
diff options
| author | Khaled Yakdan <yakdan@code-intelligence.de> | 2019-08-01 14:22:48 +0200 |
|---|---|---|
| committer | Khaled Yakdan <yakdan@code-intelligence.de> | 2019-08-01 14:22:48 +0200 |
| commit | ebf2c8caa590468e1eafbc257e44dc30af82e5f8 (patch) | |
| tree | 2b277b9bde32b82c2cedf684869c96424baa005f /docs | |
| parent | a949b40d11956f34c51f4546412a73e0400d1ffc (diff) | |
| parent | 7ca22cd552ff21ac0ef7cc1ab5e6e71912752a58 (diff) | |
| download | afl++-ebf2c8caa590468e1eafbc257e44dc30af82e5f8.tar.gz | |
Merge remote-tracking branch 'github/master' into custom_mutator
# Conflicts: # Makefile # afl-fuzz.c
Diffstat (limited to 'docs')
| -rw-r--r-- | docs/ChangeLog | 49 | ||||
| -rw-r--r-- | docs/PATCHES | 3 | ||||
| -rw-r--r-- | docs/QuickStartGuide.txt | 6 | ||||
| -rw-r--r-- | docs/README | 582 | ||||
| -rw-r--r-- | docs/README.MOpt | 51 | ||||
| l--------- | docs/README.md | 1 | ||||
| -rw-r--r-- | docs/binaryonly_fuzzing.txt | 140 | ||||
| -rw-r--r-- | docs/env_variables.txt | 48 | ||||
| -rw-r--r-- | docs/sister_projects.txt | 6 | ||||
| -rw-r--r-- | docs/unicorn_mode.txt | 107 |
10 files changed, 388 insertions, 605 deletions
diff --git a/docs/ChangeLog b/docs/ChangeLog index 0d730118..dfb2e4e7 100644 --- a/docs/ChangeLog +++ b/docs/ChangeLog @@ -13,10 +13,39 @@ Want to stay in the loop on major new features? Join our mailing list by sending a mail to <afl-users+subscribe@googlegroups.com>. ------------------------------ -Version ++2.52d (tbd): ------------------------------ - +---------------------- +Version ++2.53d (dev): +---------------------- + + - ... your patch? :) + + + +-------------------------- +Version ++2.53c (release): +-------------------------- + + - README is now README.md + - imported the few minor changes from the 2.53b release + - unicorn_mode got added - thanks to domenukk for the patch! + - fix llvm_mode AFL_TRACE_PC with modern llvm + - fix a crash in qemu_mode which also exists in stock afl + - added libcompcov, a laf-intel implementation for qemu! :) + see qemu_mode/libcompcov/README.libcompcov + - afl-fuzz now displays the selected core in the status screen (blue {#}) + - updated afl-fuzz and afl-system-config for new scaling governor location + in modern kernels + - using the old ineffective afl-gcc will now show a deprecation warning + - all queue, hang and crash files now have their discovery time in their name + - if llvm_mode was compiled, afl-clang/afl-clang++ will point to these + instead of afl-gcc + - added instrim, a much faster llvm_mode instrumentation at the cost of + path discovery. See llvm_mode/README.instrim (https://github.com/csienslab/instrim) + - added MOpt (github.com/puppet-meteor/MOpt-AFL) mode, see docs/README.MOpt + - added code to make it more portable to other platforms than Intel Linux + - added never zero counters for afl-gcc and optionally (because of an + optimization issue in llvm < 9) for llvm_mode (AFL_LLVM_NEVER_ZERO=1) + - added a new doc about binary only fuzzing: docs/binaryonly_fuzzing.txt - more cpu power for afl-system-config - added forkserver patch to afl-tmin, makes it much faster (originally from github.com/nccgroup/TriforceAFL) @@ -27,11 +56,13 @@ Version ++2.52d (tbd): see docs/python_mutators.txt (originally by choller@mozilla) - added AFL_CAL_FAST for slow applications and AFL_DEBUG_CHILD_OUTPUT for debugging - - added a -s seed switch to allow afl run with a fixed initial - seed that is not updated. this is good for performance and path discovery + - added -V time and -E execs option to better comparison runs, runs afl-fuzz + for a specific time/executions. + - added a -s seed switch to allow afl run with a fixed initial + seed that is not updated. This is good for performance and path discovery tests as the random numbers are deterministic then - - ... your idea or patch? - + - llvm_mode LAF_... env variables can now be specified as AFL_LLVM_LAF_... + that is longer but in line with other llvm specific env vars ----------------------------- @@ -41,7 +72,7 @@ Version ++2.52c (2019-06-05): - Applied community patches. See docs/PATCHES for the full list. LLVM and Qemu modes are now faster. Important changes: - afl-fuzz: -e EXTENSION commandline option + afl-fuzz: -e EXTENSION commandline option llvm_mode: LAF-intel performance (needs activation, see llvm/README.laf-intel) a few new environment variables for afl-fuzz, llvm and qemu, see docs/env_variables.txt - Added the power schedules of AFLfast by Marcel Boehme, but set the default diff --git a/docs/PATCHES b/docs/PATCHES index cb050218..8b188814 100644 --- a/docs/PATCHES +++ b/docs/PATCHES @@ -17,6 +17,9 @@ afl-qemu-optimize-entrypoint.diff by mh(at)mh-sec(dot)de afl-qemu-speed.diff by abiondo on github afl-qemu-optimize-map.diff by mh(at)mh-sec(dot)de ++ unicorn_mode (modernized and updated by domenukk) ++ instrim (https://github.com/csienslab/instrim) was integrated ++ MOpt (github.com/puppet-meteor/MOpt-AFL) was imported + AFLfast additions (github.com/mboehme/aflfast) were incorporated. + Qemu 3.1 upgrade with enhancement patches (github.com/andreafioraldi/afl) + Python mutator modules support (github.com/choller/afl) diff --git a/docs/QuickStartGuide.txt b/docs/QuickStartGuide.txt index af4fe75f..9190dc98 100644 --- a/docs/QuickStartGuide.txt +++ b/docs/QuickStartGuide.txt @@ -2,7 +2,7 @@ AFL quick start guide ===================== -You should read docs/README. It's pretty short. If you really can't, here's +You should read docs/README.md - it's pretty short. If you really can't, here's how to hit the ground running: 1) Compile AFL with 'make'. If build fails, see docs/INSTALL for tips. @@ -17,7 +17,7 @@ how to hit the ground running: The program must crash properly when a fault is encountered. Watch out for custom SIGSEGV or SIGABRT handlers and background processes. For tips on - detecting non-crashing flaws, see section 11 in docs/README. + detecting non-crashing flaws, see section 11 in docs/README.md . 