XXH3_acc_64bits, f_acc512, f_scramble); - - /* converge into final hash */ - XXH_STATIC_ASSERT(sizeof(acc) == 64); - /* do not align on 8, so that the secret is different from the accumulator */ -#define XXH_SECRET_MERGEACCS_START 11 - XXH_ASSERT(secretSize >= sizeof(acc) + XXH_SECRET_MERGEACCS_START); - return XXH3_mergeAccs(acc, secret + XXH_SECRET_MERGEACCS_START, - (xxh_u64)len * XXH_PRIME64_1); - -} - -/* - * It's important for performance that XXH3_hashLong is not inlined. - */ -XXH_NO_INLINE XXH64_hash_t XXH3_hashLong_64b_withSecret( - const xxh_u8 *XXH_RESTRICT input, size_t len, XXH64_hash_t seed64, - const xxh_u8 *XXH_RESTRICT secret, size_t secretLen) { - - (void)seed64; - return XXH3_hashLong_64b_internal(input, len, secret, secretLen, - XXH3_accumulate_512, XXH3_scrambleAcc); - -} - -/* - * XXH3_hashLong_64b_withSeed(): - * Generate a custom key based on alteration of default XXH3_kSecret with the - * seed, and then use this key for long mode hashing. - * - * This operation is decently fast but nonetheless costs a little bit of time. - * Try to avoid it whenever possible (typically when seed==0). - * - * It's important for performance that XXH3_hashLong is not inlined. Not sure - * why (uop cache maybe?), but the difference is large and easily measurable. - */ -XXH_FORCE_INLINE XXH64_hash_t XXH3_hashLong_64b_withSeed_internal( - const xxh_u8 *input, size_t len, XXH64_hash_t seed, - XXH3_f_accumulate_512 f_acc512, XXH3_f_scrambleAcc f_scramble, - XXH3_f_initCustomSecret f_initSec) { - - if (seed == 0) - return XXH3_hashLong_64b_internal( - input, len, XXH3_kSecret, sizeof(XXH3_kSecret), f_acc512, f_scramble); - { - - XXH_ALIGN(XXH_SEC_ALIGN) xxh_u8 secret[XXH_SECRET_DEFAULT_SIZE]; - f_initSec(secret, seed); - return XXH3_hashLong_64b_internal(input, len, secret, sizeof(secret), - f_acc512, f_scramble); - - } - -} - -/* - * It's important for performance that XXH3_hashLong is not inlined. - */ -XXH_NO_INLINE XXH64_hash_t XXH3_hashLong_64b_withSeed(const xxh_u8 *input, - size_t len, - XXH64_hash_t seed, - const xxh_u8 *secret, - size_t secretLen) { - - (void)secret; - (void)secretLen; - return XXH3_hashLong_64b_withSeed_internal( - input, len, seed, XXH3_accumulate_512, XXH3_scrambleAcc, - XXH3_initCustomSecret); - -} - -typedef XXH64_hash_t (*XXH3_hashLong64_f)(const xxh_u8 *XXH_RESTRICT, size_t, - XXH64_hash_t, - const xxh_u8 *XXH_RESTRICT, size_t); - -XXH_FORCE_INLINE XXH64_hash_t -XXH3_64bits_internal(const void *XXH_RESTRICT input, size_t len, - XXH64_hash_t seed64, const void *XXH_RESTRICT secret, - size_t secretLen, XXH3_hashLong64_f f_hashLong) { - - XXH_ASSERT(secretLen >= XXH3_SECRET_SIZE_MIN); - /* - * If an action is to be taken if `secretLen` condition is not respected, - * it should be done here. - * For now, it's a contract pre-condition. - * Adding a check and a branch here would cost performance at every hash. - * Also, note that function signature doesn't offer room to return an error. - */ - if (len <= 16) - return XXH3_len_0to16_64b((const xxh_u8 *)input, len, - (const xxh_u8 *)secret, seed64); - if (len <= 128) - return XXH3_len_17to128_64b((const xxh_u8 *)input, len, - (const xxh_u8 *)secret, secretLen, seed64); - if (len <= XXH3_MIDSIZE_MAX) - return XXH3_len_129to240_64b((const xxh_u8 *)input, len, - (const xxh_u8 *)secret, secretLen, seed64); - return f_hashLong((const xxh_u8 *)input, len, seed64, (const xxh_u8 *)secret, - secretLen); - -} - -/* === Public entry point === */ - -XXH_PUBLIC_API XXH64_hash_t XXH3_64bits(const void *input, size_t len) { - - return XXH3_64bits_internal(input, len, 0, XXH3_kSecret, sizeof(XXH3_kSecret), - XXH3_hashLong_64b_withSecret); - -} - -XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSecret(const void *input, - size_t len, - const void *secret, - size_t secretSize) { - - return XXH3_64bits_internal(input, len, 0, secret, secretSize, - XXH3_hashLong_64b_withSecret); - -} - -XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSeed(const void *input, size_t len, - XXH64_hash_t seed) { - - return XXH3_64bits_internal(input, len, seed, XXH3_kSecret, - sizeof(XXH3_kSecret), XXH3_hashLong_64b_withSeed); - -} - -/* === XXH3 streaming === */ - -/* - * Malloc's a pointer that is always aligned to align. - * - * This must be freed with `XXH_alignedFree()`. - * - * malloc typically guarantees 16 byte alignment on 64-bit systems and 8 byte - * alignment on 32-bit. This isn't enough for the 32 byte aligned loads in AVX2 - * or on 32-bit, the 16 byte aligned loads in SSE2 and NEON. - * - * This underalignment previously caused a rather obvious crash which went - * completely unnoticed due to XXH3_createState() not actually being tested. - * Credit to RedSpah for noticing this bug. - * - * The alignment is done manually: Functions like posix_memalign or _mm_malloc - * are avoided: To maintain portability, we would have to write a fallback - * like this anyways, and besides, testing for the existence of library - * functions without relying on external build tools is impossible. - * - * The method is simple: Overallocate, manually align, and store the offset - * to the original behind the returned pointer. - * - * Align must be a power of 2 and 8 <= align <= 128. - */ -static void *XXH_alignedMalloc(size_t s, size_t align) { - - XXH_ASSERT(align <= 128 && align >= 8); /* range check */ - XXH_ASSERT((align & (align - 1)) == 0); /* power of 2 */ - XXH_ASSERT(s != 0 && s < (s + align)); /* empty/overflow */ - { /* Overallocate to make room for manual realignment and an offset byte */ - xxh_u8 *base = (xxh_u8 *)XXH_malloc(s + align); - if (base != NULL) { - - /* - * Get the offset needed to align this pointer. - * - * Even if the returned pointer is aligned, there will always be - * at least one byte to store the offset to the original pointer. - */ - size_t offset = align - ((size_t)base & (align - 1)); /* base % align */ - /* Add the offset for the now-aligned pointer */ - xxh_u8 *ptr = base + offset; - - XXH_ASSERT((size_t)ptr % align == 0); - - /* Store the offset immediately before the returned pointer. */ - ptr[-1] = (xxh_u8)offset; - return ptr; - - } - - return NULL; - - } - -} - -/* - * Frees an aligned pointer allocated by XXH_alignedMalloc(). Don't pass - * normal malloc'd pointers, XXH_alignedMalloc has a specific data layout. - */ -static void XXH_alignedFree(void *p) { - - if (p != NULL) { - - xxh_u8 *ptr = (xxh_u8 *)p; - /* Get the offset byte we added in XXH_malloc. */ - xxh_u8 offset = ptr[-1]; - /* Free the original malloc'd pointer */ - xxh_u8 *base = ptr - offset; - XXH_free(base); - - } - -} - -XXH_PUBLIC_API XXH3_state_t *XXH3_createState(void) { - - return (XXH3_state_t *)XXH_alignedMalloc(sizeof(XXH3_state_t), 64); - -} - -XXH_PUBLIC_API XXH_errorcode XXH3_freeState(XXH3_state_t *statePtr) { - - XXH_alignedFree(statePtr); - return XXH_OK; - -} - -XXH_PUBLIC_API void XXH3_copyState(XXH3_state_t * dst_state, - const XXH3_state_t *src_state) { - - memcpy(dst_state, src_state, sizeof(*dst_state)); - -} - -static void XXH3_64bits_reset_internal(XXH3_state_t *statePtr, - XXH64_hash_t seed, const xxh_u8 *secret, - size_t secretSize) { - - XXH_ASSERT(statePtr != NULL); - memset(statePtr, 0, sizeof(*statePtr)); - statePtr->acc[0] = XXH_PRIME32_3; - statePtr->acc[1] = XXH_PRIME64_1; - statePtr->acc[2] = XXH_PRIME64_2; - statePtr->acc[3] = XXH_PRIME64_3; - statePtr->acc[4] = XXH_PRIME64_4; - statePtr->acc[5] = XXH_PRIME32_2; - statePtr->acc[6] = XXH_PRIME64_5; - statePtr->acc[7] = XXH_PRIME32_1; - statePtr->seed = seed; - XXH_ASSERT(secret != NULL); - statePtr->extSecret = secret; - XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); - statePtr->secretLimit = secretSize - XXH_STRIPE_LEN; - statePtr->nbStripesPerBlock = statePtr->secretLimit / XXH_SECRET_CONSUME_RATE; - -} - -XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset(XXH3_state_t *statePtr) { - - if (statePtr == NULL) return XXH_ERROR; - XXH3_64bits_reset_internal(statePtr, 0, XXH3_kSecret, - XXH_SECRET_DEFAULT_SIZE); - return XXH_OK; - -} - -XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSecret( - XXH3_state_t *statePtr, const void *secret, size_t secretSize) { - - if (statePtr == NULL) return XXH_ERROR; - XXH3_64bits_reset_internal(statePtr, 0, (const xxh_u8 *)secret, secretSize); - if (secret == NULL) return XXH_ERROR; - if (secretSize < XXH3_SECRET_SIZE_MIN) return XXH_ERROR; - return XXH_OK; - -} - -XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSeed(XXH3_state_t *statePtr, - XXH64_hash_t seed) { - - if (statePtr == NULL) return XXH_ERROR; - XXH3_64bits_reset_internal(statePtr, seed, XXH3_kSecret, - XXH_SECRET_DEFAULT_SIZE); - XXH3_initCustomSecret(statePtr->customSecret, seed); - statePtr->extSecret = NULL; - return XXH_OK; - -} - -XXH_FORCE_INLINE void XXH3_consumeStripes( - xxh_u64 *XXH_RESTRICT acc, size_t *XXH_RESTRICT nbStripesSoFarPtr, - size_t nbStripesPerBlock, const xxh_u8 *XXH_RESTRICT input, - size_t totalStripes, const xxh_u8 *XXH_RESTRICT secret, size_t secretLimit, - XXH3_accWidth_e accWidth, XXH3_f_accumulate_512 f_acc512, - XXH3_f_scrambleAcc f_scramble) { - - XXH_ASSERT(*nbStripesSoFarPtr < nbStripesPerBlock); - if (nbStripesPerBlock - *nbStripesSoFarPtr <= totalStripes) { - - /* need a scrambling operation */ - size_t const nbStripes = nbStripesPerBlock - *nbStripesSoFarPtr; - XXH3_accumulate(acc, input, - secret + nbStripesSoFarPtr[0] * XXH_SECRET_CONSUME_RATE, - nbStripes, accWidth, f_acc512); - f_scramble(acc, secret + secretLimit); - XXH3_accumulate(acc, input + nbStripes * XXH_STRIPE_LEN, secret, - totalStripes - nbStripes, accWidth, f_acc512); - *nbStripesSoFarPtr = totalStripes - nbStripes; - - } else { - - XXH3_accumulate(acc, input, - secret + nbStripesSoFarPtr[0] * XXH_SECRET_CONSUME_RATE, - totalStripes, accWidth, f_acc512); - *nbStripesSoFarPtr += totalStripes; - - } - -} - -/* - * Both XXH3_64bits_update and XXH3_128bits_update use this routine. - */ -XXH_FORCE_INLINE XXH_errorcode XXH3_update(XXH3_state_t *state, - const xxh_u8 *input, size_t len, - XXH3_accWidth_e accWidth, - XXH3_f_accumulate_512 f_acc512, - XXH3_f_scrambleAcc f_scramble) { - - if (input == NULL) -#if defined(XXH_ACCEPT_NULL_INPUT_POINTER) && \ - (XXH_ACCEPT_NULL_INPUT_POINTER >= 1) - return XXH_OK; -#else - return XXH_ERROR; -#endif - - { - - const xxh_u8 *const bEnd = input + len; - const unsigned char *const secret = - (state->extSecret == NULL) ? state->customSecret : state->extSecret; - - state->totalLen += len; - - if (state->bufferedSize + len <= - XXH3_INTERNALBUFFER_SIZE) { /* fill in tmp buffer */ - XXH_memcpy(state->buffer + state->bufferedSize, input, len); - state->bufferedSize += (XXH32_hash_t)len; - return XXH_OK; - - } - - /* input is now > XXH3_INTERNALBUFFER_SIZE */ - -#define XXH3_INTERNALBUFFER_STRIPES (XXH3_INTERNALBUFFER_SIZE / XXH_STRIPE_LEN) - XXH_STATIC_ASSERT(XXH3_INTERNALBUFFER_SIZE % XXH_STRIPE_LEN == - 0); /* clean multiple */ - - /* - * There is some input left inside the internal buffer. - * Fill it, then consume it. - */ - if (state->bufferedSize) { - - size_t const loadSize = XXH3_INTERNALBUFFER_SIZE - state->bufferedSize; - XXH_memcpy(state->buffer + state->bufferedSize, input, loadSize); - input += loadSize; - XXH3_consumeStripes(state->acc, &state->nbStripesSoFar, - state->nbStripesPerBlock, state->buffer, - XXH3_INTERNALBUFFER_STRIPES, secret, - state->secretLimit, accWidth, f_acc512, f_scramble); - state->bufferedSize = 0; - - } - - /* Consume input by full buffer quantities */ - if (input + XXH3_INTERNALBUFFER_SIZE <= bEnd) { - - const xxh_u8 *const limit = bEnd - XXH3_INTERNALBUFFER_SIZE; - do { - - XXH3_consumeStripes(state->acc, &state->nbStripesSoFar, - state->nbStripesPerBlock, input, - XXH3_INTERNALBUFFER_STRIPES, secret, - state->secretLimit, accWidth, f_acc512, f_scramble); - input += XXH3_INTERNALBUFFER_SIZE; - - } while (input <= limit); - - /* for last partial stripe */ - memcpy(state->buffer + sizeof(state->buffer) - XXH_STRIPE_LEN, - input - XXH_STRIPE_LEN, XXH_STRIPE_LEN); - - } - - if (input < bEnd) { /* Some remaining input: buffer it */ - XXH_memcpy(state->buffer, input, (size_t)(bEnd - input)); - state->bufferedSize = (XXH32_hash_t)(bEnd - input); - - } - - } - - return XXH_OK; - -} - -XXH_PUBLIC_API XXH_errorcode XXH3_64bits_update(XXH3_state_t *state, - const void *input, size_t len) { - - return XXH3_update(state, (const xxh_u8 *)input, len, XXH3_acc_64bits, - XXH3_accumulate_512, XXH3_scrambleAcc); - -} - -XXH_FORCE_INLINE void XXH3_digest_long(XXH64_hash_t * acc, - const XXH3_state_t * state, - const unsigned char *secret, - XXH3_accWidth_e accWidth) { - - /* - * Digest on a local copy. This way, the state remains unaltered, and it can - * continue ingesting more input afterwards. - */ - memcpy(acc, state->acc, sizeof(state->acc)); - if (state->bufferedSize >= XXH_STRIPE_LEN) { - - size_t const nbStripes = state->bufferedSize / XXH_STRIPE_LEN; - size_t nbStripesSoFar = state->nbStripesSoFar; - XXH3_consumeStripes(acc, &nbStripesSoFar, state->nbStripesPerBlock, - state->buffer, nbStripes, secret, state->secretLimit, - accWidth, XXH3_accumulate_512, XXH3_scrambleAcc); - if (state->bufferedSize % XXH_STRIPE_LEN) { /* one last partial stripe */ - XXH3_accumulate_512( - acc, state->buffer + state->bufferedSize - XXH_STRIPE_LEN, - secret + state->secretLimit - XXH_SECRET_LASTACC_START, accWidth); - - } - - } else { /* bufferedSize < XXH_STRIPE_LEN */ - - if (state->bufferedSize) { /* one last stripe */ - xxh_u8 lastStripe[XXH_STRIPE_LEN]; - size_t const catchupSize = XXH_STRIPE_LEN - state->bufferedSize; - memcpy(lastStripe, state->buffer + sizeof(state->buffer) - catchupSize, - catchupSize); - memcpy(lastStripe + catchupSize, state->buffer, state->bufferedSize); - XXH3_accumulate_512( - acc, lastStripe, - secret + state->secretLimit - XXH_SECRET_LASTACC_START, accWidth); - - } - - } - -} - -XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_digest(const XXH3_state_t *state) { - - const unsigned char *const secret = - (state->extSecret == NULL) ? state->customSecret : state->extSecret; - if (state->totalLen > XXH3_MIDSIZE_MAX) { - - XXH_ALIGN(XXH_ACC_ALIGN) XXH64_hash_t acc[XXH_ACC_NB]; - XXH3_digest_long(acc, state, secret, XXH3_acc_64bits); - return XXH3_mergeAccs(acc, secret + XXH_SECRET_MERGEACCS_START, - (xxh_u64)state->totalLen * XXH_PRIME64_1); - - } - - /* totalLen <= XXH3_MIDSIZE_MAX: digesting a short input */ - if (state->seed) - return XXH3_64bits_withSeed(state->buffer, (size_t)state->totalLen, - state->seed); - return XXH3_64bits_withSecret(state->buffer, (size_t)(state->totalLen), - secret, state->secretLimit + XXH_STRIPE_LEN); - -} - -#define XXH_MIN(x, y) (((x) > (y)) ? (y) : (x)) - -XXH_PUBLIC_API void XXH3_generateSecret(void * secretBuffer, - const void *customSeed, - size_t customSeedSize) { - - XXH_ASSERT(secretBuffer != NULL); - if (customSeedSize == 0) { - - memcpy(secretBuffer, XXH3_kSecret, XXH_SECRET_DEFAULT_SIZE); - return; - - } - - XXH_ASSERT(customSeed != NULL); - - { - - size_t const segmentSize = sizeof(XXH128_hash_t); - size_t const nbSegments = XXH_SECRET_DEFAULT_SIZE / segmentSize; - XXH128_canonical_t scrambler; - XXH64_hash_t seeds[12]; - size_t segnb; - XXH_ASSERT(nbSegments == 12); - XXH_ASSERT(segmentSize * nbSegments == - XXH_SECRET_DEFAULT_SIZE); /* exact multiple */ - XXH128_canonicalFromHash(&scrambler, XXH128(customSeed, customSeedSize, 0)); - - /* - * Copy customSeed to seeds[], truncating or repeating as necessary. - */ - { - - size_t toFill = XXH_MIN(customSeedSize, sizeof(seeds)); - size_t filled = toFill; - memcpy(seeds, customSeed, toFill); - while (filled < sizeof(seeds)) { - - toFill = XXH_MIN(filled, sizeof(seeds) - filled); - memcpy((char *)seeds + filled, seeds, toFill); - filled += toFill; - - } - - } - - /* generate secret */ - memcpy(secretBuffer, &scrambler, sizeof(scrambler)); - for (segnb = 1; segnb < nbSegments; segnb++) { - - size_t const segmentStart = segnb * segmentSize; - XXH128_canonical_t segment; - XXH128_canonicalFromHash(&segment, - XXH128(&scrambler, sizeof(scrambler), - XXH_readLE64(seeds + segnb) + segnb)); - memcpy((char *)secretBuffer + segmentStart, &segment, sizeof(segment)); - - } - - } - -} - -/* ========================================== - * XXH3 128 bits (a.k.a XXH128) - * ========================================== - * XXH3's 128-bit variant has better mixing and strength than the 64-bit - * variant, even without counting the significantly larger output size. - * - * For example, extra steps are taken to avoid the seed-dependent collisions - * in 17-240 byte inputs (See XXH3_mix16B and XXH128_mix32B). - * - * This strength naturally comes at the cost of some speed, especially on short - * lengths. Note that longer hashes are about as fast as the 64-bit version - * due to it using only a slight modification of the 64-bit loop. - * - * XXH128 is also more oriented towards 64-bit machines. It is still extremely - * fast for a _128-bit_ hash on 32-bit (it usually clears XXH64). - */ - -XXH_FORCE_INLINE XXH128_hash_t XXH3_len_1to3_128b(const xxh_u8 *input, - size_t len, - const xxh_u8 *secret, - XXH64_hash_t seed) { - - /* A doubled version of 1to3_64b with different constants. */ - XXH_ASSERT(input != NULL); - XXH_ASSERT(1 <= len && len <= 3); - XXH_ASSERT(secret != NULL); - /* - * len = 1: combinedl = { input[0], 0x01, input[0], input[0] } - * len = 2: combinedl = { input[1], 0x02, input[0], input[1] } - * len = 3: combinedl = { input[2], 0x03, input[0], input[1] } - */ - { - - xxh_u8 const c1 = input[0]; - xxh_u8 const c2 = input[len >> 1]; - xxh_u8 const c3 = input[len - 1]; - xxh_u32 const combinedl = ((xxh_u32)c1 << 16) | ((xxh_u32)c2 << 24) | - ((xxh_u32)c3 << 0) | ((xxh_u32)len << 8); - xxh_u32 const combinedh = XXH_rotl32(XXH_swap32(combinedl), 13); - xxh_u64 const bitflipl = - (XXH_readLE32(secret) ^ XXH_readLE32(secret + 4)) + seed; - xxh_u64 const bitfliph = - (XXH_readLE32(secret + 8) ^ XXH_readLE32(secret + 12)) - seed; - xxh_u64 const keyed_lo = (xxh_u64)combinedl ^ bitflipl; - xxh_u64 const keyed_hi = (xxh_u64)combinedh ^ bitfliph; - xxh_u64 const mixedl = keyed_lo * XXH_PRIME64_1; - xxh_u64 const mixedh = keyed_hi * XXH_PRIME64_5; - XXH128_hash_t h128; - h128.low64 = XXH3_avalanche(mixedl); - h128.high64 = XXH3_avalanche(mixedh); - return h128; - - } - -} - -XXH_FORCE_INLINE XXH128_hash_t XXH3_len_4to8_128b(const xxh_u8 *input, - size_t len, - const xxh_u8 *secret, - XXH64_hash_t seed) { - - XXH_ASSERT(input != NULL); - XXH_ASSERT(secret != NULL); - XXH_ASSERT(4 <= len && len <= 8); - seed ^= (xxh_u64)XXH_swap32((xxh_u32)seed) << 32; - { - - xxh_u32 const input_lo = XXH_readLE32(input); - xxh_u32 const input_hi = XXH_readLE32(input + len - 4); - xxh_u64 const input_64 = input_lo + ((xxh_u64)input_hi << 32); - xxh_u64 const bitflip = - (XXH_readLE64(secret + 16) ^ XXH_readLE64(secret + 24)) + seed; - xxh_u64 const keyed = input_64 ^ bitflip; - - /* Shift len to the left to ensure it is even, this avoids even multiplies. - */ - XXH128_hash_t m128 = XXH_mult64to128(keyed, XXH_PRIME64_1 + (len << 2)); - - m128.high64 += (m128.low64 << 1); - m128.low64 ^= (m128.high64 >> 3); - - m128.low64 = XXH_xorshift64(m128.low64, 35); - m128.low64 *= 0x9FB21C651E98DF25ULL; - m128.low64 = XXH_xorshift64(m128.low64, 28); - m128.high64 = XXH3_avalanche(m128.high64); - return m128; - - } - -} - -XXH_FORCE_INLINE XXH128_hash_t XXH3_len_9to16_128b(const xxh_u8 *input, - size_t len, - const xxh_u8 *secret, - XXH64_hash_t seed) { - - XXH_ASSERT(input != NULL); - XXH_ASSERT(secret != NULL); - XXH_ASSERT(9 <= len && len <= 16); - { - - xxh_u64 const bitflipl = - (XXH_readLE64(secret + 32) ^ XXH_readLE64(secret + 40)) - seed; - xxh_u64 const bitfliph = - (XXH_readLE64(secret + 48) ^ XXH_readLE64(secret + 56)) + seed; - xxh_u64 const input_lo = XXH_readLE64(input); - xxh_u64 input_hi = XXH_readLE64(input + len - 8); - XXH128_hash_t m128 = - XXH_mult64to128(input_lo ^ input_hi ^ bitflipl, XXH_PRIME64_1); - /* - * Put len in the middle of m128 to ensure that the length gets mixed to - * both the low and high bits in the 128x64 multiply below. - */ - m128.low64 += (xxh_u64)(len - 1) << 54; - input_hi ^= bitfliph; - /* - * Add the high 32 bits of input_hi to the high 32 bits of m128, then - * add the long product of the low 32 bits of input_hi and XXH_PRIME32_2 to - * the high 64 bits of m128. - * - * The best approach to this operation is different on 32-bit and 64-bit. - */ - if (sizeof(void *) < sizeof(xxh_u64)) { /* 32-bit */ - /* - * 32-bit optimized version, which is more readable. - * - * On 32-bit, it removes an ADC and delays a dependency between the two - * halves of m128.high64, but it generates an extra mask on 64-bit. - */ - m128.high64 += (input_hi & 0xFFFFFFFF00000000) + - XXH_mult32to64((xxh_u32)input_hi, XXH_PRIME32_2); - - } else { - - /* - * 64-bit optimized (albeit more confusing) version. - * - * Uses some properties of addition and multiplication to remove the mask: - * - * Let: - * a = input_hi.lo = (input_hi & 0x00000000FFFFFFFF) - * b = input_hi.hi = (input_hi & 0xFFFFFFFF00000000) - * c = XXH_PRIME32_2 - * - * a + (b * c) - * Inverse Property: x + y - x == y - * a + (b * (1 + c - 1)) - * Distributive Property: x * (y + z) == (x * y) + (x * z) - * a + (b * 1) + (b * (c - 1)) - * Identity Property: x * 1 == x - * a + b + (b * (c - 1)) - * - * Substitute a, b, and c: - * input_hi.hi + input_hi.lo + ((xxh_u64)input_hi.lo * (XXH_PRIME32_2 - - * 1)) - * - * Since input_hi.hi + input_hi.lo == input_hi, we get this: - * input_hi + ((xxh_u64)input_hi.lo * (XXH_PRIME32_2 - 1)) - */ - m128.high64 += - input_hi + XXH_mult32to64((xxh_u32)input_hi, XXH_PRIME32_2 - 1); - - } - - /* m128 ^= XXH_swap64(m128 >> 64); */ - m128.low64 ^= XXH_swap64(m128.high64); - - { /* 128x64 multiply: h128 = m128 * XXH_PRIME64_2; */ - XXH128_hash_t h128 = XXH_mult64to128(m128.low64, XXH_PRIME64_2); - h128.high64 += m128.high64 * XXH_PRIME64_2; - - h128.low64 = XXH3_avalanche(h128.low64); - h128.high64 = XXH3_avalanche(h128.high64); - return h128; - - } - - } - -} - -/* - * Assumption: `secret` size is >= XXH3_SECRET_SIZE_MIN - */ -XXH_FORCE_INLINE XXH128_hash_t XXH3_len_0to16_128b(const xxh_u8 *input, - size_t len, - const xxh_u8 *secret, - XXH64_hash_t seed) { - - XXH_ASSERT(len <= 16); - { - - if (len > 8) return XXH3_len_9to16_128b(input, len, secret, seed); - if (len >= 4) return XXH3_len_4to8_128b(input, len, secret, seed); - if (len) return XXH3_len_1to3_128b(input, len, secret, seed); - { - - XXH128_hash_t h128; - xxh_u64 const bitflipl = - XXH_readLE64(secret + 64) ^ XXH_readLE64(secret + 72); - xxh_u64 const bitfliph = - XXH_readLE64(secret + 80) ^ XXH_readLE64(secret + 88); - h128.low64 = XXH3_avalanche((XXH_PRIME64_1 + seed) ^ bitflipl); - h128.high64 = XXH3_avalanche((XXH_PRIME64_2 - seed) ^ bitfliph); - return h128; - - } - - } - -} - -/* - * A bit slower than XXH3_mix16B, but handles multiply by zero better. - */ -XXH_FORCE_INLINE XXH128_hash_t XXH128_mix32B(XXH128_hash_t acc, - const xxh_u8 *input_1, - const xxh_u8 *input_2, - const xxh_u8 *secret, - XXH64_hash_t seed) { - - acc.low64 += XXH3_mix16B(input_1, secret + 0, seed); - acc.low64 ^= XXH_readLE64(input_2) + XXH_readLE64(input_2 + 8); - acc.high64 += XXH3_mix16B(input_2, secret + 16, seed); - acc.high64 ^= XXH_readLE64(input_1) + XXH_readLE64(input_1 + 8); - return acc; - -} - -XXH_FORCE_INLINE XXH128_hash_t XXH3_len_17to128_128b( - const xxh_u8 *XXH_RESTRICT input, size_t len, - const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, XXH64_hash_t seed) { - - XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); - (void)secretSize; - XXH_ASSERT(16 < len && len <= 128); - - { - - XXH128_hash_t acc; - acc.low64 = len * XXH_PRIME64_1; - acc.high64 = 0; - if (len > 32) { - - if (len > 64) { - - if (len > 96) { - - acc = XXH128_mix32B(acc, input + 48, input + len - 64, secret + 96, - seed); - - } - - acc = - XXH128_mix32B(acc, input + 32, input + len - 48, secret + 64, seed); - - } - - acc = XXH128_mix32B(acc, input + 16, input + len - 32, secret + 32, seed); - - } - - acc = XXH128_mix32B(acc, input, input + len - 16, secret, seed); - { - - XXH128_hash_t h128; - h128.low64 = acc.low64 + acc.high64; - h128.high64 = (acc.low64 * XXH_PRIME64_1) + (acc.high64 * XXH_PRIME64_4) + - ((len - seed) * XXH_PRIME64_2); - h128.low64 = XXH3_avalanche(h128.low64); - h128.high64 = (XXH64_hash_t)0 - XXH3_avalanche(h128.high64); - return h128; - - } - - } - -} - -XXH_NO_INLINE XXH128_hash_t XXH3_len_129to240_128b( - const xxh_u8 *XXH_RESTRICT input, size_t len, - const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, XXH64_hash_t seed) { - - XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); - (void)secretSize; - XXH_ASSERT(128 < len && len <= XXH3_MIDSIZE_MAX); - - { - - XXH128_hash_t acc; - int const nbRounds = (int)len / 32; - int i; - acc.low64 = len * XXH_PRIME64_1; - acc.high64 = 0; - for (i = 0; i < 4; i++) { - - acc = XXH128_mix32B(acc, input + (32 * i), input + (32 * i) + 16, - secret + (32 * i), seed); - - } - - acc.low64 = XXH3_avalanche(acc.low64); - acc.high64 = XXH3_avalanche(acc.high64); - XXH_ASSERT(nbRounds >= 4); - for (i = 4; i < nbRounds; i++) { - - acc = XXH128_mix32B(acc, input + (32 * i), input + (32 * i) + 16, - secret + XXH3_MIDSIZE_STARTOFFSET + (32 * (i - 4)), - seed); - - } - - /* last bytes */ - acc = XXH128_mix32B( - acc, input + len - 16, input + len - 32, - secret + XXH3_SECRET_SIZE_MIN - XXH3_MIDSIZE_LASTOFFSET - 16, - 0ULL - seed); - - { - - XXH128_hash_t h128; - h128.low64 = acc.low64 + acc.high64; - h128.high64 = (acc.low64 * XXH_PRIME64_1) + (acc.high64 * XXH_PRIME64_4) + - ((len - seed) * XXH_PRIME64_2); - h128.low64 = XXH3_avalanche(h128.low64); - h128.high64 = (XXH64_hash_t)0 - XXH3_avalanche(h128.high64); - return h128; - - } - - } - -} - -XXH_FORCE_INLINE XXH128_hash_t XXH3_hashLong_128b_internal( - const xxh_u8 *XXH_RESTRICT input, size_t len, - const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, - XXH3_f_accumulate_512 f_acc512, XXH3_f_scrambleAcc f_scramble) { - - XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64 acc[XXH_ACC_NB] = XXH3_INIT_ACC; - - XXH3_hashLong_internal_loop(acc, input, len, secret, secretSize, - XXH3_acc_128bits, f_acc512, f_scramble); - - /* converge into final hash */ - XXH_STATIC_ASSERT(sizeof(acc) == 64); - XXH_ASSERT(secretSize >= sizeof(acc) + XXH_SECRET_MERGEACCS_START); - { - - XXH128_hash_t h128; - h128.low64 = XXH3_mergeAccs(acc, secret + XXH_SECRET_MERGEACCS_START, - (xxh_u64)len * XXH_PRIME64_1); - h128.high64 = XXH3_mergeAccs( - acc, secret + secretSize - sizeof(acc) - XXH_SECRET_MERGEACCS_START, - ~((xxh_u64)len * XXH_PRIME64_2)); - return h128; - - } - -} - -/* - * It's important for performance that XXH3_hashLong is not inlined. - */ -XXH_NO_INLINE XXH128_hash_t XXH3_hashLong_128b_defaultSecret( - const xxh_u8 *XXH_RESTRICT input, size_t len, XXH64_hash_t seed64, - const xxh_u8 *XXH_RESTRICT secret, size_t secretLen) { - - (void)seed64; - (void)secret; - (void)secretLen; - return XXH3_hashLong_128b_internal(input, len, XXH3_kSecret, - sizeof(XXH3_kSecret), XXH3_accumulate_512, - XXH3_scrambleAcc); - -} - -/* - * It's important for performance that XXH3_hashLong is not inlined. - */ -XXH_NO_INLINE XXH128_hash_t XXH3_hashLong_128b_withSecret( - const xxh_u8 *XXH_RESTRICT input, size_t len, XXH64_hash_t seed64, - const xxh_u8 *XXH_RESTRICT secret, size_t secretLen) { - - (void)seed64; - return XXH3_hashLong_128b_internal(input, len, secret, secretLen, - XXH3_accumulate_512, XXH3_scrambleAcc); - -} - -XXH_FORCE_INLINE XXH128_hash_t XXH3_hashLong_128b_withSeed_internal( - const xxh_u8 *XXH_RESTRICT input, size_t len, XXH64_hash_t seed64, - XXH3_f_accumulate_512 f_acc512, XXH3_f_scrambleAcc f_scramble, - XXH3_f_initCustomSecret f_initSec) { - - if (seed64 == 0) - return XXH3_hashLong_128b_internal( - input, len, XXH3_kSecret, sizeof(XXH3_kSecret), f_acc512, f_scramble); - { - - XXH_ALIGN(XXH_SEC_ALIGN) xxh_u8 secret[XXH_SECRET_DEFAULT_SIZE]; - f_initSec(secret, seed64); - return XXH3_hashLong_128b_internal(input, len, secret, sizeof(secret), - f_acc512, f_scramble); - - } - -} - -/* - * It's important for performance that XXH3_hashLong is not inlined. - */ -XXH_NO_INLINE XXH128_hash_t XXH3_hashLong_128b_withSeed( - const xxh_u8 *input, size_t len, XXH64_hash_t seed64, - const xxh_u8 *XXH_RESTRICT secret, size_t secretLen) { - - (void)secret; - (void)secretLen; - return XXH3_hashLong_128b_withSeed_internal( - input, len, seed64, XXH3_accumulate_512, XXH3_scrambleAcc, - XXH3_initCustomSecret); - -} - -typedef XXH128_hash_t (*XXH3_hashLong128_f)(const xxh_u8 *XXH_RESTRICT, size_t, - XXH64_hash_t, - const xxh_u8 *XXH_RESTRICT, size_t); - -XXH_FORCE_INLINE XXH128_hash_t -XXH3_128bits_internal(const void *input, size_t len, XXH64_hash_t seed64, - const xxh_u8 *XXH_RESTRICT secret, size_t secretLen, - XXH3_hashLong128_f f_hl128) { - - XXH_ASSERT(secretLen >= XXH3_SECRET_SIZE_MIN); - /* - * If an action is to be taken if `secret` conditions are not respected, - * it should be done here. - * For now, it's a contract pre-condition. - * Adding a check and a branch here would cost performance at every hash. - */ - if (len <= 16) - return XXH3_len_0to16_128b((const xxh_u8 *)input, len, secret, seed64); - if (len <= 128) - return XXH3_len_17to128_128b((const xxh_u8 *)input, len, secret, secretLen, - seed64); - if (len <= XXH3_MIDSIZE_MAX) - return XXH3_len_129to240_128b((const xxh_u8 *)input, len, secret, secretLen, - seed64); - return f_hl128((const xxh_u8 *)input, len, seed64, secret, secretLen); - -} - -/* === Public XXH128 API === */ - -XXH_PUBLIC_API XXH128_hash_t XXH3_128bits(const void *input, size_t len) { - - return XXH3_128bits_internal(input, len, 0, XXH3_kSecret, - sizeof(XXH3_kSecret), - XXH3_hashLong_128b_withSecret); - -} - -XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_withSecret(const void *input, - size_t len, - const void *secret, - size_t secretSize) { - - return XXH3_128bits_internal(input, len, 0, (const xxh_u8 *)secret, - secretSize, XXH3_hashLong_128b_defaultSecret); - -} - -XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_withSeed(const void * input, - size_t len, - XXH64_hash_t seed) { - - return XXH3_128bits_internal(input, len, seed, XXH3_kSecret, - sizeof(XXH3_kSecret), - XXH3_hashLong_128b_withSeed); - -} - -XXH_PUBLIC_API XXH128_hash_t XXH128(const void *input, size_t len, - XXH64_hash_t seed) { - - return XXH3_128bits_withSeed(input, len, seed); - -} - -/* === XXH3 128-bit streaming === */ - -/* - * All the functions are actually the same as for 64-bit streaming variant. - * The only difference is the finalizatiom routine. - */ - -static void XXH3_128bits_reset_internal(XXH3_state_t *statePtr, - XXH64_hash_t seed, const xxh_u8 *secret, - size_t secretSize) { - - XXH3_64bits_reset_internal(statePtr, seed, secret, secretSize); - -} - -XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset(XXH3_state_t *statePtr) { - - if (statePtr == NULL) return XXH_ERROR; - XXH3_128bits_reset_internal(statePtr, 0, XXH3_kSecret, - XXH_SECRET_DEFAULT_SIZE); - return XXH_OK; - -} - -XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset_withSecret( - XXH3_state_t *statePtr, const void *secret, size_t secretSize) { - - if (statePtr == NULL) return XXH_ERROR; - XXH3_128bits_reset_internal(statePtr, 0, (const xxh_u8 *)secret, secretSize); - if (secret == NULL) return XXH_ERROR; - if (secretSize < XXH3_SECRET_SIZE_MIN) return XXH_ERROR; - return XXH_OK; - -} - -XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset_withSeed(XXH3_state_t *statePtr, - XXH64_hash_t seed) { - - if (statePtr == NULL) return XXH_ERROR; - XXH3_128bits_reset_internal(statePtr, seed, XXH3_kSecret, - XXH_SECRET_DEFAULT_SIZE); - XXH3_initCustomSecret(statePtr->customSecret, seed); - statePtr->extSecret = NULL; - return XXH_OK; - -} - -XXH_PUBLIC_API XXH_errorcode XXH3_128bits_update(XXH3_state_t *state, - const void * input, - size_t len) { - - return XXH3_update(state, (const xxh_u8 *)input, len, XXH3_acc_128bits, - XXH3_accumulate_512, XXH3_scrambleAcc); - -} - -XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_digest(const XXH3_state_t *state) { - - const unsigned char *const secret = - (state->extSecret == NULL) ? state->customSecret : state->extSecret; - if (state->totalLen > XXH3_MIDSIZE_MAX) { - - XXH_ALIGN(XXH_ACC_ALIGN) XXH64_hash_t acc[XXH_ACC_NB]; - XXH3_digest_long(acc, state, secret, XXH3_acc_128bits); - XXH_ASSERT(state->secretLimit + XXH_STRIPE_LEN >= - sizeof(acc) + XXH_SECRET_MERGEACCS_START); - { - - XXH128_hash_t h128; - h128.low64 = XXH3_mergeAccs(acc, secret + XXH_SECRET_MERGEACCS_START, - (xxh_u64)state->totalLen * XXH_PRIME64_1); - h128.high64 = - XXH3_mergeAccs(acc, - secret + state->secretLimit + XXH_STRIPE_LEN - - sizeof(acc) - XXH_SECRET_MERGEACCS_START, - ~((xxh_u64)state->totalLen * XXH_PRIME64_2)); - return h128; - - } - - } - - /* len <= XXH3_MIDSIZE_MAX : short code */ - if (state->seed) - return XXH3_128bits_withSeed(state->buffer, (size_t)state->totalLen, - state->seed); - return XXH3_128bits_withSecret(state->buffer, (size_t)(state->totalLen), - secret, state->secretLimit + XXH_STRIPE_LEN); - -} - -/* 128-bit utility functions */ - -#include <string.h> /* memcmp, memcpy */ - -/* return : 1 is equal, 0 if different */ -XXH_PUBLIC_API int XXH128_isEqual(XXH128_hash_t h1, XXH128_hash_t h2) { - - /* note : XXH128_hash_t is compact, it has no padding byte */ - return !(memcmp(&h1, &h2, sizeof(h1))); - -} - -/* This prototype is compatible with stdlib's qsort(). - * return : >0 if *h128_1 > *h128_2 - * <0 if *h128_1 < *h128_2 - * =0 if *h128_1 == *h128_2 */ -XXH_PUBLIC_API int XXH128_cmp(const void *h128_1, const void *h128_2) { - - XXH128_hash_t const h1 = *(const XXH128_hash_t *)h128_1; - XXH128_hash_t const h2 = *(const XXH128_hash_t *)h128_2; - int const hcmp = (h1.high64 > h2.high64) - (h2.high64 > h1.high64); - /* note : bets that, in most cases, hash values are different */ - if (hcmp) return hcmp; - return (h1.low64 > h2.low64) - (h2.low64 > h1.low64); - -} - -/*====== Canonical representation ======*/ -XXH_PUBLIC_API void XXH128_canonicalFromHash(XXH128_canonical_t *dst, - XXH128_hash_t hash) { - - XXH_STATIC_ASSERT(sizeof(XXH128_canonical_t) == sizeof(XXH128_hash_t)); - if (XXH_CPU_LITTLE_ENDIAN) { - - hash.high64 = XXH_swap64(hash.high64); - hash.low64 = XXH_swap64(hash.low64); - - } - - memcpy(dst, &hash.high64, sizeof(hash.high64)); - memcpy((char *)dst + sizeof(hash.high64), &hash.low64, sizeof(hash.low64)); - -} - -XXH_PUBLIC_API XXH128_hash_t -XXH128_hashFromCanonical(const XXH128_canonical_t *src) { - - XXH128_hash_t h; - h.high64 = XXH_readBE64(src); - h.low64 = XXH_readBE64(src->digest + 8); - return h; - -} - -/* Pop our optimization override from above */ -#if XXH_VECTOR == XXH_AVX2 /* AVX2 */ \ - && defined(__GNUC__) && !defined(__clang__) /* GCC, not Clang */ \ - && defined(__OPTIMIZE__) && \ - !defined(__OPTIMIZE_SIZE__) /* respect -O0 and -Os */ - #pragma GCC pop_options -#endif - -#endif /* XXH3_H_1397135465 */ - diff --git a/include/xxhash.h b/include/xxhash.h index 826f39bd..006d3f3d 100644 --- a/include/xxhash.h +++ b/include/xxhash.h @@ -197,6 +197,7 @@ extern "C" { #define XXH_CAT(A, B) A##B #define XXH_NAME2(A, B) XXH_CAT(A, B) #define XXH_versionNumber XXH_NAME2(XXH_NAMESPACE, XXH_versionNumber) + /* XXH32 */ #define XXH32 XXH_NAME2(XXH_NAMESPACE, XXH32) #define XXH32_createState XXH_NAME2(XXH_NAMESPACE, XXH32_createState) #define XXH32_freeState XXH_NAME2(XXH_NAMESPACE, XXH32_freeState) @@ -208,6 +209,7 @@ extern "C" { XXH_NAME2(XXH_NAMESPACE, XXH32_canonicalFromHash) #define XXH32_hashFromCanonical \ XXH_NAME2(XXH_NAMESPACE, XXH32_hashFromCanonical) + /* XXH64 */ #define XXH64 XXH_NAME2(XXH_NAMESPACE, XXH64) #define XXH64_createState XXH_NAME2(XXH_NAMESPACE, XXH64_createState) #define XXH64_freeState XXH_NAME2(XXH_NAMESPACE, XXH64_freeState) @@ -219,14 +221,50 @@ extern "C" { XXH_NAME2(XXH_NAMESPACE, XXH64_canonicalFromHash) #define XXH64_hashFromCanonical \ XXH_NAME2(XXH_NAMESPACE, XXH64_hashFromCanonical) + /* XXH3_64bits */ + #define XXH3_64bits XXH_NAME2(XXH_NAMESPACE, XXH3_64bits) + #define XXH3_64bits_withSecret \ + XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_withSecret) + #define XXH3_64bits_withSeed XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_withSeed) + #define XXH3_createState XXH_NAME2(XXH_NAMESPACE, XXH3_createState) + #define XXH3_freeState XXH_NAME2(XXH_NAMESPACE, XXH3_freeState) + #define XXH3_copyState XXH_NAME2(XXH_NAMESPACE, XXH3_copyState) + #define XXH3_64bits_reset XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_reset) + #define XXH3_64bits_reset_withSeed \ + XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_reset_withSeed) + #define XXH3_64bits_reset_withSecret \ + XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_reset_withSecret) + #define XXH3_64bits_update XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_update) + #define XXH3_64bits_digest XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_digest) + #define XXH3_generateSecret XXH_NAME2(XXH_NAMESPACE, XXH3_generateSecret) + /* XXH3_128bits */ + #define XXH128 XXH_NAME2(XXH_NAMESPACE, XXH128) + #define XXH3_128bits XXH_NAME2(XXH_NAMESPACE, XXH3_128bits) + #define XXH3_128bits_withSeed \ + XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_withSeed) + #define XXH3_128bits_withSecret \ + XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_withSecret) + #define XXH3_128bits_reset XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_reset) + #define XXH3_128bits_reset_withSeed \ + XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_reset_withSeed) + #define XXH3_128bits_reset_withSecret \ + XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_reset_withSecret) + #define XXH3_128bits_update XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_update) + #define XXH3_128bits_digest XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_digest) + #define XXH128_isEqual XXH_NAME2(XXH_NAMESPACE, XXH128_isEqual) + #define XXH128_cmp XXH_NAME2(XXH_NAMESPACE, XXH128_cmp) + #define XXH128_canonicalFromHash \ + XXH_NAME2(XXH_NAMESPACE, XXH128_canonicalFromHash) + #define XXH128_hashFromCanonical \ + XXH_NAME2(XXH_NAMESPACE, XXH128_hashFromCanonical) #endif /* ************************************* * Version ***************************************/ #define XXH_VERSION_MAJOR 0 - #define XXH_VERSION_MINOR 7 - #define XXH_VERSION_RELEASE 4 + #define XXH_VERSION_MINOR 8 + #define XXH_VERSION_RELEASE 0 #define XXH_VERSION_NUMBER \ (XXH_VERSION_MAJOR * 100 * 100 + XXH_VERSION_MINOR * 100 + \ XXH_VERSION_RELEASE) @@ -401,145 +439,56 @@ XXH_PUBLIC_API void XXH64_canonicalFromHash(XXH64_canonical_t *dst, XXH_PUBLIC_API XXH64_hash_t XXH64_hashFromCanonical(const XXH64_canonical_t *src); - #endif /* XXH_NO_LONG_LONG */ - -#endif /* XXHASH_H_5627135585666179 */ - -#if defined(XXH_STATIC_LINKING_ONLY) && !defined(XXHASH_H_STATIC_13879238742) - #define XXHASH_H_STATIC_13879238742 -/* **************************************************************************** - * This section contains declarations which are not guaranteed to remain stable. - * They may change in future versions, becoming incompatible with a different - * version of the library. - * These declarations should only be used with static linking. - * Never use them in association with dynamic linking! - ***************************************************************************** - */ +/*-********************************************************************** + * XXH3 64-bit variant + ************************************************************************/ -/* - * These definitions are only present to allow static allocation of an XXH - * state, for example, on the stack or in a struct. - * Never **ever** access members directly. +/* ************************************************************************ + * XXH3 is a new hash algorithm featuring: + * - Improved speed for both small and large inputs + * - True 64-bit and 128-bit outputs + * - SIMD acceleration + * - Improved 32-bit viability + * + * Speed analysis methodology is explained here: + * + * https://fastcompression.blogspot.com/2019/03/presenting-xxh3.html + * + * In general, expect XXH3 to run about ~2x faster on large inputs and >3x + * faster on small ones compared to XXH64, though exact differences depend on + * the platform. + * + * The algorithm is portable: Like XXH32 and XXH64, it generates the same hash + * on all platforms. + * + * It benefits greatly from SIMD and 64-bit arithmetic, but does not require it. + * + * Almost all 32-bit and 64-bit targets that can run XXH32 smoothly can run + * XXH3 at competitive speeds, even if XXH64 runs slowly. Further details are + * explained in the implementation. + * + * Optimized implementations are provided for AVX512, AVX2, SSE2, NEON, POWER8, + * ZVector and scalar targets. This can be controlled with the XXH_VECTOR macro. + * + * XXH3 offers 2 variants, _64bits and _128bits. + * When only 64 bits are needed, prefer calling the _64bits variant, as it + * reduces the amount of mixing, resulting in faster speed on small inputs. + * + * It's also generally simpler to manipulate a scalar return type than a struct. + * + * The 128-bit version adds additional strength, but it is slightly slower. + * + * Return values of XXH3 and XXH128 are officially finalized starting + * with v0.8.0 and will no longer change in future versions. + * Avoid storing values from before that release in long-term storage. + * + * Results produced by v0.7.x are not comparable with results from v0.7.y. + * However, the API is completely stable, and it can safely be used for + * ephemeral data (local sessions). + * + * The API supports one-shot hashing, streaming mode, and custom secrets. */ -struct XXH32_state_s { - - XXH32_hash_t total_len_32; - XXH32_hash_t large_len; - XXH32_hash_t v1; - XXH32_hash_t v2; - XXH32_hash_t v3; - XXH32_hash_t v4; - XXH32_hash_t mem32[4]; - XXH32_hash_t memsize; - XXH32_hash_t - reserved; /* never read nor write, might be removed in a future version */ - -}; /* typedef'd to XXH32_state_t */ - - #ifndef XXH_NO_LONG_LONG /* defined when there is no 64-bit support */ - -struct XXH64_state_s { - - XXH64_hash_t total_len; - XXH64_hash_t v1; - XXH64_hash_t v2; - XXH64_hash_t v3; - XXH64_hash_t v4; - XXH64_hash_t mem64[4]; - XXH32_hash_t memsize; - XXH32_hash_t reserved32; /* required for padding anyway */ - XXH64_hash_t reserved64; /* never read nor write, might be removed in a future - version */ - -}; /* typedef'd to XXH64_state_t */ - - /*-********************************************************************** - * XXH3 - * New experimental hash - ************************************************************************/ - - /* ************************************************************************ - * XXH3 is a new hash algorithm featuring: - * - Improved speed for both small and large inputs - * - True 64-bit and 128-bit outputs - * - SIMD acceleration - * - Improved 32-bit viability - * - * Speed analysis methodology is explained here: - * - * https://fastcompression.blogspot.com/2019/03/presenting-xxh3.html - * - * In general, expect XXH3 to run about ~2x faster on large inputs and >3x - * faster on small ones compared to XXH64, though exact differences depend on - * the platform. - * - * The algorithm is portable: Like XXH32 and XXH64, it generates the same hash - * on all platforms. - * - * It benefits greatly from SIMD and 64-bit arithmetic, but does not require - * it. - * - * Almost all 32-bit and 64-bit targets that can run XXH32 smoothly can run - * XXH3 at competitive speeds, even if XXH64 runs slowly. Further details are - * explained in the implementation. - * - * Optimized implementations are provided for AVX512, AVX2, SSE2, NEON, - * POWER8, ZVector and scalar targets. This can be controlled with the - * XXH_VECTOR macro. - * - * XXH3 offers 2 variants, _64bits and _128bits. - * When only 64 bits are needed, prefer calling the _64bits variant, as it - * reduces the amount of mixing, resulting in faster speed on small inputs. - * - * It's also generally simpler to manipulate a scalar return type than a - * struct. - * - * The 128-bit version adds additional strength, but it is slightly slower. - * - * The XXH3 algorithm is still in development. - * The results it produces may still change in future versions. - * - * Results produced by v0.7.x are not comparable with results from v0.7.y. - * However, the API is completely stable, and it can safely be used for - * ephemeral data (local sessions). - * - * Avoid storing values in long-term storage until the algorithm is finalized. - * - * Since v0.7.3, XXH3 has reached "release candidate" status, meaning that, if - * everything remains fine, its current format will be "frozen" and become the - * final one. - * - * After which, return values of XXH3 and XXH128 will no longer change in - * future versions. - * - * XXH3's return values will be officially finalized upon reaching v0.8.0. - * - * The API supports one-shot hashing, streaming mode, and custom secrets. - */ - - #ifdef XXH_NAMESPACE - #define XXH3_64bits XXH_NAME2(XXH_NAMESPACE, XXH3_64bits) - #define XXH3_64bits_withSecret \ - XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_withSecret) - #define XXH3_64bits_withSeed \ - XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_withSeed) - - #define XXH3_createState XXH_NAME2(XXH_NAMESPACE, XXH3_createState) - #define XXH3_freeState XXH_NAME2(XXH_NAMESPACE, XXH3_freeState) - #define XXH3_copyState XXH_NAME2(XXH_NAMESPACE, XXH3_copyState) - - #define XXH3_64bits_reset XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_reset) - #define XXH3_64bits_reset_withSeed \ - XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_reset_withSeed) - #define XXH3_64bits_reset_withSecret \ - XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_reset_withSecret) - #define XXH3_64bits_update XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_update) - #define XXH3_64bits_digest XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_digest) - - #define XXH3_generateSecret XXH_NAME2(XXH_NAMESPACE, XXH3_generateSecret) - #endif - /* XXH3_64bits(): * default 64-bit variant, using default secret and default seed of 0. * It's the fastest variant. */ @@ -547,8 +496,8 @@ XXH_PUBLIC_API XXH64_hash_t XXH3_64bits(const void *data, size_t len); /* * XXH3_64bits_withSeed(): - * This variant generates a custom secret on the fly based on the default - * secret, altered using the `seed` value. + * This variant generates a custom secret on the fly + * based on default secret altered using the `seed` value. * While this operation is decently fast, note that it's not completely free. * Note: seed==0 produces the same results as XXH3_64bits(). */ @@ -559,74 +508,28 @@ XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSeed(const void *data, size_t len, * XXH3_64bits_withSecret(): * It's possible to provide any blob of bytes as a "secret" to generate the * hash. This makes it more difficult for an external actor to prepare an - * intentional collision. secretSize *must* be large enough (>= - * XXH3_SECRET_SIZE_MIN). The hash quality depends on the secret's high - * entropy, meaning that the secret should look like a bunch of random - * bytes. Avoid "trivial" sequences such as text or a bunch of repeated - * characters. If you are unsure of the "randonmess" of the blob of bytes, - * consider making it a "custom seed" instead, - * and use "XXH_generateSecret()" to generate a high quality secret. + * intentional collision. The main condition is that secretSize *must* be + * large enough (>= XXH3_SECRET_SIZE_MIN). However, the quality of produced + * hash values depends on secret's entropy. Technically, the secret must + * look like a bunch of random bytes. Avoid "trivial" or structured data + * such as repeated sequences or a text document. Whenever unsure about the + * "randomness" of the blob of bytes, consider relabelling it as a "custom + * seed" instead, and employ "XXH3_generateSecret()" (see below) to generate + * a high entropy secret derived from the custom seed. */ #define XXH3_SECRET_SIZE_MIN 136 XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSecret(const void *data, size_t len, const void *secret, size_t secretSize); - /* streaming 64-bit */ - - #if defined(__STDC_VERSION__) && (__STDC_VERSION__ >= 201112L) /* C11+ */ - #include <stdalign.h> - #define XXH_ALIGN(n) alignas(n) - #elif defined(__GNUC__) - #define XXH_ALIGN(n) __attribute__((aligned(n))) - #elif defined(_MSC_VER) - #define XXH_ALIGN(n) __declspec(align(n)) - #else - #define XXH_ALIGN(n) /* disabled */ - #endif - - /* Old GCC versions only accept the attribute after the type in structures. - */ - #if !(defined(__STDC_VERSION__) && \ - (__STDC_VERSION__ >= 201112L)) /* C11+ */ \ - && defined(__GNUC__) - #define XXH_ALIGN_MEMBER(align, type) type XXH_ALIGN(align) - #else - #define XXH_ALIGN_MEMBER(align, type) XXH_ALIGN(align) type - #endif - -typedef struct XXH3_state_s XXH3_state_t; - - #define XXH3_INTERNALBUFFER_SIZE 256 - #define XXH3_SECRET_DEFAULT_SIZE 192 -struct XXH3_state_s { - - XXH_ALIGN_MEMBER(64, XXH64_hash_t acc[8]); - /* used to store a custom secret generated from a seed */ - XXH_ALIGN_MEMBER(64, unsigned char customSecret[XXH3_SECRET_DEFAULT_SIZE]); - XXH_ALIGN_MEMBER(64, unsigned char buffer[XXH3_INTERNALBUFFER_SIZE]); - XXH32_hash_t bufferedSize; - XXH32_hash_t reserved32; - size_t nbStripesPerBlock; - size_t nbStripesSoFar; - size_t secretLimit; - XXH64_hash_t totalLen; - XXH64_hash_t seed; - XXH64_hash_t reserved64; - const unsigned char *extSecret; /* reference to external secret; - * if == NULL, use .customSecret instead */ - /* note: there may be some padding at the end due to alignment on 64 bytes */ - -}; /* typedef'd to XXH3_state_t */ - - #undef XXH_ALIGN_MEMBER - +/******* Streaming *******/ /* * Streaming requires state maintenance. * This operation costs memory and CPU. * As a consequence, streaming is slower than one-shot hashing. - * For better performance, prefer one-shot functions whenever possible. + * For better performance, prefer one-shot functions whenever applicable. */ +typedef struct XXH3_state_s XXH3_state_t; XXH_PUBLIC_API XXH3_state_t *XXH3_createState(void); XXH_PUBLIC_API XXH_errorcode XXH3_freeState(XXH3_state_t *statePtr); XXH_PUBLIC_API void XXH3_copyState(XXH3_state_t * dst_state, @@ -634,8 +537,8 @@ XXH_PUBLIC_API void XXH3_copyState(XXH3_state_t * dst_state, /* * XXH3_64bits_reset(): - * Initialize with the default parameters. - * The result will be equivalent to `XXH3_64bits()`. + * Initialize with default parameters. + * digest will be equivalent to `XXH3_64bits()`. */ XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset(XXH3_state_t *statePtr); /* @@ -647,9 +550,12 @@ XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSeed(XXH3_state_t *statePtr, XXH64_hash_t seed); /* * XXH3_64bits_reset_withSecret(): - * `secret` is referenced, and must outlive the hash streaming session, so - * be careful when using stack arrays. - * `secretSize` must be >= `XXH3_SECRET_SIZE_MIN`. + * `secret` is referenced, it _must outlive_ the hash streaming session. + * Similar to one-shot API, `secretSize` must be >= `XXH3_SECRET_SIZE_MIN`, + * and the quality of produced hash values depends on secret's entropy + * (secret's content should look like a bunch of random bytes). + * When in doubt about the randomness of a candidate `secret`, + * consider employing `XXH3_generateSecret()` instead (see below). */ XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSecret( XXH3_state_t *statePtr, const void *secret, size_t secretSize); @@ -659,31 +565,12 @@ XXH_PUBLIC_API XXH_errorcode XXH3_64bits_update(XXH3_state_t *statePtr, size_t length); XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_digest(const XXH3_state_t *statePtr); - /* 128-bit */ - - #ifdef XXH_NAMESPACE - #define XXH128 XXH_NAME2(XXH_NAMESPACE, XXH128) - #define XXH3_128bits XXH_NAME2(XXH_NAMESPACE, XXH3_128bits) - #define XXH3_128bits_withSeed \ - XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_withSeed) - #define XXH3_128bits_withSecret \ - XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_withSecret) - - #define XXH3_128bits_reset XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_reset) - #define XXH3_128bits_reset_withSeed \ - XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_reset_withSeed) - #define XXH3_128bits_reset_withSecret \ - XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_reset_withSecret) - #define XXH3_128bits_update XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_update) - #define XXH3_128bits_digest XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_digest) - - #define XXH128_isEqual XXH_NAME2(XXH_NAMESPACE, XXH128_isEqual) - #define XXH128_cmp XXH_NAME2(XXH_NAMESPACE, XXH128_cmp) - #define XXH128_canonicalFromHash \ - XXH_NAME2(XXH_NAMESPACE, XXH128_canonicalFromHash) - #define XXH128_hashFromCanonical \ - XXH_NAME2(XXH_NAMESPACE, XXH128_hashFromCanonical) - #endif +/* note : canonical representation of XXH3 is the same as XXH64 + * since they both produce XXH64_hash_t values */ + +/*-********************************************************************** + * XXH3 128-bit variant + ************************************************************************/ typedef struct { @@ -692,16 +579,28 @@ typedef struct { } XXH128_hash_t; -XXH_PUBLIC_API XXH128_hash_t XXH128(const void *data, size_t len, - XXH64_hash_t seed); XXH_PUBLIC_API XXH128_hash_t XXH3_128bits(const void *data, size_t len); -XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_withSeed( - const void *data, size_t len, XXH64_hash_t seed); /* == XXH128() */ +XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_withSeed(const void *data, size_t len, + XXH64_hash_t seed); XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_withSecret(const void *data, size_t len, const void *secret, size_t secretSize); +/******* Streaming *******/ +/* + * Streaming requires state maintenance. + * This operation costs memory and CPU. + * As a consequence, streaming is slower than one-shot hashing. + * For better performance, prefer one-shot functions whenever applicable. + * + * XXH3_128bits uses the same XXH3_state_t as XXH3_64bits(). + * Use already declared XXH3_createState() and XXH3_freeState(). + * + * All reset and streaming functions have same meaning as their 64-bit + * counterpart. + */ + XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset(XXH3_state_t *statePtr); XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset_withSeed(XXH3_state_t *statePtr, XXH64_hash_t seed); @@ -713,7 +612,10 @@ XXH_PUBLIC_API XXH_errorcode XXH3_128bits_update(XXH3_state_t *statePtr, size_t length); XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_digest(const XXH3_state_t *statePtr); -/* Note: For better performance, these functions can be inlined using +/* Following helper functions make it possible to compare XXH128_hast_t values. + * Since XXH128_hash_t is a structure, this capability is not offered by the + * language. + * Note: For better performance, these functions can be inlined using * XXH_INLINE_ALL */ /*! @@ -745,6 +647,116 @@ XXH_PUBLIC_API void XXH128_canonicalFromHash(XXH128_canonical_t *dst, XXH_PUBLIC_API XXH128_hash_t XXH128_hashFromCanonical(const XXH128_canonical_t *src); + #endif /* XXH_NO_LONG_LONG */ + +#endif /* XXHASH_H_5627135585666179 */ + +#if defined(XXH_STATIC_LINKING_ONLY) && !defined(XXHASH_H_STATIC_13879238742) + #define XXHASH_H_STATIC_13879238742 +/* **************************************************************************** + * This section contains declarations which are not guaranteed to remain stable. + * They may change in future versions, becoming incompatible with a different + * version of the library. + * These declarations should only be used with static linking. + * Never use them in association with dynamic linking! + ***************************************************************************** + */ + +/* + * These definitions are only present to allow static allocation + * of XXH states, on stack or in a struct, for example. + * Never **ever** access their members directly. + */ + +struct XXH32_state_s { + + XXH32_hash_t total_len_32; + XXH32_hash_t large_len; + XXH32_hash_t v1; + XXH32_hash_t v2; + XXH32_hash_t v3; + XXH32_hash_t v4; + XXH32_hash_t mem32[4]; + XXH32_hash_t memsize; + XXH32_hash_t + reserved; /* never read nor write, might be removed in a future version */ + +}; /* typedef'd to XXH32_state_t */ + + #ifndef XXH_NO_LONG_LONG /* defined when there is no 64-bit support */ + +struct XXH64_state_s { + + XXH64_hash_t total_len; + XXH64_hash_t v1; + XXH64_hash_t v2; + XXH64_hash_t v3; + XXH64_hash_t v4; + XXH64_hash_t mem64[4]; + XXH32_hash_t memsize; + XXH32_hash_t reserved32; /* required for padding anyway */ + XXH64_hash_t reserved64; /* never read nor write, might be removed in a future + version */ + +}; /* typedef'd to XXH64_state_t */ + + #if defined(__STDC_VERSION__) && (__STDC_VERSION__ >= 201112L) /* C11+ */ + #include <stdalign.h> + #define XXH_ALIGN(n) alignas(n) + #elif defined(__GNUC__) + #define XXH_ALIGN(n) __attribute__((aligned(n))) + #elif defined(_MSC_VER) + #define XXH_ALIGN(n) __declspec(align(n)) + #else + #define XXH_ALIGN(n) /* disabled */ + #endif + + /* Old GCC versions only accept the attribute after the type in structures. + */ + #if !(defined(__STDC_VERSION__) && \ + (__STDC_VERSION__ >= 201112L)) /* C11+ */ \ + && defined(__GNUC__) + #define XXH_ALIGN_MEMBER(align, type) type XXH_ALIGN(align) + #else + #define XXH_ALIGN_MEMBER(align, type) XXH_ALIGN(align) type + #endif + + #define XXH3_INTERNALBUFFER_SIZE 256 + #define XXH3_SECRET_DEFAULT_SIZE 192 +struct XXH3_state_s { + + XXH_ALIGN_MEMBER(64, XXH64_hash_t acc[8]); + /* used to store a custom secret generated from a seed */ + XXH_ALIGN_MEMBER(64, unsigned char customSecret[XXH3_SECRET_DEFAULT_SIZE]); + XXH_ALIGN_MEMBER(64, unsigned char buffer[XXH3_INTERNALBUFFER_SIZE]); + XXH32_hash_t bufferedSize; + XXH32_hash_t reserved32; + size_t nbStripesSoFar; + XXH64_hash_t totalLen; + size_t nbStripesPerBlock; + size_t secretLimit; + XXH64_hash_t seed; + XXH64_hash_t reserved64; + const unsigned char *extSecret; /* reference to external secret; + * if == NULL, use .customSecret instead */ + /* note: there may be some padding at the end due to alignment on 64 bytes */ + +}; /* typedef'd to XXH3_state_t */ + + #undef XXH_ALIGN_MEMBER + + /* When the XXH3_state_t structure is merely emplaced on stack, + * it should be initialized with XXH3_INITSTATE() or a memset() + * in case its first reset uses XXH3_NNbits_reset_withSeed(). + * This init can be omitted if the first reset uses default or _withSecret + * mode. This operation isn't necessary when the state is created with + * XXH3_createState(). Note that this doesn't prepare the state for a + * streaming operation, it's still necessary to use XXH3_NNbits_reset*() + * afterwards. + */ + #define XXH3_INITSTATE(XXH3_state_ptr) \ + { (XXH3_state_ptr)->seed = 0; } + /* === Experimental API === */ /* Symbols defined below must be considered tied to a specific library version. */ @@ -752,17 +764,19 @@ XXH128_hashFromCanonical(const XXH128_canonical_t *src); /* * XXH3_generateSecret(): * - * Derive a secret for use with `*_withSecret()` prototypes of XXH3. - * Use this if you need a higher level of security than the one provided by - * 64bit seed. + * Derive a high-entropy secret from any user-defined content, named customSeed. + * The generated secret can be used in combination with `*_withSecret()` + * functions. The `_withSecret()` variants are useful to provide a higher level + * of protection than 64-bit seed, as it becomes much more difficult for an + * external actor to guess how to impact the calculation logic. * - * Take as input a custom seed of any length and any content, - * generate from it a high-entropy secret of length XXH3_SECRET_DEFAULT_SIZE - * into already allocated buffer secretBuffer. - * The generated secret ALWAYS is XXH_SECRET_DEFAULT_SIZE bytes long. + * The function accepts as input a custom seed of any length and any content, + * and derives from it a high-entropy secret of length XXH3_SECRET_DEFAULT_SIZE + * into an already allocated buffer secretBuffer. + * The generated secret is _always_ XXH_SECRET_DEFAULT_SIZE bytes long. * * The generated secret can then be used with any `*_withSecret()` variant. - * The functions `XXH3_128bits_withSecret()`, `XXH3_64bits_withSecret()`, + * Functions `XXH3_128bits_withSecret()`, `XXH3_64bits_withSecret()`, * `XXH3_128bits_reset_withSecret()` and `XXH3_64bits_reset_withSecret()` * are part of this list. They all accept a `secret` parameter * which must be very long for implementation reasons (>= XXH3_SECRET_SIZE_MIN) @@ -771,8 +785,8 @@ XXH128_hashFromCanonical(const XXH128_canonical_t *src); * this function can be used to generate a secret of proper quality. * * customSeed can be anything. It can have any size, even small ones, - * and its content can be anything, even some "low entropy" source such as a - * bunch of zeroes. The resulting `secret` will nonetheless respect all expected + * and its content can be anything, even stupidly "low entropy" source such as a + * bunch of zeroes. The resulting `secret` will nonetheless provide all expected * qualities. * * Supplying NULL as the customSeed copies the default secret into @@ -783,6 +797,10 @@ XXH_PUBLIC_API void XXH3_generateSecret(void * secretBuffer, const void *customSeed, size_t customSeedSize); +/* simple short-cut to pre-selected XXH3_128bits variant */ +XXH_PUBLIC_API XXH128_hash_t XXH128(const void *data, size_t len, + XXH64_hash_t seed); + #endif /* XXH_NO_LONG_LONG */ #if defined(XXH_INLINE_ALL) || defined(XXH_PRIVATE_API) @@ -799,17 +817,23 @@ XXH_PUBLIC_API void XXH3_generateSecret(void * secretBuffer, /*-********************************************************************** * xxHash implementation *-********************************************************************** - * xxHash's implementation used to be found in xxhash.c. + * xxHash's implementation used to be hosted inside xxhash.c. * - * However, code inlining requires the implementation to be visible to the - * compiler, usually within the header. + * However, inlining requires implementation to be visible to the compiler, + * hence be included alongside the header. + * Previously, implementation was hosted inside xxhash.c, + * which was then #included when inlining was activated. + * This construction created issues with a few build and install systems, + * as it required xxhash.c to be stored in /include directory. * - * As a workaround, xxhash.c used to be included within xxhash.h. This caused - * some issues with some build systems, especially ones which treat .c files - * as source files. + * xxHash implementation is now directly integrated within xxhash.h. + * As a consequence, xxhash.c is no longer needed in /include. * - * Therefore, the implementation is now directly integrated within xxhash.h. - * Another small advantage is that xxhash.c is no longer needed in /include. + * xxhash.c is still available and is still useful. + * In a "normal" setup, when xxhash is not inlined, + * xxhash.h only exposes the prototypes and public symbols, + * while xxhash.c can be built into an object file xxhash.o + * which can then be linked into the final binary. ************************************************************************/ #if (defined(XXH_INLINE_ALL) || defined(XXH_PRIVATE_API) || \ @@ -828,10 +852,10 @@ XXH_PUBLIC_API void XXH3_generateSecret(void * secretBuffer, * Unfortunately, on some target/compiler combinations, the generated assembly * is sub-optimal. * - * The below switch allow to select a different access method for improved - * performance. + * The below switch allow selection of a different access method + * in the search for improved performance. * Method 0 (default): - * Use `memcpy()`. Safe and portable. + * Use `memcpy()`. Safe and portable. Default. * Method 1: * `__attribute__((packed))` statement. It depends on compiler extensions * and is therefore not portable. @@ -843,7 +867,7 @@ XXH_PUBLIC_API void XXH3_generateSecret(void * secretBuffer, * It can generate buggy code on targets which do not support unaligned * memory accesses. * But in some circumstances, it's the only known way to get the most - * performance (ie GCC + ARMv6) + * performance (example: GCC + ARMv6) * Method 3: * Byteshift. This can generate the best code on old compilers which don't * inline small `memcpy()` calls, and it might also be faster on @@ -924,7 +948,8 @@ XXH_PUBLIC_API void XXH3_generateSecret(void * secretBuffer, * -fno-inline with GCC or Clang, this will automatically be defined. */ #ifndef XXH_NO_INLINE_HINTS - #if defined(__OPTIMIZE_SIZE__) || defined(__NO_INLINE__) + #if defined(__OPTIMIZE_SIZE__) /* -Os, -Oz */ \ + || defined(__NO_INLINE__) /* -O0, -fno-inline */ #define XXH_NO_INLINE_HINTS 1 #else #define XXH_NO_INLINE_HINTS 0 @@ -950,8 +975,8 @@ XXH_PUBLIC_API void XXH3_generateSecret(void * secretBuffer, * Includes & Memory related functions ***************************************/ /*! - * Modify the local functions below should you wish to use some other memory - * routines for malloc() and free() + * Modify the local functions below should you wish to use + * different memory routines for malloc() and free() */ #include <stdlib.h> @@ -1137,7 +1162,8 @@ typedef enum { XXH_bigEndian = 0, XXH_littleEndian = 1 } XXH_endianess; * Try to detect endianness automatically, to avoid the nonstandard behavior * in `XXH_isLittleEndian()` */ - #if defined(_WIN32) || defined(__LITTLE_ENDIAN__) || \ + #if defined(_WIN32) /* Windows is always little endian */ \ + || defined(__LITTLE_ENDIAN__) || \ (defined(__BYTE_ORDER__) && __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__) #define XXH_CPU_LITTLE_ENDIAN 1 #elif defined(__BIG_ENDIAN__) || \ @@ -1778,13 +1804,16 @@ typedef XXH64_hash_t xxh_u64; * rerolled. */ #ifndef XXH_REROLL_XXH64 - #if (defined(__ILP32__) || defined(_ILP32)) || \ - !(defined(__x86_64__) || defined(_M_X64) || defined(_M_AMD64) || \ - defined(_M_ARM64) || defined(__aarch64__) || defined(__arm64__) || \ - defined(__PPC64__) || defined(__PPC64LE__) || \ - defined(__ppc64__) || defined(__powerpc64__) || \ - defined(__mips64__) || defined(__mips64)) || \ - (!defined(SIZE_MAX) || SIZE_MAX < ULLONG_MAX) + #if (defined(__ILP32__) || \ + defined(_ILP32)) /* ILP32 is often defined on 32-bit GCC family */ \ + || !(defined(__x86_64__) || defined(_M_X64) || \ + defined(_M_AMD64) /* x86-64 */ \ + || defined(_M_ARM64) || defined(__aarch64__) || \ + defined(__arm64__) /* aarch64 */ \ + || defined(__PPC64__) || defined(__PPC64LE__) || \ + defined(__ppc64__) || defined(__powerpc64__) /* ppc64 */ \ + || defined(__mips64__) || defined(__mips64)) /* mips64 */ \ + || (!defined(SIZE_MAX) || SIZE_MAX < ULLONG_MAX) /* check limits */ #define XXH_REROLL_XXH64 1 #else #define XXH_REROLL_XXH64 0 @@ -2428,7 +2457,3134 @@ XXH64_hashFromCanonical(const XXH64_canonical_t *src) { * New generation hash designed for speed on small keys and vectorization ************************************************************************ */ - #include "xxh3.h" + /* === Compiler specifics === */ + + #if defined(__STDC_VERSION__) && __STDC_VERSION__ >= 199901L /* >= C99 */ + #define XXH_RESTRICT restrict + #else + /* Note: it might be useful to define __restrict or __restrict__ for some + * C++ compilers */ + #define XXH_RESTRICT /* disable */ + #endif + + #if (defined(__GNUC__) && (__GNUC__ >= 3)) || \ + (defined(__INTEL_COMPILER) && (__INTEL_COMPILER >= 800)) || \ + defined(__clang__) + #define XXH_likely(x) __builtin_expect(x, 1) + #define XXH_unlikely(x) __builtin_expect(x, 0) + #else + #define XXH_likely(x) (x) + #define XXH_unlikely(x) (x) + #endif + + #if defined(__GNUC__) + #if defined(__AVX2__) + #include <immintrin.h> + #elif defined(__SSE2__) + #include <emmintrin.h> + #elif defined(__ARM_NEON__) || defined(__ARM_NEON) + #define inline __inline__ /* circumvent a clang bug */ + #include <arm_neon.h> + #undef inline + #endif + #elif defined(_MSC_VER) + #include <intrin.h> + #endif + + /* + * One goal of XXH3 is to make it fast on both 32-bit and 64-bit, while + * remaining a true 64-bit/128-bit hash function. + * + * This is done by prioritizing a subset of 64-bit operations that can be + * emulated without too many steps on the average 32-bit machine. + * + * For example, these two lines seem similar, and run equally fast on + * 64-bit: + * + * xxh_u64 x; + * x ^= (x >> 47); // good + * x ^= (x >> 13); // bad + * + * However, to a 32-bit machine, there is a major difference. + * + * x ^= (x >> 47) looks like this: + * + * x.lo ^= (x.hi >> (47 - 32)); + * + * while x ^= (x >> 13) looks like this: + * + * // note: funnel shifts are not usually cheap. + * x.lo ^= (x.lo >> 13) | (x.hi << (32 - 13)); + * x.hi ^= (x.hi >> 13); + * + * The first one is significantly faster than the second, simply because the + * shift is larger than 32. This means: + * - All the bits we need are in the upper 32 bits, so we can ignore the + * lower 32 bits in the shift. + * - The shift result will always fit in the lower 32 bits, and therefore, + * we can ignore the upper 32 bits in the xor. + * + * Thanks to this optimization, XXH3 only requires these features to be + * efficient: + * + * - Usable unaligned access + * - A 32-bit or 64-bit ALU + * - If 32-bit, a decent ADC instruction + * - A 32 or 64-bit multiply with a 64-bit result + * - For the 128-bit variant, a decent byteswap helps short inputs. + * + * The first two are already required by XXH32, and almost all 32-bit and + * 64-bit platforms which can run XXH32 can run XXH3 efficiently. + * + * Thumb-1, the classic 16-bit only subset of ARM's instruction set, is one + * notable exception. + * + * First of all, Thumb-1 lacks support for the UMULL instruction which + * performs the important long multiply. This means numerous __aeabi_lmul + * calls. + * + * Second of all, the 8 functional registers are just not enough. + * Setup for __aeabi_lmul, byteshift loads, pointers, and all arithmetic + * need Lo registers, and this shuffling results in thousands more MOVs than + * A32. + * + * A32 and T32 don't have this limitation. They can access all 14 registers, + * do a 32->64 multiply with UMULL, and the flexible operand allowing free + * shifts is helpful, too. + * + * Therefore, we do a quick sanity check. + * + * If compiling Thumb-1 for a target which supports ARM instructions, we + * will emit a warning, as it is not a "sane" platform to compile for. + * + * Usually, if this happens, it is because of an accident and you probably + * need to specify -march, as you likely meant to compile for a newer + * architecture. + * + * Credit: large sections of the vectorial and asm source code paths + * have been contributed by @easyaspi314 + */ + #if defined(__thumb__) && !defined(__thumb2__) && \ + defined(__ARM_ARCH_ISA_ARM) + #warning "XXH3 is highly inefficient without ARM or Thumb-2." + #endif + + /* ========================================== + * Vectorization detection + * ========================================== */ + #define XXH_SCALAR 0 /* Portable scalar version */ + #define XXH_SSE2 1 /* SSE2 for Pentium 4 and all x86_64 */ + #define XXH_AVX2 2 /* AVX2 for Haswell and Bulldozer */ + #define XXH_AVX512 3 /* AVX512 for Skylake and Icelake */ + #define XXH_NEON 4 /* NEON for most ARMv7-A and all AArch64 */ + #define XXH_VSX 5 /* VSX and ZVector for POWER8/z13 */ + + #ifndef XXH_VECTOR /* can be defined on command line */ + #if defined(__AVX512F__) + #define XXH_VECTOR XXH_AVX512 + #elif defined(__AVX2__) + #define XXH_VECTOR XXH_AVX2 + #elif defined(__SSE2__) || defined(_M_AMD64) || defined(_M_X64) || \ + (defined(_M_IX86_FP) && (_M_IX86_FP == 2)) + #define XXH_VECTOR XXH_SSE2 + #elif defined(__GNUC__) /* msvc support maybe later */ \ + && (defined(__ARM_NEON__) || defined(__ARM_NEON)) && \ + (defined(__LITTLE_ENDIAN__) /* We only support little endian NEON */ \ + || (defined(__BYTE_ORDER__) && \ + __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__)) + #define XXH_VECTOR XXH_NEON + #elif (defined(__PPC64__) && defined(__POWER8_VECTOR__)) || \ + (defined(__s390x__) && defined(__VEC__)) && \ + defined(__GNUC__) /* TODO: IBM XL */ + #define XXH_VECTOR XXH_VSX + #else + #define XXH_VECTOR XXH_SCALAR + #endif + #endif + + /* + * Controls the alignment of the accumulator, + * for compatibility with aligned vector loads, which are usually faster. + */ + #ifndef XXH_ACC_ALIGN + #if defined(XXH_X86DISPATCH) + #define XXH_ACC_ALIGN 64 /* for compatibility with avx512 */ + #elif XXH_VECTOR == XXH_SCALAR /* scalar */ + #define XXH_ACC_ALIGN 8 + #elif XXH_VECTOR == XXH_SSE2 /* sse2 */ + #define XXH_ACC_ALIGN 16 + #elif XXH_VECTOR == XXH_AVX2 /* avx2 */ + #define XXH_ACC_ALIGN 32 + #elif XXH_VECTOR == XXH_NEON /* neon */ + #define XXH_ACC_ALIGN 16 + #elif XXH_VECTOR == XXH_VSX /* vsx */ + #define XXH_ACC_ALIGN 16 + #elif XXH_VECTOR == XXH_AVX512 /* avx512 */ + #define XXH_ACC_ALIGN 64 + #endif + #endif + + #if defined(XXH_X86DISPATCH) || XXH_VECTOR == XXH_SSE2 || \ + XXH_VECTOR == XXH_AVX2 || XXH_VECTOR == XXH_AVX512 + #define XXH_SEC_ALIGN XXH_ACC_ALIGN + #else + #define XXH_SEC_ALIGN 8 + #endif + + /* + * UGLY HACK: + * GCC usually generates the best code with -O3 for xxHash. + * + * However, when targeting AVX2, it is overzealous in its unrolling + * resulting in code roughly 3/4 the speed of Clang. + * + * There are other issues, such as GCC splitting _mm256_loadu_si256 into + * _mm_loadu_si128 + _mm256_inserti128_si256. This is an optimization which + * only applies to Sandy and Ivy Bridge... which don't even support AVX2. + * + * That is why when compiling the AVX2 version, it is recommended to use + * either -O2 -mavx2 -march=haswell or -O2 -mavx2 + * -mno-avx256-split-unaligned-load for decent performance, or to use Clang + * instead. + * + * Fortunately, we can control the first one with a pragma that forces GCC + * into -O2, but the other one we can't control without "failed to inline + * always inline function due to target mismatch" warnings. + */ + #if XXH_VECTOR == XXH_AVX2 /* AVX2 */ \ + && defined(__GNUC__) && !defined(__clang__) /* GCC, not Clang */ \ + && defined(__OPTIMIZE__) && \ + !defined(__OPTIMIZE_SIZE__) /* respect -O0 and -Os */ + #pragma GCC push_options + #pragma GCC optimize("-O2") + #endif + + #if XXH_VECTOR == XXH_NEON + /* + * NEON's setup for vmlal_u32 is a little more complicated than it is on + * SSE2, AVX2, and VSX. + * + * While PMULUDQ and VMULEUW both perform a mask, VMLAL.U32 performs an + * upcast. + * + * To do the same operation, the 128-bit 'Q' register needs to be split + * into two 64-bit 'D' registers, performing this operation:: + * + * [ a | b ] | + * '---------. .--------' | | x | + * | .---------' '--------. | + * [ a & 0xFFFFFFFF | b & 0xFFFFFFFF ],[ a >> 32 | b >> 32 ] + * + * Due to significant changes in aarch64, the fastest method for aarch64 + * is completely different than the fastest method for ARMv7-A. + * + * ARMv7-A treats D registers as unions overlaying Q registers, so + * modifying D11 will modify the high half of Q5. This is similar to how + * modifying AH will only affect bits 8-15 of AX on x86. + * + * VZIP takes two registers, and puts even lanes in one register and odd + * lanes in the other. + * + * On ARMv7-A, this strangely modifies both parameters in place instead of + * taking the usual 3-operand form. + * + * Therefore, if we want to do this, we can simply use a D-form VZIP.32 on + * the lower and upper halves of the Q register to end up with the high + * and low halves where we want - all in one instruction. + * + * vzip.32 d10, d11 @ d10 = { d10[0], d11[0] }; d11 = { d10[1], + * d11[1] } + * + * Unfortunately we need inline assembly for this: Instructions modifying + * two registers at once is not possible in GCC or Clang's IR, and they + * have to create a copy. + * + * aarch64 requires a different approach. + * + * In order to make it easier to write a decent compiler for aarch64, many + * quirks were removed, such as conditional execution. + * + * NEON was also affected by this. + * + * aarch64 cannot access the high bits of a Q-form register, and writes to + * a D-form register zero the high bits, similar to how writes to W-form + * scalar registers (or DWORD registers on x86_64) work. + * + * The formerly free vget_high intrinsics now require a vext (with a few + * exceptions) + * + * Additionally, VZIP was replaced by ZIP1 and ZIP2, which are the + * equivalent of PUNPCKL* and PUNPCKH* in SSE, respectively, in order to + * only modify one operand. + * + * The equivalent of the VZIP.32 on the lower and upper halves would be + * this mess: + * + * ext v2.4s, v0.4s, v0.4s, #2 // v2 = { v0[2], v0[3], v0[0], v0[1] + * } zip1 v1.2s, v0.2s, v2.2s // v1 = { v0[0], v2[0] } zip2 v0.2s, + * v0.2s, v1.2s // v0 = { v0[1], v2[1] } + * + * Instead, we use a literal downcast, vmovn_u64 (XTN), and vshrn_n_u64 + * (SHRN): + * + * shrn v1.2s, v0.2d, #32 // v1 = (uint32x2_t)(v0 >> 32); + * xtn v0.2s, v0.2d // v0 = (uint32x2_t)(v0 & 0xFFFFFFFF); + * + * This is available on ARMv7-A, but is less efficient than a single + * VZIP.32. + */ + + /* + * Function-like macro: + * void XXH_SPLIT_IN_PLACE(uint64x2_t &in, uint32x2_t &outLo, uint32x2_t + * &outHi) + * { + + * outLo = (uint32x2_t)(in & 0xFFFFFFFF); + * outHi = (uint32x2_t)(in >> 32); + * in = UNDEFINED; + * } + */ + #if !defined(XXH_NO_VZIP_HACK) /* define to disable */ \ + && defined(__GNUC__) && !defined(__aarch64__) && !defined(__arm64__) + #define XXH_SPLIT_IN_PLACE(in, outLo, outHi) \ + do { \ + \ + /* Undocumented GCC/Clang operand modifier: %e0 = lower D half, \ + * %f0 = upper D half */ \ + /* https://github.com/gcc-mirror/gcc/blob/38cf91e5/gcc/config/arm/arm.c#L22486 \ + */ \ + /* https://github.com/llvm-mirror/llvm/blob/2c4ca683/lib/Target/ARM/ARMAsmPrinter.cpp#L399 \ + */ \ + __asm__("vzip.32 %e0, %f0" : "+w"(in)); \ + (outLo) = vget_low_u32(vreinterpretq_u32_u64(in)); \ + (outHi) = vget_high_u32(vreinterpretq_u32_u64(in)); \ + \ + } while (0) + + #else + #define XXH_SPLIT_IN_PLACE(in, outLo, outHi) \ + do { \ + \ + (outLo) = vmovn_u64(in); \ + (outHi) = vshrn_n_u64((in), 32); \ + \ + } while (0) + + #endif + #endif /* XXH_VECTOR == XXH_NEON */ + + /* + * VSX and Z Vector helpers. + * + * This is very messy, and any pull requests to clean this up are welcome. + * + * There are a lot of problems with supporting VSX and s390x, due to + * inconsistent intrinsics, spotty coverage, and multiple endiannesses. + */ + #if XXH_VECTOR == XXH_VSX + #if defined(__s390x__) + #include <s390intrin.h> + #else + /* gcc's altivec.h can have the unwanted consequence to unconditionally + * #define bool, vector, and pixel keywords, + * with bad consequences for programs already using these keywords for + * other purposes. The paragraph defining these macros is skipped when + * __APPLE_ALTIVEC__ is defined. + * __APPLE_ALTIVEC__ is _generally_ defined automatically by the + * compiler, but it seems that, in some cases, it isn't. Force the build + * macro to be defined, so that keywords are not altered. + */ + #if defined(__GNUC__) && !defined(__APPLE_ALTIVEC__) + #define __APPLE_ALTIVEC__ + #endif + #include <altivec.h> + #endif + +typedef __vector unsigned long long xxh_u64x2; +typedef __vector unsigned char xxh_u8x16; +typedef __vector unsigned xxh_u32x4; + + #ifndef XXH_VSX_BE + #if defined(__BIG_ENDIAN__) || \ + (defined(__BYTE_ORDER__) && \ + __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__) + #define XXH_VSX_BE 1 + #elif defined(__VEC_ELEMENT_REG_ORDER__) && \ + __VEC_ELEMENT_REG_ORDER__ == __ORDER_BIG_ENDIAN__ + #warning \ + "-maltivec=be is not recommended. Please use native endianness." + #define XXH_VSX_BE 1 + #else + #define XXH_VSX_BE 0 + #endif + #endif /* !defined(XXH_VSX_BE) */ + + #if XXH_VSX_BE + /* A wrapper for POWER9's vec_revb. */ + #if defined(__POWER9_VECTOR__) || \ + (defined(__clang__) && defined(__s390x__)) + #define XXH_vec_revb vec_revb + #else +XXH_FORCE_INLINE xxh_u64x2 XXH_vec_revb(xxh_u64x2 val) { + + xxh_u8x16 const vByteSwap = {0x07, 0x06, 0x05, 0x04, 0x03, 0x02, 0x01, 0x00, + 0x0F, 0x0E, 0x0D, 0x0C, 0x0B, 0x0A, 0x09, 0x08}; + return vec_perm(val, val, vByteSwap); + +} + + #endif + #endif /* XXH_VSX_BE */ + +/* + * Performs an unaligned load and byte swaps it on big endian. + */ +XXH_FORCE_INLINE xxh_u64x2 XXH_vec_loadu(const void *ptr) { + + xxh_u64x2 ret; + memcpy(&ret, ptr, sizeof(xxh_u64x2)); + #if XXH_VSX_BE + ret = XXH_vec_revb(ret); + #endif + return ret; + +} + + /* + * vec_mulo and vec_mule are very problematic intrinsics on PowerPC + * + * These intrinsics weren't added until GCC 8, despite existing for a + * while, and they are endian dependent. Also, their meaning swap + * depending on version. + * */ + #if defined(__s390x__) + /* s390x is always big endian, no issue on this platform */ + #define XXH_vec_mulo vec_mulo + #define XXH_vec_mule vec_mule + #elif defined(__clang__) && XXH_HAS_BUILTIN(__builtin_altivec_vmuleuw) + /* Clang has a better way to control this, we can just use the builtin + * which doesn't swap. */ + #define XXH_vec_mulo __builtin_altivec_vmulouw + #define XXH_vec_mule __builtin_altivec_vmuleuw + #else +/* gcc needs inline assembly */ +/* Adapted from + * https://github.com/google/highwayhash/blob/master/highwayhash/hh_vsx.h. */ +XXH_FORCE_INLINE xxh_u64x2 XXH_vec_mulo(xxh_u32x4 a, xxh_u32x4 b) { + + xxh_u64x2 result; + __asm__("vmulouw %0, %1, %2" : "=v"(result) : "v"(a), "v"(b)); + return result; + +} + +XXH_FORCE_INLINE xxh_u64x2 XXH_vec_mule(xxh_u32x4 a, xxh_u32x4 b) { + + xxh_u64x2 result; + __asm__("vmuleuw %0, %1, %2" : "=v"(result) : "v"(a), "v"(b)); + return result; + +} + + #endif /* XXH_vec_mulo, XXH_vec_mule */ + #endif /* XXH_VECTOR == XXH_VSX */ + + /* prefetch + * can be disabled, by declaring XXH_NO_PREFETCH build macro */ + #if defined(XXH_NO_PREFETCH) + #define XXH_PREFETCH(ptr) (void)(ptr) /* disabled */ + #else + #if defined(_MSC_VER) && \ + (defined(_M_X64) || \ + defined( \ + _M_I86)) /* _mm_prefetch() is not defined outside of x86/x64 */ + #include <mmintrin.h> /* https://msdn.microsoft.com/fr-fr/library/84szxsww(v=vs.90).aspx */ + #define XXH_PREFETCH(ptr) _mm_prefetch((const char *)(ptr), _MM_HINT_T0) + #elif defined(__GNUC__) && \ + ((__GNUC__ >= 4) || ((__GNUC__ == 3) && (__GNUC_MINOR__ >= 1))) + #define XXH_PREFETCH(ptr) \ + __builtin_prefetch((ptr), 0 /* rw==read */, 3 /* locality */) + #else + #define XXH_PREFETCH(ptr) (void)(ptr) /* disabled */ + #endif + #endif /* XXH_NO_PREFETCH */ + + /* ========================================== + * XXH3 default settings + * ========================================== */ + + #define XXH_SECRET_DEFAULT_SIZE 192 /* minimum XXH3_SECRET_SIZE_MIN */ + + #if (XXH_SECRET_DEFAULT_SIZE < XXH3_SECRET_SIZE_MIN) + #error "default keyset is not large enough" + #endif + +/* Pseudorandom secret taken directly from FARSH */ +XXH_ALIGN(64) +static const xxh_u8 XXH3_kSecret[XXH_SECRET_DEFAULT_SIZE] = { + + 0xb8, 0xfe, 0x6c, 0x39, 0x23, 0xa4, 0x4b, 0xbe, 0x7c, 0x01, 0x81, 0x2c, + 0xf7, 0x21, 0xad, 0x1c, 0xde, 0xd4, 0x6d, 0xe9, 0x83, 0x90, 0x97, 0xdb, + 0x72, 0x40, 0xa4, 0xa4, 0xb7, 0xb3, 0x67, 0x1f, 0xcb, 0x79, 0xe6, 0x4e, + 0xcc, 0xc0, 0xe5, 0x78, 0x82, 0x5a, 0xd0, 0x7d, 0xcc, 0xff, 0x72, 0x21, + 0xb8, 0x08, 0x46, 0x74, 0xf7, 0x43, 0x24, 0x8e, 0xe0, 0x35, 0x90, 0xe6, + 0x81, 0x3a, 0x26, 0x4c, 0x3c, 0x28, 0x52, 0xbb, 0x91, 0xc3, 0x00, 0xcb, + 0x88, 0xd0, 0x65, 0x8b, 0x1b, 0x53, 0x2e, 0xa3, 0x71, 0x64, 0x48, 0x97, + 0xa2, 0x0d, 0xf9, 0x4e, 0x38, 0x19, 0xef, 0x46, 0xa9, 0xde, 0xac, 0xd8, + 0xa8, 0xfa, 0x76, 0x3f, 0xe3, 0x9c, 0x34, 0x3f, 0xf9, 0xdc, 0xbb, 0xc7, + 0xc7, 0x0b, 0x4f, 0x1d, 0x8a, 0x51, 0xe0, 0x4b, 0xcd, 0xb4, 0x59, 0x31, + 0xc8, 0x9f, 0x7e, 0xc9, 0xd9, 0x78, 0x73, 0x64, 0xea, 0xc5, 0xac, 0x83, + 0x34, 0xd3, 0xeb, 0xc3, 0xc5, 0x81, 0xa0, 0xff, 0xfa, 0x13, 0x63, 0xeb, + 0x17, 0x0d, 0xdd, 0x51, 0xb7, 0xf0, 0xda, 0x49, 0xd3, 0x16, 0x55, 0x26, + 0x29, 0xd4, 0x68, 0x9e, 0x2b, 0x16, 0xbe, 0x58, 0x7d, 0x47, 0xa1, 0xfc, + 0x8f, 0xf8, 0xb8, 0xd1, 0x7a, 0xd0, 0x31, 0xce, 0x45, 0xcb, 0x3a, 0x8f, + 0x95, 0x16, 0x04, 0x28, 0xaf, 0xd7, 0xfb, 0xca, 0xbb, 0x4b, 0x40, 0x7e, + +}; + + #ifdef XXH_OLD_NAMES + #define kSecret XXH3_kSecret + #endif + + /* + * Calculates a 32-bit to 64-bit long multiply. + * + * Wraps __emulu on MSVC x86 because it tends to call __allmul when it + * doesn't need to (but it shouldn't need to anyways, it is about 7 + * instructions to do a 64x64 multiply...). Since we know that this will + * _always_ emit MULL, we use that instead of the normal method. + * + * If you are compiling for platforms like Thumb-1 and don't have a better + * option, you may also want to write your own long multiply routine here. + * + * XXH_FORCE_INLINE xxh_u64 XXH_mult32to64(xxh_u64 x, xxh_u64 y) + * { + + * return (x & 0xFFFFFFFF) * (y & 0xFFFFFFFF); + * } + */ + #if defined(_MSC_VER) && defined(_M_IX86) + #include <intrin.h> + #define XXH_mult32to64(x, y) __emulu((unsigned)(x), (unsigned)(y)) + #else + /* + * Downcast + upcast is usually better than masking on older compilers + * like GCC 4.2 (especially 32-bit ones), all without affecting newer + * compilers. + * + * The other method, (x & 0xFFFFFFFF) * (y & 0xFFFFFFFF), will AND both + * operands and perform a full 64x64 multiply -- entirely redundant on + * 32-bit. + */ + #define XXH_mult32to64(x, y) \ + ((xxh_u64)(xxh_u32)(x) * (xxh_u64)(xxh_u32)(y)) + #endif + +/* + * Calculates a 64->128-bit long multiply. + * + * Uses __uint128_t and _umul128 if available, otherwise uses a scalar version. + */ +static XXH128_hash_t XXH_mult64to128(xxh_u64 lhs, xxh_u64 rhs) { + + /* + * GCC/Clang __uint128_t method. + * + * On most 64-bit targets, GCC and Clang define a __uint128_t type. + * This is usually the best way as it usually uses a native long 64-bit + * multiply, such as MULQ on x86_64 or MUL + UMULH on aarch64. + * + * Usually. + * + * Despite being a 32-bit platform, Clang (and emscripten) define this type + * despite not having the arithmetic for it. This results in a laggy + * compiler builtin call which calculates a full 128-bit multiply. + * In that case it is best to use the portable one. + * https://github.com/Cyan4973/xxHash/issues/211#issuecomment-515575677 + */ + #if defined(__GNUC__) && !defined(__wasm__) && \ + defined(__SIZEOF_INT128__) || \ + (defined(_INTEGRAL_MAX_BITS) && _INTEGRAL_MAX_BITS >= 128) + + __uint128_t const product = (__uint128_t)lhs * (__uint128_t)rhs; + XXH128_hash_t r128; + r128.low64 = (xxh_u64)(product); + r128.high64 = (xxh_u64)(product >> 64); + return r128; + + /* + * MSVC for x64's _umul128 method. + * + * xxh_u64 _umul128(xxh_u64 Multiplier, xxh_u64 Multiplicand, xxh_u64 + * *HighProduct); + * + * This compiles to single operand MUL on x64. + */ + #elif defined(_M_X64) || defined(_M_IA64) + + #ifndef _MSC_VER + #pragma intrinsic(_umul128) + #endif + xxh_u64 product_high; + xxh_u64 const product_low = _umul128(lhs, rhs, &product_high); + XXH128_hash_t r128; + r128.low64 = product_low; + r128.high64 = product_high; + return r128; + + #else + /* + * Portable scalar method. Optimized for 32-bit and 64-bit ALUs. + * + * This is a fast and simple grade school multiply, which is shown below + * with base 10 arithmetic instead of base 0x100000000. + * + * 9 3 // D2 lhs = 93 + * x 7 5 // D2 rhs = 75 + * ---------- + * 1 5 // D2 lo_lo = (93 % 10) * (75 % 10) = 15 + * 4 5 | // D2 hi_lo = (93 / 10) * (75 % 10) = 45 + * 2 1 | // D2 lo_hi = (93 % 10) * (75 / 10) = 21 + * + 6 3 | | // D2 hi_hi = (93 / 10) * (75 / 10) = 63 + * --------- + * 2 7 | // D2 cross = (15 / 10) + (45 % 10) + 21 = 27 + * + 6 7 | | // D2 upper = (27 / 10) + (45 / 10) + 63 = 67 + * --------- + * 6 9 7 5 // D4 res = (27 * 10) + (15 % 10) + (67 * 100) = 6975 + * + * The reasons for adding the products like this are: + * 1. It avoids manual carry tracking. Just like how + * (9 * 9) + 9 + 9 = 99, the same applies with this for UINT64_MAX. + * This avoids a lot of complexity. + * + * 2. It hints for, and on Clang, compiles to, the powerful UMAAL + * instruction available in ARM's Digital Signal Processing extension + * in 32-bit ARMv6 and later, which is shown below: + * + * void UMAAL(xxh_u32 *RdLo, xxh_u32 *RdHi, xxh_u32 Rn, xxh_u32 Rm) + * { + + * xxh_u64 product = (xxh_u64)*RdLo * (xxh_u64)*RdHi + Rn + Rm; + * *RdLo = (xxh_u32)(product & 0xFFFFFFFF); + * *RdHi = (xxh_u32)(product >> 32); + * } + * + * This instruction was designed for efficient long multiplication, and + * allows this to be calculated in only 4 instructions at speeds + * comparable to some 64-bit ALUs. + * + * 3. It isn't terrible on other platforms. Usually this will be a couple + * of 32-bit ADD/ADCs. + */ + + /* First calculate all of the cross products. */ + xxh_u64 const lo_lo = XXH_mult32to64(lhs & 0xFFFFFFFF, rhs & 0xFFFFFFFF); + xxh_u64 const hi_lo = XXH_mult32to64(lhs >> 32, rhs & 0xFFFFFFFF); + xxh_u64 const lo_hi = XXH_mult32to64(lhs & 0xFFFFFFFF, rhs >> 32); + xxh_u64 const hi_hi = XXH_mult32to64(lhs >> 32, rhs >> 32); + + /* Now add the products together. These will never overflow. */ + xxh_u64 const cross = (lo_lo >> 32) + (hi_lo & 0xFFFFFFFF) + lo_hi; + xxh_u64 const upper = (hi_lo >> 32) + (cross >> 32) + hi_hi; + xxh_u64 const lower = (cross << 32) | (lo_lo & 0xFFFFFFFF); + + XXH128_hash_t r128; + r128.low64 = lower; + r128.high64 = upper; + return r128; + #endif + +} + +/* + * Does a 64-bit to 128-bit multiply, then XOR folds it. + * + * The reason for the separate function is to prevent passing too many structs + * around by value. This will hopefully inline the multiply, but we don't force + * it. + */ +static xxh_u64 XXH3_mul128_fold64(xxh_u64 lhs, xxh_u64 rhs) { + + XXH128_hash_t product = XXH_mult64to128(lhs, rhs); + return product.low64 ^ product.high64; + +} + +/* Seems to produce slightly better code on GCC for some reason. */ +XXH_FORCE_INLINE xxh_u64 XXH_xorshift64(xxh_u64 v64, int shift) { + + XXH_ASSERT(0 <= shift && shift < 64); + return v64 ^ (v64 >> shift); + +} + +/* + * This is a fast avalanche stage, + * suitable when input bits are already partially mixed + */ +static XXH64_hash_t XXH3_avalanche(xxh_u64 h64) { + + h64 = XXH_xorshift64(h64, 37); + h64 *= 0x165667919E3779F9ULL; + h64 = XXH_xorshift64(h64, 32); + return h64; + +} + +/* + * This is a stronger avalanche, + * inspired by Pelle Evensen's rrmxmx + * preferable when input has not been previously mixed + */ +static XXH64_hash_t XXH3_rrmxmx(xxh_u64 h64, xxh_u64 len) { + + /* this mix is inspired by Pelle Evensen's rrmxmx */ + h64 ^= XXH_rotl64(h64, 49) ^ XXH_rotl64(h64, 24); + h64 *= 0x9FB21C651E98DF25ULL; + h64 ^= (h64 >> 35) + len; + h64 *= 0x9FB21C651E98DF25ULL; + return XXH_xorshift64(h64, 28); + +} + +/* ========================================== + * Short keys + * ========================================== + * One of the shortcomings of XXH32 and XXH64 was that their performance was + * sub-optimal on short lengths. It used an iterative algorithm which strongly + * favored lengths that were a multiple of 4 or 8. + * + * Instead of iterating over individual inputs, we use a set of single shot + * functions which piece together a range of lengths and operate in constant + * time. + * + * Additionally, the number of multiplies has been significantly reduced. This + * reduces latency, especially when emulating 64-bit multiplies on 32-bit. + * + * Depending on the platform, this may or may not be faster than XXH32, but it + * is almost guaranteed to be faster than XXH64. + */ + +/* + * At very short lengths, there isn't enough input to fully hide secrets, or use + * the entire secret. + * + * There is also only a limited amount of mixing we can do before significantly + * impacting performance. + * + * Therefore, we use different sections of the secret and always mix two secret + * samples with an XOR. This should have no effect on performance on the + * seedless or withSeed variants because everything _should_ be constant folded + * by modern compilers. + * + * The XOR mixing hides individual parts of the secret and increases entropy. + * + * This adds an extra layer of strength for custom secrets. + */ +XXH_FORCE_INLINE XXH64_hash_t XXH3_len_1to3_64b(const xxh_u8 *input, size_t len, + const xxh_u8 *secret, + XXH64_hash_t seed) { + + XXH_ASSERT(input != NULL); + XXH_ASSERT(1 <= len && len <= 3); + XXH_ASSERT(secret != NULL); + /* + * len = 1: combined = { input[0], 0x01, input[0], input[0] } + * len = 2: combined = { input[1], 0x02, input[0], input[1] } + * len = 3: combined = { input[2], 0x03, input[0], input[1] } + */ + { + + xxh_u8 const c1 = input[0]; + xxh_u8 const c2 = input[len >> 1]; + xxh_u8 const c3 = input[len - 1]; + xxh_u32 const combined = ((xxh_u32)c1 << 16) | ((xxh_u32)c2 << 24) | + ((xxh_u32)c3 << 0) | ((xxh_u32)len << 8); + xxh_u64 const bitflip = + (XXH_readLE32(secret) ^ XXH_readLE32(secret + 4)) + seed; + xxh_u64 const keyed = (xxh_u64)combined ^ bitflip; + return XXH64_avalanche(keyed); + + } + +} + +XXH_FORCE_INLINE XXH64_hash_t XXH3_len_4to8_64b(const xxh_u8 *input, size_t len, + const xxh_u8 *secret, + XXH64_hash_t seed) { + + XXH_ASSERT(input != NULL); + XXH_ASSERT(secret != NULL); + XXH_ASSERT(4 <= len && len < 8); + seed ^= (xxh_u64)XXH_swap32((xxh_u32)seed) << 32; + { + + xxh_u32 const input1 = XXH_readLE32(input); + xxh_u32 const input2 = XXH_readLE32(input + len - 4); + xxh_u64 const bitflip = + (XXH_readLE64(secret + 8) ^ XXH_readLE64(secret + 16)) - seed; + xxh_u64 const input64 = input2 + (((xxh_u64)input1) << 32); + xxh_u64 const keyed = input64 ^ bitflip; + return XXH3_rrmxmx(keyed, len); + + } + +} + +XXH_FORCE_INLINE XXH64_hash_t XXH3_len_9to16_64b(const xxh_u8 *input, + size_t len, + const xxh_u8 *secret, + XXH64_hash_t seed) { + + XXH_ASSERT(input != NULL); + XXH_ASSERT(secret != NULL); + XXH_ASSERT(8 <= len && len <= 16); + { + + xxh_u64 const bitflip1 = + (XXH_readLE64(secret + 24) ^ XXH_readLE64(secret + 32)) + seed; + xxh_u64 const bitflip2 = + (XXH_readLE64(secret + 40) ^ XXH_readLE64(secret + 48)) - seed; + xxh_u64 const input_lo = XXH_readLE64(input) ^ bitflip1; + xxh_u64 const input_hi = XXH_readLE64(input + len - 8) ^ bitflip2; + xxh_u64 const acc = len + XXH_swap64(input_lo) + input_hi + + XXH3_mul128_fold64(input_lo, input_hi); + return XXH3_avalanche(acc); + + } + +} + +XXH_FORCE_INLINE XXH64_hash_t XXH3_len_0to16_64b(const xxh_u8 *input, + size_t len, + const xxh_u8 *secret, + XXH64_hash_t seed) { + + XXH_ASSERT(len <= 16); + { + + if (XXH_likely(len > 8)) + return XXH3_len_9to16_64b(input, len, secret, seed); + if (XXH_likely(len >= 4)) + return XXH3_len_4to8_64b(input, len, secret, seed); + if (len) return XXH3_len_1to3_64b(input, len, secret, seed); + return XXH64_avalanche( + seed ^ (XXH_readLE64(secret + 56) ^ XXH_readLE64(secret + 64))); + + } + +} + +/* + * DISCLAIMER: There are known *seed-dependent* multicollisions here due to + * multiplication by zero, affecting hashes of lengths 17 to 240. + * + * However, they are very unlikely. + * + * Keep this in mind when using the unseeded XXH3_64bits() variant: As with all + * unseeded non-cryptographic hashes, it does not attempt to defend itself + * against specially crafted inputs, only random inputs. + * + * Compared to classic UMAC where a 1 in 2^31 chance of 4 consecutive bytes + * cancelling out the secret is taken an arbitrary number of times (addressed + * in XXH3_accumulate_512), this collision is very unlikely with random inputs + * and/or proper seeding: + * + * This only has a 1 in 2^63 chance of 8 consecutive bytes cancelling out, in a + * function that is only called up to 16 times per hash with up to 240 bytes of + * input. + * + * This is not too bad for a non-cryptographic hash function, especially with + * only 64 bit outputs. + * + * The 128-bit variant (which trades some speed for strength) is NOT affected + * by this, although it is always a good idea to use a proper seed if you care + * about strength. + */ +XXH_FORCE_INLINE xxh_u64 XXH3_mix16B(const xxh_u8 *XXH_RESTRICT input, + const xxh_u8 *XXH_RESTRICT secret, + xxh_u64 seed64) { + + #if defined(__GNUC__) && !defined(__clang__) /* GCC, not Clang */ \ + && defined(__i386__) && defined(__SSE2__) /* x86 + SSE2 */ \ + && \ + !defined( \ + XXH_ENABLE_AUTOVECTORIZE) /* Define to disable like XXH32 hack */ + /* + * UGLY HACK: + * GCC for x86 tends to autovectorize the 128-bit multiply, resulting in + * slower code. + * + * By forcing seed64 into a register, we disrupt the cost model and + * cause it to scalarize. See `XXH32_round()` + * + * FIXME: Clang's output is still _much_ faster -- On an AMD Ryzen 3600, + * XXH3_64bits @ len=240 runs at 4.6 GB/s with Clang 9, but 3.3 GB/s on + * GCC 9.2, despite both emitting scalar code. + * + * GCC generates much better scalar code than Clang for the rest of XXH3, + * which is why finding a more optimal codepath is an interest. + */ + __asm__("" : "+r"(seed64)); + #endif + { + + xxh_u64 const input_lo = XXH_readLE64(input); + xxh_u64 const input_hi = XXH_readLE64(input + 8); + return XXH3_mul128_fold64(input_lo ^ (XXH_readLE64(secret) + seed64), + input_hi ^ (XXH_readLE64(secret + 8) - seed64)); + + } + +} + +/* For mid range keys, XXH3 uses a Mum-hash variant. */ +XXH_FORCE_INLINE XXH64_hash_t XXH3_len_17to128_64b( + const xxh_u8 *XXH_RESTRICT input, size_t len, + const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, XXH64_hash_t seed) { + + XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); + (void)secretSize; + XXH_ASSERT(16 < len && len <= 128); + + { + + xxh_u64 acc = len * XXH_PRIME64_1; + if (len > 32) { + + if (len > 64) { + + if (len > 96) { + + acc += XXH3_mix16B(input + 48, secret + 96, seed); + acc += XXH3_mix16B(input + len - 64, secret + 112, seed); + + } + + acc += XXH3_mix16B(input + 32, secret + 64, seed); + acc += XXH3_mix16B(input + len - 48, secret + 80, seed); + + } + + acc += XXH3_mix16B(input + 16, secret + 32, seed); + acc += XXH3_mix16B(input + len - 32, secret + 48, seed); + + } + + acc += XXH3_mix16B(input + 0, secret + 0, seed); + acc += XXH3_mix16B(input + len - 16, secret + 16, seed); + + return XXH3_avalanche(acc); + + } + +} + + #define XXH3_MIDSIZE_MAX 240 + +XXH_NO_INLINE XXH64_hash_t XXH3_len_129to240_64b( + const xxh_u8 *XXH_RESTRICT input, size_t len, + const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, XXH64_hash_t seed) { + + XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); + (void)secretSize; + XXH_ASSERT(128 < len && len <= XXH3_MIDSIZE_MAX); + + #define XXH3_MIDSIZE_STARTOFFSET 3 + #define XXH3_MIDSIZE_LASTOFFSET 17 + + { + + xxh_u64 acc = len * XXH_PRIME64_1; + int const nbRounds = (int)len / 16; + int i; + for (i = 0; i < 8; i++) { + + acc += XXH3_mix16B(input + (16 * i), secret + (16 * i), seed); + + } + + acc = XXH3_avalanche(acc); + XXH_ASSERT(nbRounds >= 8); + #if defined(__clang__) /* Clang */ \ + && (defined(__ARM_NEON) || defined(__ARM_NEON__)) /* NEON */ \ + && !defined(XXH_ENABLE_AUTOVECTORIZE) /* Define to disable */ + /* + * UGLY HACK: + * Clang for ARMv7-A tries to vectorize this loop, similar to GCC x86. + * In everywhere else, it uses scalar code. + * + * For 64->128-bit multiplies, even if the NEON was 100% optimal, it + * would still be slower than UMAAL (see XXH_mult64to128). + * + * Unfortunately, Clang doesn't handle the long multiplies properly and + * converts them to the nonexistent "vmulq_u64" intrinsic, which is then + * scalarized into an ugly mess of VMOV.32 instructions. + * + * This mess is difficult to avoid without turning autovectorization + * off completely, but they are usually relatively minor and/or not + * worth it to fix. + * + * This loop is the easiest to fix, as unlike XXH32, this pragma + * _actually works_ because it is a loop vectorization instead of an + * SLP vectorization. + */ + #pragma clang loop vectorize(disable) + #endif + for (i = 8; i < nbRounds; i++) { + + acc += + XXH3_mix16B(input + (16 * i), + secret + (16 * (i - 8)) + XXH3_MIDSIZE_STARTOFFSET, seed); + + } + + /* last bytes */ + acc += XXH3_mix16B(input + len - 16, + secret + XXH3_SECRET_SIZE_MIN - XXH3_MIDSIZE_LASTOFFSET, + seed); + return XXH3_avalanche(acc); + + } + +} + + /* ======= Long Keys ======= */ + + #define XXH_STRIPE_LEN 64 + #define XXH_SECRET_CONSUME_RATE \ + 8 /* nb of secret bytes consumed at each accumulation */ + #define XXH_ACC_NB (XXH_STRIPE_LEN / sizeof(xxh_u64)) + + #ifdef XXH_OLD_NAMES + #define STRIPE_LEN XXH_STRIPE_LEN + #define ACC_NB XXH_ACC_NB + #endif + +XXH_FORCE_INLINE void XXH_writeLE64(void *dst, xxh_u64 v64) { + + if (!XXH_CPU_LITTLE_ENDIAN) v64 = XXH_swap64(v64); + memcpy(dst, &v64, sizeof(v64)); + +} + + /* Several intrinsic functions below are supposed to accept __int64 as + * argument, as documented in + * https://software.intel.com/sites/landingpage/IntrinsicsGuide/ . However, + * several environments do not define __int64 type, requiring a workaround. + */ + #if !defined(__VMS) && \ + (defined(__cplusplus) || (defined(__STDC_VERSION__) && \ + (__STDC_VERSION__ >= 199901L) /* C99 */)) +typedef int64_t xxh_i64; + #else +/* the following type must have a width of 64-bit */ +typedef long long xxh_i64; + #endif + + /* + * XXH3_accumulate_512 is the tightest loop for long inputs, and it is the + * most optimized. + * + * It is a hardened version of UMAC, based off of FARSH's implementation. + * + * This was chosen because it adapts quite well to 32-bit, 64-bit, and SIMD + * implementations, and it is ridiculously fast. + * + * We harden it by mixing the original input to the accumulators as well as + * the product. + * + * This means that in the (relatively likely) case of a multiply by zero, the + * original input is preserved. + * + * On 128-bit inputs, we swap 64-bit pairs when we add the input to improve + * cross-pollination, as otherwise the upper and lower halves would be + * essentially independent. + * + * This doesn't matter on 64-bit hashes since they all get merged together in + * the end, so we skip the extra step. + * + * Both XXH3_64bits and XXH3_128bits use this subroutine. + */ + + #if (XXH_VECTOR == XXH_AVX512) || defined(XXH_X86DISPATCH) + + #ifndef XXH_TARGET_AVX512 + #define XXH_TARGET_AVX512 /* disable attribute target */ + #endif + +XXH_FORCE_INLINE XXH_TARGET_AVX512 void XXH3_accumulate_512_avx512( + void *XXH_RESTRICT acc, const void *XXH_RESTRICT input, + const void *XXH_RESTRICT secret) { + + XXH_ALIGN(64) __m512i *const xacc = (__m512i *)acc; + XXH_ASSERT((((size_t)acc) & 63) == 0); + XXH_STATIC_ASSERT(XXH_STRIPE_LEN == sizeof(__m512i)); + + { + + /* data_vec = input[0]; */ + __m512i const data_vec = _mm512_loadu_si512(input); + /* key_vec = secret[0]; */ + __m512i const key_vec = _mm512_loadu_si512(secret); + /* data_key = data_vec ^ key_vec; */ + __m512i const data_key = _mm512_xor_si512(data_vec, key_vec); + /* data_key_lo = data_key >> 32; */ + __m512i const data_key_lo = + _mm512_shuffle_epi32(data_key, (_MM_PERM_ENUM)_MM_SHUFFLE(0, 3, 0, 1)); + /* product = (data_key & 0xffffffff) * (data_key_lo & 0xffffffff); */ + __m512i const product = _mm512_mul_epu32(data_key, data_key_lo); + /* xacc[0] += swap(data_vec); */ + __m512i const data_swap = + _mm512_shuffle_epi32(data_vec, (_MM_PERM_ENUM)_MM_SHUFFLE(1, 0, 3, 2)); + __m512i const sum = _mm512_add_epi64(*xacc, data_swap); + /* xacc[0] += product; */ + *xacc = _mm512_add_epi64(product, sum); + + } + +} + +/* + * XXH3_scrambleAcc: Scrambles the accumulators to improve mixing. + * + * Multiplication isn't perfect, as explained by Google in HighwayHash: + * + * // Multiplication mixes/scrambles bytes 0-7 of the 64-bit result to + * // varying degrees. In descending order of goodness, bytes + * // 3 4 2 5 1 6 0 7 have quality 228 224 164 160 100 96 36 32. + * // As expected, the upper and lower bytes are much worse. + * + * Source: + * https://github.com/google/highwayhash/blob/0aaf66b/highwayhash/hh_avx2.h#L291 + * + * Since our algorithm uses a pseudorandom secret to add some variance into the + * mix, we don't need to (or want to) mix as often or as much as HighwayHash + * does. + * + * This isn't as tight as XXH3_accumulate, but still written in SIMD to avoid + * extraction. + * + * Both XXH3_64bits and XXH3_128bits use this subroutine. + */ + +XXH_FORCE_INLINE XXH_TARGET_AVX512 void XXH3_scrambleAcc_avx512( + void *XXH_RESTRICT acc, const void *XXH_RESTRICT secret) { + + XXH_ASSERT((((size_t)acc) & 63) == 0); + XXH_STATIC_ASSERT(XXH_STRIPE_LEN == sizeof(__m512i)); + { + + XXH_ALIGN(64) __m512i *const xacc = (__m512i *)acc; + const __m512i prime32 = _mm512_set1_epi32((int)XXH_PRIME32_1); + + /* xacc[0] ^= (xacc[0] >> 47) */ + __m512i const acc_vec = *xacc; + __m512i const shifted = _mm512_srli_epi64(acc_vec, 47); + __m512i const data_vec = _mm512_xor_si512(acc_vec, shifted); + /* xacc[0] ^= secret; */ + __m512i const key_vec = _mm512_loadu_si512(secret); + __m512i const data_key = _mm512_xor_si512(data_vec, key_vec); + + /* xacc[0] *= XXH_PRIME32_1; */ + __m512i const data_key_hi = + _mm512_shuffle_epi32(data_key, (_MM_PERM_ENUM)_MM_SHUFFLE(0, 3, 0, 1)); + __m512i const prod_lo = _mm512_mul_epu32(data_key, prime32); + __m512i const prod_hi = _mm512_mul_epu32(data_key_hi, prime32); + *xacc = _mm512_add_epi64(prod_lo, _mm512_slli_epi64(prod_hi, 32)); + + } + +} + +XXH_FORCE_INLINE XXH_TARGET_AVX512 void XXH3_initCustomSecret_avx512( + void *XXH_RESTRICT customSecret, xxh_u64 seed64) { + + XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE & 63) == 0); + XXH_STATIC_ASSERT(XXH_SEC_ALIGN == 64); + XXH_ASSERT(((size_t)customSecret & 63) == 0); + (void)(&XXH_writeLE64); + { + + int const nbRounds = XXH_SECRET_DEFAULT_SIZE / sizeof(__m512i); + __m512i const seed = _mm512_mask_set1_epi64( + _mm512_set1_epi64((xxh_i64)seed64), 0xAA, -(xxh_i64)seed64); + + XXH_ALIGN(64) const __m512i *const src = (const __m512i *)XXH3_kSecret; + XXH_ALIGN(64) __m512i *const dest = (__m512i *)customSecret; + int i; + for (i = 0; i < nbRounds; ++i) { + + /* GCC has a bug, _mm512_stream_load_si512 accepts 'void*', not 'void + * const*', this will warn "discards ‘const’ qualifier". */ + union { + + XXH_ALIGN(64) const __m512i *cp; + XXH_ALIGN(64) void *p; + + } remote_const_void; + + remote_const_void.cp = src + i; + dest[i] = + _mm512_add_epi64(_mm512_stream_load_si512(remote_const_void.p), seed); + + } + + } + +} + + #endif + + #if (XXH_VECTOR == XXH_AVX2) || defined(XXH_X86DISPATCH) + + #ifndef XXH_TARGET_AVX2 + #define XXH_TARGET_AVX2 /* disable attribute target */ + #endif + +XXH_FORCE_INLINE XXH_TARGET_AVX2 void XXH3_accumulate_512_avx2( + void *XXH_RESTRICT acc, const void *XXH_RESTRICT input, + const void *XXH_RESTRICT secret) { + + XXH_ASSERT((((size_t)acc) & 31) == 0); + { + + XXH_ALIGN(32) __m256i *const xacc = (__m256i *)acc; + /* Unaligned. This is mainly for pointer arithmetic, and because + * _mm256_loadu_si256 requires a const __m256i * pointer for some reason. + */ + const __m256i *const xinput = (const __m256i *)input; + /* Unaligned. This is mainly for pointer arithmetic, and because + * _mm256_loadu_si256 requires a const __m256i * pointer for some reason. */ + const __m256i *const xsecret = (const __m256i *)secret; + + size_t i; + for (i = 0; i < XXH_STRIPE_LEN / sizeof(__m256i); i++) { + + /* data_vec = xinput[i]; */ + __m256i const data_vec = _mm256_loadu_si256(xinput + i); + /* key_vec = xsecret[i]; */ + __m256i const key_vec = _mm256_loadu_si256(xsecret + i); + /* data_key = data_vec ^ key_vec; */ + __m256i const data_key = _mm256_xor_si256(data_vec, key_vec); + /* data_key_lo = data_key >> 32; */ + __m256i const data_key_lo = + _mm256_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); + /* product = (data_key & 0xffffffff) * (data_key_lo & 0xffffffff); */ + __m256i const product = _mm256_mul_epu32(data_key, data_key_lo); + /* xacc[i] += swap(data_vec); */ + __m256i const data_swap = + _mm256_shuffle_epi32(data_vec, _MM_SHUFFLE(1, 0, 3, 2)); + __m256i const sum = _mm256_add_epi64(xacc[i], data_swap); + /* xacc[i] += product; */ + xacc[i] = _mm256_add_epi64(product, sum); + + } + + } + +} + +XXH_FORCE_INLINE XXH_TARGET_AVX2 void XXH3_scrambleAcc_avx2( + void *XXH_RESTRICT acc, const void *XXH_RESTRICT secret) { + + XXH_ASSERT((((size_t)acc) & 31) == 0); + { + + XXH_ALIGN(32) __m256i *const xacc = (__m256i *)acc; + /* Unaligned. This is mainly for pointer arithmetic, and because + * _mm256_loadu_si256 requires a const __m256i * pointer for some reason. */ + const __m256i *const xsecret = (const __m256i *)secret; + const __m256i prime32 = _mm256_set1_epi32((int)XXH_PRIME32_1); + + size_t i; + for (i = 0; i < XXH_STRIPE_LEN / sizeof(__m256i); i++) { + + /* xacc[i] ^= (xacc[i] >> 47) */ + __m256i const acc_vec = xacc[i]; + __m256i const shifted = _mm256_srli_epi64(acc_vec, 47); + __m256i const data_vec = _mm256_xor_si256(acc_vec, shifted); + /* xacc[i] ^= xsecret; */ + __m256i const key_vec = _mm256_loadu_si256(xsecret + i); + __m256i const data_key = _mm256_xor_si256(data_vec, key_vec); + + /* xacc[i] *= XXH_PRIME32_1; */ + __m256i const data_key_hi = + _mm256_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); + __m256i const prod_lo = _mm256_mul_epu32(data_key, prime32); + __m256i const prod_hi = _mm256_mul_epu32(data_key_hi, prime32); + xacc[i] = _mm256_add_epi64(prod_lo, _mm256_slli_epi64(prod_hi, 32)); + + } + + } + +} + +XXH_FORCE_INLINE XXH_TARGET_AVX2 void XXH3_initCustomSecret_avx2( + void *XXH_RESTRICT customSecret, xxh_u64 seed64) { + + XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE & 31) == 0); + XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE / sizeof(__m256i)) == 6); + XXH_STATIC_ASSERT(XXH_SEC_ALIGN <= 64); + (void)(&XXH_writeLE64); + XXH_PREFETCH(customSecret); + { + + __m256i const seed = _mm256_set_epi64x(-(xxh_i64)seed64, (xxh_i64)seed64, + -(xxh_i64)seed64, (xxh_i64)seed64); + + XXH_ALIGN(64) const __m256i *const src = (const __m256i *)XXH3_kSecret; + XXH_ALIGN(64) __m256i * dest = (__m256i *)customSecret; + + #if defined(__GNUC__) || defined(__clang__) + /* + * On GCC & Clang, marking 'dest' as modified will cause the compiler: + * - do not extract the secret from sse registers in the internal loop + * - use less common registers, and avoid pushing these reg into stack + * The asm hack causes Clang to assume that XXH3_kSecretPtr aliases with + * customSecret, and on aarch64, this prevented LDP from merging two + * loads together for free. Putting the loads together before the stores + * properly generates LDP. + */ + __asm__("" : "+r"(dest)); + #endif + + /* GCC -O2 need unroll loop manually */ + dest[0] = _mm256_add_epi64(_mm256_stream_load_si256(src + 0), seed); + dest[1] = _mm256_add_epi64(_mm256_stream_load_si256(src + 1), seed); + dest[2] = _mm256_add_epi64(_mm256_stream_load_si256(src + 2), seed); + dest[3] = _mm256_add_epi64(_mm256_stream_load_si256(src + 3), seed); + dest[4] = _mm256_add_epi64(_mm256_stream_load_si256(src + 4), seed); + dest[5] = _mm256_add_epi64(_mm256_stream_load_si256(src + 5), seed); + + } + +} + + #endif + + #if (XXH_VECTOR == XXH_SSE2) || defined(XXH_X86DISPATCH) + + #ifndef XXH_TARGET_SSE2 + #define XXH_TARGET_SSE2 /* disable attribute target */ + #endif + +XXH_FORCE_INLINE XXH_TARGET_SSE2 void XXH3_accumulate_512_sse2( + void *XXH_RESTRICT acc, const void *XXH_RESTRICT input, + const void *XXH_RESTRICT secret) { + + /* SSE2 is just a half-scale version of the AVX2 version. */ + XXH_ASSERT((((size_t)acc) & 15) == 0); + { + + XXH_ALIGN(16) __m128i *const xacc = (__m128i *)acc; + /* Unaligned. This is mainly for pointer arithmetic, and because + * _mm_loadu_si128 requires a const __m128i * pointer for some reason. */ + const __m128i *const xinput = (const __m128i *)input; + /* Unaligned. This is mainly for pointer arithmetic, and because + * _mm_loadu_si128 requires a const __m128i * pointer for some reason. */ + const __m128i *const xsecret = (const __m128i *)secret; + + size_t i; + for (i = 0; i < XXH_STRIPE_LEN / sizeof(__m128i); i++) { + + /* data_vec = xinput[i]; */ + __m128i const data_vec = _mm_loadu_si128(xinput + i); + /* key_vec = xsecret[i]; */ + __m128i const key_vec = _mm_loadu_si128(xsecret + i); + /* data_key = data_vec ^ key_vec; */ + __m128i const data_key = _mm_xor_si128(data_vec, key_vec); + /* data_key_lo = data_key >> 32; */ + __m128i const data_key_lo = + _mm_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); + /* product = (data_key & 0xffffffff) * (data_key_lo & 0xffffffff); */ + __m128i const product = _mm_mul_epu32(data_key, data_key_lo); + /* xacc[i] += swap(data_vec); */ + __m128i const data_swap = + _mm_shuffle_epi32(data_vec, _MM_SHUFFLE(1, 0, 3, 2)); + __m128i const sum = _mm_add_epi64(xacc[i], data_swap); + /* xacc[i] += product; */ + xacc[i] = _mm_add_epi64(product, sum); + + } + + } + +} + +XXH_FORCE_INLINE XXH_TARGET_SSE2 void XXH3_scrambleAcc_sse2( + void *XXH_RESTRICT acc, const void *XXH_RESTRICT secret) { + + XXH_ASSERT((((size_t)acc) & 15) == 0); + { + + XXH_ALIGN(16) __m128i *const xacc = (__m128i *)acc; + /* Unaligned. This is mainly for pointer arithmetic, and because + * _mm_loadu_si128 requires a const __m128i * pointer for some reason. */ + const __m128i *const xsecret = (const __m128i *)secret; + const __m128i prime32 = _mm_set1_epi32((int)XXH_PRIME32_1); + + size_t i; + for (i = 0; i < XXH_STRIPE_LEN / sizeof(__m128i); i++) { + + /* xacc[i] ^= (xacc[i] >> 47) */ + __m128i const acc_vec = xacc[i]; + __m128i const shifted = _mm_srli_epi64(acc_vec, 47); + __m128i const data_vec = _mm_xor_si128(acc_vec, shifted); + /* xacc[i] ^= xsecret[i]; */ + __m128i const key_vec = _mm_loadu_si128(xsecret + i); + __m128i const data_key = _mm_xor_si128(data_vec, key_vec); + + /* xacc[i] *= XXH_PRIME32_1; */ + __m128i const data_key_hi = + _mm_shuffle_epi32(data_key, _MM_SHUFFLE(0, 3, 0, 1)); + __m128i const prod_lo = _mm_mul_epu32(data_key, prime32); + __m128i const prod_hi = _mm_mul_epu32(data_key_hi, prime32); + xacc[i] = _mm_add_epi64(prod_lo, _mm_slli_epi64(prod_hi, 32)); + + } + + } + +} + +XXH_FORCE_INLINE XXH_TARGET_SSE2 void XXH3_initCustomSecret_sse2( + void *XXH_RESTRICT customSecret, xxh_u64 seed64) { + + XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE & 15) == 0); + (void)(&XXH_writeLE64); + { + + int const nbRounds = XXH_SECRET_DEFAULT_SIZE / sizeof(__m128i); + + #if defined(_MSC_VER) && defined(_M_IX86) && _MSC_VER < 1900 + // MSVC 32bit mode does not support _mm_set_epi64x before 2015 + XXH_ALIGN(16) + const xxh_i64 seed64x2[2] = {(xxh_i64)seed64, -(xxh_i64)seed64}; + __m128i const seed = _mm_load_si128((__m128i const *)seed64x2); + #else + __m128i const seed = _mm_set_epi64x(-(xxh_i64)seed64, (xxh_i64)seed64); + #endif + int i; + + XXH_ALIGN(64) const float *const src = (float const *)XXH3_kSecret; + XXH_ALIGN(XXH_SEC_ALIGN) __m128i *dest = (__m128i *)customSecret; + #if defined(__GNUC__) || defined(__clang__) + /* + * On GCC & Clang, marking 'dest' as modified will cause the compiler: + * - do not extract the secret from sse registers in the internal loop + * - use less common registers, and avoid pushing these reg into stack + */ + __asm__("" : "+r"(dest)); + #endif + + for (i = 0; i < nbRounds; ++i) { + + dest[i] = _mm_add_epi64(_mm_castps_si128(_mm_load_ps(src + i * 4)), seed); + + } + + } + +} + + #endif + + #if (XXH_VECTOR == XXH_NEON) + +XXH_FORCE_INLINE void XXH3_accumulate_512_neon( + void *XXH_RESTRICT acc, const void *XXH_RESTRICT input, + const void *XXH_RESTRICT secret) { + + XXH_ASSERT((((size_t)acc) & 15) == 0); + { + + XXH_ALIGN(16) uint64x2_t *const xacc = (uint64x2_t *)acc; + /* We don't use a uint32x4_t pointer because it causes bus errors on ARMv7. + */ + uint8_t const *const xinput = (const uint8_t *)input; + uint8_t const *const xsecret = (const uint8_t *)secret; + + size_t i; + for (i = 0; i < XXH_STRIPE_LEN / sizeof(uint64x2_t); i++) { + + /* data_vec = xinput[i]; */ + uint8x16_t data_vec = vld1q_u8(xinput + (i * 16)); + /* key_vec = xsecret[i]; */ + uint8x16_t key_vec = vld1q_u8(xsecret + (i * 16)); + uint64x2_t data_key; + uint32x2_t data_key_lo, data_key_hi; + /* xacc[i] += swap(data_vec); */ + uint64x2_t const data64 = vreinterpretq_u64_u8(data_vec); + uint64x2_t const swapped = vextq_u64(data64, data64, 1); + xacc[i] = vaddq_u64(xacc[i], swapped); + /* data_key = data_vec ^ key_vec; */ + data_key = vreinterpretq_u64_u8(veorq_u8(data_vec, key_vec)); + /* data_key_lo = (uint32x2_t) (data_key & 0xFFFFFFFF); + * data_key_hi = (uint32x2_t) (data_key >> 32); + * data_key = UNDEFINED; */ + XXH_SPLIT_IN_PLACE(data_key, data_key_lo, data_key_hi); + /* xacc[i] += (uint64x2_t) data_key_lo * (uint64x2_t) data_key_hi; */ + xacc[i] = vmlal_u32(xacc[i], data_key_lo, data_key_hi); + + } + + } + +} + +XXH_FORCE_INLINE void XXH3_scrambleAcc_neon(void *XXH_RESTRICT acc, + const void *XXH_RESTRICT secret) { + + XXH_ASSERT((((size_t)acc) & 15) == 0); + + { + + uint64x2_t * xacc = (uint64x2_t *)acc; + uint8_t const *xsecret = (uint8_t const *)secret; + uint32x2_t prime = vdup_n_u32(XXH_PRIME32_1); + + size_t i; + for (i = 0; i < XXH_STRIPE_LEN / sizeof(uint64x2_t); i++) { + + /* xacc[i] ^= (xacc[i] >> 47); */ + uint64x2_t acc_vec = xacc[i]; + uint64x2_t shifted = vshrq_n_u64(acc_vec, 47); + uint64x2_t data_vec = veorq_u64(acc_vec, shifted); + + /* xacc[i] ^= xsecret[i]; */ + uint8x16_t key_vec = vld1q_u8(xsecret + (i * 16)); + uint64x2_t data_key = veorq_u64(data_vec, vreinterpretq_u64_u8(key_vec)); + + /* xacc[i] *= XXH_PRIME32_1 */ + uint32x2_t data_key_lo, data_key_hi; + /* data_key_lo = (uint32x2_t) (xacc[i] & 0xFFFFFFFF); + * data_key_hi = (uint32x2_t) (xacc[i] >> 32); + * xacc[i] = UNDEFINED; */ + XXH_SPLIT_IN_PLACE(data_key, data_key_lo, data_key_hi); + { /* + * prod_hi = (data_key >> 32) * XXH_PRIME32_1; + * + * Avoid vmul_u32 + vshll_n_u32 since Clang 6 and 7 will + * incorrectly "optimize" this: + * tmp = vmul_u32(vmovn_u64(a), vmovn_u64(b)); + * shifted = vshll_n_u32(tmp, 32); + * to this: + * tmp = "vmulq_u64"(a, b); // no such thing! + * shifted = vshlq_n_u64(tmp, 32); + * + * However, unlike SSE, Clang lacks a 64-bit multiply routine + * for NEON, and it scalarizes two 64-bit multiplies instead. + * + * vmull_u32 has the same timing as vmul_u32, and it avoids + * this bug completely. + * See https://bugs.llvm.org/show_bug.cgi?id=39967 + */ + uint64x2_t prod_hi = vmull_u32(data_key_hi, prime); + /* xacc[i] = prod_hi << 32; */ + xacc[i] = vshlq_n_u64(prod_hi, 32); + /* xacc[i] += (prod_hi & 0xFFFFFFFF) * XXH_PRIME32_1; */ + xacc[i] = vmlal_u32(xacc[i], data_key_lo, prime); + + } + + } + + } + +} + + #endif + + #if (XXH_VECTOR == XXH_VSX) + +XXH_FORCE_INLINE void XXH3_accumulate_512_vsx(void *XXH_RESTRICT acc, + const void *XXH_RESTRICT input, + const void *XXH_RESTRICT secret) { + + xxh_u64x2 *const xacc = (xxh_u64x2 *)acc; /* presumed aligned */ + xxh_u64x2 const *const xinput = + (xxh_u64x2 const *)input; /* no alignment restriction */ + xxh_u64x2 const *const xsecret = + (xxh_u64x2 const *)secret; /* no alignment restriction */ + xxh_u64x2 const v32 = {32, 32}; + size_t i; + for (i = 0; i < XXH_STRIPE_LEN / sizeof(xxh_u64x2); i++) { + + /* data_vec = xinput[i]; */ + xxh_u64x2 const data_vec = XXH_vec_loadu(xinput + i); + /* key_vec = xsecret[i]; */ + xxh_u64x2 const key_vec = XXH_vec_loadu(xsecret + i); + xxh_u64x2 const data_key = data_vec ^ key_vec; + /* shuffled = (data_key << 32) | (data_key >> 32); */ + xxh_u32x4 const shuffled = (xxh_u32x4)vec_rl(data_key, v32); + /* product = ((xxh_u64x2)data_key & 0xFFFFFFFF) * ((xxh_u64x2)shuffled & + * 0xFFFFFFFF); */ + xxh_u64x2 const product = XXH_vec_mulo((xxh_u32x4)data_key, shuffled); + xacc[i] += product; + + /* swap high and low halves */ + #ifdef __s390x__ + xacc[i] += vec_permi(data_vec, data_vec, 2); + #else + xacc[i] += vec_xxpermdi(data_vec, data_vec, 2); + #endif + + } + +} + +XXH_FORCE_INLINE void XXH3_scrambleAcc_vsx(void *XXH_RESTRICT acc, + const void *XXH_RESTRICT secret) { + + XXH_ASSERT((((size_t)acc) & 15) == 0); + + { + + xxh_u64x2 *const xacc = (xxh_u64x2 *)acc; + const xxh_u64x2 *const xsecret = (const xxh_u64x2 *)secret; + /* constants */ + xxh_u64x2 const v32 = {32, 32}; + xxh_u64x2 const v47 = {47, 47}; + xxh_u32x4 const prime = {XXH_PRIME32_1, XXH_PRIME32_1, XXH_PRIME32_1, + XXH_PRIME32_1}; + size_t i; + for (i = 0; i < XXH_STRIPE_LEN / sizeof(xxh_u64x2); i++) { + + /* xacc[i] ^= (xacc[i] >> 47); */ + xxh_u64x2 const acc_vec = xacc[i]; + xxh_u64x2 const data_vec = acc_vec ^ (acc_vec >> v47); + + /* xacc[i] ^= xsecret[i]; */ + xxh_u64x2 const key_vec = XXH_vec_loadu(xsecret + i); + xxh_u64x2 const data_key = data_vec ^ key_vec; + + /* xacc[i] *= XXH_PRIME32_1 */ + /* prod_lo = ((xxh_u64x2)data_key & 0xFFFFFFFF) * ((xxh_u64x2)prime & + * 0xFFFFFFFF); */ + xxh_u64x2 const prod_even = XXH_vec_mule((xxh_u32x4)data_key, prime); + /* prod_hi = ((xxh_u64x2)data_key >> 32) * ((xxh_u64x2)prime >> 32); */ + xxh_u64x2 const prod_odd = XXH_vec_mulo((xxh_u32x4)data_key, prime); + xacc[i] = prod_odd + (prod_even << v32); + + } + + } + +} + + #endif + +/* scalar variants - universal */ + +XXH_FORCE_INLINE void XXH3_accumulate_512_scalar( + void *XXH_RESTRICT acc, const void *XXH_RESTRICT input, + const void *XXH_RESTRICT secret) { + + XXH_ALIGN(XXH_ACC_ALIGN) + xxh_u64 *const xacc = (xxh_u64 *)acc; /* presumed aligned */ + const xxh_u8 *const xinput = + (const xxh_u8 *)input; /* no alignment restriction */ + const xxh_u8 *const xsecret = + (const xxh_u8 *)secret; /* no alignment restriction */ + size_t i; + XXH_ASSERT(((size_t)acc & (XXH_ACC_ALIGN - 1)) == 0); + for (i = 0; i < XXH_ACC_NB; i++) { + + xxh_u64 const data_val = XXH_readLE64(xinput + 8 * i); + xxh_u64 const data_key = data_val ^ XXH_readLE64(xsecret + i * 8); + xacc[i ^ 1] += data_val; /* swap adjacent lanes */ + xacc[i] += XXH_mult32to64(data_key & 0xFFFFFFFF, data_key >> 32); + + } + +} + +XXH_FORCE_INLINE void XXH3_scrambleAcc_scalar(void *XXH_RESTRICT acc, + const void *XXH_RESTRICT secret) { + + XXH_ALIGN(XXH_ACC_ALIGN) + xxh_u64 *const xacc = (xxh_u64 *)acc; /* presumed aligned */ + const xxh_u8 *const xsecret = + (const xxh_u8 *)secret; /* no alignment restriction */ + size_t i; + XXH_ASSERT((((size_t)acc) & (XXH_ACC_ALIGN - 1)) == 0); + for (i = 0; i < XXH_ACC_NB; i++) { + + xxh_u64 const key64 = XXH_readLE64(xsecret + 8 * i); + xxh_u64 acc64 = xacc[i]; + acc64 = XXH_xorshift64(acc64, 47); + acc64 ^= key64; + acc64 *= XXH_PRIME32_1; + xacc[i] = acc64; + + } + +} + +XXH_FORCE_INLINE void XXH3_initCustomSecret_scalar( + void *XXH_RESTRICT customSecret, xxh_u64 seed64) { + + /* + * We need a separate pointer for the hack below, + * which requires a non-const pointer. + * Any decent compiler will optimize this out otherwise. + */ + const xxh_u8 *kSecretPtr = XXH3_kSecret; + XXH_STATIC_ASSERT((XXH_SECRET_DEFAULT_SIZE & 15) == 0); + + #if defined(__clang__) && defined(__aarch64__) + /* + * UGLY HACK: + * Clang generates a bunch of MOV/MOVK pairs for aarch64, and they are + * placed sequentially, in order, at the top of the unrolled loop. + * + * While MOVK is great for generating constants (2 cycles for a 64-bit + * constant compared to 4 cycles for LDR), long MOVK chains stall the + * integer pipelines: + * I L S + * MOVK + * MOVK + * MOVK + * MOVK + * ADD + * SUB STR + * STR + * By forcing loads from memory (as the asm line causes Clang to assume + * that XXH3_kSecretPtr has been changed), the pipelines are used more + * efficiently: + * I L S + * LDR + * ADD LDR + * SUB STR + * STR + * XXH3_64bits_withSeed, len == 256, Snapdragon 835 + * without hack: 2654.4 MB/s + * with hack: 3202.9 MB/s + */ + __asm__("" : "+r"(kSecretPtr)); + #endif + /* + * Note: in debug mode, this overrides the asm optimization + * and Clang will emit MOVK chains again. + */ + XXH_ASSERT(kSecretPtr == XXH3_kSecret); + + { + + int const nbRounds = XXH_SECRET_DEFAULT_SIZE / 16; + int i; + for (i = 0; i < nbRounds; i++) { + + /* + * The asm hack causes Clang to assume that kSecretPtr aliases with + * customSecret, and on aarch64, this prevented LDP from merging two + * loads together for free. Putting the loads together before the stores + * properly generates LDP. + */ + xxh_u64 lo = XXH_readLE64(kSecretPtr + 16 * i) + seed64; + xxh_u64 hi = XXH_readLE64(kSecretPtr + 16 * i + 8) - seed64; + XXH_writeLE64((xxh_u8 *)customSecret + 16 * i, lo); + XXH_writeLE64((xxh_u8 *)customSecret + 16 * i + 8, hi); + + } + + } + +} + +typedef void (*XXH3_f_accumulate_512)(void *XXH_RESTRICT, const void *, + const void *); +typedef void (*XXH3_f_scrambleAcc)(void *XXH_RESTRICT, const void *); +typedef void (*XXH3_f_initCustomSecret)(void *XXH_RESTRICT, xxh_u64); + + #if (XXH_VECTOR == XXH_AVX512) + + #define XXH3_accumulate_512 XXH3_accumulate_512_avx512 + #define XXH3_scrambleAcc XXH3_scrambleAcc_avx512 + #define XXH3_initCustomSecret XXH3_initCustomSecret_avx512 + + #elif (XXH_VECTOR == XXH_AVX2) + + #define XXH3_accumulate_512 XXH3_accumulate_512_avx2 + #define XXH3_scrambleAcc XXH3_scrambleAcc_avx2 + #define XXH3_initCustomSecret XXH3_initCustomSecret_avx2 + + #elif (XXH_VECTOR == XXH_SSE2) + + #define XXH3_accumulate_512 XXH3_accumulate_512_sse2 + #define XXH3_scrambleAcc XXH3_scrambleAcc_sse2 + #define XXH3_initCustomSecret XXH3_initCustomSecret_sse2 + + #elif (XXH_VECTOR == XXH_NEON) + + #define XXH3_accumulate_512 XXH3_accumulate_512_neon + #define XXH3_scrambleAcc XXH3_scrambleAcc_neon + #define XXH3_initCustomSecret XXH3_initCustomSecret_scalar + + #elif (XXH_VECTOR == XXH_VSX) + + #define XXH3_accumulate_512 XXH3_accumulate_512_vsx + #define XXH3_scrambleAcc XXH3_scrambleAcc_vsx + #define XXH3_initCustomSecret XXH3_initCustomSecret_scalar + + #else /* scalar */ + + #define XXH3_accumulate_512 XXH3_accumulate_512_scalar + #define XXH3_scrambleAcc XXH3_scrambleAcc_scalar + #define XXH3_initCustomSecret XXH3_initCustomSecret_scalar + + #endif + + #ifndef XXH_PREFETCH_DIST + #ifdef __clang__ + #define XXH_PREFETCH_DIST 320 + #else + #if (XXH_VECTOR == XXH_AVX512) + #define XXH_PREFETCH_DIST 512 + #else + #define XXH_PREFETCH_DIST 384 + #endif + #endif /* __clang__ */ + #endif /* XXH_PREFETCH_DIST */ + +/* + * XXH3_accumulate() + * Loops over XXH3_accumulate_512(). + * Assumption: nbStripes will not overflow the secret size + */ +XXH_FORCE_INLINE void XXH3_accumulate(xxh_u64 *XXH_RESTRICT acc, + const xxh_u8 *XXH_RESTRICT input, + const xxh_u8 *XXH_RESTRICT secret, + size_t nbStripes, + XXH3_f_accumulate_512 f_acc512) { + + size_t n; + for (n = 0; n < nbStripes; n++) { + + const xxh_u8 *const in = input + n * XXH_STRIPE_LEN; + XXH_PREFETCH(in + XXH_PREFETCH_DIST); + f_acc512(acc, in, secret + n * XXH_SECRET_CONSUME_RATE); + + } + +} + +XXH_FORCE_INLINE void XXH3_hashLong_internal_loop( + xxh_u64 *XXH_RESTRICT acc, const xxh_u8 *XXH_RESTRICT input, size_t len, + const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, + XXH3_f_accumulate_512 f_acc512, XXH3_f_scrambleAcc f_scramble) { + + size_t const nbStripesPerBlock = + (secretSize - XXH_STRIPE_LEN) / XXH_SECRET_CONSUME_RATE; + size_t const block_len = XXH_STRIPE_LEN * nbStripesPerBlock; + size_t const nb_blocks = (len - 1) / block_len; + + size_t n; + + XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); + + for (n = 0; n < nb_blocks; n++) { + + XXH3_accumulate(acc, input + n * block_len, secret, nbStripesPerBlock, + f_acc512); + f_scramble(acc, secret + secretSize - XXH_STRIPE_LEN); + + } + + /* last partial block */ + XXH_ASSERT(len > XXH_STRIPE_LEN); + { + + size_t const nbStripes = + ((len - 1) - (block_len * nb_blocks)) / XXH_STRIPE_LEN; + XXH_ASSERT(nbStripes <= (secretSize / XXH_SECRET_CONSUME_RATE)); + XXH3_accumulate(acc, input + nb_blocks * block_len, secret, nbStripes, + f_acc512); + + /* last stripe */ + { + + const xxh_u8 *const p = input + len - XXH_STRIPE_LEN; + #define XXH_SECRET_LASTACC_START \ + 7 /* not aligned on 8, last secret is different from acc & scrambler */ + f_acc512(acc, p, + secret + secretSize - XXH_STRIPE_LEN - XXH_SECRET_LASTACC_START); + + } + + } + +} + +XXH_FORCE_INLINE xxh_u64 XXH3_mix2Accs(const xxh_u64 *XXH_RESTRICT acc, + const xxh_u8 *XXH_RESTRICT secret) { + + return XXH3_mul128_fold64(acc[0] ^ XXH_readLE64(secret), + acc[1] ^ XXH_readLE64(secret + 8)); + +} + +static XXH64_hash_t XXH3_mergeAccs(const xxh_u64 *XXH_RESTRICT acc, + const xxh_u8 *XXH_RESTRICT secret, + xxh_u64 start) { + + xxh_u64 result64 = start; + size_t i = 0; + + for (i = 0; i < 4; i++) { + + result64 += XXH3_mix2Accs(acc + 2 * i, secret + 16 * i); + #if defined(__clang__) /* Clang */ \ + && (defined(__arm__) || defined(__thumb__)) /* ARMv7 */ \ + && (defined(__ARM_NEON) || defined(__ARM_NEON__)) /* NEON */ \ + && !defined(XXH_ENABLE_AUTOVECTORIZE) /* Define to disable */ + /* + * UGLY HACK: + * Prevent autovectorization on Clang ARMv7-a. Exact same problem as + * the one in XXH3_len_129to240_64b. Speeds up shorter keys > 240b. + * XXH3_64bits, len == 256, Snapdragon 835: + * without hack: 2063.7 MB/s + * with hack: 2560.7 MB/s + */ + __asm__("" : "+r"(result64)); + #endif + + } + + return XXH3_avalanche(result64); + +} + + #define XXH3_INIT_ACC \ + { \ + \ + XXH_PRIME32_3, XXH_PRIME64_1, XXH_PRIME64_2, XXH_PRIME64_3, \ + XXH_PRIME64_4, XXH_PRIME32_2, XXH_PRIME64_5, XXH_PRIME32_1 \ + \ + } + +XXH_FORCE_INLINE XXH64_hash_t XXH3_hashLong_64b_internal( + const void *XXH_RESTRICT input, size_t len, const void *XXH_RESTRICT secret, + size_t secretSize, XXH3_f_accumulate_512 f_acc512, + XXH3_f_scrambleAcc f_scramble) { + + XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64 acc[XXH_ACC_NB] = XXH3_INIT_ACC; + + XXH3_hashLong_internal_loop(acc, (const xxh_u8 *)input, len, + (const xxh_u8 *)secret, secretSize, f_acc512, + f_scramble); + + /* converge into final hash */ + XXH_STATIC_ASSERT(sizeof(acc) == 64); + /* do not align on 8, so that the secret is different from the accumulator + */ + #define XXH_SECRET_MERGEACCS_START 11 + XXH_ASSERT(secretSize >= sizeof(acc) + XXH_SECRET_MERGEACCS_START); + return XXH3_mergeAccs(acc, + (const xxh_u8 *)secret + XXH_SECRET_MERGEACCS_START, + (xxh_u64)len * XXH_PRIME64_1); + +} + +/* + * It's important for performance that XXH3_hashLong is not inlined. + */ +XXH_NO_INLINE XXH64_hash_t XXH3_hashLong_64b_withSecret( + const void *XXH_RESTRICT input, size_t len, XXH64_hash_t seed64, + const xxh_u8 *XXH_RESTRICT secret, size_t secretLen) { + + (void)seed64; + return XXH3_hashLong_64b_internal(input, len, secret, secretLen, + XXH3_accumulate_512, XXH3_scrambleAcc); + +} + +/* + * It's important for performance that XXH3_hashLong is not inlined. + * Since the function is not inlined, the compiler may not be able to understand + * that, in some scenarios, its `secret` argument is actually a compile time + * constant. This variant enforces that the compiler can detect that, and uses + * this opportunity to streamline the generated code for better performance. + */ +XXH_NO_INLINE XXH64_hash_t XXH3_hashLong_64b_default( + const void *XXH_RESTRICT input, size_t len, XXH64_hash_t seed64, + const xxh_u8 *XXH_RESTRICT secret, size_t secretLen) { + + (void)seed64; + (void)secret; + (void)secretLen; + return XXH3_hashLong_64b_internal(input, len, XXH3_kSecret, + sizeof(XXH3_kSecret), XXH3_accumulate_512, + XXH3_scrambleAcc); + +} + +/* + * XXH3_hashLong_64b_withSeed(): + * Generate a custom key based on alteration of default XXH3_kSecret with the + * seed, and then use this key for long mode hashing. + * + * This operation is decently fast but nonetheless costs a little bit of time. + * Try to avoid it whenever possible (typically when seed==0). + * + * It's important for performance that XXH3_hashLong is not inlined. Not sure + * why (uop cache maybe?), but the difference is large and easily measurable. + */ +XXH_FORCE_INLINE XXH64_hash_t XXH3_hashLong_64b_withSeed_internal( + const void *input, size_t len, XXH64_hash_t seed, + XXH3_f_accumulate_512 f_acc512, XXH3_f_scrambleAcc f_scramble, + XXH3_f_initCustomSecret f_initSec) { + + if (seed == 0) + return XXH3_hashLong_64b_internal( + input, len, XXH3_kSecret, sizeof(XXH3_kSecret), f_acc512, f_scramble); + { + + XXH_ALIGN(XXH_SEC_ALIGN) xxh_u8 secret[XXH_SECRET_DEFAULT_SIZE]; + f_initSec(secret, seed); + return XXH3_hashLong_64b_internal(input, len, secret, sizeof(secret), + f_acc512, f_scramble); + + } + +} + +/* + * It's important for performance that XXH3_hashLong is not inlined. + */ +XXH_NO_INLINE XXH64_hash_t XXH3_hashLong_64b_withSeed(const void * input, + size_t len, + XXH64_hash_t seed, + const xxh_u8 *secret, + size_t secretLen) { + + (void)secret; + (void)secretLen; + return XXH3_hashLong_64b_withSeed_internal( + input, len, seed, XXH3_accumulate_512, XXH3_scrambleAcc, + XXH3_initCustomSecret); + +} + +typedef XXH64_hash_t (*XXH3_hashLong64_f)(const void *XXH_RESTRICT, size_t, + XXH64_hash_t, + const xxh_u8 *XXH_RESTRICT, size_t); + +XXH_FORCE_INLINE XXH64_hash_t +XXH3_64bits_internal(const void *XXH_RESTRICT input, size_t len, + XXH64_hash_t seed64, const void *XXH_RESTRICT secret, + size_t secretLen, XXH3_hashLong64_f f_hashLong) { + + XXH_ASSERT(secretLen >= XXH3_SECRET_SIZE_MIN); + /* + * If an action is to be taken if `secretLen` condition is not respected, + * it should be done here. + * For now, it's a contract pre-condition. + * Adding a check and a branch here would cost performance at every hash. + * Also, note that function signature doesn't offer room to return an error. + */ + if (len <= 16) + return XXH3_len_0to16_64b((const xxh_u8 *)input, len, + (const xxh_u8 *)secret, seed64); + if (len <= 128) + return XXH3_len_17to128_64b((const xxh_u8 *)input, len, + (const xxh_u8 *)secret, secretLen, seed64); + if (len <= XXH3_MIDSIZE_MAX) + return XXH3_len_129to240_64b((const xxh_u8 *)input, len, + (const xxh_u8 *)secret, secretLen, seed64); + return f_hashLong(input, len, seed64, (const xxh_u8 *)secret, secretLen); + +} + +/* === Public entry point === */ + +XXH_PUBLIC_API XXH64_hash_t XXH3_64bits(const void *input, size_t len) { + + return XXH3_64bits_internal(input, len, 0, XXH3_kSecret, sizeof(XXH3_kSecret), + XXH3_hashLong_64b_default); + +} + +XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSecret(const void *input, + size_t len, + const void *secret, + size_t secretSize) { + + return XXH3_64bits_internal(input, len, 0, secret, secretSize, + XXH3_hashLong_64b_withSecret); + +} + +XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSeed(const void *input, size_t len, + XXH64_hash_t seed) { + + return XXH3_64bits_internal(input, len, seed, XXH3_kSecret, + sizeof(XXH3_kSecret), XXH3_hashLong_64b_withSeed); + +} + +/* === XXH3 streaming === */ + +/* + * Malloc's a pointer that is always aligned to align. + * + * This must be freed with `XXH_alignedFree()`. + * + * malloc typically guarantees 16 byte alignment on 64-bit systems and 8 byte + * alignment on 32-bit. This isn't enough for the 32 byte aligned loads in AVX2 + * or on 32-bit, the 16 byte aligned loads in SSE2 and NEON. + * + * This underalignment previously caused a rather obvious crash which went + * completely unnoticed due to XXH3_createState() not actually being tested. + * Credit to RedSpah for noticing this bug. + * + * The alignment is done manually: Functions like posix_memalign or _mm_malloc + * are avoided: To maintain portability, we would have to write a fallback + * like this anyways, and besides, testing for the existence of library + * functions without relying on external build tools is impossible. + * + * The method is simple: Overallocate, manually align, and store the offset + * to the original behind the returned pointer. + * + * Align must be a power of 2 and 8 <= align <= 128. + */ +static void *XXH_alignedMalloc(size_t s, size_t align) { + + XXH_ASSERT(align <= 128 && align >= 8); /* range check */ + XXH_ASSERT((align & (align - 1)) == 0); /* power of 2 */ + XXH_ASSERT(s != 0 && s < (s + align)); /* empty/overflow */ + { /* Overallocate to make room for manual realignment and an offset byte */ + xxh_u8 *base = (xxh_u8 *)XXH_malloc(s + align); + if (base != NULL) { + + /* + * Get the offset needed to align this pointer. + * + * Even if the returned pointer is aligned, there will always be + * at least one byte to store the offset to the original pointer. + */ + size_t offset = align - ((size_t)base & (align - 1)); /* base % align */ + /* Add the offset for the now-aligned pointer */ + xxh_u8 *ptr = base + offset; + + XXH_ASSERT((size_t)ptr % align == 0); + + /* Store the offset immediately before the returned pointer. */ + ptr[-1] = (xxh_u8)offset; + return ptr; + + } + + return NULL; + + } + +} + +/* + * Frees an aligned pointer allocated by XXH_alignedMalloc(). Don't pass + * normal malloc'd pointers, XXH_alignedMalloc has a specific data layout. + */ +static void XXH_alignedFree(void *p) { + + if (p != NULL) { + + xxh_u8 *ptr = (xxh_u8 *)p; + /* Get the offset byte we added in XXH_malloc. */ + xxh_u8 offset = ptr[-1]; + /* Free the original malloc'd pointer */ + xxh_u8 *base = ptr - offset; + XXH_free(base); + + } + +} + +XXH_PUBLIC_API XXH3_state_t *XXH3_createState(void) { + + XXH3_state_t *const state = + (XXH3_state_t *)XXH_alignedMalloc(sizeof(XXH3_state_t), 64); + if (state == NULL) return NULL; + XXH3_INITSTATE(state); + return state; + +} + +XXH_PUBLIC_API XXH_errorcode XXH3_freeState(XXH3_state_t *statePtr) { + + XXH_alignedFree(statePtr); + return XXH_OK; + +} + +XXH_PUBLIC_API void XXH3_copyState(XXH3_state_t * dst_state, + const XXH3_state_t *src_state) { + + memcpy(dst_state, src_state, sizeof(*dst_state)); + +} + +static void XXH3_64bits_reset_internal(XXH3_state_t *statePtr, + XXH64_hash_t seed, const void *secret, + size_t secretSize) { + + size_t const initStart = offsetof(XXH3_state_t, bufferedSize); + size_t const initLength = + offsetof(XXH3_state_t, nbStripesPerBlock) - initStart; + XXH_ASSERT(offsetof(XXH3_state_t, nbStripesPerBlock) > initStart); + XXH_ASSERT(statePtr != NULL); + /* set members from bufferedSize to nbStripesPerBlock (excluded) to 0 */ + memset((char *)statePtr + initStart, 0, initLength); + statePtr->acc[0] = XXH_PRIME32_3; + statePtr->acc[1] = XXH_PRIME64_1; + statePtr->acc[2] = XXH_PRIME64_2; + statePtr->acc[3] = XXH_PRIME64_3; + statePtr->acc[4] = XXH_PRIME64_4; + statePtr->acc[5] = XXH_PRIME32_2; + statePtr->acc[6] = XXH_PRIME64_5; + statePtr->acc[7] = XXH_PRIME32_1; + statePtr->seed = seed; + statePtr->extSecret = (const unsigned char *)secret; + XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); + statePtr->secretLimit = secretSize - XXH_STRIPE_LEN; + statePtr->nbStripesPerBlock = statePtr->secretLimit / XXH_SECRET_CONSUME_RATE; + +} + +XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset(XXH3_state_t *statePtr) { + + if (statePtr == NULL) return XXH_ERROR; + XXH3_64bits_reset_internal(statePtr, 0, XXH3_kSecret, + XXH_SECRET_DEFAULT_SIZE); + return XXH_OK; + +} + +XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSecret( + XXH3_state_t *statePtr, const void *secret, size_t secretSize) { + + if (statePtr == NULL) return XXH_ERROR; + XXH3_64bits_reset_internal(statePtr, 0, secret, secretSize); + if (secret == NULL) return XXH_ERROR; + if (secretSize < XXH3_SECRET_SIZE_MIN) return XXH_ERROR; + return XXH_OK; + +} + +XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSeed(XXH3_state_t *statePtr, + XXH64_hash_t seed) { + + if (statePtr == NULL) return XXH_ERROR; + if (seed == 0) return XXH3_64bits_reset(statePtr); + if (seed != statePtr->seed) + XXH3_initCustomSecret(statePtr->customSecret, seed); + XXH3_64bits_reset_internal(statePtr, seed, NULL, XXH_SECRET_DEFAULT_SIZE); + return XXH_OK; + +} + +/* Note : when XXH3_consumeStripes() is invoked, + * there must be a guarantee that at least one more byte must be consumed from + * input + * so that the function can blindly consume all stripes using the "normal" + * secret segment */ +XXH_FORCE_INLINE void XXH3_consumeStripes( + xxh_u64 *XXH_RESTRICT acc, size_t *XXH_RESTRICT nbStripesSoFarPtr, + size_t nbStripesPerBlock, const xxh_u8 *XXH_RESTRICT input, + size_t nbStripes, const xxh_u8 *XXH_RESTRICT secret, size_t secretLimit, + XXH3_f_accumulate_512 f_acc512, XXH3_f_scrambleAcc f_scramble) { + + XXH_ASSERT(nbStripes <= + nbStripesPerBlock); /* can handle max 1 scramble per invocation */ + XXH_ASSERT(*nbStripesSoFarPtr < nbStripesPerBlock); + if (nbStripesPerBlock - *nbStripesSoFarPtr <= nbStripes) { + + /* need a scrambling operation */ + size_t const nbStripesToEndofBlock = nbStripesPerBlock - *nbStripesSoFarPtr; + size_t const nbStripesAfterBlock = nbStripes - nbStripesToEndofBlock; + XXH3_accumulate(acc, input, + secret + nbStripesSoFarPtr[0] * XXH_SECRET_CONSUME_RATE, + nbStripesToEndofBlock, f_acc512); + f_scramble(acc, secret + secretLimit); + XXH3_accumulate(acc, input + nbStripesToEndofBlock * XXH_STRIPE_LEN, secret, + nbStripesAfterBlock, f_acc512); + *nbStripesSoFarPtr = nbStripesAfterBlock; + + } else { + + XXH3_accumulate(acc, input, + secret + nbStripesSoFarPtr[0] * XXH_SECRET_CONSUME_RATE, + nbStripes, f_acc512); + *nbStripesSoFarPtr += nbStripes; + + } + +} + +/* + * Both XXH3_64bits_update and XXH3_128bits_update use this routine. + */ +XXH_FORCE_INLINE XXH_errorcode XXH3_update(XXH3_state_t *state, + const xxh_u8 *input, size_t len, + XXH3_f_accumulate_512 f_acc512, + XXH3_f_scrambleAcc f_scramble) { + + if (input == NULL) + #if defined(XXH_ACCEPT_NULL_INPUT_POINTER) && \ + (XXH_ACCEPT_NULL_INPUT_POINTER >= 1) + return XXH_OK; + #else + return XXH_ERROR; + #endif + + { + + const xxh_u8 *const bEnd = input + len; + const unsigned char *const secret = + (state->extSecret == NULL) ? state->customSecret : state->extSecret; + + state->totalLen += len; + + if (state->bufferedSize + len <= + XXH3_INTERNALBUFFER_SIZE) { /* fill in tmp buffer */ + XXH_memcpy(state->buffer + state->bufferedSize, input, len); + state->bufferedSize += (XXH32_hash_t)len; + return XXH_OK; + + } + + /* total input is now > XXH3_INTERNALBUFFER_SIZE */ + + #define XXH3_INTERNALBUFFER_STRIPES \ + (XXH3_INTERNALBUFFER_SIZE / XXH_STRIPE_LEN) + XXH_STATIC_ASSERT(XXH3_INTERNALBUFFER_SIZE % XXH_STRIPE_LEN == + 0); /* clean multiple */ + + /* + * Internal buffer is partially filled (always, except at beginning) + * Complete it, then consume it. + */ + if (state->bufferedSize) { + + size_t const loadSize = XXH3_INTERNALBUFFER_SIZE - state->bufferedSize; + XXH_memcpy(state->buffer + state->bufferedSize, input, loadSize); + input += loadSize; + XXH3_consumeStripes(state->acc, &state->nbStripesSoFar, + state->nbStripesPerBlock, state->buffer, + XXH3_INTERNALBUFFER_STRIPES, secret, + state->secretLimit, f_acc512, f_scramble); + state->bufferedSize = 0; + + } + + XXH_ASSERT(input < bEnd); + + /* Consume input by a multiple of internal buffer size */ + if (input + XXH3_INTERNALBUFFER_SIZE < bEnd) { + + const xxh_u8 *const limit = bEnd - XXH3_INTERNALBUFFER_SIZE; + do { + + XXH3_consumeStripes(state->acc, &state->nbStripesSoFar, + state->nbStripesPerBlock, input, + XXH3_INTERNALBUFFER_STRIPES, secret, + state->secretLimit, f_acc512, f_scramble); + input += XXH3_INTERNALBUFFER_SIZE; + + } while (input < limit); + + /* for last partial stripe */ + memcpy(state->buffer + sizeof(state->buffer) - XXH_STRIPE_LEN, + input - XXH_STRIPE_LEN, XXH_STRIPE_LEN); + + } + + XXH_ASSERT(input < bEnd); + + /* Some remaining input (always) : buffer it */ + XXH_memcpy(state->buffer, input, (size_t)(bEnd - input)); + state->bufferedSize = (XXH32_hash_t)(bEnd - input); + + } + + return XXH_OK; + +} + +XXH_PUBLIC_API XXH_errorcode XXH3_64bits_update(XXH3_state_t *state, + const void *input, size_t len) { + + return XXH3_update(state, (const xxh_u8 *)input, len, XXH3_accumulate_512, + XXH3_scrambleAcc); + +} + +XXH_FORCE_INLINE void XXH3_digest_long(XXH64_hash_t * acc, + const XXH3_state_t * state, + const unsigned char *secret) { + + /* + * Digest on a local copy. This way, the state remains unaltered, and it can + * continue ingesting more input afterwards. + */ + memcpy(acc, state->acc, sizeof(state->acc)); + if (state->bufferedSize >= XXH_STRIPE_LEN) { + + size_t const nbStripes = (state->bufferedSize - 1) / XXH_STRIPE_LEN; + size_t nbStripesSoFar = state->nbStripesSoFar; + XXH3_consumeStripes(acc, &nbStripesSoFar, state->nbStripesPerBlock, + state->buffer, nbStripes, secret, state->secretLimit, + XXH3_accumulate_512, XXH3_scrambleAcc); + /* last stripe */ + XXH3_accumulate_512(acc, + state->buffer + state->bufferedSize - XXH_STRIPE_LEN, + secret + state->secretLimit - XXH_SECRET_LASTACC_START); + + } else { /* bufferedSize < XXH_STRIPE_LEN */ + + xxh_u8 lastStripe[XXH_STRIPE_LEN]; + size_t const catchupSize = XXH_STRIPE_LEN - state->bufferedSize; + XXH_ASSERT(state->bufferedSize > + 0); /* there is always some input buffered */ + memcpy(lastStripe, state->buffer + sizeof(state->buffer) - catchupSize, + catchupSize); + memcpy(lastStripe + catchupSize, state->buffer, state->bufferedSize); + XXH3_accumulate_512(acc, lastStripe, + secret + state->secretLimit - XXH_SECRET_LASTACC_START); + + } + +} + +XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_digest(const XXH3_state_t *state) { + + const unsigned char *const secret = + (state->extSecret == NULL) ? state->customSecret : state->extSecret; + if (state->totalLen > XXH3_MIDSIZE_MAX) { + + XXH_ALIGN(XXH_ACC_ALIGN) XXH64_hash_t acc[XXH_ACC_NB]; + XXH3_digest_long(acc, state, secret); + return XXH3_mergeAccs(acc, secret + XXH_SECRET_MERGEACCS_START, + (xxh_u64)state->totalLen * XXH_PRIME64_1); + + } + + /* totalLen <= XXH3_MIDSIZE_MAX: digesting a short input */ + if (state->seed) + return XXH3_64bits_withSeed(state->buffer, (size_t)state->totalLen, + state->seed); + return XXH3_64bits_withSecret(state->buffer, (size_t)(state->totalLen), + secret, state->secretLimit + XXH_STRIPE_LEN); + +} + + #define XXH_MIN(x, y) (((x) > (y)) ? (y) : (x)) + +XXH_PUBLIC_API void XXH3_generateSecret(void * secretBuffer, + const void *customSeed, + size_t customSeedSize) { + + XXH_ASSERT(secretBuffer != NULL); + if (customSeedSize == 0) { + + memcpy(secretBuffer, XXH3_kSecret, XXH_SECRET_DEFAULT_SIZE); + return; + + } + + XXH_ASSERT(customSeed != NULL); + + { + + size_t const segmentSize = sizeof(XXH128_hash_t); + size_t const nbSegments = XXH_SECRET_DEFAULT_SIZE / segmentSize; + XXH128_canonical_t scrambler; + XXH64_hash_t seeds[12]; + size_t segnb; + XXH_ASSERT(nbSegments == 12); + XXH_ASSERT(segmentSize * nbSegments == + XXH_SECRET_DEFAULT_SIZE); /* exact multiple */ + XXH128_canonicalFromHash(&scrambler, XXH128(customSeed, customSeedSize, 0)); + + /* + * Copy customSeed to seeds[], truncating or repeating as necessary. + */ + { + + size_t toFill = XXH_MIN(customSeedSize, sizeof(seeds)); + size_t filled = toFill; + memcpy(seeds, customSeed, toFill); + while (filled < sizeof(seeds)) { + + toFill = XXH_MIN(filled, sizeof(seeds) - filled); + memcpy((char *)seeds + filled, seeds, toFill); + filled += toFill; + + } + + } + + /* generate secret */ + memcpy(secretBuffer, &scrambler, sizeof(scrambler)); + for (segnb = 1; segnb < nbSegments; segnb++) { + + size_t const segmentStart = segnb * segmentSize; + XXH128_canonical_t segment; + XXH128_canonicalFromHash(&segment, + XXH128(&scrambler, sizeof(scrambler), + XXH_readLE64(seeds + segnb) + segnb)); + memcpy((char *)secretBuffer + segmentStart, &segment, sizeof(segment)); + + } + + } + +} + +/* ========================================== + * XXH3 128 bits (a.k.a XXH128) + * ========================================== + * XXH3's 128-bit variant has better mixing and strength than the 64-bit + * variant, even without counting the significantly larger output size. + * + * For example, extra steps are taken to avoid the seed-dependent collisions + * in 17-240 byte inputs (See XXH3_mix16B and XXH128_mix32B). + * + * This strength naturally comes at the cost of some speed, especially on short + * lengths. Note that longer hashes are about as fast as the 64-bit version + * due to it using only a slight modification of the 64-bit loop. + * + * XXH128 is also more oriented towards 64-bit machines. It is still extremely + * fast for a _128-bit_ hash on 32-bit (it usually clears XXH64). + */ + +XXH_FORCE_INLINE XXH128_hash_t XXH3_len_1to3_128b(const xxh_u8 *input, + size_t len, + const xxh_u8 *secret, + XXH64_hash_t seed) { + + /* A doubled version of 1to3_64b with different constants. */ + XXH_ASSERT(input != NULL); + XXH_ASSERT(1 <= len && len <= 3); + XXH_ASSERT(secret != NULL); + /* + * len = 1: combinedl = { input[0], 0x01, input[0], input[0] } + * len = 2: combinedl = { input[1], 0x02, input[0], input[1] } + * len = 3: combinedl = { input[2], 0x03, input[0], input[1] } + */ + { + + xxh_u8 const c1 = input[0]; + xxh_u8 const c2 = input[len >> 1]; + xxh_u8 const c3 = input[len - 1]; + xxh_u32 const combinedl = ((xxh_u32)c1 << 16) | ((xxh_u32)c2 << 24) | + ((xxh_u32)c3 << 0) | ((xxh_u32)len << 8); + xxh_u32 const combinedh = XXH_rotl32(XXH_swap32(combinedl), 13); + xxh_u64 const bitflipl = + (XXH_readLE32(secret) ^ XXH_readLE32(secret + 4)) + seed; + xxh_u64 const bitfliph = + (XXH_readLE32(secret + 8) ^ XXH_readLE32(secret + 12)) - seed; + xxh_u64 const keyed_lo = (xxh_u64)combinedl ^ bitflipl; + xxh_u64 const keyed_hi = (xxh_u64)combinedh ^ bitfliph; + XXH128_hash_t h128; + h128.low64 = XXH64_avalanche(keyed_lo); + h128.high64 = XXH64_avalanche(keyed_hi); + return h128; + + } + +} + +XXH_FORCE_INLINE XXH128_hash_t XXH3_len_4to8_128b(const xxh_u8 *input, + size_t len, + const xxh_u8 *secret, + XXH64_hash_t seed) { + + XXH_ASSERT(input != NULL); + XXH_ASSERT(secret != NULL); + XXH_ASSERT(4 <= len && len <= 8); + seed ^= (xxh_u64)XXH_swap32((xxh_u32)seed) << 32; + { + + xxh_u32 const input_lo = XXH_readLE32(input); + xxh_u32 const input_hi = XXH_readLE32(input + len - 4); + xxh_u64 const input_64 = input_lo + ((xxh_u64)input_hi << 32); + xxh_u64 const bitflip = + (XXH_readLE64(secret + 16) ^ XXH_readLE64(secret + 24)) + seed; + xxh_u64 const keyed = input_64 ^ bitflip; + + /* Shift len to the left to ensure it is even, this avoids even multiplies. + */ + XXH128_hash_t m128 = XXH_mult64to128(keyed, XXH_PRIME64_1 + (len << 2)); + + m128.high64 += (m128.low64 << 1); + m128.low64 ^= (m128.high64 >> 3); + + m128.low64 = XXH_xorshift64(m128.low64, 35); + m128.low64 *= 0x9FB21C651E98DF25ULL; + m128.low64 = XXH_xorshift64(m128.low64, 28); + m128.high64 = XXH3_avalanche(m128.high64); + return m128; + + } + +} + +XXH_FORCE_INLINE XXH128_hash_t XXH3_len_9to16_128b(const xxh_u8 *input, + size_t len, + const xxh_u8 *secret, + XXH64_hash_t seed) { + + XXH_ASSERT(input != NULL); + XXH_ASSERT(secret != NULL); + XXH_ASSERT(9 <= len && len <= 16); + { + + xxh_u64 const bitflipl = + (XXH_readLE64(secret + 32) ^ XXH_readLE64(secret + 40)) - seed; + xxh_u64 const bitfliph = + (XXH_readLE64(secret + 48) ^ XXH_readLE64(secret + 56)) + seed; + xxh_u64 const input_lo = XXH_readLE64(input); + xxh_u64 input_hi = XXH_readLE64(input + len - 8); + XXH128_hash_t m128 = + XXH_mult64to128(input_lo ^ input_hi ^ bitflipl, XXH_PRIME64_1); + /* + * Put len in the middle of m128 to ensure that the length gets mixed to + * both the low and high bits in the 128x64 multiply below. + */ + m128.low64 += (xxh_u64)(len - 1) << 54; + input_hi ^= bitfliph; + /* + * Add the high 32 bits of input_hi to the high 32 bits of m128, then + * add the long product of the low 32 bits of input_hi and XXH_PRIME32_2 to + * the high 64 bits of m128. + * + * The best approach to this operation is different on 32-bit and 64-bit. + */ + if (sizeof(void *) < sizeof(xxh_u64)) { /* 32-bit */ + /* + * 32-bit optimized version, which is more readable. + * + * On 32-bit, it removes an ADC and delays a dependency between the two + * halves of m128.high64, but it generates an extra mask on 64-bit. + */ + m128.high64 += (input_hi & 0xFFFFFFFF00000000ULL) + + XXH_mult32to64((xxh_u32)input_hi, XXH_PRIME32_2); + + } else { + + /* + * 64-bit optimized (albeit more confusing) version. + * + * Uses some properties of addition and multiplication to remove the mask: + * + * Let: + * a = input_hi.lo = (input_hi & 0x00000000FFFFFFFF) + * b = input_hi.hi = (input_hi & 0xFFFFFFFF00000000) + * c = XXH_PRIME32_2 + * + * a + (b * c) + * Inverse Property: x + y - x == y + * a + (b * (1 + c - 1)) + * Distributive Property: x * (y + z) == (x * y) + (x * z) + * a + (b * 1) + (b * (c - 1)) + * Identity Property: x * 1 == x + * a + b + (b * (c - 1)) + * + * Substitute a, b, and c: + * input_hi.hi + input_hi.lo + ((xxh_u64)input_hi.lo * (XXH_PRIME32_2 - + * 1)) + * + * Since input_hi.hi + input_hi.lo == input_hi, we get this: + * input_hi + ((xxh_u64)input_hi.lo * (XXH_PRIME32_2 - 1)) + */ + m128.high64 += + input_hi + XXH_mult32to64((xxh_u32)input_hi, XXH_PRIME32_2 - 1); + + } + + /* m128 ^= XXH_swap64(m128 >> 64); */ + m128.low64 ^= XXH_swap64(m128.high64); + + { /* 128x64 multiply: h128 = m128 * XXH_PRIME64_2; */ + XXH128_hash_t h128 = XXH_mult64to128(m128.low64, XXH_PRIME64_2); + h128.high64 += m128.high64 * XXH_PRIME64_2; + + h128.low64 = XXH3_avalanche(h128.low64); + h128.high64 = XXH3_avalanche(h128.high64); + return h128; + + } + + } + +} + +/* + * Assumption: `secret` size is >= XXH3_SECRET_SIZE_MIN + */ +XXH_FORCE_INLINE XXH128_hash_t XXH3_len_0to16_128b(const xxh_u8 *input, + size_t len, + const xxh_u8 *secret, + XXH64_hash_t seed) { + + XXH_ASSERT(len <= 16); + { + + if (len > 8) return XXH3_len_9to16_128b(input, len, secret, seed); + if (len >= 4) return XXH3_len_4to8_128b(input, len, secret, seed); + if (len) return XXH3_len_1to3_128b(input, len, secret, seed); + { + + XXH128_hash_t h128; + xxh_u64 const bitflipl = + XXH_readLE64(secret + 64) ^ XXH_readLE64(secret + 72); + xxh_u64 const bitfliph = + XXH_readLE64(secret + 80) ^ XXH_readLE64(secret + 88); + h128.low64 = XXH64_avalanche(seed ^ bitflipl); + h128.high64 = XXH64_avalanche(seed ^ bitfliph); + return h128; + + } + + } + +} + +/* + * A bit slower than XXH3_mix16B, but handles multiply by zero better. + */ +XXH_FORCE_INLINE XXH128_hash_t XXH128_mix32B(XXH128_hash_t acc, + const xxh_u8 *input_1, + const xxh_u8 *input_2, + const xxh_u8 *secret, + XXH64_hash_t seed) { + + acc.low64 += XXH3_mix16B(input_1, secret + 0, seed); + acc.low64 ^= XXH_readLE64(input_2) + XXH_readLE64(input_2 + 8); + acc.high64 += XXH3_mix16B(input_2, secret + 16, seed); + acc.high64 ^= XXH_readLE64(input_1) + XXH_readLE64(input_1 + 8); + return acc; + +} + +XXH_FORCE_INLINE XXH128_hash_t XXH3_len_17to128_128b( + const xxh_u8 *XXH_RESTRICT input, size_t len, + const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, XXH64_hash_t seed) { + + XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); + (void)secretSize; + XXH_ASSERT(16 < len && len <= 128); + + { + + XXH128_hash_t acc; + acc.low64 = len * XXH_PRIME64_1; + acc.high64 = 0; + if (len > 32) { + + if (len > 64) { + + if (len > 96) { + + acc = XXH128_mix32B(acc, input + 48, input + len - 64, secret + 96, + seed); + + } + + acc = + XXH128_mix32B(acc, input + 32, input + len - 48, secret + 64, seed); + + } + + acc = XXH128_mix32B(acc, input + 16, input + len - 32, secret + 32, seed); + + } + + acc = XXH128_mix32B(acc, input, input + len - 16, secret, seed); + { + + XXH128_hash_t h128; + h128.low64 = acc.low64 + acc.high64; + h128.high64 = (acc.low64 * XXH_PRIME64_1) + (acc.high64 * XXH_PRIME64_4) + + ((len - seed) * XXH_PRIME64_2); + h128.low64 = XXH3_avalanche(h128.low64); + h128.high64 = (XXH64_hash_t)0 - XXH3_avalanche(h128.high64); + return h128; + + } + + } + +} + +XXH_NO_INLINE XXH128_hash_t XXH3_len_129to240_128b( + const xxh_u8 *XXH_RESTRICT input, size_t len, + const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, XXH64_hash_t seed) { + + XXH_ASSERT(secretSize >= XXH3_SECRET_SIZE_MIN); + (void)secretSize; + XXH_ASSERT(128 < len && len <= XXH3_MIDSIZE_MAX); + + { + + XXH128_hash_t acc; + int const nbRounds = (int)len / 32; + int i; + acc.low64 = len * XXH_PRIME64_1; + acc.high64 = 0; + for (i = 0; i < 4; i++) { + + acc = XXH128_mix32B(acc, input + (32 * i), input + (32 * i) + 16, + secret + (32 * i), seed); + + } + + acc.low64 = XXH3_avalanche(acc.low64); + acc.high64 = XXH3_avalanche(acc.high64); + XXH_ASSERT(nbRounds >= 4); + for (i = 4; i < nbRounds; i++) { + + acc = XXH128_mix32B(acc, input + (32 * i), input + (32 * i) + 16, + secret + XXH3_MIDSIZE_STARTOFFSET + (32 * (i - 4)), + seed); + + } + + /* last bytes */ + acc = XXH128_mix32B( + acc, input + len - 16, input + len - 32, + secret + XXH3_SECRET_SIZE_MIN - XXH3_MIDSIZE_LASTOFFSET - 16, + 0ULL - seed); + + { + + XXH128_hash_t h128; + h128.low64 = acc.low64 + acc.high64; + h128.high64 = (acc.low64 * XXH_PRIME64_1) + (acc.high64 * XXH_PRIME64_4) + + ((len - seed) * XXH_PRIME64_2); + h128.low64 = XXH3_avalanche(h128.low64); + h128.high64 = (XXH64_hash_t)0 - XXH3_avalanche(h128.high64); + return h128; + + } + + } + +} + +XXH_FORCE_INLINE XXH128_hash_t XXH3_hashLong_128b_internal( + const void *XXH_RESTRICT input, size_t len, + const xxh_u8 *XXH_RESTRICT secret, size_t secretSize, + XXH3_f_accumulate_512 f_acc512, XXH3_f_scrambleAcc f_scramble) { + + XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64 acc[XXH_ACC_NB] = XXH3_INIT_ACC; + + XXH3_hashLong_internal_loop(acc, (const xxh_u8 *)input, len, secret, + secretSize, f_acc512, f_scramble); + + /* converge into final hash */ + XXH_STATIC_ASSERT(sizeof(acc) == 64); + XXH_ASSERT(secretSize >= sizeof(acc) + XXH_SECRET_MERGEACCS_START); + { + + XXH128_hash_t h128; + h128.low64 = XXH3_mergeAccs(acc, secret + XXH_SECRET_MERGEACCS_START, + (xxh_u64)len * XXH_PRIME64_1); + h128.high64 = XXH3_mergeAccs( + acc, secret + secretSize - sizeof(acc) - XXH_SECRET_MERGEACCS_START, + ~((xxh_u64)len * XXH_PRIME64_2)); + return h128; + + } + +} + +/* + * It's important for performance that XXH3_hashLong is not inlined. + */ +XXH_NO_INLINE XXH128_hash_t XXH3_hashLong_128b_default( + const void *XXH_RESTRICT input, size_t len, XXH64_hash_t seed64, + const void *XXH_RESTRICT secret, size_t secretLen) { + + (void)seed64; + (void)secret; + (void)secretLen; + return XXH3_hashLong_128b_internal(input, len, XXH3_kSecret, + sizeof(XXH3_kSecret), XXH3_accumulate_512, + XXH3_scrambleAcc); + +} + +/* + * It's important for performance that XXH3_hashLong is not inlined. + */ +XXH_NO_INLINE XXH128_hash_t XXH3_hashLong_128b_withSecret( + const void *XXH_RESTRICT input, size_t len, XXH64_hash_t seed64, + const void *XXH_RESTRICT secret, size_t secretLen) { + + (void)seed64; + return XXH3_hashLong_128b_internal(input, len, (const xxh_u8 *)secret, + secretLen, XXH3_accumulate_512, + XXH3_scrambleAcc); + +} + +XXH_FORCE_INLINE XXH128_hash_t XXH3_hashLong_128b_withSeed_internal( + const void *XXH_RESTRICT input, size_t len, XXH64_hash_t seed64, + XXH3_f_accumulate_512 f_acc512, XXH3_f_scrambleAcc f_scramble, + XXH3_f_initCustomSecret f_initSec) { + + if (seed64 == 0) + return XXH3_hashLong_128b_internal( + input, len, XXH3_kSecret, sizeof(XXH3_kSecret), f_acc512, f_scramble); + { + + XXH_ALIGN(XXH_SEC_ALIGN) xxh_u8 secret[XXH_SECRET_DEFAULT_SIZE]; + f_initSec(secret, seed64); + return XXH3_hashLong_128b_internal(input, len, (const xxh_u8 *)secret, + sizeof(secret), f_acc512, f_scramble); + + } + +} + +/* + * It's important for performance that XXH3_hashLong is not inlined. + */ +XXH_NO_INLINE XXH128_hash_t +XXH3_hashLong_128b_withSeed(const void *input, size_t len, XXH64_hash_t seed64, + const void *XXH_RESTRICT secret, size_t secretLen) { + + (void)secret; + (void)secretLen; + return XXH3_hashLong_128b_withSeed_internal( + input, len, seed64, XXH3_accumulate_512, XXH3_scrambleAcc, + XXH3_initCustomSecret); + +} + +typedef XXH128_hash_t (*XXH3_hashLong128_f)(const void *XXH_RESTRICT, size_t, + XXH64_hash_t, + const void *XXH_RESTRICT, size_t); + +XXH_FORCE_INLINE XXH128_hash_t +XXH3_128bits_internal(const void *input, size_t len, XXH64_hash_t seed64, + const void *XXH_RESTRICT secret, size_t secretLen, + XXH3_hashLong128_f f_hl128) { + + XXH_ASSERT(secretLen >= XXH3_SECRET_SIZE_MIN); + /* + * If an action is to be taken if `secret` conditions are not respected, + * it should be done here. + * For now, it's a contract pre-condition. + * Adding a check and a branch here would cost performance at every hash. + */ + if (len <= 16) + return XXH3_len_0to16_128b((const xxh_u8 *)input, len, + (const xxh_u8 *)secret, seed64); + if (len <= 128) + return XXH3_len_17to128_128b((const xxh_u8 *)input, len, + (const xxh_u8 *)secret, secretLen, seed64); + if (len <= XXH3_MIDSIZE_MAX) + return XXH3_len_129to240_128b((const xxh_u8 *)input, len, + (const xxh_u8 *)secret, secretLen, seed64); + return f_hl128(input, len, seed64, secret, secretLen); + +} + +/* === Public XXH128 API === */ + +XXH_PUBLIC_API XXH128_hash_t XXH3_128bits(const void *input, size_t len) { + + return XXH3_128bits_internal(input, len, 0, XXH3_kSecret, + sizeof(XXH3_kSecret), + XXH3_hashLong_128b_default); + +} + +XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_withSecret(const void *input, + size_t len, + const void *secret, + size_t secretSize) { + + return XXH3_128bits_internal(input, len, 0, (const xxh_u8 *)secret, + secretSize, XXH3_hashLong_128b_withSecret); + +} + +XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_withSeed(const void * input, + size_t len, + XXH64_hash_t seed) { + + return XXH3_128bits_internal(input, len, seed, XXH3_kSecret, + sizeof(XXH3_kSecret), + XXH3_hashLong_128b_withSeed); + +} + +XXH_PUBLIC_API XXH128_hash_t XXH128(const void *input, size_t len, + XXH64_hash_t seed) { + + return XXH3_128bits_withSeed(input, len, seed); + +} + +/* === XXH3 128-bit streaming === */ + +/* + * All the functions are actually the same as for 64-bit streaming variant. + * The only difference is the finalizatiom routine. + */ + +static void XXH3_128bits_reset_internal(XXH3_state_t *statePtr, + XXH64_hash_t seed, const void *secret, + size_t secretSize) { + + XXH3_64bits_reset_internal(statePtr, seed, secret, secretSize); + +} + +XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset(XXH3_state_t *statePtr) { + + if (statePtr == NULL) return XXH_ERROR; + XXH3_128bits_reset_internal(statePtr, 0, XXH3_kSecret, + XXH_SECRET_DEFAULT_SIZE); + return XXH_OK; + +} + +XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset_withSecret( + XXH3_state_t *statePtr, const void *secret, size_t secretSize) { + + if (statePtr == NULL) return XXH_ERROR; + XXH3_128bits_reset_internal(statePtr, 0, secret, secretSize); + if (secret == NULL) return XXH_ERROR; + if (secretSize < XXH3_SECRET_SIZE_MIN) return XXH_ERROR; + return XXH_OK; + +} + +XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset_withSeed(XXH3_state_t *statePtr, + XXH64_hash_t seed) { + + if (statePtr == NULL) return XXH_ERROR; + if (seed == 0) return XXH3_128bits_reset(statePtr); + if (seed != statePtr->seed) + XXH3_initCustomSecret(statePtr->customSecret, seed); + XXH3_128bits_reset_internal(statePtr, seed, NULL, XXH_SECRET_DEFAULT_SIZE); + return XXH_OK; + +} + +XXH_PUBLIC_API XXH_errorcode XXH3_128bits_update(XXH3_state_t *state, + const void * input, + size_t len) { + + return XXH3_update(state, (const xxh_u8 *)input, len, XXH3_accumulate_512, + XXH3_scrambleAcc); + +} + +XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_digest(const XXH3_state_t *state) { + + const unsigned char *const secret = + (state->extSecret == NULL) ? state->customSecret : state->extSecret; + if (state->totalLen > XXH3_MIDSIZE_MAX) { + + XXH_ALIGN(XXH_ACC_ALIGN) XXH64_hash_t acc[XXH_ACC_NB]; + XXH3_digest_long(acc, state, secret); + XXH_ASSERT(state->secretLimit + XXH_STRIPE_LEN >= + sizeof(acc) + XXH_SECRET_MERGEACCS_START); + { + + XXH128_hash_t h128; + h128.low64 = XXH3_mergeAccs(acc, secret + XXH_SECRET_MERGEACCS_START, + (xxh_u64)state->totalLen * XXH_PRIME64_1); + h128.high64 = + XXH3_mergeAccs(acc, + secret + state->secretLimit + XXH_STRIPE_LEN - + sizeof(acc) - XXH_SECRET_MERGEACCS_START, + ~((xxh_u64)state->totalLen * XXH_PRIME64_2)); + return h128; + + } + + } + + /* len <= XXH3_MIDSIZE_MAX : short code */ + if (state->seed) + return XXH3_128bits_withSeed(state->buffer, (size_t)state->totalLen, + state->seed); + return XXH3_128bits_withSecret(state->buffer, (size_t)(state->totalLen), + secret, state->secretLimit + XXH_STRIPE_LEN); + +} + + /* 128-bit utility functions */ + + #include <string.h> /* memcmp, memcpy */ + +/* return : 1 is equal, 0 if different */ +XXH_PUBLIC_API int XXH128_isEqual(XXH128_hash_t h1, XXH128_hash_t h2) { + + /* note : XXH128_hash_t is compact, it has no padding byte */ + return !(memcmp(&h1, &h2, sizeof(h1))); + +} + +/* This prototype is compatible with stdlib's qsort(). + * return : >0 if *h128_1 > *h128_2 + * <0 if *h128_1 < *h128_2 + * =0 if *h128_1 == *h128_2 */ +XXH_PUBLIC_API int XXH128_cmp(const void *h128_1, const void *h128_2) { + + XXH128_hash_t const h1 = *(const XXH128_hash_t *)h128_1; + XXH128_hash_t const h2 = *(const XXH128_hash_t *)h128_2; + int const hcmp = (h1.high64 > h2.high64) - (h2.high64 > h1.high64); + /* note : bets that, in most cases, hash values are different */ + if (hcmp) return hcmp; + return (h1.low64 > h2.low64) - (h2.low64 > h1.low64); + +} + +/*====== Canonical representation ======*/ +XXH_PUBLIC_API void XXH128_canonicalFromHash(XXH128_canonical_t *dst, + XXH128_hash_t hash) { + + XXH_STATIC_ASSERT(sizeof(XXH128_canonical_t) == sizeof(XXH128_hash_t)); + if (XXH_CPU_LITTLE_ENDIAN) { + + hash.high64 = XXH_swap64(hash.high64); + hash.low64 = XXH_swap64(hash.low64); + + } + + memcpy(dst, &hash.high64, sizeof(hash.high64)); + memcpy((char *)dst + sizeof(hash.high64), &hash.low64, sizeof(hash.low64)); + +} + +XXH_PUBLIC_API XXH128_hash_t +XXH128_hashFromCanonical(const XXH128_canonical_t *src) { + + XXH128_hash_t h; + h.high64 = XXH_readBE64(src); + h.low64 = XXH_readBE64(src->digest + 8); + return h; + +} + + /* Pop our optimization override from above */ + #if XXH_VECTOR == XXH_AVX2 /* AVX2 */ \ + && defined(__GNUC__) && !defined(__clang__) /* GCC, not Clang */ \ + && defined(__OPTIMIZE__) && \ + !defined(__OPTIMIZE_SIZE__) /* respect -O0 and -Os */ + #pragma GCC pop_options + #endif #endif /* XXH_NO_LONG_LONG */ diff --git a/instrumentation/COPYING3 b/instrumentation/COPYING3 new file mode 100644 index 00000000..94a9ed02 --- /dev/null +++ b/instrumentation/COPYING3 @@ -0,0 +1,674 @@ + GNU GENERAL PUBLIC LICENSE + Version 3, 29 June 2007 + + Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/> + Everyone is permitted to copy and distribute verbatim copies + of this license document, but changing it is not allowed. + + Preamble + + The GNU General Public License is a free, copyleft license for +software and other kinds of works. + + The licenses for most software and other practical works are designed +to take away your freedom to share and change the works. By contrast, +the GNU General Public License is intended to guarantee your freedom to +share and change all versions of a program--to make sure it remains free +software for all its users. We, the Free Software Foundation, use the +GNU General Public License for most of our software; it applies also to +any other work released this way by its authors. You can apply it to +your programs, too. + + When we speak of free software, we are referring to freedom, not +price. Our General Public Licenses are designed to make sure that you +have the freedom to distribute copies of free software (and charge for +them if you wish), that you receive source code or can get it if you +want it, that you can change the software or use pieces of it in new +free programs, and that you know you can do these things. + + To protect your rights, we need to prevent others from denying you +these rights or asking you to surrender the rights. Therefore, you have +certain responsibilities if you distribute copies of the software, or if +you modify it: responsibilities to respect the freedom of others. + + For example, if you distribute copies of such a program, whether +gratis or for a fee, you must pass on to the recipients the same +freedoms that you received. You must make sure that they, too, receive +or can get the source code. And you must show them these terms so they +know their rights. + + Developers that use the GNU GPL protect your rights with two steps: +(1) assert copyright on the software, and (2) offer you this License +giving you legal permission to copy, distribute and/or modify it. + + For the developers' and authors' protection, the GPL clearly explains +that there is no warranty for this free software. For both users' and +authors' sake, the GPL requires that modified versions be marked as +changed, so that their problems will not be attributed erroneously to +authors of previous versions. + + Some devices are designed to deny users access to install or run +modified versions of the software inside them, although the manufacturer +can do so. This is fundamentally incompatible with the aim of +protecting users' freedom to change the software. The systematic +pattern of such abuse occurs in the area of products for individuals to +use, which is precisely where it is most unacceptable. Therefore, we +have designed this version of the GPL to prohibit the practice for those +products. If such problems arise substantially in other domains, we +stand ready to extend this provision to those domains in future versions +of the GPL, as needed to protect the freedom of users. + + Finally, every program is threatened constantly by software patents. +States should not allow patents to restrict development and use of +software on general-purpose computers, but in those that do, we wish to +avoid the special danger that patents applied to a free program could +make it effectively proprietary. To prevent this, the GPL assures that +patents cannot be used to render the program non-free. + + The precise terms and conditions for copying, distribution and +modification follow. + + TERMS AND CONDITIONS + + 0. Definitions. + + "This License" refers to version 3 of the GNU General Public License. + + "Copyright" also means copyright-like laws that apply to other kinds of +works, such as semiconductor masks. + + "The Program" refers to any copyrightable work licensed under this +License. Each licensee is addressed as "you". "Licensees" and +"recipients" may be individuals or organizations. + + To "modify" a work means to copy from or adapt all or part of the work +in a fashion requiring copyright permission, other than the making of an +exact copy. The resulting work is called a "modified version" of the +earlier work or a work "based on" the earlier work. + + A "covered work" means either the unmodified Program or a work based +on the Program. + + To "propagate" a work means to do anything with it that, without +permission, would make you directly or secondarily liable for +infringement under applicable copyright law, except executing it on a +computer or modifying a private copy. Propagation includes copying, +distribution (with or without modification), making available to the +public, and in some countries other activities as well. + + To "convey" a work means any kind of propagation that enables other +parties to make or receive copies. Mere interaction with a user through +a computer network, with no transfer of a copy, is not conveying. + + An interactive user interface displays "Appropriate Legal Notices" +to the extent that it includes a convenient and prominently visible +feature that (1) displays an appropriate copyright notice, and (2) +tells the user that there is no warranty for the work (except to the +extent that warranties are provided), that licensees may convey the +work under this License, and how to view a copy of this License. If +the interface presents a list of user commands or options, such as a +menu, a prominent item in the list meets this criterion. + + 1. Source Code. + + The "source code" for a work means the preferred form of the work +for making modifications to it. "Object code" means any non-source +form of a work. + + A "Standard Interface" means an interface that either is an official +standard defined by a recognized standards body, or, in the case of +interfaces specified for a particular programming language, one that +is widely used among developers working in that language. + + The "System Libraries" of an executable work include anything, other +than the work as a whole, that (a) is included in the normal form of +packaging a Major Component, but which is not part of that Major +Component, and (b) serves only to enable use of the work with that +Major Component, or to implement a Standard Interface for which an +implementation is available to the public in source code form. A +"Major Component", in this context, means a major essential component +(kernel, window system, and so on) of the specific operating system +(if any) on which the executable work runs, or a compiler used to +produce the work, or an object code interpreter used to run it. + + The "Corresponding Source" for a work in object code form means all +the source code needed to generate, install, and (for an executable +work) run the object code and to modify the work, including scripts to +control those activities. However, it does not include the work's +System Libraries, or general-purpose tools or generally available free +programs which are used unmodified in performing those activities but +which are not part of the work. For example, Corresponding Source +includes interface definition files associated with source files for +the work, and the source code for shared libraries and dynamically +linked subprograms that the work is specifically designed to require, +such as by intimate data communication or control flow between those +subprograms and other parts of the work. + + The Corresponding Source need not include anything that users +can regenerate automatically from other parts of the Corresponding +Source. + + The Corresponding Source for a work in source code form is that +same work. + + 2. Basic Permissions. + + All rights granted under this License are granted for the term of +copyright on the Program, and are irrevocable provided the stated +conditions are met. This License explicitly affirms your unlimited +permission to run the unmodified Program. The output from running a +covered work is covered by this License only if the output, given its +content, constitutes a covered work. This License acknowledges your +rights of fair use or other equivalent, as provided by copyright law. + + You may make, run and propagate covered works that you do not +convey, without conditions so long as your license otherwise remains +in force. You may convey covered works to others for the sole purpose +of having them make modifications exclusively for you, or provide you +with facilities for running those works, provided that you comply with +the terms of this License in conveying all material for which you do +not control copyright. Those thus making or running the covered works +for you must do so exclusively on your behalf, under your direction +and control, on terms that prohibit them from making any copies of +your copyrighted material outside their relationship with you. + + Conveying under any other circumstances is permitted solely under +the conditions stated below. Sublicensing is not allowed; section 10 +makes it unnecessary. + + 3. Protecting Users' Legal Rights From Anti-Circumvention Law. + + No covered work shall be deemed part of an effective technological +measure under any applicable law fulfilling obligations under article +11 of the WIPO copyright treaty adopted on 20 December 1996, or +similar laws prohibiting or restricting circumvention of such +measures. + + When you convey a covered work, you waive any legal power to forbid +circumvention of technological measures to the extent such circumvention +is effected by exercising rights under this License with respect to +the covered work, and you disclaim any intention to limit operation or +modification of the work as a means of enforcing, against the work's +users, your or third parties' legal rights to forbid circumvention of +technological measures. + + 4. Conveying Verbatim Copies. + + You may convey verbatim copies of the Program's source code as you +receive it, in any medium, provided that you conspicuously and +appropriately publish on each copy an appropriate copyright notice; +keep intact all notices stating that this License and any +non-permissive terms added in accord with section 7 apply to the code; +keep intact all notices of the absence of any warranty; and give all +recipients a copy of this License along with the Program. + + You may charge any price or no price for each copy that you convey, +and you may offer support or warranty protection for a fee. + + 5. Conveying Modified Source Versions. + + You may convey a work based on the Program, or the modifications to +produce it from the Program, in the form of source code under the +terms of section 4, provided that you also meet all of these conditions: + + a) The work must carry prominent notices stating that you modified + it, and giving a relevant date. + + b) The work must carry prominent notices stating that it is + released under this License and any conditions added under section + 7. This requirement modifies the requirement in section 4 to + "keep intact all notices". + + c) You must license the entire work, as a whole, under this + License to anyone who comes into possession of a copy. This + License will therefore apply, along with any applicable section 7 + additional terms, to the whole of the work, and all its parts, + regardless of how they are packaged. This License gives no + permission to license the work in any other way, but it does not + invalidate such permission if you have separately received it. + + d) If the work has interactive user interfaces, each must display + Appropriate Legal Notices; however, if the Program has interactive + interfaces that do not display Appropriate Legal Notices, your + work need not make them do so. + + A compilation of a covered work with other separate and independent +works, which are not by their nature extensions of the covered work, +and which are not combined with it such as to form a larger program, +in or on a volume of a storage or distribution medium, is called an +"aggregate" if the compilation and its resulting copyright are not +used to limit the access or legal rights of the compilation's users +beyond what the individual works permit. Inclusion of a covered work +in an aggregate does not cause this License to apply to the other +parts of the aggregate. + + 6. Conveying Non-Source Forms. + + You may convey a covered work in object code form under the terms +of sections 4 and 5, provided that you also convey the +machine-readable Corresponding Source under the terms of this License, +in one of these ways: + + a) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by the + Corresponding Source fixed on a durable physical medium + customarily used for software interchange. + + b) Convey the object code in, or embodied in, a physical product + (including a physical distribution medium), accompanied by a + written offer, valid for at least three years and valid for as + long as you offer spare parts or customer support for that product + model, to give anyone who possesses the object code either (1) a + copy of the Corresponding Source for all the software in the + product that is covered by this License, on a durable physical + medium customarily used for software interchange, for a price no + more than your reasonable cost of physically performing this + conveying of source, or (2) access to copy the + Corresponding Source from a network server at no charge. + + c) Convey individual copies of the object code with a copy of the + written offer to provide the Corresponding Source. This + alternative is allowed only occasionally and noncommercially, and + only if you received the object code with such an offer, in accord + with subsection 6b. + + d) Convey the object code by offering access from a designated + place (gratis or for a charge), and offer equivalent access to the + Corresponding Source in the same way through the same place at no + further charge. You need not require recipients to copy the + Corresponding Source along with the object code. If the place to + copy the object code is a network server, the Corresponding Source + may be on a different server (operated by you or a third party) + that supports equivalent copying facilities, provided you maintain + clear directions next to the object code saying where to find the + Corresponding Source. Regardless of what server hosts the + Corresponding Source, you remain obligated to ensure that it is + available for as long as needed to satisfy these requirements. + + e) Convey the object code using peer-to-peer transmission, provided + you inform other peers where the object code and Corresponding + Source of the work are being offered to the general public at no + charge under subsection 6d. + + A separable portion of the object code, whose source code is excluded +from the Corresponding Source as a System Library, need not be +included in conveying the object code work. + + A "User Product" is either (1) a "consumer product", which means any +tangible personal property which is normally used for personal, family, +or household purposes, or (2) anything designed or sold for incorporation +into a dwelling. In determining whether a product is a consumer product, +doubtful cases shall be resolved in favor of coverage. For a particular +product received by a particular user, "normally used" refers to a +typical or common use of that class of product, regardless of the status +of the particular user or of the way in which the particular user +actually uses, or expects or is expected to use, the product. A product +is a consumer product regardless of whether the product has substantial +commercial, industrial or non-consumer uses, unless such uses represent +the only significant mode of use of the product. + + "Installation Information" for a User Product means any methods, +procedures, authorization keys, or other information required to install +and execute modified versions of a covered work in that User Product from +a modified version of its Corresponding Source. The information must +suffice to ensure that the continued functioning of the modified object +code is in no case prevented or interfered with solely because +modification has been made. + + If you convey an object code work under this section in, or with, or +specifically for use in, a User Product, and the conveying occurs as +part of a transaction in which the right of possession and use of the +User Product is transferred to the recipient in perpetuity or for a +fixed term (regardless of how the transaction is characterized), the +Corresponding Source conveyed under this section must be accompanied +by the Installation Information. But this requirement does not apply +if neither you nor any third party retains the ability to install +modified object code on the User Product (for example, the work has +been installed in ROM). + + The requirement to provide Installation Information does not include a +requirement to continue to provide support service, warranty, or updates +for a work that has been modified or installed by the recipient, or for +the User Product in which it has been modified or installed. Access to a +network may be denied when the modification itself materially and +adversely affects the operation of the network or violates the rules and +protocols for communication across the network. + + Corresponding Source conveyed, and Installation Information provided, +in accord with this section must be in a format that is publicly +documented (and with an implementation available to the public in +source code form), and must require no special password or key for +unpacking, reading or copying. + + 7. Additional Terms. + + "Additional permissions" are terms that supplement the terms of this +License by making exceptions from one or more of its conditions. +Additional permissions that are applicable to the entire Program shall +be treated as though they were included in this License, to the extent +that they are valid under applicable law. If additional permissions +apply only to part of the Program, that part may be used separately +under those permissions, but the entire Program remains governed by +this License without regard to the additional permissions. + + When you convey a copy of a covered work, you may at your option +remove any additional permissions from that copy, or from any part of +it. (Additional permissions may be written to require their own +removal in certain cases when you modify the work.) You may place +additional permissions on material, added by you to a covered work, +for which you have or can give appropriate copyright permission. + + Notwithstanding any other provision of this License, for material you +add to a covered work, you may (if authorized by the copyright holders of +that material) supplement the terms of this License with terms: + + a) Disclaiming warranty or limiting liability differently from the + terms of sections 15 and 16 of this License; or + + b) Requiring preservation of specified reasonable legal notices or + author attributions in that material or in the Appropriate Legal + Notices displayed by works containing it; or + + c) Prohibiting misrepresentation of the origin of that material, or + requiring that modified versions of such material be marked in + reasonable ways as different from the original version; or + + d) Limiting the use for publicity purposes of names of licensors or + authors of the material; or + + e) Declining to grant rights under trademark law for use of some + trade names, trademarks, or service marks; or + + f) Requiring indemnification of licensors and authors of that + material by anyone who conveys the material (or modified versions of + it) with contractual assumptions of liability to the recipient, for + any liability that these contractual assumptions directly impose on + those licensors and authors. + + All other non-permissive additional terms are considered "further +restrictions" within the meaning of section 10. If the Program as you +received it, or any part of it, contains a notice stating that it is +governed by this License along with a term that is a further +restriction, you may remove that term. If a license document contains +a further restriction but permits relicensing or conveying under this +License, you may add to a covered work material governed by the terms +of that license document, provided that the further restriction does +not survive such relicensing or conveying. + + If you add terms to a covered work in accord with this section, you +must place, in the relevant source files, a statement of the +additional terms that apply to those files, or a notice indicating +where to find the applicable terms. + + Additional terms, permissive or non-permissive, may be stated in the +form of a separately written license, or stated as exceptions; +the above requirements apply either way. + + 8. Termination. + + You may not propagate or modify a covered work except as expressly +provided under this License. Any attempt otherwise to propagate or +modify it is void, and will automatically terminate your rights under +this License (including any patent licenses granted under the third +paragraph of section 11). + + However, if you cease all violation of this License, then your +license from a particular copyright holder is reinstated (a) +provisionally, unless and until the copyright holder explicitly and +finally terminates your license, and (b) permanently, if the copyright +holder fails to notify you of the violation by some reasonable means +prior to 60 days after the cessation. + + Moreover, your license from a particular copyright holder is +reinstated permanently if the copyright holder notifies you of the +violation by some reasonable means, this is the first time you have +received notice of violation of this License (for any work) from that +copyright holder, and you cure the violation prior to 30 days after +your receipt of the notice. + + Termination of your rights under this section does not terminate the +licenses of parties who have received copies or rights from you under +this License. If your rights have been terminated and not permanently +reinstated, you do not qualify to receive new licenses for the same +material under section 10. + + 9. Acceptance Not Required for Having Copies. + + You are not required to accept this License in order to receive or +run a copy of the Program. Ancillary propagation of a covered work +occurring solely as a consequence of using peer-to-peer transmission +to receive a copy likewise does not require acceptance. However, +nothing other than this License grants you permission to propagate or +modify any covered work. These actions infringe copyright if you do +not accept this License. Therefore, by modifying or propagating a +covered work, you indicate your acceptance of this License to do so. + + 10. Automatic Licensing of Downstream Recipients. + + Each time you convey a covered work, the recipient automatically +receives a license from the original licensors, to run, modify and +propagate that work, subject to this License. You are not responsible +for enforcing compliance by third parties with this License. + + An "entity transaction" is a transaction transferring control of an +organization, or substantially all assets of one, or subdividing an +organization, or merging organizations. If propagation of a covered +work results from an entity transaction, each party to that +transaction who receives a copy of the work also receives whatever +licenses to the work the party's predecessor in interest had or could +give under the previous paragraph, plus a right to possession of the +Corresponding Source of the work from the predecessor in interest, if +the predecessor has it or can get it with reasonable efforts. + + You may not impose any further restrictions on the exercise of the +rights granted or affirmed under this License. For example, you may +not impose a license fee, royalty, or other charge for exercise of +rights granted under this License, and you may not initiate litigation +(including a cross-claim or counterclaim in a lawsuit) alleging that +any patent claim is infringed by making, using, selling, offering for +sale, or importing the Program or any portion of it. + + 11. Patents. + + A "contributor" is a copyright holder who authorizes use under this +License of the Program or a work on which the Program is based. The +work thus licensed is called the contributor's "contributor version". + + A contributor's "essential patent claims" are all patent claims +owned or controlled by the contributor, whether already acquired or +hereafter acquired, that would be infringed by some manner, permitted +by this License, of making, using, or selling its contributor version, +but do not include claims that would be infringed only as a +consequence of further modification of the contributor version. For +purposes of this definition, "control" includes the right to grant +patent sublicenses in a manner consistent with the requirements of +this License. + + Each contributor grants you a non-exclusive, worldwide, royalty-free +patent license under the contributor's essential patent claims, to +make, use, sell, offer for sale, import and otherwise run, modify and +propagate the contents of its contributor version. + + In the following three paragraphs, a "patent license" is any express +agreement or commitment, however denominated, not to enforce a patent +(such as an express permission to practice a patent or covenant not to +sue for patent infringement). To "grant" such a patent license to a +party means to make such an agreement or commitment not to enforce a +patent against the party. + + If you convey a covered work, knowingly relying on a patent license, +and the Corresponding Source of the work is not available for anyone +to copy, free of charge and under the terms of this License, through a +publicly available network server or other readily accessible means, +then you must either (1) cause the Corresponding Source to be so +available, or (2) arrange to deprive yourself of the benefit of the +patent license for this particular work, or (3) arrange, in a manner +consistent with the requirements of this License, to extend the patent +license to downstream recipients. "Knowingly relying" means you have +actual knowledge that, but for the patent license, your conveying the +covered work in a country, or your recipient's use of the covered work +in a country, would infringe one or more identifiable patents in that +country that you have reason to believe are valid. + + If, pursuant to or in connection with a single transaction or +arrangement, you convey, or propagate by procuring conveyance of, a +covered work, and grant a patent license to some of the parties +receiving the covered work authorizing them to use, propagate, modify +or convey a specific copy of the covered work, then the patent license +you grant is automatically extended to all recipients of the covered +work and works based on it. + + A patent license is "discriminatory" if it does not include within +the scope of its coverage, prohibits the exercise of, or is +conditioned on the non-exercise of one or more of the rights that are +specifically granted under this License. You may not convey a covered +work if you are a party to an arrangement with a third party that is +in the business of distributing software, under which you make payment +to the third party based on the extent of your activity of conveying +the work, and under which the third party grants, to any of the +parties who would receive the covered work from you, a discriminatory +patent license (a) in connection with copies of the covered work +conveyed by you (or copies made from those copies), or (b) primarily +for and in connection with specific products or compilations that +contain the covered work, unless you entered into that arrangement, +or that patent license was granted, prior to 28 March 2007. + + Nothing in this License shall be construed as excluding or limiting +any implied license or other defenses to infringement that may +otherwise be available to you under applicable patent law. + + 12. No Surrender of Others' Freedom. + + If conditions are imposed on you (whether by court order, agreement or +otherwise) that contradict the conditions of this License, they do not +excuse you from the conditions of this License. If you cannot convey a +covered work so as to satisfy simultaneously your obligations under this +License and any other pertinent obligations, then as a consequence you may +not convey it at all. For example, if you agree to terms that obligate you +to collect a royalty for further conveying from those to whom you convey +the Program, the only way you could satisfy both those terms and this +License would be to refrain entirely from conveying the Program. + + 13. Use with the GNU Affero General Public License. + + Notwithstanding any other provision of this License, you have +permission to link or combine any covered work with a work licensed +under version 3 of the GNU Affero General Public License into a single +combined work, and to convey the resulting work. The terms of this +License will continue to apply to the part which is the covered work, +but the special requirements of the GNU Affero General Public License, +section 13, concerning interaction through a network will apply to the +combination as such. + + 14. Revised Versions of this License. + + The Free Software Foundation may publish revised and/or new versions of +the GNU General Public License from time to time. Such new versions will +be similar in spirit to the present version, but may differ in detail to +address new problems or concerns. + + Each version is given a distinguishing version number. If the +Program specifies that a certain numbered version of the GNU General +Public License "or any later version" applies to it, you have the +option of following the terms and conditions either of that numbered +version or of any later version published by the Free Software +Foundation. If the Program does not specify a version number of the +GNU General Public License, you may choose any version ever published +by the Free Software Foundation. + + If the Program specifies that a proxy can decide which future +versions of the GNU General Public License can be used, that proxy's +public statement of acceptance of a version permanently authorizes you +to choose that version for the Program. + + Later license versions may give you additional or different +permissions. However, no additional obligations are imposed on any +author or copyright holder as a result of your choosing to follow a +later version. + + 15. Disclaimer of Warranty. + + THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY +APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT +HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY +OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, +THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR +PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM +IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF +ALL NECESSARY SERVICING, REPAIR OR CORRECTION. + + 16. Limitation of Liability. + + IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING +WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS +THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY +GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE +USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF +DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD +PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), +EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF +SUCH DAMAGES. + + 17. Interpretation of Sections 15 and 16. + + If the disclaimer of warranty and limitation of liability provided +above cannot be given local legal effect according to their terms, +reviewing courts shall apply local law that most closely approximates +an absolute waiver of all civil liability in connection with the +Program, unless a warranty or assumption of liability accompanies a +copy of the Program in return for a fee. + + END OF TERMS AND CONDITIONS + + How to Apply These Terms to Your New Programs + + If you develop a new program, and you want it to be of the greatest +possible use to the public, the best way to achieve this is to make it +free software which everyone can redistribute and change under these terms. + + To do so, attach the following notices to the program. It is safest +to attach them to the start of each source file to most effectively +state the exclusion of warranty; and each file should have at least +the "copyright" line and a pointer to where the full notice is found. + + <one line to give the program's name and a brief idea of what it does.> + Copyright (C) <year> <name of author> + + This program is free software: you can redistribute it and/or modify + it under the terms of the GNU General Public License as published by + the Free Software Foundation, either version 3 of the License, or + (at your option) any later version. + + This program is distributed in the hope that it will be useful, + but WITHOUT ANY WARRANTY; without even the implied warranty of + MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the + GNU General Public License for more details. + + You should have received a copy of the GNU General Public License + along with this program. If not, see <http://www.gnu.org/licenses/>. + +Also add information on how to contact you by electronic and paper mail. + + If the program does terminal interaction, make it output a short +notice like this when it starts in an interactive mode: + + <program> Copyright (C) <year> <name of author> + This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'. + This is free software, and you are welcome to redistribute it + under certain conditions; type `show c' for details. + +The hypothetical commands `show w' and `show c' should show the appropriate +parts of the General Public License. Of course, your program's commands +might be different; for a GUI interface, you would use an "about box". + + You should also get your employer (if you work as a programmer) or school, +if any, to sign a "copyright disclaimer" for the program, if necessary. +For more information on this, and how to apply and follow the GNU GPL, see +<http://www.gnu.org/licenses/>. + + The GNU General Public License does not permit incorporating your program +into proprietary programs. If your program is a subroutine library, you +may consider it more useful to permit linking proprietary applications with +the library. If this is what you want to do, use the GNU Lesser General +Public License instead of this License. But first, please read +<http://www.gnu.org/philosophy/why-not-lgpl.html>. diff --git a/llvm_mode/LLVMInsTrim.so.cc b/instrumentation/LLVMInsTrim.so.cc index 75548266..62de6ec5 100644 --- a/llvm_mode/LLVMInsTrim.so.cc +++ b/instrumentation/LLVMInsTrim.so.cc @@ -38,7 +38,7 @@ typedef long double max_align_t; #include "MarkNodes.h" #include "afl-llvm-common.h" -#include "llvm-ngram-coverage.h" +#include "llvm-alternative-coverage.h" #include "config.h" #include "debug.h" @@ -56,7 +56,6 @@ struct InsTrim : public ModulePass { protected: uint32_t function_minimum_size = 1; - uint32_t debug = 0; char * skip_nozero = NULL; private: @@ -95,14 +94,13 @@ struct InsTrim : public ModulePass { } -#if LLVM_VERSION_MAJOR >= 4 || \ +#if LLVM_VERSION_MAJOR > 4 || \ (LLVM_VERSION_MAJOR == 4 && LLVM_VERSION_PATCH >= 1) #define AFL_HAVE_VECTOR_INTRINSICS 1 #endif bool runOnModule(Module &M) override { - char be_quiet = 0; setvbuf(stdout, NULL, _IONBF, 0); if ((isatty(2) && !getenv("AFL_QUIET")) || getenv("AFL_DEBUG") != NULL) { @@ -134,19 +132,15 @@ struct InsTrim : public ModulePass { } - if (getenv("AFL_LLVM_INSTRIM_SKIPSINGLEBLOCK") || - getenv("AFL_LLVM_SKIPSINGLEBLOCK")) - function_minimum_size = 2; - unsigned int PrevLocSize = 0; char * ngram_size_str = getenv("AFL_LLVM_NGRAM_SIZE"); if (!ngram_size_str) ngram_size_str = getenv("AFL_NGRAM_SIZE"); - char *ctx_str = getenv("AFL_LLVM_CTX"); + char *caller_str = getenv("AFL_LLVM_CALLER"); #ifdef AFL_HAVE_VECTOR_INTRINSICS unsigned int ngram_size = 0; /* Decide previous location vector size (must be a power of two) */ - VectorType *PrevLocTy; + VectorType *PrevLocTy = NULL; if (ngram_size_str) if (sscanf(ngram_size_str, "%u", &ngram_size) != 1 || ngram_size < 2 || @@ -183,10 +177,16 @@ struct InsTrim : public ModulePass { #ifdef AFL_HAVE_VECTOR_INTRINSICS // IntegerType *Int64Ty = IntegerType::getInt64Ty(C); - uint64_t PrevLocVecSize = PowerOf2Ceil(PrevLocSize); + int PrevLocVecSize = PowerOf2Ceil(PrevLocSize); IntegerType *IntLocTy = IntegerType::getIntNTy(C, sizeof(PREV_LOC_T) * CHAR_BIT); - if (ngram_size) PrevLocTy = VectorType::get(IntLocTy, PrevLocVecSize); + if (ngram_size) + PrevLocTy = VectorType::get(IntLocTy, PrevLocVecSize + #if LLVM_VERSION_MAJOR >= 12 + , + false + #endif + ); #endif /* Get globals for the SHM region and the previous location. Note that @@ -196,11 +196,11 @@ struct InsTrim : public ModulePass { new GlobalVariable(M, PointerType::get(Int8Ty, 0), false, GlobalValue::ExternalLinkage, 0, "__afl_area_ptr"); GlobalVariable *AFLPrevLoc; - GlobalVariable *AFLContext; - LoadInst * PrevCtx = NULL; // for CTX sensitive coverage + GlobalVariable *AFLContext = NULL; + LoadInst * PrevCaller = NULL; // for CALLER sensitive coverage - if (ctx_str) -#ifdef __ANDROID__ + if (caller_str) +#if defined(__ANDROID__) || defined(__HAIKU__) AFLContext = new GlobalVariable( M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_ctx"); #else @@ -211,7 +211,7 @@ struct InsTrim : public ModulePass { #ifdef AFL_HAVE_VECTOR_INTRINSICS if (ngram_size) - #ifdef __ANDROID__ + #if defined(__ANDROID__) || defined(__HAIKU__) AFLPrevLoc = new GlobalVariable( M, PrevLocTy, /* isConstant */ false, GlobalValue::ExternalLinkage, /* Initializer */ nullptr, "__afl_prev_loc"); @@ -224,7 +224,7 @@ struct InsTrim : public ModulePass { #endif else #endif -#ifdef __ANDROID__ +#if defined(__ANDROID__) || defined(__HAIKU__) AFLPrevLoc = new GlobalVariable( M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_loc"); #else @@ -243,7 +243,7 @@ struct InsTrim : public ModulePass { for (unsigned I = 0; I < PrevLocSize - 1; ++I) PrevLocShuffle.push_back(ConstantInt::get(Int32Ty, I)); - for (unsigned I = PrevLocSize; I < PrevLocVecSize; ++I) + for (int I = PrevLocSize; I < PrevLocVecSize; ++I) PrevLocShuffle.push_back(ConstantInt::get(Int32Ty, PrevLocSize)); Constant *PrevLocShuffleMask = ConstantVector::get(PrevLocShuffle); @@ -258,6 +258,8 @@ struct InsTrim : public ModulePass { u64 total_rs = 0; u64 total_hs = 0; + scanForDangerousFunctions(&M); + for (Function &F : M) { if (debug) { @@ -266,8 +268,8 @@ struct InsTrim : public ModulePass { for (auto &BB : F) if (BB.size() > 0) ++bb_cnt; - SAYF(cMGN "[D] " cRST "Function %s size %zu %u\n", - F.getName().str().c_str(), F.size(), bb_cnt); + DEBUGF("Function %s size %zu %u\n", F.getName().str().c_str(), F.size(), + bb_cnt); } @@ -396,19 +398,19 @@ struct InsTrim : public ModulePass { unsigned int cur_loc; // Context sensitive coverage - if (ctx_str && &BB == &F.getEntryBlock()) { + if (caller_str && &BB == &F.getEntryBlock()) { - PrevCtx = IRB.CreateLoad(AFLContext); - PrevCtx->setMetadata(M.getMDKindID("nosanitize"), - MDNode::get(C, None)); + PrevCaller = IRB.CreateLoad(AFLContext); + PrevCaller->setMetadata(M.getMDKindID("nosanitize"), + MDNode::get(C, None)); // does the function have calls? and is any of the calls larger than // one basic block? has_calls = 0; - for (auto &BB : F) { + for (auto &BB2 : F) { if (has_calls) break; - for (auto &IN : BB) { + for (auto &IN : BB2) { CallInst *callInst = nullptr; if ((callInst = dyn_cast<CallInst>(&IN))) { @@ -439,7 +441,7 @@ struct InsTrim : public ModulePass { } - } // END of ctx_str + } // END of caller_str if (MarkSetOpt && MS.find(&BB) == MS.end()) { continue; } @@ -452,12 +454,12 @@ struct InsTrim : public ModulePass { auto *PN = PHINode::Create(Int32Ty, 0, "", &*BB.begin()); DenseMap<BasicBlock *, unsigned> PredMap; - for (auto PI = pred_begin(&BB), PE = pred_end(&BB); PI != PE; ++PI) { + for (PI = pred_begin(&BB), PE = pred_end(&BB); PI != PE; ++PI) { BasicBlock *PBB = *PI; auto It = PredMap.insert({PBB, genLabel()}); unsigned Label = It.first->second; - cur_loc = Label; + // cur_loc = Label; PN->addIncoming(ConstantInt::get(Int32Ty, Label), PBB); } @@ -483,9 +485,9 @@ struct InsTrim : public ModulePass { #endif PrevLocTrans = IRB.CreateZExt(PrevLoc, IRB.getInt32Ty()); - if (ctx_str) + if (caller_str) PrevLocTrans = - IRB.CreateZExt(IRB.CreateXor(PrevLocTrans, PrevCtx), Int32Ty); + IRB.CreateZExt(IRB.CreateXor(PrevLocTrans, PrevCaller), Int32Ty); /* Load SHM pointer */ LoadInst *MapPtr = IRB.CreateLoad(AFLMapPtr); @@ -533,16 +535,17 @@ struct InsTrim : public ModulePass { IRB.CreateStore(Incr, MapPtrIdx) ->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); - if (ctx_str && has_calls) { + if (caller_str && has_calls) { - // in CTX mode we have to restore the original context for the + // in CALLER mode we have to restore the original context for the // caller - she might be calling other functions which need the - // correct CTX + // correct CALLER Instruction *Inst = BB.getTerminator(); if (isa<ReturnInst>(Inst) || isa<ResumeInst>(Inst)) { IRBuilder<> Post_IRB(Inst); - StoreInst * RestoreCtx = Post_IRB.CreateStore(PrevCtx, AFLContext); + StoreInst * RestoreCtx = + Post_IRB.CreateStore(PrevCaller, AFLContext); RestoreCtx->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); @@ -566,7 +569,7 @@ struct InsTrim : public ModulePass { getenv("AFL_USE_CFISAN") ? ", CFISAN" : "", getenv("AFL_USE_UBSAN") ? ", UBSAN" : ""); - OKF("Instrumented %u locations (%llu, %llu) (%s mode)\n", total_instr, + OKF("Instrumented %d locations (%llu, %llu) (%s mode)\n", total_instr, total_rs, total_hs, modeline); } diff --git a/instrumentation/Makefile b/instrumentation/Makefile new file mode 100644 index 00000000..6cdd1a07 --- /dev/null +++ b/instrumentation/Makefile @@ -0,0 +1,2 @@ +all: + @echo "no need to do make in the instrumentation/ directory :) - it is all done in the main one" diff --git a/llvm_mode/MarkNodes.cc b/instrumentation/MarkNodes.cc index 20a7df35..b77466d9 100644 --- a/llvm_mode/MarkNodes.cc +++ b/instrumentation/MarkNodes.cc @@ -332,11 +332,11 @@ bool Indistinguish(uint32_t node1, uint32_t node2) { void MakeUniq(uint32_t now) { - bool StopFlag = false; if (Marked.find(now) == Marked.end()) { for (uint32_t pred1 : t_Pred[now]) { + bool StopFlag = false; for (uint32_t pred2 : t_Pred[now]) { if (pred1 == pred2) continue; diff --git a/llvm_mode/MarkNodes.h b/instrumentation/MarkNodes.h index 8ddc978d..8ddc978d 100644 --- a/llvm_mode/MarkNodes.h +++ b/instrumentation/MarkNodes.h diff --git a/llvm_mode/README.cmplog.md b/instrumentation/README.cmplog.md index 7f426ec8..a796c7a7 100644 --- a/llvm_mode/README.cmplog.md +++ b/instrumentation/README.cmplog.md @@ -1,10 +1,11 @@ # CmpLog instrumentation -The CmpLog instrumentation enables the logging of the comparisons operands in a +The CmpLog instrumentation enables logging of comparison operands in a shared memory. These values can be used by various mutators built on top of it. -At the moment we support the RedQueen mutator (input-2-state instructions only). +At the moment we support the RedQueen mutator (input-2-state instructions only), +for details see [the RedQueen paper](https://www.syssec.ruhr-uni-bochum.de/media/emma/veroeffentlichungen/2018/12/17/NDSS19-Redqueen.pdf). ## Build @@ -13,7 +14,7 @@ program. The first version is built using the regular AFL++ instrumentation. -The second one, the CmpLog binary, with setting AFL_LLVM_CMPLOG during the compilation. +The second one, the CmpLog binary, is built with setting AFL_LLVM_CMPLOG during the compilation. For example: @@ -26,11 +27,12 @@ export AFL_LLVM_CMPLOG=1 ./configure --cc=~/path/to/afl-clang-fast make cp ./program ./program.cmplog +unset AFL_LLVM_CMPLOG ``` ## Use -AFL++ has the new -c option that can be used to specify a CmpLog binary (the second +AFL++ has the new `-c` option that needs to be used to specify the CmpLog binary (the second build). For example: @@ -39,4 +41,4 @@ For example: afl-fuzz -i input -o output -c ./program.cmplog -m none -- ./program.afl @@ ``` -Be careful to use -m none because CmpLog maps a lot of pages. +Be sure to use `-m none` because CmpLog can map a lot of pages. diff --git a/instrumentation/README.ctx.md b/instrumentation/README.ctx.md new file mode 100644 index 00000000..335e9921 --- /dev/null +++ b/instrumentation/README.ctx.md @@ -0,0 +1,38 @@ +# AFL Context Sensitive Branch Coverage + +## What is this? + +This is an LLVM-based implementation of the context sensitive branch coverage. + +Basically every function gets its own ID and, every time when an edge is logged, +all the IDs in the callstack are hashed and combined with the edge transition +hash to augment the classic edge coverage with the information about the +calling context. + +So if both function A and function B call a function C, the coverage +collected in C will be different. + +In math the coverage is collected as follows: +`map[current_location_ID ^ previous_location_ID >> 1 ^ hash_callstack_IDs] += 1` + +The callstack hash is produced XOR-ing the function IDs to avoid explosion with +recursive functions. + +## Usage + +Set the `AFL_LLVM_INSTRUMENT=CTX` or `AFL_LLVM_CTX=1` environment variable. + +It is highly recommended to increase the MAP_SIZE_POW2 definition in +config.h to at least 18 and maybe up to 20 for this as otherwise too +many map collisions occur. + +## Caller Branch Coverage + +If the context sensitive coverage introduces too may collisions and becoming +detrimental, the user can choose to augment edge coverage with just the +called function ID, instead of the entire callstack hash. + +In math the coverage is collected as follows: +`map[current_location_ID ^ previous_location_ID >> 1 ^ previous_callee_ID] += 1` + +Set the `AFL_LLVM_INSTRUMENT=CALLER` or `AFL_LLVM_CALLER=1` environment variable. diff --git a/gcc_plugin/README.md b/instrumentation/README.gcc_plugin.md index f762131e..230ceb73 100644 --- a/gcc_plugin/README.md +++ b/instrumentation/README.gcc_plugin.md @@ -1,16 +1,22 @@ # GCC-based instrumentation for afl-fuzz - (See [../README.md](../README.md) for the general instruction manual.) - (See [../llvm_mode/README.md](../llvm_mode/README.md) for the LLVM-based instrumentation.) +See [../README.md](../README.md) for the general instruction manual. +See [README.llvm.md](README.llvm.md) for the LLVM-based instrumentation. -!!! TODO items are: -!!! => inline instrumentation has to work! -!!! +This document describes how to build and use `afl-gcc-fast` and `afl-g++-fast`, +which instrument the target with the help of gcc plugins. +TLDR: + * check the version of your gcc compiler: `gcc --version` + * `apt-get install gcc-VERSION-plugin-dev` or similar to install headers for gcc plugins + * `gcc` and `g++` must match the gcc-VERSION you installed headers for. You can set `AFL_CC`/`AFL_CXX` + to point to these! + * `make` + * just use `afl-gcc-fast`/`afl-g++-fast` normally like you would do with `afl-clang-fast` ## 1) Introduction -The code in this directory allows you to instrument programs for AFL using +The code in this directory allows to instrument programs for AFL using true compiler-level instrumentation, instead of the more crude assembly-level rewriting approach taken by afl-gcc and afl-clang. This has several interesting properties: @@ -25,10 +31,10 @@ several interesting properties: - The instrumentation is CPU-independent. At least in principle, you should be able to rely on it to fuzz programs on non-x86 architectures (after - building afl-fuzz with AFL_NOX86=1). + building `afl-fuzz` with `AFL_NOX86=1`). - Because the feature relies on the internals of GCC, it is gcc-specific - and will *not* work with LLVM (see ../llvm_mode for an alternative). + and will *not* work with LLVM (see [README.llvm.md](README.llvm.md) for an alternative). Once this implementation is shown to be sufficiently robust and portable, it will probably replace afl-gcc. For now, it can be built separately and @@ -39,25 +45,32 @@ The idea and much of the implementation comes from Laszlo Szekeres. ## 2) How to use In order to leverage this mechanism, you need to have modern enough GCC -(>= version 4.5.0) and the plugin headers installed on your system. That +(>= version 4.5.0) and the plugin development headers installed on your system. That should be all you need. On Debian machines, these headers can be acquired by -installing the `gcc-<VERSION>-plugin-dev` packages. +installing the `gcc-VERSION-plugin-dev` packages. + +To build the instrumentation itself, type `make`. This will generate binaries +called `afl-gcc-fast` and `afl-g++-fast` in the parent directory. + +The gcc and g++ compiler links have to point to gcc-VERSION - or set these +by pointing the environment variables `AFL_CC`/`AFL_CXX` to them. +If the `CC`/`CXX` environment variables have been set, those compilers will be +preferred over those from the `AFL_CC`/`AFL_CXX` settings. -To build the instrumentation itself, type 'make'. This will generate binaries -called afl-gcc-fast and afl-g++-fast in the parent directory. -If the CC/CXX have been overridden, those compilers will be used from -those wrappers without using AFL_CXX/AFL_CC settings. Once this is done, you can instrument third-party code in a way similar to the standard operating mode of AFL, e.g.: - - CC=/path/to/afl/afl-gcc-fast ./configure [...options...] +``` + CC=/path/to/afl/afl-gcc-fast + CXX=/path/to/afl/afl-g++-fast + export CC CXX + ./configure [...options...] make +``` +Note: We also used `CXX` to set the C++ compiler to `afl-g++-fast` for C++ code. -Be sure to also include CXX set to afl-g++-fast for C++ code. - -The tool honors roughly the same environmental variables as afl-gcc (see -[env_variables.md](../docs/env_variables.md). This includes AFL_INST_RATIO, AFL_USE_ASAN, -AFL_HARDEN, and AFL_DONT_OPTIMIZE. +The tool honors roughly the same environmental variables as `afl-gcc` (see +[env_variables.md](../docs/env_variables.md). This includes `AFL_INST_RATIO`, +`AFL_USE_ASAN`, `AFL_HARDEN`, and `AFL_DONT_OPTIMIZE`. Note: if you want the GCC plugin to be installed on your system for all users, you need to build it before issuing 'make install' in the parent @@ -66,7 +79,7 @@ directory. ## 3) Gotchas, feedback, bugs This is an early-stage mechanism, so field reports are welcome. You can send bug -reports to <hexcoder-@github.com>. +reports to afl@aflplus.plus. ## 4) Bonus feature #1: deferred initialization @@ -82,7 +95,7 @@ file before getting to the fuzzed data. In such cases, it's beneficial to initialize the forkserver a bit later, once most of the initialization work is already done, but before the binary attempts to read the fuzzed input and parse it; in some cases, this can offer a 10x+ -performance gain. You can implement delayed initialization in LLVM mode in a +performance gain. You can implement delayed initialization in GCC mode in a fairly simple way. First, locate a suitable location in the code where the delayed cloning can @@ -111,7 +124,7 @@ With the location selected, add this code in the appropriate spot: ``` You don't need the #ifdef guards, but they will make the program still work as -usual when compiled with a tool other than afl-gcc-fast/afl-clang-fast. +usual when compiled with a compiler other than afl-gcc-fast/afl-clang-fast. Finally, recompile the program with afl-gcc-fast (afl-gcc or afl-clang will *not* generate a deferred-initialization binary) - and you should be all set! @@ -121,7 +134,7 @@ Finally, recompile the program with afl-gcc-fast (afl-gcc or afl-clang will Some libraries provide APIs that are stateless, or whose state can be reset in between processing different input files. When such a reset is performed, a single long-lived process can be reused to try out multiple test cases, -eliminating the need for repeated fork() calls and the associated OS overhead. +eliminating the need for repeated `fork()` calls and the associated OS overhead. The basic structure of the program that does this would be: @@ -141,7 +154,7 @@ The numerical value specified within the loop controls the maximum number of iterations before AFL will restart the process from scratch. This minimizes the impact of memory leaks and similar glitches; 1000 is a good starting point. -A more detailed template is shown in ../examples/persistent_demo/. +A more detailed template is shown in ../utils/persistent_mode/. Similarly to the previous mode, the feature works only with afl-gcc-fast or afl-clang-fast; #ifdef guards can be used to suppress it when using other compilers. @@ -154,5 +167,9 @@ wary of memory leaks and the state of file descriptors. When running in this mode, the execution paths will inherently vary a bit depending on whether the input loop is being entered for the first time or executed again. To avoid spurious warnings, the feature implies -AFL_NO_VAR_CHECK and hides the "variable path" warnings in the UI. +`AFL_NO_VAR_CHECK` and hides the "variable path" warnings in the UI. + +## 6) Bonus feature #3: selective instrumentation +It can be more effective to fuzzing to only instrument parts of the code. +For details see [README.instrument_list.md](README.instrument_list.md). diff --git a/instrumentation/README.instrim.md b/instrumentation/README.instrim.md new file mode 100644 index 00000000..99f6477a --- /dev/null +++ b/instrumentation/README.instrim.md @@ -0,0 +1,30 @@ +# InsTrim + +InsTrim: Lightweight Instrumentation for Coverage-guided Fuzzing + +## Introduction + +InsTrim is the work of Chin-Chia Hsu, Che-Yu Wu, Hsu-Chun Hsiao and Shih-Kun Huang. + +It uses a CFG (call flow graph) and markers to instrument just what +is necessary in the binary (ie less than llvm_mode). As a result the binary is +about 10-15% faster compared to normal llvm_mode however with some coverage loss. +It requires at least llvm version 3.8.0 to build. +If you have LLVM 7+ we recommend PCGUARD instead. + +## Usage + +Set the environment variable `AFL_LLVM_INSTRUMENT=CFG` or `AFL_LLVM_INSTRIM=1` +during compilation of the target. + +There is also special mode which instruments loops in a way so that +afl-fuzz can see which loop path has been selected but not being able to +see how often the loop has been rerun. +This again is a tradeoff for speed for less path information. +To enable this mode set `AFL_LLVM_INSTRIM_LOOPHEAD=1`. + +## Background + +The paper from Chin-Chia Hsu, Che-Yu Wu, Hsu-Chun Hsiao and Shih-Kun Huang: +[InsTrim: Lightweight Instrumentation for Coverage-guided Fuzzing] +(https://www.ndss-symposium.org/wp-content/uploads/2018/07/bar2018_14_Hsu_paper.pdf) diff --git a/instrumentation/README.instrument_list.md b/instrumentation/README.instrument_list.md new file mode 100644 index 00000000..2116d24c --- /dev/null +++ b/instrumentation/README.instrument_list.md @@ -0,0 +1,118 @@ +# Using afl++ with partial instrumentation + + This file describes two different mechanisms to selectively instrument + only specific parts in the target. + + Both mechanisms work for LLVM and GCC_PLUGIN, but not for afl-clang/afl-gcc. + +## 1) Description and purpose + +When building and testing complex programs where only a part of the program is +the fuzzing target, it often helps to only instrument the necessary parts of +the program, leaving the rest uninstrumented. This helps to focus the fuzzer +on the important parts of the program, avoiding undesired noise and +disturbance by uninteresting code being exercised. + +For this purpose, "partial instrumentation" support is provided by afl++ that +allows to specify what should be instrumented and what not. + +Both mechanisms can be used together. + +## 2) Selective instrumentation with __AFL_COVERAGE_... directives + +In this mechanism the selective instrumentation is done in the source code. + +After the includes a special define has to be made, eg.: + +``` +#include <stdio.h> +#include <stdint.h> +// ... + +__AFL_COVERAGE(); // <- required for this feature to work +``` + +If you want to disable the coverage at startup until you specify coverage +should be started, then add `__AFL_COVERAGE_START_OFF();` at that position. + +From here on out you have the following macros available that you can use +in any function where you want: + + * `__AFL_COVERAGE_ON();` - enable coverage from this point onwards + * `__AFL_COVERAGE_OFF();` - disable coverage from this point onwards + * `__AFL_COVERAGE_DISCARD();` - reset all coverage gathered until this point + * `__AFL_COVERAGE_SKIP();` - mark this test case as unimportant. Whatever happens, afl-fuzz will ignore it. + +A special function is `__afl_coverage_interesting`. +To use this, you must define `void __afl_coverage_interesting(u8 val, u32 id);`. +Then you can use this function globally, where the `val` parameter can be set +by you, the `id` parameter is for afl-fuzz and will be overwritten. +Note that useful parameters for `val` are: 1, 2, 3, 4, 8, 16, 32, 64, 128. +A value of e.g. 33 will be seen as 32 for coverage purposes. + +## 3) Selective instrumentation with AFL_LLVM_ALLOWLIST/AFL_LLVM_DENYLIST + +This feature is equivalent to llvm 12 sancov feature and allows to specify +on a filename and/or function name level to instrument these or skip them. + +### 3a) How to use the partial instrumentation mode + +In order to build with partial instrumentation, you need to build with +afl-clang-fast/afl-clang-fast++ or afl-clang-lto/afl-clang-lto++. +The only required change is that you need to set either the environment variable +AFL_LLVM_ALLOWLIST or AFL_LLVM_DENYLIST set with a filename. + +That file should contain the file names or functions that are to be instrumented +(AFL_LLVM_ALLOWLIST) or are specifically NOT to be instrumented (AFL_LLVM_DENYLIST). + +GCC_PLUGIN: you can use either AFL_LLVM_ALLOWLIST or AFL_GCC_ALLOWLIST (or the +same for _DENYLIST), both work. + +For matching to succeed, the function/file name that is being compiled must end in the +function/file name entry contained in this instrument file list. That is to avoid +breaking the match when absolute paths are used during compilation. + +**NOTE:** In builds with optimization enabled, functions might be inlined and would not match! + +For example if your source tree looks like this: +``` +project/ +project/feature_a/a1.cpp +project/feature_a/a2.cpp +project/feature_b/b1.cpp +project/feature_b/b2.cpp +``` + +and you only want to test feature_a, then create an "instrument file list" file containing: +``` +feature_a/a1.cpp +feature_a/a2.cpp +``` + +However if the "instrument file list" file contains only this, it works as well: +``` +a1.cpp +a2.cpp +``` +but it might lead to files being unwantedly instrumented if the same filename +exists somewhere else in the project directories. + +You can also specify function names. Note that for C++ the function names +must be mangled to match! `nm` can print these names. + +afl++ is able to identify whether an entry is a filename or a function. +However if you want to be sure (and compliant to the sancov allow/blocklist +format), you can specify source file entries like this: +``` +src: *malloc.c +``` +and function entries like this: +``` +fun: MallocFoo +``` +Note that whitespace is ignored and comments (`# foo`) are supported. + +### 3b) UNIX-style pattern matching + +You can add UNIX-style pattern matching in the "instrument file list" entries. +See `man fnmatch` for the syntax. We do not set any of the `fnmatch` flags. diff --git a/llvm_mode/README.laf-intel.md b/instrumentation/README.laf-intel.md index f63ab2bb..c50a6979 100644 --- a/llvm_mode/README.laf-intel.md +++ b/instrumentation/README.laf-intel.md @@ -1,5 +1,15 @@ # laf-intel instrumentation +## Introduction + +This originally is the work of an individual nicknamed laf-intel. +His blog [Circumventing Fuzzing Roadblocks with Compiler Transformations] +(https://lafintel.wordpress.com/) and gitlab repo [laf-llvm-pass] +(https://gitlab.com/laf-intel/laf-llvm-pass/) +describe some code transformations that +help afl++ to enter conditional blocks, where conditions consist of +comparisons of large values. + ## Usage By default these passes will not run when you compile programs using @@ -24,18 +34,22 @@ Enables the split-compares pass. By default it will 1. simplify operators >= (and <=) into chains of > (<) and == comparisons 2. change signed integer comparisons to a chain of sign-only comparison -and unsigned comparisons +and unsigned integer comparisons 3. split all unsigned integer comparisons with bit widths of 64, 32 or 16 bits to chains of 8 bits comparisons. You can change the behaviour of the last step by setting `export AFL_LLVM_LAF_SPLIT_COMPARES_BITW=<bit_width>`, where -bit_width may be 64, 32 or 16. +bit_width may be 64, 32 or 16. For example, a bit_width of 16 +would split larger comparisons down to 16 bit comparisons. A new experimental feature is splitting floating point comparisons into a series of sign, exponent and mantissa comparisons followed by splitting each of them into 8 bit comparisons when necessary. It is activated with the `AFL_LLVM_LAF_SPLIT_FLOATS` setting. +Please note that full IEEE 754 functionality is not preserved, that is +values of nan and infinity will probably behave differently. + Note that setting this automatically activates `AFL_LLVM_LAF_SPLIT_COMPARES` You can also set `AFL_LLVM_LAF_ALL` and have all of the above enabled :-) diff --git a/llvm_mode/README.md b/instrumentation/README.llvm.md index 22088dfd..2705ce0d 100644 --- a/llvm_mode/README.md +++ b/instrumentation/README.llvm.md @@ -1,8 +1,8 @@ # Fast LLVM-based instrumentation for afl-fuzz - (See [../README](../README.md) for the general instruction manual.) + (See [../README.md](../README.md) for the general instruction manual.) - (See [../gcc_plugin/README](../gcc_plugin/README.md) for the GCC-based instrumentation.) + (See [README.gcc_plugon.md](../README.gcc_plugin.md) for the GCC-based instrumentation.) ## 1) Introduction @@ -93,15 +93,16 @@ operating mode of AFL, e.g.: Be sure to also include CXX set to afl-clang-fast++ for C++ code. +Note that afl-clang-fast/afl-clang-fast++ are just pointers to afl-cc. +You can also use afl-cc/afl-c++ and instead direct it to use LLVM +instrumentation by either setting `AFL_CC_COMPILER=LLVM` or pass the parameter +`--afl-llvm` via CFLAGS/CXXFLAGS/CPPFLAGS. + The tool honors roughly the same environmental variables as afl-gcc (see [docs/env_variables.md](../docs/env_variables.md)). This includes AFL_USE_ASAN, AFL_HARDEN, and AFL_DONT_OPTIMIZE. However AFL_INST_RATIO is not honored -as it does not serve a good purpose with the more effective instrim CFG -analysis. - -Note: if you want the LLVM helper to be installed on your system for all -users, you need to build it before issuing 'make install' in the parent -directory. +as it does not serve a good purpose with the more effective PCGUARD, LTO and + instrim CFG analysis. ## 3) Options @@ -109,9 +110,9 @@ Several options are present to make llvm_mode faster or help it rearrange the code to make afl-fuzz path discovery easier. If you need just to instrument specific parts of the code, you can the instrument file list -which C/C++ files to actually instrument. See [README.instrument_file](README.instrument_file.md) +which C/C++ files to actually instrument. See [README.instrument_list.md](README.instrument_list.md) -For splitting memcmp, strncmp, etc. please see [README.laf-intel](README.laf-intel.md) +For splitting memcmp, strncmp, etc. please see [README.laf-intel.md](README.laf-intel.md) Then there are different ways of instrumenting the target: @@ -119,42 +120,42 @@ Then there are different ways of instrumenting the target: markers to just instrument what is needed. This increases speed by 10-15% without any disadvantages If you want to use this, set AFL_LLVM_INSTRUMENT=CFG or AFL_LLVM_INSTRIM=1 -See [README.instrim](README.instrim.md) +See [README.instrim.md](README.instrim.md) 2. An even better instrumentation strategy uses LTO and link time instrumentation. Note that not all targets can compile in this mode, however if it works it is the best option you can use. Simply use afl-clang-lto/afl-clang-lto++ to use this option. -See [README.lto](README.lto.md) +See [README.lto.md](README.lto.md) 3. Alternativly you can choose a completely different coverage method: 3a. N-GRAM coverage - which combines the previous visited edges with the current one. This explodes the map but on the other hand has proven to be effective for fuzzing. -See [README.ngram](README.ngram.md) +See [README.ngram.md](README.ngram.md) 3b. Context sensitive coverage - which combines the visited edges with an individual caller ID (the function that called the current one) -[README.ctx](README.ctx.md) +[README.ctx.md](README.ctx.md) Then - additionally to one of the instrumentation options above - there is a very effective new instrumentation option called CmpLog as an alternative to laf-intel that allow AFL++ to apply mutations similar to Redqueen. -See [README.cmplog](README.cmplog.md) +See [README.cmplog.md](README.cmplog.md) Finally if your llvm version is 8 or lower, you can activate a mode that prevents that a counter overflow result in a 0 value. This is good for path discovery, but the llvm implementation for x86 for this functionality is not optimal and was only fixed in llvm 9. You can set this with AFL_LLVM_NOT_ZERO=1 -See [README.neverzero](README.neverzero.md) +See [README.neverzero.md](README.neverzero.md) ## 4) Snapshot feature To speed up fuzzing you can use a linux loadable kernel module which enables a snapshot feature. -See [README.snapshot](README.snapshot.md) +See [README.snapshot.md](README.snapshot.md) ## 5) Gotchas, feedback, bugs @@ -167,20 +168,8 @@ This is the most powerful and effective fuzzing you can do. Please see [README.persistent_mode.md](README.persistent_mode.md) for a full explanation. -## 7) Bonus feature: 'trace-pc-guard' mode - -LLVM is shipping with a built-in execution tracing feature -that provides AFL with the necessary tracing data without the need to -post-process the assembly or install any compiler plugins. See: - - http://clang.llvm.org/docs/SanitizerCoverage.html#tracing-pcs-with-guards - -If you have not an outdated compiler and want to give it a try, build -targets this way: - -``` -AFL_LLVM_INSTRUMENT=PCGUARD make -``` +## 7) Bonus feature: 'dict2file' pass -Note that this us currently the default, as it is the best mode. -If you have llvm 11+ and compiled afl-clang-lto - this is the only better mode. +Just specify `AFL_LLVM_DICT2FILE=/absolute/path/file.txt` and during compilation +all constant string compare parameters will be written to this file to be +used with afl-fuzz' `-x` option. diff --git a/llvm_mode/README.lto.md b/instrumentation/README.lto.md index a4c969b9..81c82c4b 100644 --- a/llvm_mode/README.lto.md +++ b/instrumentation/README.lto.md @@ -17,9 +17,6 @@ This version requires a current llvm 11+ compiled from the github master. 