3) Compile the program / library to be fuzzed using afl-gcc. A common way to do this would be: @@ -48,7 +48,7 @@ how to hit the ground running: That's it. Sit back, relax, and - time permitting - try to skim through the following files: - - docs/README - A general introduction to AFL, + - docs/README.md - A general introduction to AFL, - docs/perf_tips.txt - Simple tips on how to fuzz more quickly, - docs/status_screen.txt - An explanation of the tidbits shown in the UI, - docs/parallel_fuzzing.txt - Advice on running AFL on multiple cores. diff --git a/docs/README b/docs/README deleted file mode 100644 index ca38223d..00000000 --- a/docs/README +++ /dev/null @@ -1,582 +0,0 @@ -============================ -american fuzzy lop plus plus -============================ - - Written by Michal Zalewski <lcamtuf@google.com> - - Repository: https://github.com/vanhauser-thc/AFLplusplus - - afl++ is maintained by Marc Heuse <mh@mh-sec.de> and Heiko Eissfeldt - <heiko.eissfeldt@hexco.de> as there have been no updates to afl since - November 2017. - - This version has several bug fixes, new features and speed enhancements - based on community patches from https://github.com/vanhauser-thc/afl-patches - To see the list of which patches have been applied, see the PATCHES file. - - Additionally AFLfast's power schedules by Marcel Boehme from - github.com/mboehme/aflfast have been incorporated. - - Plus it was upgraded to qemu 3.1 from 2.1 with the work of - https://github.com/andreafioraldi/afl and got the community patches applied - to it. - - C. Hoellers afl-fuzz Python mutator module and llvm_mode whitelist support - was added too (https://github.com/choller/afl) - - So all in all this is the best-of AFL that is currently out there :-) - - - Copyright 2013, 2014, 2015, 2016 Google Inc. All rights reserved. - Released under terms and conditions of Apache License, Version 2.0. - - For new versions and additional information, check out: - https://github.com/vanhauser-thc/AFLplusplus - - To compare notes with other users or get notified about major new features, - send a mail to <afl-users+subscribe@googlegroups.com>. - - ** See QuickStartGuide.txt if you don't have time to read this file. ** - - -1) Challenges of guided fuzzing -------------------------------- - -Fuzzing is one of the most powerful and proven strategies for identifying -security issues in real-world software; it is responsible for the vast -majority of remote code execution and privilege escalation bugs found to date -in security-critical software. - -Unfortunately, fuzzing is also relatively shallow; blind, random mutations -make it very unlikely to reach certain code paths in the tested code, leaving -some vulnerabilities firmly outside the reach of this technique. - -There have been numerous attempts to solve this problem. One of the early -approaches - pioneered by Tavis Ormandy - is corpus distillation. The method -relies on coverage signals to select a subset of interesting seeds from a -massive, high-quality corpus of candidate files, and then fuzz them by -traditional means. The approach works exceptionally well, but requires such -a corpus to be readily available. In addition, block coverage measurements -provide only a very simplistic understanding of program state, and are less -useful for guiding the fuzzing effort in the long haul. - -Other, more sophisticated research has focused on techniques such as program -flow analysis ("concolic execution"), symbolic execution, or static analysis. -All these methods are extremely promising in experimental settings, but tend -to suffer from reliability and performance problems in practical uses - and -currently do not offer a viable alternative to "dumb" fuzzing techniques. - - -2) The afl-fuzz approach ------------------------- - -American Fuzzy Lop is a brute-force fuzzer coupled with an exceedingly simple -but rock-solid instrumentation-guided genetic algorithm. It uses a modified -form of edge coverage to effortlessly pick up subtle, local-scale changes to -program control flow. - -Simplifying a bit, the overall algorithm can be summed up as: - - 1) Load user-supplied initial test cases into the queue, - - 2) Take next input file from the queue, - - 3) Attempt to trim the test case to the smallest size that doesn't alter - the measured behavior of the program, - - 4) Repeatedly mutate the file using a balanced and well-researched variety - of traditional fuzzing strategies, - - 5) If any of the generated mutations resulted in a new state transition - recorded by the instrumentation, add mutated output as a new entry in the - queue. - - 6) Go to 2. - -The discovered test cases are also periodically culled to eliminate ones that -have been obsoleted by newer, higher-coverage finds; and undergo several other -instrumentation-driven effort minimization steps. - -As a side result of the fuzzing process, the tool creates a small, -self-contained corpus of interesting test cases. These are extremely useful -for seeding other, labor- or resource-intensive testing regimes - for example, -for stress-testing browsers, office applications, graphics suites, or -closed-source tools. - -The fuzzer is thoroughly tested to deliver out-of-the-box performance far -superior to blind fuzzing or coverage-only tools. - - -3) Instrumenting programs for use with AFL ------------------------------------------- - -PLEASE NOTE: llvm_mode compilation with afl-clang-fast/afl-clang-fast++ -instead of afl-gcc/afl-g++ is much faster and has a few cool features. -See llvm_mode/ - however few code does not compile with llvm. -We support llvm versions 4.0 to 8. - -When source code is available, instrumentation can be injected by a companion -tool that works as a drop-in replacement for gcc or clang in any standard build -process for third-party code. - -The instrumentation has a fairly modest performance impact; in conjunction with -other optimizations implemented by afl-fuzz, most programs can be fuzzed as fast -or even faster than possible with traditional tools. - -The correct way to recompile the target program may vary depending on the -specifics of the build process, but a nearly-universal approach would be: - -$ CC=/path/to/afl/afl-gcc ./configure -$ make clean all - -For C++ programs, you'd would also want to set CXX=/path/to/afl/afl-g++. - -The clang wrappers (afl-clang and afl-clang++) can be used in the same way; -clang