5. If any problems arise be sure to set `AR=llvm-ar RANLIB=llvm-ranlib`. Some targets might need `LD=afl-clang-lto` and others `LD=afl-ld-lto`. -6. If a target uses _init functions or early constructors then additionally - set `AFL_LLVM_MAP_DYNAMIC=1` as your target will crash otherwise! - ## Introduction and problem description A big issue with how afl/afl++ works is that the basic block IDs that are @@ -63,7 +60,12 @@ AUTODICTIONARY: 11 strings found ## Getting llvm 11+ -### Installing llvm from the llvm repository (version 11) +### Installing llvm version 11 + +llvm 11 should be available in all current Linux repositories. +If you use an outdated Linux distribution read the next section. + +### Installing llvm from the llvm repository (version 12) Installing the llvm snapshot builds is easy and mostly painless: @@ -76,74 +78,99 @@ then add the pgp key of llvm and install the packages: ``` wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | apt-key add - apt-get update && apt-get upgrade -y -apt-get install -y clang-11 clang-tools-11 libc++1-11 libc++-11-dev \ - libc++abi1-11 libc++abi-11-dev libclang1-11 libclang-11-dev \ - libclang-common-11-dev libclang-cpp11 libclang-cpp11-dev liblld-11 \ - liblld-11-dev liblldb-11 liblldb-11-dev libllvm11 libomp-11-dev \ - libomp5-11 lld-11 lldb-11 llvm-11 llvm-11-dev llvm-11-runtime llvm-11-tools +apt-get install -y clang-12 clang-tools-12 libc++1-12 libc++-12-dev \ + libc++abi1-12 libc++abi-12-dev libclang1-12 libclang-12-dev \ + libclang-common-12-dev libclang-cpp12 libclang-cpp12-dev liblld-12 \ + liblld-12-dev liblldb-12 liblldb-12-dev libllvm12 libomp-12-dev \ + libomp5-12 lld-12 lldb-12 llvm-12 llvm-12-dev llvm-12-runtime llvm-12-tools ``` ### Building llvm yourself (version 12) Building llvm from github takes quite some long time and is not painless: -``` +```sh sudo apt install binutils-dev # this is *essential*! -git clone https://github.com/llvm/llvm-project +git clone --depth=1 https://github.com/llvm/llvm-project cd llvm-project mkdir build cd build -cmake -DLLVM_ENABLE_PROJECTS='clang;clang-tools-extra;compiler-rt;libclc;libcxx;libcxxabi;libunwind;lld' -DCMAKE_BUILD_TYPE=Release -DLLVM_BINUTILS_INCDIR=/usr/include/ ../llvm/ -make -j $(nproc) -export PATH=`pwd`/bin:$PATH -export LLVM_CONFIG=`pwd`/bin/llvm-config + +# Add -G Ninja if ninja-build installed +# "Building with ninja significantly improves your build time, especially with +# incremental builds, and improves your memory usage." +cmake \ + -DCLANG_INCLUDE_DOCS="OFF" \ + -DCMAKE_BUILD_TYPE=Release \ + -DLLVM_BINUTILS_INCDIR=/usr/include/ \ + -DLLVM_BUILD_LLVM_DYLIB="ON" \ + -DLLVM_ENABLE_BINDINGS="OFF" \ + -DLLVM_ENABLE_PROJECTS='clang;compiler-rt;libcxx;libcxxabi;libunwind;lld' \ + -DLLVM_ENABLE_WARNINGS="OFF" \ + -DLLVM_INCLUDE_BENCHMARKS="OFF" \ + -DLLVM_INCLUDE_DOCS="OFF" \ + -DLLVM_INCLUDE_EXAMPLES="OFF" \ + -DLLVM_INCLUDE_TESTS="OFF" \ + -DLLVM_LINK_LLVM_DYLIB="ON" \ + -DLLVM_TARGETS_TO_BUILD="host" \ + ../llvm/ +cmake --build . --parallel +export PATH="$(pwd)/bin:$PATH" +export LLVM_CONFIG="$(pwd)/bin/llvm-config" +export LD_LIBRARY_PATH="$(llvm-config --libdir)${LD_LIBRARY_PATH:+:$LD_LIBRARY_PATH}" cd /path/to/AFLplusplus/ make -cd llvm_mode -make -cd .. -make install +sudo make install ``` ## How to use afl-clang-lto Just use afl-clang-lto like you did with afl-clang-fast or afl-gcc. -Also the instrument file listing (AFL_LLVM_INSTRUMENT_FILE -> [README.instrument_file.md](README.instrument_file.md)) and +Also the instrument file listing (AFL_LLVM_ALLOWLIST/AFL_LLVM_DENYLIST -> [README.instrument_list.md](README.instrument_list.md)) and laf-intel/compcov (AFL_LLVM_LAF_* -> [README.laf-intel.md](README.laf-intel.md)) work. -InsTrim (control flow graph instrumentation) is supported and recommended! - (set `AFL_LLVM_INSTRUMENT=CFG`) Example: ``` CC=afl-clang-lto CXX=afl-clang-lto++ RANLIB=llvm-ranlib AR=llvm-ar ./configure -export AFL_LLVM_INSTRUMENT=CFG make ``` NOTE: some targets also need to set the linker, try both `afl-clang-lto` and -`afl-ld-lto` for this for `LD=` for `configure`. +`afl-ld-lto` for `LD=` before `configure`. ## AUTODICTIONARY feature -While compiling, automatically a dictionary based on string comparisons is -generated put into the target binary. This dictionary is transfered to afl-fuzz +While compiling, a dictionary based on string comparisons is automatically +generated and put into the target binary. This dictionary is transfered to afl-fuzz on start. This improves coverage statistically by 5-10% :) +Note that if for any reason you do not want to use the autodictionary feature +then just set the environment variable `AFL_NO_AUTODICT` when starting afl-fuzz. + ## Fixed memory map -To speed up fuzzing, the shared memory map is hard set to a specific address, -by default 0x10000. In most cases this will work without any problems. -On unusual operating systems/processors/kernels or weird libraries this might -fail so to change the fixed address at compile time set -AFL_LLVM_MAP_ADDR with a better value (a value of 0 or empty sets the map address -to be dynamic - the original afl way, which is slower). -AFL_LLVM_MAP_DYNAMIC can be set so the shared memory address is dynamic (which -is safer but also slower). +To speed up fuzzing a little bit more, it is possible to set a fixed shared +memory map. +Recommended is the value 0x10000. + +In most cases this will work without any problems. However if a target uses +early constructors, ifuncs or a deferred forkserver this can crash the target. + +Also on unusual operating systems/processors/kernels or weird libraries the +recommended 0x10000 address might not work, so then change the fixed address. + +To enable this feature set AFL_LLVM_MAP_ADDR with the address. + +## Document edge IDs + +Setting `export AFL_LLVM_DOCUMENT_IDS=file` will document in a file which edge +ID was given to which function. This helps to identify functions with variable +bytes or which functions were touched by an input. ## Solving difficult targets Some targets are difficult because the configure script does unusual stuff that -is unexpected for afl. See the next chapter `Potential issues` how to solve +is unexpected for afl. See the next chapter `Potential issues` for how to solve these. ### Example: ffmpeg @@ -151,7 +178,7 @@ these. An example of a hard to solve target is ffmpeg. Here is how to successfully instrument it: -1. Get and extract the current ffmpeg and change to it's directory +1. Get and extract the current ffmpeg and change to its directory 2. Running configure with --cc=clang fails and various other items will fail when compiling, so we have to trick configure: @@ -221,13 +248,13 @@ If you see this message: /bin/ld: libfoo.a: error adding symbols: archive has no index; run ranlib to add one ``` This is because usually gnu gcc ranlib is being called which cannot deal with clang LTO files. -The solution is simple: when you ./configure you have also have to set RANLIB=llvm-ranlib and AR=llvm-ar +The solution is simple: when you ./configure you also have to set RANLIB=llvm-ranlib and AR=llvm-ar Solution: ``` AR=llvm-ar RANLIB=llvm-ranlib CC=afl-clang-lto CXX=afl-clang-lto++ ./configure --disable-shared ``` -and on some target you have to to AR=/RANLIB= even for make as the configure script does not save it. +and on some targets you have to set AR=/RANLIB= even for make as the configure script does not save it. Other targets ignore environment variables and need the parameters set via `./configure --cc=... --cxx= --ranlib= ...` etc. (I am looking at you ffmpeg!). @@ -246,8 +273,8 @@ AS=llvm-as ... afl-clang-lto is still work in progress. Known issues: - * Anything that llvm 11+ cannot compile, afl-clang-lto can not compile either - obviously - * Anything that does not compile with LTO, afl-clang-lto can not compile either - obviously + * Anything that llvm 11+ cannot compile, afl-clang-lto cannot compile either - obviously + * Anything that does not compile with LTO, afl-clang-lto cannot compile either - obviously Hence if building a target with afl-clang-lto fails try to build it with llvm12 and LTO enabled (`CC=clang-12` `CXX=clang++-12` `CFLAGS=-flto=full` and @@ -259,15 +286,6 @@ If this succeeeds then there is an issue with afl-clang-lto. Please report at Even some targets where clang-12 fails can be build if the fail is just in `./configure`, see `Solving difficult targets` above. -### Target crashes immediately - -If the target is using early constructors (priority values smaller than 6) -or have their own _init/.init functions and these are instrumented then the -target will likely crash when started. This can be avoided by compiling with -`AFL_LLVM_MAP_DYNAMIC=1` . - -This can e.g. happen with OpenSSL. - ## History This was originally envisioned by hexcoder- in Summer 2019, however we saw no @@ -276,14 +294,14 @@ for this in the PassManager: EP_FullLinkTimeOptimizationLast ("Fun" info - nobody knows what this is doing. And the developer who implemented this didn't respond to emails.) -In December came then the idea to implement this as a pass that is run via +In December then came the idea to implement this as a pass that is run via the llvm "opt" program, which is performed via an own linker that afterwards calls the real linker. This was first implemented in January and work ... kinda. -The LTO time instrumentation worked, however the "how" the basic blocks were +The LTO time instrumentation worked, however "how" the basic blocks were instrumented was a problem, as reducing duplicates turned out to be very, very difficult with a program that has so many paths and therefore so many -dependencies. At lot of strategies were implemented - and failed. +dependencies. A lot of strategies were implemented - and failed. And then sat solvers were tried, but with over 10.000 variables that turned out to be a dead-end too. diff --git a/llvm_mode/README.neverzero.md b/instrumentation/README.neverzero.md index 903e5bd3..49104e00 100644 --- a/llvm_mode/README.neverzero.md +++ b/instrumentation/README.neverzero.md @@ -2,8 +2,8 @@ ## Usage -In larger, complex or reiterative programs the counters that collect the edge -coverage can easily fill up and wrap around. +In larger, complex or reiterative programs the byte sized counters that collect +the edge coverage can easily fill up and wrap around. This is not that much of an issue - unless by chance it wraps just to a value of zero when the program execution ends. In this case afl-fuzz is not able to see that the edge has been accessed and @@ -16,7 +16,7 @@ at a very little cost (one instruction per edge). (The alternative of saturated counters has been tested also and proved to be inferior in terms of path discovery.) -This is implemented in afl-gcc, however for llvm_mode this is optional if +This is implemented in afl-gcc and afl-gcc-fast, however for llvm_mode this is optional if the llvm version is below 9 - as there is a perfomance bug that is only fixed in version 9 and onwards. diff --git a/llvm_mode/README.ngram.md b/instrumentation/README.ngram.md index de3ba432..da61ef32 100644 --- a/llvm_mode/README.ngram.md +++ b/instrumentation/README.ngram.md @@ -10,8 +10,8 @@ by Jinghan Wang, et. al. Note that the original implementation (available [here](https://github.com/bitsecurerlab/afl-sensitive)) is built on top of AFL's QEMU mode. -This is essentially a port that uses LLVM vectorized instructions to achieve -the same results when compiling source code. +This is essentially a port that uses LLVM vectorized instructions (available from +llvm versions 4.0.1 and higher) to achieve the same results when compiling source code. In math the branch coverage is performed as follows: `map[current_location ^ prev_location[0] >> 1 ^ prev_location[1] >> 1 ^ ... up to n-1`] += 1` diff --git a/instrumentation/README.out_of_line.md b/instrumentation/README.out_of_line.md new file mode 100644 index 00000000..2264f91f --- /dev/null +++ b/instrumentation/README.out_of_line.md @@ -0,0 +1,19 @@ +## Using afl++ without inlined instrumentation + + This file describes how you can disable inlining of instrumentation. + + +By default, the GCC plugin will duplicate the effects of calling +`__afl_trace` (see `afl-gcc-rt.o.c`) in instrumented code, instead of +issuing function calls. + +The calls are presumed to be slower, more so because the rt file +itself is not optimized by the compiler. + +Setting `AFL_GCC_OUT_OF_LINE=1` in the environment while compiling code +with the plugin will disable this inlining, issuing calls to the +unoptimized runtime instead. + +You probably don't want to do this, but it might be useful in certain +AFL debugging scenarios, and it might work as a fallback in case +something goes wrong with the inlined instrumentation. diff --git a/llvm_mode/README.persistent_mode.md b/instrumentation/README.persistent_mode.md index 83cc7f4d..24f81ea0 100644 --- a/llvm_mode/README.persistent_mode.md +++ b/instrumentation/README.persistent_mode.md @@ -4,34 +4,39 @@ The most effective way is to fuzz in persistent mode, as the speed can easily be x10 or x20 times faster without any disadvanges. -*All professionel fuzzing is using this mode.* +*All professional fuzzing is using this mode.* This requires that the target can be called in a (or several) function(s), -and that the state can be resetted so that multiple calls be be performed -without memory leaking and former runs having no impact on following runs +and that its state can be resetted so that multiple calls can be performed +without resource leaks and former runs having no impact on following runs (this can be seen by the `stability` indicator in the `afl-fuzz` UI). -Examples can be found in [examples/persistent_mode](../examples/persistent_mode). +Examples can be found in [utils/persistent_mode](../utils/persistent_mode). ## 2) TLDR; Example `fuzz_target.c`: -``` +```c #include "what_you_need_for_your_target.h" __AFL_FUZZ_INIT(); main() { + // anything else here, eg. command line arguments, initialization, etc. + #ifdef __AFL_HAVE_MANUAL_CONTROL __AFL_INIT(); #endif unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; // must be after __AFL_INIT + // and before __AFL_LOOP! while (__AFL_LOOP(10000)) { - int len = __AFL_FUZZ_TESTCASE_LEN; + int len = __AFL_FUZZ_TESTCASE_LEN; // don't use the macro directly in a + // call! + if (len < 8) continue; // check for a required/useful minimum input length /* Setup function call, e.g. struct target *tmp = libtarget_init() */ @@ -52,10 +57,25 @@ afl-clang-fast -o fuzz_target fuzz_target.c -lwhat_you_need_for_your_target And that is it! The speed increase is usually x10 to x20. -## 3) deferred initialization +If you want to be able to compile the target without afl-clang-fast/lto then +add this just after the includes: + +```c +#ifndef __AFL_FUZZ_TESTCASE_LEN + ssize_t fuzz_len; + #define __AFL_FUZZ_TESTCASE_LEN fuzz_len + unsigned char fuzz_buf[1024000]; + #define __AFL_FUZZ_TESTCASE_BUF fuzz_buf + #define __AFL_FUZZ_INIT() void sync(void); + #define __AFL_LOOP(x) ((fuzz_len = read(0, fuzz_buf, sizeof(fuzz_buf))) > 0 ? 1 : 0) + #define __AFL_INIT() sync() +#endif +``` + +## 3) Deferred initialization AFL tries to optimize performance by executing the targeted binary just once, -stopping it just before main(), and then cloning this "main" process to get +stopping it just before `main()`, and then cloning this "main" process to get a steady supply of targets to fuzz. Although this approach eliminates much of the OS-, linker- and libc-level @@ -77,7 +97,7 @@ a location after: - The creation of any vital threads or child processes - since the forkserver can't clone them easily. - - The initialization of timers via setitimer() or equivalent calls. + - The initialization of timers via `setitimer()` or equivalent calls. - The creation of temporary files, network sockets, offset-sensitive file descriptors, and similar shared-state resources - but only provided that @@ -95,12 +115,15 @@ With the location selected, add this code in the appropriate spot: ``` You don't need the #ifdef guards, but including them ensures that the program -will keep working normally when compiled with a tool other than afl-clang-fast. +will keep working normally when compiled with a tool other than afl-clang-fast/ +afl-clang-lto/afl-gcc-fast. + +Finally, recompile the program with afl-clang-fast/afl-clang-lto/afl-gcc-fast +(afl-gcc or afl-clang will *not* generate a deferred-initialization binary) - +and you should be all set! -Finally, recompile the program with afl-clang-fast (afl-gcc or afl-clang will -*not* generate a deferred-initialization binary) - and you should be all set! -## 4) persistent mode +## 4) Persistent mode Some libraries provide APIs that are stateless, or whose state can be reset in between processing different input files. When such a reset is performed, a @@ -127,9 +150,9 @@ the impact of memory leaks and similar glitches; 1000 is a good starting point, and going much higher increases the likelihood of hiccups without giving you any real performance benefits. -A more detailed template is shown in ../examples/persistent_demo/. -Similarly to the previous mode, the feature works only with afl-clang-fast; #ifdef -guards can be used to suppress it when using other compilers. +A more detailed template is shown in `../utils/persistent_mode/.` +Similarly to the previous mode, the feature works only with afl-clang-fast; +`#ifdef` guards can be used to suppress it when using other compilers. Note that as with the previous mode, the feature is easy to misuse; if you do not fully reset the critical state, you may end up with false positives or @@ -138,10 +161,10 @@ wary of memory leaks and of the state of file descriptors. PS. Because there are task switches still involved, the mode isn't as fast as "pure" in-process fuzzing offered, say, by LLVM's LibFuzzer; but it is a lot -faster than the normal fork() model, and compared to in-process fuzzing, +faster than the normal `fork()` model, and compared to in-process fuzzing, should be a lot more robust. -## 5) shared memory fuzzing +## 5) Shared memory fuzzing You can speed up the fuzzing process even more by receiving the fuzzing data via shared memory instead of stdin or files. @@ -151,17 +174,17 @@ Setting this up is very easy: After the includes set the following macro: -``` +```c __AFL_FUZZ_INIT(); ``` Directly at the start of main - or if you are using the deferred forkserver -with `__AFL_INIT()` then *after* `__AFL_INIT? : -``` +with `__AFL_INIT()` then *after* `__AFL_INIT()` : +```c unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; ``` Then as first line after the `__AFL_LOOP` while loop: -``` +```c int len = __AFL_FUZZ_TESTCASE_LEN; ``` and that is all! diff --git a/llvm_mode/README.snapshot.md b/instrumentation/README.snapshot.md index 9c12a8ba..c40a956a 100644 --- a/llvm_mode/README.snapshot.md +++ b/instrumentation/README.snapshot.md @@ -1,7 +1,7 @@ # AFL++ snapshot feature Snapshotting is a feature that makes a snapshot from a process and then -restores it's state, which is faster then forking it again. +restores its state, which is faster then forking it again. All targets compiled with llvm_mode are automatically enabled for the snapshot feature. diff --git a/instrumentation/SanitizerCoverageLTO.so.cc b/instrumentation/SanitizerCoverageLTO.so.cc new file mode 100644 index 00000000..13a5e5fd --- /dev/null +++ b/instrumentation/SanitizerCoverageLTO.so.cc @@ -0,0 +1,1633 @@ +/* SanitizeCoverage.cpp ported to afl++ LTO :-) */ + +#define AFL_LLVM_PASS + +#include <stdio.h> +#include <stdlib.h> +#include <unistd.h> +#include <string.h> +#include <sys/time.h> + +#include <list> +#include <string> +#include <fstream> +#include <set> +#include <iostream> + +#include "llvm/Transforms/Instrumentation/SanitizerCoverage.h" +#include "llvm/ADT/ArrayRef.h" +#include "llvm/ADT/SmallVector.h" +#include "llvm/Analysis/EHPersonalities.h" +#include "llvm/Analysis/PostDominators.h" +#include "llvm/Analysis/ValueTracking.h" +#include "llvm/IR/BasicBlock.h" +#include "llvm/IR/CFG.h" +#include "llvm/IR/Constant.h" +#include "llvm/IR/DataLayout.h" +#include "llvm/IR/DebugInfo.h" +#include "llvm/IR/Dominators.h" +#include "llvm/IR/Function.h" +#include "llvm/IR/GlobalVariable.h" +#include "llvm/IR/IRBuilder.h" +#include "llvm/IR/InlineAsm.h" +#include "llvm/IR/Instructions.h" +#include "llvm/IR/IntrinsicInst.h" +#include "llvm/IR/Intrinsics.h" +#include "llvm/IR/LegacyPassManager.h" +#include "llvm/IR/LLVMContext.h" +#include "llvm/IR/MDBuilder.h" +#include "llvm/IR/Mangler.h" +#include "llvm/IR/Module.h" +#include "llvm/IR/Type.h" +#include "llvm/InitializePasses.h" +#include "llvm/Pass.h" +#include "llvm/Support/CommandLine.h" +#include "llvm/Support/Debug.h" +#include "llvm/Support/SpecialCaseList.h" +#include "llvm/Support/VirtualFileSystem.h" +#include "llvm/Support/raw_ostream.h" +#include "llvm/Transforms/Instrumentation.h" +#include "llvm/Transforms/IPO/PassManagerBuilder.h" +#include "llvm/Transforms/Utils/BasicBlockUtils.h" +#include "llvm/Transforms/Utils/BasicBlockUtils.h" +#include "llvm/Transforms/Utils/ModuleUtils.h" + +#include "config.h" +#include "debug.h" +#include "afl-llvm-common.h" + +using namespace llvm; + +#define DEBUG_TYPE "sancov" + +static const char *const SanCovTracePCIndirName = + "__sanitizer_cov_trace_pc_indir"; +static const char *const SanCovTracePCName = "__sanitizer_cov_trace_pc"; +// static const char *const SanCovTracePCGuardName = +// "__sanitizer_cov_trace_pc_guard"; +static const char *const SanCovGuardsSectionName = "sancov_guards"; +static const char *const SanCovCountersSectionName = "sancov_cntrs"; +static const char *const SanCovBoolFlagSectionName = "sancov_bools"; +static const char *const SanCovPCsSectionName = "sancov_pcs"; + +static cl::opt<int> ClCoverageLevel( + "lto-coverage-level", + cl::desc("Sanitizer Coverage. 0: none, 1: entry block, 2: all blocks, " + "3: all blocks and critical edges"), + cl::Hidden, cl::init(3)); + +static cl::opt<bool> ClTracePC("lto-coverage-trace-pc", + cl::desc("Experimental pc tracing"), cl::Hidden, + cl::init(false)); + +static cl::opt<bool> ClTracePCGuard("lto-coverage-trace-pc-guard", + cl::desc("pc tracing with a guard"), + cl::Hidden, cl::init(false)); + +// If true, we create a global variable that contains PCs of all instrumented +// BBs, put this global into a named section, and pass this section's bounds +// to __sanitizer_cov_pcs_init. +// This way the coverage instrumentation does not need to acquire the PCs +// at run-time. Works with trace-pc-guard, inline-8bit-counters, and +// inline-bool-flag. +static cl::opt<bool> ClCreatePCTable("lto-coverage-pc-table", + cl::desc("create a static PC table"), + cl::Hidden, cl::init(false)); + +static cl::opt<bool> ClInline8bitCounters( + "lto-coverage-inline-8bit-counters", + cl::desc("increments 8-bit counter for every edge"), cl::Hidden, + cl::init(false)); + +static cl::opt<bool> ClInlineBoolFlag( + "lto-coverage-inline-bool-flag", + cl::desc("sets a boolean flag for every edge"), cl::Hidden, + cl::init(false)); + +static cl::opt<bool> ClPruneBlocks( + "lto-coverage-prune-blocks", + cl::desc("Reduce the number of instrumented blocks"), cl::Hidden, + cl::init(true)); + +namespace { + +SanitizerCoverageOptions getOptions(int LegacyCoverageLevel) { + + SanitizerCoverageOptions Res; + switch (LegacyCoverageLevel) { + + case 0: + Res.CoverageType = SanitizerCoverageOptions::SCK_None; + break; + case 1: + Res.CoverageType = SanitizerCoverageOptions::SCK_Function; + break; + case 2: + Res.CoverageType = SanitizerCoverageOptions::SCK_BB; + break; + case 3: + Res.CoverageType = SanitizerCoverageOptions::SCK_Edge; + break; + case 4: + Res.CoverageType = SanitizerCoverageOptions::SCK_Edge; + Res.IndirectCalls = true; + break; + + } + + return Res; + +} + +SanitizerCoverageOptions OverrideFromCL(SanitizerCoverageOptions Options) { + + // Sets CoverageType and IndirectCalls. + SanitizerCoverageOptions CLOpts = getOptions(ClCoverageLevel); + Options.CoverageType = std::max(Options.CoverageType, CLOpts.CoverageType); + Options.IndirectCalls |= CLOpts.IndirectCalls; + Options.TracePC |= ClTracePC; + Options.TracePCGuard |= ClTracePCGuard; + Options.Inline8bitCounters |= ClInline8bitCounters; + Options.InlineBoolFlag |= ClInlineBoolFlag; + Options.PCTable |= ClCreatePCTable; + Options.NoPrune |= !ClPruneBlocks; + if (!Options.TracePCGuard && !Options.TracePC && + !Options.Inline8bitCounters && !Options.InlineBoolFlag) + Options.TracePCGuard = true; // TracePCGuard is default. + return Options; + +} + +using DomTreeCallback = function_ref<const DominatorTree *(Function &F)>; +using PostDomTreeCallback = + function_ref<const PostDominatorTree *(Function &F)>; + +class ModuleSanitizerCoverage { + + public: + ModuleSanitizerCoverage( + const SanitizerCoverageOptions &Options = SanitizerCoverageOptions()) + : Options(OverrideFromCL(Options)) { + + /* , + const SpecialCaseList * Allowlist = nullptr, + const SpecialCaseList * Blocklist = nullptr) + , + Allowlist(Allowlist), + Blocklist(Blocklist) { + + */ + + } + + bool instrumentModule(Module &M, DomTreeCallback DTCallback, + PostDomTreeCallback PDTCallback); + + private: + void instrumentFunction(Function &F, DomTreeCallback DTCallback, + PostDomTreeCallback PDTCallback); + void InjectCoverageForIndirectCalls(Function & F, + ArrayRef<Instruction *> IndirCalls); + bool InjectCoverage(Function &F, ArrayRef<BasicBlock *> AllBlocks, + bool IsLeafFunc = true); + GlobalVariable *CreateFunctionLocalArrayInSection(size_t NumElements, + Function &F, Type *Ty, + const char *Section); + GlobalVariable *CreatePCArray(Function &F, ArrayRef<BasicBlock *> AllBlocks); + void CreateFunctionLocalArrays(Function &F, ArrayRef<BasicBlock *> AllBlocks); + void InjectCoverageAtBlock(Function &F, BasicBlock &BB, size_t Idx, + bool IsLeafFunc = true); + // std::pair<Value *, Value *> CreateSecStartEnd(Module &M, const char + // *Section, + // Type *Ty); + + void SetNoSanitizeMetadata(Instruction *I) { + + I->setMetadata(I->getModule()->getMDKindID("nosanitize"), + MDNode::get(*C, None)); + + } + + std::string getSectionName(const std::string &Section) const; + // std::string getSectionStart(const std::string &Section) const; + // std::string getSectionEnd(const std::string &Section) const; + FunctionCallee SanCovTracePCIndir; + FunctionCallee SanCovTracePC /*, SanCovTracePCGuard*/; + Type *IntptrTy, *IntptrPtrTy, *Int64Ty, *Int64PtrTy, *Int32Ty, *Int32PtrTy, + *Int16Ty, *Int8Ty, *Int8PtrTy, *Int1Ty, *Int1PtrTy; + Module * CurModule; + std::string CurModuleUniqueId; + Triple TargetTriple; + LLVMContext * C; + const DataLayout *DL; + + GlobalVariable *FunctionGuardArray; // for trace-pc-guard. + GlobalVariable *Function8bitCounterArray; // for inline-8bit-counters. + GlobalVariable *FunctionBoolArray; // for inline-bool-flag. + GlobalVariable *FunctionPCsArray; // for pc-table. + SmallVector<GlobalValue *, 20> GlobalsToAppendToUsed; + SmallVector<GlobalValue *, 20> GlobalsToAppendToCompilerUsed; + + SanitizerCoverageOptions Options; + + // afl++ START + // const SpecialCaseList * Allowlist; + // const SpecialCaseList * Blocklist; + uint32_t autodictionary = 1; + uint32_t inst = 0; + uint32_t afl_global_id = 0; + uint64_t map_addr = 0; + char * skip_nozero = NULL; + std::vector<BasicBlock *> BlockList; + DenseMap<Value *, std::string *> valueMap; + std::vector<std::string> dictionary; + IntegerType * Int8Tyi = NULL; + IntegerType * Int32Tyi = NULL; + IntegerType * Int64Tyi = NULL; + ConstantInt * Zero = NULL; + ConstantInt * One = NULL; + LLVMContext * Ct = NULL; + Module * Mo = NULL; + GlobalVariable * AFLMapPtr = NULL; + Value * MapPtrFixed = NULL; + FILE * documentFile = NULL; + size_t found = 0; + // afl++ END + +}; + +class ModuleSanitizerCoverageLegacyPass : public ModulePass { + + public: + static char ID; + StringRef getPassName() const override { + + return "sancov"; + + } + + void getAnalysisUsage(AnalysisUsage &AU) const override { + + AU.addRequired<DominatorTreeWrapperPass>(); + AU.addRequired<PostDominatorTreeWrapperPass>(); + + } + + ModuleSanitizerCoverageLegacyPass( + const SanitizerCoverageOptions &Options = SanitizerCoverageOptions()) + : ModulePass(ID), Options(Options) { + + /* , + const std::vector<std::string> &AllowlistFiles = + std::vector<std::string>(), + const std::vector<std::string> &BlocklistFiles = + std::vector<std::string>()) + if (AllowlistFiles.size() > 0) + Allowlist = SpecialCaseList::createOrDie(AllowlistFiles, + *vfs::getRealFileSystem()); + if (BlocklistFiles.size() > 0) + Blocklist = SpecialCaseList::createOrDie(BlocklistFiles, + *vfs::getRealFileSystem()); + */ + initializeModuleSanitizerCoverageLegacyPassPass( + *PassRegistry::getPassRegistry()); + + } + + bool runOnModule(Module &M) override { + + ModuleSanitizerCoverage ModuleSancov(Options); + // , Allowlist.get(), Blocklist.get()); + auto DTCallback = [this](Function &F) -> const DominatorTree * { + + return &this->getAnalysis<DominatorTreeWrapperPass>(F).getDomTree(); + + }; + + auto PDTCallback = [this](Function &F) -> const PostDominatorTree * { + + return &this->getAnalysis<PostDominatorTreeWrapperPass>(F) + .getPostDomTree(); + + }; + + return ModuleSancov.instrumentModule(M, DTCallback, PDTCallback); + + } + + private: + SanitizerCoverageOptions Options; + + // std::unique_ptr<SpecialCaseList> Allowlist; + // std::unique_ptr<SpecialCaseList> Blocklist; + +}; + +} // namespace + +PreservedAnalyses ModuleSanitizerCoveragePass::run(Module & M, + ModuleAnalysisManager &MAM) { + + ModuleSanitizerCoverage ModuleSancov(Options); + // Allowlist.get(), Blocklist.get()); + auto &FAM = MAM.getResult<FunctionAnalysisManagerModuleProxy>(M).getManager(); + auto DTCallback = [&FAM](Function &F) -> const DominatorTree * { + + return &FAM.getResult<DominatorTreeAnalysis>(F); + + }; + + auto PDTCallback = [&FAM](Function &F) -> const PostDominatorTree * { + + return &FAM.getResult<PostDominatorTreeAnalysis>(F); + + }; + + if (ModuleSancov.instrumentModule(M, DTCallback, PDTCallback)) + return PreservedAnalyses::none(); + + return PreservedAnalyses::all(); + +} + +/* +std::pair<Value *, Value *> ModuleSanitizerCoverage::CreateSecStartEnd( + Module &M, const char *Section, Type *Ty) { + + GlobalVariable *SecStart = + new GlobalVariable(M, Ty, false, GlobalVariable::ExternalLinkage, nullptr, + getSectionStart(Section)); + SecStart->setVisibility(GlobalValue::HiddenVisibility); + GlobalVariable *SecEnd = + new GlobalVariable(M, Ty, false, GlobalVariable::ExternalLinkage, nullptr, + getSectionEnd(Section)); + SecEnd->setVisibility(GlobalValue::HiddenVisibility); + IRBuilder<> IRB(M.getContext()); + Value * SecEndPtr = IRB.CreatePointerCast(SecEnd, Ty); + if (!TargetTriple.isOSBinFormatCOFF()) + return std::make_pair(IRB.CreatePointerCast(SecStart, Ty), SecEndPtr); + + // Account for the fact that on windows-msvc __start_* symbols actually + // point to a uint64_t before the start of the array. + auto SecStartI8Ptr = IRB.CreatePointerCast(SecStart, Int8PtrTy); + auto GEP = IRB.CreateGEP(Int8Ty, SecStartI8Ptr, + ConstantInt::get(IntptrTy, sizeof(uint64_t))); + return std::make_pair(IRB.CreatePointerCast(GEP, Ty), SecEndPtr); + +} + +*/ + +bool ModuleSanitizerCoverage::instrumentModule( + Module &M, DomTreeCallback DTCallback, PostDomTreeCallback PDTCallback) { + + if (Options.CoverageType == SanitizerCoverageOptions::SCK_None) return false; + /* + if (Allowlist && + !Allowlist->inSection("coverage", "src", M.getSourceFileName())) + return false; + if (Blocklist && + Blocklist->inSection("coverage", "src", M.getSourceFileName())) + return false; + */ + BlockList.clear(); + valueMap.clear(); + dictionary.clear(); + C = &(M.getContext()); + DL = &M.getDataLayout(); + CurModule = &M; + CurModuleUniqueId = getUniqueModuleId(CurModule); + TargetTriple = Triple(M.getTargetTriple()); + FunctionGuardArray = nullptr; + Function8bitCounterArray = nullptr; + FunctionBoolArray = nullptr; + FunctionPCsArray = nullptr; + IntptrTy = Type::getIntNTy(*C, DL->getPointerSizeInBits()); + IntptrPtrTy = PointerType::getUnqual(IntptrTy); + Type * VoidTy = Type::getVoidTy(*C); + IRBuilder<> IRB(*C); + Int64PtrTy = PointerType::getUnqual(IRB.getInt64Ty()); + Int32PtrTy = PointerType::getUnqual(IRB.getInt32Ty()); + Int8PtrTy = PointerType::getUnqual(IRB.getInt8Ty()); + Int1PtrTy = PointerType::getUnqual(IRB.getInt1Ty()); + Int64Ty = IRB.getInt64Ty(); + Int32Ty = IRB.getInt32Ty(); + Int16Ty = IRB.getInt16Ty(); + Int8Ty = IRB.getInt8Ty(); + Int1Ty = IRB.getInt1Ty(); + + /* afl++ START */ + char * ptr; + LLVMContext &Ctx = M.getContext(); + Ct = &Ctx; + Int8Tyi = IntegerType::getInt8Ty(Ctx); + Int32Tyi = IntegerType::getInt32Ty(Ctx); + Int64Tyi = IntegerType::getInt64Ty(Ctx); + + /* Show a banner */ + setvbuf(stdout, NULL, _IONBF, 0); + if (getenv("AFL_DEBUG")) debug = 1; + + if ((isatty(2) && !getenv("AFL_QUIET")) || debug) { + + SAYF(cCYA "afl-llvm-lto" VERSION cRST + " by Marc \"vanHauser\" Heuse <mh@mh-sec.de>\n"); + + } else + + be_quiet = 1; + + skip_nozero = getenv("AFL_LLVM_SKIP_NEVERZERO"); + + if ((ptr = getenv("AFL_LLVM_LTO_STARTID")) != NULL) + if ((afl_global_id = atoi(ptr)) < 0) + FATAL("AFL_LLVM_LTO_STARTID value of \"%s\" is negative\n", ptr); + + if ((ptr = getenv("AFL_LLVM_DOCUMENT_IDS")) != NULL) { + + if ((documentFile = fopen(ptr, "a")) == NULL) + WARNF("Cannot access document file %s", ptr); + + } + + // we make this the default as the fixed map has problems with + // defered forkserver, early constructors, ifuncs and maybe more + /*if (getenv("AFL_LLVM_MAP_DYNAMIC"))*/ + map_addr = 0; + + if ((ptr = getenv("AFL_LLVM_MAP_ADDR"))) { + + uint64_t val; + if (!*ptr || !strcmp(ptr, "0") || !strcmp(ptr, "0x0")) { + + map_addr = 0; + + } else if (getenv("AFL_LLVM_MAP_DYNAMIC")) { + + FATAL( + "AFL_LLVM_MAP_ADDR and AFL_LLVM_MAP_DYNAMIC cannot be used together"); + + } else if (strncmp(ptr, "0x", 2) != 0) { + + map_addr = 0x10000; // the default + + } else { + + val = strtoull(ptr, NULL, 16); + if (val < 0x100 || val > 0xffffffff00000000) { + + FATAL( + "AFL_LLVM_MAP_ADDR must be a value between 0x100 and " + "0xffffffff00000000"); + + } + + map_addr = val; + + } + + } + + /* Get/set the globals for the SHM region. */ + + if (!map_addr) { + + AFLMapPtr = + new GlobalVariable(M, PointerType::get(Int8Tyi, 0), false, + GlobalValue::ExternalLinkage, 0, "__afl_area_ptr"); + + } else { + + ConstantInt *MapAddr = ConstantInt::get(Int64Tyi, map_addr); + MapPtrFixed = + ConstantExpr::getIntToPtr(MapAddr, PointerType::getUnqual(Int8Tyi)); + + } + + Zero = ConstantInt::get(Int8Tyi, 0); + One = ConstantInt::get(Int8Tyi, 1); + + scanForDangerousFunctions(&M); + Mo = &M; + + if (autodictionary) { + + for (auto &F : M) { + + for (auto &BB : F) { + + for (auto &IN : BB) { + + CallInst *callInst = nullptr; + CmpInst * cmpInst = nullptr; + + if ((cmpInst = dyn_cast<CmpInst>(&IN))) { + + Value * op = cmpInst->getOperand(1); + ConstantInt *ilen = dyn_cast<ConstantInt>(op); + + if (ilen && ilen->uge(0xffffffffffffffff) == false) { + + u64 val2 = 0, val = ilen->getZExtValue(); + u32 len = 0; + if (val > 0x10000 && val < 0xffffffff) len = 4; + if (val > 0x100000001 && val < 0xffffffffffffffff) len = 8; + + if (len) { + + auto c = cmpInst->getPredicate(); + + switch (c) { + + case CmpInst::FCMP_OGT: // fall through + case CmpInst::FCMP_OLE: // fall through + case CmpInst::ICMP_SLE: // fall through + case CmpInst::ICMP_SGT: + + // signed comparison and it is a negative constant + if ((len == 4 && (val & 80000000)) || + (len == 8 && (val & 8000000000000000))) { + + if ((val & 0xffff) != 1) val2 = val - 1; + break; + + } + + // fall through + + case CmpInst::FCMP_UGT: // fall through + case CmpInst::FCMP_ULE: // fall through + case CmpInst::ICMP_UGT: // fall through + case CmpInst::ICMP_ULE: + if ((val & 0xffff) != 0xfffe) val2 = val + 1; + break; + + case CmpInst::FCMP_OLT: // fall through + case CmpInst::FCMP_OGE: // fall through + case CmpInst::ICMP_SLT: // fall through + case CmpInst::ICMP_SGE: + + // signed comparison and it is a negative constant + if ((len == 4 && (val & 80000000)) || + (len == 8 && (val & 8000000000000000))) { + + if ((val & 0xffff) != 1) val2 = val - 1; + break; + + } + + // fall through + + case CmpInst::FCMP_ULT: // fall through + case CmpInst::FCMP_UGE: // fall through + case CmpInst::ICMP_ULT: // fall through + case CmpInst::ICMP_UGE: + if ((val & 0xffff) != 1) val2 = val - 1; + break; + + default: + val2 = 0; + + } + + dictionary.push_back(std::string((char *)&val, len)); + found++; + + if (val2) { + + dictionary.push_back(std::string((char *)&val2, len)); + found++; + + } + + } + + } + + } + + if ((callInst = dyn_cast<CallInst>(&IN))) { + + bool isStrcmp = true; + bool isMemcmp = true; + bool isStrncmp = true; + bool isStrcasecmp = true; + bool isStrncasecmp = true; + bool isIntMemcpy = true; + bool isStdString = true; + bool addedNull = false; + size_t optLen = 0; + + Function *Callee = callInst->getCalledFunction(); + if (!Callee) continue; + if (callInst->getCallingConv() != llvm::CallingConv::C) continue; + std::string FuncName = Callee->getName().str(); + isStrcmp &= !FuncName.compare("strcmp"); + isMemcmp &= + (!FuncName.compare("memcmp") || !FuncName.compare("bcmp")); + isStrncmp &= !FuncName.compare("strncmp"); + isStrcasecmp &= !FuncName.compare("strcasecmp"); + isStrncasecmp &= !FuncName.compare("strncasecmp"); + isIntMemcpy &= !FuncName.compare("llvm.memcpy.p0i8.p0i8.i64"); + isStdString &= + ((FuncName.find("basic_string") != std::string::npos && + FuncName.find("compare") != std::string::npos) || + (FuncName.find("basic_string") != std::string::npos && + FuncName.find("find") != std::string::npos)); + + /* we do something different here, putting this BB and the + successors in a block map */ + if (!FuncName.compare("__afl_persistent_loop")) { + + BlockList.push_back(&BB); + for (succ_iterator SI = succ_begin(&BB), SE = succ_end(&BB); + SI != SE; ++SI) { + + BasicBlock *succ = *SI; + BlockList.push_back(succ); + + } + + } + + if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && + !isStrncasecmp && !isIntMemcpy && !isStdString) + continue; + + /* Verify the strcmp/memcmp/strncmp/strcasecmp/strncasecmp function + * prototype */ + FunctionType *FT = Callee->getFunctionType(); + + isStrcmp &= FT->getNumParams() == 2 && + FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0) == + IntegerType::getInt8PtrTy(M.getContext()); + isStrcasecmp &= FT->getNumParams() == 2 && + FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0) == + IntegerType::getInt8PtrTy(M.getContext()); + isMemcmp &= FT->getNumParams() == 3 && + FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0)->isPointerTy() && + FT->getParamType(1)->isPointerTy() && + FT->getParamType(2)->isIntegerTy(); + isStrncmp &= FT->getNumParams() == 3 && + FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0) == + IntegerType::getInt8PtrTy(M.getContext()) && + FT->getParamType(2)->isIntegerTy(); + isStrncasecmp &= FT->getNumParams() == 3 && + FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0) == + IntegerType::getInt8PtrTy(M.getContext()) && + FT->getParamType(2)->isIntegerTy(); + isStdString &= FT->getNumParams() >= 2 && + FT->getParamType(0)->isPointerTy() && + FT->getParamType(1)->isPointerTy(); + + if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && + !isStrncasecmp && !isIntMemcpy && !isStdString) + continue; + + /* is a str{n,}{case,}cmp/memcmp, check if we have + * str{case,}cmp(x, "const") or str{case,}cmp("const", x) + * strn{case,}cmp(x, "const", ..) or strn{case,}cmp("const", x, ..) + * memcmp(x, "const", ..) or memcmp("const", x, ..) */ + Value *Str1P = callInst->getArgOperand(0), + *Str2P = callInst->getArgOperand(1); + std::string Str1, Str2; + StringRef TmpStr; + bool HasStr1 = getConstantStringInfo(Str1P, TmpStr); + if (TmpStr.empty()) + HasStr1 = false; + else + Str1 = TmpStr.str(); + bool HasStr2 = getConstantStringInfo(Str2P, TmpStr); + if (TmpStr.empty()) + HasStr2 = false; + else + Str2 = TmpStr.str(); + + if (debug) + fprintf(stderr, "F:%s %p(%s)->\"%s\"(%s) %p(%s)->\"%s\"(%s)\n", + FuncName.c_str(), Str1P, Str1P->getName().str().c_str(), + Str1.c_str(), HasStr1 == true ? "true" : "false", Str2P, + Str2P->getName().str().c_str(), Str2.c_str(), + HasStr2 == true ? "true" : "false"); + + // we handle the 2nd parameter first because of llvm memcpy + if (!HasStr2) { + + auto *Ptr = dyn_cast<ConstantExpr>(Str2P); + if (Ptr && Ptr->isGEPWithNoNotionalOverIndexing()) { + + if (auto *Var = dyn_cast<GlobalVariable>(Ptr->getOperand(0))) { + + if (Var->hasInitializer()) { + + if (auto *Array = dyn_cast<ConstantDataArray>( + Var->getInitializer())) { + + HasStr2 = true; + Str2 = Array->getRawDataValues().str(); + + } + + } + + } + + } + + } + + // for the internal memcpy routine we only care for the second + // parameter and are not reporting anything. + if (isIntMemcpy == true) { + + if (HasStr2 == true) { + + Value * op2 = callInst->getArgOperand(2); + ConstantInt *ilen = dyn_cast<ConstantInt>(op2); + if (ilen) { + + uint64_t literalLength = Str2.size(); + uint64_t optLength = ilen->getZExtValue(); + if (literalLength + 1 == optLength) { + + Str2.append("\0", 1); // add null byte + // addedNull = true; + + } + + } + + valueMap[Str1P] = new std::string(Str2); + + if (debug) + fprintf(stderr, "Saved: %s for %p\n", Str2.c_str(), Str1P); + continue; + + } + + continue; + + } + + // Neither a literal nor a global variable? + // maybe it is a local variable that we saved + if (!HasStr2) { + + std::string *strng = valueMap[Str2P]; + if (strng && !strng->empty()) { + + Str2 = *strng; + HasStr2 = true; + if (debug) + fprintf(stderr, "Filled2: %s for %p\n", strng->c_str(), + Str2P); + + } + + } + + if (!HasStr1) { + + auto Ptr = dyn_cast<ConstantExpr>(Str1P); + + if (Ptr && Ptr->isGEPWithNoNotionalOverIndexing()) { + + if (auto *Var = dyn_cast<GlobalVariable>(Ptr->getOperand(0))) { + + if (Var->hasInitializer()) { + + if (auto *Array = dyn_cast<ConstantDataArray>( + Var->getInitializer())) { + + HasStr1 = true; + Str1 = Array->getRawDataValues().str(); + + } + + } + + } + + } + + } + + // Neither a literal nor a global variable? + // maybe it is a local variable that we saved + if (!HasStr1) { + + std::string *strng = valueMap[Str1P]; + if (strng && !strng->empty()) { + + Str1 = *strng; + HasStr1 = true; + if (debug) + fprintf(stderr, "Filled1: %s for %p\n", strng->c_str(), + Str1P); + + } + + } + + /* handle cases of one string is const, one string is variable */ + if (!(HasStr1 ^ HasStr2)) continue; + + std::string thestring; + + if (HasStr1) + thestring = Str1; + else + thestring = Str2; + + optLen = thestring.length(); + if (optLen < 2 || (optLen == 2 && !thestring[1])) { continue; } + + if (isMemcmp || isStrncmp || isStrncasecmp) { + + Value * op2 = callInst->getArgOperand(2); + ConstantInt *ilen = dyn_cast<ConstantInt>(op2); + + if (ilen) { + + uint64_t literalLength = optLen; + optLen = ilen->getZExtValue(); + if (optLen < 2) { continue; } + if (literalLength + 1 == optLen) { // add null byte + thestring.append("\0", 1); + addedNull = true; + + } + + } + + } + + // add null byte if this is a string compare function and a null + // was not already added + if (!isMemcmp) { + + if (addedNull == false && thestring[optLen - 1] != '\0') { + + thestring.append("\0", 1); // add null byte + optLen++; + + } + + if (!isStdString) { + + // ensure we do not have garbage + size_t offset = thestring.find('\0', 0); + if (offset + 1 < optLen) optLen = offset + 1; + thestring = thestring.substr(0, optLen); + + } + + } + + if (!be_quiet) { + + std::string outstring; + fprintf(stderr, "%s: length %zu/%zu \"", FuncName.c_str(), optLen, + thestring.length()); + for (uint8_t i = 0; i < thestring.length(); i++) { + + uint8_t c = thestring[i]; + if (c <= 32 || c >= 127) + fprintf(stderr, "\\x%02x", c); + else + fprintf(stderr, "%c", c); + + } + + fprintf(stderr, "\"\n"); + + } + + // we take the longer string, even if the compare was to a + // shorter part. Note that depending on the optimizer of the + // compiler this can be wrong, but it is more likely that this + // is helping the fuzzer + if (optLen != thestring.length()) optLen = thestring.length(); + if (optLen > MAX_AUTO_EXTRA) optLen = MAX_AUTO_EXTRA; + if (optLen < MIN_AUTO_EXTRA) // too short? skip + continue; + + dictionary.push_back(thestring.substr(0, optLen)); + + } + + } + + } + + } + + } + + // afl++ END + + SanCovTracePCIndir = + M.getOrInsertFunction(SanCovTracePCIndirName, VoidTy, IntptrTy); + // Make sure smaller parameters are zero-extended to i64 as required by the + // x86_64 ABI. + AttributeList SanCovTraceCmpZeroExtAL; + if (TargetTriple.getArch() == Triple::x86_64) { + + SanCovTraceCmpZeroExtAL = + SanCovTraceCmpZeroExtAL.addParamAttribute(*C, 0, Attribute::ZExt); + SanCovTraceCmpZeroExtAL = + SanCovTraceCmpZeroExtAL.addParamAttribute(*C, 1, Attribute::ZExt); + + } + + SanCovTracePC = M.getOrInsertFunction(SanCovTracePCName, VoidTy); + + // SanCovTracePCGuard = + // M.getOrInsertFunction(SanCovTracePCGuardName, VoidTy, Int32PtrTy); + + for (auto &F : M) + instrumentFunction(F, DTCallback, PDTCallback); + + // afl++ START + if (documentFile) { + + fclose(documentFile); + documentFile = NULL; + + } + + if (!getenv("AFL_LLVM_LTO_DONTWRITEID") || dictionary.size() || map_addr) { + + // yes we could create our own function, insert it into ctors ... + // but this would be a pain in the butt ... so we use afl-llvm-rt-lto.o + + Function *f = M.getFunction("__afl_auto_init_globals"); + + if (!f) { + + fprintf(stderr, + "Error: init function could not be found (this should not " + "happen)\n"); + exit(-1); + + } + + BasicBlock *bb = &f->getEntryBlock(); + if (!bb) { + + fprintf(stderr, + "Error: init function does not have an EntryBlock (this should " + "not happen)\n"); + exit(-1); + + } + + BasicBlock::iterator IP = bb->getFirstInsertionPt(); + IRBuilder<> IRB(&(*IP)); + + if (map_addr) { + + GlobalVariable *AFLMapAddrFixed = new GlobalVariable( + M, Int64Tyi, true, GlobalValue::ExternalLinkage, 0, "__afl_map_addr"); + ConstantInt *MapAddr = ConstantInt::get(Int64Tyi, map_addr); + StoreInst * StoreMapAddr = IRB.CreateStore(MapAddr, AFLMapAddrFixed); + StoreMapAddr->setMetadata(M.getMDKindID("nosanitize"), + MDNode::get(Ctx, None)); + + } + + if (getenv("AFL_LLVM_LTO_DONTWRITEID") == NULL) { + + uint32_t write_loc = afl_global_id; + + if (afl_global_id % 8) write_loc = (((afl_global_id + 8) >> 3) << 3); + + GlobalVariable *AFLFinalLoc = + new GlobalVariable(M, Int32Tyi, true, GlobalValue::ExternalLinkage, 0, + "__afl_final_loc"); + ConstantInt *const_loc = ConstantInt::get(Int32Tyi, write_loc); + StoreInst * StoreFinalLoc = IRB.CreateStore(const_loc, AFLFinalLoc); + StoreFinalLoc->setMetadata(M.getMDKindID("nosanitize"), + MDNode::get(Ctx, None)); + + } + + if (dictionary.size()) { + + size_t memlen = 0, count = 0, offset = 0; + char * ptr; + + // sort and unique the dictionary + std::sort(dictionary.begin(), dictionary.end()); + auto last = std::unique(dictionary.begin(), dictionary.end()); + dictionary.erase(last, dictionary.end()); + + for (auto token : dictionary) { + + memlen += token.length(); + count++; + + } + + if (!be_quiet) + printf("AUTODICTIONARY: %lu string%s found\n", count, + count == 1 ? "" : "s"); + + if (count) { + + if ((ptr = (char *)malloc(memlen + count)) == NULL) { + + fprintf(stderr, "Error: malloc for %lu bytes failed!\n", + memlen + count); + exit(-1); + + } + + count = 0; + + for (auto token : dictionary) { + + if (offset + token.length() < 0xfffff0 && count < MAX_AUTO_EXTRAS) { + + ptr[offset++] = (uint8_t)token.length(); + memcpy(ptr + offset, token.c_str(), token.length()); + offset += token.length(); + count++; + + } + + } + + GlobalVariable *AFLDictionaryLen = + new GlobalVariable(M, Int32Tyi, false, GlobalValue::ExternalLinkage, + 0, "__afl_dictionary_len"); + ConstantInt *const_len = ConstantInt::get(Int32Tyi, offset); + StoreInst *StoreDictLen = IRB.CreateStore(const_len, AFLDictionaryLen); + StoreDictLen->setMetadata(M.getMDKindID("nosanitize"), + MDNode::get(Ctx, None)); + + ArrayType *ArrayTy = ArrayType::get(IntegerType::get(Ctx, 8), offset); + GlobalVariable *AFLInternalDictionary = new GlobalVariable( + M, ArrayTy, true, GlobalValue::ExternalLinkage, + ConstantDataArray::get(Ctx, + *(new ArrayRef<char>((char *)ptr, offset))), + "__afl_internal_dictionary"); + AFLInternalDictionary->setInitializer(ConstantDataArray::get( + Ctx, *(new ArrayRef<char>((char *)ptr, offset)))); + AFLInternalDictionary->setConstant(true); + + GlobalVariable *AFLDictionary = new GlobalVariable( + M, PointerType::get(Int8Tyi, 0), false, + GlobalValue::ExternalLinkage, 0, "__afl_dictionary"); + + Value *AFLDictOff = IRB.CreateGEP(AFLInternalDictionary, Zero); + Value *AFLDictPtr = + IRB.CreatePointerCast(AFLDictOff, PointerType::get(Int8Tyi, 0)); + StoreInst *StoreDict = IRB.CreateStore(AFLDictPtr, AFLDictionary); + StoreDict->setMetadata(M.getMDKindID("nosanitize"), + MDNode::get(Ctx, None)); + + } + + } + + } + + /* Say something nice. */ + + if (!be_quiet) { + + if (!inst) + WARNF("No instrumentation targets found."); + else { + + char modeline[100]; + snprintf(modeline, sizeof(modeline), "%s%s%s%s%s", + getenv("AFL_HARDEN") ? "hardened" : "non-hardened", + getenv("AFL_USE_ASAN") ? ", ASAN" : "", + getenv("AFL_USE_MSAN") ? ", MSAN" : "", + getenv("AFL_USE_CFISAN") ? ", CFISAN" : "", + getenv("AFL_USE_UBSAN") ? ", UBSAN" : ""); + OKF("Instrumented %u locations with no collisions (on average %llu " + "collisions would be in afl-gcc/vanilla AFL) (%s mode).", + inst, calculateCollisions(inst), modeline); + + } + + } + + // afl++ END + + // We don't reference these arrays directly in any of our runtime functions, + // so we need to prevent them from being dead stripped. + if (TargetTriple.isOSBinFormatMachO()) appendToUsed(M, GlobalsToAppendToUsed); + appendToCompilerUsed(M, GlobalsToAppendToCompilerUsed); + return true; + +} + +// True if block has successors and it dominates all of them. +static bool isFullDominator(const BasicBlock *BB, const DominatorTree *DT) { + + if (succ_begin(BB) == succ_end(BB)) return false; + + for (const BasicBlock *SUCC : make_range(succ_begin(BB), succ_end(BB))) { + + if (!DT->dominates(BB, SUCC)) return false; + + } + + return true; + +} + +// True if block has predecessors and it postdominates all of them. +static bool isFullPostDominator(const BasicBlock * BB, + const PostDominatorTree *PDT) { + + if (pred_begin(BB) == pred_end(BB)) return false; + + for (const BasicBlock *PRED : make_range(pred_begin(BB), pred_end(BB))) { + + if (!PDT->dominates(BB, PRED)) return false; + + } + + return true; + +} + +static bool shouldInstrumentBlock(const Function &F, const BasicBlock *BB, + const DominatorTree * DT, + const PostDominatorTree * PDT, + const SanitizerCoverageOptions &Options) { + + // Don't insert coverage for blocks containing nothing but unreachable: we + // will never call __sanitizer_cov() for them, so counting them in + // NumberOfInstrumentedBlocks() might complicate calculation of code coverage + // percentage. Also, unreachable instructions frequently have no debug + // locations. + if (isa<UnreachableInst>(BB->getFirstNonPHIOrDbgOrLifetime())) return false; + + // Don't insert coverage into blocks without a valid insertion point + // (catchswitch blocks). + if (BB->getFirstInsertionPt() == BB->end()) return false; + + // afl++ START + if (!Options.NoPrune && &F.getEntryBlock() == BB && F.size() > 1) + return false; + // afl++ END + + if (Options.NoPrune || &F.getEntryBlock() == BB) return true; + + if (Options.CoverageType == SanitizerCoverageOptions::SCK_Function && + &F.getEntryBlock() != BB) + return false; + + // Do not instrument full dominators, or full post-dominators with multiple + // predecessors. + return !isFullDominator(BB, DT) && + !(isFullPostDominator(BB, PDT) && !BB->getSinglePredecessor()); + +} + +void ModuleSanitizerCoverage::instrumentFunction( + Function &F, DomTreeCallback DTCallback, PostDomTreeCallback PDTCallback) { + + if (F.empty()) return; + if (F.getName().find(".module_ctor") != std::string::npos) + return; // Should not instrument sanitizer init functions. + if (F.getName().startswith("__sanitizer_")) + return; // Don't instrument __sanitizer_* callbacks. + // Don't touch available_externally functions, their actual body is elewhere. + if (F.getLinkage() == GlobalValue::AvailableExternallyLinkage) return; + // Don't instrument MSVC CRT configuration helpers. They may run before normal + // initialization. + if (F.getName() == "__local_stdio_printf_options" || + F.getName() == "__local_stdio_scanf_options") + return; + if (isa<UnreachableInst>(F.getEntryBlock().getTerminator())) return; + // Don't instrument functions using SEH for now. Splitting basic blocks like + // we do for coverage breaks WinEHPrepare. + // FIXME: Remove this when SEH no longer uses landingpad pattern matching. + if (F.hasPersonalityFn() && + isAsynchronousEHPersonality(classifyEHPersonality(F.getPersonalityFn()))) + return; + // if (Allowlist && !Allowlist->inSection("coverage", "fun", F.getName())) + // return; + // if (Blocklist && Blocklist->inSection("coverage", "fun", F.getName())) + // return; + + // afl++ START + if (!F.size()) return; + if (isIgnoreFunction(&F)) return; + // afl++ END + + if (Options.CoverageType >= SanitizerCoverageOptions::SCK_Edge) + SplitAllCriticalEdges( + F, CriticalEdgeSplittingOptions().setIgnoreUnreachableDests()); + SmallVector<Instruction *, 8> IndirCalls; + SmallVector<BasicBlock *, 16> BlocksToInstrument; + + const DominatorTree * DT = DTCallback(F); + const PostDominatorTree *PDT = PDTCallback(F); + bool IsLeafFunc = true; + + for (auto &BB : F) { + + for (auto &IN : BB) { + + CallInst *callInst = nullptr; + + if ((callInst = dyn_cast<CallInst>(&IN))) { + + Function *Callee = callInst->getCalledFunction(); + if (!Callee) continue; + if (callInst->getCallingConv() != llvm::CallingConv::C) continue; + StringRef FuncName = Callee->getName(); + if (FuncName.compare(StringRef("__afl_coverage_interesting"))) continue; + + Value *val = ConstantInt::get(Int32Ty, ++afl_global_id); + callInst->setOperand(1, val); + + } + + } + + if (shouldInstrumentBlock(F, &BB, DT, PDT, Options)) + BlocksToInstrument.push_back(&BB); + for (auto &Inst : BB) { + + if (Options.IndirectCalls) { + + CallBase *CB = dyn_cast<CallBase>(&Inst); + if (CB && !CB->getCalledFunction()) IndirCalls.push_back(&Inst); + + } + + } + + } + + InjectCoverage(F, BlocksToInstrument, IsLeafFunc); + InjectCoverageForIndirectCalls(F, IndirCalls); + +} + +GlobalVariable *ModuleSanitizerCoverage::CreateFunctionLocalArrayInSection( + size_t NumElements, Function &F, Type *Ty, const char *Section) { + + ArrayType *ArrayTy = ArrayType::get(Ty, NumElements); + auto Array = new GlobalVariable( + *CurModule, ArrayTy, false, GlobalVariable::PrivateLinkage, + Constant::getNullValue(ArrayTy), "__sancov_gen_"); + + if (TargetTriple.supportsCOMDAT() && !F.isInterposable()) + if (auto Comdat = + GetOrCreateFunctionComdat(F, TargetTriple, CurModuleUniqueId)) + Array->setComdat(Comdat); + Array->setSection(getSectionName(Section)); + Array->setAlignment(Align(DL->getTypeStoreSize(Ty).getFixedSize())); + GlobalsToAppendToUsed.push_back(Array); + GlobalsToAppendToCompilerUsed.push_back(Array); + MDNode *MD = MDNode::get(F.getContext(), ValueAsMetadata::get(&F)); + Array->addMetadata(LLVMContext::MD_associated, *MD); + + return Array; + +} + +GlobalVariable *ModuleSanitizerCoverage::CreatePCArray( + Function &F, ArrayRef<BasicBlock *> AllBlocks) { + + size_t N = AllBlocks.size(); + assert(N); + SmallVector<Constant *, 32> PCs; + IRBuilder<> IRB(&*F.getEntryBlock().getFirstInsertionPt()); + for (size_t i = 0; i < N; i++) { + + if (&F.getEntryBlock() == AllBlocks[i]) { + + PCs.push_back((Constant *)IRB.CreatePointerCast(&F, IntptrPtrTy)); + PCs.push_back((Constant *)IRB.CreateIntToPtr( + ConstantInt::get(IntptrTy, 1), IntptrPtrTy)); + + } else { + + PCs.push_back((Constant *)IRB.CreatePointerCast( + BlockAddress::get(AllBlocks[i]), IntptrPtrTy)); + PCs.push_back((Constant *)IRB.CreateIntToPtr( + ConstantInt::get(IntptrTy, 0), IntptrPtrTy)); + + } + + } + + auto *PCArray = CreateFunctionLocalArrayInSection(N * 2, F, IntptrPtrTy, + SanCovPCsSectionName); + PCArray->setInitializer( + ConstantArray::get(ArrayType::get(IntptrPtrTy, N * 2), PCs)); + PCArray->setConstant(true); + + return PCArray; + +} + +void ModuleSanitizerCoverage::CreateFunctionLocalArrays( + Function &F, ArrayRef<BasicBlock *> AllBlocks) { + + if (Options.TracePCGuard) + FunctionGuardArray = CreateFunctionLocalArrayInSection( + AllBlocks.size(), F, Int32Ty, SanCovGuardsSectionName); + if (Options.Inline8bitCounters) + Function8bitCounterArray = CreateFunctionLocalArrayInSection( + AllBlocks.size(), F, Int8Ty, SanCovCountersSectionName); + if (Options.InlineBoolFlag) + FunctionBoolArray = CreateFunctionLocalArrayInSection( + AllBlocks.size(), F, Int1Ty, SanCovBoolFlagSectionName); + if (Options.PCTable) FunctionPCsArray = CreatePCArray(F, AllBlocks); + +} + +bool ModuleSanitizerCoverage::InjectCoverage(Function & F, + ArrayRef<BasicBlock *> AllBlocks, + bool IsLeafFunc) { + + if (AllBlocks.empty()) return false; + CreateFunctionLocalArrays(F, AllBlocks); + + for (size_t i = 0, N = AllBlocks.size(); i < N; i++) { + + // afl++ START + if (BlockList.size()) { + + int skip = 0; + for (uint32_t k = 0; k < BlockList.size(); k++) { + + if (AllBlocks[i] == BlockList[k]) { + + if (debug) + fprintf(stderr, + "DEBUG: Function %s skipping BB with/after __afl_loop\n", + F.getName().str().c_str()); + skip = 1; + + } + + } + + if (skip) continue; + + } + + // afl++ END + + InjectCoverageAtBlock(F, *AllBlocks[i], i, IsLeafFunc); + + } + + return true; + +} + +// On every indirect call we call a run-time function +// __sanitizer_cov_indir_call* with two parameters: +// - callee address, +// - global cache array that contains CacheSize pointers (zero-initialized). +// The cache is used to speed up recording the caller-callee pairs. +// The address of the caller is passed implicitly via caller PC. +// CacheSize is encoded in the name of the run-time function. +void ModuleSanitizerCoverage::InjectCoverageForIndirectCalls( + Function &F, ArrayRef<Instruction *> IndirCalls) { + + if (IndirCalls.empty()) return; + assert(Options.TracePC || Options.TracePCGuard || + Options.Inline8bitCounters || Options.InlineBoolFlag); + for (auto I : IndirCalls) { + + IRBuilder<> IRB(I); + CallBase & CB = cast<CallBase>(*I); + Value * Callee = CB.getCalledOperand(); + if (isa<InlineAsm>(Callee)) continue; + IRB.CreateCall(SanCovTracePCIndir, IRB.CreatePointerCast(Callee, IntptrTy)); + + } + +} + +void ModuleSanitizerCoverage::InjectCoverageAtBlock(Function &F, BasicBlock &BB, + size_t Idx, + bool IsLeafFunc) { + + BasicBlock::iterator IP = BB.getFirstInsertionPt(); + bool IsEntryBB = &BB == &F.getEntryBlock(); + + if (IsEntryBB) { + + // Keep static allocas and llvm.localescape calls in the entry block. Even + // if we aren't splitting the block, it's nice for allocas to be before + // calls. + IP = PrepareToSplitEntryBlock(BB, IP); + + } + + IRBuilder<> IRB(&*IP); + if (Options.TracePC) { + + IRB.CreateCall(SanCovTracePC) +#if LLVM_VERSION_MAJOR < 12 + ->cannotMerge(); // gets the PC using GET_CALLER_PC. +#else + ->setCannotMerge(); // gets the PC using GET_CALLER_PC. +#endif + + } + + if (Options.TracePCGuard) { + + // afl++ START + ++afl_global_id; + + if (documentFile) { + + unsigned long long int moduleID = + (((unsigned long long int)(rand() & 0xffffffff)) << 32) | getpid(); + fprintf(documentFile, "ModuleID=%llu Function=%s edgeID=%u\n", moduleID, + F.getName().str().c_str(), afl_global_id); + + } + + /* Set the ID of the inserted basic block */ + + ConstantInt *CurLoc = ConstantInt::get(Int32Tyi, afl_global_id); + + /* Load SHM pointer */ + + Value *MapPtrIdx; + + if (map_addr) { + + MapPtrIdx = IRB.CreateGEP(MapPtrFixed, CurLoc); + + } else { + + LoadInst *MapPtr = IRB.CreateLoad(AFLMapPtr); + MapPtr->setMetadata(Mo->getMDKindID("nosanitize"), + MDNode::get(*Ct, None)); + MapPtrIdx = IRB.CreateGEP(MapPtr, CurLoc); + + } + + /* Update bitmap */ + + LoadInst *Counter = IRB.CreateLoad(MapPtrIdx); + Counter->setMetadata(Mo->getMDKindID("nosanitize"), MDNode::get(*Ct, None)); + + Value *Incr = IRB.CreateAdd(Counter, One); + + if (skip_nozero == NULL) { + + auto cf = IRB.CreateICmpEQ(Incr, Zero); + auto carry = IRB.CreateZExt(cf, Int8Tyi); + Incr = IRB.CreateAdd(Incr, carry); + + } + + IRB.CreateStore(Incr, MapPtrIdx) + ->setMetadata(Mo->getMDKindID("nosanitize"), MDNode::get(*Ct, None)); + + // done :) + + inst++; + // afl++ END + + /* + XXXXXXXXXXXXXXXXXXX + + auto GuardPtr = IRB.CreateIntToPtr( + IRB.CreateAdd(IRB.CreatePointerCast(FunctionGuardArray, IntptrTy), + ConstantInt::get(IntptrTy, Idx * 4)), + Int32PtrTy); + + IRB.CreateCall(SanCovTracePCGuard, GuardPtr)->setCannotMerge(); + */ + + } + + if (Options.Inline8bitCounters) { + + auto CounterPtr = IRB.CreateGEP( + Function8bitCounterArray->getValueType(), Function8bitCounterArray, + {ConstantInt::get(IntptrTy, 0), ConstantInt::get(IntptrTy, Idx)}); + auto Load = IRB.CreateLoad(Int8Ty, CounterPtr); + auto Inc = IRB.CreateAdd(Load, ConstantInt::get(Int8Ty, 1)); + auto Store = IRB.CreateStore(Inc, CounterPtr); + SetNoSanitizeMetadata(Load); + SetNoSanitizeMetadata(Store); + + } + + if (Options.InlineBoolFlag) { + + auto FlagPtr = IRB.CreateGEP( + FunctionBoolArray->getValueType(), FunctionBoolArray, + {ConstantInt::get(IntptrTy, 0), ConstantInt::get(IntptrTy, Idx)}); + auto Load = IRB.CreateLoad(Int1Ty, FlagPtr); + auto ThenTerm = + SplitBlockAndInsertIfThen(IRB.CreateIsNull(Load), &*IP, false); + IRBuilder<> ThenIRB(ThenTerm); + auto Store = ThenIRB.CreateStore(ConstantInt::getTrue(Int1Ty), FlagPtr); + SetNoSanitizeMetadata(Load); + SetNoSanitizeMetadata(Store); + + } + +} + +std::string ModuleSanitizerCoverage::getSectionName( + const std::string &Section) const { + + if (TargetTriple.isOSBinFormatCOFF()) { + + if (Section == SanCovCountersSectionName) return ".SCOV$CM"; + if (Section == SanCovBoolFlagSectionName) return ".SCOV$BM"; + if (Section == SanCovPCsSectionName) return ".SCOVP$M"; + return ".SCOV$GM"; // For SanCovGuardsSectionName. + + } + + if (TargetTriple.isOSBinFormatMachO()) return "__DATA,__" + Section; + return "__" + Section; + +} + +/* +std::string ModuleSanitizerCoverage::getSectionStart( + const std::string &Section) const { + + if (TargetTriple.isOSBinFormatMachO()) + return "\1section$start$__DATA$__" + Section; + return "__start___" + Section; + +} + +std::string ModuleSanitizerCoverage::getSectionEnd( + const std::string &Section) const { + + if (TargetTriple.isOSBinFormatMachO()) + return "\1section$end$__DATA$__" + Section; + return "__stop___" + Section; + +} + +*/ + +char ModuleSanitizerCoverageLegacyPass::ID = 0; + +INITIALIZE_PASS_BEGIN(ModuleSanitizerCoverageLegacyPass, "sancov", + "Pass for instrumenting coverage on functions", false, + false) +INITIALIZE_PASS_DEPENDENCY(DominatorTreeWrapperPass) +INITIALIZE_PASS_DEPENDENCY(PostDominatorTreeWrapperPass) +INITIALIZE_PASS_END(ModuleSanitizerCoverageLegacyPass, "sancov", + "Pass for instrumenting coverage on functions", false, + false) + +ModulePass *llvm::createModuleSanitizerCoverageLegacyPassPass( + const SanitizerCoverageOptions &Options, + const std::vector<std::string> &AllowlistFiles, + const std::vector<std::string> &BlocklistFiles) { + + return new ModuleSanitizerCoverageLegacyPass(Options); + //, AllowlistFiles, BlocklistFiles); + +} + +static void registerLTOPass(const PassManagerBuilder &, + legacy::PassManagerBase &PM) { + + auto p = new ModuleSanitizerCoverageLegacyPass(); + PM.add(p); + +} + +static RegisterStandardPasses RegisterCompTransPass( + PassManagerBuilder::EP_OptimizerLast, registerLTOPass); + +static RegisterStandardPasses RegisterCompTransPass0( + PassManagerBuilder::EP_EnabledOnOptLevel0, registerLTOPass); + +#if LLVM_VERSION_MAJOR >= 11 +static RegisterStandardPasses RegisterCompTransPassLTO( + PassManagerBuilder::EP_FullLinkTimeOptimizationLast, registerLTOPass); +#endif + diff --git a/instrumentation/SanitizerCoveragePCGUARD.so.cc b/instrumentation/SanitizerCoveragePCGUARD.so.cc new file mode 100644 index 00000000..9b1351b0 --- /dev/null +++ b/instrumentation/SanitizerCoveragePCGUARD.so.cc @@ -0,0 +1,1379 @@ +//===-- SanitizerCoverage.cpp - coverage instrumentation for sanitizers ---===// +// +// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions. +// See https://llvm.org/LICENSE.txt for license information. +// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception +// +//===----------------------------------------------------------------------===// +// +// Coverage instrumentation done on LLVM IR level, works with Sanitizers. +// +//===----------------------------------------------------------------------===// + +#include "llvm/ADT/ArrayRef.h" +#include "llvm/ADT/SmallVector.h" +#include "llvm/Analysis/EHPersonalities.h" +#include "llvm/Analysis/PostDominators.h" +#include "llvm/IR/CFG.h" +#include "llvm/IR/Constant.h" +#include "llvm/IR/DataLayout.h" +#include "llvm/IR/DebugInfo.h" +#include "llvm/IR/Dominators.h" +#include "llvm/IR/Function.h" +#include "llvm/IR/GlobalVariable.h" +#include "llvm/IR/IRBuilder.h" +#include "llvm/IR/InlineAsm.h" +#include "llvm/IR/IntrinsicInst.h" +#include "llvm/IR/Intrinsics.h" +#include "llvm/IR/LLVMContext.h" +#include "llvm/IR/MDBuilder.h" +#include "llvm/IR/Mangler.h" +#include "llvm/IR/Module.h" +#include "llvm/IR/PassManager.h" +#include "llvm/IR/Type.h" +#include "llvm/InitializePasses.h" +#include "llvm/Support/CommandLine.h" +#include "llvm/Support/Debug.h" +#include "llvm/Support/raw_ostream.h" +#include "llvm/Support/SpecialCaseList.h" +#if LLVM_MAJOR > 10 || (LLVM_MAJOR == 10 && LLVM_MINOR > 0) + #include "llvm/Support/VirtualFileSystem.h" +#endif +#include "llvm/Transforms/Instrumentation.h" +#include "llvm/Transforms/Utils/BasicBlockUtils.h" +#include "llvm/Transforms/Utils/ModuleUtils.h" + +#include "config.h" +#include "debug.h" +#include "afl-llvm-common.h" + +namespace llvm { + +/// This is the ModuleSanitizerCoverage pass used in the new pass manager. The +/// pass instruments functions for coverage, adds initialization calls to the +/// module for trace PC guards and 8bit counters if they are requested, and +/// appends globals to llvm.compiler.used. +class ModuleSanitizerCoveragePass + : public PassInfoMixin<ModuleSanitizerCoveragePass> { + + public: + explicit ModuleSanitizerCoveragePass( + SanitizerCoverageOptions Options = SanitizerCoverageOptions(), + const std::vector<std::string> &AllowlistFiles = + std::vector<std::string>(), + const std::vector<std::string> &BlocklistFiles = + std::vector<std::string>()) + : Options(Options) { + + if (AllowlistFiles.size() > 0) + Allowlist = SpecialCaseList::createOrDie(AllowlistFiles +#if LLVM_MAJOR > 10 || (LLVM_MAJOR == 10 && LLVM_MINOR > 0) + , + *vfs::getRealFileSystem() +#endif + ); + if (BlocklistFiles.size() > 0) + Blocklist = SpecialCaseList::createOrDie(BlocklistFiles +#if LLVM_MAJOR > 10 || (LLVM_MAJOR == 10 && LLVM_MINOR > 0) + , + *vfs::getRealFileSystem() +#endif + ); + + } + + PreservedAnalyses run(Module &M, ModuleAnalysisManager &AM); + static bool isRequired() { + + return true; + + } + + private: + SanitizerCoverageOptions Options; + + std::unique_ptr<SpecialCaseList> Allowlist; + std::unique_ptr<SpecialCaseList> Blocklist; + +}; + +// Insert SanitizerCoverage instrumentation. +ModulePass *createModuleSanitizerCoverageLegacyPassPass( + const SanitizerCoverageOptions &Options = SanitizerCoverageOptions(), + const std::vector<std::string> &AllowlistFiles = std::vector<std::string>(), + const std::vector<std::string> &BlocklistFiles = + std::vector<std::string>()); + +} // namespace llvm + +using namespace llvm; + +#define DEBUG_TYPE "sancov" + +static const char *const SanCovTracePCIndirName = + "__sanitizer_cov_trace_pc_indir"; +static const char *const SanCovTracePCName = "__sanitizer_cov_trace_pc"; +static const char *const SanCovTraceCmp1 = "__sanitizer_cov_trace_cmp1"; +static const char *const SanCovTraceCmp2 = "__sanitizer_cov_trace_cmp2"; +static const char *const SanCovTraceCmp4 = "__sanitizer_cov_trace_cmp4"; +static const char *const SanCovTraceCmp8 = "__sanitizer_cov_trace_cmp8"; +static const char *const SanCovTraceConstCmp1 = + "__sanitizer_cov_trace_const_cmp1"; +static const char *const SanCovTraceConstCmp2 = + "__sanitizer_cov_trace_const_cmp2"; +static const char *const SanCovTraceConstCmp4 = + "__sanitizer_cov_trace_const_cmp4"; +static const char *const SanCovTraceConstCmp8 = + "__sanitizer_cov_trace_const_cmp8"; +static const char *const SanCovTraceDiv4 = "__sanitizer_cov_trace_div4"; +static const char *const SanCovTraceDiv8 = "__sanitizer_cov_trace_div8"; +static const char *const SanCovTraceGep = "__sanitizer_cov_trace_gep"; +static const char *const SanCovTraceSwitchName = "__sanitizer_cov_trace_switch"; +static const char *const SanCovModuleCtorTracePcGuardName = + "sancov.module_ctor_trace_pc_guard"; +static const char *const SanCovModuleCtor8bitCountersName = + "sancov.module_ctor_8bit_counters"; +static const char *const SanCovModuleCtorBoolFlagName = + "sancov.module_ctor_bool_flag"; +static const uint64_t SanCtorAndDtorPriority = 2; + +static const char *const SanCovTracePCGuardName = + "__sanitizer_cov_trace_pc_guard"; +static const char *const SanCovTracePCGuardInitName = + "__sanitizer_cov_trace_pc_guard_init"; +static const char *const SanCov8bitCountersInitName = + "__sanitizer_cov_8bit_counters_init"; +static const char *const SanCovBoolFlagInitName = + "__sanitizer_cov_bool_flag_init"; +static const char *const SanCovPCsInitName = "__sanitizer_cov_pcs_init"; + +static const char *const SanCovGuardsSectionName = "sancov_guards"; +static const char *const SanCovCountersSectionName = "sancov_cntrs"; +static const char *const SanCovBoolFlagSectionName = "sancov_bools"; +static const char *const SanCovPCsSectionName = "sancov_pcs"; + +static const char *const SanCovLowestStackName = "__sancov_lowest_stack"; + +static char *skip_nozero; + +/* +static cl::opt<int> ClCoverageLevel( + "sanitizer-coverage-level", + cl::desc("Sanitizer Coverage. 0: none, 1: entry block, 2: all blocks, " + "3: all blocks and critical edges"), + cl::Hidden, cl::init(3)); + +static cl::opt<bool> ClTracePC("sanitizer-coverage-trace-pc", + cl::desc("Experimental pc tracing"), cl::Hidden, + cl::init(false)); + +static cl::opt<bool> ClTracePCGuard("sanitizer-coverage-trace-pc-guard", + cl::desc("pc tracing with a guard"), + cl::Hidden, cl::init(true)); + +// If true, we create a global variable that contains PCs of all instrumented +// BBs, put this global into a named section, and pass this section's bounds +// to __sanitizer_cov_pcs_init. +// This way the coverage instrumentation does not need to acquire the PCs +// at run-time. Works with trace-pc-guard, inline-8bit-counters, and +// inline-bool-flag. +static cl::opt<bool> ClCreatePCTable("sanitizer-coverage-pc-table", + cl::desc("create a static PC table"), + cl::Hidden, cl::init(false)); + +static cl::opt<bool> ClInline8bitCounters( + "sanitizer-coverage-inline-8bit-counters", + cl::desc("increments 8-bit counter for every edge"), cl::Hidden, + cl::init(false)); + +static cl::opt<bool> ClInlineBoolFlag( + "sanitizer-coverage-inline-bool-flag", + cl::desc("sets a boolean flag for every edge"), cl::Hidden, + cl::init(false)); + +static cl::opt<bool> ClCMPTracing( + "sanitizer-coverage-trace-compares", + cl::desc("Tracing of CMP and similar instructions"), cl::Hidden, + cl::init(false)); + +static cl::opt<bool> ClDIVTracing("sanitizer-coverage-trace-divs", + cl::desc("Tracing of DIV instructions"), + cl::Hidden, cl::init(false)); + +static cl::opt<bool> ClGEPTracing("sanitizer-coverage-trace-geps", + cl::desc("Tracing of GEP instructions"), + cl::Hidden, cl::init(false)); + +static cl::opt<bool> ClPruneBlocks( + "sanitizer-coverage-prune-blocks", + cl::desc("Reduce the number of instrumented blocks"), cl::Hidden, + cl::init(true)); + +static cl::opt<bool> ClStackDepth("sanitizer-coverage-stack-depth", + cl::desc("max stack depth tracing"), + cl::Hidden, cl::init(false)); +*/ +namespace { + +/* +SanitizerCoverageOptions getOptions(int LegacyCoverageLevel) { + + SanitizerCoverageOptions Res; + switch (LegacyCoverageLevel) { + + case 0: + Res.CoverageType = SanitizerCoverageOptions::SCK_None; + break; + case 1: + Res.CoverageType = SanitizerCoverageOptions::SCK_Function; + break; + case 2: + Res.CoverageType = SanitizerCoverageOptions::SCK_BB; + break; + case 3: + Res.CoverageType = SanitizerCoverageOptions::SCK_Edge; + break; + case 4: + Res.CoverageType = SanitizerCoverageOptions::SCK_Edge; + Res.IndirectCalls = true; + break; + + } + + return Res; + +} + +*/ + +SanitizerCoverageOptions OverrideFromCL(SanitizerCoverageOptions Options) { + + // Sets CoverageType and IndirectCalls. + // SanitizerCoverageOptions CLOpts = getOptions(ClCoverageLevel); + Options.CoverageType = + SanitizerCoverageOptions::SCK_Edge; // std::max(Options.CoverageType, + // CLOpts.CoverageType); + Options.IndirectCalls = false; // CLOpts.IndirectCalls; + Options.TraceCmp = false; //|= ClCMPTracing; + Options.TraceDiv = false; //|= ClDIVTracing; + Options.TraceGep = false; //|= ClGEPTracing; + Options.TracePC = false; //|= ClTracePC; + Options.TracePCGuard = true; // |= ClTracePCGuard; + Options.Inline8bitCounters = 0; //|= ClInline8bitCounters; + // Options.InlineBoolFlag = 0; //|= ClInlineBoolFlag; + Options.PCTable = false; //|= ClCreatePCTable; + Options.NoPrune = false; //|= !ClPruneBlocks; + Options.StackDepth = false; //|= ClStackDepth; + if (!Options.TracePCGuard && !Options.TracePC && + !Options.Inline8bitCounters && !Options.StackDepth /*&& + !Options.InlineBoolFlag*/) + Options.TracePCGuard = true; // TracePCGuard is default. + + return Options; + +} + +using DomTreeCallback = function_ref<const DominatorTree *(Function &F)>; +using PostDomTreeCallback = + function_ref<const PostDominatorTree *(Function &F)>; + +class ModuleSanitizerCoverage { + + public: + ModuleSanitizerCoverage( + const SanitizerCoverageOptions &Options = SanitizerCoverageOptions(), + const SpecialCaseList * Allowlist = nullptr, + const SpecialCaseList * Blocklist = nullptr) + : Options(OverrideFromCL(Options)), + Allowlist(Allowlist), + Blocklist(Blocklist) { + + } + + bool instrumentModule(Module &M, DomTreeCallback DTCallback, + PostDomTreeCallback PDTCallback); + + private: + void instrumentFunction(Function &F, DomTreeCallback DTCallback, + PostDomTreeCallback PDTCallback); + void InjectCoverageForIndirectCalls(Function & F, + ArrayRef<Instruction *> IndirCalls); + void InjectTraceForCmp(Function &F, ArrayRef<Instruction *> CmpTraceTargets); + void InjectTraceForDiv(Function & F, + ArrayRef<BinaryOperator *> DivTraceTargets); + void InjectTraceForGep(Function & F, + ArrayRef<GetElementPtrInst *> GepTraceTargets); + void InjectTraceForSwitch(Function & F, + ArrayRef<Instruction *> SwitchTraceTargets); + bool InjectCoverage(Function &F, ArrayRef<BasicBlock *> AllBlocks, + bool IsLeafFunc = true); + GlobalVariable *CreateFunctionLocalArrayInSection(size_t NumElements, + Function &F, Type *Ty, + const char *Section); + GlobalVariable *CreatePCArray(Function &F, ArrayRef<BasicBlock *> AllBlocks); + void CreateFunctionLocalArrays(Function &F, ArrayRef<BasicBlock *> AllBlocks, + uint32_t special); + void InjectCoverageAtBlock(Function &F, BasicBlock &BB, size_t Idx, + bool IsLeafFunc = true); + Function *CreateInitCallsForSections(Module &M, const char *CtorName, + const char *InitFunctionName, Type *Ty, + const char *Section); + std::pair<Value *, Value *> CreateSecStartEnd(Module &M, const char *Section, + Type *Ty); + + void SetNoSanitizeMetadata(Instruction *I) { + + I->setMetadata(I->getModule()->getMDKindID("nosanitize"), + MDNode::get(*C, None)); + + } + + std::string getSectionName(const std::string &Section) const; + std::string getSectionStart(const std::string &Section) const; + std::string getSectionEnd(const std::string &Section) const; + FunctionCallee SanCovTracePCIndir; + FunctionCallee SanCovTracePC, SanCovTracePCGuard; + FunctionCallee SanCovTraceCmpFunction[4]; + FunctionCallee SanCovTraceConstCmpFunction[4]; + FunctionCallee SanCovTraceDivFunction[2]; + FunctionCallee SanCovTraceGepFunction; + FunctionCallee SanCovTraceSwitchFunction; + GlobalVariable *SanCovLowestStack; + Type *IntptrTy, *IntptrPtrTy, *Int64Ty, *Int64PtrTy, *Int32Ty, *Int32PtrTy, + *Int16Ty, *Int8Ty, *Int8PtrTy, *Int1Ty, *Int1PtrTy; + Module * CurModule; + std::string CurModuleUniqueId; + Triple TargetTriple; + LLVMContext * C; + const DataLayout *DL; + + GlobalVariable *FunctionGuardArray; // for trace-pc-guard. + GlobalVariable *Function8bitCounterArray; // for inline-8bit-counters. + GlobalVariable *FunctionBoolArray; // for inline-bool-flag. + GlobalVariable *FunctionPCsArray; // for pc-table. + SmallVector<GlobalValue *, 20> GlobalsToAppendToUsed; + SmallVector<GlobalValue *, 20> GlobalsToAppendToCompilerUsed; + + SanitizerCoverageOptions Options; + + const SpecialCaseList *Allowlist; + const SpecialCaseList *Blocklist; + + uint32_t instr = 0; + GlobalVariable *AFLMapPtr = NULL; + ConstantInt * One = NULL; + ConstantInt * Zero = NULL; + +}; + +class ModuleSanitizerCoverageLegacyPass : public ModulePass { + + public: + ModuleSanitizerCoverageLegacyPass( + const SanitizerCoverageOptions &Options = SanitizerCoverageOptions(), + const std::vector<std::string> &AllowlistFiles = + std::vector<std::string>(), + const std::vector<std::string> &BlocklistFiles = + std::vector<std::string>()) + : ModulePass(ID), Options(Options) { + + if (AllowlistFiles.size() > 0) + Allowlist = SpecialCaseList::createOrDie(AllowlistFiles +#if LLVM_MAJOR > 10 || (LLVM_MAJOR == 10 && LLVM_MINOR > 0) + , + *vfs::getRealFileSystem() +#endif + ); + if (BlocklistFiles.size() > 0) + Blocklist = SpecialCaseList::createOrDie(BlocklistFiles +#if LLVM_MAJOR > 10 || (LLVM_MAJOR == 10 && LLVM_MINOR > 0) + , + *vfs::getRealFileSystem() +#endif + ); + initializeModuleSanitizerCoverageLegacyPassPass( + *PassRegistry::getPassRegistry()); + + } + + bool runOnModule(Module &M) override { + + ModuleSanitizerCoverage ModuleSancov(Options, Allowlist.get(), + Blocklist.get()); + auto DTCallback = [this](Function &F) -> const DominatorTree * { + + return &this->getAnalysis<DominatorTreeWrapperPass>(F).getDomTree(); + + }; + + auto PDTCallback = [this](Function &F) -> const PostDominatorTree * { + + return &this->getAnalysis<PostDominatorTreeWrapperPass>(F) + .getPostDomTree(); + + }; + + return ModuleSancov.instrumentModule(M, DTCallback, PDTCallback); + + } + + static char ID; // Pass identification, replacement for typeid + StringRef getPassName() const override { + + return "ModuleSanitizerCoverage"; + + } + + void getAnalysisUsage(AnalysisUsage &AU) const override { + + AU.addRequired<DominatorTreeWrapperPass>(); + AU.addRequired<PostDominatorTreeWrapperPass>(); + + } + + private: + SanitizerCoverageOptions Options; + + std::unique_ptr<SpecialCaseList> Allowlist; + std::unique_ptr<SpecialCaseList> Blocklist; + +}; + +} // namespace + +PreservedAnalyses ModuleSanitizerCoveragePass::run(Module & M, + ModuleAnalysisManager &MAM) { + + ModuleSanitizerCoverage ModuleSancov(Options, Allowlist.get(), + Blocklist.get()); + auto &FAM = MAM.getResult<FunctionAnalysisManagerModuleProxy>(M).getManager(); + auto DTCallback = [&FAM](Function &F) -> const DominatorTree * { + + return &FAM.getResult<DominatorTreeAnalysis>(F); + + }; + + auto PDTCallback = [&FAM](Function &F) -> const PostDominatorTree * { + + return &FAM.getResult<PostDominatorTreeAnalysis>(F); + + }; + + if (ModuleSancov.instrumentModule(M, DTCallback, PDTCallback)) + return PreservedAnalyses::none(); + return PreservedAnalyses::all(); + +} + +std::pair<Value *, Value *> ModuleSanitizerCoverage::CreateSecStartEnd( + Module &M, const char *Section, Type *Ty) { + + GlobalVariable *SecStart = new GlobalVariable( + M, Ty->getPointerElementType(), false, GlobalVariable::ExternalLinkage, + nullptr, getSectionStart(Section)); + SecStart->setVisibility(GlobalValue::HiddenVisibility); + GlobalVariable *SecEnd = new GlobalVariable( + M, Ty->getPointerElementType(), false, GlobalVariable::ExternalLinkage, + nullptr, getSectionEnd(Section)); + SecEnd->setVisibility(GlobalValue::HiddenVisibility); + IRBuilder<> IRB(M.getContext()); + if (!TargetTriple.isOSBinFormatCOFF()) + return std::make_pair(SecStart, SecEnd); + + // Account for the fact that on windows-msvc __start_* symbols actually + // point to a uint64_t before the start of the array. + auto SecStartI8Ptr = IRB.CreatePointerCast(SecStart, Int8PtrTy); + auto GEP = IRB.CreateGEP(Int8Ty, SecStartI8Ptr, + ConstantInt::get(IntptrTy, sizeof(uint64_t))); + return std::make_pair(IRB.CreatePointerCast(GEP, Ty), SecEnd); + +} + +Function *ModuleSanitizerCoverage::CreateInitCallsForSections( + Module &M, const char *CtorName, const char *InitFunctionName, Type *Ty, + const char *Section) { + + auto SecStartEnd = CreateSecStartEnd(M, Section, Ty); + auto SecStart = SecStartEnd.first; + auto SecEnd = SecStartEnd.second; + Function *CtorFunc; + std::tie(CtorFunc, std::ignore) = createSanitizerCtorAndInitFunctions( + M, CtorName, InitFunctionName, {Ty, Ty}, {SecStart, SecEnd}); + assert(CtorFunc->getName() == CtorName); + + if (TargetTriple.supportsCOMDAT()) { + + // Use comdat to dedup CtorFunc. + CtorFunc->setComdat(M.getOrInsertComdat(CtorName)); + appendToGlobalCtors(M, CtorFunc, SanCtorAndDtorPriority, CtorFunc); + + } else { + + appendToGlobalCtors(M, CtorFunc, SanCtorAndDtorPriority); + + } + + if (TargetTriple.isOSBinFormatCOFF()) { + + // In COFF files, if the contructors are set as COMDAT (they are because + // COFF supports COMDAT) and the linker flag /OPT:REF (strip unreferenced + // functions and data) is used, the constructors get stripped. To prevent + // this, give the constructors weak ODR linkage and ensure the linker knows + // to include the sancov constructor. This way the linker can deduplicate + // the constructors but always leave one copy. + CtorFunc->setLinkage(GlobalValue::WeakODRLinkage); + appendToUsed(M, CtorFunc); + + } + + return CtorFunc; + +} + +bool ModuleSanitizerCoverage::instrumentModule( + Module &M, DomTreeCallback DTCallback, PostDomTreeCallback PDTCallback) { + + setvbuf(stdout, NULL, _IONBF, 0); + if (getenv("AFL_DEBUG")) debug = 1; + + if ((isatty(2) && !getenv("AFL_QUIET")) || debug) { + + SAYF(cCYA "SanitizerCoveragePCGUARD" VERSION cRST "\n"); + + } else + + be_quiet = 1; + + skip_nozero = getenv("AFL_LLVM_SKIP_NEVERZERO"); + + initInstrumentList(); + scanForDangerousFunctions(&M); + + if (debug) { + + fprintf(stderr, + "SANCOV: covtype:%u indirect:%d stack:%d noprune:%d " + "createtable:%d tracepcguard:%d tracepc:%d\n", + Options.CoverageType, Options.IndirectCalls == true ? 1 : 0, + Options.StackDepth == true ? 1 : 0, Options.NoPrune == true ? 1 : 0, + // Options.InlineBoolFlag == true ? 1 : 0, + Options.PCTable == true ? 1 : 0, + Options.TracePCGuard == true ? 1 : 0, + Options.TracePC == true ? 1 : 0); + + } + + if (Options.CoverageType == SanitizerCoverageOptions::SCK_None) return false; + if (Allowlist && + !Allowlist->inSection("coverage", "src", M.getSourceFileName())) + return false; + if (Blocklist && + Blocklist->inSection("coverage", "src", M.getSourceFileName())) + return false; + C = &(M.getContext()); + DL = &M.getDataLayout(); + CurModule = &M; + CurModuleUniqueId = getUniqueModuleId(CurModule); + TargetTriple = Triple(M.getTargetTriple()); + FunctionGuardArray = nullptr; + Function8bitCounterArray = nullptr; + FunctionBoolArray = nullptr; + FunctionPCsArray = nullptr; + IntptrTy = Type::getIntNTy(*C, DL->getPointerSizeInBits()); + IntptrPtrTy = PointerType::getUnqual(IntptrTy); + Type * VoidTy = Type::getVoidTy(*C); + IRBuilder<> IRB(*C); + Int64PtrTy = PointerType::getUnqual(IRB.getInt64Ty()); + Int32PtrTy = PointerType::getUnqual(IRB.getInt32Ty()); + Int8PtrTy = PointerType::getUnqual(IRB.getInt8Ty()); + Int1PtrTy = PointerType::getUnqual(IRB.getInt1Ty()); + Int64Ty = IRB.getInt64Ty(); + Int32Ty = IRB.getInt32Ty(); + Int16Ty = IRB.getInt16Ty(); + Int8Ty = IRB.getInt8Ty(); + Int1Ty = IRB.getInt1Ty(); + LLVMContext &Ctx = M.getContext(); + + AFLMapPtr = + new GlobalVariable(M, PointerType::get(Int8Ty, 0), false, + GlobalValue::ExternalLinkage, 0, "__afl_area_ptr"); + One = ConstantInt::get(IntegerType::getInt8Ty(Ctx), 1); + Zero = ConstantInt::get(IntegerType::getInt8Ty(Ctx), 0); + + SanCovTracePCIndir = + M.getOrInsertFunction(SanCovTracePCIndirName, VoidTy, IntptrTy); + // Make sure smaller parameters are zero-extended to i64 if required by the + // target ABI. + AttributeList SanCovTraceCmpZeroExtAL; + SanCovTraceCmpZeroExtAL = + SanCovTraceCmpZeroExtAL.addParamAttribute(*C, 0, Attribute::ZExt); + SanCovTraceCmpZeroExtAL = + SanCovTraceCmpZeroExtAL.addParamAttribute(*C, 1, Attribute::ZExt); + + SanCovTraceCmpFunction[0] = + M.getOrInsertFunction(SanCovTraceCmp1, SanCovTraceCmpZeroExtAL, VoidTy, + IRB.getInt8Ty(), IRB.getInt8Ty()); + SanCovTraceCmpFunction[1] = + M.getOrInsertFunction(SanCovTraceCmp2, SanCovTraceCmpZeroExtAL, VoidTy, + IRB.getInt16Ty(), IRB.getInt16Ty()); + SanCovTraceCmpFunction[2] = + M.getOrInsertFunction(SanCovTraceCmp4, SanCovTraceCmpZeroExtAL, VoidTy, + IRB.getInt32Ty(), IRB.getInt32Ty()); + SanCovTraceCmpFunction[3] = + M.getOrInsertFunction(SanCovTraceCmp8, VoidTy, Int64Ty, Int64Ty); + + SanCovTraceConstCmpFunction[0] = M.getOrInsertFunction( + SanCovTraceConstCmp1, SanCovTraceCmpZeroExtAL, VoidTy, Int8Ty, Int8Ty); + SanCovTraceConstCmpFunction[1] = M.getOrInsertFunction( + SanCovTraceConstCmp2, SanCovTraceCmpZeroExtAL, VoidTy, Int16Ty, Int16Ty); + SanCovTraceConstCmpFunction[2] = M.getOrInsertFunction( + SanCovTraceConstCmp4, SanCovTraceCmpZeroExtAL, VoidTy, Int32Ty, Int32Ty); + SanCovTraceConstCmpFunction[3] = + M.getOrInsertFunction(SanCovTraceConstCmp8, VoidTy, Int64Ty, Int64Ty); + + { + + AttributeList AL; + AL = AL.addParamAttribute(*C, 0, Attribute::ZExt); + SanCovTraceDivFunction[0] = + M.getOrInsertFunction(SanCovTraceDiv4, AL, VoidTy, IRB.getInt32Ty()); + + } + + SanCovTraceDivFunction[1] = + M.getOrInsertFunction(SanCovTraceDiv8, VoidTy, Int64Ty); + SanCovTraceGepFunction = + M.getOrInsertFunction(SanCovTraceGep, VoidTy, IntptrTy); + SanCovTraceSwitchFunction = + M.getOrInsertFunction(SanCovTraceSwitchName, VoidTy, Int64Ty, Int64PtrTy); + + Constant *SanCovLowestStackConstant = + M.getOrInsertGlobal(SanCovLowestStackName, IntptrTy); + SanCovLowestStack = dyn_cast<GlobalVariable>(SanCovLowestStackConstant); + if (!SanCovLowestStack) { + + C->emitError(StringRef("'") + SanCovLowestStackName + + "' should not be declared by the user"); + return true; + + } + + SanCovLowestStack->setThreadLocalMode( + GlobalValue::ThreadLocalMode::InitialExecTLSModel); + if (Options.StackDepth && !SanCovLowestStack->isDeclaration()) + SanCovLowestStack->setInitializer(Constant::getAllOnesValue(IntptrTy)); + + SanCovTracePC = M.getOrInsertFunction(SanCovTracePCName, VoidTy); + SanCovTracePCGuard = + M.getOrInsertFunction(SanCovTracePCGuardName, VoidTy, Int32PtrTy); + + for (auto &F : M) + instrumentFunction(F, DTCallback, PDTCallback); + + Function *Ctor = nullptr; + + if (FunctionGuardArray) + Ctor = CreateInitCallsForSections(M, SanCovModuleCtorTracePcGuardName, + SanCovTracePCGuardInitName, Int32PtrTy, + SanCovGuardsSectionName); + if (Function8bitCounterArray) + Ctor = CreateInitCallsForSections(M, SanCovModuleCtor8bitCountersName, + SanCov8bitCountersInitName, Int8PtrTy, + SanCovCountersSectionName); + if (FunctionBoolArray) { + + Ctor = CreateInitCallsForSections(M, SanCovModuleCtorBoolFlagName, + SanCovBoolFlagInitName, Int1PtrTy, + SanCovBoolFlagSectionName); + + } + + if (Ctor && Options.PCTable) { + + auto SecStartEnd = CreateSecStartEnd(M, SanCovPCsSectionName, IntptrPtrTy); + FunctionCallee InitFunction = declareSanitizerInitFunction( + M, SanCovPCsInitName, {IntptrPtrTy, IntptrPtrTy}); + IRBuilder<> IRBCtor(Ctor->getEntryBlock().getTerminator()); + IRBCtor.CreateCall(InitFunction, {SecStartEnd.first, SecStartEnd.second}); + + } + + // We don't reference these arrays directly in any of our runtime functions, + // so we need to prevent them from being dead stripped. + if (TargetTriple.isOSBinFormatMachO()) appendToUsed(M, GlobalsToAppendToUsed); + appendToCompilerUsed(M, GlobalsToAppendToCompilerUsed); + + if (!be_quiet) { + + if (!instr) + WARNF("No instrumentation targets found."); + else { + + char modeline[100]; + snprintf(modeline, sizeof(modeline), "%s%s%s%s%s", + getenv("AFL_HARDEN") ? "hardened" : "non-hardened", + getenv("AFL_USE_ASAN") ? ", ASAN" : "", + getenv("AFL_USE_MSAN") ? ", MSAN" : "", + getenv("AFL_USE_CFISAN") ? ", CFISAN" : "", + getenv("AFL_USE_UBSAN") ? ", UBSAN" : ""); + OKF("Instrumented %u locations with no collisions (%s mode).", instr, + modeline); + + } + + } + + return true; + +} + +// True if block has successors and it dominates all of them. +static bool isFullDominator(const BasicBlock *BB, const DominatorTree *DT) { + + if (succ_begin(BB) == succ_end(BB)) return false; + + for (const BasicBlock *SUCC : make_range(succ_begin(BB), succ_end(BB))) { + + if (!DT->dominates(BB, SUCC)) return false; + + } + + return true; + +} + +// True if block has predecessors and it postdominates all of them. +static bool isFullPostDominator(const BasicBlock * BB, + const PostDominatorTree *PDT) { + + if (pred_begin(BB) == pred_end(BB)) return false; + + for (const BasicBlock *PRED : make_range(pred_begin(BB), pred_end(BB))) { + + if (!PDT->dominates(BB, PRED)) return false; + + } + + return true; + +} + +static bool shouldInstrumentBlock(const Function &F, const BasicBlock *BB, + const DominatorTree * DT, + const PostDominatorTree * PDT, + const SanitizerCoverageOptions &Options) { + + // Don't insert coverage for blocks containing nothing but unreachable: we + // will never call __sanitizer_cov() for them, so counting them in + // NumberOfInstrumentedBlocks() might complicate calculation of code coverage + // percentage. Also, unreachable instructions frequently have no debug + // locations. + if (isa<UnreachableInst>(BB->getFirstNonPHIOrDbgOrLifetime())) return false; + + // Don't insert coverage into blocks without a valid insertion point + // (catchswitch blocks). + if (BB->getFirstInsertionPt() == BB->end()) return false; + + if (Options.NoPrune || &F.getEntryBlock() == BB) return true; + + if (Options.CoverageType == SanitizerCoverageOptions::SCK_Function && + &F.getEntryBlock() != BB) + return false; + + // Do not instrument full dominators, or full post-dominators with multiple + // predecessors. + return !isFullDominator(BB, DT) && + !(isFullPostDominator(BB, PDT) && !BB->getSinglePredecessor()); + +} + +// Returns true iff From->To is a backedge. +// A twist here is that we treat From->To as a backedge if +// * To dominates From or +// * To->UniqueSuccessor dominates From +static bool IsBackEdge(BasicBlock *From, BasicBlock *To, + const DominatorTree *DT) { + + if (DT->dominates(To, From)) return true; + if (auto Next = To->getUniqueSuccessor()) + if (DT->dominates(Next, From)) return true; + return false; + +} + +// Prunes uninteresting Cmp instrumentation: +// * CMP instructions that feed into loop backedge branch. +// +// Note that Cmp pruning is controlled by the same flag as the +// BB pruning. +static bool IsInterestingCmp(ICmpInst *CMP, const DominatorTree *DT, + const SanitizerCoverageOptions &Options) { + + if (!Options.NoPrune) + if (CMP->hasOneUse()) + if (auto BR = dyn_cast<BranchInst>(CMP->user_back())) + for (BasicBlock *B : BR->successors()) + if (IsBackEdge(BR->getParent(), B, DT)) return false; + return true; + +} + +void ModuleSanitizerCoverage::instrumentFunction( + Function &F, DomTreeCallback DTCallback, PostDomTreeCallback PDTCallback) { + + if (F.empty()) return; + if (!isInInstrumentList(&F)) return; + + if (F.getName().find(".module_ctor") != std::string::npos) + return; // Should not instrument sanitizer init functions. + if (F.getName().startswith("__sanitizer_")) + return; // Don't instrument __sanitizer_* callbacks. + // Don't touch available_externally functions, their actual body is elewhere. + if (F.getLinkage() == GlobalValue::AvailableExternallyLinkage) return; + // Don't instrument MSVC CRT configuration helpers. They may run before normal + // initialization. + if (F.getName() == "__local_stdio_printf_options" || + F.getName() == "__local_stdio_scanf_options") + return; + if (isa<UnreachableInst>(F.getEntryBlock().getTerminator())) return; + // Don't instrument functions using SEH for now. Splitting basic blocks like + // we do for coverage breaks WinEHPrepare. + // FIXME: Remove this when SEH no longer uses landingpad pattern matching. + if (F.hasPersonalityFn() && + isAsynchronousEHPersonality(classifyEHPersonality(F.getPersonalityFn()))) + return; + if (Allowlist && !Allowlist->inSection("coverage", "fun", F.getName())) + return; + if (Blocklist && Blocklist->inSection("coverage", "fun", F.getName())) return; + if (Options.CoverageType >= SanitizerCoverageOptions::SCK_Edge) + SplitAllCriticalEdges( + F, CriticalEdgeSplittingOptions().setIgnoreUnreachableDests()); + SmallVector<Instruction *, 8> IndirCalls; + SmallVector<BasicBlock *, 16> BlocksToInstrument; + SmallVector<Instruction *, 8> CmpTraceTargets; + SmallVector<Instruction *, 8> SwitchTraceTargets; + SmallVector<BinaryOperator *, 8> DivTraceTargets; + SmallVector<GetElementPtrInst *, 8> GepTraceTargets; + + const DominatorTree * DT = DTCallback(F); + const PostDominatorTree *PDT = PDTCallback(F); + bool IsLeafFunc = true; + + for (auto &BB : F) { + + if (shouldInstrumentBlock(F, &BB, DT, PDT, Options)) + BlocksToInstrument.push_back(&BB); + for (auto &Inst : BB) { + + if (Options.IndirectCalls) { + + CallBase *CB = dyn_cast<CallBase>(&Inst); + if (CB && !CB->getCalledFunction()) IndirCalls.push_back(&Inst); + + } + + if (Options.TraceCmp) { + + if (ICmpInst *CMP = dyn_cast<ICmpInst>(&Inst)) + if (IsInterestingCmp(CMP, DT, Options)) + CmpTraceTargets.push_back(&Inst); + if (isa<SwitchInst>(&Inst)) SwitchTraceTargets.push_back(&Inst); + + } + + if (Options.TraceDiv) + if (BinaryOperator *BO = dyn_cast<BinaryOperator>(&Inst)) + if (BO->getOpcode() == Instruction::SDiv || + BO->getOpcode() == Instruction::UDiv) + DivTraceTargets.push_back(BO); + if (Options.TraceGep) + if (GetElementPtrInst *GEP = dyn_cast<GetElementPtrInst>(&Inst)) + GepTraceTargets.push_back(GEP); + if (Options.StackDepth) + if (isa<InvokeInst>(Inst) || + (isa<CallInst>(Inst) && !isa<IntrinsicInst>(Inst))) + IsLeafFunc = false; + + } + + } + + InjectCoverage(F, BlocksToInstrument, IsLeafFunc); + InjectCoverageForIndirectCalls(F, IndirCalls); + InjectTraceForCmp(F, CmpTraceTargets); + InjectTraceForSwitch(F, SwitchTraceTargets); + InjectTraceForDiv(F, DivTraceTargets); + InjectTraceForGep(F, GepTraceTargets); + +} + +GlobalVariable *ModuleSanitizerCoverage::CreateFunctionLocalArrayInSection( + size_t NumElements, Function &F, Type *Ty, const char *Section) { + + ArrayType *ArrayTy = ArrayType::get(Ty, NumElements); + auto Array = new GlobalVariable( + *CurModule, ArrayTy, false, GlobalVariable::PrivateLinkage, + Constant::getNullValue(ArrayTy), "__sancov_gen_"); + + if (TargetTriple.supportsCOMDAT() && !F.isInterposable()) + if (auto Comdat = + GetOrCreateFunctionComdat(F, TargetTriple, CurModuleUniqueId)) + Array->setComdat(Comdat); + Array->setSection(getSectionName(Section)); +#if LLVM_MAJOR > 10 || (LLVM_MAJOR == 10 && LLVM_MINOR > 0) + Array->setAlignment(Align(DL->getTypeStoreSize(Ty).getFixedSize())); +#else + Array->setAlignment(Align(4)); // cheating +#endif + GlobalsToAppendToUsed.push_back(Array); + GlobalsToAppendToCompilerUsed.push_back(Array); + MDNode *MD = MDNode::get(F.getContext(), ValueAsMetadata::get(&F)); + Array->addMetadata(LLVMContext::MD_associated, *MD); + + return Array; + +} + +GlobalVariable *ModuleSanitizerCoverage::CreatePCArray( + Function &F, ArrayRef<BasicBlock *> AllBlocks) { + + size_t N = AllBlocks.size(); + assert(N); + SmallVector<Constant *, 32> PCs; + IRBuilder<> IRB(&*F.getEntryBlock().getFirstInsertionPt()); + for (size_t i = 0; i < N; i++) { + + if (&F.getEntryBlock() == AllBlocks[i]) { + + PCs.push_back((Constant *)IRB.CreatePointerCast(&F, IntptrPtrTy)); + PCs.push_back((Constant *)IRB.CreateIntToPtr( + ConstantInt::get(IntptrTy, 1), IntptrPtrTy)); + + } else { + + PCs.push_back((Constant *)IRB.CreatePointerCast( + BlockAddress::get(AllBlocks[i]), IntptrPtrTy)); + PCs.push_back((Constant *)IRB.CreateIntToPtr( + ConstantInt::get(IntptrTy, 0), IntptrPtrTy)); + + } + + } + + auto *PCArray = CreateFunctionLocalArrayInSection(N * 2, F, IntptrPtrTy, + SanCovPCsSectionName); + PCArray->setInitializer( + ConstantArray::get(ArrayType::get(IntptrPtrTy, N * 2), PCs)); + PCArray->setConstant(true); + + return PCArray; + +} + +void ModuleSanitizerCoverage::CreateFunctionLocalArrays( + Function &F, ArrayRef<BasicBlock *> AllBlocks, uint32_t special) { + + if (Options.TracePCGuard) + FunctionGuardArray = CreateFunctionLocalArrayInSection( + AllBlocks.size() + special, F, Int32Ty, SanCovGuardsSectionName); + + if (Options.Inline8bitCounters) + Function8bitCounterArray = CreateFunctionLocalArrayInSection( + AllBlocks.size(), F, Int8Ty, SanCovCountersSectionName); + /* + if (Options.InlineBoolFlag) + FunctionBoolArray = CreateFunctionLocalArrayInSection( + AllBlocks.size(), F, Int1Ty, SanCovBoolFlagSectionName); + */ + if (Options.PCTable) FunctionPCsArray = CreatePCArray(F, AllBlocks); + +} + +bool ModuleSanitizerCoverage::InjectCoverage(Function & F, + ArrayRef<BasicBlock *> AllBlocks, + bool IsLeafFunc) { + + if (AllBlocks.empty()) return false; + + uint32_t special = 0; + for (auto &BB : F) { + + for (auto &IN : BB) { + + CallInst *callInst = nullptr; + + if ((callInst = dyn_cast<CallInst>(&IN))) { + + Function *Callee = callInst->getCalledFunction(); + if (!Callee) continue; + if (callInst->getCallingConv() != llvm::CallingConv::C) continue; + StringRef FuncName = Callee->getName(); + if (FuncName.compare(StringRef("__afl_coverage_interesting"))) continue; + + uint32_t id = 1 + instr + (uint32_t)AllBlocks.size() + special++; + Value * val = ConstantInt::get(Int32Ty, id); + callInst->setOperand(1, val); + + } + + } + + } + + CreateFunctionLocalArrays(F, AllBlocks, special); + for (size_t i = 0, N = AllBlocks.size(); i < N; i++) + InjectCoverageAtBlock(F, *AllBlocks[i], i, IsLeafFunc); + + instr += special; + + return true; + +} + +// On every indirect call we call a run-time function +// __sanitizer_cov_indir_call* with two parameters: +// - callee address, +// - global cache array that contains CacheSize pointers (zero-initialized). +// The cache is used to speed up recording the caller-callee pairs. +// The address of the caller is passed implicitly via caller PC. +// CacheSize is encoded in the name of the run-time function. +void ModuleSanitizerCoverage::InjectCoverageForIndirectCalls( + Function &F, ArrayRef<Instruction *> IndirCalls) { + + if (IndirCalls.empty()) return; + assert(Options.TracePC || Options.TracePCGuard || + Options.Inline8bitCounters /*|| Options.InlineBoolFlag*/); + for (auto I : IndirCalls) { + + IRBuilder<> IRB(I); + CallBase & CB = cast<CallBase>(*I); + Value * Callee = CB.getCalledOperand(); + if (isa<InlineAsm>(Callee)) continue; + IRB.CreateCall(SanCovTracePCIndir, IRB.CreatePointerCast(Callee, IntptrTy)); + + } + +} + +// For every switch statement we insert a call: +// __sanitizer_cov_trace_switch(CondValue, +// {NumCases, ValueSizeInBits, Case0Value, Case1Value, Case2Value, ... }) + +void ModuleSanitizerCoverage::InjectTraceForSwitch( + Function &, ArrayRef<Instruction *> SwitchTraceTargets) { + + for (auto I : SwitchTraceTargets) { + + if (SwitchInst *SI = dyn_cast<SwitchInst>(I)) { + + IRBuilder<> IRB(I); + SmallVector<Constant *, 16> Initializers; + Value * Cond = SI->getCondition(); + if (Cond->getType()->getScalarSizeInBits() > + Int64Ty->getScalarSizeInBits()) + continue; + Initializers.push_back(ConstantInt::get(Int64Ty, SI->getNumCases())); + Initializers.push_back( + ConstantInt::get(Int64Ty, Cond->getType()->getScalarSizeInBits())); + if (Cond->getType()->getScalarSizeInBits() < + Int64Ty->getScalarSizeInBits()) + Cond = IRB.CreateIntCast(Cond, Int64Ty, false); + for (auto It : SI->cases()) { + + Constant *C = It.getCaseValue(); + if (C->getType()->getScalarSizeInBits() < + Int64Ty->getScalarSizeInBits()) + C = ConstantExpr::getCast(CastInst::ZExt, It.getCaseValue(), Int64Ty); + Initializers.push_back(C); + + } + + llvm::sort(drop_begin(Initializers, 2), + [](const Constant *A, const Constant *B) { + + return cast<ConstantInt>(A)->getLimitedValue() < + cast<ConstantInt>(B)->getLimitedValue(); + + }); + + ArrayType *ArrayOfInt64Ty = ArrayType::get(Int64Ty, Initializers.size()); + GlobalVariable *GV = new GlobalVariable( + *CurModule, ArrayOfInt64Ty, false, GlobalVariable::InternalLinkage, + ConstantArray::get(ArrayOfInt64Ty, Initializers), + "__sancov_gen_cov_switch_values"); + IRB.CreateCall(SanCovTraceSwitchFunction, + {Cond, IRB.CreatePointerCast(GV, Int64PtrTy)}); + + } + + } + +} + +void ModuleSanitizerCoverage::InjectTraceForDiv( + Function &, ArrayRef<BinaryOperator *> DivTraceTargets) { + + for (auto BO : DivTraceTargets) { + + IRBuilder<> IRB(BO); + Value * A1 = BO->getOperand(1); + if (isa<ConstantInt>(A1)) continue; + if (!A1->getType()->isIntegerTy()) continue; + uint64_t TypeSize = DL->getTypeStoreSizeInBits(A1->getType()); + int CallbackIdx = TypeSize == 32 ? 0 : TypeSize == 64 ? 1 : -1; + if (CallbackIdx < 0) continue; + auto Ty = Type::getIntNTy(*C, TypeSize); + IRB.CreateCall(SanCovTraceDivFunction[CallbackIdx], + {IRB.CreateIntCast(A1, Ty, true)}); + + } + +} + +void ModuleSanitizerCoverage::InjectTraceForGep( + Function &, ArrayRef<GetElementPtrInst *> GepTraceTargets) { + + for (auto GEP : GepTraceTargets) { + + IRBuilder<> IRB(GEP); + for (Use &Idx : GEP->indices()) + if (!isa<ConstantInt>(Idx) && Idx->getType()->isIntegerTy()) + IRB.CreateCall(SanCovTraceGepFunction, + {IRB.CreateIntCast(Idx, IntptrTy, true)}); + + } + +} + +void ModuleSanitizerCoverage::InjectTraceForCmp( + Function &, ArrayRef<Instruction *> CmpTraceTargets) { + + for (auto I : CmpTraceTargets) { + + if (ICmpInst *ICMP = dyn_cast<ICmpInst>(I)) { + + IRBuilder<> IRB(ICMP); + Value * A0 = ICMP->getOperand(0); + Value * A1 = ICMP->getOperand(1); + if (!A0->getType()->isIntegerTy()) continue; + uint64_t TypeSize = DL->getTypeStoreSizeInBits(A0->getType()); + int CallbackIdx = TypeSize == 8 ? 0 + : TypeSize == 16 ? 1 + : TypeSize == 32 ? 2 + : TypeSize == 64 ? 3 + : -1; + if (CallbackIdx < 0) continue; + // __sanitizer_cov_trace_cmp((type_size << 32) | predicate, A0, A1); + auto CallbackFunc = SanCovTraceCmpFunction[CallbackIdx]; + bool FirstIsConst = isa<ConstantInt>(A0); + bool SecondIsConst = isa<ConstantInt>(A1); + // If both are const, then we don't need such a comparison. + if (FirstIsConst && SecondIsConst) continue; + // If only one is const, then make it the first callback argument. + if (FirstIsConst || SecondIsConst) { + + CallbackFunc = SanCovTraceConstCmpFunction[CallbackIdx]; + if (SecondIsConst) std::swap(A0, A1); + + } + + auto Ty = Type::getIntNTy(*C, TypeSize); + IRB.CreateCall(CallbackFunc, {IRB.CreateIntCast(A0, Ty, true), + IRB.CreateIntCast(A1, Ty, true)}); + + } + + } + +} + +void ModuleSanitizerCoverage::InjectCoverageAtBlock(Function &F, BasicBlock &BB, + size_t Idx, + bool IsLeafFunc) { + + BasicBlock::iterator IP = BB.getFirstInsertionPt(); + bool IsEntryBB = &BB == &F.getEntryBlock(); + + if (IsEntryBB) { + + // Keep static allocas and llvm.localescape calls in the entry block. Even + // if we aren't splitting the block, it's nice for allocas to be before + // calls. + IP = PrepareToSplitEntryBlock(BB, IP); + + } + + IRBuilder<> IRB(&*IP); + + if (Options.TracePC) { + + IRB.CreateCall(SanCovTracePC); + // ->setCannotMerge(); // gets the PC using GET_CALLER_PC. + + } + + if (Options.TracePCGuard) { + + /* Get CurLoc */ + + Value *GuardPtr = IRB.CreateIntToPtr( + IRB.CreateAdd(IRB.CreatePointerCast(FunctionGuardArray, IntptrTy), + ConstantInt::get(IntptrTy, Idx * 4)), + Int32PtrTy); + + LoadInst *CurLoc = IRB.CreateLoad(GuardPtr); + + /* Load SHM pointer */ + + LoadInst *MapPtr = IRB.CreateLoad(AFLMapPtr); + + /* Load counter for CurLoc */ + + Value * MapPtrIdx = IRB.CreateGEP(MapPtr, CurLoc); + LoadInst *Counter = IRB.CreateLoad(MapPtrIdx); + + /* Update bitmap */ + + Value *Incr = IRB.CreateAdd(Counter, One); + + if (skip_nozero == NULL) { + + auto cf = IRB.CreateICmpEQ(Incr, Zero); + auto carry = IRB.CreateZExt(cf, Int8Ty); + Incr = IRB.CreateAdd(Incr, carry); + + } + + IRB.CreateStore(Incr, MapPtrIdx); + + // done :) + + // IRB.CreateCall(SanCovTracePCGuard, Offset)->setCannotMerge(); + // IRB.CreateCall(SanCovTracePCGuard, GuardPtr)->setCannotMerge(); + ++instr; + + } + + if (Options.Inline8bitCounters) { + + auto CounterPtr = IRB.CreateGEP( + Function8bitCounterArray->getValueType(), Function8bitCounterArray, + {ConstantInt::get(IntptrTy, 0), ConstantInt::get(IntptrTy, Idx)}); + auto Load = IRB.CreateLoad(Int8Ty, CounterPtr); + auto Inc = IRB.CreateAdd(Load, ConstantInt::get(Int8Ty, 1)); + auto Store = IRB.CreateStore(Inc, CounterPtr); + SetNoSanitizeMetadata(Load); + SetNoSanitizeMetadata(Store); + + } + + /* + if (Options.InlineBoolFlag) { + + auto FlagPtr = IRB.CreateGEP( + FunctionBoolArray->getValueType(), FunctionBoolArray, + {ConstantInt::get(IntptrTy, 0), ConstantInt::get(IntptrTy, Idx)}); + auto Load = IRB.CreateLoad(Int1Ty, FlagPtr); + auto ThenTerm = + SplitBlockAndInsertIfThen(IRB.CreateIsNull(Load), &*IP, false); + IRBuilder<> ThenIRB(ThenTerm); + auto Store = ThenIRB.CreateStore(ConstantInt::getTrue(Int1Ty), FlagPtr); + SetNoSanitizeMetadata(Load); + SetNoSanitizeMetadata(Store); + + } + + */ + + if (Options.StackDepth && IsEntryBB && !IsLeafFunc) { + + // Check stack depth. If it's the deepest so far, record it. + Module * M = F.getParent(); + Function *GetFrameAddr = Intrinsic::getDeclaration( + M, Intrinsic::frameaddress, + IRB.getInt8PtrTy(M->getDataLayout().getAllocaAddrSpace())); + auto FrameAddrPtr = + IRB.CreateCall(GetFrameAddr, {Constant::getNullValue(Int32Ty)}); + auto FrameAddrInt = IRB.CreatePtrToInt(FrameAddrPtr, IntptrTy); + auto LowestStack = IRB.CreateLoad(IntptrTy, SanCovLowestStack); + auto IsStackLower = IRB.CreateICmpULT(FrameAddrInt, LowestStack); + auto ThenTerm = SplitBlockAndInsertIfThen(IsStackLower, &*IP, false); + IRBuilder<> ThenIRB(ThenTerm); + auto Store = ThenIRB.CreateStore(FrameAddrInt, SanCovLowestStack); + SetNoSanitizeMetadata(LowestStack); + SetNoSanitizeMetadata(Store); + + } + +} + +std::string ModuleSanitizerCoverage::getSectionName( + const std::string &Section) const { + + if (TargetTriple.isOSBinFormatCOFF()) { + + if (Section == SanCovCountersSectionName) return ".SCOV$CM"; + if (Section == SanCovBoolFlagSectionName) return ".SCOV$BM"; + if (Section == SanCovPCsSectionName) return ".SCOVP$M"; + return ".SCOV$GM"; // For SanCovGuardsSectionName. + + } + + if (TargetTriple.isOSBinFormatMachO()) return "__DATA,__" + Section; + return "__" + Section; + +} + +std::string ModuleSanitizerCoverage::getSectionStart( + const std::string &Section) const { + + if (TargetTriple.isOSBinFormatMachO()) + return "\1section$start$__DATA$__" + Section; + return "__start___" + Section; + +} + +std::string ModuleSanitizerCoverage::getSectionEnd( + const std::string &Section) const { + + if (TargetTriple.isOSBinFormatMachO()) + return "\1section$end$__DATA$__" + Section; + return "__stop___" + Section; + +} + +char ModuleSanitizerCoverageLegacyPass::ID = 0; + +INITIALIZE_PASS_BEGIN(ModuleSanitizerCoverageLegacyPass, "sancov", + "Pass for instrumenting coverage on functions", false, + false) +INITIALIZE_PASS_DEPENDENCY(DominatorTreeWrapperPass) +INITIALIZE_PASS_DEPENDENCY(PostDominatorTreeWrapperPass) +INITIALIZE_PASS_END(ModuleSanitizerCoverageLegacyPass, "sancov", + "Pass for instrumenting coverage on functions", false, + false) + +ModulePass *llvm::createModuleSanitizerCoverageLegacyPassPass( + const SanitizerCoverageOptions &Options, + const std::vector<std::string> &AllowlistFiles, + const std::vector<std::string> &BlocklistFiles) { + + return new ModuleSanitizerCoverageLegacyPass(Options, AllowlistFiles, + BlocklistFiles); + +} + +static void registerPCGUARDPass(const PassManagerBuilder &, + legacy::PassManagerBase &PM) { + + auto p = new ModuleSanitizerCoverageLegacyPass(); + PM.add(p); + +} + +static RegisterStandardPasses RegisterCompTransPass( + PassManagerBuilder::EP_OptimizerLast, registerPCGUARDPass); + +static RegisterStandardPasses RegisterCompTransPass0( + PassManagerBuilder::EP_EnabledOnOptLevel0, registerPCGUARDPass); + diff --git a/instrumentation/afl-compiler-rt.o.c b/instrumentation/afl-compiler-rt.o.c new file mode 100644 index 00000000..c635ae63 --- /dev/null +++ b/instrumentation/afl-compiler-rt.o.c @@ -0,0 +1,1965 @@ +/* + american fuzzy lop++ - instrumentation bootstrap + ------------------------------------------------ + + Copyright 2015, 2016 Google Inc. All rights reserved. + Copyright 2019-2020 AFLplusplus Project. All rights reserved. + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at: + + http://www.apache.org/licenses/LICENSE-2.0 + + +*/ + +#ifdef __ANDROID__ + #include "android-ashmem.h" +#endif +#include "config.h" +#include "types.h" +#include "cmplog.h" +#include "llvm-alternative-coverage.h" + +#include <stdio.h> +#include <stdlib.h> +#include <signal.h> +#include <unistd.h> +#include <string.h> +#include <assert.h> +#include <stdint.h> +#include <stddef.h> +#include <limits.h> +#include <errno.h> + +#include <sys/mman.h> +#include <sys/syscall.h> +#ifndef __HAIKU__ + #include <sys/shm.h> +#endif +#include <sys/wait.h> +#include <sys/types.h> + +#if !__GNUC__ + #include "llvm/Config/llvm-config.h" +#endif + +#ifdef __linux__ + #include "snapshot-inl.h" +#endif + +/* This is a somewhat ugly hack for the experimental 'trace-pc-guard' mode. + Basically, we need to make sure that the forkserver is initialized after + the LLVM-generated runtime initialization pass, not before. */ + +#ifndef MAP_FIXED_NOREPLACE + #ifdef MAP_EXCL + #define MAP_FIXED_NOREPLACE MAP_EXCL | MAP_FIXED + #else + #define MAP_FIXED_NOREPLACE MAP_FIXED + #endif +#endif + +#define CTOR_PRIO 3 + +#include <sys/mman.h> +#include <fcntl.h> + +/* Globals needed by the injected instrumentation. The __afl_area_initial region + is used for instrumentation output before __afl_map_shm() has a chance to + run. It will end up as .comm, so it shouldn't be too wasteful. */ + +#if MAP_SIZE <= 65536 + #define MAP_INITIAL_SIZE 2097152 +#else + #define MAP_INITIAL_SIZE MAP_SIZE +#endif + +u8 __afl_area_initial[MAP_INITIAL_SIZE]; +u8 * __afl_area_ptr_dummy = __afl_area_initial; +u8 * __afl_area_ptr = __afl_area_initial; +u8 * __afl_area_ptr_backup = __afl_area_initial; +u8 * __afl_dictionary; +u8 * __afl_fuzz_ptr; +u32 __afl_fuzz_len_dummy; +u32 *__afl_fuzz_len = &__afl_fuzz_len_dummy; + +u32 __afl_final_loc; +u32 __afl_map_size = MAP_SIZE; +u32 __afl_dictionary_len; +u64 __afl_map_addr; + +// for the __AFL_COVERAGE_ON/__AFL_COVERAGE_OFF features to work: +int __afl_selective_coverage __attribute__((weak)); +int __afl_selective_coverage_start_off __attribute__((weak)); +int __afl_selective_coverage_temp = 1; + +#if defined(__ANDROID__) || defined(__HAIKU__) +PREV_LOC_T __afl_prev_loc[NGRAM_SIZE_MAX]; +PREV_LOC_T __afl_prev_caller[CTX_MAX_K]; +u32 __afl_prev_ctx; +u32 __afl_cmp_counter; +#else +__thread PREV_LOC_T __afl_prev_loc[NGRAM_SIZE_MAX]; +__thread PREV_LOC_T __afl_prev_caller[CTX_MAX_K]; +__thread u32 __afl_prev_ctx; +__thread u32 __afl_cmp_counter; +#endif + +int __afl_sharedmem_fuzzing __attribute__((weak)); + +struct cmp_map *__afl_cmp_map; +struct cmp_map *__afl_cmp_map_backup; + +/* Child pid? */ + +static s32 child_pid; +static void (*old_sigterm_handler)(int) = 0; + +/* Running in persistent mode? */ + +static u8 is_persistent; + +/* Are we in sancov mode? */ + +static u8 _is_sancov; + +/* Debug? */ + +static u32 __afl_debug; + +/* Already initialized markers */ + +u32 __afl_already_initialized_shm; +u32 __afl_already_initialized_forkserver; +u32 __afl_already_initialized_first; +u32 __afl_already_initialized_second; + +/* Dummy pipe for area_is_valid() */ + +static int __afl_dummy_fd[2] = {2, 2}; + +/* ensure we kill the child on termination */ + +void at_exit(int signal) { + + if (child_pid > 0) { kill(child_pid, SIGKILL); } + +} + +/* Uninspired gcc plugin instrumentation */ + +void __afl_trace(const u32 x) { + + PREV_LOC_T prev = __afl_prev_loc[0]; + __afl_prev_loc[0] = (x >> 1); + + u8 *p = &__afl_area_ptr[prev ^ x]; + +#if 1 /* enable for neverZero feature. */ + #if __GNUC__ + u8 c = __builtin_add_overflow(*p, 1, p); + *p += c; + #else + *p += 1 + ((u8)(1 + *p) == 0); + #endif +#else + ++*p; +#endif + + return; + +} + +/* Error reporting to forkserver controller */ + +void send_forkserver_error(int error) { + + u32 status; + if (!error || error > 0xffff) return; + status = (FS_OPT_ERROR | FS_OPT_SET_ERROR(error)); + if (write(FORKSRV_FD + 1, (char *)&status, 4) != 4) { return; } + +} + +/* SHM fuzzing setup. */ + +static void __afl_map_shm_fuzz() { + + char *id_str = getenv(SHM_FUZZ_ENV_VAR); + + if (__afl_debug) { + + fprintf(stderr, "DEBUG: fuzzcase shmem %s\n", id_str ? id_str : "none"); + + } + + if (id_str) { + + u8 *map = NULL; + +#ifdef USEMMAP + const char *shm_file_path = id_str; + int shm_fd = -1; + + /* create the shared memory segment as if it was a file */ + shm_fd = shm_open(shm_file_path, O_RDWR, 0600); + if (shm_fd == -1) { + + fprintf(stderr, "shm_open() failed for fuzz\n"); + send_forkserver_error(FS_ERROR_SHM_OPEN); + exit(1); + + } + + map = + (u8 *)mmap(0, MAX_FILE + sizeof(u32), PROT_READ, MAP_SHARED, shm_fd, 0); + +#else + u32 shm_id = atoi(id_str); + map = (u8 *)shmat(shm_id, NULL, 0); + +#endif + + /* Whooooops. */ + + if (!map || map == (void *)-1) { + + perror("Could not access fuzzing shared memory"); + send_forkserver_error(FS_ERROR_SHM_OPEN); + exit(1); + + } + + __afl_fuzz_len = (u32 *)map; + __afl_fuzz_ptr = map + sizeof(u32); + + if (__afl_debug) { + + fprintf(stderr, "DEBUG: successfully got fuzzing shared memory\n"); + + } + + } else { + + fprintf(stderr, "Error: variable for fuzzing shared memory is not set\n"); + send_forkserver_error(FS_ERROR_SHM_OPEN); + exit(1); + + } + +} + +/* SHM setup. */ + +static void __afl_map_shm(void) { + + if (__afl_already_initialized_shm) return; + __afl_already_initialized_shm = 1; + + // if we are not running in afl ensure the map exists + if (!__afl_area_ptr) { __afl_area_ptr = __afl_area_ptr_dummy; } + + char *id_str = getenv(SHM_ENV_VAR); + + if (__afl_final_loc) { + + if (__afl_final_loc % 64) { + + __afl_final_loc = (((__afl_final_loc + 63) >> 6) << 6); + + } + + __afl_map_size = __afl_final_loc; + + if (__afl_final_loc > MAP_SIZE) { + + char *ptr; + u32 val = 0; + if ((ptr = getenv("AFL_MAP_SIZE")) != NULL) val = atoi(ptr); + if (val < __afl_final_loc) { + + if (__afl_final_loc > FS_OPT_MAX_MAPSIZE) { + + if (!getenv("AFL_QUIET")) + fprintf(stderr, + "Error: AFL++ tools *require* to set AFL_MAP_SIZE to %u " + "to be able to run this instrumented program!\n", + __afl_final_loc); + + if (id_str) { + + send_forkserver_error(FS_ERROR_MAP_SIZE); + exit(-1); + + } + + } else { + + if (!getenv("AFL_QUIET")) + fprintf(stderr, + "Warning: AFL++ tools will need to set AFL_MAP_SIZE to %u " + "to be able to run this instrumented program!\n", + __afl_final_loc); + + } + + } + + } + + } + + /* If we're running under AFL, attach to the appropriate region, replacing the + early-stage __afl_area_initial region that is needed to allow some really + hacky .init code to work correctly in projects such as OpenSSL. */ + + if (__afl_debug) { + + fprintf(stderr, + "DEBUG: (1) id_str %s, __afl_area_ptr %p, __afl_area_initial %p, " + "__afl_area_ptr_dummy 0x%p, __afl_map_addr 0x%llx, MAP_SIZE %u, " + "__afl_final_loc %u, " + "max_size_forkserver %u/0x%x\n", + id_str == NULL ? "<null>" : id_str, __afl_area_ptr, + __afl_area_initial, __afl_area_ptr_dummy, __afl_map_addr, MAP_SIZE, + __afl_final_loc, FS_OPT_MAX_MAPSIZE, FS_OPT_MAX_MAPSIZE); + + } + + if (id_str) { + + if (__afl_area_ptr && __afl_area_ptr != __afl_area_initial && + __afl_area_ptr != __afl_area_ptr_dummy) { + + if (__afl_map_addr) { + + munmap((void *)__afl_map_addr, __afl_final_loc); + + } else { + + free(__afl_area_ptr); + + } + + __afl_area_ptr = __afl_area_ptr_dummy; + + } + +#ifdef USEMMAP + const char * shm_file_path = id_str; + int shm_fd = -1; + unsigned char *shm_base = NULL; + + /* create the shared memory segment as if it was a file */ + shm_fd = shm_open(shm_file_path, O_RDWR, 0600); + if (shm_fd == -1) { + + fprintf(stderr, "shm_open() failed\n"); + send_forkserver_error(FS_ERROR_SHM_OPEN); + exit(1); + + } + + /* map the shared memory segment to the address space of the process */ + if (__afl_map_addr) { + + shm_base = + mmap((void *)__afl_map_addr, __afl_map_size, PROT_READ | PROT_WRITE, + MAP_FIXED_NOREPLACE | MAP_SHARED, shm_fd, 0); + + } else { + + shm_base = mmap(0, __afl_map_size, PROT_READ | PROT_WRITE, MAP_SHARED, + shm_fd, 0); + + } + + close(shm_fd); + shm_fd = -1; + + if (shm_base == MAP_FAILED) { + + fprintf(stderr, "mmap() failed\n"); + perror("mmap for map"); + + if (__afl_map_addr) + send_forkserver_error(FS_ERROR_MAP_ADDR); + else + send_forkserver_error(FS_ERROR_MMAP); + + exit(2); + + } + + __afl_area_ptr = shm_base; +#else + u32 shm_id = atoi(id_str); + + if (__afl_map_size && __afl_map_size > MAP_SIZE) { + + u8 *map_env = (u8 *)getenv("AFL_MAP_SIZE"); + if (!map_env || atoi((char *)map_env) < MAP_SIZE) { + + send_forkserver_error(FS_ERROR_MAP_SIZE); + _exit(1); + + } + + } + + __afl_area_ptr = (u8 *)shmat(shm_id, (void *)__afl_map_addr, 0); + + /* Whooooops. */ + + if (!__afl_area_ptr || __afl_area_ptr == (void *)-1) { + + if (__afl_map_addr) + send_forkserver_error(FS_ERROR_MAP_ADDR); + else + send_forkserver_error(FS_ERROR_SHMAT); + + perror("shmat for map"); + _exit(1); + + } + +#endif + + /* Write something into the bitmap so that even with low AFL_INST_RATIO, + our parent doesn't give up on us. */ + + __afl_area_ptr[0] = 1; + + } else if ((!__afl_area_ptr || __afl_area_ptr == __afl_area_initial) && + + __afl_map_addr) { + + __afl_area_ptr = (u8 *)mmap( + (void *)__afl_map_addr, __afl_map_size, PROT_READ | PROT_WRITE, + MAP_FIXED_NOREPLACE | MAP_SHARED | MAP_ANONYMOUS, -1, 0); + + if (__afl_area_ptr == MAP_FAILED) { + + fprintf(stderr, "can not acquire mmap for address %p\n", + (void *)__afl_map_addr); + send_forkserver_error(FS_ERROR_SHM_OPEN); + exit(1); + + } + + } else if (_is_sancov && __afl_area_ptr != __afl_area_initial) { + + free(__afl_area_ptr); + __afl_area_ptr = NULL; + + if (__afl_final_loc > MAP_INITIAL_SIZE) { + + __afl_area_ptr = (u8 *)malloc(__afl_final_loc); + + } + + if (!__afl_area_ptr) { __afl_area_ptr = __afl_area_ptr_dummy; } + + } + + __afl_area_ptr_backup = __afl_area_ptr; + + if (__afl_debug) { + + fprintf(stderr, + "DEBUG: (2) id_str %s, __afl_area_ptr %p, __afl_area_initial %p, " + "__afl_area_ptr_dummy 0x%p, __afl_map_addr 0x%llx, MAP_SIZE " + "%u, __afl_final_loc %u, " + "max_size_forkserver %u/0x%x\n", + id_str == NULL ? "<null>" : id_str, __afl_area_ptr, + __afl_area_initial, __afl_area_ptr_dummy, __afl_map_addr, MAP_SIZE, + __afl_final_loc, FS_OPT_MAX_MAPSIZE, FS_OPT_MAX_MAPSIZE); + + } + + if (__afl_selective_coverage) { + + if (__afl_map_size > MAP_INITIAL_SIZE) { + + __afl_area_ptr_dummy = (u8 *)malloc(__afl_map_size); + + if (__afl_area_ptr_dummy) { + + if (__afl_selective_coverage_start_off) { + + __afl_area_ptr = __afl_area_ptr_dummy; + + } + + } else { + + fprintf(stderr, "Error: __afl_selective_coverage failed!\n"); + __afl_selective_coverage = 0; + // continue; + + } + + } + + } + + id_str = getenv(CMPLOG_SHM_ENV_VAR); + + if (__afl_debug) { + + fprintf(stderr, "DEBUG: cmplog id_str %s\n", + id_str == NULL ? "<null>" : id_str); + + } + + if (id_str) { + + if ((__afl_dummy_fd[1] = open("/dev/null", O_WRONLY)) < 0) { + + if (pipe(__afl_dummy_fd) < 0) { __afl_dummy_fd[1] = 1; } + + } + +#ifdef USEMMAP + const char * shm_file_path = id_str; + int shm_fd = -1; + struct cmp_map *shm_base = NULL; + + /* create the shared memory segment as if it was a file */ + shm_fd = shm_open(shm_file_path, O_RDWR, 0600); + if (shm_fd == -1) { + + perror("shm_open() failed\n"); + send_forkserver_error(FS_ERROR_SHM_OPEN); + exit(1); + + } + + /* map the shared memory segment to the address space of the process */ + shm_base = mmap(0, sizeof(struct cmp_map), PROT_READ | PROT_WRITE, + MAP_SHARED, shm_fd, 0); + if (shm_base == MAP_FAILED) { + + close(shm_fd); + shm_fd = -1; + + fprintf(stderr, "mmap() failed\n"); + send_forkserver_error(FS_ERROR_SHM_OPEN); + exit(2); + + } + + __afl_cmp_map = shm_base; +#else + u32 shm_id = atoi(id_str); + + __afl_cmp_map = (struct cmp_map *)shmat(shm_id, NULL, 0); +#endif + + __afl_cmp_map_backup = __afl_cmp_map; + + if (!__afl_cmp_map || __afl_cmp_map == (void *)-1) { + + perror("shmat for cmplog"); + send_forkserver_error(FS_ERROR_SHM_OPEN); + _exit(1); + + } + + } + +} + +/* unmap SHM. */ + +static void __afl_unmap_shm(void) { + + if (!__afl_already_initialized_shm) return; + + char *id_str = getenv(SHM_ENV_VAR); + + if (id_str) { + +#ifdef USEMMAP + + munmap((void *)__afl_area_ptr, __afl_map_size); + +#else + + shmdt((void *)__afl_area_ptr); + +#endif + + } else if ((!__afl_area_ptr || __afl_area_ptr == __afl_area_initial) && + + __afl_map_addr) { + + munmap((void *)__afl_map_addr, __afl_map_size); + + } + + __afl_area_ptr = __afl_area_ptr_dummy; + + id_str = getenv(CMPLOG_SHM_ENV_VAR); + + if (id_str) { + +#ifdef USEMMAP + + munmap((void *)__afl_cmp_map, __afl_map_size); + +#else + + shmdt((void *)__afl_cmp_map); + +#endif + + __afl_cmp_map = NULL; + + } + + __afl_already_initialized_shm = 0; + +} + +#ifdef __linux__ +static void __afl_start_snapshots(void) { + + static u8 tmp[4] = {0, 0, 0, 0}; + u32 status = 0; + u32 already_read_first = 0; + u32 was_killed; + + u8 child_stopped = 0; + + void (*old_sigchld_handler)(int) = 0; // = signal(SIGCHLD, SIG_DFL); + + /* Phone home and tell the parent that we're OK. If parent isn't there, + assume we're not running in forkserver mode and just execute program. */ + + status |= (FS_OPT_ENABLED | FS_OPT_SNAPSHOT); + if (__afl_sharedmem_fuzzing != 0) status |= FS_OPT_SHDMEM_FUZZ; + if (__afl_map_size <= FS_OPT_MAX_MAPSIZE) + status |= (FS_OPT_SET_MAPSIZE(__afl_map_size) | FS_OPT_MAPSIZE); + if (__afl_dictionary_len && __afl_dictionary) status |= FS_OPT_AUTODICT; + memcpy(tmp, &status, 4); + + if (write(FORKSRV_FD + 1, tmp, 4) != 4) { return; } + + if (__afl_sharedmem_fuzzing || (__afl_dictionary_len && __afl_dictionary)) { + + if (read(FORKSRV_FD, &was_killed, 4) != 4) { _exit(1); } + + if (__afl_debug) { + + fprintf(stderr, "target forkserver recv: %08x\n", was_killed); + + } + + if ((was_killed & (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ)) == + (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ)) { + + __afl_map_shm_fuzz(); + + } + + if ((was_killed & (FS_OPT_ENABLED | FS_OPT_AUTODICT)) == + (FS_OPT_ENABLED | FS_OPT_AUTODICT) && + __afl_dictionary_len && __afl_dictionary) { + + // great lets pass the dictionary through the forkserver FD + u32 len = __afl_dictionary_len, offset = 0; + s32 ret; + + if (write(FORKSRV_FD + 1, &len, 4) != 4) { + + write(2, "Error: could not send dictionary len\n", + strlen("Error: could not send dictionary len\n")); + _exit(1); + + } + + while (len != 0) { + + ret = write(FORKSRV_FD + 1, __afl_dictionary + offset, len); + + if (ret < 1) { + + write(2, "Error: could not send dictionary\n", + strlen("Error: could not send dictionary\n")); + _exit(1); + + } + + len -= ret; + offset += ret; + + } + + } else { + + // uh this forkserver does not understand extended option passing + // or does not want the dictionary + if (!__afl_fuzz_ptr) already_read_first = 1; + + } + + } + + while (1) { + + int status; + + if (already_read_first) { + + already_read_first = 0; + + } else { + + /* Wait for parent by reading from the pipe. Abort if read fails. */ + if (read(FORKSRV_FD, &was_killed, 4) != 4) _exit(1); + + } + + #ifdef _AFL_DOCUMENT_MUTATIONS + if (__afl_fuzz_ptr) { + + static uint32_t counter = 0; + char fn[32]; + sprintf(fn, "%09u:forkserver", counter); + s32 fd_doc = open(fn, O_WRONLY | O_CREAT | O_TRUNC, 0600); + if (fd_doc >= 0) { + + if (write(fd_doc, __afl_fuzz_ptr, *__afl_fuzz_len) != *__afl_fuzz_len) { + + fprintf(stderr, "write of mutation file failed: %s\n", fn); + unlink(fn); + + } + + close(fd_doc); + + } + + counter++; + + } + + #endif + + /* If we stopped the child in persistent mode, but there was a race + condition and afl-fuzz already issued SIGKILL, write off the old + process. */ + + if (child_stopped && was_killed) { + + child_stopped = 0; + if (waitpid(child_pid, &status, 0) < 0) _exit(1); + + } + + if (!child_stopped) { + + /* Once woken up, create a clone of our process. */ + + child_pid = fork(); + if (child_pid < 0) _exit(1); + + /* In child process: close fds, resume execution. */ + + if (!child_pid) { + + //(void)nice(-20); // does not seem to improve + + signal(SIGCHLD, old_sigchld_handler); + signal(SIGTERM, old_sigterm_handler); + + close(FORKSRV_FD); + close(FORKSRV_FD + 1); + + if (!afl_snapshot_take(AFL_SNAPSHOT_MMAP | AFL_SNAPSHOT_FDS | + AFL_SNAPSHOT_REGS | AFL_SNAPSHOT_EXIT)) { + + raise(SIGSTOP); + + } + + __afl_area_ptr[0] = 1; + memset(__afl_prev_loc, 0, NGRAM_SIZE_MAX * sizeof(PREV_LOC_T)); + + return; + + } + + } else { + + /* Special handling for persistent mode: if the child is alive but + currently stopped, simply restart it with SIGCONT. */ + + kill(child_pid, SIGCONT); + child_stopped = 0; + + } + + /* In parent process: write PID to pipe, then wait for child. */ + + if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) _exit(1); + + if (waitpid(child_pid, &status, WUNTRACED) < 0) _exit(1); + + /* In persistent mode, the child stops itself with SIGSTOP to indicate + a successful run. In this case, we want to wake it up without forking + again. */ + + if (WIFSTOPPED(status)) child_stopped = 1; + + /* Relay wait status to pipe, then loop back. */ + + if (write(FORKSRV_FD + 1, &status, 4) != 4) _exit(1); + + } + +} + +#endif + +/* Fork server logic. */ + +static void __afl_start_forkserver(void) { + + if (__afl_already_initialized_forkserver) return; + __afl_already_initialized_forkserver = 1; + + struct sigaction orig_action; + sigaction(SIGTERM, NULL, &orig_action); + old_sigterm_handler = orig_action.sa_handler; + signal(SIGTERM, at_exit); + +#ifdef __linux__ + if (/*!is_persistent &&*/ !__afl_cmp_map && !getenv("AFL_NO_SNAPSHOT") && + afl_snapshot_init() >= 0) { + + __afl_start_snapshots(); + return; + + } + +#endif + + u8 tmp[4] = {0, 0, 0, 0}; + u32 status_for_fsrv = 0; + u32 already_read_first = 0; + u32 was_killed; + + u8 child_stopped = 0; + + void (*old_sigchld_handler)(int) = 0; // = signal(SIGCHLD, SIG_DFL); + + if (__afl_map_size <= FS_OPT_MAX_MAPSIZE) { + + status_for_fsrv |= (FS_OPT_SET_MAPSIZE(__afl_map_size) | FS_OPT_MAPSIZE); + + } + + if (__afl_dictionary_len && __afl_dictionary) { + + status_for_fsrv |= FS_OPT_AUTODICT; + + } + + if (__afl_sharedmem_fuzzing != 0) { status_for_fsrv |= FS_OPT_SHDMEM_FUZZ; } + if (status_for_fsrv) { status_for_fsrv |= (FS_OPT_ENABLED); } + memcpy(tmp, &status_for_fsrv, 4); + + /* Phone home and tell the parent that we're OK. If parent isn't there, + assume we're not running in forkserver mode and just execute program. */ + + if (write(FORKSRV_FD + 1, tmp, 4) != 4) { return; } + + if (__afl_sharedmem_fuzzing || (__afl_dictionary_len && __afl_dictionary)) { + + if (read(FORKSRV_FD, &was_killed, 4) != 4) _exit(1); + + if (__afl_debug) { + + fprintf(stderr, "target forkserver recv: %08x\n", was_killed); + + } + + if ((was_killed & (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ)) == + (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ)) { + + __afl_map_shm_fuzz(); + + } + + if ((was_killed & (FS_OPT_ENABLED | FS_OPT_AUTODICT)) == + (FS_OPT_ENABLED | FS_OPT_AUTODICT) && + __afl_dictionary_len && __afl_dictionary) { + + // great lets pass the dictionary through the forkserver FD + u32 len = __afl_dictionary_len, offset = 0; + + if (write(FORKSRV_FD + 1, &len, 4) != 4) { + + write(2, "Error: could not send dictionary len\n", + strlen("Error: could not send dictionary len\n")); + _exit(1); + + } + + while (len != 0) { + + s32 ret; + ret = write(FORKSRV_FD + 1, __afl_dictionary + offset, len); + + if (ret < 1) { + + write(2, "Error: could not send dictionary\n", + strlen("Error: could not send dictionary\n")); + _exit(1); + + } + + len -= ret; + offset += ret; + + } + + } else { + + // uh this forkserver does not understand extended option passing + // or does not want the dictionary + if (!__afl_fuzz_ptr) already_read_first = 1; + + } + + } + + while (1) { + + int status; + + /* Wait for parent by reading from the pipe. Abort if read fails. */ + + if (already_read_first) { + + already_read_first = 0; + + } else { + + if (read(FORKSRV_FD, &was_killed, 4) != 4) _exit(1); + + } + +#ifdef _AFL_DOCUMENT_MUTATIONS + if (__afl_fuzz_ptr) { + + static uint32_t counter = 0; + char fn[32]; + sprintf(fn, "%09u:forkserver", counter); + s32 fd_doc = open(fn, O_WRONLY | O_CREAT | O_TRUNC, 0600); + if (fd_doc >= 0) { + + if (write(fd_doc, __afl_fuzz_ptr, *__afl_fuzz_len) != *__afl_fuzz_len) { + + fprintf(stderr, "write of mutation file failed: %s\n", fn); + unlink(fn); + + } + + close(fd_doc); + + } + + counter++; + + } + +#endif + + /* If we stopped the child in persistent mode, but there was a race + condition and afl-fuzz already issued SIGKILL, write off the old + process. */ + + if (child_stopped && was_killed) { + + child_stopped = 0; + if (waitpid(child_pid, &status, 0) < 0) _exit(1); + + } + + if (!child_stopped) { + + /* Once woken up, create a clone of our process. */ + + child_pid = fork(); + if (child_pid < 0) _exit(1); + + /* In child process: close fds, resume execution. */ + + if (!child_pid) { + + //(void)nice(-20); + + signal(SIGCHLD, old_sigchld_handler); + signal(SIGTERM, old_sigterm_handler); + + close(FORKSRV_FD); + close(FORKSRV_FD + 1); + return; + + } + + } else { + + /* Special handling for persistent mode: if the child is alive but + currently stopped, simply restart it with SIGCONT. */ + + kill(child_pid, SIGCONT); + child_stopped = 0; + + } + + /* In parent process: write PID to pipe, then wait for child. */ + + if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) _exit(1); + + if (waitpid(child_pid, &status, is_persistent ? WUNTRACED : 0) < 0) + _exit(1); + + /* In persistent mode, the child stops itself with SIGSTOP to indicate + a successful run. In this case, we want to wake it up without forking + again. */ + + if (WIFSTOPPED(status)) child_stopped = 1; + + /* Relay wait status to pipe, then loop back. */ + + if (write(FORKSRV_FD + 1, &status, 4) != 4) _exit(1); + + } + +} + +/* A simplified persistent mode handler, used as explained in + * README.llvm.md. */ + +int __afl_persistent_loop(unsigned int max_cnt) { + + static u8 first_pass = 1; + static u32 cycle_cnt; + + if (first_pass) { + + /* Make sure that every iteration of __AFL_LOOP() starts with a clean slate. + On subsequent calls, the parent will take care of that, but on the first + iteration, it's our job to erase any trace of whatever happened + before the loop. */ + + if (is_persistent) { + + memset(__afl_area_ptr, 0, __afl_map_size); + __afl_area_ptr[0] = 1; + memset(__afl_prev_loc, 0, NGRAM_SIZE_MAX * sizeof(PREV_LOC_T)); + + } + + cycle_cnt = max_cnt; + first_pass = 0; + __afl_selective_coverage_temp = 1; + + return 1; + + } + + if (is_persistent) { + + if (--cycle_cnt) { + + raise(SIGSTOP); + + __afl_area_ptr[0] = 1; + memset(__afl_prev_loc, 0, NGRAM_SIZE_MAX * sizeof(PREV_LOC_T)); + __afl_selective_coverage_temp = 1; + + return 1; + + } else { + + /* When exiting __AFL_LOOP(), make sure that the subsequent code that + follows the loop is not traced. We do that by pivoting back to the + dummy output region. */ + + __afl_area_ptr = __afl_area_ptr_dummy; + + } + + } + + return 0; + +} + +/* This one can be called from user code when deferred forkserver mode + is enabled. */ + +void __afl_manual_init(void) { + + static u8 init_done; + + if (getenv("AFL_DISABLE_LLVM_INSTRUMENTATION")) { + + init_done = 1; + is_persistent = 0; + __afl_sharedmem_fuzzing = 0; + if (__afl_area_ptr == NULL) __afl_area_ptr = __afl_area_ptr_dummy; + + if (__afl_debug) { + + fprintf(stderr, + "DEBUG: disabled instrumentation because of " + "AFL_DISABLE_LLVM_INSTRUMENTATION\n"); + + } + + } + + if (!init_done) { + + __afl_start_forkserver(); + init_done = 1; + + } + +} + +/* Initialization of the forkserver - latest possible */ + +__attribute__((constructor())) void __afl_auto_init(void) { + + if (getenv("AFL_DISABLE_LLVM_INSTRUMENTATION")) return; + + if (getenv(DEFER_ENV_VAR)) return; + + __afl_manual_init(); + +} + +/* Initialization of the shmem - earliest possible because of LTO fixed mem. */ + +__attribute__((constructor(CTOR_PRIO))) void __afl_auto_early(void) { + + is_persistent = !!getenv(PERSIST_ENV_VAR); + + if (getenv("AFL_DISABLE_LLVM_INSTRUMENTATION")) return; + + __afl_map_shm(); + +} + +/* preset __afl_area_ptr #2 */ + +__attribute__((constructor(1))) void __afl_auto_second(void) { + + if (__afl_already_initialized_second) return; + __afl_already_initialized_second = 1; + + if (getenv("AFL_DEBUG")) { __afl_debug = 1; } + + if (getenv("AFL_DISABLE_LLVM_INSTRUMENTATION")) return; + u8 *ptr; + + if (__afl_final_loc) { + + if (__afl_area_ptr && __afl_area_ptr != __afl_area_initial) + free(__afl_area_ptr); + + if (__afl_map_addr) + ptr = (u8 *)mmap((void *)__afl_map_addr, __afl_final_loc, + PROT_READ | PROT_WRITE, + MAP_FIXED_NOREPLACE | MAP_SHARED | MAP_ANONYMOUS, -1, 0); + else + ptr = (u8 *)malloc(__afl_final_loc); + + if (ptr && (ssize_t)ptr != -1) { + + __afl_area_ptr = ptr; + __afl_area_ptr_backup = __afl_area_ptr; + + } + + } + +} // ptr memleak report is a false positive + +/* preset __afl_area_ptr #1 - at constructor level 0 global variables have + not been set */ + +__attribute__((constructor(0))) void __afl_auto_first(void) { + + if (__afl_already_initialized_first) return; + __afl_already_initialized_first = 1; + + if (getenv("AFL_DISABLE_LLVM_INSTRUMENTATION")) return; + u8 *ptr = (u8 *)malloc(MAP_INITIAL_SIZE); + + if (ptr && (ssize_t)ptr != -1) { + + __afl_area_ptr = ptr; + __afl_area_ptr_backup = __afl_area_ptr; + + } + +} // ptr memleak report is a false positive + +/* The following stuff deals with supporting -fsanitize-coverage=trace-pc-guard. + It remains non-operational in the traditional, plugin-backed LLVM mode. + For more info about 'trace-pc-guard', see README.llvm.md. + + The first function (__sanitizer_cov_trace_pc_guard) is called back on every + edge (as opposed to every basic block). */ + +void __sanitizer_cov_trace_pc_guard(uint32_t *guard) { + + // For stability analysis, if you want to know to which function unstable + // edge IDs belong - uncomment, recompile+install llvm_mode, recompile + // the target. libunwind and libbacktrace are better solutions. + // Set AFL_DEBUG_CHILD=1 and run afl-fuzz with 2>file to capture + // the backtrace output + /* + uint32_t unstable[] = { ... unstable edge IDs }; + uint32_t idx; + char bt[1024]; + for (idx = 0; i < sizeof(unstable)/sizeof(uint32_t); i++) { + + if (unstable[idx] == __afl_area_ptr[*guard]) { + + int bt_size = backtrace(bt, 256); + if (bt_size > 0) { + + char **bt_syms = backtrace_symbols(bt, bt_size); + if (bt_syms) { + + fprintf(stderr, "DEBUG: edge=%u caller=%s\n", unstable[idx], + bt_syms[0]); + free(bt_syms); + + } + + } + + } + + } + + */ + +#if (LLVM_VERSION_MAJOR < 9) + + __afl_area_ptr[*guard]++; + +#else + + __afl_area_ptr[*guard] = + __afl_area_ptr[*guard] + 1 + (__afl_area_ptr[*guard] == 255 ? 1 : 0); + +#endif + +} + +/* Init callback. Populates instrumentation IDs. Note that we're using + ID of 0 as a special value to indicate non-instrumented bits. That may + still touch the bitmap, but in a fairly harmless way. */ + +void __sanitizer_cov_trace_pc_guard_init(uint32_t *start, uint32_t *stop) { + + u32 inst_ratio = 100; + char *x; + + _is_sancov = 1; + + if (__afl_debug) { + + fprintf(stderr, + "Running __sanitizer_cov_trace_pc_guard_init: %p-%p (%lu edges) " + "after_fs=%u\n", + start, stop, (unsigned long)(stop - start), + __afl_already_initialized_forkserver); + + } + + if (start == stop || *start) return; + + x = getenv("AFL_INST_RATIO"); + if (x) inst_ratio = (u32)atoi(x); + + if (!inst_ratio || inst_ratio > 100) { + + fprintf(stderr, "[-] ERROR: Invalid AFL_INST_RATIO (must be 1-100).\n"); + abort(); + + } + + /* instrumented code is loaded *after* our forkserver is up. this is a + problem. We cannot prevent collisions then :( */ + if (__afl_already_initialized_forkserver && + __afl_final_loc + 1 + stop - start > __afl_map_size) { + + if (__afl_debug) { + + fprintf(stderr, "Warning: new instrumented code after the forkserver!\n"); + + } + + __afl_final_loc = 2; + + if (1 + stop - start > __afl_map_size) { + + *(start++) = ++__afl_final_loc; + + while (start < stop) { + + if (R(100) < inst_ratio) + *start = ++__afl_final_loc % __afl_map_size; + else + *start = 0; + + start++; + + } + + return; + + } + + } + + /* Make sure that the first element in the range is always set - we use that + to avoid duplicate calls (which can happen as an artifact of the underlying + implementation in LLVM). */ + + *(start++) = ++__afl_final_loc; + + while (start < stop) { + + if (R(100) < inst_ratio) + *start = ++__afl_final_loc; + else + *start = 0; + + start++; + + } + + if (__afl_debug) { + + fprintf(stderr, + "Done __sanitizer_cov_trace_pc_guard_init: __afl_final_loc = %u\n", + __afl_final_loc); + + } + + if (__afl_already_initialized_shm && __afl_final_loc > __afl_map_size) { + + if (__afl_debug) { + + fprintf(stderr, "Reinit shm necessary (+%u)\n", + __afl_final_loc - __afl_map_size); + + } + + __afl_unmap_shm(); + __afl_map_shm(); + + } + +} + +///// CmpLog instrumentation + +void __cmplog_ins_hook1(uint8_t arg1, uint8_t arg2, uint8_t attr) { + + // fprintf(stderr, "hook1 arg0=%02x arg1=%02x attr=%u\n", + // (u8) arg1, (u8) arg2, attr); + + if (unlikely(!__afl_cmp_map || arg1 == arg2)) return; + + uintptr_t k = (uintptr_t)__builtin_return_address(0); + k = (k >> 4) ^ (k << 8); + k &= CMP_MAP_W - 1; + + u32 hits; + + if (__afl_cmp_map->headers[k].type != CMP_TYPE_INS) { + + __afl_cmp_map->headers[k].type = CMP_TYPE_INS; + hits = 0; + __afl_cmp_map->headers[k].hits = 1; + __afl_cmp_map->headers[k].shape = 0; + + } else { + + hits = __afl_cmp_map->headers[k].hits++; + + } + + __afl_cmp_map->headers[k].attribute = attr; + + hits &= CMP_MAP_H - 1; + __afl_cmp_map->log[k][hits].v0 = arg1; + __afl_cmp_map->log[k][hits].v1 = arg2; + +} + +void __cmplog_ins_hook2(uint16_t arg1, uint16_t arg2, uint8_t attr) { + + if (unlikely(!__afl_cmp_map || arg1 == arg2)) return; + + uintptr_t k = (uintptr_t)__builtin_return_address(0); + k = (k >> 4) ^ (k << 8); + k &= CMP_MAP_W - 1; + + u32 hits; + + if (__afl_cmp_map->headers[k].type != CMP_TYPE_INS) { + + __afl_cmp_map->headers[k].type = CMP_TYPE_INS; + hits = 0; + __afl_cmp_map->headers[k].hits = 1; + __afl_cmp_map->headers[k].shape = 1; + + } else { + + hits = __afl_cmp_map->headers[k].hits++; + + if (!__afl_cmp_map->headers[k].shape) { + + __afl_cmp_map->headers[k].shape = 1; + + } + + } + + __afl_cmp_map->headers[k].attribute = attr; + + hits &= CMP_MAP_H - 1; + __afl_cmp_map->log[k][hits].v0 = arg1; + __afl_cmp_map->log[k][hits].v1 = arg2; + +} + +void __cmplog_ins_hook4(uint32_t arg1, uint32_t arg2, uint8_t attr) { + + // fprintf(stderr, "hook4 arg0=%x arg1=%x attr=%u\n", arg1, arg2, attr); + + if (unlikely(!__afl_cmp_map || arg1 == arg2)) return; + + uintptr_t k = (uintptr_t)__builtin_return_address(0); + k = (k >> 4) ^ (k << 8); + k &= CMP_MAP_W - 1; + + u32 hits; + + if (__afl_cmp_map->headers[k].type != CMP_TYPE_INS) { + + __afl_cmp_map->headers[k].type = CMP_TYPE_INS; + hits = 0; + __afl_cmp_map->headers[k].hits = 1; + __afl_cmp_map->headers[k].shape = 3; + + } else { + + hits = __afl_cmp_map->headers[k].hits++; + + if (__afl_cmp_map->headers[k].shape < 3) { + + __afl_cmp_map->headers[k].shape = 3; + + } + + } + + __afl_cmp_map->headers[k].attribute = attr; + + hits &= CMP_MAP_H - 1; + __afl_cmp_map->log[k][hits].v0 = arg1; + __afl_cmp_map->log[k][hits].v1 = arg2; + +} + +void __cmplog_ins_hook8(uint64_t arg1, uint64_t arg2, uint8_t attr) { + + // fprintf(stderr, "hook8 arg0=%lx arg1=%lx attr=%u\n", arg1, arg2, attr); + + if (unlikely(!__afl_cmp_map || arg1 == arg2)) return; + + uintptr_t k = (uintptr_t)__builtin_return_address(0); + k = (k >> 4) ^ (k << 8); + k &= CMP_MAP_W - 1; + + u32 hits; + + if (__afl_cmp_map->headers[k].type != CMP_TYPE_INS) { + + __afl_cmp_map->headers[k].type = CMP_TYPE_INS; + hits = 0; + __afl_cmp_map->headers[k].hits = 1; + __afl_cmp_map->headers[k].shape = 7; + + } else { + + hits = __afl_cmp_map->headers[k].hits++; + + if (__afl_cmp_map->headers[k].shape < 7) { + + __afl_cmp_map->headers[k].shape = 7; + + } + + } + + __afl_cmp_map->headers[k].attribute = attr; + + hits &= CMP_MAP_H - 1; + __afl_cmp_map->log[k][hits].v0 = arg1; + __afl_cmp_map->log[k][hits].v1 = arg2; + +} + +#ifdef WORD_SIZE_64 +// support for u24 to u120 via llvm _ExitInt(). size is in bytes minus 1 +void __cmplog_ins_hookN(uint128_t arg1, uint128_t arg2, uint8_t attr, + uint8_t size) { + + // fprintf(stderr, "hookN arg0=%llx:%llx arg1=%llx:%llx bytes=%u attr=%u\n", + // (u64)(arg1 >> 64), (u64)arg1, (u64)(arg2 >> 64), (u64)arg2, size + 1, + // attr); + + if (unlikely(!__afl_cmp_map || arg1 == arg2)) return; + + uintptr_t k = (uintptr_t)__builtin_return_address(0); + k = (k >> 4) ^ (k << 8); + k &= CMP_MAP_W - 1; + + u32 hits; + + if (__afl_cmp_map->headers[k].type != CMP_TYPE_INS) { + + __afl_cmp_map->headers[k].type = CMP_TYPE_INS; + hits = 0; + __afl_cmp_map->headers[k].hits = 1; + __afl_cmp_map->headers[k].shape = size; + + } else { + + hits = __afl_cmp_map->headers[k].hits++; + + if (__afl_cmp_map->headers[k].shape < size) { + + __afl_cmp_map->headers[k].shape = size; + + } + + } + + __afl_cmp_map->headers[k].attribute = attr; + + hits &= CMP_MAP_H - 1; + __afl_cmp_map->log[k][hits].v0 = (u64)arg1; + __afl_cmp_map->log[k][hits].v1 = (u64)arg2; + + if (size > 7) { + + __afl_cmp_map->log[k][hits].v0_128 = (u64)(arg1 >> 64); + __afl_cmp_map->log[k][hits].v1_128 = (u64)(arg2 >> 64); + + } + +} + +void __cmplog_ins_hook16(uint128_t arg1, uint128_t arg2, uint8_t attr) { + + if (unlikely(!__afl_cmp_map)) return; + + uintptr_t k = (uintptr_t)__builtin_return_address(0); + k = (k >> 4) ^ (k << 8); + k &= CMP_MAP_W - 1; + + u32 hits; + + if (__afl_cmp_map->headers[k].type != CMP_TYPE_INS) { + + __afl_cmp_map->headers[k].type = CMP_TYPE_INS; + hits = 0; + __afl_cmp_map->headers[k].hits = 1; + __afl_cmp_map->headers[k].shape = 15; + + } else { + + hits = __afl_cmp_map->headers[k].hits++; + + if (__afl_cmp_map->headers[k].shape < 15) { + + __afl_cmp_map->headers[k].shape = 15; + + } + + } + + __afl_cmp_map->headers[k].attribute = attr; + + hits &= CMP_MAP_H - 1; + __afl_cmp_map->log[k][hits].v0 = (u64)arg1; + __afl_cmp_map->log[k][hits].v1 = (u64)arg2; + __afl_cmp_map->log[k][hits].v0_128 = (u64)(arg1 >> 64); + __afl_cmp_map->log[k][hits].v1_128 = (u64)(arg2 >> 64); + +} + +#endif + +void __sanitizer_cov_trace_cmp1(uint8_t arg1, uint8_t arg2) { + + __cmplog_ins_hook1(arg1, arg2, 0); + +} + +void __sanitizer_cov_trace_const_cmp1(uint8_t arg1, uint8_t arg2) { + + __cmplog_ins_hook1(arg1, arg2, 0); + +} + +void __sanitizer_cov_trace_cmp2(uint16_t arg1, uint16_t arg2) { + + __cmplog_ins_hook2(arg1, arg2, 0); + +} + +void __sanitizer_cov_trace_const_cmp2(uint16_t arg1, uint16_t arg2) { + + __cmplog_ins_hook2(arg1, arg2, 0); + +} + +void __sanitizer_cov_trace_cmp4(uint32_t arg1, uint32_t arg2) { + + __cmplog_ins_hook4(arg1, arg2, 0); + +} + +void __sanitizer_cov_trace_cost_cmp4(uint32_t arg1, uint32_t arg2) { + + __cmplog_ins_hook4(arg1, arg2, 0); + +} + +void __sanitizer_cov_trace_cmp8(uint64_t arg1, uint64_t arg2) { + + __cmplog_ins_hook8(arg1, arg2, 0); + +} + +void __sanitizer_cov_trace_const_cmp8(uint64_t arg1, uint64_t arg2) { + + __cmplog_ins_hook8(arg1, arg2, 0); + +} + +#ifdef WORD_SIZE_64 +void __sanitizer_cov_trace_cmp16(uint128_t arg1, uint128_t arg2) { + + __cmplog_ins_hook16(arg1, arg2, 0); + +} + +#endif + +void __sanitizer_cov_trace_switch(uint64_t val, uint64_t *cases) { + + if (unlikely(!__afl_cmp_map)) return; + + for (uint64_t i = 0; i < cases[0]; i++) { + + uintptr_t k = (uintptr_t)__builtin_return_address(0) + i; + k = (k >> 4) ^ (k << 8); + k &= CMP_MAP_W - 1; + + u32 hits; + + if (__afl_cmp_map->headers[k].type != CMP_TYPE_INS) { + + __afl_cmp_map->headers[k].type = CMP_TYPE_INS; + hits = 0; + __afl_cmp_map->headers[k].hits = 1; + __afl_cmp_map->headers[k].shape = 7; + + } else { + + hits = __afl_cmp_map->headers[k].hits++; + + if (__afl_cmp_map->headers[k].shape < 7) { + + __afl_cmp_map->headers[k].shape = 7; + + } + + } + + __afl_cmp_map->headers[k].attribute = 1; + + hits &= CMP_MAP_H - 1; + __afl_cmp_map->log[k][hits].v0 = val; + __afl_cmp_map->log[k][hits].v1 = cases[i + 2]; + + } + +} + +__attribute__((weak)) void *__asan_region_is_poisoned(void *beg, size_t size) { + + return NULL; + +} + +// POSIX shenanigan to see if an area is mapped. +// If it is mapped as X-only, we have a problem, so maybe we should add a check +// to avoid to call it on .text addresses +static int area_is_valid(void *ptr, size_t len) { + + if (unlikely(!ptr || __asan_region_is_poisoned(ptr, len))) { return 0; } + + long r = syscall(SYS_write, __afl_dummy_fd[1], ptr, len); + + if (r <= 0 || r > len) return 0; + + // even if the write succeed this can be a false positive if we cross + // a page boundary. who knows why. + + char *p = (char *)ptr; + long page_size = sysconf(_SC_PAGE_SIZE); + char *page = (char *)((uintptr_t)p & ~(page_size - 1)) + page_size; + + if (page > p + len) { + + // no, not crossing a page boundary + return (int)r; + + } else { + + // yes it crosses a boundary, hence we can only return the length of + // rest of the first page, we cannot detect if the next page is valid + // or not, neither by SYS_write nor msync() :-( + return (int)(page - p); + + } + +} + +void __cmplog_rtn_hook(u8 *ptr1, u8 *ptr2) { + + /* + u32 i; + if (area_is_valid(ptr1, 32) <= 0 || area_is_valid(ptr2, 32) <= 0) return; + fprintf(stderr, "rtn arg0="); + for (i = 0; i < 32; i++) + fprintf(stderr, "%02x", ptr1[i]); + fprintf(stderr, " arg1="); + for (i = 0; i < 32; i++) + fprintf(stderr, "%02x", ptr2[i]); + fprintf(stderr, "\n"); + */ + + if (unlikely(!__afl_cmp_map)) return; + // fprintf(stderr, "RTN1 %p %p\n", ptr1, ptr2); + int l1, l2; + if ((l1 = area_is_valid(ptr1, 32)) <= 0 || + (l2 = area_is_valid(ptr2, 32)) <= 0) + return; + int len = MIN(l1, l2); + + // fprintf(stderr, "RTN2 %u\n", len); + uintptr_t k = (uintptr_t)__builtin_return_address(0); + k = (k >> 4) ^ (k << 8); + k &= CMP_MAP_W - 1; + + u32 hits; + + if (__afl_cmp_map->headers[k].type != CMP_TYPE_RTN) { + + __afl_cmp_map->headers[k].type = CMP_TYPE_RTN; + __afl_cmp_map->headers[k].hits = 1; + __afl_cmp_map->headers[k].shape = len - 1; + hits = 0; + + } else { + + hits = __afl_cmp_map->headers[k].hits++; + + if (__afl_cmp_map->headers[k].shape < len) { + + __afl_cmp_map->headers[k].shape = len - 1; + + } + + } + + hits &= CMP_MAP_RTN_H - 1; + __builtin_memcpy(((struct cmpfn_operands *)__afl_cmp_map->log[k])[hits].v0, + ptr1, len); + __builtin_memcpy(((struct cmpfn_operands *)__afl_cmp_map->log[k])[hits].v1, + ptr2, len); + // fprintf(stderr, "RTN3\n"); + +} + +// gcc libstdc++ +// _ZNKSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEE7compareEPKc +static u8 *get_gcc_stdstring(u8 *string) { + + u32 *len = (u32 *)(string + 8); + + if (*len < 16) { // in structure + + return (string + 16); + + } else { // in memory + + u8 **ptr = (u8 **)string; + return (*ptr); + + } + +} + +// llvm libc++ _ZNKSt3__112basic_stringIcNS_11char_traitsIcEENS_9allocator +// IcEEE7compareEmmPKcm +static u8 *get_llvm_stdstring(u8 *string) { + + // length is in: if ((string[0] & 1) == 0) u8 len = (string[0] >> 1); + // or: if (string[0] & 1) u32 *len = (u32 *) (string + 8); + + if (string[0] & 1) { // in memory + + u8 **ptr = (u8 **)(string + 16); + return (*ptr); + + } else { // in structure + + return (string + 1); + + } + +} + +void __cmplog_rtn_gcc_stdstring_cstring(u8 *stdstring, u8 *cstring) { + + if (unlikely(!__afl_cmp_map)) return; + if (area_is_valid(stdstring, 32) <= 0 || area_is_valid(cstring, 32) <= 0) + return; + + __cmplog_rtn_hook(get_gcc_stdstring(stdstring), cstring); + +} + +void __cmplog_rtn_gcc_stdstring_stdstring(u8 *stdstring1, u8 *stdstring2) { + + if (unlikely(!__afl_cmp_map)) return; + if (area_is_valid(stdstring1, 32) <= 0 || area_is_valid(stdstring2, 32) <= 0) + return; + + __cmplog_rtn_hook(get_gcc_stdstring(stdstring1), + get_gcc_stdstring(stdstring2)); + +} + +void __cmplog_rtn_llvm_stdstring_cstring(u8 *stdstring, u8 *cstring) { + + if (unlikely(!__afl_cmp_map)) return; + if (area_is_valid(stdstring, 32) <= 0 || area_is_valid(cstring, 32) <= 0) + return; + + __cmplog_rtn_hook(get_llvm_stdstring(stdstring), cstring); + +} + +void __cmplog_rtn_llvm_stdstring_stdstring(u8 *stdstring1, u8 *stdstring2) { + + if (unlikely(!__afl_cmp_map)) return; + if (area_is_valid(stdstring1, 32) <= 0 || area_is_valid(stdstring2, 32) <= 0) + return; + + __cmplog_rtn_hook(get_llvm_stdstring(stdstring1), + get_llvm_stdstring(stdstring2)); + +} + +/* COVERAGE manipulation features */ + +// this variable is then used in the shm setup to create an additional map +// if __afl_map_size > MAP_SIZE or cmplog is used. +// Especially with cmplog this would result in a ~260MB mem increase per +// target run. + +// disable coverage from this point onwards until turned on again +void __afl_coverage_off() { + + if (likely(__afl_selective_coverage)) { + + __afl_area_ptr = __afl_area_ptr_dummy; + __afl_cmp_map = NULL; + + } + +} + +// enable coverage +void __afl_coverage_on() { + + if (likely(__afl_selective_coverage && __afl_selective_coverage_temp)) { + + __afl_area_ptr = __afl_area_ptr_backup; + __afl_cmp_map = __afl_cmp_map_backup; + + } + +} + +// discard all coverage up to this point +void __afl_coverage_discard() { + + memset(__afl_area_ptr_backup, 0, __afl_map_size); + __afl_area_ptr_backup[0] = 1; + + if (__afl_cmp_map) { memset(__afl_cmp_map, 0, sizeof(struct cmp_map)); } + +} + +// discard the testcase +void __afl_coverage_skip() { + + __afl_coverage_discard(); + + if (likely(is_persistent && __afl_selective_coverage)) { + + __afl_coverage_off(); + __afl_selective_coverage_temp = 0; + + } else { + + exit(0); + + } + +} + +// mark this area as especially interesting +void __afl_coverage_interesting(u8 val, u32 id) { + + __afl_area_ptr[id] = val; + +} + diff --git a/instrumentation/afl-gcc-pass.so.cc b/instrumentation/afl-gcc-pass.so.cc new file mode 100644 index 00000000..41bb5152 --- /dev/null +++ b/instrumentation/afl-gcc-pass.so.cc @@ -0,0 +1,973 @@ +/* GCC plugin for instrumentation of code for american fuzzy lop. + + Copyright 2014-2019 Free Software Foundation, Inc + Copyright 2015, 2016 Google Inc. All rights reserved. + Copyright 2019-2020 AdaCore + + Written by Alexandre Oliva <oliva@adacore.com>, based on the AFL + LLVM pass by Laszlo Szekeres <lszekeres@google.com> and Michal + Zalewski <lcamtuf@google.com>, and copying a little boilerplate + from GCC's libcc1 plugin and GCC proper. Aside from the + boilerplate, namely includes and the pass data structure, and pass + initialization code and output messages borrowed and adapted from + the LLVM pass into plugin_init and plugin_finalize, the + implementation of the GCC pass proper is written from scratch, + aiming at similar behavior and performance to that of the LLVM + pass, and also at compatibility with the out-of-line + instrumentation and run times of AFL++, as well as of an earlier + GCC plugin implementation by Austin Seipp <aseipp@pobox.com>. The + implementation of Allow/Deny Lists is adapted from that in the LLVM + plugin. + + This program is free software: you can redistribute it and/or modify + it under the terms of the GNU General Public License as published by + the Free Software Foundation, either version 3 of the License, or + (at your option) any later version. + + This program is distributed in the hope that it will be useful, + but WITHOUT ANY WARRANTY; without even the implied warranty of + MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the + GNU General Public License for more details. + + You should have received a copy of the GNU General Public License + along with this program. If not, see <http://www.gnu.org/licenses/>. + + */ + +/* This file implements a GCC plugin that introduces an + instrumentation pass for AFL. What follows is the specification + used to rewrite it, extracted from the functional llvm_mode pass + and from an implementation of the gcc_plugin started by Austin + Seipp <aseipp@pobox.com>. + + Declare itself as GPL-compatible. + + Define a 'plugin_init' function. + + Check version against the global gcc_version. + + Register a PLUGIN_INFO object with .version and .help. + + Initialize the random number generator seed with GCC's + random seed. + + Set quiet mode depending on whether stderr is a terminal and + AFL_QUIET is set. + + Output some identification message if not in quiet mode. + + Parse AFL_INST_RATIO, if set, as a number between 0 and 100. Error + out if it's not in range; set up an instrumentation ratio global + otherwise. + + Introduce a single instrumentation pass after SSA. + + The new pass is to be a GIMPLE_PASS. Given the sort of + instrumentation it's supposed to do, its todo_flags_finish will + certainly need TODO_update_ssa, and TODO_cleanup_cfg. + TODO_verify_il is probably desirable, at least during debugging. + TODO_rebuild_cgraph_edges is required only in the out-of-line + instrumentation mode. + + The instrumentation pass amounts to iterating over all basic blocks + and optionally inserting one of the instrumentation sequences below + after its labels, to indicate execution entered the block. + + A block should be skipped if R(100) (from ../types.h) is >= the + global instrumentation ratio. + + A block may be skipped for other reasons, such as if all of its + predecessors have a single successor. + + For an instrumented block, a R(MAP_SIZE) say <N> should be + generated to be used as its location number. Let <C> be a compiler + constant built out of it. + + Count instrumented blocks and print a message at the end of the + compilation, if not in quiet mode. + + Instrumentation in "dumb" or "out-of-line" mode requires calling a + function, passing it the location number. The function to be + called is __afl_trace, implemented in afl-gcc-rt.o.c. Its + declaration <T> needs only be created once. + + Build the call statement <T> (<C>), then add it to the seq to be + inserted. + + Instrumentation in "fast" or "inline" mode performs the computation + of __afl_trace as part of the function. + + It needs to read and write __afl_prev_loc, a TLS u32 variable. Its + declaration <P> needs only be created once. + + It needs to read and dereference __afl_area_ptr, a pointer to (an + array of) char. Its declaration <M> needs only be created once. + + The instrumentation sequence should then be filled with the + following statements: + + Load from <P> to a temporary (<TP>) of the same type. + + Compute <TP> ^ <C> in sizetype, converting types as needed. + + Pointer-add <B> (to be introduced at a later point) and <I> into + another temporary <A>. + + Increment the <*A> MEM_REF. + + Store <C> >> 1 in <P>. + + Temporaries used above need only be created once per function. + + If any block was instrumented in a function, an initializer for <B> + needs to be introduced, loading it from <M> and inserting it in the + entry edge for the entry block. +*/ + +#include "../include/config.h" +#include "../include/debug.h" + +#include <stdio.h> +#include <stdlib.h> +#include <unistd.h> + +#ifdef likely + #undef likely +#endif +#ifdef unlikely + #undef unlikely +#endif + +#include <list> +#include <string> +#include <fstream> + +#include <algorithm> +#include <fnmatch.h> + +#include <gcc-plugin.h> +#include <plugin-version.h> +#include <toplev.h> +#include <tree-pass.h> +#include <context.h> +#include <tree.h> +#include <gimplify.h> +#include <basic-block.h> +#include <tree-ssa-alias.h> +#include <gimple-expr.h> +#include <gimple.h> +#include <gimple-iterator.h> +#include <stringpool.h> +#include <gimple-ssa.h> +#if (__GNUC__ * 10000 + __GNUC_MINOR__ * 100 + __GNUC_PATCHLEVEL__) >= \ + 60200 /* >= version 6.2.0 */ + #include <tree-vrp.h> +#endif +#include <tree-ssanames.h> +#include <tree-phinodes.h> +#include <ssa-iterators.h> + +#include <intl.h> + +/* This plugin, being under the same license as GCC, satisfies the + "GPL-compatible Software" definition in the GCC RUNTIME LIBRARY + EXCEPTION, so it can be part of an "Eligible" "Compilation + Process". */ +int plugin_is_GPL_compatible = 1; + +namespace { + +static const struct pass_data afl_pass_data = { + + .type = GIMPLE_PASS, + .name = "afl", + .optinfo_flags = OPTGROUP_NONE, + .tv_id = TV_NONE, + .properties_required = 0, + .properties_provided = 0, + .properties_destroyed = 0, + .todo_flags_start = 0, + .todo_flags_finish = (TODO_update_ssa | TODO_cleanup_cfg | TODO_verify_il), + +}; + +struct afl_pass : gimple_opt_pass { + + afl_pass(bool quiet, unsigned int ratio) + : gimple_opt_pass(afl_pass_data, g), + be_quiet(quiet), + debug(!!getenv("AFL_DEBUG")), + inst_ratio(ratio), +#ifdef AFL_GCC_OUT_OF_LINE + out_of_line(!!(AFL_GCC_OUT_OF_LINE)), +#else + out_of_line(getenv("AFL_GCC_OUT_OF_LINE")), +#endif + neverZero(!getenv("AFL_GCC_SKIP_NEVERZERO")), + inst_blocks(0) { + + initInstrumentList(); + + } + + /* Are we outputting to a non-terminal, or running with AFL_QUIET + set? */ + const bool be_quiet; + + /* Are we running with AFL_DEBUG set? */ + const bool debug; + + /* How likely (%) is a block to be instrumented? */ + const unsigned int inst_ratio; + + /* Should we use slow, out-of-line call-based instrumentation? */ + const bool out_of_line; + + /* Should we make sure the map edge-crossing counters never wrap + around to zero? */ + const bool neverZero; + + /* Count instrumented blocks. */ + unsigned int inst_blocks; + + virtual unsigned int execute(function *fn) { + + if (!isInInstrumentList(fn)) return 0; + + int blocks = 0; + + /* These are temporaries used by inline instrumentation only, that + are live throughout the function. */ + tree ploc = NULL, indx = NULL, map = NULL, map_ptr = NULL, ntry = NULL, + cntr = NULL, xaddc = NULL, xincr = NULL; + + basic_block bb; + FOR_EACH_BB_FN(bb, fn) { + + if (!instrument_block_p(bb)) continue; + + /* Generate the block identifier. */ + unsigned bid = R(MAP_SIZE); + tree bidt = build_int_cst(sizetype, bid); + + gimple_seq seq = NULL; + + if (out_of_line) { + + static tree afl_trace = get_afl_trace_decl(); + + /* Call __afl_trace with bid, the new location; */ + gcall *call = gimple_build_call(afl_trace, 1, bidt); + gimple_seq_add_stmt(&seq, call); + + } else { + + static tree afl_prev_loc = get_afl_prev_loc_decl(); + static tree afl_area_ptr = get_afl_area_ptr_decl(); + + /* Load __afl_prev_loc to a temporary ploc. */ + if (blocks == 0) + ploc = create_tmp_var(TREE_TYPE(afl_prev_loc), ".afl_prev_loc"); + auto load_loc = gimple_build_assign(ploc, afl_prev_loc); + gimple_seq_add_stmt(&seq, load_loc); + + /* Compute the index into the map referenced by area_ptr + that we're to update: indx = (sizetype) ploc ^ bid. */ + if (blocks == 0) indx = create_tmp_var(TREE_TYPE(bidt), ".afl_index"); + auto conv_ploc = + gimple_build_assign(indx, fold_convert(TREE_TYPE(indx), ploc)); + gimple_seq_add_stmt(&seq, conv_ploc); + auto xor_loc = gimple_build_assign(indx, BIT_XOR_EXPR, indx, bidt); + gimple_seq_add_stmt(&seq, xor_loc); + + /* Compute the address of that map element. */ + if (blocks == 0) { + + map = afl_area_ptr; + map_ptr = create_tmp_var(TREE_TYPE(afl_area_ptr), ".afl_map_ptr"); + ntry = create_tmp_var(TREE_TYPE(afl_area_ptr), ".afl_map_entry"); + + } + + /* .map_ptr is initialized at the function entry point, if we + instrument any blocks, see below. */ + + /* .entry = &map_ptr[.index]; */ + auto idx_map = + gimple_build_assign(ntry, POINTER_PLUS_EXPR, map_ptr, indx); + gimple_seq_add_stmt(&seq, idx_map); + + /* Increment the counter in idx_map. */ + tree memref = build2(MEM_REF, TREE_TYPE(TREE_TYPE(ntry)), ntry, + build_zero_cst(TREE_TYPE(ntry))); + if (blocks == 0) + cntr = create_tmp_var(TREE_TYPE(memref), ".afl_edge_count"); + + /* Load the count from the entry. */ + auto load_cntr = gimple_build_assign(cntr, memref); + gimple_seq_add_stmt(&seq, load_cntr); + + /* Prepare to add constant 1 to it. */ + tree incrv = build_one_cst(TREE_TYPE(cntr)); + + if (neverZero) { + + /* NeverZero: if count wrapped around to zero, advance to + one. */ + if (blocks == 0) { + + xaddc = create_tmp_var(build_complex_type(TREE_TYPE(memref)), + ".afl_edge_xaddc"); + xincr = create_tmp_var(TREE_TYPE(memref), ".afl_edge_xincr"); + + } + + /* Call the ADD_OVERFLOW builtin, to add 1 (in incrv) to + count. The builtin yields a complex pair: the result of + the add in the real part, and the overflow flag in the + imaginary part, */ + auto_vec<tree> vargs(2); + vargs.quick_push(cntr); + vargs.quick_push(incrv); + gcall *add1_cntr = + gimple_build_call_internal_vec(IFN_ADD_OVERFLOW, vargs); + gimple_call_set_lhs(add1_cntr, xaddc); + gimple_seq_add_stmt(&seq, add1_cntr); + + /* Extract the real part into count. */ + tree cntrb = build1(REALPART_EXPR, TREE_TYPE(cntr), xaddc); + auto xtrct_cntr = gimple_build_assign(cntr, cntrb); + gimple_seq_add_stmt(&seq, xtrct_cntr); + + /* Extract the imaginary part into xincr. */ + tree incrb = build1(IMAGPART_EXPR, TREE_TYPE(xincr), xaddc); + auto xtrct_xincr = gimple_build_assign(xincr, incrb); + gimple_seq_add_stmt(&seq, xtrct_xincr); + + /* Arrange for the add below to use the overflow flag stored + in xincr. */ + incrv = xincr; + + } + + /* Add the increment (1 or the overflow bit) to count. */ + auto incr_cntr = gimple_build_assign(cntr, PLUS_EXPR, cntr, incrv); + gimple_seq_add_stmt(&seq, incr_cntr); + + /* Store count in the map entry. */ + auto store_cntr = gimple_build_assign(unshare_expr(memref), cntr); + gimple_seq_add_stmt(&seq, store_cntr); + + /* Store bid >> 1 in __afl_prev_loc. */ + auto shift_loc = + gimple_build_assign(ploc, build_int_cst(TREE_TYPE(ploc), bid >> 1)); + gimple_seq_add_stmt(&seq, shift_loc); + auto store_loc = gimple_build_assign(afl_prev_loc, ploc); + gimple_seq_add_stmt(&seq, store_loc); + + } + + /* Insert the generated sequence. */ + gimple_stmt_iterator insp = gsi_after_labels(bb); + gsi_insert_seq_before(&insp, seq, GSI_SAME_STMT); + + /* Bump this function's instrumented block counter. */ + blocks++; + + } + + /* Aggregate the instrumented block count. */ + inst_blocks += blocks; + + if (blocks) { + + if (out_of_line) return TODO_rebuild_cgraph_edges; + + gimple_seq seq = NULL; + + /* Load afl_area_ptr into map_ptr. We want to do this only + once per function. */ + auto load_ptr = gimple_build_assign(map_ptr, map); + gimple_seq_add_stmt(&seq, load_ptr); + + /* Insert it in the edge to the entry block. We don't want to + insert it in the first block, since there might be a loop + or a goto back to it. Insert in the edge, which may create + another block. */ + edge e = single_succ_edge(ENTRY_BLOCK_PTR_FOR_FN(fn)); + gsi_insert_seq_on_edge_immediate(e, seq); + + } + + return 0; + + } + + /* Decide whether to instrument block BB. Skip it due to the random + distribution, or if it's the single successor of all its + predecessors. */ + inline bool instrument_block_p(basic_block bb) { + + if (R(100) >= (long int)inst_ratio) return false; + + edge e; + edge_iterator ei; + FOR_EACH_EDGE(e, ei, bb->preds) + if (!single_succ_p(e->src)) return true; + + return false; + + } + + /* Create and return a declaration for the __afl_trace rt function. */ + static inline tree get_afl_trace_decl() { + + tree type = + build_function_type_list(void_type_node, uint16_type_node, NULL_TREE); + tree decl = build_fn_decl("__afl_trace", type); + + TREE_PUBLIC(decl) = 1; + DECL_EXTERNAL(decl) = 1; + DECL_ARTIFICIAL(decl) = 1; + + return decl; + + } + + /* Create and return a declaration for the __afl_prev_loc + thread-local variable. */ + static inline tree get_afl_prev_loc_decl() { + + tree decl = build_decl(BUILTINS_LOCATION, VAR_DECL, + get_identifier("__afl_prev_loc"), uint32_type_node); + TREE_PUBLIC(decl) = 1; + DECL_EXTERNAL(decl) = 1; + DECL_ARTIFICIAL(decl) = 1; + TREE_STATIC(decl) = 1; +#if !defined(__ANDROID__) && !defined(__HAIKU__) + set_decl_tls_model( + decl, (flag_pic ? TLS_MODEL_INITIAL_EXEC : TLS_MODEL_LOCAL_EXEC)); +#endif + return decl; + + } + + /* Create and return a declaration for the __afl_prev_loc + thread-local variable. */ + static inline tree get_afl_area_ptr_decl() { + + tree type = build_pointer_type(unsigned_char_type_node); + tree decl = build_decl(BUILTINS_LOCATION, VAR_DECL, + get_identifier("__afl_area_ptr"), type); + TREE_PUBLIC(decl) = 1; + DECL_EXTERNAL(decl) = 1; + DECL_ARTIFICIAL(decl) = 1; + TREE_STATIC(decl) = 1; + + return decl; + + } + + /* This is registered as a plugin finalize callback, to print an + instrumentation summary unless in quiet mode. */ + static void plugin_finalize(void *, void *p) { + + opt_pass *op = (opt_pass *)p; + afl_pass &self = (afl_pass &)*op; + + if (!self.be_quiet) { + + if (!self.inst_blocks) + WARNF("No instrumentation targets found."); + else + OKF("Instrumented %u locations (%s mode, %s, ratio %u%%).", + self.inst_blocks, + getenv("AFL_HARDEN") ? G_("hardened") : G_("non-hardened"), + self.out_of_line ? G_("out of line") : G_("inline"), + self.inst_ratio); + + } + + } + +#define report_fatal_error(msg) BADF(msg) + + std::list<std::string> allowListFiles; + std::list<std::string> allowListFunctions; + std::list<std::string> denyListFiles; + std::list<std::string> denyListFunctions; + + /* Note: this ignore check is also called in isInInstrumentList() */ + bool isIgnoreFunction(function *F) { + + // Starting from "LLVMFuzzer" these are functions used in libfuzzer based + // fuzzing campaign installations, e.g. oss-fuzz + + static const char *ignoreList[] = { + + "asan.", + "llvm.", + "sancov.", + "__ubsan_", + "ign.", + "__afl_", + "_fini", + "__libc_csu", + "__asan", + "__msan", + "__cmplog", + "__sancov", + "msan.", + "LLVMFuzzerM", + "LLVMFuzzerC", + "LLVMFuzzerI", + "__decide_deferred", + "maybe_duplicate_stderr", + "discard_output", + "close_stdout", + "dup_and_close_stderr", + "maybe_close_fd_mask", + "ExecuteFilesOnyByOne" + + }; + + const char *name = IDENTIFIER_POINTER(DECL_NAME(F->decl)); + int len = IDENTIFIER_LENGTH(DECL_NAME(F->decl)); + + for (auto const &ignoreListFunc : ignoreList) { + + if (strncmp(name, ignoreListFunc, len) == 0) { return true; } + + } + + return false; + + } + + void initInstrumentList() { + + char *allowlist = getenv("AFL_GCC_ALLOWLIST"); + if (!allowlist) allowlist = getenv("AFL_GCC_INSTRUMENT_FILE"); + if (!allowlist) allowlist = getenv("AFL_GCC_WHITELIST"); + if (!allowlist) allowlist = getenv("AFL_LLVM_ALLOWLIST"); + if (!allowlist) allowlist = getenv("AFL_LLVM_INSTRUMENT_FILE"); + if (!allowlist) allowlist = getenv("AFL_LLVM_WHITELIST"); + char *denylist = getenv("AFL_GCC_DENYLIST"); + if (!denylist) denylist = getenv("AFL_GCC_BLOCKLIST"); + if (!denylist) denylist = getenv("AFL_LLVM_DENYLIST"); + if (!denylist) denylist = getenv("AFL_LLVM_BLOCKLIST"); + + if (allowlist && denylist) + FATAL( + "You can only specify either AFL_GCC_ALLOWLIST or AFL_GCC_DENYLIST " + "but not both!"); + + if (allowlist) { + + std::string line; + std::ifstream fileStream; + fileStream.open(allowlist); + if (!fileStream) report_fatal_error("Unable to open AFL_GCC_ALLOWLIST"); + getline(fileStream, line); + + while (fileStream) { + + int is_file = -1; + std::size_t npos; + std::string original_line = line; + + line.erase(std::remove_if(line.begin(), line.end(), ::isspace), + line.end()); + + // remove # and following + if ((npos = line.find("#")) != std::string::npos) + line = line.substr(0, npos); + + if (line.compare(0, 4, "fun:") == 0) { + + is_file = 0; + line = line.substr(4); + + } else if (line.compare(0, 9, "function:") == 0) { + + is_file = 0; + line = line.substr(9); + + } else if (line.compare(0, 4, "src:") == 0) { + + is_file = 1; + line = line.substr(4); + + } else if (line.compare(0, 7, "source:") == 0) { + + is_file = 1; + line = line.substr(7); + + } + + if (line.find(":") != std::string::npos) { + + FATAL("invalid line in AFL_GCC_ALLOWLIST: %s", original_line.c_str()); + + } + + if (line.length() > 0) { + + // if the entry contains / or . it must be a file + if (is_file == -1) + if (line.find("/") != std::string::npos || + line.find(".") != std::string::npos) + is_file = 1; + // otherwise it is a function + + if (is_file == 1) + allowListFiles.push_back(line); + else + allowListFunctions.push_back(line); + + } + + getline(fileStream, line); + + } + + if (debug) + DEBUGF("loaded allowlist with %zu file and %zu function entries\n", + allowListFiles.size(), allowListFunctions.size()); + + } + + if (denylist) { + + std::string line; + std::ifstream fileStream; + fileStream.open(denylist); + if (!fileStream) report_fatal_error("Unable to open AFL_GCC_DENYLIST"); + getline(fileStream, line); + + while (fileStream) { + + int is_file = -1; + std::size_t npos; + std::string original_line = line; + + line.erase(std::remove_if(line.begin(), line.end(), ::isspace), + line.end()); + + // remove # and following + if ((npos = line.find("#")) != std::string::npos) + line = line.substr(0, npos); + + if (line.compare(0, 4, "fun:") == 0) { + + is_file = 0; + line = line.substr(4); + + } else if (line.compare(0, 9, "function:") == 0) { + + is_file = 0; + line = line.substr(9); + + } else if (line.compare(0, 4, "src:") == 0) { + + is_file = 1; + line = line.substr(4); + + } else if (line.compare(0, 7, "source:") == 0) { + + is_file = 1; + line = line.substr(7); + + } + + if (line.find(":") != std::string::npos) { + + FATAL("invalid line in AFL_GCC_DENYLIST: %s", original_line.c_str()); + + } + + if (line.length() > 0) { + + // if the entry contains / or . it must be a file + if (is_file == -1) + if (line.find("/") != std::string::npos || + line.find(".") != std::string::npos) + is_file = 1; + // otherwise it is a function + + if (is_file == 1) + denyListFiles.push_back(line); + else + denyListFunctions.push_back(line); + + } + + getline(fileStream, line); + + } + + if (debug) + DEBUGF("loaded denylist with %zu file and %zu function entries\n", + denyListFiles.size(), denyListFunctions.size()); + + } + + } + + std::string getSourceName(function *F) { + + return DECL_SOURCE_FILE(F->decl); + + } + + bool isInInstrumentList(function *F) { + + bool return_default = true; + + // is this a function with code? If it is external we don't instrument it + // anyway and it can't be in the instrument file list. Or if it is it is + // ignored. + if (isIgnoreFunction(F)) return false; + + if (!denyListFiles.empty() || !denyListFunctions.empty()) { + + if (!denyListFunctions.empty()) { + + std::string instFunction = IDENTIFIER_POINTER(DECL_NAME(F->decl)); + + for (std::list<std::string>::iterator it = denyListFunctions.begin(); + it != denyListFunctions.end(); ++it) { + + /* We don't check for filename equality here because + * filenames might actually be full paths. Instead we + * check that the actual filename ends in the filename + * specified in the list. We also allow UNIX-style pattern + * matching */ + + if (instFunction.length() >= it->length()) { + + if (fnmatch(("*" + *it).c_str(), instFunction.c_str(), 0) == 0) { + + if (debug) + DEBUGF( + "Function %s is in the deny function list, not " + "instrumenting ... \n", + instFunction.c_str()); + return false; + + } + + } + + } + + } + + if (!denyListFiles.empty()) { + + std::string source_file = getSourceName(F); + + if (!source_file.empty()) { + + for (std::list<std::string>::iterator it = denyListFiles.begin(); + it != denyListFiles.end(); ++it) { + + /* We don't check for filename equality here because + * filenames might actually be full paths. Instead we + * check that the actual filename ends in the filename + * specified in the list. We also allow UNIX-style pattern + * matching */ + + if (source_file.length() >= it->length()) { + + if (fnmatch(("*" + *it).c_str(), source_file.c_str(), 0) == 0) { + + return false; + + } + + } + + } + + } else { + + // we could not find out the location. in this case we say it is not + // in the instrument file list + if (!be_quiet) + WARNF( + "No debug information found for function %s, will be " + "instrumented (recompile with -g -O[1-3]).", + IDENTIFIER_POINTER(DECL_NAME(F->decl))); + + } + + } + + } + + // if we do not have a instrument file list return true + if (!allowListFiles.empty() || !allowListFunctions.empty()) { + + return_default = false; + + if (!allowListFunctions.empty()) { + + std::string instFunction = IDENTIFIER_POINTER(DECL_NAME(F->decl)); + + for (std::list<std::string>::iterator it = allowListFunctions.begin(); + it != allowListFunctions.end(); ++it) { + + /* We don't check for filename equality here because + * filenames might actually be full paths. Instead we + * check that the actual filename ends in the filename + * specified in the list. We also allow UNIX-style pattern + * matching */ + + if (instFunction.length() >= it->length()) { + + if (fnmatch(("*" + *it).c_str(), instFunction.c_str(), 0) == 0) { + + if (debug) + DEBUGF( + "Function %s is in the allow function list, instrumenting " + "... \n", + instFunction.c_str()); + return true; + + } + + } + + } + + } + + if (!allowListFiles.empty()) { + + std::string source_file = getSourceName(F); + + if (!source_file.empty()) { + + for (std::list<std::string>::iterator it = allowListFiles.begin(); + it != allowListFiles.end(); ++it) { + + /* We don't check for filename equality here because + * filenames might actually be full paths. Instead we + * check that the actual filename ends in the filename + * specified in the list. We also allow UNIX-style pattern + * matching */ + + if (source_file.length() >= it->length()) { + + if (fnmatch(("*" + *it).c_str(), source_file.c_str(), 0) == 0) { + + if (debug) + DEBUGF( + "Function %s is in the allowlist (%s), instrumenting ... " + "\n", + IDENTIFIER_POINTER(DECL_NAME(F->decl)), + source_file.c_str()); + return true; + + } + + } + + } + + } else { + + // we could not find out the location. In this case we say it is not + // in the instrument file list + if (!be_quiet) + WARNF( + "No debug information found for function %s, will not be " + "instrumented (recompile with -g -O[1-3]).", + IDENTIFIER_POINTER(DECL_NAME(F->decl))); + return false; + + } + + } + + } + + return return_default; + + } + +}; + +static struct plugin_info afl_plugin = { + + .version = "20200907", + .help = G_("AFL gcc plugin\n\ +\n\ +Set AFL_QUIET in the environment to silence it.\n\ +\n\ +Set AFL_INST_RATIO in the environment to a number from 0 to 100\n\ +to control how likely a block will be chosen for instrumentation.\n\ +\n\ +Specify -frandom-seed for reproducible instrumentation.\n\ +"), + +}; + +} // namespace + +/* This is the function GCC calls when loading a plugin. Initialize + and register further callbacks. */ +int plugin_init(struct plugin_name_args * info, + struct plugin_gcc_version *version) { + + if (!plugin_default_version_check(version, &gcc_version)) + FATAL(G_("GCC and plugin have incompatible versions, expected GCC %s, " + "is %s"), + gcc_version.basever, version->basever); + + /* Show a banner. */ + bool quiet = false; + if (isatty(2) && !getenv("AFL_QUIET")) + SAYF(cCYA "afl-gcc-pass " cBRI VERSION cRST " by <oliva@adacore.com>\n"); + else + quiet = true; + + /* Decide instrumentation ratio. */ + unsigned int inst_ratio = 100U; + if (char *inst_ratio_str = getenv("AFL_INST_RATIO")) + if (sscanf(inst_ratio_str, "%u", &inst_ratio) != 1 || !inst_ratio || + inst_ratio > 100) + FATAL(G_("Bad value of AFL_INST_RATIO (must be between 1 and 100)")); + + /* Initialize the random number generator with GCC's random seed, in + case it was specified in the command line's -frandom-seed for + reproducible instrumentation. */ + srandom(get_random_seed(false)); + + const char *name = info->base_name; + register_callback(name, PLUGIN_INFO, NULL, &afl_plugin); + + afl_pass * aflp = new afl_pass(quiet, inst_ratio); + struct register_pass_info pass_info = { + + .pass = aflp, + .reference_pass_name = "ssa", + .ref_pass_instance_number = 1, + .pos_op = PASS_POS_INSERT_AFTER, + + }; + + register_callback(name, PLUGIN_PASS_MANAGER_SETUP, NULL, &pass_info); + register_callback(name, PLUGIN_FINISH, afl_pass::plugin_finalize, + pass_info.pass); + + if (!quiet) + ACTF(G_("%s instrumentation at ratio of %u%% in %s mode."), + aflp->out_of_line ? G_("Call-based") : G_("Inline"), inst_ratio, + getenv("AFL_HARDEN") ? G_("hardened") : G_("non-hardened")); + + return 0; + +} + diff --git a/instrumentation/afl-llvm-common.cc b/instrumentation/afl-llvm-common.cc new file mode 100644 index 00000000..17780143 --- /dev/null +++ b/instrumentation/afl-llvm-common.cc @@ -0,0 +1,604 @@ +#define AFL_LLVM_PASS + +#include "config.h" +#include "debug.h" + +#include <stdio.h> +#include <stdlib.h> +#include <unistd.h> +#include <sys/time.h> +#include <fnmatch.h> + +#include <list> +#include <string> +#include <fstream> + +#include <llvm/Support/raw_ostream.h> + +#define IS_EXTERN extern +#include "afl-llvm-common.h" + +using namespace llvm; + +static std::list<std::string> allowListFiles; +static std::list<std::string> allowListFunctions; +static std::list<std::string> denyListFiles; +static std::list<std::string> denyListFunctions; + +char *getBBName(const llvm::BasicBlock *BB) { + + static char *name; + + if (!BB->getName().empty()) { + + name = strdup(BB->getName().str().c_str()); + return name; + + } + + std::string Str; + raw_string_ostream OS(Str); + +#if LLVM_VERSION_MAJOR >= 4 || \ + (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR >= 7) + BB->printAsOperand(OS, false); +#endif + name = strdup(OS.str().c_str()); + return name; + +} + +/* Function that we never instrument or analyze */ +/* Note: this ignore check is also called in isInInstrumentList() */ +bool isIgnoreFunction(const llvm::Function *F) { + + // Starting from "LLVMFuzzer" these are functions used in libfuzzer based + // fuzzing campaign installations, e.g. oss-fuzz + + static const char *ignoreList[] = { + + "asan.", + "llvm.", + "sancov.", + "__ubsan", + "ign.", + "__afl", + "_fini", + "__libc_", + "__asan", + "__msan", + "__cmplog", + "__sancov", + "__san", + "__cxx_", + "__decide_deferred", + "_GLOBAL", + "_ZZN6__asan", + "_ZZN6__lsan", + "msan.", + "LLVMFuzzerM", + "LLVMFuzzerC", + "LLVMFuzzerI", + "maybe_duplicate_stderr", + "discard_output", + "close_stdout", + "dup_and_close_stderr", + "maybe_close_fd_mask", + "ExecuteFilesOnyByOne" + + }; + + for (auto const &ignoreListFunc : ignoreList) { + + if (F->getName().startswith(ignoreListFunc)) { return true; } + + } + + static const char *ignoreSubstringList[] = { + + "__asan", + "__msan", + "__ubsan", + "__lsan", + "__san", + "__sanitize", + "__cxx", + "_GLOBAL__", + "DebugCounter", + "DwarfDebug", + "DebugLoc" + + }; + + for (auto const &ignoreListFunc : ignoreSubstringList) { + + if (F->getName().contains(ignoreListFunc)) { return true; } + + } + + return false; + +} + +void initInstrumentList() { + + char *allowlist = getenv("AFL_LLVM_ALLOWLIST"); + if (!allowlist) allowlist = getenv("AFL_LLVM_INSTRUMENT_FILE"); + if (!allowlist) allowlist = getenv("AFL_LLVM_WHITELIST"); + char *denylist = getenv("AFL_LLVM_DENYLIST"); + if (!denylist) denylist = getenv("AFL_LLVM_BLOCKLIST"); + + if (allowlist && denylist) + FATAL( + "You can only specify either AFL_LLVM_ALLOWLIST or AFL_LLVM_DENYLIST " + "but not both!"); + + if (allowlist) { + + std::string line; + std::ifstream fileStream; + fileStream.open(allowlist); + if (!fileStream) report_fatal_error("Unable to open AFL_LLVM_ALLOWLIST"); + getline(fileStream, line); + + while (fileStream) { + + int is_file = -1; + std::size_t npos; + std::string original_line = line; + + line.erase(std::remove_if(line.begin(), line.end(), ::isspace), + line.end()); + + // remove # and following + if ((npos = line.find("#")) != std::string::npos) + line = line.substr(0, npos); + + if (line.compare(0, 4, "fun:") == 0) { + + is_file = 0; + line = line.substr(4); + + } else if (line.compare(0, 9, "function:") == 0) { + + is_file = 0; + line = line.substr(9); + + } else if (line.compare(0, 4, "src:") == 0) { + + is_file = 1; + line = line.substr(4); + + } else if (line.compare(0, 7, "source:") == 0) { + + is_file = 1; + line = line.substr(7); + + } + + if (line.find(":") != std::string::npos) { + + FATAL("invalid line in AFL_LLVM_ALLOWLIST: %s", original_line.c_str()); + + } + + if (line.length() > 0) { + + // if the entry contains / or . it must be a file + if (is_file == -1) + if (line.find("/") != std::string::npos || + line.find(".") != std::string::npos) + is_file = 1; + // otherwise it is a function + + if (is_file == 1) + allowListFiles.push_back(line); + else + allowListFunctions.push_back(line); + + } + + getline(fileStream, line); + + } + + if (debug) + DEBUGF("loaded allowlist with %zu file and %zu function entries\n", + allowListFiles.size(), allowListFunctions.size()); + + } + + if (denylist) { + + std::string line; + std::ifstream fileStream; + fileStream.open(denylist); + if (!fileStream) report_fatal_error("Unable to open AFL_LLVM_DENYLIST"); + getline(fileStream, line); + + while (fileStream) { + + int is_file = -1; + std::size_t npos; + std::string original_line = line; + + line.erase(std::remove_if(line.begin(), line.end(), ::isspace), + line.end()); + + // remove # and following + if ((npos = line.find("#")) != std::string::npos) + line = line.substr(0, npos); + + if (line.compare(0, 4, "fun:") == 0) { + + is_file = 0; + line = line.substr(4); + + } else if (line.compare(0, 9, "function:") == 0) { + + is_file = 0; + line = line.substr(9); + + } else if (line.compare(0, 4, "src:") == 0) { + + is_file = 1; + line = line.substr(4); + + } else if (line.compare(0, 7, "source:") == 0) { + + is_file = 1; + line = line.substr(7); + + } + + if (line.find(":") != std::string::npos) { + + FATAL("invalid line in AFL_LLVM_DENYLIST: %s", original_line.c_str()); + + } + + if (line.length() > 0) { + + // if the entry contains / or . it must be a file + if (is_file == -1) + if (line.find("/") != std::string::npos || + line.find(".") != std::string::npos) + is_file = 1; + // otherwise it is a function + + if (is_file == 1) + denyListFiles.push_back(line); + else + denyListFunctions.push_back(line); + + } + + getline(fileStream, line); + + } + + if (debug) + DEBUGF("loaded denylist with %zu file and %zu function entries\n", + denyListFiles.size(), denyListFunctions.size()); + + } + +} + +void scanForDangerousFunctions(llvm::Module *M) { + + if (!M) return; + +#if LLVM_VERSION_MAJOR > 3 || \ + (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR >= 9) + + for (GlobalIFunc &IF : M->ifuncs()) { + + StringRef ifunc_name = IF.getName(); + Constant *r = IF.getResolver(); + StringRef r_name = cast<Function>(r->getOperand(0))->getName(); + if (!be_quiet) + fprintf(stderr, + "Info: Found an ifunc with name %s that points to resolver " + "function %s, we will not instrument this, putting it into the " + "block list.\n", + ifunc_name.str().c_str(), r_name.str().c_str()); + denyListFunctions.push_back(r_name.str()); + + } + + GlobalVariable *GV = M->getNamedGlobal("llvm.global_ctors"); + if (GV && !GV->isDeclaration() && !GV->hasLocalLinkage()) { + + ConstantArray *InitList = dyn_cast<ConstantArray>(GV->getInitializer()); + + if (InitList) { + + for (unsigned i = 0, e = InitList->getNumOperands(); i != e; ++i) { + + if (ConstantStruct *CS = + dyn_cast<ConstantStruct>(InitList->getOperand(i))) { + + if (CS->getNumOperands() >= 2) { + + if (CS->getOperand(1)->isNullValue()) + break; // Found a null terminator, stop here. + + ConstantInt *CI = dyn_cast<ConstantInt>(CS->getOperand(0)); + int Priority = CI ? CI->getSExtValue() : 0; + + Constant *FP = CS->getOperand(1); + if (ConstantExpr *CE = dyn_cast<ConstantExpr>(FP)) + if (CE->isCast()) FP = CE->getOperand(0); + if (Function *F = dyn_cast<Function>(FP)) { + + if (!F->isDeclaration() && + strncmp(F->getName().str().c_str(), "__afl", 5) != 0) { + + if (!be_quiet) + fprintf(stderr, + "Info: Found constructor function %s with prio " + "%u, we will not instrument this, putting it into a " + "block list.\n", + F->getName().str().c_str(), Priority); + denyListFunctions.push_back(F->getName().str()); + + } + + } + + } + + } + + } + + } + + } + +#endif + +} + +static std::string getSourceName(llvm::Function *F) { + + // let's try to get the filename for the function + auto bb = &F->getEntryBlock(); + BasicBlock::iterator IP = bb->getFirstInsertionPt(); + IRBuilder<> IRB(&(*IP)); + DebugLoc Loc = IP->getDebugLoc(); + +#if LLVM_VERSION_MAJOR >= 4 || \ + (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR >= 7) + if (Loc) { + + StringRef instFilename; + DILocation *cDILoc = dyn_cast<DILocation>(Loc.getAsMDNode()); + + if (cDILoc) { instFilename = cDILoc->getFilename(); } + + if (instFilename.str().empty() && cDILoc) { + + /* If the original location is empty, try using the inlined location + */ + DILocation *oDILoc = cDILoc->getInlinedAt(); + if (oDILoc) { instFilename = oDILoc->getFilename(); } + + } + + return instFilename.str(); + + } + +#else + if (!Loc.isUnknown()) { + + DILocation cDILoc(Loc.getAsMDNode(F->getContext())); + + StringRef instFilename = cDILoc.getFilename(); + + /* Continue only if we know where we actually are */ + return instFilename.str(); + + } + +#endif + + return std::string(""); + +} + +bool isInInstrumentList(llvm::Function *F) { + + bool return_default = true; + + // is this a function with code? If it is external we don't instrument it + // anyway and it can't be in the instrument file list. Or if it is it is + // ignored. + if (!F->size() || isIgnoreFunction(F)) return false; + + if (!denyListFiles.empty() || !denyListFunctions.empty()) { + + if (!denyListFunctions.empty()) { + + std::string instFunction = F->getName().str(); + + for (std::list<std::string>::iterator it = denyListFunctions.begin(); + it != denyListFunctions.end(); ++it) { + + /* We don't check for filename equality here because + * filenames might actually be full paths. Instead we + * check that the actual filename ends in the filename + * specified in the list. We also allow UNIX-style pattern + * matching */ + + if (instFunction.length() >= it->length()) { + + if (fnmatch(("*" + *it).c_str(), instFunction.c_str(), 0) == 0) { + + if (debug) + DEBUGF( + "Function %s is in the deny function list, not instrumenting " + "... \n", + instFunction.c_str()); + return false; + + } + + } + + } + + } + + if (!denyListFiles.empty()) { + + std::string source_file = getSourceName(F); + + if (!source_file.empty()) { + + for (std::list<std::string>::iterator it = denyListFiles.begin(); + it != denyListFiles.end(); ++it) { + + /* We don't check for filename equality here because + * filenames might actually be full paths. Instead we + * check that the actual filename ends in the filename + * specified in the list. We also allow UNIX-style pattern + * matching */ + + if (source_file.length() >= it->length()) { + + if (fnmatch(("*" + *it).c_str(), source_file.c_str(), 0) == 0) { + + return false; + + } + + } + + } + + } else { + + // we could not find out the location. in this case we say it is not + // in the instrument file list + if (!be_quiet) + WARNF( + "No debug information found for function %s, will be " + "instrumented (recompile with -g -O[1-3]).", + F->getName().str().c_str()); + + } + + } + + } + + // if we do not have a instrument file list return true + if (!allowListFiles.empty() || !allowListFunctions.empty()) { + + return_default = false; + + if (!allowListFunctions.empty()) { + + std::string instFunction = F->getName().str(); + + for (std::list<std::string>::iterator it = allowListFunctions.begin(); + it != allowListFunctions.end(); ++it) { + + /* We don't check for filename equality here because + * filenames might actually be full paths. Instead we + * check that the actual filename ends in the filename + * specified in the list. We also allow UNIX-style pattern + * matching */ + + if (instFunction.length() >= it->length()) { + + if (fnmatch(("*" + *it).c_str(), instFunction.c_str(), 0) == 0) { + + if (debug) + DEBUGF( + "Function %s is in the allow function list, instrumenting " + "... \n", + instFunction.c_str()); + return true; + + } + + } + + } + + } + + if (!allowListFiles.empty()) { + + std::string source_file = getSourceName(F); + + if (!source_file.empty()) { + + for (std::list<std::string>::iterator it = allowListFiles.begin(); + it != allowListFiles.end(); ++it) { + + /* We don't check for filename equality here because + * filenames might actually be full paths. Instead we + * check that the actual filename ends in the filename + * specified in the list. We also allow UNIX-style pattern + * matching */ + + if (source_file.length() >= it->length()) { + + if (fnmatch(("*" + *it).c_str(), source_file.c_str(), 0) == 0) { + + if (debug) + DEBUGF( + "Function %s is in the allowlist (%s), instrumenting ... " + "\n", + F->getName().str().c_str(), source_file.c_str()); + return true; + + } + + } + + } + + } else { + + // we could not find out the location. In this case we say it is not + // in the instrument file list + if (!be_quiet) + WARNF( + "No debug information found for function %s, will not be " + "instrumented (recompile with -g -O[1-3]).", + F->getName().str().c_str()); + return false; + + } + + } + + } + + return return_default; + +} + +// Calculate the number of average collisions that would occur if all +// location IDs would be assigned randomly (like normal afl/afl++). +// This uses the "balls in bins" algorithm. +unsigned long long int calculateCollisions(uint32_t edges) { + + double bins = MAP_SIZE; + double balls = edges; + double step1 = 1 - (1 / bins); + double step2 = pow(step1, balls); + double step3 = bins * step2; + double step4 = round(step3); + unsigned long long int empty = step4; + unsigned long long int collisions = edges - (MAP_SIZE - empty); + return collisions; + +} + diff --git a/llvm_mode/afl-llvm-common.h b/instrumentation/afl-llvm-common.h index 38e0c830..a1561d9c 100644 --- a/llvm_mode/afl-llvm-common.h +++ b/instrumentation/afl-llvm-common.h @@ -37,6 +37,16 @@ bool isIgnoreFunction(const llvm::Function *F); void initInstrumentList(); bool isInInstrumentList(llvm::Function *F); unsigned long long int calculateCollisions(uint32_t edges); +void scanForDangerousFunctions(llvm::Module *M); + +#ifndef IS_EXTERN + #define IS_EXTERN +#endif + +IS_EXTERN int debug; +IS_EXTERN int be_quiet; + +#undef IS_EXTERN #endif diff --git a/instrumentation/afl-llvm-dict2file.so.cc b/instrumentation/afl-llvm-dict2file.so.cc new file mode 100644 index 00000000..c954054b --- /dev/null +++ b/instrumentation/afl-llvm-dict2file.so.cc @@ -0,0 +1,625 @@ +/* + american fuzzy lop++ - LLVM LTO instrumentation pass + ---------------------------------------------------- + + Written by Marc Heuse <mh@mh-sec.de> + + Copyright 2019-2020 AFLplusplus Project. All rights reserved. + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at: + + http://www.apache.org/licenses/LICENSE-2.0 + + This library is plugged into LLVM when invoking clang through afl-clang-lto. + + */ + +#define AFL_LLVM_PASS + +#include "config.h" +#include "debug.h" + +#include <stdio.h> +#include <stdlib.h> +#include <unistd.h> +#include <string.h> +#include <sys/time.h> +#include <sys/types.h> +#include <sys/stat.h> +#include <fcntl.h> +#include <ctype.h> + +#include <list> +#include <string> +#include <fstream> +#include <set> + +#include "llvm/Config/llvm-config.h" +#include "llvm/ADT/Statistic.h" +#include "llvm/IR/IRBuilder.h" +#include "llvm/IR/LegacyPassManager.h" +#include "llvm/IR/BasicBlock.h" +#include "llvm/IR/Module.h" +#include "llvm/IR/DebugInfo.h" +#include "llvm/IR/CFG.h" +#include "llvm/IR/Verifier.h" +#include "llvm/Support/Debug.h" +#include "llvm/Support/raw_ostream.h" +#include "llvm/Transforms/IPO/PassManagerBuilder.h" +#include "llvm/Transforms/Utils/BasicBlockUtils.h" +#include "llvm/Analysis/LoopInfo.h" +#include "llvm/Analysis/ValueTracking.h" +#include "llvm/Pass.h" +#include "llvm/IR/Constants.h" + +#include "afl-llvm-common.h" + +#ifndef O_DSYNC + #define O_DSYNC O_SYNC +#endif + +using namespace llvm; + +namespace { + +class AFLdict2filePass : public ModulePass { + + public: + static char ID; + + AFLdict2filePass() : ModulePass(ID) { + + if (getenv("AFL_DEBUG")) debug = 1; + + } + + bool runOnModule(Module &M) override; + +}; + +} // namespace + +void dict2file(int fd, u8 *mem, u32 len) { + + u32 i, j, binary = 0; + char line[MAX_AUTO_EXTRA * 8], tmp[8]; + + strcpy(line, "\""); + j = 1; + for (i = 0; i < len; i++) { + + if (isprint(mem[i]) && mem[i] != '\\' && mem[i] != '"') { + + line[j++] = mem[i]; + + } else { + + if (i + 1 != len || mem[i] != 0 || binary || len == 4 || len == 8) { + + line[j] = 0; + sprintf(tmp, "\\x%02x", (u8)mem[i]); + strcat(line, tmp); + j = strlen(line); + + } + + binary = 1; + + } + + } + + line[j] = 0; + strcat(line, "\"\n"); + if (write(fd, line, strlen(line)) <= 0) + PFATAL("Could not write to dictionary file"); + fsync(fd); + + if (!be_quiet) fprintf(stderr, "Found dictionary token: %s", line); + +} + +bool AFLdict2filePass::runOnModule(Module &M) { + + DenseMap<Value *, std::string *> valueMap; + char * ptr; + int fd, found = 0; + + /* Show a banner */ + setvbuf(stdout, NULL, _IONBF, 0); + + if ((isatty(2) && !getenv("AFL_QUIET")) || debug) { + + SAYF(cCYA "afl-llvm-dict2file" VERSION cRST + " by Marc \"vanHauser\" Heuse <mh@mh-sec.de>\n"); + + } else + + be_quiet = 1; + + scanForDangerousFunctions(&M); + + ptr = getenv("AFL_LLVM_DICT2FILE"); + + if (!ptr || *ptr != '/') + FATAL("AFL_LLVM_DICT2FILE is not set to an absolute path: %s", ptr); + + if ((fd = open(ptr, O_WRONLY | O_APPEND | O_CREAT | O_DSYNC, 0644)) < 0) + PFATAL("Could not open/create %s.", ptr); + + /* Instrument all the things! */ + + for (auto &F : M) { + + if (isIgnoreFunction(&F)) continue; + + /* Some implementation notes. + * + * We try to handle 3 cases: + * - memcmp("foo", arg, 3) <- literal string + * - static char globalvar[] = "foo"; + * memcmp(globalvar, arg, 3) <- global variable + * - char localvar[] = "foo"; + * memcmp(locallvar, arg, 3) <- local variable + * + * The local variable case is the hardest. We can only detect that + * case if there is no reassignment or change in the variable. + * And it might not work across llvm version. + * What we do is hooking the initializer function for local variables + * (llvm.memcpy.p0i8.p0i8.i64) and note the string and the assigned + * variable. And if that variable is then used in a compare function + * we use that noted string. + * This seems not to work for tokens that have a size <= 4 :-( + * + * - if the compared length is smaller than the string length we + * save the full string. This is likely better for fuzzing but + * might be wrong in a few cases depending on optimizers + * + * - not using StringRef because there is a bug in the llvm 11 + * checkout I am using which sometimes points to wrong strings + * + * Over and out. Took me a full day. damn. mh/vh + */ + + for (auto &BB : F) { + + for (auto &IN : BB) { + + CallInst *callInst = nullptr; + CmpInst * cmpInst = nullptr; + + if ((cmpInst = dyn_cast<CmpInst>(&IN))) { + + Value * op = cmpInst->getOperand(1); + ConstantInt *ilen = dyn_cast<ConstantInt>(op); + + /* We skip > 64 bit integers. why? first because their value is + difficult to obtain, and second because clang does not support + literals > 64 bit (as of llvm 12) */ + + if (ilen && ilen->uge(0xffffffffffffffff) == false) { + + u64 val2 = 0, val = ilen->getZExtValue(); + u32 len = 0; + if (val > 0x10000 && val < 0xffffffff) len = 4; + if (val > 0x100000001 && val < 0xffffffffffffffff) len = 8; + + if (len) { + + auto c = cmpInst->getPredicate(); + + switch (c) { + + case CmpInst::FCMP_OGT: // fall through + case CmpInst::FCMP_OLE: // fall through + case CmpInst::ICMP_SLE: // fall through + case CmpInst::ICMP_SGT: + + // signed comparison and it is a negative constant + if ((len == 4 && (val & 80000000)) || + (len == 8 && (val & 8000000000000000))) { + + if ((val & 0xffff) != 1) val2 = val - 1; + break; + + } + + // fall through + + case CmpInst::FCMP_UGT: // fall through + case CmpInst::FCMP_ULE: // fall through + case CmpInst::ICMP_UGT: // fall through + case CmpInst::ICMP_ULE: + if ((val & 0xffff) != 0xfffe) val2 = val + 1; + break; + + case CmpInst::FCMP_OLT: // fall through + case CmpInst::FCMP_OGE: // fall through + case CmpInst::ICMP_SLT: // fall through + case CmpInst::ICMP_SGE: + + // signed comparison and it is a negative constant + if ((len == 4 && (val & 80000000)) || + (len == 8 && (val & 8000000000000000))) { + + if ((val & 0xffff) != 1) val2 = val - 1; + break; + + } + + // fall through + + case CmpInst::FCMP_ULT: // fall through + case CmpInst::FCMP_UGE: // fall through + case CmpInst::ICMP_ULT: // fall through + case CmpInst::ICMP_UGE: + if ((val & 0xffff) != 1) val2 = val - 1; + break; + + default: + val2 = 0; + + } + + dict2file(fd, (u8 *)&val, len); + found++; + if (val2) { + + dict2file(fd, (u8 *)&val2, len); + found++; + + } + + } + + } + + } + + if ((callInst = dyn_cast<CallInst>(&IN))) { + + bool isStrcmp = true; + bool isMemcmp = true; + bool isStrncmp = true; + bool isStrcasecmp = true; + bool isStrncasecmp = true; + bool isIntMemcpy = true; + bool isStdString = true; + bool addedNull = false; + size_t optLen = 0; + + Function *Callee = callInst->getCalledFunction(); + if (!Callee) continue; + if (callInst->getCallingConv() != llvm::CallingConv::C) continue; + std::string FuncName = Callee->getName().str(); + isStrcmp &= !FuncName.compare("strcmp"); + isMemcmp &= + (!FuncName.compare("memcmp") || !FuncName.compare("bcmp")); + isStrncmp &= !FuncName.compare("strncmp"); + isStrcasecmp &= !FuncName.compare("strcasecmp"); + isStrncasecmp &= !FuncName.compare("strncasecmp"); + isIntMemcpy &= !FuncName.compare("llvm.memcpy.p0i8.p0i8.i64"); + isStdString &= ((FuncName.find("basic_string") != std::string::npos && + FuncName.find("compare") != std::string::npos) || + (FuncName.find("basic_string") != std::string::npos && + FuncName.find("find") != std::string::npos)); + + if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && + !isStrncasecmp && !isIntMemcpy && !isStdString) + continue; + + /* Verify the strcmp/memcmp/strncmp/strcasecmp/strncasecmp function + * prototype */ + FunctionType *FT = Callee->getFunctionType(); + + isStrcmp &= + FT->getNumParams() == 2 && FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0) == IntegerType::getInt8PtrTy(M.getContext()); + isStrcasecmp &= + FT->getNumParams() == 2 && FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0) == IntegerType::getInt8PtrTy(M.getContext()); + isMemcmp &= FT->getNumParams() == 3 && + FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0)->isPointerTy() && + FT->getParamType(1)->isPointerTy() && + FT->getParamType(2)->isIntegerTy(); + isStrncmp &= FT->getNumParams() == 3 && + FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0) == + IntegerType::getInt8PtrTy(M.getContext()) && + FT->getParamType(2)->isIntegerTy(); + isStrncasecmp &= FT->getNumParams() == 3 && + FT->getReturnType()->isIntegerTy(32) && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0) == + IntegerType::getInt8PtrTy(M.getContext()) && + FT->getParamType(2)->isIntegerTy(); + isStdString &= FT->getNumParams() >= 2 && + FT->getParamType(0)->isPointerTy() && + FT->getParamType(1)->isPointerTy(); + + if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && + !isStrncasecmp && !isIntMemcpy && !isStdString) + continue; + + /* is a str{n,}{case,}cmp/memcmp, check if we have + * str{case,}cmp(x, "const") or str{case,}cmp("const", x) + * strn{case,}cmp(x, "const", ..) or strn{case,}cmp("const", x, ..) + * memcmp(x, "const", ..) or memcmp("const", x, ..) */ + Value *Str1P = callInst->getArgOperand(0), + *Str2P = callInst->getArgOperand(1); + std::string Str1, Str2; + StringRef TmpStr; + bool HasStr1; + getConstantStringInfo(Str1P, TmpStr); + + if (TmpStr.empty()) { + + HasStr1 = false; + + } else { + + HasStr1 = true; + Str1 = TmpStr.str(); + + } + + bool HasStr2; + getConstantStringInfo(Str2P, TmpStr); + if (TmpStr.empty()) { + + HasStr2 = false; + + } else { + + HasStr2 = true; + Str2 = TmpStr.str(); + + } + + if (debug) + fprintf(stderr, "F:%s %p(%s)->\"%s\"(%s) %p(%s)->\"%s\"(%s)\n", + FuncName.c_str(), (void *)Str1P, + Str1P->getName().str().c_str(), Str1.c_str(), + HasStr1 == true ? "true" : "false", (void *)Str2P, + Str2P->getName().str().c_str(), Str2.c_str(), + HasStr2 == true ? "true" : "false"); + + // we handle the 2nd parameter first because of llvm memcpy + if (!HasStr2) { + + auto *Ptr = dyn_cast<ConstantExpr>(Str2P); + if (Ptr && Ptr->isGEPWithNoNotionalOverIndexing()) { + + if (auto *Var = dyn_cast<GlobalVariable>(Ptr->getOperand(0))) { + + if (Var->hasInitializer()) { + + if (auto *Array = + dyn_cast<ConstantDataArray>(Var->getInitializer())) { + + HasStr2 = true; + Str2 = Array->getRawDataValues().str(); + + } + + } + + } + + } + + } + + // for the internal memcpy routine we only care for the second + // parameter and are not reporting anything. + if (isIntMemcpy == true) { + + if (HasStr2 == true) { + + Value * op2 = callInst->getArgOperand(2); + ConstantInt *ilen = dyn_cast<ConstantInt>(op2); + if (ilen) { + + uint64_t literalLength = Str2.size(); + uint64_t optLength = ilen->getZExtValue(); + if (literalLength + 1 == optLength) { + + Str2.append("\0", 1); // add null byte + + } + + } + + valueMap[Str1P] = new std::string(Str2); + + if (debug) + fprintf(stderr, "Saved: %s for %p\n", Str2.c_str(), + (void *)Str1P); + continue; + + } + + continue; + + } + + // Neither a literal nor a global variable? + // maybe it is a local variable that we saved + if (!HasStr2) { + + std::string *strng = valueMap[Str2P]; + if (strng && !strng->empty()) { + + Str2 = *strng; + HasStr2 = true; + if (debug) + fprintf(stderr, "Filled2: %s for %p\n", strng->c_str(), + (void *)Str2P); + + } + + } + + if (!HasStr1) { + + auto Ptr = dyn_cast<ConstantExpr>(Str1P); + + if (Ptr && Ptr->isGEPWithNoNotionalOverIndexing()) { + + if (auto *Var = dyn_cast<GlobalVariable>(Ptr->getOperand(0))) { + + if (Var->hasInitializer()) { + + if (auto *Array = + dyn_cast<ConstantDataArray>(Var->getInitializer())) { + + HasStr1 = true; + Str1 = Array->getRawDataValues().str(); + + } + + } + + } + + } + + } + + // Neither a literal nor a global variable? + // maybe it is a local variable that we saved + if (!HasStr1) { + + std::string *strng = valueMap[Str1P]; + if (strng && !strng->empty()) { + + Str1 = *strng; + HasStr1 = true; + if (debug) + fprintf(stderr, "Filled1: %s for %p\n", strng->c_str(), + (void *)Str1P); + + } + + } + + /* handle cases of one string is const, one string is variable */ + if (!(HasStr1 ^ HasStr2)) continue; + + std::string thestring; + + if (HasStr1) + thestring = Str1; + else + thestring = Str2; + + optLen = thestring.length(); + + if (optLen < 2 || (optLen == 2 && !thestring[1])) { continue; } + + if (isMemcmp || isStrncmp || isStrncasecmp) { + + Value * op2 = callInst->getArgOperand(2); + ConstantInt *ilen = dyn_cast<ConstantInt>(op2); + + if (ilen) { + + uint64_t literalLength = optLen; + optLen = ilen->getZExtValue(); + if (optLen < 2) { continue; } + if (literalLength + 1 == optLen) { // add null byte + thestring.append("\0", 1); + addedNull = true; + + } + + } + + } + + // add null byte if this is a string compare function and a null + // was not already added + if (!isMemcmp) { + + if (addedNull == false && thestring[optLen - 1] != '\0') { + + thestring.append("\0", 1); // add null byte + optLen++; + + } + + if (!isStdString) { + + // ensure we do not have garbage + size_t offset = thestring.find('\0', 0); + if (offset + 1 < optLen) optLen = offset + 1; + thestring = thestring.substr(0, optLen); + + } + + } + + // we take the longer string, even if the compare was to a + // shorter part. Note that depending on the optimizer of the + // compiler this can be wrong, but it is more likely that this + // is helping the fuzzer + if (optLen != thestring.length()) optLen = thestring.length(); + if (optLen > MAX_AUTO_EXTRA) optLen = MAX_AUTO_EXTRA; + if (optLen < 3) // too short? skip + continue; + + ptr = (char *)thestring.c_str(); + + dict2file(fd, (u8 *)ptr, optLen); + found++; + + } + + } + + } + + } + + close(fd); + + /* Say something nice. */ + + if (!be_quiet) { + + if (!found) + OKF("No entries for a dictionary found."); + else + OKF("Wrote %d entries to the dictionary file.\n", found); + + } + + return true; + +} + +char AFLdict2filePass::ID = 0; + +static void registerAFLdict2filePass(const PassManagerBuilder &, + legacy::PassManagerBase &PM) { + + PM.add(new AFLdict2filePass()); + +} + +static RegisterPass<AFLdict2filePass> X("afl-dict2file", + "afl++ dict2file instrumentation pass", + false, false); + +static RegisterStandardPasses RegisterAFLdict2filePass( + PassManagerBuilder::EP_OptimizerLast, registerAFLdict2filePass); + +static RegisterStandardPasses RegisterAFLdict2filePass0( + PassManagerBuilder::EP_EnabledOnOptLevel0, registerAFLdict2filePass); + diff --git a/llvm_mode/afl-llvm-lto-instrumentation.so.cc b/instrumentation/afl-llvm-lto-instrumentation.so.cc index 3c1d3565..50306224 100644 --- a/llvm_mode/afl-llvm-lto-instrumentation.so.cc +++ b/instrumentation/afl-llvm-lto-instrumentation.so.cc @@ -31,6 +31,7 @@ #include <string> #include <fstream> #include <set> +#include <iostream> #include "llvm/Config/llvm-config.h" #include "llvm/ADT/Statistic.h" @@ -49,6 +50,7 @@ #include "llvm/Analysis/MemorySSAUpdater.h" #include "llvm/Analysis/ValueTracking.h" #include "llvm/Pass.h" +#include "llvm/IR/Constants.h" #include "afl-llvm-common.h" @@ -67,8 +69,9 @@ class AFLLTOPass : public ModulePass { if (getenv("AFL_DEBUG")) debug = 1; if ((ptr = getenv("AFL_LLVM_LTO_STARTID")) != NULL) - if ((afl_global_id = atoi(ptr)) < 0 || afl_global_id >= MAP_SIZE) - FATAL("AFL_LLVM_LTO_STARTID value of \"%s\" is not between 0 and %d\n", + if ((afl_global_id = (uint32_t)atoi(ptr)) < 0 || + afl_global_id >= MAP_SIZE) + FATAL("AFL_LLVM_LTO_STARTID value of \"%s\" is not between 0 and %u\n", ptr, MAP_SIZE - 1); skip_nozero = getenv("AFL_LLVM_SKIP_NEVERZERO"); @@ -86,9 +89,9 @@ class AFLLTOPass : public ModulePass { bool runOnModule(Module &M) override; protected: - int afl_global_id = 1, debug = 0, autodictionary = 1; + uint32_t afl_global_id = 1, autodictionary = 1; uint32_t function_minimum_size = 1; - uint32_t be_quiet = 0, inst_blocks = 0, inst_funcs = 0, total_instr = 0; + uint32_t inst_blocks = 0, inst_funcs = 0, total_instr = 0; uint64_t map_addr = 0x10000; char * skip_nozero = NULL; @@ -98,11 +101,19 @@ class AFLLTOPass : public ModulePass { bool AFLLTOPass::runOnModule(Module &M) { - LLVMContext & C = M.getContext(); - std::vector<std::string> dictionary; - std::vector<CallInst *> calls; + LLVMContext & C = M.getContext(); + std::vector<std::string> dictionary; + // std::vector<CallInst *> calls; DenseMap<Value *, std::string *> valueMap; + std::vector<BasicBlock *> BlockList; char * ptr; + FILE * documentFile = NULL; + size_t found = 0; + + srand((unsigned int)time(NULL)); + + unsigned long long int moduleID = + (((unsigned long long int)(rand() & 0xffffffff)) << 32) | getpid(); IntegerType *Int8Ty = IntegerType::getInt8Ty(C); IntegerType *Int32Ty = IntegerType::getInt32Ty(C); @@ -120,11 +131,17 @@ bool AFLLTOPass::runOnModule(Module &M) { be_quiet = 1; - if (getenv("AFL_LLVM_MAP_DYNAMIC")) map_addr = 0; + if ((ptr = getenv("AFL_LLVM_DOCUMENT_IDS")) != NULL) { - if (getenv("AFL_LLVM_INSTRIM_SKIPSINGLEBLOCK") || - getenv("AFL_LLVM_SKIPSINGLEBLOCK")) - function_minimum_size = 2; + if ((documentFile = fopen(ptr, "a")) == NULL) + WARNF("Cannot access document file %s", ptr); + + } + + // we make this the default as the fixed map has problems with + // defered forkserver, early constructors, ifuncs and maybe more + /*if (getenv("AFL_LLVM_MAP_DYNAMIC"))*/ + map_addr = 0; if ((ptr = getenv("AFL_LLVM_MAP_ADDR"))) { @@ -133,7 +150,7 @@ bool AFLLTOPass::runOnModule(Module &M) { map_addr = 0; - } else if (map_addr == 0) { + } else if (getenv("AFL_LLVM_MAP_DYNAMIC")) { FATAL( "AFL_LLVM_MAP_ADDR and AFL_LLVM_MAP_DYNAMIC cannot be used together"); @@ -183,13 +200,39 @@ bool AFLLTOPass::runOnModule(Module &M) { ConstantInt *Zero = ConstantInt::get(Int8Ty, 0); ConstantInt *One = ConstantInt::get(Int8Ty, 1); + // This dumps all inialized global strings - might be useful in the future + /* + for (auto G=M.getGlobalList().begin(); G!=M.getGlobalList().end(); G++) { + + GlobalVariable &GV=*G; + if (!GV.getName().str().empty()) { + + fprintf(stderr, "Global Variable: %s", GV.getName().str().c_str()); + if (GV.hasInitializer()) + if (auto *Val = dyn_cast<ConstantDataArray>(GV.getInitializer())) + fprintf(stderr, " Value: \"%s\"", Val->getAsString().str().c_str()); + fprintf(stderr, "\n"); + + } + + } + + */ + + scanForDangerousFunctions(&M); + /* Instrument all the things! */ int inst_blocks = 0; for (auto &F : M) { - // fprintf(stderr, "DEBUG: Function %s\n", F.getName().str().c_str()); + /*For debugging + AttributeSet X = F.getAttributes().getFnAttributes(); + fprintf(stderr, "DEBUG: Module %s Function %s attributes %u\n", + M.getName().str().c_str(), F.getName().str().c_str(), + X.getNumAttributes()); + */ if (F.size() < function_minimum_size) continue; if (isIgnoreFunction(&F)) continue; @@ -200,7 +243,8 @@ bool AFLLTOPass::runOnModule(Module &M) { if (debug) fprintf(stderr, - "DEBUG: Function %s is not the instrument file listed\n", + "DEBUG: Function %s is not in a source file that was specified " + "in the instrument file list\n", F.getName().str().c_str()); continue; @@ -243,31 +287,142 @@ bool AFLLTOPass::runOnModule(Module &M) { for (auto &IN : BB) { CallInst *callInst = nullptr; + CmpInst * cmpInst = nullptr; + + if ((cmpInst = dyn_cast<CmpInst>(&IN))) { + + Value * op = cmpInst->getOperand(1); + ConstantInt *ilen = dyn_cast<ConstantInt>(op); + + if (ilen && ilen->uge(0xffffffffffffffff) == false) { + + u64 val2 = 0, val = ilen->getZExtValue(); + u32 len = 0; + if (val > 0x10000 && val < 0xffffffff) len = 4; + if (val > 0x100000001 && val < 0xffffffffffffffff) len = 8; + + if (len) { + + auto c = cmpInst->getPredicate(); + + switch (c) { + + case CmpInst::FCMP_OGT: // fall through + case CmpInst::FCMP_OLE: // fall through + case CmpInst::ICMP_SLE: // fall through + case CmpInst::ICMP_SGT: + + // signed comparison and it is a negative constant + if ((len == 4 && (val & 80000000)) || + (len == 8 && (val & 8000000000000000))) { + + if ((val & 0xffff) != 1) val2 = val - 1; + break; + + } + + // fall through + + case CmpInst::FCMP_UGT: // fall through + case CmpInst::FCMP_ULE: // fall through + case CmpInst::ICMP_UGT: // fall through + case CmpInst::ICMP_ULE: + if ((val & 0xffff) != 0xfffe) val2 = val + 1; + break; + + case CmpInst::FCMP_OLT: // fall through + case CmpInst::FCMP_OGE: // fall through + case CmpInst::ICMP_SLT: // fall through + case CmpInst::ICMP_SGE: + + // signed comparison and it is a negative constant + if ((len == 4 && (val & 80000000)) || + (len == 8 && (val & 8000000000000000))) { + + if ((val & 0xffff) != 1) val2 = val - 1; + break; + + } + + // fall through + + case CmpInst::FCMP_ULT: // fall through + case CmpInst::FCMP_UGE: // fall through + case CmpInst::ICMP_ULT: // fall through + case CmpInst::ICMP_UGE: + if ((val & 0xffff) != 1) val2 = val - 1; + break; + + default: + val2 = 0; + + } + + dictionary.push_back(std::string((char *)&val, len)); + found++; + + if (val2) { + + dictionary.push_back(std::string((char *)&val2, len)); + found++; + + } + + } + + } + + } if ((callInst = dyn_cast<CallInst>(&IN))) { - bool isStrcmp = true; - bool isMemcmp = true; - bool isStrncmp = true; - bool isStrcasecmp = true; - bool isStrncasecmp = true; - bool isIntMemcpy = true; - bool addedNull = false; - uint8_t optLen = 0; + bool isStrcmp = true; + bool isMemcmp = true; + bool isStrncmp = true; + bool isStrcasecmp = true; + bool isStrncasecmp = true; + bool isIntMemcpy = true; + bool isStdString = true; + bool addedNull = false; + size_t optLen = 0; Function *Callee = callInst->getCalledFunction(); if (!Callee) continue; if (callInst->getCallingConv() != llvm::CallingConv::C) continue; std::string FuncName = Callee->getName().str(); isStrcmp &= !FuncName.compare("strcmp"); - isMemcmp &= !FuncName.compare("memcmp"); + isMemcmp &= + (!FuncName.compare("memcmp") || !FuncName.compare("bcmp")); isStrncmp &= !FuncName.compare("strncmp"); isStrcasecmp &= !FuncName.compare("strcasecmp"); isStrncasecmp &= !FuncName.compare("strncasecmp"); isIntMemcpy &= !FuncName.compare("llvm.memcpy.p0i8.p0i8.i64"); + isStdString &= + ((FuncName.find("basic_string") != std::string::npos && + FuncName.find("compare") != std::string::npos) || + (FuncName.find("basic_string") != std::string::npos && + FuncName.find("find") != std::string::npos)); + + /* we do something different here, putting this BB and the + successors in a block map */ + if (!FuncName.compare("__afl_persistent_loop")) { + + BlockList.push_back(&BB); + /* + for (succ_iterator SI = succ_begin(&BB), SE = + succ_end(&BB); SI != SE; ++SI) { + + BasicBlock *succ = *SI; + BlockList.push_back(succ); + + } + + */ + + } if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && - !isStrncasecmp && !isIntMemcpy) + !isStrncasecmp && !isIntMemcpy && !isStdString) continue; /* Verify the strcmp/memcmp/strncmp/strcasecmp/strncasecmp function @@ -301,9 +456,12 @@ bool AFLLTOPass::runOnModule(Module &M) { FT->getParamType(0) == IntegerType::getInt8PtrTy(M.getContext()) && FT->getParamType(2)->isIntegerTy(); + isStdString &= FT->getNumParams() >= 2 && + FT->getParamType(0)->isPointerTy() && + FT->getParamType(1)->isPointerTy(); if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && - !isStrncasecmp && !isIntMemcpy) + !isStrncasecmp && !isIntMemcpy && !isStdString) continue; /* is a str{n,}{case,}cmp/memcmp, check if we have @@ -314,17 +472,32 @@ bool AFLLTOPass::runOnModule(Module &M) { *Str2P = callInst->getArgOperand(1); std::string Str1, Str2; StringRef TmpStr; - bool HasStr1 = getConstantStringInfo(Str1P, TmpStr); - if (TmpStr.empty()) + bool HasStr1; + getConstantStringInfo(Str1P, TmpStr); + if (TmpStr.empty()) { + HasStr1 = false; - else + + } else { + + HasStr1 = true; Str1 = TmpStr.str(); - bool HasStr2 = getConstantStringInfo(Str2P, TmpStr); - if (TmpStr.empty()) + + } + + bool HasStr2; + getConstantStringInfo(Str2P, TmpStr); + if (TmpStr.empty()) { + HasStr2 = false; - else + + } else { + + HasStr2 = true; Str2 = TmpStr.str(); + } + if (debug) fprintf(stderr, "F:%s %p(%s)->\"%s\"(%s) %p(%s)->\"%s\"(%s)\n", FuncName.c_str(), Str1P, Str1P->getName().str().c_str(), @@ -346,7 +519,7 @@ bool AFLLTOPass::runOnModule(Module &M) { Var->getInitializer())) { HasStr2 = true; - Str2 = Array->getAsString().str(); + Str2 = Array->getRawDataValues().str(); } @@ -373,7 +546,7 @@ bool AFLLTOPass::runOnModule(Module &M) { if (literalLength + 1 == optLength) { Str2.append("\0", 1); // add null byte - addedNull = true; + // addedNull = true; } @@ -422,7 +595,7 @@ bool AFLLTOPass::runOnModule(Module &M) { Var->getInitializer())) { HasStr1 = true; - Str1 = Array->getAsString().str(); + Str1 = Array->getRawDataValues().str(); } @@ -462,15 +635,18 @@ bool AFLLTOPass::runOnModule(Module &M) { thestring = Str2; optLen = thestring.length(); + if (optLen < 2 || (optLen == 2 && !thestring[1])) { continue; } if (isMemcmp || isStrncmp || isStrncasecmp) { Value * op2 = callInst->getArgOperand(2); ConstantInt *ilen = dyn_cast<ConstantInt>(op2); + if (ilen) { uint64_t literalLength = optLen; optLen = ilen->getZExtValue(); + if (optLen < 2) { continue; } if (literalLength + 1 == optLen) { // add null byte thestring.append("\0", 1); addedNull = true; @@ -483,18 +659,30 @@ bool AFLLTOPass::runOnModule(Module &M) { // add null byte if this is a string compare function and a null // was not already added - if (addedNull == false && !isMemcmp) { + if (!isMemcmp) { + + if (addedNull == false && thestring[optLen - 1] != '\0') { + + thestring.append("\0", 1); // add null byte + optLen++; + + } + + if (!isStdString) { - thestring.append("\0", 1); // add null byte - optLen++; + // ensure we do not have garbage + size_t offset = thestring.find('\0', 0); + if (offset + 1 < optLen) optLen = offset + 1; + thestring = thestring.substr(0, optLen); + + } } if (!be_quiet) { - std::string outstring; - fprintf(stderr, "%s: length %u/%u \"", FuncName.c_str(), optLen, - (unsigned int)thestring.length()); + fprintf(stderr, "%s: length %zu/%zu \"", FuncName.c_str(), optLen, + thestring.length()); for (uint8_t i = 0; i < thestring.length(); i++) { uint8_t c = thestring[i]; @@ -530,15 +718,41 @@ bool AFLLTOPass::runOnModule(Module &M) { for (auto &BB : F) { - uint32_t succ = 0; + if (F.size() == 1) { + + InsBlocks.push_back(&BB); + continue; + + } + uint32_t succ = 0; for (succ_iterator SI = succ_begin(&BB), SE = succ_end(&BB); SI != SE; ++SI) if ((*SI)->size() > 0) succ++; - if (succ < 2) // no need to instrument continue; + if (BlockList.size()) { + + int skip = 0; + for (uint32_t k = 0; k < BlockList.size(); k++) { + + if (&BB == BlockList[k]) { + + if (debug) + fprintf(stderr, + "DEBUG: Function %s skipping BB with/after __afl_loop\n", + F.getName().str().c_str()); + skip = 1; + + } + + } + + if (skip) continue; + + } + InsBlocks.push_back(&BB); } @@ -550,9 +764,12 @@ bool AFLLTOPass::runOnModule(Module &M) { do { --i; + BasicBlock * newBB = NULL; BasicBlock * origBB = &(*InsBlocks[i]); std::vector<BasicBlock *> Successors; Instruction * TI = origBB->getTerminator(); + uint32_t fs = origBB->getParent()->size(); + uint32_t countto; for (succ_iterator SI = succ_begin(origBB), SE = succ_end(origBB); SI != SE; ++SI) { @@ -562,15 +779,25 @@ bool AFLLTOPass::runOnModule(Module &M) { } - if (TI == NULL || TI->getNumSuccessors() < 2) continue; + if (fs == 1) { + + newBB = origBB; + countto = 1; + + } else { + + if (TI == NULL || TI->getNumSuccessors() < 2) continue; + countto = Successors.size(); + + } // if (Successors.size() != TI->getNumSuccessors()) // FATAL("Different successor numbers %lu <-> %u\n", Successors.size(), // TI->getNumSuccessors()); - for (uint32_t j = 0; j < Successors.size(); j++) { + for (uint32_t j = 0; j < countto; j++) { - BasicBlock *newBB = llvm::SplitEdge(origBB, Successors[j]); + if (fs != 1) newBB = llvm::SplitEdge(origBB, Successors[j]); if (!newBB) { @@ -579,6 +806,13 @@ bool AFLLTOPass::runOnModule(Module &M) { } + if (documentFile) { + + fprintf(documentFile, "ModuleID=%llu Function=%s edgeID=%u\n", + moduleID, F.getName().str().c_str(), afl_global_id); + + } + BasicBlock::iterator IP = newBB->getFirstInsertionPt(); IRBuilder<> IRB(&(*IP)); @@ -611,7 +845,7 @@ bool AFLLTOPass::runOnModule(Module &M) { Value *Incr = IRB.CreateAdd(Counter, One); - if (skip_nozero) { + if (skip_nozero == NULL) { auto cf = IRB.CreateICmpEQ(Incr, Zero); auto carry = IRB.CreateZExt(cf, Int8Ty); @@ -634,6 +868,9 @@ bool AFLLTOPass::runOnModule(Module &M) { } + if (documentFile) fclose(documentFile); + documentFile = NULL; + // save highest location ID to global variable // do this after each function to fail faster if (!be_quiet && afl_global_id > MAP_SIZE && @@ -644,7 +881,7 @@ bool AFLLTOPass::runOnModule(Module &M) { pow2map++; WARNF( "We have %u blocks to instrument but the map size is only %u. Either " - "edit config.h and set MAP_SIZE_POW2 from %u to %u, then recompile " + "edit config.h and set MAP_SIZE_POW2 from %d to %u, then recompile " "afl-fuzz and llvm_mode and then make this target - or set " "AFL_MAP_SIZE with at least size %u when running afl-fuzz with this " "target.", @@ -694,9 +931,7 @@ bool AFLLTOPass::runOnModule(Module &M) { if (getenv("AFL_LLVM_LTO_DONTWRITEID") == NULL) { - uint32_t write_loc = afl_global_id; - - if (afl_global_id % 8) write_loc = (((afl_global_id + 8) >> 3) << 3); + uint32_t write_loc = (((afl_global_id + 63) >> 6) << 6); GlobalVariable *AFLFinalLoc = new GlobalVariable( M, Int32Ty, true, GlobalValue::ExternalLinkage, 0, "__afl_final_loc"); @@ -709,8 +944,12 @@ bool AFLLTOPass::runOnModule(Module &M) { if (dictionary.size()) { - size_t memlen = 0, count = 0, offset = 0; - char * ptr; + size_t memlen = 0, count = 0; + + // sort and unique the dictionary + std::sort(dictionary.begin(), dictionary.end()); + auto last = std::unique(dictionary.begin(), dictionary.end()); + dictionary.erase(last, dictionary.end()); for (auto token : dictionary) { @@ -720,14 +959,14 @@ bool AFLLTOPass::runOnModule(Module &M) { } if (!be_quiet) - printf("AUTODICTIONARY: %lu string%s found\n", count, + printf("AUTODICTIONARY: %zu string%s found\n", count, count == 1 ? "" : "s"); if (count) { if ((ptr = (char *)malloc(memlen + count)) == NULL) { - fprintf(stderr, "Error: malloc for %lu bytes failed!\n", + fprintf(stderr, "Error: malloc for %zu bytes failed!\n", memlen + count); exit(-1); @@ -735,6 +974,7 @@ bool AFLLTOPass::runOnModule(Module &M) { count = 0; + size_t offset = 0; for (auto token : dictionary) { if (offset + token.length() < 0xfffff0 && count < MAX_AUTO_EXTRAS) { @@ -798,8 +1038,8 @@ bool AFLLTOPass::runOnModule(Module &M) { getenv("AFL_USE_MSAN") ? ", MSAN" : "", getenv("AFL_USE_CFISAN") ? ", CFISAN" : "", getenv("AFL_USE_UBSAN") ? ", UBSAN" : ""); - OKF("Instrumented %u locations with no collisions (on average %llu " - "collisions would be in afl-gcc/afl-clang-fast) (%s mode).", + OKF("Instrumented %d locations with no collisions (on average %llu " + "collisions would be in afl-gcc/vanilla AFL) (%s mode).", inst_blocks, calculateCollisions(inst_blocks), modeline); } diff --git a/instrumentation/afl-llvm-lto-instrumentlist.so.cc b/instrumentation/afl-llvm-lto-instrumentlist.so.cc new file mode 100644 index 00000000..416dbb88 --- /dev/null +++ b/instrumentation/afl-llvm-lto-instrumentlist.so.cc @@ -0,0 +1,146 @@ +/* + american fuzzy lop++ - LLVM-mode instrumentation pass + --------------------------------------------------- + + Written by Laszlo Szekeres <lszekeres@google.com> and + Michal Zalewski + + LLVM integration design comes from Laszlo Szekeres. C bits copied-and-pasted + from afl-as.c are Michal's fault. + + Copyright 2015, 2016 Google Inc. All rights reserved. + Copyright 2019-2020 AFLplusplus Project. All rights reserved. + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at: + + http://www.apache.org/licenses/LICENSE-2.0 + + This library is plugged into LLVM when invoking clang through afl-clang-fast. + It tells the compiler to add code roughly equivalent to the bits discussed + in ../afl-as.h. + + */ + +#define AFL_LLVM_PASS + +#include "config.h" +#include "debug.h" + +#include <stdio.h> +#include <stdlib.h> +#include <unistd.h> + +#include <list> +#include <string> +#include <fstream> +#include <sys/time.h> +#include <fnmatch.h> + +#include "llvm/IR/DebugInfo.h" +#include "llvm/IR/BasicBlock.h" +#include "llvm/IR/IRBuilder.h" +#include "llvm/IR/LegacyPassManager.h" +#include "llvm/IR/Module.h" +#include "llvm/Support/Debug.h" +#include "llvm/Transforms/IPO/PassManagerBuilder.h" +#include "llvm/IR/CFG.h" + +#include "afl-llvm-common.h" + +using namespace llvm; + +namespace { + +class AFLcheckIfInstrument : public ModulePass { + + public: + static char ID; + AFLcheckIfInstrument() : ModulePass(ID) { + + if (getenv("AFL_DEBUG")) debug = 1; + + initInstrumentList(); + + } + + bool runOnModule(Module &M) override; + + // StringRef getPassName() const override { + + // return "American Fuzzy Lop Instrumentation"; + // } + + protected: + std::list<std::string> myInstrumentList; + +}; + +} // namespace + +char AFLcheckIfInstrument::ID = 0; + +bool AFLcheckIfInstrument::runOnModule(Module &M) { + + /* Show a banner */ + + setvbuf(stdout, NULL, _IONBF, 0); + + if ((isatty(2) && !getenv("AFL_QUIET")) || getenv("AFL_DEBUG") != NULL) { + + SAYF(cCYA "afl-llvm-lto-instrumentlist" VERSION cRST + " by Marc \"vanHauser\" Heuse <mh@mh-sec.de>\n"); + + } else if (getenv("AFL_QUIET")) + + be_quiet = 1; + + for (auto &F : M) { + + if (F.size() < 1) continue; + + // fprintf(stderr, "F:%s\n", F.getName().str().c_str()); + + if (isInInstrumentList(&F)) { + + if (debug) + DEBUGF("function %s is in the instrument file list\n", + F.getName().str().c_str()); + + } else { + + if (debug) + DEBUGF("function %s is NOT in the instrument file list\n", + F.getName().str().c_str()); + + auto & Ctx = F.getContext(); + AttributeList Attrs = F.getAttributes(); + AttrBuilder NewAttrs; + NewAttrs.addAttribute("skipinstrument"); + F.setAttributes( + Attrs.addAttributes(Ctx, AttributeList::FunctionIndex, NewAttrs)); + + } + + } + + return true; + +} + +static void registerAFLcheckIfInstrumentpass(const PassManagerBuilder &, + legacy::PassManagerBase &PM) { + + PM.add(new AFLcheckIfInstrument()); + +} + +static RegisterStandardPasses RegisterAFLcheckIfInstrumentpass( + PassManagerBuilder::EP_ModuleOptimizerEarly, + registerAFLcheckIfInstrumentpass); + +static RegisterStandardPasses RegisterAFLcheckIfInstrumentpass0( + PassManagerBuilder::EP_EnabledOnOptLevel0, + registerAFLcheckIfInstrumentpass); + diff --git a/llvm_mode/afl-llvm-pass.so.cc b/instrumentation/afl-llvm-pass.so.cc index 90cf3eb4..0f773aba 100644 --- a/llvm_mode/afl-llvm-pass.so.cc +++ b/instrumentation/afl-llvm-pass.so.cc @@ -62,7 +62,7 @@ typedef long double max_align_t; #endif #include "afl-llvm-common.h" -#include "llvm-ngram-coverage.h" +#include "llvm-alternative-coverage.h" using namespace llvm; @@ -82,10 +82,10 @@ class AFLCoverage : public ModulePass { protected: uint32_t ngram_size = 0; - uint32_t debug = 0; + uint32_t ctx_k = 0; uint32_t map_size = MAP_SIZE; uint32_t function_minimum_size = 1; - char * ctx_str = NULL, *skip_nozero = NULL; + char * ctx_str = NULL, *caller_str = NULL, *skip_nozero = NULL; }; @@ -113,7 +113,7 @@ uint64_t PowerOf2Ceil(unsigned in) { #endif /* #if LLVM_VERSION_STRING >= "4.0.1" */ -#if LLVM_VERSION_MAJOR >= 4 || \ +#if LLVM_VERSION_MAJOR > 4 || \ (LLVM_VERSION_MAJOR == 4 && LLVM_VERSION_PATCH >= 1) #define AFL_HAVE_VECTOR_INTRINSICS 1 #endif @@ -139,7 +139,6 @@ bool AFLCoverage::runOnModule(Module &M) { /* Show a banner */ - char be_quiet = 0; setvbuf(stdout, NULL, _IONBF, 0); if (getenv("AFL_DEBUG")) debug = 1; @@ -184,19 +183,21 @@ bool AFLCoverage::runOnModule(Module &M) { #endif skip_nozero = getenv("AFL_LLVM_SKIP_NEVERZERO"); - if (getenv("AFL_LLVM_INSTRIM_SKIPSINGLEBLOCK") || - getenv("AFL_LLVM_SKIPSINGLEBLOCK")) - function_minimum_size = 2; - unsigned PrevLocSize = 0; + unsigned PrevCallerSize = 0; char *ngram_size_str = getenv("AFL_LLVM_NGRAM_SIZE"); if (!ngram_size_str) ngram_size_str = getenv("AFL_NGRAM_SIZE"); + char *ctx_k_str = getenv("AFL_LLVM_CTX_K"); + if (!ctx_k_str) ctx_k_str = getenv("AFL_CTX_K"); ctx_str = getenv("AFL_LLVM_CTX"); + caller_str = getenv("AFL_LLVM_CALLER"); + + bool instrument_ctx = ctx_str || caller_str; #ifdef AFL_HAVE_VECTOR_INTRINSICS /* Decide previous location vector size (must be a power of two) */ - VectorType *PrevLocTy; + VectorType *PrevLocTy = NULL; if (ngram_size_str) if (sscanf(ngram_size_str, "%u", &ngram_size) != 1 || ngram_size < 2 || @@ -210,6 +211,31 @@ bool AFLCoverage::runOnModule(Module &M) { if (ngram_size) PrevLocSize = ngram_size - 1; else + PrevLocSize = 1; + + /* Decide K-ctx vector size (must be a power of two) */ + VectorType *PrevCallerTy = NULL; + + if (ctx_k_str) + if (sscanf(ctx_k_str, "%u", &ctx_k) != 1 || ctx_k < 1 || ctx_k > CTX_MAX_K) + FATAL("Bad value of AFL_CTX_K (must be between 1 and CTX_MAX_K (%u))", + CTX_MAX_K); + + if (ctx_k == 1) { + + ctx_k = 0; + instrument_ctx = true; + caller_str = ctx_k_str; // Enable CALLER instead + + } + + if (ctx_k) { + + PrevCallerSize = ctx_k; + instrument_ctx = true; + + } + #else if (ngram_size_str) #ifndef LLVM_VERSION_PATCH @@ -223,12 +249,41 @@ bool AFLCoverage::runOnModule(Module &M) { "%d.%d.%d!", LLVM_VERSION_MAJOR, LLVM_VERSION_MINOR, LLVM_VERSION_PATCH); #endif + if (ctx_k_str) + #ifndef LLVM_VERSION_PATCH + FATAL( + "Sorry, K-CTX branch coverage is not supported with llvm version " + "%d.%d.%d!", + LLVM_VERSION_MAJOR, LLVM_VERSION_MINOR, 0); + #else + FATAL( + "Sorry, K-CTX branch coverage is not supported with llvm version " + "%d.%d.%d!", + LLVM_VERSION_MAJOR, LLVM_VERSION_MINOR, LLVM_VERSION_PATCH); + #endif + PrevLocSize = 1; +#endif + +#ifdef AFL_HAVE_VECTOR_INTRINSICS + int PrevLocVecSize = PowerOf2Ceil(PrevLocSize); + if (ngram_size) + PrevLocTy = VectorType::get(IntLocTy, PrevLocVecSize + #if LLVM_VERSION_MAJOR >= 12 + , + false + #endif + ); #endif - PrevLocSize = 1; #ifdef AFL_HAVE_VECTOR_INTRINSICS - uint64_t PrevLocVecSize = PowerOf2Ceil(PrevLocSize); - if (ngram_size) PrevLocTy = VectorType::get(IntLocTy, PrevLocVecSize); + int PrevCallerVecSize = PowerOf2Ceil(PrevCallerSize); + if (ctx_k) + PrevCallerTy = VectorType::get(IntLocTy, PrevCallerVecSize + #if LLVM_VERSION_MAJOR >= 12 + , + false + #endif + ); #endif /* Get globals for the SHM region and the previous location. Note that @@ -238,10 +293,11 @@ bool AFLCoverage::runOnModule(Module &M) { new GlobalVariable(M, PointerType::get(Int8Ty, 0), false, GlobalValue::ExternalLinkage, 0, "__afl_area_ptr"); GlobalVariable *AFLPrevLoc; - GlobalVariable *AFLContext; + GlobalVariable *AFLPrevCaller; + GlobalVariable *AFLContext = NULL; - if (ctx_str) -#ifdef __ANDROID__ + if (ctx_str || caller_str) +#if defined(__ANDROID__) || defined(__HAIKU__) AFLContext = new GlobalVariable( M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_ctx"); #else @@ -252,7 +308,7 @@ bool AFLCoverage::runOnModule(Module &M) { #ifdef AFL_HAVE_VECTOR_INTRINSICS if (ngram_size) - #ifdef __ANDROID__ + #if defined(__ANDROID__) || defined(__HAIKU__) AFLPrevLoc = new GlobalVariable( M, PrevLocTy, /* isConstant */ false, GlobalValue::ExternalLinkage, /* Initializer */ nullptr, "__afl_prev_loc"); @@ -265,7 +321,7 @@ bool AFLCoverage::runOnModule(Module &M) { #endif else #endif -#ifdef __ANDROID__ +#if defined(__ANDROID__) || defined(__HAIKU__) AFLPrevLoc = new GlobalVariable( M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_loc"); #else @@ -275,6 +331,31 @@ bool AFLCoverage::runOnModule(Module &M) { #endif #ifdef AFL_HAVE_VECTOR_INTRINSICS + if (ctx_k) + #if defined(__ANDROID__) || defined(__HAIKU__) + AFLPrevCaller = new GlobalVariable( + M, PrevCallerTy, /* isConstant */ false, GlobalValue::ExternalLinkage, + /* Initializer */ nullptr, "__afl_prev_caller"); + #else + AFLPrevCaller = new GlobalVariable( + M, PrevCallerTy, /* isConstant */ false, GlobalValue::ExternalLinkage, + /* Initializer */ nullptr, "__afl_prev_caller", + /* InsertBefore */ nullptr, GlobalVariable::GeneralDynamicTLSModel, + /* AddressSpace */ 0, /* IsExternallyInitialized */ false); + #endif + else +#endif +#if defined(__ANDROID__) || defined(__HAIKU__) + AFLPrevCaller = + new GlobalVariable(M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, + "__afl_prev_caller"); +#else + AFLPrevCaller = new GlobalVariable( + M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_caller", + 0, GlobalVariable::GeneralDynamicTLSModel, 0, false); +#endif + +#ifdef AFL_HAVE_VECTOR_INTRINSICS /* Create the vector shuffle mask for updating the previous block history. Note that the first element of the vector will store cur_loc, so just set it to undef to allow the optimizer to do its thing. */ @@ -284,21 +365,39 @@ bool AFLCoverage::runOnModule(Module &M) { for (unsigned I = 0; I < PrevLocSize - 1; ++I) PrevLocShuffle.push_back(ConstantInt::get(Int32Ty, I)); - for (unsigned I = PrevLocSize; I < PrevLocVecSize; ++I) + for (int I = PrevLocSize; I < PrevLocVecSize; ++I) PrevLocShuffle.push_back(ConstantInt::get(Int32Ty, PrevLocSize)); Constant *PrevLocShuffleMask = ConstantVector::get(PrevLocShuffle); + + Constant * PrevCallerShuffleMask = NULL; + SmallVector<Constant *, 32> PrevCallerShuffle = {UndefValue::get(Int32Ty)}; + + if (ctx_k) { + + for (unsigned I = 0; I < PrevCallerSize - 1; ++I) + PrevCallerShuffle.push_back(ConstantInt::get(Int32Ty, I)); + + for (int I = PrevCallerSize; I < PrevCallerVecSize; ++I) + PrevCallerShuffle.push_back(ConstantInt::get(Int32Ty, PrevCallerSize)); + + PrevCallerShuffleMask = ConstantVector::get(PrevCallerShuffle); + + } + #endif // other constants we need ConstantInt *Zero = ConstantInt::get(Int8Ty, 0); ConstantInt *One = ConstantInt::get(Int8Ty, 1); - LoadInst *PrevCtx; // CTX sensitive coverage + Value * PrevCtx = NULL; // CTX sensitive coverage + LoadInst *PrevCaller = NULL; // K-CTX coverage /* Instrument all the things! */ int inst_blocks = 0; + scanForDangerousFunctions(&M); for (auto &F : M) { @@ -317,19 +416,37 @@ bool AFLCoverage::runOnModule(Module &M) { IRBuilder<> IRB(&(*IP)); // Context sensitive coverage - if (ctx_str && &BB == &F.getEntryBlock()) { + if (instrument_ctx && &BB == &F.getEntryBlock()) { + +#ifdef AFL_HAVE_VECTOR_INTRINSICS + if (ctx_k) { + + PrevCaller = IRB.CreateLoad(AFLPrevCaller); + PrevCaller->setMetadata(M.getMDKindID("nosanitize"), + MDNode::get(C, None)); + PrevCtx = + IRB.CreateZExt(IRB.CreateXorReduce(PrevCaller), IRB.getInt32Ty()); + + } else + +#endif + { - // load the context ID of the previous function and write to to a local - // variable on the stack - PrevCtx = IRB.CreateLoad(AFLContext); - PrevCtx->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); + // load the context ID of the previous function and write to to a + // local variable on the stack + LoadInst *PrevCtxLoad = IRB.CreateLoad(AFLContext); + PrevCtxLoad->setMetadata(M.getMDKindID("nosanitize"), + MDNode::get(C, None)); + PrevCtx = PrevCtxLoad; + + } // does the function have calls? and is any of the calls larger than one // basic block? - for (auto &BB : F) { + for (auto &BB_2 : F) { if (has_calls) break; - for (auto &IN : BB) { + for (auto &IN : BB_2) { CallInst *callInst = nullptr; if ((callInst = dyn_cast<CallInst>(&IN))) { @@ -353,10 +470,32 @@ bool AFLCoverage::runOnModule(Module &M) { // if yes we store a context ID for this function in the global var if (has_calls) { - ConstantInt *NewCtx = ConstantInt::get(Int32Ty, AFL_R(map_size)); - StoreInst * StoreCtx = IRB.CreateStore(NewCtx, AFLContext); - StoreCtx->setMetadata(M.getMDKindID("nosanitize"), - MDNode::get(C, None)); + Value *NewCtx = ConstantInt::get(Int32Ty, AFL_R(map_size)); +#ifdef AFL_HAVE_VECTOR_INTRINSICS + if (ctx_k) { + + Value *ShuffledPrevCaller = IRB.CreateShuffleVector( + PrevCaller, UndefValue::get(PrevCallerTy), + PrevCallerShuffleMask); + Value *UpdatedPrevCaller = IRB.CreateInsertElement( + ShuffledPrevCaller, NewCtx, (uint64_t)0); + + StoreInst *Store = + IRB.CreateStore(UpdatedPrevCaller, AFLPrevCaller); + Store->setMetadata(M.getMDKindID("nosanitize"), + MDNode::get(C, None)); + + } else + +#endif + { + + if (ctx_str) NewCtx = IRB.CreateXor(PrevCtx, NewCtx); + StoreInst *StoreCtx = IRB.CreateStore(NewCtx, AFLContext); + StoreCtx->setMetadata(M.getMDKindID("nosanitize"), + MDNode::get(C, None)); + + } } @@ -410,13 +549,20 @@ bool AFLCoverage::runOnModule(Module &M) { // in CTX mode we have to restore the original context for the caller - // she might be calling other functions which need the correct CTX - if (ctx_str && has_calls) { + if (instrument_ctx && has_calls) { Instruction *Inst = BB.getTerminator(); if (isa<ReturnInst>(Inst) || isa<ResumeInst>(Inst)) { IRBuilder<> Post_IRB(Inst); - StoreInst * RestoreCtx = Post_IRB.CreateStore(PrevCtx, AFLContext); + + StoreInst *RestoreCtx; + #ifdef AFL_HAVE_VECTOR_INTRINSICS + if (ctx_k) + RestoreCtx = IRB.CreateStore(PrevCaller, AFLPrevCaller); + else + #endif + RestoreCtx = Post_IRB.CreateStore(PrevCtx, AFLContext); RestoreCtx->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); @@ -457,7 +603,7 @@ bool AFLCoverage::runOnModule(Module &M) { #endif PrevLocTrans = PrevLoc; - if (ctx_str) + if (instrument_ctx) PrevLocTrans = IRB.CreateZExt(IRB.CreateXor(PrevLocTrans, PrevCtx), Int32Ty); else @@ -537,19 +683,27 @@ bool AFLCoverage::runOnModule(Module &M) { Store = IRB.CreateStore(ConstantInt::get(Int32Ty, cur_loc >> 1), AFLPrevLoc); + Store->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); } // in CTX mode we have to restore the original context for the caller - // she might be calling other functions which need the correct CTX. // Currently this is only needed for the Ubuntu clang-6.0 bug - if (ctx_str && has_calls) { + if (instrument_ctx && has_calls) { Instruction *Inst = BB.getTerminator(); if (isa<ReturnInst>(Inst) || isa<ResumeInst>(Inst)) { IRBuilder<> Post_IRB(Inst); - StoreInst * RestoreCtx = Post_IRB.CreateStore(PrevCtx, AFLContext); + + StoreInst *RestoreCtx; +#ifdef AFL_HAVE_VECTOR_INTRINSICS + if (ctx_k) + RestoreCtx = IRB.CreateStore(PrevCaller, AFLPrevCaller); + else +#endif + RestoreCtx = Post_IRB.CreateStore(PrevCtx, AFLContext); RestoreCtx->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); @@ -627,7 +781,7 @@ bool AFLCoverage::runOnModule(Module &M) { getenv("AFL_USE_MSAN") ? ", MSAN" : "", getenv("AFL_USE_CFISAN") ? ", CFISAN" : "", getenv("AFL_USE_UBSAN") ? ", UBSAN" : ""); - OKF("Instrumented %u locations (%s mode, ratio %u%%).", inst_blocks, + OKF("Instrumented %d locations (%s mode, ratio %u%%).", inst_blocks, modeline, inst_ratio); } diff --git a/llvm_mode/afl-llvm-rt-lto.o.c b/instrumentation/afl-llvm-rt-lto.o.c index e53785ff..e53785ff 100644 --- a/llvm_mode/afl-llvm-rt-lto.o.c +++ b/instrumentation/afl-llvm-rt-lto.o.c diff --git a/instrumentation/cmplog-instructions-pass.cc b/instrumentation/cmplog-instructions-pass.cc new file mode 100644 index 00000000..ad334d3b --- /dev/null +++ b/instrumentation/cmplog-instructions-pass.cc @@ -0,0 +1,643 @@ +/* + american fuzzy lop++ - LLVM CmpLog instrumentation + -------------------------------------------------- + + Written by Andrea Fioraldi <andreafioraldi@gmail.com> + + Copyright 2015, 2016 Google Inc. All rights reserved. + Copyright 2019-2020 AFLplusplus Project. All rights reserved. + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at: + + http://www.apache.org/licenses/LICENSE-2.0 + +*/ + +#include <stdio.h> +#include <stdlib.h> +#include <unistd.h> + +#include <iostream> +#include <list> +#include <string> +#include <fstream> +#include <sys/time.h> + +#include "llvm/Config/llvm-config.h" +#include "llvm/ADT/Statistic.h" +#include "llvm/IR/IRBuilder.h" +#include "llvm/IR/LegacyPassManager.h" +#include "llvm/IR/Module.h" +#include "llvm/Support/Debug.h" +#include "llvm/Support/raw_ostream.h" +#include "llvm/Transforms/IPO/PassManagerBuilder.h" +#include "llvm/Transforms/Utils/BasicBlockUtils.h" +#include "llvm/Pass.h" +#include "llvm/Analysis/ValueTracking.h" + +#if LLVM_VERSION_MAJOR > 3 || \ + (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR > 4) + #include "llvm/IR/Verifier.h" + #include "llvm/IR/DebugInfo.h" +#else + #include "llvm/Analysis/Verifier.h" + #include "llvm/DebugInfo.h" + #define nullptr 0 +#endif + +#include <set> +#include "afl-llvm-common.h" + +using namespace llvm; + +namespace { + +class CmpLogInstructions : public ModulePass { + + public: + static char ID; + CmpLogInstructions() : ModulePass(ID) { + + initInstrumentList(); + + } + + bool runOnModule(Module &M) override; + +#if LLVM_VERSION_MAJOR < 4 + const char *getPassName() const override { + +#else + StringRef getPassName() const override { + +#endif + return "cmplog instructions"; + + } + + private: + bool hookInstrs(Module &M); + +}; + +} // namespace + +char CmpLogInstructions::ID = 0; + +template <class Iterator> +Iterator Unique(Iterator first, Iterator last) { + + while (first != last) { + + Iterator next(first); + last = std::remove(++next, last, *first); + first = next; + + } + + return last; + +} + +bool CmpLogInstructions::hookInstrs(Module &M) { + + std::vector<Instruction *> icomps; + std::vector<SwitchInst *> switches; + LLVMContext & C = M.getContext(); + + Type * VoidTy = Type::getVoidTy(C); + IntegerType *Int8Ty = IntegerType::getInt8Ty(C); + IntegerType *Int16Ty = IntegerType::getInt16Ty(C); + IntegerType *Int32Ty = IntegerType::getInt32Ty(C); + IntegerType *Int64Ty = IntegerType::getInt64Ty(C); + IntegerType *Int128Ty = IntegerType::getInt128Ty(C); + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c1 = M.getOrInsertFunction("__cmplog_ins_hook1", VoidTy, Int8Ty, Int8Ty, + Int8Ty +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogHookIns1 = cast<Function>(c1); +#else + FunctionCallee cmplogHookIns1 = c1; +#endif + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c2 = M.getOrInsertFunction("__cmplog_ins_hook2", VoidTy, Int16Ty, Int16Ty, + Int8Ty +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogHookIns2 = cast<Function>(c2); +#else + FunctionCallee cmplogHookIns2 = c2; +#endif + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c4 = M.getOrInsertFunction("__cmplog_ins_hook4", VoidTy, Int32Ty, Int32Ty, + Int8Ty +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogHookIns4 = cast<Function>(c4); +#else + FunctionCallee cmplogHookIns4 = c4; +#endif + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c8 = M.getOrInsertFunction("__cmplog_ins_hook8", VoidTy, Int64Ty, Int64Ty, + Int8Ty +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogHookIns8 = cast<Function>(c8); +#else + FunctionCallee cmplogHookIns8 = c8; +#endif + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c16 = M.getOrInsertFunction("__cmplog_ins_hook16", VoidTy, Int128Ty, + Int128Ty, Int8Ty +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogHookIns16 = cast<Function>(c16); +#else + FunctionCallee cmplogHookIns16 = c16; +#endif + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + cN = M.getOrInsertFunction("__cmplog_ins_hookN", VoidTy, Int128Ty, + Int128Ty, Int8Ty, Int8Ty +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogHookInsN = cast<Function>(cN); +#else + FunctionCallee cmplogHookInsN = cN; +#endif + + /* iterate over all functions, bbs and instruction and add suitable calls */ + for (auto &F : M) { + + if (!isInInstrumentList(&F)) continue; + + for (auto &BB : F) { + + for (auto &IN : BB) { + + CmpInst *selectcmpInst = nullptr; + if ((selectcmpInst = dyn_cast<CmpInst>(&IN))) { + + icomps.push_back(selectcmpInst); + + } + + SwitchInst *switchInst = nullptr; + if ((switchInst = dyn_cast<SwitchInst>(BB.getTerminator()))) { + + if (switchInst->getNumCases() > 1) { switches.push_back(switchInst); } + + } + + } + + } + + } + + // unique the collected switches + switches.erase(Unique(switches.begin(), switches.end()), switches.end()); + + // Instrument switch values for cmplog + if (switches.size()) { + + if (!be_quiet) + errs() << "Hooking " << switches.size() << " switch instructions\n"; + + for (auto &SI : switches) { + + Value * Val = SI->getCondition(); + unsigned int max_size = Val->getType()->getIntegerBitWidth(), cast_size; + unsigned char do_cast = 0; + + if (!SI->getNumCases() || max_size < 16) { + + // if (!be_quiet) errs() << "skip trivial switch..\n"; + continue; + + } + + if (max_size % 8) { + + max_size = (((max_size / 8) + 1) * 8); + do_cast = 1; + + } + + IRBuilder<> IRB(SI->getParent()); + IRB.SetInsertPoint(SI); + + if (max_size > 128) { + + if (!be_quiet) { + + fprintf(stderr, + "Cannot handle this switch bit size: %u (truncating)\n", + max_size); + + } + + max_size = 128; + do_cast = 1; + + } + + // do we need to cast? + switch (max_size) { + + case 8: + case 16: + case 32: + case 64: + case 128: + cast_size = max_size; + break; + default: + cast_size = 128; + do_cast = 1; + + } + + Value *CompareTo = Val; + + if (do_cast) { + + CompareTo = + IRB.CreateIntCast(CompareTo, IntegerType::get(C, cast_size), false); + + } + + for (SwitchInst::CaseIt i = SI->case_begin(), e = SI->case_end(); i != e; + ++i) { + +#if LLVM_VERSION_MAJOR < 5 + ConstantInt *cint = i.getCaseValue(); +#else + ConstantInt *cint = i->getCaseValue(); +#endif + + if (cint) { + + std::vector<Value *> args; + args.push_back(CompareTo); + + Value *new_param = cint; + + if (do_cast) { + + new_param = + IRB.CreateIntCast(cint, IntegerType::get(C, cast_size), false); + + } + + if (new_param) { + + args.push_back(new_param); + ConstantInt *attribute = ConstantInt::get(Int8Ty, 1); + args.push_back(attribute); + if (cast_size != max_size) { + + ConstantInt *bitsize = + ConstantInt::get(Int8Ty, (max_size / 8) - 1); + args.push_back(bitsize); + + } + + switch (cast_size) { + + case 8: + IRB.CreateCall(cmplogHookIns1, args); + break; + case 16: + IRB.CreateCall(cmplogHookIns2, args); + break; + case 32: + IRB.CreateCall(cmplogHookIns4, args); + break; + case 64: + IRB.CreateCall(cmplogHookIns8, args); + break; + case 128: +#ifdef WORD_SIZE_64 + if (max_size == 128) { + + IRB.CreateCall(cmplogHookIns16, args); + + } else { + + IRB.CreateCall(cmplogHookInsN, args); + + } + +#endif + break; + default: + break; + + } + + } + + } + + } + + } + + } + + if (icomps.size()) { + + // if (!be_quiet) errs() << "Hooking " << icomps.size() << + // " cmp instructions\n"; + + for (auto &selectcmpInst : icomps) { + + IRBuilder<> IRB(selectcmpInst->getParent()); + IRB.SetInsertPoint(selectcmpInst); + + Value *op0 = selectcmpInst->getOperand(0); + Value *op1 = selectcmpInst->getOperand(1); + + IntegerType * intTyOp0 = NULL; + IntegerType * intTyOp1 = NULL; + unsigned max_size = 0, cast_size = 0; + unsigned char attr = 0; + std::vector<Value *> args; + + CmpInst *cmpInst = dyn_cast<CmpInst>(selectcmpInst); + + if (!cmpInst) { continue; } + + switch (cmpInst->getPredicate()) { + + case CmpInst::ICMP_NE: + case CmpInst::FCMP_UNE: + case CmpInst::FCMP_ONE: + break; + case CmpInst::ICMP_EQ: + case CmpInst::FCMP_UEQ: + case CmpInst::FCMP_OEQ: + attr += 1; + break; + case CmpInst::ICMP_UGT: + case CmpInst::ICMP_SGT: + case CmpInst::FCMP_OGT: + case CmpInst::FCMP_UGT: + attr += 2; + break; + case CmpInst::ICMP_UGE: + case CmpInst::ICMP_SGE: + case CmpInst::FCMP_OGE: + case CmpInst::FCMP_UGE: + attr += 3; + break; + case CmpInst::ICMP_ULT: + case CmpInst::ICMP_SLT: + case CmpInst::FCMP_OLT: + case CmpInst::FCMP_ULT: + attr += 4; + break; + case CmpInst::ICMP_ULE: + case CmpInst::ICMP_SLE: + case CmpInst::FCMP_OLE: + case CmpInst::FCMP_ULE: + attr += 5; + break; + default: + break; + + } + + if (selectcmpInst->getOpcode() == Instruction::FCmp) { + + auto ty0 = op0->getType(); + if (ty0->isHalfTy() +#if LLVM_VERSION_MAJOR >= 11 + || ty0->isBFloatTy() +#endif + ) + max_size = 16; + else if (ty0->isFloatTy()) + max_size = 32; + else if (ty0->isDoubleTy()) + max_size = 64; + else if (ty0->isX86_FP80Ty()) + max_size = 80; + else if (ty0->isFP128Ty() || ty0->isPPC_FP128Ty()) + max_size = 128; + + attr += 8; + + } else { + + intTyOp0 = dyn_cast<IntegerType>(op0->getType()); + intTyOp1 = dyn_cast<IntegerType>(op1->getType()); + + if (intTyOp0 && intTyOp1) { + + max_size = intTyOp0->getBitWidth() > intTyOp1->getBitWidth() + ? intTyOp0->getBitWidth() + : intTyOp1->getBitWidth(); + + } + + } + + if (!max_size || max_size < 16) { continue; } + + if (max_size % 8) { max_size = (((max_size / 8) + 1) * 8); } + + if (max_size > 128) { + + if (!be_quiet) { + + fprintf(stderr, + "Cannot handle this compare bit size: %u (truncating)\n", + max_size); + + } + + max_size = 128; + + } + + // do we need to cast? + switch (max_size) { + + case 8: + case 16: + case 32: + case 64: + case 128: + cast_size = max_size; + break; + default: + cast_size = 128; + + } + + // errs() << "[CMPLOG] cmp " << *cmpInst << "(in function " << + // cmpInst->getFunction()->getName() << ")\n"; + + // first bitcast to integer type of the same bitsize as the original + // type (this is a nop, if already integer) + Value *op0_i = IRB.CreateBitCast( + op0, IntegerType::get(C, op0->getType()->getPrimitiveSizeInBits())); + // then create a int cast, which does zext, trunc or bitcast. In our case + // usually zext to the next larger supported type (this is a nop if + // already the right type) + Value *V0 = + IRB.CreateIntCast(op0_i, IntegerType::get(C, cast_size), false); + args.push_back(V0); + Value *op1_i = IRB.CreateBitCast( + op1, IntegerType::get(C, op1->getType()->getPrimitiveSizeInBits())); + Value *V1 = + IRB.CreateIntCast(op1_i, IntegerType::get(C, cast_size), false); + args.push_back(V1); + + // errs() << "[CMPLOG] casted parameters:\n0: " << *V0 << "\n1: " << *V1 + // << "\n"; + + ConstantInt *attribute = ConstantInt::get(Int8Ty, attr); + args.push_back(attribute); + + if (cast_size != max_size) { + + ConstantInt *bitsize = ConstantInt::get(Int8Ty, (max_size / 8) - 1); + args.push_back(bitsize); + + } + + // fprintf(stderr, "_ExtInt(%u) castTo %u with attr %u didcast %u\n", + // max_size, cast_size, attr); + + switch (cast_size) { + + case 8: + IRB.CreateCall(cmplogHookIns1, args); + break; + case 16: + IRB.CreateCall(cmplogHookIns2, args); + break; + case 32: + IRB.CreateCall(cmplogHookIns4, args); + break; + case 64: + IRB.CreateCall(cmplogHookIns8, args); + break; + case 128: + if (max_size == 128) { + + IRB.CreateCall(cmplogHookIns16, args); + + } else { + + IRB.CreateCall(cmplogHookInsN, args); + + } + + break; + + } + + } + + } + + if (switches.size() || icomps.size()) + return true; + else + return false; + +} + +bool CmpLogInstructions::runOnModule(Module &M) { + + if (getenv("AFL_QUIET") == NULL) + printf("Running cmplog-instructions-pass by andreafioraldi@gmail.com\n"); + else + be_quiet = 1; + hookInstrs(M); + verifyModule(M); + + return true; + +} + +static void registerCmpLogInstructionsPass(const PassManagerBuilder &, + legacy::PassManagerBase &PM) { + + auto p = new CmpLogInstructions(); + PM.add(p); + +} + +static RegisterStandardPasses RegisterCmpLogInstructionsPass( + PassManagerBuilder::EP_OptimizerLast, registerCmpLogInstructionsPass); + +static RegisterStandardPasses RegisterCmpLogInstructionsPass0( + PassManagerBuilder::EP_EnabledOnOptLevel0, registerCmpLogInstructionsPass); + +#if LLVM_VERSION_MAJOR >= 11 +static RegisterStandardPasses RegisterCmpLogInstructionsPassLTO( + PassManagerBuilder::EP_FullLinkTimeOptimizationLast, + registerCmpLogInstructionsPass); +#endif + diff --git a/instrumentation/cmplog-routines-pass.cc b/instrumentation/cmplog-routines-pass.cc new file mode 100644 index 00000000..a5992c9a --- /dev/null +++ b/instrumentation/cmplog-routines-pass.cc @@ -0,0 +1,419 @@ +/* + american fuzzy lop++ - LLVM CmpLog instrumentation + -------------------------------------------------- + + Written by Andrea Fioraldi <andreafioraldi@gmail.com> + + Copyright 2015, 2016 Google Inc. All rights reserved. + Copyright 2019-2020 AFLplusplus Project. All rights reserved. + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at: + + http://www.apache.org/licenses/LICENSE-2.0 + +*/ + +#include <stdio.h> +#include <stdlib.h> +#include <unistd.h> + +#include <list> +#include <string> +#include <fstream> +#include <sys/time.h> +#include "llvm/Config/llvm-config.h" + +#include "llvm/ADT/Statistic.h" +#include "llvm/IR/IRBuilder.h" +#include "llvm/IR/LegacyPassManager.h" +#include "llvm/IR/Module.h" +#include "llvm/Support/Debug.h" +#include "llvm/Support/raw_ostream.h" +#include "llvm/Transforms/IPO/PassManagerBuilder.h" +#include "llvm/Transforms/Utils/BasicBlockUtils.h" +#include "llvm/Pass.h" +#include "llvm/Analysis/ValueTracking.h" + +#if LLVM_VERSION_MAJOR > 3 || \ + (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR > 4) + #include "llvm/IR/Verifier.h" + #include "llvm/IR/DebugInfo.h" +#else + #include "llvm/Analysis/Verifier.h" + #include "llvm/DebugInfo.h" + #define nullptr 0 +#endif + +#include <set> +#include "afl-llvm-common.h" + +using namespace llvm; + +namespace { + +class CmpLogRoutines : public ModulePass { + + public: + static char ID; + CmpLogRoutines() : ModulePass(ID) { + + initInstrumentList(); + + } + + bool runOnModule(Module &M) override; + +#if LLVM_VERSION_MAJOR < 4 + const char *getPassName() const override { + +#else + StringRef getPassName() const override { + +#endif + return "cmplog routines"; + + } + + private: + bool hookRtns(Module &M); + +}; + +} // namespace + +char CmpLogRoutines::ID = 0; + +bool CmpLogRoutines::hookRtns(Module &M) { + + std::vector<CallInst *> calls, llvmStdStd, llvmStdC, gccStdStd, gccStdC; + LLVMContext & C = M.getContext(); + + Type *VoidTy = Type::getVoidTy(C); + // PointerType *VoidPtrTy = PointerType::get(VoidTy, 0); + IntegerType *Int8Ty = IntegerType::getInt8Ty(C); + PointerType *i8PtrTy = PointerType::get(Int8Ty, 0); + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c = M.getOrInsertFunction("__cmplog_rtn_hook", VoidTy, i8PtrTy, i8PtrTy +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogHookFn = cast<Function>(c); +#else + FunctionCallee cmplogHookFn = c; +#endif + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c1 = M.getOrInsertFunction("__cmplog_rtn_llvm_stdstring_stdstring", + VoidTy, i8PtrTy, i8PtrTy +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogLlvmStdStd = cast<Function>(c1); +#else + FunctionCallee cmplogLlvmStdStd = c1; +#endif + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c2 = M.getOrInsertFunction("__cmplog_rtn_llvm_stdstring_cstring", VoidTy, + i8PtrTy, i8PtrTy +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogLlvmStdC = cast<Function>(c2); +#else + FunctionCallee cmplogLlvmStdC = c2; +#endif + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c3 = M.getOrInsertFunction("__cmplog_rtn_gcc_stdstring_stdstring", VoidTy, + i8PtrTy, i8PtrTy +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogGccStdStd = cast<Function>(c3); +#else + FunctionCallee cmplogGccStdStd = c3; +#endif + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c4 = M.getOrInsertFunction("__cmplog_rtn_gcc_stdstring_cstring", VoidTy, + i8PtrTy, i8PtrTy +#if LLVM_VERSION_MAJOR < 5 + , + NULL +#endif + ); +#if LLVM_VERSION_MAJOR < 9 + Function *cmplogGccStdC = cast<Function>(c4); +#else + FunctionCallee cmplogGccStdC = c4; +#endif + + /* iterate over all functions, bbs and instruction and add suitable calls */ + for (auto &F : M) { + + if (!isInInstrumentList(&F)) continue; + + for (auto &BB : F) { + + for (auto &IN : BB) { + + CallInst *callInst = nullptr; + + if ((callInst = dyn_cast<CallInst>(&IN))) { + + Function *Callee = callInst->getCalledFunction(); + if (!Callee) continue; + if (callInst->getCallingConv() != llvm::CallingConv::C) continue; + + FunctionType *FT = Callee->getFunctionType(); + + bool isPtrRtn = FT->getNumParams() >= 2 && + !FT->getReturnType()->isVoidTy() && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0)->isPointerTy(); + + bool isGccStdStringStdString = + Callee->getName().find("__is_charIT_EE7__value") != + std::string::npos && + Callee->getName().find( + "St7__cxx1112basic_stringIS2_St11char_traits") != + std::string::npos && + FT->getNumParams() >= 2 && + FT->getParamType(0) == FT->getParamType(1) && + FT->getParamType(0)->isPointerTy(); + + bool isGccStdStringCString = + Callee->getName().find( + "St7__cxx1112basic_stringIcSt11char_" + "traitsIcESaIcEE7compareEPK") != std::string::npos && + FT->getNumParams() >= 2 && FT->getParamType(0)->isPointerTy() && + FT->getParamType(1)->isPointerTy(); + + bool isLlvmStdStringStdString = + Callee->getName().find("_ZNSt3__1eqI") != std::string::npos && + Callee->getName().find("_12basic_stringI") != std::string::npos && + Callee->getName().find("_11char_traits") != std::string::npos && + FT->getNumParams() >= 2 && FT->getParamType(0)->isPointerTy() && + FT->getParamType(1)->isPointerTy(); + + bool isLlvmStdStringCString = + Callee->getName().find("_ZNSt3__1eqI") != std::string::npos && + Callee->getName().find("_12basic_stringI") != std::string::npos && + FT->getNumParams() >= 2 && FT->getParamType(0)->isPointerTy() && + FT->getParamType(1)->isPointerTy(); + + /* + { + + fprintf(stderr, "F:%s C:%s argc:%u\n", + F.getName().str().c_str(), + Callee->getName().str().c_str(), FT->getNumParams()); + fprintf(stderr, "ptr0:%u ptr1:%u ptr2:%u\n", + FT->getParamType(0)->isPointerTy(), + FT->getParamType(1)->isPointerTy(), + FT->getNumParams() > 2 ? + FT->getParamType(2)->isPointerTy() : 22 ); + + } + + */ + + if (isGccStdStringCString || isGccStdStringStdString || + isLlvmStdStringStdString || isLlvmStdStringCString) { + + isPtrRtn = false; + + } + + if (isPtrRtn) { calls.push_back(callInst); } + if (isGccStdStringStdString) { gccStdStd.push_back(callInst); } + if (isGccStdStringCString) { gccStdC.push_back(callInst); } + if (isLlvmStdStringStdString) { llvmStdStd.push_back(callInst); } + if (isLlvmStdStringCString) { llvmStdC.push_back(callInst); } + + } + + } + + } + + } + + if (!calls.size() && !gccStdStd.size() && !gccStdC.size() && + !llvmStdStd.size() && !llvmStdC.size()) + return false; + + /* + if (!be_quiet) + errs() << "Hooking " << calls.size() + << " calls with pointers as arguments\n"; + */ + + for (auto &callInst : calls) { + + Value *v1P = callInst->getArgOperand(0), *v2P = callInst->getArgOperand(1); + + IRBuilder<> IRB(callInst->getParent()); + IRB.SetInsertPoint(callInst); + + std::vector<Value *> args; + Value * v1Pcasted = IRB.CreatePointerCast(v1P, i8PtrTy); + Value * v2Pcasted = IRB.CreatePointerCast(v2P, i8PtrTy); + args.push_back(v1Pcasted); + args.push_back(v2Pcasted); + + IRB.CreateCall(cmplogHookFn, args); + + // errs() << callInst->getCalledFunction()->getName() << "\n"; + + } + + for (auto &callInst : gccStdStd) { + + Value *v1P = callInst->getArgOperand(0), *v2P = callInst->getArgOperand(1); + + IRBuilder<> IRB(callInst->getParent()); + IRB.SetInsertPoint(callInst); + + std::vector<Value *> args; + Value * v1Pcasted = IRB.CreatePointerCast(v1P, i8PtrTy); + Value * v2Pcasted = IRB.CreatePointerCast(v2P, i8PtrTy); + args.push_back(v1Pcasted); + args.push_back(v2Pcasted); + + IRB.CreateCall(cmplogGccStdStd, args); + + // errs() << callInst->getCalledFunction()->getName() << "\n"; + + } + + for (auto &callInst : gccStdC) { + + Value *v1P = callInst->getArgOperand(0), *v2P = callInst->getArgOperand(1); + + IRBuilder<> IRB(callInst->getParent()); + IRB.SetInsertPoint(callInst); + + std::vector<Value *> args; + Value * v1Pcasted = IRB.CreatePointerCast(v1P, i8PtrTy); + Value * v2Pcasted = IRB.CreatePointerCast(v2P, i8PtrTy); + args.push_back(v1Pcasted); + args.push_back(v2Pcasted); + + IRB.CreateCall(cmplogGccStdC, args); + + // errs() << callInst->getCalledFunction()->getName() << "\n"; + + } + + for (auto &callInst : llvmStdStd) { + + Value *v1P = callInst->getArgOperand(0), *v2P = callInst->getArgOperand(1); + + IRBuilder<> IRB(callInst->getParent()); + IRB.SetInsertPoint(callInst); + + std::vector<Value *> args; + Value * v1Pcasted = IRB.CreatePointerCast(v1P, i8PtrTy); + Value * v2Pcasted = IRB.CreatePointerCast(v2P, i8PtrTy); + args.push_back(v1Pcasted); + args.push_back(v2Pcasted); + + IRB.CreateCall(cmplogLlvmStdStd, args); + + // errs() << callInst->getCalledFunction()->getName() << "\n"; + + } + + for (auto &callInst : llvmStdC) { + + Value *v1P = callInst->getArgOperand(0), *v2P = callInst->getArgOperand(1); + + IRBuilder<> IRB(callInst->getParent()); + IRB.SetInsertPoint(callInst); + + std::vector<Value *> args; + Value * v1Pcasted = IRB.CreatePointerCast(v1P, i8PtrTy); + Value * v2Pcasted = IRB.CreatePointerCast(v2P, i8PtrTy); + args.push_back(v1Pcasted); + args.push_back(v2Pcasted); + + IRB.CreateCall(cmplogLlvmStdC, args); + + // errs() << callInst->getCalledFunction()->getName() << "\n"; + + } + + return true; + +} + +bool CmpLogRoutines::runOnModule(Module &M) { + + if (getenv("AFL_QUIET") == NULL) + printf("Running cmplog-routines-pass by andreafioraldi@gmail.com\n"); + else + be_quiet = 1; + hookRtns(M); + verifyModule(M); + + return true; + +} + +static void registerCmpLogRoutinesPass(const PassManagerBuilder &, + legacy::PassManagerBase &PM) { + + auto p = new CmpLogRoutines(); + PM.add(p); + +} + +static RegisterStandardPasses RegisterCmpLogRoutinesPass( + PassManagerBuilder::EP_OptimizerLast, registerCmpLogRoutinesPass); + +static RegisterStandardPasses RegisterCmpLogRoutinesPass0( + PassManagerBuilder::EP_EnabledOnOptLevel0, registerCmpLogRoutinesPass); + +#if LLVM_VERSION_MAJOR >= 11 +static RegisterStandardPasses RegisterCmpLogRoutinesPassLTO( + PassManagerBuilder::EP_FullLinkTimeOptimizationLast, + registerCmpLogRoutinesPass); +#endif + diff --git a/llvm_mode/compare-transform-pass.so.cc b/instrumentation/compare-transform-pass.so.cc index 2f165ea6..3ecba4e6 100644 --- a/llvm_mode/compare-transform-pass.so.cc +++ b/instrumentation/compare-transform-pass.so.cc @@ -68,16 +68,13 @@ class CompareTransform : public ModulePass { const char *getPassName() const override { #else - StringRef getPassName() const override { + StringRef getPassName() const override { #endif return "transforms compare functions"; } - protected: - int be_quiet = 0; - private: bool transformCmps(Module &M, const bool processStrcmp, const bool processMemcmp, const bool processStrncmp, @@ -104,22 +101,31 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, IntegerType * Int64Ty = IntegerType::getInt64Ty(C); #if LLVM_VERSION_MAJOR < 9 - Constant * + Function *tolowerFn; #else - FunctionCallee + FunctionCallee tolowerFn; #endif - c = M.getOrInsertFunction("tolower", Int32Ty, Int32Ty + { + +#if LLVM_VERSION_MAJOR < 9 + Constant * +#else + FunctionCallee +#endif + c = M.getOrInsertFunction("tolower", Int32Ty, Int32Ty #if LLVM_VERSION_MAJOR < 5 - , - NULL + , + NULL #endif - ); + ); #if LLVM_VERSION_MAJOR < 9 - Function *tolowerFn = cast<Function>(c); + tolowerFn = cast<Function>(c); #else - FunctionCallee tolowerFn = c; + tolowerFn = c; #endif + } + /* iterate over all functions, bbs and instruction and add suitable calls to * strcmp/memcmp/strncmp/strcasecmp/strncasecmp */ for (auto &F : M) { @@ -140,14 +146,14 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, bool isStrcasecmp = processStrcasecmp; bool isStrncasecmp = processStrncasecmp; bool isIntMemcpy = true; - bool indirect = false; Function *Callee = callInst->getCalledFunction(); if (!Callee) continue; if (callInst->getCallingConv() != llvm::CallingConv::C) continue; StringRef FuncName = Callee->getName(); isStrcmp &= !FuncName.compare(StringRef("strcmp")); - isMemcmp &= !FuncName.compare(StringRef("memcmp")); + isMemcmp &= (!FuncName.compare(StringRef("memcmp")) || + !FuncName.compare(StringRef("bcmp"))); isStrncmp &= !FuncName.compare(StringRef("strncmp")); isStrcasecmp &= !FuncName.compare(StringRef("strcasecmp")); isStrncasecmp &= !FuncName.compare(StringRef("strncasecmp")); @@ -223,9 +229,9 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, dyn_cast<ConstantDataArray>(Var->getInitializer())) { HasStr2 = true; - Str2 = Array->getAsString(); + Str2 = Array->getRawDataValues(); valueMap[Str2P] = new std::string(Str2.str()); - fprintf(stderr, "glo2 %s\n", Str2.str().c_str()); + // fprintf(stderr, "glo2 %s\n", Str2.str().c_str()); } @@ -237,7 +243,7 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, if (!HasStr2) { - auto *Ptr = dyn_cast<ConstantExpr>(Str1P); + Ptr = dyn_cast<ConstantExpr>(Str1P); if (Ptr && Ptr->isGEPWithNoNotionalOverIndexing()) { if (auto *Var = dyn_cast<GlobalVariable>(Ptr->getOperand(0))) { @@ -248,7 +254,7 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, Var->getInitializer())) { HasStr1 = true; - Str1 = Array->getAsString(); + Str1 = Array->getRawDataValues(); valueMap[Str1P] = new std::string(Str1.str()); // fprintf(stderr, "glo1 %s\n", Str1.str().c_str()); @@ -267,8 +273,6 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, } - if ((HasStr1 || HasStr2)) indirect = true; - } if (isIntMemcpy) continue; @@ -281,7 +285,6 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, Str1 = StringRef(*val); HasStr1 = true; - indirect = true; // fprintf(stderr, "loaded1 %s\n", Str1.str().c_str()); } else { @@ -291,7 +294,6 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, Str2 = StringRef(*val); HasStr2 = true; - indirect = true; // fprintf(stderr, "loaded2 %s\n", Str2.str().c_str()); } @@ -314,7 +316,7 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, uint64_t len = ilen->getZExtValue(); // if len is zero this is a pointless call but allow real // implementation to worry about that - if (!len) continue; + if (len < 2) continue; if (isMemcmp) { @@ -346,8 +348,9 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, if (!calls.size()) return false; if (!be_quiet) - errs() << "Replacing " << calls.size() - << " calls to strcmp/memcmp/strncmp/strcasecmp/strncasecmp\n"; + printf( + "Replacing %zu calls to strcmp/memcmp/strncmp/strcasecmp/strncasecmp\n", + calls.size()); for (auto &callInst : calls) { @@ -358,20 +361,23 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, Value * VarStr; bool HasStr1 = getConstantStringInfo(Str1P, Str1); bool HasStr2 = getConstantStringInfo(Str2P, Str2); - uint64_t constStrLen, constSizedLen, unrollLen; - bool isMemcmp = - !callInst->getCalledFunction()->getName().compare(StringRef("memcmp")); - bool isSizedcmp = isMemcmp || - !callInst->getCalledFunction()->getName().compare( - StringRef("strncmp")) || - !callInst->getCalledFunction()->getName().compare( - StringRef("strncasecmp")); + uint64_t constStrLen, unrollLen, constSizedLen = 0; + bool isMemcmp = false; + bool isSizedcmp = false; + bool isCaseInsensitive = false; + Function * Callee = callInst->getCalledFunction(); + if (Callee) { + + isMemcmp = Callee->getName().compare("memcmp") == 0; + isSizedcmp = isMemcmp || Callee->getName().compare("strncmp") == 0 || + Callee->getName().compare("strncasecmp") == 0; + isCaseInsensitive = Callee->getName().compare("strcasecmp") == 0 || + Callee->getName().compare("strncasecmp") == 0; + + } + Value *sizedValue = isSizedcmp ? callInst->getArgOperand(2) : NULL; bool isConstSized = sizedValue && isa<ConstantInt>(sizedValue); - bool isCaseInsensitive = !callInst->getCalledFunction()->getName().compare( - StringRef("strcasecmp")) || - !callInst->getCalledFunction()->getName().compare( - StringRef("strncasecmp")); if (!(HasStr1 || HasStr2)) { @@ -388,7 +394,7 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, if (val && !val->empty()) { Str2 = StringRef(*val); - HasStr2 = true; + // HasStr2 = true; } @@ -414,15 +420,29 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, } + if (TmpConstStr.length() < 2 || + (TmpConstStr.length() == 2 && !TmpConstStr[1])) { + + continue; + + } + // add null termination character implicit in c strings - TmpConstStr.append("\0", 1); + if (!isMemcmp && TmpConstStr[TmpConstStr.length() - 1]) { + + TmpConstStr.append("\0", 1); + + } // in the unusual case the const str has embedded null // characters, the string comparison functions should terminate // at the first null - if (!isMemcmp) + if (!isMemcmp) { + TmpConstStr.assign(TmpConstStr, 0, TmpConstStr.find('\0') + 1); + } + constStrLen = TmpConstStr.length(); // prefer use of StringRef (in comparison to std::string a StringRef has // built-in runtime bounds checking, which makes debugging easier) @@ -433,12 +453,6 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, else unrollLen = constStrLen; - if (!be_quiet) - errs() << callInst->getCalledFunction()->getName() << ": unroll len " - << unrollLen - << ((isSizedcmp && !isConstSized) ? ", variable n" : "") << ": " - << ConstStr << "\n"; - /* split before the call instruction */ BasicBlock *bb = callInst->getParent(); BasicBlock *end_bb = bb->splitBasicBlock(BasicBlock::iterator(callInst)); @@ -563,10 +577,12 @@ bool CompareTransform::transformCmps(Module &M, const bool processStrcmp, bool CompareTransform::runOnModule(Module &M) { if ((isatty(2) && getenv("AFL_QUIET") == NULL) || getenv("AFL_DEBUG") != NULL) - llvm::errs() << "Running compare-transform-pass by laf.intel@gmail.com, " - "extended by heiko@hexco.de\n"; + printf( + "Running compare-transform-pass by laf.intel@gmail.com, extended by " + "heiko@hexco.de\n"); else be_quiet = 1; + transformCmps(M, true, true, true, true, true); verifyModule(M); @@ -588,3 +604,8 @@ static RegisterStandardPasses RegisterCompTransPass( static RegisterStandardPasses RegisterCompTransPass0( PassManagerBuilder::EP_EnabledOnOptLevel0, registerCompTransPass); +#if LLVM_VERSION_MAJOR >= 11 +static RegisterStandardPasses RegisterCompTransPassLTO( + PassManagerBuilder::EP_FullLinkTimeOptimizationLast, registerCompTransPass); +#endif + diff --git a/llvm_mode/llvm-ngram-coverage.h b/instrumentation/llvm-alternative-coverage.h index 12b666e9..0d7b3957 100644 --- a/llvm_mode/llvm-ngram-coverage.h +++ b/instrumentation/llvm-alternative-coverage.h @@ -1,7 +1,7 @@ #ifndef AFL_NGRAM_CONFIG_H #define AFL_NGRAM_CONFIG_H -#include "../config.h" +#include "types.h" #if (MAP_SIZE_POW2 <= 16) typedef u16 PREV_LOC_T; @@ -14,5 +14,8 @@ typedef u64 PREV_LOC_T; /* Maximum ngram size */ #define NGRAM_SIZE_MAX 16U +/* Maximum K for top-K context sensitivity */ +#define CTX_MAX_K 32U + #endif diff --git a/llvm_mode/split-compares-pass.so.cc b/instrumentation/split-compares-pass.so.cc index 55128ca2..b02a89fb 100644 --- a/llvm_mode/split-compares-pass.so.cc +++ b/instrumentation/split-compares-pass.so.cc @@ -53,7 +53,7 @@ class SplitComparesTransform : public ModulePass { public: static char ID; - SplitComparesTransform() : ModulePass(ID) { + SplitComparesTransform() : ModulePass(ID), enableFPSplit(0) { initInstrumentList(); @@ -71,9 +71,6 @@ class SplitComparesTransform : public ModulePass { } - protected: - int be_quiet = 0; - private: int enableFPSplit; @@ -152,8 +149,11 @@ bool SplitComparesTransform::simplifyFPCompares(Module &M) { auto op1 = FcmpInst->getOperand(1); /* find out what the new predicate is going to be */ - auto pred = dyn_cast<CmpInst>(FcmpInst)->getPredicate(); + auto cmp_inst = dyn_cast<CmpInst>(FcmpInst); + if (!cmp_inst) { continue; } + auto pred = cmp_inst->getPredicate(); CmpInst::Predicate new_pred; + switch (pred) { case CmpInst::FCMP_UGE: @@ -279,8 +279,11 @@ bool SplitComparesTransform::simplifyCompares(Module &M) { auto op1 = IcmpInst->getOperand(1); /* find out what the new predicate is going to be */ - auto pred = dyn_cast<CmpInst>(IcmpInst)->getPredicate(); + auto cmp_inst = dyn_cast<CmpInst>(IcmpInst); + if (!cmp_inst) { continue; } + auto pred = cmp_inst->getPredicate(); CmpInst::Predicate new_pred; + switch (pred) { case CmpInst::ICMP_UGE: @@ -359,6 +362,8 @@ bool SplitComparesTransform::simplifyIntSignedness(Module &M) { * all signed compares to icomps vector */ for (auto &F : M) { + if (!isInInstrumentList(&F)) continue; + for (auto &BB : F) { for (auto &IN : BB) { @@ -408,12 +413,16 @@ bool SplitComparesTransform::simplifyIntSignedness(Module &M) { auto op1 = IcmpInst->getOperand(1); IntegerType *intTyOp0 = dyn_cast<IntegerType>(op0->getType()); + if (!intTyOp0) { continue; } unsigned bitw = intTyOp0->getBitWidth(); IntegerType *IntType = IntegerType::get(C, bitw); /* get the new predicate */ - auto pred = dyn_cast<CmpInst>(IcmpInst)->getPredicate(); + auto cmp_inst = dyn_cast<CmpInst>(IcmpInst); + if (!cmp_inst) { continue; } + auto pred = cmp_inst->getPredicate(); CmpInst::Predicate new_pred; + if (pred == CmpInst::ICMP_SGT) { new_pred = CmpInst::ICMP_UGT; @@ -545,6 +554,8 @@ size_t SplitComparesTransform::splitFPCompares(Module &M) { * functions were executed only these four predicates should exist */ for (auto &F : M) { + if (!isInInstrumentList(&F)) continue; + for (auto &BB : F) { for (auto &IN : BB) { @@ -554,6 +565,7 @@ size_t SplitComparesTransform::splitFPCompares(Module &M) { if ((selectcmpInst = dyn_cast<CmpInst>(&IN))) { if (selectcmpInst->getPredicate() == CmpInst::FCMP_OEQ || + selectcmpInst->getPredicate() == CmpInst::FCMP_UEQ || selectcmpInst->getPredicate() == CmpInst::FCMP_ONE || selectcmpInst->getPredicate() == CmpInst::FCMP_UNE || selectcmpInst->getPredicate() == CmpInst::FCMP_UGT || @@ -600,15 +612,16 @@ size_t SplitComparesTransform::splitFPCompares(Module &M) { if (op_size != op1->getType()->getPrimitiveSizeInBits()) { continue; } const unsigned int sizeInBits = op0->getType()->getPrimitiveSizeInBits(); - const unsigned int precision = - sizeInBits == 32 - ? 24 - : sizeInBits == 64 - ? 53 - : sizeInBits == 128 ? 113 - : sizeInBits == 16 ? 11 - /* sizeInBits == 80 */ - : 65; + + // BUG FIXME TODO: u64 does not work for > 64 bit ... e.g. 80 and 128 bit + if (sizeInBits > 64) { continue; } + + const unsigned int precision = sizeInBits == 32 ? 24 + : sizeInBits == 64 ? 53 + : sizeInBits == 128 ? 113 + : sizeInBits == 16 ? 11 + : sizeInBits == 80 ? 65 + : sizeInBits - 8; const unsigned shiftR_exponent = precision - 1; const unsigned long long mask_fraction = @@ -737,6 +750,7 @@ size_t SplitComparesTransform::splitFPCompares(Module &M) { BasicBlock * signequal2_bb = signequal_bb; switch (FcmpInst->getPredicate()) { + case CmpInst::FCMP_UEQ: case CmpInst::FCMP_OEQ: icmp_exponent_result = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_EQ, m_e0, m_e1); @@ -818,6 +832,7 @@ size_t SplitComparesTransform::splitFPCompares(Module &M) { switch (FcmpInst->getPredicate()) { + case CmpInst::FCMP_UEQ: case CmpInst::FCMP_OEQ: /* if the exponents are satifying the compare do a fraction cmp in * middle_bb */ @@ -902,11 +917,11 @@ size_t SplitComparesTransform::splitFPCompares(Module &M) { /* compare the fractions of the operands */ Instruction *icmp_fraction_result; - Instruction *icmp_fraction_result2; BasicBlock * middle2_bb = middle_bb; PHINode * PN2 = nullptr; switch (FcmpInst->getPredicate()) { + case CmpInst::FCMP_UEQ: case CmpInst::FCMP_OEQ: icmp_fraction_result = CmpInst::Create(Instruction::ICmp, CmpInst::ICMP_EQ, t_f0, t_f1); @@ -929,6 +944,8 @@ size_t SplitComparesTransform::splitFPCompares(Module &M) { case CmpInst::FCMP_OLT: case CmpInst::FCMP_ULT: { + Instruction *icmp_fraction_result2; + middle2_bb = middle_bb->splitBasicBlock( BasicBlock::iterator(middle_bb->getTerminator())); @@ -982,6 +999,7 @@ size_t SplitComparesTransform::splitFPCompares(Module &M) { switch (FcmpInst->getPredicate()) { + case CmpInst::FCMP_UEQ: case CmpInst::FCMP_OEQ: /* unequal signs cannot be equal values */ /* goto false branch */ @@ -1055,6 +1073,8 @@ size_t SplitComparesTransform::splitIntCompares(Module &M, unsigned bitw) { * were executed only these four predicates should exist */ for (auto &F : M) { + if (!isInInstrumentList(&F)) continue; + for (auto &BB : F) { for (auto &IN : BB) { @@ -1105,7 +1125,9 @@ size_t SplitComparesTransform::splitIntCompares(Module &M, unsigned bitw) { auto op0 = IcmpInst->getOperand(0); auto op1 = IcmpInst->getOperand(1); - auto pred = dyn_cast<CmpInst>(IcmpInst)->getPredicate(); + auto cmp_inst = dyn_cast<CmpInst>(IcmpInst); + if (!cmp_inst) { continue; } + auto pred = cmp_inst->getPredicate(); BasicBlock *end_bb = bb->splitBasicBlock(BasicBlock::iterator(IcmpInst)); @@ -1247,7 +1269,8 @@ size_t SplitComparesTransform::splitIntCompares(Module &M, unsigned bitw) { bool SplitComparesTransform::runOnModule(Module &M) { - int bitw = 64; + int bitw = 64; + size_t count = 0; char *bitw_env = getenv("AFL_LLVM_LAF_SPLIT_COMPARES_BITW"); if (!bitw_env) bitw_env = getenv("LAF_SPLIT_COMPARES_BITW"); @@ -1258,21 +1281,32 @@ bool SplitComparesTransform::runOnModule(Module &M) { if ((isatty(2) && getenv("AFL_QUIET") == NULL) || getenv("AFL_DEBUG") != NULL) { - errs() << "Split-compare-pass by laf.intel@gmail.com, extended by " - "heiko@hexco.de\n"; + printf( + "Split-compare-pass by laf.intel@gmail.com, extended by " + "heiko@hexco.de\n"); - if (enableFPSplit) { + } else { - errs() << "Split-floatingpoint-compare-pass: " << splitFPCompares(M) - << " FP comparisons splitted\n"; + be_quiet = 1; - } + } - } else + if (enableFPSplit) { - be_quiet = 1; + count = splitFPCompares(M); + + /* + if (!be_quiet) { - if (enableFPSplit) simplifyFPCompares(M); + errs() << "Split-floatingpoint-compare-pass: " << count + << " FP comparisons split\n"; + + } + + */ + simplifyFPCompares(M); + + } simplifyCompares(M); @@ -1281,35 +1315,35 @@ bool SplitComparesTransform::runOnModule(Module &M) { switch (bitw) { case 64: - if (!be_quiet) - errs() << "Split-integer-compare-pass " << bitw - << "bit: " << splitIntCompares(M, bitw) << " splitted\n"; - + count += splitIntCompares(M, bitw); + if (debug) + errs() << "Split-integer-compare-pass " << bitw << "bit: " << count + << " split\n"; bitw >>= 1; #if LLVM_VERSION_MAJOR > 3 || \ (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR > 7) [[clang::fallthrough]]; /*FALLTHRU*/ /* FALLTHROUGH */ #endif case 32: - if (!be_quiet) - errs() << "Split-integer-compare-pass " << bitw - << "bit: " << splitIntCompares(M, bitw) << " splitted\n"; - + count += splitIntCompares(M, bitw); + if (debug) + errs() << "Split-integer-compare-pass " << bitw << "bit: " << count + << " split\n"; bitw >>= 1; #if LLVM_VERSION_MAJOR > 3 || \ (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR > 7) [[clang::fallthrough]]; /*FALLTHRU*/ /* FALLTHROUGH */ #endif case 16: - if (!be_quiet) - errs() << "Split-integer-compare-pass " << bitw - << "bit: " << splitIntCompares(M, bitw) << " splitted\n"; - - bitw >>= 1; + count += splitIntCompares(M, bitw); + if (debug) + errs() << "Split-integer-compare-pass " << bitw << "bit: " << count + << " split\n"; + // bitw >>= 1; break; default: - if (!be_quiet) errs() << "NOT Running split-compare-pass \n"; + // if (!be_quiet) errs() << "NOT Running split-compare-pass \n"; return false; break; @@ -1333,3 +1367,9 @@ static RegisterStandardPasses RegisterSplitComparesPass( static RegisterStandardPasses RegisterSplitComparesTransPass0( PassManagerBuilder::EP_EnabledOnOptLevel0, registerSplitComparesPass); +#if LLVM_VERSION_MAJOR >= 11 +static RegisterStandardPasses RegisterSplitComparesTransPassLTO( + PassManagerBuilder::EP_FullLinkTimeOptimizationLast, + registerSplitComparesPass); +#endif + diff --git a/llvm_mode/split-switches-pass.so.cc b/instrumentation/split-switches-pass.so.cc index 44075c94..97ab04a4 100644 --- a/llvm_mode/split-switches-pass.so.cc +++ b/instrumentation/split-switches-pass.so.cc @@ -91,9 +91,6 @@ class SplitSwitchesTransform : public ModulePass { typedef std::vector<CaseExpr> CaseVector; - protected: - int be_quiet = 0; - private: bool splitSwitches(Module &M); bool transformCmps(Module &M, const bool processStrcmp, @@ -330,10 +327,11 @@ bool SplitSwitchesTransform::splitSwitches(Module &M) { } if (!switches.size()) return false; - if (!be_quiet) - errs() << "Rewriting " << switches.size() << " switch statements " - << "\n"; - + /* + if (!be_quiet) + errs() << "Rewriting " << switches.size() << " switch statements " + << "\n"; + */ for (auto &SI : switches) { BasicBlock *CurBlock = SI->getParent(); @@ -344,15 +342,17 @@ bool SplitSwitchesTransform::splitSwitches(Module &M) { BasicBlock *Default = SI->getDefaultDest(); unsigned bitw = Val->getType()->getIntegerBitWidth(); - if (!be_quiet) - errs() << "switch: " << SI->getNumCases() << " cases " << bitw - << " bit\n"; + /* + if (!be_quiet) + errs() << "switch: " << SI->getNumCases() << " cases " << bitw + << " bit\n"; + */ /* If there is only the default destination or the condition checks 8 bit or * less, don't bother with the code below. */ if (!SI->getNumCases() || bitw <= 8) { - if (!be_quiet) errs() << "skip trivial switch..\n"; + // if (!be_quiet) errs() << "skip trivial switch..\n"; continue; } @@ -418,7 +418,7 @@ bool SplitSwitchesTransform::splitSwitches(Module &M) { bool SplitSwitchesTransform::runOnModule(Module &M) { if ((isatty(2) && getenv("AFL_QUIET") == NULL) || getenv("AFL_DEBUG") != NULL) - llvm::errs() << "Running split-switches-pass by laf.intel@gmail.com\n"; + printf("Running split-switches-pass by laf.intel@gmail.com\n"); else be_quiet = 1; splitSwitches(M); @@ -442,3 +442,9 @@ static RegisterStandardPasses RegisterSplitSwitchesTransPass( static RegisterStandardPasses RegisterSplitSwitchesTransPass0( PassManagerBuilder::EP_EnabledOnOptLevel0, registerSplitSwitchesTransPass); +#if LLVM_VERSION_MAJOR >= 11 +static RegisterStandardPasses RegisterSplitSwitchesTransPassLTO( + PassManagerBuilder::EP_FullLinkTimeOptimizationLast, + registerSplitSwitchesTransPass); +#endif + diff --git a/llvm_mode/GNUmakefile b/llvm_mode/GNUmakefile deleted file mode 100644 index fbb77236..00000000 --- a/llvm_mode/GNUmakefile +++ /dev/null @@ -1,448 +0,0 @@ -# american fuzzy lop++ - LLVM instrumentation -# ----------------------------------------- -# -# Written by Laszlo Szekeres <lszekeres@google.com> and -# Michal Zalewski -# -# LLVM integration design comes from Laszlo Szekeres. -# -# Copyright 2015, 2016 Google Inc. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at: -# -# http://www.apache.org/licenses/LICENSE-2.0 -# - -# For Heiko: -#TEST_MMAP=1 -HASH=\# - -PREFIX ?= /usr/local -HELPER_PATH ?= $(PREFIX)/lib/afl -BIN_PATH ?= $(PREFIX)/bin -DOC_PATH ?= $(PREFIX)/share/doc/afl -MISC_PATH ?= $(PREFIX)/share/afl -MAN_PATH ?= $(PREFIX)/man/man8 - -VERSION = $(shell grep '^$(HASH)define VERSION ' ../config.h | cut -d '"' -f2) - -ifeq "$(shell uname)" "OpenBSD" - LLVM_CONFIG ?= $(BIN_PATH)/llvm-config - HAS_OPT = $(shell test -x $(BIN_PATH)/opt && echo 0 || echo 1) - ifeq "$(HAS_OPT)" "1" - $(error llvm_mode needs a complete llvm installation (versions 3.4 up to 12) -> e.g. "pkg_add llvm-7.0.1p9") - endif -else - LLVM_CONFIG ?= llvm-config -endif - -LLVMVER = $(shell $(LLVM_CONFIG) --version 2>/dev/null | sed 's/git//' ) -LLVM_UNSUPPORTED = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^3\.[0-3]|^19' && echo 1 || echo 0 ) -LLVM_NEW_API = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[0-9]' && echo 1 || echo 0 ) -LLVM_HAVE_LTO = $(shell $(LLVM_CONFIG) --version 2>/dev/null | egrep -q '^1[1-9]' && echo 1 || echo 0 ) -LLVM_MAJOR = $(shell $(LLVM_CONFIG) --version 2>/dev/null | sed 's/\..*//') -LLVM_BINDIR = $(shell $(LLVM_CONFIG) --bindir 2>/dev/null) -LLVM_LIBDIR = $(shell $(LLVM_CONFIG) --libdir 2>/dev/null) -LLVM_STDCXX = gnu++11 -LLVM_APPLE_XCODE = $(shell clang -v 2>&1 | grep -q Apple && echo 1 || echo 0) -LLVM_LTO = 0 - -ifeq "$(LLVMVER)" "" - $(warning [!] llvm_mode needs llvm-config, which was not found) -endif - -ifeq "$(LLVM_UNSUPPORTED)" "1" - $(warning llvm_mode only supports llvm versions 3.4 up to 12) -endif - -ifeq "$(LLVM_MAJOR)" "9" - $(info [+] llvm_mode detected llvm 9, enabling neverZero implementation) -endif - -ifeq "$(LLVM_NEW_API)" "1" - $(info [+] llvm_mode detected llvm 10+, enabling neverZero implementation and c++14) - LLVM_STDCXX = c++14 -endif - -ifeq "$(LLVM_HAVE_LTO)" "1" - $(info [+] llvm_mode detected llvm 11+, enabling afl-clang-lto LTO implementation) - LLVM_LTO = 1 - #TEST_MMAP = 1 -endif - -ifeq "$(LLVM_LTO)" "0" - $(info [+] llvm_mode detected llvm < 11, afl-clang-lto LTO will not be build.) -endif - -ifeq "$(LLVM_APPLE_XCODE)" "1" - $(warning llvm_mode will not compile with Xcode clang...) -endif - -# We were using llvm-config --bindir to get the location of clang, but -# this seems to be busted on some distros, so using the one in $PATH is -# probably better. - -CC = $(LLVM_BINDIR)/clang -CXX = $(LLVM_BINDIR)/clang++ - -# llvm-config --bindir may not providing a valid path, so ... -ifeq "$(shell test -e $(CC) || echo 1 )" "1" - # however we must ensure that this is not a "CC=gcc make" - ifeq "$(shell command -v $(CC) 2> /dev/null)" "" - # we do not have a valid CC variable so we try alternatives - ifeq "$(shell test -e '$(BIN_DIR)/clang' && echo 1)" "1" - # we found one in the local install directory, lets use these - CC = $(BIN_DIR)/clang - else - # hope for the best - $(warning we have trouble finding clang - llvm-config is not helping us) - CC = clang - endif - endif -endif -# llvm-config --bindir may not providing a valid path, so ... -ifeq "$(shell test -e $(CXX) || echo 1 )" "1" - # however we must ensure that this is not a "CC=gcc make" - ifeq "$(shell command -v $(CXX) 2> /dev/null)" "" - # we do not have a valid CC variable so we try alternatives - ifeq "$(shell test -e '$(BIN_DIR)/clang++' && echo 1)" "1" - # we found one in the local install directory, lets use these - CXX = $(BIN_DIR)/clang++ - else - # hope for the best - $(warning we have trouble finding clang++ - llvm-config is not helping us) - CXX = clang++ - endif - endif -endif - -# sanity check. -# Are versions of clang --version and llvm-config --version equal? -CLANGVER = $(shell $(CC) --version | sed -E -ne '/^.*version\ (1?[0-9]\.[0-9]\.[0-9]).*/s//\1/p') - -# I disable this because it does not make sense with what we did before (marc) -# We did exactly set these 26 lines above with these values, and it would break -# "CC=gcc make" etc. usages -ifeq "$(findstring clang, $(shell $(CC) --version 2>/dev/null))" "" - CC_SAVE := $(LLVM_BINDIR)/clang -else - CC_SAVE := $(CC) -endif -ifeq "$(findstring clang, $(shell $(CXX) --version 2>/dev/null))" "" - CXX_SAVE := $(LLVM_BINDIR)/clang++ -else - CXX_SAVE := $(CXX) -endif - -CLANG_BIN := $(CC_SAVE) -CLANGPP_BIN := $(CXX_SAVE) - -ifeq "$(CC_SAVE)" "$(LLVM_BINDIR)/clang" - USE_BINDIR = 1 -else - ifeq "$(CXX_SAVE)" "$(LLVM_BINDIR)/clang++" - USE_BINDIR = 1 - else - USE_BINDIR = 0 - endif -endif - -# On old platform we cannot compile with clang because std++ libraries are too -# old. For these we need to use gcc/g++, so if we find REAL_CC and REAL_CXX -# variable we override the compiler variables here -ifneq "$(REAL_CC)" "" -CC = $(REAL_CC) -endif -ifneq "$(REAL_CXX)" "" -CXX = $(REAL_CXX) -endif - -# After we set CC/CXX we can start makefile magic tests - -#ifeq "$(shell echo 'int main() {return 0; }' | $(CC) -x c - -march=native -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" -# CFLAGS_OPT = -march=native -#endif - -ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -flto=full -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" - AFL_CLANG_FLTO ?= -flto=full -else - ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -flto=thin -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" - AFL_CLANG_FLTO ?= -flto=thin - else - ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -flto -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" - AFL_CLANG_FLTO ?= -flto - endif - endif -endif - -ifeq "$(LLVM_LTO)" "1" - ifneq "$(AFL_CLANG_FLTO)" "" - ifeq "$(AFL_REAL_LD)" "" - ifneq "$(shell readlink $(LLVM_BINDIR)/ld.lld 2>&1)" "" - AFL_REAL_LD = $(LLVM_BINDIR)/ld.lld - else - $(warn ld.lld not found, can not enable LTO mode) - LLVM_LTO = 0 - endif - endif - endif -endif - -AFL_CLANG_FUSELD= -ifneq "$(AFL_CLANG_FLTO)" "" -ifeq "$(shell echo 'int main() {return 0; }' | $(CLANG_BIN) -x c - -fuse-ld=`command -v ld` -o .test 2>/dev/null && echo 1 || echo 0 ; rm -f .test )" "1" - AFL_CLANG_FUSELD=1 -endif -endif - -CFLAGS ?= -O3 -funroll-loops -fPIC -D_FORTIFY_SOURCE=2 -CFLAGS_SAFE := -Wall -g -Wno-pointer-sign -I ../include/ \ - -DAFL_PATH=\"$(HELPER_PATH)\" -DBIN_PATH=\"$(BIN_PATH)\" \ - -DLLVM_BINDIR=\"$(LLVM_BINDIR)\" -DVERSION=\"$(VERSION)\" \ - -DLLVM_LIBDIR=\"$(LLVM_LIBDIR)\" -DLLVM_VERSION=\"$(LLVMVER)\" \ - -DAFL_CLANG_FLTO=\"$(AFL_CLANG_FLTO)\" \ - -DAFL_REAL_LD=\"$(AFL_REAL_LD)\" -DAFL_CLANG_FUSELD=\"$(AFL_CLANG_FUSELD)\" \ - -DCLANG_BIN=\"$(CLANG_BIN)\" -DCLANGPP_BIN=\"$(CLANGPP_BIN)\" -DUSE_BINDIR=$(USE_BINDIR) -Wno-unused-function -override CFLAGS += $(CFLAGS_SAFE) - -ifdef AFL_TRACE_PC - $(info Compile option AFL_TRACE_PC is deprecated, just set AFL_LLVM_INSTRUMENT=PCGUARD to activate when compiling targets ) -endif - -CXXFLAGS ?= -O3 -funroll-loops -fPIC -D_FORTIFY_SOURCE=2 -override CXXFLAGS += -Wall -g -I ../include/ \ - -DVERSION=\"$(VERSION)\" -Wno-variadic-macros - -ifneq "$(shell $(LLVM_CONFIG) --includedir) 2> /dev/null" "" - CLANG_CFL = -I$(shell $(LLVM_CONFIG) --includedir) -endif -ifneq "$(LLVM_CONFIG)" "" - CLANG_CFL += -I$(shell dirname $(LLVM_CONFIG))/../include -endif -CLANG_CPPFL = `$(LLVM_CONFIG) --cxxflags` -fno-rtti -fPIC $(CXXFLAGS) -CLANG_LFL = `$(LLVM_CONFIG) --ldflags` $(LDFLAGS) - - -# User teor2345 reports that this is required to make things work on MacOS X. -ifeq "$(shell uname)" "Darwin" - CLANG_LFL += -Wl,-flat_namespace -Wl,-undefined,suppress -else - CLANG_CPPFL += -Wl,-znodelete -endif - -ifeq "$(shell uname)" "OpenBSD" - CLANG_LFL += `$(LLVM_CONFIG) --libdir`/libLLVM.so - CLANG_CPPFL += -mno-retpoline - CFLAGS += -mno-retpoline - # Needed for unwind symbols - LDFLAGS += -lc++abi -endif - -ifeq "$(shell echo '$(HASH)include <sys/ipc.h>@$(HASH)include <sys/shm.h>@int main() { int _id = shmget(IPC_PRIVATE, 65536, IPC_CREAT | IPC_EXCL | 0600); shmctl(_id, IPC_RMID, 0); return 0;}' | tr @ '\n' | $(CC) -x c - -o .test2 2>/dev/null && echo 1 || echo 0 ; rm -f .test2 )" "1" - SHMAT_OK=1 -else - SHMAT_OK=0 - #CFLAGS+=-DUSEMMAP=1 - LDFLAGS += -Wno-deprecated-declarations -endif - -ifeq "$(TEST_MMAP)" "1" - SHMAT_OK=0 - CFLAGS+=-DUSEMMAP=1 - LDFLAGS += -Wno-deprecated-declarations -endif - - PROGS = ../afl-clang-fast ../afl-llvm-pass.so ../afl-ld-lto ../afl-llvm-lto-instrumentlist.so ../afl-llvm-lto-instrumentation.so ../afl-llvm-lto-instrim.so ../libLLVMInsTrim.so ../afl-llvm-rt.o ../afl-llvm-rt-32.o ../afl-llvm-rt-64.o ../compare-transform-pass.so ../split-compares-pass.so ../split-switches-pass.so ../cmplog-routines-pass.so ../cmplog-instructions-pass.so - -# If prerequisites are not given, warn, do not build anything, and exit with code 0 -ifeq "$(LLVMVER)" "" - NO_BUILD = 1 -endif - -ifneq "$(LLVM_UNSUPPORTED)$(LLVM_APPLE_XCODE)" "00" - NO_BUILD = 1 -endif - -ifeq "$(NO_BUILD)" "1" - TARGETS = no_build -else - TARGETS = test_shm test_deps $(PROGS) afl-clang-fast.8 test_build all_done -endif - -LLVM_MIN_4_0_1 = $(shell awk 'function tonum(ver, a) {split(ver,a,"."); return a[1]*1000000+a[2]*1000+a[3]} BEGIN { exit tonum(ARGV[1]) >= tonum(ARGV[2]) }' $(LLVMVER) 4.0.1; echo $$?) - -all: $(TARGETS) - -ifeq "$(SHMAT_OK)" "1" - -test_shm: - @echo "[+] shmat seems to be working." - @rm -f .test2 - -else - -test_shm: - @echo "[-] shmat seems not to be working, switching to mmap implementation" - -endif - -no_build: - @printf "%b\\n" "\\033[0;31mPrerequisites are not met, skipping build llvm_mode\\033[0m" - -test_deps: - @echo "[*] Checking for working 'llvm-config'..." - ifneq "$(LLVM_APPLE_XCODE)" "1" - @type $(LLVM_CONFIG) >/dev/null 2>&1 || ( echo "[-] Oops, can't find 'llvm-config'. Install clang or set \$$LLVM_CONFIG or \$$PATH beforehand."; echo " (Sometimes, the binary will be named llvm-config-3.5 or something like that.)"; exit 1 ) - endif - @echo "[*] Checking for working '$(CC)'..." - @type $(CC) >/dev/null 2>&1 || ( echo "[-] Oops, can't find '$(CC)'. Make sure that it's in your \$$PATH (or set \$$CC and \$$CXX)."; exit 1 ) - @echo "[*] Checking for matching versions of '$(CC)' and '$(LLVM_CONFIG)'" -ifneq "$(CLANGVER)" "$(LLVMVER)" - @echo "[!] WARNING: we have llvm-config version $(LLVMVER) and a clang version $(CLANGVER)" -else - @echo "[*] We have llvm-config version $(LLVMVER) with a clang version $(CLANGVER), good." -endif - @echo "[*] Checking for '../afl-showmap'..." - @test -f ../afl-showmap || ( echo "[-] Oops, can't find '../afl-showmap'. Be sure to compile AFL first."; exit 1 ) - @echo "[+] All set and ready to build." - -afl-common.o: ../src/afl-common.c - $(CC) $(CFLAGS) -c $< -o $@ $(LDFLAGS) - -../afl-clang-fast: afl-clang-fast.c afl-common.o | test_deps - $(CC) $(CLANG_CFL) $(CFLAGS) $< afl-common.o -o $@ $(LDFLAGS) -DCFLAGS_OPT=\"$(CFLAGS_OPT)\" - ln -sf afl-clang-fast ../afl-clang-fast++ -ifneq "$(AFL_CLANG_FLTO)" "" -ifeq "$(LLVM_LTO)" "1" - ln -sf afl-clang-fast ../afl-clang-lto - ln -sf afl-clang-fast ../afl-clang-lto++ -endif -endif - -afl-llvm-common.o: afl-llvm-common.cc afl-llvm-common.h - $(CXX) $(CFLAGS) `$(LLVM_CONFIG) --cxxflags` -fno-rtti -fPIC -std=$(LLVM_STDCXX) -c $< -o $@ - -../libLLVMInsTrim.so: LLVMInsTrim.so.cc MarkNodes.cc afl-llvm-common.o | test_deps - -$(CXX) $(CLANG_CPPFL) -DLLVMInsTrim_EXPORTS -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< MarkNodes.cc -o $@ $(CLANG_LFL) afl-llvm-common.o - -../afl-llvm-pass.so: afl-llvm-pass.so.cc afl-llvm-common.o | test_deps -ifeq "$(LLVM_MIN_4_0_1)" "0" - $(info [!] N-gram branch coverage instrumentation is not available for llvm version $(LLVMVER)) -endif - $(CXX) $(CLANG_CPPFL) -DLLVMInsTrim_EXPORTS -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< -o $@ $(CLANG_LFL) afl-llvm-common.o - -../afl-llvm-lto-instrumentlist.so: afl-llvm-lto-instrumentlist.so.cc afl-llvm-common.o -ifeq "$(LLVM_LTO)" "1" - $(CXX) $(CLANG_CPPFL) -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< -o $@ $(CLANG_LFL) afl-llvm-common.o -endif - -../afl-ld-lto: afl-ld-lto.c -ifeq "$(LLVM_LTO)" "1" - $(CC) $(CFLAGS) $< -o $@ -endif - -../afl-llvm-lto-instrumentation.so: afl-llvm-lto-instrumentation.so.cc afl-llvm-common.o -ifeq "$(LLVM_LTO)" "1" - $(CXX) $(CLANG_CPPFL) -Wno-writable-strings -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< -o $@ $(CLANG_LFL) afl-llvm-common.o - $(CLANG_BIN) $(CFLAGS_SAFE) -Wno-unused-result -O0 $(AFL_CLANG_FLTO) -fPIC -c afl-llvm-rt-lto.o.c -o ../afl-llvm-rt-lto.o - @$(CLANG_BIN) $(CFLAGS_SAFE) -Wno-unused-result -O0 $(AFL_CLANG_FLTO) -m64 -fPIC -c afl-llvm-rt-lto.o.c -o ../afl-llvm-rt-lto-64.o 2>/dev/null; if [ "$$?" = "0" ]; then : ; fi - @$(CLANG_BIN) $(CFLAGS_SAFE) -Wno-unused-result -O0 $(AFL_CLANG_FLTO) -m32 -fPIC -c afl-llvm-rt-lto.o.c -o ../afl-llvm-rt-lto-32.o 2>/dev/null; if [ "$$?" = "0" ]; then : ; fi -endif - -../afl-llvm-lto-instrim.so: afl-llvm-lto-instrim.so.cc afl-llvm-common.o -ifeq "$(LLVM_LTO)" "1" - $(CXX) $(CLANG_CPPFL) -DLLVMInsTrim_EXPORTS -Wno-writable-strings -fno-rtti -fPIC -std=$(LLVM_STDCXX) -shared $< MarkNodes.cc -o $@ $(CLANG_LFL) afl-llvm-common.o -endif - -# laf -../split-switches-pass.so: split-switches-pass.so.cc afl-llvm-common.o | test_deps - $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) afl-llvm-common.o -../compare-transform-pass.so: compare-transform-pass.so.cc afl-llvm-common.o | test_deps - $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) afl-llvm-common.o -../split-compares-pass.so: split-compares-pass.so.cc afl-llvm-common.o | test_deps - $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) afl-llvm-common.o -# /laf - -../cmplog-routines-pass.so: cmplog-routines-pass.cc afl-llvm-common.o | test_deps - $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) afl-llvm-common.o - -../cmplog-instructions-pass.so: cmplog-instructions-pass.cc afl-llvm-common.o | test_deps - $(CXX) $(CLANG_CPPFL) -shared $< -o $@ $(CLANG_LFL) afl-llvm-common.o - -document: - $(CLANG_BIN) -D_AFL_DOCUMENT_MUTATIONS $(CFLAGS_SAFE) -O3 -Wno-unused-result -fPIC -c afl-llvm-rt.o.c -o ../afl-llvm-rt.o - @$(CLANG_BIN) -D_AFL_DOCUMENT_MUTATIONS $(CFLAGS_SAFE) -O3 -Wno-unused-result -m32 -fPIC -c afl-llvm-rt.o.c -o ../afl-llvm-rt-32.o 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; else echo "failed (that's fine)"; fi - @$(CLANG_BIN) -D_AFL_DOCUMENT_MUTATIONS $(CFLAGS_SAFE) -O3 -Wno-unused-result -m64 -fPIC -c afl-llvm-rt.o.c -o ../afl-llvm-rt-64.o 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; else echo "failed (that's fine)"; fi - -../afl-llvm-rt.o: afl-llvm-rt.o.c | test_deps - $(CLANG_BIN) $(CFLAGS_SAFE) -O3 -Wno-unused-result -fPIC -c $< -o $@ - -../afl-llvm-rt-32.o: afl-llvm-rt.o.c | test_deps - @printf "[*] Building 32-bit variant of the runtime (-m32)... " - @$(CLANG_BIN) $(CFLAGS_SAFE) -O3 -Wno-unused-result -m32 -fPIC -c $< -o $@ 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; else echo "failed (that's fine)"; fi - -../afl-llvm-rt-64.o: afl-llvm-rt.o.c | test_deps - @printf "[*] Building 64-bit variant of the runtime (-m64)... " - @$(CLANG_BIN) $(CFLAGS_SAFE) -O3 -Wno-unused-result -m64 -fPIC -c $< -o $@ 2>/dev/null; if [ "$$?" = "0" ]; then echo "success!"; else echo "failed (that's fine)"; fi - -test_build: $(PROGS) - @echo "[*] Testing the CC wrapper and instrumentation output..." - unset AFL_USE_ASAN AFL_USE_MSAN AFL_INST_RATIO; AFL_QUIET=1 AFL_PATH=. AFL_LLVM_LAF_SPLIT_SWITCHES=1 AFL_LLVM_LAF_TRANSFORM_COMPARES=1 AFL_LLVM_LAF_SPLIT_COMPARES=1 ../afl-clang-fast $(CFLAGS) ../test-instr.c -o test-instr $(LDFLAGS) - ASAN_OPTIONS=detect_leaks=0 ../afl-showmap -m none -q -o .test-instr0 ./test-instr < /dev/null - echo 1 | ASAN_OPTIONS=detect_leaks=0 ../afl-showmap -m none -q -o .test-instr1 ./test-instr - @rm -f test-instr - @cmp -s .test-instr0 .test-instr1; DR="$$?"; rm -f .test-instr0 .test-instr1; if [ "$$DR" = "0" ]; then echo; echo "Oops, the instrumentation does not seem to be behaving correctly!"; echo; echo "Please post to https://github.com/AFLplusplus/AFLplusplus/issues to troubleshoot the issue."; echo; exit 1; fi - @echo "[+] All right, the instrumentation seems to be working!" - -all_done: test_build - @echo "[+] All done! You can now use '../afl-clang-fast' to compile programs." - -.NOTPARALLEL: clean - -install: all - install -d -m 755 $${DESTDIR}$(BIN_PATH) $${DESTDIR}$(HELPER_PATH) $${DESTDIR}$(DOC_PATH) $${DESTDIR}$(MISC_PATH) - if [ -f ../afl-clang-fast -a -f ../libLLVMInsTrim.so -a -f ../afl-llvm-rt.o ]; then set -e; install -m 755 ../afl-clang-fast $${DESTDIR}$(BIN_PATH); ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang-fast++; install -m 755 ../libLLVMInsTrim.so ../afl-llvm-pass.so ../afl-llvm-rt.o $${DESTDIR}$(HELPER_PATH); fi - if [ -f ../afl-clang-lto ]; then set -e; ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang-lto; ln -sf afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang-lto++; install -m 755 ../afl-llvm-lto-instrumentation.so ../afl-llvm-lto-instrim.so ../afl-llvm-rt-lto*.o ../afl-llvm-lto-instrumentlist.so $${DESTDIR}$(HELPER_PATH); fi - if [ -f ../afl-ld-lto ]; then set -e; install -m 755 ../afl-ld-lto $${DESTDIR}$(BIN_PATH); fi - if [ -f ../afl-llvm-rt-32.o ]; then set -e; install -m 755 ../afl-llvm-rt-32.o $${DESTDIR}$(HELPER_PATH); fi - if [ -f ../afl-llvm-rt-64.o ]; then set -e; install -m 755 ../afl-llvm-rt-64.o $${DESTDIR}$(HELPER_PATH); fi - if [ -f ../compare-transform-pass.so ]; then set -e; install -m 755 ../compare-transform-pass.so $${DESTDIR}$(HELPER_PATH); fi - if [ -f ../split-compares-pass.so ]; then set -e; install -m 755 ../split-compares-pass.so $${DESTDIR}$(HELPER_PATH); fi - if [ -f ../split-switches-pass.so ]; then set -e; install -m 755 ../split-switches-pass.so $${DESTDIR}$(HELPER_PATH); fi - if [ -f ../cmplog-instructions-pass.so ]; then set -e; install -m 755 ../cmplog-*-pass.so $${DESTDIR}$(HELPER_PATH); fi - set -e; if [ -f ../afl-clang-fast ] ; then ln -sf ../afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang ; ln -sf ../afl-clang-fast $${DESTDIR}$(BIN_PATH)/afl-clang++ ; else ln -sf ../afl-gcc $${DESTDIR}$(BIN_PATH)/afl-clang ; ln -sf ../afl-gcc $${DESTDIR}$(BIN_PATH)/afl-clang++; fi - install -m 644 README.*.md $${DESTDIR}$(DOC_PATH)/ - install -m 644 -T README.md $${DESTDIR}$(DOC_PATH)/README.llvm_mode.md - -vpath % .. -%.8: % - @echo .TH $* 8 `date "+%Y-%m-%d"` "afl++" > ../$@ - @echo .SH NAME >> ../$@ - @echo .B $* >> ../$@ - @echo >> ../$@ - @echo .SH SYNOPSIS >> ../$@ - @../$* -h 2>&1 | head -n 3 | tail -n 1 | sed 's/^\.\///' >> ../$@ - @echo >> ../$@ - @echo .SH OPTIONS >> ../$@ - @echo .nf >> ../$@ - @../$* -h 2>&1 | tail -n +4 >> ../$@ - @echo >> ../$@ - @echo .SH AUTHOR >> ../$@ - @echo "afl++ was written by Michal \"lcamtuf\" Zalewski and is maintained by Marc \"van Hauser\" Heuse <mh@mh-sec.de>, Heiko \"hexcoder-\" Eissfeldt <heiko.eissfeldt@hexco.de>, Andrea Fioraldi <andreafioraldi@gmail.com> and Dominik Maier <domenukk@gmail.com>" >> ../$@ - @echo The homepage of afl++ is: https://github.com/AFLplusplus/AFLplusplus >> ../$@ - @echo >> ../$@ - @echo .SH LICENSE >> ../$@ - @echo Apache License Version 2.0, January 2004 >> ../$@ - ln -sf afl-clang-fast.8 ../afl-clang-fast++.8 -ifneq "$(AFL_CLANG_FLTO)" "" -ifeq "$(LLVM_LTO)" "1" - ln -sf afl-clang-fast.8 ../afl-clang-lto.8 - ln -sf afl-clang-fast.8 ../afl-clang-lto++.8 -endif -endif - -clean: - rm -f *.o *.so *~ a.out core core.[1-9][0-9]* .test2 test-instr .test-instr0 .test-instr1 *.dwo - rm -f $(PROGS) afl-common.o ../afl-clang-fast++ ../afl-clang-lto ../afl-clang-lto++ ../afl-clang*.8 ../ld ../afl-ld ../afl-llvm-rt*.o diff --git a/llvm_mode/Makefile b/llvm_mode/Makefile deleted file mode 100644 index 3666a74d..00000000 --- a/llvm_mode/Makefile +++ /dev/null @@ -1,2 +0,0 @@ -all: - @gmake all || echo please install GNUmake diff --git a/llvm_mode/README.ctx.md b/llvm_mode/README.ctx.md deleted file mode 100644 index 14255313..00000000 --- a/llvm_mode/README.ctx.md +++ /dev/null @@ -1,22 +0,0 @@ -# AFL Context Sensitive Branch Coverage - -## What is this? - -This is an LLVM-based implementation of the context sensitive branch coverage. - -Basically every function gets it's own ID and that ID is combined with the -edges of the called functions. - -So if both function A and function B call a function C, the coverage -collected in C will be different. - -In math the coverage is collected as follows: -`map[current_location_ID ^ previous_location_ID >> 1 ^ previous_callee_ID] += 1` - -## Usage - -Set the `AFL_LLVM_INSTRUMENT=CTX` or `AFL_LLVM_CTX=1` environment variable. - -It is highly recommended to increase the MAP_SIZE_POW2 definition in -config.h to at least 18 and maybe up to 20 for this as otherwise too -many map collisions occur. diff --git a/llvm_mode/README.instrim.md b/llvm_mode/README.instrim.md deleted file mode 100644 index 53a518a9..00000000 --- a/llvm_mode/README.instrim.md +++ /dev/null @@ -1,34 +0,0 @@ -# InsTrim - -InsTrim: Lightweight Instrumentation for Coverage-guided Fuzzing - -## Introduction - -InsTrim uses CFG and markers to instrument just what is necessary in the -binary in llvm_mode. It is about 10-15% faster without disadvantages. -It requires at least llvm version 3.8.0. - -## Usage - -Set the environment variable `AFL_LLVM_INSTRUMENT=CFG` or `AFL_LLVM_INSTRIM=1` -during compilation of the target. - -There is also an advanced mode which instruments loops in a way so that -afl-fuzz can see which loop path has been selected but not being able to -see how often the loop has been rerun. -This again is a tradeoff for speed for less path information. -To enable this mode set `AFL_LLVM_INSTRIM_LOOPHEAD=1`. - -There is an additional optimization option that skips single block -functions. In 95% of the C targets and (guess) 50% of the C++ targets -it is good to enable this, as otherwise pointless instrumentation occurs. -The corner case where we want this instrumentation is when vtable/call table -is used and the index to that vtable/call table is not set in specific -basic blocks. -To enable skipping these (most of the time) unnecessary instrumentations set -`AFL_LLVM_INSTRIM_SKIPSINGLEBLOCK=1` - -## Background - -The paper: [InsTrim: Lightweight Instrumentation for Coverage-guided Fuzzing] -(https://www.ndss-symposium.org/wp-content/uploads/2018/07/bar2018_14_Hsu_paper.pdf) diff --git a/llvm_mode/README.instrument_file.md b/llvm_mode/README.instrument_file.md deleted file mode 100644 index 29c40eec..00000000 --- a/llvm_mode/README.instrument_file.md +++ /dev/null @@ -1,79 +0,0 @@ -# Using afl++ with partial instrumentation - - This file describes how you can selectively instrument only the source files - that are interesting to you using the LLVM instrumentation provided by - afl++ - - Originally developed by Christian Holler (:decoder) <choller@mozilla.com>. - -## 1) Description and purpose - -When building and testing complex programs where only a part of the program is -the fuzzing target, it often helps to only instrument the necessary parts of -the program, leaving the rest uninstrumented. This helps to focus the fuzzer -on the important parts of the program, avoiding undesired noise and -disturbance by uninteresting code being exercised. - -For this purpose, I have added a "partial instrumentation" support to the LLVM -mode of AFLFuzz that allows you to specify on a source file level which files -should be compiled with or without instrumentation. - - -## 2) Building the LLVM module - -The new code is part of the existing afl++ LLVM module in the llvm_mode/ -subdirectory. There is nothing specifically to do :) - - -## 3) How to use the partial instrumentation mode - -In order to build with partial instrumentation, you need to build with -afl-clang-fast and afl-clang-fast++ respectively. The only required change is -that you need to set the environment variable AFL_LLVM_INSTRUMENT_FILE when calling -the compiler. - -The environment variable must point to a file containing all the filenames -that should be instrumented. For matching, the filename that is being compiled -must end in the filename entry contained in this the instrument file list (to avoid breaking -the matching when absolute paths are used during compilation). - -For example if your source tree looks like this: - -``` -project/ -project/feature_a/a1.cpp -project/feature_a/a2.cpp -project/feature_b/b1.cpp -project/feature_b/b2.cpp -``` - -and you only want to test feature_a, then create a the instrument file list file containing: - -``` -feature_a/a1.cpp -feature_a/a2.cpp -``` - -However if the instrument file list file contains only this, it works as well: - -``` -a1.cpp -a2.cpp -``` - -but it might lead to files being unwantedly instrumented if the same filename -exists somewhere else in the project directories. - -The created the instrument file list file is then set to AFL_LLVM_INSTRUMENT_FILE when you compile -your program. For each file that didn't match the the instrument file list, the compiler will -issue a warning at the end stating that no blocks were instrumented. If you -didn't intend to instrument that file, then you can safely ignore that warning. - -For old LLVM versions this feature might require to be compiled with debug -information (-g), however at least from llvm version 6.0 onwards this is not -required anymore (and might hurt performance and crash detection, so better not -use -g). - -## 4) UNIX-style filename pattern matching -You can add UNIX-style pattern matching in the the instrument file list entries. See `man -fnmatch` for the syntax. We do not set any of the `fnmatch` flags. diff --git a/llvm_mode/afl-clang-fast.c b/llvm_mode/afl-clang-fast.c deleted file mode 100644 index dca11bf3..00000000 --- a/llvm_mode/afl-clang-fast.c +++ /dev/null @@ -1,1011 +0,0 @@ -/* - american fuzzy lop++ - LLVM-mode wrapper for clang - ------------------------------------------------ - - Written by Laszlo Szekeres <lszekeres@google.com> and - Michal Zalewski - - LLVM integration design comes from Laszlo Szekeres. - - Copyright 2015, 2016 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This program is a drop-in replacement for clang, similar in most respects - to ../afl-gcc. It tries to figure out compilation mode, adds a bunch - of flags, and then calls the real compiler. - - */ - -#define AFL_MAIN - -#include "common.h" -#include "config.h" -#include "types.h" -#include "debug.h" -#include "alloc-inl.h" -#include "llvm-ngram-coverage.h" - -#include <stdio.h> -#include <unistd.h> -#include <stdlib.h> -#include <string.h> -#include <strings.h> -#include <limits.h> -#include <assert.h> - -#include "llvm/Config/llvm-config.h" - -static u8 * obj_path; /* Path to runtime libraries */ -static u8 **cc_params; /* Parameters passed to the real CC */ -static u32 cc_par_cnt = 1; /* Param count, including argv0 */ -static u8 llvm_fullpath[PATH_MAX]; -static u8 instrument_mode, instrument_opt_mode, ngram_size, lto_mode, cpp_mode; -static u8 *lto_flag = AFL_CLANG_FLTO; -static u8 debug; -static u8 cwd[4096]; -static u8 cmplog_mode; -u8 use_stdin = 0; /* dummy */ -// static u8 *march_opt = CFLAGS_OPT; - -enum { - - INSTURMENT_DEFAULT = 0, - INSTRUMENT_CLASSIC = 1, - INSTRUMENT_AFL = 1, - INSTRUMENT_PCGUARD = 2, - INSTRUMENT_INSTRIM = 3, - INSTRUMENT_CFG = 3, - INSTRUMENT_LTO = 4, - INSTRUMENT_OPT_CTX = 8, - INSTRUMENT_OPT_NGRAM = 16 - -}; - -char instrument_mode_string[18][18] = { - - "DEFAULT", "CLASSIC", "PCGUARD", "CFG", "LTO", "", "", "", "CTX", "", - "", "", "", "", "", "", "NGRAM", "" - -}; - -u8 *getthecwd() { - - static u8 fail[] = ""; - if (getcwd(cwd, sizeof(cwd)) == NULL) return fail; - return cwd; - -} - -/* Try to find the runtime libraries. If that fails, abort. */ - -static void find_obj(u8 *argv0) { - - u8 *afl_path = getenv("AFL_PATH"); - u8 *slash, *tmp; - - if (afl_path) { - -#ifdef __ANDROID__ - tmp = alloc_printf("%s/afl-llvm-rt.so", afl_path); -#else - tmp = alloc_printf("%s/afl-llvm-rt.o", afl_path); -#endif - - if (!access(tmp, R_OK)) { - - obj_path = afl_path; - ck_free(tmp); - return; - - } - - ck_free(tmp); - - } - - slash = strrchr(argv0, '/'); - - if (slash) { - - u8 *dir; - - *slash = 0; - dir = ck_strdup(argv0); - *slash = '/'; - -#ifdef __ANDROID__ - tmp = alloc_printf("%s/afl-llvm-rt.so", dir); -#else - tmp = alloc_printf("%s/afl-llvm-rt.o", dir); -#endif - - if (!access(tmp, R_OK)) { - - obj_path = dir; - ck_free(tmp); - return; - - } - - ck_free(tmp); - ck_free(dir); - - } - -#ifdef __ANDROID__ - if (!access(AFL_PATH "/afl-llvm-rt.so", R_OK)) { - -#else - if (!access(AFL_PATH "/afl-llvm-rt.o", R_OK)) { - -#endif - - obj_path = AFL_PATH; - return; - - } - - FATAL( - "Unable to find 'afl-llvm-rt.o' or 'afl-llvm-pass.so'. Please set " - "AFL_PATH"); - -} - -/* Copy argv to cc_params, making the necessary edits. */ - -static void edit_params(u32 argc, char **argv, char **envp) { - - u8 fortify_set = 0, asan_set = 0, x_set = 0, bit_mode = 0; - u8 *name; - - cc_params = ck_alloc((argc + 128) * sizeof(u8 *)); - - name = strrchr(argv[0], '/'); - if (!name) - name = argv[0]; - else - ++name; - - if (lto_mode) - if (lto_flag[0] != '-') - FATAL( - "Using afl-clang-lto is not possible because Makefile magic did not " - "identify the correct -flto flag"); - - if (!strcmp(name, "afl-clang-fast++") || !strcmp(name, "afl-clang-lto++") || - !strcmp(name, "afl-clang++")) { - - u8 *alt_cxx = getenv("AFL_CXX"); - if (USE_BINDIR) - snprintf(llvm_fullpath, sizeof(llvm_fullpath), "%s/clang++", LLVM_BINDIR); - else - sprintf(llvm_fullpath, CLANGPP_BIN); - cc_params[0] = alt_cxx && *alt_cxx ? alt_cxx : (u8 *)llvm_fullpath; - cpp_mode = 1; - - } else if (!strcmp(name, "afl-clang-fast") || - - !strcmp(name, "afl-clang-lto") || !strcmp(name, "afl-clang")) { - - u8 *alt_cc = getenv("AFL_CC"); - if (USE_BINDIR) - snprintf(llvm_fullpath, sizeof(llvm_fullpath), "%s/clang", LLVM_BINDIR); - else - sprintf(llvm_fullpath, CLANG_BIN); - cc_params[0] = alt_cc && *alt_cc ? alt_cc : (u8 *)llvm_fullpath; - - } else { - - fprintf(stderr, "Name of the binary: %s\n", argv[0]); - FATAL( - "Name of the binary is not a known name, expected afl-clang-fast(++) " - "or afl-clang-lto(++)"); - - } - - cc_params[cc_par_cnt++] = "-Wno-unused-command-line-argument"; - - if (lto_mode && cpp_mode) - cc_params[cc_par_cnt++] = "-lc++"; // needed by fuzzbench, early - - /* There are several ways to compile with afl-clang-fast. In the traditional - mode, we use afl-llvm-pass.so, then there is libLLVMInsTrim.so which is - faster and creates less map pollution. - Then there is the 'trace-pc-guard' mode, we use native LLVM - instrumentation callbacks instead. For trace-pc-guard see: - http://clang.llvm.org/docs/SanitizerCoverage.html#tracing-pcs-with-guards - The best instrumentatation is with the LTO modes, the classic and - InsTrimLTO, the latter is faster. The LTO modes are activated by using - afl-clang-lto(++) - */ - - if (lto_mode) { - - if (getenv("AFL_LLVM_INSTRUMENT_FILE") != NULL || - getenv("AFL_LLVM_WHITELIST")) { - - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = "-load"; - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = - alloc_printf("%s/afl-llvm-lto-instrumentlist.so", obj_path); - - } - - } - - // laf - if (getenv("LAF_SPLIT_SWITCHES") || getenv("AFL_LLVM_LAF_SPLIT_SWITCHES")) { - - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = "-load"; - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = - alloc_printf("%s/split-switches-pass.so", obj_path); - - } - - if (getenv("LAF_TRANSFORM_COMPARES") || - getenv("AFL_LLVM_LAF_TRANSFORM_COMPARES")) { - - if (!be_quiet && getenv("AFL_LLVM_LTO_AUTODICTIONARY") && lto_mode) - WARNF( - "using AFL_LLVM_LAF_TRANSFORM_COMPARES together with " - "AFL_LLVM_LTO_AUTODICTIONARY makes no sense. Use only " - "AFL_LLVM_LTO_AUTODICTIONARY."); - - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = "-load"; - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = - alloc_printf("%s/compare-transform-pass.so", obj_path); - - } - - if (getenv("LAF_SPLIT_COMPARES") || getenv("AFL_LLVM_LAF_SPLIT_COMPARES") || - getenv("AFL_LLVM_LAF_SPLIT_FLOATS")) { - - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = "-load"; - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = - alloc_printf("%s/split-compares-pass.so", obj_path); - - } - - // /laf - - unsetenv("AFL_LD"); - unsetenv("AFL_LD_CALLER"); - if (cmplog_mode) { - - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = "-load"; - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = - alloc_printf("%s/cmplog-routines-pass.so", obj_path); - - // reuse split switches from laf - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = "-load"; - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = - alloc_printf("%s/split-switches-pass.so", obj_path); - - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = "-load"; - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = - alloc_printf("%s/cmplog-instructions-pass.so", obj_path); - - cc_params[cc_par_cnt++] = "-fno-inline"; - - } - - if (lto_mode) { - - cc_params[cc_par_cnt++] = alloc_printf("-fuse-ld=%s", AFL_REAL_LD); - cc_params[cc_par_cnt++] = "-Wl,--allow-multiple-definition"; - /* - The current LTO instrim mode is not good, so we disable it - if (instrument_mode == INSTRUMENT_CFG) - cc_params[cc_par_cnt++] = - alloc_printf("-Wl,-mllvm=-load=%s/afl-llvm-lto-instrim.so", - obj_path); else - */ - cc_params[cc_par_cnt++] = alloc_printf( - "-Wl,-mllvm=-load=%s/afl-llvm-lto-instrumentation.so", obj_path); - cc_params[cc_par_cnt++] = lto_flag; - - } else { - - if (instrument_mode == INSTRUMENT_PCGUARD) { - - cc_params[cc_par_cnt++] = - "-fsanitize-coverage=trace-pc-guard"; // edge coverage by default - - } else { - - cc_params[cc_par_cnt++] = "-Xclang"; - cc_params[cc_par_cnt++] = "-load"; - cc_params[cc_par_cnt++] = "-Xclang"; - if (instrument_mode == INSTRUMENT_CFG) - cc_params[cc_par_cnt++] = - alloc_printf("%s/libLLVMInsTrim.so", obj_path); - else - cc_params[cc_par_cnt++] = alloc_printf("%s/afl-llvm-pass.so", obj_path); - - } - - } - - // cc_params[cc_par_cnt++] = "-Qunused-arguments"; - - // in case LLVM is installed not via a package manager or "make install" - // e.g. compiled download or compiled from github then it's ./lib directory - // might not be in the search path. Add it if so. - u8 *libdir = strdup(LLVM_LIBDIR); - if (cpp_mode && strlen(libdir) && strncmp(libdir, "/usr", 4) && - strncmp(libdir, "/lib", 4)) { - - cc_params[cc_par_cnt++] = "-rpath"; - cc_params[cc_par_cnt++] = libdir; - - } else { - - free(libdir); - - } - - /* Detect stray -v calls from ./configure scripts. */ - - while (--argc) { - - u8 *cur = *(++argv); - - if (!strcmp(cur, "-m32")) bit_mode = 32; - if (!strcmp(cur, "armv7a-linux-androideabi")) bit_mode = 32; - if (!strcmp(cur, "-m64")) bit_mode = 64; - - if (!strcmp(cur, "-x")) x_set = 1; - - if (!strcmp(cur, "-fsanitize=address") || !strcmp(cur, "-fsanitize=memory")) - asan_set = 1; - - if (strstr(cur, "FORTIFY_SOURCE")) fortify_set = 1; - - if (!strcmp(cur, "-Wl,-z,defs") || !strcmp(cur, "-Wl,--no-undefined")) - continue; - - if (lto_mode && !strncmp(cur, "-fuse-ld=", 9)) continue; - - cc_params[cc_par_cnt++] = cur; - - } - - if (getenv("AFL_HARDEN")) { - - cc_params[cc_par_cnt++] = "-fstack-protector-all"; - - if (!fortify_set) cc_params[cc_par_cnt++] = "-D_FORTIFY_SOURCE=2"; - - } - - if (!asan_set) { - - if (getenv("AFL_USE_ASAN")) { - - if (getenv("AFL_USE_MSAN")) FATAL("ASAN and MSAN are mutually exclusive"); - - if (getenv("AFL_HARDEN")) - FATAL("ASAN and AFL_HARDEN are mutually exclusive"); - - cc_params[cc_par_cnt++] = "-U_FORTIFY_SOURCE"; - cc_params[cc_par_cnt++] = "-fsanitize=address"; - - } else if (getenv("AFL_USE_MSAN")) { - - if (getenv("AFL_USE_ASAN")) FATAL("ASAN and MSAN are mutually exclusive"); - - if (getenv("AFL_HARDEN")) - FATAL("MSAN and AFL_HARDEN are mutually exclusive"); - - cc_params[cc_par_cnt++] = "-U_FORTIFY_SOURCE"; - cc_params[cc_par_cnt++] = "-fsanitize=memory"; - - } - - } - - if (getenv("AFL_USE_UBSAN")) { - - cc_params[cc_par_cnt++] = "-fsanitize=undefined"; - cc_params[cc_par_cnt++] = "-fsanitize-undefined-trap-on-error"; - cc_params[cc_par_cnt++] = "-fno-sanitize-recover=all"; - - } - - if (getenv("AFL_USE_CFISAN")) { - - if (!lto_mode) { - - uint32_t i = 0, found = 0; - while (envp[i] != NULL && !found) - if (strncmp("-flto", envp[i++], 5) == 0) found = 1; - if (!found) cc_params[cc_par_cnt++] = "-flto"; - - } - - cc_params[cc_par_cnt++] = "-fsanitize=cfi"; - cc_params[cc_par_cnt++] = "-fvisibility=hidden"; - - } - - if (!getenv("AFL_DONT_OPTIMIZE")) { - - cc_params[cc_par_cnt++] = "-g"; - cc_params[cc_par_cnt++] = "-O3"; - cc_params[cc_par_cnt++] = "-funroll-loops"; - // if (strlen(march_opt) > 1 && march_opt[0] == '-') - // cc_params[cc_par_cnt++] = march_opt; - - } - - if (getenv("AFL_NO_BUILTIN") || getenv("AFL_LLVM_LAF_TRANSFORM_COMPARES") || - getenv("LAF_TRANSFORM_COMPARES") || - (lto_mode && (getenv("AFL_LLVM_LTO_AUTODICTIONARY") || - getenv("AFL_LLVM_AUTODICTIONARY")))) { - - cc_params[cc_par_cnt++] = "-fno-builtin-strcmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strncmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strcasecmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strncasecmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-memcmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-bcmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strstr"; - cc_params[cc_par_cnt++] = "-fno-builtin-strcasestr"; - - } - -#if defined(USEMMAP) && !defined(__HAIKU__) - cc_params[cc_par_cnt++] = "-lrt"; -#endif - - cc_params[cc_par_cnt++] = "-D__AFL_HAVE_MANUAL_CONTROL=1"; - cc_params[cc_par_cnt++] = "-D__AFL_COMPILER=1"; - cc_params[cc_par_cnt++] = "-DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1"; - - /* When the user tries to use persistent or deferred forkserver modes by - appending a single line to the program, we want to reliably inject a - signature into the binary (to be picked up by afl-fuzz) and we want - to call a function from the runtime .o file. This is unnecessarily - painful for three reasons: - - 1) We need to convince the compiler not to optimize out the signature. - This is done with __attribute__((used)). - - 2) We need to convince the linker, when called with -Wl,--gc-sections, - not to do the same. This is done by forcing an assignment to a - 'volatile' pointer. - - 3) We need to declare __afl_persistent_loop() in the global namespace, - but doing this within a method in a class is hard - :: and extern "C" - are forbidden and __attribute__((alias(...))) doesn't work. Hence the - __asm__ aliasing trick. - - */ - - cc_params[cc_par_cnt++] = - "-D__AFL_FUZZ_INIT()=" - "int __afl_sharedmem_fuzzing = 1;" - "extern unsigned int *__afl_fuzz_len;" - "extern unsigned char *__afl_fuzz_ptr;" - "unsigned char *__afl_fuzz_alt_ptr;"; - cc_params[cc_par_cnt++] = - "-D__AFL_FUZZ_TESTCASE_BUF=(__afl_fuzz_ptr ? __afl_fuzz_ptr : " - "(__afl_fuzz_alt_ptr = (unsigned char *) malloc(1 * 1024 * 1024)))"; - cc_params[cc_par_cnt++] = - "-D__AFL_FUZZ_TESTCASE_LEN=(__afl_fuzz_ptr ? *__afl_fuzz_len : read(0, " - "__afl_fuzz_alt_ptr, 1 * 1024 * 1024))"; - - cc_params[cc_par_cnt++] = - "-D__AFL_LOOP(_A)=" - "({ static volatile char *_B __attribute__((used)); " - " _B = (char*)\"" PERSIST_SIG - "\"; " -#ifdef __APPLE__ - "__attribute__((visibility(\"default\"))) " - "int _L(unsigned int) __asm__(\"___afl_persistent_loop\"); " -#else - "__attribute__((visibility(\"default\"))) " - "int _L(unsigned int) __asm__(\"__afl_persistent_loop\"); " -#endif /* ^__APPLE__ */ - "_L(_A); })"; - - cc_params[cc_par_cnt++] = - "-D__AFL_INIT()=" - "do { static volatile char *_A __attribute__((used)); " - " _A = (char*)\"" DEFER_SIG - "\"; " -#ifdef __APPLE__ - "__attribute__((visibility(\"default\"))) " - "void _I(void) __asm__(\"___afl_manual_init\"); " -#else - "__attribute__((visibility(\"default\"))) " - "void _I(void) __asm__(\"__afl_manual_init\"); " -#endif /* ^__APPLE__ */ - "_I(); } while (0)"; - - if (x_set) { - - cc_params[cc_par_cnt++] = "-x"; - cc_params[cc_par_cnt++] = "none"; - - } - -#ifndef __ANDROID__ - switch (bit_mode) { - - case 0: - cc_params[cc_par_cnt++] = alloc_printf("%s/afl-llvm-rt.o", obj_path); - if (lto_mode) - cc_params[cc_par_cnt++] = - alloc_printf("%s/afl-llvm-rt-lto.o", obj_path); - break; - - case 32: - cc_params[cc_par_cnt++] = alloc_printf("%s/afl-llvm-rt-32.o", obj_path); - if (access(cc_params[cc_par_cnt - 1], R_OK)) - FATAL("-m32 is not supported by your compiler"); - if (lto_mode) { - - cc_params[cc_par_cnt++] = - alloc_printf("%s/afl-llvm-rt-lto-32.o", obj_path); - if (access(cc_params[cc_par_cnt - 1], R_OK)) - FATAL("-m32 is not supported by your compiler"); - - } - - break; - - case 64: - cc_params[cc_par_cnt++] = alloc_printf("%s/afl-llvm-rt-64.o", obj_path); - if (access(cc_params[cc_par_cnt - 1], R_OK)) - FATAL("-m64 is not supported by your compiler"); - if (lto_mode) { - - cc_params[cc_par_cnt++] = - alloc_printf("%s/afl-llvm-rt-lto-64.o", obj_path); - if (access(cc_params[cc_par_cnt - 1], R_OK)) - FATAL("-m64 is not supported by your compiler"); - - } - - break; - - } - -#endif - - cc_params[cc_par_cnt] = NULL; - -} - -/* Main entry point */ - -int main(int argc, char **argv, char **envp) { - - int i; - char *callname = "afl-clang-fast", *ptr = NULL; - - if (getenv("AFL_DEBUG")) { - - debug = 1; - if (strcmp(getenv("AFL_DEBUG"), "0") == 0) unsetenv("AFL_DEBUG"); - - } else if (getenv("AFL_QUIET")) - - be_quiet = 1; - - if (getenv("USE_TRACE_PC") || getenv("AFL_USE_TRACE_PC") || - getenv("AFL_LLVM_USE_TRACE_PC") || getenv("AFL_TRACE_PC")) { - - if (instrument_mode == 0) - instrument_mode = INSTRUMENT_PCGUARD; - else if (instrument_mode != INSTRUMENT_PCGUARD) - FATAL("you can not set AFL_LLVM_INSTRUMENT and AFL_TRACE_PC together"); - - } - - if (getenv("AFL_LLVM_INSTRIM") || getenv("INSTRIM") || - getenv("INSTRIM_LIB")) { - - if (instrument_mode == 0) - instrument_mode = INSTRUMENT_CFG; - else if (instrument_mode != INSTRUMENT_CFG) - FATAL( - "you can not set AFL_LLVM_INSTRUMENT and AFL_LLVM_INSTRIM together"); - - } - - if (getenv("AFL_LLVM_CTX")) instrument_opt_mode |= INSTRUMENT_OPT_CTX; - - if (getenv("AFL_LLVM_NGRAM_SIZE")) { - - instrument_opt_mode |= INSTRUMENT_OPT_NGRAM; - ngram_size = atoi(getenv("AFL_LLVM_NGRAM_SIZE")); - if (ngram_size < 2 || ngram_size > NGRAM_SIZE_MAX) - FATAL( - "NGRAM instrumentation mode must be between 2 and NGRAM_SIZE_MAX " - "(%u)", - NGRAM_SIZE_MAX); - - } - - if (getenv("AFL_LLVM_INSTRUMENT")) { - - u8 *ptr = strtok(getenv("AFL_LLVM_INSTRUMENT"), ":,;"); - - while (ptr) { - - if (strncasecmp(ptr, "afl", strlen("afl")) == 0 || - strncasecmp(ptr, "classic", strlen("classic")) == 0) { - - if (!instrument_mode || instrument_mode == INSTRUMENT_AFL) - instrument_mode = INSTRUMENT_AFL; - else - FATAL("main instrumentation mode already set with %s", - instrument_mode_string[instrument_mode]); - - } - - if (strncasecmp(ptr, "pc-guard", strlen("pc-guard")) == 0 || - strncasecmp(ptr, "pcguard", strlen("pcguard")) == 0) { - - if (!instrument_mode || instrument_mode == INSTRUMENT_PCGUARD) - instrument_mode = INSTRUMENT_PCGUARD; - else - FATAL("main instrumentation mode already set with %s", - instrument_mode_string[instrument_mode]); - - } - - if (strncasecmp(ptr, "cfg", strlen("cfg")) == 0 || - strncasecmp(ptr, "instrim", strlen("instrim")) == 0) { - - if (instrument_mode == INSTRUMENT_LTO) { - - instrument_mode = INSTRUMENT_CFG; - lto_mode = 1; - - } else if (!instrument_mode || instrument_mode == INSTRUMENT_CFG) - - instrument_mode = INSTRUMENT_CFG; - else - FATAL("main instrumentation mode already set with %s", - instrument_mode_string[instrument_mode]); - - } - - if (strncasecmp(ptr, "lto", strlen("lto")) == 0) { - - lto_mode = 1; - if (!instrument_mode || instrument_mode == INSTRUMENT_LTO) - instrument_mode = INSTRUMENT_LTO; - else if (instrument_mode != INSTRUMENT_CFG) - FATAL("main instrumentation mode already set with %s", - instrument_mode_string[instrument_mode]); - - } - - if (strncasecmp(ptr, "ctx", strlen("ctx")) == 0) { - - instrument_opt_mode |= INSTRUMENT_OPT_CTX; - setenv("AFL_LLVM_CTX", "1", 1); - - } - - if (strncasecmp(ptr, "ngram", strlen("ngram")) == 0) { - - ptr += strlen("ngram"); - while (*ptr && (*ptr < '0' || *ptr > '9')) - ptr++; - if (!*ptr) - if ((ptr = getenv("AFL_LLVM_NGRAM_SIZE")) != NULL) - FATAL( - "you must set the NGRAM size with (e.g. for value 2) " - "AFL_LLVM_INSTRUMENT=ngram-2"); - ngram_size = atoi(ptr); - if (ngram_size < 2 || ngram_size > NGRAM_SIZE_MAX) - FATAL( - "NGRAM instrumentation option must be between 2 and " - "NGRAM_SIZE_MAX " - "(%u)", - NGRAM_SIZE_MAX); - instrument_opt_mode |= (INSTRUMENT_OPT_NGRAM); - ptr = alloc_printf("%u", ngram_size); - setenv("AFL_LLVM_NGRAM_SIZE", ptr, 1); - - } - - ptr = strtok(NULL, ":,;"); - - } - - } - - if (strstr(argv[0], "afl-clang-lto") != NULL) { - - if (instrument_mode == 0 || instrument_mode == INSTRUMENT_LTO || - instrument_mode == INSTRUMENT_CFG) { - - lto_mode = 1; - callname = "afl-clang-lto"; - if (!instrument_mode) { - - instrument_mode = INSTRUMENT_LTO; - ptr = instrument_mode_string[instrument_mode]; - - } - - } else { - - if (!be_quiet) - WARNF("afl-clang-lto called with mode %s, using that mode instead", - instrument_mode_string[instrument_mode]); - - } - - } - - if (instrument_mode == 0) { - -#if LLVM_VERSION_MAJOR <= 6 - instrument_mode = INSTRUMENT_AFL; -#else - if (getenv("AFL_LLVM_INSTRUMENT_FILE") || getenv("AFL_LLVM_WHITELIST")) { - - instrument_mode = INSTRUMENT_AFL; - WARNF( - "switching to classic instrumentation because " - "AFL_LLVM_INSTRUMENT_FILE does not work with PCGUARD. Use " - "-fsanitize-coverage-allowlist=allowlist.txt if you want to use " - "PCGUARD. See " - "https://clang.llvm.org/docs/" - "SanitizerCoverage.html#partially-disabling-instrumentation"); - - } else - - instrument_mode = INSTRUMENT_PCGUARD; -#endif - - } - - if (instrument_opt_mode && lto_mode) - FATAL( - "CTX and NGRAM can not be used in LTO mode (and would make LTO " - "useless)"); - - if (!instrument_opt_mode) { - - if (lto_mode && instrument_mode == INSTRUMENT_CFG) - ptr = alloc_printf("InsTrimLTO"); - else - ptr = instrument_mode_string[instrument_mode]; - - } else if (instrument_opt_mode == INSTRUMENT_OPT_CTX) - - ptr = alloc_printf("%s + CTX", instrument_mode_string[instrument_mode]); - else if (instrument_opt_mode == INSTRUMENT_OPT_NGRAM) - ptr = alloc_printf("%s + NGRAM-%u", instrument_mode_string[instrument_mode], - ngram_size); - else - ptr = alloc_printf("%s + CTX + NGRAM-%u", - instrument_mode_string[instrument_mode], ngram_size); - -#ifndef AFL_CLANG_FLTO - if (lto_mode) - FATAL( - "instrumentation mode LTO specified but LLVM support not available " - "(requires LLVM 11 or higher)"); -#endif - - if (instrument_opt_mode && instrument_mode != INSTRUMENT_CLASSIC && - instrument_mode != INSTRUMENT_CFG) - FATAL( - "CTX and NGRAM instrumentation options can only be used with CFG " - "(recommended) and CLASSIC instrumentation modes!"); - - if (getenv("AFL_LLVM_SKIP_NEVERZERO") && getenv("AFL_LLVM_NOT_ZERO")) - FATAL( - "AFL_LLVM_NOT_ZERO and AFL_LLVM_SKIP_NEVERZERO can not be set " - "together"); - - if (instrument_mode == INSTRUMENT_PCGUARD && - (getenv("AFL_LLVM_INSTRUMENT_FILE") || getenv("AFL_LLVM_WHITELIST"))) - FATAL( - "Instrumentation type PCGUARD does not support " - "AFL_LLVM_INSTRUMENT_FILE! Use " - "-fsanitize-coverage-allowlist=allowlist.txt instead, see " - "https://clang.llvm.org/docs/" - "SanitizerCoverage.html#partially-disabling-instrumentation"); - - if (argc < 2 || strcmp(argv[1], "-h") == 0) { - - if (!lto_mode) - printf("afl-clang-fast" VERSION " by <lszekeres@google.com> in %s mode\n", - ptr); - else - printf("afl-clang-lto" VERSION - " by Marc \"vanHauser\" Heuse <mh@mh-sec.de> in %s mode\n", - ptr); - - SAYF( - "\n" - "%s[++] [options]\n" - "\n" - "This is a helper application for afl-fuzz. It serves as a drop-in " - "replacement\n" - "for clang, letting you recompile third-party code with the " - "required " - "runtime\n" - "instrumentation. A common use pattern would be one of the " - "following:\n\n" - - " CC=%s/afl-clang-fast ./configure\n" - " CXX=%s/afl-clang-fast++ ./configure\n\n" - - "In contrast to the traditional afl-clang tool, this version is " - "implemented as\n" - "an LLVM pass and tends to offer improved performance with slow " - "programs.\n\n" - - "Environment variables used:\n" - "AFL_CC: path to the C compiler to use\n" - "AFL_CXX: path to the C++ compiler to use\n" - "AFL_DEBUG: enable developer debugging output\n" - "AFL_DONT_OPTIMIZE: disable optimization instead of -O3\n" - "AFL_HARDEN: adds code hardening to catch memory bugs\n" - "AFL_INST_RATIO: percentage of branches to instrument\n" - "AFL_LLVM_NOT_ZERO: use cycling trace counters that skip zero\n" - "AFL_LLVM_SKIP_NEVERZERO: do not skip zero on trace counters\n" - "AFL_LLVM_LAF_SPLIT_COMPARES: enable cascaded comparisons\n" - "AFL_LLVM_LAF_SPLIT_COMPARES_BITW: size limit (default 8)\n" - "AFL_LLVM_LAF_SPLIT_SWITCHES: casc. comp. in 'switch'\n" - " to cascaded comparisons\n" - "AFL_LLVM_LAF_SPLIT_FLOATS: transform floating point comp. to " - "cascaded comp.\n" - "AFL_LLVM_LAF_TRANSFORM_COMPARES: transform library comparison " - "function calls\n" - "AFL_LLVM_LAF_ALL: enables all LAF splits/transforms\n" - "AFL_LLVM_INSTRUMENT_FILE: enable the instrument file listing " - "(selective " - "instrumentation)\n" - "AFL_NO_BUILTIN: compile for use with libtokencap.so\n" - "AFL_PATH: path to instrumenting pass and runtime " - "(afl-llvm-rt.*o)\n" - "AFL_QUIET: suppress verbose output\n" - "AFL_USE_ASAN: activate address sanitizer\n" - "AFL_USE_CFISAN: activate control flow sanitizer\n" - "AFL_USE_MSAN: activate memory sanitizer\n" - "AFL_USE_UBSAN: activate undefined behaviour sanitizer\n", - callname, BIN_PATH, BIN_PATH); - - SAYF( - "\nafl-clang-fast specific environment variables:\n" - "AFL_LLVM_CMPLOG: log operands of comparisons (RedQueen mutator)\n" - "AFL_LLVM_INSTRUMENT: set instrumentation mode: AFL, CFG " - "(INSTRIM), PCGUARD [DEFAULT], LTO, CTX, NGRAM-2 ... NGRAM-16\n" - " You can also use the old environment variables instead:\n" - " AFL_LLVM_USE_TRACE_PC: use LLVM trace-pc-guard instrumentation " - "[DEFAULT]\n" - " AFL_LLVM_INSTRIM: use light weight instrumentation InsTrim\n" - " AFL_LLVM_INSTRIM_LOOPHEAD: optimize loop tracing for speed (" - "option to INSTRIM)\n" - " AFL_LLVM_CTX: use context sensitive coverage\n" - " AFL_LLVM_NGRAM_SIZE: use ngram prev_loc count coverage\n"); - -#ifdef AFL_CLANG_FLTO - SAYF( - "\nafl-clang-lto specific environment variables:\n" - "AFL_LLVM_LTO_DONTWRITEID: don't write the highest ID used to a " - "global var\n" - "AFL_LLVM_LTO_STARTID: from which ID to start counting from for a " - "bb\n" - "AFL_REAL_LD: use this lld linker instead of the compiled in path\n" - "\nafl-clang-lto was built with linker target \"%s\" and LTO flags " - "\"%s\"\n" - "If anything fails - be sure to read README.lto.md!\n", - AFL_REAL_LD, AFL_CLANG_FLTO); -#endif - - SAYF( - "\nafl-clang-fast was built for llvm %s with the llvm binary path " - "of \"%s\".\n", - LLVM_VERSION, LLVM_BINDIR); - - SAYF("\n"); - - exit(1); - - } else if ((isatty(2) && !be_quiet) || - - getenv("AFL_DEBUG") != NULL) { - - if (!lto_mode) - - SAYF(cCYA "afl-clang-fast" VERSION cRST - " by <lszekeres@google.com> in %s mode\n", - ptr); - - else - - SAYF(cCYA "afl-clang-lto" VERSION cRST - " by Marc \"vanHauser\" Heuse <mh@mh-sec.de> in mode %s\n", - ptr); - - } - - u8 *ptr2; - if (!be_quiet && !lto_mode && - ((ptr2 = getenv("AFL_MAP_SIZE")) || (ptr2 = getenv("AFL_MAPSIZE")))) { - - u32 map_size = atoi(ptr2); - if (map_size != MAP_SIZE) - WARNF("AFL_MAP_SIZE is not supported by afl-clang-fast"); - - } - - if (debug) { - - SAYF(cMGN "[D]" cRST " cd \"%s\";", getthecwd()); - for (i = 0; i < argc; i++) - SAYF(" \"%s\"", argv[i]); - SAYF("\n"); - - } - - check_environment_vars(envp); - - if (getenv("AFL_LLVM_LAF_ALL")) { - - setenv("AFL_LLVM_LAF_SPLIT_SWITCHES", "1", 1); - setenv("AFL_LLVM_LAF_SPLIT_COMPARES", "1", 1); - setenv("AFL_LLVM_LAF_SPLIT_FLOATS", "1", 1); - setenv("AFL_LLVM_LAF_TRANSFORM_COMPARES", "1", 1); - - } - - cmplog_mode = getenv("AFL_CMPLOG") || getenv("AFL_LLVM_CMPLOG"); - if (!be_quiet && cmplog_mode) - printf("CmpLog mode by <andreafioraldi@gmail.com>\n"); - -#ifndef __ANDROID__ - find_obj(argv[0]); -#endif - - edit_params(argc, argv, envp); - - if (debug) { - - SAYF(cMGN "[D]" cRST " cd \"%s\";", getthecwd()); - for (i = 0; i < cc_par_cnt; i++) - SAYF(" \"%s\"", cc_params[i]); - SAYF("\n"); - - } - - execvp(cc_params[0], (char **)cc_params); - - FATAL("Oops, failed to execute '%s' - check your PATH", cc_params[0]); - - return 0; - -} - diff --git a/llvm_mode/afl-llvm-common.cc b/llvm_mode/afl-llvm-common.cc deleted file mode 100644 index 47b49358..00000000 --- a/llvm_mode/afl-llvm-common.cc +++ /dev/null @@ -1,248 +0,0 @@ -#define AFL_LLVM_PASS - -#include "config.h" -#include "debug.h" - -#include <stdio.h> -#include <stdlib.h> -#include <unistd.h> -#include <sys/time.h> -#include <fnmatch.h> - -#include <list> -#include <string> -#include <fstream> - -#include <llvm/Support/raw_ostream.h> -#include "afl-llvm-common.h" - -using namespace llvm; - -static std::list<std::string> myInstrumentList; - -char *getBBName(const llvm::BasicBlock *BB) { - - static char *name; - - if (!BB->getName().empty()) { - - name = strdup(BB->getName().str().c_str()); - return name; - - } - - std::string Str; - raw_string_ostream OS(Str); - -#if LLVM_VERSION_MAJOR >= 4 || \ - (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR >= 7) - BB->printAsOperand(OS, false); -#endif - name = strdup(OS.str().c_str()); - return name; - -} - -/* Function that we never instrument or analyze */ -/* Note: this ignore check is also called in isInInstrumentList() */ -bool isIgnoreFunction(const llvm::Function *F) { - - // Starting from "LLVMFuzzer" these are functions used in libfuzzer based - // fuzzing campaign installations, e.g. oss-fuzz - - static const char *ignoreList[] = { - - "asan.", - "llvm.", - "sancov.", - "__ubsan_handle_", - "ign.", - "__afl_", - "_fini", - "__libc_csu", - "__asan", - "__msan", - "msan.", - "LLVMFuzzer", - "maybe_duplicate_stderr", - "discard_output", - "close_stdout", - "dup_and_close_stderr", - "maybe_close_fd_mask", - "ExecuteFilesOnyByOne" - - }; - - for (auto const &ignoreListFunc : ignoreList) { - - if (F->getName().startswith(ignoreListFunc)) { return true; } - - } - - return false; - -} - -void initInstrumentList() { - - char *instrumentListFilename = getenv("AFL_LLVM_INSTRUMENT_FILE"); - if (!instrumentListFilename) - instrumentListFilename = getenv("AFL_LLVM_WHITELIST"); - if (instrumentListFilename) { - - std::string line; - std::ifstream fileStream; - fileStream.open(instrumentListFilename); - if (!fileStream) - report_fatal_error("Unable to open AFL_LLVM_INSTRUMENT_FILE"); - getline(fileStream, line); - while (fileStream) { - - myInstrumentList.push_back(line); - getline(fileStream, line); - - } - - } - -} - -bool isInInstrumentList(llvm::Function *F) { - - // is this a function with code? If it is external we dont instrument it - // anyway and cant be in the the instrument file list. Or if it is ignored. - if (!F->size() || isIgnoreFunction(F)) return false; - - // if we do not have a the instrument file list return true - if (myInstrumentList.empty()) return true; - - // let's try to get the filename for the function - auto bb = &F->getEntryBlock(); - BasicBlock::iterator IP = bb->getFirstInsertionPt(); - IRBuilder<> IRB(&(*IP)); - DebugLoc Loc = IP->getDebugLoc(); - -#if LLVM_VERSION_MAJOR >= 4 || \ - (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR >= 7) - if (Loc) { - - DILocation *cDILoc = dyn_cast<DILocation>(Loc.getAsMDNode()); - - unsigned int instLine = cDILoc->getLine(); - StringRef instFilename = cDILoc->getFilename(); - - if (instFilename.str().empty()) { - - /* If the original location is empty, try using the inlined location - */ - DILocation *oDILoc = cDILoc->getInlinedAt(); - if (oDILoc) { - - instFilename = oDILoc->getFilename(); - instLine = oDILoc->getLine(); - - } - - } - - (void)instLine; - - /* Continue only if we know where we actually are */ - if (!instFilename.str().empty()) { - - for (std::list<std::string>::iterator it = myInstrumentList.begin(); - it != myInstrumentList.end(); ++it) { - - /* We don't check for filename equality here because - * filenames might actually be full paths. Instead we - * check that the actual filename ends in the filename - * specified in the list. We also allow UNIX-style pattern - * matching */ - - if (instFilename.str().length() >= it->length()) { - - if (fnmatch(("*" + *it).c_str(), instFilename.str().c_str(), 0) == - 0) { - - return true; - - } - - } - - } - - } - - } - -#else - if (!Loc.isUnknown()) { - - DILocation cDILoc(Loc.getAsMDNode(F->getContext())); - - unsigned int instLine = cDILoc.getLineNumber(); - StringRef instFilename = cDILoc.getFilename(); - - (void)instLine; - /* Continue only if we know where we actually are */ - if (!instFilename.str().empty()) { - - for (std::list<std::string>::iterator it = myInstrumentList.begin(); - it != myInstrumentList.end(); ++it) { - - /* We don't check for filename equality here because - * filenames might actually be full paths. Instead we - * check that the actual filename ends in the filename - * specified in the list. We also allow UNIX-style pattern - * matching */ - - if (instFilename.str().length() >= it->length()) { - - if (fnmatch(("*" + *it).c_str(), instFilename.str().c_str(), 0) == - 0) { - - return true; - - } - - } - - } - - } - - } - -#endif - else { - - // we could not find out the location. in this case we say it is not - // in the the instrument file list - - return false; - - } - - // - return false; - -} - -// Calculate the number of average collisions that would occur if all -// location IDs would be assigned randomly (like normal afl/afl++). -// This uses the "balls in bins" algorithm. -unsigned long long int calculateCollisions(uint32_t edges) { - - double bins = MAP_SIZE; - double balls = edges; - double step1 = 1 - (1 / bins); - double step2 = pow(step1, balls); - double step3 = bins * step2; - double step4 = round(step3); - unsigned long long int empty = step4; - unsigned long long int collisions = edges - (MAP_SIZE - empty); - return collisions; - -} - diff --git a/llvm_mode/afl-llvm-lto-instrim.so.cc b/llvm_mode/afl-llvm-lto-instrim.so.cc deleted file mode 100644 index 880963ac..00000000 --- a/llvm_mode/afl-llvm-lto-instrim.so.cc +++ /dev/null @@ -1,951 +0,0 @@ -/* - american fuzzy lop++ - LLVM-mode instrumentation pass - --------------------------------------------------- - - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This library is plugged into LLVM when invoking clang through afl-clang-fast - or afl-clang-lto with AFL_LLVM_INSTRUMENT=CFG or =INSTRIM - - */ - -#define AFL_LLVM_PASS - -#include <stdio.h> -#include <stdlib.h> -#include <stdarg.h> -#include <unistd.h> -#include <string.h> -#include <sys/time.h> - -#include <unordered_set> -#include <list> -#include <string> -#include <fstream> -#include <set> - -#include "llvm/Config/llvm-config.h" -#include "llvm/ADT/DenseMap.h" -#include "llvm/ADT/DenseSet.h" -#include "llvm/ADT/Statistic.h" -#include "llvm/IR/BasicBlock.h" -#include "llvm/IR/CFG.h" -#include "llvm/IR/Dominators.h" -#include "llvm/IR/DebugInfo.h" -#include "llvm/IR/IRBuilder.h" -#include "llvm/IR/Instructions.h" -#include "llvm/IR/LegacyPassManager.h" -#include "llvm/IR/Module.h" -#include "llvm/IR/Verifier.h" -#include "llvm/Pass.h" -#include "llvm/Support/Debug.h" -#include "llvm/Support/raw_ostream.h" -#include "llvm/Support/CommandLine.h" -#include "llvm/Transforms/IPO/PassManagerBuilder.h" -#include "llvm/Transforms/Utils/BasicBlockUtils.h" -#include "llvm/Analysis/LoopInfo.h" -#include "llvm/Analysis/MemorySSAUpdater.h" -#include "llvm/Analysis/ValueTracking.h" - -#include "MarkNodes.h" -#include "afl-llvm-common.h" - -#include "config.h" -#include "debug.h" - -using namespace llvm; - -static cl::opt<bool> MarkSetOpt("markset", cl::desc("MarkSet"), - cl::init(false)); -static cl::opt<bool> LoopHeadOpt("loophead", cl::desc("LoopHead"), - cl::init(false)); - -namespace { - -struct InsTrimLTO : public ModulePass { - - protected: - uint32_t function_minimum_size = 1; - char * skip_nozero = NULL; - int afl_global_id = 1, debug = 0, autodictionary = 1; - uint32_t be_quiet = 0, inst_blocks = 0, inst_funcs = 0; - uint64_t map_addr = 0x10000; - - public: - static char ID; - - InsTrimLTO() : ModulePass(ID) { - - char *ptr; - - if (getenv("AFL_DEBUG")) debug = 1; - if ((ptr = getenv("AFL_LLVM_LTO_STARTID")) != NULL) - if ((afl_global_id = atoi(ptr)) < 0 || afl_global_id >= MAP_SIZE) - FATAL("AFL_LLVM_LTO_STARTID value of \"%s\" is not between 0 and %d\n", - ptr, MAP_SIZE - 1); - - skip_nozero = getenv("AFL_LLVM_SKIP_NEVERZERO"); - - } - - void getAnalysisUsage(AnalysisUsage &AU) const override { - - ModulePass::getAnalysisUsage(AU); - AU.addRequired<DominatorTreeWrapperPass>(); - AU.addRequired<LoopInfoWrapperPass>(); - - } - - StringRef getPassName() const override { - - return "InstTrim LTO Instrumentation"; - - } - - bool runOnModule(Module &M) override { - - char be_quiet = 0; - char * ptr; - uint32_t locations = 0, functions = 0; - - setvbuf(stdout, NULL, _IONBF, 0); - - if ((isatty(2) && !getenv("AFL_QUIET")) || getenv("AFL_DEBUG") != NULL) { - - SAYF(cCYA "InsTrimLTO" VERSION cRST - " by csienslab and Marc \"vanHauser\" Heuse\n"); - - } else - - be_quiet = 1; - - /* Process environment variables */ - - if (getenv("AFL_LLVM_MAP_DYNAMIC")) map_addr = 0; - - if ((ptr = getenv("AFL_LLVM_MAP_ADDR"))) { - - uint64_t val; - if (!*ptr || !strcmp(ptr, "0") || !strcmp(ptr, "0x0")) { - - map_addr = 0; - - } else if (map_addr == 0) { - - FATAL( - "AFL_LLVM_MAP_ADDR and AFL_LLVM_MAP_DYNAMIC cannot be used " - "together"); - - } else if (strncmp(ptr, "0x", 2) != 0) { - - map_addr = 0x10000; // the default - - } else { - - val = strtoull(ptr, NULL, 16); - if (val < 0x100 || val > 0xffffffff00000000) { - - FATAL( - "AFL_LLVM_MAP_ADDR must be a value between 0x100 and " - "0xffffffff00000000"); - - } - - map_addr = val; - - } - - } - - if (debug) { fprintf(stderr, "map address is %lu\n", map_addr); } - - if (getenv("AFL_LLVM_INSTRIM_LOOPHEAD") != NULL || - getenv("LOOPHEAD") != NULL) { - - LoopHeadOpt = true; - - } - - if (getenv("AFL_LLVM_INSTRIM_SKIPSINGLEBLOCK") || - getenv("AFL_LLVM_SKIPSINGLEBLOCK")) - function_minimum_size = 2; - - // this is our default - MarkSetOpt = true; - - /* Initialize LLVM instrumentation */ - - LLVMContext & C = M.getContext(); - std::vector<std::string> dictionary; - std::vector<CallInst *> calls; - DenseMap<Value *, std::string *> valueMap; - - IntegerType *Int8Ty = IntegerType::getInt8Ty(C); - IntegerType *Int32Ty = IntegerType::getInt32Ty(C); - IntegerType *Int64Ty = IntegerType::getInt64Ty(C); - - ConstantInt *Zero = ConstantInt::get(Int8Ty, 0); - ConstantInt *One = ConstantInt::get(Int8Ty, 1); - - /* Get/set globals for the SHM region. */ - - GlobalVariable *AFLMapPtr = NULL; - Value * MapPtrFixed = NULL; - - if (!map_addr) { - - AFLMapPtr = - new GlobalVariable(M, PointerType::get(Int8Ty, 0), false, - GlobalValue::ExternalLinkage, 0, "__afl_area_ptr"); - - } else { - - ConstantInt *MapAddr = ConstantInt::get(Int64Ty, map_addr); - MapPtrFixed = - ConstantExpr::getIntToPtr(MapAddr, PointerType::getUnqual(Int8Ty)); - - } - - if (autodictionary) { - - /* Some implementation notes. - * - * We try to handle 3 cases: - * - memcmp("foo", arg, 3) <- literal string - * - static char globalvar[] = "foo"; - * memcmp(globalvar, arg, 3) <- global variable - * - char localvar[] = "foo"; - * memcmp(locallvar, arg, 3) <- local variable - * - * The local variable case is the hardest. We can only detect that - * case if there is no reassignment or change in the variable. - * And it might not work across llvm version. - * What we do is hooking the initializer function for local variables - * (llvm.memcpy.p0i8.p0i8.i64) and note the string and the assigned - * variable. And if that variable is then used in a compare function - * we use that noted string. - * This seems not to work for tokens that have a size <= 4 :-( - * - * - if the compared length is smaller than the string length we - * save the full string. This is likely better for fuzzing but - * might be wrong in a few cases depending on optimizers - * - * - not using StringRef because there is a bug in the llvm 11 - * checkout I am using which sometimes points to wrong strings - * - * Over and out. Took me a full day. damn. mh/vh - */ - - for (Function &F : M) { - - for (auto &BB : F) { - - for (auto &IN : BB) { - - CallInst *callInst = nullptr; - - if ((callInst = dyn_cast<CallInst>(&IN))) { - - bool isStrcmp = true; - bool isMemcmp = true; - bool isStrncmp = true; - bool isStrcasecmp = true; - bool isStrncasecmp = true; - bool isIntMemcpy = true; - bool addedNull = false; - uint8_t optLen = 0; - - Function *Callee = callInst->getCalledFunction(); - if (!Callee) continue; - if (callInst->getCallingConv() != llvm::CallingConv::C) continue; - std::string FuncName = Callee->getName().str(); - isStrcmp &= !FuncName.compare("strcmp"); - isMemcmp &= !FuncName.compare("memcmp"); - isStrncmp &= !FuncName.compare("strncmp"); - isStrcasecmp &= !FuncName.compare("strcasecmp"); - isStrncasecmp &= !FuncName.compare("strncasecmp"); - isIntMemcpy &= !FuncName.compare("llvm.memcpy.p0i8.p0i8.i64"); - - if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && - !isStrncasecmp && !isIntMemcpy) - continue; - - /* Verify the strcmp/memcmp/strncmp/strcasecmp/strncasecmp - * function prototype */ - FunctionType *FT = Callee->getFunctionType(); - - isStrcmp &= FT->getNumParams() == 2 && - FT->getReturnType()->isIntegerTy(32) && - FT->getParamType(0) == FT->getParamType(1) && - FT->getParamType(0) == - IntegerType::getInt8PtrTy(M.getContext()); - isStrcasecmp &= FT->getNumParams() == 2 && - FT->getReturnType()->isIntegerTy(32) && - FT->getParamType(0) == FT->getParamType(1) && - FT->getParamType(0) == - IntegerType::getInt8PtrTy(M.getContext()); - isMemcmp &= FT->getNumParams() == 3 && - FT->getReturnType()->isIntegerTy(32) && - FT->getParamType(0)->isPointerTy() && - FT->getParamType(1)->isPointerTy() && - FT->getParamType(2)->isIntegerTy(); - isStrncmp &= FT->getNumParams() == 3 && - FT->getReturnType()->isIntegerTy(32) && - FT->getParamType(0) == FT->getParamType(1) && - FT->getParamType(0) == - IntegerType::getInt8PtrTy(M.getContext()) && - FT->getParamType(2)->isIntegerTy(); - isStrncasecmp &= FT->getNumParams() == 3 && - FT->getReturnType()->isIntegerTy(32) && - FT->getParamType(0) == FT->getParamType(1) && - FT->getParamType(0) == - IntegerType::getInt8PtrTy(M.getContext()) && - FT->getParamType(2)->isIntegerTy(); - - if (!isStrcmp && !isMemcmp && !isStrncmp && !isStrcasecmp && - !isStrncasecmp && !isIntMemcpy) - continue; - - /* is a str{n,}{case,}cmp/memcmp, check if we have - * str{case,}cmp(x, "const") or str{case,}cmp("const", x) - * strn{case,}cmp(x, "const", ..) or strn{case,}cmp("const", x, - * ..) memcmp(x, "const", ..) or memcmp("const", x, ..) */ - Value *Str1P = callInst->getArgOperand(0), - *Str2P = callInst->getArgOperand(1); - std::string Str1, Str2; - StringRef TmpStr; - bool HasStr1 = getConstantStringInfo(Str1P, TmpStr); - if (TmpStr.empty()) - HasStr1 = false; - else - Str1 = TmpStr.str(); - bool HasStr2 = getConstantStringInfo(Str2P, TmpStr); - if (TmpStr.empty()) - HasStr2 = false; - else - Str2 = TmpStr.str(); - - if (debug) - fprintf(stderr, "F:%s %p(%s)->\"%s\"(%s) %p(%s)->\"%s\"(%s)\n", - FuncName.c_str(), Str1P, Str1P->getName().str().c_str(), - Str1.c_str(), HasStr1 == true ? "true" : "false", Str2P, - Str2P->getName().str().c_str(), Str2.c_str(), - HasStr2 == true ? "true" : "false"); - - // we handle the 2nd parameter first because of llvm memcpy - if (!HasStr2) { - - auto *Ptr = dyn_cast<ConstantExpr>(Str2P); - if (Ptr && Ptr->isGEPWithNoNotionalOverIndexing()) { - - if (auto *Var = - dyn_cast<GlobalVariable>(Ptr->getOperand(0))) { - - if (Var->hasInitializer()) { - - if (auto *Array = dyn_cast<ConstantDataArray>( - Var->getInitializer())) { - - HasStr2 = true; - Str2 = Array->getAsString().str(); - - } - - } - - } - - } - - } - - // for the internal memcpy routine we only care for the second - // parameter and are not reporting anything. - if (isIntMemcpy == true) { - - if (HasStr2 == true) { - - Value * op2 = callInst->getArgOperand(2); - ConstantInt *ilen = dyn_cast<ConstantInt>(op2); - if (ilen) { - - uint64_t literalLength = Str2.size(); - uint64_t optLength = ilen->getZExtValue(); - if (literalLength + 1 == optLength) { - - Str2.append("\0", 1); // add null byte - addedNull = true; - - } - - } - - valueMap[Str1P] = new std::string(Str2); - - if (debug) - fprintf(stderr, "Saved: %s for %p\n", Str2.c_str(), Str1P); - continue; - - } - - continue; - - } - - // Neither a literal nor a global variable? - // maybe it is a local variable that we saved - if (!HasStr2) { - - std::string *strng = valueMap[Str2P]; - if (strng && !strng->empty()) { - - Str2 = *strng; - HasStr2 = true; - if (debug) - fprintf(stderr, "Filled2: %s for %p\n", strng->c_str(), - Str2P); - - } - - } - - if (!HasStr1) { - - auto Ptr = dyn_cast<ConstantExpr>(Str1P); - - if (Ptr && Ptr->isGEPWithNoNotionalOverIndexing()) { - - if (auto *Var = - dyn_cast<GlobalVariable>(Ptr->getOperand(0))) { - - if (Var->hasInitializer()) { - - if (auto *Array = dyn_cast<ConstantDataArray>( - Var->getInitializer())) { - - HasStr1 = true; - Str1 = Array->getAsString().str(); - - } - - } - - } - - } - - } - - // Neither a literal nor a global variable? - // maybe it is a local variable that we saved - if (!HasStr1) { - - std::string *strng = valueMap[Str1P]; - if (strng && !strng->empty()) { - - Str1 = *strng; - HasStr1 = true; - if (debug) - fprintf(stderr, "Filled1: %s for %p\n", strng->c_str(), - Str1P); - - } - - } - - /* handle cases of one string is const, one string is variable */ - if (!(HasStr1 ^ HasStr2)) continue; - - std::string thestring; - - if (HasStr1) - thestring = Str1; - else - thestring = Str2; - - optLen = thestring.length(); - - if (isMemcmp || isStrncmp || isStrncasecmp) { - - Value * op2 = callInst->getArgOperand(2); - ConstantInt *ilen = dyn_cast<ConstantInt>(op2); - if (ilen) { - - uint64_t literalLength = optLen; - optLen = ilen->getZExtValue(); - if (literalLength + 1 == optLen) { // add null byte - thestring.append("\0", 1); - addedNull = true; - - } - - } - - } - - // add null byte if this is a string compare function and a null - // was not already added - if (addedNull == false && !isMemcmp) { - - thestring.append("\0", 1); // add null byte - optLen++; - - } - - if (!be_quiet) { - - std::string outstring; - fprintf(stderr, "%s: length %u/%u \"", FuncName.c_str(), optLen, - (unsigned int)thestring.length()); - for (uint8_t i = 0; i < thestring.length(); i++) { - - uint8_t c = thestring[i]; - if (c <= 32 || c >= 127) - fprintf(stderr, "\\x%02x", c); - else - fprintf(stderr, "%c", c); - - } - - fprintf(stderr, "\"\n"); - - } - - // we take the longer string, even if the compare was to a - // shorter part. Note that depending on the optimizer of the - // compiler this can be wrong, but it is more likely that this - // is helping the fuzzer - if (optLen != thestring.length()) optLen = thestring.length(); - if (optLen > MAX_AUTO_EXTRA) optLen = MAX_AUTO_EXTRA; - if (optLen < MIN_AUTO_EXTRA) // too short? skip - continue; - - dictionary.push_back(thestring.substr(0, optLen)); - - } - - } - - } - - } - - } - - /* InsTrim instrumentation starts here */ - - u64 total_rs = 0; - u64 total_hs = 0; - - for (Function &F : M) { - - if (debug) { - - uint32_t bb_cnt = 0; - - for (auto &BB : F) - if (BB.size() > 0) ++bb_cnt; - SAYF(cMGN "[D] " cRST "Function %s size %zu %u\n", - F.getName().str().c_str(), F.size(), bb_cnt); - - } - - // if the function below our minimum size skip it (1 or 2) - if (F.size() < function_minimum_size) continue; - if (isIgnoreFunction(&F)) continue; - - functions++; - - // the instrument file list check - AttributeList Attrs = F.getAttributes(); - if (Attrs.hasAttribute(-1, StringRef("skipinstrument"))) { - - if (debug) - fprintf(stderr, - "DEBUG: Function %s is not the instrument file listed\n", - F.getName().str().c_str()); - continue; - - } - - std::unordered_set<BasicBlock *> MS; - if (!MarkSetOpt) { - - for (auto &BB : F) { - - MS.insert(&BB); - - } - - total_rs += F.size(); - - } else { - - auto Result = markNodes(&F); - auto RS = Result.first; - auto HS = Result.second; - - MS.insert(RS.begin(), RS.end()); - if (!LoopHeadOpt) { - - MS.insert(HS.begin(), HS.end()); - total_rs += MS.size(); - - } else { - - DenseSet<std::pair<BasicBlock *, BasicBlock *>> EdgeSet; - DominatorTreeWrapperPass * DTWP = - &getAnalysis<DominatorTreeWrapperPass>(F); - auto DT = &DTWP->getDomTree(); - - total_rs += RS.size(); - total_hs += HS.size(); - - for (BasicBlock *BB : HS) { - - bool Inserted = false; - for (auto BI = pred_begin(BB), BE = pred_end(BB); BI != BE; ++BI) { - - auto Edge = BasicBlockEdge(*BI, BB); - if (Edge.isSingleEdge() && DT->dominates(Edge, BB)) { - - EdgeSet.insert({*BI, BB}); - Inserted = true; - break; - - } - - } - - if (!Inserted) { - - MS.insert(BB); - total_rs += 1; - total_hs -= 1; - - } - - } - - for (auto I = EdgeSet.begin(), E = EdgeSet.end(); I != E; ++I) { - - auto PredBB = I->first; - auto SuccBB = I->second; - auto NewBB = SplitBlockPredecessors(SuccBB, {PredBB}, ".split", DT, - nullptr, nullptr, false); - MS.insert(NewBB); - - } - - } - - } - - for (BasicBlock &BB : F) { - - auto PI = pred_begin(&BB); - auto PE = pred_end(&BB); - IRBuilder<> IRB(&*BB.getFirstInsertionPt()); - Value * L = NULL; - - if (MarkSetOpt && MS.find(&BB) == MS.end()) { continue; } - - if (PI == PE) { - - L = ConstantInt::get(Int32Ty, afl_global_id++); - locations++; - - } else { - - auto *PN = PHINode::Create(Int32Ty, 0, "", &*BB.begin()); - DenseMap<BasicBlock *, unsigned> PredMap; - for (auto PI = pred_begin(&BB), PE = pred_end(&BB); PI != PE; ++PI) { - - BasicBlock *PBB = *PI; - auto It = PredMap.insert({PBB, afl_global_id++}); - unsigned Label = It.first->second; - PN->addIncoming(ConstantInt::get(Int32Ty, Label), PBB); - locations++; - - } - - L = PN; - - } - - /* Load SHM pointer */ - Value *MapPtrIdx; - - if (map_addr) { - - MapPtrIdx = IRB.CreateGEP(MapPtrFixed, L); - - } else { - - LoadInst *MapPtr = IRB.CreateLoad(AFLMapPtr); - MapPtr->setMetadata(M.getMDKindID("nosanitize"), - MDNode::get(C, None)); - MapPtrIdx = IRB.CreateGEP(MapPtr, L); - - } - - /* Update bitmap */ - LoadInst *Counter = IRB.CreateLoad(MapPtrIdx); - Counter->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); - - Value *Incr = IRB.CreateAdd(Counter, One); - - if (skip_nozero) { - - auto cf = IRB.CreateICmpEQ(Incr, Zero); - auto carry = IRB.CreateZExt(cf, Int8Ty); - Incr = IRB.CreateAdd(Incr, carry); - - } - - IRB.CreateStore(Incr, MapPtrIdx) - ->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None)); - - // done :) - - inst_blocks++; - - } - - } - - // save highest location ID to global variable - // do this after each function to fail faster - if (!be_quiet && afl_global_id > MAP_SIZE && - afl_global_id > FS_OPT_MAX_MAPSIZE) { - - uint32_t pow2map = 1, map = afl_global_id; - while ((map = map >> 1)) - pow2map++; - WARNF( - "We have %u blocks to instrument but the map size is only %u. Either " - "edit config.h and set MAP_SIZE_POW2 from %u to %u, then recompile " - "afl-fuzz and llvm_mode and then make this target - or set " - "AFL_MAP_SIZE with at least size %u when running afl-fuzz with this " - "target.", - afl_global_id, MAP_SIZE, MAP_SIZE_POW2, pow2map, afl_global_id); - - } - - if (!getenv("AFL_LLVM_LTO_DONTWRITEID") || dictionary.size() || map_addr) { - - // yes we could create our own function, insert it into ctors ... - // but this would be a pain in the butt ... so we use afl-llvm-rt-lto.o - - Function *f = M.getFunction("__afl_auto_init_globals"); - - if (!f) { - - fprintf(stderr, - "Error: init function could not be found (this should not " - "happen)\n"); - exit(-1); - - } - - BasicBlock *bb = &f->getEntryBlock(); - if (!bb) { - - fprintf(stderr, - "Error: init function does not have an EntryBlock (this should " - "not happen)\n"); - exit(-1); - - } - - BasicBlock::iterator IP = bb->getFirstInsertionPt(); - IRBuilder<> IRB(&(*IP)); - - if (map_addr) { - - GlobalVariable *AFLMapAddrFixed = - new GlobalVariable(M, Int64Ty, true, GlobalValue::ExternalLinkage, - 0, "__afl_map_addr"); - ConstantInt *MapAddr = ConstantInt::get(Int64Ty, map_addr); - StoreInst * StoreMapAddr = IRB.CreateStore(MapAddr, AFLMapAddrFixed); - StoreMapAddr->setMetadata(M.getMDKindID("nosanitize"), - MDNode::get(C, None)); - - } - - if (getenv("AFL_LLVM_LTO_DONTWRITEID") == NULL) { - - uint32_t write_loc = afl_global_id; - - if (afl_global_id % 8) write_loc = (((afl_global_id + 8) >> 3) << 3); - - GlobalVariable *AFLFinalLoc = - new GlobalVariable(M, Int32Ty, true, GlobalValue::ExternalLinkage, - 0, "__afl_final_loc"); - ConstantInt *const_loc = ConstantInt::get(Int32Ty, write_loc); - StoreInst * StoreFinalLoc = IRB.CreateStore(const_loc, AFLFinalLoc); - StoreFinalLoc->setMetadata(M.getMDKindID("nosanitize"), - MDNode::get(C, None)); - - } - - if (dictionary.size()) { - - size_t memlen = 0, count = 0, offset = 0; - char * ptr; - - for (auto token : dictionary) { - - memlen += token.length(); - count++; - - } - - if (!be_quiet) - printf("AUTODICTIONARY: %lu string%s found\n", count, - count == 1 ? "" : "s"); - - if (count) { - - if ((ptr = (char *)malloc(memlen + count)) == NULL) { - - fprintf(stderr, "Error: malloc for %lu bytes failed!\n", - memlen + count); - exit(-1); - - } - - count = 0; - - for (auto token : dictionary) { - - if (offset + token.length() < 0xfffff0 && count < MAX_AUTO_EXTRAS) { - - ptr[offset++] = (uint8_t)token.length(); - memcpy(ptr + offset, token.c_str(), token.length()); - offset += token.length(); - count++; - - } - - } - - GlobalVariable *AFLDictionaryLen = new GlobalVariable( - M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, - "__afl_dictionary_len"); - ConstantInt *const_len = ConstantInt::get(Int32Ty, offset); - StoreInst * StoreDictLen = - IRB.CreateStore(const_len, AFLDictionaryLen); - StoreDictLen->setMetadata(M.getMDKindID("nosanitize"), - MDNode::get(C, None)); - - ArrayType *ArrayTy = ArrayType::get(IntegerType::get(C, 8), offset); - GlobalVariable *AFLInternalDictionary = new GlobalVariable( - M, ArrayTy, true, GlobalValue::ExternalLinkage, - ConstantDataArray::get( - C, *(new ArrayRef<char>((char *)ptr, offset))), - "__afl_internal_dictionary"); - AFLInternalDictionary->setInitializer(ConstantDataArray::get( - C, *(new ArrayRef<char>((char *)ptr, offset)))); - AFLInternalDictionary->setConstant(true); - - GlobalVariable *AFLDictionary = new GlobalVariable( - M, PointerType::get(Int8Ty, 0), false, - GlobalValue::ExternalLinkage, 0, "__afl_dictionary"); - - Value *AFLDictOff = IRB.CreateGEP(AFLInternalDictionary, Zero); - Value *AFLDictPtr = - IRB.CreatePointerCast(AFLDictOff, PointerType::get(Int8Ty, 0)); - StoreInst *StoreDict = IRB.CreateStore(AFLDictPtr, AFLDictionary); - StoreDict->setMetadata(M.getMDKindID("nosanitize"), - MDNode::get(C, None)); - - } - - } - - } - - // count basic blocks for comparison with classic instrumentation - - u32 edges = 0; - for (auto &F : M) { - - if (F.size() < function_minimum_size) continue; - - for (auto &BB : F) { - - bool would_instrument = false; - - for (BasicBlock *Pred : predecessors(&BB)) { - - int count = 0; - for (BasicBlock *Succ : successors(Pred)) - if (Succ != NULL) count++; - - if (count > 1) would_instrument = true; - - } - - if (would_instrument == true) edges++; - - } - - } - - /* Say something nice. */ - - if (!be_quiet) { - - if (!inst_blocks) - WARNF("No instrumentation targets found."); - else { - - char modeline[100]; - snprintf(modeline, sizeof(modeline), "%s%s%s%s%s", - getenv("AFL_HARDEN") ? "hardened" : "non-hardened", - getenv("AFL_USE_ASAN") ? ", ASAN" : "", - getenv("AFL_USE_MSAN") ? ", MSAN" : "", - getenv("AFL_USE_CFISAN") ? ", CFISAN" : "", - getenv("AFL_USE_UBSAN") ? ", UBSAN" : ""); - OKF("Instrumented %u locations for %u edges in %u functions (%llu, " - "%llu) with no collisions (on " - "average %llu collisions would be in afl-gcc/afl-clang-fast for %u " - "edges) (%s mode).", - inst_blocks, locations, functions, total_rs, total_hs, - calculateCollisions(edges), edges, modeline); - - } - - } - - return true; - - } - -}; // end of struct InsTrim - -} // end of anonymous namespace - -char InsTrimLTO::ID = 0; - -static void registerInsTrimLTO(const PassManagerBuilder &, - legacy::PassManagerBase &PM) { - - PM.add(new InsTrimLTO()); - -} - -static RegisterPass<InsTrimLTO> X("afl-lto-instrim", - "afl++ InsTrim LTO instrumentation pass", - false, false); - -static RegisterStandardPasses RegisterInsTrimLTO( - PassManagerBuilder::EP_FullLinkTimeOptimizationLast, registerInsTrimLTO); - diff --git a/llvm_mode/afl-llvm-lto-instrumentlist.so.cc b/llvm_mode/afl-llvm-lto-instrumentlist.so.cc deleted file mode 100644 index 6e6199e9..00000000 --- a/llvm_mode/afl-llvm-lto-instrumentlist.so.cc +++ /dev/null @@ -1,253 +0,0 @@ -/* - american fuzzy lop++ - LLVM-mode instrumentation pass - --------------------------------------------------- - - Written by Laszlo Szekeres <lszekeres@google.com> and - Michal Zalewski - - LLVM integration design comes from Laszlo Szekeres. C bits copied-and-pasted - from afl-as.c are Michal's fault. - - Copyright 2015, 2016 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This library is plugged into LLVM when invoking clang through afl-clang-fast. - It tells the compiler to add code roughly equivalent to the bits discussed - in ../afl-as.h. - - */ - -#define AFL_LLVM_PASS - -#include "config.h" -#include "debug.h" - -#include <stdio.h> -#include <stdlib.h> -#include <unistd.h> - -#include <list> -#include <string> -#include <fstream> -#include <sys/time.h> -#include <fnmatch.h> - -#include "llvm/IR/DebugInfo.h" -#include "llvm/IR/BasicBlock.h" -#include "llvm/IR/IRBuilder.h" -#include "llvm/IR/LegacyPassManager.h" -#include "llvm/IR/Module.h" -#include "llvm/Support/Debug.h" -#include "llvm/Transforms/IPO/PassManagerBuilder.h" -#include "llvm/IR/CFG.h" - -#include "afl-llvm-common.h" - -using namespace llvm; - -namespace { - -class AFLcheckIfInstrument : public ModulePass { - - public: - static char ID; - AFLcheckIfInstrument() : ModulePass(ID) { - - int entries = 0; - - if (getenv("AFL_DEBUG")) debug = 1; - - char *instrumentListFilename = getenv("AFL_LLVM_INSTRUMENT_FILE"); - if (!instrumentListFilename) - instrumentListFilename = getenv("AFL_LLVM_WHITELIST"); - if (instrumentListFilename) { - - std::string line; - std::ifstream fileStream; - fileStream.open(instrumentListFilename); - if (!fileStream) - report_fatal_error("Unable to open AFL_LLVM_INSTRUMENT_FILE"); - getline(fileStream, line); - while (fileStream) { - - myInstrumentList.push_back(line); - getline(fileStream, line); - entries++; - - } - - } else - - PFATAL( - "afl-llvm-lto-instrumentlist.so loaded without " - "AFL_LLVM_INSTRUMENT_FILE?!"); - - if (debug) - SAYF(cMGN "[D] " cRST - "loaded the instrument file list %s with %d entries\n", - instrumentListFilename, entries); - - } - - bool runOnModule(Module &M) override; - - // StringRef getPassName() const override { - - // return "American Fuzzy Lop Instrumentation"; - // } - - protected: - std::list<std::string> myInstrumentList; - int debug = 0; - -}; - -} // namespace - -char AFLcheckIfInstrument::ID = 0; - -bool AFLcheckIfInstrument::runOnModule(Module &M) { - - /* Show a banner */ - - char be_quiet = 0; - setvbuf(stdout, NULL, _IONBF, 0); - - if ((isatty(2) && !getenv("AFL_QUIET")) || getenv("AFL_DEBUG") != NULL) { - - SAYF(cCYA "afl-llvm-lto-instrumentlist" VERSION cRST - " by Marc \"vanHauser\" Heuse <mh@mh-sec.de>\n"); - - } else if (getenv("AFL_QUIET")) - - be_quiet = 1; - - for (auto &F : M) { - - if (F.size() < 1) continue; - // fprintf(stderr, "F:%s\n", F.getName().str().c_str()); - if (isIgnoreFunction(&F)) continue; - - BasicBlock::iterator IP = F.getEntryBlock().getFirstInsertionPt(); - IRBuilder<> IRB(&(*IP)); - - if (!myInstrumentList.empty()) { - - bool instrumentFunction = false; - - /* Get the current location using debug information. - * For now, just instrument the block if we are not able - * to determine our location. */ - DebugLoc Loc = IP->getDebugLoc(); - if (Loc) { - - DILocation *cDILoc = dyn_cast<DILocation>(Loc.getAsMDNode()); - - unsigned int instLine = cDILoc->getLine(); - StringRef instFilename = cDILoc->getFilename(); - - if (instFilename.str().empty()) { - - /* If the original location is empty, try using the inlined location - */ - DILocation *oDILoc = cDILoc->getInlinedAt(); - if (oDILoc) { - - instFilename = oDILoc->getFilename(); - instLine = oDILoc->getLine(); - - } - - } - - (void)instLine; - - if (debug) - SAYF(cMGN "[D] " cRST "function %s is in file %s\n", - F.getName().str().c_str(), instFilename.str().c_str()); - /* Continue only if we know where we actually are */ - if (!instFilename.str().empty()) { - - for (std::list<std::string>::iterator it = myInstrumentList.begin(); - it != myInstrumentList.end(); ++it) { - - /* We don't check for filename equality here because - * filenames might actually be full paths. Instead we - * check that the actual filename ends in the filename - * specified in the list. */ - if (instFilename.str().length() >= it->length()) { - - if (fnmatch(("*" + *it).c_str(), instFilename.str().c_str(), 0) == - 0) { - - instrumentFunction = true; - break; - - } - - } - - } - - } - - } - - /* Either we couldn't figure out our location or the location is - * not the instrument file listed, so we skip instrumentation. - * We do this by renaming the function. */ - if (instrumentFunction == true) { - - if (debug) - SAYF(cMGN "[D] " cRST "function %s is in the instrument file list\n", - F.getName().str().c_str()); - - } else { - - if (debug) - SAYF(cMGN "[D] " cRST - "function %s is NOT in the instrument file list\n", - F.getName().str().c_str()); - - auto & Ctx = F.getContext(); - AttributeList Attrs = F.getAttributes(); - AttrBuilder NewAttrs; - NewAttrs.addAttribute("skipinstrument"); - F.setAttributes( - Attrs.addAttributes(Ctx, AttributeList::FunctionIndex, NewAttrs)); - - } - - } else { - - PFATAL("InstrumentList is empty"); - - } - - } - - return true; - -} - -static void registerAFLcheckIfInstrumentpass(const PassManagerBuilder &, - legacy::PassManagerBase &PM) { - - PM.add(new AFLcheckIfInstrument()); - -} - -static RegisterStandardPasses RegisterAFLcheckIfInstrumentpass( - PassManagerBuilder::EP_ModuleOptimizerEarly, - registerAFLcheckIfInstrumentpass); - -static RegisterStandardPasses RegisterAFLcheckIfInstrumentpass0( - PassManagerBuilder::EP_EnabledOnOptLevel0, - registerAFLcheckIfInstrumentpass); - diff --git a/llvm_mode/afl-llvm-rt.o.c b/llvm_mode/afl-llvm-rt.o.c deleted file mode 100644 index c0ed1bcf..00000000 --- a/llvm_mode/afl-llvm-rt.o.c +++ /dev/null @@ -1,1085 +0,0 @@ -/* - american fuzzy lop++ - LLVM instrumentation bootstrap - --------------------------------------------------- - - Written by Laszlo Szekeres <lszekeres@google.com> and - Michal Zalewski - - LLVM integration design comes from Laszlo Szekeres. - - Copyright 2015, 2016 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This code is the rewrite of afl-as.h's main_payload. - -*/ - -#ifdef __ANDROID__ - #include "android-ashmem.h" -#endif -#include "config.h" -#include "types.h" -#include "cmplog.h" -#include "llvm-ngram-coverage.h" - -#include <stdio.h> -#include <stdlib.h> -#include <signal.h> -#include <unistd.h> -#include <string.h> -#include <assert.h> -#include <stdint.h> -#include <errno.h> - -#include <sys/mman.h> -#include <sys/shm.h> -#include <sys/wait.h> -#include <sys/types.h> - -#ifdef __linux__ - #include "snapshot-inl.h" -#endif - -/* This is a somewhat ugly hack for the experimental 'trace-pc-guard' mode. - Basically, we need to make sure that the forkserver is initialized after - the LLVM-generated runtime initialization pass, not before. */ - -#define CONST_PRIO 5 - -#ifndef MAP_FIXED_NOREPLACE - #ifdef MAP_EXCL - #define MAP_FIXED_NOREPLACE MAP_EXCL | MAP_FIXED - #else - #define MAP_FIXED_NOREPLACE MAP_FIXED - #endif -#endif - -#include <sys/mman.h> -#include <fcntl.h> - -/* Globals needed by the injected instrumentation. The __afl_area_initial region - is used for instrumentation output before __afl_map_shm() has a chance to - run. It will end up as .comm, so it shouldn't be too wasteful. */ - -#if MAP_SIZE <= 65536 - #define MAP_INITIAL_SIZE 256000 -#else - #define MAP_INITIAL_SIZE MAP_SIZE -#endif - -#ifdef AFL_REAL_LD -u8 __afl_area_initial[MAP_INITIAL_SIZE]; -#else -u8 __afl_area_initial[MAP_SIZE]; -#endif -u8 * __afl_area_ptr = __afl_area_initial; -u8 * __afl_dictionary; -u8 * __afl_fuzz_ptr; -u32 __afl_fuzz_len_dummy; -u32 *__afl_fuzz_len = &__afl_fuzz_len_dummy; - -u32 __afl_final_loc; -u32 __afl_map_size = MAP_SIZE; -u32 __afl_dictionary_len; -u64 __afl_map_addr; - -#ifdef __ANDROID__ -PREV_LOC_T __afl_prev_loc[NGRAM_SIZE_MAX]; -u32 __afl_prev_ctx; -u32 __afl_cmp_counter; -#else -__thread PREV_LOC_T __afl_prev_loc[NGRAM_SIZE_MAX]; -__thread u32 __afl_prev_ctx; -__thread u32 __afl_cmp_counter; -#endif - -int __afl_sharedmem_fuzzing __attribute__((weak)); - -struct cmp_map *__afl_cmp_map; - -/* Running in persistent mode? */ - -static u8 is_persistent; - -/* Error reporting to forkserver controller */ - -void send_forkserver_error(int error) { - - u32 status; - if (!error || error > 0xffff) return; - status = (FS_OPT_ERROR | FS_OPT_SET_ERROR(error)); - if (write(FORKSRV_FD + 1, (char *)&status, 4) != 4) return; - -} - -/* SHM fuzzing setup. */ - -static void __afl_map_shm_fuzz() { - - char *id_str = getenv(SHM_FUZZ_ENV_VAR); - - if (id_str) { - - u8 *map = NULL; - -#ifdef USEMMAP - const char * shm_file_path = id_str; - int shm_fd = -1; - unsigned char *shm_base = NULL; - - /* create the shared memory segment as if it was a file */ - shm_fd = shm_open(shm_file_path, O_RDWR, 0600); - if (shm_fd == -1) { - - fprintf(stderr, "shm_open() failed for fuzz\n"); - send_forkserver_error(FS_ERROR_SHM_OPEN); - exit(1); - - } - - map = - (u8 *)mmap(0, MAX_FILE + sizeof(u32), PROT_READ, MAP_SHARED, shm_fd, 0); - -#else - u32 shm_id = atoi(id_str); - map = (u8 *)shmat(shm_id, NULL, 0); - -#endif - - /* Whooooops. */ - - if (!map || map == (void *)-1) { - - perror("Could not access fuzzign shared memory"); - exit(1); - - } - - __afl_fuzz_len = (u32 *)map; - __afl_fuzz_ptr = map + sizeof(u32); - - if (getenv("AFL_DEBUG")) { - - fprintf(stderr, "DEBUG: successfully got fuzzing shared memory\n"); - - } - - } else { - - fprintf(stderr, "Error: variable for fuzzing shared memory is not set\n"); - exit(1); - - } - -} - -/* SHM setup. */ - -static void __afl_map_shm(void) { - - char *id_str = getenv(SHM_ENV_VAR); - - if (__afl_final_loc) { - - if (__afl_final_loc % 8) - __afl_final_loc = (((__afl_final_loc + 7) >> 3) << 3); - - __afl_map_size = __afl_final_loc; - if (__afl_final_loc > MAP_SIZE) { - - char *ptr; - u32 val = 0; - if ((ptr = getenv("AFL_MAP_SIZE")) != NULL) val = atoi(ptr); - if (val < __afl_final_loc) { - - if (__afl_final_loc > FS_OPT_MAX_MAPSIZE) { - - fprintf(stderr, - "Error: AFL++ tools *require* to set AFL_MAP_SIZE to %u to " - "be able to run this instrumented program!\n", - __afl_final_loc); - if (id_str) { - - send_forkserver_error(FS_ERROR_MAP_SIZE); - exit(-1); - - } - - } else { - - fprintf(stderr, - "Warning: AFL++ tools will need to set AFL_MAP_SIZE to %u to " - "be able to run this instrumented program!\n", - __afl_final_loc); - - } - - } - - } - - } - - /* If we're running under AFL, attach to the appropriate region, replacing the - early-stage __afl_area_initial region that is needed to allow some really - hacky .init code to work correctly in projects such as OpenSSL. */ - - if (getenv("AFL_DEBUG")) - fprintf(stderr, - "DEBUG: id_str %s, __afl_map_addr 0x%llx, MAP_SIZE %u, " - "__afl_final_loc %u, max_size_forkserver %u/0x%x\n", - id_str == NULL ? "<null>" : id_str, __afl_map_addr, MAP_SIZE, - __afl_final_loc, FS_OPT_MAX_MAPSIZE, FS_OPT_MAX_MAPSIZE); - - if (id_str) { - -#ifdef USEMMAP - const char * shm_file_path = id_str; - int shm_fd = -1; - unsigned char *shm_base = NULL; - - /* create the shared memory segment as if it was a file */ - shm_fd = shm_open(shm_file_path, O_RDWR, 0600); - if (shm_fd == -1) { - - fprintf(stderr, "shm_open() failed\n"); - send_forkserver_error(FS_ERROR_SHM_OPEN); - exit(1); - - } - - /* map the shared memory segment to the address space of the process */ - if (__afl_map_addr) { - - shm_base = - mmap((void *)__afl_map_addr, __afl_map_size, PROT_READ | PROT_WRITE, - MAP_FIXED_NOREPLACE | MAP_SHARED, shm_fd, 0); - - } else { - - shm_base = mmap(0, __afl_map_size, PROT_READ | PROT_WRITE, MAP_SHARED, - shm_fd, 0); - - } - - if (shm_base == MAP_FAILED) { - - close(shm_fd); - shm_fd = -1; - - fprintf(stderr, "mmap() failed\n"); - if (__afl_map_addr) - send_forkserver_error(FS_ERROR_MAP_ADDR); - else - send_forkserver_error(FS_ERROR_MMAP); - exit(2); - - } - - __afl_area_ptr = shm_base; -#else - u32 shm_id = atoi(id_str); - - __afl_area_ptr = shmat(shm_id, (void *)__afl_map_addr, 0); - -#endif - - /* Whooooops. */ - - if (__afl_area_ptr == (void *)-1) { - - if (__afl_map_addr) - send_forkserver_error(FS_ERROR_MAP_ADDR); - else - send_forkserver_error(FS_ERROR_SHMAT); - _exit(1); - - } - - /* Write something into the bitmap so that even with low AFL_INST_RATIO, - our parent doesn't give up on us. */ - - __afl_area_ptr[0] = 1; - - } else if (__afl_map_addr) { - - __afl_area_ptr = - mmap((void *)__afl_map_addr, __afl_map_size, PROT_READ | PROT_WRITE, - MAP_FIXED_NOREPLACE | MAP_SHARED | MAP_ANONYMOUS, -1, 0); - if (__afl_area_ptr == MAP_FAILED) { - - fprintf(stderr, "can not aquire mmap for address %p\n", - (void *)__afl_map_addr); - exit(1); - - } - - } - - id_str = getenv(CMPLOG_SHM_ENV_VAR); - - if (getenv("AFL_DEBUG")) - fprintf(stderr, "DEBUG: cmplog id_str %s\n", - id_str == NULL ? "<null>" : id_str); - - if (id_str) { - -#ifdef USEMMAP - const char * shm_file_path = id_str; - int shm_fd = -1; - unsigned char *shm_base = NULL; - - /* create the shared memory segment as if it was a file */ - shm_fd = shm_open(shm_file_path, O_RDWR, 0600); - if (shm_fd == -1) { - - fprintf(stderr, "shm_open() failed\n"); - exit(1); - - } - - /* map the shared memory segment to the address space of the process */ - shm_base = mmap(0, sizeof(struct cmp_map), PROT_READ | PROT_WRITE, - MAP_SHARED, shm_fd, 0); - if (shm_base == MAP_FAILED) { - - close(shm_fd); - shm_fd = -1; - - fprintf(stderr, "mmap() failed\n"); - exit(2); - - } - - __afl_cmp_map = shm_base; -#else - u32 shm_id = atoi(id_str); - - __afl_cmp_map = shmat(shm_id, NULL, 0); -#endif - - if (__afl_cmp_map == (void *)-1) _exit(1); - - } - -} - -#ifdef __linux__ -static void __afl_start_snapshots(void) { - - static u8 tmp[4] = {0, 0, 0, 0}; - s32 child_pid; - u32 status = 0; - u32 already_read_first = 0; - u32 was_killed; - - u8 child_stopped = 0; - - void (*old_sigchld_handler)(int) = 0; // = signal(SIGCHLD, SIG_DFL); - - /* Phone home and tell the parent that we're OK. If parent isn't there, - assume we're not running in forkserver mode and just execute program. */ - - status |= (FS_OPT_ENABLED | FS_OPT_SNAPSHOT); - if (__afl_sharedmem_fuzzing != 0) status |= FS_OPT_SHDMEM_FUZZ; - if (__afl_map_size <= FS_OPT_MAX_MAPSIZE) - status |= (FS_OPT_SET_MAPSIZE(__afl_map_size) | FS_OPT_MAPSIZE); - if (__afl_dictionary_len && __afl_dictionary) status |= FS_OPT_AUTODICT; - memcpy(tmp, &status, 4); - - if (write(FORKSRV_FD + 1, tmp, 4) != 4) return; - - if (__afl_sharedmem_fuzzing || (__afl_dictionary_len && __afl_dictionary)) { - - if (read(FORKSRV_FD, &was_killed, 4) != 4) _exit(1); - - if (getenv("AFL_DEBUG")) - fprintf(stderr, "target forkserver recv: %08x\n", was_killed); - - if ((was_killed & (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ)) == - (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ)) { - - __afl_map_shm_fuzz(); - - } - - if ((was_killed & (FS_OPT_ENABLED | FS_OPT_AUTODICT)) == - (FS_OPT_ENABLED | FS_OPT_AUTODICT)) { - - // great lets pass the dictionary through the forkserver FD - u32 len = __afl_dictionary_len, offset = 0; - s32 ret; - - if (write(FORKSRV_FD + 1, &len, 4) != 4) { - - write(2, "Error: could not send dictionary len\n", - strlen("Error: could not send dictionary len\n")); - _exit(1); - - } - - while (len != 0) { - - ret = write(FORKSRV_FD + 1, __afl_dictionary + offset, len); - - if (ret < 1) { - - write(2, "Error: could not send dictionary\n", - strlen("Error: could not send dictionary\n")); - _exit(1); - - } - - len -= ret; - offset += ret; - - } - - } else { - - // uh this forkserver does not understand extended option passing - // or does not want the dictionary - if (!__afl_fuzz_ptr) already_read_first = 1; - - } - - } - - while (1) { - - int status; - - if (already_read_first) { - - already_read_first = 0; - - } else { - - /* Wait for parent by reading from the pipe. Abort if read fails. */ - if (read(FORKSRV_FD, &was_killed, 4) != 4) _exit(1); - - } - - #ifdef _AFL_DOCUMENT_MUTATIONS - if (__afl_fuzz_ptr) { - - static uint32_t counter = 0; - char fn[32]; - sprintf(fn, "%09u:forkserver", counter); - s32 fd_doc = open(fn, O_WRONLY | O_CREAT | O_TRUNC, 0600); - if (fd_doc >= 0) { - - if (write(fd_doc, __afl_fuzz_ptr, *__afl_fuzz_len) != *__afl_fuzz_len) { - - fprintf(stderr, "write of mutation file failed: %s\n", fn); - unlink(fn); - - } - - close(fd_doc); - - } - - counter++; - - } - - #endif - - /* If we stopped the child in persistent mode, but there was a race - condition and afl-fuzz already issued SIGKILL, write off the old - process. */ - - if (child_stopped && was_killed) { - - child_stopped = 0; - if (waitpid(child_pid, &status, 0) < 0) _exit(1); - - } - - if (!child_stopped) { - - /* Once woken up, create a clone of our process. */ - - child_pid = fork(); - if (child_pid < 0) _exit(1); - - /* In child process: close fds, resume execution. */ - - if (!child_pid) { - - //(void)nice(-20); // does not seem to improve - - signal(SIGCHLD, old_sigchld_handler); - - close(FORKSRV_FD); - close(FORKSRV_FD + 1); - - if (!afl_snapshot_take(AFL_SNAPSHOT_MMAP | AFL_SNAPSHOT_FDS | - AFL_SNAPSHOT_REGS | AFL_SNAPSHOT_EXIT)) { - - raise(SIGSTOP); - - } - - __afl_area_ptr[0] = 1; - memset(__afl_prev_loc, 0, NGRAM_SIZE_MAX * sizeof(PREV_LOC_T)); - - return; - - } - - } else { - - /* Special handling for persistent mode: if the child is alive but - currently stopped, simply restart it with SIGCONT. */ - - kill(child_pid, SIGCONT); - child_stopped = 0; - - } - - /* In parent process: write PID to pipe, then wait for child. */ - - if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) _exit(1); - - if (waitpid(child_pid, &status, WUNTRACED) < 0) _exit(1); - - /* In persistent mode, the child stops itself with SIGSTOP to indicate - a successful run. In this case, we want to wake it up without forking - again. */ - - if (WIFSTOPPED(status)) child_stopped = 1; - - /* Relay wait status to pipe, then loop back. */ - - if (write(FORKSRV_FD + 1, &status, 4) != 4) _exit(1); - - } - -} - -#endif - -/* Fork server logic. */ - -static void __afl_start_forkserver(void) { - -#ifdef __linux__ - if (/*!is_persistent &&*/ !__afl_cmp_map && !getenv("AFL_NO_SNAPSHOT") && - afl_snapshot_init() >= 0) { - - __afl_start_snapshots(); - return; - - } - -#endif - - u8 tmp[4] = {0, 0, 0, 0}; - s32 child_pid; - u32 status = 0; - u32 already_read_first = 0; - u32 was_killed; - - u8 child_stopped = 0; - - void (*old_sigchld_handler)(int) = 0; // = signal(SIGCHLD, SIG_DFL); - - if (__afl_map_size <= FS_OPT_MAX_MAPSIZE) - status |= (FS_OPT_SET_MAPSIZE(__afl_map_size) | FS_OPT_MAPSIZE); - if (__afl_dictionary_len && __afl_dictionary) status |= FS_OPT_AUTODICT; - if (__afl_sharedmem_fuzzing != 0) status |= FS_OPT_SHDMEM_FUZZ; - if (status) status |= (FS_OPT_ENABLED); - memcpy(tmp, &status, 4); - - /* Phone home and tell the parent that we're OK. If parent isn't there, - assume we're not running in forkserver mode and just execute program. */ - - if (write(FORKSRV_FD + 1, tmp, 4) != 4) return; - - if (__afl_sharedmem_fuzzing || (__afl_dictionary_len && __afl_dictionary)) { - - if (read(FORKSRV_FD, &was_killed, 4) != 4) _exit(1); - - if (getenv("AFL_DEBUG")) - fprintf(stderr, "target forkserver recv: %08x\n", was_killed); - - if ((was_killed & (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ)) == - (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ)) { - - __afl_map_shm_fuzz(); - - } - - if ((was_killed & (FS_OPT_ENABLED | FS_OPT_AUTODICT)) == - (FS_OPT_ENABLED | FS_OPT_AUTODICT)) { - - // great lets pass the dictionary through the forkserver FD - u32 len = __afl_dictionary_len, offset = 0; - s32 ret; - - if (write(FORKSRV_FD + 1, &len, 4) != 4) { - - write(2, "Error: could not send dictionary len\n", - strlen("Error: could not send dictionary len\n")); - _exit(1); - - } - - while (len != 0) { - - ret = write(FORKSRV_FD + 1, __afl_dictionary + offset, len); - - if (ret < 1) { - - write(2, "Error: could not send dictionary\n", - strlen("Error: could not send dictionary\n")); - _exit(1); - - } - - len -= ret; - offset += ret; - - } - - } else { - - // uh this forkserver does not understand extended option passing - // or does not want the dictionary - if (!__afl_fuzz_ptr) already_read_first = 1; - - } - - } - - while (1) { - - int status; - - /* Wait for parent by reading from the pipe. Abort if read fails. */ - - if (already_read_first) { - - already_read_first = 0; - - } else { - - if (read(FORKSRV_FD, &was_killed, 4) != 4) _exit(1); - - } - -#ifdef _AFL_DOCUMENT_MUTATIONS - if (__afl_fuzz_ptr) { - - static uint32_t counter = 0; - char fn[32]; - sprintf(fn, "%09u:forkserver", counter); - s32 fd_doc = open(fn, O_WRONLY | O_CREAT | O_TRUNC, 0600); - if (fd_doc >= 0) { - - if (write(fd_doc, __afl_fuzz_ptr, *__afl_fuzz_len) != *__afl_fuzz_len) { - - fprintf(stderr, "write of mutation file failed: %s\n", fn); - unlink(fn); - - } - - close(fd_doc); - - } - - counter++; - - } - -#endif - - /* If we stopped the child in persistent mode, but there was a race - condition and afl-fuzz already issued SIGKILL, write off the old - process. */ - - if (child_stopped && was_killed) { - - child_stopped = 0; - if (waitpid(child_pid, &status, 0) < 0) _exit(1); - - } - - if (!child_stopped) { - - /* Once woken up, create a clone of our process. */ - - child_pid = fork(); - if (child_pid < 0) _exit(1); - - /* In child process: close fds, resume execution. */ - - if (!child_pid) { - - //(void)nice(-20); - - signal(SIGCHLD, old_sigchld_handler); - - close(FORKSRV_FD); - close(FORKSRV_FD + 1); - return; - - } - - } else { - - /* Special handling for persistent mode: if the child is alive but - currently stopped, simply restart it with SIGCONT. */ - - kill(child_pid, SIGCONT); - child_stopped = 0; - - } - - /* In parent process: write PID to pipe, then wait for child. */ - - if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) _exit(1); - - if (waitpid(child_pid, &status, is_persistent ? WUNTRACED : 0) < 0) - _exit(1); - - /* In persistent mode, the child stops itself with SIGSTOP to indicate - a successful run. In this case, we want to wake it up without forking - again. */ - - if (WIFSTOPPED(status)) child_stopped = 1; - - /* Relay wait status to pipe, then loop back. */ - - if (write(FORKSRV_FD + 1, &status, 4) != 4) _exit(1); - - } - -} - -/* A simplified persistent mode handler, used as explained in - * llvm_mode/README.md. */ - -int __afl_persistent_loop(unsigned int max_cnt) { - - static u8 first_pass = 1; - static u32 cycle_cnt; - - if (first_pass) { - - /* Make sure that every iteration of __AFL_LOOP() starts with a clean slate. - On subsequent calls, the parent will take care of that, but on the first - iteration, it's our job to erase any trace of whatever happened - before the loop. */ - - if (is_persistent) { - - memset(__afl_area_ptr, 0, __afl_map_size); - __afl_area_ptr[0] = 1; - memset(__afl_prev_loc, 0, NGRAM_SIZE_MAX * sizeof(PREV_LOC_T)); - - } - - cycle_cnt = max_cnt; - first_pass = 0; - return 1; - - } - - if (is_persistent) { - - if (--cycle_cnt) { - - raise(SIGSTOP); - - __afl_area_ptr[0] = 1; - memset(__afl_prev_loc, 0, NGRAM_SIZE_MAX * sizeof(PREV_LOC_T)); - - return 1; - - } else { - - /* When exiting __AFL_LOOP(), make sure that the subsequent code that - follows the loop is not traced. We do that by pivoting back to the - dummy output region. */ - - __afl_area_ptr = __afl_area_initial; - - } - - } - - return 0; - -} - -/* This one can be called from user code when deferred forkserver mode - is enabled. */ - -void __afl_manual_init(void) { - - static u8 init_done; - - if (!init_done) { - - __afl_map_shm(); - __afl_start_forkserver(); - init_done = 1; - - } - -} - -/* Proper initialization routine. */ - -__attribute__((constructor(CONST_PRIO))) void __afl_auto_init(void) { - - is_persistent = !!getenv(PERSIST_ENV_VAR); - - if (getenv(DEFER_ENV_VAR)) return; - - __afl_manual_init(); - -} - -/* The following stuff deals with supporting -fsanitize-coverage=trace-pc-guard. - It remains non-operational in the traditional, plugin-backed LLVM mode. - For more info about 'trace-pc-guard', see llvm_mode/README.md. - - The first function (__sanitizer_cov_trace_pc_guard) is called back on every - edge (as opposed to every basic block). */ - -void __sanitizer_cov_trace_pc_guard(uint32_t *guard) { - - __afl_area_ptr[*guard]++; - -} - -/* Init callback. Populates instrumentation IDs. Note that we're using - ID of 0 as a special value to indicate non-instrumented bits. That may - still touch the bitmap, but in a fairly harmless way. */ - -void __sanitizer_cov_trace_pc_guard_init(uint32_t *start, uint32_t *stop) { - - u32 inst_ratio = 100; - char *x; - - if (start == stop || *start) return; - - x = getenv("AFL_INST_RATIO"); - if (x) inst_ratio = (u32)atoi(x); - - if (!inst_ratio || inst_ratio > 100) { - - fprintf(stderr, "[-] ERROR: Invalid AFL_INST_RATIO (must be 1-100).\n"); - abort(); - - } - - /* Make sure that the first element in the range is always set - we use that - to avoid duplicate calls (which can happen as an artifact of the underlying - implementation in LLVM). */ - - *(start++) = R(MAP_SIZE - 1) + 1; - - while (start < stop) { - - if (R(100) < inst_ratio) - *start = ++__afl_final_loc; - else - *start = 0; - - start++; - - } - -} - -///// CmpLog instrumentation - -void __cmplog_ins_hook1(uint8_t arg1, uint8_t arg2) { - - if (!__afl_cmp_map) return; - - uintptr_t k = (uintptr_t)__builtin_return_address(0); - k = (k >> 4) ^ (k << 8); - k &= CMP_MAP_W - 1; - - __afl_cmp_map->headers[k].type = CMP_TYPE_INS; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - // if (!__afl_cmp_map->headers[k].cnt) - // __afl_cmp_map->headers[k].cnt = __afl_cmp_counter++; - - __afl_cmp_map->headers[k].shape = 0; - - hits &= CMP_MAP_H - 1; - __afl_cmp_map->log[k][hits].v0 = arg1; - __afl_cmp_map->log[k][hits].v1 = arg2; - -} - -void __cmplog_ins_hook2(uint16_t arg1, uint16_t arg2) { - - if (!__afl_cmp_map) return; - - uintptr_t k = (uintptr_t)__builtin_return_address(0); - k = (k >> 4) ^ (k << 8); - k &= CMP_MAP_W - 1; - - __afl_cmp_map->headers[k].type = CMP_TYPE_INS; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - - __afl_cmp_map->headers[k].shape = 1; - - hits &= CMP_MAP_H - 1; - __afl_cmp_map->log[k][hits].v0 = arg1; - __afl_cmp_map->log[k][hits].v1 = arg2; - -} - -void __cmplog_ins_hook4(uint32_t arg1, uint32_t arg2) { - - if (!__afl_cmp_map) return; - - uintptr_t k = (uintptr_t)__builtin_return_address(0); - k = (k >> 4) ^ (k << 8); - k &= CMP_MAP_W - 1; - - __afl_cmp_map->headers[k].type = CMP_TYPE_INS; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - - __afl_cmp_map->headers[k].shape = 3; - - hits &= CMP_MAP_H - 1; - __afl_cmp_map->log[k][hits].v0 = arg1; - __afl_cmp_map->log[k][hits].v1 = arg2; - -} - -void __cmplog_ins_hook8(uint64_t arg1, uint64_t arg2) { - - if (!__afl_cmp_map) return; - - uintptr_t k = (uintptr_t)__builtin_return_address(0); - k = (k >> 4) ^ (k << 8); - k &= CMP_MAP_W - 1; - - __afl_cmp_map->headers[k].type = CMP_TYPE_INS; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - - __afl_cmp_map->headers[k].shape = 7; - - hits &= CMP_MAP_H - 1; - __afl_cmp_map->log[k][hits].v0 = arg1; - __afl_cmp_map->log[k][hits].v1 = arg2; - -} - -#if defined(__APPLE__) - #pragma weak __sanitizer_cov_trace_const_cmp1 = __cmplog_ins_hook1 - #pragma weak __sanitizer_cov_trace_const_cmp2 = __cmplog_ins_hook2 - #pragma weak __sanitizer_cov_trace_const_cmp4 = __cmplog_ins_hook4 - #pragma weak __sanitizer_cov_trace_const_cmp8 = __cmplog_ins_hook8 - - #pragma weak __sanitizer_cov_trace_cmp1 = __cmplog_ins_hook1 - #pragma weak __sanitizer_cov_trace_cmp2 = __cmplog_ins_hook2 - #pragma weak __sanitizer_cov_trace_cmp4 = __cmplog_ins_hook4 - #pragma weak __sanitizer_cov_trace_cmp8 = __cmplog_ins_hook8 -#else -void __sanitizer_cov_trace_const_cmp1(uint8_t arg1, uint8_t arg2) - __attribute__((alias("__cmplog_ins_hook1"))); -void __sanitizer_cov_trace_const_cmp2(uint16_t arg1, uint16_t arg2) - __attribute__((alias("__cmplog_ins_hook2"))); -void __sanitizer_cov_trace_const_cmp4(uint32_t arg1, uint32_t arg2) - __attribute__((alias("__cmplog_ins_hook4"))); -void __sanitizer_cov_trace_const_cmp8(uint64_t arg1, uint64_t arg2) - __attribute__((alias("__cmplog_ins_hook8"))); - -void __sanitizer_cov_trace_cmp1(uint8_t arg1, uint8_t arg2) - __attribute__((alias("__cmplog_ins_hook1"))); -void __sanitizer_cov_trace_cmp2(uint16_t arg1, uint16_t arg2) - __attribute__((alias("__cmplog_ins_hook2"))); -void __sanitizer_cov_trace_cmp4(uint32_t arg1, uint32_t arg2) - __attribute__((alias("__cmplog_ins_hook4"))); -void __sanitizer_cov_trace_cmp8(uint64_t arg1, uint64_t arg2) - __attribute__((alias("__cmplog_ins_hook8"))); -#endif /* defined(__APPLE__) */ - -void __sanitizer_cov_trace_switch(uint64_t val, uint64_t *cases) { - - for (uint64_t i = 0; i < cases[0]; i++) { - - uintptr_t k = (uintptr_t)__builtin_return_address(0) + i; - k = (k >> 4) ^ (k << 8); - k &= CMP_MAP_W - 1; - - __afl_cmp_map->headers[k].type = CMP_TYPE_INS; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - - __afl_cmp_map->headers[k].shape = 7; - - hits &= CMP_MAP_H - 1; - __afl_cmp_map->log[k][hits].v0 = val; - __afl_cmp_map->log[k][hits].v1 = cases[i + 2]; - - } - -} - -// POSIX shenanigan to see if an area is mapped. -// If it is mapped as X-only, we have a problem, so maybe we should add a check -// to avoid to call it on .text addresses -static int area_is_mapped(void *ptr, size_t len) { - - char *p = ptr; - char *page = (char *)((uintptr_t)p & ~(sysconf(_SC_PAGE_SIZE) - 1)); - - int r = msync(page, (p - page) + len, MS_ASYNC); - if (r < 0) return errno != ENOMEM; - return 1; - -} - -void __cmplog_rtn_hook(u8 *ptr1, u8 *ptr2) { - - if (!__afl_cmp_map) return; - - if (!area_is_mapped(ptr1, 32) || !area_is_mapped(ptr2, 32)) return; - - uintptr_t k = (uintptr_t)__builtin_return_address(0); - k = (k >> 4) ^ (k << 8); - k &= CMP_MAP_W - 1; - - __afl_cmp_map->headers[k].type = CMP_TYPE_RTN; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - - __afl_cmp_map->headers[k].shape = 31; - - hits &= CMP_MAP_RTN_H - 1; - __builtin_memcpy(((struct cmpfn_operands *)__afl_cmp_map->log[k])[hits].v0, - ptr1, 32); - __builtin_memcpy(((struct cmpfn_operands *)__afl_cmp_map->log[k])[hits].v1, - ptr2, 32); - -} - diff --git a/llvm_mode/cmplog-instructions-pass.cc b/llvm_mode/cmplog-instructions-pass.cc deleted file mode 100644 index f929361a..00000000 --- a/llvm_mode/cmplog-instructions-pass.cc +++ /dev/null @@ -1,289 +0,0 @@ -/* - american fuzzy lop++ - LLVM CmpLog instrumentation - -------------------------------------------------- - - Written by Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2015, 2016 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - -*/ - -#include <stdio.h> -#include <stdlib.h> -#include <unistd.h> - -#include <list> -#include <string> -#include <fstream> -#include <sys/time.h> -#include "llvm/Config/llvm-config.h" - -#include "llvm/ADT/Statistic.h" -#include "llvm/IR/IRBuilder.h" -#include "llvm/IR/LegacyPassManager.h" -#include "llvm/IR/Module.h" -#include "llvm/Support/Debug.h" -#include "llvm/Support/raw_ostream.h" -#include "llvm/Transforms/IPO/PassManagerBuilder.h" -#include "llvm/Transforms/Utils/BasicBlockUtils.h" -#include "llvm/Pass.h" -#include "llvm/Analysis/ValueTracking.h" - -#if LLVM_VERSION_MAJOR > 3 || \ - (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR > 4) - #include "llvm/IR/Verifier.h" - #include "llvm/IR/DebugInfo.h" -#else - #include "llvm/Analysis/Verifier.h" - #include "llvm/DebugInfo.h" - #define nullptr 0 -#endif - -#include <set> -#include "afl-llvm-common.h" - -using namespace llvm; - -namespace { - -class CmpLogInstructions : public ModulePass { - - public: - static char ID; - CmpLogInstructions() : ModulePass(ID) { - - initInstrumentList(); - - } - - bool runOnModule(Module &M) override; - -#if LLVM_VERSION_MAJOR < 4 - const char *getPassName() const override { - -#else - StringRef getPassName() const override { - -#endif - return "cmplog instructions"; - - } - - protected: - int be_quiet = 0; - - private: - bool hookInstrs(Module &M); - -}; - -} // namespace - -char CmpLogInstructions::ID = 0; - -bool CmpLogInstructions::hookInstrs(Module &M) { - - std::vector<Instruction *> icomps; - LLVMContext & C = M.getContext(); - - Type * VoidTy = Type::getVoidTy(C); - IntegerType *Int8Ty = IntegerType::getInt8Ty(C); - IntegerType *Int16Ty = IntegerType::getInt16Ty(C); - IntegerType *Int32Ty = IntegerType::getInt32Ty(C); - IntegerType *Int64Ty = IntegerType::getInt64Ty(C); - -#if LLVM_VERSION_MAJOR < 9 - Constant * -#else - FunctionCallee -#endif - c1 = M.getOrInsertFunction("__cmplog_ins_hook1", VoidTy, Int8Ty, Int8Ty -#if LLVM_VERSION_MAJOR < 5 - , - NULL -#endif - ); -#if LLVM_VERSION_MAJOR < 9 - Function *cmplogHookIns1 = cast<Function>(c1); -#else - FunctionCallee cmplogHookIns1 = c1; -#endif - -#if LLVM_VERSION_MAJOR < 9 - Constant * -#else - FunctionCallee -#endif - c2 = M.getOrInsertFunction("__cmplog_ins_hook2", VoidTy, Int16Ty, Int16Ty -#if LLVM_VERSION_MAJOR < 5 - , - NULL -#endif - ); -#if LLVM_VERSION_MAJOR < 9 - Function *cmplogHookIns2 = cast<Function>(c2); -#else - FunctionCallee cmplogHookIns2 = c2; -#endif - -#if LLVM_VERSION_MAJOR < 9 - Constant * -#else - FunctionCallee -#endif - c4 = M.getOrInsertFunction("__cmplog_ins_hook4", VoidTy, Int32Ty, Int32Ty -#if LLVM_VERSION_MAJOR < 5 - , - NULL -#endif - ); -#if LLVM_VERSION_MAJOR < 9 - Function *cmplogHookIns4 = cast<Function>(c4); -#else - FunctionCallee cmplogHookIns4 = c4; -#endif - -#if LLVM_VERSION_MAJOR < 9 - Constant * -#else - FunctionCallee -#endif - c8 = M.getOrInsertFunction("__cmplog_ins_hook8", VoidTy, Int64Ty, Int64Ty -#if LLVM_VERSION_MAJOR < 5 - , - NULL -#endif - ); -#if LLVM_VERSION_MAJOR < 9 - Function *cmplogHookIns8 = cast<Function>(c8); -#else - FunctionCallee cmplogHookIns8 = c8; -#endif - - /* iterate over all functions, bbs and instruction and add suitable calls */ - for (auto &F : M) { - - if (!isInInstrumentList(&F)) continue; - - for (auto &BB : F) { - - for (auto &IN : BB) { - - CmpInst *selectcmpInst = nullptr; - - if ((selectcmpInst = dyn_cast<CmpInst>(&IN))) { - - if (selectcmpInst->getPredicate() == CmpInst::ICMP_EQ || - selectcmpInst->getPredicate() == CmpInst::ICMP_NE || - selectcmpInst->getPredicate() == CmpInst::ICMP_UGT || - selectcmpInst->getPredicate() == CmpInst::ICMP_SGT || - selectcmpInst->getPredicate() == CmpInst::ICMP_ULT || - selectcmpInst->getPredicate() == CmpInst::ICMP_SLT || - selectcmpInst->getPredicate() == CmpInst::ICMP_UGE || - selectcmpInst->getPredicate() == CmpInst::ICMP_SGE || - selectcmpInst->getPredicate() == CmpInst::ICMP_ULE || - selectcmpInst->getPredicate() == CmpInst::ICMP_SLE) { - - auto op0 = selectcmpInst->getOperand(0); - auto op1 = selectcmpInst->getOperand(1); - - IntegerType *intTyOp0 = dyn_cast<IntegerType>(op0->getType()); - IntegerType *intTyOp1 = dyn_cast<IntegerType>(op1->getType()); - - /* this is probably not needed but we do it anyway */ - if (!intTyOp0 || !intTyOp1) { continue; } - - icomps.push_back(selectcmpInst); - - } - - } - - } - - } - - } - - if (!icomps.size()) return false; - if (!be_quiet) errs() << "Hooking " << icomps.size() << " cmp instructions\n"; - - for (auto &selectcmpInst : icomps) { - - IRBuilder<> IRB(selectcmpInst->getParent()); - IRB.SetInsertPoint(selectcmpInst); - - auto op0 = selectcmpInst->getOperand(0); - auto op1 = selectcmpInst->getOperand(1); - - IntegerType *intTyOp0 = dyn_cast<IntegerType>(op0->getType()); - IntegerType *intTyOp1 = dyn_cast<IntegerType>(op1->getType()); - - unsigned max_size = intTyOp0->getBitWidth() > intTyOp1->getBitWidth() - ? intTyOp0->getBitWidth() - : intTyOp1->getBitWidth(); - - std::vector<Value *> args; - args.push_back(op0); - args.push_back(op1); - - switch (max_size) { - - case 8: - IRB.CreateCall(cmplogHookIns1, args); - break; - case 16: - IRB.CreateCall(cmplogHookIns2, args); - break; - case 32: - IRB.CreateCall(cmplogHookIns4, args); - break; - case 64: - IRB.CreateCall(cmplogHookIns8, args); - break; - default: - break; - - } - - } - - return true; - -} - -bool CmpLogInstructions::runOnModule(Module &M) { - - if (getenv("AFL_QUIET") == NULL) - llvm::errs() - << "Running cmplog-instructions-pass by andreafioraldi@gmail.com\n"; - else - be_quiet = 1; - hookInstrs(M); - verifyModule(M); - - return true; - -} - -static void registerCmpLogInstructionsPass(const PassManagerBuilder &, - legacy::PassManagerBase &PM) { - - auto p = new CmpLogInstructions(); - PM.add(p); - -} - -static RegisterStandardPasses RegisterCmpLogInstructionsPass( - PassManagerBuilder::EP_OptimizerLast, registerCmpLogInstructionsPass); - -static RegisterStandardPasses RegisterCmpLogInstructionsPass0( - PassManagerBuilder::EP_EnabledOnOptLevel0, registerCmpLogInstructionsPass); - diff --git a/llvm_mode/cmplog-routines-pass.cc b/llvm_mode/cmplog-routines-pass.cc deleted file mode 100644 index 318193a4..00000000 --- a/llvm_mode/cmplog-routines-pass.cc +++ /dev/null @@ -1,209 +0,0 @@ -/* - american fuzzy lop++ - LLVM CmpLog instrumentation - -------------------------------------------------- - - Written by Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2015, 2016 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - -*/ - -#include <stdio.h> -#include <stdlib.h> -#include <unistd.h> - -#include <list> -#include <string> -#include <fstream> -#include <sys/time.h> -#include "llvm/Config/llvm-config.h" - -#include "llvm/ADT/Statistic.h" -#include "llvm/IR/IRBuilder.h" -#include "llvm/IR/LegacyPassManager.h" -#include "llvm/IR/Module.h" -#include "llvm/Support/Debug.h" -#include "llvm/Support/raw_ostream.h" -#include "llvm/Transforms/IPO/PassManagerBuilder.h" -#include "llvm/Transforms/Utils/BasicBlockUtils.h" -#include "llvm/Pass.h" -#include "llvm/Analysis/ValueTracking.h" - -#if LLVM_VERSION_MAJOR > 3 || \ - (LLVM_VERSION_MAJOR == 3 && LLVM_VERSION_MINOR > 4) - #include "llvm/IR/Verifier.h" - #include "llvm/IR/DebugInfo.h" -#else - #include "llvm/Analysis/Verifier.h" - #include "llvm/DebugInfo.h" - #define nullptr 0 -#endif - -#include <set> -#include "afl-llvm-common.h" - -using namespace llvm; - -namespace { - -class CmpLogRoutines : public ModulePass { - - public: - static char ID; - CmpLogRoutines() : ModulePass(ID) { - - initInstrumentList(); - - } - - bool runOnModule(Module &M) override; - -#if LLVM_VERSION_MAJOR < 4 - const char *getPassName() const override { - -#else - StringRef getPassName() const override { - -#endif - return "cmplog routines"; - - } - - protected: - int be_quiet = 0; - - private: - bool hookRtns(Module &M); - -}; - -} // namespace - -char CmpLogRoutines::ID = 0; - -bool CmpLogRoutines::hookRtns(Module &M) { - - std::vector<CallInst *> calls; - LLVMContext & C = M.getContext(); - - Type *VoidTy = Type::getVoidTy(C); - // PointerType *VoidPtrTy = PointerType::get(VoidTy, 0); - IntegerType *Int8Ty = IntegerType::getInt8Ty(C); - PointerType *i8PtrTy = PointerType::get(Int8Ty, 0); - -#if LLVM_VERSION_MAJOR < 9 - Constant * -#else - FunctionCallee -#endif - c = M.getOrInsertFunction("__cmplog_rtn_hook", VoidTy, i8PtrTy, i8PtrTy -#if LLVM_VERSION_MAJOR < 5 - , - NULL -#endif - ); -#if LLVM_VERSION_MAJOR < 9 - Function *cmplogHookFn = cast<Function>(c); -#else - FunctionCallee cmplogHookFn = c; -#endif - - /* iterate over all functions, bbs and instruction and add suitable calls */ - for (auto &F : M) { - - if (!isInInstrumentList(&F)) continue; - - for (auto &BB : F) { - - for (auto &IN : BB) { - - CallInst *callInst = nullptr; - - if ((callInst = dyn_cast<CallInst>(&IN))) { - - Function *Callee = callInst->getCalledFunction(); - if (!Callee) continue; - if (callInst->getCallingConv() != llvm::CallingConv::C) continue; - - FunctionType *FT = Callee->getFunctionType(); - - bool isPtrRtn = FT->getNumParams() >= 2 && - !FT->getReturnType()->isVoidTy() && - FT->getParamType(0) == FT->getParamType(1) && - FT->getParamType(0)->isPointerTy(); - - if (!isPtrRtn) continue; - - calls.push_back(callInst); - - } - - } - - } - - } - - if (!calls.size()) return false; - if (!be_quiet) - errs() << "Hooking " << calls.size() - << " calls with pointers as arguments\n"; - - for (auto &callInst : calls) { - - Value *v1P = callInst->getArgOperand(0), *v2P = callInst->getArgOperand(1); - - IRBuilder<> IRB(callInst->getParent()); - IRB.SetInsertPoint(callInst); - - std::vector<Value *> args; - Value * v1Pcasted = IRB.CreatePointerCast(v1P, i8PtrTy); - Value * v2Pcasted = IRB.CreatePointerCast(v2P, i8PtrTy); - args.push_back(v1Pcasted); - args.push_back(v2Pcasted); - - IRB.CreateCall(cmplogHookFn, args); - - // errs() << callInst->getCalledFunction()->getName() << "\n"; - - } - - return true; - -} - -bool CmpLogRoutines::runOnModule(Module &M) { - - if (getenv("AFL_QUIET") == NULL) - llvm::errs() - << "Running cmplog-routines-pass by andreafioraldi@gmail.com\n"; - else - be_quiet = 1; - hookRtns(M); - verifyModule(M); - - return true; - -} - -static void registerCmpLogRoutinesPass(const PassManagerBuilder &, - legacy::PassManagerBase &PM) { - - auto p = new CmpLogRoutines(); - PM.add(p); - -} - -static RegisterStandardPasses RegisterCmpLogRoutinesPass( - PassManagerBuilder::EP_OptimizerLast, registerCmpLogRoutinesPass); - -static RegisterStandardPasses RegisterCmpLogRoutinesPass0( - PassManagerBuilder::EP_EnabledOnOptLevel0, registerCmpLogRoutinesPass); - diff --git a/qemu_mode/QEMUAFL_VERSION b/qemu_mode/QEMUAFL_VERSION new file mode 100644 index 00000000..68290650 --- /dev/null +++ b/qemu_mode/QEMUAFL_VERSION @@ -0,0 +1 @@ +0fb212daab diff --git a/qemu_mode/README.md b/qemu_mode/README.md index 3cf678e4..a14cbe64 100644 --- a/qemu_mode/README.md +++ b/qemu_mode/README.md @@ -1,6 +1,6 @@ # High-performance binary-only instrumentation for afl-fuzz - (See ../docs/README.md for the general instruction manual.) + (See ../README.md for the general instruction manual.) ## 1) Introduction @@ -14,12 +14,12 @@ The usual performance cost is 2-5x, which is considerably better than seen so far in experiments with tools such as DynamoRIO and PIN. The idea and much of the initial implementation comes from Andrew Griffiths. -The actual implementation on QEMU 3 (shipped with afl++) is from +The actual implementation on current QEMU (shipped as qemuafl) is from Andrea Fioraldi. Special thanks to abiondo that re-enabled TCG chaining. -## 2) How to use +## 2) How to use qemu_mode -The feature is implemented with a patch to QEMU 3.1.1. The simplest way +The feature is implemented with a patched QEMU. The simplest way to build it is to run ./build_qemu_support.sh. The script will download, configure, and compile the QEMU binary for you. @@ -58,7 +58,7 @@ directory. If you want to specify a different path for libraries (e.g. to run an arm64 binary on x86_64) use QEMU_LD_PREFIX. -## 3) Bonus feature #1: deferred initialization +## 3) Deferred initialization As for LLVM mode (refer to its README.md for mode details) QEMU mode supports the deferred initialization. @@ -68,7 +68,7 @@ to move the forkserver to a different part, e.g. just before the file is opened (e.g. way after command line parsing and config file loading, etc.) which can be a huge speed improvement. -## 4) Bonus feature #2: persistent mode +## 4) Persistent mode AFL++'s QEMU mode now supports also persistent mode for x86, x86_64, arm and aarch64 targets. @@ -77,11 +77,40 @@ up - but worth the effort. Please see the extra documentation for it: [README.persistent.md](README.persistent.md) -## 5) Bonus feature #3: CompareCoverage +## 5) Snapshot mode + +As an extension to persistent mode, qemuafl can snapshot and restore the memory +state and brk(). Details are in the persistent mode readme. + +The env var that enables the ready to use snapshot mode is AFL_QEMU_SNAPSHOT and +takes a hex address as a value that is the snapshot entrypoint. + +Snapshot mode can work restoring all the writeable pages, that is typically slower than +fork() mode but, on the other hand, it can scale better with multicore. +If the AFL++ Snapshot kernel module is loaded, qemuafl will use it and, in this +case, the speed is better than fork() and also the scaling capabilities. + +## 6) Partial instrumentation + +You can tell QEMU to instrument only a part of the address space. + +Just set AFL_QEMU_INST_RANGES=A,B,C... + +The format of the items in the list is either a range of addresses like 0x123-0x321 +or a module name like module.so (that is matched in the mapped object filename). + +Alternatively you can tell QEMU to ignore part of an address space for instrumentation. + +Just set AFL_QEMU_EXCLUDE_RANGES=A,B,C... + +The format of the items on the list is the same as for AFL_QEMU_INST_RANGES, and excluding ranges +takes priority over any included ranges or AFL_INST_LIBS. + +## 7) CompareCoverage CompareCoverage is a sub-instrumentation with effects similar to laf-intel. -The option that enables QEMU CompareCoverage is AFL_COMPCOV_LEVEL. +The environment variable that enables QEMU CompareCoverage is AFL_COMPCOV_LEVEL. There is also ./libcompcov/ which implements CompareCoverage for *cmp functions (splitting memcmp, strncmp, etc. to make these conditions easier solvable by afl-fuzz). @@ -98,10 +127,10 @@ on the x86, x86_64, arm and aarch64 targets. Highly recommended. -## 6) CMPLOG mode +## 8) CMPLOG mode Another new feature is CMPLOG, which is based on the redqueen project. -Here all immidiates in CMP instructions are learned and put into a dynamic +Here all immediates in CMP instructions are learned and put into a dynamic dictionary and applied to all locations in the input that reached that CMP, trying to solve and pass it. This is a very effective feature and it is available for x86, x86_64, arm @@ -110,7 +139,7 @@ and aarch64. To enable it you must pass on the command line of afl-fuzz: -c /path/to/your/target -## 7) Bonus feature #4: Wine mode +## 9) Wine mode AFL++ QEMU can use Wine to fuzz WIn32 PE binaries. Use the -W flag of afl-fuzz. @@ -118,7 +147,7 @@ Note that some binaries require user interaction with the GUI and must be patche For examples look [here](https://github.com/andreafioraldi/WineAFLplusplusDEMO). -## 8) Notes on linking +## 10) Notes on linking The feature is supported only on Linux. Supporting BSD may amount to porting the changes made to linux-user/elfload.c and applying them to @@ -139,7 +168,7 @@ practice, this means two things: Setting AFL_INST_LIBS=1 can be used to circumvent the .text detection logic and instrument every basic block encountered. -## 9) Benchmarking +## 11) Benchmarking If you want to compare the performance of the QEMU instrumentation with that of afl-gcc compiled code against the same target, you need to build the @@ -154,10 +183,15 @@ Comparative measurements of execution speed or instrumentation coverage will be fairly meaningless if the optimization levels or instrumentation scopes don't match. -## 10) Gotchas, feedback, bugs +## 12) Other features + +With `AFL_QEMU_FORCE_DFL` you force QEMU to ignore the registered signal +handlers of the target. + +## 13) Gotchas, feedback, bugs If you need to fix up checksums or do other cleanup on mutated test cases, see -examples/custom_mutators/ for a viable solution. +utils/custom_mutators/ for a viable solution. Do not mix QEMU mode with ASAN, MSAN, or the likes; QEMU doesn't appreciate the "shadow VM" trick employed by the sanitizers and will probably just @@ -175,19 +209,12 @@ with -march=core2, can help. Beyond that, this is an early-stage mechanism, so fields reports are welcome. You can send them to <afl-users@googlegroups.com>. -## 11) Alternatives: static rewriting +## 14) Alternatives: static rewriting Statically rewriting binaries just once, instead of attempting to translate them at run time, can be a faster alternative. That said, static rewriting is fraught with peril, because it depends on being able to properly and fully model program control flow without actually executing each and every code path. -The best implementation is this one: - - https://github.com/vanhauser-thc/afl-dyninst - -The issue however is Dyninst which is not rewriting the binaries so that -they run stable. A lot of crashes happen, especially in C++ programs that -use throw/catch. Try it first, and if it works for you be happy as it is -2-3x as fast as qemu_mode, however usually not as fast as QEMU persistent mode. - +Checkout the "Fuzzing binary-only targets" section in our main README.md and +the docs/binaryonly_fuzzing.md document for more information and hints. diff --git a/qemu_mode/README.persistent.md b/qemu_mode/README.persistent.md index b6d5d2d0..2ca5c873 100644 --- a/qemu_mode/README.persistent.md +++ b/qemu_mode/README.persistent.md @@ -2,7 +2,7 @@ ## 1) Introduction -Persistent mode let you fuzz your target persistently between two +Persistent mode lets you fuzz your target persistently between two addresses - without forking for every fuzzing attempt. This increases the speed by a factor between x2 and x5, hence it is very, very valuable. @@ -14,15 +14,19 @@ and aarch64 targets. ### 2.1) The START address -The start of the persistent loop has to be set with AFL_QEMU_PERSISTENT_ADDR. +The start of the persistent loop has to be set with env var AFL_QEMU_PERSISTENT_ADDR. This address can be the address of whatever instruction. Setting this address to the start of a function makes the usage simple. -If the address is however within a function, either RET or OFFSET (see below -in 2.2 and 2.3) have to be set. +If the address is however within a function, either RET, OFFSET or EXITS +(see below in 2.2, 2.3, 2.6) have to be set. This address (as well as the RET address, see below) has to be defined in hexadecimal with the 0x prefix or as a decimal value. +If both RET and EXITS are not set, QEMU will assume that START points to a +function and will patch the return address (on stack or in the link register) +to return to START (like WinAFL). + *Note:* If the target is compiled with position independant code (PIE/PIC) qemu loads these to a specific base address. For 64 bit you have to add 0x4000000000 (9 zeroes) and for 32 bit 0x40000000 @@ -38,13 +42,9 @@ message that the forkserver was not found. The RET address is the last instruction of the persistent loop. The emulator will emit a jump to START when translating the instruction at RET. -It is optional, and only needed if the the return should not be +It is optional, and only needed if the return should not be at the end of the function to which the START address points into, but earlier. -If it is not set, QEMU will assume that START points to a function and will -patch the return address (on stack or in the link register) to return to START -(like WinAFL). - It is defined by setting AFL_QEMU_PERSISTENT_RET, and too 0x4000000000 has to be set if the target is position independant. @@ -58,10 +58,10 @@ been set (so the end of the loop will be at the end of the function but START will not be at the beginning of it), we need an offset from the ESP pointer to locate the return address to patch. -The value by which the ESP pointer has to be corrected has to set in the -variable AFL_QEMU_PERSISTENT_RETADDR_OFFSET +The value by which the ESP pointer has to be corrected has to be set in the +variable AFL_QEMU_PERSISTENT_RETADDR_OFFSET. -Now to get this value right here some help: +Now to get this value right here is some help: 1. use gdb on the target 2. set a breakpoint to "main" (this is required for PIE/PIC binaries so the addresses are set up) @@ -77,25 +77,51 @@ Now to get this value right here some help: ### 2.4) Resetting the register state It is very, very likely you need to restore the general purpose registers state -when starting a new loop. Because of this you 99% of the time should set +when starting a new loop. Because of this 99% of the time you should set AFL_QEMU_PERSISTENT_GPR=1 -An example, is when you want to use main() as persistent START: +An example is when you want to use main() as persistent START: ```c int main(int argc, char **argv) { if (argc < 2) return 1; - // do stuffs + // do stuff } ``` -If you don't save and restore the registers in x86_64, the paramteter argc +If you don't save and restore the registers in x86_64, the parameter `argc` will be lost at the second execution of the loop. +### 2.5) Resetting the memory state + +This option restores the memory state using the AFL++ Snapshot LKM if loaded. +Otherwise, all the writeable pages are restored. + +To enable this option, set AFL_QEMU_PERSISTENT_MEM=1. + +### 2.6) Reset on exit() + +The user can force QEMU to set the program counter to START instead of executing +the exit_group syscall and exit the program. + +The env variable is AFL_QEMU_PERSISTENT_EXITS. + +### 2.7) Snapshot + +AFL_QEMU_SNAPSHOT=address is just a "syntactical sugar" env variable that is equivalent to +the following set of variables: + +``` +AFL_QEMU_PERSISTENT_ADDR=address +AFL_QEMU_PERSISTENT_GPR=1 +AFL_QEMU_PERSISTENT_MEM=1 +AFL_QEMU_PERSISTENT_EXITS=1 +``` + ## 3) Optional parameters ### 3.1) Loop counter value @@ -114,9 +140,9 @@ the reading of the fuzzing input via a file by reading directly into the memory address space of the target process. All this needs is that the START address has a register that can reach the -memory buffer or that the memory buffer is at a know location. You probably need +memory buffer or that the memory buffer is at a known location. You probably need the value of the size of the buffer (maybe it is in a register when START is -hitted). +hit). The persistent hook will execute a function on every persistent iteration (at the start START) defined in a shared object specified with @@ -125,10 +151,25 @@ AFL_QEMU_PERSISTENT_HOOK=/path/to/hook.so. The signature is: ```c -void afl_persistent_hook(uint64_t* regs, uint64_t guest_base); +void afl_persistent_hook(struct ARCH_regs *regs, + uint64_t guest_base, + uint8_t *input_buf, + uint32_t input_buf_len); ``` +Where ARCH is one of x86, x86_64, arm or arm64. +You have to include `path/to/qemuafl/qemuafl/api.h`. + In this hook, you can inspect and change the saved GPR state at START. +You can also initialize your data structures when QEMU loads the shared object +with: + +`int afl_persistent_hook_init(void);` + +If this routine returns true, the shared mem fuzzing feature of AFL++ is used +and so the input_buf variables of the hook becomes meaningful. Otherwise, +you have to read the input from a file like stdin. + An example that you can use with little modification for your target can -be found here: [examples/qemu_persistent_hook](../examples/qemu_persistent_hook) +be found here: [utils/qemu_persistent_hook](../utils/qemu_persistent_hook) diff --git a/qemu_mode/build_qemu_support.sh b/qemu_mode/build_qemu_support.sh index a7bfe20d..38085389 100755 --- a/qemu_mode/build_qemu_support.sh +++ b/qemu_mode/build_qemu_support.sh @@ -29,13 +29,10 @@ # will be written to ../afl-qemu-trace. # - -VERSION="3.1.1" -QEMU_URL="http://download.qemu-project.org/qemu-${VERSION}.tar.xz" -QEMU_SHA384="28ff22ec4b8c957309460aa55d0b3188e971be1ea7dfebfb2ecc7903cd20cfebc2a7c97eedfcc7595f708357f1623f8b" +QEMUAFL_VERSION="$(cat ./QEMUAFL_VERSION)" echo "=================================================" -echo "AFL binary-only instrumentation QEMU build script" +echo " QemuAFL build script" echo "=================================================" echo @@ -48,7 +45,7 @@ if [ ! "`uname -s`" = "Linux" ]; then fi -if [ ! -f "patches/afl-qemu-cpu-inl.h" -o ! -f "../config.h" ]; then +if [ ! -f "../config.h" ]; then echo "[-] Error: key files not found - wrong working directory?" exit 1 @@ -62,90 +59,51 @@ if [ ! -f "../afl-showmap" ]; then fi -PREREQ_NOTFOUND= -for i in libtool wget automake autoconf sha384sum bison flex iconv patch pkg-config; do - - T=`command -v "$i" 2>/dev/null` - - if [ "$T" = "" ]; then - - echo "[-] Error: '$i' not found, please install first." - PREREQ_NOTFOUND=1 - - fi - -done - -PYTHONBIN=`command -v python3 || command -v python || command -v python2` - -if [ "$PYTHONBIN" = "" ]; then - echo "[-] Error: 'python' not found, please install using 'sudo apt install python3'." - PREREQ_NOTFOUND=1 -fi - - -if [ ! -d "/usr/include/glib-2.0/" -a ! -d "/usr/local/include/glib-2.0/" ]; then - - echo "[-] Error: devel version of 'glib2' not found, please install first." - PREREQ_NOTFOUND=1 - -fi - -if [ ! -d "/usr/include/pixman-1/" -a ! -d "/usr/local/include/pixman-1/" ]; then - - echo "[-] Error: devel version of 'pixman-1' not found, please install first." - PREREQ_NOTFOUND=1 - -fi - if echo "$CC" | grep -qF /afl-; then echo "[-] Error: do not use afl-gcc or afl-clang to compile this tool." - PREREQ_NOTFOUND=1 - -fi - -if [ "$PREREQ_NOTFOUND" = "1" ]; then exit 1 + fi echo "[+] All checks passed!" -ARCHIVE="`basename -- "$QEMU_URL"`" - -CKSUM=`sha384sum -- "$ARCHIVE" 2>/dev/null | cut -d' ' -f1` - -if [ ! "$CKSUM" = "$QEMU_SHA384" ]; then - - echo "[*] Downloading QEMU ${VERSION} from the web..." - rm -f "$ARCHIVE" - OK= - while [ -z "$OK" ]; do - wget -c -O "$ARCHIVE" -- "$QEMU_URL" && OK=1 - done - - CKSUM=`sha384sum -- "$ARCHIVE" 2>/dev/null | cut -d' ' -f1` +echo "[*] Making sure qemuafl is checked out" +git status 1>/dev/null 2>/dev/null +if [ $? -eq 0 ]; then + echo "[*] initializing qemuafl submodule" + git submodule init || exit 1 + git submodule update ./qemuafl 2>/dev/null # ignore errors +else + echo "[*] cloning qemuafl" + test -d qemuafl || { + CNT=1 + while [ '!' -d qemuafl -a "$CNT" -lt 4 ]; do + echo "Trying to clone qemuafl (attempt $CNT/3)" + git clone --depth 1 https://github.com/AFLplusplus/qemuafl + CNT=`expr "$CNT" + 1` + done + } fi -if [ "$CKSUM" = "$QEMU_SHA384" ]; then - - echo "[+] Cryptographic signature on $ARCHIVE checks out." +test -d qemuafl || { echo "[-] Not checked out, please install git or check your internet connection." ; exit 1 ; } +echo "[+] Got qemuafl." +cd "qemuafl" || exit 1 +if [ -n "$NO_CHECKOUT" ]; then + echo "[*] Skipping checkout to $QEMUAFL_VERSION" else - - echo "[-] Error: signature mismatch on $ARCHIVE (perhaps download error?), removing archive ..." - rm -f "$ARCHIVE" - exit 1 - + echo "[*] Checking out $QEMUAFL_VERSION" + sh -c 'git stash' 1>/dev/null 2>/dev/null + git checkout "$QEMUAFL_VERSION" || echo Warning: could not check out to commit $QEMUAFL_VERSION fi -echo "[*] Uncompressing archive (this will take a while)..." - -rm -rf "qemu-${VERSION}" || exit 1 -tar xf "$ARCHIVE" || exit 1 - -echo "[+] Unpacking successful." +echo "[*] Making sure imported headers matches" +cp "../../include/config.h" "./qemuafl/imported/" || exit 1 +cp "../../include/cmplog.h" "./qemuafl/imported/" || exit 1 +cp "../../include/snapshot-inl.h" "./qemuafl/imported/" || exit 1 +cp "../../include/types.h" "./qemuafl/imported/" || exit 1 if [ -n "$HOST" ]; then echo "[+] Configuring host architecture to $HOST..." @@ -169,62 +127,146 @@ if [ "$ORIG_CPU_TARGET" = "" ]; then esac fi -cd qemu-$VERSION || exit 1 - -echo Building for CPU target $CPU_TARGET - -echo "[*] Applying patches..." - -patch -p1 <../patches/elfload.diff || exit 1 -patch -p1 <../patches/bsd-elfload.diff || exit 1 -patch -p1 <../patches/cpu-exec.diff || exit 1 -patch -p1 <../patches/syscall.diff || exit 1 -patch -p1 <../patches/translate-all.diff || exit 1 -patch -p1 <../patches/tcg.diff || exit 1 -patch -p1 <../patches/i386-translate.diff || exit 1 -patch -p1 <../patches/arm-translate.diff || exit 1 -patch -p1 <../patches/arm-translate-a64.diff || exit 1 -patch -p1 <../patches/i386-ops_sse.diff || exit 1 -patch -p1 <../patches/i386-fpu_helper.diff || exit 1 -patch -p1 <../patches/softfloat.diff || exit 1 -patch -p1 <../patches/configure.diff || exit 1 -patch -p1 <../patches/tcg-runtime.diff || exit 1 -patch -p1 <../patches/tcg-runtime-head.diff || exit 1 -patch -p1 <../patches/translator.diff || exit 1 -patch -p1 <../patches/__init__.py.diff || exit 1 -patch -p1 <../patches/make_strncpy_safe.diff || exit 1 -patch -p1 <../patches/mmap_fixes.diff || exit 1 - -echo "[+] Patching done." +echo "Building for CPU target $CPU_TARGET" + +# --enable-pie seems to give a couple of exec's a second performance +# improvement, much to my surprise. Not sure how universal this is.. +QEMU_CONF_FLAGS=" \ + --audio-drv-list= \ + --disable-blobs \ + --disable-bochs \ + --disable-brlapi \ + --disable-bsd-user \ + --disable-bzip2 \ + --disable-cap-ng \ + --disable-cloop \ + --disable-curl \ + --disable-curses \ + --disable-dmg \ + --disable-fdt \ + --disable-gcrypt \ + --disable-glusterfs \ + --disable-gnutls \ + --disable-gtk \ + --disable-guest-agent \ + --disable-iconv \ + --disable-libiscsi \ + --disable-libnfs \ + --disable-libssh \ + --disable-libusb \ + --disable-linux-aio \ + --disable-live-block-migration \ + --disable-lzo \ + --disable-nettle \ + --disable-numa \ + --disable-opengl \ + --disable-parallels \ + --disable-plugins \ + --disable-qcow1 \ + --disable-qed \ + --disable-rbd \ + --disable-rdma \ + --disable-replication \ + --disable-sdl \ + --disable-seccomp \ + --disable-sheepdog \ + --disable-smartcard \ + --disable-snappy \ + --disable-spice \ + --disable-system \ + --disable-tools \ + --disable-tpm \ + --disable-usb-redir \ + --disable-vde \ + --disable-vdi \ + --disable-vhost-crypto \ + --disable-vhost-kernel \ + --disable-vhost-net \ + --disable-vhost-scsi \ + --disable-vhost-user \ + --disable-vhost-vdpa \ + --disable-vhost-vsock \ + --disable-virglrenderer \ + --disable-virtfs \ + --disable-vnc \ + --disable-vnc-jpeg \ + --disable-vnc-png \ + --disable-vnc-sasl \ + --disable-vte \ + --disable-vvfat \ + --disable-xen \ + --disable-xen-pci-passthrough \ + --disable-xfsctl \ + --target-list="${CPU_TARGET}-linux-user" \ + --without-default-devices \ + " + +if [ -n "${CROSS_PREFIX}" ]; then + + QEMU_CONF_FLAGS="$QEMU_CONF_FLAGS --cross-prefix=$CROSS_PREFIX" + +fi if [ "$STATIC" = "1" ]; then echo Building STATIC binary - ./configure --extra-cflags="-O3 -ggdb -DAFL_QEMU_STATIC_BUILD=1" \ - --disable-bsd-user --disable-guest-agent --disable-strip --disable-werror \ - --disable-gcrypt --disable-debug-info --disable-debug-tcg --disable-tcg-interpreter \ - --enable-attr --disable-brlapi --disable-linux-aio --disable-bzip2 --disable-bluez --disable-cap-ng \ - --disable-curl --disable-fdt --disable-glusterfs --disable-gnutls --disable-nettle --disable-gtk \ - --disable-rdma --disable-libiscsi --disable-vnc-jpeg --disable-lzo --disable-curses \ - --disable-libnfs --disable-numa --disable-opengl --disable-vnc-png --disable-rbd --disable-vnc-sasl \ - --disable-sdl --disable-seccomp --disable-smartcard --disable-snappy --disable-spice --disable-libssh2 \ - --disable-libusb --disable-usb-redir --disable-vde --disable-vhost-net --disable-virglrenderer \ - --disable-virtfs --disable-vnc --disable-vte --disable-xen --disable-xen-pci-passthrough --disable-xfsctl \ - --enable-linux-user --disable-system --disable-blobs --disable-tools --enable-capstone=internal \ - --target-list="${CPU_TARGET}-linux-user" --static --disable-pie --cross-prefix=$CROSS_PREFIX --python="$PYTHONBIN" \ - || exit 1 + + QEMU_CONF_FLAGS="$QEMU_CONF_FLAGS \ + --static \ + --extra-cflags=-DAFL_QEMU_STATIC_BUILD=1 \ + " else - # --enable-pie seems to give a couple of exec's a second performance - # improvement, much to my surprise. Not sure how universal this is.. + QEMU_CONF_FLAGS="${QEMU_CONF_FLAGS} --enable-pie " + +fi + +if [ "$DEBUG" = "1" ]; then + + echo Building DEBUG binary + + # --enable-gcov might go here but incurs a mesonbuild error on meson + # versions prior to 0.56: + # https://github.com/qemu/meson/commit/903d5dd8a7dc1d6f8bef79e66d6ebc07c + QEMU_CONF_FLAGS="$QEMU_CONF_FLAGS \ + --disable-strip \ + --enable-debug \ + --enable-debug-info \ + --enable-debug-mutex \ + --enable-debug-stack-usage \ + --enable-debug-tcg \ + --enable-qom-cast-debug \ + --enable-werror \ + " + +else - ./configure --disable-system \ - --enable-linux-user --disable-gtk --disable-sdl --disable-vnc --enable-capstone=internal \ - --target-list="${CPU_TARGET}-linux-user" --enable-pie $CROSS_PREFIX --python="$PYTHONBIN" || exit 1 + QEMU_CONF_FLAGS="$QEMU_CONF_FLAGS \ + --disable-debug-info \ + --disable-debug-mutex \ + --disable-debug-tcg \ + --disable-qom-cast-debug \ + --disable-stack-protector \ + --disable-werror \ + " fi +if [ "$PROFILING" = "1" ]; then + + echo Building PROFILED binary + + QEMU_CONF_FLAGS="$QEMU_CONF_FLAGS \ + --enable-gprof \ + --enable-profiler \ + " + +fi + +# shellcheck disable=SC2086 +./configure $QEMU_CONF_FLAGS || exit 1 + echo "[+] Configuration complete." echo "[*] Attempting to build QEMU (fingers crossed!)..." @@ -235,7 +277,7 @@ echo "[+] Build process successful!" echo "[*] Copying binary..." -cp -f "${CPU_TARGET}-linux-user/qemu-${CPU_TARGET}" "../../afl-qemu-trace" || exit 1 +cp -f "build/${CPU_TARGET}-linux-user/qemu-${CPU_TARGET}" "../../afl-qemu-trace" || exit 1 cd .. ls -l ../afl-qemu-trace || exit 1 @@ -285,10 +327,51 @@ else fi -echo "[+] Building libcompcov ..." -make -C libcompcov && echo "[+] libcompcov ready" -echo "[+] Building unsigaction ..." -make -C unsigaction && echo "[+] unsigaction ready" +ORIG_CROSS="$CROSS" + +if [ "$ORIG_CROSS" = "" ]; then + CROSS=$CPU_TARGET-linux-gnu-gcc + if ! command -v "$CROSS" > /dev/null + then # works on Arch Linux + CROSS=$CPU_TARGET-pc-linux-gnu-gcc + fi + if ! command -v "$CROSS" > /dev/null && [ "$CPU_TARGET" = "i386" ] + then + CROSS=i686-linux-gnu-gcc + if ! command -v "$CROSS" > /dev/null + then # works on Arch Linux + CROSS=i686-pc-linux-gnu-gcc + fi + if ! command -v "$CROSS" > /dev/null && [ "`uname -m`" = "x86_64" ] + then # set -m32 + test "$CC" = "" && CC="gcc" + CROSS="$CC" + CROSS_FLAGS=-m32 + fi + fi +fi + +if ! command -v "$CROSS" > /dev/null ; then + if [ "$CPU_TARGET" = "$(uname -m)" ] ; then + echo "[+] Building afl++ qemu support libraries with CC=$CC" + echo "[+] Building libcompcov ..." + make -C libcompcov && echo "[+] libcompcov ready" + echo "[+] Building unsigaction ..." + make -C unsigaction && echo "[+] unsigaction ready" + echo "[+] Building libqasan ..." + make -C libqasan && echo "[+] unsigaction ready" + else + echo "[!] Cross compiler $CROSS could not be found, cannot compile libcompcov libqasan and unsigaction" + fi +else + echo "[+] Building afl++ qemu support libraries with CC=\"$CROSS $CROSS_FLAGS\"" + echo "[+] Building libcompcov ..." + make -C libcompcov CC="$CROSS $CROSS_FLAGS" && echo "[+] libcompcov ready" + echo "[+] Building unsigaction ..." + make -C unsigaction CC="$CROSS $CROSS_FLAGS" && echo "[+] unsigaction ready" + echo "[+] Building libqasan ..." + make -C libqasan CC="$CROSS $CROSS_FLAGS" && echo "[+] unsigaction ready" +fi echo "[+] All done for qemu_mode, enjoy!" diff --git a/qemu_mode/libcompcov/Makefile b/qemu_mode/libcompcov/Makefile index 9ed3e3fa..c2880b99 100644 --- a/qemu_mode/libcompcov/Makefile +++ b/qemu_mode/libcompcov/Makefile @@ -16,7 +16,7 @@ PREFIX ?= /usr/local HELPER_PATH = $(PREFIX)/lib/afl DOC_PATH ?= $(PREFIX)/share/doc/afl -MAN_PATH ?= $(PREFIX)/man/man8 +MAN_PATH ?= $(PREFIX)/share/man/man8 VERSION = $(shell grep '^\#define VERSION ' ../config.h | cut -d '"' -f2) diff --git a/qemu_mode/libcompcov/libcompcov.so.c b/qemu_mode/libcompcov/libcompcov.so.c index 23f465a4..4fc84e62 100644 --- a/qemu_mode/libcompcov/libcompcov.so.c +++ b/qemu_mode/libcompcov/libcompcov.so.c @@ -29,6 +29,8 @@ #include <sys/types.h> #include <sys/shm.h> #include <stdbool.h> +#include <stdint.h> +#include <inttypes.h> #include "types.h" #include "config.h" @@ -159,14 +161,15 @@ static void __compcov_load(void) { } -static void __compcov_trace(u64 cur_loc, const u8 *v0, const u8 *v1, size_t n) { +static void __compcov_trace(uintptr_t cur_loc, const u8 *v0, const u8 *v1, + size_t n) { size_t i; if (debug_fd != 1) { char debugbuf[4096]; - snprintf(debugbuf, sizeof(debugbuf), "0x%llx %s %s %zu\n", cur_loc, + snprintf(debugbuf, sizeof(debugbuf), "0x%" PRIxPTR " %s %s %zu\n", cur_loc, v0 == NULL ? "(null)" : (char *)v0, v1 == NULL ? "(null)" : (char *)v1, n); write(debug_fd, debugbuf, strlen(debugbuf)); @@ -206,7 +209,7 @@ int strcmp(const char *str1, const char *str2) { if (n <= MAX_CMP_LENGTH) { - u64 cur_loc = (u64)retaddr; + uintptr_t cur_loc = (uintptr_t)retaddr; cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); cur_loc &= MAP_SIZE - 1; @@ -235,7 +238,7 @@ int strncmp(const char *str1, const char *str2, size_t len) { if (n <= MAX_CMP_LENGTH) { - u64 cur_loc = (u64)retaddr; + uintptr_t cur_loc = (uintptr_t)retaddr; cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); cur_loc &= MAP_SIZE - 1; @@ -265,7 +268,7 @@ int strcasecmp(const char *str1, const char *str2) { if (n <= MAX_CMP_LENGTH) { - u64 cur_loc = (u64)retaddr; + uintptr_t cur_loc = (uintptr_t)retaddr; cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); cur_loc &= MAP_SIZE - 1; @@ -296,7 +299,7 @@ int strncasecmp(const char *str1, const char *str2, size_t len) { if (n <= MAX_CMP_LENGTH) { - u64 cur_loc = (u64)retaddr; + uintptr_t cur_loc = (uintptr_t)retaddr; cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); cur_loc &= MAP_SIZE - 1; @@ -324,7 +327,7 @@ int memcmp(const void *mem1, const void *mem2, size_t len) { if (n <= MAX_CMP_LENGTH) { - u64 cur_loc = (u64)retaddr; + uintptr_t cur_loc = (uintptr_t)retaddr; cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); cur_loc &= MAP_SIZE - 1; diff --git a/qemu_mode/libcompcov/pmparser.h b/qemu_mode/libcompcov/pmparser.h index 9421d47e..0eb4fb1d 100644 --- a/qemu_mode/libcompcov/pmparser.h +++ b/qemu_mode/libcompcov/pmparser.h @@ -108,8 +108,7 @@ void pmparser_print(procmaps_struct *map, int order); procmaps_iterator *pmparser_parse(int pid) { - procmaps_iterator *maps_it = malloc(sizeof(procmaps_iterator)); - char maps_path[500]; + char maps_path[500]; if (pid >= 0) { sprintf(maps_path, "/proc/%d/maps", pid); @@ -129,8 +128,9 @@ procmaps_iterator *pmparser_parse(int pid) { } - int ind = 0; - char buf[PROCMAPS_LINE_MAX_LENGTH]; + procmaps_iterator *maps_it = malloc(sizeof(procmaps_iterator)); + int ind = 0; + char buf[PROCMAPS_LINE_MAX_LENGTH]; // int c; procmaps_struct *list_maps = NULL; procmaps_struct *tmp; diff --git a/qemu_mode/libqasan/Makefile b/qemu_mode/libqasan/Makefile new file mode 100644 index 00000000..f91debb6 --- /dev/null +++ b/qemu_mode/libqasan/Makefile @@ -0,0 +1,44 @@ +# +# american fuzzy lop++ - libqasan +# ------------------------------- +# +# Written by Andrea Fioraldi <andreafioraldi@gmail.com> +# +# Copyright 2019-2020 Andrea Fioraldi. All rights reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at: +# +# http://www.apache.org/licenses/LICENSE-2.0 +# + +PREFIX ?= /usr/local +HELPER_PATH = $(PREFIX)/lib/afl +DOC_PATH ?= $(PREFIX)/share/doc/afl +MAN_PATH ?= $(PREFIX)/share/man/man8 + +VERSION = $(shell grep '^\#define VERSION ' ../config.h | cut -d '"' -f2) + +CFLAGS += -I ../qemuafl/qemuafl/ +CFLAGS += -Wno-int-to-void-pointer-cast -ggdb +LDFLAGS += -ldl -pthread + +SRC := libqasan.c hooks.c malloc.c string.c uninstrument.c patch.c dlmalloc.c +HDR := libqasan.h + +all: libqasan.so + +libqasan.so: $(HDR) $(SRC) + $(CC) $(CFLAGS) -fPIC -shared $(SRC) -o ../../$@ $(LDFLAGS) + +.NOTPARALLEL: clean + +clean: + rm -f *.o *.so *~ a.out core core.