users may also opt to leverage a higher-performance instrumentation mode, -as described in llvm_mode/README.llvm. -Clang/LLVM has a much better performance and works from LLVM version 4.0 to 8. -Using the LAF Intel performance enhancements are also recommended, see -llvm_mode/README.laf-intel -Using partial instrumentation is also recommended, see -llvm_mode/README.whitelist - -When testing libraries, you need to find or write a simple program that reads -data from stdin or from a file and passes it to the tested library. In such a -case, it is essential to link this executable against a static version of the -instrumented library, or to make sure that the correct .so file is loaded at -runtime (usually by setting LD_LIBRARY_PATH). The simplest option is a static -build, usually possible via: - -$ CC=/path/to/afl/afl-gcc ./configure --disable-shared - -Setting AFL_HARDEN=1 when calling 'make' will cause the CC wrapper to -automatically enable code hardening options that make it easier to detect -simple memory bugs. Libdislocator, a helper library included with AFL (see -libdislocator/README.dislocator) can help uncover heap corruption issues, too. - -PS. ASAN users are advised to docs/review notes_for_asan.txt file for -important caveats. - - -4) Instrumenting binary-only apps ---------------------------------- - -When source code is *NOT* available, the fuzzer offers experimental support for -fast, on-the-fly instrumentation of black-box binaries. This is accomplished -with a version of QEMU running in the lesser-known "user space emulation" mode. - -QEMU is a project separate from AFL, but you can conveniently build the -feature by doing: - -$ cd qemu_mode -$ ./build_qemu_support.sh - -For additional instructions and caveats, see qemu_mode/README.qemu. - -The mode is approximately 2-5x slower than compile-time instrumentation, is -less conductive to parallelization, and may have some other quirks. - -If [afl-dyninst](https://github.com/vanhauser-thc/afl-dyninst) works for -your binary, then you can use afl-fuzz normally and it will have twice -the speed compared to qemu_mode. - - -5) Power schedules ------------------- - -The power schedules were copied from Marcel Böhme's excellent AFLfast -implementation and expands on the ability to discover new paths and -therefore the coverage. - -| AFL flag | Power Schedule | -| ------------- | -------------------------- | -| `-p explore` (default)| 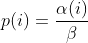 | -| `-p fast` | 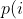=\\min\\left(\\frac{\\alpha(i)}{\\beta}\\cdot\\frac{2^{s(i)}}{f(i)},M\\right)) | -| `-p coe` | 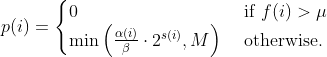 | -| `-p quad` | 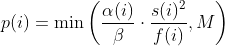 | -| `-p lin` | 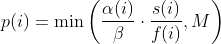 | -| `-p exploit` (AFL) | 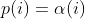 | -where *α(i)* is the performance score that AFL uses to compute for the seed input *i*, *β(i)>1* is a constant, *s(i)* is the number of times that seed *i* has been chosen from the queue, *f(i)* is the number of generated inputs that exercise the same path as seed *i*, and *μ* is the average number of generated inputs exercising a path. - -In parallel mode (-M/-S, several instances with shared queue), we suggest to -run the master using the exploit schedule (-p exploit) and the slaves with a -combination of cut-off-exponential (-p coe), exponential (-p fast; default), -and explore (-p explore) schedules. - -In single mode, using -p fast is usually more beneficial than the default -explore mode. -(We don't want to change the default behaviour of afl, so "fast" has not been -made the default mode) - -More details can be found in the paper: -[23rd ACM Conference on Computer and Communications Security (CCS'16)](https://www.sigsac.org/ccs/CCS2016/accepted-papers/). - - -6) Choosing initial test cases ------------------------------- - -To operate correctly, the fuzzer requires one or more starting file that -contains a good example of the input data normally expected by the targeted -application. There are two basic rules: - - - Keep the files small. Under 1 kB is ideal, although not strictly necessary. - For a discussion of why size matters, see perf_tips.txt. - - - Use multiple test cases only if they are functionally different from - each other. There is no point in using fifty different vacation photos - to fuzz an image library. - -You can find many good examples of starting files in the testcases/ subdirectory -that comes with this tool. - -PS. If a large corpus of data is available for screening, you may want to use -the afl-cmin utility to identify a subset of functionally distinct files that -exercise different code paths in the target binary. - - -7) Fuzzing binaries -------------------- - -The fuzzing process itself is carried out by the afl-fuzz utility. This program -requires a read-only directory with initial test cases, a separate place to -store its findings, plus a path to the binary to test. - -For target binaries that accept input directly from stdin, the usual syntax is: - -$ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program [...params...] - -For programs that take input from a file, use '@@' to mark the location in -the target's command line where the input file name should be placed. The -fuzzer will substitute this for you: - -$ ./afl-fuzz -i testcase_dir -o findings_dir /path/to/program @@ - -You can also use the -f option to have the mutated data written to a specific -file. This is useful if the program expects a particular file extension or so. - -Non-instrumented binaries can be fuzzed in the QEMU mode (add -Q in the command -line) or in a traditional, blind-fuzzer mode (specify -n). - -You can use -t and -m to override the default timeout and memory limit for the -executed process; rare examples of targets that may need these settings touched -include compilers and video decoders. - -Tips for optimizing fuzzing performance are discussed in perf_tips.txt. - -Note that afl-fuzz starts by performing an array of deterministic fuzzing -steps, which can take several days, but tend to produce neat test cases. If you -want quick & dirty results right