[1-9][0-9]* + rm -f ../../libqasan.so + +install: all + install -m 755 ../../libqasan.so $${DESTDIR}$(HELPER_PATH) + install -m 644 -T README.md $${DESTDIR}$(DOC_PATH)/README.qasan.md + diff --git a/qemu_mode/libqasan/README.md b/qemu_mode/libqasan/README.md new file mode 100644 index 00000000..4a241233 --- /dev/null +++ b/qemu_mode/libqasan/README.md @@ -0,0 +1,28 @@ +# QEMU AddressSanitizer Runtime + +This library is the injected runtime used by QEMU AddressSanitizer (QASan). + +The original repository is [here](https://github.com/andreafioraldi/qasan). + +The version embedded in qemuafl is an updated version of just the usermode part +and this runtime is injected via LD_PRELOAD (so works just for dynamically +linked binaries). + +The usage is super simple, just set the env var `AFL_USE_QASAN=1` when fuzzing +in qemu mode (-Q). afl-fuzz will automatically set AFL_PRELOAD to load this +library and enable the QASan instrumentation in afl-qemu-trace. + +For debugging purposes, we still suggest to run the original QASan as the +stacktrace support for ARM (just a debug feature, it does not affect the bug +finding capabilities during fuzzing) is WIP. + +### When should I use QASan? + +If your target binary is PIC x86_64, you should also give a try to +[retrowrite](https://github.com/HexHive/retrowrite) for static rewriting. + +If it fails, or if your binary is for another architecture, or you want to use +persistent and snapshot mode, AFL++ QASan mode is what you want/have to use. + +Note that the overhead of libdislocator when combined with QEMU mode is much +lower but it can catch less bugs. This is a short blanket, take your choice. diff --git a/qemu_mode/libqasan/dlmalloc.c b/qemu_mode/libqasan/dlmalloc.c new file mode 100644 index 00000000..aff58ad5 --- /dev/null +++ b/qemu_mode/libqasan/dlmalloc.c @@ -0,0 +1,7328 @@ +#include <features.h> + +#ifndef __GLIBC__ + +/* + This is a version (aka dlmalloc) of malloc/free/realloc written by + Doug Lea and released to the public domain, as explained at + http://creativecommons.org/publicdomain/zero/1.0/ Send questions, + comments, complaints, performance data, etc to dl@cs.oswego.edu + +* Version 2.8.6 Wed Aug 29 06:57:58 2012 Doug Lea + Note: There may be an updated version of this malloc obtainable at + ftp://gee.cs.oswego.edu/pub/misc/malloc.c + Check before installing! + +* Quickstart + + This library is all in one file to simplify the most common usage: + ftp it, compile it (-O3), and link it into another program. All of + the compile-time options default to reasonable values for use on + most platforms. You might later want to step through various + compile-time and dynamic tuning options. + + For convenience, an include file for code using this malloc is at: + ftp://gee.cs.oswego.edu/pub/misc/malloc-2.8.6.h + You don't really need this .h file unless you call functions not + defined in your system include files. The .h file contains only the + excerpts from this file needed for using this malloc on ANSI C/C++ + systems, so long as you haven't changed compile-time options about + naming and tuning parameters. If you do, then you can create your + own malloc.h that does include all settings by cutting at the point + indicated below. Note that you may already by default be using a C + library containing a malloc that is based on some version of this + malloc (for example in linux). You might still want to use the one + in this file to customize settings or to avoid overheads associated + with library versions. + +* Vital statistics: + + Supported pointer/size_t representation: 4 or 8 bytes + size_t MUST be an unsigned type of the same width as + pointers. (If you are using an ancient system that declares + size_t as a signed type, or need it to be a different width + than pointers, you can use a previous release of this malloc + (e.g. 2.7.2) supporting these.) + + Alignment: 8 bytes (minimum) + This suffices for nearly all current machines and C compilers. + However, you can define MALLOC_ALIGNMENT to be wider than this + if necessary (up to 128bytes), at the expense of using more space. + + Minimum overhead per allocated chunk: 4 or 8 bytes (if 4byte sizes) + 8 or 16 bytes (if 8byte sizes) + Each malloced chunk has a hidden word of overhead holding size + and status information, and additional cross-check word + if FOOTERS is defined. + + Minimum allocated size: 4-byte ptrs: 16 bytes (including overhead) + 8-byte ptrs: 32 bytes (including overhead) + + Even a request for zero bytes (i.e., malloc(0)) returns a + pointer to something of the minimum allocatable size. + The maximum overhead wastage (i.e., number of extra bytes + allocated than were requested in malloc) is less than or equal + to the minimum size, except for requests >= mmap_threshold that + are serviced via mmap(), where the worst case wastage is about + 32 bytes plus the remainder from a system page (the minimal + mmap unit); typically 4096 or 8192 bytes. + + Security: static-safe; optionally more or less + The "security" of malloc refers to the ability of malicious + code to accentuate the effects of errors (for example, freeing + space that is not currently malloc'ed or overwriting past the + ends of chunks) in code that calls malloc. This malloc + guarantees not to modify any memory locations below the base of + heap, i.e., static variables, even in the presence of usage + errors. The routines additionally detect most improper frees + and reallocs. All this holds as long as the static bookkeeping + for malloc itself is not corrupted by some other means. This + is only one aspect of security -- these checks do not, and + cannot, detect all possible programming errors. + + If FOOTERS is defined nonzero, then each allocated chunk + carries an additional check word to verify that it was malloced + from its space. These check words are the same within each + execution of a program using malloc, but differ across + executions, so externally crafted fake chunks cannot be + freed. This improves security by rejecting frees/reallocs that + could corrupt heap memory, in addition to the checks preventing + writes to statics that are always on. This may further improve + security at the expense of time and space overhead. (Note that + FOOTERS may also be worth using with MSPACES.) + + By default detected errors cause the program to abort (calling + "abort()"). You can override this to instead proceed past + errors by defining PROCEED_ON_ERROR. In this case, a bad free + has no effect, and a malloc that encounters a bad address + caused by user overwrites will ignore the bad address by + dropping pointers and indices to all known memory. This may + be appropriate for programs that should continue if at all + possible in the face of programming errors, although they may + run out of memory because dropped memory is never reclaimed. + + If you don't like either of these options, you can define + CORRUPTION_ERROR_ACTION and USAGE_ERROR_ACTION to do anything + else. And if if you are sure that your program using malloc has + no errors or vulnerabilities, you can define INSECURE to 1, + which might (or might not) provide a small performance improvement. + + It is also possible to limit the maximum total allocatable + space, using malloc_set_footprint_limit. This is not + designed as a security feature in itself (calls to set limits + are not screened or privileged), but may be useful as one + aspect of a secure implementation. + + Thread-safety: NOT thread-safe unless USE_LOCKS defined non-zero + When USE_LOCKS is defined, each public call to malloc, free, + etc is surrounded with a lock. By default, this uses a plain + pthread mutex, win32 critical section, or a spin-lock if if + available for the platform and not disabled by setting + USE_SPIN_LOCKS=0. However, if USE_RECURSIVE_LOCKS is defined, + recursive versions are used instead (which are not required for + base functionality but may be needed in layered extensions). + Using a global lock is not especially fast, and can be a major + bottleneck. It is designed only to provide minimal protection + in concurrent environments, and to provide a basis for + extensions. If you are using malloc in a concurrent program, + consider instead using nedmalloc + (http://www.nedprod.com/programs/portable/nedmalloc/) or + ptmalloc (See http://www.malloc.de), which are derived from + versions of this malloc. + + System requirements: Any combination of MORECORE and/or MMAP/MUNMAP + This malloc can use unix sbrk or any emulation (invoked using + the CALL_MORECORE macro) and/or mmap/munmap or any emulation + (invoked using CALL_MMAP/CALL_MUNMAP) to get and release system + memory. On most unix systems, it tends to work best if both + MORECORE and MMAP are enabled. On Win32, it uses emulations + based on VirtualAlloc. It also uses common C library functions + like memset. + + Compliance: I believe it is compliant with the Single Unix Specification + (See http://www.unix.org). Also SVID/XPG, ANSI C, and probably + others as well. + +* Overview of algorithms + + This is not the fastest, most space-conserving, most portable, or + most tunable malloc ever written. However it is among the fastest + while also being among the most space-conserving, portable and + tunable. Consistent balance across these factors results in a good + general-purpose allocator for malloc-intensive programs. + + In most ways, this malloc is a best-fit allocator. Generally, it + chooses the best-fitting existing chunk for a request, with ties + broken in approximately least-recently-used order. (This strategy + normally maintains low fragmentation.) However, for requests less + than 256bytes, it deviates from best-fit when there is not an + exactly fitting available chunk by preferring to use space adjacent + to that used for the previous small request, as well as by breaking + ties in approximately most-recently-used order. (These enhance + locality of series of small allocations.) And for very large requests + (>= 256Kb by default), it relies on system memory mapping + facilities, if supported. (This helps avoid carrying around and + possibly fragmenting memory used only for large chunks.) + + All operations (except malloc_stats and mallinfo) have execution + times that are bounded by a constant factor of the number of bits in + a size_t, not counting any clearing in calloc or copying in realloc, + or actions surrounding MORECORE and MMAP that have times + proportional to the number of non-contiguous regions returned by + system allocation routines, which is often just 1. In real-time + applications, you can optionally suppress segment traversals using + NO_SEGMENT_TRAVERSAL, which assures bounded execution even when + system allocators return non-contiguous spaces, at the typical + expense of carrying around more memory and increased fragmentation. + + The implementation is not very modular and seriously overuses + macros. Perhaps someday all C compilers will do as good a job + inlining modular code as can now be done by brute-force expansion, + but now, enough of them seem not to. + + Some compilers issue a lot of warnings about code that is + dead/unreachable only on some platforms, and also about intentional + uses of negation on unsigned types. All known cases of each can be + ignored. + + For a longer but out of date high-level description, see + http://gee.cs.oswego.edu/dl/html/malloc.html + +* MSPACES + If MSPACES is defined, then in addition to malloc, free, etc., + this file also defines mspace_malloc, mspace_free, etc. These + are versions of malloc routines that take an "mspace" argument + obtained using create_mspace, to control all internal bookkeeping. + If ONLY_MSPACES is defined, only these versions are compiled. + So if you would like to use this allocator for only some allocations, + and your system malloc for others, you can compile with + ONLY_MSPACES and then do something like... + static mspace mymspace = create_mspace(0,0); // for example + #define mymalloc(bytes) mspace_malloc(mymspace, bytes) + + (Note: If you only need one instance of an mspace, you can instead + use "USE_DL_PREFIX" to relabel the global malloc.) + + You can similarly create thread-local allocators by storing + mspaces as thread-locals. For example: + static __thread mspace tlms = 0; + void* tlmalloc(size_t bytes) { + + if (tlms == 0) tlms = create_mspace(0, 0); + return mspace_malloc(tlms, bytes); + + } + + void tlfree(void* mem) { mspace_free(tlms, mem); } + + Unless FOOTERS is defined, each mspace is completely independent. + You cannot allocate from one and free to another (although + conformance is only weakly checked, so usage errors are not always + caught). If FOOTERS is defined, then each chunk carries around a tag + indicating its originating mspace, and frees are directed to their + originating spaces. Normally, this requires use of locks. + + ------------------------- Compile-time options --------------------------- + +Be careful in setting #define values for numerical constants of type +size_t. On some systems, literal values are not automatically extended +to size_t precision unless they are explicitly casted. You can also +use the symbolic values MAX_SIZE_T, SIZE_T_ONE, etc below. + +WIN32 default: defined if _WIN32 defined + Defining WIN32 sets up defaults for MS environment and compilers. + Otherwise defaults are for unix. Beware that there seem to be some + cases where this malloc might not be a pure drop-in replacement for + Win32 malloc: Random-looking failures from Win32 GDI API's (eg; + SetDIBits()) may be due to bugs in some video driver implementations + when pixel buffers are malloc()ed, and the region spans more than + one VirtualAlloc()ed region. Because dlmalloc uses a small (64Kb) + default granularity, pixel buffers may straddle virtual allocation + regions more often than when using the Microsoft allocator. You can + avoid this by using VirtualAlloc() and VirtualFree() for all pixel + buffers rather than using malloc(). If this is not possible, + recompile this malloc with a larger DEFAULT_GRANULARITY. Note: + in cases where MSC and gcc (cygwin) are known to differ on WIN32, + conditions use _MSC_VER to distinguish them. + +DLMALLOC_EXPORT default: extern + Defines how public APIs are declared. If you want to export via a + Windows DLL, you might define this as + #define DLMALLOC_EXPORT extern __declspec(dllexport) + If you want a POSIX ELF shared object, you might use + #define DLMALLOC_EXPORT extern __attribute__((visibility("default"))) + +MALLOC_ALIGNMENT default: (size_t)(2 * sizeof(void *)) + Controls the minimum alignment for malloc'ed chunks. It must be a + power of two and at least 8, even on machines for which smaller + alignments would suffice. It may be defined as larger than this + though. Note however that code and data structures are optimized for + the case of 8-byte alignment. + +MSPACES default: 0 (false) + If true, compile in support for independent allocation spaces. + This is only supported if HAVE_MMAP is true. + +ONLY_MSPACES default: 0 (false) + If true, only compile in mspace versions, not regular versions. + +USE_LOCKS default: 0 (false) + Causes each call to each public routine to be surrounded with + pthread or WIN32 mutex lock/unlock. (If set true, this can be + overridden on a per-mspace basis for mspace versions.) If set to a + non-zero value other than 1, locks are used, but their + implementation is left out, so lock functions must be supplied manually, + as described below. + +USE_SPIN_LOCKS default: 1 iff USE_LOCKS and spin locks available + If true, uses custom spin locks for locking. This is currently + supported only gcc >= 4.1, older gccs on x86 platforms, and recent + MS compilers. Otherwise, posix locks or win32 critical sections are + used. + +USE_RECURSIVE_LOCKS default: not defined + If defined nonzero, uses recursive (aka reentrant) locks, otherwise + uses plain mutexes. This is not required for malloc proper, but may + be needed for layered allocators such as nedmalloc. + +LOCK_AT_FORK default: not defined + If defined nonzero, performs pthread_atfork upon initialization + to initialize child lock while holding parent lock. The implementation + assumes that pthread locks (not custom locks) are being used. In other + cases, you may need to customize the implementation. + +FOOTERS default: 0 + If true, provide extra checking and dispatching by placing + information in the footers of allocated chunks. This adds + space and time overhead. + +INSECURE default: 0 + If true, omit checks for usage errors and heap space overwrites. + +USE_DL_PREFIX default: NOT defined + Causes compiler to prefix all public routines with the string 'dl'. + This can be useful when you only want to use this malloc in one part + of a program, using your regular system malloc elsewhere. + +MALLOC_INSPECT_ALL default: NOT defined + If defined, compiles malloc_inspect_all and mspace_inspect_all, that + perform traversal of all heap space. Unless access to these + functions is otherwise restricted, you probably do not want to + include them in secure implementations. + +ABORT default: defined as abort() + Defines how to abort on failed checks. On most systems, a failed + check cannot die with an "assert" or even print an informative + message, because the underlying print routines in turn call malloc, + which will fail again. Generally, the best policy is to simply call + abort(). It's not very useful to do more than this because many + errors due to overwriting will show up as address faults (null, odd + addresses etc) rather than malloc-triggered checks, so will also + abort. Also, most compilers know that abort() does not return, so + can better optimize code conditionally calling it. + +PROCEED_ON_ERROR default: defined as 0 (false) + Controls whether detected bad addresses cause them to bypassed + rather than aborting. If set, detected bad arguments to free and + realloc are ignored. And all bookkeeping information is zeroed out + upon a detected overwrite of freed heap space, thus losing the + ability to ever return it from malloc again, but enabling the + application to proceed. If PROCEED_ON_ERROR is defined, the + static variable malloc_corruption_error_count is compiled in + and can be examined to see if errors have occurred. This option + generates slower code than the default abort policy. + +DEBUG default: NOT defined + The DEBUG setting is mainly intended for people trying to modify + this code or diagnose problems when porting to new platforms. + However, it may also be able to better isolate user errors than just + using runtime checks. The assertions in the check routines spell + out in more detail the assumptions and invariants underlying the + algorithms. The checking is fairly extensive, and will slow down + execution noticeably. Calling malloc_stats or mallinfo with DEBUG + set will attempt to check every non-mmapped allocated and free chunk + in the course of computing the summaries. + +ABORT_ON_ASSERT_FAILURE default: defined as 1 (true) + Debugging assertion failures can be nearly impossible if your + version of the assert macro causes malloc to be called, which will + lead to a cascade of further failures, blowing the runtime stack. + ABORT_ON_ASSERT_FAILURE cause assertions failures to call abort(), + which will usually make debugging easier. + +MALLOC_FAILURE_ACTION default: sets errno to ENOMEM, or no-op on win32 + The action to take before "return 0" when malloc fails to be able to + return memory because there is none available. + +HAVE_MORECORE default: 1 (true) unless win32 or ONLY_MSPACES + True if this system supports sbrk or an emulation of it. + +MORECORE default: sbrk + The name of the sbrk-style system routine to call to obtain more + memory. See below for guidance on writing custom MORECORE + functions. The type of the argument to sbrk/MORECORE varies across + systems. It cannot be size_t, because it supports negative + arguments, so it is normally the signed type of the same width as + size_t (sometimes declared as "intptr_t"). It doesn't much matter + though. Internally, we only call it with arguments less than half + the max value of a size_t, which should work across all reasonable + possibilities, although sometimes generating compiler warnings. + +MORECORE_CONTIGUOUS default: 1 (true) if HAVE_MORECORE + If true, take advantage of fact that consecutive calls to MORECORE + with positive arguments always return contiguous increasing + addresses. This is true of unix sbrk. It does not hurt too much to + set it true anyway, since malloc copes with non-contiguities. + Setting it false when definitely non-contiguous saves time + and possibly wasted space it would take to discover this though. + +MORECORE_CANNOT_TRIM default: NOT defined + True if MORECORE cannot release space back to the system when given + negative arguments. This is generally necessary only if you are + using a hand-crafted MORECORE function that cannot handle negative + arguments. + +NO_SEGMENT_TRAVERSAL default: 0 + If non-zero, suppresses traversals of memory segments + returned by either MORECORE or CALL_MMAP. This disables + merging of segments that are contiguous, and selectively + releasing them to the OS if unused, but bounds execution times. + +HAVE_MMAP default: 1 (true) + True if this system supports mmap or an emulation of it. If so, and + HAVE_MORECORE is not true, MMAP is used for all system + allocation. If set and HAVE_MORECORE is true as well, MMAP is + primarily used to directly allocate very large blocks. It is also + used as a backup strategy in cases where MORECORE fails to provide + space from system. Note: A single call to MUNMAP is assumed to be + able to unmap memory that may have be allocated using multiple calls + to MMAP, so long as they are adjacent. + +HAVE_MREMAP default: 1 on linux, else 0 + If true realloc() uses mremap() to re-allocate large blocks and + extend or shrink allocation spaces. + +MMAP_CLEARS default: 1 except on WINCE. + True if mmap clears memory so calloc doesn't need to. This is true + for standard unix mmap using /dev/zero and on WIN32 except for WINCE. + +USE_BUILTIN_FFS default: 0 (i.e., not used) + Causes malloc to use the builtin ffs() function to compute indices. + Some compilers may recognize and intrinsify ffs to be faster than the + supplied C version. Also, the case of x86 using gcc is special-cased + to an asm instruction, so is already as fast as it can be, and so + this setting has no effect. Similarly for Win32 under recent MS compilers. + (On most x86s, the asm version is only slightly faster than the C version.) + +malloc_getpagesize default: derive from system includes, or 4096. + The system page size. To the extent possible, this malloc manages + memory from the system in page-size units. This may be (and + usually is) a function rather than a constant. This is ignored + if WIN32, where page size is determined using getSystemInfo during + initialization. + +USE_DEV_RANDOM default: 0 (i.e., not used) + Causes malloc to use /dev/random to initialize secure magic seed for + stamping footers. Otherwise, the current time is used. + +NO_MALLINFO default: 0 + If defined, don't compile "mallinfo". This can be a simple way + of dealing with mismatches between system declarations and + those in this file. + +MALLINFO_FIELD_TYPE default: size_t + The type of the fields in the mallinfo struct. This was originally + defined as "int" in SVID etc, but is more usefully defined as + size_t. The value is used only if HAVE_USR_INCLUDE_MALLOC_H is not set + +NO_MALLOC_STATS default: 0 + If defined, don't compile "malloc_stats". This avoids calls to + fprintf and bringing in stdio dependencies you might not want. + +REALLOC_ZERO_BYTES_FREES default: not defined + This should be set if a call to realloc with zero bytes should + be the same as a call to free. Some people think it should. Otherwise, + since this malloc returns a unique pointer for malloc(0), so does + realloc(p, 0). + +LACKS_UNISTD_H, LACKS_FCNTL_H, LACKS_SYS_PARAM_H, LACKS_SYS_MMAN_H +LACKS_STRINGS_H, LACKS_STRING_H, LACKS_SYS_TYPES_H, LACKS_ERRNO_H +LACKS_STDLIB_H LACKS_SCHED_H LACKS_TIME_H default: NOT defined unless on WIN32 + Define these if your system does not have these header files. + You might need to manually insert some of the declarations they provide. + +DEFAULT_GRANULARITY default: page size if MORECORE_CONTIGUOUS, + system_info.dwAllocationGranularity in WIN32, + otherwise 64K. + Also settable using mallopt(M_GRANULARITY, x) + The unit for allocating and deallocating memory from the system. On + most systems with contiguous MORECORE, there is no reason to + make this more than a page. However, systems with MMAP tend to + either require or encourage larger granularities. You can increase + this value to prevent system allocation functions to be called so + often, especially if they are slow. The value must be at least one + page and must be a power of two. Setting to 0 causes initialization + to either page size or win32 region size. (Note: In previous + versions of malloc, the equivalent of this option was called + "TOP_PAD") + +DEFAULT_TRIM_THRESHOLD default: 2MB + Also settable using mallopt(M_TRIM_THRESHOLD, x) + The maximum amount of unused top-most memory to keep before + releasing via malloc_trim in free(). Automatic trimming is mainly + useful in long-lived programs using contiguous MORECORE. Because + trimming via sbrk can be slow on some systems, and can sometimes be + wasteful (in cases where programs immediately afterward allocate + more large chunks) the value should be high enough so that your + overall system performance would improve by releasing this much + memory. As a rough guide, you might set to a value close to the + average size of a process (program) running on your system. + Releasing this much memory would allow such a process to run in + memory. Generally, it is worth tuning trim thresholds when a + program undergoes phases where several large chunks are allocated + and released in ways that can reuse each other's storage, perhaps + mixed with phases where there are no such chunks at all. The trim + value must be greater than page size to have any useful effect. To + disable trimming completely, you can set to MAX_SIZE_T. Note that the trick + some people use of mallocing a huge space and then freeing it at + program startup, in an attempt to reserve system memory, doesn't + have the intended effect under automatic trimming, since that memory + will immediately be returned to the system. + +DEFAULT_MMAP_THRESHOLD default: 256K + Also settable using mallopt(M_MMAP_THRESHOLD, x) + The request size threshold for using MMAP to directly service a + request. Requests of at least this size that cannot be allocated + using already-existing space will be serviced via mmap. (If enough + normal freed space already exists it is used instead.) Using mmap + segregates relatively large chunks of memory so that they can be + individually obtained and released from the host system. A request + serviced through mmap is never reused by any other request (at least + not directly; the system may just so happen to remap successive + requests to the same locations). Segregating space in this way has + the benefits that: Mmapped space can always be individually released + back to the system, which helps keep the system level memory demands + of a long-lived program low. Also, mapped memory doesn't become + `locked' between other chunks, as can happen with normally allocated + chunks, which means that even trimming via malloc_trim would not + release them. However, it has the disadvantage that the space + cannot be reclaimed, consolidated, and then used to service later + requests, as happens with normal chunks. The advantages of mmap + nearly always outweigh disadvantages for "large" chunks, but the + value of "large" may vary across systems. The default is an + empirically derived value that works well in most systems. You can + disable mmap by setting to MAX_SIZE_T. + +MAX_RELEASE_CHECK_RATE default: 4095 unless not HAVE_MMAP + The number of consolidated frees between checks to release + unused segments when freeing. When using non-contiguous segments, + especially with multiple mspaces, checking only for topmost space + doesn't always suffice to trigger trimming. To compensate for this, + free() will, with a period of MAX_RELEASE_CHECK_RATE (or the + current number of segments, if greater) try to release unused + segments to the OS when freeing chunks that result in + consolidation. The best value for this parameter is a compromise + between slowing down frees with relatively costly checks that + rarely trigger versus holding on to unused memory. To effectively + disable, set to MAX_SIZE_T. This may lead to a very slight speed + improvement at the expense of carrying around more memory. +*/ + + #define USE_DL_PREFIX + + /* Version identifier to allow people to support multiple versions */ + #ifndef DLMALLOC_VERSION + #define DLMALLOC_VERSION 20806 + #endif /* DLMALLOC_VERSION */ + + #ifndef DLMALLOC_EXPORT + #define DLMALLOC_EXPORT extern + #endif + + #ifndef WIN32 + #ifdef _WIN32 + #define WIN32 1 + #endif /* _WIN32 */ + #ifdef _WIN32_WCE + #define LACKS_FCNTL_H + #define WIN32 1 + #endif /* _WIN32_WCE */ + #endif /* WIN32 */ + #ifdef WIN32 + #define WIN32_LEAN_AND_MEAN + #include <windows.h> + #include <tchar.h> + #define HAVE_MMAP 1 + #define HAVE_MORECORE 0 + #define LACKS_UNISTD_H + #define LACKS_SYS_PARAM_H + #define LACKS_SYS_MMAN_H + #define LACKS_STRING_H + #define LACKS_STRINGS_H + #define LACKS_SYS_TYPES_H + #define LACKS_ERRNO_H + #define LACKS_SCHED_H + #ifndef MALLOC_FAILURE_ACTION + #define MALLOC_FAILURE_ACTION + #endif /* MALLOC_FAILURE_ACTION */ + #ifndef MMAP_CLEARS + #ifdef _WIN32_WCE /* WINCE reportedly does not clear */ + #define MMAP_CLEARS 0 + #else + #define MMAP_CLEARS 1 + #endif /* _WIN32_WCE */ + #endif /*MMAP_CLEARS */ + #endif /* WIN32 */ + + #if defined(DARWIN) || defined(_DARWIN) + /* Mac OSX docs advise not to use sbrk; it seems better to use mmap */ + #ifndef HAVE_MORECORE + #define HAVE_MORECORE 0 + #define HAVE_MMAP 1 + /* OSX allocators provide 16 byte alignment */ + #ifndef MALLOC_ALIGNMENT + #define MALLOC_ALIGNMENT ((size_t)16U) + #endif + #endif /* HAVE_MORECORE */ + #endif /* DARWIN */ + + #ifndef LACKS_SYS_TYPES_H + #include <sys/types.h> /* For size_t */ + #endif /* LACKS_SYS_TYPES_H */ + + /* The maximum possible size_t value has all bits set */ + #define MAX_SIZE_T (~(size_t)0) + + #ifndef USE_LOCKS /* ensure true if spin or recursive locks set */ + #define USE_LOCKS \ + ((defined(USE_SPIN_LOCKS) && USE_SPIN_LOCKS != 0) || \ + (defined(USE_RECURSIVE_LOCKS) && USE_RECURSIVE_LOCKS != 0)) + #endif /* USE_LOCKS */ + + #if USE_LOCKS /* Spin locks for gcc >= 4.1, older gcc on x86, MSC >= 1310 */ + #if ((defined(__GNUC__) && \ + ((__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 1)) || \ + defined(__i386__) || defined(__x86_64__))) || \ + (defined(_MSC_VER) && _MSC_VER >= 1310)) + #ifndef USE_SPIN_LOCKS + #define USE_SPIN_LOCKS 1 + #endif /* USE_SPIN_LOCKS */ + #elif USE_SPIN_LOCKS + #error "USE_SPIN_LOCKS defined without implementation" + #endif /* ... locks available... */ + #elif !defined(USE_SPIN_LOCKS) + #define USE_SPIN_LOCKS 0 + #endif /* USE_LOCKS */ + + #ifndef ONLY_MSPACES + #define ONLY_MSPACES 0 + #endif /* ONLY_MSPACES */ + #ifndef MSPACES + #if ONLY_MSPACES + #define MSPACES 1 + #else /* ONLY_MSPACES */ + #define MSPACES 0 + #endif /* ONLY_MSPACES */ + #endif /* MSPACES */ + #ifndef MALLOC_ALIGNMENT + #define MALLOC_ALIGNMENT ((size_t)(2 * sizeof(void *))) + #endif /* MALLOC_ALIGNMENT */ + #ifndef FOOTERS + #define FOOTERS 0 + #endif /* FOOTERS */ + #ifndef ABORT + #define ABORT abort() + #endif /* ABORT */ + #ifndef ABORT_ON_ASSERT_FAILURE + #define ABORT_ON_ASSERT_FAILURE 1 + #endif /* ABORT_ON_ASSERT_FAILURE */ + #ifndef PROCEED_ON_ERROR + #define PROCEED_ON_ERROR 0 + #endif /* PROCEED_ON_ERROR */ + + #ifndef INSECURE + #define INSECURE 0 + #endif /* INSECURE */ + #ifndef MALLOC_INSPECT_ALL + #define MALLOC_INSPECT_ALL 0 + #endif /* MALLOC_INSPECT_ALL */ + #ifndef HAVE_MMAP + #define HAVE_MMAP 1 + #endif /* HAVE_MMAP */ + #ifndef MMAP_CLEARS + #define MMAP_CLEARS 1 + #endif /* MMAP_CLEARS */ + #ifndef HAVE_MREMAP + #ifdef linux + #define HAVE_MREMAP 1 + #define _GNU_SOURCE /* Turns on mremap() definition */ + #else /* linux */ + #define HAVE_MREMAP 0 + #endif /* linux */ + #endif /* HAVE_MREMAP */ + #ifndef MALLOC_FAILURE_ACTION + #define MALLOC_FAILURE_ACTION errno = ENOMEM; + #endif /* MALLOC_FAILURE_ACTION */ + #ifndef HAVE_MORECORE + #if ONLY_MSPACES + #define HAVE_MORECORE 0 + #else /* ONLY_MSPACES */ + #define HAVE_MORECORE 1 + #endif /* ONLY_MSPACES */ + #endif /* HAVE_MORECORE */ + #if !HAVE_MORECORE + #define MORECORE_CONTIGUOUS 0 + #else /* !HAVE_MORECORE */ + #define MORECORE_DEFAULT sbrk + #ifndef MORECORE_CONTIGUOUS + #define MORECORE_CONTIGUOUS 1 + #endif /* MORECORE_CONTIGUOUS */ + #endif /* HAVE_MORECORE */ + #ifndef DEFAULT_GRANULARITY + #if (MORECORE_CONTIGUOUS || defined(WIN32)) + #define DEFAULT_GRANULARITY (0) /* 0 means to compute in init_mparams */ + #else /* MORECORE_CONTIGUOUS */ + #define DEFAULT_GRANULARITY ((size_t)64U * (size_t)1024U) + #endif /* MORECORE_CONTIGUOUS */ + #endif /* DEFAULT_GRANULARITY */ + #ifndef DEFAULT_TRIM_THRESHOLD + #ifndef MORECORE_CANNOT_TRIM + #define DEFAULT_TRIM_THRESHOLD \ + ((size_t)2U * (size_t)1024U * (size_t)1024U) + #else /* MORECORE_CANNOT_TRIM */ + #define DEFAULT_TRIM_THRESHOLD MAX_SIZE_T + #endif /* MORECORE_CANNOT_TRIM */ + #endif /* DEFAULT_TRIM_THRESHOLD */ + #ifndef DEFAULT_MMAP_THRESHOLD + #if HAVE_MMAP + #define DEFAULT_MMAP_THRESHOLD ((size_t)256U * (size_t)1024U) + #else /* HAVE_MMAP */ + #define DEFAULT_MMAP_THRESHOLD MAX_SIZE_T + #endif /* HAVE_MMAP */ + #endif /* DEFAULT_MMAP_THRESHOLD */ + #ifndef MAX_RELEASE_CHECK_RATE + #if HAVE_MMAP + #define MAX_RELEASE_CHECK_RATE 4095 + #else + #define MAX_RELEASE_CHECK_RATE MAX_SIZE_T + #endif /* HAVE_MMAP */ + #endif /* MAX_RELEASE_CHECK_RATE */ + #ifndef USE_BUILTIN_FFS + #define USE_BUILTIN_FFS 0 + #endif /* USE_BUILTIN_FFS */ + #ifndef USE_DEV_RANDOM + #define USE_DEV_RANDOM 0 + #endif /* USE_DEV_RANDOM */ + #ifndef NO_MALLINFO + #define NO_MALLINFO 0 + #endif /* NO_MALLINFO */ + #ifndef MALLINFO_FIELD_TYPE + #define MALLINFO_FIELD_TYPE size_t + #endif /* MALLINFO_FIELD_TYPE */ + #ifndef NO_MALLOC_STATS + #define NO_MALLOC_STATS 0 + #endif /* NO_MALLOC_STATS */ + #ifndef NO_SEGMENT_TRAVERSAL + #define NO_SEGMENT_TRAVERSAL 0 + #endif /* NO_SEGMENT_TRAVERSAL */ + +/* + mallopt tuning options. SVID/XPG defines four standard parameter + numbers for mallopt, normally defined in malloc.h. None of these + are used in this malloc, so setting them has no effect. But this + malloc does support the following options. +*/ + + #undef M_TRIM_THRESHOLD + #undef M_GRANULARITY + #undef M_MMAP_THRESHOLD + #define M_TRIM_THRESHOLD (-1) + #define M_GRANULARITY (-2) + #define M_MMAP_THRESHOLD (-3) + +/* ------------------------ Mallinfo declarations ------------------------ */ + + #if !NO_MALLINFO + /* + This version of malloc supports the standard SVID/XPG mallinfo + routine that returns a struct containing usage properties and + statistics. It should work on any system that has a + /usr/include/malloc.h defining struct mallinfo. The main + declaration needed is the mallinfo struct that is returned (by-copy) + by mallinfo(). The malloinfo struct contains a bunch of fields that + are not even meaningful in this version of malloc. These fields are + are instead filled by mallinfo() with other numbers that might be of + interest. + + HAVE_USR_INCLUDE_MALLOC_H should be set if you have a + /usr/include/malloc.h file that includes a declaration of struct + mallinfo. If so, it is included; else a compliant version is + declared below. These must be precisely the same for mallinfo() to + work. The original SVID version of this struct, defined on most + systems with mallinfo, declares all fields as ints. But some others + define as unsigned long. If your system defines the fields using a + type of different width than listed here, you MUST #include your + system version and #define HAVE_USR_INCLUDE_MALLOC_H. + */ + + /* #define HAVE_USR_INCLUDE_MALLOC_H */ + + #ifdef HAVE_USR_INCLUDE_MALLOC_H + #include "/usr/include/malloc.h" + #else /* HAVE_USR_INCLUDE_MALLOC_H */ + #ifndef STRUCT_MALLINFO_DECLARED + /* HP-UX (and others?) redefines mallinfo unless _STRUCT_MALLINFO is + * defined */ + #define _STRUCT_MALLINFO + #define STRUCT_MALLINFO_DECLARED 1 +struct mallinfo { + + MALLINFO_FIELD_TYPE arena; /* non-mmapped space allocated from system */ + MALLINFO_FIELD_TYPE ordblks; /* number of free chunks */ + MALLINFO_FIELD_TYPE smblks; /* always 0 */ + MALLINFO_FIELD_TYPE hblks; /* always 0 */ + MALLINFO_FIELD_TYPE hblkhd; /* space in mmapped regions */ + MALLINFO_FIELD_TYPE usmblks; /* maximum total allocated space */ + MALLINFO_FIELD_TYPE fsmblks; /* always 0 */ + MALLINFO_FIELD_TYPE uordblks; /* total allocated space */ + MALLINFO_FIELD_TYPE fordblks; /* total free space */ + MALLINFO_FIELD_TYPE keepcost; /* releasable (via malloc_trim) space */ + +}; + + #endif /* STRUCT_MALLINFO_DECLARED */ + #endif /* HAVE_USR_INCLUDE_MALLOC_H */ + #endif /* NO_MALLINFO */ + +/* + Try to persuade compilers to inline. The most critical functions for + inlining are defined as macros, so these aren't used for them. +*/ + + #ifndef FORCEINLINE + #if defined(__GNUC__) + #define FORCEINLINE __inline __attribute__((always_inline)) + #elif defined(_MSC_VER) + #define FORCEINLINE __forceinline + #endif + #endif + #ifndef NOINLINE + #if defined(__GNUC__) + #define NOINLINE __attribute__((noinline)) + #elif defined(_MSC_VER) + #define NOINLINE __declspec(noinline) + #else + #define NOINLINE + #endif + #endif + + #ifdef __cplusplus +extern "C" { + + #ifndef FORCEINLINE + #define FORCEINLINE inline + #endif + #endif /* __cplusplus */ + #ifndef FORCEINLINE + #define FORCEINLINE + #endif + + #if !ONLY_MSPACES + + /* ------------------- Declarations of public routines ------------------- */ + + #ifndef USE_DL_PREFIX + #define dlcalloc calloc + #define dlfree free + #define dlmalloc malloc + #define dlmemalign memalign + #define dlposix_memalign posix_memalign + #define dlrealloc realloc + #define dlrealloc_in_place realloc_in_place + #define dlvalloc valloc + #define dlpvalloc pvalloc + #define dlmallinfo mallinfo + #define dlmallopt mallopt + #define dlmalloc_trim malloc_trim + #define dlmalloc_stats malloc_stats + #define dlmalloc_usable_size malloc_usable_size + #define dlmalloc_footprint malloc_footprint + #define dlmalloc_max_footprint malloc_max_footprint + #define dlmalloc_footprint_limit malloc_footprint_limit + #define dlmalloc_set_footprint_limit malloc_set_footprint_limit + #define dlmalloc_inspect_all malloc_inspect_all + #define dlindependent_calloc independent_calloc + #define dlindependent_comalloc independent_comalloc + #define dlbulk_free bulk_free + #endif /* USE_DL_PREFIX */ + +/* + malloc(size_t n) + Returns a pointer to a newly allocated chunk of at least n bytes, or + null if no space is available, in which case errno is set to ENOMEM + on ANSI C systems. + + If n is zero, malloc returns a minimum-sized chunk. (The minimum + size is 16 bytes on most 32bit systems, and 32 bytes on 64bit + systems.) Note that size_t is an unsigned type, so calls with + arguments that would be negative if signed are interpreted as + requests for huge amounts of space, which will often fail. The + maximum supported value of n differs across systems, but is in all + cases less than the maximum representable value of a size_t. +*/ +DLMALLOC_EXPORT void *dlmalloc(size_t); + +/* + free(void* p) + Releases the chunk of memory pointed to by p, that had been previously + allocated using malloc or a related routine such as realloc. + It has no effect if p is null. If p was not malloced or already + freed, free(p) will by default cause the current program to abort. +*/ +DLMALLOC_EXPORT void dlfree(void *); + +/* + calloc(size_t n_elements, size_t element_size); + Returns a pointer to n_elements * element_size bytes, with all locations + set to zero. +*/ +DLMALLOC_EXPORT void *dlcalloc(size_t, size_t); + +/* + realloc(void* p, size_t n) + Returns a pointer to a chunk of size n that contains the same data + as does chunk p up to the minimum of (n, p's size) bytes, or null + if no space is available. + + The returned pointer may or may not be the same as p. The algorithm + prefers extending p in most cases when possible, otherwise it + employs the equivalent of a malloc-copy-free sequence. + + If p is null, realloc is equivalent to malloc. + + If space is not available, realloc returns null, errno is set (if on + ANSI) and p is NOT freed. + + if n is for fewer bytes than already held by p, the newly unused + space is lopped off and freed if possible. realloc with a size + argument of zero (re)allocates a minimum-sized chunk. + + The old unix realloc convention of allowing the last-free'd chunk + to be used as an argument to realloc is not supported. +*/ +DLMALLOC_EXPORT void *dlrealloc(void *, size_t); + +/* + realloc_in_place(void* p, size_t n) + Resizes the space allocated for p to size n, only if this can be + done without moving p (i.e., only if there is adjacent space + available if n is greater than p's current allocated size, or n is + less than or equal to p's size). This may be used instead of plain + realloc if an alternative allocation strategy is needed upon failure + to expand space; for example, reallocation of a buffer that must be + memory-aligned or cleared. You can use realloc_in_place to trigger + these alternatives only when needed. + + Returns p if successful; otherwise null. +*/ +DLMALLOC_EXPORT void *dlrealloc_in_place(void *, size_t); + +/* + memalign(size_t alignment, size_t n); + Returns a pointer to a newly allocated chunk of n bytes, aligned + in accord with the alignment argument. + + The alignment argument should be a power of two. If the argument is + not a power of two, the nearest greater power is used. + 8-byte alignment is guaranteed by normal malloc calls, so don't + bother calling memalign with an argument of 8 or less. + + Overreliance on memalign is a sure way to fragment space. +*/ +DLMALLOC_EXPORT void *dlmemalign(size_t, size_t); + +/* + int posix_memalign(void** pp, size_t alignment, size_t n); + Allocates a chunk of n bytes, aligned in accord with the alignment + argument. Differs from memalign only in that it (1) assigns the + allocated memory to *pp rather than returning it, (2) fails and + returns EINVAL if the alignment is not a power of two (3) fails and + returns ENOMEM if memory cannot be allocated. +*/ +DLMALLOC_EXPORT int dlposix_memalign(void **, size_t, size_t); + +/* + valloc(size_t n); + Equivalent to memalign(pagesize, n), where pagesize is the page + size of the system. If the pagesize is unknown, 4096 is used. +*/ +DLMALLOC_EXPORT void *dlvalloc(size_t); + +/* + mallopt(int parameter_number, int parameter_value) + Sets tunable parameters The format is to provide a + (parameter-number, parameter-value) pair. mallopt then sets the + corresponding parameter to the argument value if it can (i.e., so + long as the value is meaningful), and returns 1 if successful else + 0. To workaround the fact that mallopt is specified to use int, + not size_t parameters, the value -1 is specially treated as the + maximum unsigned size_t value. + + SVID/XPG/ANSI defines four standard param numbers for mallopt, + normally defined in malloc.h. None of these are use in this malloc, + so setting them has no effect. But this malloc also supports other + options in mallopt. See below for details. Briefly, supported + parameters are as follows (listed defaults are for "typical" + configurations). + + Symbol param # default allowed param values + M_TRIM_THRESHOLD -1 2*1024*1024 any (-1 disables) + M_GRANULARITY -2 page size any power of 2 >= page size + M_MMAP_THRESHOLD -3 256*1024 any (or 0 if no MMAP support) +*/ +DLMALLOC_EXPORT int dlmallopt(int, int); + +/* + malloc_footprint(); + Returns the number of bytes obtained from the system. The total + number of bytes allocated by malloc, realloc etc., is less than this + value. Unlike mallinfo, this function returns only a precomputed + result, so can be called frequently to monitor memory consumption. + Even if locks are otherwise defined, this function does not use them, + so results might not be up to date. +*/ +DLMALLOC_EXPORT size_t dlmalloc_footprint(void); + +/* + malloc_max_footprint(); + Returns the maximum number of bytes obtained from the system. This + value will be greater than current footprint if deallocated space + has been reclaimed by the system. The peak number of bytes allocated + by malloc, realloc etc., is less than this value. Unlike mallinfo, + this function returns only a precomputed result, so can be called + frequently to monitor memory consumption. Even if locks are + otherwise defined, this function does not use them, so results might + not be up to date. +*/ +DLMALLOC_EXPORT size_t dlmalloc_max_footprint(void); + +/* + malloc_footprint_limit(); + Returns the number of bytes that the heap is allowed to obtain from + the system, returning the last value returned by + malloc_set_footprint_limit, or the maximum size_t value if + never set. The returned value reflects a permission. There is no + guarantee that this number of bytes can actually be obtained from + the system. +*/ +DLMALLOC_EXPORT size_t dlmalloc_footprint_limit(); + +/* + malloc_set_footprint_limit(); + Sets the maximum number of bytes to obtain from the system, causing + failure returns from malloc and related functions upon attempts to + exceed this value. The argument value may be subject to page + rounding to an enforceable limit; this actual value is returned. + Using an argument of the maximum possible size_t effectively + disables checks. If the argument is less than or equal to the + current malloc_footprint, then all future allocations that require + additional system memory will fail. However, invocation cannot + retroactively deallocate existing used memory. +*/ +DLMALLOC_EXPORT size_t dlmalloc_set_footprint_limit(size_t bytes); + + #if MALLOC_INSPECT_ALL +/* + malloc_inspect_all(void(*handler)(void *start, + void *end, + size_t used_bytes, + void* callback_arg), + void* arg); + Traverses the heap and calls the given handler for each managed + region, skipping all bytes that are (or may be) used for bookkeeping + purposes. Traversal does not include include chunks that have been + directly memory mapped. Each reported region begins at the start + address, and continues up to but not including the end address. The + first used_bytes of the region contain allocated data. If + used_bytes is zero, the region is unallocated. The handler is + invoked with the given callback argument. If locks are defined, they + are held during the entire traversal. It is a bad idea to invoke + other malloc functions from within the handler. + + For example, to count the number of in-use chunks with size greater + than 1000, you could write: + static int count = 0; + void count_chunks(void* start, void* end, size_t used, void* arg) { + + if (used >= 1000) ++count; + + } + + then: + malloc_inspect_all(count_chunks, NULL); + + malloc_inspect_all is compiled only if MALLOC_INSPECT_ALL is defined. +*/ +DLMALLOC_EXPORT void dlmalloc_inspect_all(void (*handler)(void *, void *, + size_t, void *), + void *arg); + + #endif /* MALLOC_INSPECT_ALL */ + + #if !NO_MALLINFO +/* + mallinfo() + Returns (by copy) a struct containing various summary statistics: + + arena: current total non-mmapped bytes allocated from system + ordblks: the number of free chunks + smblks: always zero. + hblks: current number of mmapped regions + hblkhd: total bytes held in mmapped regions + usmblks: the maximum total allocated space. This will be greater + than current total if trimming has occurred. + fsmblks: always zero + uordblks: current total allocated space (normal or mmapped) + fordblks: total free space + keepcost: the maximum number of bytes that could ideally be released + back to system via malloc_trim. ("ideally" means that + it ignores page restrictions etc.) + + Because these fields are ints, but internal bookkeeping may + be kept as longs, the reported values may wrap around zero and + thus be inaccurate. +*/ +DLMALLOC_EXPORT struct mallinfo dlmallinfo(void); + #endif /* NO_MALLINFO */ + +/* + independent_calloc(size_t n_elements, size_t element_size, void* chunks[]); + + independent_calloc is similar to calloc, but instead of returning a + single cleared space, it returns an array of pointers to n_elements + independent elements that can hold contents of size elem_size, each + of which starts out cleared, and can be independently freed, + realloc'ed etc. The elements are guaranteed to be adjacently + allocated (this is not guaranteed to occur with multiple callocs or + mallocs), which may also improve cache locality in some + applications. + + The "chunks" argument is optional (i.e., may be null, which is + probably the most typical usage). If it is null, the returned array + is itself dynamically allocated and should also be freed when it is + no longer needed. Otherwise, the chunks array must be of at least + n_elements in length. It is filled in with the pointers to the + chunks. + + In either case, independent_calloc returns this pointer array, or + null if the allocation failed. If n_elements is zero and "chunks" + is null, it returns a chunk representing an array with zero elements + (which should be freed if not wanted). + + Each element must be freed when it is no longer needed. This can be + done all at once using bulk_free. + + independent_calloc simplifies and speeds up implementations of many + kinds of pools. It may also be useful when constructing large data + structures that initially have a fixed number of fixed-sized nodes, + but the number is not known at compile time, and some of the nodes + may later need to be freed. For example: + + struct Node { int item; struct Node* next; }; + + struct Node* build_list() { + + struct Node** pool; + int n = read_number_of_nodes_needed(); + if (n <= 0) return 0; + pool = (struct Node**)(independent_calloc(n, sizeof(struct Node), 0); + if (pool == 0) die(); + // organize into a linked list... + struct Node* first = pool[0]; + for (i = 0; i < n-1; ++i) + pool[i]->next = pool[i+1]; + free(pool); // Can now free the array (or not, if it is needed later) + return first; + + } + +*/ +DLMALLOC_EXPORT void **dlindependent_calloc(size_t, size_t, void **); + +/* + independent_comalloc(size_t n_elements, size_t sizes[], void* chunks[]); + + independent_comalloc allocates, all at once, a set of n_elements + chunks with sizes indicated in the "sizes" array. It returns + an array of pointers to these elements, each of which can be + independently freed, realloc'ed etc. The elements are guaranteed to + be adjacently allocated (this is not guaranteed to occur with + multiple callocs or mallocs), which may also improve cache locality + in some applications. + + The "chunks" argument is optional (i.e., may be null). If it is null + the returned array is itself dynamically allocated and should also + be freed when it is no longer needed. Otherwise, the chunks array + must be of at least n_elements in length. It is filled in with the + pointers to the chunks. + + In either case, independent_comalloc returns this pointer array, or + null if the allocation failed. If n_elements is zero and chunks is + null, it returns a chunk representing an array with zero elements + (which should be freed if not wanted). + + Each element must be freed when it is no longer needed. This can be + done all at once using bulk_free. + + independent_comallac differs from independent_calloc in that each + element may have a different size, and also that it does not + automatically clear elements. + + independent_comalloc can be used to speed up allocation in cases + where several structs or objects must always be allocated at the + same time. For example: + + struct Head { ... } + struct Foot { ... } + + void send_message(char* msg) { + + int msglen = strlen(msg); + size_t sizes[3] = { sizeof(struct Head), msglen, sizeof(struct Foot) }; + void* chunks[3]; + if (independent_comalloc(3, sizes, chunks) == 0) + die(); + struct Head* head = (struct Head*)(chunks[0]); + char* body = (char*)(chunks[1]); + struct Foot* foot = (struct Foot*)(chunks[2]); + // ... + + } + + In general though, independent_comalloc is worth using only for + larger values of n_elements. For small values, you probably won't + detect enough difference from series of malloc calls to bother. + + Overuse of independent_comalloc can increase overall memory usage, + since it cannot reuse existing noncontiguous small chunks that + might be available for some of the elements. +*/ +DLMALLOC_EXPORT void **dlindependent_comalloc(size_t, size_t *, void **); + +/* + bulk_free(void* array[], size_t n_elements) + Frees and clears (sets to null) each non-null pointer in the given + array. This is likely to be faster than freeing them one-by-one. + If footers are used, pointers that have been allocated in different + mspaces are not freed or cleared, and the count of all such pointers + is returned. For large arrays of pointers with poor locality, it + may be worthwhile to sort this array before calling bulk_free. +*/ +DLMALLOC_EXPORT size_t dlbulk_free(void **, size_t n_elements); + +/* + pvalloc(size_t n); + Equivalent to valloc(minimum-page-that-holds(n)), that is, + round up n to nearest pagesize. + */ +DLMALLOC_EXPORT void *dlpvalloc(size_t); + +/* + malloc_trim(size_t pad); + + If possible, gives memory back to the system (via negative arguments + to sbrk) if there is unused memory at the `high' end of the malloc + pool or in unused MMAP segments. You can call this after freeing + large blocks of memory to potentially reduce the system-level memory + requirements of a program. However, it cannot guarantee to reduce + memory. Under some allocation patterns, some large free blocks of + memory will be locked between two used chunks, so they cannot be + given back to the system. + + The `pad' argument to malloc_trim represents the amount of free + trailing space to leave untrimmed. If this argument is zero, only + the minimum amount of memory to maintain internal data structures + will be left. Non-zero arguments can be supplied to maintain enough + trailing space to service future expected allocations without having + to re-obtain memory from the system. + + Malloc_trim returns 1 if it actually released any memory, else 0. +*/ +DLMALLOC_EXPORT int dlmalloc_trim(size_t); + +/* + malloc_stats(); + Prints on stderr the amount of space obtained from the system (both + via sbrk and mmap), the maximum amount (which may be more than + current if malloc_trim and/or munmap got called), and the current + number of bytes allocated via malloc (or realloc, etc) but not yet + freed. Note that this is the number of bytes allocated, not the + number requested. It will be larger than the number requested + because of alignment and bookkeeping overhead. Because it includes + alignment wastage as being in use, this figure may be greater than + zero even when no user-level chunks are allocated. + + The reported current and maximum system memory can be inaccurate if + a program makes other calls to system memory allocation functions + (normally sbrk) outside of malloc. + + malloc_stats prints only the most commonly interesting statistics. + More information can be obtained by calling mallinfo. +*/ +DLMALLOC_EXPORT void dlmalloc_stats(void); + +/* + malloc_usable_size(void* p); + + Returns the number of bytes you can actually use in + an allocated chunk, which may be more than you requested (although + often not) due to alignment and minimum size constraints. + You can use this many bytes without worrying about + overwriting other allocated objects. This is not a particularly great + programming practice. malloc_usable_size can be more useful in + debugging and assertions, for example: + + p = malloc(n); + assert(malloc_usable_size(p) >= 256); +*/ +size_t dlmalloc_usable_size(void *); + + #endif /* ONLY_MSPACES */ + + #if MSPACES + +/* + mspace is an opaque type representing an independent + region of space that supports mspace_malloc, etc. +*/ +typedef void *mspace; + +/* + create_mspace creates and returns a new independent space with the + given initial capacity, or, if 0, the default granularity size. It + returns null if there is no system memory available to create the + space. If argument locked is non-zero, the space uses a separate + lock to control access. The capacity of the space will grow + dynamically as needed to service mspace_malloc requests. You can + control the sizes of incremental increases of this space by + compiling with a different DEFAULT_GRANULARITY or dynamically + setting with mallopt(M_GRANULARITY, value). +*/ +DLMALLOC_EXPORT mspace create_mspace(size_t capacity, int locked); + +/* + destroy_mspace destroys the given space, and attempts to return all + of its memory back to the system, returning the total number of + bytes freed. After destruction, the results of access to all memory + used by the space become undefined. +*/ +DLMALLOC_EXPORT size_t destroy_mspace(mspace msp); + +/* + create_mspace_with_base uses the memory supplied as the initial base + of a new mspace. Part (less than 128*sizeof(size_t) bytes) of this + space is used for bookkeeping, so the capacity must be at least this + large. (Otherwise 0 is returned.) When this initial space is + exhausted, additional memory will be obtained from the system. + Destroying this space will deallocate all additionally allocated + space (if possible) but not the initial base. +*/ +DLMALLOC_EXPORT mspace create_mspace_with_base(void *base, size_t capacity, + int locked); + +/* + mspace_track_large_chunks controls whether requests for large chunks + are allocated in their own untracked mmapped regions, separate from + others in this mspace. By default large chunks are not tracked, + which reduces fragmentation. However, such chunks are not + necessarily released to the system upon destroy_mspace. Enabling + tracking by setting to true may increase fragmentation, but avoids + leakage when relying on destroy_mspace to release all memory + allocated using this space. The function returns the previous + setting. +*/ +DLMALLOC_EXPORT int mspace_track_large_chunks(mspace msp, int enable); + +/* + mspace_malloc behaves as malloc, but operates within + the given space. +*/ +DLMALLOC_EXPORT void *mspace_malloc(mspace msp, size_t bytes); + +/* + mspace_free behaves as free, but operates within + the given space. + + If compiled with FOOTERS==1, mspace_free is not actually needed. + free may be called instead of mspace_free because freed chunks from + any space are handled by their originating spaces. +*/ +DLMALLOC_EXPORT void mspace_free(mspace msp, void *mem); + +/* + mspace_realloc behaves as realloc, but operates within + the given space. + + If compiled with FOOTERS==1, mspace_realloc is not actually + needed. realloc may be called instead of mspace_realloc because + realloced chunks from any space are handled by their originating + spaces. +*/ +DLMALLOC_EXPORT void *mspace_realloc(mspace msp, void *mem, size_t newsize); + +/* + mspace_calloc behaves as calloc, but operates within + the given space. +*/ +DLMALLOC_EXPORT void *mspace_calloc(mspace msp, size_t n_elements, + size_t elem_size); + +/* + mspace_memalign behaves as memalign, but operates within + the given space. +*/ +DLMALLOC_EXPORT void *mspace_memalign(mspace msp, size_t alignment, + size_t bytes); + +/* + mspace_independent_calloc behaves as independent_calloc, but + operates within the given space. +*/ +DLMALLOC_EXPORT void **mspace_independent_calloc(mspace msp, size_t n_elements, + size_t elem_size, + void * chunks[]); + +/* + mspace_independent_comalloc behaves as independent_comalloc, but + operates within the given space. +*/ +DLMALLOC_EXPORT void **mspace_independent_comalloc(mspace msp, + size_t n_elements, + size_t sizes[], + void * chunks[]); + +/* + mspace_footprint() returns the number of bytes obtained from the + system for this space. +*/ +DLMALLOC_EXPORT size_t mspace_footprint(mspace msp); + +/* + mspace_max_footprint() returns the peak number of bytes obtained from the + system for this space. +*/ +DLMALLOC_EXPORT size_t mspace_max_footprint(mspace msp); + + #if !NO_MALLINFO +/* + mspace_mallinfo behaves as mallinfo, but reports properties of + the given space. +*/ +DLMALLOC_EXPORT struct mallinfo mspace_mallinfo(mspace msp); + #endif /* NO_MALLINFO */ + +/* + malloc_usable_size(void* p) behaves the same as malloc_usable_size; +*/ +DLMALLOC_EXPORT size_t mspace_usable_size(const void *mem); + +/* + mspace_malloc_stats behaves as malloc_stats, but reports + properties of the given space. +*/ +DLMALLOC_EXPORT void mspace_malloc_stats(mspace msp); + +/* + mspace_trim behaves as malloc_trim, but + operates within the given space. +*/ +DLMALLOC_EXPORT int mspace_trim(mspace msp, size_t pad); + +/* + An alias for mallopt. +*/ +DLMALLOC_EXPORT int mspace_mallopt(int, int); + + #endif /* MSPACES */ + + #ifdef __cplusplus + +} /* end of extern "C" */ + + #endif /* __cplusplus */ + +/* + ======================================================================== + To make a fully customizable malloc.h header file, cut everything + above this line, put into file malloc.h, edit to suit, and #include it + on the next line, as well as in programs that use this malloc. + ======================================================================== +*/ + +/* #include "malloc.h" */ + +/*------------------------------ internal #includes ---------------------- */ + + #ifdef _MSC_VER + #pragma warning(disable : 4146) /* no "unsigned" warnings */ + #endif /* _MSC_VER */ + #if !NO_MALLOC_STATS + #include <stdio.h> /* for printing in malloc_stats */ + #endif /* NO_MALLOC_STATS */ + #ifndef LACKS_ERRNO_H + #include <errno.h> /* for MALLOC_FAILURE_ACTION */ + #endif /* LACKS_ERRNO_H */ + #ifdef DEBUG + #if ABORT_ON_ASSERT_FAILURE + #undef assert + #define assert(x) \ + if (!(x)) ABORT + #else /* ABORT_ON_ASSERT_FAILURE */ + #include <assert.h> + #endif /* ABORT_ON_ASSERT_FAILURE */ + #else /* DEBUG */ + #ifndef assert + #define assert(x) + #endif + #define DEBUG 0 + #endif /* DEBUG */ + #if !defined(WIN32) && !defined(LACKS_TIME_H) + #include <time.h> /* for magic initialization */ + #endif /* WIN32 */ + #ifndef LACKS_STDLIB_H + #include <stdlib.h> /* for abort() */ + #endif /* LACKS_STDLIB_H */ + #ifndef LACKS_STRING_H + #include <string.h> /* for memset etc */ + #endif /* LACKS_STRING_H */ + #if USE_BUILTIN_FFS + #ifndef LACKS_STRINGS_H + #include <strings.h> /* for ffs */ + #endif /* LACKS_STRINGS_H */ + #endif /* USE_BUILTIN_FFS */ + #if HAVE_MMAP + #ifndef LACKS_SYS_MMAN_H + /* On some versions of linux, mremap decl in mman.h needs __USE_GNU set */ + #if (defined(linux) && !defined(__USE_GNU)) + #define __USE_GNU 1 + #include <sys/mman.h> /* for mmap */ + #undef __USE_GNU + #else + #include <sys/mman.h> /* for mmap */ + #endif /* linux */ + #endif /* LACKS_SYS_MMAN_H */ + #ifndef LACKS_FCNTL_H + #include <fcntl.h> + #endif /* LACKS_FCNTL_H */ + #endif /* HAVE_MMAP */ + #ifndef LACKS_UNISTD_H + #include <unistd.h> /* for sbrk, sysconf */ + #else /* LACKS_UNISTD_H */ + #if !defined(__FreeBSD__) && !defined(__OpenBSD__) && !defined(__NetBSD__) +extern void *sbrk(ptrdiff_t); + #endif /* FreeBSD etc */ + #endif /* LACKS_UNISTD_H */ + + /* Declarations for locking */ + #if USE_LOCKS + #ifndef WIN32 + #if defined(__SVR4) && defined(__sun) /* solaris */ + #include <thread.h> + #elif !defined(LACKS_SCHED_H) + #include <sched.h> + #endif /* solaris or LACKS_SCHED_H */ + #if (defined(USE_RECURSIVE_LOCKS) && USE_RECURSIVE_LOCKS != 0) || \ + !USE_SPIN_LOCKS + #include <pthread.h> + #endif /* USE_RECURSIVE_LOCKS ... */ + #elif defined(_MSC_VER) + #ifndef _M_AMD64 + /* These are already defined on AMD64 builds */ + #ifdef __cplusplus +extern "C" { + + #endif /* __cplusplus */ +LONG __cdecl _InterlockedCompareExchange(LONG volatile *Dest, LONG Exchange, + LONG Comp); +LONG __cdecl _InterlockedExchange(LONG volatile *Target, LONG Value); + #ifdef __cplusplus + +} + + #endif /* __cplusplus */ + #endif /* _M_AMD64 */ + #pragma intrinsic(_InterlockedCompareExchange) + #pragma intrinsic(_InterlockedExchange) + #define interlockedcompareexchange _InterlockedCompareExchange + #define interlockedexchange _InterlockedExchange + #elif defined(WIN32) && defined(__GNUC__) + #define interlockedcompareexchange(a, b, c) \ + __sync_val_compare_and_swap(a, c, b) + #define interlockedexchange __sync_lock_test_and_set + #endif /* Win32 */ + #else /* USE_LOCKS */ + #endif /* USE_LOCKS */ + + #ifndef LOCK_AT_FORK + #define LOCK_AT_FORK 0 + #endif + + /* Declarations for bit scanning on win32 */ + #if defined(_MSC_VER) && _MSC_VER >= 1300 + #ifndef BitScanForward /* Try to avoid pulling in WinNT.h */ + #ifdef __cplusplus +extern "C" { + + #endif /* __cplusplus */ +unsigned char _BitScanForward(unsigned long *index, unsigned long mask); +unsigned char _BitScanReverse(unsigned long *index, unsigned long mask); + #ifdef __cplusplus + +} + + #endif /* __cplusplus */ + + #define BitScanForward _BitScanForward + #define BitScanReverse _BitScanReverse + #pragma intrinsic(_BitScanForward) + #pragma intrinsic(_BitScanReverse) + #endif /* BitScanForward */ + #endif /* defined(_MSC_VER) && _MSC_VER>=1300 */ + + #ifndef WIN32 + #ifndef malloc_getpagesize + #ifdef _SC_PAGESIZE /* some SVR4 systems omit an underscore */ + #ifndef _SC_PAGE_SIZE + #define _SC_PAGE_SIZE _SC_PAGESIZE + #endif + #endif + #ifdef _SC_PAGE_SIZE + #define malloc_getpagesize sysconf(_SC_PAGE_SIZE) + #else + #if defined(BSD) || defined(DGUX) || defined(HAVE_GETPAGESIZE) +extern size_t getpagesize(); + #define malloc_getpagesize getpagesize() + #else + #ifdef WIN32 /* use supplied emulation of getpagesize */ + #define malloc_getpagesize getpagesize() + #else + #ifndef LACKS_SYS_PARAM_H + #include <sys/param.h> + #endif + #ifdef EXEC_PAGESIZE + #define malloc_getpagesize EXEC_PAGESIZE + #else + #ifdef NBPG + #ifndef CLSIZE + #define malloc_getpagesize NBPG + #else + #define malloc_getpagesize (NBPG * CLSIZE) + #endif + #else + #ifdef NBPC + #define malloc_getpagesize NBPC + #else + #ifdef PAGESIZE + #define malloc_getpagesize PAGESIZE + #else /* just guess */ + #define malloc_getpagesize ((size_t)4096U) + #endif + #endif + #endif + #endif + #endif + #endif + #endif + #endif + #endif + + /* ------------------- size_t and alignment properties -------------------- */ + + /* The byte and bit size of a size_t */ + #define SIZE_T_SIZE (sizeof(size_t)) + #define SIZE_T_BITSIZE (sizeof(size_t) << 3) + + /* Some constants coerced to size_t */ + /* Annoying but necessary to avoid errors on some platforms */ + #define SIZE_T_ZERO ((size_t)0) + #define SIZE_T_ONE ((size_t)1) + #define SIZE_T_TWO ((size_t)2) + #define SIZE_T_FOUR ((size_t)4) + #define TWO_SIZE_T_SIZES (SIZE_T_SIZE << 1) + #define FOUR_SIZE_T_SIZES (SIZE_T_SIZE << 2) + #define SIX_SIZE_T_SIZES (FOUR_SIZE_T_SIZES + TWO_SIZE_T_SIZES) + #define HALF_MAX_SIZE_T (MAX_SIZE_T / 2U) + + /* The bit mask value corresponding to MALLOC_ALIGNMENT */ + #define CHUNK_ALIGN_MASK (MALLOC_ALIGNMENT - SIZE_T_ONE) + + /* True if address a has acceptable alignment */ + #define is_aligned(A) (((size_t)((A)) & (CHUNK_ALIGN_MASK)) == 0) + + /* the number of bytes to offset an address to align it */ + #define align_offset(A) \ + ((((size_t)(A)&CHUNK_ALIGN_MASK) == 0) \ + ? 0 \ + : ((MALLOC_ALIGNMENT - ((size_t)(A)&CHUNK_ALIGN_MASK)) & \ + CHUNK_ALIGN_MASK)) + + /* -------------------------- MMAP preliminaries ------------------------- */ + + /* + If HAVE_MORECORE or HAVE_MMAP are false, we just define calls and + checks to fail so compiler optimizer can delete code rather than + using so many "#if"s. + */ + + /* MORECORE and MMAP must return MFAIL on failure */ + #define MFAIL ((void *)(MAX_SIZE_T)) + #define CMFAIL ((char *)(MFAIL)) /* defined for convenience */ + + #if HAVE_MMAP + + #ifndef WIN32 + #define MMAP_PROT (PROT_READ | PROT_WRITE) + #if !defined(MAP_ANONYMOUS) && defined(MAP_ANON) + #define MAP_ANONYMOUS MAP_ANON + #endif /* MAP_ANON */ + #ifdef MAP_ANONYMOUS + + #define MMAP_FLAGS (MAP_PRIVATE | MAP_ANONYMOUS) + +static FORCEINLINE void *unixmmap(size_t size) { + + void *result; + + result = mmap(0, size, MMAP_PROT, MMAP_FLAGS, -1, 0); + if (result == MFAIL) return MFAIL; + + return result; + +} + +static FORCEINLINE int unixmunmap(void *ptr, size_t size) { + + int result; + + result = munmap(ptr, size); + if (result != 0) return result; + + return result; + +} + + #define MMAP_DEFAULT(s) unixmmap(s) + #define MUNMAP_DEFAULT(a, s) unixmunmap((a), (s)) + + #else /* MAP_ANONYMOUS */ + /* + Nearly all versions of mmap support MAP_ANONYMOUS, so the following + is unlikely to be needed, but is supplied just in case. + */ + #define MMAP_FLAGS (MAP_PRIVATE) +static int dev_zero_fd = -1; /* Cached file descriptor for /dev/zero. */ + #define MMAP_DEFAULT(s) \ + ((dev_zero_fd < 0) \ + ? (dev_zero_fd = open("/dev/zero", O_RDWR), \ + mmap(0, (s), MMAP_PROT, MMAP_FLAGS, dev_zero_fd, 0)) \ + : mmap(0, (s), MMAP_PROT, MMAP_FLAGS, dev_zero_fd, 0)) + #define MUNMAP_DEFAULT(a, s) munmap((a), (s)) + #endif /* MAP_ANONYMOUS */ + + #define DIRECT_MMAP_DEFAULT(s) MMAP_DEFAULT(s) + + #else /* WIN32 */ + +/* Win32 MMAP via VirtualAlloc */ +static FORCEINLINE void *win32mmap(size_t size) { + + void *ptr; + + ptr = VirtualAlloc(0, size, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE); + if (ptr == 0) return MFAIL; + + return ptr; + +} + +/* For direct MMAP, use MEM_TOP_DOWN to minimize interference */ +static FORCEINLINE void *win32direct_mmap(size_t size) { + + void *ptr; + + ptr = VirtualAlloc(0, size, MEM_RESERVE | MEM_COMMIT | MEM_TOP_DOWN, + PAGE_READWRITE); + if (ptr == 0) return MFAIL; + + return ptr; + +} + +/* This function supports releasing coalesed segments */ +static FORCEINLINE int win32munmap(void *ptr, size_t size) { + + MEMORY_BASIC_INFORMATION minfo; + char *cptr = (char *)ptr; + + while (size) { + + if (VirtualQuery(cptr, &minfo, sizeof(minfo)) == 0) return -1; + if (minfo.BaseAddress != cptr || minfo.AllocationBase != cptr || + minfo.State != MEM_COMMIT || minfo.RegionSize > size) + return -1; + if (VirtualFree(cptr, 0, MEM_RELEASE) == 0) return -1; + cptr += minfo.RegionSize; + size -= minfo.RegionSize; + + } + + return 0; + +} + + #define MMAP_DEFAULT(s) win32mmap(s) + #define MUNMAP_DEFAULT(a, s) win32munmap((a), (s)) + #define DIRECT_MMAP_DEFAULT(s) win32direct_mmap(s) + #endif /* WIN32 */ + #endif /* HAVE_MMAP */ + + #if HAVE_MREMAP + #ifndef WIN32 + +static FORCEINLINE void *dlmremap(void *old_address, size_t old_size, + size_t new_size, int flags) { + + void *result; + + result = mremap(old_address, old_size, new_size, flags); + if (result == MFAIL) return MFAIL; + + return result; + +} + + #define MREMAP_DEFAULT(addr, osz, nsz, mv) \ + dlmremap((addr), (osz), (nsz), (mv)) + #endif /* WIN32 */ + #endif /* HAVE_MREMAP */ + + /** + * Define CALL_MORECORE + */ + #if HAVE_MORECORE + #ifdef MORECORE + #define CALL_MORECORE(S) MORECORE(S) + #else /* MORECORE */ + #define CALL_MORECORE(S) MORECORE_DEFAULT(S) + #endif /* MORECORE */ + #else /* HAVE_MORECORE */ + #define CALL_MORECORE(S) MFAIL + #endif /* HAVE_MORECORE */ + + /** + * Define CALL_MMAP/CALL_MUNMAP/CALL_DIRECT_MMAP + */ + #if HAVE_MMAP + #define USE_MMAP_BIT (SIZE_T_ONE) + + #ifdef MMAP + #define CALL_MMAP(s) MMAP(s) + #else /* MMAP */ + #define CALL_MMAP(s) MMAP_DEFAULT(s) + #endif /* MMAP */ + #ifdef MUNMAP + #define CALL_MUNMAP(a, s) MUNMAP((a), (s)) + #else /* MUNMAP */ + #define CALL_MUNMAP(a, s) MUNMAP_DEFAULT((a), (s)) + #endif /* MUNMAP */ + #ifdef DIRECT_MMAP + #define CALL_DIRECT_MMAP(s) DIRECT_MMAP(s) + #else /* DIRECT_MMAP */ + #define CALL_DIRECT_MMAP(s) DIRECT_MMAP_DEFAULT(s) + #endif /* DIRECT_MMAP */ + #else /* HAVE_MMAP */ + #define USE_MMAP_BIT (SIZE_T_ZERO) + + #define MMAP(s) MFAIL + #define MUNMAP(a, s) (-1) + #define DIRECT_MMAP(s) MFAIL + #define CALL_DIRECT_MMAP(s) DIRECT_MMAP(s) + #define CALL_MMAP(s) MMAP(s) + #define CALL_MUNMAP(a, s) MUNMAP((a), (s)) + #endif /* HAVE_MMAP */ + + /** + * Define CALL_MREMAP + */ + #if HAVE_MMAP && HAVE_MREMAP + #ifdef MREMAP + #define CALL_MREMAP(addr, osz, nsz, mv) MREMAP((addr), (osz), (nsz), (mv)) + #else /* MREMAP */ + #define CALL_MREMAP(addr, osz, nsz, mv) \ + MREMAP_DEFAULT((addr), (osz), (nsz), (mv)) + #endif /* MREMAP */ + #else /* HAVE_MMAP && HAVE_MREMAP */ + #define CALL_MREMAP(addr, osz, nsz, mv) MFAIL + #endif /* HAVE_MMAP && HAVE_MREMAP */ + + /* mstate bit set if continguous morecore disabled or failed */ + #define USE_NONCONTIGUOUS_BIT (4U) + + /* segment bit set in create_mspace_with_base */ + #define EXTERN_BIT (8U) + +/* --------------------------- Lock preliminaries ------------------------ */ + +/* + When locks are defined, there is one global lock, plus + one per-mspace lock. + + The global lock_ensures that mparams.magic and other unique + mparams values are initialized only once. It also protects + sequences of calls to MORECORE. In many cases sys_alloc requires + two calls, that should not be interleaved with calls by other + threads. This does not protect against direct calls to MORECORE + by other threads not using this lock, so there is still code to + cope the best we can on interference. + + Per-mspace locks surround calls to malloc, free, etc. + By default, locks are simple non-reentrant mutexes. + + Because lock-protected regions generally have bounded times, it is + OK to use the supplied simple spinlocks. Spinlocks are likely to + improve performance for lightly contended applications, but worsen + performance under heavy contention. + + If USE_LOCKS is > 1, the definitions of lock routines here are + bypassed, in which case you will need to define the type MLOCK_T, + and at least INITIAL_LOCK, DESTROY_LOCK, ACQUIRE_LOCK, RELEASE_LOCK + and TRY_LOCK. You must also declare a + static MLOCK_T malloc_global_mutex = { initialization values };. + +*/ + + #if !USE_LOCKS + #define USE_LOCK_BIT (0U) + #define INITIAL_LOCK(l) (0) + #define DESTROY_LOCK(l) (0) + #define ACQUIRE_MALLOC_GLOBAL_LOCK() + #define RELEASE_MALLOC_GLOBAL_LOCK() + + #else + #if USE_LOCKS > 1 + /* ----------------------- User-defined locks ------------------------ */ + /* Define your own lock implementation here */ + /* #define INITIAL_LOCK(lk) ... */ + /* #define DESTROY_LOCK(lk) ... */ + /* #define ACQUIRE_LOCK(lk) ... */ + /* #define RELEASE_LOCK(lk) ... */ + /* #define TRY_LOCK(lk) ... */ + /* static MLOCK_T malloc_global_mutex = ... */ + + #elif USE_SPIN_LOCKS + + /* First, define CAS_LOCK and CLEAR_LOCK on ints */ + /* Note CAS_LOCK defined to return 0 on success */ + + #if defined(__GNUC__) && \ + (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 1)) + #define CAS_LOCK(sl) __sync_lock_test_and_set(sl, 1) + #define CLEAR_LOCK(sl) __sync_lock_release(sl) + + #elif (defined(__GNUC__) && (defined(__i386__) || defined(__x86_64__))) +/* Custom spin locks for older gcc on x86 */ +static FORCEINLINE int x86_cas_lock(int *sl) { + + int ret; + int val = 1; + int cmp = 0; + __asm__ __volatile__("lock; cmpxchgl %1, %2" + : "=a"(ret) + : "r"(val), "m"(*(sl)), "0"(cmp) + : "memory", "cc"); + return ret; + +} + +static FORCEINLINE void x86_clear_lock(int *sl) { + + assert(*sl != 0); + int prev = 0; + int ret; + __asm__ __volatile__("lock; xchgl %0, %1" + : "=r"(ret) + : "m"(*(sl)), "0"(prev) + : "memory"); + +} + + #define CAS_LOCK(sl) x86_cas_lock(sl) + #define CLEAR_LOCK(sl) x86_clear_lock(sl) + + #else /* Win32 MSC */ + #define CAS_LOCK(sl) interlockedexchange((volatile LONG *)sl, (LONG)1) + #define CLEAR_LOCK(sl) interlockedexchange((volatile LONG *)sl, (LONG)0) + + #endif /* ... gcc spins locks ... */ + + /* How to yield for a spin lock */ + #define SPINS_PER_YIELD 63 + #if defined(_MSC_VER) + #define SLEEP_EX_DURATION 50 /* delay for yield/sleep */ + #define SPIN_LOCK_YIELD SleepEx(SLEEP_EX_DURATION, FALSE) + #elif defined(__SVR4) && defined(__sun) /* solaris */ + #define SPIN_LOCK_YIELD thr_yield(); + #elif !defined(LACKS_SCHED_H) + #define SPIN_LOCK_YIELD sched_yield(); + #else + #define SPIN_LOCK_YIELD + #endif /* ... yield ... */ + + #if !defined(USE_RECURSIVE_LOCKS) || USE_RECURSIVE_LOCKS == 0 +/* Plain spin locks use single word (embedded in malloc_states) */ +static int spin_acquire_lock(int *sl) { + + int spins = 0; + while (*(volatile int *)sl != 0 || CAS_LOCK(sl)) { + + if ((++spins & SPINS_PER_YIELD) == 0) { SPIN_LOCK_YIELD; } + + } + + return 0; + +} + + #define MLOCK_T int + #define TRY_LOCK(sl) !CAS_LOCK(sl) + #define RELEASE_LOCK(sl) CLEAR_LOCK(sl) + #define ACQUIRE_LOCK(sl) (CAS_LOCK(sl) ? spin_acquire_lock(sl) : 0) + #define INITIAL_LOCK(sl) (*sl = 0) + #define DESTROY_LOCK(sl) (0) +static MLOCK_T malloc_global_mutex = 0; + + #else /* USE_RECURSIVE_LOCKS */ + /* types for lock owners */ + #ifdef WIN32 + #define THREAD_ID_T DWORD + #define CURRENT_THREAD GetCurrentThreadId() + #define EQ_OWNER(X, Y) ((X) == (Y)) + #else + /* + Note: the following assume that pthread_t is a type that can be + initialized to (casted) zero. If this is not the case, you will need + to somehow redefine these or not use spin locks. + */ + #define THREAD_ID_T pthread_t + #define CURRENT_THREAD pthread_self() + #define EQ_OWNER(X, Y) pthread_equal(X, Y) + #endif + +struct malloc_recursive_lock { + + int sl; + unsigned int c; + THREAD_ID_T threadid; + +}; + + #define MLOCK_T struct malloc_recursive_lock +static MLOCK_T malloc_global_mutex = {0, 0, (THREAD_ID_T)0}; + +static FORCEINLINE void recursive_release_lock(MLOCK_T *lk) { + + assert(lk->sl != 0); + if (--lk->c == 0) { CLEAR_LOCK(&lk->sl); } + +} + +static FORCEINLINE int recursive_acquire_lock(MLOCK_T *lk) { + + THREAD_ID_T mythreadid = CURRENT_THREAD; + int spins = 0; + for (;;) { + + if (*((volatile int *)(&lk->sl)) == 0) { + + if (!CAS_LOCK(&lk->sl)) { + + lk->threadid = mythreadid; + lk->c = 1; + return 0; + + } + + } else if (EQ_OWNER(lk->threadid, mythreadid)) { + + ++lk->c; + return 0; + + } + + if ((++spins & SPINS_PER_YIELD) == 0) { SPIN_LOCK_YIELD; } + + } + +} + +static FORCEINLINE int recursive_try_lock(MLOCK_T *lk) { + + THREAD_ID_T mythreadid = CURRENT_THREAD; + if (*((volatile int *)(&lk->sl)) == 0) { + + if (!CAS_LOCK(&lk->sl)) { + + lk->threadid = mythreadid; + lk->c = 1; + return 1; + + } + + } else if (EQ_OWNER(lk->threadid, mythreadid)) { + + ++lk->c; + return 1; + + } + + return 0; + +} + + #define RELEASE_LOCK(lk) recursive_release_lock(lk) + #define TRY_LOCK(lk) recursive_try_lock(lk) + #define ACQUIRE_LOCK(lk) recursive_acquire_lock(lk) + #define INITIAL_LOCK(lk) \ + ((lk)->threadid = (THREAD_ID_T)0, (lk)->sl = 0, (lk)->c = 0) + #define DESTROY_LOCK(lk) (0) + #endif /* USE_RECURSIVE_LOCKS */ + + #elif defined(WIN32) /* Win32 critical sections */ + #define MLOCK_T CRITICAL_SECTION + #define ACQUIRE_LOCK(lk) (EnterCriticalSection(lk), 0) + #define RELEASE_LOCK(lk) LeaveCriticalSection(lk) + #define TRY_LOCK(lk) TryEnterCriticalSection(lk) + #define INITIAL_LOCK(lk) \ + (!InitializeCriticalSectionAndSpinCount((lk), 0x80000000 | 4000)) + #define DESTROY_LOCK(lk) (DeleteCriticalSection(lk), 0) + #define NEED_GLOBAL_LOCK_INIT + +static MLOCK_T malloc_global_mutex; +static volatile LONG malloc_global_mutex_status; + +/* Use spin loop to initialize global lock */ +static void init_malloc_global_mutex() { + + for (;;) { + + long stat = malloc_global_mutex_status; + if (stat > 0) return; + /* transition to < 0 while initializing, then to > 0) */ + if (stat == 0 && interlockedcompareexchange(&malloc_global_mutex_status, + (LONG)-1, (LONG)0) == 0) { + + InitializeCriticalSection(&malloc_global_mutex); + interlockedexchange(&malloc_global_mutex_status, (LONG)1); + return; + + } + + SleepEx(0, FALSE); + + } + +} + + #else /* pthreads-based locks */ + #define MLOCK_T pthread_mutex_t + #define ACQUIRE_LOCK(lk) pthread_mutex_lock(lk) + #define RELEASE_LOCK(lk) pthread_mutex_unlock(lk) + #define TRY_LOCK(lk) (!pthread_mutex_trylock(lk)) + #define INITIAL_LOCK(lk) pthread_init_lock(lk) + #define DESTROY_LOCK(lk) pthread_mutex_destroy(lk) + + #if defined(USE_RECURSIVE_LOCKS) && USE_RECURSIVE_LOCKS != 0 && \ + defined(linux) && !defined(PTHREAD_MUTEX_RECURSIVE) +/* Cope with old-style linux recursive lock initialization by adding */ +/* skipped internal declaration from pthread.h */ +extern int pthread_mutexattr_setkind_np __P((pthread_mutexattr_t * __attr, + int __kind)); + #define PTHREAD_MUTEX_RECURSIVE PTHREAD_MUTEX_RECURSIVE_NP + #define pthread_mutexattr_settype(x, y) \ + pthread_mutexattr_setkind_np(x, y) + #endif /* USE_RECURSIVE_LOCKS ... */ + +static MLOCK_T malloc_global_mutex = PTHREAD_MUTEX_INITIALIZER; + +static int pthread_init_lock(MLOCK_T *lk) { + + pthread_mutexattr_t attr; + if (pthread_mutexattr_init(&attr)) return 1; + #if defined(USE_RECURSIVE_LOCKS) && USE_RECURSIVE_LOCKS != 0 + if (pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE)) return 1; + #endif + if (pthread_mutex_init(lk, &attr)) return 1; + if (pthread_mutexattr_destroy(&attr)) return 1; + return 0; + +} + + #endif /* ... lock types ... */ + + /* Common code for all lock types */ + #define USE_LOCK_BIT (2U) + + #ifndef ACQUIRE_MALLOC_GLOBAL_LOCK + #define ACQUIRE_MALLOC_GLOBAL_LOCK() ACQUIRE_LOCK(&malloc_global_mutex); + #endif + + #ifndef RELEASE_MALLOC_GLOBAL_LOCK + #define RELEASE_MALLOC_GLOBAL_LOCK() RELEASE_LOCK(&malloc_global_mutex); + #endif + + #endif /* USE_LOCKS */ + +/* ----------------------- Chunk representations ------------------------ */ + +/* + (The following includes lightly edited explanations by Colin Plumb.) + + The malloc_chunk declaration below is misleading (but accurate and + necessary). It declares a "view" into memory allowing access to + necessary fields at known offsets from a given base. + + Chunks of memory are maintained using a `boundary tag' method as + originally described by Knuth. (See the paper by Paul Wilson + ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps for a survey of such + techniques.) Sizes of free chunks are stored both in the front of + each chunk and at the end. This makes consolidating fragmented + chunks into bigger chunks fast. The head fields also hold bits + representing whether chunks are free or in use. + + Here are some pictures to make it clearer. They are "exploded" to + show that the state of a chunk can be thought of as extending from + the high 31 bits of the head field of its header through the + prev_foot and PINUSE_BIT bit of the following chunk header. + + A chunk that's in use looks like: + + chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Size of previous chunk (if P = 0) | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |P| + | Size of this chunk 1| +-+ + mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | | + +- -+ + | | + +- -+ + | : + +- size - sizeof(size_t) available payload bytes -+ + : | + chunk-> +- -+ + | | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |1| + | Size of next chunk (may or may not be in use) | +-+ + mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + + And if it's free, it looks like this: + + chunk-> +- -+ + | User payload (must be in use, or we would have merged!) | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |P| + | Size of this chunk 0| +-+ + mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Next pointer | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Prev pointer | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | : + +- size - sizeof(struct chunk) unused bytes -+ + : | + chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Size of this chunk | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |0| + | Size of next chunk (must be in use, or we would have merged)| +-+ + mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | : + +- User payload -+ + : | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + |0| + +-+ + Note that since we always merge adjacent free chunks, the chunks + adjacent to a free chunk must be in use. + + Given a pointer to a chunk (which can be derived trivially from the + payload pointer) we can, in O(1) time, find out whether the adjacent + chunks are free, and if so, unlink them from the lists that they + are on and merge them with the current chunk. + + Chunks always begin on even word boundaries, so the mem portion + (which is returned to the user) is also on an even word boundary, and + thus at least double-word aligned. + + The P (PINUSE_BIT) bit, stored in the unused low-order bit of the + chunk size (which is always a multiple of two words), is an in-use + bit for the *previous* chunk. If that bit is *clear*, then the + word before the current chunk size contains the previous chunk + size, and can be used to find the front of the previous chunk. + The very first chunk allocated always has this bit set, preventing + access to non-existent (or non-owned) memory. If pinuse is set for + any given chunk, then you CANNOT determine the size of the + previous chunk, and might even get a memory addressing fault when + trying to do so. + + The C (CINUSE_BIT) bit, stored in the unused second-lowest bit of + the chunk size redundantly records whether the current chunk is + inuse (unless the chunk is mmapped). This redundancy enables usage + checks within free and realloc, and reduces indirection when freeing + and consolidating chunks. + + Each freshly allocated chunk must have both cinuse and pinuse set. + That is, each allocated chunk borders either a previously allocated + and still in-use chunk, or the base of its memory arena. This is + ensured by making all allocations from the `lowest' part of any + found chunk. Further, no free chunk physically borders another one, + so each free chunk is known to be preceded and followed by either + inuse chunks or the ends of memory. + + Note that the `foot' of the current chunk is actually represented + as the prev_foot of the NEXT chunk. This makes it easier to + deal with alignments etc but can be very confusing when trying + to extend or adapt this code. + + The exceptions to all this are + + 1. The special chunk `top' is the top-most available chunk (i.e., + the one bordering the end of available memory). It is treated + specially. Top is never included in any bin, is used only if + no other chunk is available, and is released back to the + system if it is very large (see M_TRIM_THRESHOLD). In effect, + the top chunk is treated as larger (and thus less well + fitting) than any other available chunk. The top chunk + doesn't update its trailing size field since there is no next + contiguous chunk that would have to index off it. However, + space is still allocated for it (TOP_FOOT_SIZE) to enable + separation or merging when space is extended. + + 3. Chunks allocated via mmap, have both cinuse and pinuse bits + cleared in their head fields. Because they are allocated + one-by-one, each must carry its own prev_foot field, which is + also used to hold the offset this chunk has within its mmapped + region, which is needed to preserve alignment. Each mmapped + chunk is trailed by the first two fields of a fake next-chunk + for sake of usage checks. + +*/ + +struct malloc_chunk { + + size_t prev_foot; /* Size of previous chunk (if free). */ + size_t head; /* Size and inuse bits. */ + struct malloc_chunk *fd; /* double links -- used only if free. */ + struct malloc_chunk *bk; + +}; + +typedef struct malloc_chunk mchunk; +typedef struct malloc_chunk *mchunkptr; +typedef struct malloc_chunk *sbinptr; /* The type of bins of chunks */ +typedef unsigned int bindex_t; /* Described below */ +typedef unsigned int binmap_t; /* Described below */ +typedef unsigned int flag_t; /* The type of various bit flag sets */ + +/* ------------------- Chunks sizes and alignments ----------------------- */ + + #define MCHUNK_SIZE (sizeof(mchunk)) + + #if FOOTERS + #define CHUNK_OVERHEAD (TWO_SIZE_T_SIZES) + #else /* FOOTERS */ + #define CHUNK_OVERHEAD (SIZE_T_SIZE) + #endif /* FOOTERS */ + + /* MMapped chunks need a second word of overhead ... */ + #define MMAP_CHUNK_OVERHEAD (TWO_SIZE_T_SIZES) + /* ... and additional padding for fake next-chunk at foot */ + #define MMAP_FOOT_PAD (FOUR_SIZE_T_SIZES) + + /* The smallest size we can malloc is an aligned minimal chunk */ + #define MIN_CHUNK_SIZE ((MCHUNK_SIZE + CHUNK_ALIGN_MASK) & ~CHUNK_ALIGN_MASK) + + /* conversion from malloc headers to user pointers, and back */ + #define chunk2mem(p) ((void *)((char *)(p) + TWO_SIZE_T_SIZES)) + #define mem2chunk(mem) ((mchunkptr)((char *)(mem)-TWO_SIZE_T_SIZES)) + /* chunk associated with aligned address A */ + #define align_as_chunk(A) (mchunkptr)((A) + align_offset(chunk2mem(A))) + + /* Bounds on request (not chunk) sizes. */ + #define MAX_REQUEST ((-MIN_CHUNK_SIZE) << 2) + #define MIN_REQUEST (MIN_CHUNK_SIZE - CHUNK_OVERHEAD - SIZE_T_ONE) + + /* pad request bytes into a usable size */ + #define pad_request(req) \ + (((req) + CHUNK_OVERHEAD + CHUNK_ALIGN_MASK) & ~CHUNK_ALIGN_MASK) + + /* pad request, checking for minimum (but not maximum) */ + #define request2size(req) \ + (((req) < MIN_REQUEST) ? MIN_CHUNK_SIZE : pad_request(req)) + +/* ------------------ Operations on head and foot fields ----------------- */ + +/* + The head field of a chunk is or'ed with PINUSE_BIT when previous + adjacent chunk in use, and or'ed with CINUSE_BIT if this chunk is in + use, unless mmapped, in which case both bits are cleared. + + FLAG4_BIT is not used by this malloc, but might be useful in extensions. +*/ + + #define PINUSE_BIT (SIZE_T_ONE) + #define CINUSE_BIT (SIZE_T_TWO) + #define FLAG4_BIT (SIZE_T_FOUR) + #define INUSE_BITS (PINUSE_BIT | CINUSE_BIT) + #define FLAG_BITS (PINUSE_BIT | CINUSE_BIT | FLAG4_BIT) + + /* Head value for fenceposts */ + #define FENCEPOST_HEAD (INUSE_BITS | SIZE_T_SIZE) + + /* extraction of fields from head words */ + #define cinuse(p) ((p)->head & CINUSE_BIT) + #define pinuse(p) ((p)->head & PINUSE_BIT) + #define flag4inuse(p) ((p)->head & FLAG4_BIT) + #define is_inuse(p) (((p)->head & INUSE_BITS) != PINUSE_BIT) + #define is_mmapped(p) (((p)->head & INUSE_BITS) == 0) + + #define chunksize(p) ((p)->head & ~(FLAG_BITS)) + + #define clear_pinuse(p) ((p)->head &= ~PINUSE_BIT) + #define set_flag4(p) ((p)->head |= FLAG4_BIT) + #define clear_flag4(p) ((p)->head &= ~FLAG4_BIT) + + /* Treat space at ptr +/- offset as a chunk */ + #define chunk_plus_offset(p, s) ((mchunkptr)(((char *)(p)) + (s))) + #define chunk_minus_offset(p, s) ((mchunkptr)(((char *)(p)) - (s))) + + /* Ptr to next or previous physical malloc_chunk. */ + #define next_chunk(p) ((mchunkptr)(((char *)(p)) + ((p)->head & ~FLAG_BITS))) + #define prev_chunk(p) ((mchunkptr)(((char *)(p)) - ((p)->prev_foot))) + + /* extract next chunk's pinuse bit */ + #define next_pinuse(p) ((next_chunk(p)->head) & PINUSE_BIT) + + /* Get/set size at footer */ + #define get_foot(p, s) (((mchunkptr)((char *)(p) + (s)))->prev_foot) + #define set_foot(p, s) (((mchunkptr)((char *)(p) + (s)))->prev_foot = (s)) + + /* Set size, pinuse bit, and foot */ + #define set_size_and_pinuse_of_free_chunk(p, s) \ + ((p)->head = (s | PINUSE_BIT), set_foot(p, s)) + + /* Set size, pinuse bit, foot, and clear next pinuse */ + #define set_free_with_pinuse(p, s, n) \ + (clear_pinuse(n), set_size_and_pinuse_of_free_chunk(p, s)) + + /* Get the internal overhead associated with chunk p */ + #define overhead_for(p) (is_mmapped(p) ? MMAP_CHUNK_OVERHEAD : CHUNK_OVERHEAD) + + /* Return true if malloced space is not necessarily cleared */ + #if MMAP_CLEARS + #define calloc_must_clear(p) (!is_mmapped(p)) + #else /* MMAP_CLEARS */ + #define calloc_must_clear(p) (1) + #endif /* MMAP_CLEARS */ + +/* ---------------------- Overlaid data structures ----------------------- */ + +/* + When chunks are not in use, they are treated as nodes of either + lists or trees. + + "Small" chunks are stored in circular doubly-linked lists, and look + like this: + + chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Size of previous chunk | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + `head:' | Size of chunk, in bytes |P| + mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Forward pointer to next chunk in list | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Back pointer to previous chunk in list | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Unused space (may be 0 bytes long) . + . . + . | +nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + `foot:' | Size of chunk, in bytes | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + + Larger chunks are kept in a form of bitwise digital trees (aka + tries) keyed on chunksizes. Because malloc_tree_chunks are only for + free chunks greater than 256 bytes, their size doesn't impose any + constraints on user chunk sizes. Each node looks like: + + chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Size of previous chunk | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + `head:' | Size of chunk, in bytes |P| + mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Forward pointer to next chunk of same size | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Back pointer to previous chunk of same size | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Pointer to left child (child[0]) | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Pointer to right child (child[1]) | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Pointer to parent | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | bin index of this chunk | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | Unused space . + . | +nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + `foot:' | Size of chunk, in bytes | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + + Each tree holding treenodes is a tree of unique chunk sizes. Chunks + of the same size are arranged in a circularly-linked list, with only + the oldest chunk (the next to be used, in our FIFO ordering) + actually in the tree. (Tree members are distinguished by a non-null + parent pointer.) If a chunk with the same size an an existing node + is inserted, it is linked off the existing node using pointers that + work in the same way as fd/bk pointers of small chunks. + + Each tree contains a power of 2 sized range of chunk sizes (the + smallest is 0x100 <= x < 0x180), which is is divided in half at each + tree level, with the chunks in the smaller half of the range (0x100 + <= x < 0x140 for the top nose) in the left subtree and the larger + half (0x140 <= x < 0x180) in the right subtree. This is, of course, + done by inspecting individual bits. + + Using these rules, each node's left subtree contains all smaller + sizes than its right subtree. However, the node at the root of each + subtree has no particular ordering relationship to either. (The + dividing line between the subtree sizes is based on trie relation.) + If we remove the last chunk of a given size from the interior of the + tree, we need to replace it with a leaf node. The tree ordering + rules permit a node to be replaced by any leaf below it. + + The smallest chunk in a tree (a common operation in a best-fit + allocator) can be found by walking a path to the leftmost leaf in + the tree. Unlike a usual binary tree, where we follow left child + pointers until we reach a null, here we follow the right child + pointer any time the left one is null, until we reach a leaf with + both child pointers null. The smallest chunk in the tree will be + somewhere along that path. + + The worst case number of steps to add, find, or remove a node is + bounded by the number of bits differentiating chunks within + bins. Under current bin calculations, this ranges from 6 up to 21 + (for 32 bit sizes) or up to 53 (for 64 bit sizes). The typical case + is of course much better. +*/ + +struct malloc_tree_chunk { + + /* The first four fields must be compatible with malloc_chunk */ + size_t prev_foot; + size_t head; + struct malloc_tree_chunk *fd; + struct malloc_tree_chunk *bk; + + struct malloc_tree_chunk *child[2]; + struct malloc_tree_chunk *parent; + bindex_t index; + +}; + +typedef struct malloc_tree_chunk tchunk; +typedef struct malloc_tree_chunk *tchunkptr; +typedef struct malloc_tree_chunk *tbinptr; /* The type of bins of trees */ + + /* A little helper macro for trees */ + #define leftmost_child(t) ((t)->child[0] != 0 ? (t)->child[0] : (t)->child[1]) + +/* ----------------------------- Segments -------------------------------- */ + +/* + Each malloc space may include non-contiguous segments, held in a + list headed by an embedded malloc_segment record representing the + top-most space. Segments also include flags holding properties of + the space. Large chunks that are directly allocated by mmap are not + included in this list. They are instead independently created and + destroyed without otherwise keeping track of them. + + Segment management mainly comes into play for spaces allocated by + MMAP. Any call to MMAP might or might not return memory that is + adjacent to an existing segment. MORECORE normally contiguously + extends the current space, so this space is almost always adjacent, + which is simpler and faster to deal with. (This is why MORECORE is + used preferentially to MMAP when both are available -- see + sys_alloc.) When allocating using MMAP, we don't use any of the + hinting mechanisms (inconsistently) supported in various + implementations of unix mmap, or distinguish reserving from + committing memory. Instead, we just ask for space, and exploit + contiguity when we get it. It is probably possible to do + better than this on some systems, but no general scheme seems + to be significantly better. + + Management entails a simpler variant of the consolidation scheme + used for chunks to reduce fragmentation -- new adjacent memory is + normally prepended or appended to an existing segment. However, + there are limitations compared to chunk consolidation that mostly + reflect the fact that segment processing is relatively infrequent + (occurring only when getting memory from system) and that we + don't expect to have huge numbers of segments: + + * Segments are not indexed, so traversal requires linear scans. (It + would be possible to index these, but is not worth the extra + overhead and complexity for most programs on most platforms.) + * New segments are only appended to old ones when holding top-most + memory; if they cannot be prepended to others, they are held in + different segments. + + Except for the top-most segment of an mstate, each segment record + is kept at the tail of its segment. Segments are added by pushing + segment records onto the list headed by &mstate.seg for the + containing mstate. + + Segment flags control allocation/merge/deallocation policies: + * If EXTERN_BIT set, then we did not allocate this segment, + and so should not try to deallocate or merge with others. + (This currently holds only for the initial segment passed + into create_mspace_with_base.) + * If USE_MMAP_BIT set, the segment may be merged with + other surrounding mmapped segments and trimmed/de-allocated + using munmap. + * If neither bit is set, then the segment was obtained using + MORECORE so can be merged with surrounding MORECORE'd segments + and deallocated/trimmed using MORECORE with negative arguments. +*/ + +struct malloc_segment { + + char * base; /* base address */ + size_t size; /* allocated size */ + struct malloc_segment *next; /* ptr to next segment */ + flag_t sflags; /* mmap and extern flag */ + +}; + + #define is_mmapped_segment(S) ((S)->sflags & USE_MMAP_BIT) + #define is_extern_segment(S) ((S)->sflags & EXTERN_BIT) + +typedef struct malloc_segment msegment; +typedef struct malloc_segment *msegmentptr; + + /* ---------------------------- malloc_state ----------------------------- */ + + /* + A malloc_state holds all of the bookkeeping for a space. + The main fields are: + + Top + The topmost chunk of the currently active segment. Its size is + cached in topsize. The actual size of topmost space is + topsize+TOP_FOOT_SIZE, which includes space reserved for adding + fenceposts and segment records if necessary when getting more + space from the system. The size at which to autotrim top is + cached from mparams in trim_check, except that it is disabled if + an autotrim fails. + + Designated victim (dv) + This is the preferred chunk for servicing small requests that + don't have exact fits. It is normally the chunk split off most + recently to service another small request. Its size is cached in + dvsize. The link fields of this chunk are not maintained since it + is not kept in a bin. + + SmallBins + An array of bin headers for free chunks. These bins hold chunks + with sizes less than MIN_LARGE_SIZE bytes. Each bin contains + chunks of all the same size, spaced 8 bytes apart. To simplify + use in double-linked lists, each bin header acts as a malloc_chunk + pointing to the real first node, if it exists (else pointing to + itself). This avoids special-casing for headers. But to avoid + waste, we allocate only the fd/bk pointers of bins, and then use + repositioning tricks to treat these as the fields of a chunk. + + TreeBins + Treebins are pointers to the roots of trees holding a range of + sizes. There are 2 equally spaced treebins for each power of two + from TREE_SHIFT to TREE_SHIFT+16. The last bin holds anything + larger. + + Bin maps + There is one bit map for small bins ("smallmap") and one for + treebins ("treemap). Each bin sets its bit when non-empty, and + clears the bit when empty. Bit operations are then used to avoid + bin-by-bin searching -- nearly all "search" is done without ever + looking at bins that won't be selected. The bit maps + conservatively use 32 bits per map word, even if on 64bit system. + For a good description of some of the bit-based techniques used + here, see Henry S. Warren Jr's book "Hacker's Delight" (and + supplement at http://hackersdelight.org/). Many of these are + intended to reduce the branchiness of paths through malloc etc, as + well as to reduce the number of memory locations read or written. + + Segments + A list of segments headed by an embedded malloc_segment record + representing the initial space. + + Address check support + The least_addr field is the least address ever obtained from + MORECORE or MMAP. Attempted frees and reallocs of any address less + than this are trapped (unless INSECURE is defined). + + Magic tag + A cross-check field that should always hold same value as mparams.magic. + + Max allowed footprint + The maximum allowed bytes to allocate from system (zero means no limit) + + Flags + Bits recording whether to use MMAP, locks, or contiguous MORECORE + + Statistics + Each space keeps track of current and maximum system memory + obtained via MORECORE or MMAP. + + Trim support + Fields holding the amount of unused topmost memory that should trigger + trimming, and a counter to force periodic scanning to release unused + non-topmost segments. + + Locking + If USE_LOCKS is defined, the "mutex" lock is acquired and released + around every public call using this mspace. + + Extension support + A void* pointer and a size_t field that can be used to help implement + extensions to this malloc. + */ + + /* Bin types, widths and sizes */ + #define NSMALLBINS (32U) + #define NTREEBINS (32U) + #define SMALLBIN_SHIFT (3U) + #define SMALLBIN_WIDTH (SIZE_T_ONE << SMALLBIN_SHIFT) + #define TREEBIN_SHIFT (8U) + #define MIN_LARGE_SIZE (SIZE_T_ONE << TREEBIN_SHIFT) + #define MAX_SMALL_SIZE (MIN_LARGE_SIZE - SIZE_T_ONE) + #define MAX_SMALL_REQUEST (MAX_SMALL_SIZE - CHUNK_ALIGN_MASK - CHUNK_OVERHEAD) + +struct malloc_state { + + binmap_t smallmap; + binmap_t treemap; + size_t dvsize; + size_t topsize; + char * least_addr; + mchunkptr dv; + mchunkptr top; + size_t trim_check; + size_t release_checks; + size_t magic; + mchunkptr smallbins[(NSMALLBINS + 1) * 2]; + tbinptr treebins[NTREEBINS]; + size_t footprint; + size_t max_footprint; + size_t footprint_limit; /* zero means no limit */ + flag_t mflags; + #if USE_LOCKS + MLOCK_T mutex; /* locate lock among fields that rarely change */ + #endif /* USE_LOCKS */ + msegment seg; + void * extp; /* Unused but available for extensions */ + size_t exts; + +}; + +typedef struct malloc_state *mstate; + +/* ------------- Global malloc_state and malloc_params ------------------- */ + +/* + malloc_params holds global properties, including those that can be + dynamically set using mallopt. There is a single instance, mparams, + initialized in init_mparams. Note that the non-zeroness of "magic" + also serves as an initialization flag. +*/ + +struct malloc_params { + + size_t magic; + size_t page_size; + size_t granularity; + size_t mmap_threshold; + size_t trim_threshold; + flag_t default_mflags; + +}; + +static struct malloc_params mparams; + + /* Ensure mparams initialized */ + #define ensure_initialization() (void)(mparams.magic != 0 || init_mparams()) + + #if !ONLY_MSPACES + +/* The global malloc_state used for all non-"mspace" calls */ +static struct malloc_state _gm_; + #define gm (&_gm_) + #define is_global(M) ((M) == &_gm_) + + #endif /* !ONLY_MSPACES */ + + #define is_initialized(M) ((M)->top != 0) + +/* -------------------------- system alloc setup ------------------------- */ + +/* Operations on mflags */ + + #define use_lock(M) ((M)->mflags & USE_LOCK_BIT) + #define enable_lock(M) ((M)->mflags |= USE_LOCK_BIT) + #if USE_LOCKS + #define disable_lock(M) ((M)->mflags &= ~USE_LOCK_BIT) + #else + #define disable_lock(M) + #endif + + #define use_mmap(M) ((M)->mflags & USE_MMAP_BIT) + #define enable_mmap(M) ((M)->mflags |= USE_MMAP_BIT) + #if HAVE_MMAP + #define disable_mmap(M) ((M)->mflags &= ~USE_MMAP_BIT) + #else + #define disable_mmap(M) + #endif + + #define use_noncontiguous(M) ((M)->mflags & USE_NONCONTIGUOUS_BIT) + #define disable_contiguous(M) ((M)->mflags |= USE_NONCONTIGUOUS_BIT) + + #define set_lock(M, L) \ + ((M)->mflags = \ + (L) ? ((M)->mflags | USE_LOCK_BIT) : ((M)->mflags & ~USE_LOCK_BIT)) + + /* page-align a size */ + #define page_align(S) \ + (((S) + (mparams.page_size - SIZE_T_ONE)) & \ + ~(mparams.page_size - SIZE_T_ONE)) + + /* granularity-align a size */ + #define granularity_align(S) \ + (((S) + (mparams.granularity - SIZE_T_ONE)) & \ + ~(mparams.granularity - SIZE_T_ONE)) + + /* For mmap, use granularity alignment on windows, else page-align */ + #ifdef WIN32 + #define mmap_align(S) granularity_align(S) + #else + #define mmap_align(S) page_align(S) + #endif + + /* For sys_alloc, enough padding to ensure can malloc request on success */ + #define SYS_ALLOC_PADDING (TOP_FOOT_SIZE + MALLOC_ALIGNMENT) + + #define is_page_aligned(S) \ + (((size_t)(S) & (mparams.page_size - SIZE_T_ONE)) == 0) + #define is_granularity_aligned(S) \ + (((size_t)(S) & (mparams.granularity - SIZE_T_ONE)) == 0) + + /* True if segment S holds address A */ + #define segment_holds(S, A) \ + ((char *)(A) >= S->base && (char *)(A) < S->base + S->size) + +/* Return segment holding given address */ +static msegmentptr segment_holding(mstate m, char *addr) { + + msegmentptr sp = &m->seg; + for (;;) { + + if (addr >= sp->base && addr < sp->base + sp->size) return sp; + if ((sp = sp->next) == 0) return 0; + + } + +} + +/* Return true if segment contains a segment link */ +static int has_segment_link(mstate m, msegmentptr ss) { + + msegmentptr sp = &m->seg; + for (;;) { + + if ((char *)sp >= ss->base && (char *)sp < ss->base + ss->size) return 1; + if ((sp = sp->next) == 0) return 0; + + } + +} + + #ifndef MORECORE_CANNOT_TRIM + #define should_trim(M, s) ((s) > (M)->trim_check) + #else /* MORECORE_CANNOT_TRIM */ + #define should_trim(M, s) (0) + #endif /* MORECORE_CANNOT_TRIM */ + + /* + TOP_FOOT_SIZE is padding at the end of a segment, including space + that may be needed to place segment records and fenceposts when new + noncontiguous segments are added. + */ + #define TOP_FOOT_SIZE \ + (align_offset(chunk2mem(0)) + pad_request(sizeof(struct malloc_segment)) + \ + MIN_CHUNK_SIZE) + +/* ------------------------------- Hooks -------------------------------- */ + +/* + PREACTION should be defined to return 0 on success, and nonzero on + failure. If you are not using locking, you can redefine these to do + anything you like. +*/ + + #if USE_LOCKS + #define PREACTION(M) ((use_lock(M)) ? ACQUIRE_LOCK(&(M)->mutex) : 0) + #define POSTACTION(M) \ + { \ + \ + if (use_lock(M)) RELEASE_LOCK(&(M)->mutex); \ + \ + } + #else /* USE_LOCKS */ + + #ifndef PREACTION + #define PREACTION(M) (0) + #endif /* PREACTION */ + + #ifndef POSTACTION + #define POSTACTION(M) + #endif /* POSTACTION */ + + #endif /* USE_LOCKS */ + +/* + CORRUPTION_ERROR_ACTION is triggered upon detected bad addresses. + USAGE_ERROR_ACTION is triggered on detected bad frees and + reallocs. The argument p is an address that might have triggered the + fault. It is ignored by the two predefined actions, but might be + useful in custom actions that try to help diagnose errors. +*/ + + #if PROCEED_ON_ERROR + +/* A count of the number of corruption errors causing resets */ +int malloc_corruption_error_count; + +/* default corruption action */ +static void reset_on_error(mstate m); + + #define CORRUPTION_ERROR_ACTION(m) reset_on_error(m) + #define USAGE_ERROR_ACTION(m, p) + + #else /* PROCEED_ON_ERROR */ + + #ifndef CORRUPTION_ERROR_ACTION + #define CORRUPTION_ERROR_ACTION(m) ABORT + #endif /* CORRUPTION_ERROR_ACTION */ + + #ifndef USAGE_ERROR_ACTION + #define USAGE_ERROR_ACTION(m, p) ABORT + #endif /* USAGE_ERROR_ACTION */ + + #endif /* PROCEED_ON_ERROR */ + +/* -------------------------- Debugging setup ---------------------------- */ + + #if !DEBUG + + #define check_free_chunk(M, P) + #define check_inuse_chunk(M, P) + #define check_malloced_chunk(M, P, N) + #define check_mmapped_chunk(M, P) + #define check_malloc_state(M) + #define check_top_chunk(M, P) + + #else /* DEBUG */ + #define check_free_chunk(M, P) do_check_free_chunk(M, P) + #define check_inuse_chunk(M, P) do_check_inuse_chunk(M, P) + #define check_top_chunk(M, P) do_check_top_chunk(M, P) + #define check_malloced_chunk(M, P, N) do_check_malloced_chunk(M, P, N) + #define check_mmapped_chunk(M, P) do_check_mmapped_chunk(M, P) + #define check_malloc_state(M) do_check_malloc_state(M) + +static void do_check_any_chunk(mstate m, mchunkptr p); +static void do_check_top_chunk(mstate m, mchunkptr p); +static void do_check_mmapped_chunk(mstate m, mchunkptr p); +static void do_check_inuse_chunk(mstate m, mchunkptr p); +static void do_check_free_chunk(mstate m, mchunkptr p); +static void do_check_malloced_chunk(mstate m, void *mem, size_t s); +static void do_check_tree(mstate m, tchunkptr t); +static void do_check_treebin(mstate m, bindex_t i); +static void do_check_smallbin(mstate m, bindex_t i); +static void do_check_malloc_state(mstate m); +static int bin_find(mstate m, mchunkptr x); +static size_t traverse_and_check(mstate m); + #endif /* DEBUG */ + +/* ---------------------------- Indexing Bins ---------------------------- */ + + #define is_small(s) (((s) >> SMALLBIN_SHIFT) < NSMALLBINS) + #define small_index(s) (bindex_t)((s) >> SMALLBIN_SHIFT) + #define small_index2size(i) ((i) << SMALLBIN_SHIFT) + #define MIN_SMALL_INDEX (small_index(MIN_CHUNK_SIZE)) + + /* addressing by index. See above about smallbin repositioning */ + #define smallbin_at(M, i) ((sbinptr)((char *)&((M)->smallbins[(i) << 1]))) + #define treebin_at(M, i) (&((M)->treebins[i])) + + /* assign tree index for size S to variable I. Use x86 asm if possible */ + #if defined(__GNUC__) && (defined(__i386__) || defined(__x86_64__)) + #define compute_tree_index(S, I) \ + { \ + \ + unsigned int X = S >> TREEBIN_SHIFT; \ + if (X == 0) \ + I = 0; \ + else if (X > 0xFFFF) \ + I = NTREEBINS - 1; \ + else { \ + \ + unsigned int K = (unsigned)sizeof(X) * __CHAR_BIT__ - 1 - \ + (unsigned)__builtin_clz(X); \ + I = (bindex_t)((K << 1) + ((S >> (K + (TREEBIN_SHIFT - 1)) & 1))); \ + \ + } \ + \ + } + + #elif defined(__INTEL_COMPILER) + #define compute_tree_index(S, I) \ + { \ + \ + size_t X = S >> TREEBIN_SHIFT; \ + if (X == 0) \ + I = 0; \ + else if (X > 0xFFFF) \ + I = NTREEBINS - 1; \ + else { \ + \ + unsigned int K = _bit_scan_reverse(X); \ + I = (bindex_t)((K << 1) + ((S >> (K + (TREEBIN_SHIFT - 1)) & 1))); \ + \ + } \ + \ + } + + #elif defined(_MSC_VER) && _MSC_VER >= 1300 + #define compute_tree_index(S, I) \ + { \ + \ + size_t X = S >> TREEBIN_SHIFT; \ + if (X == 0) \ + I = 0; \ + else if (X > 0xFFFF) \ + I = NTREEBINS - 1; \ + else { \ + \ + unsigned int K; \ + _BitScanReverse((DWORD *)&K, (DWORD)X); \ + I = (bindex_t)((K << 1) + ((S >> (K + (TREEBIN_SHIFT - 1)) & 1))); \ + \ + } \ + \ + } + + #else /* GNUC */ + #define compute_tree_index(S, I) \ + { \ + \ + size_t X = S >> TREEBIN_SHIFT; \ + if (X == 0) \ + I = 0; \ + else if (X > 0xFFFF) \ + I = NTREEBINS - 1; \ + else { \ + \ + unsigned int Y = (unsigned int)X; \ + unsigned int N = ((Y - 0x100) >> 16) & 8; \ + unsigned int K = (((Y <<= N) - 0x1000) >> 16) & 4; \ + N += K; \ + N += K = (((Y <<= K) - 0x4000) >> 16) & 2; \ + K = 14 - N + ((Y <<= K) >> 15); \ + I = (K << 1) + ((S >> (K + (TREEBIN_SHIFT - 1)) & 1)); \ + \ + } \ + \ + } + #endif /* GNUC */ + + /* Bit representing maximum resolved size in a treebin at i */ + #define bit_for_tree_index(i) \ + (i == NTREEBINS - 1) ? (SIZE_T_BITSIZE - 1) \ + : (((i) >> 1) + TREEBIN_SHIFT - 2) + + /* Shift placing maximum resolved bit in a treebin at i as sign bit */ + #define leftshift_for_tree_index(i) \ + ((i == NTREEBINS - 1) \ + ? 0 \ + : ((SIZE_T_BITSIZE - SIZE_T_ONE) - (((i) >> 1) + TREEBIN_SHIFT - 2))) + + /* The size of the smallest chunk held in bin with index i */ + #define minsize_for_tree_index(i) \ + ((SIZE_T_ONE << (((i) >> 1) + TREEBIN_SHIFT)) | \ + (((size_t)((i)&SIZE_T_ONE)) << (((i) >> 1) + TREEBIN_SHIFT - 1))) + + /* ------------------------ Operations on bin maps ----------------------- */ + + /* bit corresponding to given index */ + #define idx2bit(i) ((binmap_t)(1) << (i)) + + /* Mark/Clear bits with given index */ + #define mark_smallmap(M, i) ((M)->smallmap |= idx2bit(i)) + #define clear_smallmap(M, i) ((M)->smallmap &= ~idx2bit(i)) + #define smallmap_is_marked(M, i) ((M)->smallmap & idx2bit(i)) + + #define mark_treemap(M, i) ((M)->treemap |= idx2bit(i)) + #define clear_treemap(M, i) ((M)->treemap &= ~idx2bit(i)) + #define treemap_is_marked(M, i) ((M)->treemap & idx2bit(i)) + + /* isolate the least set bit of a bitmap */ + #define least_bit(x) ((x) & -(x)) + + /* mask with all bits to left of least bit of x on */ + #define left_bits(x) ((x << 1) | -(x << 1)) + + /* mask with all bits to left of or equal to least bit of x on */ + #define same_or_left_bits(x) ((x) | -(x)) + +/* index corresponding to given bit. Use x86 asm if possible */ + + #if defined(__GNUC__) && (defined(__i386__) || defined(__x86_64__)) + #define compute_bit2idx(X, I) \ + { \ + \ + unsigned int J; \ + J = __builtin_ctz(X); \ + I = (bindex_t)J; \ + \ + } + + #elif defined(__INTEL_COMPILER) + #define compute_bit2idx(X, I) \ + { \ + \ + unsigned int J; \ + J = _bit_scan_forward(X); \ + I = (bindex_t)J; \ + \ + } + + #elif defined(_MSC_VER) && _MSC_VER >= 1300 + #define compute_bit2idx(X, I) \ + { \ + \ + unsigned int J; \ + _BitScanForward((DWORD *)&J, X); \ + I = (bindex_t)J; \ + \ + } + + #elif USE_BUILTIN_FFS + #define compute_bit2idx(X, I) I = ffs(X) - 1 + + #else + #define compute_bit2idx(X, I) \ + { \ + \ + unsigned int Y = X - 1; \ + unsigned int K = Y >> (16 - 4) & 16; \ + unsigned int N = K; \ + Y >>= K; \ + N += K = Y >> (8 - 3) & 8; \ + Y >>= K; \ + N += K = Y >> (4 - 2) & 4; \ + Y >>= K; \ + N += K = Y >> (2 - 1) & 2; \ + Y >>= K; \ + N += K = Y >> (1 - 0) & 1; \ + Y >>= K; \ + I = (bindex_t)(N + Y); \ + \ + } + #endif /* GNUC */ + +/* ----------------------- Runtime Check Support ------------------------- */ + +/* + For security, the main invariant is that malloc/free/etc never + writes to a static address other than malloc_state, unless static + malloc_state itself has been corrupted, which cannot occur via + malloc (because of these checks). In essence this means that we + believe all pointers, sizes, maps etc held in malloc_state, but + check all of those linked or offsetted from other embedded data + structures. These checks are interspersed with main code in a way + that tends to minimize their run-time cost. + + When FOOTERS is defined, in addition to range checking, we also + verify footer fields of inuse chunks, which can be used guarantee + that the mstate controlling malloc/free is intact. This is a + streamlined version of the approach described by William Robertson + et al in "Run-time Detection of Heap-based Overflows" LISA'03 + http://www.usenix.org/events/lisa03/tech/robertson.html The footer + of an inuse chunk holds the xor of its mstate and a random seed, + that is checked upon calls to free() and realloc(). This is + (probabalistically) unguessable from outside the program, but can be + computed by any code successfully malloc'ing any chunk, so does not + itself provide protection against code that has already broken + security through some other means. Unlike Robertson et al, we + always dynamically check addresses of all offset chunks (previous, + next, etc). This turns out to be cheaper than relying on hashes. +*/ + + #if !INSECURE + /* Check if address a is at least as high as any from MORECORE or MMAP */ + #define ok_address(M, a) ((char *)(a) >= (M)->least_addr) + /* Check if address of next chunk n is higher than base chunk p */ + #define ok_next(p, n) ((char *)(p) < (char *)(n)) + /* Check if p has inuse status */ + #define ok_inuse(p) is_inuse(p) + /* Check if p has its pinuse bit on */ + #define ok_pinuse(p) pinuse(p) + + #else /* !INSECURE */ + #define ok_address(M, a) (1) + #define ok_next(b, n) (1) + #define ok_inuse(p) (1) + #define ok_pinuse(p) (1) + #endif /* !INSECURE */ + + #if (FOOTERS && !INSECURE) + /* Check if (alleged) mstate m has expected magic field */ + #define ok_magic(M) ((M)->magic == mparams.magic) + #else /* (FOOTERS && !INSECURE) */ + #define ok_magic(M) (1) + #endif /* (FOOTERS && !INSECURE) */ + + /* In gcc, use __builtin_expect to minimize impact of checks */ + #if !INSECURE + #if defined(__GNUC__) && __GNUC__ >= 3 + #define RTCHECK(e) __builtin_expect(e, 1) + #else /* GNUC */ + #define RTCHECK(e) (e) + #endif /* GNUC */ + #else /* !INSECURE */ + #define RTCHECK(e) (1) + #endif /* !INSECURE */ + +/* macros to set up inuse chunks with or without footers */ + + #if !FOOTERS + + #define mark_inuse_foot(M, p, s) + + /* Macros for setting head/foot of non-mmapped chunks */ + + /* Set cinuse bit and pinuse bit of next chunk */ + #define set_inuse(M, p, s) \ + ((p)->head = (((p)->head & PINUSE_BIT) | s | CINUSE_BIT), \ + ((mchunkptr)(((char *)(p)) + (s)))->head |= PINUSE_BIT) + + /* Set cinuse and pinuse of this chunk and pinuse of next chunk */ + #define set_inuse_and_pinuse(M, p, s) \ + ((p)->head = (s | PINUSE_BIT | CINUSE_BIT), \ + ((mchunkptr)(((char *)(p)) + (s)))->head |= PINUSE_BIT) + + /* Set size, cinuse and pinuse bit of this chunk */ + #define set_size_and_pinuse_of_inuse_chunk(M, p, s) \ + ((p)->head = (s | PINUSE_BIT | CINUSE_BIT)) + + #else /* FOOTERS */ + + /* Set foot of inuse chunk to be xor of mstate and seed */ + #define mark_inuse_foot(M, p, s) \ + (((mchunkptr)((char *)(p) + (s)))->prev_foot = \ + ((size_t)(M) ^ mparams.magic)) + + #define get_mstate_for(p) \ + ((mstate)(((mchunkptr)((char *)(p) + (chunksize(p))))->prev_foot ^ \ + mparams.magic)) + + #define set_inuse(M, p, s) \ + ((p)->head = (((p)->head & PINUSE_BIT) | s | CINUSE_BIT), \ + (((mchunkptr)(((char *)(p)) + (s)))->head |= PINUSE_BIT), \ + mark_inuse_foot(M, p, s)) + + #define set_inuse_and_pinuse(M, p, s) \ + ((p)->head = (s | PINUSE_BIT | CINUSE_BIT), \ + (((mchunkptr)(((char *)(p)) + (s)))->head |= PINUSE_BIT), \ + mark_inuse_foot(M, p, s)) + + #define set_size_and_pinuse_of_inuse_chunk(M, p, s) \ + ((p)->head = (s | PINUSE_BIT | CINUSE_BIT), mark_inuse_foot(M, p, s)) + + #endif /* !FOOTERS */ + +/* ---------------------------- setting mparams -------------------------- */ + + #if LOCK_AT_FORK +static void pre_fork(void) { + + ACQUIRE_LOCK(&(gm)->mutex); + +} + +static void post_fork_parent(void) { + + RELEASE_LOCK(&(gm)->mutex); + +} + +static void post_fork_child(void) { + + INITIAL_LOCK(&(gm)->mutex); + +} + + #endif /* LOCK_AT_FORK */ + +/* Initialize mparams */ +static int init_mparams(void) { + + #ifdef NEED_GLOBAL_LOCK_INIT + if (malloc_global_mutex_status <= 0) init_malloc_global_mutex(); + #endif + + ACQUIRE_MALLOC_GLOBAL_LOCK(); + if (mparams.magic == 0) { + + size_t magic; + size_t psize; + size_t gsize; + + #ifndef WIN32 + psize = malloc_getpagesize; + gsize = ((DEFAULT_GRANULARITY != 0) ? DEFAULT_GRANULARITY : psize); + #else /* WIN32 */ + { + + SYSTEM_INFO system_info; + GetSystemInfo(&system_info); + psize = system_info.dwPageSize; + gsize = + ((DEFAULT_GRANULARITY != 0) ? DEFAULT_GRANULARITY + : system_info.dwAllocationGranularity); + + } + + #endif /* WIN32 */ + + /* Sanity-check configuration: + size_t must be unsigned and as wide as pointer type. + ints must be at least 4 bytes. + alignment must be at least 8. + Alignment, min chunk size, and page size must all be powers of 2. + */ + if ((sizeof(size_t) != sizeof(char *)) || (MAX_SIZE_T < MIN_CHUNK_SIZE) || + (sizeof(int) < 4) || (MALLOC_ALIGNMENT < (size_t)8U) || + ((MALLOC_ALIGNMENT & (MALLOC_ALIGNMENT - SIZE_T_ONE)) != 0) || + ((MCHUNK_SIZE & (MCHUNK_SIZE - SIZE_T_ONE)) != 0) || + ((gsize & (gsize - SIZE_T_ONE)) != 0) || + ((psize & (psize - SIZE_T_ONE)) != 0)) + ABORT; + mparams.granularity = gsize; + mparams.page_size = psize; + mparams.mmap_threshold = DEFAULT_MMAP_THRESHOLD; + mparams.trim_threshold = DEFAULT_TRIM_THRESHOLD; + #if MORECORE_CONTIGUOUS + mparams.default_mflags = USE_LOCK_BIT | USE_MMAP_BIT; + #else /* MORECORE_CONTIGUOUS */ + mparams.default_mflags = + USE_LOCK_BIT | USE_MMAP_BIT | USE_NONCONTIGUOUS_BIT; + #endif /* MORECORE_CONTIGUOUS */ + + #if !ONLY_MSPACES + /* Set up lock for main malloc area */ + gm->mflags = mparams.default_mflags; + (void)INITIAL_LOCK(&gm->mutex); + #endif + #if LOCK_AT_FORK + pthread_atfork(&pre_fork, &post_fork_parent, &post_fork_child); + #endif + + { + + #if USE_DEV_RANDOM + int fd; + unsigned char buf[sizeof(size_t)]; + /* Try to use /dev/urandom, else fall back on using time */ + if ((fd = open("/dev/urandom", O_RDONLY)) >= 0 && + read(fd, buf, sizeof(buf)) == sizeof(buf)) { + + magic = *((size_t *)buf); + close(fd); + + } else + + #endif /* USE_DEV_RANDOM */ + #ifdef WIN32 + magic = (size_t)(GetTickCount() ^ (size_t)0x55555555U); + #elif defined(LACKS_TIME_H) + magic = (size_t)&magic ^ (size_t)0x55555555U; + #else + magic = (size_t)(time(0) ^ (size_t)0x55555555U); + #endif + magic |= (size_t)8U; /* ensure nonzero */ + magic &= ~(size_t)7U; /* improve chances of fault for bad values */ + /* Until memory modes commonly available, use volatile-write */ + (*(volatile size_t *)(&(mparams.magic))) = magic; + + } + + } + + RELEASE_MALLOC_GLOBAL_LOCK(); + return 1; + +} + +/* support for mallopt */ +static int change_mparam(int param_number, int value) { + + size_t val; + ensure_initialization(); + val = (value == -1) ? MAX_SIZE_T : (size_t)value; + switch (param_number) { + + case M_TRIM_THRESHOLD: + mparams.trim_threshold = val; + return 1; + case M_GRANULARITY: + if (val >= mparams.page_size && ((val & (val - 1)) == 0)) { + + mparams.granularity = val; + return 1; + + } else + + return 0; + case M_MMAP_THRESHOLD: + mparams.mmap_threshold = val; + return 1; + default: + return 0; + + } + +} + + #if DEBUG +/* ------------------------- Debugging Support --------------------------- */ + +/* Check properties of any chunk, whether free, inuse, mmapped etc */ +static void do_check_any_chunk(mstate m, mchunkptr p) { + + assert((is_aligned(chunk2mem(p))) || (p->head == FENCEPOST_HEAD)); + assert(ok_address(m, p)); + +} + +/* Check properties of top chunk */ +static void do_check_top_chunk(mstate m, mchunkptr p) { + + msegmentptr sp = segment_holding(m, (char *)p); + size_t sz = p->head & ~INUSE_BITS; /* third-lowest bit can be set! */ + assert(sp != 0); + assert((is_aligned(chunk2mem(p))) || (p->head == FENCEPOST_HEAD)); + assert(ok_address(m, p)); + assert(sz == m->topsize); + assert(sz > 0); + assert(sz == ((sp->base + sp->size) - (char *)p) - TOP_FOOT_SIZE); + assert(pinuse(p)); + assert(!pinuse(chunk_plus_offset(p, sz))); + +} + +/* Check properties of (inuse) mmapped chunks */ +static void do_check_mmapped_chunk(mstate m, mchunkptr p) { + + size_t sz = chunksize(p); + size_t len = (sz + (p->prev_foot) + MMAP_FOOT_PAD); + assert(is_mmapped(p)); + assert(use_mmap(m)); + assert((is_aligned(chunk2mem(p))) || (p->head == FENCEPOST_HEAD)); + assert(ok_address(m, p)); + assert(!is_small(sz)); + assert((len & (mparams.page_size - SIZE_T_ONE)) == 0); + assert(chunk_plus_offset(p, sz)->head == FENCEPOST_HEAD); + assert(chunk_plus_offset(p, sz + SIZE_T_SIZE)->head == 0); + +} + +/* Check properties of inuse chunks */ +static void do_check_inuse_chunk(mstate m, mchunkptr p) { + + do_check_any_chunk(m, p); + assert(is_inuse(p)); + assert(next_pinuse(p)); + /* If not pinuse and not mmapped, previous chunk has OK offset */ + assert(is_mmapped(p) || pinuse(p) || next_chunk(prev_chunk(p)) == p); + if (is_mmapped(p)) do_check_mmapped_chunk(m, p); + +} + +/* Check properties of free chunks */ +static void do_check_free_chunk(mstate m, mchunkptr p) { + + size_t sz = chunksize(p); + mchunkptr next = chunk_plus_offset(p, sz); + do_check_any_chunk(m, p); + assert(!is_inuse(p)); + assert(!next_pinuse(p)); + assert(!is_mmapped(p)); + if (p != m->dv && p != m->top) { + + if (sz >= MIN_CHUNK_SIZE) { + + assert((sz & CHUNK_ALIGN_MASK) == 0); + assert(is_aligned(chunk2mem(p))); + assert(next->prev_foot == sz); + assert(pinuse(p)); + assert(next == m->top || is_inuse(next)); + assert(p->fd->bk == p); + assert(p->bk->fd == p); + + } else /* markers are always of size SIZE_T_SIZE */ + + assert(sz == SIZE_T_SIZE); + + } + +} + +/* Check properties of malloced chunks at the point they are malloced */ +static void do_check_malloced_chunk(mstate m, void *mem, size_t s) { + + if (mem != 0) { + + mchunkptr p = mem2chunk(mem); + size_t sz = p->head & ~INUSE_BITS; + do_check_inuse_chunk(m, p); + assert((sz & CHUNK_ALIGN_MASK) == 0); + assert(sz >= MIN_CHUNK_SIZE); + assert(sz >= s); + /* unless mmapped, size is less than MIN_CHUNK_SIZE more than request */ + assert(is_mmapped(p) || sz < (s + MIN_CHUNK_SIZE)); + + } + +} + +/* Check a tree and its subtrees. */ +static void do_check_tree(mstate m, tchunkptr t) { + + tchunkptr head = 0; + tchunkptr u = t; + bindex_t tindex = t->index; + size_t tsize = chunksize(t); + bindex_t idx; + compute_tree_index(tsize, idx); + assert(tindex == idx); + assert(tsize >= MIN_LARGE_SIZE); + assert(tsize >= minsize_for_tree_index(idx)); + assert((idx == NTREEBINS - 1) || (tsize < minsize_for_tree_index((idx + 1)))); + + do { /* traverse through chain of same-sized nodes */ + do_check_any_chunk(m, ((mchunkptr)u)); + assert(u->index == tindex); + assert(chunksize(u) == tsize); + assert(!is_inuse(u)); + assert(!next_pinuse(u)); + assert(u->fd->bk == u); + assert(u->bk->fd == u); + if (u->parent == 0) { + + assert(u->child[0] == 0); + assert(u->child[1] == 0); + + } else { + + assert(head == 0); /* only one node on chain has parent */ + head = u; + assert(u->parent != u); + assert(u->parent->child[0] == u || u->parent->child[1] == u || + *((tbinptr *)(u->parent)) == u); + if (u->child[0] != 0) { + + assert(u->child[0]->parent == u); + assert(u->child[0] != u); + do_check_tree(m, u->child[0]); + + } + + if (u->child[1] != 0) { + + assert(u->child[1]->parent == u); + assert(u->child[1] != u); + do_check_tree(m, u->child[1]); + + } + + if (u->child[0] != 0 && u->child[1] != 0) { + + assert(chunksize(u->child[0]) < chunksize(u->child[1])); + + } + + } + + u = u->fd; + + } while (u != t); + + assert(head != 0); + +} + +/* Check all the chunks in a treebin. */ +static void do_check_treebin(mstate m, bindex_t i) { + + tbinptr * tb = treebin_at(m, i); + tchunkptr t = *tb; + int empty = (m->treemap & (1U << i)) == 0; + if (t == 0) assert(empty); + if (!empty) do_check_tree(m, t); + +} + +/* Check all the chunks in a smallbin. */ +static void do_check_smallbin(mstate m, bindex_t i) { + + sbinptr b = smallbin_at(m, i); + mchunkptr p = b->bk; + unsigned int empty = (m->smallmap & (1U << i)) == 0; + if (p == b) assert(empty); + if (!empty) { + + for (; p != b; p = p->bk) { + + size_t size = chunksize(p); + mchunkptr q; + /* each chunk claims to be free */ + do_check_free_chunk(m, p); + /* chunk belongs in bin */ + assert(small_index(size) == i); + assert(p->bk == b || chunksize(p->bk) == chunksize(p)); + /* chunk is followed by an inuse chunk */ + q = next_chunk(p); + if (q->head != FENCEPOST_HEAD) do_check_inuse_chunk(m, q); + + } + + } + +} + +/* Find x in a bin. Used in other check functions. */ +static int bin_find(mstate m, mchunkptr x) { + + size_t size = chunksize(x); + if (is_small(size)) { + + bindex_t sidx = small_index(size); + sbinptr b = smallbin_at(m, sidx); + if (smallmap_is_marked(m, sidx)) { + + mchunkptr p = b; + do { + + if (p == x) return 1; + + } while ((p = p->fd) != b); + + } + + } else { + + bindex_t tidx; + compute_tree_index(size, tidx); + if (treemap_is_marked(m, tidx)) { + + tchunkptr t = *treebin_at(m, tidx); + size_t sizebits = size << leftshift_for_tree_index(tidx); + while (t != 0 && chunksize(t) != size) { + + t = t->child[(sizebits >> (SIZE_T_BITSIZE - SIZE_T_ONE)) & 1]; + sizebits <<= 1; + + } + + if (t != 0) { + + tchunkptr u = t; + do { + + if (u == (tchunkptr)x) return 1; + + } while ((u = u->fd) != t); + + } + + } + + } + + return 0; + +} + +/* Traverse each chunk and check it; return total */ +static size_t traverse_and_check(mstate m) { + + size_t sum = 0; + if (is_initialized(m)) { + + msegmentptr s = &m->seg; + sum += m->topsize + TOP_FOOT_SIZE; + while (s != 0) { + + mchunkptr q = align_as_chunk(s->base); + mchunkptr lastq = 0; + assert(pinuse(q)); + while (segment_holds(s, q) && q != m->top && q->head != FENCEPOST_HEAD) { + + sum += chunksize(q); + if (is_inuse(q)) { + + assert(!bin_find(m, q)); + do_check_inuse_chunk(m, q); + + } else { + + assert(q == m->dv || bin_find(m, q)); + assert(lastq == 0 || is_inuse(lastq)); /* Not 2 consecutive free */ + do_check_free_chunk(m, q); + + } + + lastq = q; + q = next_chunk(q); + + } + + s = s->next; + + } + + } + + return sum; + +} + +/* Check all properties of malloc_state. */ +static void do_check_malloc_state(mstate m) { + + bindex_t i; + size_t total; + /* check bins */ + for (i = 0; i < NSMALLBINS; ++i) + do_check_smallbin(m, i); + for (i = 0; i < NTREEBINS; ++i) + do_check_treebin(m, i); + + if (m->dvsize != 0) { /* check dv chunk */ + do_check_any_chunk(m, m->dv); + assert(m->dvsize == chunksize(m->dv)); + assert(m->dvsize >= MIN_CHUNK_SIZE); + assert(bin_find(m, m->dv) == 0); + + } + + if (m->top != 0) { /* check top chunk */ + do_check_top_chunk(m, m->top); + /*assert(m->topsize == chunksize(m->top)); redundant */ + assert(m->topsize > 0); + assert(bin_find(m, m->top) == 0); + + } + + total = traverse_and_check(m); + assert(total <= m->footprint); + assert(m->footprint <= m->max_footprint); + +} + + #endif /* DEBUG */ + +/* ----------------------------- statistics ------------------------------ */ + + #if !NO_MALLINFO +static struct mallinfo internal_mallinfo(mstate m) { + + struct mallinfo nm = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0}; + ensure_initialization(); + if (!PREACTION(m)) { + + check_malloc_state(m); + if (is_initialized(m)) { + + size_t nfree = SIZE_T_ONE; /* top always free */ + size_t mfree = m->topsize + TOP_FOOT_SIZE; + size_t sum = mfree; + msegmentptr s = &m->seg; + while (s != 0) { + + mchunkptr q = align_as_chunk(s->base); + while (segment_holds(s, q) && q != m->top && + q->head != FENCEPOST_HEAD) { + + size_t sz = chunksize(q); + sum += sz; + if (!is_inuse(q)) { + + mfree += sz; + ++nfree; + + } + + q = next_chunk(q); + + } + + s = s->next; + + } + + nm.arena = sum; + nm.ordblks = nfree; + nm.hblkhd = m->footprint - sum; + nm.usmblks = m->max_footprint; + nm.uordblks = m->footprint - mfree; + nm.fordblks = mfree; + nm.keepcost = m->topsize; + + } + + POSTACTION(m); + + } + + return nm; + +} + + #endif /* !NO_MALLINFO */ + + #if !NO_MALLOC_STATS +static void internal_malloc_stats(mstate m) { + + ensure_initialization(); + if (!PREACTION(m)) { + + size_t maxfp = 0; + size_t fp = 0; + size_t used = 0; + check_malloc_state(m); + if (is_initialized(m)) { + + msegmentptr s = &m->seg; + maxfp = m->max_footprint; + fp = m->footprint; + used = fp - (m->topsize + TOP_FOOT_SIZE); + + while (s != 0) { + + mchunkptr q = align_as_chunk(s->base); + while (segment_holds(s, q) && q != m->top && + q->head != FENCEPOST_HEAD) { + + if (!is_inuse(q)) used -= chunksize(q); + q = next_chunk(q); + + } + + s = s->next; + + } + + } + + POSTACTION(m); /* drop lock */ + fprintf(stderr, "max system bytes = %10lu\n", (unsigned long)(maxfp)); + fprintf(stderr, "system bytes = %10lu\n", (unsigned long)(fp)); + fprintf(stderr, "in use bytes = %10lu\n", (unsigned long)(used)); + + } + +} + + #endif /* NO_MALLOC_STATS */ + + /* ----------------------- Operations on smallbins ----------------------- */ + + /* + Various forms of linking and unlinking are defined as macros. Even + the ones for trees, which are very long but have very short typical + paths. This is ugly but reduces reliance on inlining support of + compilers. + */ + + /* Link a free chunk into a smallbin */ + #define insert_small_chunk(M, P, S) \ + { \ + \ + bindex_t I = small_index(S); \ + mchunkptr B = smallbin_at(M, I); \ + mchunkptr F = B; \ + assert(S >= MIN_CHUNK_SIZE); \ + if (!smallmap_is_marked(M, I)) \ + mark_smallmap(M, I); \ + else if (RTCHECK(ok_address(M, B->fd))) \ + F = B->fd; \ + else { \ + \ + CORRUPTION_ERROR_ACTION(M); \ + \ + } \ + B->fd = P; \ + F->bk = P; \ + P->fd = F; \ + P->bk = B; \ + \ + } + + /* Unlink a chunk from a smallbin */ + #define unlink_small_chunk(M, P, S) \ + { \ + \ + mchunkptr F = P->fd; \ + mchunkptr B = P->bk; \ + bindex_t I = small_index(S); \ + assert(P != B); \ + assert(P != F); \ + assert(chunksize(P) == small_index2size(I)); \ + if (RTCHECK(F == smallbin_at(M, I) || \ + (ok_address(M, F) && F->bk == P))) { \ + \ + if (B == F) { \ + \ + clear_smallmap(M, I); \ + \ + } else if (RTCHECK(B == smallbin_at(M, I) || \ + \ + \ + (ok_address(M, B) && B->fd == P))) { \ + \ + F->bk = B; \ + B->fd = F; \ + \ + } else { \ + \ + CORRUPTION_ERROR_ACTION(M); \ + \ + } \ + \ + } else { \ + \ + CORRUPTION_ERROR_ACTION(M); \ + \ + } \ + \ + } + + /* Unlink the first chunk from a smallbin */ + #define unlink_first_small_chunk(M, B, P, I) \ + { \ + \ + mchunkptr F = P->fd; \ + assert(P != B); \ + assert(P != F); \ + assert(chunksize(P) == small_index2size(I)); \ + if (B == F) { \ + \ + clear_smallmap(M, I); \ + \ + } else if (RTCHECK(ok_address(M, F) && F->bk == P)) { \ + \ + F->bk = B; \ + B->fd = F; \ + \ + } else { \ + \ + CORRUPTION_ERROR_ACTION(M); \ + \ + } \ + \ + } + + /* Replace dv node, binning the old one */ + /* Used only when dvsize known to be small */ + #define replace_dv(M, P, S) \ + { \ + \ + size_t DVS = M->dvsize; \ + assert(is_small(DVS)); \ + if (DVS != 0) { \ + \ + mchunkptr DV = M->dv; \ + insert_small_chunk(M, DV, DVS); \ + \ + } \ + M->dvsize = S; \ + M->dv = P; \ + \ + } + + /* ------------------------- Operations on trees ------------------------- */ + + /* Insert chunk into tree */ + #define insert_large_chunk(M, X, S) \ + { \ + \ + tbinptr *H; \ + bindex_t I; \ + compute_tree_index(S, I); \ + H = treebin_at(M, I); \ + X->index = I; \ + X->child[0] = X->child[1] = 0; \ + if (!treemap_is_marked(M, I)) { \ + \ + mark_treemap(M, I); \ + *H = X; \ + X->parent = (tchunkptr)H; \ + X->fd = X->bk = X; \ + \ + } else { \ + \ + tchunkptr T = *H; \ + size_t K = S << leftshift_for_tree_index(I); \ + for (;;) { \ + \ + if (chunksize(T) != S) { \ + \ + tchunkptr *C = \ + &(T->child[(K >> (SIZE_T_BITSIZE - SIZE_T_ONE)) & 1]); \ + K <<= 1; \ + if (*C != 0) \ + T = *C; \ + else if (RTCHECK(ok_address(M, C))) { \ + \ + *C = X; \ + X->parent = T; \ + X->fd = X->bk = X; \ + break; \ + \ + } else { \ + \ + CORRUPTION_ERROR_ACTION(M); \ + break; \ + \ + } \ + \ + } else { \ + \ + tchunkptr F = T->fd; \ + if (RTCHECK(ok_address(M, T) && ok_address(M, F))) { \ + \ + T->fd = F->bk = X; \ + X->fd = F; \ + X->bk = T; \ + X->parent = 0; \ + break; \ + \ + } else { \ + \ + CORRUPTION_ERROR_ACTION(M); \ + break; \ + \ + } \ + \ + } \ + \ + } \ + \ + } \ + \ + } + +/* + Unlink steps: + + 1. If x is a chained node, unlink it from its same-sized fd/bk links + and choose its bk node as its replacement. + 2. If x was the last node of its size, but not a leaf node, it must + be replaced with a leaf node (not merely one with an open left or + right), to make sure that lefts and rights of descendents + correspond properly to bit masks. We use the rightmost descendent + of x. We could use any other leaf, but this is easy to locate and + tends to counteract removal of leftmosts elsewhere, and so keeps + paths shorter than minimally guaranteed. This doesn't loop much + because on average a node in a tree is near the bottom. + 3. If x is the base of a chain (i.e., has parent links) relink + x's parent and children to x's replacement (or null if none). +*/ + + #define unlink_large_chunk(M, X) \ + { \ + \ + tchunkptr XP = X->parent; \ + tchunkptr R; \ + if (X->bk != X) { \ + \ + tchunkptr F = X->fd; \ + R = X->bk; \ + if (RTCHECK(ok_address(M, F) && F->bk == X && R->fd == X)) { \ + \ + F->bk = R; \ + R->fd = F; \ + \ + } else { \ + \ + CORRUPTION_ERROR_ACTION(M); \ + \ + } \ + \ + } else { \ + \ + tchunkptr *RP; \ + if (((R = *(RP = &(X->child[1]))) != 0) || \ + ((R = *(RP = &(X->child[0]))) != 0)) { \ + \ + tchunkptr *CP; \ + while ((*(CP = &(R->child[1])) != 0) || \ + (*(CP = &(R->child[0])) != 0)) { \ + \ + R = *(RP = CP); \ + \ + } \ + if (RTCHECK(ok_address(M, RP))) \ + *RP = 0; \ + else { \ + \ + CORRUPTION_ERROR_ACTION(M); \ + \ + } \ + \ + } \ + \ + } \ + if (XP != 0) { \ + \ + tbinptr *H = treebin_at(M, X->index); \ + if (X == *H) { \ + \ + if ((*H = R) == 0) clear_treemap(M, X->index); \ + \ + } else if (RTCHECK(ok_address(M, XP))) { \ + \ + if (XP->child[0] == X) \ + XP->child[0] = R; \ + else \ + XP->child[1] = R; \ + \ + } else \ + \ + \ + CORRUPTION_ERROR_ACTION(M); \ + if (R != 0) { \ + \ + if (RTCHECK(ok_address(M, R))) { \ + \ + tchunkptr C0, C1; \ + R->parent = XP; \ + if ((C0 = X->child[0]) != 0) { \ + \ + if (RTCHECK(ok_address(M, C0))) { \ + \ + R->child[0] = C0; \ + C0->parent = R; \ + \ + } else \ + \ + \ + CORRUPTION_ERROR_ACTION(M); \ + \ + } \ + if ((C1 = X->child[1]) != 0) { \ + \ + if (RTCHECK(ok_address(M, C1))) { \ + \ + R->child[1] = C1; \ + C1->parent = R; \ + \ + } else \ + \ + \ + CORRUPTION_ERROR_ACTION(M); \ + \ + } \ + \ + } else \ + \ + \ + CORRUPTION_ERROR_ACTION(M); \ + \ + } \ + \ + } \ + \ + } + +/* Relays to large vs small bin operations */ + + #define insert_chunk(M, P, S) \ + if (is_small(S)) insert_small_chunk(M, P, S) else { \ + \ + tchunkptr TP = (tchunkptr)(P); \ + insert_large_chunk(M, TP, S); \ + \ + } + + #define unlink_chunk(M, P, S) \ + if (is_small(S)) unlink_small_chunk(M, P, S) else { \ + \ + tchunkptr TP = (tchunkptr)(P); \ + unlink_large_chunk(M, TP); \ + \ + } + +/* Relays to internal calls to malloc/free from realloc, memalign etc */ + + #if ONLY_MSPACES + #define internal_malloc(m, b) mspace_malloc(m, b) + #define internal_free(m, mem) mspace_free(m, mem); + #else /* ONLY_MSPACES */ + #if MSPACES + #define internal_malloc(m, b) \ + ((m == gm) ? dlmalloc(b) : mspace_malloc(m, b)) + #define internal_free(m, mem) \ + if (m == gm) \ + dlfree(mem); \ + else \ + mspace_free(m, mem); + #else /* MSPACES */ + #define internal_malloc(m, b) dlmalloc(b) + #define internal_free(m, mem) dlfree(mem) + #endif /* MSPACES */ + #endif /* ONLY_MSPACES */ + +/* ----------------------- Direct-mmapping chunks ----------------------- */ + +/* + Directly mmapped chunks are set up with an offset to the start of + the mmapped region stored in the prev_foot field of the chunk. This + allows reconstruction of the required argument to MUNMAP when freed, + and also allows adjustment of the returned chunk to meet alignment + requirements (especially in memalign). +*/ + +/* Malloc using mmap */ +static void *mmap_alloc(mstate m, size_t nb) { + + size_t mmsize = mmap_align(nb + SIX_SIZE_T_SIZES + CHUNK_ALIGN_MASK); + if (m->footprint_limit != 0) { + + size_t fp = m->footprint + mmsize; + if (fp <= m->footprint || fp > m->footprint_limit) return 0; + + } + + if (mmsize > nb) { /* Check for wrap around 0 */ + char *mm = (char *)(CALL_DIRECT_MMAP(mmsize)); + if (mm != CMFAIL) { + + size_t offset = align_offset(chunk2mem(mm)); + size_t psize = mmsize - offset - MMAP_FOOT_PAD; + mchunkptr p = (mchunkptr)(mm + offset); + p->prev_foot = offset; + p->head = psize; + mark_inuse_foot(m, p, psize); + chunk_plus_offset(p, psize)->head = FENCEPOST_HEAD; + chunk_plus_offset(p, psize + SIZE_T_SIZE)->head = 0; + + if (m->least_addr == 0 || mm < m->least_addr) m->least_addr = mm; + if ((m->footprint += mmsize) > m->max_footprint) + m->max_footprint = m->footprint; + assert(is_aligned(chunk2mem(p))); + check_mmapped_chunk(m, p); + return chunk2mem(p); + + } + + } + + return 0; + +} + +/* Realloc using mmap */ +static mchunkptr mmap_resize(mstate m, mchunkptr oldp, size_t nb, int flags) { + + size_t oldsize = chunksize(oldp); + (void)flags; /* placate people compiling -Wunused */ + if (is_small(nb)) /* Can't shrink mmap regions below small size */ + return 0; + /* Keep old chunk if big enough but not too big */ + if (oldsize >= nb + SIZE_T_SIZE && + (oldsize - nb) <= (mparams.granularity << 1)) + return oldp; + else { + + size_t offset = oldp->prev_foot; + size_t oldmmsize = oldsize + offset + MMAP_FOOT_PAD; + size_t newmmsize = mmap_align(nb + SIX_SIZE_T_SIZES + CHUNK_ALIGN_MASK); + char * cp = + (char *)CALL_MREMAP((char *)oldp - offset, oldmmsize, newmmsize, flags); + if (cp != CMFAIL) { + + mchunkptr newp = (mchunkptr)(cp + offset); + size_t psize = newmmsize - offset - MMAP_FOOT_PAD; + newp->head = psize; + mark_inuse_foot(m, newp, psize); + chunk_plus_offset(newp, psize)->head = FENCEPOST_HEAD; + chunk_plus_offset(newp, psize + SIZE_T_SIZE)->head = 0; + + if (cp < m->least_addr) m->least_addr = cp; + if ((m->footprint += newmmsize - oldmmsize) > m->max_footprint) + m->max_footprint = m->footprint; + check_mmapped_chunk(m, newp); + return newp; + + } + + } + + return 0; + +} + +/* -------------------------- mspace management -------------------------- */ + +/* Initialize top chunk and its size */ +static void init_top(mstate m, mchunkptr p, size_t psize) { + + /* Ensure alignment */ + size_t offset = align_offset(chunk2mem(p)); + p = (mchunkptr)((char *)p + offset); + psize -= offset; + + m->top = p; + m->topsize = psize; + p->head = psize | PINUSE_BIT; + /* set size of fake trailing chunk holding overhead space only once */ + chunk_plus_offset(p, psize)->head = TOP_FOOT_SIZE; + m->trim_check = mparams.trim_threshold; /* reset on each update */ + +} + +/* Initialize bins for a new mstate that is otherwise zeroed out */ +static void init_bins(mstate m) { + + /* Establish circular links for smallbins */ + bindex_t i; + for (i = 0; i < NSMALLBINS; ++i) { + + sbinptr bin = smallbin_at(m, i); + bin->fd = bin->bk = bin; + + } + +} + + #if PROCEED_ON_ERROR + +/* default corruption action */ +static void reset_on_error(mstate m) { + + int i; + ++malloc_corruption_error_count; + /* Reinitialize fields to forget about all memory */ + m->smallmap = m->treemap = 0; + m->dvsize = m->topsize = 0; + m->seg.base = 0; + m->seg.size = 0; + m->seg.next = 0; + m->top = m->dv = 0; + for (i = 0; i < NTREEBINS; ++i) + *treebin_at(m, i) = 0; + init_bins(m); + +} + + #endif /* PROCEED_ON_ERROR */ + +/* Allocate chunk and prepend remainder with chunk in successor base. */ +static void *prepend_alloc(mstate m, char *newbase, char *oldbase, size_t nb) { + + mchunkptr p = align_as_chunk(newbase); + mchunkptr oldfirst = align_as_chunk(oldbase); + size_t psize = (char *)oldfirst - (char *)p; + mchunkptr q = chunk_plus_offset(p, nb); + size_t qsize = psize - nb; + set_size_and_pinuse_of_inuse_chunk(m, p, nb); + + assert((char *)oldfirst > (char *)q); + assert(pinuse(oldfirst)); + assert(qsize >= MIN_CHUNK_SIZE); + + /* consolidate remainder with first chunk of old base */ + if (oldfirst == m->top) { + + size_t tsize = m->topsize += qsize; + m->top = q; + q->head = tsize | PINUSE_BIT; + check_top_chunk(m, q); + + } else if (oldfirst == m->dv) { + + size_t dsize = m->dvsize += qsize; + m->dv = q; + set_size_and_pinuse_of_free_chunk(q, dsize); + + } else { + + if (!is_inuse(oldfirst)) { + + size_t nsize = chunksize(oldfirst); + unlink_chunk(m, oldfirst, nsize); + oldfirst = chunk_plus_offset(oldfirst, nsize); + qsize += nsize; + + } + + set_free_with_pinuse(q, qsize, oldfirst); + insert_chunk(m, q, qsize); + check_free_chunk(m, q); + + } + + check_malloced_chunk(m, chunk2mem(p), nb); + return chunk2mem(p); + +} + +/* Add a segment to hold a new noncontiguous region */ +static void add_segment(mstate m, char *tbase, size_t tsize, flag_t mmapped) { + + /* Determine locations and sizes of segment, fenceposts, old top */ + char * old_top = (char *)m->top; + msegmentptr oldsp = segment_holding(m, old_top); + char * old_end = oldsp->base + oldsp->size; + size_t ssize = pad_request(sizeof(struct malloc_segment)); + char * rawsp = old_end - (ssize + FOUR_SIZE_T_SIZES + CHUNK_ALIGN_MASK); + size_t offset = align_offset(chunk2mem(rawsp)); + char * asp = rawsp + offset; + char * csp = (asp < (old_top + MIN_CHUNK_SIZE)) ? old_top : asp; + mchunkptr sp = (mchunkptr)csp; + msegmentptr ss = (msegmentptr)(chunk2mem(sp)); + mchunkptr tnext = chunk_plus_offset(sp, ssize); + mchunkptr p = tnext; + int nfences = 0; + + /* reset top to new space */ + init_top(m, (mchunkptr)tbase, tsize - TOP_FOOT_SIZE); + + /* Set up segment record */ + assert(is_aligned(ss)); + set_size_and_pinuse_of_inuse_chunk(m, sp, ssize); + *ss = m->seg; /* Push current record */ + m->seg.base = tbase; + m->seg.size = tsize; + m->seg.sflags = mmapped; + m->seg.next = ss; + + /* Insert trailing fenceposts */ + for (;;) { + + mchunkptr nextp = chunk_plus_offset(p, SIZE_T_SIZE); + p->head = FENCEPOST_HEAD; + ++nfences; + if ((char *)(&(nextp->head)) < old_end) + p = nextp; + else + break; + + } + + assert(nfences >= 2); + + /* Insert the rest of old top into a bin as an ordinary free chunk */ + if (csp != old_top) { + + mchunkptr q = (mchunkptr)old_top; + size_t psize = csp - old_top; + mchunkptr tn = chunk_plus_offset(q, psize); + set_free_with_pinuse(q, psize, tn); + insert_chunk(m, q, psize); + + } + + check_top_chunk(m, m->top); + +} + +/* -------------------------- System allocation -------------------------- */ + +/* Get memory from system using MORECORE or MMAP */ +static void *sys_alloc(mstate m, size_t nb) { + + char * tbase = CMFAIL; + size_t tsize = 0; + flag_t mmap_flag = 0; + size_t asize; /* allocation size */ + + ensure_initialization(); + + /* Directly map large chunks, but only if already initialized */ + if (use_mmap(m) && nb >= mparams.mmap_threshold && m->topsize != 0) { + + void *mem = mmap_alloc(m, nb); + if (mem != 0) return mem; + + } + + asize = granularity_align(nb + SYS_ALLOC_PADDING); + if (asize <= nb) return 0; /* wraparound */ + if (m->footprint_limit != 0) { + + size_t fp = m->footprint + asize; + if (fp <= m->footprint || fp > m->footprint_limit) return 0; + + } + + /* + Try getting memory in any of three ways (in most-preferred to + least-preferred order): + 1. A call to MORECORE that can normally contiguously extend memory. + (disabled if not MORECORE_CONTIGUOUS or not HAVE_MORECORE or + or main space is mmapped or a previous contiguous call failed) + 2. A call to MMAP new space (disabled if not HAVE_MMAP). + Note that under the default settings, if MORECORE is unable to + fulfill a request, and HAVE_MMAP is true, then mmap is + used as a noncontiguous system allocator. This is a useful backup + strategy for systems with holes in address spaces -- in this case + sbrk cannot contiguously expand the heap, but mmap may be able to + find space. + 3. A call to MORECORE that cannot usually contiguously extend memory. + (disabled if not HAVE_MORECORE) + + In all cases, we need to request enough bytes from system to ensure + we can malloc nb bytes upon success, so pad with enough space for + top_foot, plus alignment-pad to make sure we don't lose bytes if + not on boundary, and round this up to a granularity unit. + */ + + if (MORECORE_CONTIGUOUS && !use_noncontiguous(m)) { + + char * br = CMFAIL; + size_t ssize = asize; /* sbrk call size */ + msegmentptr ss = (m->top == 0) ? 0 : segment_holding(m, (char *)m->top); + ACQUIRE_MALLOC_GLOBAL_LOCK(); + + if (ss == 0) { /* First time through or recovery */ + char *base = (char *)CALL_MORECORE(0); + if (base != CMFAIL) { + + size_t fp; + /* Adjust to end on a page boundary */ + if (!is_page_aligned(base)) + ssize += (page_align((size_t)base) - (size_t)base); + fp = m->footprint + ssize; /* recheck limits */ + if (ssize > nb && ssize < HALF_MAX_SIZE_T && + (m->footprint_limit == 0 || + (fp > m->footprint && fp <= m->footprint_limit)) && + (br = (char *)(CALL_MORECORE(ssize))) == base) { + + tbase = base; + tsize = ssize; + + } + + } + + } else { + + /* Subtract out existing available top space from MORECORE request. */ + ssize = granularity_align(nb - m->topsize + SYS_ALLOC_PADDING); + /* Use mem here only if it did continuously extend old space */ + if (ssize < HALF_MAX_SIZE_T && + (br = (char *)(CALL_MORECORE(ssize))) == ss->base + ss->size) { + + tbase = br; + tsize = ssize; + + } + + } + + if (tbase == CMFAIL) { /* Cope with partial failure */ + if (br != CMFAIL) { /* Try to use/extend the space we did get */ + if (ssize < HALF_MAX_SIZE_T && ssize < nb + SYS_ALLOC_PADDING) { + + size_t esize = granularity_align(nb + SYS_ALLOC_PADDING - ssize); + if (esize < HALF_MAX_SIZE_T) { + + char *end = (char *)CALL_MORECORE(esize); + if (end != CMFAIL) + ssize += esize; + else { /* Can't use; try to release */ + (void)CALL_MORECORE(-ssize); + br = CMFAIL; + + } + + } + + } + + } + + if (br != CMFAIL) { /* Use the space we did get */ + tbase = br; + tsize = ssize; + + } else + + disable_contiguous(m); /* Don't try contiguous path in the future */ + + } + + RELEASE_MALLOC_GLOBAL_LOCK(); + + } + + if (HAVE_MMAP && tbase == CMFAIL) { /* Try MMAP */ + char *mp = (char *)(CALL_MMAP(asize)); + if (mp != CMFAIL) { + + tbase = mp; + tsize = asize; + mmap_flag = USE_MMAP_BIT; + + } + + } + + if (HAVE_MORECORE && tbase == CMFAIL) { /* Try noncontiguous MORECORE */ + if (asize < HALF_MAX_SIZE_T) { + + char *br = CMFAIL; + char *end = CMFAIL; + ACQUIRE_MALLOC_GLOBAL_LOCK(); + br = (char *)(CALL_MORECORE(asize)); + end = (char *)(CALL_MORECORE(0)); + RELEASE_MALLOC_GLOBAL_LOCK(); + if (br != CMFAIL && end != CMFAIL && br < end) { + + size_t ssize = end - br; + if (ssize > nb + TOP_FOOT_SIZE) { + + tbase = br; + tsize = ssize; + + } + + } + + } + + } + + if (tbase != CMFAIL) { + + if ((m->footprint += tsize) > m->max_footprint) + m->max_footprint = m->footprint; + + if (!is_initialized(m)) { /* first-time initialization */ + if (m->least_addr == 0 || tbase < m->least_addr) m->least_addr = tbase; + m->seg.base = tbase; + m->seg.size = tsize; + m->seg.sflags = mmap_flag; + m->magic = mparams.magic; + m->release_checks = MAX_RELEASE_CHECK_RATE; + init_bins(m); + #if !ONLY_MSPACES + if (is_global(m)) + init_top(m, (mchunkptr)tbase, tsize - TOP_FOOT_SIZE); + else + #endif + { + + /* Offset top by embedded malloc_state */ + mchunkptr mn = next_chunk(mem2chunk(m)); + init_top(m, mn, (size_t)((tbase + tsize) - (char *)mn) - TOP_FOOT_SIZE); + + } + + } + + else { + + /* Try to merge with an existing segment */ + msegmentptr sp = &m->seg; + /* Only consider most recent segment if traversal suppressed */ + while (sp != 0 && tbase != sp->base + sp->size) + sp = (NO_SEGMENT_TRAVERSAL) ? 0 : sp->next; + if (sp != 0 && !is_extern_segment(sp) && + (sp->sflags & USE_MMAP_BIT) == mmap_flag && + segment_holds(sp, m->top)) { /* append */ + sp->size += tsize; + init_top(m, m->top, m->topsize + tsize); + + } else { + + if (tbase < m->least_addr) m->least_addr = tbase; + sp = &m->seg; + while (sp != 0 && sp->base != tbase + tsize) + sp = (NO_SEGMENT_TRAVERSAL) ? 0 : sp->next; + if (sp != 0 && !is_extern_segment(sp) && + (sp->sflags & USE_MMAP_BIT) == mmap_flag) { + + char *oldbase = sp->base; + sp->base = tbase; + sp->size += tsize; + return prepend_alloc(m, tbase, oldbase, nb); + + } else + + add_segment(m, tbase, tsize, mmap_flag); + + } + + } + + if (nb < m->topsize) { /* Allocate from new or extended top space */ + size_t rsize = m->topsize -= nb; + mchunkptr p = m->top; + mchunkptr r = m->top = chunk_plus_offset(p, nb); + r->head = rsize | PINUSE_BIT; + set_size_and_pinuse_of_inuse_chunk(m, p, nb); + check_top_chunk(m, m->top); + check_malloced_chunk(m, chunk2mem(p), nb); + return chunk2mem(p); + + } + + } + + MALLOC_FAILURE_ACTION; + return 0; + +} + +/* ----------------------- system deallocation -------------------------- */ + +/* Unmap and unlink any mmapped segments that don't contain used chunks */ +static size_t release_unused_segments(mstate m) { + + size_t released = 0; + int nsegs = 0; + msegmentptr pred = &m->seg; + msegmentptr sp = pred->next; + while (sp != 0) { + + char * base = sp->base; + size_t size = sp->size; + msegmentptr next = sp->next; + ++nsegs; + if (is_mmapped_segment(sp) && !is_extern_segment(sp)) { + + mchunkptr p = align_as_chunk(base); + size_t psize = chunksize(p); + /* Can unmap if first chunk holds entire segment and not pinned */ + if (!is_inuse(p) && (char *)p + psize >= base + size - TOP_FOOT_SIZE) { + + tchunkptr tp = (tchunkptr)p; + assert(segment_holds(sp, (char *)sp)); + if (p == m->dv) { + + m->dv = 0; + m->dvsize = 0; + + } else { + + unlink_large_chunk(m, tp); + + } + + if (CALL_MUNMAP(base, size) == 0) { + + released += size; + m->footprint -= size; + /* unlink obsoleted record */ + sp = pred; + sp->next = next; + + } else { /* back out if cannot unmap */ + + insert_large_chunk(m, tp, psize); + + } + + } + + } + + if (NO_SEGMENT_TRAVERSAL) /* scan only first segment */ + break; + pred = sp; + sp = next; + + } + + /* Reset check counter */ + m->release_checks = (((size_t)nsegs > (size_t)MAX_RELEASE_CHECK_RATE) + ? (size_t)nsegs + : (size_t)MAX_RELEASE_CHECK_RATE); + return released; + +} + +static int sys_trim(mstate m, size_t pad) { + + size_t released = 0; + ensure_initialization(); + if (pad < MAX_REQUEST && is_initialized(m)) { + + pad += TOP_FOOT_SIZE; /* ensure enough room for segment overhead */ + + if (m->topsize > pad) { + + /* Shrink top space in granularity-size units, keeping at least one */ + size_t unit = mparams.granularity; + size_t extra = + ((m->topsize - pad + (unit - SIZE_T_ONE)) / unit - SIZE_T_ONE) * unit; + msegmentptr sp = segment_holding(m, (char *)m->top); + + if (!is_extern_segment(sp)) { + + if (is_mmapped_segment(sp)) { + + if (HAVE_MMAP && sp->size >= extra && + !has_segment_link(m, sp)) { /* can't shrink if pinned */ + size_t newsize = sp->size - extra; + (void)newsize; /* placate people compiling -Wunused-variable */ + /* Prefer mremap, fall back to munmap */ + if ((CALL_MREMAP(sp->base, sp->size, newsize, 0) != MFAIL) || + (CALL_MUNMAP(sp->base + newsize, extra) == 0)) { + + released = extra; + + } + + } + + } else if (HAVE_MORECORE) { + + if (extra >= HALF_MAX_SIZE_T) /* Avoid wrapping negative */ + extra = (HALF_MAX_SIZE_T) + SIZE_T_ONE - unit; + ACQUIRE_MALLOC_GLOBAL_LOCK(); + { + + /* Make sure end of memory is where we last set it. */ + char *old_br = (char *)(CALL_MORECORE(0)); + if (old_br == sp->base + sp->size) { + + char *rel_br = (char *)(CALL_MORECORE(-extra)); + char *new_br = (char *)(CALL_MORECORE(0)); + if (rel_br != CMFAIL && new_br < old_br) + released = old_br - new_br; + + } + + } + + RELEASE_MALLOC_GLOBAL_LOCK(); + + } + + } + + if (released != 0) { + + sp->size -= released; + m->footprint -= released; + init_top(m, m->top, m->topsize - released); + check_top_chunk(m, m->top); + + } + + } + + /* Unmap any unused mmapped segments */ + if (HAVE_MMAP) released += release_unused_segments(m); + + /* On failure, disable autotrim to avoid repeated failed future calls */ + if (released == 0 && m->topsize > m->trim_check) m->trim_check = MAX_SIZE_T; + + } + + return (released != 0) ? 1 : 0; + +} + +/* Consolidate and bin a chunk. Differs from exported versions + of free mainly in that the chunk need not be marked as inuse. +*/ +static void dispose_chunk(mstate m, mchunkptr p, size_t psize) { + + mchunkptr next = chunk_plus_offset(p, psize); + if (!pinuse(p)) { + + mchunkptr prev; + size_t prevsize = p->prev_foot; + if (is_mmapped(p)) { + + psize += prevsize + MMAP_FOOT_PAD; + if (CALL_MUNMAP((char *)p - prevsize, psize) == 0) m->footprint -= psize; + return; + + } + + prev = chunk_minus_offset(p, prevsize); + psize += prevsize; + p = prev; + if (RTCHECK(ok_address(m, prev))) { /* consolidate backward */ + if (p != m->dv) { + + unlink_chunk(m, p, prevsize); + + } else if ((next->head & INUSE_BITS) == INUSE_BITS) { + + m->dvsize = psize; + set_free_with_pinuse(p, psize, next); + return; + + } + + } else { + + CORRUPTION_ERROR_ACTION(m); + return; + + } + + } + + if (RTCHECK(ok_address(m, next))) { + + if (!cinuse(next)) { /* consolidate forward */ + if (next == m->top) { + + size_t tsize = m->topsize += psize; + m->top = p; + p->head = tsize | PINUSE_BIT; + if (p == m->dv) { + + m->dv = 0; + m->dvsize = 0; + + } + + return; + + } else if (next == m->dv) { + + size_t dsize = m->dvsize += psize; + m->dv = p; + set_size_and_pinuse_of_free_chunk(p, dsize); + return; + + } else { + + size_t nsize = chunksize(next); + psize += nsize; + unlink_chunk(m, next, nsize); + set_size_and_pinuse_of_free_chunk(p, psize); + if (p == m->dv) { + + m->dvsize = psize; + return; + + } + + } + + } else { + + set_free_with_pinuse(p, psize, next); + + } + + insert_chunk(m, p, psize); + + } else { + + CORRUPTION_ERROR_ACTION(m); + + } + +} + +/* ---------------------------- malloc --------------------------- */ + +/* allocate a large request from the best fitting chunk in a treebin */ +static void *tmalloc_large(mstate m, size_t nb) { + + tchunkptr v = 0; + size_t rsize = -nb; /* Unsigned negation */ + tchunkptr t; + bindex_t idx; + compute_tree_index(nb, idx); + if ((t = *treebin_at(m, idx)) != 0) { + + /* Traverse tree for this bin looking for node with size == nb */ + size_t sizebits = nb << leftshift_for_tree_index(idx); + tchunkptr rst = 0; /* The deepest untaken right subtree */ + for (;;) { + + tchunkptr rt; + size_t trem = chunksize(t) - nb; + if (trem < rsize) { + + v = t; + if ((rsize = trem) == 0) break; + + } + + rt = t->child[1]; + t = t->child[(sizebits >> (SIZE_T_BITSIZE - SIZE_T_ONE)) & 1]; + if (rt != 0 && rt != t) rst = rt; + if (t == 0) { + + t = rst; /* set t to least subtree holding sizes > nb */ + break; + + } + + sizebits <<= 1; + + } + + } + + if (t == 0 && v == 0) { /* set t to root of next non-empty treebin */ + binmap_t leftbits = left_bits(idx2bit(idx)) & m->treemap; + if (leftbits != 0) { + + bindex_t i; + binmap_t leastbit = least_bit(leftbits); + compute_bit2idx(leastbit, i); + t = *treebin_at(m, i); + + } + + } + + while (t != 0) { /* find smallest of tree or subtree */ + size_t trem = chunksize(t) - nb; + if (trem < rsize) { + + rsize = trem; + v = t; + + } + + t = leftmost_child(t); + + } + + /* If dv is a better fit, return 0 so malloc will use it */ + if (v != 0 && rsize < (size_t)(m->dvsize - nb)) { + + if (RTCHECK(ok_address(m, v))) { /* split */ + mchunkptr r = chunk_plus_offset(v, nb); + assert(chunksize(v) == rsize + nb); + if (RTCHECK(ok_next(v, r))) { + + unlink_large_chunk(m, v); + if (rsize < MIN_CHUNK_SIZE) + set_inuse_and_pinuse(m, v, (rsize + nb)); + else { + + set_size_and_pinuse_of_inuse_chunk(m, v, nb); + set_size_and_pinuse_of_free_chunk(r, rsize); + insert_chunk(m, r, rsize); + + } + + return chunk2mem(v); + + } + + } + + CORRUPTION_ERROR_ACTION(m); + + } + + return 0; + +} + +/* allocate a small request from the best fitting chunk in a treebin */ +static void *tmalloc_small(mstate m, size_t nb) { + + tchunkptr t, v; + size_t rsize; + bindex_t i; + binmap_t leastbit = least_bit(m->treemap); + compute_bit2idx(leastbit, i); + v = t = *treebin_at(m, i); + rsize = chunksize(t) - nb; + + while ((t = leftmost_child(t)) != 0) { + + size_t trem = chunksize(t) - nb; + if (trem < rsize) { + + rsize = trem; + v = t; + + } + + } + + if (RTCHECK(ok_address(m, v))) { + + mchunkptr r = chunk_plus_offset(v, nb); + assert(chunksize(v) == rsize + nb); + if (RTCHECK(ok_next(v, r))) { + + unlink_large_chunk(m, v); + if (rsize < MIN_CHUNK_SIZE) + set_inuse_and_pinuse(m, v, (rsize + nb)); + else { + + set_size_and_pinuse_of_inuse_chunk(m, v, nb); + set_size_and_pinuse_of_free_chunk(r, rsize); + replace_dv(m, r, rsize); + + } + + return chunk2mem(v); + + } + + } + + CORRUPTION_ERROR_ACTION(m); + return 0; + +} + + #if !ONLY_MSPACES + +void *dlmalloc(size_t bytes) { + + /* + Basic algorithm: + If a small request (< 256 bytes minus per-chunk overhead): + 1. If one exists, use a remainderless chunk in associated smallbin. + (Remainderless means that there are too few excess bytes to + represent as a chunk.) + 2. If it is big enough, use the dv chunk, which is normally the + chunk adjacent to the one used for the most recent small request. + 3. If one exists, split the smallest available chunk in a bin, + saving remainder in dv. + 4. If it is big enough, use the top chunk. + 5. If available, get memory from system and use it + Otherwise, for a large request: + 1. Find the smallest available binned chunk that fits, and use it + if it is better fitting than dv chunk, splitting if necessary. + 2. If better fitting than any binned chunk, use the dv chunk. + 3. If it is big enough, use the top chunk. + 4. If request size >= mmap threshold, try to directly mmap this chunk. + 5. If available, get memory from system and use it + + The ugly goto's here ensure that postaction occurs along all paths. + */ + + #if USE_LOCKS + ensure_initialization(); /* initialize in sys_alloc if not using locks */ + #endif + + if (!PREACTION(gm)) { + + void * mem; + size_t nb; + if (bytes <= MAX_SMALL_REQUEST) { + + bindex_t idx; + binmap_t smallbits; + nb = (bytes < MIN_REQUEST) ? MIN_CHUNK_SIZE : pad_request(bytes); + idx = small_index(nb); + smallbits = gm->smallmap >> idx; + + if ((smallbits & 0x3U) != 0) { /* Remainderless fit to a smallbin. */ + mchunkptr b, p; + idx += ~smallbits & 1; /* Uses next bin if idx empty */ + b = smallbin_at(gm, idx); + p = b->fd; + assert(chunksize(p) == small_index2size(idx)); + unlink_first_small_chunk(gm, b, p, idx); + set_inuse_and_pinuse(gm, p, small_index2size(idx)); + mem = chunk2mem(p); + check_malloced_chunk(gm, mem, nb); + goto postaction; + + } + + else if (nb > gm->dvsize) { + + if (smallbits != 0) { /* Use chunk in next nonempty smallbin */ + mchunkptr b, p, r; + size_t rsize; + bindex_t i; + binmap_t leftbits = (smallbits << idx) & left_bits(idx2bit(idx)); + binmap_t leastbit = least_bit(leftbits); + compute_bit2idx(leastbit, i); + b = smallbin_at(gm, i); + p = b->fd; + assert(chunksize(p) == small_index2size(i)); + unlink_first_small_chunk(gm, b, p, i); + rsize = small_index2size(i) - nb; + /* Fit here cannot be remainderless if 4byte sizes */ + if (SIZE_T_SIZE != 4 && rsize < MIN_CHUNK_SIZE) + set_inuse_and_pinuse(gm, p, small_index2size(i)); + else { + + set_size_and_pinuse_of_inuse_chunk(gm, p, nb); + r = chunk_plus_offset(p, nb); + set_size_and_pinuse_of_free_chunk(r, rsize); + replace_dv(gm, r, rsize); + + } + + mem = chunk2mem(p); + check_malloced_chunk(gm, mem, nb); + goto postaction; + + } + + else if (gm->treemap != 0 && (mem = tmalloc_small(gm, nb)) != 0) { + + check_malloced_chunk(gm, mem, nb); + goto postaction; + + } + + } + + } else if (bytes >= MAX_REQUEST) + + nb = MAX_SIZE_T; /* Too big to allocate. Force failure (in sys alloc) */ + else { + + nb = pad_request(bytes); + if (gm->treemap != 0 && (mem = tmalloc_large(gm, nb)) != 0) { + + check_malloced_chunk(gm, mem, nb); + goto postaction; + + } + + } + + if (nb <= gm->dvsize) { + + size_t rsize = gm->dvsize - nb; + mchunkptr p = gm->dv; + if (rsize >= MIN_CHUNK_SIZE) { /* split dv */ + mchunkptr r = gm->dv = chunk_plus_offset(p, nb); + gm->dvsize = rsize; + set_size_and_pinuse_of_free_chunk(r, rsize); + set_size_and_pinuse_of_inuse_chunk(gm, p, nb); + + } else { /* exhaust dv */ + + size_t dvs = gm->dvsize; + gm->dvsize = 0; + gm->dv = 0; + set_inuse_and_pinuse(gm, p, dvs); + + } + + mem = chunk2mem(p); + check_malloced_chunk(gm, mem, nb); + goto postaction; + + } + + else if (nb < gm->topsize) { /* Split top */ + size_t rsize = gm->topsize -= nb; + mchunkptr p = gm->top; + mchunkptr r = gm->top = chunk_plus_offset(p, nb); + r->head = rsize | PINUSE_BIT; + set_size_and_pinuse_of_inuse_chunk(gm, p, nb); + mem = chunk2mem(p); + check_top_chunk(gm, gm->top); + check_malloced_chunk(gm, mem, nb); + goto postaction; + + } + + mem = sys_alloc(gm, nb); + + postaction: + POSTACTION(gm); + return mem; + + } + + return 0; + +} + +/* ---------------------------- free --------------------------- */ + +void dlfree(void *mem) { + + /* + Consolidate freed chunks with preceeding or succeeding bordering + free chunks, if they exist, and then place in a bin. Intermixed + with special cases for top, dv, mmapped chunks, and usage errors. + */ + + if (mem != 0) { + + mchunkptr p = mem2chunk(mem); + #if FOOTERS + mstate fm = get_mstate_for(p); + if (!ok_magic(fm)) { + + USAGE_ERROR_ACTION(fm, p); + return; + + } + + #else /* FOOTERS */ + #define fm gm + #endif /* FOOTERS */ + if (!PREACTION(fm)) { + + check_inuse_chunk(fm, p); + if (RTCHECK(ok_address(fm, p) && ok_inuse(p))) { + + size_t psize = chunksize(p); + mchunkptr next = chunk_plus_offset(p, psize); + if (!pinuse(p)) { + + size_t prevsize = p->prev_foot; + if (is_mmapped(p)) { + + psize += prevsize + MMAP_FOOT_PAD; + if (CALL_MUNMAP((char *)p - prevsize, psize) == 0) + fm->footprint -= psize; + goto postaction; + + } else { + + mchunkptr prev = chunk_minus_offset(p, prevsize); + psize += prevsize; + p = prev; + if (RTCHECK(ok_address(fm, prev))) { /* consolidate backward */ + if (p != fm->dv) { + + unlink_chunk(fm, p, prevsize); + + } else if ((next->head & INUSE_BITS) == INUSE_BITS) { + + fm->dvsize = psize; + set_free_with_pinuse(p, psize, next); + goto postaction; + + } + + } else + + goto erroraction; + + } + + } + + if (RTCHECK(ok_next(p, next) && ok_pinuse(next))) { + + if (!cinuse(next)) { /* consolidate forward */ + if (next == fm->top) { + + size_t tsize = fm->topsize += psize; + fm->top = p; + p->head = tsize | PINUSE_BIT; + if (p == fm->dv) { + + fm->dv = 0; + fm->dvsize = 0; + + } + + if (should_trim(fm, tsize)) sys_trim(fm, 0); + goto postaction; + + } else if (next == fm->dv) { + + size_t dsize = fm->dvsize += psize; + fm->dv = p; + set_size_and_pinuse_of_free_chunk(p, dsize); + goto postaction; + + } else { + + size_t nsize = chunksize(next); + psize += nsize; + unlink_chunk(fm, next, nsize); + set_size_and_pinuse_of_free_chunk(p, psize); + if (p == fm->dv) { + + fm->dvsize = psize; + goto postaction; + + } + + } + + } else + + set_free_with_pinuse(p, psize, next); + + if (is_small(psize)) { + + insert_small_chunk(fm, p, psize); + check_free_chunk(fm, p); + + } else { + + tchunkptr tp = (tchunkptr)p; + insert_large_chunk(fm, tp, psize); + check_free_chunk(fm, p); + if (--fm->release_checks == 0) release_unused_segments(fm); + + } + + goto postaction; + + } + + } + + erroraction: + USAGE_ERROR_ACTION(fm, p); + postaction: + POSTACTION(fm); + + } + + } + + #if !FOOTERS + #undef fm + #endif /* FOOTERS */ + +} + +void *dlcalloc(size_t n_elements, size_t elem_size) { + + void * mem; + size_t req = 0; + if (n_elements != 0) { + + req = n_elements * elem_size; + if (((n_elements | elem_size) & ~(size_t)0xffff) && + (req / n_elements != elem_size)) + req = MAX_SIZE_T; /* force downstream failure on overflow */ + + } + + mem = dlmalloc(req); + if (mem != 0 && calloc_must_clear(mem2chunk(mem))) + __builtin_memset(mem, 0, req); + return mem; + +} + + #endif /* !ONLY_MSPACES */ + +/* ------------ Internal support for realloc, memalign, etc -------------- */ + +/* Try to realloc; only in-place unless can_move true */ +static mchunkptr try_realloc_chunk(mstate m, mchunkptr p, size_t nb, + int can_move) { + + mchunkptr newp = 0; + size_t oldsize = chunksize(p); + mchunkptr next = chunk_plus_offset(p, oldsize); + if (RTCHECK(ok_address(m, p) && ok_inuse(p) && ok_next(p, next) && + ok_pinuse(next))) { + + if (is_mmapped(p)) { + + newp = mmap_resize(m, p, nb, can_move); + + } else if (oldsize >= nb) { /* already big enough */ + + size_t rsize = oldsize - nb; + if (rsize >= MIN_CHUNK_SIZE) { /* split off remainder */ + mchunkptr r = chunk_plus_offset(p, nb); + set_inuse(m, p, nb); + set_inuse(m, r, rsize); + dispose_chunk(m, r, rsize); + + } + + newp = p; + + } else if (next == m->top) { /* extend into top */ + + if (oldsize + m->topsize > nb) { + + size_t newsize = oldsize + m->topsize; + size_t newtopsize = newsize - nb; + mchunkptr newtop = chunk_plus_offset(p, nb); + set_inuse(m, p, nb); + newtop->head = newtopsize | PINUSE_BIT; + m->top = newtop; + m->topsize = newtopsize; + newp = p; + + } + + } else if (next == m->dv) { /* extend into dv */ + + size_t dvs = m->dvsize; + if (oldsize + dvs >= nb) { + + size_t dsize = oldsize + dvs - nb; + if (dsize >= MIN_CHUNK_SIZE) { + + mchunkptr r = chunk_plus_offset(p, nb); + mchunkptr n = chunk_plus_offset(r, dsize); + set_inuse(m, p, nb); + set_size_and_pinuse_of_free_chunk(r, dsize); + clear_pinuse(n); + m->dvsize = dsize; + m->dv = r; + + } else { /* exhaust dv */ + + size_t newsize = oldsize + dvs; + set_inuse(m, p, newsize); + m->dvsize = 0; + m->dv = 0; + + } + + newp = p; + + } + + } else if (!cinuse(next)) { /* extend into next free chunk */ + + size_t nextsize = chunksize(next); + if (oldsize + nextsize >= nb) { + + size_t rsize = oldsize + nextsize - nb; + unlink_chunk(m, next, nextsize); + if (rsize < MIN_CHUNK_SIZE) { + + size_t newsize = oldsize + nextsize; + set_inuse(m, p, newsize); + + } else { + + mchunkptr r = chunk_plus_offset(p, nb); + set_inuse(m, p, nb); + set_inuse(m, r, rsize); + dispose_chunk(m, r, rsize); + + } + + newp = p; + + } + + } + + } else { + + USAGE_ERROR_ACTION(m, chunk2mem(p)); + + } + + return newp; + +} + +static void *internal_memalign(mstate m, size_t alignment, size_t bytes) { + + void *mem = 0; + if (alignment < MIN_CHUNK_SIZE) /* must be at least a minimum chunk size */ + alignment = MIN_CHUNK_SIZE; + if ((alignment & (alignment - SIZE_T_ONE)) != 0) { /* Ensure a power of 2 */ + size_t a = MALLOC_ALIGNMENT << 1; + while (a < alignment) + a <<= 1; + alignment = a; + + } + + if (bytes >= MAX_REQUEST - alignment) { + + if (m != 0) { /* Test isn't needed but avoids compiler warning */ + MALLOC_FAILURE_ACTION; + + } + + } else { + + size_t nb = request2size(bytes); + size_t req = nb + alignment + MIN_CHUNK_SIZE - CHUNK_OVERHEAD; + mem = internal_malloc(m, req); + if (mem != 0) { + + mchunkptr p = mem2chunk(mem); + if (PREACTION(m)) return 0; + if ((((size_t)(mem)) & (alignment - 1)) != 0) { /* misaligned */ + /* + Find an aligned spot inside chunk. Since we need to give + back leading space in a chunk of at least MIN_CHUNK_SIZE, if + the first calculation places us at a spot with less than + MIN_CHUNK_SIZE leader, we can move to the next aligned spot. + We've allocated enough total room so that this is always + possible. + */ + char * br = (char *)mem2chunk((size_t)( + ((size_t)((char *)mem + alignment - SIZE_T_ONE)) & -alignment)); + char * pos = ((size_t)(br - (char *)(p)) >= MIN_CHUNK_SIZE) + ? br + : br + alignment; + mchunkptr newp = (mchunkptr)pos; + size_t leadsize = pos - (char *)(p); + size_t newsize = chunksize(p) - leadsize; + + if (is_mmapped(p)) { /* For mmapped chunks, just adjust offset */ + newp->prev_foot = p->prev_foot + leadsize; + newp->head = newsize; + + } else { /* Otherwise, give back leader, use the rest */ + + set_inuse(m, newp, newsize); + set_inuse(m, p, leadsize); + dispose_chunk(m, p, leadsize); + + } + + p = newp; + + } + + /* Give back spare room at the end */ + if (!is_mmapped(p)) { + + size_t size = chunksize(p); + if (size > nb + MIN_CHUNK_SIZE) { + + size_t remainder_size = size - nb; + mchunkptr remainder = chunk_plus_offset(p, nb); + set_inuse(m, p, nb); + set_inuse(m, remainder, remainder_size); + dispose_chunk(m, remainder, remainder_size); + + } + + } + + mem = chunk2mem(p); + assert(chunksize(p) >= nb); + assert(((size_t)mem & (alignment - 1)) == 0); + check_inuse_chunk(m, p); + POSTACTION(m); + + } + + } + + return mem; + +} + +/* + Common support for independent_X routines, handling + all of the combinations that can result. + The opts arg has: + bit 0 set if all elements are same size (using sizes[0]) + bit 1 set if elements should be zeroed +*/ +static void **ialloc(mstate m, size_t n_elements, size_t *sizes, int opts, + void *chunks[]) { + + size_t element_size; /* chunksize of each element, if all same */ + size_t contents_size; /* total size of elements */ + size_t array_size; /* request size of pointer array */ + void * mem; /* malloced aggregate space */ + mchunkptr p; /* corresponding chunk */ + size_t remainder_size; /* remaining bytes while splitting */ + void ** marray; /* either "chunks" or malloced ptr array */ + mchunkptr array_chunk; /* chunk for malloced ptr array */ + flag_t was_enabled; /* to disable mmap */ + size_t size; + size_t i; + + ensure_initialization(); + /* compute array length, if needed */ + if (chunks != 0) { + + if (n_elements == 0) return chunks; /* nothing to do */ + marray = chunks; + array_size = 0; + + } else { + + /* if empty req, must still return chunk representing empty array */ + if (n_elements == 0) return (void **)internal_malloc(m, 0); + marray = 0; + array_size = request2size(n_elements * (sizeof(void *))); + + } + + /* compute total element size */ + if (opts & 0x1) { /* all-same-size */ + element_size = request2size(*sizes); + contents_size = n_elements * element_size; + + } else { /* add up all the sizes */ + + element_size = 0; + contents_size = 0; + for (i = 0; i != n_elements; ++i) + contents_size += request2size(sizes[i]); + + } + + size = contents_size + array_size; + + /* + Allocate the aggregate chunk. First disable direct-mmapping so + malloc won't use it, since we would not be able to later + free/realloc space internal to a segregated mmap region. + */ + was_enabled = use_mmap(m); + disable_mmap(m); + mem = internal_malloc(m, size - CHUNK_OVERHEAD); + if (was_enabled) enable_mmap(m); + if (mem == 0) return 0; + + if (PREACTION(m)) return 0; + p = mem2chunk(mem); + remainder_size = chunksize(p); + + assert(!is_mmapped(p)); + + if (opts & 0x2) { /* optionally clear the elements */ + __builtin_memset((size_t *)mem, 0, + remainder_size - SIZE_T_SIZE - array_size); + + } + + /* If not provided, allocate the pointer array as final part of chunk */ + if (marray == 0) { + + size_t array_chunk_size; + array_chunk = chunk_plus_offset(p, contents_size); + array_chunk_size = remainder_size - contents_size; + marray = (void **)(chunk2mem(array_chunk)); + set_size_and_pinuse_of_inuse_chunk(m, array_chunk, array_chunk_size); + remainder_size = contents_size; + + } + + /* split out elements */ + for (i = 0;; ++i) { + + marray[i] = chunk2mem(p); + if (i != n_elements - 1) { + + if (element_size != 0) + size = element_size; + else + size = request2size(sizes[i]); + remainder_size -= size; + set_size_and_pinuse_of_inuse_chunk(m, p, size); + p = chunk_plus_offset(p, size); + + } else { /* the final element absorbs any overallocation slop */ + + set_size_and_pinuse_of_inuse_chunk(m, p, remainder_size); + break; + + } + + } + + #if DEBUG + if (marray != chunks) { + + /* final element must have exactly exhausted chunk */ + if (element_size != 0) { + + assert(remainder_size == element_size); + + } else { + + assert(remainder_size == request2size(sizes[i])); + + } + + check_inuse_chunk(m, mem2chunk(marray)); + + } + + for (i = 0; i != n_elements; ++i) + check_inuse_chunk(m, mem2chunk(marray[i])); + + #endif /* DEBUG */ + + POSTACTION(m); + return marray; + +} + +/* Try to free all pointers in the given array. + Note: this could be made faster, by delaying consolidation, + at the price of disabling some user integrity checks, We + still optimize some consolidations by combining adjacent + chunks before freeing, which will occur often if allocated + with ialloc or the array is sorted. +*/ +static size_t internal_bulk_free(mstate m, void *array[], size_t nelem) { + + size_t unfreed = 0; + if (!PREACTION(m)) { + + void **a; + void **fence = &(array[nelem]); + for (a = array; a != fence; ++a) { + + void *mem = *a; + if (mem != 0) { + + mchunkptr p = mem2chunk(mem); + size_t psize = chunksize(p); + #if FOOTERS + if (get_mstate_for(p) != m) { + + ++unfreed; + continue; + + } + + #endif + check_inuse_chunk(m, p); + *a = 0; + if (RTCHECK(ok_address(m, p) && ok_inuse(p))) { + + void ** b = a + 1; /* try to merge with next chunk */ + mchunkptr next = next_chunk(p); + if (b != fence && *b == chunk2mem(next)) { + + size_t newsize = chunksize(next) + psize; + set_inuse(m, p, newsize); + *b = chunk2mem(p); + + } else + + dispose_chunk(m, p, psize); + + } else { + + CORRUPTION_ERROR_ACTION(m); + break; + + } + + } + + } + + if (should_trim(m, m->topsize)) sys_trim(m, 0); + POSTACTION(m); + + } + + return unfreed; + +} + + /* Traversal */ + #if MALLOC_INSPECT_ALL +static void internal_inspect_all(mstate m, + void (*handler)(void *start, void *end, + size_t used_bytes, + void * callback_arg), + void *arg) { + + if (is_initialized(m)) { + + mchunkptr top = m->top; + msegmentptr s; + for (s = &m->seg; s != 0; s = s->next) { + + mchunkptr q = align_as_chunk(s->base); + while (segment_holds(s, q) && q->head != FENCEPOST_HEAD) { + + mchunkptr next = next_chunk(q); + size_t sz = chunksize(q); + size_t used; + void * start; + if (is_inuse(q)) { + + used = sz - CHUNK_OVERHEAD; /* must not be mmapped */ + start = chunk2mem(q); + + } else { + + used = 0; + if (is_small(sz)) { /* offset by possible bookkeeping */ + start = (void *)((char *)q + sizeof(struct malloc_chunk)); + + } else { + + start = (void *)((char *)q + sizeof(struct malloc_tree_chunk)); + + } + + } + + if (start < (void *)next) /* skip if all space is bookkeeping */ + handler(start, next, used, arg); + if (q == top) break; + q = next; + + } + + } + + } + +} + + #endif /* MALLOC_INSPECT_ALL */ + +/* ------------------ Exported realloc, memalign, etc -------------------- */ + + #if !ONLY_MSPACES + +void *dlrealloc(void *oldmem, size_t bytes) { + + void *mem = 0; + if (oldmem == 0) { + + mem = dlmalloc(bytes); + + } else if (bytes >= MAX_REQUEST) { + + MALLOC_FAILURE_ACTION; + + } + + #ifdef REALLOC_ZERO_BYTES_FREES + else if (bytes == 0) { + + dlfree(oldmem); + + } + + #endif /* REALLOC_ZERO_BYTES_FREES */ + else { + + size_t nb = request2size(bytes); + mchunkptr oldp = mem2chunk(oldmem); + #if !FOOTERS + mstate m = gm; + #else /* FOOTERS */ + mstate m = get_mstate_for(oldp); + if (!ok_magic(m)) { + + USAGE_ERROR_ACTION(m, oldmem); + return 0; + + } + + #endif /* FOOTERS */ + if (!PREACTION(m)) { + + mchunkptr newp = try_realloc_chunk(m, oldp, nb, 1); + POSTACTION(m); + if (newp != 0) { + + check_inuse_chunk(m, newp); + mem = chunk2mem(newp); + + } else { + + mem = internal_malloc(m, bytes); + if (mem != 0) { + + size_t oc = chunksize(oldp) - overhead_for(oldp); + __builtin_memcpy(mem, oldmem, (oc < bytes) ? oc : bytes); + internal_free(m, oldmem); + + } + + } + + } + + } + + return mem; + +} + +void *dlrealloc_in_place(void *oldmem, size_t bytes) { + + void *mem = 0; + if (oldmem != 0) { + + if (bytes >= MAX_REQUEST) { + + MALLOC_FAILURE_ACTION; + + } else { + + size_t nb = request2size(bytes); + mchunkptr oldp = mem2chunk(oldmem); + #if !FOOTERS + mstate m = gm; + #else /* FOOTERS */ + mstate m = get_mstate_for(oldp); + if (!ok_magic(m)) { + + USAGE_ERROR_ACTION(m, oldmem); + return 0; + + } + + #endif /* FOOTERS */ + if (!PREACTION(m)) { + + mchunkptr newp = try_realloc_chunk(m, oldp, nb, 0); + POSTACTION(m); + if (newp == oldp) { + + check_inuse_chunk(m, newp); + mem = oldmem; + + } + + } + + } + + } + + return mem; + +} + +void *dlmemalign(size_t alignment, size_t bytes) { + + if (alignment <= MALLOC_ALIGNMENT) { return dlmalloc(bytes); } + return internal_memalign(gm, alignment, bytes); + +} + +int dlposix_memalign(void **pp, size_t alignment, size_t bytes) { + + void *mem = 0; + if (alignment == MALLOC_ALIGNMENT) + mem = dlmalloc(bytes); + else { + + size_t d = alignment / sizeof(void *); + size_t r = alignment % sizeof(void *); + if (r != 0 || d == 0 || (d & (d - SIZE_T_ONE)) != 0) + return EINVAL; + else if (bytes <= MAX_REQUEST - alignment) { + + if (alignment < MIN_CHUNK_SIZE) alignment = MIN_CHUNK_SIZE; + mem = internal_memalign(gm, alignment, bytes); + + } + + } + + if (mem == 0) + return ENOMEM; + else { + + *pp = mem; + return 0; + + } + +} + +void *dlvalloc(size_t bytes) { + + size_t pagesz; + ensure_initialization(); + pagesz = mparams.page_size; + return dlmemalign(pagesz, bytes); + +} + +void *dlpvalloc(size_t bytes) { + + size_t pagesz; + ensure_initialization(); + pagesz = mparams.page_size; + return dlmemalign(pagesz, + (bytes + pagesz - SIZE_T_ONE) & ~(pagesz - SIZE_T_ONE)); + +} + +void **dlindependent_calloc(size_t n_elements, size_t elem_size, + void *chunks[]) { + + size_t sz = elem_size; /* serves as 1-element array */ + return ialloc(gm, n_elements, &sz, 3, chunks); + +} + +void **dlindependent_comalloc(size_t n_elements, size_t sizes[], + void *chunks[]) { + + return ialloc(gm, n_elements, sizes, 0, chunks); + +} + +size_t dlbulk_free(void *array[], size_t nelem) { + + return internal_bulk_free(gm, array, nelem); + +} + + #if MALLOC_INSPECT_ALL +void dlmalloc_inspect_all(void (*handler)(void *start, void *end, + size_t used_bytes, + void * callback_arg), + void *arg) { + + ensure_initialization(); + if (!PREACTION(gm)) { + + internal_inspect_all(gm, handler, arg); + POSTACTION(gm); + + } + +} + + #endif /* MALLOC_INSPECT_ALL */ + +int dlmalloc_trim(size_t pad) { + + int result = 0; + ensure_initialization(); + if (!PREACTION(gm)) { + + result = sys_trim(gm, pad); + POSTACTION(gm); + + } + + return result; + +} + +size_t dlmalloc_footprint(void) { + + return gm->footprint; + +} + +size_t dlmalloc_max_footprint(void) { + + return gm->max_footprint; + +} + +size_t dlmalloc_footprint_limit(void) { + + size_t maf = gm->footprint_limit; + return maf == 0 ? MAX_SIZE_T : maf; + +} + +size_t dlmalloc_set_footprint_limit(size_t bytes) { + + size_t result; /* invert sense of 0 */ + if (bytes == 0) result = granularity_align(1); /* Use minimal size */ + if (bytes == MAX_SIZE_T) + result = 0; /* disable */ + else + result = granularity_align(bytes); + return gm->footprint_limit = result; + +} + + #if !NO_MALLINFO +struct mallinfo dlmallinfo(void) { + + return internal_mallinfo(gm); + +} + + #endif /* NO_MALLINFO */ + + #if !NO_MALLOC_STATS +void dlmalloc_stats() { + + internal_malloc_stats(gm); + +} + + #endif /* NO_MALLOC_STATS */ + +int dlmallopt(int param_number, int value) { + + return change_mparam(param_number, value); + +} + +size_t dlmalloc_usable_size(void *mem) { + + if (mem != 0) { + + mchunkptr p = mem2chunk(mem); + if (is_inuse(p)) return chunksize(p) - overhead_for(p); + + } + + return 0; + +} + + #endif /* !ONLY_MSPACES */ + +/* ----------------------------- user mspaces ---------------------------- */ + + #if MSPACES + +static mstate init_user_mstate(char *tbase, size_t tsize) { + + size_t msize = pad_request(sizeof(struct malloc_state)); + mchunkptr mn; + mchunkptr msp = align_as_chunk(tbase); + mstate m = (mstate)(chunk2mem(msp)); + __builtin_memset(m, 0, msize); + (void)INITIAL_LOCK(&m->mutex); + msp->head = (msize | INUSE_BITS); + m->seg.base = m->least_addr = tbase; + m->seg.size = m->footprint = m->max_footprint = tsize; + m->magic = mparams.magic; + m->release_checks = MAX_RELEASE_CHECK_RATE; + m->mflags = mparams.default_mflags; + m->extp = 0; + m->exts = 0; + disable_contiguous(m); + init_bins(m); + mn = next_chunk(mem2chunk(m)); + init_top(m, mn, (size_t)((tbase + tsize) - (char *)mn) - TOP_FOOT_SIZE); + check_top_chunk(m, m->top); + return m; + +} + +mspace create_mspace(size_t capacity, int locked) { + + mstate m = 0; + size_t msize; + ensure_initialization(); + msize = pad_request(sizeof(struct malloc_state)); + if (capacity < (size_t) - (msize + TOP_FOOT_SIZE + mparams.page_size)) { + + size_t rs = ((capacity == 0) ? mparams.granularity + : (capacity + TOP_FOOT_SIZE + msize)); + size_t tsize = granularity_align(rs); + char * tbase = (char *)(CALL_MMAP(tsize)); + if (tbase != CMFAIL) { + + m = init_user_mstate(tbase, tsize); + m->seg.sflags = USE_MMAP_BIT; + set_lock(m, locked); + + } + + } + + return (mspace)m; + +} + +mspace create_mspace_with_base(void *base, size_t capacity, int locked) { + + mstate m = 0; + size_t msize; + ensure_initialization(); + msize = pad_request(sizeof(struct malloc_state)); + if (capacity > msize + TOP_FOOT_SIZE && + capacity < (size_t) - (msize + TOP_FOOT_SIZE + mparams.page_size)) { + + m = init_user_mstate((char *)base, capacity); + m->seg.sflags = EXTERN_BIT; + set_lock(m, locked); + + } + + return (mspace)m; + +} + +int mspace_track_large_chunks(mspace msp, int enable) { + + int ret = 0; + mstate ms = (mstate)msp; + if (!PREACTION(ms)) { + + if (!use_mmap(ms)) { ret = 1; } + if (!enable) { + + enable_mmap(ms); + + } else { + + disable_mmap(ms); + + } + + POSTACTION(ms); + + } + + return ret; + +} + +size_t destroy_mspace(mspace msp) { + + size_t freed = 0; + mstate ms = (mstate)msp; + if (ok_magic(ms)) { + + msegmentptr sp = &ms->seg; + (void)DESTROY_LOCK(&ms->mutex); /* destroy before unmapped */ + while (sp != 0) { + + char * base = sp->base; + size_t size = sp->size; + flag_t flag = sp->sflags; + (void)base; /* placate people compiling -Wunused-variable */ + sp = sp->next; + if ((flag & USE_MMAP_BIT) && !(flag & EXTERN_BIT) && + CALL_MUNMAP(base, size) == 0) + freed += size; + + } + + } else { + + USAGE_ERROR_ACTION(ms, ms); + + } + + return freed; + +} + +/* + mspace versions of routines are near-clones of the global + versions. This is not so nice but better than the alternatives. +*/ + +void *mspace_malloc(mspace msp, size_t bytes) { + + mstate ms = (mstate)msp; + if (!ok_magic(ms)) { + + USAGE_ERROR_ACTION(ms, ms); + return 0; + + } + + if (!PREACTION(ms)) { + + void * mem; + size_t nb; + if (bytes <= MAX_SMALL_REQUEST) { + + bindex_t idx; + binmap_t smallbits; + nb = (bytes < MIN_REQUEST) ? MIN_CHUNK_SIZE : pad_request(bytes); + idx = small_index(nb); + smallbits = ms->smallmap >> idx; + + if ((smallbits & 0x3U) != 0) { /* Remainderless fit to a smallbin. */ + mchunkptr b, p; + idx += ~smallbits & 1; /* Uses next bin if idx empty */ + b = smallbin_at(ms, idx); + p = b->fd; + assert(chunksize(p) == small_index2size(idx)); + unlink_first_small_chunk(ms, b, p, idx); + set_inuse_and_pinuse(ms, p, small_index2size(idx)); + mem = chunk2mem(p); + check_malloced_chunk(ms, mem, nb); + goto postaction; + + } + + else if (nb > ms->dvsize) { + + if (smallbits != 0) { /* Use chunk in next nonempty smallbin */ + mchunkptr b, p, r; + size_t rsize; + bindex_t i; + binmap_t leftbits = (smallbits << idx) & left_bits(idx2bit(idx)); + binmap_t leastbit = least_bit(leftbits); + compute_bit2idx(leastbit, i); + b = smallbin_at(ms, i); + p = b->fd; + assert(chunksize(p) == small_index2size(i)); + unlink_first_small_chunk(ms, b, p, i); + rsize = small_index2size(i) - nb; + /* Fit here cannot be remainderless if 4byte sizes */ + if (SIZE_T_SIZE != 4 && rsize < MIN_CHUNK_SIZE) + set_inuse_and_pinuse(ms, p, small_index2size(i)); + else { + + set_size_and_pinuse_of_inuse_chunk(ms, p, nb); + r = chunk_plus_offset(p, nb); + set_size_and_pinuse_of_free_chunk(r, rsize); + replace_dv(ms, r, rsize); + + } + + mem = chunk2mem(p); + check_malloced_chunk(ms, mem, nb); + goto postaction; + + } + + else if (ms->treemap != 0 && (mem = tmalloc_small(ms, nb)) != 0) { + + check_malloced_chunk(ms, mem, nb); + goto postaction; + + } + + } + + } else if (bytes >= MAX_REQUEST) + + nb = MAX_SIZE_T; /* Too big to allocate. Force failure (in sys alloc) */ + else { + + nb = pad_request(bytes); + if (ms->treemap != 0 && (mem = tmalloc_large(ms, nb)) != 0) { + + check_malloced_chunk(ms, mem, nb); + goto postaction; + + } + + } + + if (nb <= ms->dvsize) { + + size_t rsize = ms->dvsize - nb; + mchunkptr p = ms->dv; + if (rsize >= MIN_CHUNK_SIZE) { /* split dv */ + mchunkptr r = ms->dv = chunk_plus_offset(p, nb); + ms->dvsize = rsize; + set_size_and_pinuse_of_free_chunk(r, rsize); + set_size_and_pinuse_of_inuse_chunk(ms, p, nb); + + } else { /* exhaust dv */ + + size_t dvs = ms->dvsize; + ms->dvsize = 0; + ms->dv = 0; + set_inuse_and_pinuse(ms, p, dvs); + + } + + mem = chunk2mem(p); + check_malloced_chunk(ms, mem, nb); + goto postaction; + + } + + else if (nb < ms->topsize) { /* Split top */ + size_t rsize = ms->topsize -= nb; + mchunkptr p = ms->top; + mchunkptr r = ms->top = chunk_plus_offset(p, nb); + r->head = rsize | PINUSE_BIT; + set_size_and_pinuse_of_inuse_chunk(ms, p, nb); + mem = chunk2mem(p); + check_top_chunk(ms, ms->top); + check_malloced_chunk(ms, mem, nb); + goto postaction; + + } + + mem = sys_alloc(ms, nb); + + postaction: + POSTACTION(ms); + return mem; + + } + + return 0; + +} + +void mspace_free(mspace msp, void *mem) { + + if (mem != 0) { + + mchunkptr p = mem2chunk(mem); + #if FOOTERS + mstate fm = get_mstate_for(p); + (void)msp; /* placate people compiling -Wunused */ + #else /* FOOTERS */ + mstate fm = (mstate)msp; + #endif /* FOOTERS */ + if (!ok_magic(fm)) { + + USAGE_ERROR_ACTION(fm, p); + return; + + } + + if (!PREACTION(fm)) { + + check_inuse_chunk(fm, p); + if (RTCHECK(ok_address(fm, p) && ok_inuse(p))) { + + size_t psize = chunksize(p); + mchunkptr next = chunk_plus_offset(p, psize); + if (!pinuse(p)) { + + size_t prevsize = p->prev_foot; + if (is_mmapped(p)) { + + psize += prevsize + MMAP_FOOT_PAD; + if (CALL_MUNMAP((char *)p - prevsize, psize) == 0) + fm->footprint -= psize; + goto postaction; + + } else { + + mchunkptr prev = chunk_minus_offset(p, prevsize); + psize += prevsize; + p = prev; + if (RTCHECK(ok_address(fm, prev))) { /* consolidate backward */ + if (p != fm->dv) { + + unlink_chunk(fm, p, prevsize); + + } else if ((next->head & INUSE_BITS) == INUSE_BITS) { + + fm->dvsize = psize; + set_free_with_pinuse(p, psize, next); + goto postaction; + + } + + } else + + goto erroraction; + + } + + } + + if (RTCHECK(ok_next(p, next) && ok_pinuse(next))) { + + if (!cinuse(next)) { /* consolidate forward */ + if (next == fm->top) { + + size_t tsize = fm->topsize += psize; + fm->top = p; + p->head = tsize | PINUSE_BIT; + if (p == fm->dv) { + + fm->dv = 0; + fm->dvsize = 0; + + } + + if (should_trim(fm, tsize)) sys_trim(fm, 0); + goto postaction; + + } else if (next == fm->dv) { + + size_t dsize = fm->dvsize += psize; + fm->dv = p; + set_size_and_pinuse_of_free_chunk(p, dsize); + goto postaction; + + } else { + + size_t nsize = chunksize(next); + psize += nsize; + unlink_chunk(fm, next, nsize); + set_size_and_pinuse_of_free_chunk(p, psize); + if (p == fm->dv) { + + fm->dvsize = psize; + goto postaction; + + } + + } + + } else + + set_free_with_pinuse(p, psize, next); + + if (is_small(psize)) { + + insert_small_chunk(fm, p, psize); + check_free_chunk(fm, p); + + } else { + + tchunkptr tp = (tchunkptr)p; + insert_large_chunk(fm, tp, psize); + check_free_chunk(fm, p); + if (--fm->release_checks == 0) release_unused_segments(fm); + + } + + goto postaction; + + } + + } + + erroraction: + USAGE_ERROR_ACTION(fm, p); + postaction: + POSTACTION(fm); + + } + + } + +} + +void *mspace_calloc(mspace msp, size_t n_elements, size_t elem_size) { + + void * mem; + size_t req = 0; + mstate ms = (mstate)msp; + if (!ok_magic(ms)) { + + USAGE_ERROR_ACTION(ms, ms); + return 0; + + } + + if (n_elements != 0) { + + req = n_elements * elem_size; + if (((n_elements | elem_size) & ~(size_t)0xffff) && + (req / n_elements != elem_size)) + req = MAX_SIZE_T; /* force downstream failure on overflow */ + + } + + mem = internal_malloc(ms, req); + if (mem != 0 && calloc_must_clear(mem2chunk(mem))) + __builtin_memset(mem, 0, req); + return mem; + +} + +void *mspace_realloc(mspace msp, void *oldmem, size_t bytes) { + + void *mem = 0; + if (oldmem == 0) { + + mem = mspace_malloc(msp, bytes); + + } else if (bytes >= MAX_REQUEST) { + + MALLOC_FAILURE_ACTION; + + } + + #ifdef REALLOC_ZERO_BYTES_FREES + else if (bytes == 0) { + + mspace_free(msp, oldmem); + + } + + #endif /* REALLOC_ZERO_BYTES_FREES */ + else { + + size_t nb = request2size(bytes); + mchunkptr oldp = mem2chunk(oldmem); + #if !FOOTERS + mstate m = (mstate)msp; + #else /* FOOTERS */ + mstate m = get_mstate_for(oldp); + if (!ok_magic(m)) { + + USAGE_ERROR_ACTION(m, oldmem); + return 0; + + } + + #endif /* FOOTERS */ + if (!PREACTION(m)) { + + mchunkptr newp = try_realloc_chunk(m, oldp, nb, 1); + POSTACTION(m); + if (newp != 0) { + + check_inuse_chunk(m, newp); + mem = chunk2mem(newp); + + } else { + + mem = mspace_malloc(m, bytes); + if (mem != 0) { + + size_t oc = chunksize(oldp) - overhead_for(oldp); + __builtin_memcpy(mem, oldmem, (oc < bytes) ? oc : bytes); + mspace_free(m, oldmem); + + } + + } + + } + + } + + return mem; + +} + +void *mspace_realloc_in_place(mspace msp, void *oldmem, size_t bytes) { + + void *mem = 0; + if (oldmem != 0) { + + if (bytes >= MAX_REQUEST) { + + MALLOC_FAILURE_ACTION; + + } else { + + size_t nb = request2size(bytes); + mchunkptr oldp = mem2chunk(oldmem); + #if !FOOTERS + mstate m = (mstate)msp; + #else /* FOOTERS */ + mstate m = get_mstate_for(oldp); + (void)msp; /* placate people compiling -Wunused */ + if (!ok_magic(m)) { + + USAGE_ERROR_ACTION(m, oldmem); + return 0; + + } + + #endif /* FOOTERS */ + if (!PREACTION(m)) { + + mchunkptr newp = try_realloc_chunk(m, oldp, nb, 0); + POSTACTION(m); + if (newp == oldp) { + + check_inuse_chunk(m, newp); + mem = oldmem; + + } + + } + + } + + } + + return mem; + +} + +void *mspace_memalign(mspace msp, size_t alignment, size_t bytes) { + + mstate ms = (mstate)msp; + if (!ok_magic(ms)) { + + USAGE_ERROR_ACTION(ms, ms); + return 0; + + } + + if (alignment <= MALLOC_ALIGNMENT) return mspace_malloc(msp, bytes); + return internal_memalign(ms, alignment, bytes); + +} + +void **mspace_independent_calloc(mspace msp, size_t n_elements, + size_t elem_size, void *chunks[]) { + + size_t sz = elem_size; /* serves as 1-element array */ + mstate ms = (mstate)msp; + if (!ok_magic(ms)) { + + USAGE_ERROR_ACTION(ms, ms); + return 0; + + } + + return ialloc(ms, n_elements, &sz, 3, chunks); + +} + +void **mspace_independent_comalloc(mspace msp, size_t n_elements, + size_t sizes[], void *chunks[]) { + + mstate ms = (mstate)msp; + if (!ok_magic(ms)) { + + USAGE_ERROR_ACTION(ms, ms); + return 0; + + } + + return ialloc(ms, n_elements, sizes, 0, chunks); + +} + +size_t mspace_bulk_free(mspace msp, void *array[], size_t nelem) { + + return internal_bulk_free((mstate)msp, array, nelem); + +} + + #if MALLOC_INSPECT_ALL +void mspace_inspect_all(mspace msp, + void (*handler)(void *start, void *end, + size_t used_bytes, void *callback_arg), + void *arg) { + + mstate ms = (mstate)msp; + if (ok_magic(ms)) { + + if (!PREACTION(ms)) { + + internal_inspect_all(ms, handler, arg); + POSTACTION(ms); + + } + + } else { + + USAGE_ERROR_ACTION(ms, ms); + + } + +} + + #endif /* MALLOC_INSPECT_ALL */ + +int mspace_trim(mspace msp, size_t pad) { + + int result = 0; + mstate ms = (mstate)msp; + if (ok_magic(ms)) { + + if (!PREACTION(ms)) { + + result = sys_trim(ms, pad); + POSTACTION(ms); + + } + + } else { + + USAGE_ERROR_ACTION(ms, ms); + + } + + return result; + +} + + #if !NO_MALLOC_STATS +void mspace_malloc_stats(mspace msp) { + + mstate ms = (mstate)msp; + if (ok_magic(ms)) { + + internal_malloc_stats(ms); + + } else { + + USAGE_ERROR_ACTION(ms, ms); + + } + +} + + #endif /* NO_MALLOC_STATS */ + +size_t mspace_footprint(mspace msp) { + + size_t result = 0; + mstate ms = (mstate)msp; + if (ok_magic(ms)) { + + result = ms->footprint; + + } else { + + USAGE_ERROR_ACTION(ms, ms); + + } + + return result; + +} + +size_t mspace_max_footprint(mspace msp) { + + size_t result = 0; + mstate ms = (mstate)msp; + if (ok_magic(ms)) { + + result = ms->max_footprint; + + } else { + + USAGE_ERROR_ACTION(ms, ms); + + } + + return result; + +} + +size_t mspace_footprint_limit(mspace msp) { + + size_t result = 0; + mstate ms = (mstate)msp; + if (ok_magic(ms)) { + + size_t maf = ms->footprint_limit; + result = (maf == 0) ? MAX_SIZE_T : maf; + + } else { + + USAGE_ERROR_ACTION(ms, ms); + + } + + return result; + +} + +size_t mspace_set_footprint_limit(mspace msp, size_t bytes) { + + size_t result = 0; + mstate ms = (mstate)msp; + if (ok_magic(ms)) { + + if (bytes == 0) result = granularity_align(1); /* Use minimal size */ + if (bytes == MAX_SIZE_T) + result = 0; /* disable */ + else + result = granularity_align(bytes); + ms->footprint_limit = result; + + } else { + + USAGE_ERROR_ACTION(ms, ms); + + } + + return result; + +} + + #if !NO_MALLINFO +struct mallinfo mspace_mallinfo(mspace msp) { + + mstate ms = (mstate)msp; + if (!ok_magic(ms)) { USAGE_ERROR_ACTION(ms, ms); } + return internal_mallinfo(ms); + +} + + #endif /* NO_MALLINFO */ + +size_t mspace_usable_size(const void *mem) { + + if (mem != 0) { + + mchunkptr p = mem2chunk(mem); + if (is_inuse(p)) return chunksize(p) - overhead_for(p); + + } + + return 0; + +} + +int mspace_mallopt(int param_number, int value) { + + return change_mparam(param_number, value); + +} + + #endif /* MSPACES */ + +/* -------------------- Alternative MORECORE functions ------------------- */ + +/* + Guidelines for creating a custom version of MORECORE: + + * For best performance, MORECORE should allocate in multiples of pagesize. + * MORECORE may allocate more memory than requested. (Or even less, + but this will usually result in a malloc failure.) + * MORECORE must not allocate memory when given argument zero, but + instead return one past the end address of memory from previous + nonzero call. + * For best performance, consecutive calls to MORECORE with positive + arguments should return increasing addresses, indicating that + space has been contiguously extended. + * Even though consecutive calls to MORECORE need not return contiguous + addresses, it must be OK for malloc'ed chunks to span multiple + regions in those cases where they do happen to be contiguous. + * MORECORE need not handle negative arguments -- it may instead + just return MFAIL when given negative arguments. + Negative arguments are always multiples of pagesize. MORECORE + must not misinterpret negative args as large positive unsigned + args. You can suppress all such calls from even occurring by defining + MORECORE_CANNOT_TRIM, + + As an example alternative MORECORE, here is a custom allocator + kindly contributed for pre-OSX macOS. It uses virtually but not + necessarily physically contiguous non-paged memory (locked in, + present and won't get swapped out). You can use it by uncommenting + this section, adding some #includes, and setting up the appropriate + defines above: + + #define MORECORE osMoreCore + + There is also a shutdown routine that should somehow be called for + cleanup upon program exit. + + #define MAX_POOL_ENTRIES 100 + #define MINIMUM_MORECORE_SIZE (64 * 1024U) + static int next_os_pool; + void *our_os_pools[MAX_POOL_ENTRIES]; + + void *osMoreCore(int size) + { + + void *ptr = 0; + static void *sbrk_top = 0; + + if (size > 0) + { + + if (size < MINIMUM_MORECORE_SIZE) + size = MINIMUM_MORECORE_SIZE; + if (CurrentExecutionLevel() == kTaskLevel) + ptr = PoolAllocateResident(size + RM_PAGE_SIZE, 0); + if (ptr == 0) + { + + return (void *) MFAIL; + + } + + // save ptrs so they can be freed during cleanup + our_os_pools[next_os_pool] = ptr; + next_os_pool++; + ptr = (void *) ((((size_t) ptr) + RM_PAGE_MASK) & ~RM_PAGE_MASK); + sbrk_top = (char *) ptr + size; + return ptr; + + } + + else if (size < 0) + { + + // we don't currently support shrink behavior + return (void *) MFAIL; + + } + + else + { + + return sbrk_top; + + } + + } + + // cleanup any allocated memory pools + // called as last thing before shutting down driver + + void osCleanupMem(void) + { + + void **ptr; + + for (ptr = our_os_pools; ptr < &our_os_pools[MAX_POOL_ENTRIES]; ptr++) + if (*ptr) + { + + PoolDeallocate(*ptr); + *ptr = 0; + + } + + } + +*/ + +/* ----------------------------------------------------------------------- +History: + v2.8.6 Wed Aug 29 06:57:58 2012 Doug Lea + * fix bad comparison in dlposix_memalign + * don't reuse adjusted asize in sys_alloc + * add LOCK_AT_FORK -- thanks to Kirill Artamonov for the suggestion + * reduce compiler warnings -- thanks to all who reported/suggested these + + v2.8.5 Sun May 22 10:26:02 2011 Doug Lea (dl at gee) + * Always perform unlink checks unless INSECURE + * Add posix_memalign. + * Improve realloc to expand in more cases; expose realloc_in_place. + Thanks to Peter Buhr for the suggestion. + * Add footprint_limit, inspect_all, bulk_free. Thanks + to Barry Hayes and others for the suggestions. + * Internal refactorings to avoid calls while holding locks + * Use non-reentrant locks by default. Thanks to Roland McGrath + for the suggestion. + * Small fixes to mspace_destroy, reset_on_error. + * Various configuration extensions/changes. Thanks + to all who contributed these. + + V2.8.4a Thu Apr 28 14:39:43 2011 (dl at gee.cs.oswego.edu) + * Update Creative Commons URL + + V2.8.4 Wed May 27 09:56:23 2009 Doug Lea (dl at gee) + * Use zeros instead of prev foot for is_mmapped + * Add mspace_track_large_chunks; thanks to Jean Brouwers + * Fix set_inuse in internal_realloc; thanks to Jean Brouwers + * Fix insufficient sys_alloc padding when using 16byte alignment + * Fix bad error check in mspace_footprint + * Adaptations for ptmalloc; thanks to Wolfram Gloger. + * Reentrant spin locks; thanks to Earl Chew and others + * Win32 improvements; thanks to Niall Douglas and Earl Chew + * Add NO_SEGMENT_TRAVERSAL and MAX_RELEASE_CHECK_RATE options + * Extension hook in malloc_state + * Various small adjustments to reduce warnings on some compilers + * Various configuration extensions/changes for more platforms. Thanks + to all who contributed these. + + V2.8.3 Thu Sep 22 11:16:32 2005 Doug Lea (dl at gee) + * Add max_footprint functions + * Ensure all appropriate literals are size_t + * Fix conditional compilation problem for some #define settings + * Avoid concatenating segments with the one provided + in create_mspace_with_base + * Rename some variables to avoid compiler shadowing warnings + * Use explicit lock initialization. + * Better handling of sbrk interference. + * Simplify and fix segment insertion, trimming and mspace_destroy + * Reinstate REALLOC_ZERO_BYTES_FREES option from 2.7.x + * Thanks especially to Dennis Flanagan for help on these. + + V2.8.2 Sun Jun 12 16:01:10 2005 Doug Lea (dl at gee) + * Fix memalign brace error. + + V2.8.1 Wed Jun 8 16:11:46 2005 Doug Lea (dl at gee) + * Fix improper #endif nesting in C++ + * Add explicit casts needed for C++ + + V2.8.0 Mon May 30 14:09:02 2005 Doug Lea (dl at gee) + * Use trees for large bins + * Support mspaces + * Use segments to unify sbrk-based and mmap-based system allocation, + removing need for emulation on most platforms without sbrk. + * Default safety checks + * Optional footer checks. Thanks to William Robertson for the idea. + * Internal code refactoring + * Incorporate suggestions and platform-specific changes. + Thanks to Dennis Flanagan, Colin Plumb, Niall Douglas, + Aaron Bachmann, Emery Berger, and others. + * Speed up non-fastbin processing enough to remove fastbins. + * Remove useless cfree() to avoid conflicts with other apps. + * Remove internal memcpy, memset. Compilers handle builtins better. + * Remove some options that no one ever used and rename others. + + V2.7.2 Sat Aug 17 09:07:30 2002 Doug Lea (dl at gee) + * Fix malloc_state bitmap array misdeclaration + + V2.7.1 Thu Jul 25 10:58:03 2002 Doug Lea (dl at gee) + * Allow tuning of FIRST_SORTED_BIN_SIZE + * Use PTR_UINT as type for all ptr->int casts. Thanks to John Belmonte. + * Better detection and support for non-contiguousness of MORECORE. + Thanks to Andreas Mueller, Conal Walsh, and Wolfram Gloger + * Bypass most of malloc if no frees. Thanks To Emery Berger. + * Fix freeing of old top non-contiguous chunk im sysmalloc. + * Raised default trim and map thresholds to 256K. + * Fix mmap-related #defines. Thanks to Lubos Lunak. + * Fix copy macros; added LACKS_FCNTL_H. Thanks to Neal Walfield. + * Branch-free bin calculation + * Default trim and mmap thresholds now 256K. + + V2.7.0 Sun Mar 11 14:14:06 2001 Doug Lea (dl at gee) + * Introduce independent_comalloc and independent_calloc. + Thanks to Michael Pachos for motivation and help. + * Make optional .h file available + * Allow > 2GB requests on 32bit systems. + * new WIN32 sbrk, mmap, munmap, lock code from <Walter@GeNeSys-e.de>. + Thanks also to Andreas Mueller <a.mueller at paradatec.de>, + and Anonymous. + * Allow override of MALLOC_ALIGNMENT (Thanks to Ruud Waij for + helping test this.) + * memalign: check alignment arg + * realloc: don't try to shift chunks backwards, since this + leads to more fragmentation in some programs and doesn't + seem to help in any others. + * Collect all cases in malloc requiring system memory into sysmalloc + * Use mmap as backup to sbrk + * Place all internal state in malloc_state + * Introduce fastbins (although similar to 2.5.1) + * Many minor tunings and cosmetic improvements + * Introduce USE_PUBLIC_MALLOC_WRAPPERS, USE_MALLOC_LOCK + * Introduce MALLOC_FAILURE_ACTION, MORECORE_CONTIGUOUS + Thanks to Tony E. Bennett <tbennett@nvidia.com> and others. + * Include errno.h to support default failure action. + + V2.6.6 Sun Dec 5 07:42:19 1999 Doug Lea (dl at gee) + * return null for negative arguments + * Added Several WIN32 cleanups from Martin C. Fong <mcfong at yahoo.com> + * Add 'LACKS_SYS_PARAM_H' for those systems without 'sys/param.h' + (e.g. WIN32 platforms) + * Cleanup header file inclusion for WIN32 platforms + * Cleanup code to avoid Microsoft Visual C++ compiler complaints + * Add 'USE_DL_PREFIX' to quickly allow co-existence with existing + memory allocation routines + * Set 'malloc_getpagesize' for WIN32 platforms (needs more work) + * Use 'assert' rather than 'ASSERT' in WIN32 code to conform to + usage of 'assert' in non-WIN32 code + * Improve WIN32 'sbrk()' emulation's 'findRegion()' routine to + avoid infinite loop + * Always call 'fREe()' rather than 'free()' + + V2.6.5 Wed Jun 17 15:57:31 1998 Doug Lea (dl at gee) + * Fixed ordering problem with boundary-stamping + + V2.6.3 Sun May 19 08:17:58 1996 Doug Lea (dl at gee) + * Added pvalloc, as recommended by H.J. Liu + * Added 64bit pointer support mainly from Wolfram Gloger + * Added anonymously donated WIN32 sbrk emulation + * Malloc, calloc, getpagesize: add optimizations from Raymond Nijssen + * malloc_extend_top: fix mask error that caused wastage after + foreign sbrks + * Add linux mremap support code from HJ Liu + + V2.6.2 Tue Dec 5 06:52:55 1995 Doug Lea (dl at gee) + * Integrated most documentation with the code. + * Add support for mmap, with help from + Wolfram Gloger (Gloger@lrz.uni-muenchen.de). + * Use last_remainder in more cases. + * Pack bins using idea from colin@nyx10.cs.du.edu + * Use ordered bins instead of best-fit threshhold + * Eliminate block-local decls to simplify tracing and debugging. + * Support another case of realloc via move into top + * Fix error occuring when initial sbrk_base not word-aligned. + * Rely on page size for units instead of SBRK_UNIT to + avoid surprises about sbrk alignment conventions. + * Add mallinfo, mallopt. Thanks to Raymond Nijssen + (raymond@es.ele.tue.nl) for the suggestion. + * Add `pad' argument to malloc_trim and top_pad mallopt parameter. + * More precautions for cases where other routines call sbrk, + courtesy of Wolfram Gloger (Gloger@lrz.uni-muenchen.de). + * Added macros etc., allowing use in linux libc from + H.J. Lu (hjl@gnu.ai.mit.edu) + * Inverted this history list + + V2.6.1 Sat Dec 2 14:10:57 1995 Doug Lea (dl at gee) + * Re-tuned and fixed to behave more nicely with V2.6.0 changes. + * Removed all preallocation code since under current scheme + the work required to undo bad preallocations exceeds + the work saved in good cases for most test programs. + * No longer use return list or unconsolidated bins since + no scheme using them consistently outperforms those that don't + given above changes. + * Use best fit for very large chunks to prevent some worst-cases. + * Added some support for debugging + + V2.6.0 Sat Nov 4 07:05:23 1995 Doug Lea (dl at gee) + * Removed footers when chunks are in use. Thanks to + Paul Wilson (wilson@cs.texas.edu) for the suggestion. + + V2.5.4 Wed Nov 1 07:54:51 1995 Doug Lea (dl at gee) + * Added malloc_trim, with help from Wolfram Gloger + (wmglo@Dent.MED.Uni-Muenchen.DE). + + V2.5.3 Tue Apr 26 10:16:01 1994 Doug Lea (dl at g) + + V2.5.2 Tue Apr 5 16:20:40 1994 Doug Lea (dl at g) + * realloc: try to expand in both directions + * malloc: swap order of clean-bin strategy; + * realloc: only conditionally expand backwards + * Try not to scavenge used bins + * Use bin counts as a guide to preallocation + * Occasionally bin return list chunks in first scan + * Add a few optimizations from colin@nyx10.cs.du.edu + + V2.5.1 Sat Aug 14 15:40:43 1993 Doug Lea (dl at g) + * faster bin computation & slightly different binning + * merged all consolidations to one part of malloc proper + (eliminating old malloc_find_space & malloc_clean_bin) + * Scan 2 returns chunks (not just 1) + * Propagate failure in realloc if malloc returns 0 + * Add stuff to allow compilation on non-ANSI compilers + from kpv@research.att.com + + V2.5 Sat Aug 7 07:41:59 1993 Doug Lea (dl at g.oswego.edu) + * removed potential for odd address access in prev_chunk + * removed dependency on getpagesize.h + * misc cosmetics and a bit more internal documentation + * anticosmetics: mangled names in macros to evade debugger strangeness + * tested on sparc, hp-700, dec-mips, rs6000 + with gcc & native cc (hp, dec only) allowing + Detlefs & Zorn comparison study (in SIGPLAN Notices.) + + Trial version Fri Aug 28 13:14:29 1992 Doug Lea (dl at g.oswego.edu) + * Based loosely on libg++-1.2X malloc. (It retains some of the overall + structure of old version, but most details differ.) + +*/ + +#endif // __GLIBC__ + diff --git a/qemu_mode/libqasan/hooks.c b/qemu_mode/libqasan/hooks.c new file mode 100644 index 00000000..0e6c3e08 --- /dev/null +++ b/qemu_mode/libqasan/hooks.c @@ -0,0 +1,692 @@ +/******************************************************************************* +Copyright (c) 2019-2020, Andrea Fioraldi + + +Redistribution and use in source and binary forms, with or without +modification, are permitted provided that the following conditions are met: + +1. Redistributions of source code must retain the above copyright notice, this + list of conditions and the following disclaimer. +2. Redistributions in binary form must reproduce the above copyright notice, + this list of conditions and the following disclaimer in the documentation + and/or other materials provided with the distribution. + +THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND +ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED +WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE +DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR +ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES +(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; +LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND +ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS +SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. +*******************************************************************************/ + +#include "libqasan.h" +#include "map_macro.h" + +ssize_t (*__lq_libc_write)(int, const void *, size_t); +ssize_t (*__lq_libc_read)(int, void *, size_t); +char *(*__lq_libc_fgets)(char *, int, FILE *); +int (*__lq_libc_atoi)(const char *); +long (*__lq_libc_atol)(const char *); +long long (*__lq_libc_atoll)(const char *); + +void __libqasan_init_hooks(void) { + + __libqasan_init_malloc(); + + __lq_libc_write = ASSERT_DLSYM(write); + __lq_libc_read = ASSERT_DLSYM(read); + __lq_libc_fgets = ASSERT_DLSYM(fgets); + __lq_libc_atoi = ASSERT_DLSYM(atoi); + __lq_libc_atol = ASSERT_DLSYM(atol); + __lq_libc_atoll = ASSERT_DLSYM(atoll); + +} + +ssize_t write(int fd, const void *buf, size_t count) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: write(%d, %p, %zu)\n", rtv, fd, buf, count); + QASAN_LOAD(buf, count); + ssize_t r = __lq_libc_write(fd, buf, count); + QASAN_DEBUG("\t\t = %zd\n", r); + + return r; + +} + +ssize_t read(int fd, void *buf, size_t count) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: read(%d, %p, %zu)\n", rtv, fd, buf, count); + QASAN_STORE(buf, count); + ssize_t r = __lq_libc_read(fd, buf, count); + QASAN_DEBUG("\t\t = %zd\n", r); + + return r; + +} + +#ifdef __ANDROID__ +size_t malloc_usable_size(const void *ptr) { + +#else +size_t malloc_usable_size(void *ptr) { + +#endif + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: malloc_usable_size(%p)\n", rtv, ptr); + size_t r = __libqasan_malloc_usable_size((void *)ptr); + QASAN_DEBUG("\t\t = %zu\n", r); + + return r; + +} + +void *malloc(size_t size) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: malloc(%zu)\n", rtv, size); + void *r = __libqasan_malloc(size); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *calloc(size_t nmemb, size_t size) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: calloc(%zu, %zu)\n", rtv, nmemb, size); + void *r = __libqasan_calloc(nmemb, size); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *realloc(void *ptr, size_t size) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: realloc(%p, %zu)\n", rtv, ptr, size); + void *r = __libqasan_realloc(ptr, size); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +int posix_memalign(void **memptr, size_t alignment, size_t size) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: posix_memalign(%p, %zu, %zu)\n", rtv, memptr, alignment, + size); + int r = __libqasan_posix_memalign(memptr, alignment, size); + QASAN_DEBUG("\t\t = %d [*memptr = %p]\n", r, *memptr); + + return r; + +} + +void *memalign(size_t alignment, size_t size) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: memalign(%zu, %zu)\n", rtv, alignment, size); + void *r = __libqasan_memalign(alignment, size); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *aligned_alloc(size_t alignment, size_t size) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: aligned_alloc(%zu, %zu)\n", rtv, alignment, size); + void *r = __libqasan_aligned_alloc(alignment, size); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *valloc(size_t size) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: valloc(%zu)\n", rtv, size); + void *r = __libqasan_memalign(sysconf(_SC_PAGESIZE), size); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *pvalloc(size_t size) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: pvalloc(%zu)\n", rtv, size); + size_t page_size = sysconf(_SC_PAGESIZE); + size = (size & (page_size - 1)) + page_size; + void *r = __libqasan_memalign(page_size, size); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void free(void *ptr) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: free(%p)\n", rtv, ptr); + __libqasan_free(ptr); + +} + +char *fgets(char *s, int size, FILE *stream) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: fgets(%p, %d, %p)\n", rtv, s, size, stream); + QASAN_STORE(s, size); +#ifndef __ANDROID__ + QASAN_LOAD(stream, sizeof(FILE)); +#endif + char *r = __lq_libc_fgets(s, size, stream); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +int memcmp(const void *s1, const void *s2, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: memcmp(%p, %p, %zu)\n", rtv, s1, s2, n); + QASAN_LOAD(s1, n); + QASAN_LOAD(s2, n); + int r = __libqasan_memcmp(s1, s2, n); + QASAN_DEBUG("\t\t = %d\n", r); + + return r; + +} + +void *memcpy(void *dest, const void *src, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: memcpy(%p, %p, %zu)\n", rtv, dest, src, n); + QASAN_LOAD(src, n); + QASAN_STORE(dest, n); + void *r = __libqasan_memcpy(dest, src, n); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *mempcpy(void *dest, const void *src, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: mempcpy(%p, %p, %zu)\n", rtv, dest, src, n); + QASAN_LOAD(src, n); + QASAN_STORE(dest, n); + void *r = (uint8_t *)__libqasan_memcpy(dest, src, n) + n; + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *memmove(void *dest, const void *src, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: memmove(%p, %p, %zu)\n", rtv, dest, src, n); + QASAN_LOAD(src, n); + QASAN_STORE(dest, n); + void *r = __libqasan_memmove(dest, src, n); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *memset(void *s, int c, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: memset(%p, %d, %zu)\n", rtv, s, c, n); + QASAN_STORE(s, n); + void *r = __libqasan_memset(s, c, n); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *memchr(const void *s, int c, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: memchr(%p, %d, %zu)\n", rtv, s, c, n); + void *r = __libqasan_memchr(s, c, n); + if (r == NULL) + QASAN_LOAD(s, n); + else + QASAN_LOAD(s, r - s); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *memrchr(const void *s, int c, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: memrchr(%p, %d, %zu)\n", rtv, s, c, n); + QASAN_LOAD(s, n); + void *r = __libqasan_memrchr(s, c, n); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +void *memmem(const void *haystack, size_t haystacklen, const void *needle, + size_t needlelen) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: memmem(%p, %zu, %p, %zu)\n", rtv, haystack, haystacklen, + needle, needlelen); + QASAN_LOAD(haystack, haystacklen); + QASAN_LOAD(needle, needlelen); + void *r = __libqasan_memmem(haystack, haystacklen, needle, needlelen); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +#ifndef __BIONIC__ +void bzero(void *s, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: bzero(%p, %zu)\n", rtv, s, n); + QASAN_STORE(s, n); + __libqasan_memset(s, 0, n); + +} + +#endif + +void explicit_bzero(void *s, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: bzero(%p, %zu)\n", rtv, s, n); + QASAN_STORE(s, n); + __libqasan_memset(s, 0, n); + +} + +int bcmp(const void *s1, const void *s2, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: bcmp(%p, %p, %zu)\n", rtv, s1, s2, n); + QASAN_LOAD(s1, n); + QASAN_LOAD(s2, n); + int r = __libqasan_bcmp(s1, s2, n); + QASAN_DEBUG("\t\t = %d\n", r); + + return r; + +} + +char *strchr(const char *s, int c) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strchr(%p, %d)\n", rtv, s, c); + size_t l = __libqasan_strlen(s); + QASAN_LOAD(s, l + 1); + void *r = __libqasan_strchr(s, c); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +char *strrchr(const char *s, int c) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strrchr(%p, %d)\n", rtv, s, c); + size_t l = __libqasan_strlen(s); + QASAN_LOAD(s, l + 1); + void *r = __libqasan_strrchr(s, c); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +int strcasecmp(const char *s1, const char *s2) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strcasecmp(%p, %p)\n", rtv, s1, s2); + size_t l1 = __libqasan_strlen(s1); + QASAN_LOAD(s1, l1 + 1); + size_t l2 = __libqasan_strlen(s2); + QASAN_LOAD(s2, l2 + 1); + int r = __libqasan_strcasecmp(s1, s2); + QASAN_DEBUG("\t\t = %d\n", r); + + return r; + +} + +int strncasecmp(const char *s1, const char *s2, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strncasecmp(%p, %p, %zu)\n", rtv, s1, s2, n); + size_t l1 = __libqasan_strnlen(s1, n); + QASAN_LOAD(s1, l1); + size_t l2 = __libqasan_strnlen(s2, n); + QASAN_LOAD(s2, l2); + int r = __libqasan_strncasecmp(s1, s2, n); + QASAN_DEBUG("\t\t = %d\n", r); + + return r; + +} + +char *strcat(char *dest, const char *src) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strcat(%p, %p)\n", rtv, dest, src); + size_t l2 = __libqasan_strlen(src); + QASAN_LOAD(src, l2 + 1); + size_t l1 = __libqasan_strlen(dest); + QASAN_STORE(dest, l1 + l2 + 1); + __libqasan_memcpy(dest + l1, src, l2); + dest[l1 + l2] = 0; + void *r = dest; + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +int strcmp(const char *s1, const char *s2) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strcmp(%p, %p)\n", rtv, s1, s2); + size_t l1 = __libqasan_strlen(s1); + QASAN_LOAD(s1, l1 + 1); + size_t l2 = __libqasan_strlen(s2); + QASAN_LOAD(s2, l2 + 1); + int r = __libqasan_strcmp(s1, s2); + QASAN_DEBUG("\t\t = %d\n", r); + + return r; + +} + +int strncmp(const char *s1, const char *s2, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strncmp(%p, %p, %zu)\n", rtv, s1, s2, n); + size_t l1 = __libqasan_strnlen(s1, n); + QASAN_LOAD(s1, l1); + size_t l2 = __libqasan_strnlen(s2, n); + QASAN_LOAD(s2, l2); + int r = __libqasan_strncmp(s1, s2, n); + QASAN_DEBUG("\t\t = %d\n", r); + + return r; + +} + +char *strcpy(char *dest, const char *src) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strcpy(%p, %p)\n", rtv, dest, src); + size_t l = __libqasan_strlen(src) + 1; + QASAN_LOAD(src, l); + QASAN_STORE(dest, l); + void *r = __libqasan_memcpy(dest, src, l); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +char *strncpy(char *dest, const char *src, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strncpy(%p, %p, %zu)\n", rtv, dest, src, n); + size_t l = __libqasan_strnlen(src, n); + QASAN_STORE(dest, n); + void *r; + if (l < n) { + + QASAN_LOAD(src, l + 1); + r = __libqasan_memcpy(dest, src, l + 1); + + } else { + + QASAN_LOAD(src, n); + r = __libqasan_memcpy(dest, src, n); + + } + + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +char *stpcpy(char *dest, const char *src) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: stpcpy(%p, %p)\n", rtv, dest, src); + size_t l = __libqasan_strlen(src) + 1; + QASAN_LOAD(src, l); + QASAN_STORE(dest, l); + char *r = __libqasan_memcpy(dest, src, l) + (l - 1); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +char *strdup(const char *s) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strdup(%p)\n", rtv, s); + size_t l = __libqasan_strlen(s); + QASAN_LOAD(s, l + 1); + void *r = __libqasan_malloc(l + 1); + __libqasan_memcpy(r, s, l + 1); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +size_t strlen(const char *s) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strlen(%p)\n", rtv, s); + size_t r = __libqasan_strlen(s); + QASAN_LOAD(s, r + 1); + QASAN_DEBUG("\t\t = %zu\n", r); + + return r; + +} + +size_t strnlen(const char *s, size_t n) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strnlen(%p, %zu)\n", rtv, s, n); + size_t r = __libqasan_strnlen(s, n); + QASAN_LOAD(s, r); + QASAN_DEBUG("\t\t = %zu\n", r); + + return r; + +} + +char *strstr(const char *haystack, const char *needle) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strstr(%p, %p)\n", rtv, haystack, needle); + size_t l = __libqasan_strlen(haystack) + 1; + QASAN_LOAD(haystack, l); + l = __libqasan_strlen(needle) + 1; + QASAN_LOAD(needle, l); + void *r = __libqasan_strstr(haystack, needle); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +char *strcasestr(const char *haystack, const char *needle) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: strcasestr(%p, %p)\n", rtv, haystack, needle); + size_t l = __libqasan_strlen(haystack) + 1; + QASAN_LOAD(haystack, l); + l = __libqasan_strlen(needle) + 1; + QASAN_LOAD(needle, l); + void *r = __libqasan_strcasestr(haystack, needle); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +int atoi(const char *nptr) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: atoi(%p)\n", rtv, nptr); + size_t l = __libqasan_strlen(nptr) + 1; + QASAN_LOAD(nptr, l); + int r = __lq_libc_atoi(nptr); + QASAN_DEBUG("\t\t = %d\n", r); + + return r; + +} + +long atol(const char *nptr) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: atol(%p)\n", rtv, nptr); + size_t l = __libqasan_strlen(nptr) + 1; + QASAN_LOAD(nptr, l); + long r = __lq_libc_atol(nptr); + QASAN_DEBUG("\t\t = %ld\n", r); + + return r; + +} + +long long atoll(const char *nptr) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: atoll(%p)\n", rtv, nptr); + size_t l = __libqasan_strlen(nptr) + 1; + QASAN_LOAD(nptr, l); + long long r = __lq_libc_atoll(nptr); + QASAN_DEBUG("\t\t = %lld\n", r); + + return r; + +} + +size_t wcslen(const wchar_t *s) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: wcslen(%p)\n", rtv, s); + size_t r = __libqasan_wcslen(s); + QASAN_LOAD(s, sizeof(wchar_t) * (r + 1)); + QASAN_DEBUG("\t\t = %zu\n", r); + + return r; + +} + +wchar_t *wcscpy(wchar_t *dest, const wchar_t *src) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: wcscpy(%p, %p)\n", rtv, dest, src); + size_t l = __libqasan_wcslen(src) + 1; + QASAN_LOAD(src, l * sizeof(wchar_t)); + QASAN_STORE(dest, l * sizeof(wchar_t)); + void *r = __libqasan_wcscpy(dest, src); + QASAN_DEBUG("\t\t = %p\n", r); + + return r; + +} + +int wcscmp(const wchar_t *s1, const wchar_t *s2) { + + void *rtv = __builtin_return_address(0); + + QASAN_DEBUG("%14p: wcscmp(%p, %p)\n", rtv, s1, s2); + size_t l1 = __libqasan_wcslen(s1); + QASAN_LOAD(s1, sizeof(wchar_t) * (l1 + 1)); + size_t l2 = __libqasan_wcslen(s2); + QASAN_LOAD(s2, sizeof(wchar_t) * (l2 + 1)); + int r = __libqasan_wcscmp(s1, s2); + QASAN_DEBUG("\t\t = %d\n", r); + + return r; + +} + diff --git a/qemu_mode/libqasan/libqasan.c b/qemu_mode/libqasan/libqasan.c new file mode 100644 index 00000000..9fc4ef7a --- /dev/null +++ b/qemu_mode/libqasan/libqasan.c @@ -0,0 +1,94 @@ +/******************************************************************************* +Copyright (c) 2019-2020, Andrea Fioraldi + + +Redistribution and use in source and binary forms, with or without +modification, are permitted provided that the following conditions are met: + +1. Redistributions of source code must retain the above copyright notice, this + list of conditions and the following disclaimer. +2. Redistributions in binary form must reproduce the above copyright notice, + this list of conditions and the following disclaimer in the documentation + and/or other materials provided with the distribution. + +THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND +ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED +WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE +DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR +ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES +(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; +LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND +ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS +SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. +*******************************************************************************/ + +#include "libqasan.h" + +#ifdef DEBUG +int __qasan_debug; +#endif +int __qasan_log; + +void __libqasan_print_maps(void) { + + int fd = open("/proc/self/maps", O_RDONLY); + char buf[4096] = {0}; + + read(fd, buf, 4095); + close(fd); + + size_t len = strlen(buf); + + QASAN_LOG("Guest process maps:\n"); + int i; + char *line = NULL; + for (i = 0; i < len; i++) { + + if (!line) line = &buf[i]; + if (buf[i] == '\n') { + + buf[i] = 0; + QASAN_LOG("%s\n", line); + line = NULL; + + } + + } + + if (line) QASAN_LOG("%s\n", line); + QASAN_LOG("\n"); + +} + +/*__attribute__((constructor))*/ void __libqasan_init() { + + __libqasan_init_hooks(); + +#ifdef DEBUG + __qasan_debug = getenv("QASAN_DEBUG") != NULL; +#endif + __qasan_log = getenv("QASAN_LOG") != NULL; + + QASAN_LOG("QEMU-AddressSanitizer (v%s)\n", QASAN_VERSTR); + QASAN_LOG( + "Copyright (C) 2019-2021 Andrea Fioraldi <andreafioraldi@gmail.com>\n"); + QASAN_LOG("\n"); + + if (__qasan_log) __libqasan_print_maps(); + +} + +int __libc_start_main(int (*main)(int, char **, char **), int argc, char **argv, + int (*init)(int, char **, char **), void (*fini)(void), + void (*rtld_fini)(void), void *stack_end) { + + typeof(&__libc_start_main) orig = dlsym(RTLD_NEXT, "__libc_start_main"); + + __libqasan_init(); + if (getenv("AFL_INST_LIBS")) __libqasan_hotpatch(); + + return orig(main, argc, argv, init, fini, rtld_fini, stack_end); + +} + diff --git a/qemu_mode/libqasan/libqasan.h b/qemu_mode/libqasan/libqasan.h new file mode 100644 index 00000000..43b7adb5 --- /dev/null +++ b/qemu_mode/libqasan/libqasan.h @@ -0,0 +1,132 @@ +/******************************************************************************* +Copyright (c) 2019-2020, Andrea Fioraldi + + +Redistribution and use in source and binary forms, with or without +modification, are permitted provided that the following conditions are met: + +1. Redistributions of source code must retain the above copyright notice, this + list of conditions and the following disclaimer. +2. Redistributions in binary form must reproduce the above copyright notice, + this list of conditions and the following disclaimer in the documentation + and/or other materials provided with the distribution. + +THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND +ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED +WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE +DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR +ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES +(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; +LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND +ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS +SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. +*******************************************************************************/ + +#ifndef __LIBQASAN_H__ +#define __LIBQASAN_H__ + +#define _GNU_SOURCE +#include <stdlib.h> +#include <stdint.h> +#include <stdio.h> +#include <unistd.h> +#include <fcntl.h> +#include <string.h> +#include <signal.h> +#include <ucontext.h> +#include <inttypes.h> +#include <dlfcn.h> +#include <wchar.h> + +#include "qasan.h" + +#define QASAN_LOG(msg...) \ + do { \ + \ + if (__qasan_log) { \ + \ + fprintf(stderr, "==%d== ", getpid()); \ + fprintf(stderr, msg); \ + \ + } \ + \ + } while (0) + +#ifdef DEBUG + #define QASAN_DEBUG(msg...) \ + do { \ + \ + if (__qasan_debug) { \ + \ + fprintf(stderr, "==%d== ", getpid()); \ + fprintf(stderr, msg); \ + \ + } \ + \ + } while (0) + +#else + #define QASAN_DEBUG(msg...) \ + do { \ + \ + } while (0) +#endif + +#define ASSERT_DLSYM(name) \ + ({ \ + \ + void *a = (void *)dlsym(RTLD_NEXT, #name); \ + if (!a) { \ + \ + fprintf(stderr, \ + "FATAL ERROR: failed dlsym of " #name " in libqasan!\n"); \ + abort(); \ + \ + } \ + a; \ + \ + }) + +extern int __qasan_debug; +extern int __qasan_log; + +void __libqasan_init_hooks(void); +void __libqasan_init_malloc(void); + +void __libqasan_hotpatch(void); + +size_t __libqasan_malloc_usable_size(void *ptr); +void * __libqasan_malloc(size_t size); +void __libqasan_free(void *ptr); +void * __libqasan_calloc(size_t nmemb, size_t size); +void * __libqasan_realloc(void *ptr, size_t size); +int __libqasan_posix_memalign(void **ptr, size_t align, size_t len); +void * __libqasan_memalign(size_t align, size_t len); +void * __libqasan_aligned_alloc(size_t align, size_t len); + +void * __libqasan_memcpy(void *dest, const void *src, size_t n); +void * __libqasan_memmove(void *dest, const void *src, size_t n); +void * __libqasan_memset(void *s, int c, size_t n); +void * __libqasan_memchr(const void *s, int c, size_t n); +void * __libqasan_memrchr(const void *s, int c, size_t n); +size_t __libqasan_strlen(const char *s); +size_t __libqasan_strnlen(const char *s, size_t len); +int __libqasan_strcmp(const char *str1, const char *str2); +int __libqasan_strncmp(const char *str1, const char *str2, size_t len); +int __libqasan_strcasecmp(const char *str1, const char *str2); +int __libqasan_strncasecmp(const char *str1, const char *str2, size_t len); +int __libqasan_memcmp(const void *mem1, const void *mem2, size_t len); +int __libqasan_bcmp(const void *mem1, const void *mem2, size_t len); +char * __libqasan_strstr(const char *haystack, const char *needle); +char * __libqasan_strcasestr(const char *haystack, const char *needle); +void * __libqasan_memmem(const void *haystack, size_t haystack_len, + const void *needle, size_t needle_len); +char * __libqasan_strchr(const char *s, int c); +char * __libqasan_strrchr(const char *s, int c); +size_t __libqasan_wcslen(const wchar_t *s); +wchar_t *__libqasan_wcscpy(wchar_t *d, const wchar_t *s); +int __libqasan_wcscmp(const wchar_t *s1, const wchar_t *s2); + +#endif + diff --git a/qemu_mode/libqasan/malloc.c b/qemu_mode/libqasan/malloc.c new file mode 100644 index 00000000..6fe6fc8c --- /dev/null +++ b/qemu_mode/libqasan/malloc.c @@ -0,0 +1,370 @@ +/******************************************************************************* +Copyright (c) 2019-2020, Andrea Fioraldi + + +Redistribution and use in source and binary forms, with or without +modification, are permitted provided that the following conditions are met: + +1. Redistributions of source code must retain the above copyright notice, this + list of conditions and the following disclaimer. +2. Redistributions in binary form must reproduce the above copyright notice, + this list of conditions and the following disclaimer in the documentation + and/or other materials provided with the distribution. + +THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND +ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED +WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE +DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR +ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES +(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; +LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND +ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS +SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. +*******************************************************************************/ + +#include "libqasan.h" +#include <features.h> +#include <errno.h> +#include <stddef.h> +#include <assert.h> +#include <pthread.h> + +#define REDZONE_SIZE 128 +// 50 mb quarantine +#define QUARANTINE_MAX_BYTES 52428800 + +#if __STDC_VERSION__ < 201112L || \ + (defined(__FreeBSD__) && __FreeBSD_version < 1200000) +// use this hack if not C11 +typedef struct { + + long long __ll; + long double __ld; + +} max_align_t; + +#endif + +#define ALLOC_ALIGN_SIZE (_Alignof(max_align_t)) + +struct chunk_begin { + + size_t requested_size; + void * aligned_orig; // NULL if not aligned + struct chunk_begin *next; + struct chunk_begin *prev; + char redzone[REDZONE_SIZE]; + +}; + +struct chunk_struct { + + struct chunk_begin begin; + char redzone[REDZONE_SIZE]; + size_t prev_size_padding; + +}; + +#ifdef __GLIBC__ + +void *(*__lq_libc_malloc)(size_t); +void (*__lq_libc_free)(void *); + #define backend_malloc __lq_libc_malloc + #define backend_free __lq_libc_free + + #define TMP_ZONE_SIZE 4096 +static int __tmp_alloc_zone_idx; +static unsigned char __tmp_alloc_zone[TMP_ZONE_SIZE]; + +#else + +// From dlmalloc.c +void * dlmalloc(size_t); +void dlfree(void *); + #define backend_malloc dlmalloc + #define backend_free dlfree + +#endif + +int __libqasan_malloc_initialized; + +static struct chunk_begin *quarantine_top; +static struct chunk_begin *quarantine_end; +static size_t quarantine_bytes; + +#ifdef __BIONIC__ +static pthread_mutex_t quarantine_lock; + #define LOCK_TRY pthread_mutex_trylock + #define LOCK_INIT pthread_mutex_init + #define LOCK_UNLOCK pthread_mutex_unlock +#else +static pthread_spinlock_t quarantine_lock; + #define LOCK_TRY pthread_spin_trylock + #define LOCK_INIT pthread_spin_init + #define LOCK_UNLOCK pthread_spin_unlock +#endif + +// need qasan disabled +static int quanratine_push(struct chunk_begin *ck) { + + if (ck->requested_size >= QUARANTINE_MAX_BYTES) return 0; + + if (LOCK_TRY(&quarantine_lock)) return 0; + + while (ck->requested_size + quarantine_bytes >= QUARANTINE_MAX_BYTES) { + + struct chunk_begin *tmp = quarantine_end; + quarantine_end = tmp->prev; + + quarantine_bytes -= tmp->requested_size; + + if (tmp->aligned_orig) + backend_free(tmp->aligned_orig); + else + backend_free(tmp); + + } + + ck->next = quarantine_top; + if (quarantine_top) quarantine_top->prev = ck; + quarantine_top = ck; + + LOCK_UNLOCK(&quarantine_lock); + + return 1; + +} + +void __libqasan_init_malloc(void) { + + if (__libqasan_malloc_initialized) return; + +#ifdef __GLIBC__ + __lq_libc_malloc = dlsym(RTLD_NEXT, "malloc"); + __lq_libc_free = dlsym(RTLD_NEXT, "free"); +#endif + + LOCK_INIT(&quarantine_lock, PTHREAD_PROCESS_PRIVATE); + + __libqasan_malloc_initialized = 1; + QASAN_LOG("\n"); + QASAN_LOG("Allocator initialization done.\n"); + QASAN_LOG("\n"); + +} + +size_t __libqasan_malloc_usable_size(void *ptr) { + + char *p = ptr; + p -= sizeof(struct chunk_begin); + + // Validate that the chunk marker is readable (a crude check + // to verify that ptr is a valid malloc region before we dereference it) + QASAN_LOAD(p, sizeof(struct chunk_begin) - REDZONE_SIZE); + return ((struct chunk_begin *)p)->requested_size; + +} + +void *__libqasan_malloc(size_t size) { + + if (!__libqasan_malloc_initialized) { + + __libqasan_init_malloc(); + +#ifdef __GLIBC__ + void *r = &__tmp_alloc_zone[__tmp_alloc_zone_idx]; + + if (size & (ALLOC_ALIGN_SIZE - 1)) + __tmp_alloc_zone_idx += + (size & ~(ALLOC_ALIGN_SIZE - 1)) + ALLOC_ALIGN_SIZE; + else + __tmp_alloc_zone_idx += size; + + return r; +#endif + + } + + int state = QASAN_SWAP(QASAN_DISABLED); // disable qasan for this thread + + struct chunk_begin *p = backend_malloc(sizeof(struct chunk_struct) + size); + + QASAN_SWAP(state); + + if (!p) return NULL; + + QASAN_UNPOISON(p, sizeof(struct chunk_struct) + size); + + p->requested_size = size; + p->aligned_orig = NULL; + p->next = p->prev = NULL; + + QASAN_ALLOC(&p[1], (char *)&p[1] + size); + QASAN_POISON(p->redzone, REDZONE_SIZE, ASAN_HEAP_LEFT_RZ); + if (size & (ALLOC_ALIGN_SIZE - 1)) + QASAN_POISON((char *)&p[1] + size, + (size & ~(ALLOC_ALIGN_SIZE - 1)) + 8 - size + REDZONE_SIZE, + ASAN_HEAP_RIGHT_RZ); + else + QASAN_POISON((char *)&p[1] + size, REDZONE_SIZE, ASAN_HEAP_RIGHT_RZ); + + __builtin_memset(&p[1], 0xff, size); + + return &p[1]; + +} + +void __libqasan_free(void *ptr) { + + if (!ptr) return; + +#ifdef __GLIBC__ + if (ptr >= (void *)__tmp_alloc_zone && + ptr < ((void *)__tmp_alloc_zone + TMP_ZONE_SIZE)) + return; +#endif + + struct chunk_begin *p = ptr; + p -= 1; + + // Validate that the chunk marker is readable (a crude check + // to verify that ptr is a valid malloc region before we dereference it) + QASAN_LOAD(p, sizeof(struct chunk_begin) - REDZONE_SIZE); + size_t n = p->requested_size; + + QASAN_STORE(ptr, n); + int state = QASAN_SWAP(QASAN_DISABLED); // disable qasan for this thread + + if (!quanratine_push(p)) { + + if (p->aligned_orig) + backend_free(p->aligned_orig); + else + backend_free(p); + + } + + QASAN_SWAP(state); + + if (n & (ALLOC_ALIGN_SIZE - 1)) + n = (n & ~(ALLOC_ALIGN_SIZE - 1)) + ALLOC_ALIGN_SIZE; + + QASAN_POISON(ptr, n, ASAN_HEAP_FREED); + QASAN_DEALLOC(ptr); + +} + +void *__libqasan_calloc(size_t nmemb, size_t size) { + + size *= nmemb; + +#ifdef __GLIBC__ + if (!__libqasan_malloc_initialized) { + + void *r = &__tmp_alloc_zone[__tmp_alloc_zone_idx]; + __tmp_alloc_zone_idx += size; + return r; + + } + +#endif + + char *p = __libqasan_malloc(size); + if (!p) return NULL; + + __builtin_memset(p, 0, size); + + return p; + +} + +void *__libqasan_realloc(void *ptr, size_t size) { + + char *p = __libqasan_malloc(size); + if (!p) return NULL; + + if (!ptr) return p; + + size_t n = ((struct chunk_begin *)ptr)[-1].requested_size; + if (size < n) n = size; + + __builtin_memcpy(p, ptr, n); + + __libqasan_free(ptr); + return p; + +} + +int __libqasan_posix_memalign(void **ptr, size_t align, size_t len) { + + if ((align % 2) || (align % sizeof(void *))) return EINVAL; + if (len == 0) { + + *ptr = NULL; + return 0; + + } + + size_t rem = len % align; + size_t size = len; + if (rem) size += rem; + + int state = QASAN_SWAP(QASAN_DISABLED); // disable qasan for this thread + + char *orig = backend_malloc(sizeof(struct chunk_struct) + size); + + QASAN_SWAP(state); + + if (!orig) return ENOMEM; + + QASAN_UNPOISON(orig, sizeof(struct chunk_struct) + size); + + char *data = orig + sizeof(struct chunk_begin); + data += align - ((uintptr_t)data % align); + + struct chunk_begin *p = (struct chunk_begin *)data - 1; + + p->requested_size = len; + p->aligned_orig = orig; + + QASAN_ALLOC(data, data + len); + QASAN_POISON(p->redzone, REDZONE_SIZE, ASAN_HEAP_LEFT_RZ); + if (len & (ALLOC_ALIGN_SIZE - 1)) + QASAN_POISON( + data + len, + (len & ~(ALLOC_ALIGN_SIZE - 1)) + ALLOC_ALIGN_SIZE - len + REDZONE_SIZE, + ASAN_HEAP_RIGHT_RZ); + else + QASAN_POISON(data + len, REDZONE_SIZE, ASAN_HEAP_RIGHT_RZ); + + __builtin_memset(data, 0xff, len); + + *ptr = data; + + return 0; + +} + +void *__libqasan_memalign(size_t align, size_t len) { + + void *ret = NULL; + + __libqasan_posix_memalign(&ret, align, len); + + return ret; + +} + +void *__libqasan_aligned_alloc(size_t align, size_t len) { + + void *ret = NULL; + + if ((len % align)) return NULL; + + __libqasan_posix_memalign(&ret, align, len); + + return ret; + +} + diff --git a/qemu_mode/libqasan/map_macro.h b/qemu_mode/libqasan/map_macro.h new file mode 100644 index 00000000..e9438dc5 --- /dev/null +++ b/qemu_mode/libqasan/map_macro.h @@ -0,0 +1,74 @@ +/* + * Copyright (C) 2012 William Swanson + * + * Permission is hereby granted, free of charge, to any person + * obtaining a copy of this software and associated documentation + * files (the "Software"), to deal in the Software without + * restriction, including without limitation the rights to use, copy, + * modify, merge, publish, distribute, sublicense, and/or sell copies + * of the Software, and to permit persons to whom the Software is + * furnished to do so, subject to the following conditions: + * + * The above copyright notice and this permission notice shall be + * included in all copies or substantial portions of the Software. + * + * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, + * EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF + * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND + * NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY + * CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF + * CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION + * WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. + * + * Except as contained in this notice, the names of the authors or + * their institutions shall not be used in advertising or otherwise to + * promote the sale, use or other dealings in this Software without + * prior written authorization from the authors. + */ + +#ifndef MAP_H_INCLUDED +#define MAP_H_INCLUDED + +#define EVAL0(...) __VA_ARGS__ +#define EVAL1(...) EVAL0(EVAL0(EVAL0(__VA_ARGS__))) +#define EVAL2(...) EVAL1(EVAL1(EVAL1(__VA_ARGS__))) +#define EVAL3(...) EVAL2(EVAL2(EVAL2(__VA_ARGS__))) +#define EVAL4(...) EVAL3(EVAL3(EVAL3(__VA_ARGS__))) +#define EVAL(...) EVAL4(EVAL4(EVAL4(__VA_ARGS__))) + +#define MAP_END(...) +#define MAP_OUT +#define MAP_COMMA , + +#define MAP_GET_END2() 0, MAP_END +#define MAP_GET_END1(...) MAP_GET_END2 +#define MAP_GET_END(...) MAP_GET_END1 +#define MAP_NEXT0(test, next, ...) next MAP_OUT +#define MAP_NEXT1(test, next) MAP_NEXT0(test, next, 0) +#define MAP_NEXT(test, next) MAP_NEXT1(MAP_GET_END test, next) + +#define MAP0(f, x, peek, ...) f(x) MAP_NEXT(peek, MAP1)(f, peek, __VA_ARGS__) +#define MAP1(f, x, peek, ...) f(x) MAP_NEXT(peek, MAP0)(f, peek, __VA_ARGS__) + +#define MAP_LIST_NEXT1(test, next) MAP_NEXT0(test, MAP_COMMA next, 0) +#define MAP_LIST_NEXT(test, next) MAP_LIST_NEXT1(MAP_GET_END test, next) + +#define MAP_LIST0(f, x, peek, ...) \ + f(x) MAP_LIST_NEXT(peek, MAP_LIST1)(f, peek, __VA_ARGS__) +#define MAP_LIST1(f, x, peek, ...) \ + f(x) MAP_LIST_NEXT(peek, MAP_LIST0)(f, peek, __VA_ARGS__) + +/** + * Applies the function macro `f` to each of the remaining parameters. + */ +#define MAP(f, ...) EVAL(MAP1(f, __VA_ARGS__, ()()(), ()()(), ()()(), 0)) + +/** + * Applies the function macro `f` to each of the remaining parameters and + * inserts commas between the results. + */ +#define MAP_LIST(f, ...) \ + EVAL(MAP_LIST1(f, __VA_ARGS__, ()()(), ()()(), ()()(), 0)) + +#endif + diff --git a/qemu_mode/libqasan/patch.c b/qemu_mode/libqasan/patch.c new file mode 100644 index 00000000..fbc09c99 --- /dev/null +++ b/qemu_mode/libqasan/patch.c @@ -0,0 +1,243 @@ +/******************************************************************************* +Copyright (c) 2019-2020, Andrea Fioraldi + + +Redistribution and use in source and binary forms, with or without +modification, are permitted provided that the following conditions are met: + +1. Redistributions of source code must retain the above copyright notice, this + list of conditions and the following disclaimer. +2. Redistributions in binary form must reproduce the above copyright notice, + this list of conditions and the following disclaimer in the documentation + and/or other materials provided with the distribution. + +THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND +ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED +WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE +DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR +ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES +(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; +LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND +ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS +SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. +*******************************************************************************/ + +#include "libqasan.h" +#include <sys/mman.h> + +#ifdef __x86_64__ + +uint8_t *__libqasan_patch_jump(uint8_t *addr, uint8_t *dest) { + + // mov rax, dest + addr[0] = 0x48; + addr[1] = 0xb8; + *(uint8_t **)&addr[2] = dest; + + // jmp rax + addr[10] = 0xff; + addr[11] = 0xe0; + + return &addr[12]; + +} + +#elif __i386__ + +uint8_t *__libqasan_patch_jump(uint8_t *addr, uint8_t *dest) { + + // mov eax, dest + addr[0] = 0xb8; + *(uint8_t **)&addr[1] = dest; + + // jmp eax + addr[5] = 0xff; + addr[6] = 0xe0; + + return &addr[7]; + +} + +#elif __arm__ + +// in ARM, r12 is a scratch register used by the linker to jump, +// so let's use it in our stub + +uint8_t *__libqasan_patch_jump(uint8_t *addr, uint8_t *dest) { + + // ldr r12, OFF + addr[0] = 0x0; + addr[1] = 0xc0; + addr[2] = 0x9f; + addr[3] = 0xe5; + + // add pc, pc, r12 + addr[4] = 0xc; + addr[5] = 0xf0; + addr[6] = 0x8f; + addr[7] = 0xe0; + + // OFF: .word dest + *(uint32_t *)&addr[8] = (uint32_t)dest; + + return &addr[12]; + +} + +#elif __aarch64__ + +// in ARM64, x16 is a scratch register used by the linker to jump, +// so let's use it in our stub + +uint8_t *__libqasan_patch_jump(uint8_t *addr, uint8_t *dest) { + + // ldr x16, OFF + addr[0] = 0x50; + addr[1] = 0x0; + addr[2] = 0x0; + addr[3] = 0x58; + + // br x16 + addr[4] = 0x0; + addr[5] = 0x2; + addr[6] = 0x1f; + addr[7] = 0xd6; + + // OFF: .dword dest + *(uint64_t *)&addr[8] = (uint64_t)dest; + + return &addr[16]; + +} + +#else + + #define CANNOT_HOTPATCH + +#endif + +#ifdef CANNOT_HOTPATCH + +void __libqasan_hotpatch(void) { + +} + +#else + +static void *libc_start, *libc_end; +int libc_perms; + +static void find_libc(void) { + + FILE * fp; + char * line = NULL; + size_t len = 0; + ssize_t read; + + fp = fopen("/proc/self/maps", "r"); + if (fp == NULL) return; + + while ((read = getline(&line, &len, fp)) != -1) { + + int fields, dev_maj, dev_min, inode; + uint64_t min, max, offset; + char flag_r, flag_w, flag_x, flag_p; + char path[512] = ""; + fields = sscanf(line, + "%" PRIx64 "-%" PRIx64 " %c%c%c%c %" PRIx64 + " %x:%x %d" + " %512s", + &min, &max, &flag_r, &flag_w, &flag_x, &flag_p, &offset, + &dev_maj, &dev_min, &inode, path); + + if ((fields < 10) || (fields > 11)) continue; + + if (flag_x == 'x' && (__libqasan_strstr(path, "/libc.so") || + __libqasan_strstr(path, "/libc-"))) { + + libc_start = (void *)min; + libc_end = (void *)max; + + libc_perms = PROT_EXEC; + if (flag_w == 'w') libc_perms |= PROT_WRITE; + if (flag_r == 'r') libc_perms |= PROT_READ; + + break; + + } + + } + + free(line); + fclose(fp); + +} + +/* Why this shit? https://twitter.com/andreafioraldi/status/1227635146452541441 + Unfortunatly, symbol override with LD_PRELOAD is not enough to prevent libc + code to call this optimized XMM-based routines. + We patch them at runtime to call our unoptimized version of the same routine. +*/ + +void __libqasan_hotpatch(void) { + + find_libc(); + + if (!libc_start) return; + + if (mprotect(libc_start, libc_end - libc_start, + PROT_READ | PROT_WRITE | PROT_EXEC) < 0) + return; + + void *libc = dlopen("libc.so.6", RTLD_LAZY); + + #define HOTPATCH(fn) \ + uint8_t *p_##fn = (uint8_t *)dlsym(libc, #fn); \ + if (p_##fn) __libqasan_patch_jump(p_##fn, (uint8_t *)&(fn)); + + HOTPATCH(memcmp) + HOTPATCH(memmove) + + uint8_t *p_memcpy = (uint8_t *)dlsym(libc, "memcpy"); + // fuck you libc + if (p_memcpy && p_memmove != p_memcpy) + __libqasan_patch_jump(p_memcpy, (uint8_t *)&memcpy); + + HOTPATCH(memchr) + HOTPATCH(memrchr) + HOTPATCH(memmem) + #ifndef __BIONIC__ + HOTPATCH(bzero) + HOTPATCH(explicit_bzero) + HOTPATCH(mempcpy) + HOTPATCH(bcmp) + #endif + + HOTPATCH(strchr) + HOTPATCH(strrchr) + HOTPATCH(strcasecmp) + HOTPATCH(strncasecmp) + HOTPATCH(strcat) + HOTPATCH(strcmp) + HOTPATCH(strncmp) + HOTPATCH(strcpy) + HOTPATCH(strncpy) + HOTPATCH(stpcpy) + HOTPATCH(strdup) + HOTPATCH(strlen) + HOTPATCH(strnlen) + HOTPATCH(strstr) + HOTPATCH(strcasestr) + HOTPATCH(wcslen) + HOTPATCH(wcscpy) + HOTPATCH(wcscmp) + + #undef HOTPATCH + + mprotect(libc_start, libc_end - libc_start, libc_perms); + +} + +#endif + diff --git a/qemu_mode/libqasan/string.c b/qemu_mode/libqasan/string.c new file mode 100644 index 00000000..4be01279 --- /dev/null +++ b/qemu_mode/libqasan/string.c @@ -0,0 +1,339 @@ +/******************************************************************************* +Copyright (c) 2019-2020, Andrea Fioraldi + + +Redistribution and use in source and binary forms, with or without +modification, are permitted provided that the following conditions are met: + +1. Redistributions of source code must retain the above copyright notice, this + list of conditions and the following disclaimer. +2. Redistributions in binary form must reproduce the above copyright notice, + this list of conditions and the following disclaimer in the documentation + and/or other materials provided with the distribution. + +THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND +ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED +WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE +DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR +ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES +(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; +LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND +ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS +SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. +*******************************************************************************/ + +#include "libqasan.h" +#include <ctype.h> + +void *__libqasan_memcpy(void *dest, const void *src, size_t n) { + + unsigned char * d = dest; + const unsigned char *s = src; + + if (!n) return dest; + + while (n--) { + + *d = *s; + ++d; + ++s; + + } + + return dest; + +} + +void *__libqasan_memmove(void *dest, const void *src, size_t n) { + + unsigned char * d = dest; + const unsigned char *s = src; + + if (!n) return dest; + + if (!((d + n) >= s && d <= (s + n))) // do not overlap + return __libqasan_memcpy(dest, src, n); + + d = __libqasan_malloc(n); + __libqasan_memcpy(d, src, n); + __libqasan_memcpy(dest, d, n); + + __libqasan_free(d); + + return dest; + +} + +void *__libqasan_memset(void *s, int c, size_t n) { + + unsigned char *b = s; + while (n--) + *(b++) = (unsigned char)c; + return s; + +} + +void *__libqasan_memchr(const void *s, int c, size_t n) { + + unsigned char *m = (unsigned char *)s; + size_t i; + for (i = 0; i < n; ++i) + if (m[i] == (unsigned char)c) return &m[i]; + return NULL; + +} + +void *__libqasan_memrchr(const void *s, int c, size_t n) { + + unsigned char *m = (unsigned char *)s; + long i; + for (i = n; i >= 0; --i) + if (m[i] == (unsigned char)c) return &m[i]; + return NULL; + +} + +size_t __libqasan_strlen(const char *s) { + + const char *i = s; + while (*(i++)) + ; + return i - s - 1; + +} + +size_t __libqasan_strnlen(const char *s, size_t len) { + + size_t r = 0; + while (len-- && *(s++)) + ++r; + return r; + +} + +int __libqasan_strcmp(const char *str1, const char *str2) { + + while (1) { + + const unsigned char c1 = *str1, c2 = *str2; + + if (c1 != c2) return c1 - c2; + if (!c1) return 0; + str1++; + str2++; + + } + + return 0; + +} + +int __libqasan_strncmp(const char *str1, const char *str2, size_t len) { + + while (len--) { + + unsigned char c1 = *str1, c2 = *str2; + + if (c1 != c2) return c1 - c2; + if (!c1) return 0; + str1++; + str2++; + + } + + return 0; + +} + +int __libqasan_strcasecmp(const char *str1, const char *str2) { + + while (1) { + + const unsigned char c1 = tolower(*str1), c2 = tolower(*str2); + + if (c1 != c2) return c1 - c2; + if (!c1) return 0; + str1++; + str2++; + + } + + return 0; + +} + +int __libqasan_strncasecmp(const char *str1, const char *str2, size_t len) { + + while (len--) { + + const unsigned char c1 = tolower(*str1), c2 = tolower(*str2); + + if (c1 != c2) return c1 - c2; + if (!c1) return 0; + str1++; + str2++; + + } + + return 0; + +} + +int __libqasan_memcmp(const void *mem1, const void *mem2, size_t len) { + + const char *strmem1 = (const char *)mem1; + const char *strmem2 = (const char *)mem2; + + while (len--) { + + const unsigned char c1 = *strmem1, c2 = *strmem2; + if (c1 != c2) return (c1 > c2) ? 1 : -1; + strmem1++; + strmem2++; + + } + + return 0; + +} + +int __libqasan_bcmp(const void *mem1, const void *mem2, size_t len) { + + const char *strmem1 = (const char *)mem1; + const char *strmem2 = (const char *)mem2; + + while (len--) { + + int diff = *strmem1 ^ *strmem2; + if (diff != 0) return 1; + strmem1++; + strmem2++; + + } + + return 0; + +} + +char *__libqasan_strstr(const char *haystack, const char *needle) { + + do { + + const char *n = needle; + const char *h = haystack; + + while (*n && *h && *n == *h) + n++, h++; + + if (!*n) return (char *)haystack; + + } while (*(haystack++)); + + return 0; + +} + +char *__libqasan_strcasestr(const char *haystack, const char *needle) { + + do { + + const char *n = needle; + const char *h = haystack; + + while (*n && *h && tolower(*n) == tolower(*h)) + n++, h++; + + if (!*n) return (char *)haystack; + + } while (*(haystack++)); + + return 0; + +} + +void *__libqasan_memmem(const void *haystack, size_t haystack_len, + const void *needle, size_t needle_len) { + + const char *n = (const char *)needle; + const char *h = (const char *)haystack; + if (haystack_len < needle_len) return 0; + if (needle_len == 0) return (void *)haystack; + if (needle_len == 1) return memchr(haystack, *n, haystack_len); + + const char *end = h + (haystack_len - needle_len); + + do { + + if (*h == *n) { + + if (memcmp(h, n, needle_len) == 0) return (void *)h; + + } + + } while (++h <= end); + + return 0; + +} + +char *__libqasan_strchr(const char *s, int c) { + + while (*s != (char)c) + if (!*s++) return 0; + return (char *)s; + +} + +char *__libqasan_strrchr(const char *s, int c) { + + char *r = NULL; + do + if (*s == (char)c) r = (char *)s; + while (*s++); + + return r; + +} + +size_t __libqasan_wcslen(const wchar_t *s) { + + size_t len = 0; + + while (s[len] != L'\0') { + + if (s[++len] == L'\0') return len; + if (s[++len] == L'\0') return len; + if (s[++len] == L'\0') return len; + ++len; + + } + + return len; + +} + +wchar_t *__libqasan_wcscpy(wchar_t *d, const wchar_t *s) { + + wchar_t *a = d; + while ((*d++ = *s++)) + ; + return a; + +} + +int __libqasan_wcscmp(const wchar_t *s1, const wchar_t *s2) { + + wchar_t c1, c2; + do { + + c1 = *s1++; + c2 = *s2++; + if (c2 == L'\0') return c1 - c2; + + } while (c1 == c2); + + return c1 < c2 ? -1 : 1; + +} + diff --git a/qemu_mode/libqasan/uninstrument.c b/qemu_mode/libqasan/uninstrument.c new file mode 100644 index 00000000..5bf841a3 --- /dev/null +++ b/qemu_mode/libqasan/uninstrument.c @@ -0,0 +1,83 @@ +/* + +This code is DEPRECATED! +I'm keeping it here cause maybe the uninstrumentation of a function is needed +for some strange reason. + +*/ + +/******************************************************************************* +Copyright (c) 2019-2020, Andrea Fioraldi + + +Redistribution and use in source and binary forms, with or without +modification, are permitted provided that the following conditions are met: + +1. Redistributions of source code must retain the above copyright notice, this + list of conditions and the following disclaimer. +2. Redistributions in binary form must reproduce the above copyright notice, + this list of conditions and the following disclaimer in the documentation + and/or other materials provided with the distribution. + +THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND +ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED +WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE +DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR +ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES +(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; +LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND +ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT +(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS +SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. +*******************************************************************************/ + +#include "libqasan.h" +#include "map_macro.h" +#include <sys/types.h> +#include <pwd.h> + +#define X_GET_FNPAR(type, name) name +#define GET_FNPAR(x) X_GET_FNPAR x +#define X_GET_FNTYPE(type, name) type +#define GET_FNTYPE(x) X_GET_FNTYPE x +#define X_GET_FNDECL(type, name) type name +#define GET_FNDECL(x) X_GET_FNDECL x + +#define HOOK_UNINSTRUMENT(rettype, name, ...) \ + rettype (*__lq_libc_##name)(MAP_LIST(GET_FNTYPE, __VA_ARGS__)); \ + rettype name(MAP_LIST(GET_FNDECL, __VA_ARGS__)) { \ + \ + if (!(__lq_libc_##name)) __lq_libc_##name = ASSERT_DLSYM(name); \ + int state = QASAN_SWAP(QASAN_DISABLED); \ + rettype r = __lq_libc_##name(MAP_LIST(GET_FNPAR, __VA_ARGS__)); \ + QASAN_SWAP(state); \ + \ + return r; \ + \ + } + +HOOK_UNINSTRUMENT(char *, getenv, (const char *, name)) + +/* +HOOK_UNINSTRUMENT(char*, setlocale, (int, category), (const char *, locale)) +HOOK_UNINSTRUMENT(int, setenv, (const char *, name), (const char *, value), +(int, overwrite)) HOOK_UNINSTRUMENT(char*, getenv, (const char *, name)) +HOOK_UNINSTRUMENT(char*, bindtextdomain, (const char *, domainname), (const char +*, dirname)) HOOK_UNINSTRUMENT(char*, bind_textdomain_codeset, (const char *, +domainname), (const char *, codeset)) HOOK_UNINSTRUMENT(char*, gettext, (const +char *, msgid)) HOOK_UNINSTRUMENT(char*, dgettext, (const char *, domainname), +(const char *, msgid)) HOOK_UNINSTRUMENT(char*, dcgettext, (const char *, +domainname), (const char *, msgid), (int, category)) HOOK_UNINSTRUMENT(int, +__gen_tempname, (char, *tmpl), (int, suffixlen), (int, flags), (int, kind)) +HOOK_UNINSTRUMENT(int, mkstemp, (char *, template)) +HOOK_UNINSTRUMENT(int, mkostemp, (char *, template), (int, flags)) +HOOK_UNINSTRUMENT(int, mkstemps, (char *, template), (int, suffixlen)) +HOOK_UNINSTRUMENT(int, mkostemps, (char *, template), (int, suffixlen), (int, +flags)) HOOK_UNINSTRUMENT(struct passwd *, getpwnam, (const char *, name)) +HOOK_UNINSTRUMENT(struct passwd *, getpwuid, (uid_t, uid)) +HOOK_UNINSTRUMENT(int, getpwnam_r, (const char *, name), (struct passwd *, pwd), +(char *, buf), (size_t, buflen), (struct passwd **, result)) +HOOK_UNINSTRUMENT(int, getpwuid_r, (uid_t, uid), (struct passwd *, pwd), (char +*, buf), (size_t, buflen), (struct passwd **, result)) +*/ + diff --git a/qemu_mode/patches/__init__.py.diff b/qemu_mode/patches/__init__.py.diff deleted file mode 100644 index 7e189b99..00000000 --- a/qemu_mode/patches/__init__.py.diff +++ /dev/null @@ -1,17 +0,0 @@ ---- a/scripts/tracetool/__init__.py 2020-03-28 13:42:21.937700726 +0100 -+++ b/scripts/tracetool/__init__.py 2020-03-28 13:41:50.991034257 +0100 -@@ -447,12 +447,12 @@ - import tracetool - - format = str(format) -- if len(format) is 0: -+ if len(format) == 0: - raise TracetoolError("format not set") - if not tracetool.format.exists(format): - raise TracetoolError("unknown format: %s" % format) - -- if len(backends) is 0: -+ if len(backends) == 0: - raise TracetoolError("no backends specified") - for backend in backends: - if not tracetool.backend.exists(backend): diff --git a/qemu_mode/patches/afl-qemu-common.h b/qemu_mode/patches/afl-qemu-common.h deleted file mode 100644 index 6fac32ef..00000000 --- a/qemu_mode/patches/afl-qemu-common.h +++ /dev/null @@ -1,130 +0,0 @@ -/* - american fuzzy lop++ - high-performance binary-only instrumentation - ------------------------------------------------------------------- - - Originally written by Andrew Griffiths <agriffiths@google.com> and - Michal Zalewski - - TCG instrumentation and block chaining support by Andrea Biondo - <andrea.biondo965@gmail.com> - - QEMU 3.1.1 port, TCG thread-safety, CompareCoverage and NeverZero - counters by Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2015, 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This code is a shim patched into the separately-distributed source - code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality - to implement AFL-style instrumentation and to take care of the remaining - parts of the AFL fork server logic. - - The resulting QEMU binary is essentially a standalone instrumentation - tool; for an example of how to leverage it for other purposes, you can - have a look at afl-showmap.c. - - */ - -#ifndef __AFL_QEMU_COMMON -#define __AFL_QEMU_COMMON - -#include "../../config.h" -#include "../../include/cmplog.h" - -#define PERSISTENT_DEFAULT_MAX_CNT 1000 - -#ifdef CPU_NB_REGS - #define AFL_REGS_NUM CPU_NB_REGS -#elif TARGET_ARM - #define AFL_REGS_NUM 16 -#elif TARGET_AARCH64 - #define AFL_REGS_NUM 32 -#else - #define AFL_REGS_NUM 100 -#endif - -/* NeverZero */ - -#if (defined(__x86_64__) || defined(__i386__)) && defined(AFL_QEMU_NOT_ZERO) - #define INC_AFL_AREA(loc) \ - asm volatile( \ - "addb $1, (%0, %1, 1)\n" \ - "adcb $0, (%0, %1, 1)\n" \ - : /* no out */ \ - : "r"(afl_area_ptr), "r"(loc) \ - : "memory", "eax") -#else - #define INC_AFL_AREA(loc) afl_area_ptr[loc]++ -#endif - -typedef void (*afl_persistent_hook_fn)(uint64_t *regs, uint64_t guest_base, - uint8_t *input_buf, - uint32_t input_buf_len); - -/* Declared in afl-qemu-cpu-inl.h */ - -extern unsigned char *afl_area_ptr; -extern unsigned int afl_inst_rms; -extern abi_ulong afl_entry_point, afl_start_code, afl_end_code; -extern abi_ulong afl_persistent_addr; -extern abi_ulong afl_persistent_ret_addr; -extern u8 afl_compcov_level; -extern unsigned char afl_fork_child; -extern unsigned char is_persistent; -extern target_long persistent_stack_offset; -extern unsigned char persistent_first_pass; -extern unsigned char persistent_save_gpr; -extern uint64_t persistent_saved_gpr[AFL_REGS_NUM]; -extern int persisent_retaddr_offset; - -extern u8 * shared_buf; -extern u32 *shared_buf_len; -extern u8 sharedmem_fuzzing; - -extern afl_persistent_hook_fn afl_persistent_hook_ptr; - -extern __thread abi_ulong afl_prev_loc; - -extern struct cmp_map *__afl_cmp_map; -extern __thread u32 __afl_cmp_counter; - -void afl_setup(void); -void afl_forkserver(CPUState *cpu); - -// void afl_debug_dump_saved_regs(void); - -void afl_persistent_loop(void); - -void afl_gen_tcg_plain_call(void *func); - -void afl_float_compcov_log_32(target_ulong cur_loc, float32 arg1, float32 arg2, - void *status); -void afl_float_compcov_log_64(target_ulong cur_loc, float64 arg1, float64 arg2, - void *status); -void afl_float_compcov_log_80(target_ulong cur_loc, floatx80 arg1, - floatx80 arg2); - -/* Check if an address is valid in the current mapping */ - -static inline int is_valid_addr(target_ulong addr) { - - int flags; - target_ulong page; - - page = addr & TARGET_PAGE_MASK; - - flags = page_get_flags(page); - if (!(flags & PAGE_VALID) || !(flags & PAGE_READ)) return 0; - - return 1; - -} - -#endif - diff --git a/qemu_mode/patches/afl-qemu-cpu-inl.h b/qemu_mode/patches/afl-qemu-cpu-inl.h deleted file mode 100644 index 63b7581d..00000000 --- a/qemu_mode/patches/afl-qemu-cpu-inl.h +++ /dev/null @@ -1,640 +0,0 @@ -/* - american fuzzy lop++ - high-performance binary-only instrumentation - ------------------------------------------------------------------- - - Originally written by Andrew Griffiths <agriffiths@google.com> and - Michal Zalewski - - TCG instrumentation and block chaining support by Andrea Biondo - <andrea.biondo965@gmail.com> - - QEMU 3.1.1 port, TCG thread-safety, CompareCoverage and NeverZero - counters by Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2015, 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This code is a shim patched into the separately-distributed source - code of QEMU 3.1.1. It leverages the built-in QEMU tracing functionality - to implement AFL-style instrumentation and to take care of the remaining - parts of the AFL fork server logic. - - The resulting QEMU binary is essentially a standalone instrumentation - tool; for an example of how to leverage it for other purposes, you can - have a look at afl-showmap.c. - - */ - -#include <sys/shm.h> -#include "afl-qemu-common.h" - -#ifndef AFL_QEMU_STATIC_BUILD - #include <dlfcn.h> -#endif - -/*************************** - * VARIOUS AUXILIARY STUFF * - ***************************/ - -/* We use one additional file descriptor to relay "needs translation" - messages between the child and the fork server. */ - -#define TSL_FD (FORKSRV_FD - 1) - -/* This is equivalent to afl-as.h: */ - -static unsigned char - dummy[MAP_SIZE]; /* costs MAP_SIZE but saves a few instructions */ -unsigned char *afl_area_ptr = dummy; /* Exported for afl_gen_trace */ - -/* Exported variables populated by the code patched into elfload.c: */ - -abi_ulong afl_entry_point, /* ELF entry point (_start) */ - afl_start_code, /* .text start pointer */ - afl_end_code; /* .text end pointer */ - -abi_ulong afl_persistent_addr, afl_persistent_ret_addr; -unsigned int afl_persistent_cnt; - -u8 afl_compcov_level; - -__thread abi_ulong afl_prev_loc; - -struct cmp_map *__afl_cmp_map; -__thread u32 __afl_cmp_counter; - -/* Set in the child process in forkserver mode: */ - -static int forkserver_installed = 0; -static int disable_caching = 0; - -unsigned char afl_fork_child; -unsigned int afl_forksrv_pid; -unsigned char is_persistent; -target_long persistent_stack_offset; -unsigned char persistent_first_pass = 1; -unsigned char persistent_save_gpr; -uint64_t persistent_saved_gpr[AFL_REGS_NUM]; -int persisent_retaddr_offset; - -u8 * shared_buf; -u32 *shared_buf_len; -u8 sharedmem_fuzzing; - -afl_persistent_hook_fn afl_persistent_hook_ptr; - -/* Instrumentation ratio: */ - -unsigned int afl_inst_rms = MAP_SIZE; /* Exported for afl_gen_trace */ - -/* Function declarations. */ - -static void afl_wait_tsl(CPUState *, int); -static void afl_request_tsl(target_ulong, target_ulong, uint32_t, uint32_t, - TranslationBlock *, int); - -/* Data structures passed around by the translate handlers: */ - -struct afl_tb { - - target_ulong pc; - target_ulong cs_base; - uint32_t flags; - uint32_t cf_mask; - -}; - -struct afl_tsl { - - struct afl_tb tb; - char is_chain; - -}; - -struct afl_chain { - - struct afl_tb last_tb; - uint32_t cf_mask; - int tb_exit; - -}; - -/* Some forward decls: */ - -static inline TranslationBlock *tb_find(CPUState *, TranslationBlock *, int, - uint32_t); -static inline void tb_add_jump(TranslationBlock *tb, int n, - TranslationBlock *tb_next); -int open_self_maps(void *cpu_env, int fd); -static void afl_map_shm_fuzz(void); - -/************************* - * ACTUAL IMPLEMENTATION * - *************************/ - -/* Set up SHM region and initialize other stuff. */ - -static void afl_map_shm_fuzz(void) { - - char *id_str = getenv(SHM_FUZZ_ENV_VAR); - - if (id_str) { - - u32 shm_id = atoi(id_str); - u8 *map = (u8 *)shmat(shm_id, NULL, 0); - /* Whooooops. */ - - if (!map || map == (void *)-1) { - - perror("[AFL] ERROR: could not access fuzzing shared memory"); - exit(1); - - } - - shared_buf_len = (u32 *)map; - shared_buf = map + sizeof(u32); - - if (getenv("AFL_DEBUG")) { - - fprintf(stderr, "[AFL] DEBUG: successfully got fuzzing shared memory\n"); - - } - - } else { - - fprintf(stderr, - "[AFL] ERROR: variable for fuzzing shared memory is not set\n"); - exit(1); - - } - -} - -void afl_setup(void) { - - char *id_str = getenv(SHM_ENV_VAR), *inst_r = getenv("AFL_INST_RATIO"); - - int shm_id; - - if (inst_r) { - - unsigned int r; - - r = atoi(inst_r); - - if (r > 100) r = 100; - if (!r) r = 1; - - afl_inst_rms = MAP_SIZE * r / 100; - - } - - if (id_str) { - - shm_id = atoi(id_str); - afl_area_ptr = shmat(shm_id, NULL, 0); - - if (afl_area_ptr == (void *)-1) exit(1); - - /* With AFL_INST_RATIO set to a low value, we want to touch the bitmap - so that the parent doesn't give up on us. */ - - if (inst_r) afl_area_ptr[0] = 1; - - } - - if (getenv("___AFL_EINS_ZWEI_POLIZEI___")) { // CmpLog forkserver - - id_str = getenv(CMPLOG_SHM_ENV_VAR); - - if (id_str) { - - u32 shm_id = atoi(id_str); - - __afl_cmp_map = shmat(shm_id, NULL, 0); - - if (__afl_cmp_map == (void *)-1) exit(1); - - } - - } - - if (getenv("AFL_INST_LIBS")) { - - afl_start_code = 0; - afl_end_code = (abi_ulong)-1; - - } - - if (getenv("AFL_CODE_START")) - afl_start_code = strtoll(getenv("AFL_CODE_START"), NULL, 16); - if (getenv("AFL_CODE_END")) - afl_end_code = strtoll(getenv("AFL_CODE_END"), NULL, 16); - - /* Maintain for compatibility */ - if (getenv("AFL_QEMU_COMPCOV")) { afl_compcov_level = 1; } - if (getenv("AFL_COMPCOV_LEVEL")) { - - afl_compcov_level = atoi(getenv("AFL_COMPCOV_LEVEL")); - - } - - /* pthread_atfork() seems somewhat broken in util/rcu.c, and I'm - not entirely sure what is the cause. This disables that - behaviour, and seems to work alright? */ - - rcu_disable_atfork(); - - disable_caching = getenv("AFL_QEMU_DISABLE_CACHE") != NULL; - - is_persistent = getenv("AFL_QEMU_PERSISTENT_ADDR") != NULL; - - if (is_persistent) { - - afl_persistent_addr = strtoll(getenv("AFL_QEMU_PERSISTENT_ADDR"), NULL, 0); - if (getenv("AFL_QEMU_PERSISTENT_RET")) - afl_persistent_ret_addr = - strtoll(getenv("AFL_QEMU_PERSISTENT_RET"), NULL, 0); - /* If AFL_QEMU_PERSISTENT_RET is not specified patch the return addr */ - - } - - if (getenv("AFL_QEMU_PERSISTENT_GPR")) persistent_save_gpr = 1; - - if (getenv("AFL_QEMU_PERSISTENT_HOOK")) { - -#ifdef AFL_QEMU_STATIC_BUILD - - fprintf(stderr, - "[AFL] ERROR: you cannot use AFL_QEMU_PERSISTENT_HOOK when " - "afl-qemu-trace is static\n"); - exit(1); - -#else - - persistent_save_gpr = 1; - - void *plib = dlopen(getenv("AFL_QEMU_PERSISTENT_HOOK"), RTLD_NOW); - if (!plib) { - - fprintf(stderr, "[AFL] ERROR: invalid AFL_QEMU_PERSISTENT_HOOK=%s\n", - getenv("AFL_QEMU_PERSISTENT_HOOK")); - exit(1); - - } - - int (*afl_persistent_hook_init_ptr)(void) = - dlsym(plib, "afl_persistent_hook_init"); - if (afl_persistent_hook_init_ptr) - sharedmem_fuzzing = afl_persistent_hook_init_ptr(); - - afl_persistent_hook_ptr = dlsym(plib, "afl_persistent_hook"); - if (!afl_persistent_hook_ptr) { - - fprintf(stderr, - "[AFL] ERROR: failed to find the function " - "\"afl_persistent_hook\" in %s\n", - getenv("AFL_QEMU_PERSISTENT_HOOK")); - exit(1); - - } - -#endif - - } - - if (getenv("AFL_QEMU_PERSISTENT_RETADDR_OFFSET")) - persisent_retaddr_offset = - strtoll(getenv("AFL_QEMU_PERSISTENT_RETADDR_OFFSET"), NULL, 0); - - if (getenv("AFL_QEMU_PERSISTENT_CNT")) - afl_persistent_cnt = strtoll(getenv("AFL_QEMU_PERSISTENT_CNT"), NULL, 0); - else - afl_persistent_cnt = PERSISTENT_DEFAULT_MAX_CNT; - -} - -/* Fork server logic, invoked once we hit _start. */ - -void afl_forkserver(CPUState *cpu) { - - // u32 map_size = 0; - unsigned char tmp[4] = {0}; - - if (forkserver_installed == 1) return; - forkserver_installed = 1; - - if (getenv("AFL_QEMU_DEBUG_MAPS")) open_self_maps(cpu->env_ptr, 0); - - // if (!afl_area_ptr) return; // not necessary because of fixed dummy buffer - - pid_t child_pid; - int t_fd[2]; - u8 child_stopped = 0; - u32 was_killed; - int status = 0; - - // with the max ID value - if (MAP_SIZE <= FS_OPT_MAX_MAPSIZE) - status |= (FS_OPT_SET_MAPSIZE(MAP_SIZE) | FS_OPT_MAPSIZE); - if (sharedmem_fuzzing != 0) status |= FS_OPT_SHDMEM_FUZZ; - if (status) status |= (FS_OPT_ENABLED); - if (getenv("AFL_DEBUG")) - fprintf(stderr, "Debug: Sending status %08x\n", status); - memcpy(tmp, &status, 4); - - /* Tell the parent that we're alive. If the parent doesn't want - to talk, assume that we're not running in forkserver mode. */ - - if (write(FORKSRV_FD + 1, tmp, 4) != 4) return; - - afl_forksrv_pid = getpid(); - - int first_run = 1; - - if (sharedmem_fuzzing) { - - if (read(FORKSRV_FD, &was_killed, 4) != 4) exit(2); - - if ((was_killed & (0xffffffff & (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ))) == - (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ)) - afl_map_shm_fuzz(); - else { - - fprintf(stderr, - "[AFL] ERROR: afl-fuzz is old and does not support" - " shmem input"); - exit(1); - - } - - } - - /* All right, let's await orders... */ - - while (1) { - - /* Whoops, parent dead? */ - - if (read(FORKSRV_FD, &was_killed, 4) != 4) exit(2); - - /* If we stopped the child in persistent mode, but there was a race - condition and afl-fuzz already issued SIGKILL, write off the old - process. */ - - if (child_stopped && was_killed) { - - child_stopped = 0; - if (waitpid(child_pid, &status, 0) < 0) exit(8); - - } - - if (!child_stopped) { - - /* Establish a channel with child to grab translation commands. We'll - read from t_fd[0], child will write to TSL_FD. */ - - if (pipe(t_fd) || dup2(t_fd[1], TSL_FD) < 0) exit(3); - close(t_fd[1]); - - child_pid = fork(); - if (child_pid < 0) exit(4); - - if (!child_pid) { - - /* Child process. Close descriptors and run free. */ - - afl_fork_child = 1; - close(FORKSRV_FD); - close(FORKSRV_FD + 1); - close(t_fd[0]); - return; - - } - - /* Parent. */ - - close(TSL_FD); - - } else { - - /* Special handling for persistent mode: if the child is alive but - currently stopped, simply restart it with SIGCONT. */ - - kill(child_pid, SIGCONT); - child_stopped = 0; - - } - - /* Parent. */ - - if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) exit(5); - - /* Collect translation requests until child dies and closes the pipe. */ - - afl_wait_tsl(cpu, t_fd[0]); - - /* Get and relay exit status to parent. */ - - if (waitpid(child_pid, &status, is_persistent ? WUNTRACED : 0) < 0) exit(6); - - /* In persistent mode, the child stops itself with SIGSTOP to indicate - a successful run. In this case, we want to wake it up without forking - again. */ - - if (WIFSTOPPED(status)) - child_stopped = 1; - else if (unlikely(first_run && is_persistent)) { - - fprintf(stderr, "[AFL] ERROR: no persistent iteration executed\n"); - exit(12); // Persistent is wrong - - } - - first_run = 0; - - if (write(FORKSRV_FD + 1, &status, 4) != 4) exit(7); - - } - -} - -/* A simplified persistent mode handler, used as explained in - * llvm_mode/README.md. */ - -void afl_persistent_loop(void) { - - static u32 cycle_cnt; - static struct afl_tsl exit_cmd_tsl = {{-1, 0, 0, 0}, '\0'}; - - if (!afl_fork_child) return; - - if (persistent_first_pass) { - - /* Make sure that every iteration of __AFL_LOOP() starts with a clean slate. - On subsequent calls, the parent will take care of that, but on the first - iteration, it's our job to erase any trace of whatever happened - before the loop. */ - - if (is_persistent) { - - memset(afl_area_ptr, 0, MAP_SIZE); - afl_area_ptr[0] = 1; - afl_prev_loc = 0; - - } - - cycle_cnt = afl_persistent_cnt; - persistent_first_pass = 0; - persistent_stack_offset = TARGET_LONG_BITS / 8; - - return; - - } - - if (is_persistent) { - - if (--cycle_cnt) { - - if (write(TSL_FD, &exit_cmd_tsl, sizeof(struct afl_tsl)) != - sizeof(struct afl_tsl)) { - - /* Exit the persistent loop on pipe error */ - afl_area_ptr = dummy; - exit(0); - - } - - raise(SIGSTOP); - - afl_area_ptr[0] = 1; - afl_prev_loc = 0; - - } else { - - afl_area_ptr = dummy; - exit(0); - - } - - } - -} - -/* This code is invoked whenever QEMU decides that it doesn't have a - translation of a particular block and needs to compute it, or when it - decides to chain two TBs together. When this happens, we tell the parent to - mirror the operation, so that the next fork() has a cached copy. */ - -static void afl_request_tsl(target_ulong pc, target_ulong cb, uint32_t flags, - uint32_t cf_mask, TranslationBlock *last_tb, - int tb_exit) { - - if (disable_caching) return; - - struct afl_tsl t; - struct afl_chain c; - - if (!afl_fork_child) return; - - t.tb.pc = pc; - t.tb.cs_base = cb; - t.tb.flags = flags; - t.tb.cf_mask = cf_mask; - t.is_chain = (last_tb != NULL); - - if (write(TSL_FD, &t, sizeof(struct afl_tsl)) != sizeof(struct afl_tsl)) - return; - - if (t.is_chain) { - - c.last_tb.pc = last_tb->pc; - c.last_tb.cs_base = last_tb->cs_base; - c.last_tb.flags = last_tb->flags; - c.cf_mask = cf_mask; - c.tb_exit = tb_exit; - - if (write(TSL_FD, &c, sizeof(struct afl_chain)) != sizeof(struct afl_chain)) - return; - - } - -} - -/* This is the other side of the same channel. Since timeouts are handled by - afl-fuzz simply killing the child, we can just wait until the pipe breaks. */ - -static void afl_wait_tsl(CPUState *cpu, int fd) { - - struct afl_tsl t; - struct afl_chain c; - TranslationBlock *tb, *last_tb; - - while (1) { - - u8 invalid_pc = 0; - - /* Broken pipe means it's time to return to the fork server routine. */ - - if (read(fd, &t, sizeof(struct afl_tsl)) != sizeof(struct afl_tsl)) break; - - /* Exit command for persistent */ - - if (t.tb.pc == (target_ulong)(-1)) return; - - tb = tb_htable_lookup(cpu, t.tb.pc, t.tb.cs_base, t.tb.flags, t.tb.cf_mask); - - if (!tb) { - - /* The child may request to transate a block of memory that is not - mapped in the parent (e.g. jitted code or dlopened code). - This causes a SIGSEV in gen_intermediate_code() and associated - subroutines. We simply avoid caching of such blocks. */ - - if (is_valid_addr(t.tb.pc)) { - - mmap_lock(); - tb = tb_gen_code(cpu, t.tb.pc, t.tb.cs_base, t.tb.flags, t.tb.cf_mask); - mmap_unlock(); - - } else { - - invalid_pc = 1; - - } - - } - - if (t.is_chain) { - - if (read(fd, &c, sizeof(struct afl_chain)) != sizeof(struct afl_chain)) - break; - - if (!invalid_pc) { - - last_tb = tb_htable_lookup(cpu, c.last_tb.pc, c.last_tb.cs_base, - c.last_tb.flags, c.cf_mask); -#define TB_JMP_RESET_OFFSET_INVALID 0xffff - if (last_tb && (last_tb->jmp_reset_offset[c.tb_exit] != - TB_JMP_RESET_OFFSET_INVALID)) { - - tb_add_jump(last_tb, c.tb_exit, tb); - - } - - } - - } - - } - - close(fd); - -} - diff --git a/qemu_mode/patches/afl-qemu-cpu-translate-inl.h b/qemu_mode/patches/afl-qemu-cpu-translate-inl.h deleted file mode 100644 index 8553f194..00000000 --- a/qemu_mode/patches/afl-qemu-cpu-translate-inl.h +++ /dev/null @@ -1,310 +0,0 @@ -/* - american fuzzy lop++ - high-performance binary-only instrumentation - ------------------------------------------------------------------- - - Originally written by Andrew Griffiths <agriffiths@google.com> and - Michal Zalewski - - TCG instrumentation and block chaining support by Andrea Biondo - <andrea.biondo965@gmail.com> - - QEMU 3.1.1 port, TCG thread-safety, CompareCoverage and NeverZero - counters by Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2015, 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This code is a shim patched into the separately-distributed source - code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality - to implement AFL-style instrumentation and to take care of the remaining - parts of the AFL fork server logic. - - The resulting QEMU binary is essentially a standalone instrumentation - tool; for an example of how to leverage it for other purposes, you can - have a look at afl-showmap.c. - - */ - -#include "afl-qemu-common.h" -#include "tcg.h" -#include "tcg-op.h" - -#if TCG_TARGET_REG_BITS == 64 - #define _DEFAULT_MO MO_64 -#else - #define _DEFAULT_MO MO_32 -#endif - -static void afl_gen_compcov(target_ulong cur_loc, TCGv arg1, TCGv arg2, - TCGMemOp ot, int is_imm) { - - if (cur_loc > afl_end_code || cur_loc < afl_start_code) return; - - if (__afl_cmp_map) { - - cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); - cur_loc &= CMP_MAP_W - 1; - - TCGv cur_loc_v = tcg_const_tl(cur_loc); - - switch (ot & MO_SIZE) { - - case MO_64: - gen_helper_afl_cmplog_64(cur_loc_v, arg1, arg2); - break; - case MO_32: - gen_helper_afl_cmplog_32(cur_loc_v, arg1, arg2); - break; - case MO_16: - gen_helper_afl_cmplog_16(cur_loc_v, arg1, arg2); - break; - case MO_8: - gen_helper_afl_cmplog_8(cur_loc_v, arg1, arg2); - break; - default: - break; - - } - - tcg_temp_free(cur_loc_v); - - } else if (afl_compcov_level) { - - if (!is_imm && afl_compcov_level < 2) return; - - cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); - cur_loc &= MAP_SIZE - 7; - - TCGv cur_loc_v = tcg_const_tl(cur_loc); - - if (cur_loc >= afl_inst_rms) return; - - switch (ot & MO_SIZE) { - - case MO_64: - gen_helper_afl_compcov_64(cur_loc_v, arg1, arg2); - break; - case MO_32: - gen_helper_afl_compcov_32(cur_loc_v, arg1, arg2); - break; - case MO_16: - gen_helper_afl_compcov_16(cur_loc_v, arg1, arg2); - break; - default: - break; - - } - - tcg_temp_free(cur_loc_v); - - } - -} - -/* Routines for debug */ -/* -static void log_x86_saved_gpr(void) { - - static const char reg_names[CPU_NB_REGS][4] = { - -#ifdef TARGET_X86_64 - [R_EAX] = "rax", - [R_EBX] = "rbx", - [R_ECX] = "rcx", - [R_EDX] = "rdx", - [R_ESI] = "rsi", - [R_EDI] = "rdi", - [R_EBP] = "rbp", - [R_ESP] = "rsp", - [8] = "r8", - [9] = "r9", - [10] = "r10", - [11] = "r11", - [12] = "r12", - [13] = "r13", - [14] = "r14", - [15] = "r15", -#else - [R_EAX] = "eax", - [R_EBX] = "ebx", - [R_ECX] = "ecx", - [R_EDX] = "edx", - [R_ESI] = "esi", - [R_EDI] = "edi", - [R_EBP] = "ebp", - [R_ESP] = "esp", -#endif - - }; - - int i; - for (i = 0; i < CPU_NB_REGS; ++i) { - - fprintf(stderr, "%s = %lx\n", reg_names[i], persistent_saved_gpr[i]); - - } - -} - -static void log_x86_sp_content(void) { - - fprintf(stderr, ">> SP = %lx -> %lx\n", persistent_saved_gpr[R_ESP], -*(unsigned long*)persistent_saved_gpr[R_ESP]); - -}*/ - -static void callback_to_persistent_hook(void) { - - afl_persistent_hook_ptr(persistent_saved_gpr, guest_base, shared_buf, - *shared_buf_len); - -} - -static void gpr_saving(TCGv *cpu_regs, int regs_num) { - - int i; - TCGv_ptr gpr_sv; - - TCGv_ptr first_pass_ptr = tcg_const_ptr(&persistent_first_pass); - TCGv first_pass = tcg_temp_local_new(); - TCGv one = tcg_const_tl(1); - tcg_gen_ld8u_tl(first_pass, first_pass_ptr, 0); - - TCGLabel *lbl_restore_gpr = gen_new_label(); - tcg_gen_brcond_tl(TCG_COND_NE, first_pass, one, lbl_restore_gpr); - - // save GPR registers - for (i = 0; i < regs_num; ++i) { - - gpr_sv = tcg_const_ptr(&persistent_saved_gpr[i]); - tcg_gen_st_tl(cpu_regs[i], gpr_sv, 0); - tcg_temp_free_ptr(gpr_sv); - - } - - gen_set_label(lbl_restore_gpr); - - afl_gen_tcg_plain_call(&afl_persistent_loop); - - if (afl_persistent_hook_ptr) - afl_gen_tcg_plain_call(callback_to_persistent_hook); - - // restore GPR registers - for (i = 0; i < regs_num; ++i) { - - gpr_sv = tcg_const_ptr(&persistent_saved_gpr[i]); - tcg_gen_ld_tl(cpu_regs[i], gpr_sv, 0); - tcg_temp_free_ptr(gpr_sv); - - } - - tcg_temp_free_ptr(first_pass_ptr); - tcg_temp_free(first_pass); - tcg_temp_free(one); - -} - -static void restore_state_for_persistent(TCGv *cpu_regs, int regs_num, int sp) { - - if (persistent_save_gpr) { - - gpr_saving(cpu_regs, regs_num); - - } else if (afl_persistent_ret_addr == 0) { - - TCGv_ptr stack_off_ptr = tcg_const_ptr(&persistent_stack_offset); - TCGv stack_off = tcg_temp_new(); - tcg_gen_ld_tl(stack_off, stack_off_ptr, 0); - tcg_gen_sub_tl(cpu_regs[sp], cpu_regs[sp], stack_off); - tcg_temp_free(stack_off); - - } - -} - -#define AFL_QEMU_TARGET_I386_SNIPPET \ - if (is_persistent) { \ - \ - if (s->pc == afl_persistent_addr) { \ - \ - restore_state_for_persistent(cpu_regs, AFL_REGS_NUM, R_ESP); \ - /*afl_gen_tcg_plain_call(log_x86_saved_gpr); \ - afl_gen_tcg_plain_call(log_x86_sp_content);*/ \ - \ - if (afl_persistent_ret_addr == 0) { \ - \ - TCGv paddr = tcg_const_tl(afl_persistent_addr); \ - tcg_gen_qemu_st_tl(paddr, cpu_regs[R_ESP], persisent_retaddr_offset, \ - _DEFAULT_MO); \ - tcg_temp_free(paddr); \ - \ - } \ - \ - if (!persistent_save_gpr) afl_gen_tcg_plain_call(&afl_persistent_loop); \ - /*afl_gen_tcg_plain_call(log_x86_sp_content);*/ \ - \ - } else if (afl_persistent_ret_addr && s->pc == afl_persistent_ret_addr) { \ - \ - gen_jmp_im(s, afl_persistent_addr); \ - gen_eob(s); \ - \ - } \ - \ - } - -// SP = 13, LINK = 14 - -#define AFL_QEMU_TARGET_ARM_SNIPPET \ - if (is_persistent) { \ - \ - if (dc->pc == afl_persistent_addr) { \ - \ - if (persistent_save_gpr) gpr_saving(cpu_R, AFL_REGS_NUM); \ - \ - if (afl_persistent_ret_addr == 0) { \ - \ - tcg_gen_movi_tl(cpu_R[14], afl_persistent_addr); \ - \ - } \ - \ - if (!persistent_save_gpr) afl_gen_tcg_plain_call(&afl_persistent_loop); \ - \ - } else if (afl_persistent_ret_addr && dc->pc == afl_persistent_ret_addr) { \ - \ - gen_bx_im(dc, afl_persistent_addr); \ - \ - } \ - \ - } - -// SP = 31, LINK = 30 - -#define AFL_QEMU_TARGET_ARM64_SNIPPET \ - if (is_persistent) { \ - \ - if (s->pc == afl_persistent_addr) { \ - \ - if (persistent_save_gpr) gpr_saving(cpu_X, AFL_REGS_NUM); \ - \ - if (afl_persistent_ret_addr == 0) { \ - \ - tcg_gen_movi_tl(cpu_X[30], afl_persistent_addr); \ - \ - } \ - \ - if (!persistent_save_gpr) afl_gen_tcg_plain_call(&afl_persistent_loop); \ - \ - } else if (afl_persistent_ret_addr && s->pc == afl_persistent_ret_addr) { \ - \ - gen_goto_tb(s, 0, afl_persistent_addr); \ - \ - } \ - \ - } - diff --git a/qemu_mode/patches/afl-qemu-floats.h b/qemu_mode/patches/afl-qemu-floats.h deleted file mode 100644 index 2e50cf7e..00000000 --- a/qemu_mode/patches/afl-qemu-floats.h +++ /dev/null @@ -1,223 +0,0 @@ -/* - american fuzzy lop++ - high-performance binary-only instrumentation - ------------------------------------------------------------------- - - Originally written by Andrew Griffiths <agriffiths@google.com> and - Michal Zalewski - - TCG instrumentation and block chaining support by Andrea Biondo - <andrea.biondo965@gmail.com> - - QEMU 3.1.1 port, TCG thread-safety, CompareCoverage and NeverZero - counters by Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2015, 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This code is a shim patched into the separately-distributed source - code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality - to implement AFL-style instrumentation and to take care of the remaining - parts of the AFL fork server logic. - - The resulting QEMU binary is essentially a standalone instrumentation - tool; for an example of how to leverage it for other purposes, you can - have a look at afl-showmap.c. - - */ - -#include "tcg.h" -#include "afl-qemu-common.h" - -union afl_float32 { - - float32 f; - struct { - - u64 sign : 1; - u64 exp : 7; - u64 frac : 24; - - }; - -}; - -union afl_float64 { - - float64 f; - struct { - - u64 sign : 1; - u64 exp : 11; - u64 frac : 52; - - }; - -}; - -// TODO 16 and 128 bits floats -// TODO figure out why float*_unpack_canonical does not work - -void afl_float_compcov_log_32(target_ulong cur_loc, float32 arg1, float32 arg2, - void *status) { - - cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); - cur_loc &= MAP_SIZE - 7; - - if (cur_loc >= afl_inst_rms) return; - - // float_status*s = (float_status*)status; - // FloatParts a = float32_unpack_canonical(arg1, s); - // FloatParts b = float32_unpack_canonical(arg2, s); - union afl_float32 a = {.f = arg1}; - union afl_float32 b = {.f = arg2}; - - // if (is_nan(a.cls) || is_nan(b.cls)) return; - - register uintptr_t idx = cur_loc; - - if (a.sign != b.sign) return; - INC_AFL_AREA(idx); - if (a.exp != b.exp) return; - INC_AFL_AREA(idx + 1); - - if ((a.frac & 0xff0000) == (b.frac & 0xff0000)) { - - INC_AFL_AREA(idx + 2); - if ((a.frac & 0xff00) == (b.frac & 0xff00)) { INC_AFL_AREA(idx + 3); } - - } - -} - -void afl_float_compcov_log_64(target_ulong cur_loc, float64 arg1, float64 arg2, - void *status) { - - cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); - cur_loc &= MAP_SIZE - 7; - - if (cur_loc >= afl_inst_rms) return; - - // float_status*s = (float_status*)status; - // FloatParts a = float64_unpack_canonical(arg1, s); - // FloatParts b = float64_unpack_canonical(arg2, s); - union afl_float64 a = {.f = arg1}; - union afl_float64 b = {.f = arg2}; - - // if (is_nan(a.cls) || is_nan(b.cls)) return; - - register uintptr_t idx = cur_loc; - - if (a.sign == b.sign) INC_AFL_AREA(idx); - if ((a.exp & 0xff00) == (b.exp & 0xff00)) { - - INC_AFL_AREA(idx + 1); - if ((a.exp & 0xff) == (b.exp & 0xff)) INC_AFL_AREA(idx + 2); - - } - - if ((a.frac & 0xff000000000000) == (b.frac & 0xff000000000000)) { - - INC_AFL_AREA(idx + 3); - if ((a.frac & 0xff0000000000) == (b.frac & 0xff0000000000)) { - - INC_AFL_AREA(idx + 4); - if ((a.frac & 0xff00000000) == (b.frac & 0xff00000000)) { - - INC_AFL_AREA(idx + 5); - if ((a.frac & 0xff000000) == (b.frac & 0xff000000)) { - - INC_AFL_AREA(idx + 6); - if ((a.frac & 0xff0000) == (b.frac & 0xff0000)) { - - INC_AFL_AREA(idx + 7); - if ((a.frac & 0xff00) == (b.frac & 0xff00)) INC_AFL_AREA(idx + 8); - - } - - } - - } - - } - - } - -} - -void afl_float_compcov_log_80(target_ulong cur_loc, floatx80 arg1, - floatx80 arg2) { - - cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); - cur_loc &= MAP_SIZE - 7; - - if (cur_loc >= afl_inst_rms) return; - - if (floatx80_invalid_encoding(arg1) || floatx80_invalid_encoding(arg2)) - return; - - flag a_sign = extractFloatx80Sign(arg1); - flag b_sign = extractFloatx80Sign(arg2); - - /*if (((extractFloatx80Exp(arg1) == 0x7fff) && - (extractFloatx80Frac(arg1) << 1)) || - ((extractFloatx80Exp(arg2) == 0x7fff) && - (extractFloatx80Frac(arg2) << 1))) - return;*/ - - register uintptr_t idx = cur_loc; - - if (a_sign == b_sign) INC_AFL_AREA(idx); - - if ((arg1.high & 0x7f00) == (arg2.high & 0x7f00)) { - - INC_AFL_AREA(idx + 1); - if ((arg1.high & 0xff) == (arg2.high & 0xff)) INC_AFL_AREA(idx + 2); - - } - - if ((arg1.low & 0xff00000000000000) == (arg2.low & 0xff00000000000000)) { - - INC_AFL_AREA(idx + 3); - if ((arg1.low & 0xff000000000000) == (arg2.low & 0xff000000000000)) { - - INC_AFL_AREA(idx + 4); - if ((arg1.low & 0xff0000000000) == (arg2.low & 0xff0000000000)) { - - INC_AFL_AREA(idx + 5); - if ((arg1.low & 0xff00000000) == (arg2.low & 0xff00000000)) { - - INC_AFL_AREA(idx + 6); - if ((arg1.low & 0xff000000) == (arg2.low & 0xff000000)) { - - INC_AFL_AREA(idx + 7); - if ((arg1.low & 0xff0000) == (arg2.low & 0xff0000)) { - - INC_AFL_AREA(idx + 8); - if ((arg1.low & 0xff00) == (arg2.low & 0xff00)) { - - INC_AFL_AREA(idx + 9); - // if ((arg1.low & 0xff) == (arg2.low & 0xff)) - // INC_AFL_AREA(idx + 10); - - } - - } - - } - - } - - } - - } - - } - -} - diff --git a/qemu_mode/patches/afl-qemu-tcg-inl.h b/qemu_mode/patches/afl-qemu-tcg-inl.h deleted file mode 100644 index f7c662db..00000000 --- a/qemu_mode/patches/afl-qemu-tcg-inl.h +++ /dev/null @@ -1,46 +0,0 @@ -/* - american fuzzy lop++ - high-performance binary-only instrumentation - ------------------------------------------------------------------- - - Originally written by Andrew Griffiths <agriffiths@google.com> and - Michal Zalewski - - TCG instrumentation and block chaining support by Andrea Biondo - <andrea.biondo965@gmail.com> - - QEMU 3.1.1 port, TCG thread-safety, CompareCoverage and NeverZero - counters by Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2015, 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This code is a shim patched into the separately-distributed source - code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality - to implement AFL-style instrumentation and to take care of the remaining - parts of the AFL fork server logic. - - The resulting QEMU binary is essentially a standalone instrumentation - tool; for an example of how to leverage it for other purposes, you can - have a look at afl-showmap.c. - - */ -void afl_gen_tcg_plain_call(void *func); - -void afl_gen_tcg_plain_call(void *func) { - - TCGOp *op = tcg_emit_op(INDEX_op_call); - - TCGOP_CALLO(op) = 0; - - op->args[0] = (uintptr_t)func; - op->args[1] = 0; - TCGOP_CALLI(op) = 0; - -} - diff --git a/qemu_mode/patches/afl-qemu-tcg-runtime-inl.h b/qemu_mode/patches/afl-qemu-tcg-runtime-inl.h deleted file mode 100644 index 400ebf24..00000000 --- a/qemu_mode/patches/afl-qemu-tcg-runtime-inl.h +++ /dev/null @@ -1,250 +0,0 @@ -/* - american fuzzy lop++ - high-performance binary-only instrumentation - ------------------------------------------------------------------- - - Originally written by Andrew Griffiths <agriffiths@google.com> and - Michal Zalewski - - TCG instrumentation and block chaining support by Andrea Biondo - <andrea.biondo965@gmail.com> - - QEMU 3.1.1 port, TCG thread-safety, CompareCoverage and NeverZero - counters by Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2015, 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This code is a shim patched into the separately-distributed source - code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality - to implement AFL-style instrumentation and to take care of the remaining - parts of the AFL fork server logic. - - The resulting QEMU binary is essentially a standalone instrumentation - tool; for an example of how to leverage it for other purposes, you can - have a look at afl-showmap.c. - - */ - -#include "afl-qemu-common.h" -#include "tcg.h" - -void HELPER(afl_entry_routine)(CPUArchState *env) { - - afl_forkserver(ENV_GET_CPU(env)); - -} - -void HELPER(afl_compcov_16)(target_ulong cur_loc, target_ulong arg1, - target_ulong arg2) { - - register uintptr_t idx = cur_loc; - - if ((arg1 & 0xff00) == (arg2 & 0xff00)) { INC_AFL_AREA(idx); } - -} - -void HELPER(afl_compcov_32)(target_ulong cur_loc, target_ulong arg1, - target_ulong arg2) { - - register uintptr_t idx = cur_loc; - - if ((arg1 & 0xff000000) == (arg2 & 0xff000000)) { - - INC_AFL_AREA(idx + 2); - if ((arg1 & 0xff0000) == (arg2 & 0xff0000)) { - - INC_AFL_AREA(idx + 1); - if ((arg1 & 0xff00) == (arg2 & 0xff00)) { INC_AFL_AREA(idx); } - - } - - } - -} - -void HELPER(afl_compcov_64)(target_ulong cur_loc, target_ulong arg1, - target_ulong arg2) { - - register uintptr_t idx = cur_loc; - - if ((arg1 & 0xff00000000000000) == (arg2 & 0xff00000000000000)) { - - INC_AFL_AREA(idx + 6); - if ((arg1 & 0xff000000000000) == (arg2 & 0xff000000000000)) { - - INC_AFL_AREA(idx + 5); - if ((arg1 & 0xff0000000000) == (arg2 & 0xff0000000000)) { - - INC_AFL_AREA(idx + 4); - if ((arg1 & 0xff00000000) == (arg2 & 0xff00000000)) { - - INC_AFL_AREA(idx + 3); - if ((arg1 & 0xff000000) == (arg2 & 0xff000000)) { - - INC_AFL_AREA(idx + 2); - if ((arg1 & 0xff0000) == (arg2 & 0xff0000)) { - - INC_AFL_AREA(idx + 1); - if ((arg1 & 0xff00) == (arg2 & 0xff00)) { INC_AFL_AREA(idx); } - - } - - } - - } - - } - - } - - } - -} - -void HELPER(afl_cmplog_8)(target_ulong cur_loc, target_ulong arg1, - target_ulong arg2) { - - register uintptr_t k = (uintptr_t)cur_loc; - - __afl_cmp_map->headers[k].type = CMP_TYPE_INS; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - // if (!__afl_cmp_map->headers[k].cnt) - // __afl_cmp_map->headers[k].cnt = __afl_cmp_counter++; - - __afl_cmp_map->headers[k].shape = 0; - - hits &= CMP_MAP_H - 1; - __afl_cmp_map->log[k][hits].v0 = arg1; - __afl_cmp_map->log[k][hits].v1 = arg2; - -} - -void HELPER(afl_cmplog_16)(target_ulong cur_loc, target_ulong arg1, - target_ulong arg2) { - - register uintptr_t k = (uintptr_t)cur_loc; - - __afl_cmp_map->headers[k].type = CMP_TYPE_INS; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - // if (!__afl_cmp_map->headers[k].cnt) - // __afl_cmp_map->headers[k].cnt = __afl_cmp_counter++; - - __afl_cmp_map->headers[k].shape = 1; - - hits &= CMP_MAP_H - 1; - __afl_cmp_map->log[k][hits].v0 = arg1; - __afl_cmp_map->log[k][hits].v1 = arg2; - -} - -void HELPER(afl_cmplog_32)(target_ulong cur_loc, target_ulong arg1, - target_ulong arg2) { - - register uintptr_t k = (uintptr_t)cur_loc; - - __afl_cmp_map->headers[k].type = CMP_TYPE_INS; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - - __afl_cmp_map->headers[k].shape = 3; - - hits &= CMP_MAP_H - 1; - __afl_cmp_map->log[k][hits].v0 = arg1; - __afl_cmp_map->log[k][hits].v1 = arg2; - -} - -void HELPER(afl_cmplog_64)(target_ulong cur_loc, target_ulong arg1, - target_ulong arg2) { - - register uintptr_t k = (uintptr_t)cur_loc; - - __afl_cmp_map->headers[k].type = CMP_TYPE_INS; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - - __afl_cmp_map->headers[k].shape = 7; - - hits &= CMP_MAP_H - 1; - __afl_cmp_map->log[k][hits].v0 = arg1; - __afl_cmp_map->log[k][hits].v1 = arg2; - -} - -#include <sys/mman.h> - -static int area_is_mapped(void *ptr, size_t len) { - - char *p = ptr; - char *page = (char *)((uintptr_t)p & ~(sysconf(_SC_PAGE_SIZE) - 1)); - - int r = msync(page, (p - page) + len, MS_ASYNC); - if (r < 0) return errno != ENOMEM; - return 1; - -} - -void HELPER(afl_cmplog_rtn)(CPUArchState *env) { - -#if defined(TARGET_X86_64) - - void *ptr1 = g2h(env->regs[R_EDI]); - void *ptr2 = g2h(env->regs[R_ESI]); - -#elif defined(TARGET_I386) - - target_ulong *stack = g2h(env->regs[R_ESP]); - - if (!area_is_mapped(stack, sizeof(target_ulong) * 2)) return; - - // when this hook is executed, the retaddr is not on stack yet - void * ptr1 = g2h(stack[0]); - void * ptr2 = g2h(stack[1]); - -#else - - // stupid code to make it compile - void *ptr1 = NULL; - void *ptr2 = NULL; - return; - -#endif - - if (!area_is_mapped(ptr1, 32) || !area_is_mapped(ptr2, 32)) return; - -#if defined(TARGET_X86_64) || defined(TARGET_I386) - uintptr_t k = (uintptr_t)env->eip; -#else - uintptr_t k = 0; -#endif - - k = (k >> 4) ^ (k << 8); - k &= CMP_MAP_W - 1; - - __afl_cmp_map->headers[k].type = CMP_TYPE_RTN; - - u32 hits = __afl_cmp_map->headers[k].hits; - __afl_cmp_map->headers[k].hits = hits + 1; - - __afl_cmp_map->headers[k].shape = 31; - - hits &= CMP_MAP_RTN_H - 1; - __builtin_memcpy(((struct cmpfn_operands *)__afl_cmp_map->log[k])[hits].v0, - ptr1, 32); - __builtin_memcpy(((struct cmpfn_operands *)__afl_cmp_map->log[k])[hits].v1, - ptr2, 32); - -} - diff --git a/qemu_mode/patches/afl-qemu-translate-inl.h b/qemu_mode/patches/afl-qemu-translate-inl.h deleted file mode 100644 index 09614f5b..00000000 --- a/qemu_mode/patches/afl-qemu-translate-inl.h +++ /dev/null @@ -1,75 +0,0 @@ -/* - american fuzzy lop++ - high-performance binary-only instrumentation - ------------------------------------------------------------------- - - Originally written by Andrew Griffiths <agriffiths@google.com> and - Michal Zalewski - - TCG instrumentation and block chaining support by Andrea Biondo - <andrea.biondo965@gmail.com> - - QEMU 3.1.1 port, TCG thread-safety, CompareCoverage and NeverZero - counters by Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2015, 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This code is a shim patched into the separately-distributed source - code of QEMU 3.1.0. It leverages the built-in QEMU tracing functionality - to implement AFL-style instrumentation and to take care of the remaining - parts of the AFL fork server logic. - - The resulting QEMU binary is essentially a standalone instrumentation - tool; for an example of how to leverage it for other purposes, you can - have a look at afl-showmap.c. - - */ - -#include "afl-qemu-common.h" -#include "tcg-op.h" - -void HELPER(afl_maybe_log)(target_ulong cur_loc) { - - register uintptr_t afl_idx = cur_loc ^ afl_prev_loc; - - INC_AFL_AREA(afl_idx); - - afl_prev_loc = cur_loc >> 1; - -} - -/* Generates TCG code for AFL's tracing instrumentation. */ -static void afl_gen_trace(target_ulong cur_loc) { - - /* Optimize for cur_loc > afl_end_code, which is the most likely case on - Linux systems. */ - - if (cur_loc > afl_end_code || - cur_loc < afl_start_code /*|| !afl_area_ptr*/) // not needed because of - // static dummy buffer - return; - - /* Looks like QEMU always maps to fixed locations, so ASLR is not a - concern. Phew. But instruction addresses may be aligned. Let's mangle - the value to get something quasi-uniform. */ - - cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); - cur_loc &= MAP_SIZE - 1; - - /* Implement probabilistic instrumentation by looking at scrambled block - address. This keeps the instrumented locations stable across runs. */ - - if (cur_loc >= afl_inst_rms) return; - - TCGv cur_loc_v = tcg_const_tl(cur_loc); - gen_helper_afl_maybe_log(cur_loc_v); - tcg_temp_free(cur_loc_v); - -} - diff --git a/qemu_mode/patches/arm-translate-a64.diff b/qemu_mode/patches/arm-translate-a64.diff deleted file mode 100644 index 83856217..00000000 --- a/qemu_mode/patches/arm-translate-a64.diff +++ /dev/null @@ -1,64 +0,0 @@ -diff --git a/target/arm/translate-a64.c b/target/arm/translate-a64.c -index fd36425..992bf17 100644 ---- a/target/arm/translate-a64.c -+++ b/target/arm/translate-a64.c -@@ -39,6 +39,8 @@ - #include "translate-a64.h" - #include "qemu/atomic128.h" - -+#include "../patches/afl-qemu-cpu-translate-inl.h" -+ - static TCGv_i64 cpu_X[32]; - static TCGv_i64 cpu_pc; - -@@ -3365,6 +3367,12 @@ static void disas_add_sub_imm(DisasContext *s, uint32_t insn) - return; - } - -+ if (rd == 31 && sub_op) { // cmp xX, imm -+ TCGv_i64 tcg_imm = tcg_const_i64(imm); -+ afl_gen_compcov(s->pc, tcg_rn, tcg_imm, is_64bit ? MO_64 : MO_32, 1); -+ tcg_temp_free_i64(tcg_imm); -+ } -+ - tcg_result = tcg_temp_new_i64(); - if (!setflags) { - if (sub_op) { -@@ -3972,6 +3980,9 @@ static void disas_add_sub_ext_reg(DisasContext *s, uint32_t insn) - - tcg_rm = read_cpu_reg(s, rm, sf); - ext_and_shift_reg(tcg_rm, tcg_rm, option, imm3); -+ -+ if (rd == 31 && sub_op) // cmp xX, xY -+ afl_gen_compcov(s->pc, tcg_rn, tcg_rm, sf ? MO_64 : MO_32, 0); - - tcg_result = tcg_temp_new_i64(); - -@@ -4037,6 +4048,9 @@ static void disas_add_sub_reg(DisasContext *s, uint32_t insn) - - shift_reg_imm(tcg_rm, tcg_rm, sf, shift_type, imm6); - -+ if (rd == 31 && sub_op) // cmp xX, xY -+ afl_gen_compcov(s->pc, tcg_rn, tcg_rm, sf ? MO_64 : MO_32, 0); -+ - tcg_result = tcg_temp_new_i64(); - - if (!setflags) { -@@ -4246,6 +4260,8 @@ static void disas_cc(DisasContext *s, uint32_t insn) - tcg_y = cpu_reg(s, y); - } - tcg_rn = cpu_reg(s, rn); -+ -+ afl_gen_compcov(s->pc, tcg_rn, tcg_y, sf ? MO_64 : MO_32, is_imm); - - /* Set the flags for the new comparison. */ - tcg_tmp = tcg_temp_new_i64(); -@@ -13317,6 +13333,8 @@ static void disas_data_proc_simd_fp(DisasContext *s, uint32_t insn) - static void disas_a64_insn(CPUARMState *env, DisasContext *s) - { - uint32_t insn; -+ -+ AFL_QEMU_TARGET_ARM64_SNIPPET - - insn = arm_ldl_code(env, s->pc, s->sctlr_b); - s->insn = insn; diff --git a/qemu_mode/patches/arm-translate.diff b/qemu_mode/patches/arm-translate.diff deleted file mode 100644 index daa5d43b..00000000 --- a/qemu_mode/patches/arm-translate.diff +++ /dev/null @@ -1,152 +0,0 @@ -diff --git a/target/arm/translate.c b/target/arm/translate.c -index 7c4675f..e3d999a 100644 ---- a/target/arm/translate.c -+++ b/target/arm/translate.c -@@ -59,6 +59,8 @@ - #define IS_USER(s) (s->user) - #endif - -+#include "../patches/afl-qemu-cpu-translate-inl.h" -+ - /* We reuse the same 64-bit temporaries for efficiency. */ - static TCGv_i64 cpu_V0, cpu_V1, cpu_M0; - static TCGv_i32 cpu_R[16]; -@@ -9541,6 +9543,7 @@ static void disas_arm_insn(DisasContext *s, unsigned int insn) - } else { - if (set_cc) { - gen_sub_CC(tmp, tmp, tmp2); -+ afl_gen_compcov(s->pc, tmp, tmp2, MO_32, insn & (1 << 25)); - } else { - tcg_gen_sub_i32(tmp, tmp, tmp2); - } -@@ -9550,6 +9553,7 @@ static void disas_arm_insn(DisasContext *s, unsigned int insn) - case 0x03: - if (set_cc) { - gen_sub_CC(tmp, tmp2, tmp); -+ afl_gen_compcov(s->pc, tmp, tmp2, MO_32, insn & (1 << 25)); - } else { - tcg_gen_sub_i32(tmp, tmp2, tmp); - } -@@ -9604,6 +9608,7 @@ static void disas_arm_insn(DisasContext *s, unsigned int insn) - case 0x0a: - if (set_cc) { - gen_sub_CC(tmp, tmp, tmp2); -+ afl_gen_compcov(s->pc, tmp, tmp2, MO_32, insn & (1 << 25)); - } - tcg_temp_free_i32(tmp); - break; -@@ -10565,7 +10570,7 @@ thumb2_logic_op(int op) - - static int - gen_thumb2_data_op(DisasContext *s, int op, int conds, uint32_t shifter_out, -- TCGv_i32 t0, TCGv_i32 t1) -+ TCGv_i32 t0, TCGv_i32 t1, int has_imm) - { - int logic_cc; - -@@ -10611,15 +10616,17 @@ gen_thumb2_data_op(DisasContext *s, int op, int conds, uint32_t shifter_out, - } - break; - case 13: /* sub */ -- if (conds) -+ if (conds) { - gen_sub_CC(t0, t0, t1); -- else -+ afl_gen_compcov(s->pc, t0, t1, MO_32, has_imm); -+ } else - tcg_gen_sub_i32(t0, t0, t1); - break; - case 14: /* rsb */ -- if (conds) -+ if (conds) { - gen_sub_CC(t0, t1, t0); -- else -+ afl_gen_compcov(s->pc, t0, t1, MO_32, has_imm); -+ } else - tcg_gen_sub_i32(t0, t1, t0); - break; - default: /* 5, 6, 7, 9, 12, 15. */ -@@ -11085,7 +11092,7 @@ static void disas_thumb2_insn(DisasContext *s, uint32_t insn) - conds = (insn & (1 << 20)) != 0; - logic_cc = (conds && thumb2_logic_op(op)); - gen_arm_shift_im(tmp2, shiftop, shift, logic_cc); -- if (gen_thumb2_data_op(s, op, conds, 0, tmp, tmp2)) -+ if (gen_thumb2_data_op(s, op, conds, 0, tmp, tmp2, insn & (1 << 10))) - goto illegal_op; - tcg_temp_free_i32(tmp2); - if (rd == 13 && -@@ -11955,7 +11962,7 @@ static void disas_thumb2_insn(DisasContext *s, uint32_t insn) - } - op = (insn >> 21) & 0xf; - if (gen_thumb2_data_op(s, op, (insn & (1 << 20)) != 0, -- shifter_out, tmp, tmp2)) -+ shifter_out, tmp, tmp2, insn & (1 << 10))) - goto illegal_op; - tcg_temp_free_i32(tmp2); - rd = (insn >> 8) & 0xf; -@@ -12206,8 +12213,10 @@ static void disas_thumb_insn(DisasContext *s, uint32_t insn) - if (insn & (1 << 9)) { - if (s->condexec_mask) - tcg_gen_sub_i32(tmp, tmp, tmp2); -- else -+ else { - gen_sub_CC(tmp, tmp, tmp2); -+ afl_gen_compcov(s->pc, tmp, tmp2, MO_32, insn & (1 << 10)); -+ } - } else { - if (s->condexec_mask) - tcg_gen_add_i32(tmp, tmp, tmp2); -@@ -12247,6 +12256,7 @@ static void disas_thumb_insn(DisasContext *s, uint32_t insn) - switch (op) { - case 1: /* cmp */ - gen_sub_CC(tmp, tmp, tmp2); -+ afl_gen_compcov(s->pc, tmp, tmp2, MO_32, 1); - tcg_temp_free_i32(tmp); - tcg_temp_free_i32(tmp2); - break; -@@ -12261,8 +12271,10 @@ static void disas_thumb_insn(DisasContext *s, uint32_t insn) - case 3: /* sub */ - if (s->condexec_mask) - tcg_gen_sub_i32(tmp, tmp, tmp2); -- else -+ else { - gen_sub_CC(tmp, tmp, tmp2); -+ afl_gen_compcov(s->pc, tmp, tmp2, MO_32, 1); -+ } - tcg_temp_free_i32(tmp2); - store_reg(s, rd, tmp); - break; -@@ -12308,6 +12320,7 @@ static void disas_thumb_insn(DisasContext *s, uint32_t insn) - tmp = load_reg(s, rd); - tmp2 = load_reg(s, rm); - gen_sub_CC(tmp, tmp, tmp2); -+ afl_gen_compcov(s->pc, tmp, tmp2, MO_32, 0); - tcg_temp_free_i32(tmp2); - tcg_temp_free_i32(tmp); - break; -@@ -12466,6 +12479,7 @@ static void disas_thumb_insn(DisasContext *s, uint32_t insn) - break; - case 0xa: /* cmp */ - gen_sub_CC(tmp, tmp, tmp2); -+ afl_gen_compcov(s->pc, tmp, tmp2, MO_32, 0); - rd = 16; - break; - case 0xb: /* cmn */ -@@ -13233,6 +13247,8 @@ static void arm_tr_translate_insn(DisasContextBase *dcbase, CPUState *cpu) - return; - } - -+ AFL_QEMU_TARGET_ARM_SNIPPET -+ - insn = arm_ldl_code(env, dc->pc, dc->sctlr_b); - dc->insn = insn; - dc->pc += 4; -@@ -13301,6 +13317,8 @@ static void thumb_tr_translate_insn(DisasContextBase *dcbase, CPUState *cpu) - return; - } - -+ AFL_QEMU_TARGET_ARM_SNIPPET -+ - insn = arm_lduw_code(env, dc->pc, dc->sctlr_b); - is_16bit = thumb_insn_is_16bit(dc, insn); - dc->pc += 2; diff --git a/qemu_mode/patches/bsd-elfload.diff b/qemu_mode/patches/bsd-elfload.diff deleted file mode 100644 index 19e44f5b..00000000 --- a/qemu_mode/patches/bsd-elfload.diff +++ /dev/null @@ -1,83 +0,0 @@ -diff --git a/bsd-user/elfload.c b/bsd-user/elfload.c -index 7cccf3eb..195875af 100644 ---- a/bsd-user/elfload.c -+++ b/bsd-user/elfload.c -@@ -15,6 +15,8 @@ - #undef ELF_ARCH - #endif - -+extern abi_ulong afl_entry_point, afl_start_code, afl_end_code; -+ - /* from personality.h */ - - /* -@@ -737,9 +739,13 @@ static void padzero(abi_ulong elf_bss, abi_ulong last_bss) - end_addr1 = REAL_HOST_PAGE_ALIGN(elf_bss); - end_addr = HOST_PAGE_ALIGN(elf_bss); - if (end_addr1 < end_addr) { -- mmap((void *)g2h(end_addr1), end_addr - end_addr1, -+ void *p = mmap((void *)g2h(end_addr1), end_addr - end_addr1, - PROT_READ|PROT_WRITE|PROT_EXEC, - MAP_FIXED|MAP_PRIVATE|MAP_ANON, -1, 0); -+ if (p == MAP_FAILED) { -+ perror("padzero: cannot mmap"); -+ exit(-1); -+ } - } - } - -@@ -979,9 +985,13 @@ static abi_ulong load_elf_interp(struct elfhdr * interp_elf_ex, - - /* Map the last of the bss segment */ - if (last_bss > elf_bss) { -- target_mmap(elf_bss, last_bss-elf_bss, -+ void *p = target_mmap(elf_bss, last_bss-elf_bss, - PROT_READ|PROT_WRITE|PROT_EXEC, - MAP_FIXED|MAP_PRIVATE|MAP_ANON, -1, 0); -+ if (p == MAP_FAILED) { -+ perror("load_elf_interp: cannot mmap"); -+ exit(-1); -+ } - } - free(elf_phdata); - -@@ -1522,6 +1532,8 @@ int load_elf_binary(struct linux_binprm * bprm, struct target_pt_regs * regs, - info->start_data = start_data; - info->end_data = end_data; - info->start_stack = bprm->p; -+ if (!afl_start_code) afl_start_code = vaddr; -+ if (!afl_end_code) afl_end_code = vaddr_ef; - - /* Calling set_brk effectively mmaps the pages that we need for the bss and break - sections */ -@@ -1544,11 +1556,29 @@ int load_elf_binary(struct linux_binprm * bprm, struct target_pt_regs * regs, - and some applications "depend" upon this behavior. - Since we do not have the power to recompile these, we - emulate the SVr4 behavior. Sigh. */ -- target_mmap(0, qemu_host_page_size, PROT_READ | PROT_EXEC, -+ void *p = target_mmap(0, qemu_host_page_size, PROT_READ | PROT_EXEC, - MAP_FIXED | MAP_PRIVATE, -1, 0); -+ if (p == MAP_FAILED) { -+ perror("load_elf_binary: cannot mmap"); -+ exit(-1); -+ } - } - - info->entry = elf_entry; -+ if (!afl_entry_point) { -+ char *ptr; -+ if ((ptr = getenv("AFL_ENTRYPOINT")) != NULL) { -+ afl_entry_point = strtoul(ptr, NULL, 16); -+ } else { -+ afl_entry_point = info->entry; -+ } -+#ifdef TARGET_ARM -+ /* The least significant bit indicates Thumb mode. */ -+ afl_entry_point = afl_entry_point & ~(target_ulong)1; -+#endif -+ } -+ if (getenv("AFL_DEBUG") != NULL) -+ fprintf(stderr, "AFL forkserver entrypoint: %p\n", (void*)afl_entry_point); - - return 0; - } diff --git a/qemu_mode/patches/configure.diff b/qemu_mode/patches/configure.diff deleted file mode 100644 index e265edae..00000000 --- a/qemu_mode/patches/configure.diff +++ /dev/null @@ -1,33 +0,0 @@ ---- a/configure 2019-08-02 18:04:50.000000000 +0200 -+++ b/configure 2020-02-28 06:31:30.424895061 +0100 -@@ -1479,6 +1479,8 @@ - ;; - --enable-capstone=system) capstone="system" - ;; -+ --enable-capstone=internal) capstone="internal" -+ ;; - --with-git=*) git="$optarg" - ;; - --enable-git-update) git_update=yes -@@ -4604,6 +4606,21 @@ - fi - - ########################################## -+cat > $TMPC << EOF -+#include <dlfcn.h> -+#include <stdlib.h> -+int main(int argc, char **argv) { return dlopen("libc.so", RTLD_NOW) != NULL; } -+EOF -+if compile_prog "" "" ; then -+ : -+elif compile_prog "" "-ldl" ; then -+ LIBS="-ldl $LIBS" -+ libs_qga="-ldl $libs_qga" -+else -+ error_exit "libdl check failed" -+fi -+ -+########################################## - # spice probe - if test "$spice" != "no" ; then - cat > $TMPC << EOF diff --git a/qemu_mode/patches/cpu-exec.diff b/qemu_mode/patches/cpu-exec.diff deleted file mode 100644 index 844be58c..00000000 --- a/qemu_mode/patches/cpu-exec.diff +++ /dev/null @@ -1,38 +0,0 @@ -diff --git a/accel/tcg/cpu-exec.c b/accel/tcg/cpu-exec.c -index 870027d4..0bc87dfc 100644 ---- a/accel/tcg/cpu-exec.c -+++ b/accel/tcg/cpu-exec.c -@@ -36,6 +36,8 @@ - #include "sysemu/cpus.h" - #include "sysemu/replay.h" - -+#include "../patches/afl-qemu-cpu-inl.h" -+ - /* -icount align implementation. */ - - typedef struct SyncClocks { -@@ -397,11 +399,13 @@ static inline TranslationBlock *tb_find(CPUState *cpu, - TranslationBlock *tb; - target_ulong cs_base, pc; - uint32_t flags; -+ bool was_translated = false, was_chained = false; - - tb = tb_lookup__cpu_state(cpu, &pc, &cs_base, &flags, cf_mask); - if (tb == NULL) { - mmap_lock(); - tb = tb_gen_code(cpu, pc, cs_base, flags, cf_mask); -+ was_translated = true; - mmap_unlock(); - /* We add the TB in the virtual pc hash table for the fast lookup */ - atomic_set(&cpu->tb_jmp_cache[tb_jmp_cache_hash_func(pc)], tb); -@@ -418,6 +422,10 @@ static inline TranslationBlock *tb_find(CPUState *cpu, - /* See if we can patch the calling TB. */ - if (last_tb) { - tb_add_jump(last_tb, tb_exit, tb); -+ was_chained = true; -+ } -+ if (was_translated || was_chained) { -+ afl_request_tsl(pc, cs_base, flags, cf_mask, was_chained ? last_tb : NULL, tb_exit); - } - return tb; - } diff --git a/qemu_mode/patches/elfload.diff b/qemu_mode/patches/elfload.diff deleted file mode 100644 index 011b03ea..00000000 --- a/qemu_mode/patches/elfload.diff +++ /dev/null @@ -1,70 +0,0 @@ -diff --git a/linux-user/elfload.c b/linux-user/elfload.c -index 5bccd2e2..fd7460b3 100644 ---- a/linux-user/elfload.c -+++ b/linux-user/elfload.c -@@ -20,6 +20,8 @@ - - #define ELF_OSABI ELFOSABI_SYSV - -+extern abi_ulong afl_entry_point, afl_start_code, afl_end_code; -+ - /* from personality.h */ - - /* -@@ -2301,6 +2303,21 @@ static void load_elf_image(const char *image_name, int image_fd, - info->brk = 0; - info->elf_flags = ehdr->e_flags; - -+ if (!afl_entry_point) { -+ char *ptr; -+ if ((ptr = getenv("AFL_ENTRYPOINT")) != NULL) { -+ afl_entry_point = strtoul(ptr, NULL, 16); -+ } else { -+ afl_entry_point = info->entry; -+ } -+#ifdef TARGET_ARM -+ /* The least significant bit indicates Thumb mode. */ -+ afl_entry_point = afl_entry_point & ~(target_ulong)1; -+#endif -+ } -+ if (getenv("AFL_DEBUG") != NULL) -+ fprintf(stderr, "AFL forkserver entrypoint: %p\n", (void*)afl_entry_point); -+ - for (i = 0; i < ehdr->e_phnum; i++) { - struct elf_phdr *eppnt = phdr + i; - if (eppnt->p_type == PT_LOAD) { -@@ -2335,9 +2352,11 @@ static void load_elf_image(const char *image_name, int image_fd, - if (elf_prot & PROT_EXEC) { - if (vaddr < info->start_code) { - info->start_code = vaddr; -+ if (!afl_start_code) afl_start_code = vaddr; - } - if (vaddr_ef > info->end_code) { - info->end_code = vaddr_ef; -+ if (!afl_end_code) afl_end_code = vaddr_ef; - } - } - if (elf_prot & PROT_WRITE) { -@@ -2662,6 +2681,22 @@ int load_elf_binary(struct linux_binprm *bprm, struct image_info *info) - change some of these later */ - bprm->p = setup_arg_pages(bprm, info); - -+ // On PowerPC64 the entry point is the _function descriptor_ -+ // of the entry function. For AFL to properly initialize, -+ // afl_entry_point needs to be set to the actual first instruction -+ // as opposed executed by the target program. This as opposed to -+ // where the function's descriptor sits in memory. -+ // copied from PPC init_thread -+#if defined(TARGET_PPC64) && !defined(TARGET_ABI32) -+ if (get_ppc64_abi(infop) < 2) { -+ uint64_t val; -+ get_user_u64(val, infop->entry + 8); -+ _regs->gpr[2] = val + infop->load_bias; -+ get_user_u64(val, infop->entry); -+ infop->entry = val + infop->load_bias; -+ } -+#endif -+ - scratch = g_new0(char, TARGET_PAGE_SIZE); - if (STACK_GROWS_DOWN) { - bprm->p = copy_elf_strings(1, &bprm->filename, scratch, diff --git a/qemu_mode/patches/i386-fpu_helper.diff b/qemu_mode/patches/i386-fpu_helper.diff deleted file mode 100644 index 3bd09d9c..00000000 --- a/qemu_mode/patches/i386-fpu_helper.diff +++ /dev/null @@ -1,54 +0,0 @@ -diff --git a/target/i386/fpu_helper.c b/target/i386/fpu_helper.c -index ea5a0c48..89901315 100644 ---- a/target/i386/fpu_helper.c -+++ b/target/i386/fpu_helper.c -@@ -384,10 +384,16 @@ void helper_fxchg_ST0_STN(CPUX86State *env, int st_index) - - static const int fcom_ccval[4] = {0x0100, 0x4000, 0x0000, 0x4500}; - -+#include "../patches/afl-qemu-common.h" -+ - void helper_fcom_ST0_FT0(CPUX86State *env) - { - int ret; - -+ if (afl_compcov_level > 2 && env->eip < afl_end_code && -+ env->eip >= afl_start_code) -+ afl_float_compcov_log_80(env->eip, ST0, FT0); -+ - ret = floatx80_compare(ST0, FT0, &env->fp_status); - env->fpus = (env->fpus & ~0x4500) | fcom_ccval[ret + 1]; - } -@@ -396,6 +402,10 @@ void helper_fucom_ST0_FT0(CPUX86State *env) - { - int ret; - -+ if (afl_compcov_level > 2 && env->eip < afl_end_code && -+ env->eip >= afl_start_code) -+ afl_float_compcov_log_80(env->eip, ST0, FT0); -+ - ret = floatx80_compare_quiet(ST0, FT0, &env->fp_status); - env->fpus = (env->fpus & ~0x4500) | fcom_ccval[ret + 1]; - } -@@ -407,6 +417,10 @@ void helper_fcomi_ST0_FT0(CPUX86State *env) - int eflags; - int ret; - -+ if (afl_compcov_level > 2 && env->eip < afl_end_code && -+ env->eip >= afl_start_code) -+ afl_float_compcov_log_80(env->eip, ST0, FT0); -+ - ret = floatx80_compare(ST0, FT0, &env->fp_status); - eflags = cpu_cc_compute_all(env, CC_OP); - eflags = (eflags & ~(CC_Z | CC_P | CC_C)) | fcomi_ccval[ret + 1]; -@@ -418,6 +432,10 @@ void helper_fucomi_ST0_FT0(CPUX86State *env) - int eflags; - int ret; - -+ if (afl_compcov_level > 2 && env->eip < afl_end_code && -+ env->eip >= afl_start_code) -+ afl_float_compcov_log_80(env->eip, ST0, FT0); -+ - ret = floatx80_compare_quiet(ST0, FT0, &env->fp_status); - eflags = cpu_cc_compute_all(env, CC_OP); - eflags = (eflags & ~(CC_Z | CC_P | CC_C)) | fcomi_ccval[ret + 1]; diff --git a/qemu_mode/patches/i386-ops_sse.diff b/qemu_mode/patches/i386-ops_sse.diff deleted file mode 100644 index d2779ea8..00000000 --- a/qemu_mode/patches/i386-ops_sse.diff +++ /dev/null @@ -1,61 +0,0 @@ -diff --git a/target/i386/ops_sse.h b/target/i386/ops_sse.h -index ed059897..a5296caa 100644 ---- a/target/i386/ops_sse.h -+++ b/target/i386/ops_sse.h -@@ -997,6 +997,8 @@ SSE_HELPER_CMP(cmpord, FPU_CMPORD) - - static const int comis_eflags[4] = {CC_C, CC_Z, 0, CC_Z | CC_P | CC_C}; - -+#include "../patches/afl-qemu-common.h" -+ - void helper_ucomiss(CPUX86State *env, Reg *d, Reg *s) - { - int ret; -@@ -1004,6 +1006,11 @@ void helper_ucomiss(CPUX86State *env, Reg *d, Reg *s) - - s0 = d->ZMM_S(0); - s1 = s->ZMM_S(0); -+ -+ if (afl_compcov_level > 2 && env->eip < afl_end_code && -+ env->eip >= afl_start_code) -+ afl_float_compcov_log_32(env->eip, s0, s1, &env->sse_status); -+ - ret = float32_compare_quiet(s0, s1, &env->sse_status); - CC_SRC = comis_eflags[ret + 1]; - } -@@ -1015,6 +1022,11 @@ void helper_comiss(CPUX86State *env, Reg *d, Reg *s) - - s0 = d->ZMM_S(0); - s1 = s->ZMM_S(0); -+ -+ if (afl_compcov_level > 2 && env->eip < afl_end_code && -+ env->eip >= afl_start_code) -+ afl_float_compcov_log_32(env->eip, s0, s1, &env->sse_status); -+ - ret = float32_compare(s0, s1, &env->sse_status); - CC_SRC = comis_eflags[ret + 1]; - } -@@ -1026,6 +1038,11 @@ void helper_ucomisd(CPUX86State *env, Reg *d, Reg *s) - - d0 = d->ZMM_D(0); - d1 = s->ZMM_D(0); -+ -+ if (afl_compcov_level > 2 && env->eip < afl_end_code && -+ env->eip >= afl_start_code) -+ afl_float_compcov_log_64(env->eip, d0, d1, &env->sse_status); -+ - ret = float64_compare_quiet(d0, d1, &env->sse_status); - CC_SRC = comis_eflags[ret + 1]; - } -@@ -1037,6 +1054,11 @@ void helper_comisd(CPUX86State *env, Reg *d, Reg *s) - - d0 = d->ZMM_D(0); - d1 = s->ZMM_D(0); -+ -+ if (afl_compcov_level > 2 && env->eip < afl_end_code && -+ env->eip >= afl_start_code) -+ afl_float_compcov_log_64(env->eip, d0, d1, &env->sse_status); -+ - ret = float64_compare(d0, d1, &env->sse_status); - CC_SRC = comis_eflags[ret + 1]; - } diff --git a/qemu_mode/patches/i386-translate.diff b/qemu_mode/patches/i386-translate.diff deleted file mode 100644 index f0d1393b..00000000 --- a/qemu_mode/patches/i386-translate.diff +++ /dev/null @@ -1,62 +0,0 @@ -diff --git a/target/i386/translate.c b/target/i386/translate.c -index 0dd5fbe4..0d405fb6 100644 ---- a/target/i386/translate.c -+++ b/target/i386/translate.c -@@ -32,6 +32,8 @@ - #include "trace-tcg.h" - #include "exec/log.h" - -+#include "../patches/afl-qemu-cpu-translate-inl.h" -+ - #define PREFIX_REPZ 0x01 - #define PREFIX_REPNZ 0x02 - #define PREFIX_LOCK 0x04 -@@ -1343,9 +1345,11 @@ static void gen_op(DisasContext *s1, int op, TCGMemOp ot, int d) - tcg_gen_atomic_fetch_add_tl(s1->cc_srcT, s1->A0, s1->T0, - s1->mem_index, ot | MO_LE); - tcg_gen_sub_tl(s1->T0, s1->cc_srcT, s1->T1); -+ afl_gen_compcov(s1->pc, s1->cc_srcT, s1->T1, ot, d == OR_EAX); - } else { - tcg_gen_mov_tl(s1->cc_srcT, s1->T0); - tcg_gen_sub_tl(s1->T0, s1->T0, s1->T1); -+ afl_gen_compcov(s1->pc, s1->T0, s1->T1, ot, d == OR_EAX); - gen_op_st_rm_T0_A0(s1, ot, d); - } - gen_op_update2_cc(s1); -@@ -1389,6 +1393,7 @@ static void gen_op(DisasContext *s1, int op, TCGMemOp ot, int d) - tcg_gen_mov_tl(cpu_cc_src, s1->T1); - tcg_gen_mov_tl(s1->cc_srcT, s1->T0); - tcg_gen_sub_tl(cpu_cc_dst, s1->T0, s1->T1); -+ afl_gen_compcov(s1->pc, s1->T0, s1->T1, ot, d == OR_EAX); - set_cc_op(s1, CC_OP_SUBB + ot); - break; - } -@@ -4508,6 +4513,8 @@ static target_ulong disas_insn(DisasContext *s, CPUState *cpu) - rex_w = -1; - rex_r = 0; - -+ AFL_QEMU_TARGET_I386_SNIPPET -+ - next_byte: - b = x86_ldub_code(env, s); - /* Collect prefixes. */ -@@ -5056,6 +5063,9 @@ static target_ulong disas_insn(DisasContext *s, CPUState *cpu) - tcg_gen_ext16u_tl(s->T0, s->T0); - } - next_eip = s->pc - s->cs_base; -+ if (__afl_cmp_map && next_eip >= afl_start_code && -+ next_eip < afl_end_code) -+ gen_helper_afl_cmplog_rtn(cpu_env); - tcg_gen_movi_tl(s->T1, next_eip); - gen_push_v(s, s->T1); - gen_op_jmp_v(s->T0); -@@ -6544,6 +6554,9 @@ static target_ulong disas_insn(DisasContext *s, CPUState *cpu) - tval = (int16_t)insn_get(env, s, MO_16); - } - next_eip = s->pc - s->cs_base; -+ if (__afl_cmp_map && next_eip >= afl_start_code && -+ next_eip < afl_end_code) -+ gen_helper_afl_cmplog_rtn(cpu_env); - tval += next_eip; - if (dflag == MO_16) { - tval &= 0xffff; diff --git a/qemu_mode/patches/make_strncpy_safe.diff b/qemu_mode/patches/make_strncpy_safe.diff deleted file mode 100644 index 38c7d248..00000000 --- a/qemu_mode/patches/make_strncpy_safe.diff +++ /dev/null @@ -1,31 +0,0 @@ ---- a/util/qemu-sockets.c 2020-03-28 13:55:09.511029429 +0100 -+++ b/util/qemu-sockets.c 2020-03-28 14:01:12.147693937 +0100 -@@ -877,7 +877,7 @@ - - memset(&un, 0, sizeof(un)); - un.sun_family = AF_UNIX; -- strncpy(un.sun_path, path, sizeof(un.sun_path)); -+ strncpy(un.sun_path, path, sizeof(un.sun_path) - 1); - - if (bind(sock, (struct sockaddr*) &un, sizeof(un)) < 0) { - error_setg_errno(errp, errno, "Failed to bind socket to %s", path); -@@ -922,7 +922,7 @@ - - memset(&un, 0, sizeof(un)); - un.sun_family = AF_UNIX; -- strncpy(un.sun_path, saddr->path, sizeof(un.sun_path)); -+ strncpy(un.sun_path, saddr->path, sizeof(un.sun_path) - 1); - - /* connect to peer */ - do { ---- a/block/sheepdog.c 2020-03-28 14:01:57.164360270 +0100 -+++ b/block/sheepdog.c 2020-03-28 14:02:52.781026597 +0100 -@@ -1236,7 +1236,7 @@ - * don't want the send_req to read uninitialized data. - */ - strncpy(buf, filename, SD_MAX_VDI_LEN); -- strncpy(buf + SD_MAX_VDI_LEN, tag, SD_MAX_VDI_TAG_LEN); -+ strncpy(buf + SD_MAX_VDI_LEN, tag, SD_MAX_VDI_TAG_LEN - 1); - - memset(&hdr, 0, sizeof(hdr)); - if (lock) { diff --git a/qemu_mode/patches/mmap_fixes.diff b/qemu_mode/patches/mmap_fixes.diff deleted file mode 100644 index 1882bd40..00000000 --- a/qemu_mode/patches/mmap_fixes.diff +++ /dev/null @@ -1,165 +0,0 @@ -diff --git a/exec.c b/exec.c -index df5571e..d484098 100644 ---- a/exec.c -+++ b/exec.c -@@ -2457,7 +2457,7 @@ void qemu_ram_remap(ram_addr_t addr, ram_addr_t length) - area = mmap(vaddr, length, PROT_READ | PROT_WRITE, - flags, -1, 0); - } -- if (area != vaddr) { -+ if (area == MAP_FAILED || area != vaddr) { - error_report("Could not remap addr: " - RAM_ADDR_FMT "@" RAM_ADDR_FMT "", - length, addr); -diff --git a/linux-user/mmap.c b/linux-user/mmap.c -index 41e0983..0a8b8e5 100644 ---- a/linux-user/mmap.c -+++ b/linux-user/mmap.c -@@ -612,9 +612,13 @@ static void mmap_reserve(abi_ulong start, abi_ulong size) - real_end -= qemu_host_page_size; - } - if (real_start != real_end) { -- mmap(g2h(real_start), real_end - real_start, PROT_NONE, -+ void *p = mmap(g2h(real_start), real_end - real_start, PROT_NONE, - MAP_FIXED | MAP_ANONYMOUS | MAP_PRIVATE | MAP_NORESERVE, - -1, 0); -+ if (p == MAP_FAILED) { -+ perror("mmap_reserve: cannot mmap"); -+ exit(-1); -+ } - } - } - -diff --git a/roms/SLOF/tools/sloffs.c b/roms/SLOF/tools/sloffs.c -index 9a1eace..10366f0 100644 ---- a/roms/SLOF/tools/sloffs.c -+++ b/roms/SLOF/tools/sloffs.c -@@ -308,6 +308,10 @@ sloffs_append(const int file, const char *name, const char *dest) - - fstat(fd, &stat); - append = mmap(NULL, stat.st_size, PROT_READ, MAP_SHARED, fd, 0); -+ if (append == MAP_FAILED) { -+ perror("sloffs_append: cannot mmap for read"); -+ exit(1); -+ } - header = sloffs_header(file); - - if (!header) -@@ -331,6 +335,10 @@ sloffs_append(const int file, const char *name, const char *dest) - write(out, "", 1); - write_start = mmap(NULL, new_len, PROT_READ | PROT_WRITE, - MAP_SHARED, out, 0); -+ if (write_start == MAP_FAILED) { -+ perror("sloffs_append: cannot mmap for read/write"); -+ exit(1); -+ } - - memset(write_start, 0, new_len); - memset(&new_file, 0, sizeof(struct sloffs)); -diff --git a/roms/skiboot/core/test/run-trace.c b/roms/skiboot/core/test/run-trace.c -index 9801688..236b51d 100644 ---- a/roms/skiboot/core/test/run-trace.c -+++ b/roms/skiboot/core/test/run-trace.c -@@ -178,6 +178,10 @@ static void test_parallel(void) - i = (CPUS*len + getpagesize()-1)&~(getpagesize()-1); - p = mmap(NULL, i, PROT_READ|PROT_WRITE, - MAP_ANONYMOUS|MAP_SHARED, -1, 0); -+ if (p == MAP_FAILED) { -+ perror("test_parallel: cannot mmap"); -+ exit(-1); -+ } - - for (i = 0; i < CPUS; i++) { - fake_cpus[i].trace = p + i * len; -diff --git a/roms/skiboot/external/ffspart/ffspart.c b/roms/skiboot/external/ffspart/ffspart.c -index 7703477..efbbd5b 100644 ---- a/roms/skiboot/external/ffspart/ffspart.c -+++ b/roms/skiboot/external/ffspart/ffspart.c -@@ -379,7 +379,7 @@ int main(int argc, char *argv[]) - } - - data_ptr = mmap(NULL, pactual, PROT_READ, MAP_SHARED, data_fd, 0); -- if (!data_ptr) { -+ if (data_ptr == MAP_FAILED) { - fprintf(stderr, "Couldn't mmap data file for partition '%s': %s\n", - name, strerror(errno)); - rc = -1; -diff --git a/roms/skiboot/extract-gcov.c b/roms/skiboot/extract-gcov.c -index 3d31d1b..ebc03e6 100644 ---- a/roms/skiboot/extract-gcov.c -+++ b/roms/skiboot/extract-gcov.c -@@ -229,7 +229,11 @@ int main(int argc, char *argv[]) - } - - addr = mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0); -- assert(addr != NULL); -+ assert(addr != MAP_FAILED); -+ if (addr == MAP_FAILED) { -+ perror("main: cannot mmap"); -+ exit(-1); -+ } - skiboot_dump_size = sb.st_size; - - printf("Skiboot memory dump %p - %p\n", -diff --git a/roms/skiboot/libstb/create-container.c b/roms/skiboot/libstb/create-container.c -index 5cf80a0..64699ad 100644 ---- a/roms/skiboot/libstb/create-container.c -+++ b/roms/skiboot/libstb/create-container.c -@@ -96,7 +96,11 @@ void getSigRaw(ecc_signature_t *sigraw, char *inFile) - assert(r==0); - - infile = mmap(NULL, s.st_size, PROT_READ, MAP_PRIVATE, fdin, 0); -- assert(infile); -+ assert(infile != MAP_FAILED); -+ if (infile == MAP_FAILED) { -+ perror("getSigRaw: cannot mmap"); -+ exit(-1); -+ } - - signature = d2i_ECDSA_SIG(NULL, (const unsigned char **) &infile, 7 + 2*EC_COORDBYTES); - -@@ -356,7 +360,11 @@ int main(int argc, char* argv[]) - r = fstat(fdin, &s); - assert(r==0); - infile = mmap(NULL, s.st_size, PROT_READ, MAP_PRIVATE, fdin, 0); -- assert(infile); -+ assert(infile != MAP_FAILED); -+ if (infile == MAP_FAILED) { -+ perror("main: cannot mmap"); -+ exit(-1); -+ } - fdout = open(params.imagefn, O_WRONLY|O_CREAT|O_TRUNC, S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH); - assert(fdout > 0); - -diff --git a/tests/tcg/multiarch/test-mmap.c b/tests/tcg/multiarch/test-mmap.c -index 11d0e77..14f5919 100644 ---- a/tests/tcg/multiarch/test-mmap.c -+++ b/tests/tcg/multiarch/test-mmap.c -@@ -203,6 +203,7 @@ void check_aligned_anonymous_fixed_mmaps(void) - p1 = mmap(addr, pagesize, PROT_READ, - MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED, - -1, 0); -+ fail_unless (p1 != MAP_FAILED); - /* Make sure we get pages aligned with the pagesize. - The target expects this. */ - p = (uintptr_t) p1; -@@ -234,6 +235,7 @@ void check_aligned_anonymous_fixed_mmaps_collide_with_host(void) - p1 = mmap(addr, pagesize, PROT_READ | PROT_WRITE, - MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED, - -1, 0); -+ fail_unless (p1 != MAP_FAILED); - /* Make sure we get pages aligned with the pagesize. - The target expects this. */ - p = (uintptr_t) p1; -@@ -401,6 +403,10 @@ void check_file_fixed_mmaps(void) - p4 = mmap(addr + pagesize * 3, pagesize, PROT_READ, - MAP_PRIVATE | MAP_FIXED, - test_fd, pagesize * 3); -+ fail_unless (p1 != MAP_FAILED); -+ fail_unless (p2 != MAP_FAILED); -+ fail_unless (p3 != MAP_FAILED); -+ fail_unless (p4 != MAP_FAILED); - - /* Make sure we get pages aligned with the pagesize. - The target expects this. */ - diff --git a/qemu_mode/patches/softfloat.diff b/qemu_mode/patches/softfloat.diff deleted file mode 100644 index 86ffb97f..00000000 --- a/qemu_mode/patches/softfloat.diff +++ /dev/null @@ -1,10 +0,0 @@ -diff --git a/fpu/softfloat.c b/fpu/softfloat.c -index e1eef954..2f8d0d62 100644 ---- a/fpu/softfloat.c -+++ b/fpu/softfloat.c -@@ -7205,3 +7205,5 @@ float128 float128_scalbn(float128 a, int n, float_status *status) - , status); - - } -+ -+#include "../../patches/afl-qemu-floats.h" diff --git a/qemu_mode/patches/syscall.diff b/qemu_mode/patches/syscall.diff deleted file mode 100644 index b635a846..00000000 --- a/qemu_mode/patches/syscall.diff +++ /dev/null @@ -1,102 +0,0 @@ -diff --git a/linux-user/syscall.c b/linux-user/syscall.c -index b13a170e..3f5cc902 100644 ---- a/linux-user/syscall.c -+++ b/linux-user/syscall.c -@@ -111,6 +111,9 @@ - - #include "qemu.h" - #include "fd-trans.h" -+#include <linux/sockios.h> -+ -+extern unsigned int afl_forksrv_pid; - - #ifndef CLONE_IO - #define CLONE_IO 0x80000000 /* Clone io context */ -@@ -250,7 +253,8 @@ static type name (type1 arg1,type2 arg2,type3 arg3,type4 arg4,type5 arg5, \ - #endif - - #ifdef __NR_gettid --_syscall0(int, gettid) -+#define __NR_sys_gettid __NR_gettid -+_syscall0(int, sys_gettid) - #else - /* This is a replacement for the host gettid() and must return a host - errno. */ -@@ -5384,7 +5388,7 @@ static void *clone_func(void *arg) - cpu = ENV_GET_CPU(env); - thread_cpu = cpu; - ts = (TaskState *)cpu->opaque; -- info->tid = gettid(); -+ info->tid = sys_gettid(); - task_settid(ts); - if (info->child_tidptr) - put_user_u32(info->tid, info->child_tidptr); -@@ -5529,9 +5533,9 @@ static int do_fork(CPUArchState *env, unsigned int flags, abi_ulong newsp, - mapping. We can't repeat the spinlock hack used above because - the child process gets its own copy of the lock. */ - if (flags & CLONE_CHILD_SETTID) -- put_user_u32(gettid(), child_tidptr); -+ put_user_u32(sys_gettid(), child_tidptr); - if (flags & CLONE_PARENT_SETTID) -- put_user_u32(gettid(), parent_tidptr); -+ put_user_u32(sys_gettid(), parent_tidptr); - ts = (TaskState *)cpu->opaque; - if (flags & CLONE_SETTLS) - cpu_set_tls (env, newtls); -@@ -6554,7 +6558,8 @@ static int open_self_cmdline(void *cpu_env, int fd) - return 0; - } - --static int open_self_maps(void *cpu_env, int fd) -+int open_self_maps(void *cpu_env, int fd); -+int open_self_maps(void *cpu_env, int fd) - { - CPUState *cpu = ENV_GET_CPU((CPUArchState *)cpu_env); - TaskState *ts = cpu->opaque; -@@ -7324,10 +7329,12 @@ static abi_long do_syscall1(void *cpu_env, int num, abi_long arg1, - #ifdef TARGET_NR_stime /* not on alpha */ - case TARGET_NR_stime: - { -- time_t host_time; -- if (get_user_sal(host_time, arg1)) -+ struct timespec ts; -+ ts.tv_nsec = 0; -+ if (get_user_sal(ts.tv_sec, arg1)) { - return -TARGET_EFAULT; -- return get_errno(stime(&host_time)); -+ } -+ return get_errno(clock_settime(CLOCK_REALTIME, &ts)); - } - #endif - #ifdef TARGET_NR_alarm /* not on alpha */ -@@ -10529,7 +10536,7 @@ static abi_long do_syscall1(void *cpu_env, int num, abi_long arg1, - return TARGET_PAGE_SIZE; - #endif - case TARGET_NR_gettid: -- return get_errno(gettid()); -+ return get_errno(sys_gettid()); - #ifdef TARGET_NR_readahead - case TARGET_NR_readahead: - #if TARGET_ABI_BITS == 32 -@@ -10813,8 +10820,19 @@ static abi_long do_syscall1(void *cpu_env, int num, abi_long arg1, - return get_errno(safe_tkill((int)arg1, target_to_host_signal(arg2))); - - case TARGET_NR_tgkill: -- return get_errno(safe_tgkill((int)arg1, (int)arg2, -- target_to_host_signal(arg3))); -+ { -+ int pid = (int)arg1, -+ tgid = (int)arg2, -+ sig = (int)arg3; -+ -+ /* Not entirely sure if the below is correct for all architectures. */ -+ -+ if(afl_forksrv_pid && afl_forksrv_pid == pid && sig == SIGABRT) -+ pid = tgid = getpid(); -+ -+ ret = get_errno(safe_tgkill(pid, tgid, target_to_host_signal(sig))); -+ -+ } - - #ifdef TARGET_NR_set_robust_list - case TARGET_NR_set_robust_list: diff --git a/qemu_mode/patches/tcg-runtime-head.diff b/qemu_mode/patches/tcg-runtime-head.diff deleted file mode 100644 index f250686e..00000000 --- a/qemu_mode/patches/tcg-runtime-head.diff +++ /dev/null @@ -1,19 +0,0 @@ -diff --git a/accel/tcg/tcg-runtime.h b/accel/tcg/tcg-runtime.h -index 1bd39d13..81ef3973 100644 ---- a/accel/tcg/tcg-runtime.h -+++ b/accel/tcg/tcg-runtime.h -@@ -260,3 +260,14 @@ DEF_HELPER_FLAGS_4(gvec_leu8, TCG_CALL_NO_RWG, void, ptr, ptr, ptr, i32) - DEF_HELPER_FLAGS_4(gvec_leu16, TCG_CALL_NO_RWG, void, ptr, ptr, ptr, i32) - DEF_HELPER_FLAGS_4(gvec_leu32, TCG_CALL_NO_RWG, void, ptr, ptr, ptr, i32) - DEF_HELPER_FLAGS_4(gvec_leu64, TCG_CALL_NO_RWG, void, ptr, ptr, ptr, i32) -+ -+DEF_HELPER_FLAGS_1(afl_entry_routine, TCG_CALL_NO_RWG, void, env) -+DEF_HELPER_FLAGS_1(afl_maybe_log, TCG_CALL_NO_RWG, void, tl) -+DEF_HELPER_FLAGS_3(afl_compcov_16, TCG_CALL_NO_RWG, void, tl, tl, tl) -+DEF_HELPER_FLAGS_3(afl_compcov_32, TCG_CALL_NO_RWG, void, tl, tl, tl) -+DEF_HELPER_FLAGS_3(afl_compcov_64, TCG_CALL_NO_RWG, void, tl, tl, tl) -+DEF_HELPER_FLAGS_3(afl_cmplog_8, TCG_CALL_NO_RWG, void, tl, tl, tl) -+DEF_HELPER_FLAGS_3(afl_cmplog_16, TCG_CALL_NO_RWG, void, tl, tl, tl) -+DEF_HELPER_FLAGS_3(afl_cmplog_32, TCG_CALL_NO_RWG, void, tl, tl, tl) -+DEF_HELPER_FLAGS_3(afl_cmplog_64, TCG_CALL_NO_RWG, void, tl, tl, tl) -+DEF_HELPER_FLAGS_1(afl_cmplog_rtn, TCG_CALL_NO_RWG, void, env) diff --git a/qemu_mode/patches/tcg-runtime.diff b/qemu_mode/patches/tcg-runtime.diff deleted file mode 100644 index 15456320..00000000 --- a/qemu_mode/patches/tcg-runtime.diff +++ /dev/null @@ -1,10 +0,0 @@ -diff --git a/accel/tcg/tcg-runtime.c b/accel/tcg/tcg-runtime.c -index d0d44844..009ef15a 100644 ---- a/accel/tcg/tcg-runtime.c -+++ b/accel/tcg/tcg-runtime.c -@@ -167,3 +167,5 @@ void HELPER(exit_atomic)(CPUArchState *env) - { - cpu_loop_exit_atomic(ENV_GET_CPU(env), GETPC()); - } -+ -+#include "../../../patches/afl-qemu-tcg-runtime-inl.h" diff --git a/qemu_mode/patches/tcg.diff b/qemu_mode/patches/tcg.diff deleted file mode 100644 index 0aea5afb..00000000 --- a/qemu_mode/patches/tcg.diff +++ /dev/null @@ -1,14 +0,0 @@ -diff --git a/tcg/tcg.c b/tcg/tcg.c -index e85133ef..54b9b390 100644 ---- a/tcg/tcg.c -+++ b/tcg/tcg.c -@@ -1612,6 +1612,9 @@ bool tcg_op_supported(TCGOpcode op) - } - } - -+ -+#include "../../patches/afl-qemu-tcg-inl.h" -+ - /* Note: we convert the 64 bit args to 32 bit and do some alignment - and endian swap. Maybe it would be better to do the alignment - and endian swap in tcg_reg_alloc_call(). */ diff --git a/qemu_mode/patches/translate-all.diff b/qemu_mode/patches/translate-all.diff deleted file mode 100644 index ca310b11..00000000 --- a/qemu_mode/patches/translate-all.diff +++ /dev/null @@ -1,21 +0,0 @@ -diff --git a/accel/tcg/translate-all.c b/accel/tcg/translate-all.c -index 639f0b27..21a45494 100644 ---- a/accel/tcg/translate-all.c -+++ b/accel/tcg/translate-all.c -@@ -59,6 +59,8 @@ - #include "exec/log.h" - #include "sysemu/cpus.h" - -+#include "../patches/afl-qemu-translate-inl.h" -+ - /* #define DEBUG_TB_INVALIDATE */ - /* #define DEBUG_TB_FLUSH */ - /* make various TB consistency checks */ -@@ -1721,6 +1723,7 @@ TranslationBlock *tb_gen_code(CPUState *cpu, - tcg_func_start(tcg_ctx); - - tcg_ctx->cpu = ENV_GET_CPU(env); -+ afl_gen_trace(pc); - gen_intermediate_code(cpu, tb); - tcg_ctx->cpu = NULL; - diff --git a/qemu_mode/patches/translator.diff b/qemu_mode/patches/translator.diff deleted file mode 100644 index 842e861d..00000000 --- a/qemu_mode/patches/translator.diff +++ /dev/null @@ -1,25 +0,0 @@ -diff --git a/accel/tcg/translator.c b/accel/tcg/translator.c -index afd0a49e..773ea712 100644 ---- a/accel/tcg/translator.c -+++ b/accel/tcg/translator.c -@@ -18,6 +18,8 @@ - #include "exec/log.h" - #include "exec/translator.h" - -+#include "../../../patches/afl-qemu-common.h" -+ - /* Pairs with tcg_clear_temp_count. - To be called by #TranslatorOps.{translate_insn,tb_stop} if - (1) the target is sufficiently clean to support reporting, -@@ -92,6 +94,11 @@ void translator_loop(const TranslatorOps *ops, DisasContextBase *db, - break; - } - } -+ -+ if (db->pc_next == afl_entry_point) { -+ afl_setup(); -+ gen_helper_afl_entry_routine(cpu_env); -+ } - - /* Disassemble one instruction. The translate_insn hook should - update db->pc_next and db->is_jmp to indicate what should be diff --git a/qemu_mode/qemuafl b/qemu_mode/qemuafl new file mode 160000 +Subproject 0fb212daab492411b3e323bc18a3074c1aecfd3 diff --git a/qemu_mode/unsigaction/Makefile b/qemu_mode/unsigaction/Makefile index 206a8f07..c5d2de31 100644 --- a/qemu_mode/unsigaction/Makefile +++ b/qemu_mode/unsigaction/Makefile @@ -16,19 +16,15 @@ _UNIQ=_QINU_ -TARGETCANDIDATES=unsigaction32.so unsigaction64.so +TARGETCANDIDATES=unsigaction.so _TARGETS=$(_UNIQ)$(AFL_NO_X86)$(_UNIQ) __TARGETS=$(_TARGETS:$(_UNIQ)1$(_UNIQ)=) TARGETS=$(__TARGETS:$(_UNIQ)$(_UNIQ)=$(TARGETCANDIDATES)) all: $(TARGETS) - @if [ "$(AFL_NO_X86)" != "" ]; then echo "[!] Note: skipping compilation of unsigaction (AFL_NO_X86 set)."; fi -unsigaction32.so: - @if $(CC) -m32 -fPIC -shared unsigaction.c -o unsigaction32.so 2>/dev/null ; then echo "unsigaction32 build success"; else echo "unsigaction32 build failure (that's fine)"; fi - -unsigaction64.so: - @if $(CC) -m64 -fPIC -shared unsigaction.c -o unsigaction64.so 2>/dev/null ; then echo "unsigaction64 build success"; else echo "unsigaction64 build failure (that's fine)"; fi +unsigaction.so: unsigaction.c + @if $(CC) -fPIC -shared unsigaction.c -o unsigaction.so 2>/dev/null ; then echo "unsigaction build success"; else echo "unsigaction build failure (that's fine)"; fi clean: - rm -f unsigaction32.so unsigaction64.so + rm -f unsigaction.so diff --git a/qemu_mode/update_ref.sh b/qemu_mode/update_ref.sh new file mode 100755 index 00000000..13be376f --- /dev/null +++ b/qemu_mode/update_ref.sh @@ -0,0 +1,47 @@ +#/bin/sh + +################################################## +# AFL++ internal tool to update qemuafl ref. +# Usage: ./update_ref.sh <new commit hash> +# If no commit hash was provided, it'll take HEAD. +################################################## + +UC_VERSION_FILE='./QEMUAFL_VERSION' + +NEW_VERSION="$1" + +if [ "$NEW_VERSION" = "-h" ]; then + echo "Internal script to update bound qemuafl version." + echo + echo "Usage: ./update_ref.sh <new commit hash>" + echo "If no commit hash is provided, will use HEAD." + echo "-h to show this help screen." + exit 1 +fi + +git submodule init && git submodule update || exit 1 +cd ./qemuafl || exit 1 +git fetch origin master 1>/dev/null || exit 1 +git stash 1>/dev/null 2>/dev/null +git stash drop 1>/dev/null 2>/dev/null +git checkout master +git pull origin master 1>/dev/null || exit 1 + +if [ -z "$NEW_VERSION" ]; then + # No version provided, take HEAD. + NEW_VERSION=$(git rev-parse --short HEAD) +fi + +if [ -z "$NEW_VERSION" ]; then + echo "Error getting version." + exit 1 +fi + +git checkout "$NEW_VERSION" || exit 1 + +cd .. + +rm "$UC_VERSION_FILE" +echo "$NEW_VERSION" > "$UC_VERSION_FILE" + +echo "Done. New qemuafl version is $NEW_VERSION." diff --git a/src/README.md b/src/README.md index 6da534c3..35af6ab9 100644 --- a/src/README.md +++ b/src/README.md @@ -2,23 +2,28 @@ Quick explanation about the files here: -- `afl-analyze.c` - afl-analyze binary tool +- `afl-analyze.c` - afl-analyze binary tool - `afl-as.c` - afl-as binary tool -- `afl-gotcpu.c` - afl-gotcpu binary tool -- `afl-showmap.c` - afl-showmap binary tool -- `afl-tmin.c` - afl-tmin binary tool -- `afl-fuzz.c` - afl-fuzz binary tool (just main() and usage()) +- `afl-cc.c` - afl-cc binary tool +- `afl-common.c` - common functions, used by afl-analyze, afl-fuzz, afl-showmap and afl-tmin +- `afl-forkserver.c` - forkserver implementation, used by afl-fuzz afl-showmap, afl-tmin - `afl-fuzz-bitmap.c` - afl-fuzz bitmap handling +- `afl-fuzz.c` - afl-fuzz binary tool (just main() and usage()) +- `afl-fuzz-cmplog.c` - afl-fuzz cmplog functions - `afl-fuzz-extras.c` - afl-fuzz the *extra* function calls -- `afl-fuzz-state.c` - afl-fuzz state and globals -- `afl-fuzz-init.c` - afl-fuzz initialization -- `afl-fuzz-misc.c` - afl-fuzz misc functions -- `afl-fuzz-one.c` - afl-fuzz fuzzer_one big loop, this is where the mutation is happening +- `afl-fuzz-init.c` - afl-fuzz initialization +- `afl-fuzz-misc.c` - afl-fuzz misc functions +- `afl-fuzz-mutators.c` - afl-fuzz custom mutator and python support +- `afl-fuzz-one.c` - afl-fuzz fuzzer_one big loop, this is where the mutation is happening +- `afl-fuzz-performance.c` - hash64 and rand functions - `afl-fuzz-python.c` - afl-fuzz the python mutator extension - `afl-fuzz-queue.c` - afl-fuzz handling the queue -- `afl-fuzz-run.c` - afl-fuzz running the target +- `afl-fuzz-redqueen.c` - afl-fuzz redqueen implemention +- `afl-fuzz-run.c` - afl-fuzz running the target +- `afl-fuzz-state.c` - afl-fuzz state and globals - `afl-fuzz-stats.c` - afl-fuzz writing the statistics file -- `afl-gcc.c` - afl-gcc binary tool (deprecated) -- `afl-common.c` - common functions, used by afl-analyze, afl-fuzz, afl-showmap and afl-tmin -- `afl-forkserver.c` - forkserver implementation, used by afl-fuzz and afl-tmin -afl-sharedmem.c - sharedmem implementation, used by afl-fuzz and afl-tmin +- `afl-gotcpu.c` - afl-gotcpu binary tool +- `afl-ld-lto.c` - LTO linker helper +- `afl-sharedmem.c` - sharedmem implementation, used by afl-fuzz, afl-showmap, afl-tmin +- `afl-showmap.c` - afl-showmap binary tool +- `afl-tmin.c` - afl-tmin binary tool diff --git a/src/afl-analyze.c b/src/afl-analyze.c index e6dd0fca..86b0f7e9 100644 --- a/src/afl-analyze.c +++ b/src/afl-analyze.c @@ -26,9 +26,6 @@ #define AFL_MAIN -#ifdef __ANDROID__ - #include "android-ashmem.h" -#endif #include "config.h" #include "types.h" #include "debug.h" @@ -78,9 +75,9 @@ static u64 mem_limit = MEM_LIMIT; /* Memory limit (MB) */ static s32 dev_null_fd = -1; /* FD to /dev/null */ -static u8 edges_only, /* Ignore hit counts? */ +static bool edges_only, /* Ignore hit counts? */ use_hex_offsets, /* Show hex offsets? */ - use_stdin = 1; /* Use stdin for program input? */ + use_stdin = true; /* Use stdin for program input? */ static volatile u8 stop_soon, /* Ctrl-C pressed? */ child_timed_out; /* Child timed out? */ @@ -103,20 +100,31 @@ static u32 map_size = MAP_SIZE; /* Classify tuple counts. This is a slow & naive version, but good enough here. */ +#define TIMES4(x) x, x, x, x +#define TIMES8(x) TIMES4(x), TIMES4(x) +#define TIMES16(x) TIMES8(x), TIMES8(x) +#define TIMES32(x) TIMES16(x), TIMES16(x) +#define TIMES64(x) TIMES32(x), TIMES32(x) static u8 count_class_lookup[256] = { [0] = 0, [1] = 1, [2] = 2, [3] = 4, - [4 ... 7] = 8, - [8 ... 15] = 16, - [16 ... 31] = 32, - [32 ... 127] = 64, - [128 ... 255] = 128 + [4] = TIMES4(8), + [8] = TIMES8(16), + [16] = TIMES16(32), + [32] = TIMES32(64), + [128] = TIMES64(128) }; +#undef TIMES64 +#undef TIMES32 +#undef TIMES16 +#undef TIMES8 +#undef TIMES4 + static void classify_counts(u8 *mem) { u32 i = map_size; @@ -384,7 +392,7 @@ static void show_legend(void) { /* Interpret and report a pattern in the input file. */ -static void dump_hex(u8 *buf, u32 len, u8 *b_data) { +static void dump_hex(u32 len, u8 *b_data) { u32 i; @@ -678,7 +686,7 @@ static void analyze(char **argv) { } - dump_hex(in_data, in_len, b_data); + dump_hex(in_len, b_data); SAYF("\n"); @@ -700,6 +708,7 @@ static void analyze(char **argv) { static void handle_stop_sig(int sig) { + (void)sig; stop_soon = 1; if (child_pid > 0) { kill(child_pid, SIGKILL); } @@ -742,12 +751,15 @@ static void set_up_environment(void) { } - if (!strstr(x, "symbolize=0")) { +#ifndef ASAN_BUILD + if (!getenv("AFL_DEBUG") && !strstr(x, "symbolize=0")) { FATAL("Custom ASAN_OPTIONS set without symbolize=0 - please fix!"); } +#endif + } x = get_afl_env("MSAN_OPTIONS"); @@ -773,6 +785,7 @@ static void set_up_environment(void) { "abort_on_error=1:" "detect_leaks=0:" "allocator_may_return_null=1:" + "detect_odr_violation=0:" "symbolize=0:" "handle_segv=0:" "handle_sigbus=0:" @@ -809,38 +822,7 @@ static void set_up_environment(void) { if (qemu_mode) { - u8 *qemu_preload = getenv("QEMU_SET_ENV"); - u8 *afl_preload = getenv("AFL_PRELOAD"); - u8 *buf; - - s32 i, afl_preload_size = strlen(afl_preload); - for (i = 0; i < afl_preload_size; ++i) { - - if (afl_preload[i] == ',') { - - PFATAL( - "Comma (',') is not allowed in AFL_PRELOAD when -Q is " - "specified!"); - - } - - } - - if (qemu_preload) { - - buf = alloc_printf("%s,LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - qemu_preload, afl_preload, afl_preload); - - } else { - - buf = alloc_printf("LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - afl_preload, afl_preload); - - } - - setenv("QEMU_SET_ENV", buf, 1); - - ck_free(buf); + /* afl-qemu-trace takes care of converting AFL_PRELOAD. */ } else { @@ -888,8 +870,8 @@ static void usage(u8 *argv0) { "Execution control settings:\n" " -f file - input file read by the tested program (stdin)\n" - " -t msec - timeout for each run (%d ms)\n" - " -m megs - memory limit for child process (%d MB)\n" + " -t msec - timeout for each run (%u ms)\n" + " -m megs - memory limit for child process (%u MB)\n" " -Q - use binary-only instrumentation (QEMU mode)\n" " -U - use unicorn-based instrumentation (Unicorn mode)\n" " -W - use qemu-based instrumentation with Wine (Wine " @@ -921,11 +903,12 @@ static void usage(u8 *argv0) { /* Main entry point */ -int main(int argc, char **argv, char **envp) { +int main(int argc, char **argv_orig, char **envp) { s32 opt; u8 mem_limit_given = 0, timeout_given = 0, unicorn_mode = 0, use_wine = 0; char **use_argv; + char **argv = argv_cpy_dup(argc, argv_orig); doc_path = access(DOC_PATH, F_OK) ? "docs" : DOC_PATH; diff --git a/src/afl-as.c b/src/afl-as.c index f16d6060..7de267a3 100644 --- a/src/afl-as.c +++ b/src/afl-as.c @@ -27,7 +27,7 @@ utility has right now is to be able to skip them gracefully and allow the compilation process to continue. - That said, see examples/clang_asm_normalize/ for a solution that may + That said, see utils/clang_asm_normalize/ for a solution that may allow clang users to make things work even with hand-crafted assembly. Just note that there is no equivalent for GCC. @@ -47,6 +47,7 @@ #include <stdlib.h> #include <string.h> #include <time.h> +#include <limits.h> #include <ctype.h> #include <fcntl.h> @@ -131,12 +132,17 @@ static void edit_params(int argc, char **argv) { if (!tmp_dir) { tmp_dir = "/tmp"; } as_params = ck_alloc((argc + 32) * sizeof(u8 *)); + if (unlikely((INT_MAX - 32) < argc || !as_params)) { + + FATAL("Too many parameters passed to as"); + + } as_params[0] = afl_as ? afl_as : (u8 *)"as"; as_params[argc] = 0; - for (i = 1; i < argc - 1; i++) { + for (i = 1; (s32)i < argc - 1; i++) { if (!strcmp(argv[i], "--64")) { @@ -152,7 +158,7 @@ static void edit_params(int argc, char **argv) { /* The Apple case is a bit different... */ - if (!strcmp(argv[i], "-arch") && i + 1 < argc) { + if (!strcmp(argv[i], "-arch") && i + 1 < (u32)argc) { if (!strcmp(argv[i + 1], "x86_64")) use_64bit = 1; @@ -407,7 +413,7 @@ static void add_instrumentation(void) { if (line[0] == '\t') { - if (line[1] == 'j' && line[2] != 'm' && R(100) < inst_ratio) { + if (line[1] == 'j' && line[2] != 'm' && R(100) < (long)inst_ratio) { fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); @@ -449,7 +455,7 @@ static void add_instrumentation(void) { /* Apple: L<num> / LBB<num> */ if ((isdigit(line[1]) || (clang_mode && !strncmp(line, "LBB", 3))) && - R(100) < inst_ratio) { + R(100) < (long)inst_ratio) { #else @@ -457,7 +463,7 @@ static void add_instrumentation(void) { if ((isdigit(line[2]) || (clang_mode && !strncmp(line + 1, "LBB", 3))) && - R(100) < inst_ratio) { + R(100) < (long)inst_ratio) { #endif /* __APPLE__ */ @@ -591,7 +597,7 @@ int main(int argc, char **argv) { rand_seed = tv.tv_sec ^ tv.tv_usec ^ getpid(); // in fast systems where pids can repeat in the same seconds we need this - for (i = 1; i < argc; i++) + for (i = 1; (s32)i < argc; i++) for (j = 0; j < strlen(argv[i]); j++) rand_seed += argv[i][j]; diff --git a/src/afl-cc.c b/src/afl-cc.c new file mode 100644 index 00000000..e13f285d --- /dev/null +++ b/src/afl-cc.c @@ -0,0 +1,2062 @@ +/* + american fuzzy lop++ - compiler instrumentation wrapper + ------------------------------------------------------- + + Written by Michal Zalewski, Laszlo Szekeres and Marc Heuse + + Copyright 2015, 2016 Google Inc. All rights reserved. + Copyright 2019-2020 AFLplusplus Project. All rights reserved. + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at: + + http://www.apache.org/licenses/LICENSE-2.0 + + */ + +#define AFL_MAIN + +#include "common.h" +#include "config.h" +#include "types.h" +#include "debug.h" +#include "alloc-inl.h" +#include "llvm-alternative-coverage.h" + +#include <stdio.h> +#include <unistd.h> +#include <stdlib.h> +#include <string.h> +#include <strings.h> +#include <limits.h> +#include <assert.h> + +#if (LLVM_MAJOR - 0 == 0) + #undef LLVM_MAJOR +#endif +#if !defined(LLVM_MAJOR) + #define LLVM_MAJOR 0 +#endif +#if (LLVM_MINOR - 0 == 0) + #undef LLVM_MINOR +#endif +#if !defined(LLVM_MINOR) + #define LLVM_MINOR 0 +#endif + +static u8 * obj_path; /* Path to runtime libraries */ +static u8 **cc_params; /* Parameters passed to the real CC */ +static u32 cc_par_cnt = 1; /* Param count, including argv0 */ +static u8 clang_mode; /* Invoked as afl-clang*? */ +static u8 llvm_fullpath[PATH_MAX]; +static u8 instrument_mode, instrument_opt_mode, ngram_size, ctx_k, lto_mode; +static u8 compiler_mode, plusplus_mode, have_instr_env = 0; +static u8 have_gcc, have_llvm, have_gcc_plugin, have_lto, have_instr_list = 0; +static u8 * lto_flag = AFL_CLANG_FLTO, *argvnull; +static u8 debug; +static u8 cwd[4096]; +static u8 cmplog_mode; +u8 use_stdin; /* dummy */ +// static u8 *march_opt = CFLAGS_OPT; + +enum { + + INSTRUMENT_DEFAULT = 0, + INSTRUMENT_CLASSIC = 1, + INSTRUMENT_AFL = 1, + INSTRUMENT_PCGUARD = 2, + INSTRUMENT_INSTRIM = 3, + INSTRUMENT_CFG = 3, + INSTRUMENT_LTO = 4, + INSTRUMENT_LLVMNATIVE = 5, + INSTRUMENT_GCC = 6, + INSTRUMENT_CLANG = 7, + INSTRUMENT_OPT_CTX = 8, + INSTRUMENT_OPT_NGRAM = 16, + INSTRUMENT_OPT_CALLER = 32, + INSTRUMENT_OPT_CTX_K = 64, + +}; + +char instrument_mode_string[18][18] = { + + "DEFAULT", + "CLASSIC", + "PCGUARD", + "CFG", + "LTO", + "PCGUARD-NATIVE", + "GCC", + "CLANG", + "CTX", + "CALLER", + "", + "", + "", + "", + "", + "", + "NGRAM", + "" + +}; + +enum { + + UNSET = 0, + LTO = 1, + LLVM = 2, + GCC_PLUGIN = 3, + GCC = 4, + CLANG = 5 + +}; + +char compiler_mode_string[7][12] = { + + "AUTOSELECT", "LLVM-LTO", "LLVM", "GCC_PLUGIN", + "GCC", "CLANG", "" + +}; + +u8 *getthecwd() { + + if (getcwd(cwd, sizeof(cwd)) == NULL) { + + static u8 fail[] = ""; + return fail; + + } + + return cwd; + +} + +/* Try to find a specific runtime we need, returns NULL on fail. */ + +/* + in find_object() we look here: + + 1. if obj_path is already set we look there first + 2. then we check the $AFL_PATH environment variable location if set + 3. next we check argv[0] if it has path information and use it + a) we also check ../lib/afl + 4. if 3. failed we check /proc (only Linux, Android, NetBSD, DragonFly, and + FreeBSD with procfs) + a) and check here in ../lib/afl too + 5. we look into the AFL_PATH define (usually /usr/local/lib/afl) + 6. we finally try the current directory + + if all these attempts fail - we return NULL and the caller has to decide + what to do. +*/ + +static u8 *find_object(u8 *obj, u8 *argv0) { + + u8 *afl_path = getenv("AFL_PATH"); + u8 *slash = NULL, *tmp; + + if (afl_path) { + + tmp = alloc_printf("%s/%s", afl_path, obj); + + if (debug) DEBUGF("Trying %s\n", tmp); + + if (!access(tmp, R_OK)) { + + obj_path = afl_path; + return tmp; + + } + + ck_free(tmp); + + } + + if (argv0) { + + slash = strrchr(argv0, '/'); + + if (slash) { + + u8 *dir = ck_strdup(argv0); + + slash = strrchr(dir, '/'); + *slash = 0; + + tmp = alloc_printf("%s/%s", dir, obj); + + if (debug) DEBUGF("Trying %s\n", tmp); + + if (!access(tmp, R_OK)) { + + obj_path = dir; + return tmp; + + } + + ck_free(tmp); + tmp = alloc_printf("%s/../lib/afl/%s", dir, obj); + + if (debug) DEBUGF("Trying %s\n", tmp); + + if (!access(tmp, R_OK)) { + + u8 *dir2 = alloc_printf("%s/../lib/afl", dir); + obj_path = dir2; + ck_free(dir); + return tmp; + + } + + ck_free(tmp); + ck_free(dir); + + } + +#if defined(__FreeBSD__) || defined(__DragonFly__) || defined(__linux__) || \ + defined(__ANDROID__) || defined(__NetBSD__) + #define HAS_PROC_FS 1 +#endif +#ifdef HAS_PROC_FS + else { + + char *procname = NULL; + #if defined(__FreeBSD__) || defined(__DragonFly__) + procname = "/proc/curproc/file"; + #elif defined(__linux__) || defined(__ANDROID__) + procname = "/proc/self/exe"; + #elif defined(__NetBSD__) + procname = "/proc/curproc/exe"; + #endif + if (procname) { + + char exepath[PATH_MAX]; + ssize_t exepath_len = readlink(procname, exepath, sizeof(exepath)); + if (exepath_len > 0 && exepath_len < PATH_MAX) { + + exepath[exepath_len] = 0; + slash = strrchr(exepath, '/'); + + if (slash) { + + *slash = 0; + tmp = alloc_printf("%s/%s", exepath, obj); + + if (!access(tmp, R_OK)) { + + u8 *dir = alloc_printf("%s", exepath); + obj_path = dir; + return tmp; + + } + + ck_free(tmp); + tmp = alloc_printf("%s/../lib/afl/%s", exepath, obj); + + if (debug) DEBUGF("Trying %s\n", tmp); + + if (!access(tmp, R_OK)) { + + u8 *dir = alloc_printf("%s/../lib/afl/", exepath); + obj_path = dir; + return tmp; + + } + + } + + } + + } + + } + +#endif +#undef HAS_PROC_FS + + } + + tmp = alloc_printf("%s/%s", AFL_PATH, obj); + + if (debug) DEBUGF("Trying %s\n", tmp); + + if (!access(tmp, R_OK)) { + + obj_path = AFL_PATH; + return tmp; + + } + + ck_free(tmp); + + tmp = alloc_printf("./%s", obj); + + if (debug) DEBUGF("Trying %s\n", tmp); + + if (!access(tmp, R_OK)) { + + obj_path = "."; + return tmp; + + } + + ck_free(tmp); + + if (debug) DEBUGF("Trying ... giving up\n"); + + return NULL; + +} + +/* Copy argv to cc_params, making the necessary edits. */ + +static void edit_params(u32 argc, char **argv, char **envp) { + + u8 fortify_set = 0, asan_set = 0, x_set = 0, bit_mode = 0, shared_linking = 0, + preprocessor_only = 0, have_unroll = 0, have_o = 0, have_pic = 0, + have_c = 0; + + cc_params = ck_alloc((argc + 128) * sizeof(u8 *)); + + if (lto_mode) { + + if (lto_flag[0] != '-') + FATAL( + "Using afl-clang-lto is not possible because Makefile magic did not " + "identify the correct -flto flag"); + else + compiler_mode = LTO; + + } + + if (plusplus_mode) { + + u8 *alt_cxx = getenv("AFL_CXX"); + + if (!alt_cxx) { + + if (compiler_mode >= GCC_PLUGIN) { + + if (compiler_mode == GCC) { + + alt_cxx = clang_mode ? "clang++" : "g++"; + + } else if (compiler_mode == CLANG) { + + alt_cxx = "clang++"; + + } else { + + alt_cxx = "g++"; + + } + + } else { + + if (USE_BINDIR) + snprintf(llvm_fullpath, sizeof(llvm_fullpath), "%s/clang++", + LLVM_BINDIR); + else + snprintf(llvm_fullpath, sizeof(llvm_fullpath), CLANGPP_BIN); + alt_cxx = llvm_fullpath; + + } + + } + + cc_params[0] = alt_cxx; + + } else { + + u8 *alt_cc = getenv("AFL_CC"); + + if (!alt_cc) { + + if (compiler_mode >= GCC_PLUGIN) { + + if (compiler_mode == GCC) { + + alt_cc = clang_mode ? "clang" : "gcc"; + + } else if (compiler_mode == CLANG) { + + alt_cc = "clang"; + + } else { + + alt_cc = "gcc"; + + } + + } else { + + if (USE_BINDIR) + snprintf(llvm_fullpath, sizeof(llvm_fullpath), "%s/clang", + LLVM_BINDIR); + else + snprintf(llvm_fullpath, sizeof(llvm_fullpath), CLANGPP_BIN); + alt_cc = llvm_fullpath; + + } + + } + + cc_params[0] = alt_cc; + + } + + if (compiler_mode == GCC || compiler_mode == CLANG) { + + cc_params[cc_par_cnt++] = "-B"; + cc_params[cc_par_cnt++] = obj_path; + + if (clang_mode || compiler_mode == CLANG) { + + cc_params[cc_par_cnt++] = "-no-integrated-as"; + + } + + } + + if (compiler_mode == GCC_PLUGIN) { + + char *fplugin_arg = alloc_printf("-fplugin=%s/afl-gcc-pass.so", obj_path); + cc_params[cc_par_cnt++] = fplugin_arg; + + } + + if (compiler_mode == LLVM || compiler_mode == LTO) { + + cc_params[cc_par_cnt++] = "-Wno-unused-command-line-argument"; + + if (lto_mode && plusplus_mode) + cc_params[cc_par_cnt++] = "-lc++"; // needed by fuzzbench, early + + if (lto_mode && have_instr_env) { + + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = + alloc_printf("%s/afl-llvm-lto-instrumentlist.so", obj_path); + + } + + if (getenv("AFL_LLVM_DICT2FILE")) { + + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = + alloc_printf("%s/afl-llvm-dict2file.so", obj_path); + + } + + // laf + if (getenv("LAF_SPLIT_SWITCHES") || getenv("AFL_LLVM_LAF_SPLIT_SWITCHES")) { + + if (lto_mode && !have_c) { + + cc_params[cc_par_cnt++] = alloc_printf( + "-Wl,-mllvm=-load=%s/split-switches-pass.so", obj_path); + + } else { + + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = + alloc_printf("%s/split-switches-pass.so", obj_path); + + } + + } + + if (getenv("LAF_TRANSFORM_COMPARES") || + getenv("AFL_LLVM_LAF_TRANSFORM_COMPARES")) { + + if (lto_mode && !have_c) { + + cc_params[cc_par_cnt++] = alloc_printf( + "-Wl,-mllvm=-load=%s/compare-transform-pass.so", obj_path); + + } else { + + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = + alloc_printf("%s/compare-transform-pass.so", obj_path); + + } + + } + + if (getenv("LAF_SPLIT_COMPARES") || getenv("AFL_LLVM_LAF_SPLIT_COMPARES") || + getenv("AFL_LLVM_LAF_SPLIT_FLOATS")) { + + if (lto_mode && !have_c) { + + cc_params[cc_par_cnt++] = alloc_printf( + "-Wl,-mllvm=-load=%s/split-compares-pass.so", obj_path); + + } else { + + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = + alloc_printf("%s/split-compares-pass.so", obj_path); + + } + + } + + // /laf + + unsetenv("AFL_LD"); + unsetenv("AFL_LD_CALLER"); + if (cmplog_mode) { + + if (lto_mode && !have_c) { + + cc_params[cc_par_cnt++] = alloc_printf( + "-Wl,-mllvm=-load=%s/cmplog-routines-pass.so", obj_path); + cc_params[cc_par_cnt++] = alloc_printf( + "-Wl,-mllvm=-load=%s/cmplog-instructions-pass.so", obj_path); + cc_params[cc_par_cnt++] = alloc_printf( + "-Wl,-mllvm=-load=%s/split-switches-pass.so", obj_path); + + } else { + + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = + alloc_printf("%s/cmplog-routines-pass.so", obj_path); + + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = + alloc_printf("%s/cmplog-instructions-pass.so", obj_path); + + // reuse split switches from laf + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = + alloc_printf("%s/split-switches-pass.so", obj_path); + + } + + cc_params[cc_par_cnt++] = "-fno-inline"; + + } + +#if LLVM_MAJOR >= 13 + // fuck you llvm 13 + cc_params[cc_par_cnt++] = "-fno-experimental-new-pass-manager"; +#endif + + if (lto_mode && !have_c) { + + u8 *ld_path = strdup(AFL_REAL_LD); + if (!*ld_path) ld_path = "ld.lld"; +#if defined(AFL_CLANG_LDPATH) && LLVM_MAJOR >= 12 + cc_params[cc_par_cnt++] = alloc_printf("--ld-path=%s", ld_path); +#else + cc_params[cc_par_cnt++] = alloc_printf("-fuse-ld=%s", ld_path); +#endif + + cc_params[cc_par_cnt++] = "-Wl,--allow-multiple-definition"; + + if (instrument_mode == INSTRUMENT_CFG || + instrument_mode == INSTRUMENT_PCGUARD) + cc_params[cc_par_cnt++] = alloc_printf( + "-Wl,-mllvm=-load=%s/SanitizerCoverageLTO.so", obj_path); + else + + cc_params[cc_par_cnt++] = alloc_printf( + "-Wl,-mllvm=-load=%s/afl-llvm-lto-instrumentation.so", obj_path); + cc_params[cc_par_cnt++] = lto_flag; + + } else { + + if (instrument_mode == INSTRUMENT_PCGUARD) { + +#if LLVM_MAJOR > 10 || (LLVM_MAJOR == 10 && LLVM_MINOR > 0) + #ifdef __ANDROID__ + cc_params[cc_par_cnt++] = "-fsanitize-coverage=trace-pc-guard"; + #else + if (have_instr_list) { + + if (!be_quiet) + SAYF( + "Using unoptimized trace-pc-guard, due usage of " + "-fsanitize-coverage-allow/denylist, you can use " + "AFL_LLVM_ALLOWLIST/AFL_LLMV_DENYLIST instead.\n"); + cc_params[cc_par_cnt++] = "-fsanitize-coverage=trace-pc-guard"; + + } else { + + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = + alloc_printf("%s/SanitizerCoveragePCGUARD.so", obj_path); + + } + + #endif +#else + #if LLVM_MAJOR >= 4 + if (!be_quiet) + SAYF( + "Using unoptimized trace-pc-guard, upgrade to llvm 10.0.1+ for " + "enhanced version.\n"); + cc_params[cc_par_cnt++] = "-fsanitize-coverage=trace-pc-guard"; + #else + FATAL("pcguard instrumentation requires llvm 4.0.1+"); + #endif +#endif + + } else if (instrument_mode == INSTRUMENT_LLVMNATIVE) { + +#if LLVM_MAJOR >= 4 + cc_params[cc_par_cnt++] = "-fsanitize-coverage=trace-pc-guard"; +#else + FATAL("pcguard instrumentation requires llvm 4.0.1+"); +#endif + + } else { + + cc_params[cc_par_cnt++] = "-Xclang"; + cc_params[cc_par_cnt++] = "-load"; + cc_params[cc_par_cnt++] = "-Xclang"; + if (instrument_mode == INSTRUMENT_CFG) + cc_params[cc_par_cnt++] = + alloc_printf("%s/libLLVMInsTrim.so", obj_path); + else + cc_params[cc_par_cnt++] = + alloc_printf("%s/afl-llvm-pass.so", obj_path); + + } + + } + + // cc_params[cc_par_cnt++] = "-Qunused-arguments"; + + // in case LLVM is installed not via a package manager or "make install" + // e.g. compiled download or compiled from github then its ./lib directory + // might not be in the search path. Add it if so. + u8 *libdir = strdup(LLVM_LIBDIR); + if (plusplus_mode && strlen(libdir) && strncmp(libdir, "/usr", 4) && + strncmp(libdir, "/lib", 4)) { + + cc_params[cc_par_cnt++] = "-rpath"; + cc_params[cc_par_cnt++] = libdir; + + } else { + + free(libdir); + + } + + if (lto_mode && argc > 1) { + + u32 idx; + for (idx = 1; idx < argc; idx++) { + + if (!strncasecmp(argv[idx], "-fpic", 5)) have_pic = 1; + + } + + if (!have_pic) cc_params[cc_par_cnt++] = "-fPIC"; + + } + + } + + /* Detect stray -v calls from ./configure scripts. */ + + u8 skip_next = 0; + while (--argc) { + + u8 *cur = *(++argv); + + if (skip_next) { + + skip_next = 0; + continue; + + } + + if (!strncmp(cur, "--afl", 5)) continue; + if (lto_mode && !strncmp(cur, "-fuse-ld=", 9)) continue; + if (lto_mode && !strncmp(cur, "--ld-path=", 10)) continue; + if (!strncmp(cur, "-fno-unroll", 11)) continue; + if (strstr(cur, "afl-compiler-rt") || strstr(cur, "afl-llvm-rt")) continue; + if (!strcmp(cur, "-Wl,-z,defs") || !strcmp(cur, "-Wl,--no-undefined") || + !strcmp(cur, "--no-undefined")) { + + continue; + + } + + if (!strcmp(cur, "-z")) { + + u8 *param = *(argv + 1); + if (!strcmp(param, "defs")) { + + skip_next = 1; + continue; + + } + + } + + if (!strncmp(cur, "-fsanitize=fuzzer-", strlen("-fsanitize=fuzzer-")) || + !strncmp(cur, "-fsanitize-coverage", strlen("-fsanitize-coverage"))) { + + if (!be_quiet) { WARNF("Found '%s' - stripping!", cur); } + continue; + + } + + if (!strcmp(cur, "-fsanitize=fuzzer")) { + + u8 *afllib = find_object("libAFLDriver.a", argv[0]); + + if (!be_quiet) + WARNF( + "Found erroneous '-fsanitize=fuzzer', trying to replace with " + "libAFLDriver.a"); + + if (!afllib) { + + WARNF( + "Cannot find 'libAFLDriver.a' to replace a wrong " + "'-fsanitize=fuzzer' in the flags - this will fail!"); + + } else { + + cc_params[cc_par_cnt++] = afllib; + + } + + continue; + + } + + if (!strcmp(cur, "-m32")) bit_mode = 32; + if (!strcmp(cur, "armv7a-linux-androideabi")) bit_mode = 32; + if (!strcmp(cur, "-m64")) bit_mode = 64; + + if (!strncmp(cur, "-fsanitize-coverage-", 20) && strstr(cur, "list=")) + have_instr_list = 1; + + if (!strcmp(cur, "-fsanitize=address") || !strcmp(cur, "-fsanitize=memory")) + asan_set = 1; + + if (strstr(cur, "FORTIFY_SOURCE")) fortify_set = 1; + + if (!strcmp(cur, "-x")) x_set = 1; + if (!strcmp(cur, "-E")) preprocessor_only = 1; + if (!strcmp(cur, "-shared")) shared_linking = 1; + if (!strcmp(cur, "-c")) have_c = 1; + + if (!strncmp(cur, "-O", 2)) have_o = 1; + if (!strncmp(cur, "-funroll-loop", 13)) have_unroll = 1; + + cc_params[cc_par_cnt++] = cur; + + } + + if (getenv("AFL_HARDEN")) { + + cc_params[cc_par_cnt++] = "-fstack-protector-all"; + + if (!fortify_set) cc_params[cc_par_cnt++] = "-D_FORTIFY_SOURCE=2"; + + } + + if (!asan_set) { + + if (getenv("AFL_USE_ASAN")) { + + if (getenv("AFL_USE_MSAN")) FATAL("ASAN and MSAN are mutually exclusive"); + + if (getenv("AFL_HARDEN")) + FATAL("ASAN and AFL_HARDEN are mutually exclusive"); + + cc_params[cc_par_cnt++] = "-U_FORTIFY_SOURCE"; + cc_params[cc_par_cnt++] = "-fsanitize=address"; + + } else if (getenv("AFL_USE_MSAN")) { + + if (getenv("AFL_USE_ASAN")) FATAL("ASAN and MSAN are mutually exclusive"); + + if (getenv("AFL_HARDEN")) + FATAL("MSAN and AFL_HARDEN are mutually exclusive"); + + cc_params[cc_par_cnt++] = "-U_FORTIFY_SOURCE"; + cc_params[cc_par_cnt++] = "-fsanitize=memory"; + + } + + } + + if (getenv("AFL_USE_UBSAN")) { + + cc_params[cc_par_cnt++] = "-fsanitize=undefined"; + cc_params[cc_par_cnt++] = "-fsanitize-undefined-trap-on-error"; + cc_params[cc_par_cnt++] = "-fno-sanitize-recover=all"; + + } + + if (getenv("AFL_USE_CFISAN")) { + + if (!lto_mode) { + + uint32_t i = 0, found = 0; + while (envp[i] != NULL && !found) + if (strncmp("-flto", envp[i++], 5) == 0) found = 1; + if (!found) cc_params[cc_par_cnt++] = "-flto"; + + } + + cc_params[cc_par_cnt++] = "-fsanitize=cfi"; + cc_params[cc_par_cnt++] = "-fvisibility=hidden"; + + } + + if (!getenv("AFL_DONT_OPTIMIZE")) { + + cc_params[cc_par_cnt++] = "-g"; + if (!have_o) cc_params[cc_par_cnt++] = "-O3"; + if (!have_unroll) cc_params[cc_par_cnt++] = "-funroll-loops"; + // if (strlen(march_opt) > 1 && march_opt[0] == '-') + // cc_params[cc_par_cnt++] = march_opt; + + } + + if (getenv("AFL_NO_BUILTIN") || getenv("AFL_LLVM_LAF_TRANSFORM_COMPARES") || + getenv("LAF_TRANSFORM_COMPARES") || getenv("AFL_LLVM_LAF_ALL") || + lto_mode) { + + cc_params[cc_par_cnt++] = "-fno-builtin-strcmp"; + cc_params[cc_par_cnt++] = "-fno-builtin-strncmp"; + cc_params[cc_par_cnt++] = "-fno-builtin-strcasecmp"; + cc_params[cc_par_cnt++] = "-fno-builtin-strncasecmp"; + cc_params[cc_par_cnt++] = "-fno-builtin-memcmp"; + cc_params[cc_par_cnt++] = "-fno-builtin-bcmp"; + cc_params[cc_par_cnt++] = "-fno-builtin-strstr"; + cc_params[cc_par_cnt++] = "-fno-builtin-strcasestr"; + + } + +#if defined(USEMMAP) && !defined(__HAIKU__) + if (!have_c) cc_params[cc_par_cnt++] = "-lrt"; +#endif + + cc_params[cc_par_cnt++] = "-D__AFL_HAVE_MANUAL_CONTROL=1"; + cc_params[cc_par_cnt++] = "-D__AFL_COMPILER=1"; + cc_params[cc_par_cnt++] = "-DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1"; + + /* When the user tries to use persistent or deferred forkserver modes by + appending a single line to the program, we want to reliably inject a + signature into the binary (to be picked up by afl-fuzz) and we want + to call a function from the runtime .o file. This is unnecessarily + painful for three reasons: + + 1) We need to convince the compiler not to optimize out the signature. + This is done with __attribute__((used)). + + 2) We need to convince the linker, when called with -Wl,--gc-sections, + not to do the same. This is done by forcing an assignment to a + 'volatile' pointer. + + 3) We need to declare __afl_persistent_loop() in the global namespace, + but doing this within a method in a class is hard - :: and extern "C" + are forbidden and __attribute__((alias(...))) doesn't work. Hence the + __asm__ aliasing trick. + + */ + + cc_params[cc_par_cnt++] = + "-D__AFL_FUZZ_INIT()=" + "int __afl_sharedmem_fuzzing = 1;" + "extern unsigned int *__afl_fuzz_len;" + "extern unsigned char *__afl_fuzz_ptr;" + "unsigned char __afl_fuzz_alt[1048576];" + "unsigned char *__afl_fuzz_alt_ptr = __afl_fuzz_alt;"; + + if (plusplus_mode) { + + cc_params[cc_par_cnt++] = + "-D__AFL_COVERAGE()=int __afl_selective_coverage = 1;" + "extern \"C\" void __afl_coverage_discard();" + "extern \"C\" void __afl_coverage_skip();" + "extern \"C\" void __afl_coverage_on();" + "extern \"C\" void __afl_coverage_off();"; + + } else { + + cc_params[cc_par_cnt++] = + "-D__AFL_COVERAGE()=int __afl_selective_coverage = 1;" + "void __afl_coverage_discard();" + "void __afl_coverage_skip();" + "void __afl_coverage_on();" + "void __afl_coverage_off();"; + + } + + cc_params[cc_par_cnt++] = + "-D__AFL_COVERAGE_START_OFF()=int __afl_selective_coverage_start_off = " + "1;"; + cc_params[cc_par_cnt++] = "-D__AFL_COVERAGE_ON()=__afl_coverage_on()"; + cc_params[cc_par_cnt++] = "-D__AFL_COVERAGE_OFF()=__afl_coverage_off()"; + cc_params[cc_par_cnt++] = + "-D__AFL_COVERAGE_DISCARD()=__afl_coverage_discard()"; + cc_params[cc_par_cnt++] = "-D__AFL_COVERAGE_SKIP()=__afl_coverage_skip()"; + cc_params[cc_par_cnt++] = + "-D__AFL_FUZZ_TESTCASE_BUF=(__afl_fuzz_ptr ? __afl_fuzz_ptr : " + "__afl_fuzz_alt_ptr)"; + cc_params[cc_par_cnt++] = + "-D__AFL_FUZZ_TESTCASE_LEN=(__afl_fuzz_ptr ? *__afl_fuzz_len : " + "(*__afl_fuzz_len = read(0, __afl_fuzz_alt_ptr, 1048576)) == 0xffffffff " + "? 0 : *__afl_fuzz_len)"; + + cc_params[cc_par_cnt++] = + "-D__AFL_LOOP(_A)=" + "({ static volatile char *_B __attribute__((used)); " + " _B = (char*)\"" PERSIST_SIG + "\"; " +#ifdef __APPLE__ + "__attribute__((visibility(\"default\"))) " + "int _L(unsigned int) __asm__(\"___afl_persistent_loop\"); " +#else + "__attribute__((visibility(\"default\"))) " + "int _L(unsigned int) __asm__(\"__afl_persistent_loop\"); " +#endif /* ^__APPLE__ */ + "_L(_A); })"; + + cc_params[cc_par_cnt++] = + "-D__AFL_INIT()=" + "do { static volatile char *_A __attribute__((used)); " + " _A = (char*)\"" DEFER_SIG + "\"; " +#ifdef __APPLE__ + "__attribute__((visibility(\"default\"))) " + "void _I(void) __asm__(\"___afl_manual_init\"); " +#else + "__attribute__((visibility(\"default\"))) " + "void _I(void) __asm__(\"__afl_manual_init\"); " +#endif /* ^__APPLE__ */ + "_I(); } while (0)"; + + if (x_set) { + + cc_params[cc_par_cnt++] = "-x"; + cc_params[cc_par_cnt++] = "none"; + + } + + // prevent unnecessary build errors + cc_params[cc_par_cnt++] = "-Wno-unused-command-line-argument"; + + if (preprocessor_only || have_c) { + + /* In the preprocessor_only case (-E), we are not actually compiling at + all but requesting the compiler to output preprocessed sources only. + We must not add the runtime in this case because the compiler will + simply output its binary content back on stdout, breaking any build + systems that rely on a separate source preprocessing step. */ + cc_params[cc_par_cnt] = NULL; + return; + + } + +#ifndef __ANDROID__ + + if (compiler_mode != GCC && compiler_mode != CLANG) { + + switch (bit_mode) { + + case 0: + if (!shared_linking) + cc_params[cc_par_cnt++] = + alloc_printf("%s/afl-compiler-rt.o", obj_path); + if (lto_mode) + cc_params[cc_par_cnt++] = + alloc_printf("%s/afl-llvm-rt-lto.o", obj_path); + break; + + case 32: + if (!shared_linking) { + + cc_params[cc_par_cnt++] = + alloc_printf("%s/afl-compiler-rt-32.o", obj_path); + if (access(cc_params[cc_par_cnt - 1], R_OK)) + FATAL("-m32 is not supported by your compiler"); + + } + + if (lto_mode) { + + cc_params[cc_par_cnt++] = + alloc_printf("%s/afl-llvm-rt-lto-32.o", obj_path); + if (access(cc_params[cc_par_cnt - 1], R_OK)) + FATAL("-m32 is not supported by your compiler"); + + } + + break; + + case 64: + if (!shared_linking) { + + cc_params[cc_par_cnt++] = + alloc_printf("%s/afl-compiler-rt-64.o", obj_path); + if (access(cc_params[cc_par_cnt - 1], R_OK)) + FATAL("-m64 is not supported by your compiler"); + + } + + if (lto_mode) { + + cc_params[cc_par_cnt++] = + alloc_printf("%s/afl-llvm-rt-lto-64.o", obj_path); + if (access(cc_params[cc_par_cnt - 1], R_OK)) + FATAL("-m64 is not supported by your compiler"); + + } + + break; + + } + + #if !defined(__APPLE__) && !defined(__sun) + if (shared_linking) + cc_params[cc_par_cnt++] = + alloc_printf("-Wl,--dynamic-list=%s/dynamic_list.txt", obj_path); + #endif + + } + + #if defined(USEMMAP) && !defined(__HAIKU__) + cc_params[cc_par_cnt++] = "-lrt"; + #endif + +#endif + + cc_params[cc_par_cnt] = NULL; + +} + +/* Main entry point */ + +int main(int argc, char **argv, char **envp) { + + int i, passthrough = 0; + char *callname = argv[0], *ptr = NULL; + + if (getenv("AFL_DEBUG")) { + + debug = 1; + if (strcmp(getenv("AFL_DEBUG"), "0") == 0) unsetenv("AFL_DEBUG"); + + } else if (getenv("AFL_QUIET")) + + be_quiet = 1; + + if (getenv("AFL_LLVM_INSTRUMENT_FILE") || getenv("AFL_LLVM_WHITELIST") || + getenv("AFL_LLVM_ALLOWLIST") || getenv("AFL_LLVM_DENYLIST") || + getenv("AFL_LLVM_BLOCKLIST")) { + + have_instr_env = 1; + + } + + if (getenv("AFL_PASSTHROUGH") || getenv("AFL_NOOPT")) { + + passthrough = 1; + if (!debug) { be_quiet = 1; } + + } + + if ((ptr = strrchr(callname, '/')) != NULL) callname = ptr + 1; + argvnull = (u8 *)argv[0]; + check_environment_vars(envp); + + if ((ptr = find_object("as", argv[0])) != NULL) { + + have_gcc = 1; + ck_free(ptr); + + } + +#if (LLVM_MAJOR > 2) + + if ((ptr = find_object("SanitizerCoverageLTO.so", argv[0])) != NULL) { + + have_lto = 1; + ck_free(ptr); + + } + + if ((ptr = find_object("cmplog-routines-pass.so", argv[0])) != NULL) { + + have_llvm = 1; + ck_free(ptr); + + } + +#endif + +#ifdef __ANDROID__ + have_llvm = 1; +#endif + + if ((ptr = find_object("afl-gcc-pass.so", argv[0])) != NULL) { + + have_gcc_plugin = 1; + ck_free(ptr); + + } + +#if (LLVM_MAJOR > 2) + + if (strncmp(callname, "afl-clang-fast", 14) == 0) { + + compiler_mode = LLVM; + + } else if (strncmp(callname, "afl-clang-lto", 13) == 0 || + + strncmp(callname, "afl-lto", 7) == 0) { + + compiler_mode = LTO; + + } else + +#endif + if (strncmp(callname, "afl-gcc-fast", 12) == 0 || + + strncmp(callname, "afl-g++-fast", 12) == 0) { + + compiler_mode = GCC_PLUGIN; + + } else if (strncmp(callname, "afl-gcc", 7) == 0 || + + strncmp(callname, "afl-g++", 7) == 0) { + + compiler_mode = GCC; + + } else if (strcmp(callname, "afl-clang") == 0 || + + strcmp(callname, "afl-clang++") == 0) { + + compiler_mode = CLANG; + + } + + if ((ptr = getenv("AFL_CC_COMPILER"))) { + + if (compiler_mode) { + + WARNF( + "\"AFL_CC_COMPILER\" is set but a specific compiler was already " + "selected by command line parameter or symlink, ignoring the " + "environment variable!"); + + } else { + + if (strncasecmp(ptr, "LTO", 3) == 0) { + + compiler_mode = LTO; + + } else if (strncasecmp(ptr, "LLVM", 4) == 0) { + + compiler_mode = LLVM; + + } else if (strncasecmp(ptr, "GCC_P", 5) == 0 || + + strncasecmp(ptr, "GCC-P", 5) == 0 || + strncasecmp(ptr, "GCCP", 4) == 0) { + + compiler_mode = GCC_PLUGIN; + + } else if (strcasecmp(ptr, "GCC") == 0) { + + compiler_mode = GCC; + + } else + + FATAL("Unknown AFL_CC_COMPILER mode: %s\n", ptr); + + } + + } + + if (strcmp(callname, "afl-clang") == 0 || + strcmp(callname, "afl-clang++") == 0) { + + clang_mode = 1; + compiler_mode = CLANG; + + if (strcmp(callname, "afl-clang++") == 0) { plusplus_mode = 1; } + + } + + for (i = 1; i < argc; i++) { + + if (strncmp(argv[i], "--afl", 5) == 0) { + + if (compiler_mode) + WARNF( + "--afl-... compiler mode supersedes the AFL_CC_COMPILER and " + "symlink compiler selection!"); + + ptr = argv[i]; + ptr += 5; + while (*ptr == '-') + ptr++; + + if (strncasecmp(ptr, "LTO", 3) == 0) { + + compiler_mode = LTO; + + } else if (strncasecmp(ptr, "LLVM", 4) == 0) { + + compiler_mode = LLVM; + + } else if (strncasecmp(ptr, "PCGUARD", 7) == 0 || + + strncasecmp(ptr, "PC-GUARD", 8) == 0) { + + compiler_mode = LLVM; + instrument_mode = INSTRUMENT_PCGUARD; + + } else if (strcasecmp(ptr, "INSTRIM") == 0 || + + strcasecmp(ptr, "CFG") == 0) { + + compiler_mode = LLVM; + instrument_mode = INSTRUMENT_CFG; + + } else if (strcasecmp(ptr, "AFL") == 0 || + + strcasecmp(ptr, "CLASSIC") == 0) { + + compiler_mode = LLVM; + instrument_mode = INSTRUMENT_CLASSIC; + + } else if (strcasecmp(ptr, "LLVMNATIVE") == 0 || + + strcasecmp(ptr, "LLVM-NATIVE") == 0) { + + compiler_mode = LLVM; + instrument_mode = INSTRUMENT_LLVMNATIVE; + + } else if (strncasecmp(ptr, "GCC_P", 5) == 0 || + + strncasecmp(ptr, "GCC-P", 5) == 0 || + strncasecmp(ptr, "GCCP", 4) == 0) { + + compiler_mode = GCC_PLUGIN; + + } else if (strcasecmp(ptr, "GCC") == 0) { + + compiler_mode = GCC; + + } else if (strncasecmp(ptr, "CLANG", 5) == 0) { + + compiler_mode = CLANG; + + } else + + FATAL("Unknown --afl-... compiler mode: %s\n", argv[i]); + + } + + } + + if (strlen(callname) > 2 && + (strncmp(callname + strlen(callname) - 2, "++", 2) == 0 || + strstr(callname, "-g++") != NULL)) + plusplus_mode = 1; + + if (getenv("USE_TRACE_PC") || getenv("AFL_USE_TRACE_PC") || + getenv("AFL_LLVM_USE_TRACE_PC") || getenv("AFL_TRACE_PC")) { + + if (instrument_mode == 0) + instrument_mode = INSTRUMENT_PCGUARD; + else if (instrument_mode != INSTRUMENT_PCGUARD) + FATAL("you cannot set AFL_LLVM_INSTRUMENT and AFL_TRACE_PC together"); + + } + + if (have_instr_env && getenv("AFL_DONT_OPTIMIZE")) { + + WARNF( + "AFL_LLVM_ALLOWLIST/DENYLIST and AFL_DONT_OPTIMIZE cannot be combined " + "for file matching, only function matching!"); + + } + + if (getenv("AFL_LLVM_INSTRIM") || getenv("INSTRIM") || + getenv("INSTRIM_LIB")) { + + if (instrument_mode == 0) + instrument_mode = INSTRUMENT_CFG; + else if (instrument_mode != INSTRUMENT_CFG) + FATAL("you cannot set AFL_LLVM_INSTRUMENT and AFL_LLVM_INSTRIM together"); + + } + + if (getenv("AFL_LLVM_CTX")) instrument_opt_mode |= INSTRUMENT_OPT_CTX; + if (getenv("AFL_LLVM_CALLER")) instrument_opt_mode |= INSTRUMENT_OPT_CALLER; + + if (getenv("AFL_LLVM_NGRAM_SIZE")) { + + instrument_opt_mode |= INSTRUMENT_OPT_NGRAM; + ngram_size = atoi(getenv("AFL_LLVM_NGRAM_SIZE")); + if (ngram_size < 2 || ngram_size > NGRAM_SIZE_MAX) + FATAL( + "NGRAM instrumentation mode must be between 2 and NGRAM_SIZE_MAX " + "(%u)", + NGRAM_SIZE_MAX); + + } + + if (getenv("AFL_LLVM_CTX_K")) { + + ctx_k = atoi(getenv("AFL_LLVM_CTX_K")); + if (ctx_k < 1 || ctx_k > CTX_MAX_K) + FATAL("K-CTX instrumentation mode must be between 1 and CTX_MAX_K (%u)", + CTX_MAX_K); + if (ctx_k == 1) { + + setenv("AFL_LLVM_CALLER", "1", 1); + unsetenv("AFL_LLVM_CTX_K"); + instrument_opt_mode |= INSTRUMENT_OPT_CALLER; + + } else { + + instrument_opt_mode |= INSTRUMENT_OPT_CTX_K; + + } + + } + + if (getenv("AFL_LLVM_INSTRUMENT")) { + + u8 *ptr2 = strtok(getenv("AFL_LLVM_INSTRUMENT"), ":,;"); + + while (ptr2) { + + if (strncasecmp(ptr2, "afl", strlen("afl")) == 0 || + strncasecmp(ptr2, "classic", strlen("classic")) == 0) { + + if (instrument_mode == INSTRUMENT_LTO) { + + instrument_mode = INSTRUMENT_CLASSIC; + lto_mode = 1; + + } else if (!instrument_mode || instrument_mode == INSTRUMENT_AFL) + + instrument_mode = INSTRUMENT_AFL; + else + FATAL("main instrumentation mode already set with %s", + instrument_mode_string[instrument_mode]); + + } + + if (strncasecmp(ptr2, "pc-guard", strlen("pc-guard")) == 0 || + strncasecmp(ptr2, "pcguard", strlen("pcguard")) == 0) { + + if (!instrument_mode || instrument_mode == INSTRUMENT_PCGUARD) + instrument_mode = INSTRUMENT_PCGUARD; + else + FATAL("main instrumentation mode already set with %s", + instrument_mode_string[instrument_mode]); + + } + + if (strncasecmp(ptr2, "llvmnative", strlen("llvmnative")) == 0 || + strncasecmp(ptr2, "llvm-native", strlen("llvm-native")) == 0) { + + if (!instrument_mode || instrument_mode == INSTRUMENT_LLVMNATIVE) + instrument_mode = INSTRUMENT_LLVMNATIVE; + else + FATAL("main instrumentation mode already set with %s", + instrument_mode_string[instrument_mode]); + + } + + if (strncasecmp(ptr2, "cfg", strlen("cfg")) == 0 || + strncasecmp(ptr2, "instrim", strlen("instrim")) == 0) { + + if (instrument_mode == INSTRUMENT_LTO) { + + instrument_mode = INSTRUMENT_CFG; + lto_mode = 1; + + } else if (!instrument_mode || instrument_mode == INSTRUMENT_CFG) + + instrument_mode = INSTRUMENT_CFG; + else + FATAL("main instrumentation mode already set with %s", + instrument_mode_string[instrument_mode]); + + } + + if (strncasecmp(ptr2, "lto", strlen("lto")) == 0) { + + lto_mode = 1; + if (!instrument_mode || instrument_mode == INSTRUMENT_LTO) + instrument_mode = INSTRUMENT_LTO; + else if (instrument_mode != INSTRUMENT_CFG) + FATAL("main instrumentation mode already set with %s", + instrument_mode_string[instrument_mode]); + + } + + if (strcasecmp(ptr2, "gcc") == 0) { + + if (!instrument_mode || instrument_mode == INSTRUMENT_GCC) + instrument_mode = INSTRUMENT_GCC; + else if (instrument_mode != INSTRUMENT_GCC) + FATAL("main instrumentation mode already set with %s", + instrument_mode_string[instrument_mode]); + compiler_mode = GCC; + + } + + if (strcasecmp(ptr2, "clang") == 0) { + + if (!instrument_mode || instrument_mode == INSTRUMENT_CLANG) + instrument_mode = INSTRUMENT_CLANG; + else if (instrument_mode != INSTRUMENT_CLANG) + FATAL("main instrumentation mode already set with %s", + instrument_mode_string[instrument_mode]); + compiler_mode = CLANG; + + } + + if (strncasecmp(ptr2, "ctx-", strlen("ctx-")) == 0) { + + u8 *ptr3 = ptr2 + strlen("ctx-"); + while (*ptr3 && (*ptr3 < '0' || *ptr3 > '9')) + ptr3++; + + if (!*ptr3) { + + if ((ptr3 = getenv("AFL_LLVM_CTX_K")) == NULL) + FATAL( + "you must set the K-CTX K with (e.g. for value 2) " + "AFL_LLVM_INSTRUMENT=ctx-2"); + + } + + ctx_k = atoi(ptr3); + if (ctx_k < 1 || ctx_k > CTX_MAX_K) + FATAL( + "K-CTX instrumentation option must be between 1 and CTX_MAX_K " + "(%u)", + CTX_MAX_K); + + if (ctx_k == 1) { + + instrument_opt_mode |= INSTRUMENT_OPT_CALLER; + setenv("AFL_LLVM_CALLER", "1", 1); + unsetenv("AFL_LLVM_CTX_K"); + + } else { + + instrument_opt_mode |= (INSTRUMENT_OPT_CTX_K); + u8 *ptr4 = alloc_printf("%u", ctx_k); + setenv("AFL_LLVM_CTX_K", ptr4, 1); + + } + + } + + if (strncasecmp(ptr2, "ctx", strlen("ctx")) == 0) { + + instrument_opt_mode |= INSTRUMENT_OPT_CTX; + setenv("AFL_LLVM_CTX", "1", 1); + + } + + if (strncasecmp(ptr2, "caller", strlen("caller")) == 0) { + + instrument_opt_mode |= INSTRUMENT_OPT_CALLER; + setenv("AFL_LLVM_CALLER", "1", 1); + + } + + if (strncasecmp(ptr2, "ngram", strlen("ngram")) == 0) { + + u8 *ptr3 = ptr2 + strlen("ngram"); + while (*ptr3 && (*ptr3 < '0' || *ptr3 > '9')) + ptr3++; + + if (!*ptr3) { + + if ((ptr3 = getenv("AFL_LLVM_NGRAM_SIZE")) == NULL) + FATAL( + "you must set the NGRAM size with (e.g. for value 2) " + "AFL_LLVM_INSTRUMENT=ngram-2"); + + } + + ngram_size = atoi(ptr3); + if (ngram_size < 2 || ngram_size > NGRAM_SIZE_MAX) + FATAL( + "NGRAM instrumentation option must be between 2 and " + "NGRAM_SIZE_MAX (%u)", + NGRAM_SIZE_MAX); + instrument_opt_mode |= (INSTRUMENT_OPT_NGRAM); + u8 *ptr4 = alloc_printf("%u", ngram_size); + setenv("AFL_LLVM_NGRAM_SIZE", ptr4, 1); + + } + + ptr2 = strtok(NULL, ":,;"); + + } + + } + + if ((instrument_opt_mode & INSTRUMENT_OPT_CTX) && + (instrument_opt_mode & INSTRUMENT_OPT_CALLER)) { + + FATAL("you cannot set CTX and CALLER together"); + + } + + if ((instrument_opt_mode & INSTRUMENT_OPT_CTX) && + (instrument_opt_mode & INSTRUMENT_OPT_CTX_K)) { + + FATAL("you cannot set CTX and K-CTX together"); + + } + + if ((instrument_opt_mode & INSTRUMENT_OPT_CALLER) && + (instrument_opt_mode & INSTRUMENT_OPT_CTX_K)) { + + FATAL("you cannot set CALLER and K-CTX together"); + + } + + if (instrument_opt_mode && instrument_mode == INSTRUMENT_DEFAULT && + (compiler_mode == LLVM || compiler_mode == UNSET)) { + + instrument_mode = INSTRUMENT_CLASSIC; + compiler_mode = LLVM; + + } + + if (!compiler_mode) { + + // lto is not a default because outside of afl-cc RANLIB and AR have to + // be set to llvm versions so this would work + if (have_llvm) + compiler_mode = LLVM; + else if (have_gcc_plugin) + compiler_mode = GCC_PLUGIN; + else if (have_gcc) + compiler_mode = GCC; + else if (have_lto) + compiler_mode = LTO; + else + FATAL("no compiler mode available"); + + } + + if (compiler_mode == GCC) { + + if (clang_mode) { + + instrument_mode = INSTRUMENT_CLANG; + + } else { + + instrument_mode = INSTRUMENT_GCC; + + } + + } + + if (compiler_mode == CLANG) { instrument_mode = INSTRUMENT_CLANG; } + + if (argc < 2 || strncmp(argv[1], "-h", 2) == 0) { + + printf("afl-cc" VERSION + " by Michal Zalewski, Laszlo Szekeres, Marc Heuse\n"); + + SAYF( + "\n" + "afl-cc/afl-c++ [options]\n" + "\n" + "This is a helper application for afl-fuzz. It serves as a drop-in " + "replacement\n" + "for gcc and clang, letting you recompile third-party code with the " + "required\n" + "runtime instrumentation. A common use pattern would be one of the " + "following:\n\n" + + " CC=afl-cc CXX=afl-c++ ./configure --disable-shared\n" + " cmake -DCMAKE_C_COMPILERC=afl-cc -DCMAKE_CXX_COMPILER=afl-c++ .\n" + " CC=afl-cc CXX=afl-c++ meson\n\n"); + + SAYF( + " |------------- FEATURES " + "-------------|\n" + "MODES: NCC PERSIST DICT LAF " + "CMPLOG SELECT\n" + " [LTO] llvm LTO: %s%s\n" + " PCGUARD DEFAULT yes yes yes yes yes " + " yes\n" + " CLASSIC yes yes yes yes yes " + " yes\n" + " [LLVM] llvm: %s%s\n" + " PCGUARD %s yes yes module yes yes " + "extern\n" + " CLASSIC %s no yes module yes yes " + "yes\n" + " - NORMAL\n" + " - CALLER\n" + " - CTX\n" + " - NGRAM-{2-16}\n" + " INSTRIM no yes module yes yes " + " yes\n" + " - NORMAL\n" + " - CALLER\n" + " - NGRAM-{2-16}\n" + " [GCC_PLUGIN] gcc plugin: %s%s\n" + " CLASSIC DEFAULT no yes no no no " + "yes\n" + " [GCC/CLANG] simple gcc/clang: %s%s\n" + " CLASSIC DEFAULT no no no no no " + "no\n\n", + have_lto ? "AVAILABLE" : "unavailable!", + compiler_mode == LTO ? " [SELECTED]" : "", + have_llvm ? "AVAILABLE" : "unavailable!", + compiler_mode == LLVM ? " [SELECTED]" : "", + LLVM_MAJOR > 6 ? "DEFAULT" : " ", + LLVM_MAJOR > 6 ? " " : "DEFAULT", + have_gcc_plugin ? "AVAILABLE" : "unavailable!", + compiler_mode == GCC_PLUGIN ? " [SELECTED]" : "", + have_gcc ? "AVAILABLE" : "unavailable!", + (compiler_mode == GCC || compiler_mode == CLANG) ? " [SELECTED]" : ""); + + SAYF( + "Modes:\n" + " To select the compiler mode use a symlink version (e.g. " + "afl-clang-fast), set\n" + " the environment variable AFL_CC_COMPILER to a mode (e.g. LLVM) or " + "use the\n" + " command line parameter --afl-MODE (e.g. --afl-llvm). If none is " + "selected,\n" + " afl-cc will select the best available (LLVM -> GCC_PLUGIN -> GCC).\n" + " The best is LTO but it often needs RANLIB and AR settings outside " + "of afl-cc.\n\n"); + +#if LLVM_MAJOR > 10 || (LLVM_MAJOR == 10 && LLVM_MINOR > 0) + #define NATIVE_MSG \ + " NATIVE: use llvm's native PCGUARD instrumentation (less " \ + "performant)\n" +#else + #define NATIVE_MSG "" +#endif + + SAYF( + "Sub-Modes: (set via env AFL_LLVM_INSTRUMENT, afl-cc selects the best " + "available)\n" + " PCGUARD: Dominator tree instrumentation (best!) (README.llvm.md)\n" + + NATIVE_MSG + + " CLASSIC: decision target instrumentation (README.llvm.md)\n" + " CALLER: CLASSIC + single callee context " + "(instrumentation/README.ctx.md)\n" + " CTX: CLASSIC + full callee context " + "(instrumentation/README.ctx.md)\n" + " NGRAM-x: CLASSIC + previous path " + "((instrumentation/README.ngram.md)\n" + " INSTRIM: Dominator tree (for LLVM <= 6.0) " + "(instrumentation/README.instrim.md)\n\n"); + +#undef NATIVE_MSG + + SAYF( + "Features: (see documentation links)\n" + " NCC: non-colliding coverage [automatic] (that is an amazing " + "thing!)\n" + " (instrumentation/README.lto.md)\n" + " PERSIST: persistent mode support [code] (huge speed increase!)\n" + " (instrumentation/README.persistent_mode.md)\n" + " DICT: dictionary in the target [yes=automatic or llvm module " + "pass]\n" + " (instrumentation/README.lto.md + " + "instrumentation/README.llvm.md)\n" + " LAF: comparison splitting [env] " + "(instrumentation/README.laf-intel.md)\n" + " CMPLOG: input2state exploration [env] " + "(instrumentation/README.cmplog.md)\n" + " SELECT: selective instrumentation (allow/deny) on filename or " + "function [env]\n" + " (instrumentation/README.instrument_list.md)\n\n"); + + if (argc < 2 || strncmp(argv[1], "-hh", 3)) { + + SAYF( + "To see all environment variables for the configuration of afl-cc " + "use \"-hh\".\n"); + + } else { + + SAYF( + "Environment variables used:\n" + " AFL_CC: path to the C compiler to use\n" + " AFL_CXX: path to the C++ compiler to use\n" + " AFL_DEBUG: enable developer debugging output\n" + " AFL_DONT_OPTIMIZE: disable optimization instead of -O3\n" + " AFL_NO_BUILTIN: no builtins for string compare functions (for " + "libtokencap.so)\n" + " AFL_NOOP: behave like a normal compiler (to pass configure " + "tests)\n" + " AFL_PATH: path to instrumenting pass and runtime " + "(afl-compiler-rt.*o)\n" + " AFL_IGNORE_UNKNOWN_ENVS: don't warn on unknown env vars\n" + " AFL_INST_RATIO: percentage of branches to instrument\n" + " AFL_QUIET: suppress verbose output\n" + " AFL_HARDEN: adds code hardening to catch memory bugs\n" + " AFL_USE_ASAN: activate address sanitizer\n" + " AFL_USE_CFISAN: activate control flow sanitizer\n" + " AFL_USE_MSAN: activate memory sanitizer\n" + " AFL_USE_UBSAN: activate undefined behaviour sanitizer\n"); + + if (have_gcc_plugin) + SAYF( + "\nGCC Plugin-specific environment variables:\n" + " AFL_GCC_OUT_OF_LINE: disable inlined instrumentation\n" + " AFL_GCC_SKIP_NEVERZERO: do not skip zero on trace counters\n" + " AFL_GCC_INSTRUMENT_FILE: enable selective instrumentation by " + "filename\n"); + +#if LLVM_MAJOR < 9 + #define COUNTER_BEHAVIOUR \ + " AFL_LLVM_NOT_ZERO: use cycling trace counters that skip zero\n" +#else + #define COUNTER_BEHAVIOUR \ + " AFL_LLVM_SKIP_NEVERZERO: do not skip zero on trace counters\n" +#endif + if (have_llvm) + SAYF( + "\nLLVM/LTO/afl-clang-fast/afl-clang-lto specific environment " + "variables:\n" + + COUNTER_BEHAVIOUR + + " AFL_LLVM_DICT2FILE: generate an afl dictionary based on found " + "comparisons\n" + " AFL_LLVM_LAF_ALL: enables all LAF splits/transforms\n" + " AFL_LLVM_LAF_SPLIT_COMPARES: enable cascaded comparisons\n" + " AFL_LLVM_LAF_SPLIT_COMPARES_BITW: size limit (default 8)\n" + " AFL_LLVM_LAF_SPLIT_SWITCHES: cascaded comparisons on switches\n" + " AFL_LLVM_LAF_SPLIT_FLOATS: cascaded comparisons on floats\n" + " AFL_LLVM_LAF_TRANSFORM_COMPARES: cascade comparisons for string " + "functions\n" + " AFL_LLVM_ALLOWLIST/AFL_LLVM_DENYLIST: enable " + "instrument allow/\n" + " deny listing (selective instrumentation)\n"); + + if (have_llvm) + SAYF( + " AFL_LLVM_CMPLOG: log operands of comparisons (RedQueen " + "mutator)\n" + " AFL_LLVM_INSTRUMENT: set instrumentation mode:\n" + " CLASSIC, INSTRIM, PCGUARD, LTO, GCC, CLANG, CALLER, CTX, " + "NGRAM-2 ..-16\n" + " You can also use the old environment variables instead:\n" + " AFL_LLVM_USE_TRACE_PC: use LLVM trace-pc-guard instrumentation\n" + " AFL_LLVM_INSTRIM: use light weight instrumentation InsTrim\n" + " AFL_LLVM_INSTRIM_LOOPHEAD: optimize loop tracing for speed " + "(option to INSTRIM)\n" + " AFL_LLVM_CALLER: use single context sensitive coverage (for " + "CLASSIC)\n" + " AFL_LLVM_CTX: use full context sensitive coverage (for " + "CLASSIC)\n" + " AFL_LLVM_NGRAM_SIZE: use ngram prev_loc count coverage (for " + "CLASSIC & INSTRIM)\n"); + +#ifdef AFL_CLANG_FLTO + if (have_lto) + SAYF( + "\nLTO/afl-clang-lto specific environment variables:\n" + " AFL_LLVM_MAP_ADDR: use a fixed coverage map address (speed), " + "e.g. " + "0x10000\n" + " AFL_LLVM_DOCUMENT_IDS: write all edge IDs and the corresponding " + "functions\n" + " into this file\n" + " AFL_LLVM_LTO_DONTWRITEID: don't write the highest ID used to a " + "global var\n" + " AFL_LLVM_LTO_STARTID: from which ID to start counting from for " + "a " + "bb\n" + " AFL_REAL_LD: use this lld linker instead of the compiled in " + "path\n" + "If anything fails - be sure to read README.lto.md!\n"); +#endif + + } + + SAYF( + "\nFor any information on the available instrumentations and options " + "please \n" + "consult the README.md, especially section 3.1 about instrumenting " + "targets.\n\n"); + +#if (LLVM_MAJOR > 2) + if (have_lto) + SAYF("afl-cc LTO with ld=%s %s\n", AFL_REAL_LD, AFL_CLANG_FLTO); + if (have_llvm) + SAYF("afl-cc LLVM version %d using the binary path \"%s\".\n", LLVM_MAJOR, + LLVM_BINDIR); +#endif + +#ifdef USEMMAP + #if !defined(__HAIKU__) + SAYF("Compiled with shm_open support.\n"); + #else + SAYF("Compiled with shm_open support (adds -lrt when linking).\n"); + #endif +#else + SAYF("Compiled with shmat support.\n"); +#endif + SAYF("\n"); + + SAYF( + "Do not be overwhelmed :) afl-cc uses good defaults if no options are " + "selected.\n" + "Read the documentation for FEATURES though, all are good but few are " + "defaults.\n" + "Recommended is afl-clang-lto with AFL_LLVM_CMPLOG or afl-clang-fast " + "with\n" + "AFL_LLVM_CMPLOG and AFL_LLVM_DICT2FILE.\n\n"); + + exit(1); + + } + + if (compiler_mode == LTO) { + + if (instrument_mode == 0 || instrument_mode == INSTRUMENT_LTO || + instrument_mode == INSTRUMENT_CFG || + instrument_mode == INSTRUMENT_PCGUARD) { + + lto_mode = 1; + // force CFG + // if (!instrument_mode) { + + instrument_mode = INSTRUMENT_PCGUARD; + // ptr = instrument_mode_string[instrument_mode]; + // } + + } else if (instrument_mode == INSTRUMENT_LTO || + + instrument_mode == INSTRUMENT_CLASSIC) { + + lto_mode = 1; + + } else { + + if (!be_quiet) + WARNF("afl-clang-lto called with mode %s, using that mode instead", + instrument_mode_string[instrument_mode]); + + } + + } + + if (instrument_mode == 0 && compiler_mode < GCC_PLUGIN) { + +#if LLVM_MAJOR <= 6 + instrument_mode = INSTRUMENT_AFL; +#else + #if LLVM_MAJOR < 11 && (LLVM_MAJOR < 10 || LLVM_MINOR < 1) + if (have_instr_env) { + + instrument_mode = INSTRUMENT_AFL; + if (!be_quiet) + WARNF( + "Switching to classic instrumentation because " + "AFL_LLVM_ALLOWLIST/DENYLIST does not work with PCGUARD < 10.0.1."); + + } else + + #endif + instrument_mode = INSTRUMENT_PCGUARD; + +#endif + + } + + if (instrument_opt_mode && compiler_mode != LLVM) + FATAL("CTX, CALLER and NGRAM can only be used in LLVM mode"); + + if (!instrument_opt_mode) { + + if (lto_mode && instrument_mode == INSTRUMENT_CFG) + instrument_mode = INSTRUMENT_PCGUARD; + ptr = instrument_mode_string[instrument_mode]; + + } else { + + char *ptr2 = alloc_printf(" + NGRAM-%u", ngram_size); + char *ptr3 = alloc_printf(" + K-CTX-%u", ctx_k); + + ptr = alloc_printf( + "%s%s%s%s%s", instrument_mode_string[instrument_mode], + (instrument_opt_mode & INSTRUMENT_OPT_CTX) ? " + CTX" : "", + (instrument_opt_mode & INSTRUMENT_OPT_CALLER) ? " + CALLER" : "", + (instrument_opt_mode & INSTRUMENT_OPT_NGRAM) ? ptr2 : "", + (instrument_opt_mode & INSTRUMENT_OPT_CTX_K) ? ptr3 : ""); + + ck_free(ptr2); + ck_free(ptr3); + + } + +#ifndef AFL_CLANG_FLTO + if (lto_mode) + FATAL( + "instrumentation mode LTO specified but LLVM support not available " + "(requires LLVM 11 or higher)"); +#endif + + if (instrument_opt_mode && instrument_mode == INSTRUMENT_CFG && + instrument_opt_mode & INSTRUMENT_OPT_CTX) + FATAL("CFG instrumentation mode supports NGRAM and CALLER, but not CTX."); + else if (instrument_opt_mode && instrument_mode != INSTRUMENT_CLASSIC) + // we will drop CFG/INSTRIM in the future so do not advertise + FATAL( + "CALLER, CTX and NGRAM instrumentation options can only be used with " + "the LLVM CLASSIC instrumentation mode."); + + if (getenv("AFL_LLVM_SKIP_NEVERZERO") && getenv("AFL_LLVM_NOT_ZERO")) + FATAL( + "AFL_LLVM_NOT_ZERO and AFL_LLVM_SKIP_NEVERZERO can not be set " + "together"); + +#if LLVM_MAJOR < 11 && (LLVM_MAJOR < 10 || LLVM_MINOR < 1) + if (instrument_mode == INSTRUMENT_PCGUARD && have_instr_env) { + + FATAL( + "Instrumentation type PCGUARD does not support " + "AFL_LLVM_ALLOWLIST/DENYLIST! Use LLVM 10.0.1+ instead."); + + } + +#endif + + u8 *ptr2; + + if ((ptr2 = getenv("AFL_LLVM_DICT2FILE")) != NULL && *ptr2 != '/') + FATAL("AFL_LLVM_DICT2FILE must be set to an absolute file path"); + + if ((isatty(2) && !be_quiet) || debug) { + + SAYF(cCYA + "afl-cc " VERSION cRST + " by Michal Zalewski, Laszlo Szekeres, Marc Heuse - mode: %s-%s\n", + compiler_mode_string[compiler_mode], ptr); + + } + + if (!be_quiet && (compiler_mode == GCC || compiler_mode == CLANG)) { + + WARNF( + "You are using outdated instrumentation, install LLVM and/or " + "gcc-plugin and use afl-clang-fast/afl-clang-lto/afl-gcc-fast " + "instead!"); + + } + + if (debug) { + + DEBUGF("cd '%s';", getthecwd()); + for (i = 0; i < argc; i++) + SAYF(" '%s'", argv[i]); + SAYF("\n"); + fflush(stdout); + fflush(stderr); + + } + + if (getenv("AFL_LLVM_LAF_ALL")) { + + setenv("AFL_LLVM_LAF_SPLIT_SWITCHES", "1", 1); + setenv("AFL_LLVM_LAF_SPLIT_COMPARES", "1", 1); + setenv("AFL_LLVM_LAF_SPLIT_FLOATS", "1", 1); + setenv("AFL_LLVM_LAF_TRANSFORM_COMPARES", "1", 1); + + } + + cmplog_mode = getenv("AFL_CMPLOG") || getenv("AFL_LLVM_CMPLOG"); + if (!be_quiet && cmplog_mode) + printf("CmpLog mode by <andreafioraldi@gmail.com>\n"); + +#ifndef __ANDROID__ + ptr = find_object("afl-compiler-rt.o", argv[0]); + + if (!ptr) { + + FATAL( + "Unable to find 'afl-compiler-rt.o'. Please set the AFL_PATH " + "environment variable."); + + } + + if (debug) { DEBUGF("rt=%s obj_path=%s\n", ptr, obj_path); } + + ck_free(ptr); +#endif + + edit_params(argc, argv, envp); + + if (debug) { + + DEBUGF("cd '%s';", getthecwd()); + for (i = 0; i < (s32)cc_par_cnt; i++) + SAYF(" '%s'", cc_params[i]); + SAYF("\n"); + fflush(stdout); + fflush(stderr); + + } + + if (passthrough) { + + argv[0] = cc_params[0]; + execvp(cc_params[0], (char **)argv); + + } else { + + execvp(cc_params[0], (char **)cc_params); + + } + + FATAL("Oops, failed to execute '%s' - check your PATH", cc_params[0]); + + return 0; + +} + diff --git a/src/afl-common.c b/src/afl-common.c index c023789b..7e56ce3f 100644 --- a/src/afl-common.c +++ b/src/afl-common.c @@ -26,6 +26,7 @@ #include <stdlib.h> #include <stdio.h> #include <strings.h> +#include <math.h> #include "debug.h" #include "alloc-inl.h" @@ -46,7 +47,11 @@ u8 be_quiet = 0; u8 *doc_path = ""; u8 last_intr = 0; -void detect_file_args(char **argv, u8 *prog_in, u8 *use_stdin) { +#ifndef AFL_PATH + #define AFL_PATH "/usr/local/lib/afl/" +#endif + +void detect_file_args(char **argv, u8 *prog_in, bool *use_stdin) { u32 i = 0; u8 cwd[PATH_MAX]; @@ -63,7 +68,7 @@ void detect_file_args(char **argv, u8 *prog_in, u8 *use_stdin) { if (!prog_in) { FATAL("@@ syntax is not supported by this tool."); } - *use_stdin = 0; + *use_stdin = false; if (prog_in[0] != 0) { // not afl-showmap special case @@ -108,6 +113,7 @@ char **argv_cpy_dup(int argc, char **argv) { int i = 0; char **ret = ck_alloc((argc + 1) * sizeof(char *)); + if (unlikely(!ret)) { FATAL("Amount of arguments specified is too high"); } for (i = 0; i < argc; i++) { @@ -130,6 +136,7 @@ void argv_cpy_free(char **argv) { while (argv[i]) { ck_free(argv[i]); + argv[i] = NULL; i++; } @@ -142,10 +149,24 @@ void argv_cpy_free(char **argv) { char **get_qemu_argv(u8 *own_loc, u8 **target_path_p, int argc, char **argv) { + if (unlikely(getenv("AFL_QEMU_CUSTOM_BIN"))) { + + WARNF( + "AFL_QEMU_CUSTOM_BIN is enabled. " + "You must run your target under afl-qemu-trace on your own!"); + return argv; + + } + + if (!unlikely(own_loc)) { FATAL("BUG: param own_loc is NULL"); } + + u8 *tmp, *cp = NULL, *rsl, *own_copy; + char **new_argv = ck_alloc(sizeof(char *) * (argc + 4)); - u8 * tmp, *cp = NULL, *rsl, *own_copy; + if (unlikely(!new_argv)) { FATAL("Illegal amount of arguments specified"); } - memcpy(new_argv + 3, argv + 1, (int)(sizeof(char *)) * argc); + memcpy(&new_argv[3], &argv[1], (int)(sizeof(char *)) * (argc - 1)); + new_argv[argc + 3] = NULL; new_argv[2] = *target_path_p; new_argv[1] = "--"; @@ -223,10 +244,15 @@ char **get_qemu_argv(u8 *own_loc, u8 **target_path_p, int argc, char **argv) { char **get_wine_argv(u8 *own_loc, u8 **target_path_p, int argc, char **argv) { + if (!unlikely(own_loc)) { FATAL("BUG: param own_loc is NULL"); } + + u8 *tmp, *cp = NULL, *rsl, *own_copy; + char **new_argv = ck_alloc(sizeof(char *) * (argc + 3)); - u8 * tmp, *cp = NULL, *rsl, *own_copy; + if (unlikely(!new_argv)) { FATAL("Illegal amount of arguments specified"); } - memcpy(new_argv + 2, argv + 1, (int)(sizeof(char *)) * argc); + memcpy(&new_argv[2], &argv[1], (int)(sizeof(char *)) * (argc - 1)); + new_argv[argc + 2] = NULL; new_argv[1] = *target_path_p; @@ -333,6 +359,8 @@ u8 *find_binary(u8 *fname) { struct stat st; + if (unlikely(!fname)) { FATAL("No binary supplied"); } + if (strchr(fname, '/') || !(env_path = getenv("PATH"))) { target_path = ck_strdup(fname); @@ -340,7 +368,7 @@ u8 *find_binary(u8 *fname) { if (stat(target_path, &st) || !S_ISREG(st.st_mode) || !(st.st_mode & 0111) || st.st_size < 4) { - free(target_path); + ck_free(target_path); FATAL("Program '%s' not found or not executable", fname); } @@ -354,6 +382,14 @@ u8 *find_binary(u8 *fname) { if (delim) { cur_elem = ck_alloc(delim - env_path + 1); + if (unlikely(!cur_elem)) { + + FATAL( + "Unexpected overflow when processing ENV. This should never " + "happend."); + + } + memcpy(cur_elem, env_path, delim - env_path); delim++; @@ -401,15 +437,186 @@ u8 *find_binary(u8 *fname) { } +/* Parses the kill signal environment variable, FATALs on error. + If the env is not set, sets the env to default_signal for the signal handlers + and returns the default_signal. */ +int parse_afl_kill_signal_env(u8 *afl_kill_signal_env, int default_signal) { + + if (afl_kill_signal_env && afl_kill_signal_env[0]) { + + char *endptr; + u8 signal_code; + signal_code = (u8)strtoul(afl_kill_signal_env, &endptr, 10); + /* Did we manage to parse the full string? */ + if (*endptr != '\0' || endptr == (char *)afl_kill_signal_env) { + + FATAL("Invalid AFL_KILL_SIGNAL: %s (expected unsigned int)", + afl_kill_signal_env); + + } + + return signal_code; + + } else { + + char *sigstr = alloc_printf("%d", default_signal); + if (!sigstr) { FATAL("Failed to alloc mem for signal buf"); } + + /* Set the env for signal handler */ + setenv("AFL_KILL_SIGNAL", sigstr, 1); + free(sigstr); + return default_signal; + + } + +} + +static inline unsigned int helper_min3(unsigned int a, unsigned int b, + unsigned int c) { + + return a < b ? (a < c ? a : c) : (b < c ? b : c); + +} + +// from +// https://en.wikibooks.org/wiki/Algorithm_Implementation/Strings/Levenshtein_distance#C +static int string_distance_levenshtein(char *s1, char *s2) { + + unsigned int s1len, s2len, x, y, lastdiag, olddiag; + s1len = strlen(s1); + s2len = strlen(s2); + unsigned int column[s1len + 1]; + column[s1len] = 1; + + for (y = 1; y <= s1len; y++) + column[y] = y; + for (x = 1; x <= s2len; x++) { + + column[0] = x; + for (y = 1, lastdiag = x - 1; y <= s1len; y++) { + + olddiag = column[y]; + column[y] = helper_min3(column[y] + 1, column[y - 1] + 1, + lastdiag + (s1[y - 1] == s2[x - 1] ? 0 : 1)); + lastdiag = olddiag; + + } + + } + + return column[s1len]; + +} + +#define ENV_SIMILARITY_TRESHOLD 3 + +void print_suggested_envs(char *mispelled_env) { + + size_t env_name_len = + strcspn(mispelled_env, "=") - 4; // remove the AFL_prefix + char *env_name = ck_alloc(env_name_len + 1); + memcpy(env_name, mispelled_env + 4, env_name_len); + + char *seen = ck_alloc(sizeof(afl_environment_variables) / sizeof(char *)); + int found = 0; + + int j; + for (j = 0; afl_environment_variables[j] != NULL; ++j) { + + char *afl_env = afl_environment_variables[j] + 4; + int distance = string_distance_levenshtein(afl_env, env_name); + if (distance < ENV_SIMILARITY_TRESHOLD && seen[j] == 0) { + + SAYF("Did you mean %s?\n", afl_environment_variables[j]); + seen[j] = 1; + found = 1; + + } + + } + + if (found) goto cleanup; + + for (j = 0; afl_environment_variables[j] != NULL; ++j) { + + char * afl_env = afl_environment_variables[j] + 4; + size_t afl_env_len = strlen(afl_env); + char * reduced = ck_alloc(afl_env_len + 1); + + size_t start = 0; + while (start < afl_env_len) { + + size_t end = start + strcspn(afl_env + start, "_") + 1; + memcpy(reduced, afl_env, start); + if (end < afl_env_len) + memcpy(reduced + start, afl_env + end, afl_env_len - end); + reduced[afl_env_len - end + start] = 0; + + int distance = string_distance_levenshtein(reduced, env_name); + if (distance < ENV_SIMILARITY_TRESHOLD && seen[j] == 0) { + + SAYF("Did you mean %s?\n", afl_environment_variables[j]); + seen[j] = 1; + found = 1; + + } + + start = end; + + }; + + ck_free(reduced); + + } + + if (found) goto cleanup; + + char * reduced = ck_alloc(env_name_len + 1); + size_t start = 0; + while (start < env_name_len) { + + size_t end = start + strcspn(env_name + start, "_") + 1; + memcpy(reduced, env_name, start); + if (end < env_name_len) + memcpy(reduced + start, env_name + end, env_name_len - end); + reduced[env_name_len - end + start] = 0; + + for (j = 0; afl_environment_variables[j] != NULL; ++j) { + + int distance = string_distance_levenshtein( + afl_environment_variables[j] + 4, reduced); + if (distance < ENV_SIMILARITY_TRESHOLD && seen[j] == 0) { + + SAYF("Did you mean %s?\n", afl_environment_variables[j]); + seen[j] = 1; + + } + + } + + start = end; + + }; + + ck_free(reduced); + +cleanup: + ck_free(env_name); + ck_free(seen); + +} + void check_environment_vars(char **envp) { if (be_quiet) { return; } int index = 0, issue_detected = 0; - char *env, *val; + char *env, *val, *ignore = getenv("AFL_IGNORE_UNKNOWN_ENVS"); while ((env = envp[index++]) != NULL) { - if (strncmp(env, "ALF_", 4) == 0) { + if (strncmp(env, "ALF_", 4) == 0 || strncmp(env, "_ALF", 4) == 0 || + strncmp(env, "__ALF", 5) == 0 || strncmp(env, "_AFL", 4) == 0 || + strncmp(env, "__AFL", 5) == 0) { WARNF("Potentially mistyped AFL environment variable: %s", env); issue_detected = 1; @@ -424,6 +631,7 @@ void check_environment_vars(char **envp) { env[strlen(afl_environment_variables[i])] == '=') { match = 1; + if ((val = getenv(afl_environment_variables[i])) && !*val) { WARNF( @@ -463,11 +671,13 @@ void check_environment_vars(char **envp) { } - if (match == 0) { + if (match == 0 && !ignore) { WARNF("Mistyped AFL environment variable: %s", env); issue_detected = 1; + print_suggested_envs(env); + } } @@ -605,6 +815,10 @@ u8 *stringify_float(u8 *buf, size_t len, double val) { snprintf(buf, len, "%0.01f", val); + } else if (unlikely(isnan(val) || isinf(val))) { + + strcpy(buf, "inf"); + } else { stringify_int(buf, len, (u64)val); @@ -667,16 +881,16 @@ u8 *stringify_mem_size(u8 *buf, size_t len, u64 val) { u8 *stringify_time_diff(u8 *buf, size_t len, u64 cur_ms, u64 event_ms) { - u64 delta; - s32 t_d, t_h, t_m, t_s; - u8 val_buf[STRINGIFY_VAL_SIZE_MAX]; - if (!event_ms) { snprintf(buf, len, "none seen yet"); } else { + u64 delta; + s32 t_d, t_h, t_m, t_s; + u8 val_buf[STRINGIFY_VAL_SIZE_MAX]; + delta = cur_ms - event_ms; t_d = delta / 1000 / 60 / 60 / 24; @@ -764,6 +978,10 @@ u8 *u_stringify_float(u8 *buf, double val) { sprintf(buf, "%0.01f", val); + } else if (unlikely(isnan(val) || isinf(val))) { + + strcpy(buf, "infinite"); + } else { return u_stringify_int(buf, (u64)val); @@ -825,16 +1043,16 @@ u8 *u_stringify_mem_size(u8 *buf, u64 val) { u8 *u_stringify_time_diff(u8 *buf, u64 cur_ms, u64 event_ms) { - u64 delta; - s32 t_d, t_h, t_m, t_s; - u8 val_buf[STRINGIFY_VAL_SIZE_MAX]; - if (!event_ms) { sprintf(buf, "none seen yet"); } else { + u64 delta; + s32 t_d, t_h, t_m, t_s; + u8 val_buf[STRINGIFY_VAL_SIZE_MAX]; + delta = cur_ms - event_ms; t_d = delta / 1000 / 60 / 60 / 24; @@ -854,20 +1072,20 @@ u8 *u_stringify_time_diff(u8 *buf, u64 cur_ms, u64 event_ms) { /* Reads the map size from ENV */ u32 get_map_size(void) { - uint32_t map_size = MAP_SIZE; + uint32_t map_size = DEFAULT_SHMEM_SIZE; char * ptr; if ((ptr = getenv("AFL_MAP_SIZE")) || (ptr = getenv("AFL_MAPSIZE"))) { map_size = atoi(ptr); - if (map_size < 8 || map_size > (1 << 29)) { + if (!map_size || map_size > (1 << 29)) { - FATAL("illegal AFL_MAP_SIZE %u, must be between %u and %u", map_size, 8, - 1 << 29); + FATAL("illegal AFL_MAP_SIZE %u, must be between %u and %u", map_size, 64U, + 1U << 29); } - if (map_size % 8) { map_size = (((map_size >> 3) + 1) << 3); } + if (map_size % 64) { map_size = (((map_size >> 6) + 1) << 6); } } @@ -875,3 +1093,36 @@ u32 get_map_size(void) { } +/* Create a stream file */ + +FILE *create_ffile(u8 *fn) { + + s32 fd; + FILE *f; + + fd = open(fn, O_WRONLY | O_CREAT | O_TRUNC, 0600); + + if (fd < 0) { PFATAL("Unable to create '%s'", fn); } + + f = fdopen(fd, "w"); + + if (!f) { PFATAL("fdopen() failed"); } + + return f; + +} + +/* Create a file */ + +s32 create_file(u8 *fn) { + + s32 fd; + + fd = open(fn, O_WRONLY | O_CREAT | O_TRUNC, 0600); + + if (fd < 0) { PFATAL("Unable to create '%s'", fn); } + + return fd; + +} + diff --git a/src/afl-forkserver.c b/src/afl-forkserver.c index 47493eba..68995388 100644 --- a/src/afl-forkserver.c +++ b/src/afl-forkserver.c @@ -58,8 +58,12 @@ static list_t fsrv_list = {.element_prealloc_count = 0}; static void fsrv_exec_child(afl_forkserver_t *fsrv, char **argv) { + if (fsrv->qemu_mode) { setenv("AFL_DISABLE_LLVM_INSTRUMENTATION", "1", 0); } + execv(fsrv->target_path, argv); + WARNF("Execv failed in forkserver."); + } /* Initializes the struct */ @@ -74,20 +78,24 @@ void afl_fsrv_init(afl_forkserver_t *fsrv) { fsrv->dev_urandom_fd = -1; /* Settings */ - fsrv->use_stdin = 1; - fsrv->no_unlink = 0; + fsrv->use_stdin = true; + fsrv->no_unlink = false; fsrv->exec_tmout = EXEC_TIMEOUT; + fsrv->init_tmout = EXEC_TIMEOUT * FORK_WAIT_MULT; fsrv->mem_limit = MEM_LIMIT; fsrv->out_file = NULL; + fsrv->kill_signal = SIGKILL; /* exec related stuff */ fsrv->child_pid = -1; fsrv->map_size = get_map_size(); - fsrv->use_fauxsrv = 0; - fsrv->last_run_timed_out = 0; + fsrv->use_fauxsrv = false; + fsrv->last_run_timed_out = false; + fsrv->debug = false; + fsrv->uses_crash_exitcode = false; + fsrv->uses_asan = false; fsrv->init_child_func = fsrv_exec_child; - list_append(&fsrv_list, fsrv); } @@ -96,23 +104,29 @@ void afl_fsrv_init(afl_forkserver_t *fsrv) { void afl_fsrv_init_dup(afl_forkserver_t *fsrv_to, afl_forkserver_t *from) { fsrv_to->use_stdin = from->use_stdin; - fsrv_to->out_fd = from->out_fd; fsrv_to->dev_null_fd = from->dev_null_fd; fsrv_to->exec_tmout = from->exec_tmout; + fsrv_to->init_tmout = from->init_tmout; fsrv_to->mem_limit = from->mem_limit; fsrv_to->map_size = from->map_size; fsrv_to->support_shmem_fuzz = from->support_shmem_fuzz; - + fsrv_to->out_file = from->out_file; fsrv_to->dev_urandom_fd = from->dev_urandom_fd; + fsrv_to->out_fd = from->out_fd; // not sure this is a good idea + fsrv_to->no_unlink = from->no_unlink; + fsrv_to->uses_crash_exitcode = from->uses_crash_exitcode; + fsrv_to->crash_exitcode = from->crash_exitcode; + fsrv_to->kill_signal = from->kill_signal; + fsrv_to->debug = from->debug; // These are forkserver specific. fsrv_to->out_dir_fd = -1; fsrv_to->child_pid = -1; fsrv_to->use_fauxsrv = 0; fsrv_to->last_run_timed_out = 0; - fsrv_to->out_file = NULL; - fsrv_to->init_child_func = fsrv_exec_child; + fsrv_to->init_child_func = from->init_child_func; + // Note: do not copy ->add_extra_func list_append(&fsrv_list, fsrv_to); @@ -122,8 +136,8 @@ void afl_fsrv_init_dup(afl_forkserver_t *fsrv_to, afl_forkserver_t *from) { Returns the time passed to read. If the wait times out, returns timeout_ms + 1; Returns 0 if an error occurred (fd closed, signal, ...); */ -static u32 read_s32_timed(s32 fd, s32 *buf, u32 timeout_ms, - volatile u8 *stop_soon_p) { +static u32 __attribute__((hot)) +read_s32_timed(s32 fd, s32 *buf, u32 timeout_ms, volatile u8 *stop_soon_p) { fd_set readfds; FD_ZERO(&readfds); @@ -135,7 +149,7 @@ static u32 read_s32_timed(s32 fd, s32 *buf, u32 timeout_ms, timeout.tv_sec = (timeout_ms / 1000); timeout.tv_usec = (timeout_ms % 1000) * 1000; #if !defined(__linux__) - u64 read_start = get_cur_time_us(); + u32 read_start = get_cur_time_us(); #endif /* set exceptfds as well to return when a child exited/closed the pipe. */ @@ -145,6 +159,13 @@ restart_select: if (likely(sret > 0)) { restart_read: + if (*stop_soon_p) { + + // Early return - the user wants to quit. + return 0; + + } + len_read = read(fd, (u8 *)buf, 4); if (likely(len_read == 4)) { // for speed we put this first @@ -154,7 +175,7 @@ restart_select: timeout_ms, ((u64)timeout_ms - (timeout.tv_sec * 1000 + timeout.tv_usec / 1000))); #else - u32 exec_ms = MIN(timeout_ms, get_cur_time_us() - read_start); + u32 exec_ms = MIN(timeout_ms, (get_cur_time_us() - read_start) / 1000); #endif // ensure to report 1 ms has passed (0 is an error) @@ -194,7 +215,7 @@ restart_select: static void afl_fauxsrv_execv(afl_forkserver_t *fsrv, char **argv) { unsigned char tmp[4] = {0, 0, 0, 0}; - pid_t child_pid = -1; + pid_t child_pid; if (!be_quiet) { ACTF("Using Fauxserver:"); } @@ -228,6 +249,23 @@ static void afl_fauxsrv_execv(afl_forkserver_t *fsrv, char **argv) { if (!child_pid) { // New child + close(fsrv->out_dir_fd); + close(fsrv->dev_null_fd); + close(fsrv->dev_urandom_fd); + + if (fsrv->plot_file != NULL) { + + fclose(fsrv->plot_file); + fsrv->plot_file = NULL; + + } + + // enable terminating on sigpipe in the childs + struct sigaction sa; + memset((char *)&sa, 0, sizeof(sa)); + sa.sa_handler = SIG_DFL; + sigaction(SIGPIPE, &sa, NULL); + signal(SIGCHLD, old_sigchld_handler); // FORKSRV_FD is for communication with AFL, we don't need it in the // child. @@ -243,7 +281,8 @@ static void afl_fauxsrv_execv(afl_forkserver_t *fsrv, char **argv) { *(u32 *)fsrv->trace_bits = EXEC_FAIL_SIG; - PFATAL("Execv failed in fauxserver."); + WARNF("Execv failed in fauxserver."); + break; } @@ -257,13 +296,13 @@ static void afl_fauxsrv_execv(afl_forkserver_t *fsrv, char **argv) { if (waitpid(child_pid, &status, 0) < 0) { // Zombie Child could not be collected. Scary! - PFATAL("Fauxserver could not determin child's exit code. "); + WARNF("Fauxserver could not determine child's exit code. "); } /* Relay wait status to AFL pipe, then loop back. */ - if (write(FORKSRV_FD + 1, &status, 4) != 4) { exit(0); } + if (write(FORKSRV_FD + 1, &status, 4) != 4) { exit(1); } } @@ -286,8 +325,8 @@ static void report_error_and_exit(int error) { FATAL( "the fuzzing target reports that hardcoded map address might be the " "reason the mmap of the shared memory failed. Solution: recompile " - "the target with either afl-clang-lto and the environment variable " - "AFL_LLVM_MAP_DYNAMIC set or recompile with afl-clang-fast."); + "the target with either afl-clang-lto and do not set " + "AFL_LLVM_MAP_ADDR or recompile with afl-clang-fast."); break; case FS_ERROR_SHM_OPEN: FATAL("the fuzzing target reports that the shm_open() call failed."); @@ -301,7 +340,7 @@ static void report_error_and_exit(int error) { "memory failed."); break; default: - FATAL("unknown error code %u from fuzzing target!", error); + FATAL("unknown error code %d from fuzzing target!", error); } @@ -318,15 +357,16 @@ static void report_error_and_exit(int error) { void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, volatile u8 *stop_soon_p, u8 debug_child_output) { - int st_pipe[2], ctl_pipe[2]; - s32 status; - s32 rlen; + int st_pipe[2], ctl_pipe[2]; + s32 status; + s32 rlen; + char *ignore_autodict = getenv("AFL_NO_AUTODICT"); if (!be_quiet) { ACTF("Spinning up the fork server..."); } if (fsrv->use_fauxsrv) { - /* TODO: Come up with sone nice way to initialize this all */ + /* TODO: Come up with some nice way to initialize this all */ if (fsrv->init_child_func != fsrv_exec_child) { @@ -349,11 +389,22 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, /* CHILD PROCESS */ + // enable terminating on sigpipe in the childs + struct sigaction sa; + memset((char *)&sa, 0, sizeof(sa)); + sa.sa_handler = SIG_DFL; + sigaction(SIGPIPE, &sa, NULL); + struct rlimit r; + if (!fsrv->cmplog_binary && fsrv->qemu_mode == false) { + + unsetenv(CMPLOG_SHM_ENV_VAR); // we do not want that in non-cmplog fsrv + + } + /* Umpf. On OpenBSD, the default fd limit for root users is set to soft 128. Let's try to fix that... */ - if (!getrlimit(RLIMIT_NOFILE, &r) && r.rlim_cur < FORKSRV_FD + 2) { r.rlim_cur = FORKSRV_FD + 2; @@ -420,47 +471,60 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, close(fsrv->dev_null_fd); close(fsrv->dev_urandom_fd); - if (fsrv->plot_file != NULL) { fclose(fsrv->plot_file); } + if (fsrv->plot_file != NULL) { + + fclose(fsrv->plot_file); + fsrv->plot_file = NULL; + + } /* This should improve performance a bit, since it stops the linker from doing extra work post-fork(). */ - if (!getenv("LD_BIND_LAZY")) { setenv("LD_BIND_NOW", "1", 0); } + if (!getenv("LD_BIND_LAZY")) { setenv("LD_BIND_NOW", "1", 1); } /* Set sane defaults for ASAN if nothing else specified. */ - setenv("ASAN_OPTIONS", - "abort_on_error=1:" - "detect_leaks=0:" - "malloc_context_size=0:" - "symbolize=0:" - "allocator_may_return_null=1:" - "handle_segv=0:" - "handle_sigbus=0:" - "handle_abort=0:" - "handle_sigfpe=0:" - "handle_sigill=0", - 0); + if (!getenv("ASAN_OPTIONS")) + setenv("ASAN_OPTIONS", + "abort_on_error=1:" + "detect_leaks=0:" + "malloc_context_size=0:" + "symbolize=0:" + "allocator_may_return_null=1:" + "detect_odr_violation=0:" + "handle_segv=0:" + "handle_sigbus=0:" + "handle_abort=0:" + "handle_sigfpe=0:" + "handle_sigill=0", + 1); /* Set sane defaults for UBSAN if nothing else specified. */ - setenv("UBSAN_OPTIONS", - "halt_on_error=1:" - "abort_on_error=1:" - "malloc_context_size=0:" - "allocator_may_return_null=1:" - "symbolize=0:" - "handle_segv=0:" - "handle_sigbus=0:" - "handle_abort=0:" - "handle_sigfpe=0:" - "handle_sigill=0", - 0); + if (!getenv("UBSAN_OPTIONS")) + setenv("UBSAN_OPTIONS", + "halt_on_error=1:" + "abort_on_error=1:" + "malloc_context_size=0:" + "allocator_may_return_null=1:" + "symbolize=0:" + "handle_segv=0:" + "handle_sigbus=0:" + "handle_abort=0:" + "handle_sigfpe=0:" + "handle_sigill=0", + 1); + + /* Envs for QASan */ + setenv("QASAN_MAX_CALL_STACK", "0", 0); + setenv("QASAN_SYMBOLIZE", "0", 0); /* MSAN is tricky, because it doesn't support abort_on_error=1 at this point. So, we do this in a very hacky way. */ - setenv("MSAN_OPTIONS", + if (!getenv("MSAN_OPTIONS")) + setenv("MSAN_OPTIONS", "exit_code=" STRINGIFY(MSAN_ERROR) ":" "symbolize=0:" "abort_on_error=1:" @@ -472,7 +536,7 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, "handle_abort=0:" "handle_sigfpe=0:" "handle_sigill=0", - 0); + 1); fsrv->init_child_func(fsrv, argv); @@ -480,8 +544,7 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, falling through. */ *(u32 *)fsrv->trace_bits = EXEC_FAIL_SIG; - fprintf(stderr, "Error: execv to target failed\n"); - exit(0); + FATAL("Error: execv to target failed\n"); } @@ -507,18 +570,17 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, rlen = 0; if (fsrv->exec_tmout) { - u32 time_ms = - read_s32_timed(fsrv->fsrv_st_fd, &status, - fsrv->exec_tmout * FORK_WAIT_MULT, stop_soon_p); + u32 time_ms = read_s32_timed(fsrv->fsrv_st_fd, &status, fsrv->init_tmout, + stop_soon_p); if (!time_ms) { - kill(fsrv->fsrv_pid, SIGKILL); + kill(fsrv->fsrv_pid, fsrv->kill_signal); - } else if (time_ms > fsrv->exec_tmout * FORK_WAIT_MULT) { + } else if (time_ms > fsrv->init_tmout) { fsrv->last_run_timed_out = 1; - kill(fsrv->fsrv_pid, SIGKILL); + kill(fsrv->fsrv_pid, fsrv->kill_signal); } else { @@ -568,7 +630,7 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, fsrv->use_shmem_fuzz = 1; if (!be_quiet) { ACTF("Using SHARED MEMORY FUZZING feature."); } - if ((status & FS_OPT_AUTODICT) == 0) { + if ((status & FS_OPT_AUTODICT) == 0 || ignore_autodict) { u32 send_status = (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ); if (write(fsrv->fsrv_ctl_fd, &send_status, 4) != 4) { @@ -595,11 +657,11 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, if (!fsrv->map_size) { fsrv->map_size = MAP_SIZE; } - if (unlikely(tmp_map_size % 8)) { + if (unlikely(tmp_map_size % 64)) { // should not happen WARNF("Target reported non-aligned map size of %u", tmp_map_size); - tmp_map_size = (((tmp_map_size + 8) >> 3) << 3); + tmp_map_size = (((tmp_map_size + 63) >> 6) << 6); } @@ -621,87 +683,104 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, if ((status & FS_OPT_AUTODICT) == FS_OPT_AUTODICT) { - if (fsrv->function_ptr == NULL || fsrv->function_opt == NULL) { + if (!ignore_autodict) { - // this is not afl-fuzz - we deny and return - if (fsrv->use_shmem_fuzz) - status = (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ); - else - status = (FS_OPT_ENABLED); - if (write(fsrv->fsrv_ctl_fd, &status, 4) != 4) { + if (fsrv->add_extra_func == NULL || fsrv->afl_ptr == NULL) { - FATAL("Writing to forkserver failed."); + // this is not afl-fuzz - or it is cmplog - we deny and return + if (fsrv->use_shmem_fuzz) { + + status = (FS_OPT_ENABLED | FS_OPT_SHDMEM_FUZZ); + + } else { + + status = (FS_OPT_ENABLED); + + } + + if (write(fsrv->fsrv_ctl_fd, &status, 4) != 4) { + + FATAL("Writing to forkserver failed."); + + } + + return; } - return; + if (!be_quiet) { ACTF("Using AUTODICT feature."); } - } + if (fsrv->use_shmem_fuzz) { - if (!be_quiet) { ACTF("Using AUTODICT feature."); } + status = (FS_OPT_ENABLED | FS_OPT_AUTODICT | FS_OPT_SHDMEM_FUZZ); - if (fsrv->use_shmem_fuzz) - status = (FS_OPT_ENABLED | FS_OPT_AUTODICT | FS_OPT_SHDMEM_FUZZ); - else - status = (FS_OPT_ENABLED | FS_OPT_AUTODICT); + } else { - if (write(fsrv->fsrv_ctl_fd, &status, 4) != 4) { + status = (FS_OPT_ENABLED | FS_OPT_AUTODICT); - FATAL("Writing to forkserver failed."); + } - } + if (write(fsrv->fsrv_ctl_fd, &status, 4) != 4) { - if (read(fsrv->fsrv_st_fd, &status, 4) != 4) { + FATAL("Writing to forkserver failed."); - FATAL("Reading from forkserver failed."); + } - } + if (read(fsrv->fsrv_st_fd, &status, 4) != 4) { - if (status < 2 || (u32)status > 0xffffff) { + FATAL("Reading from forkserver failed."); - FATAL("Dictionary has an illegal size: %d", status); + } - } + if (status < 2 || (u32)status > 0xffffff) { - u32 len = status, offset = 0, count = 0; - u8 *dict = ck_alloc(len); - if (dict == NULL) { + FATAL("Dictionary has an illegal size: %d", status); - FATAL("Could not allocate %u bytes of autodictionary memory", len); + } - } + u32 offset = 0, count = 0; + u32 len = status; + u8 *dict = ck_alloc(len); + if (dict == NULL) { - while (len != 0) { + FATAL("Could not allocate %u bytes of autodictionary memory", len); - rlen = read(fsrv->fsrv_st_fd, dict + offset, len); - if (rlen > 0) { + } - len -= rlen; - offset += rlen; + while (len != 0) { - } else { + rlen = read(fsrv->fsrv_st_fd, dict + offset, len); + if (rlen > 0) { + + len -= rlen; + offset += rlen; + + } else { - FATAL( - "Reading autodictionary fail at position %u with %u bytes " - "left.", - offset, len); + FATAL( + "Reading autodictionary fail at position %u with %u bytes " + "left.", + offset, len); + + } } - } + offset = 0; + while (offset < (u32)status && + (u8)dict[offset] + offset < (u32)status) { - offset = 0; - while (offset < status && (u8)dict[offset] + offset < status) { + fsrv->add_extra_func(fsrv->afl_ptr, dict + offset + 1, + (u8)dict[offset]); + offset += (1 + dict[offset]); + count++; - fsrv->function_ptr(fsrv->function_opt, dict + offset + 1, - (u8)dict[offset]); - offset += (1 + dict[offset]); - count++; + } - } + if (!be_quiet) { ACTF("Loaded %u autodictionary entries", count); } + ck_free(dict); - if (!be_quiet) { ACTF("Loaded %u autodictionary entries", count); } - ck_free(dict); + } } @@ -740,6 +819,12 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, "before receiving any input\n" " from the fuzzer! There are several probable explanations:\n\n" + " - The target binary requires a large map and crashes before " + "reporting.\n" + " Set a high value (e.g. AFL_MAP_SIZE=8000000) or use " + "AFL_DEBUG=1 to see the\n" + " message from the target binary\n\n" + " - The binary is just buggy and explodes entirely on its own. " "If so, you\n" " need to fix the underlying problem or find a better " @@ -761,6 +846,12 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, "before receiving any input\n" " from the fuzzer! There are several probable explanations:\n\n" + " - The target binary requires a large map and crashes before " + "reporting.\n" + " Set a high value (e.g. AFL_MAP_SIZE=8000000) or use " + "AFL_DEBUG=1 to see the\n" + " message from the target binary\n\n" + " - The current memory limit (%s) is too restrictive, causing " "the\n" " target to hit an OOM condition in the dynamic linker. Try " @@ -818,10 +909,12 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, } else if (!fsrv->mem_limit) { SAYF("\n" cLRD "[-] " cRST - "Hmm, looks like the target binary terminated before we could" - " complete a handshake with the injected code.\n" - "If the target was compiled with afl-clang-lto then recompiling with" - " AFL_LLVM_MAP_DYNAMIC might solve your problem.\n" + "Hmm, looks like the target binary terminated before we could complete" + " a\n" + "handshake with the injected code.\n" + "Most likely the target has a huge coverage map, retry with setting" + " the\n" + "environment variable AFL_MAP_SIZE=8000000\n" "Otherwise there is a horrible bug in the fuzzer.\n" "Poke <afl-users@googlegroups.com> for troubleshooting tips.\n"); @@ -837,6 +930,11 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, "explanations:\n\n" "%s" + + " - Most likely the target has a huge coverage map, retry with " + "setting the\n" + " environment variable AFL_MAP_SIZE=8000000\n\n" + " - The current memory limit (%s) is too restrictive, causing an " "OOM\n" " fault in the dynamic linker. This can be fixed with the -m " @@ -850,10 +948,10 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, " estimate the required amount of virtual memory for the " "binary.\n\n" - " - the target was compiled with afl-clang-lto and a constructor " + " - The target was compiled with afl-clang-lto and a constructor " "was\n" - " instrumented, recompiling with AFL_LLVM_MAP_DYNAMIC might solve " - "your\n" + " instrumented, recompiling without AFL_LLVM_MAP_ADDR might solve " + "your \n" " problem\n\n" " - Less likely, there is a horrible bug in the fuzzer. If other " @@ -875,23 +973,42 @@ void afl_fsrv_start(afl_forkserver_t *fsrv, char **argv, } -static void afl_fsrv_kill(afl_forkserver_t *fsrv) { +/* Stop the forkserver and child */ + +void afl_fsrv_kill(afl_forkserver_t *fsrv) { - if (fsrv->child_pid > 0) { kill(fsrv->child_pid, SIGKILL); } + if (fsrv->child_pid > 0) { kill(fsrv->child_pid, fsrv->kill_signal); } if (fsrv->fsrv_pid > 0) { - kill(fsrv->fsrv_pid, SIGKILL); + kill(fsrv->fsrv_pid, fsrv->kill_signal); if (waitpid(fsrv->fsrv_pid, NULL, 0) <= 0) { WARNF("error waitpid\n"); } } + close(fsrv->fsrv_ctl_fd); + close(fsrv->fsrv_st_fd); + fsrv->fsrv_pid = -1; + fsrv->child_pid = -1; + +} + +/* Get the map size from the target forkserver */ + +u32 afl_fsrv_get_mapsize(afl_forkserver_t *fsrv, char **argv, + volatile u8 *stop_soon_p, u8 debug_child_output) { + + afl_fsrv_start(fsrv, argv, stop_soon_p, debug_child_output); + return fsrv->map_size; + } /* Delete the current testcase and write the buf to the testcase file */ void afl_fsrv_write_to_testcase(afl_forkserver_t *fsrv, u8 *buf, size_t len) { - if (fsrv->shmem_fuzz) { + if (likely(fsrv->use_shmem_fuzz && fsrv->shmem_fuzz)) { + + if (unlikely(len > MAX_FILE)) len = MAX_FILE; *fsrv->shmem_fuzz_len = len; memcpy(fsrv->shmem_fuzz, buf, len); @@ -902,10 +1019,10 @@ void afl_fsrv_write_to_testcase(afl_forkserver_t *fsrv, u8 *buf, size_t len) { hash64(fsrv->shmem_fuzz, *fsrv->shmem_fuzz_len, 0xa5b35705), *fsrv->shmem_fuzz_len); fprintf(stderr, "SHM :"); - for (int i = 0; i < *fsrv->shmem_fuzz_len; i++) + for (u32 i = 0; i < *fsrv->shmem_fuzz_len; i++) fprintf(stderr, "%02x", fsrv->shmem_fuzz[i]); fprintf(stderr, "\nORIG:"); - for (int i = 0; i < *fsrv->shmem_fuzz_len; i++) + for (u32 i = 0; i < *fsrv->shmem_fuzz_len; i++) fprintf(stderr, "%02x", buf[i]); fprintf(stderr, "\n"); @@ -917,9 +1034,9 @@ void afl_fsrv_write_to_testcase(afl_forkserver_t *fsrv, u8 *buf, size_t len) { s32 fd = fsrv->out_fd; - if (fsrv->out_file) { + if (!fsrv->use_stdin && fsrv->out_file) { - if (fsrv->no_unlink) { + if (unlikely(fsrv->no_unlink)) { fd = open(fsrv->out_file, O_WRONLY | O_CREAT | O_TRUNC, 0600); @@ -932,15 +1049,24 @@ void afl_fsrv_write_to_testcase(afl_forkserver_t *fsrv, u8 *buf, size_t len) { if (fd < 0) { PFATAL("Unable to create '%s'", fsrv->out_file); } + } else if (unlikely(fd <= 0)) { + + // We should have a (non-stdin) fd at this point, else we got a problem. + FATAL( + "Nowhere to write output to (neither out_fd nor out_file set (fd is " + "%d))", + fd); + } else { lseek(fd, 0, SEEK_SET); } + // fprintf(stderr, "WRITE %d %u\n", fd, len); ck_write(fd, buf, len, fsrv->out_file); - if (!fsrv->out_file) { + if (fsrv->use_stdin) { if (ftruncate(fd, len)) { PFATAL("ftruncate() failed"); } lseek(fd, 0, SEEK_SET); @@ -992,7 +1118,19 @@ fsrv_run_result_t afl_fsrv_run_target(afl_forkserver_t *fsrv, u32 timeout, } - if (fsrv->child_pid <= 0) { FATAL("Fork server is misbehaving (OOM?)"); } + if (fsrv->child_pid <= 0) { + + if (*stop_soon_p) { return 0; } + + if ((fsrv->child_pid & FS_OPT_ERROR) && + FS_OPT_GET_ERROR(fsrv->child_pid) == FS_ERROR_SHM_OPEN) + FATAL( + "Target reported shared memory access failed (perhaps increase " + "shared memory available)."); + + FATAL("Fork server is misbehaving (OOM?)"); + + } exec_ms = read_s32_timed(fsrv->fsrv_st_fd, &fsrv->child_status, timeout, stop_soon_p); @@ -1002,7 +1140,7 @@ fsrv_run_result_t afl_fsrv_run_target(afl_forkserver_t *fsrv, u32 timeout, /* If there was no response from forkserver after timeout seconds, we kill the child. The forkserver should inform us afterwards */ - kill(fsrv->child_pid, SIGKILL); + kill(fsrv->child_pid, fsrv->kill_signal); fsrv->last_run_timed_out = 1; if (read(fsrv->fsrv_st_fd, &fsrv->child_status, 4) < 4) { exec_ms = 0; } @@ -1015,7 +1153,7 @@ fsrv_run_result_t afl_fsrv_run_target(afl_forkserver_t *fsrv, u32 timeout, "Unable to communicate with fork server. Some possible reasons:\n\n" " - You've run out of memory. Use -m to increase the the memory " "limit\n" - " to something higher than %lld.\n" + " to something higher than %llu.\n" " - The binary or one of the libraries it uses manages to " "create\n" " threads before the forkserver initializes.\n" @@ -1048,33 +1186,44 @@ fsrv_run_result_t afl_fsrv_run_target(afl_forkserver_t *fsrv, u32 timeout, /* Report outcome to caller. */ - if (WIFSIGNALED(fsrv->child_status) && !*stop_soon_p) { - - fsrv->last_kill_signal = WTERMSIG(fsrv->child_status); + /* Was the run unsuccessful? */ + if (unlikely(*(u32 *)fsrv->trace_bits == EXEC_FAIL_SIG)) { - if (fsrv->last_run_timed_out && fsrv->last_kill_signal == SIGKILL) { + return FSRV_RUN_ERROR; - return FSRV_RUN_TMOUT; + } - } + /* Did we timeout? */ + if (unlikely(fsrv->last_run_timed_out)) { - return FSRV_RUN_CRASH; + fsrv->last_kill_signal = fsrv->kill_signal; + return FSRV_RUN_TMOUT; } - /* A somewhat nasty hack for MSAN, which doesn't support abort_on_error and - must use a special exit code. */ - - if (fsrv->uses_asan && WEXITSTATUS(fsrv->child_status) == MSAN_ERROR) { - - fsrv->last_kill_signal = 0; + /* Did we crash? + In a normal case, (abort) WIFSIGNALED(child_status) will be set. + MSAN in uses_asan mode uses a special exit code as it doesn't support + abort_on_error. On top, a user may specify a custom AFL_CRASH_EXITCODE. + Handle all three cases here. */ + + if (unlikely( + /* A normal crash/abort */ + (WIFSIGNALED(fsrv->child_status)) || + /* special handling for msan */ + (fsrv->uses_asan && WEXITSTATUS(fsrv->child_status) == MSAN_ERROR) || + /* the custom crash_exitcode was returned by the target */ + (fsrv->uses_crash_exitcode && + WEXITSTATUS(fsrv->child_status) == fsrv->crash_exitcode))) { + + /* For a proper crash, set last_kill_signal to WTERMSIG, else set it to 0 */ + fsrv->last_kill_signal = + WIFSIGNALED(fsrv->child_status) ? WTERMSIG(fsrv->child_status) : 0; return FSRV_RUN_CRASH; } - // Fauxserver should handle this now. - // if (tb4 == EXEC_FAIL_SIG) return FSRV_RUN_ERROR; - + /* success :) */ return FSRV_RUN_OK; } diff --git a/src/afl-fuzz-bitmap.c b/src/afl-fuzz-bitmap.c index aa8d5a18..4ed59364 100644 --- a/src/afl-fuzz-bitmap.c +++ b/src/afl-fuzz-bitmap.c @@ -25,6 +25,9 @@ #include "afl-fuzz.h" #include <limits.h> +#if !defined NAME_MAX + #define NAME_MAX _XOPEN_NAME_MAX +#endif /* Write bitmap to file. The bitmap is useful mostly for the secret -B option, to focus a separate fuzzing session on a particular @@ -49,101 +52,6 @@ void write_bitmap(afl_state_t *afl) { } -/* Check if the current execution path brings anything new to the table. - Update virgin bits to reflect the finds. Returns 1 if the only change is - the hit-count for a particular tuple; 2 if there are new tuples seen. - Updates the map, so subsequent calls will always return 0. - - This function is called after every exec() on a fairly large buffer, so - it needs to be fast. We do this in 32-bit and 64-bit flavors. */ - -u8 has_new_bits(afl_state_t *afl, u8 *virgin_map) { - -#ifdef WORD_SIZE_64 - - u64 *current = (u64 *)afl->fsrv.trace_bits; - u64 *virgin = (u64 *)virgin_map; - - u32 i = (afl->fsrv.map_size >> 3); - -#else - - u32 *current = (u32 *)afl->fsrv.trace_bits; - u32 *virgin = (u32 *)virgin_map; - - u32 i = (afl->fsrv.map_size >> 2); - -#endif /* ^WORD_SIZE_64 */ - // the map size must be a minimum of 8 bytes. - // for variable/dynamic map sizes this is ensured in the forkserver - - u8 ret = 0; - - while (i--) { - - /* Optimize for (*current & *virgin) == 0 - i.e., no bits in current bitmap - that have not been already cleared from the virgin map - since this will - almost always be the case. */ - - // the (*current) is unnecessary but speeds up the overall comparison - if (unlikely(*current) && unlikely(*current & *virgin)) { - - if (likely(ret < 2)) { - - u8 *cur = (u8 *)current; - u8 *vir = (u8 *)virgin; - - /* Looks like we have not found any new bytes yet; see if any non-zero - bytes in current[] are pristine in virgin[]. */ - -#ifdef WORD_SIZE_64 - - if (*virgin == 0xffffffffffffffff || (cur[0] && vir[0] == 0xff) || - (cur[1] && vir[1] == 0xff) || (cur[2] && vir[2] == 0xff) || - (cur[3] && vir[3] == 0xff) || (cur[4] && vir[4] == 0xff) || - (cur[5] && vir[5] == 0xff) || (cur[6] && vir[6] == 0xff) || - (cur[7] && vir[7] == 0xff)) { - - ret = 2; - - } else { - - ret = 1; - - } - -#else - - if (*virgin == 0xffffffff || (cur[0] && vir[0] == 0xff) || - (cur[1] && vir[1] == 0xff) || (cur[2] && vir[2] == 0xff) || - (cur[3] && vir[3] == 0xff)) - ret = 2; - else - ret = 1; - -#endif /* ^WORD_SIZE_64 */ - - } - - *virgin &= ~*current; - - } - - ++current; - ++virgin; - - } - - if (unlikely(ret) && likely(virgin_map == afl->virgin_bits)) { - - afl->bitmap_changed = 1; - - } - - return ret; - -} - /* Count the number of bits set in the provided bitmap. Used for the status screen several times every second, does not have to be fast. */ @@ -192,10 +100,10 @@ u32 count_bytes(afl_state_t *afl, u8 *mem) { u32 v = *(ptr++); if (!v) { continue; } - if (v & 0x000000ff) { ++ret; } - if (v & 0x0000ff00) { ++ret; } - if (v & 0x00ff0000) { ++ret; } - if (v & 0xff000000) { ++ret; } + if (v & 0x000000ffU) { ++ret; } + if (v & 0x0000ff00U) { ++ret; } + if (v & 0x00ff0000U) { ++ret; } + if (v & 0xff000000U) { ++ret; } } @@ -219,11 +127,11 @@ u32 count_non_255_bytes(afl_state_t *afl, u8 *mem) { /* This is called on the virgin bitmap, so optimize for the most likely case. */ - if (v == 0xffffffff) { continue; } - if ((v & 0x000000ff) != 0x000000ff) { ++ret; } - if ((v & 0x0000ff00) != 0x0000ff00) { ++ret; } - if ((v & 0x00ff0000) != 0x00ff0000) { ++ret; } - if ((v & 0xff000000) != 0xff000000) { ++ret; } + if (v == 0xffffffffU) { continue; } + if ((v & 0x000000ffU) != 0x000000ffU) { ++ret; } + if ((v & 0x0000ff00U) != 0x0000ff00U) { ++ret; } + if ((v & 0x00ff0000U) != 0x00ff0000U) { ++ret; } + if ((v & 0xff000000U) != 0xff000000U) { ++ret; } } @@ -235,98 +143,46 @@ u32 count_non_255_bytes(afl_state_t *afl, u8 *mem) { and replacing it with 0x80 or 0x01 depending on whether the tuple is hit or not. Called on every new crash or timeout, should be reasonably fast. */ - +#define TIMES4(x) x, x, x, x +#define TIMES8(x) TIMES4(x), TIMES4(x) +#define TIMES16(x) TIMES8(x), TIMES8(x) +#define TIMES32(x) TIMES16(x), TIMES16(x) +#define TIMES64(x) TIMES32(x), TIMES32(x) +#define TIMES255(x) \ + TIMES64(x), TIMES64(x), TIMES64(x), TIMES32(x), TIMES16(x), TIMES8(x), \ + TIMES4(x), x, x, x const u8 simplify_lookup[256] = { - [0] = 1, [1 ... 255] = 128 + [0] = 1, [1] = TIMES255(128) }; -#ifdef WORD_SIZE_64 - -void simplify_trace(afl_state_t *afl, u64 *mem) { - - u32 i = (afl->fsrv.map_size >> 3); - - while (i--) { - - /* Optimize for sparse bitmaps. */ - - if (unlikely(*mem)) { - - u8 *mem8 = (u8 *)mem; - - mem8[0] = simplify_lookup[mem8[0]]; - mem8[1] = simplify_lookup[mem8[1]]; - mem8[2] = simplify_lookup[mem8[2]]; - mem8[3] = simplify_lookup[mem8[3]]; - mem8[4] = simplify_lookup[mem8[4]]; - mem8[5] = simplify_lookup[mem8[5]]; - mem8[6] = simplify_lookup[mem8[6]]; - mem8[7] = simplify_lookup[mem8[7]]; - - } else { - - *mem = 0x0101010101010101ULL; - - } - - ++mem; - - } - -} - -#else - -void simplify_trace(afl_state_t *afl, u32 *mem) { - - u32 i = (afl->fsrv.map_size >> 2); - - while (i--) { - - /* Optimize for sparse bitmaps. */ - - if (unlikely(*mem)) { - - u8 *mem8 = (u8 *)mem; - - mem8[0] = simplify_lookup[mem8[0]]; - mem8[1] = simplify_lookup[mem8[1]]; - mem8[2] = simplify_lookup[mem8[2]]; - mem8[3] = simplify_lookup[mem8[3]]; - - } else - - *mem = 0x01010101; - - ++mem; - - } - -} - -#endif /* ^WORD_SIZE_64 */ - /* Destructively classify execution counts in a trace. This is used as a preprocessing step for any newly acquired traces. Called on every exec, must be fast. */ -static const u8 count_class_lookup8[256] = { +const u8 count_class_lookup8[256] = { [0] = 0, [1] = 1, [2] = 2, [3] = 4, - [4 ... 7] = 8, - [8 ... 15] = 16, - [16 ... 31] = 32, - [32 ... 127] = 64, - [128 ... 255] = 128 + [4] = TIMES4(8), + [8] = TIMES8(16), + [16] = TIMES16(32), + [32] = TIMES32(64), + [128] = TIMES64(128) }; -static u16 count_class_lookup16[65536]; +#undef TIMES255 +#undef TIMES64 +#undef TIMES32 +#undef TIMES16 +#undef TIMES8 +#undef TIMES4 + +u16 count_class_lookup16[65536]; void init_count_class16(void) { @@ -345,63 +201,87 @@ void init_count_class16(void) { } -#ifdef WORD_SIZE_64 +/* Import coverage processing routines. */ -void classify_counts(afl_forkserver_t *fsrv) { +#ifdef WORD_SIZE_64 + #include "coverage-64.h" +#else + #include "coverage-32.h" +#endif - u64 *mem = (u64 *)fsrv->trace_bits; +/* Check if the current execution path brings anything new to the table. + Update virgin bits to reflect the finds. Returns 1 if the only change is + the hit-count for a particular tuple; 2 if there are new tuples seen. + Updates the map, so subsequent calls will always return 0. - u32 i = (fsrv->map_size >> 3); + This function is called after every exec() on a fairly large buffer, so + it needs to be fast. We do this in 32-bit and 64-bit flavors. */ - while (i--) { +inline u8 has_new_bits(afl_state_t *afl, u8 *virgin_map) { - /* Optimize for sparse bitmaps. */ +#ifdef WORD_SIZE_64 - if (unlikely(*mem)) { + u64 *current = (u64 *)afl->fsrv.trace_bits; + u64 *virgin = (u64 *)virgin_map; - u16 *mem16 = (u16 *)mem; + u32 i = (afl->fsrv.map_size >> 3); - mem16[0] = count_class_lookup16[mem16[0]]; - mem16[1] = count_class_lookup16[mem16[1]]; - mem16[2] = count_class_lookup16[mem16[2]]; - mem16[3] = count_class_lookup16[mem16[3]]; +#else - } + u32 *current = (u32 *)afl->fsrv.trace_bits; + u32 *virgin = (u32 *)virgin_map; - ++mem; + u32 i = (afl->fsrv.map_size >> 2); - } +#endif /* ^WORD_SIZE_64 */ -} + u8 ret = 0; + while (i--) { -#else + if (unlikely(*current)) discover_word(&ret, current, virgin); -void classify_counts(afl_forkserver_t *fsrv) { + current++; + virgin++; - u32 *mem = (u32 *)fsrv->trace_bits; + } - u32 i = (fsrv->map_size >> 2); + if (unlikely(ret) && likely(virgin_map == afl->virgin_bits)) + afl->bitmap_changed = 1; - while (i--) { + return ret; - /* Optimize for sparse bitmaps. */ +} - if (unlikely(*mem)) { +/* A combination of classify_counts and has_new_bits. If 0 is returned, then the + * trace bits are kept as-is. Otherwise, the trace bits are overwritten with + * classified values. + * + * This accelerates the processing: in most cases, no interesting behavior + * happen, and the trace bits will be discarded soon. This function optimizes + * for such cases: one-pass scan on trace bits without modifying anything. Only + * on rare cases it fall backs to the slow path: classify_counts() first, then + * return has_new_bits(). */ - u16 *mem16 = (u16 *)mem; +inline u8 has_new_bits_unclassified(afl_state_t *afl, u8 *virgin_map) { - mem16[0] = count_class_lookup16[mem16[0]]; - mem16[1] = count_class_lookup16[mem16[1]]; + /* Handle the hot path first: no new coverage */ + u8 *end = afl->fsrv.trace_bits + afl->fsrv.map_size; - } +#ifdef WORD_SIZE_64 - ++mem; + if (!skim((u64 *)virgin_map, (u64 *)afl->fsrv.trace_bits, (u64 *)end)) + return 0; - } +#else -} + if (!skim((u32 *)virgin_map, (u32 *)afl->fsrv.trace_bits, (u32 *)end)) + return 0; #endif /* ^WORD_SIZE_64 */ + classify_counts(&afl->fsrv); + return has_new_bits(afl, virgin_map); + +} /* Compact trace bytes into a smaller bitmap. We effectively just drop the count information here. This is called only sporadically, for some @@ -425,8 +305,10 @@ void minimize_bits(afl_state_t *afl, u8 *dst, u8 *src) { /* Construct a file name for a new test case, capturing the operation that led to its discovery. Returns a ptr to afl->describe_op_buf_256. */ -u8 *describe_op(afl_state_t *afl, u8 hnb) { +u8 *describe_op(afl_state_t *afl, u8 new_bits, size_t max_description_len) { + size_t real_max_len = + MIN(max_description_len, sizeof(afl->describe_op_buf_256)); u8 *ret = afl->describe_op_buf_256; if (unlikely(afl->syncing_party)) { @@ -443,31 +325,69 @@ u8 *describe_op(afl_state_t *afl, u8 hnb) { } - sprintf(ret + strlen(ret), ",time:%llu", get_cur_time() - afl->start_time); + sprintf(ret + strlen(ret), ",time:%llu", + get_cur_time() + afl->prev_run_time - afl->start_time); + + if (afl->current_custom_fuzz && + afl->current_custom_fuzz->afl_custom_describe) { - sprintf(ret + strlen(ret), ",op:%s", afl->stage_short); + /* We are currently in a custom mutator that supports afl_custom_describe, + * use it! */ - if (afl->stage_cur_byte >= 0) { + size_t len_current = strlen(ret); + ret[len_current++] = ','; + ret[len_current] = '\0'; - sprintf(ret + strlen(ret), ",pos:%d", afl->stage_cur_byte); + ssize_t size_left = real_max_len - len_current - strlen(",+cov") - 2; + if (unlikely(size_left <= 0)) FATAL("filename got too long"); - if (afl->stage_val_type != STAGE_VAL_NONE) { + const char *custom_description = + afl->current_custom_fuzz->afl_custom_describe( + afl->current_custom_fuzz->data, size_left); + if (!custom_description || !custom_description[0]) { - sprintf(ret + strlen(ret), ",val:%s%+d", - (afl->stage_val_type == STAGE_VAL_BE) ? "be:" : "", - afl->stage_cur_val); + DEBUGF("Error getting a description from afl_custom_describe"); + /* Take the stage name as description fallback */ + sprintf(ret + len_current, "op:%s", afl->stage_short); + + } else { + + /* We got a proper custom description, use it */ + strncat(ret + len_current, custom_description, size_left); } } else { - sprintf(ret + strlen(ret), ",rep:%d", afl->stage_cur_val); + /* Normal testcase descriptions start here */ + sprintf(ret + strlen(ret), ",op:%s", afl->stage_short); + + if (afl->stage_cur_byte >= 0) { + + sprintf(ret + strlen(ret), ",pos:%d", afl->stage_cur_byte); + + if (afl->stage_val_type != STAGE_VAL_NONE) { + + sprintf(ret + strlen(ret), ",val:%s%+d", + (afl->stage_val_type == STAGE_VAL_BE) ? "be:" : "", + afl->stage_cur_val); + + } + + } else { + + sprintf(ret + strlen(ret), ",rep:%d", afl->stage_cur_val); + + } } } - if (hnb == 2) { strcat(ret, ",+cov"); } + if (new_bits == 2) { strcat(ret, ",+cov"); } + + if (unlikely(strlen(ret) >= max_description_len)) + FATAL("describe string is too long"); return ret; @@ -534,14 +454,15 @@ static void write_crash_readme(afl_state_t *afl) { save or queue the input test case for further analysis if so. Returns 1 if entry is saved, 0 otherwise. */ -u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { +u8 __attribute__((hot)) +save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { if (unlikely(len == 0)) { return 0; } u8 *queue_fn = ""; - u8 hnb = '\0'; + u8 new_bits = '\0'; s32 fd; - u8 keeping = 0, res; + u8 keeping = 0, res, classified = 0; u64 cksum = 0; u8 fn[PATH_MAX]; @@ -554,19 +475,9 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { cksum = hash64(afl->fsrv.trace_bits, afl->fsrv.map_size, HASH_CONST); - struct queue_entry *q = afl->queue; - while (q) { - - if (q->exec_cksum == cksum) { - - ++q->n_fuzz; - break; - - } - - q = q->next; - - } + /* Saturated increment */ + if (afl->n_fuzz[cksum % N_FUZZ_SIZE] < 0xFFFFFFFF) + afl->n_fuzz[cksum % N_FUZZ_SIZE]++; } @@ -575,17 +486,22 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { /* Keep only if there are new bits in the map, add to queue for future fuzzing, etc. */ - if (!(hnb = has_new_bits(afl, afl->virgin_bits))) { + new_bits = has_new_bits_unclassified(afl, afl->virgin_bits); + + if (likely(!new_bits)) { if (unlikely(afl->crash_mode)) { ++afl->total_crashes; } return 0; } + classified = new_bits; + #ifndef SIMPLE_FILES - queue_fn = alloc_printf("%s/queue/id:%06u,%s", afl->out_dir, - afl->queued_paths, describe_op(afl, hnb)); + queue_fn = alloc_printf( + "%s/queue/id:%06u,%s", afl->out_dir, afl->queued_paths, + describe_op(afl, new_bits, NAME_MAX - strlen("id:000000,"))); #else @@ -593,10 +509,42 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { alloc_printf("%s/queue/id_%06u", afl->out_dir, afl->queued_paths); #endif /* ^!SIMPLE_FILES */ - + fd = open(queue_fn, O_WRONLY | O_CREAT | O_EXCL, 0600); + if (unlikely(fd < 0)) { PFATAL("Unable to create '%s'", queue_fn); } + ck_write(fd, mem, len, queue_fn); + close(fd); add_to_queue(afl, queue_fn, len, 0); - if (hnb == 2) { +#ifdef INTROSPECTION + if (afl->custom_mutators_count && afl->current_custom_fuzz) { + + LIST_FOREACH(&afl->custom_mutator_list, struct custom_mutator, { + + if (afl->current_custom_fuzz == el && el->afl_custom_introspection) { + + const char *ptr = el->afl_custom_introspection(el->data); + + if (ptr != NULL && *ptr != 0) { + + fprintf(afl->introspection_file, "QUEUE CUSTOM %s = %s\n", ptr, + afl->queue_top->fname); + + } + + } + + }); + + } else if (afl->mutation[0] != 0) { + + fprintf(afl->introspection_file, "QUEUE %s = %s\n", afl->mutation, + afl->queue_top->fname); + + } + +#endif + + if (new_bits == 2) { afl->queue_top->has_new_cov = 1; ++afl->queued_with_cov; @@ -606,9 +554,16 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { if (cksum) afl->queue_top->exec_cksum = cksum; else - afl->queue_top->exec_cksum = + cksum = afl->queue_top->exec_cksum = hash64(afl->fsrv.trace_bits, afl->fsrv.map_size, HASH_CONST); + if (afl->schedule >= FAST && afl->schedule <= RARE) { + + afl->queue_top->n_fuzz_entry = cksum % N_FUZZ_SIZE; + afl->n_fuzz[afl->queue_top->n_fuzz_entry] = 1; + + } + /* Try to calibrate inline; this also calls update_bitmap_score() when successful. */ @@ -620,10 +575,11 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { } - fd = open(queue_fn, O_WRONLY | O_CREAT | O_EXCL, 0600); - if (unlikely(fd < 0)) { PFATAL("Unable to create '%s'", queue_fn); } - ck_write(fd, mem, len, queue_fn); - close(fd); + if (likely(afl->q_testcase_max_cache_size)) { + + queue_testcase_store_mem(afl, afl->queue_top, mem); + + } keeping = 1; @@ -644,17 +600,48 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { if (likely(!afl->non_instrumented_mode)) { -#ifdef WORD_SIZE_64 - simplify_trace(afl, (u64 *)afl->fsrv.trace_bits); -#else - simplify_trace(afl, (u32 *)afl->fsrv.trace_bits); -#endif /* ^WORD_SIZE_64 */ + if (!classified) { + + classify_counts(&afl->fsrv); + classified = 1; + + } + + simplify_trace(afl, afl->fsrv.trace_bits); if (!has_new_bits(afl, afl->virgin_tmout)) { return keeping; } } ++afl->unique_tmouts; +#ifdef INTROSPECTION + if (afl->custom_mutators_count && afl->current_custom_fuzz) { + + LIST_FOREACH(&afl->custom_mutator_list, struct custom_mutator, { + + if (afl->current_custom_fuzz == el && el->afl_custom_introspection) { + + const char *ptr = el->afl_custom_introspection(el->data); + + if (ptr != NULL && *ptr != 0) { + + fprintf(afl->introspection_file, + "UNIQUE_TIMEOUT CUSTOM %s = %s\n", ptr, + afl->queue_top->fname); + + } + + } + + }); + + } else if (afl->mutation[0] != 0) { + + fprintf(afl->introspection_file, "UNIQUE_TIMEOUT %s\n", afl->mutation); + + } + +#endif /* Before saving, we make sure that it's a genuine hang by re-running the target with a more generous timeout (unless the default timeout @@ -665,6 +652,7 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { u8 new_fault; write_to_testcase(afl, mem, len); new_fault = fuzz_run_target(afl, &afl->fsrv, afl->hang_tmout); + classify_counts(&afl->fsrv); /* A corner case that one user reported bumping into: increasing the timeout actually uncovers a crash. Make sure we don't discard it if @@ -683,7 +671,8 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { #ifndef SIMPLE_FILES snprintf(fn, PATH_MAX, "%s/hangs/id:%06llu,%s", afl->out_dir, - afl->unique_hangs, describe_op(afl, 0)); + afl->unique_hangs, + describe_op(afl, 0, NAME_MAX - strlen("id:000000,"))); #else @@ -712,11 +701,9 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { if (likely(!afl->non_instrumented_mode)) { -#ifdef WORD_SIZE_64 - simplify_trace(afl, (u64 *)afl->fsrv.trace_bits); -#else - simplify_trace(afl, (u32 *)afl->fsrv.trace_bits); -#endif /* ^WORD_SIZE_64 */ + if (!classified) { classify_counts(&afl->fsrv); } + + simplify_trace(afl, afl->fsrv.trace_bits); if (!has_new_bits(afl, afl->virgin_crash)) { return keeping; } @@ -728,7 +715,7 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { snprintf(fn, PATH_MAX, "%s/crashes/id:%06llu,sig:%02u,%s", afl->out_dir, afl->unique_crashes, afl->fsrv.last_kill_signal, - describe_op(afl, 0)); + describe_op(afl, 0, NAME_MAX - strlen("id:000000,sig:00,"))); #else @@ -738,6 +725,33 @@ u8 save_if_interesting(afl_state_t *afl, void *mem, u32 len, u8 fault) { #endif /* ^!SIMPLE_FILES */ ++afl->unique_crashes; +#ifdef INTROSPECTION + if (afl->custom_mutators_count && afl->current_custom_fuzz) { + + LIST_FOREACH(&afl->custom_mutator_list, struct custom_mutator, { + + if (afl->current_custom_fuzz == el && el->afl_custom_introspection) { + + const char *ptr = el->afl_custom_introspection(el->data); + + if (ptr != NULL && *ptr != 0) { + + fprintf(afl->introspection_file, "UNIQUE_CRASH CUSTOM %s = %s\n", + ptr, afl->queue_top->fname); + + } + + } + + }); + + } else if (afl->mutation[0] != 0) { + + fprintf(afl->introspection_file, "UNIQUE_CRASH %s\n", afl->mutation); + + } + +#endif if (unlikely(afl->infoexec)) { // if the user wants to be informed on new crashes - do that diff --git a/src/afl-fuzz-cmplog.c b/src/afl-fuzz-cmplog.c index faf4dcb7..27c6c413 100644 --- a/src/afl-fuzz-cmplog.c +++ b/src/afl-fuzz-cmplog.c @@ -29,14 +29,12 @@ #include "afl-fuzz.h" #include "cmplog.h" -typedef struct cmplog_data { - -} cmplog_data_t; - void cmplog_exec_child(afl_forkserver_t *fsrv, char **argv) { setenv("___AFL_EINS_ZWEI_POLIZEI___", "1", 1); + if (fsrv->qemu_mode) { setenv("AFL_DISABLE_LLVM_INSTRUMENTATION", "1", 0); } + if (!fsrv->qemu_mode && argv[0] != fsrv->cmplog_binary) { argv[0] = fsrv->cmplog_binary; diff --git a/src/afl-fuzz-extras.c b/src/afl-fuzz-extras.c index 12771cd7..52100fa1 100644 --- a/src/afl-fuzz-extras.c +++ b/src/afl-fuzz-extras.c @@ -25,23 +25,28 @@ #include "afl-fuzz.h" -/* Helper function for load_extras. */ +/* helper function for auto_extras qsort */ +static int compare_auto_extras_len(const void *ae1, const void *ae2) { + + return ((struct auto_extra_data *)ae1)->len - + ((struct auto_extra_data *)ae2)->len; -static int compare_extras_len(const void *p1, const void *p2) { +} - struct extra_data *e1 = (struct extra_data *)p1, - *e2 = (struct extra_data *)p2; +/* descending order */ - return e1->len - e2->len; +static int compare_auto_extras_use_d(const void *ae1, const void *ae2) { + + return ((struct auto_extra_data *)ae2)->hit_cnt - + ((struct auto_extra_data *)ae1)->hit_cnt; } -static int compare_extras_use_d(const void *p1, const void *p2) { +/* Helper function for load_extras. */ - struct extra_data *e1 = (struct extra_data *)p1, - *e2 = (struct extra_data *)p2; +static int compare_extras_len(const void *e1, const void *e2) { - return e2->hit_cnt - e1->hit_cnt; + return ((struct extra_data *)e1)->len - ((struct extra_data *)e2)->len; } @@ -96,7 +101,8 @@ void load_extras_file(afl_state_t *afl, u8 *fname, u32 *min_len, u32 *max_len, if (rptr < lptr || *rptr != '"') { - FATAL("Malformed name=\"value\" pair in line %u.", cur_line); + WARNF("Malformed name=\"value\" pair in line %u.", cur_line); + continue; } @@ -115,7 +121,7 @@ void load_extras_file(afl_state_t *afl, u8 *fname, u32 *min_len, u32 *max_len, if (*lptr == '@') { ++lptr; - if (atoi(lptr) > dict_level) { continue; } + if (atoi(lptr) > (s32)dict_level) { continue; } while (isdigit(*lptr)) { ++lptr; @@ -136,19 +142,27 @@ void load_extras_file(afl_state_t *afl, u8 *fname, u32 *min_len, u32 *max_len, if (*lptr != '"') { - FATAL("Malformed name=\"keyword\" pair in line %u.", cur_line); + WARNF("Malformed name=\"keyword\" pair in line %u.", cur_line); + continue; } ++lptr; - if (!