away - akin to zzuf and other traditional -fuzzers - add the -d option to the command line. - - -8) Interpreting output ----------------------- - -See the status_screen.txt file for information on how to interpret the -displayed stats and monitor the health of the process. Be sure to consult this -file especially if any UI elements are highlighted in red. - -The fuzzing process will continue until you press Ctrl-C. At minimum, you want -to allow the fuzzer to complete one queue cycle, which may take anywhere from a -couple of hours to a week or so. - -There are three subdirectories created within the output directory and updated -in real time: - - - queue/ - test cases for every distinctive execution path, plus all the - starting files given by the user. This is the synthesized corpus - mentioned in section 2. - - Before using this corpus for any other purposes, you can shrink - it to a smaller size using the afl-cmin tool. The tool will find - a smaller subset of files offering equivalent edge coverage. - - - crashes/ - unique test cases that cause the tested program to receive a - fatal signal (e.g., SIGSEGV, SIGILL, SIGABRT). The entries are - grouped by the received signal. - - - hangs/ - unique test cases that cause the tested program to time out. The - default time limit before something is classified as a hang is - the larger of 1 second and the value of the -t parameter. - The value can be fine-tuned by setting AFL_HANG_TMOUT, but this - is rarely necessary. - -Crashes and hangs are considered "unique" if the associated execution paths -involve any state transitions not seen in previously-recorded faults. If a -single bug can be reached in multiple ways, there will be some count inflation -early in the process, but this should quickly taper off. - -The file names for crashes and hangs are correlated with parent, non-faulting -queue entries. This should help with debugging. - -When you can't reproduce a crash found by afl-fuzz, the most likely cause is -that you are not setting the same memory limit as used by the tool. Try: - -$ LIMIT_MB=50 -$ ( ulimit -Sv $[LIMIT_MB << 10]; /path/to/tested_binary ... ) - -Change LIMIT_MB to match the -m parameter passed to afl-fuzz. On OpenBSD, -also change -Sv to -Sd. - -Any existing output directory can be also used to resume aborted jobs; try: - -$ ./afl-fuzz -i- -o existing_output_dir [...etc...] - -If you have gnuplot installed, you can also generate some pretty graphs for any -active fuzzing task using afl-plot. For an example of how this looks like, -see http://lcamtuf.coredump.cx/afl/plot/. - - -9) Parallelized fuzzing ------------------------ - -Every instance of afl-fuzz takes up roughly one core. This means that on -multi-core systems, parallelization is necessary to fully utilize the hardware. -For tips on how to fuzz a common target on multiple cores or multiple networked -machines, please refer to parallel_fuzzing.txt. - -The parallel fuzzing mode also offers a simple way for interfacing AFL to other -fuzzers, to symbolic or concolic execution engines, and so forth; again, see the -last section of parallel_fuzzing.txt for tips. - - -10) Fuzzer dictionaries ----------------------- - -By default, afl-fuzz mutation engine is optimized for compact data formats - -say, images, multimedia, compressed data, regular expression syntax, or shell -scripts. It is somewhat less suited for languages with particularly verbose and -redundant verbiage - notably including HTML, SQL, or JavaScript. - -To avoid the hassle of building syntax-aware tools, afl-fuzz provides a way to -seed the fuzzing process with an optional dictionary of language keywords, -magic headers, or other special tokens associated with the targeted data type -- and use that to reconstruct the underlying grammar on the go: - - http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html - -To use this feature, you first need to create a dictionary in one of the two -formats discussed in dictionaries/README.dictionaries; and then point the fuzzer -to it via the -x option in the command line. - -(Several common dictionaries are already provided in that subdirectory, too.) - -There is no way to provide more structured descriptions of the underlying -syntax, but the fuzzer will likely figure out some of this based on the -instrumentation feedback alone. This actually works in practice, say: - - http://lcamtuf.blogspot.com/2015/04/finding-bugs-in-sqlite-easy-way.html - -PS. Even when no explicit dictionary is given, afl-fuzz will try to extract -existing syntax tokens in the input corpus by watching the instrumentation -very closely during deterministic byte flips. This works for some types of -parsers and grammars, but isn't nearly as good as the -x mode. - -If a dictionary is really hard to come by, another option is to let AFL run -for a while, and then use the token capture library that comes as a companion -utility with AFL. For that, see libtokencap/README.tokencap. - - -11) Crash triage ----------------- - -The coverage-based grouping of crashes usually produces a small data set that -can be quickly triaged manually or with a very simple GDB or Valgrind script. -Every crash is also traceable to its parent non-crashing test case in the -queue, making it easier to diagnose faults. - -Having said that, it's important to acknowledge that some fuzzing crashes can be -difficult to quickly evaluate for exploitability without a lot of debugging and -code analysis work. To assist with this task, afl-fuzz supports a very unique -"crash exploration" mode enabled with the -C flag. - -In this mode, the fuzzer takes one or more crashing test cases as the input, -and uses its feedback-driven fuzzing strategies to very quickly enumerate all -code paths that can be reached in the program while keeping it in the -crashing state. - -Mutations that do not result in a crash are rejected; so are any changes that -do not affect the execution path. - -The output is a small corpus of files that can be very rapidly examined to see -what degree of control the attacker has over the faulting address, or whether -it is possible to get past an initial out-of-bounds read - and see what lies -beneath. - -Oh, one more thing: for test case minimization, give afl-tmin a try. The tool -can be operated in a very simple way: - -$ ./afl-tmin -i test_case -o minimized_result -- /path/to/program [...] - -The tool works with crashing and non-crashing test cases alike. In the crash -mode, it will happily accept instrumented and non-instrumented binaries. In the -non-crashing mode, the minimizer relies on standard AFL instrumentation to make -the file simpler without altering the execution path. - -The minimizer accepts the -m, -t, -f and @@ syntax in a manner compatible with -afl-fuzz. - -Another recent addition to AFL is the afl-analyze tool. It takes an input -file, attempts to sequentially flip bytes, and observes the behavior of the -tested program. It then color-codes the input based on which sections appear to -be critical, and which are not; while not bulletproof, it can often offer quick -insights into complex file formats. More info about its operation can be found -near the end of technical_details.txt. - - -12) Going beyond crashes ------------------------- - -Fuzzing is a wonderful and underutilized technique for discovering non-crashing -design and implementation errors, too. Quite a few interesting bugs have been -found by modifying the target programs to call abort() when, say: - - - Two bignum libraries produce different outputs when given the same - fuzzer-generated input, - - - An image library produces different outputs when asked to decode the same - input image several times in a row, - - - A serialization / deserialization library fails to produce stable outputs - when iteratively serializing and deserializing fuzzer-supplied data, - - - A compression library produces an output inconsistent with the input file - when asked to compress and then decompress a particular blob. - -Implementing these or similar sanity checks usually takes very little time; -if you are the maintainer of a particular package, you can make this code -conditional with #ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION (a flag also -shared with libfuzzer) or #ifdef __AFL_COMPILER (this one is just for AFL). - - -13) Common-sense risks ----------------------- - -Please keep in mind that, similarly to many other computationally-intensive -tasks, fuzzing may put strain on your hardware and on the OS. In particular: - - - Your CPU will run hot and will need adequate cooling. In most cases, if - cooling is insufficient or stops working properly, CPU speeds will be - automatically throttled. That said, especially when fuzzing on less - suitable hardware (laptops, smartphones, etc), it's not entirely impossible - for something to blow up. - - - Targeted programs may end up erratically grabbing gigabytes of memory or - filling up disk space with junk files. AFL tries to enforce basic memory - limits, but can't prevent each and every possible mishap. The bottom line - is that you shouldn't be fuzzing on systems where the prospect of data loss - is not an acceptable risk. - - - Fuzzing involves billions of reads and writes to the filesystem. On modern - systems, this will be usually heavily cached, resulting in fairly modest - "physical" I/O - but there are many factors that may alter this equation. - It is your responsibility to monitor for potential trouble; with very heavy - I/O, the lifespan of many HDDs and SSDs may be reduced. - - A good way to monitor disk I/O on Linux is the 'iostat' command: - - $ iostat -d 3 -x -k [...optional disk ID...] - - -14) Known limitations & areas for improvement ---------------------------------------------- - -Here are some of the most important caveats for AFL: - - - AFL detects faults by checking for the first spawned process dying due to - a signal (SIGSEGV, SIGABRT, etc). Programs that install custom handlers for - these signals may need to have the relevant code commented out. In the same - vein, faults in child processed spawned by the fuzzed target may evade - detection unless you manually add some code to catch that. - - - As with any other brute-force tool, the fuzzer offers limited coverage if - encryption, checksums, cryptographic signatures, or compression are used to - wholly wrap the actual data format to be tested. - - To work around this, you can comment out the relevant checks (see - experimental/libpng_no_checksum/ for inspiration); if this is not possible, - you can also write a postprocessor, as explained in - experimental/post_library/ (with AFL_POST_LIBRARY) - - - There are some unfortunate trade-offs with ASAN and 64-bit binaries. This - isn't due to any specific fault of afl-fuzz; see notes_for_asan.txt for - tips. - - - There is no direct support for fuzzing network services, background - daemons, or interactive apps that require UI interaction to work. You may - need to make simple code changes to make them behave in a more traditional - way. Preeny may offer a relatively simple option, too - see: - https://github.com/zardus/preeny - - Some useful tips for modifying network-based services can be also found at: - https://www.fastly.com/blog/how-to-fuzz-server-american-fuzzy-lop - - - AFL doesn't output human-readable coverage data. If you want to monitor - coverage, use afl-cov from Michael Rash: https://github.com/mrash/afl-cov - - - Occasionally, sentient machines rise against their creators. If this - happens to you, please consult http://lcamtuf.coredump.cx/prep/. - -Beyond this, see INSTALL for platform-specific tips. - - -15) Special thanks ------------------- - -Many of the improvements to afl-fuzz wouldn't be possible without feedback, -bug reports, or patches from: - - Jann Horn Hanno Boeck - Felix Groebert Jakub Wilk - Richard W. M. Jones Alexander Cherepanov - Tom Ritter Hovik Manucharyan - Sebastian Roschke Eberhard Mattes - Padraig Brady Ben Laurie - @dronesec Luca Barbato - Tobias Ospelt Thomas Jarosch - Martin Carpenter Mudge Zatko - Joe Zbiciak Ryan Govostes - Michael Rash William Robinet - Jonathan Gray Filipe Cabecinhas - Nico Weber Jodie Cunningham - Andrew Griffiths Parker Thompson - Jonathan Neuschfer Tyler Nighswander - Ben Nagy Samir Aguiar - Aidan Thornton Aleksandar Nikolich - Sam Hakim Laszlo Szekeres - David A. Wheeler Turo Lamminen - Andreas Stieger Richard Godbee - Louis Dassy teor2345 - Alex Moneger Dmitry Vyukov - Keegan McAllister Kostya Serebryany - Richo Healey Martijn Bogaard - rc0r Jonathan Foote - Christian Holler Dominique Pelle - Jacek Wielemborek Leo Barnes - Jeremy Barnes Jeff Trull - Guillaume Endignoux ilovezfs - Daniel Godas-Lopez Franjo Ivancic - Austin Seipp Daniel Komaromy - Daniel Binderman Jonathan Metzman - Vegard Nossum Jan Kneschke - Kurt Roeckx Marcel Bohme - Van-Thuan Pham Abhik Roychoudhury - Joshua J. Drake Toby Hutton - Rene Freingruber Sergey Davidoff - Sami Liedes Craig Young - Andrzej Jackowski Daniel Hodson - -Thank you! - - -16) Contact ------------ - -Questions? Concerns? Bug reports? The contributors can be reached via -https://github.com/vanhauser-thc/AFLplusplus - -There is also a mailing list for the afl project; to join, send a mail to -<afl-users+subscribe@googlegroups.com>. Or, if you prefer to browse -archives first, try: - - https://groups.google.com/group/afl-users diff --git a/docs/README.MOpt b/docs/README.MOpt new file mode 100644 index 00000000..94e63959 --- /dev/null +++ b/docs/README.MOpt @@ -0,0 +1,51 @@ +# MOpt(imized) AFL by <puppet@zju.edu.cn> + +### 1. Description +MOpt-AFL is a AFL-based fuzzer that utilizes a customized Particle Swarm +Optimization (PSO) algorithm to find the optimal selection probability +distribution of operators with respect to fuzzing effectiveness. +More details can be found in the technical report. + +### 2. Cite Information +Chenyang Lyu, Shouling Ji, Chao Zhang, Yuwei Li, Wei-Han Lee, Yu Song and +Raheem Beyah, MOPT: Optimized Mutation Scheduling for Fuzzers, +USENIX Security 2019. + +### 3. Seed Sets +We open source all the seed sets used in the paper +"MOPT: Optimized Mutation Scheduling for Fuzzers". + +### 4. Experiment Results +The experiment results can be found in +https://drive.google.com/drive/folders/184GOzkZGls1H2NuLuUfSp9gfqp1E2-lL?usp=sharing. +We only open source the crash files since the space is limited. + +### 5. Technical Report +MOpt_TechReport.pdf is the technical report of the paper +"MOPT: Optimized Mutation Scheduling for Fuzzers", which contains more deatails. + +### 6. Parameter Introduction +Most important, you must add the parameter `-L` (e.g., `-L 0`) to launch the +MOpt scheme. + +Option '-L' controls the time to move on to the pacemaker fuzzing mode. +'-L t': when MOpt-AFL finishes the mutation of one input, if it has not +discovered any new unique crash or path for more than t minutes, MOpt-AFL will +enter the pacemaker fuzzing mode. + +Setting 0 will enter the pacemaker fuzzing mode at first, which is +recommended in a short time-scale evaluation. + +Other important parameters can be found in afl-fuzz.c, for instance, + +'swarm_num': the number of the PSO swarms used in the fuzzing process. +'period_pilot': how many times MOpt-AFL will execute the target program + in the pilot fuzzing module, then it will enter the core fuzzing module. +'period_core': how many times MOpt-AFL will execute the target program in the + core fuzzing module, then it will enter the PSO updating module. +'limit_time_bound': control how many interesting test cases need to be found + before MOpt-AFL quits the pacemaker fuzzing mode and reuses the deterministic stage. + 0 < 'limit_time_bound' < 1, MOpt-AFL-tmp. + 'limit_time_bound' >= 1, MOpt-AFL-ever. + +Have fun with MOpt in AFL! diff --git a/docs/README.md b/docs/README.md new file mode 120000 index 00000000..32d46ee8 --- /dev/null +++ b/docs/README.md @@ -0,0 +1 @@ +../README.md \ No newline at end of file diff --git a/docs/binaryonly_fuzzing.txt b/docs/binaryonly_fuzzing.txt new file mode 100644 index 00000000..53361f5f --- /dev/null +++ b/docs/binaryonly_fuzzing.txt @@ -0,0 +1,140 @@ + +Fuzzing binary-only programs with afl++ +======================================= + +afl++, libfuzzer and others are great if you have the source code, and +it allows for very fast and coverage guided fuzzing. + +However, if there is only the binary program and not source code available, +then standard afl++ (dumb mode) is not effective. + +The following is a description of how these can be fuzzed with afl++ + +!!!!! +TL;DR: try DYNINST with afl-dyninst. If it produces too many crashes then + use afl -Q qemu_mode, or better: use both in parallel. +!!!!! + + +QEMU +---- +Qemu is the "native" solution to the program. +It is available in the ./qemu_mode/ directory and once compiled it can +be accessed by the afl-fuzz -Q command line option. +The speed decrease is at about 50% +It is the easiest to use alternative and even works for cross-platform binaries. + +As it is included in afl++ this needs no URL. + + +UNICORN +------- +Unicorn is a fork of QEMU. The instrumentation is, therefore, very similar. +In contrast to QEMU, Unicorn does not offer a full system or even userland emulation. +Runtime environment and/or loaders have to be written from scratch, if needed. +On top, block chaining has been removed. This means the speed boost introduced in +to the patched QEMU Mode of afl++ cannot simply be ported over to Unicorn. +For further information, check out ./unicorn_mode.txt. + + +DYNINST +------- +Dyninst is a binary instrumentation framework similar to Pintool and Dynamorio +(see far below). However whereas Pintool and Dynamorio work at runtime, dyninst +instruments the target at load time, and then let it run. +This is great for some things, e.g. fuzzing, and not so effective for others, +e.g. malware analysis. + +So what we can do with dyninst is taking every basic block, and put afl's +instrumention code in there - and then save the binary. +Afterwards we can just fuzz the newly saved target binary with afl-fuzz. +Sounds great? It is. The issue though - it is a non-trivial problem to +insert instructions, which change addresses in the process space, so +everything is still working afterwards. Hence more often than not binaries +crash when they are run (because of instrumentation). + +The speed decrease is about 15-35%, depending on the optimization options +used with afl-dyninst. + +So if dyninst works, it is the best option available. Otherwise it