*lptr) { FATAL("Empty keyword in line %u.", cur_line); } + if (!*lptr) { + + WARNF("Empty keyword in line %u.", cur_line); + continue; + + } /* Okay, let's allocate memory and copy data between "...", handling \xNN escaping, \\, and \". */ - afl->extras = ck_realloc_block( - afl->extras, (afl->extras_cnt + 1) * sizeof(struct extra_data)); + afl->extras = + afl_realloc((void **)&afl->extras, + (afl->extras_cnt + 1) * sizeof(struct extra_data)); + if (unlikely(!afl->extras)) { PFATAL("alloc"); } wptr = afl->extras[afl->extras_cnt].data = ck_alloc(rptr - lptr); @@ -162,7 +176,9 @@ void load_extras_file(afl_state_t *afl, u8 *fname, u32 *min_len, u32 *max_len, case 1 ... 31: case 128 ... 255: - FATAL("Non-printable characters in line %u.", cur_line); + WARNF("Non-printable characters in line %u.", cur_line); + continue; + break; case '\\': @@ -178,7 +194,8 @@ void load_extras_file(afl_state_t *afl, u8 *fname, u32 *min_len, u32 *max_len, if (*lptr != 'x' || !isxdigit(lptr[1]) || !isxdigit(lptr[2])) { - FATAL("Invalid escaping (not \\xNN) in line %u.", cur_line); + WARNF("Invalid escaping (not \\xNN) in line %u.", cur_line); + continue; } @@ -202,10 +219,11 @@ void load_extras_file(afl_state_t *afl, u8 *fname, u32 *min_len, u32 *max_len, if (afl->extras[afl->extras_cnt].len > MAX_DICT_FILE) { - FATAL( + WARNF( "Keyword too big in line %u (%s, limit is %s)", cur_line, stringify_mem_size(val_bufs[0], sizeof(val_bufs[0]), klen), stringify_mem_size(val_bufs[1], sizeof(val_bufs[1]), MAX_DICT_FILE)); + continue; } @@ -220,6 +238,41 @@ void load_extras_file(afl_state_t *afl, u8 *fname, u32 *min_len, u32 *max_len, } +static void extras_check_and_sort(afl_state_t *afl, u32 min_len, u32 max_len, + u8 *dir) { + + u8 val_bufs[2][STRINGIFY_VAL_SIZE_MAX]; + + if (!afl->extras_cnt) { + + WARNF("No usable data in '%s'", dir); + return; + + } + + qsort(afl->extras, afl->extras_cnt, sizeof(struct extra_data), + compare_extras_len); + + ACTF("Loaded %u extra tokens, size range %s to %s.", afl->extras_cnt, + stringify_mem_size(val_bufs[0], sizeof(val_bufs[0]), min_len), + stringify_mem_size(val_bufs[1], sizeof(val_bufs[1]), max_len)); + + if (max_len > 32) { + + WARNF("Some tokens are relatively large (%s) - consider trimming.", + stringify_mem_size(val_bufs[0], sizeof(val_bufs[0]), max_len)); + + } + + if (afl->extras_cnt > afl->max_det_extras) { + + WARNF("More than %u tokens - will use them probabilistically.", + afl->max_det_extras); + + } + +} + /* Read extras from the extras directory and sort them by size. */ void load_extras(afl_state_t *afl, u8 *dir) { @@ -249,7 +302,8 @@ void load_extras(afl_state_t *afl, u8 *dir) { if (errno == ENOTDIR) { load_extras_file(afl, dir, &min_len, &max_len, dict_level); - goto check_and_sort; + extras_check_and_sort(afl, min_len, max_len, dir); + return; } @@ -281,18 +335,21 @@ void load_extras(afl_state_t *afl, u8 *dir) { if (st.st_size > MAX_DICT_FILE) { - FATAL( + WARNF( "Extra '%s' is too big (%s, limit is %s)", fn, stringify_mem_size(val_bufs[0], sizeof(val_bufs[0]), st.st_size), stringify_mem_size(val_bufs[1], sizeof(val_bufs[1]), MAX_DICT_FILE)); + continue; } if (min_len > st.st_size) { min_len = st.st_size; } if (max_len < st.st_size) { max_len = st.st_size; } - afl->extras = ck_realloc_block( - afl->extras, (afl->extras_cnt + 1) * sizeof(struct extra_data)); + afl->extras = + afl_realloc((void **)&afl->extras, + (afl->extras_cnt + 1) * sizeof(struct extra_data)); + if (unlikely(!afl->extras)) { PFATAL("alloc"); } afl->extras[afl->extras_cnt].data = ck_alloc(st.st_size); afl->extras[afl->extras_cnt].len = st.st_size; @@ -312,56 +369,235 @@ void load_extras(afl_state_t *afl, u8 *dir) { closedir(d); -check_and_sort: + extras_check_and_sort(afl, min_len, max_len, dir); + +} + +/* Helper function for maybe_add_auto(afl, ) */ + +static inline u8 memcmp_nocase(u8 *m1, u8 *m2, u32 len) { + + while (len--) { + + if (tolower(*(m1++)) ^ tolower(*(m2++))) { return 1; } + + } + + return 0; + +} + +/* add an extra/dict/token - no checks performed, no sorting */ + +static void add_extra_nocheck(afl_state_t *afl, u8 *mem, u32 len) { + + afl->extras = afl_realloc((void **)&afl->extras, + (afl->extras_cnt + 1) * sizeof(struct extra_data)); + + if (unlikely(!afl->extras)) { PFATAL("alloc"); } + + afl->extras[afl->extras_cnt].data = ck_alloc(len); + afl->extras[afl->extras_cnt].len = len; + memcpy(afl->extras[afl->extras_cnt].data, mem, len); + afl->extras_cnt++; + + /* We only want to print this once */ + + if (afl->extras_cnt == afl->max_det_extras + 1) { + + WARNF("More than %u tokens - will use them probabilistically.", + afl->max_det_extras); + + } + +} + +/* Sometimes strings in input is transformed to unicode internally, so for + fuzzing we should attempt to de-unicode if it looks like simple unicode */ + +void deunicode_extras(afl_state_t *afl) { + + if (!afl->extras_cnt) return; + + u32 i, j, orig_cnt = afl->extras_cnt; + u8 buf[64]; + + for (i = 0; i < orig_cnt; ++i) { + + if (afl->extras[i].len < 6 || afl->extras[i].len > 64 || + afl->extras[i].len % 2) { + + continue; + + } + + u32 k = 0, z1 = 0, z2 = 0, z3 = 0, z4 = 0, half = afl->extras[i].len >> 1; + u32 quarter = half >> 1; + + for (j = 0; j < afl->extras[i].len; ++j) { + + switch (j % 4) { - if (!afl->extras_cnt) { FATAL("No usable files in '%s'", dir); } + case 2: + if (!afl->extras[i].data[j]) { ++z3; } + // fall through + case 0: + if (!afl->extras[i].data[j]) { ++z1; } + break; + case 3: + if (!afl->extras[i].data[j]) { ++z4; } + // fall through + case 1: + if (!afl->extras[i].data[j]) { ++z2; } + break; + + } + + } + + if ((z1 < half && z2 < half) || z1 + z2 == afl->extras[i].len) { continue; } + + // also maybe 32 bit unicode? + if (afl->extras[i].len % 4 == 0 && afl->extras[i].len >= 12 && + (z3 == quarter || z4 == quarter) && z1 + z2 == quarter * 3) { + + for (j = 0; j < afl->extras[i].len; ++j) { + + if (z4 < quarter) { + + if (j % 4 == 3) { buf[k++] = afl->extras[i].data[j]; } + + } else if (z3 < quarter) { + + if (j % 4 == 2) { buf[k++] = afl->extras[i].data[j]; } + + } else if (z2 < half) { + + if (j % 4 == 1) { buf[k++] = afl->extras[i].data[j]; } + + } else { + + if (j % 4 == 0) { buf[k++] = afl->extras[i].data[j]; } + + } + + } + + add_extra_nocheck(afl, buf, k); + k = 0; + + } + + for (j = 0; j < afl->extras[i].len; ++j) { + + if (z1 < half) { + + if (j % 2 == 0) { buf[k++] = afl->extras[i].data[j]; } + + } else { + + if (j % 2 == 1) { buf[k++] = afl->extras[i].data[j]; } + + } + + } + + add_extra_nocheck(afl, buf, k); + + } qsort(afl->extras, afl->extras_cnt, sizeof(struct extra_data), compare_extras_len); - OKF("Loaded %u extra tokens, size range %s to %s.", afl->extras_cnt, - stringify_mem_size(val_bufs[0], sizeof(val_bufs[0]), min_len), - stringify_mem_size(val_bufs[1], sizeof(val_bufs[1]), max_len)); +} - if (max_len > 32) { +/* Removes duplicates from the loaded extras. This can happen if multiple files + are loaded */ - WARNF("Some tokens are relatively large (%s) - consider trimming.", - stringify_mem_size(val_bufs[0], sizeof(val_bufs[0]), max_len)); +void dedup_extras(afl_state_t *afl) { - } + if (afl->extras_cnt < 2) return; - if (afl->extras_cnt > MAX_DET_EXTRAS) { + u32 i, j, orig_cnt = afl->extras_cnt; - WARNF("More than %d tokens - will use them probabilistically.", - MAX_DET_EXTRAS); + for (i = 0; i < afl->extras_cnt - 1; ++i) { + + for (j = i + 1; j < afl->extras_cnt; ++j) { + + restart_dedup: + + // if the goto was used we could be at the end of the list + if (j >= afl->extras_cnt || afl->extras[i].len != afl->extras[j].len) + break; + + if (memcmp(afl->extras[i].data, afl->extras[j].data, + afl->extras[i].len) == 0) { + + ck_free(afl->extras[j].data); + if (j + 1 < afl->extras_cnt) // not at the end of the list? + memmove((char *)&afl->extras[j], (char *)&afl->extras[j + 1], + (afl->extras_cnt - j - 1) * sizeof(struct extra_data)); + --afl->extras_cnt; + goto restart_dedup; // restart if several duplicates are in a row + + } + + } } + if (afl->extras_cnt != orig_cnt) + afl->extras = afl_realloc_exact( + (void **)&afl->extras, afl->extras_cnt * sizeof(struct extra_data)); + } -/* Helper function for maybe_add_auto(afl, ) */ +/* Adds a new extra / dict entry. */ +void add_extra(afl_state_t *afl, u8 *mem, u32 len) { -static inline u8 memcmp_nocase(u8 *m1, u8 *m2, u32 len) { + u32 i, found = 0; - while (len--) { + for (i = 0; i < afl->extras_cnt; i++) { - if (tolower(*(m1++)) ^ tolower(*(m2++))) { return 1; } + if (afl->extras[i].len == len) { + + if (memcmp(afl->extras[i].data, mem, len) == 0) return; + found = 1; + + } else { + + if (found) break; + + } } - return 0; + if (len > MAX_DICT_FILE) { + + u8 val_bufs[2][STRINGIFY_VAL_SIZE_MAX]; + WARNF("Extra '%.*s' is too big (%s, limit is %s), skipping file!", (int)len, + mem, stringify_mem_size(val_bufs[0], sizeof(val_bufs[0]), len), + stringify_mem_size(val_bufs[1], sizeof(val_bufs[1]), MAX_DICT_FILE)); + return; + + } else if (len > 32) { + + WARNF("Extra '%.*s' is pretty large, consider trimming.", (int)len, mem); + + } + + add_extra_nocheck(afl, mem, len); + + qsort(afl->extras, afl->extras_cnt, sizeof(struct extra_data), + compare_extras_len); } /* Maybe add automatic extra. */ -/* Ugly hack: afl state is transfered as u8* because we import data via - afl-forkserver.c - which is shared with other afl tools that do not - have the afl state struct */ -void maybe_add_auto(void *afl_tmp, u8 *mem, u32 len) { +void maybe_add_auto(afl_state_t *afl, u8 *mem, u32 len) { - afl_state_t *afl = (afl_state_t *)afl_tmp; - u32 i; + u32 i; /* Allow users to specify that they don't want auto dictionaries. */ @@ -375,7 +611,7 @@ void maybe_add_auto(void *afl_tmp, u8 *mem, u32 len) { } - if (i == len) { return; } + if (i == len || unlikely(len > MAX_AUTO_EXTRA)) { return; } /* Reject builtin interesting values. */ @@ -402,7 +638,7 @@ void maybe_add_auto(void *afl_tmp, u8 *mem, u32 len) { while (i--) { - if (*((u32 *)mem) == interesting_32[i] || + if (*((u32 *)mem) == (u32)interesting_32[i] || *((u32 *)mem) == SWAP32(interesting_32[i])) { return; @@ -452,10 +688,7 @@ void maybe_add_auto(void *afl_tmp, u8 *mem, u32 len) { if (afl->a_extras_cnt < MAX_AUTO_EXTRAS) { - afl->a_extras = ck_realloc_block( - afl->a_extras, (afl->a_extras_cnt + 1) * sizeof(struct extra_data)); - - afl->a_extras[afl->a_extras_cnt].data = ck_memdup(mem, len); + memcpy(afl->a_extras[afl->a_extras_cnt].data, mem, len); afl->a_extras[afl->a_extras_cnt].len = len; ++afl->a_extras_cnt; @@ -463,9 +696,7 @@ void maybe_add_auto(void *afl_tmp, u8 *mem, u32 len) { i = MAX_AUTO_EXTRAS / 2 + rand_below(afl, (MAX_AUTO_EXTRAS + 1) / 2); - ck_free(afl->a_extras[i].data); - - afl->a_extras[i].data = ck_memdup(mem, len); + memcpy(afl->a_extras[i].data, mem, len); afl->a_extras[i].len = len; afl->a_extras[i].hit_cnt = 0; @@ -475,13 +706,13 @@ sort_a_extras: /* First, sort all auto extras by use count, descending order. */ - qsort(afl->a_extras, afl->a_extras_cnt, sizeof(struct extra_data), - compare_extras_use_d); + qsort(afl->a_extras, afl->a_extras_cnt, sizeof(struct auto_extra_data), + compare_auto_extras_use_d); /* Then, sort the top USE_AUTO_EXTRAS entries by size. */ - qsort(afl->a_extras, MIN(USE_AUTO_EXTRAS, afl->a_extras_cnt), - sizeof(struct extra_data), compare_extras_len); + qsort(afl->a_extras, MIN((u32)USE_AUTO_EXTRAS, afl->a_extras_cnt), + sizeof(struct auto_extra_data), compare_auto_extras_len); } @@ -494,7 +725,7 @@ void save_auto(afl_state_t *afl) { if (!afl->auto_changed) { return; } afl->auto_changed = 0; - for (i = 0; i < MIN(USE_AUTO_EXTRAS, afl->a_extras_cnt); ++i) { + for (i = 0; i < MIN((u32)USE_AUTO_EXTRAS, afl->a_extras_cnt); ++i) { u8 *fn = alloc_printf("%s/queue/.state/auto_extras/auto_%06u", afl->out_dir, i); @@ -544,7 +775,7 @@ void load_auto(afl_state_t *afl) { if (len >= MIN_AUTO_EXTRA && len <= MAX_AUTO_EXTRA) { - maybe_add_auto((u8 *)afl, tmp, len); + maybe_add_auto(afl, tmp, len); } @@ -559,7 +790,7 @@ void load_auto(afl_state_t *afl) { } else { - OKF("No auto-generated dictionary tokens to reuse."); + ACTF("No auto-generated dictionary tokens to reuse."); } @@ -577,15 +808,7 @@ void destroy_extras(afl_state_t *afl) { } - ck_free(afl->extras); - - for (i = 0; i < afl->a_extras_cnt; ++i) { - - ck_free(afl->a_extras[i].data); - - } - - ck_free(afl->a_extras); + afl_free(afl->extras); } diff --git a/src/afl-fuzz-init.c b/src/afl-fuzz-init.c index 9ec28cc5..06385330 100644 --- a/src/afl-fuzz-init.c +++ b/src/afl-fuzz-init.c @@ -25,13 +25,13 @@ #include "afl-fuzz.h" #include <limits.h> +#include "cmplog.h" #ifdef HAVE_AFFINITY -/* Build a list of processes bound to specific cores. Returns -1 if nothing - can be found. Assumes an upper bound of 4k CPUs. */ +/* bind process to a specific cpu. Returns 0 on failure. */ -void bind_to_free_cpu(afl_state_t *afl) { +static u8 bind_cpu(afl_state_t *afl, s32 cpuid) { #if defined(__linux__) || defined(__FreeBSD__) || defined(__DragonFly__) cpu_set_t c; @@ -41,17 +41,107 @@ void bind_to_free_cpu(afl_state_t *afl) { psetid_t c; #endif - if (afl->cpu_core_count < 2) { return; } + afl->cpu_aff = cpuid; + + #if defined(__linux__) || defined(__FreeBSD__) || defined(__DragonFly__) + + CPU_ZERO(&c); + CPU_SET(cpuid, &c); + + #elif defined(__NetBSD__) + + c = cpuset_create(); + if (c == NULL) { PFATAL("cpuset_create failed"); } + cpuset_set(cpuid, c); + + #elif defined(__sun) + + pset_create(&c); + if (pset_assign(c, cpuid, NULL)) { PFATAL("pset_assign failed"); } + + #endif + + #if defined(__linux__) + + return (sched_setaffinity(0, sizeof(c), &c) == 0); + + #elif defined(__FreeBSD__) || defined(__DragonFly__) + + return (pthread_setaffinity_np(pthread_self(), sizeof(c), &c) == 0); + + #elif defined(__NetBSD__) + + if (pthread_setaffinity_np(pthread_self(), cpuset_size(c), c)) { + + cpuset_destroy(c); + return 0; + + } + + cpuset_destroy(c); + return 1; + + #elif defined(__sun) + + if (pset_bind(c, P_PID, getpid(), NULL)) { + + pset_destroy(c); + return 0; + + } + + pset_destroy(c); + return 1; + + #else + + // this will need something for other platforms + // TODO: Solaris/Illumos has processor_bind ... might worth a try + WARNF("Cannot bind to CPU yet on this platform."); + return 1; + + #endif + +} + +/* Build a list of processes bound to specific cores. Returns -1 if nothing + can be found. Assumes an upper bound of 4k CPUs. */ + +void bind_to_free_cpu(afl_state_t *afl) { + + u8 cpu_used[4096] = {0}; + u8 lockfile[PATH_MAX] = ""; + s32 i; if (afl->afl_env.afl_no_affinity) { + if (afl->cpu_to_bind != -1) { + + FATAL("-b and AFL_NO_AFFINITY are mututally exclusive."); + + } + WARNF("Not binding to a CPU core (AFL_NO_AFFINITY set)."); return; } - u8 cpu_used[4096] = {0}, lockfile[PATH_MAX] = ""; - u32 i; + if (afl->cpu_to_bind != -1) { + + if (!bind_cpu(afl, afl->cpu_to_bind)) { + + FATAL( + "Could not bind to requested CPU %d! Make sure you passed a valid " + "-b.", + afl->cpu_to_bind); + + } + + return; + + } + + if (afl->cpu_core_count < 2) { return; } if (afl->sync_id) { @@ -167,23 +257,23 @@ void bind_to_free_cpu(afl_state_t *afl) { } - for (i = 0; i < proccount; i++) { + for (i = 0; i < (s32)proccount; i++) { #if defined(__FreeBSD__) if (!strcmp(procs[i].ki_comm, "idle")) continue; // fix when ki_oncpu = -1 - int oncpu; + s32 oncpu; oncpu = procs[i].ki_oncpu; if (oncpu == -1) oncpu = procs[i].ki_lastcpu; - if (oncpu != -1 && oncpu < sizeof(cpu_used) && procs[i].ki_pctcpu > 60) + if (oncpu != -1 && oncpu < (s32)sizeof(cpu_used) && procs[i].ki_pctcpu > 60) cpu_used[oncpu] = 1; #elif defined(__DragonFly__) - if (procs[i].kp_lwp.kl_cpuid < sizeof(cpu_used) && + if (procs[i].kp_lwp.kl_cpuid < (s32)sizeof(cpu_used) && procs[i].kp_lwp.kl_pctcpu > 10) cpu_used[procs[i].kp_lwp.kl_cpuid] = 1; @@ -222,7 +312,7 @@ void bind_to_free_cpu(afl_state_t *afl) { } - for (i = 0; i < proccount; i++) { + for (i = 0; i < (s32)proccount; i++) { if (procs[i].p_cpuid < sizeof(cpu_used) && procs[i].p_pctcpu > 0) cpu_used[procs[i].p_cpuid] = 1; @@ -266,7 +356,7 @@ void bind_to_free_cpu(afl_state_t *afl) { if (ncpus > sizeof(cpu_used)) ncpus = sizeof(cpu_used); - for (i = 0; i < ncpus; i++) { + for (i = 0; i < (s32)ncpus; i++) { k = kstat_lookup(m, "cpu_stat", i, NULL); if (kstat_read(m, k, &cs)) { @@ -293,130 +383,50 @@ void bind_to_free_cpu(afl_state_t *afl) { size_t cpu_start = 0; - try: - #if !defined(__ANDROID__) - for (i = cpu_start; i < afl->cpu_core_count; i++) { - - if (!cpu_used[i]) { break; } - - } - - if (i == afl->cpu_core_count) { + for (i = cpu_start; i < afl->cpu_core_count; i++) { #else - for (i = afl->cpu_core_count - cpu_start - 1; i > -1; i--) - if (!cpu_used[i]) break; - if (i == -1) { - - #endif - - SAYF("\n" cLRD "[-] " cRST - "Uh-oh, looks like all %d CPU cores on your system are allocated to\n" - " other instances of afl-fuzz (or similar CPU-locked tasks). " - "Starting\n" - " another fuzzer on this machine is probably a bad plan, but if " - "you are\n" - " absolutely sure, you can set AFL_NO_AFFINITY and try again.\n", - afl->cpu_core_count); - FATAL("No more free CPU cores"); - - } - - OKF("Found a free CPU core, try binding to #%u.", i); - - afl->cpu_aff = i; - - #if defined(__linux__) || defined(__FreeBSD__) || defined(__DragonFly__) - - CPU_ZERO(&c); - CPU_SET(i, &c); - - #elif defined(__NetBSD__) - - c = cpuset_create(); - if (c == NULL) PFATAL("cpuset_create failed"); - cpuset_set(i, c); - - #elif defined(__sun) + /* for some reason Android goes backwards */ -pset_create(&c); -if (pset_assign(c, i, NULL)) PFATAL("pset_assign failed"); + for (i = afl->cpu_core_count - 1; i > -1; i--) { #endif - #if defined(__linux__) + if (cpu_used[i]) { continue; } - if (sched_setaffinity(0, sizeof(c), &c)) { + OKF("Found a free CPU core, try binding to #%u.", i); - if (cpu_start == afl->cpu_core_count) { + if (bind_cpu(afl, i)) { - PFATAL("sched_setaffinity failed for CPU %d, exit", i); + /* Success :) */ + break; } - WARNF("sched_setaffinity failed to CPU %d, trying next CPU", i); + WARNF("setaffinity failed to CPU %d, trying next CPU", i); cpu_start++; - goto try - ; } - #elif defined(__FreeBSD__) || defined(__DragonFly__) + if (lockfile[0]) unlink(lockfile); - if (pthread_setaffinity_np(pthread_self(), sizeof(c), &c)) { + if (i == afl->cpu_core_count || i == -1) { - if (cpu_start == afl->cpu_core_count) - PFATAL("pthread_setaffinity failed for cpu %d, exit", i); - WARNF("pthread_setaffinity failed to CPU %d, trying next CPU", i); - cpu_start++; - goto try - ; + SAYF("\n" cLRD "[-] " cRST + "Uh-oh, looks like all %d CPU cores on your system are allocated to\n" + " other instances of afl-fuzz (or similar CPU-locked tasks). " + "Starting\n" + " another fuzzer on this machine is probably a bad plan, but if " + "you are\n" + " absolutely sure, you can set AFL_NO_AFFINITY and try again.\n", + afl->cpu_core_count); + FATAL("No more free CPU cores"); } - #elif defined(__NetBSD__) - -if (pthread_setaffinity_np(pthread_self(), cpuset_size(c), c)) { - - if (cpu_start == afl->cpu_core_count) - PFATAL("pthread_setaffinity failed for cpu %d, exit", i); - WARNF("pthread_setaffinity failed to CPU %d, trying next CPU", i); - cpu_start++; - goto try - ; - -} - -cpuset_destroy(c); - - #elif defined(__sun) - -if (pset_bind(c, P_PID, getpid(), NULL)) { - - if (cpu_start == afl->cpu_core_count) - PFATAL("pset_bind failed for cpu %d, exit", i); - WARNF("pset_bind failed to CPU %d, trying next CPU", i); - cpu_start++; - goto try - ; - -} - -pset_destroy(c); - - #else - - // this will need something for other platforms - // TODO: Solaris/Illumos has processor_bind ... might worth a try - - #endif - - if (lockfile[0]) unlink(lockfile); - // we leave the environment variable to ensure a cleanup for other processes - } #endif /* HAVE_AFFINITY */ @@ -451,6 +461,7 @@ void read_foreign_testcases(afl_state_t *afl, int first) { u32 i, iter; u8 val_buf[2][STRINGIFY_VAL_SIZE_MAX]; + u8 foreign_name[16]; for (iter = 0; iter < afl->foreign_sync_cnt; iter++) { @@ -458,11 +469,22 @@ void read_foreign_testcases(afl_state_t *afl, int first) { afl->foreign_syncs[iter].dir[0] != 0) { if (first) ACTF("Scanning '%s'...", afl->foreign_syncs[iter].dir); - time_t ctime_max = 0; + time_t mtime_max = 0; + u8 * name = strrchr(afl->foreign_syncs[iter].dir, '/'); + if (!name) { name = afl->foreign_syncs[iter].dir; } + if (!strcmp(name, "queue") || !strcmp(name, "out") || + !strcmp(name, "default")) { + + snprintf(foreign_name, sizeof(foreign_name), "foreign_%u", iter); + + } else { - /* We use scandir() + alphasort() rather than readdir() because otherwise, - the ordering of test cases would vary somewhat randomly and would be - difficult to control. */ + snprintf(foreign_name, sizeof(foreign_name), "%s_%u", name, iter); + + } + + /* We do not use sorting yet and do a more expensive mtime check instead. + a mtimesort() implementation would be better though. */ nl_cnt = scandir(afl->foreign_syncs[iter].dir, &nl, NULL, NULL); @@ -481,9 +503,13 @@ void read_foreign_testcases(afl_state_t *afl, int first) { if (nl_cnt == 0) { - if (first) + if (first) { + WARNF("directory %s is currently empty", afl->foreign_syncs[iter].dir); + + } + continue; } @@ -496,7 +522,7 @@ void read_foreign_testcases(afl_state_t *afl, int first) { afl->stage_cur = 0; afl->stage_max = 0; - for (i = 0; i < nl_cnt; ++i) { + for (i = 0; i < (u32)nl_cnt; ++i) { struct stat st; @@ -512,8 +538,8 @@ void read_foreign_testcases(afl_state_t *afl, int first) { } - /* we detect new files by their ctime */ - if (likely(st.st_ctime <= afl->foreign_syncs[iter].ctime)) { + /* we detect new files by their mtime */ + if (likely(st.st_mtime <= afl->foreign_syncs[iter].mtime)) { ck_free(fn2); continue; @@ -531,11 +557,15 @@ void read_foreign_testcases(afl_state_t *afl, int first) { if (st.st_size > MAX_FILE) { - if (first) + if (first) { + WARNF( "Test case '%s' is too big (%s, limit is %s), skipping", fn2, stringify_mem_size(val_buf[0], sizeof(val_buf[0]), st.st_size), stringify_mem_size(val_buf[1], sizeof(val_buf[1]), MAX_FILE)); + + } + ck_free(fn2); continue; @@ -564,18 +594,18 @@ void read_foreign_testcases(afl_state_t *afl, int first) { write_to_testcase(afl, mem, st.st_size); fault = fuzz_run_target(afl, &afl->fsrv, afl->fsrv.exec_tmout); - afl->syncing_party = "foreign"; + afl->syncing_party = foreign_name; afl->queued_imported += save_if_interesting(afl, mem, st.st_size, fault); afl->syncing_party = 0; munmap(mem, st.st_size); close(fd); - if (st.st_ctime > ctime_max) ctime_max = st.st_ctime; + if (st.st_mtime > mtime_max) mtime_max = st.st_mtime; } - afl->foreign_syncs[iter].ctime = ctime_max; + afl->foreign_syncs[iter].mtime = mtime_max; free(nl); /* not tracked */ } @@ -594,37 +624,43 @@ void read_foreign_testcases(afl_state_t *afl, int first) { /* Read all testcases from the input directory, then queue them for testing. Called at startup. */ -void read_testcases(afl_state_t *afl) { +void read_testcases(afl_state_t *afl, u8 *directory) { struct dirent **nl; - s32 nl_cnt; + s32 nl_cnt, subdirs = 1; u32 i; - u8 * fn1; - - u8 val_buf[2][STRINGIFY_VAL_SIZE_MAX]; + u8 * fn1, *dir = directory; + u8 val_buf[2][STRINGIFY_VAL_SIZE_MAX]; /* Auto-detect non-in-place resumption attempts. */ - fn1 = alloc_printf("%s/queue", afl->in_dir); - if (!access(fn1, F_OK)) { + if (dir == NULL) { - afl->in_dir = fn1; + fn1 = alloc_printf("%s/queue", afl->in_dir); + if (!access(fn1, F_OK)) { - } else { + afl->in_dir = fn1; + subdirs = 0; + + } else { + + ck_free(fn1); - ck_free(fn1); + } + + dir = afl->in_dir; } - ACTF("Scanning '%s'...", afl->in_dir); + ACTF("Scanning '%s'...", dir); /* We use scandir() + alphasort() rather than readdir() because otherwise, the ordering of test cases would vary somewhat randomly and would be difficult to control. */ - nl_cnt = scandir(afl->in_dir, &nl, NULL, alphasort); + nl_cnt = scandir(dir, &nl, NULL, alphasort); - if (nl_cnt < 0) { + if (nl_cnt < 0 && directory == NULL) { if (errno == ENOENT || errno == ENOTDIR) { @@ -639,37 +675,47 @@ void read_testcases(afl_state_t *afl) { } - PFATAL("Unable to open '%s'", afl->in_dir); + PFATAL("Unable to open '%s'", dir); } - if (afl->shuffle_queue && nl_cnt > 1) { + if (unlikely(afl->old_seed_selection && afl->shuffle_queue && nl_cnt > 1)) { ACTF("Shuffling queue..."); shuffle_ptrs(afl, (void **)nl, nl_cnt); } - for (i = 0; i < nl_cnt; ++i) { + for (i = 0; i < (u32)nl_cnt; ++i) { struct stat st; u8 dfn[PATH_MAX]; snprintf(dfn, PATH_MAX, "%s/.state/deterministic_done/%s", afl->in_dir, nl[i]->d_name); - u8 *fn2 = alloc_printf("%s/%s", afl->in_dir, nl[i]->d_name); + u8 *fn2 = alloc_printf("%s/%s", dir, nl[i]->d_name); u8 passed_det = 0; - free(nl[i]); /* not tracked */ - if (lstat(fn2, &st) || access(fn2, R_OK)) { PFATAL("Unable to access '%s'", fn2); } - /* This also takes care of . and .. */ + /* obviously we want to skip "descending" into . and .. directories, + however it is a good idea to skip also directories that start with + a dot */ + if (subdirs && S_ISDIR(st.st_mode) && nl[i]->d_name[0] != '.') { + + free(nl[i]); /* not tracked */ + read_testcases(afl, fn2); + ck_free(fn2); + continue; + + } + + free(nl[i]); if (!S_ISREG(st.st_mode) || !st.st_size || strstr(fn2, "/README.txt")) { @@ -680,11 +726,9 @@ void read_testcases(afl_state_t *afl) { if (st.st_size > MAX_FILE) { - WARNF("Test case '%s' is too big (%s, limit is %s), skipping", fn2, + WARNF("Test case '%s' is too big (%s, limit is %s), partial reading", fn2, stringify_mem_size(val_buf[0], sizeof(val_buf[0]), st.st_size), stringify_mem_size(val_buf[1], sizeof(val_buf[1]), MAX_FILE)); - ck_free(fn2); - continue; } @@ -695,13 +739,49 @@ void read_testcases(afl_state_t *afl) { if (!access(dfn, F_OK)) { passed_det = 1; } - add_to_queue(afl, fn2, st.st_size, passed_det); + add_to_queue(afl, fn2, st.st_size >= MAX_FILE ? MAX_FILE : st.st_size, + passed_det); + + if (unlikely(afl->shm.cmplog_mode)) { + + if (afl->cmplog_lvl == 1) { + + if (!afl->cmplog_max_filesize || + afl->cmplog_max_filesize < st.st_size) { + + afl->cmplog_max_filesize = st.st_size; + + } + + } else if (afl->cmplog_lvl == 2) { + + if (!afl->cmplog_max_filesize || + afl->cmplog_max_filesize > st.st_size) { + + afl->cmplog_max_filesize = st.st_size; + + } + + } + + } + + /* + if (unlikely(afl->schedule >= FAST && afl->schedule <= RARE)) { + + u64 cksum = hash64(afl->fsrv.trace_bits, afl->fsrv.map_size, + HASH_CONST); afl->queue_top->n_fuzz_entry = cksum % N_FUZZ_SIZE; + afl->n_fuzz[afl->queue_top->n_fuzz_entry] = 1; + + } + + */ } free(nl); /* not tracked */ - if (!afl->queued_paths) { + if (!afl->queued_paths && directory == NULL) { SAYF("\n" cLRD "[-] " cRST "Looks like there are no valid test cases in the input directory! The " @@ -716,6 +796,20 @@ void read_testcases(afl_state_t *afl) { } + if (unlikely(afl->shm.cmplog_mode)) { + + if (afl->cmplog_max_filesize < 1024) { + + afl->cmplog_max_filesize = 1024; + + } else { + + afl->cmplog_max_filesize = (((afl->cmplog_max_filesize >> 10) + 1) << 10); + + } + + } + afl->last_path_time = 0; afl->queued_at_start = afl->queued_paths; @@ -726,16 +820,28 @@ void read_testcases(afl_state_t *afl) { void perform_dry_run(afl_state_t *afl) { - struct queue_entry *q = afl->queue; - u32 cal_failures = 0; + struct queue_entry *q; + u32 cal_failures = 0, idx; u8 * skip_crashes = afl->afl_env.afl_skip_crashes; + u8 * use_mem; + + for (idx = 0; idx < afl->queued_paths; idx++) { - while (q) { + q = afl->queue_buf[idx]; + if (unlikely(!q || q->disabled)) { continue; } - u8 *use_mem; u8 res; s32 fd; + if (unlikely(!q->len)) { + + WARNF("Skipping 0-sized entry in queue (%s)", q->fname); + continue; + + } + + if (afl->afl_env.afl_cmplog_only_new) { q->colorized = CMPLOG_LVL_MAX; } + u8 *fn = strrchr(q->fname, '/') + 1; ACTF("Attempting dry run with '%s'...", fn); @@ -743,9 +849,9 @@ void perform_dry_run(afl_state_t *afl) { fd = open(q->fname, O_RDONLY); if (fd < 0) { PFATAL("Unable to open '%s'", q->fname); } - use_mem = ck_alloc_nozero(q->len); - - if (read(fd, use_mem, q->len) != q->len) { + u32 read_len = MIN(q->len, (u32)MAX_FILE); + use_mem = afl_realloc(AFL_BUF_PARAM(in), read_len); + if (read(fd, use_mem, read_len) != (ssize_t)read_len) { FATAL("Short read from '%s'", q->fname); @@ -754,7 +860,6 @@ void perform_dry_run(afl_state_t *afl) { close(fd); res = calibrate_case(afl, q, use_mem, 0, 1); - ck_free(use_mem); if (afl->stop_soon) { return; } @@ -777,32 +882,23 @@ void perform_dry_run(afl_state_t *afl) { if (afl->timeout_given) { - /* The -t nn+ syntax in the command line sets afl->timeout_given to - '2' and instructs afl-fuzz to tolerate but skip queue entries that - time out. */ + /* if we have a timeout but a timeout value was given then always + skip. The '+' meaning has been changed! */ + WARNF("Test case results in a timeout (skipping)"); + ++cal_failures; + q->cal_failed = CAL_CHANCES; + q->disabled = 1; + q->perf_score = 0; - if (afl->timeout_given > 1) { + if (!q->was_fuzzed) { - WARNF("Test case results in a timeout (skipping)"); - q->cal_failed = CAL_CHANCES; - ++cal_failures; - break; + q->was_fuzzed = 1; + --afl->pending_not_fuzzed; + --afl->active_paths; } - SAYF("\n" cLRD "[-] " cRST - "The program took more than %u ms to process one of the initial " - "test cases.\n" - " Usually, the right thing to do is to relax the -t option - " - "or to delete it\n" - " altogether and allow the fuzzer to auto-calibrate. That " - "said, if you know\n" - " what you are doing and want to simply skip the unruly test " - "cases, append\n" - " '+' at the end of the value passed to -t ('-t %u+').\n", - afl->fsrv.exec_tmout, afl->fsrv.exec_tmout); - - FATAL("Test case '%s' results in a timeout", fn); + break; } else { @@ -828,7 +924,19 @@ void perform_dry_run(afl_state_t *afl) { if (skip_crashes) { - WARNF("Test case results in a crash (skipping)"); + if (afl->fsrv.uses_crash_exitcode) { + + WARNF( + "Test case results in a crash or AFL_CRASH_EXITCODE %d " + "(skipping)", + (int)(s8)afl->fsrv.crash_exitcode); + + } else { + + WARNF("Test case results in a crash (skipping)"); + + } + q->cal_failed = CAL_CHANCES; ++cal_failures; break; @@ -914,7 +1022,62 @@ void perform_dry_run(afl_state_t *afl) { #undef MSG_ULIMIT_USAGE #undef MSG_FORK_ON_APPLE - FATAL("Test case '%s' results in a crash", fn); + if (afl->fsrv.uses_crash_exitcode) { + + WARNF( + "Test case '%s' results in a crash or AFL_CRASH_EXITCODE %d, " + "skipping", + fn, (int)(s8)afl->fsrv.crash_exitcode); + + } else { + + WARNF("Test case '%s' results in a crash, skipping", fn); + + } + + /* Remove from fuzzing queue but keep for splicing */ + + struct queue_entry *p = afl->queue; + + if (!p->was_fuzzed) { + + p->was_fuzzed = 1; + --afl->pending_not_fuzzed; + --afl->active_paths; + + } + + p->disabled = 1; + p->perf_score = 0; + + u32 i = 0; + while (unlikely(i < afl->queued_paths && afl->queue_buf[i] && + afl->queue_buf[i]->disabled)) { + + ++i; + + } + + if (i < afl->queued_paths && afl->queue_buf[i]) { + + afl->queue = afl->queue_buf[i]; + + } else { + + afl->queue = afl->queue_buf[0]; + + } + + afl->max_depth = 0; + for (i = 0; i < afl->queued_paths && likely(afl->queue_buf[i]); i++) { + + if (!afl->queue_buf[i]->disabled && + afl->queue_buf[i]->depth > afl->max_depth) + afl->max_depth = afl->queue_buf[i]->depth; + + } + + break; case FSRV_RUN_ERROR: @@ -943,8 +1106,6 @@ void perform_dry_run(afl_state_t *afl) { } - q = q->next; - } if (cal_failures) { @@ -968,6 +1129,79 @@ void perform_dry_run(afl_state_t *afl) { } + /* Now we remove all entries from the queue that have a duplicate trace map */ + + u32 duplicates = 0, i; + + for (idx = 0; idx < afl->queued_paths; idx++) { + + q = afl->queue_buf[idx]; + if (!q || q->disabled || q->cal_failed || !q->exec_cksum) { continue; } + + u32 done = 0; + for (i = idx + 1; + i < afl->queued_paths && !done && likely(afl->queue_buf[i]); i++) { + + struct queue_entry *p = afl->queue_buf[i]; + if (p->disabled || p->cal_failed || !p->exec_cksum) { continue; } + + if (p->exec_cksum == q->exec_cksum) { + + duplicates = 1; + + // we keep the shorter file + if (p->len >= q->len) { + + if (!p->was_fuzzed) { + + p->was_fuzzed = 1; + --afl->pending_not_fuzzed; + --afl->active_paths; + + } + + p->disabled = 1; + p->perf_score = 0; + + } else { + + if (!q->was_fuzzed) { + + q->was_fuzzed = 1; + --afl->pending_not_fuzzed; + --afl->active_paths; + + } + + q->disabled = 1; + q->perf_score = 0; + + done = 1; + + } + + } + + } + + } + + if (duplicates) { + + afl->max_depth = 0; + + for (idx = 0; idx < afl->queued_paths; idx++) { + + if (afl->queue_buf[idx] && !afl->queue_buf[idx]->disabled && + afl->queue_buf[idx]->depth > afl->max_depth) + afl->max_depth = afl->queue_buf[idx]->depth; + + } + + afl->queue_top = afl->queue; + + } + OKF("All test cases processed."); } @@ -1009,12 +1243,16 @@ static void link_or_copy(u8 *old_path, u8 *new_path) { void pivot_inputs(afl_state_t *afl) { - struct queue_entry *q = afl->queue; - u32 id = 0; + struct queue_entry *q; + u32 id = 0, i; ACTF("Creating hard links for all input files..."); - while (q) { + for (i = 0; i < afl->queued_paths && likely(afl->queue_buf[i]); i++) { + + q = afl->queue_buf[i]; + + if (unlikely(q->disabled)) { continue; } u8 *nfn, *rsl = strrchr(q->fname, '/'); u32 orig_id; @@ -1042,19 +1280,14 @@ void pivot_inputs(afl_state_t *afl) { afl->resuming_fuzz = 1; nfn = alloc_printf("%s/queue/%s", afl->out_dir, rsl); - /* Since we're at it, let's also try to find parent and figure out the + /* Since we're at it, let's also get the parent and figure out the appropriate depth for this entry. */ src_str = strchr(rsl + 3, ':'); if (src_str && sscanf(src_str + 1, "%06u", &src_id) == 1) { - struct queue_entry *s = afl->queue; - while (src_id-- && s) { - - s = s->next; - - } + struct queue_entry *s = afl->queue_buf[src_id]; if (s) { q->depth = s->depth + 1; } @@ -1102,7 +1335,6 @@ void pivot_inputs(afl_state_t *afl) { if (q->passed_det) { mark_as_det_done(afl, q); } - q = q->next; ++id; } @@ -1495,20 +1727,21 @@ static void handle_existing_out_dir(afl_state_t *afl) { if (afl->in_place_resume && rmdir(fn)) { - time_t cur_t = time(0); - struct tm *t = localtime(&cur_t); + time_t cur_t = time(0); + struct tm t; + localtime_r(&cur_t, &t); #ifndef SIMPLE_FILES - u8 *nfn = alloc_printf("%s.%04d-%02d-%02d-%02d:%02d:%02d", fn, - t->tm_year + 1900, t->tm_mon + 1, t->tm_mday, - t->tm_hour, t->tm_min, t->tm_sec); + u8 *nfn = + alloc_printf("%s.%04d-%02d-%02d-%02d:%02d:%02d", fn, t.tm_year + 1900, + t.tm_mon + 1, t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec); #else - u8 *nfn = alloc_printf("%s_%04d%02d%02d%02d%02d%02d", fn, t->tm_year + 1900, - t->tm_mon + 1, t->tm_mday, t->tm_hour, t->tm_min, - t->tm_sec); + u8 *nfn = + alloc_printf("%s_%04d%02d%02d%02d%02d%02d", fn, t.tm_year + 1900, + t.tm_mon + 1, t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec); #endif /* ^!SIMPLE_FILES */ @@ -1526,20 +1759,21 @@ static void handle_existing_out_dir(afl_state_t *afl) { if (afl->in_place_resume && rmdir(fn)) { - time_t cur_t = time(0); - struct tm *t = localtime(&cur_t); + time_t cur_t = time(0); + struct tm t; + localtime_r(&cur_t, &t); #ifndef SIMPLE_FILES - u8 *nfn = alloc_printf("%s.%04d-%02d-%02d-%02d:%02d:%02d", fn, - t->tm_year + 1900, t->tm_mon + 1, t->tm_mday, - t->tm_hour, t->tm_min, t->tm_sec); + u8 *nfn = + alloc_printf("%s.%04d-%02d-%02d-%02d:%02d:%02d", fn, t.tm_year + 1900, + t.tm_mon + 1, t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec); #else - u8 *nfn = alloc_printf("%s_%04d%02d%02d%02d%02d%02d", fn, t->tm_year + 1900, - t->tm_mon + 1, t->tm_mday, t->tm_hour, t->tm_min, - t->tm_sec); + u8 *nfn = + alloc_printf("%s_%04d%02d%02d%02d%02d%02d", fn, t.tm_year + 1900, + t.tm_mon + 1, t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec); #endif /* ^!SIMPLE_FILES */ @@ -1653,7 +1887,6 @@ int check_main_node_exists(afl_state_t *afl) { void setup_dirs_fds(afl_state_t *afl) { u8 *tmp; - s32 fd; ACTF("Setting up output directories..."); @@ -1779,7 +2012,7 @@ void setup_dirs_fds(afl_state_t *afl) { /* Gnuplot output file. */ tmp = alloc_printf("%s/plot_data", afl->out_dir); - fd = open(tmp, O_WRONLY | O_CREAT | O_EXCL, 0600); + int fd = open(tmp, O_WRONLY | O_CREAT | O_EXCL, 0600); if (fd < 0) { PFATAL("Unable to create '%s'", tmp); } ck_free(tmp); @@ -1789,7 +2022,7 @@ void setup_dirs_fds(afl_state_t *afl) { fprintf(afl->fsrv.plot_file, "# unix_time, cycles_done, cur_path, paths_total, " "pending_total, pending_favs, map_size, unique_crashes, " - "unique_hangs, max_depth, execs_per_sec\n"); + "unique_hangs, max_depth, execs_per_sec, total_execs, edges_found\n"); fflush(afl->fsrv.plot_file); /* ignore errors */ @@ -1828,24 +2061,26 @@ void setup_cmdline_file(afl_state_t *afl, char **argv) { void setup_stdio_file(afl_state_t *afl) { - u8 *fn; if (afl->file_extension) { - fn = alloc_printf("%s/.cur_input.%s", afl->tmp_dir, afl->file_extension); + afl->fsrv.out_file = + alloc_printf("%s/.cur_input.%s", afl->tmp_dir, afl->file_extension); } else { - fn = alloc_printf("%s/.cur_input", afl->tmp_dir); + afl->fsrv.out_file = alloc_printf("%s/.cur_input", afl->tmp_dir); } - unlink(fn); /* Ignore errors */ + unlink(afl->fsrv.out_file); /* Ignore errors */ - afl->fsrv.out_fd = open(fn, O_RDWR | O_CREAT | O_EXCL, 0600); + afl->fsrv.out_fd = open(afl->fsrv.out_file, O_RDWR | O_CREAT | O_EXCL, 0600); - if (afl->fsrv.out_fd < 0) { PFATAL("Unable to create '%s'", fn); } + if (afl->fsrv.out_fd < 0) { - ck_free(fn); + PFATAL("Unable to create '%s'", afl->fsrv.out_file); + + } } @@ -2059,6 +2294,8 @@ void check_cpu_governor(afl_state_t *afl) { "drop.\n", min / 1024, max / 1024); FATAL("Suboptimal CPU scaling governor"); +#else + (void)afl; #endif } @@ -2134,7 +2371,7 @@ void get_core_count(afl_state_t *afl) { WARNF("System under apparent load, performance may be spotty."); - } else if (cur_runnable + 1 <= afl->cpu_core_count) { + } else if ((s64)cur_runnable + 1 <= (s64)afl->cpu_core_count) { OKF("Try parallel jobs - see %s/parallel_fuzzing.md.", doc_path); @@ -2157,12 +2394,6 @@ void fix_up_sync(afl_state_t *afl) { u8 *x = afl->sync_id; - if (afl->non_instrumented_mode) { - - FATAL("-S / -M and -n are mutually exclusive"); - - } - while (*x) { if (!isalnum(*x) && *x != '_' && *x != '-') { @@ -2188,16 +2419,19 @@ void fix_up_sync(afl_state_t *afl) { static void handle_resize(int sig) { + (void)sig; afl_states_clear_screen(); } /* Check ASAN options. */ -void check_asan_opts(void) { +void check_asan_opts(afl_state_t *afl) { u8 *x = get_afl_env("ASAN_OPTIONS"); + (void)(afl); + if (x) { if (!strstr(x, "abort_on_error=1")) { @@ -2206,12 +2440,15 @@ void check_asan_opts(void) { } - if (!strstr(x, "symbolize=0")) { +#ifndef ASAN_BUILD + if (!afl->debug && !strstr(x, "symbolize=0")) { FATAL("Custom ASAN_OPTIONS set without symbolize=0 - please fix!"); } +#endif + } x = get_afl_env("MSAN_OPTIONS"); @@ -2225,7 +2462,7 @@ void check_asan_opts(void) { } - if (!strstr(x, "symbolize=0")) { + if (!afl->debug && !strstr(x, "symbolize=0")) { FATAL("Custom MSAN_OPTIONS set without symbolize=0 - please fix!"); @@ -2239,6 +2476,7 @@ void check_asan_opts(void) { static void handle_stop_sig(int sig) { + (void)sig; afl_states_stop(); } @@ -2247,6 +2485,7 @@ static void handle_stop_sig(int sig) { static void handle_skipreq(int sig) { + (void)sig; afl_states_request_skip(); } @@ -2259,6 +2498,7 @@ void setup_testcase_shmem(afl_state_t *afl) { // we need to set the non-instrumented mode to not overwrite the SHM_ENV_VAR u8 *map = afl_shm_init(afl->shm_fuzz, MAX_FILE + sizeof(u32), 1); + afl->shm_fuzz->shmemfuzz_mode = 1; if (!map) { FATAL("BUG: Zero return from afl_shm_init."); } @@ -2281,6 +2521,8 @@ void setup_testcase_shmem(afl_state_t *afl) { void check_binary(afl_state_t *afl, u8 *fname) { + if (unlikely(!fname)) { FATAL("BUG: Binary name is NULL"); } + u8 * env_path = 0; struct stat st; @@ -2309,6 +2551,7 @@ void check_binary(afl_state_t *afl, u8 *fname) { if (delim) { cur_elem = ck_alloc(delim - env_path + 1); + if (unlikely(!cur_elem)) { FATAL("Unexpected large PATH"); } memcpy(cur_elem, env_path, delim - env_path); ++delim; @@ -2352,7 +2595,9 @@ void check_binary(afl_state_t *afl, u8 *fname) { } - if (afl->afl_env.afl_skip_bin_check || afl->use_wine || afl->unicorn_mode) { + if (afl->afl_env.afl_skip_bin_check || afl->use_wine || afl->unicorn_mode || + (afl->fsrv.qemu_mode && getenv("AFL_QEMU_CUSTOM_BIN")) || + afl->non_instrumented_mode) { return; diff --git a/src/afl-fuzz-mutators.c b/src/afl-fuzz-mutators.c index b288cf9f..80df6d08 100644 --- a/src/afl-fuzz-mutators.c +++ b/src/afl-fuzz-mutators.c @@ -93,9 +93,9 @@ void setup_custom_mutators(afl_state_t *afl) { } - struct custom_mutator *mutator = load_custom_mutator_py(afl, module_name); + struct custom_mutator *m = load_custom_mutator_py(afl, module_name); afl->custom_mutators_count++; - list_append(&afl->custom_mutator_list, mutator); + list_append(&afl->custom_mutator_list, m); } @@ -122,9 +122,8 @@ void destroy_custom_mutators(afl_state_t *afl) { if (el->post_process_buf) { - ck_free(el->post_process_buf); + afl_free(el->post_process_buf); el->post_process_buf = NULL; - el->post_process_size = 0; } @@ -142,6 +141,10 @@ struct custom_mutator *load_custom_mutator(afl_state_t *afl, const char *fn) { struct custom_mutator *mutator = ck_alloc(sizeof(struct custom_mutator)); mutator->name = fn; + if (memchr(fn, '/', strlen(fn))) + mutator->name_short = strrchr(fn, '/') + 1; + else + mutator->name_short = strdup(fn); ACTF("Loading custom mutator library from '%s'...", fn); dh = dlopen(fn, RTLD_NOW); @@ -151,7 +154,11 @@ struct custom_mutator *load_custom_mutator(afl_state_t *afl, const char *fn) { /* Mutator */ /* "afl_custom_init", optional for backward compatibility */ mutator->afl_custom_init = dlsym(dh, "afl_custom_init"); - if (!mutator->afl_custom_init) FATAL("Symbol 'afl_custom_init' not found."); + if (!mutator->afl_custom_init) { + + FATAL("Symbol 'afl_custom_init' not found."); + + } /* "afl_custom_fuzz" or "afl_custom_mutator", required */ mutator->afl_custom_fuzz = dlsym(dh, "afl_custom_fuzz"); @@ -161,37 +168,74 @@ struct custom_mutator *load_custom_mutator(afl_state_t *afl, const char *fn) { WARNF("Symbol 'afl_custom_fuzz' not found. Try 'afl_custom_mutator'."); mutator->afl_custom_fuzz = dlsym(dh, "afl_custom_mutator"); - if (!mutator->afl_custom_fuzz) + if (!mutator->afl_custom_fuzz) { + WARNF("Symbol 'afl_custom_mutator' not found."); + } + + } + + /* "afl_custom_introspection", optional */ +#ifdef INTROSPECTION + mutator->afl_custom_introspection = dlsym(dh, "afl_custom_introspection"); + if (!mutator->afl_custom_introspection) { + + ACTF("optional symbol 'afl_custom_introspection' not found."); + + } + +#endif + + /* "afl_custom_fuzz_count", optional */ + mutator->afl_custom_fuzz_count = dlsym(dh, "afl_custom_fuzz_count"); + if (!mutator->afl_custom_fuzz_count) { + + ACTF("optional symbol 'afl_custom_fuzz_count' not found."); + } /* "afl_custom_deinit", optional for backward compatibility */ mutator->afl_custom_deinit = dlsym(dh, "afl_custom_deinit"); - if (!mutator->afl_custom_deinit) + if (!mutator->afl_custom_deinit) { + FATAL("Symbol 'afl_custom_deinit' not found."); + } + /* "afl_custom_post_process", optional */ mutator->afl_custom_post_process = dlsym(dh, "afl_custom_post_process"); - if (!mutator->afl_custom_post_process) + if (!mutator->afl_custom_post_process) { + ACTF("optional symbol 'afl_custom_post_process' not found."); + } + u8 notrim = 0; /* "afl_custom_init_trim", optional */ mutator->afl_custom_init_trim = dlsym(dh, "afl_custom_init_trim"); - if (!mutator->afl_custom_init_trim) + if (!mutator->afl_custom_init_trim) { + ACTF("optional symbol 'afl_custom_init_trim' not found."); + } + /* "afl_custom_trim", optional */ mutator->afl_custom_trim = dlsym(dh, "afl_custom_trim"); - if (!mutator->afl_custom_trim) + if (!mutator->afl_custom_trim) { + ACTF("optional symbol 'afl_custom_trim' not found."); + } + /* "afl_custom_post_trim", optional */ mutator->afl_custom_post_trim = dlsym(dh, "afl_custom_post_trim"); - if (!mutator->afl_custom_post_trim) + if (!mutator->afl_custom_post_trim) { + ACTF("optional symbol 'afl_custom_post_trim' not found."); + } + if (notrim) { mutator->afl_custom_init_trim = NULL; @@ -205,31 +249,54 @@ struct custom_mutator *load_custom_mutator(afl_state_t *afl, const char *fn) { /* "afl_custom_havoc_mutation", optional */ mutator->afl_custom_havoc_mutation = dlsym(dh, "afl_custom_havoc_mutation"); - if (!mutator->afl_custom_havoc_mutation) + if (!mutator->afl_custom_havoc_mutation) { + ACTF("optional symbol 'afl_custom_havoc_mutation' not found."); + } + /* "afl_custom_havoc_mutation", optional */ mutator->afl_custom_havoc_mutation_probability = dlsym(dh, "afl_custom_havoc_mutation_probability"); - if (!mutator->afl_custom_havoc_mutation_probability) + if (!mutator->afl_custom_havoc_mutation_probability) { + ACTF("optional symbol 'afl_custom_havoc_mutation_probability' not found."); + } + /* "afl_custom_queue_get", optional */ mutator->afl_custom_queue_get = dlsym(dh, "afl_custom_queue_get"); - if (!mutator->afl_custom_queue_get) + if (!mutator->afl_custom_queue_get) { + ACTF("optional symbol 'afl_custom_queue_get' not found."); + } + /* "afl_custom_queue_new_entry", optional */ mutator->afl_custom_queue_new_entry = dlsym(dh, "afl_custom_queue_new_entry"); - if (!mutator->afl_custom_queue_new_entry) + if (!mutator->afl_custom_queue_new_entry) { + ACTF("optional symbol 'afl_custom_queue_new_entry' not found"); + } + + /* "afl_custom_describe", optional */ + mutator->afl_custom_describe = dlsym(dh, "afl_custom_describe"); + if (!mutator->afl_custom_describe) { + + ACTF("Symbol 'afl_custom_describe' not found."); + + } + OKF("Custom mutator '%s' installed successfully.", fn); /* Initialize the custom mutator */ - if (mutator->afl_custom_init) + if (mutator->afl_custom_init) { + mutator->data = mutator->afl_custom_init(afl, rand_below(afl, 0xFFFFFFFF)); + } + mutator->stacked_custom = (mutator && mutator->afl_custom_havoc_mutation); mutator->stacked_custom_prob = 6; // like one of the default mutations in havoc @@ -252,16 +319,20 @@ u8 trim_case_custom(afl_state_t *afl, struct queue_entry *q, u8 *in_buf, /* Initialize trimming in the custom mutator */ afl->stage_cur = 0; - afl->stage_max = mutator->afl_custom_init_trim(mutator->data, in_buf, q->len); - if (unlikely(afl->stage_max) < 0) { + s32 retval = mutator->afl_custom_init_trim(mutator->data, in_buf, q->len); + if (unlikely(retval) < 0) { + + FATAL("custom_init_trim error ret: %d", retval); + + } else { - FATAL("custom_init_trim error ret: %d", afl->stage_max); + afl->stage_max = retval; } if (afl->not_on_tty && afl->debug) { - SAYF("[Custom Trimming] START: Max %d iterations, %u bytes", afl->stage_max, + SAYF("[Custom Trimming] START: Max %u iterations, %u bytes", afl->stage_max, q->len); } @@ -279,7 +350,7 @@ u8 trim_case_custom(afl_state_t *afl, struct queue_entry *q, u8 *in_buf, if (unlikely(!retbuf)) { - FATAL("custom_trim failed (ret %zd)", retlen); + FATAL("custom_trim failed (ret %zu)", retlen); } else if (unlikely(retlen > orig_len)) { @@ -308,20 +379,23 @@ u8 trim_case_custom(afl_state_t *afl, struct queue_entry *q, u8 *in_buf, unsuccessful trimming and skip it, instead of aborting the trimming. */ ++afl->trim_execs; - goto unsuccessful_trimming; } - write_to_testcase(afl, retbuf, retlen); + if (likely(retlen)) { - fault = fuzz_run_target(afl, &afl->fsrv, afl->fsrv.exec_tmout); - ++afl->trim_execs; + write_to_testcase(afl, retbuf, retlen); - if (afl->stop_soon || fault == FSRV_RUN_ERROR) { goto abort_trimming; } + fault = fuzz_run_target(afl, &afl->fsrv, afl->fsrv.exec_tmout); + ++afl->trim_execs; + + if (afl->stop_soon || fault == FSRV_RUN_ERROR) { goto abort_trimming; } - cksum = hash64(afl->fsrv.trace_bits, afl->fsrv.map_size, HASH_CONST); + cksum = hash64(afl->fsrv.trace_bits, afl->fsrv.map_size, HASH_CONST); + + } - if (cksum == q->exec_cksum) { + if (likely(retlen && cksum == q->exec_cksum)) { q->len = retlen; memcpy(in_buf, retbuf, retlen); @@ -342,26 +416,28 @@ u8 trim_case_custom(afl_state_t *afl, struct queue_entry *q, u8 *in_buf, if (afl->not_on_tty && afl->debug) { - SAYF("[Custom Trimming] SUCCESS: %d/%d iterations (now at %u bytes)", + SAYF("[Custom Trimming] SUCCESS: %u/%u iterations (now at %u bytes)", afl->stage_cur, afl->stage_max, q->len); } } else { - unsuccessful_trimming: - /* Tell the custom mutator that the trimming was unsuccessful */ - afl->stage_cur = mutator->afl_custom_post_trim(mutator->data, 0); - if (unlikely(afl->stage_cur < 0)) { + s32 retval2 = mutator->afl_custom_post_trim(mutator->data, 0); + if (unlikely(retval2 < 0)) { + + FATAL("Error ret in custom_post_trim: %d", retval2); + + } else { - FATAL("Error ret in custom_post_trim: %d", afl->stage_cur); + afl->stage_cur = retval2; } if (afl->not_on_tty && afl->debug) { - SAYF("[Custom Trimming] FAILURE: %d/%d iterations", afl->stage_cur, + SAYF("[Custom Trimming] FAILURE: %u/%u iterations", afl->stage_cur, afl->stage_max); } diff --git a/src/afl-fuzz-one.c b/src/afl-fuzz-one.c index 1f0bf30e..c73e394a 100644 --- a/src/afl-fuzz-one.c +++ b/src/afl-fuzz-one.c @@ -26,14 +26,13 @@ #include "afl-fuzz.h" #include <string.h> #include <limits.h> +#include "cmplog.h" /* MOpt */ -static int select_algorithm(afl_state_t *afl) { +static int select_algorithm(afl_state_t *afl, u32 max_algorithm) { - int i_puppet, j_puppet = 0, operator_number = operator_num; - - if (!afl->extras_cnt && !afl->a_extras_cnt) operator_number -= 2; + int i_puppet, j_puppet = 0, operator_number = max_algorithm; double range_sele = (double)afl->probability_now[afl->swarm_now][operator_number - 1]; @@ -77,7 +76,7 @@ static int select_algorithm(afl_state_t *afl) { static u32 choose_block_len(afl_state_t *afl, u32 limit) { u32 min_value, max_value; - u32 rlim = MIN(afl->queue_cycle, 3); + u32 rlim = MIN(afl->queue_cycle, (u32)3); if (unlikely(!afl->run_over10m)) { rlim = 1; } @@ -95,7 +94,7 @@ static u32 choose_block_len(afl_state_t *afl, u32 limit) { default: - if (rand_below(afl, 10)) { + if (likely(rand_below(afl, 10))) { min_value = HAVOC_BLK_MEDIUM; max_value = HAVOC_BLK_LARGE; @@ -167,7 +166,7 @@ static u8 could_be_arith(u32 old_val, u32 new_val, u8 blen) { /* See if one-byte adjustments to any byte could produce this result. */ - for (i = 0; i < blen; ++i) { + for (i = 0; (u8)i < blen; ++i) { u8 a = old_val >> (8 * i), b = new_val >> (8 * i); @@ -195,7 +194,7 @@ static u8 could_be_arith(u32 old_val, u32 new_val, u8 blen) { diffs = 0; - for (i = 0; i < blen / 2; ++i) { + for (i = 0; (u8)i < blen / 2; ++i) { u16 a = old_val >> (16 * i), b = new_val >> (16 * i); @@ -292,7 +291,7 @@ static u8 could_be_interest(u32 old_val, u32 new_val, u8 blen, u8 check_le) { /* See if two-byte insertions over old_val could give us new_val. */ - for (i = 0; i < blen - 1; ++i) { + for (i = 0; (u8)i < blen - 1; ++i) { for (j = 0; j < sizeof(interesting_16) / 2; ++j) { @@ -364,15 +363,15 @@ static void locate_diffs(u8 *ptr1, u8 *ptr2, u32 len, s32 *first, s32 *last) { #endif /* !IGNORE_FINDS */ -#define BUF_PARAMS(name) (void **)&afl->name##_buf, &afl->name##_size - /* Take the current entry from the queue, fuzz it for a while. This function is a tad too long... returns 0 if fuzzed successfully, 1 if skipped or bailed out. */ u8 fuzz_one_original(afl_state_t *afl) { - s32 len, fd, temp_len, i, j; + u32 len, temp_len; + u32 j; + u32 i; u8 *in_buf, *out_buf, *orig_in, *ex_tmp, *eff_map = 0; u64 havoc_queued = 0, orig_hit_cnt, new_hit_cnt = 0, prev_cksum; u32 splice_cycle = 0, perf_score = 100, orig_perf, eff_cnt = 1; @@ -382,9 +381,6 @@ u8 fuzz_one_original(afl_state_t *afl) { u8 a_collect[MAX_AUTO_EXTRA]; u32 a_len = 0; -/* Not pretty, but saves a lot of writing */ -#define BUF_PARAMS(name) (void **)&afl->name##_buf, &afl->name##_size - #ifdef IGNORE_FINDS /* In IGNORE_FINDS mode, skip any entries that weren't in the @@ -419,7 +415,7 @@ u8 fuzz_one_original(afl_state_t *afl) { if (((afl->queue_cur->was_fuzzed > 0 || afl->queue_cur->fuzz_level > 0) || !afl->queue_cur->favored) && - rand_below(afl, 100) < SKIP_TO_NEW_PROB) { + likely(rand_below(afl, 100) < SKIP_TO_NEW_PROB)) { return 1; @@ -436,11 +432,11 @@ u8 fuzz_one_original(afl_state_t *afl) { if (afl->queue_cycle > 1 && (afl->queue_cur->fuzz_level == 0 || afl->queue_cur->was_fuzzed)) { - if (rand_below(afl, 100) < SKIP_NFAV_NEW_PROB) { return 1; } + if (likely(rand_below(afl, 100) < SKIP_NFAV_NEW_PROB)) { return 1; } } else { - if (rand_below(afl, 100) < SKIP_NFAV_OLD_PROB) { return 1; } + if (likely(rand_below(afl, 100) < SKIP_NFAV_OLD_PROB)) { return 1; } } @@ -450,39 +446,22 @@ u8 fuzz_one_original(afl_state_t *afl) { if (unlikely(afl->not_on_tty)) { - ACTF("Fuzzing test case #%u (%u total, %llu uniq crashes found)...", - afl->current_entry, afl->queued_paths, afl->unique_crashes); + ACTF( + "Fuzzing test case #%u (%u total, %llu uniq crashes found, " + "perf_score=%0.0f, exec_us=%llu, hits=%u, map=%u)...", + afl->current_entry, afl->queued_paths, afl->unique_crashes, + afl->queue_cur->perf_score, afl->queue_cur->exec_us, + likely(afl->n_fuzz) ? afl->n_fuzz[afl->queue_cur->n_fuzz_entry] : 0, + afl->queue_cur->bitmap_size); fflush(stdout); } - /* Map the test case into memory. */ - - fd = open(afl->queue_cur->fname, O_RDONLY); - - if (unlikely(fd < 0)) { - - PFATAL("Unable to open '%s'", afl->queue_cur->fname); - - } - + orig_in = in_buf = queue_testcase_get(afl, afl->queue_cur); len = afl->queue_cur->len; - orig_in = in_buf = mmap(0, len, PROT_READ | PROT_WRITE, MAP_PRIVATE, fd, 0); - - if (unlikely(orig_in == MAP_FAILED)) { - - PFATAL("Unable to mmap '%s' with len %d", afl->queue_cur->fname, len); - - } - - close(fd); - - /* We could mmap() out_buf as MAP_PRIVATE, but we end up clobbering every - single byte anyway, so it wouldn't give us any performance or memory usage - benefits. */ - - out_buf = ck_maybe_grow(BUF_PARAMS(out), len); + out_buf = afl_realloc(AFL_BUF_PARAM(out), len); + if (unlikely(!out_buf)) { PFATAL("alloc"); } afl->subseq_tmouts = 0; @@ -524,10 +503,13 @@ u8 fuzz_one_original(afl_state_t *afl) { * TRIMMING * ************/ - if (!afl->non_instrumented_mode && !afl->queue_cur->trim_done && - !afl->disable_trim) { + if (unlikely(!afl->non_instrumented_mode && !afl->queue_cur->trim_done && + !afl->disable_trim)) { + + u32 old_len = afl->queue_cur->len; u8 res = trim_case(afl, afl->queue_cur, in_buf); + orig_in = in_buf = queue_testcase_get(afl, afl->queue_cur); if (unlikely(res == FSRV_RUN_ERROR)) { @@ -548,6 +530,9 @@ u8 fuzz_one_original(afl_state_t *afl) { len = afl->queue_cur->len; + /* maybe current entry is not ready for splicing anymore */ + if (unlikely(len <= 4 && old_len > 4)) --afl->ready_for_splicing_count; + } memcpy(out_buf, in_buf, len); @@ -556,16 +541,36 @@ u8 fuzz_one_original(afl_state_t *afl) { * PERFORMANCE SCORE * *********************/ - orig_perf = perf_score = calculate_score(afl, afl->queue_cur); + if (likely(!afl->old_seed_selection)) + orig_perf = perf_score = afl->queue_cur->perf_score; + else + afl->queue_cur->perf_score = orig_perf = perf_score = + calculate_score(afl, afl->queue_cur); - if (unlikely(perf_score == 0)) { goto abandon_entry; } + if (unlikely(perf_score <= 0)) { goto abandon_entry; } - if (afl->shm.cmplog_mode && !afl->queue_cur->fully_colorized) { + if (unlikely(afl->shm.cmplog_mode && + afl->queue_cur->colorized < afl->cmplog_lvl && + (u32)len <= afl->cmplog_max_filesize)) { - if (input_to_state_stage(afl, in_buf, out_buf, len, - afl->queue_cur->exec_cksum)) { + if (unlikely(len < 4)) { - goto abandon_entry; + afl->queue_cur->colorized = CMPLOG_LVL_MAX; + + } else { + + if (afl->cmplog_lvl == 3 || + (afl->cmplog_lvl == 2 && afl->queue_cur->tc_ref) || + !(afl->fsrv.total_execs % afl->queued_paths) || + get_cur_time() - afl->last_path_time > 300000) { + + if (input_to_state_stage(afl, in_buf, out_buf, len)) { + + goto abandon_entry; + + } + + } } @@ -589,8 +594,9 @@ u8 fuzz_one_original(afl_state_t *afl) { /* Skip deterministic fuzzing if exec path checksum puts this out of scope for this main instance. */ - if (afl->main_node_max && (afl->queue_cur->exec_cksum % afl->main_node_max) != - afl->main_node_id - 1) { + if (unlikely(afl->main_node_max && + (afl->queue_cur->exec_cksum % afl->main_node_max) != + afl->main_node_id - 1)) { goto custom_mutator_stage; @@ -629,6 +635,11 @@ u8 fuzz_one_original(afl_state_t *afl) { FLIP_BIT(out_buf, afl->stage_cur); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s FLIP_BIT1-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } FLIP_BIT(out_buf, afl->stage_cur); @@ -679,7 +690,7 @@ u8 fuzz_one_original(afl_state_t *afl) { if (a_len >= MIN_AUTO_EXTRA && a_len <= MAX_AUTO_EXTRA) { - maybe_add_auto((u8 *)afl, a_collect, a_len); + maybe_add_auto(afl, a_collect, a_len); } @@ -690,7 +701,7 @@ u8 fuzz_one_original(afl_state_t *afl) { if (a_len >= MIN_AUTO_EXTRA && a_len <= MAX_AUTO_EXTRA) { - maybe_add_auto((u8 *)afl, a_collect, a_len); + maybe_add_auto(afl, a_collect, a_len); } @@ -738,6 +749,11 @@ u8 fuzz_one_original(afl_state_t *afl) { FLIP_BIT(out_buf, afl->stage_cur); FLIP_BIT(out_buf, afl->stage_cur + 1); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s FLIP_BIT2-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } FLIP_BIT(out_buf, afl->stage_cur); @@ -767,6 +783,11 @@ u8 fuzz_one_original(afl_state_t *afl) { FLIP_BIT(out_buf, afl->stage_cur + 2); FLIP_BIT(out_buf, afl->stage_cur + 3); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s FLIP_BIT4-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } FLIP_BIT(out_buf, afl->stage_cur); @@ -797,7 +818,8 @@ u8 fuzz_one_original(afl_state_t *afl) { /* Initialize effector map for the next step (see comments below). Always flag first and last byte as doing something. */ - eff_map = ck_maybe_grow(BUF_PARAMS(eff), EFF_ALEN(len)); + eff_map = afl_realloc(AFL_BUF_PARAM(eff), EFF_ALEN(len)); + if (unlikely(!eff_map)) { PFATAL("alloc"); } eff_map[0] = 1; if (EFF_APOS(len - 1) != 0) { @@ -821,6 +843,11 @@ u8 fuzz_one_original(afl_state_t *afl) { out_buf[afl->stage_cur] ^= 0xFF; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s FLIP_BIT8-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } /* We also use this stage to pull off a simple trick: we identify @@ -862,7 +889,7 @@ u8 fuzz_one_original(afl_state_t *afl) { whole thing as worth fuzzing, since we wouldn't be saving much time anyway. */ - if (eff_cnt != EFF_ALEN(len) && + if (eff_cnt != (u32)EFF_ALEN(len) && eff_cnt * 100 / EFF_ALEN(len) > EFF_MAX_PERC) { memset(eff_map, 1, EFF_ALEN(len)); @@ -908,6 +935,11 @@ u8 fuzz_one_original(afl_state_t *afl) { *(u16 *)(out_buf + i) ^= 0xFFFF; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s FLIP_BIT16-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -946,6 +978,11 @@ u8 fuzz_one_original(afl_state_t *afl) { *(u32 *)(out_buf + i) ^= 0xFFFFFFFF; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s FLIP_BIT32-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -977,7 +1014,7 @@ skip_bitflip: orig_hit_cnt = new_hit_cnt; - for (i = 0; i < len; ++i) { + for (i = 0; i < (u32)len; ++i) { u8 orig = out_buf[i]; @@ -1004,6 +1041,11 @@ skip_bitflip: afl->stage_cur_val = j; out_buf[i] = orig + j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH8+-%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1020,6 +1062,11 @@ skip_bitflip: afl->stage_cur_val = -j; out_buf[i] = orig - j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH8--%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1051,7 +1098,7 @@ skip_bitflip: orig_hit_cnt = new_hit_cnt; - for (i = 0; i < len - 1; ++i) { + for (i = 0; i < (u32)len - 1; ++i) { u16 orig = *(u16 *)(out_buf + i); @@ -1084,6 +1131,11 @@ skip_bitflip: afl->stage_cur_val = j; *(u16 *)(out_buf + i) = orig + j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH16+-%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1098,6 +1150,11 @@ skip_bitflip: afl->stage_cur_val = -j; *(u16 *)(out_buf + i) = orig - j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH16--%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1116,6 +1173,11 @@ skip_bitflip: afl->stage_cur_val = j; *(u16 *)(out_buf + i) = SWAP16(SWAP16(orig) + j); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH16+BE-%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1130,6 +1192,11 @@ skip_bitflip: afl->stage_cur_val = -j; *(u16 *)(out_buf + i) = SWAP16(SWAP16(orig) - j); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH16_BE-%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1161,7 +1228,7 @@ skip_bitflip: orig_hit_cnt = new_hit_cnt; - for (i = 0; i < len - 3; ++i) { + for (i = 0; i < (u32)len - 3; ++i) { u32 orig = *(u32 *)(out_buf + i); @@ -1193,6 +1260,11 @@ skip_bitflip: afl->stage_cur_val = j; *(u32 *)(out_buf + i) = orig + j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH32+-%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1202,11 +1274,16 @@ skip_bitflip: } - if ((orig & 0xffff) < j && !could_be_bitflip(r2)) { + if ((orig & 0xffff) < (u32)j && !could_be_bitflip(r2)) { afl->stage_cur_val = -j; *(u32 *)(out_buf + i) = orig - j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH32_-%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1225,6 +1302,11 @@ skip_bitflip: afl->stage_cur_val = j; *(u32 *)(out_buf + i) = SWAP32(SWAP32(orig) + j); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH32+BE-%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1234,11 +1316,16 @@ skip_bitflip: } - if ((SWAP32(orig) & 0xffff) < j && !could_be_bitflip(r4)) { + if ((SWAP32(orig) & 0xffff) < (u32)j && !could_be_bitflip(r4)) { afl->stage_cur_val = -j; *(u32 *)(out_buf + i) = SWAP32(SWAP32(orig) - j); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s ARITH32_BE-%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1276,7 +1363,7 @@ skip_arith: /* Setting 8-bit integers. */ - for (i = 0; i < len; ++i) { + for (i = 0; i < (u32)len; ++i) { u8 orig = out_buf[i]; @@ -1291,7 +1378,7 @@ skip_arith: afl->stage_cur_byte = i; - for (j = 0; j < sizeof(interesting_8); ++j) { + for (j = 0; j < (u32)sizeof(interesting_8); ++j) { /* Skip if the value could be a product of bitflips or arithmetics. */ @@ -1306,6 +1393,11 @@ skip_arith: afl->stage_cur_val = interesting_8[j]; out_buf[i] = interesting_8[j]; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s INTERESTING8_%u_%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } out_buf[i] = orig; @@ -1361,6 +1453,11 @@ skip_arith: *(u16 *)(out_buf + i) = interesting_16[j]; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s INTERESTING16_%u_%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1377,6 +1474,11 @@ skip_arith: afl->stage_val_type = STAGE_VAL_BE; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s INTERESTING16BE_%u_%u", afl->queue_cur->fname, i, j); +#endif + *(u16 *)(out_buf + i) = SWAP16(interesting_16[j]); if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1440,6 +1542,11 @@ skip_arith: *(u32 *)(out_buf + i) = interesting_32[j]; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s INTERESTING32_%u_%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1456,6 +1563,11 @@ skip_arith: afl->stage_val_type = STAGE_VAL_BE; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s INTERESTING32BE_%u_%u", afl->queue_cur->fname, i, j); +#endif + *(u32 *)(out_buf + i) = SWAP32(interesting_32[j]); if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1496,7 +1608,7 @@ skip_interest: orig_hit_cnt = new_hit_cnt; - for (i = 0; i < len; ++i) { + for (i = 0; i < (u32)len; ++i) { u32 last_len = 0; @@ -1509,13 +1621,13 @@ skip_interest: for (j = 0; j < afl->extras_cnt; ++j) { - /* Skip extras probabilistically if afl->extras_cnt > MAX_DET_EXTRAS. Also - skip them if there's no room to insert the payload, if the token + /* Skip extras probabilistically if afl->extras_cnt > AFL_MAX_DET_EXTRAS. + Also skip them if there's no room to insert the payload, if the token is redundant, or if its entire span has no bytes set in the effector map. */ - if ((afl->extras_cnt > MAX_DET_EXTRAS && - rand_below(afl, afl->extras_cnt) >= MAX_DET_EXTRAS) || + if ((afl->extras_cnt > afl->max_det_extras && + rand_below(afl, afl->extras_cnt) >= afl->max_det_extras) || afl->extras[j].len > len - i || !memcmp(afl->extras[j].data, out_buf + i, afl->extras[j].len) || !memchr(eff_map + EFF_APOS(i), 1, @@ -1529,6 +1641,11 @@ skip_interest: last_len = afl->extras[j].len; memcpy(out_buf + i, afl->extras[j].data, last_len); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s EXTRAS_overwrite-%u-%u", afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1554,9 +1671,10 @@ skip_interest: orig_hit_cnt = new_hit_cnt; - ex_tmp = ck_maybe_grow(BUF_PARAMS(ex), len + MAX_DICT_FILE); + ex_tmp = afl_realloc(AFL_BUF_PARAM(ex), len + MAX_DICT_FILE); + if (unlikely(!ex_tmp)) { PFATAL("alloc"); } - for (i = 0; i <= len; ++i) { + for (i = 0; i <= (u32)len; ++i) { afl->stage_cur_byte = i; @@ -1575,6 +1693,11 @@ skip_interest: /* Copy tail */ memcpy(ex_tmp + i + afl->extras[j].len, out_buf + i, len - i); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s EXTRAS_insert-%u-%u", + afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, ex_tmp, len + afl->extras[j].len)) { goto abandon_entry; @@ -1602,19 +1725,20 @@ skip_user_extras: afl->stage_name = "auto extras (over)"; afl->stage_short = "ext_AO"; afl->stage_cur = 0; - afl->stage_max = MIN(afl->a_extras_cnt, USE_AUTO_EXTRAS) * len; + afl->stage_max = MIN(afl->a_extras_cnt, (u32)USE_AUTO_EXTRAS) * len; afl->stage_val_type = STAGE_VAL_NONE; orig_hit_cnt = new_hit_cnt; - for (i = 0; i < len; ++i) { + for (i = 0; i < (u32)len; ++i) { u32 last_len = 0; afl->stage_cur_byte = i; - for (j = 0; j < MIN(afl->a_extras_cnt, USE_AUTO_EXTRAS); ++j) { + u32 min_extra_len = MIN(afl->a_extras_cnt, (u32)USE_AUTO_EXTRAS); + for (j = 0; j < min_extra_len; ++j) { /* See the comment in the earlier code; extras are sorted by size. */ @@ -1631,6 +1755,11 @@ skip_user_extras: last_len = afl->a_extras[j].len; memcpy(out_buf + i, afl->a_extras[j].data, last_len); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s AUTO_EXTRAS_overwrite-%u-%u", afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -1670,109 +1799,117 @@ custom_mutator_stage: if (afl->stage_max < HAVOC_MIN) { afl->stage_max = HAVOC_MIN; } - const u32 max_seed_size = MAX_FILE; + const u32 max_seed_size = MAX_FILE, saved_max = afl->stage_max; orig_hit_cnt = afl->queued_paths + afl->unique_crashes; +#ifdef INTROSPECTION + afl->mutation[0] = 0; +#endif + LIST_FOREACH(&afl->custom_mutator_list, struct custom_mutator, { if (el->afl_custom_fuzz) { - has_custom_fuzz = true; + afl->current_custom_fuzz = el; - for (afl->stage_cur = 0; afl->stage_cur < afl->stage_max; - ++afl->stage_cur) { + if (el->afl_custom_fuzz_count) { - struct queue_entry *target; - u32 tid; - u8 * new_buf; + afl->stage_max = el->afl_custom_fuzz_count(el->data, out_buf, len); - retry_external_pick: - /* Pick a random other queue entry for passing to external API */ + } else { - do { + afl->stage_max = saved_max; - tid = rand_below(afl, afl->queued_paths); + } - } while (tid == afl->current_entry && afl->queued_paths > 1); + has_custom_fuzz = true; - target = afl->queue; + afl->stage_short = el->name_short; - while (tid >= 100) { + if (afl->stage_max) { - target = target->next_100; - tid -= 100; + for (afl->stage_cur = 0; afl->stage_cur < afl->stage_max; + ++afl->stage_cur) { - } + struct queue_entry *target = NULL; + u32 tid; + u8 * new_buf = NULL; + u32 target_len = 0; - while (tid--) { + /* check if splicing makes sense yet (enough entries) */ + if (likely(afl->ready_for_splicing_count > 1)) { - target = target->next; + /* Pick a random other queue entry for passing to external API + that has the necessary length */ - } + do { - /* Make sure that the target has a reasonable length. */ + tid = rand_below(afl, afl->queued_paths); - while (target && (target->len < 2 || target == afl->queue_cur) && - afl->queued_paths > 3) { + } while (unlikely(tid == afl->current_entry || - target = target->next; - ++afl->splicing_with; + afl->queue_buf[tid]->len < 4)); - } + target = afl->queue_buf[tid]; + afl->splicing_with = tid; - if (!target) { goto retry_external_pick; } + /* Read the additional testcase into a new buffer. */ + new_buf = queue_testcase_get(afl, target); + target_len = target->len; - /* Read the additional testcase into a new buffer. */ - fd = open(target->fname, O_RDONLY); - if (unlikely(fd < 0)) { PFATAL("Unable to open '%s'", target->fname); } + } - new_buf = ck_maybe_grow(BUF_PARAMS(out_scratch), target->len); - ck_read(fd, new_buf, target->len, target->fname); - close(fd); + u8 *mutated_buf = NULL; - u8 *mutated_buf = NULL; + size_t mutated_size = + el->afl_custom_fuzz(el->data, out_buf, len, &mutated_buf, new_buf, + target_len, max_seed_size); - size_t mutated_size = - el->afl_custom_fuzz(el->data, out_buf, len, &mutated_buf, new_buf, - target->len, max_seed_size); + if (unlikely(!mutated_buf)) { - if (unlikely(!mutated_buf)) { + FATAL("Error in custom_fuzz. Size returned: %zu", mutated_size); - FATAL("Error in custom_fuzz. Size returned: %zd", mutated_size); + } - } + if (mutated_size > 0) { - if (mutated_size > 0) { + if (common_fuzz_stuff(afl, mutated_buf, (u32)mutated_size)) { - if (common_fuzz_stuff(afl, mutated_buf, (u32)mutated_size)) { + goto abandon_entry; - goto abandon_entry; + } - } + if (!el->afl_custom_fuzz_count) { - /* If we're finding new stuff, let's run for a bit longer, limits - permitting. */ + /* If we're finding new stuff, let's run for a bit longer, limits + permitting. */ - if (afl->queued_paths != havoc_queued) { + if (afl->queued_paths != havoc_queued) { - if (perf_score <= afl->havoc_max_mult * 100) { + if (perf_score <= afl->havoc_max_mult * 100) { - afl->stage_max *= 2; - perf_score *= 2; + afl->stage_max *= 2; + perf_score *= 2; - } + } - havoc_queued = afl->queued_paths; + havoc_queued = afl->queued_paths; + + } + + } } - } + /* `(afl->)out_buf` may have been changed by the call to custom_fuzz + */ + /* TODO: Only do this when `mutated_buf` == `out_buf`? Branch vs + * Memcpy. + */ + memcpy(out_buf, in_buf, len); - /* `(afl->)out_buf` may have been changed by the call to custom_fuzz */ - /* TODO: Only do this when `mutated_buf` == `out_buf`? Branch vs Memcpy. - */ - memcpy(out_buf, in_buf, len); + } } @@ -1780,6 +1917,8 @@ custom_mutator_stage: }); + afl->current_custom_fuzz = NULL; + if (!has_custom_fuzz) goto havoc_stage; new_hit_cnt = afl->queued_paths + afl->unique_crashes; @@ -1860,25 +1999,37 @@ havoc_stage: u32 r_max, r; - if (unlikely(afl->expand_havoc)) { + r_max = 15 + ((afl->extras_cnt + afl->a_extras_cnt) ? 2 : 0); + + if (unlikely(afl->expand_havoc && afl->ready_for_splicing_count > 1)) { /* add expensive havoc cases here, they are activated after a full cycle without finds happened */ - r_max = 16 + ((afl->extras_cnt + afl->a_extras_cnt) ? 2 : 0); + r_max++; - } else { + } + + if (unlikely(get_cur_time() - afl->last_path_time > 5000 && + afl->ready_for_splicing_count > 1)) { + + /* add expensive havoc cases here if there is no findings in the last 5s */ - r_max = 15 + ((afl->extras_cnt + afl->a_extras_cnt) ? 2 : 0); + r_max++; } for (afl->stage_cur = 0; afl->stage_cur < afl->stage_max; ++afl->stage_cur) { - u32 use_stacking = 1 << (1 + rand_below(afl, HAVOC_STACK_POW2)); + u32 use_stacking = 1 << (1 + rand_below(afl, afl->havoc_stack_pow2)); afl->stage_cur_val = use_stacking; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s HAVOC-%u", + afl->queue_cur->fname, use_stacking); +#endif + for (i = 0; i < use_stacking; ++i) { if (afl->custom_mutators_count) { @@ -1893,7 +2044,7 @@ havoc_stage: el->data, out_buf, temp_len, &custom_havoc_buf, MAX_FILE); if (unlikely(!custom_havoc_buf)) { - FATAL("Error in custom_havoc (return %zd)", new_len); + FATAL("Error in custom_havoc (return %zu)", new_len); } @@ -1902,7 +2053,8 @@ havoc_stage: temp_len = new_len; if (out_buf != custom_havoc_buf) { - ck_maybe_grow(BUF_PARAMS(out), temp_len); + afl_realloc(AFL_BUF_PARAM(out), temp_len); + if (unlikely(!afl->out_buf)) { PFATAL("alloc"); } memcpy(out_buf, custom_havoc_buf, temp_len); } @@ -1921,6 +2073,10 @@ havoc_stage: /* Flip a single bit somewhere. Spooky! */ +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " FLIP_BIT1"); + strcat(afl->mutation, afl->m_tmp); +#endif FLIP_BIT(out_buf, rand_below(afl, temp_len << 3)); break; @@ -1928,6 +2084,10 @@ havoc_stage: /* Set byte to interesting value. */ +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING8"); + strcat(afl->mutation, afl->m_tmp); +#endif out_buf[rand_below(afl, temp_len)] = interesting_8[rand_below(afl, sizeof(interesting_8))]; break; @@ -1940,11 +2100,19 @@ havoc_stage: if (rand_below(afl, 2)) { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING16"); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + rand_below(afl, temp_len - 1)) = interesting_16[rand_below(afl, sizeof(interesting_16) >> 1)]; } else { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING16BE"); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + rand_below(afl, temp_len - 1)) = SWAP16( interesting_16[rand_below(afl, sizeof(interesting_16) >> 1)]); @@ -1960,11 +2128,19 @@ havoc_stage: if (rand_below(afl, 2)) { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING32"); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + rand_below(afl, temp_len - 3)) = interesting_32[rand_below(afl, sizeof(interesting_32) >> 2)]; } else { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING32BE"); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + rand_below(afl, temp_len - 3)) = SWAP32( interesting_32[rand_below(afl, sizeof(interesting_32) >> 2)]); @@ -1976,6 +2152,10 @@ havoc_stage: /* Randomly subtract from byte. */ +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH8_"); + strcat(afl->mutation, afl->m_tmp); +#endif out_buf[rand_below(afl, temp_len)] -= 1 + rand_below(afl, ARITH_MAX); break; @@ -1983,6 +2163,10 @@ havoc_stage: /* Randomly add to byte. */ +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH8+"); + strcat(afl->mutation, afl->m_tmp); +#endif out_buf[rand_below(afl, temp_len)] += 1 + rand_below(afl, ARITH_MAX); break; @@ -1996,6 +2180,10 @@ havoc_stage: u32 pos = rand_below(afl, temp_len - 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH16_-%u", pos); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + pos) -= 1 + rand_below(afl, ARITH_MAX); } else { @@ -2003,6 +2191,11 @@ havoc_stage: u32 pos = rand_below(afl, temp_len - 1); u16 num = 1 + rand_below(afl, ARITH_MAX); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH16_BE-%u_%u", pos, + num); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + pos) = SWAP16(SWAP16(*(u16 *)(out_buf + pos)) - num); @@ -2020,6 +2213,10 @@ havoc_stage: u32 pos = rand_below(afl, temp_len - 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH16+-%u", pos); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + pos) += 1 + rand_below(afl, ARITH_MAX); } else { @@ -2027,6 +2224,11 @@ havoc_stage: u32 pos = rand_below(afl, temp_len - 1); u16 num = 1 + rand_below(afl, ARITH_MAX); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH16+BE-%u_%u", pos, + num); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + pos) = SWAP16(SWAP16(*(u16 *)(out_buf + pos)) + num); @@ -2044,6 +2246,10 @@ havoc_stage: u32 pos = rand_below(afl, temp_len - 3); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH32_-%u", pos); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + pos) -= 1 + rand_below(afl, ARITH_MAX); } else { @@ -2051,6 +2257,11 @@ havoc_stage: u32 pos = rand_below(afl, temp_len - 3); u32 num = 1 + rand_below(afl, ARITH_MAX); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH32_BE-%u-%u", pos, + num); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + pos) = SWAP32(SWAP32(*(u32 *)(out_buf + pos)) - num); @@ -2068,6 +2279,10 @@ havoc_stage: u32 pos = rand_below(afl, temp_len - 3); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH32+-%u", pos); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + pos) += 1 + rand_below(afl, ARITH_MAX); } else { @@ -2075,6 +2290,11 @@ havoc_stage: u32 pos = rand_below(afl, temp_len - 3); u32 num = 1 + rand_below(afl, ARITH_MAX); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH32+BE-%u-%u", pos, + num); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + pos) = SWAP32(SWAP32(*(u32 *)(out_buf + pos)) + num); @@ -2088,6 +2308,10 @@ havoc_stage: why not. We use XOR with 1-255 to eliminate the possibility of a no-op. */ +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " RAND8"); + strcat(afl->mutation, afl->m_tmp); +#endif out_buf[rand_below(afl, temp_len)] ^= 1 + rand_below(afl, 255); break; @@ -2107,6 +2331,11 @@ havoc_stage: del_from = rand_below(afl, temp_len - del_len + 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " DEL-%u-%u", del_from, + del_len); + strcat(afl->mutation, afl->m_tmp); +#endif memmove(out_buf + del_from, out_buf + del_from + del_len, temp_len - del_from - del_len); @@ -2126,7 +2355,7 @@ havoc_stage: u32 clone_from, clone_to, clone_len; u8 *new_buf; - if (actually_clone) { + if (likely(actually_clone)) { clone_len = choose_block_len(afl, temp_len); clone_from = rand_below(afl, temp_len - clone_len + 1); @@ -2140,8 +2369,15 @@ havoc_stage: clone_to = rand_below(afl, temp_len); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " CLONE-%s-%u-%u-%u", + actually_clone ? "clone" : "insert", clone_from, clone_to, + clone_len); + strcat(afl->mutation, afl->m_tmp); +#endif new_buf = - ck_maybe_grow(BUF_PARAMS(out_scratch), temp_len + clone_len); + afl_realloc(AFL_BUF_PARAM(out_scratch), temp_len + clone_len); + if (unlikely(!new_buf)) { PFATAL("alloc"); } /* Head */ @@ -2149,7 +2385,7 @@ havoc_stage: /* Inserted part */ - if (actually_clone) { + if (likely(actually_clone)) { memcpy(new_buf + clone_to, out_buf + clone_from, clone_len); @@ -2166,9 +2402,8 @@ havoc_stage: memcpy(new_buf + clone_to + clone_len, out_buf + clone_to, temp_len - clone_to); - swap_bufs(BUF_PARAMS(out), BUF_PARAMS(out_scratch)); out_buf = new_buf; - new_buf = NULL; + afl_swap_bufs(AFL_BUF_PARAM(out), AFL_BUF_PARAM(out_scratch)); temp_len += clone_len; } @@ -2189,16 +2424,27 @@ havoc_stage: copy_from = rand_below(afl, temp_len - copy_len + 1); copy_to = rand_below(afl, temp_len - copy_len + 1); - if (rand_below(afl, 4)) { + if (likely(rand_below(afl, 4))) { - if (copy_from != copy_to) { + if (likely(copy_from != copy_to)) { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " OVERWRITE_COPY-%u-%u-%u", copy_from, copy_to, + copy_len); + strcat(afl->mutation, afl->m_tmp); +#endif memmove(out_buf + copy_to, out_buf + copy_from, copy_len); } } else { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " OVERWRITE_FIXED-%u-%u-%u", copy_from, copy_to, copy_len); + strcat(afl->mutation, afl->m_tmp); +#endif memset(out_buf + copy_to, rand_below(afl, 2) ? rand_below(afl, 256) : out_buf[rand_below(afl, temp_len)], @@ -2229,11 +2475,15 @@ havoc_stage: u32 use_extra = rand_below(afl, afl->a_extras_cnt); u32 extra_len = afl->a_extras[use_extra].len; - u32 insert_at; if (extra_len > temp_len) { break; } - insert_at = rand_below(afl, temp_len - extra_len + 1); + u32 insert_at = rand_below(afl, temp_len - extra_len + 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " AUTO_EXTRA_OVERWRITE-%u-%u", insert_at, extra_len); + strcat(afl->mutation, afl->m_tmp); +#endif memcpy(out_buf + insert_at, afl->a_extras[use_extra].data, extra_len); @@ -2243,11 +2493,15 @@ havoc_stage: u32 use_extra = rand_below(afl, afl->extras_cnt); u32 extra_len = afl->extras[use_extra].len; - u32 insert_at; if (extra_len > temp_len) { break; } - insert_at = rand_below(afl, temp_len - extra_len + 1); + u32 insert_at = rand_below(afl, temp_len - extra_len + 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " EXTRA_OVERWRITE-%u-%u", insert_at, extra_len); + strcat(afl->mutation, afl->m_tmp); +#endif memcpy(out_buf + insert_at, afl->extras[use_extra].data, extra_len); @@ -2270,18 +2524,29 @@ havoc_stage: use_extra = rand_below(afl, afl->a_extras_cnt); extra_len = afl->a_extras[use_extra].len; ptr = afl->a_extras[use_extra].data; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " AUTO_EXTRA_INSERT-%u-%u", insert_at, extra_len); + strcat(afl->mutation, afl->m_tmp); +#endif } else { use_extra = rand_below(afl, afl->extras_cnt); extra_len = afl->extras[use_extra].len; ptr = afl->extras[use_extra].data; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " EXTRA_INSERT-%u-%u", + insert_at, extra_len); + strcat(afl->mutation, afl->m_tmp); +#endif } if (temp_len + extra_len >= MAX_FILE) { break; } - out_buf = ck_maybe_grow(BUF_PARAMS(out), temp_len + extra_len); + out_buf = afl_realloc(AFL_BUF_PARAM(out), temp_len + extra_len); + if (unlikely(!out_buf)) { PFATAL("alloc"); } /* Tail */ memmove(out_buf + insert_at + extra_len, out_buf + insert_at, @@ -2308,54 +2573,24 @@ havoc_stage: /* Overwrite bytes with a randomly selected chunk from another testcase or insert that chunk. */ - if (afl->queued_paths < 4) break; - /* Pick a random queue entry and seek to it. */ u32 tid; - do - tid = rand_below(afl, afl->queued_paths); - while (tid == afl->current_entry); - - struct queue_entry *target = afl->queue_buf[tid]; - - /* Make sure that the target has a reasonable length. */ - - while (target && (target->len < 2 || target == afl->queue_cur)) - target = target->next; - - if (!target) break; - - /* Read the testcase into a new buffer. */ - - fd = open(target->fname, O_RDONLY); - - if (unlikely(fd < 0)) { + do { - PFATAL("Unable to open '%s'", target->fname); - - } - - u32 new_len = target->len; - u8 *new_buf = ck_maybe_grow(BUF_PARAMS(in_scratch), new_len); - - ck_read(fd, new_buf, new_len, target->fname); - - close(fd); + tid = rand_below(afl, afl->queued_paths); - u8 overwrite = 0; - if (temp_len >= 2 && rand_below(afl, 2)) - overwrite = 1; - else if (temp_len + HAVOC_BLK_XL >= MAX_FILE) { + } while (tid == afl->current_entry || afl->queue_buf[tid]->len < 4); - if (temp_len >= 2) - overwrite = 1; - else - break; + /* Get the testcase for splicing. */ + struct queue_entry *target = afl->queue_buf[tid]; + u32 new_len = target->len; + u8 * new_buf = queue_testcase_get(afl, target); - } + if ((temp_len >= 2 && rand_below(afl, 2)) || + temp_len + HAVOC_BLK_XL >= MAX_FILE) { - if (overwrite) { + /* overwrite mode */ u32 copy_from, copy_to, copy_len; @@ -2365,20 +2600,34 @@ havoc_stage: copy_from = rand_below(afl, new_len - copy_len + 1); copy_to = rand_below(afl, temp_len - copy_len + 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " SPLICE_OVERWRITE-%u-%u-%u-%s", copy_from, copy_to, + copy_len, target->fname); + strcat(afl->mutation, afl->m_tmp); +#endif memmove(out_buf + copy_to, new_buf + copy_from, copy_len); } else { + /* insert mode */ + u32 clone_from, clone_to, clone_len; clone_len = choose_block_len(afl, new_len); clone_from = rand_below(afl, new_len - clone_len + 1); + clone_to = rand_below(afl, temp_len + 1); - clone_to = rand_below(afl, temp_len); - - u8 *temp_buf = - ck_maybe_grow(BUF_PARAMS(out_scratch), temp_len + clone_len); + u8 *temp_buf = afl_realloc(AFL_BUF_PARAM(out_scratch), + temp_len + clone_len + 1); + if (unlikely(!temp_buf)) { PFATAL("alloc"); } +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " SPLICE_INSERT-%u-%u-%u-%s", clone_from, clone_to, + clone_len, target->fname); + strcat(afl->mutation, afl->m_tmp); +#endif /* Head */ memcpy(temp_buf, out_buf, clone_to); @@ -2391,8 +2640,8 @@ havoc_stage: memcpy(temp_buf + clone_to + clone_len, out_buf + clone_to, temp_len - clone_to); - swap_bufs(BUF_PARAMS(out), BUF_PARAMS(out_scratch)); out_buf = temp_buf; + afl_swap_bufs(AFL_BUF_PARAM(out), AFL_BUF_PARAM(out_scratch)); temp_len += clone_len; } @@ -2412,7 +2661,8 @@ havoc_stage: /* out_buf might have been mangled a bit, so let's restore it to its original size and shape. */ - out_buf = ck_maybe_grow(BUF_PARAMS(out), len); + out_buf = afl_realloc(AFL_BUF_PARAM(out), len); + if (unlikely(!out_buf)) { PFATAL("alloc"); } temp_len = len; memcpy(out_buf, in_buf, len); @@ -2462,7 +2712,7 @@ havoc_stage: retry_splicing: if (afl->use_splicing && splice_cycle++ < SPLICE_CYCLES && - afl->queued_paths > 1 && afl->queue_cur->len > 1) { + afl->ready_for_splicing_count > 1 && afl->queue_cur->len >= 4) { struct queue_entry *target; u32 tid, split_at; @@ -2485,39 +2735,18 @@ retry_splicing: tid = rand_below(afl, afl->queued_paths); - } while (tid == afl->current_entry); + } while (tid == afl->current_entry || afl->queue_buf[tid]->len < 4); + /* Get the testcase */ afl->splicing_with = tid; target = afl->queue_buf[tid]; - - /* Make sure that the target has a reasonable length. */ - - while (target && (target->len < 2 || target == afl->queue_cur)) { - - target = target->next; - ++afl->splicing_with; - - } - - if (!target) { goto retry_splicing; } - - /* Read the testcase into a new buffer. */ - - fd = open(target->fname, O_RDONLY); - - if (unlikely(fd < 0)) { PFATAL("Unable to open '%s'", target->fname); } - - new_buf = ck_maybe_grow(BUF_PARAMS(in_scratch), target->len); - - ck_read(fd, new_buf, target->len, target->fname); - - close(fd); + new_buf = queue_testcase_get(afl, target); /* Find a suitable splicing location, somewhere between the first and the last differing byte. Bail out if the difference is just a single byte or so. */ - locate_diffs(in_buf, new_buf, MIN(len, target->len), &f_diff, &l_diff); + locate_diffs(in_buf, new_buf, MIN(len, (s64)target->len), &f_diff, &l_diff); if (f_diff < 0 || l_diff < 2 || f_diff == l_diff) { goto retry_splicing; } @@ -2528,17 +2757,17 @@ retry_splicing: /* Do the thing. */ len = target->len; - memcpy(new_buf, in_buf, split_at); - swap_bufs(BUF_PARAMS(in), BUF_PARAMS(in_scratch)); - in_buf = new_buf; - - out_buf = ck_maybe_grow(BUF_PARAMS(out), len); + afl->in_scratch_buf = afl_realloc(AFL_BUF_PARAM(in_scratch), len); + memcpy(afl->in_scratch_buf, in_buf, split_at); + memcpy(afl->in_scratch_buf + split_at, new_buf, len - split_at); + in_buf = afl->in_scratch_buf; + afl_swap_bufs(AFL_BUF_PARAM(in), AFL_BUF_PARAM(in_scratch)); + + out_buf = afl_realloc(AFL_BUF_PARAM(out), len); + if (unlikely(!out_buf)) { PFATAL("alloc"); } memcpy(out_buf, in_buf, len); goto custom_mutator_stage; - /* ???: While integrating Python module, the author decided to jump to - python stage, but the reason behind this is not clear.*/ - // goto havoc_stage; } @@ -2555,18 +2784,21 @@ abandon_entry: cycle and have not seen this entry before. */ if (!afl->stop_soon && !afl->queue_cur->cal_failed && - (afl->queue_cur->was_fuzzed == 0 || afl->queue_cur->fuzz_level == 0)) { + (afl->queue_cur->was_fuzzed == 0 || afl->queue_cur->fuzz_level == 0) && + !afl->queue_cur->disabled) { - --afl->pending_not_fuzzed; - afl->queue_cur->was_fuzzed = 1; - if (afl->queue_cur->favored) { --afl->pending_favored; } + if (!afl->queue_cur->was_fuzzed) { - } + --afl->pending_not_fuzzed; + afl->queue_cur->was_fuzzed = 1; + if (afl->queue_cur->favored) { --afl->pending_favored; } - ++afl->queue_cur->fuzz_level; + } - munmap(orig_in, afl->queue_cur->len); + } + ++afl->queue_cur->fuzz_level; + orig_in = NULL; return ret_val; #undef FLIP_BIT @@ -2587,7 +2819,9 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { } - s32 len, fd, temp_len, i, j; + u32 len, temp_len; + u32 i; + u32 j; u8 *in_buf, *out_buf, *orig_in, *ex_tmp, *eff_map = 0; u64 havoc_queued = 0, orig_hit_cnt, new_hit_cnt = 0, cur_ms_lv, prev_cksum; u32 splice_cycle = 0, perf_score = 100, orig_perf, eff_cnt = 1; @@ -2606,13 +2840,14 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { #else - if (afl->pending_favored) { + if (likely(afl->pending_favored)) { /* If we have any favored, non-fuzzed new arrivals in the queue, possibly skip to them at the expense of already-fuzzed or non-favored cases. */ - if ((afl->queue_cur->was_fuzzed || !afl->queue_cur->favored) && + if (((afl->queue_cur->was_fuzzed > 0 || afl->queue_cur->fuzz_level > 0) || + !afl->queue_cur->favored) && rand_below(afl, 100) < SKIP_TO_NEW_PROB) { return 1; @@ -2627,13 +2862,14 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { The odds of skipping stuff are higher for already-fuzzed inputs and lower for never-fuzzed entries. */ - if (afl->queue_cycle > 1 && !afl->queue_cur->was_fuzzed) { + if (afl->queue_cycle > 1 && + (afl->queue_cur->fuzz_level == 0 || afl->queue_cur->was_fuzzed)) { - if (rand_below(afl, 100) < SKIP_NFAV_NEW_PROB) { return 1; } + if (likely(rand_below(afl, 100) < SKIP_NFAV_NEW_PROB)) { return 1; } } else { - if (rand_below(afl, 100) < SKIP_NFAV_OLD_PROB) { return 1; } + if (likely(rand_below(afl, 100) < SKIP_NFAV_OLD_PROB)) { return 1; } } @@ -2650,28 +2886,11 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { } /* Map the test case into memory. */ - - fd = open(afl->queue_cur->fname, O_RDONLY); - - if (fd < 0) { PFATAL("Unable to open '%s'", afl->queue_cur->fname); } - + orig_in = in_buf = queue_testcase_get(afl, afl->queue_cur); len = afl->queue_cur->len; - orig_in = in_buf = mmap(0, len, PROT_READ | PROT_WRITE, MAP_PRIVATE, fd, 0); - - if (orig_in == MAP_FAILED) { - - PFATAL("Unable to mmap '%s'", afl->queue_cur->fname); - - } - - close(fd); - - /* We could mmap() out_buf as MAP_PRIVATE, but we end up clobbering every - single byte anyway, so it wouldn't give us any performance or memory usage - benefits. */ - - out_buf = ck_maybe_grow(BUF_PARAMS(out), len); + out_buf = afl_realloc(AFL_BUF_PARAM(out), len); + if (unlikely(!out_buf)) { PFATAL("alloc"); } afl->subseq_tmouts = 0; @@ -2681,7 +2900,7 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { * CALIBRATION (only if failed earlier on) * *******************************************/ - if (afl->queue_cur->cal_failed) { + if (unlikely(afl->queue_cur->cal_failed)) { u8 res = FSRV_RUN_TMOUT; @@ -2713,9 +2932,13 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { * TRIMMING * ************/ - if (!afl->non_instrumented_mode && !afl->queue_cur->trim_done) { + if (unlikely(!afl->non_instrumented_mode && !afl->queue_cur->trim_done && + !afl->disable_trim)) { + + u32 old_len = afl->queue_cur->len; u8 res = trim_case(afl, afl->queue_cur, in_buf); + orig_in = in_buf = queue_testcase_get(afl, afl->queue_cur); if (res == FSRV_RUN_ERROR) { @@ -2736,6 +2959,9 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { len = afl->queue_cur->len; + /* maybe current entry is not ready for splicing anymore */ + if (unlikely(len <= 4 && old_len > 4)) --afl->ready_for_splicing_count; + } memcpy(out_buf, in_buf, len); @@ -2744,14 +2970,35 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { * PERFORMANCE SCORE * *********************/ - orig_perf = perf_score = calculate_score(afl, afl->queue_cur); + if (likely(!afl->old_seed_selection)) + orig_perf = perf_score = afl->queue_cur->perf_score; + else + orig_perf = perf_score = calculate_score(afl, afl->queue_cur); - if (afl->shm.cmplog_mode && !afl->queue_cur->fully_colorized) { + if (unlikely(perf_score <= 0)) { goto abandon_entry; } - if (input_to_state_stage(afl, in_buf, out_buf, len, - afl->queue_cur->exec_cksum)) { + if (unlikely(afl->shm.cmplog_mode && + afl->queue_cur->colorized < afl->cmplog_lvl && + (u32)len <= afl->cmplog_max_filesize)) { - goto abandon_entry; + if (unlikely(len < 4)) { + + afl->queue_cur->colorized = CMPLOG_LVL_MAX; + + } else { + + if (afl->cmplog_lvl == 3 || + (afl->cmplog_lvl == 2 && afl->queue_cur->tc_ref) || + !(afl->fsrv.total_execs % afl->queued_paths) || + get_cur_time() - afl->last_path_time > 300000) { + + if (input_to_state_stage(afl, in_buf, out_buf, len)) { + + goto abandon_entry; + + } + + } } @@ -2761,9 +3008,9 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { cur_ms_lv = get_cur_time(); if (!(afl->key_puppet == 0 && - ((cur_ms_lv - afl->last_path_time < afl->limit_time_puppet) || + ((cur_ms_lv - afl->last_path_time < (u32)afl->limit_time_puppet) || (afl->last_crash_time != 0 && - cur_ms_lv - afl->last_crash_time < afl->limit_time_puppet) || + cur_ms_lv - afl->last_crash_time < (u32)afl->limit_time_puppet) || afl->last_path_time == 0))) { afl->key_puppet = 1; @@ -2775,8 +3022,8 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { this entry ourselves (was_fuzzed), or if it has gone through deterministic testing in earlier, resumed runs (passed_det). */ - if (afl->skip_deterministic || afl->queue_cur->was_fuzzed || - afl->queue_cur->passed_det) { + if (likely(afl->skip_deterministic || afl->queue_cur->was_fuzzed || + afl->queue_cur->passed_det)) { goto havoc_stage; @@ -2785,8 +3032,9 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { /* Skip deterministic fuzzing if exec path checksum puts this out of scope for this main instance. */ - if (afl->main_node_max && (afl->queue_cur->exec_cksum % afl->main_node_max) != - afl->main_node_id - 1) { + if (unlikely(afl->main_node_max && + (afl->queue_cur->exec_cksum % afl->main_node_max) != + afl->main_node_id - 1)) { goto havoc_stage; @@ -2825,6 +3073,10 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { FLIP_BIT(out_buf, afl->stage_cur); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_FLIP_BIT1-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } FLIP_BIT(out_buf, afl->stage_cur); @@ -2875,7 +3127,7 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { if (a_len >= MIN_AUTO_EXTRA && a_len <= MAX_AUTO_EXTRA) { - maybe_add_auto((u8 *)afl, a_collect, a_len); + maybe_add_auto(afl, a_collect, a_len); } @@ -2886,7 +3138,7 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { if (a_len >= MIN_AUTO_EXTRA && a_len <= MAX_AUTO_EXTRA) { - maybe_add_auto((u8 *)afl, a_collect, a_len); + maybe_add_auto(afl, a_collect, a_len); } @@ -2934,6 +3186,10 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { FLIP_BIT(out_buf, afl->stage_cur); FLIP_BIT(out_buf, afl->stage_cur + 1); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_FLIP_BIT2-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } FLIP_BIT(out_buf, afl->stage_cur); @@ -2963,6 +3219,10 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { FLIP_BIT(out_buf, afl->stage_cur + 2); FLIP_BIT(out_buf, afl->stage_cur + 3); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_FLIP_BIT4-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } FLIP_BIT(out_buf, afl->stage_cur); @@ -2993,7 +3253,8 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { /* Initialize effector map for the next step (see comments below). Always flag first and last byte as doing something. */ - eff_map = ck_maybe_grow(BUF_PARAMS(eff), EFF_ALEN(len)); + eff_map = afl_realloc(AFL_BUF_PARAM(eff), EFF_ALEN(len)); + if (unlikely(!eff_map)) { PFATAL("alloc"); } eff_map[0] = 1; if (EFF_APOS(len - 1) != 0) { @@ -3017,6 +3278,10 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { out_buf[afl->stage_cur] ^= 0xFF; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_FLIP_BIT8-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } /* We also use this stage to pull off a simple trick: we identify @@ -3058,7 +3323,7 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { whole thing as worth fuzzing, since we wouldn't be saving much time anyway. */ - if (eff_cnt != EFF_ALEN(len) && + if (eff_cnt != (u32)EFF_ALEN(len) && eff_cnt * 100 / EFF_ALEN(len) > EFF_MAX_PERC) { memset(eff_map, 1, EFF_ALEN(len)); @@ -3104,6 +3369,10 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { *(u16 *)(out_buf + i) ^= 0xFFFF; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_FLIP_BIT16-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3142,6 +3411,10 @@ static u8 mopt_common_fuzzing(afl_state_t *afl, MOpt_globals_t MOpt_globals) { *(u32 *)(out_buf + i) ^= 0xFFFFFFFF; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_FLIP_BIT32-%u", + afl->queue_cur->fname, afl->stage_cur); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3173,7 +3446,7 @@ skip_bitflip: orig_hit_cnt = new_hit_cnt; - for (i = 0; i < len; ++i) { + for (i = 0; i < (u32)len; ++i) { u8 orig = out_buf[i]; @@ -3200,6 +3473,10 @@ skip_bitflip: afl->stage_cur_val = j; out_buf[i] = orig + j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_ARITH8+-%u-%u", + afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3216,6 +3493,10 @@ skip_bitflip: afl->stage_cur_val = -j; out_buf[i] = orig - j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_ARITH8_-%u-%u", + afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3280,6 +3561,10 @@ skip_bitflip: afl->stage_cur_val = j; *(u16 *)(out_buf + i) = orig + j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_ARITH16+-%u-%u", + afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3294,6 +3579,10 @@ skip_bitflip: afl->stage_cur_val = -j; *(u16 *)(out_buf + i) = orig - j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_ARITH16_-%u-%u", + afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3312,6 +3601,10 @@ skip_bitflip: afl->stage_cur_val = j; *(u16 *)(out_buf + i) = SWAP16(SWAP16(orig) + j); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_ARITH16+BE-%u-%u", afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3326,6 +3619,10 @@ skip_bitflip: afl->stage_cur_val = -j; *(u16 *)(out_buf + i) = SWAP16(SWAP16(orig) - j); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_ARITH16_BE+%u+%u", afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3389,6 +3686,10 @@ skip_bitflip: afl->stage_cur_val = j; *(u32 *)(out_buf + i) = orig + j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_ARITH32+-%u-%u", + afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3403,6 +3704,10 @@ skip_bitflip: afl->stage_cur_val = -j; *(u32 *)(out_buf + i) = orig - j; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_ARITH32_-%u-%u", + afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3421,6 +3726,10 @@ skip_bitflip: afl->stage_cur_val = j; *(u32 *)(out_buf + i) = SWAP32(SWAP32(orig) + j); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_ARITH32+BE-%u-%u", afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3435,6 +3744,10 @@ skip_bitflip: afl->stage_cur_val = -j; *(u32 *)(out_buf + i) = SWAP32(SWAP32(orig) - j); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_ARITH32_BE-%u-%u", afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3472,7 +3785,7 @@ skip_arith: /* Setting 8-bit integers. */ - for (i = 0; i < len; ++i) { + for (i = 0; i < (u32)len; ++i) { u8 orig = out_buf[i]; @@ -3502,6 +3815,10 @@ skip_arith: afl->stage_cur_val = interesting_8[j]; out_buf[i] = interesting_8[j]; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_INTERESTING8-%u-%u", afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } out_buf[i] = orig; @@ -3557,6 +3874,10 @@ skip_arith: *(u16 *)(out_buf + i) = interesting_16[j]; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_INTERESTING16-%u-%u", afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3573,6 +3894,10 @@ skip_arith: afl->stage_val_type = STAGE_VAL_BE; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_INTERESTING16BE-%u-%u", afl->queue_cur->fname, i, j); +#endif *(u16 *)(out_buf + i) = SWAP16(interesting_16[j]); if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3636,6 +3961,10 @@ skip_arith: *(u32 *)(out_buf + i) = interesting_32[j]; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_INTERESTING32-%u-%u", afl->queue_cur->fname, i, j); +#endif if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3652,6 +3981,10 @@ skip_arith: afl->stage_val_type = STAGE_VAL_BE; +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_INTERESTING32BE-%u-%u", afl->queue_cur->fname, i, j); +#endif *(u32 *)(out_buf + i) = SWAP32(interesting_32[j]); if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3692,7 +4025,7 @@ skip_interest: orig_hit_cnt = new_hit_cnt; - for (i = 0; i < len; ++i) { + for (i = 0; i < (u32)len; ++i) { u32 last_len = 0; @@ -3705,13 +4038,13 @@ skip_interest: for (j = 0; j < afl->extras_cnt; ++j) { - /* Skip extras probabilistically if afl->extras_cnt > MAX_DET_EXTRAS. Also - skip them if there's no room to insert the payload, if the token + /* Skip extras probabilistically if afl->extras_cnt > AFL_MAX_DET_EXTRAS. + Also skip them if there's no room to insert the payload, if the token is redundant, or if its entire span has no bytes set in the effector map. */ - if ((afl->extras_cnt > MAX_DET_EXTRAS && - rand_below(afl, afl->extras_cnt) >= MAX_DET_EXTRAS) || + if ((afl->extras_cnt > afl->max_det_extras && + rand_below(afl, afl->extras_cnt) >= afl->max_det_extras) || afl->extras[j].len > len - i || !memcmp(afl->extras[j].data, out_buf + i, afl->extras[j].len) || !memchr(eff_map + EFF_APOS(i), 1, @@ -3725,6 +4058,11 @@ skip_interest: last_len = afl->extras[j].len; memcpy(out_buf + i, afl->extras[j].data, last_len); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_EXTRAS_overwrite-%u-%u", afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3750,9 +4088,10 @@ skip_interest: orig_hit_cnt = new_hit_cnt; - ex_tmp = ck_maybe_grow(BUF_PARAMS(ex), len + MAX_DICT_FILE); + ex_tmp = afl_realloc(AFL_BUF_PARAM(ex), len + MAX_DICT_FILE); + if (unlikely(!ex_tmp)) { PFATAL("alloc"); } - for (i = 0; i <= len; ++i) { + for (i = 0; i <= (u32)len; ++i) { afl->stage_cur_byte = i; @@ -3771,6 +4110,11 @@ skip_interest: /* Copy tail */ memcpy(ex_tmp + i + afl->extras[j].len, out_buf + i, len - i); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_EXTRAS_insert-%u-%u", afl->queue_cur->fname, i, j); +#endif + if (common_fuzz_stuff(afl, ex_tmp, len + afl->extras[j].len)) { goto abandon_entry; @@ -3798,23 +4142,24 @@ skip_user_extras: afl->stage_name = "auto extras (over)"; afl->stage_short = "ext_AO"; afl->stage_cur = 0; - afl->stage_max = MIN(afl->a_extras_cnt, USE_AUTO_EXTRAS) * len; + afl->stage_max = MIN(afl->a_extras_cnt, (u32)USE_AUTO_EXTRAS) * len; afl->stage_val_type = STAGE_VAL_NONE; orig_hit_cnt = new_hit_cnt; - for (i = 0; i < len; ++i) { + for (i = 0; i < (u32)len; ++i) { u32 last_len = 0; afl->stage_cur_byte = i; - for (j = 0; j < MIN(afl->a_extras_cnt, USE_AUTO_EXTRAS); ++j) { + u32 min_extra_len = MIN(afl->a_extras_cnt, (u32)USE_AUTO_EXTRAS); + for (j = 0; j < min_extra_len; ++j) { /* See the comment in the earlier code; extras are sorted by size. */ - if (afl->a_extras[j].len > len - i || + if ((afl->a_extras[j].len) > (len - i) || !memcmp(afl->a_extras[j].data, out_buf + i, afl->a_extras[j].len) || !memchr(eff_map + EFF_APOS(i), 1, EFF_SPAN_ALEN(i, afl->a_extras[j].len))) { @@ -3827,6 +4172,12 @@ skip_user_extras: last_len = afl->a_extras[j].len; memcpy(out_buf + i, afl->a_extras[j].data, last_len); +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), + "%s MOPT_AUTO_EXTRAS_overwrite-%u-%u", afl->queue_cur->fname, i, + j); +#endif + if (common_fuzz_stuff(afl, out_buf, len)) { goto abandon_entry; } ++afl->stage_cur; @@ -3940,10 +4291,23 @@ pacemaker_fuzzing: havoc_queued = afl->queued_paths; + u32 r_max; + + r_max = 15 + ((afl->extras_cnt + afl->a_extras_cnt) ? 2 : 0); + + if (unlikely(afl->expand_havoc && afl->ready_for_splicing_count > 1)) { + + /* add expensive havoc cases here, they are activated after a full + cycle without finds happened */ + + ++r_max; + + } + for (afl->stage_cur = 0; afl->stage_cur < afl->stage_max; ++afl->stage_cur) { - u32 use_stacking = 1 << (1 + rand_below(afl, HAVOC_STACK_POW2)); + u32 use_stacking = 1 << (1 + rand_below(afl, afl->havoc_stack_pow2)); afl->stage_cur_val = use_stacking; @@ -3953,14 +4317,23 @@ pacemaker_fuzzing: } +#ifdef INTROSPECTION + snprintf(afl->mutation, sizeof(afl->mutation), "%s MOPT_HAVOC-%u", + afl->queue_cur->fname, use_stacking); +#endif + for (i = 0; i < use_stacking; ++i) { - switch (select_algorithm(afl)) { + switch (select_algorithm(afl, r_max)) { case 0: /* Flip a single bit somewhere. Spooky! */ FLIP_BIT(out_buf, rand_below(afl, temp_len << 3)); - MOpt_globals.cycles_v2[STAGE_FLIP1] += 1; + MOpt_globals.cycles_v2[STAGE_FLIP1]++; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " FLIP_BIT1"); + strcat(afl->mutation, afl->m_tmp); +#endif break; case 1: @@ -3968,7 +4341,11 @@ pacemaker_fuzzing: temp_len_puppet = rand_below(afl, (temp_len << 3) - 1); FLIP_BIT(out_buf, temp_len_puppet); FLIP_BIT(out_buf, temp_len_puppet + 1); - MOpt_globals.cycles_v2[STAGE_FLIP2] += 1; + MOpt_globals.cycles_v2[STAGE_FLIP2]++; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " FLIP_BIT2"); + strcat(afl->mutation, afl->m_tmp); +#endif break; case 2: @@ -3978,25 +4355,41 @@ pacemaker_fuzzing: FLIP_BIT(out_buf, temp_len_puppet + 1); FLIP_BIT(out_buf, temp_len_puppet + 2); FLIP_BIT(out_buf, temp_len_puppet + 3); - MOpt_globals.cycles_v2[STAGE_FLIP4] += 1; + MOpt_globals.cycles_v2[STAGE_FLIP4]++; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " FLIP_BIT4"); + strcat(afl->mutation, afl->m_tmp); +#endif break; case 3: if (temp_len < 4) { break; } out_buf[rand_below(afl, temp_len)] ^= 0xFF; - MOpt_globals.cycles_v2[STAGE_FLIP8] += 1; + MOpt_globals.cycles_v2[STAGE_FLIP8]++; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " FLIP_BIT8"); + strcat(afl->mutation, afl->m_tmp); +#endif break; case 4: if (temp_len < 8) { break; } *(u16 *)(out_buf + rand_below(afl, temp_len - 1)) ^= 0xFFFF; - MOpt_globals.cycles_v2[STAGE_FLIP16] += 1; + MOpt_globals.cycles_v2[STAGE_FLIP16]++; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " FLIP_BIT16"); + strcat(afl->mutation, afl->m_tmp); +#endif break; case 5: if (temp_len < 8) { break; } *(u32 *)(out_buf + rand_below(afl, temp_len - 3)) ^= 0xFFFFFFFF; - MOpt_globals.cycles_v2[STAGE_FLIP32] += 1; + MOpt_globals.cycles_v2[STAGE_FLIP32]++; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " FLIP_BIT32"); + strcat(afl->mutation, afl->m_tmp); +#endif break; case 6: @@ -4004,7 +4397,11 @@ pacemaker_fuzzing: 1 + rand_below(afl, ARITH_MAX); out_buf[rand_below(afl, temp_len)] += 1 + rand_below(afl, ARITH_MAX); - MOpt_globals.cycles_v2[STAGE_ARITH8] += 1; + MOpt_globals.cycles_v2[STAGE_ARITH8]++; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH8"); + strcat(afl->mutation, afl->m_tmp); +#endif break; case 7: @@ -4014,11 +4411,20 @@ pacemaker_fuzzing: u32 pos = rand_below(afl, temp_len - 1); *(u16 *)(out_buf + pos) -= 1 + rand_below(afl, ARITH_MAX); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH16-%u", pos); + strcat(afl->mutation, afl->m_tmp); +#endif } else { u32 pos = rand_below(afl, temp_len - 1); u16 num = 1 + rand_below(afl, ARITH_MAX); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH16BE-%u-%u", + pos, num); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + pos) = SWAP16(SWAP16(*(u16 *)(out_buf + pos)) - num); @@ -4028,18 +4434,27 @@ pacemaker_fuzzing: if (rand_below(afl, 2)) { u32 pos = rand_below(afl, temp_len - 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH16+-%u", pos); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + pos) += 1 + rand_below(afl, ARITH_MAX); } else { u32 pos = rand_below(afl, temp_len - 1); u16 num = 1 + rand_below(afl, ARITH_MAX); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH16BE+-%u-%u", + pos, num); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + pos) = SWAP16(SWAP16(*(u16 *)(out_buf + pos)) + num); } - MOpt_globals.cycles_v2[STAGE_ARITH16] += 1; + MOpt_globals.cycles_v2[STAGE_ARITH16]++; break; case 8: @@ -4048,12 +4463,21 @@ pacemaker_fuzzing: if (rand_below(afl, 2)) { u32 pos = rand_below(afl, temp_len - 3); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH32_-%u", pos); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + pos) -= 1 + rand_below(afl, ARITH_MAX); } else { u32 pos = rand_below(afl, temp_len - 3); u32 num = 1 + rand_below(afl, ARITH_MAX); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH32BE_-%u-%u", + pos, num); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + pos) = SWAP32(SWAP32(*(u32 *)(out_buf + pos)) - num); @@ -4064,18 +4488,27 @@ pacemaker_fuzzing: if (rand_below(afl, 2)) { u32 pos = rand_below(afl, temp_len - 3); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH32+-%u", pos); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + pos) += 1 + rand_below(afl, ARITH_MAX); } else { u32 pos = rand_below(afl, temp_len - 3); u32 num = 1 + rand_below(afl, ARITH_MAX); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " ARITH32BE+-%u-%u", + pos, num); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + pos) = SWAP32(SWAP32(*(u32 *)(out_buf + pos)) + num); } - MOpt_globals.cycles_v2[STAGE_ARITH32] += 1; + MOpt_globals.cycles_v2[STAGE_ARITH32]++; break; case 9: @@ -4083,7 +4516,11 @@ pacemaker_fuzzing: if (temp_len < 4) { break; } out_buf[rand_below(afl, temp_len)] = interesting_8[rand_below(afl, sizeof(interesting_8))]; - MOpt_globals.cycles_v2[STAGE_INTEREST8] += 1; + MOpt_globals.cycles_v2[STAGE_INTEREST8]++; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING8"); + strcat(afl->mutation, afl->m_tmp); +#endif break; case 10: @@ -4091,19 +4528,27 @@ pacemaker_fuzzing: if (temp_len < 8) { break; } if (rand_below(afl, 2)) { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING16"); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + rand_below(afl, temp_len - 1)) = interesting_16[rand_below(afl, sizeof(interesting_16) >> 1)]; } else { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING16BE"); + strcat(afl->mutation, afl->m_tmp); +#endif *(u16 *)(out_buf + rand_below(afl, temp_len - 1)) = SWAP16(interesting_16[rand_below( afl, sizeof(interesting_16) >> 1)]); } - MOpt_globals.cycles_v2[STAGE_INTEREST16] += 1; + MOpt_globals.cycles_v2[STAGE_INTEREST16]++; break; case 11: @@ -4113,19 +4558,27 @@ pacemaker_fuzzing: if (rand_below(afl, 2)) { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING32"); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + rand_below(afl, temp_len - 3)) = interesting_32[rand_below(afl, sizeof(interesting_32) >> 2)]; } else { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " INTERESTING32BE"); + strcat(afl->mutation, afl->m_tmp); +#endif *(u32 *)(out_buf + rand_below(afl, temp_len - 3)) = SWAP32(interesting_32[rand_below( afl, sizeof(interesting_32) >> 2)]); } - MOpt_globals.cycles_v2[STAGE_INTEREST32] += 1; + MOpt_globals.cycles_v2[STAGE_INTEREST32]++; break; case 12: @@ -4135,7 +4588,11 @@ pacemaker_fuzzing: possibility of a no-op. */ out_buf[rand_below(afl, temp_len)] ^= 1 + rand_below(afl, 255); - MOpt_globals.cycles_v2[STAGE_RANDOMBYTE] += 1; + MOpt_globals.cycles_v2[STAGE_RANDOMBYTE]++; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " RAND8"); + strcat(afl->mutation, afl->m_tmp); +#endif break; case 13: { @@ -4154,11 +4611,16 @@ pacemaker_fuzzing: del_from = rand_below(afl, temp_len - del_len + 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " DEL-%u%u", del_from, + del_len); + strcat(afl->mutation, afl->m_tmp); +#endif memmove(out_buf + del_from, out_buf + del_from + del_len, temp_len - del_from - del_len); temp_len -= del_len; - MOpt_globals.cycles_v2[STAGE_DELETEBYTE] += 1; + MOpt_globals.cycles_v2[STAGE_DELETEBYTE]++; break; } @@ -4174,7 +4636,7 @@ pacemaker_fuzzing: u32 clone_from, clone_to, clone_len; u8 *new_buf; - if (actually_clone) { + if (likely(actually_clone)) { clone_len = choose_block_len(afl, temp_len); clone_from = rand_below(afl, temp_len - clone_len + 1); @@ -4188,8 +4650,15 @@ pacemaker_fuzzing: clone_to = rand_below(afl, temp_len); - new_buf = ck_maybe_grow(BUF_PARAMS(out_scratch), - temp_len + clone_len); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " CLONE_%s-%u-%u-%u", + actually_clone ? "clone" : "insert", clone_from, + clone_to, clone_len); + strcat(afl->mutation, afl->m_tmp); +#endif + new_buf = afl_realloc(AFL_BUF_PARAM(out_scratch), + temp_len + clone_len); + if (unlikely(!new_buf)) { PFATAL("alloc"); } /* Head */ @@ -4215,10 +4684,10 @@ pacemaker_fuzzing: memcpy(new_buf + clone_to + clone_len, out_buf + clone_to, temp_len - clone_to); - swap_bufs(BUF_PARAMS(out), BUF_PARAMS(out_scratch)); out_buf = new_buf; + afl_swap_bufs(AFL_BUF_PARAM(out), AFL_BUF_PARAM(out_scratch)); temp_len += clone_len; - MOpt_globals.cycles_v2[STAGE_Clone75] += 1; + MOpt_globals.cycles_v2[STAGE_Clone75]++; } @@ -4238,16 +4707,28 @@ pacemaker_fuzzing: copy_from = rand_below(afl, temp_len - copy_len + 1); copy_to = rand_below(afl, temp_len - copy_len + 1); - if (rand_below(afl, 4)) { + if (likely(rand_below(afl, 4))) { - if (copy_from != copy_to) { + if (likely(copy_from != copy_to)) { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " OVERWRITE_COPY-%u-%u-%u", copy_from, copy_to, + copy_len); + strcat(afl->mutation, afl->m_tmp); +#endif memmove(out_buf + copy_to, out_buf + copy_from, copy_len); } } else { +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " OVERWRITE_FIXED-%u-%u-%u", copy_from, copy_to, + copy_len); + strcat(afl->mutation, afl->m_tmp); +#endif memset(out_buf + copy_to, rand_below(afl, 2) ? rand_below(afl, 256) : out_buf[rand_below(afl, temp_len)], @@ -4255,7 +4736,7 @@ pacemaker_fuzzing: } - MOpt_globals.cycles_v2[STAGE_OverWrite75] += 1; + MOpt_globals.cycles_v2[STAGE_OverWrite75]++; break; } /* case 15 */ @@ -4276,9 +4757,14 @@ pacemaker_fuzzing: u32 use_extra = rand_below(afl, afl->a_extras_cnt); u32 extra_len = afl->a_extras[use_extra].len; - if (extra_len > temp_len) break; + if (extra_len > (u32)temp_len) break; u32 insert_at = rand_below(afl, temp_len - extra_len + 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " AUTO_EXTRA_OVERWRITE-%u-%u", insert_at, extra_len); + strcat(afl->mutation, afl->m_tmp); +#endif memcpy(out_buf + insert_at, afl->a_extras[use_extra].data, extra_len); @@ -4289,16 +4775,20 @@ pacemaker_fuzzing: u32 use_extra = rand_below(afl, afl->extras_cnt); u32 extra_len = afl->extras[use_extra].len; - if (extra_len > temp_len) break; + if (extra_len > (u32)temp_len) break; u32 insert_at = rand_below(afl, temp_len - extra_len + 1); +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " EXTRA_OVERWRITE-%u-%u", insert_at, extra_len); + strcat(afl->mutation, afl->m_tmp); +#endif memcpy(out_buf + insert_at, afl->extras[use_extra].data, extra_len); } - afl->stage_cycles_puppet_v2[afl->swarm_now] - [STAGE_OverWriteExtra] += 1; + MOpt_globals.cycles_v2[STAGE_OverWriteExtra]++; break; @@ -4321,18 +4811,29 @@ pacemaker_fuzzing: use_extra = rand_below(afl, afl->a_extras_cnt); extra_len = afl->a_extras[use_extra].len; ptr = afl->a_extras[use_extra].data; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " AUTO_EXTRA_INSERT-%u-%u", insert_at, extra_len); + strcat(afl->mutation, afl->m_tmp); +#endif } else { use_extra = rand_below(afl, afl->extras_cnt); extra_len = afl->extras[use_extra].len; ptr = afl->extras[use_extra].data; +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), " EXTRA_INSERT-%u-%u", + insert_at, extra_len); + strcat(afl->mutation, afl->m_tmp); +#endif } if (temp_len + extra_len >= MAX_FILE) break; - out_buf = ck_maybe_grow(BUF_PARAMS(out), temp_len + extra_len); + out_buf = afl_realloc(AFL_BUF_PARAM(out), temp_len + extra_len); + if (unlikely(!out_buf)) { PFATAL("alloc"); } /* Tail */ memmove(out_buf + insert_at + extra_len, out_buf + insert_at, @@ -4342,17 +4843,98 @@ pacemaker_fuzzing: memcpy(out_buf + insert_at, ptr, extra_len); temp_len += extra_len; - afl->stage_cycles_puppet_v2[afl->swarm_now][STAGE_InsertExtra] += - 1; + MOpt_globals.cycles_v2[STAGE_InsertExtra]++; break; } + default: { + + if (unlikely(afl->ready_for_splicing_count < 2)) break; + + u32 tid; + do { + + tid = rand_below(afl, afl->queued_paths); + + } while (tid == afl->current_entry || + + afl->queue_buf[tid]->len < 4); + + /* Get the testcase for splicing. */ + struct queue_entry *target = afl->queue_buf[tid]; + u32 new_len = target->len; + u8 * new_buf = queue_testcase_get(afl, target); + + if ((temp_len >= 2 && rand_below(afl, 2)) || + temp_len + HAVOC_BLK_XL >= MAX_FILE) { + + /* overwrite mode */ + + u32 copy_from, copy_to, copy_len; + + copy_len = choose_block_len(afl, new_len - 1); + if (copy_len > temp_len) copy_len = temp_len; + + copy_from = rand_below(afl, new_len - copy_len + 1); + copy_to = rand_below(afl, temp_len - copy_len + 1); + +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " SPLICE_OVERWRITE-%u-%u-%u-%s", copy_from, copy_to, + copy_len, target->fname); + strcat(afl->mutation, afl->m_tmp); +#endif + memmove(out_buf + copy_to, new_buf + copy_from, copy_len); + + } else { + + /* insert mode */ + + u32 clone_from, clone_to, clone_len; + + clone_len = choose_block_len(afl, new_len); + clone_from = rand_below(afl, new_len - clone_len + 1); + clone_to = rand_below(afl, temp_len + 1); + + u8 *temp_buf = afl_realloc(AFL_BUF_PARAM(out_scratch), + temp_len + clone_len + 1); + if (unlikely(!temp_buf)) { PFATAL("alloc"); } + +#ifdef INTROSPECTION + snprintf(afl->m_tmp, sizeof(afl->m_tmp), + " SPLICE_INSERT-%u-%u-%u-%s", clone_from, clone_to, + clone_len, target->fname); + strcat(afl->mutation, afl->m_tmp); +#endif + /* Head */ + + memcpy(temp_buf, out_buf, clone_to); + + /* Inserted part */ + + memcpy(temp_buf + clone_to, new_buf + clone_from, clone_len); + + /* Tail */ + memcpy(temp_buf + clone_to + clone_len, out_buf + clone_to, + temp_len - clone_to); + + out_buf = temp_buf; + afl_swap_bufs(AFL_BUF_PARAM(out), AFL_BUF_PARAM(out_scratch)); + temp_len += clone_len; + + } + + MOpt_globals.cycles_v2[STAGE_Splice]++; + break; + + } // end of default: + } /* switch select_algorithm() */ } /* for i=0; i < use_stacking */ - *MOpt_globals.pTime += 1; + ++*MOpt_globals.pTime; u64 temp_total_found = afl->queued_paths + afl->unique_crashes; @@ -4365,7 +4947,8 @@ pacemaker_fuzzing: /* out_buf might have been mangled a bit, so let's restore it to its original size and shape. */ - out_buf = ck_maybe_grow(BUF_PARAMS(out), len); + out_buf = afl_realloc(AFL_BUF_PARAM(out), len); + if (unlikely(!out_buf)) { PFATAL("alloc"); } temp_len = len; memcpy(out_buf, in_buf, len); @@ -4449,8 +5032,9 @@ pacemaker_fuzzing: retry_splicing_puppet: - if (afl->use_splicing && splice_cycle++ < afl->SPLICE_CYCLES_puppet && - afl->queued_paths > 1 && afl->queue_cur->len > 1) { + if (afl->use_splicing && + splice_cycle++ < (u32)afl->SPLICE_CYCLES_puppet && + afl->ready_for_splicing_count > 1 && afl->queue_cur->len >= 4) { struct queue_entry *target; u32 tid, split_at; @@ -4474,46 +5058,13 @@ pacemaker_fuzzing: tid = rand_below(afl, afl->queued_paths); - } while (tid == afl->current_entry); + } while (tid == afl->current_entry || afl->queue_buf[tid]->len < 4); afl->splicing_with = tid; - target = afl->queue; - - while (tid >= 100) { - - target = target->next_100; - tid -= 100; - - } - - while (tid--) { - - target = target->next; - - } - - /* Make sure that the target has a reasonable length. */ - - while (target && (target->len < 2 || target == afl->queue_cur)) { - - target = target->next; - ++afl->splicing_with; - - } - - if (!target) { goto retry_splicing_puppet; } + target = afl->queue_buf[tid]; /* Read the testcase into a new buffer. */ - - fd = open(target->fname, O_RDONLY); - - if (fd < 0) { PFATAL("Unable to open '%s'", target->fname); } - - new_buf = ck_maybe_grow(BUF_PARAMS(in_scratch), target->len); - - ck_read(fd, new_buf, target->len, target->fname); - - close(fd); + new_buf = queue_testcase_get(afl, target); /* Find a suitable splicin g location, somewhere between the first and the last differing byte. Bail out if the difference is just a single @@ -4534,10 +5085,14 @@ pacemaker_fuzzing: /* Do the thing. */ len = target->len; - memcpy(new_buf, in_buf, split_at); - swap_bufs(BUF_PARAMS(in), BUF_PARAMS(in_scratch)); - in_buf = new_buf; - out_buf = ck_maybe_grow(BUF_PARAMS(out), len); + afl->in_scratch_buf = afl_realloc(AFL_BUF_PARAM(in_scratch), len); + memcpy(afl->in_scratch_buf, in_buf, split_at); + memcpy(afl->in_scratch_buf + split_at, new_buf, len - split_at); + in_buf = afl->in_scratch_buf; + afl_swap_bufs(AFL_BUF_PARAM(in), AFL_BUF_PARAM(in_scratch)); + + out_buf = afl_realloc(AFL_BUF_PARAM(out), len); + if (unlikely(!out_buf)) { PFATAL("alloc"); } memcpy(out_buf, in_buf, len); goto havoc_stage_puppet; @@ -4551,7 +5106,7 @@ pacemaker_fuzzing: abandon_entry: abandon_entry_puppet: - if (splice_cycle >= afl->SPLICE_CYCLES_puppet) { + if ((s64)splice_cycle >= afl->SPLICE_CYCLES_puppet) { afl->SPLICE_CYCLES_puppet = (rand_below( @@ -4573,7 +5128,7 @@ pacemaker_fuzzing: // if (afl->queue_cur->favored) --afl->pending_favored; // } - munmap(orig_in, afl->queue_cur->len); + orig_in = NULL; if (afl->key_puppet == 1) { @@ -4729,7 +5284,7 @@ u8 pilot_fuzzing(afl_state_t *afl) { void pso_updating(afl_state_t *afl) { - afl->g_now += 1; + afl->g_now++; if (afl->g_now > afl->g_max) { afl->g_now = 0; } afl->w_now = (afl->w_init - afl->w_end) * (afl->g_max - afl->g_now) / (afl->g_max) + @@ -4870,5 +5425,3 @@ u8 fuzz_one(afl_state_t *afl) { } -#undef BUF_PARAMS - diff --git a/src/afl-fuzz-python.c b/src/afl-fuzz-python.c index 2044c97d..8760194c 100644 --- a/src/afl-fuzz-python.c +++ b/src/afl-fuzz-python.c @@ -30,6 +30,9 @@ static void *unsupported(afl_state_t *afl, unsigned int seed) { + (void)afl; + (void)seed; + FATAL("Python Mutator cannot be called twice yet"); return NULL; @@ -37,9 +40,7 @@ static void *unsupported(afl_state_t *afl, unsigned int seed) { /* sorry for this makro... it just fills in `&py_mutator->something_buf, &py_mutator->something_size`. */ - #define BUF_PARAMS(name) \ - (void **)&((py_mutator_t *)py_mutator)->name##_buf, \ - &((py_mutator_t *)py_mutator)->name##_size + #define BUF_PARAMS(name) (void **)&((py_mutator_t *)py_mutator)->name##_buf static size_t fuzz_py(void *py_mutator, u8 *buf, size_t buf_size, u8 **out_buf, u8 *add_buf, size_t add_buf_size, size_t max_size) { @@ -94,7 +95,8 @@ static size_t fuzz_py(void *py_mutator, u8 *buf, size_t buf_size, u8 **out_buf, mutated_size = PyByteArray_Size(py_value); - *out_buf = ck_maybe_grow(BUF_PARAMS(fuzz), mutated_size); + *out_buf = afl_realloc(BUF_PARAMS(fuzz), mutated_size); + if (unlikely(!*out_buf)) { PFATAL("alloc"); } memcpy(*out_buf, PyByteArray_AsString(py_value), mutated_size); Py_DECREF(py_value); @@ -109,8 +111,41 @@ static size_t fuzz_py(void *py_mutator, u8 *buf, size_t buf_size, u8 **out_buf, } +static const char *custom_describe_py(void * py_mutator, + size_t max_description_len) { + + PyObject *py_args, *py_value; + + py_args = PyTuple_New(1); + + PyLong_FromSize_t(max_description_len); + + /* add_buf */ + py_value = PyLong_FromSize_t(max_description_len); + if (!py_value) { + + Py_DECREF(py_args); + FATAL("Failed to convert arguments"); + + } + + PyTuple_SetItem(py_args, 0, py_value); + + py_value = PyObject_CallObject( + ((py_mutator_t *)py_mutator)->py_functions[PY_FUNC_DESCRIBE], py_args); + + Py_DECREF(py_args); + + if (py_value != NULL) { return PyBytes_AsString(py_value); } + + return NULL; + +} + static py_mutator_t *init_py_module(afl_state_t *afl, u8 *module_name) { + (void)afl; + if (!module_name) { return NULL; } py_mutator_t *py = calloc(1, sizeof(py_mutator_t)); @@ -130,6 +165,18 @@ static py_mutator_t *init_py_module(afl_state_t *afl, u8 *module_name) { PyObject * py_module = py->py_module; PyObject **py_functions = py->py_functions; + // initialize the post process buffer; ensures it's always valid + PyObject *unused_bytes = PyByteArray_FromStringAndSize("OHAI", 4); + if (!unused_bytes) { FATAL("allocation failed!"); } + if (PyObject_GetBuffer(unused_bytes, &py->post_process_buf, PyBUF_SIMPLE) == + -1) { + + FATAL("buffer initialization failed"); + + } + + Py_DECREF(unused_bytes); + if (py_module != NULL) { u8 py_notrim = 0, py_idx; @@ -140,6 +187,10 @@ static py_mutator_t *init_py_module(afl_state_t *afl, u8 *module_name) { py_functions[PY_FUNC_FUZZ] = PyObject_GetAttrString(py_module, "fuzz"); if (!py_functions[PY_FUNC_FUZZ]) py_functions[PY_FUNC_FUZZ] = PyObject_GetAttrString(py_module, "mutate"); + py_functions[PY_FUNC_DESCRIBE] = + PyObject_GetAttrString(py_module, "describe"); + py_functions[PY_FUNC_FUZZ_COUNT] = + PyObject_GetAttrString(py_module, "fuzz_count"); if (!py_functions[PY_FUNC_FUZZ]) WARNF("fuzz function not found in python module"); py_functions[PY_FUNC_POST_PROCESS] = @@ -157,6 +208,8 @@ static py_mutator_t *init_py_module(afl_state_t *afl, u8 *module_name) { PyObject_GetAttrString(py_module, "queue_get"); py_functions[PY_FUNC_QUEUE_NEW_ENTRY] = PyObject_GetAttrString(py_module, "queue_new_entry"); + py_functions[PY_FUNC_INTROSPECTION] = + PyObject_GetAttrString(py_module, "introspection"); py_functions[PY_FUNC_DEINIT] = PyObject_GetAttrString(py_module, "deinit"); if (!py_functions[PY_FUNC_DEINIT]) FATAL("deinit function not found in python module"); @@ -165,27 +218,20 @@ static py_mutator_t *init_py_module(afl_state_t *afl, u8 *module_name) { if (!py_functions[py_idx] || !PyCallable_Check(py_functions[py_idx])) { - if (py_idx == PY_FUNC_POST_PROCESS) { - - // Implenting the post_process API is optional for now - if (PyErr_Occurred()) { PyErr_Print(); } - - } else if (py_idx >= PY_FUNC_INIT_TRIM && py_idx <= PY_FUNC_TRIM) { + if (py_idx >= PY_FUNC_INIT_TRIM && py_idx <= PY_FUNC_TRIM) { // Implementing the trim API is optional for now if (PyErr_Occurred()) { PyErr_Print(); } py_notrim = 1; - } else if ((py_idx >= PY_FUNC_HAVOC_MUTATION) && + } else if (py_idx >= PY_OPTIONAL) { - (py_idx <= PY_FUNC_QUEUE_NEW_ENTRY)) { + // Only _init and _deinit are not optional currently - // Implenting the havoc and queue API is optional for now if (PyErr_Occurred()) { PyErr_Print(); } } else { - if (PyErr_Occurred()) { PyErr_Print(); } fprintf(stderr, "Cannot find/call function with index %d in external " "Python module.\n", @@ -213,6 +259,7 @@ static py_mutator_t *init_py_module(afl_state_t *afl, u8 *module_name) { PyErr_Print(); fprintf(stderr, "Failed to load \"%s\"\n", module_name); + free(py); return NULL; } @@ -247,6 +294,8 @@ void finalize_py_module(void *py_mutator) { static void init_py(afl_state_t *afl, py_mutator_t *py_mutator, unsigned int seed) { + (void)afl; + PyObject *py_args, *py_value; /* Provide the init function a seed for the Python RNG */ @@ -309,8 +358,6 @@ struct custom_mutator *load_custom_mutator_py(afl_state_t *afl, struct custom_mutator *mutator; mutator = ck_alloc(sizeof(struct custom_mutator)); - mutator->post_process_buf = NULL; - mutator->post_process_size = 0; mutator->name = module_name; ACTF("Loading Python mutator library from '%s'...", module_name); @@ -326,9 +373,13 @@ struct custom_mutator *load_custom_mutator_py(afl_state_t *afl, if (py_functions[PY_FUNC_DEINIT]) { mutator->afl_custom_deinit = deinit_py; } - /* "afl_custom_fuzz" should not be NULL, but the interface of Python mutator - is quite different from the custom mutator. */ - mutator->afl_custom_fuzz = fuzz_py; + if (py_functions[PY_FUNC_FUZZ]) { mutator->afl_custom_fuzz = fuzz_py; } + + if (py_functions[PY_FUNC_DESCRIBE]) { + + mutator->afl_custom_describe = custom_describe_py; + + } if (py_functions[PY_FUNC_POST_PROCESS]) { @@ -342,6 +393,12 @@ struct custom_mutator *load_custom_mutator_py(afl_state_t *afl, } + if (py_functions[PY_FUNC_FUZZ_COUNT]) { + + mutator->afl_custom_fuzz_count = fuzz_count_py; + + } + if (py_functions[PY_FUNC_POST_TRIM]) { mutator->afl_custom_post_trim = post_trim_py; @@ -375,6 +432,15 @@ struct custom_mutator *load_custom_mutator_py(afl_state_t *afl, } + #ifdef INTROSPECTION + if (py_functions[PY_FUNC_INTROSPECTION]) { + + mutator->afl_custom_introspection = introspection_py; + + } + + #endif + OKF("Python mutator '%s' installed successfully.", module_name); /* Initialize the custom mutator */ @@ -387,10 +453,13 @@ struct custom_mutator *load_custom_mutator_py(afl_state_t *afl, size_t post_process_py(void *py_mutator, u8 *buf, size_t buf_size, u8 **out_buf) { - size_t py_out_buf_size; PyObject * py_args, *py_value; py_mutator_t *py = (py_mutator_t *)py_mutator; + // buffer returned previously must be released; initialized during init + // so we don't need to do comparisons + PyBuffer_Release(&py->post_process_buf); + py_args = PyTuple_New(1); py_value = PyByteArray_FromStringAndSize(buf, buf_size); if (!py_value) { @@ -410,16 +479,20 @@ size_t post_process_py(void *py_mutator, u8 *buf, size_t buf_size, if (py_value != NULL) { - py_out_buf_size = PyByteArray_Size(py_value); + if (PyObject_GetBuffer(py_value, &py->post_process_buf, PyBUF_SIMPLE) == + -1) { - ck_maybe_grow(BUF_PARAMS(post_process), py_out_buf_size); + PyErr_Print(); + FATAL( + "Python custom mutator: post_process call return value not a " + "bytes-like object"); + + } - memcpy(py->post_process_buf, PyByteArray_AsString(py_value), - py_out_buf_size); Py_DECREF(py_value); - *out_buf = py->post_process_buf; - return py_out_buf_size; + *out_buf = (u8 *)py->post_process_buf.buf; + return py->post_process_buf.len; } else { @@ -468,6 +541,44 @@ s32 init_trim_py(void *py_mutator, u8 *buf, size_t buf_size) { } +u32 fuzz_count_py(void *py_mutator, const u8 *buf, size_t buf_size) { + + PyObject *py_args, *py_value; + + py_args = PyTuple_New(1); + py_value = PyByteArray_FromStringAndSize(buf, buf_size); + if (!py_value) { + + Py_DECREF(py_args); + FATAL("Failed to convert arguments"); + + } + + PyTuple_SetItem(py_args, 0, py_value); + + py_value = PyObject_CallObject( + ((py_mutator_t *)py_mutator)->py_functions[PY_FUNC_FUZZ_COUNT], py_args); + Py_DECREF(py_args); + + if (py_value != NULL) { + + #if PY_MAJOR_VERSION >= 3 + u32 retcnt = (u32)PyLong_AsLong(py_value); + #else + u32 retcnt = PyInt_AsLong(py_value); + #endif + Py_DECREF(py_value); + return retcnt; + + } else { + + PyErr_Print(); + FATAL("Call failed"); + + } + +} + s32 post_trim_py(void *py_mutator, u8 success) { PyObject *py_args, *py_value; @@ -520,7 +631,8 @@ size_t trim_py(void *py_mutator, u8 **out_buf) { if (py_value != NULL) { ret = PyByteArray_Size(py_value); - *out_buf = ck_maybe_grow(BUF_PARAMS(trim), ret); + *out_buf = afl_realloc(BUF_PARAMS(trim), ret); + if (unlikely(!*out_buf)) { PFATAL("alloc"); } memcpy(*out_buf, PyByteArray_AsString(py_value), ret); Py_DECREF(py_value); @@ -585,7 +697,8 @@ size_t havoc_mutation_py(void *py_mutator, u8 *buf, size_t buf_size, } else { /* A new buf is needed... */ - *out_buf = ck_maybe_grow(BUF_PARAMS(havoc), mutated_size); + *out_buf = afl_realloc(BUF_PARAMS(havoc), mutated_size); + if (unlikely(!*out_buf)) { PFATAL("alloc"); } } @@ -629,6 +742,28 @@ u8 havoc_mutation_probability_py(void *py_mutator) { } +const char *introspection_py(void *py_mutator) { + + PyObject *py_args, *py_value; + + py_args = PyTuple_New(0); + py_value = PyObject_CallObject( + ((py_mutator_t *)py_mutator)->py_functions[PY_FUNC_INTROSPECTION], + py_args); + Py_DECREF(py_args); + + if (py_value == NULL) { + + return NULL; + + } else { + + return PyByteArray_AsString(py_value); + + } + +} + u8 queue_get_py(void *py_mutator, const u8 *filename) { PyObject *py_args, *py_value; diff --git a/src/afl-fuzz-queue.c b/src/afl-fuzz-queue.c index 38e95ac8..b2f88205 100644 --- a/src/afl-fuzz-queue.c +++ b/src/afl-fuzz-queue.c @@ -25,8 +25,217 @@ #include "afl-fuzz.h" #include <limits.h> #include <ctype.h> +#include <math.h> -#define BUF_PARAMS(name) (void **)&afl->name##_buf, &afl->name##_size +/* select next queue entry based on alias algo - fast! */ + +inline u32 select_next_queue_entry(afl_state_t *afl) { + + u32 s = rand_below(afl, afl->queued_paths); + double p = rand_next_percent(afl); + /* + fprintf(stderr, "select: p=%f s=%u ... p < prob[s]=%f ? s=%u : alias[%u]=%u" + " ==> %u\n", p, s, afl->alias_probability[s], s, s, afl->alias_table[s], p < + afl->alias_probability[s] ? s : afl->alias_table[s]); + */ + return (p < afl->alias_probability[s] ? s : afl->alias_table[s]); + +} + +double compute_weight(afl_state_t *afl, struct queue_entry *q, + double avg_exec_us, double avg_bitmap_size, + double avg_top_size) { + + double weight = 1.0; + + if (likely(afl->schedule >= FAST && afl->schedule <= RARE)) { + + u32 hits = afl->n_fuzz[q->n_fuzz_entry]; + if (likely(hits)) { weight *= log10(hits) + 1; } + + } + + if (likely(afl->schedule < RARE)) { weight *= (avg_exec_us / q->exec_us); } + weight *= (log(q->bitmap_size) / avg_bitmap_size); + weight *= (1 + (q->tc_ref / avg_top_size)); + if (unlikely(q->favored)) weight *= 5; + + return weight; + +} + +/* create the alias table that allows weighted random selection - expensive */ + +void create_alias_table(afl_state_t *afl) { + + u32 n = afl->queued_paths, i = 0, a, g; + double sum = 0; + + afl->alias_table = + (u32 *)afl_realloc((void **)&afl->alias_table, n * sizeof(u32)); + afl->alias_probability = (double *)afl_realloc( + (void **)&afl->alias_probability, n * sizeof(double)); + double *P = (double *)afl_realloc(AFL_BUF_PARAM(out), n * sizeof(double)); + int * S = (u32 *)afl_realloc(AFL_BUF_PARAM(out_scratch), n * sizeof(u32)); + int * L = (u32 *)afl_realloc(AFL_BUF_PARAM(in_scratch), n * sizeof(u32)); + + if (!P || !S || !L || !afl->alias_table || !afl->alias_probability) { + + FATAL("could not acquire memory for alias table"); + + } + + memset((void *)afl->alias_table, 0, n * sizeof(u32)); + memset((void *)afl->alias_probability, 0, n * sizeof(double)); + + if (likely(afl->schedule < RARE)) { + + double avg_exec_us = 0.0; + double avg_bitmap_size = 0.0; + double avg_top_size = 0.0; + u32 active = 0; + + for (i = 0; i < n; i++) { + + struct queue_entry *q = afl->queue_buf[i]; + + // disabled entries might have timings and bitmap values + if (likely(!q->disabled)) { + + avg_exec_us += q->exec_us; + avg_bitmap_size += log(q->bitmap_size); + avg_top_size += q->tc_ref; + ++active; + + } + + } + + avg_exec_us /= active; + avg_bitmap_size /= active; + avg_top_size /= active; + + for (i = 0; i < n; i++) { + + struct queue_entry *q = afl->queue_buf[i]; + + if (likely(!q->disabled)) { + + q->weight = + compute_weight(afl, q, avg_exec_us, avg_bitmap_size, avg_top_size); + q->perf_score = calculate_score(afl, q); + sum += q->weight; + + } + + } + + for (i = 0; i < n; i++) { + + // weight is always 0 for disabled entries + P[i] = (afl->queue_buf[i]->weight * n) / sum; + + } + + } else { + + for (i = 0; i < n; i++) { + + struct queue_entry *q = afl->queue_buf[i]; + + if (likely(!q->disabled)) { q->perf_score = calculate_score(afl, q); } + + sum += q->perf_score; + + } + + for (i = 0; i < n; i++) { + + // perf_score is always 0 for disabled entries + P[i] = (afl->queue_buf[i]->perf_score * n) / sum; + + } + + } + + int nS = 0, nL = 0, s; + for (s = (s32)n - 1; s >= 0; --s) { + + if (P[s] < 1) { + + S[nS++] = s; + + } else { + + L[nL++] = s; + + } + + } + + while (nS && nL) { + + a = S[--nS]; + g = L[--nL]; + afl->alias_probability[a] = P[a]; + afl->alias_table[a] = g; + P[g] = P[g] + P[a] - 1; + if (P[g] < 1) { + + S[nS++] = g; + + } else { + + L[nL++] = g; + + } + + } + + while (nL) + afl->alias_probability[L[--nL]] = 1; + + while (nS) + afl->alias_probability[S[--nS]] = 1; + + /* + #ifdef INTROSPECTION + u8 fn[PATH_MAX]; + snprintf(fn, PATH_MAX, "%s/introspection_corpus.txt", afl->out_dir); + FILE *f = fopen(fn, "a"); + if (f) { + + for (i = 0; i < n; i++) { + + struct queue_entry *q = afl->queue_buf[i]; + fprintf( + f, + "entry=%u name=%s favored=%s variable=%s disabled=%s len=%u " + "exec_us=%u " + "bitmap_size=%u bitsmap_size=%u tops=%u weight=%f perf_score=%f\n", + i, q->fname, q->favored ? "true" : "false", + q->var_behavior ? "true" : "false", q->disabled ? "true" : "false", + q->len, (u32)q->exec_us, q->bitmap_size, q->bitsmap_size, q->tc_ref, + q->weight, q->perf_score); + + } + + fprintf(f, "\n"); + fclose(f); + + } + + #endif + */ + /* + fprintf(stderr, " entry alias probability perf_score weight + filename\n"); for (u32 i = 0; i < n; ++i) fprintf(stderr, " %5u %5u %11u + %0.9f %0.9f %s\n", i, afl->alias_table[i], afl->alias_probability[i], + afl->queue_buf[i]->perf_score, afl->queue_buf[i]->weight, + afl->queue_buf[i]->fname); + */ + +} /* Mark deterministic checks as done for a particular queue entry. We use the .state file to avoid repeating deterministic fuzzing when resuming aborted @@ -78,9 +287,9 @@ void mark_as_variable(afl_state_t *afl, struct queue_entry *q) { void mark_as_redundant(afl_state_t *afl, struct queue_entry *q, u8 state) { - u8 fn[PATH_MAX]; + if (likely(state == q->fs_redundant)) { return; } - if (state == q->fs_redundant) { return; } + u8 fn[PATH_MAX]; q->fs_redundant = state; @@ -105,16 +314,22 @@ void mark_as_redundant(afl_state_t *afl, struct queue_entry *q, u8 state) { /* check if ascii or UTF-8 */ -static u8 check_if_text(struct queue_entry *q) { +static u8 check_if_text(afl_state_t *afl, struct queue_entry *q) { if (q->len < AFL_TXT_MIN_LEN) return 0; - u8 buf[MAX_FILE]; - s32 fd, len = q->len, offset = 0, ascii = 0, utf8 = 0, comp; + u8 * buf; + int fd; + u32 len = q->len, offset = 0, ascii = 0, utf8 = 0; + ssize_t comp; + if (len >= MAX_FILE) len = MAX_FILE - 1; if ((fd = open(q->fname, O_RDONLY)) < 0) return 0; - if ((comp = read(fd, buf, len)) != len) return 0; + buf = afl_realloc(AFL_BUF_PARAM(in_scratch), len + 1); + comp = read(fd, buf, len); close(fd); + if (comp != (ssize_t)len) return 0; + buf[len] = 0; while (offset < len) { @@ -138,7 +353,8 @@ static u8 check_if_text(struct queue_entry *q) { } // non-overlong 2-byte - if (((0xC2 <= buf[offset + 0] && buf[offset + 0] <= 0xDF) && + if (len - offset > 1 && + ((0xC2 <= buf[offset + 0] && buf[offset + 0] <= 0xDF) && (0x80 <= buf[offset + 1] && buf[offset + 1] <= 0xBF))) { offset += 2; @@ -149,18 +365,19 @@ static u8 check_if_text(struct queue_entry *q) { } // excluding overlongs - if ((buf[offset + 0] == 0xE0 && - (0xA0 <= buf[offset + 1] && buf[offset + 1] <= 0xBF) && - (0x80 <= buf[offset + 2] && - buf[offset + 2] <= 0xBF)) || // straight 3-byte - (((0xE1 <= buf[offset + 0] && buf[offset + 0] <= 0xEC) || - buf[offset + 0] == 0xEE || buf[offset + 0] == 0xEF) && - (0x80 <= buf[offset + 1] && buf[offset + 1] <= 0xBF) && - (0x80 <= buf[offset + 2] && - buf[offset + 2] <= 0xBF)) || // excluding surrogates - (buf[offset + 0] == 0xED && - (0x80 <= buf[offset + 1] && buf[offset + 1] <= 0x9F) && - (0x80 <= buf[offset + 2] && buf[offset + 2] <= 0xBF))) { + if ((len - offset > 2) && + ((buf[offset + 0] == 0xE0 && + (0xA0 <= buf[offset + 1] && buf[offset + 1] <= 0xBF) && + (0x80 <= buf[offset + 2] && + buf[offset + 2] <= 0xBF)) || // straight 3-byte + (((0xE1 <= buf[offset + 0] && buf[offset + 0] <= 0xEC) || + buf[offset + 0] == 0xEE || buf[offset + 0] == 0xEF) && + (0x80 <= buf[offset + 1] && buf[offset + 1] <= 0xBF) && + (0x80 <= buf[offset + 2] && + buf[offset + 2] <= 0xBF)) || // excluding surrogates + (buf[offset + 0] == 0xED && + (0x80 <= buf[offset + 1] && buf[offset + 1] <= 0x9F) && + (0x80 <= buf[offset + 2] && buf[offset + 2] <= 0xBF)))) { offset += 3; utf8++; @@ -170,19 +387,20 @@ static u8 check_if_text(struct queue_entry *q) { } // planes 1-3 - if ((buf[offset + 0] == 0xF0 && - (0x90 <= buf[offset + 1] && buf[offset + 1] <= 0xBF) && - (0x80 <= buf[offset + 2] && buf[offset + 2] <= 0xBF) && - (0x80 <= buf[offset + 3] && - buf[offset + 3] <= 0xBF)) || // planes 4-15 - ((0xF1 <= buf[offset + 0] && buf[offset + 0] <= 0xF3) && - (0x80 <= buf[offset + 1] && buf[offset + 1] <= 0xBF) && - (0x80 <= buf[offset + 2] && buf[offset + 2] <= 0xBF) && - (0x80 <= buf[offset + 3] && buf[offset + 3] <= 0xBF)) || // plane 16 - (buf[offset + 0] == 0xF4 && - (0x80 <= buf[offset + 1] && buf[offset + 1] <= 0x8F) && - (0x80 <= buf[offset + 2] && buf[offset + 2] <= 0xBF) && - (0x80 <= buf[offset + 3] && buf[offset + 3] <= 0xBF))) { + if ((len - offset > 3) && + ((buf[offset + 0] == 0xF0 && + (0x90 <= buf[offset + 1] && buf[offset + 1] <= 0xBF) && + (0x80 <= buf[offset + 2] && buf[offset + 2] <= 0xBF) && + (0x80 <= buf[offset + 3] && + buf[offset + 3] <= 0xBF)) || // planes 4-15 + ((0xF1 <= buf[offset + 0] && buf[offset + 0] <= 0xF3) && + (0x80 <= buf[offset + 1] && buf[offset + 1] <= 0xBF) && + (0x80 <= buf[offset + 2] && buf[offset + 2] <= 0xBF) && + (0x80 <= buf[offset + 3] && buf[offset + 3] <= 0xBF)) || // plane 16 + (buf[offset + 0] == 0xF4 && + (0x80 <= buf[offset + 1] && buf[offset + 1] <= 0x8F) && + (0x80 <= buf[offset + 2] && buf[offset + 2] <= 0xBF) && + (0x80 <= buf[offset + 3] && buf[offset + 3] <= 0xBF)))) { offset += 4; utf8++; @@ -215,37 +433,39 @@ void add_to_queue(afl_state_t *afl, u8 *fname, u32 len, u8 passed_det) { q->len = len; q->depth = afl->cur_depth + 1; q->passed_det = passed_det; - q->n_fuzz = 1; q->trace_mini = NULL; + q->testcase_buf = NULL; + q->mother = afl->queue_cur; + +#ifdef INTROSPECTION + q->bitsmap_size = afl->bitsmap_size; +#endif if (q->depth > afl->max_depth) { afl->max_depth = q->depth; } if (afl->queue_top) { - afl->queue_top->next = q; afl->queue_top = q; } else { - afl->q_prev100 = afl->queue = afl->queue_top = q; + afl->queue = afl->queue_top = q; } + if (likely(q->len > 4)) afl->ready_for_splicing_count++; + ++afl->queued_paths; + ++afl->active_paths; ++afl->pending_not_fuzzed; afl->cycles_wo_finds = 0; - if (!(afl->queued_paths % 100)) { - - afl->q_prev100->next_100 = q; - afl->q_prev100 = q; - - } - - struct queue_entry **queue_buf = ck_maybe_grow( - BUF_PARAMS(queue), afl->queued_paths * sizeof(struct queue_entry *)); + struct queue_entry **queue_buf = afl_realloc( + AFL_BUF_PARAM(queue), afl->queued_paths * sizeof(struct queue_entry *)); + if (unlikely(!queue_buf)) { PFATAL("alloc"); } queue_buf[afl->queued_paths - 1] = q; + q->id = afl->queued_paths - 1; afl->last_path_time = get_cur_time(); @@ -269,7 +489,7 @@ void add_to_queue(afl_state_t *afl, u8 *fname, u32 len, u8 passed_det) { } /* only redqueen currently uses is_ascii */ - if (afl->shm.cmplog_mode) q->is_ascii = check_if_text(q); + if (afl->shm.cmplog_mode) q->is_ascii = check_if_text(afl, q); } @@ -277,15 +497,16 @@ void add_to_queue(afl_state_t *afl, u8 *fname, u32 len, u8 passed_det) { void destroy_queue(afl_state_t *afl) { - struct queue_entry *q = afl->queue, *n; + u32 i; + + for (i = 0; i < afl->queued_paths; i++) { - while (q) { + struct queue_entry *q; - n = q->next; + q = afl->queue_buf[i]; ck_free(q->fname); ck_free(q->trace_mini); ck_free(q); - q = n; } @@ -308,8 +529,10 @@ void update_bitmap_score(afl_state_t *afl, struct queue_entry *q) { u64 fav_factor; u64 fuzz_p2; - if (unlikely(afl->schedule >= FAST && afl->schedule <= RARE)) - fuzz_p2 = next_pow2(q->n_fuzz); + if (unlikely(afl->schedule >= FAST && afl->schedule < RARE)) + fuzz_p2 = 0; // Skip the fuzz_p2 comparison + else if (unlikely(afl->schedule == RARE)) + fuzz_p2 = next_pow2(afl->n_fuzz[q->n_fuzz_entry]); else fuzz_p2 = q->fuzz_level; @@ -335,7 +558,8 @@ void update_bitmap_score(afl_state_t *afl, struct queue_entry *q) { u64 top_rated_fav_factor; u64 top_rated_fuzz_p2; if (unlikely(afl->schedule >= FAST && afl->schedule <= RARE)) - top_rated_fuzz_p2 = next_pow2(afl->top_rated[i]->n_fuzz); + top_rated_fuzz_p2 = + next_pow2(afl->n_fuzz[afl->top_rated[i]->n_fuzz_entry]); else top_rated_fuzz_p2 = afl->top_rated[i]->fuzz_level; @@ -416,12 +640,11 @@ void update_bitmap_score(afl_state_t *afl, struct queue_entry *q) { void cull_queue(afl_state_t *afl) { - struct queue_entry *q; - u32 len = (afl->fsrv.map_size >> 3); - u32 i; - u8 * temp_v = afl->map_tmp_buf; + if (likely(!afl->score_changed || afl->non_instrumented_mode)) { return; } - if (afl->non_instrumented_mode || !afl->score_changed) { return; } + u32 len = (afl->fsrv.map_size >> 3); + u32 i; + u8 *temp_v = afl->map_tmp_buf; afl->score_changed = 0; @@ -430,12 +653,9 @@ void cull_queue(afl_state_t *afl) { afl->queued_favored = 0; afl->pending_favored = 0; - q = afl->queue; - - while (q) { + for (i = 0; i < afl->queued_paths; i++) { - q->favored = 0; - q = q->next; + afl->queue_buf[i]->favored = 0; } @@ -474,12 +694,13 @@ void cull_queue(afl_state_t *afl) { } - q = afl->queue; + for (i = 0; i < afl->queued_paths; i++) { - while (q) { + if (likely(!afl->queue_buf[i]->disabled)) { - mark_as_redundant(afl, q, !q->favored); - q = q->next; + mark_as_redundant(afl, afl->queue_buf[i], !afl->queue_buf[i]->favored); + + } } @@ -505,7 +726,7 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { // Longer execution time means longer work on the input, the deeper in // coverage, the better the fuzzing, right? -mh - if (afl->schedule >= RARE && likely(!afl->fixed_seed)) { + if (likely(afl->schedule < RARE) && likely(!afl->fixed_seed)) { if (q->exec_us * 0.1 > avg_exec_us) { @@ -606,11 +827,9 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { } - u64 fuzz = q->n_fuzz; - u64 fuzz_total; - - u32 n_paths, fuzz_mu; - u32 factor = 1; + u32 n_paths; + double factor = 1.0; + long double fuzz_mu; switch (afl->schedule) { @@ -625,60 +844,85 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { break; case COE: - fuzz_total = 0; + fuzz_mu = 0.0; n_paths = 0; - struct queue_entry *queue_it = afl->queue; - while (queue_it) { + // Don't modify perf_score for unfuzzed seeds + if (q->fuzz_level == 0) break; + + u32 i; + for (i = 0; i < afl->queued_paths; i++) { - fuzz_total += queue_it->n_fuzz; - n_paths++; - queue_it = queue_it->next; + if (likely(!afl->queue_buf[i]->disabled)) { + + fuzz_mu += log2(afl->n_fuzz[afl->queue_buf[i]->n_fuzz_entry]); + n_paths++; + + } } if (unlikely(!n_paths)) { FATAL("Queue state corrupt"); } - fuzz_mu = fuzz_total / n_paths; - if (fuzz <= fuzz_mu) { + fuzz_mu = fuzz_mu / n_paths; - if (q->fuzz_level < 16) { + if (log2(afl->n_fuzz[q->n_fuzz_entry]) > fuzz_mu) { - factor = ((u32)(1 << q->fuzz_level)); + /* Never skip favourites */ + if (!q->favored) factor = 0; - } else { + break; - factor = MAX_FACTOR; + } - } + // Fall through + case FAST: - } else { + // Don't modify unfuzzed seeds + if (q->fuzz_level == 0) break; - factor = 0; + switch ((u32)log2(afl->n_fuzz[q->n_fuzz_entry])) { - } + case 0 ... 1: + factor = 4; + break; - break; + case 2 ... 3: + factor = 3; + break; - case FAST: - if (q->fuzz_level < 16) { + case 4: + factor = 2; + break; - factor = ((u32)(1 << q->fuzz_level)) / (fuzz == 0 ? 1 : fuzz); + case 5: + break; - } else { + case 6: + if (!q->favored) factor = 0.8; + break; - factor = MAX_FACTOR / (fuzz == 0 ? 1 : next_pow2(fuzz)); + case 7: + if (!q->favored) factor = 0.6; + break; + + default: + if (!q->favored) factor = 0.4; + break; } + if (q->favored) factor *= 1.15; + break; case LIN: - factor = q->fuzz_level / (fuzz == 0 ? 1 : fuzz); + factor = q->fuzz_level / (afl->n_fuzz[q->n_fuzz_entry] + 1); break; case QUAD: - factor = q->fuzz_level * q->fuzz_level / (fuzz == 0 ? 1 : fuzz); + factor = + q->fuzz_level * q->fuzz_level / (afl->n_fuzz[q->n_fuzz_entry] + 1); break; case MMOPT: @@ -703,8 +947,8 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { perf_score += (q->tc_ref * 10); // the more often fuzz result paths are equal to this queue entry, // reduce its value - perf_score *= - (1 - (double)((double)q->n_fuzz / (double)afl->fsrv.total_execs)); + perf_score *= (1 - (double)((double)afl->n_fuzz[q->n_fuzz_entry] / + (double)afl->fsrv.total_execs)); break; @@ -713,7 +957,7 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { } - if (unlikely(afl->schedule >= FAST && afl->schedule <= RARE)) { + if (unlikely(afl->schedule >= EXPLOIT && afl->schedule <= QUAD)) { if (factor > MAX_FACTOR) { factor = MAX_FACTOR; } perf_score *= factor / POWER_BETA; @@ -725,7 +969,7 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { perf_score *= 2; - } else if (perf_score < 1) { + } else if (afl->schedule != COE && perf_score < 1) { // Add a lower bound to AFLFast's energy assignment strategies perf_score = 1; @@ -744,3 +988,286 @@ u32 calculate_score(afl_state_t *afl, struct queue_entry *q) { } +/* after a custom trim we need to reload the testcase from disk */ + +inline void queue_testcase_retake(afl_state_t *afl, struct queue_entry *q, + u32 old_len) { + + if (likely(q->testcase_buf)) { + + u32 len = q->len; + + if (len != old_len) { + + afl->q_testcase_cache_size = afl->q_testcase_cache_size + len - old_len; + q->testcase_buf = realloc(q->testcase_buf, len); + + if (unlikely(!q->testcase_buf)) { + + PFATAL("Unable to malloc '%s' with len %u", q->fname, len); + + } + + } + + int fd = open(q->fname, O_RDONLY); + + if (unlikely(fd < 0)) { PFATAL("Unable to open '%s'", q->fname); } + + ck_read(fd, q->testcase_buf, len, q->fname); + close(fd); + + } + +} + +/* after a normal trim we need to replace the testcase with the new data */ + +inline void queue_testcase_retake_mem(afl_state_t *afl, struct queue_entry *q, + u8 *in, u32 len, u32 old_len) { + + if (likely(q->testcase_buf)) { + + u32 is_same = in == q->testcase_buf; + + if (likely(len != old_len)) { + + u8 *ptr = realloc(q->testcase_buf, len); + + if (likely(ptr)) { + + q->testcase_buf = ptr; + afl->q_testcase_cache_size = afl->q_testcase_cache_size + len - old_len; + + } + + } + + if (unlikely(!is_same)) { memcpy(q->testcase_buf, in, len); } + + } + +} + +/* Returns the testcase buf from the file behind this queue entry. + Increases the refcount. */ + +inline u8 *queue_testcase_get(afl_state_t *afl, struct queue_entry *q) { + + u32 len = q->len; + + /* first handle if no testcase cache is configured */ + + if (unlikely(!afl->q_testcase_max_cache_size)) { + + u8 *buf; + + if (unlikely(q == afl->queue_cur)) { + + buf = afl_realloc((void **)&afl->testcase_buf, len); + + } else { + + buf = afl_realloc((void **)&afl->splicecase_buf, len); + + } + + if (unlikely(!buf)) { + + PFATAL("Unable to malloc '%s' with len %u", q->fname, len); + + } + + int fd = open(q->fname, O_RDONLY); + + if (unlikely(fd < 0)) { PFATAL("Unable to open '%s'", q->fname); } + + ck_read(fd, buf, len, q->fname); + close(fd); + return buf; + + } + + /* now handle the testcase cache */ + + if (unlikely(!q->testcase_buf)) { + + /* Buf not cached, let's load it */ + u32 tid = afl->q_testcase_max_cache_count; + static u32 do_once = 0; // because even threaded we would want this. WIP + + while (unlikely( + afl->q_testcase_cache_size + len >= afl->q_testcase_max_cache_size || + afl->q_testcase_cache_count >= afl->q_testcase_max_cache_entries - 1)) { + + /* We want a max number of entries to the cache that we learn. + Very simple: once the cache is filled by size - that is the max. */ + + if (unlikely(afl->q_testcase_cache_size + len >= + afl->q_testcase_max_cache_size && + (afl->q_testcase_cache_count < + afl->q_testcase_max_cache_entries && + afl->q_testcase_max_cache_count < + afl->q_testcase_max_cache_entries) && + !do_once)) { + + if (afl->q_testcase_max_cache_count > afl->q_testcase_cache_count) { + + afl->q_testcase_max_cache_entries = + afl->q_testcase_max_cache_count + 1; + + } else { + + afl->q_testcase_max_cache_entries = afl->q_testcase_cache_count + 1; + + } + + do_once = 1; + // release unneeded memory + u8 *ptr = ck_realloc( + afl->q_testcase_cache, + (afl->q_testcase_max_cache_entries + 1) * sizeof(size_t)); + + if (ptr) { afl->q_testcase_cache = (struct queue_entry **)ptr; } + + } + + /* Cache full. We neet to evict one or more to map one. + Get a random one which is not in use */ + + do { + + // if the cache (MB) is not enough for the queue then this gets + // undesirable because q_testcase_max_cache_count grows sometimes + // although the number of items in the cache will not change hence + // more and more loops + tid = rand_below(afl, afl->q_testcase_max_cache_count); + + } while (afl->q_testcase_cache[tid] == NULL || + + afl->q_testcase_cache[tid] == afl->queue_cur); + + struct queue_entry *old_cached = afl->q_testcase_cache[tid]; + free(old_cached->testcase_buf); + old_cached->testcase_buf = NULL; + afl->q_testcase_cache_size -= old_cached->len; + afl->q_testcase_cache[tid] = NULL; + --afl->q_testcase_cache_count; + ++afl->q_testcase_evictions; + if (tid < afl->q_testcase_smallest_free) + afl->q_testcase_smallest_free = tid; + + } + + if (unlikely(tid >= afl->q_testcase_max_cache_entries)) { + + // uh we were full, so now we have to search from start + tid = afl->q_testcase_smallest_free; + + } + + // we need this while loop in case there were ever previous evictions but + // not in this call. + while (unlikely(afl->q_testcase_cache[tid] != NULL)) + ++tid; + + /* Map the test case into memory. */ + + int fd = open(q->fname, O_RDONLY); + + if (unlikely(fd < 0)) { PFATAL("Unable to open '%s'", q->fname); } + + q->testcase_buf = malloc(len); + + if (unlikely(!q->testcase_buf)) { + + PFATAL("Unable to malloc '%s' with len %u", q->fname, len); + + } + + ck_read(fd, q->testcase_buf, len, q->fname); + close(fd); + + /* Register testcase as cached */ + afl->q_testcase_cache[tid] = q; + afl->q_testcase_cache_size += len; + ++afl->q_testcase_cache_count; + if (likely(tid >= afl->q_testcase_max_cache_count)) { + + afl->q_testcase_max_cache_count = tid + 1; + + } else if (unlikely(tid == afl->q_testcase_smallest_free)) { + + afl->q_testcase_smallest_free = tid + 1; + + } + + } + + return q->testcase_buf; + +} + +/* Adds the new queue entry to the cache. */ + +inline void queue_testcase_store_mem(afl_state_t *afl, struct queue_entry *q, + u8 *mem) { + + u32 len = q->len; + + if (unlikely(afl->q_testcase_cache_size + len >= + afl->q_testcase_max_cache_size || + afl->q_testcase_cache_count >= + afl->q_testcase_max_cache_entries - 1)) { + + // no space? will be loaded regularly later. + return; + + } + + u32 tid; + + if (unlikely(afl->q_testcase_max_cache_count >= + afl->q_testcase_max_cache_entries)) { + + // uh we were full, so now we have to search from start + tid = afl->q_testcase_smallest_free; + + } else { + + tid = afl->q_testcase_max_cache_count; + + } + + while (unlikely(afl->q_testcase_cache[tid] != NULL)) + ++tid; + + /* Map the test case into memory. */ + + q->testcase_buf = malloc(len); + + if (unlikely(!q->testcase_buf)) { + + PFATAL("Unable to malloc '%s' with len %u", q->fname, len); + + } + + memcpy(q->testcase_buf, mem, len); + + /* Register testcase as cached */ + afl->q_testcase_cache[tid] = q; + afl->q_testcase_cache_size += len; + ++afl->q_testcase_cache_count; + + if (likely(tid >= afl->q_testcase_max_cache_count)) { + + afl->q_testcase_max_cache_count = tid + 1; + + } else if (unlikely(tid == afl->q_testcase_smallest_free)) { + + afl->q_testcase_smallest_free = tid + 1; + + } + +} + diff --git a/src/afl-fuzz-redqueen.c b/src/afl-fuzz-redqueen.c index 57e60c3d..9bfbf95b 100644 --- a/src/afl-fuzz-redqueen.c +++ b/src/afl-fuzz-redqueen.c @@ -28,13 +28,39 @@ #include "afl-fuzz.h" #include "cmplog.h" -///// Colorization +//#define _DEBUG +//#define CMPLOG_INTROSPECTION + +// CMP attribute enum +enum { + + IS_EQUAL = 1, // arithemtic equal comparison + IS_GREATER = 2, // arithmetic greater comparison + IS_LESSER = 4, // arithmetic lesser comparison + IS_FP = 8, // is a floating point, not an integer + /* --- below are internal settings, not from target cmplog */ + IS_FP_MOD = 16, // arithemtic changed floating point + IS_INT_MOD = 32, // arithmetic changed interger + IS_TRANSFORM = 64 // transformed integer + +}; + +// CMPLOG LVL +enum { + + LVL1 = 1, // Integer solving + LVL2 = 2, // unused except for setting the queue entry + LVL3 = 4 // expensive tranformations + +}; struct range { u32 start; u32 end; struct range *next; + struct range *prev; + u8 ok; }; @@ -44,6 +70,8 @@ static struct range *add_range(struct range *ranges, u32 start, u32 end) { r->start = start; r->end = end; r->next = ranges; + r->ok = 0; + if (likely(ranges)) ranges->prev = r; return r; } @@ -51,136 +79,320 @@ static struct range *add_range(struct range *ranges, u32 start, u32 end) { static struct range *pop_biggest_range(struct range **ranges) { struct range *r = *ranges; - struct range *prev = NULL; struct range *rmax = NULL; - struct range *prev_rmax = NULL; u32 max_size = 0; while (r) { - u32 s = r->end - r->start; - if (s >= max_size) { + if (!r->ok) { + + u32 s = 1 + r->end - r->start; + + if (s >= max_size) { - max_size = s; - prev_rmax = prev; - rmax = r; + max_size = s; + rmax = r; + + } } - prev = r; r = r->next; } - if (rmax) { + return rmax; + +} - if (prev_rmax) { +#ifdef _DEBUG +// static int logging = 0; +static void dump(char *txt, u8 *buf, u32 len) { - prev_rmax->next = rmax->next; + u32 i; + fprintf(stderr, "DUMP %s %016llx ", txt, hash64(buf, len, HASH_CONST)); + for (i = 0; i < len; i++) + fprintf(stderr, "%02x", buf[i]); + fprintf(stderr, "\n"); - } else { +} - *ranges = rmax->next; +static void dump_file(char *path, char *name, u32 counter, u8 *buf, u32 len) { - } + char fn[4096]; + if (!path) path = "."; + snprintf(fn, sizeof(fn), "%s/%s%d", path, name, counter); + int fd = open(fn, O_RDWR | O_CREAT | O_TRUNC, 0644); + if (fd >= 0) { - } + write(fd, buf, len); + close(fd); - return rmax; + } } +#endif + static u8 get_exec_checksum(afl_state_t *afl, u8 *buf, u32 len, u64 *cksum) { if (unlikely(common_fuzz_stuff(afl, buf, len))) { return 1; } *cksum = hash64(afl->fsrv.trace_bits, afl->fsrv.map_size, HASH_CONST); + return 0; } -static void rand_replace(afl_state_t *afl, u8 *buf, u32 len) { +/* replace everything with different values but stay in the same type */ +static void type_replace(afl_state_t *afl, u8 *buf, u32 len) { u32 i; + u8 c; for (i = 0; i < len; ++i) { - buf[i] = rand_below(afl, 256); + // wont help for UTF or non-latin charsets + do { + + switch (buf[i]) { + + case 'A' ... 'F': + c = 'A' + rand_below(afl, 1 + 'F' - 'A'); + break; + case 'a' ... 'f': + c = 'a' + rand_below(afl, 1 + 'f' - 'a'); + break; + case '0': + c = '1'; + break; + case '1': + c = '0'; + break; + case '2' ... '9': + c = '2' + rand_below(afl, 1 + '9' - '2'); + break; + case 'G' ... 'Z': + c = 'G' + rand_below(afl, 1 + 'Z' - 'G'); + break; + case 'g' ... 'z': + c = 'g' + rand_below(afl, 1 + 'z' - 'g'); + break; + case '!' ... '*': + c = '!' + rand_below(afl, 1 + '*' - '!'); + break; + case ',' ... '.': + c = ',' + rand_below(afl, 1 + '.' - ','); + break; + case ':' ... '@': + c = ':' + rand_below(afl, 1 + '@' - ':'); + break; + case '[' ... '`': + c = '[' + rand_below(afl, 1 + '`' - '['); + break; + case '{' ... '~': + c = '{' + rand_below(afl, 1 + '~' - '{'); + break; + case '+': + c = '/'; + break; + case '/': + c = '+'; + break; + case ' ': + c = '\t'; + break; + case '\t': + c = ' '; + break; + case '\r': + c = '\n'; + break; + case '\n': + c = '\r'; + break; + case 0: + c = 1; + break; + case 1: + c = 0; + break; + case 0xff: + c = 0; + break; + default: + if (buf[i] < 32) { + + c = (buf[i] ^ 0x1f); + + } else { + + c = (buf[i] ^ 0x7f); // we keep the highest bit + + } + + } + + } while (c == buf[i]); + + buf[i] = c; } } -static u8 colorization(afl_state_t *afl, u8 *buf, u32 len, u64 exec_cksum) { +static u8 colorization(afl_state_t *afl, u8 *buf, u32 len, + struct tainted **taints) { - struct range *ranges = add_range(NULL, 0, len); - u8 * backup = ck_alloc_nozero(len); + struct range * ranges = add_range(NULL, 0, len - 1), *rng; + struct tainted *taint = NULL; + u8 * backup = ck_alloc_nozero(len); + u8 * changed = ck_alloc_nozero(len); - u8 needs_write = 0; +#if defined(_DEBUG) || defined(CMPLOG_INTROSPECTION) + u64 start_time = get_cur_time(); +#endif - u64 orig_hit_cnt, new_hit_cnt; + u32 screen_update = 1000000 / afl->queue_cur->exec_us; + u64 orig_hit_cnt, new_hit_cnt, exec_cksum; orig_hit_cnt = afl->queued_paths + afl->unique_crashes; afl->stage_name = "colorization"; afl->stage_short = "colorization"; - afl->stage_max = 1000; - - struct range *rng = NULL; + afl->stage_max = (len << 1); afl->stage_cur = 0; + + // in colorization we do not classify counts, hence we have to calculate + // the original checksum. + if (unlikely(get_exec_checksum(afl, buf, len, &exec_cksum))) { + + goto checksum_fail; + + } + + memcpy(backup, buf, len); + memcpy(changed, buf, len); + type_replace(afl, changed, len); + while ((rng = pop_biggest_range(&ranges)) != NULL && afl->stage_cur < afl->stage_max) { - u32 s = rng->end - rng->start; + u32 s = 1 + rng->end - rng->start; + + memcpy(buf + rng->start, changed + rng->start, s); + + u64 cksum = 0; + u64 start_us = get_cur_time_us(); + if (unlikely(get_exec_checksum(afl, buf, len, &cksum))) { - if (s != 0) { + goto checksum_fail; - /* Range not empty */ + } + + u64 stop_us = get_cur_time_us(); - memcpy(backup, buf + rng->start, s); - rand_replace(afl, buf + rng->start, s); + /* Discard if the mutations change the path or if it is too decremental + in speed - how could the same path have a much different speed + though ...*/ + if (cksum != exec_cksum || + (unlikely(stop_us - start_us > 3 * afl->queue_cur->exec_us) && + likely(!afl->fixed_seed))) { - u64 cksum; - u64 start_us = get_cur_time_us(); - if (unlikely(get_exec_checksum(afl, buf, len, &cksum))) { + memcpy(buf + rng->start, backup + rng->start, s); - goto checksum_fail; + if (s > 1) { // to not add 0 size ranges + + ranges = add_range(ranges, rng->start, rng->start - 1 + s / 2); + ranges = add_range(ranges, rng->start + s / 2, rng->end); } - u64 stop_us = get_cur_time_us(); + if (ranges == rng) { + + ranges = rng->next; + if (ranges) { ranges->prev = NULL; } - /* Discard if the mutations change the paths or if it is too decremental - in speed */ - if (cksum != exec_cksum || - (stop_us - start_us > 2 * afl->queue_cur->exec_us)) { + } else if (rng->next) { - ranges = add_range(ranges, rng->start, rng->start + s / 2); - ranges = add_range(ranges, rng->start + s / 2 + 1, rng->end); - memcpy(buf + rng->start, backup, s); + rng->prev->next = rng->next; + rng->next->prev = rng->prev; } else { - needs_write = 1; + if (rng->prev) { rng->prev->next = NULL; } } + free(rng); + + } else { + + rng->ok = 1; + } - ck_free(rng); - rng = NULL; - ++afl->stage_cur; + if (++afl->stage_cur % screen_update) { show_stats(afl); }; } - if (afl->stage_cur < afl->stage_max) { afl->queue_cur->fully_colorized = 1; } + rng = ranges; + while (rng) { - new_hit_cnt = afl->queued_paths + afl->unique_crashes; - afl->stage_finds[STAGE_COLORIZATION] += new_hit_cnt - orig_hit_cnt; - afl->stage_cycles[STAGE_COLORIZATION] += afl->stage_cur; - ck_free(backup); + rng = rng->next; + + } + + u32 i = 1; + u32 positions = 0; + while (i) { + + restart: + i = 0; + struct range *r = NULL; + u32 pos = (u32)-1; + rng = ranges; + + while (rng) { + + if (rng->ok == 1 && rng->start < pos) { + + if (taint && taint->pos + taint->len == rng->start) { + + taint->len += (1 + rng->end - rng->start); + positions += (1 + rng->end - rng->start); + rng->ok = 2; + goto restart; + + } else { + + r = rng; + pos = rng->start; + + } - ck_free(rng); - rng = NULL; + } + + rng = rng->next; + + } + if (r) { + + struct tainted *t = ck_alloc_nozero(sizeof(struct tainted)); + t->pos = r->start; + t->len = 1 + r->end - r->start; + positions += (1 + r->end - r->start); + if (likely(taint)) { taint->prev = t; } + t->next = taint; + t->prev = NULL; + taint = t; + r->ok = 2; + i = 1; + + } + + } + + /* temporary: clean ranges */ while (ranges) { rng = ranges; @@ -190,38 +402,77 @@ static u8 colorization(afl_state_t *afl, u8 *buf, u32 len, u64 exec_cksum) { } - // save the input with the high entropy + new_hit_cnt = afl->queued_paths + afl->unique_crashes; - if (needs_write) { +#if defined(_DEBUG) || defined(CMPLOG_INTROSPECTION) + FILE *f = stderr; + #ifndef _DEBUG + if (afl->not_on_tty) { - s32 fd; + char fn[4096]; + snprintf(fn, sizeof(fn), "%s/introspection_cmplog.txt", afl->out_dir); + f = fopen(fn, "a"); - if (afl->no_unlink) { + } - fd = open(afl->queue_cur->fname, O_WRONLY | O_CREAT | O_TRUNC, 0600); + #endif - } else { + if (f) { - unlink(afl->queue_cur->fname); /* ignore errors */ - fd = open(afl->queue_cur->fname, O_WRONLY | O_CREAT | O_EXCL, 0600); + fprintf( + f, + "Colorization: fname=%s len=%u ms=%llu result=%u execs=%u found=%llu " + "taint=%u\n", + afl->queue_cur->fname, len, get_cur_time() - start_time, + afl->queue_cur->colorized, afl->stage_cur, new_hit_cnt - orig_hit_cnt, + positions); - } + #ifndef _DEBUG + if (afl->not_on_tty) { fclose(f); } + #endif + + } - if (fd < 0) { PFATAL("Unable to create '%s'", afl->queue_cur->fname); } +#endif - ck_write(fd, buf, len, afl->queue_cur->fname); - afl->queue_cur->len = len; // no-op, just to be 100% safe + if (taint) { - close(fd); + if (afl->colorize_success && + (len / positions == 1 && positions > CMPLOG_POSITIONS_MAX && + afl->active_paths / afl->colorize_success > CMPLOG_CORPUS_PERCENT)) { + +#ifdef _DEBUG + fprintf(stderr, "Colorization unsatisfactory\n"); +#endif + + *taints = NULL; + + struct tainted *t; + while (taint) { + + t = taint->next; + ck_free(taint); + taint = t; + + } + + } else { + + *taints = taint; + ++afl->colorize_success; + + } } + afl->stage_finds[STAGE_COLORIZATION] += new_hit_cnt - orig_hit_cnt; + afl->stage_cycles[STAGE_COLORIZATION] += afl->stage_cur; + ck_free(backup); + ck_free(changed); + return 0; checksum_fail: - if (rng) { ck_free(rng); } - ck_free(backup); - while (ranges) { rng = ranges; @@ -231,7 +482,8 @@ checksum_fail: } - // TODO: clang notices a _potential_ leak of mem pointed to by rng + ck_free(backup); + ck_free(changed); return 1; @@ -245,12 +497,19 @@ static u8 its_fuzz(afl_state_t *afl, u8 *buf, u32 len, u8 *status) { orig_hit_cnt = afl->queued_paths + afl->unique_crashes; +#ifdef _DEBUG + dump("DATA", buf, len); +#endif + if (unlikely(common_fuzz_stuff(afl, buf, len))) { return 1; } new_hit_cnt = afl->queued_paths + afl->unique_crashes; if (unlikely(new_hit_cnt != orig_hit_cnt)) { +#ifdef _DEBUG + fprintf(stderr, "NEW FIND\n"); +#endif *status = 1; } else { @@ -263,62 +522,213 @@ static u8 its_fuzz(afl_state_t *afl, u8 *buf, u32 len, u8 *status) { } -static long long strntoll(const char *str, size_t sz, char **end, int base) { +//#ifdef CMPLOG_SOLVE_TRANSFORM +static int strntoll(const char *str, size_t sz, char **end, int base, + long long *out) { char buf[64]; long long ret; const char *beg = str; - for (; beg && sz && *beg == ' '; beg++, sz--) - ; - - if (!sz || sz >= sizeof(buf)) { + if (!str || !sz) { return 1; } - if (end) *end = (char *)str; - return 0; + for (; beg && sz && *beg == ' '; beg++, sz--) {}; - } + if (!sz) return 1; + if (sz >= sizeof(buf)) sz = sizeof(buf) - 1; memcpy(buf, beg, sz); buf[sz] = '\0'; ret = strtoll(buf, end, base); - if (ret == LLONG_MIN || ret == LLONG_MAX) return ret; + if ((ret == LLONG_MIN || ret == LLONG_MAX) && errno == ERANGE) return 1; if (end) *end = (char *)beg + (*end - buf); - return ret; + *out = ret; + + return 0; } -static unsigned long long strntoull(const char *str, size_t sz, char **end, - int base) { +static int strntoull(const char *str, size_t sz, char **end, int base, + unsigned long long *out) { char buf[64]; unsigned long long ret; const char * beg = str; + if (!str || !sz) { return 1; } + for (; beg && sz && *beg == ' '; beg++, sz--) ; - if (!sz || sz >= sizeof(buf)) { - - if (end) *end = (char *)str; - return 0; - - } + if (!sz) return 1; + if (sz >= sizeof(buf)) sz = sizeof(buf) - 1; memcpy(buf, beg, sz); buf[sz] = '\0'; ret = strtoull(buf, end, base); + if (ret == ULLONG_MAX && errno == ERANGE) return 1; if (end) *end = (char *)beg + (*end - buf); + *out = ret; + + return 0; + +} + +static u8 hex_table_up[16] = {'0', '1', '2', '3', '4', '5', '6', '7', + '8', '9', 'A', 'B', 'C', 'D', 'E', 'F'}; +static u8 hex_table_low[16] = {'0', '1', '2', '3', '4', '5', '6', '7', + '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'}; +static u8 hex_table[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 0, 0, 0, + 0, 0, 0, 10, 11, 12, 13, 14, 15, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 10, 11, 12, 13, 14, 15}; + +// tests 2 bytes at location +static int is_hex(const char *str) { + + u32 i; + + for (i = 0; i < 2; i++) { + + switch (str[i]) { + + case '0' ... '9': + case 'A' ... 'F': + case 'a' ... 'f': + break; + default: + return 0; + + } + + } + + return 1; + +} + +#ifdef CMPLOG_SOLVE_TRANSFORM_BASE64 +// tests 4 bytes at location +static int is_base64(const char *str) { + + u32 i; + + for (i = 0; i < 4; i++) { + + switch (str[i]) { + + case '0' ... '9': + case 'A' ... 'Z': + case 'a' ... 'z': + case '+': + case '/': + case '=': + break; + default: + return 0; + + } + + } + + return 1; + +} + +static u8 base64_encode_table[] = + "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; +static u8 base64_decode_table[] = { + + 62, 0, 0, 0, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 0, + 0, 0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, + 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, + 0, 0, 0, 0, 0, 0, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, + 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51}; + +static u32 from_base64(u8 *src, u8 *dst, u32 dst_len) { + + u32 i, j, v; + u32 len = ((dst_len / 3) << 2); + u32 ret = 0; + + for (i = 0, j = 0; i < len; i += 4, j += 3) { + + v = base64_decode_table[src[i] - 43]; + v = (v << 6) | base64_decode_table[src[i + 1] - 43]; + v = src[i + 2] == '=' ? v << 6 + : (v << 6) | base64_decode_table[src[i + 2] - 43]; + v = src[i + 3] == '=' ? v << 6 + : (v << 6) | base64_decode_table[src[i + 3] - 43]; + + dst[j] = (v >> 16) & 0xFF; + ++ret; + + if (src[i + 2] != '=') { + + dst[j + 1] = (v >> 8) & 0xFF; + ++ret; + + } + + if (src[i + 3] != '=') { + + dst[j + 2] = v & 0xFF; + ++ret; + + } + + } + return ret; } -#define BUF_PARAMS(name) (void **)&afl->name##_buf, &afl->name##_size +static void to_base64(u8 *src, u8 *dst, u32 dst_len) { + + u32 i, j, v; + u32 len = (dst_len >> 2) * 3; + + for (i = 0, j = 0; i < len; i += 3, j += 4) { + + v = src[i]; + v = i + 1 < len ? v << 8 | src[i + 1] : v << 8; + v = i + 2 < len ? v << 8 | src[i + 2] : v << 8; + + dst[j] = base64_encode_table[(v >> 18) & 0x3F]; + dst[j + 1] = base64_encode_table[(v >> 12) & 0x3F]; + if (i + 1 < len) { + + dst[j + 2] = base64_encode_table[(v >> 6) & 0x3F]; + + } else { + + dst[j + 2] = '='; + + } + + if (i + 2 < len) { + + dst[j + 3] = base64_encode_table[v & 0x3F]; + + } else { + + dst[j + 3] = '='; + + } + + } + +} + +#endif + +//#endif static u8 cmp_extend_encoding(afl_state_t *afl, struct cmp_header *h, - u64 pattern, u64 repl, u64 o_pattern, u32 idx, - u8 *orig_buf, u8 *buf, u32 len, u8 do_reverse, - u8 *status) { + u64 pattern, u64 repl, u64 o_pattern, + u64 changed_val, u8 attr, u32 idx, u32 taint_len, + u8 *orig_buf, u8 *buf, u8 *cbuf, u32 len, + u8 do_reverse, u8 lvl, u8 *status) { u64 *buf_64 = (u64 *)&buf[idx]; u32 *buf_32 = (u32 *)&buf[idx]; @@ -329,74 +739,468 @@ static u8 cmp_extend_encoding(afl_state_t *afl, struct cmp_header *h, u16 *o_buf_16 = (u16 *)&orig_buf[idx]; u8 * o_buf_8 = &orig_buf[idx]; - u32 its_len = len - idx; - // *status = 0; + u32 its_len = MIN(len - idx, taint_len); - u8 * endptr; - u8 use_num = 0, use_unum = 0; - unsigned long long unum; - long long num; - if (afl->queue_cur->is_ascii) { + // fprintf(stderr, + // "Encode: %llx->%llx into %llx(<-%llx) at idx=%u " + // "taint_len=%u shape=%u attr=%u\n", + // o_pattern, pattern, repl, changed_val, idx, taint_len, + // h->shape + 1, attr); - endptr = buf_8; - num = strntoll(buf_8, len - idx, (char **)&endptr, 0); - if (endptr == buf_8) { + //#ifdef CMPLOG_SOLVE_TRANSFORM + // reverse atoi()/strnu?toll() is expensive, so we only to it in lvl 3 + if (afl->cmplog_enable_transform && (lvl & LVL3)) { - unum = strntoull(buf_8, len - idx, (char **)&endptr, 0); - if (endptr == buf_8) use_unum = 1; + u8 * endptr; + u8 use_num = 0, use_unum = 0; + unsigned long long unum; + long long num; - } else + if (afl->queue_cur->is_ascii) { - use_num = 1; + endptr = buf_8; + if (strntoll(buf_8, len - idx, (char **)&endptr, 0, &num)) { - } + if (!strntoull(buf_8, len - idx, (char **)&endptr, 0, &unum)) + use_unum = 1; + + } else + + use_num = 1; + + } + +#ifdef _DEBUG + if (idx == 0) + fprintf(stderr, "ASCII is=%u use_num=%u use_unum=%u idx=%u %llx==%llx\n", + afl->queue_cur->is_ascii, use_num, use_unum, idx, num, pattern); +#endif + + // num is likely not pattern as atoi("AAA") will be zero... + if (use_num && ((u64)num == pattern || !num)) { + + u8 tmp_buf[32]; + size_t num_len = snprintf(tmp_buf, sizeof(tmp_buf), "%lld", repl); + size_t old_len = endptr - buf_8; + + u8 *new_buf = afl_realloc((void **)&afl->out_scratch_buf, len + num_len); + if (unlikely(!new_buf)) { PFATAL("alloc"); } + + memcpy(new_buf, buf, idx); + memcpy(new_buf + idx, tmp_buf, num_len); + memcpy(new_buf + idx + num_len, buf_8 + old_len, len - idx - old_len); + + if (new_buf[idx + num_len] >= '0' && new_buf[idx + num_len] <= '9') { + + new_buf[idx + num_len] = ' '; + + } + + if (unlikely(its_fuzz(afl, new_buf, len, status))) { return 1; } + + } else if (use_unum && (unum == pattern || !unum)) { - if (use_num && num == pattern) { + u8 tmp_buf[32]; + size_t num_len = snprintf(tmp_buf, sizeof(tmp_buf), "%llu", repl); + size_t old_len = endptr - buf_8; - size_t old_len = endptr - buf_8; - size_t num_len = snprintf(NULL, 0, "%lld", num); + u8 *new_buf = afl_realloc((void **)&afl->out_scratch_buf, len + num_len); + if (unlikely(!new_buf)) { PFATAL("alloc"); } - u8 *new_buf = ck_maybe_grow(BUF_PARAMS(out_scratch), len + num_len); - memcpy(new_buf, buf, idx); + memcpy(new_buf, buf, idx); + memcpy(new_buf + idx, tmp_buf, num_len); + memcpy(new_buf + idx + num_len, buf_8 + old_len, len - idx - old_len); - snprintf(new_buf + idx, num_len, "%lld", num); - memcpy(new_buf + idx + num_len, buf_8 + old_len, len - idx - old_len); + if (new_buf[idx + num_len] >= '0' && new_buf[idx + num_len] <= '9') { - if (unlikely(its_fuzz(afl, new_buf, len, status))) { return 1; } + new_buf[idx + num_len] = ' '; - } else if (use_unum && unum == pattern) { + } + + if (unlikely(its_fuzz(afl, new_buf, len, status))) { return 1; } + + } + + // Try to identify transform magic + if (pattern != o_pattern && repl == changed_val && attr <= IS_EQUAL) { + + u64 b_val, o_b_val, mask; + u8 bytes; + + switch (SHAPE_BYTES(h->shape)) { + + case 0: + case 1: + bytes = 1; + break; + case 2: + bytes = 2; + break; + case 3: + case 4: + bytes = 4; + break; + default: + bytes = 8; + + } + + // necessary for preventing heap access overflow + bytes = MIN(bytes, len - idx); + + switch (bytes) { + + case 0: // cannot happen + b_val = o_b_val = mask = 0; // keep the linters happy + break; + case 1: { + + u8 *ptr = (u8 *)&buf[idx]; + u8 *o_ptr = (u8 *)&orig_buf[idx]; + b_val = (u64)(*ptr); + o_b_val = (u64)(*o_ptr % 0x100); + mask = 0xff; + break; + + } + + case 2: + case 3: { + + u16 *ptr = (u16 *)&buf[idx]; + u16 *o_ptr = (u16 *)&orig_buf[idx]; + b_val = (u64)(*ptr); + o_b_val = (u64)(*o_ptr); + mask = 0xffff; + break; + + } + + case 4: + case 5: + case 6: + case 7: { + + u32 *ptr = (u32 *)&buf[idx]; + u32 *o_ptr = (u32 *)&orig_buf[idx]; + b_val = (u64)(*ptr); + o_b_val = (u64)(*o_ptr); + mask = 0xffffffff; + break; + + } + + default: { + + u64 *ptr = (u64 *)&buf[idx]; + u64 *o_ptr = (u64 *)&orig_buf[idx]; + b_val = (u64)(*ptr); + o_b_val = (u64)(*o_ptr); + mask = 0xffffffffffffffff; + + } + + } + + // test for arithmetic, eg. "if ((user_val - 0x1111) == 0x1234) ..." + s64 diff = pattern - b_val; + s64 o_diff = o_pattern - o_b_val; + /* + fprintf(stderr, "DIFF1 idx=%03u shape=%02u %llx-%llx=%lx\n", idx, + h->shape + 1, o_pattern, o_b_val, o_diff); + fprintf(stderr, "DIFF1 %016llx %llx-%llx=%lx\n", repl, pattern, + b_val, diff);*/ + if (diff == o_diff && diff) { + + // this could be an arithmetic transformation + + u64 new_repl = (u64)((s64)repl - diff); + // fprintf(stderr, "SAME DIFF %llx->%llx\n", repl, new_repl); + + if (unlikely(cmp_extend_encoding( + afl, h, pattern, new_repl, o_pattern, repl, IS_TRANSFORM, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, status))) { + + return 1; + + } + + // if (*status == 1) { fprintf(stderr, "FOUND!\n"); } + + } + + // test for XOR, eg. "if ((user_val ^ 0xabcd) == 0x1234) ..." + if (*status != 1) { + + diff = pattern ^ b_val; + s64 o_diff = o_pattern ^ o_b_val; + + /* fprintf(stderr, "DIFF2 idx=%03u shape=%02u %llx-%llx=%lx\n", + idx, h->shape + 1, o_pattern, o_b_val, o_diff); fprintf(stderr, + "DIFF2 %016llx %llx-%llx=%lx\n", repl, pattern, b_val, diff);*/ + if (diff == o_diff && diff) { + + // this could be a XOR transformation + + u64 new_repl = (u64)((s64)repl ^ diff); + // fprintf(stderr, "SAME DIFF %llx->%llx\n", repl, new_repl); + + if (unlikely(cmp_extend_encoding( + afl, h, pattern, new_repl, o_pattern, repl, IS_TRANSFORM, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, status))) { + + return 1; + + } + + // if (*status == 1) { fprintf(stderr, "FOUND!\n"); } + + } + + } + + // test for to lowercase, eg. "new_val = (user_val | 0x2020) ..." + if (*status != 1) { + + if ((b_val | (0x2020202020202020 & mask)) == (pattern & mask)) { + + diff = 1; + + } else { + + diff = 0; - size_t old_len = endptr - buf_8; - size_t num_len = snprintf(NULL, 0, "%llu", unum); + } - u8 *new_buf = ck_maybe_grow(BUF_PARAMS(out_scratch), len + num_len); - memcpy(new_buf, buf, idx); + if ((o_b_val | (0x2020202020202020 & mask)) == (o_pattern & mask)) { - snprintf(new_buf + idx, num_len, "%llu", unum); - memcpy(new_buf + idx + num_len, buf_8 + old_len, len - idx - old_len); + o_diff = 1; - if (unlikely(its_fuzz(afl, new_buf, len, status))) { return 1; } + } else { + + diff = 0; + + } + + /* fprintf(stderr, "DIFF3 idx=%03u shape=%02u %llx-%llx=%lx\n", + idx, h->shape + 1, o_pattern, o_b_val, o_diff); fprintf(stderr, + "DIFF3 %016llx %llx-%llx=%lx\n", repl, pattern, b_val, diff);*/ + if (o_diff && diff) { + + // this could be a lower to upper + + u64 new_repl = (repl & (0x5f5f5f5f5f5f5f5f & mask)); + // fprintf(stderr, "SAME DIFF %llx->%llx\n", repl, new_repl); + + if (unlikely(cmp_extend_encoding( + afl, h, pattern, new_repl, o_pattern, repl, IS_TRANSFORM, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, status))) { + + return 1; + + } + + // if (*status == 1) { fprintf(stderr, "FOUND!\n"); } + + } + + } + + // test for to uppercase, eg. "new_val = (user_val | 0x5f5f) ..." + if (*status != 1) { + + if ((b_val & (0x5f5f5f5f5f5f5f5f & mask)) == (pattern & mask)) { + + diff = 1; + + } else { + + diff = 0; + + } + + if ((o_b_val & (0x5f5f5f5f5f5f5f5f & mask)) == (o_pattern & mask)) { + + o_diff = 1; + + } else { + + o_diff = 0; + + } + + /* fprintf(stderr, "DIFF4 idx=%03u shape=%02u %llx-%llx=%lx\n", + idx, h->shape + 1, o_pattern, o_b_val, o_diff); fprintf(stderr, + "DIFF4 %016llx %llx-%llx=%lx\n", repl, pattern, b_val, diff);*/ + if (o_diff && diff) { + + // this could be a lower to upper + + u64 new_repl = (repl | (0x2020202020202020 & mask)); + // fprintf(stderr, "SAME DIFF %llx->%llx\n", repl, new_repl); + + if (unlikely(cmp_extend_encoding( + afl, h, pattern, new_repl, o_pattern, repl, IS_TRANSFORM, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, status))) { + + return 1; + + } + + // if (*status == 1) { fprintf(stderr, "FOUND!\n"); } + + } + + } + + *status = 0; + + } } - if (SHAPE_BYTES(h->shape) >= 8 && *status != 1) { + //#endif - if (its_len >= 8 && *buf_64 == pattern && *o_buf_64 == o_pattern) { + // we only allow this for ascii2integer (above) so leave if this is the case + if (unlikely(pattern == o_pattern)) { return 0; } - *buf_64 = repl; - if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } - *buf_64 = pattern; + if ((lvl & LVL1) || attr >= IS_FP_MOD) { + + if (SHAPE_BYTES(h->shape) >= 8 && *status != 1) { + + // if (its_len >= 8) + // fprintf(stderr, + // "TestU64: %u>=8 (idx=%u attr=%u) %llx==%llx" + // " %llx==%llx <= %llx<-%llx\n", + // its_len, idx, attr, *buf_64, pattern, *o_buf_64, o_pattern, + // repl, changed_val); + + // if this is an fcmp (attr & 8 == 8) then do not compare the patterns - + // due to a bug in llvm dynamic float bitcasts do not work :( + // the value 16 means this is a +- 1.0 test case + if (its_len >= 8 && ((*buf_64 == pattern && *o_buf_64 == o_pattern) || + attr >= IS_FP_MOD)) { + + u64 tmp_64 = *buf_64; + *buf_64 = repl; + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } +#ifdef CMPLOG_COMBINE + if (*status == 1) { memcpy(cbuf + idx, buf_64, 8); } +#endif + *buf_64 = tmp_64; + + // fprintf(stderr, "Status=%u\n", *status); + + } + + // reverse encoding + if (do_reverse && *status != 1) { + + if (unlikely(cmp_extend_encoding(afl, h, SWAP64(pattern), SWAP64(repl), + SWAP64(o_pattern), SWAP64(changed_val), + attr, idx, taint_len, orig_buf, buf, + cbuf, len, 0, lvl, status))) { + + return 1; + + } + + } } - // reverse encoding - if (do_reverse && *status != 1) { + if (SHAPE_BYTES(h->shape) >= 4 && *status != 1) { - if (unlikely(cmp_extend_encoding(afl, h, SWAP64(pattern), SWAP64(repl), - SWAP64(o_pattern), idx, orig_buf, buf, - len, 0, status))) { + // if (its_len >= 4 && (attr <= 1 || attr >= 8)) + // fprintf(stderr, + // "TestU32: %u>=4 (idx=%u attr=%u) %x==%x" + // " %x==%x <= %x<-%x\n", + // its_len, idx, attr, *buf_32, (u32)pattern, *o_buf_32, + // (u32)o_pattern, (u32)repl, (u32)changed_val); - return 1; + if (its_len >= 4 && + ((*buf_32 == (u32)pattern && *o_buf_32 == (u32)o_pattern) || + attr >= IS_FP_MOD)) { + + u32 tmp_32 = *buf_32; + *buf_32 = (u32)repl; + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } +#ifdef CMPLOG_COMBINE + if (*status == 1) { memcpy(cbuf + idx, buf_32, 4); } +#endif + *buf_32 = tmp_32; + + // fprintf(stderr, "Status=%u\n", *status); + + } + + // reverse encoding + if (do_reverse && *status != 1) { + + if (unlikely(cmp_extend_encoding(afl, h, SWAP32(pattern), SWAP32(repl), + SWAP32(o_pattern), SWAP32(changed_val), + attr, idx, taint_len, orig_buf, buf, + cbuf, len, 0, lvl, status))) { + + return 1; + + } + + } + + } + + if (SHAPE_BYTES(h->shape) >= 2 && *status != 1) { + + if (its_len >= 2 && + ((*buf_16 == (u16)pattern && *o_buf_16 == (u16)o_pattern) || + attr >= IS_FP_MOD)) { + + u16 tmp_16 = *buf_16; + *buf_16 = (u16)repl; + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } +#ifdef CMPLOG_COMBINE + if (*status == 1) { memcpy(cbuf + idx, buf_16, 2); } +#endif + *buf_16 = tmp_16; + + } + + // reverse encoding + if (do_reverse && *status != 1) { + + if (unlikely(cmp_extend_encoding(afl, h, SWAP16(pattern), SWAP16(repl), + SWAP16(o_pattern), SWAP16(changed_val), + attr, idx, taint_len, orig_buf, buf, + cbuf, len, 0, lvl, status))) { + + return 1; + + } + + } + + } + + if (*status != 1) { // u8 + + // if (its_len >= 1) + // fprintf(stderr, + // "TestU8: %u>=1 (idx=%u attr=%u) %x==%x %x==%x <= %x<-%x\n", + // its_len, idx, attr, *buf_8, (u8)pattern, *o_buf_8, + // (u8)o_pattern, (u8)repl, (u8)changed_val); + + if (its_len >= 1 && + ((*buf_8 == (u8)pattern && *o_buf_8 == (u8)o_pattern) || + attr >= IS_FP_MOD)) { + + u8 tmp_8 = *buf_8; + *buf_8 = (u8)repl; + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } +#ifdef CMPLOG_COMBINE + if (*status == 1) { cbuf[idx] = *buf_8; } +#endif + *buf_8 = tmp_8; } @@ -404,23 +1208,109 @@ static u8 cmp_extend_encoding(afl_state_t *afl, struct cmp_header *h, } - if (SHAPE_BYTES(h->shape) >= 4 && *status != 1) { + // here we add and subract 1 from the value, but only if it is not an + // == or != comparison + // Bits: 1 = Equal, 2 = Greater, 4 = Lesser, 8 = Float + // 16 = modified float, 32 = modified integer (modified = wont match + // in original buffer) - if (its_len >= 4 && *buf_32 == (u32)pattern && - *o_buf_32 == (u32)o_pattern) { + //#ifdef CMPLOG_SOLVE_ARITHMETIC + if (!afl->cmplog_enable_arith || lvl < LVL3 || attr == IS_TRANSFORM) { - *buf_32 = (u32)repl; - if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } - *buf_32 = pattern; + return 0; + + } + + if (!(attr & (IS_GREATER | IS_LESSER)) || SHAPE_BYTES(h->shape) < 4) { + + return 0; + + } + + // transform >= to < and <= to > + if ((attr & IS_EQUAL) && (attr & (IS_GREATER | IS_LESSER))) { + + if (attr & 2) { + + attr += 2; + + } else { + + attr -= 2; } - // reverse encoding - if (do_reverse && *status != 1) { + } + + // lesser/greater FP comparison + if (attr >= IS_FP && attr < IS_FP_MOD) { + + u64 repl_new; + + if (attr & IS_GREATER) { - if (unlikely(cmp_extend_encoding(afl, h, SWAP32(pattern), SWAP32(repl), - SWAP32(o_pattern), idx, orig_buf, buf, - len, 0, status))) { + if (SHAPE_BYTES(h->shape) == 4 && its_len >= 4) { + + float *f = (float *)&repl; + float g = *f; + g += 1.0; + u32 *r = (u32 *)&g; + repl_new = (u32)*r; + + } else if (SHAPE_BYTES(h->shape) == 8 && its_len >= 8) { + + double *f = (double *)&repl; + double g = *f; + g += 1.0; + + u64 *r = (u64 *)&g; + repl_new = *r; + + } else { + + return 0; + + } + + changed_val = repl_new; + + if (unlikely(cmp_extend_encoding( + afl, h, pattern, repl_new, o_pattern, changed_val, 16, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, status))) { + + return 1; + + } + + } else { + + if (SHAPE_BYTES(h->shape) == 4) { + + float *f = (float *)&repl; + float g = *f; + g -= 1.0; + u32 *r = (u32 *)&g; + repl_new = (u32)*r; + + } else if (SHAPE_BYTES(h->shape) == 8) { + + double *f = (double *)&repl; + double g = *f; + g -= 1.0; + u64 *r = (u64 *)&g; + repl_new = *r; + + } else { + + return 0; + + } + + changed_val = repl_new; + + if (unlikely(cmp_extend_encoding( + afl, h, pattern, repl_new, o_pattern, changed_val, 16, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, status))) { return 1; @@ -428,25 +1318,62 @@ static u8 cmp_extend_encoding(afl_state_t *afl, struct cmp_header *h, } - } + // transform double to float, llvm likes to do that internally ... + if (SHAPE_BYTES(h->shape) == 8 && its_len >= 4) { - if (SHAPE_BYTES(h->shape) >= 2 && *status != 1) { + double *f = (double *)&repl; + float g = (float)*f; + repl_new = 0; +#if (__BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__) + memcpy((char *)&repl_new, (char *)&g, 4); +#else + memcpy(((char *)&repl_new) + 4, (char *)&g, 4); +#endif + changed_val = repl_new; + h->shape = 3; // modify shape - if (its_len >= 2 && *buf_16 == (u16)pattern && - *o_buf_16 == (u16)o_pattern) { + // fprintf(stderr, "DOUBLE2FLOAT %llx\n", repl_new); - *buf_16 = (u16)repl; - if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } - *buf_16 = (u16)pattern; + if (unlikely(cmp_extend_encoding( + afl, h, pattern, repl_new, o_pattern, changed_val, 16, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, status))) { + + h->shape = 7; // recover shape + return 1; + + } + + h->shape = 7; // recover shape } - // reverse encoding - if (do_reverse && *status != 1) { + } + + else if (attr < IS_FP) { - if (unlikely(cmp_extend_encoding(afl, h, SWAP16(pattern), SWAP16(repl), - SWAP16(o_pattern), idx, orig_buf, buf, - len, 0, status))) { + // lesser/greater integer comparison + + u64 repl_new; + + if (attr & IS_GREATER) { + + repl_new = repl + 1; + changed_val = repl_new; + if (unlikely(cmp_extend_encoding( + afl, h, pattern, repl_new, o_pattern, changed_val, 32, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, status))) { + + return 1; + + } + + } else { + + repl_new = repl - 1; + changed_val = repl_new; + if (unlikely(cmp_extend_encoding( + afl, h, pattern, repl_new, o_pattern, changed_val, 32, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, status))) { return 1; @@ -456,13 +1383,92 @@ static u8 cmp_extend_encoding(afl_state_t *afl, struct cmp_header *h, } - if (SHAPE_BYTES(h->shape) >= 1 && *status != 1) { + //#endif /* CMPLOG_SOLVE_ARITHMETIC + + return 0; + +} - if (its_len >= 1 && *buf_8 == (u8)pattern && *o_buf_8 == (u8)o_pattern) { +#ifdef WORD_SIZE_64 + +static u8 cmp_extend_encodingN(afl_state_t *afl, struct cmp_header *h, + u128 pattern, u128 repl, u128 o_pattern, + u128 changed_val, u8 attr, u32 idx, + u32 taint_len, u8 *orig_buf, u8 *buf, u8 *cbuf, + u32 len, u8 do_reverse, u8 lvl, u8 *status) { + + u8 *ptr = (u8 *)&buf[idx]; + u8 *o_ptr = (u8 *)&orig_buf[idx]; + u8 *p = (u8 *)&pattern; + u8 *o_p = (u8 *)&o_pattern; + u8 *r = (u8 *)&repl; + u8 backup[16]; + u32 its_len = MIN(len - idx, taint_len); + u32 shape = h->shape + 1; + #if (__BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__) + size_t off = 0; + #else + size_t off = 16 - shape; + #endif + + if (its_len >= shape) { + + #ifdef _DEBUG + fprintf(stderr, "TestUN: %u>=%u (len=%u idx=%u attr=%u off=%lu) (%u) ", + its_len, shape, len, idx, attr, off, do_reverse); + u32 i; + u8 *o_r = (u8 *)&changed_val; + for (i = 0; i < shape; i++) + fprintf(stderr, "%02x", ptr[i]); + fprintf(stderr, "=="); + for (i = 0; i < shape; i++) + fprintf(stderr, "%02x", p[off + i]); + fprintf(stderr, " "); + for (i = 0; i < shape; i++) + fprintf(stderr, "%02x", o_ptr[i]); + fprintf(stderr, "=="); + for (i = 0; i < shape; i++) + fprintf(stderr, "%02x", o_p[off + i]); + fprintf(stderr, " <= "); + for (i = 0; i < shape; i++) + fprintf(stderr, "%02x", r[off + i]); + fprintf(stderr, "<-"); + for (i = 0; i < shape; i++) + fprintf(stderr, "%02x", o_r[off + i]); + fprintf(stderr, "\n"); + #endif + + if (!memcmp(ptr, p + off, shape) && !memcmp(o_ptr, o_p + off, shape)) { + + memcpy(backup, ptr, shape); + memcpy(ptr, r + off, shape); - *buf_8 = (u8)repl; if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } - *buf_8 = (u8)pattern; + + #ifdef CMPLOG_COMBINE + if (*status == 1) { memcpy(cbuf + idx, r, shape); } + #endif + + memcpy(ptr, backup, shape); + + #ifdef _DEBUG + fprintf(stderr, "Status=%u\n", *status); + #endif + + } + + // reverse encoding + if (do_reverse && *status != 1) { + + if (unlikely(cmp_extend_encodingN( + afl, h, SWAPN(pattern, (shape << 3)), SWAPN(repl, (shape << 3)), + SWAPN(o_pattern, (shape << 3)), SWAPN(changed_val, (shape << 3)), + attr, idx, taint_len, orig_buf, buf, cbuf, len, 0, lvl, + status))) { + + return 1; + + } } @@ -472,6 +1478,8 @@ static u8 cmp_extend_encoding(afl_state_t *afl, struct cmp_header *h, } +#endif + static void try_to_add_to_dict(afl_state_t *afl, u64 v, u8 shape) { u8 *b = (u8 *)&v; @@ -486,7 +1494,7 @@ static void try_to_add_to_dict(afl_state_t *afl, u64 v, u8 shape) { } else if (b[k] == 0xff) { - ++cons_0; + ++cons_ff; } else { @@ -498,7 +1506,7 @@ static void try_to_add_to_dict(afl_state_t *afl, u64 v, u8 shape) { } - maybe_add_auto((u8 *)afl, (u8 *)&v, shape); + maybe_add_auto(afl, (u8 *)&v, shape); u64 rev; switch (shape) { @@ -507,43 +1515,108 @@ static void try_to_add_to_dict(afl_state_t *afl, u64 v, u8 shape) { break; case 2: rev = SWAP16((u16)v); - maybe_add_auto((u8 *)afl, (u8 *)&rev, shape); + maybe_add_auto(afl, (u8 *)&rev, shape); break; case 4: rev = SWAP32((u32)v); - maybe_add_auto((u8 *)afl, (u8 *)&rev, shape); + maybe_add_auto(afl, (u8 *)&rev, shape); break; case 8: rev = SWAP64(v); - maybe_add_auto((u8 *)afl, (u8 *)&rev, shape); + maybe_add_auto(afl, (u8 *)&rev, shape); break; } } -static u8 cmp_fuzz(afl_state_t *afl, u32 key, u8 *orig_buf, u8 *buf, u32 len) { +#ifdef WORD_SIZE_64 +static void try_to_add_to_dictN(afl_state_t *afl, u128 v, u8 size) { - struct cmp_header *h = &afl->shm.cmp_map->headers[key]; - u32 i, j, idx; + u8 *b = (u8 *)&v; + + u32 k; + u8 cons_ff = 0, cons_0 = 0; + #if (__BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__) + u32 off = 0; + for (k = 0; k < size; ++k) { + + #else + u32 off = 16 - size; + for (k = 16 - size; k < 16; ++k) { + + #endif + if (b[k] == 0) { + + ++cons_0; + + } else if (b[k] == 0xff) { + + ++cons_ff; + + } else { + + cons_0 = cons_ff = 0; + + } + + } + + maybe_add_auto(afl, (u8 *)&v + off, size); + u128 rev = SWAPN(v, size); + maybe_add_auto(afl, (u8 *)&rev + off, size); - u32 loggeds = h->hits; - if (h->hits > CMP_MAP_H) { loggeds = CMP_MAP_H; } +} + +#endif - u8 status = 0; - // opt not in the paper - u32 fails; - u8 found_one = 0; +#define SWAPA(_x) ((_x & 0xf8) + ((_x & 7) ^ 0x07)) + +static u8 cmp_fuzz(afl_state_t *afl, u32 key, u8 *orig_buf, u8 *buf, u8 *cbuf, + u32 len, u32 lvl, struct tainted *taint) { + + struct cmp_header *h = &afl->shm.cmp_map->headers[key]; + struct tainted * t; + u32 i, j, idx, taint_len, loggeds; + u32 have_taint = 1; + u8 status = 0, found_one = 0; /* loop cmps are useless, detect and ignore them */ +#ifdef WORD_SIZE_64 + u32 is_n = 0; + u128 s128_v0 = 0, s128_v1 = 0, orig_s128_v0 = 0, orig_s128_v1 = 0; +#endif u64 s_v0, s_v1; u8 s_v0_fixed = 1, s_v1_fixed = 1; u8 s_v0_inc = 1, s_v1_inc = 1; u8 s_v0_dec = 1, s_v1_dec = 1; - for (i = 0; i < loggeds; ++i) { + if (h->hits > CMP_MAP_H) { - fails = 0; + loggeds = CMP_MAP_H; + + } else { + + loggeds = h->hits; + + } + +#ifdef WORD_SIZE_64 + switch (SHAPE_BYTES(h->shape)) { + + case 1: + case 2: + case 4: + case 8: + break; + default: + is_n = 1; + + } + +#endif + + for (i = 0; i < loggeds; ++i) { struct cmp_operands *o = &afl->shm.cmp_map->log[key][i]; @@ -580,55 +1653,176 @@ static u8 cmp_fuzz(afl_state_t *afl, u32 key, u8 *orig_buf, u8 *buf, u32 len) { } - for (idx = 0; idx < len && fails < 8; ++idx) { +#ifdef _DEBUG + fprintf(stderr, "Handling: %llx->%llx vs %llx->%llx attr=%u shape=%u\n", + orig_o->v0, o->v0, orig_o->v1, o->v1, h->attribute, + SHAPE_BYTES(h->shape)); +#endif + + t = taint; + while (t->next) { + + t = t->next; + + } + +#ifdef WORD_SIZE_64 + if (unlikely(is_n)) { + + s128_v0 = ((u128)o->v0) + (((u128)o->v0_128) << 64); + s128_v1 = ((u128)o->v1) + (((u128)o->v1_128) << 64); + orig_s128_v0 = ((u128)orig_o->v0) + (((u128)orig_o->v0_128) << 64); + orig_s128_v1 = ((u128)orig_o->v1) + (((u128)orig_o->v1_128) << 64); + + } + +#endif + + for (idx = 0; idx < len; ++idx) { + + if (have_taint) { + + if (!t || idx < t->pos) { + + continue; + + } else { + + taint_len = t->pos + t->len - idx; + + if (idx == t->pos + t->len - 1) { t = t->prev; } + + } + + } else { + + taint_len = len - idx; + + } status = 0; - if (unlikely(cmp_extend_encoding(afl, h, o->v0, o->v1, orig_o->v0, idx, - orig_buf, buf, len, 1, &status))) { - return 1; +#ifdef WORD_SIZE_64 + if (is_n) { // _ExtInt special case including u128 + + if (s128_v0 != orig_s128_v0 && orig_s128_v0 != orig_s128_v1) { + + if (unlikely(cmp_extend_encodingN( + afl, h, s128_v0, s128_v1, orig_s128_v0, orig_s128_v1, + h->attribute, idx, taint_len, orig_buf, buf, cbuf, len, 1, + lvl, &status))) { + + return 1; + + } + + } + + if (status == 1) { + + found_one = 1; + break; + + } + + if (s128_v1 != orig_s128_v1 && orig_s128_v1 != orig_s128_v0) { + + if (unlikely(cmp_extend_encodingN( + afl, h, s128_v1, s128_v0, orig_s128_v1, orig_s128_v0, + SWAPA(h->attribute), idx, taint_len, orig_buf, buf, cbuf, len, + 1, lvl, &status))) { + + return 1; + + } + + } + + if (status == 1) { + + found_one = 1; + break; + + } } - if (status == 2) { +#endif + + // even for u128 and _ExtInt we do cmp_extend_encoding() because + // if we got here their own special trials failed and it might just be + // a cast from e.g. u64 to u128 from the input data. + + if ((o->v0 != orig_o->v0 || lvl >= LVL3) && orig_o->v0 != orig_o->v1) { - ++fails; + if (unlikely(cmp_extend_encoding( + afl, h, o->v0, o->v1, orig_o->v0, orig_o->v1, h->attribute, idx, + taint_len, orig_buf, buf, cbuf, len, 1, lvl, &status))) { - } else if (status == 1) { + return 1; + } + + } + + if (status == 1) { + + found_one = 1; break; } status = 0; - if (unlikely(cmp_extend_encoding(afl, h, o->v1, o->v0, orig_o->v1, idx, - orig_buf, buf, len, 1, &status))) { + if ((o->v1 != orig_o->v1 || lvl >= LVL3) && orig_o->v0 != orig_o->v1) { - return 1; + if (unlikely(cmp_extend_encoding(afl, h, o->v1, o->v0, orig_o->v1, + orig_o->v0, SWAPA(h->attribute), idx, + taint_len, orig_buf, buf, cbuf, len, 1, + lvl, &status))) { - } + return 1; - if (status == 2) { + } - ++fails; + } - } else if (status == 1) { + if (status == 1) { + found_one = 1; break; } } - if (status == 1) { found_one = 1; } +#ifdef _DEBUG + fprintf(stderr, + "END: %llx->%llx vs %llx->%llx attr=%u i=%u found=%u " + "isN=%u size=%u\n", + orig_o->v0, o->v0, orig_o->v1, o->v1, h->attribute, i, found_one, + is_n, SHAPE_BYTES(h->shape)); +#endif // If failed, add to dictionary - if (fails == 8) { + if (!found_one) { if (afl->pass_stats[key].total == 0) { - try_to_add_to_dict(afl, o->v0, SHAPE_BYTES(h->shape)); - try_to_add_to_dict(afl, o->v1, SHAPE_BYTES(h->shape)); +#ifdef WORD_SIZE_64 + if (unlikely(is_n)) { + + try_to_add_to_dictN(afl, s128_v0, SHAPE_BYTES(h->shape)); + try_to_add_to_dictN(afl, s128_v1, SHAPE_BYTES(h->shape)); + + } else + +#endif + { + + try_to_add_to_dict(afl, o->v0, SHAPE_BYTES(h->shape)); + try_to_add_to_dict(afl, o->v1, SHAPE_BYTES(h->shape)); + + } } @@ -658,53 +1852,455 @@ static u8 cmp_fuzz(afl_state_t *afl, u32 key, u8 *orig_buf, u8 *buf, u32 len) { } -static u8 rtn_extend_encoding(afl_state_t *afl, struct cmp_header *h, - u8 *pattern, u8 *repl, u8 *o_pattern, u32 idx, - u8 *orig_buf, u8 *buf, u32 len, u8 *status) { +static u8 rtn_extend_encoding(afl_state_t *afl, u8 *pattern, u8 *repl, + u8 *o_pattern, u8 *changed_val, u8 plen, u32 idx, + u32 taint_len, u8 *orig_buf, u8 *buf, u8 *cbuf, + u32 len, u8 lvl, u8 *status) { - u32 i; - u32 its_len = MIN(32, len - idx); +#ifndef CMPLOG_COMBINE + (void)(cbuf); +#endif + //#ifndef CMPLOG_SOLVE_TRANSFORM + // (void)(changed_val); + //#endif - u8 save[32]; - memcpy(save, &buf[idx], its_len); + u8 save[40]; + u32 saved_idx = idx, pre, from = 0, to = 0, i, j; + u32 its_len = MIN((u32)plen, len - idx); + its_len = MIN(its_len, taint_len); + u32 saved_its_len = its_len; - *status = 0; + if (lvl & LVL3) { - for (i = 0; i < its_len; ++i) { + u32 max_to = MIN(4U, idx); + if (!(lvl & LVL1) && max_to) { from = 1; } + to = max_to; - if (pattern[idx + i] != buf[idx + i] || - o_pattern[idx + i] != orig_buf[idx + i] || *status == 1) { + } - break; + memcpy(save, &buf[saved_idx - to], its_len + to); + (void)(j); + +#ifdef _DEBUG + fprintf(stderr, "RTN T idx=%u lvl=%02x ", idx, lvl); + for (j = 0; j < 8; j++) + fprintf(stderr, "%02x", orig_buf[idx + j]); + fprintf(stderr, " -> "); + for (j = 0; j < 8; j++) + fprintf(stderr, "%02x", o_pattern[j]); + fprintf(stderr, " <= "); + for (j = 0; j < 8; j++) + fprintf(stderr, "%02x", repl[j]); + fprintf(stderr, "\n"); + fprintf(stderr, " "); + for (j = 0; j < 8; j++) + fprintf(stderr, "%02x", buf[idx + j]); + fprintf(stderr, " -> "); + for (j = 0; j < 8; j++) + fprintf(stderr, "%02x", pattern[j]); + fprintf(stderr, " <= "); + for (j = 0; j < 8; j++) + fprintf(stderr, "%02x", changed_val[j]); + fprintf(stderr, "\n"); +#endif + + // Try to match the replace value up to 4 bytes before the current idx. + // This allows matching of eg.: + // if (memcmp(user_val, "TEST") == 0) + // if (memcmp(user_val, "TEST-VALUE") == 0) ... + // We only do this in lvl 3, otherwise we only do direct matching + + for (pre = from; pre <= to; pre++) { + + if (*status != 1 && (!pre || !memcmp(buf + saved_idx - pre, repl, pre))) { + + idx = saved_idx - pre; + its_len = saved_its_len + pre; + + for (i = 0; i < its_len; ++i) { + + if ((pattern[i] != buf[idx + i] && o_pattern[i] != orig_buf[idx + i]) || + *status == 1) { + + break; + + } + + buf[idx + i] = repl[i]; + + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + +#ifdef CMPLOG_COMBINE + if (*status == 1) { memcpy(cbuf + idx, &buf[idx], i); } +#endif + + } + + memcpy(&buf[idx], save + to - pre, i); + + } + + } + + //#ifdef CMPLOG_SOLVE_TRANSFORM + + if (*status == 1) return 0; + + if (afl->cmplog_enable_transform && (lvl & LVL3)) { + + u32 toupper = 0, tolower = 0, xor = 0, arith = 0, tohex = 0, fromhex = 0; +#ifdef CMPLOG_SOLVE_TRANSFORM_BASE64 + u32 tob64 = 0, fromb64 = 0; +#endif + u32 from_0 = 0, from_x = 0, from_X = 0, from_slash = 0, from_up = 0; + u32 to_0 = 0, to_x = 0, to_slash = 0, to_up = 0; + u8 xor_val[32], arith_val[32], tmp[48]; + + idx = saved_idx; + its_len = saved_its_len; + + memcpy(save, &buf[idx], its_len); + + for (i = 0; i < its_len; ++i) { + + xor_val[i] = pattern[i] ^ buf[idx + i]; + arith_val[i] = pattern[i] - buf[idx + i]; + + if (i == 0) { + + if (orig_buf[idx] == '0') { + + from_0 = 1; + + } else if (orig_buf[idx] == '\\') { + + from_slash = 1; + + } + + if (repl[0] == '0') { + + to_0 = 1; + + } else if (repl[0] == '\\') { + + to_slash = 1; + + } + + } else if (i == 1) { + + if (orig_buf[idx + 1] == 'x') { + + from_x = 1; + + } else if (orig_buf[idx + 1] == 'X') { + + from_X = from_x = 1; + + } + + if (repl[1] == 'x' || repl[1] == 'X') { to_x = 1; } + + } + + if (i < 16 && is_hex(repl + (i << 1))) { + + ++tohex; + + if (!to_up) { + + if (repl[i << 1] >= 'A' && repl[i << 1] <= 'F') + to_up = 1; + else if (repl[i << 1] >= 'a' && repl[i << 1] <= 'f') + to_up = 2; + if (repl[(i << 1) + 1] >= 'A' && repl[(i << 1) + 1] <= 'F') + to_up = 1; + else if (repl[(i << 1) + 1] >= 'a' && repl[(i << 1) + 1] <= 'f') + to_up = 2; + + } + + } + + if ((i % 2)) { + + if (len > idx + i && is_hex(orig_buf + idx + i)) { + + fromhex += 2; + + if (!from_up) { + + if (orig_buf[idx + i] >= 'A' && orig_buf[idx + i] <= 'F') + from_up = 1; + else if (orig_buf[idx + i] >= 'a' && orig_buf[idx + i] <= 'f') + from_up = 2; + if (orig_buf[idx + i - 1] >= 'A' && orig_buf[idx + i - 1] <= 'F') + from_up = 1; + else if (orig_buf[idx + i - 1] >= 'a' && + orig_buf[idx + i - 1] <= 'f') + from_up = 2; + + } + + } + + } + +#ifdef CMPLOG_SOLVE_TRANSFORM_BASE64 + if (i % 3 == 2 && i < 24) { + + if (is_base64(repl + ((i / 3) << 2))) tob64 += 3; + + } + + if (i % 4 == 3 && i < 24) { + + if (is_base64(orig_buf + idx + i - 3)) fromb64 += 4; + + } + +#endif + + if ((o_pattern[i] ^ orig_buf[idx + i]) == xor_val[i] && xor_val[i]) { + + ++xor; + + } + + if ((o_pattern[i] - orig_buf[idx + i]) == arith_val[i] && arith_val[i]) { + + ++arith; + + } + + if ((buf[idx + i] | 0x20) == pattern[i] && + (orig_buf[idx + i] | 0x20) == o_pattern[i]) { + + ++tolower; + + } + + if ((buf[idx + i] & 0x5a) == pattern[i] && + (orig_buf[idx + i] & 0x5a) == o_pattern[i]) { + + ++toupper; + + } + +#ifdef _DEBUG + fprintf(stderr, + "RTN idx=%u loop=%u xor=%u arith=%u tolower=%u toupper=%u " + "tohex=%u fromhex=%u to_0=%u to_slash=%u to_x=%u " + "from_0=%u from_slash=%u from_x=%u\n", + idx, i, xor, arith, tolower, toupper, tohex, fromhex, to_0, + to_slash, to_x, from_0, from_slash, from_x); + #ifdef CMPLOG_SOLVE_TRANSFORM_BASE64 + fprintf(stderr, "RTN idx=%u loop=%u tob64=%u from64=%u\n", tob64, + fromb64); + #endif +#endif + +#ifdef CMPLOG_SOLVE_TRANSFORM_BASE64 + // input is base64 and converted to binary? convert repl to base64! + if ((i % 4) == 3 && i < 24 && fromb64 > i) { + + to_base64(repl, tmp, i + 1); + memcpy(buf + idx, tmp, i + 1); + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + // fprintf(stderr, "RTN ATTEMPT fromb64 %u result %u\n", fromb64, + // *status); + + } + + // input is converted to base64? decode repl with base64! + if ((i % 3) == 2 && i < 24 && tob64 > i) { + + u32 olen = from_base64(repl, tmp, i + 1); + memcpy(buf + idx, tmp, olen); + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + // fprintf(stderr, "RTN ATTEMPT tob64 %u idx=%u result %u\n", tob64, + // idx, *status); + + } + +#endif + + // input is converted to hex? convert repl to binary! + if (i < 16 && tohex > i) { + + u32 off; + if (to_slash + to_x + to_0 == 2) { + + off = 2; + + } else { + + off = 0; + + } + + for (j = 0; j <= i; j++) + tmp[j] = (hex_table[repl[off + (j << 1)] - '0'] << 4) + + hex_table[repl[off + (j << 1) + 1] - '0']; + + memcpy(buf + idx, tmp, i + 1); + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + // fprintf(stderr, "RTN ATTEMPT tohex %u result %u\n", tohex, *status); + + } + + // input is hex and converted to binary? convert repl to hex! + if (i && (i % 2) && i < 16 && fromhex && + fromhex + from_slash + from_x + from_0 > i) { + + u8 off = 0; + if (from_slash && from_x) { + + tmp[0] = '\\'; + if (from_X) { + + tmp[1] = 'X'; + + } else { + + tmp[1] = 'x'; + + } + + off = 2; + + } else if (from_0 && from_x) { + + tmp[0] = '0'; + if (from_X) { + + tmp[1] = 'X'; + + } else { + + tmp[1] = 'x'; + + } + + off = 2; + + } + + if (to_up == 1) { + + for (j = 0; j <= (i >> 1); j++) { + + tmp[off + (j << 1)] = hex_table_up[repl[j] >> 4]; + tmp[off + (j << 1) + 1] = hex_table_up[repl[j] % 16]; + + } + + } else { + + for (j = 0; j <= (i >> 1); j++) { + + tmp[off + (j << 1)] = hex_table_low[repl[j] >> 4]; + tmp[off + (j << 1) + 1] = hex_table_low[repl[j] % 16]; + + } + + } + + memcpy(buf + idx, tmp, i + 1 + off); + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + // fprintf(stderr, "RTN ATTEMPT fromhex %u result %u\n", fromhex, + // *status); + memcpy(buf + idx + i, save + i, i + 1 + off); + + } + + if (xor > i) { + + for (j = 0; j <= i; j++) + buf[idx + j] = repl[j] ^ xor_val[j]; + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + // fprintf(stderr, "RTN ATTEMPT xor %u result %u\n", xor, *status); + + } + + if (arith > i && *status != 1) { + + for (j = 0; j <= i; j++) + buf[idx + j] = repl[j] - arith_val[j]; + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + // fprintf(stderr, "RTN ATTEMPT arith %u result %u\n", arith, *status); + + } + + if (toupper > i && *status != 1) { + + for (j = 0; j <= i; j++) + buf[idx + j] = repl[j] | 0x20; + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + // fprintf(stderr, "RTN ATTEMPT toupper %u result %u\n", toupper, + // *status); + + } + + if (tolower > i && *status != 1) { + + for (j = 0; j <= i; j++) + buf[idx + j] = repl[j] & 0x5f; + if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + // fprintf(stderr, "RTN ATTEMPT tolower %u result %u\n", tolower, + // *status); + + } + +#ifdef CMPLOG_COMBINE + if (*status == 1) { memcpy(cbuf + idx, &buf[idx], i + 1); } +#endif + + if ((i >= 7 && + (i >= xor&&i >= arith &&i >= tolower &&i >= toupper &&i > tohex &&i > + (fromhex + from_0 + from_x + from_slash + 1) +#ifdef CMPLOG_SOLVE_TRANSFORM_BASE64 + && i > tob64 + 3 && i > fromb64 + 4 +#endif + )) || + repl[i] != changed_val[i] || *status == 1) { + + break; + + } } - buf[idx + i] = repl[idx + i]; - if (unlikely(its_fuzz(afl, buf, len, status))) { return 1; } + memcpy(&buf[idx], save, i); } - memcpy(&buf[idx], save, i); + //#endif + return 0; } -static u8 rtn_fuzz(afl_state_t *afl, u32 key, u8 *orig_buf, u8 *buf, u32 len) { +static u8 rtn_fuzz(afl_state_t *afl, u32 key, u8 *orig_buf, u8 *buf, u8 *cbuf, + u32 len, u8 lvl, struct tainted *taint) { + struct tainted * t; struct cmp_header *h = &afl->shm.cmp_map->headers[key]; - u32 i, j, idx; + u32 i, j, idx, have_taint = 1, taint_len, loggeds; + u8 status = 0, found_one = 0; - u32 loggeds = h->hits; - if (h->hits > CMP_MAP_RTN_H) { loggeds = CMP_MAP_RTN_H; } + if (h->hits > CMP_MAP_RTN_H) { - u8 status = 0; - // opt not in the paper - u32 fails = 0; - u8 found_one = 0; + loggeds = CMP_MAP_RTN_H; - for (i = 0; i < loggeds; ++i) { + } else { - fails = 0; + loggeds = h->hits; + + } + + for (i = 0; i < loggeds; ++i) { struct cmpfn_operands *o = &((struct cmpfn_operands *)afl->shm.cmp_map->log[key])[i]; @@ -724,53 +2320,92 @@ static u8 rtn_fuzz(afl_state_t *afl, u32 key, u8 *orig_buf, u8 *buf, u32 len) { } - for (idx = 0; idx < len && fails < 8; ++idx) { + /* + struct cmp_header *hh = &afl->orig_cmp_map->headers[key]; + fprintf(stderr, "RTN N hits=%u id=%u shape=%u attr=%u v0=", h->hits, h->id, + h->shape, h->attribute); for (j = 0; j < 8; j++) fprintf(stderr, "%02x", + o->v0[j]); fprintf(stderr, " v1="); for (j = 0; j < 8; j++) fprintf(stderr, + "%02x", o->v1[j]); fprintf(stderr, "\nRTN O hits=%u id=%u shape=%u attr=%u + o0=", hh->hits, hh->id, hh->shape, hh->attribute); for (j = 0; j < 8; j++) + fprintf(stderr, "%02x", orig_o->v0[j]); + fprintf(stderr, " o1="); + for (j = 0; j < 8; j++) + fprintf(stderr, "%02x", orig_o->v1[j]); + fprintf(stderr, "\n"); + */ + + t = taint; + while (t->next) { + + t = t->next; - if (unlikely(rtn_extend_encoding(afl, h, o->v0, o->v1, orig_o->v0, idx, - orig_buf, buf, len, &status))) { + } - return 1; + for (idx = 0; idx < len; ++idx) { - } + if (have_taint) { - if (status == 2) { + if (!t || idx < t->pos) { - ++fails; + continue; - } else if (status == 1) { + } else { - break; + taint_len = t->pos + t->len - idx; + + if (idx == t->pos + t->len - 1) { t = t->prev; } + + } + + } else { + + taint_len = len - idx; } - if (unlikely(rtn_extend_encoding(afl, h, o->v1, o->v0, orig_o->v1, idx, - orig_buf, buf, len, &status))) { + status = 0; + + if (unlikely(rtn_extend_encoding( + afl, o->v0, o->v1, orig_o->v0, orig_o->v1, SHAPE_BYTES(h->shape), + idx, taint_len, orig_buf, buf, cbuf, len, lvl, &status))) { return 1; } - if (status == 2) { + if (status == 1) { + + found_one = 1; + break; + + } - ++fails; + status = 0; - } else if (status == 1) { + if (unlikely(rtn_extend_encoding( + afl, o->v1, o->v0, orig_o->v1, orig_o->v0, SHAPE_BYTES(h->shape), + idx, taint_len, orig_buf, buf, cbuf, len, lvl, &status))) { + return 1; + + } + + if (status == 1) { + + found_one = 1; break; } } - if (status == 1) { found_one = 1; } - // If failed, add to dictionary - if (fails == 8) { + if (!found_one && (lvl & LVL1)) { - if (afl->pass_stats[key].total == 0) { + if (unlikely(!afl->pass_stats[key].total)) { - maybe_add_auto((u8 *)afl, o->v0, SHAPE_BYTES(h->shape)); - maybe_add_auto((u8 *)afl, o->v1, SHAPE_BYTES(h->shape)); + maybe_add_auto(afl, o->v0, SHAPE_BYTES(h->shape)); + maybe_add_auto(afl, o->v1, SHAPE_BYTES(h->shape)); } @@ -796,54 +2431,147 @@ static u8 rtn_fuzz(afl_state_t *afl, u32 key, u8 *orig_buf, u8 *buf, u32 len) { ///// Input to State stage // afl->queue_cur->exec_cksum -u8 input_to_state_stage(afl_state_t *afl, u8 *orig_buf, u8 *buf, u32 len, - u64 exec_cksum) { +u8 input_to_state_stage(afl_state_t *afl, u8 *orig_buf, u8 *buf, u32 len) { u8 r = 1; - if (afl->orig_cmp_map == NULL) { + if (unlikely(!afl->pass_stats)) { - afl->orig_cmp_map = ck_alloc_nozero(sizeof(struct cmp_map)); + afl->pass_stats = ck_alloc(sizeof(struct afl_pass_stat) * CMP_MAP_W); } - if (afl->pass_stats == NULL) { + struct tainted *taint = NULL; - afl->pass_stats = ck_alloc(sizeof(struct afl_pass_stat) * CMP_MAP_W); + if (!afl->queue_cur->taint || !afl->queue_cur->cmplog_colorinput) { + + if (unlikely(colorization(afl, buf, len, &taint))) { return 1; } + + // no taint? still try, create a dummy to prevent again colorization + if (!taint) { + +#ifdef _DEBUG + fprintf(stderr, "TAINT FAILED\n"); +#endif + afl->queue_cur->colorized = CMPLOG_LVL_MAX; + return 0; + + } + +#ifdef _DEBUG + else if (taint->pos == 0 && taint->len == len) { + + fprintf(stderr, "TAINT FULL\n"); + + } + +#endif + + } else { + + buf = afl->queue_cur->cmplog_colorinput; + taint = afl->queue_cur->taint; + + } + + struct tainted *t = taint; + + while (t) { + +#ifdef _DEBUG + fprintf(stderr, "T: idx=%u len=%u\n", t->pos, t->len); +#endif + t = t->next; + + } + +#if defined(_DEBUG) || defined(CMPLOG_INTROSPECTION) + u64 start_time = get_cur_time(); + u32 cmp_locations = 0; +#endif + + // Generate the cmplog data + + // manually clear the full cmp_map + memset(afl->shm.cmp_map, 0, sizeof(struct cmp_map)); + if (unlikely(common_fuzz_cmplog_stuff(afl, orig_buf, len))) { + + afl->queue_cur->colorized = CMPLOG_LVL_MAX; + while (taint) { + + t = taint->next; + ck_free(taint); + taint = t; + + } + + return 1; } - // do it manually, forkserver clear only afl->fsrv.trace_bits - memset(afl->shm.cmp_map->headers, 0, sizeof(afl->shm.cmp_map->headers)); + if (unlikely(!afl->orig_cmp_map)) { - if (unlikely(common_fuzz_cmplog_stuff(afl, buf, len))) { return 1; } + afl->orig_cmp_map = ck_alloc_nozero(sizeof(struct cmp_map)); + + } memcpy(afl->orig_cmp_map, afl->shm.cmp_map, sizeof(struct cmp_map)); + memset(afl->shm.cmp_map->headers, 0, sizeof(struct cmp_header) * CMP_MAP_W); + if (unlikely(common_fuzz_cmplog_stuff(afl, buf, len))) { - if (unlikely(colorization(afl, buf, len, exec_cksum))) { return 1; } + afl->queue_cur->colorized = CMPLOG_LVL_MAX; + while (taint) { - // do it manually, forkserver clear only afl->fsrv.trace_bits - memset(afl->shm.cmp_map->headers, 0, sizeof(afl->shm.cmp_map->headers)); + t = taint->next; + ck_free(taint); + taint = t; - if (unlikely(common_fuzz_cmplog_stuff(afl, buf, len))) { return 1; } + } + + return 1; + + } + +#ifdef _DEBUG + dump("ORIG", orig_buf, len); + dump("NEW ", buf, len); +#endif + + // Start insertion loop u64 orig_hit_cnt, new_hit_cnt; u64 orig_execs = afl->fsrv.total_execs; orig_hit_cnt = afl->queued_paths + afl->unique_crashes; + u64 screen_update = 100000 / afl->queue_cur->exec_us, + execs = afl->fsrv.total_execs; afl->stage_name = "input-to-state"; afl->stage_short = "its"; afl->stage_max = 0; afl->stage_cur = 0; + u32 lvl = (afl->queue_cur->colorized ? 0 : LVL1) + + (afl->cmplog_lvl == CMPLOG_LVL_MAX ? LVL3 : 0); + +#ifdef CMPLOG_COMBINE + u8 *cbuf = afl_realloc((void **)&afl->in_scratch_buf, len + 128); + memcpy(cbuf, orig_buf, len); + u8 *virgin_backup = afl_realloc((void **)&afl->ex_buf, afl->shm.map_size); + memcpy(virgin_backup, afl->virgin_bits, afl->shm.map_size); +#else + u8 *cbuf = NULL; +#endif + u32 k; for (k = 0; k < CMP_MAP_W; ++k) { if (!afl->shm.cmp_map->headers[k].hits) { continue; } - if (afl->pass_stats[k].total && - (rand_below(afl, afl->pass_stats[k].total) >= - afl->pass_stats[k].faileds || - afl->pass_stats[k].total == 0xff)) { + if (afl->pass_stats[k].faileds >= CMPLOG_FAIL_MAX || + afl->pass_stats[k].total >= CMPLOG_FAIL_MAX) { + +#ifdef _DEBUG + fprintf(stderr, "DISABLED %u\n", k); +#endif afl->shm.cmp_map->headers[k].hits = 0; // ignore this cmp @@ -851,12 +2579,13 @@ u8 input_to_state_stage(afl_state_t *afl, u8 *orig_buf, u8 *buf, u32 len, if (afl->shm.cmp_map->headers[k].type == CMP_TYPE_INS) { - afl->stage_max += MIN((u32)afl->shm.cmp_map->headers[k].hits, CMP_MAP_H); + afl->stage_max += + MIN((u32)(afl->shm.cmp_map->headers[k].hits), (u32)CMP_MAP_H); } else { afl->stage_max += - MIN((u32)afl->shm.cmp_map->headers[k].hits, CMP_MAP_RTN_H); + MIN((u32)(afl->shm.cmp_map->headers[k].hits), (u32)CMP_MAP_RTN_H); } @@ -866,13 +2595,37 @@ u8 input_to_state_stage(afl_state_t *afl, u8 *orig_buf, u8 *buf, u32 len, if (!afl->shm.cmp_map->headers[k].hits) { continue; } +#if defined(_DEBUG) || defined(CMPLOG_INTROSPECTION) + ++cmp_locations; +#endif + if (afl->shm.cmp_map->headers[k].type == CMP_TYPE_INS) { - if (unlikely(cmp_fuzz(afl, k, orig_buf, buf, len))) { goto exit_its; } + if (unlikely(cmp_fuzz(afl, k, orig_buf, buf, cbuf, len, lvl, taint))) { - } else { + goto exit_its; + + } + + } else if ((lvl & LVL1) + + //#ifdef CMPLOG_SOLVE_TRANSFORM + || ((lvl & LVL3) && afl->cmplog_enable_transform) + //#endif + ) { + + if (unlikely(rtn_fuzz(afl, k, orig_buf, buf, cbuf, len, lvl, taint))) { + + goto exit_its; + + } + + } + + if (afl->fsrv.total_execs - execs > screen_update) { - if (unlikely(rtn_fuzz(afl, k, orig_buf, buf, len))) { goto exit_its; } + execs = afl->fsrv.total_execs; + show_stats(afl); } @@ -881,11 +2634,122 @@ u8 input_to_state_stage(afl_state_t *afl, u8 *orig_buf, u8 *buf, u32 len, r = 0; exit_its: + + if (afl->cmplog_lvl == CMPLOG_LVL_MAX) { + + afl->queue_cur->colorized = CMPLOG_LVL_MAX; + + ck_free(afl->queue_cur->cmplog_colorinput); + while (taint) { + + t = taint->next; + ck_free(taint); + taint = t; + + } + + afl->queue_cur->taint = NULL; + + } else { + + afl->queue_cur->colorized = LVL2; + + if (!afl->queue_cur->taint) { afl->queue_cur->taint = taint; } + + if (!afl->queue_cur->cmplog_colorinput) { + + afl->queue_cur->cmplog_colorinput = ck_alloc_nozero(len); + memcpy(afl->queue_cur->cmplog_colorinput, buf, len); + memcpy(buf, orig_buf, len); + + } + + } + +#ifdef CMPLOG_COMBINE + if (afl->queued_paths + afl->unique_crashes > orig_hit_cnt + 1) { + + // copy the current virgin bits so we can recover the information + u8 *virgin_save = afl_realloc((void **)&afl->eff_buf, afl->shm.map_size); + memcpy(virgin_save, afl->virgin_bits, afl->shm.map_size); + // reset virgin bits to the backup previous to redqueen + memcpy(afl->virgin_bits, virgin_backup, afl->shm.map_size); + + u8 status = 0; + its_fuzz(afl, cbuf, len, &status); + + // now combine with the saved virgin bits + #ifdef WORD_SIZE_64 + u64 *v = (u64 *)afl->virgin_bits; + u64 *s = (u64 *)virgin_save; + u32 i; + for (i = 0; i < (afl->shm.map_size >> 3); i++) { + + v[i] &= s[i]; + + } + + #else + u32 *v = (u32 *)afl->virgin_bits; + u32 *s = (u32 *)virgin_save; + u32 i; + for (i = 0; i < (afl->shm.map_size >> 2); i++) { + + v[i] &= s[i]; + + } + + #endif + + #ifdef _DEBUG + dump("COMB", cbuf, len); + if (status == 1) { + + fprintf(stderr, "NEW CMPLOG_COMBINED\n"); + + } else { + + fprintf(stderr, "NO new combined\n"); + + } + + #endif + + } + +#endif + new_hit_cnt = afl->queued_paths + afl->unique_crashes; afl->stage_finds[STAGE_ITS] += new_hit_cnt - orig_hit_cnt; afl->stage_cycles[STAGE_ITS] += afl->fsrv.total_execs - orig_execs; - memcpy(orig_buf, buf, len); +#if defined(_DEBUG) || defined(CMPLOG_INTROSPECTION) + FILE *f = stderr; + #ifndef _DEBUG + if (afl->not_on_tty) { + + char fn[4096]; + snprintf(fn, sizeof(fn), "%s/introspection_cmplog.txt", afl->out_dir); + f = fopen(fn, "a"); + + } + + #endif + + if (f) { + + fprintf(f, + "Cmplog: fname=%s len=%u ms=%llu result=%u finds=%llu entries=%u\n", + afl->queue_cur->fname, len, get_cur_time() - start_time, r, + new_hit_cnt - orig_hit_cnt, cmp_locations); + + #ifndef _DEBUG + if (afl->not_on_tty) { fclose(f); } + #endif + + } + +#endif return r; diff --git a/src/afl-fuzz-run.c b/src/afl-fuzz-run.c index 6e3be72b..0b84a542 100644 --- a/src/afl-fuzz-run.c +++ b/src/afl-fuzz-run.c @@ -28,6 +28,9 @@ #include <sys/time.h> #include <signal.h> #include <limits.h> +#if !defined NAME_MAX + #define NAME_MAX _XOPEN_NAME_MAX +#endif #include "cmplog.h" @@ -38,8 +41,8 @@ u64 time_spent_working = 0; /* Execute target application, monitoring for timeouts. Return status information. The called program will update afl->fsrv->trace_bits. */ -fsrv_run_result_t fuzz_run_target(afl_state_t *afl, afl_forkserver_t *fsrv, - u32 timeout) { +fsrv_run_result_t __attribute__((hot)) +fuzz_run_target(afl_state_t *afl, afl_forkserver_t *fsrv, u32 timeout) { #ifdef PROFILING static u64 time_spent_start = 0; @@ -62,8 +65,6 @@ fsrv_run_result_t fuzz_run_target(afl_state_t *afl, afl_forkserver_t *fsrv, time_spent_start = (spec.tv_sec * 1000000000) + spec.tv_nsec; #endif - // TODO: Don't classify for faults? - classify_counts(fsrv); return res; } @@ -72,13 +73,15 @@ fsrv_run_result_t fuzz_run_target(afl_state_t *afl, afl_forkserver_t *fsrv, old file is unlinked and a new one is created. Otherwise, afl->fsrv.out_fd is rewound and truncated. */ -void write_to_testcase(afl_state_t *afl, void *mem, u32 len) { +void __attribute__((hot)) +write_to_testcase(afl_state_t *afl, void *mem, u32 len) { #ifdef _AFL_DOCUMENT_MUTATIONS s32 doc_fd; char fn[PATH_MAX]; snprintf(fn, PATH_MAX, "%s/mutations/%09u:%s", afl->out_dir, - afl->document_counter++, describe_op(afl, 0)); + afl->document_counter++, + describe_op(afl, 0, NAME_MAX - strlen("000000000:"))); if ((doc_fd = open(fn, O_WRONLY | O_CREAT | O_TRUNC, 0600)) >= 0) { @@ -92,9 +95,9 @@ void write_to_testcase(afl_state_t *afl, void *mem, u32 len) { if (unlikely(afl->custom_mutators_count)) { - u8 * new_buf = NULL; ssize_t new_size = len; - void * new_mem = mem; + u8 * new_mem = mem; + u8 * new_buf = NULL; LIST_FOREACH(&afl->custom_mutator_list, struct custom_mutator, { @@ -136,24 +139,88 @@ void write_to_testcase(afl_state_t *afl, void *mem, u32 len) { /* The same, but with an adjustable gap. Used for trimming. */ -static void write_with_gap(afl_state_t *afl, void *mem, u32 len, u32 skip_at, +static void write_with_gap(afl_state_t *afl, u8 *mem, u32 len, u32 skip_at, u32 skip_len) { s32 fd = afl->fsrv.out_fd; u32 tail_len = len - skip_at - skip_len; + /* + This memory is used to carry out the post_processing(if present) after copying + the testcase by removing the gaps. This can break though + */ + u8 *mem_trimmed = afl_realloc(AFL_BUF_PARAM(out_scratch), len - skip_len + 1); + if (unlikely(!mem_trimmed)) { PFATAL("alloc"); } + + ssize_t new_size = len - skip_len; + u8 * new_mem = mem; + + bool post_process_skipped = true; + + if (unlikely(afl->custom_mutators_count)) { + + u8 *new_buf = NULL; + new_mem = mem_trimmed; + + LIST_FOREACH(&afl->custom_mutator_list, struct custom_mutator, { + + if (el->afl_custom_post_process) { + + // We copy into the mem_trimmed only if we actually have custom mutators + // *with* post_processing installed + + if (post_process_skipped) { + + if (skip_at) { memcpy(mem_trimmed, (u8 *)mem, skip_at); } + + if (tail_len) { + + memcpy(mem_trimmed + skip_at, (u8 *)mem + skip_at + skip_len, + tail_len); + + } + + post_process_skipped = false; + + } + + new_size = + el->afl_custom_post_process(el->data, new_mem, new_size, &new_buf); + + if (unlikely(!new_buf || (new_size <= 0))) { + + FATAL("Custom_post_process failed (ret: %lu)", + (long unsigned)new_size); + + } + + } + + new_mem = new_buf; + + }); + + } + if (afl->fsrv.shmem_fuzz) { - if (skip_at) { memcpy(afl->fsrv.shmem_fuzz, mem, skip_at); } + if (!post_process_skipped) { - if (tail_len) { + // If we did post_processing, copy directly from the new_mem buffer - memcpy(afl->fsrv.shmem_fuzz + skip_at, (u8 *)mem + skip_at + skip_len, - tail_len); + memcpy(afl->fsrv.shmem_fuzz, new_mem, new_size); } - *afl->fsrv.shmem_fuzz_len = len - skip_len; + else { + + memcpy(afl->fsrv.shmem_fuzz, mem, skip_at); + + memcpy(afl->fsrv.shmem_fuzz, mem + skip_at + skip_len, tail_len); + + } + + *afl->fsrv.shmem_fuzz_len = new_size; #ifdef _DEBUG if (afl->debug) { @@ -163,10 +230,10 @@ static void write_with_gap(afl_state_t *afl, void *mem, u32 len, u32 skip_at, hash64(afl->fsrv.shmem_fuzz, *afl->fsrv.shmem_fuzz_len, 0xa5b35705), *afl->fsrv.shmem_fuzz_len); fprintf(stderr, "SHM :"); - for (int i = 0; i < *afl->fsrv.shmem_fuzz_len; i++) + for (u32 i = 0; i < *afl->fsrv.shmem_fuzz_len; i++) fprintf(stderr, "%02x", afl->fsrv.shmem_fuzz[i]); fprintf(stderr, "\nORIG:"); - for (int i = 0; i < *afl->fsrv.shmem_fuzz_len; i++) + for (u32 i = 0; i < *afl->fsrv.shmem_fuzz_len; i++) fprintf(stderr, "%02x", (u8)((u8 *)mem)[i]); fprintf(stderr, "\n"); @@ -178,7 +245,7 @@ static void write_with_gap(afl_state_t *afl, void *mem, u32 len, u32 skip_at, } else if (afl->fsrv.out_file) { - if (afl->no_unlink) { + if (unlikely(afl->no_unlink)) { fd = open(afl->fsrv.out_file, O_WRONLY | O_CREAT | O_TRUNC, 0600); @@ -197,18 +264,21 @@ static void write_with_gap(afl_state_t *afl, void *mem, u32 len, u32 skip_at, } - if (skip_at) { ck_write(fd, mem, skip_at, afl->fsrv.out_file); } + if (!post_process_skipped) { + + ck_write(fd, new_mem, new_size, afl->fsrv.out_file); + + } else { - u8 *memu8 = mem; - if (tail_len) { + ck_write(fd, mem, skip_at, afl->fsrv.out_file); - ck_write(fd, memu8 + skip_at + skip_len, tail_len, afl->fsrv.out_file); + ck_write(fd, mem + skip_at + skip_len, tail_len, afl->fsrv.out_file); } if (!afl->fsrv.out_file) { - if (ftruncate(fd, len - skip_len)) { PFATAL("ftruncate() failed"); } + if (ftruncate(fd, new_size)) { PFATAL("ftruncate() failed"); } lseek(fd, 0, SEEK_SET); } else { @@ -226,11 +296,11 @@ static void write_with_gap(afl_state_t *afl, void *mem, u32 len, u32 skip_at, u8 calibrate_case(afl_state_t *afl, struct queue_entry *q, u8 *use_mem, u32 handicap, u8 from_queue) { + if (unlikely(afl->shm.cmplog_mode)) { q->exec_cksum = 0; } + u8 fault = 0, new_bits = 0, var_detected = 0, hnb = 0, first_run = (q->exec_cksum == 0); - - u64 start_us, stop_us; - + u64 start_us, stop_us, diff_us; s32 old_sc = afl->stage_cur, old_sm = afl->stage_max; u32 use_tmout = afl->fsrv.exec_tmout; u8 *old_sn = afl->stage_name; @@ -264,7 +334,7 @@ u8 calibrate_case(afl_state_t *afl, struct queue_entry *q, u8 *use_mem, } afl_fsrv_start(&afl->fsrv, afl->argv, &afl->stop_soon, - afl->afl_env.afl_debug_child_output); + afl->afl_env.afl_debug_child); if (afl->fsrv.support_shmem_fuzz && !afl->fsrv.use_shmem_fuzz) { @@ -310,6 +380,11 @@ u8 calibrate_case(afl_state_t *afl, struct queue_entry *q, u8 *use_mem, } +#ifdef INTROSPECTION + if (unlikely(!q->bitsmap_size)) q->bitsmap_size = afl->bitsmap_size; +#endif + + classify_counts(&afl->fsrv); cksum = hash64(afl->fsrv.trace_bits, afl->fsrv.map_size, HASH_CONST); if (q->exec_cksum != cksum) { @@ -326,6 +401,8 @@ u8 calibrate_case(afl_state_t *afl, struct queue_entry *q, u8 *use_mem, unlikely(afl->first_trace[i] != afl->fsrv.trace_bits[i])) { afl->var_bytes[i] = 1; + // ignore the variable edge by setting it to fully discovered + afl->virgin_bits[i] = 0; } @@ -345,15 +422,32 @@ u8 calibrate_case(afl_state_t *afl, struct queue_entry *q, u8 *use_mem, } - stop_us = get_cur_time_us(); + if (unlikely(afl->fixed_seed)) { + + diff_us = (u64)(afl->fsrv.exec_tmout - 1) * (u64)afl->stage_max; + + } else { + + stop_us = get_cur_time_us(); + diff_us = stop_us - start_us; + if (unlikely(!diff_us)) { ++diff_us; } - afl->total_cal_us += stop_us - start_us; + } + + afl->total_cal_us += diff_us; afl->total_cal_cycles += afl->stage_max; /* OK, let's collect some stats about the performance of this test case. This is used for fuzzing air time calculations in calculate_score(). */ - q->exec_us = (stop_us - start_us) / afl->stage_max; + if (unlikely(!afl->stage_max)) { + + // Pretty sure this cannot happen, yet scan-build complains. + FATAL("BUG: stage_max should not be 0 here! Please report this condition."); + + } + + q->exec_us = diff_us / afl->stage_max; q->bitmap_size = count_bytes(afl, afl->fsrv.trace_bits); q->handicap = handicap; q->cal_failed = 0; @@ -414,7 +508,7 @@ void sync_fuzzers(afl_state_t *afl) { DIR * sd; struct dirent *sd_ent; u32 sync_cnt = 0, synced = 0, entries = 0; - u8 path[PATH_MAX + 256]; + u8 path[PATH_MAX + 1 + NAME_MAX]; sd = opendir(afl->sync_dir); if (!sd) { PFATAL("Unable to open '%s'", afl->sync_dir); } @@ -517,9 +611,10 @@ void sync_fuzzers(afl_state_t *afl) { u8 entry[12]; sprintf(entry, "id:%06u", next_min_accept); + while (m < n) { - if (memcmp(namelist[m]->d_name, entry, 9)) { + if (strncmp(namelist[m]->d_name, entry, 9)) { m++; @@ -532,9 +627,8 @@ void sync_fuzzers(afl_state_t *afl) { } if (m >= n) { goto close_sync; } // nothing new - o = n - 1; - while (o >= m) { + for (o = m; o < n; o++) { s32 fd; struct stat st; @@ -542,7 +636,6 @@ void sync_fuzzers(afl_state_t *afl) { snprintf(path, sizeof(path), "%s/%s", qd_path, namelist[o]->d_name); afl->syncing_case = next_min_accept; next_min_accept++; - o--; /* Allow this to fail in case the other fuzzer is resuming or so... */ @@ -604,7 +697,7 @@ void sync_fuzzers(afl_state_t *afl) { // same time. If so, the first temporary main node running again will demote // themselves so this is not an issue - u8 path[PATH_MAX]; + // u8 path2[PATH_MAX]; afl->is_main_node = 1; sprintf(path, "%s/is_main_node", afl->out_dir); int fd = open(path, O_CREAT | O_RDWR, 0644); @@ -614,6 +707,8 @@ void sync_fuzzers(afl_state_t *afl) { if (afl->foreign_sync_cnt) read_foreign_testcases(afl, 0); + afl->last_sync_time = get_cur_time(); + } /* Trim all new test cases to save cycles when doing deterministic checks. The @@ -622,6 +717,8 @@ void sync_fuzzers(afl_state_t *afl) { u8 trim_case(afl_state_t *afl, struct queue_entry *q, u8 *in_buf) { + u32 orig_len = q->len; + /* Custom mutator trimmer */ if (afl->custom_mutators_count) { @@ -639,6 +736,12 @@ u8 trim_case(afl_state_t *afl, struct queue_entry *q, u8 *in_buf) { }); + if (orig_len != q->len || custom_trimmed) { + + queue_testcase_retake(afl, q, orig_len); + + } + if (custom_trimmed) return trimmed_case; } @@ -663,12 +766,12 @@ u8 trim_case(afl_state_t *afl, struct queue_entry *q, u8 *in_buf) { len_p2 = next_pow2(q->len); - remove_len = MAX(len_p2 / TRIM_START_STEPS, TRIM_MIN_BYTES); + remove_len = MAX(len_p2 / TRIM_START_STEPS, (u32)TRIM_MIN_BYTES); /* Continue until the number of steps gets too high or the stepover gets too small. */ - while (remove_len >= MAX(len_p2 / TRIM_END_STEPS, TRIM_MIN_BYTES)) { + while (remove_len >= MAX(len_p2 / TRIM_END_STEPS, (u32)TRIM_MIN_BYTES)) { u32 remove_pos = remove_len; @@ -687,13 +790,14 @@ u8 trim_case(afl_state_t *afl, struct queue_entry *q, u8 *in_buf) { write_with_gap(afl, in_buf, q->len, remove_pos, trim_avail); fault = fuzz_run_target(afl, &afl->fsrv, afl->fsrv.exec_tmout); - ++afl->trim_execs; if (afl->stop_soon || fault == FSRV_RUN_ERROR) { goto abort_trimming; } /* Note that we don't keep track of crashes or hangs here; maybe TODO? */ + ++afl->trim_execs; + classify_counts(&afl->fsrv); cksum = hash64(afl->fsrv.trace_bits, afl->fsrv.map_size, HASH_CONST); /* If the deletion had no impact on the trace, make it permanent. This @@ -745,22 +849,35 @@ u8 trim_case(afl_state_t *afl, struct queue_entry *q, u8 *in_buf) { s32 fd; - if (afl->no_unlink) { + if (unlikely(afl->no_unlink)) { fd = open(q->fname, O_WRONLY | O_CREAT | O_TRUNC, 0600); + if (fd < 0) { PFATAL("Unable to create '%s'", q->fname); } + + u32 written = 0; + while (written < q->len) { + + ssize_t result = write(fd, in_buf, q->len - written); + if (result > 0) written += result; + + } + } else { unlink(q->fname); /* ignore errors */ fd = open(q->fname, O_WRONLY | O_CREAT | O_EXCL, 0600); - } + if (fd < 0) { PFATAL("Unable to create '%s'", q->fname); } + + ck_write(fd, in_buf, q->len, q->fname); - if (fd < 0) { PFATAL("Unable to create '%s'", q->fname); } + } - ck_write(fd, in_buf, q->len, q->fname); close(fd); + queue_testcase_retake_mem(afl, q, in_buf, q->len, orig_len); + memcpy(afl->fsrv.trace_bits, afl->clean_trace, afl->fsrv.map_size); update_bitmap_score(afl, q); @@ -777,7 +894,8 @@ abort_trimming: error conditions, returning 1 if it's time to bail out. This is a helper function for fuzz_one(). */ -u8 common_fuzz_stuff(afl_state_t *afl, u8 *out_buf, u32 len) { +u8 __attribute__((hot)) +common_fuzz_stuff(afl_state_t *afl, u8 *out_buf, u32 len) { u8 fault; diff --git a/src/afl-fuzz-state.c b/src/afl-fuzz-state.c index 66280ed1..3d36e712 100644 --- a/src/afl-fuzz-state.c +++ b/src/afl-fuzz-state.c @@ -30,9 +30,9 @@ s8 interesting_8[] = {INTERESTING_8}; s16 interesting_16[] = {INTERESTING_8, INTERESTING_16}; s32 interesting_32[] = {INTERESTING_8, INTERESTING_16, INTERESTING_32}; -char *power_names[POWER_SCHEDULES_NUM] = {"explore", "exploit", "fast", - "coe", "lin", "quad", - "rare", "mmopt", "seek"}; +char *power_names[POWER_SCHEDULES_NUM] = {"explore", "mmopt", "exploit", + "fast", "coe", "lin", + "quad", "rare", "seek"}; /* Initialize MOpt "globals" for this afl state */ @@ -87,13 +87,27 @@ void afl_state_init(afl_state_t *afl, uint32_t map_size) { afl->w_end = 0.3; afl->g_max = 5000; afl->period_pilot_tmp = 5000.0; - afl->schedule = EXPLORE; /* Power schedule (default: EXPLORE)*/ + afl->schedule = FAST; /* Power schedule (default: FAST) */ afl->havoc_max_mult = HAVOC_MAX_MULT; afl->clear_screen = 1; /* Window resized? */ afl->havoc_div = 1; /* Cycle count divisor for havoc */ afl->stage_name = "init"; /* Name of the current fuzz stage */ afl->splicing_with = -1; /* Splicing with which test case? */ + afl->cpu_to_bind = -1; + afl->havoc_stack_pow2 = HAVOC_STACK_POW2; + afl->cal_cycles = CAL_CYCLES; + afl->cal_cycles_long = CAL_CYCLES_LONG; + afl->hang_tmout = EXEC_TIMEOUT; + afl->stats_update_freq = 1; + afl->stats_avg_exec = 0; + afl->skip_deterministic = 1; + afl->cmplog_lvl = 1; +#ifndef NO_SPLICING + afl->use_splicing = 1; +#endif + afl->q_testcase_max_cache_size = TESTCASE_CACHE_SIZE * 1048576UL; + afl->q_testcase_max_cache_entries = 64 * 1024; #ifdef HAVE_AFFINITY afl->cpu_aff = -1; /* Selected CPU core */ @@ -111,48 +125,16 @@ void afl_state_init(afl_state_t *afl, uint32_t map_size) { afl->fsrv.use_stdin = 1; afl->fsrv.map_size = map_size; - afl->fsrv.function_opt = (u8 *)afl; - afl->fsrv.function_ptr = &maybe_add_auto; - - afl->cal_cycles = CAL_CYCLES; - afl->cal_cycles_long = CAL_CYCLES_LONG; - + // afl_state_t is not available in forkserver.c + afl->fsrv.afl_ptr = (void *)afl; + afl->fsrv.add_extra_func = (void (*)(void *, u8 *, u32)) & add_extra; afl->fsrv.exec_tmout = EXEC_TIMEOUT; - afl->hang_tmout = EXEC_TIMEOUT; - afl->fsrv.mem_limit = MEM_LIMIT; - - afl->stats_update_freq = 1; - afl->fsrv.dev_urandom_fd = -1; afl->fsrv.dev_null_fd = -1; - afl->fsrv.child_pid = -1; afl->fsrv.out_dir_fd = -1; - afl->cmplog_prev_timed_out = 0; - - /* statis file */ - afl->last_bitmap_cvg = 0; - afl->last_stability = 0; - afl->last_eps = 0; - - /* plot file saves from last run */ - afl->plot_prev_qp = 0; - afl->plot_prev_pf = 0; - afl->plot_prev_pnf = 0; - afl->plot_prev_ce = 0; - afl->plot_prev_md = 0; - afl->plot_prev_qc = 0; - afl->plot_prev_uc = 0; - afl->plot_prev_uh = 0; - - afl->stats_last_stats_ms = 0; - afl->stats_last_plot_ms = 0; - afl->stats_last_ms = 0; - afl->stats_last_execs = 0; - afl->stats_avg_exec = -1; - init_mopt_globals(afl); list_append(&afl_states, afl); @@ -173,6 +155,14 @@ void read_afl_environment(afl_state_t *afl, char **envp) { WARNF("Potentially mistyped AFL environment variable: %s", env); issue_detected = 1; + } else if (strncmp(env, "USE_", 4) == 0) { + + WARNF( + "Potentially mistyped AFL environment variable: %s, did you mean " + "AFL_%s?", + env, env); + issue_detected = 1; + } else if (strncmp(env, "AFL_", 4) == 0) { int i = 0, match = 0; @@ -246,6 +236,13 @@ void read_afl_environment(afl_state_t *afl, char **envp) { afl->afl_env.afl_custom_mutator_only = get_afl_env(afl_environment_variables[i]) ? 1 : 0; + } else if (!strncmp(env, "AFL_CMPLOG_ONLY_NEW", + + afl_environment_variable_len)) { + + afl->afl_env.afl_cmplog_only_new = + get_afl_env(afl_environment_variables[i]) ? 1 : 0; + } else if (!strncmp(env, "AFL_NO_UI", afl_environment_variable_len)) { afl->afl_env.afl_no_ui = @@ -279,11 +276,13 @@ void read_afl_environment(afl_state_t *afl, char **envp) { afl->afl_env.afl_bench_until_crash = get_afl_env(afl_environment_variables[i]) ? 1 : 0; - } else if (!strncmp(env, "AFL_DEBUG_CHILD_OUTPUT", + } else if (!strncmp(env, "AFL_DEBUG_CHILD", + afl_environment_variable_len) || + !strncmp(env, "AFL_DEBUG_CHILD_OUTPUT", afl_environment_variable_len)) { - afl->afl_env.afl_debug_child_output = + afl->afl_env.afl_debug_child = get_afl_env(afl_environment_variables[i]) ? 1 : 0; } else if (!strncmp(env, "AFL_AUTORESUME", @@ -314,6 +313,13 @@ void read_afl_environment(afl_state_t *afl, char **envp) { afl->afl_env.afl_cal_fast = get_afl_env(afl_environment_variables[i]) ? 1 : 0; + } else if (!strncmp(env, "AFL_STATSD", + + afl_environment_variable_len)) { + + afl->afl_env.afl_statsd = + get_afl_env(afl_environment_variables[i]) ? 1 : 0; + } else if (!strncmp(env, "AFL_TMPDIR", afl_environment_variable_len)) { @@ -347,6 +353,86 @@ void read_afl_environment(afl_state_t *afl, char **envp) { afl->afl_env.afl_preload = (u8 *)get_afl_env(afl_environment_variables[i]); + } else if (!strncmp(env, "AFL_MAX_DET_EXTRAS", + + afl_environment_variable_len)) { + + afl->afl_env.afl_max_det_extras = + (u8 *)get_afl_env(afl_environment_variables[i]); + + } else if (!strncmp(env, "AFL_FORKSRV_INIT_TMOUT", + + afl_environment_variable_len)) { + + afl->afl_env.afl_forksrv_init_tmout = + (u8 *)get_afl_env(afl_environment_variables[i]); + + } else if (!strncmp(env, "AFL_TESTCACHE_SIZE", + + afl_environment_variable_len)) { + + afl->afl_env.afl_testcache_size = + (u8 *)get_afl_env(afl_environment_variables[i]); + + } else if (!strncmp(env, "AFL_TESTCACHE_ENTRIES", + + afl_environment_variable_len)) { + + afl->afl_env.afl_testcache_entries = + (u8 *)get_afl_env(afl_environment_variables[i]); + + } else if (!strncmp(env, "AFL_STATSD_HOST", + + afl_environment_variable_len)) { + + afl->afl_env.afl_statsd_host = + (u8 *)get_afl_env(afl_environment_variables[i]); + + } else if (!strncmp(env, "AFL_STATSD_PORT", + + afl_environment_variable_len)) { + + afl->afl_env.afl_statsd_port = + (u8 *)get_afl_env(afl_environment_variables[i]); + + } else if (!strncmp(env, "AFL_STATSD_TAGS_FLAVOR", + + afl_environment_variable_len)) { + + afl->afl_env.afl_statsd_tags_flavor = + (u8 *)get_afl_env(afl_environment_variables[i]); + + } else if (!strncmp(env, "AFL_CRASH_EXITCODE", + + afl_environment_variable_len)) { + + afl->afl_env.afl_crash_exitcode = + (u8 *)get_afl_env(afl_environment_variables[i]); + +#if defined USE_COLOR && !defined ALWAYS_COLORED + + } else if (!strncmp(env, "AFL_NO_COLOR", + + afl_environment_variable_len)) { + + afl->afl_env.afl_statsd_tags_flavor = + (u8 *)get_afl_env(afl_environment_variables[i]); + + } else if (!strncmp(env, "AFL_NO_COLOUR", + + afl_environment_variable_len)) { + + afl->afl_env.afl_statsd_tags_flavor = + (u8 *)get_afl_env(afl_environment_variables[i]); +#endif + + } else if (!strncmp(env, "AFL_KILL_SIGNAL", + + afl_environment_variable_len)) { + + afl->afl_env.afl_kill_signal = + (u8 *)get_afl_env(afl_environment_variables[i]); + } } else { @@ -400,6 +486,8 @@ void read_afl_environment(afl_state_t *afl, char **envp) { WARNF("Mistyped AFL environment variable: %s", env); issue_detected = 1; + print_suggested_envs(env); + } } @@ -419,13 +507,13 @@ void afl_state_deinit(afl_state_t *afl) { if (afl->pass_stats) { ck_free(afl->pass_stats); } if (afl->orig_cmp_map) { ck_free(afl->orig_cmp_map); } - if (afl->queue_buf) { free(afl->queue_buf); } - if (afl->out_buf) { free(afl->out_buf); } - if (afl->out_scratch_buf) { free(afl->out_scratch_buf); } - if (afl->eff_buf) { free(afl->eff_buf); } - if (afl->in_buf) { free(afl->in_buf); } - if (afl->in_scratch_buf) { free(afl->in_scratch_buf); } - if (afl->ex_buf) { free(afl->ex_buf); } + afl_free(afl->queue_buf); + afl_free(afl->out_buf); + afl_free(afl->out_scratch_buf); + afl_free(afl->eff_buf); + afl_free(afl->in_buf); + afl_free(afl->in_scratch_buf); + afl_free(afl->ex_buf); ck_free(afl->virgin_bits); ck_free(afl->virgin_tmout); @@ -453,8 +541,8 @@ void afl_states_stop(void) { LIST_FOREACH(&afl_states, afl_state_t, { - if (el->fsrv.child_pid > 0) kill(el->fsrv.child_pid, SIGKILL); - if (el->fsrv.fsrv_pid > 0) kill(el->fsrv.fsrv_pid, SIGKILL); + if (el->fsrv.child_pid > 0) kill(el->fsrv.child_pid, el->fsrv.kill_signal); + if (el->fsrv.fsrv_pid > 0) kill(el->fsrv.fsrv_pid, el->fsrv.kill_signal); }); diff --git a/src/afl-fuzz-stats.c b/src/afl-fuzz-stats.c index 7b30b5ea..99059a2d 100644 --- a/src/afl-fuzz-stats.c +++ b/src/afl-fuzz-stats.c @@ -24,32 +24,180 @@ */ #include "afl-fuzz.h" +#include "envs.h" #include <limits.h> -/* Update stats file for unattended monitoring. */ +/* Write fuzzer setup file */ -void write_stats_file(afl_state_t *afl, double bitmap_cvg, double stability, - double eps) { +void write_setup_file(afl_state_t *afl, u32 argc, char **argv) { + + u8 fn[PATH_MAX]; + snprintf(fn, PATH_MAX, "%s/fuzzer_setup", afl->out_dir); + FILE *f = create_ffile(fn); + u32 i; + + fprintf(f, "# environment variables:\n"); + u32 s_afl_env = (u32)sizeof(afl_environment_variables) / + sizeof(afl_environment_variables[0]) - + 1U; + + for (i = 0; i < s_afl_env; ++i) { + + char *val; + if ((val = getenv(afl_environment_variables[i])) != NULL) { + + fprintf(f, "%s=%s\n", afl_environment_variables[i], val); + + } + + } + + fprintf(f, "# command line:\n"); + + size_t j; + for (i = 0; i < argc; ++i) { + + if (i) fprintf(f, " "); +#ifdef __ANDROID__ + if (memchr(argv[i], '\'', sizeof(argv[i]))) { + +#else + if (index(argv[i], '\'')) { -#ifndef __HAIKU__ - struct rusage rus; #endif - unsigned long long int cur_time = get_cur_time(); - u8 fn[PATH_MAX]; - s32 fd; - FILE * f; - u32 t_bytes = count_non_255_bytes(afl, afl->virgin_bits); + fprintf(f, "'"); + for (j = 0; j < strlen(argv[i]); j++) + if (argv[i][j] == '\'') + fprintf(f, "'\"'\"'"); + else + fprintf(f, "%c", argv[i][j]); + fprintf(f, "'"); + + } else { + + fprintf(f, "'%s'", argv[i]); + + } + } + + fprintf(f, "\n"); + + fclose(f); + (void)(afl_environment_deprecated); + +} + +/* load some of the existing stats file when resuming.*/ +void load_stats_file(afl_state_t *afl) { + + FILE *f; + u8 buf[MAX_LINE]; + u8 * lptr; + u8 fn[PATH_MAX]; + u32 lineno = 0; snprintf(fn, PATH_MAX, "%s/fuzzer_stats", afl->out_dir); + f = fopen(fn, "r"); + if (!f) { + + WARNF("Unable to load stats file '%s'", fn); + return; + + } + + while ((lptr = fgets(buf, MAX_LINE, f))) { + + lineno++; + u8 *lstartptr = lptr; + u8 *rptr = lptr + strlen(lptr) - 1; + u8 keystring[MAX_LINE]; + while (*lptr != ':' && lptr < rptr) { + + lptr++; + + } + + if (*lptr == '\n' || !*lptr) { + + WARNF("Unable to read line %d of stats file", lineno); + continue; + + } - fd = open(fn, O_WRONLY | O_CREAT | O_TRUNC, 0600); + if (*lptr == ':') { + + *lptr = 0; + strcpy(keystring, lstartptr); + lptr++; + char *nptr; + switch (lineno) { + + case 3: + if (!strcmp(keystring, "run_time ")) + afl->prev_run_time = 1000 * strtoull(lptr, &nptr, 10); + break; + case 5: + if (!strcmp(keystring, "cycles_done ")) + afl->queue_cycle = + strtoull(lptr, &nptr, 10) ? strtoull(lptr, &nptr, 10) + 1 : 0; + break; + case 7: + if (!strcmp(keystring, "execs_done ")) + afl->fsrv.total_execs = strtoull(lptr, &nptr, 10); + break; + case 10: + if (!strcmp(keystring, "paths_total ")) + afl->queued_paths = strtoul(lptr, &nptr, 10); + break; + case 12: + if (!strcmp(keystring, "paths_found ")) + afl->queued_discovered = strtoul(lptr, &nptr, 10); + break; + case 13: + if (!strcmp(keystring, "paths_imported ")) + afl->queued_imported = strtoul(lptr, &nptr, 10); + break; + case 14: + if (!strcmp(keystring, "max_depth ")) + afl->max_depth = strtoul(lptr, &nptr, 10); + break; + case 21: + if (!strcmp(keystring, "unique_crashes ")) + afl->unique_crashes = strtoull(lptr, &nptr, 10); + break; + case 22: + if (!strcmp(keystring, "unique_hangs ")) + afl->unique_hangs = strtoull(lptr, &nptr, 10); + break; + default: + break; - if (fd < 0) { PFATAL("Unable to create '%s'", fn); } + } + + } + + } + + return; + +} + +/* Update stats file for unattended monitoring. */ + +void write_stats_file(afl_state_t *afl, u32 t_bytes, double bitmap_cvg, + double stability, double eps) { - f = fdopen(fd, "w"); +#ifndef __HAIKU__ + struct rusage rus; +#endif - if (!f) { PFATAL("fdopen() failed"); } + u64 cur_time = get_cur_time(); + u8 fn[PATH_MAX]; + FILE *f; + + snprintf(fn, PATH_MAX, "%s/fuzzer_stats", afl->out_dir); + f = create_ffile(fn); /* Keep last values in case we're called from another context where exec/sec stats and such are not readily available. */ @@ -71,8 +219,8 @@ void write_stats_file(afl_state_t *afl, double bitmap_cvg, double stability, cur_time - afl->last_avg_exec_update >= 60000))) { afl->last_avg_execs_saved = - (float)(1000 * (afl->fsrv.total_execs - afl->last_avg_execs)) / - (float)(cur_time - afl->last_avg_exec_update); + (double)(1000 * (afl->fsrv.total_execs - afl->last_avg_execs)) / + (double)(cur_time - afl->last_avg_exec_update); afl->last_avg_execs = afl->fsrv.total_execs; afl->last_avg_exec_update = cur_time; @@ -116,17 +264,21 @@ void write_stats_file(afl_state_t *afl, double bitmap_cvg, double stability, "edges_found : %u\n" "var_byte_count : %u\n" "havoc_expansion : %u\n" + "testcache_size : %llu\n" + "testcache_count : %u\n" + "testcache_evict : %u\n" "afl_banner : %s\n" "afl_version : " VERSION "\n" "target_mode : %s%s%s%s%s%s%s%s%s\n" "command_line : %s\n", - afl->start_time / 1000, cur_time / 1000, - (cur_time - afl->start_time) / 1000, (u32)getpid(), - afl->queue_cycle ? (afl->queue_cycle - 1) : 0, afl->cycles_wo_finds, - afl->fsrv.total_execs, + (afl->start_time - afl->prev_run_time) / 1000, cur_time / 1000, + (afl->prev_run_time + cur_time - afl->start_time) / 1000, + (u32)getpid(), afl->queue_cycle ? (afl->queue_cycle - 1) : 0, + afl->cycles_wo_finds, afl->fsrv.total_execs, afl->fsrv.total_execs / - ((double)(get_cur_time() - afl->start_time) / 1000), + ((double)(afl->prev_run_time + get_cur_time() - afl->start_time) / + 1000), afl->last_avg_execs_saved, afl->queued_paths, afl->queued_favored, afl->queued_discovered, afl->queued_imported, afl->max_depth, afl->current_entry, afl->pending_favored, afl->pending_not_fuzzed, @@ -149,7 +301,9 @@ void write_stats_file(afl_state_t *afl, double bitmap_cvg, double stability, #else -1, #endif - t_bytes, afl->var_byte_count, afl->expand_havoc, afl->use_banner, + t_bytes, afl->var_byte_count, afl->expand_havoc, + afl->q_testcase_cache_size, afl->q_testcase_cache_count, + afl->q_testcase_evictions, afl->use_banner, afl->unicorn_mode ? "unicorn" : "", afl->fsrv.qemu_mode ? "qemu " : "", afl->non_instrumented_mode ? " non_instrumented " : "", @@ -163,17 +317,18 @@ void write_stats_file(afl_state_t *afl, double bitmap_cvg, double stability, ? "" : "default", afl->orig_cmdline); + /* ignore errors */ if (afl->debug) { - uint32_t i = 0; + u32 i = 0; fprintf(f, "virgin_bytes :"); for (i = 0; i < afl->fsrv.map_size; i++) { if (afl->virgin_bits[i] != 0xff) { - fprintf(f, " %d[%02x]", i, afl->virgin_bits[i]); + fprintf(f, " %u[%02x]", i, afl->virgin_bits[i]); } @@ -183,7 +338,7 @@ void write_stats_file(afl_state_t *afl, double bitmap_cvg, double stability, fprintf(f, "var_bytes :"); for (i = 0; i < afl->fsrv.map_size; i++) { - if (afl->var_bytes[i]) { fprintf(f, " %d", i); } + if (afl->var_bytes[i]) { fprintf(f, " %u", i); } } @@ -197,16 +352,19 @@ void write_stats_file(afl_state_t *afl, double bitmap_cvg, double stability, /* Update the plot file if there is a reason to. */ -void maybe_update_plot_file(afl_state_t *afl, double bitmap_cvg, double eps) { +void maybe_update_plot_file(afl_state_t *afl, u32 t_bytes, double bitmap_cvg, + double eps) { - if (unlikely(afl->plot_prev_qp == afl->queued_paths && + if (unlikely(afl->stop_soon) || + unlikely(afl->plot_prev_qp == afl->queued_paths && afl->plot_prev_pf == afl->pending_favored && afl->plot_prev_pnf == afl->pending_not_fuzzed && afl->plot_prev_ce == afl->current_entry && afl->plot_prev_qc == afl->queue_cycle && afl->plot_prev_uc == afl->unique_crashes && afl->plot_prev_uh == afl->unique_hangs && - afl->plot_prev_md == afl->max_depth) || + afl->plot_prev_md == afl->max_depth && + afl->plot_prev_ed == afl->fsrv.total_execs) || unlikely(!afl->queue_cycle) || unlikely(get_cur_time() - afl->start_time <= 60)) { @@ -222,19 +380,21 @@ void maybe_update_plot_file(afl_state_t *afl, double bitmap_cvg, double eps) { afl->plot_prev_uc = afl->unique_crashes; afl->plot_prev_uh = afl->unique_hangs; afl->plot_prev_md = afl->max_depth; + afl->plot_prev_ed = afl->fsrv.total_execs; /* Fields in the file: unix_time, afl->cycles_done, cur_path, paths_total, paths_not_fuzzed, - favored_not_fuzzed, afl->unique_crashes, afl->unique_hangs, afl->max_depth, - execs_per_sec */ + favored_not_fuzzed, unique_crashes, unique_hangs, max_depth, + execs_per_sec, edges_found */ fprintf(afl->fsrv.plot_file, - "%llu, %llu, %u, %u, %u, %u, %0.02f%%, %llu, %llu, %u, %0.02f\n", + "%llu, %llu, %u, %u, %u, %u, %0.02f%%, %llu, %llu, %u, %0.02f, %llu, " + "%u\n", get_cur_time() / 1000, afl->queue_cycle - 1, afl->current_entry, afl->queued_paths, afl->pending_not_fuzzed, afl->pending_favored, bitmap_cvg, afl->unique_crashes, afl->unique_hangs, afl->max_depth, - eps); /* ignore errors */ + eps, afl->plot_prev_ed, t_bytes); /* ignore errors */ fflush(afl->fsrv.plot_file); @@ -311,28 +471,37 @@ void show_stats(afl_state_t *afl) { /* Calculate smoothed exec speed stats. */ - if (!afl->stats_last_execs) { + if (unlikely(!afl->stats_last_execs)) { - afl->stats_avg_exec = - ((double)afl->fsrv.total_execs) * 1000 / (cur_ms - afl->start_time); + if (likely(cur_ms != afl->start_time)) { + + afl->stats_avg_exec = ((double)afl->fsrv.total_execs) * 1000 / + (afl->prev_run_time + cur_ms - afl->start_time); + + } } else { - double cur_avg = ((double)(afl->fsrv.total_execs - afl->stats_last_execs)) * - 1000 / (cur_ms - afl->stats_last_ms); + if (likely(cur_ms != afl->stats_last_ms)) { - /* If there is a dramatic (5x+) jump in speed, reset the indicator - more quickly. */ + double cur_avg = + ((double)(afl->fsrv.total_execs - afl->stats_last_execs)) * 1000 / + (cur_ms - afl->stats_last_ms); - if (cur_avg * 5 < afl->stats_avg_exec || - cur_avg / 5 > afl->stats_avg_exec) { + /* If there is a dramatic (5x+) jump in speed, reset the indicator + more quickly. */ - afl->stats_avg_exec = cur_avg; + if (cur_avg * 5 < afl->stats_avg_exec || + cur_avg / 5 > afl->stats_avg_exec) { - } + afl->stats_avg_exec = cur_avg; - afl->stats_avg_exec = afl->stats_avg_exec * (1.0 - 1.0 / AVG_SMOOTHING) + - cur_avg * (1.0 / AVG_SMOOTHING); + } + + afl->stats_avg_exec = afl->stats_avg_exec * (1.0 - 1.0 / AVG_SMOOTHING) + + cur_avg * (1.0 / AVG_SMOOTHING); + + } } @@ -364,18 +533,31 @@ void show_stats(afl_state_t *afl) { if (cur_ms - afl->stats_last_stats_ms > STATS_UPDATE_SEC * 1000) { afl->stats_last_stats_ms = cur_ms; - write_stats_file(afl, t_byte_ratio, stab_ratio, afl->stats_avg_exec); + write_stats_file(afl, t_bytes, t_byte_ratio, stab_ratio, + afl->stats_avg_exec); save_auto(afl); write_bitmap(afl); } + if (unlikely(afl->afl_env.afl_statsd)) { + + if (cur_ms - afl->statsd_last_send_ms > STATSD_UPDATE_SEC * 1000) { + + /* reset counter, even if send failed. */ + afl->statsd_last_send_ms = cur_ms; + if (statsd_send_metric(afl)) { WARNF("could not send statsd metric."); } + + } + + } + /* Every now and then, write plot data. */ if (cur_ms - afl->stats_last_plot_ms > PLOT_UPDATE_SEC * 1000) { afl->stats_last_plot_ms = cur_ms; - maybe_update_plot_file(afl, t_byte_ratio, afl->stats_avg_exec); + maybe_update_plot_file(afl, t_bytes, t_byte_ratio, afl->stats_avg_exec); } @@ -463,6 +645,13 @@ void show_stats(afl_state_t *afl) { #define SP10 SP5 SP5 #define SP20 SP10 SP10 + /* Since `total_crashes` does not get reloaded from disk on restart, + it indicates if we found crashes this round already -> paint red. + If it's 0, but `unique_crashes` is set from a past run, paint in yellow. */ + char *crash_color = afl->total_crashes ? cLRD + : afl->unique_crashes ? cYEL + : cRST; + /* Lord, forgive me this. */ SAYF(SET_G1 bSTG bLT bH bSTOP cCYA @@ -507,7 +696,7 @@ void show_stats(afl_state_t *afl) { } - u_stringify_time_diff(time_tmp, cur_ms, afl->start_time); + u_stringify_time_diff(time_tmp, afl->prev_run_time + cur_ms, afl->start_time); SAYF(bV bSTOP " run time : " cRST "%-33s " bSTG bV bSTOP " cycles done : %s%-5s " bSTG bV "\n", time_tmp, tmp, u_stringify_int(IB(0), afl->queue_cycle - 1)); @@ -550,7 +739,7 @@ void show_stats(afl_state_t *afl) { u_stringify_time_diff(time_tmp, cur_ms, afl->last_crash_time); SAYF(bV bSTOP " last uniq crash : " cRST "%-33s " bSTG bV bSTOP " uniq crashes : %s%-6s" bSTG bV "\n", - time_tmp, afl->unique_crashes ? cLRD : cRST, tmp); + time_tmp, crash_color, tmp); sprintf(tmp, "%s%s", u_stringify_int(IB(0), afl->unique_hangs), (afl->unique_hangs >= KEEP_UNIQUE_HANG) ? "+" : ""); @@ -633,15 +822,13 @@ void show_stats(afl_state_t *afl) { SAYF(bV bSTOP " total execs : " cRST "%-20s " bSTG bV bSTOP " new crashes : %s%-22s" bSTG bV "\n", - u_stringify_int(IB(0), afl->fsrv.total_execs), - afl->unique_crashes ? cLRD : cRST, tmp); + u_stringify_int(IB(0), afl->fsrv.total_execs), crash_color, tmp); } else { SAYF(bV bSTOP " total execs : " cRST "%-20s " bSTG bV bSTOP " total crashes : %s%-22s" bSTG bV "\n", - u_stringify_int(IB(0), afl->fsrv.total_execs), - afl->unique_crashes ? cLRD : cRST, tmp); + u_stringify_int(IB(0), afl->fsrv.total_execs), crash_color, tmp); } @@ -890,19 +1077,19 @@ void show_stats(afl_state_t *afl) { if (afl->cpu_aff >= 0) { SAYF("%s" cGRA "[cpu%03u:%s%3u%%" cGRA "]\r" cRST, spacing, - MIN(afl->cpu_aff, 999), cpu_color, MIN(cur_utilization, 999)); + MIN(afl->cpu_aff, 999), cpu_color, MIN(cur_utilization, (u32)999)); } else { SAYF("%s" cGRA " [cpu:%s%3u%%" cGRA "]\r" cRST, spacing, cpu_color, - MIN(cur_utilization, 999)); + MIN(cur_utilization, (u32)999)); } #else SAYF("%s" cGRA " [cpu:%s%3u%%" cGRA "]\r" cRST, spacing, cpu_color, - MIN(cur_utilization, 999)); + MIN(cur_utilization, (u32)999)); #endif /* ^HAVE_AFFINITY */ @@ -929,11 +1116,10 @@ void show_stats(afl_state_t *afl) { void show_init_stats(afl_state_t *afl) { - struct queue_entry *q = afl->queue; - u32 min_bits = 0, max_bits = 0; + struct queue_entry *q; + u32 min_bits = 0, max_bits = 0, max_len = 0, count = 0, i; u64 min_us = 0, max_us = 0; u64 avg_us = 0; - u32 max_len = 0; u8 val_bufs[4][STRINGIFY_VAL_SIZE_MAX]; #define IB(i) val_bufs[(i)], sizeof(val_bufs[(i)]) @@ -944,7 +1130,10 @@ void show_init_stats(afl_state_t *afl) { } - while (q) { + for (i = 0; i < afl->queued_paths; i++) { + + q = afl->queue_buf[i]; + if (unlikely(q->disabled)) { continue; } if (!min_us || q->exec_us < min_us) { min_us = q->exec_us; } if (q->exec_us > max_us) { max_us = q->exec_us; } @@ -954,11 +1143,11 @@ void show_init_stats(afl_state_t *afl) { if (q->len > max_len) { max_len = q->len; } - q = q->next; + ++count; } - SAYF("\n"); + // SAYF("\n"); if (avg_us > ((afl->fsrv.qemu_mode || afl->unicorn_mode) ? 50000 : 10000)) { @@ -969,7 +1158,11 @@ void show_init_stats(afl_state_t *afl) { /* Let's keep things moving with slow binaries. */ - if (avg_us > 50000) { + if (unlikely(afl->fixed_seed)) { + + afl->havoc_div = 1; + + } else if (avg_us > 50000) { afl->havoc_div = 10; /* 0-19 execs/sec */ @@ -1020,17 +1213,18 @@ void show_init_stats(afl_state_t *afl) { OKF("Here are some useful stats:\n\n" cGRA " Test case count : " cRST - "%u favored, %u variable, %u total\n" cGRA " Bitmap range : " cRST + "%u favored, %u variable, %u ignored, %u total\n" cGRA + " Bitmap range : " cRST "%u to %u bits (average: %0.02f bits)\n" cGRA " Exec timing : " cRST "%s to %s us (average: %s us)\n", - afl->queued_favored, afl->queued_variable, afl->queued_paths, min_bits, - max_bits, + afl->queued_favored, afl->queued_variable, afl->queued_paths - count, + afl->queued_paths, min_bits, max_bits, ((double)afl->total_bitmap_size) / (afl->total_bitmap_entries ? afl->total_bitmap_entries : 1), stringify_int(IB(0), min_us), stringify_int(IB(1), max_us), stringify_int(IB(2), avg_us)); - if (!afl->timeout_given) { + if (afl->timeout_given != 1) { /* Figure out the appropriate timeout. The basic idea is: 5x average or 1x max, rounded up to EXEC_TM_ROUND ms and capped at 1 second. @@ -1039,7 +1233,11 @@ void show_init_stats(afl_state_t *afl) { random scheduler jitter is less likely to have any impact, and because our patience is wearing thin =) */ - if (avg_us > 50000) { + if (unlikely(afl->fixed_seed)) { + + afl->fsrv.exec_tmout = avg_us * 5 / 1000; + + } else if (avg_us > 50000) { afl->fsrv.exec_tmout = avg_us * 2 / 1000; @@ -1073,6 +1271,11 @@ void show_init_stats(afl_state_t *afl) { ACTF("Applying timeout settings from resumed session (%u ms).", afl->fsrv.exec_tmout); + } else { + + ACTF("-t option specified. We'll use an exec timeout of %u ms.", + afl->fsrv.exec_tmout); + } /* In non-instrumented mode, re-running every timing out test case with a @@ -1081,7 +1284,7 @@ void show_init_stats(afl_state_t *afl) { if (afl->non_instrumented_mode && !(afl->afl_env.afl_hang_tmout)) { - afl->hang_tmout = MIN(EXEC_TIMEOUT, afl->fsrv.exec_tmout * 2 + 100); + afl->hang_tmout = MIN((u32)EXEC_TIMEOUT, afl->fsrv.exec_tmout * 2 + 100); } diff --git a/src/afl-fuzz-statsd.c b/src/afl-fuzz-statsd.c new file mode 100644 index 00000000..461bbbf6 --- /dev/null +++ b/src/afl-fuzz-statsd.c @@ -0,0 +1,273 @@ +/* + * This implements rpc.statsd support, see docs/rpc_statsd.md + * + */ + +#include <stdio.h> +#include <stdlib.h> +#include <sys/socket.h> +#include <arpa/inet.h> +#include <string.h> +#include <sys/types.h> +#include <netdb.h> +#include <unistd.h> +#include "afl-fuzz.h" + +#define MAX_STATSD_PACKET_SIZE 4096 +#define MAX_TAG_LEN 200 +#define METRIC_PREFIX "fuzzing" + +/* Tags format for metrics + DogStatsD: + metric.name:<value>|<type>|#key:value,key2:value2 + + InfluxDB + metric.name,key=value,key2=value2:<value>|<type> + + Librato + metric.name#key=value,key2=value2:<value>|<type> + + SignalFX + metric.name[key=value,key2=value2]:<value>|<type> + +*/ + +// after the whole metric. +#define DOGSTATSD_TAGS_FORMAT "|#banner:%s,afl_version:%s" + +// just after the metric name. +#define LIBRATO_TAGS_FORMAT "#banner=%s,afl_version=%s" +#define INFLUXDB_TAGS_FORMAT ",banner=%s,afl_version=%s" +#define SIGNALFX_TAGS_FORMAT "[banner=%s,afl_version=%s]" + +// For DogstatsD +#define STATSD_TAGS_TYPE_SUFFIX 1 +#define STATSD_TAGS_SUFFIX_METRICS \ + METRIC_PREFIX \ + ".cycle_done:%llu|g%s\n" METRIC_PREFIX \ + ".cycles_wo_finds:%llu|g%s\n" METRIC_PREFIX \ + ".execs_done:%llu|g%s\n" METRIC_PREFIX \ + ".execs_per_sec:%0.02f|g%s\n" METRIC_PREFIX \ + ".paths_total:%u|g%s\n" METRIC_PREFIX \ + ".paths_favored:%u|g%s\n" METRIC_PREFIX \ + ".paths_found:%u|g%s\n" METRIC_PREFIX \ + ".paths_imported:%u|g%s\n" METRIC_PREFIX ".max_depth:%u|g%s\n" METRIC_PREFIX \ + ".cur_path:%u|g%s\n" METRIC_PREFIX ".pending_favs:%u|g%s\n" METRIC_PREFIX \ + ".pending_total:%u|g%s\n" METRIC_PREFIX \ + ".variable_paths:%u|g%s\n" METRIC_PREFIX \ + ".unique_crashes:%llu|g%s\n" METRIC_PREFIX \ + ".unique_hangs:%llu|g%s\n" METRIC_PREFIX \ + ".total_crashes:%llu|g%s\n" METRIC_PREFIX \ + ".slowest_exec_ms:%u|g%s\n" METRIC_PREFIX \ + ".edges_found:%u|g%s\n" METRIC_PREFIX \ + ".var_byte_count:%u|g%s\n" METRIC_PREFIX ".havoc_expansion:%u|g%s\n" + +// For Librato, InfluxDB, SignalFX +#define STATSD_TAGS_TYPE_MID 2 +#define STATSD_TAGS_MID_METRICS \ + METRIC_PREFIX \ + ".cycle_done%s:%llu|g\n" METRIC_PREFIX \ + ".cycles_wo_finds%s:%llu|g\n" METRIC_PREFIX \ + ".execs_done%s:%llu|g\n" METRIC_PREFIX \ + ".execs_per_sec%s:%0.02f|g\n" METRIC_PREFIX \ + ".paths_total%s:%u|g\n" METRIC_PREFIX \ + ".paths_favored%s:%u|g\n" METRIC_PREFIX \ + ".paths_found%s:%u|g\n" METRIC_PREFIX \ + ".paths_imported%s:%u|g\n" METRIC_PREFIX ".max_depth%s:%u|g\n" METRIC_PREFIX \ + ".cur_path%s:%u|g\n" METRIC_PREFIX ".pending_favs%s:%u|g\n" METRIC_PREFIX \ + ".pending_total%s:%u|g\n" METRIC_PREFIX \ + ".variable_paths%s:%u|g\n" METRIC_PREFIX \ + ".unique_crashes%s:%llu|g\n" METRIC_PREFIX \ + ".unique_hangs%s:%llu|g\n" METRIC_PREFIX \ + ".total_crashes%s:%llu|g\n" METRIC_PREFIX \ + ".slowest_exec_ms%s:%u|g\n" METRIC_PREFIX \ + ".edges_found%s:%u|g\n" METRIC_PREFIX \ + ".var_byte_count%s:%u|g\n" METRIC_PREFIX ".havoc_expansion%s:%u|g\n" + +void statsd_setup_format(afl_state_t *afl) { + + if (afl->afl_env.afl_statsd_tags_flavor && + strcmp(afl->afl_env.afl_statsd_tags_flavor, "dogstatsd") == 0) { + + afl->statsd_tags_format = DOGSTATSD_TAGS_FORMAT; + afl->statsd_metric_format = STATSD_TAGS_SUFFIX_METRICS; + afl->statsd_metric_format_type = STATSD_TAGS_TYPE_SUFFIX; + + } else if (afl->afl_env.afl_statsd_tags_flavor && + + strcmp(afl->afl_env.afl_statsd_tags_flavor, "librato") == 0) { + + afl->statsd_tags_format = LIBRATO_TAGS_FORMAT; + afl->statsd_metric_format = STATSD_TAGS_MID_METRICS; + afl->statsd_metric_format_type = STATSD_TAGS_TYPE_MID; + + } else if (afl->afl_env.afl_statsd_tags_flavor && + + strcmp(afl->afl_env.afl_statsd_tags_flavor, "influxdb") == 0) { + + afl->statsd_tags_format = INFLUXDB_TAGS_FORMAT; + afl->statsd_metric_format = STATSD_TAGS_MID_METRICS; + afl->statsd_metric_format_type = STATSD_TAGS_TYPE_MID; + + } else if (afl->afl_env.afl_statsd_tags_flavor && + + strcmp(afl->afl_env.afl_statsd_tags_flavor, "signalfx") == 0) { + + afl->statsd_tags_format = SIGNALFX_TAGS_FORMAT; + afl->statsd_metric_format = STATSD_TAGS_MID_METRICS; + afl->statsd_metric_format_type = STATSD_TAGS_TYPE_MID; + + } else { + + // No tags at all. + afl->statsd_tags_format = ""; + // Still need to pick a format. Doesn't change anything since if will be + // replaced by the empty string anyway. + afl->statsd_metric_format = STATSD_TAGS_MID_METRICS; + afl->statsd_metric_format_type = STATSD_TAGS_TYPE_MID; + + } + +} + +int statsd_socket_init(afl_state_t *afl) { + + /* Default port and host. + Will be overwritten by AFL_STATSD_PORT and AFL_STATSD_HOST environment + variable, if they exists. + */ + u16 port = STATSD_DEFAULT_PORT; + char *host = STATSD_DEFAULT_HOST; + + if (afl->afl_env.afl_statsd_port) { + + port = atoi(afl->afl_env.afl_statsd_port); + + } + + if (afl->afl_env.afl_statsd_host) { host = afl->afl_env.afl_statsd_host; } + + int sock; + if ((sock = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP)) == -1) { + + FATAL("Failed to create socket"); + + } + + memset(&afl->statsd_server, 0, sizeof(afl->statsd_server)); + afl->statsd_server.sin_family = AF_INET; + afl->statsd_server.sin_port = htons(port); + + struct addrinfo *result; + struct addrinfo hints; + + memset(&hints, 0, sizeof(struct addrinfo)); + hints.ai_family = AF_INET; + hints.ai_socktype = SOCK_DGRAM; + + if ((getaddrinfo(host, NULL, &hints, &result))) { + + FATAL("Fail to getaddrinfo"); + + } + + memcpy(&(afl->statsd_server.sin_addr), + &((struct sockaddr_in *)result->ai_addr)->sin_addr, + sizeof(struct in_addr)); + freeaddrinfo(result); + + return sock; + +} + +int statsd_send_metric(afl_state_t *afl) { + + char buff[MAX_STATSD_PACKET_SIZE] = {0}; + + /* afl->statsd_sock is set once in the initialisation of afl-fuzz and reused + each time If the sendto later fail, we reset it to 0 to be able to recreates + it. + */ + if (!afl->statsd_sock) { + + afl->statsd_sock = statsd_socket_init(afl); + if (!afl->statsd_sock) { + + WARNF("Cannot create socket"); + return -1; + + } + + } + + statsd_format_metric(afl, buff, MAX_STATSD_PACKET_SIZE); + if (sendto(afl->statsd_sock, buff, strlen(buff), 0, + (struct sockaddr *)&afl->statsd_server, + sizeof(afl->statsd_server)) == -1) { + + if (!close(afl->statsd_sock)) { PFATAL("Cannot close socket"); } + afl->statsd_sock = 0; + WARNF("Cannot sendto"); + return -1; + + } + + return 0; + +} + +int statsd_format_metric(afl_state_t *afl, char *buff, size_t bufflen) { + + char tags[MAX_TAG_LEN * 2] = {0}; + if (afl->statsd_tags_format) { + + snprintf(tags, MAX_TAG_LEN * 2, afl->statsd_tags_format, afl->use_banner, + VERSION); + + } + + /* Sends multiple metrics with one UDP Packet. + bufflen will limit to the max safe size. + */ + if (afl->statsd_metric_format_type == STATSD_TAGS_TYPE_SUFFIX) { + + snprintf( + buff, bufflen, afl->statsd_metric_format, + afl->queue_cycle ? (afl->queue_cycle - 1) : 0, tags, + afl->cycles_wo_finds, tags, afl->fsrv.total_execs, tags, + afl->fsrv.total_execs / + ((double)(get_cur_time() + afl->prev_run_time - afl->start_time) / + 1000), + tags, afl->queued_paths, tags, afl->queued_favored, tags, + afl->queued_discovered, tags, afl->queued_imported, tags, + afl->max_depth, tags, afl->current_entry, tags, afl->pending_favored, + tags, afl->pending_not_fuzzed, tags, afl->queued_variable, tags, + afl->unique_crashes, tags, afl->unique_hangs, tags, afl->total_crashes, + tags, afl->slowest_exec_ms, tags, + count_non_255_bytes(afl, afl->virgin_bits), tags, afl->var_byte_count, + tags, afl->expand_havoc, tags); + + } else if (afl->statsd_metric_format_type == STATSD_TAGS_TYPE_MID) { + + snprintf( + buff, bufflen, afl->statsd_metric_format, tags, + afl->queue_cycle ? (afl->queue_cycle - 1) : 0, tags, + afl->cycles_wo_finds, tags, afl->fsrv.total_execs, tags, + afl->fsrv.total_execs / + ((double)(get_cur_time() + afl->prev_run_time - afl->start_time) / + 1000), + tags, afl->queued_paths, tags, afl->queued_favored, tags, + afl->queued_discovered, tags, afl->queued_imported, tags, + afl->max_depth, tags, afl->current_entry, tags, afl->pending_favored, + tags, afl->pending_not_fuzzed, tags, afl->queued_variable, tags, + afl->unique_crashes, tags, afl->unique_hangs, tags, afl->total_crashes, + tags, afl->slowest_exec_ms, tags, + count_non_255_bytes(afl, afl->virgin_bits), tags, afl->var_byte_count, + tags, afl->expand_havoc); + + } + + return 0; + +} + diff --git a/src/afl-fuzz.c b/src/afl-fuzz.c index 5bedf6e1..ff4c5281 100644 --- a/src/afl-fuzz.c +++ b/src/afl-fuzz.c @@ -26,6 +26,7 @@ #include "afl-fuzz.h" #include "cmplog.h" #include <limits.h> +#include <stdlib.h> #ifndef USEMMAP #include <sys/mman.h> #include <sys/stat.h> @@ -40,7 +41,7 @@ extern u64 time_spent_working; static void at_exit() { - int i; + s32 i, pid1 = 0, pid2 = 0; char *list[4] = {SHM_ENV_VAR, SHM_FUZZ_ENV_VAR, CMPLOG_SHM_ENV_VAR, NULL}; char *ptr; @@ -48,10 +49,10 @@ static void at_exit() { if (ptr && *ptr) unlink(ptr); ptr = getenv("__AFL_TARGET_PID1"); - if (ptr && *ptr && (i = atoi(ptr)) > 0) kill(i, SIGKILL); + if (ptr && *ptr && (pid1 = atoi(ptr)) > 0) kill(pid1, SIGTERM); ptr = getenv("__AFL_TARGET_PID2"); - if (ptr && *ptr && (i = atoi(ptr)) > 0) kill(i, SIGKILL); + if (ptr && *ptr && (pid2 = atoi(ptr)) > 0) kill(pid2, SIGTERM); i = 0; while (list[i] != NULL) { @@ -75,11 +76,18 @@ static void at_exit() { } + int kill_signal = SIGKILL; + /* AFL_KILL_SIGNAL should already be a valid int at this point */ + if ((ptr = getenv("AFL_KILL_SIGNAL"))) { kill_signal = atoi(ptr); } + + if (pid1 > 0) { kill(pid1, kill_signal); } + if (pid2 > 0) { kill(pid2, kill_signal); } + } /* Display usage hints. */ -static void usage(afl_state_t *afl, u8 *argv0, int more_help) { +static void usage(u8 *argv0, int more_help) { SAYF( "\n%s [ options ] -- /path/to/fuzzed_app [ ... ]\n\n" @@ -89,21 +97,25 @@ static void usage(afl_state_t *afl, u8 *argv0, int more_help) { " -o dir - output directory for fuzzer findings\n\n" "Execution control settings:\n" - " -p schedule - power schedules compute a seed's performance score. " - "<explore\n" - " (default), fast, coe, lin, quad, exploit, mmopt, " - "rare, seek>\n" - " see docs/power_schedules.md\n" + " -p schedule - power schedules compute a seed's performance score:\n" + " fast(default), explore, exploit, seek, rare, mmopt, " + "coe, lin\n" + " quad -- see docs/power_schedules.md\n" " -f file - location read by the fuzzed program (default: stdin " "or @@)\n" - " -t msec - timeout for each run (auto-scaled, 50-%d ms)\n" - " -m megs - memory limit for child process (%d MB)\n" + " -t msec - timeout for each run (auto-scaled, default %u ms). " + "Add a '+'\n" + " to auto-calculate the timeout, the value being the " + "maximum.\n" + " -m megs - memory limit for child process (%u MB, 0 = no limit " + "[default])\n" " -Q - use binary-only instrumentation (QEMU mode)\n" " -U - use unicorn-based instrumentation (Unicorn mode)\n" " -W - use qemu-based instrumentation with Wine (Wine " "mode)\n\n" "Mutator settings:\n" + " -D - enable deterministic fuzzing (once per queue entry)\n" " -L minutes - use MOpt(imize) mode and set the time limit for " "entering the\n" " pacemaker mode (minutes of no new paths). 0 = " @@ -112,43 +124,57 @@ static void usage(afl_state_t *afl, u8 *argv0, int more_help) { " See docs/README.MOpt.md\n" " -c program - enable CmpLog by specifying a binary compiled for " "it.\n" - " if using QEMU, just use -c 0.\n\n" - + " if using QEMU, just use -c 0.\n" + " -l cmplog_opts - CmpLog configuration values (e.g. \"2AT\"):\n" + " 1=small files (default), 2=larger files, 3=all " + "files,\n" + " A=arithmetic solving, T=transformational solving.\n\n" "Fuzzing behavior settings:\n" - " -N - do not unlink the fuzzing input file (only for " - "devices etc.!)\n" - " -d - quick & dirty mode (skips deterministic steps)\n" + " -Z - sequential queue selection instead of weighted " + "random\n" + " -N - do not unlink the fuzzing input file (for devices " + "etc.)\n" " -n - fuzz without instrumentation (non-instrumented mode)\n" - " -x dict_file - optional fuzzer dictionary (see README.md, its really " - "good!)\n\n" + " -x dict_file - fuzzer dictionary (see README.md, specify up to 4 " + "times)\n\n" "Testing settings:\n" " -s seed - use a fixed seed for the RNG\n" - " -V seconds - fuzz for a specific time then terminate\n" - " -E execs - fuzz for a approx. no of total executions then " + " -V seconds - fuzz for a specified time then terminate\n" + " -E execs - fuzz for an approx. no. of total executions then " "terminate\n" " Note: not precise and can have several more " "executions.\n\n" "Other stuff:\n" " -M/-S id - distributed mode (see docs/parallel_fuzzing.md)\n" - " use -D to force -S secondary to perform deterministic " - "fuzzing\n" + " -M auto-sets -D, -Z (use -d to disable -D) and no " + "trimming\n" " -F path - sync to a foreign fuzzer queue directory (requires " "-M, can\n" " be specified up to %u times)\n" + " -d - skip deterministic fuzzing in -M mode\n" " -T text - text banner to show on the screen\n" " -I command - execute this command/script when a new crash is " "found\n" //" -B bitmap.txt - mutate a specific test case, use the out/fuzz_bitmap //" "file\n" " -C - crash exploration mode (the peruvian rabbit thing)\n" + " -b cpu_id - bind the fuzzing process to the specified CPU core " + "(0-...)\n" " -e ext - file extension for the fuzz test input file (if " "needed)\n\n", argv0, EXEC_TIMEOUT, MEM_LIMIT, FOREIGN_SYNCS_MAX); if (more_help > 1) { +#if defined USE_COLOR && !defined ALWAYS_COLORED + #define DYN_COLOR \ + "AFL_NO_COLOR or AFL_NO_COLOUR: switch colored console output off\n" +#else + #define DYN_COLOR +#endif + SAYF( "Environment variables used:\n" "LD_BIND_LAZY: do not set LD_BIND_NOW env var for target\n" @@ -159,34 +185,55 @@ static void usage(afl_state_t *afl, u8 *argv0, int more_help) { "AFL_AUTORESUME: resume fuzzing if directory specified by -o already exists\n" "AFL_BENCH_JUST_ONE: run the target just once\n" "AFL_BENCH_UNTIL_CRASH: exit soon when the first crashing input has been found\n" + "AFL_CMPLOG_ONLY_NEW: do not run cmplog on initial testcases (good for resumes!)\n" + "AFL_CRASH_EXITCODE: optional child exit code to be interpreted as crash\n" "AFL_CUSTOM_MUTATOR_LIBRARY: lib with afl_custom_fuzz() to mutate inputs\n" "AFL_CUSTOM_MUTATOR_ONLY: avoid AFL++'s internal mutators\n" + "AFL_CYCLE_SCHEDULES: after completing a cycle, switch to a different -p schedule\n" "AFL_DEBUG: extra debugging output for Python mode trimming\n" - "AFL_DEBUG_CHILD_OUTPUT: do not suppress stdout/stderr from target\n" + "AFL_DEBUG_CHILD: do not suppress stdout/stderr from target\n" "AFL_DISABLE_TRIM: disable the trimming of test cases\n" "AFL_DUMB_FORKSRV: use fork server without feedback from target\n" "AFL_EXIT_WHEN_DONE: exit when all inputs are run and no new finds are found\n" + "AFL_EXPAND_HAVOC_NOW: immediately enable expand havoc mode (default: after 60 minutes and a cycle without finds)\n" "AFL_FAST_CAL: limit the calibration stage to three cycles for speedup\n" "AFL_FORCE_UI: force showing the status screen (for virtual consoles)\n" + "AFL_FORKSRV_INIT_TMOUT: time spent waiting for forkserver during startup (in milliseconds)\n" "AFL_HANG_TMOUT: override timeout value (in milliseconds)\n" "AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES: don't warn about core dump handlers\n" + "AFL_IGNORE_UNKNOWN_ENVS: don't warn on unknown env vars\n" "AFL_IMPORT_FIRST: sync and import test cases from other fuzzer instances first\n" + "AFL_KILL_SIGNAL: Signal ID delivered to child processes on timeout, etc. (default: SIGKILL)\n" "AFL_MAP_SIZE: the shared memory size for that target. must be >= the size\n" " the target was compiled for\n" + "AFL_MAX_DET_EXTRAS: if more entries are in the dictionary list than this value\n" + " then they are randomly selected instead all of them being\n" + " used. Defaults to 200.\n" "AFL_NO_AFFINITY: do not check for an unused cpu core to use for fuzzing\n" "AFL_NO_ARITH: skip arithmetic mutations in deterministic stage\n" + "AFL_NO_AUTODICT: do not load an offered auto dictionary compiled into a target\n" "AFL_NO_CPU_RED: avoid red color for showing very high cpu usage\n" "AFL_NO_FORKSRV: run target via execve instead of using the forkserver\n" "AFL_NO_SNAPSHOT: do not use the snapshot feature (if the snapshot lkm is loaded)\n" "AFL_NO_UI: switch status screen off\n" + + DYN_COLOR + "AFL_PATH: path to AFL support binaries\n" "AFL_PYTHON_MODULE: mutate and trim inputs with the specified Python module\n" "AFL_QUIET: suppress forkserver status messages\n" "AFL_PRELOAD: LD_PRELOAD / DYLD_INSERT_LIBRARIES settings for target\n" "AFL_SHUFFLE_QUEUE: reorder the input queue randomly on startup\n" - "AFL_SKIP_BIN_CHECK: skip the check, if the target is an excutable\n" + "AFL_SKIP_BIN_CHECK: skip the check, if the target is an executable\n" "AFL_SKIP_CPUFREQ: do not warn about variable cpu clocking\n" "AFL_SKIP_CRASHES: during initial dry run do not terminate for crashing inputs\n" + "AFL_STATSD: enables StatsD metrics collection\n" + "AFL_STATSD_HOST: change default statsd host (default 127.0.0.1)\n" + "AFL_STATSD_PORT: change default statsd port (default: 8125)\n" + "AFL_STATSD_TAGS_FLAVOR: set statsd tags format (default: disable tags)\n" + " Supported formats are: 'dogstatsd', 'librato',\n" + " 'signalfx' and 'influxdb'\n" + "AFL_TESTCACHE_SIZE: use a cache for testcases, improves performance (in MB)\n" "AFL_TMPDIR: directory to use for input file generation (ramdisk recommended)\n" //"AFL_PERSISTENT: not supported anymore -> no effect, just a warning\n" //"AFL_DEFER_FORKSRV: not supported anymore -> no effect, just a warning\n" @@ -208,7 +255,37 @@ static void usage(afl_state_t *afl, u8 *argv0, int more_help) { SAYF("Compiled without python module support\n"); #endif - SAYF("For additional help please consult %s/README.md\n\n", doc_path); +#ifdef USEMMAP + SAYF("Compiled with shm_open support.\n"); +#else + SAYF("Compiled with shmat support.\n"); +#endif + +#ifdef ASAN_BUILD + SAYF("Compiled with ASAN_BUILD\n\n"); +#endif + +#ifdef NO_SPLICING + SAYF("Compiled with NO_SPLICING\n\n"); +#endif + +#ifdef PROFILING + SAYF("Compiled with PROFILING\n\n"); +#endif + +#ifdef INTROSPECTION + SAYF("Compiled with INTROSPECTION\n\n"); +#endif + +#ifdef _DEBUG + SAYF("Compiled with _DEBUG\n\n"); +#endif + +#ifdef _AFL_DOCUMENT_MUTATIONS + SAYF("Compiled with _AFL_DOCUMENT_MUTATIONS\n\n"); +#endif + + SAYF("For additional help please consult %s/README.md :)\n\n", doc_path); exit(1); #undef PHYTON_SUPPORT @@ -235,16 +312,29 @@ static int stricmp(char const *a, char const *b) { int main(int argc, char **argv_orig, char **envp) { - s32 opt; - u64 prev_queued = 0; - u32 sync_interval_cnt = 0, seek_to, show_help = 0, map_size = MAP_SIZE; - u8 * extras_dir = 0; - u8 mem_limit_given = 0, exit_1 = 0, debug = 0; + s32 opt, i, auto_sync = 0 /*, user_set_cache = 0*/; + u64 prev_queued = 0; + u32 sync_interval_cnt = 0, seek_to = 0, show_help = 0, + map_size = get_map_size(); + u8 *extras_dir[4]; + u8 mem_limit_given = 0, exit_1 = 0, debug = 0, + extras_dir_cnt = 0 /*, have_p = 0*/; char **use_argv; struct timeval tv; struct timezone tz; + #if defined USE_COLOR && defined ALWAYS_COLORED + if (getenv("AFL_NO_COLOR") || getenv("AFL_NO_COLOUR")) { + + WARNF( + "Setting AFL_NO_COLOR has no effect (colors are configured on at " + "compile time)"); + + } + + #endif + char **argv = argv_cpy_dup(argc, argv_orig); afl_state_t *afl = calloc(1, sizeof(afl_state_t)); @@ -252,17 +342,16 @@ int main(int argc, char **argv_orig, char **envp) { if (get_afl_env("AFL_DEBUG")) { debug = afl->debug = 1; } - map_size = get_map_size(); afl_state_init(afl, map_size); afl->debug = debug; afl_fsrv_init(&afl->fsrv); - + if (debug) { afl->fsrv.debug = true; } read_afl_environment(afl, envp); if (afl->shm.map_size) { afl->fsrv.map_size = afl->shm.map_size; } exit_1 = !!afl->afl_env.afl_bench_just_one; SAYF(cCYA "afl-fuzz" VERSION cRST - " based on afl by Michal Zalewski and a big online community\n"); + " based on afl by Michal Zalewski and a large online community\n"); doc_path = access(DOC_PATH, F_OK) != 0 ? (u8 *)"docs" : (u8 *)DOC_PATH; @@ -271,16 +360,34 @@ int main(int argc, char **argv_orig, char **envp) { afl->shmem_testcase_mode = 1; // we always try to perform shmem fuzzing - while ((opt = getopt(argc, argv, - "+c:i:I:o:f:F:m:t:T:dDnCB:S:M:x:QNUWe:p:s:V:E:L:hRP:")) > - 0) { + while ((opt = getopt( + argc, argv, + "+b:B:c:CdDe:E:hi:I:f:F:l:L:m:M:nNo:p:RQs:S:t:T:UV:Wx:Z")) > 0) { switch (opt) { + case 'Z': + afl->old_seed_selection = 1; + break; + case 'I': afl->infoexec = optarg; break; + case 'b': { /* bind CPU core */ + + if (afl->cpu_to_bind != -1) FATAL("Multiple -b options not supported"); + + if (sscanf(optarg, "%d", &afl->cpu_to_bind) < 0) { + + FATAL("Bad syntax used for -b"); + + } + + break; + + } + case 'c': { afl->shm.cmplog_mode = 1; @@ -291,6 +398,7 @@ int main(int argc, char **argv_orig, char **envp) { case 's': { + if (optarg == NULL) { FATAL("No valid seed provided. Got NULL."); } rand_set_seed(afl, strtoul(optarg, 0L, 10)); afl->fixed_seed = 1; break; @@ -327,22 +435,26 @@ int main(int argc, char **argv_orig, char **envp) { afl->schedule = RARE; - } else if (!stricmp(optarg, "seek")) { - - afl->schedule = SEEK; + } else if (!stricmp(optarg, "explore") || !stricmp(optarg, "afl") || - } else if (!stricmp(optarg, "explore") || !stricmp(optarg, "default") || + !stricmp(optarg, "default") || - !stricmp(optarg, "normal") || !stricmp(optarg, "afl")) { + !stricmp(optarg, "normal")) { afl->schedule = EXPLORE; + } else if (!stricmp(optarg, "seek")) { + + afl->schedule = SEEK; + } else { FATAL("Unknown -p power schedule"); } + // have_p = 1; + break; case 'e': @@ -356,6 +468,7 @@ int main(int argc, char **argv_orig, char **envp) { case 'i': /* input dir */ if (afl->in_dir) { FATAL("Multiple -i options not supported"); } + if (optarg == NULL) { FATAL("Invalid -i option (got NULL)."); } afl->in_dir = optarg; if (!strcmp(afl->in_dir, "-")) { afl->in_place_resume = 1; } @@ -372,8 +485,28 @@ int main(int argc, char **argv_orig, char **envp) { u8 *c; + if (afl->non_instrumented_mode) { + + FATAL("-M is not supported in non-instrumented mode"); + + } + if (afl->sync_id) { FATAL("Multiple -S or -M options not supported"); } + + /* sanity check for argument: should not begin with '-' (possible + * option) */ + if (optarg && *optarg == '-') { + + FATAL( + "argument for -M started with a dash '-', which is used for " + "options"); + + } + afl->sync_id = ck_strdup(optarg); + afl->skip_deterministic = 0; // force deterministic fuzzing + afl->old_seed_selection = 1; // force old queue walking seed selection + afl->disable_trim = 1; // disable trimming if ((c = strchr(afl->sync_id, ':'))) { @@ -399,23 +532,57 @@ int main(int argc, char **argv_orig, char **envp) { case 'S': /* secondary sync id */ + if (afl->non_instrumented_mode) { + + FATAL("-S is not supported in non-instrumented mode"); + + } + if (afl->sync_id) { FATAL("Multiple -S or -M options not supported"); } + + /* sanity check for argument: should not begin with '-' (possible + * option) */ + if (optarg && *optarg == '-') { + + FATAL( + "argument for -M started with a dash '-', which is used for " + "options"); + + } + afl->sync_id = ck_strdup(optarg); afl->is_secondary_node = 1; - afl->skip_deterministic = 1; - afl->use_splicing = 1; break; case 'F': /* foreign sync dir */ - if (!afl->is_main_node) + if (!optarg) { FATAL("Missing path for -F"); } + if (!afl->is_main_node) { + FATAL( "Option -F can only be specified after the -M option for the " "main fuzzer of a fuzzing campaign"); - if (afl->foreign_sync_cnt >= FOREIGN_SYNCS_MAX) + + } + + if (afl->foreign_sync_cnt >= FOREIGN_SYNCS_MAX) { + FATAL("Maximum %u entried of -F option can be specified", FOREIGN_SYNCS_MAX); + + } + afl->foreign_syncs[afl->foreign_sync_cnt].dir = optarg; + while (afl->foreign_syncs[afl->foreign_sync_cnt] + .dir[strlen(afl->foreign_syncs[afl->foreign_sync_cnt].dir) - + 1] == '/') { + + afl->foreign_syncs[afl->foreign_sync_cnt] + .dir[strlen(afl->foreign_syncs[afl->foreign_sync_cnt].dir) - 1] = + 0; + + } + afl->foreign_sync_cnt++; break; @@ -428,8 +595,13 @@ int main(int argc, char **argv_orig, char **envp) { case 'x': /* dictionary */ - if (extras_dir) { FATAL("Multiple -x options not supported"); } - extras_dir = optarg; + if (extras_dir_cnt >= 4) { + + FATAL("More than four -x options are not supported"); + + } + + extras_dir[extras_dir_cnt++] = optarg; break; case 't': { /* timeout */ @@ -438,7 +610,8 @@ int main(int argc, char **argv_orig, char **envp) { if (afl->timeout_given) { FATAL("Multiple -t options not supported"); } - if (sscanf(optarg, "%u%c", &afl->fsrv.exec_tmout, &suffix) < 1 || + if (!optarg || + sscanf(optarg, "%u%c", &afl->fsrv.exec_tmout, &suffix) < 1 || optarg[0] == '-') { FATAL("Bad syntax used for -t"); @@ -523,7 +696,6 @@ int main(int argc, char **argv_orig, char **envp) { case 'd': /* skip deterministic */ afl->skip_deterministic = 1; - afl->use_splicing = 1; break; case 'B': /* load bitmap */ @@ -542,7 +714,6 @@ int main(int argc, char **argv_orig, char **envp) { if (afl->in_bitmap) { FATAL("Multiple -B options not supported"); } afl->in_bitmap = optarg; - read_bitmap(afl->in_bitmap, afl->virgin_bits, afl->fsrv.map_size); break; case 'C': /* crash mode */ @@ -553,6 +724,12 @@ int main(int argc, char **argv_orig, char **envp) { case 'n': /* dumb mode */ + if (afl->is_main_node || afl->is_secondary_node) { + + FATAL("Non instrumented mode is not supported with -M / -S"); + + } + if (afl->non_instrumented_mode) { FATAL("Multiple -n options not supported"); @@ -589,7 +766,7 @@ int main(int argc, char **argv_orig, char **envp) { case 'N': /* Unicorn mode */ if (afl->no_unlink) { FATAL("Multiple -N options not supported"); } - afl->no_unlink = 1; + afl->fsrv.no_unlink = (afl->no_unlink = true); break; @@ -615,7 +792,8 @@ int main(int argc, char **argv_orig, char **envp) { case 'V': { afl->most_time_key = 1; - if (sscanf(optarg, "%llu", &afl->most_time) < 1 || optarg[0] == '-') { + if (!optarg || sscanf(optarg, "%llu", &afl->most_time) < 1 || + optarg[0] == '-') { FATAL("Bad syntax used for -V"); @@ -626,7 +804,8 @@ int main(int argc, char **argv_orig, char **envp) { case 'E': { afl->most_execs_key = 1; - if (sscanf(optarg, "%llu", &afl->most_execs) < 1 || optarg[0] == '-') { + if (!optarg || sscanf(optarg, "%llu", &afl->most_execs) < 1 || + optarg[0] == '-') { FATAL("Bad syntax used for -E"); @@ -634,6 +813,49 @@ int main(int argc, char **argv_orig, char **envp) { } break; + case 'l': { + + if (!optarg) { FATAL("missing parameter for 'l'"); } + char *c = optarg; + while (*c) { + + switch (*c) { + + case '0': + case '1': + afl->cmplog_lvl = 1; + break; + case '2': + afl->cmplog_lvl = 2; + break; + case '3': + afl->cmplog_lvl = 3; + break; + case 'a': + case 'A': + afl->cmplog_enable_arith = 1; + break; + case 't': + case 'T': + afl->cmplog_enable_transform = 1; + break; + default: + FATAL("Unknown option value '%c' in -l %s", *c, optarg); + + } + + ++c; + + } + + if (afl->cmplog_lvl == CMPLOG_LVL_MAX) { + + afl->cmplog_max_filesize = MAX_FILE; + + } + + } break; + case 'L': { /* MOpt mode */ if (afl->limit_time_sig) { FATAL("Multiple -L options not supported"); } @@ -662,7 +884,7 @@ int main(int argc, char **argv_orig, char **envp) { u64 limit_time_puppet2 = afl->limit_time_puppet * 60 * 1000; - if (limit_time_puppet2 < afl->limit_time_puppet) { + if ((s32)limit_time_puppet2 < afl->limit_time_puppet) { FATAL("limit_time overflow"); @@ -672,7 +894,7 @@ int main(int argc, char **argv_orig, char **envp) { afl->swarm_now = 0; if (afl->limit_time_puppet == 0) { afl->key_puppet = 1; } - int i; + int j; int tmp_swarm = 0; if (afl->g_now > afl->g_max) { afl->g_now = 0; } @@ -685,70 +907,70 @@ int main(int argc, char **argv_orig, char **envp) { double total_puppet_temp = 0.0; afl->swarm_fitness[tmp_swarm] = 0.0; - for (i = 0; i < operator_num; ++i) { + for (j = 0; j < operator_num; ++j) { - afl->stage_finds_puppet[tmp_swarm][i] = 0; - afl->probability_now[tmp_swarm][i] = 0.0; - afl->x_now[tmp_swarm][i] = + afl->stage_finds_puppet[tmp_swarm][j] = 0; + afl->probability_now[tmp_swarm][j] = 0.0; + afl->x_now[tmp_swarm][j] = ((double)(random() % 7000) * 0.0001 + 0.1); - total_puppet_temp += afl->x_now[tmp_swarm][i]; - afl->v_now[tmp_swarm][i] = 0.1; - afl->L_best[tmp_swarm][i] = 0.5; - afl->G_best[i] = 0.5; - afl->eff_best[tmp_swarm][i] = 0.0; + total_puppet_temp += afl->x_now[tmp_swarm][j]; + afl->v_now[tmp_swarm][j] = 0.1; + afl->L_best[tmp_swarm][j] = 0.5; + afl->G_best[j] = 0.5; + afl->eff_best[tmp_swarm][j] = 0.0; } - for (i = 0; i < operator_num; ++i) { + for (j = 0; j < operator_num; ++j) { - afl->stage_cycles_puppet_v2[tmp_swarm][i] = - afl->stage_cycles_puppet[tmp_swarm][i]; - afl->stage_finds_puppet_v2[tmp_swarm][i] = - afl->stage_finds_puppet[tmp_swarm][i]; - afl->x_now[tmp_swarm][i] = - afl->x_now[tmp_swarm][i] / total_puppet_temp; + afl->stage_cycles_puppet_v2[tmp_swarm][j] = + afl->stage_cycles_puppet[tmp_swarm][j]; + afl->stage_finds_puppet_v2[tmp_swarm][j] = + afl->stage_finds_puppet[tmp_swarm][j]; + afl->x_now[tmp_swarm][j] = + afl->x_now[tmp_swarm][j] / total_puppet_temp; } double x_temp = 0.0; - for (i = 0; i < operator_num; ++i) { + for (j = 0; j < operator_num; ++j) { - afl->probability_now[tmp_swarm][i] = 0.0; - afl->v_now[tmp_swarm][i] = - afl->w_now * afl->v_now[tmp_swarm][i] + + afl->probability_now[tmp_swarm][j] = 0.0; + afl->v_now[tmp_swarm][j] = + afl->w_now * afl->v_now[tmp_swarm][j] + RAND_C * - (afl->L_best[tmp_swarm][i] - afl->x_now[tmp_swarm][i]) + - RAND_C * (afl->G_best[i] - afl->x_now[tmp_swarm][i]); + (afl->L_best[tmp_swarm][j] - afl->x_now[tmp_swarm][j]) + + RAND_C * (afl->G_best[j] - afl->x_now[tmp_swarm][j]); - afl->x_now[tmp_swarm][i] += afl->v_now[tmp_swarm][i]; + afl->x_now[tmp_swarm][j] += afl->v_now[tmp_swarm][j]; - if (afl->x_now[tmp_swarm][i] > v_max) { + if (afl->x_now[tmp_swarm][j] > v_max) { - afl->x_now[tmp_swarm][i] = v_max; + afl->x_now[tmp_swarm][j] = v_max; - } else if (afl->x_now[tmp_swarm][i] < v_min) { + } else if (afl->x_now[tmp_swarm][j] < v_min) { - afl->x_now[tmp_swarm][i] = v_min; + afl->x_now[tmp_swarm][j] = v_min; } - x_temp += afl->x_now[tmp_swarm][i]; + x_temp += afl->x_now[tmp_swarm][j]; } - for (i = 0; i < operator_num; ++i) { + for (j = 0; j < operator_num; ++j) { - afl->x_now[tmp_swarm][i] = afl->x_now[tmp_swarm][i] / x_temp; - if (likely(i != 0)) { + afl->x_now[tmp_swarm][j] = afl->x_now[tmp_swarm][j] / x_temp; + if (likely(j != 0)) { - afl->probability_now[tmp_swarm][i] = - afl->probability_now[tmp_swarm][i - 1] + - afl->x_now[tmp_swarm][i]; + afl->probability_now[tmp_swarm][j] = + afl->probability_now[tmp_swarm][j - 1] + + afl->x_now[tmp_swarm][j]; } else { - afl->probability_now[tmp_swarm][i] = afl->x_now[tmp_swarm][i]; + afl->probability_now[tmp_swarm][j] = afl->x_now[tmp_swarm][j]; } @@ -763,13 +985,13 @@ int main(int argc, char **argv_orig, char **envp) { } - for (i = 0; i < operator_num; ++i) { + for (j = 0; j < operator_num; ++j) { - afl->core_operator_finds_puppet[i] = 0; - afl->core_operator_finds_puppet_v2[i] = 0; - afl->core_operator_cycles_puppet[i] = 0; - afl->core_operator_cycles_puppet_v2[i] = 0; - afl->core_operator_cycles_puppet_v3[i] = 0; + afl->core_operator_finds_puppet[j] = 0; + afl->core_operator_finds_puppet_v2[j] = 0; + afl->core_operator_cycles_puppet[j] = 0; + afl->core_operator_cycles_puppet_v2[j] = 0; + afl->core_operator_cycles_puppet_v3[j] = 0; } @@ -796,20 +1018,18 @@ int main(int argc, char **argv_orig, char **envp) { if (optind == argc || !afl->in_dir || !afl->out_dir || show_help) { - usage(afl, argv[0], show_help); + usage(argv[0], show_help); } - if (!mem_limit_given && afl->shm.cmplog_mode) afl->fsrv.mem_limit += 260; + if (afl->fsrv.mem_limit && afl->shm.cmplog_mode) afl->fsrv.mem_limit += 260; OKF("afl++ is maintained by Marc \"van Hauser\" Heuse, Heiko \"hexcoder\" " "Eißfeldt, Andrea Fioraldi and Dominik Maier"); OKF("afl++ is open source, get it at " "https://github.com/AFLplusplus/AFLplusplus"); - OKF("Power schedules from github.com/mboehme/aflfast"); - OKF("Python Mutator and llvm_mode instrument file list from " - "github.com/choller/afl"); - OKF("MOpt Mutator from github.com/puppet-meteor/MOpt-AFL"); + OKF("NOTE: This is v3.x which changes defaults and behaviours - see " + "README.md"); if (afl->sync_id && afl->is_main_node && afl->afl_env.afl_custom_mutator_only) { @@ -836,11 +1056,23 @@ int main(int argc, char **argv_orig, char **envp) { #endif + afl->fsrv.kill_signal = + parse_afl_kill_signal_env(afl->afl_env.afl_kill_signal, SIGKILL); + setup_signal_handlers(); - check_asan_opts(); + check_asan_opts(afl); afl->power_name = power_names[afl->schedule]; + if (!afl->non_instrumented_mode && !afl->sync_id) { + + auto_sync = 1; + afl->sync_id = ck_strdup("default"); + afl->is_secondary_node = 1; + OKF("No -M/-S set, autoconfiguring for \"-S %s\"", afl->sync_id); + + } + if (afl->sync_id) { fix_up_sync(afl); } if (!strcmp(afl->in_dir, afl->out_dir)) { @@ -865,6 +1097,8 @@ int main(int argc, char **argv_orig, char **envp) { } + if (unlikely(afl->afl_env.afl_statsd)) { statsd_setup_format(afl); } + if (strchr(argv[optind], '/') == NULL && !afl->unicorn_mode) { WARNF(cLRD @@ -903,7 +1137,7 @@ int main(int argc, char **argv_orig, char **envp) { OKF("Using seek power schedule (SEEK)"); break; case EXPLORE: - OKF("Using exploration-based constant power schedule (EXPLORE, default)"); + OKF("Using exploration-based constant power schedule (EXPLORE)"); break; default: FATAL("Unknown power schedule"); @@ -911,6 +1145,15 @@ int main(int argc, char **argv_orig, char **envp) { } + if (afl->shm.cmplog_mode) { OKF("CmpLog level: %u", afl->cmplog_lvl); } + + /* Dynamically allocate memory for AFLFast schedules */ + if (afl->schedule >= FAST && afl->schedule <= RARE) { + + afl->n_fuzz = ck_alloc(N_FUZZ_SIZE * sizeof(u32)); + + } + if (get_afl_env("AFL_NO_FORKSRV")) { afl->no_forkserver = 1; } if (get_afl_env("AFL_NO_CPU_RED")) { afl->no_cpu_meter_red = 1; } if (get_afl_env("AFL_NO_ARITH")) { afl->no_arith = 1; } @@ -931,63 +1174,119 @@ int main(int argc, char **argv_orig, char **envp) { if (afl->afl_env.afl_hang_tmout) { - afl->hang_tmout = atoi(afl->afl_env.afl_hang_tmout); - if (!afl->hang_tmout) { FATAL("Invalid value of AFL_HANG_TMOUT"); } + s32 hang_tmout = atoi(afl->afl_env.afl_hang_tmout); + if (hang_tmout < 1) { FATAL("Invalid value for AFL_HANG_TMOUT"); } + afl->hang_tmout = (u32)hang_tmout; } - if (afl->non_instrumented_mode == 2 && afl->no_forkserver) { + if (afl->afl_env.afl_max_det_extras) { - FATAL("AFL_DUMB_FORKSRV and AFL_NO_FORKSRV are mutually exclusive"); + s32 max_det_extras = atoi(afl->afl_env.afl_max_det_extras); + if (max_det_extras < 1) { FATAL("Invalid value for AFL_MAX_DET_EXTRAS"); } + afl->max_det_extras = (u32)max_det_extras; + + } else { + + afl->max_det_extras = MAX_DET_EXTRAS; } - afl->fsrv.use_fauxsrv = afl->non_instrumented_mode == 1 || afl->no_forkserver; + if (afl->afl_env.afl_testcache_size) { - if (getenv("LD_PRELOAD")) { + afl->q_testcase_max_cache_size = + (u64)atoi(afl->afl_env.afl_testcache_size) * 1048576; - WARNF( - "LD_PRELOAD is set, are you sure that is what to you want to do " - "instead of using AFL_PRELOAD?"); + } + + if (afl->afl_env.afl_testcache_entries) { + + afl->q_testcase_max_cache_entries = + (u32)atoi(afl->afl_env.afl_testcache_entries); + + // user_set_cache = 1; } - if (afl->afl_env.afl_preload) { + if (!afl->afl_env.afl_testcache_size || !afl->afl_env.afl_testcache_entries) { - if (afl->fsrv.qemu_mode) { + afl->afl_env.afl_testcache_entries = 0; + afl->afl_env.afl_testcache_size = 0; - u8 *qemu_preload = getenv("QEMU_SET_ENV"); - u8 *afl_preload = getenv("AFL_PRELOAD"); - u8 *buf; + } - s32 i, afl_preload_size = strlen(afl_preload); - for (i = 0; i < afl_preload_size; ++i) { + if (!afl->q_testcase_max_cache_size) { - if (afl_preload[i] == ',') { + ACTF( + "No testcache was configured. it is recommended to use a testcache, it " + "improves performance: set AFL_TESTCACHE_SIZE=(value in MB)"); - PFATAL( - "Comma (',') is not allowed in AFL_PRELOAD when -Q is " - "specified!"); + } else if (afl->q_testcase_max_cache_size < 2 * MAX_FILE) { - } + FATAL("AFL_TESTCACHE_SIZE must be set to %u or more, or 0 to disable", + (2 * MAX_FILE) % 1048576 == 0 ? (2 * MAX_FILE) / 1048576 + : 1 + ((2 * MAX_FILE) / 1048576)); - } + } else { + + OKF("Enabled testcache with %llu MB", + afl->q_testcase_max_cache_size / 1048576); - if (qemu_preload) { + } - buf = alloc_printf("%s,LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - qemu_preload, afl_preload, afl_preload); + if (afl->afl_env.afl_forksrv_init_tmout) { - } else { + afl->fsrv.init_tmout = atoi(afl->afl_env.afl_forksrv_init_tmout); + if (!afl->fsrv.init_tmout) { - buf = alloc_printf("LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - afl_preload, afl_preload); + FATAL("Invalid value of AFL_FORKSRV_INIT_TMOUT"); - } + } + + } else { + + afl->fsrv.init_tmout = afl->fsrv.exec_tmout * FORK_WAIT_MULT; + + } + + if (afl->afl_env.afl_crash_exitcode) { + + long exitcode = strtol(afl->afl_env.afl_crash_exitcode, NULL, 10); + if ((!exitcode && (errno == EINVAL || errno == ERANGE)) || + exitcode < -127 || exitcode > 128) { + + FATAL("Invalid crash exitcode, expected -127 to 128, but got %s", + afl->afl_env.afl_crash_exitcode); + + } + + afl->fsrv.uses_crash_exitcode = true; + // WEXITSTATUS is 8 bit unsigned + afl->fsrv.crash_exitcode = (u8)exitcode; + + } + + if (afl->non_instrumented_mode == 2 && afl->no_forkserver) { + + FATAL("AFL_DUMB_FORKSRV and AFL_NO_FORKSRV are mutually exclusive"); - setenv("QEMU_SET_ENV", buf, 1); + } + + afl->fsrv.use_fauxsrv = afl->non_instrumented_mode == 1 || afl->no_forkserver; - ck_free(buf); + if (getenv("LD_PRELOAD")) { + + WARNF( + "LD_PRELOAD is set, are you sure that is what to you want to do " + "instead of using AFL_PRELOAD?"); + + } + + if (afl->afl_env.afl_preload) { + + if (afl->fsrv.qemu_mode) { + + /* afl-qemu-trace takes care of converting AFL_PRELOAD. */ } else { @@ -1042,12 +1341,19 @@ int main(int argc, char **argv_orig, char **envp) { bind_to_free_cpu(afl); #endif /* HAVE_AFFINITY */ - afl->fsrv.trace_bits = - afl_shm_init(&afl->shm, afl->fsrv.map_size, afl->non_instrumented_mode); + #ifdef __HAIKU__ + /* Prioritizes performance over power saving */ + set_scheduler_mode(SCHEDULER_MODE_LOW_LATENCY); + #endif - if (!afl->in_bitmap) { memset(afl->virgin_bits, 255, afl->fsrv.map_size); } - memset(afl->virgin_tmout, 255, afl->fsrv.map_size); - memset(afl->virgin_crash, 255, afl->fsrv.map_size); + #ifdef __APPLE__ + if (pthread_set_qos_class_self_np(QOS_CLASS_USER_INTERACTIVE, 0) != 0) { + + WARNF("general thread priority settings failed"); + + } + + #endif init_count_class16(); @@ -1056,12 +1362,14 @@ int main(int argc, char **argv_orig, char **envp) { WARNF("it is wasteful to run more than one main node!"); sleep(1); - } + } else if (!auto_sync && afl->is_secondary_node && - if (afl->is_secondary_node && check_main_node_exists(afl) == 0) { + check_main_node_exists(afl) == 0) { - WARNF("no -M main node found. You need to run one main instance!"); - sleep(3); + WARNF( + "no -M main node found. It is recommended to run exactly one main " + "instance."); + sleep(1); } @@ -1073,18 +1381,17 @@ int main(int argc, char **argv_orig, char **envp) { setup_custom_mutators(afl); + write_setup_file(afl, argc, argv); + setup_cmdline_file(afl, argv + optind); - read_testcases(afl); + read_testcases(afl, NULL); // read_foreign_testcases(afl, 1); for the moment dont do this - - load_auto(afl); + OKF("Loaded a total of %u seeds.", afl->queued_paths); pivot_inputs(afl); - if (extras_dir) { load_extras(afl, extras_dir); } - - if (!afl->timeout_given) { find_timeout(afl); } + if (!afl->timeout_given) { find_timeout(afl); } // only for resumes! if ((afl->tmp_dir = afl->afl_env.afl_tmpdir) != NULL && !afl->in_place_resume) { @@ -1122,10 +1429,10 @@ int main(int argc, char **argv_orig, char **envp) { if (!afl->fsrv.out_file) { - u32 i = optind + 1; - while (argv[i]) { + u32 j = optind + 1; + while (argv[j]) { - u8 *aa_loc = strstr(argv[i], "@@"); + u8 *aa_loc = strstr(argv[j], "@@"); if (aa_loc && !afl->fsrv.out_file) { @@ -1148,7 +1455,7 @@ int main(int argc, char **argv_orig, char **envp) { } - ++i; + ++j; } @@ -1164,7 +1471,11 @@ int main(int argc, char **argv_orig, char **envp) { } - if (!afl->fsrv.qemu_mode) { check_binary(afl, afl->cmplog_binary); } + if (!afl->fsrv.qemu_mode && !afl->non_instrumented_mode) { + + check_binary(afl, afl->cmplog_binary); + + } } @@ -1194,7 +1505,74 @@ int main(int argc, char **argv_orig, char **envp) { } + if (afl->non_instrumented_mode || afl->fsrv.qemu_mode || afl->unicorn_mode) { + + map_size = afl->fsrv.map_size = MAP_SIZE; + afl->virgin_bits = ck_realloc(afl->virgin_bits, map_size); + afl->virgin_tmout = ck_realloc(afl->virgin_tmout, map_size); + afl->virgin_crash = ck_realloc(afl->virgin_crash, map_size); + afl->var_bytes = ck_realloc(afl->var_bytes, map_size); + afl->top_rated = ck_realloc(afl->top_rated, map_size * sizeof(void *)); + afl->clean_trace = ck_realloc(afl->clean_trace, map_size); + afl->clean_trace_custom = ck_realloc(afl->clean_trace_custom, map_size); + afl->first_trace = ck_realloc(afl->first_trace, map_size); + afl->map_tmp_buf = ck_realloc(afl->map_tmp_buf, map_size); + + } + afl->argv = use_argv; + afl->fsrv.trace_bits = + afl_shm_init(&afl->shm, afl->fsrv.map_size, afl->non_instrumented_mode); + + if (!afl->non_instrumented_mode && !afl->fsrv.qemu_mode && + !afl->unicorn_mode) { + + if (map_size <= DEFAULT_SHMEM_SIZE && !afl->non_instrumented_mode && + !afl->fsrv.qemu_mode && !afl->unicorn_mode) { + + afl->fsrv.map_size = DEFAULT_SHMEM_SIZE; // dummy temporary value + char vbuf[16]; + snprintf(vbuf, sizeof(vbuf), "%u", DEFAULT_SHMEM_SIZE); + setenv("AFL_MAP_SIZE", vbuf, 1); + + } + + u32 new_map_size = afl_fsrv_get_mapsize( + &afl->fsrv, afl->argv, &afl->stop_soon, afl->afl_env.afl_debug_child); + + // only reinitialize when it makes sense + if ((map_size < new_map_size /*|| + (new_map_size != MAP_SIZE && new_map_size < map_size && + map_size - new_map_size > MAP_SIZE)*/)) { + + OKF("Re-initializing maps to %u bytes", new_map_size); + + afl->virgin_bits = ck_realloc(afl->virgin_bits, new_map_size); + afl->virgin_tmout = ck_realloc(afl->virgin_tmout, new_map_size); + afl->virgin_crash = ck_realloc(afl->virgin_crash, new_map_size); + afl->var_bytes = ck_realloc(afl->var_bytes, new_map_size); + afl->top_rated = + ck_realloc(afl->top_rated, new_map_size * sizeof(void *)); + afl->clean_trace = ck_realloc(afl->clean_trace, new_map_size); + afl->clean_trace_custom = + ck_realloc(afl->clean_trace_custom, new_map_size); + afl->first_trace = ck_realloc(afl->first_trace, new_map_size); + afl->map_tmp_buf = ck_realloc(afl->map_tmp_buf, new_map_size); + + afl_fsrv_kill(&afl->fsrv); + afl_shm_deinit(&afl->shm); + afl->fsrv.map_size = new_map_size; + afl->fsrv.trace_bits = + afl_shm_init(&afl->shm, new_map_size, afl->non_instrumented_mode); + setenv("AFL_NO_AUTODICT", "1", 1); // loaded already + afl_fsrv_start(&afl->fsrv, afl->argv, &afl->stop_soon, + afl->afl_env.afl_debug_child); + + map_size = new_map_size; + + } + + } if (afl->cmplog_binary) { @@ -1205,22 +1583,157 @@ int main(int argc, char **argv_orig, char **envp) { afl->cmplog_fsrv.qemu_mode = afl->fsrv.qemu_mode; afl->cmplog_fsrv.cmplog_binary = afl->cmplog_binary; afl->cmplog_fsrv.init_child_func = cmplog_exec_child; - afl_fsrv_start(&afl->cmplog_fsrv, afl->argv, &afl->stop_soon, - afl->afl_env.afl_debug_child_output); + + if ((map_size <= DEFAULT_SHMEM_SIZE || + afl->cmplog_fsrv.map_size < map_size) && + !afl->non_instrumented_mode && !afl->fsrv.qemu_mode && + !afl->unicorn_mode) { + + afl->cmplog_fsrv.map_size = MAX(map_size, (u32)DEFAULT_SHMEM_SIZE); + char vbuf[16]; + snprintf(vbuf, sizeof(vbuf), "%u", afl->cmplog_fsrv.map_size); + setenv("AFL_MAP_SIZE", vbuf, 1); + + } + + u32 new_map_size = + afl_fsrv_get_mapsize(&afl->cmplog_fsrv, afl->argv, &afl->stop_soon, + afl->afl_env.afl_debug_child); + + // only reinitialize when it needs to be larger + if (map_size < new_map_size) { + + OKF("Re-initializing maps to %u bytes due cmplog", new_map_size); + + afl->virgin_bits = ck_realloc(afl->virgin_bits, new_map_size); + afl->virgin_tmout = ck_realloc(afl->virgin_tmout, new_map_size); + afl->virgin_crash = ck_realloc(afl->virgin_crash, new_map_size); + afl->var_bytes = ck_realloc(afl->var_bytes, new_map_size); + afl->top_rated = + ck_realloc(afl->top_rated, new_map_size * sizeof(void *)); + afl->clean_trace = ck_realloc(afl->clean_trace, new_map_size); + afl->clean_trace_custom = + ck_realloc(afl->clean_trace_custom, new_map_size); + afl->first_trace = ck_realloc(afl->first_trace, new_map_size); + afl->map_tmp_buf = ck_realloc(afl->map_tmp_buf, new_map_size); + + afl_fsrv_kill(&afl->fsrv); + afl_fsrv_kill(&afl->cmplog_fsrv); + afl_shm_deinit(&afl->shm); + + afl->cmplog_fsrv.map_size = new_map_size; // non-cmplog stays the same + map_size = new_map_size; + + setenv("AFL_NO_AUTODICT", "1", 1); // loaded already + afl->fsrv.trace_bits = + afl_shm_init(&afl->shm, new_map_size, afl->non_instrumented_mode); + afl->cmplog_fsrv.trace_bits = afl->fsrv.trace_bits; + afl_fsrv_start(&afl->fsrv, afl->argv, &afl->stop_soon, + afl->afl_env.afl_debug_child); + afl_fsrv_start(&afl->cmplog_fsrv, afl->argv, &afl->stop_soon, + afl->afl_env.afl_debug_child); + + } + OKF("Cmplog forkserver successfully started"); } + if (afl->debug) { + + printf("NORMAL %u, CMPLOG %u\n", afl->fsrv.map_size, + afl->cmplog_fsrv.map_size); + fprintf(stderr, "NORMAL %u, CMPLOG %u\n", afl->fsrv.map_size, + afl->cmplog_fsrv.map_size); + + } + + load_auto(afl); + + if (extras_dir_cnt) { + + for (i = 0; i < extras_dir_cnt; i++) { + + load_extras(afl, extras_dir[i]); + + } + + } + + deunicode_extras(afl); + dedup_extras(afl); + if (afl->extras_cnt) { OKF("Loaded a total of %u extras.", afl->extras_cnt); } + + // after we have the correct bitmap size we can read the bitmap -B option + // and set the virgin maps + if (afl->in_bitmap) { + + read_bitmap(afl->in_bitmap, afl->virgin_bits, afl->fsrv.map_size); + + } else { + + memset(afl->virgin_bits, 255, map_size); + + } + + memset(afl->virgin_tmout, 255, map_size); + memset(afl->virgin_crash, 255, map_size); + perform_dry_run(afl); + if (afl->q_testcase_max_cache_entries) { + + afl->q_testcase_cache = + ck_alloc(afl->q_testcase_max_cache_entries * sizeof(size_t)); + if (!afl->q_testcase_cache) { PFATAL("malloc failed for cache entries"); } + + } + cull_queue(afl); + // ensure we have at least one seed that is not disabled. + u32 entry, valid_seeds = 0; + for (entry = 0; entry < afl->queued_paths; ++entry) + if (!afl->queue_buf[entry]->disabled) { ++valid_seeds; } + + if (!afl->pending_not_fuzzed || !valid_seeds) { + + FATAL("We need at least one valid input seed that does not crash!"); + + } + + if (afl->timeout_given == 2) { // -t ...+ option + + if (valid_seeds == 1) { + + WARNF( + "Only one valid seed is present, auto-calculating the timeout is " + "disabled!"); + afl->timeout_given = 1; + + } else { + + u64 max_ms = 0; + + for (entry = 0; entry < afl->queued_paths; ++entry) + if (!afl->queue_buf[entry]->disabled) + if (afl->queue_buf[entry]->exec_us > max_ms) + max_ms = afl->queue_buf[entry]->exec_us; + + afl->fsrv.exec_tmout = max_ms; + + } + + } + show_init_stats(afl); - seek_to = find_start_position(afl); + if (unlikely(afl->old_seed_selection)) seek_to = find_start_position(afl); - write_stats_file(afl, 0, 0, 0); - maybe_update_plot_file(afl, 0, 0); + afl->start_time = get_cur_time(); + if (afl->in_place_resume || afl->afl_env.afl_autoresume) load_stats_file(afl); + write_stats_file(afl, 0, 0, 0, 0); + maybe_update_plot_file(afl, 0, 0, 0); save_auto(afl); if (afl->stop_soon) { goto stop_fuzzing; } @@ -1229,8 +1742,7 @@ int main(int argc, char **argv_orig, char **envp) { if (!afl->not_on_tty) { - sleep(4); - afl->start_time += 4000; + sleep(1); if (afl->stop_soon) { goto stop_fuzzing; } } @@ -1239,28 +1751,58 @@ int main(int argc, char **argv_orig, char **envp) { // real start time, we reset, so this works correctly with -V afl->start_time = get_cur_time(); - while (1) { + u32 runs_in_current_cycle = (u32)-1; + u32 prev_queued_paths = 0; + u8 skipped_fuzz; - u8 skipped_fuzz; + #ifdef INTROSPECTION + char ifn[4096]; + snprintf(ifn, sizeof(ifn), "%s/introspection.txt", afl->out_dir); + if ((afl->introspection_file = fopen(ifn, "w")) == NULL) { + + PFATAL("could not create '%s'", ifn); + + } + + setvbuf(afl->introspection_file, NULL, _IONBF, 0); + OKF("Writing mutation introspection to '%s'", ifn); + #endif + + while (likely(!afl->stop_soon)) { cull_queue(afl); - if (!afl->queue_cur) { + if (unlikely((!afl->old_seed_selection && + runs_in_current_cycle > afl->queued_paths) || + (afl->old_seed_selection && !afl->queue_cur))) { ++afl->queue_cycle; - afl->current_entry = 0; + runs_in_current_cycle = (u32)-1; afl->cur_skipped_paths = 0; - afl->queue_cur = afl->queue; - while (seek_to) { + if (unlikely(afl->old_seed_selection)) { - ++afl->current_entry; - --seek_to; - afl->queue_cur = afl->queue_cur->next; + afl->current_entry = 0; + while (unlikely(afl->current_entry < afl->queued_paths && + afl->queue_buf[afl->current_entry]->disabled)) { - } + ++afl->current_entry; + + } + + if (afl->current_entry >= afl->queued_paths) { afl->current_entry = 0; } + + afl->queue_cur = afl->queue_buf[afl->current_entry]; - // show_stats(afl); + if (unlikely(seek_to)) { + + afl->current_entry = seek_to; + afl->queue_cur = afl->queue_buf[seek_to]; + seek_to = 0; + + } + + } if (unlikely(afl->not_on_tty)) { @@ -1272,46 +1814,72 @@ int main(int argc, char **argv_orig, char **envp) { /* If we had a full queue cycle with no new finds, try recombination strategies next. */ - if (afl->queued_paths == prev_queued && - (get_cur_time() - afl->start_time) >= 3600) { + if (unlikely(afl->queued_paths == prev_queued && + (get_cur_time() - afl->start_time) >= 3600)) { if (afl->use_splicing) { ++afl->cycles_wo_finds; + + if (unlikely(afl->shm.cmplog_mode && + afl->cmplog_max_filesize < MAX_FILE)) { + + afl->cmplog_max_filesize <<= 4; + + } + switch (afl->expand_havoc) { case 0: + // this adds extra splicing mutation options to havoc mode afl->expand_havoc = 1; break; case 1: - if (afl->limit_time_sig == 0) { + // add MOpt mutator + /* + if (afl->limit_time_sig == 0 && !afl->custom_only && + !afl->python_only) { afl->limit_time_sig = -1; afl->limit_time_puppet = 0; } + */ afl->expand_havoc = 2; + if (afl->cmplog_lvl && afl->cmplog_lvl < 2) afl->cmplog_lvl = 2; break; case 2: - // afl->cycle_schedules = 1; + // increase havoc mutations per fuzz attempt + afl->havoc_stack_pow2++; afl->expand_havoc = 3; break; case 3: + // further increase havoc mutations per fuzz attempt + afl->havoc_stack_pow2++; + afl->expand_havoc = 4; + break; + case 4: + afl->expand_havoc = 5; + if (afl->cmplog_lvl && afl->cmplog_lvl < 3) afl->cmplog_lvl = 3; + break; + case 5: + // if not in sync mode, enable deterministic mode? + // if (!afl->sync_id) afl->skip_deterministic = 0; + afl->expand_havoc = 6; + case 6: // nothing else currently break; } - if (afl->expand_havoc) { - - } else - - afl->expand_havoc = 1; - } else { + #ifndef NO_SPLICING afl->use_splicing = 1; + #else + afl->use_splicing = 0; + #endif } @@ -1357,12 +1925,14 @@ int main(int argc, char **argv_orig, char **envp) { } - struct queue_entry *q = afl->queue; // we must recalculate the scores of all queue entries - while (q) { + for (i = 0; i < (s32)afl->queued_paths; i++) { - update_bitmap_score(afl, q); - q = q->next; + if (likely(!afl->queue_buf[i]->disabled)) { + + update_bitmap_score(afl, afl->queue_buf[i]); + + } } @@ -1379,38 +1949,89 @@ int main(int argc, char **argv_orig, char **envp) { } - skipped_fuzz = fuzz_one(afl); + ++runs_in_current_cycle; - if (!skipped_fuzz && !afl->stop_soon && afl->sync_id) { + do { - if (unlikely(afl->is_main_node)) { + if (likely(!afl->old_seed_selection)) { - if (!(sync_interval_cnt++ % (SYNC_INTERVAL / 3))) { sync_fuzzers(afl); } + if (unlikely(prev_queued_paths < afl->queued_paths)) { - } else { + // we have new queue entries since the last run, recreate alias table + prev_queued_paths = afl->queued_paths; + create_alias_table(afl); - if (!(sync_interval_cnt++ % SYNC_INTERVAL)) { sync_fuzzers(afl); } + } + + afl->current_entry = select_next_queue_entry(afl); + afl->queue_cur = afl->queue_buf[afl->current_entry]; } - } + skipped_fuzz = fuzz_one(afl); + + if (unlikely(!afl->stop_soon && exit_1)) { afl->stop_soon = 2; } + + if (unlikely(afl->old_seed_selection)) { + + while (++afl->current_entry < afl->queued_paths && + afl->queue_buf[afl->current_entry]->disabled) + ; + if (unlikely(afl->current_entry >= afl->queued_paths || + afl->queue_buf[afl->current_entry] == NULL || + afl->queue_buf[afl->current_entry]->disabled)) + afl->queue_cur = NULL; + else + afl->queue_cur = afl->queue_buf[afl->current_entry]; + + } + + } while (skipped_fuzz && afl->queue_cur && !afl->stop_soon); + + if (likely(!afl->stop_soon && afl->sync_id)) { + + if (likely(afl->skip_deterministic)) { - if (!afl->stop_soon && exit_1) { afl->stop_soon = 2; } + if (unlikely(afl->is_main_node)) { - if (afl->stop_soon) { break; } + if (unlikely(get_cur_time() > + (SYNC_TIME >> 1) + afl->last_sync_time)) { - afl->queue_cur = afl->queue_cur->next; - ++afl->current_entry; + if (!(sync_interval_cnt++ % (SYNC_INTERVAL / 3))) { + + sync_fuzzers(afl); + + } + + } + + } else { + + if (unlikely(get_cur_time() > SYNC_TIME + afl->last_sync_time)) { + + if (!(sync_interval_cnt++ % SYNC_INTERVAL)) { sync_fuzzers(afl); } + + } + + } + + } else { + + sync_fuzzers(afl); + + } + + } } write_bitmap(afl); - maybe_update_plot_file(afl, 0, 0); + maybe_update_plot_file(afl, 0, 0, 0); save_auto(afl); stop_fuzzing: - write_stats_file(afl, 0, 0, 0); + write_stats_file(afl, 0, 0, 0, 0); afl->force_ui_update = 1; // ensure the screen is reprinted show_stats(afl); // print the screen one last time @@ -1477,6 +2098,7 @@ stop_fuzzing: ck_free(afl->fsrv.target_path); ck_free(afl->fsrv.out_file); ck_free(afl->sync_id); + if (afl->q_testcase_cache) { ck_free(afl->q_testcase_cache); } afl_state_deinit(afl); free(afl); /* not tracked */ diff --git a/src/afl-gcc.c b/src/afl-gcc.c deleted file mode 100644 index 22e6be8e..00000000 --- a/src/afl-gcc.c +++ /dev/null @@ -1,488 +0,0 @@ -/* - american fuzzy lop++ - wrapper for GCC and clang - ------------------------------------------------ - - Originally written by Michal Zalewski - - Now maintained by Marc Heuse <mh@mh-sec.de>, - Heiko Eißfeldt <heiko.eissfeldt@hexco.de> and - Andrea Fioraldi <andreafioraldi@gmail.com> - - Copyright 2016, 2017 Google Inc. All rights reserved. - Copyright 2019-2020 AFLplusplus Project. All rights reserved. - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at: - - http://www.apache.org/licenses/LICENSE-2.0 - - This program is a drop-in replacement for GCC or clang. The most common way - of using it is to pass the path to afl-gcc or afl-clang via CC when invoking - ./configure. - - (Of course, use CXX and point it to afl-g++ / afl-clang++ for C++ code.) - - The wrapper needs to know the path to afl-as (renamed to 'as'). The default - is /usr/local/lib/afl/. A convenient way to specify alternative directories - would be to set AFL_PATH. - - If AFL_HARDEN is set, the wrapper will compile the target app with various - hardening options that may help detect memory management issues more - reliably. You can also specify AFL_USE_ASAN to enable ASAN. - - If you want to call a non-default compiler as a next step of the chain, - specify its location via AFL_CC or AFL_CXX. - - */ - -#define AFL_MAIN - -#include "config.h" -#include "types.h" -#include "debug.h" -#include "alloc-inl.h" - -#include <stdio.h> -#include <unistd.h> -#include <stdlib.h> -#include <string.h> - -static u8 * as_path; /* Path to the AFL 'as' wrapper */ -static u8 **cc_params; /* Parameters passed to the real CC */ -static u32 cc_par_cnt = 1; /* Param count, including argv0 */ -static u8 be_quiet, /* Quiet mode */ - clang_mode; /* Invoked as afl-clang*? */ - -/* Try to find our "fake" GNU assembler in AFL_PATH or at the location derived - from argv[0]. If that fails, abort. */ - -static void find_as(u8 *argv0) { - - u8 *afl_path = getenv("AFL_PATH"); - u8 *slash, *tmp; - - if (afl_path) { - - tmp = alloc_printf("%s/as", afl_path); - - if (!access(tmp, X_OK)) { - - as_path = afl_path; - ck_free(tmp); - return; - - } - - ck_free(tmp); - - } - - slash = strrchr(argv0, '/'); - - if (slash) { - - u8 *dir; - - *slash = 0; - dir = ck_strdup(argv0); - *slash = '/'; - - tmp = alloc_printf("%s/afl-as", dir); - - if (!access(tmp, X_OK)) { - - as_path = dir; - ck_free(tmp); - return; - - } - - ck_free(tmp); - ck_free(dir); - - } - - if (!access(AFL_PATH "/as", X_OK)) { - - as_path = AFL_PATH; - return; - - } - - FATAL("Unable to find AFL wrapper binary for 'as'. Please set AFL_PATH"); - -} - -/* Copy argv to cc_params, making the necessary edits. */ - -static void edit_params(u32 argc, char **argv) { - - u8 fortify_set = 0, asan_set = 0; - u8 *name; - -#if defined(__FreeBSD__) && defined(WORD_SIZE_64) - u8 m32_set = 0; -#endif - - cc_params = ck_alloc((argc + 128) * sizeof(u8 *)); - - name = strrchr(argv[0], '/'); - if (!name) { - - name = argv[0]; - - /* This should never happen but fixes a scan-build warning */ - if (!name) { FATAL("Empty argv set"); } - - } else { - - ++name; - - } - - if (!strncmp(name, "afl-clang", 9)) { - - clang_mode = 1; - - setenv(CLANG_ENV_VAR, "1", 1); - - if (!strcmp(name, "afl-clang++")) { - - u8 *alt_cxx = getenv("AFL_CXX"); - cc_params[0] = alt_cxx && *alt_cxx ? alt_cxx : (u8 *)"clang++"; - - } else if (!strcmp(name, "afl-clang")) { - - u8 *alt_cc = getenv("AFL_CC"); - cc_params[0] = alt_cc && *alt_cc ? alt_cc : (u8 *)"clang"; - - } else { - - fprintf(stderr, "Name of the binary: %s\n", argv[0]); - FATAL("Name of the binary is not a known name, expected afl-clang(++)"); - - } - - } else { - - /* With GCJ and Eclipse installed, you can actually compile Java! The - instrumentation will work (amazingly). Alas, unhandled exceptions do - not call abort(), so afl-fuzz would need to be modified to equate - non-zero exit codes with crash conditions when working with Java - binaries. Meh. */ - -#ifdef __APPLE__ - - if (!strcmp(name, "afl-g++")) { - - cc_params[0] = getenv("AFL_CXX"); - - } else if (!strcmp(name, "afl-gcj")) { - - cc_params[0] = getenv("AFL_GCJ"); - - } else if (!strcmp(name, "afl-gcc")) { - - cc_params[0] = getenv("AFL_CC"); - - } else { - - fprintf(stderr, "Name of the binary: %s\n", argv[0]); - FATAL("Name of the binary is not a known name, expected afl-gcc/g++/gcj"); - - } - - if (!cc_params[0]) { - - SAYF("\n" cLRD "[-] " cRST - "On Apple systems, 'gcc' is usually just a wrapper for clang. " - "Please use the\n" - " 'afl-clang' utility instead of 'afl-gcc'. If you really have " - "GCC installed,\n" - " set AFL_CC or AFL_CXX to specify the correct path to that " - "compiler.\n"); - - FATAL("AFL_CC or AFL_CXX required on MacOS X"); - - } - -#else - - if (!strcmp(name, "afl-g++")) { - - u8 *alt_cxx = getenv("AFL_CXX"); - cc_params[0] = alt_cxx && *alt_cxx ? alt_cxx : (u8 *)"g++"; - - } else if (!strcmp(name, "afl-gcj")) { - - u8 *alt_cc = getenv("AFL_GCJ"); - cc_params[0] = alt_cc && *alt_cc ? alt_cc : (u8 *)"gcj"; - - } else if (!strcmp(name, "afl-gcc")) { - - u8 *alt_cc = getenv("AFL_CC"); - cc_params[0] = alt_cc && *alt_cc ? alt_cc : (u8 *)"gcc"; - - } else { - - fprintf(stderr, "Name of the binary: %s\n", argv[0]); - FATAL("Name of the binary is not a known name, expected afl-gcc/g++/gcj"); - - } - -#endif /* __APPLE__ */ - - } - - while (--argc) { - - u8 *cur = *(++argv); - - if (!strncmp(cur, "-B", 2)) { - - if (!be_quiet) { WARNF("-B is already set, overriding"); } - - if (!cur[2] && argc > 1) { - - argc--; - argv++; - - } - - continue; - - } - - if (!strcmp(cur, "-integrated-as")) { continue; } - - if (!strcmp(cur, "-pipe")) { continue; } - -#if defined(__FreeBSD__) && defined(WORD_SIZE_64) - if (!strcmp(cur, "-m32")) m32_set = 1; -#endif - - if (!strcmp(cur, "-fsanitize=address") || - !strcmp(cur, "-fsanitize=memory")) { - - asan_set = 1; - - } - - if (strstr(cur, "FORTIFY_SOURCE")) { fortify_set = 1; } - - cc_params[cc_par_cnt++] = cur; - - } - - cc_params[cc_par_cnt++] = "-B"; - cc_params[cc_par_cnt++] = as_path; - - if (clang_mode) { cc_params[cc_par_cnt++] = "-no-integrated-as"; } - - if (getenv("AFL_HARDEN")) { - - cc_params[cc_par_cnt++] = "-fstack-protector-all"; - - if (!fortify_set) { cc_params[cc_par_cnt++] = "-D_FORTIFY_SOURCE=2"; } - - } - - if (asan_set) { - - /* Pass this on to afl-as to adjust map density. */ - - setenv("AFL_USE_ASAN", "1", 1); - - } else if (getenv("AFL_USE_ASAN")) { - - if (getenv("AFL_USE_MSAN")) { - - FATAL("ASAN and MSAN are mutually exclusive"); - - } - - if (getenv("AFL_HARDEN")) { - - FATAL("ASAN and AFL_HARDEN are mutually exclusive"); - - } - - cc_params[cc_par_cnt++] = "-U_FORTIFY_SOURCE"; - cc_params[cc_par_cnt++] = "-fsanitize=address"; - - } else if (getenv("AFL_USE_MSAN")) { - - if (getenv("AFL_USE_ASAN")) { - - FATAL("ASAN and MSAN are mutually exclusive"); - - } - - if (getenv("AFL_HARDEN")) { - - FATAL("MSAN and AFL_HARDEN are mutually exclusive"); - - } - - cc_params[cc_par_cnt++] = "-U_FORTIFY_SOURCE"; - cc_params[cc_par_cnt++] = "-fsanitize=memory"; - - } - - if (getenv("AFL_USE_UBSAN")) { - - cc_params[cc_par_cnt++] = "-fsanitize=undefined"; - cc_params[cc_par_cnt++] = "-fsanitize-undefined-trap-on-error"; - cc_params[cc_par_cnt++] = "-fno-sanitize-recover=all"; - - } - -#if defined(USEMMAP) && !defined(__HAIKU__) - cc_params[cc_par_cnt++] = "-lrt"; -#endif - - if (!getenv("AFL_DONT_OPTIMIZE")) { - -#if defined(__FreeBSD__) && defined(WORD_SIZE_64) - - /* On 64-bit FreeBSD systems, clang -g -m32 is broken, but -m32 itself - works OK. This has nothing to do with us, but let's avoid triggering - that bug. */ - - if (!clang_mode || !m32_set) cc_params[cc_par_cnt++] = "-g"; - -#else - - cc_params[cc_par_cnt++] = "-g"; - -#endif - - cc_params[cc_par_cnt++] = "-O3"; - cc_params[cc_par_cnt++] = "-funroll-loops"; - - /* Two indicators that you're building for fuzzing; one of them is - AFL-specific, the other is shared with libfuzzer. */ - - cc_params[cc_par_cnt++] = "-D__AFL_COMPILER=1"; - cc_params[cc_par_cnt++] = "-DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1"; - - } - - if (getenv("AFL_NO_BUILTIN")) { - - cc_params[cc_par_cnt++] = "-fno-builtin-strcmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strncmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strcasecmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strncasecmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-memcmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-bcmp"; - cc_params[cc_par_cnt++] = "-fno-builtin-strstr"; - cc_params[cc_par_cnt++] = "-fno-builtin-strcasestr"; - - } - - cc_params[cc_par_cnt] = NULL; - -} - -/* Main entry point */ - -int main(int argc, char **argv) { - - char *env_info = - "Environment variables used by afl-gcc:\n" - "AFL_CC: path to the C compiler to use\n" - "AFL_CXX: path to the C++ compiler to use\n" - "AFL_GCJ: path to the java compiler to use\n" - "AFL_PATH: path to the instrumenting assembler\n" - "AFL_DONT_OPTIMIZE: disable optimization instead of -O3\n" - "AFL_NO_BUILTIN: compile for use with libtokencap.so\n" - "AFL_QUIET: suppress verbose output\n" - "AFL_CAL_FAST: speed up the initial calibration\n" - "AFL_HARDEN: adds code hardening to catch memory bugs\n" - "AFL_USE_ASAN: activate address sanitizer\n" - "AFL_USE_MSAN: activate memory sanitizer\n" - "AFL_USE_UBSAN: activate undefined behaviour sanitizer\n" - - "\nEnvironment variables used by afl-as (called by afl-gcc):\n" - "AFL_AS: path to the assembler to use\n" - "TMPDIR: set the directory for temporary files of afl-as\n" - "TEMP: fall back path to directory for temporary files\n" - "TMP: fall back path to directory for temporary files\n" - "AFL_INST_RATIO: percentage of branches to instrument\n" - "AFL_QUIET: suppress verbose output\n" - "AFL_KEEP_ASSEMBLY: leave instrumented assembly files\n" - "AFL_AS_FORCE_INSTRUMENT: force instrumentation for asm sources\n"; - - if (argc == 2 && strcmp(argv[1], "-h") == 0) { - - printf("afl-cc" VERSION " by Michal Zalewski\n\n"); - printf("%s \n\n", argv[0]); - printf("afl-gcc has no command line options\n\n%s\n", env_info); - printf( - "NOTE: afl-gcc is deprecated, llvm_mode is much faster and has more " - "options\n"); - return -1; - - } - - if ((isatty(2) && !getenv("AFL_QUIET")) || getenv("AFL_DEBUG") != NULL) { - - SAYF(cCYA "afl-cc" VERSION cRST " by Michal Zalewski\n"); - SAYF(cYEL "[!] " cBRI "NOTE: " cRST - "afl-gcc is deprecated, llvm_mode is much faster and has more " - "options\n"); - - } else { - - be_quiet = 1; - - } - - if (argc < 2) { - - SAYF( - "\n" - "This is a helper application for afl-fuzz. It serves as a drop-in " - "replacement\n" - "for gcc or clang, letting you recompile third-party code with the " - "required\n" - "runtime instrumentation. A common use pattern would be one of the " - "following:\n\n" - - " CC=%s/afl-gcc ./configure\n" - " CXX=%s/afl-g++ ./configure\n\n%s" - - , - BIN_PATH, BIN_PATH, env_info); - - exit(1); - - } - - u8 *ptr; - if (!be_quiet && - ((ptr = getenv("AFL_MAP_SIZE")) || (ptr = getenv("AFL_MAPSIZE")))) { - - u32 map_size = atoi(ptr); - if (map_size != MAP_SIZE) { - - WARNF("AFL_MAP_SIZE is not supported by afl-gcc"); - - } - - } - - find_as(argv[0]); - - edit_params(argc, argv); - - execvp(cc_params[0], (char **)cc_params); - - FATAL("Oops, failed to execute '%s' - check your PATH", cc_params[0]); - - return 0; - -} - diff --git a/src/afl-gotcpu.c b/src/afl-gotcpu.c index bd0f7de6..ac002a93 100644 --- a/src/afl-gotcpu.c +++ b/src/afl-gotcpu.c @@ -35,9 +35,6 @@ #define _GNU_SOURCE #endif -#ifdef __ANDROID__ - #include "android-ashmem.h" -#endif #include <stdio.h> #include <stdlib.h> #include <unistd.h> @@ -65,7 +62,6 @@ #define cpu_set_t cpuset_t #elif defined(__NetBSD__) #include <pthread.h> - #include <sched.h> #elif defined(__APPLE__) #include <pthread.h> #include <mach/thread_act.h> diff --git a/llvm_mode/afl-ld-lto.c b/src/afl-ld-lto.c index 1b59bb4a..0a978653 100644 --- a/llvm_mode/afl-ld-lto.c +++ b/src/afl-ld-lto.c @@ -45,6 +45,15 @@ #include <dirent.h> +#if defined(__FreeBSD__) || defined(__OpenBSD__) || defined(__NetBSD__) || \ + defined(__DragonFly__) + #include <limits.h> +#endif + +#ifdef __APPLE__ + #include <sys/syslimits.h> +#endif + #define MAX_PARAM_COUNT 4096 static u8 **ld_params; /* Parameters passed to the real 'ld' */ @@ -74,7 +83,7 @@ static void edit_params(int argc, char **argv) { if (!passthrough) { - for (i = 1; i < argc; i++) { + for (i = 1; i < (u32)argc; i++) { if (strstr(argv[i], "/afl-llvm-rt-lto.o") != NULL) rt_lto_present = 1; if (strstr(argv[i], "/afl-llvm-rt.o") != NULL) rt_present = 1; @@ -82,7 +91,7 @@ static void edit_params(int argc, char **argv) { } - for (i = 1; i < argc && !gold_pos; i++) { + for (i = 1; i < (u32)argc && !gold_pos; i++) { if (strcmp(argv[i], "-plugin") == 0) { @@ -91,7 +100,9 @@ static void edit_params(int argc, char **argv) { if (strcasestr(argv[i], "LLVMgold.so") != NULL) gold_present = gold_pos = i + 1; - } else if (i < argc && strcasestr(argv[i + 1], "LLVMgold.so") != NULL) { + } else if (i < (u32)argc && + + strcasestr(argv[i + 1], "LLVMgold.so") != NULL) { gold_present = gold_pos = i + 2; @@ -103,7 +114,7 @@ static void edit_params(int argc, char **argv) { if (!gold_pos) { - for (i = 1; i + 1 < argc && !gold_pos; i++) { + for (i = 1; i + 1 < (u32)argc && !gold_pos; i++) { if (argv[i][0] != '-') { @@ -182,14 +193,14 @@ static void edit_params(int argc, char **argv) { instrim = 1; if (debug) - SAYF(cMGN "[D] " cRST - "passthrough=%s instrim=%d, gold_pos=%d, gold_present=%s " - "inst_present=%s rt_present=%s rt_lto_present=%s\n", - passthrough ? "true" : "false", instrim, gold_pos, - gold_present ? "true" : "false", inst_present ? "true" : "false", - rt_present ? "true" : "false", rt_lto_present ? "true" : "false"); + DEBUGF( + "passthrough=%s instrim=%u, gold_pos=%u, gold_present=%s " + "inst_present=%s rt_present=%s rt_lto_present=%s\n", + passthrough ? "true" : "false", instrim, gold_pos, + gold_present ? "true" : "false", inst_present ? "true" : "false", + rt_present ? "true" : "false", rt_lto_present ? "true" : "false"); - for (i = 1; i < argc; i++) { + for (i = 1; i < (u32)argc; i++) { if (ld_param_cnt >= MAX_PARAM_COUNT) FATAL( @@ -249,10 +260,9 @@ static void edit_params(int argc, char **argv) { int main(int argc, char **argv) { s32 pid, i, status; - u8 * ptr; char thecwd[PATH_MAX]; - if ((ptr = getenv("AFL_LD_CALLER")) != NULL) { + if (getenv("AFL_LD_CALLER") != NULL) { FATAL("ld loop detected! Set AFL_REAL_LD!\n"); @@ -278,9 +288,9 @@ int main(int argc, char **argv) { if (debug) { - (void)getcwd(thecwd, sizeof(thecwd)); + if (getcwd(thecwd, sizeof(thecwd)) != 0) strcpy(thecwd, "."); - SAYF(cMGN "[D] " cRST "cd \"%s\";", thecwd); + DEBUGF("cd \"%s\";", thecwd); for (i = 0; i < argc; i++) SAYF(" \"%s\"", argv[i]); SAYF("\n"); @@ -315,8 +325,8 @@ int main(int argc, char **argv) { if (debug) { - SAYF(cMGN "[D]" cRST " cd \"%s\";", thecwd); - for (i = 0; i < ld_param_cnt; i++) + DEBUGF("cd \"%s\";", thecwd); + for (i = 0; i < (s32)ld_param_cnt; i++) SAYF(" \"%s\"", ld_params[i]); SAYF("\n"); @@ -333,7 +343,7 @@ int main(int argc, char **argv) { if (pid < 0) PFATAL("fork() failed"); if (waitpid(pid, &status, 0) <= 0) PFATAL("waitpid() failed"); - if (debug) SAYF(cMGN "[D] " cRST "linker result: %d\n", status); + if (debug) DEBUGF("linker result: %d\n", status); if (!just_version) { diff --git a/src/afl-performance.c b/src/afl-performance.c index 0c1697a8..89b170eb 100644 --- a/src/afl-performance.c +++ b/src/afl-performance.c @@ -22,16 +22,10 @@ #include <stdint.h> #include "afl-fuzz.h" #include "types.h" -#include "xxh3.h" -/* we use xoshiro256** instead of rand/random because it is 10x faster and has - better randomness properties. */ - -static inline uint64_t rotl(const uint64_t x, int k) { - - return (x << k) | (x >> (64 - k)); - -} +#define XXH_INLINE_ALL +#include "xxhash.h" +#undef XXH_INLINE_ALL void rand_set_seed(afl_state_t *afl, s64 init_seed) { @@ -39,102 +33,49 @@ void rand_set_seed(afl_state_t *afl, s64 init_seed) { afl->rand_seed[0] = hash64((u8 *)&afl->init_seed, sizeof(afl->init_seed), HASH_CONST); afl->rand_seed[1] = afl->rand_seed[0] ^ 0x1234567890abcdef; - afl->rand_seed[2] = afl->rand_seed[0] & 0x0123456789abcdef; - afl->rand_seed[3] = afl->rand_seed[0] | 0x01abcde43f567908; + afl->rand_seed[2] = (afl->rand_seed[0] & 0x1234567890abcdef) ^ + (afl->rand_seed[1] | 0xfedcba9876543210); } -uint64_t rand_next(afl_state_t *afl) { - - const uint64_t result = - rotl(afl->rand_seed[0] + afl->rand_seed[3], 23) + afl->rand_seed[0]; - - const uint64_t t = afl->rand_seed[1] << 17; +#define ROTL(d, lrot) ((d << (lrot)) | (d >> (8 * sizeof(d) - (lrot)))) - afl->rand_seed[2] ^= afl->rand_seed[0]; - afl->rand_seed[3] ^= afl->rand_seed[1]; - afl->rand_seed[1] ^= afl->rand_seed[2]; - afl->rand_seed[0] ^= afl->rand_seed[3]; +#ifdef WORD_SIZE_64 +// romuDuoJr +inline AFL_RAND_RETURN rand_next(afl_state_t *afl) { - afl->rand_seed[2] ^= t; - - afl->rand_seed[3] = rotl(afl->rand_seed[3], 45); - - return result; + AFL_RAND_RETURN xp = afl->rand_seed[0]; + afl->rand_seed[0] = 15241094284759029579u * afl->rand_seed[1]; + afl->rand_seed[1] = afl->rand_seed[1] - xp; + afl->rand_seed[1] = ROTL(afl->rand_seed[1], 27); + return xp; } -/* This is the jump function for the generator. It is equivalent - to 2^128 calls to rand_next(); it can be used to generate 2^128 - non-overlapping subsequences for parallel computations. */ - -void jump(afl_state_t *afl) { - - static const uint64_t JUMP[] = {0x180ec6d33cfd0aba, 0xd5a61266f0c9392c, - 0xa9582618e03fc9aa, 0x39abdc4529b1661c}; - int i, b; - uint64_t s0 = 0; - uint64_t s1 = 0; - uint64_t s2 = 0; - uint64_t s3 = 0; - for (i = 0; i < sizeof JUMP / sizeof *JUMP; i++) - for (b = 0; b < 64; b++) { - - if (JUMP[i] & UINT64_C(1) << b) { - - s0 ^= afl->rand_seed[0]; - s1 ^= afl->rand_seed[1]; - s2 ^= afl->rand_seed[2]; - s3 ^= afl->rand_seed[3]; - - } - - rand_next(afl); - - } - - afl->rand_seed[0] = s0; - afl->rand_seed[1] = s1; - afl->rand_seed[2] = s2; - afl->rand_seed[3] = s3; +#else +// RomuTrio32 +inline AFL_RAND_RETURN rand_next(afl_state_t *afl) { + + AFL_RAND_RETURN xp = afl->rand_seed[0], yp = afl->rand_seed[1], + zp = afl->rand_seed[2]; + afl->rand_seed[0] = 3323815723u * zp; + afl->rand_seed[1] = yp - xp; + afl->rand_seed[1] = ROTL(afl->rand_seed[1], 6); + afl->rand_seed[2] = zp - yp; + afl->rand_seed[2] = ROTL(afl->rand_seed[2], 22); + return xp; } -/* This is the long-jump function for the generator. It is equivalent to - 2^192 calls to rand_next(); it can be used to generate 2^64 starting points, - from each of which jump() will generate 2^64 non-overlapping - subsequences for parallel distributed computations. */ - -void long_jump(afl_state_t *afl) { - - static const uint64_t LONG_JUMP[] = {0x76e15d3efefdcbbf, 0xc5004e441c522fb3, - 0x77710069854ee241, 0x39109bb02acbe635}; - - int i, b; - uint64_t s0 = 0; - uint64_t s1 = 0; - uint64_t s2 = 0; - uint64_t s3 = 0; - for (i = 0; i < sizeof LONG_JUMP / sizeof *LONG_JUMP; i++) - for (b = 0; b < 64; b++) { - - if (LONG_JUMP[i] & UINT64_C(1) << b) { - - s0 ^= afl->rand_seed[0]; - s1 ^= afl->rand_seed[1]; - s2 ^= afl->rand_seed[2]; - s3 ^= afl->rand_seed[3]; +#endif - } +#undef ROTL - rand_next(afl); +/* returns a double between 0.000000000 and 1.000000000 */ - } +inline double rand_next_percent(afl_state_t *afl) { - afl->rand_seed[0] = s0; - afl->rand_seed[1] = s1; - afl->rand_seed[2] = s2; - afl->rand_seed[3] = s3; + return (double)(((double)rand_next(afl)) / (double)0xffffffffffffffff); } @@ -145,7 +86,7 @@ void long_jump(afl_state_t *afl) { u32 hash32(u8 *key, u32 len, u32 seed) { #else -u32 inline hash32(u8 *key, u32 len, u32 seed) { +inline u32 hash32(u8 *key, u32 len, u32 seed) { #endif @@ -157,7 +98,7 @@ u32 inline hash32(u8 *key, u32 len, u32 seed) { u64 hash64(u8 *key, u32 len, u64 seed) { #else -u64 inline hash64(u8 *key, u32 len, u64 seed) { +inline u64 hash64(u8 *key, u32 len, u64 seed) { #endif diff --git a/src/afl-sharedmem.c b/src/afl-sharedmem.c index 6eb63949..3241a130 100644 --- a/src/afl-sharedmem.c +++ b/src/afl-sharedmem.c @@ -66,9 +66,17 @@ static list_t shm_list = {.element_prealloc_count = 0}; void afl_shm_deinit(sharedmem_t *shm) { - if (shm == NULL) return; - + if (shm == NULL) { return; } list_remove(&shm_list, shm); + if (shm->shmemfuzz_mode) { + + unsetenv(SHM_FUZZ_ENV_VAR); + + } else { + + unsetenv(SHM_ENV_VAR); + + } #ifdef USEMMAP if (shm->map != NULL) { @@ -94,6 +102,8 @@ void afl_shm_deinit(sharedmem_t *shm) { if (shm->cmplog_mode) { + unsetenv(CMPLOG_SHM_ENV_VAR); + if (shm->cmp_map != NULL) { munmap(shm->cmp_map, shm->map_size); @@ -205,7 +215,7 @@ u8 *afl_shm_init(sharedmem_t *shm, size_t map_size, /* map the shared memory segment to the address space of the process */ shm->cmp_map = mmap(0, map_size, PROT_READ | PROT_WRITE, MAP_SHARED, shm->cmplog_g_shm_fd, 0); - if (shm->map == MAP_FAILED) { + if (shm->cmp_map == MAP_FAILED) { close(shm->cmplog_g_shm_fd); shm->cmplog_g_shm_fd = -1; @@ -248,22 +258,26 @@ u8 *afl_shm_init(sharedmem_t *shm, size_t map_size, } - shm_str = alloc_printf("%d", shm->shm_id); + if (!non_instrumented_mode) { - /* If somebody is asking us to fuzz instrumented binaries in non-instrumented - mode, we don't want them to detect instrumentation, since we won't be - sending fork server commands. This should be replaced with better - auto-detection later on, perhaps? */ + shm_str = alloc_printf("%d", shm->shm_id); - if (!non_instrumented_mode) { setenv(SHM_ENV_VAR, shm_str, 1); } + /* If somebody is asking us to fuzz instrumented binaries in + non-instrumented mode, we don't want them to detect instrumentation, + since we won't be sending fork server commands. This should be replaced + with better auto-detection later on, perhaps? */ - ck_free(shm_str); + setenv(SHM_ENV_VAR, shm_str, 1); - if (shm->cmplog_mode) { + ck_free(shm_str); + + } + + if (shm->cmplog_mode && !non_instrumented_mode) { shm_str = alloc_printf("%d", shm->cmplog_shm_id); - if (!non_instrumented_mode) { setenv(CMPLOG_SHM_ENV_VAR, shm_str, 1); } + setenv(CMPLOG_SHM_ENV_VAR, shm_str, 1); ck_free(shm_str); @@ -274,6 +288,7 @@ u8 *afl_shm_init(sharedmem_t *shm, size_t map_size, if (shm->map == (void *)-1 || !shm->map) { shmctl(shm->shm_id, IPC_RMID, NULL); // do not leak shmem + if (shm->cmplog_mode) { shmctl(shm->cmplog_shm_id, IPC_RMID, NULL); // do not leak shmem @@ -291,11 +306,8 @@ u8 *afl_shm_init(sharedmem_t *shm, size_t map_size, if (shm->cmp_map == (void *)-1 || !shm->cmp_map) { shmctl(shm->shm_id, IPC_RMID, NULL); // do not leak shmem - if (shm->cmplog_mode) { - shmctl(shm->cmplog_shm_id, IPC_RMID, NULL); // do not leak shmem - - } + shmctl(shm->cmplog_shm_id, IPC_RMID, NULL); // do not leak shmem PFATAL("shmat() failed"); diff --git a/src/afl-showmap.c b/src/afl-showmap.c index 71e975a1..7bf5a9c7 100644 --- a/src/afl-showmap.c +++ b/src/afl-showmap.c @@ -31,9 +31,6 @@ #define AFL_MAIN -#ifdef __ANDROID__ - #include "android-ashmem.h" -#endif #include "config.h" #include "types.h" #include "debug.h" @@ -42,6 +39,7 @@ #include "sharedmem.h" #include "forkserver.h" #include "common.h" +#include "hash.h" #include <stdio.h> #include <unistd.h> @@ -68,9 +66,11 @@ static char *stdin_file; /* stdin file */ static u8 *in_dir = NULL, /* input folder */ *out_file = NULL, *at_file = NULL; /* Substitution string for @@ */ -static u8 *in_data; /* Input data */ +static u8 *in_data, /* Input data */ + *coverage_map; /* Coverage map */ -static u32 total, highest; /* tuple content information */ +static u64 total; /* tuple content information */ +static u32 tcnt, highest; /* tuple content information */ static u32 in_len, /* Input data length */ arg_offset; /* Total number of execs */ @@ -83,7 +83,11 @@ static u8 quiet_mode, /* Hide non-essential messages? */ cmin_mode, /* Generate output in afl-cmin mode? */ binary_mode, /* Write output as a binary map */ keep_cores, /* Allow coredumps? */ - remove_shm = 1; /* remove shmem? */ + remove_shm = 1, /* remove shmem? */ + collect_coverage, /* collect coverage */ + have_coverage, /* have coverage? */ + no_classify, /* do not classify counts */ + debug; /* debug mode */ static volatile u8 stop_soon, /* Ctrl-C pressed? */ child_crashed; /* Child crashed? */ @@ -95,11 +99,24 @@ static sharedmem_t * shm_fuzz; /* Classify tuple counts. Instead of mapping to individual bits, as in afl-fuzz.c, we map to more user-friendly numbers between 1 and 8. */ +#define TIMES4(x) x, x, x, x +#define TIMES8(x) TIMES4(x), TIMES4(x) +#define TIMES16(x) TIMES8(x), TIMES8(x) +#define TIMES32(x) TIMES16(x), TIMES16(x) +#define TIMES64(x) TIMES32(x), TIMES32(x) +#define TIMES96(x) TIMES64(x), TIMES32(x) +#define TIMES128(x) TIMES64(x), TIMES64(x) static const u8 count_class_human[256] = { - [0] = 0, [1] = 1, [2] = 2, [3] = 3, - [4 ... 7] = 4, [8 ... 15] = 5, [16 ... 31] = 6, [32 ... 127] = 7, - [128 ... 255] = 8 + [0] = 0, + [1] = 1, + [2] = 2, + [3] = 3, + [4] = TIMES4(4), + [8] = TIMES8(5), + [16] = TIMES16(6), + [32] = TIMES96(7), + [128] = TIMES128(8) }; @@ -109,14 +126,22 @@ static const u8 count_class_binary[256] = { [1] = 1, [2] = 2, [3] = 4, - [4 ... 7] = 8, - [8 ... 15] = 16, - [16 ... 31] = 32, - [32 ... 127] = 64, - [128 ... 255] = 128 + [4] = TIMES4(8), + [8] = TIMES8(16), + [16] = TIMES16(32), + [32] = TIMES32(64), + [128] = TIMES64(128) }; +#undef TIMES128 +#undef TIMES96 +#undef TIMES64 +#undef TIMES32 +#undef TIMES16 +#undef TIMES8 +#undef TIMES4 + static void classify_counts(afl_forkserver_t *fsrv) { u8 * mem = fsrv->trace_bits; @@ -175,6 +200,25 @@ static void at_exit_handler(void) { } +/* Analyze results. */ + +static void analyze_results(afl_forkserver_t *fsrv) { + + u32 i; + for (i = 0; i < map_size; i++) { + + if (fsrv->trace_bits[i]) { + + total += fsrv->trace_bits[i]; + if (fsrv->trace_bits[i] > highest) highest = fsrv->trace_bits[i]; + if (!coverage_map[i]) { coverage_map[i] = 1; } + + } + + } + +} + /* Write results. */ static u32 write_results_to_file(afl_forkserver_t *fsrv, u8 *outfile) { @@ -187,6 +231,13 @@ static u32 write_results_to_file(afl_forkserver_t *fsrv, u8 *outfile) { if (!outfile) { FATAL("Output filename not set (Bug in AFL++?)"); } + if (cmin_mode && + (fsrv->last_run_timed_out || (!caa && child_crashed != cco))) { + + return ret; + + } + if (!strncmp(outfile, "/dev/", 5)) { fd = open(outfile, O_WRONLY); @@ -233,9 +284,6 @@ static u32 write_results_to_file(afl_forkserver_t *fsrv, u8 *outfile) { if (cmin_mode) { - if (fsrv->last_run_timed_out) { break; } - if (!caa && child_crashed != cco) { break; } - fprintf(f, "%u%u\n", fsrv->trace_bits[i], i); } else { @@ -256,11 +304,13 @@ static u32 write_results_to_file(afl_forkserver_t *fsrv, u8 *outfile) { /* Execute target application. */ -static void showmap_run_target_forkserver(afl_forkserver_t *fsrv, char **argv, - u8 *mem, u32 len) { +static void showmap_run_target_forkserver(afl_forkserver_t *fsrv, u8 *mem, + u32 len) { afl_fsrv_write_to_testcase(fsrv, mem, len); + if (!quiet_mode) { SAYF("-- Program output begins --\n" cRST); } + if (afl_fsrv_run_target(fsrv, fsrv->exec_tmout, &stop_soon) == FSRV_RUN_ERROR) { @@ -268,7 +318,50 @@ static void showmap_run_target_forkserver(afl_forkserver_t *fsrv, char **argv, } - classify_counts(fsrv); + if (fsrv->trace_bits[0] == 1) { + + fsrv->trace_bits[0] = 0; + have_coverage = 1; + + } else { + + have_coverage = 0; + + } + + if (!no_classify) { classify_counts(fsrv); } + + if (!quiet_mode) { SAYF(cRST "-- Program output ends --\n"); } + + if (!fsrv->last_run_timed_out && !stop_soon && + WIFSIGNALED(fsrv->child_status)) { + + child_crashed = 1; + + } else { + + child_crashed = 0; + + } + + if (!quiet_mode) { + + if (fsrv->last_run_timed_out) { + + SAYF(cLRD "\n+++ Program timed off +++\n" cRST); + + } else if (stop_soon) { + + SAYF(cLRD "\n+++ Program aborted by user +++\n" cRST); + + } else if (child_crashed) { + + SAYF(cLRD "\n+++ Program killed by signal %u +++\n" cRST, + WTERMSIG(fsrv->child_status)); + + } + + } if (stop_soon) { @@ -409,7 +502,18 @@ static void showmap_run_target(afl_forkserver_t *fsrv, char **argv) { } - classify_counts(fsrv); + if (fsrv->trace_bits[0] == 1) { + + fsrv->trace_bits[0] = 0; + have_coverage = 1; + + } else { + + have_coverage = 0; + + } + + if (!no_classify) { classify_counts(fsrv); } if (!quiet_mode) { SAYF(cRST "-- Program output ends --\n"); } @@ -444,6 +548,7 @@ static void showmap_run_target(afl_forkserver_t *fsrv, char **argv) { static void handle_stop_sig(int sig) { + (void)sig; stop_soon = 1; afl_fsrv_killall(); @@ -458,6 +563,7 @@ static void set_up_environment(afl_forkserver_t *fsrv) { "detect_leaks=0:" "allocator_may_return_null=1:" "symbolize=0:" + "detect_odr_violation=0:" "handle_segv=0:" "handle_sigbus=0:" "handle_abort=0:" @@ -493,38 +599,7 @@ static void set_up_environment(afl_forkserver_t *fsrv) { if (fsrv->qemu_mode) { - u8 *qemu_preload = getenv("QEMU_SET_ENV"); - u8 *afl_preload = getenv("AFL_PRELOAD"); - u8 *buf; - - s32 i, afl_preload_size = strlen(afl_preload); - for (i = 0; i < afl_preload_size; ++i) { - - if (afl_preload[i] == ',') { - - PFATAL( - "Comma (',') is not allowed in AFL_PRELOAD when -Q is " - "specified!"); - - } - - } - - if (qemu_preload) { - - buf = alloc_printf("%s,LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - qemu_preload, afl_preload, afl_preload); - - } else { - - buf = alloc_printf("LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - afl_preload, afl_preload); - - } - - setenv("QEMU_SET_ENV", buf, 1); - - ck_free(buf); + /* afl-qemu-trace takes care of converting AFL_PRELOAD. */ } else { @@ -580,19 +655,25 @@ static void usage(u8 *argv0) { "Execution control settings:\n" " -t msec - timeout for each run (none)\n" - " -m megs - memory limit for child process (%d MB)\n" + " -m megs - memory limit for child process (%u MB)\n" " -Q - use binary-only instrumentation (QEMU mode)\n" " -U - use Unicorn-based instrumentation (Unicorn mode)\n" " -W - use qemu-based instrumentation with Wine (Wine mode)\n" " (Not necessary, here for consistency with other afl-* " "tools)\n\n" "Other settings:\n" - " -i dir - process all files in this directory, -o must be a " + " -i dir - process all files in this directory, must be combined " + "with -o.\n" + " With -C, -o is a file, without -C it must be a " "directory\n" " and each bitmap will be written there individually.\n" + " -C - collect coverage, writes all edges to -o and gives a " + "summary\n" + " Must be combined with -i.\n" " -q - sink program's output and don't show messages\n" " -e - show edge coverage only, ignore hit counts\n" " -r - show real tuple values instead of AFL filter values\n" + " -s - do not classify the map\n" " -c - allow core dumps\n\n" "This tool displays raw tuple data captured by AFL instrumentation.\n" @@ -603,10 +684,15 @@ static void usage(u8 *argv0) { "AFL_CMIN_CRASHES_ONLY: (cmin_mode) only write tuples for crashing " "inputs\n" "AFL_CMIN_ALLOW_ANY: (cmin_mode) write tuples for crashing inputs also\n" + "AFL_CRASH_EXITCODE: optional child exit code to be interpreted as " + "crash\n" "AFL_DEBUG: enable extra developer output\n" + "AFL_FORKSRV_INIT_TMOUT: time spent waiting for forkserver during " + "startup (in milliseconds)\n" + "AFL_KILL_SIGNAL: Signal ID delivered to child processes on timeout, " + "etc. (default: SIGKILL)\n" "AFL_MAP_SIZE: the shared memory size for that target. must be >= the " - "size\n" - " the target was compiled for\n" + "size the target was compiled for\n" "AFL_PRELOAD: LD_PRELOAD / DYLD_INSERT_LIBRARIES settings for target\n" "AFL_QUIET: do not print extra informational output\n", argv0, MEM_LIMIT, doc_path); @@ -623,12 +709,12 @@ int main(int argc, char **argv_orig, char **envp) { s32 opt, i; u8 mem_limit_given = 0, timeout_given = 0, unicorn_mode = 0, use_wine = 0; - u32 tcnt = 0; char **use_argv; char **argv = argv_cpy_dup(argc, argv_orig); afl_forkserver_t fsrv_var = {0}; + if (getenv("AFL_DEBUG")) { debug = 1; } fsrv = &fsrv_var; afl_fsrv_init(fsrv); map_size = get_map_size(); @@ -638,10 +724,19 @@ int main(int argc, char **argv_orig, char **envp) { if (getenv("AFL_QUIET") != NULL) { be_quiet = 1; } - while ((opt = getopt(argc, argv, "+i:o:f:m:t:A:eqZQUWbcrh")) > 0) { + while ((opt = getopt(argc, argv, "+i:o:f:m:t:A:eqCZQUWbcrsh")) > 0) { switch (opt) { + case 's': + no_classify = 1; + break; + + case 'C': + collect_coverage = 1; + quiet_mode = 1; + break; + case 'i': if (in_dir) { FATAL("Multiple -i options not supported"); } in_dir = optarg; @@ -709,8 +804,10 @@ int main(int argc, char **argv_orig, char **envp) { case 'f': // only in here to avoid a compiler warning for use_stdin - fsrv->use_stdin = 0; FATAL("Option -f is not supported in afl-showmap"); + // currently not reached: + fsrv->use_stdin = 0; + fsrv->out_file = strdup(optarg); break; @@ -744,7 +841,6 @@ int main(int argc, char **argv_orig, char **envp) { case 'q': - if (quiet_mode) { FATAL("Multiple -q options not supported"); } quiet_mode = 1; break; @@ -819,6 +915,13 @@ int main(int argc, char **argv_orig, char **envp) { if (optind == argc || !out_file) { usage(argv[0]); } + if (in_dir) { + + if (!out_file && !collect_coverage) + FATAL("for -i you need to specify either -C and/or -o"); + + } + if (fsrv->qemu_mode && !mem_limit_given) { fsrv->mem_limit = MEM_LIMIT_QEMU; } if (unicorn_mode && !mem_limit_given) { fsrv->mem_limit = MEM_LIMIT_UNICORN; } @@ -826,7 +929,7 @@ int main(int argc, char **argv_orig, char **envp) { if (getenv("AFL_DEBUG")) { - SAYF(cMGN "[D]" cRST); + DEBUGF(""); for (i = 0; i < argc; i++) SAYF(" %s", argv[i]); SAYF("\n"); @@ -835,14 +938,16 @@ int main(int argc, char **argv_orig, char **envp) { // if (afl->shmem_testcase_mode) { setup_testcase_shmem(afl); } + setenv("AFL_NO_AUTODICT", "1", 1); + /* initialize cmplog_mode */ shm.cmplog_mode = 0; - fsrv->trace_bits = afl_shm_init(&shm, map_size, 0); setup_signal_handlers(); set_up_environment(fsrv); fsrv->target_path = find_binary(argv[optind]); + fsrv->trace_bits = afl_shm_init(&shm, map_size, 0); if (!quiet_mode) { @@ -853,7 +958,6 @@ int main(int argc, char **argv_orig, char **envp) { if (in_dir) { - if (at_file) { PFATAL("Options -A and -i are mutually exclusive"); } detect_file_args(argv + optind, "", &fsrv->use_stdin); } else { @@ -895,6 +999,7 @@ int main(int argc, char **argv_orig, char **envp) { /* initialize cmplog_mode */ shm_fuzz->cmplog_mode = 0; u8 *map = afl_shm_init(shm_fuzz, MAX_FILE + sizeof(u32), 1); + shm_fuzz->shmemfuzz_mode = 1; if (!map) { FATAL("BUG: Zero return from afl_shm_init."); } #ifdef USEMMAP setenv(SHM_FUZZ_ENV_VAR, shm_fuzz->g_shm_file_path, 1); @@ -907,13 +1012,50 @@ int main(int argc, char **argv_orig, char **envp) { fsrv->shmem_fuzz_len = (u32 *)map; fsrv->shmem_fuzz = map + sizeof(u32); + if (!fsrv->qemu_mode && !unicorn_mode) { + + u32 save_be_quiet = be_quiet; + be_quiet = !debug; + fsrv->map_size = 4194304; // dummy temporary value + u32 new_map_size = + afl_fsrv_get_mapsize(fsrv, use_argv, &stop_soon, + (get_afl_env("AFL_DEBUG_CHILD") || + get_afl_env("AFL_DEBUG_CHILD_OUTPUT")) + ? 1 + : 0); + be_quiet = save_be_quiet; + + if (new_map_size) { + + // only reinitialize when it makes sense + if (map_size < new_map_size || + (new_map_size > map_size && new_map_size - map_size > MAP_SIZE)) { + + if (!be_quiet) + ACTF("Aquired new map size for target: %u bytes\n", new_map_size); + + afl_shm_deinit(&shm); + afl_fsrv_kill(fsrv); + fsrv->map_size = new_map_size; + fsrv->trace_bits = afl_shm_init(&shm, new_map_size, 0); + + } + + map_size = new_map_size; + + } + + fsrv->map_size = map_size; + + } + if (in_dir) { - DIR * dir_in, *dir_out; + DIR * dir_in, *dir_out = NULL; struct dirent *dir_ent; - int done = 0; - u8 infile[PATH_MAX], outfile[PATH_MAX]; - u8 wait_for_gdb = 0; + // int done = 0; + u8 infile[PATH_MAX], outfile[PATH_MAX]; + u8 wait_for_gdb = 0; #if !defined(DT_REG) struct stat statbuf; #endif @@ -923,20 +1065,43 @@ int main(int argc, char **argv_orig, char **envp) { fsrv->dev_null_fd = open("/dev/null", O_RDWR); if (fsrv->dev_null_fd < 0) { PFATAL("Unable to open /dev/null"); } + // if a queue subdirectory exists switch to that + u8 *dn = alloc_printf("%s/queue", in_dir); + if ((dir_in = opendir(dn)) != NULL) { + + closedir(dir_in); + in_dir = dn; + + } else + + ck_free(dn); + if (!be_quiet) ACTF("Reading from directory '%s'...", in_dir); + if (!(dir_in = opendir(in_dir))) { PFATAL("cannot open directory %s", in_dir); } - if (!(dir_out = opendir(out_file))) { + if (!collect_coverage) { + + if (!(dir_out = opendir(out_file))) { - if (mkdir(out_file, 0700)) { + if (mkdir(out_file, 0700)) { - PFATAL("cannot create output directory %s", out_file); + PFATAL("cannot create output directory %s", out_file); + + } } + } else { + + if ((coverage_map = (u8 *)malloc(map_size)) == NULL) + FATAL("coult not grab memory"); + edges_only = 0; + raw_instr_output = 1; + } u8 *use_dir = "."; @@ -948,10 +1113,12 @@ int main(int argc, char **argv_orig, char **envp) { } - stdin_file = - alloc_printf("%s/.afl-showmap-temp-%u", use_dir, (u32)getpid()); + stdin_file = at_file ? strdup(at_file) + : (char *)alloc_printf("%s/.afl-showmap-temp-%u", + use_dir, (u32)getpid()); unlink(stdin_file); atexit(at_exit_handler); + fsrv->out_file = stdin_file; fsrv->out_fd = open(stdin_file, O_RDWR | O_CREAT | O_EXCL, 0600); if (fsrv->out_fd < 0) { PFATAL("Unable to create '%s'", out_file); } @@ -963,11 +1130,11 @@ int main(int argc, char **argv_orig, char **envp) { if (get_afl_env("AFL_DEBUG")) { - int i = optind; - SAYF(cMGN "[D]" cRST " %s:", fsrv->target_path); - while (argv[i] != NULL) { + int j = optind; + DEBUGF("%s:", fsrv->target_path); + while (argv[j] != NULL) { - SAYF(" \"%s\"", argv[i++]); + SAYF(" \"%s\"", argv[j++]); } @@ -975,13 +1142,51 @@ int main(int argc, char **argv_orig, char **envp) { } + if (getenv("AFL_FORKSRV_INIT_TMOUT")) { + + s32 forksrv_init_tmout = atoi(getenv("AFL_FORKSRV_INIT_TMOUT")); + if (forksrv_init_tmout < 1) { + + FATAL("Bad value specified for AFL_FORKSRV_INIT_TMOUT"); + + } + + fsrv->init_tmout = (u32)forksrv_init_tmout; + + } + + fsrv->kill_signal = + parse_afl_kill_signal_env(getenv("AFL_KILL_SIGNAL"), SIGKILL); + + if (getenv("AFL_CRASH_EXITCODE")) { + + long exitcode = strtol(getenv("AFL_CRASH_EXITCODE"), NULL, 10); + if ((!exitcode && (errno == EINVAL || errno == ERANGE)) || + exitcode < -127 || exitcode > 128) { + + FATAL("Invalid crash exitcode, expected -127 to 128, but got %s", + getenv("AFL_CRASH_EXITCODE")); + + } + + fsrv->uses_crash_exitcode = true; + // WEXITSTATUS is 8 bit unsigned + fsrv->crash_exitcode = (u8)exitcode; + + } + afl_fsrv_start(fsrv, use_argv, &stop_soon, - get_afl_env("AFL_DEBUG_CHILD_OUTPUT") ? 1 : 0); + (get_afl_env("AFL_DEBUG_CHILD") || + get_afl_env("AFL_DEBUG_CHILD_OUTPUT")) + ? 1 + : 0); + + map_size = fsrv->map_size; if (fsrv->support_shmem_fuzz && !fsrv->use_shmem_fuzz) shm_fuzz = deinit_shmem(fsrv, shm_fuzz); - while (done == 0 && (dir_ent = readdir(dir_in))) { + while ((dir_ent = readdir(dir_in))) { if (dir_ent->d_name[0] == '.') { @@ -1004,7 +1209,8 @@ int main(int argc, char **argv_orig, char **envp) { if (-1 == stat(infile, &statbuf) || !S_ISREG(statbuf.st_mode)) continue; #endif - snprintf(outfile, sizeof(outfile), "%s/%s", out_file, dir_ent->d_name); + if (!collect_coverage) + snprintf(outfile, sizeof(outfile), "%s/%s", out_file, dir_ent->d_name); if (read_file(infile)) { @@ -1016,9 +1222,12 @@ int main(int argc, char **argv_orig, char **envp) { } - showmap_run_target_forkserver(fsrv, use_argv, in_data, in_len); + showmap_run_target_forkserver(fsrv, in_data, in_len); ck_free(in_data); - tcnt = write_results_to_file(fsrv, outfile); + if (collect_coverage) + analyze_results(fsrv); + else + tcnt = write_results_to_file(fsrv, outfile); } @@ -1029,6 +1238,13 @@ int main(int argc, char **argv_orig, char **envp) { closedir(dir_in); if (dir_out) { closedir(dir_out); } + if (collect_coverage) { + + memcpy(fsrv->trace_bits, coverage_map, map_size); + tcnt = write_results_to_file(fsrv, out_file); + + } + } else { if (fsrv->support_shmem_fuzz && !fsrv->use_shmem_fuzz) @@ -1036,14 +1252,26 @@ int main(int argc, char **argv_orig, char **envp) { showmap_run_target(fsrv, use_argv); tcnt = write_results_to_file(fsrv, out_file); + if (!quiet_mode) { + + OKF("Hash of coverage map: %llx", + hash64(fsrv->trace_bits, fsrv->map_size, HASH_CONST)); + + } } - if (!quiet_mode) { + if (!quiet_mode || collect_coverage) { - if (!tcnt) { FATAL("No instrumentation detected" cRST); } - OKF("Captured %u tuples (highest value %u, total values %u) in '%s'." cRST, + if (!tcnt && !have_coverage) { FATAL("No instrumentation detected" cRST); } + OKF("Captured %u tuples (highest value %u, total values %llu) in " + "'%s'." cRST, tcnt, highest, total, out_file); + if (collect_coverage) + OKF("A coverage of %u edges were achieved out of %u existing (%.02f%%) " + "with %llu input files.", + tcnt, map_size, ((float)tcnt * 100) / (float)map_size, + fsrv->total_execs); } @@ -1059,13 +1287,24 @@ int main(int argc, char **argv_orig, char **envp) { afl_shm_deinit(&shm); if (fsrv->use_shmem_fuzz) shm_fuzz = deinit_shmem(fsrv, shm_fuzz); - u32 ret = child_crashed * 2 + fsrv->last_run_timed_out; + u32 ret; + + if (cmin_mode && !!getenv("AFL_CMIN_CRASHES_ONLY")) { + + ret = fsrv->last_run_timed_out; + + } else { + + ret = child_crashed * 2 + fsrv->last_run_timed_out; + + } if (fsrv->target_path) { ck_free(fsrv->target_path); } afl_fsrv_deinit(fsrv); if (stdin_file) { ck_free(stdin_file); } + if (collect_coverage) { free(coverage_map); } argv_cpy_free(argv); if (fsrv->qemu_mode) { free(use_argv[2]); } diff --git a/src/afl-tmin.c b/src/afl-tmin.c index 68fcdd14..7ef8b9bf 100644 --- a/src/afl-tmin.c +++ b/src/afl-tmin.c @@ -29,10 +29,6 @@ #define AFL_MAIN -#ifdef __ANDROID__ - #include "android-ashmem.h" -#endif - #include "config.h" #include "types.h" #include "debug.h" @@ -51,6 +47,7 @@ #include <signal.h> #include <dirent.h> #include <fcntl.h> +#include <limits.h> #include <sys/wait.h> #include <sys/time.h> @@ -82,7 +79,8 @@ static u8 crash_mode, /* Crash-centric mode? */ edges_only, /* Ignore hit counts? */ exact_mode, /* Require path match for crashes? */ remove_out_file, /* remove out_file on exit? */ - remove_shm = 1; /* remove shmem on exit? */ + remove_shm = 1, /* remove shmem on exit? */ + debug; /* debug mode */ static volatile u8 stop_soon; /* Ctrl-C pressed? */ @@ -97,20 +95,31 @@ static sharedmem_t * shm_fuzz; /* Classify tuple counts. This is a slow & naive version, but good enough here. */ +#define TIMES4(x) x, x, x, x +#define TIMES8(x) TIMES4(x), TIMES4(x) +#define TIMES16(x) TIMES8(x), TIMES8(x) +#define TIMES32(x) TIMES16(x), TIMES16(x) +#define TIMES64(x) TIMES32(x), TIMES32(x) static const u8 count_class_lookup[256] = { [0] = 0, [1] = 1, [2] = 2, [3] = 4, - [4 ... 7] = 8, - [8 ... 15] = 16, - [16 ... 31] = 32, - [32 ... 127] = 64, - [128 ... 255] = 128 + [4] = TIMES4(8), + [8] = TIMES8(16), + [16] = TIMES16(32), + [32] = TIMES32(64), + [128] = TIMES64(128) }; +#undef TIMES64 +#undef TIMES32 +#undef TIMES16 +#undef TIMES8 +#undef TIMES4 + static sharedmem_t *deinit_shmem(afl_forkserver_t *fsrv, sharedmem_t * shm_fuzz) { @@ -250,7 +259,7 @@ static s32 write_to_file(u8 *path, u8 *mem, u32 len) { /* Execute target application. Returns 0 if the changes are a dud, or 1 if they should be kept. */ -static u8 tmin_run_target(afl_forkserver_t *fsrv, char **argv, u8 *mem, u32 len, +static u8 tmin_run_target(afl_forkserver_t *fsrv, u8 *mem, u32 len, u8 first_run) { afl_fsrv_write_to_testcase(fsrv, mem, len); @@ -342,7 +351,7 @@ static u8 tmin_run_target(afl_forkserver_t *fsrv, char **argv, u8 *mem, u32 len, /* Actually minimize! */ -static void minimize(afl_forkserver_t *fsrv, char **argv) { +static void minimize(afl_forkserver_t *fsrv) { static u32 alpha_map[256]; @@ -380,7 +389,7 @@ static void minimize(afl_forkserver_t *fsrv, char **argv) { memset(tmp_buf + set_pos, '0', use_len); u8 res; - res = tmin_run_target(fsrv, argv, tmp_buf, in_len, 0); + res = tmin_run_target(fsrv, tmp_buf, in_len, 0); if (res) { @@ -453,7 +462,7 @@ next_del_blksize: /* Tail */ memcpy(tmp_buf + del_pos, in_data + del_pos + del_len, tail_len); - res = tmin_run_target(fsrv, argv, tmp_buf, del_pos + tail_len, 0); + res = tmin_run_target(fsrv, tmp_buf, del_pos + tail_len, 0); if (res) { @@ -524,7 +533,7 @@ next_del_blksize: } - res = tmin_run_target(fsrv, argv, tmp_buf, in_len, 0); + res = tmin_run_target(fsrv, tmp_buf, in_len, 0); if (res) { @@ -560,7 +569,7 @@ next_del_blksize: if (orig == '0') { continue; } tmp_buf[i] = '0'; - res = tmin_run_target(fsrv, argv, tmp_buf, in_len, 0); + res = tmin_run_target(fsrv, tmp_buf, in_len, 0); if (res) { @@ -623,6 +632,7 @@ finalize_all: static void handle_stop_sig(int sig) { + (void)sig; stop_soon = 1; afl_fsrv_killall(); @@ -655,6 +665,7 @@ static void set_up_environment(afl_forkserver_t *fsrv) { unlink(out_file); + fsrv->out_file = out_file; fsrv->out_fd = open(out_file, O_RDWR | O_CREAT | O_EXCL, 0600); if (fsrv->out_fd < 0) { PFATAL("Unable to create '%s'", out_file); } @@ -671,12 +682,15 @@ static void set_up_environment(afl_forkserver_t *fsrv) { } - if (!strstr(x, "symbolize=0")) { +#ifndef ASAN_BUILD + if (!getenv("AFL_DEBUG") && !strstr(x, "symbolize=0")) { FATAL("Custom ASAN_OPTIONS set without symbolize=0 - please fix!"); } +#endif + } x = get_afl_env("MSAN_OPTIONS"); @@ -703,6 +717,7 @@ static void set_up_environment(afl_forkserver_t *fsrv) { "detect_leaks=0:" "allocator_may_return_null=1:" "symbolize=0:" + "detect_odr_violation=0:" "handle_segv=0:" "handle_sigbus=0:" "handle_abort=0:" @@ -738,38 +753,7 @@ static void set_up_environment(afl_forkserver_t *fsrv) { if (fsrv->qemu_mode) { - u8 *qemu_preload = getenv("QEMU_SET_ENV"); - u8 *afl_preload = getenv("AFL_PRELOAD"); - u8 *buf; - - s32 i, afl_preload_size = strlen(afl_preload); - for (i = 0; i < afl_preload_size; ++i) { - - if (afl_preload[i] == ',') { - - PFATAL( - "Comma (',') is not allowed in AFL_PRELOAD when -Q is " - "specified!"); - - } - - } - - if (qemu_preload) { - - buf = alloc_printf("%s,LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - qemu_preload, afl_preload, afl_preload); - - } else { - - buf = alloc_printf("LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - afl_preload, afl_preload); - - } - - setenv("QEMU_SET_ENV", buf, 1); - - ck_free(buf); + /* afl-qemu-trace takes care of converting AFL_PRELOAD. */ } else { @@ -818,8 +802,8 @@ static void usage(u8 *argv0) { "Execution control settings:\n" " -f file - input file read by the tested program (stdin)\n" - " -t msec - timeout for each run (%d ms)\n" - " -m megs - memory limit for child process (%d MB)\n" + " -t msec - timeout for each run (%u ms)\n" + " -m megs - memory limit for child process (%u MB)\n" " -Q - use binary-only instrumentation (QEMU mode)\n" " -U - use unicorn-based instrumentation (Unicorn mode)\n" " -W - use qemu-based instrumentation with Wine (Wine " @@ -836,16 +820,18 @@ static void usage(u8 *argv0) { "For additional tips, please consult %s/README.md.\n\n" "Environment variables used:\n" - "TMPDIR: directory to use for temporary input files\n" - "ASAN_OPTIONS: custom settings for ASAN\n" - " (must contain abort_on_error=1 and symbolize=0)\n" - "MSAN_OPTIONS: custom settings for MSAN\n" - " (must contain exitcode="STRINGIFY(MSAN_ERROR)" and symbolize=0)\n" + "AFL_CRASH_EXITCODE: optional child exit code to be interpreted as crash\n" + "AFL_FORKSRV_INIT_TMOUT: time spent waiting for forkserver during startup (in milliseconds)\n" + "AFL_KILL_SIGNAL: Signal ID delivered to child processes on timeout, etc. (default: SIGKILL)\n" "AFL_MAP_SIZE: the shared memory size for that target. must be >= the size\n" " the target was compiled for\n" "AFL_PRELOAD: LD_PRELOAD / DYLD_INSERT_LIBRARIES settings for target\n" "AFL_TMIN_EXACT: require execution paths to match for crashing inputs\n" - + "ASAN_OPTIONS: custom settings for ASAN\n" + " (must contain abort_on_error=1 and symbolize=0)\n" + "MSAN_OPTIONS: custom settings for MSAN\n" + " (must contain exitcode="STRINGIFY(MSAN_ERROR)" and symbolize=0)\n" + "TMPDIR: directory to use for temporary input files\n" , argv0, EXEC_TIMEOUT, MEM_LIMIT, doc_path); exit(1); @@ -863,6 +849,7 @@ int main(int argc, char **argv_orig, char **envp) { char **argv = argv_cpy_dup(argc, argv_orig); afl_forkserver_t fsrv_var = {0}; + if (getenv("AFL_DEBUG")) { debug = 1; } fsrv = &fsrv_var; afl_fsrv_init(fsrv); map_size = get_map_size(); @@ -1059,10 +1046,10 @@ int main(int argc, char **argv_orig, char **envp) { if (optind == argc || !in_file || !output_file) { usage(argv[0]); } check_environment_vars(envp); + setenv("AFL_NO_AUTODICT", "1", 1); /* initialize cmplog_mode */ shm.cmplog_mode = 0; - fsrv->trace_bits = afl_shm_init(&shm, map_size, 0); atexit(at_exit_handler); setup_signal_handlers(); @@ -1070,6 +1057,7 @@ int main(int argc, char **argv_orig, char **envp) { set_up_environment(fsrv); fsrv->target_path = find_binary(argv[optind]); + fsrv->trace_bits = afl_shm_init(&shm, map_size, 0); detect_file_args(argv + optind, out_file, &fsrv->use_stdin); if (fsrv->qemu_mode) { @@ -1103,11 +1091,45 @@ int main(int argc, char **argv_orig, char **envp) { SAYF("\n"); + if (getenv("AFL_FORKSRV_INIT_TMOUT")) { + + s32 forksrv_init_tmout = atoi(getenv("AFL_FORKSRV_INIT_TMOUT")); + if (forksrv_init_tmout < 1) { + + FATAL("Bad value specified for AFL_FORKSRV_INIT_TMOUT"); + + } + + fsrv->init_tmout = (u32)forksrv_init_tmout; + + } + + fsrv->kill_signal = + parse_afl_kill_signal_env(getenv("AFL_KILL_SIGNAL"), SIGKILL); + + if (getenv("AFL_CRASH_EXITCODE")) { + + long exitcode = strtol(getenv("AFL_CRASH_EXITCODE"), NULL, 10); + if ((!exitcode && (errno == EINVAL || errno == ERANGE)) || + exitcode < -127 || exitcode > 128) { + + FATAL("Invalid crash exitcode, expected -127 to 128, but got %s", + getenv("AFL_CRASH_EXITCODE")); + + } + + fsrv->uses_crash_exitcode = true; + // WEXITSTATUS is 8 bit unsigned + fsrv->crash_exitcode = (u8)exitcode; + + } + shm_fuzz = ck_alloc(sizeof(sharedmem_t)); /* initialize cmplog_mode */ shm_fuzz->cmplog_mode = 0; u8 *map = afl_shm_init(shm_fuzz, MAX_FILE + sizeof(u32), 1); + shm_fuzz->shmemfuzz_mode = 1; if (!map) { FATAL("BUG: Zero return from afl_shm_init."); } #ifdef USEMMAP setenv(SHM_FUZZ_ENV_VAR, shm_fuzz->g_shm_file_path, 1); @@ -1122,8 +1144,51 @@ int main(int argc, char **argv_orig, char **envp) { read_initial_file(); - afl_fsrv_start(fsrv, use_argv, &stop_soon, - get_afl_env("AFL_DEBUG_CHILD_OUTPUT") ? 1 : 0); + if (!fsrv->qemu_mode && !unicorn_mode) { + + fsrv->map_size = 4194304; // dummy temporary value + u32 new_map_size = + afl_fsrv_get_mapsize(fsrv, use_argv, &stop_soon, + (get_afl_env("AFL_DEBUG_CHILD") || + get_afl_env("AFL_DEBUG_CHILD_OUTPUT")) + ? 1 + : 0); + + if (new_map_size) { + + if (map_size < new_map_size || + (new_map_size > map_size && new_map_size - map_size > MAP_SIZE)) { + + if (!be_quiet) + ACTF("Aquired new map size for target: %u bytes\n", new_map_size); + + afl_shm_deinit(&shm); + afl_fsrv_kill(fsrv); + fsrv->map_size = new_map_size; + fsrv->trace_bits = afl_shm_init(&shm, new_map_size, 0); + afl_fsrv_start(fsrv, use_argv, &stop_soon, + (get_afl_env("AFL_DEBUG_CHILD") || + get_afl_env("AFL_DEBUG_CHILD_OUTPUT")) + ? 1 + : 0); + + } + + map_size = new_map_size; + + } + + fsrv->map_size = map_size; + + } else { + + afl_fsrv_start(fsrv, use_argv, &stop_soon, + (get_afl_env("AFL_DEBUG_CHILD") || + get_afl_env("AFL_DEBUG_CHILD_OUTPUT")) + ? 1 + : 0); + + } if (fsrv->support_shmem_fuzz && !fsrv->use_shmem_fuzz) shm_fuzz = deinit_shmem(fsrv, shm_fuzz); @@ -1131,7 +1196,7 @@ int main(int argc, char **argv_orig, char **envp) { ACTF("Performing dry run (mem limit = %llu MB, timeout = %u ms%s)...", fsrv->mem_limit, fsrv->exec_tmout, edges_only ? ", edges only" : ""); - tmin_run_target(fsrv, use_argv, in_data, in_len, 1); + tmin_run_target(fsrv, in_data, in_len, 1); if (hang_mode && !fsrv->last_run_timed_out) { @@ -1169,7 +1234,7 @@ int main(int argc, char **argv_orig, char **envp) { } - minimize(fsrv, use_argv); + minimize(fsrv); ACTF("Writing output to '%s'...", output_file); diff --git a/test-instr.c b/test-instr.c index 84ac0036..00799103 100644 --- a/test-instr.c +++ b/test-instr.c @@ -32,7 +32,8 @@ int main(int argc, char **argv) { } else { - if (argc >= 3 && strcmp(argv[1], "-f") == 0) + if (argc >= 3 && strcmp(argv[1], "-f") == 0) { + if ((fd = open(argv[2], O_RDONLY)) < 0) { fprintf(stderr, "Error: unable to open %s\n", argv[2]); @@ -40,6 +41,8 @@ int main(int argc, char **argv) { } + } + if (read(fd, buf, sizeof(buf)) < 1) { printf("Hum?\n"); diff --git a/test/checkcommit.sh b/test/checkcommit.sh index 27d08d36..35eae540 100755 --- a/test/checkcommit.sh +++ b/test/checkcommit.sh @@ -34,7 +34,7 @@ time nice -n -20 ./afl-fuzz -i "$INDIR" -s 123 -o out-profile -- $CMDLINE 2>> $C STOP=`date +%s` echo $STOP >> $C.out echo RUNTIME: `expr $STOP - $START` >> $C.out -cat out-profile/fuzzer_stats >> $C.out +cat out-profile/default/fuzzer_stats >> $C.out gprof ./afl-fuzz gmon.out >> $C.out make clean >/dev/null 2>&1 diff --git a/test/test-all.sh b/test/test-all.sh new file mode 100755 index 00000000..8df4bef9 --- /dev/null +++ b/test/test-all.sh @@ -0,0 +1,23 @@ +#!/bin/sh + +. ./test-pre.sh + +. ./test-basic.sh + +. ./test-llvm.sh + +. ./test-llvm-lto.sh + +. ./test-gcc-plugin.sh + +. ./test-libextensions.sh + +. ./test-qemu-mode.sh + +. ./test-unicorn-mode.sh + +. ./test-custom-mutators.sh + +. ./test-unittests.sh + +. ./test-post.sh diff --git a/test/test-basic.sh b/test/test-basic.sh new file mode 100755 index 00000000..b4bb9df2 --- /dev/null +++ b/test/test-basic.sh @@ -0,0 +1,269 @@ +#!/bin/sh + +. ./test-pre.sh + + +AFL_GCC=afl-gcc +$ECHO "$BLUE[*] Testing: ${AFL_GCC}, afl-showmap, afl-fuzz, afl-cmin and afl-tmin" +test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" -o "$SYS" = "i386" && { + test -e ../${AFL_GCC} -a -e ../afl-showmap -a -e ../afl-fuzz && { + ../${AFL_GCC} -o test-instr.plain -O0 ../test-instr.c > /dev/null 2>&1 + AFL_HARDEN=1 ../${AFL_GCC} -o test-compcov.harden test-compcov.c > /dev/null 2>&1 + test -e test-instr.plain && { + $ECHO "$GREEN[+] ${AFL_GCC} compilation succeeded" + echo 0 | AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.0 -r -- ./test-instr.plain > /dev/null 2>&1 + AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.1 -r -- ./test-instr.plain < /dev/null > /dev/null 2>&1 + test -e test-instr.plain.0 -a -e test-instr.plain.1 && { + diff test-instr.plain.0 test-instr.plain.1 > /dev/null 2>&1 && { + $ECHO "$RED[!] ${AFL_GCC} instrumentation should be different on different input but is not" + CODE=1 + } || { + $ECHO "$GREEN[+] ${AFL_GCC} instrumentation present and working correctly" + } + } || { + $ECHO "$RED[!] ${AFL_GCC} instrumentation failed" + CODE=1 + } + rm -f test-instr.plain.0 test-instr.plain.1 + SKIP= + TUPLES=`echo 1|AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.plain 2>&1 | grep Captur | awk '{print$3}'` + test "$TUPLES" -gt 1 -a "$TUPLES" -lt 12 && { + $ECHO "$GREEN[+] ${AFL_GCC} run reported $TUPLES instrumented locations which is fine" + } || { + $ECHO "$RED[!] ${AFL_GCC} instrumentation produces weird numbers: $TUPLES" + CODE=1 + } + test "$TUPLES" -lt 3 && SKIP=1 + true # this is needed because of the test above + } || { + $ECHO "$RED[!] ${AFL_GCC} failed" + echo CUT------------------------------------------------------------------CUT + uname -a + ../${AFL_GCC} -o test-instr.plain -O0 ../test-instr.c + echo CUT------------------------------------------------------------------CUT + CODE=1 + } + test -e test-compcov.harden && { + grep -Eq$GREPAOPTION 'stack_chk_fail|fstack-protector-all|fortified' test-compcov.harden > /dev/null 2>&1 && { + $ECHO "$GREEN[+] ${AFL_GCC} hardened mode succeeded and is working" + } || { + $ECHO "$RED[!] ${AFL_GCC} hardened mode is not hardened" + CODE=1 + } + rm -f test-compcov.harden + } || { + $ECHO "$RED[!] ${AFL_GCC} hardened mode compilation failed" + CODE=1 + } + # now we want to be sure that afl-fuzz is working + # make sure core_pattern is set to core on linux + (test "$(uname -s)" = "Linux" && test "$(sysctl kernel.core_pattern)" != "kernel.core_pattern = core" && { + $ECHO "$YELLOW[-] we should not run afl-fuzz with enabled core dumps. Run 'sudo sh afl-system-config'.$RESET" + true + }) || + # make sure crash reporter is disabled on Mac OS X + (test "$(uname -s)" = "Darwin" && test $(launchctl list 2>/dev/null | grep -q '\.ReportCrash$') && { + $ECHO "$RED[!] we cannot run afl-fuzz with enabled crash reporter. Run 'sudo sh afl-system-config'.$RESET" + true + }) || { + mkdir -p in + echo 0 > in/in + test -z "$SKIP" && { + $ECHO "$GREY[*] running afl-fuzz for ${AFL_GCC}, this will take approx 10 seconds" + { + ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -D -- ./test-instr.plain >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000002* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with ${AFL_GCC}" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with ${AFL_GCC}" + CODE=1 + } + } + echo 000000000000000000000000 > in/in2 + echo 111 > in/in3 + mkdir -p in2 + ../afl-cmin -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null 2>&1 # why is afl-forkserver writing to stderr? + CNT=`ls in2/* 2>/dev/null | wc -l` + case "$CNT" in + *2) $ECHO "$GREEN[+] afl-cmin correctly minimized the number of testcases" ;; + *) $ECHO "$RED[!] afl-cmin did not correctly minimize the number of testcases ($CNT)" + CODE=1 + ;; + esac + rm -f in2/in* + export AFL_QUIET=1 + if command -v bash >/dev/null ; then { + ../afl-cmin.bash -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null + CNT=`ls in2/* 2>/dev/null | wc -l` + case "$CNT" in + *2) $ECHO "$GREEN[+] afl-cmin.bash correctly minimized the number of testcases" ;; + *) $ECHO "$RED[!] afl-cmin.bash did not correctly minimize the number of testcases ($CNT)" + CODE=1 + ;; + esac + } else { + $ECHO "$GREY[*] no bash available, cannot test afl-cmin.bash" + } + fi + ../afl-tmin -m ${MEM_LIMIT} -i in/in2 -o in2/in2 -- ./test-instr.plain > /dev/null 2>&1 + SIZE=`ls -l in2/in2 2>/dev/null | awk '{print$5}'` + test "$SIZE" = 1 && $ECHO "$GREEN[+] afl-tmin correctly minimized the testcase" + test "$SIZE" = 1 || { + $ECHO "$RED[!] afl-tmin did incorrectly minimize the testcase to $SIZE" + CODE=1 + } + rm -rf in out errors in2 + unset AFL_QUIET + } + rm -f test-instr.plain + } || { + $ECHO "$YELLOW[-] afl is not compiled, cannot test" + INCOMPLETE=1 + } + if [ ${AFL_GCC} = "afl-gcc" ] ; then AFL_GCC=afl-clang ; else AFL_GCC=afl-gcc ; fi + $ECHO "$BLUE[*] Testing: ${AFL_GCC}, afl-showmap, afl-fuzz, afl-cmin and afl-tmin" + SKIP= + test -e ../${AFL_GCC} -a -e ../afl-showmap -a -e ../afl-fuzz && { + ../${AFL_GCC} -o test-instr.plain -O0 ../test-instr.c > /dev/null 2>&1 + AFL_HARDEN=1 ../${AFL_GCC} -o test-compcov.harden test-compcov.c > /dev/null 2>&1 + test -e test-instr.plain && { + $ECHO "$GREEN[+] ${AFL_GCC} compilation succeeded" + echo 0 | AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.0 -r -- ./test-instr.plain > /dev/null 2>&1 + AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.1 -r -- ./test-instr.plain < /dev/null > /dev/null 2>&1 + test -e test-instr.plain.0 -a -e test-instr.plain.1 && { + diff test-instr.plain.0 test-instr.plain.1 > /dev/null 2>&1 && { + $ECHO "$RED[!] ${AFL_GCC} instrumentation should be different on different input but is not" + CODE=1 + } || { + $ECHO "$GREEN[+] ${AFL_GCC} instrumentation present and working correctly" + } + } || { + $ECHO "$RED[!] ${AFL_GCC} instrumentation failed" + CODE=1 + } + rm -f test-instr.plain.0 test-instr.plain.1 + TUPLES=`echo 1|AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.plain 2>&1 | grep Captur | awk '{print$3}'` + test "$TUPLES" -gt 1 -a "$TUPLES" -lt 12 && { + $ECHO "$GREEN[+] ${AFL_GCC} run reported $TUPLES instrumented locations which is fine" + } || { + $ECHO "$RED[!] ${AFL_GCC} instrumentation produces weird numbers: $TUPLES" + CODE=1 + } + test "$TUPLES" -lt 3 && SKIP=1 + true # this is needed because of the test above + } || { + $ECHO "$RED[!] ${AFL_GCC} failed" + echo CUT------------------------------------------------------------------CUT + uname -a + ../${AFL_GCC} -o test-instr.plain ../test-instr.c + echo CUT------------------------------------------------------------------CUT + CODE=1 + } + test -e test-compcov.harden && { + grep -Eq$GREPAOPTION 'stack_chk_fail|fstack-protector-all|fortified' test-compcov.harden > /dev/null 2>&1 && { + $ECHO "$GREEN[+] ${AFL_GCC} hardened mode succeeded and is working" + } || { + $ECHO "$RED[!] ${AFL_GCC} hardened mode is not hardened" + CODE=1 + } + rm -f test-compcov.harden + } || { + $ECHO "$RED[!] ${AFL_GCC} hardened mode compilation failed" + CODE=1 + } + # now we want to be sure that afl-fuzz is working + # make sure core_pattern is set to core on linux + (test "$(uname -s)" = "Linux" && test "$(sysctl kernel.core_pattern)" != "kernel.core_pattern = core" && { + $ECHO "$YELLOW[-] we should not run afl-fuzz with enabled core dumps. Run 'sudo sh afl-system-config'.$RESET" + true + }) || + # make sure crash reporter is disabled on Mac OS X + (test "$(uname -s)" = "Darwin" && test $(launchctl list 2>/dev/null | grep -q '\.ReportCrash$') && { + $ECHO "$RED[!] we cannot run afl-fuzz with enabled crash reporter. Run 'sudo sh afl-system-config'.$RESET" + true + }) || { + mkdir -p in + echo 0 > in/in + test -z "$SKIP" && { + $ECHO "$GREY[*] running afl-fuzz for ${AFL_GCC}, this will take approx 10 seconds" + { + ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -D -- ./test-instr.plain >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000002* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with ${AFL_GCC}" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with ${AFL_GCC}" + CODE=1 + } + } + echo 000000000000000000000000 > in/in2 + echo AAA > in/in3 + mkdir -p in2 + ../afl-cmin -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null 2>&1 # why is afl-forkserver writing to stderr? + CNT=`ls in2/* 2>/dev/null | wc -l` + case "$CNT" in + *2) $ECHO "$GREEN[+] afl-cmin correctly minimized the number of testcases" ;; + \ *1|1) { # allow leading whitecase for portability + test -s in2/* && $ECHO "$YELLOW[?] afl-cmin did minimize to one testcase. This can be a bug or due compiler optimization." + test -s in2/* || { + $ECHO "$RED[!] afl-cmin did not correctly minimize the number of testcases ($CNT)" + CODE=1 + } + } + ;; + *) $ECHO "$RED[!] afl-cmin did not correctly minimize the number of testcases ($CNT)" + CODE=1 + ;; + esac + rm -f in2/in* + export AFL_QUIET=1 + if command -v bash >/dev/null ; then { + ../afl-cmin.bash -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null + CNT=`ls in2/* 2>/dev/null | wc -l` + case "$CNT" in + *2) $ECHO "$GREEN[+] afl-cmin.bash correctly minimized the number of testcases" ;; + \ *1|1) { # allow leading whitecase for portability + test -s in2/* && $ECHO "$YELLOW[?] afl-cmin.bash did minimize to one testcase. This can be a bug or due compiler optimization." + test -s in2/* || { + $ECHO "$RED[!] afl-cmin.bash did not correctly minimize the number of testcases ($CNT)" + CODE=1 + } + } + ;; + *) $ECHO "$RED[!] afl-cmin.bash did not correctly minimize the number of testcases ($CNT)" + CODE=1 + ;; + esac + } else { + $ECHO "$GREY[*] no bash available, cannot test afl-cmin.bash" + } + fi + ../afl-tmin -m ${MEM_LIMIT} -i in/in2 -o in2/in2 -- ./test-instr.plain > /dev/null 2>&1 + SIZE=`ls -l in2/in2 2>/dev/null | awk '{print$5}'` + test "$SIZE" = 1 && $ECHO "$GREEN[+] afl-tmin correctly minimized the testcase" + test "$SIZE" = 1 || { + $ECHO "$RED[!] afl-tmin did incorrectly minimize the testcase to $SIZE" + CODE=1 + } + rm -rf in out errors in2 + unset AFL_QUIET + } + rm -f test-instr.plain + } || { + $ECHO "$YELLOW[-] afl is not compiled, cannot test" + INCOMPLETE=1 + } +} || { + $ECHO "$GREY[*] not an intel platform, skipped tests of afl-gcc" + #this is not incomplete as this feature doesnt exist, so all good + AFL_TEST_COUNT=$((AFL_TEST_COUNT-1)) +} + +. ./test-post.sh diff --git a/test/test-cmplog.c b/test/test-cmplog.c new file mode 100644 index 00000000..b077e3ab --- /dev/null +++ b/test/test-cmplog.c @@ -0,0 +1,23 @@ +#include <stdio.h> +#include <string.h> +#include <stdarg.h> +#include <stdlib.h> +#include <stdint.h> +#include <unistd.h> +int main(int argc, char *argv[]) { + + char buf[1024]; + ssize_t i; + if ((i = read(0, buf, sizeof(buf) - 1)) < 24) return 0; + buf[i] = 0; + if (buf[0] != 'A') return 0; + if (buf[1] != 'B') return 0; + if (buf[2] != 'C') return 0; + if (buf[3] != 'D') return 0; + if (memcmp(buf + 4, "1234", 4) || memcmp(buf + 8, "EFGH", 4)) return 0; + if (strncmp(buf + 12, "IJKL", 4) == 0 && strcmp(buf + 16, "DEADBEEF") == 0) + abort(); + return 0; + +} + diff --git a/test/test-custom-mutators.sh b/test/test-custom-mutators.sh new file mode 100755 index 00000000..bae4220f --- /dev/null +++ b/test/test-custom-mutators.sh @@ -0,0 +1,125 @@ +#!/bin/sh + +. ./test-pre.sh + +$ECHO "$BLUE[*] Testing: custom mutator" +test "1" = "`../afl-fuzz | grep -i 'without python' >/dev/null; echo $?`" && { + # normalize path + CUSTOM_MUTATOR_PATH=$(cd $(pwd)/../utils/custom_mutators;pwd) + test -e test-custom-mutator.c -a -e ${CUSTOM_MUTATOR_PATH}/example.c -a -e ${CUSTOM_MUTATOR_PATH}/example.py && { + unset AFL_CC + # Compile the vulnerable program for single mutator + test -e ../afl-clang-fast && { + ../afl-clang-fast -o test-custom-mutator test-custom-mutator.c > /dev/null 2>&1 + } || { + test -e ../afl-gcc-fast && { + ../afl-gcc-fast -o test-custom-mutator test-custom-mutator.c > /dev/null 2>&1 + } || { + ../afl-gcc -o test-custom-mutator test-custom-mutator.c > /dev/null 2>&1 + } + } + # Compile the vulnerable program for multiple mutators + test -e ../afl-clang-fast && { + ../afl-clang-fast -o test-multiple-mutators test-multiple-mutators.c > /dev/null 2>&1 + } || { + test -e ../afl-gcc-fast && { + ../afl-gcc-fast -o test-multiple-mutators test-multiple-mutators.c > /dev/null 2>&1 + } || { + ../afl-gcc -o test-multiple-mutators test-multiple-mutators.c > /dev/null 2>&1 + } + } + # Compile the custom mutator + cc -D_FIXED_CHAR=0x41 -g -fPIC -shared -I../include ../utils/custom_mutators/simple_example.c -o libexamplemutator.so > /dev/null 2>&1 + cc -D_FIXED_CHAR=0x42 -g -fPIC -shared -I../include ../utils/custom_mutators/simple_example.c -o libexamplemutator2.so > /dev/null 2>&1 + test -e test-custom-mutator -a -e ./libexamplemutator.so && { + # Create input directory + mkdir -p in + echo "00000" > in/in + + # Run afl-fuzz w/ the C mutator + $ECHO "$GREY[*] running afl-fuzz for the C mutator, this will take approx 10 seconds" + { + AFL_CUSTOM_MUTATOR_LIBRARY=./libexamplemutator.so AFL_CUSTOM_MUTATOR_ONLY=1 ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -- ./test-custom-mutator >>errors 2>&1 + } >>errors 2>&1 + + # Check results + test -n "$( ls out/default/crashes/id:000000* 2>/dev/null )" && { # TODO: update here + $ECHO "$GREEN[+] afl-fuzz is working correctly with the C mutator" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with the C mutator" + CODE=1 + } + + # Clean + rm -rf out errors core.* + + # Run afl-fuzz w/ multiple C mutators + $ECHO "$GREY[*] running afl-fuzz with multiple custom C mutators, this will take approx 10 seconds" + { + AFL_CUSTOM_MUTATOR_LIBRARY="./libexamplemutator.so;./libexamplemutator2.so" AFL_CUSTOM_MUTATOR_ONLY=1 ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -- ./test-multiple-mutators >>errors 2>&1 + } >>errors 2>&1 + + test -n "$( ls out/default/crashes/id:000000* 2>/dev/null )" && { # TODO: update here + $ECHO "$GREEN[+] afl-fuzz is working correctly with multiple C mutators" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with multiple C mutators" + CODE=1 + } + + # Clean + rm -rf out errors core.* + + # Run afl-fuzz w/ the Python mutator + $ECHO "$GREY[*] running afl-fuzz for the Python mutator, this will take approx 10 seconds" + { + export PYTHONPATH=${CUSTOM_MUTATOR_PATH} + export AFL_PYTHON_MODULE=example + AFL_CUSTOM_MUTATOR_ONLY=1 ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -- ./test-custom-mutator >>errors 2>&1 + unset PYTHONPATH + unset AFL_PYTHON_MODULE + } >>errors 2>&1 + + # Check results + test -n "$( ls out/default/crashes/id:000000* 2>/dev/null )" && { # TODO: update here + $ECHO "$GREEN[+] afl-fuzz is working correctly with the Python mutator" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with the Python mutator" + CODE=1 + } + + # Clean + rm -rf in out errors core.* + rm -rf ${CUSTOM_MUTATOR_PATH}/__pycache__/ + rm -f test-multiple-mutators test-custom-mutator libexamplemutator.so libexamplemutator2.so + } || { + ls . + ls ${CUSTOM_MUTATOR_PATH} + $ECHO "$RED[!] cannot compile the test program or the custom mutator" + CODE=1 + } + + #test "$CODE" = 1 && { $ECHO "$YELLOW[!] custom mutator tests currently will not fail travis" ; CODE=0 ; } + + make -C ../utils/custom_mutators clean > /dev/null 2>&1 + rm -f test-custom-mutator + rm -f test-custom-mutators + } || { + $ECHO "$YELLOW[-] no custom mutators in $CUSTOM_MUTATOR_PATH, cannot test" + INCOMPLETE=1 + } + unset CUSTOM_MUTATOR_PATH +} || { + $ECHO "$YELLOW[-] no python support in afl-fuzz, cannot test" + INCOMPLETE=1 +} + +. ./test-post.sh diff --git a/test/test-floatingpoint.c b/test/test-floatingpoint.c index acecd55a..febfae05 100644 --- a/test/test-floatingpoint.c +++ b/test/test-floatingpoint.c @@ -14,9 +14,16 @@ int main(void) { while (__AFL_LOOP(INT_MAX)) { - if (__AFL_FUZZ_TESTCASE_LEN != sizeof(float)) return 1; - /* 15 + 1/2 + 1/8 + 1/32 + 1/128 */ - if ((-*magic == 15.0 + 0.5 + 0.125 + 0.03125 + 0.0078125)) abort(); + int len = __AFL_FUZZ_TESTCASE_LEN; + if (len < sizeof(float)) return 1; + + /* 15 + 1/2 = 15.5 */ + /* 15 + 1/2 + 1/8 = 15.625 */ + /* 15 + 1/2 + 1/8 + 1/32 = 15.65625 */ + /* 15 + 1/2 + 1/8 + 1/32 + 1/128 = 15.6640625 */ + if ((*magic >= 15.0 + 0.5 + 0.125 + 0.03125) && + (*magic <= 15.0 + 0.5 + 0.125 + 0.03125 + 0.0078125)) + abort(); } diff --git a/test/test-gcc-plugin.sh b/test/test-gcc-plugin.sh new file mode 100755 index 00000000..4c36b6c9 --- /dev/null +++ b/test/test-gcc-plugin.sh @@ -0,0 +1,120 @@ +#!/bin/sh + +. ./test-pre.sh + +$ECHO "$BLUE[*] Testing: gcc_plugin" +test -e ../afl-gcc-fast -a -e ../afl-compiler-rt.o && { + SAVE_AFL_CC=${AFL_CC} + export AFL_CC=`command -v gcc` + ../afl-gcc-fast -o test-instr.plain.gccpi ../test-instr.c > /dev/null 2>&1 + AFL_HARDEN=1 ../afl-gcc-fast -o test-compcov.harden.gccpi test-compcov.c > /dev/null 2>&1 + test -e test-instr.plain.gccpi && { + $ECHO "$GREEN[+] gcc_plugin compilation succeeded" + echo 0 | AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.0 -r -- ./test-instr.plain.gccpi > /dev/null 2>&1 + AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.1 -r -- ./test-instr.plain.gccpi < /dev/null > /dev/null 2>&1 + test -e test-instr.plain.0 -a -e test-instr.plain.1 && { + diff test-instr.plain.0 test-instr.plain.1 > /dev/null 2>&1 && { + $ECHO "$RED[!] gcc_plugin instrumentation should be different on different input but is not" + CODE=1 + } || { + $ECHO "$GREEN[+] gcc_plugin instrumentation present and working correctly" + TUPLES=`echo 0|AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.plain.gccpi 2>&1 | grep Captur | awk '{print$3}'` + test "$TUPLES" -gt 1 -a "$TUPLES" -lt 9 && { + $ECHO "$GREEN[+] gcc_plugin run reported $TUPLES instrumented locations which is fine" + } || { + $ECHO "$RED[!] gcc_plugin instrumentation produces a weird numbers: $TUPLES" + $ECHO "$YELLOW[-] this is a known issue in gcc, not afl++. It is not flagged as an error because travis builds would all fail otherwise :-(" + #CODE=1 + } + test "$TUPLES" -lt 2 && SKIP=1 + true + } + } || { + $ECHO "$RED[!] gcc_plugin instrumentation failed" + CODE=1 + } + rm -f test-instr.plain.0 test-instr.plain.1 + } || { + $ECHO "$RED[!] gcc_plugin failed" + CODE=1 + } + + test -e test-compcov.harden.gccpi && test_compcov_binary_functionality ./test-compcov.harden.gccpi && { + grep -Eq$GREPAOPTION 'stack_chk_fail|fstack-protector-all|fortified' test-compcov.harden.gccpi > /dev/null 2>&1 && { + $ECHO "$GREEN[+] gcc_plugin hardened mode succeeded and is working" + } || { + $ECHO "$RED[!] gcc_plugin hardened mode is not hardened" + CODE=1 + } + rm -f test-compcov.harden.gccpi + } || { + $ECHO "$RED[!] gcc_plugin hardened mode compilation failed" + CODE=1 + } + # now we want to be sure that afl-fuzz is working + (test "$(uname -s)" = "Linux" && test "$(sysctl kernel.core_pattern)" != "kernel.core_pattern = core" && { + $ECHO "$YELLOW[-] we should not run afl-fuzz with enabled core dumps. Run 'sudo sh afl-system-config'.$RESET" + true + }) || + # make sure crash reporter is disabled on Mac OS X + (test "$(uname -s)" = "Darwin" && test $(launchctl list 2>/dev/null | grep -q '\.ReportCrash$') && { + $ECHO "$RED[!] we cannot run afl-fuzz with enabled crash reporter. Run 'sudo sh afl-system-config'.$RESET" + CODE=1 + true + }) || { + test -z "$SKIP" && { + mkdir -p in + echo 0 > in/in + $ECHO "$GREY[*] running afl-fuzz for gcc_plugin, this will take approx 10 seconds" + { + ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -D -- ./test-instr.plain.gccpi >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000002* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with gcc_plugin" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with gcc_plugin" + CODE=1 + } + rm -rf in out errors + } + } + rm -f test-instr.plain.gccpi + + # now for the special gcc_plugin things + echo foobar.c > instrumentlist.txt + AFL_GCC_INSTRUMENT_FILE=instrumentlist.txt ../afl-gcc-fast -o test-compcov test-compcov.c > /dev/null 2>&1 + test -x test-compcov && test_compcov_binary_functionality ./test-compcov && { + echo 1 | AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o - -r -- ./test-compcov 2>&1 | grep -q "Captured 0 tuples" && { + $ECHO "$GREEN[+] gcc_plugin instrumentlist feature works correctly" + } || { + $ECHO "$RED[!] gcc_plugin instrumentlist feature failed" + CODE=1 + } + } || { + $ECHO "$RED[!] gcc_plugin instrumentlist feature compilation failed." + CODE=1 + } + rm -f test-compcov test.out instrumentlist.txt + ../afl-gcc-fast -o test-persistent ../utils/persistent_mode/persistent_demo.c > /dev/null 2>&1 + test -e test-persistent && { + echo foo | AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -q -r ./test-persistent && { + $ECHO "$GREEN[+] gcc_plugin persistent mode feature works correctly" + } || { + $ECHO "$RED[!] gcc_plugin persistent mode feature failed to work" + CODE=1 + } + } || { + $ECHO "$RED[!] gcc_plugin persistent mode feature compilation failed" + CODE=1 + } + rm -f test-persistent + export AFL_CC=${SAVE_AFL_CC} +} || { + $ECHO "$YELLOW[-] gcc_plugin not compiled, cannot test" + INCOMPLETE=1 +} + +. ./test-post.sh diff --git a/test/test-libextensions.sh b/test/test-libextensions.sh new file mode 100755 index 00000000..40a898c8 --- /dev/null +++ b/test/test-libextensions.sh @@ -0,0 +1,41 @@ +#!/bin/sh + +. ./test-pre.sh + +test -z "$AFL_CC" && unset AFL_CC + +$ECHO "$BLUE[*] Testing: shared library extensions" +cc $CFLAGS -o test-compcov test-compcov.c > /dev/null 2>&1 +test -e ../libtokencap.so && { + AFL_TOKEN_FILE=token.out LD_PRELOAD=../libtokencap.so DYLD_INSERT_LIBRARIES=../libtokencap.so DYLD_FORCE_FLAT_NAMESPACE=1 ./test-compcov foobar > /dev/null 2>&1 + grep -q BUGMENOT token.out > /dev/null 2>&1 && { + $ECHO "$GREEN[+] libtokencap did successfully capture tokens" + } || { + $ECHO "$RED[!] libtokencap did not capture tokens" + CODE=1 + } + rm -f token.out +} || { + $ECHO "$YELLOW[-] libtokencap is not compiled, cannot test" + INCOMPLETE=1 +} +test -e ../libdislocator.so && { + { + ulimit -c 1 + # DYLD_INSERT_LIBRARIES and DYLD_FORCE_FLAT_NAMESPACE is used on Darwin/MacOSX + LD_PRELOAD=../libdislocator.so DYLD_INSERT_LIBRARIES=../libdislocator.so DYLD_FORCE_FLAT_NAMESPACE=1 ./test-compcov BUFFEROVERFLOW > test.out 2>/dev/null + } > /dev/null 2>&1 + grep -q BUFFEROVERFLOW test.out > /dev/null 2>&1 && { + $ECHO "$RED[!] libdislocator did not detect the memory corruption" + CODE=1 + } || { + $ECHO "$GREEN[+] libdislocator did successfully detect the memory corruption" + } + rm -f test.out core test-compcov.core core.test-compcov +} || { + $ECHO "$YELLOW[-] libdislocator is not compiled, cannot test" + INCOMPLETE=1 +} +rm -f test-compcov + +. ./test-post.sh diff --git a/test/test-llvm-lto.sh b/test/test-llvm-lto.sh new file mode 100755 index 00000000..3e762acf --- /dev/null +++ b/test/test-llvm-lto.sh @@ -0,0 +1,78 @@ +#!/bin/sh + +. ./test-pre.sh + +$ECHO "$BLUE[*] Testing: LTO llvm_mode" +test -e ../afl-clang-lto -a -e ../afl-llvm-lto-instrumentation.so && { + # on FreeBSD need to set AFL_CC + test `uname -s` = 'FreeBSD' && { + if type clang >/dev/null; then + export AFL_CC=`command -v clang` + else + export AFL_CC=`$LLVM_CONFIG --bindir`/clang + fi + } + + ../afl-clang-lto -o test-instr.plain ../test-instr.c > /dev/null 2>&1 + test -e test-instr.plain && { + $ECHO "$GREEN[+] llvm_mode LTO compilation succeeded" + echo 0 | AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.0 -r -- ./test-instr.plain > /dev/null 2>&1 + AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.1 -r -- ./test-instr.plain < /dev/null > /dev/null 2>&1 + test -e test-instr.plain.0 -a -e test-instr.plain.1 && { + diff -q test-instr.plain.0 test-instr.plain.1 > /dev/null 2>&1 && { + $ECHO "$RED[!] llvm_mode LTO instrumentation should be different on different input but is not" + CODE=1 + } || { + $ECHO "$GREEN[+] llvm_mode LTO instrumentation present and working correctly" + TUPLES=`echo 0|AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.plain 2>&1 | grep Captur | awk '{print$3}'` + test "$TUPLES" -gt 2 -a "$TUPLES" -lt 7 && { + $ECHO "$GREEN[+] llvm_mode LTO run reported $TUPLES instrumented locations which is fine" + } || { + $ECHO "$RED[!] llvm_mode LTO instrumentation produces weird numbers: $TUPLES" + CODE=1 + } + } + } || { + $ECHO "$RED[!] llvm_mode LTO instrumentation failed" + CODE=1 + } + rm -f test-instr.plain.0 test-instr.plain.1 + } || { + $ECHO "$RED[!] LTO llvm_mode failed" + CODE=1 + } + rm -f test-instr.plain + + echo foobar.c > instrumentlist.txt + AFL_DEBUG=1 AFL_LLVM_INSTRUMENT_FILE=instrumentlist.txt ../afl-clang-lto -o test-compcov test-compcov.c > test.out 2>&1 + test -e test-compcov && { + grep -q "No instrumentation targets found" test.out && { + $ECHO "$GREEN[+] llvm_mode LTO instrumentlist feature works correctly" + } || { + $ECHO "$RED[!] llvm_mode LTO instrumentlist feature failed" + CODE=1 + } + } || { + $ECHO "$RED[!] llvm_mode LTO instrumentlist feature compilation failed" + CODE=1 + } + rm -f test-compcov test.out instrumentlist.txt + ../afl-clang-lto -o test-persistent ../utils/persistent_mode/persistent_demo.c > /dev/null 2>&1 + test -e test-persistent && { + echo foo | AFL_QUIET=1 ../afl-showmap -m none -o /dev/null -q -r ./test-persistent && { + $ECHO "$GREEN[+] llvm_mode LTO persistent mode feature works correctly" + } || { + $ECHO "$RED[!] llvm_mode LTO persistent mode feature failed to work" + CODE=1 + } + } || { + $ECHO "$RED[!] llvm_mode LTO persistent mode feature compilation failed" + CODE=1 + } + rm -f test-persistent +} || { + $ECHO "$YELLOW[-] LTO llvm_mode not compiled, cannot test" + INCOMPLETE=1 +} + +. ./test-post.sh diff --git a/test/test-llvm.sh b/test/test-llvm.sh new file mode 100755 index 00000000..aa36af1b --- /dev/null +++ b/test/test-llvm.sh @@ -0,0 +1,235 @@ +#!/bin/sh + +. ./test-pre.sh + +$ECHO "$BLUE[*] Testing: llvm_mode, afl-showmap, afl-fuzz, afl-cmin and afl-tmin" +test -e ../afl-clang-fast -a -e ../split-switches-pass.so && { + # on FreeBSD need to set AFL_CC + test `uname -s` = 'FreeBSD' && { + if type clang >/dev/null; then + export AFL_CC=`command -v clang` + else + export AFL_CC=`$LLVM_CONFIG --bindir`/clang + fi + } + ../afl-clang-fast -o test-instr.plain ../test-instr.c > /dev/null 2>&1 + AFL_HARDEN=1 ../afl-clang-fast -o test-compcov.harden test-compcov.c > /dev/null 2>&1 + test -e test-instr.plain && { + $ECHO "$GREEN[+] llvm_mode compilation succeeded" + echo 0 | AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.0 -r -- ./test-instr.plain > /dev/null 2>&1 + AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.1 -r -- ./test-instr.plain < /dev/null > /dev/null 2>&1 + test -e test-instr.plain.0 -a -e test-instr.plain.1 && { + diff test-instr.plain.0 test-instr.plain.1 > /dev/null 2>&1 && { + $ECHO "$RED[!] llvm_mode instrumentation should be different on different input but is not" + CODE=1 + } || { + $ECHO "$GREEN[+] llvm_mode instrumentation present and working correctly" + TUPLES=`echo 0|AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.plain 2>&1 | grep Captur | awk '{print$3}'` + test "$TUPLES" -gt 2 -a "$TUPLES" -lt 8 && { + $ECHO "$GREEN[+] llvm_mode run reported $TUPLES instrumented locations which is fine" + } || { + $ECHO "$RED[!] llvm_mode instrumentation produces weird numbers: $TUPLES" + CODE=1 + } + test "$TUPLES" -lt 3 && SKIP=1 + true + } + } || { + $ECHO "$RED[!] llvm_mode instrumentation failed" + CODE=1 + } + rm -f test-instr.plain.0 test-instr.plain.1 + } || { + $ECHO "$RED[!] llvm_mode failed" + CODE=1 + } + test -e test-compcov.harden && test_compcov_binary_functionality ./test-compcov.harden && { + grep -Eq$GREPAOPTION 'stack_chk_fail|fstack-protector-all|fortified' test-compcov.harden > /dev/null 2>&1 && { + $ECHO "$GREEN[+] llvm_mode hardened mode succeeded and is working" + } || { + $ECHO "$RED[!] llvm_mode hardened mode is not hardened" + CODE=1 + } + rm -f test-compcov.harden + } || { + $ECHO "$RED[!] llvm_mode hardened mode compilation failed" + CODE=1 + } + # now we want to be sure that afl-fuzz is working + (test "$(uname -s)" = "Linux" && test "$(sysctl kernel.core_pattern)" != "kernel.core_pattern = core" && { + $ECHO "$YELLOW[-] we should not run afl-fuzz with enabled core dumps. Run 'sudo sh afl-system-config'.$RESET" + true + }) || + # make sure crash reporter is disabled on Mac OS X + (test "$(uname -s)" = "Darwin" && test $(launchctl list 2>/dev/null | grep -q '\.ReportCrash$') && { + $ECHO "$RED[!] we cannot run afl-fuzz with enabled crash reporter. Run 'sudo sh afl-system-config'.$RESET" + CODE=1 + true + }) || { + mkdir -p in + echo 0 > in/in + test -z "$SKIP" && { + $ECHO "$GREY[*] running afl-fuzz for llvm_mode, this will take approx 10 seconds" + { + ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -D -- ./test-instr.plain >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000002* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with llvm_mode" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with llvm_mode" + CODE=1 + } + } + test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" || { + echo 000000000000000000000000 > in/in2 + echo 111 > in/in3 + mkdir -p in2 + ../afl-cmin -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null 2>&1 # why is afl-forkserver writing to stderr? + CNT=`ls in2/* 2>/dev/null | wc -l` + case "$CNT" in + *2) $ECHO "$GREEN[+] afl-cmin correctly minimized the number of testcases" ;; + *) $ECHO "$RED[!] afl-cmin did not correctly minimize the number of testcases ($CNT)" + CODE=1 + ;; + esac + rm -f in2/in* + export AFL_QUIET=1 + if type bash >/dev/null ; then { + ../afl-cmin.bash -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null + CNT=`ls in2/* 2>/dev/null | wc -l` + case "$CNT" in + *2) $ECHO "$GREEN[+] afl-cmin.bash correctly minimized the number of testcases" ;; + *) $ECHO "$RED[!] afl-cmin.bash did not correctly minimize the number of testcases ($CNT)" + CODE=1 + ;; + esac + } else { + $ECHO "$YELLOW[-] no bash available, cannot test afl-cmin.bash" + INCOMPLETE=1 + } + fi + ../afl-tmin -m ${MEM_LIMIT} -i in/in2 -o in2/in2 -- ./test-instr.plain > /dev/null 2>&1 + SIZE=`ls -l in2/in2 2>/dev/null | awk '{print$5}'` + test "$SIZE" = 1 && $ECHO "$GREEN[+] afl-tmin correctly minimized the testcase" + test "$SIZE" = 1 || { + $ECHO "$RED[!] afl-tmin did incorrectly minimize the testcase to $SIZE" + CODE=1 + } + rm -rf in2 + } + rm -rf in out errors + } + rm -f test-instr.plain + + # now for the special llvm_mode things + test -e ../libLLVMInsTrim.so && { + AFL_LLVM_INSTRUMENT=CFG AFL_LLVM_INSTRIM_LOOPHEAD=1 ../afl-clang-fast -o test-instr.instrim ../test-instr.c > /dev/null 2>test.out + test -e test-instr.instrim && { + TUPLES=`echo 0|AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.instrim 2>&1 | grep Captur | awk '{print$3}'` + test "$TUPLES" -gt 1 -a "$TUPLES" -lt 5 && { + $ECHO "$GREEN[+] llvm_mode InsTrim reported $TUPLES instrumented locations which is fine" + } || { + $ECHO "$RED[!] llvm_mode InsTrim instrumentation produces weird numbers: $TUPLES" + CODE=1 + } + rm -f test-instr.instrim test.out + } || { + cat test.out + $ECHO "$RED[!] llvm_mode InsTrim compilation failed" + CODE=1 + } + } || { + $ECHO "$YELLOW[-] llvm_mode InsTrim not compiled, cannot test" + INCOMPLETE=1 + } + AFL_LLVM_INSTRUMENT=AFL AFL_DEBUG=1 AFL_LLVM_LAF_SPLIT_SWITCHES=1 AFL_LLVM_LAF_TRANSFORM_COMPARES=1 AFL_LLVM_LAF_SPLIT_COMPARES=1 ../afl-clang-fast -o test-compcov.compcov test-compcov.c > test.out 2>&1 + test -e test-compcov.compcov && test_compcov_binary_functionality ./test-compcov.compcov && { + grep --binary-files=text -Eq " [ 123][0-9][0-9] location| [3-9][0-9] location" test.out && { + $ECHO "$GREEN[+] llvm_mode laf-intel/compcov feature works correctly" + } || { + $ECHO "$RED[!] llvm_mode laf-intel/compcov feature failed" + CODE=1 + } + } || { + $ECHO "$RED[!] llvm_mode laf-intel/compcov feature compilation failed" + CODE=1 + } + rm -f test-compcov.compcov test.out + AFL_LLVM_INSTRUMENT=AFL AFL_LLVM_LAF_SPLIT_FLOATS=1 ../afl-clang-fast -o test-floatingpoint test-floatingpoint.c >errors 2>&1 + test -e test-floatingpoint && { + mkdir -p in + echo ZZZZ > in/in + $ECHO "$GREY[*] running afl-fuzz with floating point splitting, this will take max. 45 seconds" + { + AFL_BENCH_UNTIL_CRASH=1 AFL_NO_UI=1 ../afl-fuzz -Z -s 123 -V50 -m ${MEM_LIMIT} -i in -o out -D -- ./test-floatingpoint >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/crashes/id:* 2>/dev/null )" && { + $ECHO "$GREEN[+] llvm_mode laf-intel floatingpoint splitting feature works correctly" + } || { + cat errors + $ECHO "$RED[!] llvm_mode laf-intel floatingpoint splitting feature failed" + CODE=1 + } + } || { + $ECHO "$RED[!] llvm_mode laf-intel floatingpoint splitting feature compilation failed" + CODE=1 + } + rm -f test-floatingpoint test.out in/in errors core.* + echo foobar.c > instrumentlist.txt + AFL_DEBUG=1 AFL_LLVM_INSTRUMENT_FILE=instrumentlist.txt ../afl-clang-fast -o test-compcov test-compcov.c > test.out 2>&1 + test -e test-compcov && test_compcov_binary_functionality ./test-compcov && { + grep -q "No instrumentation targets found" test.out && { + $ECHO "$GREEN[+] llvm_mode instrumentlist feature works correctly" + } || { + $ECHO "$RED[!] llvm_mode instrumentlist feature failed" + CODE=1 + } + } || { + $ECHO "$RED[!] llvm_mode instrumentlist feature compilation failed" + CODE=1 + } + rm -f test-compcov test.out instrumentlist.txt + AFL_LLVM_CMPLOG=1 ../afl-clang-fast -o test-cmplog test-cmplog.c > /dev/null 2>&1 + test -e test-cmplog && { + $ECHO "$GREY[*] running afl-fuzz for llvm_mode cmplog, this will take approx 10 seconds" + { + mkdir -p in + echo 0000000000000000000000000 > in/in + AFL_BENCH_UNTIL_CRASH=1 ../afl-fuzz -m none -V60 -i in -o out -c./test-cmplog -- ./test-cmplog >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/crashes/id:000000* out/default/hangs/id:000000* 2>/dev/null )" & { + $ECHO "$GREEN[+] afl-fuzz is working correctly with llvm_mode cmplog" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with llvm_mode cmplog" + CODE=1 + } + } || { + $ECHO "$YELLOW[-] we cannot test llvm_mode cmplog because it is not present" + INCOMPLETE=1 + } + rm -rf errors test-cmplog in core.* + ../afl-clang-fast -o test-persistent ../utils/persistent_mode/persistent_demo.c > /dev/null 2>&1 + test -e test-persistent && { + echo foo | AFL_QUIET=1 ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -q -r ./test-persistent && { + $ECHO "$GREEN[+] llvm_mode persistent mode feature works correctly" + } || { + $ECHO "$RED[!] llvm_mode persistent mode feature failed to work" + CODE=1 + } + } || { + $ECHO "$RED[!] llvm_mode persistent mode feature compilation failed" + CODE=1 + } + rm -f test-persistent +} || { + $ECHO "$YELLOW[-] llvm_mode not compiled, cannot test" + INCOMPLETE=1 +} + +. ./test-post.sh diff --git a/test/test-performance.sh b/test/test-performance.sh index cee46060..cd9f6caf 100755 --- a/test/test-performance.sh +++ b/test/test-performance.sh @@ -4,7 +4,7 @@ # you can set the AFL_PERFORMANCE_FILE environment variable: FILE=$AFL_PERFORMANCE_FILE # otherwise we use ~/.afl_performance -test -z "$FILE" && FILE=~/.afl_performance +test -z "$FILE" && FILE=.afl_performance test -e $FILE || { echo Warning: This script measure the performance of afl++ and saves the result for future comparisons into $FILE @@ -12,7 +12,11 @@ test -e $FILE || { read IN } +test -e ./test-performance.sh || { echo Error: this script must be run from the directory in which it lies. ; exit 1 ; } + export AFL_QUIET=1 +export AFL_PATH=`pwd`/.. + unset AFL_EXIT_WHEN_DONE unset AFL_SKIP_CPUFREQ unset AFL_DEBUG @@ -36,8 +40,10 @@ test -e /usr/local/bin/opt && { # afl-gcc does not work there test `uname -s` = 'Darwin' -o `uname -s` = 'FreeBSD' && { AFL_GCC=afl-clang + CC=clang } || { AFL_GCC=afl-gcc + CC=gcc } ECHO="printf %b\\n" @@ -57,9 +63,9 @@ RED="\\033[0;31m" YELLOW="\\033[1;93m" RESET="\\033[0m" -MEM_LIMIT=150 +MEM_LIMIT=500 ->> $FILE || { echo Error: can not write to $FILE ; exit 1 ; } +touch $FILE || { echo Error: can not write to $FILE ; exit 1 ; } echo Warning: this script is setting performance parameters with afl-system-config sleep 1 @@ -81,8 +87,8 @@ test -e ../${AFL_GCC} -a -e ../afl-fuzz && { { ../afl-fuzz -V 30 -s 123 -m ${MEM_LIMIT} -i in -o out-gcc -- ./test-instr.plain } >>errors 2>&1 - test -n "$( ls out-gcc/queue/id:000002* 2> /dev/null )" && { - GCC=`grep execs_done out-gcc/fuzzer_stats | awk '{print$3}'` + test -n "$( ls out-gcc/default/queue/id:000002* 2> /dev/null )" && { + GCC=`grep execs_done out-gcc/default/fuzzer_stats | awk '{print$3}'` } || { echo CUT---------------------------------------------------------------- cat errors @@ -105,8 +111,8 @@ test -e ../afl-clang-fast -a -e ../afl-fuzz && { { ../afl-fuzz -V 30 -s 123 -m ${MEM_LIMIT} -i in -o out-llvm -- ./test-instr.llvm } >>errors 2>&1 - test -n "$( ls out-llvm/queue/id:000002* 2> /dev/null )" && { - LLVM=`grep execs_done out-llvm/fuzzer_stats | awk '{print$3}'` + test -n "$( ls out-llvm/default/queue/id:000002* 2> /dev/null )" && { + LLVM=`grep execs_done out-llvm/default/fuzzer_stats | awk '{print$3}'` } || { echo CUT---------------------------------------------------------------- cat errors @@ -117,10 +123,34 @@ test -e ../afl-clang-fast -a -e ../afl-fuzz && { } || $ECHO "$RED[!] llvm_mode instrumentation failed" } || $ECHO "$YELLOW[-] llvm_mode is not compiled, cannot test" +$ECHO "$BLUE[*] Testing: gcc_plugin" +GCCP=x +test -e ../afl-gcc-fast -a -e ../afl-fuzz && { + ../afl-gcc-fast -o test-instr.gccp ../test-instr.c > /dev/null 2>&1 + test -e test-instr.gccp && { + $ECHO "$GREEN[+] gcc_plugin compilation succeeded" + mkdir -p in + echo 0 > in/in + $ECHO "$GREY[*] running afl-fuzz for gcc_plugin for 30 seconds" + { + ../afl-fuzz -V 30 -s 123 -m ${MEM_LIMIT} -i in -o out-gccp -- ./test-instr.gccp + } >>errors 2>&1 + test -n "$( ls out-gccp/default/queue/id:000002* 2> /dev/null )" && { + GCCP=`grep execs_done out-gccp/default/fuzzer_stats | awk '{print$3}'` + } || { + echo CUT---------------------------------------------------------------- + cat errors + echo CUT---------------------------------------------------------------- + $ECHO "$RED[!] afl-fuzz is not working correctly with gcc_plugin" + } + rm -rf in out-gccp errors test-instr.gccp + } || $ECHO "$RED[!] gcc_plugin instrumentation failed" +} || $ECHO "$YELLOW[-] gcc_plugin is not compiled, cannot test" + $ECHO "$BLUE[*] Testing: qemu_mode" QEMU=x test -e ../afl-qemu-trace -a -e ../afl-fuzz && { - cc -o test-instr.qemu ../test-instr.c > /dev/null 2>&1 + $CC -o test-instr.qemu ../test-instr.c > /dev/null 2>&1 test -e test-instr.qemu && { $ECHO "$GREEN[+] native compilation with cc succeeded" mkdir -p in @@ -129,10 +159,11 @@ test -e ../afl-qemu-trace -a -e ../afl-fuzz && { { ../afl-fuzz -Q -V 30 -s 123 -m ${MEM_LIMIT} -i in -o out-qemu -- ./test-instr.qemu } >>errors 2>&1 - test -n "$( ls out-qemu/queue/id:000002* 2> /dev/null )" && { - QEMU=`grep execs_done out-qemu/fuzzer_stats | awk '{print$3}'` + test -n "$( ls out-qemu/default/queue/id:000002* 2> /dev/null )" && { + QEMU=`grep execs_done out-qemu/default/fuzzer_stats | awk '{print$3}'` } || { echo CUT---------------------------------------------------------------- + echo ../afl-fuzz -Q -V 30 -s 123 -m ${MEM_LIMIT} -i in -o out-qemu -- ./test-instr.qemu cat errors echo CUT---------------------------------------------------------------- $ECHO "$RED[!] afl-fuzz is not working correctly with qemu_mode" @@ -147,6 +178,9 @@ LAST_GCC= LOW_LLVM= HIGH_LLVM= LAST_LLVM= +LOW_GCCP= +HIGH_GCCP= +LAST_GCCP= LOW_QEMU= HIGH_QEMU= LAST_QEMU= @@ -155,12 +189,15 @@ test -s $FILE && { while read LINE; do G=`echo $LINE | awk '{print$1}'` L=`echo $LINE | awk '{print$2}'` - Q=`echo $LINE | awk '{print$3}'` + P=`echo $LINE | awk '{print$3}'` + Q=`echo $LINE | awk '{print$4}'` test "$G" = x && G= test "$L" = x && L= + test "$P" = x && P= test "$Q" = x && Q= test -n "$G" && LAST_GCC=$G test -n "$L" && LAST_LLVM=$L + test -n "$P" && LAST_GCCP=$P test -n "$Q" && LAST_QEMU=$Q test -n "$G" -a -z "$LOW_GCC" && LOW_GCC=$G || { test -n "$G" -a "$G" -lt "$LOW_GCC" 2> /dev/null && LOW_GCC=$G @@ -168,6 +205,9 @@ test -s $FILE && { test -n "$L" -a -z "$LOW_LLVM" && LOW_LLVM=$L || { test -n "$L" -a "$L" -lt "$LOW_LLVM" 2> /dev/null && LOW_LLVM=$L } + test -n "$P" -a -z "$LOW_GCCP" && LOW_GCCP=$P || { + test -n "$P" -a "$P" -lt "$LOW_GCCP" 2> /dev/null && LOW_GCCP=$P + } test -n "$Q" -a -z "$LOW_QEMU" && LOW_QEMU=$Q || { test -n "$Q" -a "$Q" -lt "$LOW_QEMU" 2> /dev/null && LOW_QEMU=$Q } @@ -177,6 +217,9 @@ test -s $FILE && { test -n "$L" -a -z "$HIGH_LLVM" && HIGH_LLVM=$L || { test -n "$L" -a "$L" -gt "$HIGH_LLVM" 2> /dev/null && HIGH_LLVM=$L } + test -n "$P" -a -z "$HIGH_GCCP" && HIGH_GCCP=$P || { + test -n "$P" -a "$P" -gt "$HIGH_GCCP" 2> /dev/null && HIGH_GCCP=$P + } test -n "$Q" -a -z "$HIGH_QEMU" && HIGH_QEMU=$Q || { test -n "$Q" -a "$Q" -gt "$HIGH_QEMU" 2> /dev/null && HIGH_QEMU=$Q } @@ -184,11 +227,12 @@ test -s $FILE && { $ECHO "$YELLOW[!] Reading saved data from $FILE completed, please compare the results:" $ECHO "$BLUE[!] afl-cc: lowest=$LOW_GCC highest=$HIGH_GCC last=$LAST_GCC current=$GCC" $ECHO "$BLUE[!] llvm_mode: lowest=$LOW_LLVM highest=$HIGH_LLVM last=$LAST_LLVM current=$LLVM" + $ECHO "$BLUE[!] gcc_plugin: lowest=$LOW_GCCP highest=$HIGH_GCCP last=$LAST_GCCP current=$GCCP" $ECHO "$BLUE[!] qemu_mode: lowest=$LOW_QEMU highest=$HIGH_QEMU last=$LAST_QEMU current=$QEMU" } || { $ECHO "$YELLOW[!] First run, just saving data" - $ECHO "$BLUE[!] afl-gcc=$GCC llvm_mode=$LLVM qemu_mode=$QEMU" + $ECHO "$BLUE[!] afl-gcc=$GCC llvm_mode=$LLVM gcc_plugin=$GCCP qemu_mode=$QEMU" } -echo "$GCC $LLVM $QEMU" >> $FILE +echo "$GCC $LLVM $GCCP $QEMU" >> $FILE $ECHO "$GREY[*] done." $ECHO "$RESET" diff --git a/test/test-post.sh b/test/test-post.sh new file mode 100755 index 00000000..0911e2cd --- /dev/null +++ b/test/test-post.sh @@ -0,0 +1,14 @@ +#!/bin/sh +AFL_TEST_DEPTH=$((AFL_TEST_DEPTH-1)) + +if [ $AFL_TEST_DEPTH = 0 ]; then +# All runs done :) + +$ECHO "$GREY[*] $AFL_TEST_COUNT test cases completed.$RESET" +test "$INCOMPLETE" = "0" && $ECHO "$GREEN[+] all test cases executed" +test "$INCOMPLETE" = "1" && $ECHO "$YELLOW[-] not all test cases were executed" +test "$CODE" = "0" && $ECHO "$GREEN[+] all tests were successful :-)$RESET" +test "$CODE" = "0" || $ECHO "$RED[!] failure in tests :-($RESET" +exit $CODE + +fi diff --git a/test/test-pre.sh b/test/test-pre.sh new file mode 100755 index 00000000..85ac320b --- /dev/null +++ b/test/test-pre.sh @@ -0,0 +1,139 @@ +#!/bin/sh + +# All tests should start with sourcing test-pre.sh and finish with sourcing test-post.sh +# They may set an error code with $CODE=1 +# If tests are incomplete, they may set $INCOMPLETE=1 + +AFL_TEST_COUNT=$((AFL_TEST_COUNT+1)) +AFL_TEST_DEPTH=$((AFL_TEST_DEPTH+1)) + +if [ $AFL_TEST_DEPTH = 1 ]; then +# First run :) + +# +# Ensure we have: test, type, diff, grep -qE +# +test -z "" 2>/dev/null || { echo Error: test command not found ; exit 1 ; } +GREP=`type grep > /dev/null 2>&1 && echo OK` +test "$GREP" = OK || { echo Error: grep command not found ; exit 1 ; } +echo foobar | grep -qE 'asd|oob' 2>/dev/null || { echo Error: grep command does not support -q and/or -E option ; exit 1 ; } +test -e ./test-all.sh || cd $(dirname $0) || exit 1 +test -e ./test-all.sh || { echo Error: you must be in the test/ directory ; exit 1 ; } +export AFL_PATH=`pwd`/.. +export AFL_NO_AFFINITY=1 # workaround for travis that fails for no avail cores + +echo 1 > test.1 +echo 1 > test.2 +OK=OK +diff test.1 test.2 >/dev/null 2>&1 || OK= +rm -f test.1 test.2 +test -z "$OK" && { echo Error: diff is not working ; exit 1 ; } +test -z "$LLVM_CONFIG" && LLVM_CONFIG=llvm-config + +# check for '-a' option of grep +if grep -a test test-all.sh >/dev/null 2>&1; then + GREPAOPTION=' -a' +else + GREPAOPTION= +fi + +test_compcov_binary_functionality() { + RUN="../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- $1" + $RUN 'LIBTOKENCAP' | grep 'your string was LIBTOKENCAP' \ + && $RUN 'BUGMENOT' | grep 'your string was BUGMENOT' \ + && $RUN 'BANANA' | grep 'your string started with BAN' \ + && $RUN 'APRI' | grep 'your string was APRI' \ + && $RUN 'kiWI' | grep 'your string was Kiwi' \ + && $RUN 'Avocado' | grep 'your string was avocado' \ + && $RUN 'GRAX' 3 | grep 'your string was a prefix of Grapes' \ + && $RUN 'LOCALVARIABLE' | grep 'local var memcmp works!' \ + && $RUN 'abc' | grep 'short local var memcmp works!' \ + && $RUN 'GLOBALVARIABLE' | grep 'global var memcmp works!' +} > /dev/null + +ECHO="printf %b\\n" +$ECHO \\101 2>&1 | grep -qE '^A' || { + ECHO= + test -e /bin/printf && { + ECHO="/bin/printf %b\\n" + $ECHO "\\101" 2>&1 | grep -qE '^A' || ECHO= + } +} +test -z "$ECHO" && { printf Error: printf command does not support octal character codes ; exit 1 ; } + +export AFL_EXIT_WHEN_DONE=1 +export AFL_SKIP_CPUFREQ=1 +export AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=1 +unset AFL_NO_X86 +unset AFL_QUIET +unset AFL_DEBUG +unset AFL_HARDEN +unset AFL_USE_ASAN +unset AFL_USE_MSAN +unset AFL_USE_UBSAN +unset AFL_TMPDIR +unset AFL_CC +unset AFL_PRELOAD +unset AFL_GCC_INSTRUMENT_FILE +unset AFL_LLVM_INSTRUMENT_FILE +unset AFL_LLVM_INSTRIM +unset AFL_LLVM_LAF_SPLIT_SWITCHES +unset AFL_LLVM_LAF_TRANSFORM_COMPARES +unset AFL_LLVM_LAF_SPLIT_COMPARES +unset AFL_QEMU_PERSISTENT_ADDR +unset AFL_QEMU_PERSISTENT_RETADDR_OFFSET +unset AFL_QEMU_PERSISTENT_GPR +unset AFL_QEMU_PERSISTENT_RET +unset AFL_QEMU_PERSISTENT_HOOK +unset AFL_QEMU_PERSISTENT_CNT +unset AFL_CUSTOM_MUTATOR_LIBRARY +unset AFL_PYTHON_MODULE +unset AFL_PRELOAD +unset LD_PRELOAD +unset SKIP + +rm -rf in in2 out + +test -z "$TRAVIS_OS_NAME" && { + export ASAN_OPTIONS=detect_leaks=0:allocator_may_return_null=1:abort_on_error=1:symbolize=0 +} +test -n "$TRAVIS_OS_NAME" && { + export ASAN_OPTIONS=detect_leaks=0:allocator_may_return_null=1:abort_on_error=1:symbolize=1 +} + +export AFL_LLVM_INSTRUMENT=AFL + +# on OpenBSD we need to work with llvm from /usr/local/bin +test -e /usr/local/bin/opt && { + export PATH="/usr/local/bin:${PATH}" +} +# on MacOS X we prefer afl-clang over afl-gcc, because +# afl-gcc does not work there +test `uname -s` = 'Darwin' -o `uname -s` = 'FreeBSD' && { + AFL_GCC=afl-clang +} || { + AFL_GCC=afl-gcc +} +command -v gcc >/dev/null 2>&1 || AFL_GCC=afl-clang + +SYS=`uname -m` + +GREY="\\033[1;90m" +BLUE="\\033[1;94m" +GREEN="\\033[0;32m" +RED="\\033[0;31m" +YELLOW="\\033[1;93m" +RESET="\\033[0m" + +MEM_LIMIT=none + +export PATH="${PATH}:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin" + +$ECHO "${RESET}${GREY}[*] starting afl++ test framework ..." + +test -z "$SYS" && $ECHO "$YELLOW[-] uname -m did not succeed" + +CODE=0 +INCOMPLETE=0 + +fi diff --git a/test/test-qemu-mode.sh b/test/test-qemu-mode.sh new file mode 100755 index 00000000..85578d55 --- /dev/null +++ b/test/test-qemu-mode.sh @@ -0,0 +1,220 @@ +#!/bin/sh + +. ./test-pre.sh + +$ECHO "$BLUE[*] Testing: qemu_mode" +test -z "$AFL_CC" && { + if type gcc >/dev/null; then + export AFL_CC=gcc + else + if type clang >/dev/null; then + export AFL_CC=clang + fi + fi +} + +test -e ../afl-qemu-trace && { + cc -pie -fPIE -o test-instr ../test-instr.c + cc -o test-compcov test-compcov.c + test -e test-instr -a -e test-compcov && { + { + mkdir -p in + echo 00000 > in/in + $ECHO "$GREY[*] running afl-fuzz for qemu_mode, this will take approx 10 seconds" + { + ../afl-fuzz -m ${MEM_LIMIT} -V10 -Q -i in -o out -- ./test-instr >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000002* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with qemu_mode" + RUNTIME=`grep execs_done out/default/fuzzer_stats | awk '{print$3}'` + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with qemu_mode" + CODE=1 + } + rm -f errors + + $ECHO "$GREY[*] running afl-fuzz for qemu_mode AFL_ENTRYPOINT, this will take approx 6 seconds" + { + { + export AFL_ENTRYPOINT=`printf 1 | AFL_DEBUG=1 ../afl-qemu-trace ./test-instr 2>&1 >/dev/null | awk '/forkserver/{print $4; exit}'` + $ECHO AFL_ENTRYPOINT=$AFL_ENTRYPOINT - $(nm test-instr | grep "T main") - $(file ./test-instr) + ../afl-fuzz -m ${MEM_LIMIT} -V2 -Q -i in -o out -- ./test-instr + unset AFL_ENTRYPOINT + } >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000001* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with qemu_mode AFL_ENTRYPOINT" + RUNTIME=`grep execs_done out/default/fuzzer_stats | awk '{print$3}'` + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with qemu_mode AFL_ENTRYPOINT" + CODE=1 + } + rm -f errors + + test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" -o "$SYS" = "aarch64" -o ! "${SYS%%arm*}" && { + test -e ../libcompcov.so && { + $ECHO "$GREY[*] running afl-fuzz for qemu_mode compcov, this will take approx 10 seconds" + { + export AFL_PRELOAD=../libcompcov.so + export AFL_COMPCOV_LEVEL=2 + ../afl-fuzz -m ${MEM_LIMIT} -V10 -Q -i in -o out -- ./test-compcov >>errors 2>&1 + unset AFL_PRELOAD + unset AFL_COMPCOV_LEVEL + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000001* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with qemu_mode compcov" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with qemu_mode compcov" + CODE=1 + } + } || { + $ECHO "$YELLOW[-] we cannot test qemu_mode compcov because it is not present" + INCOMPLETE=1 + } + rm -f errors + } || { + $ECHO "$YELLOW[-] not an intel or arm platform, cannot test qemu_mode compcov" + } + + test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" -o "$SYS" = "aarch64" -o ! "${SYS%%arm*}" && { + $ECHO "$GREY[*] running afl-fuzz for qemu_mode cmplog, this will take approx 10 seconds" + { + ../afl-fuzz -m none -V10 -Q -c 0 -i in -o out -- ./test-compcov >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000001* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with qemu_mode cmplog" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with qemu_mode cmplog" + CODE=1 + } + rm -f errors + } || { + $ECHO "$YELLOW[-] not an intel or arm platform, cannot test qemu_mode cmplog" + } + + test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" -o "$SYS" = "aarch64" -o ! "${SYS%%arm*}" && { + $ECHO "$GREY[*] running afl-fuzz for persistent qemu_mode, this will take approx 10 seconds" + { + if file test-instr | grep -q "32-bit"; then + # for 32-bit reduce 8 nibbles to the lower 7 nibbles + ADDR_LOWER_PART=`nm test-instr | grep "T main" | awk '{print $1}' | sed 's/^.//'` + else + # for 64-bit reduce 16 nibbles to the lower 9 nibbles + ADDR_LOWER_PART=`nm test-instr | grep "T main" | awk '{print $1}' | sed 's/^.......//'` + fi + export AFL_QEMU_PERSISTENT_ADDR=`expr 0x4${ADDR_LOWER_PART}` + export AFL_QEMU_PERSISTENT_GPR=1 + $ECHO "Info: AFL_QEMU_PERSISTENT_ADDR=$AFL_QEMU_PERSISTENT_ADDR <= $(nm test-instr | grep "T main" | awk '{print $1}')" + env|grep AFL_|sort + file test-instr + ../afl-fuzz -m ${MEM_LIMIT} -V10 -Q -i in -o out -- ./test-instr + unset AFL_QEMU_PERSISTENT_ADDR + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000002* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with persistent qemu_mode" + RUNTIMEP=`grep execs_done out/default/fuzzer_stats | awk '{print$3}'` + test -n "$RUNTIME" -a -n "$RUNTIMEP" && { + DIFF=`expr $RUNTIMEP / $RUNTIME` + test "$DIFF" -gt 1 && { # must be at least twice as fast + $ECHO "$GREEN[+] persistent qemu_mode was noticeable faster than standard qemu_mode" + } || { + $ECHO "$YELLOW[-] persistent qemu_mode was not noticeable faster than standard qemu_mode" + } + } || { + $ECHO "$YELLOW[-] we got no data on executions performed? weird!" + } + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with persistent qemu_mode" + CODE=1 + } + rm -rf in out errors + } || { + $ECHO "$YELLOW[-] not an intel or arm platform, cannot test persistent qemu_mode" + } + + test -e ../qemu_mode/unsigaction/unsigaction32.so && { + ${AFL_CC} -o test-unsigaction32 -m32 test-unsigaction.c >> errors 2>&1 && { + ./test-unsigaction32 + RETVAL_NORMAL32=$? + LD_PRELOAD=../qemu_mode/unsigaction/unsigaction32.so ./test-unsigaction32 + RETVAL_LIBUNSIGACTION32=$? + test $RETVAL_NORMAL32 = "2" -a $RETVAL_LIBUNSIGACTION32 = "0" && { + $ECHO "$GREEN[+] qemu_mode unsigaction library (32 bit) ignores signals" + } || { + test $RETVAL_NORMAL32 != "2" && { + $ECHO "$RED[!] cannot trigger signal in test program (32 bit)" + } + test $RETVAL_LIBUNSIGACTION32 != "0" && { + $ECHO "$RED[!] signal in test program (32 bit) is not ignored with unsigaction" + } + CODE=1 + } + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] cannot compile test program (32 bit) for unsigaction library" + CODE=1 + } + } || { + $ECHO "$YELLOW[-] we cannot test qemu_mode unsigaction library (32 bit) because it is not present" + INCOMPLETE=1 + } + test -e ../qemu_mode/unsigaction/unsigaction64.so && { + ${AFL_CC} -o test-unsigaction64 -m64 test-unsigaction.c >> errors 2>&1 && { + ./test-unsigaction64 + RETVAL_NORMAL64=$? + LD_PRELOAD=../qemu_mode/unsigaction/unsigaction64.so ./test-unsigaction64 + RETVAL_LIBUNSIGACTION64=$? + test $RETVAL_NORMAL64 = "2" -a $RETVAL_LIBUNSIGACTION64 = "0" && { + $ECHO "$GREEN[+] qemu_mode unsigaction library (64 bit) ignores signals" + } || { + test $RETVAL_NORMAL64 != "2" && { + $ECHO "$RED[!] cannot trigger signal in test program (64 bit)" + } + test $RETVAL_LIBUNSIGACTION64 != "0" && { + $ECHO "$RED[!] signal in test program (64 bit) is not ignored with unsigaction" + } + CODE=1 + } + unset LD_PRELOAD + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] cannot compile test program (64 bit) for unsigaction library" + CODE=1 + } + } || { + $ECHO "$YELLOW[-] we cannot test qemu_mode unsigaction library (64 bit) because it is not present" + INCOMPLETE=1 + } + rm -rf errors test-unsigaction32 test-unsigaction64 + } + } || { + $ECHO "$RED[!] gcc compilation of test targets failed - what is going on??" + CODE=1 + } + + rm -f test-instr test-compcov +} || { + $ECHO "$YELLOW[-] qemu_mode is not compiled, cannot test" + INCOMPLETE=1 +} + +. ./test-post.sh diff --git a/test/test-unicorn-mode.sh b/test/test-unicorn-mode.sh new file mode 100755 index 00000000..e197e226 --- /dev/null +++ b/test/test-unicorn-mode.sh @@ -0,0 +1,112 @@ +#!/bin/sh + +. ./test-pre.sh + +$ECHO "$BLUE[*] Testing: unicorn_mode" +test -d ../unicorn_mode/unicornafl -a -e ../unicorn_mode/unicornafl/samples/shellcode && { + test -e ../unicorn_mode/samples/simple/simple_target.bin -a -e ../unicorn_mode/samples/compcov_x64/compcov_target.bin && { + { + # We want to see python errors etc. in logs, in case something doesn't work + export AFL_DEBUG_CHILD=1 + + # some python version should be available now + PYTHONS="`command -v python3` `command -v python` `command -v python2`" + EASY_INSTALL_FOUND=0 + for PYTHON in $PYTHONS ; do + + if $PYTHON -c "import setuptools" ; then + + EASY_INSTALL_FOUND=1 + PY=$PYTHON + break + + fi + + done + if [ "0" = $EASY_INSTALL_FOUND ]; then + + echo "[-] Error: Python setup-tools not found. Run 'sudo apt-get install python-setuptools'." + PREREQ_NOTFOUND=1 + + fi + + + cd ../unicorn_mode/samples/persistent + make >>errors 2>&1 + $ECHO "$GREY[*] running afl-fuzz for unicorn_mode (persistent), this will take approx 25 seconds" + AFL_DEBUG_CHILD=1 ../../../afl-fuzz -m none -V25 -U -i sample_inputs -o out -d -- ./harness @@ >>errors 2>&1 + test -n "$( ls out/default/queue/id:000002* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with unicorn_mode (persistent)" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with unicorn_mode (persistent)" + CODE=1 + } + + rm -rf out errors >/dev/null + make clean >/dev/null + cd ../../../test + + # travis workaround + test "$PY" = "/opt/pyenv/shims/python" -a -x /usr/bin/python && PY=/usr/bin/python + mkdir -p in + echo 0 > in/in + $ECHO "$GREY[*] Using python binary $PY" + if ! $PY -c 'import unicornafl' 2>/dev/null ; then + $ECHO "$YELLOW[-] we cannot test unicorn_mode for python because it is not present" + INCOMPLETE=1 + else + { + $ECHO "$GREY[*] running afl-fuzz for unicorn_mode in python, this will take approx 25 seconds" + { + ../afl-fuzz -m ${MEM_LIMIT} -V25 -U -i in -o out -d -- "$PY" ../unicorn_mode/samples/simple/simple_test_harness.py @@ >>errors 2>&1 + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000002* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with unicorn_mode" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with unicorn_mode" + CODE=1 + } + rm -f errors + + printf '\x01\x01' > in/in + # This seed is close to the first byte of the comparison. + # If CompCov works, a new tuple will appear in the map => new input in queue + $ECHO "$GREY[*] running afl-fuzz for unicorn_mode compcov, this will take approx 35 seconds" + { + export AFL_COMPCOV_LEVEL=2 + ../afl-fuzz -m ${MEM_LIMIT} -V35 -U -i in -o out -d -- "$PY" ../unicorn_mode/samples/compcov_x64/compcov_test_harness.py @@ >>errors 2>&1 + unset AFL_COMPCOV_LEVEL + } >>errors 2>&1 + test -n "$( ls out/default/queue/id:000001* 2>/dev/null )" && { + $ECHO "$GREEN[+] afl-fuzz is working correctly with unicorn_mode compcov" + } || { + echo CUT------------------------------------------------------------------CUT + cat errors + echo CUT------------------------------------------------------------------CUT + $ECHO "$RED[!] afl-fuzz is not working correctly with unicorn_mode compcov" + CODE=1 + } + rm -rf in out errors + } + fi + + unset AFL_DEBUG_CHILD + + } + } || { + $ECHO "$RED[!] missing sample binaries in unicorn_mode/samples/ - what is going on??" + CODE=1 + } + +} || { + $ECHO "$YELLOW[-] unicorn_mode is not compiled, cannot test" + INCOMPLETE=1 +} + +. ./test-post.sh diff --git a/test/test-unittests.sh b/test/test-unittests.sh new file mode 100755 index 00000000..9a405e2f --- /dev/null +++ b/test/test-unittests.sh @@ -0,0 +1,11 @@ +#!/bin/sh + +. ./test-pre.sh + +$ECHO "$BLUE[*] Execution cmocka Unit-Tests $GREY" +unset AFL_CC +make -C .. unit || CODE=1 INCOMPLETE=1 : +rm -rf unittests/unit_hash unittests/unit_rand + +. ./test-post.sh + diff --git a/test/test.sh b/test/test.sh deleted file mode 100755 index 76b089e7..00000000 --- a/test/test.sh +++ /dev/null @@ -1,1154 +0,0 @@ -#!/bin/sh - -# -# Ensure we have: test, type, diff, grep -qE -# -test -z "" 2>/dev/null || { echo Error: test command not found ; exit 1 ; } -GREP=`type grep > /dev/null 2>&1 && echo OK` -test "$GREP" = OK || { echo Error: grep command not found ; exit 1 ; } -echo foobar | grep -qE 'asd|oob' 2>/dev/null || { echo Error: grep command does not support -q and/or -E option ; exit 1 ; } -echo 1 > test.1 -echo 1 > test.2 -OK=OK -diff test.1 test.2 >/dev/null 2>&1 || OK= -rm -f test.1 test.2 -test -z "$OK" && { echo Error: diff is not working ; exit 1 ; } -test -z "$LLVM_CONFIG" && LLVM_CONFIG=llvm-config - -# check for '-a' option of grep -if grep -a test test.sh >/dev/null 2>&1; then - GREPAOPTION=' -a' -else - GREPAOPTION= -fi - -test_compcov_binary_functionality() { - RUN="../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- $1" - $RUN 'LIBTOKENCAP' | grep 'your string was LIBTOKENCAP' \ - && $RUN 'BUGMENOT' | grep 'your string was BUGMENOT' \ - && $RUN 'BANANA' | grep 'your string started with BAN' \ - && $RUN 'APRI' | grep 'your string was APRI' \ - && $RUN 'kiWI' | grep 'your string was Kiwi' \ - && $RUN 'Avocado' | grep 'your string was avocado' \ - && $RUN 'GRAX' 3 | grep 'your string was a prefix of Grapes' \ - && $RUN 'LOCALVARIABLE' | grep 'local var memcmp works!' \ - && $RUN 'abc' | grep 'short local var memcmp works!' \ - && $RUN 'GLOBALVARIABLE' | grep 'global var memcmp works!' -} > /dev/null - -ECHO="printf %b\\n" -$ECHO \\101 2>&1 | grep -qE '^A' || { - ECHO= - test -e /bin/printf && { - ECHO="/bin/printf %b\\n" - $ECHO "\\101" 2>&1 | grep -qE '^A' || ECHO= - } -} -test -z "$ECHO" && { printf Error: printf command does not support octal character codes ; exit 1 ; } - -CODE=0 -INCOMPLETE=0 - -export AFL_EXIT_WHEN_DONE=1 -export AFL_SKIP_CPUFREQ=1 -export AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=1 -unset AFL_NO_X86 -unset AFL_QUIET -unset AFL_DEBUG -unset AFL_HARDEN -unset AFL_USE_ASAN -unset AFL_USE_MSAN -unset AFL_USE_UBSAN -unset AFL_TMPDIR -unset AFL_CC -unset AFL_PRELOAD -unset AFL_GCC_INSTRUMENT_FILE -unset AFL_LLVM_INSTRUMENT_FILE -unset AFL_LLVM_INSTRIM -unset AFL_LLVM_LAF_SPLIT_SWITCHES -unset AFL_LLVM_LAF_TRANSFORM_COMPARES -unset AFL_LLVM_LAF_SPLIT_COMPARES -unset AFL_QEMU_PERSISTENT_ADDR -unset AFL_QEMU_PERSISTENT_RETADDR_OFFSET -unset AFL_QEMU_PERSISTENT_GPR -unset AFL_QEMU_PERSISTENT_RET -unset AFL_QEMU_PERSISTENT_HOOK -unset AFL_QEMU_PERSISTENT_CNT -unset AFL_CUSTOM_MUTATOR_LIBRARY -unset AFL_PYTHON_MODULE -unset AFL_PRELOAD -unset LD_PRELOAD - -rm -rf in in2 out - -export ASAN_OPTIONS=detect_leaks=0:allocator_may_return_null=1:abort_on_error=1:symbolize=0 -export AFL_LLVM_INSTRUMENT=AFL - -# on OpenBSD we need to work with llvm from /usr/local/bin -test -e /usr/local/bin/opt && { - export PATH="/usr/local/bin:${PATH}" -} -# on MacOS X we prefer afl-clang over afl-gcc, because -# afl-gcc does not work there -test `uname -s` = 'Darwin' -o `uname -s` = 'FreeBSD' && { - AFL_GCC=afl-clang -} || { - AFL_GCC=afl-gcc -} -command -v gcc >/dev/null 2>&1 || AFL_GCC=afl-clang - -SYS=`uname -m` - -GREY="\\033[1;90m" -BLUE="\\033[1;94m" -GREEN="\\033[0;32m" -RED="\\033[0;31m" -YELLOW="\\033[1;93m" -RESET="\\033[0m" - -MEM_LIMIT=none - -export PATH="${PATH}:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin" - -$ECHO "${RESET}${GREY}[*] starting afl++ test framework ..." - -test -z "$SYS" && $ECHO "$YELLOW[-] uname -m did not succeed" - -$ECHO "$BLUE[*] Testing: ${AFL_GCC}, afl-showmap, afl-fuzz, afl-cmin and afl-tmin" -test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" -o "$SYS" = "i386" && { - test -e ../${AFL_GCC} -a -e ../afl-showmap -a -e ../afl-fuzz && { - ../${AFL_GCC} -o test-instr.plain ../test-instr.c > /dev/null 2>&1 - AFL_HARDEN=1 ../${AFL_GCC} -o test-compcov.harden test-compcov.c > /dev/null 2>&1 - test -e test-instr.plain && { - $ECHO "$GREEN[+] ${AFL_GCC} compilation succeeded" - echo 0 | ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.0 -r -- ./test-instr.plain > /dev/null 2>&1 - ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.1 -r -- ./test-instr.plain < /dev/null > /dev/null 2>&1 - test -e test-instr.plain.0 -a -e test-instr.plain.1 && { - diff test-instr.plain.0 test-instr.plain.1 > /dev/null 2>&1 && { - $ECHO "$RED[!] ${AFL_GCC} instrumentation should be different on different input but is not" - CODE=1 - } || { - $ECHO "$GREEN[+] ${AFL_GCC} instrumentation present and working correctly" - } - } || { - $ECHO "$RED[!] ${AFL_GCC} instrumentation failed" - CODE=1 - } - rm -f test-instr.plain.0 test-instr.plain.1 - TUPLES=`echo 0|../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.plain 2>&1 | grep Captur | awk '{print$3}'` - test "$TUPLES" -gt 3 -a "$TUPLES" -lt 11 && { - $ECHO "$GREEN[+] ${AFL_GCC} run reported $TUPLES instrumented locations which is fine" - } || { - $ECHO "$RED[!] ${AFL_GCC} instrumentation produces weird numbers: $TUPLES" - CODE=1 - } - } || { - $ECHO "$RED[!] ${AFL_GCC} failed" - echo CUT------------------------------------------------------------------CUT - uname -a - ../${AFL_GCC} -o test-instr.plain ../test-instr.c - echo CUT------------------------------------------------------------------CUT - CODE=1 - } - test -e test-compcov.harden && { - grep -Eq$GREPAOPTION 'stack_chk_fail|fstack-protector-all|fortified' test-compcov.harden > /dev/null 2>&1 && { - $ECHO "$GREEN[+] ${AFL_GCC} hardened mode succeeded and is working" - } || { - $ECHO "$RED[!] ${AFL_GCC} hardened mode is not hardened" - CODE=1 - } - rm -f test-compcov.harden - } || { - $ECHO "$RED[!] ${AFL_GCC} hardened mode compilation failed" - CODE=1 - } - # now we want to be sure that afl-fuzz is working - # make sure core_pattern is set to core on linux - (test "$(uname -s)" = "Linux" && test "$(sysctl kernel.core_pattern)" != "kernel.core_pattern = core" && { - $ECHO "$YELLOW[-] we should not run afl-fuzz with enabled core dumps. Run 'sudo sh afl-system-config'.$RESET" - true - }) || - # make sure crash reporter is disabled on Mac OS X - (test "$(uname -s)" = "Darwin" && test $(launchctl list 2>/dev/null | grep -q '\.ReportCrash$') && { - $ECHO "$RED[!] we cannot run afl-fuzz with enabled crash reporter. Run 'sudo sh afl-system-config'.$RESET" - true - }) || { - mkdir -p in - echo 0 > in/in - $ECHO "$GREY[*] running afl-fuzz for ${AFL_GCC}, this will take approx 10 seconds" - { - ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -- ./test-instr.plain >>errors 2>&1 - } >>errors 2>&1 - test -n "$( ls out/queue/id:000002* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with ${AFL_GCC}" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with ${AFL_GCC}" - CODE=1 - } - echo 000000000000000000000000 > in/in2 - echo 111 > in/in3 - mkdir -p in2 - ../afl-cmin -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null 2>&1 # why is afl-forkserver writing to stderr? - CNT=`ls in2/* 2>/dev/null | wc -l` - case "$CNT" in - *2) $ECHO "$GREEN[+] afl-cmin correctly minimized the number of testcases" ;; - *) $ECHO "$RED[!] afl-cmin did not correctly minimize the number of testcases ($CNT)" - CODE=1 - ;; - esac - rm -f in2/in* - export AFL_QUIET=1 - if command -v bash >/dev/null ; then { - AFL_PATH=`pwd`/.. ../afl-cmin.bash -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null - CNT=`ls in2/* 2>/dev/null | wc -l` - case "$CNT" in - *2) $ECHO "$GREEN[+] afl-cmin.bash correctly minimized the number of testcases" ;; - *) $ECHO "$RED[!] afl-cmin.bash did not correctly minimize the number of testcases ($CNT)" - CODE=1 - ;; - esac - } else { - $ECHO "$YELLOW[-] no bash available, cannot test afl-cmin.bash" - INCOMPLETE=1 - } - fi - ../afl-tmin -m ${MEM_LIMIT} -i in/in2 -o in2/in2 -- ./test-instr.plain > /dev/null 2>&1 - SIZE=`ls -l in2/in2 2>/dev/null | awk '{print$5}'` - test "$SIZE" = 1 && $ECHO "$GREEN[+] afl-tmin correctly minimized the testcase" - test "$SIZE" = 1 || { - $ECHO "$RED[!] afl-tmin did incorrectly minimize the testcase to $SIZE" - CODE=1 - } - rm -rf in out errors in2 - unset AFL_QUIET - } - rm -f test-instr.plain - } || { - $ECHO "$YELLOW[-] afl is not compiled, cannot test" - INCOMPLETE=1 - } -} || { - $ECHO "$YELLOW[-] not an intel platform, cannot test afl-gcc" -} - -$ECHO "$BLUE[*] Testing: llvm_mode, afl-showmap, afl-fuzz, afl-cmin and afl-tmin" -test -e ../afl-clang-fast -a -e ../split-switches-pass.so && { - # on FreeBSD need to set AFL_CC - test `uname -s` = 'FreeBSD' && { - if type clang >/dev/null; then - export AFL_CC=`command -v clang` - else - export AFL_CC=`$LLVM_CONFIG --bindir`/clang - fi - } - ../afl-clang-fast -o test-instr.plain ../test-instr.c > /dev/null 2>&1 - AFL_HARDEN=1 ../afl-clang-fast -o test-compcov.harden test-compcov.c > /dev/null 2>&1 - test -e test-instr.plain && { - $ECHO "$GREEN[+] llvm_mode compilation succeeded" - echo 0 | ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.0 -r -- ./test-instr.plain > /dev/null 2>&1 - ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.1 -r -- ./test-instr.plain < /dev/null > /dev/null 2>&1 - test -e test-instr.plain.0 -a -e test-instr.plain.1 && { - diff test-instr.plain.0 test-instr.plain.1 > /dev/null 2>&1 && { - $ECHO "$RED[!] llvm_mode instrumentation should be different on different input but is not" - CODE=1 - } || { - $ECHO "$GREEN[+] llvm_mode instrumentation present and working correctly" - TUPLES=`echo 0|../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.plain 2>&1 | grep Captur | awk '{print$3}'` - test "$TUPLES" -gt 3 -a "$TUPLES" -lt 7 && { - $ECHO "$GREEN[+] llvm_mode run reported $TUPLES instrumented locations which is fine" - } || { - $ECHO "$RED[!] llvm_mode instrumentation produces weird numbers: $TUPLES" - CODE=1 - } - } - } || { - $ECHO "$RED[!] llvm_mode instrumentation failed" - CODE=1 - } - rm -f test-instr.plain.0 test-instr.plain.1 - } || { - $ECHO "$RED[!] llvm_mode failed" - CODE=1 - } - test -e test-compcov.harden && test_compcov_binary_functionality ./test-compcov.harden && { - grep -Eq$GREPAOPTION 'stack_chk_fail|fstack-protector-all|fortified' test-compcov.harden > /dev/null 2>&1 && { - $ECHO "$GREEN[+] llvm_mode hardened mode succeeded and is working" - } || { - $ECHO "$RED[!] llvm_mode hardened mode is not hardened" - CODE=1 - } - rm -f test-compcov.harden - } || { - $ECHO "$RED[!] llvm_mode hardened mode compilation failed" - CODE=1 - } - # now we want to be sure that afl-fuzz is working - (test "$(uname -s)" = "Linux" && test "$(sysctl kernel.core_pattern)" != "kernel.core_pattern = core" && { - $ECHO "$YELLOW[-] we should not run afl-fuzz with enabled core dumps. Run 'sudo sh afl-system-config'.$RESET" - true - }) || - # make sure crash reporter is disabled on Mac OS X - (test "$(uname -s)" = "Darwin" && test $(launchctl list 2>/dev/null | grep -q '\.ReportCrash$') && { - $ECHO "$RED[!] we cannot run afl-fuzz with enabled crash reporter. Run 'sudo sh afl-system-config'.$RESET" - CODE=1 - true - }) || { - mkdir -p in - echo 0 > in/in - $ECHO "$GREY[*] running afl-fuzz for llvm_mode, this will take approx 10 seconds" - { - ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -- ./test-instr.plain >>errors 2>&1 - } >>errors 2>&1 - test -n "$( ls out/queue/id:000002* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with llvm_mode" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with llvm_mode" - CODE=1 - } - test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" || { - echo 000000000000000000000000 > in/in2 - echo 111 > in/in3 - mkdir -p in2 - ../afl-cmin -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null 2>&1 # why is afl-forkserver writing to stderr? - CNT=`ls in2/* 2>/dev/null | wc -l` - case "$CNT" in - *2) $ECHO "$GREEN[+] afl-cmin correctly minimized the number of testcases" ;; - *) $ECHO "$RED[!] afl-cmin did not correctly minimize the number of testcases ($CNT)" - CODE=1 - ;; - esac - rm -f in2/in* - export AFL_QUIET=1 - if type bash >/dev/null ; then { - AFL_PATH=`pwd`/.. ../afl-cmin.bash -m ${MEM_LIMIT} -i in -o in2 -- ./test-instr.plain >/dev/null - CNT=`ls in2/* 2>/dev/null | wc -l` - case "$CNT" in - *2) $ECHO "$GREEN[+] afl-cmin.bash correctly minimized the number of testcases" ;; - *) $ECHO "$RED[!] afl-cmin.bash did not correctly minimize the number of testcases ($CNT)" - CODE=1 - ;; - esac - } else { - $ECHO "$YELLOW[-] no bash available, cannot test afl-cmin.bash" - INCOMPLETE=1 - } - fi - ../afl-tmin -m ${MEM_LIMIT} -i in/in2 -o in2/in2 -- ./test-instr.plain > /dev/null 2>&1 - SIZE=`ls -l in2/in2 2>/dev/null | awk '{print$5}'` - test "$SIZE" = 1 && $ECHO "$GREEN[+] afl-tmin correctly minimized the testcase" - test "$SIZE" = 1 || { - $ECHO "$RED[!] afl-tmin did incorrectly minimize the testcase to $SIZE" - CODE=1 - } - rm -rf in2 - } - rm -rf in out errors - } - rm -f test-instr.plain - - # now for the special llvm_mode things - test -e ../libLLVMInsTrim.so && { - AFL_LLVM_INSTRUMENT=CFG AFL_LLVM_INSTRIM_LOOPHEAD=1 ../afl-clang-fast -o test-instr.instrim ../test-instr.c > /dev/null 2>test.out - test -e test-instr.instrim && { - TUPLES=`echo 0|../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.instrim 2>&1 | grep Captur | awk '{print$3}'` - test "$TUPLES" -gt 2 -a "$TUPLES" -lt 5 && { - $ECHO "$GREEN[+] llvm_mode InsTrim reported $TUPLES instrumented locations which is fine" - } || { - $ECHO "$RED[!] llvm_mode InsTrim instrumentation produces weird numbers: $TUPLES" - CODE=1 - } - rm -f test-instr.instrim test.out - } || { - $ECHO "$RED[!] llvm_mode InsTrim compilation failed" - CODE=1 - } - } || { - $ECHO "$YELLOW[-] llvm_mode InsTrim not compiled, cannot test" - INCOMPLETE=1 - } - AFL_LLVM_INSTRUMENT=AFL AFL_DEBUG=1 AFL_LLVM_LAF_SPLIT_SWITCHES=1 AFL_LLVM_LAF_TRANSFORM_COMPARES=1 AFL_LLVM_LAF_SPLIT_COMPARES=1 ../afl-clang-fast -o test-compcov.compcov test-compcov.c > test.out 2>&1 - test -e test-compcov.compcov && test_compcov_binary_functionality ./test-compcov.compcov && { - grep --binary-files=text -Eq " [ 123][0-9][0-9] location| [3-9][0-9] location" test.out && { - $ECHO "$GREEN[+] llvm_mode laf-intel/compcov feature works correctly" - } || { - $ECHO "$RED[!] llvm_mode laf-intel/compcov feature failed" - CODE=1 - } - } || { - $ECHO "$RED[!] llvm_mode laf-intel/compcov feature compilation failed" - CODE=1 - } - rm -f test-compcov.compcov test.out - AFL_LLVM_INSTRUMENT=AFL AFL_LLVM_LAF_ALL=1 ../afl-clang-fast -o test-floatingpoint test-floatingpoint.c > test.out 2>&1 - test -e test-floatingpoint && { - mkdir -p in - echo ZZ > in/in - $ECHO "$GREY[*] running afl-fuzz with floating point splitting, this will take max. 30 seconds" - { - AFL_BENCH_UNTIL_CRASH=1 AFL_NO_UI=1 ../afl-fuzz -s 123 -V30 -m ${MEM_LIMIT} -i in -o out -- ./test-floatingpoint >>errors 2>&1 - } >>errors 2>&1 - test -n "$( ls out/crashes/id:* 2>/dev/null )" && { - $ECHO "$GREEN[+] llvm_mode laf-intel floatingpoint splitting feature works correctly" - } || { - $ECHO "$RED[!] llvm_mode laf-intel floatingpoint splitting feature failed" - CODE=1 - } - } || { - $ECHO "$RED[!] llvm_mode laf-intel floatingpoint splitting feature compilation failed" - CODE=1 - } - rm -f test-floatingpoint test.out in/in - echo foobar.c > instrumentlist.txt - AFL_DEBUG=1 AFL_LLVM_INSTRUMENT_FILE=instrumentlist.txt ../afl-clang-fast -o test-compcov test-compcov.c > test.out 2>&1 - test -e test-compcov && test_compcov_binary_functionality ./test-compcov && { - grep -q "No instrumentation targets found" test.out && { - $ECHO "$GREEN[+] llvm_mode instrumentlist feature works correctly" - } || { - $ECHO "$RED[!] llvm_mode instrumentlist feature failed" - CODE=1 - } - } || { - $ECHO "$RED[!] llvm_mode instrumentlist feature compilation failed" - CODE=1 - } - rm -f test-compcov test.out instrumentlist.txt - ../afl-clang-fast -o test-persistent ../examples/persistent_demo/persistent_demo.c > /dev/null 2>&1 - test -e test-persistent && { - echo foo | ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -q -r ./test-persistent && { - $ECHO "$GREEN[+] llvm_mode persistent mode feature works correctly" - } || { - $ECHO "$RED[!] llvm_mode persistent mode feature failed to work" - CODE=1 - } - } || { - $ECHO "$RED[!] llvm_mode persistent mode feature compilation failed" - CODE=1 - } - rm -f test-persistent -} || { - $ECHO "$YELLOW[-] llvm_mode not compiled, cannot test" - INCOMPLETE=1 -} - -$ECHO "$BLUE[*] Testing: LTO llvm_mode" -test -e ../afl-clang-lto -a -e ../afl-llvm-lto-instrumentation.so && { - # on FreeBSD need to set AFL_CC - test `uname -s` = 'FreeBSD' && { - if type clang >/dev/null; then - export AFL_CC=`command -v clang` - else - export AFL_CC=`$LLVM_CONFIG --bindir`/clang - fi - } - - ../afl-clang-lto -o test-instr.plain ../test-instr.c > /dev/null 2>&1 - test -e test-instr.plain && { - $ECHO "$GREEN[+] llvm_mode LTO compilation succeeded" - echo 0 | ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.0 -r -- ./test-instr.plain > /dev/null 2>&1 - ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.1 -r -- ./test-instr.plain < /dev/null > /dev/null 2>&1 - test -e test-instr.plain.0 -a -e test-instr.plain.1 && { - diff -q test-instr.plain.0 test-instr.plain.1 > /dev/null 2>&1 && { - $ECHO "$RED[!] llvm_mode LTO instrumentation should be different on different input but is not" - CODE=1 - } || { - $ECHO "$GREEN[+] llvm_mode LTO instrumentation present and working correctly" - TUPLES=`echo 0|../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.plain 2>&1 | grep Captur | awk '{print$3}'` - test "$TUPLES" -gt 3 -a "$TUPLES" -lt 7 && { - $ECHO "$GREEN[+] llvm_mode LTO run reported $TUPLES instrumented locations which is fine" - } || { - $ECHO "$RED[!] llvm_mode LTO instrumentation produces weird numbers: $TUPLES" - CODE=1 - } - } - } || { - $ECHO "$RED[!] llvm_mode LTO instrumentation failed" - CODE=1 - } - rm -f test-instr.plain.0 test-instr.plain.1 - } || { - $ECHO "$RED[!] LTO llvm_mode failed" - CODE=1 - } - rm -f test-instr.plain - - echo foobar.c > instrumentlist.txt - AFL_DEBUG=1 AFL_LLVM_INSTRUMENT_FILE=instrumentlist.txt ../afl-clang-lto -o test-compcov test-compcov.c > test.out 2>&1 - test -e test-compcov && { - grep -q "No instrumentation targets found" test.out && { - $ECHO "$GREEN[+] llvm_mode LTO instrumentlist feature works correctly" - } || { - $ECHO "$RED[!] llvm_mode LTO instrumentlist feature failed" - CODE=1 - } - } || { - $ECHO "$RED[!] llvm_mode LTO instrumentlist feature compilation failed" - CODE=1 - } - rm -f test-compcov test.out instrumentlist.txt - ../afl-clang-lto -o test-persistent ../examples/persistent_demo/persistent_demo.c > /dev/null 2>&1 - test -e test-persistent && { - echo foo | ../afl-showmap -m none -o /dev/null -q -r ./test-persistent && { - $ECHO "$GREEN[+] llvm_mode LTO persistent mode feature works correctly" - } || { - $ECHO "$RED[!] llvm_mode LTO persistent mode feature failed to work" - CODE=1 - } - } || { - $ECHO "$RED[!] llvm_mode LTO persistent mode feature compilation failed" - CODE=1 - } - rm -f test-persistent -} || { - $ECHO "$YELLOW[-] LTO llvm_mode not compiled, cannot test" - INCOMPLETE=1 -} - -$ECHO "$BLUE[*] Testing: gcc_plugin" -test -e ../afl-gcc-fast -a -e ../afl-gcc-rt.o && { - SAVE_AFL_CC=${AFL_CC} - export AFL_CC=`command -v gcc` - ../afl-gcc-fast -o test-instr.plain.gccpi ../test-instr.c > /dev/null 2>&1 - AFL_HARDEN=1 ../afl-gcc-fast -o test-compcov.harden.gccpi test-compcov.c > /dev/null 2>&1 - test -e test-instr.plain.gccpi && { - $ECHO "$GREEN[+] gcc_plugin compilation succeeded" - echo 0 | ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.0 -r -- ./test-instr.plain.gccpi > /dev/null 2>&1 - ../afl-showmap -m ${MEM_LIMIT} -o test-instr.plain.1 -r -- ./test-instr.plain.gccpi < /dev/null > /dev/null 2>&1 - test -e test-instr.plain.0 -a -e test-instr.plain.1 && { - diff test-instr.plain.0 test-instr.plain.1 > /dev/null 2>&1 && { - $ECHO "$RED[!] gcc_plugin instrumentation should be different on different input but is not" - CODE=1 - } || { - $ECHO "$GREEN[+] gcc_plugin instrumentation present and working correctly" - TUPLES=`echo 0|../afl-showmap -m ${MEM_LIMIT} -o /dev/null -- ./test-instr.plain.gccpi 2>&1 | grep Captur | awk '{print$3}'` - test "$TUPLES" -gt 3 -a "$TUPLES" -lt 7 && { - $ECHO "$GREEN[+] gcc_plugin run reported $TUPLES instrumented locations which is fine" - } || { - $ECHO "$RED[!] gcc_plugin instrumentation produces a weird numbers: $TUPLES" - $ECHO "$YELLOW[-] this is a known issue in gcc, not afl++. It is not flagged as an error because travis builds would all fail otherwise :-(" - #CODE=1 - } - } - } || { - $ECHO "$RED[!] gcc_plugin instrumentation failed" - CODE=1 - } - rm -f test-instr.plain.0 test-instr.plain.1 - } || { - $ECHO "$RED[!] gcc_plugin failed" - CODE=1 - } - - test -e test-compcov.harden.gccpi && test_compcov_binary_functionality ./test-compcov.harden.gccpi && { - grep -Eq$GREPAOPTION 'stack_chk_fail|fstack-protector-all|fortified' test-compcov.harden.gccpi > /dev/null 2>&1 && { - $ECHO "$GREEN[+] gcc_plugin hardened mode succeeded and is working" - } || { - $ECHO "$RED[!] gcc_plugin hardened mode is not hardened" - CODE=1 - } - rm -f test-compcov.harden.gccpi - } || { - $ECHO "$RED[!] gcc_plugin hardened mode compilation failed" - CODE=1 - } - # now we want to be sure that afl-fuzz is working - (test "$(uname -s)" = "Linux" && test "$(sysctl kernel.core_pattern)" != "kernel.core_pattern = core" && { - $ECHO "$YELLOW[-] we should not run afl-fuzz with enabled core dumps. Run 'sudo sh afl-system-config'.$RESET" - true - }) || - # make sure crash reporter is disabled on Mac OS X - (test "$(uname -s)" = "Darwin" && test $(launchctl list 2>/dev/null | grep -q '\.ReportCrash$') && { - $ECHO "$RED[!] we cannot run afl-fuzz with enabled crash reporter. Run 'sudo sh afl-system-config'.$RESET" - CODE=1 - true - }) || { - mkdir -p in - echo 0 > in/in - $ECHO "$GREY[*] running afl-fuzz for gcc_plugin, this will take approx 10 seconds" - { - ../afl-fuzz -V10 -m ${MEM_LIMIT} -i in -o out -- ./test-instr.plain.gccpi >>errors 2>&1 - } >>errors 2>&1 - test -n "$( ls out/queue/id:000002* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with gcc_plugin" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with gcc_plugin" - CODE=1 - } - rm -rf in out errors - } - rm -f test-instr.plain.gccpi - - # now for the special gcc_plugin things - echo foobar.c > instrumentlist.txt - AFL_GCC_INSTRUMENT_FILE=instrumentlist.txt ../afl-gcc-fast -o test-compcov test-compcov.c > /dev/null 2>&1 - test -e test-compcov && test_compcov_binary_functionality ./test-compcov && { - echo 1 | ../afl-showmap -m ${MEM_LIMIT} -o - -r -- ./test-compcov 2>&1 | grep -q "Captured 1 tuples" && { - $ECHO "$GREEN[+] gcc_plugin instrumentlist feature works correctly" - } || { - $ECHO "$RED[!] gcc_plugin instrumentlist feature failed" - CODE=1 - } - } || { - $ECHO "$RED[!] gcc_plugin instrumentlist feature compilation failed" - CODE=1 - } - rm -f test-compcov test.out instrumentlist.txt - ../afl-gcc-fast -o test-persistent ../examples/persistent_demo/persistent_demo.c > /dev/null 2>&1 - test -e test-persistent && { - echo foo | ../afl-showmap -m ${MEM_LIMIT} -o /dev/null -q -r ./test-persistent && { - $ECHO "$GREEN[+] gcc_plugin persistent mode feature works correctly" - } || { - $ECHO "$RED[!] gcc_plugin persistent mode feature failed to work" - CODE=1 - } - } || { - $ECHO "$RED[!] gcc_plugin persistent mode feature compilation failed" - CODE=1 - } - rm -f test-persistent - export AFL_CC=${SAVE_AFL_CC} -} || { - $ECHO "$YELLOW[-] gcc_plugin not compiled, cannot test" - INCOMPLETE=1 -} - -test -z "$AFL_CC" && unset AFL_CC - -$ECHO "$BLUE[*] Testing: shared library extensions" -cc $CFLAGS -o test-compcov test-compcov.c > /dev/null 2>&1 -test -e ../libtokencap.so && { - AFL_TOKEN_FILE=token.out LD_PRELOAD=../libtokencap.so DYLD_INSERT_LIBRARIES=../libtokencap.so DYLD_FORCE_FLAT_NAMESPACE=1 ./test-compcov foobar > /dev/null 2>&1 - grep -q BUGMENOT token.out > /dev/null 2>&1 && { - $ECHO "$GREEN[+] libtokencap did successfully capture tokens" - } || { - $ECHO "$RED[!] libtokencap did not capture tokens" - CODE=1 - } - rm -f token.out -} || { - $ECHO "$YELLOW[-] libtokencap is not compiled, cannot test" - INCOMPLETE=1 -} -test -e ../libdislocator.so && { - { - ulimit -c 1 - # DYLD_INSERT_LIBRARIES and DYLD_FORCE_FLAT_NAMESPACE is used on Darwin/MacOSX - LD_PRELOAD=../libdislocator.so DYLD_INSERT_LIBRARIES=../libdislocator.so DYLD_FORCE_FLAT_NAMESPACE=1 ./test-compcov BUFFEROVERFLOW > test.out 2>/dev/null - } > /dev/null 2>&1 - grep -q BUFFEROVERFLOW test.out > /dev/null 2>&1 && { - $ECHO "$RED[!] libdislocator did not detect the memory corruption" - CODE=1 - } || { - $ECHO "$GREEN[+] libdislocator did successfully detect the memory corruption" - } - rm -f test.out core test-compcov.core core.test-compcov -} || { - $ECHO "$YELLOW[-] libdislocator is not compiled, cannot test" - INCOMPLETE=1 -} -rm -f test-compcov -#test -e ../libradamsa.so && { -# # on FreeBSD need to set AFL_CC -# test `uname -s` = 'FreeBSD' && { -# if type clang >/dev/null; then -# export AFL_CC=`command -v clang` -# else -# export AFL_CC=`$LLVM_CONFIG --bindir`/clang -# fi -# } -# test -e test-instr.plain || ../afl-clang-fast -o test-instr.plain ../test-instr.c > /dev/null 2>&1 -# test -e test-instr.plain || ../afl-gcc-fast -o test-instr.plain ../test-instr.c > /dev/null 2>&1 -# test -e test-instr.plain || ../${AFL_GCC} -o test-instr.plain ../test-instr.c > /dev/null 2>&1 -# test -e test-instr.plain && { -# mkdir -p in -# printf 1 > in/in -# $ECHO "$GREY[*] running afl-fuzz with radamsa, this will take approx 10 seconds" -# { -# ../afl-fuzz -RR -V10 -m ${MEM_LIMIT} -i in -o out -- ./test-instr.plain -# } >>errors 2>&1 -# test -n "$( ls out/queue/id:000001* 2>/dev/null )" && { -# $ECHO "$GREEN[+] libradamsa performs good - and very slow - mutations" -# } || { -# echo CUT------------------------------------------------------------------CUT -# cat errors -# echo CUT------------------------------------------------------------------CUT -# $ECHO "$RED[!] libradamsa failed" -# CODE=1 -# } -# rm -rf in out errors test-instr.plain -# } || { -# $ECHO "$YELLOW[-] compilation of test target failed, cannot test libradamsa" -# INCOMPLETE=1 -# } -#} || { -# $ECHO "$YELLOW[-] libradamsa is not compiled, cannot test" -# INCOMPLETE=1 -#} - -test -z "$AFL_CC" && { - if type gcc >/dev/null; then - export AFL_CC=gcc - else - if type clang >/dev/null; then - export AFL_CC=clang - fi - fi -} - -$ECHO "$BLUE[*] Testing: qemu_mode" -test -e ../afl-qemu-trace && { - cc -pie -fPIE -o test-instr ../test-instr.c - cc -o test-compcov test-compcov.c - test -e test-instr -a -e test-compcov && { - { - mkdir -p in - echo 00000 > in/in - $ECHO "$GREY[*] running afl-fuzz for qemu_mode, this will take approx 10 seconds" - { - ../afl-fuzz -m ${MEM_LIMIT} -V10 -Q -i in -o out -- ./test-instr >>errors 2>&1 - } >>errors 2>&1 - test -n "$( ls out/queue/id:000002* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with qemu_mode" - RUNTIME=`grep execs_done out/fuzzer_stats | awk '{print$3}'` - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with qemu_mode" - CODE=1 - } - rm -f errors - - $ECHO "$GREY[*] running afl-fuzz for qemu_mode AFL_ENTRYPOINT, this will take approx 6 seconds" - { - { - if file test-instr | grep -q "32-bit"; then - # for 32-bit reduce 8 nibbles to the lower 7 nibbles - ADDR_LOWER_PART=`nm test-instr | grep "T main" | awk '{print $1}' | sed 's/^.//'` - else - # for 64-bit reduce 16 nibbles to the lower 9 nibbles - ADDR_LOWER_PART=`nm test-instr | grep "T main" | awk '{print $1}' | sed 's/^.......//'` - fi - export AFL_ENTRYPOINT=`expr 0x4${ADDR_LOWER_PART}` - $ECHO AFL_ENTRYPOINT=$AFL_ENTRYPOINT - $(nm test-instr | grep "T main") - $(file ./test-instr) - ../afl-fuzz -m ${MEM_LIMIT} -V2 -Q -i in -o out -- ./test-instr - unset AFL_ENTRYPOINT - } >>errors 2>&1 - } >>errors 2>&1 - test -n "$( ls out/queue/id:000001* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with qemu_mode AFL_ENTRYPOINT" - RUNTIME=`grep execs_done out/fuzzer_stats | awk '{print$3}'` - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with qemu_mode AFL_ENTRYPOINT" - CODE=1 - } - rm -f errors - - test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" -o "$SYS" = "aarch64" -o ! "${SYS%%arm*}" && { - test -e ../libcompcov.so && { - $ECHO "$GREY[*] running afl-fuzz for qemu_mode compcov, this will take approx 10 seconds" - { - export AFL_PRELOAD=../libcompcov.so - export AFL_COMPCOV_LEVEL=2 - ../afl-fuzz -m ${MEM_LIMIT} -V10 -Q -i in -o out -- ./test-compcov >>errors 2>&1 - unset AFL_PRELOAD - unset AFL_COMPCOV_LEVEL - } >>errors 2>&1 - test -n "$( ls out/queue/id:000001* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with qemu_mode compcov" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with qemu_mode compcov" - CODE=1 - } - } || { - $ECHO "$YELLOW[-] we cannot test qemu_mode compcov because it is not present" - INCOMPLETE=1 - } - rm -f errors - } || { - $ECHO "$YELLOW[-] not an intel or arm platform, cannot test qemu_mode compcov" - } - - test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" -o "$SYS" = "aarch64" -o ! "${SYS%%arm*}" && { - $ECHO "$GREY[*] running afl-fuzz for qemu_mode cmplog, this will take approx 10 seconds" - { - ../afl-fuzz -m none -V10 -Q -c 0 -i in -o out -- ./test-compcov >>errors 2>&1 - } >>errors 2>&1 - test -n "$( ls out/queue/id:000001* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with qemu_mode cmplog" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with qemu_mode cmplog" - CODE=1 - } - rm -f errors - } || { - $ECHO "$YELLOW[-] not an intel or arm platform, cannot test qemu_mode cmplog" - } - - test "$SYS" = "i686" -o "$SYS" = "x86_64" -o "$SYS" = "amd64" -o "$SYS" = "i86pc" -o "$SYS" = "aarch64" -o ! "${SYS%%arm*}" && { - $ECHO "$GREY[*] running afl-fuzz for persistent qemu_mode, this will take approx 10 seconds" - { - if file test-instr | grep -q "32-bit"; then - # for 32-bit reduce 8 nibbles to the lower 7 nibbles - ADDR_LOWER_PART=`nm test-instr | grep "T main" | awk '{print $1}' | sed 's/^.//'` - else - # for 64-bit reduce 16 nibbles to the lower 9 nibbles - ADDR_LOWER_PART=`nm test-instr | grep "T main" | awk '{print $1}' | sed 's/^.......//'` - fi - export AFL_QEMU_PERSISTENT_ADDR=`expr 0x4${ADDR_LOWER_PART}` - export AFL_QEMU_PERSISTENT_GPR=1 - $ECHO "Info: AFL_QEMU_PERSISTENT_ADDR=$AFL_QEMU_PERSISTENT_ADDR <= $(nm test-instr | grep "T main" | awk '{print $1}')" - env|grep AFL_|sort - file test-instr - ../afl-fuzz -m ${MEM_LIMIT} -V10 -Q -i in -o out -- ./test-instr - unset AFL_QEMU_PERSISTENT_ADDR - } >>errors 2>&1 - test -n "$( ls out/queue/id:000002* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with persistent qemu_mode" - RUNTIMEP=`grep execs_done out/fuzzer_stats | awk '{print$3}'` - test -n "$RUNTIME" -a -n "$RUNTIMEP" && { - DIFF=`expr $RUNTIMEP / $RUNTIME` - test "$DIFF" -gt 1 && { # must be at least twice as fast - $ECHO "$GREEN[+] persistent qemu_mode was noticeable faster than standard qemu_mode" - } || { - $ECHO "$YELLOW[-] persistent qemu_mode was not noticeable faster than standard qemu_mode" - } - } || { - $ECHO "$YELLOW[-] we got no data on executions performed? weird!" - } - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with persistent qemu_mode" - CODE=1 - } - rm -rf in out errors - } || { - $ECHO "$YELLOW[-] not an intel or arm platform, cannot test persistent qemu_mode" - } - - test -e ../qemu_mode/unsigaction/unsigaction32.so && { - ${AFL_CC} -o test-unsigaction32 -m32 test-unsigaction.c >> errors 2>&1 && { - ./test-unsigaction32 - RETVAL_NORMAL32=$? - LD_PRELOAD=../qemu_mode/unsigaction/unsigaction32.so ./test-unsigaction32 - RETVAL_LIBUNSIGACTION32=$? - test $RETVAL_NORMAL32 = "2" -a $RETVAL_LIBUNSIGACTION32 = "0" && { - $ECHO "$GREEN[+] qemu_mode unsigaction library (32 bit) ignores signals" - } || { - test $RETVAL_NORMAL32 != "2" && { - $ECHO "$RED[!] cannot trigger signal in test program (32 bit)" - } - test $RETVAL_LIBUNSIGACTION32 != "0" && { - $ECHO "$RED[!] signal in test program (32 bit) is not ignored with unsigaction" - } - CODE=1 - } - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] cannot compile test program (32 bit) for unsigaction library" - CODE=1 - } - } || { - $ECHO "$YELLOW[-] we cannot test qemu_mode unsigaction library (32 bit) because it is not present" - INCOMPLETE=1 - } - test -e ../qemu_mode/unsigaction/unsigaction64.so && { - ${AFL_CC} -o test-unsigaction64 -m64 test-unsigaction.c >> errors 2>&1 && { - ./test-unsigaction64 - RETVAL_NORMAL64=$? - LD_PRELOAD=../qemu_mode/unsigaction/unsigaction64.so ./test-unsigaction64 - RETVAL_LIBUNSIGACTION64=$? - test $RETVAL_NORMAL64 = "2" -a $RETVAL_LIBUNSIGACTION64 = "0" && { - $ECHO "$GREEN[+] qemu_mode unsigaction library (64 bit) ignores signals" - } || { - test $RETVAL_NORMAL64 != "2" && { - $ECHO "$RED[!] cannot trigger signal in test program (64 bit)" - } - test $RETVAL_LIBUNSIGACTION64 != "0" && { - $ECHO "$RED[!] signal in test program (64 bit) is not ignored with unsigaction" - } - CODE=1 - } - unset LD_PRELOAD - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] cannot compile test program (64 bit) for unsigaction library" - CODE=1 - } - } || { - $ECHO "$YELLOW[-] we cannot test qemu_mode unsigaction library (64 bit) because it is not present" - INCOMPLETE=1 - } - rm -rf errors test-unsigaction32 test-unsigaction64 - } - } || { - $ECHO "$RED[!] gcc compilation of test targets failed - what is going on??" - CODE=1 - } - - rm -f test-instr test-compcov -} || { - $ECHO "$YELLOW[-] qemu_mode is not compiled, cannot test" - INCOMPLETE=1 -} - -$ECHO "$BLUE[*] Testing: unicorn_mode" -test -d ../unicorn_mode/unicornafl && { - test -e ../unicorn_mode/samples/simple/simple_target.bin -a -e ../unicorn_mode/samples/compcov_x64/compcov_target.bin && { - { - # We want to see python errors etc. in logs, in case something doesn't work - export AFL_DEBUG_CHILD_OUTPUT=1 - - # some python version should be available now - PYTHONS="`command -v python3` `command -v python` `command -v python2`" - EASY_INSTALL_FOUND=0 - for PYTHON in $PYTHONS ; do - - if $PYTHON -c "help('easy_install');" </dev/null | grep -q module ; then - - EASY_INSTALL_FOUND=1 - PY=$PYTHON - break - - fi - - done - if [ "0" = $EASY_INSTALL_FOUND ]; then - - echo "[-] Error: Python setup-tools not found. Run 'sudo apt-get install python-setuptools'." - PREREQ_NOTFOUND=1 - - fi - - - cd ../unicorn_mode/samples/persistent - make >>errors 2>&1 - $ECHO "$GREY[*] running afl-fuzz for unicorn_mode (persistent), this will take approx 25 seconds" - AFL_DEBUG_CHILD_OUTPUT=1 ../../../afl-fuzz -m none -V25 -U -i sample_inputs -o out -d -- ./harness @@ >>errors 2>&1 - test -n "$( ls out/queue/id:000002* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with unicorn_mode (persistent)" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with unicorn_mode (persistent)" - CODE=1 - } - - rm -rf out errors >/dev/null - make clean >/dev/null - cd ../../../test - - # travis workaround - test "$PY" = "/opt/pyenv/shims/python" -a -x /usr/bin/python && PY=/usr/bin/python - mkdir -p in - echo 0 > in/in - $ECHO "$GREY[*] Using python binary $PY" - if ! $PY -c 'import unicornafl' 2>/dev/null ; then - $ECHO "$YELLOW[-] we cannot test unicorn_mode for python because it is not present" - INCOMPLETE=1 - else - { - $ECHO "$GREY[*] running afl-fuzz for unicorn_mode in python, this will take approx 25 seconds" - { - ../afl-fuzz -m ${MEM_LIMIT} -V25 -U -i in -o out -d -- "$PY" ../unicorn_mode/samples/simple/simple_test_harness.py @@ >>errors 2>&1 - } >>errors 2>&1 - test -n "$( ls out/queue/id:000002* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with unicorn_mode" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with unicorn_mode" - CODE=1 - } - rm -f errors - - printf '\x01\x01' > in/in - # This seed is close to the first byte of the comparison. - # If CompCov works, a new tuple will appear in the map => new input in queue - $ECHO "$GREY[*] running afl-fuzz for unicorn_mode compcov, this will take approx 35 seconds" - { - export AFL_COMPCOV_LEVEL=2 - ../afl-fuzz -m ${MEM_LIMIT} -V35 -U -i in -o out -d -- "$PY" ../unicorn_mode/samples/compcov_x64/compcov_test_harness.py @@ >>errors 2>&1 - unset AFL_COMPCOV_LEVEL - } >>errors 2>&1 - test -n "$( ls out/queue/id:000001* 2>/dev/null )" && { - $ECHO "$GREEN[+] afl-fuzz is working correctly with unicorn_mode compcov" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with unicorn_mode compcov" - CODE=1 - } - rm -rf in out errors - } - fi - - unset AFL_DEBUG_CHILD_OUTPUT - - } - } || { - $ECHO "$RED[!] missing sample binaries in unicorn_mode/samples/ - what is going on??" - CODE=1 - } - -} || { - $ECHO "$YELLOW[-] unicorn_mode is not compiled, cannot test" - INCOMPLETE=1 -} - -$ECHO "$BLUE[*] Testing: custom mutator" -test "1" = "`../afl-fuzz | grep -i 'without python' >/dev/null; echo $?`" && { - # normalize path - CUSTOM_MUTATOR_PATH=$(cd $(pwd)/../examples/custom_mutators;pwd) - test -e test-custom-mutator.c -a -e ${CUSTOM_MUTATOR_PATH}/example.c -a -e ${CUSTOM_MUTATOR_PATH}/example.py && { - unset AFL_CC - # Compile the vulnerable program for single mutator - test -e ../afl-clang-fast && { - ../afl-clang-fast -o test-custom-mutator test-custom-mutator.c > /dev/null 2>&1 - } || { - test -e ../afl-gcc-fast && { - ../afl-gcc-fast -o test-custom-mutator test-custom-mutator.c > /dev/null 2>&1 - } || { - ../afl-gcc -o test-custom-mutator test-custom-mutator.c > /dev/null 2>&1 - } - } - # Compile the vulnerable program for multiple mutators - test -e ../afl-clang-fast && { - ../afl-clang-fast -o test-multiple-mutators test-multiple-mutators.c > /dev/null 2>&1 - } || { - test -e ../afl-gcc-fast && { - ../afl-gcc-fast -o test-multiple-mutators test-multiple-mutators.c > /dev/null 2>&1 - } || { - ../afl-gcc -o test-multiple-mutators test-multiple-mutators.c > /dev/null 2>&1 - } - } - # Compile the custom mutator - cc -D_FIXED_CHAR=0x41 -g -fPIC -shared -I../include ../examples/custom_mutators/simple_example.c -o libexamplemutator.so > /dev/null 2>&1 - cc -D_FIXED_CHAR=0x42 -g -fPIC -shared -I../include ../examples/custom_mutators/simple_example.c -o libexamplemutator2.so > /dev/null 2>&1 - test -e test-custom-mutator -a -e ./libexamplemutator.so && { - # Create input directory - mkdir -p in - echo "00000" > in/in - - # Run afl-fuzz w/ the C mutator - $ECHO "$GREY[*] running afl-fuzz for the C mutator, this will take approx 5 seconds" - { - AFL_CUSTOM_MUTATOR_LIBRARY=./libexamplemutator.so AFL_CUSTOM_MUTATOR_ONLY=1 ../afl-fuzz -V1 -m ${MEM_LIMIT} -i in -o out -- ./test-custom-mutator >>errors 2>&1 - } >>errors 2>&1 - - # Check results - test -n "$( ls out/crashes/id:000000* 2>/dev/null )" && { # TODO: update here - $ECHO "$GREEN[+] afl-fuzz is working correctly with the C mutator" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with the C mutator" - CODE=1 - } - - # Clean - rm -rf out errors - - # Run afl-fuzz w/ multiple C mutators - $ECHO "$GREY[*] running afl-fuzz with multiple custom C mutators, this will take approx 5 seconds" - { - AFL_CUSTOM_MUTATOR_LIBRARY="./libexamplemutator.so;./libexamplemutator2.so" AFL_CUSTOM_MUTATOR_ONLY=1 ../afl-fuzz -V1 -m ${MEM_LIMIT} -i in -o out -- ./test-multiple-mutators >>errors 2>&1 - } >>errors 2>&1 - - test -n "$( ls out/crashes/id:000000* 2>/dev/null )" && { # TODO: update here - $ECHO "$GREEN[+] afl-fuzz is working correctly with multiple C mutators" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with multiple C mutators" - CODE=1 - } - - # Clean - rm -rf out errors - - # Run afl-fuzz w/ the Python mutator - $ECHO "$GREY[*] running afl-fuzz for the Python mutator, this will take approx 5 seconds" - { - export PYTHONPATH=${CUSTOM_MUTATOR_PATH} - export AFL_PYTHON_MODULE=example - AFL_CUSTOM_MUTATOR_ONLY=1 ../afl-fuzz -V5 -m ${MEM_LIMIT} -i in -o out -- ./test-custom-mutator >>errors 2>&1 - unset PYTHONPATH - unset AFL_PYTHON_MODULE - } >>errors 2>&1 - - # Check results - test -n "$( ls out/crashes/id:000000* 2>/dev/null )" && { # TODO: update here - $ECHO "$GREEN[+] afl-fuzz is working correctly with the Python mutator" - } || { - echo CUT------------------------------------------------------------------CUT - cat errors - echo CUT------------------------------------------------------------------CUT - $ECHO "$RED[!] afl-fuzz is not working correctly with the Python mutator" - CODE=1 - } - - # Clean - rm -rf in out errors - rm -rf ${CUSTOM_MUTATOR_PATH}/__pycache__/ - rm -f test-multiple-mutators test-custom-mutator libexamplemutator.so libexamplemutator2.so - } || { - ls . - ls ${CUSTOM_MUTATOR_PATH} - $ECHO "$RED[!] cannot compile the test program or the custom mutator" - CODE=1 - } - - #test "$CODE" = 1 && { $ECHO "$YELLOW[!] custom mutator tests currently will not fail travis" ; CODE=0 ; } - - make -C ../examples/custom_mutators clean > /dev/null 2>&1 - rm -f test-custom-mutator - rm -f test-custom-mutators - } || { - $ECHO "$YELLOW[-] no custom mutators in $CUSTOM_MUTATOR_PATH, cannot test" - INCOMPLETE=1 - } - unset CUSTOM_MUTATOR_PATH -} || { - $ECHO "$YELLOW[-] no python support in afl-fuzz, cannot test" - INCOMPLETE=1 -} - -$ECHO "$BLUE[*] Execution cmocka Unit-Tests $GREY" -unset AFL_CC -make -C .. unit || CODE=1 INCOMPLETE=1 : - -$ECHO "$GREY[*] all test cases completed.$RESET" -test "$INCOMPLETE" = "0" && $ECHO "$GREEN[+] all test cases executed" -test "$INCOMPLETE" = "1" && $ECHO "$YELLOW[-] not all test cases were executed" -test "$CODE" = "0" && $ECHO "$GREEN[+] all tests were successful :-)$RESET" -test "$CODE" = "0" || $ECHO "$RED[!] failure in tests :-($RESET" -exit $CODE diff --git a/test/travis/bionic/Dockerfile b/test/travis/bionic/Dockerfile index d1b53e70..00ab96f9 100644 --- a/test/travis/bionic/Dockerfile +++ b/test/travis/bionic/Dockerfile @@ -31,6 +31,7 @@ RUN apt-get update && apt-get -y install \ ENV AFL_NO_UI=1 ENV AFL_I_DONT_CARE_ABOUT_MISSING_CRASHES=1 +ENV LLVM_CONFIG=llvm-config-6.0 RUN cd / && \ git clone https://github.com/AFLplusplus/AFLplusplus && \ diff --git a/test/unittests/unit_hash.c b/test/unittests/unit_hash.c index 041d107a..22245ed6 100644 --- a/test/unittests/unit_hash.c +++ b/test/unittests/unit_hash.c @@ -30,6 +30,7 @@ extern void exit(int status); extern void __real_exit(int status); void __wrap_exit(int status); void __wrap_exit(int status) { + (void)status; assert(0); } @@ -39,11 +40,13 @@ extern int printf(const char *format, ...); extern int __real_printf(const char *format, ...); int __wrap_printf(const char *format, ...); int __wrap_printf(const char *format, ...) { + (void)format; return 1; } /* Rand with 0 seed would broke in the past */ static void test_hash(void **state) { + (void)state; char bitmap[64] = {0}; u64 hash0 = hash64(bitmap, sizeof(bitmap), 0xa5b35705); @@ -62,6 +65,8 @@ static void test_hash(void **state) { } int main(int argc, char **argv) { + (void)argc; + (void)argv; const struct CMUnitTest tests[] = { cmocka_unit_test(test_hash) diff --git a/test/unittests/unit_list.c b/test/unittests/unit_list.c index 4c2063b6..43665f1a 100644 --- a/test/unittests/unit_list.c +++ b/test/unittests/unit_list.c @@ -27,23 +27,26 @@ extern void mock_assert(const int result, const char* const expression, (compile with `--wrap=exit`) */ extern void exit(int status); extern void __real_exit(int status); -void __wrap_exit(int status); +//void __wrap_exit(int status); void __wrap_exit(int status) { + (void)status; assert(0); } /* ignore all printfs */ #undef printf extern int printf(const char *format, ...); -extern int __real_printf(const char *format, ...); +//extern int __real_printf(const char *format, ...); int __wrap_printf(const char *format, ...); int __wrap_printf(const char *format, ...) { + (void)format; return 1; } static list_t testlist = {.element_prealloc_count = 0}; static void test_contains(void **state) { + (void)state; u32 one = 1; u32 two = 2; @@ -56,6 +59,7 @@ static void test_contains(void **state) { } static void test_foreach(void **state) { + (void)state; u32 one = 1; u32 two = 2; @@ -75,6 +79,7 @@ static void test_foreach(void **state) { } static void test_long_list(void **state) { + (void)state; u32 result1 = 0; u32 result2 = 0; @@ -118,6 +123,8 @@ static void test_long_list(void **state) { } int main(int argc, char **argv) { + (void)argc; + (void)argv; const struct CMUnitTest tests[] = { cmocka_unit_test(test_contains), diff --git a/test/unittests/unit_maybe_alloc.c b/test/unittests/unit_maybe_alloc.c index 429d38ed..e452e2f2 100644 --- a/test/unittests/unit_maybe_alloc.c +++ b/test/unittests/unit_maybe_alloc.c @@ -28,6 +28,7 @@ void __wrap_exit(int status); extern void exit(int status); extern void __real_exit(int status); void __wrap_exit(int status) { + (void) status; assert(0); } @@ -35,12 +36,30 @@ int __wrap_printf(const char *format, ...); /* ignore all printfs */ #undef printf extern int printf(const char *format, ...); -extern int __real_printf(const char *format, ...); +//extern int __real_printf(const char *format, ...); int __wrap_printf(const char *format, ...) { + (void)format; return 1; } -#define BUF_PARAMS (void **)&buf, &size +#define VOID_BUF (void **)&buf + +static void *create_fake_maybe_grow_of(size_t size) { + + size += AFL_ALLOC_SIZE_OFFSET; + + // fake a realloc buf + + struct afl_alloc_buf *buf = malloc(size); + if (!buf) { + perror("Could not allocate fake buf"); + return NULL; + } + buf->complete_size = size; // The size + void *actual_buf = (void *)(buf->buf); + return actual_buf; + +} /* static int setup(void **state) { @@ -50,90 +69,132 @@ static int setup(void **state) { } */ +static void test_pow2(void **state) { + (void)state; + + assert_int_equal(next_pow2(64), 64); + assert_int_equal(next_pow2(63), 64); + assert_int_not_equal(next_pow2(65), 65); + assert_int_equal(next_pow2(0x100), 0x100); + assert_int_equal(next_pow2(0x180), 0x200); + assert_int_equal(next_pow2(108), 0x80); + assert_int_equal(next_pow2(0), 0); + assert_int_equal(next_pow2(1), 1); + assert_int_equal(next_pow2(2), 2); + assert_int_equal(next_pow2(3), 4); + assert_int_equal(next_pow2(0xFFFFFF), 0x1000000); + assert_int_equal(next_pow2(0xFFFFFFF), 0x10000000); + assert_int_equal(next_pow2(0xFFFFFF0), 0x10000000); + assert_int_equal(next_pow2(SIZE_MAX), 0); + assert_int_equal(next_pow2(-1), 0); + assert_int_equal(next_pow2(-2), 0); + +} + static void test_null_allocs(void **state) { + (void)state; void *buf = NULL; - size_t size = 0; - void *ptr = ck_maybe_grow(BUF_PARAMS, 100); + void *ptr = afl_realloc(VOID_BUF, 100); + if (unlikely(!buf)) { PFATAL("alloc"); } + size_t size = afl_alloc_bufsize(buf); assert_true(buf == ptr); assert_true(size >= 100); - ck_free(ptr); + afl_free(ptr); } static void test_nonpow2_size(void **state) { + (void)state; + + char *buf = create_fake_maybe_grow_of(150); - char *buf = ck_alloc(150); - size_t size = 150; buf[140] = '5'; - char *ptr = ck_maybe_grow(BUF_PARAMS, 160); + + char *ptr = afl_realloc(VOID_BUF, 160); + if (unlikely(!ptr)) { PFATAL("alloc"); } + size_t size = afl_alloc_bufsize(buf); assert_ptr_equal(buf, ptr); assert_true(size >= 160); assert_true(buf[140] == '5'); - ck_free(ptr); + afl_free(ptr); } static void test_zero_size(void **state) { + (void)state; char *buf = NULL; size_t size = 0; - assert_non_null(maybe_grow(BUF_PARAMS, 0)); - free(buf); + char *new_buf = afl_realloc(VOID_BUF, 0); + assert_non_null(new_buf); + assert_ptr_equal(buf, new_buf); + afl_free(buf); buf = NULL; size = 0; - char *ptr = ck_maybe_grow(BUF_PARAMS, 100); + char *ptr = afl_realloc(VOID_BUF, 100); + if (unlikely(!ptr)) { PFATAL("alloc"); } + size = afl_alloc_bufsize(buf); assert_non_null(ptr); assert_ptr_equal(buf, ptr); assert_true(size >= 100); - expect_assert_failure(ck_maybe_grow(BUF_PARAMS, 0)); - - ck_free(ptr); + afl_free(ptr); } + static void test_unchanged_size(void **state) { + (void)state; + + // fake a realloc buf + void *actual_buf = create_fake_maybe_grow_of(100); - void *buf = ck_alloc(100); - size_t size = 100; - void *buf_before = buf; - void *buf_after = ck_maybe_grow(BUF_PARAMS, 100); - assert_ptr_equal(buf, buf_after); + void *buf_before = actual_buf; + void *buf_after = afl_realloc(&actual_buf, 100); + if (unlikely(!buf_after)) { PFATAL("alloc"); } + assert_ptr_equal(actual_buf, buf_after); assert_ptr_equal(buf_after, buf_before); - ck_free(buf); + afl_free(buf_after); } static void test_grow_multiple(void **state) { + (void)state; char *buf = NULL; size_t size = 0; - char *ptr = ck_maybe_grow(BUF_PARAMS, 100); + char *ptr = afl_realloc(VOID_BUF, 100); + if (unlikely(!ptr)) { PFATAL("alloc"); } + size = afl_alloc_bufsize(ptr); assert_ptr_equal(ptr, buf); assert_true(size >= 100); - assert_int_equal(size, next_pow2(size)); + assert_int_equal(size, next_pow2(size) - AFL_ALLOC_SIZE_OFFSET); buf[50] = '5'; - ptr = (char *)ck_maybe_grow(BUF_PARAMS, 1000); + ptr = (char *)afl_realloc(VOID_BUF, 1000); + if (unlikely(!ptr)) { PFATAL("alloc"); } + size = afl_alloc_bufsize(ptr); assert_ptr_equal(ptr, buf); assert_true(size >= 100); - assert_int_equal(size, next_pow2(size)); + assert_int_equal(size, next_pow2(size) - AFL_ALLOC_SIZE_OFFSET); buf[500] = '5'; - ptr = (char *)ck_maybe_grow(BUF_PARAMS, 10000); + ptr = (char *)afl_realloc(VOID_BUF, 10000); + if (unlikely(!ptr)) { PFATAL("alloc"); } + size = afl_alloc_bufsize(ptr); assert_ptr_equal(ptr, buf); assert_true(size >= 10000); - assert_int_equal(size, next_pow2(size)); + assert_int_equal(size, next_pow2(size) - AFL_ALLOC_SIZE_OFFSET); buf[5000] = '5'; assert_int_equal(buf[50], '5'); assert_int_equal(buf[500], '5'); assert_int_equal(buf[5000], '5'); - ck_free(buf); + afl_free(buf); } @@ -146,8 +207,11 @@ static int teardown(void **state) { */ int main(int argc, char **argv) { + (void)argc; + (void)argv; const struct CMUnitTest tests[] = { + cmocka_unit_test(test_pow2), cmocka_unit_test(test_null_allocs), cmocka_unit_test(test_nonpow2_size), cmocka_unit_test(test_zero_size), diff --git a/test/unittests/unit_preallocable.c b/test/unittests/unit_preallocable.c index b0963a15..2f9c0b91 100644 --- a/test/unittests/unit_preallocable.c +++ b/test/unittests/unit_preallocable.c @@ -29,6 +29,7 @@ extern void exit(int status); extern void __real_exit(int status); void __wrap_exit(int status); void __wrap_exit(int status) { + (void)status; assert(0); } @@ -36,8 +37,9 @@ void __wrap_exit(int status) { #undef printf extern int printf(const char *format, ...); extern int __real_printf(const char *format, ...); -int __wrap_printf(const char *format, ...); +//int __wrap_printf(const char *format, ...); int __wrap_printf(const char *format, ...) { + (void)format; return 1; } @@ -47,15 +49,16 @@ typedef struct prealloc_me u8 *content[128]; -} prealloc_me_t; +} element_t; #define PREALLOCED_BUF_SIZE (64) -prealloc_me_t prealloc_me_buf[PREALLOCED_BUF_SIZE]; -size_t prealloc_me_size = 0; +element_t prealloc_me_buf[PREALLOCED_BUF_SIZE]; +s32 prealloc_me_size = 0; static void test_alloc_free(void **state) { + (void)state; - prealloc_me_t *prealloced = NULL; + element_t *prealloced = NULL; PRE_ALLOC(prealloced, prealloc_me_buf, PREALLOCED_BUF_SIZE, prealloc_me_size); assert_non_null(prealloced); PRE_FREE(prealloced, prealloc_me_size); @@ -63,9 +66,10 @@ static void test_alloc_free(void **state) { } static void test_prealloc_overflow(void **state) { + (void)state; u32 i = 0; - prealloc_me_t *prealloced[PREALLOCED_BUF_SIZE + 10]; + element_t *prealloced[PREALLOCED_BUF_SIZE + 10]; for (i = 0; i < PREALLOCED_BUF_SIZE + 10; i++) { @@ -102,6 +106,8 @@ static void test_prealloc_overflow(void **state) { } int main(int argc, char **argv) { + (void)argc; + (void)argv; const struct CMUnitTest tests[] = { cmocka_unit_test(test_alloc_free), diff --git a/test/unittests/unit_rand.c b/test/unittests/unit_rand.c index 0a90d8d1..1ad02a80 100644 --- a/test/unittests/unit_rand.c +++ b/test/unittests/unit_rand.c @@ -29,8 +29,9 @@ extern void mock_assert(const int result, const char* const expression, (compile with `--wrap=exit`) */ extern void exit(int status); extern void __real_exit(int status); -void __wrap_exit(int status); +//void __wrap_exit(int status); void __wrap_exit(int status) { + (void)status; assert(0); } @@ -40,11 +41,13 @@ extern int printf(const char *format, ...); extern int __real_printf(const char *format, ...); int __wrap_printf(const char *format, ...); int __wrap_printf(const char *format, ...) { + (void)format; return 1; } /* Rand with 0 seed would broke in the past */ static void test_rand_0(void **state) { + (void)state; afl_state_t afl = {0}; rand_set_seed(&afl, 0); @@ -58,6 +61,7 @@ static void test_rand_0(void **state) { } static void test_rand_below(void **state) { + (void)state; afl_state_t afl = {0}; rand_set_seed(&afl, 1337); @@ -70,6 +74,8 @@ static void test_rand_below(void **state) { } int main(int argc, char **argv) { + (void)argc; + (void)argv; const struct CMUnitTest tests[] = { cmocka_unit_test(test_rand_0), diff --git a/unicorn_mode/README.md b/unicorn_mode/README.md index f6bd4d12..b3df44fa 100644 --- a/unicorn_mode/README.md +++ b/unicorn_mode/README.md @@ -8,19 +8,19 @@ The CompareCoverage and NeverZero counters features are by Andrea Fioraldi <andr ## 1) Introduction -The code in ./unicorn_mode allows you to build a standalone feature that -leverages the Unicorn Engine and allows callers to obtain instrumentation +The code in ./unicorn_mode allows you to build the (Unicorn Engine)[https://github.com/unicorn-engine/unicorn] with afl support. +This means, you can run anything that can be emulated in unicorn and obtain instrumentation output for black-box, closed-source binary code snippets. This mechanism can be then used by afl-fuzz to stress-test targets that couldn't be built -with afl-gcc or used in QEMU mode, or with other extensions such as -TriforceAFL. +with afl-cc or used in QEMU mode. There is a significant performance penalty compared to native AFL, but at least we're able to use AFL++ on these binaries, right? ## 2) How to use -Requirements: you need an installed python environment. +First, you will need a working harness for your target in unicorn, using Python, C, or Rust. +For some pointers for more advanced emulation, take a look at [BaseSAFE](https://github.com/fgsect/BaseSAFE) and [Qiling](https://github.com/qilingframework/qiling). ### Building AFL++'s Unicorn Mode @@ -34,23 +34,23 @@ cd unicorn_mode ``` NOTE: This script checks out a Unicorn Engine fork as submodule that has been tested -and is stable-ish, based on the unicorn engine master. +and is stable-ish, based on the unicorn engine `next` branch. Building Unicorn will take a little bit (~5-10 minutes). Once it completes it automatically compiles a sample application and verifies that it works. ### Fuzzing with Unicorn Mode -To really use unicorn-mode effectively you need to prepare the following: +To use unicorn-mode effectively you need to prepare the following: * Relevant binary code to be fuzzed * Knowledge of the memory map and good starting state * Folder containing sample inputs to start fuzzing with + Same ideas as any other AFL inputs - + Quality/speed of results will depend greatly on quality of starting + + Quality/speed of results will depend greatly on the quality of starting samples + See AFL's guidance on how to create a sample corpus - * Unicornafl-based test harness which: + * Unicornafl-based test harness in Rust, C, or Python, which: + Adds memory map regions + Loads binary code into memory + Calls uc.afl_fuzz() / uc.afl_start_forkserver @@ -59,13 +59,13 @@ To really use unicorn-mode effectively you need to prepare the following: the test harness + Presumably the data to be fuzzed is at a fixed buffer address + If input constraints (size, invalid bytes, etc.) are known they - should be checked after the file is loaded. If a constraint - fails, just exit the test harness. AFL will treat the input as + should be checked in the place_input handler. If a constraint + fails, just return false from the handler. AFL will treat the input as 'uninteresting' and move on. + Sets up registers and memory state for beginning of test - + Emulates the interested code from beginning to end + + Emulates the interesting code from beginning to end + If a crash is detected, the test harness must 'crash' by - throwing a signal (SIGSEGV, SIGKILL, SIGABORT, etc.) + throwing a signal (SIGSEGV, SIGKILL, SIGABORT, etc.), or indicate a crash in the crash validation callback. Once you have all those things ready to go you just need to run afl-fuzz in 'unicorn-mode' by passing in the '-U' flag: @@ -79,11 +79,12 @@ AFL's main documentation for more info about how to use afl-fuzz effectively. For a much clearer vision of what all of this looks like, please refer to the sample provided in the 'unicorn_mode/samples' directory. There is also a blog -post that goes over the basics at: +post that uses slightly older concepts, but describes the general ideas, at: [https://medium.com/@njvoss299/afl-unicorn-fuzzing-arbitrary-binary-code-563ca28936bf](https://medium.com/@njvoss299/afl-unicorn-fuzzing-arbitrary-binary-code-563ca28936bf) -The 'helper_scripts' directory also contains several helper scripts that allow you + +The ['helper_scripts'](./helper_scripts) directory also contains several helper scripts that allow you to dump context from a running process, load it, and hook heap allocations. For details on how to use this check out the follow-up blog post to the one linked above. @@ -92,10 +93,10 @@ A example use of AFL-Unicorn mode is discussed in the paper Unicorefuzz: ## 3) Options -As for the QEMU-based instrumentation, the afl-unicorn twist of afl++ -comes with a sub-instruction based instrumentation similar in purpose to laf-intel. +As for the QEMU-based instrumentation, unicornafl comes with a sub-instruction based instrumentation similar in purpose to laf-intel. The options that enable Unicorn CompareCoverage are the same used for QEMU. +This will split up each multi-byte compare to give feedback for each correct byte. AFL_COMPCOV_LEVEL=1 is to instrument comparisons with only immediate values. AFL_COMPCOV_LEVEL=2 instruments all comparison instructions. @@ -119,6 +120,20 @@ unicornafl.monkeypatch() This will replace all unicorn imports with unicornafl inputs. -Refer to the [samples/arm_example/arm_tester.c](samples/arm_example/arm_tester.c) for an example -of how to do this properly! If you don't get this right, AFL will not -load any mutated inputs and your fuzzing will be useless! +5) Examples + +Apart from reading the documentation in `afl.c` and the python bindings of unicornafl, the best documentation are the [samples/](./samples). +The following examples exist at the time of writing: + +- c: A simple example how to use the c bindings +- compcov_x64: A python example that uses compcov to traverse hard-to-reach blocks +- persistent: A c example using persistent mode for maximum speed, and resetting the target state between each iteration +- simple: A simple python example +- speedtest/c: The c harness for an example target, used to compare c, python, and rust bindings and fix speed issues +- speedtest/python: Fuzzing the same target in python +- speedtest/rust: Fuzzing the same target using a rust harness + +Usually, the place to look at is the `harness` in each folder. The source code in each harness is pretty well documented. +Most harnesses also have the `afl-fuzz` commandline, or even offer a `make fuzz` Makefile target. +Targets in these folders, if x86, can usually be made using `make target` in each folder or get shipped pre-built (plus their source). +Especially take a look at the [speedtest documentation](./samples/speedtest/README.md) to see how the languages compare.