just doesn't +work well. + +https://github.com/vanhauser-thc/afl-dyninst + + +INTEL-PT +-------- +If you have a newer Intel CPU, you can make use of Intels processor trace. +The big issue with Intel's PT is the small buffer size and the complex +encoding of the debug information collected through PT. +This makes the decoding very CPU intensive and hence slow. +As a result, the overall speed decrease is about 70-90% (depending on +the implementation and other factors). + +There are two afl intel-pt implementations: + +1. https://github.com/junxzm1990/afl-pt + => this needs Ubuntu 14.04.05 without any updates and the 4.4 kernel. + +2. https://github.com/hunter-ht-2018/ptfuzzer + => this needs a 4.14 or 4.15 kernel. the "nopti" kernel boot option must + be used. This one is faster than the other. + + +CORESIGHT +--------- + +Coresight is ARM's answer to Intel's PT. +There is no implementation so far which handle coresight and getting +it working on an ARM Linux is very difficult due to custom kernel building +on embedded systems is difficult. And finding one that has coresight in +the ARM chip is difficult too. +My guess is that it is slower than Qemu, but faster than Intel PT. +If anyone finds any coresight implementation for afl please ping me: +vh@thc.org + + +PIN & DYNAMORIO +--------------- + +Pintool and Dynamorio are dynamic instrumentation engines, and they can be +used for getting basic block information at runtime. +Pintool is only available for Intel x32/x64 on Linux, Mac OS and Windows +whereas Dynamorio is additionally available for ARM and AARCH64. +Dynamorio is also 10x faster than Pintool. + +The big issue with Dynamorio (and therefore Pintool too) is speed. +Dynamorio has a speed decrease of 98-99% +Pintool has a speed decrease of 99.5% + +Hence Dynamorio is the option to go for if everything fails, and Pintool +only if Dynamorio fails too. + +Dynamorio solutions: + https://github.com/vanhauser-thc/afl-dynamorio + https://github.com/mxmssh/drAFL + https://github.com/googleprojectzero/winafl/ <= very good but windows only + +Pintool solutions: + https://github.com/vanhauser-thc/afl-pin + https://github.com/mothran/aflpin + https://github.com/spinpx/afl_pin_mode <= only old Pintool version supported + + +Non-AFL solutions +----------------- + +There are many binary-only fuzzing frameworks. Some are great for CTFs but don't +work with large binaries, others are very slow but have good path discovery, +some are very hard to set-up ... + +QSYM: https://github.com/sslab-gatech/qsym +Manticore: https://github.com/trailofbits/manticore +S2E: https://github.com/S2E +<please send me any missing that are good> + + + +That's it! +News, corrections, updates? +Email vh@thc.org diff --git a/docs/env_variables.txt b/docs/env_variables.txt index f5db3b4f..36fdc369 100644 --- a/docs/env_variables.txt +++ b/docs/env_variables.txt @@ -7,8 +7,8 @@ Environmental variables users or for some types of custom fuzzing setups. See README for the general instruction manual. -1) Settings for afl-gcc, afl-clang, and afl-as ----------------------------------------------- +1) Settings for afl-gcc, afl-clang, and afl-as - and gcc_plugin afl-gcc-fast +---------------------------------------------------------------------------- Because they can't directly accept command-line options, the compile-time tools make fairly broad use of environmental variables: @@ -82,18 +82,22 @@ discussed in section #1, with the exception of: - TMPDIR and AFL_KEEP_ASSEMBLY, since no temporary assembly files are created. + - AFL_INST_RATIO, as we switched for instrim instrumentation which + is more effective but makes not much sense together with this option. + Then there are a few specific features that are only available in llvm_mode: LAF-INTEL ========= This great feature will split compares to series of single byte comparisons - to allow afl-fuzz to find otherwise rather impossible paths. + to allow afl-fuzz to find otherwise rather impossible paths. It is not + restricted to Intel CPUs ;-) - - Setting LAF_SPLIT_SWITCHES will split switch()es + - Setting AFL_LLVM_LAF_SPLIT_SWITCHES will split switch()es - - Setting LAF_TRANSFORM_COMPARES will split string compare functions + - Setting AFL_LLVM_LAF_TRANSFORM_COMPARES will split string compare functions - - Setting LAF_SPLIT_COMPARES will split > 8 bit CMP instructions + - Setting AFL_LLVM_LAF_SPLIT_COMPARES will split > 8 bit CMP instructions See llvm_mode/README.laf-intel for more information. @@ -102,13 +106,33 @@ Then there are a few specific features that are only available in llvm_mode: This feature allows selectively instrumentation of the source - Setting AFL_LLVM_WHITELIST with a filename will only instrument those - files that match these names. + files that match the names listed in this file. See llvm_mode/README.whitelist for more information. -Note that AFL_INST_RATIO will behave a bit differently than for afl-gcc, -because functions are *not* instrumented unconditionally - so low values -will have a more striking effect. For this tool, 0 is not a valid choice. + INSTRIM + ======= + This feature increases the speed by whopping 20% but at the cost of a + lower path discovery and therefore coverage. + + - Setting AFL_LLVM_INSTRIM activates this mode + + - Setting AFL_LLVM_INSTRIM_LOOPHEAD=1 expands on INSTRIM to optimize loops. + afl-fuzz will only be able to see the path the loop took, but not how + many times it was called (unless it is a complex loop). + + See llvm_mode/README.instrim + + NOT_ZERO + ======== + + - Setting AFL_LLVM_NOT_ZERO=1 during compilation will use counters + that skip zero on overflow. This is the default for llvm >= 9, + however for llvm versions below that this will increase an unnecessary + slowdown due a performance issue that is only fixed in llvm 9+. + This feature increases path discovery by a little bit. + + See llvm_mode/README.neverzero 3) Settings for afl-fuzz ------------------------ @@ -220,6 +244,10 @@ The QEMU wrapper used to instrument binary-only code supports several settings: - Setting AFL_INST_LIBS causes the translator to also instrument the code inside any dynamically linked libraries (notably including