\ No newline at end of file diff --git a/unicorn_mode/UNICORNAFL_VERSION b/unicorn_mode/UNICORNAFL_VERSION index 02736b77..d9ae5590 100644 --- a/unicorn_mode/UNICORNAFL_VERSION +++ b/unicorn_mode/UNICORNAFL_VERSION @@ -1 +1 @@ -c6d66471 +fb2fc9f2 diff --git a/unicorn_mode/build_unicorn_support.sh b/unicorn_mode/build_unicorn_support.sh index 841728d7..6c376f8d 100755 --- a/unicorn_mode/build_unicorn_support.sh +++ b/unicorn_mode/build_unicorn_support.sh @@ -44,7 +44,7 @@ echo "[*] Performing basic sanity checks..." PLT=`uname -s` -if [ ! "$PLT" = "Linux" ] && [ ! "$PLT" = "Darwin" ] && [ ! "$PLT" = "FreeBSD" ] && [ ! "$PLT" = "NetBSD" ] && [ ! "$PLT" = "OpenBSD" ]; then +if [ ! "$PLT" = "Linux" ] && [ ! "$PLT" = "Darwin" ] && [ ! "$PLT" = "FreeBSD" ] && [ ! "$PLT" = "NetBSD" ] && [ ! "$PLT" = "OpenBSD" ] && [ ! "$PLT" = "DragonFly" ]; then echo "[-] Error: Unicorn instrumentation is unsupported on $PLT." exit 1 @@ -70,6 +70,11 @@ MAKECMD=make TARCMD=tar if [ "$PLT" = "Linux" ]; then + MUSL=`ldd --version 2>&1 | head -n 1 | cut -f 1 -d " "` + if [ "musl" = $MUSL ]; then + echo "[-] Error: Unicorn instrumentation is unsupported with the musl's libc." + exit 1 + fi CORES=`nproc` fi @@ -84,6 +89,12 @@ if [ "$PLT" = "FreeBSD" ]; then TARCMD=gtar fi +if [ "$PLT" = "DragonFly" ]; then + MAKECMD=gmake + CORES=`sysctl -n hw.ncpu` + TARCMD=tar +fi + if [ "$PLT" = "NetBSD" ] || [ "$PLT" = "OpenBSD" ]; then MAKECMD=gmake CORES=`sysctl -n hw.ncpu` @@ -106,19 +117,19 @@ done # some python version should be available now PYTHONS="`command -v python3` `command -v python` `command -v python2`" -EASY_INSTALL_FOUND=0 +SETUPTOOLS_FOUND=0 for PYTHON in $PYTHONS ; do if $PYTHON -c "import setuptools" ; then - EASY_INSTALL_FOUND=1 + SETUPTOOLS_FOUND=1 PYTHONBIN=$PYTHON break fi done -if [ "0" = $EASY_INSTALL_FOUND ]; then +if [ "0" = $SETUPTOOLS_FOUND ]; then echo "[-] Error: Python setup-tools not found. Run 'sudo apt-get install python-setuptools', or install python3-setuptools, or run '$PYTHONBIN -m ensurepip', or create a virtualenv, or ..." PREREQ_NOTFOUND=1 @@ -136,6 +147,8 @@ if [ "$PREREQ_NOTFOUND" = "1" ]; then exit 1 fi +unset CFLAGS + echo "[+] All checks passed!" echo "[*] Making sure unicornafl is checked out" @@ -144,7 +157,8 @@ git status 1>/dev/null 2>/dev/null if [ $? -eq 0 ]; then echo "[*] initializing unicornafl submodule" git submodule init || exit 1 - git submodule update 2>/dev/null # ignore errors + git submodule update ./unicornafl 2>/dev/null # ignore errors + git submodule sync ./unicornafl 2>/dev/null # ignore errors else echo "[*] cloning unicornafl" test -d unicornafl || { @@ -165,8 +179,9 @@ echo "[*] Checking out $UNICORNAFL_VERSION" sh -c 'git stash && git stash drop' 1>/dev/null 2>/dev/null git checkout "$UNICORNAFL_VERSION" || exit 1 -echo "[*] making sure config.h matches" -cp "../../config.h" "." || exit 1 +echo "[*] making sure afl++ header files match" +cp "../../include/config.h" "." || exit 1 +cp "../../include/types.h" "." || exit 1 echo "[*] Configuring Unicorn build..." diff --git a/unicorn_mode/helper_scripts/unicorn_dumper_gdb.py b/unicorn_mode/helper_scripts/unicorn_dumper_gdb.py index 22b9fd47..1ac4c9f3 100644 --- a/unicorn_mode/helper_scripts/unicorn_dumper_gdb.py +++ b/unicorn_mode/helper_scripts/unicorn_dumper_gdb.py @@ -1,13 +1,13 @@ """ unicorn_dumper_gdb.py - + When run with GDB sitting at a debug breakpoint, this dumps the current state (registers/memory/etc) of - the process to a directory consisting of an index - file with register and segment information and + the process to a directory consisting of an index + file with register and segment information and sub-files containing all actual process memory. - - The output of this script is expected to be used + + The output of this script is expected to be used to initialize context for Unicorn emulation. ----------- @@ -44,30 +44,32 @@ MAX_SEG_SIZE = 128 * 1024 * 1024 # Name of the index file INDEX_FILE_NAME = "_index.json" -#---------------------- -#---- Helper Functions + +# ---------------------- +# ---- Helper Functions + def map_arch(): - arch = get_arch() # from GEF - if 'x86_64' in arch or 'x86-64' in arch: + arch = get_arch() # from GEF + if "x86_64" in arch or "x86-64" in arch: return "x64" - elif 'x86' in arch or 'i386' in arch: + elif "x86" in arch or "i386" in arch: return "x86" - elif 'aarch64' in arch or 'arm64' in arch: + elif "aarch64" in arch or "arm64" in arch: return "arm64le" - elif 'aarch64_be' in arch: + elif "aarch64_be" in arch: return "arm64be" - elif 'armeb' in arch: + elif "armeb" in arch: # check for THUMB mode - cpsr = get_register('cpsr') - if (cpsr & (1 << 5)): + cpsr = get_register("$cpsr") + if cpsr & (1 << 5): return "armbethumb" else: return "armbe" - elif 'arm' in arch: + elif "arm" in arch: # check for THUMB mode - cpsr = get_register('cpsr') - if (cpsr & (1 << 5)): + cpsr = get_register("$cpsr") + if cpsr & (1 << 5): return "armlethumb" else: return "armle" @@ -75,8 +77,9 @@ def map_arch(): return "" -#----------------------- -#---- Dumping functions +# ----------------------- +# ---- Dumping functions + def dump_arch_info(): arch_info = {} @@ -88,19 +91,15 @@ def dump_regs(): reg_state = {} for reg in current_arch.all_registers: reg_val = get_register(reg) - # current dumper script looks for register values to be hex strings -# reg_str = "0x{:08x}".format(reg_val) -# if "64" in get_arch(): -# reg_str = "0x{:016x}".format(reg_val) -# reg_state[reg.strip().strip('$')] = reg_str - reg_state[reg.strip().strip('$')] = reg_val + reg_state[reg.strip().strip("$")] = reg_val + return reg_state def dump_process_memory(output_dir): # Segment information dictionary final_segment_list = [] - + # GEF: vmmap = get_process_maps() if not vmmap: @@ -110,45 +109,91 @@ def dump_process_memory(output_dir): for entry in vmmap: if entry.page_start == entry.page_end: continue - - seg_info = {'start': entry.page_start, 'end': entry.page_end, 'name': entry.path, 'permissions': { - "r": entry.is_readable() > 0, - "w": entry.is_writable() > 0, - "x": entry.is_executable() > 0 - }, 'content_file': ''} + + seg_info = { + "start": entry.page_start, + "end": entry.page_end, + "name": entry.path, + "permissions": { + "r": entry.is_readable() > 0, + "w": entry.is_writable() > 0, + "x": entry.is_executable() > 0, + }, + "content_file": "", + } # "(deleted)" may or may not be valid, but don't push it. - if entry.is_readable() and not '(deleted)' in entry.path: + if entry.is_readable() and not "(deleted)" in entry.path: try: # Compress and dump the content to a file seg_content = read_memory(entry.page_start, entry.size) - if(seg_content == None): - print("Segment empty: @0x{0:016x} (size:UNKNOWN) {1}".format(entry.page_start, entry.path)) + if seg_content == None: + print( + "Segment empty: @0x{0:016x} (size:UNKNOWN) {1}".format( + entry.page_start, entry.path + ) + ) else: - print("Dumping segment @0x{0:016x} (size:0x{1:x}): {2} [{3}]".format(entry.page_start, len(seg_content), entry.path, repr(seg_info['permissions']))) + print( + "Dumping segment @0x{0:016x} (size:0x{1:x}): {2} [{3}]".format( + entry.page_start, + len(seg_content), + entry.path, + repr(seg_info["permissions"]), + ) + ) compressed_seg_content = zlib.compress(seg_content) md5_sum = hashlib.md5(compressed_seg_content).hexdigest() + ".bin" seg_info["content_file"] = md5_sum - + # Write the compressed contents to disk - out_file = open(os.path.join(output_dir, md5_sum), 'wb') + out_file = open(os.path.join(output_dir, md5_sum), "wb") out_file.write(compressed_seg_content) out_file.close() except: - print("Exception reading segment ({}): {}".format(entry.path, sys.exc_info()[0])) + print( + "Exception reading segment ({}): {}".format( + entry.path, sys.exc_info()[0] + ) + ) else: - print("Skipping segment {0}@0x{1:016x}".format(entry.path, entry.page_start)) + print( + "Skipping segment {0}@0x{1:016x}".format(entry.path, entry.page_start) + ) # Add the segment to the list final_segment_list.append(seg_info) - return final_segment_list -#---------- -#---- Main - + +# --------------------------------------------- +# ---- ARM Extention (dump floating point regs) + + +def dump_float(rge=32): + reg_convert = "" + if ( + map_arch() == "armbe" + or map_arch() == "armle" + or map_arch() == "armbethumb" + or map_arch() == "armbethumb" + ): + reg_state = {} + for reg_num in range(32): + value = gdb.selected_frame().read_register("d" + str(reg_num)) + reg_state["d" + str(reg_num)] = int(str(value["u64"]), 16) + value = gdb.selected_frame().read_register("fpscr") + reg_state["fpscr"] = int(str(value), 16) + + return reg_state + + +# ---------- +# ---- Main + + def main(): print("----- Unicorn Context Dumper -----") print("You must be actively debugging before running this!") @@ -159,32 +204,35 @@ def main(): print("!!! GEF not running in GDB. Please run gef.py by executing:") print('\tpython execfile ("<path_to_gef>/gef.py")') return - + try: - + # Create the output directory - timestamp = datetime.datetime.fromtimestamp(time.time()).strftime('%Y%m%d_%H%M%S') + timestamp = datetime.datetime.fromtimestamp(time.time()).strftime( + "%Y%m%d_%H%M%S" + ) output_path = "UnicornContext_" + timestamp if not os.path.exists(output_path): os.makedirs(output_path) print("Process context will be output to {}".format(output_path)) - + # Get the context context = { "arch": dump_arch_info(), - "regs": dump_regs(), + "regs": dump_regs(), + "regs_extended": dump_float(), "segments": dump_process_memory(output_path), } # Write the index file - index_file = open(os.path.join(output_path, INDEX_FILE_NAME), 'w') + index_file = open(os.path.join(output_path, INDEX_FILE_NAME), "w") index_file.write(json.dumps(context, indent=4)) - index_file.close() + index_file.close() print("Done.") - + except Exception as e: print("!!! ERROR:\n\t{}".format(repr(e))) - + + if __name__ == "__main__": main() - diff --git a/unicorn_mode/helper_scripts/unicorn_dumper_ida.py b/unicorn_mode/helper_scripts/unicorn_dumper_ida.py index 6cf9f30f..fa29fb90 100644 --- a/unicorn_mode/helper_scripts/unicorn_dumper_ida.py +++ b/unicorn_mode/helper_scripts/unicorn_dumper_ida.py @@ -31,8 +31,9 @@ MAX_SEG_SIZE = 128 * 1024 * 1024 # Name of the index file INDEX_FILE_NAME = "_index.json" -#---------------------- -#---- Helper Functions +# ---------------------- +# ---- Helper Functions + def get_arch(): if ph.id == PLFM_386 and ph.flag & PR_USE64: @@ -52,6 +53,7 @@ def get_arch(): else: return "" + def get_register_list(arch): if arch == "arm64le" or arch == "arm64be": arch = "arm64" @@ -59,84 +61,174 @@ def get_register_list(arch): arch = "arm" registers = { - "x64" : [ - "rax", "rbx", "rcx", "rdx", "rsi", "rdi", "rbp", "rsp", - "r8", "r9", "r10", "r11", "r12", "r13", "r14", "r15", - "rip", "rsp", "efl", - "cs", "ds", "es", "fs", "gs", "ss", + "x64": [ + "rax", + "rbx", + "rcx", + "rdx", + "rsi", + "rdi", + "rbp", + "rsp", + "r8", + "r9", + "r10", + "r11", + "r12", + "r13", + "r14", + "r15", + "rip", + "rsp", + "efl", + "cs", + "ds", + "es", + "fs", + "gs", + "ss", + ], + "x86": [ + "eax", + "ebx", + "ecx", + "edx", + "esi", + "edi", + "ebp", + "esp", + "eip", + "esp", + "efl", + "cs", + "ds", + "es", + "fs", + "gs", + "ss", ], - "x86" : [ - "eax", "ebx", "ecx", "edx", "esi", "edi", "ebp", "esp", - "eip", "esp", "efl", - "cs", "ds", "es", "fs", "gs", "ss", - ], - "arm" : [ - "R0", "R1", "R2", "R3", "R4", "R5", "R6", "R7", - "R8", "R9", "R10", "R11", "R12", "PC", "SP", "LR", + "arm": [ + "R0", + "R1", + "R2", + "R3", + "R4", + "R5", + "R6", + "R7", + "R8", + "R9", + "R10", + "R11", + "R12", + "PC", + "SP", + "LR", "PSR", ], - "arm64" : [ - "X0", "X1", "X2", "X3", "X4", "X5", "X6", "X7", - "X8", "X9", "X10", "X11", "X12", "X13", "X14", - "X15", "X16", "X17", "X18", "X19", "X20", "X21", - "X22", "X23", "X24", "X25", "X26", "X27", "X28", - "PC", "SP", "FP", "LR", "CPSR" + "arm64": [ + "X0", + "X1", + "X2", + "X3", + "X4", + "X5", + "X6", + "X7", + "X8", + "X9", + "X10", + "X11", + "X12", + "X13", + "X14", + "X15", + "X16", + "X17", + "X18", + "X19", + "X20", + "X21", + "X22", + "X23", + "X24", + "X25", + "X26", + "X27", + "X28", + "PC", + "SP", + "FP", + "LR", + "CPSR" # "NZCV", - ] + ], } - return registers[arch] + return registers[arch] + + +# ----------------------- +# ---- Dumping functions -#----------------------- -#---- Dumping functions def dump_arch_info(): arch_info = {} arch_info["arch"] = get_arch() return arch_info + def dump_regs(): reg_state = {} for reg in get_register_list(get_arch()): reg_state[reg] = GetRegValue(reg) return reg_state + def dump_process_memory(output_dir): # Segment information dictionary segment_list = [] - + # Loop over the segments, fill in the info dictionary for seg_ea in Segments(): seg_start = SegStart(seg_ea) seg_end = SegEnd(seg_ea) seg_size = seg_end - seg_start - + seg_info = {} - seg_info["name"] = SegName(seg_ea) + seg_info["name"] = SegName(seg_ea) seg_info["start"] = seg_start - seg_info["end"] = seg_end - + seg_info["end"] = seg_end + perms = getseg(seg_ea).perm seg_info["permissions"] = { - "r": False if (perms & SEGPERM_READ) == 0 else True, + "r": False if (perms & SEGPERM_READ) == 0 else True, "w": False if (perms & SEGPERM_WRITE) == 0 else True, - "x": False if (perms & SEGPERM_EXEC) == 0 else True, + "x": False if (perms & SEGPERM_EXEC) == 0 else True, } if (perms & SEGPERM_READ) and seg_size <= MAX_SEG_SIZE and isLoaded(seg_start): try: # Compress and dump the content to a file seg_content = get_many_bytes(seg_start, seg_end - seg_start) - if(seg_content == None): - print("Segment empty: {0}@0x{1:016x} (size:UNKNOWN)".format(SegName(seg_ea), seg_ea)) + if seg_content == None: + print( + "Segment empty: {0}@0x{1:016x} (size:UNKNOWN)".format( + SegName(seg_ea), seg_ea + ) + ) seg_info["content_file"] = "" else: - print("Dumping segment {0}@0x{1:016x} (size:{2})".format(SegName(seg_ea), seg_ea, len(seg_content))) + print( + "Dumping segment {0}@0x{1:016x} (size:{2})".format( + SegName(seg_ea), seg_ea, len(seg_content) + ) + ) compressed_seg_content = zlib.compress(seg_content) md5_sum = hashlib.md5(compressed_seg_content).hexdigest() + ".bin" seg_info["content_file"] = md5_sum - + # Write the compressed contents to disk - out_file = open(os.path.join(output_dir, md5_sum), 'wb') + out_file = open(os.path.join(output_dir, md5_sum), "wb") out_file.write(compressed_seg_content) out_file.close() except: @@ -145,12 +237,13 @@ def dump_process_memory(output_dir): else: print("Skipping segment {0}@0x{1:016x}".format(SegName(seg_ea), seg_ea)) seg_info["content_file"] = "" - + # Add the segment to the list - segment_list.append(seg_info) - + segment_list.append(seg_info) + return segment_list + """ TODO: FINISH IMPORT DUMPING def import_callback(ea, name, ord): @@ -169,41 +262,47 @@ def dump_imports(): return import_dict """ - -#---------- -#---- Main - + +# ---------- +# ---- Main + + def main(): try: print("----- Unicorn Context Dumper -----") print("You must be actively debugging before running this!") - print("If it fails, double check that you are actively debugging before running.") + print( + "If it fails, double check that you are actively debugging before running." + ) # Create the output directory - timestamp = datetime.datetime.fromtimestamp(time.time()).strftime('%Y%m%d_%H%M%S') + timestamp = datetime.datetime.fromtimestamp(time.time()).strftime( + "%Y%m%d_%H%M%S" + ) output_path = os.path.dirname(os.path.abspath(GetIdbPath())) output_path = os.path.join(output_path, "UnicornContext_" + timestamp) if not os.path.exists(output_path): os.makedirs(output_path) print("Process context will be output to {}".format(output_path)) - + # Get the context context = { "arch": dump_arch_info(), - "regs": dump_regs(), + "regs": dump_regs(), "segments": dump_process_memory(output_path), - #"imports": dump_imports(), + # "imports": dump_imports(), } # Write the index file - index_file = open(os.path.join(output_path, INDEX_FILE_NAME), 'w') + index_file = open(os.path.join(output_path, INDEX_FILE_NAME), "w") index_file.write(json.dumps(context, indent=4)) - index_file.close() + index_file.close() print("Done.") - + except Exception, e: print("!!! ERROR:\n\t{}".format(str(e))) - + + if __name__ == "__main__": main() diff --git a/unicorn_mode/helper_scripts/unicorn_dumper_lldb.py b/unicorn_mode/helper_scripts/unicorn_dumper_lldb.py index 3c019d77..179d062a 100644 --- a/unicorn_mode/helper_scripts/unicorn_dumper_lldb.py +++ b/unicorn_mode/helper_scripts/unicorn_dumper_lldb.py @@ -50,10 +50,11 @@ UNICORN_PAGE_SIZE = 0x1000 # Alignment functions to align all memory segments to Unicorn page boundaries (4KB pages only) ALIGN_PAGE_DOWN = lambda x: x & ~(UNICORN_PAGE_SIZE - 1) -ALIGN_PAGE_UP = lambda x: (x + UNICORN_PAGE_SIZE - 1) & ~(UNICORN_PAGE_SIZE-1) +ALIGN_PAGE_UP = lambda x: (x + UNICORN_PAGE_SIZE - 1) & ~(UNICORN_PAGE_SIZE - 1) + +# ---------------------- +# ---- Helper Functions -#---------------------- -#---- Helper Functions def overlap_alignments(segments, memory): final_list = [] @@ -61,33 +62,40 @@ def overlap_alignments(segments, memory): curr_end_addr = 0 curr_node = None current_segment = None - sorted_segments = sorted(segments, key=lambda k: (k['start'], k['end'])) + sorted_segments = sorted(segments, key=lambda k: (k["start"], k["end"])) if curr_seg_idx < len(sorted_segments): current_segment = sorted_segments[curr_seg_idx] - for mem in sorted(memory, key=lambda k: (k['start'], -k['end'])): + for mem in sorted(memory, key=lambda k: (k["start"], -k["end"])): if curr_node is None: - if current_segment is not None and current_segment['start'] == mem['start']: + if current_segment is not None and current_segment["start"] == mem["start"]: curr_node = deepcopy(current_segment) - curr_node['permissions'] = mem['permissions'] + curr_node["permissions"] = mem["permissions"] else: curr_node = deepcopy(mem) - curr_end_addr = curr_node['end'] - - while curr_end_addr <= mem['end']: - if curr_node['end'] == mem['end']: - if current_segment is not None and current_segment['start'] > curr_node['start'] and current_segment['start'] < curr_node['end']: - curr_node['end'] = current_segment['start'] - if(curr_node['end'] > curr_node['start']): + curr_end_addr = curr_node["end"] + + while curr_end_addr <= mem["end"]: + if curr_node["end"] == mem["end"]: + if ( + current_segment is not None + and current_segment["start"] > curr_node["start"] + and current_segment["start"] < curr_node["end"] + ): + curr_node["end"] = current_segment["start"] + if curr_node["end"] > curr_node["start"]: final_list.append(curr_node) curr_node = deepcopy(current_segment) - curr_node['permissions'] = mem['permissions'] - curr_end_addr = curr_node['end'] + curr_node["permissions"] = mem["permissions"] + curr_end_addr = curr_node["end"] else: - if(curr_node['end'] > curr_node['start']): + if curr_node["end"] > curr_node["start"]: final_list.append(curr_node) # if curr_node is a segment - if current_segment is not None and current_segment['end'] == mem['end']: + if ( + current_segment is not None + and current_segment["end"] == mem["end"] + ): curr_seg_idx += 1 if curr_seg_idx < len(sorted_segments): current_segment = sorted_segments[curr_seg_idx] @@ -98,50 +106,56 @@ def overlap_alignments(segments, memory): break # could only be a segment else: - if curr_node['end'] < mem['end']: + if curr_node["end"] < mem["end"]: # check for remaining segments and valid segments - if(curr_node['end'] > curr_node['start']): + if curr_node["end"] > curr_node["start"]: final_list.append(curr_node) - + curr_seg_idx += 1 if curr_seg_idx < len(sorted_segments): current_segment = sorted_segments[curr_seg_idx] else: current_segment = None - - if current_segment is not None and current_segment['start'] <= curr_end_addr and current_segment['start'] < mem['end']: + + if ( + current_segment is not None + and current_segment["start"] <= curr_end_addr + and current_segment["start"] < mem["end"] + ): curr_node = deepcopy(current_segment) - curr_node['permissions'] = mem['permissions'] + curr_node["permissions"] = mem["permissions"] else: # no more segments curr_node = deepcopy(mem) - - curr_node['start'] = curr_end_addr - curr_end_addr = curr_node['end'] - return final_list + curr_node["start"] = curr_end_addr + curr_end_addr = curr_node["end"] + + return final_list + # https://github.com/llvm-mirror/llvm/blob/master/include/llvm/ADT/Triple.h def get_arch(): - arch, arch_vendor, arch_os = lldb.target.GetTriple().split('-') - if arch == 'x86_64': + arch, arch_vendor, arch_os = lldb.target.GetTriple().split("-") + if arch == "x86_64": return "x64" - elif arch == 'x86' or arch == 'i386': + elif arch == "x86" or arch == "i386": return "x86" - elif arch == 'aarch64' or arch == 'arm64': + elif arch == "aarch64" or arch == "arm64": return "arm64le" - elif arch == 'aarch64_be': + elif arch == "aarch64_be": return "arm64be" - elif arch == 'armeb': + elif arch == "armeb": return "armbe" - elif arch == 'arm': + elif arch == "arm": return "armle" else: return "" -#----------------------- -#---- Dumping functions +# ----------------------- +# ---- Dumping functions + def dump_arch_info(): arch_info = {} @@ -152,56 +166,64 @@ def dump_arch_info(): def dump_regs(): reg_state = {} for reg_list in lldb.frame.GetRegisters(): - if 'general purpose registers' in reg_list.GetName().lower(): + if "general purpose registers" in reg_list.GetName().lower(): for reg in reg_list: reg_state[reg.GetName()] = int(reg.GetValue(), 16) return reg_state + def get_section_info(sec): - name = sec.name if sec.name is not None else '' + name = sec.name if sec.name is not None else "" if sec.GetParent().name is not None: - name = sec.GetParent().name + '.' + sec.name + name = sec.GetParent().name + "." + sec.name module_name = sec.addr.module.file.GetFilename() - module_name = module_name if module_name is not None else '' - long_name = module_name + '.' + name - + module_name = module_name if module_name is not None else "" + long_name = module_name + "." + name + return sec.addr.load_addr, (sec.addr.load_addr + sec.size), sec.size, long_name - + def dump_process_memory(output_dir): # Segment information dictionary raw_segment_list = [] raw_memory_list = [] - + # 1st pass: # Loop over the segments, fill in the segment info dictionary for module in lldb.target.module_iter(): for seg_ea in module.section_iter(): - seg_info = {'module': module.file.GetFilename() } - seg_info['start'], seg_info['end'], seg_size, seg_info['name'] = get_section_info(seg_ea) + seg_info = {"module": module.file.GetFilename()} + ( + seg_info["start"], + seg_info["end"], + seg_size, + seg_info["name"], + ) = get_section_info(seg_ea) # TODO: Ugly hack for -1 LONG address on 32-bit - if seg_info['start'] >= sys.maxint or seg_size <= 0: - print "Throwing away page: {}".format(seg_info['name']) + if seg_info["start"] >= sys.maxint or seg_size <= 0: + print "Throwing away page: {}".format(seg_info["name"]) continue # Page-align segment - seg_info['start'] = ALIGN_PAGE_DOWN(seg_info['start']) - seg_info['end'] = ALIGN_PAGE_UP(seg_info['end']) - print("Appending: {}".format(seg_info['name'])) + seg_info["start"] = ALIGN_PAGE_DOWN(seg_info["start"]) + seg_info["end"] = ALIGN_PAGE_UP(seg_info["end"]) + print ("Appending: {}".format(seg_info["name"])) raw_segment_list.append(seg_info) # Add the stack memory region (just hardcode 0x1000 around the current SP) sp = lldb.frame.GetSP() start_sp = ALIGN_PAGE_DOWN(sp) - raw_segment_list.append({'start': start_sp, 'end': start_sp + 0x1000, 'name': 'STACK'}) + raw_segment_list.append( + {"start": start_sp, "end": start_sp + 0x1000, "name": "STACK"} + ) # Write the original memory to file for debugging - index_file = open(os.path.join(output_dir, DEBUG_MEM_FILE_NAME), 'w') + index_file = open(os.path.join(output_dir, DEBUG_MEM_FILE_NAME), "w") index_file.write(json.dumps(raw_segment_list, indent=4)) - index_file.close() + index_file.close() - # Loop over raw memory regions + # Loop over raw memory regions mem_info = lldb.SBMemoryRegionInfo() start_addr = -1 next_region_addr = 0 @@ -218,15 +240,20 @@ def dump_process_memory(output_dir): end_addr = mem_info.GetRegionEnd() # Unknown region name - region_name = 'UNKNOWN' + region_name = "UNKNOWN" # Ignore regions that aren't even mapped if mem_info.IsMapped() and mem_info.IsReadable(): - mem_info_obj = {'start': start_addr, 'end': end_addr, 'name': region_name, 'permissions': { - "r": mem_info.IsReadable(), - "w": mem_info.IsWritable(), - "x": mem_info.IsExecutable() - }} + mem_info_obj = { + "start": start_addr, + "end": end_addr, + "name": region_name, + "permissions": { + "r": mem_info.IsReadable(), + "w": mem_info.IsWritable(), + "x": mem_info.IsExecutable(), + }, + } raw_memory_list.append(mem_info_obj) @@ -234,65 +261,89 @@ def dump_process_memory(output_dir): for seg_info in final_segment_list: try: - seg_info['content_file'] = '' - start_addr = seg_info['start'] - end_addr = seg_info['end'] - region_name = seg_info['name'] + seg_info["content_file"] = "" + start_addr = seg_info["start"] + end_addr = seg_info["end"] + region_name = seg_info["name"] # Compress and dump the content to a file err = lldb.SBError() - seg_content = lldb.process.ReadMemory(start_addr, end_addr - start_addr, err) - if(seg_content == None): - print("Segment empty: @0x{0:016x} (size:UNKNOWN) {1}".format(start_addr, region_name)) - seg_info['content_file'] = '' + seg_content = lldb.process.ReadMemory( + start_addr, end_addr - start_addr, err + ) + if seg_content == None: + print ( + "Segment empty: @0x{0:016x} (size:UNKNOWN) {1}".format( + start_addr, region_name + ) + ) + seg_info["content_file"] = "" else: - print("Dumping segment @0x{0:016x} (size:0x{1:x}): {2} [{3}]".format(start_addr, len(seg_content), region_name, repr(seg_info['permissions']))) + print ( + "Dumping segment @0x{0:016x} (size:0x{1:x}): {2} [{3}]".format( + start_addr, + len(seg_content), + region_name, + repr(seg_info["permissions"]), + ) + ) compressed_seg_content = zlib.compress(seg_content) md5_sum = hashlib.md5(compressed_seg_content).hexdigest() + ".bin" - seg_info['content_file'] = md5_sum - + seg_info["content_file"] = md5_sum + # Write the compressed contents to disk - out_file = open(os.path.join(output_dir, md5_sum), 'wb') + out_file = open(os.path.join(output_dir, md5_sum), "wb") out_file.write(compressed_seg_content) out_file.close() - + except: - print("Exception reading segment ({}): {}".format(region_name, sys.exc_info()[0])) - + print ( + "Exception reading segment ({}): {}".format( + region_name, sys.exc_info()[0] + ) + ) + return final_segment_list -#---------- -#---- Main - + +# ---------- +# ---- Main + + def main(): try: - print("----- Unicorn Context Dumper -----") - print("You must be actively debugging before running this!") - print("If it fails, double check that you are actively debugging before running.") - + print ("----- Unicorn Context Dumper -----") + print ("You must be actively debugging before running this!") + print ( + "If it fails, double check that you are actively debugging before running." + ) + # Create the output directory - timestamp = datetime.datetime.fromtimestamp(time.time()).strftime('%Y%m%d_%H%M%S') + timestamp = datetime.datetime.fromtimestamp(time.time()).strftime( + "%Y%m%d_%H%M%S" + ) output_path = "UnicornContext_" + timestamp if not os.path.exists(output_path): os.makedirs(output_path) - print("Process context will be output to {}".format(output_path)) - + print ("Process context will be output to {}".format(output_path)) + # Get the context context = { "arch": dump_arch_info(), - "regs": dump_regs(), + "regs": dump_regs(), "segments": dump_process_memory(output_path), } - + # Write the index file - index_file = open(os.path.join(output_path, INDEX_FILE_NAME), 'w') + index_file = open(os.path.join(output_path, INDEX_FILE_NAME), "w") index_file.write(json.dumps(context, indent=4)) - index_file.close() - print("Done.") - + index_file.close() + print ("Done.") + except Exception, e: - print("!!! ERROR:\n\t{}".format(repr(e))) - + print ("!!! ERROR:\n\t{}".format(repr(e))) + + if __name__ == "__main__": main() elif lldb.debugger: diff --git a/unicorn_mode/helper_scripts/unicorn_dumper_pwndbg.py b/unicorn_mode/helper_scripts/unicorn_dumper_pwndbg.py index dc56b2aa..eccbc8bf 100644 --- a/unicorn_mode/helper_scripts/unicorn_dumper_pwndbg.py +++ b/unicorn_mode/helper_scripts/unicorn_dumper_pwndbg.py @@ -59,45 +59,47 @@ MAX_SEG_SIZE = 128 * 1024 * 1024 # Name of the index file INDEX_FILE_NAME = "_index.json" -#---------------------- -#---- Helper Functions +# ---------------------- +# ---- Helper Functions + def map_arch(): - arch = pwndbg.arch.current # from PWNDBG - if 'x86_64' in arch or 'x86-64' in arch: + arch = pwndbg.arch.current # from PWNDBG + if "x86_64" in arch or "x86-64" in arch: return "x64" - elif 'x86' in arch or 'i386' in arch: + elif "x86" in arch or "i386" in arch: return "x86" - elif 'aarch64' in arch or 'arm64' in arch: + elif "aarch64" in arch or "arm64" in arch: return "arm64le" - elif 'aarch64_be' in arch: + elif "aarch64_be" in arch: return "arm64be" - elif 'arm' in arch: - cpsr = pwndbg.regs['cpsr'] - # check endianess - if pwndbg.arch.endian == 'big': + elif "arm" in arch: + cpsr = pwndbg.regs["cpsr"] + # check endianess + if pwndbg.arch.endian == "big": # check for THUMB mode - if (cpsr & (1 << 5)): + if cpsr & (1 << 5): return "armbethumb" else: return "armbe" else: # check for THUMB mode - if (cpsr & (1 << 5)): + if cpsr & (1 << 5): return "armlethumb" else: return "armle" - elif 'mips' in arch: - if pwndbg.arch.endian == 'little': - return 'mipsel' + elif "mips" in arch: + if pwndbg.arch.endian == "little": + return "mipsel" else: - return 'mips' + return "mips" else: return "" -#----------------------- -#---- Dumping functions +# ----------------------- +# ---- Dumping functions + def dump_arch_info(): arch_info = {} @@ -110,26 +112,26 @@ def dump_regs(): for reg in pwndbg.regs.all: reg_val = pwndbg.regs[reg] # current dumper script looks for register values to be hex strings -# reg_str = "0x{:08x}".format(reg_val) -# if "64" in get_arch(): -# reg_str = "0x{:016x}".format(reg_val) -# reg_state[reg.strip().strip('$')] = reg_str - reg_state[reg.strip().strip('$')] = reg_val + # reg_str = "0x{:08x}".format(reg_val) + # if "64" in get_arch(): + # reg_str = "0x{:016x}".format(reg_val) + # reg_state[reg.strip().strip('$')] = reg_str + reg_state[reg.strip().strip("$")] = reg_val return reg_state def dump_process_memory(output_dir): # Segment information dictionary final_segment_list = [] - + # PWNDBG: vmmap = pwndbg.vmmap.get() - + # Pointer to end of last dumped memory segment - segment_last_addr = 0x0; + segment_last_addr = 0x0 start = None - end = None + end = None if not vmmap: print("No address mapping information found") @@ -141,86 +143,107 @@ def dump_process_memory(output_dir): continue start = entry.start - end = entry.end + end = entry.end - if (segment_last_addr > entry.start): # indicates overlap - if (segment_last_addr > entry.end): # indicates complete overlap, so we skip the segment entirely + if segment_last_addr > entry.start: # indicates overlap + if ( + segment_last_addr > entry.end + ): # indicates complete overlap, so we skip the segment entirely continue - else: + else: start = segment_last_addr - - - seg_info = {'start': start, 'end': end, 'name': entry.objfile, 'permissions': { - "r": entry.read, - "w": entry.write, - "x": entry.execute - }, 'content_file': ''} + + seg_info = { + "start": start, + "end": end, + "name": entry.objfile, + "permissions": {"r": entry.read, "w": entry.write, "x": entry.execute}, + "content_file": "", + } # "(deleted)" may or may not be valid, but don't push it. - if entry.read and not '(deleted)' in entry.objfile: + if entry.read and not "(deleted)" in entry.objfile: try: # Compress and dump the content to a file seg_content = pwndbg.memory.read(start, end - start) - if(seg_content == None): - print("Segment empty: @0x{0:016x} (size:UNKNOWN) {1}".format(entry.start, entry.objfile)) + if seg_content == None: + print( + "Segment empty: @0x{0:016x} (size:UNKNOWN) {1}".format( + entry.start, entry.objfile + ) + ) else: - print("Dumping segment @0x{0:016x} (size:0x{1:x}): {2} [{3}]".format(entry.start, len(seg_content), entry.objfile, repr(seg_info['permissions']))) + print( + "Dumping segment @0x{0:016x} (size:0x{1:x}): {2} [{3}]".format( + entry.start, + len(seg_content), + entry.objfile, + repr(seg_info["permissions"]), + ) + ) compressed_seg_content = zlib.compress(str(seg_content)) md5_sum = hashlib.md5(compressed_seg_content).hexdigest() + ".bin" seg_info["content_file"] = md5_sum - + # Write the compressed contents to disk - out_file = open(os.path.join(output_dir, md5_sum), 'wb') + out_file = open(os.path.join(output_dir, md5_sum), "wb") out_file.write(compressed_seg_content) out_file.close() except Exception as e: traceback.print_exc() - print("Exception reading segment ({}): {}".format(entry.objfile, sys.exc_info()[0])) + print( + "Exception reading segment ({}): {}".format( + entry.objfile, sys.exc_info()[0] + ) + ) else: print("Skipping segment {0}@0x{1:016x}".format(entry.objfile, entry.start)) - + segment_last_addr = end # Add the segment to the list final_segment_list.append(seg_info) - return final_segment_list -#---------- -#---- Main - + +# ---------- +# ---- Main + + def main(): print("----- Unicorn Context Dumper -----") print("You must be actively debugging before running this!") print("If it fails, double check that you are actively debugging before running.") - + try: # Create the output directory - timestamp = datetime.datetime.fromtimestamp(time.time()).strftime('%Y%m%d_%H%M%S') + timestamp = datetime.datetime.fromtimestamp(time.time()).strftime( + "%Y%m%d_%H%M%S" + ) output_path = "UnicornContext_" + timestamp if not os.path.exists(output_path): os.makedirs(output_path) print("Process context will be output to {}".format(output_path)) - + # Get the context context = { "arch": dump_arch_info(), - "regs": dump_regs(), + "regs": dump_regs(), "segments": dump_process_memory(output_path), } # Write the index file - index_file = open(os.path.join(output_path, INDEX_FILE_NAME), 'w') + index_file = open(os.path.join(output_path, INDEX_FILE_NAME), "w") index_file.write(json.dumps(context, indent=4)) - index_file.close() + index_file.close() print("Done.") - + except Exception as e: print("!!! ERROR:\n\t{}".format(repr(e))) - + + if __name__ == "__main__" and pwndbg_loaded: main() - diff --git a/unicorn_mode/helper_scripts/unicorn_loader.py b/unicorn_mode/helper_scripts/unicorn_loader.py index adf21b64..1914a83d 100644 --- a/unicorn_mode/helper_scripts/unicorn_loader.py +++ b/unicorn_mode/helper_scripts/unicorn_loader.py @@ -1,8 +1,8 @@ """ unicorn_loader.py - - Loads a process context dumped created using a - Unicorn Context Dumper script into a Unicorn Engine + + Loads a process context dumped created using a + Unicorn Context Dumper script into a Unicorn Engine instance. Once this is performed emulation can be started. """ @@ -26,6 +26,13 @@ from unicorn.arm64_const import * from unicorn.x86_const import * from unicorn.mips_const import * +# If Capstone libraries are availible (only check once) +try: + from capstone import * + CAPSTONE_EXISTS = 1 +except: + CAPSTONE_EXISTS = 0 + # Name of the index file INDEX_FILE_NAME = "_index.json" @@ -86,7 +93,7 @@ class UnicornSimpleHeap(object): total_chunk_size = UNICORN_PAGE_SIZE + ALIGN_PAGE_UP(size) + UNICORN_PAGE_SIZE # Gross but efficient way to find space for the chunk: chunk = None - for addr in xrange(self.HEAP_MIN_ADDR, self.HEAP_MAX_ADDR, UNICORN_PAGE_SIZE): + for addr in range(self.HEAP_MIN_ADDR, self.HEAP_MAX_ADDR, UNICORN_PAGE_SIZE): try: self._uc.mem_map(addr, total_chunk_size, UC_PROT_READ | UC_PROT_WRITE) chunk = self.HeapChunk(addr, total_chunk_size, size) @@ -97,7 +104,7 @@ class UnicornSimpleHeap(object): continue # Something went very wrong if chunk == None: - return 0 + return 0 self._chunks.append(chunk) return chunk.data_addr @@ -112,8 +119,8 @@ class UnicornSimpleHeap(object): old_chunk = None for chunk in self._chunks: if chunk.data_addr == ptr: - old_chunk = chunk - new_chunk_addr = self.malloc(new_size) + old_chunk = chunk + new_chunk_addr = self.malloc(new_size) if old_chunk != None: self._uc.mem_write(new_chunk_addr, str(self._uc.mem_read(old_chunk.data_addr, old_chunk.data_size))) self.free(old_chunk.data_addr) @@ -184,39 +191,27 @@ class AflUnicornEngine(Uc): # Load the registers regs = context['regs'] reg_map = self.__get_register_map(self._arch_str) - for register, value in regs.iteritems(): - if debug_print: - print("Reg {0} = {1}".format(register, value)) - if not reg_map.has_key(register.lower()): - if debug_print: - print("Skipping Reg: {}".format(register)) - else: - reg_write_retry = True - try: - self.reg_write(reg_map[register.lower()], value) - reg_write_retry = False - except Exception as e: - if debug_print: - print("ERROR writing register: {}, value: {} -- {}".format(register, value, repr(e))) + self.__load_registers(regs, reg_map, debug_print) + # If we have extra FLOATING POINT regs, load them in! + if 'regs_extended' in context: + if context['regs_extended']: + regs_extended = context['regs_extended'] + reg_map = self.__get_registers_extended(self._arch_str) + self.__load_registers(regs_extended, reg_map, debug_print) + + # For ARM, sometimes the stack pointer is erased ??? (I think I fixed this (issue with ordering of dumper.py, I'll keep the write anyways) + if self.__get_arch_and_mode(self.get_arch_str())[0] == UC_ARCH_ARM: + self.reg_write(UC_ARM_REG_SP, regs['sp']) - if reg_write_retry: - if debug_print: - print("Trying to parse value ({}) as hex string".format(value)) - try: - self.reg_write(reg_map[register.lower()], int(value, 16)) - except Exception as e: - if debug_print: - print("ERROR writing hex string register: {}, value: {} -- {}".format(register, value, repr(e))) - # Setup the memory map and load memory content self.__map_segments(context['segments'], context_directory, debug_print) - + if enable_trace: self.hook_add(UC_HOOK_BLOCK, self.__trace_block) self.hook_add(UC_HOOK_CODE, self.__trace_instruction) self.hook_add(UC_HOOK_MEM_WRITE | UC_HOOK_MEM_READ, self.__trace_mem_access) self.hook_add(UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, self.__trace_mem_invalid_access) - + if debug_print: print("Done loading context.") @@ -228,7 +223,7 @@ class AflUnicornEngine(Uc): def get_arch_str(self): return self._arch_str - + def force_crash(self, uc_error): """ This function should be called to indicate to AFL that a crash occurred during emulation. You can pass the exception received from Uc.emu_start @@ -253,21 +248,76 @@ class AflUnicornEngine(Uc): for reg in sorted(self.__get_register_map(self._arch_str).items(), key=lambda reg: reg[0]): print(">>> {0:>4}: 0x{1:016x}".format(reg[0], self.reg_read(reg[1]))) + def dump_regs_extended(self): + """ Dumps the contents of all the registers to STDOUT """ + try: + for reg in sorted(self.__get_registers_extended(self._arch_str).items(), key=lambda reg: reg[0]): + print(">>> {0:>4}: 0x{1:016x}".format(reg[0], self.reg_read(reg[1]))) + except Exception as e: + print("ERROR: Are extended registers loaded?") + # TODO: Make this dynamically get the stack pointer register and pointer width for the current architecture """ def dump_stack(self, window=10): + arch = self.get_arch() + mode = self.get_mode() + # Get stack pointers and bit sizes for given architecture + if arch == UC_ARCH_X86 and mode == UC_MODE_64: + stack_ptr_addr = self.reg_read(UC_X86_REG_RSP) + bit_size = 8 + elif arch == UC_ARCH_X86 and mode == UC_MODE_32: + stack_ptr_addr = self.reg_read(UC_X86_REG_ESP) + bit_size = 4 + elif arch == UC_ARCH_ARM64: + stack_ptr_addr = self.reg_read(UC_ARM64_REG_SP) + bit_size = 8 + elif arch == UC_ARCH_ARM: + stack_ptr_addr = self.reg_read(UC_ARM_REG_SP) + bit_size = 4 + elif arch == UC_ARCH_ARM and mode == UC_MODE_THUMB: + stack_ptr_addr = self.reg_read(UC_ARM_REG_SP) + bit_size = 4 + elif arch == UC_ARCH_MIPS: + stack_ptr_addr = self.reg_read(UC_MIPS_REG_SP) + bit_size = 4 + print("") print(">>> Stack:") stack_ptr_addr = self.reg_read(UC_X86_REG_RSP) for i in xrange(-window, window + 1): addr = stack_ptr_addr + (i*8) print("{0}0x{1:016x}: 0x{2:016x}".format( \ - 'SP->' if i == 0 else ' ', addr, \ + 'SP->' if i == 0 else ' ', addr, \ struct.unpack('<Q', self.mem_read(addr, 8))[0])) """ #----------------------------- #---- Loader Helper Functions + def __load_registers(self, regs, reg_map, debug_print): + for register, value in regs.items(): + if debug_print: + print("Reg {0} = {1}".format(register, value)) + if register.lower() not in reg_map: + if debug_print: + print("Skipping Reg: {}".format(register)) + else: + reg_write_retry = True + try: + self.reg_write(reg_map[register.lower()], value) + reg_write_retry = False + except Exception as e: + if debug_print: + print("ERROR writing register: {}, value: {} -- {}".format(register, value, repr(e))) + + if reg_write_retry: + if debug_print: + print("Trying to parse value ({}) as hex string".format(value)) + try: + self.reg_write(reg_map[register.lower()], int(value, 16)) + except Exception as e: + if debug_print: + print("ERROR writing hex string register: {}, value: {} -- {}".format(register, value, repr(e))) + def __map_segment(self, name, address, size, perms, debug_print=False): # - size is unsigned and must be != 0 # - starting address must be aligned to 4KB @@ -289,7 +339,7 @@ class AflUnicornEngine(Uc): def __map_segments(self, segment_list, context_directory, debug_print=False): for segment in segment_list: - + # Get the segment information from the index name = segment['name'] seg_start = segment['start'] @@ -297,7 +347,7 @@ class AflUnicornEngine(Uc): perms = \ (UC_PROT_READ if segment['permissions']['r'] == True else 0) | \ (UC_PROT_WRITE if segment['permissions']['w'] == True else 0) | \ - (UC_PROT_EXEC if segment['permissions']['x'] == True else 0) + (UC_PROT_EXEC if segment['permissions']['x'] == True else 0) if debug_print: print("Handling segment {}".format(name)) @@ -349,12 +399,12 @@ class AflUnicornEngine(Uc): content_file = open(content_file_path, 'rb') compressed_content = content_file.read() content_file.close() - self.mem_write(seg_start, zlib.decompress(compressed_content)) + self.mem_write(seg_start, zlib.decompress(compressed_content)) else: if debug_print: print("No content found for segment {0} @ {1:016x}".format(name, seg_start)) - self.mem_write(seg_start, '\x00' * (seg_end - seg_start)) + self.mem_write(seg_start, b'\x00' * (seg_end - seg_start)) def __get_arch_and_mode(self, arch_str): arch_map = { @@ -398,7 +448,6 @@ class AflUnicornEngine(Uc): "r14": UC_X86_REG_R14, "r15": UC_X86_REG_R15, "rip": UC_X86_REG_RIP, - "rsp": UC_X86_REG_RSP, "efl": UC_X86_REG_EFLAGS, "cs": UC_X86_REG_CS, "ds": UC_X86_REG_DS, @@ -415,13 +464,12 @@ class AflUnicornEngine(Uc): "esi": UC_X86_REG_ESI, "edi": UC_X86_REG_EDI, "ebp": UC_X86_REG_EBP, - "esp": UC_X86_REG_ESP, "eip": UC_X86_REG_EIP, "esp": UC_X86_REG_ESP, - "efl": UC_X86_REG_EFLAGS, + "efl": UC_X86_REG_EFLAGS, # Segment registers removed... # They caused segfaults (from unicorn?) when they were here - }, + }, "arm" : { "r0": UC_ARM_REG_R0, "r1": UC_ARM_REG_R1, @@ -476,7 +524,7 @@ class AflUnicornEngine(Uc): "fp": UC_ARM64_REG_FP, "lr": UC_ARM64_REG_LR, "nzcv": UC_ARM64_REG_NZCV, - "cpsr": UC_ARM_REG_CPSR, + "cpsr": UC_ARM_REG_CPSR, }, "mips" : { "0" : UC_MIPS_REG_ZERO, @@ -499,13 +547,13 @@ class AflUnicornEngine(Uc): "t9": UC_MIPS_REG_T9, "s0": UC_MIPS_REG_S0, "s1": UC_MIPS_REG_S1, - "s2": UC_MIPS_REG_S2, + "s2": UC_MIPS_REG_S2, "s3": UC_MIPS_REG_S3, "s4": UC_MIPS_REG_S4, "s5": UC_MIPS_REG_S5, - "s6": UC_MIPS_REG_S6, + "s6": UC_MIPS_REG_S6, "s7": UC_MIPS_REG_S7, - "s8": UC_MIPS_REG_S8, + "s8": UC_MIPS_REG_S8, "k0": UC_MIPS_REG_K0, "k1": UC_MIPS_REG_K1, "gp": UC_MIPS_REG_GP, @@ -517,44 +565,127 @@ class AflUnicornEngine(Uc): "lo": UC_MIPS_REG_LO } } - return registers[arch] + return registers[arch] + def __get_registers_extended(self, arch): + # Similar to __get_register_map, but for ARM floating point registers + if arch == "arm64le" or arch == "arm64be": + arch = "arm64" + elif arch == "armle" or arch == "armbe" or "thumb" in arch: + arch = "arm" + elif arch == "mipsel": + arch = "mips" + + registers = { + "arm": { + "d0": UC_ARM_REG_D0, + "d1": UC_ARM_REG_D1, + "d2": UC_ARM_REG_D2, + "d3": UC_ARM_REG_D3, + "d4": UC_ARM_REG_D4, + "d5": UC_ARM_REG_D5, + "d6": UC_ARM_REG_D6, + "d7": UC_ARM_REG_D7, + "d8": UC_ARM_REG_D8, + "d9": UC_ARM_REG_D9, + "d10": UC_ARM_REG_D10, + "d11": UC_ARM_REG_D11, + "d12": UC_ARM_REG_D12, + "d13": UC_ARM_REG_D13, + "d14": UC_ARM_REG_D14, + "d15": UC_ARM_REG_D15, + "d16": UC_ARM_REG_D16, + "d17": UC_ARM_REG_D17, + "d18": UC_ARM_REG_D18, + "d19": UC_ARM_REG_D19, + "d20": UC_ARM_REG_D20, + "d21": UC_ARM_REG_D21, + "d22": UC_ARM_REG_D22, + "d23": UC_ARM_REG_D23, + "d24": UC_ARM_REG_D24, + "d25": UC_ARM_REG_D25, + "d26": UC_ARM_REG_D26, + "d27": UC_ARM_REG_D27, + "d28": UC_ARM_REG_D28, + "d29": UC_ARM_REG_D29, + "d30": UC_ARM_REG_D30, + "d31": UC_ARM_REG_D31, + "fpscr": UC_ARM_REG_FPSCR + } + } + + return registers[arch]; #--------------------------- - # Callbacks for tracing + # Callbacks for tracing - # TODO: Make integer-printing fixed widths dependent on bitness of architecture - # (i.e. only show 4 bytes for 32-bit, 8 bytes for 64-bit) - # TODO: Figure out how best to determine the capstone mode and architecture here - """ - try: - # If Capstone is installed then we'll dump disassembly, otherwise just dump the binary. - from capstone import * - cs = Cs(CS_ARCH_MIPS, CS_MODE_MIPS32 + CS_MODE_BIG_ENDIAN) - def __trace_instruction(self, uc, address, size, user_data): - mem = uc.mem_read(address, size) - for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite(bytes(mem), size): - print(" Instr: {:#016x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr)) - except ImportError: - def __trace_instruction(self, uc, address, size, user_data): - print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) - """ + # TODO: Extra mode for Capstone (i.e. Cs(cs_arch, cs_mode + cs_extra) not implemented + def __trace_instruction(self, uc, address, size, user_data): - print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) - + if CAPSTONE_EXISTS == 1: + # If Capstone is installed then we'll dump disassembly, otherwise just dump the binary. + arch = self.get_arch() + mode = self.get_mode() + bit_size = self.bit_size_arch() + # Map current arch to capstone labeling + if arch == UC_ARCH_X86 and mode == UC_MODE_64: + cs_arch = CS_ARCH_X86 + cs_mode = CS_MODE_64 + elif arch == UC_ARCH_X86 and mode == UC_MODE_32: + cs_arch = CS_ARCH_X86 + cs_mode = CS_MODE_32 + elif arch == UC_ARCH_ARM64: + cs_arch = CS_ARCH_ARM64 + cs_mode = CS_MODE_ARM + elif arch == UC_ARCH_ARM and mode == UC_MODE_THUMB: + cs_arch = CS_ARCH_ARM + cs_mode = CS_MODE_THUMB + elif arch == UC_ARCH_ARM: + cs_arch = CS_ARCH_ARM + cs_mode = CS_MODE_ARM + elif arch == UC_ARCH_MIPS: + cs_arch = CS_ARCH_MIPS + cs_mode = CS_MODE_MIPS32 # No other MIPS supported in program + + cs = Cs(cs_arch, cs_mode) + mem = uc.mem_read(address, size) + if bit_size == 4: + for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite(bytes(mem), size): + print(" Instr: {:#08x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr)) + else: + for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite(bytes(mem), size): + print(" Instr: {:#16x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr)) + else: + print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) + def __trace_block(self, uc, address, size, user_data): print("Basic Block: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) - + def __trace_mem_access(self, uc, access, address, size, value, user_data): if access == UC_MEM_WRITE: print(" >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) else: - print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size)) + print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size)) def __trace_mem_invalid_access(self, uc, access, address, size, value, user_data): if access == UC_MEM_WRITE_UNMAPPED: print(" >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) else: - print(" >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size)) - + print(" >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size)) + + def bit_size_arch(self): + arch = self.get_arch() + mode = self.get_mode() + # Get bit sizes for given architecture + if arch == UC_ARCH_X86 and mode == UC_MODE_64: + bit_size = 8 + elif arch == UC_ARCH_X86 and mode == UC_MODE_32: + bit_size = 4 + elif arch == UC_ARCH_ARM64: + bit_size = 8 + elif arch == UC_ARCH_ARM: + bit_size = 4 + elif arch == UC_ARCH_MIPS: + bit_size = 4 + return bit_size diff --git a/unicorn_mode/samples/c/COMPILE.md b/unicorn_mode/samples/c/COMPILE.md index 7857e5bf..7da140f7 100644 --- a/unicorn_mode/samples/c/COMPILE.md +++ b/unicorn_mode/samples/c/COMPILE.md @@ -17,6 +17,6 @@ You shouldn't need to compile simple_target.c since a X86_64 binary version is pre-built and shipped in this sample folder. This file documents how the binary was built in case you want to rebuild it or recompile it for any reason. -The pre-built binary (simple_target_x86_64.bin) was built using -g -O0 in gcc. +The pre-built binary (persistent_target_x86_64) was built using -g -O0 in gcc. We then load the binary and execute the main function directly. diff --git a/unicorn_mode/samples/compcov_x64/compcov_test_harness.py b/unicorn_mode/samples/compcov_x64/compcov_test_harness.py index b9ebb61d..f0749d1b 100644 --- a/unicorn_mode/samples/compcov_x64/compcov_test_harness.py +++ b/unicorn_mode/samples/compcov_x64/compcov_test_harness.py @@ -22,48 +22,81 @@ from unicornafl import * from unicornafl.x86_const import * # Path to the file containing the binary to emulate -BINARY_FILE = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'compcov_target.bin') +BINARY_FILE = os.path.join( + os.path.dirname(os.path.abspath(__file__)), "compcov_target.bin" +) # Memory map for the code to be tested -CODE_ADDRESS = 0x00100000 # Arbitrary address where code to test will be loaded +CODE_ADDRESS = 0x00100000 # Arbitrary address where code to test will be loaded CODE_SIZE_MAX = 0x00010000 # Max size for the code (64kb) STACK_ADDRESS = 0x00200000 # Address of the stack (arbitrarily chosen) -STACK_SIZE = 0x00010000 # Size of the stack (arbitrarily chosen) -DATA_ADDRESS = 0x00300000 # Address where mutated data will be placed +STACK_SIZE = 0x00010000 # Size of the stack (arbitrarily chosen) +DATA_ADDRESS = 0x00300000 # Address where mutated data will be placed DATA_SIZE_MAX = 0x00010000 # Maximum allowable size of mutated data try: # If Capstone is installed then we'll dump disassembly, otherwise just dump the binary. from capstone import * + cs = Cs(CS_ARCH_X86, CS_MODE_64) + def unicorn_debug_instruction(uc, address, size, user_data): mem = uc.mem_read(address, size) - for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite(bytes(mem), size): + for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite( + bytes(mem), size + ): print(" Instr: {:#016x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr)) + + except ImportError: + def unicorn_debug_instruction(uc, address, size, user_data): print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) + def unicorn_debug_block(uc, address, size, user_data): print("Basic Block: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) + def unicorn_debug_mem_access(uc, access, address, size, value, user_data): if access == UC_MEM_WRITE: - print(" >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) + print( + " >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format( + address, size, value + ) + ) else: print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size)) + def unicorn_debug_mem_invalid_access(uc, access, address, size, value, user_data): if access == UC_MEM_WRITE_UNMAPPED: - print(" >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) + print( + " >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format( + address, size, value + ) + ) else: - print(" >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size)) + print( + " >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size) + ) + def main(): parser = argparse.ArgumentParser(description="Test harness for compcov_target.bin") - parser.add_argument('input_file', type=str, help="Path to the file containing the mutated input to load") - parser.add_argument('-t', '--trace', default=False, action="store_true", help="Enables debug tracing") + parser.add_argument( + "input_file", + type=str, + help="Path to the file containing the mutated input to load", + ) + parser.add_argument( + "-t", + "--trace", + default=False, + action="store_true", + help="Enables debug tracing", + ) args = parser.parse_args() # Instantiate a MIPS32 big endian Unicorn Engine instance @@ -73,13 +106,16 @@ def main(): uc.hook_add(UC_HOOK_BLOCK, unicorn_debug_block) uc.hook_add(UC_HOOK_CODE, unicorn_debug_instruction) uc.hook_add(UC_HOOK_MEM_WRITE | UC_HOOK_MEM_READ, unicorn_debug_mem_access) - uc.hook_add(UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, unicorn_debug_mem_invalid_access) + uc.hook_add( + UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, + unicorn_debug_mem_invalid_access, + ) - #--------------------------------------------------- + # --------------------------------------------------- # Load the binary to emulate and map it into memory print("Loading data input from {}".format(args.input_file)) - binary_file = open(BINARY_FILE, 'rb') + binary_file = open(BINARY_FILE, "rb") binary_code = binary_file.read() binary_file.close() @@ -93,11 +129,11 @@ def main(): uc.mem_write(CODE_ADDRESS, binary_code) # Set the program counter to the start of the code - start_address = CODE_ADDRESS # Address of entry point of main() - end_address = CODE_ADDRESS + 0x55 # Address of last instruction in main() + start_address = CODE_ADDRESS # Address of entry point of main() + end_address = CODE_ADDRESS + 0x55 # Address of last instruction in main() uc.reg_write(UC_X86_REG_RIP, start_address) - #----------------- + # ----------------- # Setup the stack uc.mem_map(STACK_ADDRESS, STACK_SIZE) @@ -106,8 +142,7 @@ def main(): # Mapping a location to write our buffer to uc.mem_map(DATA_ADDRESS, DATA_SIZE_MAX) - - #----------------------------------------------- + # ----------------------------------------------- # Load the mutated input and map it into memory def place_input_callback(uc, input, _, data): @@ -121,7 +156,7 @@ def main(): # Write the mutated command into the data buffer uc.mem_write(DATA_ADDRESS, input) - #------------------------------------------------------------ + # ------------------------------------------------------------ # Emulate the code, allowing it to process the mutated input print("Starting the AFL fuzz") @@ -129,8 +164,9 @@ def main(): input_file=args.input_file, place_input_callback=place_input_callback, exits=[end_address], - persistent_iters=1 + persistent_iters=1, ) + if __name__ == "__main__": main() diff --git a/unicorn_mode/samples/persistent/simple_target_noncrashing.c b/unicorn_mode/samples/persistent/simple_target_noncrashing.c index 00764473..9257643b 100644 --- a/unicorn_mode/samples/persistent/simple_target_noncrashing.c +++ b/unicorn_mode/samples/persistent/simple_target_noncrashing.c @@ -10,7 +10,7 @@ * Written by Nathan Voss <njvoss99@gmail.com> * Adapted by Lukas Seidel <seidel.1@campus.tu-berlin.de> */ - +#include <string.h> int main(int argc, char** argv) { if(argc < 2){ @@ -19,15 +19,19 @@ int main(int argc, char** argv) { char *data_buf = argv[1]; - if len(data_buf < 20) { - if (data_buf[20] != 0) { + if (strlen(data_buf) >= 21 && data_buf[20] != 0) { printf("Not crashing"); - } else if (data_buf[0] > 0x10 && data_buf[0] < 0x20 && data_buf[1] > data_buf[2]) { + } else if (strlen(data_buf) > 1 + && data_buf[0] > 0x10 && data_buf[0] < 0x20 && data_buf[1] > data_buf[2]) { printf("Also not crashing with databuf[0] == %c", data_buf[0]) - } else if (data_buf[9] == 0x00 && data_buf[10] != 0x00 && data_buf[11] == 0x00) { + } +#if 0 + // not possible with argv (zero terminated strings) (hexcoder-) + // do not try to access data_buf[10] and beyond + else if (data_buf[9] == 0x00 && data_buf[10] != 0x00 && data_buf[11] == 0x00) { // Cause a crash if data[10] is not zero, but [9] and [11] are zero unsigned char invalid_read = *(unsigned char *) 0x00000000; } - +#endif return 0; } diff --git a/unicorn_mode/samples/simple/simple_test_harness.py b/unicorn_mode/samples/simple/simple_test_harness.py index f4002ca8..cd04ad3a 100644 --- a/unicorn_mode/samples/simple/simple_test_harness.py +++ b/unicorn_mode/samples/simple/simple_test_harness.py @@ -1,4 +1,4 @@ -#!/usr/bin/env python +#!/usr/bin/env python3 """ Simple test harness for AFL's Unicorn Mode. @@ -22,48 +22,81 @@ from unicornafl import * from unicornafl.mips_const import * # Path to the file containing the binary to emulate -BINARY_FILE = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'simple_target.bin') +BINARY_FILE = os.path.join( + os.path.dirname(os.path.abspath(__file__)), "simple_target.bin" +) # Memory map for the code to be tested -CODE_ADDRESS = 0x00100000 # Arbitrary address where code to test will be loaded +CODE_ADDRESS = 0x00100000 # Arbitrary address where code to test will be loaded CODE_SIZE_MAX = 0x00010000 # Max size for the code (64kb) STACK_ADDRESS = 0x00200000 # Address of the stack (arbitrarily chosen) -STACK_SIZE = 0x00010000 # Size of the stack (arbitrarily chosen) -DATA_ADDRESS = 0x00300000 # Address where mutated data will be placed +STACK_SIZE = 0x00010000 # Size of the stack (arbitrarily chosen) +DATA_ADDRESS = 0x00300000 # Address where mutated data will be placed DATA_SIZE_MAX = 0x00010000 # Maximum allowable size of mutated data try: # If Capstone is installed then we'll dump disassembly, otherwise just dump the binary. from capstone import * + cs = Cs(CS_ARCH_MIPS, CS_MODE_MIPS32 + CS_MODE_BIG_ENDIAN) + def unicorn_debug_instruction(uc, address, size, user_data): mem = uc.mem_read(address, size) - for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite(bytes(mem), size): + for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite( + bytes(mem), size + ): print(" Instr: {:#016x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr)) + + except ImportError: + def unicorn_debug_instruction(uc, address, size, user_data): - print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) + print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) + def unicorn_debug_block(uc, address, size, user_data): print("Basic Block: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) - + + def unicorn_debug_mem_access(uc, access, address, size, value, user_data): if access == UC_MEM_WRITE: - print(" >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) + print( + " >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format( + address, size, value + ) + ) else: - print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size)) + print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size)) + def unicorn_debug_mem_invalid_access(uc, access, address, size, value, user_data): if access == UC_MEM_WRITE_UNMAPPED: - print(" >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) + print( + " >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format( + address, size, value + ) + ) else: - print(" >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size)) + print( + " >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size) + ) + def main(): parser = argparse.ArgumentParser(description="Test harness for simple_target.bin") - parser.add_argument('input_file', type=str, help="Path to the file containing the mutated input to load") - parser.add_argument('-t', '--trace', default=False, action="store_true", help="Enables debug tracing") + parser.add_argument( + "input_file", + type=str, + help="Path to the file containing the mutated input to load", + ) + parser.add_argument( + "-t", + "--trace", + default=False, + action="store_true", + help="Enables debug tracing", + ) args = parser.parse_args() # Instantiate a MIPS32 big endian Unicorn Engine instance @@ -73,13 +106,16 @@ def main(): uc.hook_add(UC_HOOK_BLOCK, unicorn_debug_block) uc.hook_add(UC_HOOK_CODE, unicorn_debug_instruction) uc.hook_add(UC_HOOK_MEM_WRITE | UC_HOOK_MEM_READ, unicorn_debug_mem_access) - uc.hook_add(UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, unicorn_debug_mem_invalid_access) + uc.hook_add( + UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, + unicorn_debug_mem_invalid_access, + ) - #--------------------------------------------------- + # --------------------------------------------------- # Load the binary to emulate and map it into memory print("Loading data input from {}".format(args.input_file)) - binary_file = open(BINARY_FILE, 'rb') + binary_file = open(BINARY_FILE, "rb") binary_code = binary_file.read() binary_file.close() @@ -93,11 +129,11 @@ def main(): uc.mem_write(CODE_ADDRESS, binary_code) # Set the program counter to the start of the code - start_address = CODE_ADDRESS # Address of entry point of main() - end_address = CODE_ADDRESS + 0xf4 # Address of last instruction in main() + start_address = CODE_ADDRESS # Address of entry point of main() + end_address = CODE_ADDRESS + 0xF4 # Address of last instruction in main() uc.reg_write(UC_MIPS_REG_PC, start_address) - #----------------- + # ----------------- # Setup the stack uc.mem_map(STACK_ADDRESS, STACK_SIZE) @@ -106,14 +142,14 @@ def main(): # reserve some space for data uc.mem_map(DATA_ADDRESS, DATA_SIZE_MAX) - #----------------------------------------------------- + # ----------------------------------------------------- # Set up a callback to place input data (do little work here, it's called for every single iteration) # We did not pass in any data and don't use persistent mode, so we can ignore these params. # Be sure to check out the docstrings for the uc.afl_* functions. def place_input_callback(uc, input, persistent_round, data): # Apply constraints to the mutated input if len(input) > DATA_SIZE_MAX: - #print("Test input is too long (> {} bytes)") + # print("Test input is too long (> {} bytes)") return False # Write the mutated command into the data buffer @@ -122,5 +158,6 @@ def main(): # Start the fuzzer. uc.afl_fuzz(args.input_file, place_input_callback, [end_address]) + if __name__ == "__main__": main() diff --git a/unicorn_mode/samples/simple/simple_test_harness_alt.py b/unicorn_mode/samples/simple/simple_test_harness_alt.py index 9c3dbc93..3249b13d 100644 --- a/unicorn_mode/samples/simple/simple_test_harness_alt.py +++ b/unicorn_mode/samples/simple/simple_test_harness_alt.py @@ -25,50 +25,79 @@ from unicornafl import * from unicornafl.mips_const import * # Path to the file containing the binary to emulate -BINARY_FILE = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'simple_target.bin') +BINARY_FILE = os.path.join( + os.path.dirname(os.path.abspath(__file__)), "simple_target.bin" +) # Memory map for the code to be tested -CODE_ADDRESS = 0x00100000 # Arbitrary address where code to test will be loaded +CODE_ADDRESS = 0x00100000 # Arbitrary address where code to test will be loaded CODE_SIZE_MAX = 0x00010000 # Max size for the code (64kb) STACK_ADDRESS = 0x00200000 # Address of the stack (arbitrarily chosen) -STACK_SIZE = 0x00010000 # Size of the stack (arbitrarily chosen) -DATA_ADDRESS = 0x00300000 # Address where mutated data will be placed +STACK_SIZE = 0x00010000 # Size of the stack (arbitrarily chosen) +DATA_ADDRESS = 0x00300000 # Address where mutated data will be placed DATA_SIZE_MAX = 0x00010000 # Maximum allowable size of mutated data try: # If Capstone is installed then we'll dump disassembly, otherwise just dump the binary. from capstone import * + cs = Cs(CS_ARCH_MIPS, CS_MODE_MIPS32 + CS_MODE_BIG_ENDIAN) + def unicorn_debug_instruction(uc, address, size, user_data): mem = uc.mem_read(address, size) - for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite(bytes(mem), size): + for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite( + bytes(mem), size + ): print(" Instr: {:#016x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr)) + + except ImportError: + def unicorn_debug_instruction(uc, address, size, user_data): - print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) + print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) + def unicorn_debug_block(uc, address, size, user_data): print("Basic Block: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) - + + def unicorn_debug_mem_access(uc, access, address, size, value, user_data): if access == UC_MEM_WRITE: - print(" >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) + print( + " >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format( + address, size, value + ) + ) else: - print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size)) + print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size)) + def unicorn_debug_mem_invalid_access(uc, access, address, size, value, user_data): if access == UC_MEM_WRITE_UNMAPPED: - print(" >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) + print( + " >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format( + address, size, value + ) + ) else: - print(" >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size)) + print( + " >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size) + ) + def force_crash(uc_error): # This function should be called to indicate to AFL that a crash occurred during emulation. # Pass in the exception received from Uc.emu_start() mem_errors = [ - UC_ERR_READ_UNMAPPED, UC_ERR_READ_PROT, UC_ERR_READ_UNALIGNED, - UC_ERR_WRITE_UNMAPPED, UC_ERR_WRITE_PROT, UC_ERR_WRITE_UNALIGNED, - UC_ERR_FETCH_UNMAPPED, UC_ERR_FETCH_PROT, UC_ERR_FETCH_UNALIGNED, + UC_ERR_READ_UNMAPPED, + UC_ERR_READ_PROT, + UC_ERR_READ_UNALIGNED, + UC_ERR_WRITE_UNMAPPED, + UC_ERR_WRITE_PROT, + UC_ERR_WRITE_UNALIGNED, + UC_ERR_FETCH_UNMAPPED, + UC_ERR_FETCH_PROT, + UC_ERR_FETCH_UNALIGNED, ] if uc_error.errno in mem_errors: # Memory error - throw SIGSEGV @@ -80,11 +109,22 @@ def force_crash(uc_error): # Not sure what happened - throw SIGABRT os.kill(os.getpid(), signal.SIGABRT) + def main(): parser = argparse.ArgumentParser(description="Test harness for simple_target.bin") - parser.add_argument('input_file', type=str, help="Path to the file containing the mutated input to load") - parser.add_argument('-d', '--debug', default=False, action="store_true", help="Enables debug tracing") + parser.add_argument( + "input_file", + type=str, + help="Path to the file containing the mutated input to load", + ) + parser.add_argument( + "-d", + "--debug", + default=False, + action="store_true", + help="Enables debug tracing", + ) args = parser.parse_args() # Instantiate a MIPS32 big endian Unicorn Engine instance @@ -94,13 +134,16 @@ def main(): uc.hook_add(UC_HOOK_BLOCK, unicorn_debug_block) uc.hook_add(UC_HOOK_CODE, unicorn_debug_instruction) uc.hook_add(UC_HOOK_MEM_WRITE | UC_HOOK_MEM_READ, unicorn_debug_mem_access) - uc.hook_add(UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, unicorn_debug_mem_invalid_access) + uc.hook_add( + UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, + unicorn_debug_mem_invalid_access, + ) - #--------------------------------------------------- + # --------------------------------------------------- # Load the binary to emulate and map it into memory print("Loading data input from {}".format(args.input_file)) - binary_file = open(BINARY_FILE, 'rb') + binary_file = open(BINARY_FILE, "rb") binary_code = binary_file.read() binary_file.close() @@ -114,11 +157,11 @@ def main(): uc.mem_write(CODE_ADDRESS, binary_code) # Set the program counter to the start of the code - start_address = CODE_ADDRESS # Address of entry point of main() - end_address = CODE_ADDRESS + 0xf4 # Address of last instruction in main() + start_address = CODE_ADDRESS # Address of entry point of main() + end_address = CODE_ADDRESS + 0xF4 # Address of last instruction in main() uc.reg_write(UC_MIPS_REG_PC, start_address) - #----------------- + # ----------------- # Setup the stack uc.mem_map(STACK_ADDRESS, STACK_SIZE) @@ -127,10 +170,10 @@ def main(): # reserve some space for data uc.mem_map(DATA_ADDRESS, DATA_SIZE_MAX) - #----------------------------------------------------- + # ----------------------------------------------------- # Kick off AFL's fork server - # THIS MUST BE DONE BEFORE LOADING USER DATA! - # If this isn't done every single run, the AFL fork server + # THIS MUST BE DONE BEFORE LOADING USER DATA! + # If this isn't done every single run, the AFL fork server # will not be started appropriately and you'll get erratic results! print("Starting the AFL forkserver") @@ -142,12 +185,12 @@ def main(): else: out = lambda x, y: print(x.format(y)) - #----------------------------------------------- + # ----------------------------------------------- # Load the mutated input and map it into memory # Load the mutated input from disk out("Loading data input from {}", args.input_file) - input_file = open(args.input_file, 'rb') + input_file = open(args.input_file, "rb") input = input_file.read() input_file.close() @@ -159,7 +202,7 @@ def main(): # Write the mutated command into the data buffer uc.mem_write(DATA_ADDRESS, input) - #------------------------------------------------------------ + # ------------------------------------------------------------ # Emulate the code, allowing it to process the mutated input out("Executing until a crash or execution reaches 0x{0:016x}", end_address) @@ -175,5 +218,6 @@ def main(): # UC_AFL_RET_FINISHED = 3 out("Done. AFL Mode is {}", afl_mode) + if __name__ == "__main__": main() diff --git a/unicorn_mode/samples/speedtest/.gitignore b/unicorn_mode/samples/speedtest/.gitignore new file mode 100644 index 00000000..78310c60 --- /dev/null +++ b/unicorn_mode/samples/speedtest/.gitignore @@ -0,0 +1,6 @@ +output +harness +harness-debug +target +target.o +target.offsets.* diff --git a/unicorn_mode/samples/speedtest/Makefile b/unicorn_mode/samples/speedtest/Makefile new file mode 100644 index 00000000..23f5cb07 --- /dev/null +++ b/unicorn_mode/samples/speedtest/Makefile @@ -0,0 +1,17 @@ +CFLAGS += -Wall -Werror -Wextra -Wpedantic -Og -g -fPIE + +.PHONY: all clean + +all: target target.offsets.main + +clean: + rm -rf *.o target target.offsets.* + +target.o: target.c + ${CC} ${CFLAGS} -c target.c -o $@ + +target: target.o + ${CC} ${CFLAGS} target.o -o $@ + +target.offsets.main: target + ./get_offsets.py
\ No newline at end of file diff --git a/unicorn_mode/samples/speedtest/README.md b/unicorn_mode/samples/speedtest/README.md new file mode 100644 index 00000000..3c1184a2 --- /dev/null +++ b/unicorn_mode/samples/speedtest/README.md @@ -0,0 +1,65 @@ +# Speedtest + +This is a simple sample harness for a non-crashing file, +to show the raw speed of C, Rust, and Python harnesses. + +## Compiling... + +Make sure, you built unicornafl first (`../../build_unicorn_support.sh`). +Then, follow these individual steps: + +### Rust + +```bash +cd rust +cargo build --release +../../../afl-fuzz -i ../sample_inputs -o out -- ./target/release/harness @@ +``` + +### C + +```bash +cd c +make +../../../afl-fuzz -i ../sample_inputs -o out -- ./harness @@ +``` + +### python + +```bash +cd python +../../../afl-fuzz -i ../sample_inputs -o out -U -- python3 ./harness.py @@ +``` + +## Results + +TODO: add results here. + + +## Compiling speedtest_target.c + +You shouldn't need to compile simple_target.c since a X86_64 binary version is +pre-built and shipped in this sample folder. This file documents how the binary +was built in case you want to rebuild it or recompile it for any reason. + +The pre-built binary (simple_target_x86_64.bin) was built using -g -O0 in gcc. + +We then load the binary and execute the main function directly. + +## Addresses for the harness: +To find the address (in hex) of main, run: +```bash +objdump -M intel -D target | grep '<main>:' | cut -d" " -f1 +``` +To find all call sites to magicfn, run: +```bash +objdump -M intel -D target | grep '<magicfn>$' | cut -d":" -f1 +``` +For malloc callsites: +```bash +objdump -M intel -D target | grep '<malloc@plt>$' | cut -d":" -f1 +``` +And free callsites: +```bash +objdump -M intel -D target | grep '<free@plt>$' | cut -d":" -f1 +``` diff --git a/unicorn_mode/samples/speedtest/c/Makefile b/unicorn_mode/samples/speedtest/c/Makefile new file mode 100644 index 00000000..ce784d4f --- /dev/null +++ b/unicorn_mode/samples/speedtest/c/Makefile @@ -0,0 +1,54 @@ +# UnicornAFL Usage +# Original Unicorn Example Makefile by Nguyen Anh Quynh <aquynh@gmail.com>, 2015 +# Adapted for AFL++ by domenukk <domenukk@gmail.com>, 2020 +.POSIX: +UNAME_S =$(shell uname -s)# GNU make +UNAME_S:sh=uname -s # BSD make +_UNIQ=_QINU_ + +LIBDIR = ../../../unicornafl +BIN_EXT = +AR_EXT = a + +# Verbose output? +V ?= 0 + +CFLAGS += -Wall -Werror -Wextra -Wno-unused-parameter -I../../../unicornafl/include + +LDFLAGS += -L$(LIBDIR) -lpthread -lm + +_LRT = $(_UNIQ)$(UNAME_S:Linux=) +__LRT = $(_LRT:$(_UNIQ)=-lrt) +LRT = $(__LRT:$(_UNIQ)=) + +LDFLAGS += $(LRT) + +_CC = $(_UNIQ)$(CROSS) +__CC = $(_CC:$(_UNIQ)=$(CC)) +MYCC = $(__CC:$(_UNIQ)$(CROSS)=$(CROSS)gcc) + +.PHONY: all clean + +all: fuzz + +clean: + rm -rf *.o harness harness-debug + +harness.o: harness.c ../../../unicornafl/include/unicorn/*.h + ${MYCC} ${CFLAGS} -O3 -c harness.c -o $@ + +harness-debug.o: harness.c ../../../unicornafl/include/unicorn/*.h + ${MYCC} ${CFLAGS} -fsanitize=address -g -Og -c harness.c -o $@ + +harness: harness.o + ${MYCC} -L${LIBDIR} harness.o ../../../unicornafl/libunicornafl.a $(LDFLAGS) -o $@ + +harness-debug: harness-debug.o + ${MYCC} -fsanitize=address -g -Og -L${LIBDIR} harness-debug.o ../../../unicornafl/libunicornafl.a $(LDFLAGS) -o harness-debug + +../target: + $(MAKE) -C .. + +fuzz: ../target harness + rm -rf ./output + SKIP_BINCHECK=1 ../../../../afl-fuzz -s 1 -i ../sample_inputs -o ./output -- ./harness @@ diff --git a/unicorn_mode/samples/speedtest/c/harness.c b/unicorn_mode/samples/speedtest/c/harness.c new file mode 100644 index 00000000..e8de3d80 --- /dev/null +++ b/unicorn_mode/samples/speedtest/c/harness.c @@ -0,0 +1,390 @@ +/* + Simple test harness for AFL++'s unicornafl c mode. + + This loads the simple_target_x86_64 binary into + Unicorn's memory map for emulation, places the specified input into + argv[1], sets up argv, and argc and executes 'main()'. + If run inside AFL, afl_fuzz automatically does the "right thing" + + Run under AFL as follows: + + $ cd <afl_path>/unicorn_mode/samples/simple/ + $ make + $ ../../../afl-fuzz -m none -i sample_inputs -o out -- ./harness @@ +*/ + +// This is not your everyday Unicorn. +#define UNICORN_AFL + +#include <string.h> +#include <inttypes.h> +#include <stdint.h> +#include <stdio.h> +#include <stdlib.h> +#include <stdbool.h> +#include <unistd.h> +#include <sys/stat.h> +#include <fcntl.h> +#include <sys/mman.h> + +#include <unicorn/unicorn.h> + +// Path to the file containing the binary to emulate +#define BINARY_FILE ("../target") + +// Memory map for the code to be tested +// Arbitrary address where code to test will be loaded +static const int64_t BASE_ADDRESS = 0x0; +// Max size for the code (64kb) +static const int64_t CODE_SIZE_MAX = 0x00010000; +// Location where the input will be placed (make sure the emulated program knows this somehow, too ;) ) +static const int64_t INPUT_ADDRESS = 0x00100000; +// Maximum size for our input +static const int64_t INPUT_MAX = 0x00100000; +// Where our pseudo-heap is at +static const int64_t HEAP_ADDRESS = 0x00200000; +// Maximum allowable size for the heap +static const int64_t HEAP_SIZE_MAX = 0x000F0000; +// Address of the stack (Some random address again) +static const int64_t STACK_ADDRESS = 0x00400000; +// Size of the stack (arbitrarily chosen, just make it big enough) +static const int64_t STACK_SIZE = 0x000F0000; + +// Alignment for unicorn mappings (seems to be needed) +static const int64_t ALIGNMENT = 0x1000; + +static void hook_block(uc_engine *uc, uint64_t address, uint32_t size, void *user_data) { + printf(">>> Tracing basic block at 0x%"PRIx64 ", block size = 0x%x\n", address, size); +} + +static void hook_code(uc_engine *uc, uint64_t address, uint32_t size, void *user_data) { + printf(">>> Tracing instruction at 0x%"PRIx64 ", instruction size = 0x%x\n", address, size); +} + +/* Unicorn page needs to be 0x1000 aligned, apparently */ +static uint64_t pad(uint64_t size) { + if (size % ALIGNMENT == 0) { return size; } + return ((size / ALIGNMENT) + 1) * ALIGNMENT; +} + +/* returns the filesize in bytes, -1 or error. */ +static off_t afl_mmap_file(char *filename, char **buf_ptr) { + + off_t ret = -1; + + int fd = open(filename, O_RDONLY); + + struct stat st = {0}; + if (fstat(fd, &st)) goto exit; + + off_t in_len = st.st_size; + if (in_len == -1) { + /* This can only ever happen on 32 bit if the file is exactly 4gb. */ + fprintf(stderr, "Filesize of %s too large\n", filename); + goto exit; + } + + *buf_ptr = mmap(0, in_len, PROT_READ | PROT_WRITE, MAP_PRIVATE, fd, 0); + + if (*buf_ptr != MAP_FAILED) ret = in_len; + +exit: + close(fd); + return ret; + +} + +/* Place the input at the right spot inside unicorn. + This code path is *HOT*, do as little work as possible! */ +static bool place_input_callback( + uc_engine *uc, + char *input, + size_t input_len, + uint32_t persistent_round, + void *data +){ + // printf("Placing input with len %ld to %x\n", input_len, DATA_ADDRESS); + if (input_len >= INPUT_MAX) { + // Test input too short or too long, ignore this testcase + return false; + } + + // We need a valid c string, make sure it never goes out of bounds. + input[input_len-1] = '\0'; + + // Write the testcase to unicorn. + uc_mem_write(uc, INPUT_ADDRESS, input, input_len); + + return true; +} + +// exit in case the unicorn-internal mmap fails. +static void mem_map_checked(uc_engine *uc, uint64_t addr, size_t size, uint32_t mode) { + size = pad(size); + //printf("SIZE %llx, align: %llx\n", size, ALIGNMENT); + uc_err err = uc_mem_map(uc, addr, size, mode); + if (err != UC_ERR_OK) { + printf("Error mapping %ld bytes at 0x%lx: %s (mode: %d)\n", size, addr, uc_strerror(err), mode); + exit(1); + } +} + +// allocates an array, reads all addrs to the given array ptr, returns a size +ssize_t read_all_addrs(char *path, uint64_t *addrs, size_t max_count) { + + FILE *f = fopen(path, "r"); + if (!f) { + perror("fopen"); + fprintf(stderr, "Could not read %s, make sure you ran ./get_offsets.py\n", path); + exit(-1); + } + for (size_t i = 0; i < max_count; i++) { + bool end = false; + if(fscanf(f, "%lx", &addrs[i]) == EOF) { + end = true; + i--; + } else if (fgetc(f) == EOF) { + end = true; + } + if (end) { + printf("Set %ld addrs for %s\n", i + 1, path); + fclose(f); + return i + 1; + } + } + return max_count; +} + +// Read all addresses from the given file, and set a hook for them. +void set_all_hooks(uc_engine *uc, char *hook_file, void *hook_fn) { + + FILE *f = fopen(hook_file, "r"); + if (!f) { + fprintf(stderr, "Could not read %s, make sure you ran ./get_offsets.py\n", hook_file); + exit(-1); + } + uint64_t hook_addr; + for (int hook_count = 0; 1; hook_count++) { + if(fscanf(f, "%lx", &hook_addr) == EOF) { + printf("Set %d hooks for %s\n", hook_count, hook_file); + fclose(f); + return; + } + printf("got new hook addr %lx (count: %d) ohbytw: sizeof %lx\n", hook_addr, hook_count, sizeof(uc_hook)); + hook_addr += BASE_ADDRESS; + // We'll leek these hooks like a good citizen. + uc_hook *hook = calloc(1, sizeof(uc_hook)); + if (!hook) { + perror("calloc"); + exit(-1); + } + uc_hook_add(uc, hook, UC_HOOK_CODE, hook_fn, NULL, hook_addr, hook_addr); + // guzzle up newline + if (fgetc(f) == EOF) { + printf("Set %d hooks for %s\n", hook_count, hook_file); + fclose(f); + return; + } + } + +} + +// This is a fancy print function that we're just going to skip for fuzzing. +static void hook_magicfn(uc_engine *uc, uint64_t address, uint32_t size, void *user_data) { + address += size; + uc_reg_write(uc, UC_X86_REG_RIP, &address); +} + +static bool already_allocated = false; + +// We use a very simple malloc/free stub here, that only works for exactly one allocation at a time. +static void hook_malloc(uc_engine *uc, uint64_t address, uint32_t size, void *user_data) { + if (already_allocated) { + printf("Double malloc, not supported right now!\n"); + abort(); + } + // read the first param. + uint64_t malloc_size; + uc_reg_read(uc, UC_X86_REG_RDI, &malloc_size); + if (malloc_size > HEAP_SIZE_MAX) { + printf("Tried to allocated %ld bytes, but we only support up to %ld\n", malloc_size, HEAP_SIZE_MAX); + abort(); + } + uc_reg_write(uc, UC_X86_REG_RAX, &HEAP_ADDRESS); + address += size; + uc_reg_write(uc, UC_X86_REG_RIP, &address); + already_allocated = true; +} + +// No real free, just set the "used"-flag to false. +static void hook_free(uc_engine *uc, uint64_t address, uint32_t size, void *user_data) { + if (!already_allocated) { + printf("Double free detected. Real bug?\n"); + abort(); + } + // read the first param. + uint64_t free_ptr; + uc_reg_read(uc, UC_X86_REG_RDI, &free_ptr); + if (free_ptr != HEAP_ADDRESS) { + printf("Tried to free wrong mem region: 0x%lx at code loc 0x%lx\n", free_ptr, address); + abort(); + } + address += size; + uc_reg_write(uc, UC_X86_REG_RIP, &address); + already_allocated = false; +} + +int main(int argc, char **argv, char **envp) { + if (argc == 1) { + printf("Test harness to measure speed against Rust and python. Usage: harness [-t] <inputfile>\n"); + exit(1); + } + bool tracing = false; + char *filename = argv[1]; + if (argc > 2 && !strcmp(argv[1], "-t")) { + tracing = true; + filename = argv[2]; + } + + uc_engine *uc; + uc_err err; + uc_hook hooks[2]; + char *file_contents; + + // Initialize emulator in X86_64 mode + err = uc_open(UC_ARCH_X86, UC_MODE_64, &uc); + if (err) { + printf("Failed on uc_open() with error returned: %u (%s)\n", + err, uc_strerror(err)); + return -1; + } + + // If we want tracing output, set the callbacks here + if (tracing) { + // tracing all basic blocks with customized callback + uc_hook_add(uc, &hooks[0], UC_HOOK_BLOCK, hook_block, NULL, 1, 0); + uc_hook_add(uc, &hooks[1], UC_HOOK_CODE, hook_code, NULL, 1, 0); + } + + printf("The input testcase is set to %s\n", filename); + + + printf("Loading target from %s\n", BINARY_FILE); + off_t len = afl_mmap_file(BINARY_FILE, &file_contents); + printf("Binary file size: %lx\n", len); + if (len < 0) { + perror("Could not read binary to emulate"); + return -2; + } + if (len == 0) { + fprintf(stderr, "File at '%s' is empty\n", BINARY_FILE); + return -3; + } + if (len > CODE_SIZE_MAX) { + fprintf(stderr, "Binary too large, increase CODE_SIZE_MAX\n"); + return -4; + } + + // Map memory. + mem_map_checked(uc, BASE_ADDRESS, len, UC_PROT_ALL); + fflush(stdout); + + // write machine code to be emulated to memory + if (uc_mem_write(uc, BASE_ADDRESS, file_contents, len) != UC_ERR_OK) { + puts("Error writing to CODE"); + exit(-1); + } + + // Release copied contents + munmap(file_contents, len); + + // Set the program counter to the start of the code + FILE *f = fopen("../target.offsets.main", "r"); + if (!f) { + perror("fopen"); + puts("Could not read offset to main function, make sure you ran ./get_offsets.py"); + exit(-1); + } + uint64_t start_address; + if(fscanf(f, "%lx", &start_address) == EOF) { + puts("Start address not found in target.offests.main"); + exit(-1); + } + fclose(f); + start_address += BASE_ADDRESS; + printf("Execution will start at 0x%lx", start_address); + // Set the program counter to the start of the code + uc_reg_write(uc, UC_X86_REG_RIP, &start_address); // address of entry point of main() + + // Setup the Stack + mem_map_checked(uc, STACK_ADDRESS, STACK_SIZE, UC_PROT_READ | UC_PROT_WRITE); + // Setup the stack pointer, but allocate two pointers for the pointers to input + uint64_t val = STACK_ADDRESS + STACK_SIZE - 16; + //printf("Stack at %lu\n", stack_val); + uc_reg_write(uc, UC_X86_REG_RSP, &val); + + // reserve some space for our input data + mem_map_checked(uc, INPUT_ADDRESS, INPUT_MAX, UC_PROT_READ); + + // argc = 2 + val = 2; + uc_reg_write(uc, UC_X86_REG_RDI, &val); + //RSI points to our little 2 QWORD space at the beginning of the stack... + val = STACK_ADDRESS + STACK_SIZE - 16; + uc_reg_write(uc, UC_X86_REG_RSI, &val); + + //... which points to the Input. Write the ptr to mem in little endian. + uint32_t addr_little = STACK_ADDRESS; +#if __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__ + // The chances you are on a big_endian system aren't too high, but still... + __builtin_bswap32(addr_little); +#endif + + uc_mem_write(uc, STACK_ADDRESS + STACK_SIZE - 16, (char *)&addr_little, 4); + + set_all_hooks(uc, "../target.offsets.malloc", hook_malloc); + set_all_hooks(uc, "../target.offsets.magicfn", hook_magicfn); + set_all_hooks(uc, "../target.offsets.free", hook_free); + + int exit_count_max = 100; + // we don't need more exits for now. + uint64_t exits[exit_count_max]; + + ssize_t exit_count = read_all_addrs("../target.offsets.main_ends", exits, exit_count_max); + if (exit_count < 1) { + printf("Could not find exits! aborting.\n"); + abort(); + } + + printf("Starting to fuzz. Running from addr %ld to one of these %ld exits:\n", start_address, exit_count); + for (ssize_t i = 0; i < exit_count; i++) { + printf(" exit %ld: %ld\n", i, exits[i]); + } + + fflush(stdout); + + // let's gooo + uc_afl_ret afl_ret = uc_afl_fuzz( + uc, // The unicorn instance we prepared + filename, // Filename of the input to process. In AFL this is usually the '@@' placeholder, outside it's any input file. + place_input_callback, // Callback that places the input (automatically loaded from the file at filename) in the unicorninstance + exits, // Where to exit (this is an array) + exit_count, // Count of end addresses + NULL, // Optional calback to run after each exec + false, // true, if the optional callback should be run also for non-crashes + 1000, // For persistent mode: How many rounds to run + NULL // additional data pointer + ); + switch(afl_ret) { + case UC_AFL_RET_ERROR: + printf("Error starting to fuzz"); + return -3; + break; + case UC_AFL_RET_NO_AFL: + printf("No AFL attached - We are done with a single run."); + break; + default: + break; + } + return 0; +} diff --git a/unicorn_mode/samples/speedtest/get_offsets.py b/unicorn_mode/samples/speedtest/get_offsets.py new file mode 100755 index 00000000..c9dc76df --- /dev/null +++ b/unicorn_mode/samples/speedtest/get_offsets.py @@ -0,0 +1,77 @@ +#!/usr/bin/env python3 + +"""This simple script uses objdump to parse important addresses from the target""" +import shlex +import subprocess + +objdump_output = subprocess.check_output( + shlex.split("objdump -M intel -D target") +).decode() +main_loc = None +main_ends = [] +main_ended = False +magicfn_calls = [] +malloc_calls = [] +free_calls = [] +strlen_calls = [] + + +def line2addr(line): + return "0x" + line.split(":", 1)[0].strip() + + +last_line = None +for line in objdump_output.split("\n"): + line = line.strip() + + def read_addr_if_endswith(findme, list_to): + """ + Look, for example, for the addr like: + 12a9: e8 f2 fd ff ff call 10a0 <free@plt> + """ + if line.endswith(findme): + list_to.append(line2addr(line)) + + if main_loc is not None and main_ended is False: + # We want to know where main ends. An empty line in objdump. + if len(line) == 0: + main_ends.append(line2addr(last_line)) + main_ended = True + elif "ret" in line: + main_ends.append(line2addr(line)) + + if "<main>:" in line: + if main_loc is not None: + raise Exception("Found multiple main functions, odd target!") + # main_loc is the label, so it's parsed differntly (i.e. `0000000000001220 <main>:`) + main_loc = "0x" + line.strip().split(" ", 1)[0].strip() + else: + [ + read_addr_if_endswith(*x) + for x in [ + ("<free@plt>", free_calls), + ("<malloc@plt>", malloc_calls), + ("<strlen@plt>", strlen_calls), + ("<magicfn>", magicfn_calls), + ] + ] + + last_line = line + +if main_loc is None: + raise ( + "Could not find main in ./target! Make sure objdump is installed and the target is compiled." + ) + +with open("target.offsets.main", "w") as f: + f.write(main_loc) +with open("target.offsets.main_ends", "w") as f: + f.write("\n".join(main_ends)) +with open("target.offsets.magicfn", "w") as f: + f.write("\n".join(magicfn_calls)) +with open("target.offsets.malloc", "w") as f: + f.write("\n".join(malloc_calls)) +with open("target.offsets.free", "w") as f: + f.write("\n".join(free_calls)) +with open("target.offsets.strlen", "w") as f: + f.write("\n".join(strlen_calls)) diff --git a/unicorn_mode/samples/speedtest/python/Makefile b/unicorn_mode/samples/speedtest/python/Makefile new file mode 100644 index 00000000..4282c6cb --- /dev/null +++ b/unicorn_mode/samples/speedtest/python/Makefile @@ -0,0 +1,8 @@ +all: fuzz + +../target: + $(MAKE) -C .. + +fuzz: ../target + rm -rf ./ouptput + ../../../../afl-fuzz -s 1 -U -i ../sample_inputs -o ./output -- python3 harness.py @@ diff --git a/unicorn_mode/samples/speedtest/python/harness.py b/unicorn_mode/samples/speedtest/python/harness.py new file mode 100644 index 00000000..801ef4d1 --- /dev/null +++ b/unicorn_mode/samples/speedtest/python/harness.py @@ -0,0 +1,277 @@ +#!/usr/bin/env python3 +""" + Simple test harness for AFL's Unicorn Mode. + + This loads the speedtest target binary (precompiled X64 code) into + Unicorn's memory map for emulation, places the specified input into + Argv, and executes main. + There should not be any crashes - it's a speedtest against Rust and c. + + Before running this harness, call make in the parent folder. + + Run under AFL as follows: + + $ cd <afl_path>/unicorn_mode/samples/speedtest/python + $ ../../../../afl-fuzz -U -i ../sample_inputs -o ./output -- python3 harness.py @@ +""" + +import argparse +import os +import struct + +from unicornafl import * +from unicornafl.unicorn_const import UC_ARCH_X86, UC_HOOK_CODE, UC_MODE_64 +from unicornafl.x86_const import ( + UC_X86_REG_RAX, + UC_X86_REG_RDI, + UC_X86_REG_RIP, + UC_X86_REG_RSI, + UC_X86_REG_RSP, +) + +# Memory map for the code to be tested +BASE_ADDRESS = 0x0 # Arbitrary address where the (PIE) target binary will be loaded to +CODE_SIZE_MAX = 0x00010000 # Max size for the code (64kb) +INPUT_ADDRESS = 0x00100000 # where we put our stuff +INPUT_MAX = 0x00100000 # max size for our input +HEAP_ADDRESS = 0x00200000 # Heap addr +HEAP_SIZE_MAX = 0x000F0000 # Maximum allowable size for the heap +STACK_ADDRESS = 0x00400000 # Address of the stack (arbitrarily chosen) +STACK_SIZE = 0x000F0000 # Size of the stack (arbitrarily chosen) + +target_path = os.path.abspath( + os.path.join(os.path.dirname(os.path.abspath(__file__)), "..") +) +target_bin = os.path.join(target_path, "target") + + +def get_offsets_for(name): + full_path = os.path.join(target_path, f"target.offsets.{name}") + with open(full_path) as f: + return [int(x, 16) + BASE_ADDRESS for x in f.readlines()] + + +# Read all offsets from our objdump file +main_offset = get_offsets_for("main")[0] +main_ends = get_offsets_for("main_ends") +malloc_callsites = get_offsets_for("malloc") +free_callsites = get_offsets_for("free") +magicfn_callsites = get_offsets_for("magicfn") +# Joke's on me: strlen got inlined by my compiler +strlen_callsites = get_offsets_for("strlen") + +try: + # If Capstone is installed then we'll dump disassembly, otherwise just dump the binary. + from capstone import * + + cs = Cs(CS_ARCH_MIPS, CS_MODE_MIPS32 + CS_MODE_BIG_ENDIAN) + + def unicorn_debug_instruction(uc, address, size, user_data): + mem = uc.mem_read(address, size) + for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite( + bytes(mem), size + ): + print(" Instr: {:#016x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr)) + + +except ImportError: + + def unicorn_debug_instruction(uc, address, size, user_data): + print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) + + +def unicorn_debug_block(uc, address, size, user_data): + print("Basic Block: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) + + +def unicorn_debug_mem_access(uc, access, address, size, value, user_data): + if access == UC_MEM_WRITE: + print( + " >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format( + address, size, value + ) + ) + else: + print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size)) + + +def unicorn_debug_mem_invalid_access(uc, access, address, size, value, user_data): + if access == UC_MEM_WRITE_UNMAPPED: + print( + " >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format( + address, size, value + ) + ) + else: + print( + " >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size) + ) + + +already_allocated = False + + +def malloc_hook(uc, address, size, user_data): + """ + We use a very simple malloc/free stub here, that only works for exactly one allocation at a time. + """ + global already_allocated + if already_allocated: + print("Double malloc, not supported right now!") + os.abort() + # read the first param + malloc_size = uc.reg_read(UC_X86_REG_RDI) + if malloc_size > HEAP_SIZE_MAX: + print( + f"Tried to allocate {malloc_size} bytes, aint't nobody got space for that! (We may only allocate up to {HEAP_SIZE_MAX})" + ) + os.abort() + uc.reg_write(UC_X86_REG_RAX, HEAP_ADDRESS) + uc.reg_write(UC_X86_REG_RIP, address + size) + already_allocated = True + + +def free_hook(uc, address, size, user_data): + """ + No real free, just set the "used"-flag to false. + """ + global already_allocated + if not already_allocated: + print("Double free detected. Real bug?") + os.abort() + # read the first param + free_ptr = uc.reg_read(UC_X86_REG_RDI) + if free_ptr != HEAP_ADDRESS: + print( + f"Tried to free wrong mem region: {hex(free_ptr)} at code loc {hex(address)}" + ) + os.abort() + uc.reg_write(UC_X86_REG_RIP, address + size) + already_allocated = False + + +# def strlen_hook(uc, address, size, user_data): +# """ +# No real strlen, we know the len is == our input. +# This completely ignores '\0', but for this target, do we really care? +# """ +# global input_len +# print(f"Returning len {input_len}") +# uc.reg_write(UC_X86_REG_RAX, input_len) +# uc.reg_write(UC_X86_REG_RIP, address + size) + + +def magicfn_hook(uc, address, size, user_data): + """ + This is a fancy print function that we're just going to skip for fuzzing. + """ + uc.reg_write(UC_X86_REG_RIP, address + size) + + +def main(): + + parser = argparse.ArgumentParser(description="Test harness for simple_target.bin") + parser.add_argument( + "input_file", + type=str, + help="Path to the file containing the mutated input to load", + ) + parser.add_argument( + "-t", + "--trace", + default=False, + action="store_true", + help="Enables debug tracing", + ) + args = parser.parse_args() + + # Instantiate a MIPS32 big endian Unicorn Engine instance + uc = Uc(UC_ARCH_X86, UC_MODE_64) + + if args.trace: + uc.hook_add(UC_HOOK_BLOCK, unicorn_debug_block) + uc.hook_add(UC_HOOK_CODE, unicorn_debug_instruction) + uc.hook_add(UC_HOOK_MEM_WRITE | UC_HOOK_MEM_READ, unicorn_debug_mem_access) + uc.hook_add( + UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, + unicorn_debug_mem_invalid_access, + ) + + print("The input testcase is set to {}".format(args.input_file)) + + # --------------------------------------------------- + # Load the binary to emulate and map it into memory + with open(target_bin, "rb") as f: + binary_code = f.read() + + # Apply constraints to the mutated input + if len(binary_code) > CODE_SIZE_MAX: + print("Binary code is too large (> {} bytes)".format(CODE_SIZE_MAX)) + return + + # Write the binary to its place in mem + uc.mem_map(BASE_ADDRESS, CODE_SIZE_MAX) + uc.mem_write(BASE_ADDRESS, binary_code) + + # Set the program counter to the start of the code + uc.reg_write(UC_X86_REG_RIP, main_offset) + + # Setup the stack. + uc.mem_map(STACK_ADDRESS, STACK_SIZE) + # Setup the stack pointer, but allocate two pointers for the pointers to input. + uc.reg_write(UC_X86_REG_RSP, STACK_ADDRESS + STACK_SIZE - 16) + + # Setup our input space, and push the pointer to it in the function params + uc.mem_map(INPUT_ADDRESS, INPUT_MAX) + # We have argc = 2 + uc.reg_write(UC_X86_REG_RDI, 2) + # RSI points to our little 2 QWORD space at the beginning of the stack... + uc.reg_write(UC_X86_REG_RSI, STACK_ADDRESS + STACK_SIZE - 16) + # ... which points to the Input. Write the ptr to mem in little endian. + uc.mem_write(STACK_ADDRESS + STACK_SIZE - 16, struct.pack("<Q", INPUT_ADDRESS)) + + for addr in malloc_callsites: + uc.hook_add(UC_HOOK_CODE, malloc_hook, begin=addr, end=addr) + + for addr in free_callsites: + uc.hook_add(UC_HOOK_CODE, free_hook, begin=addr, end=addr) + + if len(strlen_callsites): + # strlen got inlined for my compiler. + print( + "Oops, your compiler emitted strlen as function. You may have to change the harness." + ) + # for addr in strlen_callsites: + # uc.hook_add(UC_HOOK_CODE, strlen_hook, begin=addr, end=addr) + + for addr in magicfn_callsites: + uc.hook_add(UC_HOOK_CODE, magicfn_hook, begin=addr, end=addr + 1) + + # ----------------------------------------------------- + # Set up a callback to place input data (do little work here, it's called for every single iteration! This code is *HOT*) + # We did not pass in any data and don't use persistent mode, so we can ignore these params. + # Be sure to check out the docstrings for the uc.afl_* functions. + def place_input_callback(uc, input, persistent_round, data): + # Apply constraints to the mutated input + input_len = len(input) + # global input_len + if input_len > INPUT_MAX: + # print("Test input is too long (> {} bytes)") + return False + + # print(f"Placing input: {input} in round {persistent_round}") + + # Make sure the string is always 0-terminated (as it would be "in the wild") + input[-1] = b"\0" + + # Write the mutated command into the data buffer + uc.mem_write(INPUT_ADDRESS, input) + # uc.reg_write(UC_X86_REG_RIP, main_offset) + + print(f"Starting to fuzz. Running from addr {main_offset} to one of {main_ends}") + # Start the fuzzer. + uc.afl_fuzz(args.input_file, place_input_callback, main_ends, persistent_iters=1000) + + +if __name__ == "__main__": + main() diff --git a/unicorn_mode/samples/speedtest/rust/.gitignore b/unicorn_mode/samples/speedtest/rust/.gitignore new file mode 100644 index 00000000..a9d37c56 --- /dev/null +++ b/unicorn_mode/samples/speedtest/rust/.gitignore @@ -0,0 +1,2 @@ +target +Cargo.lock diff --git a/unicorn_mode/samples/speedtest/rust/Cargo.toml b/unicorn_mode/samples/speedtest/rust/Cargo.toml new file mode 100644 index 00000000..c19ee0a1 --- /dev/null +++ b/unicorn_mode/samples/speedtest/rust/Cargo.toml @@ -0,0 +1,15 @@ +[package] +name = "unicornafl_harness" +version = "0.1.0" +authors = ["Dominik Maier <domenukk@gmail.com>"] +edition = "2018" + +[profile.release] +lto = true +opt-level = 3 +panic = "abort" + +[dependencies] +unicornafl = { path = "../../../unicornafl/bindings/rust/", version="1.0.0" } +capstone="0.6.0" +libc="0.2.66"
\ No newline at end of file diff --git a/unicorn_mode/samples/speedtest/rust/Makefile b/unicorn_mode/samples/speedtest/rust/Makefile new file mode 100644 index 00000000..fe18d6ee --- /dev/null +++ b/unicorn_mode/samples/speedtest/rust/Makefile @@ -0,0 +1,17 @@ +all: fuzz + +clean: + cargo clean + +./target/release/unicornafl_harness: ./src/main.rs + cargo build --release + +./target/debug/unicornafl_harness: ./src/main.rs + cargo build + +../target: + $(MAKE) -c .. + +fuzz: ../target ./target/release/unicornafl_harness + rm -rf ./output + SKIP_BINCHECK=1 ../../../../afl-fuzz -s 1 -i ../sample_inputs -o ./output -- ./target/release/unicornafl_harness @@ diff --git a/unicorn_mode/samples/speedtest/rust/src/main.rs b/unicorn_mode/samples/speedtest/rust/src/main.rs new file mode 100644 index 00000000..1e35ff0b --- /dev/null +++ b/unicorn_mode/samples/speedtest/rust/src/main.rs @@ -0,0 +1,232 @@ +extern crate capstone; +extern crate libc; + +use core::cell::Cell; +use std::{ + env, + fs::File, + io::{self, Read}, + process::abort, + str, +}; + +use unicornafl::{ + unicorn_const::{uc_error, Arch, Mode, Permission}, + RegisterX86::{self, *}, + Unicorn, UnicornHandle, +}; + +const BINARY: &str = &"../target"; + +// Memory map for the code to be tested +// Arbitrary address where code to test will be loaded +const BASE_ADDRESS: u64 = 0x0; +// Max size for the code (64kb) +const CODE_SIZE_MAX: u64 = 0x00010000; +// Location where the input will be placed (make sure the uclated program knows this somehow, too ;) ) +const INPUT_ADDRESS: u64 = 0x00100000; +// Maximum size for our input +const INPUT_MAX: u64 = 0x00100000; +// Where our pseudo-heap is at +const HEAP_ADDRESS: u64 = 0x00200000; +// Maximum allowable size for the heap +const HEAP_SIZE_MAX: u64 = 0x000F0000; +// Address of the stack (Some random address again) +const STACK_ADDRESS: u64 = 0x00400000; +// Size of the stack (arbitrarily chosen, just make it big enough) +const STACK_SIZE: u64 = 0x000F0000; + +fn read_file(filename: &str) -> Result<Vec<u8>, io::Error> { + let mut f = File::open(filename)?; + let mut buffer = Vec::new(); + f.read_to_end(&mut buffer)?; + Ok(buffer) +} + +/// Our location parser +fn parse_locs(loc_name: &str) -> Result<Vec<u64>, io::Error> { + let contents = &read_file(&format!("../target.offsets.{}", loc_name))?; + //println!("Read: {:?}", contents); + Ok(str_from_u8_unchecked(&contents) + .split("\n") + .map(|x| { + //println!("Trying to convert {}", &x[2..]); + let result = u64::from_str_radix(&x[2..], 16); + result.unwrap() + }) + .collect()) +} + +// find null terminated string in vec +pub fn str_from_u8_unchecked(utf8_src: &[u8]) -> &str { + let nul_range_end = utf8_src + .iter() + .position(|&c| c == b'\0') + .unwrap_or(utf8_src.len()); + unsafe { str::from_utf8_unchecked(&utf8_src[0..nul_range_end]) } +} + +fn align(size: u64) -> u64 { + const ALIGNMENT: u64 = 0x1000; + if size % ALIGNMENT == 0 { + size + } else { + ((size / ALIGNMENT) + 1) * ALIGNMENT + } +} + +fn main() { + let args: Vec<String> = env::args().collect(); + if args.len() == 1 { + println!("Missing parameter <uclation_input> (@@ for AFL)"); + return; + } + let input_file = &args[1]; + println!("The input testcase is set to {}", input_file); + fuzz(input_file).unwrap(); +} + +fn fuzz(input_file: &str) -> Result<(), uc_error> { + let mut unicorn = Unicorn::new(Arch::X86, Mode::MODE_64, 0)?; + let mut uc: UnicornHandle<'_, _> = unicorn.borrow(); + + let binary = read_file(BINARY).expect(&format!("Could not read modem image: {}", BINARY)); + let _aligned_binary_size = align(binary.len() as u64); + // Apply constraints to the mutated input + if binary.len() as u64 > CODE_SIZE_MAX { + println!("Binary code is too large (> {} bytes)", CODE_SIZE_MAX); + } + + // Write the binary to its place in mem + uc.mem_map(BASE_ADDRESS, CODE_SIZE_MAX as usize, Permission::ALL)?; + uc.mem_write(BASE_ADDRESS, &binary)?; + + // Set the program counter to the start of the code + let main_locs = parse_locs("main").unwrap(); + //println!("Entry Point: {:x}", main_locs[0]); + uc.reg_write(RegisterX86::RIP as i32, main_locs[0])?; + + // Setup the stack. + uc.mem_map( + STACK_ADDRESS, + STACK_SIZE as usize, + Permission::READ | Permission::WRITE, + )?; + // Setup the stack pointer, but allocate two pointers for the pointers to input. + uc.reg_write(RSP as i32, STACK_ADDRESS + STACK_SIZE - 16)?; + + // Setup our input space, and push the pointer to it in the function params + uc.mem_map(INPUT_ADDRESS, INPUT_MAX as usize, Permission::READ)?; + // We have argc = 2 + uc.reg_write(RDI as i32, 2)?; + // RSI points to our little 2 QWORD space at the beginning of the stack... + uc.reg_write(RSI as i32, STACK_ADDRESS + STACK_SIZE - 16)?; + // ... which points to the Input. Write the ptr to mem in little endian. + uc.mem_write( + STACK_ADDRESS + STACK_SIZE - 16, + &(INPUT_ADDRESS as u32).to_le_bytes(), + )?; + + let already_allocated = Cell::new(false); + + let already_allocated_malloc = already_allocated.clone(); + // We use a very simple malloc/free stub here, + // that only works for exactly one allocation at a time. + let hook_malloc = move |mut uc: UnicornHandle<'_, _>, addr: u64, size: u32| { + if already_allocated_malloc.get() { + println!("Double malloc, not supported right now!"); + abort(); + } + // read the first param + let malloc_size = uc.reg_read(RDI as i32).unwrap(); + if malloc_size > HEAP_SIZE_MAX { + println!( + "Tried to allocate {} bytes, but we may only allocate up to {}", + malloc_size, HEAP_SIZE_MAX + ); + abort(); + } + uc.reg_write(RAX as i32, HEAP_ADDRESS).unwrap(); + uc.reg_write(RIP as i32, addr + size as u64).unwrap(); + already_allocated_malloc.set(true); + }; + + let already_allocated_free = already_allocated.clone(); + // No real free, just set the "used"-flag to false. + let hook_free = move |mut uc: UnicornHandle<'_, _>, addr, size| { + if already_allocated_free.get() { + println!("Double free detected. Real bug?"); + abort(); + } + // read the first param + let free_ptr = uc.reg_read(RDI as i32).unwrap(); + if free_ptr != HEAP_ADDRESS { + println!( + "Tried to free wrong mem region {:x} at code loc {:x}", + free_ptr, addr + ); + abort(); + } + uc.reg_write(RIP as i32, addr + size as u64).unwrap(); + already_allocated_free.set(false); + }; + + /* + BEGIN FUNCTION HOOKS + */ + + // This is a fancy print function that we're just going to skip for fuzzing. + let hook_magicfn = move |mut uc: UnicornHandle<'_, _>, addr, size| { + uc.reg_write(RIP as i32, addr + size as u64).unwrap(); + }; + + for addr in parse_locs("malloc").unwrap() { + //hook!(addr, hook_malloc, "malloc"); + uc.add_code_hook(addr, addr, Box::new(hook_malloc.clone()))?; + } + + for addr in parse_locs("free").unwrap() { + uc.add_code_hook(addr, addr, Box::new(hook_free.clone()))?; + } + + for addr in parse_locs("magicfn").unwrap() { + uc.add_code_hook(addr, addr, Box::new(hook_magicfn.clone()))?; + } + + let place_input_callback = + |mut uc: UnicornHandle<'_, _>, afl_input: &mut [u8], _persistent_round| { + // apply constraints to the mutated input + if afl_input.len() > INPUT_MAX as usize { + //println!("Skipping testcase with leng {}", afl_input.len()); + return false; + } + + afl_input[afl_input.len() - 1] = b'\0'; + uc.mem_write(INPUT_ADDRESS, afl_input).unwrap(); + true + }; + + // return true if the last run should be counted as crash + let crash_validation_callback = + |_uc: UnicornHandle<'_, _>, result, _input: &[u8], _persistent_round| { + result != uc_error::OK + }; + + let end_addrs = parse_locs("main_ends").unwrap(); + + let ret = uc.afl_fuzz( + input_file, + Box::new(place_input_callback), + &end_addrs, + Box::new(crash_validation_callback), + false, + 1000, + ); + + match ret { + Ok(_) => {} + Err(e) => panic!(format!("found non-ok unicorn exit: {:?}", e)), + } + + Ok(()) +} diff --git a/unicorn_mode/samples/speedtest/sample_inputs/a b/unicorn_mode/samples/speedtest/sample_inputs/a new file mode 100644 index 00000000..78981922 --- /dev/null +++ b/unicorn_mode/samples/speedtest/sample_inputs/a @@ -0,0 +1 @@ +a diff --git a/unicorn_mode/samples/speedtest/target.c b/unicorn_mode/samples/speedtest/target.c new file mode 100644 index 00000000..8359a110 --- /dev/null +++ b/unicorn_mode/samples/speedtest/target.c @@ -0,0 +1,77 @@ +/* + * Sample target file to test afl-unicorn fuzzing capabilities. + * This is a very trivial example that will, however, never crash. + * Crashing would change the execution speed. + * + */ +#include <stdint.h> +#include <string.h> +#include <stdio.h> +#include <stdlib.h> + +// Random print function we can hook in our harness to test hook speeds. +char magicfn(char to_print) { + puts("Printing a char, just minding my own business: "); + putchar(to_print); + putchar('\n'); + return to_print; +} + +int main(int argc, char** argv) { + if (argc < 2) { + printf("Gimme input pl0x!\n"); + return -1; + } + + // Make sure the hooks work... + char *test = malloc(1024); + if (!test) { + printf("Uh-Oh, malloc doesn't work!"); + abort(); + } + free(test); + + char *data_buf = argv[1]; + // We can start the unicorn hooking here. + uint64_t data_len = strlen(data_buf); + if (data_len < 20) return -2; + + for (; data_len --> 0 ;) { + char *buf_cpy = NULL; + if (data_len) { + buf_cpy = malloc(data_len); + if (!buf_cpy) { + puts("Oof, malloc failed! :/"); + abort(); + } + memcpy(buf_cpy, data_buf, data_len); + } + if (data_len >= 18) { + free(buf_cpy); + continue; + } + if (data_len > 2 && data_len < 18) { + buf_cpy[data_len - 1] = (char) 0x90; + } else if (data_buf[9] == (char) 0x90 && data_buf[10] != 0x00 && buf_cpy[11] == (char) 0x90) { + // Cause a crash if data[10] is not zero, but [9] and [11] are zero + unsigned char valid_read = buf_cpy[10]; + if (magicfn(valid_read) != valid_read) { + puts("Oof, the hook for data_buf[10] is broken?"); + abort(); + } + } + free(buf_cpy); + } + if (data_buf[0] > 0x10 && data_buf[0] < 0x20 && data_buf[1] > data_buf[2]) { + // Cause an 'invalid read' crash if (0x10 < data[0] < 0x20) and data[1] > data[2] + unsigned char valid_read = data_buf[0]; + if (magicfn(valid_read) != valid_read) { + puts("Oof, the hook for data_buf[0] is broken?"); + abort(); + } + } + + magicfn('q'); + + return 0; +} diff --git a/unicorn_mode/unicornafl b/unicorn_mode/unicornafl -Subproject c6d6647161a32bae88785a618fcd828d1711d9e +Subproject fb2fc9f25df32f17f6b6b859e4dbd70f9a857e0 diff --git a/unicorn_mode/update_uc_ref.sh b/unicorn_mode/update_uc_ref.sh index a2613942..7c1c7778 100755 --- a/unicorn_mode/update_uc_ref.sh +++ b/unicorn_mode/update_uc_ref.sh @@ -19,7 +19,7 @@ if [ "$NEW_VERSION" = "-h" ]; then exit 1 fi -git submodule init && git submodule update || exit 1 +git submodule init && git submodule update unicornafl || exit 1 cd ./unicornafl || exit 1 git fetch origin dev 1>/dev/null || exit 1 git stash 1>/dev/null 2>/dev/null diff --git a/examples/README.md b/utils/README.md index d28aadbe..336b6b6c 100644 --- a/examples/README.md +++ b/utils/README.md @@ -39,15 +39,15 @@ Here's a quick overview of the stuff you can find in this directory: - libpng_no_checksum - a sample patch for removing CRC checks in libpng. - - persistent_demo - an example of how to use the LLVM persistent process + - persistent_mode - an example of how to use the LLVM persistent process mode to speed up certain fuzzing jobs. - socket_fuzzing - a LD_PRELOAD library 'redirects' a socket to stdin for fuzzing access with afl++ -Note that the minimize_corpus.sh tool has graduated from the examples/ +Note that the minimize_corpus.sh tool has graduated from the utils/ directory and is now available as ../afl-cmin. The LLVM mode has likewise -graduated to ../llvm_mode/*. +graduated to ../instrumentation/*. Most of the tools in this directory are meant chiefly as examples that need to be tweaked for your specific needs. They come with some basic documentation, diff --git a/examples/afl_frida/Makefile b/utils/afl_frida/GNUmakefile index c154f3a4..8b56415b 100644 --- a/examples/afl_frida/Makefile +++ b/utils/afl_frida/GNUmakefile @@ -11,7 +11,7 @@ libfrida-gum.a: @exit 1 afl-frida: afl-frida.c libfrida-gum.a - $(CC) -g $(OPT) -o afl-frida -Wno-format -Wno-pointer-sign -I. -fpermissive -fPIC afl-frida.c ../../afl-llvm-rt.o libfrida-gum.a -ldl -lresolv -pthread + $(CC) -g $(OPT) -o afl-frida -Wno-format -Wno-pointer-sign -I. -fpermissive -fPIC afl-frida.c ../../afl-compiler-rt.o libfrida-gum.a -ldl -lresolv -pthread libtestinstr.so: libtestinstr.c $(CC) -g -O0 -fPIC -o libtestinstr.so -shared libtestinstr.c diff --git a/examples/afl_network_proxy/Makefile b/utils/afl_frida/Makefile index 0b306dde..0b306dde 100644 --- a/examples/afl_network_proxy/Makefile +++ b/utils/afl_frida/Makefile diff --git a/examples/afl_frida/README.md b/utils/afl_frida/README.md index 7743479b..68b62009 100644 --- a/examples/afl_frida/README.md +++ b/utils/afl_frida/README.md @@ -20,7 +20,7 @@ search and edit the `STEP 1`, `STEP 2` and `STEP 3` locations. Example (after modifying afl-frida.c to your needs and compile it): ``` -LD_LIBRARY_PATH=/path/to/the/target/library afl-fuzz -i in -o out -- ./afl-frida +LD_LIBRARY_PATH=/path/to/the/target/library/ afl-fuzz -i in -o out -- ./afl-frida ``` (or even remote via afl-network-proxy). diff --git a/utils/afl_frida/afl-frida.c b/utils/afl_frida/afl-frida.c new file mode 100644 index 00000000..711d8f33 --- /dev/null +++ b/utils/afl_frida/afl-frida.c @@ -0,0 +1,397 @@ +/* + american fuzzy lop++ - afl-frida skeleton example + ------------------------------------------------- + + Copyright 2020 AFLplusplus Project. All rights reserved. + + Written mostly by meme -> https://github.com/meme/hotwax + + Modifications by Marc Heuse <mh@mh-sec.de> + + Licensed under the Apache License, Version 2.0 (the "License"); + you may not use this file except in compliance with the License. + You may obtain a copy of the License at: + + http://www.apache.org/licenses/LICENSE-2.0 + + HOW-TO + ====== + + You only need to change the following: + + 1. set the defines and function call parameters. + 2. dl load the library you want to fuzz, lookup the functions you need + and setup the calls to these. + 3. in the while loop you call the functions in the necessary order - + incl the cleanup. the cleanup is important! + + Just look these steps up in the code, look for "// STEP x:" + +*/ + +#include <stdio.h> +#include <stdint.h> +#include <unistd.h> +#include <stdint.h> +#include <stddef.h> +#include <sys/shm.h> +#include <dlfcn.h> + +#ifdef __APPLE__ + #include <mach/mach.h> + #include <mach-o/dyld_images.h> +#else + #include <sys/wait.h> + #include <sys/personality.h> +#endif + +int debug = 0; + +// STEP 1: + +// The presets are for the example libtestinstr.so: + +/* What is the name of the library to fuzz */ +#define TARGET_LIBRARY "libtestinstr.so" + +/* What is the name of the function to fuzz */ +#define TARGET_FUNCTION "testinstr" + +/* here you need to specify the parameter for the target function */ +static void *(*o_function)(uint8_t *, int); + +// END STEP 1 + +#include "frida-gum.h" + +void instr_basic_block(GumStalkerIterator *iterator, GumStalkerOutput *output, + gpointer user_data); +void afl_setup(void); +void afl_start_forkserver(void); +int __afl_persistent_loop(unsigned int max_cnt); + +#include "../../config.h" + +// Shared memory fuzzing. +int __afl_sharedmem_fuzzing = 1; +extern unsigned int * __afl_fuzz_len; +extern unsigned char *__afl_fuzz_ptr; + +// Notify AFL about persistent mode. +static volatile char AFL_PERSISTENT[] = "##SIG_AFL_PERSISTENT##\0"; +int __afl_persistent_loop(unsigned int); + +// Notify AFL about deferred forkserver. +static volatile char AFL_DEFER_FORKSVR[] = "##SIG_AFL_DEFER_FORKSRV##\0"; +void __afl_manual_init(); + +// Because we do our own logging. +extern uint8_t * __afl_area_ptr; +static __thread guint64 previous_pc; + +// Frida stuff below. +typedef struct { + + GumAddress base_address; + guint64 code_start, code_end; + GumAddress current_log_impl; + uint64_t afl_prev_loc; + +} range_t; + +inline static void afl_maybe_log(guint64 current_pc) { + + // fprintf(stderr, "PC: %p ^ %p\n", current_pc, previous_pc); + + current_pc = (current_pc >> 4) ^ (current_pc << 8); + current_pc &= MAP_SIZE - 1; + + __afl_area_ptr[current_pc ^ previous_pc]++; + previous_pc = current_pc >> 1; + +} + +#if GUM_NATIVE_CPU == GUM_CPU_AMD64 + +static const guint8 afl_maybe_log_code[] = { + + 0x9c, // pushfq + 0x50, // push rax + 0x51, // push rcx + 0x52, // push rdx + 0x56, // push rsi + + 0x89, 0xf8, // mov eax, edi + 0xc1, 0xe0, 0x08, // shl eax, 8 + 0xc1, 0xef, 0x04, // shr edi, 4 + 0x31, 0xc7, // xor edi, eax + 0x0f, 0xb7, 0xc7, // movzx eax, di + 0x48, 0x8d, 0x0d, 0x30, 0x00, 0x00, 0x00, // lea rcx, sym._afl_area_ptr_ptr + 0x48, 0x8b, 0x09, // mov rcx, qword [rcx] + 0x48, 0x8b, 0x09, // mov rcx, qword [rcx] + 0x48, 0x8d, 0x15, 0x1b, 0x00, 0x00, 0x00, // lea rdx, sym._afl_prev_loc_ptr + 0x48, 0x8b, 0x32, // mov rsi, qword [rdx] + 0x48, 0x8b, 0x36, // mov rsi, qword [rsi] + 0x48, 0x31, 0xc6, // xor rsi, rax + 0xfe, 0x04, 0x31, // inc byte [rcx + rsi] + + 0x48, 0xd1, 0xe8, // shr rax, 1 + 0x48, 0x8b, 0x0a, // mov rcx, qword [rdx] + 0x48, 0x89, 0x01, // mov qword [rcx], rax + + 0x5e, // pop rsi + 0x5a, // pop rdx + 0x59, // pop rcx + 0x58, // pop rax + 0x9d, // popfq + + 0xc3, // ret + // Read-only data goes here: + // uint64_t* afl_prev_loc_ptr + // uint8_t** afl_area_ptr_ptr + // unsigned int afl_instr_rms + +}; + +#else + +static void on_basic_block(GumCpuContext *context, gpointer user_data) { + + afl_maybe_log((guint64)user_data); + +} + +#endif + +void instr_basic_block(GumStalkerIterator *iterator, GumStalkerOutput *output, + gpointer user_data) { + + range_t *range = (range_t *)user_data; + + const cs_insn *instr; + gboolean begin = TRUE; + while (gum_stalker_iterator_next(iterator, &instr)) { + + if (begin) { + + if (instr->address >= range->code_start && + instr->address <= range->code_end) { + +#if GUM_NATIVE_CPU == GUM_CPU_AMD64 + GumX86Writer *cw = output->writer.x86; + if (range->current_log_impl == 0 || + !gum_x86_writer_can_branch_directly_between( + cw->pc, range->current_log_impl) || + !gum_x86_writer_can_branch_directly_between( + cw->pc + 128, range->current_log_impl)) { + + gconstpointer after_log_impl = cw->code + 1; + + gum_x86_writer_put_jmp_near_label(cw, after_log_impl); + + range->current_log_impl = cw->pc; + gum_x86_writer_put_bytes(cw, afl_maybe_log_code, + sizeof(afl_maybe_log_code)); + + uint64_t *afl_prev_loc_ptr = &range->afl_prev_loc; + uint8_t **afl_area_ptr_ptr = &__afl_area_ptr; + gum_x86_writer_put_bytes(cw, (const guint8 *)&afl_prev_loc_ptr, + sizeof(afl_prev_loc_ptr)); + gum_x86_writer_put_bytes(cw, (const guint8 *)&afl_area_ptr_ptr, + sizeof(afl_area_ptr_ptr)); + gum_x86_writer_put_label(cw, after_log_impl); + + } + + gum_x86_writer_put_lea_reg_reg_offset(cw, GUM_REG_RSP, GUM_REG_RSP, + -GUM_RED_ZONE_SIZE); + gum_x86_writer_put_push_reg(cw, GUM_REG_RDI); + gum_x86_writer_put_mov_reg_address(cw, GUM_REG_RDI, + GUM_ADDRESS(instr->address)); + gum_x86_writer_put_call_address(cw, range->current_log_impl); + gum_x86_writer_put_pop_reg(cw, GUM_REG_RDI); + gum_x86_writer_put_lea_reg_reg_offset(cw, GUM_REG_RSP, GUM_REG_RSP, + GUM_RED_ZONE_SIZE); +#else + gum_stalker_iterator_put_callout(iterator, on_basic_block, + (gpointer)instr->address, NULL); +#endif + begin = FALSE; + + } + + } + + gum_stalker_iterator_keep(iterator); + + } + +} + +/* Because this CAN be called more than once, it will return the LAST range */ +static int enumerate_ranges(const GumRangeDetails *details, + gpointer user_data) { + + GumMemoryRange *code_range = (GumMemoryRange *)user_data; + memcpy(code_range, details->range, sizeof(*code_range)); + return 0; + +} + +int main(int argc, char **argv) { + +#ifndef __APPLE__ + (void)personality(ADDR_NO_RANDOMIZE); // disable ASLR +#endif + + // STEP 2: load the library you want to fuzz and lookup the functions, + // inclusive of the cleanup functions. + // If there is just one function, then there is nothing to change + // or add here. + + void *dl = NULL; + if (argc > 2) { + + dl = dlopen(argv[1], RTLD_LAZY); + + } else { + + dl = dlopen(TARGET_LIBRARY, RTLD_LAZY); + + } + + if (!dl) { + + if (argc > 2) + fprintf(stderr, "Could not load %s\n", argv[1]); + else + fprintf(stderr, "Could not load %s\n", TARGET_LIBRARY); + exit(-1); + + } + + if (argc > 2) + o_function = dlsym(dl, argv[2]); + else + o_function = dlsym(dl, TARGET_FUNCTION); + if (!o_function) { + + if (argc > 2) + fprintf(stderr, "Could not find function %s\n", argv[2]); + else + fprintf(stderr, "Could not find function %s\n", TARGET_FUNCTION); + exit(-1); + + } + + // END STEP 2 + + if (!getenv("AFL_FRIDA_TEST_INPUT")) { + + gum_init_embedded(); + if (!gum_stalker_is_supported()) { + + gum_deinit_embedded(); + return 1; + + } + + GumStalker *stalker = gum_stalker_new(); + + GumAddress base_address; + if (argc > 2) + base_address = gum_module_find_base_address(argv[1]); + else + base_address = gum_module_find_base_address(TARGET_LIBRARY); + GumMemoryRange code_range; + if (argc > 2) + gum_module_enumerate_ranges(argv[1], GUM_PAGE_RX, enumerate_ranges, + &code_range); + else + gum_module_enumerate_ranges(TARGET_LIBRARY, GUM_PAGE_RX, enumerate_ranges, + &code_range); + + guint64 code_start = code_range.base_address; + guint64 code_end = code_range.base_address + code_range.size; + range_t instr_range = {0, code_start, code_end, 0, 0}; + + printf("Frida instrumentation: base=0x%lx instrumenting=0x%lx-%lx\n", + base_address, code_start, code_end); + if (!code_start || !code_end) { + + if (argc > 2) + fprintf(stderr, "Error: no valid memory address found for %s\n", + argv[1]); + else + fprintf(stderr, "Error: no valid memory address found for %s\n", + TARGET_LIBRARY); + exit(-1); + + } + + GumStalkerTransformer *transformer = + gum_stalker_transformer_make_from_callback(instr_basic_block, + &instr_range, NULL); + + // to ensure that the signatures are not optimized out + memcpy(__afl_area_ptr, (void *)AFL_PERSISTENT, sizeof(AFL_PERSISTENT)); + memcpy(__afl_area_ptr + 32, (void *)AFL_DEFER_FORKSVR, + sizeof(AFL_DEFER_FORKSVR)); + __afl_manual_init(); + + // + // any expensive target library initialization that has to be done just once + // - put that here + // + + gum_stalker_follow_me(stalker, transformer, NULL); + + while (__afl_persistent_loop(UINT32_MAX) != 0) { + + previous_pc = 0; // Required! + +#ifdef _DEBUG + fprintf(stderr, "CLIENT crc: %016llx len: %u\n", + hash64(__afl_fuzz_ptr, *__afl_fuzz_len), *__afl_fuzz_len); + fprintf(stderr, "RECV:"); + for (int i = 0; i < *__afl_fuzz_len; i++) + fprintf(stderr, "%02x", __afl_fuzz_ptr[i]); + fprintf(stderr, "\n"); +#endif + + // STEP 3: ensure the minimum length is present and setup the target + // function to fuzz. + + if (*__afl_fuzz_len > 0) { + + __afl_fuzz_ptr[*__afl_fuzz_len] = 0; // if you need to null terminate + (*o_function)(__afl_fuzz_ptr, *__afl_fuzz_len); + + } + + // END STEP 3 + + } + + gum_stalker_unfollow_me(stalker); + + while (gum_stalker_garbage_collect(stalker)) + g_usleep(10000); + + g_object_unref(stalker); + g_object_unref(transformer); + gum_deinit_embedded(); + + } else { + + char buf[8 * 1024] = {0}; + int count = read(0, buf, sizeof(buf)); + buf[8 * 1024 - 1] = '\0'; + (*o_function)(buf, count); + + } + + return 0; + +} + diff --git a/examples/afl_frida/afl-frida.h b/utils/afl_frida/afl-frida.h index efa3440f..efa3440f 100644 --- a/examples/afl_frida/afl-frida.h +++ b/utils/afl_frida/afl-frida.h diff --git a/utils/afl_frida/android/README.md b/utils/afl_frida/android/README.md new file mode 100644 index 00000000..044b48a1 --- /dev/null +++ b/utils/afl_frida/android/README.md @@ -0,0 +1 @@ +For android, frida-gum package (ex. https://github.com/frida/frida/releases/download/14.2.6/frida-gum-devkit-14.2.6-android-arm64.tar.xz) is needed to be extracted in the directory. diff --git a/utils/afl_frida/android/frida-gum-example.c b/utils/afl_frida/android/frida-gum-example.c new file mode 100644 index 00000000..14d98248 --- /dev/null +++ b/utils/afl_frida/android/frida-gum-example.c @@ -0,0 +1,130 @@ +/* + * Compile with: + * + * clang -fPIC -DANDROID -ffunction-sections -fdata-sections -Os -pipe -g3 frida-gum-example.c -o frida-gum-example -L. -lfrida-gum -llog -ldl -lm -pthread -Wl,--gc-sections,-z,noexecstack,-z,relro,-z,now -fuse-ld=gold -fuse-ld=gold -Wl,--icf=all + * + * Visit https://frida.re to learn more about Frida. + */ + +#include "frida-gum.h" + +#include <fcntl.h> +#include <unistd.h> + +typedef struct _ExampleListener ExampleListener; +typedef enum _ExampleHookId ExampleHookId; + +struct _ExampleListener +{ + GObject parent; + + guint num_calls; +}; + +enum _ExampleHookId +{ + EXAMPLE_HOOK_OPEN, + EXAMPLE_HOOK_CLOSE +}; + +static void example_listener_iface_init (gpointer g_iface, gpointer iface_data); + +#define EXAMPLE_TYPE_LISTENER (example_listener_get_type ()) +G_DECLARE_FINAL_TYPE (ExampleListener, example_listener, EXAMPLE, LISTENER, GObject) +G_DEFINE_TYPE_EXTENDED (ExampleListener, + example_listener, + G_TYPE_OBJECT, + 0, + G_IMPLEMENT_INTERFACE (GUM_TYPE_INVOCATION_LISTENER, + example_listener_iface_init)) + +int +main (int argc, + char * argv[]) +{ + GumInterceptor * interceptor; + GumInvocationListener * listener; + + gum_init_embedded (); + + interceptor = gum_interceptor_obtain (); + listener = g_object_new (EXAMPLE_TYPE_LISTENER, NULL); + + gum_interceptor_begin_transaction (interceptor); + gum_interceptor_attach (interceptor, + GSIZE_TO_POINTER (gum_module_find_export_by_name (NULL, "open")), + listener, + GSIZE_TO_POINTER (EXAMPLE_HOOK_OPEN)); + gum_interceptor_attach (interceptor, + GSIZE_TO_POINTER (gum_module_find_export_by_name (NULL, "close")), + listener, + GSIZE_TO_POINTER (EXAMPLE_HOOK_CLOSE)); + gum_interceptor_end_transaction (interceptor); + + close (open ("/etc/hosts", O_RDONLY)); + close (open ("/etc/fstab", O_RDONLY)); + + g_print ("[*] listener got %u calls\n", EXAMPLE_LISTENER (listener)->num_calls); + + gum_interceptor_detach (interceptor, listener); + + close (open ("/etc/hosts", O_RDONLY)); + close (open ("/etc/fstab", O_RDONLY)); + + g_print ("[*] listener still has %u calls\n", EXAMPLE_LISTENER (listener)->num_calls); + + g_object_unref (listener); + g_object_unref (interceptor); + + gum_deinit_embedded (); + + return 0; +} + +static void +example_listener_on_enter (GumInvocationListener * listener, + GumInvocationContext * ic) +{ + ExampleListener * self = EXAMPLE_LISTENER (listener); + ExampleHookId hook_id = GUM_IC_GET_FUNC_DATA (ic, ExampleHookId); + + switch (hook_id) + { + case EXAMPLE_HOOK_OPEN: + g_print ("[*] open(\"%s\")\n", (const gchar *) gum_invocation_context_get_nth_argument (ic, 0)); + break; + case EXAMPLE_HOOK_CLOSE: + g_print ("[*] close(%d)\n", GPOINTER_TO_INT (gum_invocation_context_get_nth_argument (ic, 0))); + break; + } + + self->num_calls++; +} + +static void +example_listener_on_leave (GumInvocationListener * listener, + GumInvocationContext * ic) +{ +} + +static void +example_listener_class_init (ExampleListenerClass * klass) +{ + (void) EXAMPLE_IS_LISTENER; + (void) glib_autoptr_cleanup_ExampleListener; +} + +static void +example_listener_iface_init (gpointer g_iface, + gpointer iface_data) +{ + GumInvocationListenerInterface * iface = g_iface; + + iface->on_enter = example_listener_on_enter; + iface->on_leave = example_listener_on_leave; +} + +static void +example_listener_init (ExampleListener * self) +{ +} diff --git a/examples/afl_frida/libtestinstr.c b/utils/afl_frida/libtestinstr.c index 96b1cf21..96b1cf21 100644 --- a/examples/afl_frida/libtestinstr.c +++ b/utils/afl_frida/libtestinstr.c diff --git a/examples/afl_network_proxy/GNUmakefile b/utils/afl_network_proxy/GNUmakefile index 25a3df82..0b55dc2c 100644 --- a/examples/afl_network_proxy/GNUmakefile +++ b/utils/afl_network_proxy/GNUmakefile @@ -1,5 +1,6 @@ PREFIX ?= /usr/local BIN_PATH = $(PREFIX)/bin +HELPER_PATH = $(PREFIX)/lib/afl DOC_PATH = $(PREFIX)/share/doc/afl PROGRAMS = afl-network-client afl-network-server @@ -31,7 +32,7 @@ afl-network-client: afl-network-client.c $(CC) $(CFLAGS) -I../../include -o afl-network-client afl-network-client.c $(LDFLAGS) afl-network-server: afl-network-server.c - $(CC) $(CFLAGS) -I../../include -o afl-network-server afl-network-server.c ../../src/afl-forkserver.c ../../src/afl-sharedmem.c ../../src/afl-common.c -DBIN_PATH=\"$(BIN_PATH)\" $(LDFLAGS) + $(CC) $(CFLAGS) -I../../include -o afl-network-server afl-network-server.c ../../src/afl-forkserver.c ../../src/afl-sharedmem.c ../../src/afl-common.c -DAFL_PATH=\"$(HELPER_PATH)\" -DBIN_PATH=\"$(BIN_PATH)\" $(LDFLAGS) clean: rm -f $(PROGRAMS) *~ core diff --git a/utils/afl_network_proxy/Makefile b/utils/afl_network_proxy/Makefile new file mode 100644 index 00000000..0b306dde --- /dev/null +++ b/utils/afl_network_proxy/Makefile @@ -0,0 +1,2 @@ +all: + @echo please use GNU make, thanks! diff --git a/examples/afl_network_proxy/README.md b/utils/afl_network_proxy/README.md index a5ac3578..a5ac3578 100644 --- a/examples/afl_network_proxy/README.md +++ b/utils/afl_network_proxy/README.md diff --git a/examples/afl_network_proxy/afl-network-client.c b/utils/afl_network_proxy/afl-network-client.c index a2451fdc..a2451fdc 100644 --- a/examples/afl_network_proxy/afl-network-client.c +++ b/utils/afl_network_proxy/afl-network-client.c diff --git a/examples/afl_network_proxy/afl-network-server.c b/utils/afl_network_proxy/afl-network-server.c index ab7874fd..0dfae658 100644 --- a/examples/afl_network_proxy/afl-network-server.c +++ b/utils/afl_network_proxy/afl-network-server.c @@ -24,10 +24,6 @@ #define AFL_MAIN -#ifdef __ANDROID__ - #include "android-ashmem.h" -#endif - #include "config.h" #include "types.h" #include "debug.h" @@ -73,9 +69,9 @@ static u8 *in_file, /* Minimizer input test case */ static u8 *in_data; /* Input data for trimming */ static u8 *buf2; -static s32 in_len; -static u32 map_size = MAP_SIZE; -static size_t buf2_len; +static s32 in_len; +static s32 buf2_len; +static u32 map_size = MAP_SIZE; static volatile u8 stop_soon; /* Ctrl-C pressed? */ @@ -241,38 +237,7 @@ static void set_up_environment(afl_forkserver_t *fsrv) { if (fsrv->qemu_mode) { - u8 *qemu_preload = getenv("QEMU_SET_ENV"); - u8 *afl_preload = getenv("AFL_PRELOAD"); - u8 *buf; - - s32 i, afl_preload_size = strlen(afl_preload); - for (i = 0; i < afl_preload_size; ++i) { - - if (afl_preload[i] == ',') { - - PFATAL( - "Comma (',') is not allowed in AFL_PRELOAD when -Q is " - "specified!"); - - } - - } - - if (qemu_preload) { - - buf = alloc_printf("%s,LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - qemu_preload, afl_preload, afl_preload); - - } else { - - buf = alloc_printf("LD_PRELOAD=%s,DYLD_INSERT_LIBRARIES=%s", - afl_preload, afl_preload); - - } - - setenv("QEMU_SET_ENV", buf, 1); - - ck_free(buf); + /* afl-qemu-trace takes care of converting AFL_PRELOAD. */ } else { @@ -343,7 +308,7 @@ static void usage(u8 *argv0) { } -int recv_testcase(int s, void **buf, size_t *max_len) { +int recv_testcase(int s, void **buf) { u32 size; s32 ret; @@ -358,7 +323,8 @@ int recv_testcase(int s, void **buf, size_t *max_len) { if ((size & 0xff000000) != 0xff000000) { - *buf = ck_maybe_grow(buf, max_len, size); + *buf = afl_realloc(buf, size); + if (unlikely(!*buf)) { PFATAL("Alloc"); } received = 0; // fprintf(stderr, "unCOMPRESS (%u)\n", size); while (received < size && @@ -370,7 +336,8 @@ int recv_testcase(int s, void **buf, size_t *max_len) { #ifdef USE_DEFLATE u32 clen; size -= 0xff000000; - *buf = ck_maybe_grow(buf, max_len, size); + *buf = afl_realloc(buf, size); + if (unlikely(!*buf)) { PFATAL("Alloc"); } received = 0; while (received < 4 && (ret = recv(s, &clen + received, 4 - received, 0)) > 0) @@ -379,15 +346,16 @@ int recv_testcase(int s, void **buf, size_t *max_len) { // fprintf(stderr, "received clen information of %d\n", clen); if (clen < 1) FATAL("did not receive valid compressed len information: %u", clen); - buf2 = ck_maybe_grow((void **)&buf2, &buf2_len, clen); + buf2 = afl_realloc((void **)&buf2, clen); + buf2_len = clen; + if (unlikely(!buf2)) { PFATAL("Alloc"); } received = 0; while (received < clen && (ret = recv(s, buf2 + received, clen - received, 0)) > 0) received += ret; if (received != clen) FATAL("did not receive compressed information"); if (libdeflate_deflate_decompress(decompressor, buf2, clen, (char *)*buf, - *max_len, - &received) != LIBDEFLATE_SUCCESS) + size, &received) != LIBDEFLATE_SUCCESS) FATAL("decompression failed"); // fprintf(stderr, "DECOMPRESS (%u->%u):\n", clen, received); // for (u32 i = 0; i < clen; i++) fprintf(stderr, "%02x", buf2[i]); @@ -413,7 +381,6 @@ int recv_testcase(int s, void **buf, size_t *max_len) { int main(int argc, char **argv_orig, char **envp) { s32 opt, s, sock, on = 1, port = -1; - size_t max_len = 0; u8 mem_limit_given = 0, timeout_given = 0, unicorn_mode = 0, use_wine = 0; char **use_argv; struct sockaddr_in6 serveraddr, clientaddr; @@ -568,7 +535,8 @@ int main(int argc, char **argv_orig, char **envp) { sharedmem_t shm = {0}; fsrv->trace_bits = afl_shm_init(&shm, map_size, 0); - in_data = ck_maybe_grow((void **)&in_data, &max_len, 65536); + in_data = afl_realloc((void **)&in_data, 65536); + if (unlikely(!in_data)) { PFATAL("Alloc"); } atexit(at_exit_handler); setup_signal_handlers(); @@ -633,13 +601,18 @@ int main(int argc, char **argv_orig, char **envp) { if (listen(sock, 1) < 0) { PFATAL("listen() failed"); } - afl_fsrv_start(fsrv, use_argv, &stop_soon, - get_afl_env("AFL_DEBUG_CHILD_OUTPUT") ? 1 : 0); + afl_fsrv_start( + fsrv, use_argv, &stop_soon, + (get_afl_env("AFL_DEBUG_CHILD") || get_afl_env("AFL_DEBUG_CHILD_OUTPUT")) + ? 1 + : 0); #ifdef USE_DEFLATE compressor = libdeflate_alloc_compressor(1); decompressor = libdeflate_alloc_decompressor(); - buf2 = ck_maybe_grow((void **)&buf2, &buf2_len, map_size + 16); + buf2 = afl_realloc((void **)&buf2, map_size + 16); + buf2_len = map_size + 16; + if (unlikely(!buf2)) { PFATAL("alloc"); } lenptr = (u32 *)(buf2 + 4); fprintf(stderr, "Compiled with compression support\n"); #endif @@ -664,7 +637,7 @@ int main(int argc, char **argv_orig, char **envp) { #endif - while ((in_len = recv_testcase(s, (void **)&in_data, &max_len)) > 0) { + while ((in_len = recv_testcase(s, (void **)&in_data)) > 0) { // fprintf(stderr, "received %u\n", in_len); (void)run_target(fsrv, use_argv, in_data, in_len, 1); @@ -697,9 +670,9 @@ int main(int argc, char **argv_orig, char **envp) { afl_shm_deinit(&shm); afl_fsrv_deinit(fsrv); if (fsrv->target_path) { ck_free(fsrv->target_path); } - if (in_data) { ck_free(in_data); } + afl_free(in_data); #if USE_DEFLATE - if (buf2) { ck_free(buf2); } + afl_free(buf2); libdeflate_free_compressor(compressor); libdeflate_free_decompressor(decompressor); #endif diff --git a/examples/afl_proxy/Makefile b/utils/afl_proxy/Makefile index 4b368f8d..4b368f8d 100644 --- a/examples/afl_proxy/Makefile +++ b/utils/afl_proxy/Makefile diff --git a/examples/afl_proxy/README.md b/utils/afl_proxy/README.md index 3c768a19..3c768a19 100644 --- a/examples/afl_proxy/README.md +++ b/utils/afl_proxy/README.md diff --git a/examples/afl_proxy/afl-proxy.c b/utils/afl_proxy/afl-proxy.c index f2dfeac1..aa7a361a 100644 --- a/examples/afl_proxy/afl-proxy.c +++ b/utils/afl_proxy/afl-proxy.c @@ -213,7 +213,7 @@ int main(int argc, char *argv[]) { u32 len; /* here you specify the map size you need that you are reporting to - afl-fuzz. */ + afl-fuzz. Any value is fine as long as it can be divided by 32. */ __afl_map_size = MAP_SIZE; // default is 65536 /* then we initialize the shared memory map and start the forkserver */ diff --git a/examples/afl_untracer/Makefile b/utils/afl_untracer/Makefile index 14a09b41..14a09b41 100644 --- a/examples/afl_untracer/Makefile +++ b/utils/afl_untracer/Makefile diff --git a/examples/afl_untracer/README.md b/utils/afl_untracer/README.md index ada0c916..ada0c916 100644 --- a/examples/afl_untracer/README.md +++ b/utils/afl_untracer/README.md diff --git a/examples/afl_untracer/TODO b/utils/afl_untracer/TODO index fffffacf..fffffacf 100644 --- a/examples/afl_untracer/TODO +++ b/utils/afl_untracer/TODO diff --git a/examples/afl_untracer/afl-untracer.c b/utils/afl_untracer/afl-untracer.c index 68658bfd..2baeb58d 100644 --- a/examples/afl_untracer/afl-untracer.c +++ b/utils/afl_untracer/afl-untracer.c @@ -56,9 +56,9 @@ #include <sys/shm.h> #include <sys/wait.h> #include <sys/types.h> -#include <sys/personality.h> #if defined(__linux__) + #include <sys/personality.h> #include <sys/ucontext.h> #elif defined(__APPLE__) && defined(__LP64__) #include <mach-o/dyld_images.h> @@ -115,10 +115,10 @@ static library_list_t liblist[MAX_LIB_COUNT]; static u32 liblist_cnt; static void sigtrap_handler(int signum, siginfo_t *si, void *context); -static void fuzz(); +static void fuzz(void); /* read the library information */ -void read_library_information() { +void read_library_information(void) { #if defined(__linux__) FILE *f; @@ -143,7 +143,7 @@ void read_library_information() { b = buf; m = index(buf, '-'); e = index(buf, ' '); - if ((n = rindex(buf, '/')) == NULL) n = rindex(buf, ' '); + if ((n = strrchr(buf, '/')) == NULL) n = strrchr(buf, ' '); if (n && ((*n >= '0' && *n <= '9') || *n == '[' || *n == '{' || *n == '(')) n = NULL; @@ -284,7 +284,7 @@ library_list_t *find_library(char *name) { // this seems to work for clang too. nice :) requires gcc 4.4+ #pragma GCC push_options #pragma GCC optimize("O0") -void breakpoint() { +void breakpoint(void) { if (debug) fprintf(stderr, "Breakpoint function \"breakpoint\" reached.\n"); @@ -437,6 +437,8 @@ inline static u32 __afl_next_testcase(u8 *buf, u32 max_len) { if (write(FORKSRV_FD + 1, &pid, 4) != 4) do_exit = 1; // fprintf(stderr, "write1 %d\n", do_exit); + __afl_area_ptr[0] = 1; // put something in the map + return status; } @@ -461,7 +463,7 @@ inline static void __afl_end_testcase(int status) { ((uintptr_t)addr & 0x3) * 0x10000000000)) #endif -void setup_trap_instrumentation() { +void setup_trap_instrumentation(void) { library_list_t *lib_base = NULL; size_t lib_size = 0; @@ -478,6 +480,9 @@ void setup_trap_instrumentation() { // Index into the coverage bitmap for the current trap instruction. #ifdef __aarch64__ uint64_t bitmap_index = 0; + #ifdef __APPLE__ + pthread_jit_write_protect_np(0); + #endif #else uint32_t bitmap_index = 0; #endif @@ -506,7 +511,6 @@ void setup_trap_instrumentation() { lib_size); lib_addr = (u8 *)lib_base->addr_start; - // Make library code writable. if (mprotect((void *)lib_addr, lib_size, PROT_READ | PROT_WRITE | PROT_EXEC) != 0) @@ -566,7 +570,7 @@ void setup_trap_instrumentation() { lib_addr[offset] = 0xcc; // replace instruction with debug trap if (debug) fprintf(stderr, - "Patch entry: %p[%x] = %p = %02x -> SHADOW(%p) #%d -> %08x\n", + "Patch entry: %p[%lx] = %p = %02x -> SHADOW(%p) #%d -> %08x\n", lib_addr, offset, lib_addr + offset, orig_byte, shadow, bitmap_index, *shadow); @@ -580,7 +584,7 @@ void setup_trap_instrumentation() { *patch_bytes = 0xd4200000; // replace instruction with debug trap if (debug) fprintf(stderr, - "Patch entry: %p[%x] = %p = %02x -> SHADOW(%p) #%d -> %016x\n", + "Patch entry: %p[%lx] = %p = %02x -> SHADOW(%p) #%d -> %016x\n", lib_addr, offset, lib_addr + offset, orig_bytes, shadow, bitmap_index, *shadow); @@ -623,8 +627,13 @@ static void sigtrap_handler(int signum, siginfo_t *si, void *context) { // Must re-execute the instruction, so decrement PC by one instruction. ucontext_t *ctx = (ucontext_t *)context; #if defined(__APPLE__) && defined(__LP64__) + #if defined(__x86_64__) ctx->uc_mcontext->__ss.__rip -= 1; addr = ctx->uc_mcontext->__ss.__rip; + #else + ctx->uc_mcontext->__ss.__pc -= 4; + addr = ctx->uc_mcontext->__ss.__pc; + #endif #elif defined(__linux__) #if defined(__x86_64__) || defined(__i386__) ctx->uc_mcontext.gregs[REG_RIP] -= 1; @@ -674,7 +683,9 @@ static void sigtrap_handler(int signum, siginfo_t *si, void *context) { /* the MAIN function */ int main(int argc, char *argv[]) { +#if defined(__linux__) (void)personality(ADDR_NO_RANDOMIZE); // disable ASLR +#endif pid = getpid(); if (getenv("AFL_DEBUG")) debug = 1; @@ -748,7 +759,7 @@ int main(int argc, char *argv[]) { inline #endif static void - fuzz() { + fuzz(void) { // STEP 3: call the function to fuzz, also the functions you might // need to call to prepare the function and - important! - diff --git a/examples/afl_untracer/ghidra_get_patchpoints.java b/utils/afl_untracer/ghidra_get_patchpoints.java index d341bea4..2a93642b 100644 --- a/examples/afl_untracer/ghidra_get_patchpoints.java +++ b/utils/afl_untracer/ghidra_get_patchpoints.java @@ -13,7 +13,7 @@ * See the License for the specific language governing permissions and * limitations under the License. */ -// Find patch points for untracer tools (e.g. afl++ examples/afl_untracer) +// Find patch points for untracer tools (e.g. afl++ utils/afl_untracer) // // Copy to ..../Ghidra/Features/Search/ghidra_scripts/ // Writes the results to ~/Desktop/patches.txt diff --git a/examples/afl_untracer/ida_get_patchpoints.py b/utils/afl_untracer/ida_get_patchpoints.py index 43cf6d89..807685b3 100644 --- a/examples/afl_untracer/ida_get_patchpoints.py +++ b/utils/afl_untracer/ida_get_patchpoints.py @@ -11,6 +11,7 @@ import idc # See https://www.hex-rays.com/products/ida/support/ida74_idapython_no_bc695_porting_guide.shtml from os.path import expanduser + home = expanduser("~") patchpoints = set() @@ -18,7 +19,7 @@ patchpoints = set() max_offset = 0 for seg_ea in idautils.Segments(): name = idc.get_segm_name(seg_ea) - #print("Segment: " + name) + # print("Segment: " + name) if name != "__text" and name != ".text": continue @@ -26,7 +27,7 @@ for seg_ea in idautils.Segments(): end = idc.get_segm_end(seg_ea) first = 0 subtract_addr = 0 - #print("Start: " + hex(start) + " End: " + hex(end)) + # print("Start: " + hex(start) + " End: " + hex(end)) for func_ea in idautils.Functions(start, end): f = idaapi.get_func(func_ea) if not f: @@ -37,10 +38,10 @@ for seg_ea in idautils.Segments(): if block.start_ea >= 0x1000: subtract_addr = 0x1000 first = 1 - + max_offset = max(max_offset, block.start_ea) patchpoints.add(block.start_ea - subtract_addr) - #else: + # else: # print("Warning: broken CFG?") # Round up max_offset to page size @@ -52,11 +53,11 @@ if rem != 0: print("Writing to " + home + "/Desktop/patches.txt") with open(home + "/Desktop/patches.txt", "w") as f: - f.write(ida_nalt.get_root_filename() + ':' + hex(size) + '\n') - f.write('\n'.join(map(hex, sorted(patchpoints)))) - f.write('\n') + f.write(ida_nalt.get_root_filename() + ":" + hex(size) + "\n") + f.write("\n".join(map(hex, sorted(patchpoints)))) + f.write("\n") print("Done, found {} patchpoints".format(len(patchpoints))) # For headless script running remove the comment from the next line -#ida_pro.qexit() +# ida_pro.qexit() diff --git a/examples/afl_untracer/libtestinstr.c b/utils/afl_untracer/libtestinstr.c index 96b1cf21..96b1cf21 100644 --- a/examples/afl_untracer/libtestinstr.c +++ b/utils/afl_untracer/libtestinstr.c diff --git a/utils/afl_untracer/patches.txt b/utils/afl_untracer/patches.txt new file mode 100644 index 00000000..7e964249 --- /dev/null +++ b/utils/afl_untracer/patches.txt @@ -0,0 +1,34 @@ +libtestinstr.so:0x1000 +0x10 +0x12 +0x20 +0x36 +0x30 +0x40 +0x50 +0x63 +0x6f +0x78 +0x80 +0xa4 +0xb0 +0xb8 +0x100 +0xc0 +0xc9 +0xd7 +0xe3 +0xe8 +0xf8 +0x105 +0x11a +0x135 +0x141 +0x143 +0x14e +0x15a +0x15c +0x168 +0x16a +0x16b +0x170 diff --git a/utils/aflpp_driver/GNUmakefile b/utils/aflpp_driver/GNUmakefile new file mode 100644 index 00000000..c1a087d7 --- /dev/null +++ b/utils/aflpp_driver/GNUmakefile @@ -0,0 +1,46 @@ +ifeq "" "$(LLVM_CONFIG)" + LLVM_CONFIG=llvm-config +endif + +LLVM_BINDIR = $(shell $(LLVM_CONFIG) --bindir 2>/dev/null) +ifneq "" "$(LLVM_BINDIR)" + LLVM_BINDIR := $(LLVM_BINDIR)/ +endif + +CFLAGS := -O3 -funroll-loops -g + +all: libAFLDriver.a libAFLQemuDriver.a aflpp_qemu_driver_hook.so + +aflpp_driver.o: aflpp_driver.c + -$(LLVM_BINDIR)clang -I. -I../../include $(CFLAGS) -c aflpp_driver.c + +libAFLDriver.a: aflpp_driver.o + ar ru libAFLDriver.a aflpp_driver.o + cp -vf libAFLDriver.a ../../ + +debug: + $(LLVM_BINDIR)clang -Wno-deprecated -I../../include $(CFLAGS) -D_DEBUG=\"1\" -c -o afl-performance.o ../../src/afl-performance.c + $(LLVM_BINDIR)clang -I../../include -D_DEBUG=\"1\" -g -funroll-loops -c aflpp_driver.c + #$(LLVM_BINDIR)clang -S -emit-llvm -Wno-deprecated -I../../include $(CFLAGS) -D_DEBUG=\"1\" -c -o afl-performance.ll ../../src/afl-performance.c + #$(LLVM_BINDIR)clang -S -emit-llvm -I../../include -D_DEBUG=\"1\" -g -funroll-loops -c aflpp_driver.c + ar ru libAFLDriver.a afl-performance.o aflpp_driver.o + +aflpp_qemu_driver.o: aflpp_qemu_driver.c + $(LLVM_BINDIR)clang $(CFLAGS) -O0 -funroll-loops -c aflpp_qemu_driver.c + +libAFLQemuDriver.a: aflpp_qemu_driver.o + ar ru libAFLQemuDriver.a aflpp_qemu_driver.o + cp -vf libAFLQemuDriver.a ../../ + +aflpp_qemu_driver_hook.so: aflpp_qemu_driver_hook.o + $(LLVM_BINDIR)clang -shared aflpp_qemu_driver_hook.o -o aflpp_qemu_driver_hook.so + +aflpp_qemu_driver_hook.o: aflpp_qemu_driver_hook.c + $(LLVM_BINDIR)clang -fPIC $(CFLAGS) -funroll-loops -c aflpp_qemu_driver_hook.c + +test: debug + #clang -S -emit-llvm -D_DEBUG=\"1\" -I../../include -Wl,--allow-multiple-definition -funroll-loops -o aflpp_driver_test.ll aflpp_driver_test.c + afl-clang-fast -D_DEBUG=\"1\" -I../../include -Wl,--allow-multiple-definition -funroll-loops -o aflpp_driver_test aflpp_driver_test.c libAFLDriver.a afl-performance.o + +clean: + rm -f *.o libAFLDriver*.a libAFLQemuDriver.a aflpp_qemu_driver_hook.so *~ core aflpp_driver_test diff --git a/examples/aflpp_driver/Makefile b/utils/aflpp_driver/Makefile index 3666a74d..3666a74d 100644 --- a/examples/aflpp_driver/Makefile +++ b/utils/aflpp_driver/Makefile diff --git a/utils/aflpp_driver/aflpp_driver.c b/utils/aflpp_driver/aflpp_driver.c new file mode 100644 index 00000000..f0f3a47d --- /dev/null +++ b/utils/aflpp_driver/aflpp_driver.c @@ -0,0 +1,284 @@ +//===- afl_driver.cpp - a glue between AFL++ and libFuzzer ------*- C++ -* ===// +//===----------------------------------------------------------------------===// + +/* This file allows to fuzz libFuzzer-style target functions + (LLVMFuzzerTestOneInput) with AFL++ using persistent in-memory fuzzing. + +Usage: +################################################################################ +cat << EOF > test_fuzzer.cc +#include <stddef.h> +#include <stdint.h> +extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) { + + if (size > 0 && data[0] == 'H') + if (size > 1 && data[1] == 'I') + if (size > 2 && data[2] == '!') + __builtin_trap(); + return 0; + +} + +EOF +# Build your target with -fsanitize-coverage=trace-pc-guard using fresh clang. +clang -c aflpp_driver.c +# Build afl-compiler-rt.o.c from the AFL distribution. +clang -c $AFL_HOME/instrumentation/afl-compiler-rt.o.c +# Build this file, link it with afl-compiler-rt.o.o and the target code. +afl-clang-fast -o test_fuzzer test_fuzzer.cc afl-compiler-rt.o aflpp_driver.o +# Run AFL: +rm -rf IN OUT; mkdir IN OUT; echo z > IN/z; +$AFL_HOME/afl-fuzz -i IN -o OUT ./a.out +################################################################################ +*/ + +#include <assert.h> +#include <errno.h> +#include <stdarg.h> +#include <stdint.h> +#include <stdio.h> +#include <stdlib.h> +#include <string.h> +#include <unistd.h> +#include <limits.h> +#include <sys/types.h> +#include <sys/stat.h> +#include <fcntl.h> +#include <sys/mman.h> + +#include "config.h" +#include "types.h" +#include "cmplog.h" + +#ifdef _DEBUG + #include "hash.h" +#endif + +int __afl_sharedmem_fuzzing = 1; +extern unsigned int * __afl_fuzz_len; +extern unsigned char *__afl_fuzz_ptr; + +// libFuzzer interface is thin, so we don't include any libFuzzer headers. +int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size); +__attribute__((weak)) int LLVMFuzzerInitialize(int *argc, char ***argv); + +// Notify AFL about persistent mode. +static volatile char AFL_PERSISTENT[] = "##SIG_AFL_PERSISTENT##"; +int __afl_persistent_loop(unsigned int); + +// Notify AFL about deferred forkserver. +static volatile char AFL_DEFER_FORKSVR[] = "##SIG_AFL_DEFER_FORKSRV##"; +void __afl_manual_init(); + +// Use this optionally defined function to output sanitizer messages even if +// user asks to close stderr. +__attribute__((weak)) void __sanitizer_set_report_fd(void *); + +// Keep track of where stderr content is being written to, so that +// dup_and_close_stderr can use the correct one. +static FILE *output_file; + +// Experimental feature to use afl_driver without AFL's deferred mode. +// Needs to run before __afl_auto_init. +__attribute__((constructor(0))) static void __decide_deferred_forkserver(void) { + + if (getenv("AFL_DRIVER_DONT_DEFER")) { + + if (unsetenv("__AFL_DEFER_FORKSRV")) { + + perror("Failed to unset __AFL_DEFER_FORKSRV"); + abort(); + + } + + } + +} + +// If the user asks us to duplicate stderr, then do it. +static void maybe_duplicate_stderr() { + + char *stderr_duplicate_filename = + getenv("AFL_DRIVER_STDERR_DUPLICATE_FILENAME"); + + if (!stderr_duplicate_filename) return; + + FILE *stderr_duplicate_stream = + freopen(stderr_duplicate_filename, "a+", stderr); + + if (!stderr_duplicate_stream) { + + fprintf( + stderr, + "Failed to duplicate stderr to AFL_DRIVER_STDERR_DUPLICATE_FILENAME"); + abort(); + + } + + output_file = stderr_duplicate_stream; + +} + +// Most of these I/O functions were inspired by/copied from libFuzzer's code. +static void discard_output(int fd) { + + FILE *temp = fopen("/dev/null", "w"); + if (!temp) abort(); + dup2(fileno(temp), fd); + fclose(temp); + +} + +static void close_stdout() { + + discard_output(STDOUT_FILENO); + +} + +// Prevent the targeted code from writing to "stderr" but allow sanitizers and +// this driver to do so. +static void dup_and_close_stderr() { + + int output_fileno = fileno(output_file); + int output_fd = dup(output_fileno); + if (output_fd <= 0) abort(); + FILE *new_output_file = fdopen(output_fd, "w"); + if (!new_output_file) abort(); + if (!__sanitizer_set_report_fd) return; + __sanitizer_set_report_fd((void *)(long int)output_fd); + discard_output(output_fileno); + +} + +// Close stdout and/or stderr if user asks for it. +static void maybe_close_fd_mask() { + + char *fd_mask_str = getenv("AFL_DRIVER_CLOSE_FD_MASK"); + if (!fd_mask_str) return; + int fd_mask = atoi(fd_mask_str); + if (fd_mask & 2) dup_and_close_stderr(); + if (fd_mask & 1) close_stdout(); + +} + +// Define LLVMFuzzerMutate to avoid link failures for targets that use it +// with libFuzzer's LLVMFuzzerCustomMutator. +size_t LLVMFuzzerMutate(uint8_t *Data, size_t Size, size_t MaxSize) { + + // assert(false && "LLVMFuzzerMutate should not be called from afl_driver"); + return 0; + +} + +// Execute any files provided as parameters. +static int ExecuteFilesOnyByOne(int argc, char **argv) { + + unsigned char *buf = (unsigned char *)malloc(MAX_FILE); + for (int i = 1; i < argc; i++) { + + int fd = open(argv[i], O_RDONLY); + if (fd == -1) continue; + ssize_t length = read(fd, buf, MAX_FILE); + if (length > 0) { + + printf("Reading %zu bytes from %s\n", length, argv[i]); + LLVMFuzzerTestOneInput(buf, length); + printf("Execution successful.\n"); + + } + + } + + free(buf); + return 0; + +} + +int main(int argc, char **argv) { + + printf( + "======================= INFO =========================\n" + "This binary is built for afl++.\n" + "To run the target function on individual input(s) execute this:\n" + " %s INPUT_FILE1 [INPUT_FILE2 ... ]\n" + "To fuzz with afl-fuzz execute this:\n" + " afl-fuzz [afl-flags] -- %s [-N]\n" + "afl-fuzz will run N iterations before re-spawning the process (default: " + "INT_MAX)\n" + "======================================================\n", + argv[0], argv[0]); + + if (getenv("AFL_GDB")) { + + char cmd[64]; + snprintf(cmd, sizeof(cmd), "cat /proc/%d/maps", getpid()); + system(cmd); + fprintf(stderr, "DEBUG: aflpp_driver pid is %d\n", getpid()); + sleep(1); + + } + + output_file = stderr; + maybe_duplicate_stderr(); + maybe_close_fd_mask(); + if (LLVMFuzzerInitialize) { + + fprintf(stderr, "Running LLVMFuzzerInitialize ...\n"); + LLVMFuzzerInitialize(&argc, &argv); + fprintf(stderr, "continue...\n"); + + } + + // Do any other expensive one-time initialization here. + + uint8_t dummy_input[64] = {0}; + memcpy(dummy_input, (void *)AFL_PERSISTENT, sizeof(AFL_PERSISTENT)); + memcpy(dummy_input + 32, (void *)AFL_DEFER_FORKSVR, + sizeof(AFL_DEFER_FORKSVR)); + int N = INT_MAX; + if (argc == 2 && argv[1][0] == '-') + N = atoi(argv[1] + 1); + else if (argc == 2 && (N = atoi(argv[1])) > 0) + printf("WARNING: using the deprecated call style `%s %d`\n", argv[0], N); + else if (argc > 1) { + + __afl_sharedmem_fuzzing = 0; + __afl_manual_init(); + return ExecuteFilesOnyByOne(argc, argv); + + } + + assert(N > 0); + + // if (!getenv("AFL_DRIVER_DONT_DEFER")) + __afl_manual_init(); + + // Call LLVMFuzzerTestOneInput here so that coverage caused by initialization + // on the first execution of LLVMFuzzerTestOneInput is ignored. + LLVMFuzzerTestOneInput(dummy_input, 1); + + int num_runs = 0; + while (__afl_persistent_loop(N)) { + +#ifdef _DEBUG + fprintf(stderr, "CLIENT crc: %016llx len: %u\n", + hash64(__afl_fuzz_ptr, *__afl_fuzz_len, 0xa5b35705), + *__afl_fuzz_len); + fprintf(stderr, "RECV:"); + for (int i = 0; i < *__afl_fuzz_len; i++) + fprintf(stderr, "%02x", __afl_fuzz_ptr[i]); + fprintf(stderr, "\n"); +#endif + if (*__afl_fuzz_len) { + + num_runs++; + LLVMFuzzerTestOneInput(__afl_fuzz_ptr, *__afl_fuzz_len); + + } + + } + + printf("%s: successfully executed %d input(s)\n", argv[0], num_runs); + +} + diff --git a/utils/aflpp_driver/aflpp_driver_test.c b/utils/aflpp_driver/aflpp_driver_test.c new file mode 100644 index 00000000..fe05b4f8 --- /dev/null +++ b/utils/aflpp_driver/aflpp_driver_test.c @@ -0,0 +1,26 @@ +#include <stdio.h> +#include <stdlib.h> +#include <stdint.h> + +#include "hash.h" + +void __attribute__((noinline)) crashme(const uint8_t *Data, size_t Size) { + + if (Size < 5) return; + + if (Data[0] == 'F') + if (Data[1] == 'A') + if (Data[2] == '$') + if (Data[3] == '$') + if (Data[4] == '$') abort(); + +} + +int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) { + + if (Size) crashme(Data, Size); + + return 0; + +} + diff --git a/examples/aflpp_driver/aflpp_qemu_driver.c b/utils/aflpp_driver/aflpp_qemu_driver.c index 4f3e5f71..79de5af6 100644 --- a/examples/aflpp_driver/aflpp_qemu_driver.c +++ b/utils/aflpp_driver/aflpp_qemu_driver.c @@ -6,8 +6,8 @@ int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size); __attribute__((weak)) int LLVMFuzzerInitialize(int *argc, char ***argv); -static const size_t kMaxAflInputSize = 1 * 1024 * 1024; -static uint8_t AflInputBuf[kMaxAflInputSize]; +#define kMaxAflInputSize (1 * 1024 * 1024) +static uint8_t AflInputBuf[kMaxAflInputSize]; void __attribute__((noinline)) afl_qemu_driver_stdin_input(void) { diff --git a/examples/aflpp_driver/aflpp_qemu_driver_hook.c b/utils/aflpp_driver/aflpp_qemu_driver_hook.c index 823cc42d..823cc42d 100644 --- a/examples/aflpp_driver/aflpp_qemu_driver_hook.c +++ b/utils/aflpp_driver/aflpp_qemu_driver_hook.c diff --git a/utils/analysis_scripts/queue2csv.sh b/utils/analysis_scripts/queue2csv.sh new file mode 100755 index 00000000..2528b438 --- /dev/null +++ b/utils/analysis_scripts/queue2csv.sh @@ -0,0 +1,122 @@ +#!/bin/bash + +test -z "$1" -o -z "$2" -o "$1" = "-h" -o "$1" = "-hh" -o "$1" = "--help" -o '!' -d "$1" && { + echo "Syntax: [-n] $0 out-directory file.csv [\"tools/target --opt @@\"]" + echo Option -n will suppress the CSV header. + echo If the target execution command is supplied then also edge coverage is gathered. + exit 1 +} + +function getval() { + VAL="" + if [ "$file" != "${file/$1/}" ]; then + TMP="${file/*$1:/}" + VAL="${TMP/,*/}" + fi +} + +SKIP= +if [ "$1" = "-n" ]; then + SKIP=1 + shift +fi + +test -n "$4" && { echo "Error: too many commandline options. Target command and options including @@ have to be passed within \"\"!"; exit 1; } + +test -d "$1"/queue && OUT="$1/queue" || OUT="$1" + +OK=`ls $OUT/id:000000,time:0,orig:* 2> /dev/null` +if [ -n "$OK" ]; then + LISTCMD="ls $OUT/id:"* +else + LISTCMD="ls -tr $OUT/" +fi + +ID=;SRC=;TIME=;OP=;POS=;REP=;EDGES=;EDGES_TOTAL=; +DIR="$OUT/../stats" +rm -rf "$DIR" +> "$2" || exit 1 +mkdir "$DIR" || exit 1 +> "$DIR/../edges.txt" || exit 1 + +{ + + if [ -z "$SKIP" ]; then + echo "time;\"filename\";id;src;new_cov;edges;total_edges;\"op\";pos;rep;unique_edges" + fi + + $LISTCMD | grep -v ,sync: | sed 's/.*id:/id:/g' | while read file; do + + if [ -n "$3" ]; then + + TMP=${3/@@/$OUT/$file} + + if [ "$TMP" = "$3" ]; then + + cat "$OUT/$file" | afl-showmap -o "$DIR/$file" -q -- $3 >/dev/null 2>&1 + + else + + afl-showmap -o "$DIR/$file" -q -- $TMP >/dev/null 2>&1 + + fi + + { cat "$DIR/$file" | sed 's/:.*//' ; cat "$DIR/../edges.txt" ; } | sort -nu > $DIR/../edges.txt.tmp + mv $DIR/../edges.txt.tmp $DIR/../edges.txt + EDGES=$(cat "$DIR/$file" | wc -l) + EDGES_TOTAL=$(cat "$DIR/../edges.txt" | wc -l) + + fi + + getval id; ID="$VAL" + getval src; SRC="$VAL" + getval time; TIME="$VAL" + getval op; OP="$VAL" + getval pos; POS="$VAL" + getval rep; REP="$VAL" + if [ "$file" != "${file/+cov/}" ]; then + COV=1 + else + COV="" + fi + + if [ -n "$3" -a -s "$DIR/../edges.txt" ]; then + echo "$TIME;\"$file\";$ID;$SRC;$COV;$EDGES;$EDGES_TOTAL;\"$OP\";$POS;$REP;UNIQUE$file" + else + echo "$TIME;\"$file\";$ID;$SRC;$COV;;;\"$OP\";$POS;$REP;" + fi + + done + +} | tee "$DIR/../queue.csv" > "$2" || exit 1 + +if [ -n "$3" -a -s "$DIR/../edges.txt" ]; then + + cat "$DIR/"* | sed 's/:.*//' | sort -n | uniq -c | egrep '^[ \t]*1 ' | awk '{print$2}' > $DIR/../unique.txt + + if [ -s "$DIR/../unique.txt" ]; then + + ls "$DIR/id:"* | grep -v ",sync:" |sed 's/.*\/id:/id:/g' | while read file; do + + CNT=$(sed 's/:.*//' "$DIR/$file" | tee "$DIR/../tmp.txt" | wc -l) + DIFF=$(diff -u "$DIR/../tmp.txt" "$DIR/../unique.txt" | egrep '^-[0-9]' | wc -l) + UNIQUE=$(($CNT - $DIFF)) + sed -i "s/;UNIQUE$file/;$UNIQUE/" "$DIR/../queue.csv" "$2" + + done + + rm -f "$DIR/../tmp.txt" + + else + + sed -i 's/;UNIQUE.*/;/' "$DIR/../queue.csv" "$2" + + fi + +fi + +mv "$DIR/../queue.csv" "$DIR/queue.csv" +if [ -e "$DIR/../edges.txt" ]; then mv "$DIR/../edges.txt" "$DIR/edges.txt"; fi +if [ -e "$DIR/../unique.txt" ]; then mv "$DIR/../unique.txt" "$DIR/unique.txt"; fi + +echo "Created $2" diff --git a/examples/argv_fuzzing/Makefile b/utils/argv_fuzzing/Makefile index 5a0ac6e6..5a0ac6e6 100644 --- a/examples/argv_fuzzing/Makefile +++ b/utils/argv_fuzzing/Makefile diff --git a/examples/argv_fuzzing/README.md b/utils/argv_fuzzing/README.md index fa8cad80..fa8cad80 100644 --- a/examples/argv_fuzzing/README.md +++ b/utils/argv_fuzzing/README.md diff --git a/examples/argv_fuzzing/argv-fuzz-inl.h b/utils/argv_fuzzing/argv-fuzz-inl.h index c15c0271..c15c0271 100644 --- a/examples/argv_fuzzing/argv-fuzz-inl.h +++ b/utils/argv_fuzzing/argv-fuzz-inl.h diff --git a/examples/argv_fuzzing/argvfuzz.c b/utils/argv_fuzzing/argvfuzz.c index 4251ca4c..4251ca4c 100644 --- a/examples/argv_fuzzing/argvfuzz.c +++ b/utils/argv_fuzzing/argvfuzz.c diff --git a/examples/asan_cgroups/limit_memory.sh b/utils/asan_cgroups/limit_memory.sh index 1f0f04ad..1f0f04ad 100755 --- a/examples/asan_cgroups/limit_memory.sh +++ b/utils/asan_cgroups/limit_memory.sh diff --git a/examples/bash_shellshock/shellshock-fuzz.diff b/utils/bash_shellshock/shellshock-fuzz.diff index 3fa05bf8..3fa05bf8 100644 --- a/examples/bash_shellshock/shellshock-fuzz.diff +++ b/utils/bash_shellshock/shellshock-fuzz.diff diff --git a/examples/canvas_harness/canvas_harness.html b/utils/canvas_harness/canvas_harness.html index a37b6937..a37b6937 100644 --- a/examples/canvas_harness/canvas_harness.html +++ b/utils/canvas_harness/canvas_harness.html diff --git a/examples/clang_asm_normalize/as b/utils/clang_asm_normalize/as index 45537cae..45537cae 100755 --- a/examples/clang_asm_normalize/as +++ b/utils/clang_asm_normalize/as diff --git a/examples/crash_triage/triage_crashes.sh b/utils/crash_triage/triage_crashes.sh index bf763cba..a752458d 100755 --- a/examples/crash_triage/triage_crashes.sh +++ b/utils/crash_triage/triage_crashes.sh @@ -60,12 +60,12 @@ if fi if [ ! -f "$BIN" -o ! -x "$BIN" ]; then - echo "[-] Error: binary '$2' not found or is not executable." 1>&2 + echo "[-] Error: binary '$BIN' not found or is not executable." 1>&2 exit 1 fi if [ ! -d "$DIR/queue" ]; then - echo "[-] Error: directory '$1' not found or not created by afl-fuzz." 1>&2 + echo "[-] Error: directory '$DIR' not found or not created by afl-fuzz." 1>&2 exit 1 fi diff --git a/examples/custom_mutators/Makefile b/utils/custom_mutators/Makefile index 9849f3f4..9849f3f4 100644 --- a/examples/custom_mutators/Makefile +++ b/utils/custom_mutators/Makefile diff --git a/examples/custom_mutators/README.md b/utils/custom_mutators/README.md index a81538e6..655f7a5e 100644 --- a/examples/custom_mutators/README.md +++ b/utils/custom_mutators/README.md @@ -1,7 +1,7 @@ # Examples for the custom mutator These are example and helper files for the custom mutator feature. -See [docs/custom_mutators.md](../docs/custom_mutators.md) for more information +See [docs/custom_mutators.md](../../docs/custom_mutators.md) for more information Note that if you compile with python3.7 you must use python3 scripts, and if you use python2.7 to compile python2 scripts! diff --git a/examples/custom_mutators/XmlMutatorMin.py b/utils/custom_mutators/XmlMutatorMin.py index 4c80a2ba..3e6cd0ff 100644 --- a/examples/custom_mutators/XmlMutatorMin.py +++ b/utils/custom_mutators/XmlMutatorMin.py @@ -12,12 +12,13 @@ import random, re, io # The XmlMutatorMin class # ########################### + class XmlMutatorMin: """ - Optionals parameters: - seed Seed used by the PRNG (default: "RANDOM") - verbose Verbosity (default: False) + Optionals parameters: + seed Seed used by the PRNG (default: "RANDOM") + verbose Verbosity (default: False) """ def __init__(self, seed="RANDOM", verbose=False): @@ -41,7 +42,12 @@ class XmlMutatorMin: self.tree = None # High-level mutators (no database needed) - hl_mutators_delete = ["del_node_and_children", "del_node_but_children", "del_attribute", "del_content"] # Delete items + hl_mutators_delete = [ + "del_node_and_children", + "del_node_but_children", + "del_attribute", + "del_content", + ] # Delete items hl_mutators_fuzz = ["fuzz_attribute"] # Randomly change attribute values # Exposed mutators @@ -74,7 +80,9 @@ class XmlMutatorMin: """ Serialize a XML document. Basic wrapper around lxml.tostring() """ - return ET.tostring(tree, with_tail=False, xml_declaration=True, encoding=tree.docinfo.encoding) + return ET.tostring( + tree, with_tail=False, xml_declaration=True, encoding=tree.docinfo.encoding + ) def __ver(self, version): @@ -161,7 +169,7 @@ class XmlMutatorMin: # Randomly pick one the function calls (func, args) = random.choice(l) # Split by "," and randomly pick one of the arguments - value = random.choice(args.split(',')) + value = random.choice(args.split(",")) # Remove superfluous characters unclean_value = value value = value.strip(" ").strip("'") @@ -170,49 +178,49 @@ class XmlMutatorMin: value = attrib_value # For each type, define some possible replacement values - choices_number = ( \ - "0", \ - "11111", \ - "-128", \ - "2", \ - "-1", \ - "1/3", \ - "42/0", \ - "1094861636 idiv 1.0", \ - "-1123329771506872 idiv 3.8", \ - "17=$numericRTF", \ - str(3 + random.randrange(0, 100)), \ - ) - - choices_letter = ( \ - "P" * (25 * random.randrange(1, 100)), \ - "%s%s%s%s%s%s", \ - "foobar", \ - ) - - choices_alnum = ( \ - "Abc123", \ - "020F0302020204030204", \ - "020F0302020204030204" * (random.randrange(5, 20)), \ - ) + choices_number = ( + "0", + "11111", + "-128", + "2", + "-1", + "1/3", + "42/0", + "1094861636 idiv 1.0", + "-1123329771506872 idiv 3.8", + "17=$numericRTF", + str(3 + random.randrange(0, 100)), + ) + + choices_letter = ( + "P" * (25 * random.randrange(1, 100)), + "%s%s%s%s%s%s", + "foobar", + ) + + choices_alnum = ( + "Abc123", + "020F0302020204030204", + "020F0302020204030204" * (random.randrange(5, 20)), + ) # Fuzz the value - if random.choice((True,False)) and value == "": + if random.choice((True, False)) and value == "": # Empty new_value = value - elif random.choice((True,False)) and value.isdigit(): + elif random.choice((True, False)) and value.isdigit(): # Numbers new_value = random.choice(choices_number) - elif random.choice((True,False)) and value.isalpha(): + elif random.choice((True, False)) and value.isalpha(): # Letters new_value = random.choice(choices_letter) - elif random.choice((True,False)) and value.isalnum(): + elif random.choice((True, False)) and value.isalnum(): # Alphanumeric new_value = random.choice(choices_alnum) @@ -232,22 +240,25 @@ class XmlMutatorMin: # Log something if self.verbose: - print("Fuzzing attribute #%i '%s' of tag #%i '%s'" % (rand_attrib_id, rand_attrib, rand_elem_id, rand_elem.tag)) + print( + "Fuzzing attribute #%i '%s' of tag #%i '%s'" + % (rand_attrib_id, rand_attrib, rand_elem_id, rand_elem.tag) + ) # Modify the attribute rand_elem.set(rand_attrib, new_value.decode("utf-8")) def __del_node_and_children(self): - """ High-level minimizing mutator - Delete a random node and its children (i.e. delete a random tree) """ + """High-level minimizing mutator + Delete a random node and its children (i.e. delete a random tree)""" self.__del_node(True) def __del_node_but_children(self): - """ High-level minimizing mutator - Delete a random node but its children (i.e. link them to the parent of the deleted node) """ + """High-level minimizing mutator + Delete a random node but its children (i.e. link them to the parent of the deleted node)""" self.__del_node(False) @@ -270,7 +281,10 @@ class XmlMutatorMin: # Log something if self.verbose: but_or_and = "and" if delete_children else "but" - print("Deleting tag #%i '%s' %s its children" % (rand_elem_id, rand_elem.tag, but_or_and)) + print( + "Deleting tag #%i '%s' %s its children" + % (rand_elem_id, rand_elem.tag, but_or_and) + ) if delete_children is False: # Link children of the random (soon to be deleted) node to its parent @@ -282,8 +296,8 @@ class XmlMutatorMin: def __del_content(self): - """ High-level minimizing mutator - Delete the attributes and children of a random node """ + """High-level minimizing mutator + Delete the attributes and children of a random node""" # Select a node to modify (rand_elem_id, rand_elem) = self.__pick_element() @@ -297,8 +311,8 @@ class XmlMutatorMin: def __del_attribute(self): - """ High-level minimizing mutator - Delete a random attribute from a random node """ + """High-level minimizing mutator + Delete a random attribute from a random node""" # Select a node to modify (rand_elem_id, rand_elem) = self.__pick_element() @@ -318,7 +332,10 @@ class XmlMutatorMin: # Log something if self.verbose: - print("Deleting attribute #%i '%s' of tag #%i '%s'" % (rand_attrib_id, rand_attrib, rand_elem_id, rand_elem.tag)) + print( + "Deleting attribute #%i '%s' of tag #%i '%s'" + % (rand_attrib_id, rand_attrib, rand_elem_id, rand_elem.tag) + ) # Delete the attribute rand_elem.attrib.pop(rand_attrib) @@ -329,4 +346,3 @@ class XmlMutatorMin: # High-level mutation self.__exec_among(self, self.hl_mutators_all, min, max) - diff --git a/examples/custom_mutators/common.py b/utils/custom_mutators/common.py index 9a1ef0a3..44a5056a 100644 --- a/examples/custom_mutators/common.py +++ b/utils/custom_mutators/common.py @@ -1,6 +1,6 @@ #!/usr/bin/env python # encoding: utf-8 -''' +""" Module containing functions shared between multiple AFL modules @author: Christian Holler (:decoder) @@ -12,7 +12,7 @@ License, v. 2.0. If a copy of the MPL was not distributed with this file, You can obtain one at http://mozilla.org/MPL/2.0/. @contact: choller@mozilla.com -''' +""" from __future__ import print_function import random @@ -23,18 +23,18 @@ import re def randel(l): if not l: return None - return l[random.randint(0, len(l)-1)] + return l[random.randint(0, len(l) - 1)] def randel_pop(l): if not l: return None - return l.pop(random.randint(0, len(l)-1)) + return l.pop(random.randint(0, len(l) - 1)) def write_exc_example(data, exc): - exc_name = re.sub(r'[^a-zA-Z0-9]', '_', repr(exc)) + exc_name = re.sub(r"[^a-zA-Z0-9]", "_", repr(exc)) if not os.path.exists(exc_name): - with open(exc_name, 'w') as f: + with open(exc_name, "w") as f: f.write(data) diff --git a/examples/custom_mutators/custom_mutator_helpers.h b/utils/custom_mutators/custom_mutator_helpers.h index 0848321f..62e6efba 100644 --- a/examples/custom_mutators/custom_mutator_helpers.h +++ b/utils/custom_mutators/custom_mutator_helpers.h @@ -13,7 +13,7 @@ #define BUF_VAR(type, name) \ type * name##_buf; \ size_t name##_size; -/* this filles in `&structptr->something_buf, &structptr->something_size`. */ +/* this fills in `&structptr->something_buf, &structptr->something_size`. */ #define BUF_PARAMS(struct, name) \ (void **)&struct->name##_buf, &struct->name##_size @@ -324,8 +324,8 @@ static inline void *maybe_grow(void **buf, size_t *size, size_t size_needed) { } /* Swaps buf1 ptr and buf2 ptr, as well as their sizes */ -static inline void swap_bufs(void **buf1, size_t *size1, void **buf2, - size_t *size2) { +static inline void afl_swap_bufs(void **buf1, size_t *size1, void **buf2, + size_t *size2) { void * scratch_buf = *buf1; size_t scratch_size = *size1; diff --git a/examples/custom_mutators/example.c b/utils/custom_mutators/example.c index 23add128..23add128 100644 --- a/examples/custom_mutators/example.c +++ b/utils/custom_mutators/example.c diff --git a/examples/custom_mutators/example.py b/utils/custom_mutators/example.py index cf659e5a..3a6d22e4 100644 --- a/examples/custom_mutators/example.py +++ b/utils/custom_mutators/example.py @@ -1,6 +1,6 @@ #!/usr/bin/env python # encoding: utf-8 -''' +""" Example Python Module for AFLFuzz @author: Christian Holler (:decoder) @@ -12,7 +12,7 @@ License, v. 2.0. If a copy of the MPL was not distributed with this file, You can obtain one at http://mozilla.org/MPL/2.0/. @contact: choller@mozilla.com -''' +""" import random @@ -26,12 +26,12 @@ COMMANDS = [ def init(seed): - ''' + """ Called once when AFLFuzz starts up. Used to seed our RNG. @type seed: int @param seed: A 32-bit random value - ''' + """ random.seed(seed) @@ -40,7 +40,7 @@ def deinit(): def fuzz(buf, add_buf, max_size): - ''' + """ Called per fuzzing iteration. @type buf: bytearray @@ -55,13 +55,14 @@ def fuzz(buf, add_buf, max_size): @rtype: bytearray @return: A new bytearray containing the mutated data - ''' + """ ret = bytearray(100) ret[:3] = random.choice(COMMANDS) return ret + # Uncomment and implement the following methods if you want to use a custom # trimming algorithm. See also the documentation for a better API description. diff --git a/examples/custom_mutators/post_library_gif.so.c b/utils/custom_mutators/post_library_gif.so.c index 2d72400c..ac10f409 100644 --- a/examples/custom_mutators/post_library_gif.so.c +++ b/utils/custom_mutators/post_library_gif.so.c @@ -94,7 +94,13 @@ void *afl_custom_init(void *afl) { } state->buf = calloc(sizeof(unsigned char), 4096); - if (!state->buf) { return NULL; } + if (!state->buf) { + + free(state); + perror("calloc"); + return NULL; + + } return state; diff --git a/examples/custom_mutators/post_library_png.so.c b/utils/custom_mutators/post_library_png.so.c index 7c1ea93e..941f7e55 100644 --- a/examples/custom_mutators/post_library_png.so.c +++ b/utils/custom_mutators/post_library_png.so.c @@ -54,7 +54,13 @@ void *afl_custom_init(void *afl) { } state->buf = calloc(sizeof(unsigned char), 4096); - if (!state->buf) { return NULL; } + if (!state->buf) { + + free(state); + perror("calloc"); + return NULL; + + } return state; diff --git a/examples/custom_mutators/simple-chunk-replace.py b/utils/custom_mutators/simple-chunk-replace.py index df2f4ca7..c57218dd 100644 --- a/examples/custom_mutators/simple-chunk-replace.py +++ b/utils/custom_mutators/simple-chunk-replace.py @@ -1,6 +1,6 @@ #!/usr/bin/env python # encoding: utf-8 -''' +""" Simple Chunk Cross-Over Replacement Module for AFLFuzz @author: Christian Holler (:decoder) @@ -12,24 +12,24 @@ License, v. 2.0. If a copy of the MPL was not distributed with this file, You can obtain one at http://mozilla.org/MPL/2.0/. @contact: choller@mozilla.com -''' +""" import random def init(seed): - ''' + """ Called once when AFLFuzz starts up. Used to seed our RNG. @type seed: int @param seed: A 32-bit random value - ''' + """ # Seed our RNG random.seed(seed) def fuzz(buf, add_buf, max_size): - ''' + """ Called per fuzzing iteration. @type buf: bytearray @@ -44,7 +44,7 @@ def fuzz(buf, add_buf, max_size): @rtype: bytearray @return: A new bytearray containing the mutated data - ''' + """ # Make a copy of our input buffer for returning ret = bytearray(buf) @@ -58,7 +58,9 @@ def fuzz(buf, add_buf, max_size): rand_dst_idx = random.randint(0, len(buf)) # Make the chunk replacement - ret[rand_dst_idx:rand_dst_idx + fragment_len] = add_buf[rand_src_idx:rand_src_idx + fragment_len] + ret[rand_dst_idx : rand_dst_idx + fragment_len] = add_buf[ + rand_src_idx : rand_src_idx + fragment_len + ] # Return data return ret diff --git a/examples/custom_mutators/simple_example.c b/utils/custom_mutators/simple_example.c index a351d787..d888ec1f 100644 --- a/examples/custom_mutators/simple_example.c +++ b/utils/custom_mutators/simple_example.c @@ -8,7 +8,7 @@ #include <stdio.h> #ifndef _FIXED_CHAR - #define 0x41 + #define _FIXED_CHAR 0x41 #endif typedef struct my_mutator { diff --git a/examples/custom_mutators/wrapper_afl_min.py b/utils/custom_mutators/wrapper_afl_min.py index ecb03b55..5cd60031 100644 --- a/examples/custom_mutators/wrapper_afl_min.py +++ b/utils/custom_mutators/wrapper_afl_min.py @@ -27,7 +27,7 @@ def log(text): def init(seed): """ - Called once when AFL starts up. Seed is used to identify the AFL instance in log files + Called once when AFL starts up. Seed is used to identify the AFL instance in log files """ global __mutator__ @@ -72,7 +72,10 @@ def fuzz(buf, add_buf, max_size): if via_buffer: try: __mutator__.init_from_string(buf_str) - log("fuzz(): Mutator successfully initialized with AFL buffer (%d bytes)" % len(buf_str)) + log( + "fuzz(): Mutator successfully initialized with AFL buffer (%d bytes)" + % len(buf_str) + ) except Exception: via_buffer = False log("fuzz(): Can't initialize mutator with AFL buffer") @@ -104,7 +107,7 @@ def fuzz(buf, add_buf, max_size): # Main (for debug) -if __name__ == '__main__': +if __name__ == "__main__": __log__ = True __log_file__ = "/dev/stdout" @@ -112,7 +115,9 @@ if __name__ == '__main__': init(__seed__) - in_1 = bytearray("<foo ddd='eeee'>ffff<a b='c' d='456' eee='ffffff'>zzzzzzzzzzzz</a><b yyy='YYY' zzz='ZZZ'></b></foo>") + in_1 = bytearray( + "<foo ddd='eeee'>ffff<a b='c' d='456' eee='ffffff'>zzzzzzzzzzzz</a><b yyy='YYY' zzz='ZZZ'></b></foo>" + ) in_2 = bytearray("<abc abc123='456' abcCBA='ppppppppppppppppppppppppppppp'/>") out = fuzz(in_1, in_2) print(out) diff --git a/examples/defork/Makefile b/utils/defork/Makefile index e8240dba..e8240dba 100644 --- a/examples/defork/Makefile +++ b/utils/defork/Makefile diff --git a/examples/defork/README.md b/utils/defork/README.md index 7e950323..7e950323 100644 --- a/examples/defork/README.md +++ b/utils/defork/README.md diff --git a/examples/defork/defork.c b/utils/defork/defork.c index f71d1124..c9be3283 100644 --- a/examples/defork/defork.c +++ b/utils/defork/defork.c @@ -1,10 +1,11 @@ -#define __GNU_SOURCE +#define _GNU_SOURCE #include <dlfcn.h> #include <unistd.h> #include <stdio.h> #include <stdbool.h> #include "../../include/config.h" +#include "../../include/types.h" /* we want to fork once (for the afl++ forkserver), then immediately return as child on subsequent forks. */ diff --git a/examples/defork/forking_target.c b/utils/defork/forking_target.c index 98f6365a..628d23c9 100644 --- a/examples/defork/forking_target.c +++ b/utils/defork/forking_target.c @@ -26,6 +26,7 @@ int main(int argc, char **argv) { FILE *f = fopen(argv[1], "r"); char buf[4096]; fread(buf, 1, 4096, f); + fclose(f); uint32_t offset = buf[100] + (buf[101] << 8); char test_val = buf[offset]; return test_val < 100; diff --git a/examples/distributed_fuzzing/sync_script.sh b/utils/distributed_fuzzing/sync_script.sh index c45ae69b..b28ff6cd 100755 --- a/examples/distributed_fuzzing/sync_script.sh +++ b/utils/distributed_fuzzing/sync_script.sh @@ -39,8 +39,11 @@ FUZZ_USER=bob # Directory to synchronize SYNC_DIR='/home/bob/sync_dir' -# Interval (seconds) between sync attempts -SYNC_INTERVAL=$((30 * 60)) +# We only capture -M main nodes, set the name to your chosen naming scheme +MAIN_NAME='main' + +# Interval (seconds) between sync attempts (eg one hour) +SYNC_INTERVAL=$((60 * 60)) if [ "$AFL_ALLOW_TMP" = "" ]; then @@ -63,7 +66,7 @@ while :; do echo "[*] Retrieving data from ${host}.${FUZZ_DOMAIN}..." ssh -o 'passwordauthentication no' ${FUZZ_USER}@${host}.$FUZZ_DOMAIN \ - "cd '$SYNC_DIR' && tar -czf - ${host}_*/[qf]*" >".sync_tmp/${host}.tgz" + "cd '$SYNC_DIR' && tar -czf - ${host}_${MAIN_NAME}*/" > ".sync_tmp/${host}.tgz" done @@ -80,7 +83,7 @@ while :; do echo " Sending fuzzer data from ${src_host}.${FUZZ_DOMAIN}..." ssh -o 'passwordauthentication no' ${FUZZ_USER}@$dst_host \ - "cd '$SYNC_DIR' && tar -xkzf -" <".sync_tmp/${src_host}.tgz" + "cd '$SYNC_DIR' && tar -xkzf - " < ".sync_tmp/${src_host}.tgz" done diff --git a/libdislocator/Makefile b/utils/libdislocator/Makefile index f9c4cb65..f0b4bb72 100644 --- a/libdislocator/Makefile +++ b/utils/libdislocator/Makefile @@ -16,28 +16,28 @@ PREFIX ?= /usr/local HELPER_PATH = $(PREFIX)/lib/afl -VERSION = $(shell grep '^\#define VERSION ' ../config.h | cut -d '"' -f2) +VERSION = $(shell grep '^\#define VERSION ' ../../config.h | cut -d '"' -f2) CFLAGS ?= -O3 -funroll-loops -D_FORTIFY_SOURCE=2 -CFLAGS += -I ../include/ -Wall -g -Wno-pointer-sign +override CFLAGS += -I ../../include/ -Wall -g -Wno-pointer-sign CFLAGS_ADD=$(USEHUGEPAGE:1=-DUSEHUGEPAGE) CFLAGS += $(CFLAGS_ADD) all: libdislocator.so -VPATH = .. -libdislocator.so: libdislocator.so.c ../config.h - $(CC) $(CFLAGS) -shared -fPIC libdislocator.so.c -o ../$@ $(LDFLAGS) +libdislocator.so: libdislocator.so.c ../../config.h + $(CC) $(CFLAGS) $(CPPFLAGS) -shared -fPIC libdislocator.so.c -o $@ $(LDFLAGS) + cp -fv libdislocator.so ../../ .NOTPARALLEL: clean clean: rm -f *.o *.so *~ a.out core core.[1-9][0-9]* - rm -f ../libdislocator.so + rm -f ../../libdislocator.so install: all install -m 755 -d $${DESTDIR}$(HELPER_PATH) - install -m 755 ../libdislocator.so $${DESTDIR}$(HELPER_PATH) + install -m 755 ../../libdislocator.so $${DESTDIR}$(HELPER_PATH) install -m 644 -T README.md $${DESTDIR}$(HELPER_PATH)/README.dislocator.md diff --git a/libdislocator/README.md b/utils/libdislocator/README.md index 873d8806..d0340af0 100644 --- a/libdislocator/README.md +++ b/utils/libdislocator/README.md @@ -1,6 +1,6 @@ # libdislocator, an abusive allocator - (See ../docs/README.md for the general instruction manual.) + (See ../../README.md for the general instruction manual.) This is a companion library that can be used as a drop-in replacement for the libc allocator in the fuzzed binaries. It improves the odds of bumping into diff --git a/libdislocator/libdislocator.so.c b/utils/libdislocator/libdislocator.so.c index 2324e390..c041fec6 100644 --- a/libdislocator/libdislocator.so.c +++ b/utils/libdislocator/libdislocator.so.c @@ -345,10 +345,10 @@ void free(void *ptr) { len = PTR_L(ptr); total_mem -= len; + u8 *ptr_ = ptr; if (align_allocations && (len & (ALLOC_ALIGN_SIZE - 1))) { - u8 * ptr_ = ptr; size_t rlen = (len & ~(ALLOC_ALIGN_SIZE - 1)) + ALLOC_ALIGN_SIZE; for (; len < rlen; ++len) if (ptr_[len] != TAIL_ALLOC_CANARY) @@ -359,11 +359,13 @@ void free(void *ptr) { /* Protect everything. Note that the extra page at the end is already set as PROT_NONE, so we don't need to touch that. */ - ptr -= PAGE_SIZE * PG_COUNT(len + 8) - len - 8; + ptr_ -= PAGE_SIZE * PG_COUNT(len + 8) - len - 8; - if (mprotect(ptr - 8, PG_COUNT(len + 8) * PAGE_SIZE, PROT_NONE)) + if (mprotect(ptr_ - 8, PG_COUNT(len + 8) * PAGE_SIZE, PROT_NONE)) FATAL("mprotect() failed when freeing memory"); + ptr = ptr_; + /* Keep the mapping; this is wasteful, but prevents ptr reuse. */ } diff --git a/examples/libpng_no_checksum/libpng-nocrc.patch b/utils/libpng_no_checksum/libpng-nocrc.patch index 0a3793a0..0a3793a0 100644 --- a/examples/libpng_no_checksum/libpng-nocrc.patch +++ b/utils/libpng_no_checksum/libpng-nocrc.patch diff --git a/libtokencap/Makefile b/utils/libtokencap/Makefile index 8bdfa5ac..b81e1729 100644 --- a/libtokencap/Makefile +++ b/utils/libtokencap/Makefile @@ -16,35 +16,34 @@ PREFIX ?= /usr/local HELPER_PATH = $(PREFIX)/lib/afl DOC_PATH ?= $(PREFIX)/share/doc/afl -MAN_PATH ?= $(PREFIX)/man/man8 +MAN_PATH ?= $(PREFIX)/share/man/man8 -VERSION = $(shell grep '^\#define VERSION ' ../config.h | cut -d '"' -f2) +VERSION = $(shell grep '^\#define VERSION ' ../../config.h | cut -d '"' -f2) CFLAGS ?= -O3 -funroll-loops -D_FORTIFY_SOURCE=2 -CFLAGS += -I ../include/ -Wall -g -Wno-pointer-sign +override CFLAGS += -I ../../include/ -Wall -g -Wno-pointer-sign UNAME_S =$(shell uname -s)# GNU make UNAME_S:sh=uname -s # BSD make _UNIQ=_QINU_ - _OS_DL = $(_UNIQ)$(UNAME_S) - __OS_DL = $(_OS_DL:$(_UNIQ)Linux=$(_UNIQ)) - ___OS_DL = $(__OS_DL:$(_UNIQ)Darwin=$(_UNIQ)) - ____OS_DL = $(___OS_DL:$(_UNIQ)DragonFly=$(_UNIQ)) - _____OS_DL = $(____OS_DL:$(_UNIQ)$(UNAME_S)=) -______OS_DL = $(_____OS_DL:$(_UNIQ)="-ldl") + _OS_DL = $(_UNIQ)$(UNAME_S) + __OS_DL = $(_OS_DL:$(_UNIQ)Linux=$(_UNIQ)) + ___OS_DL = $(__OS_DL:$(_UNIQ)Darwin=$(_UNIQ)) + ____OS_DL = $(___OS_DL:$(_UNIQ)$(UNAME_S)=) +_____OS_DL = $(____OS_DL:$(_UNIQ)="-ldl") - _OS_TARGET = $(____OS_DL:$(_UNIQ)FreeBSD=$(_UNIQ)) + _OS_TARGET = $(___OS_DL:$(_UNIQ)FreeBSD=$(_UNIQ)) __OS_TARGET = $(_OS_TARGET:$(_UNIQ)OpenBSD=$(_UNIQ)) ___OS_TARGET = $(__OS_TARGET:$(_UNIQ)NetBSD=$(_UNIQ)) ____OS_TARGET = $(___OS_TARGET:$(_UNIQ)Haiku=$(_UNIQ)) _____OS_TARGET = $(____OS_TARGET:$(_UNIQ)SunOS=$(_UNIQ)) -______OS_TARGET = $(____OS_TARGET:$(_UNIQ)$(UNAME_S)=) +______OS_TARGET = $(_____OS_TARGET:$(_UNIQ)$(UNAME_S)=) -TARGETS = $(_____OS_TARGET:$(_UNIQ)=libtokencap.so) +TARGETS = $(______OS_TARGET:$(_UNIQ)=libtokencap.so) -LDFLAGS += $(______OS_DL) +LDFLAGS += $(_____OS_DL) #ifeq "$(shell uname)" "Linux" # TARGETS = libtokencap.so @@ -69,9 +68,9 @@ LDFLAGS += $(______OS_DL) #endif all: $(TARGETS) -VPATH = .. -libtokencap.so: libtokencap.so.c ../config.h - $(CC) $(CFLAGS) -shared -fPIC $< -o ../$@ $(LDFLAGS) +libtokencap.so: libtokencap.so.c ../../config.h + $(CC) $(CFLAGS) $(CPPFLAGS) -shared -fPIC $< -o $@ $(LDFLAGS) + cp -f libtokencap.so ../../ .NOTPARALLEL: clean @@ -87,9 +86,9 @@ debug: clean: rm -f *.o *.so *~ a.out core core.[1-9][0-9]* - rm -f ../libtokencap.so + rm -fv ../../libtokencap.so install: all install -m 755 -d $${DESTDIR}$(HELPER_PATH) - install -m 755 ../libtokencap.so $${DESTDIR}$(HELPER_PATH) + install -m 755 ../../libtokencap.so $${DESTDIR}$(HELPER_PATH) install -m 644 -T README.md $${DESTDIR}$(DOC_PATH)/README.tokencap.md diff --git a/libtokencap/README.md b/utils/libtokencap/README.md index 0a3591eb..a39ed3a5 100644 --- a/libtokencap/README.md +++ b/utils/libtokencap/README.md @@ -1,6 +1,11 @@ # strcmp() / memcmp() token capture library - (See ../docs/README.md for the general instruction manual.) + NOTE: libtokencap is only recommended for binary-only targets or targets that + do not compile with afl-clang-fast/afl-clang-lto. + The afl-clang-fast AFL_LLVM_DICT2FILE feature is much better, afl-clang-lto + has that feature automatically integrated. + + (See ../../README.md for the general instruction manual.) This companion library allows you to instrument `strcmp()`, `memcmp()`, and related functions to automatically extract syntax tokens passed to any of diff --git a/libtokencap/libtokencap.so.c b/utils/libtokencap/libtokencap.so.c index 21bac082..3629e804 100644 --- a/libtokencap/libtokencap.so.c +++ b/utils/libtokencap/libtokencap.so.c @@ -275,8 +275,8 @@ static void __tokencap_load_mappings(void) { for (c = map; r > 0; c++, r -= sizeof(prmap_t)) { - __tokencap_ro[__tokencap_ro_cnt].st = c->pr_vaddr; - __tokencap_ro[__tokencap_ro_cnt].en = c->pr_vaddr + c->pr_size; + __tokencap_ro[__tokencap_ro_cnt].st = (void *)c->pr_vaddr; + __tokencap_ro[__tokencap_ro_cnt].en = (void *)(c->pr_vaddr + c->pr_size); if (++__tokencap_ro_cnt == MAX_MAPPINGS) break; diff --git a/utils/persistent_mode/Makefile b/utils/persistent_mode/Makefile new file mode 100644 index 00000000..e348c46c --- /dev/null +++ b/utils/persistent_mode/Makefile @@ -0,0 +1,10 @@ +all: + ../../afl-clang-fast -o persistent_demo persistent_demo.c + ../../afl-clang-fast -o persistent_demo_new persistent_demo_new.c + AFL_DONT_OPTIMIZE=1 ../../afl-clang-fast -o test-instr test-instr.c + +document: + AFL_DONT_OPTIMIZE=1 ../../afl-clang-fast -D_AFL_DOCUMENT_MUTATIONS -o test-instr test-instr.c + +clean: + rm -f persistent_demo persistent_demo_new test-instr diff --git a/examples/persistent_demo/persistent_demo.c b/utils/persistent_mode/persistent_demo.c index 4cedc32c..f5e43728 100644 --- a/examples/persistent_demo/persistent_demo.c +++ b/utils/persistent_mode/persistent_demo.c @@ -27,9 +27,15 @@ #include <unistd.h> #include <signal.h> #include <string.h> +#include <limits.h> /* Main entry point. */ +/* To ensure checks are not optimized out it is recommended to disable + code optimization for the fuzzer harness main() */ +#pragma clang optimize off +#pragma GCC optimize("O0") + int main(int argc, char **argv) { ssize_t len; /* how much input did we read? */ @@ -42,7 +48,7 @@ int main(int argc, char **argv) { and similar hiccups. */ __AFL_INIT(); - while (__AFL_LOOP(1000)) { + while (__AFL_LOOP(UINT_MAX)) { /*** PLACEHOLDER CODE ***/ diff --git a/examples/persistent_demo/persistent_demo_new.c b/utils/persistent_mode/persistent_demo_new.c index e4e328b0..285f50aa 100644 --- a/examples/persistent_demo/persistent_demo_new.c +++ b/utils/persistent_mode/persistent_demo_new.c @@ -27,11 +27,32 @@ #include <unistd.h> #include <signal.h> #include <string.h> +#include <limits.h> + +/* this lets the source compile without afl-clang-fast/lto */ +#ifndef __AFL_FUZZ_TESTCASE_LEN + +ssize_t fuzz_len; +unsigned char fuzz_buf[1024000]; + + #define __AFL_FUZZ_TESTCASE_LEN fuzz_len + #define __AFL_FUZZ_TESTCASE_BUF fuzz_buf + #define __AFL_FUZZ_INIT() void sync(void); + #define __AFL_LOOP(x) \ + ((fuzz_len = read(0, fuzz_buf, sizeof(fuzz_buf))) > 0 ? 1 : 0) + #define __AFL_INIT() sync() + +#endif __AFL_FUZZ_INIT(); /* Main entry point. */ +/* To ensure checks are not optimized out it is recommended to disable + code optimization for the fuzzer harness main() */ +#pragma clang optimize off +#pragma GCC optimize("O0") + int main(int argc, char **argv) { ssize_t len; /* how much input did we read? */ @@ -43,13 +64,13 @@ int main(int argc, char **argv) { and similar hiccups. */ __AFL_INIT(); - buf = __AFL_FUZZ_TESTCASE_BUF; + buf = __AFL_FUZZ_TESTCASE_BUF; // this must be assigned before __AFL_LOOP! - while (__AFL_LOOP(1000)) { // increase if you have good stability + while (__AFL_LOOP(UINT_MAX)) { // increase if you have good stability - len = __AFL_FUZZ_TESTCASE_LEN; + len = __AFL_FUZZ_TESTCASE_LEN; // do not use the macro directly in a call! - fprintf(stderr, "input: %zd \"%s\"\n", len, buf); + // fprintf(stderr, "input: %zd \"%s\"\n", len, buf); /* do we have enough data? */ if (len < 8) continue; @@ -71,7 +92,7 @@ int main(int argc, char **argv) { if (buf[4] == '!') { printf("five\n"); - if (buf[6] == '!') { + if (buf[5] == '!') { printf("six\n"); abort(); diff --git a/examples/persistent_demo/test-instr.c b/utils/persistent_mode/test-instr.c index a6188b22..6da511de 100644 --- a/examples/persistent_demo/test-instr.c +++ b/utils/persistent_mode/test-instr.c @@ -17,15 +17,21 @@ #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> +#include <limits.h> __AFL_FUZZ_INIT(); +/* To ensure checks are not optimized out it is recommended to disable + code optimization for the fuzzer harness main() */ +#pragma clang optimize off +#pragma GCC optimize("O0") + int main(int argc, char **argv) { __AFL_INIT(); unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; - while (__AFL_LOOP(2147483647)) { // MAX_INT if you have 100% stability + while (__AFL_LOOP(UINT_MAX)) { // if you have 100% stability unsigned int len = __AFL_FUZZ_TESTCASE_LEN; diff --git a/qbdi_mode/README.md b/utils/qbdi_mode/README.md index 641a6e85..641a6e85 100755 --- a/qbdi_mode/README.md +++ b/utils/qbdi_mode/README.md diff --git a/qbdi_mode/assets/screen1.png b/utils/qbdi_mode/assets/screen1.png Binary files differindex 3cf1cb76..3cf1cb76 100644 --- a/qbdi_mode/assets/screen1.png +++ b/utils/qbdi_mode/assets/screen1.png diff --git a/qbdi_mode/build.sh b/utils/qbdi_mode/build.sh index b10971d9..2527bd26 100755 --- a/qbdi_mode/build.sh +++ b/utils/qbdi_mode/build.sh @@ -51,7 +51,7 @@ ${compiler_prefix}${CC} -shared -o libdemo.so demo-so.c -w -g echo "[+] Building afl-fuzz for Android" # build afl-fuzz -cd .. -${compiler_prefix}${CC} -DANDROID_DISABLE_FANCY=1 -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -I include/ -DAFL_PATH=\"/usr/local/lib/afl\" -DBIN_PATH=\"/usr/local/bin\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -Wno-unused-function src/afl-fuzz-*.c src/afl-fuzz.c src/afl-common.c src/afl-sharedmem.c src/afl-forkserver.c -o qbdi_mode/afl-fuzz -ldl -w +cd ../.. +${compiler_prefix}${CC} -DANDROID_DISABLE_FANCY=1 -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -I include/ -DAFL_PATH=\"/usr/local/lib/afl\" -DBIN_PATH=\"/usr/local/bin\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -Wno-unused-function src/afl-fuzz-*.c src/afl-fuzz.c src/afl-common.c src/afl-sharedmem.c src/afl-forkserver.c -o utils/qbdi_mode/afl-fuzz -ldl -w echo "[+] All done. Enjoy!" diff --git a/qbdi_mode/demo-so.c b/utils/qbdi_mode/demo-so.c index dd367036..dd367036 100755 --- a/qbdi_mode/demo-so.c +++ b/utils/qbdi_mode/demo-so.c diff --git a/qbdi_mode/template.cpp b/utils/qbdi_mode/template.cpp index 55c5a3f3..b2066cc8 100755 --- a/qbdi_mode/template.cpp +++ b/utils/qbdi_mode/template.cpp @@ -44,7 +44,7 @@ target_func p_target_func = NULL; rword module_base = 0; rword module_end = 0; static unsigned char - dummy[MAP_SIZE]; /* costs MAP_SIZE but saves a few instructions */ + dummy[MAP_SIZE]; /* costs MAP_SIZE but saves a few instructions */ unsigned char *afl_area_ptr = NULL; /* Exported for afl_gen_trace */ unsigned long afl_prev_loc = 0; diff --git a/utils/qemu_persistent_hook/Makefile b/utils/qemu_persistent_hook/Makefile new file mode 100644 index 00000000..85db1b46 --- /dev/null +++ b/utils/qemu_persistent_hook/Makefile @@ -0,0 +1,6 @@ +all: + $(CC) -no-pie test.c -o test + $(CC) -fPIC -shared read_into_rdi.c -o read_into_rdi.so + +clean: + rm -rf in out test read_into_rdi.so diff --git a/examples/qemu_persistent_hook/README.md b/utils/qemu_persistent_hook/README.md index 3278b60c..3f908c22 100644 --- a/examples/qemu_persistent_hook/README.md +++ b/utils/qemu_persistent_hook/README.md @@ -3,8 +3,7 @@ Compile the test binary and the library: ``` -gcc -no-pie test.c -o test -gcc -fPIC -shared read_into_rdi.c -o read_into_rdi.so +make ``` Fuzz with: diff --git a/utils/qemu_persistent_hook/read_into_rdi.c b/utils/qemu_persistent_hook/read_into_rdi.c new file mode 100644 index 00000000..f4a8ae59 --- /dev/null +++ b/utils/qemu_persistent_hook/read_into_rdi.c @@ -0,0 +1,34 @@ +#include "../../qemu_mode/qemuafl/qemuafl/api.h" + +#include <stdio.h> +#include <string.h> + +void afl_persistent_hook(struct x86_64_regs *regs, uint64_t guest_base, + uint8_t *input_buf, uint32_t input_buf_len) { +\ +#define g2h(x) ((void *)((unsigned long)(x) + guest_base)) +#define h2g(x) ((uint64_t)(x)-guest_base) + + // In this example the register RDI is pointing to the memory location + // of the target buffer, and the length of the input is in RSI. + // This can be seen with a debugger, e.g. gdb (and "disass main") + + printf("Placing input into 0x%lx\n", regs->rdi); + + if (input_buf_len > 1024) input_buf_len = 1024; + memcpy(g2h(regs->rdi), input_buf, input_buf_len); + regs->rsi = input_buf_len; + +#undef g2h +#undef h2g + +} + +int afl_persistent_hook_init(void) { + + // 1 for shared memory input (faster), 0 for normal input (you have to use + // read(), input_buf will be NULL) + return 1; + +} + diff --git a/examples/qemu_persistent_hook/test.c b/utils/qemu_persistent_hook/test.c index afeff202..a0e815dc 100644 --- a/examples/qemu_persistent_hook/test.c +++ b/utils/qemu_persistent_hook/test.c @@ -2,7 +2,7 @@ int target_func(unsigned char *buf, int size) { - printf("buffer:%p, size:%p\n", buf, size); + printf("buffer:%p, size:%d\n", buf, size); switch (buf[0]) { case 1: diff --git a/examples/socket_fuzzing/Makefile b/utils/socket_fuzzing/Makefile index 9476e2d5..9476e2d5 100644 --- a/examples/socket_fuzzing/Makefile +++ b/utils/socket_fuzzing/Makefile diff --git a/examples/socket_fuzzing/README.md b/utils/socket_fuzzing/README.md index 79f28bea..79f28bea 100644 --- a/examples/socket_fuzzing/README.md +++ b/utils/socket_fuzzing/README.md diff --git a/examples/socket_fuzzing/socketfuzz.c b/utils/socket_fuzzing/socketfuzz.c index 3ec8383b..3ec8383b 100644 --- a/examples/socket_fuzzing/socketfuzz.c +++ b/utils/socket_fuzzing/socketfuzz.c |
{kind=link}
{kind=link}
{kind=link}