glibc). + + - Setting AFL_QEMU_COMPCOV enables the CompareCoverage tracing of all + cmp and sub in x86 and x86_64. Support for other architectures and + comparison functions (mem/strcmp et al.) is planned. - The underlying QEMU binary will recognize any standard "user space emulation" variables (e.g., QEMU_STACK_SIZE), but there should be no diff --git a/docs/sister_projects.txt b/docs/sister_projects.txt index 41701e2f..a2eb2a22 100644 --- a/docs/sister_projects.txt +++ b/docs/sister_projects.txt @@ -6,6 +6,10 @@ Sister projects designed for, or meant to integrate with AFL. See README for the general instruction manual. +!!! +!!! This list is outdated and needs an update, missing: e.g. Angora, FairFuzz +!!! + ------------------------------------------- Support for other languages / environments: ------------------------------------------- @@ -263,7 +267,7 @@ Static binary-only instrumentation (Aleksandar Nikolich) reports better performance compared to QEMU, but occasional translation errors with stripped binaries. - https://github.com/vrtadmin/moflow/tree/master/afl-dyninst + https://github.com/vanhauser-thc/afl-dyninst AFL PIN (Parker Thompson) ------------------------- diff --git a/docs/unicorn_mode.txt b/docs/unicorn_mode.txt new file mode 100644 index 00000000..ae6a2bde --- /dev/null +++ b/docs/unicorn_mode.txt @@ -0,0 +1,107 @@ +========================================================= +Unicorn-based binary-only instrumentation for afl-fuzz +========================================================= + +1) Introduction +--------------- + +The code in ./unicorn_mode allows you to build a standalone feature that +leverages the Unicorn Engine and allows callers to obtain instrumentation +output for black-box, closed-source binary code snippets. This mechanism +can be then used by afl-fuzz to stress-test targets that couldn't be built +with afl-gcc or used in QEMU mode, or with other extensions such as +TriforceAFL. + +There is a significant performance penalty compared to native AFL, +but at least we're able to use AFL on these binaries, right? + +The idea and much of the implementation comes from Nathan Voss <njvoss299@gmail.com>. + +2) How to use +------------- + +*** Building AFL's Unicorn Mode *** + +First, make afl as usual. +Once that completes successfully you need to build and add in the Unicorn Mode +features: + + $ cd unicorn_mode + $ ./build_unicorn_support.sh + +NOTE: This script downloads a recent Unicorn Engine commit that has been tested +and is stable-ish from the Unicorn github page. If you are offline, you'll need +to hack up this script a little bit and supply your own copy of Unicorn's latest +stable release. It's not very hard, just check out the beginning of the +build_unicorn_support.sh script and adjust as necessary. + +Building Unicorn will take a little bit (~5-10 minutes). Once it completes +it automatically compiles a sample application and verify that it works. + +*** Fuzzing with Unicorn Mode *** + +To really use unicorn-mode effectively you need to prepare the following: + + * Relevant binary code to be fuzzed + * Knowledge of the memory map and good starting state + * Folder containing sample inputs to start fuzzing with + - Same ideas as any other AFL inputs + - Quality/speed of results will depend greatly on quality of starting + samples + - See AFL's guidance on how to create a sample corpus + * Unicorn-based test harness which: + - Adds memory map regions + - Loads binary code into memory + - Emulates at least one instruction* + - Yeah, this is lame. See 'Gotchas' section below for more info + - Loads and verifies data to fuzz from a command-line specified file + - AFL will provide mutated inputs by changing the file passed to + the test harness + - Presumably the data to be fuzzed is at a fixed buffer address + - If input constraints (size, invalid bytes, etc.) are known they + should be checked after the file is loaded. If a constraint + fails, just exit the test harness. AFL will treat the input as + 'uninteresting' and move on. + - Sets up registers and memory state for beginning of test + - Emulates the interested code from beginning to end + - If a crash is detected, the test harness must 'crash' by + throwing a signal (SIGSEGV, SIGKILL, SIGABORT, etc.) + +Once you have all those things ready to go you just need to run afl-fuzz in +'unicorn-mode' by passing in the '-U' flag: + + $ afl-fuzz -U -m none -i /path/to/inputs -o /path/to/results -- ./test_harness @@ + +The normal afl-fuzz command line format applies to everything here. Refer to +AFL's main documentation for more info about how to use afl-fuzz effectively. + +For a much clearer vision of what all of this looks like, please refer to the +sample provided in the 'unicorn_mode/samples' directory. There is also a blog +post that goes over the basics at: + +https://medium.com/@njvoss299/afl-unicorn-fuzzing-arbitrary-binary-code-563ca28936bf + +The 'helper_scripts' directory also contains several helper scripts that allow you +to dump context from a running process, load it, and hook heap allocations. For details +on how to use this check out the follow-up blog post to the one linked above. + +A example use of AFL-Unicorn mode is discussed in the Paper Unicorefuzz: +https://www.usenix.org/conference/woot19/presentation/maier + +3) Gotchas, feedback, bugs +-------------------------- + +To make sure that AFL's fork server starts up correctly the Unicorn test +harness script must emulate at least one instruction before loading the +data that will be fuzzed from the input file. It doesn't matter what the +instruction is, nor if it is valid. This is an artifact of how the fork-server +is started and could likely be fixed with some clever re-arranging of the +patches applied to Unicorn. + +Running the build script builds Unicorn and its python bindings and installs +them on your system. This installation will supersede any existing Unicorn +installation with the patched afl-unicorn version. + +Refer to the unicorn_mode/samples/arm_example/arm_tester.c for an example +of how to do this properly! If you don't get this right, AFL will not +load any mutated inputs and your fuzzing will be useless! |